搜索引擎
- 222 次浏览
【全文搜索】全文搜索 PostgreSQL 或 ElasticSearch
在本文中,我记录了在 PostgreSQL(使用 Django ORM)和 ElasticSearch 中实现全文搜索 (FTS) 时的一些发现。
作为一名 Django 开发人员,我开始寻找可用的选项来在大约一百万行的标准大小上执行全文搜索。有两个值得尝试的选项:PostgreSQL 和 ElasticSearch。
在深入研究我的发现之前,让我们澄清一下全文搜索 (FTS)(或“搜索”)与数据库过滤器或查询之间的区别。 “搜索”涉及从零开始,然后向其中添加结果。数据库过滤从一个集合开始,然后根据条件从中删除条目。过滤不适用于模糊输入,但可以使用模糊输入完成“搜索”。
PostgreSQL 全文搜索
我的大部分项目都使用 Django Web 框架和 PostgreSQL。 PostgreSQL 从 2008 年开始支持全文搜索 (FTS),Django 从 1.10 (2016) 开始通过 django.contrib.postgres 支持 FTS。因此,它是我集成的最快和最简单的选择。以下是我的一些发现:
这是一种更便宜、更快捷的选择,因为它不需要任何额外的设置和维护。
在我的本地(Razer Blade 2.4 GHz 6 Core i7)测试中,使用 GIN Index 的多达 500,000 条记录始终在大约 30 毫秒左右得到结果。在网上查看其他人所做的基准测试时,我发现它会在大约 30-50 毫秒内返回 150 万条记录的结果。
使用 Trigram 最多可以将其减慢 5 倍。
当前的 Django 集成不直接支持 Stemming 或 Fuzziness
ElasticSearch
ElasticSearch 是一个非常成熟的名称,有很多库可用于与 Django 和其他框架集成。 以下是调查结果:
该技术仅针对搜索进行了优化,但设置和维护基础架构可能非常耗时。
自己设置需要专用的服务器或服务,这比 PostgreSQL 选项昂贵。
随着数据的增长进行扩展更易于管理,它支持所有搜索选项,例如 Trigram、EdgeGram、Stemming、Fuzziness
在我的本地(Razer Blade 2.4 GHz 6 Core i7)测试多达 500,000 条记录时,它始终在大约 25 毫秒内返回结果。 在网上查看其他人所做的基准测试时,我发现它会在大约 5-30 毫秒内返回 150 万条记录的结果。
比较图
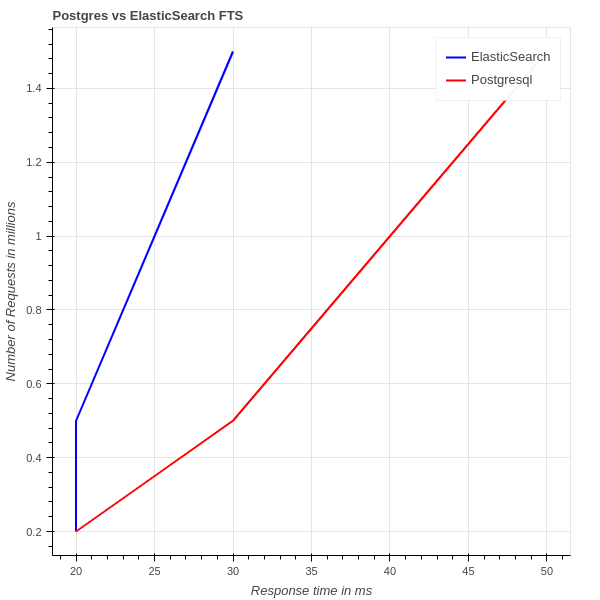
Postgresql vs ElasticSearch performance graph
结论
随着 PostgreSQL 的每个新版本,搜索响应时间都在改进,并且与 ElasticSearch 相比,它正在朝着苹果与苹果的比较前进。因此,如果项目不打算拥有数百万条记录或大规模数据,Postgresql 全文搜索将是最佳选择。
术语
- 词干提取:这是将单词简化为其根形式的过程,以确保该单词的变体在搜索过程中与结果匹配。例如,Referencing、Reference、References 可以归结为一个词 Refer 并且在搜索词时,refer 将返回具有该词的任何变体的结果。
- NGram:它就像一个在单词上移动的滑动窗口——一个连续的字符序列,直到指定长度。例如,术语 Refer 将变成 [R, RE, REF, E, EF, EFE, F, FE, FER]。 NGram 可用于部分搜索单词,甚至从中间搜索单词。最常用的 NGram 类型是 Trigram 和 EdgeGram。
- 模糊性:模糊匹配允许您获得不完全匹配的结果。例如,搜索单词框也会返回包含 fox 的结果。常见应用包括拼写检查和垃圾邮件过滤。
原文:https://fueled.com/the-cache/posts/backend/fulltext-search-postgresql-v…
- 148 次浏览
【全文搜索】全文搜索之战:PostgreSQL vs Elasticsearch
2020-09-08 更新:使用一个 GIN 索引而不是两个,websearch_to_tsquery,添加 LIMIT,并将 TSVECTOR 存储为单独的列。 更多细节在文章末尾。
我最近开始研究全文搜索选项。 用例是实时搜索键值对,其中键是字符串,值是字符串、数字或日期。 它应该启用对键和值的全文搜索以及对数字和日期的范围查询,并将 150 万个唯一键值对作为预期的最大搜索索引大小。 搜索公司 Algolia 建议端到端延迟预算不超过 50 毫秒,因此我们将使用它作为我们的阈值。
PostgreSQL
我已经熟悉 PostgreSQL,所以让我们看看它是否满足这些要求。 首先,创建一个表,
CREATE TABLE IF NOT EXISTS search_idx
(
id BIGINT PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY,
key_str TEXT NOT NULL,
val_str TEXT NOT NULL,
val_int INT,
val_date TIMESTAMPTZ
);接下来,用半真实的数据播种它。 以下可以将〜20,000行/秒插入到没有索引的表中,
const pgp = require("pg-promise")();
const faker = require("faker");
const Iterations = 150;
const seedDb = async () => {
const db = pgp({
database: process.env.DATABASE_NAME,
user: process.env.DATABASE_USER,
password: process.env.DATABASE_PASSWORD,
max: 30,
});
const columns = new pgp.helpers.ColumnSet(
["key_str", "val_str", "val_int", "val_date"],
{ table: "search_idx" }
);
const getNextData = (_, pageIdx) =>
Promise.resolve(
pageIdx > Iterations - 1
? null
: Array.from(Array(10000)).map(() => ({
key_str: `${faker.lorem.word()} ${faker.lorem.word()}`,
val_str: faker.lorem.words(),
val_int: Math.floor(faker.random.float()),
val_date: faker.date.past(),
}))
);
console.debug(
await db.tx("seed-db", (t) =>
t.sequence((idx) =>
getNextData(t, idx).then((data) => {
if (data) return t.none(pgp.helpers.insert(data, columns));
})
)
)
);
};
seedDb();现在已经加载了 150 万行,添加全文搜索 GIN 索引(详细信息),
CREATE INDEX search_idx_key_str_idx ON search_idx
USING GIN (to_tsvector('english'::regconfig, key_str));
CREATE INDEX search_idx_val_str_idx ON search_idx
USING GIN (to_tsvector('english'::regconfig, val_str));注意:如果在创建索引后向表中添加更多数据,VACUUM ANALYZE search_idx; 更新表统计信息并改进查询计划。
是时候测试以下查询的性能了,
-- Prefix query across FTS columns
SELECT *
FROM search_idx
WHERE to_tsvector('english'::regconfig, key_str)
@@ to_tsquery('english'::regconfig, 'qui:*')
OR to_tsvector('english'::regconfig, val_str)
@@ to_tsquery('english'::regconfig, 'qui:*');
-- Wildcard query on key (not supported by GIN index)
SELECT *
FROM search_idx
WHERE key_str ILIKE '%quis%';
-- Specific key and value(s) query
SELECT *
FROM search_idx
WHERE to_tsvector('english'::regconfig, key_str)
@@ to_tsquery('english'::regconfig, 'quis')
AND (to_tsvector('english'::regconfig, val_str)
@@ to_tsquery('english'::regconfig, 'nulla')
OR (to_tsvector('english'::regconfig, val_str)
@@ to_tsquery('english'::regconfig, 'velit')));
-- Contrived range query, one field wouldn't have both val_int and val_date populated
SELECT *
FROM search_idx
WHERE to_tsvector('english'::regconfig, key_str)
@@ to_tsquery('english'::regconfig, 'quis')
AND val_int > 1000
AND val_date > '2020-01-01';在任何查询前添加 EXPLAIN 以确保它使用索引而不是进行全表扫描。 在前面添加 EXPLAIN ANALYZE 将提供时间信息,但是,如文档中所述,这会增加开销,并且有时会比正常执行查询花费更长的时间。
在我的 MacBook Pro(2.4 GHz 8 核 i9,32 GB RAM)上,我总是在第一个可能是最常见的查询上得到大约 100 毫秒。 这远远超过了 50 毫秒的阈值。
Elasticsearch
接下来,让我们试试 Elasticsearch。 启动它并确保状态为绿色,如下所示,
docker run -d -p 9200:9200 -p 9300:9300
-e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.9.0
curl -sX GET "localhost:9200/_cat/health?v&pretty" -H "Accept: application/json"接下来,为索引播种。 第一个脚本创建一个文件,每行一个半真实的文档,
const faker = require("faker");
const { writeFileSync } = require("fs");
const Iterations = 1_500_000;
writeFileSync(
"./dataset.ndjson",
Array.from(Array(Iterations))
.map(() =>
JSON.stringify({
key: `${faker.lorem.word()} ${faker.lorem.word()}`,
val: faker.lorem.words(),
valInt: Math.floor(faker.random.float()),
valDate: faker.date.past(),
})
)
.join("\n")
);第二个脚本将 ~150 MB 文件中的每个文档添加到索引中,
const { createReadStream } = require("fs");
const split = require("split2");
const { Client } = require("@elastic/elasticsearch");
const Index = "search-idx";
const seedIndex = async () => {
const client = new Client({ node: "http://localhost:9200" });
console.debug(
await client.helpers.bulk({
datasource: createReadStream("./dataset.ndjson").pipe(split()),
onDocument(doc) {
return { index: { _index: Index } };
},
onDrop(doc) {
b.abort();
},
})
);
};
seedIndex();注意:此脚本可用于测试目的,但在生产中,请遵循有关调整批量请求大小和使用多线程的最佳实践。
现在,运行一些查询,
curl -sX GET "localhost:9200/search-idx/_search?pretty" \
-H 'Content-Type: application/json' \
-d'
{
"query": {
"simple_query_string" : {
"query": "\"repellat sunt\" -quis",
"fields": ["key", "val"],
"default_operator": "and"
}
}
}
'我在低端聚集的 136 个匹配结果上得到 5-24 毫秒,运行查询的次数越多。 这比 PostgreSQL 快约 5 倍。 因此,为了获得我所追求的性能,维护 Elasticsearch 集群的额外开销似乎是值得的。
2020-09-08 更新
在@samokhvalov 的帮助下,我创建了一个 GIN 索引而不是使用两个,
CREATE INDEX search_idx_key_str_idx ON search_idx
USING GIN ((setweight(to_tsvector('english'::regconfig, key_str), 'A') ||
setweight(to_tsvector('english'::regconfig, val_str), 'B')));但是,我在生产中使用 PostgreSQL 10,因为我使用的是最新版本的 Elasticsearch,所以拉取最新版本的 PostgreSQL 是公平的(在撰写本文时,postgres:12.4-alpine)。 然后我更新了查询以使用新索引 websearch_to_tsquery,并添加了 Elasticsearch 使用的相同默认 LIMIT,
SELECT *
FROM search_idx
WHERE (setweight(to_tsvector('english'::regconfig, key_str), 'A') ||
setweight(to_tsvector('english'::regconfig, val_str), 'B')) @@
websearch_to_tsquery('english'::regconfig, '"repellat sunt" -quis')
LIMIT 10000;这更像是一个苹果与苹果的比较,并在我的 MacBook Pro 上大幅减少了 172 个匹配结果的查询时间,从 ~100 毫秒到 ~13-16 毫秒!
作为最后的测试,我创建了一个独立的列来保存 TSVECTOR,如文档中所述。 它通过触发器保持最新,
CREATE TABLE IF NOT EXISTS search_idx
(
id BIGINT PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY,
key_str TEXT NOT NULL,
val_str TEXT NOT NULL,
val_int INT,
val_date TIMESTAMPTZ,
fts TSVECTOR
);
CREATE FUNCTION fts_trigger() RETURNS trigger AS
$$
BEGIN
new.fts :=
setweight(to_tsvector('pg_catalog.english', new.key_str), 'A') ||
setweight(to_tsvector('pg_catalog.english', new.val_str), 'B');
return new;
END
$$ LANGUAGE plpgsql;
CREATE TRIGGER tgr_search_idx_fts_update
BEFORE INSERT OR UPDATE
ON search_idx
FOR EACH ROW
EXECUTE FUNCTION fts_trigger();
CREATE INDEX search_idx_fts_idx ON search_idx USING GIN (fts);
SELECT *
FROM search_idx
WHERE fts @@ websearch_to_tsquery('english'::regconfig, '"repellat sunt" -quis')
LIMIT 10000;在 psql 中测量时,这会将查询缩短到 6-10 毫秒,实际上与针对此特定查询的 Elasticsearch 相同。
如果有人知道进一步的优化,我会更新我的粗略数字和代码片段以包含它们。
原文:https://www.rocky.dev/full-text-search
本文:https://jiagoushi.pro/node/2018
- 415 次浏览
【全文搜索】如何为您的应用程序启用强大的全文搜索 - MySQL 与 Elasticsearch
MySQL 和 Elasticsearch 之间全文搜索和比较的分步指南
您是否曾经在超市或百货公司四处走动,但找不到您要找的物品?在网上购物时,您可能会遇到同样的情况。尽管大多数网站按类别排列产品,但如果您不知道目标产品的类别,浏览类别仍然是一件苦差事。搜索栏为我们节省了大量时间,因为我们可以简单地输入关键字或文本短语,然后它会向我们显示所有相关项目。毫无疑问,全文搜索是所有电子商务网站的基本功能。
全文搜索是 MySQL 和 Elasticsearch 等许多数据库支持的流行功能。但是,在全文搜索能力方面,MySQL 和 Elasticsearch 有什么区别呢?如果您正在寻找实现全文搜索的解决方案,则无法在不了解差异的情况下做出正确的决定。在本文中,我将向您展示 MySQL 和 Elasticsearch 上全文搜索的用法,并强调它们的区别。
什么是全文搜索?
如果搜索引擎通过完全匹配来查找数据记录,您几乎不会得到任何搜索结果。例如,下面的 SQL 语句不太可能返回任何记录,因为可能不存在名称或描述与名称或描述中的文本短语“鱼和番茄罐头”完全相同的此类产品。
SELECT * FROM products WHERE name = ‘canned food with fish and tomato’ OR description = ‘canned food with fish and tomato’
如果我们使用通配符“LIKE %”可能会有所帮助,但您只会收到在数据字段中包含确切文本短语的记录。
SELECT * FROM products WHERE name LIKE ‘%canned food with fish and tomato%’ OR description LIKE ‘%canned food with fish and tomato%’
全文搜索的想法是将文本短语分解为标记。上例中的文本短语分为以下标记:“罐头”、“食物”、“与”、“鱼”、“和”和“番茄”。然后,搜索引擎查找与任何一个标记匹配的所有记录。记录匹配的标记越多,它与文本短语的相关性就越高。因此,搜索引擎通过在搜索结果中分配分数来指示相关性。如果您的查询字符串中的标记包含诸如“食物”之类的常用词,并且许多产品可能匹配一个或多个标记,您可能会收到包含大量记录的搜索结果。但是,您始终可以按分数过滤结果,以获得最相关的记录。
全文搜索是 MySQL 和 Elasticsearch 等许多数据库支持的流行功能。启用此功能的设置实际上非常简单明了。例如,您可以在 MySQL 上打开选定数据字段的全文搜索功能,而无需对表架构进行任何更改。说到 Elasticsearch 就更直接了,因为它默认支持全文搜索,不需要额外的配置。
全文搜索概览 — MySQL 与 Elasticsearch
简而言之,MySQL 和 Elasticsearch 在全文搜索方面有着相似的想法。它是通过将文本内容分解为标记来创建索引。然后,查询会将查询文本分解为标记并与索引匹配。根据匹配结果,搜索引擎计算得分并分配给代表相关性的搜索结果。
主要区别在于固定解决方案和可配置解决方案之间的解决方案方法。 MySQL 以 3 种不同的模式提供全文搜索的固定功能——自然语言、布尔和扩展查询。它几乎没有调整和微调的空间。
相反,Elasticsearch 的设计是高度可配置的。标记分解和查询执行的过程是基于分析器、标记器和过滤器的集合来执行的。这些组件可以定制并组合在一起,以实现更高级的功能。
我将逐步介绍 MySQL 和 Elasticsearch 上的全文搜索用法。
样本数据集
全文搜索功能的演示基于一个样本数据集,该样本数据集是一组图书馆图书记录。架构相当简单,包含以下列:id、title 和 publicationPlace。

MySQL
运行下面的 SQL 语句创建图书馆图书表并导入示例数据。
CREATE TABLE `library-book` (
`id` int(11) NOT NULL,
`title` text COLLATE utf8_unicode_ci,
`publicationPlace` text COLLATE utf8_unicode_ci
);
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`)
VALUES ('1', 'How To Grow Your Own Fruit and Veg: A Week-by-week Guide to
Wild-life Friendly Fruit and Vegetable Gardening - Recipes Of Natural
Balance Gardening', 'London');
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`)
VALUES ('2', 'The Life of God in the Soul of the Church: The Root and
Fruit of Spiritual Fellowship', 'Edinburgh');
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`)
VALUES ('3', 'Fruit and vegetable production in Africa - The important
fruits are bananas, pineapples, dates, figs, olives, and citrus;
the principal vegetables include tomatoes and onions', 'London');
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`)
VALUES ('4', 'Silver fruit upon silver trees', 'London');
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`)
VALUES ('5', 'A life to live', 'New York');
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`)
VALUES ('6', 'The emergency medical services in Edinburgh', 'New York');
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`)
VALUES ('7', 'SIMPLE GREEN SUPPERS: A FRESH STRATEGY FOR ONE-DISH
VEGETARIAN MEALS BY SUSIE MIDDLETON - Delicious Dishes And Unusual
Herb Recipes', 'Auckland');
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`)
VALUES ('8', 'Good Food For Bad Days - Tasty vegan meals really
don''t have to take all the time in the world or grand ingredients', 'Edinburgh');
MySQL 需要为全文搜索设置索引,假设读者有兴趣根据这两个数据字段查找书籍,则运行以下语句为“title”和“publicationPlace”创建全文索引。
ALTER TABLE `library`.`books` ADD FULLTEXT `book_free_text_index` (`title`, `publicationPlace`);
Elasticsearch
Elasticsearch 的所有 CRUD 操作都是通过 REST API 调用来完成的。 要将同一组示例书籍记录加载到 Elasticsearch 中,请运行下面的 curl 命令,该命令会提交 POST 请求以进行批量数据插入。 如果您想知道如何在本地机器上运行 Elasticsearch 和 Kibana 进行测试,请按照本文在 docker 上部署 Elasticsearch 节点。
与 MySQL 不同,Elasticsearch 是一个 NoSQL 数据库,无需事先创建表模式即可完成数据插入。 Elasticsearch中的“索引”是指关系数据库中的数据库,如果该索引尚不存在,它会自动创建一个名为“library-book”的索引,如请求中指定的那样。 此外,无需创建全文搜索索引,因为 Elasticsearch 在数据插入或更新过程中将文本内容分解为令牌并存储在索引中。
curl --request POST \
--url 'http://localhost:9200/_bulk?pretty=' \
--header 'Content-Type: application/json' \
--data '{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "1" } }
{ "title" : "How To Grow Your Own Fruit and Veg: A Week-by-week Guide to
Wild-life Friendly Fruit and Vegetable Gardening - Recipes Of Natural
Balance Gardening", "publicationPlace": "London"}
{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "2" } }
{ "title" : "The Life of God in the Soul of the Church: The Root and
Fruit of Spiritual Fellowship", "publicationPlace": "Edinburgh" }
{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "3" } }
{ "title" : "Fruit and vegetable production in Africa - The important fruits
are bananas, pineapples, dates, figs, olives, and citrus; the principal
vegetables include tomatoes and onions", "publicationPlace": "London"}
{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "4" } }
{ "title" : "Silver fruit upon silver trees", "publicationPlace": "London" }
{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "5" } }
{ "title" : "A life to live", "publicationPlace": "New York" }
{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "6" } }
{ "title" : "The emergency medical services in Edinburgh",
"publicationPlace": "New York" }
{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "7" } }
{ "title" : "SIMPLE GREEN SUPPERS: A FRESH STRATEGY FOR ONE-DISH
VEGETARIAN MEALS BY SUSIE MIDDLETON - Delicious Dishes And Unusual
Herb Recipes", "publicationPlace": "Auckland" }
{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "8" } }
{ "title" : "Good Food For Bad Days - Tasty vegan meals really
don'\''t have to take all the time in the world or grand ingredients",
"publicationPlace": "Edinburgh" }简单的关键字搜索
让我们从一个简单的搜索开始,假设我们搜索一个关键字“爱丁堡”。
MySQL
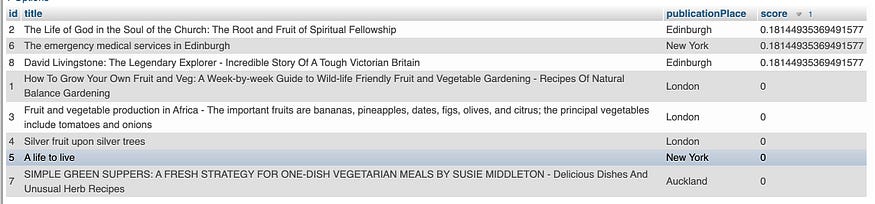
要查找与该关键字匹配的所有记录,请在 MySQL 中使用 match() 以布尔模式进行全文查询。 运行此 SQL 语句以搜索“爱丁堡”。
SELECT id, title, publicationPlace,
MATCH (title, publicationPlace) AGAINST ('edinburgh' IN BOOLEAN MODE) AS score
FROM `library-book`
ORDER BY score DESC
搜索结果为每条记录分配一个分数,以显示相关性。 分数越高,记录与关键字的相关性越高。 有 3 条记录的得分 > 0,因为标题和 publicationPlace 与关键字“爱丁堡”匹配,而其他记录与关键字不匹配,因此分配零分。
Elasticsearch
Elasticsearch 支持多种查询方法,例如关键字、文本短语、前缀等。我们在此示例中使用查询类型“multi_match”来搜索多个数据字段——“title”和“publicationPlace”。 提交此 POST 请求以搜索关键字“edinburgh”。
curl --request POST \
--url http://localhost:9200/library-book/_search \
--header 'Content-Type: application/json' \
--data '{
"query": {
"multi_match": {
"query": "edinburgh",
"fields": [
"title",
"publicationPlace"
]
}
}
}'

根据指定数据字段微调分数
对于某些用例,某些数据字段更重要,这些字段上的关键字匹配应给予更高的分数。 虽然 MySQL 不提供这种灵活性,但可以在 Elasticsearch 中通过将插入符号“^”附加到数据字段来实现它。 此处的示例将“title”字段的重要性设置为 3 倍。
curl --request POST \
--url http://localhost:9200/library-book/_search \
--header 'Content-Type: application/json' \
--data '{
"query": {
"multi_match": {
"query": "edinburgh",
"fields": [
"title^3",
"publicationPlace"
]
}
}
}'由于“title”更重要,“title”字段与关键字匹配的记录得分更高。

使用逻辑条件搜索
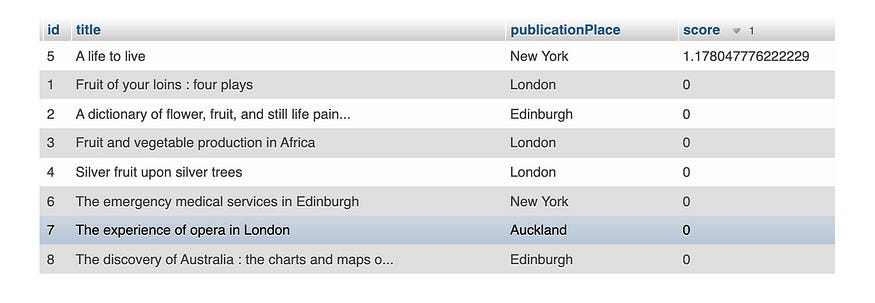
您可能想要指定某些搜索条件,例如 AND / OR / NOT。 比如说,我们想搜索同时匹配关键字“生活”和“生活”的书籍。 为此,我们在每个关键字前面添加一个符号“+”,以表明它是一个“AND”条件。
MySQL
MySQL 提供的 BOOLEAN 模式支持带逻辑条件的查询。 让我们搜索关键字“生活”和“生活”的书籍。
SELECT id, title, publicationPlace,
MATCH (title, publicationPlace) AGAINST ('+life +live' IN BOOLEAN MODE) AS score
FROM `library-book`
ORDER BY score DESC;现在只有“A life to live”这本书与 score > 0 相关,而所有其余书籍的 score = 0。
布尔模式不仅支持 AND 运算符(+),还支持其他符号,如 NOT(~)、高相关性(>)、低相关性(<)等,具体请参考 MySQL 官方参考。
弹性搜索
同一组符号可以应用于 Elasticsearch。 我们可以在带有逻辑条件的文本短语的 POST 请求中使用查询类型“simple_query_string”。
curl --request POST \
--url http://localhost:9200/library-book/_search \
--header 'Content-Type: application/json' \
--data '{
"query": {
"simple_query_string": {
"query": "+life +live",
"fields": [
"title",
"publicationPlace"
]
}
}
}'结果只显示一条记录,与 MySQL 的结果相同。

