Spark生态



【Spark】介绍Databricks运行时7.0中提供的Apache Spark 3.0
我们激动地宣布,作为Databricks运行时7.0的一部分,可以在Databricks上使用Apache SparkTM 3.0.0版本。3.0.0版本包含超过3400个补丁,是开源社区做出巨大贡献的顶峰,带来了Python和SQL功能方面的重大进步,并关注于开发和生产的易用性。这些举措反映了该项目如何发展,以满足更多的用例和更广泛的受众,今年是它作为一个开源项目的10周年纪念日。
以下是Spark 3.0最大的新特性:
- TPC-DS比Spark 2.4的性能提高了2倍,支持自适应查询执行、动态分区剪枝和其他优化
- ANSI SQL合规
- 对panda api进行了重大改进,包括Python类型提示和额外的panda udf
- 更好的Python错误处理,简化PySpark异常
- 结构化流的新UI
- 调用R用户定义函数的速度可达到40x
- 3400多张Jira票已经解决
采用这个版本的Apache Spark不需要做大的代码更改。有关更多信息,请查看迁移指南。
庆祝Spark发展和演变的10年
Spark的前身是加州大学伯克利分校的AMPlab实验室,这是一个专注于数据密集型计算的研究实验室。AMPlab的研究人员与大型互联网公司合作研究他们的数据和人工智能问题,但是他们发现这些同样的问题也会被所有拥有大量且不断增长的数据的公司所面临。该团队开发了一个新的引擎来处理这些新兴的工作负载,同时使开发人员更容易访问用于处理大数据的api。
社区的贡献很快就加入进来,将Spark扩展到不同的领域,提供了围绕流、Python和SQL的新功能,这些模式现在构成了Spark的一些主要用例。这种持续的投资为它带来了今天的火花,成为数据处理、数据科学、机器学习和数据分析工作负载事实上的引擎。Apache Spark 3.0延续了这一趋势,显著改进了对SQL和Python(目前Spark使用最广泛的两种语言)的支持,并对Spark其余部分的性能和可操作性进行了优化。
改进Spark SQL引擎
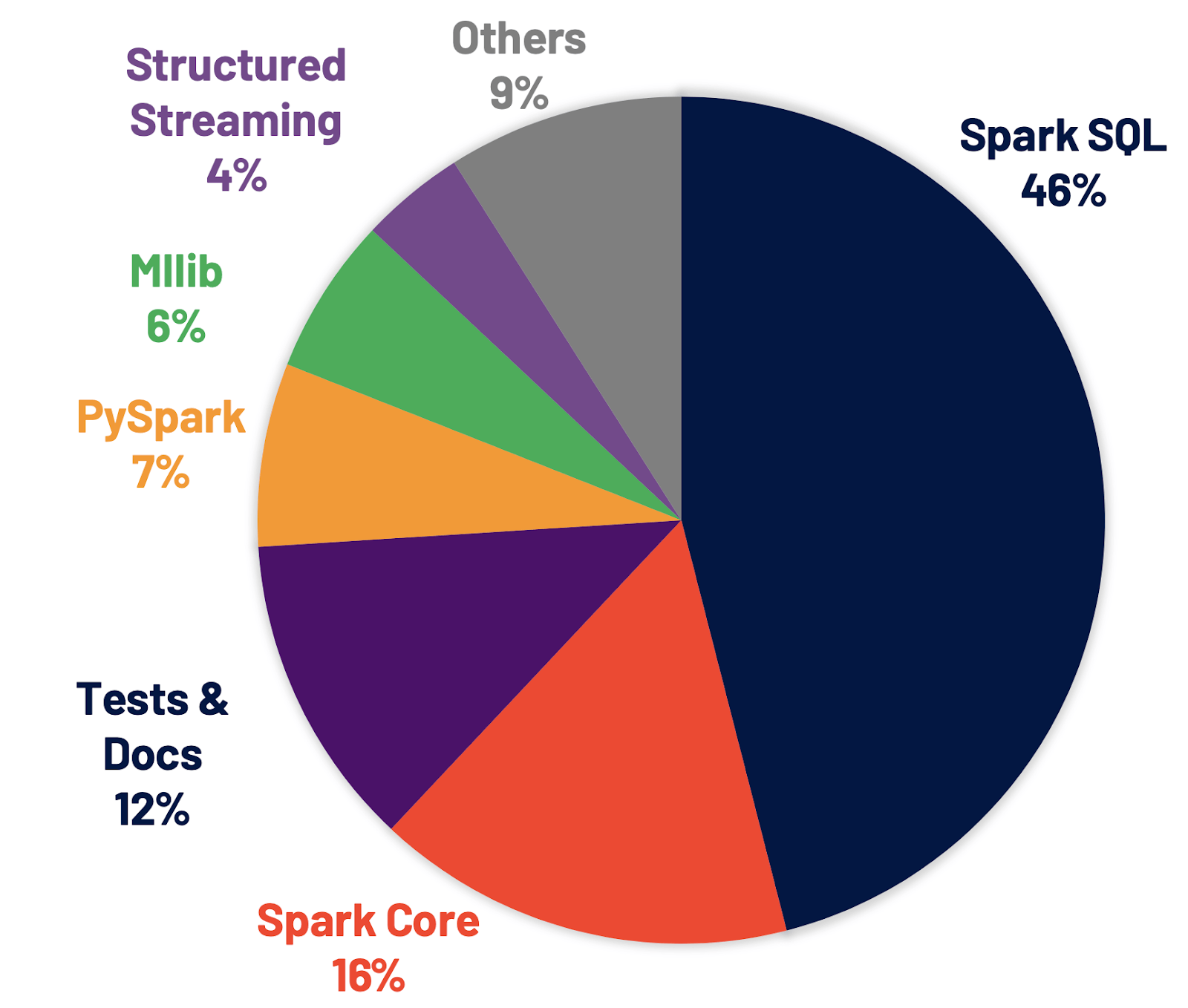
Spark SQL是支持大多数Spark应用程序的引擎。例如,在Databricks上,我们发现超过90%的Spark API调用使用DataFrame、Dataset和SQL API以及其他由SQL优化器优化的库。这意味着即使是Python和Scala开发人员也要通过Spark SQL引擎来传递他们的大部分工作。在Spark 3.0版本中,46%的补丁是针对SQL的,从而提高了性能和ANSI兼容性。如下所示,Spark 3.0在运行时的总体性能大约比Spark 2.4好2倍。接下来,我们将解释Spark SQL引擎中的四个新特性。

新的自适应查询执行(AQE)框架通过在运行时生成更好的执行计划来改进性能和简化调优,即使初始计划由于缺乏/不准确的数据统计和错误估计的成本而不是最优的。由于Spark中的存储和计算分离,数据到达可能是不可预测的。由于所有这些原因,与传统系统相比,Spark的运行时适应性变得更加关键。这个版本引入了三个主要的自适应优化:
- 动态合并洗牌分区可以简化甚至避免调整洗牌分区的数量。用户可以在开始时设置相对大量的转移分区,然后AQE可以在运行时将相邻的小分区合并为较大的分区。
- 动态切换连接策略可以部分避免执行由于缺少统计信息和/或大小估计错误而导致的次优计划。这种自适应优化可以在运行时自动将排序合并连接转换为广播散列连接,从而进一步简化调优并提高性能。
