软件测试
- 142 次浏览
[敏捷软件测试】应对敏捷时代的软件测试挑战
挣扎是真的
由于软件开发领域的重大转变,测试行业正在经历快速而深远的变革。软件的开发和部署速度比以往任何时候都快,这为测试人员带来了一系列新的挑战。过去为质量保证部门服务的传统程序和技术已不再适用。
你将学到什么
- 在本指南中,我们将软件开发中的两位思想领袖聚集在一起,以提供有关测试未来和成功团队如何随着时代变化而发展的观点。
里面是什么?
- 测试人员如何获得在敏捷环境中有效规划和测试所需的洞察力。
- 关于如何找到正确的测试方法组合的指导 - 自动化,探索性和用户验收测试。
- 探索性测试如何帮助解决现代开发,持续部署和快速反馈循环的压力。
- 何时以及如何使用探索性测试作为开发过程的一部分。
- 最好的测试人员如何将测试过程分解为一个简单的三个问题:为什么,什么以及如何?
原文:https://www.qasymphony.com/landing-pages/tackling-testing-challenges-in-the-agile-era/
- 68 次浏览
【Kafka】测试Kafka:我是如何学习东西的
当我开始测试Kafka的任务时,我意识到我有很多要理解的主题。在任务期间,我花时间积极学习这些主题,以及在任务期间出现的任何其他主题,例如AWS。
这篇博文介绍了各种主题。它不会详细介绍其中任何一个(我可能会在其他博客文章中介绍一些内容),而是我会专注于我如何学习这个项目的一部分。
- Kafka:这可能是一个明显的主题,但我需要了解Kafka与其可靠性,弹性,可扩展性相关的特定方面,并找到监控其行为的方法。我最后还学习了如何编写Kafka客户端,实现和配置SASL_SSL安全性以及如何配置它。
- VMWare:VMWare Enterprise技术将用于某些运行时环境。多年来我一直没有使用VMWare,并决定学习如何在几个小而又充满代表性的服务器上配置,监控和运行ESXi。这将使我既可以在客户端环境中工作,也可以独立地运行其他测试,而不是等待足够的环境和VM按需提供(由于内部流程和组织结构,企业往往移动得更慢)。
- 如何'性能测试'Kafka:我们有几个想法,并且发现Kafka包含了一个“性能测试”实用程序。我们需要了解该实用程序如何生成消息和测量性能。它也可能不是最适合项目需求的工具。
- 如何降低系统性能并暴露系统中的缺陷会对项目中使用Kafka的价值产生不利影响。如果可以直接访问机器和测试环境,则断开网络电缆,查杀进程等非常容易。但是,我们需要能够引入更复杂的故障条件,并且能够远程注入故障。
这些是我在任务开始时所知道的。还出现了几个,包括:
- 在AWS中创建测试环境。这包括在VPC之间创建区域间对等,创建Kafka和Zookeeper集群,以及多个负载生成器和负载消费者实例来执行各种性能和负载测试。虽然有各种“快速入门”,包括用于部署Kafka集群的快速入门https://github.com/aws-quickstart/quickstart-confluent-kafka;最后我们不得不创建自…,堡垒主机和VPC。快速入门脚本经常失败,然后环境在失败后需要进行额外的清理。
- Jepsen和其他类似的混沌生成工具。 Jepsen在几个主要版本之前测试了Kafka https://aphyr.com/posts/293-jepsen-kafka这些工具是可用的和开源的,但它们是否适合我们的环境和技能组合?
- 在我们最终确定修改开源独立负载生成器并编写互惠负载消费者之前,各种开源负载生成器,包括与jmeter集成的2个。
- Linux实用程序:我们广泛使用它来处理环境和自动化测试。类似地,在一些较大的体积负载测试之后,我们编写了实用程序脚本来监视,清理和重置集群和环境。
- 启用主题自动创建的细微差别和影响。
- KIP(卡夫卡改进提案):
- 报告和分析:客户对报告内容以及报告方式有特别的期望。一些工具没有以足够的粒度提供结果,例如他们只提供“平均值”,我们需要校准工具,以便我们可以信任他们发出的数字。
注意:以下按主题或概念排序,而不是按时间顺序排序。
我是如何学习与测试Kafka相关的东西的
我知道从一开始就要学到很多东西。因此,我决定在合同签订之前投入时间和金钱,这样我就可以立即投入。值得庆幸的是,所有软件都是免费提供的,并且通常是开源的(这意味着我们可以阅读代码以帮助理解它,甚至修改它以帮助我们完成工作和学习)。
大多数学习都沉浸在实践中,我和我的同事会在各种测试环境中尝试,并通过实践,观察和实验来学习。 (我将在这里提到一些测试环境,并可能在其他博客文章中更详细地介绍方面。)
我发现并且第一次感谢在线课程的支付范围,深度和价值。虽然他们不一定像参加商业培训课程一样好,房间里有导师并且可以立即获得建议,但范围,价格和可用性是一个启示,我购买的所有课程的财务成本低于65英镑(90美元)。
阅读也很关键,网上有很多博客文章和文章,包括直接参与开发和测试Kafka的人的几篇重要文章。我还搜索了经过同行评审的学术文章。我只找到了一对 - 可惜的是,书面的学术研究是对商业和/或个人非正式报道的一种不可思议的补充。
我们花了很多时间阅读源代码,然后修改我们希望在适应后适合的代码。值得庆幸的是,客户同意我们可以公开提供我们的非机密工作,并在宽松的开源和创意公共许可下提供。
Udemy
几年前我第一次使用udemy课程来尝试学习几种技术。当时我没有得到或得到很多价值,但经常打折的价格足够低,我不介意太多。相比之下,这次我发现udemy课程非常有价值且相关。 udemy提供的课程的丰富性,范围和深度令人难以置信,并且有足够的优质课程可用于相关主题(特别是在Kafka,AWS和较小程度上的VMWare),以便能够快速,实用地取得进展。学习这些关键主题的方方面面。
我真的很感激能够不仅观看几个介绍性视频,还能看到我发现的每个潜在比赛中更高级主题的例子。观看这些是免费的,并不需要很长的时间,并使我能够很好地了解主持人的方法和材料是否值得我给我知道和我想要实现的目标。
如果我认为我至少要学习该课程中的几个具体项目,我就采取了支付课程费用的方法。与他们在我的意识和理解中释放的知识的潜在价值相比,成本很小。
有时,即使是看似做得不好的课程,也有助于我理解哪些概念很容易混淆和/或很难理解。如果主持人感到困惑 - 也许我也会感到困惑????那就是说,对我来说最有价值的来自以下与我特别相关的课程:
https://www.udemy.com/apache-kafka/learn/v4/overview
https://www.udemy.com/kafka-cluster-setup/learn/v4/overview
https://www.udemy.com/apache-kafka-security/learn/v4/overview
https://www.udemy.com/aws-certified-solutions-architect-associate/learn…
https://www.udemy.com/vmwarecloudaws/learn/v4/overview
前三个课程由同一位主持人Stephane Maarek领导。他特别有魅力。当我通过udemy的平台向他发送问题时,他也很有帮助和反应灵敏。
发表文章和博客文章
我不会在这里列出文章或博客文章。有太多,我怀疑过多的链接会对你有多大帮助。在学习方面,一些主要挑战在于确定这些文章是否与我们正在测试的Kafka版本实现的目标相关。例如,许多在Kafka版本0.10之前编写的文章不再具有相关性,并且复制测试和示例有时太耗时而无法证明所需的时间。
此外,项目想要使用Kafka的方式很少被覆盖,我们发现我们需要使用的一些关键配置设置极大地改变了Kafka的行为,这再次意味着许多文章和博客文章没有直接应用。
我使用了一个名为Zotero的软件工具来管理我的笔记和参考资料(我已经使用了几年作为我的博士研究的一部分)并且在那里记录了超过100篇已识别的文章。我在作业期间读了很多文章,可能多达1000篇。
学术研究
我发现的最好的文章比较了Kafka和RabbitMQ在工业研究环境中的作用。有几个版本可用。同行评审的文章可以在https://doi.org/10.1145/3093742.3093908找到,但是除非您有合适的订阅,否则您可能需要为此版本付费。最新版本似乎是https://arxiv.org/abs/1709.00333v1,可以免费下载和阅读。
测试环境
在这里,我会简短。我计划稍后深入介绍测试环境。我们的测试环境包括Raspberry Pi集群(使用MirrorMaker等进行复制),Docker容器,运行ESXi的廉价物理机架式服务器以及多个AWS环境。 Docker和AWS都经常被引用,例如我之前提到的udemy kafka课程使用AWS作为他们的机器。
原文: http://blog.bettersoftwaretesting.com/2018/04/testing-kafka-how-i-learned-stuff/
- 88 次浏览
【合约测试】Pact 101 - Pact和消费者驱动的合同测试入门
所以你听说过Pact并希望开始。本指南应该有助于您朝着正确的方向前进。
什么是契约?
Pact系列测试框架(Pact-JVM,Pact Ruby,Pact .NET,Pact Go,Pact.js,Pact Swift等)为依赖系统之间的消费者驱动合同测试提供支持,其中集成基于HTTP(或消息)某些实现的队列)。它们对于μ服务特别有用,在这些服务中可能存在大量相互依赖的服务,并且集成测试很快变得不可行。
在我们深入了解Pact之前,您需要了解消费者驱动的合同。
什么是消费者驱动的合同?
消费者驱动的合同是一种模式或方法,其中相互依赖的服务之间的合同是从服务消费者的角度设计的。它的主要文章是消费者驱动的合同:服务进化模式,但它在技术方面有点过时(它谈论了很多关于XML和模式)。但是文章中表达的概念与我们今天构建的计算机系统有关。
我发现很多时候构建μ服务或内部API的团队都遵循与外部或公共API相同的思路。服务提供商或API团队会考虑其服务的任何消费者需要的所有内容(在此过程中做出许多假设),然后提供服务以及如何使用它的文档。他们建立它并希望消费者来。
当他们稍后需要更改它时,他们会进行更改,然后将其与所有消费者需要遵循的说明一起发布以使用更新的API。它们可能包含多个版本的服务,以保护消费者免受重大变化的影响。

我目睹了第一手开发和使用API的两个团队。 在构建消费者和提供者之后,他们花了很多天才在集成测试环境中进行交互,因为消费者团队认为API将基于发布JSON文档(它是从Web浏览器调用),而 提供程序团队实现了application / x-www-form-urlencoded POST API。
但具有讽刺意味的是,对于内部API和服务而言,要弄清楚服务的所有消费者是谁以及他们的要求是什么并不难。 大多数时候,他们都在同一个组织工作。
消费者驱动的合同扭转了这一切。 交互合同由服务的消费者开发。

这种方法的好处是,您知道您的服务的所有消费者是谁,您将知道何时进行重大更改,以便更容易进行更改,合同也是一种文档形式。 其次,您将确切地知道需要提供哪些功能,以便您可以实现消费者所需的正确服务,并遵循YAGNI原则。
交互的发展始于消费者方面,希望通过测试。 消费者团队定义交互合同并根据合同实现服务使用者。

然后将此合同提供给提供者团队(在某些情况下,它是同一个团队),并且实施提供者服务以履行合同。

开始时我需要做什么?
大多数信息可以在Github页面上找到,用于各种Pact实现。 Ruby Pact在wiki中有很多信息。
- Ruby Pact: https://github.com/realestate-com-au/pact
- JVM Pact: https://github.com/DiUS/pact-jvm
- .Net Pact: https://github.com/SEEK-Jobs/pact-net
- Pact Go: https://github.com/pact-foundation/pact-go
- Pact.js: https://github.com/pact-foundation/pact-js
- Pact Swift: https://github.com/DiUS/pact-consumer-swift
- Pact Python: https://github.com/pact-foundation/pact-python
特别是,要了解Pact的工作原理,请阅读:https://github.com/realestate-com-au/pact#how-does-it-work。
从消费者测试开始
这完全是关于消费者的,所以从那里开始。支持许多测试框架,因此根据您使用的测试工具,请阅读相关文档。
对于Ruby和RSpec,请阅读使用pacts简化微服务测试的示例。
对于基于JVM的测试框架(JUnit,Groovy等),请查看https://github.com/DiUS/pact-jvm#service-consumers。 JUnit似乎是最受欢迎的。有很多示例测试。
一旦运行了消费者测试,就应该生成pact文件。这些是消费者驱动合同意义上的合同。您可以通过多种方式发布这些文件。常见的方法是将它们提交到源存储库,将它们上载到文件服务器,将它们存储为CI构建中的工件或将它们上载到Pact Broker。
验证您的提供商
该方法的后半部分是验证您的提供商实际上是否符合消费者的期望。对于已实现消费者测试的每个消费者,您应该在某处发布pact文件。通常,您希望在其CI构建中验证您的提供商,以便您知道更改何时破坏了与消费者的交互,并且您还将知道您受影响的消费者。
给定一组已发布的pact文件,有两种主要方法可以验证您的提供程序是否遵守pact文件中封装的合同。
使用构建插件来验证协议
第一种方法是使用构建插件,该插件可以在pact文件中针对您的提供者执行请求。在某些情况下(如Ruby Rake任务),提供程序从测试工具(Rack Test for ruby)中启动,重放请求,然后将响应与pact文件的预期响应进行比较。在其他情况下(如Maven和Gradle插件),实际的提供程序需要运行,构建插件会向正在运行的提供程序发出实际请求。
有关为Ruby提供程序使用Ruby Rake任务的示例,请阅读使用pacts简化微服务测试的“提供程序”部分。
JVM构建插件(Maven,Gradle,Leiningen和SBT)的自述文件包含有关如何使用这些工具的更多信息。在大多数情况下,您需要能够事先启动您的提供程序并在之后停止它,并且有办法提供协议所需的测试数据。有关更多信息,请参阅Pact-JVM自述文件的“服务提供程序”部分。
Pact具有状态更改机制,用于在验证测试运行期间控制提供程序的状态。本质上,这是一个可以在每个请求之前调用的钩子,其中描述了提供者为了能够成功处理请求而需要的预期状态。例如“用户Andy应该存在”或“订单表应该为空”。 Ruby实现允许定义设置和拆除块,而JVM构建插件允许定义状态更改URL,该URL将在实际请求发出之前接收具有状态描述的POST请求。
使用测试框架来验证契约
使用某些构建插件的最大缺点是,您需要让您的提供程序运行,并且您需要能够设置测试数据。这涉及预先加载所有契约所需的夹具数据,或者使用状态更改机制来动态更改提供者的状态。这两种方法都需要相当多的编排,尤其是在CI环境中。
由于社区贡献,Pact JUnit提供程序运行程序可供使用基于JVM的提供程序的人员使用。它允许您仅处理提供者处理请求的部分提供者代码,并且您可以使用JUnit设置和拆除机制以及状态注释标记来设置协议所需的数据。您也可以使用标准的模拟框架来存根依赖关系,尽管我会添加一个警告,以确保您不会影响您的模拟和存根的行为。自述文件包含更多信息。
我在哪里可以获得支持?
与大多数开源项目一样,Pact拥有一个充满活力的在线社区。有一个用于Ruby和JVM版本的Google组和Gitter通道(单击Github页面上的Gitter图像)。我建议您在那里搜索或发布您的问题,有人肯定会回答。
原文:https://dius.com.au/2016/02/03/microservices-pact/
本文:http://pub.intelligentx.net/node/524
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 132 次浏览
【合约测试】合同测试无服务器和异步应用程序 - 第2部分
我们现在已进入无服务器功能的时代,我们不再需要担心代码的运行位置和方式。别人会为我们担心(以名义价格),我们只需要关心我们的职能,以实现他们的命运,并成为他们所能做的一切。这提出了一些与我们的测试实践相关的问题。好吧,它也提出了其他问题,但是对于这篇重要的博客文章而言。
从技术上讲,仍有讨厌的服务器。我们无法看到我们的功能正在运行的数据中心,或者在什么计算机上,或者实际上,如果它们在计算机或其他人的冰箱上运行。但是我们的函数以异步方式相互交互,将事件作为输入消耗并生成输出,这反过来导致消耗更多事件。我们在消息队列中测试与消费者和提供者的合同所做的所有想法都可以在这里同样适用。
无服务器世界中的合同测试
对于这篇文章,我们将使用AWS Lambda函数作为示例。我假设一切都适用于Google Cloud Functions和Microsoft Azure功能,但我从未使用过。
我使用的第一个Lambda函数帮助我们打破了传统单片系统的功能。我们需要添加一个功能,通过电子邮件将PDF发送给客户的客户,我们不希望必须完成大型应用程序的发布过程。解决方案是将遗留系统中最小的代码放在遗留系统中,一旦数据耗尽,我们就可以使用所有AWS服务并启用持续交付管道。

在这种情况下,我们选择更新遗留系统以编写包含S3存储桶所需的所有必要数据的JSON文件。 这是一个小小的改变,给了我们很大的灵活性。 从那里(一旦部署了更改),我们可以连接一个函数来响应存储桶事件,将PDF渲染回存储桶,然后让另一个函数响应这些事件以通过电子邮件发送它。 这真是太棒了。
直到有人没有通过电子邮件获取他们的PDF。
原始系统中模型类的一个小变化导致JSON格式发生变化,导致lambda函数失败。 没有工作的lambda函数意味着没有PDF,这反过来导致没有lambda函数调用和没有电子邮件。 没有警报意味着没有人在Cloud Watch日志中看到错误日志。 事实证明,交付经理因缺乏交付而感到非常不安。 谁知道?
看起来合同测试是有序的。 我们只需要确定合同的位置。
在这种情况下,我们可以使用与上一篇文章中描述的相同的Message Pact解决方案来测试此合同。 S3存储桶和S3事件只是传输机制。 实际合同介于我们添加到遗留系统的代码和lambda函数之间。 如果我们一直在关注,我们应该注意到将JSON文件写入S3存储桶正在跨越上下文边界,我们应该进行合同测试。 我们也应该对我们的日志发出警报。 而且喝得少,运动量更多,吃得更健康。 但这是狂野的无服务器西部的日子。 当然,这当然不是借口。
下面是使用Pact的基于异步消息的合同测试流程图:

Lambda函数是JSON消息的使用者,遗留应用程序是提供者。嗯,它比那复杂一点。该消息不是实际的JSON数据,而是包含对存储在S3存储桶上的JSON文件的引用的S3事件。 AWS S3服务和Lambda执行服务之间还有一个HTTP请求,但我们可以只关注更高级别,并假设我们通过S3存储桶传递一个异步S3事件传递给我们的函数。
Lambda函数消费者
大多数Lambda函数可能都是用Node.js编写的,但在这种情况下,我们精通Java PDF生成库,因此我们选择将其编写为Groovy JVM函数。使用基于JVM的Lambda函数的开销是可以的,因为只要PDF在下一个工作日开始时通过电子邮件发送,该函数响应事件的时间并不重要。然后我们也可以使用Spock编写测试和Pact-JVM来测试它。
消费者Pact测试基于我们的JSON数据有效负载定义消息交互,并将其包装在S3事件的模拟中。它看起来像这样:
class PoToPdfHandlerPactSpec extends Specification { // our Lambda function handler private PoToPdfHandler handler // mock of the service which will generate the PDF file private PDFGenerator pdfGenerator // mock of the service that will fetch the JSON from the S3 bucket private PurchaseOrderService orderService def setup() { pdfGenerator = Mock() orderService = Mock() handler = new PoToPdfHandler(pdfGenerator, orderService) } def 'has a contract with the Big Bad Legacy App with regards to POs'() { given: def poStream = new PactMessageBuilder().call { serviceConsumer 'PoToPdfHandlerLambdaFunction' hasPactWith 'Big Bad Legacy App' given('there is a valid address and email') expectsToReceive 'a purchase order in json format' withContent(contentType: 'application/json') { supplierName string('Test Supplier') supplierOrderId identifier() processingCentreId identifier() orderDate timestamp('yyyy-MM-dd\'T\'HH:mm:ss') lineItems minLike(1) { productCode regexp(~/\d+/, '000011') productDescription string('JIM BEAM WHITE LABEL COLA') // oh, yeah quantityOrdered integer(20) } summary { orderTotalExTax decimal(2000.0) orderTotalIncTax decimal(2200.0) } supplierEmail string('TestSupplier@wild-serverless-west.com') senderEmail string('buyers@wild-serverless-west.com') } } def bucket = 'testbucket' def inputKey = 'po.json' def outputKey = 'po.pdf' // We need to mock out the AWS objects for this test, // as the handler will use the AWS SDK to fetch the // actual message from the S3 bucket using the information // from the event we receive Context context = [:] as Context def poBytes def mockS3Object = Mock(S3Object) { getObjectContent() >> { new S3ObjectInputStream( new ByteArrayInputStream(poBytes), null) } } // The event JSON we will receive def eventJson = [ records: [ [s3: [bucket: [name: bucket], object: [key: inputKey]]] ] ] def event = Gson.newInstance().fromJson(JsonOutput.toJson(eventJson), S3Event) when: poStream.run { Message message -> // The actual JSON from the message will be wrapped in an input stream // which will be read by our handler via the mocked AWS SDK call poBytes = message.contentsAsBytes() // An we now invoke the handler handler.handleRequest(event, context) } then: // We expect the PDF generator to be called. It means we were // able to correctly process the JSON from the downstream system 1 * pdfGenerator.generate(_) >> new byte[1] 1 * orderService.fetch(bucket, inputKey) >> mockS3Object 1 * orderService.save(bucket, outputKey, _) } }
该测试将预期消息设置为消息契约。然后,它通过AWS SDK调用来模拟S3事件以返回预期消息的消息有效负载。第三,它使用模拟事件调用lambda函数,然后验证调用的PDF和持久性服务。
运行此测试会导致使用我们预期的JSON格式生成Message Pact文件。这与前一篇文章中的消费者测试几乎相同(除了嘲笑AWS的东西)。但是,我们假装响应AWS事件,而不是测试从消息队列中消费消息。
旧版应用程序提供商
现在是重要的一部分。嗯,这一切都很重要。所以,现在更重要的部分。我们希望确保我们添加到遗留应用程序的代码位始终生成可由Lambda函数处理的JSON文件。我们可以通过使用我们用于消息提供程序的Message Pact验证来实现。我们创建了一个使用@PactVerifyProvider注释注释的测试方法,该注释与来自使用者测试的pact文件中的描述相匹配。此方法必须调用生成JSON数据的代码,该数据通常会写入S3存储桶并返回,以便可以根据我们的Lambda函数预期进行验证。
与大多数遗留应用程序一样,编写起来并不像我们嘲笑很多合作者来使其工作那么容易,我不会厌倦这些细节。以下是验证功能的简化版本:
class SubmittableSupplierOrderPact { @PactVerifyProvider('a purchase order in json format') String jsonForPurchaseOrder() { // This was the cause of our failure. A change in these classes // caused the generated JSON to change SupplierOrderView supplierOrder = supplierOrderViewFixture() ISupplierOrderItemView item1 = new SupplierOrderItemView() item1.with { setProductCode('1234') setProductDescription('Test Product 1') setPurchaseOrderQuantity(10) setListPrice(200) setTotalPriceExTax(100) } ISupplierOrderItemView item2 = new SupplierOrderItemView() item2.with { setProductCode('1235') setProductDescription('Test Product 2') setPurchaseOrderQuantity(50) setListPrice(200) setTotalPriceExTax(900) } List orderItems = [ item1, item2 ] IOrganisation organisation = [ getEmailAddress: { 'TestSupplier@wild-serverless-west.com' } ] as IOrganisation // The model class that gets rendered to JSON def subject = new SubmittableSupplierOrder(supplierOrder, orderItems, organisation, // yikes! timezones! SystemParameterManager.timeZoneId) // This is the Object mapper used to convert the model classes to JSON. Hopefully nobody // changes the actual code to use something else. But as it is a legacy application, it // is unlikely. def mapper = new JSONMapperModule().provideReportObjectMapper() // return the JSON representation mapper.writeValueAsString(subject) } }
运行Pact-JVM验证程序将导致调用函数jsonForPurchaseOrder,并根据pact文件中的消息有效内容验证结果。现在,如果从遗留应用程序生成的JSON发生变化,我们的Lambda函数无法处理它,我们将获得失败的构建。
对我们来说,这导致客户总是按照承诺获得他们的PDF,并且更快乐的交付经理。但我怀疑最后一点只是巧合。
看,马,我有一个合同测试锤!
既然我们已经对消息队列实现了合同测试,并且已经对Lambda函数调用实现了合同测试,我们就开始在我们可以使用这些异步合同测试的地方看到模式。我们还了解了Context Boundary作为进行合同测试的重要场所。
我们在一个有限的上下文中有一个服务,它创建了一个事件,需要将它传递给另一个有界上下文中的服务。您可以使用的模式是在边界上具有可以接受请求的适配器服务。但在我们的情况下,我们没有太多时间(第二个上下文中的大多数服务尚未存在),并且数据的所有权随着调用传递(数据现在由新服务拥有,只有参考存储到前一个上下文中的数据)。数据流也是此阶段的一种方式。
![]()
有人认为,通过合同测试,我们可以将JSON文档以正确的格式推送到文档存储。实质上,我们可以将文档存储视为传输机制,就像我们将S3存储桶视为一个一样。服务1A是提供者,JSON文档是消息有效负载,而另一方(服务2A)的服务是消费者。
综上所述
合同测试无服务器功能与我们之前完成的合同测试没有什么不同。他们在中间有输入,输出和东西,喜欢与常规功能(和孩子)一样行为不端。如果数据格式发生变化,任何异步调用(如响应事件而调用的Lambda函数)以及以非结构化格式(如JSON)传递的数据也可能容易失败。而且数据的格式也会发生变化。事实上,你的JSON格式可能已经改变了,你可能还没有注意到它。
与消息队列一样,当您需要更改消息格式时,知道谁正在消费您的消息以及消费它们的方式可能是一件幸事。与无服务器功能相同。知道哪些函数将响应您写入该S3存储桶的JSON文件,以便将来更容易更改该JSON文件。你将来必须改变它。或者你可能已经改变了它,你还没注意到它!
原文:https://dius.com.au/2018/10/01/contract-testing-serverless-and-asynchronous-applications-part-2/
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 65 次浏览
【合约测试】合同测试无服务器和异步应用程序
随着向微服务转移,或μ服务更时尚,使用Pact进行消费者驱动的合同测试,这是一种策略,可以确定我们所有的服务是否能够正确地相互通信。不要求我们所有的服务都相互通信。它还使我们能够确定任何服务的消费者是谁。这很有帮助,因为如果你知道你的消费者是谁,那么当你想破坏某些东西时,你就知道该和谁交谈。或者当他们破坏某些东西时
我们为基于HTTP的微服务做了这个。然后我们添加了一些消息队列和lambda函数。只是因为我们可以。
通过消息队列进行异步通信
我们开发的一些服务开始以异步方式通过消息队列进行通信。很明显,现在知道消息的消费者是谁更为重要。使用同步通信,如果出现故障,参与者是谁是明显的。使用邮件队列,您可能不知道谁正在使用您的邮件,或者是否由于邮件更改而导致任何失败。
我觉得,典型的态度是生成消息,将其扔到队列中,这不再是你的问题。看起来非常类似于我们尝试使用Restful API和微服务进行更改的想法。
我目睹了由于消息中格式错误的日期导致两个团队之间的服务系统故障。通过多次部署到QA环境,需要数天才能解决。
关于如何确保服务通过消息队列进行通信的问题没有受到格式错误的消息的影响,让我想到了联系测试。进行合同测试以确保消息生产者和消费者能够正确地进行通信似乎是正确的想法。但问题比基于HTTP的服务更复杂,我们可以在HTTP级别模拟事物。一切都讲HTTP。说到消息队列,根据使用的消息队列,协议会有所不同。而且我不想创建一个模拟ActiveMQ,RabbitMQ,SQS,Kafka和Kinesis服务器,仅举几例。
这导致认识到,为了验证合同,底层消息队列通常是无关紧要的。只要您可以确保消息生成器生成格式正确的消息,并且使用者能够使用它,您就不需要实际的消息队列。这让我很开心。

