软件开发
【软件】软件综述
视频号

微信公众号

知识星球

软件是一组用于操作计算机和执行特定任务的指令、数据或程序。它与描述计算机物理方面的硬件相反。软件是一个通用术语,用于指在设备上运行的应用程序、脚本和程序。它可以被认为是计算机的可变部分,而硬件是不变的部分。
软件的两个主要类别是应用软件和系统软件。应用程序是满足特定需求或执行任务的软件。系统软件设计用于运行计算机硬件,并为应用程序提供运行平台。
其他类型的软件包括编程软件,它提供软件开发人员所需的编程工具;中间件,位于系统软件和应用程序之间;以及操作计算机设备和外围设备的驱动程序软件。
早期的软件是为特定的计算机编写的,并与运行的硬件一起销售。20世纪80年代,软件开始在软盘上销售,后来在CD和DVD上销售。如今,大多数软件都是通过互联网购买并直接下载的。软件可以在供应商网站或应用程序服务提供商网站上找到。
软件示例和类型
在各种类型的软件中,最常见的类型包括以下几种:
- 应用软件。最常见的软件类型,应用软件是为用户或在某些情况下为另一应用程序执行特定功能的计算机软件包。应用程序可以是自包含的,也可以是为用户运行应用程序的一组程序。现代应用程序的例子包括办公套件、图形软件、数据库和数据库管理程序、网络浏览器、文字处理器、软件开发工具、图像编辑器和通信平台。
- 系统软件。这些软件程序设计用于运行计算机的应用程序和硬件。系统软件协调硬件和软件的活动和功能。此外,它控制计算机硬件的操作,并为所有其他类型的软件提供工作环境或平台。操作系统是系统软件的最佳示例;它管理所有其他计算机程序。系统软件的其他示例包括固件、计算机语言翻译器和系统实用程序。
- 驱动程序软件。这种软件也被称为设备驱动程序,通常被认为是一种系统软件。设备驱动程序控制连接到计算机的设备和外围设备,使它们能够执行特定任务。每个连接到计算机的设备都需要至少一个设备驱动程序才能正常工作。示例包括任何非标准硬件附带的软件,包括特殊的游戏控制器,以及启用标准硬件的软件,如USB存储设备、键盘、耳机和打印机。
- 中间件。术语中间件描述了在应用程序和系统软件之间或两种不同类型的应用程序软件之间进行中介的软件。例如,中间件使Microsoft Windows能够与Excel和Word进行通信。它还用于将远程工作请求从具有一种操作系统的计算机中的应用程序发送到具有不同操作系统的应用程序。它还使较新的应用程序能够与旧的应用程序协同工作。
- 编程软件。计算机程序员使用编程软件编写代码。编程软件和编程工具使开发人员能够开发、编写、测试和调试其他软件程序。编程软件的例子包括汇编程序、编译器、调试器和解释器。

软件是如何工作的?
所有软件都提供了计算机工作所需的方向和数据,并满足了用户的需求。然而,这两种不同的类型——应用软件和系统软件——以截然不同的方式工作。
应用软件
应用软件由许多程序组成,这些程序为最终用户执行特定功能,例如编写报告和浏览网站。应用程序还可以为其他应用程序执行任务。计算机上的应用程序不能单独运行;它们需要计算机的操作系统以及其他支持系统的软件程序才能工作。
这些桌面应用程序安装在用户的计算机上,并使用计算机内存执行任务。它们占用了电脑硬盘上的空间,不需要互联网连接即可工作。但是,桌面应用程序必须遵守其运行的硬件设备的要求。
另一方面,网络应用程序只需要访问互联网即可工作;它们不依赖于硬件和系统软件来运行。因此,用户可以从具有网络浏览器的设备启动网络应用程序。由于负责应用程序功能的组件在服务器上,用户可以从Windows、Mac、Linux或任何其他操作系统启动应用程序。
系统软件
系统软件位于计算机硬件和应用软件之间。用户不直接与系统软件交互,因为系统软件在后台运行,处理计算机的基本功能。该软件协调系统的硬件和软件,以便用户可以运行高级应用软件来执行特定操作。系统软件在计算机系统启动时执行,并在系统打开时继续运行。

设计和实施
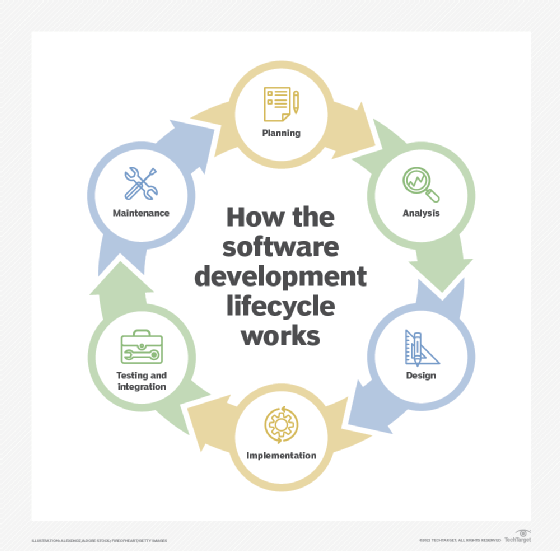
软件开发生命周期是项目经理用来描述与设计软件相关的阶段和任务的框架。设计生命周期中的第一步是规划工作,然后分析将使用软件的个人的需求,并创建详细的需求。在最初的需求分析之后,设计阶段旨在指定如何满足这些用户需求。
下一步是实现,完成开发工作,然后进行软件测试。维护阶段包括保持系统运行所需的任何任务。
软件设计包括对将要实现的软件结构、数据模型、系统组件之间的接口以及软件工程师可能使用的算法的描述。
软件设计过程将用户需求转换为计算机程序员可以用来进行软件编码和实现的形式。软件工程师迭代地开发软件设计,在开发过程中添加细节并更正设计。
不同类型的软件设计包括以下内容:
- 架构设计。这是基础设计,它使用建筑设计工具确定了系统的整体结构、主要组件及其相互关系。
- 高级设计。这是设计的第二层,重点是如何以软件堆栈支持的模块形式实现系统及其所有组件。高级设计描述了数据流与系统的各种模块和功能之间的关系。
- 详细设计。第三层设计的重点是指定体系结构所需的所有实现细节。
如何保持软件质量
软件质量衡量软件是否同时满足其功能和非功能需求。
- 功能需求确定了软件应该做什么。它们包括技术细节、数据操作和处理、计算或任何其他指定应用程序目标的特定功能。
- 非功能需求——也称为质量属性——决定了系统应该如何工作。非功能需求包括可移植性、灾难恢复、安全性、隐私和可用性。
- 软件测试检测并解决软件源代码中的技术问题,并评估产品的整体可用性、性能、安全性和兼容性,以确保其满足要求。
软件质量的维度包括以下特征:
- 无障碍。不同人群,包括需要语音识别和屏幕放大镜等自适应技术的个人,能够舒适地使用该软件的程度。
- 兼容性。软件适用于各种环境,例如不同操作系统、设备和浏览器。
- 效率。软件在不浪费精力、资源、精力、时间或金钱的情况下运行良好的能力。
- 功能。软件执行其指定功能的能力。
- 可安装性。软件在指定环境中安装的能力。
- 本地化。软件可以使用的各种语言、时区和其他此类功能。
- 可维护性。修改软件以添加和改进功能、修复错误等的容易程度。
- 性能。软件在特定负载下的执行速度。
- 便携性。软件易于从一个位置转移到另一个位置的能力。
- 可靠性。软件在特定条件下在规定的时间段内执行所需功能而没有任何错误的能力。
- 可扩展性。衡量软件响应处理需求变化而提高或降低性能的能力。
- 安全。该软件能够防止未经授权的访问、侵犯隐私、盗窃、数据丢失、恶意软件等。
- 可测试性。测试软件是多么容易。
- 可用性。使用这个软件是多么容易。
为了在部署后保持软件质量,开发人员必须不断地对其进行调整,以满足新的客户需求并处理客户发现的问题。这包括改进功能、修复错误和调整软件代码以防止出现问题。一个产品在市场上能持续多久取决于开发人员满足这些维护要求的能力。
在执行维护时,开发人员可以进行四种类型的更改,包括:
- 纠正。用户经常发现并报告开发人员必须修复的错误,包括编码错误和其他使软件无法满足其要求的问题。
- 自适应。开发人员必须定期对其软件进行更改,以确保其与不断变化的硬件和软件环境兼容,例如当新版本的操作系统问世时。
- 完美。这些是改进系统功能的更改,例如改进用户界面或调整软件代码以提高性能。
- 预防性的。这些更改是为了防止软件出现故障,并包括重组和优化代码等任务。
现代软件开发
DevOps是一种将软件开发和IT运营团队聚集在一起的组织方法。它促进了这两个群体之间的沟通与合作。该术语还描述了使用自动化和可编程基础设施的迭代软件开发实践的使用。在我们的DevOps终极指南中了解全貌。
软件许可和专利
软件许可证是一种具有法律约束力的文件,限制软件的使用和分发。
通常,软件许可证在不侵犯版权的情况下为用户提供一个或多个软件副本的权利。许可证概述了协议各方的责任,并可能对软件的使用方式进行限制。
软件许可条款和条件通常包括软件的合理使用、责任限制、保证、免责声明和保护,如果软件或其使用侵犯了他人的知识产权。
许可证通常用于专有软件,该软件仍然是创建该软件的组织、团体或个人的财产;或者免费软件,用户可以运行、研究、更改和分发软件。开放源代码是一种协作开发的软件,其源代码是免费提供的。有了开源软件许可证,用户可以运行、复制、共享和更改类似于免费软件的软件。
在过去的二十年里,软件供应商已经从一次性销售软件许可证转向了软件即服务订阅模式。软件供应商将软件托管在云中,并向客户提供,客户支付订阅费并通过互联网访问软件。
尽管版权可以阻止其他人复制开发人员的代码,但版权不能阻止他们在不复制的情况下独立开发相同的软件。另一方面,专利使开发人员能够阻止另一个人使用开发人员在专利中声称的软件的功能方面,即使该另一个人独立开发了该软件。
一般来说,技术含量越高的软件,获得专利的可能性就越大。例如,如果一个软件产品创建了一种新的数据库结构或增强了计算机的整体性能和功能,它就可以获得专利。
软件历史
“软件”一词直到20世纪50年代末才被使用。在此期间,尽管正在创建不同类型的编程软件,但它们通常无法商业化。因此,用户——大多数是科学家和大型企业——往往不得不编写自己的软件。
以下是软件历史的简要时间表:
- 1948年6月21日。计算机科学家Tom Kilburn在英国曼彻斯特大学为曼彻斯特婴儿电脑编写了世界上第一个软件。
- 20世纪50年代初。通用汽车公司为IBM 701电子数据处理机创造了第一个操作系统。它被称为通用汽车操作系统。
- 1958年,统计学家John Tukey在一篇关于计算机编程的文章中创造了软件一词。
- 20世纪60年代末。软盘在20世纪80年代和90年代被引入并用于分发软件。
- 1971年11月3日。AT&T发布了Unix操作系统的第一版。
- 1977年,苹果公司发布了Apple II,消费者软件开始腾飞。
- 1979年,VisiCorp为Apple II发布了VisiCalc,这是第一款用于个人电脑的电子表格软件。
- 1981年,微软发布了MS-DOS操作系统,许多早期的IBM计算机都在该操作系统上运行。IBM开始销售软件,普通消费者可以使用商业软件。
- 20世纪80年代。硬盘成为个人电脑的标准配置,制造商开始将软件捆绑在电脑中。
- 1983年,Richard Stallman的GNU(GNU不是Unix)Linux项目发起了自由软件运动,旨在创建一个类似Unix的操作系统,其源代码可以自由复制、修改和分发。
- 1984年,Mac操作系统发布,运行苹果的Macintosh系列。
- 1980年代中期。发布了包括AutoDesk AutoCAD、Microsoft Word和Microsoft Excel在内的关键软件应用程序。
- 1985.Microsoft Windows 1.0发布。
- 1989年,CD-ROM成为标准,它比软盘能容纳更多的数据。大型软件程序可以快速、轻松且相对便宜地分发。
- 1991年,作为开源Linux操作系统基础的Linux内核发布。
- 1997年,DVD被引入,并且能够比CD容纳更多的数据,这使得将捆绑的程序(如Microsoft Office Suite)放在一个磁盘上成为可能。
- 1999年。Salesforce.com使用云计算开创了互联网上的软件交付。
- 2000年,软件即服务(SaaS)一词开始流行起来。
- 2007年,IPhone推出,移动应用程序开始站稳脚跟。
- 2010年至今。随着用户从互联网和云端购买和下载软件,DVD正变得过时。供应商转向基于订阅的模式,SaaS已经变得很普遍。
- 254 次浏览
【软件开发】软件估计的不确定性锥介绍
视频号
微信公众号
知识星球
目录
- 软件估计的不确定性锥介绍
- 缩小不确定性的范围
- 不确定性锥与承诺之间的关系
- 不确定性锥与迭代发展
- 相关资源
不确定性锥简介
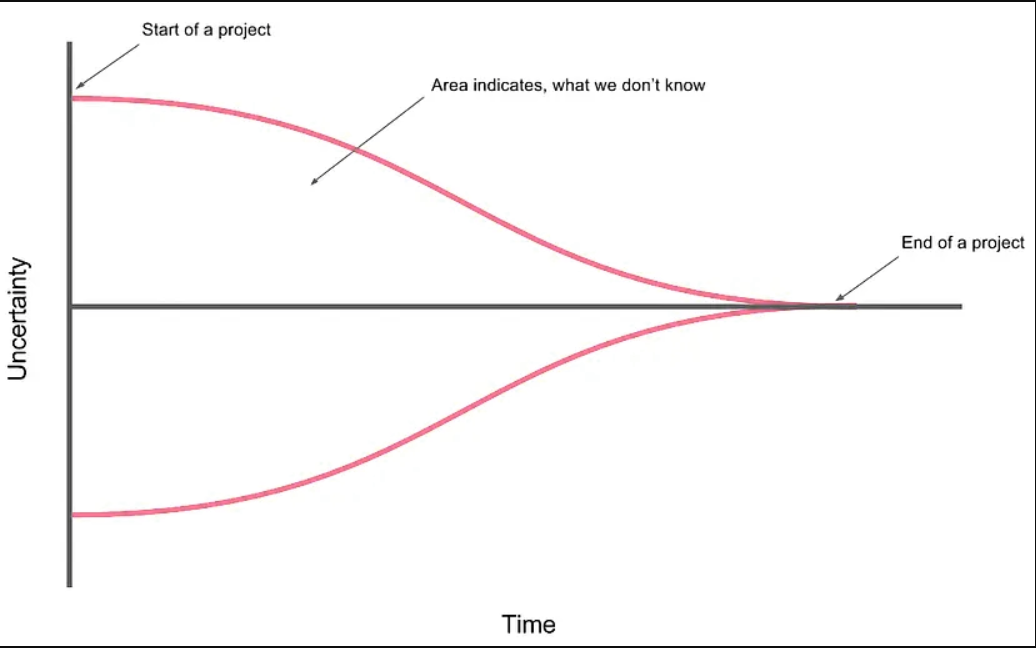
在项目的早期,要构建的软件的性质的具体细节、具体需求的细节、解决方案的细节、项目计划、人员配置和其他项目变量都不清楚。这些因素的可变性导致了项目估计的可变性——对可变现象的准确估计必须包括现象本身的可变性。随着对这些可变性来源的进一步调查和确定,项目中的可变性会减少,因此项目估算中的可变性也会减少。这种现象被称为“不确定性锥”,如下图所示。如图所示,在项目总日历时间的前20-30%期间,不确定性锥显著缩小。
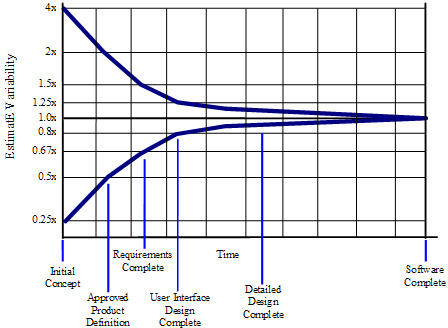
Figure 1 The Cone of Uncertainty?
横轴包含常见的项目里程碑,如初始概念、批准的产品定义、需求完成等。由于其起源,这个术语听起来有点面向产品。“产品定义”只是指商定的软件愿景或“软件概念”,同样适用于web服务、内部业务系统和大多数其他类型的软件项目。
纵轴包含在项目中各个点由熟练的估算人员创建的估算中发现的误差程度。估计可以是特定功能集的成本和交付该功能集所需的工作量,也可以是特定工作量或时间表可以交付多少功能。本书使用通用术语“范围”来指代项目的工作量、成本、功能或某些组合。
从图1中可以看出,在项目早期创建的估计值有很大的误差。在初始概念时间创建的估计可能不准确,高侧为4倍,低侧为4×(也表示为0.25x,仅为1除以4)。从高估计值到低估计值的总范围是4倍除以0.25倍,即16倍。
缩小不确定性的范围
经理和客户会问的一个问题是,“如果我再给你一周的时间来做你的估计,你能完善它吗?”这是一个合理的要求,但不幸的是,不可能满足这个要求。研究发现,软件估计的准确性取决于软件定义的细化程度。定义越精细,估计就越准确。估计包含可变性的原因是软件项目本身包含可变性。减少估算可变性的唯一方法是减少项目本身的可变性。
一个重要但困难的概念是,不确定性锥代表了在项目中不同点的软件估计中可能具有的最佳情况准确性。Cone表示由熟练的估算者产生的估算误差。做得更糟很容易。再准确不过了;只有更幸运的可能。
Cone代表最佳情况估计的另一种方式是,如果项目没有得到很好的控制,或者如果评估人员不是很熟练,估计可能无法改善,如Cone所示。图2显示了当项目没有以减少可变性的方式进行时会发生什么——不确定性不是Cone,而是持续到项目结束的Cloud。问题并不是估计值不一致;问题是项目本身没有收敛,也就是说,它没有排除足够的可变性来支持更准确的估计。
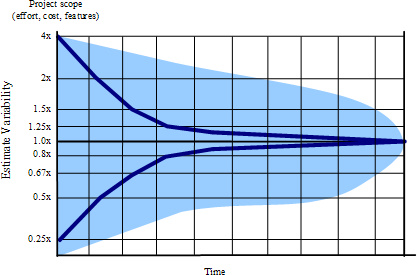
Figure 2 The Cloud of Uncertainty
只有当您做出消除可变性的决策时,“圆锥体”才会变窄。如图3所示,定义产品愿景(包括承诺你不会做的事情)可以减少可变性。定义需求——再次包括您不打算做的事情——进一步消除了可变性。设计用户界面有助于降低因误解需求而产生的可变性风险。当然,如果产品没有真正定义,或者产品定义后来被重新定义,那么Cone会变得更宽,估计精度会更差。
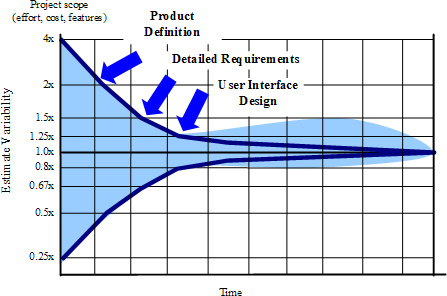
Figure 3 Forcing the Cone of Uncertainty to Narrow
不确定性锥与承诺之间的关系
软件组织在不确定性锥中过早地做出承诺,无意中破坏了他们自己的项目。如果一个组织在初始概念或产品定义时做出承诺,其估计误差为2到4倍。在项目中过早做出的承诺会破坏可预测性,增加风险,增加项目效率低下,并削弱项目管理的能力。
在锥体早期广泛的地区不可能作出有意义的承诺。有效的组织推迟其承诺,直到他们完成了迫使锥缩小的工作。在项目的早期和中期(约占项目的30%)做出有意义的承诺是可能的,也是适当的。
不确定性锥与迭代发展
不确定性锥在迭代项目中的应用比在顺序项目中更为复杂。
如果您正在处理一个项目,该项目在每次迭代中都有一个完整的开发周期——也就是说,从需求定义到发布——那么您将在每次迭代上经历一个小型Cone。在你为迭代做需求工作之前,你将在Cone的“批准的产品定义”部分,从高到低的估计值有4倍的可变性。通过短迭代(不到一个月),您可以在几天内从“批准的产品定义”转变为“需求完成”和“用户界面设计完成”,将可变性从4倍减少到1.6倍。如果您的时间表是固定的,1.6倍的可变性将适用于您可以在可用时间内交付的特定功能,而不是工作或时间表。
对于在每次迭代开始之前都没有定义需求的方法,您放弃的是对成本、进度和功能组合的长期可预测性,您将在未来交付几次迭代。你的企业可能会高度重视这种灵活性,也可能更喜欢你的项目提供更多的可预测性。
许多开发团队都选择了中间立场,其中大多数需求都是在项目的前端定义的,但设计、构建、测试和发布都是在短时间内完成的。换句话说,项目依次通过用户界面设计完成里程碑(大约占项目日历时间的30%),然后从那时起转向更迭代的方法。这将Cone产生的可变性降低到约±25%,这允许足够好的项目控制来实现目标,同时仍然利用迭代开发的主要好处。项目团队可以在项目结束时为尚未确定的需求留出一些计划时间。这引入了一点与功能集相关的可变性,在这种情况下,这是正可变性,因为只有当您确定要实现的理想功能时,您才会使用它。这种中间立场支持成本和进度的长期可预测性,以及适度的需求灵活性。
- 83 次浏览
开发管理
- 219 次浏览
【数据库迁移】Capital One 使用Flyway进行数据库迁移

