生成式人工智能



【GAI】生成技术市场地图和5层技术堆栈
视频号
微信公众号
知识星球

这是NFX的Generative Tech市场地图。目前已有550多家公司参与其中。再加上它。我们正在开源。
如果你正在创办一家涉及生成人工智能的公司,请与我们联系。
下面,我们将讨论我们所看到的作为5层生成技术堆栈的发展,以帮助指导您对公司的思考。
五层生成技术堆栈
我们看到生成技术堆栈分解为5层。作为创始人,你必须决定你想在产品中包括哪一层或哪几层。
- 5.应用层
- 4.操作系统或API层
- 3.超局部人工智能模型
- 2.具体的人工智能模型
- 1.通用人工智能模型
让我们走过这些。

人工智能模型层:通用、特定和超局部
实现生成技术的人工智能引擎有三层。根据您的市场需求,以及所需的细微差别和专业化水平,您可以使用这三种功能。
- 通用人工智能模型是核心技术突破。它类似于GPT-3用于文本,DALL-E-2用于图像,Whisper用于语音,或Stable Diffusion。这些模型处理广泛类别的输出:文本、图像、视频、语音、游戏。它们将是开源的,易于使用,并且擅长上述所有方面。这是生成技术革命的起点,但不是它的终点。
- 特定的人工智能模型为特定的工作捕捉到了更多的细微差别,如写推特、广告文案、歌词,或生成电子商务照片、3D室内设计图像等。这些模型是在更窄、更专业的数据上训练的,这应该使它们在特定的轮罩中优于普通模型。其中一些最终也将是开源的。
- 超局部人工智能模型是专家。超局部人工智能模型可以用《自然》杂志喜欢的风格写一篇科学文章。它创造了适合特定人审美的室内设计模型。它可以以单个公司的特定风格编写代码。它可以根据特定公司的电子商务照片进行精确的明暗处理。这个模型是在超局部数据上训练的,通常是专有数据。
这些模型显然是他们所训练的数据的子代。当你向上移动时,数据会变得更加差异化,从而产生一个更加细微的模型。人们很容易认为,这种差异化的数据是持久成功的关键。
它可能是,也可能不是。
有人说,Generative Tech实际上是一场为人工智能训练获取数据的竞赛。但是,正如我们之前所讨论的,数据并不总是提供强大的防御能力。即使竞争对手无法获得您的确切数据集,他们也可能找到类似的数据集。即使他们的型号没有你的好,客户也不能总是说出来,竞争对手也可以声称他们的销售资料中有你的。这意味着大多数数据网络效应随着时间的推移呈渐近线。一个比竞争对手好5%甚至20%的人工智能模型是一个相当微弱的防御能力。
还有一个更大的挑战:人类欣赏所产生的东西的能力是有限的。人工智能正在迅速达到这个极限。
例如,人类无法区分4K照片和8K照片,因为我们的眼睛无法拍摄更多的像素。人们的大脑将无法在24个月内区分人类写作和人工智能写作。大多数人将在36个月后欣赏人工智能创作的音乐和歌词。(是的,这让很多人感到非常不舒服)。
人工智能模型的发展速度非常快,因此许多通用和特定模型不需要很长时间,可能需要3年的时间就能相互接近并达到人类的极限。假设每代几美分,速度几秒,这些模型的差异化能力就止步于这些极限。
[注:截至今天,在其他人工智能开始有钱支付超过人类极限的生成内容之前,还没有“超过人类极限”的生成人工智能。]
因此,探索人工智能模型中数据网络效应的最佳场所可能是第3级,即超本地层,它受益于专有和可信的数据。
操作系统和API层
这是位于工作流应用程序和下面的人工智能模型之间的一层。我可能有一个制作电子商务网站的申请。需要几个不同的人使用该应用程序。他们每个人都需要不同的模型来发挥自己的作用。这个API层或Generative OS帮助应用程序访问应用程序需要的所有AI模型。这一层还允许人工智能模型随意切换。这当然倾向于将它们商品化。
该层简化了应用程序和工作流的互操作性。它有助于跟踪身份、支付、法律问题、服务条款、存储等。它帮助应用程序开发人员更快地尝试更多功能,并使其更快地启动和运行。对于最终用户来说,它消除了下面的人工智能模型和上面的应用程序供应商的麻烦。该层应具有强大的网络效果和嵌入特性。
应用程序层
这些应用程序是人和机器协作的接口。这些工作流程工具使人工智能模型能够以一种使商业客户或消费者娱乐的方式访问。
在这一层中,很容易想象网络效应或嵌入防御。
在未来两年内,将有10000个这样的应用程序用于满足各种需求。现任软件供应商将增加生成功能。新公司将创造旧公司的竞争对手,强调生成性是一个楔子。新公司将创建全新的应用程序,人们将以生成人工智能为起点使用这些应用程序。
如何在当代科技中获胜
考虑到现在每个人都有类似的想法(请参阅NFX的Generative Tech Market Map——这些公司总共已经筹集了140多亿美元),那么你如何竞争?
1.产品速度
你需要把产品投放市场,看看什么有效,什么无效。看看是什么让人们感到不舒服——让他们度过这个周期。密切关注您的竞争对手,并借鉴最佳创意。不要让它变得完美。如果以牺牲堆栈中的其他层(应用程序、API或操作系统层)为代价来构建完美模型,那么不要花费太多时间寻找特定数据。首先启动该功能,让模型随着时间的推移而学习。
2.销售速度
随着Generative AI从功能到产品再到真正的业务,你可能会认为,2023-2024年将主导积极的销售和营销,而不仅仅是AI和ML。积极的销售将有助于将您的产品融入客户,并使您有权扩展到其他类别。积极的销售将帮助你建立网络效应,帮助你的防御能力。销售将帮助您获得上述第2和第1项优势。
3.网络效应
网络效果将帮助您获胜,尤其是在应用程序和OS/API级别。我们已经编写了一本手册,并制作了一个3小时的大师班季,以帮助您思考这些问题。
4. Embedding(植入)
如果1-3层的人工智能模型倾向于商品,那么看看你在其上构建的应用程序和API如何通过将其嵌入客户的工作流程或日常生活来帮助你留住他们可能是有意义的。
5.找一个会和你一起冲刺的投资者
利用这项技术并与之一起冲刺。你需要一位与你一起冲刺的投资者。来和我们谈谈。
- 106 次浏览
【生成人工智能】什么是生成人工智能?你需要知道的一切
视频号
微信公众号
知识星球
生成人工智能是一种人工智能技术,可以生成各种类型的内容,包括文本、图像、音频和合成数据。最近围绕生成人工智能的热潮是由新用户界面的简单性推动的,这些界面可以在几秒钟内创建高质量的文本、图形和视频。
应该指出的是,这项技术并不是全新的。生成人工智能于20世纪60年代在聊天机器人中引入。但直到2014年,随着生成对抗性网络(GANs)——一种机器学习算法——的引入,生成人工智能才能够创造出令人信服的真实真人图像、视频和音频。
一方面,这种新发现的能力带来了机会,包括更好的电影配音和丰富的教育内容。它还释放了人们对deepfakes(数字伪造的图像或视频)和对企业的有害网络安全攻击的担忧,包括真实模仿员工老板的邪恶请求。
下面将更详细地讨论的另外两个最新进展在生成人工智能成为主流方面发挥了关键作用:转换器和它们所实现的突破性语言模型。变形金刚是一种机器学习,它使研究人员可以训练更大的模型,而不必预先标记所有数据。因此,新的模型可以在数十亿页的文本上进行训练,从而得到更深入的答案。此外,transformers解锁了一个名为注意力的新概念,使模型能够跟踪页面、章节和书籍中单词之间的联系,而不仅仅是单个句子中的联系。不仅仅是文字:变形金刚还可以利用它们追踪连接的能力来分析代码、蛋白质、化学物质和DNA。
所谓的大型语言模型(LLM)——即具有数十亿甚至数万亿参数的模型——的快速发展开启了一个新时代,在这个时代,生成性人工智能模型可以书写引人入胜的文本,绘制逼真的图像,甚至可以在飞行中创作一些有趣的情景喜剧。此外,多模式人工智能的创新使团队能够在多种类型的媒体上生成内容,包括文本、图形和视频。这是Dall-E等工具的基础,这些工具可以根据文本描述自动创建图像或根据图像生成文本字幕。
尽管取得了这些突破,但我们仍处于使用生成人工智能创建可读文本和逼真风格化图形的早期阶段。早期的实现存在准确性和偏见问题,并且容易产生幻觉和吐出奇怪的答案。尽管如此,迄今为止的进展表明,这类人工智能的固有能力可能会从根本上改变业务。展望未来,这项技术可以帮助编写代码、设计新药、开发产品、重新设计业务流程和转变供应链。

