图形数据库
- 118 次浏览
【关系知识图谱】微软元老鲍勃·穆格利亚:关系知识图谱将改变商业
微软资深人士鲍勃·穆格利亚(Bob Muglia)表示,我们正处于知识图表的全新时代的开始,这与2013年现代数据堆栈的到来类似。
Bob Muglia表示,二十年来在数据库创新方面的工作将把E.F.Codd的关系演算引入知识图,他称之为“关系知识图”,从而彻底改变商业分析。
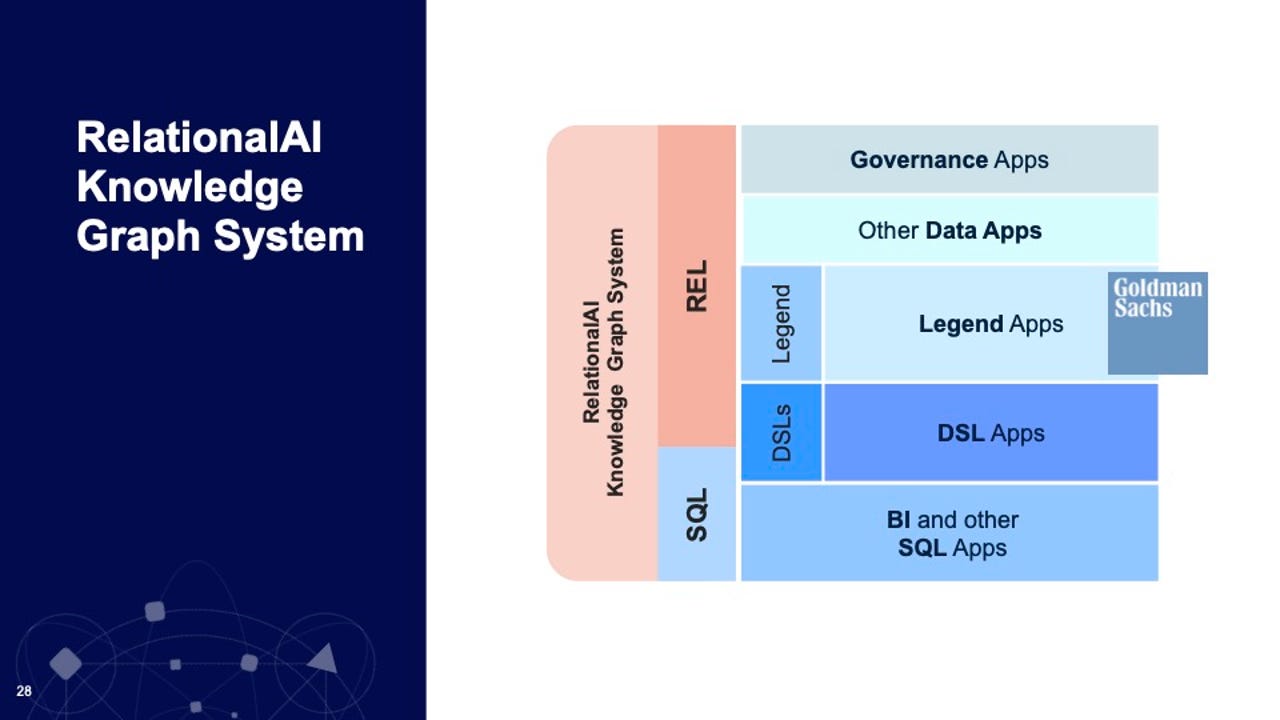
关系AI
鲍勃·穆格利亚有点像一个数据库诗人,能够讲述技术发展中的故事。
这就是周三上午,微软前高管、前Snowflake首席执行官穆格利亚在纽约知识图谱会议上发表主旨演讲时所做的。
他演讲的主题是“从现代数据堆栈到知识图”,以一种新的形式结合了大约50年的数据库技术。
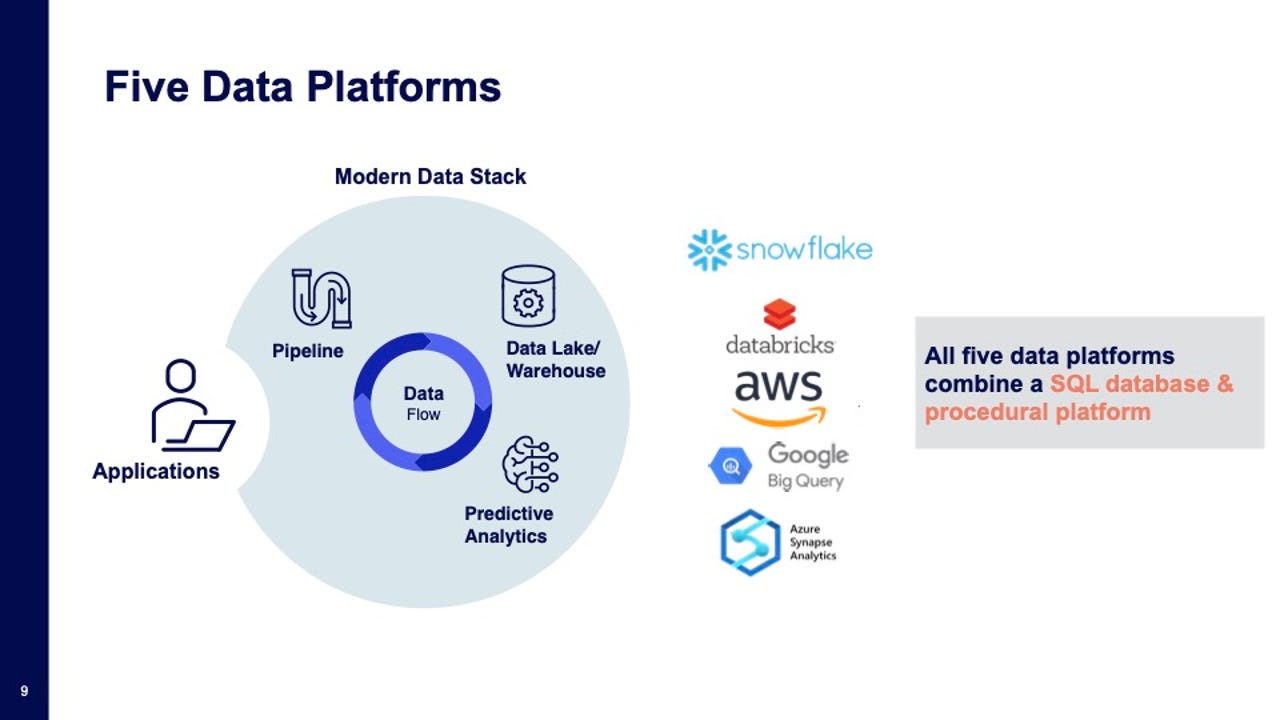
基本情况是这样的:五家公司创建了现代数据分析平台,Snowflake、Amazon、Databricks、Google和Azure,但这些数据分析平台无法进行业务分析,最重要的是,它们代表了作为合规和治理基础的规则。
穆格利亚说:“业界知道这是一个问题。”。他说,这五个平台代表了“现代数据堆栈”,允许“新一代的这些非常、非常重要的数据应用程序得以构建”。“然而,”当我们审视现代数据堆栈,审视我们可以有效地做什么和不能有效地做哪些时,我想说,客户在这五个平台中面临的首要问题是治理。"
此外:以太网创建者梅特卡夫:Web3将具有各种“网络效应”
Muglia在微软经营SQL Server业务,在30年的数据库职业生涯中取得了其他成就,他举例说明了数据平台无法建模的业务规则。
“所以,如果你想执行一个查询,说‘嘿,告诉我Fred Jones在这个组织中可以访问的所有资源’,这是一个很难写的查询,”他说。“事实上,如果组织非常庞大和复杂,这是一个可能无法在任何现代SQL数据库上有效执行的查询。”
Muglia说,问题是基于结构化查询语言(SQL)的算法无法执行如此复杂的“递归”查询。
作为一种数据库技术的吟游诗人,Muglia经常用华丽的修辞来传达技术细节:Binary Join!二进制联接!二进制联接!
2022年知识图谱会议
穆格利亚说:“已经有很多代算法都是围绕着二进制一的思想创建的。”。“它们有两个表,键将这两个表连接在一起,然后得到一个结果集,查询优化器将获取并优化这些连接的顺序-二进制连接、二进制连接、二元连接!”
他说,弗雷德·琼斯(Fred Jones)的权限等递归问题“无法用这些算法有效地解决”
Muglia表示,与数据关系不同的业务关系的正确结构是知识图。
“什么是知识图表?”穆格利亚用修辞的方式问道。他为一个有时神秘的概念给出了自己的定义。知识图是一个数据库,它对业务概念、它们之间的关系以及相关的业务规则和约束进行建模
Muglia现在是初创公司Relational AI的董事会成员,他告诉观众,业务应用程序的未来将是建立在数据分析之上的知识图,但有一个转折点,即它们将使用关系演算,一直追溯到关系数据库先驱E.F.Codd。
“回到开头,”穆格利亚催促道。“关系技术的基本算法能力是什么?可以用它做什么?”
Muglia指出,有五个基于SQL的分析平台,但没有一个平台能够单独进行业务分析,而不是数据分析。
关系AI
“如果我们看看Codd在20世纪70年代创造的东西,这个定理说关系代数和关系查询在表达能力上是完全等价的-太有趣了!我一直知道这很有趣,现在我知道为什么了。”
Muglia表示,使用关系人工智能的技术,特别是创始人兼首席执行官Molham Aref开发的用于查询优化的技术,结合知识图,可以将相同的关系代数应用于业务概念的组织。
“如果我们转向关系知识图,我们现在就转向关系演算的基础,我们发布的关系演算语句是无序的,它们包含业务规则和约束。”

Muglia说,SQL不会消失,但它无法真正处理业务分析的查询。
关系AI
穆格利亚说,“从根本上重新定义我们如何使用关系代数”的工作已经进行了大约20年,但在2010年,随着阿雷夫的工作,以及在众多大学和公司内部的工作,这项工作得到了发展,发表了数百篇关于这个主题的论文。
他说:“这是全世界研究界之间令人难以置信的合作努力。”。“物化在他们执行的物化内部以一种基本的方式使用它。LinkedIn通过他们使用的称为Liquid的图形数据库采用了这一点。”
关系知识图引入了一种称为Rel的新语言,尽管Muglia说,“SQL仍然很重要”,“SQL不会消失”,因为它是关系知识图新世界的一种入口。
“我甚至可以说,SQL最好的日子还在后头。”
Muglia在谈到关系知识图时表示:“从软件开发的角度来看,他预见到了惊人的、惊人的潜力,所有的事情都来自于此。”。“随着技术的成熟——我想重点关注的是,它还没有成熟——但随着技术的发展,我们将看到我们可以用它做一些我们甚至做梦都想不到的事情。”
这包括在商业分析中更多地使用机器学习,正如Relational AI这个名字所暗示的那样。此外,Muglia表示,业务模型将不再是“我们在白板上张贴的东西,工程师需要查看这些东西来编写一些Java代码。”
穆格利亚说:“模型变成了程序,因此业务分析师可以参与其中,并对数据结构进行更改。”
“想想成千上万了解这项业务的人参与进来——想想看!”
他说,目前,关系型人工智能的技术是“漂亮的白手套”。“我们有很多组织在做有限的试验,”该公司希望明年“开放自助服务”,“广泛的开发者测试版,让人们可以注册并开始使用该系统。”。
穆格利亚说:“我们正处于一个全新时代的开端。”。“这就像2013年、2014年的现代数据堆栈——这就是我们在生命周期中所处的位置。
“就像现代数据堆栈彻底改变了分析一样,我完全相信知识图,尤其是关系知识图,将改变企业的运行方式。”
知识图谱会议已进入第四个年头,2019年在哥伦比亚大学的一个舞厅里开始了一场小小的活动。今年,经过两年的纯虚拟会议,会议发展成为一场规模庞大的混合活动,在纽约市罗斯福岛的康奈尔理工学院校园举行了数十场专题讨论会和现场会议。该计划将持续到5月6日。
- 102 次浏览
【图型数据库】在Windows上安装PostgreSQL+Apache AGE的分步指南
视频号

