分布式平台
【Distriuted platform】使用Helix任务框架管理分布式任务
无状态任务被广泛用于服务大规模数据处理系统。许多请求都是由依赖Apache Helix的系统提出的,因为无状态任务管理功能将被添加到Apache Helix中。最近,我们的团队决定探索管理无状态任务的新方法,以及我们正在进行的支持Helix的工作。这些努力的结果是Helix Task Framework,一个为无状态任务的分布式执行提供动力的引擎。在这篇文章中,我们将介绍Helix任务框架,它在Helix中作为高级功能提供。
关于Helix
Apache Helix是一种通用的集群管理框架,用于自动管理托管在节点集群上的分区和复制分布式系统。在节点故障恢复,群集扩展和重新配置的情况下,Helix会自动调整和替换分区及其副本。
Helix通过声明状态机表示应用程序的生命周期,将集群管理与应用程序逻辑分开。 Apache Helix网站详细描述了Helix的体系结构以及如何使用它来管理分布式系统。还有一些公开的博客文章提供了Helix内部的演练。
Helix最初是在LinkedIn开发的,目前管理关键基础设施,如Espresso(No-SQL数据存储),Brooklin(搜索即服务系统),Venice(派生数据服务平台)以及离线数据基础设施存储和处理。有关这些系统的更多信息,请点击此处。
任务框架上的分布式任务
任务框架
Helix Task Framework支持短期运行和长期运行任务的分布式执行。任务框架将作业划分为任务并安排它们在集群中的Helix Participants(节点)上执行。实际调度是通过将任务分配给可用的参与者节点来完成的,并且这些任务经历执行阶段并且相应地用Helix Task StateModel中的相应状态标记。
任务框架随后可以并行地触发任务的执行或调度任务。 Helix Controller监控集群中的所有任务执行,避免裂脑问题,并通过Helix定义的有限状态机和约束启用故障恢复。
概念
任务有三个抽象级别:工作流,工作和任务。工作流由一个或多个作业组成。作业由一个或多个任务组成。任务被定义为最小的,相互独立的可执行工作单元,其逻辑由用户实现。以下小节深入研究了这些抽象的实际用例。
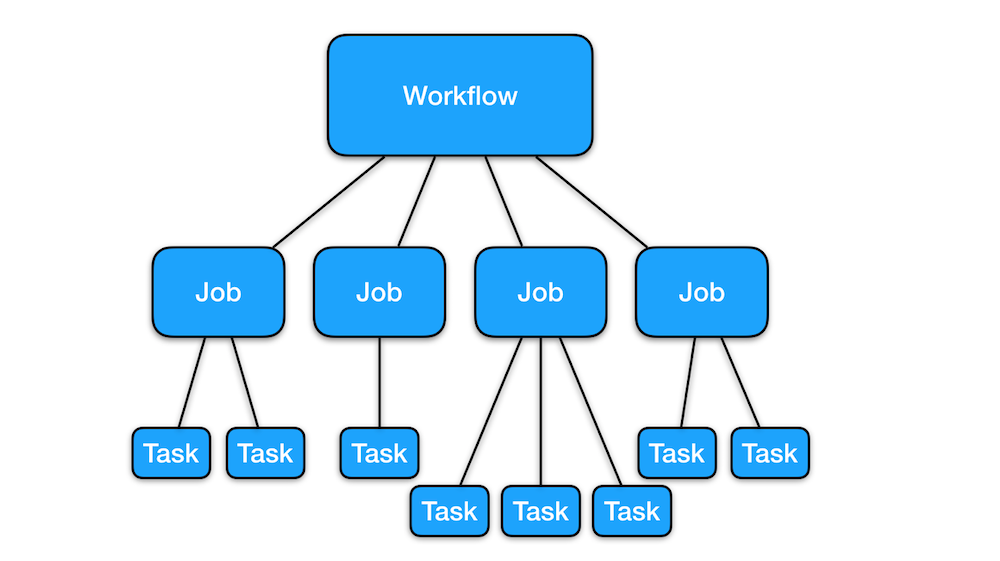
工作流程
有两种类型的工作流:通用工作流和作业队列。
通用工作流是作业之间依赖关系的有向无环图(DAG)表示。 这些依赖关系明确定义了必须运行作业的顺序。 根据DAG,可能存在多种可能的排序。
作业队列是一种特殊类型的工作流。 作业队列与常规工作流程的不同之处在于作业之间的依赖关系是线性的。 因此,在队列中的所有其他作业运行并成功完成之前,不会安排作业。 但是,请注意,任务框架允许用户更改此行为 - 例如,通过修改配置参数,您可以允许作业运行,即使在依赖关系链中的某个位置之前存在失败的作业。