生成人工智能是如何工作的?
生成人工智能从一个提示开始,该提示可以是文本、图像、视频、设计、音符或人工智能系统可以处理的任何输入。然后,各种人工智能算法会根据提示返回新内容。内容可以包括文章、问题的解决方案,或者根据一个人的图片或音频制作的逼真赝品。
早期版本的生成性人工智能要求通过API或其他复杂的过程提交数据。开发人员必须熟悉特殊工具,并使用Python等语言编写应用程序。
现在,生成人工智能的先驱们正在开发更好的用户体验,让你用通俗易懂的语言描述请求。在最初的响应之后,您还可以自定义结果,并提供有关风格、语气和其他元素的反馈,以反映生成的内容。

生成型人工智能模型
生成型人工智能模型结合了各种人工智能算法来表示和处理内容。例如,为了生成文本,各种自然语言处理技术将原始字符(例如,字母、标点符号和单词)转换为句子、词性、实体和动作,使用多种编码技术将其表示为向量。类似地,图像被转换成各种视觉元素,也被表示为向量。一个警告是,这些技术也可能对训练数据中包含的偏见、种族主义、欺骗和夸大进行编码。
一旦开发人员确定了一种表示世界的方式,他们就会应用特定的神经网络来生成新的内容,以响应查询或提示。GAN和变分自动编码器(VAE)等技术——具有解码器和编码器的神经网络——适用于生成逼真的人脸、用于人工智能训练的合成数据,甚至特定人类的传真。
转换器的最新进展,如谷歌的双向编码器转换器表示(BERT)、OpenAI的GPT和谷歌AlphaFold,也产生了不仅可以编码语言、图像和蛋白质,还可以生成新内容的神经网络。
神经网络如何改变生成型人工智能
自人工智能诞生之初,研究人员就一直在创建人工智能和其他工具,以编程方式生成内容。最早的方法被称为基于规则的系统,后来被称为“专家系统”,使用明确制定的规则来生成响应或数据集。
神经网络是当今许多人工智能和机器学习应用的基础,它扭转了这个问题。神经网络旨在模仿人脑的工作方式,通过在现有数据集中寻找模式来“学习”规则。第一批神经网络开发于20世纪50年代和60年代,由于缺乏计算能力和数据集小而受到限制。直到2000年代中期大数据的出现和计算机硬件的改进,神经网络才成为生成内容的实用工具。
当研究人员找到一种方法,让神经网络在计算机游戏行业用于渲染视频游戏的图形处理单元(GPU)上并行运行时,这一领域加速了发展。过去十年中开发的新机器学习技术,包括上述生成对抗性网络和转换器,为人工智能生成内容的最新显著进步奠定了基础。
Dall-E、ChatGPT和Bard是什么?
ChatGPT、Dall-E和Bard是流行的生成人工智能接口。
Dall-E.
Dall-E经过大量图像数据集及其相关文本描述的训练,是一个多模式人工智能应用程序的例子,该应用程序可以识别视觉、文本和音频等多种媒体之间的连接。在这种情况下,它将单词的含义与视觉元素联系起来。它是在2021年使用OpenAI的GPT实现构建的。Dall-E2是第二个功能更强的版本,于2022年发布。它使用户能够在用户提示的驱动下生成多种风格的图像。
ChatGPT
2022年11月席卷全球的人工智能聊天机器人是建立在OpenAI的GPT-3.5实现之上的。OpenAI提供了一种通过具有交互式反馈的聊天界面进行交互和微调文本响应的方法。早期版本的GPT只能通过API访问。GPT-4于2023年3月14日发布。ChatGPT将其与用户的对话历史记录纳入其结果中,模拟真实的对话。在新的GPT界面大受欢迎后,微软宣布对OpenAI进行重大新投资,并将GPT的一个版本集成到其Bing搜索引擎中。
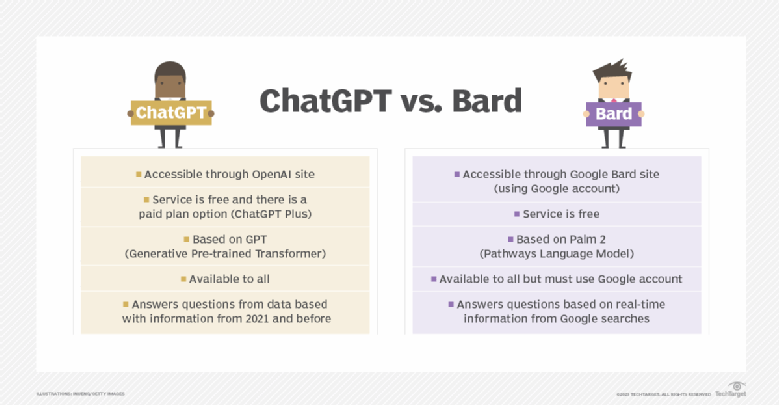
Here is a snapshot of the differences between ChatGPT and Bard.
Bard
谷歌是另一个早期的领导者,在处理语言、蛋白质和其他类型的内容方面开创了变压器人工智能技术。它为研究人员开放了其中一些模型。然而,它从未为这些模型发布过公共界面。微软决定在必应中实现GPT,这促使谷歌急于推出一款面向公众的聊天机器人Google Bard,该机器人基于其大型语言模型LaMDA家族的轻量级版本。在巴德匆忙亮相后,谷歌股价大幅下跌,因为语言模型错误地说韦布望远镜是第一个在外国太阳系中发现行星的望远镜。与此同时,由于不准确的结果和不稳定的行为,微软和ChatGPT的实现在早期也失去了面子。此后,谷歌推出了基于其最先进的LLM PaLM 2的新版Bard,该LLM使Bard在响应用户查询时更加高效和可视化。
生成人工智能的用例是什么?
生成型人工智能可以应用于各种用例,以生成几乎任何类型的内容。由于GPT等可以针对不同应用进行调整的尖端突破,这项技术越来越容易被各种用户使用。生成人工智能的一些用例包括以下内容:
- 为客户服务和技术支持实施聊天机器人。
- 部署deepfakes来模仿人们甚至特定的个人。
- 改进不同语言的电影和教育内容的配音。
- 撰写电子邮件回复、约会简介、简历和学期论文。
- 以一种特殊的风格创作逼真的艺术作品。
- 改进产品演示视频。
- 建议测试新药化合物。
- 设计实体产品和建筑。
- 优化新芯片设计。
- 以特定的风格或音调创作音乐。
生成人工智能的好处是什么?
生成型人工智能可以广泛应用于商业的许多领域。它可以更容易地解释和理解现有内容,并自动创建新内容。开发人员正在探索生成人工智能可以改进现有工作流程的方法,以期完全适应工作流程,从而利用这项技术。实施生成人工智能的一些潜在好处包括以下方面:
- 自动化手动编写内容的过程。
- 减少回复电子邮件的工作量。
- 改进对具体技术问题的回应。
- 创造真实的人物形象。
- 把复杂的信息总结成连贯的叙述。
- 简化以特定样式创建内容的过程。
生成人工智能的局限性是什么?
生成人工智能的早期实现生动地说明了它的许多局限性。生成人工智能提出的一些挑战来自于用于实现特定用例的特定方法。例如,一个复杂主题的摘要比包含支持关键点的各种来源的解释更容易阅读。然而,摘要的可读性是以用户能够审查信息来源为代价的。
以下是在实现或使用生成型人工智能应用程序时需要考虑的一些限制:
- 它并不总是识别内容的来源。
- 评估原始来源的偏差可能具有挑战性。
- 听起来真实的内容使识别不准确的信息变得更加困难。
- 很难理解如何适应新的环境。
- 结果可以掩盖偏见、偏见和仇恨。
注意是你所需要的:变压器带来了新的功能
2017年,谷歌报告了一种新型神经网络架构,该架构显著提高了自然语言处理等任务的效率和准确性。这种突破性的方法被称为变形金刚,是基于注意力的概念。
在高层次上,注意力是指事物(如单词)如何相互关联、互补和修饰的数学描述。研究人员在他们的开创性论文《注意力就是你所需要的一切》中描述了这种架构,展示了变压器神经网络如何能够比其他神经网络更准确地在英语和法语之间进行翻译,并且只需四分之一的训练时间。这项突破性的技术还可以发现数据中隐藏的其他事物之间的关系或隐藏顺序,而这些事物可能由于过于复杂而无法表达或辨别,因此人类可能并不知道。
Transformer架构自推出以来发展迅速,产生了GPT-3等LLM和谷歌的BERT等更好的预训练技术。
围绕生成人工智能的担忧是什么?
生成人工智能的兴起也引发了各种各样的担忧。这些与结果的质量、滥用和滥用的可能性以及破坏现有商业模式的可能性有关。以下是生成人工智能的现状所带来的一些具体类型的问题:
- 它可能提供不准确和误导性的信息。
- 如果不知道信息的来源和出处,就更难信任。
- 它可能会助长无视内容创作者和原创内容艺术家权利的新型抄袭行为。
- 它可能会破坏围绕搜索引擎优化和广告构建的现有商业模式。
- 这使得产生假新闻变得更加容易。
- 这使得人们更容易声称不法行为的真实照片证据只是人工智能生成的赝品。
- 它可以模仿人们进行更有效的社会工程网络攻击。
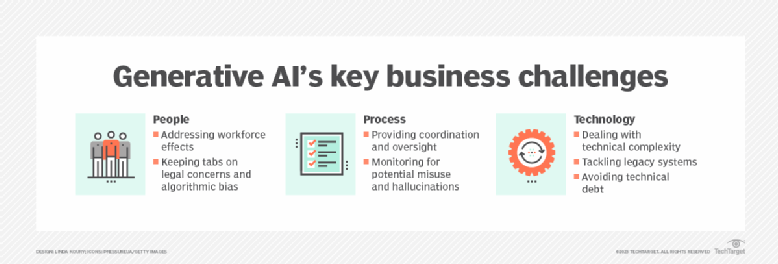
Implementing generative AI is not just about technology. Businesses must also consider its impact on people and processes.
生成人工智能工具的一些例子是什么?
生成人工智能工具适用于各种形式,如文本、图像、音乐、代码和语音。一些流行的人工智能内容生成器包括以下内容:
- 文本生成工具包括GPT、Jasper、AI Writer和Lex。
- 图像生成工具包括Dall-E2、Midjourney 和Stable Diffusion。
- 音乐生成工具包括Amper、Dadabots和MuseNet。
- 代码生成工具包括CodeStarter、Codex、GitHub Copilot和Tabnine。
- 语音合成工具包括Descriptt、Listnr和Podcast.ai。
- 人工智能芯片设计工具公司包括Synopsys、Cadence、谷歌和英伟达。
按行业划分的生成人工智能用例
新的生成性人工智能技术有时被描述为类似于蒸汽动力、电力和计算的通用技术,因为它们可以深刻影响许多行业和用例。必须记住的是,与以前的通用技术一样,人们通常需要几十年的时间才能找到组织工作流的最佳方式,以利用新方法,而不是加快现有工作流的一小部分。以下是生成型人工智能应用可能影响不同行业的一些方式:
- 金融可以在个人历史的背景下观察交易,以建立更好的欺诈检测系统。
- 律师事务所可以使用生成人工智能来设计和解释合同、分析证据和提出论点。
- 制造商可以使用生成人工智能将摄像头、X射线和其他指标的数据结合起来,更准确、更经济地识别缺陷零件和根本原因。
- 电影和媒体公司可以使用生成人工智能更经济地制作内容,并用演员自己的声音将其翻译成其他语言。
- 医疗行业可以使用生成人工智能更有效地识别有前景的候选药物。
- 建筑公司可以使用生成人工智能更快地设计和调整原型。
- 游戏公司可以使用生成人工智能来设计游戏内容和关卡。
GPT加入通用技术的万神殿
人工智能研究和部署公司OpenAI采用了Transformer背后的核心思想来训练其版本,称为Generative Pre-trained Transformer或GPT。观察人士注意到,GPT是用于描述蒸汽机、电力和计算等通用技术的首字母缩写。大多数人都同意,随着研究人员发现将GPT和其他转换器应用于工业、科学、商业、建筑和医学的方法,GPT和其它转换器实现已经名副其实。
生成人工智能中的伦理与偏见
尽管他们做出了承诺,但新的生成人工智能工具在准确性、可信度、偏见、幻觉和剽窃方面打开了一个漏洞——这些伦理问题可能需要数年时间才能解决。这些问题对人工智能来说都不是什么新鲜事。例如,微软2016年首次进军聊天机器人Tay,在推特上开始发表煽动性言论后,不得不关闭。
新的是,最新一批生成型人工智能应用程序表面上听起来更连贯。但这种类人语言和连贯性的结合并不是人类智能的同义词,目前关于生成人工智能模型是否可以被训练成具有推理能力存在很大争议。一位谷歌工程师甚至在公开宣布该公司的生成人工智能应用程序对话应用程序语言模型(LaMDA)具有感知能力后被解雇。
生成人工智能内容令人信服的现实主义引入了一系列新的人工智能风险。它使检测人工智能生成的内容变得更加困难,更重要的是,使检测错误变得更加困难。当我们依赖生成的人工智能结果来编写代码或提供医疗建议时,这可能是一个大问题。生成人工智能的许多结果都是不透明的,因此很难确定它们是否侵犯了版权,或者它们得出结果的原始来源是否存在问题。如果你不知道人工智能是如何得出结论的,你就无法解释为什么它可能是错误的。

