【LLM】大型语言模型与ML基础结构堆栈的未来
视频号

微信公众号

知识星球

本文分享了我们对大型语言模型(LLM)将如何影响机器学习项目以及为其提供动力的基础设施堆栈的看法。我们相信,LLM和其他基础模型将作为ML堆栈中一个强大的新模型家族而被采用-增强而不是取代它。有关如何开始使用Metaflow进行LLM实验的技术细节,请参阅我们关于使用Metaflow训练Dolly模型的文章。
在过去的一年里,大型语言模型和计算机视觉已经经历了登月时刻。有一种感觉,一个全新的可能性宇宙已经打开,尽管没有人确切知道会发生什么变化,如何变化,何时变化,由谁改变。
目睹不可能变成可能,令人激动。这可能会迅速而发自内心地发生——想象一下,目睹莱特兄弟的首次飞行,阿姆斯特朗登上月球的第一步,或者现在的聊天GPT。然而,与以前的许多时候一样,我们可能在短期内高估了这些技术的影响,而在长期内低估了它们的效果。
虽然很容易看出最初的兴奋是如何产生过于生动的梦境和噩梦的,但长期影响往往被低估了,因为当一项新技术逐渐被越来越多样化的人和公司所使用时,很难想象会发生什么。
尽管互联网和网络在2001年非常受公众关注,但没有人能预测到TikTok的成功或互联网可租赁踏板车的普遍存在。与最初的乌托邦相比,长期的成功故事往往会让人感到奇怪的平凡,因为闪亮的新技术交织在我们的日常生活中,融合了过去和未来。
虽然我们无法预见新模式将如何影响我们未来的生活,但我们知道那里的旅程是什么样子的。我们需要通过以人为中心的软件包来提供新技术,使其易于使用,这样所有好奇的组织都可以开始独立创新,探索由自己的领域知识和未来愿景驱动的各种用例。
1943年,IBM总裁估计“可能有五台计算机的世界市场”,当时已经证明这台计算机的制造是可行的(至少在不考虑成本的情况下),但操作起来绝对痛苦(在大多数用例中,投资回报率都有问题)。同样,到2023年,人们可能会估计,世界只需要少数几个将通过API使用的大型语言模型,因为LLM的构建成本高得令人瞠目结舌,而且在今天操作起来很痛苦。
大型语言模型和ML基础设施堆栈
正如我们过去在计算机、互联网或移动应用程序中看到的那样,当新技术从一种由少数人控制的昂贵的派对把戏成熟为无数公司和个人可以轻松访问的东西时,真正的革命就会发生。从这些过去的采用曲线中学习,我们可以预测未来会发生什么。
首先,没有理由相信LLM和其他基金会模式会改变公司采用技术的方式。与任何其他技术组件一样,LLM的采用需要一轮又一轮的评估和实验。使用LLM的工作流需要开发并集成到周围的系统中,并且需要由人类不断改进、调整、监控和控制。和以前一样,一些公司准备比其他公司更早地踏上这段旅程。
其次,除了概念验证之外,新技术并不能免费提供不可预测或不受欢迎的用户体验。LLM将成为工具箱中的一个新工具,使公司能够提供令人愉快和差异化的体验,一些公司将学会比其他公司更好地利用这些体验。特别是,受监管行业的公司需要像对待其技术堆栈的任何其他部分一样谨慎对待LLM,因为监管机构肯定会把重点放在人工智能上。
从这个角度来看,LLM是ML基础设施堆栈中其他模型中的模型,其他层中的一层:
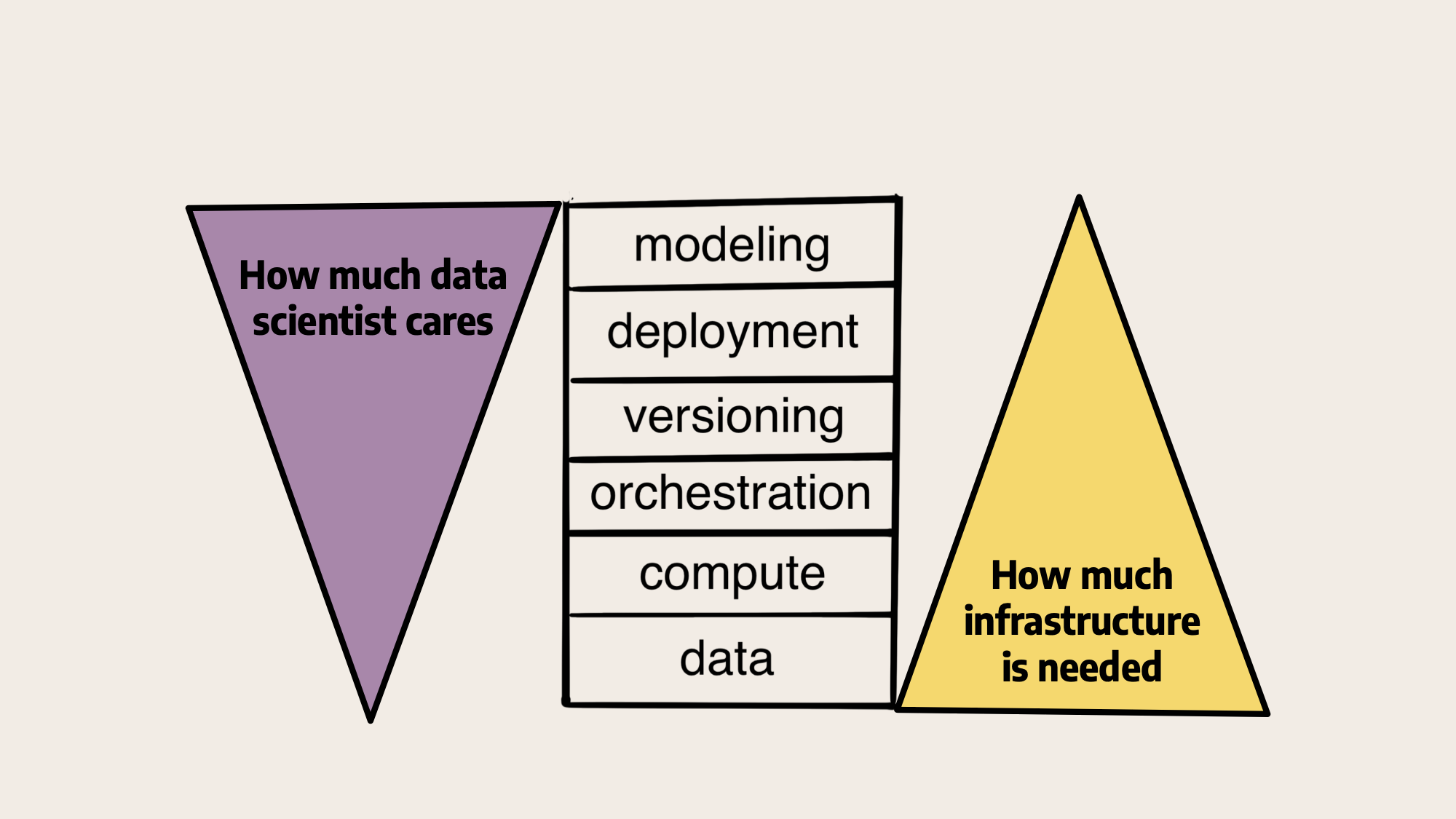
在我们对上面堆栈的原始说明中,左边的数据科学家主要关注与建模密切相关的问题,而逐渐较少关注较低级别的基础设施,而基础设施提供商,如我们在Outerbounds或内部平台团队,则相反。最近,LLM使每个人的注意力更加集中,如下所示:

大多数讨论都围绕着模型本身以及它们所带来的令人兴奋的演示展开。或者,在基础设施方面,重点是大规模的数据集或训练模型所需的巨大计算能力。中间的操作问题没有得到太多关注。我们相信,随着公司开始认真考虑如何在实践中使用这些模型,这种情况即将改变。
2025年及以后的ML项目
我们相信,LLM和其他基础模型将作为ML堆栈中一个强大的新模型家族被采用——对其进行扩充,而不是取代。在某些情况下,特别是当涉及文本和图像时,新技术将实现全新的用例。在其他情况下,它们将用于改进现有的ML模型和数据科学项目,如下所述。

根据用例的不同,公司选择拥有一些模型,如图中基于通用基础模型的微调LLM或嵌入生成LLM。在其他情况下,通过API使用供应商拥有的模型是有意义的。在任何情况下,公司都希望仔细考虑他们希望在其治理边界内拥有和控制系统的哪些部分,以及哪些功能可以安全地外包给第三方供应商。
所有这些系统都将由人类通过结合数据、代码和模型进行设计。相应地,ML基础设施堆栈所解决的所有基本问题都保持不变:系统需要轻松访问数据和计算。它们被构造为工作流,通过多个版本迭代构建。结果以各种方式部署,利用最适合每项工作的模型。
今天,一些人认为,与其他ML模型相比,LLM和其他基础模型将需要一种根本不同的方法。也许新型号太大、太复杂、太昂贵,大多数公司都无法处理。或者,可以提供一种通用的模式作为服务,减轻公司处理自己问题的需要。
我们认为有两种强大的顺风作为反作用力:
- 在工程方面,学术界、供应商和非营利组织的集体力量将生产许可的、优化的基础模型、数据集和库,这将使特定领域模型的培训和微调变得更加便宜,因此对于合理规模的公司来说是可以实现的。此外,模型蒸馏等技术可以从根本上减少生产模型的规模和成本。
- 在建模方面,许多公司将意识到,他们可以——也必须——将人工智能作为其通常ML计划的一部分。他们希望像以前一样保留对其数据、产品体验和专有IP的控制权,将其自定义模型保持在其治理边界内。
因此,更多的公司能够并且愿意独立创新。我们很可能会看到,拥有深度领域专业知识的公司构建的较小模型优于没有领域专业知识构建的通用模型。新的人工智能技术将成为那些学会将其无缝集成到现有产品和工作流程中的公司的竞争优势。
接下来的步骤
新的人工智能技术成为ML基础设施堆栈的一部分而不是替代品的一个重要含义是,您可以继续使用开源Metaflow等经得起未来考验的工具来实现数据和ML堆栈的现代化。现实地说,绝大多数公司仍处于ML之旅的早期阶段,因此从奠定坚实的基础开始是有意义的。
实现这一目标的所有工作都是相关的,一旦你准备好开始采用最新的人工智能技术,就会有回报。如果您想要以最少的工程工作量打下坚实的基础,我们可以让您快速开始使用托管Outerbounds平台,该平台为所有ML/AI实验和生产应用程序提供了一个易于使用、优化和安全的环境。
要了解更多关于Metaflow和基础模型的信息,请参阅我们关于以下主题的最新文章:使用Metaflow训练一个大型语言模型,以Dolly为特色,它演示了如何使用Metaflow微调最先进的LLM Databricks的Dolly。您也可以阅读我们以前关于使用稳定扩散生成图像和使用Whisper进行文本到语音翻译的文章。
- 316 次浏览