- 动态优化倾斜连接是另一个关键的性能增强,因为倾斜连接会导致工作的极度不平衡并严重降低性能。在AQE从shuffle文件统计数据中检测到任何倾斜后,它可以将倾斜分区分割成更小的分区,并将它们与另一端的相应分区连接起来。该优化可以并行化倾斜处理,获得更好的整体性能。
基于3TB的TPC-DS基准测试,与没有AQE相比,Spark与AQE可以对两个查询产生超过1.5倍的性能加速,对另外37个查询产生超过1.1倍的性能加速。

当优化器在编译时无法识别它可以跳过的分区时,将应用动态分区剪枝。
这在星型模式中并不少见,星型模式由一个或多个事实表组成,这些表引用任意数量的维度表。在这样的连接操作中,我们可以通过标识那些过滤维度表的分区来删除连接从事实表中读取的分区。在TPC-DS基准测试中,102个查询中有60个查询的速度显著提高了2倍到18倍。
ANSI SQL遵从性对于从其他SQL引擎到Spark SQL的工作负载迁移至关重要。
为了提高兼容性,该版本切换到预期的公历,还允许用户禁止使用保留的ANSI SQL关键字作为标识符。此外,我们还在数值操作中引入了运行时溢出检查,并在使用预定义模式将数据插入表时引入了编译时类型强制。这些新的验证可以提高数据质量。
连接提示:
虽然我们继续改进编译器,但不能保证编译器总是在每种情况下做出最优决策——连接算法的选择是基于统计和启发式的。当编译器无法做出最佳选择时,用户可以使用连接提示来影响优化器选择更好的计划。这个版本通过添加新的提示扩展了现有的连接提示:SHUFFLE_MERGE、SHUFFLE_HASH和SHUFFLE_REPLICATE_NL。
增强Python api: PySpark和Koalas
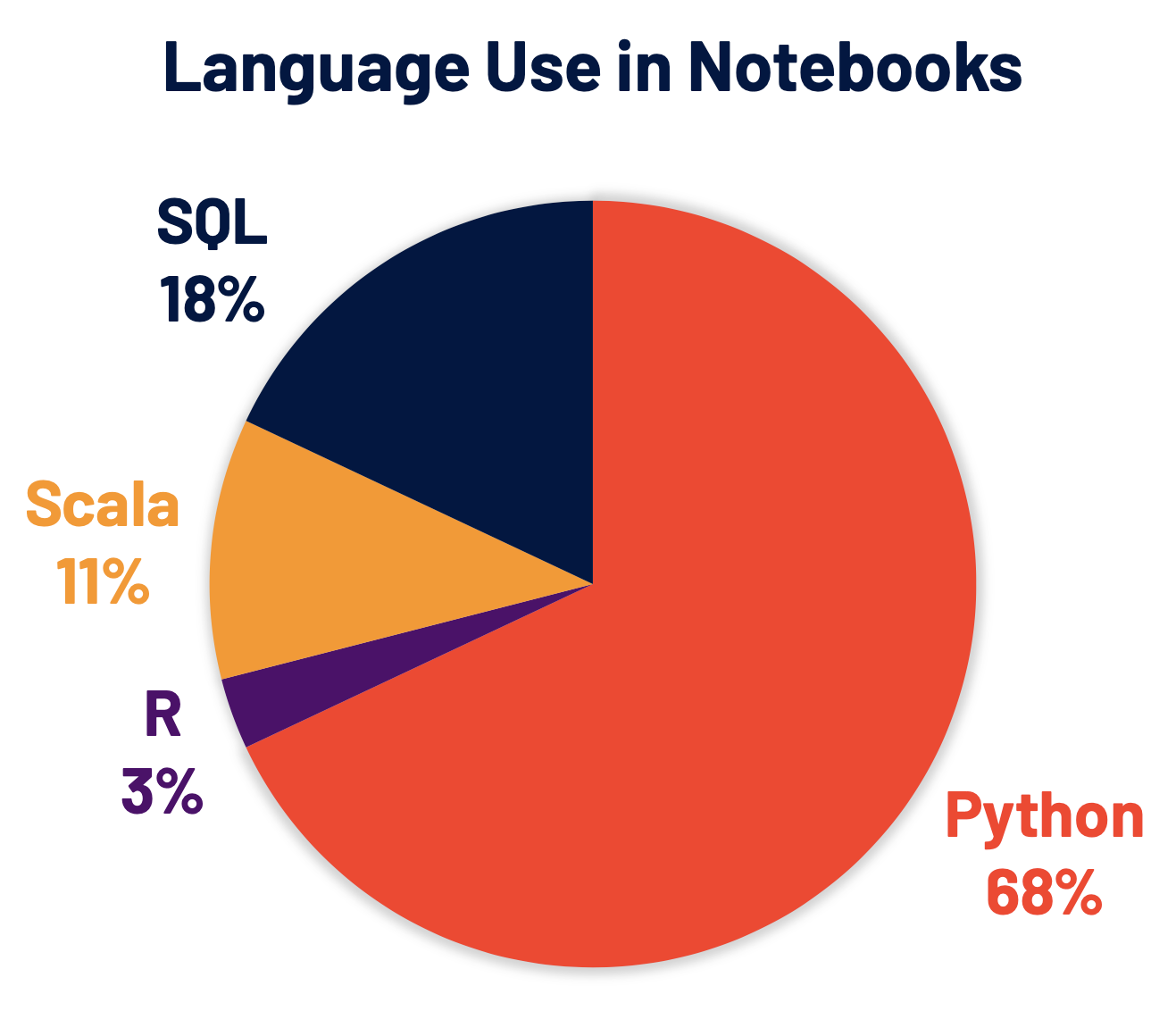
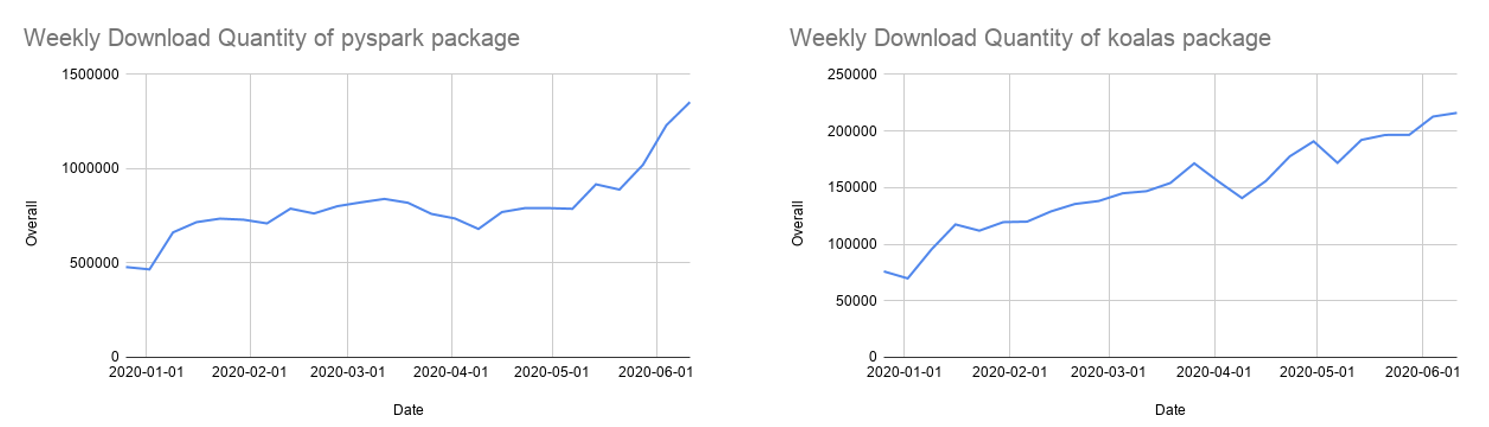
Python现在是Spark上使用最广泛的语言,因此,它是Spark 3.0开发的一个关键关注领域。Databricks上68%的笔记本命令是用Python编写的。Apache Spark Python API PySpark每月在Python包索引PyPI上的下载量超过500万次。
许多Python开发人员使用pandas API进行数据结构和数据分析,但是它仅限于单节点处理。我们还在继续开发考拉(Koalas),这是在Apache Spark上实现的panda API,使数据科学家在分布式环境中处理大数据时更有效率。Koalas不需要在PySpark中构建许多函数(例如,绘图支持),从而实现跨集群的高效性能。
经过一年多的发展,考拉对熊猫的API覆盖率接近80%。每月的PyPI下载量已经迅速增长到85万,而且考拉也以每两周发布一次的节奏迅速发展。虽然考拉可能是从单节点熊猫代码进行迁移的最简单方法,但许多考拉仍然使用PySpark api,而PySpark api也在日益流行。
Spark 3.0增强了PySpark api:
- 带有类型提示的pandas API:熊猫udf最初是在Spark 2.3中引入的,用于扩展PySpark中的用户定义函数,并将熊猫api集成到PySpark应用程序中。但是,当添加更多的UDF类型时,现有的接口很难理解。这个版本引入了一个新的panda UDF接口,它利用Python类型提示来解决panda UDF类型的激增问题。新的接口变得更加python化和自描述。
