【软件工程】软件工程|耦合与内聚
视频号

微信公众号

知识星球

Chinese, Simplified
简介:软件开发生命周期中设计阶段的目的是为SRS(软件需求规范)文档中给出的问题提供解决方案。设计阶段的输出是软件设计文档(SDD)。
耦合和内聚是软件工程中用来衡量软件系统设计质量的两个关键概念。
- 耦合是指软件模块之间的相互依赖程度。高耦合意味着模块紧密连接,一个模块中的变化可能会影响其他模块。低耦合意味着模块是独立的,一个模块中的变化对其他模块的影响很小。
- 内聚性是指模块中的元素协同工作以实现单一、明确定义的目的的程度。高内聚性意味着要素密切相关并专注于单一目的,而低内聚性则意味着要素松散相关并服务于多个目的。
- 耦合和内聚是决定软件系统可维护性、可扩展性和可靠性的重要因素。高耦合和低内聚性会使系统难以更改和测试,而低耦合和高内聚性则使系统更容易维护和改进。
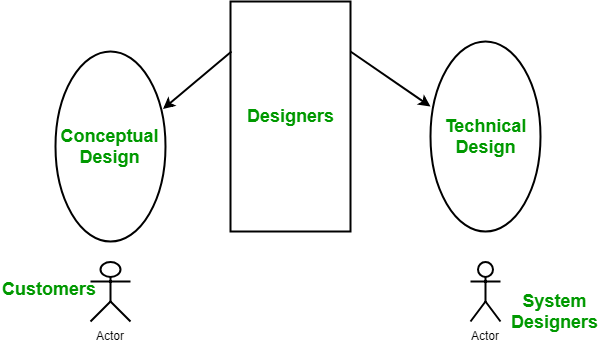
基本上,设计是一个由两部分组成的迭代过程。第一部分是概念设计,告诉客户系统将做什么。第二部分是技术设计,让系统建设者了解解决客户问题所需的实际硬件和软件。
耦合和高内聚
系统概念设计:
- 用简单的语言书写,即客户可以理解的语言。
- 关于系统特性的详细说明。
- 描述系统的功能。
- 它独立于实施。
- 与需求文档链接。
系统技术设计:
- 硬件组件和设计。
- 软件组件的功能和层次结构。
- 软件体系结构
- 网络架构
- 数据结构和数据流。
- 系统的I/O组件。
- 显示界面。
模块化:
模块化是将软件系统划分为多个独立模块的过程,每个模块独立工作。模块化在软件工程中有许多优点。其中一些如下所示:
- 易于理解系统。
- 系统维护很容易。
- 一个模块可以根据其需求多次使用。不需要一遍又一遍地写。
耦合:
耦合是衡量模块之间相互依存程度的指标。一个好的软件将具有低耦合。
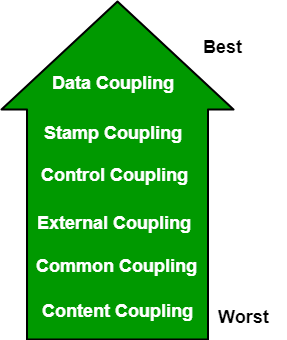
耦合类型:
- 数据耦合:如果模块之间的依赖关系是基于它们只通过传递数据进行通信的事实,那么这些模块就被认为是数据耦合的。在数据耦合中,组件相互独立,并通过数据进行通信。模块通信不包含不定期数据。客户计费系统示例。
- 印记耦合(Stamp Coupling)。在印记耦合中,完整的数据结构从一个模块传递到另一个模块。因此,它涉及不定期数据。由于效率因素,这可能是必要的——这个选择是由富有洞察力的设计师做出的,而不是懒惰的程序员。
- 控制耦合:如果模块通过传递控制信息进行通信,则称其为控制耦合。如果参数指示完全不同的行为,这可能是坏的,而如果参数允许功能的分解和重用,这是好的。示例-将比较函数作为参数的排序函数。
- 外部耦合:在外部耦合中,模块依赖于正在开发的软件或特定类型硬件外部的其他模块。Ex-协议、外部文件、设备格式等。
- 公共耦合:模块具有共享数据,如全局数据结构。全局数据的变化意味着要追溯到访问该数据的所有模块,以评估变化的影响。因此,它存在模块重用困难、数据访问控制能力降低、可维护性降低等缺点。
- 内容耦合:在内容耦合中,一个模块可以修改另一个模块的数据,或者控制流从一个模块传递到另一个。这是最糟糕的耦合形式,应该避免。
- 时间耦合:当两个模块取决于事件的时间或顺序时,就会发生时间耦合,例如一个模块需要在另一个模块之前执行。这种类型的耦合可能会导致设计问题以及测试和维护方面的困难。
- 顺序耦合:当一个模块的输出用作另一个模块输入时,会发生顺序耦合,从而创建依赖关系链或序列。这种类型的联轴器可能难以维护和修改。
- 通信耦合:当两个或多个模块共享一个公共通信机制(如共享消息队列或数据库)时,就会发生通信耦合。这种类型的耦合可能会导致性能问题和调试困难。
- 功能耦合:当两个模块依赖于彼此的功能时,就会发生功能耦合,例如一个模块从另一个模块调用函数。这种类型的耦合可能导致难以修改和维护的紧密耦合代码。
- 数据结构耦合:当两个或多个模块共享一个公共数据结构(如数据库表或数据文件)时,会发生数据结构耦合。这种类型的耦合可能导致难以维护数据结构的完整性,并可能导致性能问题。
内聚性:
内聚性是衡量模块元素在功能上相关程度的指标。它是指向执行单个任务的所有元素都包含在组件中的程度。基本上,内聚性是将模块保持在一起的内部粘合剂。一个好的软件设计将具有很高的内聚性。
