【负责的AI】衡量公平性
视频号

微信公众号

知识星球

衡量公平性
你如何确保一个模型同样适用于不同的人群?事实证明,在许多情况下,这比你想象的要困难。
问题是,有不同的方法来衡量模型的准确性,而且通常在数学上不可能在各组之间都相等。
我们将通过创建一个(假)医学模型来对这些人进行疾病筛查,从而说明这种情况是如何发生的。
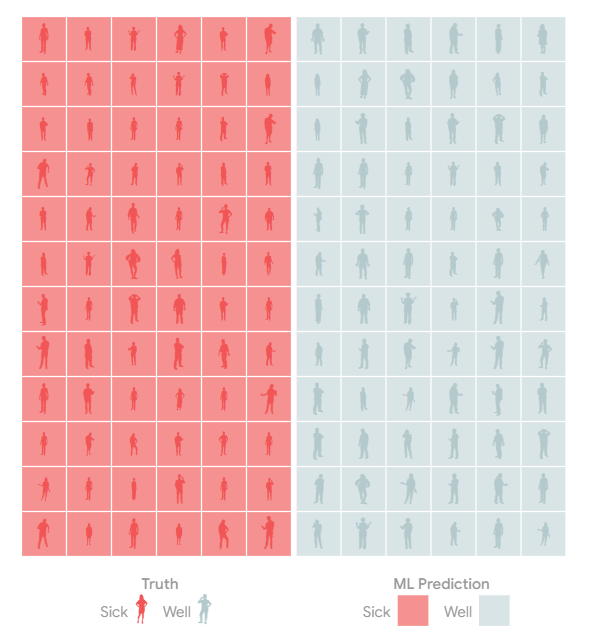
基本事实
这些人中大约有一半实际上患有甲型肝炎;其中一半没有。

模型预测
在一个完美的世界里,只有病人的检测结果呈阳性,只有健康人的检测结果为阴性。
模型错误
但模型和测试并不完美。
该模型可能会犯错误,将生病的人标记为健康的c。
或者相反:将一个健康的人标记为生病的f。
千万不要错过疾病。。。
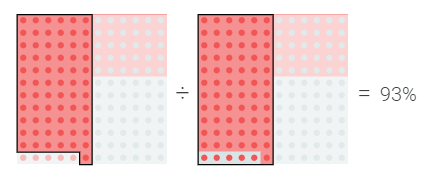
如果有一个简单的后续测试,我们可以让该模型积极地称为密切病例,这样它就很少错过这种疾病。
我们可以通过测量检测呈阳性的病人的百分比来量化这一点
…还是避免过度拥挤?
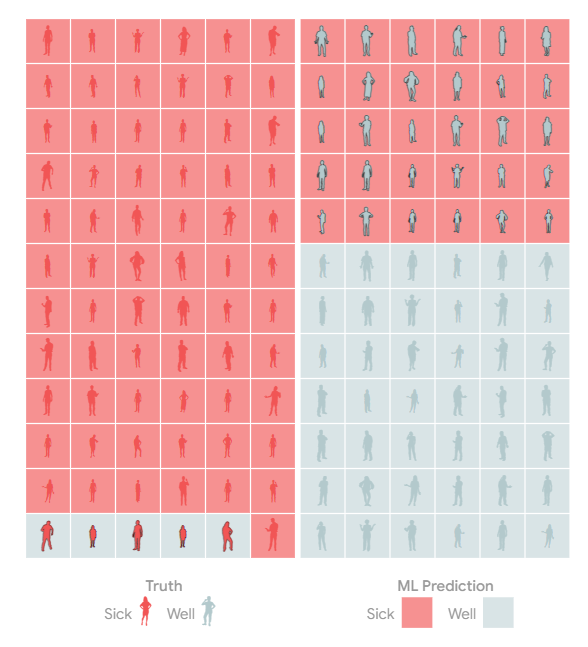
另一方面,如果没有二次检测,或者治疗使用的药物供应有限,我们可能更关心检测呈阳性的人中实际患病的百分比。
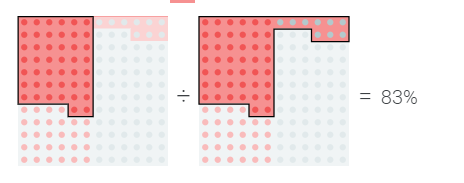
模型优化中的这些问题和权衡并不是什么新鲜事,但当我们有能力精确调整疾病诊断的积极性时,它们就会成为焦点。

