【数据库选型】再见MongoDB,您好PostgreSQL
Olery成立于5年前。随着时间的流逝,最初由Ruby开发机构开发的单一产品(Olery声望)逐渐发展成为一套不同的产品和许多不同的应用程序。今天,我们不仅拥有信誉产品,还拥有Olery反馈,酒店点评数据API,可嵌入网站上的小部件以及不久的将来更多产品/服务。
在应用程序数量方面,我们也有了长足的发展。今天,我们部署了超过25种不同的应用程序(全部为Ruby),其中一些是Web应用程序(Rails或Sinatra),但大多数是后台处理应用程序。
尽管我们可以为迄今为止所取得的成就感到非常自豪,但总会有一些隐患:我们的主数据库。从Olery开始,我们就已经建立了一个数据库设置,其中涉及MySQL来存储关键数据(用户,合同等),而MongoDB则用于存储评论和类似数据(本质上是在数据丢失的情况下我们可以轻松检索的数据)。尽管此设置对我们非常有用,但随着我们的发展,特别是在MongoDB中,我们开始遇到各种问题。这些问题中的一些是由于应用程序与数据库交互的方式所致,有些是由于数据库本身所致。
例如,在某个时间点,我们必须从MongoDB中删除大约一百万个文档,然后在以后重新插入它们。此过程的结果是数据库几乎处于完全锁定状态,持续了几个小时,导致性能下降。直到我们执行数据库修复(使用MongoDB的repairDatabase命令)。由于数据库的大小,此修复程序本身也花费了数小时才能完成。
在另一个实例中,我们注意到应用程序性能下降,并设法将其追溯到我们的MongoDB集群。但是,经过进一步检查,我们无法找到问题的真正原因。无论我们安装了什么度量标准,使用的工具或运行的命令,我们都找不到原因。直到我们替换了集群的主节点,性能才恢复到正常水平。
这只是两个例子,随着时间的流逝,我们遇到了很多这样的情况。这里的核心问题不仅在于我们的数据库正在运行,而且每当我们调查数据库时,都根本没有迹象表明导致问题的原因。
无模式问题
我们面临的另一个核心问题是MongoDB(或任何其他无模式存储引擎)的基本功能之一:缺少模式。缺少模式听起来可能很有趣,并且在某些情况下,它当然可以带来好处。但是,对于许多人而言,无模式存储引擎的使用会导致隐式模式的问题。这些架构不是由您的存储引擎定义的,而是根据应用程序的行为和期望定义的。
例如,您可能有一个页面集合,其中您的应用程序需要一个带有字符串类型的标题字段。尽管没有明确定义,但这里的模式非常多。如果数据的结构随时间而变化,这是有问题的,尤其是如果旧数据没有迁移到新的结构中(在无模式存储引擎中这是很成问题的)。例如,假设您具有以下Ruby代码:
#!ruby post_slug = post.title.downcase.gsub(/\W+/, '-')
这将适用于每个带有标题字段且返回字符串的文档。 对于使用其他字段名称(例如post_title)或根本没有标题的字段的文档,这将不起作用。 要处理这种情况,您需要按以下方式调整代码:
#!ruby if post.title post_slug = post.title.downcase.gsub(/\W+/, '-') else # ... end
解决此问题的另一种方法是在模型中定义架构。例如,Mongoid是流行的Ruby MongoDB ODM,可以让您做到这一点。但是,在使用此类工具定义架构时,应该思考为什么他们没有在数据库本身中定义架构。这样做将解决另一个问题:可重用性。如果只有一个应用程序,那么在代码中定义架构并不是什么大问题。但是,当您有数十个应用程序时,这很快就会变成一团糟。