所以我创建了消息合约。
这与常规Pact测试的工作方式类似。 我们创建一个消费者测试,生成并发布一个pact文件,然后验证我们的消息提供者是否生成了正确的消息。

消费者测试
大多数消息队列使用者是使用回调机制实现的,通常是某种消息监听器,它通过与SDK库集成从消息队列接收消息。为了能够测试我的消费者,我将使用者分成两个类,一个与消息队列库集成的消息监听器,以及一个处理消息的消息处理程序。除了将消息传递给处理程序之外,消息侦听器不执行任何操作。通过这种方式,我可以只使用不需要消息队列的处理程序编写消费者合同测试。
消费者合同测试以类似的方式工作。我指定了我希望收到的消息,然后获得Pact测试框架以使用每条消息调用消息处理程序。到目前为止,这已经用于测试Kafka,SQS和Kinesis消息消费者。
下面是一个JVM消息处理程序的示例,它将处理来自Kafka主题的消息作为Spock测试。但是你应该能够使用任何测试框架,比如JUnit或TestNG。
第1步 - 定义消息期望
消费者测试从定义消息期望开始。基本上,我们正在设置我们希望收到的信息。我们使用PactMessageBuilder来设置协议和消息。
given: def messageStream = new PactMessageBuilder().call { serviceConsumer 'messageConsumer' hasPactWith 'messageProducer' given 'order with id 10000004 exists' expectsToReceive 'an order confirmation message' withMetaData(type: 'OrderConfirmed') // Can define any key-value pairs here withContent(contentType: 'application/json') { type 'OrderConfirmed' audit { userCode string('messageService') } origin string('message-service') referenceId regexp('\\d+\\-\\d', '10000004-2') timeSent timestamp value { orderId regexp('\\d+', '10000004') value decimal(10.00) fee decimal(10.00) gst decimal(15.00) } } }
第2步 - 使用生成的消息调用消息处理程序
此示例测试从Kafka主题获取消息的消息处理程序。 在这种情况下,Pact消息被包装为Kafka MessageAndMetadata类。
when: messageStream.run { Message message -> messageHandler.handleMessage(new MessageAndMetadata('topic', 1, new kafka.message.Message(message.contentsAsBytes()), 0, null, valueDecoder)) }
类似地,对于处理程序从SQS接收消息的示例,该消息是由像Jackson这样的库反序列化的对象,您可以执行以下操作:
when: messageStream.run { Message message -> def order = objectMapper.readValue(message.contentsAsBytes(), Order) assert messageHandler.handleMessage(order) != null }
这里的objectMapper是Jackson库中的ObjectMapper。 以与收到实际消息时相同的方式对消息进行反序列化非常重要。
第3步 - 验证消息是否已正确处理
我们的处理程序应该接收消息并将订单详细信息保存到我们的订单存储库中,因此我们可以检查它是否正常工作。
then: def order = orderRepository.getOrder('10000004') assert order.status == 'confirmed' assert order.value == 10.0
Pact在这里没有做任何事情,它只是将DSL的期望转换为JSON文档,并将其传递给一些要执行的代码。实质上,它假装是一个消息队列。如果一切都通过,则生成pact文件。这是重要的一点,因为我们现在可以发布它。
验证我们的消息提供商
关闭循环的下一步是验证提供程序服务是否正确生成消息。我们通过让Pact以与消费者测试相反的方式工作来实现这一目标。同样,Pact将伪装成消息队列并让消息提供者向其发送消息。这将与已发布的pact文件进行匹配。
我们通过从消息生成代码中分割消息发送代码来实现此目的。这样,负责将消息放入消息队列的类委托给另一个类来生成实际消息。然后我们可以调用后一类在验证测试期间生成一条消息,以确定它是否正确生成消息。唯一需要注意的是,以这种方式测试的类必须是实际用于生成真实消息的类。
Pact-JVM使用Java注释来查找可以调用消息生成器并返回生成的消息的测试类。如果您使用的是JUnit,则可以使用AmqpTarget来驱动此行为,而不是用于常规pact验证测试的HttpTarget。另请参阅在Gradle中验证消息提供程序和在Maven中验证消息提供程序,以获取有关如何在这些工具中启用此功能的信息。
现在,当我们验证消息pact文件时,Pact-JVM将在测试类路径中查找使用@PactVerifyProvider注释的方法,这些方法与pact文件中的内容具有匹配的描述。在我们之前的示例中,它是订单确认消息。
因此,这是一个验证来自先前的消费者测试的消息的示例。
class ConfirmationKafkaMessageBuilderTest { @PactVerifyProvider('an order confirmation message') String verifyMessageForOrder() { Order order = new Order() order.setId(10000004) order.setExchange('ASX') order.setSecurityCode('CBA') order.setPrice(BigDecimal.TEN) order.setUnits(15) order.setGst(15.0) order.setFees(BigDecimal.TEN) def message = new ConfirmationKafkaMessageBuilder() .withOrder(order) .build() JsonOutput.toJson(message) } }
在这种情况下,ConfirmationKafkaMessageBuilder是用于生成发送到Kafka主题的消息的类。但是这可以用于任何消息队列,因为我们没有使用任何特定的Kafka。 Pact-JVM现在将调用verifyMessageForOrder方法并验证返回的内容是否与pact文件中的消息内容匹配。
综上所述
我们可以使用联系测试之类的策略来验证通过消息队列进行通信的使用者和提供者是否可以工作而无需实际运行的消息队列。我们通过以下步骤执行此操作:
- 将消息使用者拆分为特定于队列的消息处理程序和处理该消息的类。
- 编写一个调用消息处理类的消费者测试。
- 发布生成的pact文件。
- 将我们的消息提供程序拆分为特定于队列的发布者和消息生成器
- 设置我们的验证(使用Pact-JVM)来调用使用@PactVerifyProvider注释的测试类的方法
- 获取带注释的测试方法以从消息生成器返回消息JSON。
现在我们可以在部署之前捕获这些日期格式问题。
在本博客的第二部分中,我将向您展示如何使用相同的技术来验证与AWS lambda函数的合同。
原文:https://dius.com.au/2017/09/22/contract-testing-serverless-and-asynchronous-applications/
本文:
讨论:请加入只是星球或者小红圈【首席架构师圈】
- 43 次浏览
【敏捷测试】敏捷方法论:理解敏捷测试的完整指南
在过去几年中,一种创建软件的新方式已经风靡软件开发和测试世界:敏捷。
事实上,根据VersionOne的敏捷状态报告,截至2018年,97%的组织以某种形式实践敏捷。 然而,受访者表示,这种采用在其组织中并不总是很普遍,这意味着在采用和成熟方面还有很长的路要走。
那么究竟什么是敏捷的,为什么它如此迅速地变得如此受欢迎? 让我们更详细地探索敏捷方法所涉及的内容以及如何在组织中引入它。 具体来说,我们将涵盖:
- 测试如何适应敏捷方法?
- 在敏捷团队上测试的不同方法有哪些?
- 敏捷运动的下一步是什么?
关于敏捷方法论
敏捷方法已经风靡软件开发世界并迅速巩固其作为“黄金标准”的地位。敏捷方法论都是基于敏捷宣言中概述的四个核心原则开始的。这些方法植根于适应性规划,早期交付和持续改进,所有这些都着眼于能够快速,轻松地响应变化。因此,在VersionOne的2017年敏捷状态报告中,88%的受访者认为“适应变化的能力”是拥抱敏捷的头号优势,这一点也就不足为奇了。
然而,随着越来越多的开发团队采用敏捷理念,测试人员一直在努力跟上步伐。这是因为敏捷的广泛采用促使团队更频繁地发布版本和完全无证的软件。这种频率迫使测试人员在进行测试时,他们如何与开发人员和BA一起工作,甚至他们进行的测试,同时保持质量标准。
对敏捷团队进行测试意味着什么?
敏捷原则都是关于协作,灵活和适应性的。它建立在现在世界变化的前提下,这意味着软件团队不再需要多年才能将新产品推向市场。在那段时间内,竞争对手的产品或客户期望可能会发生变化,而团队的风险则无关紧要。敏捷通过适应团队成功所需的内容,帮助团队更多地协作,从而最大限度地降低风险。它通过鼓励团队定期展示他们的工作并收集反馈以便他们能够快速适应变化来实现这一目标。
快速启动您的敏捷协作:阅读我们的文章“开发人员和测试人员之间保持一致的秘密”。
缩小测试范围,敏捷开发的快节奏为测试人员带来了几个必要条件:
- 根据风险确定需求的优先级,因为无法测试所有内容
- 自动化测试以提高效率
- 增加探索性测试的使用,以加快从代码交付到测试完成的时间,并强调创建有效代码的必要性
- 适应从冲刺到冲刺的变化
第四个必要条件 - 适应性 - 特别重要,因为它要求测试人员具有更广泛的跨功能测试技能,这代表了与瀑布环境中经常需要的较窄测试技能的背离。此外,与瀑布环境不同,遵循敏捷方法的测试人员需要与开发人员保持密切联系,以便在整个软件开发生命周期中协作进行测试。在瀑布式方法中,通常会有一个大型的需求文档供测试人员测试。该文档不会经常更改,因此测试人员可以相当独立于开发人员而存在。但是,大多数敏捷方法对文档都很清楚,新功能的要求可能只在需求跟踪系统中的票证中,而没有列出所有边缘情况。这些场景中的测试人员需要与开发和业务团队进行高度沟通,因为几周前他们编写的测试可能很快就会过时。为了取得成功,测试人员需要灵活并能够适应移动目标。
为了取得成功,测试人员需要灵活并能够适应移动目标。
一般而言,敏捷宣言有四个核心原则,对于测试人员来说很重要:
- 个人和流程与工具之间的互动
- 通过综合文档工作软件
- 响应遵循计划的变更
- 通过合同谈判与客户合作
所有这一切的底线是,每个人 - 测试人员,开发人员和其他人 - 必须发展才能拥抱敏捷的工作方式。
敏捷不是放之四海而皆准的
每个组织都是独一无二的,面临着不同的内部因素(即组织规模和利益相关者)和外部因素(即客户和法规)。 为了帮助满足不同组织的不同需求,您可以在其中一种敏捷方法中使用各种敏捷方法和几种不同类型的测试。 哪种组合适合您的团队取决于您的内部和外部因素,需求和目标。 让我们来看看一些最流行的敏捷方法和测试方法,包括:
敏捷方法论
- Scrum
- 看板
测试方法
-
行为驱动开发(BDD)
-
验收测试驱动开发(ATDD)
-
探索性测试
-
基于会话的测试
2敏捷方法论类型
1)Scrum

它是什么?作为最受欢迎的软件测试方法之一(58%的组织已根据VersionOne采用了敏捷方法),Scrum采用高度迭代的方法,专注于在每个sprint之前定义关键特性和目标。它旨在降低风险,同时快速提供价值。
Scrum从一个需求或用户故事开始,概述了功能应该如何执行和测试。然后,该团队通过一系列冲刺循环,以快速提供小规模的价值爆发。为了帮助团队以这种灵活的方式工作并避免改变优先级,Scrum要求从一开始就回答问题。
它和瀑布有什么不同?瀑布包括在发布产品之前的几个测试和错误修复周期,而Scrum更具协作性和迭代性。其中一个最大的区别是瀑布早期需要大量文档。这个文档使得在过程继续进行时更改功能变得更加困难,这在某些环境(例如消费级软件)中可能是负面的,而在其他环境中则是积极的(例如团队试图发射火箭的那些)没有人想要经常危险移动的要求)。也就是说,您可能会认为Scrum就像许多“迷你瀑布”一样,因为每个冲刺开始时需求都很明确,不应该在其中移动。不同之处在于,下一个冲刺的详细要求不是提前几个月设定的。
潜水更深入,Scrum要求测试人员,开发人员和BA之间进行更多定期协作,通常采用每日站立和冲刺回顾的形式,以确保正确的沟通和协调。此外,还有一位Scrum Master通过删除团队中的阻截者来确保他们最有效,从而帮助项目完成任务。 Scrum Master可以是团队中的任何人,例如开发人员或测试人员。
采用有什么意义? Scrum为来自瀑布环境的团队提供了最简单的转换之一,因为它基于时间的冲刺和发布仍然可以提前计划。也就是说,它确实需要更快的迭代和更强的协作。
它是谁的?由于其快速迭代,Scrum最适合那些客户和利益相关者希望通过在展示会议上定期查看工作产品而积极参与的团队。此协作允许团队对即将到来的陈列柜进行更改。在采用Scrum方法时应该参与的主要团队成员包括:
- 产品拥有者
- Scrum Master
- 开发商
- 自动化工程师
- 测试者
- 利益相关者
什么是最佳做法?除了强大的沟通,协作和适应性之外,遵循Scrum方法的测试人员的其他最佳实践还包括:
- 根据销售代表或客户的通信(通常以用户故事的形式)确定验收标准(注意:此直接连接应有助于减少误传)
- 使用验收标准开发代码并确保团队批准该代码
- 在将其部署到生产环境之前,在类似沙箱的环境以及类似生产的环境中测试代码
2)看板

它是什么?看板是一种非常简单的基于敏捷的方法,植根于制造业(它由丰田公司开发,旨在帮助提高工厂的生产率)。在它的核心,看板可以被认为是一个大的,优先的待办事项列表。与Scrum一样,看板中的需求由其当前阶段(待办,开发,测试,完成)跟踪。
与Scrum不同,看板不是基于时间的。相反,它完全基于优先权。当开发人员准备好完成下一个任务时,他/她将其从待办事项列表中拉出来。由于计划会议较少,这种方法意味着团队需要非常接近。在这种类型的环境中,如果开发人员的工作速度比测试人员快得多,那么就会出现瓶颈。在这些情况下,团队中的任何人都应该跳进并帮助不同的领域。当然,满足这种需求需要很大的灵活性和适应性。
它和瀑布有什么不同?看板仍然有像瀑布这样的要求,但是由于测试团队没有开始考虑测试每个要求,直到开发人员从积压的顶部选择它,因此需求可能会发生变化。相比之下,瀑布是基于时间的,在计划中有很多开销。在某些情况下,在瀑布环境中进行繁重的规划是很好的,例如在建造昂贵的东西时,但并不总是必要的。使用看板,版本仍然有计划,但团队通常不会在某些日期向任何人提供功能,除非相关项目位于待办事项的顶部。
采用有什么意义?看板为正确的团队提供简单的过渡。为了顺利过渡到看板,业务分析师,开发人员,测试人员和利益相关者应该坐在一起并定期沟通。转换到看板时,重要的是要记住这种方法提供了将代码投入生产的最快方法,但代码可能会有一些技术债务。这是因为开发时并不总是知道接下来的内容并不一定能够生成最可重用的代码。
它是谁的?看板最适合不为公众制作功能和/或承诺发布某些日期的小型团队或团队。此外,它是主要专注于维护工作的任何产品或团队的首选方法选择,因为错误并不总是直截了当,往往需要研究解决,这使得时间管理具有挑战性。根据Scrum或Waterfall方法,不能最小化问题规划量的团队可能会更好。
应参与看板环境的主要团队成员包括:
- 产品拥有者
- 专案经理
- 开发商
- 自动化工程师
- 测试者
什么是最佳做法?除了保持可见性和优先协作之外,遵循看板方法的测试人员的最佳实践还包括:
- 在业务所有者,开发人员和测试人员之间保持非常开放的沟通渠道
- 确保团队可以灵活地承担其核心职责之外的其他角色,以帮助消除瓶颈
- 让每个人都成为产品的所有者,以便他们完全关注结果
4敏捷测试方法
1)行为驱动开发(BDD)

它是什么?很多人都听说过或使用过测试驱动开发(TDD)。例如,开发人员在编写代码之前使用TDD编写单元测试失败。 BDD基于与TDD相同的原则,但它不是单元测试,而是要求在业务级别进行更高级别的测试。 BDD不是像TDD那样从面向技术的单元测试开始,而是从基于最终用户行为的初始需求开始,并且需要“人类可读”的测试,甚至可以替换一些需求文档。此要求基于产品应展示的行为,为工程师在开发测试时使用创建气密指南。
有关更多信息,请阅读我们的文章:“为什么BDD是DevOps中的测试秘诀。”
具体来说,BDD使用Gherkin Given / When / Then语法从功能规范开始。然后,该规范指导跨功能的开发人员,测试人员和产品所有者。正如他们所做的那样,他们使用自动化测试功能来确定完整性,改进代码直到通过测试,就像TDD方法一样,除了团队级别。为了确保测试通过(并且通常需要多次尝试),开发人员应该只重构代码,而不是添加任何新功能。
总而言之,BDD需要一种“智能”自动化策略,以提高效率。该策略将BDD与其他敏捷方法区分开来。
它与标准瀑布测试有何不同? BDD与标准的瀑布测试极为不同,因为前者要求在需求的早期编写测试用例,并要求在开发周期结束时执行这些测试。但是,在敏捷环境中使用BDD,测试不是基于需求,测试是在功能开发的情况下进行的。
此外,在Waterfall方法中,测试人员是编写测试用例的人。另一方面,BDD方法适用于编写测试的企业主。此开关可减少业务分析人员,开发人员和测试人员之间的通信(或沟通错误)。
采用有什么意义?当团队习惯于传统的测试方式时,更改为BDD方法可能具有挑战性。它需要BA或测试人员预先编写测试,并且开发人员要在代码中编写测试规范以进行匹配。这是团队内部的一种新型协调方式,但非常积极的是团队合作为一个单元,包括业务用户。
它是谁的? BDD方法非常适合从事以功能为中心的软件和/或将用户体验放在首位的团队的团队。应参与BDD环境的主要团队成员包括:
- 产品负责人/业务分析师
- 专案经理
- 开发商
- 自动化工程师/测试员
什么是最佳做法?遵循BDD方法的测试人员的最佳实践包括:
- 简化文档以保持整个流程的精益
- 采用“三友”模式,产品所有者,开发人员和测试人员组成一个有凝聚力的团队
- 使用像Cucumber这样的测试框架来定义标准
- 以尽可能容易重用的方式构建自动化测试
- 让业务分析师学习Gherkin语法并直接编写测试用例
2)验收测试驱动开发(ATDD)

它是什么? ATDD就像BDD一样,它要求首先创建测试,并要求编写代码以通过这些测试。然而,与TDD中的测试通常是面向技术的单元测试不同,在ATDD中,测试通常是面向客户的验收测试。
ATDD背后的想法是用户对产品的感知与功能同样重要,因此这种感知应该推动产品性能,以帮助提高采用率。为了实现这一想法,ATDD收集客户的意见,使用该输入来制定验收标准,将该标准转换为手动或自动验收测试,然后根据这些测试开发代码。与TDD和BDD一样,ATDD是测试优先的方法,而不是需求驱动的过程。
与TDD和BDD方法一样,ATDD通过消除开发人员解释产品使用方式的需要,帮助消除潜在的误解区域。 ATDD比TDD和BDD更进一步,因为它直接进入源(也就是客户)以了解产品的使用方式。理想情况下,这种直接连接应有助于最大限度地减少在新版本中重新设计功能的需要。
它与标准瀑布测试有何不同? ATDD与标准瀑布测试不同,因为它是测试优先方法。标准瀑布测试要求根据需求预先编写测试用例,而ATDD不是需求驱动的测试过程。
采用有什么意义?因为ATDD代表了与传统方法的背离,所以从一个到另一个并不容易让团队去做。为了处于采用ATDD方法的最佳位置,团队需要获得利益相关者的支持,这有时会证明是有挑战性的。
它是谁的?由于强调用户感知,ATDD最适合专注于用户体验的团队,具有高采用率的目标,并希望在未来版本中尽量减少功能更改的数量。应参与ATDD环境的主要团队成员包括:
- 客户/客户代言人
- 开发人员
- 产品负责人/业务分析师
- 自动化工程师/测试员
- 专案经理
什么是最佳做法?遵循ATDD敏捷方法的测试人员的最佳做法包括:
- 与客户密切互动,例如通过焦点小组,以确定期望
- 倾向于面向客户的团队成员,如销售代表,客户服务代理和客户经理,以了解客户的期望
- 根据客户期望制定验收标准
- 优先考虑两个问题:
如果是X,客户会使用该系统吗?
我们如何验证系统是否支持X?
3)探索性测试

它是什么?接下来我们进行探索性测试,这实际上是一种功能测试,但在敏捷环境中非常重要。探索性测试使测试人员对代码拥有所有权,以有组织,混乱的方式对其进行测试。在这种情况下,测试人员不会遵循测试步骤,而是以标准或巧妙的方式使用软件来尝试打破它。测试人员将像往常一样记录缺陷,但并不总是提供有关应用程序测试内容和方式的详细文档。
探索性测试不是脚本化的。相反,它是基于每个独特的软件开发最佳测试。由于其无脚本方法,探索性测试通常模仿用户在现实生活中如何与软件交互。
总体而言,探索性测试遵循以下四个关键原则:
- 并行测试计划,测试设计和测试执行
- 具体而灵活
- 协调调查潜在的机会
- 知识共享
它与标准瀑布测试有何不同?探索性测试实际上可以在Waterfall和Agile环境中完成,但是敏捷环境中测试人员和开发人员之间的紧密集成有助于缓解在瀑布环境中运行探索性测试时可能出现的任何瓶颈。
此外,为了在Waterfall环境中运行探索性测试,必须提供有关测试结果的文档,并且该文档应该易于追溯到需求。当然,这种类型的文档在任何环境中都是有用的。
采用有什么意义?拥抱探索性测试相对容易,因为它可以快速启动(和扩展),简单易学并为整个团队带来好处。也就是说,重要的是要记住,它不应该是唯一的测试形式(相反,它应该告知接下来会发生什么类型的测试)。此外,即使它没有脚本,探索性测试也不应该是非结构化的(测试人员仍然需要设置目标,记录您的活动并采取特定用户角色的思维模式)。
它是谁的?探索性测试有助于减少测试时间,发现更多缺陷并提高代码覆盖率。因此,探索性测试最适合受时间限制的团队,需要帮助确定要运行的最佳测试类型的团队(特别是在没有开发人员规范的情况下)以及希望确保他们没有的团队以前的测试都不会错过任何东西。应参与探索性测试的主要团队成员包括:
- 测试人员(虽然团队中的每个人都应该以某种方式参与)
什么是最佳做法?使用探索性测试的测试人员的最佳实践包括:
- 使用Mindmap或电子表格等组织应用程序中的功能
- 专注于某些领域或某些场景
- 跟踪经过测试的内容,以帮助重现任何错误
- 在qTest Explorer之类的工具中记录结果,因此对测试的内容有一定的责任感
4)基于会话的测试

