【LLM】Cerebras GPT:一个开放的、计算高效的大型语言模型家族
视频号

微信公众号

知识星球

Cerebras开源了7个GPT-3模型,参数从1.11亿到130亿不等。这些模型使用Chinchilla公式进行训练,为准确性和计算效率树立了新的基准。
摘要
最先进的语言模型在训练方面极具挑战性;它们需要庞大的计算预算、复杂的分布式计算技术和深厚的ML专业知识。因此,很少有组织从头开始训练大型语言模型(LLM)。越来越多拥有资源和专业知识的人没有公开结果,这标志着几个月前的重大变化。
在Cerebras,我们相信要促进开放获取最先进的模型。考虑到这一点,我们很自豪地宣布向开源社区发布Cerebras GPT,这是一个由7个GPT模型组成的家族,参数范围从1.11亿到130亿不等。这些模型使用Chinchilla公式进行训练,在给定的计算预算下提供了最高的精度。与迄今为止任何公开可用的模型相比,Cerebras GPT具有更快的训练时间、更低的训练成本和更少的能量消耗。
所有模型都是在CS-2系统上训练的,CS-2系统是仙女座人工智能超级计算机的一部分,使用我们简单的数据并行权重流架构。由于不必担心模型分区,我们能够在短短几周内训练这些模型。训练这七个模型使我们能够推导出一个新的比例定律。缩放定律基于训练计算预算预测模型精度,在指导人工智能研究方面具有巨大影响力。据我们所知,Cerebras GPT是第一个预测公共数据集模型性能的缩放定律。
今天的版本旨在供任何人使用和复制。所有型号、重量和检查点都可以在Hugging Face和GitHub上使用Apache 2.0许可证。此外,我们在论文“Cerebras GPT:在Cerebras晶圆级集群上训练的开放计算优化语言模型”中提供了有关我们的训练方法和性能结果的详细信息。用于训练的Cerebras CS-2系统也可通过Cerebras Model Studio按需提供。
Cerebras GPT:开放式LLM开发的新模型
人工智能有可能改变世界经济,但它的使用越来越受到限制。最新的大型语言模型——OpenAI的GPT4——发布时没有关于其模型架构、训练数据、训练硬件或超参数的信息。越来越多的公司使用封闭的数据集构建大型模型,并仅通过API访问提供模型输出。
