Python开发
【Django 框架】Django 框架死了吗?
了解 Django 是否适合您的 Web 开发需求。
我已经学习了一些 JavaScript 和 Python,并且计划学习一个后端框架。我不知道我应该选择基于 Node.js 的框架还是基于 Django 的框架。我看到很多基于 Node.js 的框架得到了很多炒作。 Django 框架现在死了吗?
不,不是。 Django 被 StackOverflow 开发者调查选为 2021 年最受欢迎的 Web 开发框架,这意味着它在 2022 年具有巨大的潜力。我有很多 Django 开发者朋友,他们作为自由开发者或全职开发者做得很好。
如果你想知道 Django 是否适合你,你可以使用这些参数。
为什么使用 Django?
- 可扩展性:Django 因其缓存选项和代码可重用特性而具有可扩展性,使 Django 应用程序有效地处理流量需求。
- 安全性:默认情况下,Django 帮助开发人员避免许多安全问题,例如 SQL 注入、CSRF 攻击和 XSS。
- Added Battery:由于这个特殊功能,开发人员可以利用包来包含功能,而不是从一开始就编写代码。它节省时间,开发人员可以专注于其他应用程序领域。
- 异步编程:根据模型-视图-模板架构,基于 Python 的 Django 可以在任何地方运行,并支持反应式和异步编程。
- SEO 优化:基于 Django 的应用程序易于优化且对 SEO 友好,因为您可以通过 URL 而不是 IP 地址在服务器上维护它们。
- 快速开发:Django 使开发人员能够同时利用多个元素。您不必为任何新功能编写单独的代码。此外,它有助于快速创建 MVP。
- 更大的社区支持:Django 拥有一个拥有超过 2000 名开发人员的广泛社区。有了这样的帮助,您可以比以往更快地为您的问题找到最佳解决方案。
- 多功能用例:Django 提供了创建所有类型网站的范围,从 CMS(内容管理系统)到社交网络和新闻网站。
为什么不使用 Django?
- 您的项目/应用程序非常庞大,您无法将所有内容都保存在一个代码库中。
- 您可能希望将您的应用程序分解为微服务。每一层都可能由专门的团队和流程更好地处理。最好为每个用例使用不同的技术。 Django 可能会在某些特定的用例中有所帮助,但使用 Django(或单独的任何其他框架)开发所有东西可能并不明智。
- 你需要构建一个非常基本的应用程序,它不需要数据库、文件操作,甚至任何远程复杂的东西。
- 微框架更适合这些用例。 Flask 是用 Python 编写的最流行的微框架之一。类似的微框架可用于其他技术,例如。 PHP 中的 Slim、Java 中的 Apache Spark、Node.js 中的 Express.js 等。
- 如果您想从头开始构建所有内容,并且您知道自己在做什么。
- 您或您的团队成员根本不熟悉 Django/Python,而且您无法投入时间和资源来收集所需的技能。在这种情况下,最好的解决方案是使用您最了解的内容。如果你采用新的技术或框架,把事情搞砸的机会会增加很多倍。
所以…
Django 框架死了吗?
从来没有,我想它永远不会死。许多受欢迎的公司,如 Instagram、国家地理、Mozilla、Spotify、Pinterest、Disqus、Bitbucket 和 Eventbrite 都在使用 Django。相反,我会越来越受欢迎。
这里有一些 Django Web 开发领域可以帮助你快速完成项目……
我对使用 Django 的建议
但是,我再次告诉您,即使您想制作小型应用程序或非常基本的 Web 应用程序,也要选择 Django。 Django 开箱即用地完成了大部分工作。我们要做的任务是建模、查看和一些渲染。所以,Django 适合那些珍惜时间的人。
原文:https://python.plainenglish.io/is-the-django-framework-dead-591f9a533ba
- 99 次浏览
【Django 框架】关于 Django 4.0 你需要知道的 10 件事
Django 4.0 于 2021 年 12 月 7 日发布

Python 兼容性
Django 4.0 支持 Python 3.8、3.9 和 3.10。强烈推荐,并且仅官方支持每个系列的最新版本。
注意力:
Django 3.2.x 系列是最后一个支持 Python 3.6 和 3.7
关于 Django 4.0 你需要知道的那些事
1-您可以使用 Scrypt 密码哈希
新的 scrypt 密码散列器比 PBKDF2 更安全,推荐使用。但是,它不是默认设置,因为它需要 OpenSSL 1.1+ 和更多内存。
scrypt 与 PBKDF2 和 bcrypt 类似,它利用一定数量的迭代来减缓暴力攻击。但是,由于 PBKDF2 和 bcrypt 不需要大量内存,因此资源充足的攻击者可以发起大规模并行攻击,以加快攻击进程。与其他基于密码的密钥派生函数相比,scrypt 专门设计为使用更多内存,以限制攻击者可以使用的并行量。
要使用 scrypt 作为您的默认存储算法,
修改 PASSWORD_HASHERS 以首先列出 ScryptPasswordHasher。也就是说,在您的设置文件中:
PASSWORD_HASHERS = [ 'django.contrib.auth.hashers.ScryptPasswordHasher', 'django.contrib.auth.hashers.PBKDF2PasswordHasher', 'django.contrib.auth.hashers.PBKDF2SHA1PasswordHasher', 'django.contrib.auth.hashers.Argon2PasswordHasher', 'django.contrib.auth.hashers.BCryptSHA256PasswordHasher', ]
2-请求和响应
SecurityMiddleware 现在添加了值为 'same-origin' 的 Cross-Origin Opener Policy 标头,以防止跨域弹出窗口共享相同的浏览上下文。您可以通过将 SECURE_CROSS_ORIGIN_OPENER_POLICY 设置设置为 None 来防止添加此标头。
3- SecurityMiddleware 不再设置 X-XSS-Production 标头
如果 SECURE_BROWSER_XSS_FILTER 设置为 True,SecurityMiddleware 不再设置 X-XSS-Protection 标头。该设置被删除。
大多数现代浏览器不支持 X-XSS-Protection HTTP 标头。您可以使用 Content-Security-Policy 而不允许使用“不安全内联”脚本。
如果您想支持旧版浏览器并设置标头,请在自定义中间件中使用此行:
response.headers.setdefault('X-XSS-Protection', '1; mode=block')
4- CSRF-TOKEN
CSRF 保护现在会参考 Origin 标头(如果存在)。为此,需要对 CSRF_TRUSTED_ORIGINS 设置进行一些更改。
5- 通用视图
DeleteView 现在使用 FormMixin 来处理 POST 请求。因此,delete() 处理程序中的任何自定义删除逻辑都应移至 form_valid() 或共享辅助方法(如果需要)。
6- 表格
ModelChoiceField 现在包括在引发的 ValidationError 的 params 参数中为 invalid_choice 错误消息提供的值。这允许自定义错误消息使用 %(value)s 占位符。
BaseFormSet 现在使用额外的非形式类呈现非形式错误,以帮助将它们与特定于表单的错误区分开来。
BaseFormSet 现在允许自定义通过 can_delete 删除表单时使用的小部件,方法是设置 delete_widget 属性或覆盖 get_deletion_widget() 方法。
7-模型
新的 QuerySet.contains(obj) 方法返回查询集是否包含给定对象。这试图以最简单和最快的方式执行查询。
Round() 数据库函数的新精度参数允许指定舍入后的小数位数。
QuerySet.bulk_create() 现在在使用 SQLite 3.35+ 时设置对象的主键。