- pandas UDF的新类型和熊猫函数api:该版本添加了两种新的熊猫UDF类型,即对级数的迭代器添加级数的迭代器,对级数的迭代器添加多级数的迭代器。它对于数据预取和昂贵的初始化非常有用。另外,还添加了两个新的pandas-function api map和co- grouping map。更多的细节可以在这篇博客文章中找到。
- 更好的错误处理:PySpark错误处理对Python用户并不总是友好的。这个版本简化了PySpark异常,隐藏了不必要的JVM堆栈跟踪,并使它们更符合python风格。
改进Spark中的Python支持和可用性仍然是我们的最高优先级之一。
Hydrogen,流化和延展性
通过Spark 3.0,我们完成了Hydrogen项目的关键组件,并引入了改进流和可扩展性的新功能。
基于加速器的调度:
Hydrogen项目是Spark的一个主要项目,旨在更好地统一Spark上的深度学习和数据处理。gpu和其他加速器已被广泛用于加速深度学习工作负载。为了让Spark在目标平台上利用硬件加速器,这个版本增强了现有的调度器,使集群管理器能够感知加速器。用户可以在发现脚本的帮助下通过配置指定加速器。然后,用户可以调用新的RDD api来利用这些加速器。
用于结构化流的新UI:
结构化流最初是在Spark 2.0中引入的。在数据库里的使用增长了4倍之后,每天有超过5万亿条记录在数据库里被结构化流媒体处理。这个版本添加了一个专用的新的Spark UI,用于检查这些流作业。这个新的UI提供了两组统计信息:1)已完成的流化查询作业的聚合信息和2)流化查询的详细统计信息。
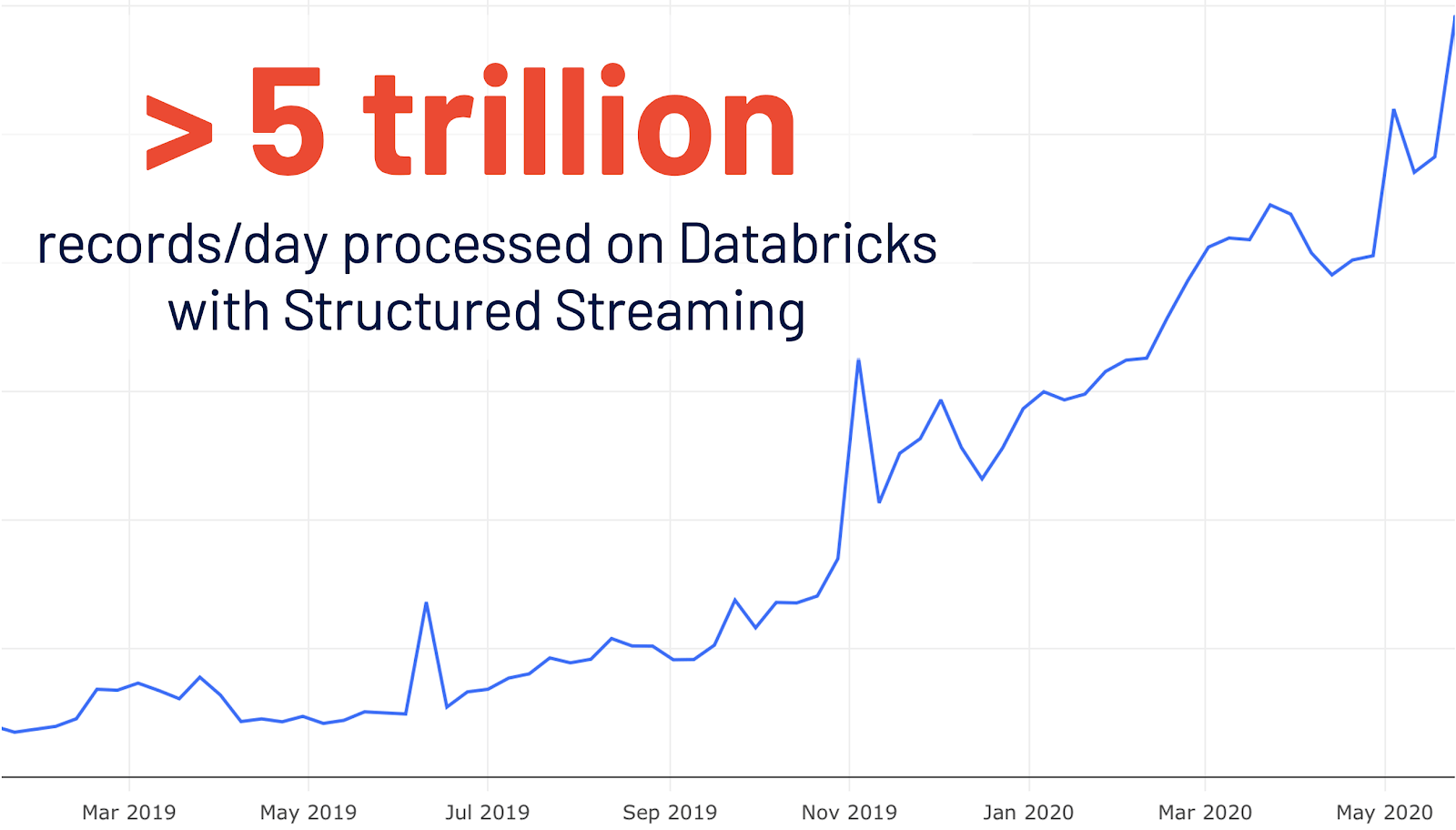
可观察指标:
持续监控数据质量的变化是管理数据管道的一个非常理想的特性。这个版本引入了对批处理和流应用程序的监视。可观察指标是可以在查询(DataFrame)上定义的任意聚合函数。一旦一个DataFrame的执行达到一个完成点(例如,完成批处理查询或到达流历元),一个命名的事件就会发出,它包含了自最后一个完成点以来处理的数据的度量。
新的目录插件API:
现有的数据源API缺乏访问和操作外部数据源的元数据的能力。这个版本丰富了数据源V2 API,并引入了新的目录插件API。对于既实现了目录插件API又实现了数据源V2 API的外部数据源,在注册了相应的外部目录之后,用户可以通过多部分标识符直接操作外部表的数据和元数据。
Spark 3.0中的其他更新
Spark 3.0是该社区的一个主要发行版,解决了超过3400个Jira罚单。它是超过440名贡献者的贡献,包括个人和公司,如Databricks,谷歌,微软,英特尔,IBM,阿里巴巴,Facebook, Nvidia, Netflix, Adobe等。在这篇博客文章中,我们强调了Spark在SQL、Python和流媒体方面的一些关键改进,但是在这个3.0里程碑中,还有许多其他功能没有在这里介绍。在发布说明中了解更多信息,并发现Spark的所有其他改进,包括数据源、生态系统、监控等等。
现在就开始使用Spark 3.0吧
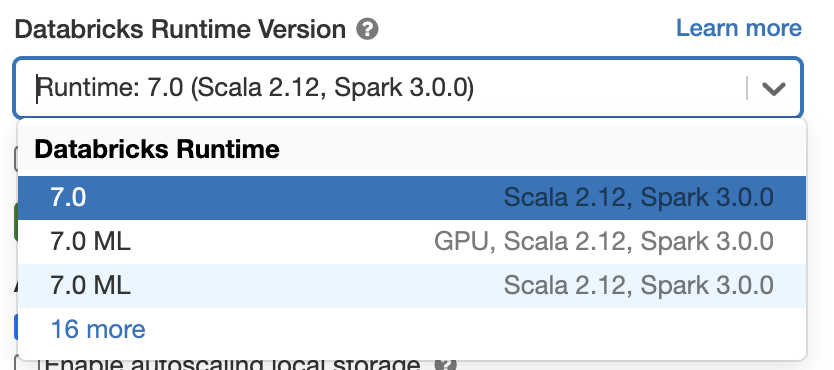
如果您想在Databricks运行时7.0中试用Apache Spark 3.0,请注册一个免费试用帐户,并在几分钟内启动。使用Spark 3.0就像在启动集群时选择version“7.0”一样简单。
本文:http://jiagoushi.pro/node/1190
讨论:请加入知识星球【首席架构师圈】或者加小号【jiagoushi_pro】或者微信圈【11107777】
- 115 次浏览
【Spark生态】Big SQL vs Spark SQL 100TB:它们如何叠加?