微信公众号

知识星球

在这篇文章中,我们将逐步讨论如何在Windows机器上安装PostgreSQL和ApacheAGE。在本指南结束时,您将拥有一个功能齐全的PostgreSQL数据库和ApacheAGE图形数据库,可以用于数据驱动的应用程序。
什么是PostgreSQL?
PostgreSQL是世界上最著名的关系数据库之一,旨在管理和存储大量结构化数据。
PostgreSQL是开源的,以其可靠性、健壮性和可扩展性而闻名。它提供了各种高级功能,包括对事务、存储过程和触发器的支持。
PostgreSQL支持广泛的数据类型,包括文本、数字和日期/时间数据,以及更复杂的数据结构,如数组、JSON和XML。
什么是Apache AGE?
ApacheAGE是一个建立在PostgreSQL之上的图形数据库系统。它允许用户以高性能和可扩展的方式存储、管理和分析大规模图形数据。
ApacheAGE将强大的关系数据库管理系统(PostgreSQL)的优势与图形数据库的灵活性和可扩展性相结合。这意味着用户可以以关系格式存储数据,还可以对数据执行基于图的查询和分析。
如何安装PostgreSQL和Apache Age?
目前,Apache AGE不支持Windows。因此,在本教程中,我们将使用Windows Subsystem for Linux(WSL)作为替代方案。
1. Install WSL.
To enable WSL on your computer, follow these steps: First, go to the Control Panel, and then select Programs. Next, select Turn Windows features on or off. From the list of features, enable both Virtual Machine Platform and Windows Subsystem for Linux, as shown in the image

After enabling WSL, the next step is to install a Linux distribution for Windows. To do this, open the Microsoft Store and search for 'Linux.' You will see several options available, and you can choose the one you prefer. For the purposes of this tutorial, we will be using 'Ubuntu 22.04.2 LTS'.
2. Installing PostgreSQL from source code.
Please note that currently, Apache AGE only supports PostgreSQL versions 11 and 12, so we must install one of these versions. Before proceeding, we need to install some dependencies. To do this, open a bash terminal by navigating to any directory and typing 'bash' in the address bar, and then run the appropriate command.
sudo apt install git libreadline-dev zlib1g-dev bison flex build-essential
Next, create a directory where you want to install PostgreSQL and clone the Postgres repository into it.
mkdir postgres-AGE-project
cd postgres-AGE-project
git clone https://git.postgresql.org/git/postgresql.git
Navigate to the 'postgresql' directory and switch to a compatible version branch. For the purposes of this tutorial, we'll be using version 12.
cd postgresql
git checkout REL_12_STABLE
Compile the source code and specify the directory where you want the binaries to be installed. Note that this process may take some time to complete.
./configure –prefix=/usr/local/pgsql-12
make
After the compilation process is complete, run the following command to add permissions for the binaries directory and replace user by your username. Once this is done, proceed to install PostgreSQL
sudo mkdir /usr/local/pgsql-12
sudo chown user /usr/local/pgsql-12
make install
To ensure that PostgreSQL can be accessed from anywhere in the terminal, it is necessary to set up the following environment variables
These commands will add the PostgreSQL binaries directory to the system path and set the PGDATA directory to the location of the PostgreSQL data files.
export PATH=/usr/local/pgsql-12/bin/:$PATH
export PGDATA=/usr/local/pgsql-12/bin/data
Now that you have installed PostgreSQL, you can create a new cluster, which is a collection of databases managed by a single instance of the PostgreSQL server. To create a new cluster, run the following command:
initdb
After initializing the cluster, you can start the PostgreSQL server by running the following command:
pg_ctl -D /usr/local/pgsql-12/bin/data -l logfile start
Now you can start PostgreSQL by running the following command:
psql postgres
Congratulations! You have successfully installed and started PostgreSQL.
To exit PostgreSQL run \q
To stop the server run the following command:
pg_ctl -D /usr/local/pgsql-12/bin/data -l logfile stop
If you would like more detailed information about the installation process, you can visit the following link: PostgreSQL documentation
3. Installing Apache AGE from source code.
To install Apache AGE from source code, go to the main directory of the postgres-AGE-project that we created earlier and execute the following command to clone the AGE project.
git clone https://github.com/apache/age.git
To proceed with the installation, navigate to the project directory and switch to the latest stable release, which is version 1.1.0.
cd age
git checkout release/PG12/1.1.0
Set the environment variable PG_CONFIG. we need to set the PG_CONFIG environment variable to specify the location of the PostgreSQL pg_config utility. pg_config is a command-line utility that provides information about the installed version of PostgreSQL, including the location of files and libraries required for compiling and linking programs against PostgreSQL. Apache AGE uses pg_config to determine the location of the PostgreSQL header files and libraries needed to compile the AGE extension.
export PG_CONFIG=/usr/local/pgsql-12/bin/pg_config
Then install AGE extension by running this command:
make install
Now you have AGE installed to add the extension in your postgres server run the following SQL commands:
CREATE EXTENSION age;
Then every time you want to use AGE you must load the extension.
LOAD 'age';
Great job! You have successfully installed Apache AGE on your system.
You can find further information on AGE installation and usage on the official Apache AGE documentation at AGE documentation.
References
PostgreSQL
AGE - Installation giude
Contribute to Apache AGE
Apache AGE website: https://age.apache.org/
Apache AGE Github: https://github.com/apache/age
- 559 次浏览
【图型数据库】在您的计算机上安装Apache AGE
视频号
微信公众号
知识星球
Install AGE & PSQL from Source
You can convert your existing relational database to a graph database by simply adding an extension. Apache AGE is a PostgreSQL extension that provides graph database functionality. It enables users to leverage a graph database on top of the existing relational databases.
We will take a look at
- Installing Postgres from source.
- Installing & configuring Apache AGE with Postgres.
- Installing AGE-Viewer for Graphs analysis.
This article will explain to you how to install age on your Linux machine from the source. For macOS users, there is a detailed video for the overall installation process. Linux users can also watch this video as most of the steps are identical.
Getting Started
We gonna install the age and PostgreSQL from the source and configure it.
mkdir age_installation
cd age_installation
mkdir pg
cd pg
Dependencies
Install the following essential libraries before the installation. Dependencies may differ based on each OS You can refer to this for further details https://age.apache.org/age-manual/master/intro/setup.html#pre-installation.
So in case, you have ubuntu installed
sudo apt-get install build-essential libreadline-dev zlib1g-dev flex bison
It is also recommended to install postgresql-server-dev-xx package. These are development files for PostgreSQL server-side programming. For example if you are using ubuntu.
sudo apt install postgresql-server-dev-11
Further you can refer to https://age.apache.org/age-manual/master/intro/setup.html#postgres-11
Installing From source
PostgreSQL
Downloading
You will need to install an AGE-compatible version of Postgres, for now AGE only supports Postgres 11 and 12. Download the source package for postgresql-11.8 https://www.postgresql.org/ftp/source/v11.18/
Downloading it and extracting it to the /age_installation/pg
wget https://ftp.postgresql.org/pub/source/v11.18/postgresql-11.18.tar.gz && tar -xvf postgresql-11.18.tar.gz && rm -f postgresql-11.18.tar.gz
This will download the tar file for the Linux users and also extract it in the working directory.
Installing
Now we will install the pg. The —prefix have the path where we need to install the psql. In this case, we are installing it in the current directory pwd .
cd postgresql-11.18
# configure by setting flags
./configure --enable-debug --enable-cassert --prefix=$(pwd) CFLAGS="-ggdb -Og -fno-omit-frame-pointer"
# now install
make install
# go back
cd ../../
We should configure it by setting the debugging flags. In case of the macOS users
./configure --enable-debug --enable-cassert --prefix=$(pwd) CFLAGS="-glldb -ggdb -Og -g3 -fno-omit-frame-pointer"
AGE
Downloading
Now download the AGE from the GitHub repo https://github.com/apache/age. Clone it under /age_installation directory.
git clone https://github.com/apache/age.git
Installing
Now we will configure age with PostgreSQL.
cd age/
# install
sudo make PG_CONFIG=/home/imran/age_installation/pg/postgresql-11.18/bin/pg_config install
# install check
make PG_CONFIG=/home/imran/age_installation/pg/postgresql-11.18/bin/pg_config installcheck
PG_CONFIG require the path to the pg_config file. Give the path from the recently installed PostgreSQL.

DB Initialization
Now we will initialize the database cluster using the initdb
cd postgresql-11.18/
# intitialization
bin/initdb demo
So we named our database cluster demo.
Start Server
Now start the server and make a database named demodb
bin/pg_ctl -D demo -l logfile start
bin/createdb demodb
If you wanna change the port number use bin/createdb --port=5430 demodb
Start Querying
AGE added to pg successfully. Now we can enter in to pg_sql console to start testing.
bin/psql demodb
If you have server running on some other port like in my case it is 5430 use bin/createdb --port=5430 demodb
Now when you have initialize a new DB we have to load the AGE extension in order to start using AGE. Also, we need to set search_path and other variables if didn’t set them earlier in the /postgresql.conf file.
Note that you can also set these parameter in the
postgresql.conffile. See more
CREATE EXTENSION age;
LOAD 'age';
SET search_path = ag_catalog, "$user", public;
Now try some queries having cypher commands.
SELECT create_graph('demo_graph');
SELECT * FROM cypher('demo_graph', $$ CREATE (n:Person {name : "james", bornIn : "US"}) $$) AS (a agtype);
SELECT * FROM cypher('demo_graph', $$ MATCH (v) RETURN v $$) as (v agtype);

Installing AGE-Viewer
So age-viewer is a web app that helps us visualize our data.
Dependencies
Install nodejs and npm to run that app. You are recommended to install node version 14.16.0. You can install the specific version using the nvm install 14.16.0. You can install nvm from https://www.freecodecamp.org/news/node-version-manager-nvm-install-guide/.
sudo apt install nodejs npm
or
# recommended
nvm install 14.16.0
Downloading
Go back to directory /age_installation
git clone https://github.com/apache/age-viewer.git
Starting
Now set up the environment.
cd age-viewer
npm run setup
npm run start
Viewer will now be running on the localhost. Now connect the viewer with the database server.Enter the details required to login
# address (default : localhost)
url: server_url;
# port_num (default 5432)
port: port_num;
# username for the database
username: username;
# password for the user
pass: password;
# database name you wanna connect to
dbname: demodb;
Note that If you are following the above steps and installed postgres form source, then postgres a user would be created automatically during the installation. The username will be same as the name of your linux user. In my case a user with name imran was created as my linux user name was imran. Also there would be no password on this default user, you can set the password later.
In my case i used the following settings.
url: localhost;
port: 5432;
username: imran;
# radom pass as password is not set for this user.
pass: 1234;
dbname: demodb;

Visualizing Graphs
Now try creating some nodes and then you can visualize their relationship on the age-viewer.
First we will create PERSON nodes
SELECT * FROM cypher('demo_graph', $$ CREATE (n:Person {name : "imran", bornIn : "Pakistan"}) $$) AS (a agtype);
SELECT * FROM cypher('demo_graph', $$ CREATE (n:Person {name : "ali", bornIn : "Pakistan"}) $$) AS (a agtype);
SELECT * FROM cypher('demo_graph', $$ CREATE (n:Person {name : "usama", bornIn : "Pakistan"}) $$) AS (a agtype);
SELECT * FROM cypher('demo_graph', $$ CREATE (n:Person {name : "akabr", bornIn : "Pakistan"}) $$) AS (a agtype);
SELECT * FROM cypher('demo_graph', $$ CREATE (n:Person {name : "james", bornIn : "US"}) $$) AS (a agtype);
SELECT * FROM cypher('demo_graph', $$ CREATE (n:Person {name : "david", bornIn : "US"}) $$) AS (a agtype);
Now creates some nodes of COUNTRY.
SELECT * FROM cypher('demo_graph', $$ CREATE (n:Country{name : "Pakistan"}) $$) AS (a agtype);
SELECT * FROM cypher('demo_graph', $$ CREATE (n:Country{name : "US"}) $$) AS (a agtype);
Now create a relationship between them.
SELECT * FROM cypher('demo_graph', $$ MATCH (a:Person), (b:Country) WHERE a.bornIn = b.name CREATE (a)-[r:BORNIN]->(b) RETURN r $$) as (r agtype);
Now we can visualize our whole graph created.
SELECT * from cypher('demo_graph', $$ MATCH (a:Person)-[r]-(b:Country) WHERE a.bornIn = b.name RETURN a, r, b $$) as (a agtype, r agtype, b agtype);

