【数据目录】Databook:优步内部元数据目录为可扩展数据发现提供动力
视频号

微信公众号

知识星球

什么是Databook?
Databook是优步的内部元数据管理平台,可大规模实现数据发现和探索的民主化。Databook之于优步,Amundsen之于Lyft,DataHub之于LinkedIn,Metacat之于Netflix。
2010年,优步彻底改变了交通行业,目前在全球拥有数百万用户的10000多个城市运营。自成立以来,优步在很大程度上实现了业务多元化。它将乘客与司机、美食家与餐馆、承运人与托运人等联系起来。该组织处理针对用户乘车请求、付款、餐厅订单、运输详细信息等产生的大量每日实时数据。Databook跟踪所有这些不同的数据源,并维护数据目录。
为什么要建立Databook?
Databook旨在对与优步数据集、仪表盘、位置数据、分析和营销指标相关的元数据进行编目。优步旨在帮助员工利用数据目录中的上下文信息,探索并最终将数PB的实时运营数据转换为智能。
Databook的演变(2016-2020)
优步于2016年推出了第一个Databook,当时整体数据基础设施简单,分布相对较少。在此之前,优步使用静态HTML页面对其数据集和表进行编目,并手动维护和更新。随着公司的发展,优步Databook 取代了静态HTML页面,这种页面在一段时间内运行得相当好。
优步随后建立了新的业务链来扩大其合资企业,包括优步美食、优步电梯、优步货运和自行车。这种扩展导致了指数级的数据增长,并认为有必要开发更先进的数据目录软件。
优步的员工开始对数据进行更详细的分类。他们收集了有关数据集、其所有者、如何生成数据、从数据集派生出哪些业务指标、构建了哪些仪表板、有关数据存储管道的信息以及各种表列的描述的详细信息。
2017年,优步从头开始重新设计了Databook(Databook2.0),以适应这些变化,因为它称赞了决策过程,并帮助推导出有意义的商业见解。更新后的Databook具有响应式用户界面,并针对新的数据需求改进了功能。
优步在Databook中添加了更多关于其数据收集策略的信息。他们引入了Querybuilder,一种搜索和发现优步数据库的前端功能,以及Dashbuilder,这是一种高级元数据可视化工具,可以帮助用户学习和更好地理解数据关系。
优步Databook架构
最初的Databook架构专注于搜索数据集、呈现描述和所有者的基本系统,当他们的数据格局开始在数量和复杂性上蓬勃发展时,这远远不够。
本节讨论了帮助重新设计、重新评估和重建Databook体系结构的原则。基于这些原则,我们将讨论Databook2.0的各种体系结构组件。
Databook体系结构原理
Databook设计原则是重要的指导方针,有助于为重组战略奠定坚实的基础。其中包括:
- 元数据的意义很重要
- 真正可扩展的数据模型
- 集中式元数据系统与去中心化元数据系统
- 关注用户体验
- 数据实体之间关系的重要性
元数据的意义很重要
随着数据实体和元数据来源的增加,数据文档变得不一致。为了更好地管理元数据,开发了一种名为Dragon的模式生成工具,该工具有助于构建和维护一致的元数据词汇表。
真正可扩展的数据模型
第一个Databook将元数据限制在特定的数据集,而忽略了仪表板和业务指标等非数据集源。在一个模型中添加不同的数据条目会损害其清晰度和可理解性。优步建立了一个灵活且可扩展的数据模型,以插入具有不同元数据的数据实体,而不是将它们拟合到预定义的数据模型中。
集中式元数据系统与去中心化元数据系统
随着元数据源的增加,复制具有类似用例的元数据系统是不利的。优步开发了一个用于处理所有元数据源和数据实体的集中式系统。
关注用户体验
优步鼓励其开发人员、分析师和数据本最终用户就改进数据本功能提供反馈。基于用户体验,优步精简了元数据接收管道,并改进了Databook UI,以实现更好的元数据发现。
数据实体之间关系的重要性
优步应用程序中的数据从Kafka到Hive等不同路线流入。向系统中添加更多的数据实体增加了这些路由的复杂性。优步使用Graph数据结构来准确地表示这些复杂数据实体之间的关系。
