事件枢纽
-【首席架构师看Event Hub】Kafka深挖第1部分:错误处理、消息转换和事务支持
接下来是《如何在您的Spring启动应用程序中使用Apache Kafka》https://www.confluent.io/blog/apache-kafka-spring-boot-application ,这展示了如何开始使用Spring启动和Apache Kafka®,这里我们将更深入地挖掘Apache Kafka项目的Spring提供的一些附加功能。
Apache Kafka的Spring为Kafka带来了熟悉的Spring编程模型。它提供了用于发布记录的KafkaTemplate和用于异步执行POJO侦听器的侦听器容器。Spring引导自动配置连接了许多基础设施,因此您可以将精力集中在业务逻辑上。

错误恢复
考虑一下这个简单的POJO监听器方法:
@KafkaListener(id = "fooGroup", topics = "topic1")
public void listen(String in) {
logger.info("Received: " + in);
if (in.startsWith("foo")) {
throw new RuntimeException("failed");
}
}
默认情况下,失败的记录会被简单地记录下来,然后我们继续下一个。但是,我们可以在侦听器容器中配置一个错误处理程序来执行一些其他操作。为此,我们用我们自己的来覆盖Spring Boot的自动配置容器工厂:
@Bean
public ConcurrentKafkaListenerContainerFactory kafkaListenerContainerFactory(
ConcurrentKafkaListenerContainerFactoryConfigurer configurer,
ConsumerFactory<Object, Object> kafkaConsumerFactory) {
ConcurrentKafkaListenerContainerFactory<Object, Object> factory = new ConcurrentKafkaListenerContainerFactory<>();
configurer.configure(factory, kafkaConsumerFactory);
factory.setErrorHandler(new SeekToCurrentErrorHandler()); // <<<<<<
return factory;
}
注意,我们仍然可以利用大部分的自动配置。
SeekToCurrentErrorHandler丢弃轮询()中的剩余记录,并在使用者上执行查找操作来重置偏移量,以便在下一次轮询时再次获取被丢弃的记录。默认情况下,错误处理程序跟踪失败的记录,在10次提交尝试后放弃,并记录失败的记录。但是,我们也可以将失败的消息发送到另一个主题。我们称这是一个毫无意义的话题。
下面的例子把这一切放在一起:
@Bean
public ConcurrentKafkaListenerContainerFactory kafkaListenerContainerFactory(
ConcurrentKafkaListenerContainerFactoryConfigurer configurer,
ConsumerFactory<Object, Object> kafkaConsumerFactory,
KafkaTemplate<Object, Object> template) {
ConcurrentKafkaListenerContainerFactory<Object, Object> factory = new ConcurrentKafkaListenerContainerFactory<>();
configurer.configure(factory, kafkaConsumerFactory);
factory.setErrorHandler(new SeekToCurrentErrorHandler(
new DeadLetterPublishingRecoverer(template), 3));
return factory;
}@KafkaListener(id = "fooGroup", topics = "topic1")
public void listen(String in) {
logger.info("Received: " + in);
if (in.startsWith("foo")) {
throw new RuntimeException("failed");
}
}@KafkaListener(id = "dltGroup", topics = "topic1.DLT")
public void dltListen(String in) {
logger.info("Received from DLT: " + in);
}
反序列化错误
但是,在Spring获得记录之前发生的反序列化异常又如何呢?进入ErrorHandlingDeserializer。此反序列化器包装委托反序列化器并捕获任何异常。然后将它们转发给侦听器容器,后者将它们直接发送给错误处理程序。异常包含源数据,因此可以诊断问题。
域对象并推断类型
考虑下面的例子:
@Bean
public RecordMessageConverter converter() {
return new StringJsonMessageConverter();
}@KafkaListener(id = "fooGroup", topics = "topic1")
public void listen(Foo2 foo) {
logger.info("Received: " + foo);
if (foo.getFoo().startsWith("fail")) {
throw new RuntimeException("failed");
}
}@KafkaListener(id = "dltGroup", topics = "topic1.DLT")
public void dltListen(Foo2 in) {
logger.info("Received from DLT: " + in);
}
注意,我们现在正在使用类型为Foo2的对象。消息转换器bean推断要转换为方法签名中的参数类型的类型。
转换器自动“信任”类型。Spring Boot自动将转换器配置到侦听器容器中。
在生产者方面,发送的对象可以是一个不同的类(只要它的类型兼容):
@RestController
public class Controller {@Autowired
private KafkaTemplate<Object, Object> template;@PostMapping(path = "/send/foo/{what}")
public void sendFoo(@PathVariable String what) {
this.template.send("topic1", new Foo1(what));
}}
和:
spring:
kafka:
producer:
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer$ curl -X POST http://localhost:8080/send/foo/fail
这里,我们在消费者端使用StringDeserializer和“智能”消息转换器。
多种监听器
我们还可以使用单个侦听器容器,并根据类型路由到特定的方法。这次我们不能推断类型,因为类型是用来选择要调用的方法的。
相反,我们依赖于在记录头中传递的类型信息来将源类型映射到目标类型。此外,由于我们没有推断类型,所以需要将消息转换器配置为“信任”映射类型的包。
在本例中,我们将在两端使用消息转换器(以及StringSerializer和StringDeserializer)。下面是消费者端转换器的例子:
@Bean
public RecordMessageConverter converter() {
StringJsonMessageConverter converter = new StringJsonMessageConverter();
DefaultJackson2JavaTypeMapper typeMapper = new DefaultJackson2JavaTypeMapper();
typeMapper.setTypePrecedence(TypePrecedence.TYPE_ID);
typeMapper.addTrustedPackages("com.common");
Map<String, Class<?>> mappings = new HashMap<>();
mappings.put("foo", Foo2.class);
mappings.put("bar", Bar2.class);
typeMapper.setIdClassMapping(mappings);
converter.setTypeMapper(typeMapper);
return converter;
}
在这里,我们从“foo”映射到类Foo2,从“bar”映射到类Bar2。注意,我们必须告诉它使用TYPE_ID头来确定转换的类型。同样,Spring Boot会自动将消息转换器配置到容器中。下面是应用程序片段中的生产端类型映射。yml文件;格式是一个逗号分隔的令牌列表:FQCN:
spring:
kafka:
producer:
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
properties:
spring.json.type.mapping: foo:com.common.Foo1,bar:com.common.Bar1
这个配置将类Foo1映射到“foo”,将类Bar1映射到“bar”。
监听器:
@Component
@KafkaListener(id = "multiGroup", topics = { "foos", "bars" })
public class MultiMethods {@KafkaHandler
public void foo(Foo1 foo) {
System.out.println("Received: " + foo);
}@KafkaHandler
public void bar(Bar bar) {
System.out.println("Received: " + bar);
}@KafkaHandler(isDefault = true)
public void unknown(Object object) {
System.out.println("Received unknown: " + object);
}}
生产者:
@RestController
public class Controller {@Autowired
private KafkaTemplate<Object, Object> template;@PostMapping(path = "/send/foo/{what}")
public void sendFoo(@PathVariable String what) {
this.template.send(new GenericMessage<>(new Foo1(what),
Collections.singletonMap(KafkaHeaders.TOPIC, "foos")));
}@PostMapping(path = "/send/bar/{what}")
public void sendBar(@PathVariable String what) {
this.template.send(new GenericMessage<>(new Bar(what),
Collections.singletonMap(KafkaHeaders.TOPIC, "bars")));
}@PostMapping(path = "/send/unknown/{what}")
public void sendUnknown(@PathVariable String what) {
this.template.send(new GenericMessage<>(what,
Collections.singletonMap(KafkaHeaders.TOPIC, "bars")));
}}
事务
通过在应用程序中设置transactional-id前缀来启用事务。yml文件:
spring:
kafka:
producer:
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
transaction-id-prefix: tx.
consumer:
properties:
isolation.level: read_committed
当使用spring-kafka 1.3时。x或更高版本和支持事务的kafka-clients版本(0.11或更高版本),在@KafkaListener方法中执行的任何KafkaTemplate操作都将参与事务,而侦听器容器将在提交事务之前向事务发送偏移量。请注意,我们还为使用者设置了隔离级别,使其无法看到未提交的记录。下面的例子暂停监听器,这样我们可以看到效果:
@KafkaListener(id = "fooGroup2", topics = "topic2")
public void listen(List foos) throws IOException {
logger.info("Received: " + foos);
foos.forEach(f -> kafkaTemplate.send("topic3", f.getFoo().toUpperCase()));
logger.info("Messages sent, hit enter to commit tx");
System.in.read();
}@KafkaListener(id = "fooGroup3", topics = "topic3")
public void listen(String in) {
logger.info("Received: " + in);
}
本例中的生产者在一个事务中发送多条记录:
@PostMapping(path = "/send/foos/{what}")
public void sendFoo(@PathVariable String what) {
this.template.executeInTransaction(kafkaTemplate -> {
StringUtils.commaDelimitedListToSet(what).stream()
.map(s -> new Foo1(s))
.forEach(foo -> kafkaTemplate.send("topic2", foo));
return null;
});
}curl -X POST http://localhost:8080/send/foos/a,b,c,d,e
Received: [Foo2 [foo=a], Foo2 [foo=b], Foo2 [foo=c], Foo2 [foo=d], Foo2 [foo=e]]
Messages sent, hit Enter to commit txReceived: [A, B, C, D, E]
结论
在Apache Kafka中使用Spring可以消除很多样板代码。它还增加了诸如错误处理、重试和记录筛选等功能——而我们只是触及了表面。
本文:https://pub.intelligentx.net/node/782
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 120 次浏览
【Kafka】 将ACID测试应用于Apache Kafka,Kafka是一个数据库吗?

前往旧金山的旅行,我的房子已经六年了,房价迫使向东移动,总是令人兴奋。海景,美味的印度美食和冲浪的回忆让我怀念孩子们的婚姻生活。最令人兴奋的是关于最新热门技术的嗡嗡声,紧迫感和夸张。
在这次旅行中,Confluent的Kafka峰会令人兴奋。正如我上个月在Eckerson.com上所写的那样,超低延迟,高度可扩展的分布式Apache Kafka数据流平台开创了实时数据集成,处理和分析的新纪元。借助Kafka,企业可以解决新的高级分析用例,并从更多数据中提取更多价值。他们正在实施Kafka和流媒体替代方案,例如Amazon Kinesis和Azure Event Hub,以实现数据湖流式传输,具有许多大数据端点的复杂消息队列,微服务数据共享以及机器学习的预处理。
所有好东西。但是Kafka取代数据架构支柱,比如数据库吗?
剑桥大学研究员马丁·克莱普曼在上周的会议上提出了他所谓的“略带挑衅性的问题”,“Kafka是一个数据库吗?”克莱普曼缩小了数据库的一个定义特征,即它支持ACID的能力 - 兼容数据集。
正如许多读者所知,ACID指的是四种数据库属性 - 原子性,一致性,隔离性和持久性 - 通常被认为对事务数据有效性至关重要。 ACID数据库通过错误,断电或其他组件故障来维护数据完整性。另一种方式考虑,有效的事务要求其所有相关的DB操作都符合ACID。 ACID已成为35年来数据库的黄金标准。
在一次深思熟虑的25分钟会议中,Kleppmann在逻辑上将ACID测试应用于Kafka。我建议观看视频。以下是他的想法摘要。
持久化
Kleppmann从这里开始,因为耐用性似乎是最简单的解决方案。即使系统崩溃,软件发生故障等,持久数据仍然可用并提交。通常,这意味着数据和一个或多个副本被写入非易失性存储器,例如磁盘。 Kafka经纪人可以通过将记录(通常是跨复制分区的多个副本)保存到基于磁盘的文件系统来满足此要求。与其他数据系统一样,这些记录也可以备份到远程位置,以便在发生灾难时提供额外的持久性。
原子性
原子数据库事务作为单个单元运行,可以是成功的,也可以是完全失败的。这是什么意思?事务永远不会被部分提交。如果所有写入都未完全完成,则必须回滚所有内容。 Kleppmann说,Kafka满足了这个属性,因为生产者以一种全有或全无的方式将每条记录写入一个不可变的日志。数据库,缓存和搜索索引都独立地从日志中消耗该记录,而不会相互干扰。作为另一个例子,可以原子地处理包括来自一个帐户的借方和贷方到另一个帐户的交易。这是通过使用流处理算法来实现的,该算法发出这两个相互关联的事件,信用卡和借记卡,用于在Kafka平台上进行协调处理。
隔离性
事务通常同时执行,例如,同时写入多个位置和从多个位置读取。这就产生了隔离的需要,或者确保并发执行的事务反映了正确的顺序。通过将事务逻辑构建到流处理器中,Kafka可以实现序列化,即最高级别的隔离,确保事务不会重叠或以其他方式影响彼此的记录序列。可序列化隔离有效地意味着事务可以表现得就像数据库是所有数据库一样,没有干扰活动。
一致性
Kafka的最终ACID测试是一致性,这意味着根据定义的约束和其他规则,事务是有效的。例如,规则可能指定用户名必须是唯一的。 Kafka再一次依靠流处理算法来清除这个障碍,例如检查任何事务请求的有效性。
Kafka的变形
因此,在流处理算法的帮助下,Kleppmann得出结论,Kafka确实可以符合ACID标准。这为Kafka管理的数据的完整性和下游使用的有效性提供了新的信心。然而,虽然Kafka可以无限期地保留数据,但很少有架构师或开发人员希望Kafka能够很快取代数据库。实际上,Kleppmann建议临时查询最好留给数据库和数据仓库领域,并且最终没有明确说明Kafka实际上是一个数据库。
Kleppmann的论文涉及将Kafka视为数据流平台的更大趋势。
Confluent首席执行官Jay Kreps建议Kafka将事件处理作为数据架构基础的合法位置。
事实上,企业本质上是一系列事件和对这些事件的反应。数据仓库基于事实表,事实是事件,与Kafka相比,这使得数据仓库成为“一个非常慢的事件流”。在这里,克雷普斯遵循硅谷悠久的传统,将新技术定位为既定秩序的破坏者。
这个论点是有道理的。作为符合ACID标准,可扩展,超低延迟的数据流平台,Kafka可以作为微服务,事件监控/分析和各种类型实时应用的中心企业推动者。
实际上,企业正在采用Kafka为用例提供数据流,例如流数据湖摄取,消息排队,机器学习预处理和微服务支持。某些数据集成产品会自动将生产数据库事务发布到Kafka记录流,以解决这些用例。 Kafka在这些组织的数据架构中发挥了关键作用。
从业人员的小提示
在可预见的未来,数据流媒体从业者 - 包括架构师,开发人员及其经理 - 不希望Kafka很快取代数据库或数据仓库。相反,Kafka将作为实时运河系统发挥关键作用,在当今日益异构的环境中,在平台之间和跨管道之间移动数据。您可以配置一个数据库生产者将主题流发送给几十个不同的消费者,从Spark驱动的数据湖到微服务平台,再到各种NoSQL存储库。在大多数情况下,这些消费者最适合管理分析。
所以Kafka是一个实时的数据运河系统,也是无与伦比的一个,但不是数据库。如果Kafka Summit的嗡嗡声有任何迹象,那么Kafka运河将成为许多组织在未来几年投资的一个令人信服的选择。
Kevin是Eckerson Group的贡献分析师,以及Attunity的产品营销高级总监。 要了解有关CDC在Kafka,数据湖和云环境中的作用的更多信息,请查看Kevin共同撰写的书,Streaming Change Data Capture:现代数据架构基础,O'Reilly 2018。
原文:https://www.eckerson.com/articles/applying-the-acid-test-to-apache-kafka
- 139 次浏览
【Kafka】Kafka测试的快速实用的例子
1.简介
在本教程中,我们将快速探索一些基本的高级方法,用于测试使用Kafka构建的微服务应用程序。此外,我们将了解以传统/现有测试方式测试Kafka应用程序的声明方式的优势。
对于此处解释的所有内容,我们可以在本文的“结论”部分找到正在运行的代码示例。
为了使教程简明扼要,我们将仅演示以下方面。
- 制造者测试
- 消费者测试
- 挂钩生产者和消费者测试
- 生成RAW记录和JSON记录
- 使用RAW记录和JSON记录
- 传统的测试挑战。
- 声明式测试的优点(IEEE论文)
- 将REST API测试与Kafka测试相结合
- 在Docker中旋转Kafka - 单节点和多节点
在继续本教程之前,我强烈建议您阅读我们需要了解的Kafka测试最低要求。
有关Kafka流以及如何开发流应用程序的更多详细信息,请访问Confluent开发流媒体应用程序教程。
2.Kafka测试挑战
困难的部分是应用程序逻辑的某些部分或数据库过程不断地为主题生成记录,应用程序的另一部分继续使用记录并根据业务规则不断处理它们。
记录,分区,偏移,异常情况等不断变化,使得难以根据测试内容,何时测试以及如何测试进行思考。