无模式存储引擎通过消除对模式的担心,有望使您的生活更轻松。实际上,这些系统只是让您自己负责确保数据一致性。在某些情况下,这可能会解决,但我敢打赌,对于大多数情况而言,这只会适得其反。
好的数据库的要求
这使我想到了一个好的数据库的要求,更具体地说是Olery的要求。对于系统,尤其是数据库,我们重视以下方面:
一致性。数据的可见性和系统的行为。正确性和明确性。可扩展性。
一致性很重要,因为它有助于设定对系统的明确期望。如果数据总是以某种方式存储,那么使用该数据的系统将变得更加简单。如果在数据库级别需要某个字段,则应用程序无需检查该字段是否存在。数据库即使在高压下也应该能够保证某些操作的完成。没有什么比仅插入数据而令人沮丧的了,只有在几分钟之后才显示数据。
可见性适用于两件事:系统本身以及从其中获取数据的难易程度。如果系统出现异常,则应易于调试。反过来,如果用户想查询数据,这也应该很容易。
正确性意味着系统的行为符合预期。如果将某个字段定义为数字值,则不应将文本插入该字段。 MySQL的缺点是众所周知的,因为它可以让您准确地做到这一点,结果您可能会得到虚假数据。
可伸缩性不仅适用于性能,而且还适用于财务方面,以及系统如何满足随着时间变化的需求。一个系统的性能可能非常好,但是却不能以大量金钱为代价,也不会减慢依赖于它的系统的开发周期。
远离MongoDB
考虑到以上值,我们着手寻找MongoDB的替代者。上面提到的值通常是传统RDBMS的一组核心功能,因此我们着眼于两个候选对象:MySQL和PostgreSQL。
MySQL是第一个候选对象,因为我们已经在一些关键数据中使用它。但是MySQL并非没有问题。例如,在将字段定义为int(11)时,您可以轻松地插入文本数据,MySQL会尝试对其进行转换。一些例子:
mysql> create table example ( `number` int(11) not null ); Query OK, 0 rows affected (0.08 sec) mysql> insert into example (number) values (10); Query OK, 1 row affected (0.08 sec) mysql> insert into example (number) values ('wat'); Query OK, 1 row affected, 1 warning (0.10 sec) mysql> insert into example (number) values ('what is this 10 nonsense'); Query OK, 1 row affected, 1 warning (0.14 sec) mysql> insert into example (number) values ('10 a'); Query OK, 1 row affected, 1 warning (0.09 sec) mysql> select * from example; +--------+ | number | +--------+ | 10 | | 0 | | 0 | | 10 | +--------+ 4 rows in set (0.00 sec)
值得注意的是,在这种情况下,MySQL会发出警告。 但是,由于警告只是警告,因此常常(即使不是总是)将它们忽略。
MySQL的另一个问题是任何表修改(例如添加列)都会导致表被锁定以进行读取和写入。 这意味着使用此类表的任何操作都必须等待修改完成。 对于具有大量数据的表,这可能需要数小时才能完成,这可能导致应用程序停机。 这已导致SoundCloud等公司开发诸如lhm之类的工具来解决这一问题。