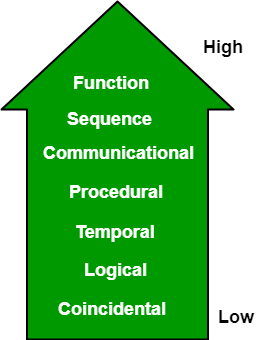
内聚类型:
- 函数内聚:单个计算的每个基本元素都包含在组件中。功能衔接执行任务和功能。这是一个理想的情况。
- 顺序衔接:一个元素输出一些数据,这些数据成为另一个元素的输入,即各部分之间的数据流。它自然地出现在函数式编程语言中。
- 通讯衔接:两个元素对相同的输入数据进行操作或对相同的输出数据做出贡献。示例-更新数据库中的记录并将其发送到打印机。
- 过程衔接:程序衔接的要素保证了执行的秩序。操作仍然是弱连接的,不太可能被重用。例如计算学生平均成绩,打印学生记录,计算累计平均成绩,印刷累计平均成绩。
- 时间衔接:这些元素因其所涉及的时间而相关。一个与时间衔接相连的模块,所有任务都必须在同一时间段内执行。这种衔接包含用于初始化系统所有部分的代码。在单位时间内会发生许多不同的活动。
- 逻辑衔接:这些元素在逻辑上是相关的,而不是功能性的。Ex-一个组件从磁带、磁盘和网络读取输入。这些函数的所有代码都在同一个组件中。操作是相关的,但功能明显不同。
- 巧合衔接:元素不相关(不相关)。除了源代码中的位置之外,这些元素没有其他概念关系。这是偶然的,也是最糟糕的凝聚力。Ex-打印下一行,并反转单个组件中字符串的字符。
- ----------------------------------
- 过程衔接:当元素或任务根据其执行顺序在模块中分组时,就会发生这种衔接,例如按特定顺序执行一组相关过程的模块。过程衔接可以在结构化编程语言中找到。
- 交际衔接:当元素或任务根据彼此之间的互动被分组到一个模块中时,就会发生交际衔接,例如处理与特定外部系统或模块的所有互动的模块。这种类型的内聚可以在面向对象的编程语言中找到。
- 时间衔接:当元素或任务根据执行的时间或频率在一个模块中分组时,就会发生时间衔接,例如处理系统中所有周期性或计划任务的模块。时间内聚通常用于实时和嵌入式系统。
- 信息衔接:当元素或任务根据它们与特定数据结构或对象的关系(例如对特定数据类型或对象进行操作的模块)在模块中分组时,就会发生信息衔接。信息内聚通常用于面向对象编程。
- 功能衔接:当一个模块中的所有元素或任务都为一个定义明确的功能或目的做出贡献,并且元素之间几乎没有耦合时,就会发生这种类型的衔接。函数内聚被认为是最理想的内聚类型,因为它可以产生更可维护和可重用的代码。
- 层内聚:当模块中的元素或任务根据其抽象级别或职责分组在一起时,就会发生层内聚,例如只处理低级硬件交互的模块或只处理高级业务逻辑的模块。层内聚通常用于大型软件系统,将代码组织成可管理的层。
低耦合的优点:
- 提高了可维护性:低耦合减少了一个模块中的更改对其他模块的影响,使修改或更换单个组件变得更容易,而不会影响整个系统。
- 增强的模块性:低耦合允许隔离开发和测试模块,提高了代码的模块性和可重用性。
- 更好的可扩展性:低耦合便于添加新模块和删除现有模块,从而更容易根据需要扩展系统。
高内聚力的优点:
- 提高了可读性和可理解性:高内聚性产生了具有单一、明确目的的清晰、集中的模块,使开发人员更容易理解代码并进行更改。
- 更好的错误隔离:高内聚性降低了模块某个部分的更改影响其他部分的可能性,使
- 隔离并修复错误。提高了可靠性:高内聚性导致模块不太容易出错,并且功能更一致,
- 从而导致系统的可靠性的整体提高。
高耦合的缺点:
- 复杂性增加:高度耦合增加了模块之间的相互依赖性,使系统更加复杂和难以理解。
- 灵活性降低:高度耦合使得在不影响整个系统的情况下修改或更换单个组件变得更加困难。
- 模块性降低:高耦合性使得隔离开发和测试模块变得更加困难,降低了代码的模块性和可重用性。
内聚力低的缺点:
- 代码重复增加:内聚性低可能导致代码重复,因为属于一起的元素被拆分为单独的模块。
- 功能减少:低内聚性可能导致模块缺乏明确的目的,并且包含不属于一起的元素,从而减少其功能并使其更难维护。
- 理解模块的困难:低内聚性会使开发人员更难理解模块的目的和行为,从而导致错误和缺乏清晰度。
本文地址
https://architect.pub/software-engineering-coupling-and-cohesion
- 336 次浏览
SEO Title
Software Engineering | Coupling and Cohesion