介绍:
SQL over Hadoop 领域的早期采用者现在正在创建大型数据库来存储他们更珍贵的商品和数据。 IBM在2014年10月发布了第一个(也是唯一一个)经过独立审计的Hadoop-DS基准测试时预测了这一趋势.Hadoop-DS是行业标准TPC-DS基准测试的衍生产品,经过定制,可以更好地匹配SQL over Hadoop空间的功能在Data Lake环境中。那时,IBM使用10TB的比例因子来比较Big SQL与其他领先的SQL Over Hadoop解决方案,即Hive 0.13和Impala 1.4.1。从那时起,所有产品都在性能和可扩展性方面取得了重大进步。 HortonWorks和Cloudera也投入了大量资金来丰富他们对SQL语言的支持(IBM已经在那里)。
Spark已成为开源社区中分析的最爱,Spark SQL允许用户使用熟悉的SQL语言向Spark提出问题。因此,有什么更好的方法来比较Spark的功能,而不是通过它的步伐,并使用Hadoop-DS基准来比较性能,吞吐量和SQL与Big SQL的兼容性。由于这是2017年,Data Lakes日渐变大,我们选择使用100TB的比例因子。
本研究将再次强调SQL over Hadoop引擎的需求,该引擎不仅快速高效,而且更重要的是可以成功地对大数据执行复杂查询。在选择SQL over Hadoop解决方案时,性能不是唯一的因素。该解决方案还需要由成熟且强大的运行时环境进行备份。成本仍然是采用SQL Over Hadoop解决方案的企业的主要吸引力之一(特别是与传统的RDBM相比),但无论出于何种原因,失败的查询将严重影响生产力并降低这些SQL相对于Hadoop解决方案的成本效益。没有交付。
摘要
在项目过程中,我们发现Big SQL是唯一能够在100 TB下执行所有未修改的99个查询的解决方案,可以比Spark SQL快3倍,同时使用更少的资源。 这些事实使我们得出结论,使用Big SQL的Data Professional比使用Spark SQL的数据提高了3倍。
测试环境:
Big SQL和Spark SQL测试都在同一个集群上执行。 该集群的构建基于Spark; 也就是说,它有大量的内存和SSD取代了传统的旋转磁盘。
使用了28节点集群,包括:
- 2 management nodes (Lenovo x3650 M5), collocated with data nodes
- 28 data nodes (Lenovo x3650 M5)
- 2 racks, 20x 2U servers per rack (42U racks)
- 1 switch, 100GbE, 32 ports, 1U, (Mellanox SN2700)
每个数据节点包括:
- CPU: 2x E5-2697 v4 @ 2.3GHz (Broardwell) (18c) Passmark: 23,054 / 46,108
- Memory: 1.5TB per server, 24x 64GB DDR4 2400MHz
- Flash Storage: 8x 2TB SSD PCIe MVMe (Intel DC P3700), 16TB per server
- Network: 100GbE adapter (Mellanox ConnectX-5 EN)
- IO Bandwidth per server: 16GB/s, Network bandwidth 12.5GB/s
- IO Bandwidth per cluster: 480GB/s, Network bandwidth 375GB/s
配置和调整:
产品的配置和调整由两个不同的团队进行; IBM的Big SQL性能团队和Spark SQL性能团队。
Spark团队使用了最新发布的Spark SQL 2.1版。 Spark的调优符合Hadoop-DS规范中规定的规则,但有一个关键的例外。传递给Spark SQL shell的执行程序属性的数量针对单流和4流运行进行了不同的调整。 4流运行中的每个流都传递了执行器值,该值是用于单个流运行的值的四分之一。这阻止了4流中的任何一个流都抓住了集群上的所有执行槽,这实际上会导致每个查询串行执行。虽然这很简单,有些人可能会说逻辑调整,但实际上不可能在生产集群上有效地执行此操作,在生产集群中不会知道并发执行查询的数量。但是,该团队决定,如果没有这一调整,就无法与Big SQL进行公平的比较。
Big SQL Worker
Big SQL团队使用了Big SQL版本4.3的技术预览版。技术预览包含对新功能的支持,其中每个物理节点可以托管多个Big SQL工作进程(以前,每个物理节点上只允许一个Big SQL工作进程)。单个物理节点上的多个Big SQL工作程序在Big SQL环境中提供了更大的操作并行化,从而提高了性能。考虑到测试集群中计算机的大量内存和CPU资源,团队将每个物理节点配置为包含12个Big SQL worker - 如图1所示。
与Spark SQL不同,Big SQL不需要基于并发查询流的数量进行微调,因此使用了单流和4流运行的相同配置。这是可能的,因为Big SQL具有成熟的自治,包括:
- 自调整内存管理器(STMM),它根据查询并发性动态管理消费者之间的内存分配
- 一个复杂的工作负载管理器(WLM),可以控制工作负载优先级,有助于维持一致的响应时间并实施SLA
- 在查询执行时自动调整并行度以考虑系统活动
这些都是关键功能,可以解决调整Big SQL的痛苦 - 无论是在基准测试环境还是现实环境中 - 多年来,组织一直认为这些功能在关系数据库中是必不可少的,以支持生产环境。那么为什么在Big SQL中找到这些功能而在Hadoop解决方案中找不到大多数其他SQL?简而言之,这是因为IBM围绕我们现有的关系数据库技术(已经在生产系统中运行了25年)构建了Big SQL的核心。因此,Big SQL具有强化,成熟且非常高效的SQL优化器和运行时,以及一组支持生产级部署的功能 - 这些是Big SQL世界级可伸缩性和性能的关键。
对于此基准测试,大多数Big SQL调优工作都集中在单个节点上共存的多个Big SQL工作者(这是此功能首次在此规模上进行了道路测试)。此功能在Big SQL v4.3 Technology Preview中可用,并且可以在安装后通过Ambari手动添加逻辑Big SQL worker。 Big SQL工程团队正在利用从本练习中获得的经验来改进自动化,并为Big SQL v4.3版本设置有意义的开箱即用默认值。因此,Big SQL客户不必自己进行任何调整。 Spark SQL团队的经验被用于创建一组最佳实践。在Spark SQL具有一组成熟的自我调整和工作负载管理功能之前,必须手动应用这些最佳实践。
查询执行:
使用100TB数据,使用Big SQL v4.3在4个并发查询流中成功执行了源自TPC-DS工作负载的所有99个查询(总共创建了396个查询)。在第一次运行三个Big SQL查询时,执行时间比预期的要长。使用统计视图和列组统计信息调整这些查询。这些独特的功能对Big SQL客户来说非常宝贵;允许他们收集有关复杂关系的详细信息,这些信息通常存在于现实数据中,从而提高性能。跨比例因子的Spark查询失败
图3:跨不同比例因子的Spark SQL查询
图4:Spark SQL查询失败的分类
虽然Spark SQL v2.1可以在1GB和1TB上成功执行所有99个查询(并且自v2.0以来已经能够执行),但是在10TB时两个查询失败,并且在100TB时失败的次数明显更多。在花费大量精力调整Spark(由Spark工程师,而不是Big SQL工程师)之后,总共可以在100TB的4个流中成功执行83个查询。为了确保苹果与苹果的比较,这组83个查询被用作比较Big SQL与Spark SQL性能的基础。图4:100TB的Big SQL vs Spark SQL查询细分
图5:100TB的Big SQL和Spark SQL查询细分
Spark故障可分为2大类; 1)查询未在合理的时间内完成(少于10小时),以及2)运行时故障。此外,几乎一半(7)的Spark SQL查询在100TB时失败,本质上是复杂的。事实的这种组合表明Spark SQL在更大规模的因素下与更复杂的查询斗争;因为Spark是一种缺乏现代RDBMS成熟度的相对较新的技术,所以这应该不会让人感到惊讶。这些发现也与2014年最初的Hadoop-DS工作一致; Hive和Impala都在使用复杂的查询(所有这些都是10TB),但Big SQL能够成功执行所有99个查询,在30TB的4个流中。
数据专业人员或任何用户的主要抑制因素是浪费宝贵的时间将有效查询重写为SQL解释器可以理解的表单,以及执行引擎可以成功完成的表单。重要信息本研究中的数据表明,使用Spark SQL的Data Professional将花费宝贵的时间重新编写或调整,每10个查询中有1个或2个(确切地说是16%)。不幸的是,对于不成熟的SQL引擎,尤其是SQL over Hadoop空间中的那些,通常就是这种情况。在10TB的原始Hadoop-DS评估中,Hive和Impala首先突出了这个问题,今天仍然适用于Spark SQL。值得注意的是,对于许多SQL over Hadoop引擎,以较低比例因子成功执行查询并不能保证真正的大数据成功。
构建一个100TB的数据库
毫无疑问,100TB这是一个大数据工作负载 - 最终数据库包含超过五万亿行:
大事实表被分区以利用Big SQL v4.2以后的新“分区消除串联连接密钥”功能。所有销售表都在各自的'* _SOLD_DATE_SK'列上进行了分区,并在各自的'* _RETURN_DATE_SK'列中返回表。以这种方式进行分区符合原始TPC-DS规范,并允许在查询执行期间删除分区 - 这可以极大地提高查询的时间和效率。图7:100TB数据库构建
图7:100TB数据库构建时间(秒)
数据库构建包括两个不同的操作,即加载阶段和统计信息收集阶段。加载阶段从数据生成器生成的原始文本中获取数据,并将其转换为Parquet存储格式。 Parquet是Big SQL和Spark SQL中查询的最佳存储格式,是这些测试的理想选择。加载阶段对于Big SQL和Spark SQL都是通用的,只需要超过39个小时即可完成。
39小时中的大部分用于加载STORE_SALES表的NULL分区(SS_SOLD_DATE_SK = NULL)。事实证明,STORE_SALES表在空分区上严重偏斜(大小约为570GB,而其他分区大约为20GB)。由于查询是重复执行的,而数据库构建是一次性操作,因此两个团队都没有专门用于提高负载性能的资源。但实际数据集中的严重偏差很常见。此数据集中所选分区列的严重偏差给执行某些更复杂的查询带来了挑战。工程团队致力于改进Big SQL Scheduler以应对这些挑战,这些改进将在Big SQL v4.3中提供。
收集统计信息使Big SQL基于成本的优化器能够就最有效的访问策略做出明智的决策,并且是Big SQL可以执行具有领先性能的所有99个TPC-DS查询的关键原因。目前,Spark SQL不需要收集相同级别的统计信息,因为它的优化程序还不够成熟,无法使用这些详细的统计信息。但是,随着Spark优化器的成熟,它对详细统计数据的依赖性会增加,收集所述统计数据的时间也会增加,但查询过程时间也会随之改善。
比较Big SQL和Spark SQL性能:
在现实生活中,单个用户不能单独使用组织的Hadoop集群。因此,我们专注于比较4个并发查询流中Big SQL和Spark SQL的性能。为了进行苹果与苹果的比较,生成的工作负载仅包括在合理的时间内(少于10小时)在Spark SQL中成功完成的83个查询。删除Spark SQL无法在10小时内完成的查询会使结果偏向于Spark,因为保留四个超时的查询几乎会使Spark SQL执行时间翻倍。
图8比较了在Spark SQL和Big SQL中完成所有4个流(总共332个查询)的83个查询所用的时间,以及Big SQL在4个流中完成所有99个查询所用的时间(总计396个查询)。 Spark SQL花了超过43个小时来完成测试,而Big SQL在13.5个小时内完成了相同数量的查询 - 使Big SQL比Spark SQL快3.2倍。
图8:4个查询流的100TB工作负载经历时间
图8:100TB的工作负载经历时间
事实上,Big SQL能够完成一个4流工作负载,每个流执行99个查询的完整补充,几乎比Spark SQL每个流执行83个查询快2倍。当您考虑到Spark SQL无法执行的16个查询中的7个是工作负载中最复杂的查询时,这会更令人印象深刻。
虽然对于Big SQL来说令人印象深刻,但如果查询集包含来自99的原始集合中的那些查询,那么性能差异会大得多,这些查询在10小时后在Spark SQL中超时。
重要信息将这些结果输入到现实环境中意味着使用Big SQL的数据专业人员的效率比使用Spark SQL的数据专业人员高三倍。图9:平均CPU消耗的比较
图9:100TB的4流的平均CPU消耗
对整个群集的CPU消耗的分析表明,Big SQL在工作负载持续时间内平均为76.4%,Spark SQL为88.2%。虽然Big SQL和Spark SQL之间消耗的用户CPU百分比大致相同,但Spark SQL的系统CPU几乎是Big SQL的3倍。系统CPU周期是不合需要的CPU周期,它们没有代表您的应用程序执行有用的工作。注意:两种产品的IO等待CPU时间可以忽略不计。
当然,由于Spark SQL测试需要花费3倍的时间才能完成,因此在执行工作负载中的所有332个查询的过程中,Spark SQL实际上消耗的CPU周期比Big SQL多3倍,系统CPU周期比Big SQL多9倍 - 突出显示随着Big SQL优化器和运行时的成熟,效率更高。 Big SQL不仅比Spark SQL快3.2倍,而且使用更少的CPU资源也实现了这一点。
图10:100TB(每个节点)的4个流的平均I / O速率
在检查测试期间进行的I / O量时,Big SQL的效率也会突出显示。 Spark SQL的平均读取速率平均比Big SQL大3.6倍,而其写入速率平均高出9.4倍。在测试期间推断平均I / O速率(Big SQL比Spark SQL快3.2倍),然后Spark SQL实际读取的数据几乎是Big SQL的12倍,并且写入数据增加了30倍。
图11:100TB(每个节点)的4个流的最大I / O速率
有趣的是,Big SQL具有更高的最大I / O吞吐量,表明在需要时,Big SQL可以通过I / O子系统提高吞吐量,而不是Spark SQL。
读取/写入的数据量的巨大差异,以及Big SQL可以更加强大地驱动I / O子系统的事实,是Big SQL中更高效率的简单但有效的指标。
重要信息将这一点重新回到现实生活中,我们的Data Professional不仅使用Big SQL提高了三倍的效率,而且使用更少的资源来完成工作,这反过来又允许其他数据专业人员在集群上运行更多分析同时.
