事件驱动架构
「事件驱动架构」事件驱动2.0 事件,存储和处理统一到一个平台
将来,数据将像现在的基础设施一样自动化和自助服务。您将打开一个控制台,列出贵公司可用的数据;定义您需要的部分,您想要的格式以及您希望它们如何结合在一起;启动一个新的端点:一个数据库,缓存,微服务或无服务器功能,你就可以了。
这些是现代时代的事件驱动架构 - 但消息传递不仅仅是将系统连接在一起的简单管道。部件消息传递系统,部分分布式数据库,流式系统允许您在公司内部存储,Join,聚合和改造数据,然后在需要的地方推送数据,无论是笨重的数据仓库还是微小的无服务器功能。
与公共云和私有云结合使用时,可以动态配置基础架构,从而使数据完全自助服务。许多公司已经实施了这个未来的某些版本。
他们采取的不同方法可分为四大类,我们看到的公司和项目通常一次采用一种:
- 1.全球事件流媒体平台
- 2.中央活动商店
- 3.事件优先和事件流应用程序
- 4.自动数据配置
我们所知道的任何一家公司都没有掌握它们,但所有这些类别都以某种形式存在于生产中。
1.全局事件流平台
这是最容易理解的,因为它类似于旧的企业消息传递模式。组织采用事件驱动的方法,使用流经ApacheKafka®等事件流平台的核心数据集(应用程序之间共享的数据集,如订单,客户,支付,账户,交易等)。
这些通过单一基础架构取代了传统的点对点通信,使应用程序可以在不同地理位置或云提供商中大规模,实时地运行。
因此,一家公司可能在旧金山运行旧式大型机,在开普敦和伦敦设有区域办事处,并且在AWS和GCP上运行高度可用的微服务,所有这些都与相同的事件主干相连。更极端的用例包括通过卫星或汽车通过移动连接船只。
公司几乎在每个行业都实施这种模式。例如Netflix,Audi,Salesforce,HomeAway,ING和RBC,仅举几例。
2.中央事件存储
流平台可以在一段定义的时间段内缓存事件或无限期地存储它们,从而创建一个类型或组织分类帐或事件存储。
一些公司使用这种模式来推动回顾性分析,例如,训练在一级方程式赛后分析中用于欺诈检测或倒带时间的机器学习模型。其他人将模式应用于许多团队。
这样就可以构建新的应用程序,而无需源系统重新发布先前的事件,这一特性对于难以从其原始源重放的数据集非常有用,例如大型机,外部或遗留系统。
一些组织将所有数据保存在Kafka中。该模式被称为前向事件缓存,事件流作为事实的来源,kappa架构或简单事件溯源。
最后,有状态流处理需要事件存储,这通常用于从许多不同的数据源创建丰富的,自给自足的事件。例如,这可能是通过客户或帐户信息丰富订单。
丰富的事件更容易从微服务或FaaS实现中消费,因为它们提供了服务所需的所有数据。它们还可用于为数据库提供非规范化输入。执行这些丰富的流处理器需要事件存储来保存支持表格操作的数据(Join客户,帐户等)。
3.事件优先和事件流应用
大多数传统应用程序通过将来自不同位置的数据集导入其数据库(例如,ETL)来工作,在数据库中可以对其进行清理,连接,过滤和聚合。
对于创建报告,仪表板,在线服务等的应用程序,这仍然是最佳选择,但对于业务处理,通过将实时事件直接推送到微服务或无服务器功能来跳过数据库步骤通常更有效。
在这种方法中,像Kafka Streams或KSQL这样的流处理器通过在将事件流推入微服务或FaaS之前清理,Join,过滤和聚合事件流来执行数据库在传统方法中所执行的数据操作。
例如,考虑使用像KSQL这样的流处理器将订单和付款连接在一起的限制检查服务,提取相关的记录/字段并将它们传递到微服务或作为检查限制的服务的功能 - 没有数据库的工作流程完全使用。
由于它们的事件驱动性质,这样的系统响应更快。它们通常也更简单,构建速度更快,因为维护的基础架构和数据更少,工具集自然可以处理异步连接的环境。
更丰富的示例直接包含流分析,例如检测信用卡支付中的异常行为或优化智能电网中的能量输送。这样的系统通常作为链存在,其中阶段分离有状态和无状态操作,可以独立地扩展并利用事务保证来保证正确性。
我们看到这种类型的应用程序出现在许多行业中:金融,游戏,零售,物联网等,跨越离线和在线用例。
4.自动数据分配
最终模式是其他模式的结晶,与PaaS /无服务器实现相结合,使数据配置完全自助服务。
用户定义他们需要的数据(实时或历史),应采取的形式以及应该在何处落地,无论是在数据库,分布式缓存,微服务,FaaS还是在任何地方。 (通常,这与可发现的模式的中央存储库结合使用。)
系统配置基础架构,在必要时预先填充它并管理事件流。流处理器过滤,操作和缓冲各种共享数据流,并根据用户的规范进行模拟。
因此,进行风险分析的财务用户可能会启动一个新的Elasticsearch实例,该实例预先填充了三个月的交易,风险结果和账簿。或者,零售公司可能会关联实时订单,付款和客户数据,并将其推送到微服务或FaaS,向客户发送付款确认。
随着组织转向公共云和私有云,基于云的基础架构的动态特性使这种模式越来越实用,从而带来系统性好处。可以快速启动新项目,环境或实验。
由于数据集被缓存或存储在消息传递系统中,因此鼓励用户仅在某个时间点获取他们需要的数据(与传统消息传递不同,传统消息传递倾向于消耗和保留整个数据集以防以后再次需要)。这可以最大限度地减少团队之间的摩擦,并使应用程序接近单一,共享的真实来源。
我们所知道的组织很少能够完全达到这种自动化水平,但这种模式的核心要素被用于金融,零售和互联网领域的几个客户的生产中,无论是在内部还是在云中。
事件驱动2.0:一个进化和一个新的开始
多年来,事件驱动的架构自然发展。最初,他们只进行了消息传递:通过传统消息系统应用的通知和状态转移。
后来,企业服务总线通过更丰富的开箱即用连接和更好的集中控制来点缀它们。集中控制变成了喜忧参半,因为它提供的标准化经常使团队进步更加困难。
最近,像事件溯源(Event Sourcing)和CQRS这样的存储模式已经变得很流行,正如Martin Fowler在他的文章中所讨论的“事件驱动”是什么意思?
我所描述的四种模式都建立在这个基础上,但今天的现代事件流系统使我们能够通过将事件,存储和处理统一到一个平台中来进一步发展。这种统一很重要,因为这些系统不是将数据锁定在一个地方的数据库;它们不是消息传递系统,数据是短暂的和短暂的。他们坐在两者之间。
通过在这两个传统类别之间取得平衡,公司已经能够跨地区和跨云实现全球连接,数据 - 他们最宝贵的商品 - 作为服务提供,无论是否意味着将其推入数据库,缓存,机器学习模型,微服务或无服务器功能。
所以,总结一下:
- 广播事件
- 缓存日志中的共享数据集并使其可被发现。
- 让用户直接操纵事件流(例如,使用像KSQL这样的流媒体引擎)
- 驱动简单的微服务或FaaS,或在您选择的数据库中创建特定于用例的视图
- 253 次浏览
【事件驱动架构】Apache Kafka云平衡协议:静态成员
静态会员是对当前再平衡协议的一种增强,旨在减少由一般Apache Kafka®客户实现的过度和不必要的再平衡造成的停机时间。这适用于Kafka消费者、Kafka Connect和Kafka流。为了更好地理解再平衡协议,我们将深入研究这个概念并解释它的含义。如果你已经知道卡夫卡平衡是什么,请直接跳到下面的章节来节省时间:我们什么时候触发不必要的平衡?
对于Kafka来说,“再平衡”意味着什么?
Kafka再平衡是一种分布式协议,用于客户端应用程序在一个动态组中处理一组公共资源。本议定书的两个主要目标是:
- 组织资源分配
- 会员更改捕获
以卡夫卡消费者为例。一组Kafka使用者通过订阅从Kafka读取输入数据,主题分区是他们的共享任务单元。三个消费者(C1、C2和C3)、两个主题(T1和T2),每个主题有三个分区,订阅如下所示:
C1: T1, T2 C2: T2 C3: T1
重新平衡协议确保C1和C2从主题T2*获得不重叠的分配,对于T1的C1和C3也是如此。一个有效的赋值是这样的:
C1: t1-p1, t2-p1 C2: t2-p2, t2-p3 C3: t1-p2, t1-p3
*注意,消费者不会检查转让人返回的赋值是否遵守这些规则。如果您的自定义的assignor将分区分配给多个所有者,它仍然会被静默地接受并导致双重抓取。严格地说,只有内置的再平衡分配程序才遵守此资源隔离规则
但是,下面的分配是不允许的,因为它引入了重叠分配:
C1: t1-p1, t2-p1 C2: t2-p1, t2-p2, t2-p3 C3: t1-p2, t1-p3
再平衡协议还需要妥善处理成员国变化。对于上述情况,如果新成员C4订阅T2加入,再平衡协议将尝试调整组内负载:
C1: t1-p1, t2-p1 C2: t2-p3 C3: t1-p2, t1-p3 C4: t2-p2
总之,再平衡协议需要在扩展时“平衡”客户机组中的负载,同时保证任务所有权的安全。与大多数分布式共识算法相似,Kafka采用了两阶段的方法。为了简单起见,我们将坚持使用卡夫卡消费者。
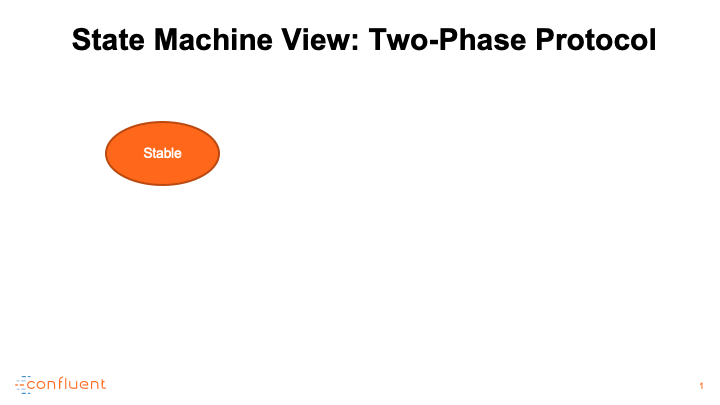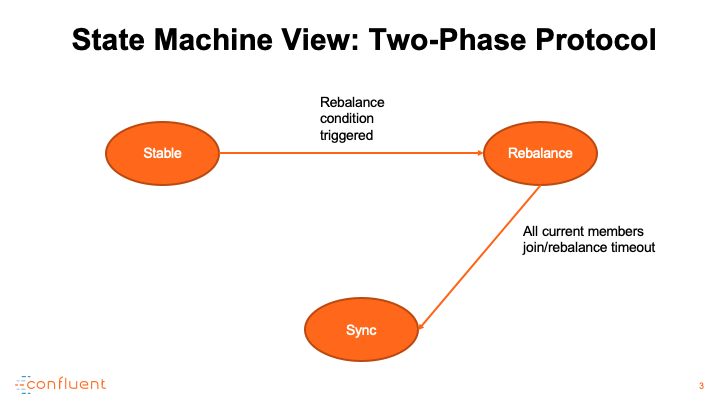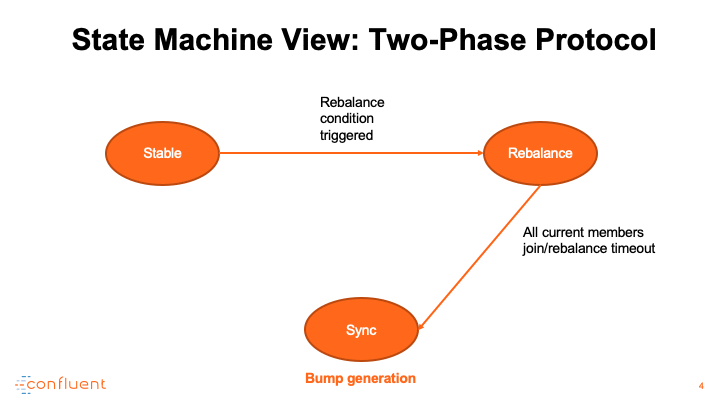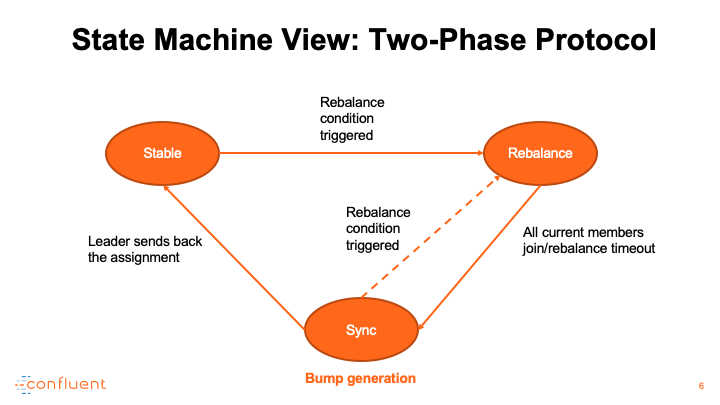
消费者调整演示
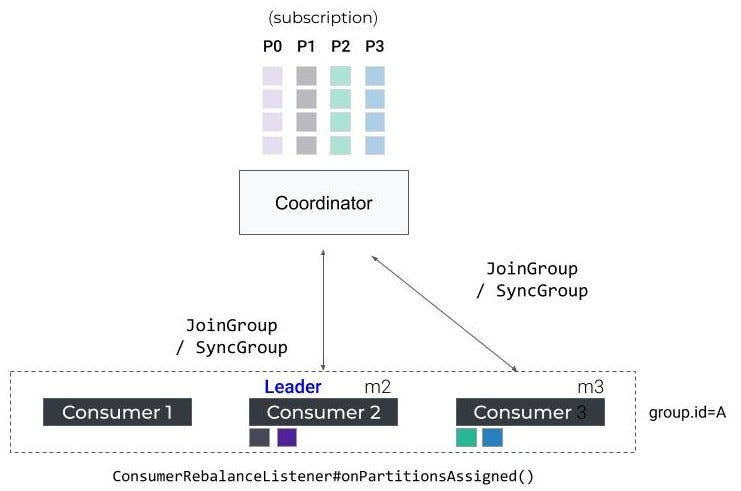
使用者提交进度的端点称为组协调器,它托管在指定的代理上。它还作为集团再平衡的中央管理者。当组开始再平衡时,组协调器首先将其状态切换为再平衡,以便通知所有交互的使用者重新加入组。在所有成员重新加入或协调器等待足够长的时间并达到再平衡超时之前,组继续进入另一个称为sync的阶段,该阶段正式宣布有效使用者组的形成。为了区分在此过程中退出组的成员,每个成功的再平衡都会增加一个名为generation ID的计数器,并将其值传播给所有加入的成员,以便可以隔离下一代成员。
在同步阶段,组协调器用最新的生成信息答复所有成员。具体地说,它指定其中一个成员作为leader,并用已编码的成员资格和订阅元数据对leader进行应答。
领导根据成员和主题元数据信息完成任务,并将任务信息回复协调员。在此期间,所有追随者都需要发送一个同步组请求,以获得他们的实际任务,并进入一个等待池,直到leader完成对协调器的任务传输。在接收到分配后,协调器将组从同步转换到稳定。所有未决的和即将到来的追随者同步请求将回答与个人分配。
这里,我们描述两个演示用例:一个是实际的再平衡演练,另一个是高级状态机。注意,在同步阶段,如果触发了再平衡条件,比如添加新成员、主题分区扩展等,我们总是可以切换到再平衡模式。

再平衡协议在实时平衡任务处理负载和允许用户自由伸缩应用程序方面非常有效,但它也是一个相当重的操作,需要整个消费组暂时停止工作。成员被期望撤销正在进行的任务,并在每次重新平衡开始和结束时初始化新的任务。这样的操作会带来开销,特别是对于有状态的操作,其中任务需要在提供服务之前首先从其备份主题恢复本地状态。
从本质上讲,当满足以下条件时,再平衡就开始了:
- 组成员变更,例如新成员加入
- 成员订阅更改,例如一个使用者更改订阅的主题
- 资源更改,例如向订阅主题添加更多分区
我们什么时候触发不必要的再平衡?
在现实世界中,有许多场景中,组协调器会触发不必要的重新平衡,这对应用程序性能有害。第一种情况是临时成员超时。要理解这一点,我们需要首先介绍两个概念:使用者心跳和会话超时。
消费者心跳和会话超时
Kafka使用者维护一个后台线程,定期向协调器发送心跳请求,以表明它的活性。使用者配置称为session.timeout。ms定义了协调器在成员最后一次心跳之后等待多长时间,然后才假定该成员失败。当此值设置得过低时,网络抖动或长时间垃圾收集(GC)可能会导致活性检查失败,从而导致组协调器删除此成员并开始重新平衡。解决方案很简单:与其使用缺省的10秒会话超时,不如将其设置为更大的值,以极大地减少由故障引起的暂态重平衡。
注意,会话超时设置的时间越长,用户实际失败时部分不可用的时间就越长。我们将在后面关于如何选择静态成员关系的部分中解释如何选择此值。
滚动反弹过程
有时,我们需要重新启动应用程序、部署新代码或执行回滚等。在最坏的情况下,这些操作可能导致大量的重新平衡。当一个使用者实例关闭时,它向组协调器发送一个请假组请求,让它自己从组中删除,然后触发另一次再平衡。当这个消费者在一次反弹后恢复时,它会向组协调器发送一个加入组请求,从而触发另一次再平衡。
在滚动弹跳过程中,连续的重新平衡被触发,实例被关闭和恢复,分区被来回重新分配。最终的赋值结果是完全随机的,并且会为任务变换和重新初始化付出很大代价。
让成员选择不离开小组怎么样?也不是一个选择。要理解其中的原因,我们需要先讨论一下成员ID。
消费者会员ID
当新成员加入组时,请求不包含成员信息。组协调器将为该成员分配一个统一惟一标识符(UUID),作为其成员ID,将该ID放入缓存中,并将该信息嵌入到对该成员的响应中。在这个使用者的生命周期内,它可以重用相同的成员ID,而不需要协调器在重新加入时触发再平衡,除非在诸如leader重新加入这样的边缘情况下。
回到滚动反弹的情况下,重新启动成员将删除内存中的会员信息和加入该组织成员ID或生成ID。自从加入消费者会被认为是一个全新的组的成员,该组织协调并不能保证其旧任务分配方案。如您所见,成员离开组并不是造成不必要任务变换的根本原因—丢失身份才是。
什么是静态会员?
与动态成员关系不同,静态成员关系旨在跨组的多个代保持成员身份。这里的目标是重用相同的订阅信息,并使协调器“可识别”旧成员。静态成员关系引入了一个名为group.instance的新的使用者配置。id,由用户配置,以惟一地标识其使用者实例。尽管在重启过程中丢失了协调器分配的成员ID,但是协调器仍然将根据join请求中提供的组实例ID识别该成员。因此,保证了相同的赋值。
静态成员关系对于云应用程序的设置非常友好,因为现在Kubernetes等部署技术对于管理应用程序的运行状况非常自包含。为了修复死去的或性能不佳的用户,Kubernetes可以很容易地关闭相关实例,然后使用相同的实例ID启动一个新的实例。
下面是静态成员关系如何工作的快速演示。

如何选择成为静态会员
自从Apache Kafka 2.3发布以来,静态成员已经成为社区的普遍可用性。如果你想成为一个阿尔法用户,这里有说明:
- 将您的代理升级到2.3或更高。具体来说,您需要升级inter.broker.protocol。版本升级到2.3或更高,以启用此特性。
- 在客户端:
- 将客户端库升级到2.3或更高版本。
- 定义较长且合理的会话超时。如前所述,紧张的会话超时值可能会使组不稳定,因为成员会由于缺少单个心跳而被逐出组。您应该根据部分不可用的业务容忍度将会话超时设置为合理的值。例如,对于能够容忍15分钟不可用的业务,将会话超时设置为10分钟是合理的,而将其设置为5秒则不合理。
- 设置group.instance。id配置为用户的惟一id。如果你是Kafka流的用户,对你的流实例使用相同的配置。
- 将新代码部署到应用程序中。静态会员将在您的下一次滚动反弹中生效。
静态成员只有在遵循这些指令的情况下才能正常工作。尽管如此,我们还是采取了一些预防措施,以减少人为失误的潜在风险。
错误处理
有时用户可能会忘记升级代理。当使用者首次启动时,它获得指定代理的API版本。如果客户端配置了组实例ID,并且代理是旧版本的,那么应用程序将立即崩溃,因为代理还不支持静态成员关系。
如果用户未能惟一地配置组实例ID,这意味着有两个或多个成员使用相同的实例ID配置,则需要使用隔离逻辑。当一个已知的静态成员没有一个成员ID,协调器生成一个新的UUID回复这个成员作为其新成员ID。与此同时,该组织协调维护映射实例ID的最新成员分配ID。如果一个已知的静态成员和一个有效的成员ID不匹配的缓存ID,它会立即被协调坚固的回应。这消除了重复静态成员并发处理的风险。
在第一个版本中,我们预计会出现一些错误,这些错误可能会使处理语义失效或阻碍防护逻辑。其中一些问题已经在主干中得到了解决,比如KAFKA-8715,我们仍在积极寻找更多问题。
原文:https://www.confluent.io/blog/kafka-rebalance-protocol-static-membership/
本文:http://jiagoushi.pro/node/1116
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 112 次浏览
【事件驱动架构】Apache Kafka再平衡协议:再平衡协议101
自从Apache Kafka 2.3.0以来,Kafka Connect和消费者特别使用的内部再平衡协议经历了几次重大变化。
再平衡协议不是一件简单的事情,有时看起来像魔术。在这篇文章中,我建议回到这个协议的基础,也就是Apache Kafka消费机制的核心。然后,我们将讨论其局限性和目前的改进。
Kafka和再平衡协议101
让我们回到一些基本的东西
Apache Kafka是一个基于分布式发布/订阅模式的流媒体平台。首先,称为生产者的流程将消息发送到主题中,主题由代理集群管理和存储。然后,称为消费者的流程订阅这些主题,以获取和处理发布的消息。
主题分布在许多代理中,以便每个代理管理每个主题的消息子集——这些子集称为分区。分区的数量是在创建主题时定义的,可以随着时间的推移而增加(但是要小心操作)。
要理解的重要一点是,对于Kafka的生产者和消费者来说,分区实际上是并行的单位。
在生成器端,分区允许并行地写入消息。如果使用密钥发布消息,那么在默认情况下,生成器将散列给定的密钥以确定目标分区。这保证了具有相同密钥的所有消息都将被发送到相同的分区。此外,使用者将保证按照该分区的顺序获得消息传递。
在使用者方面,主题的分区数量限制了使用者组中活动使用者的最大数量。使用者组是Kafka提供的一种机制,用于将多个使用者客户机分组为一个逻辑组,以便负载平衡分区的使用。Kafka保证一个主题分区只分配给组中的一个使用者。
例如,下图描述了一个名为a的消费者组,其中有三个消费者。用户已经订阅了主题A,分区分配为:P0到C1、P1到C2、P2到C3和P1。
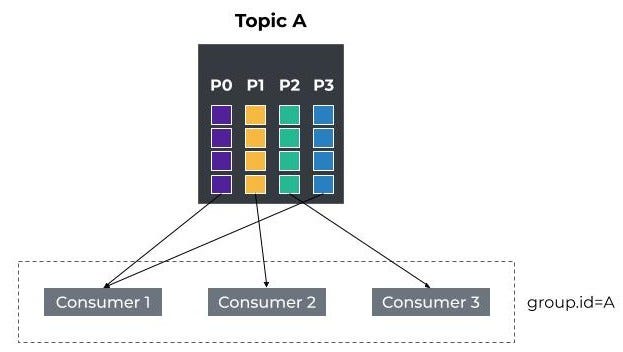
Apache Kafka -消费者组
如果一个使用者在有控制的关闭或崩溃后离开组,那么它的所有分区将在其他使用者之间自动重新分配。同样,如果一个使用者(重新)加入一个现有组,那么所有分区也将在组成员之间重新平衡。
消费者和客户在一个动态群体中合作的能力是通过使用所谓的Kafka再平衡协议而实现的。
让我们深入研究这个协议,了解它是如何工作的。
再平衡协议简述
首先,让我们给出一个术语“再平衡”在Apache Kafka上下文中含义的定义。
再平衡/再平衡:一系列使用Kafka客户端和/或Kafka协调器的分布式进程组成一个公共组,并在组的成员之间分配一组资源的过程(来源:增量合作再平衡:支持和政策)。
上面的定义实际上没有引用消费者或分区的概念。相反,它使用成员和资源的概念。造成这种情况的主要原因是,rebalance协议不仅限于管理使用者,还可以用于协调任何一组流程。
以下是一些协议再平衡的用法:
- Confluent模式注册表依赖重新平衡来选择leader节点。
- Kafka Connect使用它在工人(workers)之间分配任务和连接器。
- Kafka Streams使用它为应用程序流实例分配任务和分区。
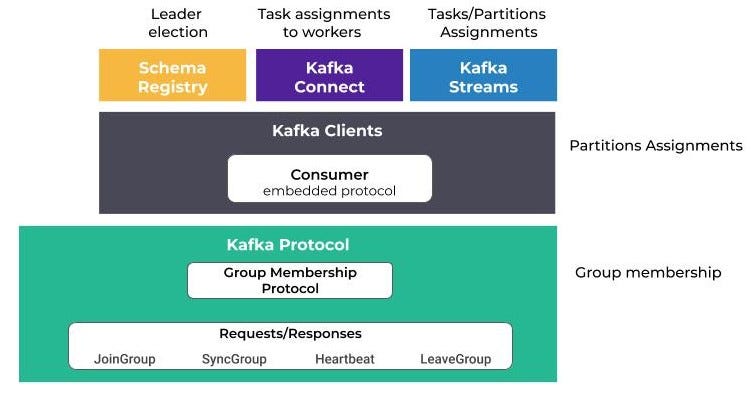
Apache Kafka重新平衡协议和组件
另外,真正需要理解的是,再平衡机制实际上是围绕两种协议构建的:组成员协议和嵌入客户端协议。
组成员协议,顾名思义,负责组成员之间的协调。参与组的客户机将使用充当协调器的Kafka代理执行一系列请求/响应。
第二个协议在客户端执行,允许通过嵌入第一个协议来扩展第一个协议。例如,使用者使用的协议将把主题分区分配给成员。
现在我们对什么是再平衡协议有了更好的理解,让我们来演示它在消费者组中分配分区的实现。
JoinGroup
当使用者启动时,它发送第一个FindCoordinator请求,以获得负责其组的Kafka代理协调器。然后,它通过发送一个JoinGroup请求来启动再平衡协议。
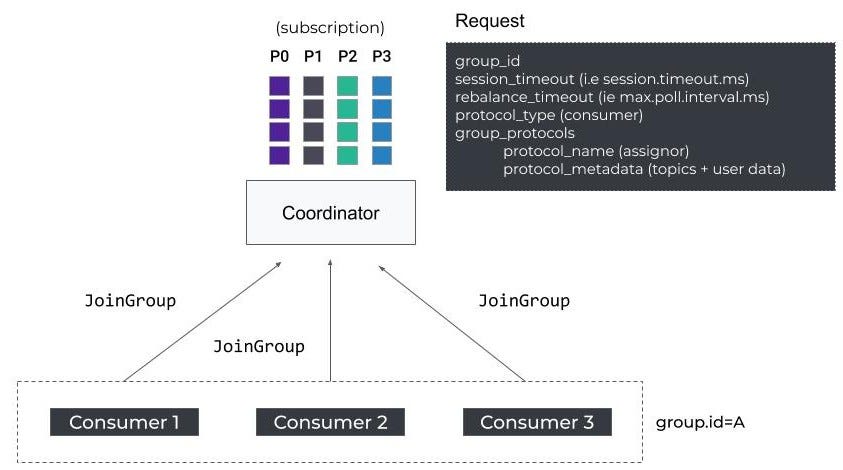
用户-再平衡协议-同步组请求
可以看到,JoinGroup包含一些客户端配置,比如session.timeout。和最大值。max.poll.interval.ms。如果成员不响应,协调器将使用这些属性将其踢出组。
此外,该请求还包含两个非常重要的字段:成员支持的客户端协议列表,以及用于执行嵌入式客户端协议之一的元数据。在我们的示例中,客户机协议是为使用者(i)配置的分区分配程序列表。i.e : partition.assignment.strategy)。元数据包含使用者订阅的主题列表。
请注意,如果您不知道这些属性是干什么用的,我建议您阅读官方文档。
JoinGroup充当屏障,意味着只要没有接收到所有消费者请求,协调器就不会发送响应(i.e group.initial.rebalance.delay.ms)或达到重新平衡超时。
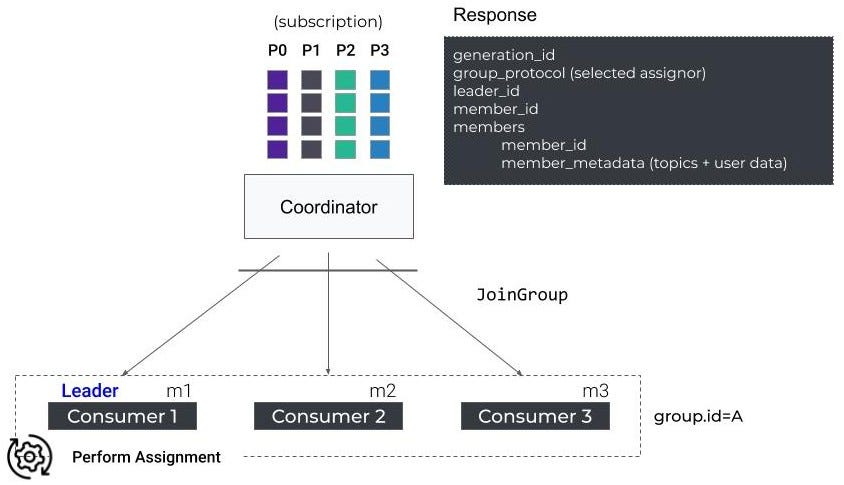
用户-再平衡协议-同步组请求
组中的第一个使用者接收活动成员列表和所选的分配策略,并充当组长,而其他使用者接收空响应。组长负责在本地执行分区分配。
SyncGroup
接下来,所有成员向协调器发送一个SyncGroup请求。组长附加了计算后的分配,而其他人只是响应一个空请求。
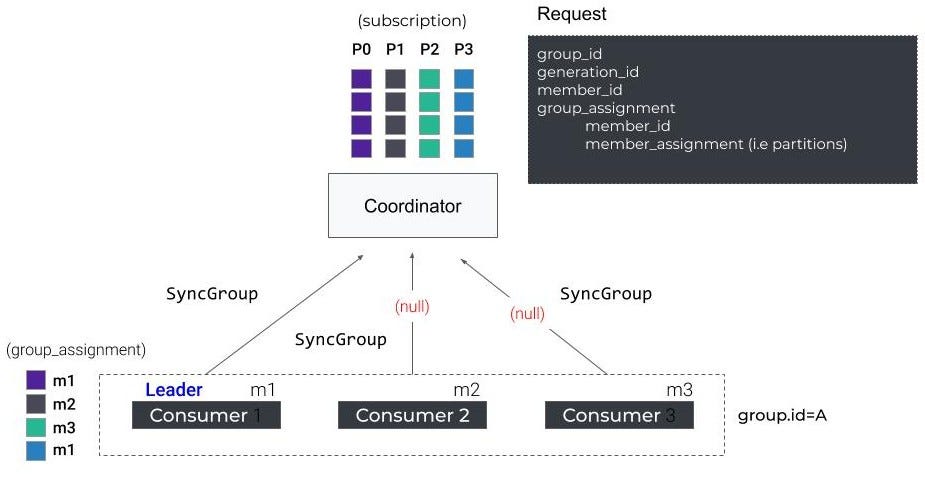
一旦协调器响应allsyncgrouprequest,每个使用者就会接收到他们分配的分区,调用配置的侦听器上的theonPartitionsAssignedMethod,然后开始获取消息。
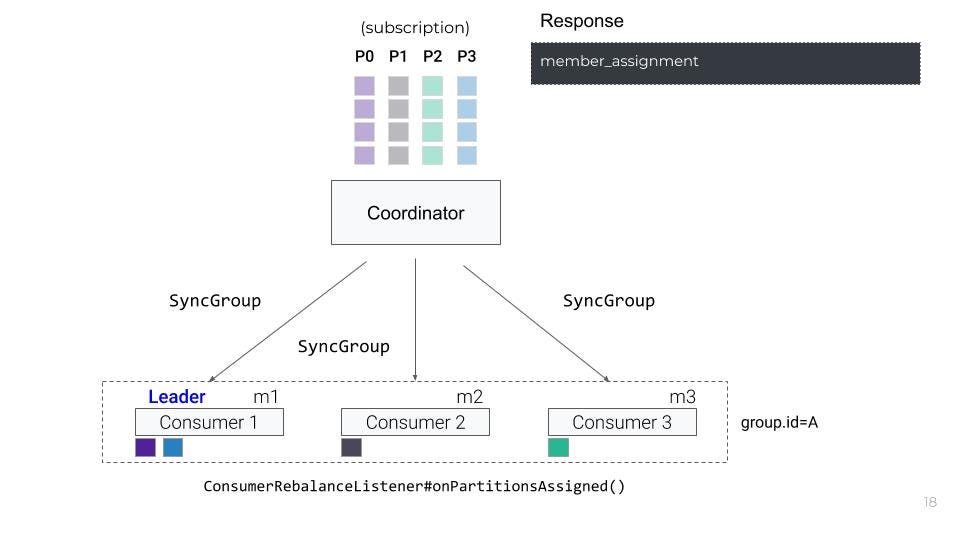
消费者-再平衡协议-同步集团反应
心跳
最后但并非最不重要的是,每个使用者定期向代理协调器发送一个Heatbeat请求,以使其会话保持活动状态(参见:heartbeat.interval.ms)。
如果再平衡正在进行,协调者使用Heatbeat响应来指示消费者,他们需要重新加入该组织。
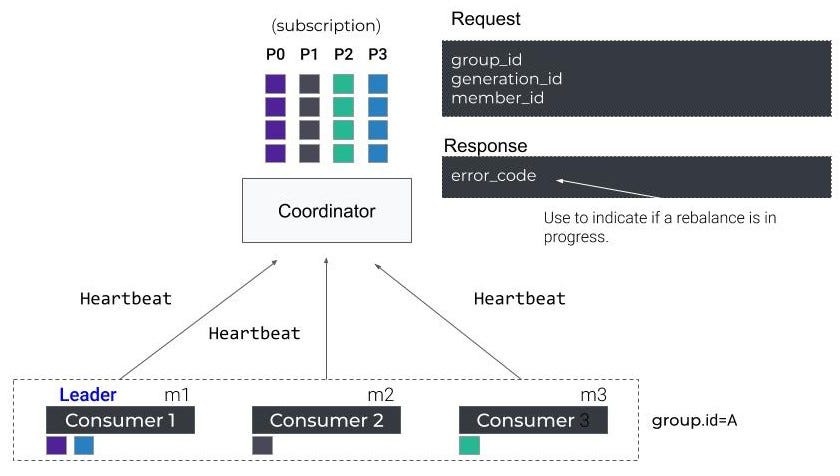
消费者-再平衡协议-心跳
到目前为止一切都很好,但是正如您应该知道的那样,在实际情况中,尤其是在分布式系统中,会发生故障。硬件可以失败。网络或用户可能会出现瞬态故障。不幸的是,对于所有这些情况,再平衡也可能被触发。
一些警告
再平衡协议的第一个限制是,我们不能简单地再平衡一个成员而不停止整个集团(停止世界效应)。
例如,让我们正确地停止一个实例。在第一个重新平衡场景中,使用者将在停止之前向协调器发送一个LeaveGroup请求。
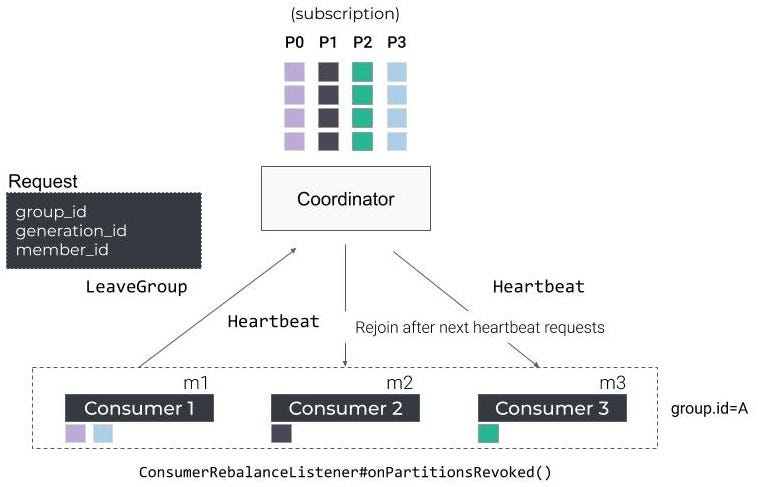
消费者-再平衡协议-离开集团
剩余的使用者将被通知必须在下一个心跳上执行再平衡,并将启动一个新的JoinGroup/SyncGroup往返,以便重新分配分区。
消费者-再平衡协议-重新加入
在整个重新平衡过程中,即只要没有重新分配分区,消费者就不再处理任何数据。默认情况下,重新平衡超时固定为5分钟,这可能是一段很长的时间,在此期间不断增加的用户延迟可能会成为一个问题。
但是,如果使用者只是在短暂故障后重新启动,会发生什么呢?嗯,消费者在重新加入这个群体的同时,将触发一种新的再平衡,导致所有消费者(再一次)停止消费。
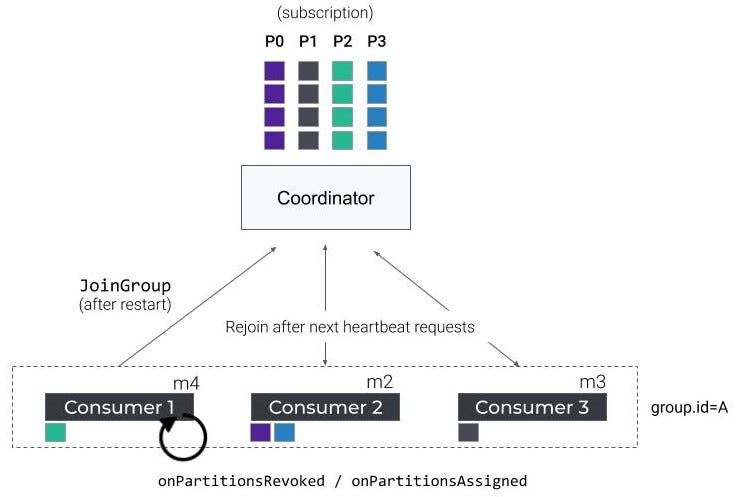
消费者-再平衡协议-重启
另一个可能导致消费者重启的原因是集团的滚动升级。不幸的是,这种情况对消费组来说是灾难性的。实际上,对于一组三个使用者,这样的操作将触发6个重新平衡,这可能对消息处理产生重大影响。
最后,在Java中运行Kafka使用者时的一个常见问题是,由于网络中断或长时间GC暂停而丢失一个心跳请求,或者由于处理时间过长而没有定期调用KafkaConsumer#poll()方法。在第一种情况下,协调器不会接收到超过session.timeout的心跳。认为消费者已经死了。在第二个示例中,处理轮询记录所需的时间优于max.poll.inteval.ms。
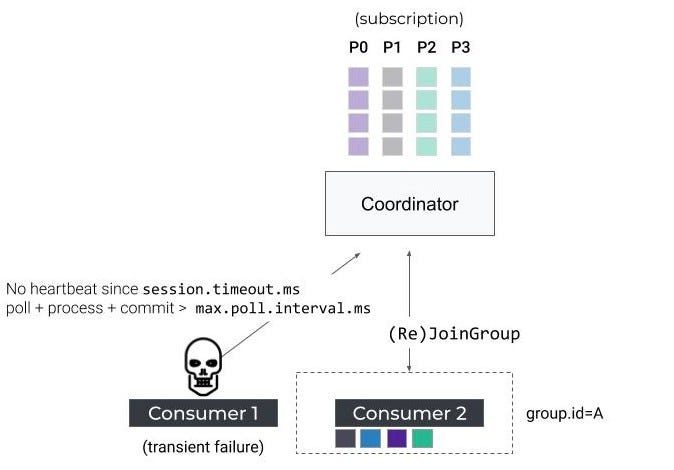
消费者-再平衡协议-超时
本文:http://jiagoushi.pro/node/1113
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 112 次浏览
【事件驱动架构】EMQX MQTT 和 Kafka 对比
视频号