DurationField 现在支持 SQLite 上的标量值乘除。
QuerySet.bulk_update() 现在返回更新的对象数。
新的 Expression.empty_result_set_value 属性允许指定在函数用于空结果集时要返回的值。
MariaDB 10.6+ 现在允许使用 QuerySet.select_for_update() 的 skip_locked 参数。
查找表达式现在可以在 QuerySet 注释、聚合中使用,也可以直接在过滤器中使用。
内置聚合的新默认参数允许指定在查询集(或分组)不包含条目时返回的值,而不是 None。
8- 功能独特的约束
UniqueConstraint() 的新 *expressions 位置参数允许在表达式和数据库函数上创建功能唯一约束。例如:
from django.db import models
from django.db.models import UniqueConstraint
from django.db.models.functions import Lower
class MyModel(models.Model):
first_name = models.CharField(max_length=255)
last_name = models.CharField(max_length=255)
class Meta:
constraints = [
UniqueConstraint(
Lower('first_name'),
Lower('last_name').desc(),
name='first_last_name_unique',
),
]
使用 Meta.constraints 选项将功能唯一约束添加到模型中。
9- 模板
基于模板的表单渲染
现在使用模板引擎呈现 Forms、Formsets 和 ErrorList 以增强自定义。请参见 Formset 的新 render()、get_context() 和 template_name 和 Formset 渲染。
floatformat 模板过滤器现在允许使用 u 后缀来强制禁用本地化。
10-管理命令
runserver 管理命令现在支持 --skip-checks 选项。
在 PostgreSQL 上,dbshell 现在支持指定密码文件。
shell 命令现在在启动时尊重 sys.__interactivehook__。这允许在交互式会话之间加载 shell 历史记录。因此,如果在隔离模式下运行,则不再加载 readline。
新的 BaseCommand.suppressed_base_arguments 属性允许在帮助输出中抑制不支持的默认命令选项。
新的 startapp --exclude 和 startproject --exclude 选项允许从模板中排除目录。
原文:https://aliarefwriorr.medium.com/top-10-things-you-need-to-know-about-d…
本文:https://jiagoushi.pro/top-10-things-you-need-know-about-django-40
- 76 次浏览
【Python 开发】2022 年开始使用的 3 个 Python 包
1.Mito
Mito 是 Python 的电子表格界面——你可以在你的 Python 环境中调用 Mito,你在电子表格中所做的每次编辑都会在下面的代码单元格中生成等效的 Python。 想象一下,如果你在 Excel 中所做的一切都可以生成 Python 代码——那就是 Mito。
为 Mito 安装命令:
python -m pip install mitoinstaller python -m mitoinstaller install
然后打开 Jupyter Lab 并调用 Mitosheet
import mitosheet mitosheet.sheet()
完整的说明可以在 Mito 网站的“docs”下找到。
Mito 是一种快速完成数据科学任务的快速方法,无需完美的语法——Mito 为您编写代码。
功能包括:
- 绘图
- 数据透视表
- 过滤器
- 合并
- 排序
- 汇总统计
- 导入和导出 Excel 文件
- 去重
- 添加和删除列
- 编辑特定单元格
- 和更多!
2. Plotly
Plotly 是 Python 的开源图形库。 他们的图表涵盖了一些特定领域的领域,例如金融和地理——这将它们与像 Matplotlib 这样的包区分开来。 Plotly 专注于允许用户创建交互式图表。 这些图表不仅允许创建者从数据中展示他们的见解,而且还允许查看者做出自己的见解。
您可以使用以下命令安装 Plotly:
$ pip install plotly==5.5.0
这是最简单的 Plotly 图表之一的示例:
import plotly.express as px fig = px.bar(x=["a", "b", "c"], y=[1, 3, 2]) fig.show()
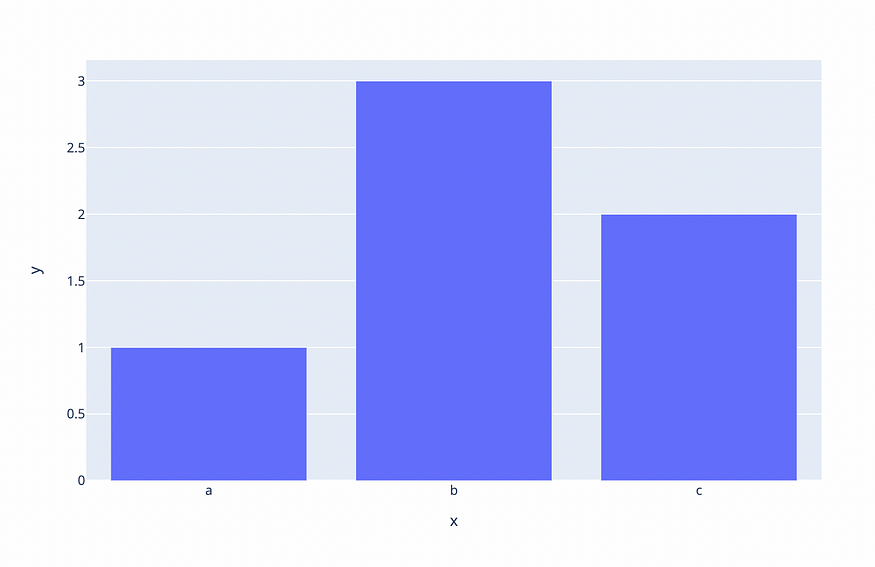
在图像中很难看到,但在笔记本中,如果您将鼠标悬停在此图表上,您将有许多选项与此图表进行交互,包括放大数据和导出为 PNG。
从下面的示例中可以看出,Plotly 提供了各种易于使用但功能强大的图表。
3.Streamlit
Streamlit 旨在快速构建数据应用程序。 近年来,将“应用程序”作为内部和外部业务工具的想法广受欢迎(我可以为此写一个完整的博客!)。 似乎它们的崛起与 Mito 和 Plotly 等低代码/无代码工具的兴起同步并可能受到了刺激,这些工具允许较少技术用户进入数据科学领域。
这是来自 Data Professor 的关于 Streamlit 的演示。
要导入 Streamlit,请运行以下命令:
import streamlit as st
Streamlit 还具有“组件”,它们是可用于您的应用程序和仪表板的第三方功能。 例如,您可以在 Streamlit 中使用 AGgrid、Bokeh 或 Pandas Profiling。
以下是他们网站上的一些 Streamlit 应用程序示例:
您可以在 Github 上为 Streamlit 加注星标,请点击此处。
我希望这些软件包对您有所帮助。 他们三人的共同点是,他们都明白数据科学和 Python 在传统数据科学团队之外的应用越来越广泛。 营销人员、销售专家、运营专家、财务专家以及介于两者之间的每个人都已经在与数据科学工作流程进行交互。 这些工具可帮助技术和非技术受众聚集在一起,共同推动数据科学向前发展 :)
原文:https://medium.com/trymito/3-python-packages-to-start-using-in-2022-42f…
本文:
- 86 次浏览
【Python开发】Python 3.10 发布——你应该知道的 5 大新特性
Python 已经在市场上出现了很长一段时间,作为一名 Python 开发人员,我很高兴能与大家分享 Python 正在逐步更新并随着每个新版本的发布而改进。
Python 的最新版本 3.10 有一些重大改进,我将在此处列出这些更新。 我在下面捆绑了与这个新版本的 Python 一起发布的前 5 个新更新。
1.改进的错误信息
这个很大。 对于 Python 开发人员,当您编写代码并遇到错误时,错误消息可以帮助您找出代码中的错误。 与使用以前的 Python 版本相比,改进的错误消息使您的生活更加轻松。
例如,考虑以下代码,其中第二行末尾没有括号:
# I am coding in Python and this is first line ;) my_list = ["Hello", "Python!" print(my_list)
在以前的版本中——Python3.9 和更早的版本,你会看到如下错误——
File "my_precious.py", line 3 print(my_list) ^ SyntaxError: invalid syntax
嗯,语法无效! 现在,作为开发人员,您从这个错误消息中理解了什么? 好吧,就我个人而言,除了在第 3 行的某处添加了错误的语法这一事实之外,我什么都不明白。
但是,错误真的在第 3 行吗?
