【LLM】构建LLM驱动的应用程序:您需要了解的内容
视频号

微信公众号

知识星球

构建LLM驱动的应用程序
对于有兴趣部署人工智能应用程序的开发人员来说,过去几周是令人兴奋的。该领域发展迅速,现在可以构建人工智能驱动的应用程序,而无需花费数月或数年时间学习机器学习的来龙去脉。这打开了一个充满可能性的全新世界,因为开发人员现在可以以前所未有的方式试验人工智能。
基础模型,特别是大型语言模型(LLM),现在对机器学习或数据科学背景很低或没有背景的开发人员来说是可以访问的。这些敏捷团队擅长快速迭代,可以快速开发、测试和完善在Product Hunt等平台上展示的创新应用程序。值得注意的是,与大多数数据和人工智能团队相比,这群开发人员的运作速度要快得多。
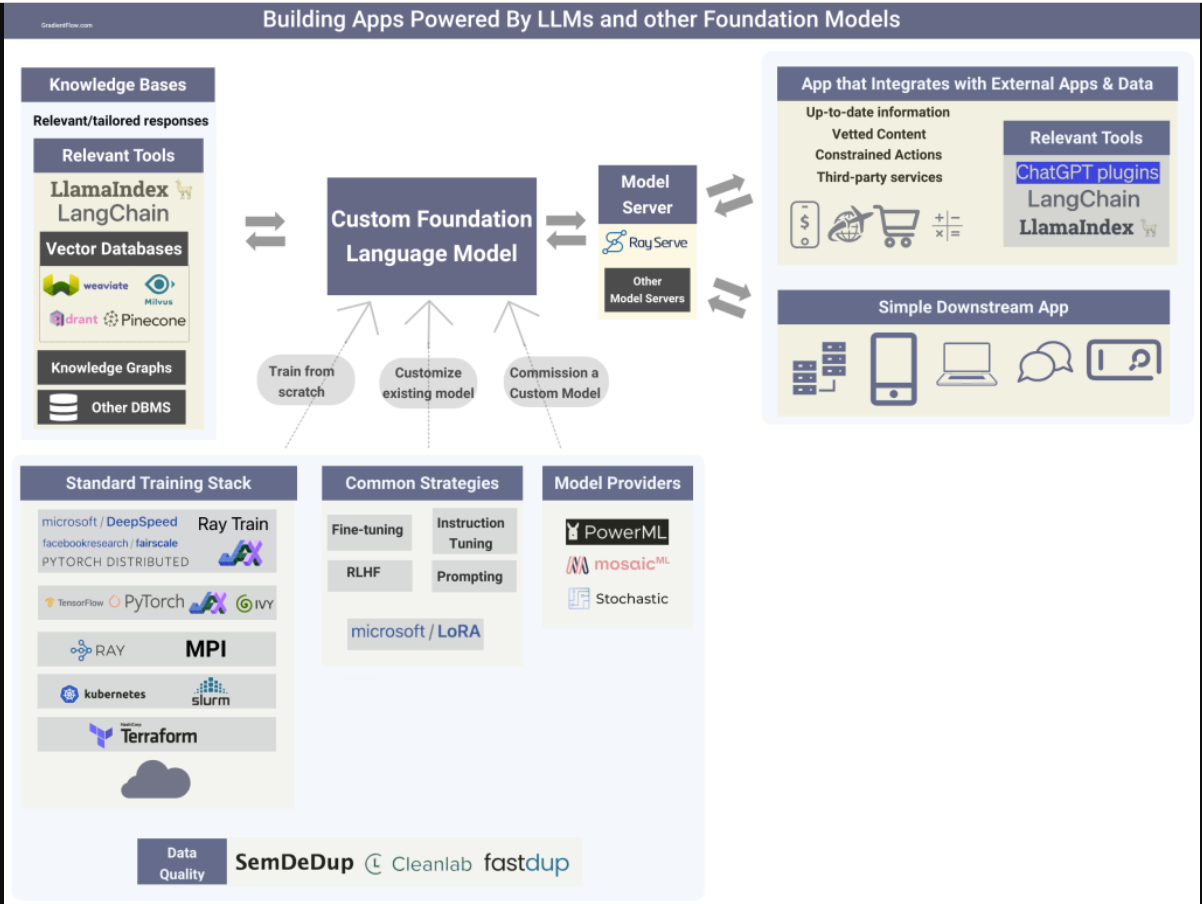
Building apps that rely on LLMs and other foundation models.
自定义模型
目前开发人员普遍采用的方法是通过API使用专有的LLM。然而,正如我们在最近的一篇文章中所解释的那样,领域特异性、安全性、隐私、法规、知识产权保护和控制等因素将促使更多组织选择投资于自己的定制LLM。例如,彭博社最近详细介绍了他们是如何建立BloombergGPT的,这是一家金融LLM。此外,几个经过精细调整的中型模型的例子吸引了研究人员和开发人员的注意,为更多的研究人员创建自己的自定义LLM铺平了道路。
- 委托定制模型:有一些新的初创公司提供必要的资源和专业知识,帮助公司调整甚至培训自己的大型语言模型。例如,PowerML使组织能够通过利用RLHF和对自己的数据进行微调技术来超越通用LLM的性能。
- 对现有模型进行微调:我在上一篇文章中描述了流行的微调技术。我预计会有更多的开源资源,包括具有适当许可证的模型和数据集,使团队能够将其作为构建自己的自定义模型的起点。例如,Cerebras刚刚在Apache 2.0许可证下开源了一组LLM。
- 从头开始训练模型:在对LLM的制作进行在线研究并从有训练工具经验的朋友那里收集见解后,很明显,有许多开源组件通常用于训练基础模型。分布式计算框架Ray被广泛用于训练基础模型。虽然PyTorch是许多LLM创建者使用的深度学习框架,但一些团队更喜欢JAX等替代框架,甚至是在中国流行的本土库。Ivy是一种创新的开源解决方案,能够在机器学习框架之间进行代码转换,促进各种来源之间的无缝协作和多功能性。
许多开发基础模型的组织都有专门的团队负责安全、协调和负责任的人工智能。选择建立自己的自定义模型的团队应该进行类似的投资。
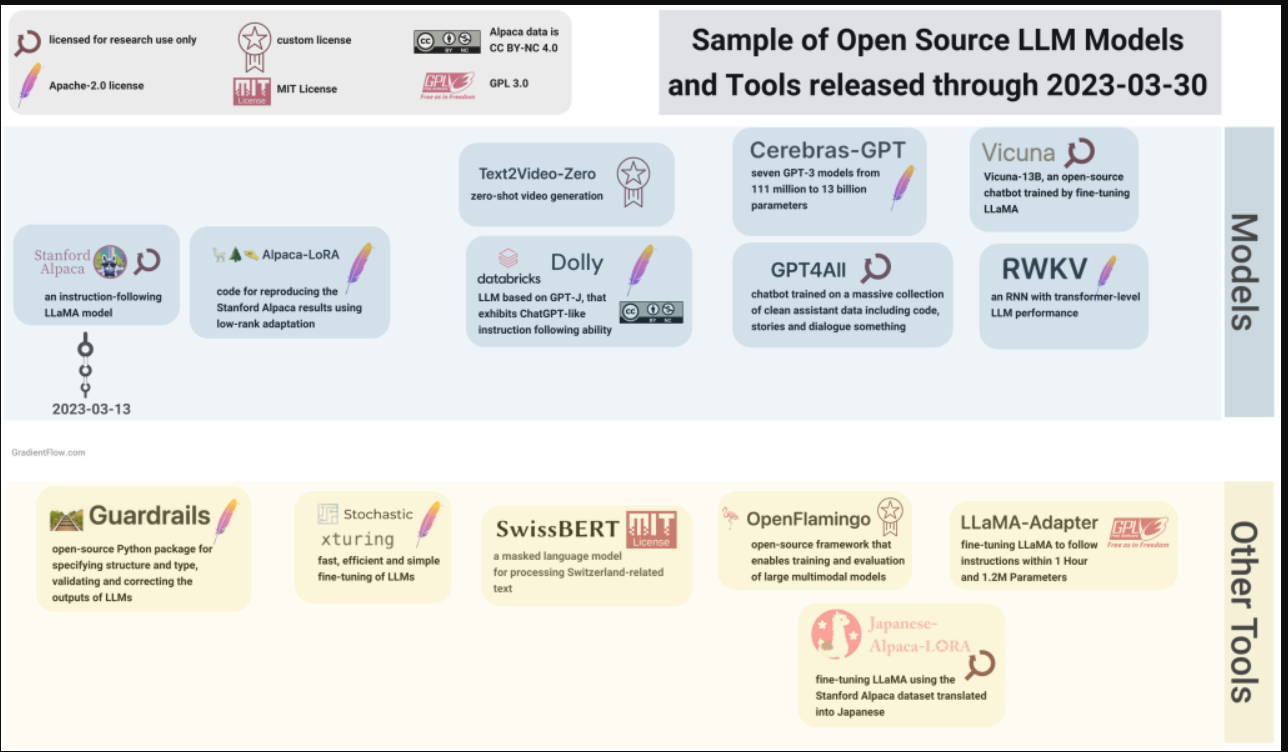
The recent proliferation of open-source models and tools has significantly expanded the available options for teams seeking to create custom LLMs.
第三方集成