微信公众号

知识星球


MQTT与Kafka完全不同。MQTT是由OASIS技术委员会的成员(大多数是IBM和Microsoft的高级工程师)开发的协议和技术标准。Kafka是LinkedIn首次实现的开源流平台。2011年开放源码后被Apache孵化器孵化,成为Apache软件基金会的顶级项目。
两者之间唯一的联系是它们都与发布/订阅模式相关。MQTT是基于发布/订阅模式的消息传递协议,而ApacheKafka的生产和消费过程也是发布/订阅模式的一部分。如果我们实现基于MQTT协议的消息代理,从发布/订阅模式的角度来看,这个MQTT代理是否等同于Kafka?答案仍然是否定的。
虽然Kafka也是一个基于发布/订阅模式的消息传递系统,但它也被称为“分布式提交日志”或“分布式流平台”。它的主要功能是实现分布式持久数据保存。Kafka的数据单元可以理解为数据库中的一行“数据”或一条“记录”。Kafka按主题分类。当Kafka的制作者发布特定主题的消息时,消费者就消费该特定主题的消息。事实上,生产者和消费者可以理解为发布者和订阅者,主题就像数据库中的一个表。每个主题包含多个分区,分区可以分布在不同的服务器上。也就是说,通过这种方式存储和读取分布式数据。Kafka的分布式体系结构有助于读写系统的扩展和维护(例如,通过备份服务器实现冗余备份,通过构建多个服务器节点实现性能改进)。在许多有大数据分析需求的大型企业中,Kafka将被用作数据流处理平台。
MQTT最初是为物联网设备的网络访问而设计的。大多数物联网设备都是低性能、低功耗的计算机设备,网络连接质量不可靠。因此,在设计协议时需要考虑以下几个关键点:
- 该协议应该足够轻量级,以允许嵌入式设备快速解析和响应。
- 足够灵活,以支持物联网设备和服务的多样化。
- 它应该被设计成异步消息协议而不是异步协议。这是因为大多数物联网设备的网络延迟很可能非常不稳定。如果使用同步消息协议,IoT设备需要等待来自服务器的响应。为大量物联网设备提供服务显然是非常不现实的。
- 必须是双向通信,并且服务器和客户端应该能够互相发送消息。
MQTT协议完美地满足了上述要求,最新版本的MQTT v5.0协议已经过优化,使其比之前的v3.1.1版本更灵活,占用的带宽更少。
对于基于mqtt的消息代理和Kafka的区别,EMQ先生认为这是因为他们的关注点不同。Kafka专注于数据的存储和读取,针对高实时性能的流式数据处理场景,而MQTT Broker则侧重于客户端和服务器之间的通信。
MQTT broker和Kafka采用的消息交换模式非常相似,因此将它们结合起来显然是个好主意。事实上,一些MQTT代理,例如EMQ X MQTT broker, 已经实现了MQTT-broker和Kafka之间的桥接。MQTT-broker用于快速接收和处理来自大量物联网设备的消息,Kafka收集并存储这些大量数据并将其发送给数据分析员来分析和处理消息。
本文:https://jiagoushi.pro/node/1098
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 1556 次浏览
【事件驱动架构】Kafka vs. RabbitMQ:架构、性能和用例
如果你正在考虑是否卡夫卡RabbitMQ最适合你的用例,请继续阅读,了解这些工具背后的不同的架构和方法,如何处理信息不同,和他们的性能优缺点。我们将讨论的最佳用例的每个工具,当它可能比依赖于一个完整的端到端流处理的解决方案。
在这个页面:
- 什么是Apache Kafka和RabbitMQ?
- Kafkavs RabbitMQ -有什么区别?
- 他们如何处理信息
- 他们的表现如何
- 他们最好的用例
- 流处理的端到端平台
什么是Apache Kafka和RabbitMQ?
Apache Kafka和RabbitMQ是两个开源的、有商业支持的发布/订阅系统,很容易被企业采用。RabbitMQ是2007年发布的一个较老的工具,是消息传递和SOA系统中的主要组件。今天,它还被用于流用例。Kafka是一个较新的工具,发布于2011年,它从一开始就是为流媒体场景设计的。
RabbitMQ是一种通用消息代理,支持协议包括MQTT、AMQP和STOMP。它可以处理高吞吐量用例,比如在线支付处理。它可以处理后台作业或充当微服务之间的消息代理。
Kafka是为高接入数据重放和流开发的消息总线。Kafka是一个持久的消息代理,它使应用程序能够处理、持久化和重新处理流数据。Kafka有一个直接的路由方法,它使用一个路由密钥将消息发送到一个主题。
Kafka vs RabbitMQ -架构上的差异
RabbitMQ架构
- 通用消息代理—使用请求/应答、点到点和发布-子通信模式的变体。
- 智能代理/哑消费者模型——以与代理监视消费者状态相同的速度向消费者交付消息。
- 成熟的平台——良好的支持,可用于Java、客户机库、。net、Ruby、node.js。提供几十个插件。
- 通信——可以是同步的或异步的。
- 部署场景——提供分布式部署场景。
- 多节点集群到集群联合——不依赖于外部服务,但是,特定的集群形成插件可以使用DNS、api、领事等。
Apache Kafka架构
- 高容量的发布-订阅消息和流平台——持久、快速和可伸缩。
- 持久消息存储——类似于日志,运行在服务器集群中,它在主题(类别)中保存记录流。
- 消息——由值、键和时间戳组成。
- 愚蠢的代理/聪明的消费者模型——不试图跟踪哪些消息被消费者读了,只保留未读的消息。卡夫卡在一段时间内保存所有消息。
- 需要外部服务运行在某些情况下Apache Zookeeper。
拉vs推
Apache Kafka:基于拉的方法
Kafka使用了拉模型。使用者请求来自特定偏移量的成批消息。Kafka允许 long-pooling, ,这可以防止在没有消息超过偏移量时出现紧循环。
由于它的分区,拉式模型对Kafka来说是合乎逻辑的。Kafka在没有竞争消费者的分区中提供消息顺序。这允许用户利用消息批处理来实现有效的消息传递和更高的吞吐量。
RabbitMQ:基于推的方法
RabbitMQ使用了一个推模型,并通过在使用者上定义的预取限制来阻止过多的使用者。这可以用于低延迟的消息传递。
推模型的目的是快速地独立地分发消息,确保工作均匀地并行化,并按照消息到达队列的大致顺序处理消息。
他们如何处理消息?
Kafka vs RabbitMQ性能
Apache Kafka:
Kafka提供了比RabbitMQ等消息代理更高的性能。它使用顺序磁盘I/O来提高性能,使其成为实现队列的合适选项。它可以在有限的资源下实现高吞吐量(每秒数百万条消息),这是大数据用例所必需的。
RabbitMQ:
RabbitMQ也可以每秒处理100万条消息,但是需要更多的资源(大约30个节点)。您可以使用RabbitMQ实现与Kafka相同的许多用例,但是您需要将它与其他工具(如Apache Cassandra)结合使用。
最好的用例是什么?
Apache Kafka用例
Apache Kafka提供了代理本身,并针对流处理场景设计。最近,它增加了Kafka Streams,一个用于构建应用程序和微服务的客户端库。Apache Kafka支持诸如度量、活动跟踪、日志聚合、流处理、提交日志和事件来源等用例。
下面的消息传递场景特别适合Kafka:
- 具有复杂路由的流,事件吞吐量为100K/sec或更多,“至少一次”分区排序
- 需要流历史记录的应用程序,以“至少一次”分区顺序交付。客户端可以看到事件流的“重播”。
- 事件溯源,将系统建模为事件序列。
- 在多级管道中进行数据流处理。管道生成实时数据流的图形。
RabbitMQ的用例
当web服务器需要快速响应请求时,可以使用RabbitMQ。这消除了在用户等待结果时执行资源密集型活动的需要。RabbitMQ还用于向不同的接收者传递消息,以供使用或在高负载(每秒20K+消息)下在工作人员之间共享负载。
场景,RabbitMQ可以用于:
- 需要支持遗留协议的应用程序,如STOMP、MQTT、AMQP、0-9-1。
- 对每条消息的一致性/保证集的粒度控制
- 到消费者的复杂路由
- 需要各种发布/订阅、点对点请求/应答消息传递功能的应用程序。
Kafka和RabbitMQ:总结
本指南涵盖了Apache Kafka和RabbitMQ之间的主要区别和相似之处。虽然它们的架构不同,但它们每秒都可以消耗数百万条消息,而且在某些环境中性能更好。RabbitMQ几乎在内存中控制它的消息,使用大集群(30多个节点)。相比之下,Kafka利用顺序磁盘I/O操作,因此需要较少的硬件。
原文:https://www.upsolver.com/blog/kafka-versus-rabbitmq-architecture-performance-use-case
本文:http://jiagoushi.pro/node/1124
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 207 次浏览
【事件驱动架构】Kafka中的模式注册表和模式演化

在这篇文章中,我们将通过Kafka模式注册表来研究Kafka中的模式演化和兼容性类型。通过对兼容性类型的良好理解,我们可以安全地随着时间的推移对模式进行更改,而不会无意中破坏生产者或消费者的利益。
数据集
在我们的“真实世界中的Hadoop开发者”课程中,有一章专门讨论Kafka。在这一章中,我们从Meetup.com直播RSVP数据到Kafka编写我们自己的产品质量,部署就绪,生产者和消费者与Spring Kafka集成。我们将使用来自Meetup.com的RSVP数据流来解释Kafka模式注册表的模式演化和兼容类型。
用例和项目设置
假设Meetup.com决定使用Kafka来分发RSVPs。在这种情况下,producer程序将由Meetup.com管理,如果我想使用Meetup.com生成的RSVPs,我必须连接到Kakfa集群并使用RSVPs。对于我来说,作为一个消费消息的消费者,我首先需要知道的是模式,即RSVP消息的结构。Kafka中消息的典型模式是这样的。
{
"namespace": "com.hirw.kafkaschemaregistry.producer",
"type": "record",
"name": "Rsvp",
"fields": [
{
"name": "rsvp_id",
"type": "long"
},
{
"name": "group_name",
"type": "string"
},
{
"name": "event_id",
"type": "string"
},
{
"name": "event_name",
"type": "string"
},
{
"name": "member_id",
"type": "int"
},
{
"name": "member_name",
"type": "string"
}
]
}
该模式列出了消息中的字段以及数据类型。您可以将模式想象为生产者和消费者之间的契约。当producer生成消息时,它将使用此模式来生成消息。因此,在本例中,每个RSVP消息将具有rsvp_id、group_name、event_id、event_name、member_id和member_name。
Producer是一个Spring Kafka项目,使用上述模式向Kafka编写Rsvp消息。因此,所有发送到Kafka主题的消息都将使用上述模式编写,并使用Avro序列化。我们假设producer代码是由meetup.com维护的。Consumer也是Spring Kafka项目,消费写给Kafka的消息。消费者还将使用上面的模式并使用Avro反序列化Rsvp消息。我们维护消费者项目。
问题
Meetup.com采用了这种分发回函的新方式——通过Kafka。生产者和消费者都同意这个模式,一切都很好。认为模式会永远这样是愚蠢的。假设meetup.com觉得提供member_id字段没有价值并删除了它。你认为会发生什么?这会影响到消费者吗?
member_id字段没有默认值,它被认为是必需的列,因此此更改将影响用户。当生产者删除一个必需的字段时,消费者将看到如下错误
导致:org.apache. kafaca .common. Error . serializationexception:反序列化id为63的Avro消息错误
引起的:org.apache.avro。AvroTypeException:发现com.hirw.kafkaschemaregistry.producer.Rsvp,
期待com.hirw.kafkaschemaregistry.producer.Rsvp,缺少必需字段member_id
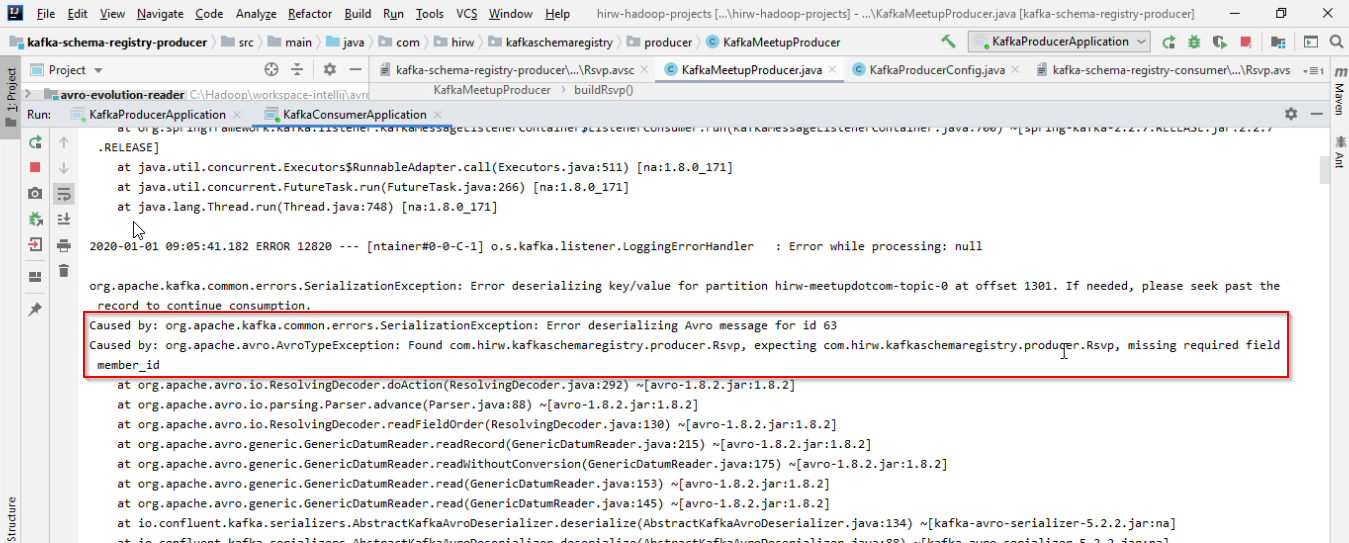
如果消费者付钱给消费者,他们会很生气,这将是一个代价非常高昂的错误。有办法避免这样的错误吗?幸运的是,有一些方法可以避免Kafka模式注册表和兼容性类型的错误。Kafka模式注册表为我们提供了检查我们对提议的新模式所做更改的方法,并确保我们对模式所做的更改与现有模式兼容。对于我们的模式,哪些更改是允许的,哪些更改是不允许的,这取决于在主题级别定义的兼容性类型。
在Kafka中有几种兼容性类型。现在让我们逐个研究一下。
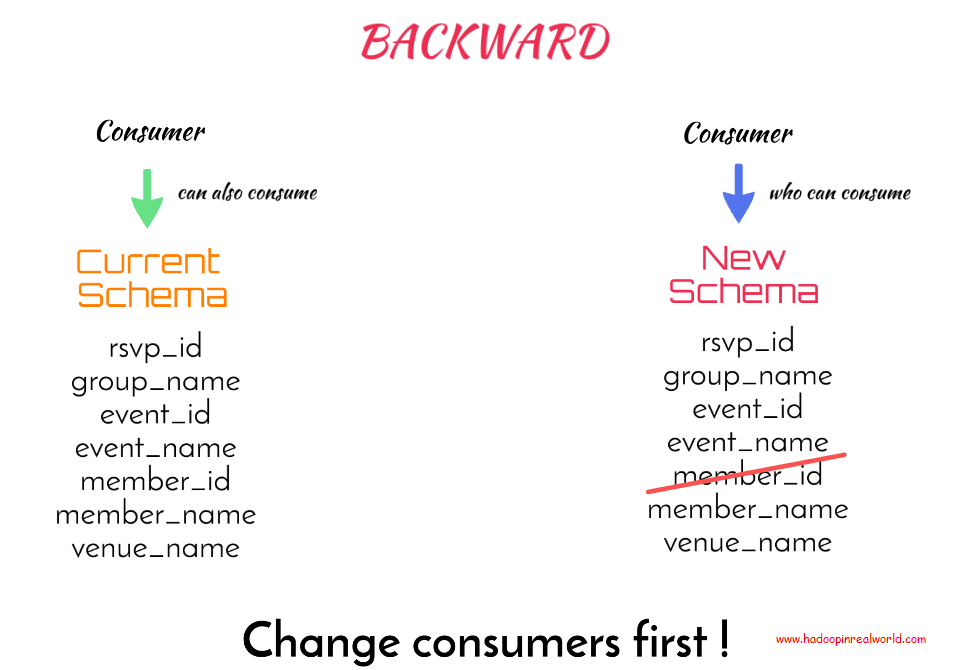
落后的(BACKWARD)
如果能够使用新模式生成的数据的使用者也能够使用当前模式生成的数据,则认为模式是向后兼容的。
如果没有显式指定兼容性类型,则向后兼容性类型是架构注册表的默认兼容性类型。现在让我们尝试理解当我们从新模式中删除member_id字段时发生了什么。新的模式向后兼容吗?
在新的模式中,我们删除了member_id。假设消费者已经在使用新模式生成的数据—我们需要询问他是否可以使用旧模式生成的数据。答案是肯定的。在新的模式中,member_id不存在,所以如果向消费者提供了member_id数据,也就是在当前模式中,他读取数据没有问题,因为额外的字段是可以的。所以我们可以说新模式是向后兼容的,Kafka模式注册表将允许这个新模式。
但不幸的是,正如我们在演示中看到的那样,这个变化将影响现有的客户。因此,在向后兼容模式中,使用者应该首先进行更改以适应新模式。这意味着,我们需要首先对消费者进行模式更改,然后才能对生产者进行更改。
如果您对使用者有控制权,或者使用者正在驱动对模式的更改,那么这是可以的。在某些情况下,消费者不会乐意为自己做出改变,尤其是如果他们是付费消费者的话。在这种情况下,向后兼容并不是最好的选择。
如果消费者受到更改的影响,为什么架构注册表首先允许更改?
兼容性类型并不保证所有的更改对所有人都是透明的。它为我们提供了一个指导原则,帮助我们理解对于给定的兼容性类型,哪些更改是允许的,哪些更改是不允许的。当允许对兼容类型进行更改时,通过对兼容类型的良好理解,我们将能够更好地了解谁将受到影响,从而能够采取适当的措施。
在我们的当前实例中,允许根据向后兼容类型在新模式中删除member_id。因为根据向后兼容性,能够使用带有新模式的out member_id的RSVP的使用者将能够使用带有member_id的旧模式的RSVP。因此,根据向后兼容性允许进行更改,但这并不意味着如果处理不当,更改不会造成破坏。
在向后兼容模式下,最好在更改模式之前先通知使用者。在我们的例子中,meetup.com应该通知消费者member_id将被删除,并让消费者先删除对member_id的引用,然后改变生产者来删除member_id。这是处理这种特定模式更改的最合适的方法。
在向后兼容模式下,我可以在新模式中添加一个没有默认值的字段吗?
这里,我们试图添加一个名为response的新字段,它实际上是用户的RSVP响应,并且没有默认值。在向后兼容类型中,这种模式更改是否可以接受?你觉得呢?
让我们来看看。通过向后兼容模式,能够使用新模式生成的数据的使用者也能够使用当前模式生成的数据。
因此,假设消费者已经在使用没有默认值的response数据,这意味着它是必需的字段。现在,他可以使用没有响应的当前模式生成的数据吗?答案是否定的,因为使用者希望在数据中得到响应,因为它是必需的字段。因此,建议的模式更改不是向后兼容的,而且模式注册表一开始就不允许这种更改。
这个错误非常清楚,说明“正在注册的模式与以前的模式不兼容”
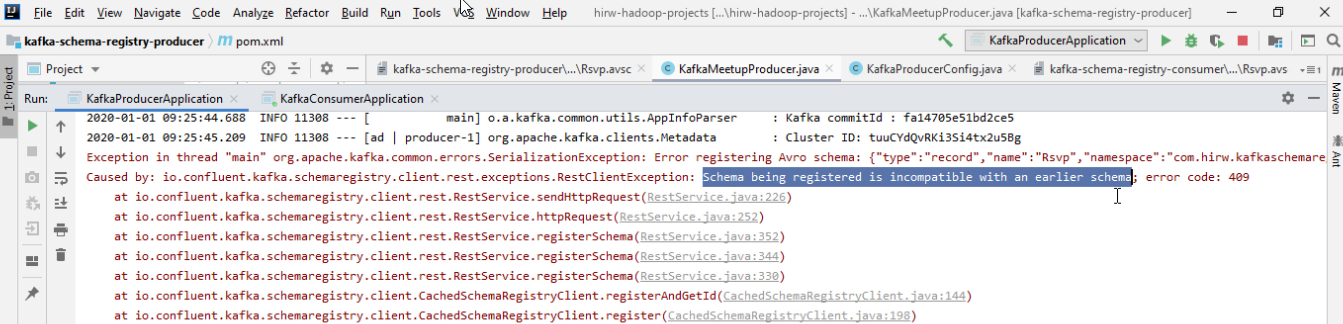
因此,如果模式与设置的兼容性类型不兼容,模式注册表将拒绝更改,这是为了防止意外更改。
如果我们用默认值更改字段响应会怎样?这种更改是否被认为是向后兼容的?
回答这个问题——“已经在使用响应默认值为“无响应”的数据的消费者是否可以使用当前模式生成的没有响应的数据?”
答案是肯定的,因为当缺少响应字段时,使用带有response的新模式生成的数据的消费者将替换默认值,这是使用当前模式生成数据时的情况。
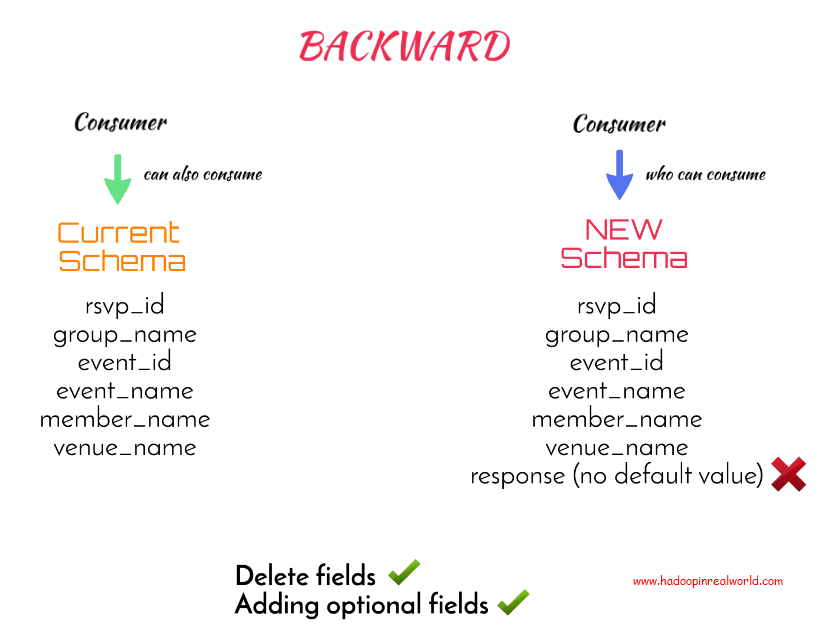
为了总结,向后兼容性允许删除和添加具有默认值的字段到模式中。与使用默认值添加字段不同,删除字段将影响用户,因此最好首先使用向后兼容类型更新用户。
BACKWARD_TRANSITIVE
向后兼容性类型检查新版本和当前版本,如果需要对所有注册版本进行此检查,则需要使用向后兼容性类型。

向前(FORWARD)
好的,到目前为止,我们已经看到了向后和向后传递兼容性类型。
但是,如果我们不希望模式改变影响当前的消费者呢?也就是说,我们希望避免在从模式中删除member_id时发生的情况。当我们删除member_id时,它突然影响了我们的消费者。如果消费者是付费客户,他们会很生气,这会对你的声誉造成打击。那么,我们如何避免这种情况呢?
我们可以使用向前兼容类型,而不是向后使用默认兼容类型。如果使用当前模式生成的数据的消费者也能够使用新模式生成的数据,则认为模式是转发兼容的。
使用此规则,我们将不能删除新模式中没有默认值的列,因为这会影响使用当前模式的消费者。所以添加字段是可以的,删除可选字段也可以。
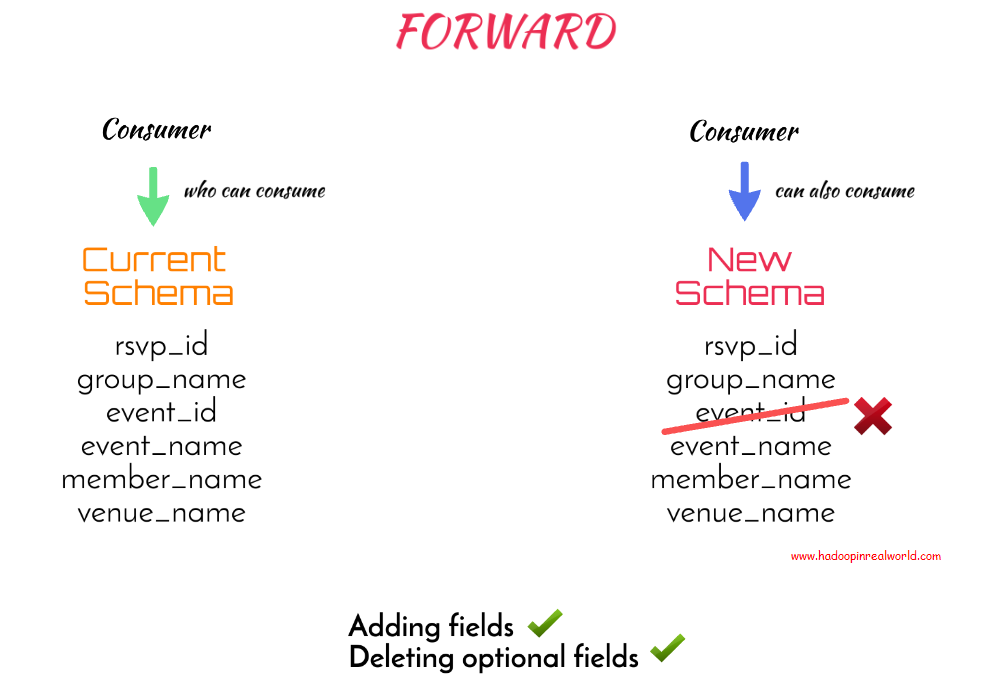
如何改变一个主题的兼容性类型?
在指定主题名称的配置上发出PUT请求,并在请求的主体中将兼容性指定为FORWARD。就是这样。让我们发出请求。
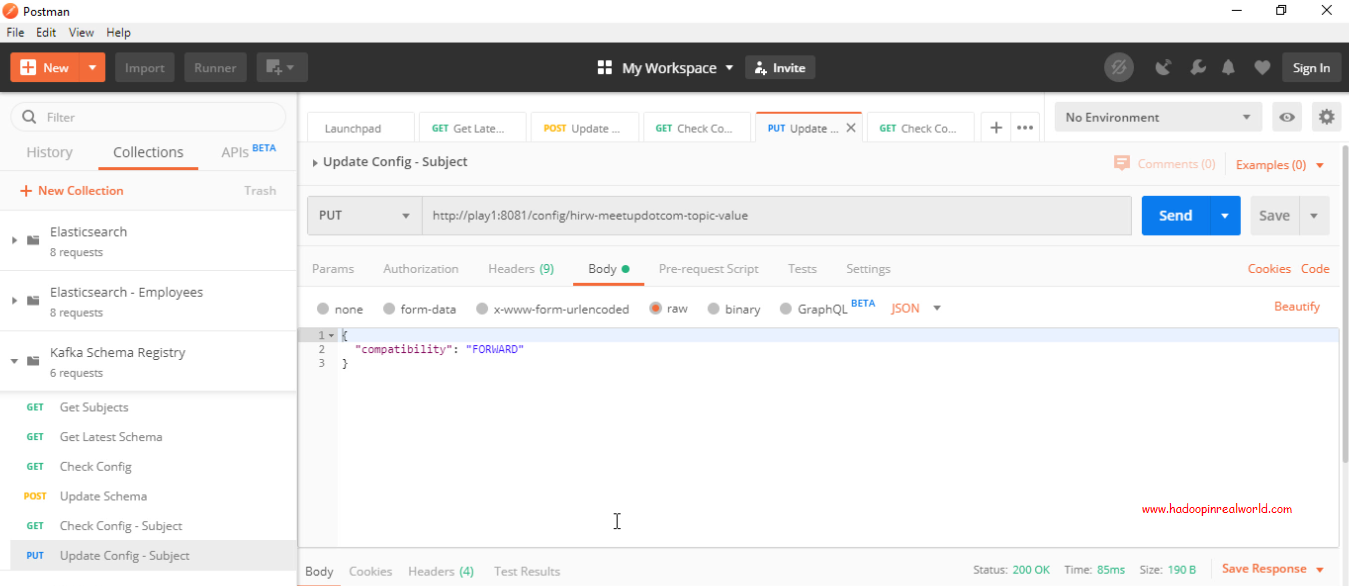
现在,当我们检查主题上的配置时,我们会看到兼容性类型现在被设置为FORWARD。既然主题的兼容性类型已更改为FORWARD,我们就不允许删除必需的字段,即没有默认值的列。让我们确认。为什么我们不尝试删除event_id字段,这是一个必需字段。
让我们通过发出REST命令来更新主题的模式。要更新模式,我们将发布一个包含新模式主体的POST。在这个模式中,我们删除了字段event_id。
{“schema”:”{\”type\”:\”record\”,\”name\”:\”Rsvp\”,\”namespace\”:\”com.hirw.kafkaschemaregistry.producer\”,\”fields\”:[{\”name\”:\”rsvp_id\”,\”type\”:\”long\”},{\”name\”:\”group_name\”,\”type\”:\”string\”},{\”name\”:\”event_name\”,\”type\”:\”string\”},{\”name\”:\”member_name\”,\”type\”:\”string\”},{\”name\”:\”venue_name\”,\”type\”:\”string\”,\”default\”:\”Not Available\”}]}”}
请参阅将兼容性类型设置为转发更新实际失败。即使更改了代码、更新了模式并推出了RSVPs,也会收到相同的响应。使用前向兼容性类型,可以保证使用当前模式的消费者能够使用新模式。
FORWARD_TRANSITIVE
仅FORWARD检查带有当前模式的新模式,如果您想检查所有注册的模式,需要将兼容性类型更改为,您猜对了——FORWARD_TRANSITIVE。

