【大语言模型】NLP•检索增强生成之一
视频号

微信公众号

知识星球

Chinese, Simplified
- 概述
- 动机
- 神经检索
- 检索增强生成(RAG)流水线
- RAG的好处
- RAG与微调
- RAG合奏
- 使用特征矩阵选择矢量数据库
- 构建RAG管道
- 摄入
- Chucking
- 嵌入
- 句子嵌入:内容和原因
- 背景:与BERT等代币级别模型相比的差异
- 相关:句子转换器的训练过程与令牌级嵌入模型
- 句子变换器在RAG中的应用
- 句子嵌入:内容和原因
- 检索
- 标准/天真的方法
- 优势
- 缺点
- 语句窗口检索/从小到大分块
- 优势
- 缺点
- 自动合并检索器/层次检索器
- 优势
- 缺点
- 计算出理想的块大小
- 寻回器镶嵌和重新排列
- 使用近似最近邻进行检索
- 重新排序
- 标准/天真的方法
- 响应生成/合成
- 迷失在中间:语言模型如何使用长上下文
- “大海捞针”测试
- 摄入
- 组件式评估
- 检索度量
- 上下文精度
- 上下文回忆
- 上下文相关性
- 生成度量
- 脚踏实地
- 回答相关性
- 端到端评估
- 回答语义相似性
- 答案正确性
- 检索度量
- 多模式RAG
- 改进RAG系统
- 相关论文
- 知识密集型NLP任务的检索增强生成
- 主动检索增强生成
- 多模式检索增强生成器
- 假设文档嵌入(HyDE)
- RAGAS:检索增强生成的自动评估
- 微调还是检索?LLM中知识注入的比较
- 密集X检索:我们应该使用什么检索粒度?
- ARES:一种用于检索增强生成系统的自动评估框架
- 引用
概述
- 检索增强生成(RAG)是一种通过引入外部知识来增强语言模型生成的技术。
- 这通常是通过从大型文档语料库中检索相关信息并使用该信息来通知生成过程来完成的。
- 让我们深入研究以下细节。
动机
- 在许多情况下,客户拥有大量的专有文件,如技术手册,并要求从这些海量内容中提取特定信息。这项任务可以比作大海捞针。
- 最近,OpenAI推出了一种新的模型GPT4-Turbo,它拥有处理大型文档的能力,有可能解决这一需求。然而,由于“迷失在中间”现象,这种模式并不完全有效。这种现象反映了这样一种体验,即类似于完整阅读《圣经》,但很难回忆起《撒母耳记》之后的内容,模型往往会忘记位于上下文窗口中间的内容。
- 为了规避这一限制,已经开发了一种称为检索增强生成(RAG)的替代方法。这种方法包括为文档中的每个段落创建一个索引。当进行查询时,最相关的段落会被迅速识别,然后输入到像GPT4这样的大型语言模型(LLM)中。这种只提供选定段落而不是整个文档的策略,防止了LLM中的信息过载,并显著提高了结果的质量。
神经检索
- 在我们进入RAG之前,让我们花点时间全面讨论一下神经检索器。
- 神经检索器是一种使用神经网络将查询与相关文档匹配的信息检索模型。它们将查询和文档编码为密集向量表示,并计算它们之间的相似性得分。这使它们能够超越词汇匹配并获取语义相关性。
- 神经检索器代表着从传统的基于关键词的信息检索系统到能够理解文本数据中潜在含义和关系的信息检索方法的重大转变。以下是对它们如何工作及其意义的扩展解释:
- 以下是它们的一般操作方式:
- 矢量编码:
- 查询和文档都被转换为高维空间中的向量。这个过程是由基于神经网络的编码器完成的,这些编码器经过训练,可以捕捉文本的语义本质。
- 在训练过程中,这些模型经常接触大量的文本,使他们能够学习单词和短语之间的复杂模式和关系。
- 语义匹配:
- 使用诸如余弦相似度之类的度量来计算查询向量和文档向量之间的相似度。这允许系统根据内容的含义而不仅仅是关键字重叠来确定哪些文档与查询最相关。
- 这个过程可以捕捉到细微的关系,比如同义词或相关概念,而传统方法可能会错过这些关系。
- 矢量编码:
- 神经检索器的优点:
- 神经检索器可以理解术语的使用上下文,当查询或文档具有歧义或多重含义时,可以进行更准确的检索。
- 他们擅长处理长而复杂的查询,因为他们可以掌握整体意图,而不仅仅是孤立的术语。
- 许多神经检索器都是在多语言数据集上训练的,使它们能够有效地处理不同语言的查询。
- 挑战和注意事项:
- 神经模型,特别是那些用于编码大型文档的模型,需要大量的计算能力来进行训练和推理。
- 神经检索器的性能在很大程度上取决于它们所训练的数据,并且它们可能会继承训练数据中存在的偏差。
- 保持文档表示的最新状态是一项挑战,尤其是对于动态更改内容而言。
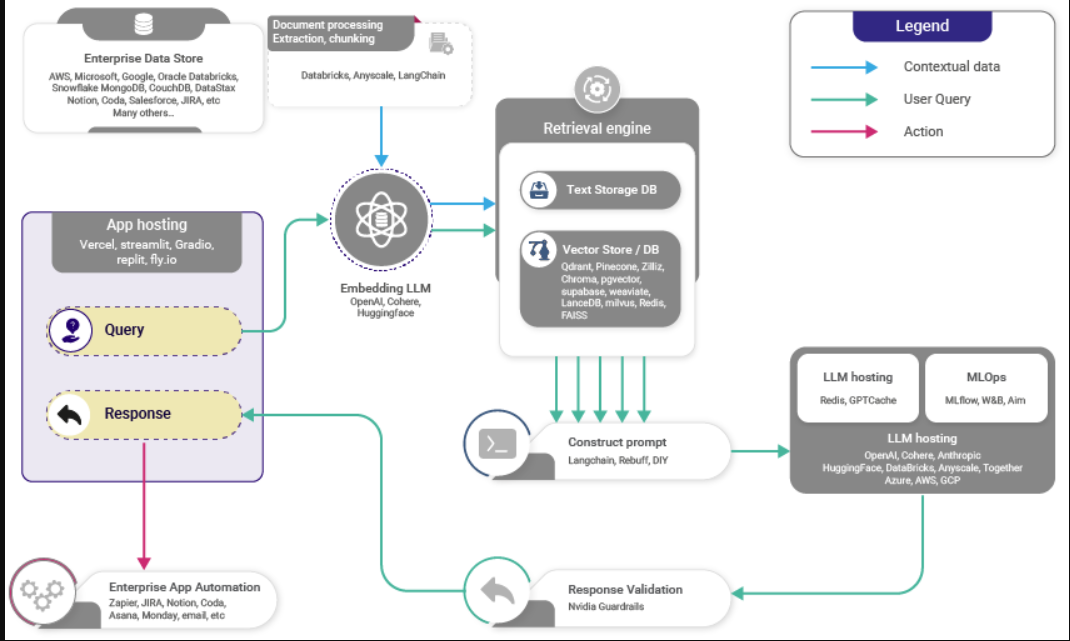
检索增强生成(RAG)流水线
- 有了RAG,LLM能够通过提供对数据库等外部知识源的访问,利用不一定在其权重中的知识和信息。
- 它利用检索器来找到相关的上下文来调节LLM,通过这种方式,RAG能够用相关的文档来增强LLM的知识库。
- 这里的检索器可以是以下任何一种,具体取决于是否需要语义检索:
- 矢量数据库:通常,使用BERT等模型嵌入查询,以生成密集的矢量嵌入。或者,像TF-IDF这样的传统方法可以用于稀疏嵌入。然后基于术语频率或语义相似性来进行搜索。
- 图形数据库:从文本中提取的实体关系构建知识库。这种方法是精确的,但可能需要精确的查询匹配,这在某些应用程序中可能会受到限制。
- 常规SQL数据库:提供结构化数据存储和检索,但可能缺乏矢量数据库的语义灵活性。
- 下面的图片来自Damien Benveniste博士,他谈到了RAG使用Graph和Vector数据库之间的区别。

