【隐私保护】教程:在数据仓库中扫描个人身份信息(PII)的两种方法
视频号

微信公众号

知识星球

实现数据隐私和保护的重要一步是在数据仓库中查找和编目敏感的PII或PHI数据。像Datahub和Amundsen这样的开源数据目录可以对仓库中的信息进行编目,但缺乏扫描、检测和标记包含此类敏感信息的表或列的框架。
这篇文章描述了扫描和检测PII的两种策略,介绍了开源项目PIICatcher,这是一种隔离存储在数据仓库中的信息的工具。
什么是个人身份信息(PII)?
PII或个人身份信息是指能够识别特定个人的任何信息。传统的PII示例包括电子邮件地址、社会安全号码、个人文档ID和金融账户信息。随着技术的发展,PII现在扩展到登录ID、IP地址、地理位置和生物识别。
PII分为两种类型:
- 敏感:与您的身份直接相关的任何数据(信用卡信息、护照号码、SSN、法定姓名)
- 非敏感:可以识别个人身份并可能从互联网上获得的任何数据(地址、种族、IP地址)
世界各地的合规法律对PII的构成有类似的定义:
通用数据保护条例(GDPR)(欧盟):PII是任何有助于识别个人的数据。一些传统上被视为个人身份信息的例子包括英国的国家保险号码、您的邮寄地址、电子邮件地址和电话号码加州消费者保护法(CCPA)(美国):CCPA对“个人信息”或PI有广泛的定义,将其称为“直接或间接识别、涉及、描述、能够与特定消费者或家庭相关或可能合理联系的信息。”其他合规法,包括PDPA(新加坡和泰国)、PIPL(中国)和CPPA(加拿大),也以类似方式提及PII。
除了这些一般定义之外,企业可能会为其独特的需求收集特定的PII数据。例如,医疗保健行业的公司收集个人健康信息(PHI),而银行账户或加密货币钱包ID与金融行业相关。无论行业如何,任何组织都需要管理一个基本的PII:
- 电话
- 电子邮件
- 信用卡
- 住址
- 人员/姓名
- 地方
- 日期
- 性别
- 国籍
- IP地址
- SSN(序列号)
- 用户名
- 密码
PII扫描面临的挑战
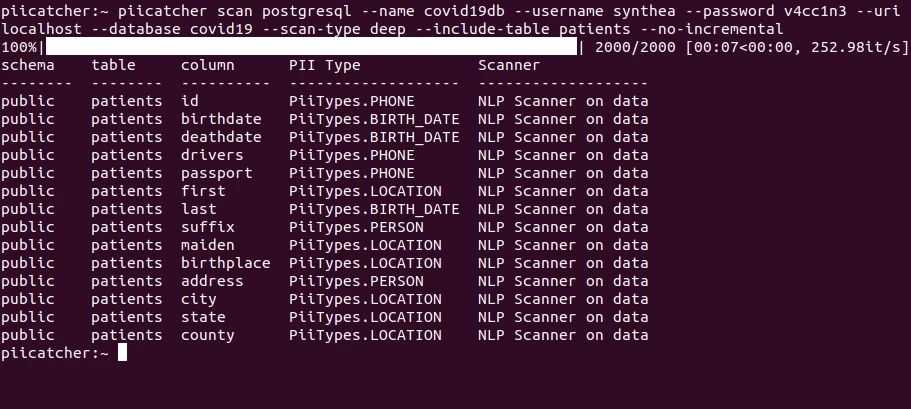
下面显示的是新冠肺炎合成患者记录中患者表中的示例记录:
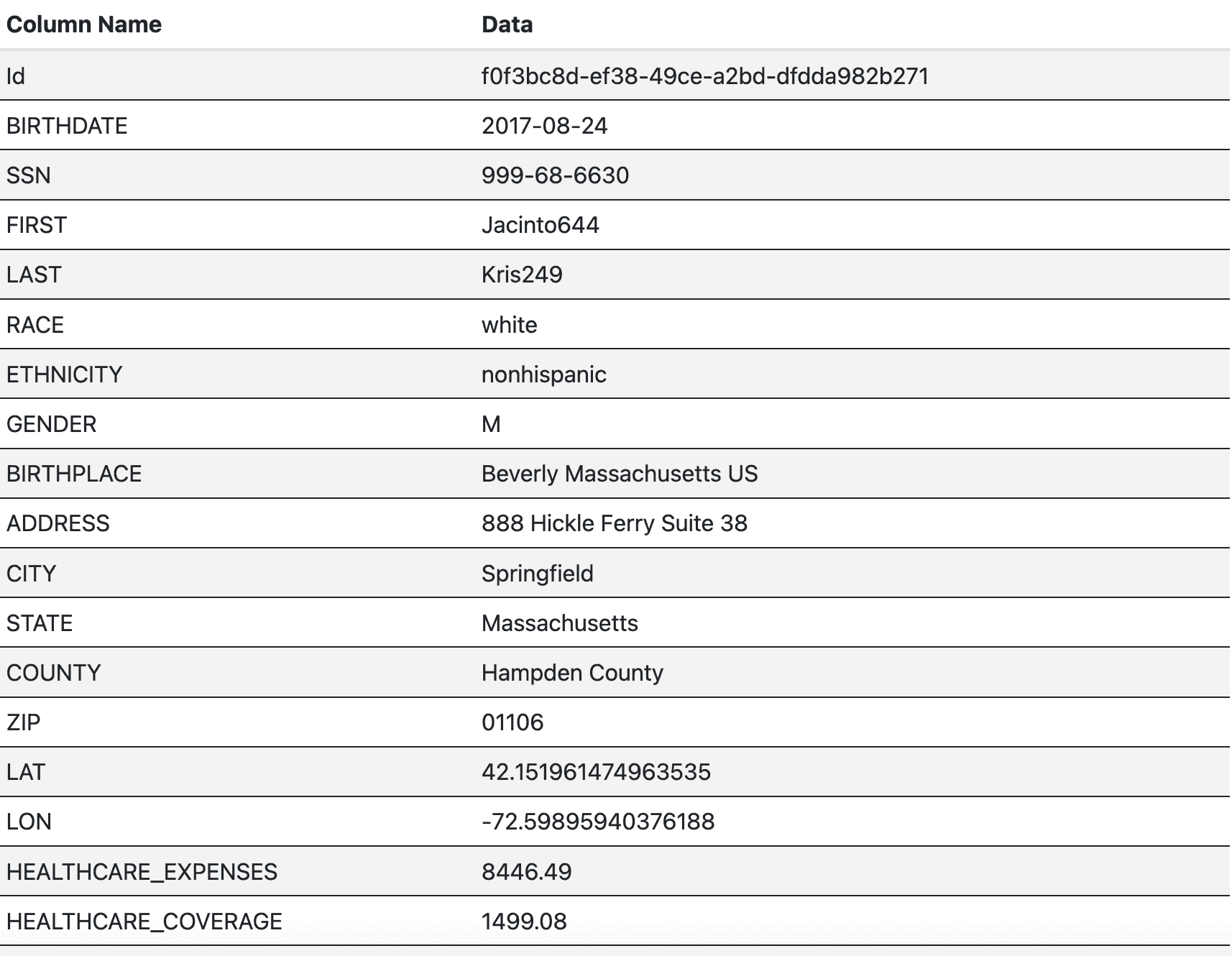