完整和没有(FULL & NONE)
还有另外3种兼容性类型。如果希望模式向前兼容和向后兼容,那么可以使用FULL。对于完全兼容类型,只允许添加或删除具有默认值的可选字段。使用当前模式完全检查新模式。如果希望根据所有注册的模式检查新模式,可以使用FULL_TRANSITIVE。与其他类型相比,完全和完全传递兼容性类型具有更多的限制性。
最后一种兼容类型是NONE。NONE表示禁用所有兼容类型。这意味着所有更改都是可能的,这是有风险的,通常不会在生产中使用。
原文:https://www.hadoopinrealworld.com/schema-registry-schema-evolution-in-kafka/
本文:http://jiagoushi.pro/node/1107
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 119 次浏览
【事件驱动架构】专家组:事件驱动的大规模架构
赖斯:欢迎来到我们关于架构的专题小组,你们一直想知道轨道。该专题小组称为事件驱动的大规模架构。当您思考事件驱动架构时,您会想到什么?这是规模、性能和灵活性的好处吗?也许你想到了一个你可能经历过的特殊问题。也许你从技术的角度来考虑,比如说无服务器,或者流处理,比如Kafka?不管您如何看待事件驱动的架构,您可能有一些问题。我们将深入探讨事件驱动系统的主题,我们将与一个专家小组进行讨论,他们一直在大规模地操作这些系统,并且拥有丰富的经验。
我和三位软件领域的杰出领导者一起工作。他们来自操作当今软件中一些最大和最知名系统的地方。
背景
我叫韦斯·赖斯。我是VMware的平台架构师,在Tanzu上工作。我主持QCON旧金山软件会议。我很幸运能成为InfoQ播客的共同主持人之一。
格温,我想让你做的是自我介绍,也许可以谈谈你建立的系统。那么,您是如何在事件驱动上着陆的?什么风把你吹来了?
沙皮拉:基本上,我是一名软件工程师,是Confluent的首席工程师。我领导云端本地Kafka团队。我们将Kafka作为一项面向客户的大规模服务。在那之前,我是一名工程师,是阿帕奇·Kafka的提交人。
Confluent是如何在事件驱动架构上实现的
基本上,在我们尝试了所有其他方法之后,我们以事件驱动的方式着陆。不是那样的。我花了很多时间与已经在使用Kafka进行事件驱动的客户在一起。我必须与我的客户一起学习模式,以及他们如何解决问题。它解决了什么问题。它创造了什么。然后当我开始管理云中的Kafka时,我们发现自己有一块巨石(monolith),我们知道我们必须解决它。你总是从一块巨石开始。他们写得很快。我们知道我们想要更好的东西,我们有很多不同的选择。真正让我们成为事件驱动型的是,它让我们避免了团队之间的指责,因为一切都是通过事件进行的。它永远被记录下来。如果需要,您可以在登台环境中查看发送了哪些消息,并重构系统的整个逻辑流。如果您在生产中看到了一些东西,而不是您所期望的,那么您实际上可以了解整个事件主题,并了解在另一个系统中发生了什么。对我们来说,这是巨大的。这不是我的责任,你的责任。我们必须非常明确,这是你拥有的。这些是你对事件的反应,我们可以从中吸取教训。
赖斯:不过,这也带来了很多其他问题,比如事情对所有这些事件的实际反应以及它们是如何编排的。伊恩,你呢?
背景,以及PokerStars sports是如何在事件驱动架构上实现的
托马斯:我是一名高级首席工程师,在弗利特(Flutter )国际公司工作,这是我七年前开始的一份工作的化身,在天空投注公司工作。我从事博彩业。这些年来,我一直致力于天空投注,投注,现在横向扑克明星体育。从事件驱动的角度来看,我有几个不同的角度。我很有兴趣了解更多关于我自己的一个方面是PokerStars多年来的发展,因为这是最大的实时事件驱动系统之一,我认为可能存在于这个地方。
我在2014年加入了天空赌局(Sky Bet back)。当时我们采用的主要方式是从一个单片系统(一个庞大的Informix数据库)中提取数据,并将其分发给组织内的工程团队,以允许他们控制数据,然后他们可以构建可扩展的前端。从那以后,我一直致力于各种其他系统的化身,包括一些由Kafka支持的系统,这些系统非常成功。看看我们如何实际使用它来管理自己的状态,这是一个非常有趣的旅程。有很多不同的角度。我最近一直在做的一件事是研究我们如何在前端使用实时事件,并将扑克传统应用到体育博彩和游戏中。
背景,以及BBC是如何在事件驱动架构上着陆的
克拉克:我是马修。我是英国广播公司的架构主管。我相信大家都知道BBC。我们有几十个网站和应用程序,有了这些,我们就有了数百项服务。这是一个相当广泛的事情。保持领先是很有趣的,但是有很多微服务思维和基于云的思维,所以基于事件的架构必须属于这一类。这不是教条式的事情。并不是说我们在任何地方都使用它。基于大量时间请求的系统是更好的解决方案。一直以来都有这些优点和缺点。基于事件的方法必须在它有很多优势的地方发挥作用。从根本上说,如果你有一个搜索引擎或推荐引擎之类的东西,它不会自己填满。您需要这些事件进入并填充它,因此它成为一个好的服务。
使用事件驱动系统时了解域模型的重要性
Reisz:我首先想问的问题之一,可能只是一些你进入事件驱动系统时没有想到的事情,一些让你大吃一惊的事情。这是你旅程的早期。我将从我自己的角度给你举一个例子。我发现当我使用事件驱动系统时,它有点难。在我参与之前,我必须非常了解这个领域,才能真正理解正在发生的舞蹈编排。格温,你谈了一些舞蹈和编曲。例如,当您使用事件驱动系统时,真正了解域模型的重要性是什么?
夏皮拉:尤其是作为一个试图为其他团队提供建议的架构师,你还必须知道你不知道的东西。你的很多工作就是划清这件事的界限,然后说,这是你所拥有的,不要走出去。如果你想在你发送的信息之外做点什么,别人会拥有它。相信他们做正确的事情,他们拥有自己的领域。文化和架构是如何协同工作的,这很有趣,因为如果你试图编写一个协调的系统而不是编舞,你实际上必须了解每个人的逻辑。你就是那个,我会打电话给你,这会发生的。然后我们再叫另一件事。如果这失败了,我就不得不称之为另一件事。我觉得,在很多方面,舞蹈文化意味着你是你领域的专家,你定义了界限。那么你就不必担心其他领域了。还有其他专家,你可以相信他们。我认为这是一种良好的公司文化。
事件驱动系统带来的惊喜
Reisz:Ian,当你从一个更经典的单片系统开始使用事件驱动系统时,有哪些事情让你感到惊讶?
托马斯:我认为大的一次似乎一次又一次地出现,从这个同步的东西到有时间轴的东西也要考虑。特别是当您有可能不同的数据源,或不同的数据生产者,并且思考,这是否真的发生在这之前?我该怎么处理?然后,从这一点开始思考,如果我看到这个事件两次会发生什么?如果我从未见过它会发生什么?我如何协调时间过后的一致性?如果你仅仅从人们从同步编程模型到异步编程模型的角度来看待它,你可以看到到处都是这种情况,就在一个整体中。你也有类似的情况。当这些数据也分布在不同的系统中时,您需要了解,我如何去检查这些数据,或者如何在另一个系统中看到这些数据,或者如何回放日志?这很有挑战性。我会说是的,可能是时间因素。
瑞兹:马修,有什么想法吗?
克拉克:是的,我同意你所说的。是的,了解事物的状态,你是否失去了什么,你是否有比赛条件,这些事情变得非常困难,非常坚毅,绝对。我们谈论无状态是一个多么美妙的范例。您可以通过无服务器功能实现这一点。你需要关心,你只需要担心当下的时刻。然而在一个事件驱动的世界里,你有你的微服务,它有很多状态。它收到了很多活动。如果你失去了一些,你就有麻烦了。它可能不得不把它传给其他东西。如果失败了,或者需要重新部署或其他什么,会发生什么?突然间,你看了看,这不是一个小问题。这不是梦想。当我从我非常满意的经典restapi转移过来时,它非常简单,突然间这不是灵丹妙药,是吗?它有各种各样的挑战。
如何处理无序事件
Reisz:人们想学习的一个问题是如何处理那些无序事件。伊恩,你说了一点关于必须处理不同时间发生的不同事件。您如何处理这样一种想法,即该事件可能不一定以这种同步事件顺序出现?你怎么处理这样的事情?
托马斯:对我们来说,当我们看到这一点时,最重要的地方是下注的位置,也就是说,有人真的在你身上花了一些钱。被抛来抛去的关键词是幂等性,确保你的事件可以在没有严重后果的情况下重演,特别是财务方面。这是一个真正的教育案例,所以要理解这是一种可能性,并在设计系统时牢记这一点,就像大多数事情一样。我们有很多事情需要考虑,如果我们多次遇到这个事件,我们如何丢弃这些东西?如果我们没有看到它,我们如何回放或将新事件推送到系统中,以尝试获得正确的一致性?然后,我们的一些运营人员对我们最大的一个阻碍是,在生产中这样做是对还是错,或者你做了什么。你自己决定吧。如果您有一个数据库,并且您的数据不一致,那么您至少有能力进入并调整它。您可以运行一些SQL命令。“我可以解决这个问题。”当你依靠回放的事件日志时,你必须考虑控制平面是什么样的?我用什么方法使自己恢复良好状态?
回到一个好的,已知的状态
瑞兹:格温,你有什么建议让人们考虑让自己回到一个众所周知的状态?
沙皮拉:我非常相信确保一切都是幂等的。你再往回走一点,相信如果你重播,它不会让你陷入更糟糕的状态。在我看来,真正做异步事件的最大障碍,并不是异步事件真的那么难,而是人们在内心深处没有接受这是唯一的方法。做一些同步的事情,做一些可扩展的事情,做一些性能好的事情,基本上你不会得到这三个。它可以是同步的、高性能的,但不能扩展。您可以同步并尝试扩展,但您将拥有非常大的队列。它不会有太多的表现。如果您想要性能和可扩展的东西,您必须是异步的。一旦你开始走,我就得走了。那么,真的,有一个幂等事件有那么难吗?通常没那么难。只是你必须,我在一个新的世界里,我不想用新的工具创造我的旧世界。事实上,我现在身处一个新世界。
编舞与精心编曲(Choreography vs well-defined orchestration)
Reisz:Nandip问了一个关于定义良好的业务流程的问题。当我看到这篇文章时,我读到的是编舞与配器,回到我们之前讨论的内容。是否总是有这样一种情况,即一切都应该是编舞,或者是否有这样一种情况,即我们需要有单独步骤的定义良好的编排?马太福音?
克拉克:从来没有一个正确的答案。我们有两种方法。有时您可以使用编排设置来操作它,有时则不能。我们之前说过的是,假设您在某个时候会被重放,无论您使用什么,您都会在事件驱动的消息中发现bug,例如,您需要重放内容的地方。即使您的技术非常擅长在正确的位置发布正确的内容,并保证至少一次一致性,您也必须在某个时候处理内容的重复,因为这只是您工作的一部分。
瑞兹:伊恩,格温,有什么想法吗?
托马斯:我真的很喜欢燕翠,他在这一点上做出了妥协,这是在一个有界的背景下,编曲可能是正确的选择。当你观察不同环境之间的交流时,事件驱动的编舞才真正开始发挥作用,而且它很强大。当然,这还不是一个完全的扣篮。我认为这可能是一个很好的定义起点。
赖斯:那是个好主意。燕翠,这也正是我的想法。他有一篇很好的博文,如果你想更多地了解这两者之间的区别的话,可以深入探讨这一点。
在Kafka架构上分离事件和创建主题
格温,这里有一个问题是关于分离事件,以及你如何真正开始思考你的话题。当有人走到你面前,问你关于分离事件和创建Kafka架构主题的问题时,你如何与他们谈论这一点?你让他们想些什么?你告诉他们要考虑什么?
夏皮拉:这很有趣,因为我过去常常回答数据库的问题,这个积分应该是什么,什么应该是分离维度。感觉就像是同样的事情不断重演。首先,就像得到一本关于数据建模的好的、非常古老的书一样,基本上不会有什么伤害,就像建模就是建模一样。你有一本领域驱动的设计书。另一方面,您有一个老式的数据仓库建模或数据建模系统。在Kafka中,您需要考虑的是一些规模要求。这就是它所做的稍微不同的事情。如果某个事件非常常见,那么您可能希望将主要度量和度量主题与稍微不常见的内容分开。因为它们可能会被单独处理,你会希望在不同的时间内对它们做出反应。另一件重要的事情是排序保证,这在数据库中是不会发生的。如果内容在不同的主题中,那么您将无法控制它们的顺序。它们可以按任何顺序处理,你需要对此表示同意。如果你想让事情有一个顺序,你把它们放在同一个分区的同一个主题上,你就有了这个完整的顺序,它就在那里。那么很多只是业务逻辑。我看到一个关于一个事件应该有多大的问题经过。这就像一个函数应该有多大。如果它变得过大,可能是一种气味。一天结束时,你的模型有好的边界吗?在您的企业中,事件是真实世界的事件吗?它是否与正在进行的某项业务保持一致?这是主要考虑因素。你不想用不同的方式人为地把东西切碎吗?
托马斯:我们曾经与工程师们进行过很多对话,他们专门关注Kafka和Kafka流,了解主题设计如何影响他们的流,因为有很多长期影响。特别是,如果您使用它来存储状态和压缩主题。人们从一开始就设置了错误数量的分区。
Shapira:有一件事我要提醒周围的人,也要提醒内部和我的云管理者,你们不想把暂时的限制变成一种宗教。如果你认为某件事是正确的商业行为,但你必须做出妥协,因为技术迫使妥协,你想非常清楚地记录我们想要做X,但实际上这是不可能的。因为那时你不知道,也许一年后X将成为可能,你可以回到它。例如,Kafka过去的分区数量是有限的。它早就消失了,而且正在变得更加消失。人们围绕它设计了整个世界的意识形态,很难说,你这样做是因为它是正确的,还是因为你相信事实上已经不存在的局限性。
赖斯:伊恩,我想让你双击一下。你说你的主题设计的长期影响,比如什么?再多描述一下?
Thomas:有时候,考虑到根据事实改变事情是多么容易,并考虑到您可能需要的吞吐量,这有点幼稚。对于Gwen在那里提到的事件大小,如果您的事件太大,那么您想要的复制模型以及在代理之间要发送的通信量就会出现问题。对我们来说,最主要的是,如果我们把状态保存在一个压缩的主题中,然后你突然意识到,等等,我们没有足够的分区来支持我们现在所拥有的吞吐量,因为这已经增加了。如果您尝试扩展,则所有这些以前的事件都将位于错误的分区上。你必须和这样的人一起玩,如果你将来需要的话,你打算如何扩大规模?您知道您现在选择的约束条件是什么吗?
我们倾向于尝试在Amazon 1型和2型框架中建模。比如,这是你现在就可以做而不用担心的事情吗?它在未来很容易改变吗?我认为,如果你不一定对系统的工作原理或者你正在使用的实际技术有足够的了解,你就不可能在没有真正意义的情况下很容易地把一个2型的东西变成一个1型的东西。它可以确保人们意识到这是一个限制,在设计系统以及如何通过这项技术放置数据时,请记住这一点。
克拉克:事实上,我发现即使是伟大的1型,2型,这个想法,这是一个可逆的决定吗?这是我在事件驱动架构中遇到的挑战之一。它会把你锁在以后很难改变的事情里。一旦有多个客户机正在接受您的事件,更改事件格式就变得非常棘手了。您希望可以在客户不关心的情况下向JSON或其他任何内容添加新字段,但这样做总是让人感到非常紧张。我想我们还没弄清楚你是怎么处理的。
夏皮拉:这方面有一整本书。格雷格·杨的书。
瑞兹:让我们谈谈这个,格温,因为有一些问题出现了。你如何解决这样的问题?
格温,你说的是一本书?
夏皮拉:是的。这是格雷格·杨的作品。他写了一整本关于事件版本控制的书,这表明这不是一个容易的问题,我现在不打算在五分钟内为你们解决它。Kafka以其对稳定的狂热而闻名于世。你可以像一个0.8的经纪人、一个3.0的制作人和一个1.0的消费者那样,让一切都运转起来。它的代价是你进化的速度极其缓慢。如果每个客户端和每个应用程序都有一个大的,如果你得到版本1的事件,如果你得到版本2的事件,这是非常不神奇的。
第2天,与事件驱动系统相关的问题
Reisz:今天早上,Katharina Probst在她的主旨演讲中提到了一系列针对微服务的第二天操作。她列举了一些事情,比如负载测试、混沌工程、AIOps监控。当我们谈论事件驱动系统时,您需要考虑哪些第二天的问题?例如,您谈到了版本控制。什么是你需要思考的事情,也许你真的没有考虑过?
克拉克:我想到的是一对夫妇,斯凯尔绝对是其中之一。如果大量事件已重新发布,会发生什么情况?通常,你会发现,如果你是一个微服务所有者,你可能会发现你的一个攻击性玩家突然出于任何原因选择发布东西。也许他们有个臭虫什么的。你需要有能力处理这件事。或者,至少,您前面可能有一个队列,您可以从中处理积压工作。您不希望积压工作持续很长时间。你有一个有趣的规模挑战,从任何地方,所有的交通可以来自所有这些事件。事实上,你正在存储状态,你是如何存储状态的?如果你重新部署自己会怎么样?你确定在这些时刻你没有掉东西吗?
赖斯:伊恩,你的想法是什么?
托马斯:我完全同意这两个观点。也许随着时间的推移,我注意到的其中一个问题是第二天过去了,但更像是第600天,当构建系统的人继续前进时,人们害怕新的人进来,试图弄清楚这件事是如何运作的,无法改变事情,并且感到担忧。很多都像你在开始时提到的,领域,以及它是如何记录的?人们是如何改变事情的?实际上,冷淡地尝试采用这个系统,并使其适应公司当前的需求是什么样的?
瑞兹:格温,你有什么想法吗?
夏皮拉:是的,我觉得我的第二天活动,我们应该在第0天完成,诸如此类的事情。测试框架,您拥有所有这些微服务,您将独立升级它们。人们都在谈论建立信心,所以你真的要做一个改变,你想有一个测试框架,运行时间不会太长,也许一两个小时,但不会太长。B、 大多数情况下都会通过。它每天应该很少有绿色建筑。第三,相当容易使用、发展和诊断。我在第二天发现,实际上升级和发布都很困难,因为我们没有一个很好的测试框架,现在我们必须基本上停止一系列生产项目,重新开始。我们有50,60个服务,我们甚至没有那么大,我们如何实际测试不断发展的场景,所有这些场景,以确信我们没有破坏其他任何东西?
事件驱动系统的监测和可观测性
赖斯:这里有一大堆关于可观察性、监控和诸如此类的问题。我想换个话题,给你们每个人一个机会谈谈可观察性、监控事件驱动系统和任何工具的重要性。我想,伊恩,当我们交换一些电子邮件时,你谈到了第二天的想法,实际上是在你正在使用的东西中加入一些监控类型的工具。我很想知道,你们每个人关于监控事件驱动系统的一些提示、技巧和想法。
托马斯:其中一些给我们带来最大价值的东西是添加跟踪,以便在消息和记录通过系统的各个部分时能够看到它们的生命周期。再加上Kibana这样的工具,可以非常强大地准确地理解事物是如何在X应用程序上移动的。我们经常被问到的一个问题是,我们看到了吗?有一件事你并不总是有奢侈的是,你是制片人,这是事件的来源。对于我们来说,我们从第三方供应商那里获取了大量数据,这些供应商在足球比赛中有球探并发布更新,我们只是不太知道,这种情况发生了吗?我们应该看到这场足球赛的比分达到了3-0,或者别的什么,但是我们没有那种状态,所以我们看到了什么比赛,什么顺序?我们构建了一些工具,使我们能够真正快速地进入生产箱并回放一些事件。
在我们花时间围绕这一点构建内部工具之前,总是让我们绊倒的事情是,我们希望在代理和客户之间建立TLS。这是Kafka特有的。这强制了我们的ACL,所以您可能没有查看特定主题的权限,您必须考虑一下,您在那里做什么。如果您确实有一些调试工具,请确保您不会干扰实际的生产客户,这样他们就不会到处乱打,并且确保您正在考虑它实际上会如何影响工作系统。然后,如果我们需要提取数据,通常情况下,我不知道每个人的系统是否都不同,因此我们有多个级别的跳转帖子来联系实际的Kafka经纪人。然后你会想,我如何从中提取有用的信息,然后把它拿走,在PIR中分类,或者类似的东西?归根结底是这样的,直到你需要它们,你才真正发现你的需求,这就是确保你已经把时间放在一边,把精力放在构建你需要的东西上。
赖斯:你的里程数可能会有所不同。绝对地Matthew,你们在可观察性方面学到的任何东西都可能是对其他人的好建议。
克拉克:正如伊恩所说,追踪真的很好,不是吗?我们在Amazon X-Ray上做了很多工作,效果非常好。然后,在每一个微服务级别上,您都能正确地记录日志,以便能够诊断哪里存在问题。只要你在每一个微服务之间都有一些经纪人,不管是Kafka,还是动情,或者其他什么,那么你就有希望发现并分离出让你失望的微服务,并尽快解决它。
瑞兹:格温,你有什么消息吗?
沙皮拉:我要补充的唯一一件事可能是采样的想法,你可以有一个外部系统来对一些事件进行采样,特别是如果正在进行的一切都是非常大规模的。然后,在后台仔细检查是否存在异常值,并确保没有任何意外情况,比如事物不会过大。伊恩刚刚对它说,你知道你的数据的形状应该是什么样的。这就是你如何检测我们是否应该看到它,而它不在这里,诸如此类的事情。我们也知道,我们不应该期望一秒钟内有许多授权尝试。如果我们明白了,可能是出了严重的问题。我们已经建立了这个系统,它在后台运行,并对样本的一些规则进行了双重检查。我认为这对我们很有帮助。
从战争故事中吸取的教训
瑞兹:格温,我要从你开始谈这件事,因为我想你已经提到了一件。对于不同的战争故事有很多要求,这让你学到了一些不同的课程。你从一些战争故事中学到了什么教训?告诉我们关于战争的故事,也许还有教训?
Shapira:我认为这与前面的版本控制讨论有关。我们基本上想升级很多东西。我们有大约1000个单一服务类型的实例,我们只想升级它们。这是一个无状态的服务,这使它变得简单。我们刚刚通过我们的管道推送了大约1000个升级事件,希望所有事件都能得到处理,其中997个能够随着时间的推移自行升级,而3个不会。我们甚至不知道为什么。活动即将开始,一切看起来都很好。我们有痕迹。我们到处都有原木。最终,我们发现这是我们最古老的三项服务,基本上就像我们拥有的前三个客户一样,可以追溯到2017年。他们有一些不同的授权密钥,阻止他们下载这些他们需要下载的东西来升级自己。甚至没有人确切记得钥匙是怎么到那里的。显然,这是一个不同类型的事件。才三点。我们最终野蛮地强迫他们。这类事情,即使你对进化非常小心,比如一步一步地进化成一个系统,它将与2017年发生的任何事情完全不兼容,甚至没有人记得。我认为这里的主要教训就是不要有任何悬而未决的东西。每三个月、六个月都要升级一次,如果你在做什么项目时没有太多的变动,那么可能还要再升级一点。
瑞兹:伊恩,你呢,告诉我们一些战争故事?
托马斯:当你问这个问题时,我突然想到了一对夫妇。他们都是几年前的人,所以我不认为我说这些话伤害了任何人的感情。其中一个是关于事件的大小,或者更确切地说是与事件相关的事物的大小。在Sky Bet上,构建页面的方法之一是,从Informix流出的信息流经过各种rabbitmq,然后由节点处理,最终存储在Mongo文档中。由于更新发生的方式,我们倾向于从Mongo读取文档,找出这对文档意味着什么,然后将其写回。这种逻辑中存在一个缺陷,这意味着我们从未真正从Mongo文档中删除过内容。因为它是一个主页,我想它是网站上的赛马主页,它只是逐渐变大了。虽然这并不明显,但不幸的是,当该网站在节礼日(在英国,这是一个体育博彩的大日子)宕机时,所有这些事情都出了问题。我们不知道为什么。这基本上是因为我们频繁地从Mongo中提取文档,从而使我们的网络饱和,以至于我们无法再实际处理它。那是非常有趣的一天。
我能想到的另一个问题是,很难解决,可能涉及到与Kafka合作的最佳实践,那就是我们有两个制作人的情况非常奇怪,所以这很简单。我们有两个制作人编写一个主题,但具有相同密钥的记录最终出现在不同的分区上。其中一个基本上是一个节点应用程序,另一个是用Kotlin编写的。密钥的使用方式和用于生成实际分区散列的数据类型意味着整数在Kotlin中使用,因此溢出。它实际上是在生成与Node.js不同的散列。那是一个相当不错的一天,寻找它。
夏皮拉:你是怎么发现的?
托马斯:我不记得了。那是几年前的事了。我们只是在这些节目中逐行播放,有什么不同?我们最后得出的唯一结论是这一个是节点,而那一个基本上就是JVM。实现中可能有什么不同?这只是一个数字。
我能想到的另一个问题是,很难解决,可能涉及到与Kafka合作的最佳实践,那就是我们有两个制作人的情况非常奇怪,所以这很简单。我们有两个制作人编写一个主题,但具有相同密钥的记录最终出现在不同的分区上。其中一个基本上是一个节点应用程序,另一个是用Kotlin编写的。密钥的使用方式和用于生成实际分区散列的数据类型意味着整数在Kotlin中使用,因此溢出。它实际上是在生成与Node.js不同的散列。那是一个相当不错的一天,寻找它。
夏皮拉:你是怎么发现的?
托马斯:我不记得了。那是几年前的事了。我们只是在这些节目中逐行播放,有什么不同?我们最后得出的唯一结论是这一个是节点,而那一个基本上就是JVM。实现中可能有什么不同?这只是一个数字。
第二天,关于操作事件驱动系统的建议
Reisz:我想把重点放在第二天,如果你能和某人坐下来,就第二天或事件驱动系统的长期运行给他们一点建议。我们一直在谈论Kafka。你有什么建议?不一定非要和Kafka在一起?你有什么建议吗?
克拉克:尽你最大的努力让事情尽可能简单,因为这些事情变得如此复杂真是不可思议。如果我们有时间的话,我会说的故事是,我们如何有一个时刻,所有这些不同的系统在做所有这些不同的事件,如果我们将这些事件标准化,并将它们放在一起,并将所有事件作为一个超级主题,这不是很好吗?当然,那是个糟糕的主意。因为它们都有不同的属性,以不同的方式扩展,以不同的方式需要。就像微服务的概念一样,让事情分开,让事情简单。不要以为事件驱动就是答案,因为它是一个很好的解决方案,但并不总是正确的解决方案。请注意,它可能不像最初看起来那么简单。
不是事件驱动系统的最佳系统
Reisz:对于事件驱动系统,哪些系统可能不是最好的?你有什么想法吗,马修?
克拉克:从根本上说,如果你是一个面向用户的东西,它会以一个请求结束,不是吗?一个用户出现了,给我一个东西。在某个时刻,您的事件必须转变为请求。这一切都是为了找出它在哪里。在英国广播公司,我们更喜欢有它,所以实际上我们会根据用户的到来做很多请求,这样我们就可以回应他们是谁。我们希望在这方面充满活力。这是一个例子。你不能现实地提前准备,因为你想对当下做出反应。
对于事件驱动系统和第二天推荐来说,不太好的事情
赖斯:伊恩,哪些东西不是伟大的事件驱动系统?那么,第二天你对某人的建议是什么?
托马斯:不好的事情?我认为考虑它的一个好方法是,如果我有一个工作流,你希望能够识别该工作流中的所有步骤,并将其作为一个深思熟虑的实体加以关注。这是一种很好的编排方式,而不是事件驱动。我的建议与此类似,不要强制在不需要的地方安装它,但在设计数据时也要非常慎重,以允许其不断发展。请记住,您选择的实现方式。你需要SNS、SQS还是运动?考虑一下您正在使用和设计的实际代理和系统的约束,而不是针对它们。
什么时候不使用事件驱动?我几乎可以这样说,从节点开始,寻找需要这种可靠性水平或重放能力的地方,以及真正强大的大规模解耦。基本上,请注意什么时候需要事件驱动而不是启动程序,因为我确实觉得它增加了一层复杂性,可能你永远都无法实现,谁知道呢?也许你的创业不会那么成功。
就第二天而言,我会稍微为自己着想,并说你确实可以选择不以自己的身份排名。它只是消除了一系列的痛苦,然后把它交给一个实际上相当兴奋和乐意照顾它的人。我认为这在总体上是正确的,就像我们不做自己的监控一样。我们有一群第三方提供商为我们进行监控。我们不经营我们自己的Kubernetes,我们用AKS,EKS,GKE来做这些。是的,基本上,偶尔有一些你不必担心的事情是很好的。
- 132 次浏览
【事件驱动架构】事件溯源,CQRS,流处理和Apache Kafka:关联是什么?
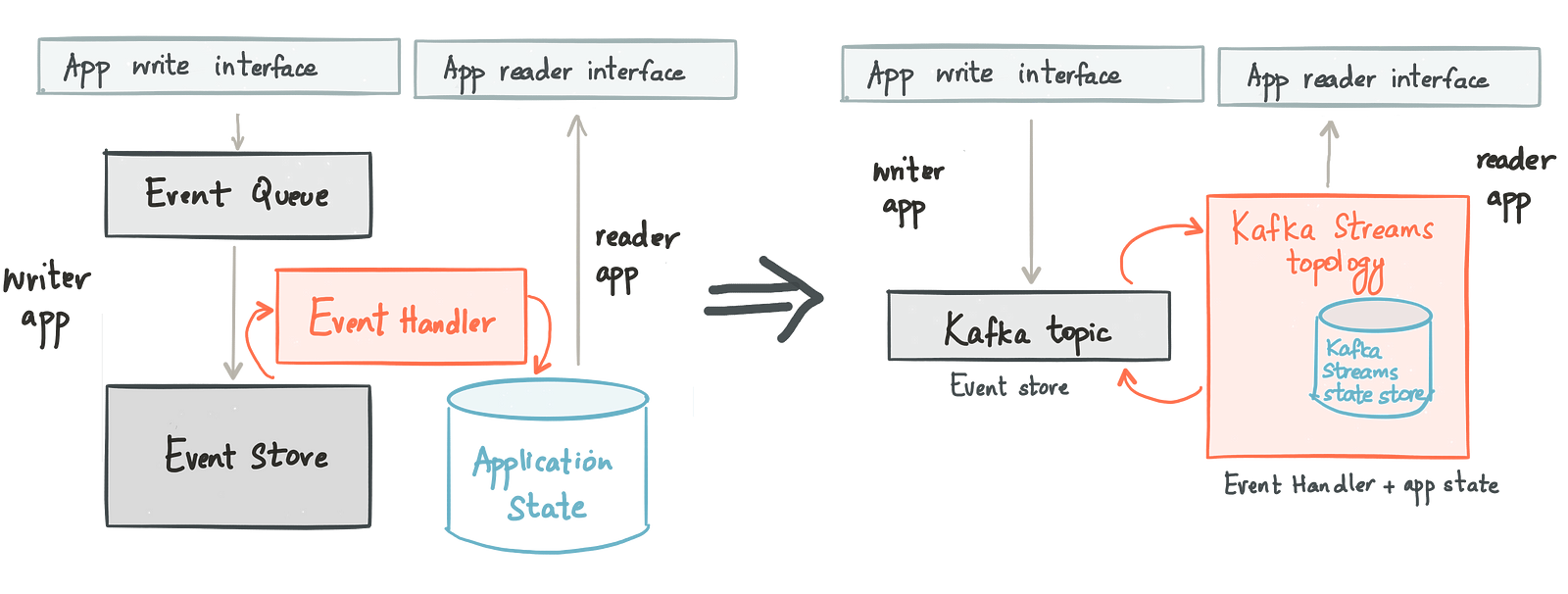
事件源作为一种应用程序体系结构模式越来越流行。事件源涉及将应用程序进行的状态更改建模为事件的不可变序列或“日志”。事件源不是在现场修改应用程序的状态,而是将触发状态更改的事件存储在不可变的日志中,并将状态更改建模为对日志中事件的响应。我们之前曾写过有关事件源,Apache Kafka及其相关性的文章。在本文中,我将进一步探讨这些想法,并展示流处理(尤其是Kafka Streams)如何帮助将事件源和CQRS付诸实践。
让我们举个例子。考虑一个类似于Facebook的社交网络应用程序(尽管完全是假设的),当用户更新其Facebook个人资料时会更新个人资料数据库。当用户更新其个人资料时,需要通知多个应用程序-搜索应用程序,以便可以将用户的个人资料重新编制索引以便可以在更改的属性上进行搜索;新闻订阅源应用程序,以便用户的联系可以找到有关个人资料更新的信息;数据仓库ETL应用程序将最新的概要文件数据加载到支持各种分析查询等的中央数据仓库中。

基于事件源的架构
事件来源涉及更改配置文件Web应用程序,以将配置文件更新建模为事件(发生的重要事件),并将其写入中央日志(例如Kafka主题)。在这种情况下,所有需要响应配置文件更新事件的应用程序,只需订阅Kafka主题并创建各自的物化视图-可以写缓存,在Elasticsearch中为事件建立索引或简单地计算in -内存聚合。个人档案Web应用程序本身也订阅了相同的Kafka主题,并将更新内容写入个人档案数据库。
事件溯源:一些权衡
使用事件源对应用程序进行建模有许多优点-它提供了对对象进行的每个状态更改的完整日志;因此故障排除更加容易。通过将用户意图表示为不可变事件的有序日志,事件源为企业提供了审核和合规性日志,这还具有提供数据源的额外好处。它支持弹性应用程序;回滚应用程序等于倒退事件日志和重新处理数据。具有较好的性能特点;写入和读取可以独立缩放。它实现了松散耦合的应用程序体系结构。它使向基于微服务的体系结构过渡变得更容易。但最重要的是:
事件源支持构建前向兼容的应用程序体系结构,即将来可以添加更多需要处理同一事件但创建不同实例化视图的应用程序的能力。
对于上述优点,也有一些缺点。事件源具有更高的学习曲线;这是一个陌生的新编程模型。事件日志可能涉及更多的查询工作,因为它需要将事件转换为适合查询的所需物化状态。
那是对事件源和一些权衡的快速介绍。本文无意探讨事件源的细节或提倡其用途。您可以在此处阅读有关事件来源和各种折衷方法的更多信息。
Kafka作为事件溯源的支柱
事件源与Apache Kafka相关。这是如何进行的-事件来源涉及维护多个应用程序可以订阅的不可变事件序列。 Kafka是一种高性能,低延迟,可扩展和持久的日志,已被全球数千家公司使用,并经过了大规模的实战测试。因此,Kafka是存储事件的自然支柱,同时向基于事件源的应用程序体系结构发展。
事件溯源和CQRS
此外,事件源和CQRS应用程序体系结构模式也相关。命令查询责任隔离(CQRS)是最常用于事件源的应用程序体系结构模式。 CQRS涉及在内部将应用程序分为两部分-命令端命令系统更新状态,而查询端则在不更改状态的情况下获取信息。 CQRS提供了关注点分离–命令或写端与业务有关;它不关心查询,数据上的不同实例化视图,针对性能的实例化视图的最佳存储等。另一方面,查询或读取端全部与读取访问权限有关。其主要目的是使查询快速高效。

Refactoring an application using event sourcing and CQRS
事件源与CQRS一起工作的方式是使应用程序的一部分在对事件日志或Kafka主题的写入过程中对更新进行建模。这与事件处理程序配对,该事件处理程序订阅Kafka主题,根据需要转换事件,并将实例化视图写入读取存储。最后,应用程序的读取部分针对读取存储发出查询。
CQRS具有一些优点-它使负载与写入和读取分离,从而可以分别缩放。各种读取路径本身可以独立缩放。此外,可以针对应用程序的查询模式优化读取存储;图形应用程序可以将Neo4j用作其读取存储,搜索应用程序可以使用Lucene索引,而简单的内容服务Web应用程序可以使用嵌入式缓存。除了技术优势之外,CQRS还具有组织上的优势-通过将写入和读取路径分离,您可以使负责写入和读取路径的业务逻辑的团队脱钩。
本文仅涉及CQRS细微差别的表面。如果您想了解更多信息,建议阅读Martin Fowler和Udi Dahan关于该主题的文章。
到目前为止,我已经对事件源和CQRS进行了介绍,并描述了Kafka如何自然地将这些应用程序架构模式付诸实践。但是,流处理在何处以及如何进入画面?
CQRS和Kafka的Streams API
这是流处理,尤其是Kafka Streams如何启用CQRS的方法。事件处理程序订阅事件日志(Kafka主题),使用事件,处理这些事件,并将结果更新应用于读取存储。对事件流进行低延迟转换的过程称为流处理。在Apache Kafka的0.10版本中,社区发布了Kafka Streams。一个强大的流处理引擎,用于对Kafka主题上的转换进行建模。
Kafka Streams非常适合在应用程序内部构建事件处理程序组件,该应用程序旨在使用CQRS进行事件来源。它是一个库,因此可以将其嵌入任何标准Java应用程序中,以对事件流进行转换建模。例如,这是一个使用Kafka Streams进行字数统计的代码片段;您可以在Confluent示例github存储库中访问整个程序的代码。
KStreamBuilder builder = new KStreamBuilder();
KStream<String, String> textLines = builder.stream(stringSerde, stringSerde,"TextLinesTopic");
Pattern pattern = Pattern.compile("\\W+", Pattern.UNICODE_CHARACTER_CLASS);
KStream<String, Long> wordCounts = textLines
.flatMapValues(value-> Arrays.asList(pattern.split(value.toLowerCase())))
.map((key, word) -> new KeyValue<>(word, word))
.countByKey("Counts")
.toStream();
wordCounts.to(stringSerde, longSerde, "WordsWithCountsTopic");
KafkaStreams streams = new KafkaStreams(builder, streamsConfiguration);
streams.start();
因此,可以轻松地将应用程序内的事件处理程序表示为Kafka Streams拓扑,但更进一步,有两个不同的选项可用于将事件处理程序的输出建模为对应用程序状态进行建模的数据存储的更新。
采取1:将应用程序状态建模为外部数据存储
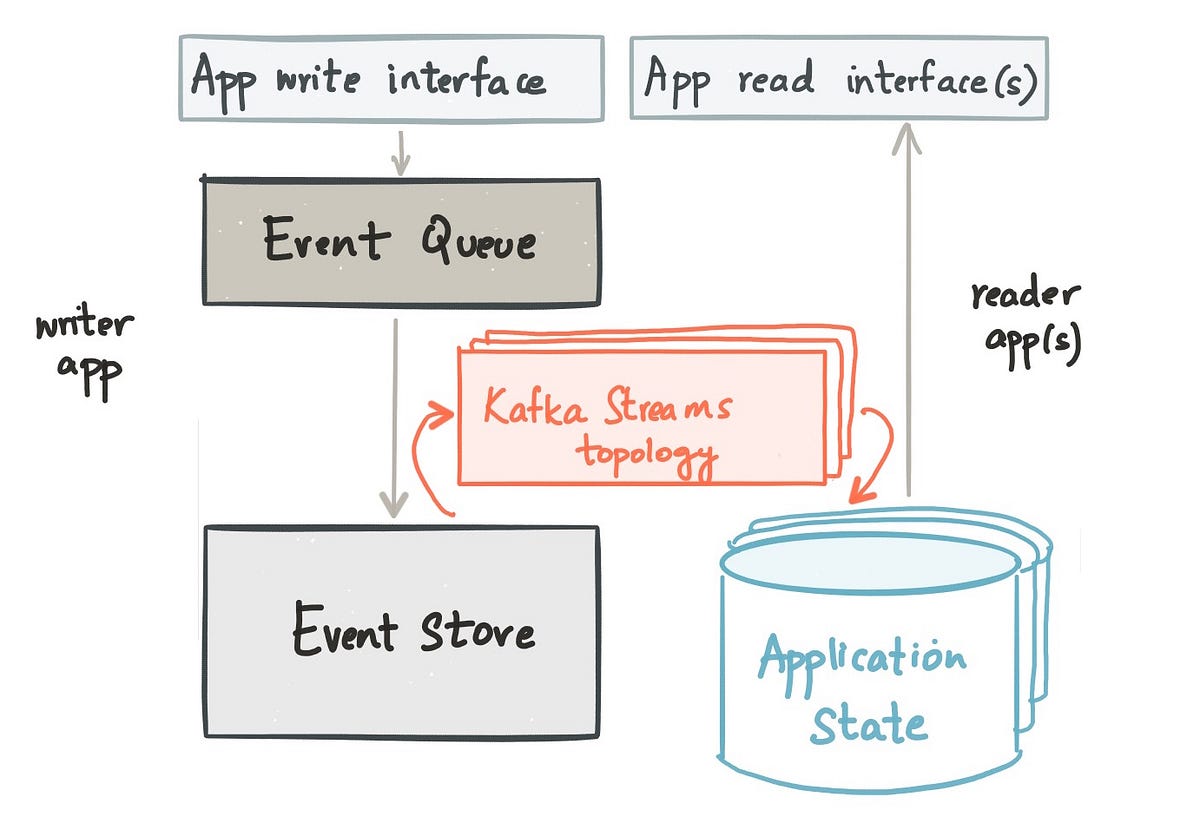
Kafka Streams拓扑的输出可以是Kafka主题(如上例所示),也可以写入外部数据存储(如关系数据库)。 从世界的角度来看,事件处理程序建模为Kafka Streams拓扑,而应用程序状态建模为用户信任和操作的外部数据存储。 执行CQRS的此选项主张使用Kafka Streams仅对事件处理程序建模,而将应用程序状态保留在外部数据存储中,该外部数据存储是Kafka Streams拓扑的最终输出。
以2:在Kafka Streams中将应用程序状态建模为本地状态
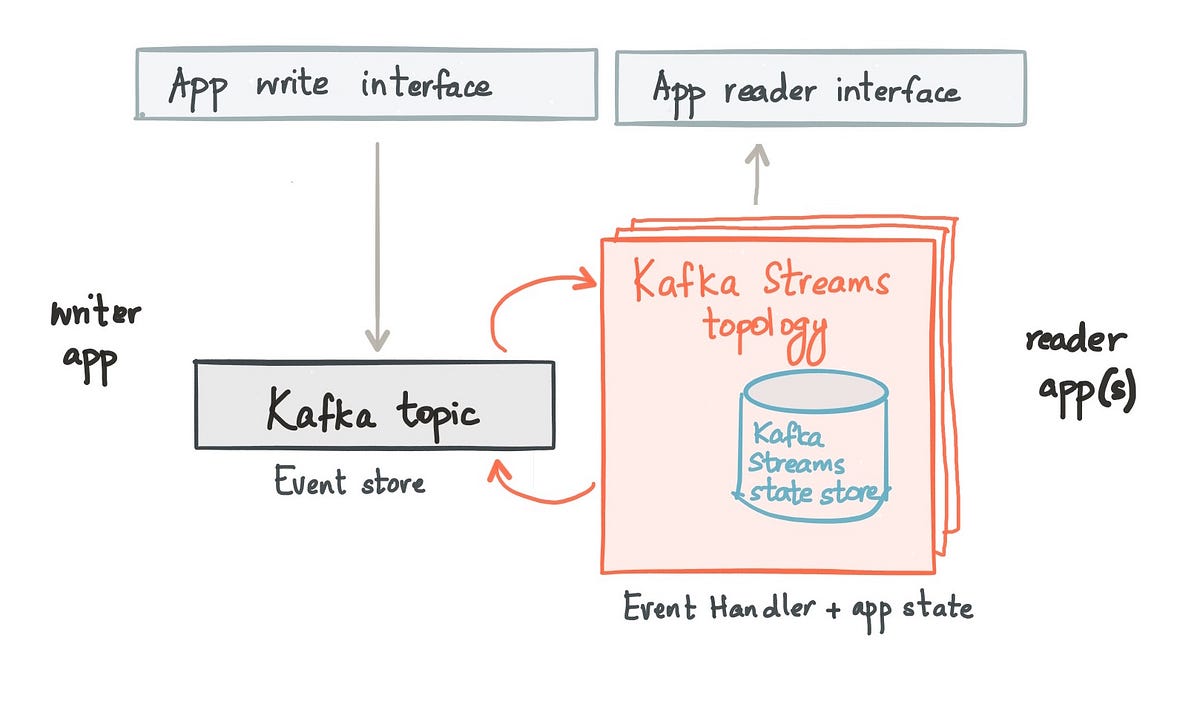
作为一种替代方法,除了对事件处理程序进行建模之外,Kafka Streams还提供了一种对应用程序状态进行建模的有效方法-它支持开箱即用的本地,分区和持久状态。此本地状态可以是RocksDB存储,也可以是内存中的哈希映射。
运作方式是,将嵌入Kafka Streams库以进行有状态流处理的应用程序的每个实例都托管应用程序状态的子集,建模为状态存储的碎片或分区。状态存储区的分区方式与应用程序的密钥空间相同。结果,服务于到达特定应用程序实例的查询所需的所有数据在状态存储碎片中本地可用。 Kafka Streams通过透明地将对状态存储所做的所有更新记录到高度可用且持久的Kafka主题中,来提供对该本地状态存储的容错功能。因此,如果应用程序实例死亡,并且托管的本地状态存储碎片丢失,则Kafka Streams只需读取高度可用的Kafka主题并将状态数据重新填充即可重新创建状态存储碎片。
实际上,Kafka Streams将Kafka用作其本地嵌入式数据库的提交日志。这正是在封面下设计传统数据库的方式-事务或重做日志是事实的源头,而表只是对存储在事务日志中的数据的物化视图。
Kafka Streams中的本地,分区,持久状态
将Kafka Streams用于使用CQRS构建的有状态应用程序还具有更多优势– Kafka Streams还内置了负载平衡和故障转移功能。如果一个应用程序实例失败,则Kafka Streams会自动在其余应用程序实例之间重新分配Kafka主题的分区以及内部状态存储碎片。同样,Kafka Streams允许弹性缩放。如果启动了使用Kafka Streams执行CQRS的应用程序的新实例,它将自动在新启动的应用程序实例之间平均移动状态存储的现有碎片以及Kafka主题的分区。所有这些功能都以透明的方式提供给Kafka Streams用户。
需要使用Kafka Streams转换为基于CQRS的模式的应用程序不必担心应用程序及其状态的容错性,可用性和可伸缩性。
该嵌入式,分区且持久的状态存储通过Kafka Streams独有的一流抽象-KTable向用户公开。
Kafka流中的交互式查询
在即将发布的Apache Kafka版本中,Kafka Streams将允许其嵌入式状态存储可查询。
Kafka Streams中的这一独特功能-交互式查询(以前被Kafka社区称为Queryable State)-也使其适合将CQRS设计模式应用于应用程序。事件处理程序被建模为Kafka Streams拓扑,该拓扑将数据生成到读取存储,该存储不过是Kafka Streams内部的嵌入式状态存储。应用程序的读取部分将StateStore API用于状态存储,并基于其get()API来提供读取服务。
使用Kafka和Kafka Streams的事件源和基于CQRS的应用程序
Kafka Streams中的交互式查询的情况
请注意,使用交互式查询功能在Kafka Streams中使用嵌入式状态存储纯粹是可选的,并非对所有应用程序都有意义。有时,您只想使用您知道并信任的外部数据库。或者,在使用Kafka Streams时,您也可以将数据发送到外部数据库(例如Cassandra),并让应用程序的读取部分查询该数据。
但是,何时使用像这样的本地嵌入式应用程序状态才有意义?这里有一些利弊考虑-
缺点
- 现在生成的应用程序是有状态的,需要多加注意才能进行管理。
- 它涉及远离您知道和信任的数据存储。
优点
- 移动的零件更少;只是您的应用程序和Kafka集群。您不必部署,维护和操作外部数据库即可存储应用程序所需的状态。
- 它可以更快,更有效地使用应用程序状态。数据对于您的应用程序是本地的(在内存中或可能在SSD上);您可以快速访问它。这对于需要访问大量应用程序状态的应用程序特别有用。而且,在进行聚合以进行流处理的商店和商店应答查询之间没有数据重复。
- 它提供了更好的隔离;状态在应用程序内。一个恶意应用程序无法淹没其他有状态应用程序共享的中央数据存储。
- 它具有灵活性。内部应用程序状态可以针对应用程序所需的查询模式进行优化。
使用Kafka做事件溯源和CQRS:大赢家
我上面列出的利弊体现了所涉及的各种折衷,但是,我认为,朝着此应用程序体系结构迈进的最重要的胜利就是应用程序升级变得更加简单。处理应用程序的非停机升级的传统模型(依赖于外部数据库来确定其应用程序状态)相当复杂。无需停机升级就不需要同时运行新版本和旧版本的应用程序。升级几个实例后,如果发现错误,则需要能够透明地将负载切换回同一应用程序的旧实例。鉴于新实例和旧实例将需要更新外部数据库中的相同表,因此需要格外小心,以在不破坏状态存储中数据的情况下进行此类无停机升级。
现在,对于依赖于本地嵌入式状态的有状态应用程序,考虑相同的无停机升级问题。通过此模型,您可以与旧版本一起推出新版本的应用程序(在Kafka Streams中具有不同的应用程序ID)。每个人都拥有按照其应用程序业务逻辑版本指示的方式处理的应用程序状态副本。您可以逐步将流量从旧的引导到新的。如果新版本的某个错误会在应用程序状态存储区中产生意外结果,那么您始终可以将其丢弃,修复该错误,重新部署该应用程序并让其从日志中重建其状态。
放在一起:零售库存应用
现在让我们以一个例子来说明如何将本文介绍的概念付诸实践-如何使用Kafka和Kafka Streams为应用程序启用事件源和CQRS。
样本零售应用程序体系结构
考虑一个实体零售商的应用程序,该应用程序管理所有商店的库存; 当新货到达或发生新销售时,它会更新库存表,并且要知道商店库存的当前状态,它会查询库存表。
具有事件源的零售应用程序架构—由Kafka提供支持
如果我们将事件采购体系结构模式应用于此Inventory应用,则新的货件将在Shipments Kafka主题中表示为事件。 同样,新销售将以Sales Kafka主题(可能由Sales应用程序编写)中的事件表示。 为简单起见,我们假设“销售”和“发货”主题中的Kafka消息的关键字是{商店ID,商品ID},而值是商店中商品数量的计数。
Inventory应用程序内的事件处理程序被建模为Kafka Streams拓扑,该拓扑连接了Sales和Shipments Kafka主题。 联接操作创建并更新状态存储库InventoryTable,该状态存储库表示以连续方式更新的清单的当前状态。