Python 3.10 是这种情况下的救星,它的最新更新。 对于同一段代码,Python 3.10 将抛出以下错误消息——
File "my_precious.py", line 2 news = ["Hello", "Python!" ^ SyntaxError: '[' was never closed
呜呼! 行号和非常具体的错误消息将允许您直接进入,修复错误并继续编码!
我个人尝试查看错误消息是否足够清晰的另一个示例 -
# missing_comma.py
dc_characters = {
1: "Superman" # Comma missing
2: "Batman",
3: "Joker"
}....
Output:
File "dc_characters.py", line 4
10: "October"
^^^^^^^^^
SyntaxError: invalid syntax. Perhaps you forgot a comma?这确实是 Python 3.10 版本中的一个很酷的更新,请在本文的评论部分分享您的想法。
2. 更简单的联合类型语法
Typing 模块用于向 Python 添加静态类型。 在过去的 Python 版本中,更多的工具已经从类型转移到内置功能,以避免每次都必须导入静态类型。
现在让我们看看这里到底发生了什么变化——
# Before Python 3.10 Release
from typing import Union
def f(list: List[Union[int, str]], param: Optional[int]):
pass# In Python 3.10 Release
def f(list: List[int | str], param: int | None):
pass# Calling the function
f([1, "abc"], None)
在 Python 3.10 中,现在您可以使用管道运算符 (|) 来指定类型联合,而不是从类型模块中导入联合。
此外,现有的 typing.Union 和 | 语法应该与下面的比较相同 -
int | str == typing.Union[int, str] typing.Union[int, int] == int int | int == int
3. 跨多行使用多个 `with` 语句
Python 确实通过使用反斜杠 (\) 来支持多行语句,但是 Python 中的一些结构不应该要求使用斜杠来编写多行语句。 其中之一是具有多行 with() 语句的上下文管理器。 例如 -
# Before Python 3.10 Releasewith (open("a_really_long_foo") as foo,
open("a_really_long_bar") as bar):
pass
Traceback (most recent call last):
File "<input>", line 1, in <module>
File "demo.py", line 19
with (open("a_really_long_foo") as foo,
^
SyntaxError: invalid syntax
是的,这看起来不像是一项功能,但它是对先前版本的一项重大改进,因为您可能遇到过使用多行上下文管理器的用例,但由于上述错误而无法做到这一点。
如果您仍然感到困惑,让我们举更多示例来说明您可以在 Python 3.10 版本中使用上下文管理器做什么——
# After Python 3.10 Releasefrom contextlib import contextmanager
@contextmanager
def f(x):
try:
yield x
finally:
pass# Example 1
with f('c') as a,
f('a') as b:
pass# Example 2
with f('c') as a,
f('a') as b,
f('a') as c:
pass
您现在可以拥有多行上下文管理器语句,而无需使用反斜杠。 很棒吧?
4. 更好的类型别名
类型别名允许您快速定义可以为复杂类型声明创建的新别名。 例如 -
# Before Python 3.10 UserInfo = tuple[str, int]
这通常可以正常工作。 但是,类型检查器通常不可能知道这样的语句是类型别名还是只是常规全局变量的定义。
# In Python 3.10from typing import TypeAlias Card: TypeAlias = tuple[str, str] Deck: TypeAlias = list[Card]
上面的 python 代码为 tuple[str, str] 声明了一个别名 UserInfo,因为它是一种组合了多种类型值的数据类型。 在我们的例子中,它是一个字符串和一个整数。 此外,添加 TypeAlias 注释可以澄清意图,无论是对类型检查器还是对任何阅读您的代码的人。
5. 更严格的序列压缩
zip() 是 Python 中的一个内置函数,您可能在组合多个列表/序列时使用过它。 Python3.10 引入了新的 strict 参数,它添加了一个运行时测试来检查所有被压缩的序列是否具有相同的长度。
例如 -
# Before Python 3.10 names = ["Tom", "Harry", "Jessica", "Robert", "Kevin"] numbers = ["21024", "75978", "92176", "75192", "34323"]
zip() 可用于并行迭代这三个列表:
list(zip(names, numbers))..... Output: [(Tom, 21024), (Harry, 75978), (Jessica, 92176), (Robert, 75192), (Kevin, 34323)]
让我们再次使用上面显示的这两个序列的名称和编号。 现在,这些序列之间的唯一区别是数字与序列名称的长度不同,如下所示 -
# Before Python 3.10 names = ["Tom", "Harry", "Jessica", "Robert"] # Kevin is missing numbers = ["21024", "75978", "92176", "75192", "34323"]# Zipping using zip() list(zip(names, numbers))...... Output [(Tom, 21024), (Harry, 75978), (Jessica, 92176), (Robert, 75192)]
请注意,关于名字的所有信息——凯文消失了!
