【数据质量】数据质量应该是共享的,而不是拥有的
视频号

微信公众号

知识星球

我们如何在OpenMetadata中民主化数据质量?
企业已经将目光转向数据。它不再将数据视为实现公司愿景的必要燃料,而是成为推动市场的产品。
- 谷歌为我们精心绘制了一幅描述网络的巨大图表,以准确地找到我们需要的东西。
- 脸书对每一位用户进行了简介,以帮助营销人员接触到的不是更广泛的受众,而是他们的目标。
- 数据分析师构建仪表盘来推动高管的决策。
是什么让你的仪表盘与众不同?为什么数百万用户选择谷歌?脸书是如何在网络广告市场占据主导地位这么长时间的?相信
有很多数据质量工具可以提供信任,但团队仍在努力维护和扩展数据质量实践。在这篇文章中,我们将讨论如何在OpenMetadata中打破竖井并使数据质量民主化。
不同的人物有不同的需求
一名数据工程师、一名数据分析师和一名数据科学家走进酒吧。他们都订购不同的东西,因为他们是不同的人,有不同的需求,使用不同的工具。
作为数据从业者,我们已经意识到,我们的工作不会在发送表、管道或仪表板时结束。从数据资产转移到数据产品需要用户信任我们想要提供的见解。然而,数据质量工具专注于单个角色,而不考虑为数据平台提供动力的多个配置文件。
数据工程师致力于验证管道和内部流程。他们必须确保数据在规定的时间到达目的地,并达到预期的记录数量。
- DBA监控数据的使用情况及其在数据库中占用的物理空间,重点关注速度和优化。
- 数据分析师了解业务,知道数据中有必须遵守的规则。
- 数据科学家利用他们的统计知识来检查数据分布中的特征漂移和任何演变。经过训练的ML模型不会永远存在!
单个数据资产具有许多质量需求,这些需求对于不同的人物角色是不同的。
此外,这些角色与数据的交互方式也有所不同。他们的知识和工具针对他们需要实现的目标。但数据质量解决方案试图找到一个中间立场,这意味着必须有人妥协。要么很难在面向工程师的实现上构建和添加测试,要么由于高层抽象,测试变得有限和僵化。
数据质量所有权
当一个团队成为单一的数据质量提供商时,就会出现摩擦,这是一个很难解决的问题。这项任务通常落在工程师的肩上,他们知道如何进行测试,但离业务更远。
这导致了外部用户请求的连续队列,这些请求并不总是共享相同的语言或期望。在这里,我们不仅需要考虑跨团队调整路线图的困难,还需要考虑降低个人和团队自主权的后果,这会降低他们对数据产品的所有权和数据质量要求。
数据质量民主化
不一致、不正确和碎片化的元数据使组织无法释放其全部数据潜力。在数据质量问题上抛出另一个工具只会增加(元)数据与人之间的脱节。
我们在OpenMetadata的目标是创建一个集中和共享的元数据平台,该平台涉及数据质量测试的整个生命周期。数据质量民主化意味着使所有数据从业者能够独立满足数据质量需求,而不会出现团队之间的通信差距和瓶颈,也不会影响或限制功能。
我们已经能够率先推动这一民主化进程;得益于两种主要成分:
- 一个由JSONSchema提供支持的元数据标准,它帮助我们围绕数据质量测试指定一种通用语言。有了这样的定义,我们可以使用OpenMetadata中直接定义的测试,也可以集成来自Great Expectations或 DBT.等工具的测试结果。
- 以API为中心的模型,允许用户与不同级别的数据质量测试交互:UI、编程语言SDK和/或通过API调用与服务器直接通信。
OpenMetadata的所有开发都是从构建API开始的。用户可以通过UI执行的任何操作都是一个API调用,可以在需要时自动执行,没有任何限制。
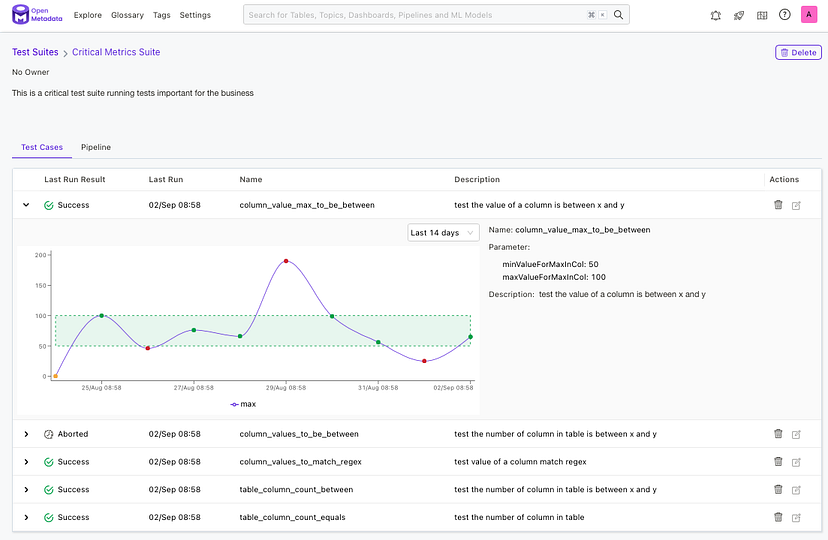
Data Quality view in OpenMetadata
结果如何?数据分析师和数据科学家可以100%依赖UI来创建测试、运行和安排测试,并在出现任何问题时向Slack或Teams添加通知。不需要其他团队的干预!
任何其他自动化都可以通过依赖Python SDK使用OpenMetadata的工作流定义或与API交互来实现,以创建新的测试并从现有的数据质量过程中发送测试结果。
OpenMetadata没有强迫团队根据其提供的交互选择工具,而是在各个级别上提供了对数据质量功能的完全控制:从无代码到直接API通信。
使用OpenMetadata建立数据信任
您想看到OpenMetadata的强大数据质量功能发挥作用吗?观看我们的网络研讨会,开始在任何级别建立对您数据的信任:
- 从OpenMetadata UI,
- 使用Python客户端拥有您的工作流,
- 或者直接使用API创建自己的测试定义。
- 56 次浏览