Help
Config File
In case you want to change the port number (default5432) and other variables you can take a look at thedemo/postgresql.conf file. You have to restart the server after that. Setting the parameters here will save you from the initialization commands like LOAD 'age'; as used earlier.
nano demo/postgresql.conf
# In postgresql.conf file update and uncomment
port = 5432 #new port if wanted
shared_preload_libraris = 'age'
search_path = 'ag_catalog, "$user", public'
You can also set these variables using the commands shown earlier.
Error with WSL
When installing age-viewer. If you are using WSL restart it from PowerShell after installing node, npm using wsl --shutdown. WSL path variable can intermingle with node path variable installed on windows. https://stackoverflow.com/questions/67938486/after-installing-npm-on-wsl-ubuntu-20-04-i-get-the-message-usr-bin-env-bash
Now start WSL again. Don’t forget to start the pg server again after the WSL restart. Run server again using bin/pg_ctl -D demo -l logfile start .
Acknowledgment
These resources helped me a lot during the installation. You can also refer to these if help is needed.
- 239 次浏览
【图型数据库】基于PostgreSQL的图型数据库Apache Age 介绍
视频号
微信公众号
知识星球
Age 是一个领先的多模型图形数据库
关系数据库的图形处理与分析
 什么是Apache AGE?
什么是Apache AGE?
ApacheAGE是PostgreSQL的扩展,它允许用户在现有关系数据库的基础上利用图形数据库。AGE是图形扩展的缩写,其灵感来自Bitnine的AgentsGraph,PostgreSQL的一个多模型数据库分支。该项目的基本原则是创建一个处理关系数据模型和图形数据模型的单一存储,以便用户可以使用标准的ANSI SQL以及当今最流行的图形查询语言之一openCypher。

由于AGE基于功能强大的PostgreSQL RDBMS,因此它是健壮的,功能齐全。AGE针对处理复杂的连通图数据进行了优化。它提供了大量对数据库环境至关重要的健壮数据库功能,包括ACID事务、多版本并发控制(MVCC)、存储过程、触发器、约束、复杂的监控和灵活的数据模型(JSON)。具有关系数据库背景、需要图形数据分析的用户可以毫不费力地使用此扩展,因为他们可以在不进行迁移的情况下使用现有数据。
强烈需要有凝聚力、易于实现的多模型数据库。作为PostgreSQL的扩展,AGE支持PostgreSQL所有的功能和特性,同时还提供了一个可引导的图形模型。
 总览
总览
Apache AGE是:
- 强大:为已经流行的PostgreSQL数据库添加了图形数据库支持:苹果、Spotify和美国国家航空航天局等组织都在使用PostgreSQL。
- 灵活:允许您执行openCypher查询,这使复杂的查询更容易编写。它还允许同时查询多个图。
- 智能:允许您执行图形查询,这些查询是许多下一级web服务的基础,如欺诈检测、主数据管理、产品推荐、身份和关系管理、体验个性化、知识管理等。
 特性
特性

Cypher Query:支持图形查询语言
- 混合查询:启用SQL和/或Cypher
- 查询:启用多个图
- 层次结构:图形标签组织
- 特性索引:在顶点(节点)和边上
- 完整的PostgreSQL:支持PG功能
- 375 次浏览
【图型数据库】数据库深度探索:JanusGraph
在数据库深度挖掘的第三部分中,我们与JanusGraph PMC成员Florian Hockmann和Jason Plurad进行了交流,以获得关于广泛的Graph世界的一些指导。

