文档数据库
【MongoDB】开源MongoDB替代FerretDB现已全面可用
视频号

微信公众号

知识星球

FerretDB,一个开源的MongoDB替代数据库,最近宣布全面可用。该项目以Apache 2.0许可证发布,允许开发人员使用现有的PostgreSQL基础架构来运行MongoDB工作负载。
FerretDB充当代理,将MongoDB有线协议查询转换为SQL,PostgreSQL作为数据库后端。FerretDB最初是MongoDB的开源替代品,它提供了相同的MongoDB API,而开发人员无需学习新的语言或命令。FerretDB联合创始人兼首席执行官Peter Farkas解释道:
我们正在为文档数据库创建一个与MongoDB兼容的新标准。FerretDB是MongoDB的替代品,但它也旨在制定一个新的标准,不仅将易于使用的文档数据库带回其开源根源,还使不同的数据库引擎能够使用标准化接口运行文档数据库工作负载。
虽然FerretDB是在PostgreSQL上构建的,但该数据库采用可插拔架构设计,以支持其他后端,目前正在进行针对Tigris、SAP HANA和SQLite的项目。该项目最初是在Go中编写的,因为MongoDB在2018年采用的服务器端公共许可证(SSPL)不符合开源计划设定的所有开源软件标准。FerretDB背后的团队写道:
MongoDB最初是作为开源软件构建的,它改变了许多开发人员的游戏规则,使他们能够构建快速而强大的应用程序。它的易用性和丰富的文档使它成为许多寻找开源数据库的开发人员的首选。然而,当他们转向SSPL许可证,远离开源根源时,所有这些都发生了变化。
Farkas表示,流行的数据库管理工具,如mongosh、MongoDB Compass、NoSQL Booster和Mingo,已经与FerretDB的当前功能集兼容。自由软件基金会在其月度新闻摘要中评论道:
对于那些理所当然地关心MongoDB在2018年更改许可条件的人来说,这确实是一个好消息。
在1.0版本中,FerretDB添加了对createIndexes命令的支持,而1.1.0版本包括添加renameCollection、对投影字段分配的支持、$project管道聚合阶段,以及在SAP HANA处理程序中创建和删除命令。
在Reddit上,MongoDB的替代品的普遍可用性得到了褒贬不一的反馈,一些用户支持抽象层,而另一些用户则不认为FerretDB是一个“真正的”数据库。YugabyteDB和AWS Data Hero的开发倡导者Franck Pachot最近写了一篇文章,介绍如何在YugabyteDB上启用与MongoDB兼容的API:
想要在分布式SQL数据库上使用与MongoDB兼容的API吗?很容易将FerretDB连接到YugabyteDB,所有这些都是开源的。
FerretDB并不是MongoDB的唯一替代品:其他支持MongoDB API的基于无架构文档的数据库包括Amazon DocumentDB、Azure CosmosDB和MariaDB MaxScale。在最近的一次网络研讨会上,Udemy的首席数据库可靠性工程师David Murphy将CosmosDB、DocumentDB、MongoDB和FerretDB作为文档数据库进行了比较。
FerretDB项目和路线图可在GitHub上获得,包括Docker镜像、RPM和DEB包。
- 408 次浏览
【性能优化】如何优化MongoDB和Mongoose 的性能

表现是避免不必要工作的艺术。这些是我关于优化MongoDB查询的发现,你可以滚动下面的性能测试和结果。
1. 对GET操作使用精益查询
这可能是提高查询性能的最好方法。Mongoose允许您在查询的末尾添加.lean(),通过返回纯JSON对象而不是Mongoose文档,可以极大地提高查询的性能。
默认情况下,Mongoose 查询返回一个Mongoose 文档类的实例。文档比普通的JavaScript对象要重得多,因为它们有很多内部状态需要跟踪更改。启用lean option将告诉Mongoose跳过实例化完整的Mongoose文档,而只给您POJO。
精益选项告诉Mongoose 跳过补水的结果文件。这使得查询速度更快,内存消耗更少,但是结果文档是普通的旧式JavaScript对象(pojo),而不是Mongoose 文档。
然而,这是有代价的,这意味着精益文档没有:
- 更改跟踪
- 铸造和验证
- getter和setter
- 虚拟(包括“id”)
- save()函数
因此,对于不使用.save()或virtuals的GET端点和.find()操作通常是最优的。
2. 为您的查询创建自定义索引
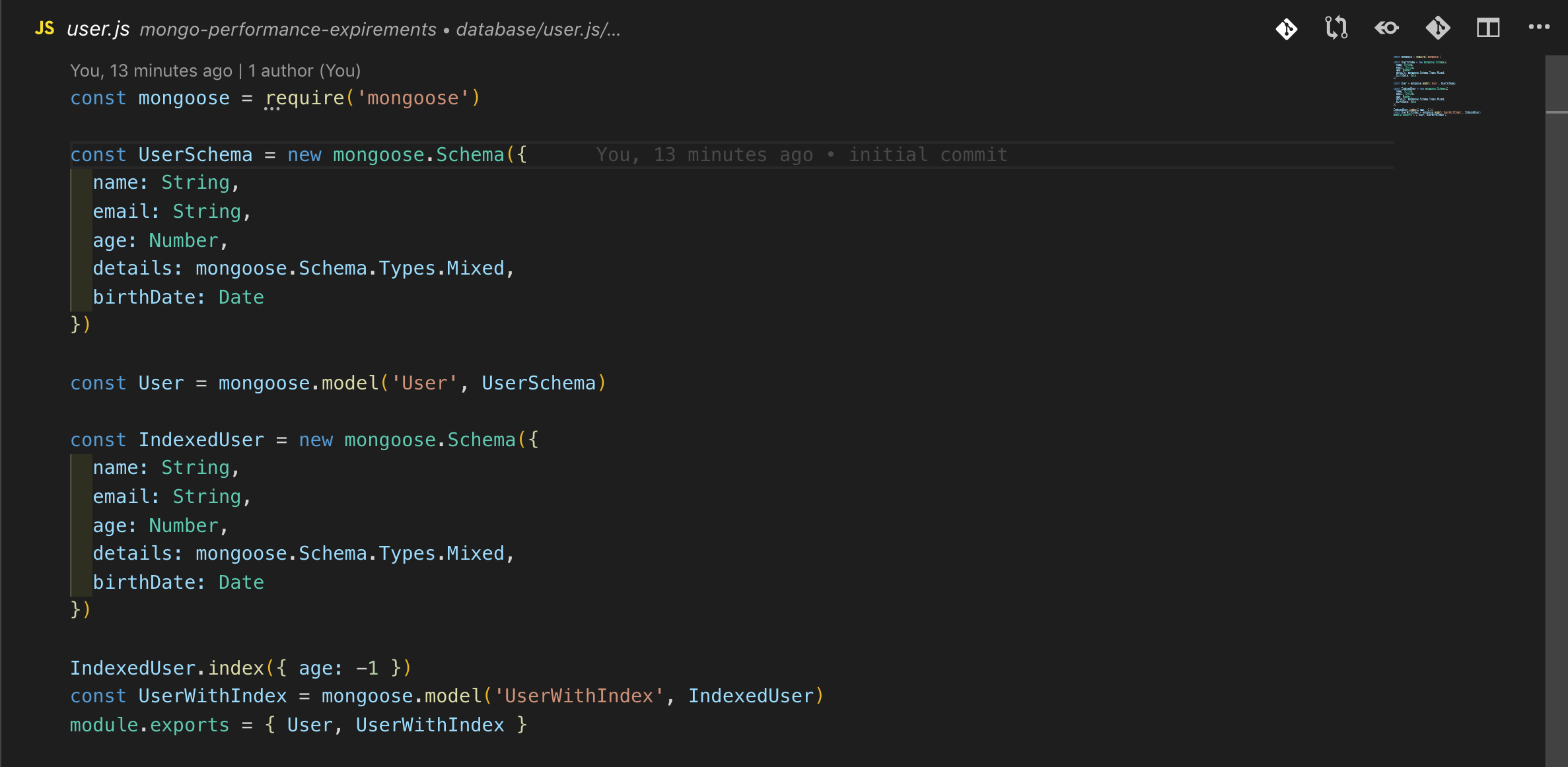
MongoDB允许您在模式中的其他属性上创建索引,而不是默认的“_id”索引。这样,您的文档就可以根据您在数据库中定义的属性建立索引,以便更快地访问。
您还可以创建多个属性的复合索引。如果您要查询多个字段,这将非常有用。假设你有一些数据库,你想找到所有灭绝的动物,你可能会写一个查询模型这样。Model.find({type: “Animal”, status: “extinct"})
MongoDB将不得不查看所有的文档来找到符合这个条件的,为了优化这个查询,你可以通过添加ModelSchema为“type”和“status”创建一个复合索引。ModelSchema.index({type: 1, status: 1}).MongoDB现在会去哪里查找相关文档。
“1”或“-1”表示属性的排序顺序。字段添加到索引中的顺序很重要。有关索引的更详细说明,请参见
https://mongoosejs.com/docs/guide.html#indexes and https://docs.mongodb.com/manual/indexes/
3.最小化DB请求(如果可能,避免.populate())