它是什么?最后,让我们回顾一下基于会话的测试。基于会话的测试建立在探索性测试的基础上,提供更多结构因为探索性测试完全没有脚本,所以它使问责制变得困难,并且在很大程度上依赖于所涉及的测试人员的技能和经验。基于会话的测试旨在通过为探索性测试带来更多结构来缓解这些缺点,而不会剥夺探索性测试提供的好处,例如更好地模仿用户体验和通过测试获得创造性的能力。
基于会话的测试通过在时间限制的,不间断的会话期间进行测试,针对章程进行测试并要求测试人员报告每个会话期间发生的测试来提供此结构。此外,基于会话的测试应该通过测试人员和管理人员之间的“汇报”进行限制,其中包括五个PROOF点:发生了什么(过去),取得了什么(结果),阻碍了什么(障碍) ),还有什么需要做的(Outlook)以及测试人员对此的感受(感受)。
它与标准瀑布测试有何不同?与探索性测试相同,基于会话的测试可以在Agile和Waterfall环境中运行,但它更有利于敏捷环境中常见的测试人员和开发人员之间的紧密协作。
采用有什么意义?与探索性测试非常相似,采用基于会话的测试证明相对容易,因为它易于快速启动和启动。对于已经习惯于探索性测试的测试人员来说,最大的障碍是采用基于会话的测试调用的附加结构。与探索性测试一样,运行基于会话的测试的团队应该记住它不是最后一站,而是一种帮助确定下一步要进行的最佳测试类型的方法。
它是谁的?基于会话的测试有助于缩短测试时间,同时增加缺陷发现和代码覆盖率,使其成为面临时间限制并需要更多指导以确定要运行的测试类型的团队的理想选择。对于在探索性测试中获益但需要在整个过程中改进问责制的团队而言,它也是理想的选择。应参与基于会话的测试的主要团队成员包括:
- 测试者
- 经理
什么是最佳做法?使用基于会话的测试的测试人员的最佳实践包括:
- 概述任务,以便测试人员清楚他们正在测试的软件
- 开发一个明确的章程,指明任务,要测试的软件区域,运行会话的测试人员,会话将在何时进行,以及设计和执行的测试,发现的错误和整体说明(与探索性测试一样,像qTest Explorer这样的文档工具可以在这里提供帮助)
- 在没有任何中断的情况下运行测试会话
- 在会议报告中明确记录会议期间的活动和说明
- 在测试人员和经理之间进行汇报,以审查会议的结果并讨论下一步的测试步骤
如何使测试与敏捷交付流程保持一致
一旦确定哪种测试方法适合您的组织,您就还没有完成。您仍需要将测试与交付一致。为实现这一目标,我们建议采用三管齐下的方法:
1)尽早参与开发过程
测试人员越早参与,越好。理想情况下,测试人员应该从第一天起就在场。这是因为让测试人员在桌面上的每一步都能提供更高水平的需求和目标洞察力,鼓励合作并帮助确定频繁(如果不是连续)测试的必要性。
2)经常测试,但是很周到
随着越来越多的团队采用敏捷方法,效率就是一切。这种对速度的需求促使团队采用DevOps和持续集成以保持移动,这需要更频繁地进行测试。但是在效率和频率集中的重组中,测试人员需要保持周到,以免产生更多开销并运行不必要的测试,这实际上会减慢过程。
3)通过测试创建来运行
牢记在当今敏捷,DevOps驱动的世界中对速度的需求,测试人员需要在创建测试时立即投入运行。具体来说,越多的测试人员可以减少从需求收集到测试创建的时间越多越好。从一开始就在所有谈话中坐下来应该有助于这方面。
敏捷测试的下一步是什么?
虽然敏捷已经在软件开发生命周期中取得了重大进展,但仍有很长的路要走,特别是在测试团队中。
展望未来,更广泛的采用和更加成熟的敏捷方法将要求测试人员超越测试创建和执行,并开始专注于代码交付和集成。与此同时,测试人员需要磨练自己的自动化技能,更多地参与整个软件开发过程,并继续与开发人员建立协作关系。最终,这些变化还将要求测试人员成为开发和产品使用方面的专家,以便提供更全面的测试策略并承担“质量冠军”的角色。
将来,对于在敏捷环境中工作的测试人员来说,三个关键原则将变得尤为重要:
1)沟通
敏捷需要测试人员和开发人员之间的紧密协作,而这种协作使通信成为测试人员的首要任务。此外,在质量成为每个人的责任的世界中,测试人员将成为内部专家的“质量冠军”,这将使他们能够在聚光灯下清晰地传达测试需求和推理。
2)技能多样性
在敏捷环境中,一切都可以改变,这需要测试人员适应。这种适应性的一部分是拥有多样化的技能组合,以便测试人员可以根据需要改变方向。例如,功能测试人员需要将他们的技能扩展到手动脚本执行之外。这种多样化的技能组合是必须的,因为不同的冲刺需要在短时间内执行不同类型的测试。
3)商业心态
最后,Agile采用以客户为中心的方法,以确保客户尽可能快地尽早获得尽可能多的价值。测试人员在提供这一价值方面发挥着重要作用,但它需要他们采取商业思维方式,以便他们能够理解客户的期望,愿望和关注,并相应地制定他们的测试策略。
为什么领先的公司正在通过敏捷测试实现敏捷
超过300家领先的公司选择改进他们的软件测试流程,并通过采用敏捷。以下是其中一些领导者为什么选择使用qTest而说的原因:
“我们能够快速将所有测试案例从惠普质量中心缓解到qTest,并在短短几周内启动并运行团队。实施过程非常好“
-Radka Iordanova,Office Depot,Inc。电子商务总监
“当你转向敏捷时,仅仅改变你的开发方法还不够,你必须升级你的软件工具...... QASymphony正是我们所寻找的。”
-Alex Bantz,Salesforce Marketing Cloud质量工程总监
“我们已经看到了测试者错误的大幅减少,现在我们已经有了缺陷的历史。我们可以看到问题所在。 American Equity和QASymphony之间的合作非常精彩。“
-Dennis Young,美国股票QA助理副总裁
“我们评估了很多其他测试平台,发现qTest是最好的,而且到目前为止最直观......自首次实施qTest以来,我们的效率提高了至少50%。”
-Jesse Reynosa,Zappos高级质量工程师
特别感谢Ali Huffstetler为这个博客绘制图像。
原文: https://www.qasymphony.com/blog/agile-methodology-guide-agile-testing/ ,
- 409 次浏览
【软件开发】TDD,救世主还是噩梦?
测试驱动开发是一种编程方法,其中在编码之前创建测试。 下面,我列出了使其应用程序有用的一些原因。
- 1.测试可以作为代码的蓝图:在建造房屋之前,制定蓝图来帮助房屋建造者。 构建测试可帮助您了解应用程序的工作原理。 此外,它可以帮助您创建更优化的代码。
- 2.帮助开发者了解客户需求。
- 3. 可维护的代码,有利于团队合作,帮助未来的开发者。
- 4. 预防性,不仅仅是纠正性:构建测试可以让开发人员更加意识到可能发生的错误和边缘情况。
TDD 的三个阶段
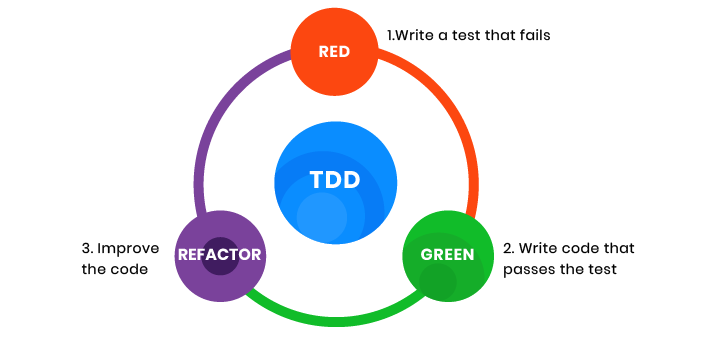
TDD 的三个核心步骤:创建测试——实现代码——重构
1. 创建测试
此阶段将在提交消息中以“[RED]”开头。测试脚本需要精确但简单且可重用。例如,当您有一个按钮时,您可以检查它们在被单击后是否重定向到正确的路径。如果稍后您添加另一个,您可以重复使用它们。从这一步开始,您决定要实现的特定功能。使其具体而小。
然后,想象一下这个功能是如何工作的,可能的边缘情况是什么,将使用哪些组件,以及在制作测试脚本时它们将如何相互交互。您不必首先实现全部功能。测试一个小功能——实现——并迭代。
2. 实施代码
此阶段将在提交消息中以“[GREEN]”开头。对你来说可能是最令人兴奋的部分😜。开发人员将根据书面场景对功能进行编码。目的是从测试中消除当前的错误。
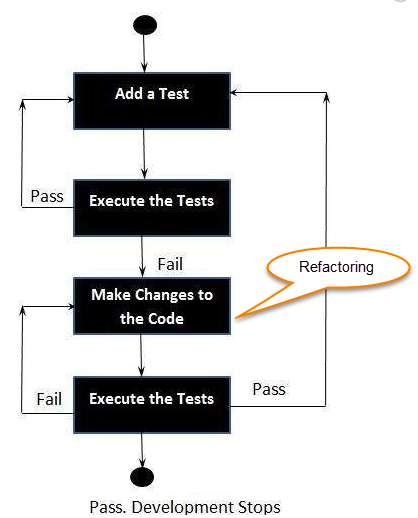
3.重构
此阶段将在提交消息中以“[REFACTOR]”开头。 在这个阶段,开发人员通过删除冗余而不改变程序的行为来优化他们的代码。
功能测试的类型
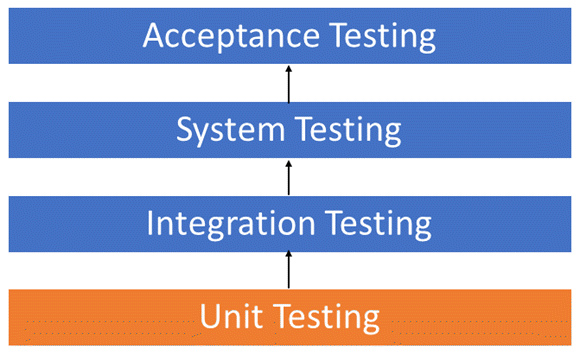
- 单元测试:检查最小的单元,如函数或方法,以使其正常工作。 自动化便宜。
- 集成测试:检查所有使用的模块是否可以很好地协同工作。 示例:对数据库的 API 调用。
- 验收测试:在发布前测试端到端产品。
..还有很多。 那么,您是否仍然怀疑最初的努力是否值得花时间? 事实上,测试并不是一个简单的概念。 你需要大量的练习才能获得最大的好处。 由于 TDD 起初可能看起来令人生畏,因此以下心态可以帮助您开始。
- 从一个小功能开始。
- 如果您从事单个项目,请对功能的流程充满想象力。 如果您与 PM 和其他用户一起工作,请有效地验证产品规格。
在行业中,测试的角色可以分配给软件工程师、QA 工程师或 SDET(测试中的软件开发人员)。 这取决于公司的政策。
我如何在我的项目中实现 TDD
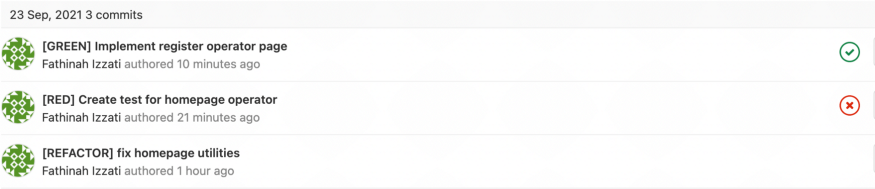