3.测试解决方案方法
我们可以采用端到端的测试方法,该方法将验证生产,消费和DLQ记录以及应用程序处理逻辑。 这将使我们有信心将我们的应用程序发布到更高的环境。
我们可以通过在Docker化容器中创建Kafka或将我们的测试指向我们的Kubernetes-Kafka集群或任何其他微服务基础架构中的任何集成测试环境来实现。
在这里,我们选择一个功能,生成所需的记录并验证,使用预期的记录并验证,以及HTTP REST或SOAP API验证,这有助于保持我们的测试更清洁,更少噪音。

4.生产者测试
当我们为主题创建记录时,我们可以验证来自Kafka经纪人的确认。 此验证采用recordMetadata格式。
例如,将“recordMetaData”可视化为JSON将如下所示:
Response from the broker after a successful "produce".
{"recordMetadata": {"offset": 0,"timestamp": 1547760760264,"serializedKeySize": 13,"serializedValueSize": 34,"topicPartition": {"hash": 749715182,"partition": 0, //<--- To which partition the record landed"topic": "demo-topic"}}}
5.消费者测试
当我们从主题中阅读或使用时,我们可以验证从主题中获取的记录。 在这里,我们也可以验证/断言一些元数据,但大多数时候您可能只需要处理记录(而不是元数据)。
例如,有时我们只能验证记录的数量,即只有大小,而不是实际记录
例如,将获取的“记录”可视化为JSON将如下所示:
Records fetched after a successful "consume".{"records": [{"topic": "demo-topic","key": "1547792460796","value": "Hello World 1"},{// ...}]}
包含元数据信息的完整记录看起来就像我们在下面得到的那样,如果我们有测试要求,我们也可以验证/断言。
The fetched records with the metadata from the broker.{"records": [{"topic": "demo-topic","partition": 0,"offset": 3,"key": "1547792460796", //<---- Record key"value": "Hello World", //<---- Record value}]}
6.生产者和消费者测试
在相同的端到端测试中,我们可以对相同的记录执行以下两个步骤:
步骤1:
生成主题“demo-topic”并验证来自代理的receivedrecordMetadata。
例如,使用“key”生成记录:“1234”,“value”:“Hello World”
第2步:
从同一主题“demo-topic”中获取并验证记录。
断言响应中存在相同的记录,即“密钥”:“1234”,“值”:“Hello World”。
如果在我们开始消费之前将它们生成到同一主题,我们可能已经消耗了多条记录。
7.传统测试方式的挑战
第1点
首先,传统风格没有任何问题。但是,对于Kafka经纪人来说,它有一个陡峭的学习曲线来处理。
例如,当我们处理经纪人时,我们需要彻底了解Kafka客户端API,例如: Key-SerDe,Value-SerDe,Time-Outs,同时记录Poolings,commitSyncs,recordTypes等,以及API级别的更多内容。
对于功能测试,我们并不需要在API级别了解这些概念。
第2点
我们的测试代码与客户端API代码紧密结合。这意味着我们在维护测试套件以及测试框架的代码时引入了许多挑战。
8.声明式测试的优点
为了绘制一个明喻,“docker-compose”作品的有趣方式被称为“声明方式”。我们告诉Docker Compose框架(在YAML文件中)在某些端口上启动某些东西,将某些服务链接到其他服务等,框架为我们完成了一些事情。我们也可以用类似的声明方式驱动我们的测试,我们将在下一节中看到。
这有多整洁?试想一下,如果我们必须为相同的重复性任务编写代码/ shell脚本,那将是多么麻烦。
第1点
在声明式样式中,我们可以完全跳过处理代理的API级别,并且只关注测试场景。但是,我们仍然可以灵活地使用Kafka Client API并为其添加自己的风格。
第2点
这有助于发现更多缺陷,因为我们不会花时间编写代码,而是花更多的时间编写测试并覆盖更多的业务场景/用户旅程。
怎么样?
在这里,我们告诉测试使用Kafka-Topic,这是我们的“终点”或“url”
即“url”:“kafka-topic:demo-topic”
接下来,我们告诉测试使用操作“生产”
即“操作”:“生产”
接下来,我们需要将记录发送到请求有效负载:
"request": {"records": [{"key": "KEY-1234","value": "Hello World"}]}
然后,我们告诉测试我们期望响应“status”返回为“Ok”和来自代理的一些记录元数据,即非空值。这是我们测试的“断言”部分。
"assertions": {"status" : "Ok","recordMetadata" : "$NOT.NULL"}
注意:我们甚至可以立即声明所有'recordMetadata,我们将在后面的部分中看到。现在,让我们保持简单并继续。
完成后,我们的完整测试将如下所示:
{"name": "produce_a_record","url": "kafka-topic:demo-topic","operation": "produce","request": {"recordType" : "RAW","records": [{"key": 101,"value": "Hello World"}]},"assertions": {"status": "Ok","recordMetadata": "$NOT.NULL"}}
就是这样。我们完成了测试用例并准备运行。
现在,看看上面的测试,任何人都可以轻松找出正在测试的场景。
注意:
- 我们使用客户端API消除了编码麻烦,以处理Kafka经纪人。
- 我们通过遍历其对象路径,解析请求 - 有效负载,解析响应 - 有效负载等,消除了断言每个字段键/值的编码麻烦。
同时,我们使用框架的JSON比较功能立即断言结果,因此,使测试更容易和更清洁。
我们在测试时逃脱了两个主要的麻烦。
并且,字段的顺序在这里无关紧要。以下代码也是正确的(字段顺序交换)。
"assertions": {"recordMetadata": "$NOT.NULL""status": "Ok",}
9.使用JUnit运行单个测试
这非常容易。 我们只需要将JUnit @Test方法指向JSON文件即可。 真的是这样的。
@TargetEnv("kafka_servers/kafka_test_server.properties")@RunWith(ZeroCodeUnitRunner.class)public class KafkaProduceTest {@Test@JsonTestCase("kafka/produce/test_kafka_produce.json")public void testProduce() throws Exception {// No code is needed here. What?// Where are the 'assertions' gone ?}}
在上面的代码中:
'test_kafka_produce.json'是测试用例,其中包含我们之前讨论过的JSON步骤。
'kafka_test_server.properties'包含“Broker”详细信息和生产者/消费者配置。
'@RunWith(ZeroCodeUnitRunner.class)'是运行测试的JUnit自定义运行器。
此外,我们可以使用Suite runner或Package runner来运行整个测试套件。
请访问这些RAW和JSON示例和说明。
10.写我们的第一个制造者测试
我们在上面的部分中学习了如何生成记录并断言代理响应/确认。
但我们不必止步于此。 我们可以进一步要求我们的测试逐字段断言“recordMetadata”以验证它是否写入了正确“主题”的正确“分区”等等,如下所示。
"assertions": {"status": "Ok","recordMetadata": {"offset": 0, //<--- This is the record 'offset' in the partition"topicPartition": {"partition": 0, //<--- This is the partition number"topic": "demo-topic" //<--- This is the topic name}}}
而已。在上面的“断言”块中,我们完成了预期值与实际值的比较。
注意:比较和断言立即完成。 “断言”块立即与从Kafka Broker收到的实际“status”和“recordMetadata”进行比较。字段的顺序在这里并不重要。如果字段值或结构不匹配,则测试仅失败。
11.编写我们的首次消费者测试
同样,要编写“消费者”测试,我们需要知道:
主题名称'demo-topic'是我们的“终点”,a.k.a。“url”:“url”:“kafka-topic:demo-topic”。
操作,即“消费”:“操作”:“消费”。
在使用主题消息时,我们需要发送如下信息:“request”:{}
上述“请求”意味着什么也不做,只是消费而不做“提交”。
或者我们可以在测试中提及在消费或消费记录后做某些事情。
"request": {"consumerLocalConfigs": {"commitSync": true,"maxNoOfRetryPollsOrTimeouts": 3}}
“commitSync”:true:在这里,我们告诉测试在使用消息之后执行`commitSync`,这意味着,当你下次`poll`时它不再读取消息。它只会在有关主题的情况下阅读新消息。
“maxNoOfRetryPollsOrTimeouts”:3:在这里,我们告诉测试最多显示轮询三次,然后停止轮询。如果我们有更多记录,我们可以将其设置为更大的值。默认值为1。
“pollingTime”:500:在这里,我们告诉测试每次轮询时轮询500毫秒。如果跳过此标志,则默认值为100毫秒。
访问此页面以获取所有可配置密钥 - 来自源代码的ConsumerLocalConfigs。
访问HelloWorld Kafka示例仓库,在家中试用。
注意:这些配置值可以在属性文件中全局设置为所有测试,这意味着它将应用于我们的测试包中的所有测试。此外,我们可以覆盖套件内特定测试或测试的任何配置。因此,它为我们提供了覆盖所有测试场景的灵活性。
好吧,设置这些属性并不是什么大问题,我们必须这样做才能将它们外化。因此,维护起来越简单,对我们来说就越好!但我们必须了解其中的内容。
我们将在接下来的章节中讨论这个问题。
12.将REST API测试与Kafka测试相结合
大多数时候,在微服务架构中,我们使用RESTful服务,SOAP服务(可能是遗留的)和Kafka来构建应用程序。
因此,我们需要涵盖端到端测试场景中的所有API合同验证,包括Kafka。
但这并不是什么大问题,因为毕竟这里没有什么变化,除了我们只是将我们的“url”指向我们的REST或SOAP服务的HTTP端点,然后相应地操纵有效负载/断言块。真的是这样的。
请访问将Kafka测试与REST API测试结合使用,以获得完整的逐步方法。
如果我们有一个用例:
步骤1:Kafka调用 - 我们向“地址主题”发送ID为“id-lon-123”的“地址”记录,该记录最终被处理并写入“地址”数据库(例如Postgres或Hadoop)。然后我们断言经纪人确认。
步骤2:REST调用 - 使用“/ api / v1 / addresses / id-lon-123”查询(GET)“地址”REST API并断言响应。
相应的测试用例如下所示。
{"scenarioName": "Kafka and REST api validation example","steps": [{"name": "produce_to_kafka","url": "kafka-topic:people-address","operation": "produce","request": {"recordType" : "JSON","records": [{"key": "id-lon-123","value": {"id": "id-lon-123","postCode": "UK-BA9"}}]},"assertions": {"status": "Ok","recordMetadata" : "$NOT.NULL"}},{"name": "verify_updated_address","url": "/api/v1/addresses/${$.produce_to_kafka.request.records[0].value.id}","operation": "GET","request": {"headers": {"X-GOVT-API-KEY": "top-key-only-known-to-secu-cleared"}},"assertions": {"status": 200,"value": {"id": "${$.produce_to_kafka.request.records[0].value.id}","postCode": "${$.produce_to_kafka.request.records[0].value.postcode}"}}}]}
易于阅读!容易写!
字段通过JSON路径重用值而不是硬编码。这是一个很好的节省时间!
13.生成RAW记录与JSON记录
在RAW的情况下,我们只是静静地说:
“recordType”:“RAW”,
然后,我们的测试用例如下所示:
{"name": "produce_a_record","url": "kafka-topic:demo-topic","operation": "produce","request": {"recordType" : "RAW","records": [{"key": 101,"value": "Hello World"}]},"assertions": {"status": "Ok","recordMetadata": "$NOT.NULL"}}
2.对于JSON记录,我们以相同的方式提及它:
“recordType”:“JSON”
而且,我们的测试用例如下所示:
{"name": "produce_a_record","url": "kafka-topic:demo-topic","operation": "produce","request": {"recordType" : "JSON","records": [{"key": 101,"value": {"name" : "Jey"}}]},"assertions": {"status": "Ok","recordMetadata": "$NOT.NULL"}}
注意:“value”部分这次有一个JSON记录。
14.Kafka在Docker容器中
理想情况下,本节应该在开头。但是,只是在不知道结果的情况下运行docker-compose文件有什么意义呢?我们可以在这里找到让每个人的生活变得轻松!
我们可以在下面找到docker-compose文件和分步说明。
Docker中的单节点Kafka
Docker中的多节点Kafka集群
15.结论
在本教程中,我们以声明的方式学习了Kafka测试的一些基本方面。此外,我们学习了如何轻松地测试涉及Kafka和REST的微服务。
使用这种方法,我们已经测试并验证了集群Kafka数据管道到Hadoop以及部署在Kubernetes Orchestrated pod中的Http REST / SOAP API。我们发现这种方法非常非常直接并且降低了复杂性,以便将工件维护和推广到更高的环境。
通过这种方法,我们能够完全清晰地涵盖了许多测试场景,并且在开发周期的早期阶段发现了更多缺陷,即使没有编写任何测试代码也是如此。这有助于我们以简单,干净的方式构建和维护我们的回归包。
下面给出了repo GitHub(在家尝试)的这些示例的完整源代码。
要运行任何测试,我们可以直接导航到'src / test / java'下相应的JUnit @Test。在点击任何Junit测试之前,我们需要使用kafka调出Docker。
使用“kafka-schema-registry.yml(参见Wiki)”可以运行所有测试。
- Produce Tests (RAW and JSON)
- Consume Tests (RAW and JSON)
- Produce Records Directly From File
- Consume Records and Dump to File
如果您发现此页面对测试Kafka和HTTP API很有帮助,请在GitHub上留下“明星”!
快乐的测试!
原文:https://dzone.com/articles/a-quick-and-practical-example-of-kafka-testing
- 126 次浏览
【Kafka】用于测试kafka的工具
上下文
我意识到软件工具可以帮助我们在两个关键方面测试kafka:性能和稳健性。我从很少了解工具或它们的能力开始,虽然我知道十年前我曾经简要使用的jmeter。
我最初的目标是找到一种可以生成和消耗负载的方法。然后,这个负载将成为试验稳健性测试的背景,以了解系统和数据复制在恶劣条件下的工作和处理能力。通过inclement我的意思是不同程度的不利条件,如网络条件差,复杂的错误条件,在升级过程中“错误的”节点被取下而系统试图赶上积压的交易等等。我出现了我正在分别写下Beaufort环境条件的概念。
稳健性测试工具
我的研究很快就让我开始了凯尔金斯伯里的工作。他有一些优秀的视频https://www.youtube.com/watch?v=NsI51Mo6r3o和https://www.youtube.com/watch?v=tpbNTEYE9NQ以及开源软件工具和各种文章https:// aphyr .com /关于测试各种技术的帖子https://jepsen.io/analyses包括Zookeeper和Kafka。 Jay Kreps提供了他对Kyle测试的看法http://blog.empathybox.com/post/62279088548/a-few-notes-on-kafka-and-je…。
到现在为止还挺好…
然而,当我开始研究使用jepsen测试新版Kafka的实际方面时,我至少遇到了一些重大挑战。我找不到原始脚本,我找到的那些脚本https://github.com/gator1/jepsen/tree/master/kafka是一个Clojure,一种不熟悉的语言,以及旧版本的Kafka(0.10。 2.0)。更重要的是它依赖于docker。虽然docker是一个非常强大和快速的工具,但客户端不愿意相信在docker环境中运行的测试(我们的环境至少需要20个实例来测试最小的配置)。
下一个要尝试的项目是https://github.com/mbsimonovic/jepsen-python,这是我和其他团队成员充分了解的语言。但是我们又遇到了它使用docker的拦截器。但是,如果我们可以获得支持docker swarm的依赖项之一,那么似乎有一些测试集群的潜力。那个项目是Blockade。我问是如何添加对docker swarm的支持;根据项目团队之一https://github.com/worstcase/blockade/issues/67,相当多。
到目前为止,我们需要继续前进并专注于测试Kafka的性能,可伸缩性和延迟,包括区域间数据复制,因此我们不得不暂停搜索自动化工具或框架来控制测试的稳健性方面。
性能测试工具
目前我将继续专注于工具而不是尝试定义性能测试与负载测试等,因为在区分这些术语和其他相关术语方面存在许多分歧。我们知道我们需要生成流量模式的方法,范围从简单的文本到与预期的生产流量配置文件非常相似的流量模式。
在项目期间,我们发现了至少5个生成负载的候选者:
- kafkameter https://github.com/BrightTag/kafkameter
- pepper-box:https://github.com/GSLabDev/pepper-box
- kafka工具:https://github.com/apache/kafka
- sangrenel:https://github.com/jamiealquiza/sangrenel
- ducktape:https://github.com/confluentinc/ducktape
kafkameter和胡椒盒都集成了jmeter。其中胡椒盒更新,灵感来自kafkameter。 kafkameter显然需要大量的工作来满足我们的需求,所以我们开始尝试胡椒盒。我们很快分叉了项目,因此我们可以轻松地试验和添加功能,而不会干扰父项目,或者通过等待批准等延迟我们需要做的测试。
我已经将使用胡椒盒的细节移到了一个单独的博客文章http://blog.bettersoftwaretesting.com/2018/04/working-with-pepper-box-t…
我希望我们有更多的时间
可以做很多工作来改进工具和使用测试工具来测试Kafka的方法。我们需要在分配期间立即关注,以便快速提供反馈和结果。此外,测试特别是在早期阶段进入杂草,正确配置Kafka作为几种技术的新手非常耗时。我们确实希望在项目早期进行更多测试,并建立定期,可靠和值得信赖的测试结果。
有足够的空间来改进辣椒盒和分析工具。其中一些已经在各自的github存储库中被识别出来。
https://github.com/commercetest/pepper-box/issues
https://github.com/commercetest/pepperbox-analysis/issues
我接下来要探索的是什么
至少在我看来,最大的直接改进是专注于使用可信赖的统计分析工具(如R),以便我们可以自动化更多的测试处理和图形方面。
更多主题
以下是我希望在以后的文章中介绍的主题:
- 管理和扩展测试,特别是如何运行许多测试并跟踪结果,同时保持环境的健康和清洁。
- 设计生产者和消费者,以便我们可以使用消费者代码收集的结果来测量吞吐量和延迟。
- 消息保真度与增加保真度的开销之间的权衡(高保真成本比运行时的低保真成本更高)。
- 我们在建立值得信赖,可靠的测试环境以及简单地执行测试时遇到的许多不利因素
原文 :http://blog.bettersoftwaretesting.com/2018/04/tools-for-testing-kafka/
- 225 次浏览
【事件枢纽】对AWS托管Apache Kafka的真实回顾:亚马逊MSK
AWS刚刚在Re-Invent 2018上发布了一个托管Apache Kafka服务。我跳过它来弄清楚产品。炒作值得吗?你应该用吗?其他供应商应该担心吗?这是我的评论!
TLDR:虽然我认为亚马逊MSK是一个公开的预览,并且它表现出良好的性能,但截至今天我发现它缺乏主要功能,包括适当的安全性,这使得MSK目前无法推荐。
我应该开心......但我不是
对我来说,使用Apache Kafka的人越多,我获得的业务就越多。当我在Udemy上在线教Apache Kafka时(https://kafka-tutorials.com/上的链接),从AWS获得想要学习Apache Kafka的整个用户群的前景令人兴奋!作为Apache Kafka顾问,花费时间部署数据管道比部署基础架构总是更有趣。
不幸的是,今天发布的AWS错过了这个标志。我认为它让人联想到AWS整体上的开源软件托管服务:它们早期发布,缺乏我认为应该是MVP的功能。在我看来,这将阻止未来的用户。
你得到什么
让我们开始谈论积极的方面。只需几次点击和15到30分钟的等待时间,您就可以获得完全复制的多AZ Kafka群集。它还配备了Zookeeper管理,数据存储由EBS卷支持。您为EC2实例支付双倍的价格,但这是托管服务的价格。 EBS成本与您自己使用EBS卷的成本相同。