文本短语搜索
“Recipes Of A Delicious And Tasty Meal”的文本短语的搜索结果是什么? 由于文本短语被分解为小写“recipes”、“of”、“a”、“delicious”、“and”、“tasty”和“meal”的标记。 记录匹配更多标记,这意味着它与文本短语更相关。
人们自然会用人类语言输入文本短语以进行查询。 考虑到人类语言,需要进行特殊处理才能产生准确的结果。 例如,匹配那些在英语中出现频率很高的单词,如“a”、“an”、“of”、“the”等,就不太可能产生有意义的结果。 这些词被称为“停用词”,搜索引擎应该在文本短语查询中忽略它们。
MySQL
MySQL 支持忽略“停用词”并运行不区分大小写的搜索的自然语言模式。 运行此查询语句以搜索文本短语。
SELECT id, title, publicationPlace,
MATCH (title, publicationPlace) AGAINST
('Recipes Of A Delicious And Tasty Meal' IN NATURAL LANGUAGE MODE) AS score
FROM `library-book`
ORDER BY score DESC;得分最高的前 3 条记录与搜索文本短语中的大多数标记匹配。

Elasticsearch
Elasticsearch 的默认索引设置不具备 MySQL 提供的自然语言模式等功能。
当您将此 POST 请求发送到 Elasticsearch 以搜索相同的文本短语时,您将看到不同的结果。
curl --request POST \
--url http://localhost:9200/library-book/_search \
--header 'Content-Type: application/json' \
--data '{
"query": {
"multi_match": {
"query": "Recipes Of A Delicious And Tasty Meal",
"fields": [
"title",
"publicationPlace"
]
}
}
}'默认设置将停用词考虑在内以进行匹配和分数计算。 结果,与“of”和“and”等大多数停用词匹配的得分最高的搜索结果显然是不相关的。

不用担心,Elasticsearch 实际上是一个非常强大的搜索引擎,可以通过在索引设置中为停用词配置标记过滤器来支持自然语言搜索。
Elasticsearch 提供了 15 个 tokenzier 和 50 多个适用于各种用例的 token 过滤器。 要实现类似于 MySQL 的全文搜索,只需在分析器中添加停用词标记过滤器即可。 下图显示分析仪由以下组件组成:
- 标准分析器——将文本短语分解为标记
- 小写标记过滤器 - 将标记转换为小写以进行不区分大小写的搜索
- 停用词标记过滤器 - 删除常用词的标记,例如“of”、“a”、“and”等。
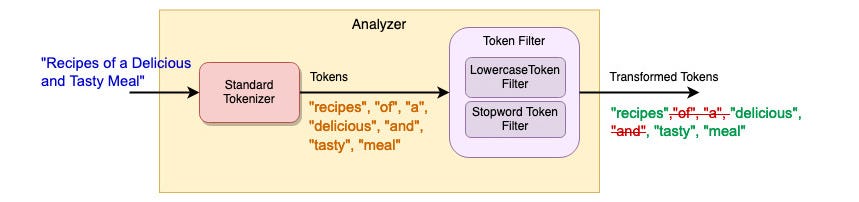
Analyzer 在索引设置中配置,并映射到数据字段“title”和“publicationPlace”。
提交此 PUT 请求以使用新的分析器配置和字段映射创建一个名为“library-book-text-phrase”的新索引(即 Elasticsearch 中的数据库)。
curl --request PUT \
--url http://localhost:9200/library-book-text-phrase \
--header 'Content-Type: application/json' \
--data '
{
"settings": {
"analysis": {
"analyzer": {
"english_analyzer": {
"tokenizer": "standard",
"filter": ["lowercase", "english_stop_filter"]
}
},
"filter": {
"english_stop_filter": {
"type": "stop",
"stopwords": "_english_"
}
}
}
},
"mappings": {
"_doc": {
"properties": {
"title": {
"type": "text",
"analyzer": "english_analyzer"
},
"description": {
"type": "text",
"analyzer": "english_analyzer"
},
"publicationPlace": {
"type": "text",
"analyzer": "keyword"
}
}
}
}
}'然后,提交这个 POST 请求,将数据从原始索引“library-book”复制到新创建的索引“library-book-text-phrase”。
curl --request POST \
--url 'http://localhost:9200/_reindex \
--header 'Content-Type: application/json' \
--data '{
"source": {
"index": "library-book"
},
"dest": {
"index": "library-book-text-phrase"
}
}'让我们对新索引“library-book-text-phrase”运行相同的查询。 结果现在更有意义了。
curl --request POST \
--url http://localhost:9200/library-book-text-phrase/_search \
--header 'Content-Type: application/json' \
--data '{
"query": {
"multi_match": {
"query": "Recipes Of A Delicious And Tasty Meal",
"fields": [
"title",
"publicationPlace"
]
}
}
MySQL — 扩展搜索条件
强大的搜索引擎不仅可以通过token匹配进行搜索,还可以理解关键字并扩展搜索其他具有相似含义的关键字。 例如,当您搜索关键字“woods”时,预计搜索引擎应该寻找与“timber”、“lumber”和“trees”等其他类似关键字匹配的记录。
MySQL 能够使用“QUERY EXPANSION”模式猜测您要查找的内容。
SELECT id, title, publicationPlace,
MATCH (title, publicationPlace) AGAINST ('green' WITH QUERY EXPANSION) AS score
FROM `library-book`
ORDER BY score DESC当我们搜索关键字“绿色”时。 将返回 3 条记录。 第 2 条和第 3 条记录的标题字段实际上并不包含关键字“green”,但搜索引擎以某种方式猜测这些记录的内容与关键字“green”相关

但是,当我们在搜索条件中添加更多关键字时,搜索结果会包含更多“噪音”。 几乎所有的图书记录都在查询扩展模式下搜索到了文本短语“美好生活”。
如果您对准确性不满意,则无法微调搜索结果。

Elasticsearch - 使用同义词标记过滤器的广泛搜索
Elasticsearch 提供了多种方式来实现类似于 MySQL 支持的扩展模式的扩展搜索。 令牌过滤器的使用不是提供固定的解决方案,而是可以实现高级全文搜索的能力。
我们来看看对同义词搜索的支持。 我们配置令牌过滤器,以便将搜索扩展到同义词。 我们使用了一个名为 WordNet 的免费词汇数据库。 一般来说,它存储超过 2 万个单词和同义词的映射。
配置是为同义词添加新的标记过滤器,过滤器从 WordNet 文件中读取同义词映射。

要启用新的索引设置,请下载 WordNet 文件并复制到 [elasticsearch 文件夹]/config/analysis,然后提交此 PUT 请求以创建一个名为“library-book-synonym-wordnet”的新索引
curl --request PUT \
--url http://localhost:9200/library-book-synonym-wordnet \
--header 'Content-Type: application/json' \
--data '
{
"settings": {
"analysis": {
"analyzer": {
"english_analyzer": {
"tokenizer": "standard",
"filter": ["lowercase", "english_stop_filter", "synonym_filter"]
}
},
"filter": {
"english_stop_filter": {
"type": "stop",
"stopwords": "_english_"
},
"synonym_filter": {
"type": "synonym",
"format": "wordnet",
"lenient": true,
"synonyms_path": "analysis/wn_s.pl"
},
}
}
},
"mappings": {
"_doc": {
"properties": {
"title": {
"type": "text",
"analyzer": "english_analyzer"
},
"description": {
"type": "text",
"analyzer": "english_analyzer"
},
"publicationPlace": {
"type": "text",
"analyzer": "keyword"
}
}
}
}
}'然后,提交这个 POST 请求,将数据从原始索引“library-book”复制到新创建的索引“library-book-synonym-wordnet”。
curl --request POST \
--url 'http://localhost:9200/_reindex' \
--header 'Content-Type: application/json' \
--data '{
"source": {
"index": "library-book"
},
"dest": {
"index": "library-book-synonym-wordnet"
}
}'现在,在新索引上搜索关键字“green”。 然后,您将获得与“green”同义词匹配的记录列表。
curl --request POST \
--url http://localhost:9200/library-book-synonym-wordnet/_search \
--header 'Content-Type: application/json' \
--data '{
"query": {
"multi_match": {
"query": "green",
"fields": [
"title",
"publicationPlace"
]
}
}
}'结果:

具有自定义词映射的 Elasticsearch 令牌同义词过滤器
如果 WordNet 不能满足您的需求,Elasticsearch 支持自定义同义词映射。 我们配置了一个同义词标记过滤器,以便将关键字“fruit”映射到关键字列表——“banana”、“pineapple”、“date”、“fig”、“olive”和“citrus”。 因此,搜索关键字“banana”将匹配任何带有“fruit”的记录。
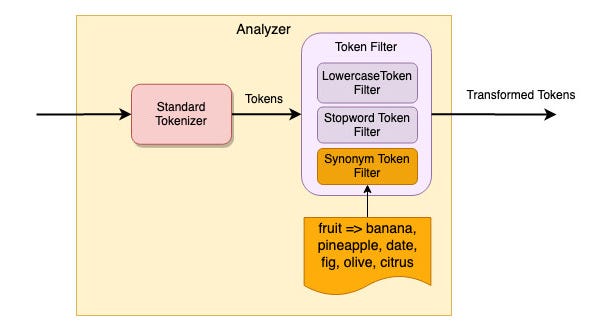
提交此 PUT 请求以使用令牌过滤器“synonym_filter”创建新索引和自定义分析器。
curl --request PUT \
--url http://localhost:9200/library-book-custom-synonym \
--header 'Content-Type: application/json' \
--data '
{
"settings": {
"analysis": {
"analyzer": {
"english_analyzer": {
"tokenizer": "standard",
"filter": ["lowercase", "english_stop_filter", "synonym_filter"]
}
},
"filter": {
"english_stop_filter": {
"type": "stop",
"stopwords": "_english_"
},
"synonym_filter": {
"type": "synonym",
"lenient": true,
"synonyms": [
"fruit => banana, pineapple, date, fig, olive, citrus"
]
},
}
}
},
"mappings": {
"_doc": {
"properties": {
"title": {
"type": "text",
"analyzer": "english_analyzer"
},
"description": {
"type": "text",
"analyzer": "english_analyzer"
},
"publicationPlace": {
"type": "text",
"analyzer": "keyword"
}
}
}
}
}'将数据复制到新创建的索引后,提交此 POST 请求以搜索关键字“banana”。 然后,您将看到结果包含与“fruit”关键字匹配的所有记录。
curl --request POST \
--url http://localhost:9200/library-book-custom-synonym/_search \
--header 'Content-Type: application/json' \
--data '{
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "banana"
}
}
]
}
}
}'结果:

最后的想法
MySQL 和 Elasticsearch 都提供了强大的全文搜索能力。 如果您的系统使用 MySQL 作为数据存储,则可以通过为目标数据字段创建全文索引来快速启用全文搜索功能。 该解决方案适用于大多数用例,因为它为用户提供了一种在多个数据字段上搜索关键字和文本短语的快捷方式。 但是,在搜索结果微调和自定义方面,MySQL 中可用的选项有限。 因此,Elasticsearch 可能是高级功能和定制搜索行为的更好选择,因为该解决方案具有高度可配置性且更加灵活。
原文:https://blog.devgenius.io/how-to-enable-powerful-full-text-search-for-y…
- 126 次浏览
【内容处理】Aspire内容处理4.0
Aspire是一种专门为非结构化数据(如Office文档、pdf、web页面、图像、声音和视频)设计的内容摄取和处理技术。它提供了超过40个连接到各种企业内容源的连接器,包括文件共享、SharePoint、Documentum、OneDrive和Box。SalesForce.com, ServiceNow, Confluence, Yammer等。
Aspire提供了一种强大的解决方案,用于连接、清理、充实和向企业搜索、非结构化内容分析和自然语言处理应用程序发布内容。
作为我们支持搜索和非结构化内容分析的技术资产集合的一部分,Aspire可以独立使用,也可以作为应用智能平台AIP+的一部分使用。
今年秋天,我们的团队激动地宣布了Aspire最新的增强版本——Aspire 4.0——带有显著的创新进展。
Aspire 4.0的新增强
1. 现在可以使用Elasticsearch来保存Aspire爬行数据库。
Aspire将此数据库用于内部处理和作业队列。
已经使用Elasticsearch作为搜索引擎的客户端可以使用同一个服务器集群来保存Aspire的抓取数据库。这可以极大地减少使用Aspire和Elasticsearch的客户对基础设施、硬件和技术的需求。
在Aspire 4.0中,MongoDB和HBase仍然是可供选择的数据库提供者。
2. 新的端点用于接收已配置内容源的实时文档更新。
除了实时更新之外,这些新的端点还可以用于重新处理可能在下游系统中失败的文档更新,或者根据审计检查发现的文档更新。
3.后台处理和二进制存储层
——我们的智能文档x射线计划的一部分——允许在资源可用时对运行缓慢的后台任务进行排队和处理。
对于长时间运行的进程,如机器学习和光学字符识别(OCR),这是一个理想的框架。
目前,只允许文件存储作为存储层。其他存储层,例如Amazon S3、Azure Blobs、谷歌云平台存储,将在不久的将来提供。
4. 提供了许多bug修复以及稳定性和性能改进。

其他主要特点
Aspire 4.0还包括:
- 重构故障转移实现以获得更高的稳定性、准确性和可用性
- 内置在连接器框架中的节流功能支持内容爬行节流,以保护遗留系统不过载。以前,这是通过减少线程数来实现的。新的框架强制执行更精确的每秒文档控制。
- 增强的安全措施,允许编写业务规则脚本来处理特殊的安全需求,例如,根据用户的电子邮件地址自动添加组
- 有助于简化安装和许可证管理的改进
- 在我们不断增长的40多个连接器中增加了新的和改进的连接器,这些连接器支持从企业存储库获取非结构化内容
- 充分改进了Confluence连接器,具有完整的层次安全支持
- 谷歌云搜索的改进出版商
- 一个新的“测试爬行”特性可以帮助快速、轻松地测试新的内容源
- 用户界面改进和样式调整
本文:http://jiagoushi.pro/aspire-content-processing-40
讨论:请加入知识星球【首席架构师智库】或者小号【jiagoushi_pro】
- 172 次浏览
【技术选型】Elasticsearch vs. Solr-选择您的开源搜索引擎
我们为什么在这里?我存在的目的是什么?我应该运动还是休息并节省能量?早起上班或晚起并整夜工作?我应该将炸薯条和番茄酱或蛋黄酱一起吃吗?
这些都是古老的问题,可能有也可能没有答案。其中一些是非常困难或非常主观的。但是,让我付出一些努力来尝试回答其中之一:我应该使用Elasticsearch还是Solr?
这是场景。您的组织正在寻求实现您的第一个搜索引擎,并切换到另一个搜索引擎-呼吁所有Google Search Appliance(GSA)用户寻找替代品! -或尝试通过开源来省钱。作为一个熟练而有能力的开发人员,您已经被要求解决一个难题。您的问题有许多业务需求,但从根本上讲,这是一个“大数据和搜索”问题。
您需要从多个数据源中提取大量内容,并从这些数据中获取见解,以帮助您的公司发展并实现其今年的目标。
一击致命
这里有很多危险。您不会错过任何一个镜头。您需要合适的搜索引擎来工作,您正在考虑开放源代码,并且有两个受欢迎的选择:Elasticsearch或Solr,根据DB-的说法,这两个都稳居开放源和商业搜索引擎的前两位。引擎。

您会选择哪个开源搜索引擎?
这不是抛硬币也不是容易的选择。两种搜索引擎都很棒,没有一个“正确”的选择。这完全取决于您的要求。
因此,第一步是了解您必须构建什么应用程序。然后,下一步是查看每个搜索引擎必须提供的功能。顺便说一句,如果您仍处于开源与商业解决方案的交汇处,请获取我们的免费电子书,以深入了解选择搜索引擎时要考虑的10个关键标准。
功能概要
几年前,我们写了一个关于Elasticsearch vs. Solr的高级概述博客,其中讨论了总体趋势和非技术见解。现在,随着Elasticsearch的发展壮大并成为开放源代码搜索引擎市场的主导者,让我们重新审视一下每个领域,看看它将带给我们什么。
年龄和成熟度
在这种情况下,可以说Solr的历史悠久,它由CNET Networks的Yonik Seely于2004年创建,后来在2006年将其贡献给Apache。它最终在2007年毕业于顶级项目。我们拥有的是Elasticsearch,该软件于2010年正式创建,尽管它实际上是由其创始人Shay Bannon于2001年以Compass的名字开始的。从那时起,Kibana,Logstash和Beats的创建者加入了Elasticsearch,创建了Elastic Stack产品系列,该产品系列已成为搜索和日志分析领域的强大参与者。话虽如此,Solr的优势在于可以较早地在市场上看到。
社区和开源
两者都有非常活跃的社区。如果您查看Github,您会发现它们是非常受欢迎的开源项目,发布了很多版本。

一个非常重要的细节是,尽管两者都是在Apache许可下发布的,并且都是开源的,但是它们的工作方式却有所不同。 Solr确实是开源的-任何人都可以提供帮助和贡献。使用Elasticsearch,尽管人们仍然可以提供他们的捐款,但是只有Elastic的员工(Elasticsearch和Elastic Stack背后的公司)可以接受这些捐款。
这是好事还是坏事?这取决于你怎么看了。这意味着,如果有您需要的功能,并且您以足够的质量向社区做出了贡献,那么它可以被Solr接受。借助Elasticsearch,由Elastic来决定是否接受捐助。因此,Solr上可能有更多功能选项。另一方面,对Elasticsearch的贡献要经过更高级别的质量检查,可能会提供更高的一致性和质量。
文献资料
Elasticsearch和Solr都有文档齐全的参考指南。 Elasticsearch在Github之上运行,而Solr使用Atlassian Confluence。您可以通过下面的链接找到它们。
Elasticsearch参考指南
Solr参考指南
核心技术
让我们多一点技术。 Elasticsearch和Solr是两个不同的搜索引擎。但在下面,它们都使用Lucene,这意味着两者都建立在“巨人的肩膀”上。
对于那些想知道为什么我将Lucene视为“巨人”的人来说,它是许多搜索引擎支持下的实际信息检索软件库。它非常快速,稳定,并且可能无法比这更好。 Lucene是由Hadoop的创建者之一Doug Cutting于1999年创建的。因此,Lucene是在搜索引擎中使用的理想选择。
Java API和REST
Elasticsearch具有更多的“ Web 2.0” REST API,但是Solr的SolrJ确实有更好的Java API-如果使用Microsoft技术,则为SolrNet。 Elasticsearch拥有Nest和Elasticsearch.Net。 Solr的REST API可能没有那么灵活,但是它可以很好地满足您的需求:建立索引和查询。 Elasticsearch会说JSON,因此,如果您周围都使用JSON,那么这是一个不错的选择。 Solr也支持JSON,但是它是在以后的阶段添加的,因为它最初是针对XML的。
内容处理
内容处理由于它们都公开了API,因此很容易从您的自定义应用程序或已经存在且可配置的应用程序中索引内容。例如,我们的Aspire内容处理框架能够连接到多个数据源并发布到Elasticsearch或Solr。
Solr还具有使用Apache Tika从二进制文件提取文本的功能。因此,您可以通过ExtractRequestHandler上传PDF,Solr将知道如何处理它。
另一方面,Elasticsearch与Logstash配合良好,后者可以处理任何来源的数据并为其编制索引。
可扩展性
缩放是一个关键的考虑因素。在这种情况下,当Solr仍然受限于Master-Slave时,Elasticsearch赢得了比赛。但是,SolrCloud最近才进入游戏。在Zookeeper的帮助下,现在可以以更加轻松快捷的方式扩展Solr集群-与具有Master-Slave的旧版本Solr相比,这是一个增强。仍然需要进行大量改进,但是就可以在Solr中摄取和搜索的数据集的大小而言,前途一片光明。
供应商支持
有几家公司不得不决定哪种产品最适合他们。例如,Cloudera选择了Solr作为他们的搜索引擎,以集成到开源CDH(包括Hadoop的Cloudera Distribution)中。另一方面,还有其他供应商选择Elasticsearch作为其解决方案的搜索引擎。 Search Technologies的我们将为两个搜索引擎提供咨询,部署和支持。
愿景与生态
Solr更加侧重于文本搜索。 Elasticsearch迅速树立了自己的利基市场,通过创建Elastic Stack(以前称为ELK Stack)来进行日志分析,Elastic Stack代表Elasticsearch,Logstash,Kibana和Beats。双方都有清晰的愿景,并且正在朝着自己的方向大步前进。
值得重申的一件事是,如何将两个搜索引擎用作许多领先搜索和大数据平台的基础。例如,Elasticsearch是Microsoft Azure搜索的一部分,而Solr已集成到Cloudera Search中。
性能
在性能方面,根据我从许多开发人员那里获得的经验,我们可以说这两个引擎都表现出色。因此,对于大多数用例而言,无论是内部还是外部搜索应用程序,只要开发人员正确设计和配置它们,性能都不会成为问题。
网络管理
Solr捆绑了Web管理,而Elasticsearch还有其他多个高级插件可用于安全性,警报和监视。此列表展示了Elastic的整个产品系列。
可视化
有许多方法可以在Elasticsearch和Solr中可视化数据-您可以构建自定义可视化仪表板,也可以使用搜索引擎的标准可视化功能(可能需要进行一些调整)。但是有一个区别值得一提。
Solr主要专注于文本搜索。它在这方面做得很好,成为了搜索应用程序的标准。但是,Elasticsearch朝着另一个方向发展,它超越了搜索范围,可以通过Elastic Stack解决日志分析和可视化问题。以下是您可以使用Kibana 5进行的一些可视化处理。

这并不意味着一个人胜于另一个。 它仅表示每个搜索引擎在不同的用例和需求中都有自己的优势,而您的选择将在很大程度上取决于您的组织要完成的工作。
长话短说,Elasticsearch和Solr都是出色的开源选择,将帮助您从数据中获取更多收益。 这完全取决于您的要求,预算,时间安排以及项目的复杂性。
有用的资源
- 这本电子书详细介绍了选择搜索引擎的关键条件。 它可以帮助指导您完成决策过程。
- 如果您正在寻找评估搜索引擎和实施方案的专家帮助,请与我们联系以详细了解我们的评估。
原文:https://www.searchtechnologies.com/blog/solr-vs-elasticsearch-top-open-source-search
本文:http://jiagoushi.pro/node/908
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 72 次浏览
【技术选型】Solr与Elasticsearch:性能差异及更多。如何决定哪一个最适合你
“Solr还是Elasticsearch ?至少这是我们从Sematext的咨询服务客户和潜在客户那里听到的普遍问题。Solr和Elasticsearch哪个更好?哪个更快?哪一种比较好?哪一个更容易管理?我们应该使用哪一个?从Solr迁移到Elasticsearch有什么好处吗?-还有很多。
这些都是伟大的问题,虽然不总是有明确的,普遍适用的答案。那么我们建议你使用哪一种呢?你最终如何选择?那么,让我们分享一下我们如何看待Solr和Elasticsearch的过去、现在和未来,让我们做一些比较,希望通过总结Solr和Elasticsearch之间最重要的差异,帮助您根据特定需求做出正确的选择。