上面是一个用 Jest 编写的典型前端单元测试的例子。 我创建了一个测试来检查操作员注册页面是否正确呈现(第 52-65 行)。 语法如下,
expect(/*get the component/).TestingFunction()
— 断言测试是否按照我们想要的方式运行。
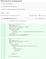
A. 红色的
使用旧的提交消息约定,我首先为即将推出的功能创建了失败测试。 下面,我创建了两个测试来检查 1) 运营商注册页面是否正确呈现,以及 2) 当正确的用户通过身份验证时,运营商主页是否会正确呈现。 管道将失败,因为我还没有实现该功能。
 b. 绿色
b. 绿色
然后,我根据之前创建的测试实现了该功能。 下面是实现运营商注册页面的代码片段。 我只添加了一条新路由并将角色添加为组件的新参数,因此注册页面也相应呈现。
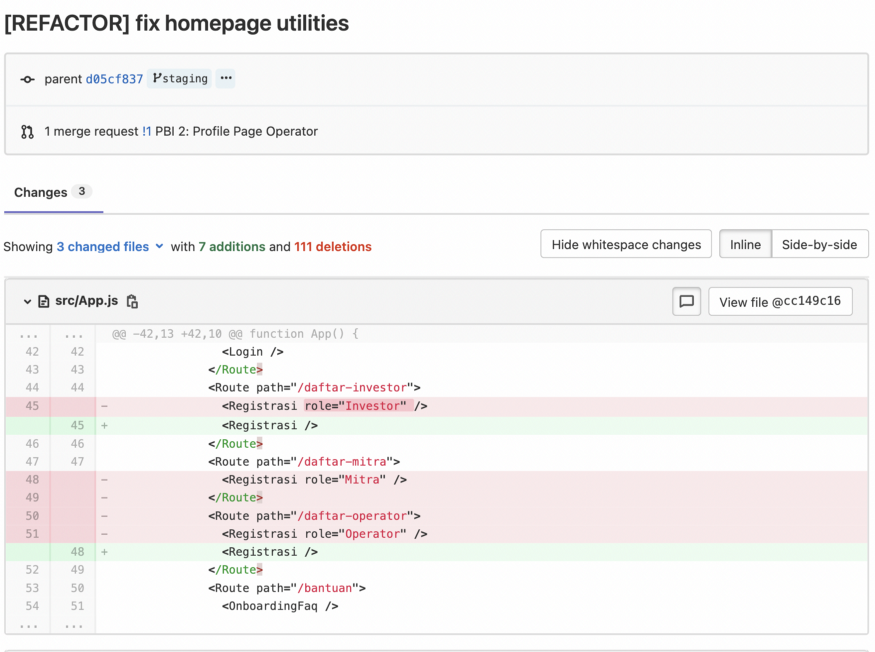
C. 重构
在重构阶段,我通过删除冗余代码块来修复我的代码。
实现功能后,您应该检查测试覆盖率。 测试覆盖率是一种衡量我们的应用程序代码有多少部分被测试的技术。 数字越高,测试的案例和功能就越多。 因此,100% 是一个完美的分数。
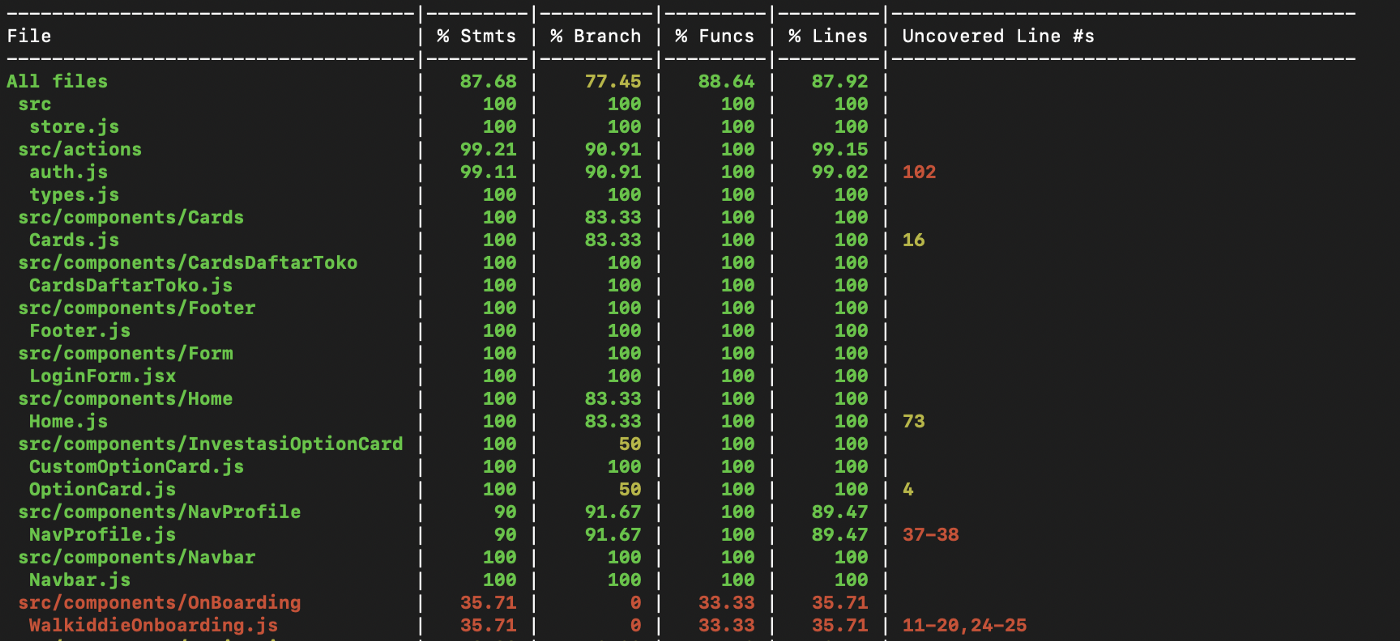
运行 npm test (执行 react-scripts test )后,会给出如上的报告。 如何解释报告的数字如下:
- 语句:程序中的每条语句都执行了吗?
- 分支:在 if/else 等条件语句中,会创建场景分支。 那么,程序中的每个分支都经过测试了吗?
- Funcs:程序中的每个函数都被调用了吗?
- 行数:测试了多少行代码?
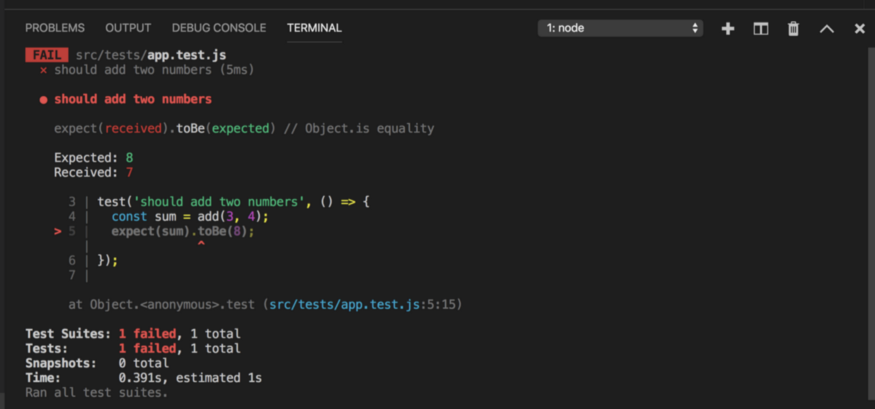
上面的错误说明给定的两个数之和应该是8,但收到的是7。这种错误是我们将反复看到的,以检查我们的功能实现是否正确。
我的想法
TDD 是一种应用于大多数公司的实践,已经显示出一些长期的好处。学习编码不是一次性的活动,您还需要维护它。让您(和其他人)轻松维护代码的一种方法是使用 TDD。
优势 - TDD 如何提高我们的团队绩效
- 更简单的代码。由于我们需要先创建测试,所以我们不能随意编写实现代码。开发人员在创建良好的功能流方面变得更加周到,因为测试也可以作为蓝图。
- 可维护。如果我们在 backlog 上有另一个特性,我们首先创建测试。代码库变得更加模块化和干净。它可以节省我们调试的时间。
- 测试也可以作为文档。它们帮助我们的团队更好地理解彼此的代码,因为测试具有该功能如何工作的有序场景。
缺点
- 较慢的过程。开发可能会更慢,因为我们需要先进行测试,但它会以更少的调试时间进行权衡。
- 不是 100% 保证的。尤其是覆盖率不高的时候。有时,他们不知道错误的确切位置。
来源
- https://www.browserstack.com/guide/what-is-test-driven-development
- https://rubygarage.org/blog/tdd-in-react-apps
- https://www.linkedin.com/pulse/how-read-test-coverage-report-generated-using-jest-singhal/
原文:https://fathinah.medium.com/tdd-a-savior-or-nightmare-bfcf42a6ac55
- 70 次浏览
【软件测试】Java消费者驱动的合同测试
Java中的Pact-JVM和Gradle
介绍
在这篇文章中,我们将在Gradle Spring Boot虚拟提供程序(RESTful Web Service)和Gradle虚拟使用者之间编写一个Consumer Driven Contract Test。
我们将使用Pact-JVM,它将为消费者项目提供模拟服务以生成Pact,并为提供者项目验证能力以验证Pact。
安装
Gradle
Gradle Wrapper允许任何人在不必安装Gradle的情况下处理您的项目。它确保构建的正确版本的Gradle作为此项目存储库的一部分提供。首先克隆包含虚拟提供者和虚拟消费者的样本库:
bash-3.2$ git clone https://github.com/the-creative-tester/consumer-driven-contract-testing-example.git Cloning into 'consumer-driven-contract-testing-example'...
remote: Counting objects: 47, done.
remote: Compressing objects: 100% (33/33), done.
remote: Total 47 (delta 2), reused 42 (delta 1), pack-reused 0 Unpacking objects: 100% (47/47), done.
Checking connectivity... done.
提供者设置
导航到提供程序目录,您将在其中看到通过本指南使用Sprint Boot和Gradle构建的示例RESTful Web Service。尝试使用以下命令运行该服务:
bash-3.2$ ./gradlew clean build && java -jar build/libs/gs-actuator-service-0.1.0.jar
.. 2016-07-03 14:49:59.367 INFO 32114 --- [ main] hello.HelloWorldConfiguration : Started HelloWorldConfiguration in 6.782 seconds (JVM running for 7.452)
您现在应该能够通过导航到http:// localhost:8080 / hello-world或使用curl来达到服务(观察每次向服务发出请求时id增加):
bash-3.2$ curl http://localhost:8080/hello-world {"id":2,"content":"Hello World!"}
消费者设置
从消费者的角度来看,总是要生成契约。这一代可以分为三个部分。
第1部分:契约规则
在这一部分中,我们定义了一个模拟服务器的主机和端口来表示提供者:
@Rule
public PactRule rule = new PactRule(Configuration.MOCK_HOST, Configuration.MOCK_HOST_PORT, this);
private DslPart helloWorldResults;
第2部分:契约片段
在这一部分中,我们构建了一个Pact Fragment,它定义了一个提供者的预期契约:
@Pact(state = "HELLO WORLD", provider = Configuration.DUMMY_PROVIDER, consumer = Configuration.DUMMY_CONSUMER)
public PactFragment createFragment(ConsumerPactBuilder.PactDslWithProvider.PactDslWithState builder)
{
helloWorldResults = new PactDslJsonBody()
.id()
.stringType("content")
.asBody();
return builder
.uponReceiving("get hello world response")
.path("/hello-world")
.method("GET")
.willRespondWith()
.status(200)
.headers(Configuration.getHeaders())
.body(helloWorldResults)
.toFragment();
}
第3部分:契约验证
在这一部分中,我们确保第2部分中构造的片段与模拟服务器的响应匹配:
@Test
@PactVerification("HELLO WORLD")
public void shouldGetHelloWorld() throws IOException
{
DummyConsumer restClient = new DummyConsumer(Configuration.SERVICE_URL);
assertEquals(helloWorldResults.toString(), restClient.getHelloWorld());
}
尝试使用消费者目录中的Gradle生成Pact:
bash-3.2$ ./gradlew test
:compileJava UP-TO-DATE
:processResources UP-TO-DATE
:classes UP-TO-DATE
:compileTestJava
:processTestResources UP-TO-DATE
:testClasses
:testBUILD SUCCESSFUL
Total time: 10.67 secs
然后将生成Pact并将其存储在pacts目录中,但它看起来像这样:
{
"provider" : {
"name" : "dummy-provider"
},
"consumer" : {
"name" : "dummy-consumer"
},
"interactions" : [ {
"providerState" : "HELLO WORLD",
"description" : "get hello world response",
"request" : {
"method" : "GET",
"path" : "/hello-world"
},
"response" : {
"status" : 200,
"headers" : {
"Content-Type" : "application/json;charset=UTF-8"
},
"body" : {
"id" : 5677679801,
"content" : "dugNvVPasiFRnzqpPNuq"
},
"responseMatchingRules" : {
"$.body.id" : {
"match" : "type"
},
"$.body.content" : {
"match" : "type"
}
}
}
} ],
"metadata" : {
"pact-specification" : {
"version" : "2.0.0"
},
"pact-jvm" : {
"version" : "2.1.12"
}
}
}
提供者
现在,Pact已由Consumer生成,并假设Provider(RESTful Web Service)正在运行。您可以从提供程序目录运行以下命令,以确保提供程序满足Consumer的所有期望:
bash-3.2$ ./gradlew pactVerify
:pactVerify_dummyProviderVerifying a pact between dummy-consumer and dummyProvider
[Using file /Users/jasonthye/Dev/pact-example-gradle/pacts/dummy-consumer-dummy-provider.json]
Given HELLO WORLD
WARNING: State Change ignored as there is no stateChange URL
get hello world response
returns a response which
has status code 200 (OK)
includes headers
"Content-Type" with value "application/json;charset=UTF-8" (OK)
has a matching body (OK)
:pactVerifyBUILD SUCCESSFUL
Total time: 9.936 secs
完整的例子
https://github.com/the-creative-tester/consumer-driven-contract-testing-example
- 68 次浏览
【软件测试】ducktape :分布式系统集成与性能测试库
Ducktape包含用于运行系统集成和性能测试的工具。 它提供以下功能:
- 以简单的单元测试样式编写分布式系统的测试
- 默认情况下隔离,因此系统测试尽可能可靠。
- 用于在不同环境中集群提升和拆除服务的实用程序(例如本地,自定义集群,Vagrant,K8s,Mesos,Docker,云提供商等)
- 触发特殊事件(例如弹出服务)
- 收集结果(例如日志,控制台输出)
- 报告结果(例如满足预期条件,绩效结果等)
- 73 次浏览
【软件测试】企业环境中的验收测试
画景观
在专注于任何功能测试自动化技术和工具之前,先看大局总是一个好主意。 这里有一些值得强调的点。
遵循正确的模式
众所周知,在设计自动化测试和持续集成管道时,应该遵循测试金字塔概念(而不是测试冰淇淋蛋卷)。
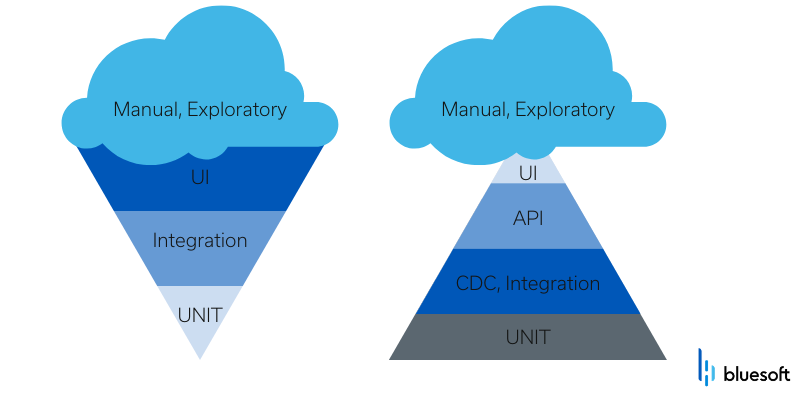
这背后的原因很简单——金字塔底层的测试执行得更快,而且实施起来通常更便宜。此外——我们越早发现错误——越好。这并不意味着自动化更高级别的测试(验证所有系统组件)不那么重要。
保持平衡
决定哪些测试应该自动化以及自动化程度如何始终是测试策略的关键部分。遵循测试金字塔是一个很好的起点,但同样重要的是不要低估其他测试技术的价值,包括功能性(例如探索性)和非功能性(代码分析、性能、弹性、安全性……)。在自动化功能测试时,根据经验,用户界面测试应保持在最低限度(涵盖关键业务路径),并尽可能地通过 API 进行测试。
选择你的工具
单元和集成测试的工具选择与开发组件的技术密切相关。 JUnit、Mockito、Jest 等工具可帮助开发人员在早期构建阶段实现测试覆盖。
我们可以在测试金字塔的更高层次上开始思考常见的测试框架。由 Spring Cloud Contract 和 PACT 等工具支持的 Consumer Driven Contracts 作为早期非功能性 API 合同验证的手段越来越受欢迎。
但是,如何在多个组件和服务协同工作的集成环境中验证对我们的业务至关重要的逻辑呢?我们如何组织我们的测试场景并通过合理的努力使它们可执行?
这就是端到端测试框架可能派上用场的地方!
那里有很多商业框架,但我们决定采用开源并使用大型社区支持的成熟解决方案。
我们选择背后的原因是:
- 当事情成熟到可以正常工作时,我们喜欢它
- 我们希望从开源框架的广泛集成和定制可能性中受益
- 我们已经使用下面详细描述的工具集成功地满足了验收测试的内部和商业需求。
端到端测试框架
概述
我们的框架旨在支持自动化验收测试,旨在同时适应 API 和 GUI 测试。
它在 JAVA 中实现,如果需要,可以轻松扩展以连接到数据库和消息队列。
场景(与企业主/分析师一起创建)是用 Cucumber(Gherkin 语法)编写的,并被分组为特性。
基于场景标签(指定严重性、组件等)使用 TestNG+CubumberJVM 和 Maven 执行测试。测试可以并行运行;可以使用 TestNG 或 Cucumber hooks 设置测试数据。
引擎盖下是什么?
- Cucumber (Gherkin) –> 场景和功能
- RestAssured -> REST API 步骤定义,
- JAX-WS -> SOAP API 步骤定义,
- Selenium -> GUI 步骤定义
- Zalenium -> 在不同浏览器上运行 GUI 场景,视频录制仪表板
- Allure -> 通用格式 HTML 测试报告
- 支持库:
- Swagger Codegen -> 从 Swagger 生成类模型
- Apache CXF -> 从 WSDL 生成类模型
- Java Faker -> 假数据生成器
- Waiter -> selenium 等待包装器
- TestNG+CucumberJVM, Maven -> 运行测试,钩子之前/之后
- Jenkins (或类似的)-> CI/CD
优点和特点
准备部署
“样板”已准备好部署为本地或云中的 Docker 容器,例如作为 Openshift 或 K8s 项目(这是我们的开箱即用方法中的首选,以实现最高效的执行环境)。
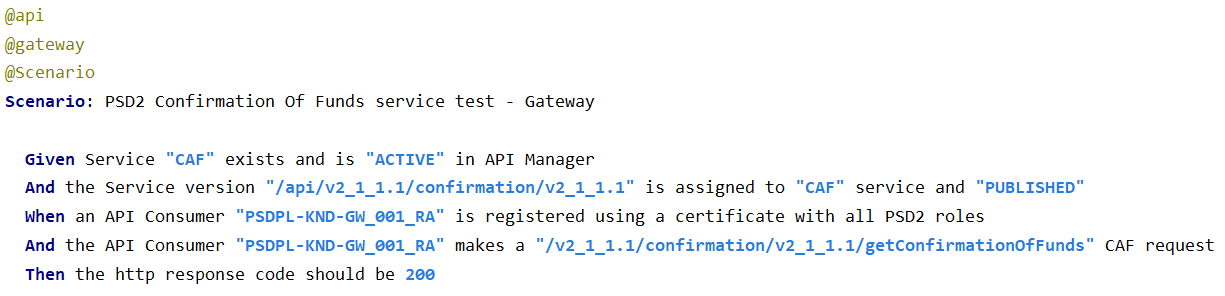
可执行的测试规范
Gherkin 为人类友好的测试规范提供语法,可以作为代码实现和运行。特性、场景和步骤组成了面向业务的测试规范,而步骤定义和支持代码一起执行测试任务。
以下是可执行测试场景的两个示例。
API(基本场景):
GUI (using a Scenario Outline):
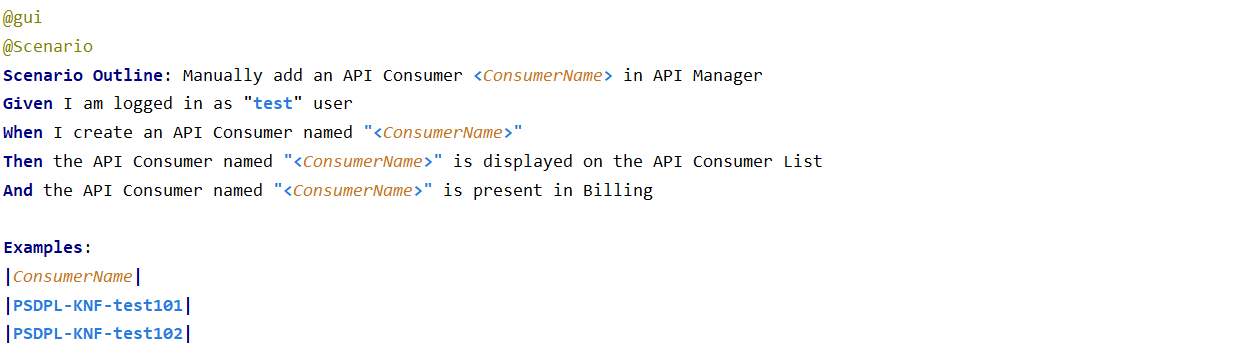
请注意,使用数据驱动场景就像在“示例”表中添加新行一样简单!
友好的报告
Allure 为 RestAssured、Cucumber 和 Jenkins 提供美观的 HTML 报告和开箱即用的集成。
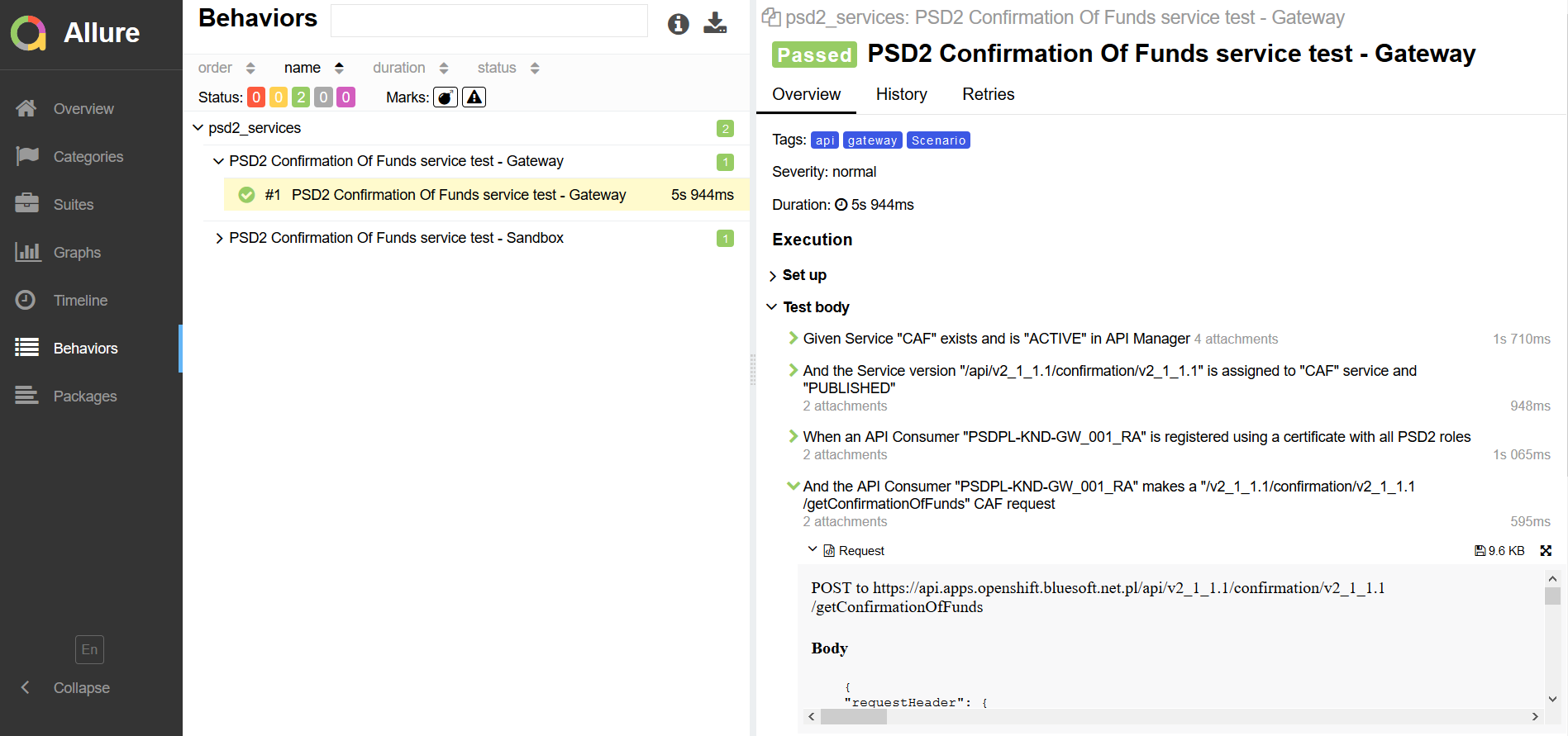
我们进一步定制了我们的报告,以提供:
对 GUI 测试执行的视频记录的引用
链接到票据管理系统(例如 JIRA)
需要时,还可以将执行结果报告回 JIRA(通过自定义“@after”钩子)。
最佳实践
以下是实施和执行方案时要遵循的一些最佳实践:
- 场景应与企业主/分析师一起准备,并用 Cucumber (Gherkin) 编写,同时利用其功能,例如:
- 场景大纲和示例
- 数据表
- 标签(例如“@gui”、“@api”、“@blocker”等)
- 场景必须相互独立,即它们中的每一个都应该能够单独运行(测试数据不应“泄漏”到其他场景)
- 场景不应包含不必要的技术细节,并且应该易于理解
- 场景应该根据测试的业务领域分组在 *.feature 文件中(不一定每个用户故事)
- 实现 GUI 步骤定义时:
- 推荐使用页面对象模式
- 禁止“Sleeps”
- id、css 选择器优于 xpath
- 实现 API 步骤定义时:
- 公共属性应与 RestAssured RequestSpecifications 一起重用
- 过滤器应该用于记录
- 只要有可能,应该从 API 定义(.wsdl、.swagger)创建 DTO
- 测试应在专用环境中/使用专用测试数据运行(以避免干扰手动测试)
- 自动生成的数据应加前缀或后缀(以便与手动测试数据分开)
- 应该模拟集成范围之外的系统(我们在环境中无法控制)
为什么不使用 Postman 和 Cypress.io 呢?
Postman(与 Newman 一起)和 Cypress.io 都是很棒的(半商业)工具,尽管有些有限。在大型企业环境中工作,对自动化测试的要求有时会更加苛刻。以 API 测试为例——我们实际上使用 Postman 作为开发(和测试开发)辅助工具,但 RestAssured 让您可以更好地控制测试的组织和执行。
一个很好的例子是我们最近必须涵盖的一个测试场景,它需要控制 SSL 会话。虽然 Postman 在请求之间保持 SSL 会话打开(以不可配置的方式),但 RestAssured 允许您选择是保持 SSL 连接处于活动状态还是在后续请求之后关闭它(通过其 connection-config 方法)。
Cypress.io 的受欢迎程度正在增长,但是当需要完整的浏览器控制(使用选项卡和 iframe)和跨浏览器测试时,Selenium 尽管有缺点,但仍然可以提供更多功能。
(请注意,框架组件可以根据项目需求进行修改和调整)
保持在一起
以下是有关如何充分利用自动化端到端测试的一些更一般的提示。
与您的 CI/CD 管道集成
自动化验收测试应集成到 CI/CD 管道中,作为将应用程序自动部署到专用测试环境(例如使用 OpenShift 项目模板创建)之后的下一步。验收测试失败意味着部署失败!
使您的自动化测试成为开发过程的一部分
自动化测试场景应该与产品开发一起编写。与开发功能并行编写测试(而不是事后才进行测试)将帮助您缩短反馈循环并提供更好的产品。
与利益相关者合作
邀请利益相关者(业务分析师、手动测试人员)参与 BDD 测试场景将使您的团队更好地沟通,甚至可能有助于在将错误/差距转化为代码之前识别它们。无处不在的领域语言将有助于避免误解。
不要重复你自己(和你的测试)
应避免跨不同测试级别重复业务逻辑覆盖。端到端测试应该只涵盖应用程序中最重要的用户旅程。
根据反馈采取行动
在任何测试步骤中发现的错误都应该被测试金字塔最低级别的测试覆盖。
注意执行时间
就 e2e 测试套件执行的时间预算达成一致是个好主意,例如 15 分钟。请记住,您的自动化测试是一个“安全网”,不应使部署过程过长而令人不安。
原文:https://bluesoft.com/acceptance-testing-in-enterprise-environments/
- 88 次浏览
【软件测试】实用测试金字塔
“测试金字塔”是一个比喻,它告诉我们将软件测试分组到不同粒度的桶中。它还给出了我们应该在每个组中进行多少次测试的概念。尽管测试金字塔的概念已经存在了一段时间,但是团队仍然在努力将其正确地付诸实践。本文回顾了测试金字塔的原始概念,并展示了如何将其付诸实践。它显示了您应该在金字塔的不同级别中寻找哪种类型的测试,并给出了如何实现这些测试的实际示例。

生产就绪的软件需要在投入生产之前进行测试。随着软件开发学科的成熟,软件测试方法也日趋成熟。开发团队不再拥有大量的手工软件测试人员,而是将测试工作的大部分自动化。自动化测试使团队能够在几秒钟或几分钟内而不是几天或几周内知道他们的软件是否被破坏。
自动化测试大大缩短了反馈循环,与敏捷开发实践、持续交付和DevOps文化密切相关。拥有一个有效的软件测试方法可以让团队快速而有信心地前进。
本文探讨了一个全面的测试组合应该是什么样子的,以保证响应性、可靠性和可维护性——无论您正在构建的是微服务体系结构、移动应用程序还是物联网生态系统。我们还将讨论构建有效且可读的自动化测试的细节。
(测试)自动化的重要性
软件已经成为我们生活的世界的重要组成部分。它已经超越了其早期的唯一目的——提高企业效率。如今,企业都在想方设法成为一流的数字企业。作为用户,我们每个人每天都在与越来越多的软件进行交互。创新的车轮正在加速转动。
如果你想跟上步伐,你就必须想办法在不牺牲软件质量的前提下更快地交付你的软件。持续交付(Continuous delivery)可以帮助您实现这一点,在这种实践中,您可以自动确保您的软件可以在任何时候发布到生产环境中。通过持续交付,您可以使用构建管道来自动测试您的软件,并将其部署到您的测试和生产环境中。
手工构建、测试和部署越来越多的软件很快就不可能了——除非您想把所有的时间都花在手工的、重复的工作上,而不是交付工作软件。自动化一切——从构建到测试、部署和基础设施——是您前进的唯一道路。

图1:使用构建管道自动可靠地将软件投入生产
传统上,软件测试是过度手工的工作,将应用程序部署到测试环境中,然后执行一些黑箱风格的测试,例如单击用户界面查看是否有损坏。通常这些测试将由测试脚本指定,以确保测试人员执行一致的检查。
很明显,手工测试所有更改是费时、重复和乏味的。重复性工作很无聊,无聊会导致错误,让你在周末之前找一份不同的工作。
幸运的是,对于重复性任务有一个补救方法:自动化。
作为一名软件开发人员,自动化您的重复测试可以极大地改变您的生活。自动化这些测试,您就不再需要盲目地遵循点击协议来检查您的软件是否仍然正常工作。自动化您的测试,您可以毫不费力地更改您的代码基。如果您曾经尝试过在没有适当测试套件的情况下进行大规模重构,我敢打赌您一定知道这是一种多么可怕的体验。如果你在路上不小心弄坏了东西,你怎么知道?好吧,您点击所有的手动测试用例,就是这样。但说实话:你真的喜欢那样吗?如果你能做出更大的改变,知道你是否在喝咖啡的几秒钟内就把东西弄坏了呢?如果你问我,听起来会更有趣。
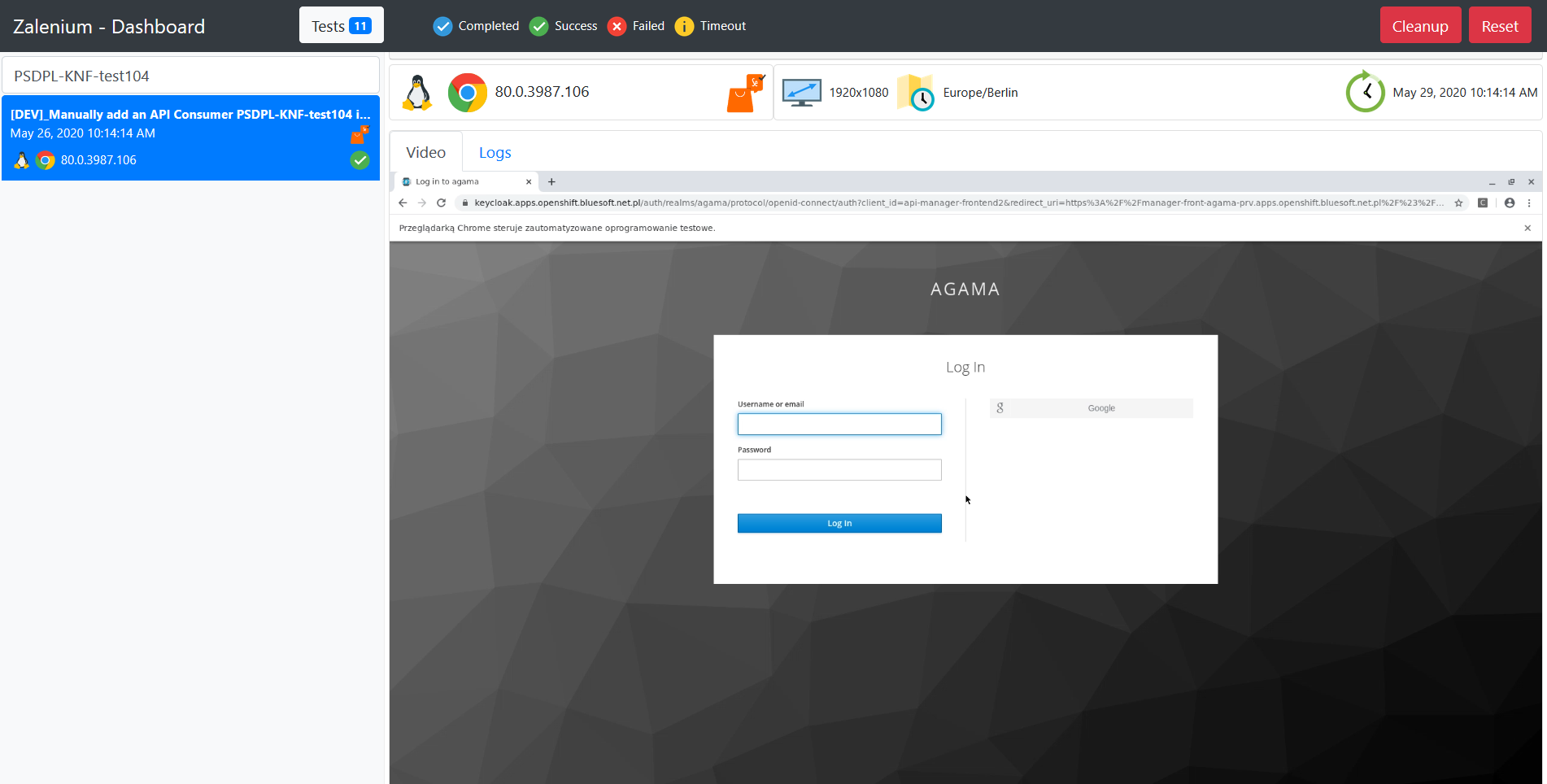
测试金字塔
如果你想认真对待软件的自动化测试,有一个关键的概念你应该知道:测试金字塔。Mike Cohn在他的书《成功与敏捷》中提出了这个概念。这是一个很好的视觉隐喻,告诉你要考虑不同层次的测试。它还告诉您在每个层上要做多少测试。
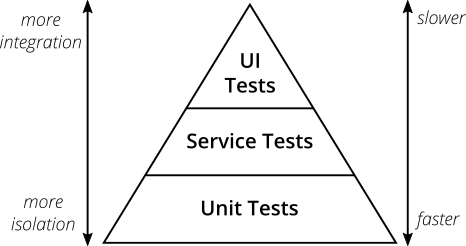
图2:测试金字塔
Mike Cohn最初的测试金字塔由三层组成,你的测试套件应该包括(从下到上):
- 单元测试
- 服务测试
- 用户界面测试
不幸的是,如果你仔细看的话,测试金字塔的概念有点短。有些人认为迈克·科恩的测试金字塔的命名或某些概念方面并不理想,我不得不同意这一点。从现代的观点来看,测试金字塔似乎过于简单,因此可能具有误导性。
尽管如此,由于它的简单性,当您建立自己的测试套件时,测试金字塔的本质是一个很好的经验法则。你最好记住科恩最初的测试金字塔中的两件事:
- 编写不同粒度的测试
- 级别越高,应该进行的测试就越少
坚持使用金字塔形状来得到一个健康、快速和可维护的测试套件:编写大量小而快速的单元测试。编写一些更粗粒度的测试和很少的高级测试来从头到尾测试您的应用程序。小心,你不会得到一个测试冰淇淋甜筒,这将是一个噩梦,维护和运行太长时间。
不要过于依赖科恩测试金字塔中各个层的名称。事实上,它们可能非常具有误导性:服务测试是一个很难理解的术语(Cohn自己谈到了许多开发人员完全忽略这一层的观察结果)。在使用react、angular、ember.js等单页面应用程序框架的日子里,UI测试显然不必位于金字塔的最高层——你完全可以在所有这些框架中对UI进行单元测试。
考虑到原始名称的缺点,为测试层提供其他名称是完全可以的,只要在代码库和团队讨论中保持一致即可。
工具和库
- JUnit:我们的测试运行器
- mockkito:用于mock依赖项
- Wiremock:用于清除外部服务
- PACT :用于编写CDC测试
- Selenium:用于编写ui驱动的端到端测试
- REST-assured:用于编写REST api驱动的端到端测试
样例应用程序
我已经编写了一个简单的微服务,包括一个测试套件,其中包含针对测试金字塔不同层的测试。
示例应用程序显示了典型微服务的特征。它提供一个REST接口,与数据库对话并从第三方REST服务获取信息。它是在Spring Boot中实现的,即使您以前从未使用过Spring Boot,也应该能够理解它。
确保在Github上查看代码。readme包含在您的机器上运行应用程序及其自动化测试所需的说明。
功能
应用程序的功能很简单。它提供了一个有三个端点的REST接口:
| GET /hello | 返回“Hello World”。总是这样。 |
| GET /hello/{lastname} | 查找提供姓氏的人。如果这个人是已知的,返回“Hello {Firstname} {Lastname}”。 |
| GET /weather | 返回德国汉堡的当前天气状况。 |
获取/天气返回德国汉堡的当前天气状况。
高层结构
在高层次上,该系统具有以下结构:
图3:我们的微服务系统的高层结构
我们的微服务提供了一个可以通过HTTP调用的REST接口。对于某些端点,服务将从数据库获取信息。在其他情况下,服务将通过HTTP调用外部天气API来获取和显示当前天气条件。
内部架构
在内部,Spring服务有一个典型的Spring架构:
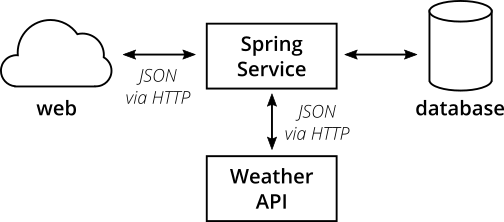
图4:我们的微服务的内部结构
- 控制器类提供REST端点并处理HTTP请求和响应
- Repository类与数据库接口,负责将数据写入或从持久存储中读取
- 客户机类与其他API通信,在我们的示例中,它通过HTTPS从darksky.net weather API获取JSON
- 域类捕获我们的域模型,包括域逻辑(公平地说,在我们的例子中,域逻辑非常简单)。
有经验的Spring开发人员可能会注意到这里缺少一个常用的层:受领域驱动设计的启发,许多开发人员构建了一个由服务类组成的服务层。我决定不在这个应用程序中包含服务层。一个原因是我们的应用程序足够简单,服务层可能是不必要的间接层。另一个原因是我认为人们在服务层上做得太多了。我经常遇到这样的代码库,其中整个业务逻辑都在服务类中捕获。域模型仅仅成为一个数据层,而不是行为层(一个贫血的域模型)。对于每个重要的应用程序,这都浪费了保持代码良好结构和可测试性的大量潜力,并且没有充分利用面向对象的功能。
我们的存储库非常简单,并且提供了简单的CRUD功能。为了保持代码简单,我使用了Spring Data。Spring Data为我们提供了一个简单而通用的CRUD存储库实现,我们可以使用它来代替自己滚动。它还负责为我们的测试构建内存中的数据库,而不是像在生产中那样使用真正的PostgreSQL数据库。
看一下代码库,熟悉一下内部结构。这对于我们下一步:测试应用程序非常有用!
单元测试
测试套件的基础将由单元测试组成。您的单元测试确保代码基的某个单元(您正在测试的主题)按预期工作。在您的测试套件中,单元测试的范围是所有测试中最窄的。测试套件中的单元测试数量将大大超过任何其他类型的测试。