该表中的大多数字段存储PII,但甚至检测列是否存储PII以及如果存储PII的话,检测该PII的类型都可能会令人困惑。例如,如果扫描仪只扫描SSN字段中的数据,则SSN可能被检测为电话号码。同样,文本信息本身,如性别领域的“M”或“F”,或种族领域的“白人”,并不能提供足够的上下文来确定PII的类型。在这两种情况下,扫描字段头会更有效。然而,在某些情况下,实际数据需要扫描。因此,用于扫描数据仓库的技术取决于所讨论字段的上下文。
PII扫描技术
根据上一节中强调的挑战,有两种技术可以扫描数据仓库中的PII:
- 扫描列和表名
- 扫描列内的数据
扫描数据仓库元数据(包括列和表名)
通常,数据工程师会用简单的术语命名数据仓库中的表和列,以便于用户理解。因此,这些名称通常为存储的数据类型提供线索。例如:
- first_name、last_name、full_name或name可能存储一个人的名字。
- ssn或social_security用于存储美国ssn号码。
- phone或phone_number用于存储电话号码。
此外,数据仓库提供了一个信息模式来提取模式、表和列信息。例如,以下查询可用于从Snowflake获取元数据:
SELECT
lower(c.column_name) AS col_name,
lower(c.column_name) AS col_name,
c.comment AS col_description,
lower(c.data_type) AS col_type,
lower(c.ordinal_position) AS col_sort_order,
lower(c.table_catalog) AS database,
lower({cluster_source}) AS cluster,
lower(c.table_schema) AS schema,
lower(c.table_name) AS name,
t.comment AS description,
decode(lower(t.table_type), 'view', 'true', 'false') AS is_view
FROM
{database}.{schema}.COLUMNS AS c
LEFT JOIN
{database}.{schema}.TABLES t
ON c.TABLE_NAME = t.TABLE_NAME
AND c.TABLE_SCHEMA = t.TABLE_SCHEMA