如果您是Elasticsearch和Solr的新手,那么阅读我们的Elasticsearch教程和Solr教程可能会使您受益匪浅。
Elasticsearch和Solr是两个领先的、相互竞争的开源搜索引擎,任何曾经研究过(开源)搜索的人都知道它们。它们都是围绕核心的底层搜索库Lucene构建的,但是它们在可伸缩性、部署便利性、社区存在性等功能方面有所不同。对于静态数据,Solr有更多的优势,因为它有缓存,并且能够使用一个非反向读取器进行面形和排序——例如,电子商务。另一方面,Elasticsearch更适合——而且使用频率更高——用于timeseries数据用例,比如日志分析用例。
在选择Solr和Elasticsearch时,它们都有各自的优缺点,因此没有对错之分。虽然看起来Elasticsearch更受欢迎,但根据您的需要和期望,它们的适用性可能更好或更差。
我们希望这两个领先的开源搜索引擎的对比能够提供足够的信息和指导,帮助您为您的组织做出正确的选择:
比较Solr和Elasticsearch:主要区别是什么?
两个搜索引擎都在迅速发展,因此,无需多说,以下是关于Elasticsearch和Solr之间差异的最新信息:
1. Solr与Elasticsearch Engine的性能和可伸缩性基准测试
在性能方面,Solr和Elasticsearch大致相同。我们说“粗略”是因为没有人做过好的、全面的、公正的基准。对于95%的用例来说,这两个选择在性能方面都很好,剩下的5%需要用它们特定的数据和特定的访问模式来测试这两个解决方案。
也就是说,如果您的数据大多是静态的,并且需要数据分析的完全精度和非常快的性能,那么应该考虑Solr。
你也可以观看视频从我们的两个工程师——拉和拉法ł给并排Elasticsearch & Solr第2部分——性能和可伸缩性(或者你可以查看演示幻灯片)在柏林流行语。这次演讲——包括现场演示、视频演示和幻灯片——深入探讨了Elasticsearch和Solr如何伸缩和执行,这些见解在2015年仍然有效。
Radu和Rafal向与会者展示了如何针对两个常见用例调整Elasticsearch和Solr:日志和产品搜索。然后他们展示了调谐后得到的数字。还分享了一些最佳实践,用于扩展大规模的Elasticsearch和Solr集群;例如,如何将数据划分为考虑增长的碎片和索引/集合,何时使用路由,以及如何确保协调的节点不会失去响应。
通过这个视频中提到的测试,我们看到了在静态数据上Solr是非常棒的。
更重要的是,与Elasticsearch相比,Solr中的facet是精确的,不会失去精度,这在Elasticsearch中并不总是正确的。在某些边缘情况下,您可能会发现Elasticsearch聚合中的结果并不精确,这是因为碎片中的数据是如何放置的。
2. 年龄、成熟度和搜索趋势
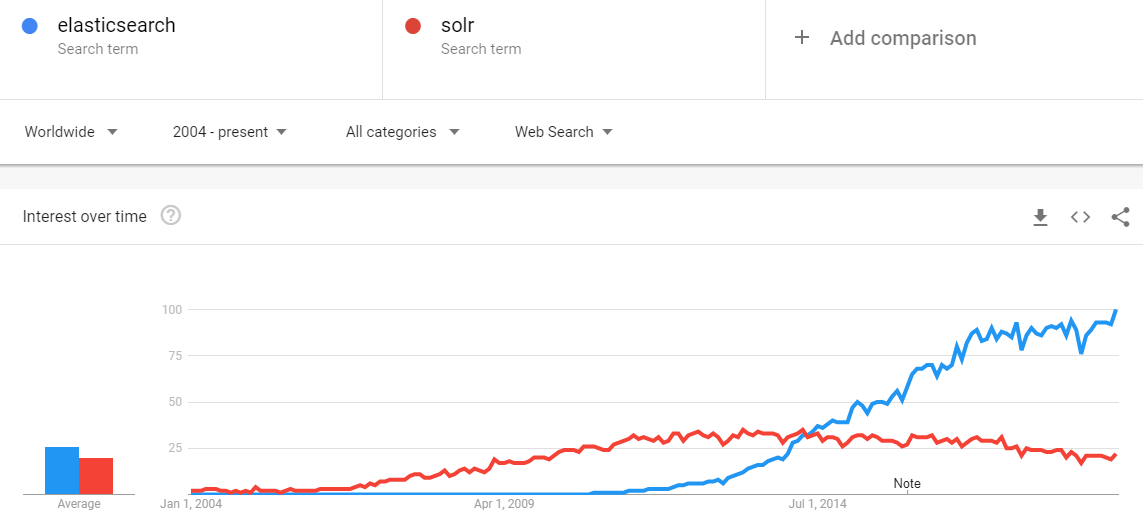
索拉还没死。根据db引擎,Elasticsearch和Solr都是开发人员社区中最流行的搜索引擎。以下是支持这一点的最新使用统计数据:
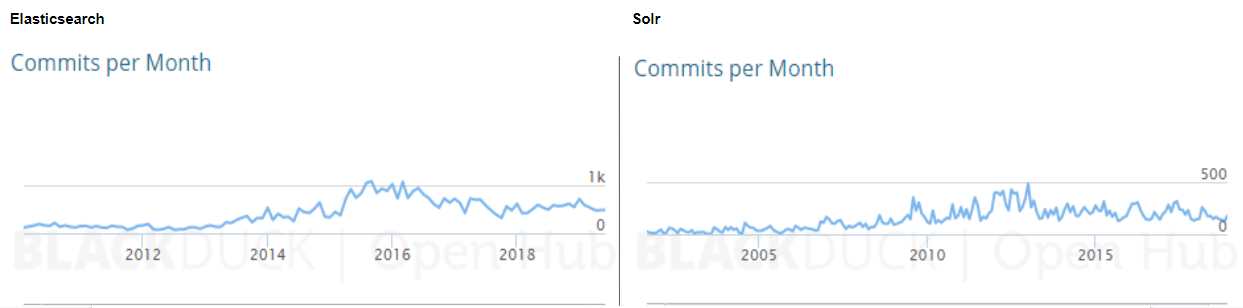
Apache Solr是一个成熟的项目,背后有一个活跃的大型开发和用户社区,以及Apache品牌。
Solr在2006年首次发布为开源版本,长期以来一直主导着搜索引擎领域,是任何需要搜索功能的人的首选引擎。它的成熟转化为丰富的功能,超越了普通的文本索引和搜索;如人脸识别、分组(即字段崩溃)、强大的过滤、可插入的文档处理、可插入的搜索链组件、语言检测等。
然后,在2010年左右,Elasticsearch作为另一种选择出现在市场上。那时,它还远没有Solr那么稳定,没有Solr那样的功能深度,没有认同度和品牌等等。但是它还有一些其他的优点:Elasticsearch还很年轻,建立在更现代的原则之上,针对更现代的用例,并使处理大索引和高查询率更容易。
此外,因为它是那么年轻,没有一个社区,它在跳跃前进的自由,不需要任何形式的共识或与他人合作(用户或开发人员),向后兼容,或者其他更成熟的软件通常必须处理。因此,它在Solr之前就公开了一些非常受欢迎的功能(例如,近实时搜索)。
从技术上讲,NRT搜索的能力实际上来自Lucene,它是Solr和Elasticsearch使用的底层搜索库。具有讽刺意味的是,由于Elasticsearch首先暴露了NRT搜索,人们将NRT搜索与Elasticsearch关联起来,尽管Solr和Lucene都是同一个Apache项目的一部分,因此,人们希望Solr首先具有如此高要求的功能。
Elasticsearch,更现代,呼吁几个团体的人和组织:
- 那些还没有自己的搜索引擎,也没有投入大量时间、金钱和精力去采用、整合搜索引擎的人。
- 那些需要处理大量数据、需要更容易地分片和复制数据(搜索索引)以及缩小或扩大搜索集群的公司
当然,让我们承认,也总会有一些人喜欢跳到新的闪亮的东西上。
快进到2020年。弹性搜索不再是新的,但它仍然闪亮。它弥补了与Solr的功能差距,在某些情况下甚至超过了它。它当然有更多的传闻。在这一点上,两个项目都非常成熟。两者都有很多特点。两者都是稳定的。我们不得不说,我们确实看到了更多的Elasticsearch集群问题,但我们认为这主要是因为以下几个原因:
- Elasticsearch在传统上更容易上手,这使得任何人都可以开箱即用,而不需要对其工作原理有太多了解。开始时这样做很好,但是当数据/集群增长时就会很危险。
- Elasticsearch使其易于伸缩,吸引了需要更多数据和更多节点的更大集群的用例。
- Elasticsearch更具动态性——当节点来来往往时,数据可以轻松地在集群中移动,这可能会影响集群的稳定性和性能。
- 虽然Solr传统上更适合于文本搜索,但Elasticsearch的目标是处理分析类型的查询,而这样的查询是有代价的。
尽管这听起来很可怕,但让我这样说吧——Elasticsearch暴露了大量的控制旋钮,人们可以玩来控制野兽。当然,关键是你必须知道所有可能的旋钮,知道它们的作用,并利用它们。例如,尽管你刚刚读过关于Elasticsearch的内容,但在我们的组织中,我们在几个不同的产品中都使用了它,尽管我们对Solr和Elasticsearch都很了解。
不是完全重叠的
Solr呢?Solr并没有完全静止不动。Elasticsearch的出现实际上对Solr及其开发人员和用户社区很有帮助。尽管Solr已经有14岁以上的历史,但它的开发速度比以往任何时候都要快。它现在也有一个友好的API。它还能够更容易地扩展和缩小集群,更动态地创建索引,动态地对它们进行分片,路由文档和查询,等等。注意:当人们提到SolrCloud时,他们指的是这种非常分布式的、类似于elasticsearch的Solr部署。
我们参加了在华盛顿特区举行的Lucene/Solr革命会议,并惊喜地看到:一个强大的社区,健康的项目,许多知名公司不仅使用Solr,而且通过采用、通过开发/工程时间对其进行投资,等等。如果你只关注新闻,你会被引导相信Solr已经死了,所有人都蜂拥到Elasticsearch。事实并非如此。Elasticsearch更新了,写起来自然更有趣。Solr是10多年前的新闻。当然,当Elasticsearch出现的时候,也有一些人从Solr转向Elasticsearch——一开始,根本没有Elasticsearch用户。
3.开源
Elasticsearch在开源日志管理用例中占主导地位——许多组织在Elasticsearch中索引他们的日志,使其可搜索。虽然Solr现在也可以用于此目的(请参阅Solr对日志进行索引和搜索,并对Solr进行日志调优),但它在此方面错过了人心。
Elasticsearch和Solr都是在Apache软件许可下发布的,然而,Solr是真正的开源——社区而不是代码。Solr代码并不总是那么漂亮,但是一旦该特性存在,它通常会一直存在,不会从代码库中删除。任何人都可以为Solr做出贡献,如果你对这个项目表现出兴趣和持续的支持,新的Solr开发人员(又名提交者)将根据成绩选出。此外,提交者来自不同的公司,并且没有单一的公司控制代码库。
另一方面,Elasticsearch在技术上是开源的,但在精神上却并非如此。任何人都可以在Github上看到源代码,任何人都可以改变它并提供贡献,但是只有Elastic的员工才能真正对Elasticsearch做出改变,所以你必须成为Elastic公司的一员才能成为提交者。
此外,Elasticsearch背后的公司Elastic混合了Apache 2.0软件许可下发布的代码,而code one只允许在商业许可下使用。毫无疑问,Elasticsearch用户社区对此并不满意。AWS在Apache许可下构建了自己的Elasticsearch发行版,并捆绑了许多特性,比如警报、安全等。您可以看到Sematext对AWS Elasticsearch开放发行版的回顾。
许多组织选择Solr而不是Elasticsearch作为他们的竞争对手(例如Cloudera, Hortonworks, MapR等),尽管他们也与Elasticsearch合作。
社区和开发人员
Solr和Elasticsearch都拥有活跃的用户和开发人员社区,并且正在迅速开发中。
如果您需要向Solr或Elasticsearch添加某些缺失的功能,那么使用Solr可能会更幸运。诚然,古老的Solr JIRA问题仍然存在,但至少它们仍然是开放的,而不是关闭的。在Solr世界中,社区有更多的发言权,尽管最终还是由Solr开发人员来接受和处理贡献。
这里有一些图表来说明我们的意思:
Elasticsearch与Solr贡献者(来源:Opensee)单击放大
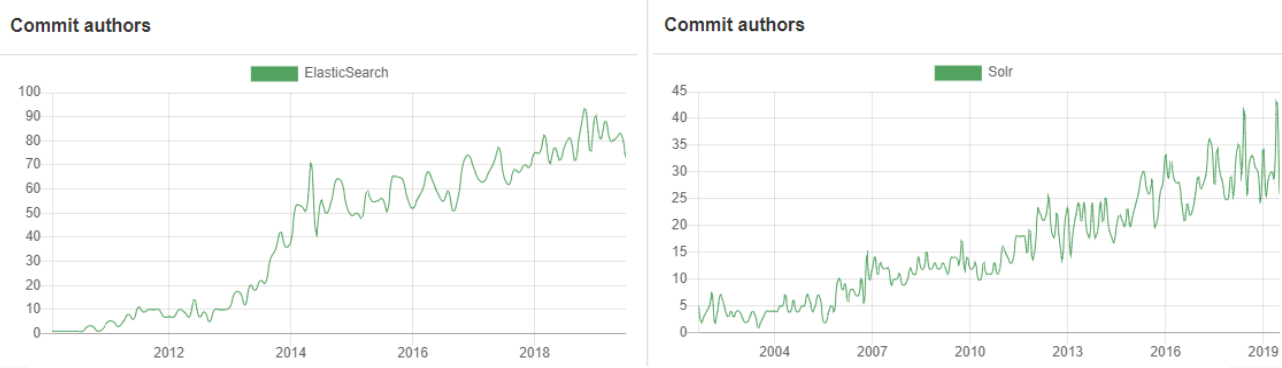
Elasticsearch vs. Solr Commits (source: Open Hub) click to enlarge
如您所见,Elasticsearch数量呈急剧上升趋势,现在Solr提交活动已超过两倍。这不是一种非常精确或绝对正确的比较开源项目的方法,但它给了我们一个想法。例如,Elasticsearch是在Github上开发的,这使得合并其他人的Pull请求变得非常容易,而Solr贡献者倾向于创建补丁,将它们上送到JIRA,在那里Solr提交者在应用之前对它们进行审查——这是一个不那么流畅的过程。此外,Elasticsearch存储库包含文档,而不仅仅是代码,而Solr在Wiki中保存文档。这使得对于Elasticsearch的提交和贡献者都有更高的数字。
4. 学习曲线和支持
Elasticsearch更容易启动—只需一个下载和一个命令就可以启动一切。Solr在传统上需要更多的工作和知识,但是Solr最近在消除这一点上取得了很大的进步,现在只需要改变它的声誉。
从操作上讲,Elasticsearch更简单一点,它只有一个过程。Solr在其elasticsearch式完全分布式部署模式(SolrCloud)中依赖于Apache ZooKeeper。ZooKeeper非常成熟,应用非常广泛,等等,但它还是另一个让人感动的部分。也就是说,如果您正在使用Hadoop、HBase、Spark、Kafka或其他一些较新的分布式软件,那么您可能已经在组织的某个地方运行了ZooKeeper。
虽然Elasticsearch有内置的类似于zookeperzen的组件,但ZooKeeper能更好地防止在Elasticsearch集群中有时会出现的可怕的裂脑问题。公平地说,Elasticsearch开发人员已经意识到这个问题,并在过去几年改进了Elasticsearch的这方面。
两者都有良好的商业支持(咨询、生产支持、培训、集成等)。两者都有很好的操作工具,不过Elasticsearch由于其API更易于使用,吸引了很多DevOps用户,因此围绕它形成了一个更活跃的工具生态系统。
5. 配置
让我们快速了解一下Solr和Elasticsearch是如何配置的。让我们从索引结构开始。
在Solr中,需要托管模式文件(以前的schema.xml)来定义索引结构、定义字段及其类型。当然,您可以将所有字段定义为动态字段并动态地创建它们,但是您仍然至少需要某种程度的索引配置。但是在大多数情况下,您将创建一个schema.xml来匹配您的数据结构。
Elasticsearch有点不同——它可以称为无模式搜索。你可能会问,这到底是什么意思。简而言之,这意味着可以启动Elasticsearch并开始向它发送文档,以便在不创建任何索引模式的情况下为它们建立索引,而Elasticsearch将尝试猜测字段类型。它并不总是100%准确的,至少与手动创建索引映射相比是这样,但它工作得相当好。
当然,您也可以定义索引结构(称为映射),然后使用这些映射创建索引,或者甚至为索引中存在的每种类型创建映射文件,并让Elasticsearch在创建新索引时使用它。听起来很酷,对吧?此外,当在索引的文档中发现一个以前未见的新字段时,Elasticsearch将尝试创建该字段并猜测其类型。可以想象,这种行为是可以关闭的。
让我们讨论一下Solr和Elasticsearch的实际配置。在Solr中,所有组件、搜索处理程序、索引特定内容(如合并因子或缓冲区、缓存等)的配置都在solrconfig.xml文件中定义。每次更改之后,都需要重新启动Solr节点或重新加载它。
在Elasticsearch中的所有配置都被写入到Elasticsearch.yml文件,它只是另一个配置文件。然而,这并不是存储和更改Elasticsearch设置的唯一方法。Elasticsearch公开的许多设置(虽然不是全部)可以在活动集群中更改——例如,您可以更改碎片和副本在集群中的放置方式,而Elasticsearch节点不需要重新启动。在Elasticsearch碎片放置控制中了解更多。
6. 节点的发现
Elasticsearch和Solr之间的另一个主要区别是节点发现和集群管理。发现的主要目的是监视节点的状态,选择主节点,在某些情况下还存储共享的配置文件。
当集群最初形成时,当一个新的节点加入或集群中的某个节点发生故障时,根据给定的条件,必须有一些东西来决定应该做什么。这是所谓的节点发现的职责之一。
Elasticsearch使用它自己的发现实现Zen,为了实现全容错(即不受网络分割的影响),建议至少有三个专用主节点。Solr使用Apache ZooKeeper进行发现和领袖选举。在这种情况下,建议使用外部ZooKeeper集成,对于容错和完全可用的SolrCloud集群,它至少需要三个ZooKeeper实例。
Apache Solr使用一种不同的方法来处理搜索集群。Solr使用Apache ZooKeeper集成——它基本上是一个或多个一起运行的ZooKeeper实例。ZooKeeper用于存储配置文件和监控——用于跟踪所有节点的状态和整个集群的状态。为了让新节点加入现有的集群,Solr需要知道要连接到哪个ZooKeeper集合。
原文:https://sematext.com/blog/solr-vs-elasticsearch-differences/
本文:
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 255 次浏览
【技术选型】Solr与Elasticsearch:性能差异及更多。如何决定哪一个最适合你(续)
比较Solr和Elasticsearch:主要区别是什么?
两个搜索引擎都在迅速发展,因此,无需多说,以下是关于Elasticsearch和Solr之间差异的最新信息:
7. 切分位置
一般来说,就建立索引和碎片的位置而言,Elasticsearch是非常动态的。当某个动作发生时,它可以在集群周围移动碎片——例如,当一个新节点加入或从集群中删除一个节点时。我们可以通过使用感知标签来控制碎片应该放在哪里和不应该放在哪里,我们还可以告诉Elasticsearch使用API调用按需移动碎片。
Solr往往是更静态的开箱。默认情况下,当Solr节点加入或离开集群时,Solr自己不做任何事情。但是,在Solr 7及以后版本中,我们有了自动排序API:我们现在可以定义整个集群范围的规则和特定于集合的策略来控制分片的位置,我们可以自动添加副本,并告诉Solr根据已定义的规则在集群中使用节点。
8. API
如果您了解Apache Solr或Elasticsearch,您就会知道它们公开了HTTP API。
熟悉Solr的人都知道,为了从它获得搜索结果,需要查询一个已定义的请求处理程序,并传递定义查询条件的参数。根据您选择使用的查询解析器的不同,这些参数将有所不同,但方法仍然是相同的——将一个HTTP GET请求发送给Solr以获取搜索结果。
这样做的好处是您不必局限于单一的响应格式—您可以选择XML格式、JavaBin格式的JSON格式以及其他一些由响应编写器开发的格式来获得结果。因此,您可以选择对您和您的搜索应用程序最方便的格式。当然,Solr API不仅用于查询,因为您还可以获得关于不同搜索组件或控制Solr行为(例如集合创建)的一些统计信息。
那么Elasticsearch呢?Elasticsearch公开了一个可以使用HTTP GET、DELETE、POST和PUT方法访问的REST API。它的API不仅允许查询或删除文档,还允许创建索引、管理它们、控制分析并获得描述Elasticsearch当前状态和配置的所有指标。如果您需要了解有关Elasticsearch的任何信息,您可以通过REST API获得它(我们在Sematext云中也使用它来获取日志和事件)。
如果您习惯了Solr,那么有一件事在一开始可能会让您感到奇怪——Elasticsearch只能以JSON格式响应——例如,它没有XML响应。Elasticsearch和Solr之间的另一个大区别是查询。在Solr中,所有查询参数都是作为URL参数传递的,而在Elasticsearch中查询是JSON表示的。以JSON对象的形式结构化的查询给了一个很大的控制权,可以控制Elasticsearch应该如何理解查询,以及返回什么结果。
9. 缓存
另一个很大的不同是Elasticsearch和Solr的架构。为了不深入讨论这两个产品的缓存是如何工作的,我们只指出它们之间的主要区别。
让我们从什么是分段开始。段是Lucene索引的一部分,由各种文件构建,大部分是不可变的,并且包含数据。当你建立数据索引时,Lucene会生成段,并且可以在段合并的过程中将多个较小的、已经存在的段合并为较大的段。
Solr具有全局cashes,即一个片段的给定类型的单一缓存实例,用于其所有段。当单个段发生更改时,需要使整个缓存失效并刷新。这需要时间和硬件资源。
在Elasticsearch中,缓存是每段的,这意味着如果只有一个段更改,那么只有一小部分缓存的数据需要无效和刷新。我们将很快讨论这种方法的利弊。
10. 分析引擎
Solr非常大,有很多数据分析功能。我们可以从好的、旧的方面开始——第一个实现允许对数据进行切分以理解并了解它。然后是具有类似特性的JSON facet,但速度更快,占用内存更少,最后是基于流的表达式,称为流表达式,它可以组合来自多个来源的数据(如SQL、Solr、facet),并使用各种表达式(排序、提取、计算重要术语等)对其进行修饰。
Elasticsearch提供了一个强大的聚合引擎,它不仅可以像Solr遗留平面(facet)一样进行一级数据分析但是也可以嵌套数据的分析(例如,计算平均价格为每一个产品类别在每个商店部门),但支持分析聚合结果,导致功能像移动平均计算。最后,虽然还处于实验阶段,但Elasticsearch提供了对矩阵聚合的支持,它可以计算一组字段的统计信息。
11. 全文搜索功能
当然,Solr和Elasticsearch都利用了Lucene接近实时的功能。这使得查询可以在文档被索引后立即匹配文档。
在查看Solr代码库时,与全文搜索相关的特性和接近全文搜索的特性非常丰富。
我们的Solr培训班上就满是这种东西!从广泛的请求解析器选择开始,通过各种建议器实现,到使用拼写检查器纠正用户拼写错误的能力,以及高度可配置的广泛突出显示支持。
Elasticsearch有专门建议案API隐藏了实现细节的用户给我们一个更简单的方法实现建议的成本降低灵活性和当然强调不如强调可配置在Solr(虽然都是基于Lucene高亮显示功能)。
Solr仍然更加面向文本搜索。另一方面,Elasticsearch通常用于过滤和分组(分析查询工作负载),而不一定用于文本搜索。
Elasticsearch开发人员在Lucene和Elasticsearch级别上都投入了大量精力来提高查询效率(降低内存占用和CPU使用)。
12. DevOps友好
如果你问一个DevOps人员,他喜欢Elasticsearch的哪些方面,答案可能是它的API、可管理性和易于安装。当涉及到故障排除时,Elasticsearch很容易获得关于其状态的信息——从磁盘使用情况信息,通过内存和垃圾收集工作统计数据,到Elasticsearch内部的缓存、缓冲区和线程池使用情况。
Solr还没有到那一步——您可以通过JMX MBean和新的Solr Metrics API从它那里获得一些信息,但这意味着您必须查看一些地方,并不是所有的东西都在那里,尽管它正在到达那里。
13. 非平面数据处理
你有非平面数据,在一个嵌套对象中有很多嵌套对象在另一个嵌套对象中你不想让数据变得扁平,而只是索引你漂亮的MongoDB JSON对象并准备好全文搜索?Elasticsearch将是实现这一目标的完美工具,它支持对象、嵌套文档和父子关系。Solr可能不是最适合这里的,但请记住,在索引XML文档和JSON时,它还支持父-子文档和嵌套文档。此外,还有一件非常重要的事情—Solr支持不同集合内部和跨不同集合的查询时间连接,因此您不受索引时间父-子处理的限制。
14. 查询DSL
我们大声说,Elasticsearch的查询语言真的很棒。如果你喜欢JSON,那就是。它允许您使用JSON构造查询,因此它将具有良好的结构并使您能够控制整个逻辑。您可以混合不同类型的查询来编写非常复杂的匹配逻辑。当然,全文搜索不是一切,你可以包括聚合,结果崩溃等等-基本上你需要从你的数据的一切都可以用查询语言表达。
在Solr 7之前,Solr仍然在使用URI搜索,至少在其最广泛使用的API中是这样。所有参数都进入了URI,这可能导致长且复杂的查询。从Solr 7开始,JSON API部分得到了扩展,现在可以运行结构化查询来更好地表达您的需求。
15. 索引/收集领导人控制
当谈到集群周围的切分位置时,Elasticsearch本质上是动态的,但对于哪些切分将充当主切分,哪些切分将作为副本,我们并没有太多的控制权。这是我们无法控制的。
与Elasticsearch相比,在Solr中,你有这种控制,这是一件很好的事情,当你考虑到在索引期间,领导者做了更多的工作,因为他们把数据转发给所有的副本。通过对leader碎片位置的精确信息,我们能够重新平衡leader碎片的位置,或者明确地指出它们应该放在哪里,这样我们就能够在整个集群中平衡负载。
16. 机器学习
Solr中的机器学习以一种contrib模块的形式免费提供,并建立在流聚合框架之上。通过使用contrib模块中的其他库,您可以在Solr之上使用机器学习的排序模型和特征提取,而基于流聚合的机器学习主要关注使用逻辑回归的文本分类。
另一方面,我们有Elasticsearch和它的X-Pack商业产品,附带一个Kibana插件,支持机器学习算法,专注于异常检测和时间序列数据中的离群点检测。这是一套捆绑了专业服务的不错的工具,但价格相当昂贵。因此,我们对X-Pack进行了拆解,并列出了可用的X-Pack替代品:来自开源工具、商业替代品或云服务。
17. 生态系统
说到生态系统,Solr附带的工具很好,但它们让人感觉很谦虚。我们有一个叫做Banana的Kibana端口,它走自己的路,还有像Apache Zeppelin integration这样的工具,它允许在Apache Solr上运行SQL。当然,还有其他工具可以从Solr读取数据、将数据发送到Solr或使用Solr作为数据源—例如Flume。大多数工具都是由各种爱好者开发和支持的。
相比之下,如果你看看Elasticsearch周围的生态系统,它是非常现代和有序的。你有一个新版本的Kibana,每个月都有新功能出现。如果你不喜欢Kibana,你有Grafana,它现在是一个提供多种功能的产品,你有一长串的数据传送者和工具可以使用Elasticsearch作为数据源。最后,这些产品不仅得到了爱好者的支持,还得到了大型商业实体的支持。
18. 指标
如果你喜欢监控和测量,那么有了Elasticsearch,你将会感觉非常棒。除夕夜,它比你能挤进时代广场的人还要多!Solr提供了关键指标,但远不及Elasticsearch那么多。无论如何,如果您想处理指标和其他操作数据,那么拥有像Sematext Cloud这样全面的监控和集中的日志记录工具是非常必要的,尤其是当它们像这两者一样无缝地协同工作时。
综上所述,以下是Solr和Elasticsearch之间的主要区别:
Top Solr和Elasticsearch的区别
Feature |
Solr/SolrCloud |
Elasticsearch |
|---|---|---|
|
社区和开发人员 |
Apache软件基金会和社区支持 | 单一商业实体及其雇员 |
| 节点的发现 | Apache Zookeeper,成熟且经过了大量项目的实战测试 | Zen内置在Elasticsearch中,它要求专用的主节点用于验证脑裂 |
| 切分位置 | 本质上是静态的,需要手工迁移碎片,从Solr 7开始——自动缩放API允许一些动态操作 | 根据集群状态,可以根据需要移动动态的碎片 |
| 缓存 | 全局的,随着每一段的改变而失效 | 每段,更好地动态更改数据 |
| 分析引擎 | 平面和强大的流聚合 | 复杂和高度灵活的聚合 |
| 优化查询执行 | 目前没有 | 根据上下文更快的范围查询 |
| 搜索速度 | 最适合静态数据,因为有缓存和非反向读取器 | 非常适合快速更改数据,因为每段缓存 |
| 分析引擎的性能 | 非常适合精确计算的静态数据 | 结果的准确性取决于数据位置 |
| 全文检索功能 | 基于Lucene的语言分析,多种暗示,拼写检查,丰富的高亮显示支持 | 语言分析基于Lucene,单一建议API实现,突出 rescoring |
| DevOps 友好性 | 还没有完全实现,但即将实现 | 很好的API |
| 非扁平数据处理 | 嵌套文档和父-子支持 | 自然支持嵌套和对象类型,允许无限嵌套和父-子支持 |
| Query DSL | JSON(有限)、XML(有限)或URL参数 | JSON |
| 索引/收集领导人控制 | Leader放置控制和Leader再平衡的可能性来平衡节点上的负载 | 不可能的 |
| 机器学习 | 内置-在流媒体聚合的基础上,专注于逻辑回归和学习排名contrib模块 | 商业特征,专注于异常和异常值和时间序列数据 |
| 生态系统 | Modest – Banana, Zeppelin 与社区支持 | Rich – Kibana, Grafana, 拥有庞大的实体支持和庞大的用户基础 |
Lucene呢?
由于Solr和Elasticsearch都基于Apache Lucene,您可能想知道是否使用纯Lucene会更好。可以这样想:Lucene是Linux内核,而Solr或Elasticsearch是Ubuntu。
您可以直接使用内核并在其上构建自己的应用程序。如果您对内核有很好的理解,并且用例比较狭窄,那么这将是您的选择。同样,Lucene是一个用Java编写的搜索引擎库。你可以在它上面写你自己的搜索引擎(用Java),你可以完全控制Lucene做什么。
就像内核的例子一样,如果你不熟悉Lucene,可能会花费很长时间和大量的试验和错误。但是假设你知道Lucene。如果您有广泛的用例,比如需要使您的搜索引擎分布式,那么您可能最终会得到一个解决方案,它可以完成Solr和Elasticsearch已经完成的工作。
Solr和Elasticsearch都提供了最有用的功能——尽管不是全部!- Lucene功能通过一个REST API。就像Ubuntu对Linux所做的一样,Solr和Elasticsearch在上面添加了它们自己的功能。比如分布式模型、安全性、管理api、复杂分析(方面、流聚合)等等。大多数用例都需要这种功能。
Solr和Elasticsearch。给我总结一下:哪个是最好的?
这显然不是Solr和Elasticsearch不同之处的详尽列表,当然也不是要告诉您选择哪一个。我们可以继续写几篇博客文章,然后把它写成一本书,但希望下面的列表能让你知道从其中一篇和另一篇中可以期待什么,这样你就可以根据你的需要来看待它。
总之,以下是我们认为对那些不得不做出选择的人来说影响最大的几点:
- 如果您已经在Solr上投入了大量时间,请坚持使用它,除非有它不能很好地处理的特定用例。如果您认为是这样的话,请与熟悉Solr和Elasticsearch项目的人交谈,以节省您的时间、猜测、研究和避免错误。
- 如果您是真正开源的忠实信徒,那么Solr比Elasticsearch更接近于此,由一家公司控制Elasticsearch可能会让您感到厌恶。
- 如果您需要一个除了文本搜索之外还能处理分析查询的数据存储,那么Elasticsearch是当前更好的选择,特别是考虑到更大的生态系统的可用性。
原文:https://sematext.com/blog/solr-vs-elasticsearch-differences
本文:http://jiagoushi.pro/node/1179
讨论:请加入知识星球【首席架构师圈】或者微信小号【jiagoushi_pro】
- 521 次浏览
【搜索引擎】Apache Solr 神经搜索
Sease[1] 与 Alessandro Benedetti(Apache Lucene/Solr PMC 成员和提交者)和 Elia Porciani(Sease 研发软件工程师)共同为开源社区贡献了 Apache Solr 中神经搜索的第一个里程碑。
它依赖于 Apache Lucene 实现 [2] 进行 K-最近邻搜索。
特别感谢 Christine Poerschke、Cassandra Targett、Michael Gibney 和所有其他在贡献的最后阶段提供了很大帮助的审稿人。即使是一条评论也受到了高度赞赏,如果我们取得进展,总是要感谢社区。
让我们从简短的介绍开始,介绍神经方法如何改进搜索。
我们可以将搜索概括为四个主要领域:
- 生成指定信息需求的查询表示
- 生成捕获包含的信息的文档的表示
- 匹配来自信息语料库的查询和文档表示
- 为每个匹配的文档分配一个分数,以便根据结果中的相关性建立一个有意义的文档排名
神经搜索是神经信息检索[3] 学术领域的行业衍生产品,它专注于使用基于神经网络的技术改进这些领域中的任何一个。
人工智能、深度学习和向量表示
我们越来越频繁地听到人工智能(从现在开始是人工智能)如何渗透到我们生活的许多方面。
当我们谈论人工智能时,我们指的是一组使机器能够学习和显示与人类相似的智能的技术。
随着最近计算机能力的强劲和稳定发展,人工智能已经复苏,现在它被用于许多领域,包括软件工程和信息检索(管理搜索引擎和类似系统的科学)。
特别是,深度学习 [4] 的出现引入了使用深度神经网络来解决对经典算法非常具有挑战性的复杂问题。
就这篇博文而言,只要知道深度学习可用于在信息语料库中生成查询和文档的向量表示就足够了。
密集向量表示
可以认为传统的倒排索引将文本建模为“稀疏”向量,其中语料库中的每个词项对应一个向量维度。在这样的模型中(另见词袋方法),维数对应于术语字典基数,并且任何给定文档的向量大部分包含零(因此它被称为稀疏,因为只有少数术语存在于整个字典中将出现在任何给定的文档中)。
密集向量表示与基于术语的稀疏向量表示形成对比,因为它将近似语义意义提取为固定(和有限)数量的维度。
这种方法的维数通常远低于稀疏情况,并且任何给定文档的向量都是密集的,因为它的大部分维数都由非零值填充。
与稀疏方法(标记器用于直接从文本输入生成稀疏向量)相比,生成向量的任务必须在 Apache Solr 外部的应用程序逻辑中处理。
BERT[5] 等各种深度学习模型能够将文本信息编码为密集向量,用于密集检索策略。
有关更多信息,您可以参考我们的这篇博文。
近似最近邻
给定一个对信息需求进行建模的密集向量 v,提供密集向量检索的最简单方法是计算 v 与代表信息语料库中文档的每个向量 d 之间的距离(欧几里得、点积等)。
这种方法非常昂贵,因此目前正在积极研究许多近似策略。
近似最近邻搜索算法返回结果,其与查询向量的距离最多为从查询向量到其最近向量的距离的 c 倍。
这种方法的好处是,在大多数情况下,近似最近邻几乎与精确最近邻一样好。
特别是,如果距离测量准确地捕捉到用户质量的概念,那么距离的微小差异应该无关紧要[6]
分层导航小图
在 Apache Lucene 中实现并由 Apache Solr 使用的策略基于 Navigable Small-world 图。
它为高维向量提供了一种有效的近似最近邻搜索[7][8][9][10]。
Hierarchical Navigable Small World Graph (HNSW) 是一种基于邻近邻域图概念的方法:
与信息语料库相关联的向量空间中的每个向量都唯一地与一个
vertex 