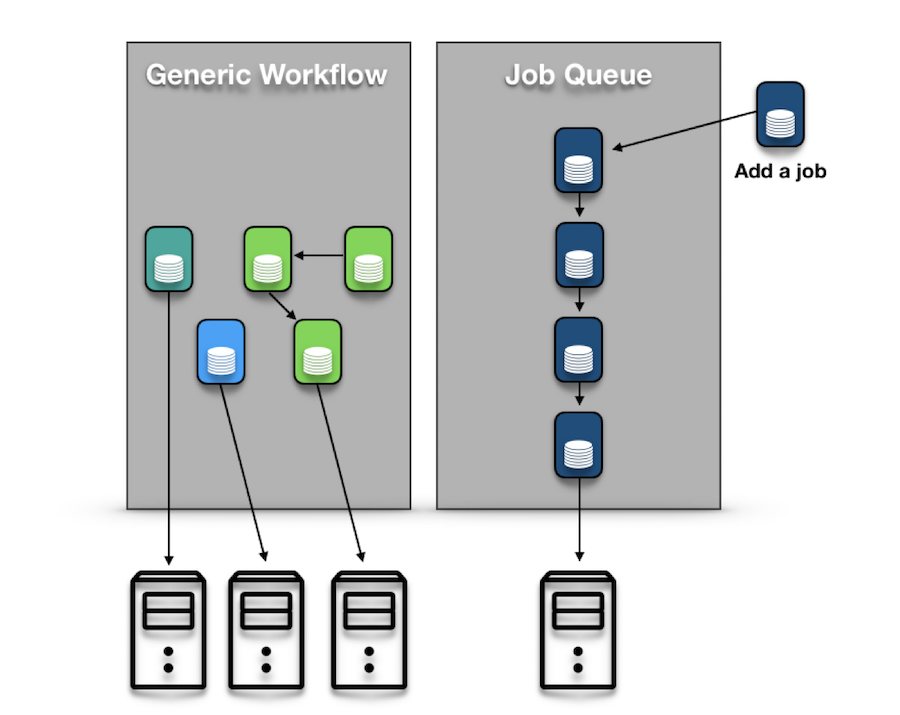
任务框架还允许工作流程是一次性的或经常性的。上面描述的通用工作流默认是一次性的,并且在完成时将从Task Framework的元数据存储中丢弃。但是,循环工作流或作业队列适用于需要定期运行业务逻辑的用例。要创建循环工作流,用户必须创建所谓的“模板”。此模板包含用于创建工作流的一次性实例的信息和参数(例如频率,开始时间,任务逻辑等)。然后,任务框架将按照给定模板的定义自动创建和提交工作流,从而消除了用户使用其他调度工具(例如cron)的需要。
工作
作业是任务框架中的下一级抽象。工作可以有许多相同或不相同的任务。工作是否成功完成取决于其任务的状态;例如,如果其任务未在超时阈值内完成或因任何原因失败,则作业将被标记为超时或失败。只有在所有任务成功完成后,作业才会标记为已完成。
任务框架中支持两种类型的作业:通用作业和目标作业。默认情况下,作业是通用作业。它由一个或多个任务组成,每个任务由Helix Controller生成的分配分布在多个节点上。但是,目标作业绑定到“目标”,它是非任务Helix资源的分区(此处的“Helix资源”表示由Helix管理的实体,例如数据库分区)。假设在Helix上运行的分布式数据库系统想要运行备份作业。这意味着必须在“目标”数据库分区所在的节点上安排并精确运行备份任务。有针对性的工作完全实现了这一点;它有一个“目标”资源(本例中为分布式数据库),其任务将在为该目标资源的分区提供服务的所有计算机上运行。也可以指定目标的状态(由Helix的StateModel定义),这意味着目标任务将仅在指定目标分区的副本处于目标状态的机器上运行。
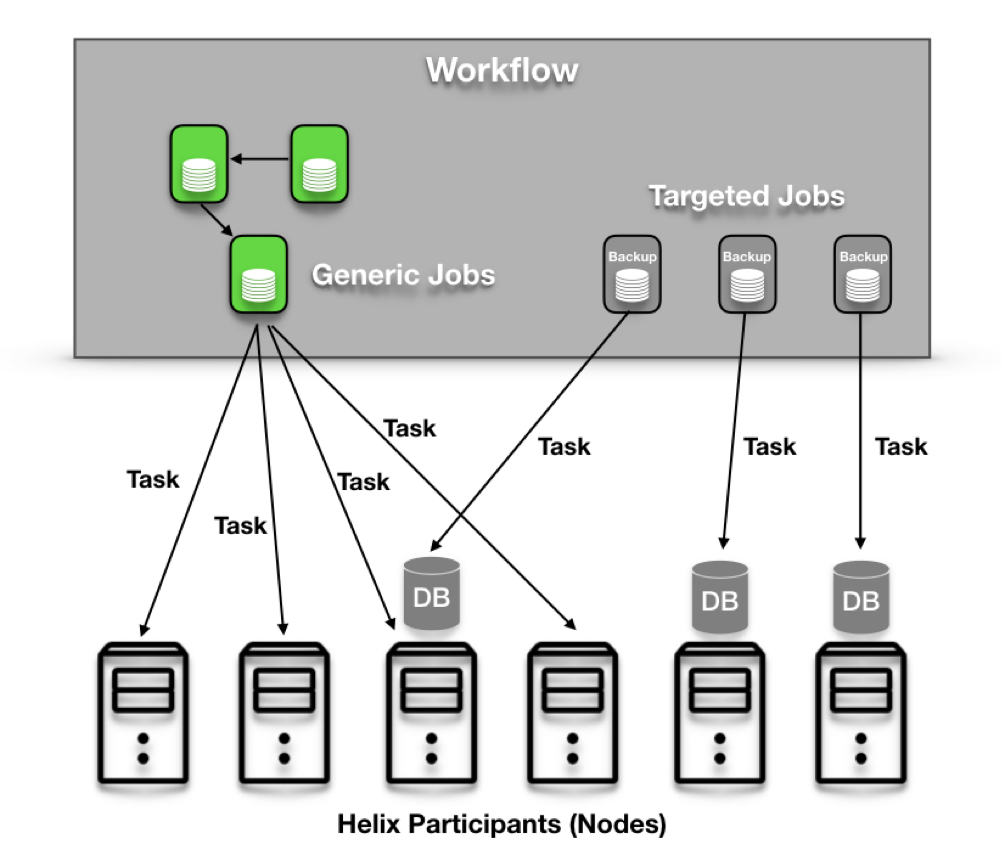
任务
任务是最小的独立工作单元,其逻辑由用户实现。 在内部,每个单独的任务都遵循Helix定义的Task StateModel。 任务框架中的分配和调度以任务粒度进行。 以下是Task接口的代码片段:

强大分布式系统:任务框架的应用
在Espresso中管理分布式数据库作业
Espresso曾经有一种传统的备份方法,每个节点在本地运行备份调度程序,备份它托管的每个分区。这种方法有以下两个限制。
- 缺乏集中,协调的调度程序:由于备份是在每个节点上独立调度的,并且每个节点都不知道其他节点正在备份,因此对于分区的每个副本,存在大量相同分区的重复备份。虽然节点彼此发送异步消息以跟踪正在备份的分区,但由于竞争条件,这是不可靠的。更糟糕的是,有时候我们看不到分区的备份了!