是什么让这份报告有所不同?
已经有越来越多的基于Hadoop解决方案的SQL基准测试报告;一些显示解决方案x比y快许多倍,而其他人表明y比x快 - 但两者都是如此?我是许多竞争基准的老手,我可以诚实地说,通过定义测试的范围来赢得和失去基准。每个供应商都会最大限度地影响基准规范,以突出其自身产品的优势以及竞争对手的弱点。这正是今天SQL over Hadoop空间正在发生的事情,也是组织面对这些解决方案时过多的冲突性能信息的原因。那么,是什么让这份报告与众不同:
比例因子 - 毕竟,我们正在谈论大数据!这是唯一一份以100TB发布的报告。以较小比例因子发布的许多其他报告甚至不使用整个数据集。
它很全面。它不会挑选查询来强调一种解决方案相对于另一种解决方案的好处。根据最初的Hadoop-DS基准测试,IBM将苹果与苹果进行了比较,比较了适用于这两种产品的所有查询。
这些产品由两个竞争(但友好)的IBM团队调整,两者都在努力突出其产品的优势。最后,两个团队的经验将使他们各自的产品受益。
它遵循Hadoop-DS规范的规则(基于行业标准TPC-DS基准)
摘要:
毫无疑问,Spark SQL在很短的时间内已经走过了漫长的道路。 Spark SQL可以在100TB完成99个查询中的83个,这是开源社区推动这个项目的证明。但是,仍然没有替代产品的成熟度,而Big SQL的优势在于它建立在IBM的数据库技术之上。正是这种谱系在SQL over Hadoop空间中将Big SQL提升到了其他供应商之上。
图12:作者在Hadoop Marketplace上的SQL视图
图12:作者在Hadoop Marketplace上的SQL视图
作者对此空间的看法虽然相当不科学,如图12所示.Big SQL优于Hadoop解决方案的开源SQL包,主要是因为Big SQL继承了IBM数据库的大量丰富功能(和性能)。遗产。假设Spark SQL保持其当前的势头,它可能最终超过Big SQL的速度,可扩展性和功能。然而,随着技术的成熟,它们的改进速度会慢下来 - 毕竟,对于一年前的产品而言,仅仅因为在产品生命的早期阶段,将十年的产品改进10倍就更容易了 - 酒吧的周期要低得多。
总而言之,这份报告显示了Big SQL:
可以在100TB,4个并发流中执行所有99个TPC-DS查询,以及
可以这样做至少比Spark SQL快3倍,而且
使用较少的群集资源来实现此类领先的性能。
但对于考虑购买SQL over Hadoop解决方案的组织来说,这意味着什么呢?重要的是,简单来说,这意味着Big SQL使他们的数据专业人员和业务分析师的工作效率(至少)提高了3倍。使用Big SQL可能需要3个小时才能完成深度分析,使用Spark SQL需要9个小时(或一个工作日)。在一天内,Big SQL用户可以使用不同的输入组合运行3次分析,以模拟不同的场景。使用Spark SQL完成相同的分析至少需要3个工作日;可能更长,因为查询无法完成的可能性更高,调整Spark SQL查询所需的持续时间通常更长。
我们还提供YouTube视频(https://www.youtube.com/watch?v=M5zqykmEu9U),详细介绍了我们的体验。
- 99 次浏览
【大数据】Apache Flink vs Spark——一方会超越另一方吗?
视频号
微信公众号
知识星球
Apache Flink vs Spark,是大数据行业的热门新话题。了解Apache Spark是否会被Apache Flink推到图片之外。
Apache Spark和Apache Flink都是开源的分布式处理框架,旨在减少Hadoop Mapreduce在快速数据处理中的延迟。人们普遍误解Apache Flink将取代Spark,或者这两种大数据技术可能共存,从而满足容错、快速数据处理的类似需求。Apache Spark和Flink可能与那些没有使用过这两种技术,只熟悉Hadoop的人相似,很明显,他们会觉得Apache Flink的开发大多是多余的。但Flink之所以能够在游戏中保持领先,是因为它的流处理功能能够实时处理一行又一行的数据——这在Apache Spark的批处理方法中是不可能的。这使得Flink比Spark更快。
根据IBM的这项研究,我们每天创建大约2.5万亿字节的数据,而且这种数据生成速度仍在以前所未有的速度增长。从另一个角度来看,尽管万维网已经向公众开放了20多年,但世界上现有的所有数据中,约90%是在过去两年中创建的。在过去的十年里,随着互联网的发展,用户数量的增加和对内容日益增长的需求为Web 2.0铺平了道路。这是第一次允许用户在互联网上创建自己的数据,并准备被渴望数据的观众消费。
目录
- Apache Spark
- Spark的优点
- Apache闪烁
- Flink的优势
- Apache Flink vs Spark
- 成长故事——火花与闪烁
- 2021的增长故事——Spark和Flink
然后轮到社交媒体侵入我们的生活了。根据wersm(我们是社交媒体)的报告,脸书在一分钟内获得了超过400万个赞!在我们了解这些数据是如何消耗的之前,信息图中提到了其他流行来源产生的数据(取自同一项wersm研究)。

“如何存储这些巨大的数据?”这是一个让科技极客在过去十年的大部分时间里都很忙的问题陈述。社交媒体的突然兴起并没有让他们的任务变得更容易。然而,云计算等新时代的存储解决方案已经彻底改变了行业,并提供了尽可能好的解决方案。在当前的十年里,问题陈述已经转变为“如何处理海量数据?”数据分析成为最终目标,但在此之前,需要做大量工作来整合不同来源以不同格式存储的数据,并为处理和分析做好准备,这是一项艰巨的任务。
我们今天的两个主题——Apache Spark和Apache Flink——试图回答这个问题以及更多问题。
Apache Spark
Spark是一个开源的集群计算框架,拥有庞大的全球用户群。它是用Scala、Java、R和Python编写的,为程序员提供了一个基于容错、只读多组分布式数据项的应用程序编程接口(API)。自首次发布(2014年5月)以来的短短2年时间里,由于其速度快、易用性强以及能够处理复杂的分析需求,它在实时、内存和高级分析方面获得了广泛的接受。
Spark的优点
与传统的基于大数据和MapReduce的技术相比,Apache Spark有几个优势。突出的是。它本质上将MapReduce提升到了一个新的水平,其性能提高了数倍。Spark的一个关键区别是它能够将中间结果保存在内存中,而不是写回磁盘并再次从中读取,这对于基于迭代的用例至关重要。
- 速度–Spark执行批处理作业的速度是MapReduce的10到100倍。这并不意味着它在必须向磁盘写入数据(和从磁盘提取数据)时落后,因为它是大规模磁盘上排序的世界纪录保持者。
- 易用性–Apache Spark具有易于使用的API,专为在大型数据集上操作而构建。
- 统一引擎–Spark可以在Hadoop之上运行,利用其集群管理器(YARN)和底层存储(HDFS、HBase等)。然而,它也可以独立于Hadoop运行,与其他集群管理器和存储平台(如Cassandra和Amazon S3)合作。它还提供了更高级别的库,支持SQL查询、数据流、机器学习和图形处理。
- 从Java、Scala或Python中进行选择–Spark不会将您束缚在特定的语言上,而是允许您从流行的语言中进行选择,如Java、Scala、Python、R甚至Clojure。
- 内存中的数据共享–不同的作业可以在内存中共享数据,这使其成为迭代、交互和事件流处理任务的理想选择。