- 在上面链接的帖子中,Damien表示,与矢量数据库相比,图形数据库更适合于检索增强生成(RAG)。虽然矢量数据库使用LLM编码的矢量对数据进行分区和索引,允许语义相似的矢量检索,但它们可能会获取不相关的数据。
- 另一方面,图形数据库从文本中提取的实体关系中构建知识库,使检索简洁明了。但是,它需要精确的查询匹配,这可能是有限制的。
- 一个潜在的解决方案可能是结合这两个数据库的优势:在图数据库中用矢量表示索引解析的实体关系,以实现更灵活的信息检索。这种混合模式是否存在还有待观察。
- 检索后,您可能希望通过添加排名和/或精细排名层来进一步筛选候选者,这些层允许您筛选出与业务规则不匹配、不针对用户、当前上下文或响应限制进行个性化设置的候选者。
- 让我们简要总结一下RAG的过程,然后深入研究它的优缺点:
- 矢量数据库创建:RAG首先将内部数据集转换为矢量,并将其存储在矢量数据库(或您选择的数据库)中。
- 用户输入:用户以自然语言提供查询,寻求答案或完成。
- 信息检索:检索机制扫描矢量数据库,以识别在语义上与用户的查询(也是嵌入的)相似的片段。然后将这些片段提供给LLM,以丰富其生成响应的上下文。
- 组合数据:从数据库中选择的数据段与用户的初始查询相组合,创建一个扩展的提示。
- 生成文本:放大的提示,填充了添加的上下文,然后提供给LLM,LLM制作最终的上下文感知响应。
- 下图(来源)显示了RAG的高级工作
RAG的好处
- 那么,为什么要在应用程序中使用RAG呢?
- 有了RAG,LLM能够通过提供对外部知识库的访问,利用不一定在其权重中的知识和信息。
- RAG不需要模型再训练,节省了时间和计算资源。
- 即使使用有限的标记数据,它也很有效。
- 然而,它也有其缺点,即RAG的性能取决于检索器知识库的全面性和正确性。
- RAG最适合于未标记数据丰富但标记数据稀少的场景,非常适合于需要实时访问产品手册等特定信息的虚拟助理等应用程序。
- 有大量未标记数据但很少标记数据的场景:RAG在有大量可用数据的情况下很有用,但其中大多数数据没有以对训练模型有用的方式进行分类或标记。例如,互联网上有大量的文本,但其中大部分的组织方式并不能直接回答特定的问题。
- 此外,RAG是虚拟助理等应用程序的理想选择:Siri或Alexa等虚拟助理需要从各种来源获取信息,以实时回答问题。他们需要理解问题,检索相关信息,然后做出连贯准确的回答。
- 需要实时访问产品手册等特定信息:这是RAG模型特别有用的一个例子。想象一下,你问一个虚拟助理一个关于产品的特定问题,比如“我如何重置XYZ品牌的恒温器?”RAG模型将首先从产品手册或其他资源中检索相关信息,然后使用这些信息生成清晰、简洁的答案。
- 总之,RAG模型非常适合有大量可用信息的应用,但这些信息的组织或标记并不整齐。
- 下面,让我们来看看介绍RAG的出版物,以及原始论文是如何实现该框架的。
RAG与微调
下表(来源)比较了RAG与微调。

