【MLOps】生产用例的并行Stable Diffusion
视频号

微信公众号

知识星球


Tl;dr
- Stable Diffusion是一种令人兴奋的新图像生成技术,您可以轻松地在本地运行或使用Google Colab等工具;
- 这些工具非常适合探索和实验,但如果你想通过围绕Stable Diffusion构建自己的应用程序或大规模运行来将其提升到一个新的水平,那么这些工具就不合适了;
- Metaflow是一个开源的机器学习框架,为Netflix的数据科学家生产力开发,现在由Outerbounds支持,它允许您为生产用例大规模并行化Stable Diffusion,以高度可用的方式自动生成新图像。
有大量新兴的机器学习技术和技术允许人类使用计算机生成大量的自然语言(例如GPT-3)和图像,如DALL-E。最近,Stable Diffusion风靡全球,因为它允许任何拥有互联网连接和笔记本电脑(或手机!)的开发者使用Python通过提供文本提示来生成图像。
例如,使用拥抱脸库 Diffusers,,您可以用7行代码生成“尼古拉斯·凯奇作为教父(或其他任何人)的画作”。

Paintings of Nicolas Cage as He-Man, Thor, Superman, and the Godfather generated by Stable Diffusion.
在这篇文章中,我们展示了如何使用Metaflow,这是一个开源的机器学习框架,为Netflix的数据科学家生产力开发,现在由Outerbounds支持,为生产用例大规模并行化Stable Diffusion。在此过程中,我们展示了Metaflow如何允许您使用Stable Diffusion这样的模型作为真实产品的一部分,以高度可用的方式自动生成新图像。这篇文章中概述的模式已经准备好制作,并在数百家公司(如23andMe, Realtor.com, CNN, and Netflix等)与Metaflow进行了战斗测试。您可以在自己的系统中使用这些模式作为构建块。
我们还将展示,在大规模生成1000张这样的图像时,如何跟踪使用哪些提示和模型运行来生成哪些图像,以及Metaflow如何提供有用的元数据和开箱即用的模型/结果版本控制,以及可视化工具,这一点很重要。所有代码都可以在此存储库中找到。
作为一个示例,我们将展示如何使用Metaflow从许多提示样式对中快速生成图像,如下所示。您只会受到您对云(如AWS)帐户中可用GPU的访问限制:使用6个GPU在23分钟内同时为我们提供1680个图像,即每个GPU每分钟超过12个图像,但您可以生成的图像数量与您使用的GPU数量成比例,因此云是有限的!

Historic figures by historic styles using Stable Diffusion and Metaflow. Styles from left to right are: Banksy, Frida Kahlo, Vincent Van Gogh, Andy Warhol, Pablo Picasso, Jean-Michel Basquiat.
本地和Colab上使用Stable Diffusion及其局限性
有几种方法可以通过“拥抱面漫射器”库使用“稳定漫射”。其中两个最简单的是:
- 如果你的笔记本电脑上有GPU,你可以使用本地系统来遵循这个Github存储库README中的说明;
- 使用谷歌Colab免费利用基于云的GPU和这样的笔记本电脑。
用于在Colab笔记本中生成上面的“尼古拉斯·凯奇作为教父的画作”的7行代码是:

这两种方法都是启动和运行的好方法,它们允许您生成图像,但速度相对较慢。例如,使用Colab,谷歌的免费GPU供应将您的速率限制在每分钟3张左右。这就引出了一个问题:如果你想扩大规模以使用更多的GPU,你该如何琐碎地做到这一点?除此之外,Colab笔记本和本地计算非常适合实验和探索,但如果你想将Stable Diffusion模型嵌入到更大的应用程序中,还不清楚如何使用这些工具。
此外,当扩展以生成潜在数量级的更多图像时,对模型、运行和图像进行版本控制变得越来越重要。这并不是要给你的本地工作站或Colab笔记本蒙上阴影:他们从来没有打算实现这些目标,而且他们的工作做得很好!
但问题仍然存在:我们如何大规模扩展我们的Stable Diffusion图像生成,对我们的模型和图像进行版本化,并创建一个可以嵌入大型生产应用程序的机器学习工作流?Metaflow救援!
使用Metaflow实现具有Stable Diffusion的大规模并行图像生成
Metaflow使我们能够通过提供以下API来解决这些挑战:
- 通过分支实现大规模并行化,
- 版本控制,
- 数据科学和机器学习工作流程的生产协调,以及
- 可视化。
Metaflow API允许您使用越来越常见的有向无环图(DAG)抽象来开发、测试和部署机器学习工作流,其中您将工作流定义为一组步骤:这里的基本思想是,当使用Stable Diffusion生成图像时,您有一个分支工作流,其中
- 每个分支在不同的GPU上执行,并且