- 缺少任务进度监控:备份调度程序将消息发送到存储节点以触发备份任务。但是,此消息仅启动备份任务 - 我们需要一种方法来跟踪其进度。为了跟踪,我们经常向Helix发送getStatus消息,Helix在Zookeeper中创建了一个新节点。然而,这种方法很快就被证明是有问题的,因为它产生的大量消息试图备份数百个分区。
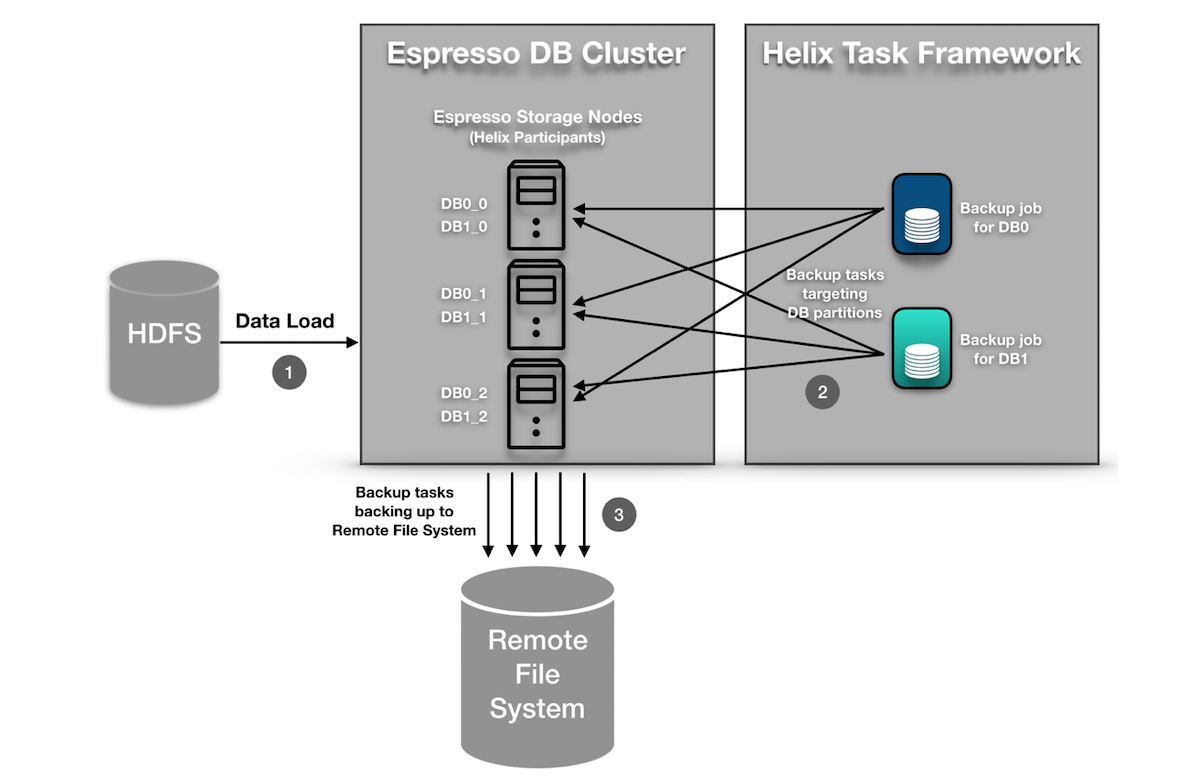
Espresso现在在Task Framework上运行其备份作业。这很有用,因为Espresso已经在其数据库分区中使用了Helix的通用资源管理功能。 Helix Controller了解数据库分区周围发生的状态变化,因此能够轻松确定哪些任务需要绑定到哪些数据库分区。此外,Helix Controller充当集中式调度程序,可以控制并发任务的数量并确定何时应运行备份任务(以避免高峰时段)。以下部分提供了更详细的演练。
Espresso如何在Task Framework上运行备份任务
任务框架要求用户实现两个Java接口:Task和TaskFactory。 Helix将使用TaskFactory在运行时生成Task的实例。下一步是告诉Espresso的节点(由Espresso称为存储节点,Helix称为Participants),我们将在其上运行任务。这是通过将TaskFactory注册到StateMachineEngine(通过HelixManager访问)来完成的。然后,Espresso的中央控制器/调度程序已准备好使用TaskDriver中的一组API创建和提交任务。 TaskDriver提供了一组易于使用的API,允许用户创建,运行,停止和删除工作流。此外,用户可以通过TaskDriver检索每个工作流的状态信息。
监测和操作
为了增强可操作性和用户体验,Helix提供轻量级REST服务Helix REST 2.0和Helix UI。 Helix UI与Helix REST交谈以掌握所有配置并跟踪任务框架状态。
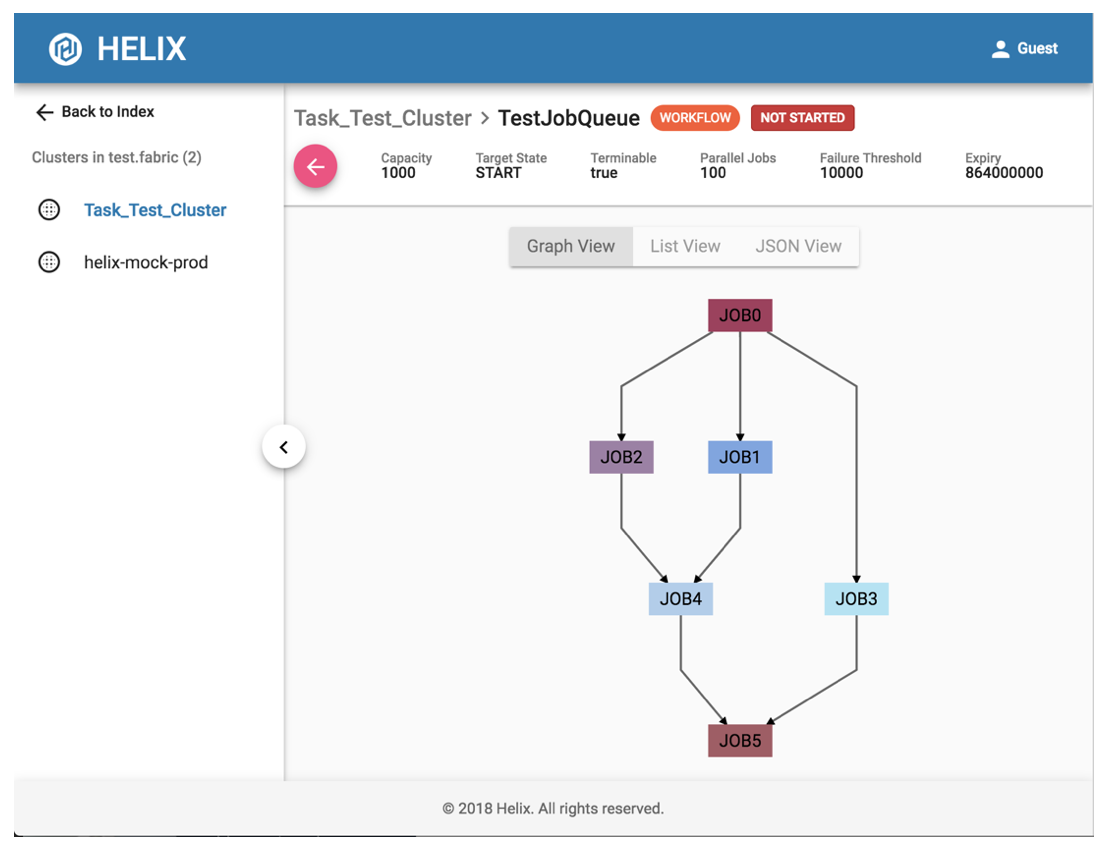
如上所述,Espresso使用目标作业进行备份。 Helix UI对于发现作业执行中的任何异常非常有用。用户可以轻松访问Helix UI以监控现有工作流和作业的状态并执行简单操作。此外,Helix UI支持身份验证,操作授权和审计日志记录,这为使用Helix构建的分布式应用程序添加了一层安全性。
最近的性能和稳定性改进
最小化冗余ZNode创建
IdealState和ExternalView是反映Helix定义的资源的未来状态和当前状态的元数据信息。在较旧的Task Framework实现中,作业被视为Helix资源,例如DB分区。这意味着在创建时为每个作业生成IdealState ZNode和ExternalView ZNode。这是有问题的,因为Task Framework作业和通用Helix资源本质上是不同的:作业往往是短暂的,经常创建和删除的瞬态实体,但是通用Helix资源往往是持久且继续为请求提供服务的持久实体。因此,创建和删除如此多的ZNode被证明是昂贵的,不再适合工作。这些ZNode将保留在ZooKeeper中,直到指定的数据到期时间(通常为一天或更长时间)。对于循环作业来说更糟糕的是 - 正在为原始作业模板创建一组IdealState / ExternalView ZNode,并且将为作业的每个计划运行创建另一组IdealState / ExternalView ZNode。进行了一项改进,以便作业的IdealState ZNode仅在计划运行时生成,并在作业完成后立即删除。实际上,每个工作流程应该只有少数作业同时运行,因此在任何给定时间每个工作流程只会存在少量的IdealState ZNode。此外,默认情况下将不再创建作业的ExternalView ZNode。
安排重复工作的问题
我们发现在从循环工作流调度重复作业时,计时器不稳定。这主要是因为我们为每个作业添加到周期性作业队列时设置了一个计时器,并且因为为所有当前和未来的作业维护大量计时器容易出错。此外,在Helix Controller的领导交接期间,这些计时器未被正确转移到新的领导者控制器。通过使任务框架为每个工作流而不是作业设置计时器来解决这个问题。现在Helix需要跟踪的定时器要少得多,而且在Helix Controller的领导交接过程中,新的领导者Controller将扫描所有现有的工作流程并适当地重置定时器。
任务元数据累积
我们观察到,当Task Framework负载繁重时,任务元数据(ZNodes)很快就会堆积在ZooKeeper中,不断将任务分配给节点。这会影响性能和可扩展性。提出并实施了两个修复:定期清除作业ZNode和批量读取元数据。删除终端状态中的作业会定期有效地缩短元数据保留周期,从而减少任何给定执行点上存在的任务元数据的数量。批量读取有效地减少了读取流量的数量和频率,解决了Zookeeper冗余读取的开销问题。
任务框架的后续步骤
重构ZooKeeper中的元数据层次结构
正如本文前面部分所讨论的,任务框架的性能直接受ZooKeeper中存在的Zookeeper存储结构(ZNodes)数量的影响。 Helix将工作流和作业配置以及上下文(工作流/作业的当前状态)的ZNode存储在一个展平目录中。这意味着理论上每次数据更改都会触发目录中所有ZNode的读取,当目录下的ZNode数量很高时,这可能会导致灾难性的减速。尽管批量读取等小改进缓解了这个问题,但我们发现问题的根源在于存储ZNode的方式。在不久的将来,将向Helix引入新的ZNode结构,以便任务框架ZNode将反映工作流,作业和任务的层次结构特性。这将大大减少ZooKeeper的读写延迟,使Task Framework能够更快地执行更多任务。
更先进的分配算法和策略