为了使LLM成为一种开放和可访问的技术,我们认为获得开放、可复制、免版税的最先进模型对于研究和商业应用都很重要。为此,我们使用最新的技术和我们称之为Cerebras GPT的开放数据集训练了一系列转换器模型。这些模型是第一个使用Chinchilla公式训练并通过Apache 2.0许可证发布的GPT模型家族。
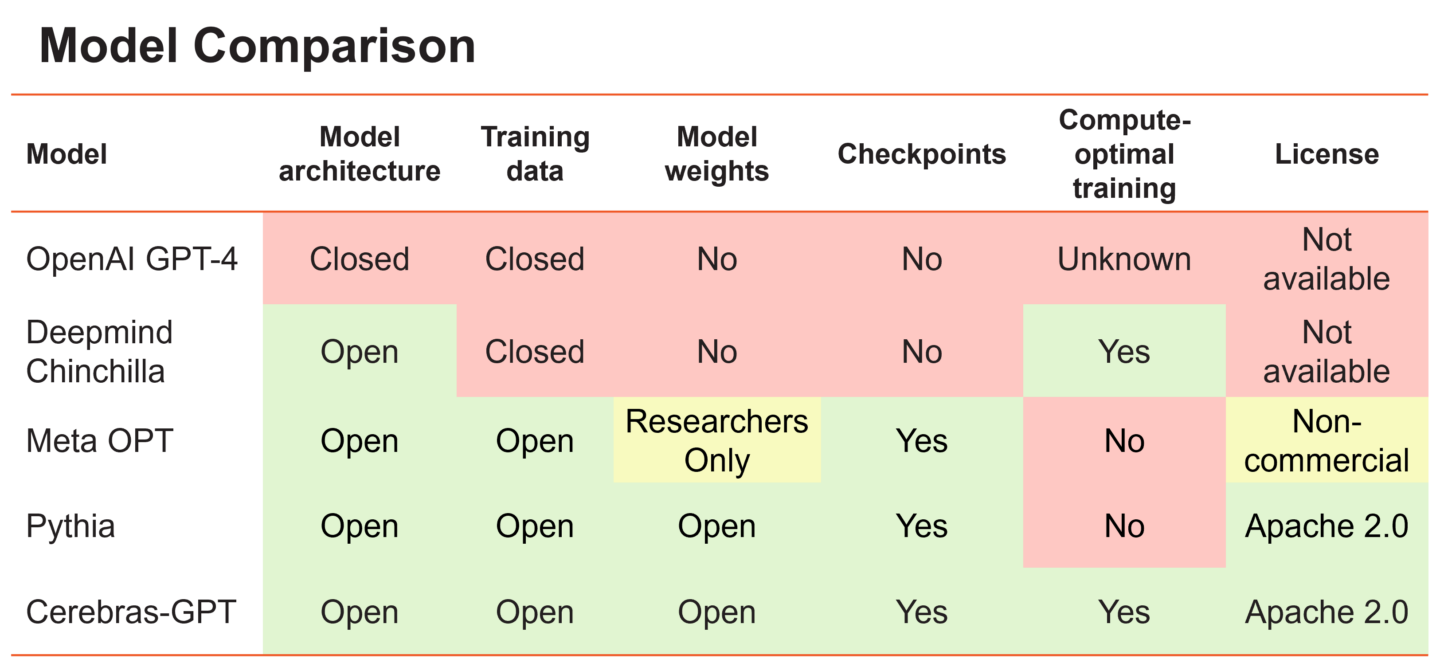
Figure 1. A comparison of different large language models and their openness and training philosophy.
大型语言模型可以大致分为两大阵营。第一组包括OpenAI的GPT-4和DeepMind的Chinchilla等模型,它们在私人数据上进行训练,以实现最高水平的准确性。然而,这些模型的训练权重和源代码对公众是不可用的。第二组包括Meta的OPT和Eleuther的Pythia等模型,它们是开源的,但没有以计算优化的方式进行训练。
所谓“计算最优”,我们指的是DeepMind的发现,当模型中的每个参数都使用20个数据令牌时,大型语言模型在固定的计算预算下实现了最高的精度。因此,应该在200亿个数据令牌上训练10亿个参数模型,以在固定的训练预算下达到最佳结果。这有时被称为“龙猫配方(Chinchilla recipe)”
这一发现的一个含义是,在训练一系列模型尺寸时,使用相同数量的训练数据并不是最佳的。例如,用太多数据训练一个小模型会导致收益递减,每个FLOP的精度增益较小——最好使用数据较少的大模型。相比之下,在太少的数据上训练的大型模型并没有发挥其潜力——最好缩小模型大小并为其提供更多的数据。在每种情况下,根据Chinchilla配方,每个参数使用20个令牌是最佳的。
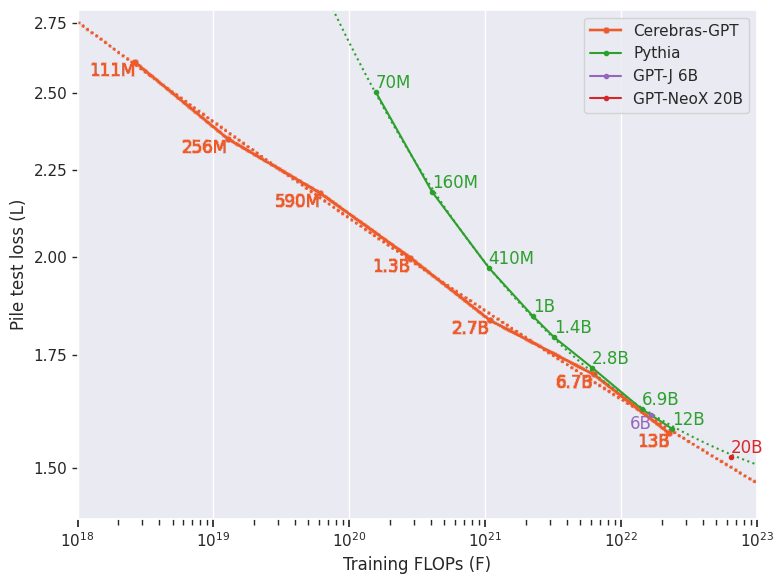 Figure 2. Cerebras-GPT vs. Pythia. Lower curves show greater compute efficiency for a given loss level.