如果您的数据集更大,则很难发现此类错误。 即使你发现有问题,诊断和修复也并不总是那么容易。
被压缩的序列将具有相同长度的假设不仅可以帮助您避免这种差异。
在 Python 3.10 中,strict 参数可以帮助您在一开始就避免这种情况——
# In Python 3.10 names = ["Tom", "Harry", "Jessica", "Robert"] # Kevin is missing # Zipping using zip() with additional Parameter strict=True numbers = ["21024", "75978", "92176", "75192", "34323"] list(zip(names, numbers, strict=True)).... Output: Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: zip() argument 2 is shorter than argument 1
虽然 strict 并没有真正为 zip() 添加任何新功能,但它可以帮助您避免那些难以发现的错误。
Python 3.10 中的其他更新
这个版本有很多错误修复和一些其他小更新,如果您有兴趣,可以在官方发布页面上找到
原文:https://blog.varunsingh.in/python-3-10-released-top-5-new-features-you-…
- 75 次浏览
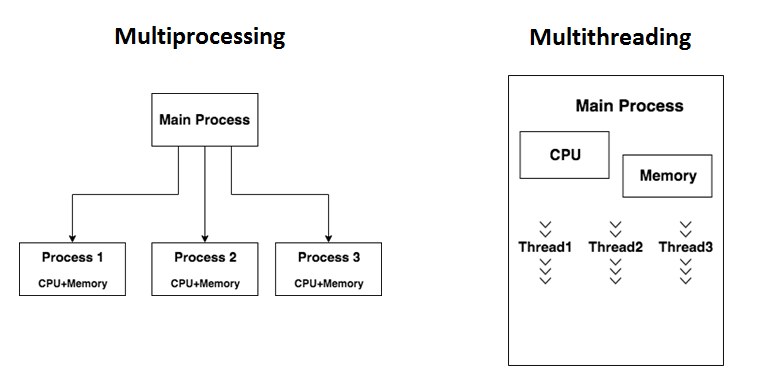
【Python开发】Python中的多处理
- Why Python Multiprocessing
- 在 Python 中,单 CPU 使用是由全局解释器锁 (GIL) 引起的,它在任何给定时间只允许一个线程携带 Python 解释器。实现 GIL 是为了处理内存管理问题,但因此,Python 仅限于使用单个处理器。
- 模块的多处理允许程序员充分利用给定机器上的多个处理器。使用的 API 类似于经典的线程模块。它提供本地和远程并发。
- 多处理模块通过使用子进程而不是线程来避免全局解释器锁 (GIL) 的限制。多处理代码的执行顺序与串行代码不同。不能保证第一个创建的进程将是第一个完成的。
为什么多处理有用?
计算从 1 到 1000 的所有数字的最快方法是什么?
- Python 一次只使用一个内核来工作。想想在解决一个简单的数学问题时做什么更快。
- 通过将结果一一相加,并以递增方式将总和相加(1+2=3、3+3=6,6+4=1000,依此类推)。一个核心正在处理这项任务。
- 预先将值拆分为单独的块,然后先将那里的值相加(1 到 300、301 到 600 和 601 到 1000)。三个核心将同时工作(最后一步是将收到的三个值相加)。
一个好的起点是了解 Python 中的多处理库是如何工作的。
你应该使用什么?
- 如果你的代码有很多 I/O 或网络使用:多线程是你最好的选择,因为它的开销很低
- 如果你有一个 GUI:多线程,这样你的 UI 线程就不会被锁定
- 如果您的代码受 CPU 限制:您应该使用多处理(如果您的机器有多个内核)
多处理示例
- Multiprocessing 是一个使用类似于 threading 模块的 API 支持生成进程的包。
- multiprocessing 包提供本地和远程并发,通过使用子进程而不是线程来有效地避开全局解释器锁。
- 因此,模块的多处理允许程序员充分利用给定机器上的多个处理器。 它可以在 Unix 和 Windows 上运行。
- 这个使用 Pool 的数据并行的基本示例,
from multiprocessing import Pool
def f(x):
return x*x
if __name__ == '__main__':
with Pool(5) as p:
print(p.map(f, [1, 2, 3]))将打印到标准输出:
[1, 4, 9]
进程类
在多处理中,进程是通过创建一个 Process 对象然后调用它的 start() 方法来产生的。 进程遵循threading.Thread的API。 多进程程序的一个简单示例是
from multiprocessing import Process
def f(name):
print('hello', name)
if __name__ == '__main__':
p = Process(target=f, args=('bob',))
p.start()
p.join()为了显示所涉及的各个进程 ID,这是一个扩展示例:
from multiprocessing import Process
import os
def info(title):
print(title)
print('module name:', __name__)
print('parent process:', os.getppid())
print('process id:', os.getpid())
def f(name):
info('function f')
print('hello', name)
if __name__ == '__main__':
info('main line')
p = Process(target=f, args=('bob',))
p.start()
p.join()
过程和例外:
- run():方法代表进程的活动。
- start():启动进程的活动。
- join([timeout]):如果可选参数 timeout 为 None(默认值),则该方法将阻塞,直到调用该方法的 join() 的进程终止。
- 名称:进程的名称。该名称是一个仅用于识别目的的字符串。
- is_alive():返回进程是否存活。
- terminate():终止进程
- kill():与 terminate() 相同,但在 Unix 上使用 SIGKILL 信号。
- close():关闭 Process 对象,释放与之相关的所有资源。
- 异常 multiprocessing.ProcessError:所有多处理异常的基类。
- 异常 multiprocessing.BufferTooShort:当提供的缓冲区对象太小而无法读取消息时,Connection.recv_bytes_into() 会引发异常。
- 异常 multiprocessing.AuthenticationError:出现身份验证错误时引发
- 异常 multiprocessing.TimeoutError:超时到期时由具有超时的方法引发
管道和队列
当使用多个进程时,通常使用消息传递来进行进程之间的通信,并避免使用任何同步原语,如锁。
对于传递消息,可以使用 Pipe()(用于两个进程之间的连接)或队列(允许多个生产者和消费者)。
结论
- 如果没有多处理,Python 程序会因为 GIL(全局解释器锁)而无法最大化系统的规格。
- 多处理允许您创建可以同时运行的程序(绕过 GIL)并使用整个 CPU 内核。 虽然它与线程库根本不同,但语法非常相似。 多处理库为每个进程提供了自己的 Python 解释器和自己的 GIL。
- 因此,与线程相关的常见问题(例如数据损坏和死锁)不再是问题。 由于进程不共享内存,因此它们不能同时修改相同的内存。
谢谢阅读。 如果您觉得这篇文章有用,请不要忘记鼓掌并与您的朋友和同事分享。 如果您有任何问题,请随时与我联系。
原文:https://hiteshmishra708.medium.com/multiprocessing-in-python-c6735fa70f…
- 113 次浏览
【Python架构】在 Python 中使用架构模式管理复杂性
你的源代码是不是感觉像一个大泥球?依赖项是否在您的代码库中交织在一起,以至于改变感觉很危险或不可能?