正则表达式可以匹配表名或列名。例如,下面的正则表达式检测存储社会安全号码的列:
^.*(ssn|social).*$
扫描存储在列中的数据
另一种检测PII的方法包括使用两种策略的组合扫描存储在列内的数据:
- 使用正则表达式检测预期模式
- 调用NLP库,如Stanford NER Detector和Spacy
这种方法的一个缺点是NLP库的计算量很大。即使在中等大小的表上运行NLP扫描程序的成本也会迅速上升,更不用说数百万或数十亿行了。取而代之的是,一个随机的行样本进行扫描。数据库提供了选择随机样本的内置函数,例如下面的Snowflake查询:
select {column_list} from {schema_name}.{table_name} TABLESAMPLE BERNOULLI (10 ROWS)
生成随机行后,可以使用regex或NLP库对其进行处理,以检测PII的存在。
断开连接
根据上下文,检测PII数据需要上述两种技术。然而,这些很容易出现假阳性和假阴性。此外,不同的方法往往会提出相互冲突的PII类型。确定正确的类型是未来博客文章的主题。
PIICatcher:扫描数据仓库中的PII数据
PIICatcher执行上述策略来扫描和检测数据仓库中的PII数据。
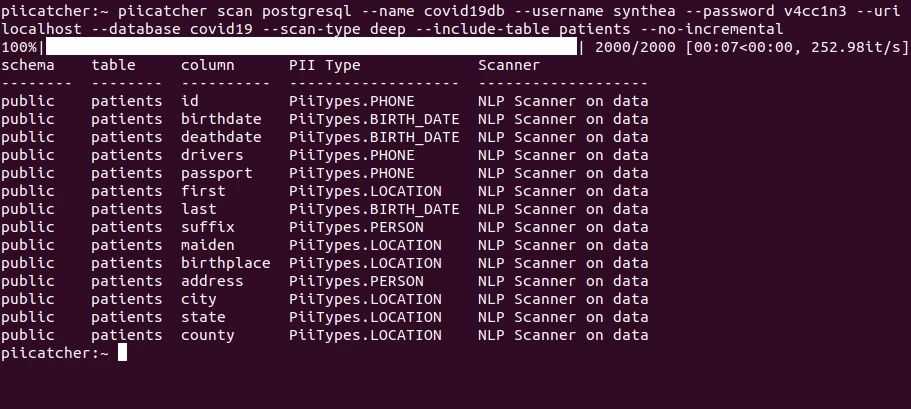
特征
PIICatcher可以使用任何一种方法扫描数据仓库。它battery-included,,有越来越多的正则表达式用于扫描列名和这些列中的数据。目前,它甚至包括Spacy。
PIICatcher支持增量扫描,并且只扫描等待扫描的新列或现有列。这些功能允许轻松安排扫描。它还提供了强大的选项来包括或排除模式和表,以管理计算资源。此外,Datahub和Amundsen的功能还包括摄取功能,这些功能将用“PII”和“PII类型”标记列和表。
查看AWS Glue&Lake Formation Privilege Analyzer,了解PIIcatcher在生产中的使用示例。
结论
扫描表中的列名和数据有助于检测数据库中的PII。这两种策略都需要可靠地检测PII数据。PIICatcher是一个开源应用程序,可以实现这两种策略。它可以用PII和PII类型标记数据集,使数据管理员能够在数据隐私和安全方面做出更明智的决定。
- 279 次浏览