图5:单元测试通常用测试替身替换外部协作者
单位是什么?
如果你问三个不同的人“单元”在单元测试上下文中是什么意思,你可能会得到四个不同的,稍微有些细微差别的答案。在某种程度上,这取决于你自己的定义,没有标准答案也没关系。
如果您使用的是函数式语言,那么单元很可能是单个函数。您的单元测试将调用具有不同参数的函数,并确保它返回预期值。在面向对象的语言中,单元可以从单个方法到整个类。
善于交际和孤独的
一些人认为,所有被测试对象的合作者(例如,被测试类调用的其他类)都应该用mock或stub替换,以实现完美的隔离,并避免副作用和复杂的测试设置。其他人则认为,只有那些速度较慢或副作用较大的协作者(例如访问数据库或进行网络调用的类)才应该被忽略或嘲笑。
偶尔人们会将这两种测试标记为单独的单元测试,用于存根所有协作者的测试,以及用于允许与真正协作者对话的测试的社会性单元测试(Jay Fields有效地使用单元测试创造了这些术语)。如果你有一些空闲时间,你可以深入了解不同学派的优缺点。
在一天结束的时候,决定是进行单独的单元测试还是社交单元测试并不重要。编写自动化测试是重要的。就我个人而言,我发现自己一直在使用这两种方法。如果使用真正的协作者变得很困难,我将大量使用mock和stub。如果我想让真正的合作者参与到测试中来,这会让我在测试中更有信心,那么我只会将服务的最外层存根。
通过模拟和存根
mock和存根是两种不同的测试替身(不止这两种)。许多人将Mock和存根这两个术语互换使用。我认为精确地记住它们的特定性质是有好处的。您可以使用test double用一个帮助您进行测试的实现来替换您在生产中使用的对象。
简单地说,它的意思是用一个伪版本替换一个真实的东西(例如类、模块或函数)。假版本的外观和行为与真实版本类似(对相同方法调用的答案),但是答案包含在单元测试开始时定义的固定响应。
使用测试双精度并不特定于单元测试。可以使用更精细的测试替身以受控的方式模拟系统的整个部分。然而,在单元测试中,您很可能会遇到很多mock和存根(这取决于您是喜欢交际的开发人员还是喜欢独处的开发人员),原因很简单,因为许多现代语言和库使设置mock和存根变得简单和舒适。
无论您选择哪种技术,很有可能您的语言的标准库或一些流行的第三方库将为您提供设置模拟的优雅方法。甚至从头开始编写自己的模拟也只是编写一个具有与实际签名相同的伪类/模块/函数,并在测试中设置伪类/模块/函数。
您的单元测试将运行得非常快。在一台不错的机器上,您可以期望在几分钟内运行数千个单元测试。单独测试代码基的一小部分,避免攻击数据库、文件系统或触发HTTP查询(通过对这些部分使用mock和存根),以保持测试速度。
一旦你掌握了编写单元测试的窍门,你就会越来越熟练地编写它们。排除外部合作者,设置一些输入数据,调用被测试对象,并检查返回的值是否符合您的期望。研究测试驱动开发,让您的单元测试指导您的开发;如果应用正确,它可以帮助您进入一个伟大的流程,并提出一个良好的和可维护的设计,同时自动生成一个全面的和完全自动化的测试套件。不过,这并不是什么灵丹妙药。去吧,给它一个真正的机会,看看它是否适合你。
测试什么?
单元测试的好处是,您可以为所有的生产代码类编写它们,不管它们的功能是什么,也不管它们属于内部结构的哪个层。您可以对控制器进行单元测试,就像您可以对存储库、域类或文件读取器进行单元测试一样。简单地按照每个生产类的经验规则坚持一个测试类,您就有了一个良好的开端。
单元测试类至少应该测试类的公共接口。不能测试私有方法,因为您不能从不同的测试类调用它们。从测试类中可以访问Protected或package-private(假定您的测试类的包结构与生产类相同),但是测试这些方法可能已经走得太远了。
当涉及到编写单元测试时,有一条很好的线:它们应该确保测试了所有非平凡的代码路径(包括幸福路径和边缘用例)。同时,它们不应该与您的实现太紧密地联系在一起。
为什么?
过于接近生产代码的测试很快就会变得令人讨厌。一旦重构了生产代码(快速回顾:重构意味着在不更改外部可见行为的情况下更改代码的内部结构),单元测试就会崩溃。
这样,您就失去了单元测试的一大好处:充当代码更改的安全网。每次重构时,您都会对那些愚蠢的测试失败感到厌倦,导致更多的工作而不是提供帮助;这个愚蠢的测试是谁的主意?
你会怎么做呢?不要在单元测试中反映内部代码结构。测试可观察的行为。思考
如果我输入值x和y,结果会是z吗?
而不是
如果我输入x和y,这个方法会先调用类A,然后调用类B,然后返回类A的结果加上类B的结果吗?
通常应该将私有方法视为实现细节。这就是为什么你甚至不应该有测试它们的冲动。
我经常听到反对单元测试(或TDD)的人说,编写单元测试是没有意义的工作,您必须测试所有方法才能得到一个高测试覆盖率。他们经常引用一些场景,在这些场景中,过于热切的团队领导强迫他们为getter和setter以及所有其他类型的琐碎代码编写单元测试,以便获得100%的测试覆盖率。
这有很多问题。
是的,您应该测试公共接口。然而,更重要的是,您不测试普通的代码。别担心,肯特·贝克说没事的。测试简单的getter或setter或其他简单的实现(例如,没有任何条件逻辑)不会给您带来任何好处。节省时间,这是你可以参加的另一个会议,万岁!
但我真的需要测试这个私有方法
如果你发现自己真的需要测试一个私有方法,你应该退一步问问自己为什么。
我很确定这更多的是一个设计问题而不是范围问题。很可能您觉得需要测试一个私有方法,因为它很复杂,并且通过类的公共接口测试这个方法需要进行很多笨拙的设置。
每当我发现自己处于这种情况时,我通常会得出这样的结论:我正在测试的类已经太复杂了。它做得太多,违反了单一的责任原则——五项基本原则的原则。
通常对我有效的解决方案是将原来的类分成两个类。通常只需要一到两分钟的思考就能找到一个好方法,把一个大班分成两个小班,每个班都有自己的责任。我将私有方法(我迫切需要测试的方法)移动到新类,并让旧类调用新方法。瞧,我的私有测试方法现在是公共的,可以很容易地进行测试。除此之外,我还通过坚持单一职责原则改进了代码的结构。
测试结构
一个适用于所有测试(不限于单元测试)的良好结构是:
- 设置测试数据
- 调用正在测试的方法
- 断言返回了预期的结果
有一个很好的助记符来记住这个结构:“Arrange, Act, Assert”。您可以使用的另一个方法是从BDD中获得灵感。它是“given”、“when”、“then”三元组,其中given表示设置,when方法调用,然后是断言部分。
这种模式也可以应用于其他更高级的测试。在每种情况下,它们都确保您的测试保持简单和一致。最重要的是,用这种结构编写的测试往往更短,更有表现力。
实现单元测试
现在我们知道了要测试什么以及如何构建单元测试,我们终于可以看到一个真实的例子了。
让我们以ExampleController类的简化版本为例:
@RestController
public class ExampleController {
private final PersonRepository personRepo;
@Autowired
public ExampleController(final PersonRepository personRepo) {
this.personRepo = personRepo;
}
@GetMapping("/hello/{lastName}")
public String hello(@PathVariable final String lastName) {
Optional<Person> foundPerson = personRepo.findByLastName(lastName);
return foundPerson
.map(person -> String.format("Hello %s %s!",
person.getFirstName(),
person.getLastName()))
.orElse(String.format("Who is this '%s' you're talking about?",
lastName));
}
}hello(lastname)方法的单元测试可能是这样的:
public class ExampleControllerTest {
private ExampleController subject;
@Mock
private PersonRepository personRepo;
@Before
public void setUp() throws Exception {
initMocks(this);
subject = new ExampleController(personRepo);
}
@Test
public void shouldReturnFullNameOfAPerson() throws Exception {
Person peter = new Person("Peter", "Pan");
given(personRepo.findByLastName("Pan"))
.willReturn(Optional.of(peter));
String greeting = subject.hello("Pan");
assertThat(greeting, is("Hello Peter Pan!"));
}
@Test
public void shouldTellIfPersonIsUnknown() throws Exception {
given(personRepo.findByLastName(anyString()))
.willReturn(Optional.empty());
String greeting = subject.hello("Pan");
assertThat(greeting, is("Who is this 'Pan' you're talking about?"));
}
}我们使用JUnit编写单元测试,JUnit实际上是Java的标准测试框架。我们使用Mockito将实际的PersonRepository类替换为测试的存根。这个存根允许我们定义存根方法在这个测试中应该返回的固定响应。存根使我们的测试更加简单、可预测,并允许我们轻松地设置测试数据。
按照arrangement、act、assert结构,我们编写了两个单元测试——一个是阳性的情况,另一个是无法找到被搜索的人的情况。第一个测试用例创建了一个新的person对象,并告诉模拟存储库在调用该对象时返回该对象,并将“Pan”作为lastName参数的值。然后测试继续调用应该测试的方法。最后,它断言响应等于预期的响应。
第二个测试的工作原理类似,但是测试的方法没有为给定的参数找到person。
集成测试
所有重要的应用程序都将与其他部分集成(数据库、文件系统、对其他应用程序的网络调用)。在编写单元测试时,为了得到更好的隔离性和更快的测试,您通常会遗漏这些部分。不过,您的应用程序将与其他部分进行交互,这需要进行测试。集成测试可以提供帮助。它们测试应用程序与应用程序外部的所有部分的集成。
对于自动化测试,这意味着您不仅需要运行自己的应用程序,还需要运行与之集成的组件。如果要测试与数据库的集成,则需要在运行测试时运行数据库。为了测试您是否可以从磁盘读取文件,您需要将文件保存到磁盘并在集成测试中加载它。
我之前提到过“单元测试”是一个模糊的术语,对于“集成测试”更是如此。对于某些人来说,集成测试意味着通过连接到系统中其他应用程序的整个应用程序堆栈进行测试。我喜欢更严格地对待集成测试,每次测试一个集成点,用测试替身替换单独的服务和数据库。结合契约测试和对测试加倍运行契约测试,以及实际实现,您可以得到更快、更独立、通常更容易推理的集成测试。
窄集成测试位于服务的边界。从概念上讲,它们总是触发导致与外部部分(文件系统、数据库、独立服务)集成的操作。数据库集成测试应该是这样的:
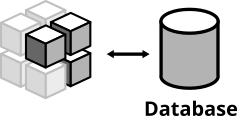
图6:数据库集成测试将您的代码与实际数据库集成
- 启动数据库
- 将应用程序连接到数据库
- 在代码中触发一个函数,该函数将数据写入数据库
- 通过从数据库中读取数据,检查预期的数据是否已写入数据库
另一个例子,测试你的服务通过一个REST API集成到一个单独的服务可能是这样的:
图7:这种集成测试检查应用程序是否能够正确地与单独的服务通信
- 启动您的应用程序
- 启动独立服务的实例(或具有相同接口的测试double)
- 在代码中触发从独立服务的API读取的函数
- 检查应用程序能否正确解析响应
您的集成测试—就像单元测试—可以是相当白盒的。一些框架允许您启动应用程序,同时仍然能够模拟应用程序的其他部分,以便检查是否发生了正确的交互。
为序列化或反序列化数据的所有代码段编写集成测试。这种情况发生的频率比你想象的要高。思考:
- 调用服务的REST API
- 读取和写入数据库
- 调用其他应用程序的api
- 读取和写入队列
- 写入文件系统
围绕这些边界编写集成测试可以确保向这些外部协作者编写数据和从这些外部协作者读取数据的工作正常。
在编写窄范围集成测试时,您的目标应该是在本地运行外部依赖项:启动本地MySQL数据库,在本地ext4文件系统上进行测试。如果要与单独的服务集成,要么在本地运行该服务的实例,要么构建并运行一个模仿真实服务行为的伪版本。
如果无法在本地运行第三方服务,您应该选择运行专用的测试实例,并在运行集成测试时指向该测试实例。避免在自动化测试中与实际生产系统集成。对生产系统发出数千个测试请求肯定会引起人们的愤怒,因为您弄乱了他们的日志(在最好的情况下),甚至拒绝了他们的服务(在最坏的情况下)。通过网络与服务集成是广泛集成测试的一个典型特征,这会使您的测试速度变慢,并且通常更难编写。
关于测试金字塔,集成测试比单元测试处于更高的级别。集成较慢的部分(如文件系统和数据库)往往比运行单元测试时将这些部分去掉要慢得多。它们也比小型和独立的单元测试更难编写,毕竟您必须将外部部分作为测试的一部分来处理。尽管如此,它们的优点是让您相信您的应用程序可以正确地处理它需要与之通信的所有外部部分。单元测试在这方面帮不了你。
数据库集成
PersonRepository是代码库中惟一的repository类。它依赖于Spring数据,没有实际的实现。它只是扩展了CrudRepository接口并提供了一个方法头。剩下的就是春天的魔力。
public interface PersonRepository extends CrudRepository<Person, String> {
Optional<Person> findByLastName(String lastName);
}通过CrudRepository接口,Spring Boot提供了一个功能齐全的CRUD存储库,其中包含findOne、findAll、save、update和delete方法。我们的自定义方法定义(findByLastName())扩展了这一基本功能,并为我们提供了一种按姓氏获取人员的方法。Spring Data分析方法的返回类型及其方法名,并根据命名约定检查方法名,以确定它应该做什么。
尽管Spring Data承担了实现数据库存储库的重任,但我仍然编写了一个数据库集成测试。您可能会认为这是在测试框架,我应该避免这样做,因为我们测试的不是我们的代码。尽管如此,我相信这里至少有一个集成测试是至关重要的。首先,它测试自定义findByLastName方法的实际行为是否符合预期。其次,证明了我们的存储库正确使用了Spring的连接,可以连接到数据库。
为了让您更容易地在您的机器上运行测试(无需安装PostgreSQL数据库),我们的测试连接到内存中的H2数据库。
我将H2定义为构建中的一个测试依赖项。gradle文件。应用程序。测试目录中的属性不定义任何spring。数据源的属性。这告诉Spring Data使用内存中的数据库。当它在类路径中找到H2时,它在运行我们的测试时只使用H2。
当运行带有int概要文件的实际应用程序时(例如,通过将SPRING_PROFILES_ACTIVE=int作为环境变量),它连接到应用程序int.properties中定义的PostgreSQL数据库。
我知道,有很多Spring的细节需要了解和理解。要做到这一点,你必须仔细阅读大量的文档。生成的代码看起来很简单,但是如果不了解Spring的详细信息,就很难理解。
除此之外,使用内存数据库是有风险的。毕竟,我们的集成测试运行在与生产环境不同的数据库类型上。您可以自己决定是否更喜欢Spring magic和简单的代码,而不是显式的更详细的实现。
已经有足够的解释了,下面是一个简单的集成测试,它将一个人保存到数据库中,并根据他的姓找到他:
@RunWith(SpringRunner.class)
@DataJpaTest
public class PersonRepositoryIntegrationTest {
@Autowired
private PersonRepository subject;
@After
public void tearDown() throws Exception {
subject.deleteAll();
}
@Test
public void shouldSaveAndFetchPerson() throws Exception {
Person peter = new Person("Peter", "Pan");
subject.save(peter);
Optional<Person> maybePeter = subject.findByLastName("Pan");
assertThat(maybePeter, is(Optional.of(peter)));
}
}您可以看到,我们的集成测试遵循与单元测试相同的安排、行为和断言结构。告诉你这是一个普遍的概念!
与独立服务集成
我们的微服务与darksky.net对话,后者是一个天气REST API。当然,我们希望确保我们的服务发送请求并正确解析响应。
在运行自动化测试时,我们希望避免触及真正的darksky服务器。我们免费计划的配额限制只是部分原因。真正的原因是脱钩。我们的测试应该独立于darksky.net上那些可爱的人正在做的事情。即使您的机器无法访问darksky服务器或darksky服务器停机进行维护。
我们可以在运行集成测试时运行我们自己的、假的darksky服务器,从而避免触及真正的darksky服务器。这听起来像是一项艰巨的任务。多亏了像Wiremock这样的工具,这很容易。看这个:
@RunWith(SpringRunner.class)
@SpringBootTest
public class WeatherClientIntegrationTest {
@Autowired
private WeatherClient subject;
@Rule
public WireMockRule wireMockRule = new WireMockRule(8089);
@Test
public void shouldCallWeatherService() throws Exception {
wireMockRule.stubFor(get(urlPathEqualTo("/some-test-api-key/53.5511,9.9937"))
.willReturn(aResponse()
.withBody(FileLoader.read("classpath:weatherApiResponse.json"))
.withHeader(CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE)
.withStatus(200)));
Optional<WeatherResponse> weatherResponse = subject.fetchWeather();
Optional<WeatherResponse> expectedResponse = Optional.of(new WeatherResponse("Rain"));
assertThat(weatherResponse, is(expectedResponse));
}
}为了使用Wiremock,我们在一个固定端口(8089)上实例化一个WireMockRule。使用DSL,我们可以设置Wiremock服务器,定义它应该监听的端点,并设置它应该使用的固定响应。
接下来,我们调用要测试的方法,即调用第三方服务的方法,并检查结果是否正确解析。
理解测试如何知道它应该调用伪Wiremock服务器而不是真正的darksky API是很重要的。秘密就在我们的申请中。包含在src/test/resources中的属性文件。这是运行测试时Spring加载的属性文件。在这个文件中,我们覆盖的配置,如API键和url的值适合我们的测试目的,例如调用假的Wiremock服务器,而不是真正的:
weather.url = http://localhost:8089
注意,这里定义的端口必须与我们在测试中实例化WireMockRule时定义的端口相同。在我们的测试中,通过在WeatherClient类的构造函数中注入URL,可以用一个假的URL替换真实天气API的URL:
@Autowired
public WeatherClient(final RestTemplate restTemplate,
@Value("${weather.url}") final String weatherServiceUrl,
@Value("${weather.api_key}") final String weatherServiceApiKey) {
this.restTemplate = restTemplate;
this.weatherServiceUrl = weatherServiceUrl;
this.weatherServiceApiKey = weatherServiceApiKey;
}通过这种方式,我们告诉WeatherClient从天气中读取weatherUrl参数的值。我们在应用程序属性中定义url属性。
使用Wiremock之类的工具,为单独的服务编写窄范围的集成测试非常容易。不幸的是,这种方法有一个缺点:如何确保我们设置的假服务器的行为与真实服务器一样?使用当前的实现,单独的服务可以更改它的API,我们的测试仍然可以通过。现在,我们只是在测试我们的WeatherClient是否能够解析伪服务器发送的响应。这是一个开始,但它很脆弱。使用端到端测试并针对真实服务的测试实例运行测试,而不是使用虚假服务,可以解决这个问题,但是会使我们依赖于测试服务的可用性。幸运的是,对于这个困境有一个更好的解决方案:对伪服务器和真实服务器运行契约测试,确保我们在集成测试中使用的伪服务器是一个忠实的测试副本。接下来让我们看看它是如何工作的。
合同的测试
更现代的软件开发组织已经找到了通过将系统开发分散到不同的团队来扩展开发工作的方法。单独的团队构建单独的、松散耦合的服务,而不需要彼此介入,并将这些服务集成到一个大型的、内聚的系统中。最近围绕微服务的热议正聚焦于此。
将您的系统分割为许多小型服务通常意味着这些服务需要通过某些接口(希望定义良好,有时意外地增长)彼此通信。
不同应用程序之间的接口可以有不同的形状和技术。常见的是
- 通过HTTPS实现REST和JSON
- 使用诸如gRPC之类的东西的RPC
- 使用队列构建事件驱动的体系结构
对于每个接口,都涉及两个方面:提供者和使用者。提供者向使用者提供数据。使用者处理从提供者获得的数据。在REST世界中,提供者使用所有需要的端点构建一个REST API;使用者调用此REST API来获取数据或触发其他服务中的更改。在异步的、事件驱动的世界中,提供者(通常称为发布者)将数据发布到队列;使用者(通常称为订阅者)订阅这些队列并读取和处理数据。
图8:每个接口都有一个提供方(或发布方)和一个消费方(或订阅方)。接口的规范可以看作是契约。
由于您经常将消费和提供服务分散到不同的团队中,您会发现必须清楚地指定这些服务之间的接口(所谓的契约)。传统上,公司处理这个问题的方法如下:
- 编写一个长而详细的接口规范(合同)
- 根据定义的合同实现提供的服务
- 将接口规范抛给消费团队
- 等待,直到它们实现使用接口的那一部分
- 运行一些大型手动系统测试,看看是否一切正常
- 希望两个团队永远坚持接口定义,不要搞砸
更现代的软件开发团队已经取代了步骤5。和6。使用更自动化的东西:自动化契约测试确保消费者和提供者端上的实现仍然坚持已定义的契约。它们可以作为一个很好的回归测试套件,并确保尽早发现与契约的偏差。
在一个更敏捷的组织中,你应该采取更有效和更少浪费的方式。您在同一个组织中构建应用程序。与其他服务的开发人员直接对话,而不是将过于详细的文档抛到一边,应该不会太难。毕竟,他们是你的同事,而不是你只能通过客户支持或合法的防弹合同与之交谈的第三方供应商。
消费者驱动的契约测试(CDC测试)让消费者驱动契约的实现。使用CDC,接口的使用者编写测试,检查接口中所需的所有数据。然后,消费团队发布这些测试,以便发布团队能够轻松地获取和执行这些测试。现在,提供团队可以通过运行CDC测试来开发他们的API。一旦所有测试通过,他们就知道已经实现了消费团队所需的所有东西。
图9:契约测试确保接口的提供者和所有使用者都遵守定义的接口契约。在CDC测试中,接口的消费者以自动化测试的形式发布他们的需求;提供者不断地获取和执行这些测试
这种方法允许提供团队只实现真正需要的东西(保持事情简单,YAGNI等等)。提供接口的团队应该连续获取并运行这些CDC测试(在他们的构建管道中),以立即发现任何中断的更改。如果他们破坏了接口,他们的CDC测试就会失败,从而阻止破坏的更改生效。只要测试保持绿色,团队就可以进行他们喜欢的任何更改,而不必担心其他团队。消费者驱动的契约方法将使您的流程如下:
- 消费团队编写具有所有消费者期望的自动化测试
- 他们为提供团队发布测试
- 提供团队持续运行CDC测试并保持测试绿色
- 一旦CDC测试中断,两个团队就会互相交谈
如果您的组织采用微服务方法,那么进行CDC测试是建立自治团队的重要一步。CDC测试是一种促进团队沟通的自动化方法。它们确保团队之间的接口在任何时候都能正常工作。失败的CDC测试是一个很好的指示器,说明您应该走到受影响的团队,与他们讨论任何即将发生的API更改,并确定您希望如何继续前进。
CDC测试的简单实现可以简单到针对API发出请求并断言响应包含所需的所有内容。然后将这些测试打包为可执行文件(。并将其上传到其他团队可以获取它的地方(例如,像 Artifactory这样的工件存储库)。
在过去的几年里,CDC的方法变得越来越流行,并且开发了一些工具来简化编写和交换。
Pact可能是这些天来最突出的一个。它有一种为消费者和提供者编写测试的复杂方法,为独立的服务提供开箱即用的存根,并允许您与其他团队交换CDC测试。Pact已经被移植到许多平台上,可以与JVM语言、Ruby、. net、JavaScript以及更多其他语言一起使用。
如果你想从信用违约掉期开始,却不知道如何开始,那么签订协议可能是一个明智的选择。一开始, documentation可能非常多。要有耐心,并坚持到底。它有助于对CDCs有一个牢固的了解,从而使您在与其他团队合作时更容易提倡使用CDCs。
消费者驱动的契约测试可以真正改变游戏规则,从而建立能够快速且自信地行动的自主团队。帮你自己一个忙,通读一下这个概念并试一试。一套可靠的CDC测试是非常宝贵的,它能够在不破坏其他服务和对其他团队造成很多挫折的情况下快速移动。
消费者测试(我们的团队)
我们的微服务使用天气API。因此,编写一个消费者测试是我们的责任,它定义了我们对微服务和天气服务之间的契约(API)的期望。
首先,我们在我们的建筑中包含了一个用于编写契约消费者测试的库。
testCompile (“au.com.dius: pact-jvm-consumer-junit_2.11:3.5.5”)
多亏了这个库,我们可以实现一个消费者测试和使用pact的模拟服务:
@RunWith(SpringRunner.class)
@SpringBootTest
public class WeatherClientConsumerTest {
@Autowired
private WeatherClient weatherClient;
@Rule
public PactProviderRuleMk2 weatherProvider =
new PactProviderRuleMk2("weather_provider", "localhost", 8089, this);
@Pact(consumer="test_consumer")
public RequestResponsePact createPact(PactDslWithProvider builder) throws IOException {
return builder
.given("weather forecast data")
.uponReceiving("a request for a weather request for Hamburg")
.path("/some-test-api-key/53.5511,9.9937")
.method("GET")
.willRespondWith()
.status(200)
.body(FileLoader.read("classpath:weatherApiResponse.json"),
ContentType.APPLICATION_JSON)
.toPact();
}
@Test
@PactVerification("weather_provider")
public void shouldFetchWeatherInformation() throws Exception {
Optional<WeatherResponse> weatherResponse = weatherClient.fetchWeather();
assertThat(weatherResponse.isPresent(), is(true));
assertThat(weatherResponse.get().getSummary(), is("Rain"));
}
}如果您仔细观察,您会发现WeatherClientConsumerTest与WeatherClientIntegrationTest非常相似。这次我们使用Pact代替Wiremock作为服务器存根。事实上,消费者测试与集成测试完全一样,我们用存根替换真正的第三方服务器,定义预期的响应,并检查客户机是否能够正确解析响应。在这个意义上,WeatherClientConsumerTest本身就是一个狭窄的集成测试。与基于wiremock的测试相比,该测试的优点是每次运行时都会生成一个协议文件(可以在target/pacts/&pact-name>.json中找到)。这个契约文件以一种特殊的JSON格式描述了我们对契约的期望。然后可以使用这个契约文件来验证存根服务器的行为是否与真正的服务器一样。我们可以将契约文件交给提供接口的团队。他们使用这个契约文件并使用其中定义的期望编写一个提供者测试。通过这种方式,他们测试他们的API是否满足我们的所有期望。
这就是CDC的消费者驱动部分的来源。消费者通过描述他们的期望来驱动接口的实现。提供者必须确保它们满足所有的期望,并且它们已经完成。没有镀金,没有雅格尼之类的东西。
将契约文件提供给团队可以通过多种方式进行。一个简单的方法是将它们签入版本控制并告诉提供程序团队始终获取最新版本的pact文件。更先进的方法是使用工件存储库,如Amazon的S3或pact broker之类的服务。从简单的开始,根据你的需要成长。
在实际的应用程序中,不需要同时进行集成测试和客户端类的消费者测试。示例代码基包含这两个代码基,以向您展示如何使用其中一个。如果您想使用pact编写CDC测试,我建议坚持使用后者。编写测试的工作是相同的。使用pact的好处是,您可以自动获得一个pact文件,其中包含对契约的期望,其他团队可以使用该文件轻松地实现他们的提供者测试。当然,只有当你能够说服其他团队也使用pact时,这才有意义。如果这不起作用,使用集成测试和Wiremock组合是一个不错的方案b。
提供者测试(另一个团队)
提供者测试必须由提供weather API的人员实现。我们正在使用一个由darksky.net提供的公共API。理论上,darksky团队将在他们的端上实现提供者测试,以检查他们是否违反了他们的应用程序和我们的服务之间的契约。
很明显,他们不关心我们可怜的样本应用程序,也不会为我们实现CDC测试。这就是面向公众的API和采用微服务的组织之间的巨大区别。面向公众的api不能考虑每一个消费者,否则它们将无法前进。在你自己的组织中,你可以而且应该这么做。你的应用很可能只服务少数人,最多几十个消费者。为了保持系统稳定,您可以为这些接口编写提供者测试。
提供团队获取契约文件并对其提供的服务运行它。为此,它们实现了一个提供者测试,该测试读取契约文件,生成一些测试数据,并对它们的服务运行契约文件中定义的期望。
契约人员编写了几个库来实现提供者测试。他们的主要GitHub repo为您提供了一个很好的概述:哪些消费者和哪些提供者库可用。选择一个最适合你的技术堆栈。
为了简单起见,我们假设darksky API也在Spring Boot中实现。在这种情况下,他们可以使用Spring pact提供程序,它很好地挂钩到Spring的MockMVC机制。darksky.net团队将实现的一个假设的提供者测试可能是这样的:
@RunWith(RestPactRunner.class)
@Provider("weather_provider") // same as the "provider_name" in our clientConsumerTest
@PactFolder("target/pacts") // tells pact where to load the pact files from
public class WeatherProviderTest {
@InjectMocks
private ForecastController forecastController = new ForecastController();
@Mock
private ForecastService forecastService;
@TestTarget
public final MockMvcTarget target = new MockMvcTarget();
@Before
public void before() {
initMocks(this);
target.setControllers(forecastController);
}
@State("weather forecast data") // same as the "given()" in our clientConsumerTest
public void weatherForecastData() {
when(forecastService.fetchForecastFor(any(String.class), any(String.class)))
.thenReturn(weatherForecast("Rain"));
}
}您可以看到,提供者测试所要做的就是加载一个契约文件(例如,通过使用@PactFolder注释来加载以前下载的契约文件),然后定义应该如何提供预定义状态的测试数据(例如,使用Mockito mocks)。没有要实现的自定义测试。这些都是从契约文件派生出来的。提供者测试必须具有与使用者测试中声明的提供者名称和状态匹配的对应项。
供应商测试(我们的团队)
我们已经了解了如何测试我们的服务和天气提供商之间的契约。通过这个接口,我们的服务充当消费者,天气服务充当提供者。进一步考虑一下,我们将看到我们的服务还充当了其他服务的提供者:我们提供了一个REST API,它提供了几个端点,可以供其他服务使用。
由于我们刚刚了解到契约测试非常流行,所以我们当然也为这个契约编写了一个契约测试。幸运的是,我们使用的是消费者驱动的契约,所以所有的消费团队都向我们发送了他们的契约,我们可以使用这些契约来实现REST API的提供者测试。
让我们先把Spring的Pact provider库添加到我们的项目中:
testCompile (“au.com.dius: pact-jvm-provider-spring_2.12:3.5.5”)
实现提供者测试遵循与前面描述的相同的模式。为了简单起见,我只是将契约文件从简单的使用者签入服务的存储库。这使我们的目的更容易实现,在真实的场景中,您可能要使用更复杂的机制来分发约定文件。
@RunWith(RestPactRunner.class)
@Provider("person_provider")// same as in the "provider_name" part in our pact file
@PactFolder("target/pacts") // tells pact where to load the pact files from
public class ExampleProviderTest {
@Mock
private PersonRepository personRepository;
@Mock
private WeatherClient weatherClient;
private ExampleController exampleController;
@TestTarget
public final MockMvcTarget target = new MockMvcTarget();
@Before
public void before() {
initMocks(this);
exampleController = new ExampleController(personRepository, weatherClient);
target.setControllers(exampleController);
}
@State("person data") // same as the "given()" part in our consumer test
public void personData() {
Person peterPan = new Person("Peter", "Pan");
when(personRepository.findByLastName("Pan")).thenReturn(Optional.of
(peterPan));
}
}所示的ExampleProviderTest需要根据给定的契约文件提供状态,仅此而已。一旦运行提供者测试,Pact将获取Pact文件并对我们的服务发出HTTP请求,然后根据我们设置的状态进行响应。
用户界面测试
大多数应用程序都有某种用户界面。通常,我们在web应用程序上下文中讨论的是web接口。人们常常忘记,REST API或命令行界面与web用户界面一样,都是用户界面。
UI测试测试应用程序的用户界面是否正常工作。用户输入应该触发正确的动作,数据应该呈现给用户,UI状态应该按照预期进行更改。
UI测试和端到端测试有时(如Mike Cohn的例子)被认为是同一件事。对我来说,这合并了两个相当正交的概念。
是的,端到端测试应用程序通常意味着通过用户界面驱动测试。然而,反过来说就不成立了。
测试用户界面不需要以端到端方式完成。根据使用的技术不同,测试用户界面可以非常简单,只需为前端javascript代码编写一些单元测试,并去掉后端代码。
对于传统的web应用程序,可以使用Selenium等工具来测试用户界面。如果您认为REST API是您的用户界面,那么您应该通过围绕API编写适当的集成测试来获得所需的一切。
对于web界面,您可能希望围绕UI测试多个方面:行为、布局、可用性或对公司设计的坚持性只是其中的几个方面。
幸运的是,测试用户界面的行为非常简单。单击这里,在那里输入数据,并希望用户界面的状态相应地更改。现代单页应用程序框架(react, vue)。js、Angular等等)通常都自带工具和助手,它们允许您以一种相当低层次(单元测试)的方式彻底测试这些交互。即使您使用普通javascript滚动自己的前端实现,也可以使用常规的测试工具,如Jasmine或Mocha。对于更传统的服务器端呈现应用程序,基于硒的测试将是您的最佳选择。
测试web应用程序的布局是否保持不变要稍微困难一些。根据您的应用程序和用户的需要,您可能希望确保代码更改不会意外破坏网站的布局。
问题在于,计算机在检查某样东西是否“看起来不错”方面出了名的糟糕(也许一些聪明的机器学习算法可以在未来改变这一点)。
如果您想在构建管道中自动检查web应用程序的设计,可以尝试一些工具。这些工具中的大多数都使用Selenium以不同的浏览器和格式打开web应用程序,进行截图,并将这些截图与之前的截图进行比较。如果旧截图和新截图有意想不到的不同,这个工具会让你知道。
盖伦就是这些工具之一。但是,如果您有特殊的需求,即使使用您自己的解决方案也不是太难。我与构建阵容及其基于java的近亲j阵容合作过的一些团队也实现了类似的目标。这两个工具都采用了我前面描述的基于selenium的方法。
一旦您想要测试可用性和“看起来不错”的因素,您就离开了自动化测试领域。在这个领域,您应该依赖探索性测试、可用性测试(甚至可以像走廊测试一样简单),并向用户展示他们是否喜欢使用您的产品,以及是否可以使用所有特性而不会感到沮丧或烦恼。
端到端测试
通过已部署的应用程序的用户界面进行测试是您可以测试应用程序的最端到端方式。前面描述的webdriver驱动的UI测试是端到端测试的一个很好的例子。
图11:端到端测试测试整个、完全集成的系统
端到端测试(也称为广义堆栈测试)在您需要决定软件是否工作时给您最大的信心。Selenium和WebDriver协议允许您通过对已部署的服务自动驱动(无头)浏览器、执行单击、输入数据和检查用户界面状态来自动化测试。您可以直接使用Selenium,或者使用构建在它之上的工具,夜视就是其中之一。
端到端测试本身也有一些问题。他们是出了名的脆弱,经常因为意想不到和无法预见的原因而失败。他们的失败往往是一种错误的肯定。用户界面越复杂,测试就越脆弱。浏览器的怪圈、计时问题、动画和意想不到的弹出对话框只是让我花了比我愿意承认的更多时间进行调试的部分原因。
在微服务世界中,还有一个大问题是谁负责编写这些测试。因为它们跨越多个服务(您的整个系统),所以没有一个团队负责编写端到端测试。
如果你有一个集中的质量保证团队,他们看起来很合适。同样,拥有一个集中的QA团队是一个很大的反模式,不应该在DevOps世界中占有一席之地,因为在DevOps世界中,您的团队应该是真正跨功能的。谁应该拥有端到端测试并没有简单的答案。也许您的组织有一个实践社区或质量协会可以处理这些问题。找到正确答案在很大程度上取决于您的组织。
此外,端到端测试需要大量的维护,运行速度非常慢。考虑一个有多个微服务的场景,您甚至不能在本地运行端到端测试——因为这也需要在本地启动所有微服务。祝您在开发机器上运行数百个应用程序时好运,而不会破坏RAM。
由于它们的高维护成本,您应该将端到端测试的数量减少到最小。
考虑用户与应用程序之间的高价值交互。尝试提出定义产品核心价值的用户旅程,并将这些用户旅程中最重要的步骤转换为自动化的端到端测试。
如果你正在建立一个电子商务网站,你最有价值的客户旅程可能是一个用户搜索产品,把它放在购物篮和结帐。就是这样。只要这次旅行还有效,你就不会有太大的麻烦。也许您会发现一个或两个更重要的用户旅程,您可以将它们转换为端到端测试。任何超过这一点的事情都可能是痛苦多于有益的。
记住:在您的测试金字塔中有许多较低的级别,您已经测试了各种边缘用例以及与系统其他部分的集成。没有必要在更高的级别上重复这些测试。高维护工作量和大量的误报会降低您的速度,并导致您对测试失去信任,这迟早都会发生。
用户界面端到端测试
对于端到端测试,Selenium和WebDriver协议是许多开发人员选择的工具。使用Selenium,您可以选择一个您喜欢的浏览器,让它自动调用您的网站,点击这里和那里,输入数据,并检查用户界面中的内容是否发生了更改。
Selenium需要一个可以启动并用于运行测试的浏览器。对于不同的浏览器,您可以使用多个所谓的“驱动程序”。选择一个(或多个)并将其添加到build.gradle中。无论选择哪种浏览器,都需要确保团队和CI服务器中的所有开发人员都在本地安装了正确版本的浏览器。保持同步可能会很痛苦。对于Java,有一个叫做webdrivermanager的小库,可以自动下载并设置您想使用的浏览器的正确版本。将这两个依赖项添加到构建中。格勒德,你可以走了:
testCompile (“org.seleniumhq.selenium: selenium-chrome-driver: 2.53.1”)
testCompile (“io.github.bonigarcia: webdrivermanager: 1.7.2”)
在您的测试套件中运行一个功能齐全的浏览器可能会很麻烦。特别是在使用连续交付时,运行管道的服务器可能无法启动包含用户界面的浏览器(例如,因为没有可用的X-Server)。您可以通过启动像xvfb这样的虚拟x服务器来解决这个问题。
最近的一种方法是使用无头浏览器(即没有用户界面的浏览器)来运行web驱动程序测试。直到最近PhantomJS还是领先的用于浏览器自动化的无头浏览器。自从Chromium和Firefox都宣布在他们的浏览器PhantomJS中实现了无头模式后,PhantomJS突然就过时了。毕竟,最好使用用户实际使用的浏览器(比如Firefox和Chrome)来测试您的网站,而不是使用人工浏览器,因为这对开发人员来说很方便。
无头火狐和Chrome都是全新的浏览器,还没有被广泛应用于webdriver测试。我们想让事情变得简单。让我们坚持使用Selenium和常规浏览器的经典方式,而不是使用最前沿的无头模式。一个简单的端到端测试,启动Chrome,导航到我们的服务,并检查网站的内容如下:
@RunWith(SpringRunner.class)
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
public class HelloE2ESeleniumTest {
private WebDriver driver;
@LocalServerPort
private int port;
@BeforeClass
public static void setUpClass() throws Exception {
ChromeDriverManager.getInstance().setup();
}
@Before
public void setUp() throws Exception {
driver = new ChromeDriver();
}
@After
public void tearDown() {
driver.close();
}
@Test
public void helloPageHasTextHelloWorld() {
driver.get(String.format("http://127.0.0.1:%s/hello", port));
assertThat(driver.findElement(By.tagName("body")).getText(), containsString("Hello World!"));
}
}请注意,只有在运行此测试的系统(本地机器、CI服务器)上安装了Chrome,此测试才会在您的系统上运行。
测试很简单。它使用@SpringBootTest在一个随机端口上启动整个Spring应用程序。然后,我们实例化一个新的Chrome webdriver,让它导航到我们的微服务的/hello端点,并检查它是否在浏览器窗口上打印“hello World!”酷炫的东西!
REST API端到端测试
在测试应用程序时避免使用图形用户界面,这是一个好主意,因为这样的测试比完整的端到端测试更可靠,同时仍然覆盖应用程序堆栈的大部分。当通过应用程序的web界面进行测试特别困难时,这一点非常有用。也许您甚至没有web UI,而是提供了一个REST API(因为您有一个单独的页面应用程序在某个地方与该API对话,或者仅仅因为您轻视所有漂亮的东西)。无论哪种方式,一种皮下测试,它只在图形用户界面下进行测试,可以让你在不损害信心的情况下走得更远。如果你提供的是REST API,就像我们在示例代码中所做的那样,那么这是正确的:
@RestController
public class ExampleController {
private final PersonRepository personRepository;
// shortened for clarity
@GetMapping("/hello/{lastName}")
public String hello(@PathVariable final String lastName) {
Optional<Person> foundPerson = personRepository.findByLastName(lastName);
return foundPerson
.map(person -> String.format("Hello %s %s!",
person.getFirstName(),
person.getLastName()))
.orElse(String.format("Who is this '%s' you're talking about?",
lastName));
}
}让我再向您展示一个库,它在测试提供REST API的服务时非常有用。REST-assured是一个库,它为您提供了一个良好的DSL,用于针对API触发真正的HTTP请求并评估您收到的响应。
首先:将依赖项添加到build.gradle。
testCompile('io.rest-assured:rest-assured:3.0.3')有了这个库,我们可以为我们的REST API实现端到端的测试:
@RunWith(SpringRunner.class)
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
public class HelloE2ERestTest {
@Autowired
private PersonRepository personRepository;
@LocalServerPort
private int port;
@After
public void tearDown() throws Exception {
personRepository.deleteAll();
}
@Test
public void shouldReturnGreeting() throws Exception {
Person peter = new Person("Peter", "Pan");
personRepository.save(peter);
when()
.get(String.format("http://localhost:%s/hello/Pan", port))
.then()
.statusCode(is(200))
.body(containsString("Hello Peter Pan!"));
}
}同样,我们使用@SpringBootTest启动整个Spring应用程序。在本例中,我们@Autowire PersonRepository,这样我们就可以轻松地将测试数据写入数据库。当我们现在要求REST API向我们的朋友“Pan先生”说“hello”时,我们得到了一个很好的问候。神奇的!如果您甚至不使用web接口,那么端到端测试就足够了。
验收测试——您的特性工作正常吗?
您在测试金字塔中的位置越高,就越有可能从用户的角度测试您正在构建的特性是否正确工作。您可以将您的应用程序视为一个黑盒子,并将测试中的焦点从
when I enter the values
xandy, the return value should beztowards
given there's a logged in user
and there's an article "bicycle"
when the user navigates to the "bicycle" article's detail page
and clicks the "add to basket" button
then the article "bicycle" should be in their shopping basket
有时您会听到这类测试的术语功能测试或验收测试。有时候人们会告诉你功能测试和验收测试是两码事。有时这些术语会被合并。有时人们会无休止地争论措辞和定义。这种讨论通常会引起很大的困惑。
事情是这样的:在某一点上,您应该确保从用户的角度测试您的软件是否正确工作,而不仅仅是从技术的角度。你所谓的测试其实并不那么重要。然而,进行这些测试是必要的。选择一个术语,坚持它,并编写这些测试。
这也是人们谈论BDD和允许您以BDD方式实现测试的工具的时刻。编写测试的BDD或BDD风格的方法是一个很好的技巧,可以将您的思维从实现细节转移到用户的需求。去试试吧。
您甚至不需要采用成熟的BDD工具,比如Cucumber(尽管您可以)。一些断言库(如cai .js)允许您使用should风格的关键字编写断言,从而使您的测试读起来更像北斗。即使您不使用提供这种表示法的库,聪明且经过良好分解的代码也将允许您编写关注用户行为的测试。一些辅助方法/函数可以让你走很长的路:
# a sample acceptance test in Python
def test_add_to_basket():
# given
user = a_user_with_empty_basket()
user.login()
bicycle = article(name="bicycle", price=100)
# when
article_page.add_to_.basket(bicycle)
# then
assert user.basket.contains(bicycle)验收测试可以有不同的粒度级别。大多数情况下,它们将相当高级,并通过用户界面测试您的服务。但是,最好理解在技术上没有必要在测试金字塔的最高级别上编写验收测试。如果您手头的应用程序设计和场景允许您在较低的级别上编写验收测试,那么就去做吧。进行低级测试比进行高级测试要好。验收测试的概念—证明您的特性为用户正确工作—与您的测试金字塔完全正交。
探索性测试
即使是最勤奋的测试自动化工作也不是完美的。有时您会在自动化测试中遗漏某些边缘情况。有时候,通过编写单元测试几乎不可能检测到特定的bug。某些质量问题甚至不会在您的自动化测试中变得明显(考虑设计或可用性)。尽管您对测试自动化的意图是最好的,但是某些类型的手工测试仍然是一个好主意。
图12:使用探索性测试来发现构建管道没有发现的所有质量问题
在您的测试组合中包括探索性测试。它是一种手工测试方法,强调测试人员发现运行系统中的质量问题的自由和创造性。只需在常规的时间表上花些时间,卷起袖子,试着打破你的应用程序。使用一种破坏性的思维方式,想出一些方法来引发应用程序中的问题和错误。记录下你找到的所有东西。注意bug、设计问题、慢响应时间、丢失或误导错误消息,以及所有其他可能会惹恼您的软件用户的事情。
好消息是,您可以愉快地使用自动化测试自动化您的大部分发现。为您发现的bug编写自动化测试可以确保将来不会出现任何bug的回归。此外,它还可以帮助您在修复bug期间缩小问题的根源。
在探索性测试期间,您将发现在构建管道中未被注意到的问题。不要沮丧。这是关于构建管道成熟度的重要反馈。和任何反馈一样,一定要付诸行动:想想你能做些什么来避免未来出现这类问题。也许您错过了一组特定的自动化测试。也许您只是在这个迭代中草率地使用了自动化测试,并且需要在将来进行更彻底的测试。也许有一个闪亮的新工具或方法,您可以在您的管道中使用,以避免这些问题在未来。一定要采取行动,这样您的管道和整个软件交付就会随着时间的推移而变得更加成熟。
测试术语的混淆
讨论不同的测试分类总是困难的。我所说的单元测试可能与您的理解略有不同。而集成测试则更糟。对某些人来说,集成测试是一项非常广泛的活动,它通过整个系统的许多不同部分进行测试。对我来说,这是一件相当狭隘的事情,一次只测试一个外部部分的集成。有些将它们称为集成测试,有些将它们称为组件测试,有些更喜欢使用服务测试这个术语。甚至有人会说,这三个词完全是两码事。没有对错之分。软件开发社区还没有设法解决围绕测试的定义良好的术语。
不要太拘泥于模棱两可的术语。无论您将其称为端到端测试、宽堆栈测试还是功能测试,都没有关系。您的集成测试对您和其他公司的人是否有不同的意义并不重要。是的,如果我们的专业能在一些定义明确的术语上达成一致并坚持下去,那就太好了。不幸的是,这还没有发生。由于在编写测试时存在许多细微差别,所以它实际上更像是一个频谱,而不是一堆离散的桶,这使得一致的命名更加困难。
重要的是,您应该找到适合您和您的团队的术语。要清楚要编写的不同类型的测试。在您的团队中就命名达成一致,并就每种测试类型的范围达成一致。如果你在你的团队中(甚至在你的组织中)保持这种一致性,这才是你真正应该关心的。Simon Stewart在描述谷歌使用的方法时很好地总结了这一点。我认为这很好地说明了过多地关注名称和命名约定是不值得这么麻烦的。
将测试放入部署管道中
如果您正在使用持续集成或持续交付,那么您将拥有一个部署管道,它将在您每次对软件进行更改时运行自动化测试。通常,这个管道被分成几个阶段,这些阶段会逐渐让您更加确信您的软件已经准备好部署到生产环境中。听到所有这些不同类型的测试,您可能想知道应该如何将它们放置在部署管道中。要回答这个问题,您只需要考虑持续交付的一个非常基本的价值(实际上是极限编程和敏捷软件开发的核心价值之一):快速反馈。
一个好的构建管道会告诉您,您已经尽可能快地搞砸了。您不希望仅仅等待一个小时就发现您最新的更改破坏了一些简单的单元测试。如果你的管道花了那么长时间给你反馈,你很可能已经回家了。通过将快速运行的测试放在管道的早期阶段,您可以在几秒钟内,甚至几分钟内获得这些信息。相反,您将较长时间运行的测试(通常是范围更广的测试)放在后面的阶段,以避免延迟来自快速运行测试的反馈。您可以看到,定义部署管道的阶段不是由测试类型驱动的,而是由测试的速度和范围驱动的。记住,它可以是一个非常合理的决定的范围较窄,湍急的集成测试在同一阶段作为单元测试-仅仅是因为他们给你更快的反馈,而不是因为你想画线测试的正式类型。
避免重复测试
既然您已经知道应该编写不同类型的测试,那么还有一个需要避免的陷阱:在金字塔的不同层中复制测试。虽然你的直觉可能会说没有太多的测试,但我向你保证,确实有。您测试套件中的每一个测试都是额外的负担,并不是免费的。编写和维护测试需要时间。阅读和理解他人的测试需要时间。当然,运行测试需要时间。
与生产代码一样,您应该力求简单并避免重复。在实现测试金字塔的过程中,你应该记住两条经验法则:
- 如果高级测试发现错误,并且没有低级测试失败,则需要编写低级测试
- 把你的测试尽可能往下推
第一个规则很重要,因为较低级别的测试允许您更好地缩小错误范围,并以独立的方式复制它们。当您调试手头的问题时,它们将运行得更快,并且不会那么臃肿。它们将成为未来很好的回归测试。第二条规则对于保持测试套件的速度非常重要。如果您已经在较低级别的测试中自信地测试了所有条件,那么没有必要在您的测试套件中保留较高级别的测试。它只是没有增加更多的信心,一切都在工作。在日常工作中进行冗余的测试会变得很烦人。您的测试套件将变慢,当您更改代码的行为时,您需要更改更多的测试。
让我们换一种说法:如果更高级别的测试让您对应用程序的正确工作更有信心,那么您应该拥有它。为控制器类编写单元测试有助于测试控制器本身中的逻辑。不过,这并不能告诉您这个控制器提供的REST端点是否实际响应HTTP请求。因此,您向上移动测试金字塔,并添加一个测试来精确地检查它——但仅此而已。您不需要再次测试低级测试中已经包含的所有条件逻辑和边缘用例。确保高级测试集中于低级测试不能覆盖的部分。
当涉及到消除没有任何价值的测试时,我是严格的。我删除已经在较低级别上覆盖的高级测试(假定它们不提供额外的价值)。如果可能的话,我用较低级别的测试替换较高级别的测试。有时候这很难,尤其是当你知道做一个测试是件很辛苦的事情的时候。小心沉没成本谬论,按下删除键。没有理由在没有价值的测试上浪费更多宝贵的时间。
编写干净的测试代码
与编写一般代码一样,编写好的、干净的测试代码需要非常小心。这里有更多的提示,让你在使用你的自动化测试套件之前,可以使用可维护的测试代码:
测试代码和生产代码一样重要。给予同样的关心和关注。“这只是测试代码”并不是为草率的代码辩解的有效借口
每个测试测试一个条件。这有助于你保持你的测试简短和容易推理
“安排、执行、断言”或“给定、何时、然后”是保持测试结构良好的很好的助记符
可读性很重要。不要太干。如果可以提高可读性,复制是可以的。试着在干燥和潮湿的代码之间找到一个平衡
当有疑问时,使用三原则来决定何时重构。使用之前重用
结论
就是这样!我知道这是一个漫长而艰难的阅读来解释为什么以及如何测试你的软件。好消息是,这些信息是非常永恒的,并且与您正在构建的软件类型无关。无论您是在开发微服务、物联网设备、移动应用程序还是web应用程序,本文的经验教训都可以应用到所有这些方面。
我希望本文能对您有所帮助。现在继续检查示例代码,并将这里解释的一些概念放入您的测试组合中。拥有一个可靠的测试组合需要一些努力。相信我,从长远来看,这样做是有回报的,它会让你作为一个开发者的生活更加平静。
确认
感谢Clare Sudbery、Chris Ford、Martha Rohte、Andrew Jones-Weiss David Swallow、Aiko Klostermann、Bastian Stein、Sebastian Roidl和Birgitta Bockeler为本文的早期草稿提供反馈和建议。感谢Martin Fowler的建议、见解和支持。
原文:https://martinfowler.com/articles/practical-test-pyramid.html
本文:http://pub.intelligentx.net/node/512
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 130 次浏览
【软件测试】快速软件测试方法
我称之为快速软件测试。
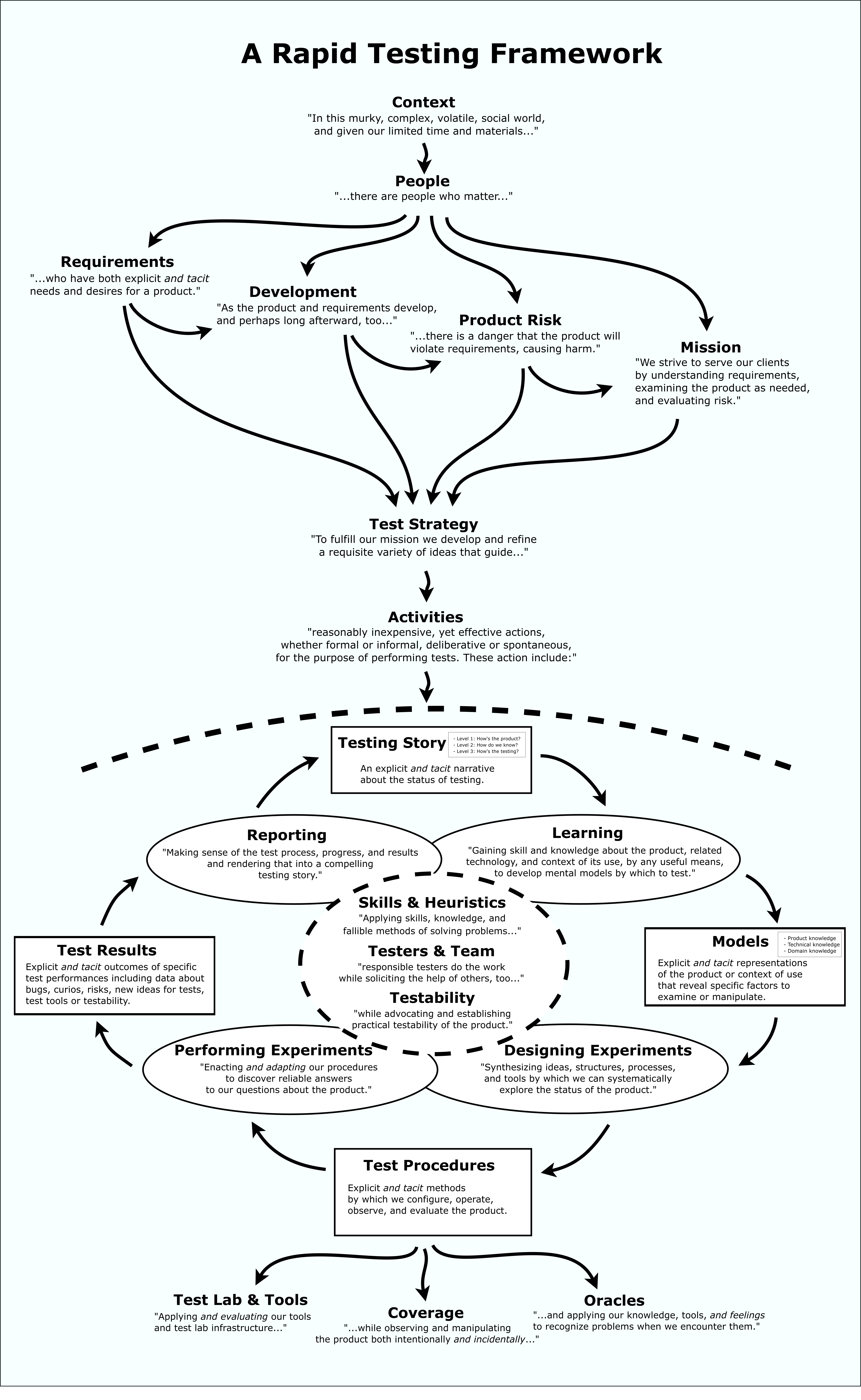
我们为什么要测试?我们测试以全面了解产品及其周围的风险。我们进行测试以发现威胁产品价值的问题,或者威胁按时,成功完成任何类型的开发工作的问题。我们进行测试以帮助业务,经理和开发人员确定他们所拥有的产品是否是他们想要的产品。
最重要的是,我们测试是因为它是负责任的事情。我们有责任关心我们的团队,组织,客户和社会。发布经过严格测试的软件将违反该义务。
快速软件测试(RST)就是这样。它是一种负责任的软件测试方法,以测试人员和需要测试的人为中心。它是一种方法(在“方法系统”的意义上)包含工具(又名“自动化”),但强调指导和推动过程的熟练技术人员的作用。
这种方法的本质在于它的本体论(我们如何组织和定义各种优先级,想法,活动和其他测试要素),人文主义(我们通过将方法置于每个从业者的控制下来培养责任和应对能力),以及启发式(解决问题的错误方法)。
RST不是一组模板和规则,而是一种心态和技能。这是了解测试的一种方式;这是测试人员知道如何做的一系列事情。
我的意思是迅速
我不是在谈论打字或点击更快。我说的是更好的测试策略。这基本上意味着九件事:
- 掌控自己的工作。除非您受到对您的工作负责的人的直接监督,否则您不得盲目地遵循任何指示或过程。这意味着您使用的任何实践,无论您如何与项目中的其他流程协调,请自行决定。不要将测试基于您不理解的测试用例。如果您不了解某些事情,请在研究之前研究它,停止这样做,或者建议您的客户盲目地工作。
- 停止做有帮助的事情。很难说哪些活动真的是浪费时间而哪些不是浪费时间,但这是一条黄金法则:如果你认为自己在做一些浪费时间的事情,就不要再做了。
- 拥抱探索和实验。快速做好测试的一部分是快速了解产品,这不仅仅需要阅读规范或重新利用旧的测试用例。您必须潜入并与产品互动。这有助于您更快地建立它的心理模型。
- 专注于产品风险。一种尺寸的测试并不适合所有人。在需要的地方进行更深入的测试,并在潜在的产品风险较低时进行浅层测试或根本不进行测试。
- 使用轻量级,灵活的启发式方法来指导您的工作。 RST方法包括许多旨在帮助构建您的工作的启发式模型。这些模型简洁明了,可用于支持从自发和非正式测试到审议和正式测试的任何级别的测试。它们始终在您的控制之下。
- 使用解决问题的最简洁的文档形式。文档可能会对任何项目造成巨大拖累。它很难创建并且难以维护。要么避免它,要么使用最轻的形式的文档来传达需要它的特定人员所需要的东西。
- 使用工具加速工作。测试人员不一定需要编写代码,但他们确实需要强大的工具。无论您是自己创建工具还是寻求其他人的帮助,您都可以将工具(包括自动检查)应用于测试过程的所有方面
- 解释你的测试及其价值。当您能够以注重价值的方式清晰快速地解释测试的重要性时,您的客户和团队成员将会感觉到您的时间得到充分利用,因此足够快。
- 提高您的技能,以便您可以完成上述所有工作。我们不提供可以吞咽的药丸,让您可以做这些事情。但我们确实向您展示了如何发展您的技能,以及如何发展它们。通过培养判断力和对不同技术,工具和流程的广泛了解,您可以选择一种快速的测试方法来满足所有业务需求。
想了解详情?
以下是RST的许多元素的路线图:
可以在此处找到一些表达RST的参考文档。
RST的基础是什么?
RST受到Gerald M. Weinberg,Cem Kaner和Billy Vaughan Koen,以及社会学家Harry Collins,家庭治疗师Virginia Satir以及诺贝尔奖获得者Herbert Simon,Richard Feynman,工作和科学方法的强烈影响。和Daniel Kahneman。如果您钦佩他们的工作,您会发现很多因我们提供的方法和课堂体验而产生共鸣。
RST还基于Cem Kaner,James Bach和Bret Pettichord的“软件测试经验教训:上下文驱动的方法”并与之相关。以及我的书“海盗 - 学者的秘密”中描述的自我教育和独立思考的生活方式。
以下是RST的具体前提,由我和Michael Bolton撰写。方法论中的所有内容都以某种方式来自这个基础。这些前提来自我几十年的经验,研究和讨论。
- 软件项目和产品是人与人之间的关系,人是情感和理性思想的生物。是的,还有技术,物理和逻辑元素,这些元素非常重要。但软件开发主要受人类方面的影响:政治,情感,心理,感知和认知。项目经理可以声明任何给定的技术问题对于企业来说根本不是问题。用户可能需要他们永远不会使用的功能。你的神奇工作可能会被拒绝,因为程序员不喜欢你。新手用户的足够快的性能对于有经验的用户来说可能是不可接受的。对于重要的人来说,质量始终是有价值的。产品质量是产品与人之间的关系,绝不是可以与人类环境隔离的属性。
- 每个项目都在不确定和时间压力的条件下进行。某些程度的混乱,复杂性,波动性和紧迫性困扰着每个项目。混乱可能是瘫痪,复杂性压倒性,波动性令人震惊,紧迫性迫在眉睫。原因很简单:新颖,雄心和经济。每个软件项目都试图生成新的东西,以解决问题。软件开发人员渴望解决这些问题。与此同时,他们经常尝试做的事情远远超过他们所拥有的资源。这不是人类的任何道德错误。相反,它是演化理论所谓的“红皇后”效应的结果:你必须尽可能快地跑到同一个地方。如果您的组织没有承担风险,您的竞争对手将 - 并最终您将为他们工作,或根本不工作。
- 尽管我们有最好的希望和意图,但某种程度的缺乏经验,粗心大意和无能是正常的。这个前提很容易验证。首先要诚实地看待自己。您是否拥有在不熟悉的领域或不熟悉的产品中工作所需的所有知识和经验?你有没有犯过你没有抓到的拼写错误?您仔细阅读了哪些测试教科书?你有多少学术论文?您是否熟悉集合论,图论和组合学?你是否精通至少一种编程语言?您现在可以坐下来使用de Bruijn序列来优化您的测试数据吗?你知道什么时候避免使用它吗?您是否完全熟悉所测试产品中使用的所有技术?可能不 - 而且没关系。创新的软件开发工作的本质是扩展即使是最有能力的人的极限。其他方法似乎假设每个人都能够并且将会在正确的时间做正确的事情。我们发现这令人难以置信。任何忽视人类易犯错误的方法都是幻想。通过说人类的错误是正常的,我们不是试图为它辩护或为它道歉,但我们指出,我们必须期望在我们自己和其他人中遇到它,以富有同情心的方式处理它,并充分利用它我们学习手艺和建立技能的机会。
- 测试是一项活动;它是性能,而不是工件。大多数测试人员会随便说他们“编写测试”或者他们“创建测试用例。”这很好,就目前而言。这意味着他们构思了想法,数据,程序,以及可能使某项任务或其他任务自动化的程序;他们可能已经用书面或程序代码表达了这些想法。当任何这些事物与它们所代表的想法混淆时,以及当表示与实际测试产品混淆时,就会出现问题。这是一种称为物化的谬误,即将抽象视为事物的错误。在某个测试人员使用该产品之前,观察并解释这些观察结果,没有进行任何测试。即使您编写了一个完全自动的检查流程,该流程的结果也必须由负责人审核和解释。
- 测试的目的是发现产品的状态及其价值的任何威胁,以便我们的客户能够做出明智的决策。当人们使用“测试”这个词时,会有其他目的。对于某些人来说,测试可能是检查基本功能似乎有效的一种仪式。这不是我们的观点。我们正在寻找重要的问题。我们寻求对产品的全面了解。我们这样做是为了满足客户的需求,无论他们是谁。为客户服务所需的测试水平会有所不同。在某些情况下,测试将更加正式和简单,在其他情况下,非正式和精细。在所有情况下,测试人员都必须向那些必须对其做出决策的人提供有关产品的重要信息。测试人员照亮了路。
- 我们承诺进行可信的,具有成本效益的测试,并且我们将告知客户任何威胁该承诺的事情。 Rapid Testing寻求完全满足测试任务的最快,最便宜的测试。当10美元的测试能够完成这项工作时,我们不应该建议进行百万美元的测试。我们测试得还不够;鉴于项目的局限性,我们必须进行良好的测试。此外,当我们受到一些可能妨碍我们做好工作的约束时,测试人员必须与客户合作解决这些问题。无论我们做什么,我们都必须准备好证明和解释它。
- 我们不会故意或疏忽地误导我们的客户和同事。这种道德前提推动了快速软件测试的许多结构。测试人员经常成为客户善意但无理或无知的要求的目标。我们可能会被要求压制坏消息,创建我们无意使用的测试文档,或者生成无效指标来衡量进度。我们必须礼貌而坚决地抵制这些要求,除非我们认为它们符合我们客户的更好利益。至少我们必须告知客户任何阻碍我们测试的任务或工作模式的影响,或者造成测试的错误印象。
- 尽管测试人员无法控制产品的质量,但他们对工作质量负责。测试需要许多互锁技能。测试是一项工程活动,需要大量的设计工作来构思和执行。像许多其他高度认知的工作一样,例如调查报告,驾驶飞机或编程,对于没有实际工作的人来说很难有效地监督它。因此,测试人员不得放弃对自己工作的责任。出于同样的原因,我们不能对产品本身的质量承担责任,因为它不在我们的控制范围内。只有程序员和他们的管理层才能控制。有时测试称为“质量保证”。如果是这样,请将其视为质量协助,而非质量保证。
RST的演变
快速软件测试的起源是我在Apple Computer和Borland International运行测试团队的经历,可以追溯到1987年。我一直在寻找测试的本质,而不是在当时的任何标准或书籍中找到它。然后我收到了Ed Yourdon,Tom DeMarco,Tim Lister和Jerry Weinberg的重要线索。他们促使我考虑一般系统思考。他们开始思考心理学在工程学中的关键作用。然后在90年代中期,在旧金山举行的测试会议上进行的通宵谈话中,Cem Kaner敦促我探索认知心理学和认识论。这些领域提供了我新兴方法的组织框架。
我曾经给出的关于测试方法的第一次谈话叫做动态软件质量保证。我是在1990年为Apple大学做过的。我希望我还有那个录像带。这是我最后一次没有留胡子的视频。我在谈论启发式和系统思考,但我认为我不知道这些话。
我在1993年举行的第一次重要的会议讨论叫做“持久性特别测试”。我在谈论探索性测试的非凡价值,尽管我不会在今年晚些时候开始使用该术语。
我的测试方法的第一个公开版本体现在1995年的一个名为市场驱动的软件测试的类中。然后我创建了一个基于风险的测试课程,以及业界第一个探索性测试课程。 2001年,我将这些课程结合起来,开始将该方法正式化,将课程重命名为Rapid Software Testing。
2004年,Michael Bolton将他作为开发人员,测试人员,文档管理员和项目经理的经验带到课堂上,添加了新的练习,谜题和主题。 Michael在商业和金融服务软件方面的工作增加并影响了关于形式和文档角色的想法,并于2006年成为该课程和方法的共同作者。多年来,他帮助改进了RST,提高了词汇量,并在检查 - 原则上可以由机械完成的测试的一部分 - 和测试之间引入了至关重要的区别 - 这需要测试人员的明确和隐性知识。
Paul Holland(来自嵌入式系统和电信),Huib Schoots(金融服务)和Griffin Jones(医疗设备和其他监管领域)各自将他们的想法,经验和教学方式融入其中。 我们的每位教师都受益于其他人的工作,每个人都教授自己的个人RST变体。
RST历来专注于测试和测试人员。 但是我们最近重新调整了一点,因为许多进行测试的人要么没有被称为测试人员,要么除了测试之外还做其他事情。 如今,我们的客户需要了解RST如何与Agile和DevOps集成。
这是我们的敏捷快速测试网格,它可以帮助我们解释:
方法与什么兼容
RST是一种上下文驱动的方法。这意味着我们的课程不是专门针对敏捷,DevOps,精益,瀑布或受监管环境中的测试;它也不包含您可能用于模拟用户或支持任何其他测试方面的任何特定测试工具。但是,我们通过让您控制流程来帮助您将这些内容应用于测试,以便您解决实际存在于您的上下文中的问题。
关键问题是责任。作为测试人员,责任意味着做出独立的专业判断,以应用实践和工具来发现您特定项目的每个重要问题。责任意味着在项目和产品风险需要时进行深度测试。负责任地应用诸如“单元测试”或“行为驱动的开发”之类的实践意味着在适合您的环境时选择它,而不是因为您听说Facebook和Google这样做,或者因为您被命令这样做。负责任地使用自动化包括在更有效,更高效或解决自动化忽略的问题时考虑自动化之外的方法。责任意味着当你说“可能什么都不会出错”时,你不仅仅是在猜测。
RST不告诉你该怎么做。相反,它是一个负责任和有文化地考虑做什么的框架。 RST的教师具有广泛的环境经验,可以帮助您定制材料以满足您的需求。因此,我们有很多关于如何将自动化应用于测试,或如何在文档密集型项目中进行良好测试的想法。
有一点特别是RST方法与以下方面不兼容:假测试。是的,有些组织有目的地最大限度地利用文书工作,并鼓励他们知道很少发现错误的浅层测试脚本。 “工厂式”测试通常相当于假测试,因为它看起来很合理,尽管未达到其明显的目的。一些公司 - 大型测试外包公司因此而闻名 - 甚至这是一种商业模式,可以最大化计费时间。这些公司不希望更有效地进行测试,因为这会减少他们的计费时间。他们希望对那些不了解深度测试的人看起来很有成效。如果您为这样的公司工作,如果您参加RST课程,您的老板会非常恼火。它会让你提出不舒服的问题。
以下是有关RST如何与其他一些流行的测试方法进行比较的其他详细信息。
原文:https://www.satisfice.com/rapid-testing-methodology
讨论: 知识星球【数字化和智能转型】
- 63 次浏览
【软件测试】用于衡量质量保证成功的64项基本测试指标
软件测试指标是衡量和监控测试活动的一种方法。 更重要的是,它们可以深入了解您的团队的测试进度,生产力和被测系统的质量。 当我们问自己“我们测试了什么?”时,指标会给我们提供更好的答案,而不仅仅是“我们已经测试过。”不同的团队根据他们想要跟踪和控制或改进的内容来衡量各个方面。
度量通常基于数据组合传达结果或预测。
结果指标:
指标主要是完成的活动/流程的绝对指标。
示例:在套件中运行一组测试用例所花费的时间
预测指标:
作为衍生工具的指标,并作为不利结果的早期预警信号。
示例:创建的缺陷与已解决的图表显示缺陷修复率。如果此速率低于所需速率,则会引起团队注意。
为何选择测试指标?你为什么要关心?
收集测试指标的目的是使用数据来改进测试过程,而不是仅显示花哨的报告。这包括找到问题的切实答案:
- 测试需要多长时间?
- 测试需要多少钱?
- 虫子有多糟糕?
- 发现了多少个错误?重新打开?关闭?延期?
- 测试团队找不到多少错误?
- 测试了多少软件?
- 测试会按时完成吗?软件可以按时发货吗?
- 测试有多好?我们使用的是低价值的测试用例吗?
- 测试成本是多少?
- 测试工作是否足够?我们可以在此版本中进行更多测试吗?
这些问题的好答案需要衡量。这篇文章包括测试人员和QA经理最常使用的64个绝对,衍生,结果和预测指标。
基本指标
作为测试人员,您的指标创建之路必须从某个地方开始。基本QA指标是绝对数字的组合,然后可用于生成衍生指标。
绝对数字
-
测试用例总数
-
通过的测试用例数
-
测试用例数失败
-
被阻止的测试用例数
-
发现的缺陷数量
-
接受的缺陷数量
-
拒绝的缺陷数量
-
延迟的缺陷数量
-
关键缺陷的数量
-
计划的考试时数
-
实际测试小时数
-
发货后发现的错误数量
衍生指标
绝对数字是一个很好的起点,但通常只有它们是不够的。
例如,如果您报告跟随网格,这可能不足以理解我们是否按计划完成,或者我们应该每天查看的结果。
| Day | Day 1 | Day 2 | Day 3 |
| Results Completed | 35 | 40 | 45 |
在这种情况下,绝对数字产生的问题多于答案。 借助衍生指标,我们可以深入探讨如何解决测试过程中的问题。
测试跟踪和效率
以下是有助于测试跟踪和效率的派生指标:
| 13. |  |
| 14. |  |
| 15. |  |
| 16. |  |
| 17. |  |
| 18. |  |
| 19. |  |
| 20. |  |
| 21. |  |
测试努力
测试工作指标将回答有关您的测试工作的“多长时间,多少次以及多少”的问题。 这些指标非常适合为将来的测试计划建立基线。 但是,您需要记住这些指标是平均值。 一半的价值落在平均值上,其中一半价格低于平均值。
一些具体措施是:
| 22. |  |
| 23. |  |
| 24. |  |
| 25. |  |
| 26. |  |
| 27. |  |
测试有效性
测试有效性答案,“测试有多好?”或“我们是否运行高价值测试用例?”它是测试集的错误发现能力和质量的衡量标准。 测试有效性指标通常显示测试团队发现的缺陷数量与软件发现的整体缺陷之间的差异百分比值。
28. 基于度量:使用缺陷遏制效率的测试有效性