任务框架使用Consistent Hashing来计算可用节点的任务分配。有两种方法可以改进任务分配。首先,Helix Controller当前计算其管道的每次运行中的任务分配。请注意,此管道在Helix的通用资源管理中共享,这意味着管道的某些运行可能与任务框架无关,导致Helix Controller计算任务分配无效。换句话说,我们观察到了相当多的冗余计算。此外,Consistent Hashing可能不是任务的适当分配策略。直观地说,将任务与节点匹配应该很简单:只要节点能够承担任务,它就应该尽快完成。使用Consistent Hashing,您可能会看到一些节点忙于执行任务,而其他节点将处于空闲状态。
已经确定生产者 - 消费者模式是用于在一组节点上分配任务的更合适的模型 - 生产者是Controller,并且可用节点的集合是消费者。我们相信这种新的分发策略将极大地提高任务框架的可扩展性。
任务框架作为一个独立的框架
Helix最初是作为通用资源/集群管理的框架,而任务框架是通过将作业作为具有自己的状态模型的特殊资源来开发的。但是,我们现在只有LinkedIn用户使用Helix的任务框架功能。任务框架已经看到了其增长份额,为了满足用户不断增长的可扩展性需求,我们决定将其与通用资源管理分离是不可避免的。
分离工作有三个方面:1)减少资源竞争; 2)删除不必要的冗余; 3)删除部署依赖项。任务框架和通用资源管理框架的工作由单个中央调度程序:Helix Controller管理。这意味着单个Controller在一个JVM中运行而没有隔离,我们无法阻止资源管理的减速影响任务的分配和调度,反之亦然。换句话说,两个实体之间存在资源竞争。从这个意义上讲,我们需要将一个Helix控制器分成两个独立运行的独立控制器 - 一个Helix控制器和一个Task Framework Controller。
这种分离自然解决了管道中出现冗余计算的问题,如上一节所述。通用资源的更改将不再触发任务框架控制器中不必要的管道运行。此外,我们计划将此分离扩展到部署/存储库级别,以便新部署/回滚不会相互影响。我们相信这不仅可以提高两个组件的整体性能,还可以改善开发人员的体验。
结论
在这篇文章中,我们探讨了Task Framework,它是Apache Helix中不断增长的组件,可帮助您管理分布式任务。我们还讨论了系统的当前局限性以及我们正在进行的改进,以便将Helix的任务框架定位为LinkedIn以及开源社区中其他人的可靠分布式基础架构。
致谢
我们要感谢我们的工程师Jiajun Wang和Harry Zhang以及我们的SRE,Eric Blumenau。另外,感谢Yun Sun,Wei Song,Hung Tran,Kuai Yu以及来自LinkedIn数据基础架构的其他开发人员和SRE,感谢他们对Helix的宝贵意见和反馈。此外,我们要感谢Kishore Gopalakrishna,Apache Helix社区的其他提交者,以及校友Eric Kim,Weihan Kong和Vivo Xu的贡献。最后,我们要感谢雷管,Ivo Dimitrov和Swee Lim的管理层的不断鼓励和支持。
- 128 次浏览
【分布式平台】Helix提供支持的公司
公司
LinkedIn:
Helix在LinkedIn上广泛用于管理后端系统,例如Espresso(分布式NoSQL数据存储),Databus(变更数据捕获系统),Seas(搜索服务),Pinot(实时分析系统)
雅虎:
https://github.com/yahoo/Pistachio。 Pistachio被用作雅虎大规模广告服务产品的用户档案存储。
Uber:
Uber的流数据传输系统Streamio使用Helix提供高可用性,因为它可以跨Kafka,数据库,HBase和HDFS移动数据。
Box:
Box Notes - 使用Helix来分区我们的笔记并充当分布式锁管理器。我们从Helix获得的一些好处是它在故障期间自动重新平衡分区并改变容量。
Pinterest:
我们使用Helix在HDFS / Hadoop之上为我们的KV商店进行集群管理。 Helix可以轻松实现容量扩展/减少和故障恢复的自动化。
Redhat:
在jBPM中进行聚类。 http://planet.jboss.org/post/clustering_in_jbpm_v6
Instagram:
Instagram直接消息
Airbnb:
Turn:
我们正在使用Helix来管理我们的高性能键值存储。该商店每秒可以看到大约1.7MM的查找请求和相当数量的写入,从而使高可用性和快速可扩展性对项目至关重要。我们使用Helix将连续块中的密钥空间分配给不同的服务器计算机(Dynamo样式的固定存储桶分区),管理这些分区并在从集群中添加和删除新计算机时自动执行迁移过程
X15:
X15是一个并行机器数据管理平台,能够摄取,索引,搜索和查询大量机器数据(即日志数据)。 X15使用Helix来实现分区表的容错和负载平衡,以及系统中控制模块的领导者选择。
原文: https://cwiki.apache.org/confluence/display/HELIX/Powered+By+Helix
- 95 次浏览
【分布式计算】Helix: 基于配额的任务调度
介绍

基于配额的任务调度是Helix任务框架的一项功能添加,它使任务框架的用户能够在分布式任务管理中应用类别的概念。
目的
随着Helix Task Framework在其他开源框架(如Apache Gobblin和Apache Pinot)中的使用,它也看到了它所管理的分布式任务类型的多样性。 Helix也有明确的功能请求,通过创建相应的配额来区分不同类型的任务。
基于配额的任务调度旨在通过允许用户定义由配额类型及其相应配额组成的配额配置文件来满足这些请求。此功能的目标有三个:
- 1)用户将能够优先考虑一种类型的工作流/作业/任务,
- 2)实现任务类型之间的隔离;
- 3)通过跟踪分布状态使监控更容易按类型执行。
词汇表和定义
- 任务框架:Apache Helix的一个组件。用户可以以分布式方式定义和运行工作流,作业和任务的框架。
- 工作流程:任务框架中最大的工作单元。工作流由一个或多个作业组成。有两种类型的工作流程:
通用工作流:通用工作流是由用于一般目的的作业(作业DAG)组成的工作流。如果过期或超时,可以删除通用工作流程。
作业队列:作业队列是一种特殊类型的工作流,由往往具有线性依赖关系的作业组成(但这种依赖关系是可配置的)。作业队列没有到期 - 它一直存在直到被删除。