OpenAI最近为其ChatGPT语言模型推出了一项名为“插件”的新功能,该功能允许开发人员创建可以访问最新信息、运行计算或使用第三方服务的工具。Expedia、Instacart和Shopify等公司已经使用该功能创建插件。第三方开发人员可以开发插件,从简单的计算器到更复杂的工具,如语言翻译和WolframAlpha集成。
正如Terraform的创建者所指出的那样,ChatGPT插件界面非常容易使用:“你为你的API编写一个OpenAPI清单,使用人类语言描述一切,就这样。你让模型知道如何进行身份验证、链接调用、处理中间的数据、格式化以供查看等等。绝对没有粘合代码。”
其他LLM提供商可能会提供类似的资源来帮助开发人员与外部服务集成。LangChain和LlamaIndex等开源工具很早就帮助开发人员构建依赖外部服务和源代码的应用程序。我预计在不久的将来,用于构建LLM支持的应用程序的第三方集成工具将迅速取得进展。
LangChain和LlamaIndex等工具,甚至是LLM之间插件共享的潜在开放协议,对寻求灵活交换模型或针对多个LLM提供商的开发人员具有吸引力。这样的工具允许开发人员将最佳LLM用于特定任务,而无需锁定在单个提供程序中。
知识库
知识图和其他外部数据源可以通过提供补充的、特定领域的事实信息来增强LLM。我们开始看到有助于连接现有数据源和格式的工具,包括连接矢量数据库等新系统。这些工具能够在结构化和非结构化数据上创建索引,从而实现上下文学习。此外,它们提供了一个用于查询索引和获得知识增强输出的接口,这增强了所提供信息的准确性和相关性。
服务模型
软件服务需要几个关键功能来满足现代计算的需求。它们必须具有响应能力、高可用性、安全性、灵活性和跨平台和系统的互操作性,同时能够处理大量用户并提供实时处理和分析能力。LLM的部署由于其规模、复杂性和成本而带来了独特的挑战。
- 开源库Ray Serve完全符合人工智能应用程序的要求,因为它使开发人员能够构建一个可扩展、高效和灵活的推理服务,能够集成多个机器学习模型和基于Python的业务逻辑。下面是一个如何使用Ray Serve部署LLM的示例。
- 更小、更精简的模型的兴起将提高LLM在一系列应用中的效率。我们开始看到令人印象深刻的LLM,如LLaMA和Chinchilla,它们的尺寸只是现有最大型号的一小部分。此外,压缩和优化技术,如修剪、量化和蒸馏,将在LLM的使用中发挥越来越重要的作用,遵循计算机视觉设定的路径,著名的早期例子是DistilBERT、Hugging Face DistilGPT2、distill-bloom和PyTorch量化。
总结
用于构建LLM驱动的应用程序的工具和资源的激增为开发人员打开了一个充满可能性的新世界。这些工具使开发人员能够利用人工智能的力量,而不必学习机器学习的复杂性。随着越来越多的组织投资于自己的自定义LLM,开源资源变得越来越广泛,LLM驱动的应用程序的前景将变得更加多样化和分散。这给开发人员带来了机遇和挑战。
重要的是要记住,权力越大,责任越大。组织必须投资于安全性、一致性和负责任的人工智能,以确保LLM驱动的应用程序用于积极和道德目的。

