【NLP】2023年迄今为止最受欢迎的12个NLP项目
视频号

微信公众号

知识星球

自然语言处理仍然是2022年最热门的话题之一。通过使用GitHub明星(尽管肯定不是唯一的衡量标准)作为受欢迎程度的指标,我们了解了今年迄今为止哪些NLP项目最受欢迎,就像我们最近对机器学习项目所做的那样。这是一个有一些熟悉名字的列表,但也有很多惊喜!
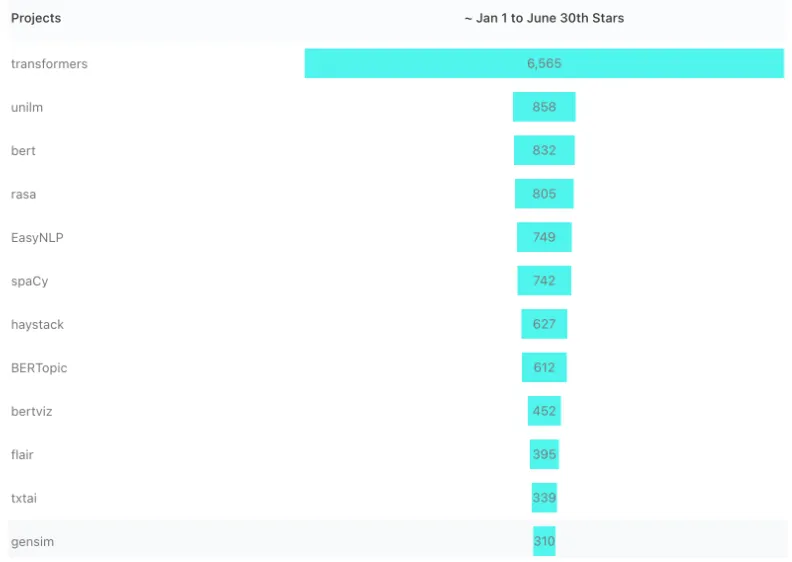
#1:Transformers:
Pytorch、TensorFlow和JAX的最先进机器学习
https://github.com/huggingface/transformers
从业者们喜欢变压器项目,自1月份以来,它有2154颗星,很容易成为我们的首选。该库提供了易于使用的、最先进的模型,这些模型已经扩展到NLP转换器之外,包括PyTorch、JAX和TensorFlow。为使用预训练模型提供统一的API,可以降低人工智能从业者在NLP理解和生成以及计算机视觉和音频任务中的进入门槛。
#2:UniLM
跨任务、语言和模式的大规模自我监督预培训
|https://github.com/microsoft/unilm
UniLM是由李东等人在一篇论文中提出的,并在一些顶级学术会议上发表,包括Neurips(19)、ICML(20)和ACL(21)。UniLM是一个统一的预训练语言模型(UniLM),可以针对自然语言理解和生成任务进行微调。使用三种类型的语言建模任务对模型进行预训练:单向、双向和序列到序列预测。它仍然是一个受欢迎和活跃的项目,最近添加了新的预训练模型,包括BEiT-3、SimLM、DiT、LayoutLMv3和MetaLM等。
#3:BERT
BERT的TensorFlow代码和预训练模型
https://github.com/google-research/bert
在2018年的一篇论文中提出,被引用超过46500次,你可能已经知道BERT及其在NLP革命中的变革作用。BERT的体系结构使其能够理解双向内容,从而在NER、语言理解、问答和其他一些通用NLP任务方面提供最先进的结果。在大规模语料库上预先训练(按照2018年的标准),它在今天的LLM(大型语言模型)空间中仍然非常流行。这并不是最活跃的项目,最近一次更新是在2020年3月,该项目增加了20多个较小的BERT模型。
两个流行的相关项目是BERTopic(Star Gain,612),用于利用BERT和c-TF-IDF创建易于解释的主题,以及BertViz(Star Gain,452),一个交互式工具,用于在诸如BERT、GPT2或T5的Transformer语言模型中可视化注意力。