随着业务的增长和领域模型(您在应用程序中解决的业务问题)变得更加复杂,我们如何在不从头开始重新编写所有内容的情况下解开我们创建的混乱?更好的是,我们如何避免一开始就陷入混乱?
鸟瞰图
以下是 Python 架构模式中介绍的技术的简要总结:
分层架构
- 单一职责
- 视图 vs 服务 vs 存储库 vs ORM vs 域
- 依赖倒置
- 高级与低级模块
- 抽象
领域驱动设计
- 先说“业务上下文”
- 领域建模(事件风暴等)
- 实体 vs ValueObjects vs 域服务
- 数据类
测试驱动开发
- 什么是TDD
- 在服务层进行高速测试
- 在域中进行低速测试
设计模式
- 存储库模式
- 服务层模式
- 工作单元模式
- 聚合模式
事件驱动架构
- 活动
- 消息总线
- 事件处理程序作为服务层
- 时间解耦
- 队列和代理
- 幂等性、故障和监控
- 命令
- CQRS
- 简单读取与复杂命令
- 非规范化、缓存和最终一致性
我将简要介绍这些主题中的每一个,但我不会在这篇博文中重新打印这本书。这些将是我自己的话和我的解释,所以如果你想要“真正的交易”,我建议你去源头找一本这本书:)
分层架构
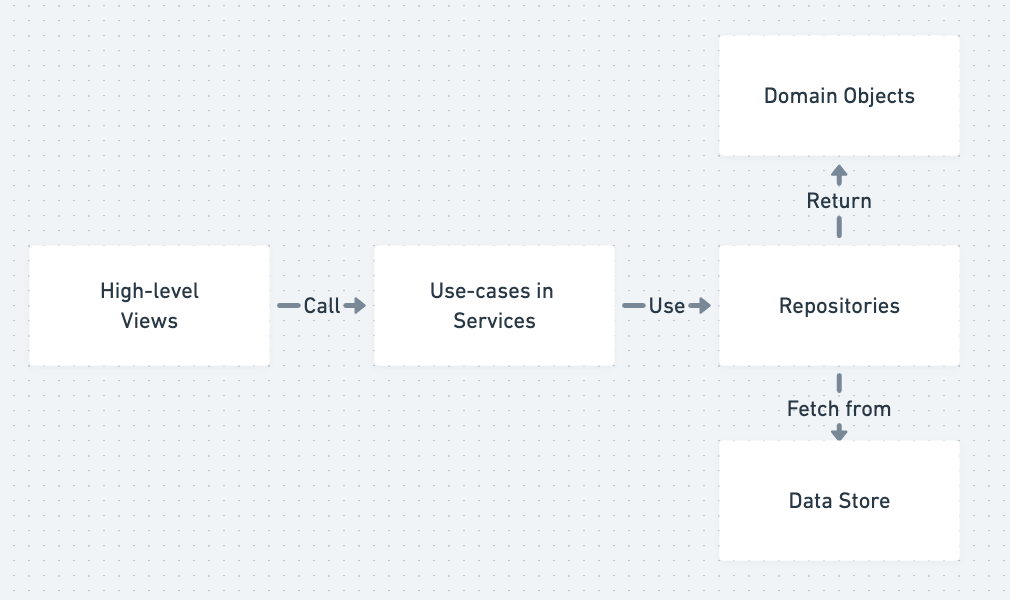
A simplified summary of Layered Architecture
- SOLID 原则大量存在于良好的设计中。简而言之,如果您不知道,我将解释这些是什么。 S,Single Responsibility,意味着代码应该有一个改变的理由,而且只有一个理由。 O,对于 Open-Closed,意味着您的代码应该对扩展开放但对修改关闭。 L,对于 Liskov Substitution,意味着子类的实例可以在不改变行为的情况下替换其父类的用法。我,对于接口隔离,意味着你的代码不应该被迫实现它不使用的行为。最后,D,表示依赖倒置,意味着一种松散耦合。
- 单一职责是分层架构背后的动机。也就是说,您的 Django 视图负责处理 HTTP 事务——获取输入、发送输出和状态码。这些视图应该委托给编排业务逻辑的服务。服务实现用例并且应该依赖于围绕低级细节的抽象,这些抽象可以包括存储库(用于存储抽象)和工作单元(用于事务或原子操作管理)。
- 这些层(视图、服务、存储库/UoW)从您的业务与特定用例/端点/网页相关的高层开始。然后他们使用抽象层直到我们写入数据库(在存储库中)或与其他系统通信等的低级操作。这就是依赖倒置的原理。
- 依赖倒置原则有两个部分。首先,高级模块不应该依赖于低级模块,两者都应该依赖于抽象。其次,抽象不应该依赖于细节,而细节应该依赖于抽象。因为这是一个如此复杂的话题,我不会详述它,如果你有兴趣,我建议你在这里、这里、甚至在本书中找到更好的阅读材料!
领域驱动设计

source: https://pixabay.com/photos/engineer-engineering-4941336/
也称为 DDD。成为您领域的主人!什么是域?好吧,实际上,这取决于您要解决的业务问题!不,我不是在开玩笑。这实际上取决于 - 域的定义是您要解决的业务问题!
也就是说,如果您在一家航运公司工作,那么当您为您的域建模时,您会发现您可能有“ShippingContainers”和“Ships”或“Trucks”等。您可能有“SalesReports”和“PackingManifests” ”。但是,如果你要为一家软件公司工作,那么这些域对象就没有多大意义,你将拥有一个完全不同的域模型。
找出你的领域模型的过程被称为……“领域建模”。您可以为此使用几种不同的技术,我最喜欢的技术之一是“事件风暴”(https://eventstorming.com/)。不过,基本上,TLDR 是您需要与利益相关者(需要解决问题的人)坐下来弄清楚他们使用的语言。写下名词和动词,将它们连接在一起,并弄清楚你的领域是如何工作的。做对了,它会使剩下的过程变得更容易。
然后,您需要将此域模型转换为实际代码。出于我们的目的,我们专注于“实体”和“值对象”——区别在于实体具有永久身份(例如 ID 字段),而值对象根据其……嗯……值……来改变身份。例如,“用户”将有一个 ID 字段,您可以在不更改实际用户的情况下更改用户的电子邮件。然而,ValueObject 类似于地址。如果你改变地址的值,你就有了一个新的地址!看看它是如何工作的?