顶点基于它们的接近度通过边缘连接,更近的(根据距离函数)连接。
构建图受超参数的影响,这些超参数调节每层要构建多少个连接以及要构建多少层。
在查询时,邻居结构被导航以找到离目标最近的向量,从种子节点开始,随着我们越来越接近目标而迭代。
我发现这个博客对于深入研究该主题非常有用。
Apache Lucene 实现
首先要注意的是当前的 Lucene 实现不是分层的。
所以图中只有一层,请参阅原始 Jira 问题中的最新评论,跟踪开发进度[11]。
主要原因是为了在 Apache Lucene 生态系统中为这种简化的实现找到更容易的设计、开发和集成过程。
一致认为,引入分层分层结构将在低维向量管理和查询时间(减少候选节点遍历)方面带来好处。
该实施正在进行中[12]。
那么,与 Navigable Small World Graph 和 K-Nearest Neighbors 功能相关的 Apache Lucene 组件有哪些?
让我们探索代码:
注:如果您对 Lucene 内部结构和编解码器不感兴趣,可以跳过这一段
org.apache.lucene.document.KnnVectorField 是入口点:
它在索引时需要向量维度和相似度函数(构建 NSW 图时使用的向量距离函数)。
这些是通过 #setVectorDimensionsAndSimilarityFunction 方法在 org.apache.lucene.document.FieldType 中设置的。
更新文档字段架构 org.apache.lucene.index.IndexingChain#updateDocFieldSchema 时,信息从 FieldType 中提取并保存在 org.apache.lucene.index.IndexingChain.FieldSchema 中。
并且从 FieldSchema KnnVectorField 配置最终到达 org.apache.lucene.index.IndexingChain#initializeFieldInfo 中的 org.apache.lucene.index.FieldInfo。
现在,Lucene 编解码器具有构建 NSW 图形所需的所有特定于字段的配置。
让我们看看如何:
首先,从 org.apache.lucene.codecs.lucene90.Lucene90Codec#Lucene90Codec 你可以看到 KNN 向量的默认格式是 org.apache.lucene.codecs.lucene90.Lucene90HnswVectorsFormat。
关联的索引编写器是 org.apache.lucene.codecs.lucene90.Lucene90HnswVectorsWriter。
该组件可以访问之前在将字段写入 org.apache.lucene.codecs.lucene90.Lucene90HnswVectorsWriter#writeField 中的索引时初始化的 FieldInfo。
在编写 KnnVectorField 时,涉及到 org.apache.lucene.util.hnsw.HnswGraphBuilder,最后是
org.apache.lucene.util.hnsw.HnswGraph 已构建。
Apache Solr 实现
可从 Apache Solr 9.0 获得
预计 2022 年第一季度
这第一个贡献允许索引单值密集向量场并使用近似距离函数搜索 K-最近邻。
当前特点:
- DenseVectorField 类型
- Knn 查询解析器
密集向量场(DenseVectorField)
密集向量字段提供了索引和搜索浮点元素的密集向量的可能性。
例如
[1.0, 2.5, 3.7, 4.1]
以下是 DenseVectorField 应如何在模式中配置:
<fieldType name="knn_vector" class="solr.DenseVectorField"
vectorDimension="4" similarityFunction="cosine"/>
<field name="vector" type="knn_vector" indexed="true" stored="true"/>-----------------------------------------------------------------------------------------------------
|Parameter Name | Required | Default | Description |Accepted values|
-----------------------------------------------------------------------------------------------------
|vectorDimension | True | |The dimension of the dense
vector to pass in. |Integer < = 1024|
—————————————————————————————————————————
|similarityFunction | False | euclidean |Vector similarity function;
used in search to return top K most similar vectors to a target vector.
| euclidean, dot_product or cosine.
———————————————————————————————————————
- 欧几里得:欧几里得距离
- dot_product:点积。注意:这种相似性旨在作为执行余弦相似性的优化方式。为了使用它,所有向量必须是单位长度的,包括文档向量和查询向量。对非单位长度的向量使用点积可能会导致错误或搜索结果不佳。
- 余弦:余弦相似度。注意:执行余弦相似度的首选方法是将所有向量归一化为单位长度,而不是使用 DOT_PRODUCT。只有在需要保留原始向量且无法提前对其进行归一化时,才应使用此函数。
DenseVectorField 支持属性:索引、存储。
注:目前不支持多值
自定义索引编解码器
要使用以下自定义编解码器格式的高级参数和 HNSW 算法的超参数,请确保在 solrconfig.xml 中设置此配置:
<codecFactory class="solr.SchemaCodecFactory"/> ... 以下是如何使用高级编解码器超参数配置 DenseVectorField: <fieldType name="knn_vector" class="solr.DenseVectorField" vectorDimension="4"similarityFunction="cosine" codecFormat="Lucene90HnswVectorsFormat" hnswMaxConnections="10" hnswBeamWidth="40"/> <field name="vector" type="knn_vector" indexed="true" stored="true"/>
| Parameter Name | Required | Default | Description | Accepted values |
codecFormat |
False |
|
Specifies the knn codec implementation to use |
|
|
False | 16 |
Lucene90HnswVectorsFormat only:Controls how many of the nearest neighbor candidates are connected to the new node. It has the same meaning as M from the paper[8]. |
Integer |
hnswBeamWidth |
False | 100 |
Lucene90HnswVectorsFormat only: It is the number of nearest neighbor candidates to track while searching the graph for each newly inserted node.It has the same meaning as efConstruction from the paper[8]. |
Integer |
请注意,codecFormat 接受的值可能会在未来版本中更改。
注意 Lucene 索引向后兼容仅支持默认编解码器。如果您选择在架构中自定义 codecFormat,升级到 Solr 的未来版本可能需要您切换回默认编解码器并优化索引以在升级之前将其重写为默认编解码器,或者重新构建整个索引升级后从头开始。
对于 HNSW 实现的超参数,详见[8]。
如何索引向量
下面是 DenseVectorField 应该如何被索引:
JSON
[{ "id": "1",
"vector": [1.0, 2.5, 3.7, 4.1]
},
{ "id": "2",
"vector": [1.5, 5.5, 6.7, 65.1]
}
]XML
<field name="id">1 <field name="vector">1.0 <field name="vector">2.5 <field name="vector">3.7 <field name="vector">4.1 <field name="id">2 <field name="vector">1.5 <field name="vector">5.5 <field name="vector">6.7 <field name="vector">65.1
Java – SolrJ
final SolrClient client = getSolrClient();
final SolrInputDocument d1 = new SolrInputDocument();
d1.setField("id", "1");
d1.setField("vector", Arrays.asList(1.0f, 2.5f, 3.7f, 4.1f));
final SolrInputDocument d2 = new SolrInputDocument();
d2.setField("id", "2");
d2.setField("vector", Arrays.asList(1.5f, 5.5f, 6.7f, 65.1f));
client.add(Arrays.asList(d1, d2));knn 查询解析器
knn K-Nearest Neighbors 查询解析器允许根据给定字段中的索引密集向量查找与目标向量最近的 k 文档。
它采用以下参数:
| Parameter Name | Required | Default | Description |
f |
True | The DenseVectorField to search in. | |
topK |
False | 10 | How many k-nearest results to return. |
以下是运行 KNN 搜索的方法:
&q={!knn f=vector topK=10}[1.0, 2.0, 3.0, 4.0]
检索到的搜索结果是输入 [1.0, 2.0, 3.0, 4.0] 中与向量最近的 K-nearest,由在索引时配置的similarityFunction 排序。
与过滤查询一起使用
knn 查询解析器可用于过滤查询:
&q=id:(1 2 3)&fq={!knn f=vector topK=10}[1.0, 2.0, 3.0, 4.0]
knn 查询解析器可以与过滤查询一起使用:
&q={!knn f=vector topK=10}[1.0, 2.0, 3.0, 4.0]&fq=id:(1 2 3)
重要:
在这些场景中使用 knn 时,请确保您清楚地了解过滤器查询在 Apache Solr 中的工作方式:
由主查询 q 产生的文档 ID 排名列表与从每个过滤器查询派生的文档 ID 集合相交 fq.egRanked List from q=[ID1, ID4, ID2, ID10] Set from fq={ID3, ID2 , ID9, ID4} = [ID4,ID2]
用作重新排序查询
knn 查询解析器可用于重新排列第一遍查询结果:
&q=id:(3 4 9 2)&rq={!rerank reRankQuery=$rqq reRankDocs=4 reRankWeight=1}
&rqq={!knn f=vector topK=10}[1.0, 2.0, 3.0, 4.0]
重要:
在重新排序中使用 knn 时,请注意 topK 参数。
仅当来自第一遍的文档 d 在要搜索的目标向量的 K 最近邻(在整个索引中)内时,才计算第二遍分数(从 knn 派生)。
这意味着无论如何都会在整个索引上执行第二遍 knn,这是当前的限制。
最终排序的结果列表将第一次通过分数(主查询 q)加上第二次通过分数(到要搜索的目标向量的近似相似度函数距离)乘以乘法因子(reRankWeight)。
因此,如果文档 d 不存在于 knn 结果中,即使与目标查询向量的距离向量计算不为零,您对原始分数的贡献也为零。
有关使用 ReRank 查询解析器的详细信息,请参阅 Apache Solr Wiki[13] 部分。
未来的作品
这只是 Apache Solr 神经功能的开始,更多功能即将推出!
我希望您喜欢概述并继续关注更新!
参考
- [6] Andoni, A.; Indyk, P. (2006-10-01). “Near-Optimal Hashing Algorithms for Approximate Nearest Neighbor in High Dimensions”. 2006 47th Annual IEEE Symposium on Foundations of Computer Science (FOCS’06). pp. 459–468. CiteSeerX 10.1.1.142.3471. doi:10.1109/FOCS.2006.49. ISBN 978-0-7695-2720-8.
- [7] Yury Malkov, Alexander Ponomarenko, Andrey Logvinov, Vladimir Krylov,Approximate nearest neighbor algorithm based on navigable small world graphs,Information Systems,Volume 45,2014,Pages 61-68,ISSN 0306-4379,https://doi.org/10.1016/j.is.2013.10.006.
- [8] Malkov, Yury; Yashunin, Dmitry (2016). “Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs”. arXiv:1603.09320 [cs.DS].
- 88 次浏览
【搜索引擎】Solr:提高批量索引的性能
几个月前,我致力于提高“完整”索引器的性能。 我觉得这种改进足以分享这个故事。 完整索引器是 Box 从头开始创建搜索索引的过程,从 hbase 表中读取我们所有的文档并将文档插入到 Solr 索引中。
我们根据 id 对索引文档进行分片,同样的文档 id 也被用作 hbase 表中的 key。 我们的 Solr 分片公式是 id % number_of_shards。 mapreduce 作业扫描 hbase 表,通过上述分片公式计算每个文件的目标分片,并将每个文档插入相应的 solr 分片中。 这是在过去几年中为我们提供良好服务的初始模型的示意图:
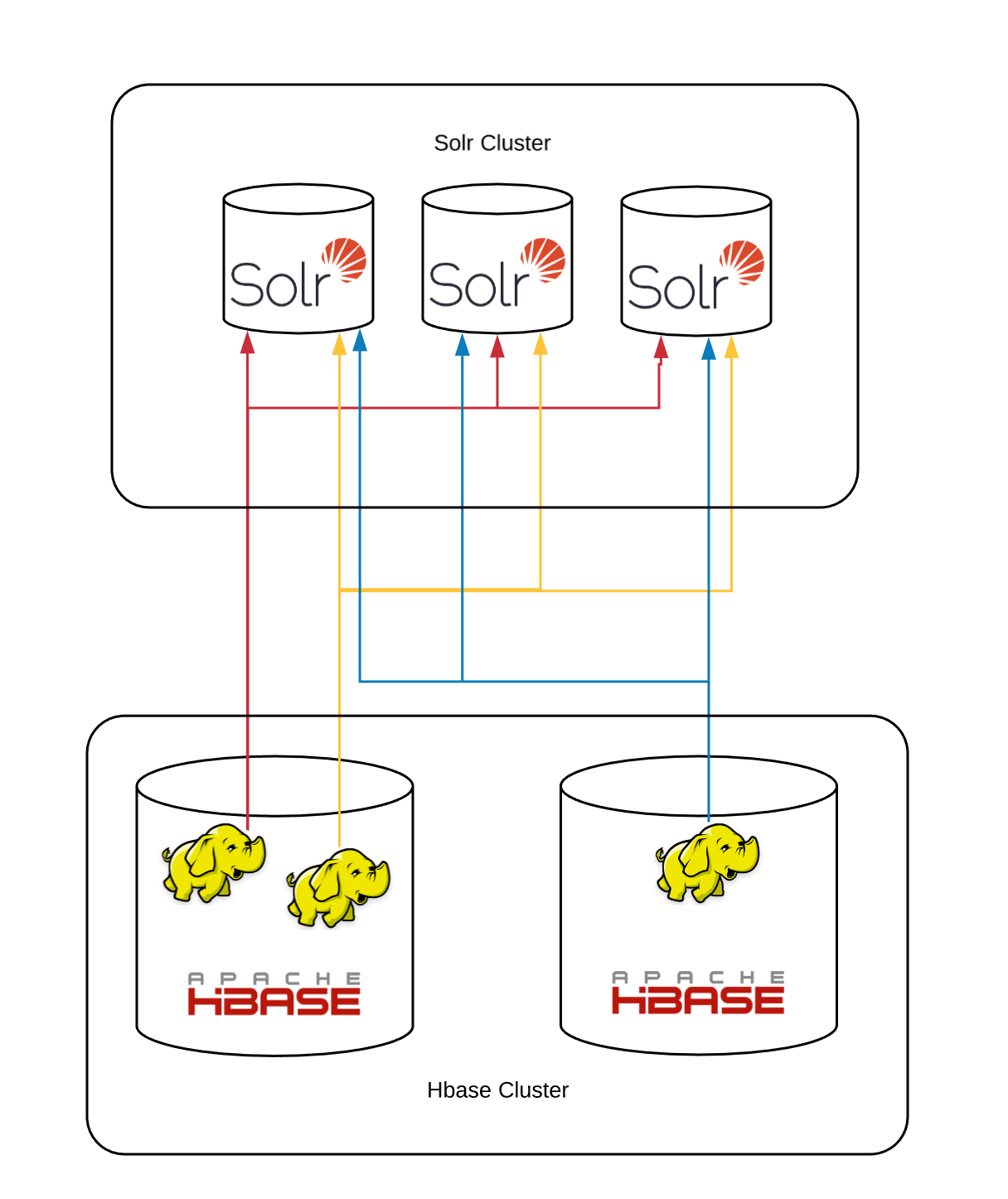
所有 mapreduce 作业都与所有分片对话,因为每个分片的数据分布在所有 hbase 区域中。 该作业是仅地图作业,没有减少作业。 hbase 表扫描以及更新请求都在映射器中完成。
在每个映射器中,都有一个批处理作业的共享队列; 和一个 http 客户端共享池,它们从队列中获取作业并将其发送到相应的分片。 每个单独的文档都不会直接插入到队列中。 相反,需要在同一个分片上索引的文档在插入队列之前会一起批处理(当前默认值为 10)。 队列是有界的,当它已满时,文档生产者必须等待才能扫描更多行。