请求越多,应用程序的响应时间就越慢。尽可能地将数据库查询最小化,并将它们组合在一起,或者通过消除重复或不必要的db操作来完全避免它们。你也可以在redis中缓存你的数据库结果。
尝试以不需要过多依赖.populate()和模型之间的双向关系的方式定义模式。因为这是NoSQL数据库不是很理想的地方。在模型中添加的每个属性都将从查询中返回,因此,如果在这些字段中有数组或嵌套对象,那么文档将很容易极大地降低查询的性能。
如果你的文档包含一个数组的引用其他模型,你使用.populate()之间加入数据集合,使用.populate()将需要运行额外的查询来获取数组的实际文档里面,所以它类似于运行额外的每个id为每个文档查询。如果确实需要,最好使用.aggregate()而不是.populate()。
4. 使用.select()选择要返回的特定属性
当查询数据库中的文档时,查询将返回整个文档,但有时您有带有大量字段的大型文档,而字段是如上所述的数组/对象,因此您实际上不需要使用所有返回的属性。
为了防止数据库做额外的工作来返回这些字段增加返回文档的大小,你可以使用mongoose .select()来包括/排除你想要你的查询返回的字段,具体如下:
Model.find({type: "Animal"}).select({name: 1})
Protip:如果您使用的是GraphQL,那么它的工作效果非常好,这样您就可以确切地知道客户机请求的字段,并且可以从数据库中选择这些字段。我在这里写了另一篇文章
https://itnext.io/graphql-performance-tip-database-projection-82795e434b44
5. 并行运行数据库操作
当人们使用异步/等待时,我在NodeJS代码中看到的一个常见错误是人们在不需要的时候一个接一个地运行操作。例如:
const user = new User({name: "bob"})
const post = new Post({title: "hello"})
await user.save()
await post.save()没有理由等待用户被保存后再保存post。相反,可以使用Promise并行运行数据库操作。所有的如下:
const [user, post] = await Promise.all([user.save(), post.save()])
虽然这可以提高API级别上的性能,但我们仍然要对数据库执行两个请求,所以如果您想批量执行多个操作,使用insertMany()或bulkwrite()会更好。
6. 缓存/重用mongoose 连接
确保不要在每次想要从数据库插入/查询内容时或每次端点被触发时连接和断开与数据库的连接。相反,您应该在应用程序开始时连接一次,然后重用该连接。
这是因为建立一个新的TCP连接在时间、网络请求和内存方面都很昂贵,而且新的连接还意味着MongoDB要使用数据库上的内存创建一个新线程。
让我们编写一些性能测试来查看结果
这些技巧能在多大程度上提高您的查询性能?让我们通过编写一些脚本来测试这些差异。
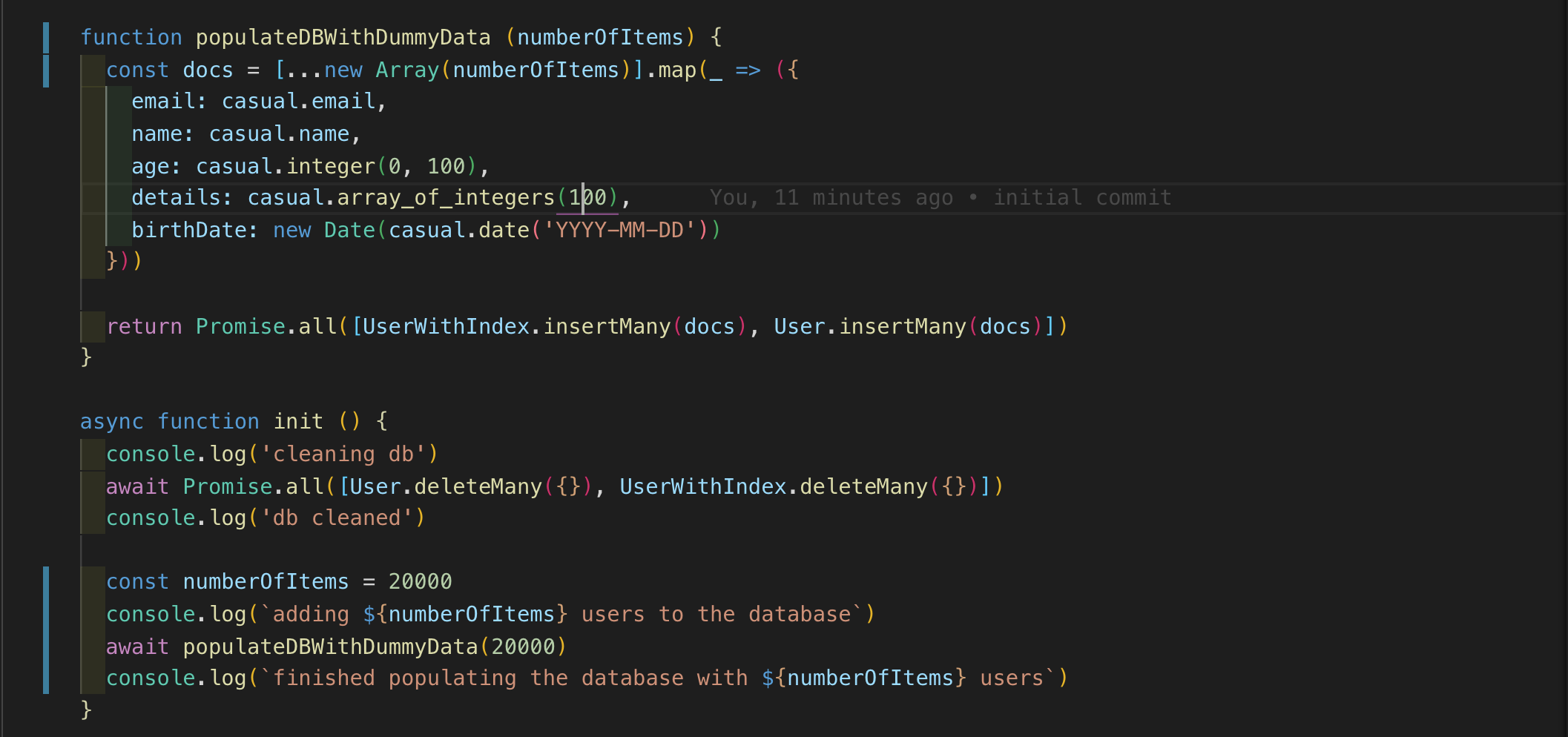
我运行了MongoDB的本地安装,并编写了一个NodeJS脚本,该脚本使用随机生成的用户列表填充数据库。目标是找到年龄超过22岁的用户。
我结合上面提到的方法以不同的方式编写查询,并在使用相同数据集填充的两个不同的数据库集合上尝试它们。一个集合对“age”属性有索引,而另一个没有。使用console.time() API测量结果,使用NodeJS (v12.7.0)和mongoose (v5.6.7)的最新当前版本运行测试。
首先让我们从out模式开始,这里我对用户集合/模式进行了定义,其中一个在age属性上有索引,而其他没有。
现在让我们编写一些代码来用随机数据填充数据库。我使用了临时库,它非常方便地生成语义模拟数据
既然数据库已经准备好了,让我们来编写查询
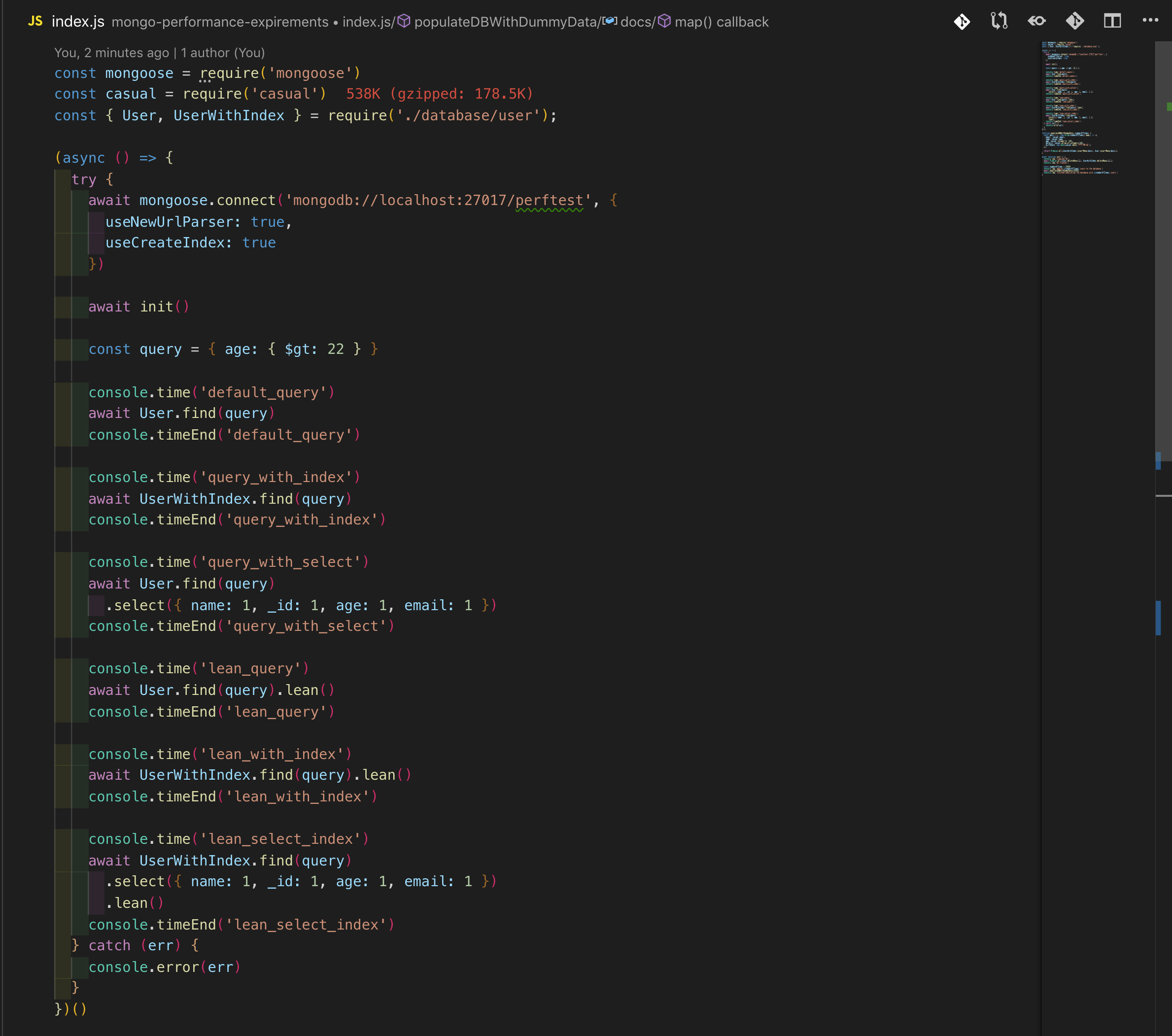
Performance Results & Observations
With 1k users
default_query: 135.646ms
query_with_index: 168.763ms
query_with_select: 27.781ms
query_with_select_index: 55.686ms
lean_query: 7.191ms
lean_with_index: 7.341ms
lean_with_select: 4.226ms
lean_select_index: 7.881ms
With 10k users in the database
default_query: 323.278ms
query_with_index: 355.693ms
query_with_select: 212.403ms
query_with_select_index: 183.736ms
lean_query: 92.935ms
lean_with_index: 92.755ms
lean_with_select: 36.175ms
lean_select_index: 38.456ms
With 100K Users in the database
default_query: 2425.857ms
query_with_index: 2371.716ms
query_with_select: 1580.393ms
query_with_select_index: 1583.015ms
lean_query: 858.839ms
lean_with_index: 944.712ms
lean_with_select: 383.548ms
lean_select_index: 458.000ms
如您所见,使用.lean() .select()和Schema.index({})的优化版本的查询比默认查询快了10倍,这是一个巨大的胜利!