注意:你只能拥有一个经纪人,这个经纪人是你要部署的AZ数量的倍数......这是件好事!
从那里,您将获得一个引导服务器URL和一个Zookeeper DNS名称,您可以点击并开始使用Kafka。 要获取URL,您必须使用CLI ...
$ aws kafka list-clusters { "ClusterInfoList": [ { "BrokerNodeGroupInfo": { "BrokerAZDistribution": "DEFAULT", "ClientSubnets": [ "subnet-c69251b1", "subnet-07816c5e", "subnet-fc512699" ], "InstanceType": "kafka.m5.large", "StorageInfo": { "EbsStorageInfo": { "VolumeSize": 1000 } } }, "ClusterArn": "arn:aws:kafka:us-east-1:160803060715:cluster/test/9d2be72e-0d3b-4a2a-abbd-d8708ec4dca8-3", "ClusterName": "test", "CreationTime": "2018-11-30T08:21:36.824Z", "CurrentBrokerSoftwareInfo": { "KafkaVersion": "1.1.1" }, "CurrentVersion": "K13V1IB3VIYZZH", "EncryptionInfo": { "EncryptionAtRest": { "DataVolumeKMSKeyId": "arn:aws:kms:us-east-1:160803060715:key/c8a78efb-4daa-48ee-9fe8-26d40c274aaf" } }, "EnhancedMonitoring": "DEFAULT", "NumberOfBrokerNodes": 3, "State": "ACTIVE", "ZookeeperConnectString": "172.31.31.89:2181,172.31.9.136:2181,172.31.73.166:2181" } ] }$ aws kafka get-bootstrap-brokers --cluster-arn arn:aws:kafka:us-east-1:160803060715:cluster/test/9d2be72e-0d3b-4a2a-abbd-d8708ec4dca8-3 { "BootstrapBrokerString": "172.31.72.155:9092,172.31.10.218:9092,172.31.18.106:9092" }
就卡夫卡版而言,你得到...... 1.1.1。它真的很旧,我们现在有2.1和2.0.1可用......哦。您已经拥有的所有Kafka客户都应该工作,包括Kafka Connect,Kafka Streams,连接Kafka的监控解决方案等。
监控明智,我们可以在CloudWatch中查看指标,我想这是一个值得欢迎的补充。 “默认”监控级别是免费的,您必须为“每个经纪人”和“每个经纪人的每个主题”支付额外费用。这有点荒谬,因为每个经纪人都需要“每个主题”。只需将其纳入经纪人的成本,并让所有人免费......呃。指标列表虽然很好,但我很高兴他们揭露了一些最重要的指标:https://docs.aws.amazon.com/msk/latest/developerguide/monitoring.html#metrics-details
最后,因为您购买了EC2实例,所以您可以自由使用您喜欢的任何网络带宽。与其他管理的Kafka提供商相比,我认为这是AWS产品的一个重要区别。
我创建了一个集群,我用3个代理m5.large和一个机器m5a.large作为客户端进行了快速性能测试。性能方面,集群看起来很稳固,我能够以70MB /秒的速度获得峰值吞吐量。
$ kafka-topics.sh — zookeeper 172.31.31.89:2181,172.31.9.136:2181,172.31.73.166:2181 — create — topic test — replication-factor 3 — partitions 12 Created topic “test”.$ kafka-producer-perf-test.sh — topic test — throughput 10000 — num-records 10000000000 — producer-props acks=all linger.ms=10 batch.size=65536 bootstrap.servers=172.31.72.155:9092,172.31.10.218:9092,172.31.18.106:9092 — record-size 1000 49912 records sent, 9968.4 records/sec (9.51 MB/sec), 17.4 ms avg latency, 236.0 max latency. 50076 records sent, 10011.2 records/sec (9.55 MB/sec), 10.6 ms avg latency, 35.0 max latency. 49994 records sent, 9994.8 records/sec (9.53 MB/sec), 10.0 ms avg latency, 29.0 max latency. 50074 records sent, 10014.8 records/sec (9.55 MB/sec), 9.9 ms avg latency, 33.0 max latency.$ kafka-producer-perf-test.sh — topic test — throughput 50000 — num-records 10000000000 — producer-props acks=all linger.ms=10 batch.size=65536 bootstrap.servers=172.31.72.155:9092,172.31.10.218:9092,172.31.18.106:9092 — record-size 1000 249251 records sent, 49820.3 records/sec (47.51 MB/sec), 26.0 ms avg latency, 226.0 max latency. 250275 records sent, 50055.0 records/sec (47.74 MB/sec), 13.7 ms avg latency, 34.0 max latency. 250079 records sent, 49985.8 records/sec (47.67 MB/sec), 13.6 ms avg latency, 35.0 max latency.$ kafka-producer-perf-test.sh — topic test — throughput 100000 — num-records 10000000000 — producer-props acks=all linger.ms=10 batch.size=65536 bootstrap.servers=172.31.72.155:9092,172.31.10.218:9092,172.31.18.106:9092 — record-size 1000 369975 records sent, 73906.3 records/sec (70.48 MB/sec), 343.9 ms avg latency, 1112.0 max latency. 351592 records sent, 70290.3 records/sec (67.03 MB/sec), 444.9 ms avg latency, 1402.0 max latency. 351236 records sent, 70233.2 records/sec (66.98 MB/sec), 453.6 ms avg latency, 1359.0 max latency. 354300 records sent, 70845.8 records/sec (67.56 MB/sec), 447.4 ms avg latency, 1365.0 max latency.
我们没有得到什么
首先,我想在房间里找到大象:安全。
对我来说,MSK并不安全
我认为任何人使用MSK的主要原因是为了安全。好的,我在自己的云中有一个Apache Kafka集群,所以我是唯一可以访问它的人,这是一个很大的优势。 AWS做了什么?好吧,它由KMS支持加密EBS卷,而且你没有SSH访问你的数据,这是好的。这为您的数据提供了“静态加密”功能。
但是,自从3岁以上的Kafka v0.9起,我们就拥有了适当的Kafka安全性。在每个Kafka版本中,它都在使用新的安全机制进行改进。今天我们在Kafka Security中有两个组件:
- 飞行中的SSL加密:你没有得到MSK(现在)。 https://aws.amazon.com/msk/faqs/。这意味着您的网络周围的所有数据都完全未加密。 Route53和ACM的整合有望在以后出现......但是现在你已经暴露了。
- 身份验证和授权:所以这是我最大的问题:您创建了一个MSK群集,并且您认为它是安全的,因为营销登录页面告诉您它是安全的。好吧,一点也不。它绝对使用NO安全机制,因此任何人都可以创建/读取/写入/删除任何主题的数据。哦,任何人都可以改变Zookeeper。我的意思是,每个受管理的Kafka提供商都提供安全保障。它有多种形式:SASL / GSSAPI,SASL / OAUTH,SASL / PLAIN,SASL / SCRAM和AWS没有实现任何这些。实际上,当您考虑AWS和安全性时,您认为是IAM。 SASL / IAM将成为杀手锏。 AWS IAM内部的身份验证和授权,梦想。嗯......不会很快发生的。
因此,当您获得所有奇特的网络和服务控制安全性时,您的实际Kafka群集将尽可能地打开。这意味着您在当前系统中如此难以处理的数据的任何安全控制在MSK中完全丢失。对我来说,这对我所有咨询客户来说都是一个破坏性的交易。
让我细微一点:这是MSK的预览,我确信在积压的某个地方,AWS确实有一张大卡可以实现并释放某种真正的安全性。但是,当您发布服务时,您只有一次机会给人留下印象,而且您发布的内容有点完整。 AWS在这里错过了标记,很长一段时间,我认为MSK是不安全的。即使有一天它变得“安全”,它也表明AWS缺乏支持安全第一卡夫卡的承诺,这反映了产品的思维方式:营销能力。
我们没有得到的其他东西
除了安全性,这里还有我想念的衣物清单:
- 托管的结构模式注册表
- 能够放入Kafka的jar(适用于度量报告者,特定类,Java代理)
- 指向并单击镜像制造商/复制
- 指向并单击备份到S3
- 点击并点击Kinesis与Kafka的链接
- 管理Kafka Connect
- 控制Kafka配置(虽然你可以使用kafka-configs命令破解它...你欢迎AWS)
- 扩展集群
- 来自控制台的主题管理
- 通过控制台管理几乎所有内容
- 您的群集支持 - 对于我来说,这是一个很大的未知,因为AWS支持是否能够支持您的Kafka群集。根据我的经验,支持Kafka集群并不容易,这是其他管理的Kafka供应商可能真正擅长的。另一个区别
AWS和开源世界
AWS喜欢从开源世界中获取产品并将其作为服务付费。 Elastic Search和Envoy是两个例子,现在我们有Apache Kafka。问题在于,从历史上看,AWS并没有给予它带来大量现金的项目。这对于这些项目来说是个大问题,因为他们生活在社区支持之下。
请证明我错了AWS:
公平地说,AWS已经开始开源今年非常大的FireCracker,这可能预示着思维方式的转变......时间会证明。

