【容器云架构】设置高可用性Kubernetes Master
您可以使用kube-up或kube-down脚本为Google Compute Engine复制Kubernetes masters。本文档介绍了如何使用kube-up / down脚本来管理高可用性(HA)masters,以及如何实现HA masters以与GCE一起使用。
- 在你开始之前
- 启动与HA兼容的集群
- 添加新的主副本
- 删除主副本
- 处理主副本故障
- 复制HA群集的主服务器的最佳做法
- 实施说明
- 补充阅读
在你开始之前
您需要具有Kubernetes集群,并且必须将kubectl命令行工具配置为与集群通信。如果您还没有集群,则可以使用Minikube创建一个集群,也可以使用以下Kubernetes游乐场之一:
要检查版本,请输入kubectl版本。
启动与HA兼容的集群
要创建新的HA兼容群集,必须在kube-up脚本中设置以下标志:
- MULTIZONE = true-防止从服务器默认区域以外的区域中删除主副本kubelet。如果要在不同区域中运行主副本,则为必需项(建议)。
- ENABLE_ETCD_QUORUM_READ = true-确保从所有API服务器进行的读取将返回最新数据。如果为true,则读取将定向到领导者etcd副本。将此值设置为true是可选的:读取将更可靠,但也将更慢。
(可选)您可以指定要在其中创建第一个主副本的GCE区域。设置以下标志:
- KUBE_GCE_ZONE = zone -第一个主副本将在其中运行的区域。
以下示例命令在GCE区域europe-west1-b中设置了HA兼容的集群:
MULTIZONE=true KUBE_GCE_ZONE=europe-west1-b ENABLE_ETCD_QUORUM_READS=true ./cluster/kube-up.sh
请注意,以上命令创建了一个具有一个主节点的集群;但是,您可以使用后续命令将新的主副本添加到群集中
添加新的主副本
创建与HA兼容的群集后,可以向其添加主副本。您可以通过使用带有以下标志的kube-up脚本来添加主副本:
- KUBE_REPLICATE_EXISTING_MASTER=true-创建现有masters的副本。
- KUBE_GCE_ZONE = zone-主副本将在其中运行的区域。必须与其他副本的区域位于同一区域。
您不需要设置MULTIZONE或ENABLE_ETCD_QUORUM_READS标志,因为这些标志是从启动HA兼容群集时继承的。
以下示例命令在现有的HA兼容群集上复制主服务器:
KUBE_GCE_ZONE=europe-west1-c KUBE_REPLICATE_EXISTING_MASTER=true ./cluster/kube-up.sh
删除主副本
您可以使用带有以下标志的kube-down脚本从HA群集中删除主副本:
- KUBE_DELETE_NODES = false-禁止删除kubelet。
- KUBE_GCE_ZONE = zone-将要从其中删除主副本的区域。
- KUBE_REPLICA_NAME =replica_name-(可选)要删除的主副本的名称。如果为空:将删除给定区域中的任何副本。
以下示例命令从现有的HA集群中删除主副本:
KUBE_DELETE_NODES=false KUBE_GCE_ZONE=europe-west1-c ./cluster/kube-down.sh
处理主副本故障