.lean()似乎对性能的影响最大,其次是.select(),这是因为我的自定义索引在这种情况下不起作用,因为索引的选择性不够,因为它只减少了50%的扫描文档。
您可以找到用于这些测试的脚本,您甚至可以自己在https://github.com/khaledosman/mongo- performanceexpirequirements中试用它
原文:https://itnext.io/performance-tips-for-mongodb-mongoose-190732a5d382
本文:http://jiagoushi.pro/node/1175
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 692 次浏览
【文档数据库】Apache Couchdb 最终一致性
1.3 最终一致性
在上一个文档“为什么选择CouchDB?”中,我们看到CouchDB的灵活性使我们能够随着应用程序的增长和变化而发展数据。在本主题中,我们将探讨CouchDB的“细化”工作如何提高应用程序的简单性,并帮助我们自然地构建可扩展的分布式系统。
1.3.1 与Grain合作
分布式系统是可以在广泛的网络上稳定运行的系统。网络计算的一个特殊功能是网络链接可能会消失,并且有许多策略可以管理这种类型的网络分段。 CouchDB与其他数据库的不同之处在于,它接受最终的一致性,而不是像RDBMS或Paxos这样在原始可用性之前放置绝对一致性。这些系统的共同点是认识到,当许多人同时访问数据时,数据的行为会有所不同。在优先考虑一致性,可用性或分区容忍的哪些方面时,他们的方法有所不同。
工程分布式系统是棘手的。随着时间的推移,您将要面对的许多警告和“陷阱”并不是立即显而易见的。我们还没有所有解决方案,而且CouchDB并非万能药,但是当您使用CouchDB的精髓而不是反对时,阻力最小的途径将使您自然地扩展应用程序。
当然,构建分布式系统仅仅是开始。一个仅拥有一半时间可访问数据库的网站几乎一文不值。不幸的是,传统的关系数据库一致性方法使应用程序程序员很容易依赖全局状态,全局时钟和其他高可用性,甚至没有意识到自己正在这样做。在研究CouchDB如何提高可伸缩性之前,我们将研究分布式系统面临的约束。当我们看到了当您的应用程序的各个部分无法相互依赖时会出现的问题之后,我们将看到CouchDB提供了一种直观且有用的方式来围绕高可用性对应用程序进行建模。
1.3.2 CAP定理
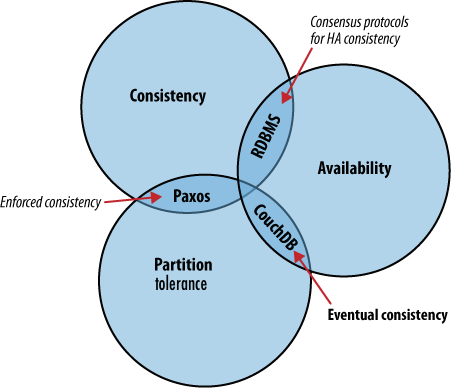
CAP定理描述了用于在网络之间分布应用程序逻辑的几种不同策略。 CouchDB的解决方案使用复制在参与的节点之间传播应用程序更改。这是与共识算法和关系数据库根本不同的方法,共识算法和关系数据库在一致性,可用性和分区容忍度的不同交集处运行。
CAP定理,如图1所示。CAP定理确定了三个不同的问题:
- 一致性:即使并发更新,所有数据库客户端也可以看到相同的数据。
- 可用性:所有数据库客户端都可以访问某些版本的数据。
- 分区容限:数据库可以拆分到多个服务器上。
选择两个。
当系统增长到足以使单个数据库节点无法处理施加在其上的负载时,明智的解决方案是添加更多服务器。添加节点时,我们必须开始考虑如何在它们之间分区数据。我们有几个共享完全相同数据的数据库吗?我们是否将不同的数据集放在不同的数据库服务器上?我们是否只允许某些数据库服务器写入数据,而让其他服务器处理读取?
无论采用哪种方法,我们都会遇到的一个问题是使所有这些数据库服务器保持同步。如果您将某些信息写入一个节点,那么如何确保对另一台数据库服务器的读取请求反映了此最新信息?这些事件可能相隔毫秒。即使只有少量的数据库服务器,此问题也会变得非常复杂。
当绝对至关重要的是,所有客户端都必须看到一致的数据库视图时,一个节点的用户将必须等待其他任何节点达成协议,才能读取或写入数据库。在这种情况下,我们看到可用性在一致性方面倒退了。但是,在某些情况下,可用性比一致性要好:
系统中的每个节点都应该能够纯粹基于本地状态做出决策。如果您需要在高负载下做某事且发生故障并且需要达成协议,那么您会迷失方向。如果您担心可扩展性,那么任何迫使您达成协议的算法最终都会成为瓶颈。以此为前提。
—亚马逊首席技术官兼副总裁沃纳·沃格斯(Werner Vogels)
如果优先考虑可用性,我们可以让客户端将数据写入数据库的一个节点,而无需等待其他节点达成协议。如果数据库知道如何照顾节点之间的这些操作,那么我们将获得某种“最终一致性”,以换取高可用性。对于许多应用来说,这是一个令人惊讶的适用折衷。
与传统的关系数据库不同,传统的关系数据库必须对每个执行的操作进行数据库范围的一致性检查,而CouchDB使得构建应用程序变得非常简单,而这些应用程序却牺牲了即时一致性,以简化简单分发带来的巨大性能提升。
1.3.3 本地一致性
在尝试了解CouchDB如何在群集中运行之前,重要的是我们了解单个CouchDB节点的内部工作原理。 CouchDB API旨在提供围绕数据库核心的便捷但精简的包装。通过仔细研究数据库核心的结构,我们将更好地了解围绕它的API。
1.3.3.1 数据的Key
CouchDB的核心是功能强大的B树存储引擎。 B树是一种排序的数据结构,允许以对数时间进行搜索,插入和删除。如图2所示。对视图请求的剖析表明,CouchDB使用此B树存储引擎存储所有内部数据,文档和视图。如果我们理解一个,我们将全部理解。
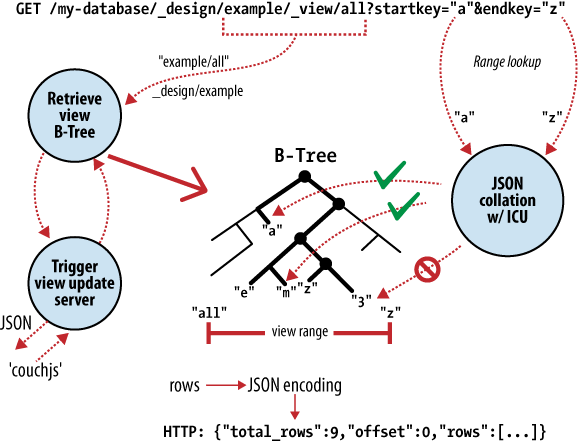
CouchDB使用MapReduce来计算视图的结果。 MapReduce利用了两个函数,即“ map”和“ reduce”,它们分别应用于每个文档。能够隔离这些操作意味着视图计算可以进行并行和增量计算。更重要的是,由于这些函数产生键/值对,因此CouchDB能够将它们按键排序插入B树存储引擎。通过键或键范围进行的查找是使用B树的极其有效的操作,用大O表示法分别表示为O(log N)和O(log N + K)。
在CouchDB中,我们按键或键范围访问文档并查看结果。这是对CouchDB的B树存储引擎上执行的基础操作的直接映射。与文档插入和更新一起,这种直接映射是我们将CouchDB的API描述为围绕数据库核心的薄包装的原因。
只能通过键访问结果是一个非常重要的限制,因为它使我们获得了巨大的性能提升。除了大幅提高速度外,我们还可以在多个节点上划分数据,而不会影响我们独立查询每个节点的能力。正是由于这些原因,BigTable,Hadoop,SimpleDB和memcached通过键限制了对象查找。
1.3.3.2 无锁
关系数据库中的表是单个数据结构。如果要修改表(例如,更新行),数据库系统必须确保没有其他人试图更新该行,并且在更新该行时没有人可以从该行中读取数据。解决此问题的常用方法是使用锁。如果多个客户端要访问一个表,则第一个客户端将获得锁,从而使其他所有人都在等待。当第一个客户的请求得到处理时,下一个客户将获得访问权限,而其他人都将等待,依此类推。即使是并行到达请求,这种串行执行请求也会浪费大量服务器的处理能力。在高负载下,关系数据库比进行任何实际工作要花费更多的时间来确定允许谁执行什么工作以及按照什么顺序执行。
注意
现代的关系数据库通过在幕后实施MVCC来避免锁定,但对最终用户隐藏了MVCC,要求它们协调单个行或字段的并发更改。
CouchDB使用多版本并发控制(MVCC)代替锁,来管理对数据库的并发访问。图3. MVCC表示没有锁定说明了MVCC和传统锁定机制之间的差异。 MVCC意味着CouchDB即使在高负载下也可以一直全速运行。请求是并行运行的,从而充分利用了服务器必须提供的每最后一滴处理能力。

图3. MVCC意味者没有锁定
CouchDB中的文档已经过版本控制,就像在常规版本控制系统(例如Subversion)中一样。如果要更改文档中的值,请创建该文档的全新版本并将其保存在旧版本上。完成此操作后,您将获得同一文档的两个版本,一个旧版本,一个新版本。
这如何提供对锁的改进?考虑一组想要访问文档的请求。第一个请求读取文档。在处理过程中,第二个请求更改了文档。由于第二个请求包含文档的全新版本,因此CouchDB可以简单地将其附加到数据库,而不必等待读取请求完成。
当第三个请求要读取相同的文档时,CouchDB将其指向刚刚编写的新版本。在整个过程中,第一个请求可能仍在读取原始版本。
读取请求在请求开始时始终会看到您数据库的最新快照。
1.3.4 验证方式
作为应用程序开发人员,我们必须考虑应该接受什么样的输入以及应该拒绝什么输入。在传统的关系数据库中对复杂数据进行这种类型的验证的表达能力尚有许多不足之处。幸运的是,CouchDB提供了一种从数据库内部执行按文档验证的强大方法。
CouchDB可以使用类似于MapReduce的JavaScript函数来验证文档。每次您尝试修改文档时,CouchDB都会通过验证功能以传递现有文档的副本,新文档的副本以及其他信息的集合,例如用户身份验证详细信息。验证功能现在可以批准或拒绝更新。
通过使用Grain并让CouchDB为我们做到这一点,我们为自己节省了大量的CPU周期,否则这些CPU周期将被用于从SQL序列化对象图,将它们转换为域对象并使用这些对象进行应用程序级验证。
1.3.5 分布式一致性
对于大多数数据库而言,在单个数据库节点内维护一致性相对容易。当您尝试维护多个数据库服务器之间的一致性时,真正的问题开始浮出水面。如果客户端在服务器A上执行写操作,我们如何确保它与服务器B或C或D一致?对于关系数据库而言,这是一个非常复杂的问题,整本书都专门针对其解决方案。您可以使用多主机,单主机,分区,分片,直写式高速缓存以及各种其他复杂技术。
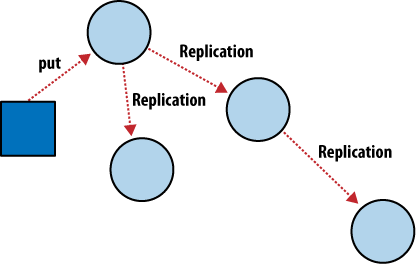
1.3.6 增量复制
CouchDB的操作在单个文档的上下文中进行。由于CouchDB通过使用增量复制实现了多个数据库之间最终的一致性,因此您不必担心数据库服务器能够保持持续的通信。增量复制是在服务器之间定期复制文档更改的过程。我们能够构建所谓的无共享数据库集群,其中每个节点都是独立且自给自足的,在整个系统中不存在任何争用点。