试着调整模型在诊断疾病方面的积极性
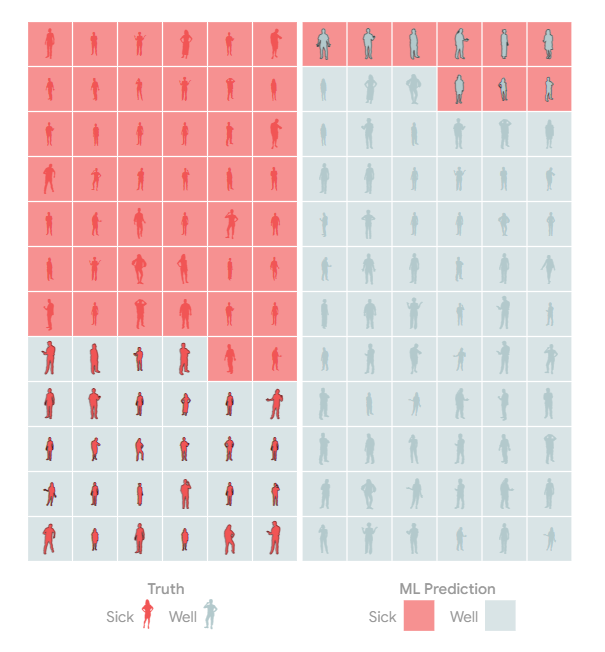
分组分析
当我们检查模型是否公平对待不同的群体时,事情变得更加复杂。¹
无论我们在这些指标之间的权衡方面做出什么决定,我们都可能希望它们在不同的人群中大致持平。
如果我们试图平均分配资源,那么让该模型遗漏的儿童病例比成年人多就不好了!
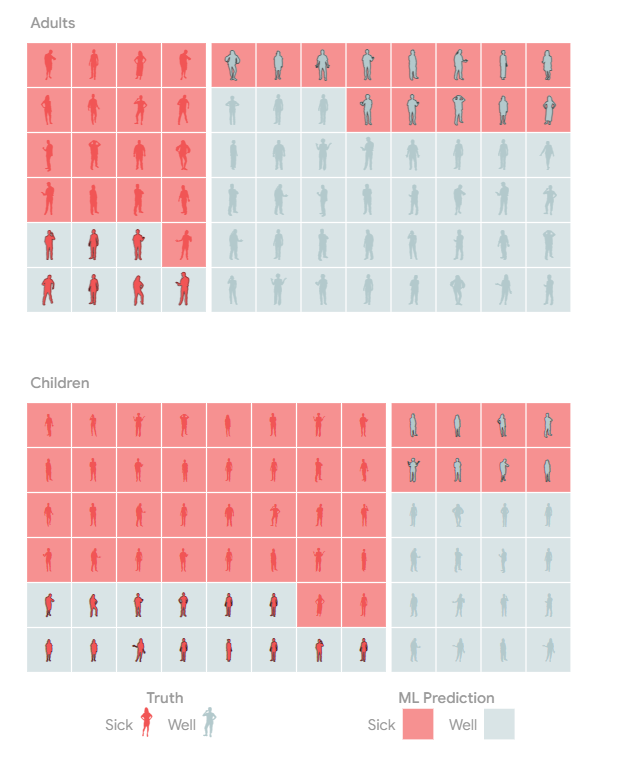
基本发病率
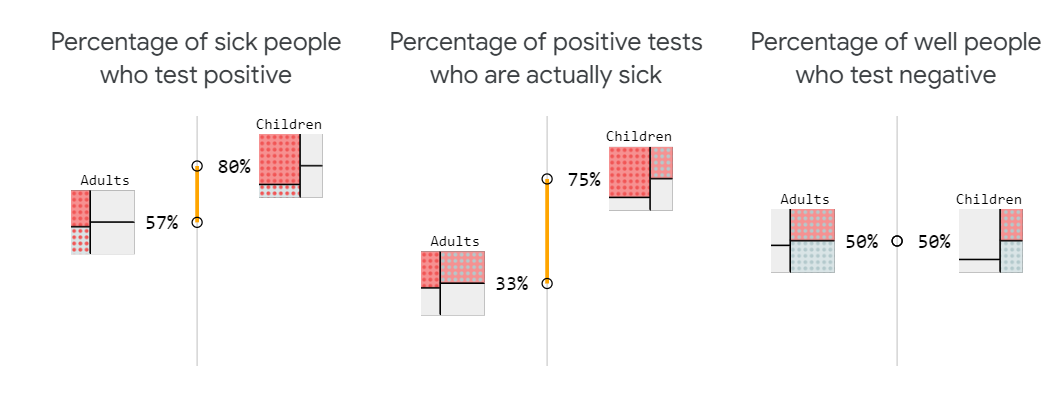
如果你仔细观察,你会发现这种疾病在儿童中更为普遍。也就是说,不同群体的疾病“基本发病率”不同。
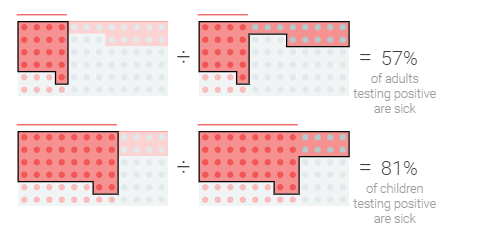
基本利率的不同使情况变得异常棘手。首先,尽管该检测检测到的患病成年人和患病儿童的比例相同,但检测呈阳性的成年人感染该疾病的可能性低于检测呈阳性儿童。
不平衡指标
为什么儿童和成人在诊断方面存在差异?健康成年人的比例更高,因此测试中的错误会导致更多健康成年人被标记为“阳性”,而不是健康儿童(同样,错误的阴性)。
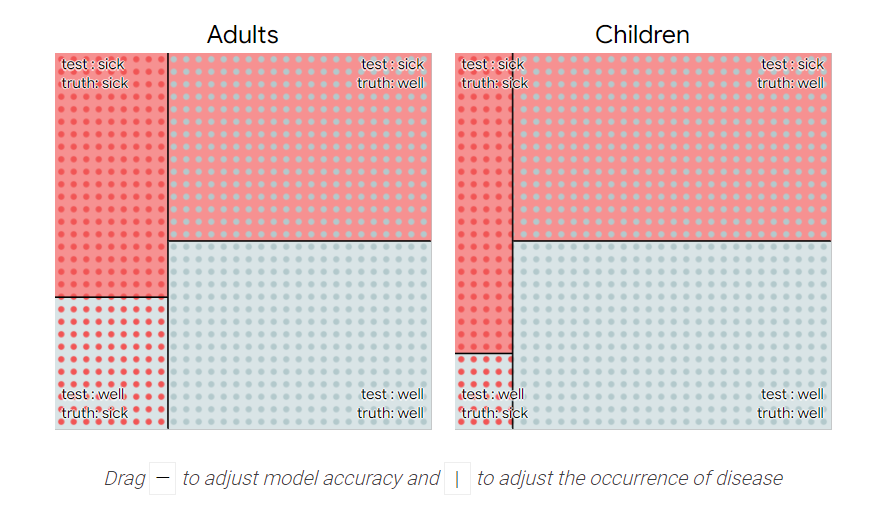
为了解决这个问题,我们可以让模型将年龄考虑在内。