JanusGraph是一个可扩展的图形数据库,用于存储和查询分布在多机集群中的包含数千亿顶点和边的图形。该项目由Titan出资,并于2017年由Linux基金会(Linux Foundation)开放管理。
阅读下面的文章,从G Data的Florian Hockmann和IBM的Jason Plurad那里了解JanusGraph是如何与Neo4j进行比较的,为什么应该关注TinkerPop 4,并获得关于图形数据建模的专家提示。
跟我们谈谈你自己和你今天在做什么?
弗洛里安·霍克曼(FH):我的名字是弗洛里安·霍克曼,我是德国杀毒软件供应商G DATA的一名研发工程师。我所在的团队负责分析我们每天收到的成千上万的恶意软件样本。我们使用一个图形数据库来存储关于这些恶意软件样本的信息,以便能够在相似的恶意软件样本之间找到连接。
Jason Plurad (JP):我是Jason Plurad,一名开放源码开发人员,也是IBM认知应用程序的倡导者。我一直活跃在像JanusGraph和Apache TinkerPop这样的图形社区中,帮助发展这些开源社区,并使我们的产品团队和客户能够使用图形和其他开源数据技术。我也和我的团队一起探索其他新兴的开源数据和人工智能项目。
你是怎么和JanusGraph合作的?
JP: IBM是JanusGraph的创始成员之一,我是这个团队的一员。我们一直在用它的前身Titan生产几种不同的产品。我们喜欢Titan是因为它的开源许可,以及它在构建整体图形平台方面给予我们的灵活性。
当创建泰坦的Aurelius公司被DataStax收购时,开源社区都在猜测泰坦的未来会是什么样子。最终,DataStax发布了作为DataStax企业一部分的图,但是没有开源选项。我们知道我们并不是唯一想要开源图形数据库的人,所以我们在社区中找到了其他人,一起创建了Titan,并将JanusGraph带到了Linux基金会。
我们最初使用的是泰坦,它是JanusGraph的前身。Titan很适合我们,因为我们正在寻找一个可以水平伸缩的数据库,使我们能够找到恶意软件样本之间的连接,这是一个典型的图形数据库用例。在开发Titan的公司被收购后不久,它就停止了在Titan上的所有工作,我们剩下的数据库系统不再需要维护了。所以,当IBM和其他公司在Titan上创建JanusGraph时,我们当然非常高兴,我们想为这个新项目贡献自己的力量,以确保JanusGraph成功地成为一个可扩展的开源图形数据库。
我已经参与了Apache tinkerpop的开发——主要开发Gremlin. net变体Gremlin。因此,为JanusGraph贡献一个扩展库是很自然的。但我也为项目的其他部分做出了小小的贡献,帮助了邮件列表或StackOverflow上的新用户。这是一个很好的方式,让我了解这个项目的各个部分,让我更多地参与其中。
在选择Neo4j和JanusGraph时,人们应该知道什么?
JP:人们还应该知道JanusGraph和Neo4j支持Apache TinkerPop图形框架。TinkerPop使您能够使用相同的图结构和Gremlin图遍历语言,使用相同的代码来生成多个图数据库。TinkerPop与许多其他供应商兼容,包括Amazon Neptune、Microsoft Azure Cosmos DB和DataStax Enterprise Graph,不过请记住,许多TinkerPop实现都不是免费的开源的。
这可能不是人们所期望的答案,但是团队应该与他们的律师一起评估许可证,以确定哪种许可证适合他们的需要。JanusGraph使用Apache许可证,这是一个自由的开放源码许可证,允许您使用它几乎没有限制。Neo4j Community Edition使用GNU通用公共许可证,该许可证对发布软件有更严格的要求。许多开发人员最终需要Neo4j企业版提供的可伸缩性和可用性特性,而Neo4j企业版需要商业订阅许可证。
FH:我认为这两种图形数据库之间主要存在两个区别因素。首先,Neo4j基本上是一个自包含的项目。我这么说的意思是,它实现了自己的存储引擎、索引、服务器组件、网络协议和查询语言。
另一方面,JanusGraph在这些方面的大部分都依赖于第三方项目。这背后的原因是,对于这些问题,已经有了适合其具体工作的解决方案。通过使用它们,JanusGraph可以真正专注于图形方面,而不必再去解决这些问题。
例如,JanusGraph可以使用Elasticsearch或Apache Solr实现高级索引功能(如全文搜索),并使用可伸缩数据库(如Apache Cassandra或HBase)存储数据。正因为如此,使用Neo4j可能更容易上手,因为涉及的移动部件更少,但是JanusGraph提供了更大的灵活性,用户可以根据自己的特定需求在不同的存储和索引后端之间进行选择。用户可以自己决定他们喜欢哪种方法。
我看到的其他关键区别因素是这两个图形数据库面向用户的界面,查询语言是其中的中心方面。JanusGraph为此实现了TinkerPop(它可以被认为是图形数据库事实上的标准,因为目前大多数图形数据库都实现了它),它为用户提供了跨越不同图形数据库的基本相同的体验,类似于SQL在关系数据库中扮演的角色。
虽然也可以将TinkerPop及其查询语言Gremlin和Neo4j一起使用,但Neo4j主要是促进它们自己的查询语言——cipher。因此,大多数Neo4j用户最终可能会使用这种语言。
当然,用户必须再次自己决定他们更喜欢哪种查询语言,Gremlin还是Cipher,以及能够在将来的某个时候轻松切换到另一个图形数据库对他们来说有多重要。
当然,除了这些技术方面,我还想指出JanusGraph是一个完全由社区驱动的开源项目。因此,希望看到某个特性实现的用户可以自己实现它。
对于想要在生产环境中部署JanusGraph的人,您有什么建议?
FH:我已经提到JanusGraph使用几个不同的组件来创建图形数据库,它提供了丰富的功能,比如索引和存储引擎。虽然这种方法为用户提供了极大的灵活性和丰富的特性集,但它也可能让新用户感到有些难以承受。
但是,我想指出,开始使用JanusGraph并不需要对所有组件都有深入的了解。当我开始使用泰坦的时候——基本上和janusgraph一样——我对Cassandra和Elasticsearch一无所知,但我仍然能够通过这些后端快速地安装和部署泰坦。
多年来,我们从Cassandra切换到Scylla,添加了用于机器学习的Apache Spark,并通过将JanusGraph移动到Docker容器中,使我们的部署更易于扩展。
因此,我的建议是先进行小型而简单的部署,然后根据需要增加部署的规模和复杂性。JanusGraph的文档还包含“部署场景”一章,描述了一个相对简单的开始场景,以及如何将其发展成更高级的场景。
另一个对JanusGraph非常重要的项目是TinkerPop,我已经提到过几次了。因此,我建议新用户熟悉TinkerPop,最重要的是,熟悉它的图形查询语言Gremlin。有很多很好的资源可以帮助你入门,比如TinkerPop的教程或者免费的电子书Practical Gremlin。
JP:首先,也是最重要的,准备好完全接受开源并为之做出贡献。JanusGraph是一个社区项目,它不是由单个供应商拥有或驱动的。您的团队应该与JanusGraph社区合作,识别并解决您遇到的bug,因为您最有动力去修复它们。随着时间的推移,通过持续的贡献,您的团队可以成为JanusGraph的领导者,帮助推动项目向前发展。在团队进入生产阶段时,操作可能是一个大障碍。当您在处理团队可能尚未熟悉的大量技术时,您应该花足够的精力来理解如何保持数据基础设施正常运行。由于JanusGraph依赖于外部存储后端(如Apache Cassandra或Apache HBase),最终,您的团队将需要部署和操作那些水平可扩展数据库及其依赖关系的技能。当然,您也应该参与这些开源社区。
在接下来的几年里,你对JanusGraph和TinkerPop有什么期待?
帕森斯:我从事图形数据领域已经好几年了,但它仍处于新兴阶段。在接下来的几年里,我很乐意看到图形生态系统中工具的改进。这将包括用于图形建模、图形可视化和图形数据库操作的工具。
在总体数据体系结构中,图通常不是唯一的,因此能够在图数据和其他数据模型之间架起桥梁的工具将有助于推动图数据进入主流。
今年,W3C对图形数据(包括属性图、RDF和SQL)的标准化越来越感兴趣。有了图形数据的开放标准规范,图形数据库供应商就可以更好地提高它们在数据库市场上的份额。
FH:特别是对于JanusGraph来说,很难预测未来的发展,因为这个项目完全是由社区驱动的,而且很多贡献都来自于那些对JanusGraph感兴趣的用户,他们希望根据自己的经验和需求来改进JanusGraph。
除了许多小的性能改进之外,JanusGraph很可能很快就会有一个性能得到显著改善的内存后端,也可以用于生产使用,而不是目前的内存后端,后者仅用于测试目的。这个改进后的后端是JanusGraph用户做出贡献的一个很好的例子,在这个例子中是高盛的开发人员。
总的来说,我希望JanusGraph在接下来的几年里在后端有实质性的改进。当然,我们只是从新发布的后端本身的改进中获益,但是全新的后端也可以为JanusGraph提供巨大的改进或全新的功能。
例如,FoundationDB看起来非常有前途,因为它完全专注于实现一个可伸缩的存储引擎,提供具有ACID属性的事务,而其他层可以添加丰富的数据模型或高级索引功能等特性。这种方法似乎很适合JanusGraph的模块化架构,并且有可能解决JanusGraph的一些常见问题,比如存储超级节点或执行升级。
但是,很高兴你还提到了TinkerPop,因为JanusGraph的许多改进实际上来自TinkerPop,尤其是下一个主要版本TinkerPop 4的发布。
TinkerPop 4的开发仍处于非常早期的状态,但是一些主要的改进已经可以确定了。我个人尤其期待的是为Gremlin遍历提供更广泛的执行引擎。现在,人们可以选择使用单个线程执行遍历(这非常适合实时使用情况),或者在使用Spark的计算集群上执行遍历(例如,用于机器学习或图形分析)。
在G数据,我们往往用例在中间的这两个选项,因为他们应该回答的几秒也不太可能引发,因为它有一些空中他们涉及穿越大量的边缘,也不是一个适合单线程执行。一个额外的执行引擎能够使用更多的计算资源,但不需要首先加载整个图,它可能非常适合这些用例。
目前,人们还花费了大量精力为TinkerPop创建一个更抽象的数据模型,该模型并不特定于图形。这有可能使TinkerPop也可以用于非图形数据库和计算引擎。所以,它真的可以增加支持tinkerpop的数据库的生态系统。
你有什么提示或技巧的性能图形建模?
FH:这可能听起来很明显,但我认为许多用户仍然没有这样做——即在将模式投入生产之前评估新的模式或对其进行重大更改。
如果可能的话,应该使用真实的数据来完成,并且评估应该包括建模实际用例的查询。确实没有其他方法可以确保您的模式实际上很好地适合您的用例,并且在生产后期更改模式要比进行初始评估花费更多的时间。
对于所有的图形数据库来说,超级节点是一个非常重要的主题,因为超级节点非常麻烦,并且会导致非常高的查询执行时间。因此,最好尽早检查数据模型中是否会出现超级节点,然后绕过它们,例如,通过相应地更改模式。
对于图模型,另一个需要考虑的问题是,某个东西是否应该是一个顶点上的属性,还是它自己连接到另一个带边的顶点上的另一个顶点。我通常的方法是决定我是否希望能够搜索具有相同属性值的其他顶点,在这种情况下,我将它建模为自己的顶点,用边将它连接到所有具有该值的顶点。否则,它通常只能是一个顶点属性。
JP:图形建模需要时间。从一个幼稚的图形模型开始是很容易的,但是,您很可能不会在第一次尝试时就得到最好的模型。通常需要几次迭代才能得到适合您的用例的模型。
准备好使用您的域的一个小的代表性数据集和您想要运行的查询列表,这样您就可以看到模型对您的用例的执行情况。当您从一个顶点跳到另一个顶点时,请密切关注分支因子。即使给定顶点上有合理数量的边,查询将触及的图元素的数量也会随着几次跳跃呈指数增长。考虑将图结构反规范化,这样就可以更好地利用过滤(在标签或属性上匹配)来减少查询早期的元素数量。
怎样才能和JanusGraph联系起来呢?
FH:这取决于您是想贡献代码、改进文档,还是想以其他方式提供帮助,比如帮助邮件中遇到问题并知道如何解决的其他用户。
对于代码或文档更改,您可以在GitHub上查看我们的开放问题,找到您感兴趣的,或者创建一个新问题来描述建议的改进,然后提交一个pull request。
这与其他开源项目没有什么不同。可能JanusGraph新的贡献者的一个优点是,它由很多不同的模块,还有一个广泛的话题作出贡献,卡桑德拉等一些特定于某个后端或Elasticsearch核心领域像如何执行一个查询工具方面JanusGraph像模式管理或客户端库在一定的编程语言。所以,你可以选择一个你已经了解或感兴趣的领域来做贡献。
如果有人有兴趣为JanusGraph做贡献,但需要一些指导才能开始,那么当然总是可以问我或其他积极贡献者,我们非常乐意帮助。
JP: JanusGraph是一个开放的社区,我们社区的多样性帮助推动了这个项目向许多新的方向发展。我们的社区为扩展JanusGraph做出了坚实的贡献,为不同的编程语言提供了驱动程序,为不同的数据库后端提供了存储适配器。
我们IBM的开发人员将贡献的特性返回到开源服务器,用于服务器上的动态图形管理。我们已经收到了对构建和测试基础设施的改进,以及与Docker和Apache Ambari的集成。
我们希望看到更多的人参与进来,除了编写源代码之外,还有很多方法可以提供帮助。我认为作为一个协作社区,人们分享他们的知识和经验是最重要的——通过在论坛上回答问题,通过更新JanusGraph文档,通过以创新的方式构建使用JanusGraph的示例项目,通过在JanusGraph的本地会议或会议上展示。最好的接触方式是在我们的谷歌组。如果谷歌受到您公司防火墙或地理位置的限制,您可以通过邮件地址订阅他们。https://github.com/JanusGraph/janusgraph/#community
原文:https://www.ibm.com/cloud/blog/database-deep-dives-janusgraph
本文:http://jiagoushi.pro/node/1143
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 173 次浏览
【图型数据库】用Apache AGE实现最短路径(Dijkstra)
视频号
微信公众号
知识星球
Apache AGE is a PostgreSQL extension that provides graph database functionality. The goal of the Apache AGE project is to create single storage that can handle both relational and graph model data so that users can use standard ANSI SQL along with openCypher, the Graph query language. This repository hosts the development of the Python driver for this Apache extension (currently in Incubator status). Thanks for checking it out.
Apache AGE is:
- Powerful -- AGE adds graph database support to the already popular PostgreSQL database: PostgreSQL is used by organizations including Apple, Spotify, and NASA.
- Flexible -- AGE allows you to perform openCypher queries, which make complex queries much easier to write.
- Intelligent -- AGE allows you to perform graph queries that are the basis for many next level web services such as fraud & intrustion detection, master data management, product recommendations, identity and relationship management, experience personalization, knowledge management and more.
Features
- Shortest Path implemented using dijkstra algorithm
- Used Apache AGE graph database
Installation
Requirements
- Python 3.9 or higher
- This module runs on psycopg2 and antlr4-python3
sudo apt-get update
sudo apt-get install python3-dev libpq-dev
pip install --no-binary :all: psycopg2
Install via PIP
pip install apache-age-dijkstra
pip install antlr4-python3-runtime==4.9.3
Build from Source
git clone https://github.com/Munmud/apache-age-dijkstra
cd apache-age-python
python setup.py install
View Samples
Instruction
Import
from age_dijkstra import Age_Dijkstra
Making connection to postgresql (when using this docker reepository)
con = Age_Dijkstra()
con.connect(
host="localhost", # default is "172.17.0.2"
port="5430", # default is "5432"
dbname="postgresDB", # default is "postgres"
user="postgresUser", # default is "postgres"
password="postgresPW", # default is "agens"
printMessage = True # default is False
)
Get all edges
edges = con.get_all_edge()
- structure :
{ v1 : start_vertex, v2 : end_vertex, e : edge_object }
Get all vertices
nodes = []
for x in con.get_all_vertices():
nodes.append(x['property_name'])
Create adjacent matrices using edges
init_graph = {}
for node in nodes:
init_graph[node] = {}
for edge in edges :
v1 = edge['v1']['vertices_property_name']
v2 = edge['v2']['vertices_property_name']
dist = int(edge['e']['edge_property_name'])
init_graph
init_graph[v1][v2] = dist
Initialized Graph
from age_dijkstra import Graph
graph = Graph(nodes, init_graph)
Use dijkstra Algorithm
previous_nodes, shortest_path = Graph.dijkstra_algorithm(graph=graph, start_node="vertices_property_name")
Print shortest Path
Graph.print_shortest_path(previous_nodes, shortest_path, start_node="vertices_property_name", target_node="vertices_property_name")
Create Vertices
con.set_vertices(
graph_name = "graph_name",
label="label_name",
property={"key1" : "val1",}
)
Create Edge
con.set_edge(
graph_name = "graph_name",
label1="label_name1",
prop1={"key1" : "val1",},
label2="label_name2",
prop2={"key1" : "val1",},
edge_label = "Relation_name",
edge_prop = {"relation_property_name":"relation_property_value"}
)
For more information about Apache AGE
- Apache Incubator Age: https://age.apache.org/
- Github: https://github.com/apache/incubator-age
- Documentation: https://age.incubator.apache.org/docs/
- apache-age-dijkstra GitHub: https://github.com/Munmud/apache-age-dijkstra
- apache-age-python GitHub: https://github.com/rhizome-ai/apache-age-python
- 112 次浏览
【图型计算架构】GraphTech生态系统2019-第1部分:图形数据库
这篇文章是关于GraphTech生态系统的3篇文章的一部分,截至2019年。这是第一部分。它涵盖了图形数据库环境。第三部分是图形可视化工具。

The graph database landscape in 2019
动态生态系统
图形存储系统的吸引力比以往任何时候都强劲,自2013年以来,人们对图形存储系统的兴趣稳步增长。
A dynamic ecosystem
The traction for graph storage systems is stronger than ever, with interest steadily growing since 2013.