基于上述考虑,我们开始研究PostgreSQL。 PostgreSQL在很多方面做得很好,而MySQL则做不到。 例如,您不能将文本数据插入数字字段:
olery_development=# create table example ( number int not null ); CREATE TABLE olery_development=# insert into example (number) values (10); INSERT 0 1 olery_development=# insert into example (number) values ('wat'); ERROR: invalid input syntax for integer: "wat" LINE 1: insert into example (number) values ('wat'); ^ olery_development=# insert into example (number) values ('what is this 10 nonsense'); ERROR: invalid input syntax for integer: "what is this 10 nonsense" LINE 1: insert into example (number) values ('what is this 10 nonsen... ^ olery_development=# insert into example (number) values ('10 a'); ERROR: invalid input syntax for integer: "10 a" LINE 1: insert into example (number) values ('10 a');
PostgreSQL还具有以各种方式更改表的功能,而无需为每个操作锁定表。例如,添加一个没有默认值并且可以设置为NULL的列可以快速完成,而无需锁定整个表。
PostgreSQL中还有许多其他有趣的功能,例如:基于Trigram的索引和搜索,全文本搜索,对JSON查询的支持,对查询/存储键值对的支持,对发布/订阅的支持等等。
所有PostgreSQL中最重要的是在性能,可靠性,正确性和一致性之间取得平衡。
迁移到PostgreSQL
最后,我们决定与PostgreSQL达成和解,以便在我们关心的各个主题之间取得平衡。从MongoDB迁移整个平台到完全不同的数据库的过程并非易事。为了简化过渡过程,我们将这个过程大致分为3个步骤:
设置PostgreSQL数据库并迁移一小部分数据。
更新所有依赖MongoDB来使用PostgreSQL的应用程序,以及支持此功能所需的任何重构。
将生产数据迁移到新数据库并部署新平台。
迁移子集
在我们甚至考虑迁移所有数据之前,我们需要使用一小部分最终数据来运行测试。如果您知道即使是一小部分数据也会给您带来很多麻烦,那么迁移毫无意义。
虽然存在可以解决此问题的工具,但我们还必须转换一些数据(例如,重命名字段,更改类型等),因此必须为此编写自己的工具。这些工具大部分是一次性的Ruby脚本,每个脚本执行特定的任务,例如移交评论,清理编码,更正主键序列等。
最初的测试阶段并未发现任何可能阻碍迁移过程的问题,尽管我们的某些数据部分存在问题。例如,某些用户提交的内容并非总是正确地编码,因此,如果不先清除它们就无法导入。需要进行的另一个有趣的更改是将评论的语言名称从其全名(“荷兰语”,“英语”等)更改为语言代码,因为我们的新情感分析堆栈使用语言代码代替了全名。
更新应用