连接操作的内部结构以构建库存表
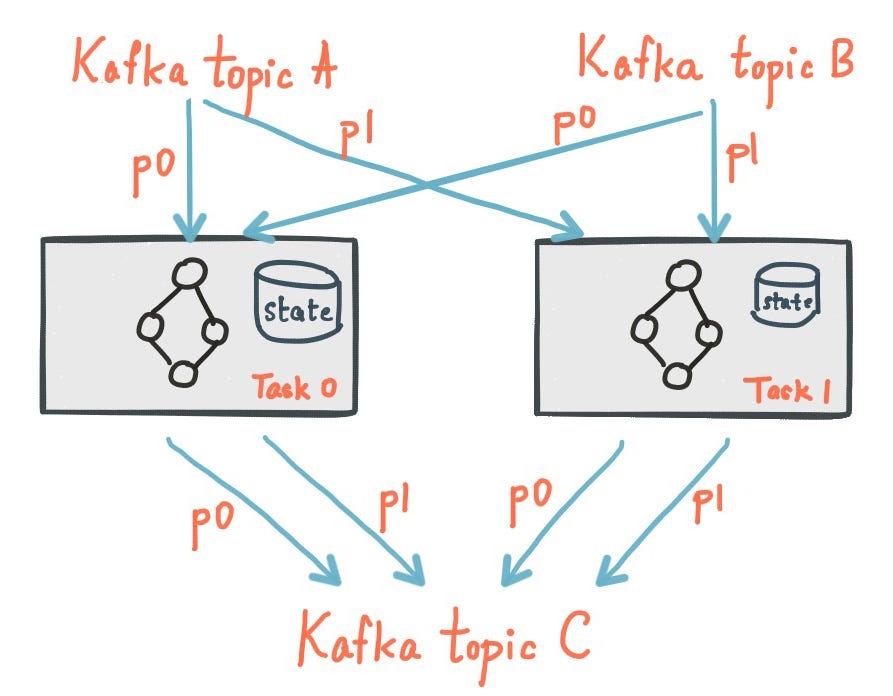
可以将这样的应用程序部署在不同计算机上的多个实例中(如下图所示)。而且,InventoryApp的每个实例都承载InventoryTable的分片的子集,其中包含此联接操作的结果。当用户查询InventoryApp来了解商店中某商品的当前库存数量时,
- 运行InventoryApp的随机服务器收到一个请求:GET / inventory / stores / {store id} / items / {item id} / count
- 它使用Kafka Streams实例上的metadataForKey()API来获取商店的StreamsMetadata和密钥。 StreamsMetadata保存Kafka Streams拓扑中每个商店的主机和端口信息。应用程序使用StreamsMetadata检查该实例是否具有包含关键字{store id,item id}的InventoryTable分区。如果是这样,它将使用本地Kafka Streams实例上的store(“ InventoryTable”)api来获取该商店并对其进行查询。
- 如果不是,它将为当前持有包含{store id,item id}的Kafka分区的实例找到主机/端口,并转发GET请求到/ inventory / stores / {store id} / items / {item id} / count到在该主机上运行的InventoryApp实例。
- 向用户返回库存盘点
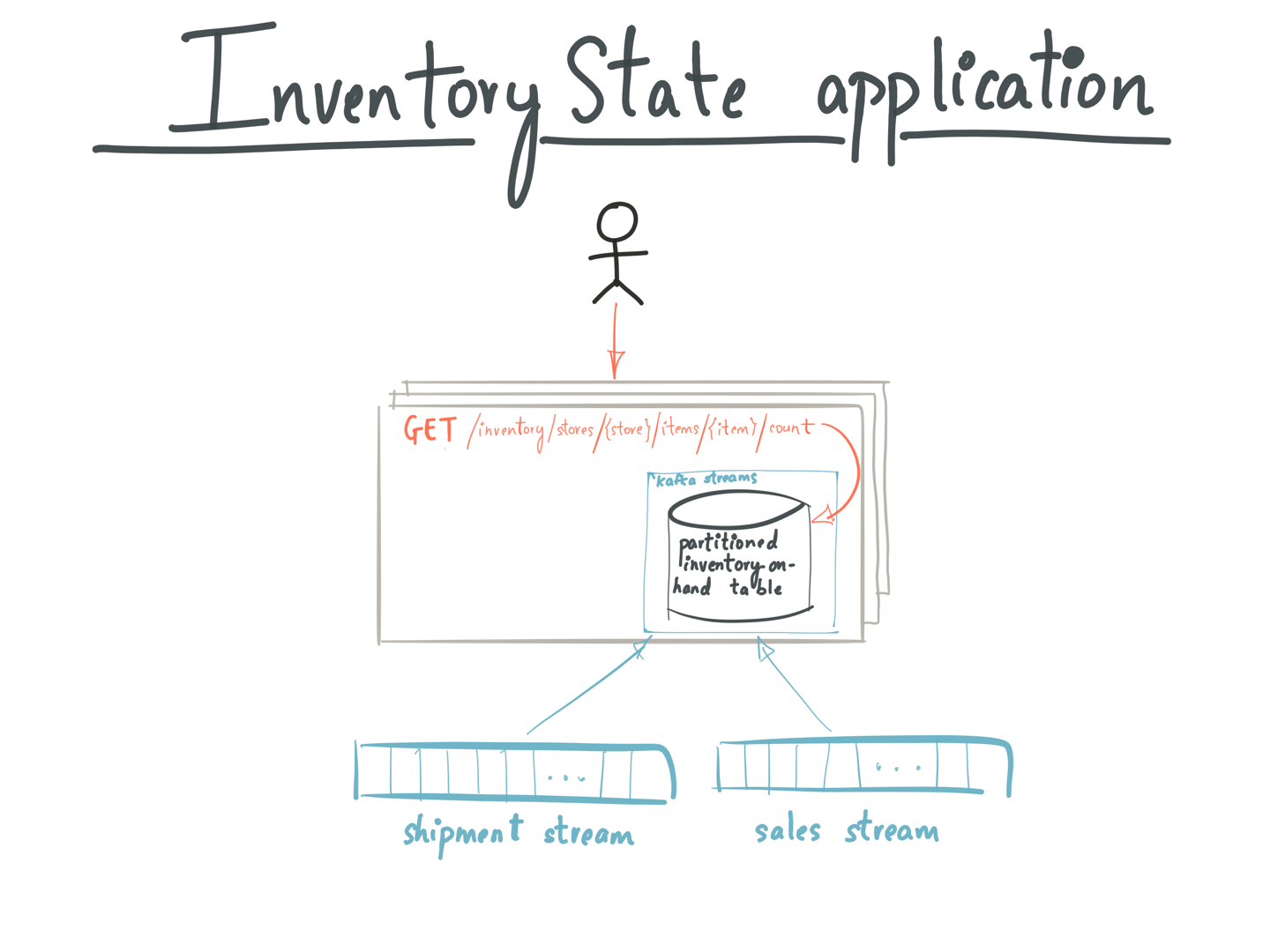
在Kafka Streams中使用交互式查询的InventoryState应用程序
要了解有关“交互式查询”功能的更多信息,请阅读其文档。除了这些资源之外,请参阅Capital One的演示文稿,该演示文稿将在实践中应用本文中介绍的一些思想,并概述使用Kafka Streams的基于REST,事件源,CQRS和响应流处理的应用程序体系结构。
如上例所示,存储和查询本地状态对于某些有状态应用程序可能没有意义。有时,您想将状态存储在您知道并信任的外部数据库中。例如,在上面的示例中,您可以使用Kafka Streams通过join操作来计算库存数量,但选择将结果写入外部数据库并查询。
但是,值得注意的是,构建具有查询本地状态的有状态应用程序有许多优点,如本文前面所述。
结论性思想
事件寻源为应用程序使用零损失协议记录其固有的不可避免的状态变化提供了一种有效的方法。这意味着恢复既简单又高效,因为它完全基于日记或像Kafka这样的有序日志。 CQRS更进一步,将原始事件变成可查询的视图;精心形成的与其他业务流程相关的视图。 Kafka的Streams API提供了以流方式创建这些视图所需的声明性功能,以及可扩展的查询层,因此用户可以直接与此视图进行交互。结果是在Apache Kafka上构建了适用的基于事件源和CQRS的应用程序体系结构;允许此类应用程序还利用Kafka的核心竞争力-性能,可伸缩性,安全性,可靠性和大规模采用。
最重要的是,以这种方式构建有状态的应用程序可使组织最终获得松散耦合的应用程序体系结构-一种具有弹性和可伸缩性,更易于故障排除和升级的应用程序体系结构,最重要的是,该体系结构具有前向兼容性。
对更多感兴趣?
如果您喜欢本文,则可能需要继续使用以下资源,以了解有关Apache Kafka上流处理的更多信息:
- 使用Apache Kafka的流SQL引擎KSQL入门,并遵循Stream Processing Cookbook中的各种教程和示例快速入门。
- 开始使用Kafka Streams API来构建自己的实时应用程序和微服务。
- 观看我们的分为三部分的在线讲座系列,了解KSQL如何工作的来龙去脉,并学习如何有效地使用它来执行监视,安全性和异常检测,在线数据集成,应用程序开发,流ETL等。
- 通过Docker浏览有关Kafka Streams API的Confluent教程,并使用我们的Confluent演示应用程序。
原文:https://www.confluent.io/blog/event-sourcing-cqrs-stream-processing-apache-kafka-whats-connection/
本文:https://pub.intelligentx.net/node/788
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 296 次浏览
【事件驱动架构】事件管理状态
虽然事件驱动架构的主要关注点是处理事件,但在某些情况下,您需要将事件保留用于后处理和其他应用程序的查询。事件主干具有内置事件日志,可用于存储和回复发布到主干的事件。但是,考虑到事件驱动解决方案的全部范围,可以支持其他用例和商店类型:
- 针对分析进行了优化的事件存储
- 事件源作为记录跨分布式系统的状态更改和更新的模式
- 命令查询响应分离(CQRS)作为一种优化,可以跨不同的存储区分更新和读取
当系统状态发生变化时,应用程序会发出有关状态更改的通知事件。任何有兴趣的人士都可以成为活动的消费者并采取必要的行动。状态更改事件按时间顺序存储在事件日志或事件存储中。事件日志或商店成为事实的主要来源。通过在将来的任何时间重新处理事件,可以将系统状态重新创建到某个时间点。状态变化的历史成为业务的审计记录,并且通常是数据科学家获取业务洞察力的有用数据来源。

在某些情况下,事件源模式通过使用事件日志和Kafka流完全在事件主干内实现。但是,您还可以考虑使用外部事件存储来实现模式,该存储提供了如何访问和使用数据的优化。例如,IBM®Db2®EventStore可以提供连接到主干的处理程序和事件存储,并为数据的下游分析处理提供优化。
在操作中,事件存储将按时间顺序保留具有时间戳的对象的所有状态更改事件,从而为对象创建时间序列的更改。您可以通过重播时间系列中的事件来派生对象的当前状态。事件存储只需要存储三条信息:
- 事件或聚合的类型
- 事件的序列号
- 数据作为序列化blob
您可以添加更多数据来帮助进行诊断和审计,但核心功能只需要一组很小的字段。这种方法导致数据设计可以大大优化,以便附加和检索记录序列。
命令查询责任分离(CQRS)
事件日志会导致更多工作来支持业务查询,因为它需要将事件转换为适合查询的应用程序状态。
CQRS应用模式经常与事件源有关。在此模式中,您将命令操作与查询/读取操作分开。使用事件源模式和CQRS,您通常会得到一种模式,其中更新作为状态通知事件(状态更改)完成。这些事件将保留在事件日志或存储中。在读取方面,您可以将状态保留在针对其他应用程序可能查询或读取数据的方式进行优化的不同存储中。

事件溯源,CQRS和微服务
随着微服务的采用,你有一个明确分离的状态,以便微服务与自己的状态有关。此外,通过使用事件源,您可以创建难以查询的历史记录日志。当您需要实现需要从多个服务加入数据的查询时,就会遇到挑战。要解决服务编排问题,您可以使用API组合或CQRS模式。
对于API组合,查询由与所有其他微服务集成的操作支持,并且可能转换数据以组合结果。使用此模式,您需要评估聚合要求,因为它们可以显着影响性能。您可能需要评估此API组合组件的放置位置。该组件可以是API网关,后端前端(BFF)的一部分,甚至是它自己的微服务。
另一个答案是实现CQRS模式,其中状态更改由相关业务对象作为事件发布。每个更改都保留在事件日志或事件存储中,更高级别的操作将订阅每个事件,并将数据保留在可查询数据存储中。
下一步是什么
阅读有关CQRS模式的更多信息。
讨论;加入知识星球【首席架构师圈】
- 59 次浏览
【事件驱动架构】事件驱动的云原生应用程序
事件驱动的体系结构必须跨越您的应用程序平台。开发人员构建与事件交互的应用程序,并且应用程序是事件驱动的。也就是说,它们都通过使用事件主干来生成和使用事件。在这种情况下,将事件主干视为微服务网格的一部分,提供微服务之间的发布和订阅通信,并支持松散耦合的事件驱动的微服务。
微服务是云原生平台上的首选应用程序架构。随着企业成为事件驱动,事件驱动模式需要扩展到您的微服务应用程序中。您的微服务仍在对着名的微服务进行REST调用。但是,他们必须回应并发送事件。在事件驱动的条件下,他们需要成为事件生产者和消费者来强制解耦。
事件主干:微服务的发布和订阅通信和数据共享
随着微服务的采用,对服务之间同步通信的关注正在增加。服务网格包(如Istio)可帮助您管理此同步通信环境中的通信,服务发现,负载平衡和可见性。
利用事件驱动的微服务,通信点成为事件主干的发布 - 订阅层。通过采用基于事件的方法实现微服务之间的相互通信,微服务应用程序自然响应(事件驱动)。这种方法增强了微服务的松散耦合性质,因为它使生产者和消费者脱钩。它还可以通过事件日志跨微服务共享数据。
在开发微服务应用程序时,这些事件类型特征是越来越重要的考虑因素。实际上,微服务应用程序是同步API驱动和异步事件驱动通信方式的组合。从实现视图中,使用一组已建立的模式,例如每服务数据库,事件源,命令查询责任分离(CQRS)和Saga。

带容器的事件驱动应用程序
虽然使用IBM®CloudFunctions的无服务器方法提供了简化的基于事件的编程模型,但大多数微服务应用程序是为基于容器的云原生堆栈开发和部署的。在云原生景观中,Kubernetes是容器编排的标准平台,也是事件驱动架构中容器平台的基础。
事件主干是用于微服务的共享数据的发布 - 订阅通信提供者和事件日志。在这种情况下,微服务是通过使用主题开发为骨干事件的直接消费者和生产者。此环境中的额外工作是管理消费者实例以响应事件流的需求。您必须确定需要运行多少消费者微服务实例才能跟上或始终可用于运行微服务以响应到达事件。
事件驱动的微服务模式
采用发布和订阅作为微服务通信骨干至少涉及以下模式:
- 通过子域分解:事件驱动的微服务仍然是微服务,因此您需要找到它们。域驱动子域的使用是识别和分类业务功能的一种好方法,因此也就是微服务。使用事件风暴方法,聚合有助于找到那些负责的子域。
- 每个服务一个数据库:此模式强制每个服务私有地保留数据,并且只能通过其API访问。
- Saga模式:微服务在其控制范围内发生某些事件时发布事件,例如他们负责的业务实体中的更新。对其他业务实体感兴趣的微服务订阅这些事件,并且当微服务接收到这样的事件时可以更新其自己的状态和业务实体。业务实体密钥必须是唯一且不可变的。
- 事件溯源:此模式将业务实体的状态保持为一系列状态改变事件。
- CQRS有助于将查询与命令分开,并解决具有跨微服务边界的查询。
其他考虑因素
- 业务事务跨越服务,并且是一系列步骤。每个步骤都由微服务支持,微服务负责更新自己的实体,从而最终实现数据的一致性。
- 事件主干必须保证事件至少传递一次。微服务负责管理它们与流源的偏移量,并通过检测重复事件来处理不一致性。
- 在微服务级别,更新数据和发出事件需要是原子操作,以避免在更新数据源之后和事件发出之前服务失败时的不一致。此操作可以通过向微服务数据源添加eventTable并使事件发布者定期读取此表并在发布时更改事件的状态来完成。另一种解决方案是让数据库事务日志读取器或挖掘器负责在日志中的新行上发布事件。
- 另一种避免两阶段提交和不一致的方法是使用事件存储或事件源模式来跟踪业务实体上的操作,并使用足够的数据来重建数据。事件正在成为描述业务实体状态变化的事实。
下一步是什么
-
Take the Deploy a microservices app on IBM Cloud by using Kubernetes tutorial.
-
Get answers to your questions about IBM Cloud Kubernetes Service: Manage apps in containers and clusters on cloud.
讨论:加入知识星球【首席架构师圈】
- 116 次浏览
【事件驱动架构】事件驱动的参考架构
云原生事件驱动架构必须至少支持以下功能:
- 通讯和持久化事件
- 对事件采取直接行动
- 处理事件流以获得洞察力和智能
- 提供事件驱动的微服务和功能之间的通信
在事件驱动的参考架构中,事件主干提供组件之间的连接:

原文:https://www.ibm.com/cloud/garage/architectures/eventDrivenArchitecture/reference-architecture
讨论: 加入右边知识星球【首席架构师圈】
- 159 次浏览
【事件驱动架构】事件骨干
事件主干是事件驱动架构的中心。骨干为事件通信和持久层提供了以下功能:
- 事件生成者和使用者之间的发布和订阅事件通信
- 用于在特定时间段内保留事件的事件日志
- 重播事件
- 来自消费者的订阅
事件主干是事件驱动架构中的通信层。它提供事件驱动功能之间的连接。在云原生架构中,它成为事件驱动的微服务的发布 - 订阅通信层。
事件主干可以使用两种类型的相关技术:消息代理和事件日志。您可以使用两种技术类型通过使用发布和订阅模型来实现事件通信样式。但是,请考虑事件驱动解决方案中经常使用的其他功能:
- 事件记录为时间顺序“事件发生”记录事件(事实来源)
- 直接重播事件
- 事件源作为记录分布式系统中状态变化的一种方式
- 以编程方式访问连续事件流
基于事件日志的技术可以提供支持所有这些更广泛功能的中央组件,而消息代理必须与其他组件一起扩展。