Figure 2. Cerebras-GPT vs. Pythia. Lower curves show greater compute efficiency for a given loss level.
EleutherAI的Pythia开源模型套件对研究界非常有价值,因为它在受控训练方法下使用公共Pile数据集提供了广泛的模型大小。然而,Pythia在所有模型大小中使用固定数量的令牌进行训练,目的是在所有模型中提供一个苹果对苹果的基线。
Cerebras GPT旨在与Pythia互补,旨在使用相同的公共Pile数据集覆盖广泛的模型大小,并建立训练有效的缩放定律和模型族。Cerebras GPT由七个模型组成,参数分别为111M、256M、590M、1.3B、2.7B、6.7B和13B,所有这些模型都使用每个参数20个令牌进行训练。通过使用每个模型大小的最佳训练令牌,Cerebras GPT在所有模型大小中实现了每单位计算的最低损失(图2)。
新扩展定律
训练一个大型语言模型可能是一个昂贵且耗时的过程。它需要大量的计算资源和专业知识来优化模型的性能。解决这一挑战的一种方法是训练一系列不同大小的模型,这有助于建立描述训练计算和模型性能之间关系的缩放定律。
![]() Figure 3. Cerebras-GPT scaling law
Figure 3. Cerebras-GPT scaling law
缩放定律对LLM的开发至关重要,因为它们允许研究人员在训练前预测模型的预期损失,从而避免昂贵的超参数搜索。OpenAI是第一个建立缩放定律的人,该定律显示了计算和模型损失之间的幂律关系。DeepMind随后进行了Chinchilla研究,证明了计算和数据之间的最佳比例。然而,这些研究是使用封闭的数据集进行的,这使得它们很难将结果应用于其他数据集。
Cerebras GPT通过在开放式Pile数据集的基础上建立缩放定律,继续这一研究方向。由此产生的缩放定律为使用Pile训练任何大小的LLM提供了计算高效的配方。通过发表我们的研究结果,我们希望为社区提供宝贵的资源,并进一步推动大型语言模型的发展。
下游任务的模型性能
我们评估了Cerebras GPT在一些特定任务语言任务(如句子完成和问答)上的表现。这些都很重要,因为即使模型可能具有良好的自然语言理解能力,但这可能无法转化为专门的下游任务。我们表明,Cerebras GPT为大多数常见的下游任务保留了最先进的训练效率,如图4中的示例所示。值得注意的是,尽管以前的缩放定律已经显示了训练前损失的缩放,但这是首次发布显示下游自然语言任务的缩放结果。