作为Capital One的软件工程师,我为我们的商业银行开发了新的应用程序。我和我的团队最近以银行关系经理和分析师的网络应用程序的形式构建了一个数据管理工具。该团队包括两名软件工程师,四名数据分析师和科学家,以及一名产品经理。我们在原型设计的前五个月中进行了交叉协作,以定义满足用户分析需求的数据库模式。
在此期间,我的技术主管和我决定探索模式迁移工具,以便在我们设计数据库时简化开发。我们为数据库确定的是Flyway。 Flyway是一个开源数据库迁移工具,使开发人员能够将版本控制实践应用于他们的数据库。虽然我们查看了其他几个架构迁移工具,但这个工具似乎最适合我们的特定用例。
为什么我们需要架构迁移工具?
架构迁移和工具的好处
随着敏捷方法的发展并在21世纪初被广泛采用,对模式迁移工具的需求变得更大。允许数据库设计随着应用程序的发展而发展的技术允许工程师更有效地迭代软件。
在此期间,数据库迁移工具越来越受欢迎。架构迁移为数据库添加版本控制功能。迁移是逐步管理的,并且是可逆的。 Flyway等工具可以在处理多个环境(例如dev,test和prod)或切换分支时阻止数据库模式不匹配。它们允许开发人员从头开始重新创建数据库,这在创建新环境时很有用。迁移工具可确保应用程序将以数据库的当前状态运行。例如,这可以防止开发人员遇到列未找到错误。
Flyway概述
Flyway对数据库所做的更改称为迁移。在Flyway中,迁移有两种类型;它们可以是版本化的也可以是可重复的,版本化是最常见的。
版本化迁移具有版本,描述和校验和,并且按顺序应用一次。可重复迁移具有描述和校验和,并在每次校验和更改时重新应用。当需要更改数据库的模式时,开发人员会添加SQL脚本,通常位于db / migrations目录中。
将Flyway指向数据库后,它开始扫描应用程序的文件系统以进行迁移。它第一次运行第一次迁移时,会创建一个名为schema_version的表,其中包含多个列,包括版本,描述,脚本和校验和。该表用于跟踪数据库的状态。迁移根据其版本号进行排序并按顺序执行。
应用每个迁移后,schema_version表会相应更新。每次Flyway扫描应用程序的文件系统进行迁移时,它都会查询schema_version表以查看数据库所处的版本,并相应地升级数据库。
可用但未应用的迁移称为挂起迁移。
我们的用例的优点
使用迁移工具的最大优点是,它确保始终使用数据库的匹配状态提供软件版本。这对我们的产品尤其重要,因为我们快速迭代并且需要能够快速,自信地部署功能以收集用户反馈。
将Flyway集成到现有项目中很简单,因为设置所需的配置很少。该过程中的最小步骤包括通过在配置文件conf / flyway.conf中指定url,username和password将工具指向数据库。
Flyway严格的迁移规则强制执行纪律,因此也是最佳实践。这可以类似于禁用git中的force push。严格的规则Flyway强制执行与在部署到环境后保持SQL文件不可变的做法一致。由于我们的团队致力于遵循最佳软件工程实践,因此Flyway适合我们的产品。
作为对数据库迁移工具缺乏经验的人,Flyway易于学习且易于使用。以增量方式捕获所有架构迁移。 API公开了六种基本方法 - 迁移,清理,信息,验证,基线和修复。 (您可以在此处了解有关这些命令的更多信息)。这些方法使我们的团队能够将Flyway集成到我们的CircleCI部署命令中。
最后,Flyway既灵活又强大 - 它只需几个简单的命令即可修改列名,并将数据从一列传输到另一列。
我们的用例的缺点
如前所述,Flyway在迁移文件更改方面非常严格。在签入之后更改迁移并不容易。更改文件的内容或名称可能会导致每台具有该文件先前版本的计算机上的迁移失败。
即使需要进行简单的更改(例如调整字段名称),通常也需要新的迁移脚本。作为我的技术主管和我快速迭代,我们发现自己每周都会添加Flyway Scripts。这导致我们的迁移文件夹中存在过多的文件。在我们的原型设计的前五个月中,我们的应用程序仅部署到开发环境中,几乎不需要在我们的应用程序中逐步保留微小的模式更改。
值得一提的是,可以编辑以前执行的迁移,但只有高级用户才能这样做,因为它需要更新schema_version表中的行以调整校验和值。
当团队成员在不同分支上并行工作时,版本号可能会发生冲突。有一些过程可以解决此问题,例如使用版本号的时间戳而不是整数,并设置选项outOfOfOrder = true。
撤消迁移(例如删除先前迁移中添加的列)可能会非常棘手,并且通常需要开发人员创建数据备份。
我们应用的结果
事后看来,如果我们稍后在应用程序和数据库设计成熟时将其集成,我的团队可以更好地利用Flyway。为了在原型设计的第一阶段实现快速迭代,我认为我们的双人工程团队只需要一个定义初始模式的SQL文件,一个模拟数据文件和一个用于加载我们的表的脚本就足够了。模拟数据集。
使用这种方法,我们可以通过修改git分支中的初始模式和模拟数据文件来更改模式。在每次合并以构建或部署到环境之后,通过CircleCI启动的步骤,数据库将使用模式和模拟数据集进行转储,拆除,重新创建和重新加载。我认为Flyway可以最好地应用于存在多个环境的应用程序中,并且围绕数据库更改的决策的波动性较小。
Flyway是一种有价值的工具,许多优点都超过了它们的缺点。在我们的产品开发过程中,它确保我们的应用程序始终以数据库的匹配状态运行。从我们的主分支中提取更改时,遇到数据库不匹配错误的风险几乎为零。我们的迁移文件夹也是历史记录;我们的团队能够跟踪我们的数据库设计随时间的变化。
作为我的技术主管,我与我们团队的数据科学家合作,提供数据库状态的透明度是关键。在我们的CICD平台的帮助下,每次迁移的部署导致我们几乎没有停机时间。
Flyway是我使用迁移工具的第一次经历,它被证明可以有效地管理数据库的状态。如果在正确的阶段集成到应用程序中,它有可能更加强大。
原文 : https://medium.com/capital-one-tech/database-migrations-with-flyway-16b6478e55a6
- 99 次浏览
【数据库迁移】在大型项目中使用Flyway进行数据库迁移

在过去的四年中,我们一直在使用Flyway在大型客户端项目中迁移我们的数据库。该项目涉及多个站点的100多人。随着时间的推移,应用程序和数据迅速增长。因此,数据库必须发展以应对应用程序的更改。我们在临时环境中迁移数据库时遇到了一些挑战。在这篇博文中,我想分享我们如何使用Flyway迁移数据库。
使用Flyway进行数据库迁移
以代码开发迁移脚本
作为启动,我们在一组JPA实体中定义域模型。我们还使用JPA注释来约束不可为空的数据类型max。然后我们使用JPA mapping-tool生成与JPA实体对应的DDL,并使用DDL设置初始数据库。这组DDL与源代码一起被检入Git存储库。当开发人员对数据库进行更改时,他必须再次生成DDL,然后创建对数据库的更改集。他可以看到Git中当前DDL与之前DDL之间差异的变化。根据差异,开发人员为数据库迁移创建了一些脚本。脚本还迁移数据库模式和现有数据。
我们在scrum中开发并在sprint结束时提供发布包(我将其命名为增量)。下图说明了不同增量的脚本。

Database migration scripts in different versions
当sprint结束时,我们的jenkins发布版本将Flyway脚本打包到新版本包中。 通常,脚本放在我们讨论过并与DevOps达成一致的目录中。 DevOps将Flyway配置为在预定义目录中扫描。 在部署新应用程序之前,他们运行Flyway来执行找到的脚本。 通过这种方式,数据库迁移以受控方式工作。
我们使用Flyway迁移数据库的工作流程
我们有一个经典的分期流程来促进我们增加到PROD(生产)阶段。 下图是从DEV到PROD的开发过程的简化版本。 如图所示,我们有三个阶段,DEV,TEST和PROD。

The promotion of increment from Local to PROD
在sprint结束时,我们将新增量提供给最低测试环境(DEV)。 DevOps接收传递并在DEV上部署增量以进行测试。 如果测试并批准了此增量,那么他们会将其部署到TEST。 我们不会等待外出增量的测试结果,而是继续开发新版本,然后在下一个sprint中提供它。 如果在暂存环境中通过测试找到问题,我们将在同一个git分支中修复它。 根据修复,我们构建一个新的增量,并将其作为修补程序提供给同一个阶段。
使用Flyway架构历史诊断数据库
完成Flyway迁移后,我们可以在架构历史记录表中看到更改历史记录。 模式历史记录记录执行的Flyway脚本的所有重要信息。 下图显示了环境DEV,TEST和PROD的简化模式历史记录。

Flyway Schema History
当您获得一个损坏的数据库并且您应该修复它时,架构历史记录中的信息可能非常有用。由于我们使用Flyway自动化数据库迁移,因此我们可以轻松找出数据库发生的情况和时间,然后快速识别不规则性。有时,如果在环境中部署了先前的修补程序,则可能会很棘手,因为架构历史记录包含额外的修补程序脚本。在下一节中,我将解释修补程序迁移的处理方法。
Flyway的修补程序
我们不时会在某个临时环境中发现问题。如上所述,我们通过修补程序修复问题。我们遇到了修补程序开发中的一些挑战。例如,一个挑战是以正确的时间顺序保持每个阶段环境的数据库模式历史。
通常,我们开始在最高阶段修复问题,然后尝试将数据库更改填充到其他分段环境。我们使用一些技术转换脚本以避免重复执行的副作用。
首先修复问题环境
通常,如果舞台环境中出现问题,我们会在同一个git分支上解决该问题,然后将修补程序提供给该环境。这对我们来说是最简单,最省时的方式。
假设我们在版本7的PROD上检测到数据库相关问题,那么我们使用包含一些脚本的修补程序v7.1来处理它。当版本8的应用程序增量到达PROD时,Flyway可以识别出v8中的脚本版本高于PROD上的版本7.1并且在v7.1之上执行v8的脚本。对于Flyway来说,脚本版本应该始终是升序而不是降序。

Hotfix v7.1 is deployed on PROD
将Flyway脚本从修补程序合并回主流
在部署了修补程序v7.1之后,我们在PROD上完成了数据库更改,这在DEV和TEST上是不存在的。 我们如何使DEV和TEST DB与PROD保持一致? 简短的回答是将v7.1中的脚本合并回主流。

Merge Flyway scripts from hotfix back to main stream
上图显示了从修补程序v7.1到主流(v10)的合并。乍一看似乎很简单,因为我们可以挑选修补程序提交并将脚本移动到主流中。实际上,简单的复制粘贴不起作用,因为Flyway只在最高版本之上执行脚本。我们可以回想一下,TEST中数据库模式历史记录中的最高版本是版本8和DEV版本9.Mayway会注意到v7.1脚本的版本低于v8或v9,因此在DEV和TEST上都忽略它们。同样,Flyway的默认行为是按升序执行脚本。
现在让我解释一下我们如何合并脚本。
- 首先,我们将修补程序中的脚本合并到具有更高版本号的开发分支
- 其次,我们重写脚本,使它们可重新运行并具有幂等性。具体来说,合并的脚本能够发现是否在数据库上完成了相同的操作,然后相应地跳过它们自己。当新的增量随后部署在PROD上时,这些“新”脚本将自行跳过,因为之前已经部署了修补程序。
零停机时间使用Flyway迁移数据库
由于我们的应用程序是24×7在线,因此不允许在生产环境中停机。这意味着当我们迁移数据库时,应用程序必须保持活动状态。
蓝绿色部署零停机时间
我们遵循的策略是所谓的蓝绿色部署。也就是说我们在每个阶段同时维护2台服务器。下图描述了蓝绿部署的工作原理。如图所示,两台服务器共享一个数据库。

Blue green deployment before and after
在部署之前,路由器将请求重新路由到具有较新版本的蓝色服务器,而具有旧版本的绿色服务器则作为备份。当新版本发布并交付到此阶段时,我们将新版本部署到绿色服务器。我们通常在部署之前迁移数据库。
在数据库上迁移并且绿色服务器上的部署完成后,我们将请求重新路由到绿色服务器。然后,此服务器开始主动提供请求,我们现在将其称为活动服务器。下次将另一个新版本发送到此阶段时,它将部署到蓝色服务器。我们一遍又一遍地重复相同的过程。
两阶段数据库迁移,以支持蓝色和绿色服务器
由于我们让蓝色和绿色服务器共享数据库,因此该数据库必须在每次迁移后支持两个服务器。这样,如果新部署的版本无效,我们可以切换回旧版本的服务器。我们对此用例应用了所谓的两阶段迁移技术。例如,假设我们要从表USER中删除列PHONE。下图说明了我们的工作:
在第一阶段,我们删除了应用程序v6中对列的引用。没有架构更改。由v6插入的记录不包含colum PHONE的值。如果我们需要切换回v5,我们会创建一个触发器,它会使PHONE列填充一些值。因此,带有v5的服务器仍然可以使用新插入的数据。
在第二阶段,我们从表USER中删除列PHONE。数据库架构更改。但它完全没问题,因为两个服务器(v7和v8)都没有列的引用。