如果所有 Solr 分片继续以一致且一致的速度*摄取文档,则该系统以稳定的速度运行。 但是,Solr 时不时地会将内存中的结构刷新到文件中,这种 I/O 可能会导致一些索引操作暂时变慢。 在这个阶段,集群不提供查询服务,所以这不是问题。
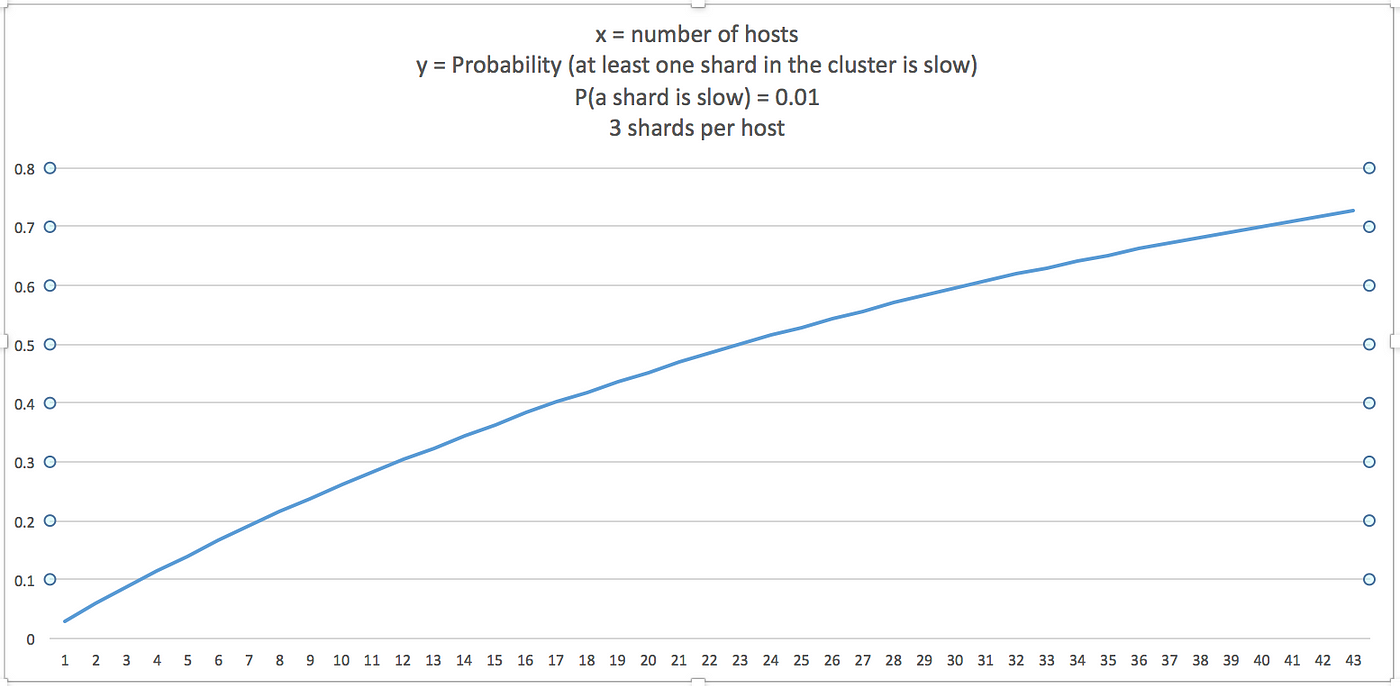
如果分片的总数为 n,并且给定分片的间歇性慢索引速率的概率为 p,则:
- P(至少 n 个分片中的一个很慢)= P(恰好一个分片很慢)+ P(正好两个分片很慢)+ ... + P(所有 n 个分片都很慢)
要么
- P(至少一个分片很慢)= 1 - P(没有一个分片很慢)
- P(n 个分片中至少有 1 个很慢)= 1 — (1-p)ⁿ
如果我们假设对于给定的时间间隔 p = 0.01,这是 P 的图表(集群中至少有一个分片很慢):
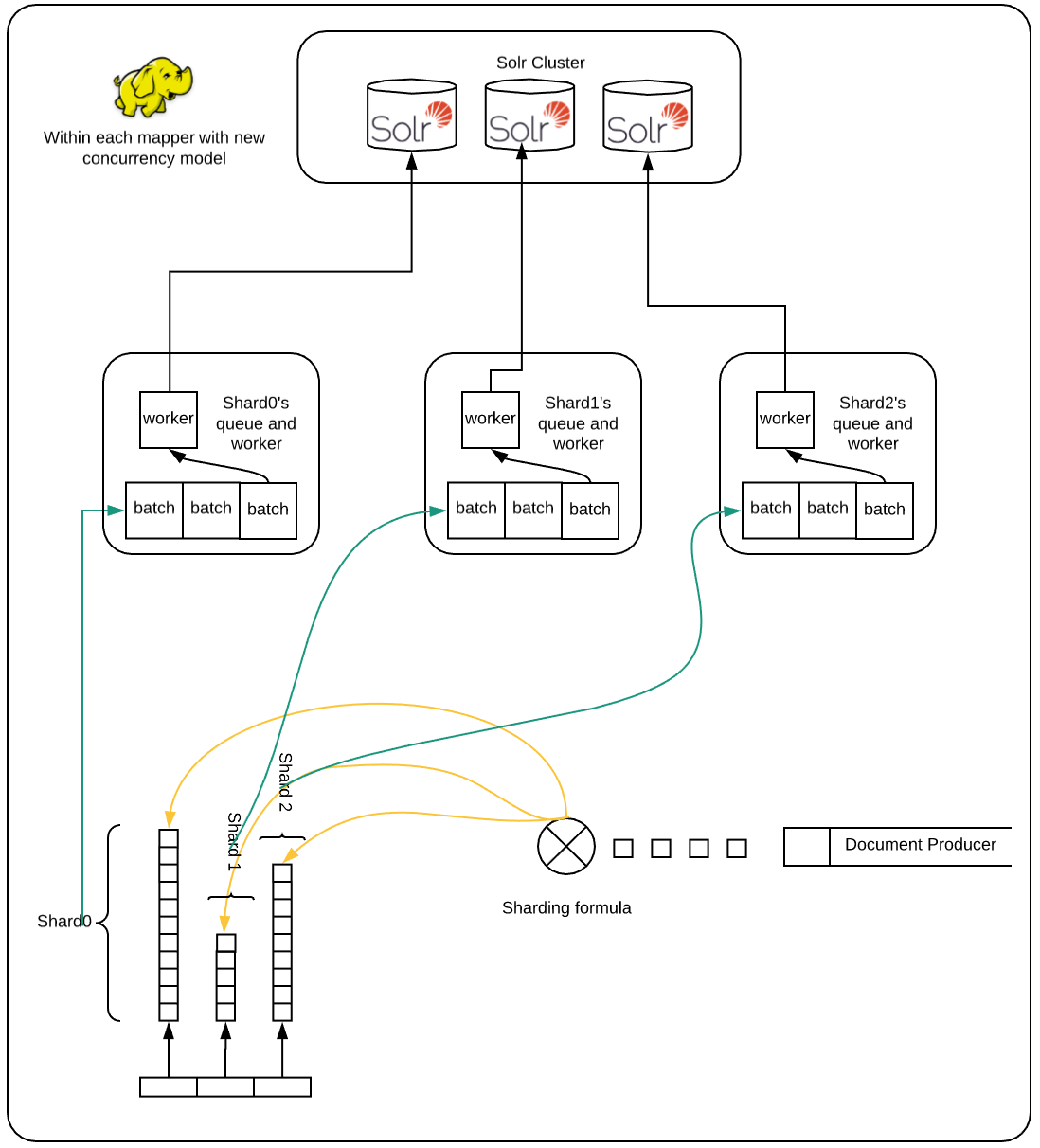
这意味着要在更多分片上获得良好的索引性能,我们需要隔离一个分片的瓶颈,以免影响其他分片的索引。我的第一个尝试是增加工作人员池,这样如果一些工作人员由于速度慢而被卡在一个分片上,那么其余工作人员可以继续处理队列。这有所帮助,但仍然有可能让所有或许多工人在选择工作时陷入困境,这些工作会间歇性地进入缓慢的分片。在这种情况下,文档生产者线程将不会创建新文档,因为队列已满,并且所有工作人员都无法继续进行,因为他们正在等待缓慢的工作完成。在我的第二次尝试中,我为每个分片(在每个映射器上)创建了单独的队列和工作人员,这确保了如果一些分片很慢,那么其余分片不必闲置,因为他们的工作人员将继续阅读队列中的作业并将它们发送以进行索引。最终,正在呼吸的碎片将再次开始更快地索引,而其他一些碎片可能会开始缓慢响应等等。这极大地改善了系统的总流量。
这是具有较旧并发模型的 39 台主机的图表。 该作业在运行三天后崩溃。 即使在崩溃之前,它的表现也不一致。 此外,分片的平均索引速度低于我们过去看到的总分片较少的情况。
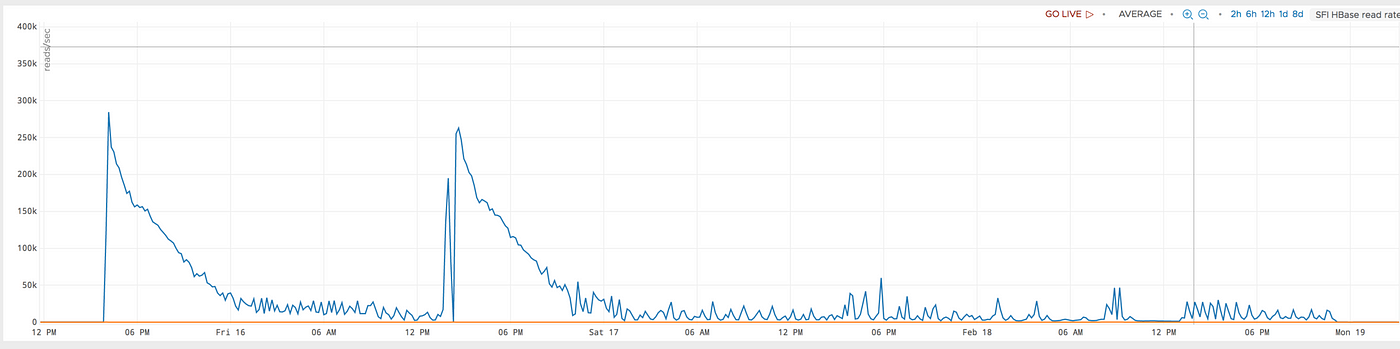
这是在具有新并发模型的同一组主机上执行的相同工作,它的性能要好得多且更一致:
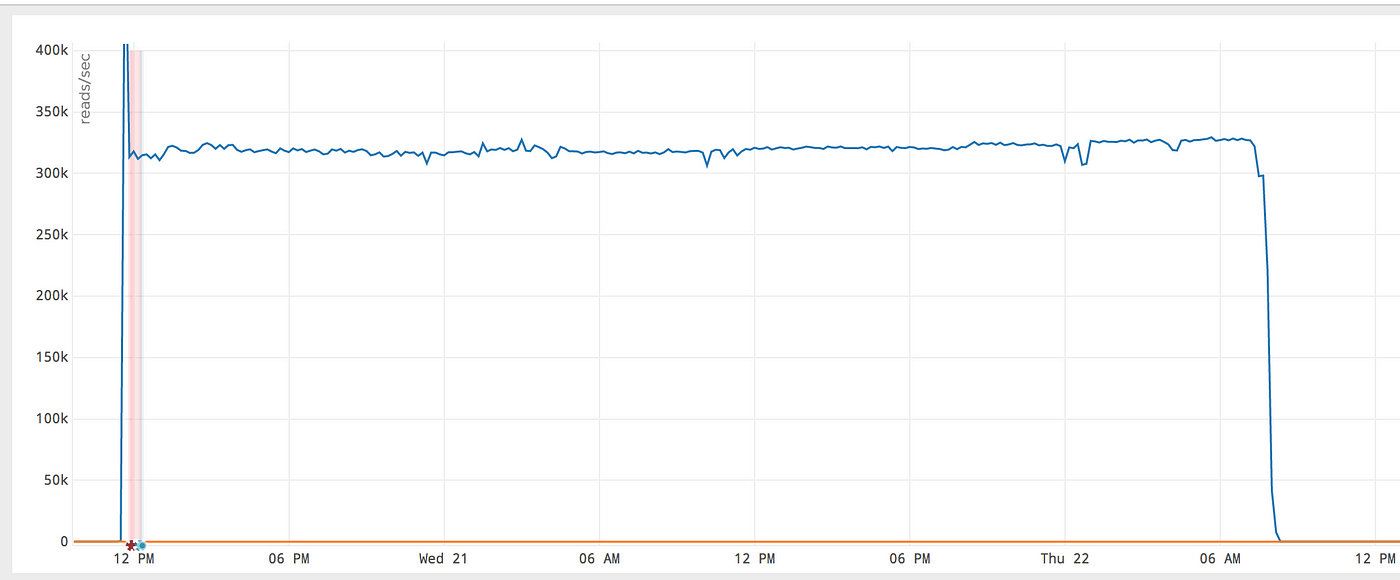
y 轴上的单位是每秒读取次数。它增加了一倍多。 Box 拥有近 500 亿份文档**,通过改进,完整索引器能够在不到两天的时间内完成此索引阶段。
但是,这种新模型也有其缺点,例如:
- 此模型在针对同一分片的工作人员之间没有通信。因此,当一个分片响应缓慢时,来自其他并行运行的映射器的工作人员继续向它发送请求(并且失败,然后重试),即使一个或多个工作人员(在其他映射器中)已经确定该分片很慢。
- 由于每个映射器为每个分片分配一个固定长度的队列,因此设计不会扩展到超过一定数量的分片;因为队列的内存需求将超过映射器的堆大小。
更具可扩展性的模型将涉及映射器和 Solr 分片之间的队列。并且应该有特定于分片的客户端,它们可能运行在分片的主机上,它将从队列中读取分片的文档并发送到 Solr 进行索引(通过 REST API 或 SolrJ)。
* Hbase 表扫描和文档生成器不是我们的瓶颈,因此我在这里只提到 Solr 索引性能。
原文:https://medium.com/box-tech-blog/solr-improving-performance-for-batch-i…
- 70 次浏览
【搜索引擎】如何选择企业搜索引擎
在本博客系列的第一部分中,我们详细展示了智能企业搜索的旅程:起点、要访问的地标和预想的目的地。这篇后续的博客文章是关于导航到我们之前定义的一个里程碑:选择企业搜索引擎。
人们很容易认为搜索引擎的选择是一项技术任务:哪个引擎比其他引擎更好?然而,如果单纯考虑搜索引擎的功能,您可能会发现不同搜索引擎之间的差异是微乎其微的。当比较智能搜索引擎增加的人工智能认知功能时,这种差异就更明显了。尽管如此,在我们的旅程中还是有很多变量需要考虑。
我将描述为我们的客户在选择他们的新搜索引擎时工作良好的步骤。
选择企业搜索引擎

5步选择企业搜索引擎
步骤1:确定潜在的搜索引擎
让我们先列出所有可能适合您需要的搜索引擎。
列表的第一个来源是您当前的供应商。您的组织中可能已经有两个或更多的搜索引擎在运行。任何由供应商或活跃的开源社区维护和支持的当前部署的搜索引擎都可以考虑。如果你的搜索引擎还没有升级到最新的稳定版本也没关系。在这种情况下,将搜索引擎的最新版本添加到您的列表中,以便您最终将最新版本与其他选项进行比较。
第二个来源可能是分析师报告,比如Gartner的Insight引擎魔力象限报告或Forrester Wave™认知搜索报告。一定要找最新的。这些资源为你的研究提供了很好的概览信息。
如果您从事电子商务或其他特定领域,那么除了针对您所在行业的专门功能外,您可能还希望寻找具有强大嵌入式搜索的目标应用程序的报告。在这种情况下,您可能寻找的不是企业搜索引擎,而是更侧重于用例的搜索解决方案。本博客仍然适用于选择这样的搜索平台。
行业分析师通常根据某些条件创建他们的列表,可能不会产生一个详尽的列表。因此,完成你的列表的第三个来源将是任何你可能读到或听说过的搜索引擎。它可能是您尚未从现有供应商使用的产品。或者你在营销邮件、会议、网络研讨会上看到的东西。
第二步:缩小你的候选搜索引擎列表
如果你的列表中有超过12个搜索引擎,我建议你将搜索范围缩小到几个——也就是说五个或更少。对于我们通常做的评估类型,我更喜欢最多使用三个引擎。
为了从名单中删除一些候选人,我喜欢从检查每个候选人与主要破坏者之间的关系开始。通常情况下,我只需要做一点点工作就可以取消一些申请者的资格。下面的列表展示了我过去看到的一些潜在的阻碍。每个组织都是不同的,有些组织可能有反对或支持下面一项或多项内容的政策或指示。所以,在经历每一件事的时候,考虑一下你目前的情况和对未来的期望。
- 自托管。这是DIY模型。无论它在您的数据中心还是基于云的虚拟机中,您都负责部署、配置、维护和更新搜索引擎。许多组织正在远离这种传统的模型,以避免需要在内部管理软件。如果您更喜欢托管服务,那么任何自托管引擎都将从列表中消失。
- 来自搜索引擎供应商的软件即服务(SaaS)或平台即服务(PaaS)。这些是托管云服务,如AWS Elasticsearch或Amazon Kendra,谷歌云搜索,Azure认知搜索等。我的一些客户更喜欢PaaS而不是SaaS,因为PaaS方法提供了额外的数据控制。您可能需要与您的安全、隐私或法律团队就遵从性进行检查。这有助于迅速取消一些候选人的资格。
- 封闭引擎。您可能熟悉现已停产的谷歌搜索设备(GSA)。它对于某些应用程序或组织来说很好,但对于其他应用程序或组织来说还不够。这基本上是一个黑箱解决方案。虽然有像GSA这样的产品,但需要定制或更多的控制将取消一个封闭引擎的资格。
- 混合式。混合式有多种变种。它可能是一个整合了推荐服务的自托管搜索引擎;您的私有云与本地云的组合;或您的私有云与第三方云服务;等。这些是更复杂的解决方案,但是组织有合理的理由要求这样的部署。有些搜索引擎在混合解决方案中表现不佳,因此不适合进行评估。
根据您的组织需求,您可能有一组更具体的项目。可能有基于预先批准的供应商列表的限制,因为加入一个新的供应商可能太耗时或复杂。我们的目标是在没有太多分析的情况下,快速地将一些搜索引擎从列表中划掉。请记住,我们试图将我们的名单缩小到最有前途的候选人,希望缩小到三个或一个可管理的名单,以便进行更深入的比较。
第三步:定义评估标准
根据我的经验,当你与多个利益相关者打交道时,你选择一个多年有用的搜索引擎的几率会增加。与你当前的搜索利益相关者合作,但不要忘记未来的利益相关者。同时考虑当前和未来的搜索客户端,可以让你更好地评估现有的选择。
虽然您组织的一些应用程序可能已经具有了搜索功能,但它们可以从企业平台而不是筒仓实现中获益。
以下是你的评估标准的一些一般类别。我将深入到每个类别,并概述我们的客户通常需要或希望拥有的特定元素。
- 连接器或爬虫。这些机制用于将数据从源加载到搜索引擎中。对于需要索引的数据源,搜索引擎有多少个连接器?除了现在必须索引的源之外,还应该包括将来可能索引的源。如果您计划在一到两年内停用一个源,您可能想要排除该源,因为您可能不希望在其数据迁移到新的源之前对其进行索引。
- 索引前的数据处理。为索引准备数据是最有价值的活动之一,但在搜索实现中经常被忽略。为了提高可查找性、搜索相关性计算、过滤、排序或其他需要,数据需要清理、规范化或丰富。一些搜索引擎包括开箱即用的数据处理器,并支持针对特定数据处理需求的定制处理器。
- 查询处理。搜索术语,或者在某些情况下,用于查询的非结构化文本也可以从搜索方面的一些准备中获益。就像它在索引、查询清理、规范化或充实方面所做的那样,这将使搜索引擎能够更好地查找匹配的文档或根据相关性对它们进行评分。一些搜索引擎提供了您可能会使用的具有特定意图的开箱即用的查询解析器。最后,寻找将来可能需要添加自定义查询组件的可扩展性功能。
- 语言学的支持。如果您的内容采用多种语言,那么支持或可扩展性能力可能是选择一种引擎而不是另一种引擎的关键原因。语言通常同时应用于索引端和查询端。语言学可以用作处理管道组件或文本分析特性。
- 第三方系统集成。随着时间的推移,一些搜索引擎与内容管理系统或软件结成了强大的合作伙伴关系,甚至可能为软件中的搜索功能提供支持。在这种情况下,搜索引擎可能已经与其他软件进行了本地集成。这是针对特定搜索需求的加速器。
- 搜索结果安全性调整。企业搜索应用程序必须保证用户只能从为他们准备的数据集获得搜索结果。许多搜索引擎提供对文档级别或元数据字段的访问控制。然而,一些搜索引擎足够灵活,可以实现字段级安全性。有些引擎不提供开箱即用的安全性调整,但可以通过自定义集成或插件来支持它。
- 用户界面(UI)工具包。虽然您可能拥有自己的UI开发团队,但您可能需要开箱即用的UI组件来促进搜索客户机应用程序的集成。一些发动机带有这样的部件;其他一些工具允许您创建独立的搜索应用程序或完整的搜索结果页面(SERP),以嵌入到您自己的系统中。
- 搜索分析和网站分析。搜索引擎通常生成或允许生成搜索信号或事件。不断增长的搜索和网站分析功能使智能搜索引擎能够提供更相关和个性化的搜索结果。这些分析特性可以使用机器学习(ML)或其他高级方法来分析信号或产生见解。
- 高级人工智能(AI)功能。智能搜索引擎获得他们的资格基于他们提供的人工智能功能。相关性评分、基于mlb的查询建议、推荐、查询意图和各种其他ai支持的特性的自动调优并不是搜索引擎的标准,这可能是选择一个而不是另一个的原因。
- 授权模型。与任何软件一样,许可证是至关重要的。供应商使用的模型规定了成本、可扩展性、可伸缩性或其他需要为您的需求仔细分析的条件。
- 测试支持。一些引擎内置了执行A/B测试、ML模型测试或比较、相关性排名评估等功能。我很高兴看到添加了这些特性,使产品负责人、搜索管理员和开发人员更容易改进相关性。
您可以使用其他标准来扩展上述列表,如管理用户界面、软件开发工具包(SDK)、日志、监控、文档或其他您感兴趣的领域。
第四步:根据标准评估你的候选搜索引擎
你现在应该有了三个左右的候选人,以及评估标准。多年来,我和我的同事制作了多个电子表格用于搜索引擎评估。一般流程如下:
- 创建一个表
- 列举您定义的所有标准
- 确定每个标准的权重
- 评估所有候选搜索引擎的每个标准
- 将你对该标准的评估与分配的权重相乘,这会生成每个引擎的标准得分
- 在搜索引擎的所有标准中总结得分
在步骤4之后,您应该对所有潜在搜索引擎的所有标准进行评估。这一步包括研究搜索引擎的文档,咨询搜索引擎专家,在某些情况下,联系供应商。
第五步:检查你的分数卡,选择最合适的
电子表格的目的是为潜在的搜索引擎提供一个客观的评估。这个步骤应该很简单,因为电子表格已经计算了每个类别的分数以及每个搜索引擎的总分数。
但通常情况下,不同选项的总分差别并不大。这时分类就派上用场了。您可以根据对您的需要更重要的某些类别来选择最终的引擎。如果你选择把重点放在比较某些类别的小计分值上,就不要有一个非常主观的因素,因为它可能会在最终的选择中造成偏差。
旅程的下一站:计划您的搜索引擎实现
恭喜你!经过仔细的评估,您已经选择了您的下一个企业搜索引擎。旅程还在继续,但在实施之前还有很多事情要做:
- 计划实施新的搜索引擎,
- 准备一个多学科的团队以确保成功的实施,
- 规划对现有引擎的支持,
- 培训你的员工使用新引擎
- 还有很多其他的东西。
它可能是压倒性的…因此,计划你的下一段旅程是必要的。还记得我在本系列的第一部分中描述的地标吗?在搜索引擎选择过程中,您可能会识别出其他地标,并弄清楚如何到达它们。
我相信你会有一个更好的想法,下一步后评估候选人搜索引擎对你的详细要求和期望。例如,在实现新的搜索引擎时,可能需要调整资源来维护当前的搜索引擎。您可能需要将搜索与一些现有的应用程序解耦,甚至可能需要开发一个API层来最小化以后更改搜索引擎的影响。因此,确保在实现所选搜索引擎之前访问了这些准备里程碑。
本文:http://jiagoushi.pro/node/1153
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 138 次浏览
【搜索引擎】提高 Solr 性能
这是一个关于我们如何设法克服搜索和相关性堆栈的稳定性和性能问题的简短故事。
语境
在过去的 10 个月里,我很高兴与个性化和相关性团队合作。我们负责根据排名和机器学习向用户提供“个性化和相关的内容”。我们通过一组提供三个公共端点的微服务来做到这一点,即 Home Feed、Search 和 Related items API。我记得加入团队几个月后,下一个挑战是能够为更大的关键国家提供优质服务。目标是保持我们在较小国家/地区已经拥有的完美性能和稳定性。
我们使用 Zookeeper 在 Openshift 上的 AWS 中使用 SolrCloud (v 7.7)。在撰写本文时,我们很自豪地提到,该 API 每分钟服务约 15 万个请求,并每小时向我们最大区域的 Solr 发送约 21 万个更新。
基线
在我们最大的市场中部署 Solr 后,我们必须对其进行测试。我们使用内部工具进行压力测试,我们可以大致获得所需的流量。我们相信 Solr 配置良好,因此团队致力于提高客户端的性能并针对 Solr 设置更高的超时时间。最后我们同意我们可以稍微松散地处理交通。
迁移后
服务以可接受的响应时间进行响应,Solr 客户端表现非常好,直到由于超时而开始打开一些断路器。超时是由 Solr 副本响应时间过长的明显随机问题产生的,这些问题在没有信息显示的情况下更频繁地影响前端客户端。以下是我们遇到的一些问题:
- 高比例的副本进入恢复并且需要很长时间才能恢复
- 副本中的错误无法到达领导者,因为它们太忙了
- 领导者承受过多的负载(来自索引、查询和副本同步),这导致它们无法正常运行并导致分片崩溃
- 对“索引/更新服务”的怀疑,因为减少其到 Solr 的流量会阻止副本停止或进入恢复模式
- 完整的垃圾收集器经常运行(老年代和年轻代)。
- 运行在 CPU 之上的 SearchExecutor 线程,以及垃圾收集器
- SearchExecutor 线程在缓存预热时抛出异常 (LRUCache.warm)
- 响应时间从 ~30 ms 增加到 ~1500 ms
- 发现某些 Solr EBS 卷上的 IOPS 达到 100%
处理问题
分析
作为分析的一部分,我们提出了以下主题
Lucene 设置
Apache Solr 是一个广泛使用的搜索和排名引擎,经过深思熟虑并在后台使用 Lucene 进行设计(也与 ElasticSearch 共享)。 Lucene 是所有计算背后的引擎,并为排名和 Faceting 创造了魔力。是否可以对 Lucene 进行数学运算并检查设置?我可以根据大量文档和论坛阅读资料分享一个近似结果,但是它的配置不如 Solr 的数学那么重。
调整 Lucene 是可能的,前提是您愿意牺牲文档的结构。真的值得努力吗?不,当您进一步阅读时,您会发现更多信息。
文档与磁盘大小
假设我们有大约 1000 万个文档。假设平均文档大小为 2 kb。最初,您的磁盘空间将至少占用以下空间:

分片
一个集合拥有多个分片并不一定会产生更具弹性的 Solr。当一个分片出现问题而其他分片无论如何都可以响应时,时间响应或阻塞器将是最慢的分片。
当我们有多个分片时,我们将文档总数除以分片数。这减少了缓存和磁盘大小并改进了索引过程。
索引/更新过程
是否有可能我们有一个过度杀伤的索引/更新过程?鉴于我们的经验,这并不过分。我将把这个问题的分析留给另一篇文章。否则,这将过于广泛。在我们的主要市场,我们已经达到每小时 21 万次更新(高峰流量)。
Zookeeper
Apache Zookeeper 在此环境中的唯一工作是尽可能准确地保持所有节点的集群状态可用。如果副本恢复过于频繁,一个常见问题是集群状态可能与 Zookeeper 不同步。这将在正在运行的副本之间产生不一致的状态,并且尝试恢复的副本最终会进入一个可能持续数小时的长循环。 Zookeeper 非常稳定,它可能仅由于网络资源而失败,或者更好地说是缺少它。
我们有足够的内存吗?
理论
Solr 性能最重要的驱动因素之一是 RAM。 Solr 需要足够的内存用于 Java 堆,并需要可用内存用于 OS 磁盘缓存。
强烈建议 Solr 在 64 位 Java 上运行,因为 32 位 Java 被限制为 2GB 堆,这可能会导致更大的堆不存在的人为限制(在本文后面部分讨论) .
让我们快速了解一下 Solr 是如何使用内存的。首先,Solr 使用两种类型的内存:堆内存和直接内存。直接内存用于缓存从文件系统读取的块(类似于 Linux 中的文件系统缓存)。 Solr 使用直接内存来缓存从磁盘读取的数据,主要是索引,以提高性能。
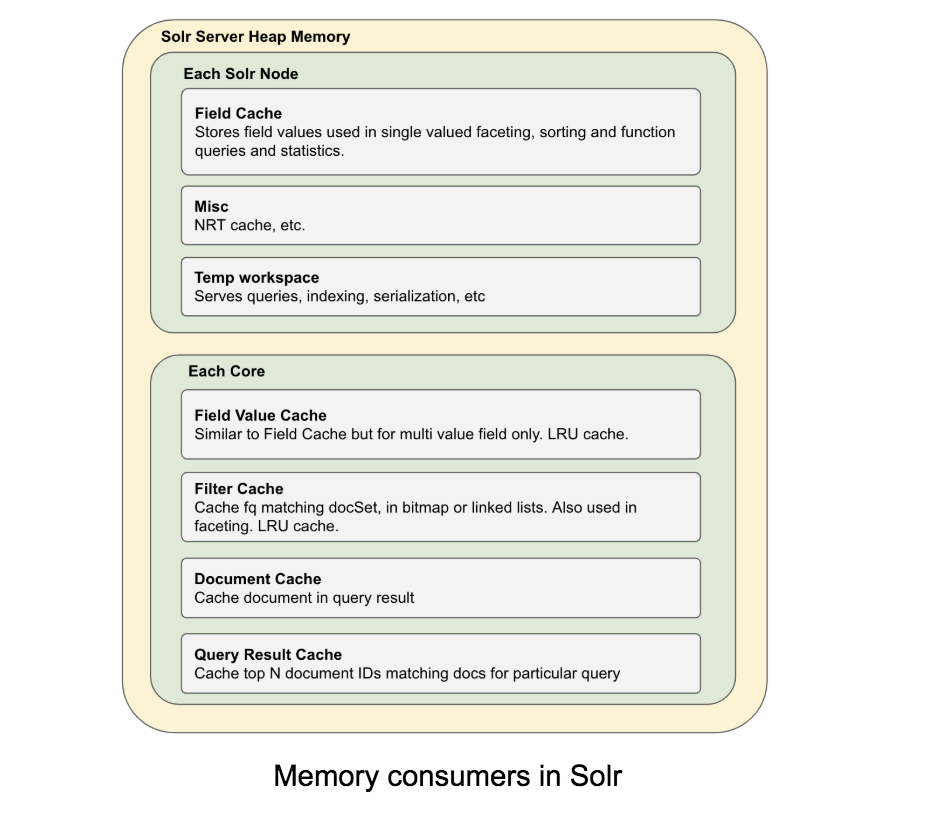
当它被暴露时,大部分堆内存被多个缓存使用。
JVM 堆大小需要与 Solr 堆需求估计相匹配,以及更多用于缓冲目的。 堆和操作系统内存设置的这种差异为环境提供了一些空间来适应零星的内存使用高峰,例如后台合并或昂贵的查询,并允许 JVM 有效地执行 GC。 例如,在 28Gb RAM 计算机中设置 18Gb 堆。
让我们记住我们一直在为 Solr 改进的方程式,与内存调整最相关的领域如下:

虽然下面的解释很长而且很复杂,但是为了建立另一个帖子,我仍然想分享我们一直在研究的数学。 我们在解决问题之初就使用了自己的计算器,只是为了实现后来在线社区共享的类似问题。
此外,我们确保在启动 Solr 时在 JVM Args 中正确启用垃圾收集器。

缓存证据
我们根据 Solr 管理面板中的证据调整缓存,如下所示:
- queryResultCache 的命中率为 0.01
- filterCache 的命中率为 0.43
- documentCache 的命中率为 0.01
垃圾收集器和堆
使用 New Relic,我们可以检查实例上的内存和 GC 活动,并注意到 NR 代理由于内存阈值而频繁打开其断路器(浅红色竖线):20%; 垃圾收集 CPU 阈值:10%。 此行为是实例上可用内存问题的明确证据。
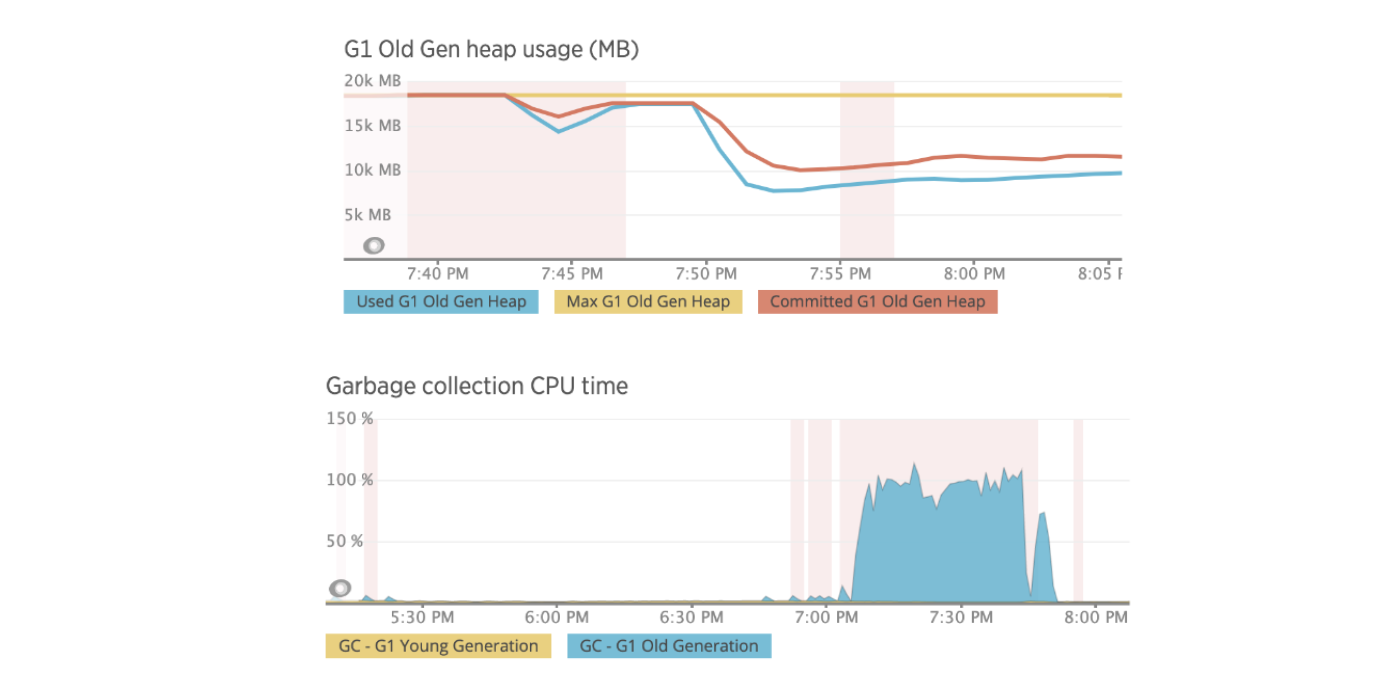
我们还可以监控一些高 CPU 实例进程,发现在 searcherExecutor 线程使用 100% 的 CPU 时占用了大约 99% 的堆。 使用 JMX 和 JConsole,我们遇到了包含以下内容的异常:
…org.apache.solr.search.LRUCache.warm(LRUCache.java:299) …作为堆栈跟踪的一部分。 上述异常与缓存设置大小和预热有关。
磁盘活动 — AWS IOPS
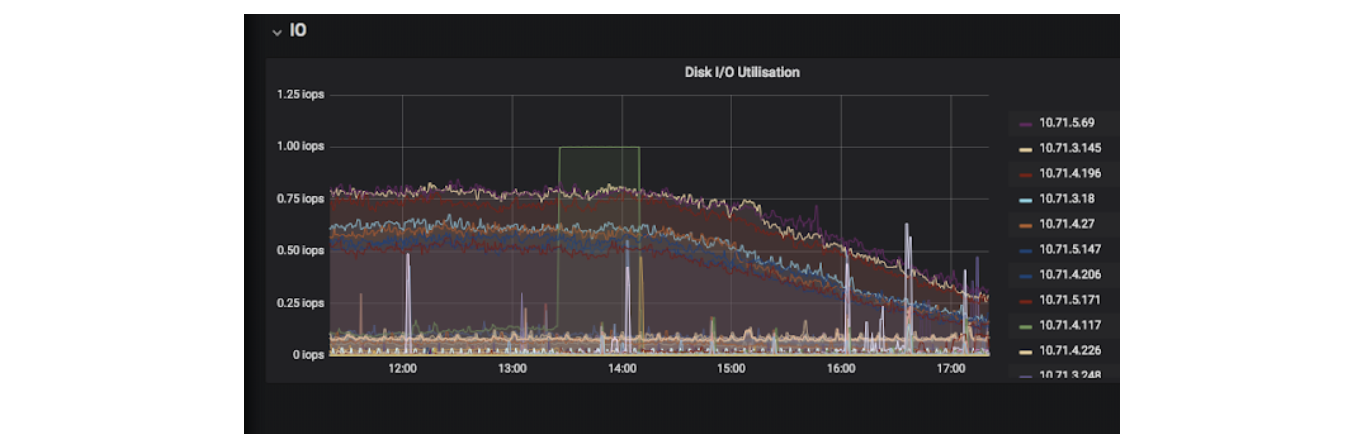
开始解决问题
搜索结果容错
为前端客户端提供搜索结果的第一个想法是始终让 Solr 副本仍然存在以响应查询,以防集群由于副本处于恢复甚至消失状态而变得不稳定。 Solr 7 引入了在领导者及其副本之间同步数据的新方法:
- NRT 副本:在 SolrCloud 中处理复制的旧方法。
- TLOG replicas:它使用事务日志和二进制复制。
- PULL 副本:仅从领导者复制并使用二进制复制。
长话短说,NRT 副本可以执行三个最重要的任务,索引、搜索和引导。另一方面,TLOG 副本将以稍微不同的方式处理索引,搜索和引导。差异因素在于 PULL 副本,它只为带有搜索的查询提供服务。
通过应用这种配置,我们可以保证只要分片有领导者,PULL 副本就会响应,从而大大提高可靠性。此外,这种副本不会像处理索引过程的副本那样频繁地进行恢复。
当索引服务满负荷时,我们仍然面临问题,导致 TLog 副本进入恢复。
调整 Solr 内存
基于这个问题我们是否有足够的 RAM 来存储文档数量?,我们决定进行实验。最初的担忧是为什么我们在文档的“单位”中配置这些值,如下所示:

根据之前共享的公式,考虑到我们有 700 万份文档,估计的 RAM 约为 3800 Gb。 但是,假设我们有 5 个分片,那么每个分片将处理大约 140 万个直接影响副本的文档。 我们可以估计,使用该分片配置,所需的 RAM 约为 3420 Gb。 这不会产生根本性的变化,所以我们继续前进。
缓存结果
从缓存证据中,我们可以看到只有一个缓存被使用得最好,即 filterCache。 测试的解决方案如下:

通过之前的缓存配置,我们获得了以下结果:
- queryResultCache 的命中率为 0.01
- filterCache 的命中率为 0.99
- documentCache 的命中率为 0.02
垃圾收集器结果
在本节中,我们可以看到 New Relic 提供的垃圾收集器指标。 我们没有老年代活动,通常会导致 New Relic 代理打开它的断路器(内存耗尽)。
磁盘活动结果
我们在磁盘活动方面也取得了惊人的成果,索引也大幅下降。
外部服务结果
其中一项访问 Solr 的服务在 New Relic 中的响应时间和错误率显着下降。
调整 Solr 集群
多分片模式的一个缺点是,如果任何副本被破坏,分片领导者将比其对等节点花费更多的时间来回答。这导致分片中最差的时间响应,因为 Solr 会在提供最终响应之前等待所有分片回答。
为了缓解上述问题并考虑到前面描述的结果,我们决定开始逐渐减少节点和分片的数量,这对降低内部复制因子有影响。
结论
经过数周的调查、测试和调优,我们不仅摆脱了最初暴露的问题,而且通过减少延迟提高了性能,通过设置更少的分片和更少的副本降低了管理复杂性,获得了对索引/更新的信任服务满负荷工作,并通过使用几乎一半的 AWS EC2 实例帮助公司减少开支。
我要特别感谢使这成为可能的团队,以及 SRE 和 AWS TAM 的指导和支持。
原文:https://tech.olx.com/improving-solr-performance-f4202d28b72d
本文:https://tech.olx.com/improving-solr-performance-f4202d28b72d
- 155 次浏览
【搜索引擎】搜索和非结构化数据分析:2020年值得关注的5大趋势
大多数组织都很好地利用了结构化数据(表格、电子表格等),但是很多未开发的业务关键的见解都在非结构化数据中。
80%组织正在意识到他们80%的内容是非结构化的。
企业中近80%的数据是非结构化的——工作描述、简历、电子邮件、文本文档、研究和法律报告、录音、视频、图片和社交媒体帖子。虽然这些数据过去非常难以处理和使用,但神经网络、搜索引擎和机器学习的新技术发展,正在扩展我们使用非结构化内容进行企业知识发现、搜索、业务洞察和行动的能力。
搜索加人工智能正在解决现实世界的问题
想想你智能手机上的应用程序——Siri, Alexa, Shazam, Lyft等等。您可能没有意识到这一点,但它们都是由一大批搜索引擎在幕后工作提供动力的。这些应用程序将搜索与人工智能技术(如自然语言处理、神经网络和机器学习)相结合,可以处理你的语音命令或文本输入,搜索不同的数据源,并返回所需的答案,所有这些都是实时且非常准确的。
在企业内部,这些技术可以将员工与他们所需要的内容和答案联系起来,而不管答案在哪里——在文档、财务系统、人力资源系统或政策和程序数据库中。

搜索已经从寻找文件发展到提供答案
到2020年,我们希望看到更多的人工智能搜索和基于搜索的分析应用支持企业。
下面是搜索和非结构化数据分析领域中值得关注的五大趋势。
1. 神经网络和搜索引擎
埃森哲的《峡湾趋势2020》显示,神经网络是支持创新型企业人工智能系统的关键技术,它可以通过模式识别“学习”执行任务。通过分析大量的数字数据,神经网络可以学会识别照片,识别语音命令,并对自然语言搜索查询作出反应。神经网络超越了简单的关键词搜索,使搜索引擎能够理解用户的意思和意图,从而提供最个性化、最相关的结果。
最新的神经网络(BERT及其衍生产品)能够创建一个“语义空间”——对企业内容的抽象理解——可以用于:
- 深入搜索:识别具有相同含义的句子,而不是仅仅包含相同的搜索关键词(如“公司费用政策”和“商务旅行报销”)
- 更好的分类:为更好的导航或管理对内容进行分类(例如,合规性、筛选、补救等)
- 提问/回答:从文件中提取事实,回答与原始材料相关的具体问题(例如:“美国上季度的收入是多少?”)
这些神经网络已经被用于高度管理的内容,如知识库文章、政策和程序、文档、测试标准等等。在接下来的几年里,我们希望看到更多的组织应用神经网络来更好地理解他们的文档内容和用户查询,提供高度相关的、基于上下文的答案。
2. 语义搜索
语义搜索扩展到神经网络,处理范围广泛的企业用户的查询和请求,并可以直接从业务系统得到即时的回答。这使得语义搜索成为用户社区所需的文档、问题、事实和业务数据的单一访问点。语义搜索的目的是为用户的问题提供精确、准确、即时的答案,包括短尾和长尾。语义搜索包括四个部分:
- 理解查询中的实体(业务对象)
- 理解查询的目的
- 将请求映射到应答代理
- 获取答案并将其报告给最终用户
语义搜索已经使搜索引擎从基于关键词显示结果列表发展到理解这些词的意图并显示用户真正需要的目标内容。如果用户正在搜索“Q1营收”,他/她可能不是在寻找包含“Q1营收”的结果列表,而是一个快速响应,比如“1.23亿美元”。“更多的是什么?也许收入数字甚至可以按市场细分进行细分。
许多因素支持语义搜索的兴起:
- 数据仓库、数据湖和内容摄入技术的增长正在打破数据竖井,使有价值的内容在组织之间随时可用。
- 为实现业务应用程序语义搜索而设计的新工具的出现,帮助组织解决了集成挑战,并极大地降低了实现成本。
- 新的机器学习方法,如先进的神经网络,允许语义搜索引擎更好地理解用户的搜索请求,分析查询中的对象,并将查询映射到意图和确定回答代理。
请阅读我的短文,进一步了解语义搜索和示例业务用例。
3.文档的理解
当计算机阅读文档时,它们不会注意文体细节,比如某个单词在页面上的位置,或者它与其他单词的关系。但是表示元素——定位、颜色、字体、图形元素等等——包含了文本本身无法传达的重要语义信息。作为人类,我们无需思考就能理解这一切。例如,我们知道,字体大小可以表示重要性,标题、段落或图像的位置可以影响这些项目在文档中的意义。然而,由于计算机目前忽略了大多数这些表示元素,组织无法从其文档中提取实质性的价值。
人工智能正在通过检查这些表现元素,使从非结构化内容中提取洞察力成为可能。可以对智能文档处理引擎进行培训,使其能够阅读这种表示性信息并向最终用户交付洞察力。想象一下可以利用文档理解的各种企业用例:
- 自动PDF发票处理:提取表,总计,名称/值对
- 从纸质流程到电子流程的转变:药品生产从批记录到电子批记录;或从pdf文件到实验室信息管理系统记录实验室测试程序
- PowerPoint内容搜索:搜索幻灯片,突出显示幻灯片内的搜索,提取标题,删除页脚
- 搜索地球科学报告:找到测井、地震剖面、地图和其他元素,并将这些项目与全球的地理位置联系起来
- 自动邮件路由和表格填写:减少邮件项目的处理时间,包括蜗牛邮件和电子邮件
- 工程图纸的自动转换:转换为材料清单,并最终转换为连接图和流程图
- 策略和过程文档搜索:搜索和匹配各个段落,或从文本中提取直接答案
- 和更多的
阅读更多关于我们如何为企业构建这些文档理解应用程序的内容。
4. 图像和语音搜索
2019年埃森哲数字消费者调查发现,大约一半的受访者已经在使用数字语音助手(DVA), 14%的人计划在未来12个月内购买。虚拟助手——Siri、Alexa、谷歌助理等等——正变得无处不在。在人工智能技术的推动下,它们使人类和计算机在日常互动中能够对话。它们带来了更深入的自然语言理解,不仅增强了搜索功能,而且提供了一种全新的查找信息的方式。
语音助理已经进入企业,使客户和员工能够更容易地与企业数据进行交互。例如,员工现在可以问“我们在欧洲的数据科学专家是谁?”或“我如何预订巴黎办公室的会议室?”从外部来看,语音和图像搜索功能超越了传统的文本搜索,为客户和合作伙伴提供了在公司网站上查找信息的更简单的方法。
“到2021年,那些重新设计网站以支持视觉和语音搜索的早期采用率品牌将增加30%的数字商务收入。
这些工具和语义搜索(上面讨论过)之间有天然的协同作用。在许多情况下,聊天机器人可以被删除——后端可以完全由一个健壮而全面的语义搜索引擎来处理。
5. 知识图谱
根据我们去年的预测,知识图的发展将继续推动整个企业更智能的搜索交互。
将组织的现有数据聚合到一个存储库(通常是企业数据湖)是一个起点。但是我们如何利用这些数据呢?我们需要给它添加上下文、关系和意义。从不同企业功能的片段数据记录中,自然语言理解(NLU)算法可以创建一个相互连接的信息网络,表明数据记录是如何相互连接的,从而创建企业知识图。当用户提出问题时,搜索引擎和问答系统可以立即抓取相关信息的快照,并提供相关的见解。
请注意,知识图可以跨越广泛的复杂性:
- 适度相互联系:
- 雇员和雇员信息
- 业务单位和主要团队成员
- 办公室的位置
- 产品和支持人员
- 物理平面机械位置
- 丰富的相互关联的:
- 组织层次结构
- 办公室走廊、楼梯和会议室位置
- 机器部件及其邻近性/相互连接性
- 产品类别、血统及配套配件
- 物理设备和机器的相互连接
- 客户、联系人、销售人员和购买的产品
- 策略和过程约束、条件和要求
随着新的数据点和深刻的关系的无限增加,知识图将会不断增长。
除了搜索
展望2020年和未来几年,我们预计这五项发展将进一步发展,并在企业内部得到更广泛的利用。重点将放在如何应用这些智能技术来发现和最大限度地使用非结构化数据。超越传统的搜索应用程序,新的搜索和人工智能驱动的用例每天都被发明出来,以提供更多的价值和更好的结果。随着人工智能技术和方法的改进,它们可以被组织用来以更低的成本和更强大的结果解决技术和组织的挑战。有了实际的策略、领域的专业知识和专家的实施,组织可以为创新释放无限的机会。
本文:http://jiagoushi.pro/node/1156
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 211 次浏览
【搜索引擎】搜索引擎过时了,“寻找引擎”流行起来
研究报告简述
- 多年来,像谷歌这样的搜索引擎一直在改变内容的呈现方式,通过更好地理解用户需求,提供更准确的结果。
- 现在,技术使得组织采用这种新的语义搜索功能比以往任何时候都更容易。
- 这使得企业内部大量的知识得以释放,并将其置于员工的指尖。
- 因此,搜索引擎正在成为“寻找引擎”,寻找用户需要的答案。
如果你理解用户在搜索什么,你可以制作一个更好的搜索引擎:更好的理解=更好的结果。这是贯穿整个搜索引擎发展的指导原则。问题是,语言是复杂的。一个搜索查询中可能有很多单词——更不用说这些单词和它们不同的意思可能的组合——直到现在我们才开发出更好地理解用户意图并使更好的搜索成为现实的工具。
花点时间考虑这些统计数据,您就会明白为什么过去许多提高语义理解的尝试都失败了。迄今为止规模最大的百分比的话(超过90%)将只用于我们日常生活的一个小的次数,因此在任何数据集。太少的出现使得这些话不适合机器学习(ML)方法需要大量的训练数据集。
另一方面,有一小部分词汇使用所有的时间(这样的词“的”或“和”),变得过于模糊,因此也不适合毫升。这使得少量常用的“金发姑娘”字足以产生足够的例子,但不是经常,他们变得无用。所以,第一个挑战就是识别这些词——大海捞针。
第二个挑战是理解人们在对话中使用这些词汇时通过共享的世界知识给语言带来的意义。这就解释了为什么过去的语义搜索方法没有成功,为什么花了这么长时间才达到今天的水平。
但是,如果我们能够训练计算机,使其获得有效理解语言所必需的世界知识,并将其应用于语义搜索,情况会怎样呢?
一个搜索查询中可能有太多的单词,直到现在我们才开发工具来更好地理解用户意图,并使更好的搜索成为现实。
欢迎来到新的语义搜索时代
新的语义搜索已经将搜索引擎从基于用户在搜索栏中输入的字面词来显示内容,转向理解这些词的意图并显示用户真正需要的内容。换句话说,搜索引擎正变得越来越像文字搜索引擎。
例如,请考虑在谷歌这样的搜索引擎中输入“1 USD in GBP”或“country code 56”会产生什么结果。搜索结果会给出你想要的答案,而不仅仅是一系列包含你的搜索语言的结果。
新的语义搜索已经将搜索引擎从基于用户在搜索栏中输入的字面词来显示内容,转向理解这些词的意图并显示用户真正需要的内容。
通过从外部获取文本数据,新的语义搜索方法比过去的方法对细微差别有更广泛和更准确的理解。多亏了神经网络(NNs)和通用句子编码器,计算机正在接受阅读句子的训练,并对内容进行“抽象语义理解”。例如,搜索“1美元兑换成英镑”或“1美元兑换成英镑”可以用来训练系统将查询“理解”为[数字][货币][动作或短语][货币]。这个模式的意思是“将一种货币转换成另一种货币。”
通常,这些网络神经网络都是使用维基百科和MedLine等来源的内容广泛、目的交叉的文本进行培训的。有了足够的文本,我们就会有更多的例子来说明单词(和短语)是如何使用的,这会让我们对内容有更丰富的理解。通过这种方式,我们将外部世界的知识引入到我们的“搜索和发现”经验中,从而产生更好的结果。
为企业带来新的语义搜索
谷歌引入了新的语义搜索功能,通过真正理解用户的需求,它开始重新定义当前的挑战。这听起来很简单,作为消费者,我们已经开始期待每个服务提供商和搜索引擎都能提供这种搜索能力。
但在企业中,这并不总是可能的。由于无法访问成千上万的数据科学家和机器学习专家来实现更复杂的语义搜索功能,组织在很大程度上难以驾驭这种方法。语义搜索功能既昂贵又费时。
根据我们的经验,采用企业范围的搜索方法也遇到了三个主要障碍:
- 1. 传统上,数据是不可访问的,被锁在孤立的业务系统中。
- 2. 到目前为止,将最好的搜索引擎与最好的机器学习和自然语言处理(NLP)功能集成起来是很困难的,而且几乎是不可能的。
- 3.为了解决语言歧义问题,需要手工编码,因此技术未能有效和大规模地解决这个问题。
幸运的是,这些障碍正在逐渐消失。
对此,我们有信心-新语义搜索将成为每一个组织的信息的瑞士军刀。
数据仓库、数据湖和数据摄取工具的增长正在打破竖井,使数据更容易跨组织使用。专门为实现业务应用程序语义搜索而设计的新工具的出现,正在解决集成的挑战。
虽然搜索引擎、ML和NLP仍然是不同的技术,但我们正在更好地集成它们。事实上,许多搜索引擎公司和云服务提供商(如谷歌、微软和AWS)现在都提供了现成的伞形解决方案。此外,技术的发展使得不需要编码就可以实现更准确的模糊解决方案和NLP,这意味着新的语义搜索正在迅速成为企业组织现实和可维护的选择。
以我们的一个航空航天制造客户为例。制造车间的员工只需将条形码阅读器对准飞机部件的条形码,该工具的系统就会对如何使用或维护该部件进行全公司范围的搜索,只显示最相关的信息。我们将条形码解释为用户的查询“告诉我这部分的一切,包括如何维护或更换它。”
通过从组织内的专家那里获取企业知识,并通过这个新的语义搜索功能使这些知识变得可操作,我们帮助缩短了用户和所有业务系统之间的距离,并收集了知识。
与其去金融网站查询发票号码或去IT网站询问技术问题,不如想象一下拥有一个能够理解你的需求并提供正确回复的搜索工具的价值。
如果语义搜索最终是创造获取答案和信息的途径,那么创造一个单一的真理来源将是不可分割的一部分。设想使用一个查找工具来查找整个组织中所有问题的答案。在更广泛的业务环境中,可以使用新的语义搜索来改进对任意数量的信息点的访问,例如产品名称、收费代码、电子邮件地址、发票和合同编号、办公地点等等。
与其去金融网站查询发票号码、电子邮件地址,或者去IT网站询问技术问题,不如想象一下拥有一个能够理解你的需求并提供正确答复的搜索工具的价值——更不用说安慰了。
对此,我们有信心-新语义搜索将成为瑞士军刀的每一个组织的信息。公共搜索引擎提升了游戏的实用性和用户体验。现在企业也可以为客户和员工做同样的事情。
原文:https://www.accenture.com/us-en/insights/digital/find-engines
本文:http://jiagoushi.pro/node/1158
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 82 次浏览
【搜索引擎】智慧企业搜索之旅
您当前的企业搜索引擎提供商宣布了该软件的生命周期。供应商建议迁移到一个更现代的引擎。您要考虑他们提供的服务和您组织的需求。此时,您可能会遇到以下一个或多个场景:
- 您将从具有可预测成本计算的固定许可模式转向可变定价模式。
- 您将从一个包含所有所需组件的搜索引擎,转变为以搜索应用程序所需的任何方式集成来自供应商新平台的服务。
- 如果您决定迁移到新搜索引擎,那么在迁移到新引擎时必须维护当前的搜索引擎。
当然,你的情况可能与上述情况有所不同。也许你的搜索引擎来自一家最近宣布被收购的公司(比如ServiceNow在2019年10月宣布收购Attivio搜索引擎)。母公司会继续提供这款引擎并对其进行改进,还是会让它退役?
也许你收购的公司有价值的数字资产存在于不同的搜索引擎中;又一个要添加到您的搜索软件列表管理。这增加了您组织的压力,要求您选择一个引擎来支持所有自定义企业搜索功能,从而降低成本和复杂性。我所说的定制是指您实现和维护的搜索功能,而不是那些已经嵌入的开箱即用的功能。
你在人工智能和云计算时代的企业搜索策略
评估和选择一个搜索引擎是困难的,而且我敢说,随着云计算、分析和人工智能(AI)技术推动的革命,这变得更加困难。但是由于这些技术,现代企业搜索引擎已经发展成为智能搜索引擎(也被称为问答系统、认知搜索或洞察力引擎),提供答案而不仅仅是结果列表。
我开始写这个博客的时候,再次帮助一个组织选择一个新的搜索引擎。这是他们旅程的第一站:绘制出他们想要的企业搜索的路径。这篇文章旨在为你提供实际的开始步骤。