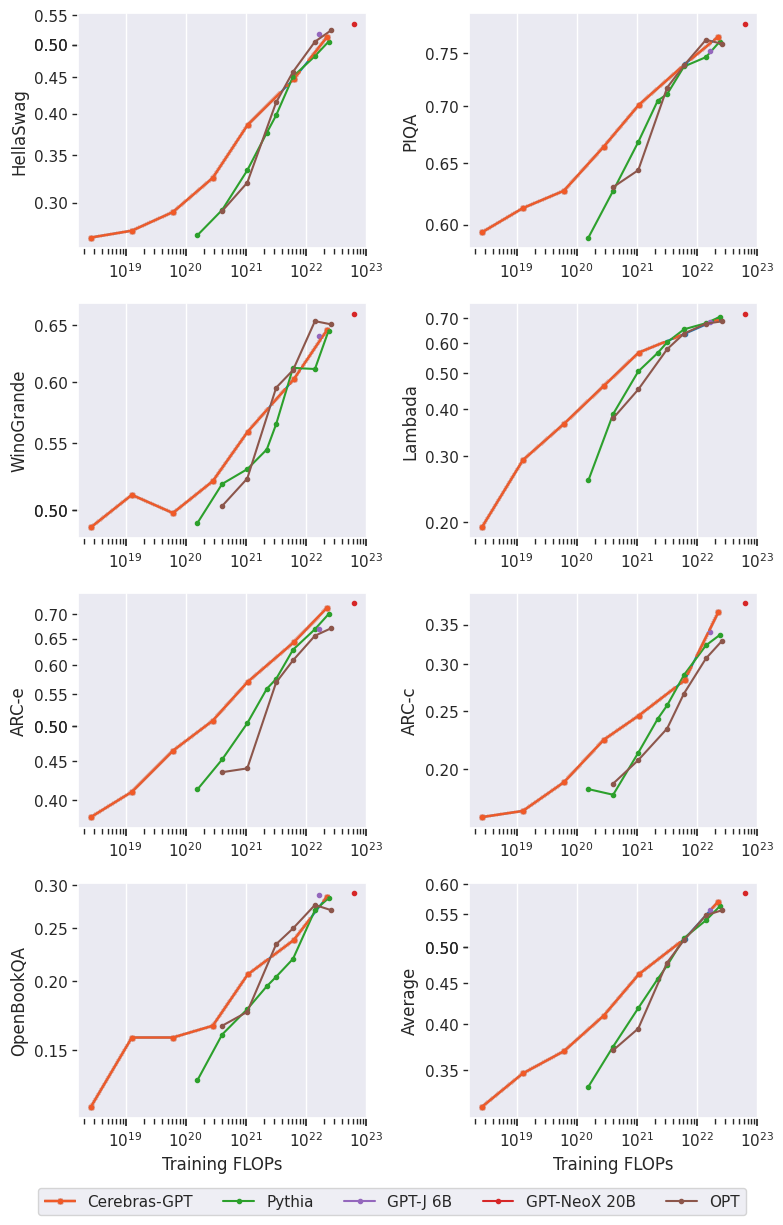 Figure 4 Example downstream task performance comparison of Cerebras-GPT and other open-source models. Cerebras-GPT preserves the training efficiency advantage across downstream tasks.
Figure 4 Example downstream task performance comparison of Cerebras-GPT and other open-source models. Cerebras-GPT preserves the training efficiency advantage across downstream tasks.
Cerebras CS-2:简单的数据并行训练
在GPU上训练非常大的模型需要大量的技术专业知识。在最近发布的GPT-4技术报告中,OpenAI仅在计算基础设施和扩展方面就贡献了30多个贡献者。为了理解原因,我们将查看图5所示GPU上现有的LLM缩放技术。
最简单的扩展方式是数据并行。数据并行缩放在每个设备中复制模型,并在这些设备上使用不同的训练批次,对其梯度进行平均。显然,这并不能解决模型大小的问题——如果整个模型不适合单个GPU,它就会失败。