- 分支在连接步骤中连接在一起。
举个例子,假设我们想要生成大量的主题-风格对:给定大量的主题,通过提示并行化计算是有意义的。您可以在以下流程示意图中看到这种分支是如何工作的:
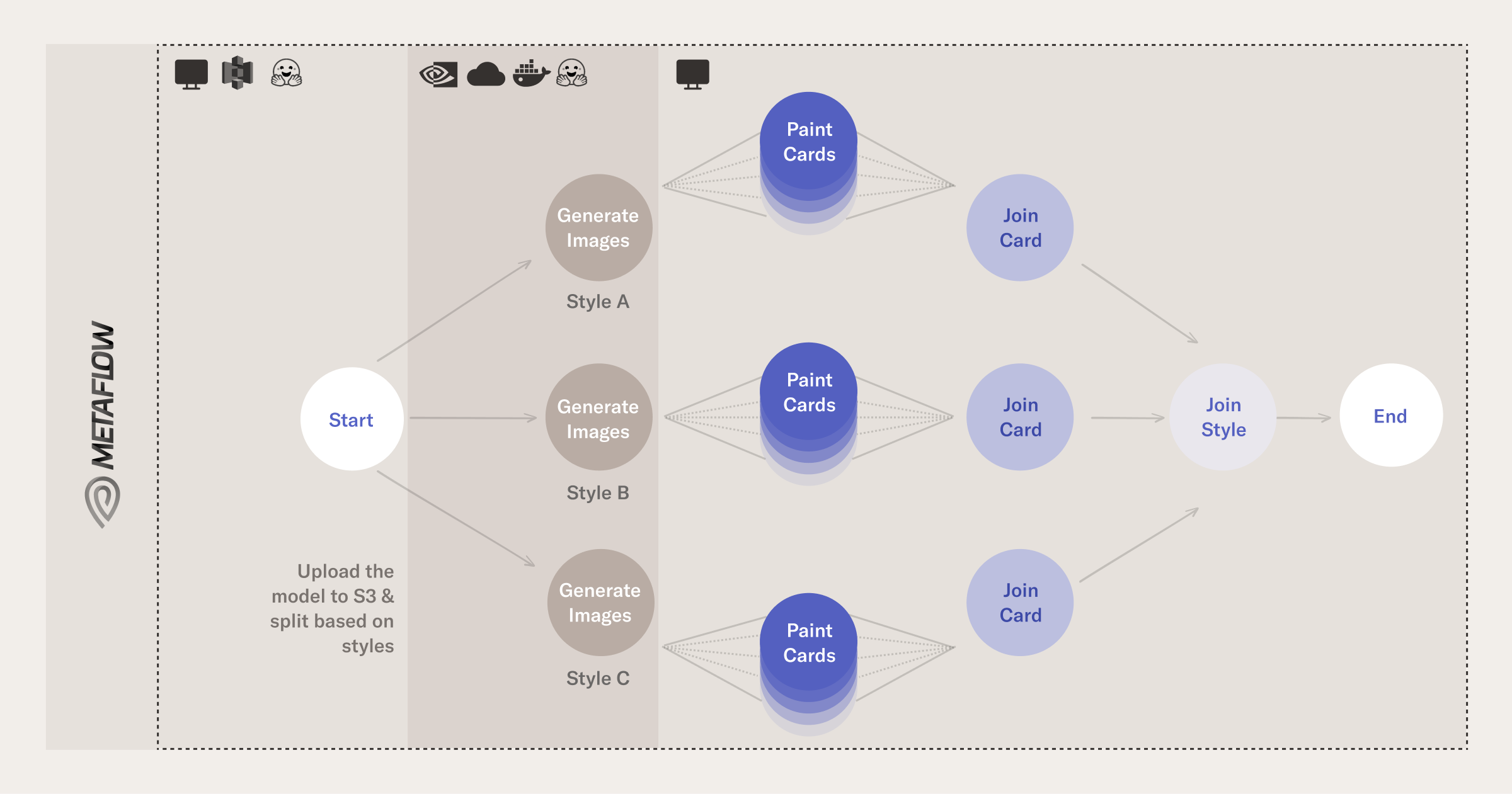
Visualization of the flow that generates images
generate_images步骤的关键元素如下(您可以在这里的存储库中看到整个步骤):
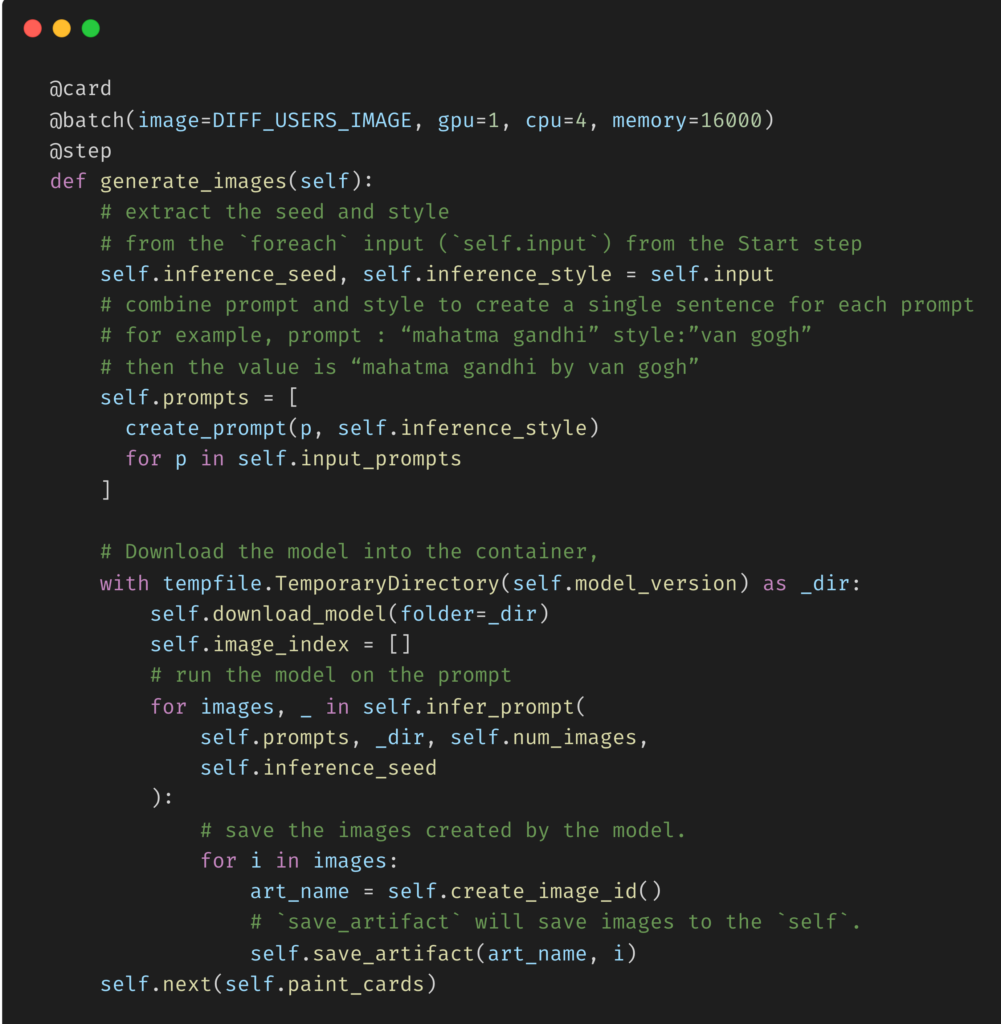
Key elements of the generate_images step
要了解这段代码中发生了什么,首先要注意,当从命令行执行Metaflow流时,用户已经包含了主题和样式。例如:
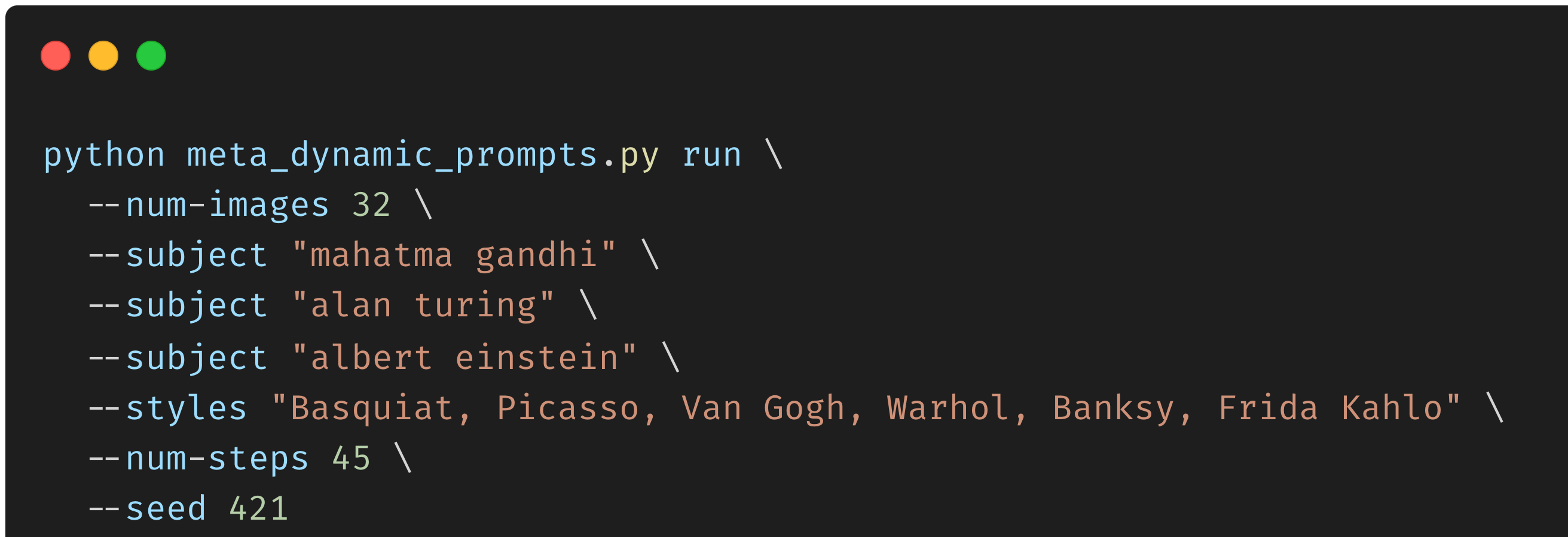
Command to run the image generation flow
样式、主题和种子(为了再现性)存储为一种称为Parameters的特殊类型的Metaflow对象,我们可以分别使用self.styles、self.subject和self.seed在整个流中访问它。更一般地说,self.X等实例变量可以在任何流步骤中使用,以创建和访问可以在步骤之间传递的对象。例如,在我们的开始步骤中,我们将随机种子和样式打包到实例变量self.style_rand_seeds中,如下所示:

正如generate_images步骤中的注释所指出的,我们正在做的是
- 在实例变量self.init中提取从开始步骤传递的种子和样式(之所以是self.init,是因为从一开始就有分支:有关更多技术细节,请查看Metaflow的foreach),
- 将主题和风格结合起来,为每个提示创建一个句子,例如主题“mahatma gandhi”和风格“van gogh”创建提示“mahatta gandhi by van gogh),以及
- 将模型下载到容器中,在提示下运行模型并保存模型创建的图像。
请注意,为了将计算发送到云,我们所需要做的就是将@batch装饰器添加到步骤generate_images中。Metaflow的这种可供性使数据科学家能够在原型代码和模型之间快速切换,并将它们发送到生产中,从而关闭了原型和生产模型之间的迭代循环。在这种情况下,我们使用的是AWS批处理,但您可以使用最适合您组织需求的云提供商。
关于整个流,关键在于(计算)细节,所以现在让我们更全面地了解Metaflow流中发生了什么,注意我们在运行流之前将Stable Diffusion模型从Hugging Face(HF)下载到本地工作站。
- start:[Local execution]我们将HF模型缓存到一个公共数据源(在我们的例子中,S3)。缓存后,根据主题/图像的数量并行运行接下来的步骤;
- generate_images:[Remote execution]对于每种风格,我们在一个独特的GPU上运行一个docker容器,该容器为主题+风格组合创建图像;
- paint_cards:[Local Execution]对于每种风格,我们将生成的图像分为多个批次,并使用Metaflow卡为每个批次生成可视化效果;
- join_cards:[Local Execution]我们为生成的卡加入并行化的分支;
- join_styles:[Local Execution]我们加入所有样式的并行分支;
- end:[Local execution]:结束步骤。
在paint_cards步骤完成执行后,用户可以访问Metaflow UI来检查模型创建的图像。用户可以监控不同任务的状态及其时间表:
https://outerbounds.com/assets/stable-diff-mf-ui-demo.mp4
探索Metaflow UI
您也可以自己在Metaflow UI中探索结果,并查看我们在执行代码时生成的图像。
一旦流完成运行,用户就可以使用Jupyter笔记本根据提示和/或样式搜索和过滤图像(我们在配套存储库中提供了这样一个笔记本)。由于Metaflow版本来自不同运行的所有工件,用户可以比较和对比多次运行的结果。随着模型、运行和图像的版本控制变得越来越重要,当扩展到生成1000张(如果不是1000张中的10张)图像时,这是关键:
https://outerbounds.com/assets/stable-diff-notebook.mp4
结论
Stable Diffusion是一种新的、流行的从文本提示生成图像的方法。在这篇文章中,我们看到了使用Stable Diffusion生成图像的几种方法,如Colab笔记本,这些方法非常适合探索和实验,但这些方法确实有局限性,使用Metaflow有以下启示:
- 并行性,因为您可以将机器学习工作流程扩展到任何云;
- 所有MLOps构建块都封装在一个方便的Python接口中(如版本控制、实验跟踪、工作流等);
- 最重要的是,您可以使用这些构建块实际构建一个生产级、高可用性、SLA满意的系统或应用程序。数百家公司在使用Metaflow之前就已经这样做了,因此该解决方案也是久经沙场的。
- 279 次浏览