5个步骤定义一个实用的企业搜索策略
第一步:我们在哪里?对情况进行评估
很可能你已经有了一个现代的搜索引擎。然而,它并不是一个简单的升级到最新版本的项目,因为:
- 它的实现方式阻碍了搜索引擎最大限度地发挥自己的功能;
- 在部署过程中,搜索引擎无法从云计算或人工智能等强大技术中获益;
- 以前的一些架构决策限制了您添加新的需求或提供新的搜索应用程序;或
- 描述一下你的问题…
无论你现在的情况如何,把它看作是一种交通需求。如果不提供当前位置,你就无法得到正确的驾驶指南或拼车服务。所以,首先要正确地确定你的搜索引擎在哪里。这是搜索系统的当前状况,而不是它的服务器、数据中心或云位置。
第二步:我们要去哪里?定义目标
如果你还没有,这将是你戴上未来视力眼镜的最佳时机。5年或5年以后,你的搜索解决方案需要在哪里?您肯定对搜索相关功能有一些短期需求。但是,长远的考虑会使你选择搜索引擎的过程变得更容易,选择一个仍能满足你不断变化的需求的搜索引擎,希望包括那些你现在无法想象的搜索引擎。如果你需要一些灵感,请阅读我们的创新引领最近的博客。我将总结一下那篇文章中讨论的主要企业搜索趋势:
- 神经网络和搜索引擎
- 语义搜索
- 文档的理解
- 图像和语音搜索
- 知识图
在定义你的搜索视觉时,你还可以考虑很多其他的特性:认知搜索、洞察和分析、上下文搜索、自然语言处理(NLP)等等。我建议您超越术语,尝试理解每个概念在您的上下文中的含义。关键是向前看,同时保持现实。例如,当你的组织没有当前或计划的人工智能能力时,你会从允许你加入自己的人工智能的搜索引擎中受益吗?在这种情况下,内置的人工智能搜索解决方案或人工智能服务合作伙伴可能比建立自己的更好。
在此步骤中,下面的成熟度模型可以作为评估您的情况和定义企业搜索远景的指导方针。

第三步:对我们有什么好处?设定清晰的期望
现在,你应该有一个清晰的开始和结束你的旅程。作为可视化未来搜索的一个副作用,你可能会想,并希望写下你的理由和好处。我这里并不是在谈论具体的要求。以下是在此阶段需要考虑的一些领域:
- 为终端用户提供更多的自助服务机会
- 搜索引擎的基础设施更少
- 更自动化的管理和操作
- 提高了生产率
- 超越更好的搜索:发现数据和产生见解
稍后将有时间深入每个领域的细节。记住,我们只是清楚地定义了你努力的期望和目的。如果你在去目的地的路上迷路了,他们会提醒你为什么开始旅行。
第四步:沿途我们会在哪些地方停留?计划的旅程
在我写这一部分的时候,我对“旅程”这个词产生了好奇。我了解到,当然是通过一个主要的互联网搜索引擎,这个词有拉丁语和法语的起源。在这两种情况下,这个词都指在一天内发生的事情。持续一天的旅行。最初,这也是它在英语中的用法。然而,它的现代用途,通常是用于需要超过一天的事情。同时,在前进的道路上也可能会遇到阻碍或改变。这就是为什么我将它与搜索应用程序相关联。仅仅实现就可能花费数周的时间,甚至对于小型、简单的搜索索引,从开始到生产都有多个里程碑。
巧合的是,当我在考虑企业搜索引擎选择过程中的站点时,我听到有人在一个项目的上下文中说的是“里程碑”而不是“里程碑”。“里程碑”这个词意味着度量。您可以估计到达每个项目里程碑所需的工作量、时间和其他资源。我们还没到那一步。相反,地标是你在旅行中想要去的地方,但你不一定知道怎么去或什么时候去。你需要在你出发前往下一个地标前弄清楚这些细节。
我想您的不是一个简单的搜索应用程序。您已经读到这里,因为为您的需求选择下一个企业搜索引擎是复杂的。即使是确定要比较的合适候选技术也具有挑战性。我建议你在旅途中确定你想要到达的地标。现在,不用担心订单的问题。简单地列出它们,这样当你更精确地定义事物时就可以引用它们。
以下是一些改变搜索引擎地标的一般例子:
- 选择一个搜索引擎(开源的,如Elasticsearch和Solr;商业引擎,如SharePoint搜索,Sinequa等;或基于云的搜索引擎,如谷歌云搜索、Amazon Kendra、Azure搜索、Microsoft搜索等)
- 扩充你的搜索团队
- 将现有应用程序迁移到新的搜索引擎
- 添加更多搜索应用程序
- 使用基本人工智能增强搜索,如内容丰富、基于人工智能的相关性排名和调优、聚类,或其他现代搜索引擎中已经包含的功能
- 结合高级人工智能,如高级自然语言理解和处理(NLU/NLP),你自己的机器学习模型,与第三方人工智能库或服务(视觉,音频,或其他)集成,等等。
针对您的具体情况,尝试定义比上述示例更具体的里程碑。这些界标不一定每次都是这个顺序。您可能决定首先迁移关键搜索应用程序,为这些应用程序实现一些AI功能,然后返回迁移现有应用程序的另一个子集。或者您可能会发现,您希望从向搜索团队添加人员开始,或者将当前单独的人员加入到单个、集中的搜索团队中。这样做可以从高级搜索团队成员中腾出一些时间来选择下一个引擎。
第五步:想象你的旅程
是时候把所有的东西放在一起了。现在我们有了在地图上绘制我们旅行的主要元素:
- 起点
- 地标性建筑
- 目的地
你甚至可能知道一路上应该拍些什么:你对旅程的期待。你可能会注意到,我们还没有确定到达每个地标的具体方向。现在还可以。我们有一个参照来指导我们从开始到结束,连同主要的转弯和停止。
您的列表中的一些里程碑可能是您的组织所独有的。这个过程应该会帮助您认识到搜索不仅仅是搜索团队的责任。它应该是一种数字资产,将使您的组织的许多部分受益。因此,决定访问它们的顺序可能需要来自多个业务功能的协调和参与。您还应该有一个沟通工具来支持这个过程,并在更新搜索的同时让涉众参与进来。
下一步:选择你的企业搜索引擎
虽然搜索引擎选择可能不会成为你访问的下一个里程碑,但在某种程度上它会。这是我们非常熟悉的旅程的一部分,我将在下一篇博客文章中描述。
本文:http://jiagoushi.pro/node/1155
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 64 次浏览
【搜索引擎】智能企业搜索:为什么知识图和NLP可以提供所有正确答案
在获取信息和洞察力方面,我们正处于一个彻底转变的边缘,我们需要更聪明、更有效地工作。在这篇博客中,我将展示人工智能技术如何增强互联网搜索,现在如何应用于组织内部,从而彻底改变企业搜索所能实现的目标。
信息指数增长
我们所能得到的信息量是惊人的。而且它一直在呈指数级增长:数据量已经达到了44千兆字节,预计在未来五年内将达到175千兆字节(IDC)。80%的数据是非结构化的(电子邮件、文本文档、音频、视频、社交帖子等等),只有20%是某种结构化的系统。
为了从这些海量资源中找到答案,并准确定位我们要寻找的东西,我们需要一种方法从文件中提取事实,并将这些事实存储在便于获取的地方。今天,搜索引擎巨头谷歌和必应正是这样做的,他们将这些事实存储在一个“知识图”中,这个图与他们已经使用多年的搜索引擎紧密相连。
他们的方法是否有效?它如此成功地提供了答案——并且以惊人的规模提供了答案——以至于我们认为这一切都是理所当然的。
搜索变得越来越智能
在过去的几年里,你会注意到我们在日常生活中使用搜索引擎寻找答案的方式发生了微妙而深刻的变化。
当搜索引擎首次被引入时,人们很快就发现,问题越长越复杂,得到正确答案的可能性就越小。因为像“乐购最畅销的汤里有多少卡路里?”虽然不太可能产生结果,但我们成了关键词搜索方面的专家。通过将我们的查询转换成带有“Tesco soup nutrition”这样的关键词的短语,我们发现搜索引擎提供了更多相关的文件,甚至提供了直接的答案,挖掘出了一些重要的信息,这些信息可以让我们改进工作任务,加深我们的知识,或者解决争论。
然而,如今,我们对搜索的期望更多地与我们使用数字助手的方式一致,如Siri、谷歌Home和Alexa,所有这些都是由幕后的搜索引擎驱动的。当我们向他们提问时,我们得到了事实作为回报。因此,我们看到搜索引擎的查询在本质上变得越来越“发现事实”。
大的变化?现在,搜索引擎可以找到,优先排序,并显示我们需要的事实。它们不再像以前那样简单地返回页面(url)列表。相反,它们在可能的时间和地点为问题提供答案,同时提供详细的知识卡片和其他相关的搜索查询,所有这些都旨在帮助我们缩短访问关键事实所需的时间。同样令人印象深刻的是,搜索引擎和数字助手返回的结果比以往任何时候都更准确、更直观。
这对企业搜索意味着什么?
像谷歌和必应这样的搜索引擎在很大程度上归功于两项重大创新。首先,在2012年,谷歌在其搜索引擎中添加了一个知识图。后来,在2015年,该公司推出了RankBrain。两者都是具有里程碑意义的进展。
同样的方法现在也可以应用于企业搜索。将这一技术层添加到企业搜索引擎中,有可能使它们比以往任何时候都更智能。这里的游戏规则改变者是智能企业搜索(也被称为认知搜索或洞察力引擎)。通过将搜索与大量人工智能技术(如自然语言处理、语义理解、机器学习和知识图)相结合,智能企业搜索可以为用户提供一个显著改进的搜索体验——具有更多的洞察力。
知识图谱——为知识建模的一种非常强大的方法
第一个图的知识。在将其搜索引擎转变为“知识引擎”的过程中,谷歌一直在使用知识图来提供有关人物、地点、公司和主题等实体的结构化和详细信息。回想一下你最近一次搜索名人的年龄或者当地药剂师的营业时间,而不是浏览搜索结果列表而直接得到答案的情形。这些信息可能来自知识图,而不是搜索引擎。
因此,它们在问答系统中被证明是非常强大的。知识图越含水,搜索就变得越有洞察力。从结构化数据填充知识图相对简单(假设您信任数据源),从非结构化数据填充知识图需要使用复杂的自然语言处理(NLP)技术和文档权限模型。
为了说明可以实现什么,考虑下面的一段文字。里面有很多信息:
Gillian Russell出生在Invercargill。她是Gingerbeard有限公司的首席执行官,也是Gingerbeard咨询集团的公司秘书。Gillian和她的丈夫Phil Lewis住在英国的沃金厄姆。”
我们可以使用NLP来提取和分类文本示例中提到的事实作为语义三元组。这是三种信息:主体-谓词-对象,它们几乎可以建模实体之间的任何关系。这种编码信息的方法使知识能够以机器可读的方式呈现。
从这些语义三元组中可以生成表示相关实体的知识图。这个知识图是问答系统的强大基础,然后可以遍历它以提供答案,甚至是复杂的问题。
然而,在我们把知识图表放在所有文档上之前,有许多事情需要考虑:
- 我们是否信任此位置的数据源/文档中的信息?
- 吉尔/吉莉安和上面提到的吉莉安·拉塞尔是同一个人吗?
- 是“姜胡子”公司吗?还是海盗类型的人?
- 我们想要提取和记住这些实体之间的什么关系?
- 当他们询问时,谁被允许“接受”这些事实?
假设我们可以为一个给定的用例解决这些类型的问题,下面说明了建模知识和从这个文本示例创建知识图的一般过程。

图1所示。建模知识
这个知识模型可以开始回答如下问题:
- Gillian Russell是哪家公司的顶级员工?
- 谁是姜须有限公司的老板?
- 吉尔认识菲尔·刘易斯吗?
- 沃金厄姆有谁出生在Invercargill?
正如你所看到的,这是一种强大的资源。
单词向量——机器理解意思的方式
这个领域的第二个创新是“单词向量”,它利用机器学习技术来模拟单词含义的多样性和深度。巧妙的是,通过将单词表示为向量,基于人工智能的系统建立了一种我们如何使用单词以及它们之间关联的感觉。
例如,在一个基于人工智能的系统的简化的“心理空间”中,单词“阿姨”(一个亲戚)与“Beeb阿姨”(英国新闻频道BBC的昵称)占据了不同的“心理空间”。“山姆大叔”(联邦政府)和“叔叔”的意思不一样。而在人工智能的“心理空间”中,“阿姨”和“叔叔”的意思是紧密相连的,而“Beeb阿姨”和“山姆大叔”则不是。

图2:将单词表示为向量
以人工智能为基础的系统甚至可以理解一些单词的意思是如何随时间变化的(见图3)。单词向量让搜索引擎知道,当搜索50年代的“radio broadcasts”时,不应该找到写于19世纪50年代的含有“broadcast”的文件。

图3。单词的意思会随着时间而变化
毫不奇怪,对于某些查询类型,单词向量立即使谷歌的准确性提高了15%。随后的创新,如BERT和其他创新,进一步细化了性能,使人们能够更好地理解所使用的词汇。
为企业带来更智能的搜索
对企业来说,真正令人兴奋的事情是什么?我们现在可以开始在组织内部复制谷歌式的搜索体验——重新定义当人们被智能机器增强时可以实现的目标。
谷歌、亚马逊和微软的云搜索产品最近都宣布了与知识图集成的增强企业搜索解决方案。其他传统的内部搜索解决方案也开始意识到与知识图集成的好处。
我们可以利用表面上迥然不同的技术创新带来的巨大碰撞,来彻底改变人们寻找事实并得到他们想要答案的方式。
我已经在搜索行业工作了30年,为世界各地的组织工作过数百个企业搜索项目。而且从来没有这么多的机会来彻底重新定义搜索的功能。利用最新的技术,我们可以从支离破碎的数据点中创造新的价值。现在可以对多个数据片段如何组合在一起获得独特的见解。
由于人工智能技术如NLP和知识图正在迅速成熟,企业将受益于这些技术不断发展的解决问题的能力。不久,我们将能够比以往更准确、更快地回答令人难以置信的复杂问题。无论是发现新的医疗方法,发现看不见的市场变化,还是发现欺诈,每个行业的组织都将获得巨大的利益。
本文:http://jiagoushi.pro/node/1154
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 63 次浏览
【搜索引擎】配置 Solr 以获得最佳性能
Apache Solr 是广泛使用的搜索引擎。有几个著名的平台使用 Solr; Netflix 和 Instagram 是其中的一些名称。我们在 tajawal 的应用程序中一直使用 Solr 和 ElasticSearch。在这篇文章中,我将为您提供一些关于如何编写优化的 Schema 文件的技巧。我们不会讨论 Solr 的基础知识,我希望您了解它的工作原理。
虽然您可以在 Schema 文件中定义字段和一些默认值,但您不会获得必要的性能提升。您必须注意某些关键配置。在这篇文章中,我将讨论这些配置,您可以使用它们在性能方面充分利用 Solr。
事不宜迟,让我们开始了解这些配置是什么。
1.配置缓存
Solr 缓存与索引搜索器的特定实例相关联,索引的特定视图在该搜索器的生命周期内不会更改。
为了最大化性能,配置缓存是最重要的一步。
配置`filterCache`:
过滤器缓存由 SolrIndexSearcher 用于过滤器。过滤器缓存允许您控制过滤器查询的处理方式,以最大限度地提高性能。 FilterCache 的主要好处是当打开一个新的搜索器时,它的缓存可以使用旧搜索器的缓存中的数据进行预填充或“自动预热”。所以它肯定有助于最大限度地提高性能。例如:
<filterCache class="solr.FastLRUCache" size="512" initialSize="512" autowarmCount="0" />
类:SolrCache 实现 LRUCache(LRUCache 或 FastLRUCache)
size:缓存中的最大条目数
initialSize:缓存的初始容量(条目数)。 (参见 java.util.HashMap)
autowarmCount:要从旧缓存预填充的条目数。
配置`queryResultCache`和`documentCache`:
queryResultCache 缓存保存先前搜索的结果:基于查询、排序和请求的文档范围的文档 ID 的有序列表 (DocList)。
documentCache 缓存保存 Lucene Document 对象(每个文档的存储字段)。由于 Lucene 内部文档 ID 是瞬态的,因此该缓存不会自动预热。
您可以根据您的应用程序配置它们。它在您主要使用只读用例的情况下提供更好的性能。
假设您有一个博客,一个博客可以在帖子上有帖子和评论。在 Post 的情况下,我们可以启用这些缓存,因为在这种情况下,数据库读取远远超过写入。所以在这种情况下,我们可以为 Posts 启用这些缓存。
例如:
<queryResultCache class="solr.LRUCache" size="512" initialSize="512" autowarmCount="0" /><documentCache class="solr.LRUCache" size="512" initialSize="512" autowarmCount="0" />
如果您主要使用只写用例,请在每次软提交时禁用 queryResultCache 和 documentCache,这些缓存会被刷新,并且不会产生太大的性能影响。 因此请记住上面提到的博客示例,我们可以在评论的情况下禁用这些缓存。
2.配置SolrCloud