你可以很简单地使用“@dataclass”在 python 中表示你的域模型,它为你设置了你的构造函数和其他一些简洁的东西。这可以为您提供一个非常简单的对象,该对象仅用于存储特定属性(例如,城市、州、zip 或名字、姓氏等)。然后您可以从您的存储库中返回这些对象,并且您将有一个一致的结构来传递您的应用程序。让您的领域模型通过 ID 相互引用并根据需要进行水合,可选择存储在缓存中,然后您就可以参加比赛了。
测试驱动开发
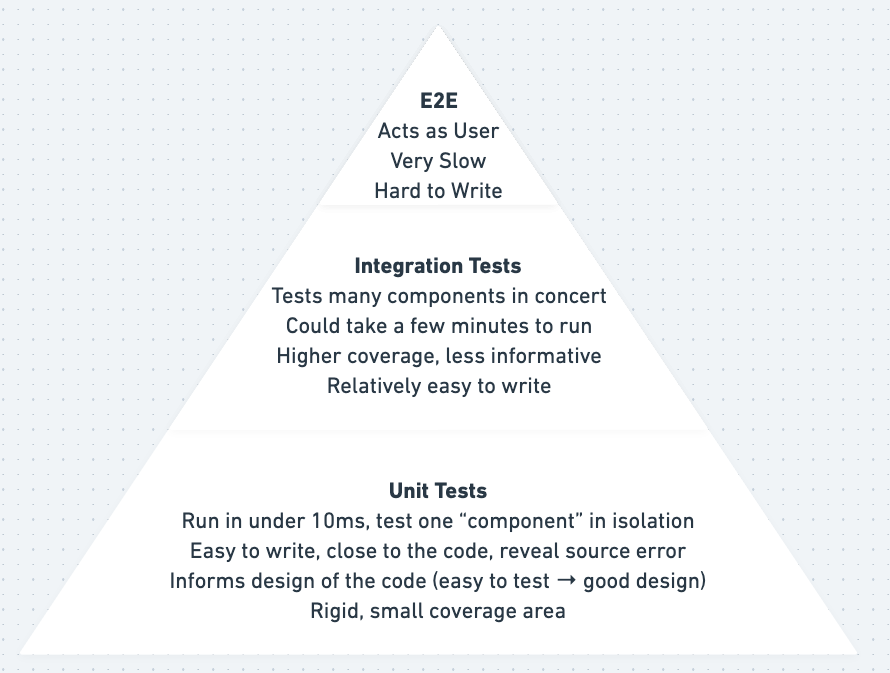
The “Testing Pyramid” with explanations
对于某些人来说,TDD 是一个有争议的话题。如果你不熟悉,TDD 的基本前提是只有三个规则:
- 除非您的测试失败,否则您不得编写任何代码。
- 你一次只能写一个测试用例,它应该开始失败。
- 一旦你有一个失败的测试,你应该只写足够的代码来使测试通过。
而已。然后你重复。人们说这个完整的循环是一个 30 秒的过程——我怀疑他们练习它的时间比我多一点。这也被称为“进攻性”测试,而不是我们都习惯的“防御性”测试——也就是说,防御性测试是在事后编写测试以“保护”自己。防御性测试可以为您提供一些保护,但要获得高覆盖率要困难得多。进攻性测试为您提供 100% 的覆盖率,并*迫使*您使用抽象等编写可测试的代码。
也就是说,TDD 不是灵丹妙药。它不是一种宗教。有(很少)TDD 不起作用的情况。 TDD 也不会阻止您编写错误或编写糟糕的代码(您仍然也可以编写糟糕的测试)。考虑到这一点,重要的是通过在可能时以“高速档”进行测试并在必要时以“低速档”进行测试,从而最大限度地提高测试的价值。
高速档与低速档测试是本书中讨论的一个概念。总而言之,“高级”是指您在服务层或使用其他高级模块编写测试(参见上面的“分层架构”)。它们往往涵盖更多代码,并且最适合添加新功能或修复简单错误。 “低档”测试是在域级别和其他低级别模块。当面临特别困难的错误或进行非常大的重构时,低档是最好的。
设计模式

A simple layout of the design patterns we talk about
有很多设计模式值得了解。其他一些书籍,如“设计模式:可重用面向对象软件的元素”涵盖了其中的几本。 Python 中的架构模式特别关注四种模式:存储库模式、服务层模式、工作单元模式和聚合模式。
存储库是围绕您的存储机制的抽象。您可以为 Redis、CSV 文件、数据库等创建一个存储库。它们都可以满足一个通用接口,如果您真的愿意,您可以将一个交换为另一个。目标是抽象出低级细节,以便您的高级模块不依赖于低级细节。这对于分层架构很重要,这也是本书广泛使用存储库模式的原因。
服务层只是您的业务逻辑的编排。当您第一次开始编写 API 端点时,倾向于将所有业务逻辑放在一个处理 API 请求的函数中。这违反了单一职责原则,因为 API 端点处理程序现在负责管理 HTTP 输入、响应以及业务逻辑的所有各个方面,如创建用户、验证输入、登录等。这些较低级别(尽管不是最低级别)任务可以委托给每个用例都有方法的服务。也就是说,该服务将具有注册用户、登录用户等的方法。这些方法将调用存储库并接收回域对象。
工作单元用于原子操作。想想“数据库事务”和“锁”,通常封装相关的操作。如果您需要“预订酒店房间”,那么您可以有一个包含此逻辑的“工作单元”。如果在查找可用房间并将房间分配给某人并处理此人的付款信息期间发生某种错误,那么工作单元将很好地为您回滚所有这些逻辑。您可以依赖低级别的数据库事务(并且您的工作单元可能在后台执行此操作),但是在您的服务函数中内联该逻辑开始混淆您的代码。使用工作单元来处理这些原子操作提供了一个干净的接口,可以利用 Python 强大的“with”语句并根据需要在您之后自动清理。
聚合是具有共同一致性边界的领域对象的集合。购物车之类的东西可以是一个聚合体——购物车内有几个领域对象,甚至购物车内可能还有其他聚合体。但是,在结账时,将购物车视为一个单元是很有用的。您可以将聚合视为对象树,并且可以通过根来引用聚合。
关于聚合的另一个注意事项是每个存储库应该有一个聚合。换句话说,您不应该拥有不是聚合的域对象的存储库。这样,聚合就形成了领域模型的“公共”API。
事件驱动架构
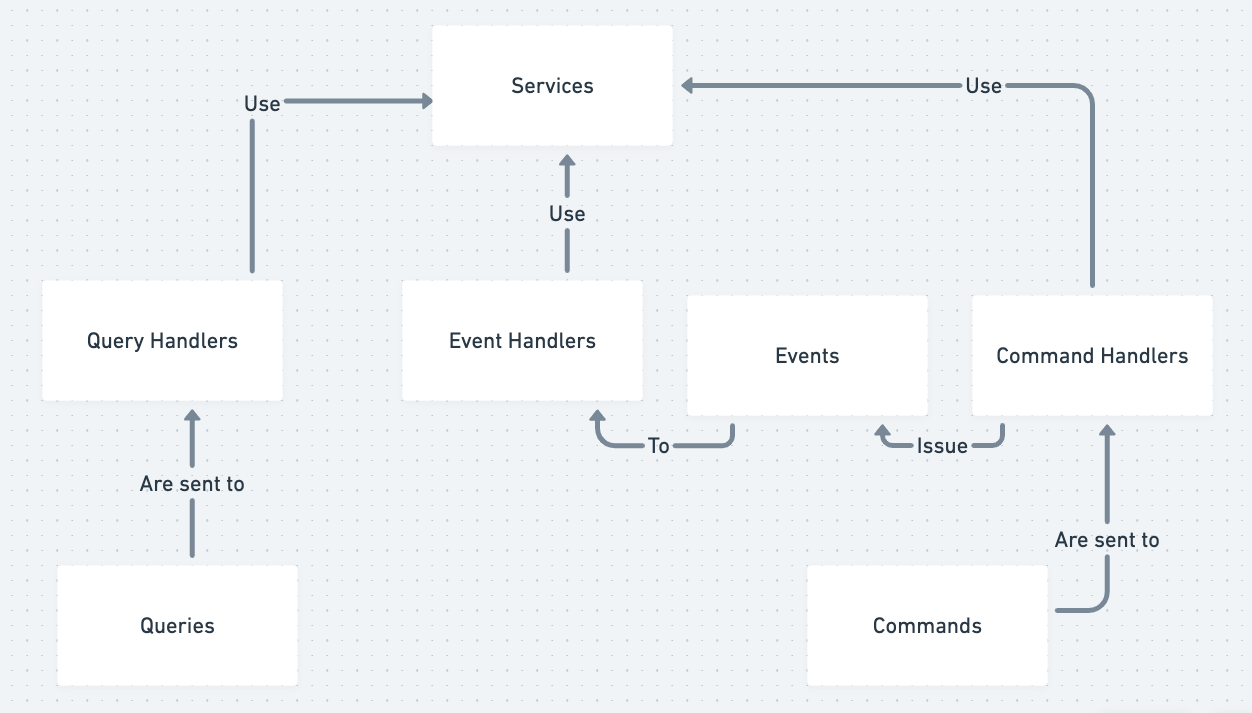
Simplified overview of Event Driven Architecture and CQRS
简而言之,EDA 就是您使用“事件”作为系统的输入。事件(或领域事件)是一个 ValueObject,您可以有内部和外部事件。内部事件永远不会离开您的系统,通常由消息总线(将事件映射到事件处理程序的简单路由器)之类的东西处理。外部事件被发送到其他系统并且非常适合“时间解耦”——您可以向消息代理发出事件,该消息代理异步管理一系列队列工作程序。
所有事件都可能失败,我们如何处理失败很重要。我们需要监控以了解事件何时失败以及哪些事件失败。我们还需要我们的事件处理程序是幂等的,所以当我们重试事件时,不会发生任何意外。常规事件可以在不影响整体操作的情况下安全地失败,这是事件和命令之间的重要区别。