测试有效性百分比越高,测试集越好,长期测试用例维护工作量就越少。
示例:如果一个版本的测试有效性为80%,则意味着20%的缺陷从测试团队中脱离出来。
- 该数字应导致对改进测试集的调查,回顾和纠正措施,从而增加测试集的缺陷识别率。
- 测试有效性永远不会是100%。因此,团队应该瞄准更高的价值,如果不是100,不应该失望。
- 平均有效率超过版本将显示测试集改进的努力是否给出了积极的结果。
29.基于情境:使用团队评估测试有效性
在以下情况下使用缺陷控制效率指标可能不起作用
- 该产品已经成熟
- 产品不稳定且有缺陷
- 由于时间/资源限制,未完成足够的测试
在这种情况下,我们需要另一种方法来衡量基于意见或背景的测试集有效性。
您可以要求您的团队对测试集的评分进行评分。在您这样做之前,告诉您的团队不偏不倚并定义一个好的测试集意味着什么是很重要的。例如,您的团队可能会认为一个好的测试集应该能够充分满足高风险要求。切合实际,专注于应用程序的最关键领域。
您的团队也可以使用主观缩放方法。在100%评级(1到10分)中,请您的团队给测试集评分,以确定测试集的完整性,最新性和有效性。获得平均得分,以获得团队感知的平均测试效果。从主题专家的角度谈论哪些测试的好与坏,证明是缩小测试重点的有意义的练习。
告诉您的团队不偏不倚并定义一个好的测试集意味着什么是很重要的。
测试覆盖率
软件质量指标衡量正在测试的应用程序的运行状况。不可避免的是,您要分析的下一个核心指标集围绕着覆盖范围。测试覆盖率指标衡量测试工作量并帮助回答“测试了多少应用程序?”
例如,“在这些通过或失败的测试中,我的应用程序的工件或区域是什么,它们旨在确保我的产品以高质量生产。”以下是一些关键的测试覆盖率指标。
| 30. |  |
这让我们了解了与未完成的测试运行相比所执行的总测试。 它通常以百分比值表示。
| 31. |  |
要获得有关测试覆盖范围的要求的高级视图,您只需要划分sprint,发布或项目的范围要求总数所涵盖的要求数量。
这通常只显示是否存在关联测试,而不是显示测试运行的结果。
32.按要求测试案例
最常见的方法是查看正在测试的功能,并查看我们与用户故事或要求一致的测试数量。
| REQ | TC Name | Test Result |
| REQ 1 | TC Name1 | Pass |
| REQ 2 | TC Name2 | Failed |
| REQ 3 | TC Name3 | Incomplete |
33.每项要求的缺陷(要求缺陷密度)
每个要求的缺陷密度有助于发现哪个要求比其他要求更具风险。 例如,测试用例可能没问题,但要求可能是造成所有问题的原因。
| Req name | Total # of Defects |
| Req A | 25 |
| Req B | 2 |
34.没有测试范围的要求
重要的是要知道您是否已准备好通过适当的测试覆盖率将需求推向生产。
这表明哪些要求没有测试覆盖率以及需求处于什么阶段。例如,处于“完成”状态的要求比“待办事项”状态中的要求风险更大。
| REQ ID | REQ NAME | REQ STATUS |
| REQ001 | REQ A | To Do |
| REQ002 | REQ B | Done |