- 活跃、不断扩大的用户社区——活跃的用户社区使Spark在首次发布后的2年内稳定发布(2016年6月)。这充分说明了它在世界范围内的可接受性,这种可接受性正在上升。
Apache Flink
Apache Flink在德语中是“快速”或“灵活”的意思,是最新加入专注于大数据分析的开源框架名单的公司,这些框架正试图取代Hadoop老化的MapReduce,就像Spark一样。Flink于2016年3月发布了第一个API稳定版本,与Spark一样,它是为批处理数据的内存处理而构建的。当需要对同一数据进行重复传递时,此模型非常方便。这使其成为机器学习和其他需要自适应学习、自学习网络等的用例的理想候选者。随着物联网(IoT)空间的不可避免的繁荣,Flink用户社区有一些令人兴奋的挑战值得期待。
Flink的优势
实际的流处理引擎,可以近似于批处理,而不是相反。
- 更好的内存管理——显式内存管理消除了Spark框架中偶尔出现的峰值。
- 速度–它允许在同一节点上进行迭代处理,而不是让集群独立运行,从而管理更快的速度。它的性能可以通过调整来进一步调整,只重新处理发生变化的那部分数据,而不是整个数据集。与标准处理算法相比,它的速度提高了五倍。
- 配置较少
Apache Flink vs Spark
当Flink出现时,Apache Spark已经成为世界各地许多组织的快速内存大数据分析需求的事实框架。这让Flink显得多余。毕竟,在现有的数据处理引擎还没有定论的情况下,为什么还要需要另一个数据处理引擎?人们必须更深入地挖掘Flink的功能,以观察它的与众不同之处,尽管许多分析师将其称为“数据分析的4G”。
Flink瞄准并试图利用Spark设置中的一个小弱点。尽管出于随意讨论的目的,Spark并不纯粹是一个流处理引擎。正如Ian Pointer在InfoWorld的文章《Apache Flink:新的Hadoop竞争者与Spark较量》中所观察到的那样,Spark本质上是一种快速批处理操作,在一个时间单位内只处理一小部分传入数据。Spark在其官方文档中将其称为“微批量”。这个问题不太可能对操作有任何实际意义,除非用例需要低延迟(金融系统),因为毫秒级的延迟会造成重大影响。话虽如此,Flink几乎是一项正在进行的工作,目前还不能宣称取代Spark。
Flink是一个流处理框架,可以运行需要批处理的杂务,让您可以选择在两种模式下使用相同的算法,而不必求助于像Apache Storm这样需要低延迟响应的技术。
Spark和Flink都支持内存处理,这使它们在速度上优于其他框架。在实时处理传入数据方面,Flink无法与Spark抗衡,尽管它有能力执行实时处理任务。
Spark和Flink都可以处理迭代的内存处理。在速度方面,Flink占据了上风,因为它可以被编程为只处理发生变化的数据,这就是它在Spark之上的表现。
成长故事——Spark与Flink
任何软件框架都需要的不仅仅是技术专长,还需要帮助企业获得最大价值。在本节中,我们深入研究Databricks撰写的Apache Spark 2015 Year In Review文章,了解它在全球用户和开发人员社区中的表现。这一年共发布了4个版本(1.3到1.6),每个版本都有数百个修复程序来改进框架。吸引我们眼球的是贡献开发者数量的增长——从2014年的500人增长到2015年的1000多人!Spark的另一个值得注意的地方是它的用户很容易过渡到新版本。报告提到,在三个月内,大多数用户都会接受最新版本。这些事实增强了它作为最积极开发(和采用)的开源数据工具的声誉。
Flink在竞争中相对较晚,但2015年在其官方网站上的回顾表明了它为什么会成为最完整的开源流处理框架。Flink的github存储库(Get the repository–Here)显示,2015年社区规模翻了一番,从75个贡献者增加到150个。存储库分叉在这一年中增加了两倍多,存储库的恒星数量也增加了三倍多。从德国柏林开始,它的用户社区已经跨越各大洲发展到北美和亚洲。Flink Forward会议是Flink的又一个里程碑,有250多名与会者参加,100多名与会者从全球各地赶来,参加了来自谷歌、MongoDB、电信、NFLabs、RedHat、IBM、华为、爱立信、Capital One、Amadeus等组织的技术会谈。
尽管从这两个框架中选出一个作为明显的赢家还为时过早,但我们认为,与其让许多框架做同样的事情,不如让新进入者做不同的事情,补充现有的事情,而不是与它们竞争,从而更好地服务于科技世界。
2021的增长故事——Spark和Flink
任何软件框架都需要的不仅仅是技术专长,还需要帮助企业获得最大价值。在本节中,我们深入研究了过去十年对Apache Spark的回顾,以了解它在全球用户和开发人员社区中的表现。2020年,Apache 3.0发布,这是迄今为止最大的一次发布,有超过3400张已解决的社区Ticket。此版本的首要活动组件是Spark SQL,因为已解决的票证中约46%与SparkSQL引擎(所有数据帧API调用的底层引擎)有关。这次更新让世界见证了阿里巴巴基于Apache Hadoop和Spark的云E-MapReduce,创造了TPC-DS Benchmark的新世界纪录。如果您不知道,TPC-DS是基于SQL的大数据系统的第一个基准测试。Spark这个新版本的另一个值得注意的地方是,它收集了大量的Spark生态系统项目,包括 Koalas, Delta-Lake、推广Spark作为流行数据科学库(如sci-kit learn)的扩展后端等。吸引我们眼球的是,Spark社区注意到切换到最新版本的过程尽可能顺利。这些事实增强了它作为最积极开发(和采用)的开源数据工具的声誉。
Flink在比赛中相对较晚,但2020年Flink Forward全球虚拟会议
显示它拥有Apache软件基金会中最活跃的社区成员之一。Flink的GitHub存储库(Get the repository–Here)显示,该社区的规模已经大幅增长,从2015年的75个贡献者增长到现在的895个。社区成员的这种热情为Flink带来了许多令人兴奋的功能,如世界级的统一SQL、CDC集成、状态处理器API、Hive集成等等。
虽然在流媒体功能方面,Flink肯定被认为比Spark更快,但很难挑出其中一个作为明显的赢家,因为后者拥有更强大、更古老的社区支持。我们认为,与其让许多框架做同样的事情,不如让新进入者做不同的事情,补充现有的框架,而不是与它们竞争,从而更好地服务于科技世界。
- 593 次浏览
【大数据】Flink与Spark的对比:Flink和Spark的区别[2023]
视频号
微信公众号
知识星球
介绍
如今,大多数成功的企业都与技术领域有关,并在网上运营。他们的消费者活动每秒都会产生大量数据,这些数据需要高速处理,并以同样的速度产生结果。这些发展产生了对数据处理(如流处理和批处理)的需求。
有了这个,大数据可以通过多种方式进行存储、获取、分析和处理。因此,一旦接收到数据,就可以查询连续的数据流或集群,并且可以快速检测条件。Apache Flink和Apache Spark都是为此目的创建的开源平台。
然而,由于用户对研究Flink Vs Spark感兴趣,本文提供了它们的功能差异。
什么是Apache Flink?
Apache Flink是一个用于流处理的开源框架,它在分布式系统上以高性能、高稳定性和高准确性快速处理数据。它提供了低数据延迟和高容错性。Flink的显著特点是能够实时处理数据。它是由Apache软件基金会开发的。
什么是Apache Spark?