需要扩展您的CouchDB数据库集群吗?只需投入另一台服务器即可。
如图4所示。在CouchDB节点之间进行增量复制,并使用CouchDB进行增量复制,您可以在任意两个数据库之间随时随地同步数据。复制后,每个数据库都可以独立工作。
您可以使用此功能通过cron之类的作业调度程序在群集内或数据中心之间同步数据库服务器,也可以使用它在便携式计算机上同步数据与笔记本电脑以进行离线工作。可以按常规方式使用每个数据库,并且以后可以在两个方向上同步数据库之间的更改。
当您在两个不同的数据库中更改同一文档并希望彼此同步时会发生什么? CouchDB的复制系统带有自动冲突检测和解决方案。当CouchDB在两个数据库中都检测到文档已被更改时,它将标记该文档为冲突文档,就像它们在常规版本控制系统中一样。
这并不像第一次听起来那样麻烦。如果在复制过程中两个版本的文档发生冲突,则胜出版本将另存为文档历史记录中的最新版本。 CouchDB不会像您期望的那样丢掉丢失的版本,而是将其保存为文档历史记录中的先前版本,以便您可以在需要时访问它。这是自动且一致地发生的,因此两个数据库都将做出完全相同的选择。
由您决定以对您的应用程序有意义的方式来处理冲突。您可以将选定的文档版本保留在原位,还原为较旧的版本,或尝试合并两个版本并保存结果。
1.3.7 案例分析
朋友和同事Greg Borenstein建立了一个小型库,用于将Songbird播放列表转换为JSON对象,并决定将它们存储在CouchDB中作为备份应用程序的一部分。完整的软件使用CouchDB的MVCC和文档修订版,以确保在节点之间可靠地备份Songbird播放列表。
注意
Songbird是基于Mozilla XULRunner平台的具有集成Web浏览器的免费软件媒体播放器。 Songbird适用于Microsoft Windows,Apple Mac OS X,Solaris和Linux。
让我们检查Songbird备份应用程序的工作流程,首先是作为用户从单台计算机备份,然后使用Songbird在多台计算机之间同步播放列表。我们将看到文档修订如何将本来很棘手的问题变成可以解决的问题。
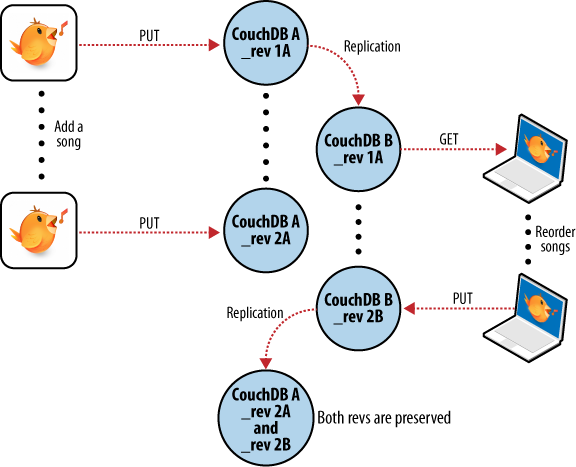
第一次使用此备份应用程序时,我们会将播放列表馈入该应用程序并启动备份。每个播放列表都将转换为JSON对象,并传递到CouchDB数据库。如图5所示。备份到单个数据库时,CouchDB会将每个播放列表的文档ID和修订版本保存到数据库中。
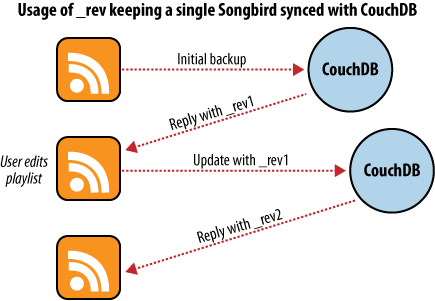
几天后,我们发现我们的播放列表已更新,我们希望备份所做的更改。将播放列表馈入备份应用程序后,它会从CouchDB获取最新版本以及相应的文档修订版。当应用程序移交新的播放列表文档时,CouchDB要求文档修订包含在请求中。
然后,CouchDB确保请求中传递给它的文档修订与数据库中保存的当前修订匹配。因为CouchDB每次修改都会更新修订,所以如果这两个修改不同步,则表明在我们从数据库请求文档到发送更新之间,有人对文档进行了更改。在其他人没有先检查那些更改的情况下对其进行更改通常是一个坏主意。
强迫客户交出正确的文档修订版是CouchDB乐观并发的核心。
我们有一台笔记本电脑,希望与台式机保持同步。在台式机上播放所有播放列表后,第一步是“从备份还原”到笔记本电脑上。这是我们第一次这样做,因此之后我们的笔记本电脑应保留桌面播放列表集合的精确副本。
在笔记本电脑上编辑我们的阿根廷探戈播放列表以添加一些我们购买的新歌曲后,我们要保存更改。备份应用程序替换了我们笔记本电脑CouchDB数据库中的播放列表文档,并生成了新的文档修订版。几天后,我们记住了我们的新歌曲,并希望将播放列表复制到我们的台式计算机上。如图6所示,备份应用程序在两个数据库之间进行同步,将新文档和新修订版本复制到桌面CouchDB数据库中。现在,两个CouchDB数据库都具有相同的文档修订版。
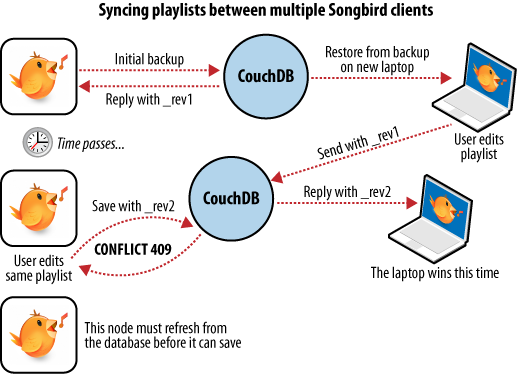
因为CouchDB跟踪文档修订,所以它确保仅当这些更新基于当前信息时这些更新才有效。 如果我们在同步之间对播放列表备份进行了修改,那么事情就不会那么顺利。
我们在笔记本电脑上备份了一些更改,却忘记了同步。 几天后,我们正在台式计算机上编辑播放列表,进行备份,并希望将其同步到笔记本电脑。 如图7所示。两个数据库之间的同步冲突,当我们的备份应用程序尝试在两个数据库之间复制时,CouchDB看到从台式机发送的更改是对过时文档的修改,并有帮助地通知我们 一直是一个冲突。
从应用程序的角度来看,从此错误中恢复很容易完成。 只需下载CouchDB的播放列表版本,即可提供合并更改或将本地修改保存到新播放列表中的机会。
1.3.8 总结
CouchDB的设计大量借鉴了Web架构,并汲取了在该架构上部署大规模分布式系统的经验教训。 通过了解这种体系结构为何能以这种方式工作,并通过学习发现可以轻松分发应用程序的哪些部分而不能轻松分发哪些部分,可以增强使用CouchDB或不使用CouchDB来设计分布式和可伸缩应用程序的能力。
我们已经介绍了有关CouchDB一致性模型的主要问题,并暗示了在使用CouchDB而不是反对使用CouchDB时将获得的一些好处。 但是有足够的理论–让我们开始并运行,看看大惊小怪的是什么!
原文:https://docs.couchdb.org/en/stable/intro/consistency.html
本文:http://jiagoushi.pro/node/919
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 157 次浏览
【文档数据库】IBM Cloudant 取消计划为 CouchDB 的新基础层提供资金
Apache 项目正在考虑下一次大升级的选项,因为 Big Blue 专注于 3.x 迭代
IBM Cloudant 软件团队决定停止推动创建一个新的数据库引擎,该引擎支持 Apache CouchDB,这是 BBC、Apple 和原子研究机构 CERN 使用的 NoSQL 文档存储。
在 Apache 名单上的一篇文章中,前 IBM Cloudant 员工和 Apache CouchDB 项目管理委员会成员 Robert Newson 解释说,IBM Cloudant 支持“使用 FoundationDB 数据库引擎作为其新基础构建下一代 CouchDB 版本的计划”。 。”
“他们不会继续资助这个版本的开发,而是将精力重新集中在 CouchDB 3.x 上,”他说。
CouchDB 的最新版本是 3.2.1,于去年 11 月发布。
使用由 Apple 推出的 Apache 开源项目 FoundationDB 作为基础支持层将有利于可扩展性,但也可以在 1.0 版本后项目留下的集群内重建一致性。
然而,这些改进是有代价的,最终对 IBM Cloudant 来说太高了,Newson 说。
CouchDB 提交者兼顾问 Jan Lehnardt 解释说,并非所有的好处都会以预期的方式实现。首先,3.x 中的某些 API 保证无法使用本机 FoundationDB 功能重新创建。
“我们还了解到,运营 FoundationDB 集群是一项重大工作,这在某种程度上违背了 CouchDB 的大部分“正常工作”性质,”Lehnardt 在线程上说。
他解释说,IBM 取消对在 4.0 版本中过渡到新基础层的支持使该项目有一些选项需要考虑。
鉴于对于 CouchDB 的大用户来说过渡到 FoundationDB 可能是值得的,因此维护两个并行代码库可能是值得的,但是 3.x/4.x 命名将不起作用。
然后选项是为 FoundationDB-CouchDB 提供自己独立的项目名称和版本控制,并在它们之间进行清晰的划分。
Google 追赶 JSON 对分布式 RDBMS Spanner 的支持
DataStax 埋葬了 Apache 的斧头并推出了使 NoSQL Cassandra 更快、更安全和更可图形化的功能
10 岁的 Apache Cassandra:让社区相信 NoSQL
墨西哥退税网站开放了 400GB 敏感客户信息
World-Check 恐怖嫌疑人 DB 在网上仅售 6750 美元
“我们必须维护两个完整的项目,包括发布管理、漏洞管理等。目前,CouchDB 有足够多的人以合理的速度为 [前进] 做出贡献。
“加倍努力可能会很棘手。虽然我们最近有大量贡献者涌入,但这可能需要更专门的计划和外展,”他观察到。
这也意味着新的 API 功能必须实施两次才能保持重叠,给贡献者带来另一个额外的负担。他说可能还有更多选择,并邀请进一步讨论。
咨询和支持公司 Percona 的开源战略负责人 Matt Yonkovit 表示,从长远来看,FoundationDB 可能会支持更新版本的 CouchDB,这取决于社区的承诺。
“整个社区需要或要求的功能往往是独立于赞助商开发的,赞助商只是加快了路线图的速度。
“租用的功能只会持续到资金或公司利益用完为止。您经常会看到通过这种方法引入的一些功能后来在资金用完时被撕掉或转移到生命终止状态,”他说。
原文:https://www.theregister.com/2022/03/15/ibm_cloudant_couchdb/
- 35 次浏览
【文档数据库】数据库深度探索:CouchDB
欢迎来到数据库深度挖掘,这是一系列的采访,在这里我们将与数据库世界的建设者、工程师和领导者进行交谈。

最近,我们有幸与Apache CouchDB项目管理委员会的Adam Kocoloski (@kocolosk)和Jan Lehnardt (@janl)进行了交流。查看下面的采访,了解更多关于Apache CouchDB的优点和缺点、项目的发展方向,以及他们对希望在Kubernetes上运行CouchDB的人的专家建议。
跟我们谈谈你自己和你今天在做什么?
