【搜索引擎】使用LangChain和Ray在100行中构建LLM开源搜索引擎
视频号

微信公众号

知识星球

这是博客系列的第一部分。在这个博客中,我们将向您介绍LangChain和Ray Serve,以及如何使用它们来使用LLM嵌入和向量数据库构建搜索引擎。在未来的部分中,我们将向您展示如何对嵌入进行涡轮增压,以及如何将向量数据库和LLM结合起来创建基于事实的问答服务。此外,我们将优化代码并衡量性能:成本、延迟和吞吐量。
在本博客中,我们将介绍:
- LangChain的介绍,并展示它为什么很棒。
- Ray如何通过以下方式补充LangChain的解释:
- 展示了通过一些小的更改,我们可以将流程的部分速度提高4倍或更多
- 使用Ray Serve使LangChain的功能在云中可用
- 通过在同一Ray集群中运行Ray Serve、LangChain和模型来使用自托管模型,而不必担心维护单个机器。
介绍
Ray是一个非常强大的ML编排框架,但强大的功能带来了大量的文档。事实上是120兆字节。我们如何才能使该文档更易于访问?
答案:让它可以搜索!过去,创建自己的高质量搜索结果很难。但通过使用LangChain,我们可以在大约100行代码中构建它
这就是LangChain的用武之地。LangChain为LLM提供了一套令人惊叹的工具。它有点像HuggingFace,但专门用于LLM。有一些工具(链)用于提示、索引、生成和汇总文本。虽然Ray是一个令人惊叹的工具,但使用它可以使LangChain变得更加强大。特别是,它可以:
- 简单快捷地帮助您部署LangChain服务
- 不依赖远程API调用,允许Chains与LLM本身在同一位置运行并可自动缩放。这带来了我们在上一篇博客文章中讨论过的所有优势:更低的成本、更低的延迟和对数据的控制。
建立索引
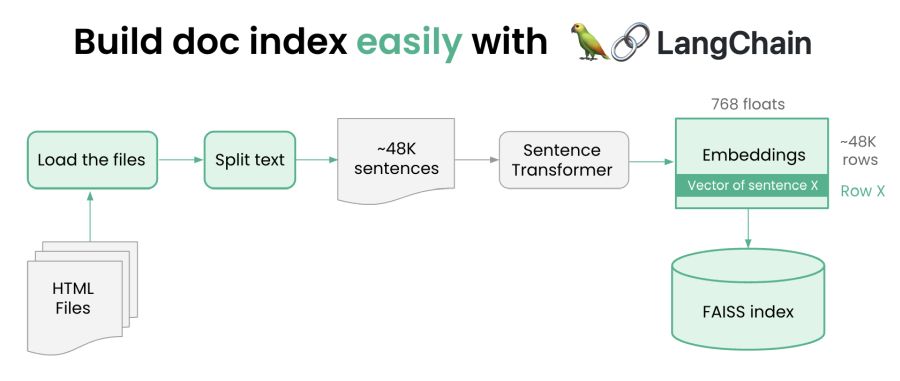
使用Ray和Langchain轻松构建文档索引
首先,我们将通过以下步骤构建索引
- 下载我们要在本地建立索引的内容
- 阅读内容并将其切成小块(每个大约一句话)。这是因为将查询与页面的各个部分进行匹配比与整个页面进行匹配更容易。
- 使用HuggingFace中的句子转换器库生成每个句子的矢量表示
- 将这些向量嵌入到向量数据库中(我们使用FAISS,但您可以使用任何您喜欢的方法)
这个代码的神奇之处在于它是如此简单——请参阅此处。正如你将看到的,多亏了LangChain,我们完成了所有繁重的工作。让我们摘录一些内容
假设我们已经下载了Ray文档,这就是我们要读取的所有文档:
loader = ReadTheDocsLoader("docs.ray.io/en/master/")
docs = loader.load() 下一步是将每个文档分成小块。LangChain使用拆分器来执行此操作。所以我们要做的就是:
chunks = text_splitter.create_documents(