一种常见的替代方法是流水线模型并行,它在不同的GPU上运行不同的层作为流水线。然而,随着管道的增长,激活内存会随着管道深度的二次方增加,这对于大型模型来说可能是令人望而却步的。为了避免这种情况,另一种常见的方法是在GPU之间划分层,称为张量模型并行,但这会在GPU之间强加大量的通信,这会使实现复杂化,并且可能很慢。
由于这些复杂性,目前没有单一的方法来扩展GPU集群。在GPU上训练大型模型需要一种具有各种形式并行性的混合方法;实现很复杂,很难提出,并且存在严重的性能问题
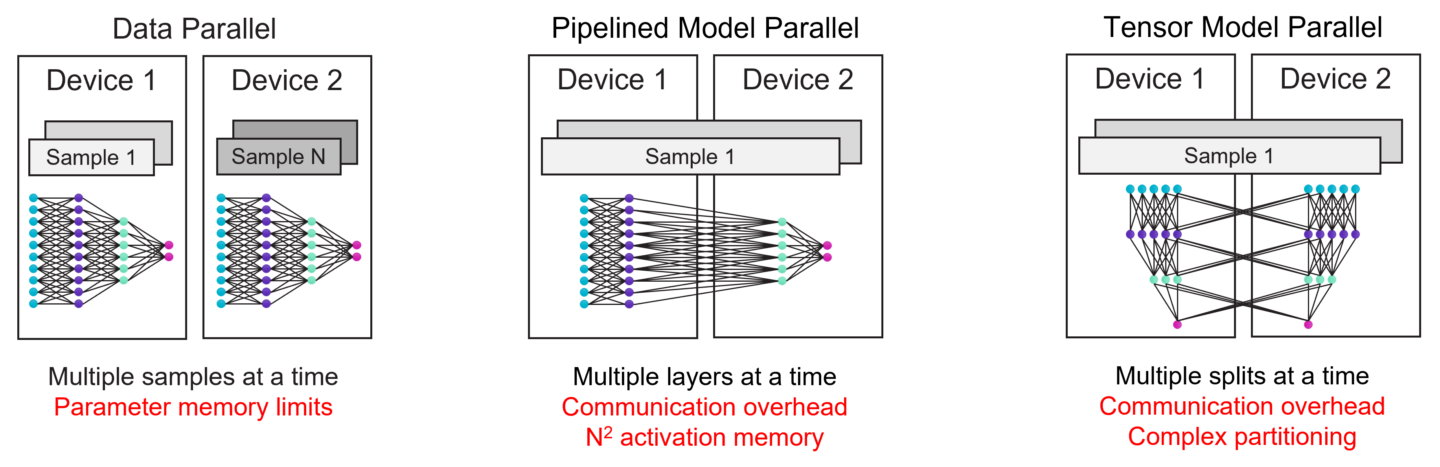
Figure 5 Existing scaling techniques on distributed GPU clusters and their challenges. Scaling on GPU clusters requires a complex combination of all forms of parallelism.
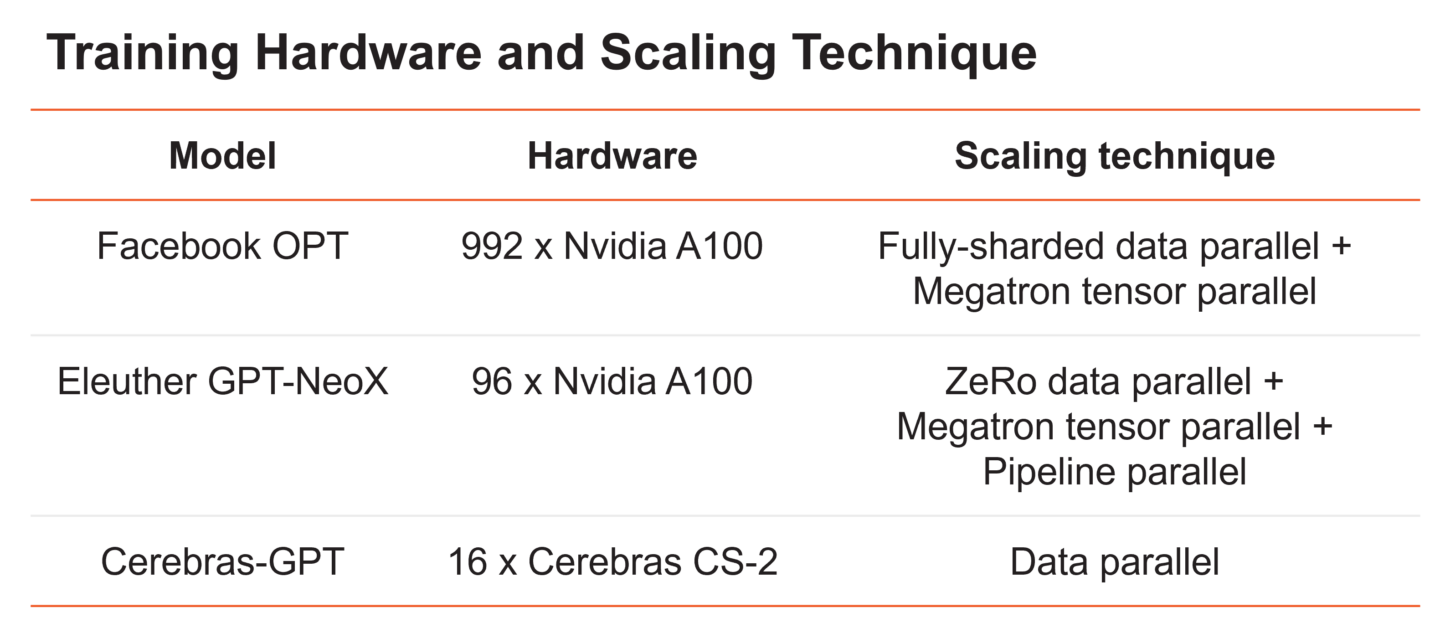
最近的两个大型语言模型说明了在许多GPU之间拆分大型语言模型所涉及的复杂性(图6)。Meta的OPT模型,参数范围从125M到175B,在992个GPU上使用数据并行性和张量并行性的组合以及各种内存优化技术进行训练。Eleuther的20B参数GPT-NeoX使用数据、张量和流水线并行度的组合,在96个GPU上训练模型。