Adam Kocoloski (AK):当然,我的名字是Adam Kocoloski,这些天我在做的是IBM云中的数据库和数据服务的技术策略。我们有一整套数据库和相关的东西来搬运数据,分析数据,并从中提取见解。我的工作是尝试并引导他们形成一个连贯的投资组合,以满足我们客户的需求,并使我们与市场上的其他公司处于一个强有力的竞争地位。
简·莱纳特(左壹):我是简·莱纳特。我做开源工作已经有20年了,CouchDB做了12年。大约五年前,我和我的公司睦邻hoodie一起,开始使我的Apache CouchDB工作服务和支持变得专业化。当我不运行它的时候,我正在开发CouchDB 3.0和4.0,我们决定同时进行,这非常令人兴奋。另外,我们正在开发opservator(我们最近宣布了它),这是一个用于CouchDB安装的连续观察工具。
您是如何加入CouchDB的?
AK:我之所以加入CouchDB,是因为我和我在麻省理工学院的同事们有开公司的想法。我们的一个想法是在数据库空间。我们看到,在2007年和2008年,有各种各样的人在探索不同类型的数据库,而不是传统的用于支持LAMP堆栈应用程序的通用数据库。作为实践中的物理学家,我们有很多处理非传统数据集和非传统管理方法的实用经验。我们认为这可能是一个有趣的方式来应用我们的技能。
我们遇到CouchDB因为它似乎有着很多相同的原则我们的数据分布方法,关注数据的安全性和耐久性,的拥抱网络与数据交互的媒介如您构建您的应用程序。我们认为,与其坐下来构建一个看起来和感觉上像CouchDB的东西,不如更有效地参与到社区中,看看我们是否能在那里做出贡献。这就是我们想要建立的公司的基础。
JL:我当时主要是做LAMP的顾问。我最终擅长于让团队思考“可伸缩”,利用PHP无共享架构的所有优点和基本的最佳实践。我在某个地方的博客上发现了CouchDB,并对它做了一些研究。不到一个星期,我就开始恐慌了,因为如果CouchDB流行起来,我很快就会失业。我想我最好弄清楚如何熟练地使用它,看看它会发展成什么样子。CouchDB取代了所有东西,但结果并没有像我想象的那样。但是我没有错,一些看起来和感觉上像CouchDB的东西现在是数据库领域的主要参与者。我就是这样开始的,从来没有离开过。
您认为CouchDB的优势和劣势是什么?
JL:有一件事使CouchDB独一无二,[这]就是如果您按照动作构建数据库系统,您会被问到“为什么要这样做?”CouchDB存在的原因是其独特的复制功能,它可以从低级点对点(像物联网或移动设备收集数据并相互通信)到完全的多区域集群到集群复制同步数据。正是这种技术允许使用CouchDB的这些用例,而其他数据库实际上没有这种形式或形式。具体来说,CouchDB的复制更像Git而不是MySQL复制。
与其他数据库相比,它的主要优势在于数据的持久性;就像前面提到的Adam一样,它从来不会丢失任何数据!很难搞砸。在设计CouchDB时,我们默认选择安全和可靠,这使得操作非常简单。使用CouchDB很容易启动和运行,如果您不想了解太多的话,它可以完成您需要它完成的工作。
我们还花了几年时间思考REST API。从平易近人、长期有用的角度来看,这仍然是有回报的,而且它对我们来说很有效。我个人认为,使用文档数据库编程比使用其他SQL数据库编程更自然。这可能只是我的观点。
AK:我想我必须回应Jan的大部分评论。2009年,有人胆敢用这种技术创办了一家“数据库即服务”公司,我很感激我们对数据安全性和持久性的重视。在100次中,CouchDB只有99次能够自己解决如何让事情恢复正常运行的问题,我们真的很欣赏这一点。显然,当您遇到CouchDB考虑世界的方式以及在对等点之间复制和同步数据的方式所形成的问题时,复制支持一组用例,这些用例显然是用于该工作的正确工具。
这些绝对是系统的优点。说到缺点——要使CouchDB成为开箱即用的低延迟系统并不容易。您必须了解与web服务的性能访问相关的所有事情。我们看到一些客户端对每个请求都建立一个新的TLS连接。这里有很多来回的握手,这确实没有必要,但是因为它是一个web服务,如果您希望它这样做,CouchDB将很乐意与您协商这些连接。它将继续运行并保持可用性,但很难做到那么快。
我还想说,作为一个社区,我们在客户端库上的投入可能比其他一些项目要少一些。部分原因是我们说:“嗨,我们有这个很好的REST API。它是一种web服务,如果你知道如何与web服务对话,你就知道如何与数据库对话。”
虽然这是真的,但我们不时地看到,它让学习曲线变得比原本更陡峭。一些数据库投入了大量的时间、金钱(和人员)来构建一组不同的客户端库,这些库掩盖了来自最终用户的API的一些细节,并在每个流行框架和生态系统中提供了一个更惯用的编程模型。我认为这是我们近年来学到的东西,并投入了更多的精力。不过,我要说的是,在这一点上,我们还没有那么强大。
你见过的有关Couch的最酷或者最有趣的用例有哪些?
AK:在谈到这些新奇的东西之前,我应该说一件事,那就是我们很高兴CouchDB成为IBM Cloud中大量用例的基础。它为IBM云提供了基础级的支持,如果CouchDB有朝一日垮掉了,云也会垮掉。我认为这很酷,即使大多数用例可能是普通的、无聊的、数据库前的应用程序。它可以工作,可以扩展,可以满足我们的需求。
我们看到人们开发了很多手机游戏和手机钱包。我们看到一些人拿着一堆关系数据库和一大堆存储过程说:“天哪,我们不能再对这个堆栈做任何更改了,我们的存储过程涉及的是一家20年前就倒闭了的公司!”我们如何把这些都拿出来,并给我们的团队一个开发环境,让我们能够以业务所需的速度移动?像CouchDB这样的文档数据库非常适合。它简化了数据模型,并能够适应多年来在不同系统中可能出现的怪癖。
JL:我不得不附和亚当。我对Couch的评价是:“这是一个很好的通用数据库,80%的应用程序可以使用任何数据库,那么为什么不使用Couch呢?”“不过我们也看到了一些很酷的东西。
有一个公司在全球范围内运送货物。任何超出人手可携带范围的内容都通过多区域CouchDB集群进行管理。另一家公司是一家提供飞行娱乐系统的公司,在任何给定时间都有3000架飞机在飞行中使用CouchDB。我们还参与了人道主义危机,比如2016年的埃博拉救援工作,大约有四五个西非国家因为疫情爆发而基本停止了行动。
我们碰巧建立了一个离线的,第一个响应工具来帮助他们比在纸和笔上更快地处理危机,这是在没有电力、边缘网络或3G等基础设施的情况下做事情的通常方法。如果没有CouchDB,这一切都不可能实现。
我们还帮助开发了一款针对该环境的疫苗接种试验软件,从而研制出了第一款埃博拉疫苗。从个人角度来说,这是非常令人羞愧的。如果我们看看过去100年人类取得的重大成就,第一种埃博拉疫苗肯定在其中。就个人而言,或者即使我只是在CouchDB上工作,这都是非常棒的
你对CouchDB 3.0和4.0有什么期待?
JL:我们决定同时做CouchDB 3.0和4.0是有原因的。它们将按顺序发布,但我们正在同时考虑和工作。4.0的主要变化是以CouchDB为基础的重大技术转变。但在此之前,3.0中现有的基础将是我们所做过的最好的CouchDB。不是用“最新最伟大”的营销术语,而是从人们碰到、抱怨或马上询问的10件事的角度来看。CouchDB 3.0将简单地解决所有这些问题。
我们非常感谢IBM将他们在IBM与Cloudant公司合作开发的产品开源,我们也可以将其作为开源产品添加进来,同时我们也在开发其他一些产品,以确保我们能够提供最好的沙发平台。它包含了我们在过去10-15年使用CouchDB的所有经验教训,为需要长期使用该平台的人们提供了一个非常坚实的基础。对于CouchDB 4.0, Adam你可能想谈谈这个。
正义与发展党:是的,当然。因此,4.0版本包含了一个被称为FoundationDB的分布式事务键-值存储系统。这是我个人非常兴奋的事情,对于任何一个足够接近这个项目的人来说,也会对这里的潜力感到兴奋。
FoundationDB是一个商业软件,被苹果收购后关闭了。几年后,它被开源。这为我们提供了运行CouchDB环境的能力,这些环境能够向外扩展到单个区域,同时仍然为更新提供完全强大的一致性。如果你看看我们在Couch 2.0中所做的事情和我们将在3.0中保留的事情,就会发现我们在处理更新的方式和让各个副本相互协调的方式上是不同的。
而且,尽管这是一种持久且可适当扩展的设计,但它也给我们留下了一些难以编程的缺点。有可能让你的数据库在一个区域中出现编辑冲突,尽管你在编辑器中只是循环和写入数据库。我们希望通过使用Couch 4.0和使用FoundationDB来消除这种行为。
另一个是我们在CouchDB中使用分散-聚集机制执行视图索引的方式。它让人们通过高写入数据库提供了大量的索引吞吐量——将这些东西分片,然后每个索引将并行地构建其分片的视图。但查询这些东西是一个相当昂贵的主张。随着数据库变得更大,查询的成本将继续上升。
相反,当我们让视图在FoundationDB上运行时,我们将让它们在一个机器集群中重新组织和重新分发,这样大规模查询视图就像检索单个文档一样便宜。我认为这为采用CouchDB的人们打开了一大堆额外的高吞吐量/高规模用例。这是一个巨大的转变。这实际上意味着现在CouchDB逻辑是部署在FoundationDB之上的无状态应用程序层,它负责数据的所有有状态性、持久性和物化。
这不是我们掉以轻心的事情。我们总是非常重视数据的安全性、持久性以及正确处理人们的数据。我们在分析FoundationDB时也采用了同样的视角,我们很高兴地说,他们的项目与CouchDB有着相同的重点和关注点。
JL:我花了很多时间在台上谈论CouchDB,并向人们解释什么是CouchDB。问题经常出现在最终的一致性和复制,在2.0或3.0中的Dynamo模型集群。这样做的缺点是值得的,因为如果你想要创建一个分布式的、一致的数据库,你就需要找10个世界上最顶尖的分布式系统工程师,给他们5-10年的时间来做正确的事情。没有人有那样的时间。
它是被苹果收购之前的公司,而苹果的需求与之一致。我们面临的[开放]问题是:“我们是应该将我们的CouchDB转换成类似于FoundationDB的东西,还是仅仅在FoundationDB之上构建CouchDB,实现跨行业发展?”