DBMS popularity trend by database model between 2013 and 2019 — Source: DB-Engine
图形数据库的市场份额不断增加,市场上的产品数量也在增加,供应商数量是5年前的7倍。新的市场研究和越来越大的财务预测每学期出版。有人说,图表数据库市场在2017年为3900万美元,其他为6.6亿美元,预测范围从2024年的4.45亿美元到2023年的24亿美元。
虽然很难就确切的数字达成一致,但所有报告都指出了相同的增长动力:
- 需要速度和改进的性能以减少发现新数据相关性的成本和时间
- 当前实时处理多维数据技术的局限性
- 基于图形的人工智能与机器学习工具与服务的开发
- 在金融犯罪、欺诈和安全等特定领域:更快速地解决现有风险和利用相关数据的迫切需要。
总而言之,我们有越来越多的应用程序依赖于连接的数据来产生洞察力,以及处理不断增长的数据量和复杂性的紧迫技术问题,这些都推动了图形市场的发展。
很难追踪。在这篇文章中,我建议至少尽可能地展示当前的市场。我将图形生态系统划分为三个主要层,尽管现实更复杂,而且这些层通常是可渗透的。
The GraphTech ecosystem layers
图形数据库布局
GraphTech的第一层在生态系统增长中起着关键作用。图形数据库管理系统(GDBMS)正在驱动生态系统。他们是它的主要演员。这些系统帮助组织解决存储复杂的连接数据和从非常大的数据集中提取见解的技术挑战。
塑造市场
自20世纪60年代以来,网络模型已经出现在数据库领域,但图结构的使用仍然局限于学术界。性能和模型还不是最佳的,我们不得不等到21世纪初和引入ACID图形数据库后才能看到更大规模的采用。从那时起,图形数据库开始作为一种合法的业务解决方案出现,以解决关系系统的一些缺点。
专门为存储类似图形的数据而构建的本机系统和具有不同主数据模型(例如关系数据库或其他NoSQL数据库)的非本机系统构成了市场。在这两个方面,我们发现商业和开源系统以及属性图和RDF三元组存储是存储图形数据的两个主要模型。
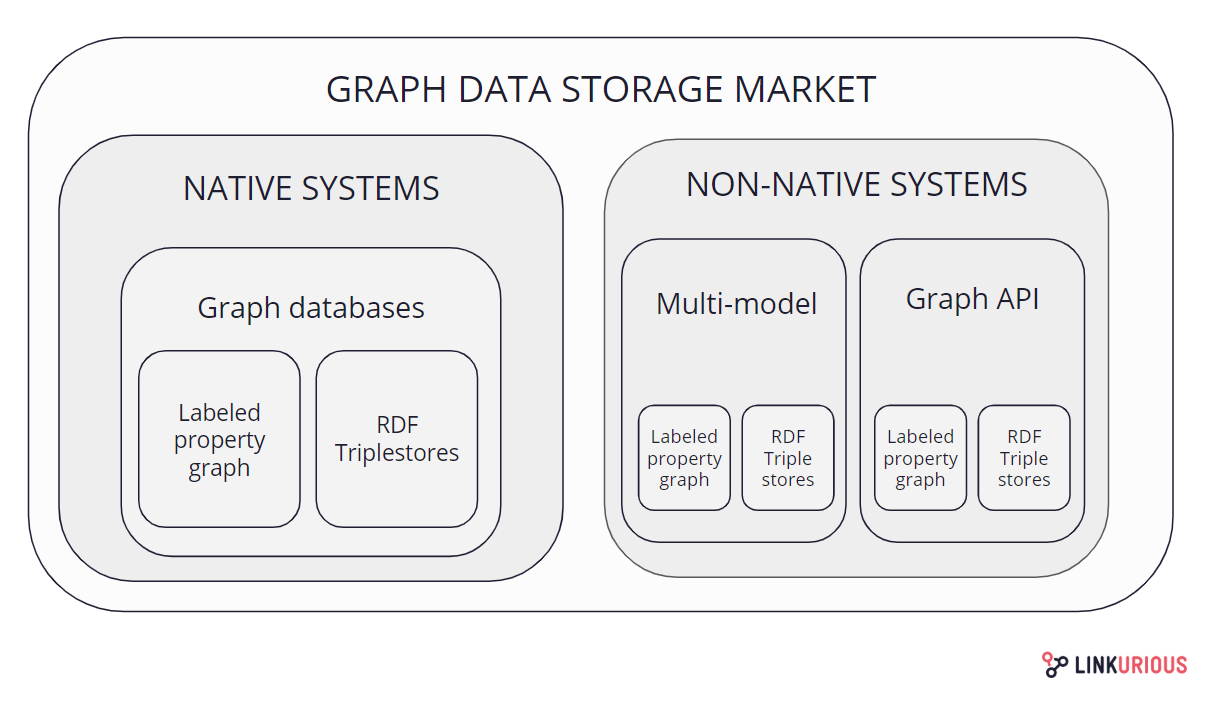
Type of storage for graph-like data
原生系统
在主要的原生系统中,Neo4j是市场领导者,这些系统的模型都经过了完全优化,可以处理类似图形的数据。NativeGraph数据库的第一个版本于2010年发布,提出了一个双重商业和开源版本,供开发人员试验图形。此后,该公司获得了大量客户,募集资金超过1.5亿美元。
在开源社区,JanusGraph接管了Titan项目,其母公司于2015年被DataStax收购。JanusGraph项目现在提出了一个分布式的、开源的图形数据库,这个数据库最近受到了广泛的关注。DGraph是另一个用Go编写的开源项目,在2017年发布了一个可供生产的版本,同时筹集了300万美元的种子资金。
其他的解决方案包括Stardog、RDF的知识图三重存储,或者最近发布的TigerGraph(以前称为GraphSQL)。商业系统InfiniteGraph和Sparksee已经出现了一段时间。其他开源系统,如HypergraphDB,提出了基于有向超图的数据库。
多模型数据库和混合系统
随着NoSQL模型的成功,多模型数据库应运而生,以解决筒仓系统的倍增所带来的复杂性。这些数据库旨在支持各种数据类型,在一个单独的数据存储中处理各种模型,如文档、键值、RDF和图形。如果您需要处理多种数据类型,但又希望避免管理各种筒仓的操作复杂性,则它们特别方便。
在包含graph作为支持模型的原生多模型数据库中,我们可以将ArangoDB命名为ArangoDB。这个开源的多模型数据库于2011年发布,支持三种数据模型:key/value、documents和graph。cosmosdb是微软Azure在多模型领域的最新产品。该分布式云数据库于2017年推出,支持四种数据类型:键值、文档、列族和图形。datatax Enterprise也是一个分布式云数据库,构建在开源nosql apache cassandra系统之上。自2016年新增数据税企业图以来,系统支持列族、单据、键值、图形。最后,MarkLogic是一个历史上的涉众,他在2013年为其现有的受支持文档模型添加了rdf triples支持。
另一个强烈的市场吸引力信号是数据库主要参与者策略的演变。在过去的几年中,我们看到传统的关系存储重量级者通过专用的api将图形功能添加到他们的系统中。2012年,IBM在其数据库中添加了NoSQL图形存储DB2-RDF。一年后,甲骨文将它的数据库图形选项更名为oraclespatial和graph,今天称为Oracle大数据空间和图形。最近在2016年,SAP Hana宣布发布SAP Hana Graph,通过对图形的支持扩展了其关系型DBMS的功能。
在下面的演示中,我列出并展示了大多数用于图形数据的存储系统。

Slide presentation of the graph database landscape
原文:https://medium.com/@Elise_Deux/the-graphtech-ecosystem-2019-part-1-graph-databases-c7c2f8a5e6bd
本文:http://jiagoushi.pro/node/1092
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 87 次浏览
【图形数据库】图形查询语言比较:Gremlin与Cypher与nQL
视频号
微信公众号
知识星球
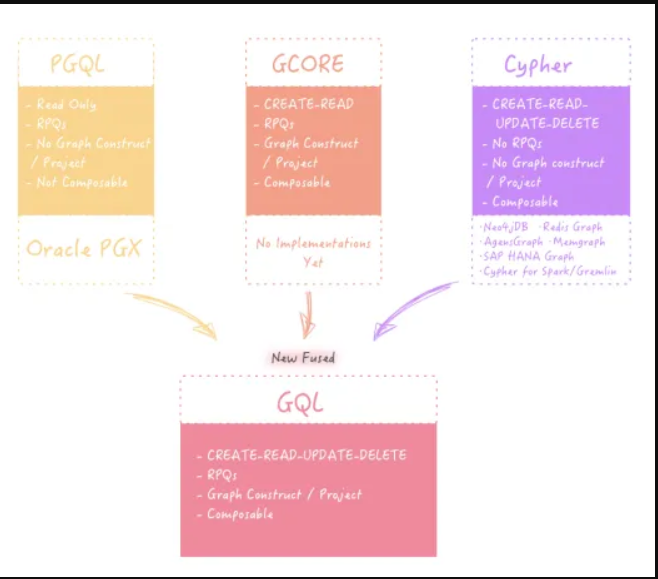
要比较哪些图查询语言
Gremlin
Gremlin是Apache TinkerPop开发的一种图遍历语言,已被许多图数据库解决方案所采用。它可以是声明性的,也可以是命令性的。
Gremlin是基于Groovy的,但有许多语言变体,允许开发人员用许多现代编程语言(如Java、JavaScript、Python、Scala、Clojure和Groovy)本地编写Gremlin查询。
支持的图形数据库:Janus graph、InfiniteGraph、Cosmos DB、DataStax Enterprise(5.0+)和Amazon Neptune。
Cypher
Cypher是一种声明性图查询语言,它允许在属性图中进行富有表现力和高效的数据查询。
该语言是利用SQL的强大功能设计的。Cypher语言的关键字不区分大小写,但属性、标签、关系类型和变量区分大小写。
支持的图形数据库:Neo4j、AgentsGraph和RedisGraph
nQL
NebulaGraph引入了自己的查询语言nQL,这是一种与SQL类似的声明性文本查询语言,但专为图形设计。
nQL语言的关键字是区分大小写的,它支持语句组合,因此不需要嵌入语句。
支持图形数据库:Nebula graph
术语比较
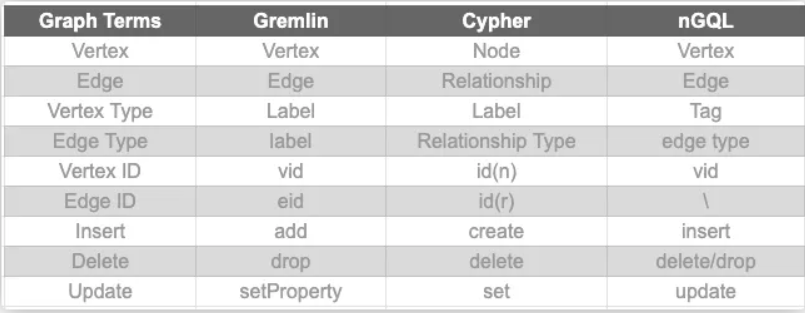
在比较这三种图查询语言之前,让我们先来看看它们的术语和概念。下表解释了这些语言如何定义节点和边:
语法比较--CRUD
在理解了Gremlin、Cypher和nQL中的常见术语后,让我们来看看这些图查询语言的一般语法。
本节将分别介绍Gremlin、Cypher和nQL的基本CRUD语法。
图表
请参阅以下关于如何创建图形空间的示例。我们省略了Cypher,因为在向图数据库添加任何数据之前,您不需要创建图空间。
# Create a graph that Gremlin can traverse
g = TinkerGraph.open().traversal()# Create a graph space in nGQL
CREATE SPACE gods
角顶
我们都知道图是由节点和边组成的。Cypher中的节点在Gremlin和nQL中称为顶点。边是两个节点之间的连接。
请参阅以下分别在这些查询语言中插入新顶点的示例。
# Insert vertex in Gremlin
g.addV(vertexLabel).property()# Insert vertex in Cypher
CREATE (:nodeLabel {property})# Insert vertex in nGQL
INSERT VERTEX tagName (propNameList) VALUES vid:(tagKey propValue)
顶点类型
节点/顶点可以有类型。它们在Gremlin和Cypher中称为标签,在nQL中称为标记。
一个顶点类型可以具有多个特性。例如,顶点类型Person有两个属性,即name和age。

