【数据架构】数据湖/网格/数据编织及其之间的一切(活动元数据)
视频号

微信公众号

知识星球

我对Gartner®2023年数据与分析峰会的印象和展望-第3部分。
本博客系列的内容:
- 有目的的领导。与信任建立联系。产生影响。
- ChatGPT时代的数据与分析治理。
- 数据湖/网格/数据结构和介于两者之间的一切(活动元数据)。
- 数据业务的未来。
在上一篇博客中,我谈到了治理如何为企业在保持质量的同时实现技术突破做好准备。在这篇博客中,我讲述了数据管理新时代的黎明:活动元数据的兴起,它是不同组件之间的粘合剂,也是增强治理和数据结构/数据网格的推动者。
Gartner将20世纪20年代命名为“主动元数据时代”(而不是将2010年代称为“LDW时代”,将21世纪初称为“后EDW时代”)[1]。在Data Lake、Data Mesh、Data Fabric、DataOps、Metadata和其他流行的流行语之间,以及Generative AI工具的兴起,我觉得组织很难决定首先去哪里。
我总结了2023年Gartner数据与分析峰会上关于这些数据管理主题的多个会议,以帮助您理解定义、实施、利弊、长期战略和优先级等。
但第一件事是:我们将在“元数据时代”中使用的底层数据基础设施是什么?我希望,到目前为止,你们中的许多人都会回答“数据湖”
数据湖
“通过满足现代湖泊需求避免数据湖故障”[2]是唐纳德·范伯格关于数据湖以及如何使其工作的会议。随着唐纳德最近宣布退役,我很高兴有机会(对我来说)在舞台上听到唐纳德的最后一次讲话。
数据湖的概念并不新鲜,我们曾经期望ApacheHadoop是一种预处理数据湖,但当然,它没有ACID或治理。根据我使用Hadoop的经验,它主要用于数据科学项目。根据演示,这是一个典型的用例。众所周知,大多数Hadoop安装都不起作用。由于没有管理,Hadoop只是一个巨大的文件包,它需要人才才能访问ETL或商业智能应用程序中的数据。原来是沼泽地。
有趣的是,历史仍然在重演:数据湖应该有元数据、治理和数据区来服务于操作和分析用例。否则,它们很快就会变成沼泽。
Don表示,如果你成功地实现了数据湖,你应该预计数据科学、自助服务、客户360、仓储和报告等用例会呈指数级增长,你应该为此做好准备。
Don的准备建议是使用一个云,而不是在prem或多云上。
此外,Data Lakes应在D&A卓越中心(Architect、Steward、DS/DE/MDM)和职能部门(公民一切)之间进行多方合作。你知道所有关于不同单位“将数据保密”的恐怖故事——这不会随着数据湖而飞。
那么,我们如何促进合作呢?唐说:
- “控制你的数据湖-为了确保所需的数据存在,减少数据冗余,执行数据标准并控制数据保留。
- 管理湖泊数据的使用-为了商业合规、隐私和安全。
- 需要不同的语义(元数据、目录、谱系)——作为湖泊数据的文档,以便于数据探索和重用,并避免沼泽。”
阳光下没有什么是永恒的,正如我所了解到的,数据湖今天正面临一个平稳期,成功使用它们的可寻址市场总数接近20-25%。那么,数据湖之后的下一步是什么呢?湖畔小屋!
湖屋:是什么?Lakehouse是一种将仓库和数据湖结合在同一平台上的架构。如果你实现了它,计划有很多熟练的人才来支持它:从数据架构师和建模师到DE,再到DataOps,从语义专家到DPM、Stewards、DS和业务分析师。
我知道Hadoop的成功实现率在两位数以下,与Lakes类似。你应该如何增加你最终站在这一统计数据正面的机会?
Don建议:
- 专注于提供业务价值:为多个用例设计数据湖,以实现更高的业务价值。
- 选择数据管理工具来支持多种接收、细化、处理和交付方法。
- 向数据生态系统发展:规划所有这些和其他数据湖组件的变化和增长。
- 数据湖的员工和技能提升:数据产品经理、数据科学家和数据工程都备受瞩目。
- 确保你的湖不会变得浑浊:对允许的数据进行管理和保护。
唐纳德引用他的同事Guido De Simoni的话,为他的会议选择了一个有趣的结局:“元数据是数据湖中的鱼类发现者。”如果您现在还不明白它的意思,请继续阅读,直到“活动元数据”部分。
现在,我们已经将数据湖作为现代数据堆栈的主要数据基础设施组件进行了介绍,让我们看看它是如何与数据管理难题中的其他元素相连接的。
数据编织(Data Fabric)
Ehtisham Zaidi在其“实用数据结构-如何构建下一代数据管理设计”课程中提供了对数据结构的深入研究[3]。
正如著名的Simon Sinek所说,“让我们从为什么开始”——为什么我们需要Data Fabric?根据Ehtisham Zaidi在本次会议的开幕词,“Data Fabric为所有数据消费者提供集成数据。”