基本上,他们做了一件不可思议的事情,而且做得很好。野外有足够的证据证明他们的做法是正确的。非常非常高兴看到它,而且我们很幸运它是开源的。
最后需要注意的是,这是一个过程问题,但是CouchDB项目并没有正式宣布4.0就是我们刚刚讨论的内容。它很可能很快就会这样做。如果任何CouchDB开发人员正在阅读,那么要使其正式运行需要一些过程。
听到核心代码库的改进是令人兴奋的,但是围绕CouchDB的生态系统并没有停滞不前。随着Kubernetes和它的朋友的出现,您会给想要在容器上部署CouchDB的人们什么建议?
AK:所以,我想我要说的是选择在容器上部署CouchDB,特别是将CouchDB与Kubernetes环境协调在一起,这是一个决定,它将使您能够获得进一步的改进。
我们在这里投入了时间和精力,以确保它是一种开箱即用的体验,能够满足各种应用程序的需求。这是一个不断变化的目标,不仅因为CouchDB支持Kubernetes和基于容器的部署,而且因为整个行业都是这样。
我们看到,今天每个人都在构建掌舵图表来支撑数据库,明天每个人都在构建操作符来管理这些数据库的生命周期。因为空间移动得非常快,所以要记录的东西很多。如果你想在生产中做这些事情,你就必须关注并与社区保持联系。但是,我们对推动支持感兴趣。我认为它提供了一种潜在的体验,在这种体验中,大多数配置在第一次就正确地完成了。
设置分布式系统的一些复杂性是我们可以在Kubernetes这样的受限环境中更好地进行自动检测和自动化,而不是在VMware环境中的虚拟机。
JL:是的,我绝对同意潜在的部分。但是,我要提一下,我们为Couch提供专业的服务,我们现在赚钱的一个领域就是让人们不再用Docker运行CouchDB。我认为这就是缺点所在。
对于某些工作负载,这项技术还不够成熟。并不是说Docker是唯一的容器解决方案,也不是说Kubernetes是我们能进入的唯一的分布情况,但是couchdb——作为一个分布式数据库——充分利用了低延迟、高带宽的网络以及极快的IO吞吐量和磁盘访问。
在某些越来越小的情况下,Kubernetes和Docker都阻碍了这一点。此时,CouchDB会变慢,或者会出现无法解释的超时错误。总的来说,如果你创建了一个知道如何重试的应用,这不是一个大问题,但它是一个不断变化的目标。
我建议,除非您有一个专门的团队负责保持Kubernetes集群上的服务正常运行(尤其是数据库),否则它已经超出了目前大多数用例的范围。在IBM cloud、Microsoft或谷歌上的云虚拟机周围安装一些自动化就可以达到这个目的。
通常,从工作负载的角度来看,移动数据是比较昂贵的部分。因此,增加更多的工作人员在一个小时内处理数据库事务——在数据到达新节点之前,您需要等待半天才能处理这个峰值。所以在[向外扩展]场景中,它的用途有限,这就是为什么许多人从应用程序的角度对它感兴趣的原因(它在今天工作得非常好)。
当涉及到Adam刚才所说的内容时,请确保部署和集群管理或分发管理工作良好,并以声明的方式而不是功能的方式完成。这就是你要使用它的地方。如果您对资源的需求较低,但是想要获得在容器或kubernet中运行的好处——当然,尽管去做吧,只要知道[某些指标的限制],并且如果没有一个专门的团队,您可能会更好地离开。今天的情况有好有坏,但我等不及这一切什么时候结束,什么时候方向很明确。并不是说这永远不会发生,只是等待底层技术赶上现实。
对于那些想要加入社区但以前没有使用过Erlang的人,您有什么建议?
AK:学习Erlang当然不是加入CouchDB社区的先决条件。我们希望在JavaScript层、文档系统和Elixir(我们现在正在移植测试套件以在Elixir中运行)上做出贡献。Elixir是一种极好的方式,可以让您深入了解基于erlang的、基于Beam的vm的系统,这些系统具有吸引开发人员的社区、采用、吸引力,并且与CouchDB的世界很好地结合。
但我认为,总的来说,这是关于参与开源项目的评论。人们会认为,有时候你需要弄清楚这个系统中最深、最黑暗的部分是如何运作的,并进行疯狂的公关才能参与其中。这不是真的。即使没有别的,我们也可以从各个领域的贡献中受益。作为项目管理委员会的成员,我们工作的一部分就是鼓励多样性的贡献,以确保我们有一个全面、包容的社区,让人们参与进来。这里的建议是举起你的手。我们绝对会找到包括你在内的方法,并充分利用你所能带来的:
JL:这都是非常好的建议,我只是想补充一点,虽然一开始可能会让人望而生畏,但Erlang并不像乍一看那样糟糕或困难。它可能看起来很奇怪,但是如果您愿意接受它,您可以在浏览一堆教程之后立即提交富有成效的补丁。有一件事很有帮助——我们基于web的HTTP JSON API可以在一个小时内学会。
然后,您所要做的就是在后台查看HTTP请求是如何处理的,这个JSON是如何解析的,然后就可以开始深入到堆栈中去了。我们帮助没有任何Erlang经验的用户在一个下午就完成了一个小的CouchDB功能。当然,我们引导他们,但如果你有更多的耐心,可能需要一个周末。
AK:说得好,jan。我不知道你是怎么想的,但是我是通过阅读CouchDB源代码和使用Couch来学习Erlang的。
莱托:相同。
感谢我们的受访者抽出时间来分享他们的知识。如果你想更广泛地了解CouchDB,请查看Adam的视频“CouchDB解释”
原文:https://www.ibm.com/cloud/blog/database-deep-dives-couchdb
本文:http://jiagoushi.pro/node/1141
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 131 次浏览
【文档数据库】数据库深度探索:MongoDB
欢迎回到数据库深度探索,在这里我们将与数据库领域的工程师、构建者和领导者进行一对一的交流。最近,我们采访了来自MongoDB的Richard Kreuter。

阅读下面的采访,了解Atlas跨越多个云的未来发展方向,他们如何从一个数据库转变为一个拥有Atlas数据湖的数据平台,以及他们如何在NoSQL数据存储中构建和交付事务。
跟我们谈谈你自己和你今天在做什么?
理查德·克罗伊特(RK):我是理查德·克罗伊特,MongoDB的现场工程高级副总裁。我负责许多面向客户和合作伙伴的团队——我们的解决方案架构师、业务价值顾问、项目经理、咨询工程师、客户成功经理,以及支持我们合作伙伴的技术架构师。
你是如何接触到MongoDB的?
(RK):我第一次了解MongoDB是在2009年11月。我是一名软件工程师,在过去的十年里,我从事的项目确实需要一个比市场上现有的数据库更灵活的数据库。当我第一次看到MongoDB时,我想,“哇,我希望我以前的项目也有这样的功能。”
我申请了一个职位,并在2010年1月加入了公司,负责我们的软件产品。当我加入这家公司的时候,我们还不到10人,而现在,我们已经是一家拥有1500多人的公司,服务着14000多名客户。
我们于2017年10月上市——这是25年来第一家达到这一里程碑的数据库公司。在过去的几年中,我们已经收购了一些公司,这大大加快了我们的增长。在过去的几年中,我们已经将我们的产品从核心数据库扩展到了不同的产品平台,这些产品涵盖了数据管理和数据生命周期的几个不同方面。
随着Atlas的成功和更广泛的支持应用开发服务的生态系统(如Stitch和Charts),你认为MongoDB在未来5-10年将走向何方?
(RK):我们正在完善智能数据平台,这是一套集成的产品和功能,通过MongoDB的文档模型为用户提供处理数据的最佳方式。文档——灵活的、受json启发的文档——比许多人熟悉的处理数据的严格结构的传统方式更加简单、自然、通用和高性能。
如今,我们在核心数据库和其他产品中都有能力,我们正在不断开发这些产品,以使客户能够在全球范围内战略性地放置他们的数据。这可能意味着将数据保存在更接近大用户群的地方,以便为这些用户提供较低的延迟体验,或者为了遵守监管要求,将数据保存在国家和其他地理边界内。
我们还将继续致力于为客户提供在他们需要的任何地方运行MongoDB的自由。我们有可以在移动设备、标准服务器级硬件、云实例、IBM大型机和其他硬件上运行的MongoDB版本。它能够移动工作负载,在许多不同的环境中运行MongoDB软件,这是人们采用MongoDB的一个关键原因。
当然,从长远来看,人们都在为向云计算的宏观过渡而奋斗。但是,在可预见的未来,不同种类的工作负载和环境、国家、行业等仍然在本地运行。MongoDB的平台无论你是在自己的数据中心自己运行,还是通过MongoDB Atlas在公共云上为你运行,在两者之间的所有点上运行,基本上都是一样的。
作为这个更大故事的一部分,我们正在扩展我们平台提供的整体功能集。例如,我们最近发布了一个新产品——Atlas Data lake,它可以利用存储在对象存储中的数据,比如S3,在云中可用。
Atlas数据湖提供了MongoDB查询语言的全部功能,MongoDB查询语言是一种非常强大且丰富的查询语言,人们在操作数据库上下文中已经享受了多年,并将这种能力带到了对象存储中的数据中。由于人们在S3中存储大量数据,其中大部分数据倾向于以常见格式存储,如JSON、逗号分隔值或其他格式。我们可以利用MongoDB查询语言,它非常适合于像JSON这样的半结构化和层次化数据,从而能够充分利用存储在S3 bucket中的信息。
我们最近还收购了一家移动数据库公司,Realm,它有一种非常类似mongodb的灵活方式来处理移动设备中的数据。随着MongoDB的发展,我们从用户和客户那里得知,MongoDB在数据库级别上所解决的挑战在其他领域仍然存在。MongoDB希望将其为开发人员提供处理数据的最佳方式的使命带到更多的数据生态系统中。
让我们来谈谈多文档事务——为什么需要它,公司是如何交付这个特性的?