在16个CS-2系统上使用标准数据并行性对脑GPT进行训练。这是可能的,因为Cerebras CS-2系统配备了足够的内存,即使是最大的模型也可以在单个设备上运行,而无需拆分模型。然后,我们围绕CS-2设计了专门构建的脑晶圆秤集群,以实现轻松的扩展。它使用一种称为权重流的硬件/软件联合设计的执行,可以在没有模型并行的情况下独立缩放模型大小和集群大小。使用这种体系结构,扩展到更大的集群就像更改配置文件中的系统数量一样简单,如图7所示。
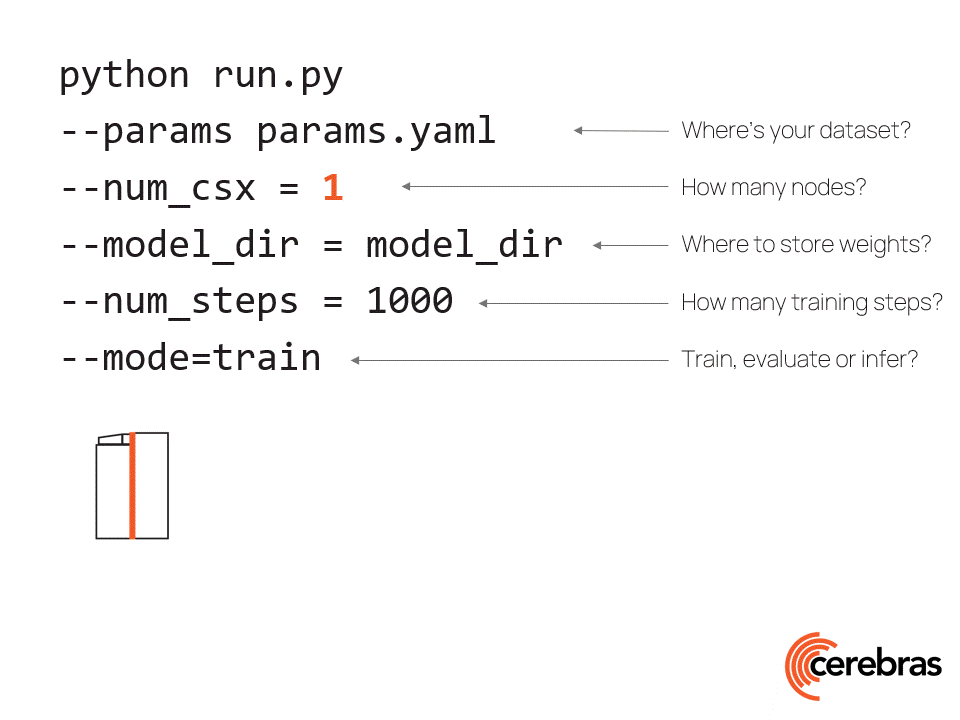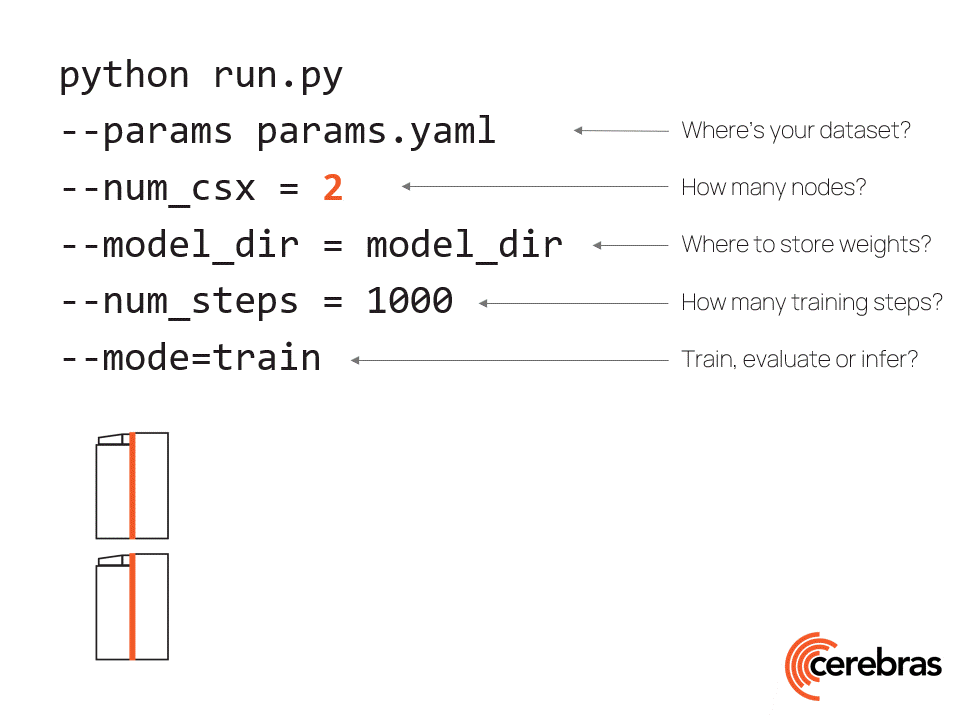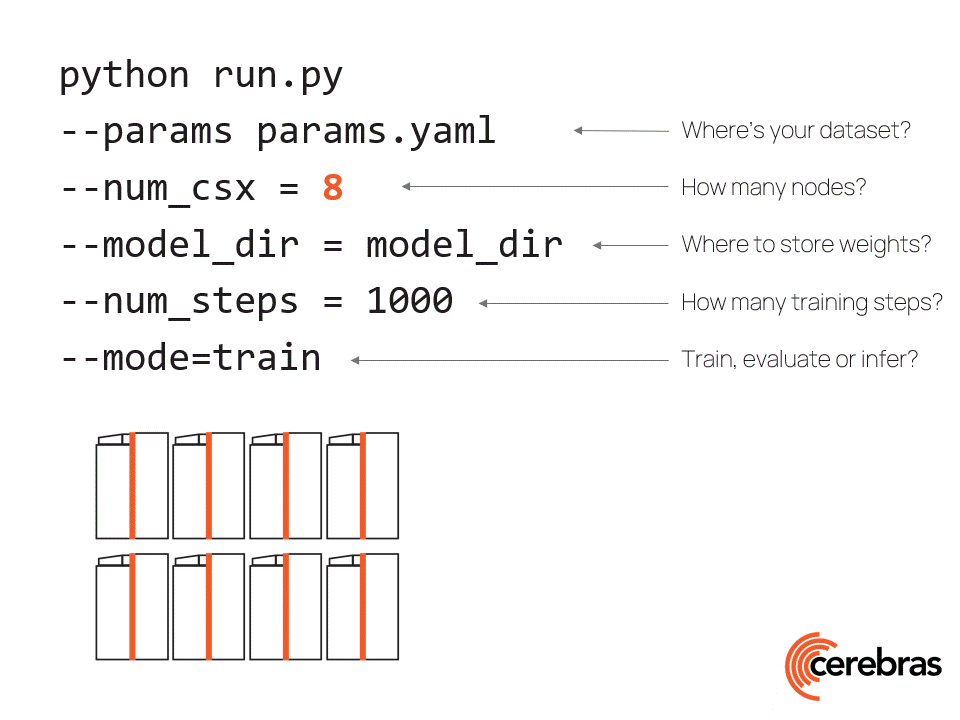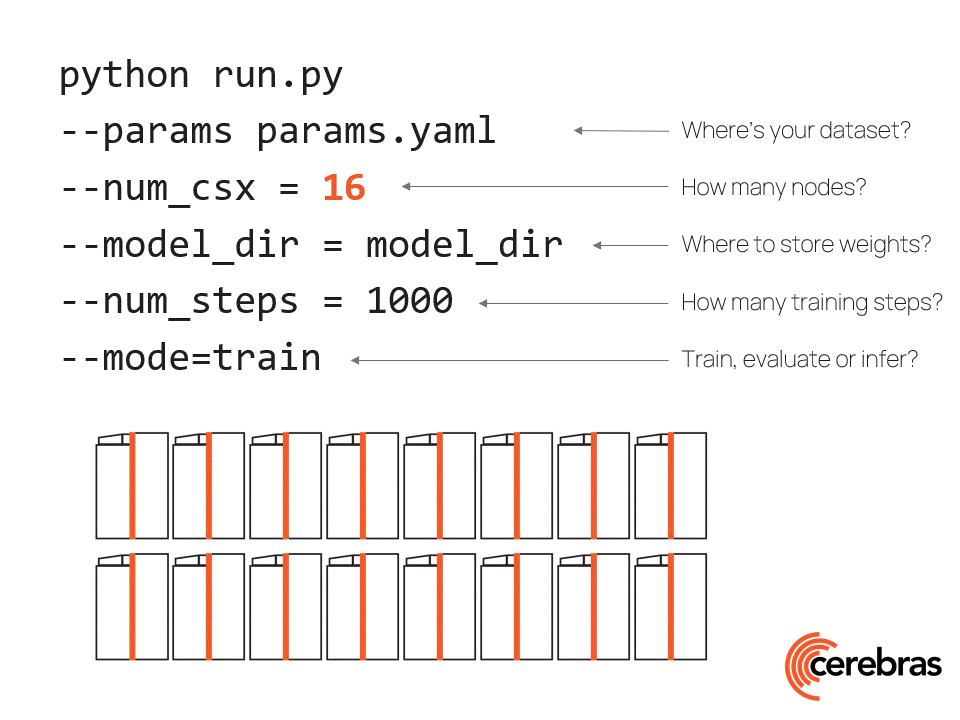 Figure 7. Push-button scaling to multiple CS-2 systems in the Cerebras Wafer-Scale Cluster using only simple data parallel scaling.
Figure 7. Push-button scaling to multiple CS-2 systems in the Cerebras Wafer-Scale Cluster using only simple data parallel scaling.
我们在一个名为仙女座的16x CS-2脑晶圆级集群上训练了所有的脑GPT模型。该集群使所有实验能够快速完成,而无需GPU集群所需的传统分布式系统工程和模型并行调整。最重要的是,它使我们的研究人员能够专注于ML的设计,而不是分布式系统。我们相信,轻松训练大型模型的能力是广泛社区的关键推动者,因此我们通过Cerebras AI模型工作室在云上提供了Cerebras晶圆级集群。
结论
在Cerebras,我们认为大型模型的民主化既需要解决培训基础设施的挑战,也需要向社区开放更多的模型。为此,我们设计了具有按钮缩放功能的Cerebras晶圆秤集群,我们正在开源Cerebras GPT家族的大型生成模型。我们希望,作为第一个具有最先进训练效率的公共大型GPT模型套件,Cerebras GPT将成为高效训练的配方,并作为进一步社区研究的参考。此外,我们正在通过Cerebras人工智能模型工作室在云上提供基础设施和模型。我们相信,只有通过更好的培训基础设施和更多的社区共享,我们才能共同推动大型生成性人工智能行业。
- 119 次浏览