生成型人工智能与人工智能
生成人工智能生成新内容、聊天响应、设计、合成数据或深度伪造。另一方面,传统的人工智能专注于检测模式、做出决策、完善分析、对数据进行分类和检测欺诈。
如上所述,生成型人工智能通常使用变压器、GANs和VAE等神经网络技术。不同的是,其他类型的人工智能使用的技术包括卷积神经网络、递归神经网络和强化学习。
生成型人工智能通常以提示开始,允许用户或数据源提交开始查询或数据集来指导内容生成。这可能是一个探索内容变化的迭代过程。传统的人工智能算法处理新数据以返回简单的结果。
生成型人工智能能历史
Joseph Weizenbaum在20世纪60年代创建的Eliza聊天机器人是生成人工智能最早的例子之一。这些早期的实现使用了基于规则的方法,由于词汇有限、缺乏上下文和过度依赖模式等缺点,这种方法很容易被打破。早期的聊天机器人也很难定制和扩展。
2010年,随着神经网络和深度学习的进步,该领域出现了复兴,使该技术能够自动学习解析现有文本、分类图像元素和转录音频。
Ian Goodfellow于2014年引入了GANs。这种深度学习技术为组织竞争性神经网络生成内容变化并对其进行评级提供了一种新的方法。这些可以产生逼真的人物、声音、音乐和文本。这激发了人们对如何利用生成性人工智能创建逼真的deepfakes的兴趣和恐惧,这些deepfake模仿视频中的声音和人。
从那时起,其他神经网络技术和架构的进步有助于扩展生成人工智能的能力。技术包括VAE、长短期记忆、变换器、扩散模型和神经辐射场。