2 phase database migration
具有零停机时间要求的迁移结果
- 蓝色和绿色服务器在每个阶段共享一个数据库,而此数据库随时支持两个服务器。
- 我们总是有一台主动服务请求的服务器,另一台服务器待命。
- 如果新应用程序失败,我们可以将被动服务器重新联机。但我们不撤消数据库迁移。
环境特定数据库迁移
通常,我们使用相同的迁移脚本在每个环境中设置数据库。有时,这将无法正常工作,而数据库表的某些配置因环境而异。例如,我们在表CUSTOMER中有一个LOCALE列用于语言首选项。然后我们使用该列的默认值“EN”编写初始迁移脚本,这对于西方国家的环境是正确的。但对于欧洲以外的环境来说并非总是如此。在中国等非英语国家的环境中,该列的默认值应为“CN”。困境在于设计脚本以便在环境与环境之间以不同的方式工作将是一种过度的做法。
幸运的是,Flyway可以选择这种情况。我们将原始脚本复制到不同的目录中并根据目标位置进行调整,然后在中国环境中配置Flyway以在此目录中扫描脚本。这样,该目录中的迁移脚本可以根据环境正确设置LOCALE列。
此环境特定目录的解决方案使Flyway能够解析数据库模式中的本地依赖关系。但是,这种方法应该谨慎使用,因为它可能导致不同环境中的不同模式历史记录,并且模式历史记录的差异将使数据库分析变得复杂。
使用Flyway迁移大表
生产数据库中的一些表包含数千万条记录。那些大表使迁移比我们预期的更复杂。简而言之,迁移大型表需要更长的时间。由于每个Flyway脚本都在事务中运行,因此我们需要更大的磁盘空间来启用回滚。当我们迁移大型表时,阻止了其他访问(从应用程序)到大型表。在最坏的情况下,访问在迁移完成之前达到超时并失败。
迁移大表的数据
在实践中,我们将在迁移数据之前分析大表。我们总是在真实PROD数据库的副本上组织测试运行,以查看迁移需要多长时间。如果迁移到一个大型表是一个长时间运行的过程,比如超过30秒,我们只需将该脚本从Flyway中取出,进行优化并手动执行。此外,我们必须应用分而治之的原则。那就是将数据分成适当的部分,然后在提交中迁移每个部分。我们将阈值定义为30秒,因为应用程序事务在30秒后超时。
迁移大表的模式
触摸大桌子有点可怕,因为你害怕受到伤害。但是,我们必须更改架构,否则它无法支持应用程序更改。如果更改是数据库上的REORG挂起操作,那么我们必须对该表执行REORG。没有DBA会在PROD数据库的大表上批准这样的REORG,因为它将完全阻止对表的访问很长时间,这违反了零停机时间策略。
目前,我们正在实践一个概念来解决这个问题。我们所做的是将大表重命名为USER to USER_OLD,然后立即创建一个具有相同名称和我们想要的正确模式的新空表USER。之后,我们将旧数据从表USER_OLD递增传输到新表USER。诀窍是我们必须在单个事务中进行重命名和创建。这样就可以优雅地完成模式迁移,应用程序甚至不会注意到表已经更改。
总结
Flyway帮助我们以可控的方式管理所有临时环境中的复杂数据库迁移。我们开发迁移脚本并将其包含在交付包中。然后,DevOps负责暂存环境中的其余部分。虽然我们仍然需要与DBA密切合作,但开发人员不再需要负担数据库迁移的负担。如果出现数据库问题,则Flyway架构历史记录是检查数据库状态的便捷工具。
除了与Flyway的例行数据库迁移之外,由于我们项目中的挑战,以下几点是调整。
- 合并的修补程序脚本必须是幂等的,同时将修补程序合并回主流。
- 我们应用蓝绿部署和两阶段数据库迁移,以便应用程序具有零停机时间。
- 分别迁移大表
原文:https://www.novatec-gmbh.de/en/blog/database-migration-flyway-large-project/
本文:http://jiagoushi.pro/database-migration-flyway-large-project
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 380 次浏览
【管理】在非技术角色中提升性能思维
性能测试和工程通常被认为是纯粹的技术问题。然而,根据我们在许多不同行业和组织中的经验,关键非技术角色的人员可以对最终产品的性能和交付团队的理智产生最大的影响。
转移性能(进一步)
许多系统质量问题(包括性能)可以追溯到交付项目生命周期早期的重大决策。这种理解正在推动整个行业的左转趋势 - 在生命周期的早期推动质量活动。
不幸的是,Performance Engineering中的左移通常会停止在开发人员身上。开发团队与测试人员和运营团队密切合作,尽早调整和缓解性能问题。但我们需要更进一步 - 回到产品负责人认为“哎呀,我敢打赌我们的客户会喜欢功能X,让我们为此做一个商业案例”。从那时起,每个人都应该在计划和做出决策时开始考虑性能。
很多时候,从构思到开发(有时甚至是过去),功能性都是很酷的孩子。每个人都很容易对花哨的新功能X及其可以做的很酷的事情感到兴奋,并且简单地假设类似Google的速度和规模将免费提供。功能X获得批准,通过通常的分析和设计过程,开始开发。这通常留给那些必须成为坏消息的承担者的测试人员和开发人员,他们说,'嘿功能X非常棒,但如果超过5个人尝试同时使用它,则响应时间超过2分钟'。
在经历了所有的努力和兴奋之后,可怜的旧功能X已经从今年的英雄功能版本发布到了将项目烧毁到地面的性能垃圾火灾。最重要的是,现在你有:
愤怒的产品负责人甚至不知道这可能是一个问题
一个吓坏了的PM,他没有分配足够的时间或预算来调整性能问题
一个迷茫的BA在非功能性需求上做一个速成课程
一个沮丧的用户体验设计师认为这与他们无关
性能思维
通常关于这一点,我们的测试和优化专家会被召唤来帮助灭火。大多数时候,我们可以弄清楚如何使它全部工作和嗡嗡声,并实现产品负责人首先设想的功能X的潜力。但是,当每个人都有一个表现思维时,对于每个人来说,在考虑性能时,它会更加轻松(通常也会更便宜)。
拥有“表现心态”究竟意味着什么?它不是要成为性能调优专家。这意味着在接近您的日常任务时考虑性能和功能。
具体而言,产品负责人,PM,BA和UX设计师可以做些什么来帮助避免上述情况?以下是将伟大与单纯善良分开的一些关键行为。
产品所有者:
请记住,用户要求的性能与酷炫的新功能一样多,甚至更多。如果功能不执行,用户将讨厌功能X.
请注意,某些功能会导致性能折衷。尽早向您的工程师提供X特征X,以确定是否需要进行成本/收益分析。
考虑功能X将如何影响用户数量和行为。您期望有多少新用户?您是定位移动用户吗?他们会生活在农村地区,网络连接不稳定吗?
功能X将如何推出?随着大张旗鼓和公布的开始日期/时间? (认为人口普查)。或者在无数天/小时或用户群中交错?
项目经理:
预算时间在开发冲刺/阶段内预先进行性能优化,而不仅仅是“必要时临时”。
在进入下一个sprint /阶段之前,确保性能标准是“完成定义”的必要部分。
通过采购和推动及时提供,确保您的团队装备精良,提前计划并节省浪费的时间
适合用途的性能测试环境。
充分的应用和基础设施性能监控。
数据依赖性和要求。
适当的凭据,许可证和访问权限。
业务分析师:
专注于实时和理解非功能性需求。了解它们是什么以及它们为何重要。在设计和开发之前准备好这些,以便工程师可以准确地估计广告,围绕他们的系统架构做出最佳选择。
研究详细的指标以告知详细要求。模糊的非功能性要求是非常无用的,例如“功能x应在3秒内响应”。目标是“功能x应在3秒内响应,同时在50,000个用户会话的持续负载下,每秒520个请求”。
熟悉与性能相关的多种信息来源。即使您无法自己捕获信息(例如原始日志数据),也要了解要查找的内容,并让其他人捕获它。
历史用法例如营销分析,应用程序性能监控,操作日志分析。
预测用量,例如产品所有者,业务案例,使用报告,财务预测。
UX设计师:
研究并了解前端性能的原理。
探索设计师通过巧妙地使用(或避免)诸如旋转器,启动页面,骨架图像/图标等内容来使应用程序“感觉”高效的方式。
考虑屏幕上元素数量对性能的影响。
尽可能减少图像文件的大小
使用巧妙的设计吸引注意页面/功能的关键部分,而背景或屏幕外元素可以继续加载而不被注意。
使命
我们作为测试和优化顾问的使命不仅仅是'测试x'或'让你快速'。这是为了使我们的专业知识尽可能有价值,这意味着帮助您首先避免这些性能火灾。有点像那部精彩的电影'Inception' - 如果你能早点进入并在所有利益相关者中灌输'表现心态',那么每个人都会获胜。
- 133 次浏览
【软件工程】5个必要的软件工程实践
有人说编程是一门科学,有些人说它是一门艺术,还有一些人认为它是两门艺术。无论哪个是真的,没有工程师提供的稳定的手和实际的重点,程序员只会给我们科学理论和大胆的艺术视野。得益于工程实践,我们拥有适合我们口袋的工作设备,只需轻点几下即可获得全世界的知识。
自从它是国家工程师周以来,唯一有意义的是庆祝工程学科如何使计算机变得可访问,必不可少,值得信赖和变革。我收集了自己的想法,甚至是一些个人经历,提出了五种必不可少的工程实践,这些实践总是落后于人类产生的最佳软件。当这些系统出现崩溃或故障时,故障可能不在于工程师,而在于喜怒无常的艺术家或云端科学家。
测试至关重要
每个程序员都知道进行黑客攻击是什么感觉,像机枪一样吐出一行代码。当你对这个架构有一个宏伟的愿景时,你永远不能把它变成代码。这就是米开朗基罗画西斯廷教堂时的感觉,但在一个72小时的延伸中。
虽然弯曲机的代码通常很棒,但它通常是毛茸茸的,并且在某些地方都没有完成。更糟糕的是,作者并不总是记得以后留下空隙的地方。对于所有代码的宏大艺术,它还没有准备好发货。我们将粗略的初稿转化为完成的代码的方式是使用顶级应用程序安全测试工具之一进行严格的严格测试。
在过去的十年中,测试变得比以往任何时候都更好,因为开发团队已经创建了强大的协议并构建了自动化功能来实施它们。团队正在使用新的持续集成机制,它们接受我们的代码并在我们检查后立即开始戳戳和刺激它。只要我们构建良好的单元测试 - 这是它自己的挑战类型 - 测试自动化机器人将确保我们的代码向前推进。如果我们犯错误,它会抓住它们并麻烦我们直到它们被修复。当我们的代码通过所有单元测试时,我们可以确定它不会失败 - 至少不是我们在编写测试时预期的方式。不能保证代码真正没有错误,但是测试严格确保我们得到了明显的代码。
存储库让我们修复我们的错误
你犯了多少次错误,并希望你能及时回过头来修复它?我们走了一条路,扯开代码并粘在新结构中,却发现这都是错误的。原始代码更好。
幸运的是,我们在编码过程中将工作提交给版本控制系统。良好的版本控制存储库(如CVS,Subversion和Git)可以实验代码并对其进行改进,而无需担心我们可能会朝错误的方向前进。存储库跟踪代码的演变,如果一切都是错误的话,让我们回过头来。
存储库还允许我们同步我们的项目工作,跟踪差异,并在时机成熟时将我们的工作与其他人合并。如果没有这种稳定,中立的服务来协同工作,团队会发现构建可靠的代码要困难得多,并且他们会害怕尝试新的功能。
开发方法很重要
大胆的心灵可能会跳入深渊,但是理性的头脑会形成一个战略性的计划,可以轻轻地下降到它的深处。如果没有仔细地将所有这些疯狂的直觉,直觉和梦想融合到一个理性的,完全规划的工作流程中,我们将无法构建大型或中型软件项目。
关于不同类型的编程方法存在持续的争论,其中许多方法相互对立。例如,有些人完全相信,如果没有敏捷方法的灵活性,就无法建立好的软件。然后还有其他人将敏捷抛到一边,因为它过于反复无常。就个人而言,我喜欢的敏捷过程有很多方面,但是当太多的程序员在牧场外游荡时,我发现它会误入歧途。
软件工程师一直在思考如何共同编写代码。他们尚未达成共识,但这并不意味着这些想法并非总比没有好。我们的野心如此之大,以至于我们需要数十人,如果不是数百人或数千人,他们一起工作,没有协调就会变得混乱。你可以选择你喜欢的任何一方 - 只要你选择一方。
代码必须继续存在
软件存在缺陷和局限性,但年龄不是其中之一。钢铁锈和有机材料破坏了,但软件的逻辑继续存在。正如我们所说的那样,IBM大型机运行COBOL代码,这些代码由从未长时间发送推文或在Facebook上发布状态更新的人编写。它们可能已经消失,但它们的代码依然存在。
应用程序仅在与当前系统不兼容或者当前软件产品中没有新功能和更新时才会出现与年龄相关的问题。只有代码维护才能使旧应用程序保持有用。
良好的代码维护从良好的工程开始。当团队使用模块化接口编写记录良好的代码时,他们的工作可以继续运行。软件工程使我们中的一部分人能够继续生活。这与将我们的灵魂下载到矩阵中的方式不同,但确实有相似之处。
代码分析
很久以前,我错误地对赖斯定理过于相信,赖斯定理是计算机科学的一个重要部分,它指出一个计算机程序无法分析另一个计算机程序并决定它是否具有一些非常重要的属性。而这个定理在最抽象的意义上意味着“非平凡”。如果某些程序的某些属性是真的而不是其他程序,那么它被认为是“非常重要的”。
该定理似乎表明,花费任何时间尝试编写寻找错误或发现错误的代码是徒劳的。但是这个定理实际上说机器智能不能一直正确地做到这一点。我假设没有代码可以查找错误并发现错误。
软件工程师并没有被深刻的理论结果所迷惑。他们知道编写可以扫描我们的代码并查找常见错误或不良实践的软件是可能的。好的工具可以查找诸如未初始化的变量和缓冲区溢出或SQL注入漏洞等更深层问题之类的草率错误。
这是良好工程的教训。它不需要是完美的。它不需要很深。它不需要令人惊讶。只需要勤勉而有条不紊地专注于正确性,就需要精心打造。这个过程可能永远不会纠正所有的错误,但这并不意味着我们不能乐于找到它们中的一些。如果重复这个过程,我们可以足够接近。
您认为什么是软件开发中最重要的工程实践?
讨论:请加入知识星球【首席架构师圈】
- 115 次浏览
【软件工程】代码质量综合指南:最佳实践和工具
当您的软件团队快速增长时,确保代码质量是一个巨大的挑战。但是,即使有固定数量的软件开发人员,维护代码质量也会引起麻烦。
如果没有工具和一致的系统,整个项目可能积累巨大的技术债务,长期造成的问题比短期解决的问题要多。
最好的事情是,你不必成为一个火箭科学家来避免这一点(当然,如果你是火箭科学家的话,这不是问题)。
我们提供了一个很重的指南,帮助您从根本上提高团队生成的代码的质量,无论您是与内部团队还是软件外包公司合作。
这篇文章的某些部分可能看起来很明显,但其价值在于这些部分是如何连接起来并建立起一个有效的代码质量保证系统的。
- 代码质量到底是什么?
- 为什么要关心代码质量?
- 为您的团队构建代码质量保证体系
- 确保代码质量和透明度的版本控制工具
- 可读和可理解代码的样式指南
- 通过功能测试提高代码质量
- 如何测量测试
- 用户界面测试
- 使用持续集成工具
- 后期代码质量
- 案例研究
代码质量到底是什么?
代码质量是一组不同的属性和需求,由您的业务决定和确定优先级。以下是可用于确定它的主要属性:
- 清晰:对于不是代码创建者的人来说,阅读和监督都很容易。如果很容易理解,那么维护和扩展代码就容易多了。不仅仅是计算机,人类也需要理解它。
- 可维护性:高质量的代码并不复杂。任何使用代码的人如果想做任何更改,都必须理解代码的整个上下文。
- 文档化:最好的事情是当代码是自解释的,但是总是建议在代码中添加注释来解释它的角色和功能。它使没有参与编写代码的人更容易理解和维护代码。
- 重构:代码格式需要一致,并遵循语言的编码约定。这里有一些代码重构技巧。
- 测试良好:代码的错误越少,质量就越高。彻底的测试会过滤掉关键的错误,确保软件按照预期的方式工作。
- 可扩展:你收到的代码必须是可扩展的。几周后你不得不扔掉它,这真的不太好。
- 效率:高质量的代码不会使用不必要的资源来执行所需的操作。
质量代码不一定满足上述所有属性,但满足的越多,质量就越高。这些需求更像是取决于项目特性的优先级列表。
为什么要关心代码质量?
伟大的作家写的书有引人入胜的故事,很容易阅读和理解。从某些方面来说,作者的工作类似于开发人员的工作。主要区别在于开发人员使用不同的行话。
由于作者的写作必须易于阅读和全面,所以软件开发人员的代码也应该如此。
我知道,当你在压力下不得不在下一个截止日期前完成工作时,很难关注代码质量,但是如果你想长远考虑,你肯定需要生成可读和可维护的代码。以下是代码质量重要的三个主要原因:
- 可读性:使代码更可读,更容易理解,为每个人在项目上工作。读和理解一个质量低劣的代码要比写它困难得多。
- 可维护性:维护和测试质量代码更容易、更安全、更省时。
- 较低的技术债务:高质量的代码可以加速长期的软件开发,因为它可以重用,开发人员不必花那么多时间修复旧的错误和抛光代码。它还使新的项目成员更容易加入项目。
质量代码是软件质量的基石,无论你从事什么行业,质量软件都能让你的生活更轻松。
Robertc对干净码的定义。马丁“鲍勃叔叔”
干净的代码可以让你快速工作
基本的主题是,如果你想走得快,满足时间表,让你的客户和经理高兴,保持你的代码尽可能干净。没有什么比保持工作区整洁和坚持高编码标准更能让您更快地构建软件了。
测量函数的大小
您可以测量方法或函数的大小。这本干净的代码书的很大一部分都围绕着这个想法。这很简单:把你的函数做得尽可能小。
一旦超过五行或六行代码,它们就开始变得太大。许多程序员发现小函数的想法令人不安。这对他们来说是新鲜事,他们担心这会压倒他们。
把你的功能命名好
但这不会让你不知所措,因为你需要说出他们的名字,这是一次让人大开眼界的经历。你必须想出一些小概念的名字。他们的名字往往很长,因为概念非常精确,所以需要几个词来描述。
所以函数的名字几乎都是句子。当你把它们和“if”和“while”语句混合在一起时,你就开始形成完整的句子。然后你的代码开始像自然语言一样阅读。
保持函数尽可能小,命名好就等于好的代码,保证了高的结构质量。
为您的团队构建代码质量保证体系
在这一部分中,我将向您展示如何使用版本控制、样式指南和自动化测试来确保我们的代码符合预定义的质量标准。
通过遵循这些方法,您可以轻松地复制我们的系统,并从根本上提高您的团队生成的代码质量。您只需执行以下步骤:
- 安装程序版本控制
- 确定惯例
- 运行功能质量测试
一。版本控制工具,确保代码质量和透明度
版本控制工具是我们系统的基础。
最流行的版本控制工具是Git。它还提供了一个分支样式的指南,称为GitFlow,它支持团队成员之间的无缝协作,并使扩展开发团队变得容易。
它提供了一个易于跟踪的系统,将活动产品与具有未发布特性的不太稳定的开发人员分支分离开来。
当我们团队的开发人员完成一个特性时,他/她会在GitHub上发送一个pull请求。这描述了请求的内容和详细信息。
此系统确保没有未查看的代码将与主分支合并。代码检查很重要,您需要正确的工具来完成它。
以下是我们的流程:
- 一个团队成员向开发分支发送一个pull请求。
- 这将出现在“准备审阅”部分中,等待项目成员审阅(同行审阅)。
- 团队成员审查请求,如果它满足需求,它将被合并到开发分支。
这是一个很好的控制版本和使每个人的工作完全透明的系统。Git有很多GUI扩展,比如支持Gitflow的GitKraken。在这里您可以看到如何轻松地启用它。
但是你如何决定代码是否足够好呢?
在下一部分中,我将向您展示跟踪代码质量的工具和可用于度量代码质量的度量。
1。可读和可理解代码的样式指南

样式指南是最佳实践和约定的集合。使用样式指南可以确保每个开发人员的代码看起来完全相同,从而使代码更易于检查和使用。
幸运的是,您不必创建自己的样式指南。有许多免费的样式指南,主要针对不同的编程语言和范围:
公司:像Airbnb和Google这样的酷公司已经创建并发布了他们自己的风格指南。这是Airbnb的JavaScript风格指南。
项目:公司内不同的项目或产品可能有不同的约定。我们并不推荐基于项目的风格指南,因为它使人们在项目之间切换变得更加困难。
使用linters自动测试代码样式
linter 是款式指南的一部分。它是一个小软件,可以自动检查代码是否符合预定义的代码约定规则。您不必手动检查代码库来检查样式。
几乎每种编程语言都有linter,仅举几个例子:
- JavaScript ESLint
- TypeScript TSlint
- Python pylint /flake8
- Sass/SCSS sass-lint
- Go golang lint
- Bash ShellCheck
您也可以在这里查看我们自己的 JavaScript style guide here (尽管需要更新)。
许多代码编辑器都支持可配置的linting,例如VSCode。这里有一个如何设置自己的 linter的指南。
EditorConfig 帮助开发人员定义和维护不同编辑器和ide之间的一致编码样式。EditorConfig项目由一个用于定义编码样式的文件格式和一组文本编辑器插件组成,这些插件使编辑器能够读取文件格式并遵循定义的样式。
3。通过功能测试提高代码质量
当使用linter的样式指南测试代码的外观时,功能质量测试显示代码是否实际工作。
这个简单的金字塔显示了一个测试过程的结构和你的努力方向。