Create Vertex Type
请参阅以下关于顶点类型创建的示例。我们省略了Cypher,因为在插入数据之前不需要标签。
# Create vertex type in Gremlin
g.addV(vertexLabel).property()# Create vertex type in nGQL
CREATE tagName(PropNameList)
请注意,Gremlin和nQL都支持IF NOT EXISTS。该关键字会自动检测是否存在相应的顶点类型。如果它不存在,则会创建一个新的。否则,不会创建任何顶点类型。
Show Vertex Types
创建顶点类型后,可以使用以下查询显示它们。它们将列出所有标签/标记,而不是某些标签/标记。
# Show vertex types in Gremlin
g.V().label().dedup();# Show vertex types in Cypher method 1
MATCH (n)
RETURN DISTINCT labels(n)
# Show vertex types in Cypher method 2
CALL db.labels();# Show vertex types in nGQL
SHOW TAGS
顶点上的CRUD
本节介绍使用三种查询语言对顶点进行的基本CRUD操作。
插入顶点
Insert Vertices# Insert vertex of certain type in Gremlin
g.addV(String vertexLabel).property()# Insert vertex of certain type in Cypher
CREATE (node:label) # Insert vertex of certain type in nGQL
INSERT VERTEX <tag_name> (prop_name_list) VALUES <vid>:(prop_value_list)Get Vertices# Fetch vertices in Gremlin
g.V(<vid>)# Fetch vertices in Cypher
MATCH (n)
WHERE condition
RETURN properties(n)# Fetch vertices in nGQL
FETCH PROP ON <tag_name> <vid>Delete Vertices# Delete vertex in Gremlin
g.V(<vid>).drop()# Delete a vertex in Cypher
MATCH (node:label)
DETACH DELETE node# Delete vertex in nGQL
DELETE VERTEX <vid>Update a Vertex's Property
本节介绍如何更新顶点的特性。
# Update vertex in Gremlin
g.V(<vid>).property()# Update vertex in Cypher
SET n.prop = V# Update vertex in nGQL
UPDATE VERTEX <vid> SET <update_columns>
Cypher和nQL都使用关键字SET来设置顶点类型,只是在nQL中添加了UPDATE关键字来标识操作。Gremlin的操作与上述获取顶点的操作类似,只是添加了更改属性的操作。
边
本节介绍边缘上的基本CRUD操作。
边缘类型
与顶点一样,边也可以具有类型。
# Create an edge type in Gremlin
g.edgeLabel()# Create an edge type in nGQL
CREATE EDGE edgeTypeName(propNameList)
边缘CRUD
Insert Edges of Certain Types
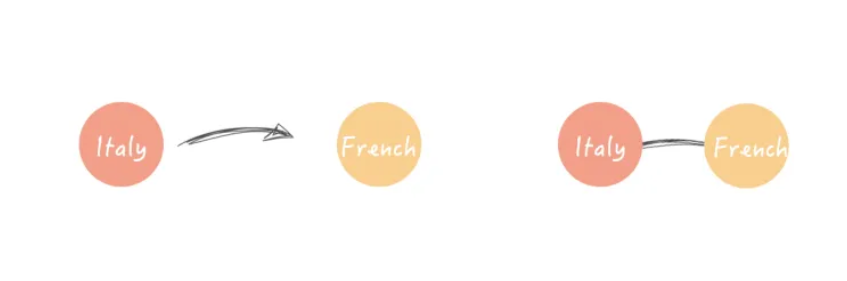
插入边类似于插入顶点。Cypher使用-[]->和nQL分别使用->来表示边。Gremlin使用关键字to()来指示边缘方向。
默认情况下,边以三种语言定向。下面左边的图表是有向边,而右边的图表是无向边。
# Insert edge of certain type in Gremlin
g.addE(String edgeLabel).from(v1).to(v2).property()# Insert edge of certain type in Cypher
CREATE (<node1-name>:<label1-name>)-
[(<relationship-name>:<relationship-label-name>)]
->(<node2-name>:<label2-name>)# Insert edge of certain type in nGQL
INSERT EDGE <edge_name> ( <prop_name_list> ) VALUES <src_vid> ->
<dst_vid>: ( <prop_value_list> )Delete Edges# Delete edge in Gremlin
g.E(<eid>).drop()# Delete edge in Cypher
MATCH (<node1-name>:<label1-name>)-[r:relationship-label-name]->()
DELETE r# Delete edge in nGQL
DELETE EDGE <edge_type> <src_vid> -> <dst_vid>Fetch Edges# Fetch edges in Gremlin
g.E(<eid>)# Fetch edges in Cypher
MATCH (n)-[r:label]->()
WHERE condition
RETURN properties(r)# Fetch edges in nGQL
FETCH PROP ON <edge_name> <src_vid> -> <dst_vid>
其他操作
除了顶点和边上常见的CRUD之外,我们还将向您展示三种图查询语言中的一些组合查询。
遍历边
# Traverse edges with specified vertices in Gremlin
g.V(<vid>).outE(<edge>)# Traverse edges with specified vertices in Cypher
Match (n)->[r:label]->[]
WHERE id(n) = vid
RETURN r# Traverse edges with specified vertices in nGQL
GO FROM <vid> OVER <edge>
反向遍历边
在反向遍历中,Gremlin使用中表示反转,Cypher使用<-。nQL使用关键字REVERSELY。
# Traverse edges reversely with specified vertices Gremlin
g.V(<vid>).in(<edge>)# Traverse edges reversely with specified vertices Cypher
MATCH (n)<-[r:label]-()# Traverse edges reversely with specified vertices nGQL
GO FROM <vid> OVER <edge> REVERSELY
双向遍历边
如果边缘方向不相关(任何一个方向都可以接受),则Gremlin使用bothE(),Cypher使用-[]-,nQL使用关键字BIDIRECT。
# Traverse edges reversely with specified vertices Gremlin
g.V(<vid>).bothE(<edge>)# Traverse edges reversely with specified vertices Cypher
MATCH (n)-[r:label]-()# Traverse edges reversely with specified vertices nGQL
GO FROM <vid> OVER <edge> BIDIRECT
沿指定边缘查询N个跃点
Gremlin和nQL分别使用时间和STEP来表示N个跳。Cypher使用关系*N。
# Query N hops along specified edge in Gremlin
g.V(<vid>).repeat(out(<edge>)).times(N)# Query N hops along specified edge in Cypher
MATCH (n)-[r:label*N]->()
WHERE condition
RETURN r# Query N hops along specified edge in nGQL
GO N STEPS FROM <vid> OVER <edge>
查找两个顶点之间的路径
# Find paths between two vertices in Gremlin
g.V(<vid>).repeat(out()).until(<vid>).path()# Find paths between two vertices in Cypher
MATCH p =(a)-[.*]->(b)
WHERE condition
RETURN p# Find paths between two vertices in nGQL
FIND ALL PATH FROM <vid> TO <vid> OVER *
查询示例
本节介绍一些演示查询。
演示模型:众神之图
本节中的示例广泛使用了Janus graph分发的玩具图,称为“众神之图”,如下图所示
这个例子描述了罗马万神殿的存在和地点之间的关系。

Inserting data
# Inserting vertices
## nGQL
nebula> INSERT VERTEX character(name, age, type) VALUES hash("saturn")
:("saturn", 10000, "titan"), hash("jupiter"):("jupiter", 5000, "god");
## Gremlin
gremlin> saturn = g.addV("character").property(T.id, 1).property('name', 'saturn').property('age', 10000).property('type', 'titan').next();
==>v[1]
gremlin> jupiter = g.addV("character").property(T.id, 2).property('name', 'jupiter').property('age', 5000).property('type', 'god').next();
==>v[2]
gremlin> prometheus = g.addV("character").property(T.id, 31).property('name', 'prometheus').property('age', 1000).property('type', 'god').next();
==>v[31]
gremlin> jesus = g.addV("character").property(T.id, 32).property('name', 'jesus').property('age', 5000).property('type', 'god').next();
==>v[32]
## Cypher
cypher> CREATE (src:character {name:"saturn", age: 10000, type:"titan"})
cypher> CREATE (dst:character {name:"jupiter", age: 5000, type:"god"})# Inserting edges
## nGQL
nebula> INSERT EDGE father() VALUES hash("jupiter")->hash("saturn"):();
## Gremlin
gremlin> g.addE("father").from(jupiter).to(saturn).property(T.id, 13);
==>e[13][2-father->1]
## Cypher
cypher> CREATE (src)-[rel:father]->(dst)
Deleting
# nGQL
nebula> DELETE VERTEX hash("prometheus");
# Gremlin
gremlin> g.V(prometheus).drop();
# Cypher
cypher> MATCH (n:character {name:"prometheus"}) DETACH DELETE n
Updating
# nGQL
nebula> UPDATE VERTEX hash("jesus") SET character.type = 'titan';
# Gremlin
gremlin> g.V(jesus).property('age', 6000);
==>v[32]
# Cypher
cypher> MATCH (n:character {name:"jesus"}) SET n.type = 'titan';
Fetching/Reading
# nGQL
nebula> FETCH PROP ON character hash("saturn");
===================================================
| character.name | character.age | character.type |
===================================================
| saturn | 10000 | titan |
---------------------------------------------------
# Gremlin
gremlin> g.V(saturn).valueMap();
==>[name:[saturn],type:[titan],age:[10000]]
# Cypher
cypher> MATCH (n:character {name:"saturn"}) RETURN properties(n)
╒════════════════════════════════════════════╕
│"properties(n)" │
╞════════════════════════════════════════════╡
│{"name":"saturn","type":"titan","age":10000}│
└────────────────────────────────────────────┘
Finding the name of Hercules’s Father
# nGQL
nebula> LOOKUP ON character WHERE character.name == 'hercules' | \
-> GO FROM $-.VertexID OVER father YIELD $$.character.name;
=====================
| $$.character.name |
=====================
| jupiter |
---------------------
# Gremlin
gremlin> g.V().hasLabel('character').has('name','hercules').
out('father').values('name');
==>jupiter
# Cypher
cypher> MATCH (src:character{name:"hercules"})-[:father]->
(dst:character) RETURN dst.name
╒══════════╕
│"dst.name"│
╞══════════╡
│"jupiter" │
└──────────┘
Finding the name of Hercules’s Grandfather
# nGQL
nebula> LOOKUP ON character WHERE character.name == 'hercules' | \
-> GO 2 STEPS FROM $-.VertexID OVER father YIELD $$.character.name;
=====================
| $$.character.name |
=====================
| saturn |
---------------------
# Gremlin
gremlin> g.V().hasLabel('character').has('name','hercules').out('father').
out('father').values('name');
==>saturn
# Cypher
cypher> MATCH (src:character{name:"hercules"})-[:father*2]->
(dst:character) RETURN dst.name
╒══════════╕
│"dst.name"│
╞══════════╡
│"saturn" │
└──────────┘
Find the characters with age > 100
# nGQL
nebula> LOOKUP ON character WHERE character.age > 100 YIELD
character.name, character.age;
=========================================================
| VertexID | character.name | character.age |
=========================================================
| 6761447489613431910 | pluto | 4000 |
---------------------------------------------------------
| -5860788569139907963 | neptune | 4500 |
---------------------------------------------------------
| 4863977009196259577 | jupiter | 5000 |
---------------------------------------------------------
| -4316810810681305233 | saturn | 10000 |
---------------------------------------------------------
# Gremlin
gremlin> g.V().hasLabel('character').has('age',gt(100)).values('name');
==>saturn
==>jupiter
==>neptune
==>pluto
# Cypher
cypher> MATCH (src:character) WHERE src.age > 100 RETURN src.name
╒═══════════╕
│"src.name" │
╞═══════════╡
│ "saturn" │
├───────────┤
│ "jupiter" │
├───────────┤
│ "neptune" │
│───────────│
│ "pluto" │
└───────────┘
Find who are Pluto’s cohabitants, excluding Pluto himself
# nGQL
nebula> GO FROM hash("pluto") OVER lives YIELD lives._dst AS place |
GO FROM $-.place OVER lives REVERSELY WHERE \
$$.character.name != "pluto" YIELD $$.character.name AS cohabitants;
===============
| cohabitants |
===============
| cerberus |
---------------
# Gremlin
gremlin> g.V(pluto).out('lives').in('lives').where(is(neq(pluto))).
values('name');
==>cerberus
# Cypher
cypher> MATCH (src:character{name:"pluto"})-[:lives]->()<-[:lives]-
(dst:character) RETURN dst.name
╒══════════╕
│"dst.name"│
╞══════════╡
│"cerberus"│
└──────────┘
Pluto’s Brothers
# which brother lives in which place?
## nGQL
nebula> GO FROM hash("pluto") OVER brother YIELD brother._dst AS god | \
GO FROM $-.god OVER lives YIELD $^.character.name AS Brother,
$$.location.name AS Habitations;
=========================
| Brother | Habitations |
=========================
| jupiter | sky |
-------------------------
| neptune | sea |
-------------------------
## Gremlin
gremlin> g.V(pluto).out('brother').as('god').out('lives').as('place').
select('god','place').by('name');
==>[god:jupiter, place:sky]
==>[god:neptune, place:sea]
## Cypher
cypher> MATCH (src:Character{name:"pluto"})-[:brother]->
(bro:Character)-[:lives]->(dst)
RETURN bro.name, dst.name
╒═════════════════════════╕
│"bro.name" │"dst.name"│
╞═════════════════════════╡
│ "jupiter" │ "sky" │
├─────────────────────────┤
│ "neptune" │ "sea" │
└─────────────────────────┘
除了三种图查询语言中的基本操作外,我们还将对这些语言中的高级操作进行另一项比较。敬请期待!
- 234 次浏览
【图形计算】用Scylla+JanusGraph赋能图形数据系统