(RK): MongoDB总是在单个文档级别上具有ACID事务能力。Richard,如果你正在建模关于我的所有数据,作为你公司的一个客户,你可能会存储关于我的大部分信息在一个文档中。当文档从一种状态更改到另一种状态时,我们总是在单文档级别上有ACID事务。
但是,当我们的客户不确定未来的需求是什么时,为了让他们的应用程序经得起时间的限制,多文档事务提供了一个保证,即使他们的应用程序的需求会随着时间的推移而变化,客户也不会以某种方式达到MongoDB能为他们做的极限。MongoDB能够在单个事务中封装跨多个集合和文档的多个操作。
的业务分析为什么我们想要在这个方向提供了完整的、传统的、会话事务应用程序可以做任意的事情的范围内事务和不需要,例如,预定义的操作可以在事务作用域或限制哪些操作可以在执行一个事务。
对多文档事务的技术需求始于MongoDB的第一次收购,一个名为WiredTiger的数据库存储引擎,它是由创建BerkeleyDB嵌入式数据库(世界上最流行的数据库引擎之一)的人创建的。
WiredTiger存储引擎,自从几年前MongoDB 3.2以来就一直是默认的存储引擎,实际上已经支持了多记录事务的底层能力。然后,我们的工程师通过MongoDB的查询语言、复制协议、分片架构将该功能向上线程化,这样MongoDB应用程序就可以利用底层存储引擎提供的这种功能。
今天,我们的客户开始以非常先进的方式利用这些交易。在这方面,它使从传统的表格数据库到MongoDB更容易一些。
你认为在Mongo堆栈中哪里有改进的空间?
(RK):我们正在用MongoDB Atlas扩展我们的多云能力,这可能是我们目前正在做的工作,它最能引起我们最大客户的共鸣。
今天,如果你想启动MongoDB Atlas部署,你必须选择一个特定的云,如IBM云、AWS、Azure或GCP。每个单独的MongoDB部署可以跨越这些云中的多个区域,但不能跨越多个云。
我们的目标是让单个MongoDB部署跨越不同的云提供商,让客户能够利用每个不同云提供的最佳技术。因此,如果他们想利用Amazon特有的一些功能,他们可以这样做,并让这些功能在MongoDB中读写他们的数据。当我们提供跨云集群时,相同管理域下、相同用户权限和访问控制角色下的相同集群也将能够通过复制存在于其他云中,这样用户就可以利用Azure或GCP中可用的技术。
你对自己运行MongoDB的人有什么建议?
(RK):首先,如果你自己运行MongoDB,你就会疏忽,不去看MongoDB Atlas可以提供的功能。Atlas是获得MongoDB好处的最简单方式,因为坦率地说,我们将为您运行它。所以,你会得到你投入到任务和升级操作,安全操作,等等的资源。这是一种让您的团队更高效、更快的方法,同时让构建MongoDB的专家们安心地运行操作。
如果你现在在一些on-prem或其他自管理的情况下运行MongoDB,你应该看看MongoDB的管理工具。我们有几个不同的管理套件,其中一个叫做MongoDB云管理器,它可以在云环境中协调、运行、监控和备份MongoDB。
我们也有一个打包的,on-prem版本的相同功能称为MongoDB Ops Manager,它是运行MongoDB最完整的管理工具套件,包含了你需要的所有功能,包括编排、升级、维护任务、监控和警报。
MongoDB专家组成了一个庞大的生态系统,这也是一个有价值的资源。我们的核心数据库已经有超过7500万的下载量,在线教育平台MongoDB University的注册人数也超过了100万。有非常支持的论坛,如谷歌组为用户支持,以及堆栈溢出为其他关于MongoDB技术的问答。当然,在MongoDB,我们有大量的MongoDB专家,如果你自己运行MongoDB,你需要额外的帮助,他们可以以各种方式帮助你。
原文:https://www.ibm.com/cloud/blog/database-deep-dives-mongodb
本文:http://jiagoushi.pro/node/1144
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 76 次浏览
【文档数据库】时间序列数据与MongoDB:第一部分-简介
时间序列数据正日益成为现代应用的核心——比如物联网、股票交易、点击流、社交媒体等等。随着批量系统向实时系统的转变,对时间序列数据的有效捕获和分析可以使组织能够更好地检测和响应事件,领先于竞争对手,或提高操作效率,以降低成本和风险。使用时间序列数据通常不同于常规应用程序数据,您应该观察一些最佳实践。这个博客系列试图提供这些最佳实践,当你在MongoDB上构建你的时间序列应用程序:
- 介绍时间序列数据的概念,并描述与这类数据相关的一些挑战
- 如何查询、分析和呈现时序数据
- 提供发现问题,帮助您收集成功交付时间序列应用程序所需的技术需求。
什么是时间序列数据?
虽然并非所有的数据在本质上都是时间序列,但越来越多的数据可以被归类为时间序列——这是由允许我们实时而不是批量利用数据流的技术所推动的。每个行业、每个公司都需要对时间序列数据进行查询、分析和报告。假设一个股票日内交易员不断地查看股票价格的feed,并运行算法来分析趋势和确定机会。他们在一段时间内查看数据,例如每小时或每天。联网的汽车公司可以获得发动机性能和能源消耗等遥测数据,以改进零部件设计,并监测磨损率,以便在问题发生前安排车辆维修。他们也会在一段时间内查看数据。
为什么时间序列数据具有挑战性?
时间序列数据可以包括以固定时间间隔捕获的数据(如每秒的设备测量),也可以包括以不规则时间间隔捕获的数据(如从警报和审计事件用例生成的时间间隔)。时间序列数据通常还带有诸如设备类型和事件位置之类的属性,并且每个设备可能提供数量可变的附加元数据。数据模型能够灵活地满足各种快速变化的数据摄入和存储需求,这使得具有严格模式的传统关系(表格)数据库系统难以有效地处理时间序列数据。此外,还有可伸缩性的问题。由于多个传感器或事件产生的高频率读数,时间序列应用程序可以产生大量的数据流,需要消化和分析。因此,允许数据向外扩展并跨许多节点分布的平台比扩展的单块表格数据库更适合这种用例。
时间序列数据可以来自不同的来源,每个来源生成需要存储和分析的不同属性。数据生命周期的每个阶段都对数据库提出了不同的要求——从摄入到使用和归档。
- 在数据摄取期间,数据库主要执行写密集操作,主要包括偶尔更新的插入操作。当数据流在摄入期间检测到异常(例如超过某个阈值)时,数据使用者可能希望得到实时警报。
- 随着越来越多的数据被摄入,消费者可能想要查询这些数据以获得具体的见解,并发现趋势。在数据生命周期的这个阶段,工作负载是读的,而不是写的,但是数据库仍然需要保持较高的写率,因为数据是并发地摄取然后查询的。
- 消费者可能希望查询历史数据,并利用机器学习算法进行预测分析,以预测未来行为或识别趋势。这将对数据库施加额外的读取负载。
- 最后,根据应用程序的需求,捕获的数据可能有一个保质期,需要在一段时间后进行归档或删除。
正如您所看到的,处理时间序列数据不仅仅是简单地存储数据,还需要广泛的数据平台功能,包括处理同时的读和写需求、高级查询功能和归档等等。
谁在使用MongoDB处理时间序列数据?
- MongoDB提供了满足高性能时间序列应用程序需求所需的所有功能。定量投资管理公司Man AHL利用了MongoDB的时间序列能力。
- Man AHL的Arctic应用利用MongoDB存储高频金融服务市场数据(大约每秒250M嘀嗒)。这家对冲基金经理的定量研究人员(“quants”)利用Arctic和MongoDB研究、构建和部署新的交易模型,以了解市场的行为。与现有的私有数据库相比,使用MongoDB, Man AHL节省了40倍的成本。除了节省成本之外,它们还能将处理性能比以前的解决方案提高25倍。Man AHL在GitHub上开源了他们的北极项目。
- 博世集团是一家跨国工程集团,拥有近30万名员工,是全球最大的汽车零部件制造商。物联网是博世的一项战略举措,因此公司选择MongoDB作为物联网套件的数据平台层。该套件不仅为博世集团内部的物联网应用提供了动力,也为其在工业互联网应用领域的许多客户提供了动力,如汽车、制造业、智慧城市、精准农业等。如果您想了解更多关于管理由物联网平台生成的多样化、快速变化和高容量时间序列数据集所面临的主要挑战,请下载Bosch和MongoDB白皮书。
- 西门子是一家专注于电气化、自动化和数字化领域的全球性公司。西门子开发了MongoDB支持的“Monet”平台,提供先进的能源管理服务。Monet使用MongoDB进行实时原始数据存储、查询和分析。
关注应用程序需求
在处理时间序列数据时,您必须投入足够的时间来理解如何创建、查询和过期数据。有了这些信息,您可以优化模式设计和部署架构,以最佳地满足应用程序的需求。
在没有捕获应用程序的需求的情况下,您不应该同意性能指标或sla。
当你开始你的时间序列项目与MongoDB,你应该得到以下问题的答案:
写工作负载
- 摄入的速率是多少?每秒有多少次插入和更新?
随着插入速度的增加,您的设计可能会受益于通过MongoDB自动分片的水平扩展,允许您跨多个节点分区和扩展数据
- 同时有多少客户端连接?
虽然单个MongoDB节点可以处理来自数以万计的物联网设备的同时连接,但您需要考虑通过分片将其扩展,以满足预期的客户机负载。
- 需要存储所有原始数据点吗?还是可以预先聚合数据?如果是预聚合的,可以存储什么粒度或间隔的摘要级别?每分钟?每15分钟吗?