#4:Rasa
用于对话管理的开源机器学习框架
https://github.com/RasaHQ/rasa
会话助手是NLP的一个顶级用例,Rasa是一个基于python的开源机器学习框架,用于在Twillo、Slack、MS Bot、Facebook Messenger等平台上实现基于文本和语音的助手自动化。Rasa模块包括处理自然语言理解的NLU和处理API并利用LSTM和强化学习等深度学习模型提供文本预测的Core。
#5:EasyNLP
全面易用的NLP工具包
https://github.com/alibaba/EasyNLP
今年6月刚刚发布的这个基于PyTorch的NLP项目很快吸引了一批追随者。EasyNLP最初由阿里巴巴于2021年构建,它提供了易于使用且简洁的命令来调用尖端模型,这些模型涵盖了许多常见NLP现实世界应用程序的NLP算法的广泛集合。它集成了知识提取和少量学习,用于着陆大型预训练模型,以及包括DKPLM和KGBERT在内的各种流行的多模态预训练模型。它是另一个统一的框架,包括模型训练、推理和部署。
#6:spaCy
Python中的工业实力自然语言处理
https://github.com/explosion/spaCy
spaCy是任何python开发人员最喜欢的库,是端到端NLP工作流的首选库。它不仅处理基本的NLP任务,如标记化、解析、NER、标记和文本分类,而且现在还包含了预训练的转换器模型,如BERT。开发ML管道是当今NLP系统的重要组成部分,spaCy训练管道将解析器、标记器、NER和引理器等各种组件编织在一起,以帮助实现NLP工作流的自动化。您可以通过替换、添加和删除各种组件来轻松地定制您的管道,以构建可扩展的生产级NLP。
#7:HayStack
利用预先训练的Transformer模型的开源NLP框架
https://github.com/deepset-ai/haystack
综上所述,Haystack是一个问答框架,根据其Github的描述,“Haystack是一个端到端的框架,使您能够为不同的搜索用例构建强大的、可用于生产的管道。无论您是想执行问答还是语义文档搜索,您都可以在Haystack中使用最先进的NLP模型来提供独特的搜索体验,并允许您的用户使用自然语言进行查询。Haystack以模块化的方式构建,因此您可以结合其他开源项目的最佳技术,如Huggingface的Transformers、Elasticsearch或Milvus。”
#8: Flair
最先进的自然语言处理的一个非常简单的框架
https://github.com/flairNLP/flair
另一个PyTorch和Python库Flair除了构建自己的模型外,还包括文本分类、预训练的名称实体识别和词性标记。Fliar的与众不同之处在于其简单的API,它封装了BERT、ELMo和其他流行的模型。Flair序列标记模型,如NER和词性标记等,现在托管在HuggingFace模型中心上。Flair类似于spaCy,但可能有更好的语言支持,根据使用情况,Flair可能更适合
#9:Txtai
构建人工智能支持的语义搜索应用程序
|https://github.com/neuml/txtai
由于性能的提高,语义搜索正在加快其进入ML工作流的速度,开源项目正在引领这一潮流。Txtai擅长使用向量来识别不同关键字中具有相同含义的搜索结果。基于HuggingFace Transformers和FastAPI的构建不仅提供了模型培训,还提供了工作流和管道,其中包括问题解答、零样本标记、机器翻译、语言检测和文本音频文件等。其他Txtai用例包括文本标记、图像搜索、文章汇总数据和实体提取。

#10:Gensim
面向人类的主题建模
https://github.com/RaRe-Technologies/gensim
近年来,主题建模已经从简单的文档中类似作品的提取和分组扩展到更强大的技术。十多年来,Gensim是NLP项目中最受欢迎的基于Python的无监督主题建模库之一。关键功能包括轻松添加自己的语料库的能力,以及流行主题建模算法的广泛实现,包括在线word2vec深度学习、潜在狄利克雷分配(LDA)、随机投影(RP)、分层狄利克雷过程(HDP)等。由于其许多算法的多核实现,它具有可扩展性,并且可以快速轻松地处理大量文档
#11:NLTK
自然语言工具包
如果不提及目前为3.10版的NLTK,就没有完整的NLP项目和工具包清单。这个扩展的Python工具包还包括支持研究和开发的数据集和教程。NLKT通常与spaCy相比,并被标记为研究工具而非生产工具,它确实提供了对NLP任务的更直接的访问(更少的抽象)。由于其全面的基本NLP任务库,它无疑是初学者的首选库。
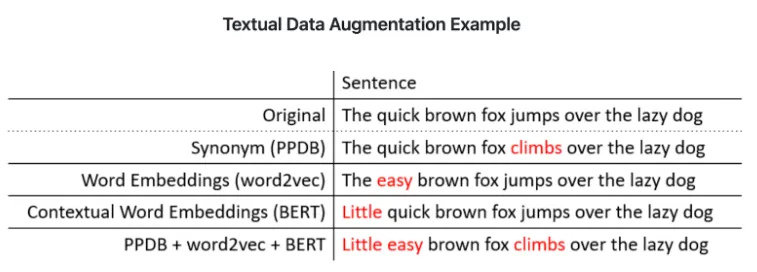
#12:nlpaug
NLP的数据扩充
https://github.com/makcedward/nlpaug
由于大型语言模型(LLM)和NLP的其他趋势,数据扩充和合成数据生成正在获得更多的关注,但对于许多人工智能从业者来说,这仍然是相对较新的领域,当然也是新的技术。数据扩充的目标是在不增加数据收集的情况下增加训练数据的多样性。nlpaug是一个python库,可以帮助您为机器学习项目增强NLP。该库包括两个关键模块:增广器,这是增广的基本元素,而Flow是将多个增广器编排在一起的管道。该库可以在几行代码中生成合成数据,并与其他流行的框架(包括Tensorflow、PyTorch和sci kit-learn)配合良好。
在ODSC West 2022了解更多关于NLP和NLP项目的信息
关于这些趋势NLP项目,如何使用NLP,以及如何在业务中实现NLP,有很多东西需要学习。通过今年11月1日至3日参加ODSC West 2022,并查看NLP Track,您可以通过专家主导的讲座、培训课程和研讨会了解如何做到这一切。这里有一些你可以参加的会议。
- Self-Supervised and Unsupervised Learning for Conversational AI and NLP
- Building Modern Search Pipelines with Haystack, Large Language Models, and Hybrid Retrieval
- Bagging to BERT — A Tour of Applied NLP
- Applications of NLP in Retail/E-commerce
- Hyper-productive NLP with Hugging Face Transformers
- The Next Thousand Languages
- Transforming The Retail Industry with Transformers
- 989 次浏览