结束思考
我认为管理卡夫卡空间的竞争越来越激烈。它充满了伟大的演员,如Confluent,Aiven,CloudKarafka,Instaclustr,Landoop,Heroku以及其他我可能缺少的演员。 AWS肯定会增加很多压力,但是现在亚马逊MSK非常小,我不推荐它。你最终还是会管理很多,这不是你首先注册的,是吗?
本文 :http://pub.intelligentx.net/node/367
讨论:请加入知识星球【首席架构师圈】
- 128 次浏览
【企业事件平台】自动化Kafka测试
概观
Apache Kafka正在被普遍利用,并且在世界上形成一些大规模和重要的系统,每天处理数万亿条消息。它是许多金融和科技行业公司的管道骨干。
在继续之前,我想提出一些期望。本文的重点不是解释Kafka及其架构的复杂性或用例,而是清楚地说明可用于执行Kafka测试的库之一以及我们的方法和经验。 Zerocode如何允许我们执行集成,单元和端到端(E2E)测试。本文适用于那些已经熟悉Kafka的人,其应用或至少具有很强的理论知识水平。要按照我们的设置,您需要克隆https://github.com/authorjapps/zerocode并安装一些监控工具(Confluent Control Center)。
用例
由于项目的机密性和我们对客户的承诺,我会用我们在测试Kafka时可能遇到的一般情况来打扮我们的用例。请随时通过评论或LinkedIn与您讨论您的具体情况。该项目有30多个微服务,向Kafka生成和使用消息,并对流程中的消息执行某些转换和验证。
我们的方法
我们决定使用Zerocode,因为它的步长链,简单和水平可扩展格式允许我们用简单的JSON格式编写带有效负载和响应断言的测试(利用JSON路径:https://github.com/json-path /JsonPath/blob/master/README.md#path-examples)
Confluent Center(本地)是我们选择的平台,可以获得对测试用例的可视性和监控。
为了模拟我们的测试场景之一(即消息可能来自微服务A然后被消费并需要从微服务B消费和验证)我们向topic_A发出消息并利用KSQL将这些消息写入topic_B并从topic_B和执行断言然后执行另一个KSQL查询以在topic_C上传递该有效负载并重复。 Zerocode的JSON声明式风格使我们能够有效地完成这项工作。
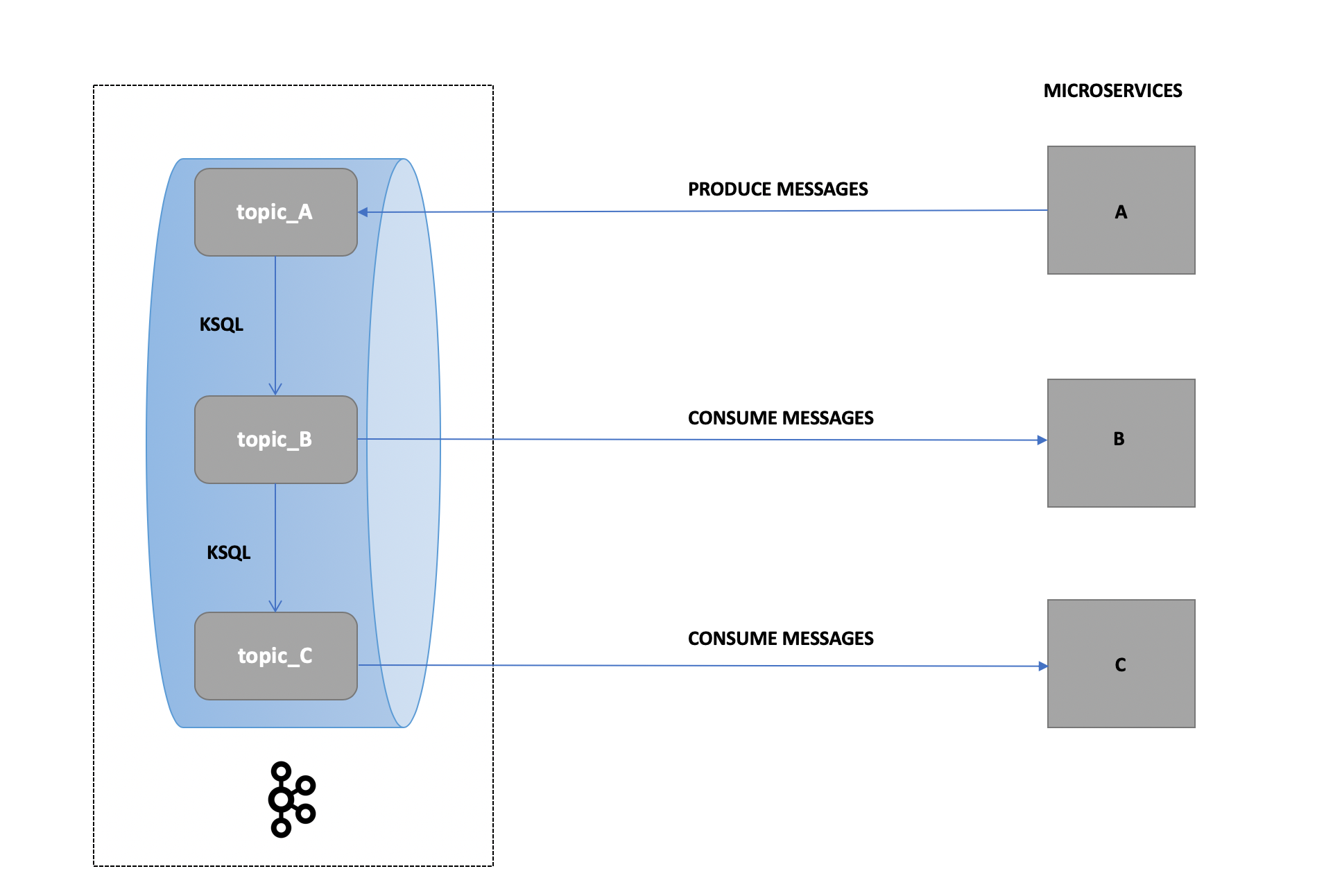
挑战
作为一个常识,我们知道卡夫卡的消息没有订购!
ZEROCODE的建议:
在我们与Zerocode社区的讨论中,可以使用以下选项来解决:
client.id in:/zerocode/kafka-testing/src/test/resources/kafka_servers/kafka_producer.properties
group.id in:/zerocode/kafka-testing/src/test/resources/kafka_servers/kafka_consumer.properties
注意:
在Kafka; client.id:允许您轻松地将代理上的请求与创建它的客户端实例相关联。查看更多示例和详细信息:https://docs.confluent.io/current/clients/producer.html
并且,group.id:property为同一个使用者组中的一组使用者定义唯一标识。您可以在此处了解更多信息:https://jaceklaskowski.gitbooks.io/apache-kafka/kafka-properties-client-id.html?q = group.id
例1:
Zerocode允许您配置例如client.id = zerocode-producer _ $ {RANDOM.NUMBER}以及其他各种占位符。保持其独特性有助于跟踪和测试目的。
通过上面定义的client.id,为每个执行的测试分配一个唯一的ID。
以下示例结果:
第一次运行 - client.id = test_producer_1553209530873
第二次运行 - client.id = test_producer_1553209530889
第3次运行 - client.id = test_producer_1553209530893
此后缀数字ID是唯一的,因为它是当前时间戳的数字等效值。
例2:
Zerocode社区的另一个建议方法是将client.id定义为时间戳,因为它是测试和跟踪的理想选择
client.id = test_producer _ $ {LOCAL.DATE.TODAY:yyyy-MM-dd}
例如
第1天 - client.id = test_producer_2018-03-18
第二天 - client.id = test_producer_2018-03-19
第3天 - client.id = test_producer_2018-03-20
有关其他占位符的信息,请参阅以下链接以定义client.id https://github.com/authorjapps/zerocode#localdate-and-localdatetime-for…,在适合您项目要求的README文件中进行说明。
根据Kafka的要求,group.id在kafka_consumer.properties中定义。
例如group.id = consumerGroup14等
将其定义为唯一可以帮助您实现端到端的测试。此外,这可能会重新运行整个测试套件/包,即使您的CI构建管道可重复。
这种独特性将允许消费者获取旧+新消息(如果它有帮助)。
更多示例和详细信息:https://docs.confluent.io/current/clients/consumer.html
我们的经验和学习
Zerocode允许我们使用带有Java runner(Junit)的JSON配置文件和可配置的Kafka服务器,生产者和消费者属性的Java runner实现这一目标。
我们使用KSQL将数据从一个主题移动到另一个主题,以模拟多微服务的参与,如上所述。
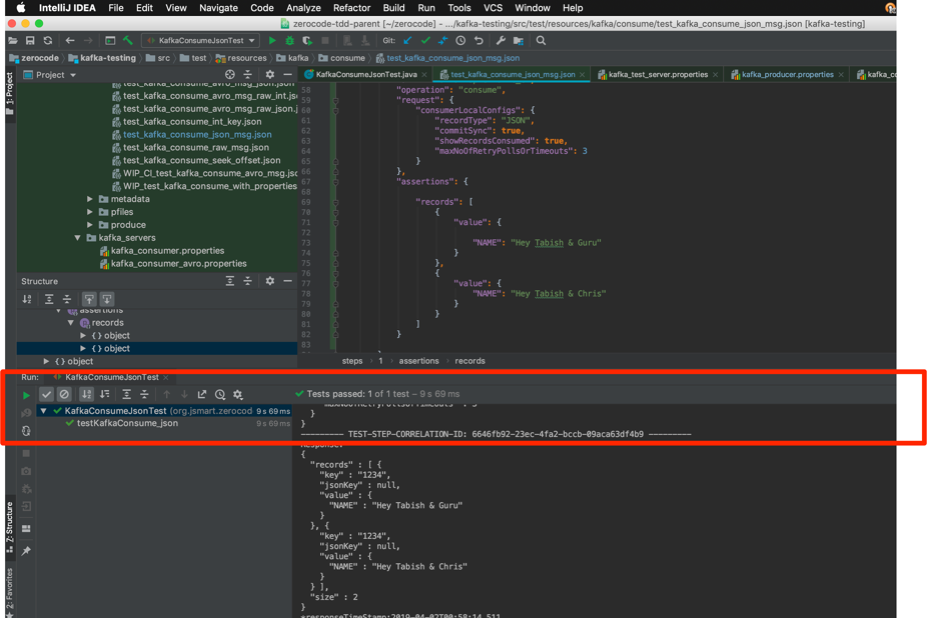
下面分享了一些测试截图:
1.开始使用实例
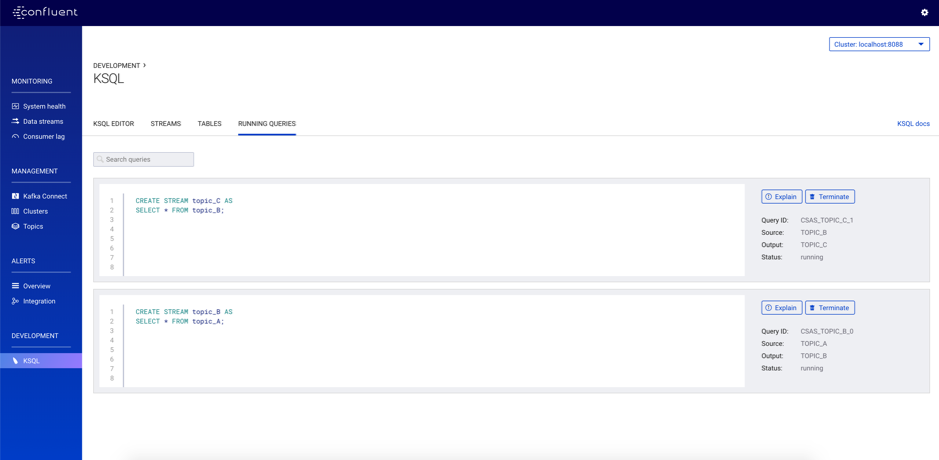
2. KSQL QUERIES
查看我们用于在不同主题之间移动数据的模拟KSQL查询的快照。
请仔细检查您的存储库中是否添加了以下依赖项:
<dependency>
<groupId>org.jsmart</groupId>
<artifactId>zerocode-tdd</artifactId>
<version>1.3.5</version>
</dependency>
属性配置示例包括:
Producer属性:https://github.com/authorjapps/hello-kafka-stream-testing/blob/master/src/test/resources/kafka_servers/kafka_producer_unique.properties
Consumer属性:https://github.com/authorjapps/hello-kafka-stream-testing/blob/master/src/test/resources/kafka_servers/kafka_consumer_unique.properties
要运行的示例测试用例:
KafkaProduceUniqueClientIdTest.java:
https://github.com/authorjapps/hello-kafka-stream-testing/blob/master/s…
KafkaConsumeUniqueGroupIdTest.java:
https://github.com/authorjapps/hello-kafka-stream-testing/blob/master/s…
下面是我们在一个测试场景中使用的示例JSON配置:
检测结果
安全
在Zerocode提供的安全性方面如下:
- 对于Oauth2,请在DZone安全区查看一个非常简短且精确的博客:https://dzone.com/articles/oauth2-authentication-in-zerocode如果您需要更多信息,请联系社区或Zerocode。
- 对于企业代理配置,您可以按照此处的自述文件部分进行操作:https://github.com/authorjapps/zerocode#soap-method-invocation-where-corporate-proxy-enabled
- 这适用于任何Http API调用,例如REST,SOAP等
- 具有工作示例的SAML / JWT是:https://github.com/authorjapps/zerocode#using-any-properties-file-key-value-in-the-steps repo
- 如果令牌是动态的,那么在运行时将它们注入头部仍然很容易:https://github.com/santhoshTpixler在他的博客中解释过
- 如果您使用OpenAM或RedHat SSO或Simple Basic Auth。您可以参考自述文件https://github.com/authorjapps/zerocode#http-basic-authentication-step-…。您可以手动使用每个测试用例或将其嵌入到HttpClient中,这是一次性的(并且维护开销较少)
- 自定义HTTP客户端:无论如何,Zerocode的Http客户端支持Http和Https连接。但您可以覆盖并添加/删除安全功能以满足您的项目要求。
请参阅示例:https://github.com/authorjapps/zerocode-hello-world/blob/master/src/main/java/org/jsmart/zerocode/zerocodejavaexec/httpclient/CustomHttpClient.java#L46