命令是一种特殊类型的事件。一个常规事件可以有多个处理程序,而一个命令只有一个处理程序。一个命令,当它失败时,应该将异常重新抛出堆栈,而当一个事件失败时,应该有一些优雅的异常处理。命令通常会修改数据并触发副作用,将其与“返回数据”操作分开是 CQRS(Command/Query Responsibility Segregation)的目标。
CQRS 背后的主要动机是命令昂贵且复杂,通常需要一定程度的原子性以及即时一致性。另一方面,查询是简单的读取操作。查询通常不依赖于域(业务逻辑),而命令通常依赖于域。可以针对只读副本执行查询,其中命令通常最好针对主数据存储执行。查询还可以利用非规范化数据和最终一致性。这很好,因为查询通常比命令多几个数量级,这有助于系统更好地扩展。
应用所有这些
总而言之,重要的是逐个进行。您无需一次完成所有这些操作。如果您对尝试工作单元犹豫不决,或者您没有立即使用聚合,或者您甚至没有领域模型,那没关系!您可以从使用分层架构开始的最简单和最有效的事情之一 - 看看您是否可以使用服务将较低级别的模块与较高级别的模块解耦。看看您是否可以将您的存储逻辑隔离到您的服务使用的存储库中。如果您还可以绘制一些简单的数据类来表示您的域对象并让您的 ORM 依赖于这些,那就更好了。
如果您将依赖于自身的逻辑组合在一起,并使用抽象将模块分开,那么您将成为其中的一部分。查看接缝的位置并开始将代码拆分为可测试的块。有关这方面的一些优秀示例,请查看“有效地使用遗留代码”,这本书既是一本好书,又被“Python 中的架构模式”引用。
哦,如果您还没有阅读“Python 中的架构模式”,请特别注意结尾部分!这将为您提供更多关于我上面提到的所有内容的背景信息。我用大约 5 页总结了一本 300 多页的书,所以肯定有一些东西我遗漏了 :)
原文:https://klaviyo.tech/managing-complexity-with-architecture-patterns-in-…
- 356 次浏览
【数据科学家】无需花费一分钱即可成为数据科学家的完整路线图

今天我想分享一下我是如何在 16 岁成为一名专业的数据科学家的。我的旅程长达两年,但这篇文章并不能结束我的整个旅程。
在这篇文章中,我将分享我的旅程以及我在此过程中犯的所有错误,这样你就不会再犯那些错误了
学习基础
第 1 步:学习 Python
有人说你应该学习数据科学所需的数学。但我建议你应该先学习一门编程语言(如 Python、R)。我现在不会说为什么。不过后面会讲。
为什么选择 Python?:我建议学习 Python,因为它比 R 更广泛使用。
我使用的资源:
学习 Python — 初学者完整课程 [教程]
这是我用来学习Python的。我之所以更喜欢 Mike Dane 的教程,是因为他解释得非常清楚,而且风格惊人。
但我很快会在我的频道 DataBeast 中发布一个完整的初学者教程(即使是小孩子)
但是仅仅通过这个不会帮助你学到很多python,你应该练习它。有一个网站叫做 HackerRank。解决其中的问题。这就是你学习 Python 的全部内容
第 2 步:学习数学
您需要学习几个主题。我知道对某些人来说“数学刺痛”。但不要担心,尽可能多地学习。但它并不比我们想象的要难。主要是统计,概率,有时是线性代数和微积分。但我敢打赌这会很容易。
以下是我比较喜欢的课程:
如果您是青少年或不太了解这些主题的基础知识,我更喜欢您使用可汗学院,您可以在那里学习所有基础知识。然后我更喜欢采取:
- 概率与统计:概率与统计:到 p 还是不到 p? coursera 中的课程。我知道这门课程是付费的,但只有在您需要证书时才付费。我负担不起价格,所以我只是审核课程(您不必为此花一分钱)
- 线性代数:线性代数 - 完整的大学课程 - YouTube
- 微积分:来自 coursera 的微积分入门。这是一个了不起的课程。它几乎教会了你很多你需要的东西。那么你需要参加这门课程。
- 机器学习数学:多元微积分
我的学习建议是用 Python 编写你学到的东西(数学)。
我将很快发布我自己的教程,从基础到高等数学。
为此,请点击 Medium 以及我的 YouTube 频道 DataBeast 上的订阅按钮。启用通知铃以查看我何时发布视频
这是我犯第一个错误的地方:我没有给予太多关注。但有时它非常重要。
数据科学基础
第 3 步:用于数据科学的 Python 库
Python 有一些用于数据科学的库,称为 NumPy、Pandas 等……。我们也需要熟悉它们
用于数据科学的 Python |伟大的学习
这是我个人喜欢的教程之一。她从基础开始涵盖每一个概念
第 4 步:数据科学工具
这是我的第二个错误 我并不真正关心这些人
- SQL:SQL 教程 - 面向初学者的完整数据库课程
- MongoDB:MongoDB 初学者教程 |完整课程
第 5 步:机器学习
ML 是不需要任何介绍的东西。 ML 是数据科学中最重要的部分之一,也是研究人员中最热门的研究课题,因此每年都会在这方面取得新的进展。
这是我认为最适合机器学习的唯一课程:机器学习(Coursera,审核课程不会花费您,但不会获得证书)。这门课程很棒,并提供了扎实的基础知识。但是所有这些都是在MATLAB上学的,所以你需要在python中做
所以我更愿意再次参加这门课程:免费 10 小时机器学习课程 - freeCodeCamp
这是您需要开始练习的时期。