一般来说,我们可以说您必须运行大量的单元测试,更少的集成测试,甚至更少的端到端测试。
通过单元测试,您可以通过模拟依赖项来检查软件的一个模块。集成测试显示了在端到端测试检查整个客户机-服务器循环时,不同组件如何协同工作。
对于运行单元和集成测试,可以使用以下工具:
对于端到端测试,我们建议使用:
附加阅读:Mobile Labs Inc在部署任何应用程序之前都会列出一个很酷的清单。
如何测量测试

衡量测试有效性的最佳方法是跟踪测试覆盖率。它显示了测试算法所覆盖的代码的百分比。为了更好地理解,有必要分解测试覆盖率:
- 语句覆盖率(%):测试期间执行的语句数除以所有语句
- 分支覆盖率(%):执行的条件数除以所有条件
- 函数覆盖率(%):执行的函数数除以所有函数
- 行覆盖率(%):测试期间运行的行数除以所有行数
Istanbul 尔是一个很酷的工具,用于测量JavaScript代码库的测试覆盖率。

用户界面测试
UI测试也可以自动化,但它需要更多的资源,特别是当组件正在更改时,因此应该重写完整的测试环境。
自动用户界面测试有很酷的应用程序:用于Android UI压力测试的Monkey测试、用于跨浏览器测试的Saucelabs和用于更全面的端到端测试(包括用户界面)的dragor。
使用持续集成工具
我们的理念是总是对我们正在构建的软件的状况有反馈。这就是图中的持续集成。我们最喜欢的博主之一,Martin Fowler,明确了持续集成的定义。
“持续集成是一种软件开发实践,在这种实践中,团队成员经常集成他们的工作,通常每个人至少每天集成一次,导致每天进行多个集成。每个集成都由自动化构建(包括测试)进行验证,以尽快检测集成错误。”
马丁·福勒
以下是我们的流程:
- 持续集成平台将在代码上运行linter。如果失败了,这个过程将在此停止,开发人员必须修复与样式相关的问题。
- 如果代码按照计划运行,它将运行功能测试并转到下一步。
- 然后开始计算测试覆盖率。如果它不符合预定义的阈值,它将失败。
- 如果请求正在与主分支合并,那么也应该部署它。
推荐工具:
后期代码质量
你真的不应该在产品上线后就放弃质量跟踪。诸如Sentry和Newrelic之类的工具可以实时监控错误,这样就不必要求用户报告崩溃和错误,因为系统会自动通知您。你只需要在你的应用程序中添加一小段代码。
工具:
案例研究
艾伦·叶芝
首席技术官
袖珍手有限公司
“我们认为,尽可能避免技术债务是最好的办法。通过代码审查,确保代码标准得到遵守,避免黑客攻击,您可以及早发现许多问题。
很明显,有时在项目的最后期限和里程碑到来时,你无法避免增加技术债务。那么最好把所有的事情都记录下来。我们保留一份文件,其中列出了所有问题,它们在哪里,为什么要这样做,以及哪些可能的措施可以解决这些问题。这样我们就可以跟踪我们在哪里看到的问题,以及什么时候它在我们的脑海里是新鲜的。
当涉及到提高代码质量时,它会根据具体情况工作。有时候你不得不接受一些永远无法解决的问题,在解决的时候记住它。其他时候,它可以被安排到未来的sprint中,以便在下一次需要查看该功能时进行修复。”
结论
就这样。这就是您如何为您的团队创建一个工作流,确保每个人的代码遵循相同的样式指南,并通过预定义的测试来检查功能质量。
除了在发布前测试代码质量之外,您还需要监视用户开始使用应用程序时发生的情况。
我们知道编写没有bug的代码是不可能的,但是遵循上面提到的过程肯定会提高团队代码的质量。
原文:https://codingsans.com/blog/code-quality
本文:http://jiagoushi.pro/comprehensive-guide-code-quality-best-practices-and-tools
讨论:请加入知识星球【首席架构师圈】或者微信圈子【首席架构师圈】
- 404 次浏览
【软件开发】2021 年顶级 Github 存储库趋势
视频号
微信公众号
知识星球
从 2021 年顶级明星 Github 存储库中了解技术趋势、人口统计和开发者文化

动机、方法和热门领域
动机:Github 是世界上最大的源代码托管商,拥有超过 2.54 亿个存储库(根据 x-lab 报告,2020 年至少有 5200 万个公共存储库)。 除了源代码之外,Github 已成为全球超过 7300 万开发人员(2021 年新增 1600 万)的更广泛的社区中心。
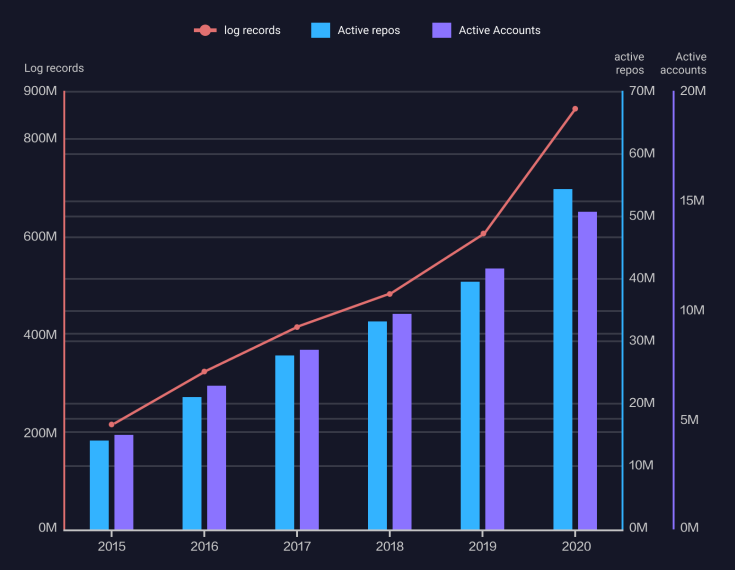
方法论:截至 12 月 27 日,我在 Github 上下载了 247 个热门存储库的数据(按净明星增长),并有条不紊地对每个存储库进行分类:首先是技术存储库还是教育存储库,然后是子类别。
出现了六个明显的趋势领域——每个领域都深入到以下部分:
- 教育资源(~70/250):模式、面试准备、构建列表……
- Web 开发技术 (~43/250):框架上的框架
- 开发人员工具 (~35/250):IDE、终端和真正随机的东西
- 数据、人工智能、机器学习(~21/250):主要是深度学习
- 新语言:TypeScript、Go 和 Rust
- MISC:微软、Dev Counterculture 和 Surveillance
可以在此处下载完整的存储库列表(包括每个存储库的描述、总贡献者、分叉、问题和拉取请求计数),我在下面提供了一个汇总表。
| Category | Subcategory | Total # Repos | Total 2021 New Stars | |
|---|---|---|---|---|
| Tech | webdev | 43 | 601,062 | |
| Other | 35 | 342,338 | ||
| Dev-utility | 28 | 339,440 | ||
| Data, AI, ML | 16 | 162,183 | ||
| App | 8 | 84,383 | ||
| Dev-misc | 7 | 67,452 | ||
| Crypto | 5 | 53,638 | ||
| Programming language | 4 | 41,489 | ||
| Education | Other | 27 | 422,935 | |
| Patterns | 20 | 317,162 | ||
| Interview Prep | 6 | 111,918 | ||
| Interviews-leetcode | 6 | 96,322 | ||
| Build | 6 | 84,508 | ||
| Data, AI, ML | 5 | 64,338 | ||
| webdev | 1 | 43,460 | ||
| Cybersecurity | 1 | 9,226 | ||
| MISC | 29 | 401,110 | ||
| Grand Total | 247 | 3,242,964 |
领域 #1:教育资源
虽然 Github 旨在存储代码,但它已成为众包知识和教育资源的主要枢纽。事实上,今天只有 3/10 的顶级 Github 存储库是“技术”(Vue、React 和 Tensorflow),而到目前为止,Github 上最受欢迎的存储库是一个免费的、非盈利的编码营。
值得注意的子类别和示例:
- 模式列表:各种编程语言(例如 javascript、python、unix、go)中流行算法的最佳实践实现
- 面试准备:面向工作面试准备的资源(例如编码面试大学、技术面试手册)。其中一半是面向 leetcode 平台的,其中大部分也有中文翻译。
- 构建项目:精选的 DIY 项目列表,以提高技能并获得乐趣(例如,构建您自己的 x、应用程序创意、初学者真棒、首次贡献)
我们可以从开发者文化和人口统计中推断出什么?
大量劳动力正在进行技能培训。全球有数百万人第一次学习编程——他们的动机通常是经济解放。这是强大的,但也受到劳动力市场深刻变化的推动。世界经济论坛估计,到 2025 年,技术将消除约 8500 万个工作岗位,同时创造约 9700 万个新工作岗位(链接)。不是每个人都能成功地实现这一转变,我们需要记住这一点,我们需要机制来支持那些没有成功的人。
开发人员❤️ 学习和构建。我最喜欢在科技行业工作的一件事是参与其中的人:喜欢持续学习的书呆子和喜欢建造的创客!
创始人和创业领袖能带走什么?
内容营销为王:通过为持续学习者和/或为喜欢构建的制造者提供教育来编写好的内容😃
标记“良好的第一个问题”可能是有效的:一些“构建项目”列表实际上主要是开源存储库中标记为“良好的第一个问题”的问题的汇编……如果你,新开发人员可以磨练他们的技能,同时成为你的项目的贡献者引导他们走向更容易的机会。在 Github 的 2021 Octoverse 报告中,实际上有一整节是关于使用这个标签的效果的!
给予获得:教育可用于创建护城河并解锁新的 TAM。例如,dbt Labs 社区已成为整整一代数据分析师寻求提升技能的事实上的来源,并正在帮助数千家公司加入现代数据堆栈。他们有自己的一套在线课程。甚至还有一些独立的项目,例如分析工程师俱乐部,提供为期 10 周的基于群组的项目。
另一个有趣的例子是 Conduktor,该公司利用广受欢迎的在线 Udemy 课程并围绕企业 Kafka 平台建立了一个社区,该平台简化了 pub 子系统的管理。
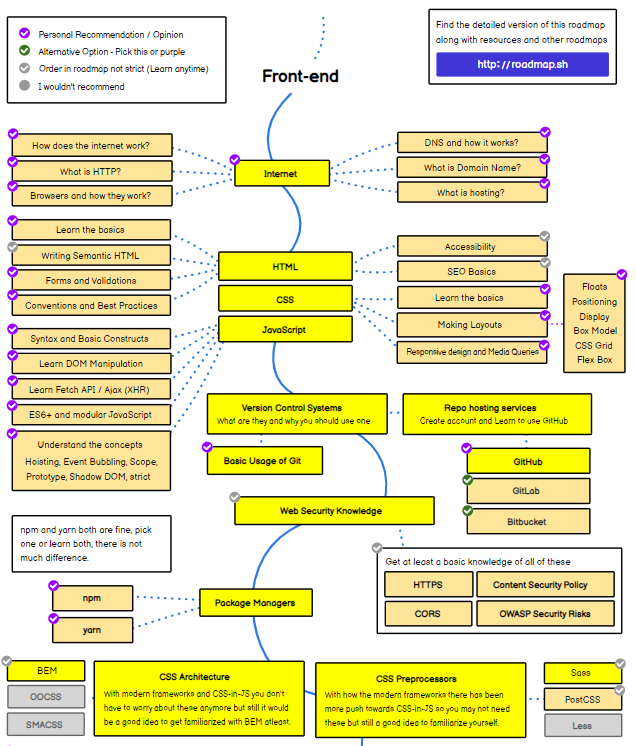
亮点:开发者路线图
作为出色可视化的粉丝,我想重点介绍我最喜欢的教育资源库之一:Kamran Ahmed 的开发者路线图。 请注意,有前端、后端、DevOps 和特定语言的交互式版本。 它们非常酷,请在 https://roadmap.sh/ 上找到它们,这对于试图在更高层次上理解各种技术领域的人们也很有用。
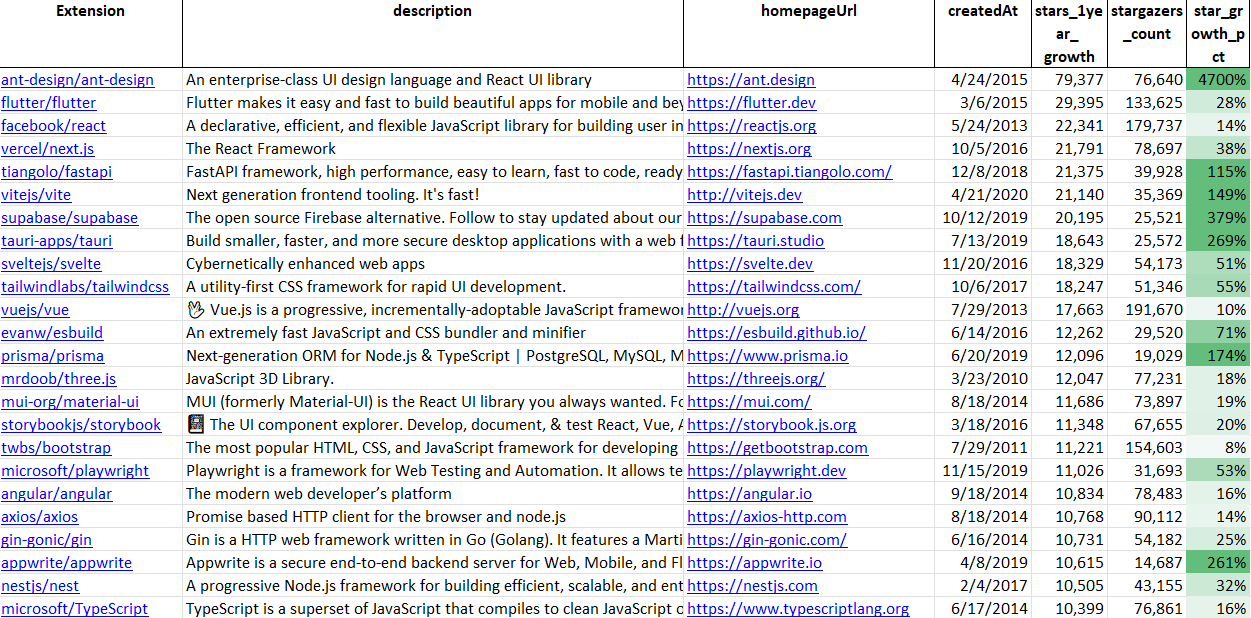
领域 #2:Web 开发
我包括下面的顶级仓库。 Ant-design 位居榜首,尽管我怀疑手头有一个数据怪癖。
跨平台框架正在流行:谷歌的多平台框架 Flutter 越来越受欢迎。 Tauri 是一个利用前端技术开发桌面应用程序的框架,是该列表中相对增长最快的框架之一。 WebAssembly 的发展将如何进一步启用这个空间仍然待定。
名单上有两个 Firebase 的开源替代品:Supabase 和 Appwrite。 我将在即将发布的文章中撰写有关开源替代方案的文章。
关于前端 Web 开发技术的短暂性的说明
Web 开发技术发展得非常快,Web 开发人员的偏好非常短暂。 例如,请参见下面的两个图表:
随着时间的推移,顶级 Web 开发存储库的贡献者
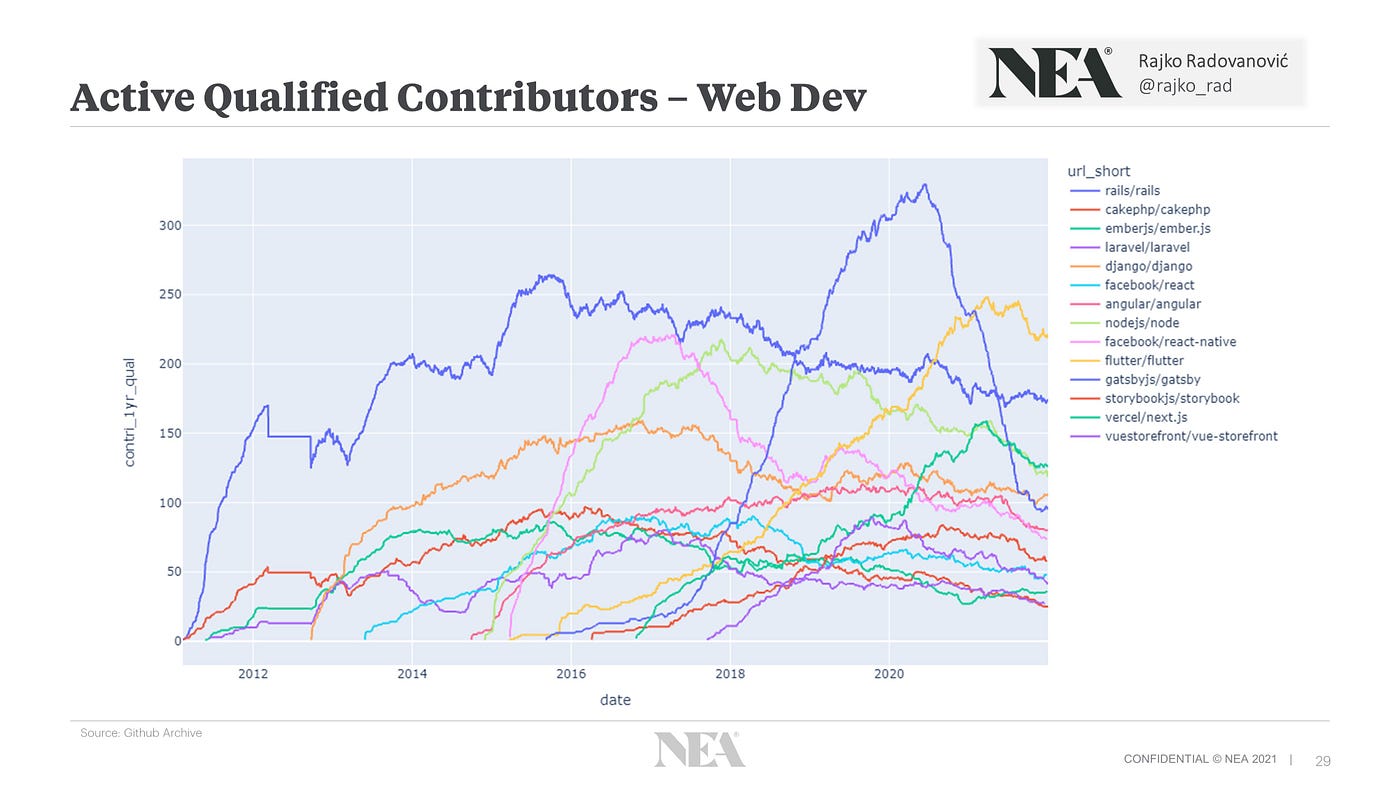
前端框架相当善变:
- Gatsby,后来的紫色高峰,从 2017 年 6 月到 2020 年 6 月飙升,然后同样迅速下降
- Flutter,黄色,在 2021 年 3 月达到顶峰,然后开始突然下降
- 甚至 Next.js 也在 2021 年 3 月左右开始略有下降
- React-native,粉红色,在 2017 年左右迅速达到顶峰,然后开始下降)
后端框架更持久:尤其是 Rails、Django 和 Node
随着时间的推移,顶级 SRE¹(想想云原生)存储库的贡献者
请注意,SRE¹ 堆栈的核心技术的崛起速度和持久性似乎要慢得多,尤其是紫色的 Kubernetes,它是所有项目中活跃和合格贡献者数量最多的。
注意:我将在以后的文章中写更多关于这种方法的内容,以及从这个角度来看更详细的基准测试......
创始人和创业领袖能带走什么?
不要成为一招一式的小马,尤其是在前端:考虑到该领域的变化速度,单一的趋势 Web 开发技术不太可能维持一家大型且经久不衰的公司。即使在开发偏好更加持久的领域(想想早期的数据基础设施公司锁定 Hadoop),坚持单一核心技术也是公司的垮台。认识到这一点,在 Next.JS 仍然广受欢迎的同时扩展它,并聘请 Svelte 的创建者,是 Guillame Rauch 才华横溢的一部分。我们可能会开玩笑说每个人都会为 Vercel 工作,但这可能是该领域罕见的可行持久策略!
知道你的社区生活在哪里:
至少在 Github 上,Web 开发人员的数量仍然远大于数据或其他开发人员的数量。 在 2021 年的前 250 个存储库中,Web 开发存储库收集了约 60 万颗星,而与数据、AI 和 ML 相关的存储库仅约为 162K,减少了 4 倍。 请注意,根据以下 2018 年 Slashdata 的估计,Github 可能准确地表明当今世界上以网络为中心与以数据为中心的*开发者*要多得多。