[doc.page_content for doc in docs],
metadatas=[doc.metadata for doc in docs])我们希望保留原始URL的元数据,因此我们确保将元数据与这些文档一起保留
现在我们有了块,我们可以将它们作为向量嵌入。LLM提供商确实提供了远程实现这一点的API(这就是大多数人使用LangChain的方式)。但是,只需一点胶水,我们就可以从HuggingFace下载句子转换器,并在本地运行它们(灵感来自LangChain对llama.cpp的支持)。以下是胶水代码
通过这样做,我们可以减少延迟,保持开源技术,并且不需要HuggingFace密钥或支付API使用费用
最后,我们有了嵌入,现在我们可以使用向量数据库——在本例中为FAISS——来存储嵌入。矢量数据库经过优化,可以在高维空间中进行快速搜索。同样,LangChain让这一切变得毫不费力。
from langchain.vectorstores import FAISS
db = FAISS.from_documents(chunks, embeddings)
db.save_local(FAISS_INDEX_PATH)就这样。代码在这里。现在我们可以建造商店了。
% python build_vector_store.py
这大约需要8分钟才能执行。大部分时间都花在了嵌入上。当然,在这种情况下这并不是什么大不了的事,但想象一下,如果你索引的是数百GB,而不是数百MB。
使用Ray加速索引
[注意:这是一个稍微高级一点的话题,第一次阅读时可以跳过。它只是展示了我们如何更快地完成它——速度快4到8倍]
我们如何才能加快索引速度?最棒的是嵌入很容易并行化。如果我们:
- 将区块列表分割为8个碎片
- 分别嵌入8个碎片中的每一个。
- 合并碎片。
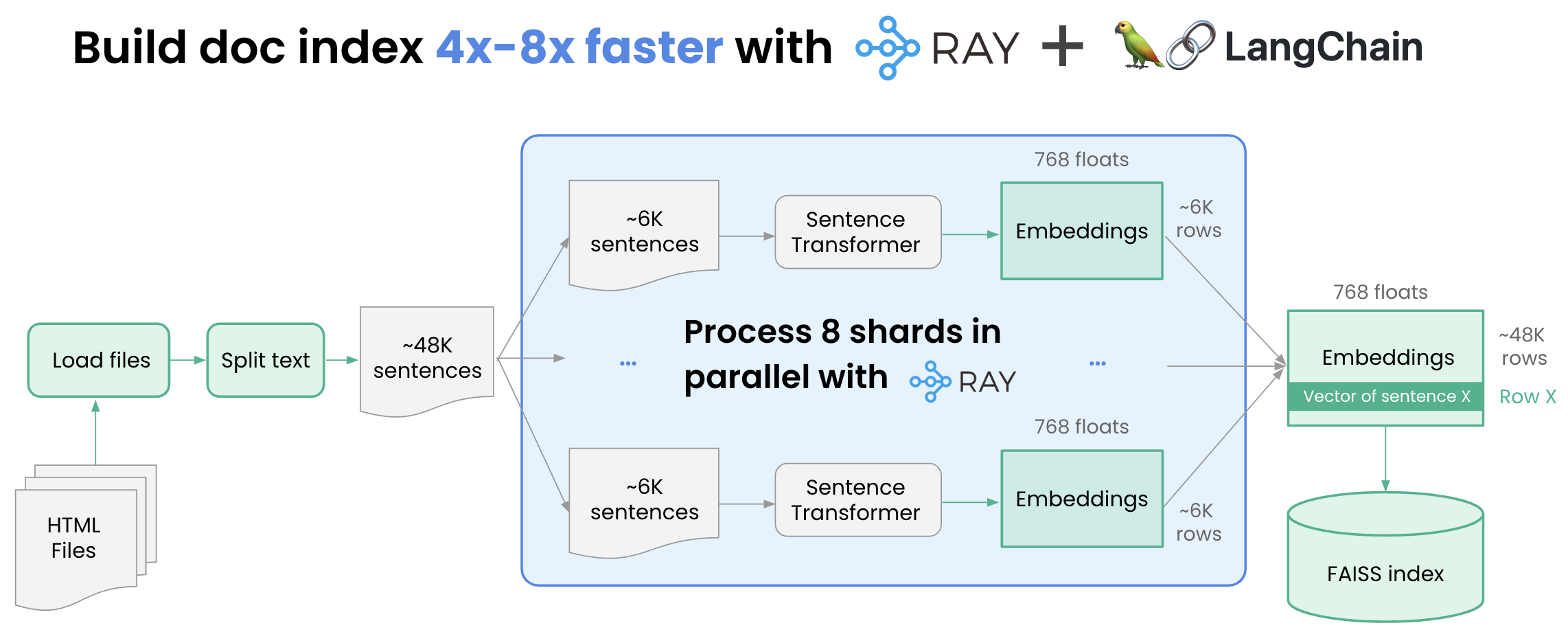
使用Ray建立文档索引的速度快4-8倍
要实现的一个关键是嵌入是GPU加速的,所以如果我们想做到这一点,我们需要8个GPU。多亏了Ray,这8个GPUS不必在同一台机器上。但是,即使在一台机器上,使用Ray也有显著的优势。而且不必考虑设置Ray集群的复杂性,您所需要做的就是pip安装Ray[默认值],然后导入Ray
这需要对代码进行一些小手术。这是我们必须做的。
首先,创建一个创建嵌入的任务,然后使用它来索引碎片。注意Ray注释,我们告诉我们每个任务都需要一个完整的GPU。
@ray.remote(num_gpus=1)
def process_shard(shard):
embeddings = LocalHuggingFaceEmbeddings('multi-qa-mpnet-base-dot-v1')
result = FAISS.from_documents(shard, embeddings)
return result
接下来,将工作负载拆分到碎片中。NumPy来救援!这是一行:
shards = np.array_split(chunks, db_shards)然后,为每个碎片创建一个任务,并等待结果。
futures = [process_shard.remote(shards[i]) for i in range(db_shards)]
results = ray.get(futures)最后,让我们将碎片合并在一起。我们使用简单的线性合并来实现这一点
db = results[0]
for i in range(1,db_shards):
db.merge_from(results[i])
你可能想知道,这真的有效吗?我们在一个带有8个GPU的g4dn.metal实例上运行了一些测试。原始代码花了313秒创建嵌入,新代码花了70秒,这大约是4.5倍的改进。创建任务、设置GPU等仍有一些一次性开销。这会随着数据的增加而减少。例如,我们用4倍的数据做了一个简单的测试,它大约是理论最大性能的80%(即比8个GPU快6.5倍的理论最大速度快8倍)
我们可以使用Ray Dashboard来查看这些GPU的工作情况。果不其然,它们都接近100%运行我们刚刚编写的process_shard方法。
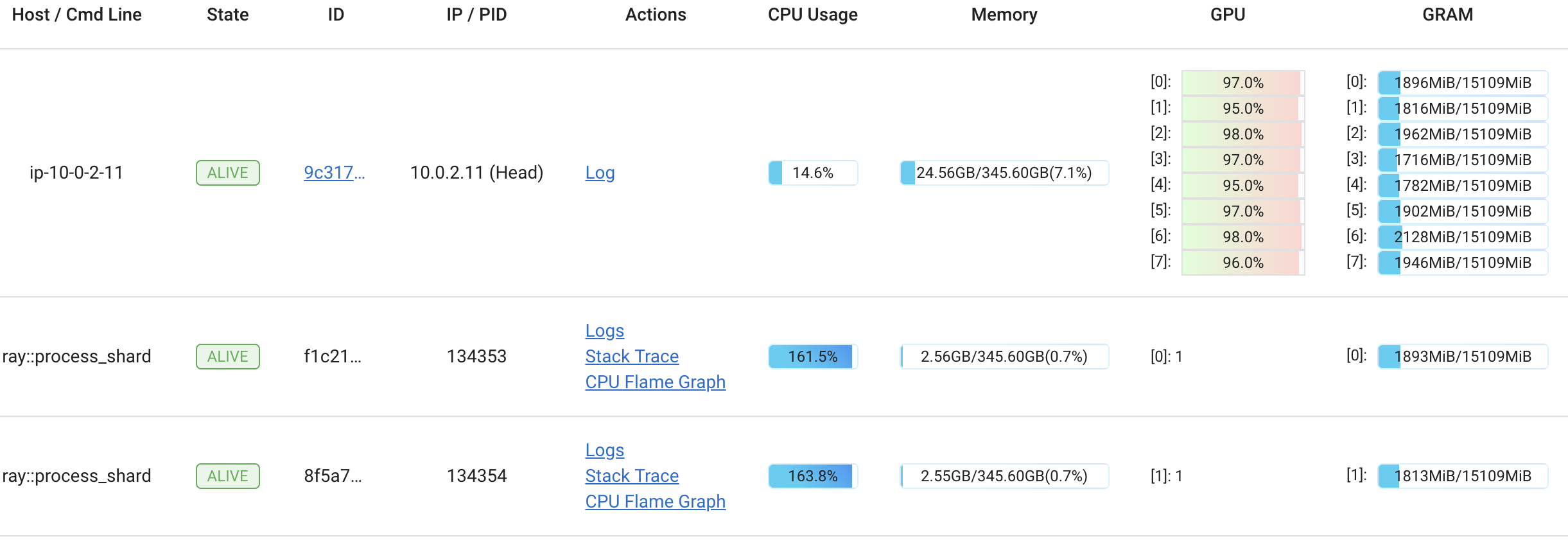
仪表板显示GPU利用率在所有实例中都达到了最大值
事实证明,合并向量数据库非常快,只需0.3秒就可以将所有8个碎片合并
服务
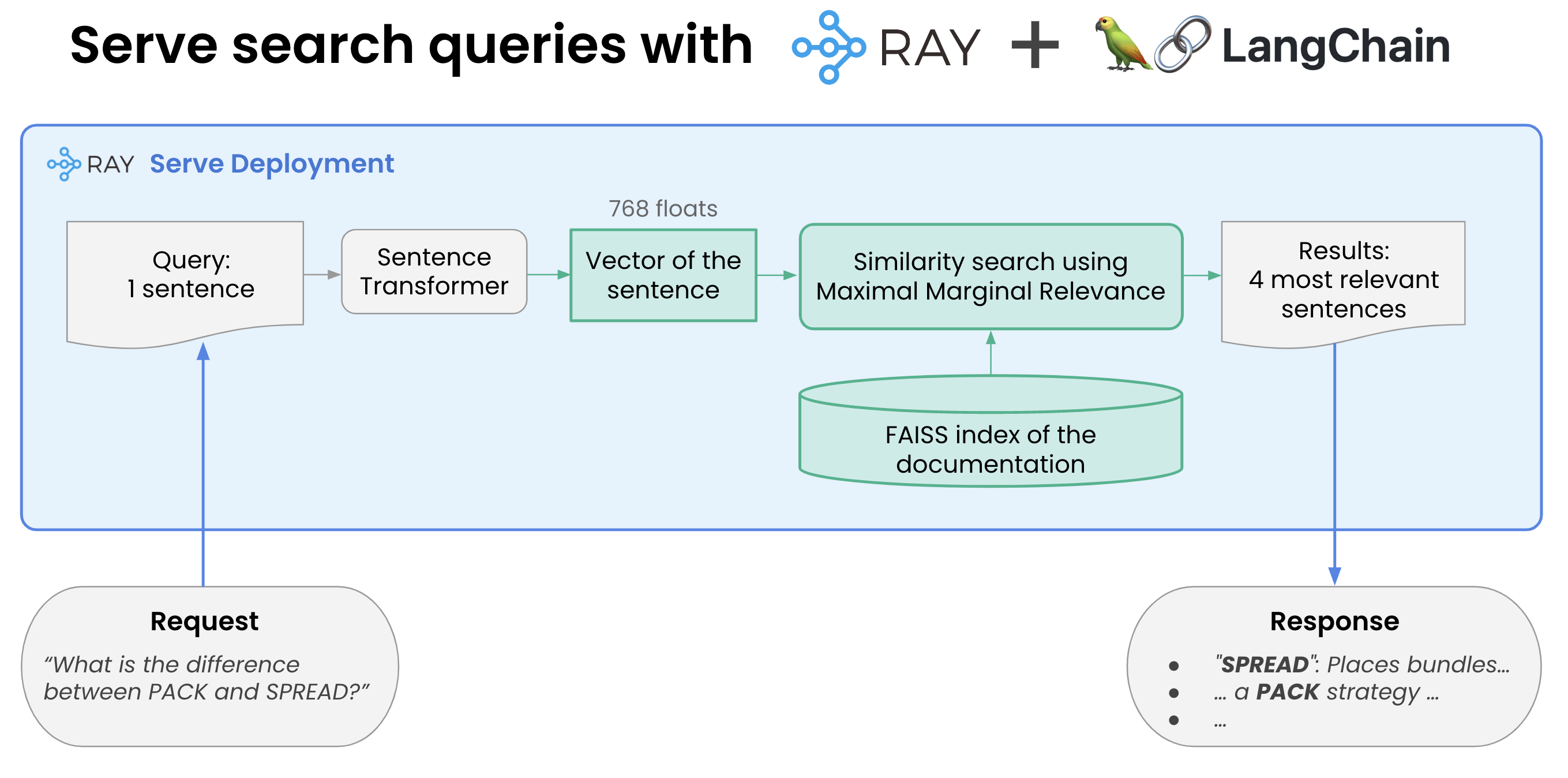
使用Ray和Langchain提供搜索查询
服务是LangChain和Ray Serve的结合展示其力量的另一个领域。这只是触及了表面:我们将在本系列的下一篇博客文章中探索独立自动缩放和请求批处理等令人惊叹的功能。
执行此操作所需的步骤是:
- 加载我们创建的FAISS数据库并实例化嵌入
- 开始使用FAISS进行相似性搜索。
Ray Serve让这一切变得神奇地简单。Ray使用“部署”来包装一个简单的python类。__init__方法完成加载,然后__call__才是实际完成工作的方法。Ray负责将它连接到互联网,提供服务,http等等。
以下是代码的简化版本:
@serve.deployment
class VectorSearchDeployment:
def __init__(self):
self.embeddings = …
self.db = FAISS.load_local(FAISS_INDEX_PATH, self.embeddings)
def search(self,query):
results = self.db.max_marginal_relevance_search(query)
retval = <some string processing of the results>
return retval
async def __call__(self, request: Request) -> List[str]:
return self.search(request.query_params["query"])
deployment = VectorSearchDeployment.bind()就是这样!
现在让我们用命令行启动此服务(当然,Serve有更多的部署选项,但这是一种简单的方法):
% serve run serve_vector_store:deployment现在我们可以编写一个简单的python脚本来查询服务以获取相关向量(它只是一个运行在8000端口上的web服务器)。
import requests
import sys
query = sys.argv[1]
response = requests.post(f'http://localhost:8000/?query={query}')
print(response.content.decode())现在让我们来试试:
$ python query.py 'Does Ray Serve support batching?'
From http://docs.ray.io/en/master/serve/performance.html
You can check out our microbenchmark instructions
to benchmark Ray Serve on your hardware.
Request Batching#
====
From http://docs.ray.io/en/master/serve/performance.html
You can enable batching by using the ray.serve.batch decorator. Let’s take a look at a simple example by modifying the MyModel class to accept a batch.
from ray import serve
import ray
@serve.deployment
class Model:
def __call__(self, single_sample: int) -> int:
return single_sample * 2
====
From http://docs.ray.io/en/master/ray-air/api/doc/ray.train.lightgbm.LightGBMPredictor.preferred_batch_format.html
native batch format.
DeveloperAPI: This API may change across minor Ray releases.
====
From http://docs.ray.io/en/master/serve/performance.html