然后它非常简单直接使用如下 -
只需注释您的测试类或套件类。
@UseHttpClient(CustomHttpClient.class)
以类似的方式,您可以注入所需的任何自定义标头。
https://github.com/authorjapps/zerocode-hello-world/blob/master/src/mai…
例如
特色与未来
在与Zerocode广泛贡献社区的讨论中,关于特征比较前端,Zerocode正在收集来自客户的反馈/数据以捕获对Zerocode的好处和偏好,例如
- 从Postman(collections)到Zerocode
- 从其他基于Step-Definition的BDD工具到Zerocode等。
我们和Zerocode很乐意听取您对此的反馈。
预热
分布式测试非常棘手,没有灵丹妙药,因其独特的角落案例而闻名。要解决这些问题,需要从流程设计到生产的大量设计思路和SDLC(软件开发生命周期)实践。本博客的目标是根据需要分享一些有关如何处理和扩展测试的见解,以及现有的经过深思熟虑和文档选项Zerocode旨在保持质量。
重要的是要清楚地概述Zerocode是特殊的:
- 应用集成测试
- 端到端测试
- 系统集成测试
- 负载/压力测试
- API模拟制作(使用wiremock JSON DSL)
以声明的方式将开发人员/测试人员的麻烦减少到零。
我们选择合适的测试库或框架的结论是:
- 便于使用
- 减少语法开销
- 易于处理和断言有效载荷
- 易于扩展测试跑步者
- 易于添加自定义安全功能
- 便于手动测试人员了解测试流程
我们真诚地希望这能在一定程度上帮助社区,并帮助我们与来自Zerocode的同类精神弥合和填补空白。
尊敬的参考文献
有关如何测试Kafka或REST API生成和使用Kafka的更多详细信息,请参阅以下链接或通过以下评论与我们联系:https://github.com/authorjapps/zerocode
- 248 次浏览
【存储架构】使用Apache Pulsar分层存储省钱
随着公司开始考虑推出实时消息传递系统,查看总体硬件成本是很重要的。通过一些前瞻性的规划,公司可以节省高达85%的总体存储成本。
在我们开始进行成本比较之前,让我简要地说明apache kafka和apache pulsar是如何存储数据的,它们有什么不同,以及为什么这些不同很重要。
数据存储在Kafka
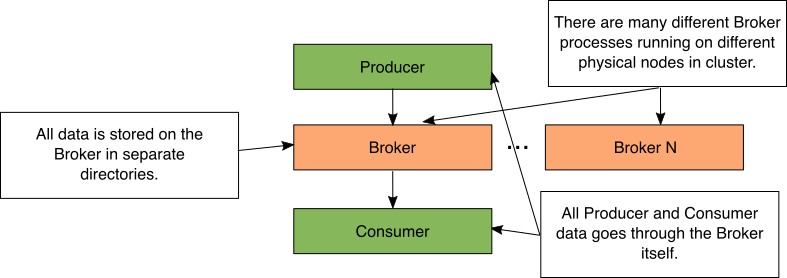
Figure 1: Simple Kafka storage diagram
在Kafka中,代理进程执行所有数据移动和存储。当生产者发送数据时,它被发送到代理进程。当使用者轮询数据时,将从代理检索数据。当代理进程接收数据时,它将数据存储在单独的本地目录中。
在Kafka集群中,有许多不同的代理进程正在运行。这些代理进程中的每一个都在物理上独立的计算机或容器上运行。
数据存储在Pulsar
有几种不同的方法可以建立一个Pulsar集群。这种级别的可扩展性是我们优化存储成本的方法。
简单Pulsar设置
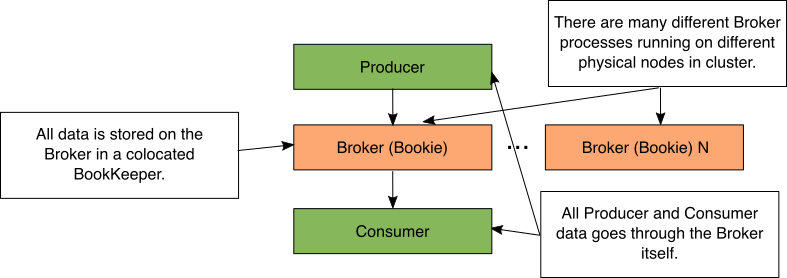
Figure 2: Simple Pulsar storage diagram
在Pulsar中,代理进程执行所有数据移动。当生产者发送数据时,它被发送到代理进程。当消费者将数据推送到代理时,数据来自代理。当Broker进程接收数据时,它将数据存储在一个并置的bookeeper Bookie中。BookKeeper Bookie是BookKeeper中存储数据的进程的名称。
在Pulsar集群中,有许多不同的代理进程在运行。这些代理进程中的每一个都在物理上独立的计算机或容器上运行。
带Bookkeeper的Pulsar集群
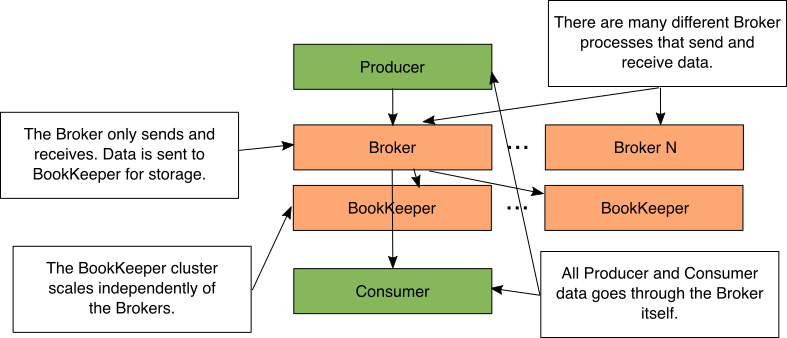
Figure 3: Pulsar with separate BookKeeper cluster
正如您刚才看到的,数据不是直接由Pulsar代理存储的。相反,Pulsar代理使用ApacheBookKeeper来存储他们的数据。数据的发送/接收和存储的这种解耦允许您让BookKeeper在另一台物理上独立的计算机或容器上运行。
当代理保存消息时,它将简单地将数据发送到BookKeeper流程。这允许BookKeeper集群和Pulsar集群彼此独立缩放。您可以发送/接收大量短时间内存储的消息(许多Pulsar经纪人和很少的预订)。你可以收到很少的信息并长期存储(很少的Pulsar经纪人和许多预订)。
一个常见的问题是,如果在单独的机器上有经纪人和簿记会导致性能问题。代理保留最近消息的内存缓存。事实上,99.9%的消息将是缓存命中,因为大多数消费者只是接收最新消息。
卸载至S3
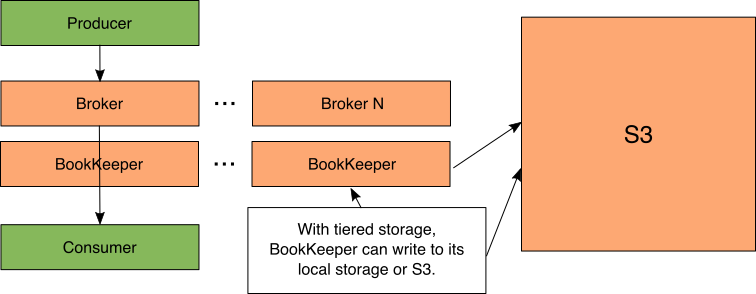
Figure 4: Pulsar with separate BookKeeper cluster that is offloading to S3
Pulsar的解耦存储体系结构在Pulsar中有一个新特性,称为分层存储,这一特性非常出色。这允许BookKeeper根据管理员配置的策略自动将数据从存储在簿记台上移动到存储在S3中。
注意:虽然我把S3作为赌注者的一个选择,但它并不是唯一受支持的技术。目前支持Google云存储,即将支持Azure Blob存储。您可以将S3看作是您所选择的支持云存储选项的缩写。
尽管数据存储在S3中,但经纪人仍然可以访问S3中的数据,因为赌注经纪人负责数据移动。S3的IO比本地存储的数据慢。
存储的关键区别
如你所见,Kafka和Pulsar在存储方面的主要区别在于耦合。在Kafka中,存储耦合到代理。在Pulsar中,存储与簿记分离。
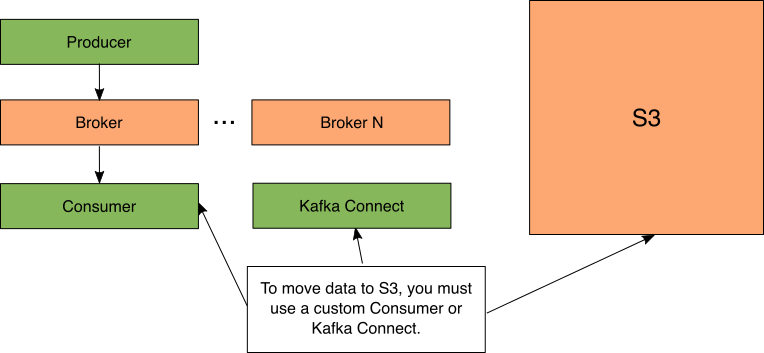
Figure 5: Kafka Offload
你可能知道,Kafka确实有能力将数据放入S3。这可以通过设置Kafka Connect或编写自定义使用者手动完成。
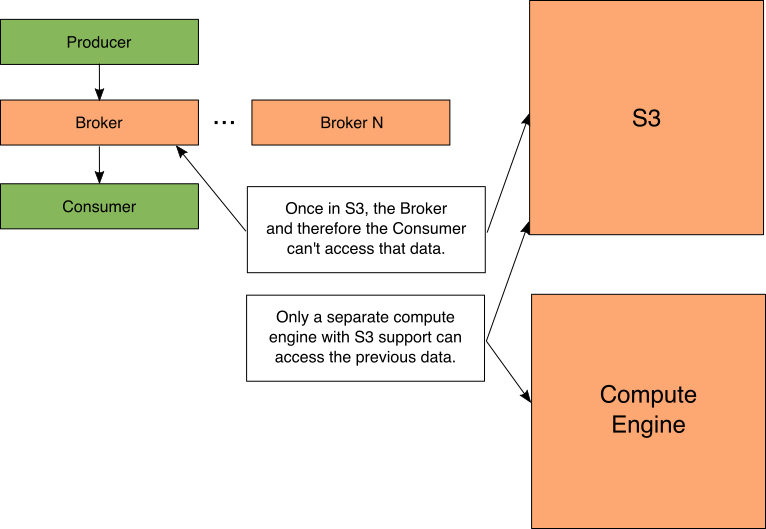
Figure 6: Kafka access
这种对S3的卸载确实带来了一个重要的警告,如图6所示。现在,数据的所有后续处理或消耗都必须使用另一个支持S3的计算引擎来完成,否则数据必须重新流回到Kafka主题并进行处理。
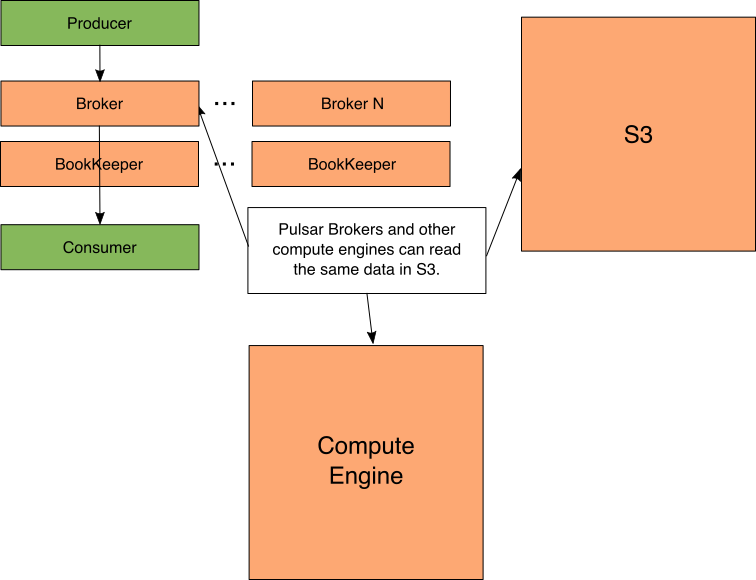
Figure 7: Pulsar access
使用Pulsar,数据可以与计算引擎共享。这两方面都是最好的,因为代理仍然可以访问旧消息,而计算引擎也可以。
例如,Spark可以处理存储在S3中的旧消息,同时Pulsar用户可以请求这些消息。请注意,在其他计算引擎中读取Pulsar的数据需要一个能够理解Pulsar磁盘格式的自定义输入格式。在撰写本文时,Pulsar支持Spark和Presto的连接器。
计算成本
既然我们了解了Kafka如何存储数据以及Pulsar存储数据的各种方法,我们就可以开始计算成本了。为了让这个过程更简单更具体,我们将根据亚马逊网络服务的美国东部(俄亥俄州)地区2019年1月的定价来确定我们的数字。对于S3,每个GB月的成本为0.023美元;对于EBS Amazon EBS通用SSD,每个GB月的配置存储成本为0.10美元。
在这个场景中,假设我们每天存储500 GB的消息。我们需要将这些消息存储14天。大约有7000 GB的原始事件消息。在Kafka和Pulsar中,数据被保存了3次以实现冗余。这使我们的存储需求高达21000 GB。对于Kafka和Pulsar(没有S3),光是存储成本每年就要25200美元。
有了Pulsar和S3,我们不需要在BookKeeper那里存储14天。我们只需要在Pulsar中存储一天,在S3中存储另外13天(您消耗的大部分时间都是几分钟前的数据)。这意味着我们需要1500 GB的EBS(500 GBx3副本)和6500 GB的S3(请记住,S3不直接收取冗余费用)。EBS和S3每年的成本分别为1794美元和1800美元,总计3594美元。这显然不包括S3请求的成本,但这些成本每年应该在50-300美元之间。
这两者的价格相差85.7%,数据可用性没有损失。这显然是一个例子。为了帮助您估计成本差异,我创建了一个Pulsar存储节省电子表格。只要输入你的数据,它会给你的价格差异。
更多关于成本的信息
对于云用户来说,S3中数据的存档存储已经纳入预算。这可能使节省更高。
还有其他更便宜的S3层。它们的sla更低,但成本更低。你也许可以走得更低,像冰川Glacier这些S3层。冰川Glacier的价格从0.023美元一路下跌到0.004美元。
考虑到您的用例和集群需求,您可以通过选择正确数量的Pulsar代理和bookeeper Bookie节点来进一步优化成本。您的EC2成本通常比存储成本高得多。
通过了解Kafka和Pulsar的存储差异,您可以真正优化您的存储开销。这使您能够灵活地交付业务所需的内容,同时仍能降低IT开销。
完全披露:这篇文章得到了Streamlio的支持。Streamlio提供了一个由apache pulsar和其他开源技术支持的解决方案。
原文:https://www.splunk.com/en_us/blog/it/saving-money-with-apache-pulsar-ti…
本文:http://jiagoushi.pro/node/1508
讨论:请加入知识星球【首席架构师圈】或者微信【csa_cea_cto】或者QQ【2808908662】
- 206 次浏览
【消息中间件】Redis vs Kafka vs RabbitMQ
对微服务使用异步通信时,通常使用消息代理。代理确保不同微服务之间的通信可靠且稳定,消息在系统内得到管理和监控,并且消息不会丢失。您可以从几个消息代理中进行选择,它们的规模和数据功能各不相同。这篇博文将比较三种最受欢迎的代理:RabbitMQ、Kafka 和 Redis。
微服务通信:同步和异步
微服务之间有两种常见的通信方式:同步和异步。在同步通信中,调用者在发送下一条消息之前等待响应,它作为 HTTP 之上的 REST 协议运行。相反,在异步通信中,消息是在不等待响应的情况下发送的。这适用于分布式系统,通常需要消息代理来管理消息。
您选择的通信类型应考虑不同的参数,例如您如何构建微服务、您拥有的基础设施、延迟、规模、依赖关系和通信目的。异步通信的建立可能更复杂,需要向堆栈中添加更多组件,但对微服务使用异步通信的优点大于缺点。
异步通信优势
首先,异步通信根据定义是非阻塞的。它还支持比同步操作更好的扩展。第三,在微服务崩溃的情况下,异步通信机制提供了各种恢复技术,并且通常更擅长处理与崩溃有关的错误。此外,当使用代理而不是 REST 协议时,接收通信的服务实际上不需要相互了解。甚至可以在旧服务运行很长时间后引入新服务,即更好的解耦服务。
最后,在选择异步操作时,您可以提高未来创建中央发现、监控、负载平衡甚至策略执行器的能力。这将为您的代码和系统构建提供灵活性、可扩展性和更多功能。
选择正确的消息代理
异步通信通常通过消息代理进行管理。还有其他方法,例如 aysncio,但它们更加稀缺和有限。
在选择代理来执行异步操作时,您应该考虑以下几点:
Broker Scale — 系统中每秒发送的消息数。
数据持久性——恢复消息的能力。
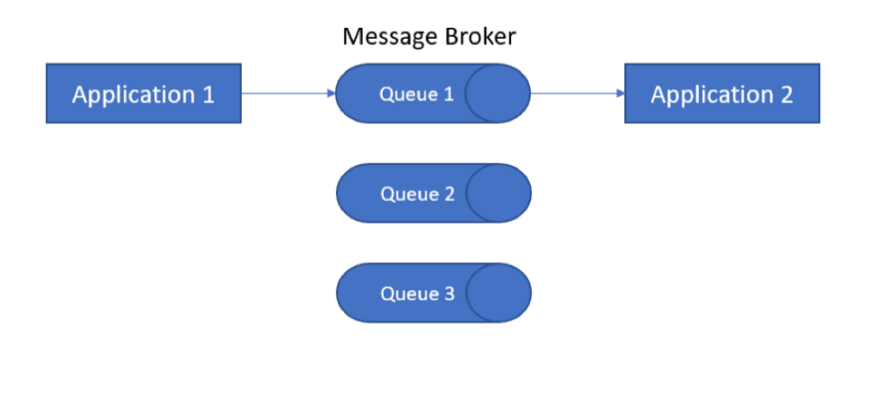
消费者能力——经纪人是否能够管理一对一和/或一对多的消费者。
一对一
一对多
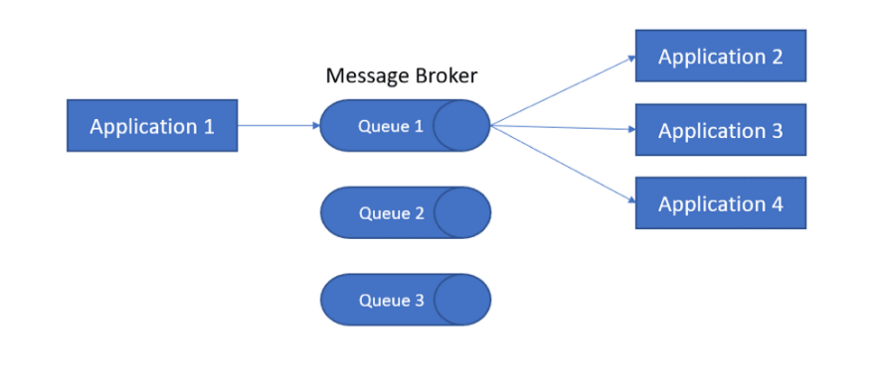
我们检查了最新和最好的服务,以找出这三个类别中最强大的提供商。
比较不同的消息代理
RabbitMQ (AMQP)
规模:
根据配置和资源,这里的大概是每秒 50K msg。
持久性:
支持持久性和瞬态消息。
一对一与一对多消费者:
两者兼而有之。
RabbitMQ 于 2007 年发布,是最早创建的通用消息代理之一。它是一个开源软件,通过实现高级消息队列协议 (AMQP),通过点对点和发布-订阅方法传递消息。它旨在支持复杂的路由逻辑。
有一些托管服务允许您将其用作 SaaS,但它不是本地主要云提供商堆栈的一部分。 RabbitMQ 支持所有主要语言,包括 Python、Java、.NET、PHP、Ruby、JavaScript、Go、Swift 等。
在持久模式下会出现一些性能问题。
卡夫卡
规模:
每秒最多可以发送一百万条消息。
持久化:
是的。
一对一 vs 一对多消费者:
只有一对多(乍一看似乎很奇怪,对吧?!)。
Kafka 由 Linkedin 于 2011 年创建,用于处理高吞吐量、低延迟的处理。作为分布式流媒体平台,Kafka 复制了发布订阅服务。它提供数据持久性并存储记录流,使其能够交换质量消息。
Kafka 在 Azure、AWS 和 Confluent 上管理了 SaaS。他们都是Kafka项目的创造者和主要贡献者。 Kafka 支持所有主要语言,包括 Python、Java、C/C++、Clojure、.NET、PHP、Ruby、JavaScript、Go、Swift 等。
Redis
规模:
每秒最多可以发送一百万条消息。
持久性:
基本上,没有——它是一个内存中的数据存储。
一对一与一对多消费者:
两者兼而有之。
Redis 与其他消息代理略有不同。从本质上讲,Redis 是一种内存中数据存储,可用作高性能键值存储或消息代理。另一个区别是 Redis 没有持久性,而是将其内存转储到磁盘/数据库中。它也非常适合实时数据处理。
最初,Redis 不是一对一和一对多的。然而,自从 Redis 5.0 引入了 pub-sub,功能得到了提升,一对多成为了一个真正的选择。
每个用例的消息代理
我们介绍了 RabbitMQ、Kafka 和 Redis 的一些特性。这三者都是同类中的野兽,但正如所描述的,它们的运作方式大不相同。以下是我们针对不同用例使用的正确消息代理的建议。
短命消息:Redis
Redis 的内存数据库几乎非常适合具有不需要持久性的短期消息的用例。因为它提供极快的服务和内存中的功能,Redis 是短保留消息的完美候选者,在这种情况下,持久性不是那么重要,您可以容忍一些损失。随着 5.0 中 Redis 流的发布,它也是一对多用例的候选者,由于限制和旧的 pub-sub 功能,这是绝对需要的。
海量数据:Kafka
Kafka 是一个高吞吐量的分布式队列,专为长时间存储大量数据而构建。 Kafka 非常适合需要持久性的一对多用例。
复杂路由:RabbitMQ
RabbitMQ 是一个较旧但成熟的代理,具有许多支持复杂路由的特性和功能。当要求的速率不高(超过几万条消息/秒)时,它甚至会支持复杂的路由通信。
考虑您的软件堆栈
当然,最后要考虑的是您当前的软件堆栈。如果您正在寻找一个相对简单的集成过程,并且您不想在一个堆栈中维护不同的代理,您可能更倾向于使用您的堆栈已经支持的代理。
例如,如果您在 RabbitMQ 之上的系统中使用 Celery for Task Queue,您将有动力使用 RabbitMQ 或 Redis,而不是 Kafka,后者不受支持并且需要一些重写。
我们在 Otonomo 已经通过我们的平台演变和增长使用了上述所有内容,然后是一些!重要的是要记住,每种工具都有自己的优缺点,关键是要了解它们并为工作以及特定时刻、情况和要求选择合适的工具。
原文:https://blog.devgenius.io/redis-vs-kafka-vs-rabbitmq-e935ebbc7ec
本文:https://jiagoushi.pro/node/1639
- 474 次浏览
【首席架构师看Event Hub】Kafka深挖 -第2部分:Apache Kafka和Spring Cloud Stream
在这个博客系列的第1部分之后,Apache Kafka的Spring——第1部分:错误处理、消息转换和事务支持,在这里的第2部分中,我们将关注另一个增强开发者在Kafka上构建流应用程序时体验的项目:Spring Cloud Stream。
我们将在这篇文章中讨论以下内容:
- Spring云流及其编程模型概述
- Apache Kafka®集成在Spring云流
- Spring Cloud Stream如何让Kafka开发人员更轻松地开发应用程序
- 使用Kafka流和Spring云流进行流处理
让我们首先看看什么是Spring Cloud Stream,以及它如何与Apache Kafka一起工作。
什么是Spring Cloud Stream?
Spring Cloud Stream是一个框架,它允许应用程序开发人员编写消息驱动的微服务。这是通过使用Spring Boot提供的基础来实现的,同时还支持其他Spring组合项目(如Spring Integration、Spring Cloud函数和Project Reactor)公开的编程模型和范例。它支持使用描述输入和输出组件的类型安全编程模型编写应用程序。应用程序的常见示例包括源(生产者)、接收(消费者)和处理器(生产者和消费者)。
典型的Spring cloud stream 应用程序包括用于通信的输入和输出组件。这些输入和输出被映射到Kafka主题。Spring cloud stream应用程序可以接收来自Kafka主题的输入数据,它可以选择生成另一个Kafka主题的输出。这些与Kafka连接接收器和源不同。有关各种Spring Cloud流开箱即用应用程序的更多信息,请访问项目页面。
消息传递系统和Spring cloud stream之间的桥梁是通过绑定器抽象实现的。绑定器适用于多个消息传递系统,但最常用的绑定器之一适用于Apache Kafka。
Kafka绑定器扩展了Spring Boot、Apache Kafka的Spring和Spring集成的坚实基础。由于绑定器是一个抽象,所以其他消息传递系统也有可用的实现。
Spring Cloud Stream支持发布/订阅语义、消费者组和本机分区,并尽可能将这些职责委派给消息传递系统。对于Kafka绑定器,这些概念在内部映射并委托给Kafka,因为Kafka本身就支持它们。当消息传递系统本身不支持这些概念时,Spring Cloud Stream将它们作为核心特性提供。
以下是绑定器抽象如何与输入和输出工作的图示:

使用Spring Cloud Stream创建Kafka应用程序
Spring Initializr是使用Spring Cloud Stream创建新应用程序的最佳场所。这篇博文介绍了如何在Spring启动应用程序中使用Apache Kafka,涵盖了从Spring Initializr创建应用程序所需的所有步骤。对于Spring Cloud Stream,惟一的区别是您需要“Cloud Stream”和“Kafka”作为组件。以下是你需要选择的一个例子:

Initializr包含开发流应用程序所需的所有依赖项。通过使用Initializr,您还可以选择构建工具(如Maven或Gradle)和目标JVM语言(如Java或Kotlin)。
该构建将生成一个能够作为独立应用程序(例如,从命令行)运行的uber JAR。
Apache Kafka的Spring cloud stream编程模型
Spring Cloud Stream提供了一个编程模型,支持与Apache Kafka的即时连接。应用程序需要在其类路径中包含Kafka绑定,并添加一个名为@EnableBinding的注释,该注释将Kafka主题绑定到它的输入或输出(或两者)。
Spring Cloud Stream提供了三个与@EnableBinding绑定的方便接口:Source(单个输出)、Sink(单个输入)和Processor(单个输入和输出)。它还可以扩展到具有多个输入和输出的自定义接口。
下面的代码片段展示了Spring Cloud Stream的基本编程模型:
@SpringBootApplication
@EnableBinding(Processor.class)
public class UppercaseProcessor {@StreamListener(Processor.INPUT)
@SendTo(Processor.OUTPUT)
public String process(String s) {
return s.toUpperCase();
}
}
在这个应用程序中,注意这个方法是用@StreamListener注释的,它是由Spring Cloud Stream提供的,用于接收来自Kafka主题的消息。同样的方法也使用SendTo进行注释,SendTo是将消息发送到输出目的地的方便注释。这是一个Spring云流处理器应用程序,它使用来自输入的消息并将消息生成到输出。
在前面的代码中没有提到Kafka主题。此时可能出现的一个自然问题是,“这个应用程序如何与Kafka通信?”答案是:入站和出站主题是通过使用Spring Boot支持的许多配置选项之一来配置的。在本例中,我们使用一个名为application的YAML配置文件。yml,它是默认搜索的。下面是输入和输出目的地的配置:
spring.cloud.stream.bindings:
input:
destination: topic1
output:
destination: topic2
Spring Cloud Stream将输入映射到topic1,将输出映射到topic2。这是一组非常少的配置,但是可以使用更多的选项来进一步定制应用程序。默认情况下,主题是用单个分区创建的,但是可以由应用程序覆盖。更多信息请参考这些文档。
最重要的是,开发人员可以简单地专注于编写核心业务逻辑,让Spring Cloud Stream和Spring Boot来处理基础设施问题(比如连接到Kafka、配置和调优应用程序等等)。
下面的例子展示了另一个简单的应用程序(消费者):
@SpringBootApplication
@EnableBinding(Sink.class)
public class LoggingConsumerApplication {@StreamListener(Sink.INPUT)
public void handle(Person person) {
System.out.println("Received: " + person);
}public static class Person {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String toString() {
return this.name;
}
}
}
注意,@EnableBinding提供了一个接收器,这表明这是一个消费者。与前一个应用程序的一个主要区别是,使用@StreamListener注释的方法将一个名为Person的POJO作为参数,而不是字符串。来自Kafka主题的消息是如何转换成这个POJO的?Spring Cloud Stream提供了自动的内容类型转换。默认情况下,它使用application/JSON作为内容类型,但也支持其他内容类型。您可以通过使用属性spring.cloud.stream.binding .input来提供内容类型。然后将其设置为适当的内容类型,如application/Avro。
适当的消息转换器由Spring Cloud Stream根据这个配置来选择。如果应用程序希望使用Kafka提供的本地序列化和反序列化,而不是使用Spring Cloud Stream提供的消息转换器,那么可以设置以下属性。
序列化:
spring.cloud.stream.bindings.output.useNativeEncoding=true
反序列化:
spring.cloud.stream.bindings.input.useNativeDecoding=true
Auto-provisioning of topic
Apache Kafka绑定器提供了一个在启动时配置主题的配置程序。如果在代理上启用了主题创建,Spring Cloud Stream应用程序可以在应用程序启动时创建和配置Kafka主题。
例如,可以向供应者提供分区和其他主题级配置。这些定制可以在绑定器级别进行,绑定器级别将应用于应用程序中使用的所有主题,也可以在单独的生产者和消费者级别进行。这非常方便,特别是在应用程序的开发和测试期间。有许多关于如何为多个分区配置主题的示例。
支持使用者组和分区
可以使用Spring Cloud Stream配置众所周知的属性,如用户组和分区。消费者组可以通过属性设置:
spring.cloud.stream.bindings.input.group =组名称
如前所述,在内部,这个组将被翻译成Kafka的消费者组。
在编写生产者应用程序时,Spring Cloud Stream提供了将数据发送到特定分区的选项。同样,在内部,框架将这些职责委托给Kafka。
对于使用者,如果禁用自动再平衡(这是一个需要覆盖的简单配置属性),则特定的应用程序实例可以限制为使用来自一组特定分区的消息。有关详细信息,请参阅这些配置选项。
绑定可视化和控制
通过使用Spring Boot的致动器机制,我们现在能够控制Spring cloud stream中的各个绑定。
在运行时,可以使用执行器端点来停止、暂停、恢复等,执行器端点是Spring Boot的机制,用于在将应用程序推向生产环境时监视和管理应用程序。该特性使用户能够对应用程序处理来自Kafka的数据的方式有更多的控制。如果应用程序因绑定而暂停,那么来自该特定主题的处理记录将暂停,直到恢复。
Spring Cloud Stream还集成了Micrometer,以启用更丰富的指标、发出混乱的速率并提供其他与监视相关的功能。这些系统可以与许多其他监测系统进一步集成。Kafka绑定器提供了扩展的度量功能,为主题的消费者滞后提供了额外的见解。
Spring Boot通过一个特殊的健康状况端点提供应用程序健康状况检查。Kafka绑定器提供了一个健康指示器的特殊实现,它考虑到代理的连接性,并检查所有的分区是否都是健康的。如果发现任何分区没有leader,或者代理无法连接,那么health check将报告相应的状态。
Kafka流在Spring cloud stream中的支持概述
在编写流处理应用程序时,Spring Cloud stream提供了另一个专门用于Kafka流的绑定器。与常规的Kafka绑定器一样,Kafka Streams绑定器也关注开发人员的生产力,因此开发人员可以专注于为KStream、KTable、GlobalKTable等编写业务逻辑,而不是编写基础结构代码。绑定器负责连接到Kafka,以及创建、配置和维护流和主题。例如,如果应用程序方法具有KStream签名,则绑定器将连接到目标主题,并在后台从该主题生成流。应用程序开发人员不必显式地这样做,因为绑定器已经为应用程序提供了绑定。
其他类型(如KTable和GlobalKTable)也是如此。底层的KafkaStreams对象由绑定器提供,用于依赖注入,因此,应用程序不直接维护它。更确切地说,它是由春天的云流为你做的。
要使用Spring Cloud Stream开始Kafka流,请转到Spring Initializr并选择如下图所示的选项,以生成一个应用程序,该应用程序带有使用Spring Cloud Stream编写Kafka流应用程序的依赖项:

下面的例子展示了一个用Spring Cloud Stream编写的Kafka Streams应用程序:
@SpringBootApplication
public class KafkaStreamsTableJoin {@EnableBinding(StreamTableProcessor.class)
public static class KStreamToTableJoinApplication {@StreamListener
@SendTo("output")
public KStream<String, Long> process(@Input("input1") KStream<String, Long> userClicksStream,
@Input("input2") KTable<String, String> userRegionsTable) {return userClicksStream
.leftJoin(userRegionsTable,
(clicks, region) -> new RegionWithClicks(region == null ? "UNKNOWN" : region, clicks),
Joined.with(Serdes.String(), Serdes.Long(), null))
.map((user, regionWithClicks) -> new KeyValue<>(regionWithClicks.getRegion(), regionWithClicks.getClicks()))
.groupByKey(Serialized.with(Serdes.String(), Serdes.Long()))
.reduce((firstClicks, secondClicks) -> firstClicks + secondClicks)
.toStream();
}
}interface StreamTableProcessor {
@Input("input1")
KStream inputStream();@Output("output")
KStreamoutputStream();@Input("input2")
KTable inputTable();
}
}
在前面的代码中有几件事情需要注意。在@StreamListener方法中,没有用于设置Kafka流组件的代码。应用程序不需要构建流拓扑,以便将KStream或KTable与Kafka主题关联起来,启动和停止流,等等。所有这些机制都是由Kafka流的Spring Cloud Stream binder处理的。在调用该方法时,已经创建了一个KStream和一个KTable供应用程序使用。
应用程序创建一个名为StreamTableProcessor的自定义接口,该接口指定用于输入和输出绑定的Kafka流类型。此接口与@EnableBinding一起使用。此接口的使用方式与我们在前面的处理器和接收器接口示例中使用的方式相同。与常规的Kafka绑定器类似,Kafka上的目的地也是通过使用Spring云流属性指定的。您可以为前面的应用程序提供这些配置选项来创建必要的流和表:
spring.cloud.stream.bindings.input1.destination=userClicksTopic spring.cloud.stream.bindings.input2.destination=userRegionsTopic spring.cloud-stream.bindings.output.destination=userClickRegionsTopic
我们使用两个Kafka主题来创建传入流:一个用于将消息消费为KStream,另一个用于消费为KTable。框架根据自定义接口StreamTableProcessor中提供的绑定适当地使用所需的类型。然后,这些类型将与方法签名配对,以便在应用程序代码中使用。在出站时,出站的KStream被发送到输出Kafka主题。
Kafka流中可查询的状态存储支持
Kafka流为编写有状态应用程序提供了第一类原语。当使用Spring Cloud Stream和Kafka流构建有状态应用程序时,就有可能使用RESTful应用程序从RocksDB的持久状态存储中提取信息。下面是一个Spring REST应用程序的例子,它依赖于Kafka流中的状态存储:
@RestController
public class FooController {private final Log logger = LogFactory.getLog(getClass());
@Autowired
private InteractiveQueryService interactiveQueryService;@RequestMapping("/song/id")
public SongBean song(@RequestParam(value="id") Long id) {final ReadOnlyKeyValueStore<Long, Song> songStore =
interactiveQueryService.getQueryableStore(“STORE-NAME”,
QueryableStoreTypes.<Long, Song>keyValueStore());final Song song = songStore.get(id);
if (song == null) {
throw new IllegalArgumentException("Song not found.");
}
return new SongBean(song.getArtist(), song.getAlbum(), song.getName());
}
}
InteractiveQueryService是Apache Kafka Streams绑定器提供的一个API,应用程序可以使用它从状态存储中检索数据。应用程序可以使用此服务按名称查询状态存储,而不是直接通过底层流基础设施访问状态存储。当Kafka Streams应用程序的多个实例运行时,该服务还提供了用户友好的方式来访问服务器主机信息,这些实例之间有分区。
通常在这种情况下,应用程序必须通过直接访问Kafka Streams API来找到密钥所在的分区所在的主机。InteractiveQueryService提供了这些API方法的包装器。一旦应用程序获得了对状态存储的访问权,它就可以通过查询来形成进一步的见解。最终,可以通过上面所示的REST端点来提供这些见解。您可以在GitHub上找到一个使用Spring Cloud Stream编写的Kafka Streams应用程序的示例,在这个示例中,它使用本节中提到的特性来适应Kafka音乐示例。
Branching in Kafka Streams
通过使用SendTo注释,可以在Spring Cloud流中原生地使用Kafka流的分支特性。
@StreamListener("input")
@SendTo({“englishTopic”, “frenchTopic”, “spanishTopic”})
public KStream<?, WordCount>[] process(KStream<Object, String> input) {Predicate<Object, WordCount> isEnglish = (k, v) -> v.word.equals("english");
Predicate<Object, WordCount> isFrench = (k, v) -> v.word.equals("french");
Predicate<Object, WordCount> isSpanish = (k, v) -> v.word.equals("spanish");return input
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.groupBy((key, value) -> value)
.windowedBy(timeWindows)
.count(Materialized.as("WordCounts-1"))
.toStream()
.map((key, value) -> new KeyValue<>(null, new WordCount(key.key(), value, new Date(key.window().start()), new Date(key.window().end()))))
.branch(isEnglish, isFrench, isSpanish);
}
注意,SendTo注释有三个不同输出的绑定,方法本身返回一个KStream[]。Spring Cloud Stream在内部将分支发送到输出绑定到的Kafka主题。观察SendTo注释中指定的输出顺序。这些输出绑定将与输出的KStream[]按其在数组中的顺序配对。
数组的第一个索引中的第一个KStream可以映射到englishTopic,然后将下一个映射到frenchTopic,以此类推。这里的想法是,应用程序可以专注于功能方面的事情,并使用Spring Cloud Stream设置所有这些输出流,否则开发人员将不得不为每个流单独做这些工作。
Spring cloud stream中的错误处理
Spring Cloud Stream提供了错误处理机制来处理失败的消息。它们可以被发送到死信队列(DLQ),这是Spring Cloud Stream创建的一个特殊的Kafka主题。当失败的记录被发送到DLQ时,头信息被添加到记录中,其中包含关于失败的更多信息,如异常堆栈跟踪、消息等。
发送到DLQ是可选的,框架提供各种配置选项来定制它。
对于Spring Cloud Stream中的Kafka Streams应用程序,错误处理主要集中在反序列化错误上。Apache Kafka Streams绑定器提供了使用Kafka Streams提供的反序列化处理程序的能力。它还提供了在主流继续处理时将失败的记录发送到DLQ的能力。当应用程序需要返回来访问错误记录时,这是非常有用的。
模式演化和Confluent 模式注册
Spring Cloud Stream支持模式演化,它提供了与Confluent模式注册中心以及Spring Cloud Stream提供的本地模式注册中心服务器一起工作的功能。应用程序通过在应用程序级别上包含@EnableSchemaRegistryClient注释来启用模式注册表。Spring Cloud Stream提供了各种基于Avro的消息转换器,可以方便地与模式演化一起使用。在使用Confluent模式注册表时,Spring Cloud Stream提供了一个应用程序需要作为SchemaRegistryClient bean提供的特殊客户端实现(ConfluentSchemaRegistryClient)。
结论
Spring Cloud Stream通过自动处理其他同等重要的非功能需求(如供应、自动内容转换、错误处理、配置管理、用户组、分区、监视、健康检查等),使应用程序开发人员更容易关注业务逻辑,从而提高了使用Apache Kafka的生产率。
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】或者关注【首席架构师智库】
- 161 次浏览
【首席架构师看Event Hub】如何在您的Spring启动应用程序中使用Apache Kafka
在体系结构规划期间选择正确的消息传递系统始终是一个挑战,但这是需要确定的最重要的考虑因素之一。作为一名开发人员,我每天都要编写需要服务大量用户并实时处理大量数据的应用程序。
通常,我将Java与Spring框架(Spring Boot、Spring数据、Spring云、Spring缓存等)一起使用。Spring Boot是一个框架,它允许我比以前更快更轻松地完成开发过程。它已在我的组织中发挥了关键作用。随着用户数量的快速增长,我们意识到我们显然需要每秒处理1,000,000个事件。
当我们发现Apache Kafka®时,我们发现它满足了我们的需求,可以快速处理数百万条消息。这就是为什么我们决定尝试一下。从那一刻起,卡夫卡就成了我口袋里的重要工具。你会问,我为什么选择它?
Apache Kafka是:
- 可伸缩的
- 容错
- 一个很棒的发布-订阅消息传递系统
- 与大多数消息传递系统相比,具有更高的吞吐量
- 高度耐用
- 高度可靠
- 高的性能
这就是为什么我决定在我的项目中使用它。根据我的经验,我在这里提供了一个循序渐进的指南,介绍如何在Spring启动应用程序中包含Apache Kafka,以便您也可以开始利用它的优点。
先决条件
- 本文要求您拥有Confluent平台
- 手动安装使用ZIP和TAR档案
- 下载
- 解压缩它
- 按照逐步说明,您将在本地环境中启动和运行Kafka
我建议在您的开发中使用Confluent CLI来启动和运行Apache Kafka和流平台的其他组件。
你会从这本指南中得到什么
阅读完本指南后,您将拥有一个Spring Boot应用程序,其中包含一个Kafka生成器,用于向您的Kafka主题发布消息,以及一个Kafka使用者,用于读取这些消息。
好了,让我们开始吧!
表的内容
- 步骤1:生成项目
- 步骤2:发布/读取来自Kafka主题的消息
- 步骤3:通过应用程序配置Kafka。yml配置文件
- 步骤4:创建一个生产者
- 第五步:创造一个消费者
- 步骤6:创建一个REST控制器
步骤1:生成项目
首先,让我们使用Spring Initializr来生成我们的项目。我们的项目将有Spring MVC/web支持和Apache Kafka支持。

一旦你解压缩了这个项目,你将会有一个非常简单的结构。我将在本文的最后向您展示项目的外观,以便您能够轻松地遵循相同的结构。我将使用Intellij IDEA,但是你可以使用任何Java IDE。
步骤2:发布/读取来自Kafka主题的消息
现在,你可以看到它是什么样的。让我们继续讨论来自Kafka主题的发布/阅读消息。
首先创建一个简单的Java类,我们将使用它作为示例:package com.demo.models;
public class User {
private String name;
private int age;public User(String name, int age) {
this.name = name;
this.age = age;
}
}