试着调整滑块,使模型级成人的攻击性低于儿童。

结论
值得庆幸的是,你选择满足的公平概念将取决于你的模型的上下文,所以虽然不可能满足公平的每一个定义,但你可以专注于对你的用例有意义的公平概念。
即使不可能在各个方面都做到公平,我们也不应该停止检查偏见。隐藏的偏见探索概述了人类偏见可以输入ML模型的不同方式。
更多阅读
在某些情况下,为不同人群设定不同的阈值可能是不可接受的。你能让人工智能比法官更公平吗?探索了一种可以把人送进监狱的算法。
有很多不同的指标可以用来确定算法是否公平。用更智能的机器学习来攻击歧视,这表明了其中一些是如何工作的。将公平指标与假设工具和其他公平工具结合使用,您可以根据常用的公平指标测试自己的模型。
机器学习从业者使用“回忆”等词来描述检测呈阳性的病人的百分比。查看PAIR指南手册词汇表,了解如何与构建模型的人员交谈。
附录
这篇文章使用了非常学术的、数学的公平标准,并没有涵盖我们在口语中可能包含的公平的所有内容。这里对算法的技术描述与它们所部署的社会环境之间存在差距。
²有时我们可能更关心不同人群中的不同错误模式。如果儿童的治疗风险更大,我们可能希望该模型在诊断方面不那么激进。
³上面的例子假设模型根据人们生病的可能性对他们进行分类和评分。通过完全控制模型在两组中诊断不足和过度的确切比率,实际上有可能将我们迄今为止讨论的两个指标保持一致。试着调整下面的模型,使两者对齐。
再加上第三个指标,即e检测呈阴性的健康人的百分比,就不可能实现完美的公平。你能明白为什么除非两个人群的基本发病率相同,否则这三个指标都不会一致吗?
信用
Adam Pearce//2020年5月
感谢Carey Radebaugh、Dan Nanas、David Weinberger、Emily Denton、Emily Reif、Fernanda Viégas、Hal Abelson、James Wexler、Kristen Olson、Lucas Dixon、Mahima Pushkarna、Martin Wattenberg、Michael Terry、Rebecca Salois、Timnit Gebru、Tulsee Doshi、Yannick Assogba、Yoni Halpern、Zan Armstrong和我在谷歌的其他同事对这篇文章的帮助。
- 59 次浏览