到目前为止,大部分时间都花在了更新应用程序上,尤其是那些严重依赖MongoDB聚合框架的应用程序。投入一些测试覆盖率较低的旧版Rails应用程序,您将有数周的工作时间。这些应用程序的更新过程基本上如下:
- 将MongoDB驱动程序/模型设置代码替换为PostgreSQL相关代码
- 运行测试
- 修复一些测试
- 再次运行测试,冲洗并重复直到所有测试通过
对于非Rails应用程序,我们决定使用Sequel,而我们在Rails应用程序中坚持使用ActiveRecord(至少现在是这样)。 Sequel是一个很棒的数据库工具包,它支持我们可能想使用的大多数(如果不是全部)PostgreSQL特定功能。与ActiveRecord相比,其查询构建DSL的功能也要强大得多,尽管有时可能会有些冗长。
例如,假设您要计算使用某个语言环境的用户数量以及每个语言环境的百分比(相对于整个集合)。在普通的SQL中,这样的查询如下所示:
#!sql SELECT locale, count(*) AS amount, (count(*) / sum(count(*)) OVER ()) * 100.0 AS percentage FROM users GROUP BY locale ORDER BY percentage DESC;
在我们的例子中,这将产生以下输出(使用PostgreSQL命令行界面时):
locale | amount | percentage --------+--------+-------------------------- en | 2779 | 85.193133047210300429000 nl | 386 | 11.833231146535867566000 it | 40 | 1.226241569589209074000 de | 25 | 0.766400980993255671000 ru | 17 | 0.521152667075413857000 | 7 | 0.214592274678111588000 fr | 4 | 0.122624156958920907000 ja | 1 | 0.030656039239730227000 ar-AE | 1 | 0.030656039239730227000 eng | 1 | 0.030656039239730227000 zh-CN | 1 | 0.030656039239730227000 (11 rows)
Sequel允许您使用纯Ruby编写上述查询,而无需字符串片段(这是ActiveRecord经常需要的):
#!ruby star = Sequel.lit('*') User.select(:locale) .select_append { count(star).as(:amount) } .select_append { ((count(star) / sum(count(star)).over) * 100.0).as(:percentage) } .group(:locale) .order(Sequel.desc(:percentage))
如果您不喜欢使用Sequel.lit('*'),也可以使用以下语法:
#!ruby User.select(:locale) .select_append { count(users.*).as(:amount) } .select_append { ((count(users.*) / sum(count(users.*)).over) * 100.0).as(:percentage) } .group(:locale) .order(Sequel.desc(:percentage))