An early sign that more tools are on the way: the Winter/2023 YC batch includes new tools to help teams build, customize, deploy, and manage LLMs in the future.
数据交换播客
1.数据和人工智能是如何发生的。Chris Wiggins是哥伦比亚大学的教授,也是《纽约时报》的首席数据科学家。他还是《数据是如何发生的》一书的合著者,这是一本引人入胜的历史探索,探讨了从人口普查到优生学再到谷歌搜索,数据是如何被用作塑造社会的工具的。这本书追溯了数据的轨迹,探索了新的数学和计算技术,这些技术有助于塑造人、思想、社会和经济。
2.揭示人工智能趋势:开拓性研究和未知领域。Zeta Alpha创始人兼首席执行官Jakub Zavrel讨论了2022年被引用最多的100篇人工智能论文、今年的趋势研究主题,以及语言模型、多模态人工智能等的未来。他强调了变形金刚的主导地位、多模态模型的兴起、合成数据的重要性、自定义大语言模型、思维链推理和下一代搜索技术。

聚光灯
- 1.引入NLP测试。这个急需的开源工具有助于提高NLP模型的质量和可靠性。它使用简单,提供了全面的测试覆盖范围,有助于确保模型安全、有效和负责任。该库提供了50多种与流行的NLP库和任务兼容的测试类型,在部署到生产系统之前解决了模型质量方面的问题,如鲁棒性、偏差、公平性、表示性和准确性。
- 2..Microwave from BNH.。微波炉是一种免费的基于人工智能的偏见评估工具,旨在帮助企业遵守纽约市第144号地方法律。这项立法要求对自动化就业决策系统中的潜在偏见进行评估。它已被用于审计从财富100强公司到软件初创公司等客户的人工智能系统,帮助他们衡量和管理人工智能风险。
- 3.使用Alpa和Ray在1000 GPU规模下训练175B参数语言模型。Alpa是一个开源编译器系统,用于自动化和民主化大型深度学习模型的模型并行训练。它生成的并行化计划与手动调整模型并行训练系统相匹配或优于手动调整模型平行训练系统,即使是在为其设计的模型上也是如此。本文讨论了Alpa和Ray的集成,以训练一个175B参数模型,该模型等效于具有流水线并行性的GPT-3(OPT-175B)模型。基准测试表明,Alpa可以扩展到1000个GPU以上,实现最先进的峰值GPU利用率,并使用单行装饰器执行自动LLM并行化和分区。
如果您喜欢这篇文章,请鼓励您的朋友和同事订阅我们的时事通讯,以支持我们的工作:
- 103 次浏览