- 总结上表:
- 检索系统(RAG)使LLM系统能够访问真实的、受访问控制的、及时的信息。微调无法做到这一点,因此没有竞争。
- 微调(而非RAG)调整LLM的风格、音调和词汇,使您的语言“画笔”与所需的领域和风格相匹配
- 总而言之,首先关注RAG。一个成功的LLM应用程序必须将专用数据连接到LLM工作流。一旦您有了第一个完整的应用程序,您就可以添加微调来改进系统的风格和词汇。如果RAG与数据的连接构建不正确,那么微调将无法挽救您的生命。
RAG合奏/合唱
- 利用RAG系统的集成为模型生成丰富且上下文准确的文本的能力提供了实质性的升级。以下是该程序如何工作的增强细分:
- 知识来源:RAG模型从外部知识库中检索信息,以增强其在特定领域的知识。这些可以包括维基百科、书籍、新闻、数据库等领域的文章、表格、图像等。
- 组合来源:在推理时,多个检索器可以从不同的语料库中提取相关内容。例如,一个检索器搜索维基百科,另一个搜索新闻来源。他们的结果被连接到一组汇集的候选者中。
- 排名:该模型根据汇集的候选人与上下文的相关性对其进行排名。
- 选择:选择排名靠前的候选者,以调节语言模型的生成条件。
- 集合:可以集合专门针对不同语料库的独立RAG模型。它们的输出被合并、排序并进行投票。
- 多个知识源可以通过汇集和集合来增强RAG模型。仔细的排名和选择有助于整合这些不同的来源,以提高世代。
- 使用多个检索器时需要记住的一件事是,在合并它们以形成响应之前,对每个检索器的不同输出进行排序。这可以通过多种方式实现,使用LTR算法、多武装土匪框架、多目标优化,或根据特定的业务用例。
使用特征矩阵选择矢量数据库
- 为了比较过多的Vector DB产品,一个突出Vector DB之间的差异以及在哪个场景中使用哪个的特征矩阵是必不可少的。
- VectorHub的Vector DB Comparison (Vector DB Comparison by VectorHub)提供了一个跨越37家供应商和29个功能的强大比较(截至本文撰写之时)。

- 作为次要资源,下表(来源)(source)显示了Vector DB在各种功能维度上提供的一些流行功能的比较:

在此处访问完整的电子表格
本文地址
https://architect.pub
- 96 次浏览
SEO Title
NLP • Retrieval Augmented Generation : part1