如今,云计算非常流行,它允许您管理可扩展性、高可用性和容错性。 Solr 能够设置结合容错和高可用性的 Solr 服务器集群。
在 setupSolrCloud 环境中,您可以配置“主”和“从”复制。 使用“主”实例来索引信息,并使用多个从属(基于需求)来查询信息。 在主服务器上的 solrconfig.xml 文件中,包括以下配置:
<str name="confFiles"> solrconfig_slave.xml:solrconfig.xml,x.xml,y.xml </str>
查看 Solr Docs 了解更多详细信息。
3.配置`Commits`
为了使数据可用于搜索,我们必须将其提交到索引。在某些情况下,当您拥有数十亿条记录时,提交可能会很慢,Solr 使用不同的选项来控制提交时间,让您可以更好地控制何时提交数据,您必须根据您的应用程序选择选项。
“提交”或“软提交”:
您可以通过发送 commit=true 参数和更新请求来简单地将数据提交到索引,它将对所有 Lucene 索引文件进行硬提交到稳定存储,它将确保所有索引段都应该更新,并且成本可能很高当你有大数据时。
为了使数据立即可用于搜索,可以使用附加标志 softCommit=true,它会快速提交您对 Lucene 数据结构的更改但不保证将 Lucene 索引文件写入稳定存储,此实现称为Near Real Time,一项提高文档可见性的功能,因为您不必等待后台合并和存储(如果使用 SolrCloud,则为 ZooKeeper)完成,然后再进行其他操作。
自动提交:
autoCommit 设置控制挂起更新自动推送到索引的频率。您可以设置时间限制或最大更新文档限制来触发此提交。也可以在发送更新请求时使用 `autoCommit` 参数定义。您还可以在 Request Handler 中定义如下:
<autoCommit> <maxDocs>20000</maxDocs> <maxTime>50000</maxTime> <openSearcher>false</openSearcher> </autoCommit>
maxDocs:自上次提交以来发生的更新数。
maxTime:自最旧的未提交更新以来的毫秒数
openSearcher:执行提交时是否打开一个新的搜索器。如果这是错误的,则提交会将最近的索引更改刷新到稳定存储,但不会导致打开新的搜索器以使这些更改可见。默认值为真。
在某些情况下,您可以完全禁用 autoCommit,例如,如果您将数百万条记录从不同的数据源迁移到 Solr,您不希望在每次插入时都提交数据,甚至不希望在批量的情况下提交数据。每 2、4 或 6 千次插入都不需要它,因为它仍然会减慢迁移速度。在这种情况下,您可以完全禁用 `autoCommit` 并在迁移结束时进行提交,或者您可以将其设置为较大的值,例如 3 小时(即 3*60*60*1000)。您还可以添加 <maxDocs>50000000</maxDocs>,这意味着仅在添加 5000 万个文档后才会自动提交。发布所有文档后,手动或从 SolrJ 调用一次 commit - 提交需要一段时间,但总体上会快得多。
此外,在您完成批量导入后,减少 maxTime 和 maxDocs,以便您对 Solr 所做的任何增量帖子都会更快地提交。
4.配置动态字段
Apache Solr 的一项惊人功能是 dynamicField。当您有数百个字段并且您不想定义所有字段时,它非常方便。
动态字段与常规字段一样,只是它的名称中带有通配符。在索引文档时,不匹配任何明确定义的字段的字段可以与动态字段匹配。
例如,假设您的架构包含一个名为 *_i 的动态字段。如果您尝试使用 cost_i 字段索引文档,但架构中没有明确定义 cost_i 字段,则 cost_i 字段将具有为 *_i 定义的字段类型和分析。
但是你在使用dynamicField时必须小心,不要广泛使用它,因为它也有一些缺点,如果你使用投影(如“abc.*.xyz.*.fieldname”)来获取特定的动态字段列,使用正则表达式解析字段需要时间。在返回查询结果的同时也增加了解析时间,下面是创建动态字段的示例。
<dynamicField name="*.fieldname" type="boolean" multiValued="true" stored="true" />
使用动态字段意味着您可以在字段名称中拥有无限数量的组合,因为您指定了通配符,有时可能会很昂贵,因为 Lucene 为每个唯一字段(列)名称分配内存,这意味着如果您有一行包含列A、B、C、D 和另一行有 E、F、C、D,Lucene 将分配 6 块内存而不是 4 块,因为有 6 个唯一列名,所以即使有 6 个唯一列名,万一百万行,它可能会使堆崩溃,因为它将使用 50% 的额外内存。
5. 配置索引与存储字段
索引字段意味着您正在使字段可搜索,indexed="true" 使字段可搜索、可排序和可分面,例如,如果您有一个名为 test1 且 indexed="true" 的字段,那么您可以像 q= 一样搜索它test1:foo,其中 foo 是您要搜索的值,因此,仅将搜索所需的那些字段设置为 indexed="true",如果需要,其余字段应为 indexed="false"在搜索结果中。例如:
<field name="foo" type="int" stored="true" indexed="false"/>
这意味着我们可以减少重新索引时间,因为在每次重新索引时,Solr 都会应用过滤器、标记器和分析器,这会增加一些处理时间,如果我们的索引数量较少的话。
6.配置复制字段
Solr 提供了非常好的功能,称为 copyField,它是一种将多个字段的副本存储到单个字段的机制。 copyField 的使用取决于场景,但最常见的是创建单个“搜索”字段,当用户或客户端未指定要查询的字段时,该字段将用作默认查询字段。
对所有通用文本字段使用copyField并将它们复制到一个文本字段中,并使用它进行搜索,它会减少索引大小并为您提供更好的性能,例如,如果您有像ab_0_aa_1_abcd这样的动态数据,并且您想要复制所有 具有后缀 _abcd 到一个字段的字段。 您可以在 schema.xml 中创建一个 copyField,如下所示:
<copyField source="*_abcd" dest="wxyz"/>
source:要复制的字段的名称
dest:复制字段的名称
7. 使用过滤查询‘fq’
在搜索中使用 Filter Query fq 参数对于最大化性能非常有用,它定义了一个查询,可用于限制可以返回的文档的超集,而不影响分数,它独立缓存查询。
Filter Queryfq 对于加速复杂查询非常有用,因为使用 fq 指定的查询独立于主查询进行缓存。 当后面的查询使用相同的过滤器时,会发生缓存命中,并且过滤器结果会从缓存中快速返回。
下面是使用过滤器查询的 curl 示例:
POST
{
"form_params": {
"fq": "id=1234",
"fl": "abc cde",
"wt": "json"
},
"query": {
"q": "*:*"
}
}过滤 qeury 参数也可以在单个搜索 qeury 中多次使用。 查看 Solr Filter Qeury 文档以获取更多详细信息。
8. 使用构面查询
Apache Solr 中的 Faceting 用于将搜索结果分类为不同的类别,执行聚合操作(如按特定字段分组、计数、分组等)非常有帮助,因此,对于所有聚合特定查询,您可以使用 Facet 来 开箱即用地进行聚合,它也将成为性能提升器,因为它纯粹是为此类操作而设计的。
下面是向 solr 发送构面请求的 curl 示例。
{
"form_params": {
"fq" : "fieldName:value",
"fl" : "fieldName",
"facet" : "true",
"facet.mincount": 1,
"facet.limit" : -1,
"facet.field" : "fieldName",
"wt" : "json",
},
"query" : {
"q": "*:*",
},
}fq:过滤查询
fl:结果中要返回的字段列表
facet:true/false 启用/禁用构面计数
facet.mincount:排除计数低于 1 的范围
facet.limit:限制结果中返回的组数,-1 表示全部
facet.field:该字段应被视为构面(对结果进行分组)
结论:
将 Solr 投入生产时,性能改进是关键步骤。 Solr 中有许多调整旋钮可以帮助您最大限度地提高系统的性能,其中一些我们在本博客中讨论过,在 solr-config 文件中进行更改以使用最佳配置,使用适当的索引选项或字段更新架构文件 类型,尽可能使用过滤器 queriesfq 并使用适当的缓存选项,但这又取决于您的应用程序。
这就结束了。 我希望这篇文章对您有所帮助,如果您想了解更多信息,请查看下面链接的 Solr 参考
原文:https://medium.com/tech-tajawal/tips-and-tricks-to-maximize-apache-solr…
本文:https://jiagoushi.pro/configuring-solr-optimum-performance
- 146 次浏览
【搜索引擎选型】Solr vs. Elasticsearch:选择开源搜索引擎时应考虑的事项
结合了云,分析和认知搜索的观察结果
Solr vs. Elasticsearch在我们的客户项目和企业搜索社区中经常讨论。但是,随着传统企业搜索已演变为Gartner所谓的“ Insight Engines”,我们重新讨论了该主题,以提供结合了Cloud,Analytics和Cognitive Search功能的最新观察结果,以帮助您评估Solr和Elasticsearch。
通常,当我们帮助客户进行围绕其企业解决方案中使用开源搜索引擎的评估时,会提出以下问题:“ Solr还是Elasticsearch,哪个更好?”虽然可能会有先入为主的观念,这个问题比另一个要好,当被圈定为“哪个对我更好?”时,这个问题更相关。
可以使用多种搜索引擎技术,但是最受欢迎的开放源代码变体是那些依赖于Apache Lucene底层核心功能的技术,从本质上讲,这是使搜索引擎正常工作的部分。 Solr和Elasticsearch是搜索库之上的组件,为完整的搜索产品提供了自己的实现和功能。 Lucene的核心功能为Solr和Elasticsearch的基本搜索功能提供了相同的体验,但是围绕Lucene的实现方法才是差异化的原因。
搜索引擎的作用已经从有效地查找信息转变为在内容分析,预测建模以及与认知/智能搜索功能(例如自然语言处理(NLP),机器学习(ML)和相关性)的集成中发挥关键作用得分。我们已经在客户工作中探索并实现了这些智能功能-在此处了解更多信息。
Solr vs. Elasticsearch:哪个对我的组织更好?
这得看情况。
关于采用一种技术而不是另一种技术有许多用例。但是当被问到这个问题时,我通常会从运营管理的角度来类比地回答:“ Solr就像Linux。您可以根据自己的需求进行大量自定义和定制Solr,但与Elasticsearch所需的工作相比,管理和部署要涉及更多的资源,而且要消耗大量资源。 Elasticsearch具有非常好的设计的用户界面(Kibana),非常易于部署,管理和监视(使用X-Pack),该界面允许进行数据探索和创建分析可视化,但是自定义其功能是有限的,并且使用插件框架。
如果您愿意,Elasticsearch可能适合您:
- 使您的搜索引擎快速启动并运行,而几乎不会产生任何开销;
- 尽快开始探索您的数据;和
- 将分析和可视化视为用例的核心组成部分。
如果您满足以下条件,Solr可能适合您:
- 需要大规模索引和重新处理大量数据;
- 有可用的资源来投资于管理Solr和可用于交互的工具;和
- 具有可与Solr配合使用的现有企业框架(例如其他Apache产品(例如Hadoop)或企业框架(例如Cloudera,Hortonworks或基于Hadoop的HDInsights))。
这并不是说Hadoop平台无法与Elasticsearch配合使用(我们已向客户提出了此方案),但是某些平台(尤其是Cloudera和Hortonworks)提供了额外的工具和方法来对生态系统内的数据建立索引和管理Solr(尤其是即将发布的支持Solr 7的Cloudera CDH 6版本。
观察结果:性能,功能和用例
根据经验,评估可以为帮助客户定义策略和实施路线图提供巨大的价值。在评估过程中,我们使用搜索引擎比较矩阵,根据特定客户的优先级,采用加权评分机制,根据特定客户的需求和用例评估搜索引擎的适用性。基于此分析,在为搜索引擎提出整体建议时,有一些共同的功能和用例可作为关注点。
The chart below captures some of the observations about Solr and Elasticsearch:
| SOLR | ELASTICSEARCH | |
|---|---|---|
| Use Cases |
|
|
| Visualization Tools |
|
|
| Cloud and Big Data |
|
|
| Cognitive Search Capabilities and Integration |
|
|
| Management and Operations |
|
|
| Development Architecture |
|
|
| Cluster State Management |
|
|
| Security |
|
|
| Bulk Indexing Tools |
|
|
| Near Real Time (NRT) Indexing (not a comprehensive list) |
|
|
| Analytics |
|
|
| Nested Data Structures |
|
|
| Query Operations |
|
|
| API Interaction |
|
|
在Solr和Elasticsearch之间选择?考虑这些
决定哪种搜索引擎最适合您的特定用例和需求,不应基于“非此即彼”的假设。 Solr中特定功能的总体重要性可能超过Elasticsearch中的运营优势,例如:
在一个客户端的情况下,与Solr部署相关联的开销以及必须使用SolrNET的过期客户端(当时)的开销被Solr的可插入性所抵消。需要使用自定义加密更新和请求处理程序,才能使用旋转数据加密密钥对索引内容进行加密,从而需要在Elasticsearch上使用Solr。索引加密过程所需的功能无法在Elasticsearch中有效实现。
相反,在不考虑大数据或分析因素的情况下,针对一般搜索用例评估搜索引擎选项时,由于减少了维护和部署的开销以及用于完全托管和托管环境的选项,Elasticsearch成为更受欢迎的选项。
在某些情况下,根据对客户最重要的因素,尽管应用了计分规则,但尚不清楚哪个搜索引擎(包括商业引擎)最能满足客户的需求。在这种情况下,可以使用样本数据集进行“烘焙”,以评估每个引擎在一组特定用例中的表现,从而对客户进行评估。
归根结底,Solr和Elasticsearch都是强大,灵活,可扩展且功能强大的开源搜索引擎。总体用例和业务需求,以及所需的功能,操作注意事项以及与新的认知搜索和分析功能的集成,最终将决定您选择Solr还是Elasticsearch。
本文:http://jiagoushi.pro/node/906
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 179 次浏览
【数据库】Elasticsearch PostgreSQL 比较:6 个关键差异
数据现在被认为是任何组织最有价值的资产之一。它使企业内的交易更容易,并促进运营的顺畅流动。随着组织比以往任何时候都更依赖基于证据的决策,数据也充当了关键的决策工具。因此,每个组织都在寻找一种以最有效的方式存储数据的方法。
在选择现代数据库时,公司通常会在选择像 PostgreSQL 这样的 SQL 数据库还是像 Elasticsearch 这样的 NoSQL 数据库方面遇到难题。尽管这两者对于企业来说都是可行的选择,但它们之间存在一些必须考虑的关键差异。考虑到这些差异后,组织应该能够判断哪个数据库适合他们的要求。
本文将帮助您了解 PostgreSQL Elasticsearch 的各种差异,从而帮助您针对您独特的业务和数据需求做出明智的决定。
目录
- 什么是弹性搜索?
- 了解 Elasticsearch 的主要功能
- 什么是 PostgreSQL?
- 了解 PostgreSQL 的主要特性
- ElasticSearch PostgreSQL 主要区别
- Elasticsearch PostgreSQL 主要区别:数据库模型
- Elasticsearch PostgreSQL 主要区别:事务支持
- Elasticsearch PostgreSQL 主要区别:架构灵活性
- Elasticsearch PostgreSQL 主要区别:CAP 定理实现
- Elasticsearch PostgreSQL 主要区别:安全性
- Elasticsearch PostgreSQL 主要区别:基于云的产品
- 结论
什么是Elasticsearch ?
Elasticsearch 可以定义为一个免费的、分布式的、开源的搜索和分析引擎,可用于处理多种类型的数据,例如数字、文本、结构化、非结构化等。Elasticsearch 的第一个版本于 2010 年发布,建立在一个名为 Apache Lucene 的搜索引擎软件库之上。 Elasticsearch 现在以其简单的 REST API、速度、分布式特性和可扩展性而闻名。 Elasticsearch 现在也是 Elastic Stack 的核心组件,这是一组免费的开源工具,允许用户无缝地执行数据摄取和丰富、数据分析和可视化。
Elasticsearch 将数据存储为相互关联的文档集合,因此可以被视为面向文档的搜索引擎,可用于存储、管理和检索结构化、半结构化或非结构化数据。 Elasticsearch 将数据存储为 JSON 文档,这意味着每个文档都由一组键及其对应的值组成。
Elasticsearch 利用一种称为倒排索引的数据结构,使其能够执行异常快速的全文搜索。 Elasticsearch 存储所有文档并在索引过程中构建一个倒排索引,使其能够实时搜索文档数据。
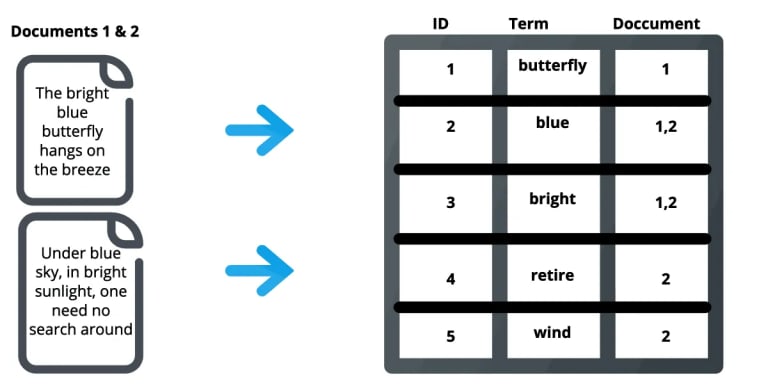
了解 Elasticsearch 的主要功能
Elasticsearch 的主要特点如下:
- 快速数据访问:Elasticsearch 中的所有文档都存储在靠近索引中相应元数据的位置。这减少了数据所需的读取操作次数,从而缩短了整体搜索结果响应时间。
- 自动节点恢复:如果节点因节点故障、故意移除等任何原因离开 Elasticsearch 集群,主节点会采取必要的措施,将节点替换为其副本并重新平衡所有分片以自动管理负载。
- 升级助手 API:升级助手 API 使用户能够检查其 Elasticsearch 集群的升级状态并重新索引在以前版本的 Elasticsearch 中创建的索引。该助手可帮助用户为 Elasticsearch 的下一个主要版本做好准备。
- 索引生命周期管理:Elasticsearch 索引生命周期管理 (ILM) 允许用户定义和自动化许多策略,这些策略有助于控制 Elasticsearch 索引在每个阶段的生存时间。它还允许用户设置在每个阶段对索引执行的操作。
- 搜索引擎的可扩展性:Elasticsearch 实现了一个分布式架构,使其能够扩展到数千台服务器并处理 PB 级的数据,而不会遇到任何性能问题。这种分布式设计由 Elasticsearch 自动处理,因此客户可以专注于执行所需的操作。
什么是 PostgreSQL?
PostgreSQL 是一个免费的开源数据库。它现在被认为是市场上最强大的关系数据库管理系统 (RDBMS) 之一。它结合了 SQL 并添加了一组新功能,允许将 PostgreSQL 用于事务性数据库并用作用于分析目的的数据仓库。
使用 PostgreSQL 最显着的优势之一以及为什么它成为大多数使用关系数据库的企业的首选是它支持对象关系模型的能力,它允许用户根据应用程序中的用例定义自定义数据类型。
了解 PostgreSQL 的主要特性
PostgreSQL 的主要特性如下:
- 数据完整性:PostgreSQL 通过让用户能够创建主键和外键、唯一和非空约束、显式和咨询锁、排除约束等来确保数据完整性。
- 多种数据类型:PostgreSQL 支持多种数据类型,包括 Integer、String、Boolean 等原始数据类型,数组、日期、时间等结构化数据类型,以及 Document 数据类型等如 XML、JSON 等。
- 高度可扩展性:PostgreSQL 被认为具有高度可扩展性,因为它支持各种过程语言,例如 PL/pgSQL、Perl、Python 等、JSON/SQL 路径表达式、可用于通过标准连接到不同数据库的外部数据包装器SQL 接口。
- 强大的安全性:PostgreSQL 拥有强大的访问控制系统以及多个安全身份验证,包括轻量级目录访问协议 (LDAP)、SCRAM-SHA-256 等,使其成为可用的最安全的关系数据库管理系统 (RDBMS) 之一。
- 高度可靠:PostgreSQL 支持多种灾难恢复技术,例如 Active Standbys、时间点恢复 (PITR)、表空间,以及多种类型的复制,例如逻辑、同步和异步
Elasticsearch PostgreSQL 主要差异
虽然 Elasticsearch 和 PostgreSQL 都是著名的数据库管理系统,但它们之间有很多不同之处,如下所示:
- Elasticsearch PostgreSQL 主要区别:数据库模型
- Elasticsearch PostgreSQL 主要区别:事务支持
- Elasticsearch PostgreSQL 主要区别:架构灵活性
- Elasticsearch PostgreSQL 主要区别:CAP 定理实现
- Elasticsearch PostgreSQL 主要区别:安全性
- Elasticsearch PostgreSQL 主要区别:基于云的产品
1) Elasticsearch PostgreSQL 主要区别:数据库模型
PostgreSQL 是一个关系数据库管理系统 (RDBMS),因此,它以行和列的形式在众多表中存储数据。 它还使用户能够在表之间形成关系。 PostgreSQL 是一种 SQL 数据库,允许使用结构化查询语言 (SQL) 来查询数据。 一个示例 PostgreSQL 数据库如下:
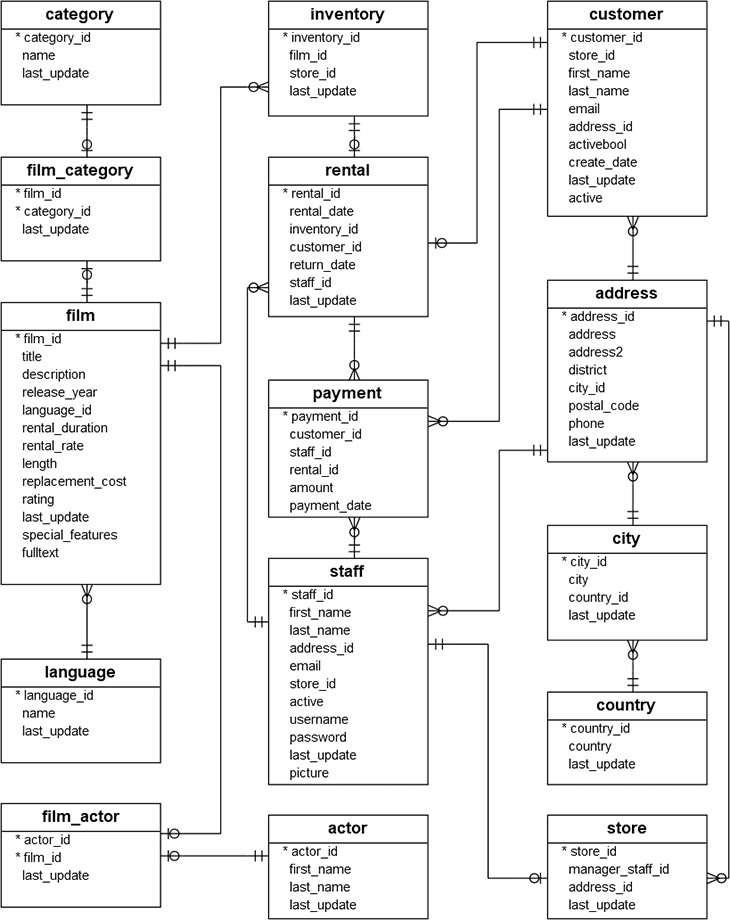
Elasticsearch 是一个 NoSQL 分布式文档存储。 这意味着 Elasticsearch 不是将数据存储在表中,而是存储复杂的数据结构,序列化为 JSON 文档。 这些文档分布在集群中的多个节点上,如果需要,可以从任何节点立即访问。 Elasticsearch 中的示例索引如下:
2) Elasticsearch PostgreSQL 主要区别:事务支持
Elasticsearch 旨在为其用户提供高速数据库操作。由于将数据库功能作为事务执行需要复杂的操作,这会减慢进程,因此 Elasticsearch 不包含典型意义上的事务支持。因此,无法回滚已提交的文档或提交一组文档,并在 Elasticsearch 中索引全部或不索引。相反,Elasticsearch 包含一个预写日志,它只能帮助确保所有数据库操作的持久性,而无需执行任何提交。用户还可以选择指定索引操作的一致性级别,即有多少副本必须在返回之前确认数据库操作。
另一方面,PostgreSQL 支持健壮的事务机制。 PostgreSQL 中的事务将多个步骤捆绑为一个,或者所有这些步骤都被执行,或者一个都不被执行。用户可以利用 BEGIN 和 COMMIT 命令将操作捆绑在一起,并利用 ROLLBACK 和 SAVEPOINT 命令将操作回滚到给定点。
3) Elasticsearch PostgreSQL 主要区别:架构灵活性
用户不必预先指定 Elasticsearch 索引的架构。 Elasticsearch 可以通过分析用户尝试存储的数据来自动推断数据类型。它在识别数字、布尔值和时间戳方面做得相当不错。它利用标准分析器来识别字符串。
然而,PostgreSQL 实现了一个严格的模式。这意味着模式必须包含带有类型列的预定义表。严格的模式允许 PostgreSQL 提供一组丰富的功能,否则这些功能是不可能的。
4) Elasticsearch PostgreSQL 主要区别:CAP 定理实现
任何数据库管理系统都可以提供的三个特性如下:
一致性:连接到数据库的所有客户端看到相同的数据,这意味着一旦在数据库中写入或更新任何数据,也应该在其所有副本上执行相同的操作。
可用性:来自客户端的任何请求至少会从数据库中获得一些响应。
分区容限:即使很少有节点宕机,集群也会继续执行所需的操作。
CAP 定理指出,任何数据库都只能提供三个 CAP 属性中的两个。
PostgreSQL 只能为其用户提供一致性和可用性,但不能提供分区容差,而 Elasticsearch 可以为其用户提供可用性和分区容差。然而,ElasticSearch 仅确保每个文档的一致性,这意味着所有写入将自动在“文档所有者”分片上执行,并最终在副本分片上复制。
5) Elasticsearch PostgreSQL 主要区别:安全性
Elasticsearch 不包含任何内置功能来确保用户身份验证或授权。这意味着任何能够连接到 Elasticsearch 集群的用户都将拥有管理员权限。因此,用户必须在其应用层中配置授权和身份验证机制,因为 Elasticsearch 会将每个用户都视为超级用户。
PostgreSQL 拥有强大的访问控制系统以及多种安全身份验证,包括轻量级目录访问协议 (LDAP)、SCRAM-SHA-256 等,使其成为最安全的关系数据库管理系统 (RDBMS) 之一。
6) Elasticsearch PostgreSQL 主要区别:基于云的产品
Elasticsearch 为其用户提供了许多不同层次的基于云的官方产品。每层提供的定价和功能如下:

PostgreSQL 不提供任何基于云的官方产品或解决方案。因此,用户将不得不依赖 PostgreSQL 开发人员推荐的第三方供应商。这些第三方供应商包括 2ndQuadrant、Aiven、Amazon Web Services 等等。
结论
本文让您深入了解 Elasticsearch 和 PostgreSQL 以及 Elasticsearch PostgreSQL 的各种差异。除非知道需求,否则不能说一个数据库比另一个更好。因此,您可以在了解各种 Elasticsearch PostgreSQL 差异后,根据您的业务用例和数据需求做出最终选择。
当今大多数现代企业都使用多个数据库进行运营。这导致了一种复杂的情况,因为如果必须执行整合来自所有这些数据库的数据的通用分析,这可能是一项复杂的任务。必须首先构建一个数据集成解决方案,该解决方案可以集成来自这些数据库的所有数据并将其存储在一个集中位置。企业可以选择制作自己的数据集成解决方案,也可以使用现有的自动化无代码平台,如 Hevo Data。
- 442 次浏览