使用生成人工智能的最佳实践
使用生成人工智能的最佳实践将因模式、工作流程和期望目标而异。也就是说,在使用生成人工智能时,考虑准确性、透明度和易用性等基本因素很重要。以下实践有助于实现这些因素:
- 为用户和消费者清楚地标注所有生成的人工智能内容。
- 在适用的情况下,使用主要来源审查生成内容的准确性。
- 考虑一下偏见如何融入生成的人工智能结果中。
- 使用其他工具仔细检查人工智能生成的代码和内容的质量。
- 了解每种生成人工智能工具的优势和局限性。
- 熟悉结果中常见的失败模式,并解决这些问题。
生成人工智能的未来
ChatGPT令人难以置信的深度和易用性为生成人工智能的广泛采用显示了巨大的前景。可以肯定的是,它也表明了安全和负责任地推出这项技术的一些困难。但这些早期的实现问题激发了人们对检测人工智能生成的文本、图像和视频的更好工具的研究。工业和社会还将建立更好的工具来追踪信息的来源,以创造更值得信赖的人工智能。
此外,人工智能开发平台的改进将有助于加快未来文本、图像、视频、3D内容、药品、供应链、物流和商业流程等更好的生成人工智能能力的研发。尽管这些新的一次性工具很好,但生成人工智能最重要的影响将来自于将这些功能直接嵌入我们已经使用的工具版本中。
语法检查会越来越好。设计工具将把更有用的建议无缝地直接嵌入到工作流程中。培训工具将能够自动识别组织某一部门的最佳做法,以帮助更有效地培训其他部门。这些只是生成人工智能改变我们工作方式的一小部分。

