【安全战略】跨AWS帐户架构安全性和治理第2部分:AWS上的事件响应。

这是“跨AWS帐户架构安全性和治理”的第二部分。”系列。在这一部分中,我们将在AWS cloud上浏览事件响应规划的窄巷;我们还将使用云托管实现有趣的自动事件响应活动。
“建立声誉需要20年的时间,而几分钟的网络事件就能毁掉它。——史蒂芬·纳波
NIST,安全事件”的发生实际上或潜在危害的保密性,完整性或可用性的信息系统或信息系统流程、商店、传送或构成违反或违反安全策略的迫在眉睫的威胁,安全程序,或可接受的使用政策”。
好吧,满嘴都是,我们化简一下。意外事件是对您的IT服务的意外降级。
在本部分中,我们将介绍您轻松应对安全漏洞的过程、AWS服务和策略。
有很多事件响应框架,它们详细地解释了您需要实现哪些内容,以便围绕流程实现有效的事件响应团队、剧本和自动化。
让我们从讨论事件响应阶段和AWS上的攻击面开始,然后尝试招募AWS Lambda到我们的事件响应团队中,在出现问题时提供帮助;我希望我们能负担得起Lambda的薪水:)
云中的事件响应阶段(NIST)

参考文献:NIST SP 800-53,修订版4
当涉及到对安全事件的响应时,与传统数据中心相比,云中的阶段并没有发生太大的变化,但是技术实现确实发生了巨大的变化,变得更好。让我们来探索这些阶段。
高效运行手册的七个事件响应阶段

1-准备阶段:

准备阶段
你猜对了,这个阶段就是准备阶段。我们需要做好准备,完成威胁建模,缩小攻击面,并采取任何必要的主动措施,从一开始就防止安全事件的发生。我们需要启用日志记录、监控、加密和限制爆炸半径。
采取积极措施做好准备:
- 数据分类:识别数据敏感性级别、所有者和安全需求。
- 所有权:所有资源都应该被标记,很高兴知道谁拥有一组受损的资源,至少所有者可以提供关于资源或配置中数据存储的敏感性级别的信息,这可能会导致折衷。提示:我们应该始终标记我们的资源!
- 风险管理:识别威胁、风险和漏洞,确定您的风险偏好,然后根据您愿意容忍的风险级别管理您的风险和漏洞。
- 弹性:架构师高度可用,容错基础设施。提示:使用AWS well architect工具并阅读well-architect白皮书。
- 最小特权原则:使用AWS IAM和资源策略,只授予需要访问数据或操作环境的人有限的访问权限。
- 测试(比赛日):测试您的事件响应计划。我相信在真正的安全事件发生之前,您会发现可以解决的缺点。
准备好一切:
没有理由不在所有帐户和区域上启用CloudTrail和其他日志服务。你将没有法医学来告诉你的资产发生了什么事,在事件的违反。
当您启用CloudTrail时,您接触的任何AWS服务都将在CloudTrail中记录对它们采取的操作,CloudTrail还可以与CloudWatch和日志集成,并将存储在一个集中的s3存储桶中。
CloudWatch事件可以被AWS Lambda用于实时修复,也可以被SNS用于实时通知。无论您使用的是SDK、控制台还是AWS CLI,所有操作都将被记录下来。你对AWS资源采取的任何行动都可能被用来对付你:)我知道这是坏的,我保证不再这样做。最后一点,请不要忘记启用ClouTrail日志文件验证。

CloudTrail工作流
通过限制爆炸半径来准备

爆炸半径
使用AWS组织和VPC、子网NACLs、EC2安全组等,根据业务单元、产品等隔离AWS帐户和资源,限制爆炸半径。
这种方法与深度防御等原则相结合,可以提供更大的保护,抵御威胁。
准备加密一切:
数据隐私专家会告诉你,“对待你的数据就像每个人都在看它一样,因为他们可能一直在看。”
加密是使用加密算法和加密密钥屏蔽数据的过程。如果使用了健壮的加密算法,如果坏人能够在传输过程中拦截数据或在静止时访问数据,他们就无法将数据读取为明文。
AWS提供了加密数据的选项,包括但不限于KMS。
AWS KMS和其他直接加密数据的服务使用一种称为信封加密的方法来提供性能和安全性之间的平衡。见下文:

服务器端加密
2-鉴定阶段:

识别阶段
折衷的指标有很多,比如AWS GuardDuty high severity alert,它说明您的EC2实例正在向与比特币挖掘相关的域发出出站调用,或者最好不是正在下降的生产服务。
识别阶段是我们发现事件正在实现的阶段。实现标识阶段的最佳方法是确保为所有您认为重要的安全发现(如AWS root帐户登录)设置警报。
以下是当你意识到某个事件已经发生时,你需要回答的一些问题:
- 原因:了解攻击背后的意图可以帮助您确定产品和资源的范围和攻击的性质。
- 内容:识别丢失的数据和损坏的资源,以及您需要清理、隔离和减轻哪些工作和资源。
- 如何:找出他们利用的弱点,以获得未经授权的访问您的系统。
- When:确保你记录下所有的事件
- 谁:谁是坏演员。
在识别安全问题时,依赖于人类是一种不好的做法,因为我们在关联异常值和异常方面不如机器。使用AWS服务的自动事件响应是解决之道,您还可以通过应用机器学习和安全分析来解决这一问题。
3-围堵阶段:

控制阶段:
你已经经历了所有繁琐的识别步骤现在怎么办?这一阶段涉及的是消除安全威胁。
我们应该有一个Cloudformation或Terraform模板,它拥有构建用于取证调查的隔离环境所需的所有资源。我们需要采取的一些行动是:
- 将您的AWS帐户移动到一个组织单元,该组织单元具有非常严格的AWS组织服务控制策略。
- 拒绝访问s3桶
- 限制安全小组,所以他们只允许指定的港口进行调查。
- 全球拒绝* IAM政策应附加到所有实体,不涉及此阶段
应该部署自动化来停止受损害的资源、快照卷、禁用KMS加密密钥和更改的Route53记录集。
4-调查阶段:

调查阶段
调查阶段包括包含阶段之后的活动,包括但不限于取证和一般日志分析。调查阶段应披露事件发生的时间,以及不法分子为进入我们的系统采取了什么行动,这次入侵的副作用是什么,以及根据目前收集到的证据,这次入侵再次发生的可能性。如前所述,调查应在一个孤立的环境中进行。
你可以使用的服务:
- VPC Flow Logs.
- CloudTrail.
- CloudWatch.
- Athena for analyzing logs.
5-根除阶段:

根除阶段
这个阶段涉及到对受影响资源的仔细处理。如果有必要,我们会删除资源,并将健康和清洁资源转移到更安全的环境中。
加密的数据应该是无法被攻击者破译的,这意味着我们可以执行以下一些操作:
- 禁用或删除KMS密钥
- 从EBS卷中删除溢出的文件,并将干净的数据转移到新的加密的EBS卷
- 删除s3服务器端加密的加密s3对象
- 删除使用KMS或客户密钥加密的s3对象和s3对象的加密CMKs
如果数据没有加密,您唯一的选择是将存储资源从最后一个已知的良好状态恢复到您可以保证它没有被篡改的状态。
6-恢复阶段:
经济复苏阶段
现在我们已经做了一切来确定发生了什么,并且已经尽我们最大的能力进行了数据清理,我们需要将操作恢复到正常状态。
我们可以在这个舞台上表演的一些动作:
- 恢复资源。
- 恢复网络连接。
- 使用新的和改进的访问控制策略和加密密钥。
- 监控你的环境是否有任何不寻常的行为。
7-后续阶段:

后续阶段
后续阶段,也就是事后分析,是关于吸取的教训和需要采取的后续行动,以避免发生新的安全事件,并改进我们的事件运行记录。
自动化
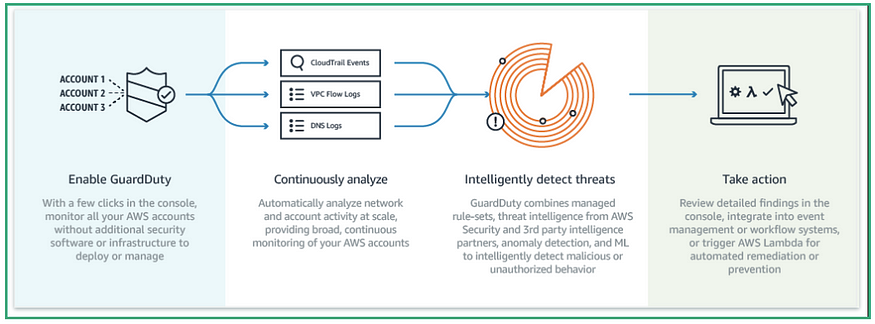
AWS警卫自动化工作流程
如果你已经做到了,谢谢你!让我们动手看看一个用例,这个用例应该能够使我们到目前为止所讨论的思想深入人心。最后,如果你不付诸行动,只有一个可靠的计划是不够的。
为此,我们需要:
- 孤立的AWS环境。请不要使用您的生产环境,因为此活动可能会占用资源。
- 在孤立的AWS环境中,必须启用AWS GuardDuty,以便生成将由CloudWatch事件和AWS Lambda使用的结果。
- EC2实例(t2.micro),为了生成一些安全结果,我们可以打开所有端口或类似的东西。
- 我们将设置Cloud保管器,以便它部署此活动所需的无服务器组件。
注意:您需要将云托管部署到您启用GuardDuty的同一区域。
当我们的云托管策略检测到AWS GuardDuty生成的中/高严重性发现时,它应该对范围内的资源采取行动,这个解决方案非常简单。
托管方将对受影响的EC2实例采取什么行动:
- 删除附加到EC2实例的IAM角色。
- 停止EC2实例。
- 取证调查卷快照。
让我们从安装云托管开始,并编写我们的第一个策略。在你的终端机运行以下命令安装抄送:

安装云托管
然后,创建一个名为custodian.yml,内容如下:
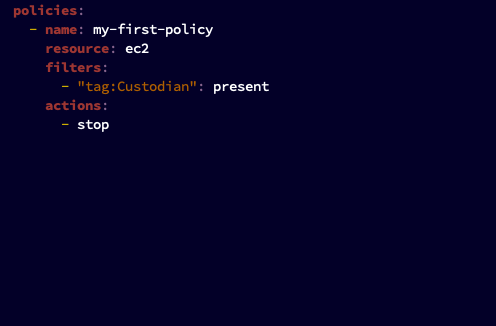
你的第一个政策

这个策略所做的就是,停止任何具有标记键“托管人”的EC2实例。
执行您的第一个策略:
我假设你使用概要文件访问通过CLI AWS帐户,如果不是你可以查找如何验证使用API密钥托管,或托管人承担角色的命令,如果你正在使用一个配置文件,下面是如何使用AWS CLI概要文件在本地运行政策,意味着这一政策不会运行基于CloudTrail所产生的一个事件或一个预定义的时间表。
如果成功,您应该在命令行上看到类似于下面的输出:

现在您是一个云托管专家,可以在AWS上实现安全自动化,让我们拿出真正的策略!

真正的交易
遵循您的第一份保单提供的步骤;编写策略,保存策略,并将其部署到一个独立的AWS环境中,然后观察其神奇之处。如果GuardDuty生成结果,策略Lambda将使用生成的事件,并通过执行我们在上面解释的操作进行响应。
好吧!这就是事件响应部分!

本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 67 次浏览