我想有两种力量在起作用,会改变这种动态:1)随着时间的推移,越来越多的“软件工程师”将开始主要利用数据基础设施与 Web 框架并与之交互,2)越来越多的非技术数据从业者(任何业务分析师)都将变得越来越技术化,无论是通过学习 Python 还是 SQL/dbt……虽然不太确定是否会成为 Github 的铁杆用户!
领域 #3:开发工具
老实说,我在这里没什么好说的……Github 上到处都是古怪而酷的开发者工具。其中一些顶级存储库是 shell、终端、IDE 或代码编辑器,它们可能是开发人员体验中最重要的组成部分:
- 微软的 VS Code 以 20K 星位居榜首,并且可能是当今最好的代码编辑器之一,这对许多人来说是一个难以接受的事实 😅 Ofc,Powershell 也在 2021 年以约 9K 星位居榜首
- Coder — 浏览器中的 VS Code,也是其他活动指标增长最快的存储库之一
- 列表中还有一些新的 shell,包括 Tabby 和 Nushell,它们都有大约 7K 星,尽管 Nushell 是一个更新得多的项目
还有一些有趣的插件,同一组工具的附加组件:
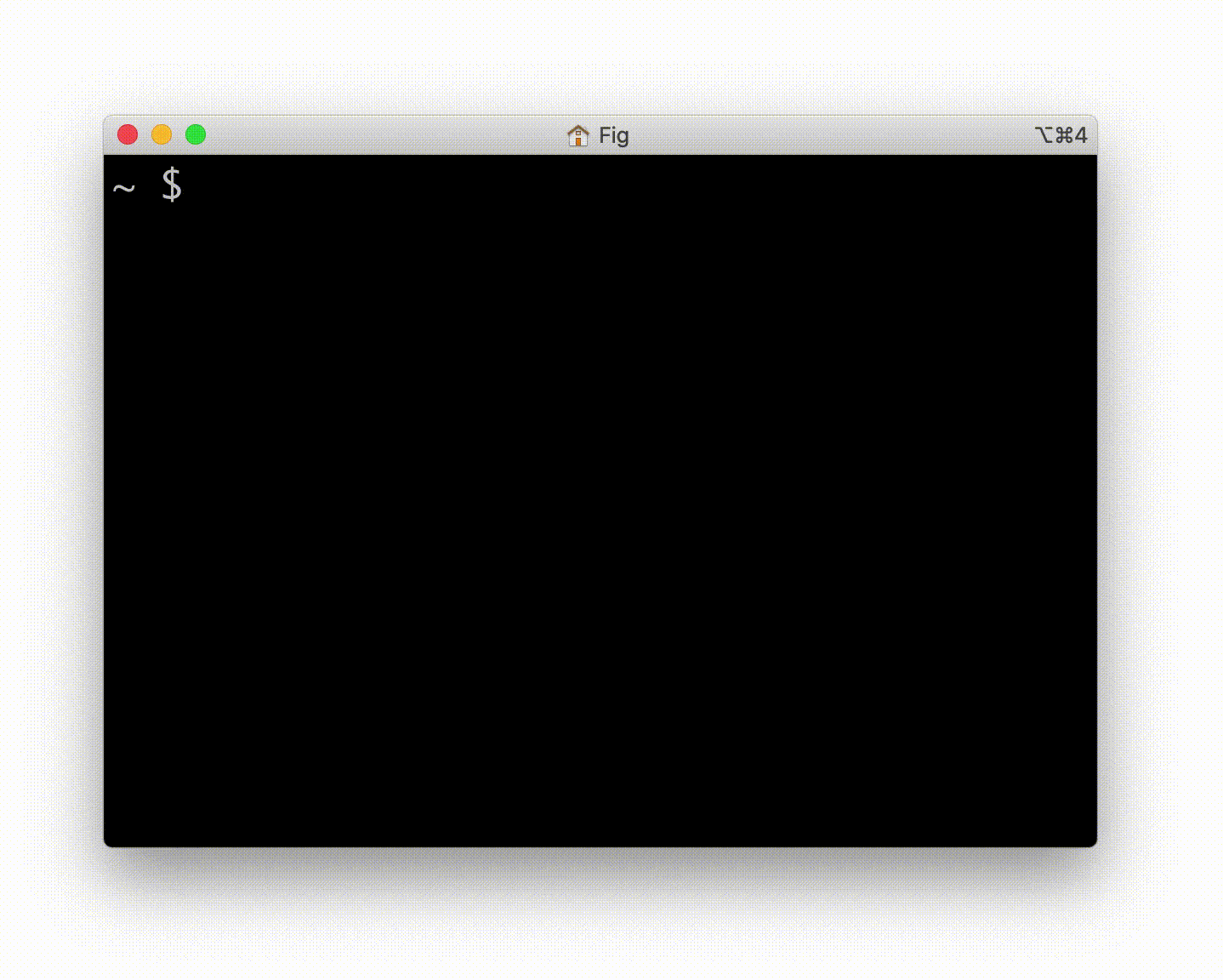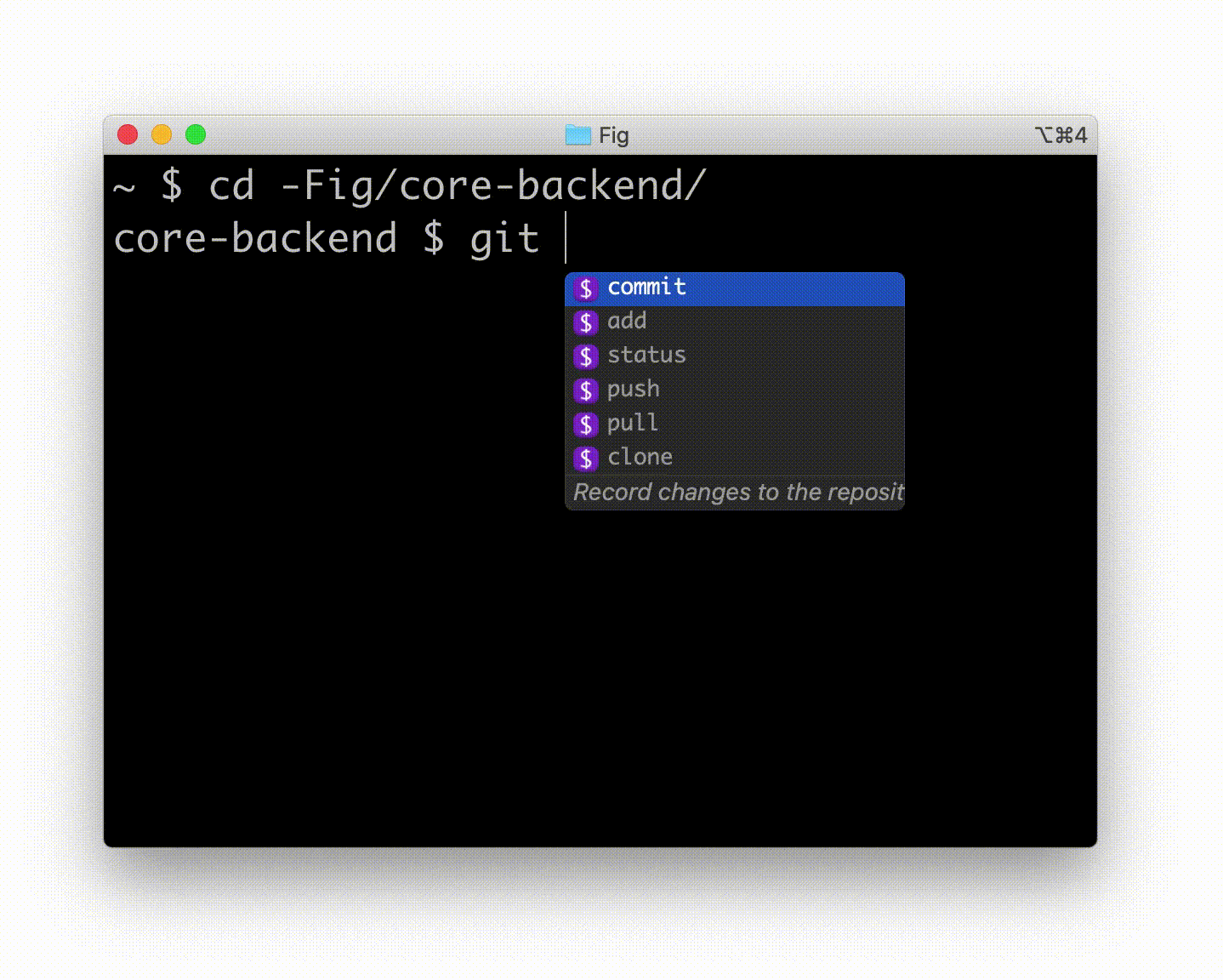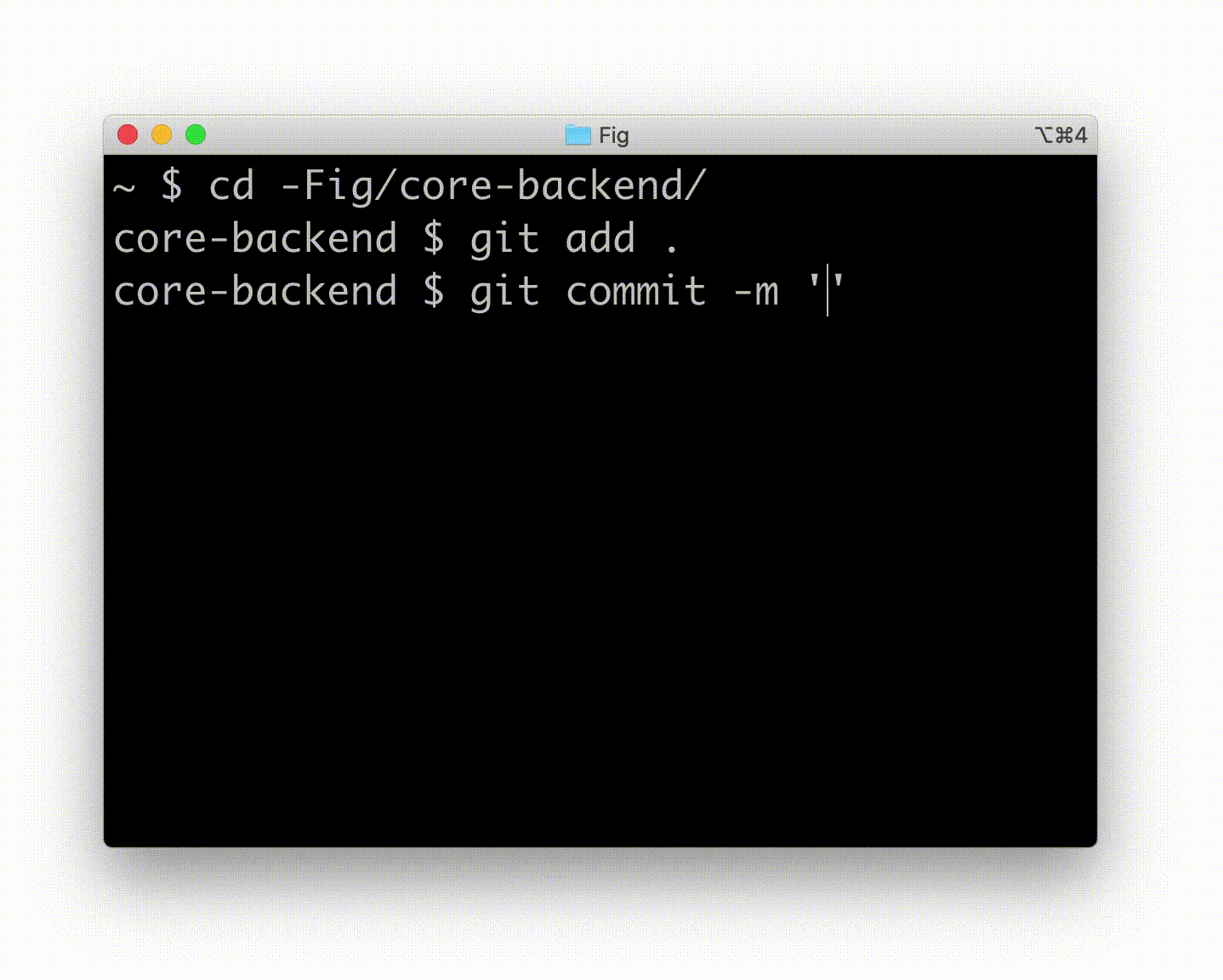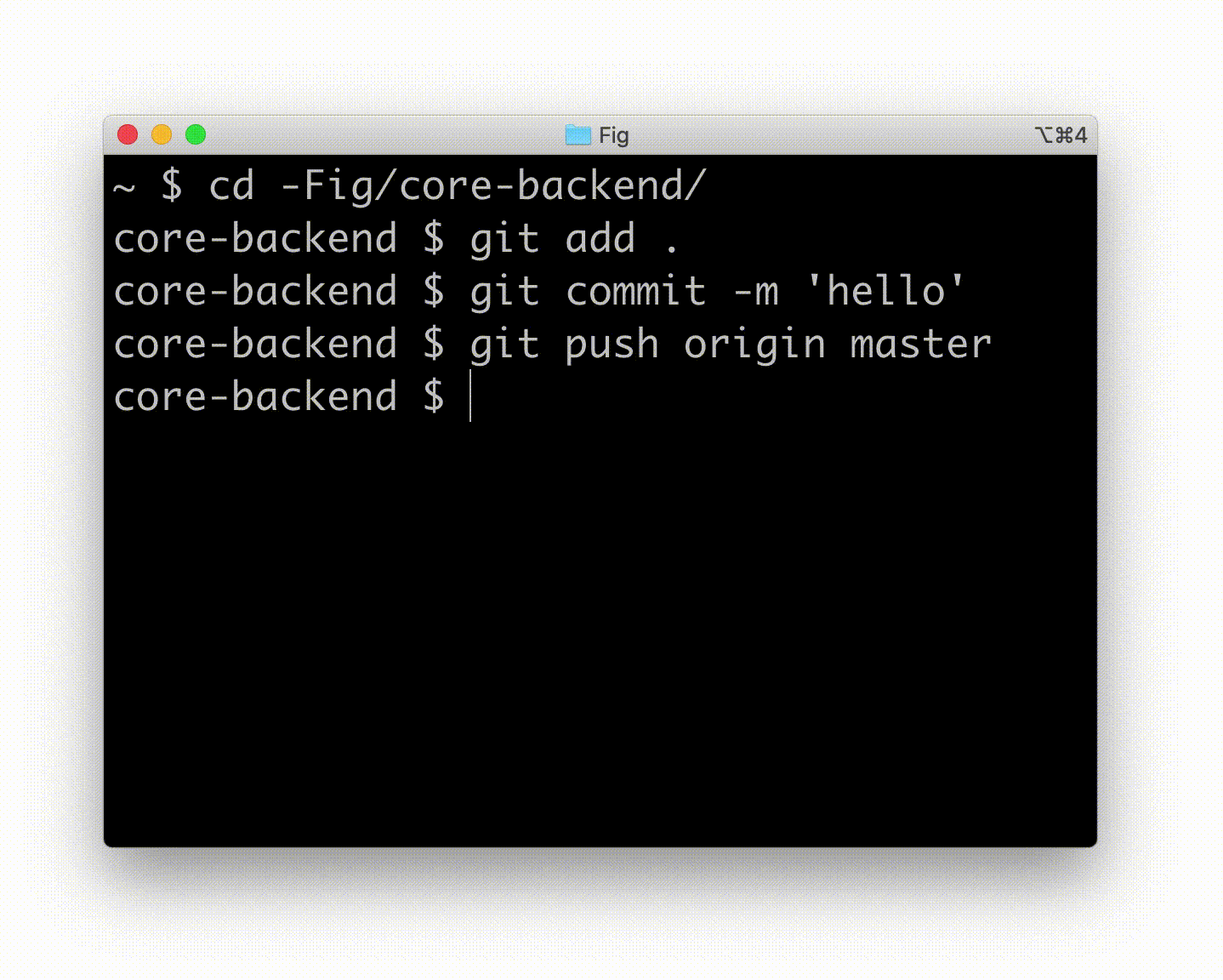
- Fig 于 2020 年底开始,今年几乎从零开始增长了约 8000 颗星,它为您的终端添加了高级自动完成功能,无论您选择使用哪个
- 有点滑稽的是,Github(65K 星)上较旧且更受欢迎的实用程序和总体上更受欢迎的存储库之一是“thefuck”,它会自动更正您以前的控制台命令
- 另一方面,Starship 有助于自定义您可能正在使用的任何 shell 的提示
领域 #4:数据、人工智能和机器学习
这并不奇怪:深度学习是最受欢迎的子类别,包括面部转换器存储库、YOLOv5、Tensorflow 和 Deepmind 的 Alphafold。令人惊讶的是,列表中唯一合适的基础设施-ey 存储库是 Meilisearch 和 Clickhouse,考虑到 VC 世界中收到的所有炒作数据基础设施,这有点令人惊讶,但同样,可能只是最终用户人口规模的问题 + 是否有数据科学家们在 Github vs. Web Developers 上花费了大量时间……
我还有很多关于数据的文章要写,计划发布未来的帖子……现在,我将重点介绍另外两个很酷的资源:
AI 专家路线图(交互式网页)
似乎从上面链接的开发人员路线图中获得了灵感,非常棒。我喜欢他们如何区分不同的角色,从数据科学家到机器学习,再到深度学习,再到数据工程等等。浏览起来真的很棒而且很有趣!将其与前面提到的开发者路线图以及分析工程师俱乐部并列也很有趣,因为他们收集了很多现代技术,有点 MECE² (#BCG) 方式😃
2. 我喜欢的第二个仓库是 Eugene Yan 的 Applied ML 仓库。
这是一个绝妙的想法,实际上是我计划在我不存在的空闲时间随意做的事情……无论如何,这是一份来自顶级工程团队(Netflix、亚马逊、Pinterest、Linkedin 等)的技术帖子的精选列表.) 详细说明他们如何构建不同类型的 AI/ML 系统(例如预测、推荐、搜索和排名等)。 Ofc,它专注于 AI/ML,但可以为传统或面向 BI 的分析堆栈以及流媒体世界制作类似的东西,对从业者来说超高价值!顺便说一句,我在 BCG 最喜欢的事情之一是查看我们的 IT 架构团队的参考架构图……理解技术的最佳方式是查看大量的东西是如何构建的……它很有趣!
区域#5:街区的新语言
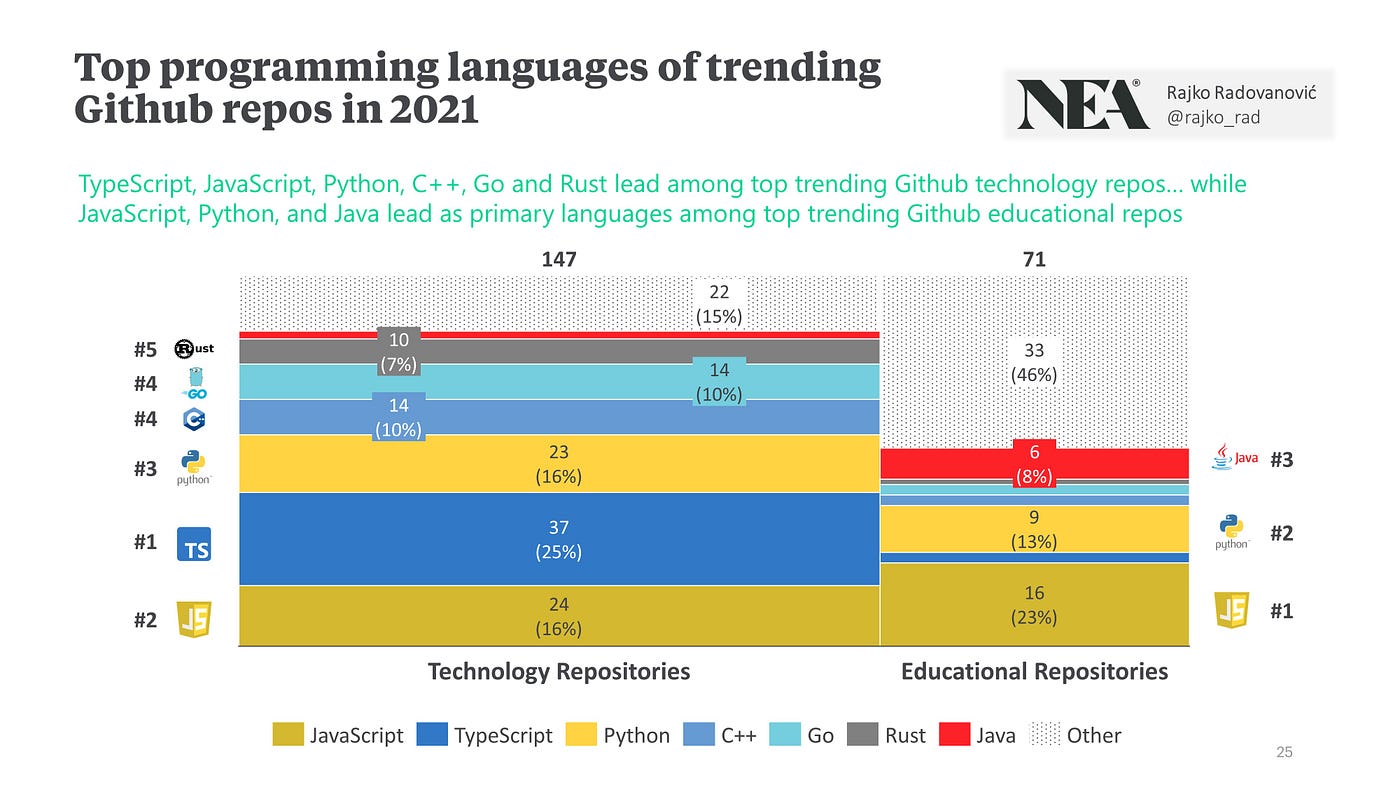
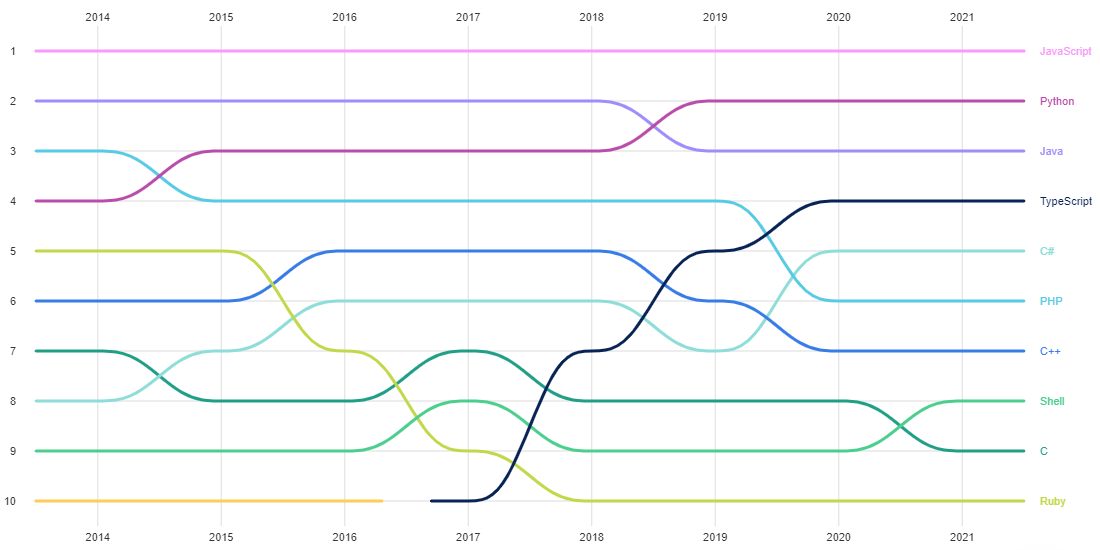
迄今为止,Typescript 是 2021 年热门技术存储库中的主导编程语言,其次是 Javacript、Python、C++、Go 和 Rust。有点有趣的是,顶级教育存储库的组成非常不同,Javascript #1、Python #2 和 Java 仍然排在第 3 位。
技术存储库可能反映了黑客对什么和未来感到兴奋,而教育存储库则反映了当今哪些语言仍然最受欢迎。一位朋友向我建议,这也与“最容易进入障碍”的语言有关,这是有道理的!
为此,我在下面比较了另外三个编程语言流行度的数据源。看起来,查看热门的 Github 存储库实际上是未来最强大的前瞻性指标!
Github 实际上发布了他们自己在整个服务中使用的编程语言的排名:
您可以在下面看到 Typescript 的趋势有多强,尽管 Rust 和 Go 甚至还没有进入该列表!
2. 也许最普遍的来源是 TIOBE 索引,它聚合了跨搜索引擎对不同编程语言的搜索。
令人惊讶的是,Java 和 C 在这个榜单上仍然占据主导地位,Python 仅在上个月超过了它们!
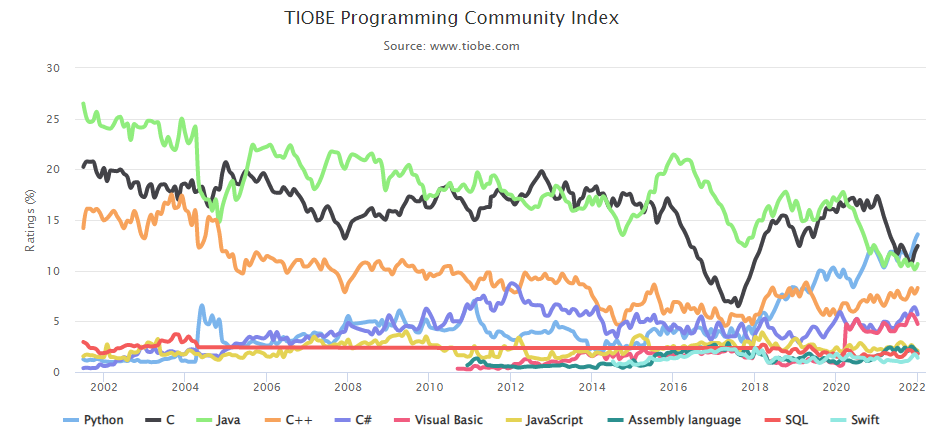
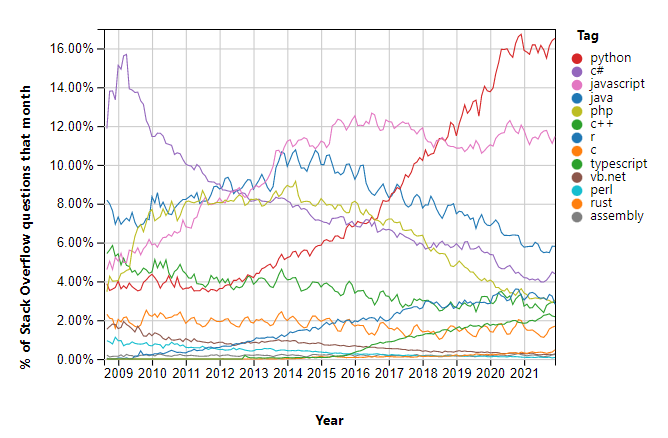
3. 另一个有趣的来源是查看 Stack Overflow 上的标签。
Python 在这里确实占主导地位,但我确实认为,大量面向数据的人利用该网站可能存在一些选择偏差……但是,C# 是 2009 年平台上最流行的,而 JavaScript 仍然表现良好。 你也可以看到 Typescript 的好转。
区域 #6:几个 MISC 点
A.就开源、开发人员友好性和更广泛的公司战略而言,微软已经走了很长一段路。
微软的高级战略主管曾经将开源公司比作那些导致互联网泡沫危机的公司——不负责任和不计后果地免费提供服务。比尔盖茨甚至曾经声称开源对工作不利😂
2014 年任命 Satya Nadella 为 CEO 以及 .NET 堆栈的开源(维基百科对这一切都有很好的回顾)带来了重大变化。今天,微软在 Github 上发现了 2021 年最受欢迎的 8 个存储库:
- 三门教育课程——面向初学者的 Web Dev、ML 和 IoT。注意重新使用教育资源作为营销策略,至少 ML 课程链接到各种 Azure 服务。谷歌也经常这样做,Collab notebooks 经常被用来演示教育材料。
- 开发工具和实用程序,包括 VS Code、Microsoft Terminal 和 PowerToys,
- Web 开发技术,包括占主导地位的 TypeScript 语言,以及用于浏览器自动化测试的越来越流行的 Selenium 替代品:Playwright
B.黑客体现了一种健康的反文化
反买东西,反广告,强烈支持劳工💪
- 绕过付费墙 chrome 是一个插件,它完全按照它所说的那样做,让用户绕过网站付费墙来访问内容。请注意,如果可以,请为优质新闻付费。
- 阻止现场有助于阻止互联网上的广告。我不喜欢隐藏的、广告驱动的商业模式。这实际上是我更广泛地喜欢企业与消费者技术、更清洁和合乎道德的商业模式的重要原因
- 996.ICU 是一个了不起的资料库,基本上是中国不良科技雇主的名单(现在可能更广泛)。它在 2019 年开始流行时受到了媒体的极大关注。他们自己的描述如下:
996.ICU这个名字指的是“996工作,ICU病房”,这是中国开发者的讽刺谚语,意思是按照“996”的工作时间表,你有进入ICU(重症监护室)的风险。 )
C.有一些粗略的趋势,并不是所有的技术都很好(例如,结束事情的一种不那么有趣的方式)
AI/ML 很棒,会给世界带来很多好处,但也存在严重的风险和安全考虑。加强监视和国家控制肯定是其中之一,也许最成熟的滥用用例之一就是面部识别。 2021 年最热门的存储库之一是腾讯的 GFPGAN,它“旨在开发用于真实世界面部恢复的实用算法”。另一个趋势库是 DeepFaceLab,用于创建深度伪造。
顺便说一句:在这个名为 Awful AI 的存储库中有一个非常好的 AI 糟糕用例汇编
另外两个趋势存储库用于在社交媒体帐户中定位人们:Sherlock 项目和社交分析器 - 有点粗略地看到像这样的技术在公共和易于下载的域中漂浮,并很好地提醒我们在互联网上的生活是多么公开。
[1] SRE — 站点可靠性工程,例如CNCF
[2] MECE — 互斥、集体详尽、超级咨询发言(链接)
- 112 次浏览
【软件开发】不确定度锥-第Cinq部分(更新版)
视频号
微信公众号
知识星球
不确定性锥的概念已经存在了一段时间。Barry Boehm在“软件工程经济学”的著作。普伦蒂斯·霍尔,1981年。下面的帖子来自Steve McConnell的网站,它清楚地说明了一些事情。
但首先,让我们建立一个框架假设。当你听说项目的不确定性没有随着项目的进展而减少时,问一个简单的问题。为什么会出现这种情况?为什么随着项目的进展,新的信息、交付的产品、降低的风险,整体的不确定性没有减少?在声称不确定性没有减少之前,先去找出造成这种情况的根本原因。不确定性作为所有项目的原则,应该通过项目管理的直接行动来减少。如果不确定性没有减少,情况可能是——糟糕的管理,失控的项目,或者你在纯粹的研究世界里工作,诸如此类的事情就会发生。
那么什么是不确定性锥呢?
- Cone是一个项目管理框架,描述了估算(成本和进度)和其他项目属性(成本、进度和技术性能参数)的不确定性方面。与锥体右侧的估计相比,锥体左侧的成本、进度和技术性能估计具有较低的精确性和准确性。这是由于许多原因造成的。一个是项目早期的不确定性水平。解释性和认识性的不确定性,给项目的成功带来了风险。造成风险的其他不确定性包括:
- 不切实际的绩效期望,缺少有效性衡量标准和绩效衡量标准
- 对风险的评估不充分,以及通过适当的处理计划未减轻对这些风险的暴露。
- 与保持有效性的替代计划和解决方案有关的未预料到的技术问题
- 由于所有项目工作都包含不确定性,减少这种不确定性——这降低了风险——是项目团队及其管理层的职责。团队本身、项目经理或项目经理,或大型项目的风险管理所有者。
以下是不确定性锥的简单定义:
不确定性锥描述了项目期间不确定性度量的演变。为了项目的成功,不确定性不仅必须随着时间的推移而减少,而且必须减少其对项目结果的影响。这是通过积极的风险管理,通过概率决策来实现的。在项目开始时,通常对产品或工作结果知之甚少。估计是必要的,但存在很大的不确定性。随着更多的研究和开发工作的进行,人们了解到了更多关于该项目的信息,不确定性随之降低,当所有风险都得到缓解或转移时,不确定性达到0%。这通常发生在项目结束时。
那么问题是?-为了提高项目成功的概率,项目属性(风险、有效性、性能、成本、进度——如下所示)需要在多大程度上减少差异?这是闭环项目控制的基础。对所需不确定性减少的估计、对不确定性可能减少的估计以及对这些减少工作的有效性的估计是闭环项目控制系统的基础。
这是不确定性锥的范式——它是一个计划开发合规性工程工具,而不是事后数据收集工具。
Cone不是项目过去表现的结果。Cone是项目进行过程中所需减少不确定性(或其他性能指标)的计划边界(上限和下限)。当成本、进度和技术性能的实际指标超出计划的不确定性范围时,如果项目要达到成本、进度或技术性能目标,就必须采取纠正措施,将这些不确定性转移到不确定性范围内。
如果你的项目的不确定性在计划范围之外,而此时它们本应在计划范围之内,那么你并没有降低项目成功的风险
在不确定性锥中建模的度量是建立绩效度量目标的控制过程的定量基础。获取实际性能,将其与计划性能进行比较,并遵守控制上限和下限,为进行调整以将变量性能保持在可接受的范围内提供了指导。
使用不确定性锥的好处
计划值、控制上限和下限、实际值的测量值形成闭环控制系统-一个基于测量的反馈过程,通过[1]提高项目管理过程的有效性和效率
分析有助于尽早关注问题领域的趋势——当受控变量开始行为不端时,可以采取干预措施。没有必要等到最后才发现你活不下去了。
- 提供对易出错产品的早期见解,然后可以更早地进行纠正,从而降低成本——当趋势走向UCL和LCL时,可以进行干预。
- 通过及早发现成本超支和进度延误,通过观察违反UCL和LCL的趋势,避免或最大限度地减少成本超支和工期延误。
- 在项目中足以实施纠正措施
- 执行更好的技术规划,并根据计划进度和实际进度之间的差异对资源进行调整。
所有项目工作的一个关键成功因素是风险管理。风险管理包括对各种风险的管理。风险来源于各种不确定性,包括技术风险、成本风险、进度风险、管理风险。这些不确定性及其产生的风险中的每一个都可以采用概率和统计分布函数描述的一系列值。了解哪些范围是可能的,哪些范围是可接受的,是项目成功的关键因素。
我们需要知道影响我们项目成功的所有变量的范围的控制上限(UCL)和控制下限(LCL)。我们需要知道这些范围是时间的函数。通过这种范式,我们将项目管理过程与控制系统过程逻辑连接起来。如果由UCL和LCL之外的不确定性造成的差异。这是一篇正在进行的论文“项目管理有一个基本理论吗”,它解决了项目活动控制的一些问题。
以下是一些计划差异和实际差异管理的例子,以确保项目按计划进行。
作为程序成熟度增加的函数的产品重量。在这种情况下,计划基本重量,并将每个主要子系统的计划重量作为时间的函数进行布局。项目基本权重的公差带为管理层提供了有关项目进展的可操作信息。如果车辆超重,则需要金钱和时间来纠正不希望出现的偏差。这是一个闭环控制系统,用于通过技术性能度量(TPM)管理程序。也可以采用成本和进度绩效衡量标准。
下面是具有错误带的“权重减少”属性的另一个示例。在本例中(与上述示例类似的实际车辆),当程序从左向右进行时,必须减轻重量。我们在测试准备审查中的目标重量为23KG。提案中出售了一辆25公斤的汽车,我们需要一个有安全裕度的目标重量,因此23公斤是我们的目标。
随着项目的进行,有UCL和LCL波段遵循计划的重量。橙色圆点是来自各种来源的实际重量——设计模型(3D Catia CAD系统)、详细设计模型、可测量的台式模型、非飞行原型,然后是第一次飞行文章)。随着程序的进行,每个模型到最终产品的每个重量测量值都会与计划重量进行比较。如果我们要坚持计划,我们需要将这些值保持在“需要减肥”的误差范围内。
这是成功项目管理的关键概念
我们必须为项目的关键属性——任务有效性、技术性能、关键性能参数——制定计划。如果这些不符合要求,项目将成为程序性能不足的根本原因之一。我们必须有一个燃耗或燃耗计划,以便在项目过程中为项目产生与这些参数相匹配的最终项目交付物。当然,我们一开始对每一项都有广泛的可能结果。随着程序的进行,这些项目的差异度量朝着符合目标数字的方向发展,在这种情况下为权重。
这是不确定性锥的另一个例子,在这种情况下,不确定性是由工程团队设计的烤箱的温度。UCL和LCL是在项目开始之前定义的。这些信息用于在项目进行过程中告知设计者项目的进展情况。保持在控制范围内是实现最终目标的计划进度路径——在这种情况下是温度。
不确定锥是闭环控制系统的信号边界,用于管理项目的成功
事实证明,圆锥体也可以是一个平坦的范围,具有正在开发的变量的控制上限和控制下限——一种对变量的设计——在本例中是一种性能度量。在这种情况下,当项目通过大门时,需要保持在上限和下限范围内的绩效衡量标准。如果这个变量超出了界限,项目将不得不以某种方式支付费用,才能将其退还给Green。
性能度量表征了在特定条件下测量或估计的与系统运行相关的物理或功能属性。性能度量是(1)确保系统有能力和能力执行的属性;(2)对系统进行评估,以确保其满足设计要求,从而满足有效性度量;(3)当实际性能超出控制上限和控制下限时,采取纠正措施,使实际性能恢复到计划性能。同样,这是简单的统计过程控制,使用反馈采取纠正措施来控制未来的结果——前馈。在概率和统计程序管理范式中,前馈控制使用过去的性能,以及未来的模型(未来行为的蒙特卡洛模型)来确定需要采取哪些纠正措施来保持程序的绿色。
另一种锥形风格是对交货日期的信心锥形。实际情况是低地球轨道飞行器的发射日期。在这种情况下,随着程序从左向右移动,我们需要确保启动日期从低置信度日期移动到有可能正确的日期。蓝色条是当前估计日期的概率范围。随着程序的推进,如果我们要根据需要出现,这些范围必须缩小。计划日期和带边距的日期是生成日期。随着程序的移动,日期的可信度必须增加,并朝着需要的日期移动。