Generative AI will find its way into many business functions.
生成AI常见问题
以下是人们对生成人工智能的一些常见问题。
谁创造了生成人工智能?
Joseph Weizenbaum在20世纪60年代创建了第一个生成人工智能,作为Eliza聊天机器人的一部分。
伊恩·古德费罗在2014年展示了生成对抗性网络,用于生成长相和声音逼真的人。
随后,Open AI和谷歌对LLM的研究点燃了最近的热情,并发展成为ChatGPT、Google Bard和Dall-E等工具。
生成人工智能如何取代工作?
生成型人工智能有潜力取代各种工作,包括以下工作:
- 编写产品说明。
- 正在创建市场营销副本。
- 正在生成基本web内容。
- 发起互动式销售推广。
- 回答客户的问题。
- 为网页制作图形。
一些公司将在可能的情况下寻找替代人类的机会,而另一些公司将使用生成人工智能来增加和增强现有的劳动力。
你如何建立一个生成的人工智能模型?
生成人工智能模型首先要有效地编码您想要生成的内容的表示。例如,文本的生成人工智能模型可能首先找到一种方法,将单词表示为向量,以表征同一句子中经常使用的单词或意思相似的单词之间的相似性。
LLM研究的最新进展帮助该行业实施了同样的过程来表示图像、声音、蛋白质、DNA、药物和3D设计中的模式。这种生成人工智能模型提供了一种有效的方式来表示所需类型的内容,并有效地迭代有用的变体。
如何训练生成人工智能模型?
生成人工智能模型需要针对特定的用例进行训练。LLM的最新进展为针对不同用例定制应用程序提供了一个理想的起点。例如,OpenAI开发的流行GPT模型已被用于根据书面描述编写文本、生成代码和创建图像。
训练包括针对不同的用例调整模型的参数,然后在给定的训练数据集上微调结果。例如,呼叫中心可能会针对服务代理从各种客户类型中获得的各种问题以及服务代理作为回报给出的回答来训练聊天机器人。与文本不同,图像生成应用程序可能从描述图像内容和风格的标签开始,以训练模型生成新图像。
生成人工智能如何改变创造性工作?
生成型人工智能有望帮助创造性工作者探索各种想法。艺术家可以从一个基本的设计概念开始,然后探索变化。工业设计师可以探索产品的变化。建筑师可以探索不同的建筑布局,并将其视为进一步完善的起点。
它还可以帮助创造性工作的某些方面民主化。例如,商业用户可以使用文本描述来探索产品营销图像。他们可以使用简单的命令或建议来进一步完善这些结果。
生成人工智能的下一步是什么?
ChatGPT生成类人文本的能力引发了人们对生成人工智能潜力的广泛好奇。它还揭示了未来的许多问题和挑战。
短期内,工作将侧重于使用生成人工智能工具改善用户体验和工作流程。建立对人工智能生成结果的信任也是至关重要的。
许多公司还将根据自己的数据定制生成人工智能,以帮助改善品牌和沟通。编程团队将使用生成人工智能来执行公司特定的最佳实践,以编写和格式化更可读、更一致的代码。
供应商将把生成人工智能功能集成到他们的附加工具中,以简化内容生成工作流程。这将推动这些新功能如何提高生产力的创新。
作为增强分析工作流程的一部分,生成人工智能还可以在数据处理、转换、标记和审查的各个方面发挥作用。语义网络应用程序可以使用生成人工智能自动将描述工作技能的内部分类法映射到技能培训和招聘网站上的不同分类法。同样,业务团队将使用这些模型转换和标记第三方数据,以实现更复杂的风险评估和机会分析功能。
未来,生成人工智能模型将扩展到支持3D建模、产品设计、药物开发、数字孪生、供应链和业务流程。这将使产生新的产品想法、尝试不同的组织模式和探索各种商业想法变得更容易。
定义了最新生成式人工智能技术
AI艺术(人工智能艺术)
人工智能艺术是用人工智能工具创造或增强的任何形式的数字艺术。阅读更多
自动GPT
Auto GPT是一种基于GPT-4语言模型的实验性开源自主人工智能代理,它自动将任务链接在一起,以实现用户设定的全局目标。阅读更多
谷歌搜索生成体验
谷歌搜索生成体验(SGE)是一套搜索和界面功能,将生成的人工智能结果集成到谷歌搜索引擎查询响应中。阅读更多
增强学习
Q学习是一种机器学习方法,它使模型能够通过采取正确的行动随着时间的推移迭代学习和改进。阅读更多
谷歌搜索实验室(GSE)
GSE是Alphabet旗下谷歌部门的一项举措,旨在在谷歌搜索公开之前,以预览形式为其提供新的功能和实验。阅读更多
Inception score
初始得分(IS)是一种数学算法,用于测量或确定生成人工智能通过生成对抗性网络(GAN)创建的图像的质量。“开端”一词指的是人类传统上经历的创造力的火花或思想或行动的最初开端。阅读更多
从人类反馈中强化学习(RLHF)
RLHF是一种机器学习方法,它将强化学习技术(如奖励和比较)与人类指导相结合,以训练人工智能代理。阅读更多
可变自动编码器(VAE)
变分自动编码器是一种生成人工智能算法,使用深度学习生成新内容、检测异常和去除噪声。阅读更多
自然语言处理的一些生成模型是什么?
一些用于自然语言处理的生成模型包括以下内容:
- 卡内基梅隆大学XLNet
- OpenAI的GPT(Generative Pre-trained Transformer)
- 谷歌的ALBERT(“精简版”BERT)
- 谷歌BERT
- 谷歌LaMDA
人工智能会获得意识吗?
一些人工智能支持者认为,生成人工智能是迈向通用人工智能甚至意识的重要一步。谷歌LaMDA聊天机器人的一位早期测试者甚至在公开宣称它有感知能力时引起了轰动。然后他被公司解雇了。
1993年,美国科幻作家和计算机科学家Vernor Vinge提出,30年后,我们将有技术能力创造出“超人的智能”——一种比人类更智能的人工智能——之后人类时代将结束。人工智能先驱Ray Kurzweil预测到2045年会出现这样的“奇点”。
许多其他人工智能专家认为这可能会更进一步。机器人先驱罗德尼·布鲁克斯预测,人工智能在他有生之年不会获得6岁孩子的感知能力,但到2048年,它可能会像狗一样聪明和专注。
最新生成的人工智能新闻和趋势
生成型人工智能——下一个最大的网络安全威胁?
在2022年11月推出ChatGPT之后,出现了几份报告,试图确定生成人工智能在网络安全中的影响。不可否认,网络安全中的生成人工智能是一把双刃剑,但范式会朝着有利于机会还是有利于风险的方向转变吗?阅读更多
SHRM首席执行官在人力资源领域解决人工智能“噩梦”
人力资源管理公司首席执行官约翰尼·泰勒鼓励人们对人工智能在人力资源领域的乐观态度,认为人工智能将增加工作岗位,而不是使其自动化。阅读更多
AWS投资1亿美元用于新的生成人工智能项目
Generative AI创新中心将把AWS机器学习专家和数据科学家与企业联系起来。企业还可以使用AWS服务来培训和扩展模型。阅读更多
监控客户体验中的生成人工智能——否则
随着营销人员和客户服务领导者部署技术供应商正在迅速商业化的生成性人工智能工具,他们应该监督美国联邦贸易委员会的指导。阅读更多
万事达、莫德纳期待人工智能改善就业和生产力
万事达和莫德纳认为,人工智能未来对就业的影响是积极的,但他们都强调有必要提高员工的技能。阅读更多
- 180 次浏览
【生成型人工智能】生成型人工智能:一个创造性的新世界
视频号
微信公众号
知识星球
一类强大的新型大型语言模型使机器能够编写、编码、绘制和创建可信的、有时甚至是超人的结果。
人类善于分析事物。机器甚至更好。机器可以分析一组数据,并在其中找到多种用例的模式,无论是欺诈还是垃圾邮件检测,预测你的交付预计到达时间,还是预测下一步要向你展示哪个TikTok视频。他们在这些任务上越来越聪明。这被称为“分析人工智能”或传统人工智能。
但人类不仅善于分析我们也善于创造的东西。我们写诗、设计产品、制作游戏和编写代码。直到最近,机器还没有机会在创造性工作中与人类竞争——它们被降级为分析和死记硬背的认知劳动。但机器才刚刚开始擅长创造感性和美丽的东西。这个新类别被称为“生成人工智能”,这意味着机器正在生成新的东西,而不是分析已经存在的东西。
生成式人工智能正在变得不仅更快、更便宜,而且在某些情况下比人类手工创造的更好。每一个需要人类创造原创作品的行业,从社交媒体到游戏,从广告到建筑,从编码到平面设计,从产品设计到法律,从营销到销售,都需要重新创造。某些功能可能会被生成型人工智能完全取代,而其他功能则更有可能在人和机器之间的紧密迭代创造周期中蓬勃发展,但生成型人工智慧应该能在广泛的终端市场上解锁更好、更快、更便宜的创造。我们的梦想是,生成性人工智能将创造和知识工作的边际成本降至零,创造巨大的劳动生产率和经济价值,并创造相应的市值。
生成人工智能处理知识工作和创造性工作的领域包括数十亿工人。生成人工智能可以使这些工人的效率和/或创造力提高至少10%:他们不仅变得更快、更高效,而且比以前更有能力。因此,Generative AI有潜力创造数万亿美元的经济价值。
为什么是现在?
生成型人工智能与更广泛的人工智能具有相同的“为什么现在”:更好的模型、更多的数据、更多的计算。这一类别的变化速度比我们所能捕捉到的要快,但值得粗略地讲述最近的历史,以将当前时刻放在上下文中。
第1波:小模型占主导地位(2015年前)
5多年前,小模型被认为是理解语言的“最先进”。这些小模型擅长分析任务,并可用于从交付时间预测到欺诈分类的工作。然而,对于通用生成任务来说,它们的表达能力不够。生成人类级别的写作或代码仍然是一个白日梦。
果不其然,随着模型越来越大,它们开始提供人类水平的结果,然后是超人的结果。
第二波:规模竞争(2015年至今)
谷歌研究公司的一篇里程碑式论文(注意力就是你所需要的一切)描述了一种新的用于自然语言理解的神经网络架构,称为transformer,它可以生成高质量的语言模型,同时更具并行性,训练时间也大大减少。这些模型是少数镜头学习器,可以相对容易地针对特定领域进行定制。
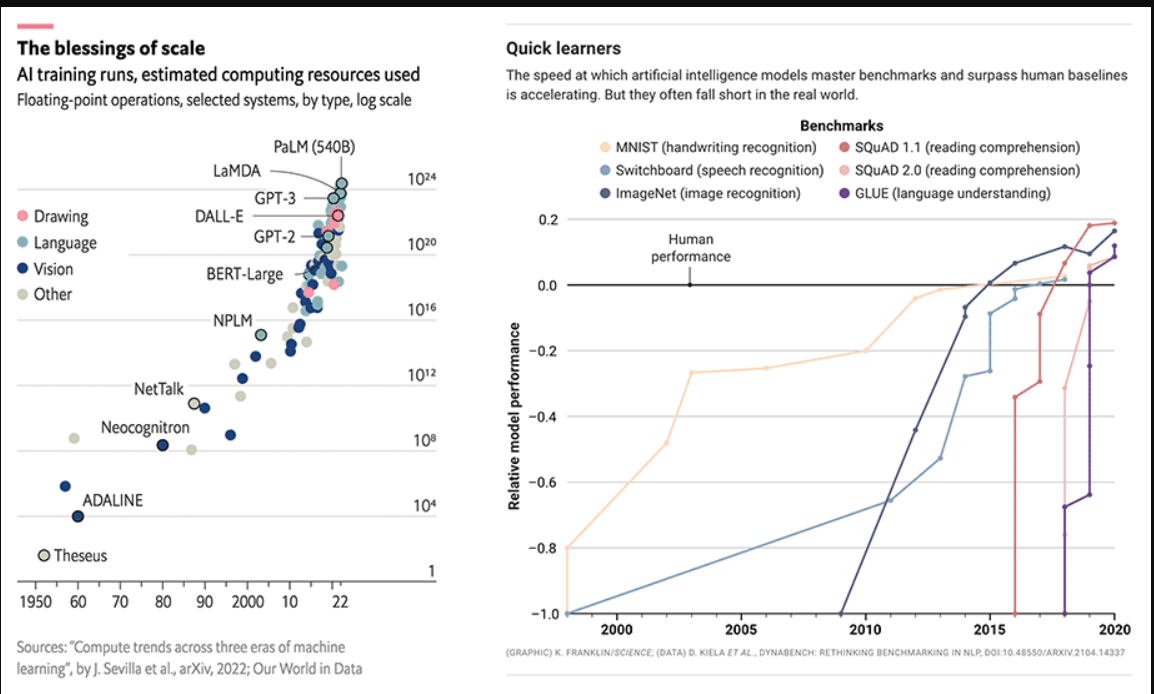
随着人工智能模型越来越大,它们已经开始超越主要的人类性能基准。来源:©《经济学人》报业有限公司,伦敦,2022年6月11日。保留所有权利;SCIENCE.ORG/CONTENT/ARTICLE/COMPUTERS-ACE-IQ-TESTS-STILL-MAKE-DUMB-mistocks-CAN-DIFFERENT-TESTS-HELP科学网站
果不其然,随着模型越来越大,它们开始提供人类水平的结果,然后是超人的结果。2015年至2020年间,用于训练这些模型的计算量增加了6个数量级,其结果在手写、语音和图像识别、阅读理解和语言理解方面超过了人类表现基准。OpenAI的GPT-3脱颖而出:该模型的性能比GPT-2有了巨大的飞跃,并在推特上提供了从代码生成到尖刻笑话写作的诱人演示。
正如移动通过GPS、摄像头和移动连接等新功能释放出新类型的应用程序一样,我们预计这些大型模型将激发新一波生成性人工智能应用程序。
尽管取得了所有的基础研究进展,但这些模型并不普遍。它们很大,很难运行(需要GPU协调),不可广泛访问(不可用或仅限封闭测试版),并且用作云服务的成本很高。尽管存在这些限制,但最早的一代人工智能应用程序开始加入竞争。
第三波:更好、更快、更便宜(2022年+)
计算越来越便宜。新技术,如扩散模型,降低了训练和运行推理所需的成本。研究界继续开发更好的算法和更大的模型。开发人员访问权限从封闭测试扩展到开放测试,或者在某些情况下扩展到开源。
对于那些缺乏LLM访问权限的开发人员来说,现在为探索和应用程序开发打开了闸门。应用程序开始大量涌现。