- 工作:任务框架中的第二大工作单元。作业由一个或多个相互独立的任务组成。有两种类型的工作:
通用作业:通用作业是由一个或多个任务组成的作业。
目标作业:目标作业与通用作业的不同之处在于,这些作业必须具有目标资源,属于此类作业的任务将与目标资源的分区一起安排。为了说明,Task Framework的Espresso用户可能希望在他们的一个名为MemberDataDB的DB上安排备份作业。此DB将分为多个分区(_MemberDataDB_1,_MemberDataDB2,... MemberDataDBN),并假设已提交目标作业,以使其任务与每个分区配对。这种“配对”是必要的,因为此任务是一个备份任务,需要与任务备份的那些分区位于同一物理机器上。
- 任务:任务框架中最小的工作单元。任务是一个独立的工作单元。
- 配额资源类型:表示特定类型的资源。示例可以是JVM线程计数,内存,CPU资源等。通常,在Helix Participant(= instance,worker,node)上运行的每个任务都占用一定量的资源。请注意,只有JVM线程计数是Task Framework当前支持的唯一配额资源类型,每个任务占用每个Helix Participant(实例)可用的40个线程中的1个线程。
- 配额类型:表示给定作业及其基础任务应归类为哪个类别。例如,您可以使用两种配额类型定义配额配置,键入“备份”,然后键入“聚合”和默认类型“DEFAULT”。您可以通过为备份类型提供更高的配额比例(例如20:10:10)来确定备份类型的优先级。当有提交的作业流时,您可以预期每个参与者(假设它总共有40个JVM线程)将具有20个“备份”任务,10个“聚合”任务和10个“默认”任务。配额类型在作业级别定义和应用,这意味着属于具有配额类型的特定作业的所有任务都将具有该配额类型。请注意,如果为工作流设置了配额类型,则属于该工作流的所有作业都将从工作流继承该类型。
- 配额:一个数字,指的是确定给定资源的哪一部分应分配给特定配额类型的相对比率。
例如,TYPE_0:40,TYPE_1:20,...,默认值:40
- 配额配置:一组字符串整数映射,指示配额资源类型,配额类型和相应的配额。任务框架将配额配置存储在ClusterConfig中。
架构
- AssignableInstance
AssignableInstance是一个抽象,表示能够从Controller接受任务的每个实时参与者。每个AssignableInstance将缓存它运行的任务以及基于配额的容量计算中的剩余任务计数。
- AssignableInstanceManager
AssignableInstanceManager管理所有AssignableInstances。它还充当Controller和每个AssignableInstance之间的连接层。 AssignableInstanceManager还提供了一组接口,允许Controller轻松确定AssignableInstance是否能够承担更多任务。
- TaskAssigner
TaskAssigner接口提供基本API方法,涉及基于配额约束的任务分配。 目前,任务框架仅涉及参与者端JVM线程的数量,每个线程对应于活动任务。
- RuntimeJobDag(JobDagIterator)
这个新组件充当Controller的JobDAG的迭代器。 以前,任务分配要求Controller迭代所有作业及其基础任务,以确定是否有任何需要分配和调度的任务。 事实证明这是低效的,并且随着我们对Task Framework的负担越来越大而无法扩展。 每个RuntimeJobDag记录状态,也就是说,它知道需要向Controller提供哪些任务以进行调度。 每次通过Task管道的TaskSchedulingStage时,这都会为Controller节省冗余计算。

用户手册
这个怎么运作
基于配额的任务调度的工作原理如下。 如果设置了配额类型,则任务框架将计算与每个配额类型的所有配额配置数之和的比率。 然后,它将应用该比率来查找分配给每个配额类型的实际资源量。 以下是一个示例:假设配额配置如下:
"QUOTA_TYPES":{
"A":"2"
,"B":"1"
,"DEFAULT":"1"
}基于这些原始数据,任务框架将计算比率。 使用这些比率,任务框架将应用它们来查找每个配额类型的实际资源量。 下表总结了这些计算,假设每个实例有40个JVM线程:
| Quota Type | Quota Config | Ratio | Actual Resource Allotted (# of JVM Threads) |
| A | 2 | 50% | 20 |
| B | 1 | 25% | 10 |
| DEFAULT | 1 | 25% | 10 |
每个实例(节点)都将具有如下所示的配额配置文件。这有一些影响。首先,这允许通过将更多资源分配给相应的配额类型来对某些作业进行优先级排序。从这个意义上讲,您可以将配额配置号/比率视为用户定义的优先级值。更具体地说,在上面的示例中采用配额配置文件。在这种情况下,当为每种配额类型提交100个作业时,类型A的作业将更快完成;换句话说,由于配额比率是其他配额类型的两倍,配额类型A在连续的工作流时会看到两倍的吞吐量。
基于配额的任务调度还允许在调度作业中进行隔离/划分。假设有两类工作,第一类是紧急工作,这些工作是短暂的,但需要立即运行。另一方面,假设第二类工作往往需要更长时间,但它们并不那么紧迫,可以花时间运行。以前,这两种类型的工作将被分配,计划和运行,确实难以确保第一类工作以紧急方式处理。基于配额的调度通过允许用户创建具有不同特征和要求的“类别”模型的配额类型来解决此问题。
如何使用
在ClusterConfig中设置配额配置
要使用基于配额的任务计划,您必须首先建立配额配置。这是一次性操作,一旦您确认您的ClusterConfig具有配额配置集,就不需要再次设置它。请参阅以下代码段,例如:
ClusterConfig clusterConfig = _manager.getConfigAccessor().getClusterConfig(CLUSTER_NAME); // Retrieve ClusterConfig