优步Databook功能
根据上面讨论的五个原则,Databook 2.0体系结构衍生出以下功能:
- 元数据关联的标准词汇
- 可扩展的数据模型,以适应不同的元数据及其各自的关系
- 通过Databook UI和API改善用户体验
优步Databook的组成部分
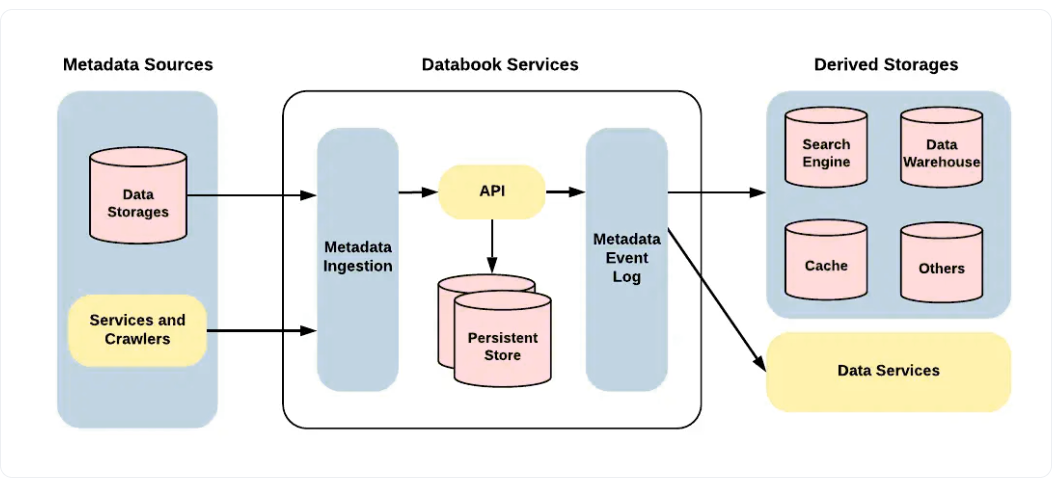
优步接收来自各种输入源的数据,这些数据经过处理并存储在多个数据存储库中。Databook 2.0添加了各种元数据源、存储单元、摄取机制和事件日志,以管理大量传入数据,并为优步的进一步数据服务提供燃料。以下是组成部分:
- 元数据源
- 元数据摄入
- 永久存储
- 元数据事件日志
- 派生存储器
每个Databook组件的详细描述如下:
元数据源
优步使用存储在各种存储单元中的数据实体进行操作,如Hive、Cassandra、MySQL、Vertica等。Databook有一个灵活的框架来支持许多用例,以调整数据存储系统或提供输入的网络爬虫中的数据实体。Databook使用统一的输入过程和标准化的API来确保可扩展性。
元数据摄入
不同的团队成员需要通过访问元数据源来执行各种任务。元数据接收过程有助于组织成员的数据,并使用更改的所有详细信息和历史记录更新事件日志。
永久存储
MySQL用于保存数据的整个轨迹和相关的关系。它为Databook体系结构提供了灵活性、可访问性和可扩展性。ElasticSearch还用于改进索引和加快元数据搜索。
元数据事件日志
在获取元数据之后,转换的详细信息会列在Kafka的事件日志中。这些数据有助于审核、重建存储库和触发各种任务。事件日志跟踪数据本活动并实时更新更改。
派生存储器
派生存储使用元数据事件日志来帮助各种用例和需求。优步捕获了由不同存储单元维护的基本元数据,因为单个存储库无法管理不同的模式和数据需求。
Databook用例
通过重新设计的架构,优步改进并启用了Databook的以下用例:
发现
优步用户经常在Databook上搜索与其工作场所相关的数据实体或该组织的其他流行数据条目。优步引入了有组织的数据实体表示,以改进Databook接口。在跟踪用户的活动和偏好后,优步增加了一项功能,可以推荐他们感兴趣的实体。搜索引擎经过优化,可以智能地解释关键词并产生相关结果。
理解
在引导用户进行搜索后,优步团队希望继续前进,帮助他们了解有关数据的复杂细节。通过添加更多关于数据实体的信号,如使用分析、数据质量和隐私指标,重新设计了Databook架构。
Databook web UI使用红绿灯指示器表示来显示资产的数据质量或状态。红绿灯信号颜色有助于通知用户资产的可用性或异常的存在。
管理
用不同的数据实体和元数据源扩展数据模型使系统过载。优步希望简化沟通渠道,直接联系数据提供商,询问问题并提供反馈。
优步建立了一个界面,在一个页面上处理所有数据实体,用户可以在其中发布问题并报告问题。为数据手册用户提供了基于知识的表示,而不是基于wiki的模型来管理数据实体。该接口在后端跟踪问题,并将查询路由到可用的成员。
优步Databook是开源的吗?
优步Databook不是一个开源的元数据编目工具。Databook是优步的内部平台,其代码库不会在GitHub上公开共享。
然而,Databook架构设计及其完整的重组过程细节是公开的。它为有兴趣构建开放数据目录软件的组织提供了指南。
结论
本文讨论了Databook,这是优步为满足其不断增长的数据发现、探索和管理需求而构建的元数据目录。我们已经介绍了Databook的组件、设计原则和基本功能,这些功能可以让您深入了解Databook的工作原理。
有兴趣了解其他大型科技公司是如何管理其不断发展的数据需求的?深入研究这个顶级开源数据目录软件列表。
此外,如果你想为自己的团队部署数据目录,你可能想看看Atlan,这是一个第三代数据目录,它是对传统软件的飞跃,建立在最好的开源基础上。
- 37 次浏览