如果你在读这个博客,你可能已经意识到Scylla 提供的力量和速度。也许您已经在生产中使用Scylla 来支持高I/O实时应用程序。但是当你遇到一个需要一些本地Scylla 不易实现的特性的问题时,会发生什么呢?
我最近在一家大型网络安全公司从事主数据管理(MDM)项目。他们的分析团队希望为业务用户提供更好、更快、更具洞察力的客户和供应链活动视图。
但是,任何试图构建这样一个解决方案的人都知道,主要的困难之一是包含现有数据源的绝对数量和复杂性。这些数据源通常作为独立设计和实现的系统的后端。每一个都包含了客户活动的整体情况。为了提供一个真正的解决方案,我们需要能够将这些不同的数据放在一起。
这个过程不仅需要性能和可伸缩性,还需要灵活性和快速迭代的能力。我们试图揭示重要的关系,并使它们成为数据模型本身的一个明确部分。
以JanusGraph为基础,以Scylla 为后盾的图形数据系统非常适合解决这一问题。
什么是图形数据系统?
我们将它分成两部分:
- 图形-我们将数据建模为图形,顶点和边表示我们的每个实体和关系
- 数据系统-我们将使用几个组件来构建一个单一的系统来存储和检索我们的数据
市场上有几种图形数据库的选择,但是当我们需要可伸缩性、灵活性和性能的结合时,我们可以寻找由JanusGraph、Scylla和Elasticsearch构建的系统。
在较高的层次上,它看起来是这样的:
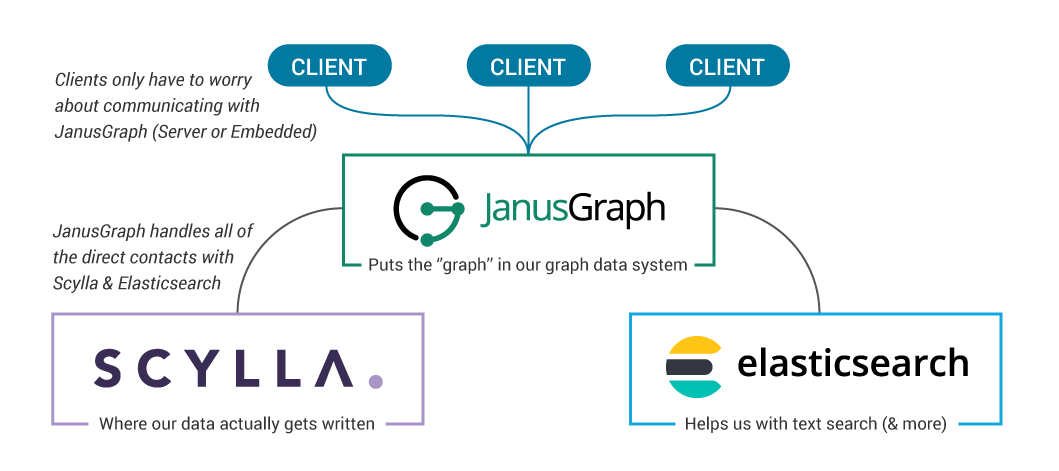
让我们重点介绍这个数据系统真正闪耀的三个核心领域:
- 灵活性
- 模式/纲要支持
- OLTP+OLAP支持
1 . 灵活性
虽然我们当然关心数据加载和查询性能,但图形数据系统的致命特性是灵活性。大多数数据库在启动后都会将您锁定到数据模型中。定义一些支持系统业务逻辑的表,然后存储和检索这些表中的数据。当您需要添加新的数据源、交付新的应用程序功能或提出创新性问题时,您最好希望它可以在现有模式中完成!如果您必须打开现有数据模式的引擎盖,那么您已经开始了一个耗时且容易出错的更改管理过程。
不幸的是,这不是企业成长的方式。毕竟,今天要问的最有价值的问题是那些我们昨天都没有想到的问题。
另一方面,我们的图形数据系统允许我们灵活地随着时间发展我们的数据模型。这意味着,当我们了解更多关于数据的信息时,我们可以在模型上迭代以匹配我们的理解,而不必从头开始。(请查看本文以了解该过程的更完整的演练)。
这对我们的实践有什么帮助?这意味着我们可以将新的数据源合并为新的顶点和边,而不必破坏图上现有的工作负载。我们还可以立即将查询结果写入到图表中—消除每天运行的重复OLAP工作负载,这些工作负载只会产生相同的结果。每一个新的分析都可以建立在之前的基础之上,为我们提供了一种在业务团队之间共享生产质量结果的强大方式。所有这些都意味着我们可以用我们的数据来回答更具洞察力的问题。
2. 纲要/模式强制
虽然schema lite乍一看似乎不错,但使用这样的数据库意味着我们将大量工作卸载到应用程序层中。一阶和二阶效果是跨多个使用者应用程序复制的代码,由不同的团队用不同的语言编写。强制执行应该包含在数据库层中的逻辑是一个巨大的负担。
JanusGraph提供了灵活的模式支持,可以在不惹麻烦的情况下减轻我们的痛苦。它具有现成的可靠数据类型支持,我们可以使用它预先定义给定顶点或边可以包含的属性,而不需要每个顶点都必须包含所有这些已定义的属性。同样,我们可以定义允许哪些边类型连接一对顶点,但这对顶点不会自动强制具有该边。当我们决定为一个现有的顶点定义一个新的属性时,我们不必为已经存储在图中的每个现有顶点编写该属性,而是可以只在适用的顶点插入中包含它。
这种模式实施方法对于管理大型数据集(尤其是将用于MDM工作负载的数据集)非常有帮助。当我们的图表看到新的用例时,它简化了测试需求,并且清晰地将数据完整性维护和业务逻辑分开。
3.OLTP+OLAP支持
与任何数据系统一样,我们可以将工作负载分为两类:事务性和分析性。JanusGraph遵循Apache TinkerPop项目的图形计算方法。总的来说,我们的目标是“遍历”我们的图,通过连接边从一个顶点到另一个顶点。我们使用Gremlin图遍历语言来实现这一点。幸运的是,我们可以使用相同的Gremlin遍历语言来编写OLTP和OLAP工作负载。
事务性工作负载从少量顶点开始(在索引的帮助下找到),然后遍历相当少量的边和顶点以返回结果或添加新的图形元素。我们可以将这些事务性工作负载描述为图形本地遍历。我们对这些遍历的目标是最小化延迟。
分析工作负载需要遍历图中的大部分顶点和边才能找到答案。许多经典的分析图算法都适合这个领域。我们可以将其描述为图全局遍历。我们对这些遍历的目标是最大化吞吐量。
有了我们的JanusGraph-Scylla图形数据系统,我们可以混合这两种功能。在“Scylla ”高IO性能的支持下,我们可以为事务性工作负载实现可伸缩的单位数毫秒响应。我们还可以利用Spark来处理大规模的分析工作。
部署我们的数据系统
这在理论上是很好的,所以让我们开始实际部署这个图形数据系统。我们将在Google云平台上进行部署,但是下面描述的所有内容都应该可以在您选择的任何平台上复制。
下面是我们将要部署的图形数据系统的设计:
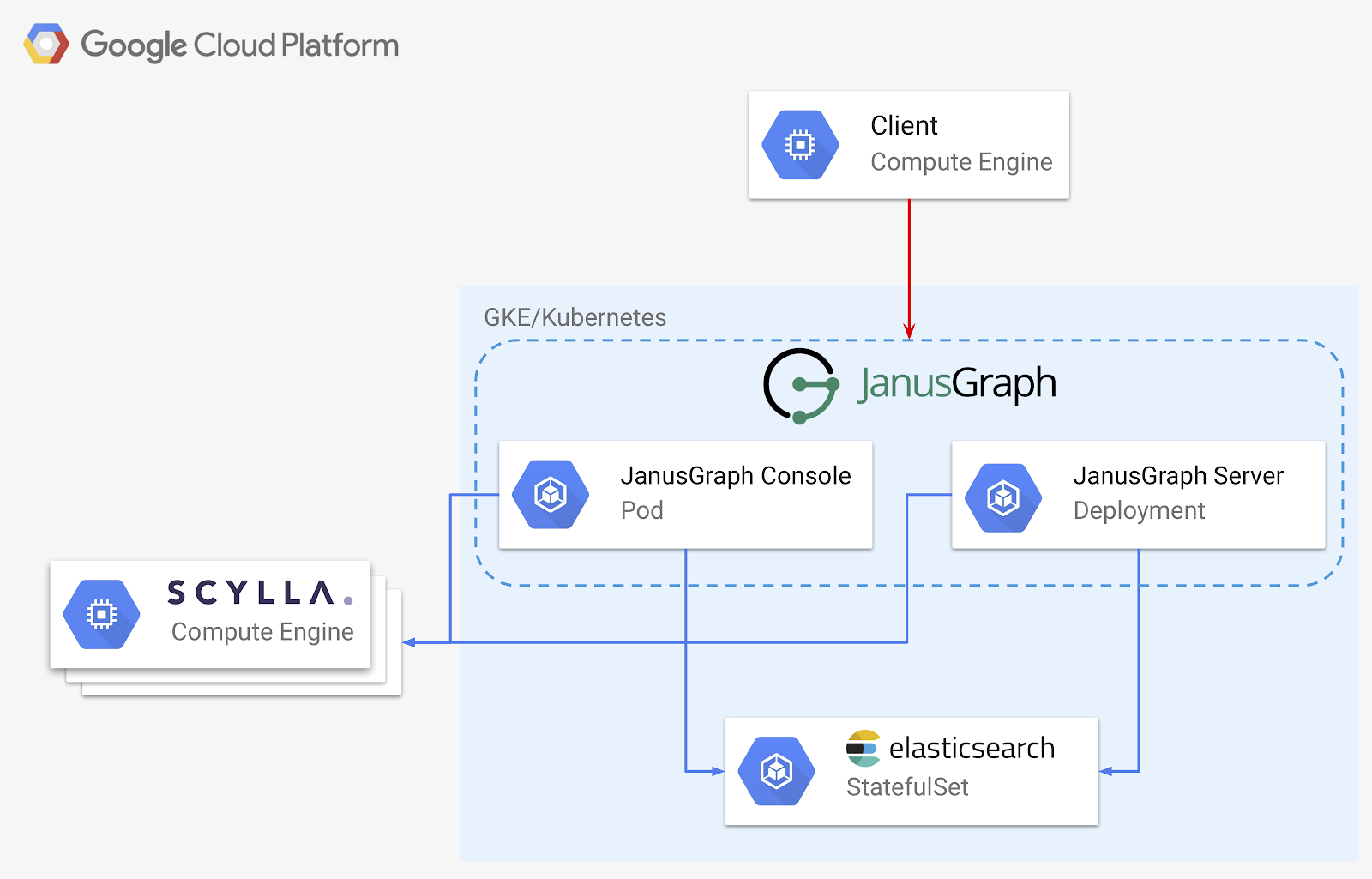
我们的架构有三个关键部分:
- Scylla ——我们的存储后端,我们数据存储的最终场所
- Elasticsearch–我们的索引后端,加速了一些搜索,并提供强大的范围和模糊匹配功能
- JanusGraph–提供我们的图形本身,作为服务器或嵌入到独立应用程序中
我们将尽可能多地使用Kubernetes进行部署。这使得扩展和部署变得容易和可重复,而不管部署具体在哪里进行。
我们是否选择使用K8s来部署“Scylla ”,这取决于我们有多冒险!“Scylla ”小组一直在努力为K8s(Kubernetes:Scylla Operator)的生产准备部署。目前作为Alpha版本提供,Scylla 操作员遵循CoreOS Kubernetes“操作员”范式。虽然我认为这最终将是JanusGraph的100%k8s部署的一个极好的选择,但现在我们将研究VMs上更传统的Scylla部署。
为了继续,您可以在 https://github.com/EnharmonicAI/scylla-janusgraph-examples。在进入生产阶段时,您会希望更改一些选项,但这个起点应该演示概念并使您快速前进。
最好在GCP虚拟机上运行此部署,并完全访问Google云api。您可以使用已有的虚拟机,也可以创建新的虚拟机。
gcloud compute instances create deployment-manager \
--zone us-west1-b \
--machine-type n1-standard-1 \
--scopes=https://www.googleapis.com/auth/cloud-platform \
--image 'centos-7-v20190423' --image-project 'centos-cloud' \
--boot-disk-size 10 --boot-disk-type "pd-standard"然后ssh进入VM:
gcloud compute ssh deployment-manager [ryan@deployment-manager ~]$ ..
我们假设所有其他东西都是从这个GCP VM运行的。让我们安装一些prereq:
sudo yum install -y bzip2 kubectl docker git sudo systemctl start docker curl -O https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh sh Miniconda3-latest-Linux-x86_64.sh
部署Scylla
我们可以使用Scylla 自己的Google计算引擎部署脚本作为Scylla 集群部署的起点。
git clone https://github.com/scylladb/scylla-code-samples.git cd scylla-code-samples/gce_deploy_and_install_scylla_cluster
创建一个新的conda环境并安装一些必需的包,包括Ansible。
conda create --name graphdev python=3.7 -y conda activate graphdev pip install ruamel-yaml==0.15.94 ansible==2.7.10 gremlinpython==3.4.0 absl-py==0.7.1
我们还将做一些ssh密钥管理和应用项目范围的元数据,这将简化到我们的实例的连接。
touch ~/.ssh/known_hosts SSH_USERNAME=$(whoami) KEY_PATH=$HOME/.ssh/id_rsa ssh-keygen -t rsa -f $KEY_PATH -C $SSH_USERNAME chmod 400 $KEY_PATH gcloud compute project-info add-metadata --metadata ssh-keys="$SSH_USERNAME:$(cat $KEY_PATH.pub)"
我们现在可以设置集群了。在上面克隆的scylla-code-samples/gce_deploy_and_install_scylla_cluster 目录中,我们将运行gce_deploy_and_install_scylla_cluster.sh。我们将创建一个由三个Scylla 3.0节点组成的集群,每个节点都是一个n1-standard-16vm,带有两个NVMe本地ssd。
./gce_deploy_and_install_scylla_cluster.sh \
-p symphony-graph17038 \
-z us-west1-b \
-t n1-standard-4 \
-n -c2 \
-v3.0完成配置需要几分钟的时间,但完成后,我们可以继续部署JanusGraph的其余组件。
克隆 scylla-janusgraph-examples GitHub repo:
git clone https://github.com/EnharmonicAI/scylla-janusgraph-examples cd scylla-janusgraph-examples
接下来的每个命令都将从克隆的repo的顶级目录运行。
建立Kubernetes集群
为了保持部署的灵活性,而不是锁定在任何云提供商的基础设施中,我们将通过Kubernetes部署所有其他内容。Google Cloud通过他们的Google Kubernetes引擎(GKE)服务提供一个托管的Kubernetes集群。
让我们用足够的资源创建一个新的集群。
gcloud container clusters create graph-deployment \
--project [MY-PROJECT] \
--zone us-west1-b \
--machine-type n1-standard-4 \
--num-nodes 3 \
--cluster-version 1.12.7-gke.10 \
--disk-size=40我们还需要创建一个防火墙规则,允许GKE pod访问其他非GKE vm。
CLUSTER_NETWORK=$(gcloud container clusters describe graph-deployment \
--format=get"(network)" --zone us-west1-b)
CLUSTER_IPV4_CIDR=$(gcloud container clusters describe graph-deployment \
--format=get"(clusterIpv4Cidr)" --zone us-west1-b)
gcloud compute firewall-rules create "graph-deployment-to-all-vms-on-network" \
--network="$CLUSTER_NETWORK" \
--source-ranges="$CLUSTER_IPV4_CIDR" \
--allow=tcp,udp,icmp,esp,ah,sctpDeploying Elasticsearch
部署Elasticsearch
在GCP上部署Elasticsearch有很多方法——我们将选择在Kubernetes上部署ES集群作为有状态集。我们将从一个3节点集群开始,每个节点有10 GB的可用磁盘。