如果你的应用需要证明这一点,MongoDB可以存储你所有的原始数据。但是,请记住,通过预聚合减少数据大小将产生更低的数据集和索引存储,并提高查询性能。
- 每个事件中存储的数据大小是多少?
MongoDB的单个文档大小限制为16 MB,如果你的应用程序需要在一个文档中存储更大的数据,比如二进制文件,你可能想要利用MongoDB GridFS。理想情况下,在存储大量时间序列数据时,最好保持文档大小较小,大约一个磁盘块大小。
阅读工作负载:
- 每秒有多少读取查询?
更高的读取查询负载可能得益于额外的索引或通过MongoDB自动分片进行的水平伸缩。
与写卷一样,读卷可以通过自动分片进行缩放。还可以跨副本集中的辅助副本分布读取负载。
- 客户是地理分散还是位于同一地区?
通过部署地理上更接近数据使用者的只读辅助副本,可以减少网络读取延迟。
- 您需要支持哪些常见的数据访问模式?例如,您是按单个值(如时间)检索数据,还是需要更复杂的查询,即按属性组合(如事件类、按区域、按时间)查找数据?
当创建了适当的索引时,查询性能是最佳的。了解如何查询数据并定义适当的索引对数据库性能至关重要。同时,能够在不干扰系统的情况下实时修改索引策略,是时间序列平台的一个重要属性。
- 您的用户将使用哪些分析库或工具?
如果您的数据消费者正在使用像Hadoop或Spark这样的工具,MongoDB有一个MongoDB Spark连接器,它集成了这些技术。MongoDB也有Python、R、Matlab和其他用于分析和数据科学的平台的驱动程序。
- 您的组织是否使用BI可视化工具来创建报告或分析数据?
MongoDB通过MongoDB BI连接器集成了大多数主要BI报告工具,包括Tableau、QlikView、Microstrategy、TIBCO等。MongoDB还有一个叫做MongoDB Charts的本地BI报告工具,它提供了在MongoDB中可视化数据的最快方法,而不需要任何第三方产品。
数据保存和归档:
- 什么是数据保留策略?数据可以被删除或存档吗?如果有,在什么年龄?
- 如果存档,存档需要多长时间以及可访问性如何?存档数据需要是活动的,还是可以从备份中恢复?
在MongoDB中有不同的删除和归档数据的策略。其中一些策略包括使用TTL索引、可查询备份、分区分片(允许您创建分层存储模式),或者简单地创建一个体系结构,在该体系结构中,您只需在不再需要时删除数据集合。
安全:
- 需要定义哪些用户和角色,每个实体所需的最低特权权限是什么?
- 加密要求是什么?您是否需要同时支持时间序列数据的空中(网络)加密和静止(存储)加密?
- 是否所有针对数据的活动都需要记录在审计日志中?
- 应用程序是否需要符合GDPR、HIPAA、PCI或任何其他监管框架?
监管框架可能需要启用加密、审计和其他安全措施。MongoDB支持这些遵从性所需的安全配置,包括静态和动态加密、审计和基于角色的粒度访问控制。
虽然不是所有可能考虑的事情的详尽列表,但它将帮助您思考应用程序需求及其对MongoDB模式设计和数据库配置的影响。在下一篇博客文章“第2部分:MongoDB中时间序列数据的模式设计”中,我们将探索为不同需求集构建模式的各种方法,以及它们对应用程序性能和规模的相应影响。在第3部分“时间序列数据和MongoDB:第3部分—查询、分析和呈现时间序列数据”中,我们将展示如何查询、分析和呈现时间序列数据。
原文:https://www.mongodb.com/blog/post/time-series-data-and-mongodb-part-1-introduction
本文:http://jiagoushi.pro/node/1334
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 159 次浏览
【文档数据库选型】从MongoDB迁移到Apache CouchDB

本文将指导您完成使用简单的python脚本将数据从MongoDB迁移到Apache CouchDB的步骤。
由于多种原因,包括源数据库和目标数据库之间的基本架构和设计差异,将数据从一个数据库迁移到另一个数据库可能会遇到挑战。
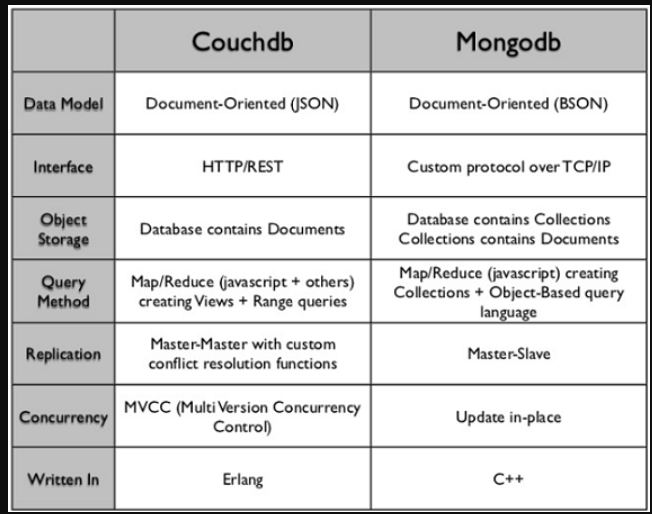
MongoDB和CouchDB都是文档数据库,它们存储一组类似JSON的独立文档。 本文假定您对这两个数据库有基本的了解,并且熟悉如何在这两个数据库中存储数据。 下表提供了两个数据库之间的高级比较。 要获得更深入的了解,您可以访问官方文档,网址为docs.mongodb.com和couchdb.apache.org。
迁移环境
本文支持所有环境,无论您的数据库托管在容器,VM还是裸机系统中。
下图显示了此迁移示例中涉及的组件。
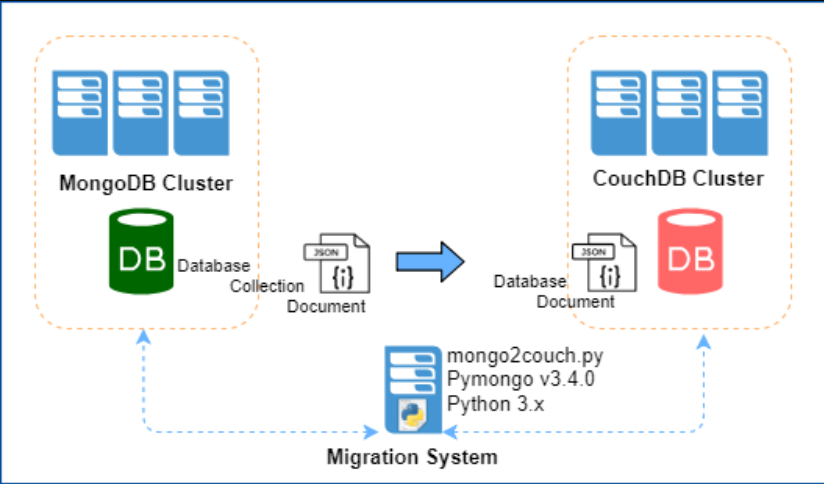
- 源数据库:一个三节点的MongoDB版本3.4.1集群。它具有多个数据库,集合和文档,需要迁移。数据库和相关文件存储在网络文件系统(NFS)共享上。
- 目标数据库:三个节点的CouchDB 2.2版集群。它仅具有在新的CouchDB安装期间创建的默认数据库。新数据库将在迁移过程中即时创建。本文假定您已经在环境中完成了CouchDB的安装。
- 迁移系统:这是一个运行最新的Ubuntu OS,pymongo版本3.4.0,python 3.x,python请求(HTTP库)二进制文件的系统。这用作执行python迁移脚本的迁移系统。该系统能够与MongoDB和CouchDB端点通信。
迁移方式:
以下步骤定义了此示例中遵循的迁移方法。
- 使用pymongo MongoClient启动与MongoDB服务端点的客户端会话。
- 查询和查看MongoDB中的数据库列表。
- 查询MongoDB中的每个数据库,并创建数据库中存在的所有集合的列表。
- 遍历每个集合并一次复制一个文档以进行迁移。
- 使用服务URL和标头信息建立CouchDB REST API连接。
- 使用与MongoDB中相同的数据库名称连接到CouchDB数据库。如果您是第一次连接数据库,则在CouchDB中将不可用。因此,该脚本将创建一个新的数据库,然后插入在步骤4中复制的第一个文档。该脚本将继续所有集合和数据库的文档迁移。
本文介绍的迁移方法适用于较小的数据库
迁移之前
在开始迁移之前,您需要了解这两个数据库之间的关键区别。 MongoDB将文档存储在集合中,而CouchDB将文档直接存储在数据库中(请参阅本文开头显示的比较表中的“对象存储”)。
记住上述差异,此示例在迁移过程中在CouchDB中创建新数据库时将集合名称附加到数据库名称中。参见下面的示例,
MongoDB: Database = SalesDB, Collection = Atlanta Database = SalesDB, Collection = Ohio CouchDB: Database = SalesDB-Atlanta Database = SalesDB-Ohio
在CouchDB数据库中追加集合名称仅出于理智的目的,而不是迁移所必需的。您可以选择使用与MongoDB中相同的数据库名称来创建CouchDB数据库,只要这些名称是唯一的即可。
不支持:此迁移示例不支持包含带有附件的文档的数据库。
让我们迁移
您应该在要运行迁移脚本的迁移系统上安装以下依赖项。
pymongo version 3.4.0
python 3.x
接下来,将下面列出的python脚本(mongo2couch.py)复制到迁移系统,并使用以下命令运行迁移脚本。确保根据您的环境用适当的值替换MongoDB和CouchDB端点。
$ python mongo2couch.py -c 'http://admin:password@testcouchdb:5984' -m 'mongodb://localhost:27017'
档案:mongo2couch.py
https://gist.github.com/Kailashcj/d91ed66e2885db968fecf5de2c9b056d
运行脚本后,它将测试与CouchDB和MongoDB端点的连接。建立成功的连接后,它将读取MongoDB中存在的所有数据库。接下来,它将遍历除“ admin”和“ local”数据库之外的每个数据库中的集合,因为它们是MongoDB的特殊内部数据库。该脚本将读取每个集合中存在的文档,并将其复制到CouchDB数据库。首次插入文档时,它将在CouchDB中创建适当的数据库。
该脚本将报告执行期间的所有错误。默认情况下,所有报告“不可JSON可序列化”错误的文档都会被跳过。如果您的环境中有这些错误,可以参考README.md来解决。
最后,脚本将生成一个迁移摘要,如下所示。

您可以登录到CouchDB Web管理仪表板,以验证新数据库的创建以及这些数据库中已迁移的文档。
摘要
我希望这篇文章易于理解,并能帮助您成功地将文档迁移到CouchDB数据库。
祝好运。
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 167 次浏览