尽管更高的测试覆盖率和图表可以增加对测试工作的信心,但它是一个相对值。就像我们找不到所有错误一样,我们无法创建足够的测试来实现100%的测试覆盖率。这不是测试人员的限制,而是由于所有系统都未绑定的现实。当我们考虑字段,功能和端到端测试级别时,有无数的测试。因此,最好确定将有资格作为100%测试覆盖率限定为有限的测试库存。
在WhiteBoard Friday视频系列中了解有关充分利用软件测试指标的更多提示:重要的指标。
测试经济学指标
人员(时间),基础设施和工具有助于降低测试成本。测试项目没有无限的货币资源可供支出。因此,重要的是要知道你打算花多少钱,以及你最终花多少钱在现实中。以下是一些测试经济学指标,可以帮助您当前和未来的预算计划。
35.测试的总分配成本
CIO和QA董事为单个项目或整年的所有测试活动和资源编制的预算金额
36.实际测试成本
进入测试的实际美元时间
计算此成本的一种方法是测量每个要求,每个测试用例或每个测试小时的测试成本。
例如,如果您的预算是1000美元并且包括测试100个要求,则测试要求的成本是1000/100 = 10美元。每个测试小时的成本,100小时1000美元意味着每小时10美元。当然,这假设所有要求在复杂性和可测试性方面都是相同的。
这些数字对于充当基线很重要,有助于估算项目的未来预算。
37.预算差异
实际成本与计划成本之间的差异
38.附表差异
完成测试的实际时间与计划时间之间的差异
如果实际成本低于分配预算(负差额),这对项目来说是个好消息。但是,这也可能意味着估计不正确。方差为零是优选的。
请阅读此处了解更多信息
39.每个bug修复的成本
这是通过每个开发人员在缺陷上花费的金额来计算的
如果开发人员花了10个小时来修复错误并且开发人员的每小时费用是60美元,那么错误修复的成本是10 * 60美元= 600美元。
有些团队还会考虑重新测试的成本,以获得更准确的测量结果。
40.不测试的成本
如果一组新功能投入生产但需要返工,那么返工所需的所有费用等于未测试的成本。
不测试的成本也可以追溯到更主观的价值,例如一个人的观点。以下是未测试的主观成本的一些示例:
- 更多客户服务电话/服务请求
- 生产性停电
- 失去用户/客户信任等
- 失去客户忠诚度
- 品牌知名度不高
测试团队指标
这些指标可用于了解每个测试团队成员的工作分配是否统一,以及是否有任何团队成员需要更多的流程/项目知识说明。永远不应该使用这些指标来归咎于责备,而应该帮助知识共享,而不应该用它来归咎于责备。
41.返回缺陷的分布,团队成员明智 - 见解2.0