(Diagram: The Practical Data Fabric — How to Architect the Next-Generation Data Management Design, Ehtisham Zaidi, Gartner Data & Analytics Summit, Orlando, Florida, 20–22 March, 2023)
什么是数据结构?
根据Ehtisham的说法,“Data Fabric不是一种单一的工具或技术。它是一种新兴的数据管理设计,用于实现灵活的可重复使用和增强的数据集成管道;利用知识图、语义和基于主动元数据的自动化;支持更快的数据访问和共享,在某些情况下,支持自动化的数据访问与共享,而不考虑部署选项、用例和/或体系结构方法。或者,“Data Fabric=元数据分析+建议。它充当智能编排引擎。”
如果你觉得这很复杂,你并不孤单:我有幸与之交谈的大多数峰会与会者还没有最终确定他们对这种方法的意见。
Data Fabric实现带来的预期好处可以掩盖这粒复杂的苦果(你可能还记得去年D&A峰会博客中的这句话):
根据Ehtisham的介绍,到2025年,“数据结构中的主动元数据辅助自动化功能将:
- 将人力投入减少一半。
- 数据利用效率提高了四倍。”
据我所知,这些好处应该遍布整个组织:从促进业务用户的自助服务,通过提高数据团队的效率水平,到整个组织的数据素养水平,这将提高数据资产的利用率。
Ehtisham继续实施数据结构的九个实际步骤:首先,从建立元数据集合开始,就像我们几十年前对数据所做的那样。如果没有这个集合,用于管理它的工具将无关紧要。
Ehtisham列出了以下类型的元数据:
- 技术(模式、日志、数据模型)
- 操作(ETL、沿袭、性能)
- 业务(本体论、分类学)
- 社交(查询、观点、部落知识、反馈)
通过观察和比较这些不同类型的元数据,您将能够看到计划与实际用户行为之间的差异。
数据结构实现的第二步是元数据激活。
在过去的几年里,我们听到了很多“元数据激活”。它是什么?
在下图中,Ehtisham解释了元数据激活工具的作用——包括警报、建议、准备和编排。当前状态是“在情况发生变化时发送警报”。激活元数据是通过图形分析和处理异常的建议来完成的。