MIDJOURNEY生成的插图
第4波:杀手级应用程序出现(现在)
随着平台层的固化,模型不断变得更好/更快/更便宜,模型访问趋于免费和开源,应用层的创造力爆发已经成熟。
正如移动通过GPS、摄像头和移动连接等新功能释放出新类型的应用程序一样,我们预计这些大型模型将激发新一波生成性人工智能应用程序。正如十年前移动技术的拐点为少数杀手级应用程序创造了市场机会一样,我们预计Generative AI将出现杀手级应用。竞争正在进行。
市场前景
下面是一个示意图,描述了将为每个类别提供动力的平台层以及将在其上构建的潜在应用程序类型。

模型
- 文本是最高级的领域。然而,自然语言很难正确,质量很重要。如今,这些模型在通用的中/短格式写作方面相当出色(但即便如此,它们通常用于迭代或初稿)。随着时间的推移,随着模型的改进,我们应该期待看到更高质量的输出、更长的形式内容和更好的垂直特定调整。
- GitHub CoPilot显示,代码生成可能在短期内对开发人员的生产力产生重大影响。它还将使非开发人员更容易创造性地使用代码。
- 图片是最近才出现的现象,但它们已经在网上疯传:在推特上分享生成的图片比分享文本有趣得多!我们看到了具有不同美学风格的图像模型的出现,以及编辑和修改生成图像的不同技术。
- 语音合成已经存在了一段时间(你好Siri!),但消费者和企业应用程序才刚刚好起来。对于电影和播客等高端应用程序来说,对于听起来不机械的一次性人类质量语音来说,门槛相当高。但就像图像一样,今天的模型为实用应用程序的进一步细化或最终输出提供了一个起点。
- 视频和3D模型正在迅速崛起。人们对这些模式开启电影、游戏、VR、建筑和实体产品设计等大型创意市场的潜力感到兴奋。就在我们讲话的时候,研究机构正在发布基础的3D和视频模型。
- 其他领域:从音频和音乐到生物学和化学(生成蛋白质和分子,有人吗?),许多领域都在进行基础模型研发。
下图说明了我们如何期望看到基本模型的进展以及相关的应用程序成为可能的时间表。2025年及以后只是一个猜测。

应用
以下是我们感到兴奋的一些应用程序。我们在这个页面上捕捉到的远不止这些,创始人和开发人员正在梦想的创造性应用程序让我们着迷。
- 文案:对个性化网络和电子邮件内容的需求不断增长,以推动销售和营销策略以及客户支持,这是语言模型的完美应用。措辞的简短和风格化,再加上这些团队面临的时间和成本压力,应该会推动对自动化和增强解决方案的需求。
- 纵向写作助理:如今大多数写作助理都是横向的;我们相信有机会为特定的终端市场构建更好的生成应用程序,从法律合同写作到编剧。这里的产品差异在于针对特定工作流程对模型和用户体验模式进行微调。
- 代码生成:当前的应用程序为开发人员提供了动力,使他们更有效率:GitHub Copilot现在在安装它的项目中生成了近40%的代码。但更大的机会可能是为消费者开放编码。学习提示可能成为终极的高级编程语言。
- 艺术一代:艺术史和流行文化的整个世界现在都被编码在这些大型模型中,让任何人都可以随意探索以前需要一生才能掌握的主题和风格。
- 游戏:梦想是使用自然语言来创建复杂的场景或模型;这种最终状态可能还有很长的路要走,但有更直接的选择在短期内更可行,比如生成纹理和skybox艺术。
- 媒体/广告:想象一下为消费者实现代理工作自动化、优化广告文案和创意的潜力。这里提供了多模式生成的绝佳机会,将销售信息与互补的视觉效果配对。
- 设计:数字和物理产品的原型制作是一个劳动密集型的迭代过程。粗略草图和提示的高保真度渲染已经成为现实。随着三维模型的出现,生成设计过程将从制造和生产文本延伸到对象。你的下一个iPhone应用程序或运动鞋可能是由机器设计的。
- 社交媒体和数字社区:有没有使用生成工具表达自己的新方式?随着消费者学会在公共场合创造新的社交体验,像Midtravel这样的新应用程序正在创造新的社会体验。

ILLUSTRATION GENERATED WITH MIDJOURNEY
最好的Generative AI公司可以通过在用户参与度/数据和模型性能之间坚持不懈地执行,从而产生可持续的竞争优势。
一个生成型人工智能应用程序的剖析
生成型人工智能应用程序会是什么样子?以下是一些预测。
- 智能和模型微调
生成型人工智能应用程序建立在GPT-3或稳定扩散等大型模型之上。随着这些应用程序获得更多的用户数据,它们可以对模型进行微调,以:1)提高特定问题空间的模型质量/性能;2) 降低模型尺寸/成本。
我们可以将Generative AI应用程序视为UI层和“小大脑”,它位于大型通用模型“大大脑”之上。
- 外形尺寸
如今,Generative AI应用程序在很大程度上以插件的形式存在于现有的软件生态系统中。代码完成发生在IDE中;图像生成发生在Figma或Photoshop中;即使是Discord机器人也是将生成性人工智能注入数字/社交社区的容器。
还有少量独立的Generative AI网络应用程序,如用于文案的Jasper和Copy.AI,用于视频编辑的Runway,以及用于笔记的Mem。
插件可能是引导您自己的应用程序的一个有效楔子,它可能是克服用户数据和模型质量的鸡和蛋问题的一种精明方法(您需要分发以获得足够的使用量来改进您的模型;您需要好的模型来吸引用户)。我们已经看到这种分销策略在其他市场类别中得到了回报,比如消费者/社交。
- 互动的范式
如今,大多数Generative AI演示都是“一次性完成”的:你提供一个输入,机器吐出一个输出,你可以保留它,也可以扔掉它,然后再试一次。越来越多的模型变得越来越迭代,在那里你可以使用输出来修改、精细化、加倍和生成变化。
如今,Generative AI输出被用作原型或初稿。应用程序非常善于提出多种不同的想法来推动创作过程(例如,徽标或建筑设计的不同选项),并且非常善于建议用户需要精心处理才能达到最终状态的初稿(例如博客文章或代码自动完成)。随着模型变得越来越智能,部分脱离了用户数据,我们应该期待这些草案变得越来越好,直到它们足够好,可以用作最终产品。
- 持续的类别领导地位
最好的Generative AI公司可以通过在用户参与度/数据和模型性能之间坚持不懈地执行,从而产生可持续的竞争优势。要想获胜,团队必须拥有出色的用户参与度→ 2) 将更多的用户参与转化为更好的模型性能(及时改进、模型微调、用户选择作为标记的训练数据)→ 3) 使用出色的模型性能来推动更多的用户增长和参与。他们可能会进入特定的问题空间(例如,代码、设计、游戏),而不是试图成为每个人的一切。他们可能会首先深入集成到应用程序中以进行杠杆作用和分发,然后尝试用人工智能原生工作流取代现有应用程序。以正确的方式构建这些应用程序以积累用户和数据需要时间,但我们相信最好的应用程序将是持久的,并有机会变得庞大。
生成人工智能还很早。平台层刚刚变得不错,而应用程序空间几乎没有发展起来。
障碍和风险
尽管Generative AI具有潜力,但在商业模式和技术方面仍有很多问题需要解决。版权、信任和安全以及成本等重要问题远未解决。
睁大眼睛
生成人工智能还很早。平台层刚刚变得不错,而应用程序空间几乎没有发展起来。
需要明确的是,我们不需要大型语言模型来写托尔斯泰的小说,就可以很好地利用Generative AI。这些模型今天已经足够好了,可以写博客文章的初稿,生成徽标和产品界面的原型。在近中期内,将会有大量的价值创造。
第一波Generative AI应用程序类似于iPhone首次推出时的移动应用程序格局,有些噱头和单薄,竞争差异化和商业模式不明确。然而,其中一些应用程序为未来的发展提供了一个有趣的一瞥。一旦你看到一台机器产生复杂的功能代码或精彩的图像,你就很难想象未来机器不会在我们的工作和创造中发挥根本作用。
如果我们允许自己梦想几十年,那么很容易想象一个未来,在这个未来,世代人工智能深深植根于我们的工作、创造和游戏方式:自己写的备忘录;3D打印任何你能想象到的东西;从文字到皮克斯电影;像Roblox一样的游戏体验,我们可以尽可能快地创造出丰富的世界。虽然这些经历在今天看起来像科幻小说,但进展速度之快令人难以置信——我们在几年内从狭隘的语言模型发展到代码自动完成——如果我们继续保持这种变化速度,遵循“大模型摩尔定律”,那么这些牵强的场景可能会进入可能的领域。
呼吁创业
我们正处于技术平台转变的开端。我们已经在这一领域进行了大量投资,并被在这一空间建设的雄心勃勃的创始人所激励。
- 194 次浏览
【生成式人工智能】生成人工智能创新的历史跨越了90年
视频号
微信公众号
知识星球
ChatGPT的首次亮相引发了围绕生成人工智能的广泛宣传和争议,生成人工智能是人工智能的一个子集,在历史里程碑中根深蒂固。
随着ChatGPT的推出,围绕生成人工智能的热议愈演愈烈,该公司在推出后的两个月内就增长到了1亿多用户。但ChatGPT只是生成人工智能的冰山一角。
世代人工智能的历史实际上可以追溯到90年前。尽管创新和发展比比皆是,但其商业进展相对缓慢——直到最近。在过去五年里,更大的标记数据集、更快的计算机和自动编码未标记数据的新方法的结合加速了生成人工智能的发展。仅在去年一年,就出现了近乎感知的聊天机器人,数十种用于从描述中生成图像的新服务,以及大型语言模型(LLM)几乎适用于业务的各个方面。
今天的许多发展都建立在计算语言学和自然语言处理的进步之上。同样,早期的程序性内容生成工作导致了游戏中的内容生成,参数化设计工作为工业设计奠定了基础。
90年,还在继续
许多关键里程碑点缀着生成型人工智能的发展和创新。
1932
Georges Artsrouni发明了一种机器,据报道,他称之为机械大脑,在编码到穿孔卡片上的机械计算机上进行语言之间的翻译。他制作了第二个版本,并于1937年在巴黎的一次展览上获得了机械学的主要奖项。
1957
语言学家诺姆·乔姆斯基发表了《句法结构》一书,描述了自然语言句子解析和生成的语法规则。这本书还支持语法解析和语法检查等技术。
1963
计算机科学教授Ivan Sutherland介绍了Sketchpad,这是一个交互式3D软件平台,允许用户按程序修改2D和3D内容。1968年,萨瑟兰和同为教授的大卫·埃文斯创办了Evans&Sutherland。他们的一些学生后来创办了皮克斯、Adobe和Silicon Graphics。
1964
数学家兼建筑师克里斯托弗·亚历山大出版了《形式综合笔记》,阐述了自动化设计的原则,这些原则后来影响了产品的参数化和生成设计。1976年,他撰写了《模式语言》,这本书在体系结构中很有影响力,并启发了新的软件开发方法。