定义事件主干
这些功能对事件主干至关重要:
- 提供发布和订阅通信
- 支持许多消费者,作为共享的中心真理来源
- 存储事件一段时间(事件日志)
- 为历史演变应用程序实例提供历史事件的重播
- 提供对连续事件流数据的编程访问
- 具有高度可扩展性和对云部署级别的弹性
鉴于可用技术以及围绕这些技术的采用量和社区活动,Kafka可以成为事件主干的有效开源技术基础。 有关更多信息,请参阅Apache Kafka项目。
下一步是什么
Learn how to deploy real-time event processing and analytics on IBM Cloud Private by using a Kafka open source distribution or IBM Event Streams.
原文:https://www.ibm.com/cloud/garage/architectures/eventDrivenArchitecture/event-driven-event-backbone
讨论:加入知识星球【首席架构师圈】
- 74 次浏览
【事件驱动架构】从Apache Kafka消费者再平衡的渴望到更聪明
每个人都希望他们的基础设施具有高可用性,ksqlDB也不例外。但是,像高可用性这样的关键特性,必须经过深思熟虑和严格的设计才能实现。我们认真考虑了如何在保证最少一次和精确一次处理的同时实现这一点。要了解我们是如何做到这一点的,现在是时候剥开ksqlDB下面的层,用Apache Kafka®再平衡协议来动手了。
消费者团体和再平衡协议
Kafka消费者组协议允许独立的资源管理和负载平衡,这是任何分布式系统对于应用程序开发人员和操作人员都必须具备的。通过指定一个代理(Broker)作为组的联络点,可以在组协调器中隔离所有组管理,并允许每个使用者只关注使用消息的应用程序级工作。
组协调器最终负责跟踪两件事:订阅主题的分区和组中的成员。对这些内容的任何更改都要求该组作出反应,以确保所有主题分区都是由其使用的,并且所有成员都是积极使用的。因此,当它检测到这些变化时,组织协调者就会拿出它唯一的工具:消费者组再平衡。
再平衡的前提简单而自我描述。所有成员被告知重新加入组,当前资源被刷新并“平均地”重新分配。当然,每个应用程序都是不同的,这意味着每个消费群体也是不同的。“均匀”平衡的负载可能意味着不同的事情,甚至对于共享相同代理的两个使用者组的组协调器也是如此。认识到这一点,再平衡协议早就被推到客户端,并完全从组协调器中抽象化了。这意味着不同的Kafka客户端可以插入不同的再平衡协议。
这篇博客文章主要关注消费者客户端和构建在消费者客户端的Kafka Streams。Konstantine Karantasis在他的博客文章《Apache Kafka中的增量合作再平衡:当你可以改变世界时,为什么要停止它》中详细讨论了Kafka Connect的协议。
为了让客户指定一组没有通信用户所遵循的协议,将选择一个成员作为重新平衡的组长,然后再平衡将分两个阶段进行。在第一阶段,组协调器等待每个成员加入组。这需要发送一个恰当命名的JoinGroup请求,其中每个成员编码一个订阅,包括任何感兴趣的主题和客户端定义的用户数据。订阅由代理合并,并在JoinGroup响应中发送给组长。
leader解码订阅,然后计算并编码分配给每个使用者的分区。然后在leader的SyncGroup请求中发送给组协调器。这是重新平衡的第二阶段:所有成员必须向代理发送一个SyncGroup请求,然后代理在SyncGroup响应中向它们发送分区分配。在整个再平衡阶段,成员之间从不直接交流。它们只能通过与经纪端组协调器对话来相互传播信息。
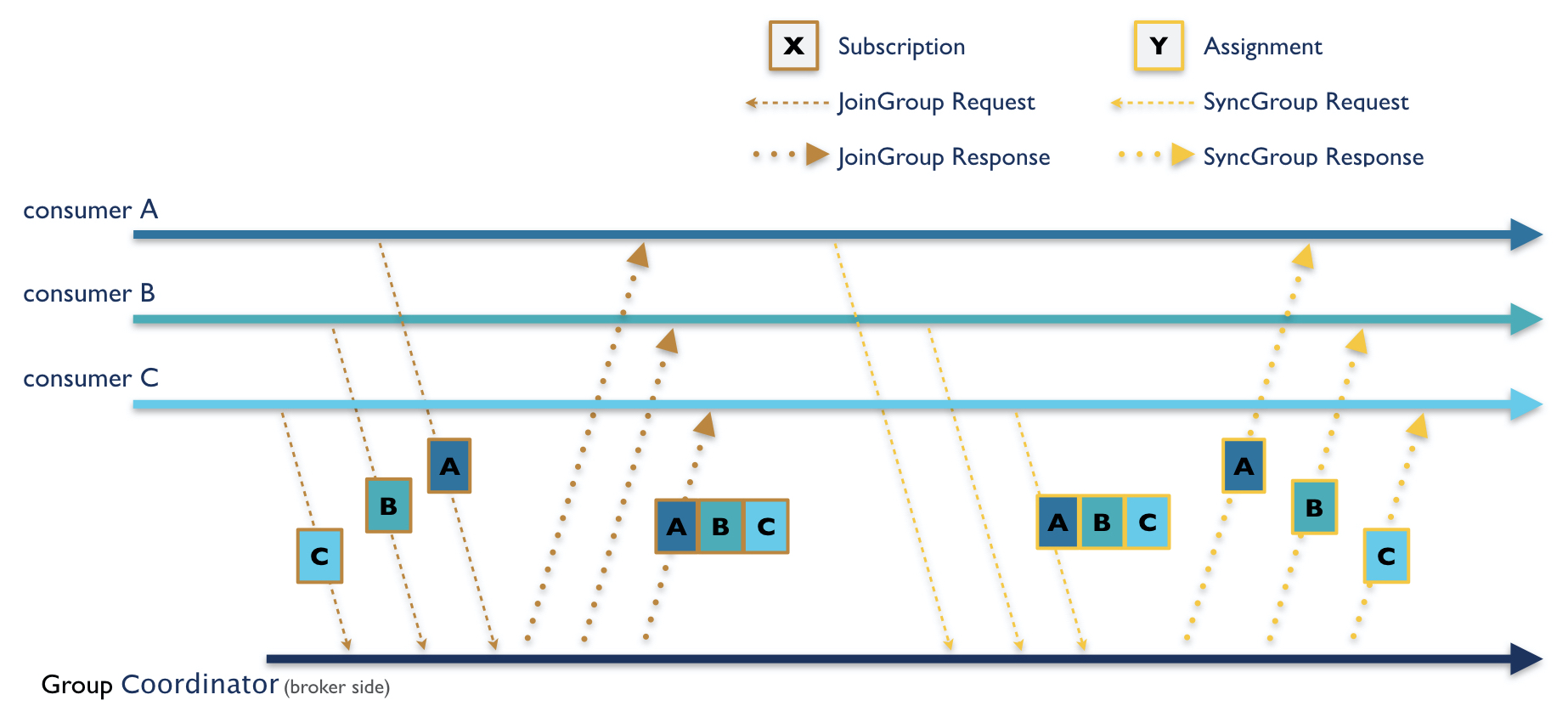
图1所示。有三个消费者的两阶段再平衡协议。在这种情况下,消费者C是组长。
使用者客户端进一步将给使用者的分区分配抽象为一个可插入的接口,称为ConsumerPartitionAssignor。如果分区转让者满足其消费者到所有分区的一对多映射契约,那么再平衡协议将负责其余的工作。这包括管理分区所有权从一个使用者到另一个使用者的转移,同时保证一个组中没有一个分区同时属于多个使用者。
这条规则听起来很简单,但在分布式系统中可能很难满足:“在同一时间”这个短语可能会在您的头脑中引起警报。
因此,为了使协议尽可能简单,迫切重新平衡协议诞生了:每个成员都需要在发送JoinGroup请求并参与重新平衡之前撤销其所有的分区。因此,该协议强制执行同步屏障;当JoinGroup响应被发送到leader时,所有的分区都是无主的,并且分区分配者可以自由地按照自己的意愿分配它们。
就安全性而言,这一切都是好的,但这个“停止世界”协议有严重的缺点:
- 在再平衡期间,该集团的任何成员都不能做任何工作
- 重新平衡持续时间随着分区计数的变化而变化,因为每个成员必须撤销并恢复分配的每个分区
每一个问题本身就已经够糟糕的了。综合起来,它们给消费者组协议的用户带来了一个严重的问题:在整个再平衡期间,所有分区和组的所有成员都将停机。这意味着从发送JoinGroup请求到接收SyncGroup响应,每个使用者都无所事事,如图2所示。
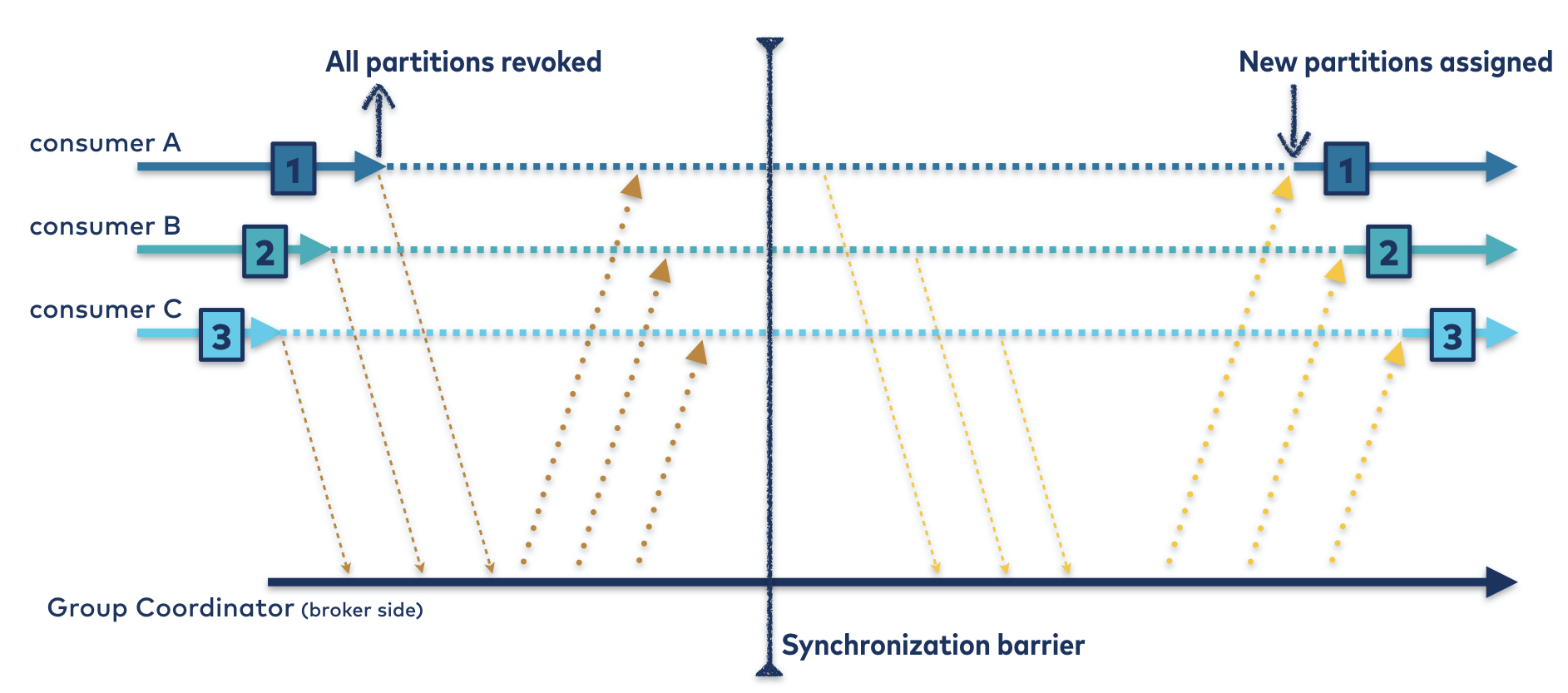
图2。迫切的再平衡协议。即使每个分区被重新分配给它的原始所有者,所有三个使用者都无法在虚线所指示的持续时间内使用分区。
虽然这在不经常重新平衡和资源很少的环境中是可以接受的,但大多数应用程序不属于这一类。我们已经做出了重大改进,减少了不稳定环境中不必要的再平衡。但只要有资源可管理,就需要重新平衡。也许我们可以通过更智能的客户端协议来减轻再平衡的痛苦。
理想的再平衡协议
要解决这个问题,请后退一步,问问在理想世界中最优的再平衡协议是什么样子的。设想一个没有节点故障、网络分区和竞争条件的世界——很好,对吗?现在考虑一下当组成员来来往往时重新分配分区的最简单方法。以这个特定的向外扩展的例子为例:
消费者A和B使用一个三分区主题。两个分区分配给A,一个分配给b。注意到负载不均匀,您决定添加第三个使用者。消费者C加入了这个群体。你希望这种再平衡如何发挥作用?
您所要做的就是将一个分区从消费者A移动到消费者c。所有三个消费者都必须重新加入组以确认它们的活动成员身份,但是对于消费者B来说,应该停止参与。在这个理想的世界中,使用者B没有理由停止处理它的分区,更不用说撤销和/或恢复它了。这意味着消费者B不会停机,如图3所示。
当然,消费者A必须撤销一个分区,但只有一个分区。一旦它放弃了它的第二个分区,它就可以愉快地返回来处理它的剩余分区。在整个重新平衡过程中,用户A并没有处于闲置状态,相反,它的停机时间只会持续到撤销一个分区所需的时间。
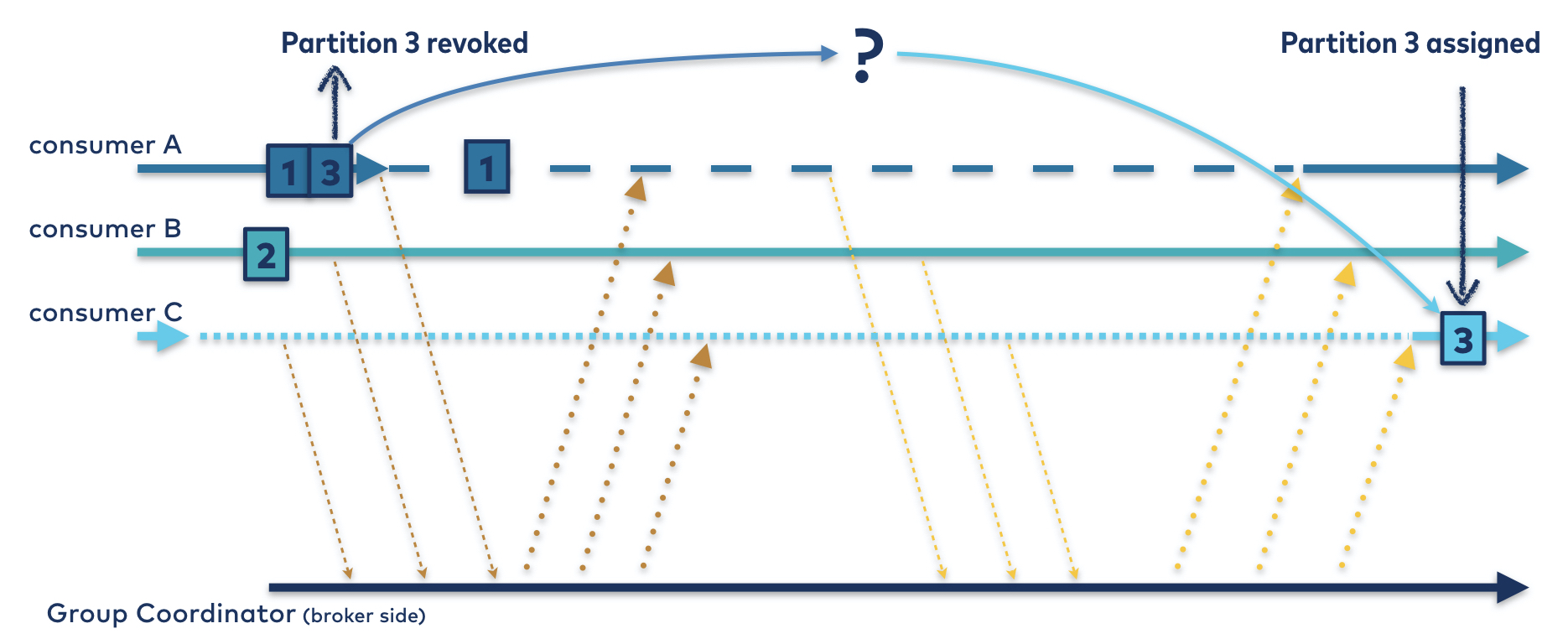
图3。你想要的再平衡协议。分区1和分区2被持续使用,分区3仅在将所有权从使用者A转移到C时停止工作。
总而言之,最佳再平衡只涉及那些需要移动以创建平衡分配的分区。您可以从最初的分配开始,并逐步移动分区以到达新的分配,而不是完全清除旧的分配以重新开始。
在理想世界和这里之间
不幸的是,回到现实世界的时候到了。消费者崩溃,不同步,拒绝合作。在这个美好的愿景完全消失之前,你所能希望的就是有一天能回来的具体计划。所以为什么不掸去旧地图绘制工具的灰尘,试着从你现在使用的渴望协议映射到一个更合作的协议呢?
要规划这一进程,你首先需要了解阻碍你前进的是什么。这又回到了上面介绍的规则:任何时候都不能有两个使用者声明同一分区的所有权。任何时候,只要放下同步屏障,就会面临风险。请记住,当前维护屏障的方法是强制所有成员在重新加入组之前撤销所有分区。
是不是太严格了?你大概可以猜到答案是肯定的。毕竟,这个障碍只需要对正在转移所有权的分区实施。重新分配给同一使用者的分区很容易满足该规则。其他分区则带来了挑战,因为使用者事先不知道他们的哪些分区将被重新分配到其他地方。显然,它们必须等待分区转让者确定分区到使用者的新映射。但是,一旦新的分配被发送到组的所有成员,同步就结束了。
如果要将一个分区从使用者a迁移到使用者B,那么B必须等待a放弃所有权后,B才能获得该分区。但是B无法知道A何时撤销了分区。请记住,吊销可以像从内存列表中删除分区那样简单,也可以像提交偏移量、刷新磁盘和清除所有相关资源那样复杂。例如,Kafka Streams用户启动状态严重的应用程序时非常清楚撤销一个分区需要多长时间。
显然,您需要某种方法让使用者指示何时重新分配其旧分区是安全的。但消费者只能在再平衡期间进行沟通,而最近一次再平衡刚刚结束。
当然,没有法律说你不能连续进行两次再平衡。如果你能让每次再平衡都不那么痛苦,那么第二次再平衡听起来就没那么糟糕了。这能以某种方式杠杆化到你想去的地方吗?渴望实现再平衡的隧道尽头是否有一线光明?
增量合作再平衡协议
好消息!您已经拥有了形成安全可靠的再平衡协议所需的所有组件。让我们退后一步,看看这种新的合作再平衡。
与前面一样,所有成员必须先发送一个JoinGroup请求。但这次,每个人都可以保留自己所有的分区。每个使用者并不撤销它们,而是在其订阅中对它们进行编码并将其发送给组协调器。
组协调器组装所有订阅并将它们发回给组组长,与前面一样。leader按照自己的意愿将分区分配给使用者,但是它必须从分配中删除所有正在转移所有权的分区。转让人可以利用每个订阅中编码的拥有分区来实施该规则。
从那里,新的分配—减去当前拥有的任何将要撤消的分区—传递给每个成员。使用者接受当前分配的差异,然后撤销新分配中没有出现的分区。同样地,他们将在分配中添加任何新的分区。对于出现在新旧分配中的每个分区,它们不需要做任何事情。很少有再平衡需要在用户之间进行分区迁移,因此在大多数情况下,几乎不需要做任何事情。
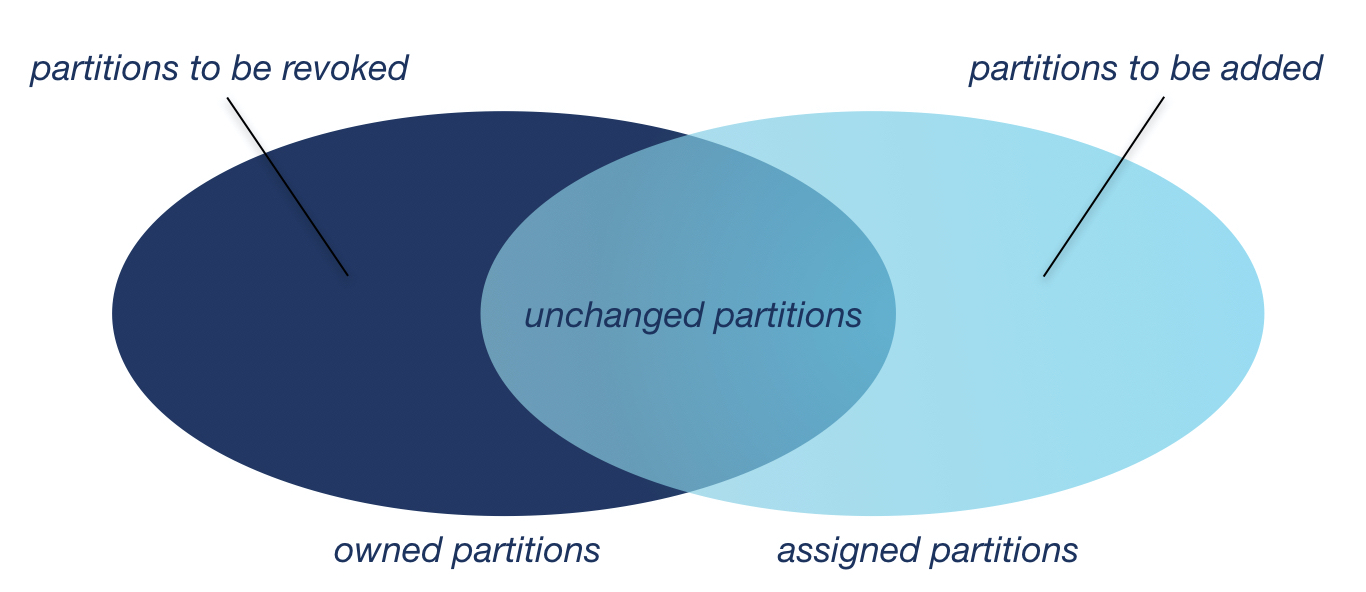
图4。分区的维恩图。既然可以撤销需要撤销的,为什么要撤销一切?
然后,被撤销分区的任何成员重新加入组,触发第二次再平衡,以便可以分配被撤销的分区。在此之前,这些分区是无主的和未分配的。同步障碍根本没有被消除;结果是,它只需要被移动。
在进行后续的再平衡时,所有已成功撤销的分区根据定义将不在已编码的拥有分区中。分割转让人可以自由地将它们分配给其合法的所有者。
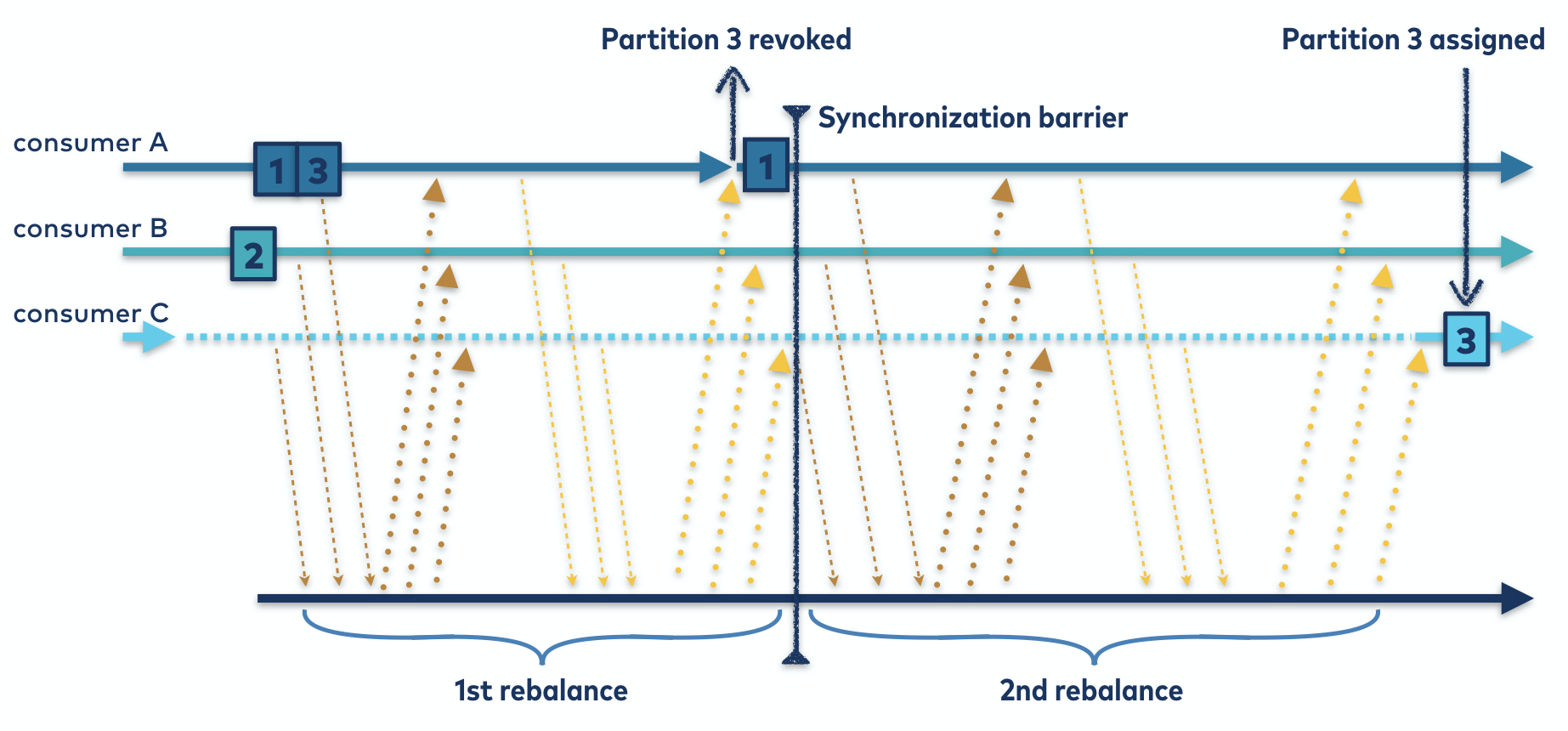
图5。合作再平衡协议。通过进行第二次再平衡以强制同步障碍,可以避免撤销所有使用者的所有分区。
DIY合作再平衡
您可能已经猜到,这取决于分区转让人来完成这项工作。不太明显的是,这只取决于分区转让者——您可以通过简单地插入一个协作转让者来开启协作再平衡。
幸运的是,工具箱中已经添加了一个新的开箱即用分区转让者:CooperativeStickyAssignor。你可能对现有的粘性分派很熟悉——CooperativeStickyAssignor更进一步,它既粘性又具有协作性。
我们引入这个assignor是为了使Apache Kafka中的协作再平衡像设置配置一样简单,而不需要引入另一个客户端配置。但更微妙的动机在于把它包装成一个粘性转让者。通过这样做,我们可以保证让与人很好地遵守合作协议。
这意味着什么?为什么它如此重要?以RoundRobinAssignor为例,它不能很好地发挥合作再平衡。每次组成员关系或主题元数据更改时,轮询调度转让者生成的分配都会更改。它不试图粘贴返回分区到它们以前的所有者。但请记住,这是一个渐进的合作再平衡协议。整个算法通过一个分区一个分区地让分配增量地从旧的分配到新的分配来工作。如果新的赋值与之前的完全不同,那么增量变化就是整个赋值。你只会回到你开始的那个热切的协议,但是有更多的重新平衡。
所以粘性和合作在新转让人中同样重要。而且,由于订阅中编码了拥有的分区,粘贴就像以前一样容易。
除了具有粘性外,CooperativeStickyAssignor还必须确保从分配中删除所有必须撤销的分区。任何声称支持合作协议的转让人都必须履行该合同。所以,如果你想自己动手做一个定制的合作转让人,你可以从零开始写一个,甚至改编一个老的渴望转让人;只要确保它符合新规定就行了。
对于那些希望通过实时升级或转让者交换切换到新协议的人,最后要警告的是:遵循推荐的升级路径。滚动升级将触发重新平衡,你不希望陷入一半人遵循旧协议,另一半人遵循新协议的中间。有关如何安全升级到协作再平衡的更多细节,请参阅发布说明。
你能在Kafka流DIY吗?
如果你是一个Kafka流用户并且已经做到了这一步,你可能会想知道这一切是如何影响你的。当您不能选择使用哪个分区转让人时,您如何使用这个新协议?
幸运的是,你不必这么做。重新平衡协议的管理和选择嵌入到StreamsPartitionAssignor中,现在在默认情况下打开协作重新平衡。您只需要启动应用程序并观察它的运行。事实上,你甚至不需要去看它——但是监控你的应用程序始终是一个很好的练习。
那么这对流意味着什么呢?为了理解什么发生了改变,什么没有,让我们跟随一个虚构的卡夫卡流开发者的冒险——叫他弗朗茨。Franz正在运行一个使用Kafka流2.3版本的应用程序。他的拓扑使用了许多本地状态存储,他的输入主题有数百个分区,并且他的应用程序依赖于交互查询(IQ)特性在处理期间查询这些状态存储中的数据。
事情似乎进展顺利,但由于负责任的监控,Franz注意到他的实例正在以最大容量运行。是时候扩大规模了。不幸的是,添加新实例需要整个组重新平衡。Franz很沮丧地看到,每个实例已经停止处理每个分区,并且在重新平衡期间交互查询被禁用。此外,再平衡需要很长时间,考虑到需要关闭和重新打开许多州商店和分区,这一点也不奇怪。但是,他们真的需要吗?
幸运的是,他看到Kafka 2.4引入了一个新的再平衡协议,他希望这将有所帮助。Franz升级了他的Streams应用程序,小心地遵循发布说明中列出的特定升级路径,以确保安全滚动升级到合作协议。一旦群体稳定下来,它就试图再次扩大规模。
这一次,情况好多了。并不是每个商店都关闭并重新开业,只有在新实例上的少数分区被撤销。Franz还发现IQ在所有运行的实例上都是可用的,并且那些仍然在恢复数据到其状态存储的实例能够在整个再平衡过程中继续这样做。备用副本还会继续使用其存储的changelog主题,这使它们有时间赶上活动副本,并在发生故障时用很少的恢复时间接管。
更妙的是,当Franz升级到Kafka的最新版本时,他发现即使是正在运行的活动任务也可以在整个平衡过程中继续处理新记录,并且整个应用程序一直保持运行。他不再被迫在扩展和避免应用程序范围内停机之间做出选择。
渴望与合作:谁赢了?
尽管合作进行再平衡有明显的优势,但具体数字总是有最后发言权。因此,我们运行了一个基准来定量地比较两种再平衡协议并确定赢家。
我们用10个实例运行了一个简单的有状态Kafka流应用程序的基准测试。为了模拟一个常见的重新平衡触发场景,我们在组达到稳定运行状态后执行滚动反弹。应用程序在一段时间内的总吞吐量如下所示。这里的吞吐量是用每秒处理的记录数来度量的,通过误差条对10个实例进行汇总,以反映它们的方差。单从吞吐量的下降就可以很明显地看出滚动反弹的开始和结束。
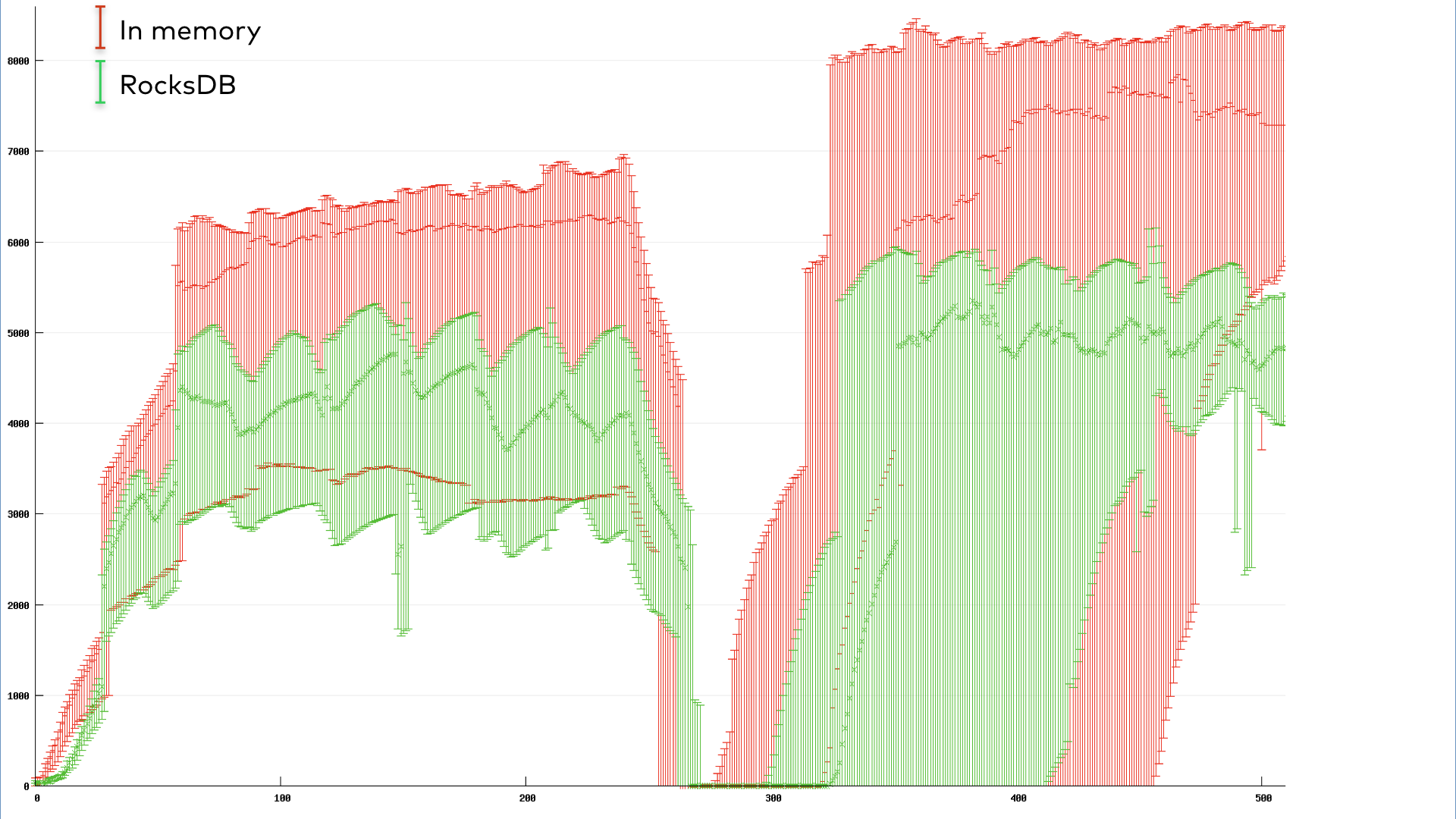
图6。吞吐量(记录/秒)与时间(秒)对于经历滚动反弹的10个实例的迫切再平衡流应用程序。
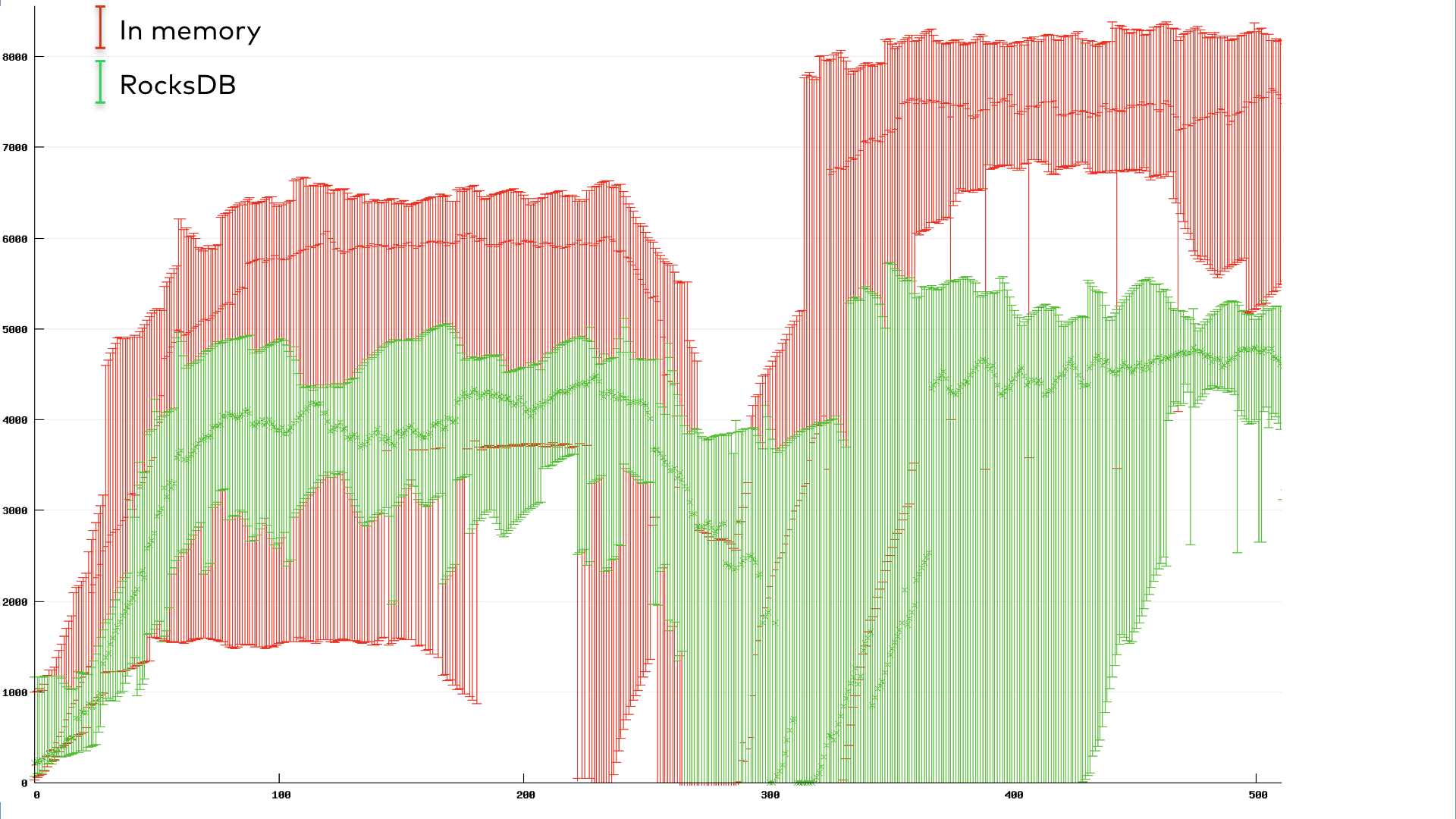
图7。吞吐量(记录/秒)与时间(秒)对一个10个实例的协作再平衡应用程序进行滚动反弹。
绿色对应使用默认rocksdb支持的状态存储的应用程序,而红色对应内存中存储。由于重新平衡开销,协作RocksDB应用程序在弹跳期间的吞吐量只有轻微下降。有趣的是,协作内存中的应用程序似乎在吞吐量上仍然受到很大的影响,尽管它的恢复速度确实比急切的情况要快。这反映了在选择备份状态存储时的一种内在权衡:内存中的存储在稳定状态下速度更快,但在重启时遭受更大的挫折,因为它必须将所有临时数据从changelog主题恢复到内存中。
图6和图7中的图形为合作协议提供了一个视觉上引人注目的情况。但数据同样惊人:eager协议的暂停时间为37138毫秒,而cooperative协议的暂停时间仅为3522毫秒。当然,数字会因情况而异。我们鼓励您在您的应用程序中尝试合作再平衡,并自己衡量差异。
结论
从一开始,停止世界的再平衡协议就困扰着Kafka客户端的用户,包括Kafka Streams和堆栈上的ksqlDB。但是,重新平衡对于有效、均匀地分配资源是至关重要的,随着越来越多的应用程序迁移到云上并需要动态伸缩,这种情况只会越来越普遍。在渐进式的合作再平衡中,这未必会造成伤害。
基本的协作再平衡协议是在Apache Kafka 2.4版本中引入的。在版本2.5中添加了轮询新数据和释放增量协作再平衡的全部力量的能力。如果您一直生活在频繁重新平衡的阴影下,或者担心向外扩展会导致停机,那么请下载Confluent平台,它构建在Kafka的最新版本之上。
改善Kafka流和管理大量状态的ksqlDB应用程序可用性的进一步工作即将到来。使用KIP-441,在切换新实例之前,我们将开始在新实例上预热任务,从而缩小另一个随状态量而增大的可用性差距。与增量的协作再平衡相结合,它将允许您启动真正可伸缩和高可用性的应用程序——即使在再平衡期间也是如此。
无论您是从头开始构建一个普通的消费者应用程序,还是使用Kafka流进行一些复杂的流处理,还是使用ksqlDB解锁新的强大用例,消费者组协议都是应用程序的核心。这使得ksqlDB应用程序能够伸缩并平稳地处理故障。偷窥背后的真相是很有趣的,但是再平衡协议最好的部分是你不必这样做。作为用户,您所需要知道的是,您的ksqlDB应用程序可以在不牺牲高可用性的情况下容错。
原文:https://www.confluent.io/blog/cooperative-rebalancing-in-kafka-streams-consumer-ksqldb/
本文:http://jiagoushi.pro/node/1117
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 130 次浏览
【事件驱动架构】何时使用RabbitMQ或Apache Kafka
如果你问自己是否Apache Kafka比RabbitMQ更好或RabbitMQ是否比Apache Kafka更可靠,我想在这里阻止你。本文将从更广泛的角度讨论这两种情况。它关注的是这两个系统提供的功能,并将指导您做出正确的决定,决定何时使用哪个系统。
web上的一些文章让Apache Kafka在RabbitMQ面前大出风头,而另一些文章则恰恰相反。我们中的很多人可能会因为听了大肆宣传,跟着人群跑而认罪。我觉得重要的是要知道是使用RabbitMQ还是Kafka取决于您项目的需求,只有当您在合适的场景中使用了正确的设置,才能进行真正的比较。
我和84codes在业界工作了很长时间,通过服务CloudAMQP为RabbitMQ提供托管解决方案,通过服务CloudKarafka为Apache Kafka提供托管解决方案。由于我已经看到了CloudAMQP和CloudKarafka用户的许多用例和不同的应用程序设置,我觉得我可以根据我的经验,在RabbitMQ和Apache Kafka上权威地回答用例问题。
在本文中,我的任务是根据多年来开发人员与开发人员之间的许多交谈来分享自己的见解,并试图传达他们关于为什么选择特定的message broker服务而不是其他服务的想法。
本文中使用的术语包括:
消息队列在RabbitMQ中是一个队列,而这个“队列”在Kafka中被称为日志,但是为了简化本文中的信息,我将一直使用队列而不是切换到“日志”。
卡夫卡的信息通常被称为记录,但是,为了简化这里的信息,我将再次提到信息。
当我在Kafka中撰写一个主题时,您可以把它看作是消息队列中的一个分类。卡夫卡主题被分成若干分区,这些分区以不变的顺序包含记录。
这两个系统都通过队列或主题在生产者和消费者之间传递消息。消息可以包含任何类型的信息。例如,它可以包含网站上发生的事件的信息,也可以是触发另一个应用程序上的事件的简单文本消息。
这种系统非常适合于连接不同的组件、构建微服务、实时数据流或将工作传递给远程工作者。
根据Confluent的数据,超过三分之一的财富500强公司使用Apache Kafka。各种大型行业也依赖于RabbitMQ,如Zalando、WeWork、Wunderlist和Bloomberg。
最大的问题;什么时候使用Kafka,什么时候使用RabbitMQ?
不久前,我在Stackoverflow上写了一个答案来回答这个问题,“有任何理由使用RabbitMQ而不是Kafka吗?”答案只有几行字,但它已经被证明是一个许多人发现有用的答案。
我将试着把答案分解成子答案,并试着解释每一部分。首先,我写道——“RabbitMQ是一个可靠的、成熟的、通用的消息代理,它支持一些协议,如AMQP、MQTT、STOMP等。RabbitMQ可以处理高吞吐量。它的一个常见用例是处理后台作业或充当微服务之间的消息代理。Kafka是一个消息总线优化的高接入数据流和重放。Kafka可以看作是一个持久的消息代理,应用程序可以在其中处理和重新处理磁盘上的流数据。
关于“成熟”一词;RabbitMQ在市场上出现的时间比Kafka(分别是2007年和2011年)要长。RabbitMQ和Kafka都是“成熟的”,这意味着它们都被认为是可靠的、可扩展的消息传递系统。
消息处理(消息重放)
这是他们之间的主要区别;与大多数消息传递系统不同,Kafka中的消息队列是持久的。发送的数据将一直存储到经过指定的保留期(一段时间或一个大小限制)为止。消息将一直停留在队列中,直到超过保留期/大小限制,这意味着消息被使用后不会被删除。相反,它可以被重放或多次使用,这是一个可以调整的设置。
在RabbitMQ中,消息被存储起来,直到接收应用程序连接并接收到队列外的消息。客户端可以在接收到消息或在完全处理完消息后ack(确认)消息。在任何一种情况下,一旦消息被处理,它就会从队列中删除。
如果您在Kafka中使用重播,请确保您使用它的方式和原因是正确的。将一个事件重复播放多次,而这个事件应该只发生一次;例如,如果您碰巧多次保存客户订单,在大多数使用场景中并不理想。当用户中存在需要部署新版本的bug,并且需要重新处理部分或全部消息时,重播就会派上用场了。
协议
我还提到了“RabbitMQ支持一些标准化协议,如AMQP, MQTT, STOMP等”,其中它本机实现AMQP 0.9.1。使用标准化消息协议允许您将RabbitMQ代理替换为任何基于AMQP的代理。
Kafka在TCP/IP之上使用自定义协议在应用程序和集群之间进行通信。Kafka不能被简单地移除和替换,因为它是唯一实现这个协议的软件。
RabbitMQ支持不同协议的能力意味着它可以在许多不同的场景中使用。
AMQP的最新版本与官方支持的0.9.1版本有很大不同。RabbitMQ不太可能偏离AMQP 0.9.1。该协议的1.0版本于2011年10月30日发布,但尚未获得开发人员的广泛支持。AMQP 1.0可通过插件使用。
路由
答案的下一部分是关于路由的,我写道:“Kafka有一个非常简单的路由方法。如果你需要以复杂的方式将消息传递给用户,RabbitMQ有更好的选择。”
RabbitMQ的主要优点是能够灵活地路由消息。直接或基于正则表达式的路由允许消息到达特定队列,而无需附加代码。RabbitMQ有四种不同的路由选择:直接、主题、扇出和头交换。直接交换路由消息到所有队列,这些队列与所谓的路由密钥完全匹配。扇形交换器可以向绑定到该交换器的每个队列广播一条消息。topics方法类似于direct,因为它使用一个路由键,但是允许通配符匹配和精确匹配。有关不同交换类型的更多信息可以在这里找到。
Kafka不支持路由;Kafka主题被划分为多个分区,这些分区以不变的顺序包含消息。您可以使用消费者组和持久主题来替代RabbitMQ中的路由,在该路由中,您将所有消息发送到一个主题,但让您的消费者组从不同的偏移量订阅。
您可以在Kafka streams的帮助下自己创建动态路由,即动态地将事件路由到主题,但这不是默认特性。
消息优先级
RabbitMQ支持所谓的优先队列,这意味着队列可以被设置为具有一系列优先级。可以在发布消息时设置每个消息的优先级。根据消息的优先级,它被放置在适当的优先级队列中。那么,什么时候可以使用优先队列呢?下面是一个简单的示例:我们每天都在为托管的数据库服务ElephantSQL运行数据库备份。数以千计的备份事件被无序地添加到RabbitMQ中。客户还可以按需触发备份,如果发生这种情况,我将一个新的备份事件添加到队列中,但具有更高的优先级。
在卡夫卡中,消息不能以优先级发送,也不能按优先级顺序发送。无论客户端有多忙,Kafka中的所有消息都按照接收它们的顺序存储和发送。
确认(提交或确认)
“确认”是在通信进程之间传递的信号,表示确认。,接收发送或处理的信息。
Kafka和RabbitMQ都支持生产者确认(RabbitMQ中的发布者确认),以确保发布的消息已安全到达代理。
当节点向使用者传递消息时,它必须决定是否应将该消息视为由使用者处理(或至少是接收)。客户端可以在接收到消息时或在客户端完全处理完消息后进行ack。
RabbitMQ可以考虑发送出去的消息,也可以等待使用者在收到消息后手动确认。
Kafka为分区中的每条消息维护一个偏移量。提交的位置是保存的最后一个偏移量。如果进程失败并重新启动,这是它将恢复到的偏移量吗?Kafka中的使用者既可以定期地自动提交偏移量,也可以选择手动控制提交的位置。
在不同版本的Apache Kafka中,Kafka是如何记录哪些被使用了,哪些没有被使用的。在早期版本中,使用者跟踪偏移量。
当RabbitMQ客户端不能处理消息时,它也可以nack(否定确认)消息。消息将被返回到它来自的队列中,就像它是一个新消息一样;这在客户端出现临时故障时非常有用。
如何处理队列?
RabbitMQ的队列在空的时候是最快的,而Kafka被设计用来保存和分发大量的消息。Kafka用很少的开销保留大量的数据。
尝试RabbitMQ的人可能没有意识到惰性队列的特性。惰性队列是将消息自动存储到磁盘的队列,从而最大限度地减少RAM的使用,但延长了吞吐量时间。根据我们的经验,惰性队列创建了更稳定的集群,具有更好的预测性能。如果你要一次发送很多消息(例如处理批处理任务),或者你认为你的用户跟不上发布者的速度,我们建议你启用惰性队列。
扩展
扩展是指增加或减少系统容量的过程。RabbitMQ和Kafka可以以不同的方式伸缩,你可以调整消费者的数量,代理的能力或者向系统中添加更多的节点。
消费者扩展
如果发布速度更快,那么就可以使用RabbitMQ,那么队列将开始增长,最终可能会产生数百万条消息,最终导致RabbitMQ耗尽内存。在这种情况下,您可以扩展处理(消费)您的消息的消费者数量。RabbitMQ中的每个队列可以有许多使用者,而这些使用者都可以“竞争”使用来自队列的消息。消息处理分布在所有活动的使用者中,因此在RabbitMQ中通过简单地添加和删除使用者就可以实现上下伸缩。
在Kafka中,分配使用者的方法是使用主题分区,其中组中的每个使用者专用于一个或多个分区。您可以使用分区机制按业务键(例如,按用户id、位置等)向每个分区发送不同的消息集。
扩展代理
我在stackoverflow的回答中写道;“Kafka是基于水平扩展(添加更多机器)的想法而建立的,而RabbitMQ主要是为垂直扩展(添加更多功能)而设计的。”答案的这一部分是提供有关运行Kafka或RabbitMQ的机器的信息。
在RabbitMQ中,水平伸缩并不总是提供更好的性能。通过垂直扩展(添加更多Power)可以获得最佳性能级别。在RabbitMQ中可以进行水平伸缩,但这意味着必须在节点之间建立集群,这可能会降低设置的速度。
在Kafka中,您可以通过向集群添加更多节点或向主题添加更多分区来扩展。这有时比像在RabbitMQ中那样在现有的机器中添加CPU或内存更容易。
许多人和博客,包括Confluent,都在谈论Kafka在缩放方面有多棒。当然,卡夫卡可以比RabbitMQ扩展得更远,因为对于你能买到的机器的强度总是有限制的。但是,在这种情况下,我们需要记住使用代理的原因。你可能有一个Kafka和RabbitMQ都可以支持的消息量,而没有任何问题,我们大多数人不会处理RabbitMQ耗尽空间的规模。
日志压缩
值得一提的是,在Apache Kafka中,RabbitMQ中不存在的一个特性是日志压缩策略。日志压缩确保Kafka始终保留单个主题分区队列中每个消息键的最后已知值。Kafka只是简单地保留消息的最新版本,并用相同的密钥删除旧版本。
日志压缩可以看作是使用Kafka作为数据库的一种方式。您可以将保留期设置为“永久”,或者对某个主题启用日志压缩,这样数据就会永久存储。
使用日志压缩的一个示例是,在数千个正在运行的集群中显示一个集群的最新状态。我们存储最终状态,而不是存储集群是否一直在响应。可以立即获得最新信息,比如队列中当前有多少条消息。
监控
RabbitMQ有一个用户友好的界面,让你监控和处理你的RabbitMQ服务器从一个网络浏览器。除了其他功能外,队列、连接、通道、交换器、用户和用户权限可以在浏览器中处理(创建、删除和列出),并且可以手动监控消息率和发送/接收消息。
对于Kafka,我们有很多用于监控的开源工具,也有一些商业工具,提供管理和监控功能。有关Kafka的不同监视工具的信息可以在这里找到。
推或拉
消息从RabbitMQ推送到使用者。配置预取限制以防止令使用者不堪重负(如果消息到达队列的速度比使用者处理它们的速度快)是很重要的。消费者也可以从RabbitMQ获取消息,但不推荐这样做。另一方面,Kafka使用拉取模型,如前所述,消费者从给定的偏移量请求一批消息。
许可证
RabbitMQ最初由Rabbit Technologies Ltd公司创建。该项目于2013年5月成为Pivotal Software的一部分。RabbitMQ的源代码是在Mozilla公共许可下发布的。牌照从未更改(截至2019年11月)。
Kafka最初是由LinkedIn创建的。2011年,它被授予开源地位,并移交给了Apache基金会。Apache Kafka受Apache 2.0许可证的保护。一些经常与Kafka组合使用的组件由另一个名为Confluent Community许可证所涵盖,例如Rest Proxy、Schema Registry和KSL。这个许可证仍然允许人们免费下载、修改和重新分发代码(非常像Apache 2.0所做的),但是它不允许任何人以SaaS的形式提供软件。
这两个许可证都是免费和开源软件许可证。如果Kafka再一次将许可证更改为更严格的东西,这就是RabbitMQ的优势所在,因为它可以很容易地被另一个AMQP经纪人取代,而Kafka不能。
复杂性
就我个人而言,我认为开始使用RabbitMQ更容易,并且发现它很容易使用。正如我们的一位客户所说;
“我们没有花任何时间学习RabbitMQ,它工作了很多年。在DoorDash的高速增长期间,它无疑降低了大量的运营成本。”Zhaobang Liu Doordash
在我看来,Kafka的架构带来了更多的复杂性,因为它从一开始就包含了更多的概念,比如主题/分区/消息偏移量等等。你必须熟悉消费者群体以及如何处理抵消。
作为Kafka和RabbitMQ操作符,我们觉得在Kafka中处理失败有点复杂。恢复或修复某些东西的过程通常更耗费时间,也更麻烦一些。
卡夫卡的生态系统
Kafka不仅仅是一个经纪人,它是一个流媒体平台,还有很多工具可以在主发行版之外很容易地与Kafka集成。Kafka生态系统由Kafka核心、Kafka流、Kafka连接、Kafka REST代理和模式注册表组成。请注意,Kafka生态系统的大多数附加工具都来自于Confluent,而不是Apache的一部分。
所有这些工具的好处是,您可以在需要编写一行代码之前配置一个巨大的系统。
Kafka Connect让您集成其他系统与Kafka。您可以添加一个数据源,允许您使用来自该数据源的数据并将其存储在Kafka中,或者相反,将主题中的所有数据发送到另一个系统进行处理或存储。使用Kafka Connect有很多可能性,而且很容易上手,因为已经有很多可用的连接器。
Kafka REST代理让您有机会从集群接收元数据,并通过简单的REST API生成和使用消息。可以从集群的控制面板轻松启用该特性。
常见用例——RabbitMQ vs Apache Kafka
关于一个系统能做什么或不能做什么,有很多信息。下面是两个主要用例,描述了我和我们的许多客户是如何考虑和决定使用哪个系统的。当然,我们也看到过这样的情况:客户在构建一个系统时,应该使用一个系统,而不是另一个系统。
RabbitMQ的用例
一般来说,如果您想要一个简单/传统的发布-订阅消息代理,那么RabbitMQ是一个明显的选择,因为它的规模很可能比您所需要的更大。如果我的需求足够简单,可以通过通道/队列来处理系统通信,并且不需要保留和流,我就会选择RabbitMQ。
我选择RabbitMQ主要有两种情况;对于长时间运行的任务,当我需要运行可靠的后台作业时。以及应用程序内部和应用程序之间的通信和集成。e作为微服务之间的中间人,系统只需通知系统的另一部分开始处理一项任务,比如在网上商店的订单处理(下订单、更新订单状态、发送订单、付款等)。
长时间运行的任务
消息队列支持异步处理,这意味着它们允许您在不立即处理消息的情况下将消息放入队列。RabbitMQ非常适合长时间运行的任务。
在我们的RabbitMQ初学者指南中可以找到一个例子,它遵循一个经典的场景,即一个web应用程序允许用户上传信息到一个web站点。该网站将处理这些信息,生成PDF,并通过电子邮件发送给用户。完成本例中的任务需要几秒钟,这就是为什么要使用消息队列的原因之一。
我们的许多客户让RabbitMQ队列充当事件总线,使web服务器能够快速响应请求,而不是被迫当场执行计算密集型任务。
以Softonic为例,他们https://www.cloudamqp.com/blog/2019-01-18 softonic-userstoryy-rabbitmq-eventbasedcommunication.html在一个每月支持1亿用户的基于事件的微服务体系结构中使用了RabbitMQ。
微服务架构中的中间人
RabbitMQ也被许多客户用于微服务体系结构,作为应用程序之间通信的一种方式,避免了传递消息的瓶颈。
例如,您可以阅读Parkster(一个数字停车服务)如何使用RabbitMQ将一个系统分解为多个微服务。
MapQuest是一个大方向服务,每月支持2310万独立移动用户。地图更新被发布到组织和公司的个人设备和软件上。这里,RabbitMQ主题分布在适当数量的队列上。数千万用户通过该框架接收到准确的企业级地图信息。
Apache Kafka的用例
通常,如果您需要一个用于存储、读取(重复读取)和分析流数据的框架,请使用Apache Kafka。它非常适合被审计的系统或需要永久存储消息的系统。这些也可以分解为两个主要用例,用于分析数据(跟踪、摄取、日志记录、安全等)或实时处理。
数据分析:跟踪、摄入、日志记录、安全
在所有这些情况下,需要收集、存储和处理大量的数据。需要洞察数据、提供搜索功能、审计或分析大量数据的公司证明使用Kafka是合理的。
据Apache Kafka的创建者说,Kafka最初的用例是跟踪网站活动,包括页面浏览、搜索、上传或用户可能采取的其他行动。这种类型的活动跟踪通常需要非常高的吞吐量,因为会为每个操作和每个用户生成消息。许多这些活动——实际上是所有的系统活动——都可以存储在Kafka中并根据需要进行处理。
数据生产者只需要将数据发送到单个位置,而后端服务主机可以根据需要使用数据。主要的分析、搜索和存储系统都与Kafka集成。
Kafka可以用来将大量的信息流传输到存储系统中,而且这些天硬盘空间的花费并不大。
实时处理
Kafka作为一个高吞吐量分布式系统;源服务将数据流推入目标服务,目标服务实时拉出数据流。
卡夫卡可以在系统处理许多生产者实时与少数消费者;例如,财务IT系统监控股票数据。
从Spotify到荷兰合作银行的流媒体服务通过Kafka实时发布信息。实时处理高吞吐量的能力增强了应用程序的能力。,使得这些应用程序比以往任何时候都更强大。
CloudAMQP在服务器设置的自动化过程中使用了RabbitMQ,但我们在发布日志和指标时使用了Kafka。
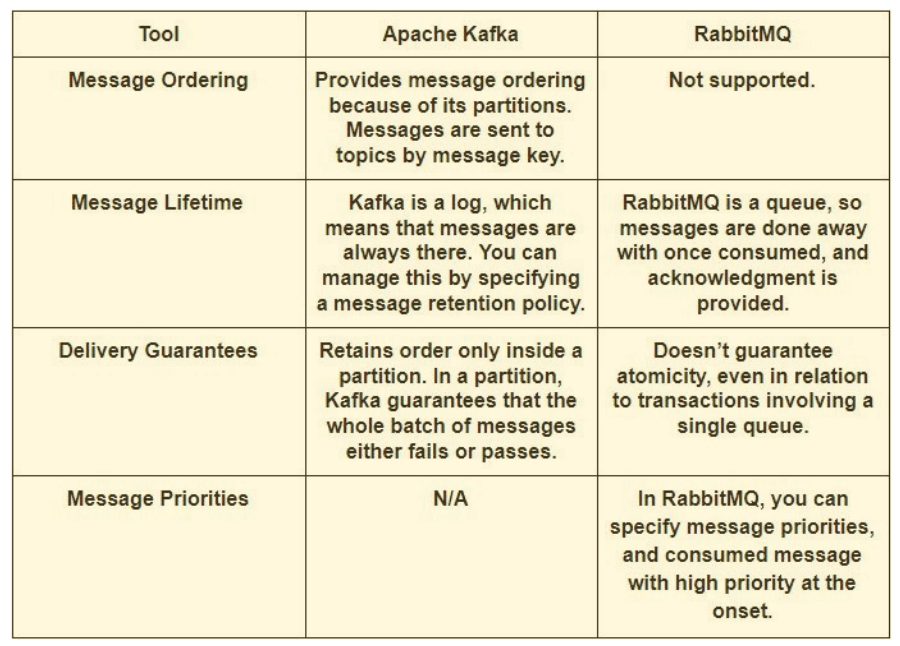
| RabbitMQ | Apache Kafka | |
|---|---|---|
| 是什么 | RabbitMQ是一种可靠、成熟、通用的消息代理 | Apache Kafka是一种为高接入数据流和重放而优化的消息总线 |
| 主要用途 | 用于应用程序内部和应用程序之间通信和集成的消息队列。用于长时间运行的任务,或需要运行可靠的后台作业时。 | 用于存储、读取(重复读取)和分析流数据的框架。 |
| 许可证 | 开放源码:Mozilla公共许可证 | 开放源码:Apache License 2.0 |
| Written in | Erlang | Scala (JVM) |
|
第一个版 本发布 |
2007 | 2011 |
| 持久性 | 持久化消息,直到在确认接收时丢弃它们为止 | 在保留期结束后保留带有要删除选项的消息 |
| 重播 | No | Yes |
| 路由 | 支持可将信息返回到使用者节点的灵活路由 | 不支持灵活的路由,必须通过单独的主题来完成 |
| 消息优先级 | Supported | Not supported |
| 监控 | 可通过内置UI使用 | 可以通过第三方工具使用,比如部署在CloudKarafka或通过Confluent |
| 语言支持 | 支持大多数语言 | 支持大多数语言 |
| 安全认证 | 支持标准认证和OAuth2 | 支持Kerberos、OAuth2和标准身份验证 |
原文:https://www.cloudamqp.com/blog/2019-12-12-when-to-use-rabbitmq-or-apache-kafka.html
本文:http://jiagoushi.pro/node/1187
讨论:请加入知识星球【首席架构师圈】或者加小号【jiagoushi_pro】或者QQ群【11107777】
- 164 次浏览
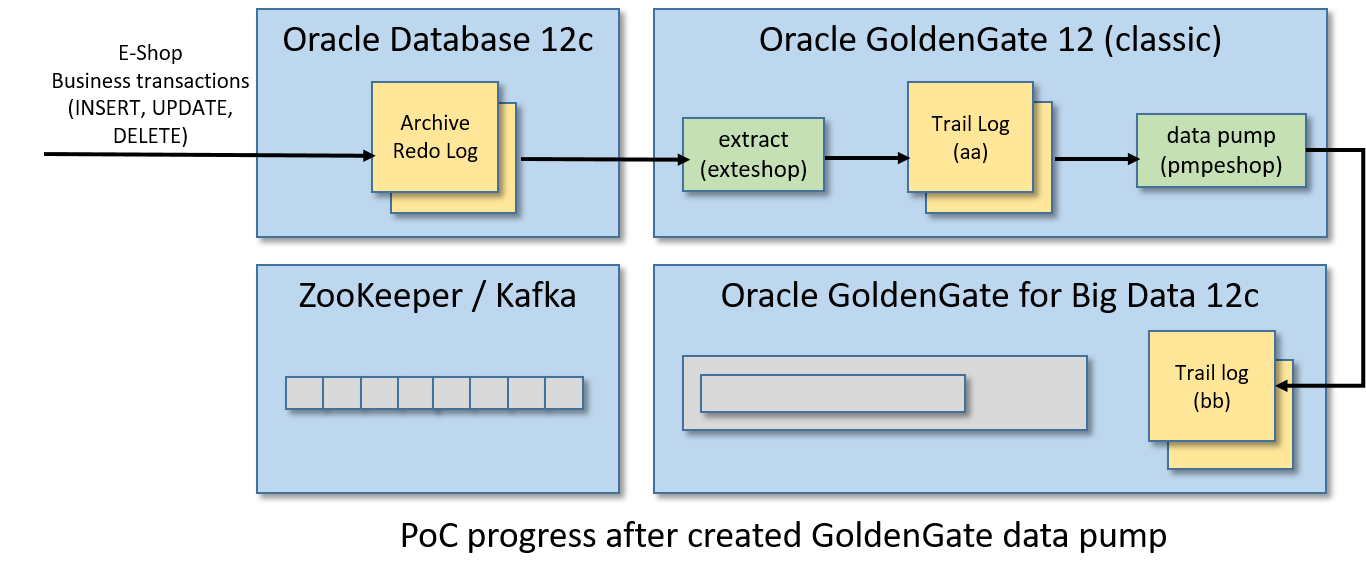
【事件驱动架构】使用GoldenGate创建从Oracle数据库到Kafka的CDC事件流
我们通过GoldenGate技术在Oracle DB和Kafka代理之间创建集成,该技术实时发布Kafka中的CDC事件流。
Oracle在其Oracle GoldenGate for Big Data套件中提供了一个Kafka连接处理程序,用于将CDC(更改数据捕获)事件流推送到Apache Kafka集群。
因此,对于给定的Oracle数据库,成功完成的业务事务中的任何DML操作(插入、更新、删除)都将转换为实时发布的Kafka消息。
这种集成对于这类用例非常有趣和有用:
- 如果遗留的单片应用程序使用Oracle数据库作为单一数据源,那么应该可以通过监视相关表的更改来创建实时更新事件流。换句话说,我们可以实现来自遗留应用程序的数据管道,而无需更改它们。
- 我们需要承认只有在数据库事务成功完成时才会发布Kafka消息。为了赋予这个特性,我们可以(始终以事务的方式)在一个由GoldenGate特别监视的表中编写Kafka消息,通过它的Kafka连接处理程序,将发布一个“插入”事件来存储原始的Kafka消息。
在本文中,我们将逐步说明如何通过GoldenGate技术实现PoC(概念验证)来测试Oracle数据库与Kafka之间的集成。
PoC的先决条件
我们将安装所有的东西在一个本地虚拟机,所以你需要:
- 安装Oracle VirtualBox(我在Oracle VirtualBox 5.2.20上测试过)
- 16 gb的RAM。
- 大约75GB的磁盘空间空闲。
- 最后但并非最不重要的是:了解vi。
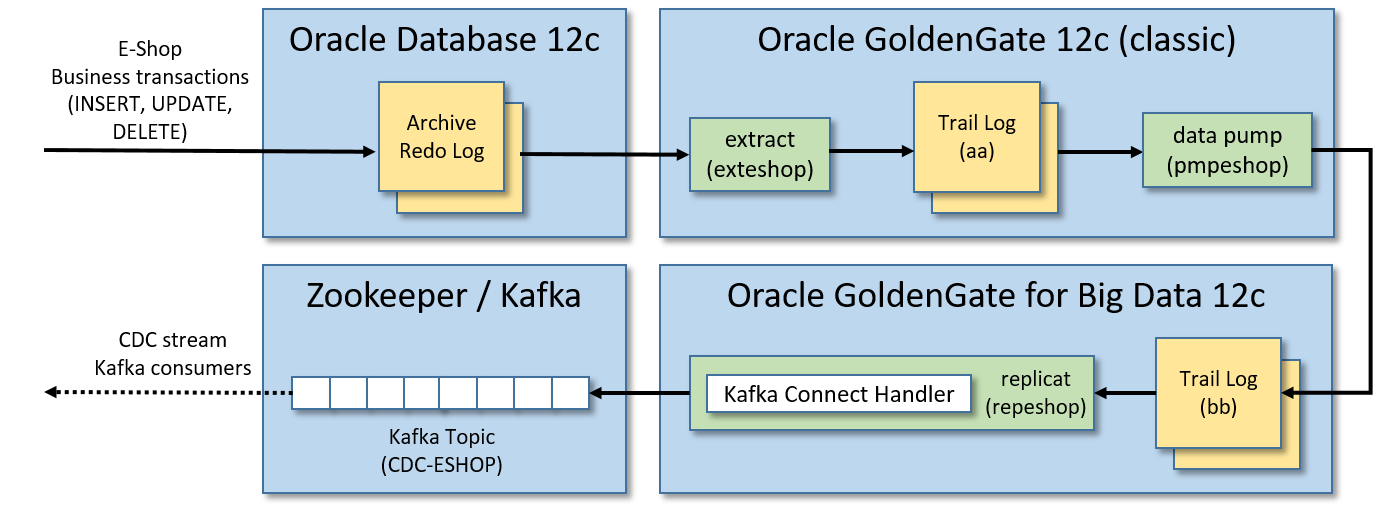
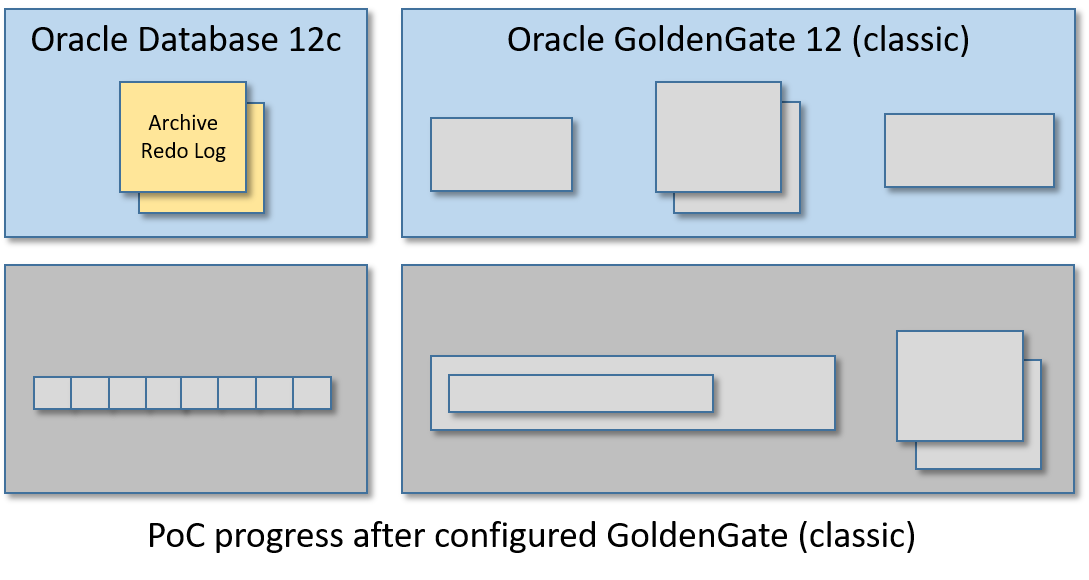
PoC架构
本指南将创建一个单一的虚拟机有:
- Oracle数据库12c:要监视的表存储在其中。
- Oracle GoldenGate 12c(经典版本):将应用于监视表的业务事务实时提取,以中间日志格式(trail log)存储,并将其输送到另一个GoldenGate(用于大数据)实例管理的远程日志。
- Oracle GoldenGate for Big Data 12c:pumped的业务事务并将其复制到Kafka消息中。
- Apache Zookeeper/Apache Kafka实例:在这里发布Kafka消息中转换的业务事务。
换句话说,在某些Oracle表上应用的任何插入、更新和删除操作都将生成Kafka消息的CDC事件流,该事件流将在单个Kafka主题中发布。
下面是我们将要创建的架构和实时数据流:
步骤1/12:启动Oracle数据库
您可以自由地安装Oracle数据库和Oracle GoldenGate手动。但幸运的是……)Oracle共享了一些虚拟机,这些虚拟机已经安装了所有的东西,可以随时进行开发。
Oracle虚拟机可以在这里下载,你需要一个免费的Oracle帐户来获得它们。
我使用了Oracle Big Data Lite虚拟机(ver)。4.11),它包含了很多Oracle产品,包括:
- Oracle数据库12c第一版企业版(12.1.0.2)
- Oracle GoldenGate 12c (12.3.0.1.2)
从上述下载页面获取所有7-zip文件(约22GB),提取VM映像文件BigDataLite411。在Oracle VirtualBox中双击文件,打开导入向导。完成导入过程后,一个名为BigDataLite-4.11的VM将可用。
启动BigDataLite-4.11并使用以下凭证登录:
- 用户:oracle
- 密码:welcome1
一个舒适的Linux桌面环境将会出现。
双击桌面上的“开始/停止服务”图标,然后:
- 检查第一项ORCL (Oracle数据库12c)。
- 不要检查所有其他的东西(对PoC无用且有害)。
- 按回车确认选择。
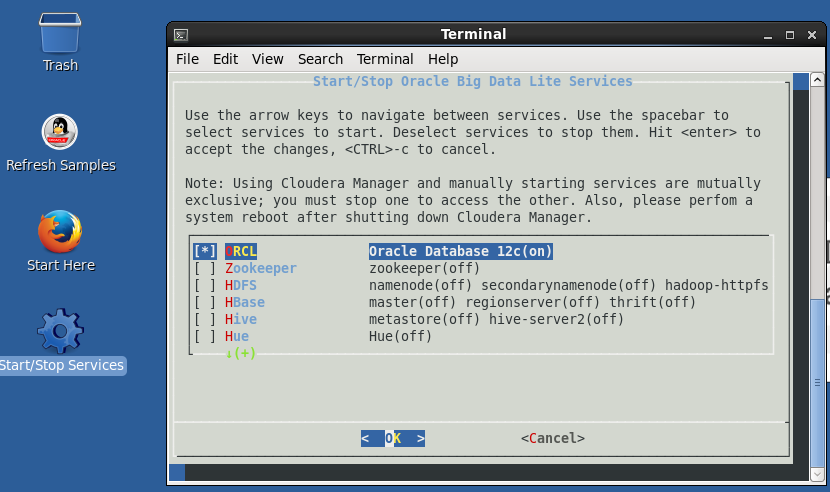
最后,Oracle数据库将启动。
当您重新启动虚拟机时,Oracle数据库将自动启动。
与下载的虚拟机有关的其他有用信息:
- Oracle主文件夹($ORACLE_HOME)是/u01/app/ Oracle /product/12.1.0.2/dbhome_1
- GoldenGate (classic)安装在/u01/ogg中
- SQL Developer安装在/u01/sqldeveloper中。您可以从上面工具栏中的图标启动SQL Developer。
- Oracle数据库是作为多租户容器数据库(CDB)安装的。
- Oracle数据库监听端口是1521
- 根容器的Oracle SID是cdb
- PDB(可插拔数据库)的Oracle SID是orcl
- 所有Oracle数据库用户(SYS、SYSTEM等)的密码都是welcome1
- 连接到PDB数据库的tnsname别名是ORCL(参见$ORACLE_HOME/network/admin/tnsnames)。ora文件内容)。
- Java主文件夹($JAVA_HOME)是/usr/java/latest
- $JAVA_HOME中安装的Java开发工具包是JDK8更新151。
步骤2/12:在Oracle中启用归档日志
我们需要在Oracle中启用归档日志来使用GoldenGate (classic)。
从VM的Linux shell中启动SQL Plus作为SYS:
sqlplus sys/welcome1 as sysdba
然后从SQL + shell运行这个命令列表(我建议一次启动一个):
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;ALTER DATABASE FORCE LOGGING;ALTER SYSTEM SWITCH LOGFILE;ALTER SYSTEM SET ENABLE_GOLDENGATE_REPLICATION=TRUE;SHUTDOWN IMMEDIATE;STARTUP MOUNT;ALTER DATABASE ARCHIVELOG;ALTER DATABASE OPEN;
然后检查存档日志是否成功启用:
ARCHIVE LOG LIST;
输出应该是这样的:
Database log mode Archive ModeAutomatic archival EnabledArchive destination USE_DB_RECOVERY_FILE_DESTOldest online log sequence 527Next log sequence to archive 529Current log sequence 529
步骤3/12:创建一个ggadmin用户
需要为GoldenGate (classic)创建一个特殊的Oracle管理员用户。
同样,从VM的Linux shell中打开SQL Plus:
sqlplus sys/welcome1作为sysdba
并通过运行这个脚本创建ggadmin用户:
ALTER SESSION SET "_ORACLE_SCRIPT"=TRUE;CREATE USER ggadmin IDENTIFIED BY ggadmin;GRANT CREATE SESSION, CONNECT, RESOURCE, ALTER SYSTEM TO ggadmin;EXEC DBMS_GOLDENGATE_AUTH.GRANT_ADMIN_PRIVILEGE(grantee=>'ggadmin', privilege_type=>'CAPTURE', grant_optional_privileges=>'*');GRANT SELECT ANY DICTIONARY TO ggadmin;GRANT UNLIMITED TABLESPACE TO ggadmin;
步骤4/12 -创建ESHOP模式
我们将创建一个模式(ESHOP),其中只有两个表(CUSTOMER_ORDER和CUSTOMER_ORDER_ITEM),用于生成要推送到Kafka中的CDC事件流。
使用SQL Plus(或者,如果您愿意,也可以使用SQL Developer)连接orcl作为SID的Oracle PDB:
sqlplus sys/welcome1@ORCL as sysdba
运行这个脚本:
-- init sessionALTER SESSION SET "_ORACLE_SCRIPT"=TRUE;-- create tablespace for eshopCREATE TABLESPACE eshop_tbs DATAFILE 'eshop_tbs.dat' SIZE 10M AUTOEXTEND ON;CREATE TEMPORARY TABLESPACE eshop_tbs_temp TEMPFILE 'eshop_tbs_temp.dat' SIZE 5M AUTOEXTEND ON;-- create user schema eshop, please note that the password is eshopCREATE USER ESHOP IDENTIFIED BY eshop DEFAULT TABLESPACE eshop_tbs TEMPORARY TABLESPACE eshop_tbs_temp;-- grant eshop user permissionsGRANT CREATE SESSION TO ESHOP;GRANT CREATE TABLE TO ESHOP;GRANT UNLIMITED TABLESPACE TO ESHOP;GRANT RESOURCE TO ESHOP;GRANT CONNECT TO ESHOP;GRANT CREATE VIEW TO ESHOP;-- create eshop sequencesCREATE SEQUENCE ESHOP.CUSTOMER_ORDER_SEQ START WITH 1 INCREMENT BY 1 NOCACHE NOCYCLE;CREATE SEQUENCE ESHOP.CUSTOMER_ORDER_ITEM_SEQ START WITH 1 INCREMENT BY 1 NOCACHE NOCYCLE;-- create eshop tablesCREATE TABLE ESHOP.CUSTOMER_ORDER (ID NUMBER(19) PRIMARY KEY,CODE VARCHAR2(10),CREATED DATE,STATUS VARCHAR2(32),UPDATE_TIME TIMESTAMP);CREATE TABLE ESHOP.CUSTOMER_ORDER_ITEM (ID NUMBER(19) PRIMARY KEY,ID_CUSTOMER_ORDER NUMBER(19),DESCRIPTION VARCHAR2(255),QUANTITY NUMBER(3),CONSTRAINT FK_CUSTOMER_ORDER FOREIGN KEY (ID_CUSTOMER_ORDER) REFERENCES ESHOP.CUSTOMER_ORDER (ID));
步骤5/12:初始化GoldenGate Classic
现在是时候在BigDataListe-4.11虚拟机中安装GoldenGate (classic)实例了。
从Linux shell运行:
cd /u01/ogg./ggsci
GoldenGate CLI(命令行界面)将启动:
Oracle GoldenGate Command Interpreter for OracleVersion 12.2.0.1.0 OGGCORE_12.2.0.1.0_PLATFORMS_151101.1925.2_FBOLinux, x64, 64bit (optimized), Oracle 12c on Nov 11 2015 03:53:23Operating system character set identified as UTF-8.Copyright (C) 1995, 2015, Oracle and/or its affiliates. All rights reserved.GGSCI (bigdatalite.localdomain) 1>
从GoldenGate CLI启动经理与以下命令:
start mgr
它将引导GoldenGate的主控制器进程(监听端口7810)。
现在创建一个凭据库来存储ggadmin用户凭据(并使用具有相同名称的别名来引用它们):
add credentialstorealter credentialstore add user ggadmin password ggadmin alias ggadmin
现在,通过使用刚才创建的ggadmin别名连接到Oracle数据库,并启用对存储在名为orcl的PDB中的eshop模式的附加日志:
dblogin useridalias ggadminadd schematrandata orcl.eshop
步骤6/12:制作金门果提取物
在此步骤中,我们将创建一个GoldenGate摘要,此过程将监视Oracle archive重做日志,以捕获与ESHOP表相关的数据库事务,并将此SQL修改流写入另一个名为trail log的日志文件中。
从GoldenGate CLI运行:
edit params exteshop
该命令将打开一个引用新空文件的vi实例。在vi编辑器中放入以下内容:
EXTRACT exteshopUSERIDALIAS ggadminEXTTRAIL ./dirdat/aaTABLE orcl.eshop.*;
保存内容并退出vi,以便返回GoldenGate CLI。
保存的内容将存储在/u01/ogg/dirprm/exteshop中。人口、难民和移民事务局文件。您也可以在外部编辑它的内容,而不需要再次从GoldenGate CLI运行“edit params exteshop”命令。
现在在Oracle中注册提取过程,从GoldenGate CLI运行以下命令:
dblogin useridalias ggadminregister extract exteshop database container (orcl)
最后一个命令的输出应该是这样的:
OGG-02003 Extract EXTESHOP successfully registered with database at SCN 13624423.
使用所示的SCN号来完成提取配置。从GoldenGate CLI:
add extract exteshop, integrated tranlog, scn 13624423add exttrail ./dirdat/aa, extract exteshop
现在我们可以启动名为exteshop的GoldenGate提取过程:
start exteshop
你可以使用以下命令中的on来检查进程的状态:
info exteshopview report exteshop
验证提取过程是否正常工作以完成此步骤。从Linux shell运行以下命令,用SQL Plus(或SQL Developer)连接到ESHOP模式:
sqlplus eshop / eshop@ORCL
创建一个模拟客户订单:
INSERT INTO CUSTOMER_ORDER (ID, CODE, CREATED, STATUS, UPDATE_TIME)VALUES (CUSTOMER_ORDER_SEQ.NEXTVAL, 'AAAA01', SYSDATE, 'DRAFT', SYSTIMESTAMP);INSERT INTO CUSTOMER_ORDER_ITEM (ID, ID_CUSTOMER_ORDER, DESCRIPTION, QUANTITY)VALUES (CUSTOMER_ORDER_ITEM_SEQ.NEXTVAL, CUSTOMER_ORDER_SEQ.CURRVAL, 'Toy Story', 1);COMMIT;
最后,从GoldenGate CLI跑出来:
stats exteshop
并验证前面的插入操作是否已计算在内。下面是stats命令输出的一个小示例:
Extracting from ORCL.ESHOP.CUSTOMER_ORDER to ORCL.ESHOP.CUSTOMER_ORDER:*** Total statistics since 2019-05-29 09:18:12 ***Total inserts 1.00Total updates 0.00Total deletes 0.00Total discards 0.00Total operations 1.00
检查提取过程是否正常工作的另一种方法是检查GoldenGate跟踪日志文件的时间戳。在Linux shell中运行“ls -l /u01/ogg/dirdat/”,并验证以“aa”开头的文件的时间戳已经更改。
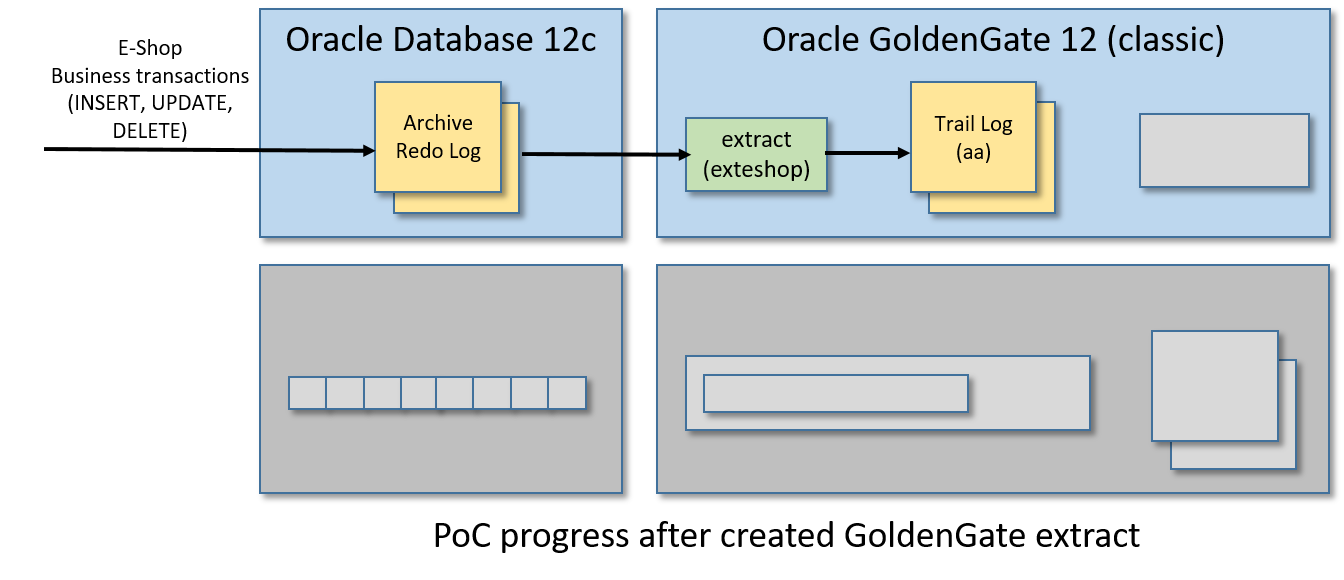
步骤7/12:安装并运行Apache Kafka
从VM的桌面环境中打开Firefox并下载Apache Kafka(我使用的是kafka_2.11-2.1.1.tgz)。
现在,打开一个Linux shell并重置CLASSPATH环境变量(在BigDataLite-4.11虚拟机中设置的当前值会在Kafka中产生冲突):
declare -x CLASSPATH=""
从同一个Linux shell中,解压缩压缩包,启动ZooKeeper和Kafka:
cdtar zxvf Downloads/kafka_2.11-2.1.1.tgzcd kafka_2.11-2.1.1./bin/zookeeper-server-start.sh -daemon config/zookeeper.properties./bin/kafka-server-start.sh -daemon config/server.properties
你可以通过启动“echo stats | nc localhost 2181”来检查ZooKeeper是否正常:
[oracle@bigdatalite ~]$ echo stats | nc localhost 2181Zookeeper version: 3.4.5-cdh5.13.1--1, built on 11/09/2017 16:28 GMTClients:/127.0.0.1:34997[1](queued=0,recved=7663,sent=7664)/0:0:0:0:0:0:0:1:17701[0](queued=0,recved=1,sent=0)Latency min/avg/max: 0/0/25Received: 8186Sent: 8194Connections: 2Outstanding: 0Zxid: 0x3fMode: standaloneNode count: 25
您可以检查Kafka是否与“echo dump | nc localhost 2181 | grep代理”(一个字符串/brokers/ids/0应该出现)
[oracle@bigdatalite ~]$ echo dump | nc localhost 2181 | grep brokers/brokers/ids/0
用于PoC的BigDataLite-4.11虚拟机已经在启动虚拟机时启动了一个较老的ZooKeeper实例。因此,请确保禁用了步骤1中描述的所有服务。
此外,当您打开一个新的Linux shell时,请注意在启动ZooKeeper和Kafka之前总是要重置CLASSPATH环境变量,这一点在步骤开始时已经解释过了。
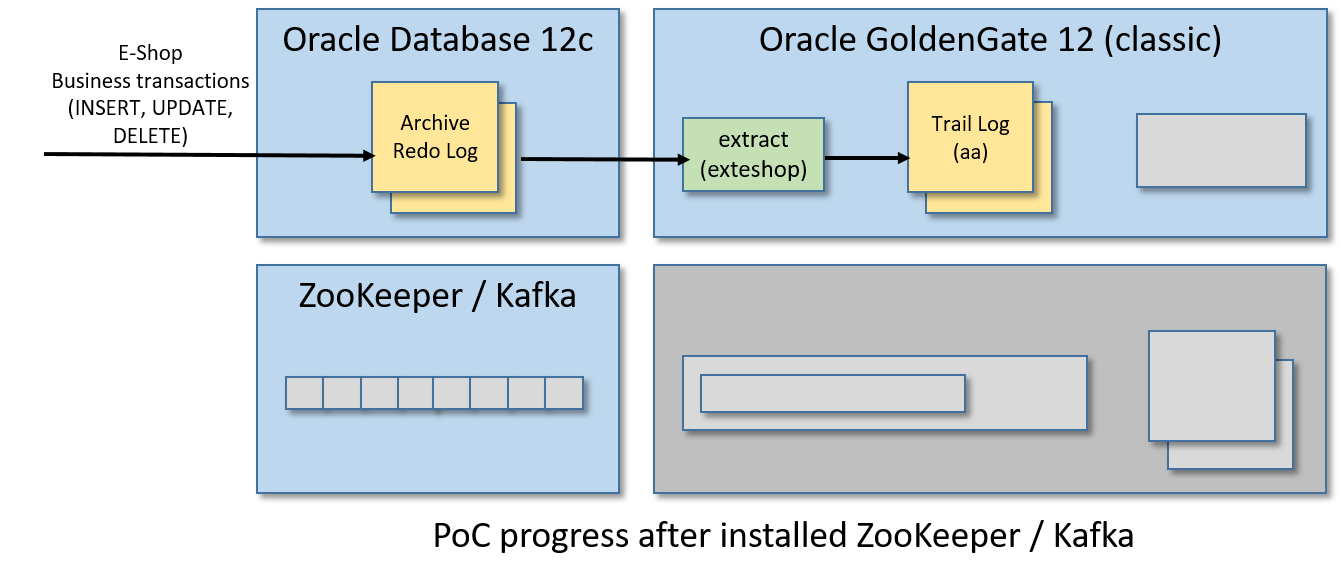
步骤8/12:为大数据安装GoldenGate
同样,从这个页面下载Oracle GoldenGate for Big Data 12c只需要使用VM中安装的Firefox浏览器(我在Linux x86-64上使用Oracle GoldenGate for Big Data 12.3.2.1.1)。请注意,您需要一个(免费)Oracle帐户来获得它。
安装很容易,只是爆炸压缩包内的下载:
cd ~/Downloadsunzip OGG_BigData_Linux_x64_12.3.2.1.1.zipcd ..mkdir ogg-bd-poccd ogg-bd-poctar xvf ../Downloads/OGG_BigData_Linux_x64_12.3.2.1.1.tar
就这样,GoldenGate for Big Data 12c被安装在/home/oracle/ogg-bd-poc文件夹中。
同样,BigDataLite-4.11虚拟机已经在/u01/ogg-bd文件夹中安装了用于大数据的GoldenGate。但它是一个较旧的版本,连接Kafka的选项较少。
步骤9/12:启动GoldenGate for Big Data Manager
打开大数据大门
cd ~/ogg-bd-poc./ggsci
需要更改管理器端口,否则之前启动的与GoldenGate (classic)管理器的冲突将被引发。
因此,从大数据的GoldenGate来看,CLI运行:
create subdirsedit params mgr
一个vi实例将开始,只是写这个内容:
PORT 27801
然后保存内容,退出vi,返回CLI,我们终于可以启动GoldenGate for Big Data manager监听端口27081:
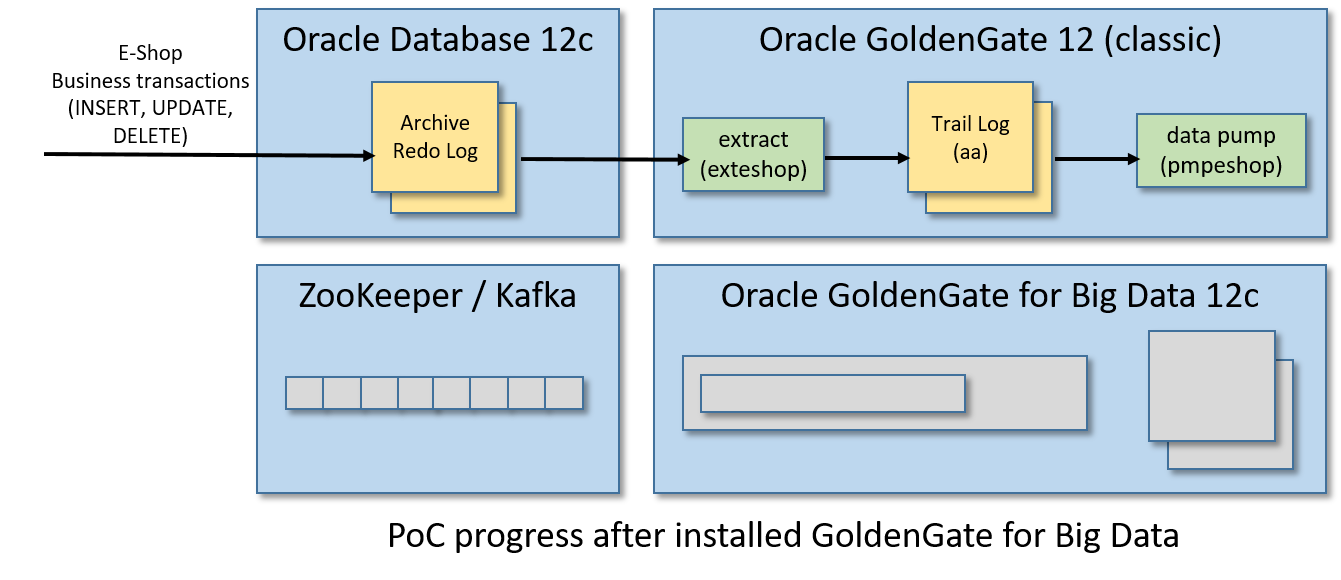
步骤10/12:创建数据泵(Data Pump)
现在,我们需要创建在GoldenGate世界中被称为数据泵的东西。数据泵是一个提取过程,它监视一个跟踪日志,并(实时地)将任何更改推到另一个由不同的(通常是远程的)GoldenGate实例管理的跟踪日志。
对于这个PoC,由GoldenGate (classic)管理的trail log aa将被泵送至GoldenGate管理的trail log bb进行大数据处理。
因此,如果您关闭它,请回到来自Linux shell的GoldenGate(经典)CLI:
cd /u01/ogg./ggsci
来自GoldenGate(经典)CLI:
edit params pmpeshop
并在vi中加入以下内容:
EXTRACT pmpeshopUSERIDALIAS ggadminSETENV (ORACLE_SID='orcl')-- GoldenGate for Big Data address/port:RMTHOST localhost, MGRPORT 27801RMTTRAIL ./dirdat/bbPASSTHRU-- The "tokens" part it is useful for writing in the Kafka messages-- the Transaction ID and the database Change Serial NumberTABLE orcl.eshop.*, tokens(txid = @GETENV('TRANSACTION', 'XID'), csn = @GETENV('TRANSACTION', 'CSN'));
保存内容并退出vi。
正如已经解释的提取器,保存的内容将存储在/u01/ogg/dirprm/pmpeshop中。人口、难民和移民事务局文件。
现在我们要注册并启动数据泵,从GoldenGate CLI:
dblogin useridalias ggadminadd extract pmpeshop, exttrailsource ./dirdat/aa begin nowadd rmttrail ./dirdat/bb extract pmpeshopstart pmpeshop
通过从CLI运行以下命令之一来检查数据泵的状态:
info pmpeshopview report pmpeshop
你甚至可以在金门大数据的dirdat文件夹中查看trail log bb是否已经创建:
[oracle@bigdatalite dirdat]$ ls -l ~/ogg-bd-poc/dirdattotal 0-rw-r-----. 1 oracle oinstall 0 May 30 13:22 bb000000000[oracle@bigdatalite dirdat]$
那检查泵送过程呢?来自Linux shell:
sqlplus eshop/eshop@ORCL
执行这个SQL脚本创建一个新的模拟客户订单:
INSERT INTO CUSTOMER_ORDER (ID, CODE, CREATED, STATUS, UPDATE_TIME)VALUES (CUSTOMER_ORDER_SEQ.NEXTVAL, 'AAAA02', SYSDATE, 'SHIPPING', SYSTIMESTAMP);INSERT INTO CUSTOMER_ORDER_ITEM (ID, ID_CUSTOMER_ORDER, DESCRIPTION, QUANTITY)VALUES (CUSTOMER_ORDER_ITEM_SEQ.NEXTVAL, CUSTOMER_ORDER_SEQ.CURRVAL, 'Inside Out', 1);COMMIT;
现在从GoldenGate(经典)CLI运行:
stats pmpeshop
用于检查插入操作是否正确计数(在输出的一部分下面):
GGSCI (bigdatalite.localdomain as ggadmin@cdb/CDB$ROOT) 11> stats pmpeshopSending STATS request to EXTRACT PMPESHOP ...Start of Statistics at 2019-05-30 14:49:00.Output to ./dirdat/bb:Extracting from ORCL.ESHOP.CUSTOMER_ORDER to ORCL.ESHOP.CUSTOMER_ORDER:*** Total statistics since 2019-05-30 14:01:56 ***Total inserts 1.00Total updates 0.00Total deletes 0.00Total discards 0.00Total operations 1.00
此外,您还可以验证GoldenGate中存储的用于测试泵过程的大数据的跟踪日志的时间戳。事务提交后,从Linux shell运行:“ln -l ~/og -bd-poc/dirdat”,并检查最后一个以“bb”作为前缀的文件的时间戳。
步骤11/12:将事务发布到Kafka
最后,我们将在GoldenGate中为BigData创建一个副本流程,以便在Kafka主题中发布泵出的业务事务。replicat将从trail日志bb读取事务中的插入、更新和删除操作,并将它们转换为JSON编码的Kafka消息。
因此,创建一个名为eshop_kafkaconnect的文件。文件夹/home/oracle/ogg-bd- pocd /dirprm中的属性包含以下内容:
# File: /home/oracle/ogg-bd-poc/dirprm/eshop_kafkaconnect.properties# -----------------------------------------------------------# address/port of the Kafka brokerbootstrap.servers=localhost:9092acks=1#JSON Converter Settingskey.converter=org.apache.kafka.connect.json.JsonConverterkey.converter.schemas.enable=falsevalue.converter=org.apache.kafka.connect.json.JsonConvertervalue.converter.schemas.enable=false#Adjust for performancebuffer.memory=33554432batch.size=16384linger.ms=0# This property fix a start-up error as explained by Oracle Support here:# https://support.oracle.com/knowledge/Middleware/2455697_1.htmlconverter.type=key
在同一个文件夹中,创建一个名为eshop_kc的文件。具有以下内容的道具:
# File: /home/oracle/ogg-bd-poc/dirprm/eshop_kc.props# ---------------------------------------------------gg.handlerlist=kafkaconnect#The handler propertiesgg.handler.kafkaconnect.type=kafkaconnectgg.handler.kafkaconnect.kafkaProducerConfigFile=eshop_kafkaconnect.propertiesgg.handler.kafkaconnect.mode=tx#The following selects the topic name based only on the schema namegg.handler.kafkaconnect.topicMappingTemplate=CDC-${schemaName}#The following selects the message key using the concatenated primary keysgg.handler.kafkaconnect.keyMappingTemplate=${primaryKeys}#The formatter propertiesgg.handler.kafkaconnect.messageFormatting=opgg.handler.kafkaconnect.insertOpKey=Igg.handler.kafkaconnect.updateOpKey=Ugg.handler.kafkaconnect.deleteOpKey=Dgg.handler.kafkaconnect.truncateOpKey=Tgg.handler.kafkaconnect.treatAllColumnsAsStrings=falsegg.handler.kafkaconnect.iso8601Format=falsegg.handler.kafkaconnect.pkUpdateHandling=abendgg.handler.kafkaconnect.includeTableName=truegg.handler.kafkaconnect.includeOpType=truegg.handler.kafkaconnect.includeOpTimestamp=truegg.handler.kafkaconnect.includeCurrentTimestamp=truegg.handler.kafkaconnect.includePosition=truegg.handler.kafkaconnect.includePrimaryKeys=truegg.handler.kafkaconnect.includeTokens=truegoldengate.userexit.writers=javawriterjavawriter.stats.display=TRUEjavawriter.stats.full=TRUEgg.log=log4jgg.log.level=INFOgg.report.time=30sec# Apache Kafka Classpath# Put the path of the "libs" folder inside the Kafka home pathgg.classpath=/home/oracle/kafka_2.11-2.1.1/libs/*javawriter.bootoptions=-Xmx512m -Xms32m -Djava.class.path=.:ggjava/ggjava.jar:./dirprm
如果关闭,重启大数据CLI的GoldenGate:
cd ~/ogg-bd-poc./ggsci
and start to create a replicat from the CLI with:
edit params repeshop
in vi put this content:
REPLICAT repeshopTARGETDB LIBFILE libggjava.so SET property=dirprm/eshop_kc.propsGROUPTRANSOPS 1000MAP orcl.eshop.*, TARGET orcl.eshop.*;
然后保存内容并退出vi。现在将replicat与trail log bb关联,并使用以下命令启动replicat进程,以便从GoldenGate启动大数据CLI:
add replicat repeshop, exttrail ./dirdat/bbstart repeshop
Check that the replicat is live and kicking with one of these commands:
info repeshopview report repeshop
Now, connect to the ESHOP schema from another Linux shell:
sqlplus eshop/eshop@ORCL
and commit something:
INSERT INTO CUSTOMER_ORDER (ID, CODE, CREATED, STATUS, UPDATE_TIME)VALUES (CUSTOMER_ORDER_SEQ.NEXTVAL, 'AAAA03', SYSDATE, 'DELIVERED', SYSTIMESTAMP);INSERT INTO CUSTOMER_ORDER_ITEM (ID, ID_CUSTOMER_ORDER, DESCRIPTION, QUANTITY)VALUES (CUSTOMER_ORDER_ITEM_SEQ.NEXTVAL, CUSTOMER_ORDER_SEQ.CURRVAL, 'Cars 3', 2);COMMIT;
From the GoldenGate for Big Data CLI, check that the INSERT operation was counted for the replicat process by running:
stats repeshop
And (hurrah!) we can have a look inside Kafka, as the Linux shell checks that the topic named CDC-ESHOP was created:
cd ~/kafka_2.11-2.1.1/bin./kafka-topics.sh --list --zookeeper localhost:2181
and from the same folder run the following command for showing the CDC events stored in the topic:
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic CDC-ESHOP --from-beginning
You should see something like:
[oracle@bigdatalite kafka_2.11-2.1.1]$ ./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic CDC-ESHOP --from-beginning{"table":"ORCL.ESHOP.CUSTOMER_ORDER","op_type":"I","op_ts":"2019-05-31 04:24:34.000327","current_ts":"2019-05-31 04:24:39.637000","pos":"00000000020000003830","primary_keys":["ID"],"tokens":{"txid":"9.32.6726","csn":"13906131"},"before":null,"after":{"ID":11.0,"CODE":"AAAA03","CREATED":"2019-05-31 04:24:34","STATUS":"DELIVERED","UPDATE_TIME":"2019-05-31 04:24:34.929950000"}}{"table":"ORCL.ESHOP.CUSTOMER_ORDER_ITEM","op_type":"I","op_ts":"2019-05-31 04:24:34.000327","current_ts":"2019-05-31 04:24:39.650000","pos":"00000000020000004074","primary_keys":["ID"],"tokens":{"txid":"9.32.6726","csn":"13906131"},"before":null,"after":{"ID":11.0,"ID_CUSTOMER_ORDER":11.0,"DESCRIPTION":"Cars 3","QUANTITY":2}}
For a better output, install jq:
sudo yum -y install jq./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic CDC-ESHOP --from-beginning | jq .
and here is how will appear the JSON events:
{"table": "ORCL.ESHOP.CUSTOMER_ORDER","op_type": "I","op_ts": "2019-05-31 04:24:34.000327","current_ts": "2019-05-31 04:24:39.637000","pos": "00000000020000003830","primary_keys": ["ID"],"tokens": {"txid": "9.32.6726","csn": "13906131"},"before": null,"after": {"ID": 11,"CODE": "AAAA03","CREATED": "2019-05-31 04:24:34","STATUS": "DELIVERED","UPDATE_TIME": "2019-05-31 04:24:34.929950000"}}{"table": "ORCL.ESHOP.CUSTOMER_ORDER_ITEM","op_type": "I","op_ts": "2019-05-31 04:24:34.000327","current_ts": "2019-05-31 04:24:39.650000","pos": "00000000020000004074","primary_keys": ["ID"],"tokens": {"txid": "9.32.6726","csn": "13906131"},"before": null,"after": {"ID": 11,"ID_CUSTOMER_ORDER": 11,"DESCRIPTION": "Cars 3","QUANTITY": 2}}
现在打开Kafka -console-consumer.sh进程,并在ESHOP上执行其他一些数据库事务,以便实时打印发送给Kafka的CDC事件流。
以下是一些用于更新和删除操作的JSON事件示例:
// Generated with: UPDATE CUSTOMER_ORDER SET STATUS='DELIVERED' WHERE ID=8;{"table": "ORCL.ESHOP.CUSTOMER_ORDER","op_type": "U","op_ts": "2019-05-31 06:22:07.000245","current_ts": "2019-05-31 06:22:11.233000","pos": "00000000020000004234","primary_keys": ["ID"],"tokens": {"txid": "14.6.2656","csn": "13913689"},"before": {"ID": 8,"CODE": null,"CREATED": null,"STATUS": "SHIPPING","UPDATE_TIME": null},"after": {"ID": 8,"CODE": null,"CREATED": null,"STATUS": "DELIVERED","UPDATE_TIME": null}}// Generated with: DELETE CUSTOMER_ORDER_ITEM WHERE ID=3;{"table": "ORCL.ESHOP.CUSTOMER_ORDER_ITEM","op_type": "D","op_ts": "2019-05-31 06:25:59.000916","current_ts": "2019-05-31 06:26:04.910000","pos": "00000000020000004432","primary_keys": ["ID"],"tokens": {"txid": "14.24.2651","csn": "13913846"},"before": {"ID": 3,"ID_CUSTOMER_ORDER": 1,"DESCRIPTION": "Toy Story","QUANTITY": 1},"after": null}
恭喜你!你完成了PoC:
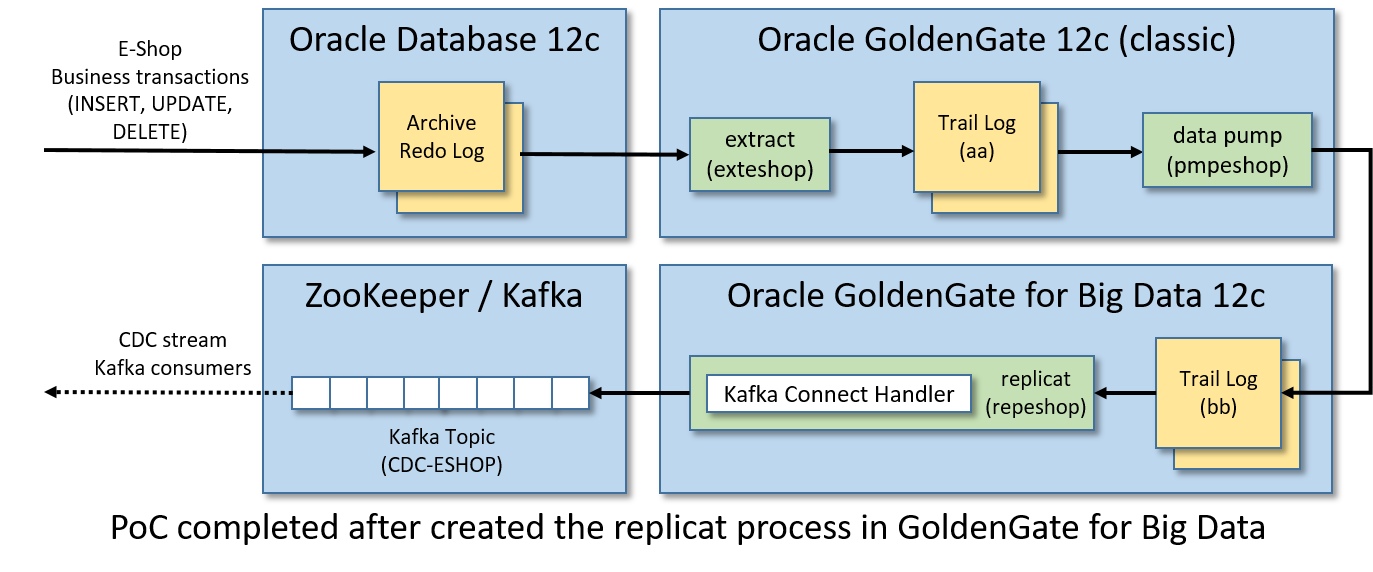
步骤12/12:使用PoC
GoldenGate中提供的Kafka Connect处理程序有很多有用的选项,可以根据需要定制集成。点击这里查看官方文件。
例如,您可以选择为CDC流中涉及的每个表创建不同的主题,只需在eshop_kc.props中编辑此属性:
gg.handler.kafkaconnect.topicMappingTemplate=CDC-${schemaName}-${tableName}更改后重新启动replicat,从GoldenGate for Big Data CLI:
stop repeshopstart repeshop
您可以在“~/og -bd-poc/AdapterExamples/big-data/kafka_connect”文件夹中找到其他配置示例。
结论
在本文中,我们通过GoldenGate技术在Oracle数据库和Kafka代理之间创建了一个完整的集成。CDC事件流以Kafka实时发布。
为了简单起见,我们使用了一个已经全部安装的虚拟机,但是您可以在不同的主机上免费安装用于大数据的GoldenGate和Kafka。
请在评论中告诉我您对这种集成的潜力(或限制)的看法。
原文:https://dzone.com/articles/creates-a-cdc-stream-from-oracle-database-to-kafka
本文:https://pub.intelligentx.net/node/839
讨论:请加入知识星球【首席架构师圈】或者飞聊小组【首席架构师智库】
- 166 次浏览
【事件驱动架构】理解何时使用RabbitMQ或Apache Kafka
人类如何做决定?在日常生活中,情感往往是触发一个复杂或压倒性决定的断路器因素。但是,专家们做出的复杂决定会带来长期后果,这不能纯粹是一时冲动。高绩效者通常只有在他们的专家、潜意识已经吸收了做决定所需的所有事实之后,才会使用“本能”、“直觉”或其他情感的断路器。
今天,市场上有几十种消息传递技术、无数esb和将近100家iPaaS供应商。自然,这就产生了如何根据您的需要选择正确的消息传递技术的问题——特别是对于那些已经在特定选择上进行了投资的技术。我们是否要大规模地转换?只是用合适的工具做合适的工作?我们是否正确地为业务需求制定了手头的工作?考虑到这一点,什么才是适合我的工具呢?更糟糕的是,详尽的市场分析可能永远不会结束,但考虑到集成代码的平均寿命,尽职调查至关重要。
这篇文章让那些无意识的专家们开始考虑一些治疗方法,从最现代、最流行的选择开始:RabbitMQ和Apache Kafka。每个都有自己的起源故事、设计意图、使用案例、集成能力和开发经验。起源揭示了任何一款软件的总体设计意图,是一个很好的起点。但是需要注意的是,在本文中,我的目标是围绕message broker重叠的用例比较这两个用例,而不是Kafka现在擅长的“事件存储/事件来源”用例。
起源
RabbitMQ是一种实现各种消息传递协议的“传统”消息代理。它是第一批实现合理级别的特性、客户机库、开发工具和高质量文档的开放源码消息代理之一。RabbitMQ最初是为了实现AMQP而开发的,AMQP是一种具有强大路由特性的消息传递开放线协议。虽然Java有JMS这样的消息传递标准,但它对需要分布式消息传递的非Java应用程序没有帮助,因为分布式消息传递严重限制了任何集成场景(微服务或单片集成)。随着AMQP的出现,对于开源消息代理来说,跨语言的灵活性变得真实了。
Apache Kafka是用Scala开发的,最初是在LinkedIn作为连接不同内部系统的一种方式。当时,LinkedIn正在转向一个更加分布式的架构,需要重新设想数据集成和实时流处理等功能,摆脱以前解决这些问题的单一方法。Kafka今天在Apache软件基金会的产品生态系统中得到了很好的采用,并且在事件驱动的架构中特别有用。
架构和设计
RabbitMQ被设计成一个通用消息代理,它采用了点对点、请求/应答和发布-子通信样式模式的几种变体。它使用智能代理/哑消费者模型,专注于以与代理跟踪消费者状态大致相同的速度向消费者交付消息。它很成熟,在正确配置的情况下性能很好,得到了很好的支持(客户端库Java、. net、node)。js, Ruby, PHP和更多的语言),并且有几十个插件可以扩展到更多的用例和集成场景。
图1 -简化的RabbitMQ整体架构来源:http://kth.diva-portal.org/smash/get/diva2:813137 FULLTEXT01.pdf
根据需要,RabbitMQ中的通信可以是同步的,也可以是异步的。发布者向交换器发送消息,使用者从队列中检索消息。通过交换器将生产者从队列中解耦,可以确保生产者不必为硬编码的路由决策所累。RabbitMQ还提供了许多分布式部署场景(并要求所有节点都能够解析主机名)。可以将多节点集群设置为集群联合,并且不依赖于外部服务(但是一些集群形成插件可以使用AWS api、DNS、领事、etcd)。
Apache Kafka是为高容量发布-订阅消息和流而设计的,这意味着它是持久的、快速的和可伸缩的。从本质上讲,Kafka提供了一种持久的消息存储,类似于日志,运行在服务器集群中,以称为主题的类别存储记录流。
图2 -全局Apache Kafka架构(1个主题,1个分区,复制因子4)
每个消息由一个键、一个值和一个时间戳组成。与RabbitMQ几乎相反的是,Kafka雇佣了一个愚蠢的经纪人,并使用聪明的消费者来读取它的缓冲区。Kafka不尝试跟踪每个消费者读了哪些消息,只保留未读的消息;相反,Kafka将所有消息保留一段时间,使用者负责跟踪它们在每个日志中的位置(使用者状态)。因此,有了合适的开发人才来创建消费者代码,Kafka就可以支持大量的消费者,并以很少的开销保留大量的数据。正如上面的图表所示,Kafka确实需要外部服务来运行——在这个例子中是Apache Zookeeper,通常认为理解、设置和操作这些服务并不简单。
需求和用例
许多开发人员开始研究消息传递,是因为他们意识到必须将许多东西连接在一起,而共享数据库等其他集成模式不可行或太危险。
Apache Kafka包含了代理本身,这实际上是其中最著名和最流行的部分,并针对流处理场景进行了设计和营销。除此之外,Apache Kafka最近还添加了Kafka Streams,它将自己定位为流媒体平台的替代品,如Apache Spark、Apache Flink、Apache Beam/谷歌云数据流和Spring云数据流。文档很好地讨论了流行的用例,如网站活动跟踪、度量、日志聚合、流处理、事件来源和提交日志。它描述的其中一个用例是消息传递,这可能会产生一些混乱。因此,让我们来解包一点,得到一些明确的消息传递场景是最适合Kafka的,例如:
- 流从A流到B流,无需复杂的路由,最大吞吐量(100k/sec+),至少按分区顺序发送一次。
- 当您的应用程序需要访问流历史记录时,至少按分区顺序交付一次。Kafka是一个持久的消息存储,客户端可以根据需要获得事件流的“重播”,这与更传统的消息代理不同,后者一旦消息被发送,就会从队列中删除。
- 流处理
- 事件溯源
RabbitMQ是一种通用的消息传递解决方案,通常用于允许web服务器快速响应请求,而不是在用户等待结果时被迫执行大量资源的过程。它还适合将消息分发给多个收件人,以便在高负载(20k+/秒)情况下在工作人员之间平衡负载。当您的需求超出吞吐量时,RabbitMQ可以提供很多功能:可靠交付、路由、联合、HA、安全、管理工具和其他功能。让我们检查一些场景最好的RabbitMQ,如:
- 您的应用程序需要使用现有协议的任何组合,如AMQP 0-9-1、STOMP、MQTT、AMQP 1.0。
- 您需要对每条消息(死信队列等)进行更细粒度的一致性控制/保证。然而,Kafka最近为事务添加了更好的支持。
- 您的应用程序需要点到点、请求/应答和发布/订阅消息传递方面的多样性
- 对消费者的复杂路由,集成多个具有重要路由逻辑的服务/应用程序
RabbitMQ也可以有效地解决卡夫卡的几个强大的使用案例,但在附加软件的帮助下。当应用程序需要访问流历史记录时,RabbitMQ通常与Apache Cassandra一起使用,或者与LevelDB插件一起用于需要“无限”队列的应用,但这两个特性都不是与RabbitMQ一起发布的。
想要更深入地了解微服务——Kafka和RabbitMQ的特定用例,请访问关键博客并阅读Fred Melo的这篇短文。
开发人员的经验
RabbitMQ正式支持Java, Spring,。net, PHP, Python, Ruby, JavaScript, Go, Elixir, Objective-C, Swift -通过社区插件与许多其他客户端和devtools。RabbitMQ客户端库是成熟的,并且有良好的文档记录。
Apache Kafka在这个领域已经取得了很大的进步,虽然它只提供Java客户端,但是社区开源客户端、生态系统项目以及适配器SDK都在不断增长,允许您构建自己的系统集成。大部分配置都是通过.properties文件或编程方式完成的。
这两种选择的流行对许多其他软件供应商有强烈的影响,他们确保RabbitMQ和Kafka与他们的技术很好地工作。
至于开发者的体验…值得一提的是我们在Spring Kafka、Spring Cloud Stream等中提供的支持。
安全与操作
这两者都是RabbitMQ的优势。RabbitMQ管理插件提供了一个HTTP API,一个基于浏览器的管理和监控UI,以及针对操作人员的CLI工具。长期监视数据存储需要像CollectD、Datadog或New Relic这样的外部工具。RabbitMQ还提供了用于监控、审计和应用程序故障排除的API和工具。除了支持TLS之外,RabbitMQ附带了由内置数据存储、LDAP或外部基于http的提供者支持的RBAC,并支持使用x509证书而不是用户名/密码对进行身份验证。使用插件可以相当直接地开发其他身份验证方法。
这些领域对Apache Kafka提出了挑战。在安全方面,最近的Kafka 0.9版本增加了TLS、基于JAAS角色的访问控制和kerberos/plain/scram认证,使用CLI来管理安全策略。这对以前的版本有很大的改进,以前的版本只能在网络级别锁定访问,这在共享或多租户方面不太好用。
Kafka使用由shell脚本、属性文件和特定格式的JSON文件组成的管理CLI。Kafka经纪人、生产者和消费者通过Yammer/JMX发布指标,但不维护任何历史,这实际上意味着使用第三方监控系统。使用这些工具,操作能够管理分区和主题,检查消费者偏移位置,并使用Apache Zookeeper为Kafka提供的HA和FT功能。虽然许多人对Zookeeper的需求持高度怀疑态度,但它确实为Kafka用户带来了集群的好处。
例如,一个3节点的Kafka集群即使在出现2次故障后仍然可以正常工作。然而,如果你想在Zookeeper中支持同样多的失败,你需要额外的5个Zookeeper节点,因为Zookeeper是基于quorum的系统,只能容忍N/2+1个失败。这些显然不应该与Kafka节点位于同一位置——所以要建立一个3节点的Kafka系统,你需要~ 8台服务器。在考虑Kafka系统的可用性时,操作人员必须考虑ZK集群的属性,包括资源消耗和设计。
性能
Kafka在这里的亮点在于设计:100k/秒的性能通常是人们选择Apache Kafka的关键驱动因素。
当然,要描述和量化每秒消息率是很棘手的,因为它们很大程度上取决于您的环境和硬件、工作负载的性质、使用哪种交付保证(例如,持久的代价是昂贵的,镜像的代价更大),等等。
每秒发送20K条消息很容易通过单只RabbitMQ,实际上,超过20K条消息并不难,因为保证的要求并不多。队列是由一个Erlang轻量级线程获得合作计划在一个本地操作系统线程池,所以它变成了一个自然瓶颈或瓶颈作为一个单独的队列是永远不会做更多的工作比CPU周期工作。
提高每秒的消息量通常要合理利用环境中的并行性,比如通过巧妙的路由来中断跨多个队列的流量(以便不同队列可以并发运行)。当RabbitMQ达到每秒100万条消息时,这个用例基本上是完全明智地做到这一点——但是实现时使用了大量资源,大约30个RabbitMQ节点。大多数RabbitMQ用户在使用由3到7个RabbitMQ节点组成的集群时都可以享受卓越的性能。
原文:https://tanzu.vmware.com/content/blog/understanding-when-to-use-rabbitmq-or-apache-kafka
本文:http://jiagoushi.pro/node/1188
讨论:请加入知识星球【首席架构师圈】或者加小号【jiagoushi_pro】或者QQ群【11107777】
- 140 次浏览
【事件驱动架构】走向事件驱动的微服务之旅
许多组织正在采用微服务架构,以减少系统组件之间的依赖关系,并允许更频繁的发布周期和更灵活的可伸缩性。但是,除非他们清楚地了解底层交互模式,否则团队可能会构建紧密耦合的分布式单体。
本文介绍了支持微服务交互的模式,并解释了事件流如何使事件驱动架构(EDA)支持松散耦合的微服务原则。
成熟的微服务景观
通常,团队通过一小组微服务和他们之间的有限数量的交互开始旅程。随着微服务数量的增长,它们之间的相互作用也在增长。了解这些交互对于维护松散耦合的微服务至关重要。
作为架构师,我们需要更加关注区域内发生的事情而不是区域之间发生的事情 - 构建微服务(Sam Newman)
推理这些交互的一步是将它们分类为命令,查询和事件。
| 命令 | 事件 | 查询 | |
| 定义 | 命令是我们想要发生的事情 | 事件是发生了什么事情 | 查询是查找内容的请求 |
| 生产 - 消费者关系 | 生产者(发送命令)和消费者(接受并执行命令)之间的一对一连接 | 它由发布者发送,该发布者不知道并且不关心该事件的(0-N)订阅者 | 请求者(提交查询)和响应者(用查询结果响应)之间的一对一交互 |
| 对系统状态的影响 | 命令改变系统状态。 通常,发送人对结果感兴趣 | 事件是系统中状态更改的通知。 订阅者对此信息感兴趣。 | 查询不会更改系统的可观察状态(没有副作用)。 请求者对结果感兴趣 |
| 交互模式 | 非常适合请求 - 响应模式 | 非常适合发布 - 订阅模式 | 非常适合请求 - 响应模式 |
虽然许多组织已经熟练使用现代API实现命令和查询,但大多数组织尚未充分利用事件驱动架构的优势。
在不断发展的生态系统中,服务需要独立发展,命令和查询会增加很多耦合,在运行时将服务捆绑在一起。事件有助于缓解这种紧密耦合,同时仍然促进服务之间的协作。
同步呼叫被认为是有害的 - 微服务(Martin Fowler)
HTTP API需要一个伴侣
HTTP是一种同步的请求 - 响应协议,客户端向已知服务器发送请求并期望来自服务器的响应;它假设服务器可用并且能够响应。此交互样式非常适合实现命令和查询,但不适合基于事件的通信。使用发布 - 订阅模式可以最好地实现基于事件的通信。
事件代表了通知和状态分布的宝贵组合。
事件=通知+状态
事件为应用程序提供了一个选择:继续执行命令和查询或包含事件以触发其进程并引用事件以提取数据供其私人使用。
随着服务生态系统的发展,架构师建议将事件建模为一等公民,并考虑服务需要与外界分享的重要商业事实。
组织经常难以识别其业务流程中的重要事件。 Event Storming研讨会可以帮助克服这个最初的障碍,因为它们是有趣的,自由流动的研讨会,将开发人员和领域专家聚集在一起,目的是将业务流程表达为一系列重要事件。
并非所有事件都是平等的,有些事件不会引起反应;然而,最重要的事件引起反应,这些事件应该在我们的软件系统中建模。
拥抱事件减少了对命令和查询的依赖。事件在服务之间传输状态,减少了它们之间的查询需求。他们还通知服务更广泛的生态系统中发生的重大事件,使服务能够做出适当的反应,从而为触发业务流程提供命令式交互的替代方案。
事件通知状态变化。命令导致状态改变。
持久化你的事件流
即使事件跨服务传输状态,订阅者也需要存储事件流的表示以避免远程查询。随着新事件的发布以及数据存储数量的增加,这些本地数据存储必须保持同步,因此数据漂移的可能性也会增加。
持久化事件流使服务能够直接引用共享事件流并从中创建自己的私有视图。 他们不再需要在本地存储事件的副本。
除了缓解一些复杂性之外,事件流开始提供新的机会。 由此产生的历史参考是新服务可以插入的内容,并且是一个强大的引导工具,可以将体系结构打开到扩展。
服务可以参考的事实的中央记录必然会带来很高的回报。
这种类型的持久性事件流可以实现为分布式提交日志。
不可否认,事件驱动架构的承诺已经存在了很长时间,但它是分布式提交日志基础,这次使事情变得与众不同,并释放其真正的潜力。
分布式提交日志在概念上类似于数据库事务日志,有时称为预写日志或提交日志,其是由数据库管理系统执行的动作的历史。
分布式提交日志将消息的消耗与消息的存储分离。这种解耦提供了许多好处,与事件驱动架构最相关的三个好处是
- 事实来源:日志可以成为事实的来源。事件永久存储在日志中,订阅者可以随时引用。
- 事件重播和审计跟踪:由于事件是不可变的并且永久存储,因此默认情况下您将获得审计,监视和事件重播。除了允许现有订户重放事件历史记录外,它还允许新订户插入事件流并消耗过去的事件。
- 流处理:即使在数据进入分析引擎之前,处理提交日志中的数据也可以实现实时业务洞察。
基于分布式提交日志的事件驱动架构(EDA)使组织能够扩展其微服务架构,并从服务之间交换的数据中获得实时洞察。
EDA是微服务架构发展的下一个阶段,毫不奇怪,Google,Azure,Hortonworks等所有主要供应商都拥有支持这种发展的工具。
Apache Kafka是一种广泛采用的实现,还有像AWS Kinesis这样的云原生解决方案。
最后的想法
微服务在组织中越来越重要,这些服务之间交换的数据非常宝贵,利用这些数据进行架构可以为组织提供竞争优势,并且是微服务发展的下一个合乎逻辑的步骤。
原文:https://platform.deloitte.com.au/articles/2018/event-driven-microservices
- 164 次浏览
【事件驱动架构】连续流式事件处理
现代事件驱动解决方案的基本要素之一是能够处理连续事件流以获得洞察力和智能。您可以使用专门的流分析引擎跨事件流运行状态分析和复杂事件处理工作负载,同时保持低延迟处理时间。
通过将这些引擎作为事件驱动架构的一部分,您可以启用以下功能:
分析和理解事件流
从流中提取事件数据,以便数据科学家可以理解并推导出机器学习模型
针对事件流运行分析过程和机器学习模型
跨流和时间窗匹配复杂事件模式以做出决策并采取行动
流分析
流分析提供了查看和理解流经无界事件流的事件的功能。流应用程序处理事件流,并允许将数据和分析功能应用于流中的信息。这些应用程序被编写为跨这些功能的多步流程:
- 摄取许多事件来源
- 通过转换,过滤,关联和聚合某些指标以及使用其他数据源进行数据丰富来准备数据
- 使用评分和分类检测和预测事件模式
- 通过应用业务规则和业务逻辑来决定
- 直接运行操作,或者在事件驱动的系统中,发布事件通知或命令