(Diagram: The Practical Data Fabric — How to Architect the Next-Generation Data Management Design, Ehtisham Zaidi, Gartner Data & Analytics Summit, Orlando, Florida, 20–22 March, 2023)
步骤3:创建知识图并用语义丰富它们:
“当使用传统的数据建模和集成方法时,大多数关系见解都会丢失[…]数据结构将多关系数据呈现为知识图。”在这里,我们看到了数据结构和元数据激活如何利用知识图作为推荐的底层技术。
步骤4:使用Data Fabric的自动化建议:
元数据激活自动化功能将包括通过语义和搜索进行参与,深入了解异常和敏感数据标记,甚至自动更正模式漂移和数据源优先级。
步骤5:探索自助式编排机会:
重要的是要记住,数据结构的实现不需要完全自动化,正如Ehtisham Zaidi所指出的:“数据结构不需要数据管理优化,但它确实实现了它——不需要自动化。”因此,即使使用当前的(部分自动化)工具,也可以实现它。
步骤6:利用DataOps优化数据集成交付:
过去几年的另一个趋势术语是DataOps,这是有充分理由的:案例研究表明,“到2025年,一个以DataOps实践和工具为指导的数据工程团队的生产力将比没有这样做的团队高10倍。”听起来值得进一步探索!那么什么是DataOps呢?
DataOps是数据编排、数据可观测性、测试/部署自动化、环境配置管理、版本控制、CI/CD/Git/Jenkins的组合。就像Data Fabric一样,这不是从单个工具或供应商那里获得的功能,而是从上述类别中组装工具。
步骤7:将集成数据作为数据产品交付(或网格式交付)-准备就绪时:
在我看来,本次会议中讨论的所有内容的最终目标都是建立一个可靠的基础,允许为不同业务领域的自助消费提供数据产品。根据Ehtisham的说法,这种交付的运营模式可以是“枢纽和轮辐”(步骤8)。在我之前的博客中,它被称为“特许经营”。在这种方法中,中心团队拥有技术所有权、资源整合、治理和体系结构,数据产品用于业务功能。
埃蒂沙姆属于这种罕见的人,他将长期战略眼光与非常务实、务实的建议方法结合在一起,但如果你有机会与他交谈一次,你可能就会知道这一点。他继续进行最后也是最重要的第9步,根据组织对数据和业务问题的熟悉程度,提出了将Data Fabric投入生产的三条路径:基础路径、高级路径和自动化路径:
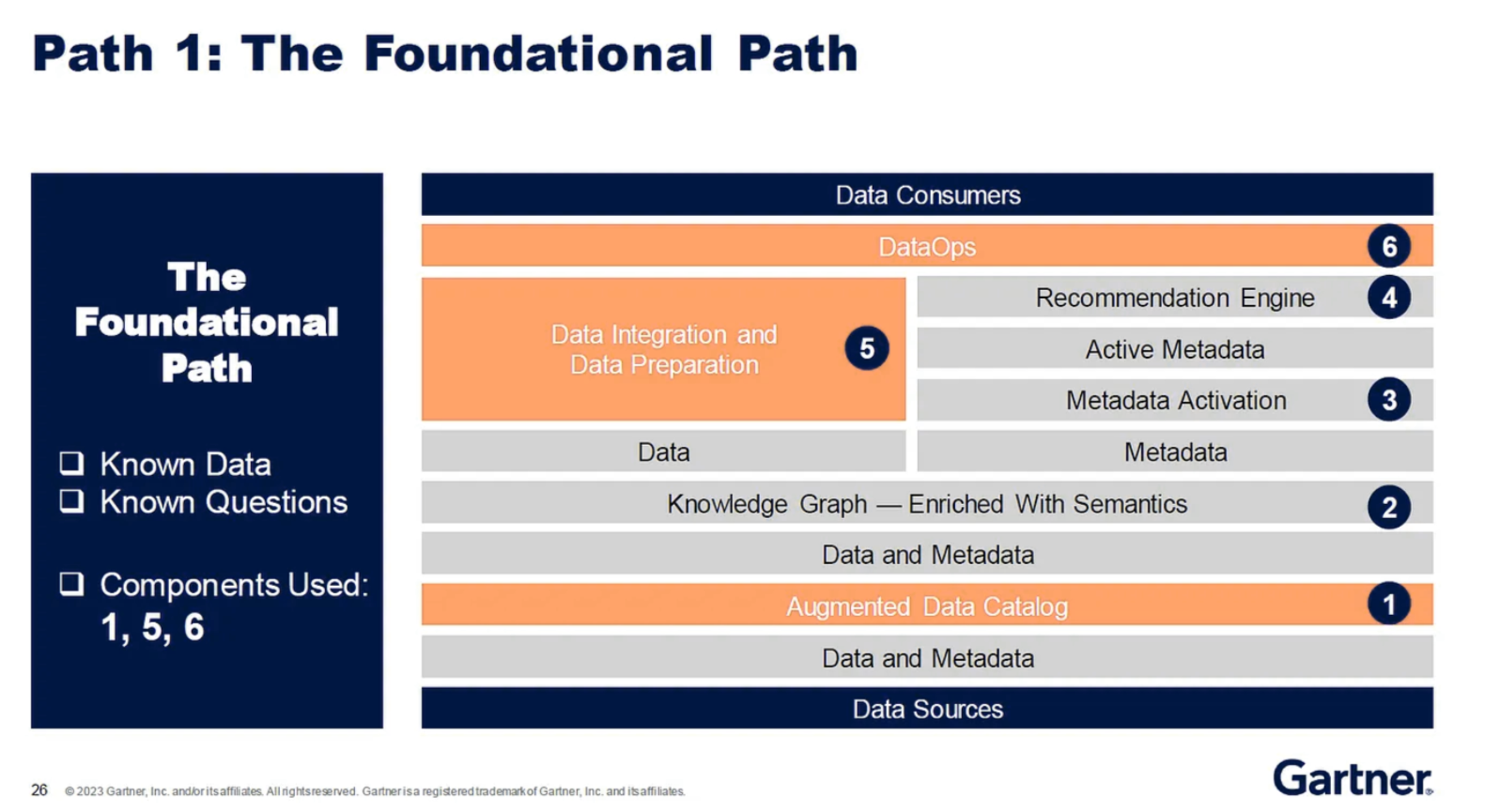