42. 每个测试团队成员重新测试的开放缺陷的分布 - 洞察力2.0

43. 根据测试团队成员见解2.0分配的测试用例


44. 由测试团队成员执行的测试用例 - 见解2.0

通常,饼图或直方图用于快速获取工作分配的快照。 下面的图表立即引起我们的注意,鲍勃超额预订,大卫未得到充分利用。 这使测试主管/经理有机会研究为什么会这样,并在需要时采取纠正措施。
测试执行状态
测试执行快照图表显示组织为已通过,失败,阻止,未完成和未执行的总执行次数,以便轻松吸收测试运行状态。 这些图表是日常状态会议的绝佳视觉辅助工具,因为原始数字有更高的机会滑落人们的思维。 不断增长和萎缩的酒吧吸引了人们的注意力,更有效地传达了进步和速度。
45.测试执行状态图表




测试执行/缺陷查找率跟踪
这些图表有助于理解测试速率和缺陷发现率与期望值的比较。
取累积缺陷计数和测试执行率,绘制理论曲线。 与实际值相比,这将触发早期的红色标记,如果要达到目标,测试过程需要更改。
46.测试执行跟踪和缺陷查找速率跟踪


更多信息和图片来源:
https://www.stickyminds.com/sites/default/files/presentation/file/2013/06STRER_…
变更指标的有效性
软件经历了变化 - 频繁,极少,远在中间。必须监控所包含的变更,以了解它们对现有系统稳定性的影响。变化通常会导致新的缺陷,降低应用稳定性,导致时间线滑落,危及质量等。
这些措施可以帮助我们更好地了解影
47.测试变化的影响
可归因于更改的缺陷总数。这可能意味着确保缺陷得到适当影响,并在向开发报告时附加固定视觉。将这些缺陷归类为变更相关与否,这是一种努力,但这是值得的。
48.缺陷注射率
可归因于更改的已测试更改/问题的数量
例如:如果对系统进行了10次更改,并且30个缺陷可归因于更改,则每次更改最终会注入三个缺陷,并且每次更改的缺陷注入率为3。
知道这个数字将有助于预测每次新变化可能出现的缺陷数量。这允许测试团队战略性地使用回顾会议来了解他们帮助识别和修复来自新变更的缺陷的能力。
缺陷分布图
缺陷可以根据类型,根本原因,严重程度,优先级,模块/组件/功能区域,平台/环境,负责测试人员,测试类型等进行分类。您团队的权利如何设置完整的精细分类列表用于缺陷报告。
缺陷分布图有助于理解分布并确定目标区域以最大程度地去除缺陷。通过使用直方图,饼图或帕累托图表来显示开发和测试工作的位置。
49.由于原因导致的缺陷分布
50.模块/功能区域的缺陷分布
51.严重程度的缺陷分发
52.按优先顺序分配的缺陷
53.按类型分发缺陷
54.测试人员(或测试人员类型)的缺陷分布 - Dev,QA,UAT或最终用户
55.按测试类型分发缺陷 - 审查,演练,测试执行,探索等。
56.平台/环境的缺陷分发
直方图或饼图显示对高度受影响区域的即时视觉识别。但是,当参数太多而没有难以辨别的模式时,您可能必须使用帕累托图。缺陷
分配饼图:
这仅用于一个目的。它可以帮助您快速找到最密集的区域(大多数缺陷的原因)。


缺陷分布直方图:
创建直方图时,请务必将数据值从高到低或从低到高组织起来以产生最大影响。


您可以在此处停止,但要从指标中获得更多信息,请继续执行下一步。
将直方图与每个原因中的缺陷严重性分布相结合。 这将为您提供您应该更准确地关注的领域。
例如:我们知道造成大多数缺陷的区域是用户数据输入,但仅仅因为计数很高,我们不必首先关注那个,因为大多数“用户数据输入”都很低(绿色)。 缺陷数量最多且严重问题较多的下一类是“代码错误”。 因此,此图表将改进我们的数据,并让我们更深入地了解在何处引导进一步开发和修复工作。


缺陷分布帕累托图:
您还可以创建一个帕累托图表来查找哪些原因可以解决大多数缺陷。 在大多数情况下,可能不需要帕累托图。 但是,如果原因太多而且直方图或饼图不足以清楚地显示趋势,那么帕累托图可以派上用场。

要知道要关注哪些原因以便以最少的工作来修复最大缺陷(或者20%的原因可以修复80%的缺陷),在辅助轴上绘制一条80%标记的线并将其放到 X轴,如下:

导致用户数据输入和代码错误的原因应该比其他更重要。
随着时间的推移缺陷分布图表
测试周期结束时或测试周期中某一点的缺陷分布是该时间点缺陷数据的快照。如果事情变得更好或更糟,它不能用于得出结论。例如:在某个时间点,您将知道X个严重错误。我们不知道X是否超过最后一个周期或更少或相同。
随着时间的推移,您将了解每个类别中的缺陷。我们可以看到缺陷是否随着时间的推移或过度释放而增加,减少或稳定。
随时间的缺陷分布是多线图,显示一段时间内每个原因/模块/严重性趋势的缺陷。
57.原因导致的缺陷分布
58.模块随时间的缺陷分布
59.严重程度随时间的缺陷分布
60.平台随时间的缺陷分布
对于以下数据:
| Test Cycle | Code Error | Security Problem(access permissions) | User error(data entry) |
| Cycle 1 | 8 | 4 | 15 |
| Cycle 2 | 7 | 3 | 13 |
| Cycle 3 | 1 | 5 | 9 |
| Cycle 4 | 1 | 5 | 4 |
| Cycle 5 | 0 | 4 | 1 |
在5个周期内绘制3个原因的多线图,如下所示:

以下是图表可以帮助我们理解的内容:
- 最初的两个周期中的代码错误一直很高,但是从第3周期开始显着下降并保持低水平。这表明开发工作的有效性。
- 用户数据输入错误已从初始版本中暴露出来;这表明用户对产品的熟悉程度和接受度增加
- 随着测试周期的进行,安全相关的缺陷保持稳定并且没有改善(即数量减少)。这意味着,这些必须作为优先事项处理和处理。
限制:
- 对于负趋势,即对于发布/测试周期,如果缺陷计数在特定原因类别中增加,则此图表告诉我们这是什么,但不告诉我们原因。
- 当工作原因很少时,它是最有效的。想象一下,这个图表有10个原因类别,而不是3个,这将是太多的线条使它太繁忙和难以解释。
创建缺陷与缺陷已解决图表
61.缺陷创建与缺陷解决图表
找到的错误与固定图表相比,是一个缺陷分析折线图,可让我们查看缺陷删除过程模式并了解缺陷管理的有效性
要开始创建固定与发现图表,您必须先收集编号。发现的缺陷和没有。每天在测试周期中解决的缺陷。这是需要累积数字才有意义的图表之一。在10天的测试周期中考虑以下缺陷数据:
| Test Cycle 1- Date | Bugs created | Bugs resolved | Cumulative bugs created(Total no. of bugs created so far) | Cumulative bugs resolved(Total number of bugs resolved so far) |
| 10/10/2016 | 6 | 4 | 6 | 4 |
| 10/11/2016 | 3 | 0 | 9 | 4 |
| 10/12/2016 | 4 | 4 | 13 | 8 |
| 10/13/2016 | 2 | 4 | 15 | 12 |
| 10/14/2016 | 2 | 3 | 17 | 15 |
| 10/15/2016 | 0 | 0 | 17 | 15 |
| 10/16/2016 | 1 | 0 | 18 | 15 |
| 10/17/2016 | 0 | 2 | 18 | 17 |
| 10/18/2016 | 0 | 2 | 18 | 19 |
| 10/19/2016 | 0 | 0 | 18 | 19 |
针对上述数据创建的缺陷与已解决的图表如下所示:

这张图很棒,但有太多的线条让我们分心。 因为创建和解决的错误的原始数量是没有意义的,您可以从图表中删除它们以获得更清晰的创建与已解决的图表,如下所示。

此图表回答了以下问题:
- 我们准备好了吗?
- 软件是否在测试结束时获得稳定性?
- 缺陷管理系统是否有效?
这是如何做:
- 1.在测试周期结束时,绿线变得更直,更平坦或更稳定 - 这表明错误发现率已经下降,累积错误数量不变 - 因此,它有助于我们回答问题 - “我们测试的足够吗? “或”产品是否已准备好发货?“
如果绿线越来越陡峭,这意味着即使在测试结束时,找到错误的速度也没有下降。因此,需要进行更多测试,产品尚未发货。
- 2.在曲线的末端,创建和解析的线会聚(或多或少)。这也是一个好兆头,因为它表明缺陷管理过程正在发挥作用并且正在有效地解决问题。
如果蓝线低于绿线,则意味着缺陷未及时解决,我们可能需要改进流程。
限制:虽然此图表回答了许多重要问题,但它确实有其局限性。
- 绿色线中的尖峰可能在测试周期开始时发生,此时错误发现率通常很高。当开发团队完成所有缺陷并将其中的大部分标记为已完成时,也可能出现蓝线尖峰。这可能会导致对正在发生的事情的一时的恐慌。
- 该图表显示了正在发生的事情,但需要进一步研究以了解“为什么”。
参考文献:
https://confluence.atlassian.com/jira064/created-vs-resolved-issues-rep…
管理测试过程 - 由雷克斯黑色。第4章“缺陷去除的进展情况”。
http://www.wiley.com/WileyCDA/WileyTitle/productCd-0470404159.html
更多缺陷度量标准
62.缺陷去除效率/缺陷差距分析
缺陷删除效率是指开发团队能够处理和删除测试团队报告的有效缺陷的程度。
要计算缺陷差距,请计算提交给开发团队的总缺陷数以及在循环结束时修复的缺陷总数。使用公式计算快速百分比,

示例:在测试周期中,如果QA团队报告了100个缺陷,其中20个无效(不是错误,重复等),如果开发团队已经解决了其中的65个,则缺陷缺口%为:(65 / 100- 20)X100 = 81%(约)
在一段时间内收集数据时,缺陷差距分析也可以绘制为如下图形:

差距很大,表明开发过程需要改变。
更多信息:https://www.equinox.co.nz/blog/software-testing-metrics-defect-removal-efficien…
63.缺陷密度
缺陷密度定义为软件的软件或应用程序区域的每个大小的缺陷数。

如果测试周期结束时的缺陷总数为30,并且它们全部来自6个模块,则缺陷密度为5。
更多信息:http://www.softwaretestinghelp.com/defect-density/
64.缺陷年龄
缺陷年龄是一种衡量标准,可帮助我们跟踪开发团队开始修复缺陷并解决缺陷所需的平均时间。 缺陷年龄通常以单位天数来衡量,但对于每周或每天发布的快速部署模型团队,项目应以小时为单位进行衡量。
对于具有高效开发和测试流程的团队而言,低缺陷年龄标志着错误修复的更快转变。
缺陷年龄=创建时间差异和花费时间
了解如何使用qTest Insights 2.0在点播网络研讨会和幻灯片中分析软件质量,测试覆盖率和测试速度。
这篇文章由Swati Seela和Ryan Yackel撰写。
原文:https://www.qasymphony.com/blog/64-test-metrics/
- 399 次浏览
【软件测试】软件测试的未来:12测试专家分享他们的预测

你将学到什么
毫无疑问,软件测试领域目前正处于重大转型的中期。 软件在我们日常工作和个人生活中的普及对新软件提出了更高的期望,并迫使软件更快地推向市场。
因此,软件测试人员的角色也在发生变化,包括他们做什么,何时做以及与谁合作。 在自动化和人工智能无处不在的世界中,软件测试角色会变成什么样?
这本免费的20页指南采访了12位经验丰富的行业专家,分享他们对软件测试行业的预测并回答关键问题,例如:
- 软件测试领域的变化到底意味着什么?
- 软件测试人员如何为正在进行的转型做好准备?
- 拥抱新变化的最大挑战是什么?
- 领导人看到了哪些转变?
原文:https://www.qasymphony.com/landing-pages/future-software-testing-ebook/
讨论请加【数字化和智能转型】知识星球
- 33 次浏览
【软件测试】阳性与阴性与破坏性测试案例
视频号

微信公众号

知识星球

测试用例是一组条件或变量,测试人员将在这些条件或变量下确定应用程序、软件系统或网站是否符合规范并按预期运行。测试用例可以是肯定的,也可以是否定的,这意味着它测试的是正确的功能还是缺失的功能。
什么是测试用例?
测试用例是一组条件或变量,测试人员将在这些条件或变量下确定应用程序、软件系统或其功能之一是否正常工作。测试用例主要有三种类型:
- 阳性测试案例:在这些案例中,被测试的系统有望正常工作。这些测试旨在表明系统能够处理有效的输入并产生预期的输出。
- 阴性测试案例:这些是被测试系统预计会失败的案例。这些测试有助于确保系统能够优雅地处理无效输入,并在必要时产生错误消息或其他适当的输出。
- 破坏性测试案例:这些案例中,被测试的系统被故意破坏,以测试其恢复能力。这些测试有助于确保系统能够承受意外故障,并且仍然正常工作。
什么是阳性检测案例?
阳性测试用例是验证系统或应用程序在有效或预期输入条件下正确运行的能力的测试。
- 阳性测试案例的示例包括验证表单提交的正确数据输出、验证用户是否能够成功登录应用程序,或确认支付交易是否成功。
- 积极的测试用例对软件质量保证至关重要,有助于确保系统按预期运行,并在给出有效输入时产生正确的结果。
- 阳性测试用例用于评估系统或应用程序在给定有效输入或理想条件下的行为。
- 这些测试有助于确保应用程序按预期运行,并确保用户体验令人满意。
- 应该为应用程序的所有特性和功能编写阳性测试用例,并且应该包括边界值和边缘用例的测试用例。
- 阳性测试用例通常由对测试的应用程序或系统有深入了解的QA工程师或测试人员编写。
- 测试人员应该清楚地了解功能和期望的结果,并且应该熟悉应用程序的源代码和设计。
什么是阴性测试案例?
阴性测试用例用于测试系统的无效输入和意外行为。它们的设计目的是确保系统在给定无效或意外输入时按预期运行。
- 阴性测试案例很重要,因为它们可以发现错误,否则这些错误将无法被发现。
- 负测试用例是那些旨在证明系统在给定无效输入时不能按预期工作的测试。例如,登录系统的阴性测试用例可能输入了不正确的用户名和密码组合。这将确保系统不会对没有正确凭据的用户进行身份验证。
- 阴性测试用例也可以用于检查意外行为。例如,搜索引擎的否定测试用例可能是输入具有意外格式的查询。这将确保系统在给出意外输入时不会提供意外结果。
- 阴性测试用例对于确保系统安全也很重要。
- 它们可用于测试输入验证、身份验证、授权、访问控制和其他安全措施。例如,身份验证系统的阴性测试用例可能输入了无效的用户名或密码。这将确保系统不会对没有正确凭据的用户进行身份验证。
什么是破坏性测试案例?
破坏性测试用例是一种软件测试,旨在识别系统暴露在极端条件下时发生的软件故障。这些测试包括故意将系统置于异常或极端条件下,以确定其断裂点和造成的损坏程度。
- 破坏性测试的目的是在现场发生潜在的系统故障之前识别这些故障,并帮助确保系统能够承受这些条件。
- 破坏性测试可能涉及多种情况,例如故意引入不正确的数据,使系统过载,请求超过其处理能力,或者模拟可能导致硬件故障的极端温度。
- 这些测试旨在模拟真实世界的条件,并揭示系统中任何隐藏的弱点。这有助于在系统发布给用户之前识别和解决任何问题,确保产品更加可靠。
- 破坏性测试通常在受控环境中进行,在受控环境下可以密切监测测试条件,并可以快速将系统恢复到其原始状态。
- 这使得跟踪测试结果、识别任何问题和开发解决方案变得更加容易。
破坏性测试并不是软件测试的唯一类型。其他类型的软件测试包括功能测试、回归测试和性能测试。每种类型的软件测试都有自己的好处,可以与破坏性测试结合使用,以提供系统的全面视图。
阳性测试用例与阴性测试用例与破坏性测试用例
以下是阳性测试用例、阴性测试用例和破坏性测试用例之间的差异:
| Factor | Positive Test Cases | Negative Test Cases | Destructive Test Cases |
|---|---|---|---|
| Functionality | Test cases that test the basic functionality of the software. | Test cases that test for errors or unexpected behavior. | Test cases that delete or modify data. |
| Usability | Test cases that test for user-friendliness and easy navigation. | Test cases that test for confusing interfaces or difficult navigation. | Test cases that delete user data or preferences. |
| Performance | Test cases that test for fast loading times and response times. | Test cases that test for slow loading times and response times. | Test cases that delete cached data or user preferences. |
| Security | Test cases that test for proper authentication and authorization. | Test cases that test for vulnerabilities and exploits. | Test cases that delete user data or preferences. |
| Design | Test cases are tests that are designed to ensure that a system works as expected. | Test cases are tests that are designed to ensure that a system does not work as expected. | Test cases are tests that are designed to deliberately break a system in order to test its robustness. |
| Data | A positive test case is run on unaltered data | A negative test case is run on altered data | A destructive test case is run on permanently altered data. |
| Example |
|
|
|
如何选择使用哪种类型的测试用例?
在决定使用哪种类型的测试用例时,需要考虑以下几个因素:
- 你测试的目的:如果你试图在你的软件中找到错误,那么你会想要使用阳性的测试用例。这些测试软件的预期行为。如果您试图了解软件在遇到意外输入时的反应,那么您将希望使用阴性测试用例。这些测试软件的意外行为。最后,如果您试图确定您的软件是否能够处理极端条件(如大量数据),那么您将希望使用破坏性测试用例。这些人故意试图破坏软件,看看它是如何响应的。
- 时间:正测试用例和负测试用例可以相对快速地编写,因为它们只需要几个不同的输入值。破坏性测试用例需要更长的时间来编写,因为它们必须非常具体和精心制作,才能有机会破坏软件。
- 成本:破坏性测试用例是迄今为止最昂贵的测试用例类型,因为它们通常需要专门的硬件和/或环境才能正常运行。阳性和阴性测试用例的成本要低得多,因为它们可以在没有特殊要求的任何系统上运行。考虑所有这些因素将帮助您决定哪种类型的测试用例适合您的需求。
- 88 次浏览
软件测试资料
实际软件工程中是否真的需要100%代码覆盖率(code coverage)?
https://www.zhihu.com/question/29528349
浅谈代码覆盖率
https://tech.youzan.com/code-coverage/
品质管理 如何量化测试覆盖率
https://testerhome.com/topics/10052
测试覆盖(率)到底有什么用?
https://www.infoq.cn/article/test-coverage-rate-role
64 Essential Testing Metrics for Measuring Quality Assurance Success
https://www.qasymphony.com/blog/64-test-metrics/
- 136 次浏览