clusterConfig.resetTaskQuotaRatioMap(); // Optional: you may want to reset the quota config before creating a new quota config
clusterConfig.setTaskQuotaRatio(DEFAULT_QUOTA_TYPE, 10); // Define the default quota (DEFAULT_QUOTA_TYPE = "DEFAULT")
clusterConfig.setTaskQuotaRatio("A", 20); // Define quota type A
clusterConfig.setTaskQuotaRatio("B", 10); // Define quota type B
_manager.getConfigAccessor().setClusterConfig(CLUSTER_NAME, clusterConfig); // Set the new ClusterConfig需要注意的是 - 如果设置了配额配置,则必须始终定义默认配额类型(使用“DEFAULT”键)。 否则,将不再安排和运行没有类型信息的作业。 如果您在基于配额的计划开始之前一直使用任务框架,那么您可能具有其作业没有任何类型集的重复工作流。 如果您忽略包含默认配额类型,则这些重复工作流将无法正确执行。
在ClusterConfig中设置配额配置后,您将在JK格式的ZooKeeper集群配置ZNode中看到更新的字段。 请参阅以下示例:
{ "id":"Example_Cluster" ,"simpleFields":{ "allowParticipantAutoJoin":"true" } ,"listFields":{ } ,"mapFields":{ "QUOTA_TYPES":{ "A":"20" ,"B":"10" ,"DEFAULT":"10" } } }
为工作流和作业设置配额类型Workders for WorkflowConfig和JobConfig提供了一种设置作业的配额类型的方法。请参阅以下内容:
jobBuilderA = new JobConfig.Builder().setCommand(JOB_COMMAND).setJobCommandConfigMap(_jobCommandMap) .addTaskConfigs(taskConfigsA).setNumConcurrentTasksPerInstance(50).setJobType("A"); // Setting the job quota type as "A" workflowBuilder.addJob("JOB_A", jobBuilderA);
常问问题
- 如果我没有在ClusterConfig中设置配额配置会怎么样?
如果在ClusterConfig中未找到配额配置,则任务框架会将所有传入作业视为默认值,并将100%的配额资源提供给默认类型。
- 如果我的工作没有设置配额类型会怎样?
如果任务框架遇到没有配额类型的作业(即,缺少quotaType字段,是空字符串或文字“null”),则该作业将被视为DEFAULT作业。
- 如果在ClusterConfig中的配额配置中存在配额类型不存在的工作流/作业,该怎么办?
任务框架将无法找到正确的配额类型,因此它会将其视为DEFAULT类型,并将使用DEFAULT类型的配额进行相应的分配和计划。
目标工作怎么样?
配额也将应用于目标作业,目标作业的每个任务占用预设资源量(当前每个任务占用1个JVM线程)。
- 工作队列怎么样?
基于配额的计划适用于所有类型的工作流 - 通用工作流和作业队列。对用户要注意的是要小心并始终验证是否已正确设置作业的配额类型。任务框架不会自动删除或通知用户因配额类型无效而卡住的作业,因此我们提醒所有用户通过在ClusterConfig中查询其设置来确保配额类型存在。
下来的步骤
基于配额的任务调度已在LinkedIn内部进行了测试,并已集成到Apache Gobblin中,使Helix Task Framework和Gobblin的Job Launcher用户能够定义类别和相应的配额值。有一些即时待办事项可以改善此功能的可用性:
- 更细粒度的配额文件
目前,配额配置文件适用于整个群集;也就是说,ClusterConfig中定义的一个配额配置文件将全局适用于所有参与者。但是,某些用例可能要求每个参与者具有不同的配额配置文件。
- 使参与者的最大JVM线程容量可配置
Helix Task Framework的最大任务线程数设置为40.使这个可配置将允许一些用户根据执行此类任务的持续时间来增加任务的吞吐量。
- 向配额资源类型添加更多维度
目前,每个Participant的JVM线程数是Helix Task Framework定义配额的唯一维度。但是,如前面部分所述,这可以扩展到常用的约束,如CPU使用率,内存使用率或磁盘使用率。随着新维度的添加,需要额外实现TaskAssigner接口,该接口根据约束生成任务分配。
原文 : https://helix.apache.org/0.8.4-docs/quota_scheduling.html
- 147 次浏览
【分布式计算平台】用于分区和复制的分布式资源的集群管理框架
架构
Helix旨在为分布式系统提供以下功能:
- 自动管理托管分区,复制资源的集群
- 软硬故障检测和处理
- 通过基于服务器容量和资源配置文件(分区大小,访问模式等)在服务器(节点)上智能放置资源来实现自动负载平衡
- 集中配置管理和自我发现,无需修改每个节点上的配置
- 群集扩展期间的容错和优化的重新平衡
- 管理节点的整个运营生命周期。无需停机即可添加,启动,停止,启用和禁用
- 监控群集运行状况并警告SLA违规
- 用于路由请求的服务发现机制
要构建这样的系统,我们需要一种机制来协调系统中不同节点和其他组件。这种机制可以通过软件来实现,该软件可以对集群中的任何变化做出反应,并提供一组使集群处于稳定状态所需的任务。该组任务将分配给群集中的一个或多个节点。 Helix用于管理群集中的各种组件。