Apache Spark是一个开源的集群计算框架,工作速度非常快,用于大规模数据处理。它以速度、易用性和复杂的分析为基础,这使它在各个行业的企业中都很受欢迎。
它最初由加州大学伯克利分校开发,后来捐赠给了Apache软件基金会。
Flink与Spark
Apache Flink和Apache Spark都是通用数据处理平台,它们各自有许多应用程序。它们都可以在独立模式下使用,并且具有强大的性能。
它们有一些相似之处,例如类似的API和组件,但在数据处理方面有几个不同之处。以下是在检查Flink与Spark时的差异列表。
| Flink | Spark |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
结论
Flink和Spark都是在科技行业广受欢迎的大数据技术工具,因为它们为大数据问题提供了快速解决方案。但在分析Flink与Spark的速度时,Flink比Spark更好,因为它的底层架构。
另一方面,Spark拥有强大的社区支持和大量贡献者。在比较两者的流传输能力时,Flink处理数据流要好得多,而Spark处理微批处理。
通过本文,介绍了数据处理的基本知识,并对ApacheFlink和ApacheSpark进行了描述。对Flink和Spark的功能进行了比较和简要解释,根据处理速度给用户一个明显的赢家。然而,最终的选择取决于用户及其所需的功能。
- 457 次浏览
【大数据】为什么适用Ceph上运行Spark ?(三部分第一部分)
几年前,一些大公司开始运行Spark和Hadoop分析集群,使用共享Ceph对象存储来扩充和/或取代HDFS。
我们开始调查他们为什么要这么做,以及它的表现如何。
具体来说,我们想知道以下三个问题的第一手答案:
- 公司为什么要这么做?(这篇文章)
- 主流的分析作业会直接运行在Ceph对象存储上吗?(见“为什么Ceph上有Spark ?”(第三部分第二部分)”)
- 它的运行速度会比在HDFS上的本机慢多少?(见“为什么Ceph上有Spark ?”(第三部分)")
我们将在一个由三部分组成的博客系列中对这些问题提供摘要级别的答案。此外,对于那些想要更深入的人,我们将交叉链接到一个独立的参考体系结构博客系列,提供详细的描述、测试数据和配置场景。和Ceph在英特尔硬件上工作得更好,并帮助企业有效地扩大规模。
第1部分:公司为什么要这么做?
众人的敏捷,一人的力量。
许多分析集群的敏捷性,以及一个共享数据存储的能力。
(好吧…简单的对联已经够多了。)
以下是我在与30多家公司交谈后发现的一些常见问题:
- 共享相同分析集群的团队经常会感到沮丧,因为其他人的工作经常妨碍他们按时完成工作。
- 另外,一些团队希望在他们的集群中保持旧的分析工具版本的稳定性,而他们的同行团队需要加载最新和最好的工具版本。
- 因此,许多团队需要自己独立的分析集群,这样他们的工作就不会与其他团队争夺资源,因此他们可以根据自己的需求调整集群。
- 但是,每个单独的分析集群通常都有自己的非共享HDFS数据存储——创建数据竖井。
- 为了跨竖井提供对相同数据集的访问,数据平台团队经常在HDFS竖井之间复制数据集,试图保持它们的一致和最新。
- 结果,公司最终维护了许多独立的、固定的分析集群(一种情况下超过50个),每个集群都有自己的HDFS数据竖井,其中包含数据PBs的冗余副本,同时维护一个容易出错的脚本迷宫,以保持竖井之间的数据集更新。
- 但是,在不同的HDFS筒仓上维护5、10或20个多pb数据集副本的成本对许多公司来说都是高昂的(包括CapEx和OpEx)。
在图片中,他们的核心问题和最终选择如下所示:
 Figure 1. Core problems
Figure 1. Core problems

Figure 2. Resulting Options
事实证明,AWS生态系统多年前就通过Hadoop S3A文件系统客户端为选择#3(见上面的图2)构建了一个解决方案。在AWS中,您可以在EC2实例上启动许多分析集群,并在它们之间在Amazon S3上共享数据集(例如,请参阅Cloudera CDH对Amazon S3的支持)。在启动新的集群后,不再有冗长的延迟混合HDFS存储,或者在集群终止时去staging HDFS数据。使用Hadoop S3A文件系统客户端,Spark/Hadoop作业和查询可以直接针对共享S3数据存储中的数据运行。
底线……越来越多的数据科学家和分析师习惯于在AWS上快速创建分析集群,访问共享数据集,而不需要耗时的HDFS数据混合和分离循环,并期望在本地拥有相同的功能。
Ceph是排名第一的开源私有云对象存储平台,提供与s3兼容的对象存储。对于那些希望为其本地分析师提供兼容s3的共享数据湖体验的公司来说,这是(现在也是)自然的选择。
要了解更多信息,请继续本系列的下一篇文章,“为什么在Ceph上使用Spark ?(第三部分):主流的分析作业会直接运行在Ceph对象存储上吗?
原文:https://www.redhat.com/en/blog/why-spark-ceph-part-1-3
本文:http://jiagoushi.pro/node/1502
讨论:请加入知识星球【首席架构师圈】或者小号【cea_csa_cto】或者QQ【2808908662】
- 146 次浏览
【大数据】为什么适用Ceph上运行Spark ?(三部分第三部分)
介绍
几年前,一些大公司开始运行Spark和Hadoop分析集群,使用共享Ceph对象存储来扩充和/或取代HDFS。
我们开始调查他们为什么要这么做,以及它的表现如何。
具体来说,我们Red Hat Storage解决方案架构团队想要知道以下三个问题的第一手答案:
- 公司为什么要这么做?(见“为什么Ceph上有Spark ?”(第三部分第一部分)”)
- 主流的分析作业会直接运行在Ceph对象存储上吗?(见“为什么Ceph上有Spark ?”(第三部分第二部分)”)
- 它的运行速度会比在HDFS上的本机慢多少?(这篇文章)
对于那些想要更深入,我们将交联到一个单独的architect-level博客系列,提供详细的描述,测试数据,和配置场景,我们记录与英特尔这个播客,我们谈论我们的关注使火花,Hadoop, Ceph在英特尔工作更好的硬件和帮助企业有效地扩展。
研究结果总结
我们用不同的工作负载做了Ceph和HDFS的测试(关于一般工作负载的描述,请参阅博客第2部分和第3部分)。正如预期的那样,价格/性能比较基于以下几个因素而有所不同。
显然,许多因素影响着整体解决方案的价格。由于存储容量通常是大数据解决方案价格的主要组成部分,我们在价格/性能比较中选择了它作为价格的简单代理。
在我们的比较中,影响存储容量价格的主要因素是使用的数据持久性方案。由于复制数据持久性为3倍,客户需要购买3PB的原始存储容量来获得1PB的可用容量。在erasure code 4:2的数据持久性下,客户只需要购买1.5PB的原始存储容量就可以得到1PB的可用容量。HDFS使用的主要数据持久性方案是3倍复制(对HDFS擦除编码的支持正在出现,但在一些发行版中仍处于试验阶段)。Ceph多年来一直支持擦除编码或3倍复制数据持久性方案。所有与我们合作的Spark-on-Ceph早期采用者都出于成本效率的原因使用擦除编码。因此,我们的大多数测试都是使用Ceph擦除编码的集群(我们选择EC 4:2)。我们还用Ceph的3倍复制集群进行了一些测试,为这些测试提供了苹果对苹果的比较。
使用上面提到的相对价格的代理,图1提供了一个HDFS v. Ceph价格/性能的总结:

Figure 1: Relative price/performance comparison, based on results from eight different workloads
图1描述了基于八种不同工作负载的价格/性能比较。这8个工作负载中的每一个都使用HDFS和Ceph存储后端运行。Ceph解决方案相对于HDFS解决方案的存储容量价格要么相同,要么少50%。当使用复制了3倍的Ceph集群运行工作负载时,存储容量的价格显示为与HDFS相同。当使用Ceph erasure编码的4:2集群运行工作负载时,Ceph存储容量的价格显示为比HDFS低50%。(参见前面关于数据持久性方案如何影响解决方案价格的讨论。)
例如,工作负载8对于Ceph或HDFS存储具有类似的性能,但是Ceph存储容量的价格是HDFS存储容量价格的50%,因为Ceph运行的是一个擦除编码的4:2集群。在其他示例中,工作负载1和2使用Ceph或HDFS存储具有类似的性能,并且具有相同的存储容量价格(工作负载1和2使用复制了3倍的Ceph集群运行)。
发现细节
这里提供了一些使用Ceph和HDFS存储测试的工作负载的细节,如图1所示。
细节1
这个工作负载是一个通过TestDFSIO比较聚合读吞吐量的简单测试。如图2所示,当Ceph也使用3x复制时,HDFS和Ceph之间进行了比较。当Ceph使用擦除编码4:2时,对于更少的并发客户端(<300),工作负载比HDFS或Ceph的3倍表现得更好。然而,在更多的客户机并发性下,Ceph 4:2上的工作负载性能由于主轴争用而下降(一个带有擦除编码的4:2存储的读取需要4次磁盘访问,而一个带有3倍复制存储的磁盘访问需要4次磁盘访问)。

Figure 2: TestDFSIO read results
细节2
这个工作负载比较了一个单用户执行一系列查询(54个TPC-DS查询,如博客2或3所述)的SparkSQL查询性能。如图3所示,当在HDFS或Ceph的3倍复制存储上运行时,总的查询时间是相当的。在运行Ceph EC4:2时,聚合查询时间翻了一番。

Figure 3: Single-user Spark query set results
细节3