流分析的基本功能
为了支持无界事件流的分析处理,这些功能对于事件流处理组件至关重要:
- 连续事件摄取和分析处理
- 跨事件流处理
- 低延迟处理,不需要存储数据
- 处理高容量和高速数据流
- 持续查询和分析Feed
- 事件和流之间的相关性
- 窗口化和有状态处理
- 查询和分析存储的数据
- 开发和运行数据管道
- 开发和运行分析管道
- 在事件流处理中对机器学习模型进行评分
支持分析和决策
除了基本的流功能之外,还可以考虑在事件流处理组件中支持其他常见的事件流类型和处理功能。通过在流应用程序代码中为这些流类型和流程创建函数,您可以简化问题并缩短开发时间。此列表包含其他事件流类型和进程的示例:
- 地理空间
- 基于位置的分析
- 地理围栏和地图匹配
- 时空聚会检测
- 时间序列分析
- 带时间戳的数据分析
- 异常检测和预测
- 文本分析
- 自然语言处理(NLP)和自然语言理解(NLU)
- 情感分析和实体提取
- 视频和音频
- 语音到文本转换
- 图像识别
- 规则:被描述为业务逻辑的决策
- 复杂事件处理(CEP):时间模式检测
- 实体分析
- 实体之间的关系
- 概率匹配
应用程序编程语言和标准
事件流应用程序和语言几乎没有标准。通常,流引擎提供与特定平台相关的特定于语言的编程模型。常用语言如下:
- Python支持数据处理,深受数据科学家和数据工程师的欢迎。
- Java™是一种普遍的应用程序开发语言。
- Scala将函数式编程和不可变对象添加到Java中。
其他平台特定的语言出现,因为实时处理需要更严格的性能要求。例如,Google启动了Apache Beam项目,为流分析应用程序提供统一的编程模型。 Beam是一种更高级别的统一编程模型,它提供了使用许多支持语言(包括Java,Python,Go和SQL)编写流分析应用程序的标准方法。流分析引擎通常通过Beam运行器支持此统一编程模型,该运行器获取代码并将其转换为特定引擎的平台本地可执行代码。
有关更多信息,请参阅支持引擎和功能的详细信息。领先的引擎包括Google Cloud Dataflow,Apache Flink,Apache Spark,Apache Apex和IBM®Streams。
运行时特性
在运营方面,流式分析引擎必须持续接收和分析到达的数据:
- Feed从不结束:
- 该系列无限制。
- 该模型不基于请求响应集。
- 消防水带不停止:
- 继续喝酒,保持健康。
- 处理速率大于或等于进给速率。
- 分析引擎必须具有弹性和自我修复能力。
许多其他信息处理环境中没有这些专门的需求和关注点。这些问题导致高度优化的运行时和引擎,用于跨事件流对分析工作负载进行状态,并行处理。
原文: https://www.ibm.com/cloud/garage/architectures/eventDrivenArchitecture/event-driven-event-streams
讨论:加入知识星球【首席架构师圈】
- 228 次浏览
【事件驱动架构】针对云原生架构的事件驱动解决方案
现代数字业务实时运作。当它们发生时,它会向感兴趣的各方通报感兴趣的事物。它可以从越来越多的资源中获取并获得洞察力。它学习,预测并且聪明。从本质上讲,它是事件驱动的。
事件是捕获事实陈述的一种方式。事件发生时,事件会连续发生。通过利用这种连续流,应用程序可以根据过去发生的事情对未来作出反应和推理。
对于企业IT团队而言,采用事件驱动的开发是下一代数字业务应用程序的基础。 IT团队必须以云原生样式设计,开发,部署和运营事件驱动的解决方案。
事件驱动的体系结构和反应式编程模型不是新概念。但是,当您迁移到具有微服务,基于容器的工作负载和无服务器计算的云原生架构时,您可以在云原生环境中重新访问事件驱动的方法。将事件驱动的体系结构视为将云原生体系结构的弹性,敏捷性和可扩展特性扩展为具有响应性和响应性。
云原生架构的两个方面对于开发事件驱动架构至关重要:
- 微服务提供松散耦合的应用程序体系结构,支持以高度分布的模式进行部署,以实现弹性,灵活性和扩展性。
- 具有容器和无服务器部署的云原生平台提供了实现微服务架构的弹性,灵活性和可伸缩性的应用程序平台和工具。
事件驱动架构(EDA)是一种应用程序部署模式,至少在20年前创建并被许多公司使用。 通过混合云本机实现和微服务采用,EDA通过帮助解决微服务的松散耦合需求并避免复杂的通信集成而获得了新的关注点。 采用发布/订阅通信模型,事件源,命令查询责任隔离(CQRS)和Saga模式有助于实现支持云部署的高可扩展性和弹性的微服务。 EDA正在成为敏捷架构的强制方法,并为开发事件和处理事件流以添加人工智能服务提供机会,从而获得分析。
Jerome Boyer, STSM, Cloud Architecture Solution Engineering
事件
事件是状态变化的通知。发布或发布通知,感兴趣的各方可以订阅并采取行动。通常,通知的发布者不知道采取了什么动作,并且没有收到通知被处理的相应反馈。
通常,事件代表业务感兴趣的事物的状态变化。事件是发生的事情的记录。它们无法改变。你无法改变过去发生的事情。
事件流
事件流是一系列连续无限的事件。在开始处理流之前,可能会启动流的开始。流的结尾在未来的某个未知点。
事件按每个事件发生的时间排序。在开发事件驱动的解决方案时,通常会看到以下两种类型的事件流:
- 其事件被定义并作为解决方案的一部分发布到流中的流。
- 连接到事件流的流。示例包括来自物联网(IoT)设备的事件流,来自电话系统的语音流,视频流,或来自全球定位系统的船或平面位置。
命令
命令是做某事的指令。通常,命令指向特定的消费者。消费者运行所需的命令或过程并将确认传递回发行者。确认表明该命令已被处理。
事件和消息
消息传递在IT系统中有着悠久的历史。您可以在消息传递系统和消息的上下文中看到事件驱动的解决方案和事件。但是,这些特性值得考虑:
- 消息传输有效负载并持续存在直到它们被消耗。消息使用者通常直接被定位并且与关心消息被传递和处理的制作者相关。
- 事件将作为可重播的流历史记录保留。事件消费者与生产者无关。事件是发生事件的记录,因此无法更改。