- 概率完成时间随着程序的成熟而变化。
- 产生这些改进的努力必须加以界定和管理。
- 评估点的误差带也必须包括风险缓解活动。
- 计划的活动显示了误差带是如何随着时间的推移而变窄的:
- 这是风险容忍计划的基础。
- 随着风险缓解和成熟度评估增加了对计划发射日期的信心,概率区间变得更加可靠。
再次提醒一下——不确定性锥是一条理想的路径,而不是非托管项目结果的结果。
风险管理,如下所示,是成年人管理项目的方式
不确定性锥的目的和价值误区综述
当你听到。。。
我有数据表明,不确定性(或任何其他需要的属性)不会减少,因此COU是一个假的。。。或者。。。我看到我的项目数据,随着我们的前进,差异越来越大,而不是像计划COU告诉我们的那样缩小,应该实现我们的目标。。。
……然后该项目就失去了控制,从一个缺失的指导目标开始,这意味着它是开环控制,而且会迟到,超出预算,很可能无法达到所需的有效性和性能参数。当你看到这些失控的情况时,去寻找根本原因并制定纠正措施。
这些数据是对一个项目没有得到管理的观察,正如Tim Lister所建议的那样——风险管理就是成年人如何管理项目。
如果这些观察结果是在没有对绩效不足的根本原因采取纠正措施的情况下进行的,那么管理层的行为就很糟糕。他们只是对即将发生的火车事故的观察者。
不确定锥模型的工程原因及其对设计人员的价值
不确定性锥不是项目行为的输出,到那时已经太晚了。
不确定锥是管理框架的指导目标,用于增加项目成功的可能性。
这是项目的程序管理,以支持项目的技术管理。过程是一门工程学科。系统工程、风险工程、安全和任务保证工程是我们工作的典型角色。
否则的建议就是颠倒范式,从项目绩效的事后观察中去除任何价值。到那时已经太晚了,马已经离开了,再也回不来了。
在项目中的计划点定义计划和所需的方差水平是闭环控制系统的基础,需要提高成功的概率。
当出现计划差异之外的差异时,必须找到这些差异的根本原因并采取纠正措施。
以下是Galorath演示中的一个例子,使用了不确定性锥的框架,以及如何将这些放在一起的实际项目锥。再次重申,不确定性锥是
计划减少项目关键绩效指标的不确定性。
如果你的项目没有按计划减少这些关键性能指标(成本、进度和技术性能)的不确定性,那么它就会陷入麻烦,你甚至可能不知道。
Resources
[1] Systems Engineering Measurement Primer, INCOSE
[2] System Analysis, Design, and Development Concepts, Principles, and Practices, Charles Wasson, John Wiley & Sons
[3] SMC Systems Engineering Primer & Handbook: Concept, Processes, and Techniques, Space & Missle Systems Center, U.S. Air Force
[4] Defense Acquisition Guide, Chapter 4, Systems Engineering, 15 May 2013.
[5] Program Managers Tool Kit, 16th Edition, Defense Acquisition University.
[6] "Open Loop / Close Loop Project Controls"
[7] "Reducing Estimation Uncertainty with Continuous Assessment: Tracking the 'Cone of Uncertainty'," Pongtip Aroonvatanaporn, Chatchai Sinthop, Barry Boehm. ASE’10, September 20–24, 2010, Antwerp, Belgium.
[8] Boehm, B. “Software Engineering Economics”. Prentice-Hall, 1981.
[9] Boehm, B., Abts, C., Brown, A. W., Chulani, S., Clark, B. K., Horowitz, E., Madachy, R., Reifer, D. J., and Steece, B. Software Cost Estimation with COCOMO II, Prentice-Hall,
2000.
[10] Boehm, B., Egyed, A., Port, D., Shah, A., Kwan, J., and Madachy, R. "Using the WinWin Spiral Model: A Case Study," IEEE Computer, Volume 31, Number 7, July 1998, pp. 33-44
[11] Cohn, M. Agile Estimating and Planning, Prentice-Hall, 2005
[12] DeMarco, T. Controlling Software Projects: Management, Measurement, and Estimation, Yourdon Press, 1982.
[13] Fleming, Q. W. and Koppelman, J. M. Earned Value Project Management, 2nd edition, Project Management Institute, 2000
[14] Galorath, D. and Evans, M. Software Sizing, Estimation, and Risk Management, Auer-bach, 2006
[15]Jorgensen, M. and Boehm, B. “Software Development Effort Estimation: Formal Models or Expert Judgment?” IEEE Software, March-April 2009, pp. 14-19
[16] Jorgensen, M. and Shepperd, M. “A Systematic Review of Software Development Cost Estimation Studies,” IEEE Trans. Software Eng., vol. 33, no. 1, 2007, pp. 33-53
[17] Krebs, W., Kroll, P., and Richard, E. Un-assessments –reflections by the team, for the team. Agile 2008 Conference
[18] McConnell, S. Software Project Survival Guide, Microsoft Press, 1998
[19] Nguyen, V., Deeds-Rubin, S., Tan, T., and Boehm, B. "A SLOC Counting Standard," COCOMO II Forum 2007
[20] Putnam L. and Fitzsimmons, A. “Estimating Software Costs, Parts 1,2 and 3,” Datamation, September through December 1979
[21] Stutzke, R. D. Estimating Software-Intensive Systems, Pearson Education, Inc, 2005.
Related articles
- 57 次浏览
【软件开发】如何使用代码生成和脚手架工具加快开发速度?
视频号
微信公众号
知识星球
如何使用代码生成和脚手架工具加快开发速度?
- 什么是代码生成?
- 什么是脚手架?
- 代码生成和脚手架如何加快开发速度?
- 您可以使用哪些工具来生成代码和搭建脚手架?
- 如何学习和使用代码生成和脚手架工具?
什么是代码生成?
代码生成是从更高级别的表示(如模型、模板或规范)创建源代码或配置文件的过程。代码生成可以自动化常见或冗长的任务,例如创建CRUD操作、数据库模式、API端点或UI组件。代码生成还可以确保一致性、质量以及符合标准和最佳实践。
什么是脚手架?
脚手架是一种特殊类型的代码生成,它基于一些预定义的选项或参数为项目创建基本结构或骨架。脚手架可以帮助您引导新项目、设置初始文件和文件夹、安装依赖项以及配置环境。脚手架还可以提供一些示例代码或测试,让您开始使用。
代码生成和脚手架如何加快开发速度?
代码生成和脚手架可以在几个方面加快您的开发。首先,它们可以通过生成代码来节省您的时间和精力,否则您将不得不手动编写或复制粘贴这些代码。其次,他们可以通过创建遵循语言或框架的约定和语法的代码来减少错误和bug。第三,它们可以让你专注于项目的核心逻辑和功能,而不是样板或设置,从而提高你的生产力和专注力。第四,他们可以通过向您展示最佳实践和模式来增强您的技能和知识,您可以从中学习并应用于自己的代码。
您可以使用哪些工具来生成代码和搭建脚手架?
根据您的语言、框架和偏好,有许多工具可用于代码生成和脚手架。例如,如果您使用Java,您可以将Spring Boot、JHipster或Lombok用于web应用程序、微服务或数据访问层。或者,如果您使用Python,Cookiecutter、Django或FastAPI可以用于构建项目、web框架或RESTful API。同样,如果您使用JavaScript,Yeoman、Create React App或Angular CLI可以创建和管理项目、UI库或单页应用程序。最后,对于C#开发。NET Core CLI、Entity Framework Core或Blazor可以为跨平台应用程序、数据库模型或web组件生成代码。
如何学习和使用代码生成和脚手架工具?
要学习和使用代码生成和脚手架工具,您需要进行一些研究和实验。您可以先查看您感兴趣的工具的官方文档和教程,看看它们提供了哪些功能和选项。您还可以查找涵盖这些工具及其用例的在线课程、书籍或博客。然后,您可以尝试将这些工具用于自己的项目,或者创建一些示例项目来练习和测试它们。您还可以比较和对比不同的工具,看看哪些更适合您的需求和偏好。
代码生成和脚手架是强大的技术,可以帮助您加快开发速度并提高代码质量。通过为您的语言和框架使用正确的工具,您可以自动化和简化许多任务,并专注于项目中最重要的方面。您还可以从工具生成的代码中学习,并采用可以增强您的技能和知识的最佳实践和模式。
以下是其他需要考虑的事项
这是一个分享不适合前面任何部分的例子、故事或见解的空间。您还想添加什么?
- 49 次浏览
【软件开发】文档系统:文献大统一理论
为了编写好的软件文档,需要了解一个秘密:没有一种叫做文档的东西,有四种。
它们是:教程、操作指南、技术参考和解释。 它们代表四种不同的目的或功能,并且需要四种不同的方法来创建它们。 了解这一点的含义将有助于改进大多数文档——通常是极大的。
关于系统
此处概述的文档系统是一个简单、全面且几乎普遍适用的方案。它已在广泛的领域和应用中得到实践证明。
有一些非常简单的原则来管理文档,这些原则很少被阐明。它们似乎是一个秘密,尽管它们不应该是。
如果您能将这些原则付诸实践,它将使您的文档变得更好,并使您的项目、产品或团队更加成功——这是一个承诺。
该系统广泛用于大小、开放和专有的文档项目。
- 介绍
- 问题和解决方案
- 它解决的问题
- “秘密”
- 使文档工作
- 对于作者
- 对于读者
- 问题和解决方案
- 教程
- 烹饪类比
- 如何写出好的教程
- 让用户边做边学
- 让用户开始
- 确保您的教程有效
- 确保用户立即看到结果
- 使您的教程可重复
- 专注于具体步骤,而不是抽象概念
- 提供最低限度的必要解释
- 只关注用户需要采取的步骤
- Divio 文档中的示例
- 操作指南
- 烹饪类比
- 如何编写好的操作指南
- 提供一系列步骤
- 关注结果
- 解决特定问题
- 不要解释概念
- 允许一些灵活性
- 把事情放在一边
- 名称指导很好
- Divio 文档中的示例
- 参考指南
- 烹饪类比
- 如何编写好的参考指南
- 围绕代码构建文档
- 始终如一
- 除了描述什么都不做
- 准确无误
- Divio 文档中的示例
- 烹饪类比
- 解释
- 烹饪类比
- 如何写一个好的解释
- 提供上下文
- 讨论替代方案和意见
- 不指导或提供技术参考
- Divio 文档中的示例
- 关于结构
- 为什么这不明显?
- 崩溃的趋势
- 系统的采用
- 关于分析及其应用
- 谁在使用该系统?
- 其他提及和感兴趣的参考
原文:https://documentation.divio.com/
本文:https://jiagoushi.pro/documentation-systemp-grand-unified-theory-docume…
- 54 次浏览
【软件开发】软件开发中的不确定性锥
视频号
微信公众号
知识星球
不确定性锥只是意味着估计不确定性随着项目的进展而减少。
不确定性锥的概念是过去50年软件项目统计的结果。20世纪50年代引入工程和化学工程,并在20世纪80年代进一步推进软件开发。不确定性锥的概念最早是由AACE国际(美国成本工程师协会)的创始人根据维基百科介绍的,用于化学工业的工程和施工研究。后来,不确定性锥被广泛用作飓风预测中的图形,其最具标志性的用法更正式地称为NHC跟踪预测锥,更常见的是称为误差锥、概率锥或死亡锥。在软件行业,项目经理和软件开发人员使用不确定性锥来指导和管理项目估计。
在软件开发中,史蒂夫·麦康奈尔(Steve McConnell)在1997年出版的《软件项目生存指南》(software Project Survival Guide)一书中首次使用了“不确定性锥”一词,当时他将其作为估计具有不确定性或未知性的分类系统的标准类型。它说明了在项目的生命周期中,估计是如何变得更加准确的。
“软件评估的主要目的不是预测项目的结果,而是确定项目的目标是否足够现实,以使项目能够得到控制,从而实现这些目标”——Steve McConnell。
在软件项目的早期阶段,准确性水平较低,因此误差幅度较大。该项目可能会从许多未知和不明确的需求开始。在项目管理的最初收集需求阶段,任何任务估计都将非常松散,并且可能非常不准确。在软件生命周期中,随着项目接近完成阶段,可变性程度降低,这是一种常见的模式。了解可变性是制定现实项目计划的关键,因此项目可能会在初始规划阶段以正负40%的粗略估计开始。
不确定度图的圆锥体由横轴上的时间和纵轴上的估计方差表示。随着时间的推移,图向右移动,高估线的范围收敛到接近零。在项目开始时,时间线上的不确定性在圆锥体的大端最大,圆锥体的小端在所有细节都已知的末端。
使用不确定性锥的主要好处:
在软件开发中,不确定性锥用于管理需求和任务不断变化的项目,包括产品开发中使用的业务需求和技术。在工程成本和软件开发中的不确定性数量之间建立直接关系。
为什么不确定性锥很重要
在项目经理估计软件需求的交付成本的情况下,不确定性锥是非常可取的。它影响软件团队估计生产工作量、业务流程、时间表和功能的能力。开发人员离实际实现软件需求目标越远,他们的估计就越不确定和不准确。
- 减少不确定性
- 真实准确的估计
- 有效的规划
- 降低风险
- 度量资源分配
- 确定期望值
- 44 次浏览
需求分析
- 282 次浏览
【需求分析】用户故事vs用例
“用户故事和用例是一样的吗?”人们经常会问这个问题,关于敏捷团队应该实践使用故事还是用例的争论已经持续多年了。用户故事和用例是一回事吗?如果不是,哪一个更好?你应该使用哪一个?或者两者都使用?