kubectl apply -f k8s/elasticsearch/es-storage.yaml kubectl apply -f k8s/elasticsearch/es-service.yaml kubectl apply -f k8s/elasticsearch/es-statefulset.yaml
(感谢Bayu Aldi Yansyah和他的媒体文章为部署Elasticsearch设计了这个框架)
运行Gremlin控制台
我们现在已经启动并运行了存储和索引后端,所以让我们为图形定义一个初始模式。一个简单的方法是启动一个控制台连接到我们运行的Scylla 和Elasticsearch集群。
构建JanusGraph docker映像并将其部署到Google容器注册中心。
scripts/setup/build_and_deploy_janusgraph_image.sh -p [MY-PROJECT]
更新k8s/gremlin-console/janusgraph-gremlin-console.yaml使用项目名指向GCR存储库映像名的文件,并添加Scylla 节点之一的正确主机名。您会注意到在YAML文件中,我们使用环境变量帮助创建JanusGraph属性文件,我们将使用该文件在控制台中用JanusGraphFactory实例化JanusGraph对象。
创建并连接到JanusGraph Gremlin控制台:
kubectl create -f k8s/gremlin-console/janusgraph-gremlin-console.yaml
kubectl exec -it janusgraph-gremlin-console -- bin/gremlin.sh
\,,,/
(o o)
-----oOOo-(3)-oOOo-----
...
gremlin> graph = JanusGraphFactory.open('/etc/opt/janusgraph/janusgraph.properties')现在我们可以继续为我们的图创建一个初始模式。我们将在这里从更高的层次讨论这个问题,但我将在本文中详细讨论模式创建和管理过程。
在本例中,我们将查看联邦选举委员会关于2020年总统竞选捐款的数据样本。样本数据已经过分析,并对其进行了一些清理(向我的兄弟Patrick Stauffer致敬,因为他允许我利用他在这个数据集上的一些工作),并且作为资源包含在repo中/贡献.csv.
以下是我们的贡献数据集的架构定义的开始:
mgmt = graph.openManagement()
// Define Vertex labels
Candidate = mgmt.makeVertexLabel("Candidate").make()
ename = mgmt.makePropertyKey("name").
dataType(String.class).cardinality(Cardinality.SINGLE).make()
filerCommitteeIdNumber = mgmt.makePropertyKey("filerCommitteeIdNumber").
dataType(String.class).cardinality(Cardinality.SINGLE).make()
mgmt.addProperties(Candidate, type, name, filerCommitteeIdNumber)
mgmt.commit()您可以在scripts/load/define中找到完整的模式定义代码_schema.groovy模式存储库中的文件。只需将其复制并粘贴到Gremlin控制台中即可执行。
加载模式后,我们可以关闭Gremlin控制台并删除pod。
kubectl delete -f k8s/gremlin-console/janusgraph-gremlin-console.yaml
部署JanusGraph服务器
最后,让我们将JanusGraph部署为服务器,准备接受客户机请求。我们将利用JanusGraph对Apache TinkerPop的Gremlin服务器的内置支持,这意味着我们的图形将可以被多种客户端语言(包括Python)访问。
编辑k8s/janusgraph/janusgraph-server-service.yaml指向正确的GCR存储库映像名的文件。部署JanusGraph服务器现在非常简单:
kubectl apply -f k8s/janusgraph/janusgraph-server-service.yaml kubectl apply -f k8s/janusgraph/janusgraph-server.yaml
加载数据
我们将通过在图中加载一些初始数据来演示对JanusGraph服务器部署的访问。
无论何时我们将数据加载到任何类型的数据库(Scylla 、关系、图表等),我们都需要定义源数据将如何映射到数据库中定义的模式。对于graph,我喜欢使用一个简单的映射文件。回购协议中包含了一个示例,下面是一个小示例:
vertices:
- vertex_label: Candidate
lookup_properties:
FilerCommitteeIdNumber: filerCommitteeIdNumber
other_properties:
CandidateName: name
edges:
- edge_label: CONTRIBUTION_TO
out_vertex:
vertex_label: Contribution
lookup_properties:
TransactionId: transactionId
in_vertex:
vertex_label: Candidate
lookup_properties:
FilerCommitteeIdNumber: filerCommitteeIdNumber此映射是为演示目的而设计的,因此您可能会注意到此映射定义中存在重复数据。这个简单的映射结构允许客户端保持相对“哑”的状态,而不是强制它预处理映射文件。
我们的示例repo包含一个简单的Python脚本load_fron_csv.py年,它接受一个CSV文件和一个映射文件作为输入,然后将每一行加载到图形中。它一般采用您想要的任何映射文件和CSV,但它是单线程的,不是为速度而构建的,它旨在演示从客户端加载数据的概念。
python scripts/load/load_from_csv.py \
--data ~/scylla-janusgraph-examples/resources/Contributions.csv \
--mapping ~/scylla-janusgraph-examples/resources/campaign_mapping.yaml \
--hostname [MY-JANUSGRAPH-SERVER-LOAD-BALANCER-IP] \
--row_limit 1000这样,我们就可以启动并运行数据系统,包括定义数据模式和加载一些初始记录。
结束
我希望你喜欢这个进入JanusGraph-Scylla 图形数据系统的短暂尝试。它应该为您提供一个良好的起点,并演示如何轻松地部署所有组件。记住关闭任何不想保留的云资源,以避免产生费用。
我们真的只是触及了这个强大的系统所能完成的事情的表面,而你的胃口也被激起了。请给我任何想法和问题,我期待着看到你的建设!
原文:https://www.scylladb.com/2019/05/14/powering-a-graph-data-system-with-scylla-janusgraph/
本文:http://jiagoushi.pro/node/1045
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 203 次浏览
【知识图谱】实现知识图谱——Python
视频号
微信公众号
知识星球
在这个由两部分组成的系列的第一部分(链接到第一部分)中,我们看到了如何使用知识图来模拟思维过程。在这部分,让我们把手弄脏!😄
我们将使用一个名为Cayley的开源图形数据库作为KG后端。根据您的操作系统,从这里获取最新的二进制文件。下载后,转到根目录并找到cayley.yml文件。如果它不存在,请创建它。应该有一个cayley_example.yml文件来指导您。该文件是cayley的配置文件。该文件的一个重要用途是设置存储图形的后端数据库。有几个选项可用(请参阅文档)。我们将使用MySQL作为数据库。我假设你已经安装了MySQL。如果没有,安装它非常简单(谷歌:P)。现在,请确保您的cayley.yml文件如下所示:(将<your_root_password>替换为MySQL根的实际密码,并将<your_database_name>替换为数据库名称。
cayley.yml:
store:
# backend to use
backend: "mysql"
# address or path for the database
address: "root:<your_root_password>#@tcp(localhost:3306)/<your_database_name>"
# open database in read-only mode
read_only: false
# backend-specific options
options:
nosync: false
query:
timeout: 30s
load:
ignore_duplicates: false
ignore_missing: false
batch: 10000now let’s start our graph I am using windows so exact commands might differ from Mac and Linux. You can see (this file):
打开命令提示符/terminal,转到cayley根目录,并在terminal中键入以下内容:
cayley init
Cayley将自动检测Cayley.yml文件中的配置并建立数据库。现在要加载一个图形数据库,我们需要了解一种叫做“模式”的东西。
模式是表示信息的一种特定方式。例如,JSON(JavaScript对象表示法)就是模式的一个例子。有关模式的更多信息,请访问Schema.org的网站。在这里,我们将使用一个名为“N-quads”的模式。有关N-quad的更多信息,请点击此处。
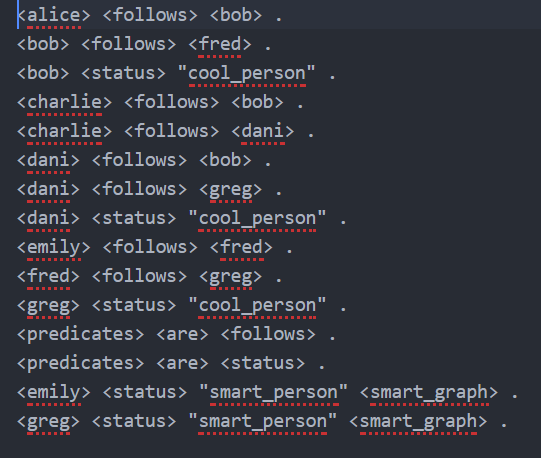
在上面的示例N-quad文件中,我们有一个类似的模式:<person><follows><person><status>。这意味着两个<person>是图的节点,<followes>是它们之间的“方向关系”<status>是可选的,并对关系进行了更多描述。
现在,下一步是将其加载到我们的MySQL数据库中。要执行此操作,请运行:
cayley load -i <path_to_nquads_file>
将<path_to_quads_file>替换为N-quads文件的相对路径。制作一个N-quad文件很容易。只需在N-quad模式中写入并使用“.nq”扩展名保存即可。
将图形加载到cayley后,您可以运行一个web实例,使用gizmo查询语言(这并不难理解)与您的KG进行交互和可视化。运行:
cayley http
Go to localhost:64210 on your browser and you can see something like this:
您可以在此处键入任何查询以与您的KG交互。示例查询为:
g.V().All()
这意味着获取图形对象“g”的所有顶点。有关查询语言的更多信息,请点击此处。
您还可以在web应用程序中可视化图形。阅读文档以便能够做到这一点。
现在是有趣的部分(没有人告诉你):
我们使用Cayley图数据库和MySql实现了一个简单的知识图。我们可以在不使用网络应用程序的情况下远程与此图形交互吗?对Cayley向API端点公开图形:http://127.0.0.1:64210/api/v1/query/gizmo
我们可以使用python“requests”库来进行POST请求,并在任何需要的地方查询Graph(Cayley应该在后台运行以提供API端点)。
import requests import jsonquery = "g.V().All()" endpoint = "http://127.0.0.1:64210/api/v1/query/gizmo" response = requests.post(endpoint, data=query)#the response is a JSON object json_response = response.json() print(json_response)
在Jupyter Notebook中运行上面的代码,您应该能够看到API的JSON响应并使用它!
那都是人!希望你喜欢这个。
- 203 次浏览