该工作负载比较了10个用户每个并发执行一系列查询的Impala查询性能(54个TPC-DS查询由每个用户以随机顺序执行)。如图1所示,Ceph EC4:2上这个工作负载的总执行时间比HDFS慢了57%。但是,价格/性能几乎可以比较,因为HDFS的存储容量成本是Ceph EC4:2的2倍。
细节4
这种混合工作负载的特点是并发执行一个单用户运行SparkSQL查询(54个),每个10个用户运行Impala查询(每个54个),以及一个数据集合并/连接作业,用合成的点击流日志丰富TPC-DS web销售数据。如图1所示,Ceph EC4:2上这种混合工作负载的总执行时间比HDFS慢48%。但是,价格/性能几乎可以比较,因为HDFS的存储容量成本是Ceph EC4:2的2倍。
细节5
这个工作负载是通过TestDFSIO比较聚合写吞吐量的一个简单测试。如图1所示,这个工作负载在Ceph EC4:2上执行的平均速度比HDFS慢50%,跨一系列并发客户机/写入器。但是,价格/性能几乎可以比较,因为HDFS的存储容量成本是Ceph EC4:2的2倍。
细节6
这个工作负载比较了单用户执行一系列查询(54个TPC-DS查询,如博客2或3所述)的SparkSQL查询性能。如图3所示,当运行在HDFS或Ceph 3倍复制存储时,总的查询时间是相当的。在运行Ceph EC4:2时,聚合查询时间翻了一番。然而,在Ceph EC4:2上运行时,价格/性能几乎可以比较,因为HDFS的存储容量成本是Ceph EC4:2的2倍。
细节7
这个工作负载的特点是用合成的点击流日志丰富(合并/连接)TPC-DS网络销售数据,然后写入更新的网络销售数据。如图4所示,Ceph EC4:2上的工作负载比HDFS慢37%。但是,价格/性能对Ceph是有利的,因为HDFS的存储容量成本是Ceph EC4:2的2倍。

Figure 4: Data set enrichment (merge/join/update) job results
细节8
这个工作负载比较了10个用户每个并发执行一系列查询的SparkSQL查询性能(54个TPC-DS查询由每个用户以随机顺序执行)。如图1所示,尽管只需要50%的存储容量成本,但Ceph EC4:2上这个工作负载的总执行时间与HDFS的大致相当。这个工作负载的价格/性能因此有利于Ceph的2倍。要更深入地了解这种工作负载性能,请参见图5。在这个盒须图中,每个点反映了单个SparkSQL查询执行时间。因为这10个用户中的每个都同时执行54个查询,所以每个系列有540个点。显示的三个系列是Ceph EC4:2(绿色)、Ceph 3x(红色)和HDFS 3x(蓝色)。Ceph EC4:2框显示了相当于HDFS 3倍的中间执行时间,并在中间2个四分位数显示了更一致的查询时间。

Figure 5: Multi-user Spark query set results
奖励结果部分:24小时摄入
我们的一个潜在Spark-on-Ceph客户最近要求我们说明Ceph集群在24小时内的持续摄取率。对于这些测试,我们使用了博客2 / 3中描述的实验室变体。如图6所示,我们在配置了700个HDD数据驱动器(Ceph OSDs)的Ceph EC4:2集群中测量了每天大约1.3 PiB的原始摄取速率。

Figure 6: Daily data ingest rate into Ceph clusters of various sizes
结论观察
总之,下面是我们对上述结果的成本/收益分析,总结了本系列博客。
Spark-on- ceph vs. Spark在传统HDFS上的好处:
- 通过减少重复减少资本支出:当多个分析集群需要访问相同的数据集时,减少购买在HDFS筒仓中存储重复数据集的冗余存储容量的PBs。
- 降低OpEx/risk:当多个分析集群需要访问相同的数据集时,消除HDFS竖井之间的脚本/调度数据集副本的成本,并降低在HDFS竖井上试图维护这些重复数据集之间的一致性时的人为错误风险。
- 从新的数据科学集群加速洞察:通过在共享数据存储库中原位分析数据,而不是在开始分析之前将数据复制到一个新集群,从而在创建新的数据科学集群时减少洞察时间。
- 满足不同数据团队的不同工具/版本需求:在团队之间共享数据集的同时,允许每个集群内的用户选择适合其工作的Spark/Hadoop工具集和版本,而不会干扰其他需要不同工具/版本的团队的用户。
- 适当大小的CapEx基础设施成本:通过适当大小的计算需求(vCPU/RAM),独立于存储容量需求(吞吐量/TB),减少传统HDFS集群中常见的计算或存储过度供应,通过增加通用节点(无论是否只需要更多的CPU核或存储容量)。
- 通过提高数据持久性效率来降低资本支出:Ceph erasure编码效率比HDFS默认的3倍复制降低了高达50%的存储容量购买的资本支出。
Spark-on- ceph vs. Spark在传统HDFS上:
- 查询性能:Spark/Impala查询任务执行时间延长0% ~ 131%(单用户和多用户并发测试)。
- 写作业性能:面向写作业(加载、转换、充实)的性能范围为37%-200%+更长的执行时间。[注意:当下游发行版对Hadoop S3A客户端采用以下上游增强Hadoop -13600、Hadoop -13786、Hadoop -12891]时,写作业性能有望显著改善。
- 混合工作负载性能:并发执行多个查询和充实作业的性能导致执行时间延长90%。
要了解更多细节(以及亲身体验此解决方案的机会),请继续关注这个Red Hat Storage博客位置的架构级博客系列。感谢你的阅读。
原文:https://www.redhat.com/en/blog/why-spark-ceph-part-3-3
本文:http://jiagoushi.pro/node/1504
讨论:请加入知识星球【首席架构师圈】或者小号【cea_csa_cto】或者QQ【2808908662】
- 249 次浏览
【大数据】为什么适用Ceph上运行Spark ?(三部分第二部分)
介绍
几年前,一些大公司开始运行Spark和Hadoop分析集群,使用共享Ceph对象存储来扩充和/或取代HDFS。
我们开始调查他们为什么要这么做,以及它的表现如何。
具体来说,我们想知道以下三个问题的第一手答案:
- 公司为什么要这么做?(见“为什么Ceph上有Spark ?”(第三部分第一部分)”)
- 主流的分析作业会直接运行在Ceph对象存储上吗?(这篇文章)
- 它的运行速度会比在HDFS上的本机慢多少?(见“为什么Ceph上的Spark(第三部分)”)
对于那些想要更深入,我们将交联到一个单独的architect-level博客系列提供详细描述,测试数据,和配置场景,我们记录与英特尔这个播客,我们谈论我们的关注使火花,Hadoop, Ceph在英特尔工作更好的硬件和帮助企业有效地扩展。
使用Ceph对象存储的基本分析管道
我们的早期采用者客户正在直接摄取、查询和转换数据到共享的Ceph对象存储。换句话说,他们的分析工作的目标数据位置是Ceph中的“s3://bucket-name/path-to-file- In -bucket”,而不是“hdfs:///path-to-file”。通过Spark、Hive和Impala等分析工具直接访问s3兼容的对象存储,可以通过Hadoop S3A客户端实现。
我们与几个客户合作,使用以下分析工具,成功地直接针对Ceph对象存储运行了1000多个分析作业:

Figure 1: Analytics tools tested with shared Ceph object store
除了运行像TestDFSIO这样的简单测试外,我们还希望运行能够代表现实世界工作负载的分析作业。为此,我们基于摄取、转换和查询作业的TPC-DS基准测试进行测试。TPC-DS生成合成数据集,并提供一组示例查询,用于模拟大型零售公司的分析环境,该公司拥有来自商店、目录和web的销售操作。它的模式有10个表,有些表中有数十亿条记录。它定义了99个预先配置的查询,我们从中选择了54个io密集的输出测试。与业内合作伙伴一起,我们还用模拟的点击流日志补充了TPC-DS数据集,比TPC-DS数据集大10倍,并添加了SparkSQL作业,以将这些日志与TPC-DS web销售数据连接起来。
总之,我们直接对Ceph对象存储运行了以下操作:
- 批量摄取(批量负荷工作-模拟1PB+/天的大容量流摄取)
- 摄取(MapReduce工作)
- 转换(Hive或SparkSQL作业,将纯文本数据转换为Parquet或ORC柱状压缩格式)
- 查询(Hive或SparkSQL作业-经常以批处理/非交互模式运行,因为这些工具会自动重启失败的作业)
- 交互式查询(Impala或Presto作业)
- 合并/连接(Hive或SparkSQL作业将半结构化的点击流数据与结构化的web销售数据连接起来)
架构概述
在过去的一年中,我们与4个大客户运行了上述测试的变体。一般来说,我们的架构是这样的:

Figure 2: High-level lab architecture
它工作了吗?
是的,上面描述的1000个分析任务成功完成了。SparkSQL、Hive、MapReduce、Impala作业都使用S3A客户端直接读写数据到共享的Ceph对象存储中。相关的架构级博客系列将详细记录所获得的经验教训和配置技术。
在本博客系列的最后一集中,我们将会看到最重要的一点——与传统HDFS相比,性能如何?有关答案,请继续阅读本系列的第3部分....
原文:https://www.redhat.com/en/blog/why-spark-ceph-part-2-3
本文:http://jiagoushi.pro/node/1503
讨论:请加入知识星球【首席架构师圈】或者小号【cea_csa_cto】或者QQ【2808908662】
- 88 次浏览