如果高可用性群集中的一个主副本失败,则最佳实践是从群集中删除该副本,并在同一区域中添加一个新副本。以下示例命令演示了此过程:
删除损坏的副本:
KUBE_DELETE_NODES=false KUBE_GCE_ZONE=replica_zone KUBE_REPLICA_NAME=replica_name ./cluster/kube-down.sh
添加一个新副本来代替旧副本:
KUBE_GCE_ZONE=replica-zone KUBE_REPLICATE_EXISTING_MASTER=true ./cluster/kube-up.sh
复制HA群集的主服务器的最佳做法
- 尝试将主副本放置在不同的区域中。在区域故障期间,放置在区域内的所有主设备都会发生故障。为了使区域失效,还要将节点放置在多个区域中(有关详细信息,请参阅多个区域)。
- 不要将群集与两个主副本一起使用。更改永久状态时,两副本群集上的共识要求两个副本同时运行。结果,两个副本都是必需的,任何副本的故障都会使群集变为多数故障状态。因此,就HA而言,两个副本群集不如单个副本群集。
- 添加主副本时,群集状态(etcd)将复制到新实例。如果群集很大,则可能需要很长时间才能复制其状态。可以通过迁移etcd数据目录来加快此操作,如此处所述(我们正在考虑在将来增加对etcd数据目录迁移的支持)。
实施说明
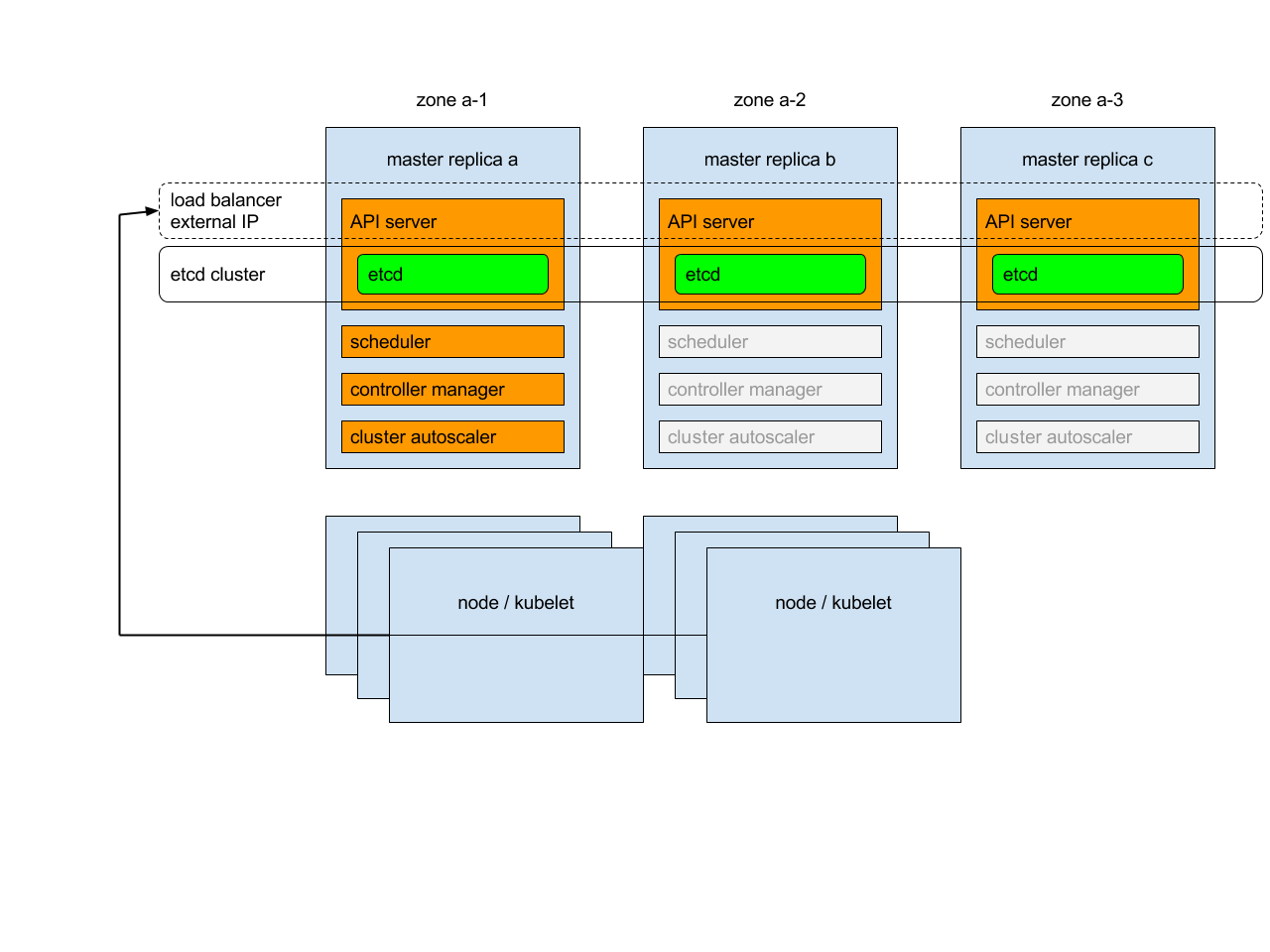
总览
每个主副本将在以下模式下运行以下组件:
- etcd实例:将使用共识将所有实例聚在一起;
- API服务器:每个服务器都将与本地etcd通信-群集中的所有API服务器将可用;
- 控制器,调度程序和集群自动缩放器:将使用租借机制-它们中的每个实例只有一个在集群中处于活动状态;
- 加载项管理员:每个管理员将独立工作,以使加载项保持同步。
此外,API服务器之前将有一个负载平衡器,它将外部和内部流量路由到它们。
负载均衡
启动第二个主副本时,将创建一个包含两个副本的负载均衡器,并将第一个副本的IP地址提升为负载均衡器的IP地址。同样,在删除倒数第二个主副本之后,将删除负载均衡器,并将其IP地址分配给最后剩余的副本。请注意,创建和删除负载平衡器是复杂的操作,传播它们可能需要一些时间(约20分钟)。
主服务和kubelets
系统没有尝试在Kubernetes服务中保留Kubernetes apiserver的最新列表,而是将所有流量定向到外部IP:
- 在一个主群集中,IP指向单个主群集,
- 在多主机集群中,IP指向主机前面的负载均衡器。
同样,外部IP将由kubelet用于与主机通信。
Master证书
Kubernetes为每个副本的外部公共IP和本地IP生成主TLS证书。没有用于副本的临时公共IP的证书;要通过其短暂的公共IP访问副本,必须跳过TLS验证。
集群etcd
为了允许etcd集群,将打开在etcd实例之间进行通信所需的端口(用于内部集群通信)。为了确保这种部署的安全性,etcd实例之间的通信使用SSL授权。
原文:https://kubernetes.io/docs/tasks/administer-cluster/highly-available-master/
本文:http://jiagoushi.pro/set-high-availability-kubernetes-masters
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 106 次浏览