松耦合
松耦合是事件驱动处理的主要优点之一。它允许事件生成器发出事件,而不知道谁将使用这些事件。同样,事件使用者不需要知道事件发射器。由于松耦合,事件消耗模块和事件生成器模块可以用不同语言实现,或者使用不同且适合特定作业的技术。
松散耦合的模块更适合独立发展。当它们正确实现时,松散耦合的模块会导致系统复杂性显着降低。
然而,松耦合并不意味着“没有耦合”。事件使用者使用有助于实现其目标的事件,并且这样做可以确定所需的数据以及该数据的类型和格式。事件生产者发布它希望被消费者理解和使用的事件,与潜在消费者建立隐含的合同。
例如,XML格式的事件通知必须符合消费者和生产者必须知道的某个模式。在事件驱动的系统中减少耦合可以做的最重要的事情之一是减少在模块之间流动的不同事件类型的数量。要减少事件类型的数量,请注意这些模块的内聚性。
凝聚
内聚是相关事物封装在同一软件模块中的程度。出于本讨论的目的,模块是具有高内聚性的可独立部署的软件单元。 Cohesion与耦合有关,因为高度内聚的模块与其他模块的通信较少,减少了系统中事件和事件类型的数量。
模块之间相互作用的频率越低,它们的耦合就越少。在优化模块尺寸以实现灵活性和适应性的同时实现软件的凝聚力是困难的,但是需要努力。设计凝聚力始于理解问题领域和良好的分析工作。有时,您还必须考虑支持软件环境的约束。避免使用过于细粒度的单片实现和实现。
下一步是什么
既然您已了解事件驱动解决方案的概念和价值,那么请学习如何在事件驱动的参考架构中构建一个。
原文 : https://www.ibm.com/cloud/garage/architectures/eventDrivenArchitecture
讨论: 知识星球【首席架构师圈】
- 90 次浏览
【事件驱动架构】针对云原生架构的事件驱动解决方案
现代数字业务实时运作。当它们发生时,它会向感兴趣的各方通报感兴趣的事物。它可以从越来越多的资源中获取并获得洞察力。它学习,预测并且聪明。从本质上讲,它是事件驱动的。
事件是捕获事实陈述的一种方式。事件发生时,事件会连续发生。通过利用这种连续流,应用程序可以根据过去发生的事情对未来作出反应和推理。
对于企业IT团队而言,采用事件驱动的开发是下一代数字业务应用程序的基础。 IT团队必须以云原生样式设计,开发,部署和运营事件驱动的解决方案。
事件驱动的体系结构和反应式编程模型不是新概念。但是,当您迁移到具有微服务,基于容器的工作负载和无服务器计算的云原生架构时,您可以在云原生环境中重新访问事件驱动的方法。将事件驱动的体系结构视为将云原生体系结构的弹性,敏捷性和可扩展特性扩展为具有响应性和响应性。
云原生架构的两个方面对于开发事件驱动架构至关重要:
- 微服务提供松散耦合的应用程序体系结构,支持以高度分布的模式进行部署,以实现弹性,灵活性和扩展性。
- 具有容器和无服务器部署的云原生平台提供了实现微服务架构的弹性,灵活性和可伸缩性的应用程序平台和工具。
事件驱动架构(EDA)是一种应用程序部署模式,至少在20年前创建并被许多公司使用。 通过混合云本机实现和微服务采用,EDA通过帮助解决微服务的松散耦合需求并避免复杂的通信集成而获得了新的关注点。 采用发布/订阅通信模型,事件源,命令查询责任隔离(CQRS)和Saga模式有助于实现支持云部署的高可扩展性和弹性的微服务。 EDA正在成为敏捷架构的强制方法,并为开发事件和处理事件流以添加人工智能服务提供机会,从而获得分析。 ----- Jerome Boyer,STSM,云架构解决方案工程
事件
事件是状态变化的通知。发布或发布通知,感兴趣的各方可以订阅并采取行动。通常,通知的发布者不知道采取了什么动作,并且没有收到通知被处理的相应反馈。
通常,事件代表业务感兴趣的事物的状态变化。事件是发生的事情的记录。它们无法改变。你无法改变过去发生的事情。
事件流
事件流是一系列连续无限的事件。在开始处理流之前,可能会启动流的开始。流的结尾在未来的某个未知点。
事件按每个事件发生的时间排序。在开发事件驱动的解决方案时,通常会看到以下两种类型的事件流:
- 其事件被定义并作为解决方案的一部分发布到流中的流。
- 连接到事件流的流。示例包括来自物联网(IoT)设备的事件流,来自电话系统的语音流,视频流,或来自全球定位系统的船或平面位置。
命令
命令是做某事的指令。通常,命令指向特定的消费者。消费者运行所需的命令或过程并将确认传递回发行者。确认表明该命令已被处理。
事件和消息
消息传递在IT系统中有着悠久的历史。您可以在消息传递系统和消息的上下文中看到事件驱动的解决方案和事件。但是,这些特性值得考虑:
- 消息传输有效负载并持续存在直到它们被消耗。消息使用者通常直接被定位并且与关心消息被传递和处理的制作者相关。
- 事件将作为可重播的流历史记录保留。事件消费者与生产者无关。事件是发生事件的记录,因此无法更改。
松耦合
松耦合是事件驱动处理的主要优点之一。它允许事件生成器发出事件,而不知道谁将使用这些事件。同样,事件使用者不需要知道事件发射器。由于松耦合,事件消耗模块和事件生成器模块可以用不同语言实现,或者使用不同且适合特定作业的技术。
松散耦合的模块更适合独立发展。当它们正确实现时,松散耦合的模块会导致系统复杂性显着降低。
然而,松耦合并不意味着“没有耦合”。事件使用者使用有助于实现其目标的事件,并且这样做可以确定所需的数据以及该数据的类型和格式。事件生产者发布它希望被消费者理解和使用的事件,与潜在消费者建立隐含的合同。
例如,XML格式的事件通知必须符合消费者和生产者必须知道的某个模式。在事件驱动的系统中减少耦合可以做的最重要的事情之一是减少在模块之间流动的不同事件类型的数量。要减少事件类型的数量,请注意这些模块的内聚性。
凝聚
内聚是相关事物封装在同一软件模块中的程度。出于本讨论的目的,模块是具有高内聚性的可独立部署的软件单元。 Cohesion与耦合有关,因为高度内聚的模块与其他模块的通信较少,减少了系统中事件和事件类型的数量。
模块之间相互作用的频率越低,它们的耦合就越少。在优化模块尺寸以实现灵活性和适应性的同时实现软件的凝聚力是困难的,但是需要努力。设计凝聚力始于理解问题领域和良好的分析工作。有时,您还必须考虑支持软件环境的约束。避免使用过于细粒度的单片实现和实现。
下一步是什么
既然您已了解事件驱动解决方案的概念和价值,那么请学习如何在事件驱动的参考架构中构建一个。
原文:https://www.ibm.com/cloud/garage/architectures/eventDrivenArchitecture
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 105 次浏览
【日志架构】ELK Stack + Kafka 端到端练习
在前一章中,我们已经学习了如何从头到尾地配置ELK堆栈。这样的配置能够支持大多数用例。然而,对于一个无限扩展的生产环境,瓶颈仍然存在:
- Logstash需要使用管道和过滤器处理日志,这需要花费大量的时间,如果日志爆发,可能会成为瓶颈;
- 弹性搜索需要对日志进行索引,这也消耗了时间,当日志爆发时,它就成为了一个瓶颈。
上面提到的瓶颈可以通过添加更多的Logstash部署和缩放Elasticsearch集群来平滑,当然,也可以通过在中间引入缓存层来平滑,就像所有其他的IT解决方案一样(比如在数据库访问路径的中间引入Redis)。利用缓存层最流行的解决方案之一是将Kafka集成到ELK堆栈中。我们将在本章讨论如何建立这样的环境。
架构
当Kafka被用作ELK栈中的缓存层时,将使用如下架构:
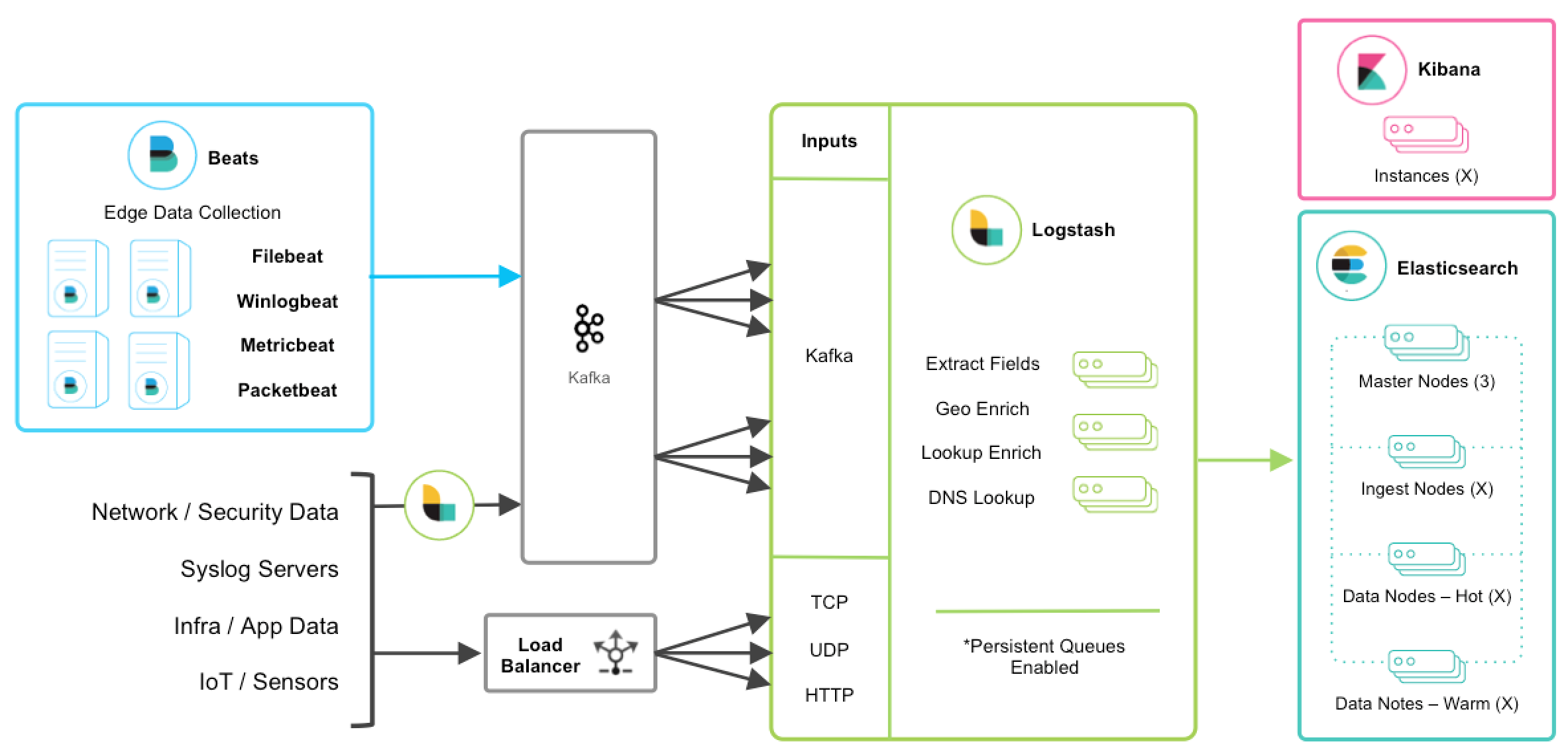
这方面的细节可以从部署和扩展Logstash中找到
演示环境
基于以上介绍的知识,我们的演示环境将构建如下:
The detailed enviroment is as below:
- logstash69167/69168 (hostnames: e2e-l4-0690-167/168): receive logs from syslog, filebeat, etc. and forward/produce logs to Kafka topics;
- kafka69155/156/157 (hostnames: e2e-l4-0690-155/156/157): kafka cluster
- zookeeper will also be installed on these 3 x nodes;
- kafka manager will be installed on kafka69155;
- logstash69158/69159 (hostnames: e2e-l4-0690-158/159): consume logs from kafka topics, process logs with pipelines, and send logs to Elasticsearch;
- elasticsearch69152/69153/69154 (hostnames: e2e-l4-0690-152/153/154): Elasticsearch cluster
- Kibana will be installed on elasticsearch69152
- Data sources such as syslog, filebeat, etc. follow the same configuration as when Kafka is not used, hence we ignore their configuration in this chapter.
部署
Elasticsearch部署
安装过程已经由本文档记录,请参阅前面的章节。在本节中,我们将只列出配置和命令。
-
Install Elasticsearch on elasticsearch69152/69153/69154;
-
Configs on each node (/etc/elasticsearch/elasticsearch.yml):
-
elasticsearch69152
cluster.name: edc-elasticsearch node.name: e2e-l4-0690-152 path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch network.host: 0.0.0.0 discovery.seed_hosts: ["e2e-l4-0690-152", "e2e-l4-0690-153", "e2e-l4-0690-154"] cluster.initial_master_nodes: ["e2e-l4-0690-152", "e2e-l4-0690-153", "e2e-l4-0690-154"]
-
elasticsearch69153
cluster.name: edc-elasticsearch node.name: e2e-l4-0690-153 path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch network.host: 0.0.0.0 discovery.seed_hosts: ["e2e-l4-0690-152", "e2e-l4-0690-153", "e2e-l4-0690-154"] cluster.initial_master_nodes: ["e2e-l4-0690-152", "e2e-l4-0690-153", "e2e-l4-0690-154"]
-
elasticsearch69154
cluster.name: edc-elasticsearch node.name: e2e-l4-0690-154 path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch network.host: 0.0.0.0 discovery.seed_hosts: ["e2e-l4-0690-152", "e2e-l4-0690-153", "e2e-l4-0690-154"] cluster.initial_master_nodes: ["e2e-l4-0690-152", "e2e-l4-0690-153", "e2e-l4-0690-154"]
-
-
Start Elasticsearch service on each node:
systemctl disable firewalld systemctl enable elasticsearch systemctl start elasticsearch
-
Verify (on any node): 3 x alive nodes should exist and one master node is elected successfully
[root@e2e-l4-0690-152]# curl -XGET 'http://localhost:9200/_cluster/state?pretty'
Kibana部署
安装过程已经由本文档记录,请参阅前面的章节。在本节中,我们将只列出配置和命令。
-
Install Kibana on elasticsearch69152;
-
Configure Kibana(/etc/kibana/kibana.yml):
server.host: "0.0.0.0" server.name: "e2e-l4-0690-152" elasticsearch.hosts: ["http://e2e-l4-0690-152:9200", "http://e2e-l4-0690-153:9200", "http://e2e-l4-0690-154:9200"]
-
Start the service on each node:
systemctl enable kibana systemctl start kibana
-
Verify: access http://10.226.69.152:5601 to verify that Kibana is up and running.
Zookeeper 部署
Zookeeper is a must before running a Kafka cluster. For demonstration purpose, we deploy a Zookeeper cluster on the same nodes as the Kafka cluster, A.K.A kafka69155/69156/69157.
-
There is no need to do any installation, decompressing the package is enough;
-
Configure zookeeper on each node(conf/zoo.cfg):
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/var/lib/zookeeper clientPort=2181 server.1=10.226.69.155:2888:3888 server.2=10.226.69.156:2888:3888 server.3=10.226.69.157:2888:3888
-
Create file /var/lib/zookeeper/myid with content 1/2/3 on each node:
echo 1 > /var/lib/zookeeper/myid # kafka69155 echo 2 > /var/lib/zookeeper/myid # kafka69156 echo 3 > /var/lib/zookeeper/myid # kafka69157
-
Start Zookeeper on all nodes:
./bin/zkServer.sh start ./bin/zkServer.sh status
-
Connect to Zooper for verification:
./bin/zkCli.sh -server 10.226.69.155:2181,10.226.69.156:2181,10.226.69.157:2181
Kafka 部署
A Kafka cluster will be deployed on kafka69155/69156/69157.
-
Kafka does not need any installation, downloading and decompressing a tarball is enough. Please refer to Kafka Quickstart for reference;
-
The Kafka cluster will run on kafka69155/156/157 where a Zookeeper cluster is already running. To enable the Kafka cluster, configure each node as below(config/server.properties):
-
kafka69155:
broker.id=0 listeners=PLAINTEXT://0.0.0.0:9092 advertised.listeners=PLAINTEXT://10.226.69.155:9092 zookeeper.connect=10.226.69.155:2181,10.226.69.156:2181:10.226.69.157:2181
-
kafka69156:
broker.id=1 listeners=PLAINTEXT://0.0.0.0:9092 advertised.listeners=PLAINTEXT://10.226.69.156:9092 zookeeper.connect=10.226.69.155:2181,10.226.69.156:2181:10.226.69.157:2181
-
kafka69157:
broker.id=1 listeners=PLAINTEXT://0.0.0.0:9092 advertised.listeners=PLAINTEXT://10.226.69.157:9092 zookeeper.connect=10.226.69.155:2181,10.226.69.156:2181:10.226.69.157:2181
-
-
Start Kafka on all nodes:
./bin/kafka-server-start.sh -daemon config/server.properties
Once the Kafka cluster is running, we can go ahead configuring Logstash. When it is required to make changes to the Kafka cluster, we should shut down the cluster gracefully as below, then make changes and start the cluster again:
./bin/kafka-server-stop.sh
Kafka Manager 部署
可以使用CLI命令管理Kafka集群。然而,它并不是非常方便。Kafka Manager是一个基于web的工具,它使基本的Kafka管理任务变得简单明了。该工具目前由雅虎维护,并已被重新命名为CMAK (Apache Kafka的集群管理)。无论如何,我们更喜欢称之为Kafka经理。
The Kafka manager will be deployed on kafka69155.
-
Download the application from its github repo;
-
After decompressing the package, change the zookeeper option as below in conf/application.conf:
kafka-manager.zkhosts="e2e-l4-0690-155:2181,e2e-l4-0690-156:2181,e2e-l4-0690-157:2181"
-
Create the app deployment(a zip file will be created):
./sbt clean dist
-
Unzip the newly created zip file (kafka-manager-2.0.0.2.zip in this demo) and start the service:
unzip kafka-manager-2.0.0.2.zip cd kafka-manager-2.0.0.2 bin/kafka-manager
-
The Kafka manager can be accessed from http://10.226.69.155:9000/ after a while;
-
Click Cluster->Add Cluster and enter below information to manage our Kafka cluster:
- Cluster Name: assign a meaningful name for this cluster
- Cluster Zookeeper Hosts: 10.226.69.155:2181,10.226.69.156:2181,10.226.69.157:2181
- Enable JMX Polling: yes
-
Done.
Logstash部署
基于我们对演示环境的介绍,我们有两套Logstash部署:
-
Log Producers: logstash69167/69168
Collect logs from data sources (such as syslog, filebeat, etc.) and forward log entries to corresponding Kafka topics. The num. of such Logstash instances can be determined based on the amount of data generated by data sources.
Actually, such Logstash instances are separated from each other. In other words, they work as standalone instances and have no knowledge on others.
-
Log Consumers: logstash69158/69159
Consume logs from Kafka topics, modify logs based on pipeline definitions and ship modified logs to Elasticsearch.
Such Logstash instances have the identical pipeline configurations (except for client_id) and belong to the same Kafka consumer group which load balance each other.
The installation of Logstash has been covered in previous chapters, we won’t cover them again in this chapter, instead, we will focus our effort on the clarification of pipeline definitions when Kafka is leveraged in the middle.
Logstash产生日志到Kafka
每个Logstash实例负责合并某些指定数据源的日志。
- logstash69167: consolidate logs for storage arrays and application solutions based on Linux;
- logstash69168: consolidate logs for ethernet switches and application solutions based on Windows.
-
Define pipelines(/etc/logstash/conf.d)
-
logstash69167
# /etc/logstash/conf.d/ps_rhel.conf input { beats { port => 5045 tags => ["server", "filebeat", "ps", "rhel"] } } filter { mutate { rename => ["host", "server"] } } output { kafka { id => "ps-rhel" topic_id => "ps-rhel" codec => "json" bootstrap_servers => "10.226.69.155:9092,10.226.69.156:9092,10.226.69.157:9092" } } # /etc/logstash/conf.d/sc_sles.conf input { beats { port => 5044 tags => ["server", "filebeat", "sc", "sles"] } } filter { mutate { rename => ["host", "server"] } } output { kafka { id => "sc-sles" topic_id => "sc-sles" codec => "json" bootstrap_servers => "10.226.69.155:9092,10.226.69.156:9092,10.226.69.157:9092" } } # /etc/logstash/conf.d/pssc.conf input { udp { port => 514 tags => ["array", "syslog", "sc", "ps"] } } output { kafka { id => "pssc" topic_id => "pssc" codec => "json" bootstrap_servers => "10.226.69.155:9092,10.226.69.156:9092,10.226.69.157:9092" } } # /etc/logstash/conf.d/unity.conf input { udp { port => 5000 tags => ["array", "syslog", "unity"] } } output { kafka { id => "unity" topic_id => "unity" codec => "json" bootstrap_servers => "10.226.69.155:9092,10.226.69.156:9092,10.226.69.157:9092" } } # /etc/logstash/conf.d/xio.conf input { udp { port => 5002 tags => ["array", "syslog", "xio"] } } output { kafka { id => "xio" topic_id => "xio" codec => "json" bootstrap_servers => "10.226.69.155:9092,10.226.69.156:9092,10.226.69.157:9092" } } -
logstash69168
# /etc/logstash/conf.d/ethernet_switch.conf input { udp { port => 514 tags => ["switch", "syslog", "network", "ethernet"] } } output { kafka { id => "ether-switch" topic_id => "ether-switch" codec => "json" bootstrap_servers => "10.226.69.155:9092,10.226.69.156:9092,10.226.69.157:9092" } } # /etc/logstash/conf.d/vnx_exchange.conf input { beats { port => 5044 tags => ["server", "winlogbeat", "vnx", "windows", "exchange"] } } filter { mutate { rename => ["host", "server"] } } output { kafka { id => "vnx-exchange" topic_id => "vnx-exchange" codec => "json" bootstrap_servers => "10.226.69.155:9092,10.226.69.156:9092,10.226.69.157:9092" } } # /etc/logstash/conf.d/vnx_mssql.conf input { beats { port => 5045 tags => ["server", "winlogbeat", "vnx", "windows", "mssql"] } } filter { mutate { rename => ["host", "server"] } } output { kafka { id => "vnx-mssql" topic_id => "vnx-mssql" codec => "json" bootstrap_servers => "10.226.69.155:9092,10.226.69.156:9092,10.226.69.157:9092" } }
-
-
Enable pipelines (/etc/logstash/pipelines.yml):
-
logstash69167:
- pipeline.id: ps_rhel path.config: "/etc/logstash/conf.d/ps_rhel.conf" - pipeline.id: sc_sles path.config: "/etc/logstash/conf.d/sc_sles.conf" - pipeline.id: pssc path.config: "/etc/logstash/conf.d/pssc.conf" - pipeline.id: unity path.config: "/etc/logstash/conf.d/unity.conf" - pipeline.id: xio path.config: "/etc/logstash/conf.d/xio.conf"
-
logstash69168:
- pipeline.id: ethernet_switch path.config: "/etc/logstash/conf.d/ethernet_switch.conf" - pipeline.id: vnx_exchange path.config: "/etc/logstash/conf.d/vnx_exchange.conf" - pipeline.id: vnx_mssql path.config: "/etc/logstash/conf.d/vnx_mssql.conf"
-
-
Start Logstash servers on all nodes:
systemctl start logstash
-
Verify topics are successfully created on Kafka:
ssh root@kafka69155/156/157 ./bin/kafka-topics.sh -bootstrap-server "10.226.69.155:9092,10.226.69.156:9092,10.226.69.157:9092" --list
-
Verify logs are sent to Kafka successfully:
ssh root@kafka69155/156/157 ./bin/kafka-console-consumer.sh -bootstrap-server "10.226.69.155:9092,10.226.69.156:9092,10.226.69.157:9092" --topic <topic name>
现在,我们已经将Logstash实例配置为Kafka producer。在继续之前,有必要介绍一些关于使用Kafka作为输出插件时的管道配置的技巧。
不要为这类Logstash实例的管道定义复杂的过滤器,因为它们可能增加延迟;
- 在输入部分添加标签,以简化Kibana的日志搜索/分类工作;
- 为不同的管道指定不同的id和有意义的名称;
- 如果syslog也是设置中的数据源,则将主机字段重命名为其他有意义的名称。关于这个问题的解释,请参考tips章节。
Logstash,它消耗来自Kafka的日志
我们将为logstash69158/69159配置管道。这两个Logstash实例具有相同的管道定义(除了client_id之外),并通过利用Kafka的消费者组特性均匀地使用来自Kafka主题的消息。
由于日志被安全地缓存在Kafka中,所以在将日志实体发送到Elasticsearch之前,使用管道定义复杂的过滤器来修改日志实体是正确的。这不会导致瓶颈,因为Kafka中已经有日志了,唯一的影响是您可能需要等待一段时间才能看到Elasticsearch/Kibana中的日志。如果查看来自Elasticsearch/Kibana的日志对时间很敏感,那么可以添加属于同一使用者组的更多Logstash实例来平衡处理的负载。
-
Define pipelines(/etc/logstash/conf.d): client_id should always be set with different values
# /etc/logstash/conf.d/kafka_array.conf input { kafka { client_id => "logstash69158-array" # client_id => "logstash69159-array" group_id => "logstash-array" topics => ["unity", "vnx", "xio", "pssc", "powerstore"] codec => "json" bootstrap_servers => "10.226.69.155:9092,10.226.69.156:9092,10.226.69.157:9092" } } output { elasticsearch { hosts => ["http://e2e-l4-0690-152:9200", "http://e2e-l4-0690-153:9200", "http://e2e-l4-0690-154:9200"] index => "edc-storage-%{+YYYY.MM.dd}" } } # /etc/logstash/conf.d/kafka_server.conf input { kafka { client_id => "logstash69158-server" # client_id => "logstash69159-server" group_id => "logstash-server" topics => ["sc-sles", "ps-rhel", "vnx-exchange", "vnx-mssql"] codec => "json" bootstrap_servers => "10.226.69.155:9092,10.226.69.156:9092,10.226.69.157:9092" } } output { elasticsearch { hosts => ["http://e2e-l4-0690-152:9200", "http://e2e-l4-0690-153:9200", "http://e2e-l4-0690-154:9200"] index => "edc-server-%{+YYYY.MM.dd}" } } # /etc/logstash/conf.d/kafka_switch.conf input { kafka { client_id => "logstash69158-switch" # client_id => "logstash69159-switch" group_id => "logstash-switch" topics => ["ether-switch"] codec => "json" bootstrap_servers => "10.226.69.155:9092,10.226.69.156:9092,10.226.69.157:9092" } } output { elasticsearch { hosts => ["http://e2e-l4-0690-152:9200", "http://e2e-l4-0690-153:9200", "http://e2e-l4-0690-154:9200"] index => "edc-ethernet-%{+YYYY.MM.dd}" } } -
Enable pipelines on all nodes(/etc/logstash/pipelines.yml):
- pipeline.id: kafka_array path.config: "/etc/logstash/conf.d/kafka_array.conf" - pipeline.id: kafka_server path.config: "/etc/logstash/conf.d/kafka_server.conf" - pipeline.id: kafka_switch path.config: "/etc/logstash/conf.d/kafka_switch.conf"
-
Start logstash on all nodes:
systemctl start logstash
配置并启动Logstash之后,日志应该能够发送到Elasticsearch,并可以从Kibana检查。
现在,我们已经将Logstash实例配置为Kafka使用者。在继续之前,有必要介绍一些在使用Kafka作为输入插件时的管道配置技巧。
- 对于不同Logstash实例上的每个管道,应该始终使用不同的值设置client_id。该字段用于识别Kafka上的消费者;
- 对于不同Logstsh实例上的相同管道,group_id应该设置恒等值。这个字段用于标识Kafka上的消费者组,如果值不同,负载平衡就无法工作。
数据源配置
数据源是服务器、交换机、阵列等,它们通过beat、syslog等将日志发送到Logstash。配置它们的步骤与没有Kafka集成时相同,请参照前一章。
结论
我们已经配置了一个集成了Kafka和ELK堆栈的演示环境。通过集成Kafka,可以提高日志处理性能(添加缓存层),还可以集成更多潜在的应用程序(使用来自Kafka的日志消息并执行一些特殊操作,如ML)。
原文:https://elastic-stack.readthedocs.io/en/latest/e2e_kafkapractices.html
本文:http://jiagoushi.pro/node/1135
讨论:请加入知识星球【首席架构师圈】或者微信小号【jiagoushi_pro】
- 445 次浏览
【首席看事件溯源】Oracle中事件溯源的想法 Log Miner 或有其他选择?
使用微服务,架构师希望拆除单片数据库并复制数据,而不是共享数据。然后,需要对修改完成的地方(如CQRS中的C)进行审计。为了恢复,Oracle数据库已经这样做了,在修改数据块之前构建重做记录,但这是一个物理变化矢量。我们需要一些有更多可能性的逻辑来过滤和转换。有多种可能的方法。但不幸的是,自从Oracle收购了Golden GAte并将其单独出售后,数据库中构建的那些就慢慢被删除了。
- 流在12c中被弃用
- 在12c中不赞成高级复制
- 更改数据捕获在12c中是不赞成的
- LogMiner连续矿在12c就被废弃了
deprecated变成了desupport,甚至在以后的版本中被移除,比如19c的Continuous Mine——12cR2的最终路径集:
ORA-44609: CONTINOUS_MINE is desupported for use with DBMS_LOGMNR.START_LOGMNR
文档表示,替代产品是“Golden Gate”,但那是另一种需要购买的产品,功能强大但价格昂贵(而且没有标准版)。
Debezium dbz - 137
Debezium是一个用于更改数据捕获的开源分布式平台,它正在开发一个Oracle数据库连接器。许多想法在https://issues.jboss.org/browse/DBZ-137中被提及,在这篇文章中我给出了我的想法。
甲骨文xstream
完美的解决方案,因为它对源代码的开销最小,而且非常高效。但是它需要获得Golden Gate许可,因此可能不是开源产品的最佳解决方案。
甲骨文LogMiner
LogMiner包含在所有版本中,读取重做流(归档和在线重做日志)并提取所有信息。在启用补充日志记录时,我们有足够的信息来构建逻辑更改信息。许多解决方案已经基于此。但我认为它有两个问题。
LogMiner限制:
基本上,LogMiner不是用于复制的。这个想法更多的是提供一个故障排除工具来理解数据上发生了什么:什么导致了太多的重做?谁删除了一些数据?哪些会话锁定了行?有一些限制,比如不支持的数据类型。它的设计不是为了提高效率。但也有可能在另一个系统上进行开采。但是,我认为这些限制对于简单数据库上的开放源码解决方案来说是可以接受的,因为它的更改率很低。
LogMiner的未来:
更让人好奇的是,Oracle是如何去掉那些可能会替代Golden Gate的特性的。在19世纪,持续的 CONTINUOUS_MINE 被移除。这意味着我们需要不断地打开和读取整个重做日志。当甲骨文在未来的版本中看到一个与Golden Gate竞争的健壮的开源产品时,我们知道甲骨文会删除什么吗?
在DBZ-137上有一些关于RAC的注释,因为有许多重做线程,所以RAC更加复杂。我不认为RAC在这个范围内。RAC是一个昂贵的选项,只有在负载非常高的大型数据库上才需要它。这更符合Golden Gate的范围。
注意,我们可以解析V$LOGMINER_CONTENTS中的SQL_REDO和SQL_UNDO,但是也可以从dbms_logmnr.mine_value中获取它们
挖掘二进制日志流
有人尝试挖掘二进制重做日志。一些众所周知的商业产品和一些开源尝试。这非常复杂,但对于开放源码社区来说也很有趣。重做日志结构是私有的,但是Oracle不会经常更改它,因为所有可用性特性(恢复、备用……)都基于它。然而,由于这种挖掘暴露了重做的专有格式,因此可能存在一个开放源代码的法律问题。Oracle许可证明确禁止反向工程。
连续查询的通知
我研究了dbms_change_notification作为CDC备选方案的用法:https://blog.dbi-services.com/event-sourcing-cqn-is-not-a-replace -for- CDC。该特性针对几乎静态的数据,以便使缓存失效并刷新。它不是为高变化率而设计的,在这方面一点效率都没有。
客户端结果缓存
与从不经常更改的数据中刷新缓存相同,可以考虑使用客户端结果缓存进行查询,因为当修改发生时,它有一种机制可以使缓存失效。但是,这里的粒度很差,因为对表的任何更改都会使其上的所有查询无效。
物化视图日志
所有更改都可以记录在物化视图日志中。该功能是为物化视图快速刷新而建立的,是一种复制。这与LogMiner使用的重做日志无关。对于物化视图日志,更改存储在表中,必须在使用时删除。但是这个特性存在了很长时间,并且得到了广泛的应用。但是,如果需要重复写入、读取和删除,只是为了将相同的数据放到另一个地方,那么我将严肃地质疑这种体系结构。
触发器
使用触发器,我们可以像使用物化视图日志一样记录更改。它提供了更多的可能性,比如发送更改而不是将其存储在数据库中(但是我们必须管理事务的可见性)。Connor McDonald发布了一个存储经过审计的更改的优化示例:
https://blogs.oracle.com/oraclemagazine/a-fresh-look-at-auditing-row-ch…
但是这仍然是很大的开销,需要在添加或删除列时进行调整。
ORA_ROWSCN
当启用行依赖项时,ORA_ROWSCN伪列可以帮助筛选最近更新的行。然而,这种方法有两个问题。
完全读:如果我们想要一个接近实时的复制,我们可能会频繁地为更改池。如果被索引,ORA_ROWSCN会很好,但事实并非如此。它只读取存储在表块中的信息。这意味着要找到在过去5分钟内完成的更改,我们需要完全扫描表,然后ORA_ROWSCN将帮助识别那些被更改的行。它是“最后更新”列时间戳的透明替代方案,但无助于快速访问这些行。
提交时间:任何读取“更改”时间戳的内容都存在一个普遍问题。假设我每5分钟收集一次变化。我有一个很长的事务,它在12:39更新一行,并在12:42提交。在12:40运行的池,查找12:35以后的更改,由于还没有提交,所以看不到更改。在12:45运行的池可以看到它,但是当它过滤自上次运行(即12:20)以来发生的更改时,就看不到它了。这意味着每次运行都必须查看更大的窗口,包括最长的事务启动时间。然后它必须处理重复项,因为前一次运行已经捕获了一些更改。当没有可用的“提交SCN”时,这是一个普遍的问题。
Userenv (“commitscn”)
在讨论可见性时间(提交SCN)与更改时,有一种没有文档记录的方法可以获得它。使用userenv(' commitscn ')进行插入或更新,这将在事务结束时神奇地返回到表行,以设置提交SCN。它不受支持,而且它只能在事务中调用一次,然后不能在触发器中自动添加。
甲骨文闪回查询
如果我们不想在DML上添加额外的审计,那么重做日志并不是惟一的内部日志记录。Oracle还会记录一致读取的撤消信息(MVCC),并且在不增加修改开销的情况下,可以显示表中发生的所有更改。基本上,我们可以选择…从…版本之间的SCN…和…所有的变化都将是可见的与新的和旧的值和附加的信息有关的操作和事务。
但是,它没有被索引。就像使用ORA_ROWSCN一样,我们需要对表进行全扫描,由于撤消操作,一致的读操作将构建以前版本的块。
闪回数据档案
闪回查询可以重构最近的更改,这些更改受到撤消保留和最近发生的DDL的限制。Flashback数据存档(称为完全回忆)可以更进一步。该特性在企业版中可用,不需要额外的选项。它可以超越撤销保留并允许一些DDL。但是,再次强调,它没有经过优化以获得自特定时间点以来的所有更改。其思想是,当您知道要读取的行时,它就可以转到以前的版本。
最小触发+闪回查询
其中一些解决方案可以组合使用。例如,触发器只能记录更改行的ROWID,而复制过程将通过flashback查询获得关于这些行的更多信息。这降低了更改的开销,同时仍然避免了对复制进行全面扫描。或者,您可以直接从定制挖掘重做日志中获得这些ROWID,这比试图从中获取所有信息要简单得多。
DDL触发器
SQL是敏捷的,允许结构更改。如果添加一个列破坏了整个复制,那么就有问题了。上述所有解决方案都需要处理这些更改。重做日志包含字典中的更改,但是解码起来可能很复杂。所有其他解决方案都必须适应这些更改,这意味着要有DDL触发器并处理不同类型的更改。
不容易…
总结一下,没有简单的解决方案,最简单的方案已经被Oracle移除,以推动金门的销售。当有人想要复制更改并从另一个地方查询它时,我的第一个建议是:不要这样做。关系数据库用于获取新的数据和修改,并能够查询不同的目的。我们有以不同格式显示数据的视图。我们有索引来快速访问不同的用例。甲骨文并不像它的许多竞争对手。从第一个版本开始,它就针对混合工作负载进行了优化。您可以查询发生更改的同一个数据库,因为SELECT不会锁定任何内容。您有一个资源管理器来确保失控的查询不会减慢事务活动。如果正确地调优,这些查询的CPU使用率很少会高于将更改流到另一个数据库所需实现的复制活动。
那么,事件源应该建立在哪种技术上呢?LogMiner看起来很适合基本使用的小型数据库。而且该项目应该适应Oracle将来删除的特性。
混合触发器/闪回查询
当只涉及到几个表时,生成DML触发器可能是最简单的,特别是当它们只记录最小值时,比如ROWID。只有在提交事务时,ROWID才可见。然后复制过程必须使用闪回查询,只从ROWID中读取那些块。这里的好处是,flashback查询显示的是更改何时可见(提交时间),而不是更改时间,这使得过滤上次运行时已经处理的更改变得更容易。
这是一个想法,当一个触发器日志的ROWID变成了一个DEMO_CDC表,我们查询:
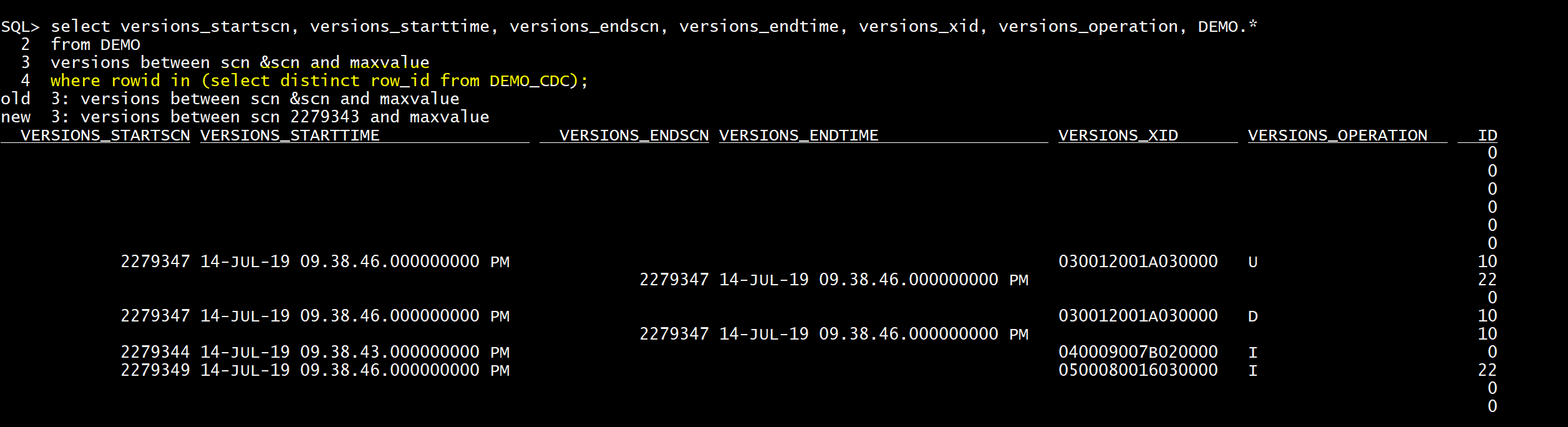
执行计划显示最佳访问与ROWID:
Explain Plan ------------------------------------------------ PLAN_TABLE_OUTPUT Plan hash value: 3039832324------------------------------------------------ | Id | Operation | Name | ------------------------------------------------ | 0 | SELECT STATEMENT | | | 1 | NESTED LOOPS | | | 2 | SORT UNIQUE | | | 3 | TABLE ACCESS FULL | DEMO_CDC | | 4 | TABLE ACCESS BY USER ROWID| DEMO | ------------------------------------------------
这里重要的一点是,查询成本与更改成比例,而不是与表的完整大小成比例。触发器开销仅限于ROWID。不需要将已经存储在基表和撤消段中的值存储在表中。如果频繁地读取这个数据,那么所涉及的所有块(ROWID列表、UNDO记录和表块)很可能仍然在缓冲区缓存中。
原文:https://medium.com/@FranckPachot/ideas-for-event-sourcing-in-oracle-d4e016e90af6
本文:https://pub.intelligentx.net/ideas-event-sourcing-oraclelog-miner-or-are-there-other-alternatives
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 236 次浏览