虽然用户故事和用例之间有一些相似之处,但用户故事和用例是不可互换的;用户场景和用例都标识用户,它们都描述了目标,但是它们服务于不同的目的。
用户场景集中于您所描述的结果和好处,而用例可以更细粒度地描述系统将如何运行。用例在敏捷中有一席之地吗?或者它们可以相互结合使用吗?
本文将告诉您用户故事和用例之间的区别。
用户故事vs用例
用户故事往往一开始一样的用例,在每个描述了一种使用该系统,是围绕一个目标,从用户的角度来看,使用业务的自然语言,——自己不告诉整个故事。
用户故事与用例的相似性
如果我们考虑这两种方法的关键组成部分:
- 用户故事包含用户角色、目标和验收标准。
- 用例包含等价的元素:参与者、事件流和post条件分别(一个详细的用例模板可能包含更多的其他元素)。
用户故事与用例的区别
- 用户故事的细节可能不像用例那样被记录到相同的极端。
- 用户故事故意省略了许多重要的细节。用户故事的目的是通过在scrum会议上提出问题来引出对话。
- 为了更频繁地获得反馈而进行小的增量,而不是像用例中那样拥有更详细的预先需求规格说明。
什么是用户故事?
用户故事是一个记录,它捕捉用户在其工作中所做的或需要做的事情。每个用户故事都由一段用自然语言从用户的角度编写的简短描述组成。与传统的需求捕获不同,用户描述关注的是用户的需求,而不是系统应该交付的内容。这为进一步讨论解决方案和系统结果留下了空间,该系统能够真正适应客户的业务流程,解决他们的操作问题,最重要的是为组织增加价值。
3C的概念
3C指的是优秀用户故事的三个关键方面。这个概念是由用户故事实践的共同发明人Ron Jeffries提出的。现在,当我们谈到用户故事时,我们通常指的是由这三个方面组成的用户故事。
卡(Card)
用户故事被写成卡片。每个用户故事卡上都有一个简短的句子和足够的文字来提醒每个人故事是关于什么的。