虽然这两个查询可能都比较冗长,但它们更易于重用部分查询,而不必诉诸字符串连接。
将来,我们可能还会将Rails应用程序移至Sequel,但是考虑到Rails与ActiveRecord紧密相连,我们尚不确定是否值得花时间和精力。
迁移生产数据
最终,这使我们进入了迁移生产数据的过程。基本上有两种方法可以执行此操作:
- 关闭所有平台,并在所有数据迁移后使其重新联机。
- 在保持运行的同时迁移数据。
选项1有一个明显的缺点:停机时间。另一方面,方法2不需要停机,但是很难处理。例如,在此设置中,您在迁移数据时必须考虑添加的所有数据,否则会丢失数据。
幸运的是,Olery具有相当独特的设置,因为对数据库的大多数写入操作仅在相当固定的时间间隔内进行。确实更改频率更高的数据(例如用户和合同信息)是相当少量的数据,这意味着与我们的评论数据相比,迁移所需的时间要少得多。
这部分的基本流程是:
- 迁移关键数据,例如用户,合同,基本上是我们以任何方式无法承受的所有数据。
- 迁移不太重要的数据(我们可以重新刮擦,重新计算的数据等)。
- 测试是否一切正常并在一组单独的服务器上运行。
- 将生产环境切换到这些新服务器。
- 重新迁移步骤1的数据,确保在此期间创建的数据不会丢失。
第2步花费了迄今为止最长的时间,大约是24小时。另一方面,迁移步骤1和5中提到的数据仅花费了大约45分钟。
结论
自我们完成迁移以来已经快一个月了,到目前为止,我们感到非常满意。到目前为止,所产生的影响不过是积极的,在各种情况下甚至导致我们应用程序的性能大大提高。例如,由于迁移,我们的酒店评论数据API(在Sinatra上运行)最终获得了比以前更低的响应时间:
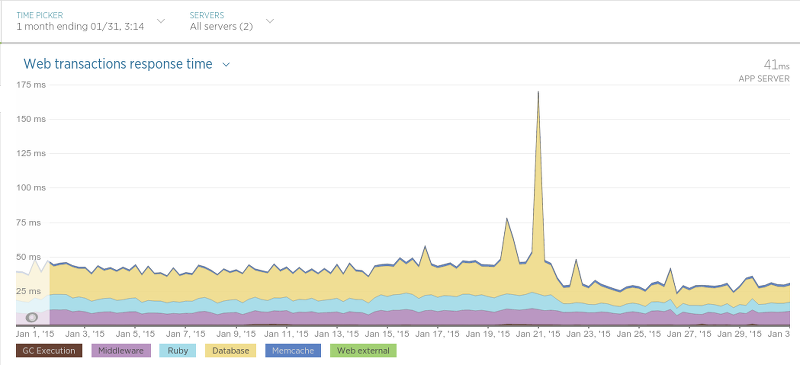
迁移是在1月21日进行的,最大的高峰只是应用程序执行了硬重启(导致该过程中的响应时间稍慢)。 21日之后,平均响应时间几乎缩短了一半。
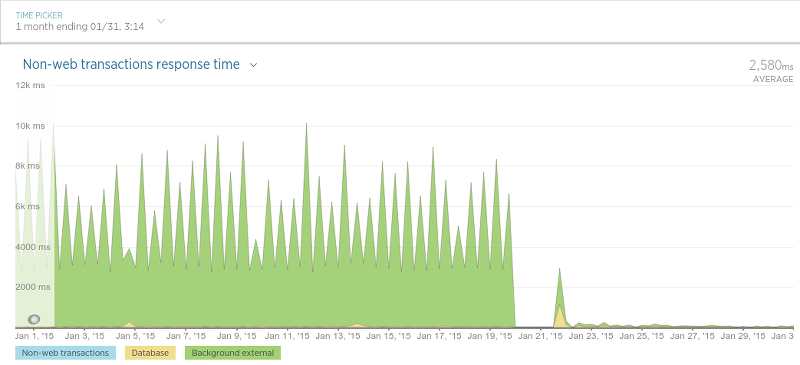
我们看到性能大幅提高的另一种情况就是所谓的“审查持久性”。 这个应用程序(作为守护程序运行)的目的很简单:保存评论数据(评论,评论等级等)。 尽管我们最终对该应用程序进行了一些非常大的更改以进行迁移,但结果却非常有益:
我们的刮板也最终更快了:
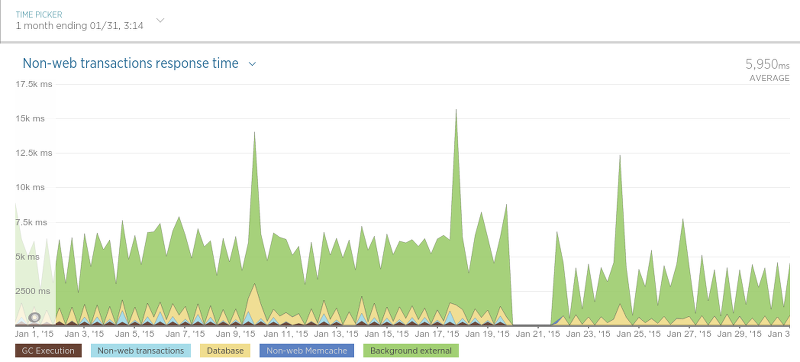
区别并不像复审持久性那么大,但是由于抓取工具仅使用数据库来检查是否存在复审(相对较快的操作),因此这并不奇怪。
最后是计划抓取过程的应用程序(简称为“调度程序”):
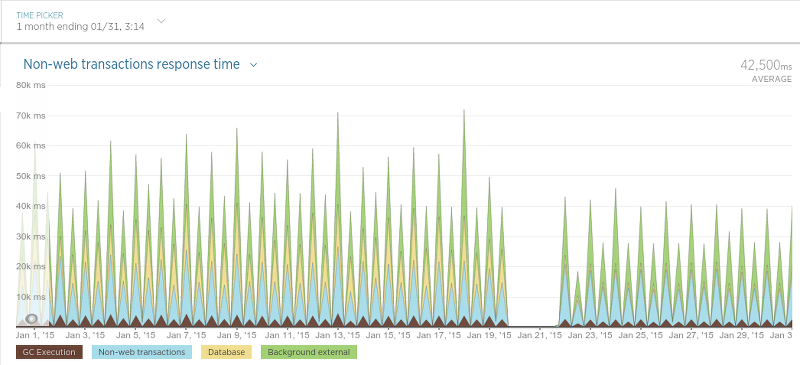
由于调度程序仅按特定的间隔运行,因此该图有些难以理解,但是迁移后的平均处理时间明显减少了。
最后,我们对到目前为止的结果非常满意,我们当然不会错过MongoDB。 性能非常好,与之相比,围绕它的工具使其他数据库显得苍白,与MongoDB相比(尤其是对于非开发人员而言),查询数据要轻松得多。 尽管确实有一个服务(Olery Feedback)仍在使用MongoDB(尽管是一个单独的相当小的集群),但我们打算将来也将其迁移到PostgreSQL。
原文:https://developer.olery.com/blog/goodbye-mongodb-hello-postgresql/
本文:http://jiagoushi.pro/goodbye-mongodb-hello-postgresql
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 226 次浏览