1966
麻省理工学院教授Joseph Weizenbaum创建了第一个聊天机器人Eliza,它模拟与心理治疗师的对话。《麻省理工学院新闻》2008年报道称,魏岑鲍姆“对人工智能越来越怀疑”,“震惊地发现,许多用户都认真对待他的程序,并对其敞开心扉。”
自动语言处理咨询委员会(ALPAC)报告称,机器翻译和计算语言学没有兑现承诺,并导致未来20年这两项技术的研究资金削减。
数学家Leonard E.Baum介绍了概率隐马尔可夫模型,该模型后来被用于语音识别、分析蛋白质和生成响应。
1968
计算机科学教授Terry Winograd创建了SHRDLU,这是第一个可以根据用户的指令操纵和推理出区块世界的多模式人工智能。
1969
William A.Woods介绍了增广转换网络,这是一种用于将信息转换为计算机可以处理的形式的图论结构。他为美国国家航空航天局载人航天中心建造了第一个名为LUNAR的自然语言系统,以回答有关阿波罗11号月球岩石的问题。
1970
耶鲁大学计算机科学和心理学教授、认知科学学会联合创始人罗杰·尚克开发了概念依赖理论,以数学方式描述自然语言理解和推理过程。
1978
Don Worth在加州大学洛杉矶分校当程序员时,为Apple II创建了类似流氓的游戏《苹果庄园之下》。该游戏使用程序性内容生成以编程方式创建了一个丰富的游戏世界,可以在当时有限的计算机硬件上运行。
1980
Michael Toy和Glenn Wichman开发了基于Unix的游戏Rogue,该游戏使用程序性内容生成来动态生成新的游戏级别。Toy与人共同创立了A.I.Design公司,几年后将游戏移植到PC上。该游戏激发了后来在游戏行业使用程序内容生成来生成关卡、角色、纹理和其他元素的兴趣。
1985
计算机科学家和哲学家Judea Pearl介绍了贝叶斯网络因果分析,该分析提供了表示不确定性的统计技术,从而产生了以特定风格、语气或长度生成内容的方法。
1986
Michael Irwin Jordan出版了《串行顺序:一种并行分布式处理方法》,为递归神经网络(RNN)的现代应用奠定了基础。他的创新使用反向传播来减少误差,这为进一步研究和几年后RNN在处理语言中的广泛采用打开了大门。
1988
软件提供商PTC推出了Pro/Engineer,这是第一个允许设计师通过可控方式调整参数和约束来快速生成新设计的应用程序。现在被称为PTC Creo的实体建模软件可以帮助卡特彼勒和约翰迪尔等公司更快地开发工业设备。
1989
Yann LeCun、Yoshua Bengio和Patrick Haffner演示了如何使用卷积神经网络来识别图像。LeNet-5是准确识别手写数字的新技术的早期实现。尽管这需要一些时间,但由于2006年的ImageNet数据库和2012年的AlexNet CNN架构,计算机硬件和标记数据集的改进使新方法有可能扩大规模。