步骤3:通过应用程序配置Kafka.yml配置文件
接下来,我们需要创建配置文件。我们需要以某种方式配置我们的Kafka生产者和消费者,使他们能够发布和从主题读取消息。我们可以使用任意一个应用程序,而不是创建一个Java类,并用@Configuration注释标记它。属性文件或application.yml。Spring Boot允许我们避免过去编写的所有样板代码,并为我们提供了更智能的配置应用程序的方法,如下所示:
server: port: 9000
spring:
kafka:
consumer:
bootstrap-servers: localhost:9092
group-id: group_id
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
bootstrap-servers: localhost:9092
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
如果您想了解更多关于Spring引导自动配置的信息,可以阅读这篇简短而有用的文章。有关可用配置属性的完整列表,请参阅官方文档。
步骤4:创建一个生产者
创建生产者将把我们的消息写入主题。
@Service
public class Producer {private static final Logger logger = LoggerFactory.getLogger(Producer.class);
private static final String TOPIC = "users";@Autowired
private KafkaTemplate<String, String> kafkaTemplate;public void sendMessage(String message) {
logger.info(String.format("#### -> Producing message -> %s", message));
this.kafkaTemplate.send(TOPIC, message);
}
}
我们只是自动连接KafkaTemplate,并将使用此实例发布消息到主题——这就是生产者!
第五步:创造一个消费者
Consumer是负责根据您自己的业务逻辑的需要读取消息并对其进行处理的服务。要设置它,请输入以下内容:
@Service
public class Consumer {private final Logger logger = LoggerFactory.getLogger(Producer.class);
@KafkaListener(topics = "users", groupId = "group_id")
public void consume(String message) throws IOException {
logger.info(String.format("#### -> Consumed message -> %s", message));
}
}
在这里,我们告诉我们的方法void consumption (String message)订阅用户的主题,并将每个消息发送到应用程序日志。在实际的应用程序中,可以按照业务需要的方式处理消息。
步骤6:创建一个REST控制器
如果我们已经有了一个消费者,那么我们就已经拥有了消费Kafka消息所需的一切。
为了完整地显示我们创建的所有内容是如何工作的,我们需要创建一个具有单个端点的控制器。消息将被发布到这个端点,然后由我们的生产者进行处理。
然后,我们的使用者将以登录到控制台的方式捕获和处理它。
@RestController
@RequestMapping(value = "/kafka")
public class KafkaController {private final Producer producer;
@Autowired
KafkaController(Producer producer) {
this.producer = producer;
}@PostMapping(value = "/publish")
public void sendMessageToKafkaTopic(@RequestParam("message") String message) {
this.producer.sendMessage(message);
}
}
让我们用cURL把信息发送给Kafka:
curl -X POST -F 'message=test' http://localhost:9000/kafka/publish

基本上,这是它!在不到10个步骤中,您就了解了将Apache Kafka添加到Spring启动项目是多么容易。如果您遵循了这个指南,您现在就知道如何将Kafka集成到您的Spring Boot项目中,并且您已经准备好使用这个超级工具了!
对更感兴趣吗?
如果您想了解更多信息,可以下载Confluent平台,这是Apache Kafka的领先发行版。您还可以在GitHub上找到本文中的所有代码。
这是Igor Kosandyak的一篇客座文章,他是Oril的一名Java软件工程师,在各个开发领域都有丰富的经验。
原文:https://www.confluent.io/blog/apache-kafka-spring-boot-application
本文:https://pub.intelligentx.net/how-work-apache-kafka-your-spring-boot-application
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 75 次浏览
【首席架构师看事件流架构】 Kafka深挖第3部分:Apache Kafka和Spring Cloud data Flow
后第1部分和第2部分的弹簧为Apache卡夫卡深潜水的博客系列,在第3部分中我们将讨论另一个项目从春天团队:春云数据流,其重点是使开发人员能够轻松地开发、部署和协调事件流管道基于Apache卡夫卡®。作为前一篇博客系列文章的延续,本文解释了Spring Cloud数据流如何帮助您提高开发人员的工作效率并管理基于apache - kafka的事件流应用程序开发。
我们将在这篇文章中讨论以下内容:
- Spring云数据流生态系统概述
- 如何使用Spring云数据流来开发、部署和编排事件流管道和应用程序
Spring Cloud Data Flow生态系统
Spring Cloud Data Flow是一个用于设计、开发和持续交付数据管道的工具包。它支持从设计到生产部署的事件流应用程序开发的集中管理。在Spring Cloud数据流中,数据管道可以是事件流(实时长时间运行)或任务/批处理(短期)数据密集型应用程序的组合。与Spring Cloud数据流交互的方式多种多样:
- 仪表板GUI
- 命令行Shell
- 流Java DSL(领域特定语言)
- 通过curl的RESTful api,等等。
为了将事件流管道部署到Cloud Foundry (CF)和Kubernetes (K8s)等平台,Spring Cloud数据流将应用程序生命周期操作(部署、更新、回滚)委托给另一个名为Spring Cloud Skipper的服务器组件。虽然事件流管道部署由Spring Cloud Skipper处理,但将短时间(任务/批处理)数据管道部署到目标平台则由Spring Cloud数据流本身管理。
Spring Cloud数据流和Spring Cloud Skipper运行时都配置为通过OAuth 2.0和OpenID连接提供身份验证和授权。Spring Cloud Data Flow使用基于微米的集成来帮助监视事件流应用程序,并提供Grafana仪表板,您可以安装和定制它。
开发事件流应用程序
在Spring Cloud Data Flow中,事件流管道通常由Spring Cloud Stream应用程序组成,不过任何定制构建的应用程序都可以安装在管道中。开发人员可以直接使用或扩展任何开箱即用的实用程序事件流应用程序来覆盖常见的用例,或者使用Spring Cloud Stream编写自定义应用程序。
所有开箱即用的事件流应用程序是:
- 可作为Apache Maven构件或Docker映像使用
- 使用RabbitMQ或Apache Kafka Spring云流绑定器构建
- 内置 Prometheus和InfluxDB 监测系统
开箱即用的应用程序与Kafka Connect应用程序类似,不同之处是它们使用Spring Cloud Stream框架进行集成和调试。
为了构建一个事件流管道,Spring Cloud数据流提供了一组应用程序类型:
- 源表示数据管道中的第一步,它是一个生产者,从数据库、文件系统、FTP服务器、物联网设备等外部系统中提取数据。
- 处理器表示可以从上游生产者(源或处理器)消费的应用程序,对消费的数据执行业务操作,并将处理后的数据发出供下游消费
- sink表示数据管道的最后一个阶段,它可以将消耗的数据写入外部系统,如Cassandra、PostgreSQL、Amazon S3等。
需要注意的是,在Spring Cloud数据流中,事件流数据管道默认是线性的。这意味着管道中的每个应用程序使用单个目的地(例如Kafka主题)与另一个应用程序通信,数据从生产者线性地流向消费者。然而,在某些用例中,流管道是非线性的,并且可以有多个输入和输出——这是Kafka Streams应用程序的典型设置。
在事件流数据管道中也可以有非spring - cloud - stream应用程序(Kafka连接应用程序、Polygot应用程序等)。
Spring Cloud Data Flow使用流应用程序DSL支持这些情况,并使用应用程序类型app突出显示这些应用程序。

上面的可视化演示了一个由两个应用程序组成的事件流管道,其中可以使用Spring Cloud数据流部署http和jdbc。这两个应用程序都是使用Spring Cloud Stream框架构建的,我们在第2部分中介绍了这个框架,它们都可以在公共Maven存储库/Docker Hub中使用。管道符号|(即。在流DSL中表示一个事件流平台,如Apache Kafka,配置为事件流应用程序的通信。
事件流平台或消息传递中间件提供了流的生产者http源和消费者jdbc接收器应用程序之间的松散耦合。这种松散耦合对于云本地部署模型至关重要,因为管道内的应用程序可以独立地发展、扩展或执行滚动升级,而不会影响上游生产者或下游消费者。当Spring Cloud数据流将Apache Kafka用于事件流应用程序时,它与流媒体平台上的各种产品产生了良好的共鸣。
Spring Cloud data flow环境设置
Spring Cloud Data Flow网站已经开始为本地、Kubernetes和Cloud Foundry提供指南。对于本博客,让我们使用Docker在本地运行这个设置。首先,您需要从Spring Cloud数据流GitHub repo下载Docker撰写文件。
这个Docker的撰写配置有:
- Apache Kafka
- Spring Cloud Data Flow server
- Spring Cloud Skipper server
- Prometheus (application metrics and monitoring)
- Grafana (data visualization)
- Automatic registration of out-of-the-box event streaming applications
由于以上所有组件将与事件流应用程序一起在我们的Docker环境中运行,请确保为您的Docker设置分配最少6GB的空间。
接下来,安装docker-compose并运行以下命令:
export DATAFLOW_VERSION=2.1.0.RELEASE
export SKIPPER_VERSION=2.0.2.RELEASE
docker-compose up
启动所有组件后,可以通过http://localhost:9393/dashboard访问Spring Cloud Data flow仪表板,并注册以下开箱即用的事件流应用程序:

创建事件流管道
让我们使用上一篇博客文章中介绍的相同的大写处理器和日志接收应用程序在Spring Cloud数据流中创建一个事件管道。使用这些应用程序,让我们创建一个简单的流http-events-transformer,如下所示:

- http源侦听http web端点以获取传入数据,并将它们发布到Kafka主题。
- 转换处理器使用来自Kafka主题的事件,其中http源发布步骤1中的数据。然后应用转换逻辑—将传入的有效负载转换为大写,并将处理后的数据发布到另一个Kafka主题。
- 日志接收器使用第2步中转换处理器的输出Kafka主题中的事件,它的职责只是在日志中显示结果。
Spring Cloud数据流中的流DSL语法应该是这样的:
http | transform | log
在Spring Cloud数据流仪表板的“Streams”页面中,您可以创建一个新的流,如下所示。
输入以下流DSL文本:
http-events-transformer=http --server.port=9000 | transform --expression=payload.toUpperCase() | log

当部署流时,有两种类型的属性可以被覆盖:
- 应用程序级属性,这是Spring云流应用程序的配置属性
- 部署目标平台的属性,如本地、Kubernetes或Cloud Foundry
在Spring Cloud Data Flow dashboard的“Streams”页面中,选择stream http-events-transformer,然后单击“deploy”。
在部署流时,请确保将平台选择为本地平台,以便在本地环境中部署流。将日志应用程序的本地平台部署者属性inheritLogging设置为true(如下面的屏幕截图所示),这样可以将日志应用程序的日志文件复制到Spring Cloud Skipper服务器日志中。将应用程序日志放在Skipper服务器日志下可以简化演示。

在部署流时,将检索各个应用程序的http、转换和日志,并将每个应用程序的部署请求发送到目标平台(即、本地、Kubernetes和CloudFoundry)的数据流。同样,当应用程序引导时,以下Kafka主题由Spring Cloud Stream框架自动创建,这就是这些应用程序如何在运行时作为连贯的事件流管道组合在一起。
- http-events-transformer.http(将http源的输出连接到转换处理器的输入的主题)
- http-events-transformer.transform(将转换处理器的输出连接到日志接收器的输入的主题)
Kafka主题名是由Spring云数据流根据流和应用程序命名约定派生的。您可以通过使用适当的Spring云流绑定属性来覆盖这些名称。
要查看所有的运行时流应用程序,请参阅“运行时”页面:

成功部署流之后,HTTP应用程序就可以接收http://localhost:9000上的数据了。让我们发布一些测试数据到http web端点:
curl -X POST http://localhost:9000 -d "spring" -H "Content-Type: text/plain"
因为我们继承了日志应用的日志,所以Spring Cloud Skipper server日志中日志应用的输出可以看作:
log-sink : SPRING
调试流应用程序
您可以在运行时调试部署的应用程序。调试配置根据目标平台而异。请参阅在本地、Kubernetes和Cloud Foundry目标环境中调试部署的应用程序的文档。要在本地开发环境中调试应用程序,只需传递本地部署器属性debugPort即可。
监控事件流应用程序
对于当前的设置,我们使用基于prometheus的应用程序监控,并在缺省情况下使用admin/admin设置一个Grafana仪表板。
通过从Spring Cloud数据流仪表板的“Streams”页面单击事件流http-events-transformer的“Grafana dashboard”图标,可以从Grafana仪表板监视事件流部署。

审计用户操作
Spring Cloud Data Flow server涉及的所有操作都经过审计,审计记录可以从Spring Cloud Data Flow dashboard中的“审计记录”页面访问。

您可以通过单击“Streams”页面中http-events-transformer的Destroy stream选项来删除流。
有关事件流应用程序开发和部署的详细信息,请参阅流开发人员指南。
使用Kafka Streams应用程序开发事件流管道
当您有一个使用Kafka Streams应用程序的事件流管道时,它们可以在Spring Cloud数据流事件流管道中用作处理器应用程序。在下面的示例中,您将看到如何将Kafka Streams应用程序注册为Spring Cloud数据流处理器应用程序,并随后在事件流管道中使用。
本博客中使用的所有样例应用程序都可以在GitHub上找到。应用程序kstreams-word-count是一个Kafka Streams应用程序,它使用Spring Cloud Stream框架来计算给定时间窗口内输入的单词。该应用程序被构建并发布到Spring Maven repo中。
在Spring Cloud Data Flow“Apps”页面的“Add Application(s)”中,您可以通过选择其应用程序类型作为处理器来注册kstreams-word-count应用程序,以及其Maven URI:

让我们使用开箱即用的http源应用程序,它在http web端点http://localhost:9001处侦听传入的数据,并将使用的数据发布到上面步骤中注册的kstream-wordcount处理器。Kafka Streams处理器根据时间窗口计算字数,然后将其输出传播到开箱即用的日志应用程序,该应用程序将字数计数Kafka Streams处理器的结果记录下来。
从Spring Cloud数据流仪表板中的“Streams”页面,使用stream DSL创建一个流:

通过将平台指定为本地,从“Streams”页面部署kstream-wc-sample流。另外,指定部署程序属性local。将日志应用程序的继承日志记录设置为true。

当流成功部署后,所有http、kstream-word-count和log都作为分布式应用程序运行,通过事件流管道中配置的特定Kafka主题连接。
现在,你可以张贴一些字卡夫卡流的应用程序来处理:
curl -X POST http://localhost:9001 -H "Content-Type: text/plain" -d "Baby shark, doo doo doo doo doo doo"
你可以看到日志应用程序现在有以下:
skipper | 2019-03-25 09:53:37.228 INFO 66 --- [container-0-C-1] log-sink : {"word":"baby","count":1,"start":"2019-03-25T09:53:30.000+0000","end":"2019-03-25T09:54:00.000+0000"}
skipper | 2019-03-25 09:53:37.229 INFO 66 --- [container-0-C-1] log-sink : {"word":"shark","count":1,"start":"2019-03-25T09:53:30.000+0000","end":"2019-03-25T09:54:00.000+0000"}
skipper | 2019-03-25 09:53:37.234 INFO 66 --- [container-0-C-1] log-sink : {"word":"doo","count":6,"start":"2019-03-25T09:53:30.000+0000","end":"2019-03-25T09:54:00.000+0000"}
从上面的示例中,您可以看到Kafka Streams应用程序如何适应事件流数据管道。您还看到了如何在Spring Cloud数据流中管理这样的事件流管道。此时,您可以从kstream-wc-sample流页面取消部署并删除流。
结论
对于使用Apache Kafka的事件流应用程序开发人员和数据爱好者来说,本博客提供了Spring Cloud数据流如何帮助开发和部署具有所有基本特性的事件流应用程序,如易于开发和管理、监控和安全性。
Spring Cloud Data Flow提供了一系列工具和自动化来跨云原生平台部署和管理事件流管道。本系列的第4部分将提供通用的事件流拓扑和连续部署模式,作为Spring Cloud数据流中的事件流应用程序的原生集。请继续关注!
本文:https://pub.intelligentx.net/node/785
讨论:请加入知识星球或者小红圈【首席架构师圈】
知识星球:
- 123 次浏览