我建议在 Kaggle 上创建一个帐户并开始练习。
Kaggle 有很多数据集,拿走这些数据集,操作后应该洗手。通过一些机器学习来运行它
第 6 步:深度学习
事情变得有趣起来。深度学习是我在整个旅程中学到的最喜欢的东西。这绝对是辉煌的。您真正使用以前学过的数学的地方。
我强烈建议参加斯坦福的 CS230 讲座。在我看来,这让我们的手很脏。但是您需要学习如何更专业地编码。有两个流行的深度学习框架,名为 TensorFlow 和 PyTorch。我个人更喜欢学习 PyTorch,因为它更动态,而且 PyTorch 代码比 TensorFlow 更容易为更难的问题编写代码。
要学习 PyTorch,我更喜欢这门课程:PyTorch for Deep Learning — Full Course / Tutorial — YouTube
在此之后开始做 Kaggle 比赛。第一次获胜会非常困难,但如果你输掉比赛并从他们的解决方案中学习,你就能获胜。
原文:https://medium.com/@mrizin2013/a-complete-roadmap-to-become-a-data-scie…
- 118 次浏览
【编程语言】Python不是未来的编程语言
由于它在过去的十年中越来越受欢迎,人们可以想象它是一种语言,它是在这个千年的同一开始开发的。 事实并非如此:它的起源可以追溯到 1980 年代中期,当时它首次被引入。 Guus van Rossum 是 CWI(荷兰政府赞助的研究中心)的一名研究人员,同意在 1989 年 12 月推出该项目,作为一项业余爱好,他开发了一个 工作。 该项目的实施于当月开始。
它因范罗苏姆对巨蟒喜剧团的钦佩而得名,其设计的重点是使其易于使用和理解,同时不影响其特性和功能。 可供公众使用的硬件资源稀缺是其在推出时缺乏知名度的主要原因。
硬件技术的进步为产品的普及提供了必要的保障。但是,随着人工智能、数据学习、数据科学学习以及数据科学的发展,来自不同来源的大数据的大量增加,作为员工的一个新的体验,已经完全改变了数据科学。
许多工具已经出现,并且是由数据科学和机器学习科学所使用的,它们都是用Python编写的,或者是用Python之类的语言编写的,以便与thém进行交互,使thém更容易与thém一起工作。
让我们分析一下为什么Python现在很流行
Python不是一种新的编程语言,它可能被编程人员“使用”。它是一种理所当然的通用编程语言,被许多公司所使用。g、 Googlíe、Facíe book、Instagram、Spotify和Nétflix等。实际上,Instagram对Python的整合比平台的增长更重要。
为什么Python的扩展速度如此之快?
这种编程语言有一个由编程人员组成的社区,但它是一种软件,这在学习如何编程时是至关重要的,它允许您快速学习曲线。这可能是流行语言出现的部分原因。
另一方面,Rust是统计单位中薪酬最高的编程语言,平均工资超过19万美元,其次是Go,平均工资为18.5万美元,Scala的平均工资为18万美元,它最流行的编程语言经常以每年135000美元的价格进行比较,这一数字大大增加了165000美元。
你认为机器维修的rts费用为146000美元,而生锈的情况比国家的汽车要严重得多。
事实上,受欢迎并不总是与收入挂钩;例如,如果一种程序编程很受欢迎,很可能会导致véryoné的员工数量不足,从而导致salariés的专业水平不高。
来自 O'Reilly 最新的 2021 Data 和 Ai Pay Survey 的数据特别有趣,因为它揭示了程序编程是最受欢迎的,甚至根据他们的平均工资排名。
根据 Rust 编程语言开发人员的说法,一些薪酬最高的职位包括游戏引擎程序员的角色和软件工程师、后端工程师和区块链工程师的职责。
就游戏引擎程序员而言,英国的平均工资约为每年 60,000 欧元; 软件工程师在英国的平均年薪为 45,000 欧元; 后端工程师的平均年薪为 70,000 美元; 区块链工程师每年的平均收入为 55,000 欧元。
正因为如此,锈菌的数量正在快速增长。如果你想要一个光明的未来和一个新的发展,你可能会考虑除掉蟒蛇之外的锈菌,这在标记t中变得越来越重要。
结论
我们可能认为Python是一种复杂的语言,拥有一个由开发人员、文档和标准生产应用程序组成的社区。
在很大程度上,像语言这样的东西在使用中的必要开发是机器学习和数据挖掘的技术开发,其中,语言以及其他编程语言是主要的语言。
R、 另一方面,是一种高度专业化的语言,它起源于统计学。Python来自另一方面,是一种具有广泛应用范围的通用编程语言。
另一个非常重要的指标,主要基于Googl上编程流行程度的théPYPL,将Python列为第二大最流行的编程语言,其流行程度比其他五种语言高10%。
特殊情况下,当它与数据域通信时,其相似性更具灾难性。Googl拥有的统计机器学习平台,可以随时进行研究,在该平台上可以获取有关数据中rts倾斜的信息。
在这组数据中有一个非常重要的信息:对以下问题的回应:您建议新手数据科学家首先学习哪个计算机程序? 超过 63% 的响应者选择 Python 作为解决方案
原文:https://blog.devgenius.io/why-python-is-not-the-programming-language-of…
本文:
- 62 次浏览