谈话(Conversation)
在整个软件项目中,通过客户和开发团队之间的持续对话来发现和重新确定需求。重要的想法和决定会在涉众会议期间被发现并记录下来。

确认(Confirmation)
确认也称为用户故事的验收标准。在讨论需求的过程中,客户不仅告诉分析师他/她想要什么,还确认在什么条件和标准下接受或拒绝工作软件。定义的案例以确认书的形式书写。注意,确认关注于验证相应用户描述工作的正确性。它不是一个集成测试。

什么是用例?
用例是在20多年前由Ivar Jacobson引入的,用于在描述系统的功能需求时捕获用户(参与者)的观点。它们描述了用户使用软件系统一步步完成目标的过程。

用例是对最终用户想要“使用”系统的所有方式的描述。用例捕获用户和系统交互的所有可能方式,从而使用户实现目标。它们还捕捉了在过程中可能出现的所有问题,这些问题会妨碍用户实现目标。
用例模型由许多模型元素组成。最重要的模型元素是:
- 用例,
- 演员
- 以及它们之间的关系。
详细的用例说明
用例规范是系统提供的功能的文本描述。它捕获了角色与系统的交互。也就是说,它指定用户如何与系统交互,以及系统如何响应用户的操作。它通常以参与者和系统之间对话的形式出现。用例规格说明在用例图中由一个椭圆形表示,并且是大多数人在听到术语用例时想到的。

为什么我们仍然需要用例?
Alistair Cockburn解释说,他发现(在他咨询的公司)用户故事有三个主要问题:
- 缺乏背景(最大的目标是什么)
- 完成感,你涵盖了与目标相关的所有基础。
- 没有预见未来工作的机制。
集成用例、用户故事和故事映射技术
Visual Paradigm提供了一个完整的敏捷环境,它将用例、用户故事、故事映射、关联评估和看板集成到一个完全无缝的、自动化的端到端流程中。这个过程可以通过补充用例和故事映射工具来解决Alistair在上面提到的用户故事技术的缺点。为了更快、更好、更智能地管理您的敏捷项目,还整合了其他有用的敏捷工具。
下面的概念图概述了Visual Paradigm支持的敏捷工具。
- 将可视化模型中的需求作为产品待办事项列表项发送(用于构建故事图)
- 故事图中的用户活动,它代表了一个大的系统上下文作为一个整体
- 活动、任务和故事的垂直结构——待办事项的完整性
- 发布管理
- 根据用户的开发工作和风险评估用户描述
- 使用sprint管理开发活动
- 使用sprint任务板跟踪进度
第1点到第3点是用来补充用户故事不足的工具。其他用户敏捷工具列在第4到第7点。

原文:https://www.visual-paradigm.com/guide/agile-software-development/user-story-vs-use-case/
本文:http://jiagoushi.pro/node/1218
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 279 次浏览
【需求分析】需求分析技术
需求分析,也称为需求工程,是定义用户对正在构建或修改的新软件的期望的过程。在软件工程中,它有时被一些松散的名称所引用,例如需求收集或需求捕获。需求分析包括那些为一个新的或改变的产品或项目确定需要或满足的条件的任务,考虑不同涉众的可能冲突的需求,分析、记录、验证和管理软件或系统需求。以下是在软件项目的早期阶段进行需求分析的目标:
- 从什么到如何(From What to How):
- 弥合系统需求工程和软件设计之间差距的软件工程任务。
- 3个正交视图:为软件设计人员提供如下模型:
-
系统信息(静态视图)
-
函数(功能视图)
-
行为(动态视图)
-
- 软件架构:模型可以转换为数据、体系结构和组件级设计。
- 迭代和增量过程:期望在分析期间做一点设计,在设计期间做一点分析。
需求是什么?
软件需求是用户解决问题或实现目标所需要的能力。换句话说,需求是系统或系统组件必须满足或拥有的软件能力,以满足合同、标准、规格说明或其他正式强加的文档。最终,我们想要实现的是在预算范围内及时开发出满足客户实际需求的高质量软件。
也许软件开发人员面临的最大挑战是与客户共享最终产品的远景。项目中的所有涉众——开发人员、终端用户、软件经理、客户经理——必须对产品将会是什么样子以及要做什么有一个共同的理解,否则当产品交付时,会有人感到惊讶。软件领域的意外几乎从来不是好消息。
因此,在指定软件产品的需求时,我们需要一些方法来准确地捕获、解释和表示客户的声音。
需求分析的活动
需求分析对系统或软件项目的成功或失败至关重要。需求应该被记录下来,可操作的,可测量的,可测试的,可跟踪的,与已识别的业务需求或机会相关的,并且被定义到足以用于系统设计的详细级别。从概念上讲,需求分析包括四种类型的活动:
- 获取需求:与客户和用户沟通以确定他们的需求的任务。这有时也称为需求收集。
- 分析需求:确定所陈述的需求是否不清楚、不完整、含糊或矛盾,然后解决这些问题。
- 需求建模:需求可能以各种形式被记录,例如自然语言文档、用例、用户故事或过程规范。
- 评审(review)和回顾(retrospective):团队成员对迭代中发生的事情进行反思,并确定下一步改进的行动。
需求分析是一项团队工作,需要硬件、软件和人的因素、工程专业知识以及与人打交道的技能的结合。以下是在需求分析中涉及到的主要活动:
- 确定客户的需求。
- 评估系统的可行性。
- 进行经济和技术分析。
- 分配功能到系统元素。
- 制定时间表和约束条件。
- 创建系统定义。
需求分析技术
需求分析帮助组织确定涉众的实际需求。同时,它使开发团队能够用他们能够理解的语言(如图表、模型、流程图)与涉众进行交流,而不是使用页面文本。
一旦收集了需求,我们就将需求记录在软件需求规范(SRS)文档、用例或用户故事中,与涉众共享以获得批准。该文档对于普通用户和开发人员来说都很容易理解。要求中的任何变更也要形成文件,并通过变更控制程序,并在批准后定稿。
业务需求vs软件需求
一个商业计划或项目需要各种各样的需求来帮助定义目标和建立将要进行的工作的范围。需求还提供了环境和客观的方法来度量进展和成功。一旦建立了业务需求,就可以定义和开发软件需求,以便将项目向前推进。
业务需求
业务需求与业务的目标、愿景和目标相关。它们还提供了需要通过特定活动或项目来解决的业务需求或问题的范围。例如,如果一个行业协会的目标是促进其成员提供的服务,那么项目的业务需求可能包括创建一个成员目录,以提高成员的认知度。良好的业务需求必须是:
- 清晰的,通常在一个非常高的层次上定义。
- 提供足够的信息和指导,以帮助确保项目满足确定的需求。
- 理解组织的任务、目标或目标、特定的业务需求或正在处理的问题
- 在开发业务需求之前,应该清楚地定义和理解。
- 需求或问题可以与组织或业务有关,也可以集中于利益相关者群体,如客户、客户、供应商、员工或其他群体。
软件需求
软件需求分解满足业务需求或需求所需的步骤。业务需求描述了项目的“为什么”,而软件需求则描述了“是什么”。
例如,如果业务需求是创建一个贸易协会成员的一个目录,软件需求将概述谁有权访问的目录,有会员注册目录,谁会有数据的所有权,将使用什么车辆或车辆如一个网站或纸质目录,等等。
发现业务需求的技术
根据业务改进和软件开发过程,可以使用各种需求分析技术。下面列出了其中的一些技术。
使用BPMN或ArchiMate进行Gap分析
差距常被说成是“你现在的位置和你想要的位置之间的距离”。差距分析是基线和目标业务场景之间的比较过程。换句话说,差距分析是对企业当前在做什么以及未来想要去哪里的研究,是作为一种连接两者之间空间的手段。差距分析的目标是确定在优化性能方面的差距。这为企业提供了对潜在改进的洞察。它回答了一些问题,比如项目的当前状态是什么?我们想去哪里?等。
ArchiMate - Gap分析
ArchiMate是一种开放和独立的企业架构建模语言,支持以明确的方式描述、分析和可视化业务域内和跨业务域的架构。它是一个完美的建模工具,具有执行差距分析所需的符号。
BPMN -原有和将来的分析
原有流程
我们将要演示的示例是关于销售商品的在线商店的当前情况(原有流程)。该流程从销售代表收到客户的采购订单开始,然后检查库存水平。如果手头有足够的存货来满足订单的要求,销售代表将对其进行包装。这个过程结束于将它们连同发票一起发送。当库存不足时,销售代表将建议客户修改采购订单。
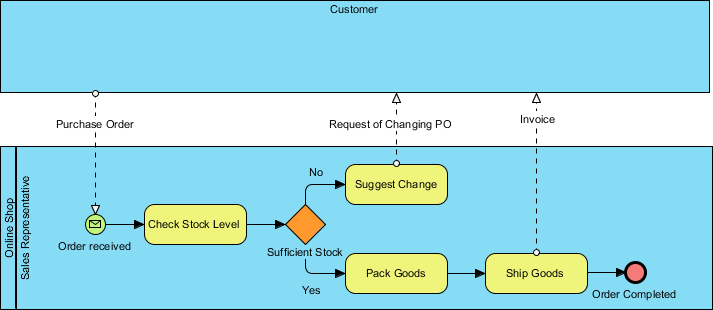
将来流程
假设我们的生意发展得很好,我们现在有一个仓库来存放我们的存货。因此,我们正在寻找改进现有流程的方法,以更好地分配新资源。此外,我们将在下面的将来流程图中展示一个对增强进行建模的示例。
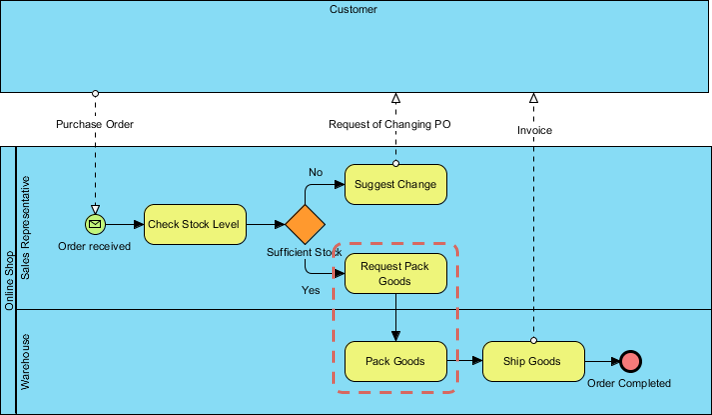
业务动机模型
如果一个企业为其业务活动规定了某种方法,它应该能够说出该方法要达到的原因(why)和目的(what)。业务动机模型(BMM)是一种OMG建模符号,用于支持关于如何对不断变化的世界作出反应的业务决策。企业可以通过获取BMM建模工具来使用它,然后创建自己的BMM——用特定于企业的业务信息填充模型。主要有两个目的:
- 获取关于对变化的反应的决策和做出决策的理由,目的是使它们可分享,增加清晰度,并通过经验学习来改进决策。
- 参考决策的结果及其对运营业务的影响(例如,对业务流程和组织责任的变更),提供从影响者到运营变更的可追溯性。

End :定义一个企业想要成为什么样子——它想要进入的状态。
Means (意味者):——定义一个企业需要做什么来实现它的目标。
Influencer (影响者)——是企业决定可能影响它的东西。
Assessment (评估)——当影响者引起重大变化时,企业对其影响进行评估,识别风险和潜在回报。可能会有多个评估,可能来自不同的利益相关者。
客户旅程映射
客户旅程图是一项非常有用的技术,它可以帮助你理解是什么激发了你的客户——他们的需求是什么,他们的犹豫和担忧。尽管大多数组织相当擅长收集关于客户的数据,但仅凭数据无法传达客户所经历的挫折和体验。一个故事可以做到这一点,而商业中最好的讲故事工具之一就是客户旅程图。
客户旅程地图(Customer journey map)使用讲故事和视觉效果来说明客户在一段时间内与企业之间的关系。故事是从客户的角度讲述的,这提供了对客户整体体验的洞察。它帮助您的团队更好地理解和解决客户的需求和痛点,因为他们在体验您的产品或服务。换句话说,规划好客户之旅可以让你的企业有机会看到你的品牌如何首先吸引潜在客户,然后再通过整个销售过程的接触点。
最后,团队可以针对每个接触点提出改进或采取的行动。这些建议的行动可能是软件需求的潜在来源。
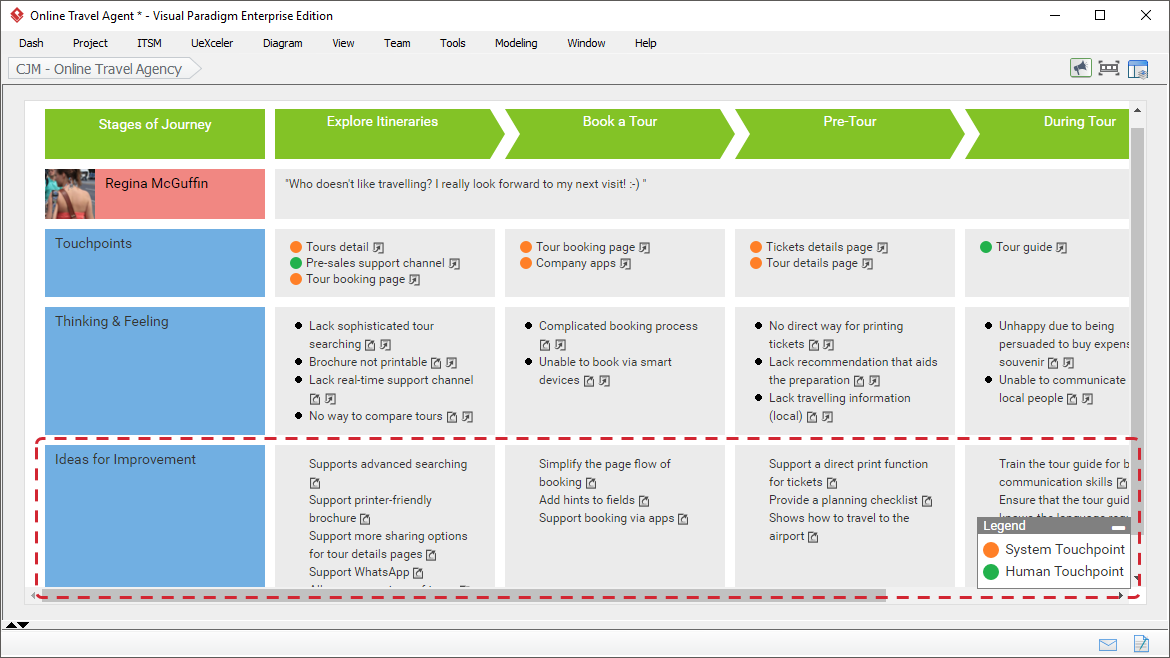
从业务需求中识别软件需求的技术
数据流图
数据流程图(DFD)可在SDLC(系统开发生命周期)内分析阶段的需求引出过程的早期设计,以界定项目范围。DFD通常用作创建系统概述的一个初步步骤,而不需要详细说明,稍后可以详细说明。
例如,如果需要在某个特定流程中显示更多细节,则该流程将在较低级别的DFD中分解为许多较小的流程。这样,内容图或上下文层次的DFD被标记为“0级DFD”,下一级分解被标记为“1级DFD”,下一级分解被标记为“2级DFD”,以此类推。
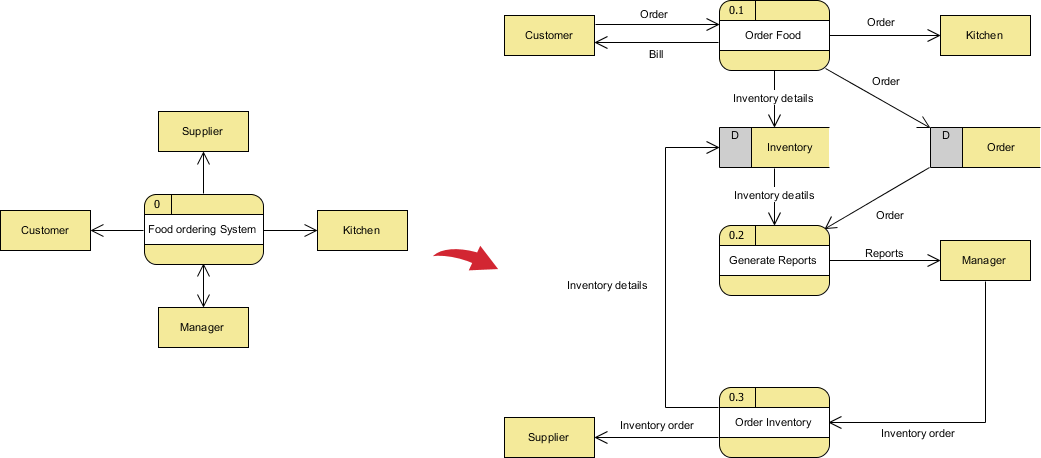
用例
UML用例图是未开发的新软件程序的系统/软件需求的主要形式。用例指定了预期的行为(什么),而不是使其发生的确切方法(如何发生)。用例一旦指定,就可以同时表示为文本和可视化表示(例如UML)。用例建模的一个关键概念是,它帮助我们从最终用户的角度设计系统。它是一种通过指定所有外部可见的系统行为来用用户的术语交流系统行为的有效技术。
- 用例图通常很简单。它没有显示用例的细节。
- 它只是总结了用例、参与者和系统之间的一些关系。
- 它没有显示为实现每个用例的目标而执行的步骤的顺序。
用例图的标准形式是用统一建模语言定义的,如下面的用例图示例所示:
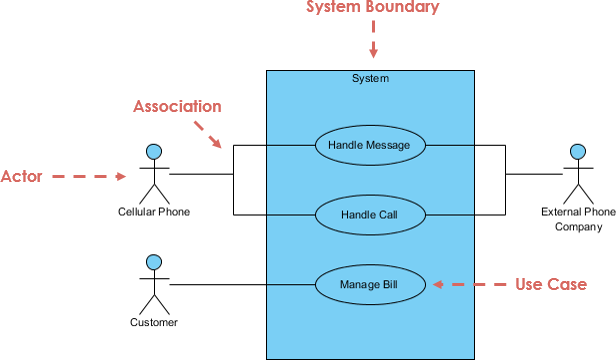
用户故事
用户故事是捕捉用户在工作中所做或需要做的事情的注释。每个用户故事都由一段用自然语言从用户的角度编写的简短描述组成。与传统的需求捕获不同,用户描述关注的是用户需要什么,而不是系统应该交付什么。这为进一步讨论解决方案和系统结果留下了空间,该系统能够真正适应客户的业务流程,解决他们的操作问题,最重要的是为组织增加价值。用户故事与其他敏捷软件开发技术和方法(如scrum和极限编程)很好地兼容。
用户故事与用例的相似性
如果我们考虑这两种方法的关键组成部分:
- 用户故事包含用户角色、目标和验收标准。
- 用例包含等价的元素:参与者、事件流和分别的post条件(一个详细的用例模板可能包含更多的其他元素)。
用户故事与用例的区别
- 用户故事的细节可能不像用例那样被记录到相同的极端。
- 用户故事故意省略了许多重要的细节。用户故事的目的是通过在scrum会议上提出问题来引出对话。
- 为了更频繁地获得反馈而进行小的增量,而不是像用例中那样拥有更详细的预先需求规格说明。

原文:https://www.visual-paradigm.com/guide/requirements-gathering/requirement-analysis-techniques/
本文:http://jiagoushi.pro/node/1216
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 226 次浏览