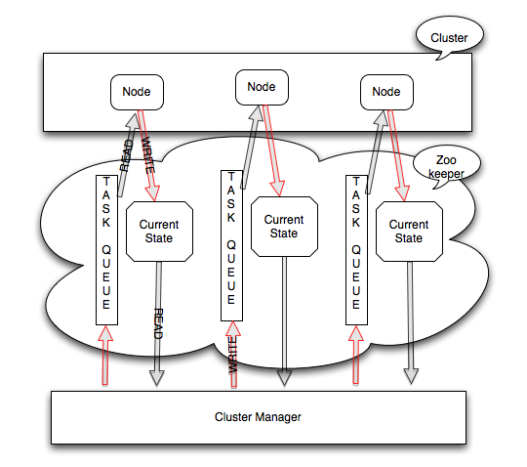
分布式系统组件
通常,任何分布式系统集群都将具有以下组件和属性:
- 一组节点也称为实例
- 一组资源,可以是数据库,lucene索引或任务
- 将每个资源细分为一个或多个分区
- 每个资源的副本称为副本
- 每个副本的状态,例如 主人,奴隶,领袖,待命,在线,离线等
角色
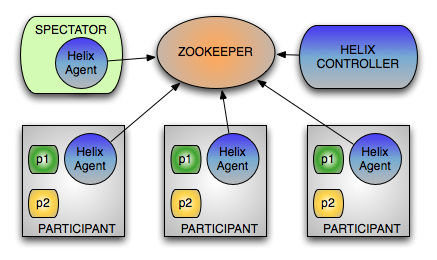
并非分布式系统中的所有节点都将执行类似的功能。例如,一些节点可能正在处理请求,一些节点可能正在发送请求,而一些其他节点可能正在控制集群中的节点。因此,Helix按照系统中的特定角色对节点进行分类。
Helix根据职责将节点划分为3个逻辑组件:
- 参与者:实际托管分布式资源的节点
- 观察者:简单地观察每个参与者的当前状态并相应地路由请求的节点。例如,路由器需要知道托管分区的实例及其状态,以便将请求路由到适当的端点
- 控制器:观察和控制参与者节点的节点。它负责协调集群中的所有转换,并确保满足状态约束,同时保持集群稳定性
这些只是逻辑组件,可以根据系统要求进行部署。例如,控制器:
- 可以作为单独的服务部署
- 可以与参与者一起部署,但在任何给定时间只有一个控制器处于活动状态。
两者都有利有弊,稍后将对此进行讨论,并且可以根据系统需要选择部署模式。
群集状态元数据存储
我们需要一个分布式存储来维护集群的状态,并且需要一个通知系统来通知集群状态是否有任何变化。 Helix使用Apache ZooKeeper来实现此功能。
Zookeeper提供:
- 一种表示PERSISTENT状态的方法,直到删除为止
- 表示当创建状态的进程死亡时消失的TRANSIENT / EPHEMERAL状态的方法
- 当PERSISTENT和EPHEMERAL状态发生变化时的通知机制
ZooKeeper提供的命名空间非常类似于标准文件系统。名称是由斜杠(/)分隔的路径元素序列。 ZooKeeper命名空间中的每个节点(ZNode)都由路径标识。
有关Zookeeper的更多信息,请访问http://zookeeper.apache.org
状态机和约束
尽管资源,分区和副本的概念对于大多数分布式系统是通用的,但是将一个分布式系统与另一个分布式系统区分开来的一个方面是为每个分区分配状态的方式以及每个状态的约束。
例如:
- 如果系统提供只读数据,那么所有分区的副本都是等效的,它们可以是ONLINE或OFFLINE。
- 如果系统同时进行读取和写入,但必须确保写入仅通过一个分区,则状态将为MASTER,SLAVE和OFFLINE。写入通过MASTER并复制到SLAVE。可选地,读取可以通过SLAVE。
除了为每个分区定义状态之外,状态之间的转换路径可以是特定于应用程序的。例如,为了成为MASTER,可能需要首先成为SLAVE。这确保了如果SLAVE没有将数据作为OFFLINE-SLAVE转换的一部分,它可以从系统中的其他节点引导数据。
Helix提供了一种配置特定于应用程序的状态机以及每个状态的约束的方法。除了对STATE的约束外,Helix还提供了一种指定转换约束的方法。 (稍后会详细介绍。)
OFFLINE | SLAVE | MASTER
_____________________________
| | | |
OFFLINE | N/A | SLAVE | SLAVE |
|__________|________|_________|
| | | |
SLAVE | OFFLINE | N/A | MASTER |
|__________|________|_________|
| | | |
MASTER | SLAVE | SLAVE | N/A |
|__________|________|_________|
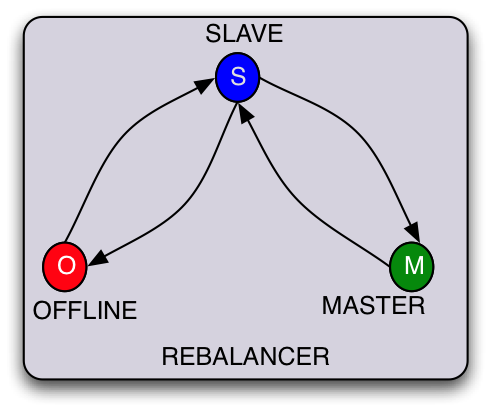
概念
Helix中使用以下术语来模拟状态机之后的资源。
- IdealState:如果所有节点都已启动并运行,我们需要群集进入的状态。换句话说,满足所有状态约束。
- CurrentState:集群中每个节点的实际当前状态
- ExternalView:所有节点的CurrentState的组合视图。
Helix的目标始终是使系统的CurrentState(以及扩展名为ExternalView)与IdealState相同。有些情况可能并非如此:
- 部分或全部节点已关闭
- 一个或多个节点失败
- 添加了新节点,需要重新分配分区
IdealState
Helix允许应用程序为每个资源定义IdealState。它包括:
分区列表,例如64
每个分区的副本数量,例如3
为每个副本分配的节点和状态
例:
- Partition-1,replica-1:Master,Node-1
- Partition-1,replica-2:Slave,Node-2
- Partition-1,replica-3:Slave,Node-3
- ... ..
- ... ..
- Partition-p,replica-r:Slave,Node-n
Helix附带了各种算法来自动将分区分配给节点。默认算法最小化将新节点添加到系统时发生的混洗次数。
当前状态
群集中的每个参与者都托管资源的一个或多个分区。每个分区都具有与之关联的状态。
Example Node-1
- Partition-1, Master
- Partition-2, Slave
- ….
- ….
- Partition-p, Slave
ExternalView
外部客户端需要知道群集中每个分区的状态以及托管该分区的节点。 Helix为Spectators提供了一个系统视图作为ExternalView。 ExternalView只是所有节点CurrentStates的聚合。
- Partition-1, replica-1, Master, Node-1
- Partition-1, replica-2, Slave, Node-2
- Partition-1, replica-3, Slave, Node-3
- …..
- …..