Convolutional neural networks are among the older and more popular deep learning models compared to the relatively new generative adversarial networks.
1990
Sepp Hochreiter和Jurgen Schmidhuber引入了长短期记忆(LSTM)架构,这有助于克服RNN的一些问题。LSTM为RNN提供了对记忆的支持,并有助于推动对分析较长文本序列的工具的研究。
贝尔通讯研究所、芝加哥大学和西安大略大学的一组研究人员发表了论文《潜在语义分析索引》。这项新技术提供了一种识别训练文本样本中单词之间语义关系的方法,为word2vec和BERT(来自变压器的双向编码器表示)等深度学习技术铺平了道路。
2000
蒙特利尔大学的Yoshua Bengio、Rejean Ducharme、Pascal Vincent和Christian Jauvin发表了《神经概率语言模型》,提出了一种使用前馈神经网络对语言建模的方法。该论文进一步研究了将单词自动编码为表示其含义和上下文的向量的技术。它还展示了反向传播如何帮助训练建模语言的RNN。
2006
数据科学家李飞飞建立了ImageNet数据库,为视觉对象识别奠定了基础。该数据库为使用AlexNet识别物体并稍后生成物体的进步埋下了种子。
IBM Watson最初的目标是在标志性的智力竞赛节目《危险边缘》中击败一个人!。2011年,问答计算机系统击败了该节目的历史(人类)冠军肯·詹宁斯。
2011
苹果公司发布了Siri,这是一款语音个人助理,可以生成响应并根据语音请求采取行动。
2012
Alex Krizhevsky设计了AlexNet CNN架构,开创了一种利用GPU最新进展自动训练神经网络的新方法。在当年的ImageNet大规模视觉识别挑战赛中,AlexNet识别出的图像错误率比亚军低10.8%以上。它启发了在GPU上并行扩展深度学习算法的研究。
2013
谷歌研究员Tomas Mikolov及其同事引入word2vec来自动识别单词之间的语义关系。这项技术使将原始文本转换为深度学习算法可以处理的向量变得更容易。
2014
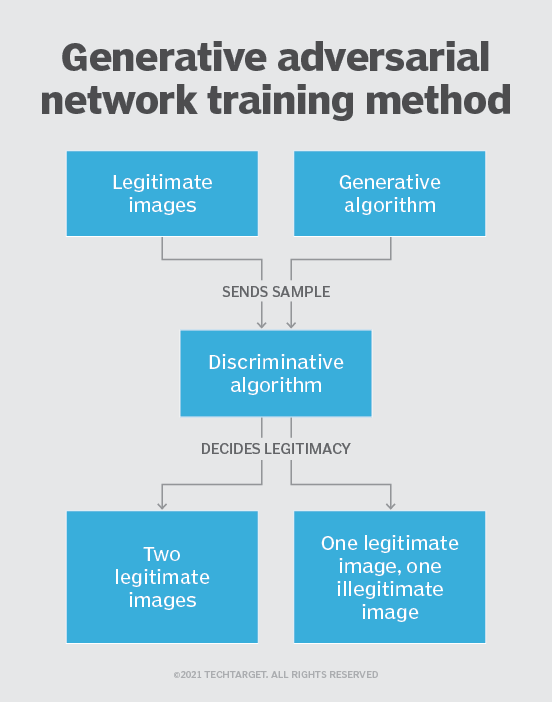
研究科学家伊恩·古德费罗开发了生成对抗性网络,使两个神经网络相互对抗,以生成越来越逼真的内容。一个神经网络生成新的内容,而另一个则区分真实数据和生成的数据。随着时间的推移,这两个网络的改进带来了更高质量的内容。
Diederik Kingma和Max Welling介绍了用于生成建模的变分自动编码器。VAE用于生成图像、视频和文本。该算法找到了更好的方法来表示输入数据,并将其转换回原始格式或另一种格式。
2015
Autodesk开始发表关于Project Dreamcatcher的研究,这是一种使用算法创建新设计的生成设计工具。用户可以描述预期的特性,如材料、尺寸和重量。
斯坦福大学的研究人员在论文《使用非平衡热力学的深度无监督学习》中发表了关于扩散模型的研究。这项技术提供了一种对最终图像添加噪声的过程进行逆向工程的方法。它合成图片和视频,生成文本并为语言建模。
2016
微软发布了聊天机器人TAY(想着你),它回答了通过推特提交的问题。用户很快就开始在推特上向聊天机器人发布煽动性的概念,这很快就产生了种族主义和性指控的信息作为回应。微软在16小时后关闭了它。
2017
谷歌宣布将利用人工智能设计用于深度学习工作负载的TPU(张量处理单元)芯片。
谷歌研究人员在开创性的论文《注意力就是你所需要的一切》中提出了转换器的概念。这篇文章启发了随后对可以自动将未标记文本解析为LLM的工具的研究。
西门子与Frustum合作,将生成设计能力集成到西门子NX产品设计工具中。新功能使用人工智能生成新的设计变体。西门子的竞争对手PTC于次年收购了Frustum,以提供自己的生成设计产品。
Autodesk首次将其Project Dreamcatcher研究作为Autodesk Generative Design进行商业化实施。
2018
谷歌研究人员在BERT中实现了转换器,该转换器对超过33亿个单词进行了训练,由1.1亿个参数组成,可以自动学习句子、段落甚至书籍中单词之间的关系,以预测文本的含义。
谷歌DeepMind的研究人员开发了用于预测蛋白质结构的AlphaFold。这项创新技术为生成人工智能在医学研究、药物开发和化学领域的应用奠定了基础。
OpenAI发布了GPT(Generative Pre-trained Transformer)。GPT接受了约40 GB数据的培训,由1.17亿个参数组成,为随后的内容生成、聊天机器人和语言翻译LLM铺平了道路。

The GPT-4 large language model far outweighs its predecessor in parameters and capabilities.
2019
“不再疟疾”慈善机构和足球明星大卫·贝克汉姆使用深度伪造技术将他的讲话和面部动作翻译成九种语言,这是在全球范围内结束疟疾的紧急呼吁的一部分。
英国一家能源公司的首席执行官在收到一项紧急请求后,利用音频深度假冒技术冒充其母公司老板,向匈牙利一家银行转账22万欧元(合24.3万美元)。全世界都注意到了社会工程网络攻击的新时代。
OpenAI发布了具有15亿个参数的GPT-2。GPT-2在800万个网页的数据集上进行了训练,其目标是预测下一个单词,给定一些文本中所有以前的单词。
2020
开放人工智能发布了GPT-3,这是有史以来最大的神经网络,由1750亿个参数组成,需要800 GB的存储空间。在最初的九个月里,OpenAI报告称,有300多个应用程序正在使用GPT-3,数千名开发人员正在该平台上进行构建。
谷歌、加州大学伯克利分校和加州大学圣地亚哥分校的研究人员发表了《NeRF:将场景表示为视图合成的神经辐射场》。这项新技术激发了3D内容生成的研究和创新。
微软的研究人员开发了不带字幕数据的图像字幕算法的VIVO预训练。测试表明,这种训练可以超越许多人工字幕。
2021
Cerebras Systems使用人工智能帮助生成WSE-2的设计,这是一个完整硅片大小的单芯片,有超过85万个核心和2.6万亿个晶体管。
OpenAI引入了Dall-E,它可以根据文本提示生成图像。这个名字是一个虚构机器人的名字WALL-E和艺术家萨尔瓦多·达利的组合。新工具引入了对比语言图像预训练(CLIP)的概念,对互联网上发现的图像的字幕进行排名。
2022
OpenAI发布了Dall-E2,这是一款更小、更高效的图像生成器,使用扩散模型生成图像。人工智能系统可以根据自然语言的描述生成图像和艺术。
英伟达创建了NGP Instant NeRF代码,用于将图片快速转换为3D图像和内容。
谷歌DeepMind发布了一篇关于Gato的论文,Gato是一种通用的多模式人工智能,可以执行600多项任务,包括为文本添加字幕、生成机器人指令、玩视频游戏和导航环境。
Runway Research、Stability AI和CompVis LMU的研究人员发布了Stable Diffusion作为开源代码,可以通过文本提示自动生成图像内容。这项技术是一种结合自动编码器将数据转换为中间格式的新方法,因此扩散模型可以更有效地处理数据。
OpenAI于11月发布了ChatGPT,为其GPT 3.5 LLM提供了一个基于聊天的接口。它在两个月内吸引了超过1亿用户,这是有史以来消费者采用服务最快的一次。
2023
Getty Images 和一群艺术家分别起诉了几家实施Stable Diffusion的公司侵犯版权。他们的诉讼声称,Stability AI、Midtravel和DeviantArt等公司未经同意擅自剽窃了盖蒂的内容。
微软在其必应搜索引擎中集成了一个版本的ChatGPT。谷歌紧随其后,计划发布基于Lamda引擎的Bard聊天服务。关于检测人工智能生成的内容的争议也随之升温。
OpenAI发布了GPT-4多模式LLM,它可以接收文本和图像提示。包括埃隆·马斯克(Elon Musk)、史蒂夫·沃兹尼亚克(Steve Wozniak)和数千名签名者在内的技术领袖名人录呼吁暂停开发“比GPT-4更强大”的先进人工智能系统
人工智能的未来
ChatGPT的深度和易用性为生成人工智能的广泛采用显示出了巨大的前景。但安全、负责任地推出聊天机器人的问题激发了人们对检测人工智能生成的文本、图像和视频的更好工具的研究。工业和社会还将建立更好的工具来跟踪信息的来源,以创建更值得信赖的人工智能。
人工智能开发平台的改进将有助于加快文本、图像、视频、3D内容、制药、供应链、物流和业务流程的更好生成人工智能能力的研发。尽管这些新的一次性工具很好,但当这些功能直接嵌入当今工具的更好版本中时,生成人工智能的最重大影响将得以实现。
语法检查会提高。设计工具将把更有用的建议无缝地直接嵌入到工作流程中。培训工具将自动识别组织某个领域的最佳实践,以帮助更有效地培训其他领域。
- 230 次浏览