(Diagram: The Practical Data Fabric — How to Architect the Next-Generation Data Management Design, Ehtisham Zaidi, Gartner Data & Analytics Summit, Orlando, Florida, 20–22 March, 2023.)
如果我试着把注意力集中在Ehtisham Zaidi的会议上,会弹出以下要点:
不要指望“购买”Data Fabric——这是一个概念框架,主要来自具有高度自动化的新技术解决方案。
激活您的元数据,但首先要收集它!
您的实施计划应包括获取利用DataOps的技能。
但是,如果不提及数据网格,我们怎么能谈论这么长时间的数据结构呢?对于这些有些冲突的方法,这似乎是社区中一个两极分化的论点。我在这里有很大的偏见,你可能会觉得这是通过下面这部分的总结得出的。
数据结构或数据网格:决定未来的数据管理体系结构
Robert Thanaraj和Ehtisham Zaidi联合参加了那场会议(“数据结构或数据网格:关于决定未来数据管理架构的辩论”),这场会议非常壮观[1]。
根据会议开幕式,回顾过去,我们可以说,数据架构的演变在经历了2010年代的“LDW时代”和2000年代的“后EDW时代”之后,在20世纪20年代实现了“主动元数据时代”的第三阶段。这种演变最初允许提供碎片化的分析,但后来统一,最后增强。

(Diagram: Data Fabric or Data Mesh: Debate on Deciding Your Future Data Management Architecture, Robert Thanaraj and Ehtisham Zaidi, Gartner Data & Analytics Summit, Orlando, Florida, 20–22 March, 2023)
尽管大多数组织都面临着采用数据网格或数据结构概念的决定,但正如演讲者所提醒的那样,值得记住的是,Gartner的2022年数据管理炒作周期,在该周期中,数据网格出现为“高原之前的过时”,数据结构刚刚通过“膨胀预期的峰值”进入“幻灭的低谷”,你同意吗?
另一方面,Data Fabric的优势被评为“转型”,具有新兴技术的成熟度、1-5%的目标受众市场渗透率,以及5-10年的主流采用时间。
下面的幻灯片显示了数据结构实现的技术支柱,颜色编码从表示成熟度的绿色到表示新兴的黄色,再到表示最新功能的红色。

(Diagram: Data Fabric or Data Mesh: Debate on Deciding Your Future Data Management Architecture, Robert Thanaraj and Ehtisham Zaidi, Gartner Data & Analytics Summit, Orlando, Florida, 20–22 March, 2023)
在会议的剩余部分,发言者强调了数据结构对数据团队的“共同试点”性质,以及它给业务用户的自助服务带来的信心。
现在来看数据网格:数据网格不是一种既定的最佳实践;它是一种新兴的数据管理方法,是一种领域主导的实践(数据由领域团队中的SME管理和治理),用于定义、交付、维护和治理数据产品(灵活、可重复使用和增强的数据工件)。
或者,换句话说:

(Diagram: Data Fabric or Data Mesh: Debate on Deciding Your Future Data Management Architecture, Robert Thanaraj and Ehtisham Zaidi, Gartner Data & Analytics Summit, Orlando, Florida, 20–22 March, 2023.)
正如Robert Thanaraj和Ehtisham Zaidi所介绍的,Gartner对Data Mesh效益的评估被评为“低”,技术成熟度低,目标受众市场渗透率为1-5%,预计在稳定下来并被其他产品或方法吸收之前就会过时。
根据Robert的观点,Mesh的优点包括消费准备、通过市场批准托管人使用、为数据产品消费者自助、由主题所有者审计以及由数据产品经理管理的生命周期。对我来说,这听起来与Medium上Mesh“圣经”中的原始定义非常相似。
有了上面详述的所有缺点和风险,为什么组织要探索数据网格作为其数据管理实践的有效可能性?
据我所知,原因是:
- 失败的部署经常会危及集中式设置。
- 竞争紧迫的业务优先级-通过在业务功能中实现网格,绕过IT以获得速度和规模。
- 快速访问公民分析师的自助服务。
- 克服像意大利面条一样的点对点集成。
Robert和Ehtisham分享了Gartner进行的一项调查的统计数据:
- 大多数组织都让IT部门实施Mesh
- 80%的人对域级别的治理实施不满意
- 另一个风险-数据网格的实施咨询量很大
- 项目通常以手动硬编码的语义层结束
在会话中听了所有这些之后,我看不出Mesh和实现数据仓库硬编码语义层之间的区别!
“2021年Gartner D&A治理调查显示,只有18%的受访者表示,他们的治理已经成熟,并在整个企业中扩展。这一类人在实现治理成果方面的总体成功率远高于其他人。”
那么,什么时候应该使用网格呢?仅当元数据成熟度较低且治理成熟度较高时(!)!!!
85%的组织在这两方面都很低(!!!)那么我们能做什么呢?坚持使用DW并开始捕获元数据。
追求两个“低点”的Mesh将带你回到2000年代的筒仓。
最后,本次会议最重要的幻灯片是:

(Diagram: Data Fabric or Data Mesh: Debate on Deciding Your Future Data Management Architecture, Robert Thanaraj and Ehtisham Zaidi, Gartner Data & Analytics Summit, Orlando, Florida, 20–22 March, 2023.)
你可能还记得,元数据是这个博客每一部分的共同主题——从你应该在哪里存储数据(中央数据湖)、如何最大限度地提高其价值(通过治理和管理),以及是优先考虑数据网格还是数据结构框架。这清楚地表明,在引领Data Fabric实现的惊涛骇浪之前,必须谨慎而勤奋地处理元数据。
数据质量是每个人的工作,所以它不是任何人的责任。为了解决这个问题,选择你的冠军,理想情况下,如果你有资源,一次开始所有四个步骤的十二个动作:
- 确定业务用例(并非所有数据都同等重要)-受(较差)数据质量影响的主要业务结果是什么?
- 发现IT部门的利益相关者也倾向于业务职能。教他们DQ的通用语言。
- 确定最关键的DQ问题:通常是在法规遵从性方面。为您的用例定义什么是“足够好的”,定期重新检查,并分析错误容忍度。
- DQ应该是治理倡议的一部分,永远不要单独处理。不仅要与治理委员会对话,还要与其业务利益相关者进行对话。
- 技能:聘请精通沟通和项目管理、政治头脑强、具有商业头脑、数据和分析技能的数据管理员。他们会调查问题,有时甚至会解决问题;策划和管理元数据;定义和监控规则;并协调DQ最佳实践。
- DQ对业务和IT的兴趣是一项团队运动。从最能受益的个人开始,向他们展示成功故事,以及利益集团领导人,激发激情。
- 数据分析和监控:找到一个工具来量化你的DQ。监测异常情况和基准品位。
- 制定一个改进计划,包括短期分析、预防计划和补救任务。
- 从基于真相的模型切换到基于信任的模型。打破信任介绍级别(有保证的、肯定的、证明的、承认的、断言的、未知的)。为每个数据资产定义所需的级别,并确定改进的优先级。这是索尔演讲的一部分(如上所述)。
- 利用自动化和扩充:否则就不可能进行扩展。使用AI/ML的活动元数据是需要查找的工具。
- 将DQ纳入业务工作流程。分析DQ问题发生的频率,并通过集中的DQ服务交付解决这些问题。
- 数据素养:接受DQ思维,让人们关心,并促进知识转移。
我们正处于世代人工智能时代的边缘,ChatGPT在微软强大的品牌支持下率先发展。在将这些先进的Generative AI工具应用于您的数据环境之前,必须解决数据质量和治理问题。否则,我们最终会得到一个更昂贵的“垃圾进垃圾出”版本。但这还不够:你还需要控制Generative AI工具如何将其数据模型解释(或映射)到你自己的数据模型-如果这种映射做得不正确,例如,供应商帐户被错误地映射到客户帐户,即使数据质量最好,我们也会得到错误的结果。因此,治理不仅不会很快取得进展,而且在不久的将来将成为不可或缺的工具。然而,它必须经过高度的自动化才能有效地应对这些新的挑战。自动化或至少增强治理是可能的,其中一种方法是激活元数据。我将在本系列的后面讨论这个问题。
噢,孩子!如果你读了这句话,那就太好了。你在这个博客里熬到了最后!
我选择将Data Lake、Data Fabric、Data Mesh和Active Metadata的主题结合起来,因为它们都解决了我们必须面对和解决的范式转变,以实现第一篇博客中讨论的新现实,并支持我在第二篇博客中涵盖的治理,使其值得信赖。在本系列博客的最后一部分,我将介绍峰会上讨论的数据业务的未来。
[1] Gartner, “Data and Analytics Governance: Foundations and Prospects,” Gartner Data & Analytics Summit, Orlando, Florida, 20–22 March, 2023.
[2] Gartner, “Deploy Data and Analytics Governance Effectively to Drive Better Decisions,” Gartner Data & Analytics Summit, Orlando, Florida, 20–22 March, 2023.
[3] Gartner, “Twelve Actions to Improve and Sustain Your Data Quality,” Gartner Data & Analytics Summit, Orlando, Florida, 20–22 March, 2023.
- 161 次浏览