- Partition-p, replica-3, Slave, Node-n
流程/工作流程
集群中的操作模式
节点进程可以是以下之一:
- 参与者:进程在集群中注册自身,并对其队列中收到的消息进行操作并更新当前状态。示例:分布式数据库中的存储节点
- 观众:该过程只对ExternalView中的变化感兴趣。
- 控制器:此过程通过响应群集状态的更改并向参与者发送状态转换消息来主动控制群集。
参与者节点过程
- 当参与者启动时,它会在LiveInstances下注册
- 注册后,它会等待消息队列中的新消息
- 当它收到消息时,它将执行消息中指示的所需任务
- 任务完成后,根据任务结果更新CurrentState
控制器流程
- 观看IdealState
- 当参与者出现故障,出现,添加或被删除时通知。观看群集中每个参与者的短暂LiveInstance ZNode和CurrentState
- 通过向参与者发送消息来触发适当的状态转换
观众过程
- 当进程启动时,它会要求Helix代理通知ExternalView中的更改
- 每当收到通知时,它都会读取ExternalView并执行所需的任务
控制器,参与者和观众之间的互动
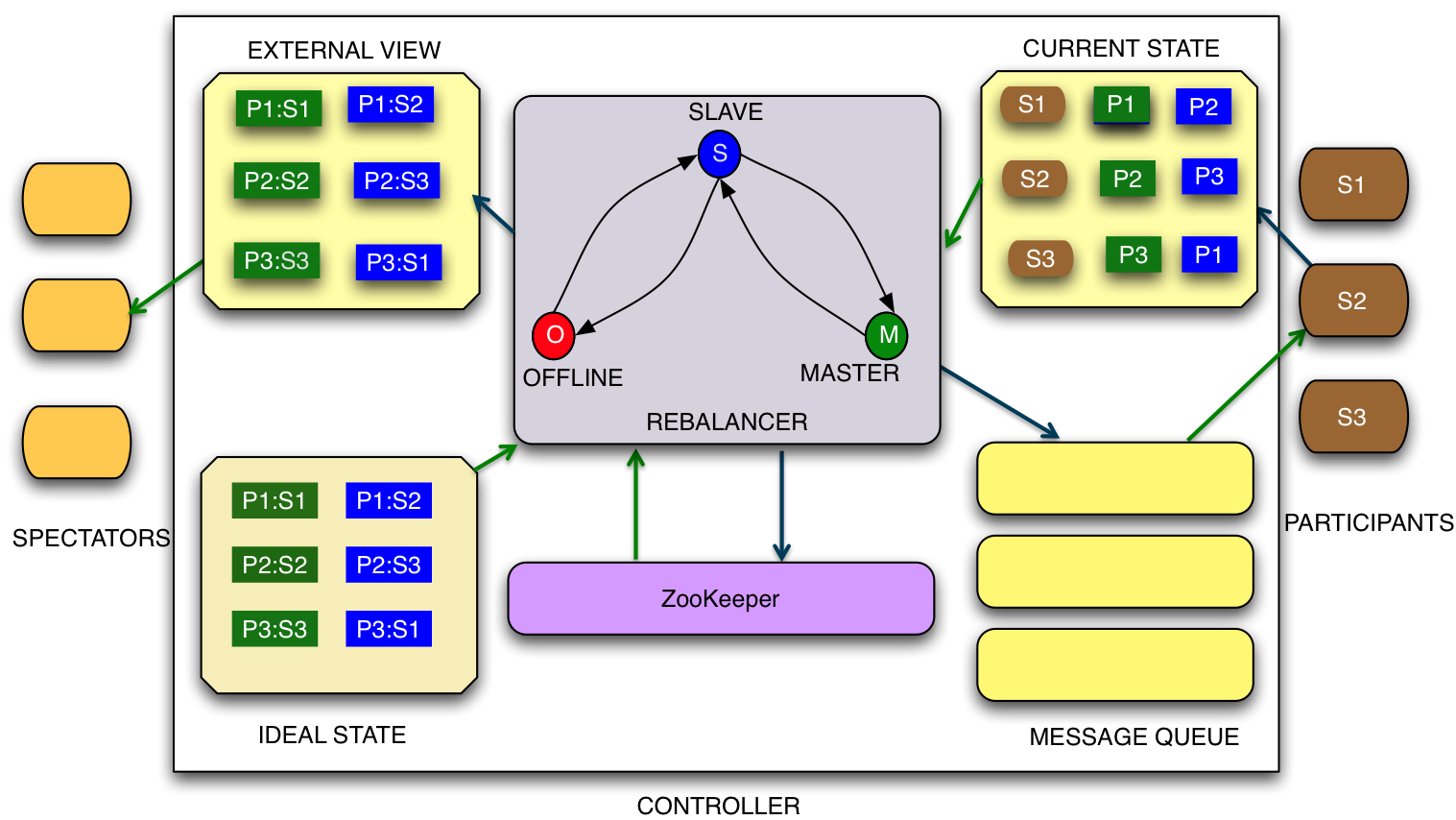
核心控制器算法
- 从ZooKeeper获取活动存储节点的IdealState和CurrentState
- 计算所有Participant节点上每个分区副本的IdealState和CurrentState之间的增量
- 对于基于状态机表的每个分区计算任务。可以在状态转换上配置优先级。例如,在MasterSlave的情况下:
- 如果可能,尝试主控权转移而不违反约束
- 分区添加
- 分区下降
- 如果可能,将并行转换任务添加到每个存储节点的相应队列中(如果添加的任务相互独立)
- 如果转换任务依赖于正在完成的另一个任务,请不要添加该任务
- 在参与者完成任何任务后,控制器会收到更改通知,并重新运行算法,直到CurrentState与IdealState匹配。
Helix ZNode布局
Helix以多个级别在群集名称下组织ZNodes。
顶级(在群集名称下)ZNodes都是Helix定义的,大写:
- PROPERTYSTORE: application property store
- STATEMODELDEFES: state model definitions
- INSTANCES: instance runtime information including current state and messages
- CONFIGS: configurations
- IDEALSTATES: ideal states
- EXTERNALVIEW: external views
- LIVEINSTANCES: live instances
- CONTROLLER: cluster controller runtime information
在INSTANCES下,每个实例都有运行时ZNode。一个实例按如下方式组织ZNodes:
- CURRENTSTATES
- sessionId
- resourceName
- ERRORS
- STATUSUPDATES
- MESSAGES
- HEALTHREPORT
在CONFIGS下,有不同的配置范围:
- RESOURCE: contains resource scope configurations
- CLUSTER: contains cluster scope configurations
- PARTICIPANT: contains participant scope configurations
下图显示了名为“test-cluster”的集群的Helix ZNode布局示例:
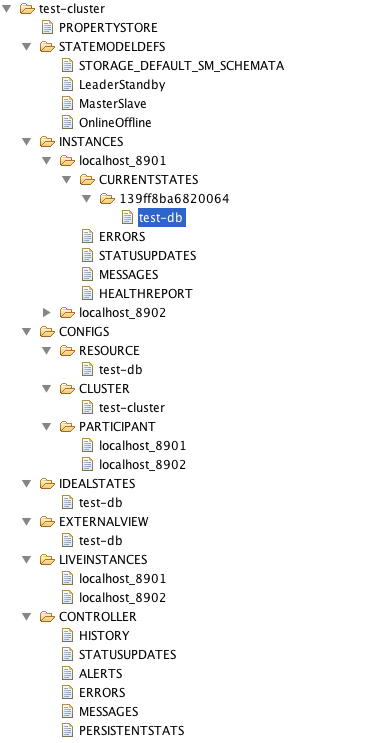
原文 :https://helix.apache.org/Architecture.html
讨论: 请加知识星球【首席架构师圈】
- 145 次浏览