Machine Learning (ML) frameworks such as Tensorflow, PyTorch, and Scikit-Learn support evaluating multiple samples at the same time.
Ray Serve allows you to take advantage of this feature via dynamic request batching.
====结论
我们在上面的代码中展示了构建基于LLM的搜索引擎的关键组件是多么容易,并通过结合LangChain和Ray serve的力量为整个世界提供响应。而且我们不需要处理一个讨厌的API密钥!
请收看第2部分,我们将展示如何将其变成一个类似聊天的应答系统。我们将使用像Dolly 2.0这样的开源LLM来实现这一点
最后,我们将分享第3部分,其中我们将讨论可扩展性和成本。以上内容对于每秒几百个查询来说是可以的,但如果您需要扩展到更多查询呢?关于延迟的说法正确吗?
接下来的步骤
See part 2 here.
Review the code and data used in this blog in the following Github repo.
See our earlier blog series on solving Generative AI infrastructure with Ray.
If you are interested in learning more about Ray, see Ray.io and Docs.Ray.io.
To connect with the Ray community join #LLM on the Ray Slack or our Discuss forum.
If you are interested in our Ray hosted service for ML Training and Serving, see Anyscale.com/Platform and click the 'Try it now' button
Ray Summit 2023: If you are interested to learn much more about how Ray can be used to build performant and scalable LLM applications and fine-tune/train/serve LLMs on Ray, join Ray Summit on September 18-20th! We have a set of great keynote speakers including John Schulman from OpenAI and Aidan Gomez from Cohere, community and tech talks about Ray as well as practical training focused on LLMs.
- 927 次浏览