【数据合同】实施数据合同
视频号

微信公众号

知识星球

trust no one
数据合约可以帮助您通过数据管道和处理系统对记录的形状和元数据进行记录和强制执行。他们的主要目标是减少意外,并消除未记录的更改。
例如,如果数据生产者和数据消费者同意他们之间交换的数据具有特定的模式,则可以(也应该)对每条消息进行验证。
如果生产者一方的模式发生了变化,而消费者没有意识到这一点,那么他们很快就会崩溃,所以这些合同必须存储在某个地方,并由双方通过自动验证检查来维护。
本文中提到的所有代码片段都可以在这个存储库中找到。
学说
实际上,有很多方法可以定义数据生产者和消费者之间的合同。例如,Kafka有一个很好的工具,称为Schema Registry。
没有任何合同的主管道可能是这样的
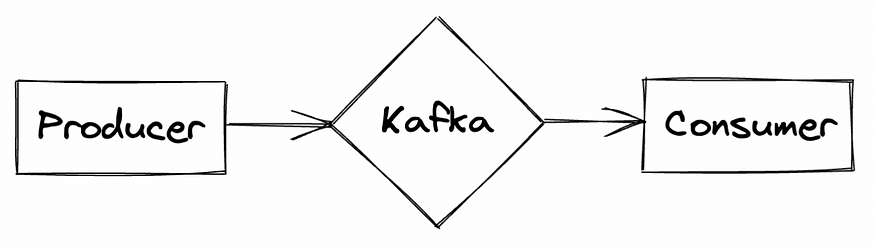
生产者应用程序可以自由地将数据推送到Kafka中,消费者将读取来自该主题的所有传入数据。您可以想象,由于某种原因(可能是业务逻辑的更改或生产者使用的源数据的更改),消息模式发生更改的情况;在数据真正到达之前,消费者没有办法知道这些变化。
输入架构注册表
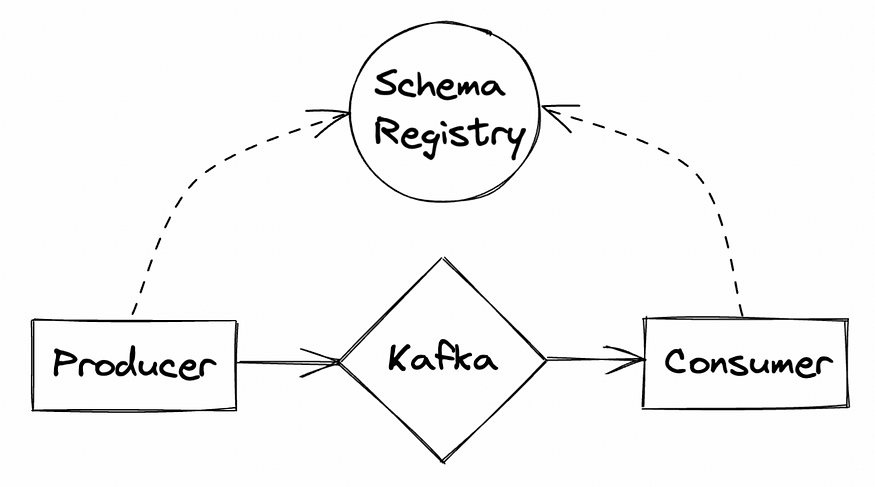
Schema Registry是一个独立的进程,位于集群之外,生产者和消费者同时使用它来推送/消费来自Kafka的消息。
架构注册表为您的消息存储和提供元数据。模式是有版本控制的,注册表还提供了各种兼容性设置,这些设置支持消息的模式演变。
你可以在其他各种博客上阅读更多关于数据合约背后的想法。对于我们这些通过这种方式学习得更好的人来说,这篇文章将重点关注一个非常小的实现。
实施
让我们先实现我们的无数据契约示例,以展示漂移情况。
我们可以快速构建一个Confluent集群,将它们出色的Docker图像与Docker compose相结合
version: '3'
services:
broker:
image: confluentinc/cp-kafka:7.2.1
hostname: broker
container_name: broker
ports:
- "9092:9092"
- "9101:9101"
environment:
KAFKA_BROKER_ID: 1
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: 'CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT'
KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://broker:29092,PLAINTEXT_HOST://localhost:9092'
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_JMX_PORT: 9101
KAFKA_JMX_HOSTNAME: localhost
KAFKA_PROCESS_ROLES: 'broker,controller'
KAFKA_NODE_ID: 1
KAFKA_CONTROLLER_QUORUM_VOTERS: '1@broker:29093'
KAFKA_LISTENERS: 'PLAINTEXT://broker:29092,CONTROLLER://broker:29093,PLAINTEXT_HOST://0.0.0.0:9092'
KAFKA_INTER_BROKER_LISTENER_NAME: 'PLAINTEXT'
KAFKA_CONTROLLER_LISTENER_NAMES: 'CONTROLLER'
KAFKA_LOG_DIRS: '/tmp/kraft-combined-logs'
volumes:
- ./update_run.sh:/tmp/update_run.sh
command: "bash -c 'if [ ! -f /tmp/update_run.sh ]; then echo \"ERROR: Did you forget the update_run.sh file that came with this docker-compose.yml file?\" && exit 1 ; else /tmp/update_run.sh && /etc/confluent/docker/run ; fi'"
schema-registry:
image: confluentinc/cp-schema-registry:7.2.1
hostname: schema-registry
container_name: schema-registry
depends_on:
- broker
ports:
- "8081:8081"
environment:
SCHEMA_REGISTRY_HOST_NAME: schema-registry
SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS: 'broker:29092'
SCHEMA_REGISTRY_LISTENERS: http://0.0.0.0:8081
control-center:
image: confluentinc/cp-enterprise-control-center:7.2.1
hostname: control-center
container_name: control-center
depends_on:
- broker
- schema-registry
ports:
- "9021:9021"
environment:
CONTROL_CENTER_BOOTSTRAP_SERVERS: 'broker:29092'
CONTROL_CENTER_SCHEMA_REGISTRY_URL: "http://schema-registry:8081"
CONTROL_CENTER_REPLICATION_FACTOR: 1
CONTROL_CENTER_INTERNAL_TOPICS_PARTITIONS: 1
CONTROL_CENTER_MONITORING_INTERCEPTOR_TOPIC_PARTITIONS: 1
CONFLUENT_METRICS_TOPIC_REPLICATION: 1
PORT: 9021没有Zookeeper 👀, 耶!
接下来,让我们将一些伪造的用户数据生成到一个名为USERS的主题中。
TOPIC = "USERS"
def push_messages():
producer = KafkaProducer(
bootstrap_servers=BOOTSTRAP_SERVERS,
)
fake = Faker()
for i in range(100):
data = {
"ts": datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f"),
"name": fake.name(),
"country": fake.country(),
"age": str(fake.random_int(0, 100)),
}
producer.send(topic=TOPIC, key=str(i).encode("utf-8"), value=json.dumps(data).encode("utf-8"))
print(f"Sent message {i} -> {data}")
sleep(2)
if __name__ == "__main__":
push_messages()在我们的Kafka集群激活后,我们可以通过运行上面的脚本开始生成数据:python producer.py。
我们可以查看包含的控制中心(可访问localhost:9021),以验证数据是否确实被推送到了我们的目标主题中。
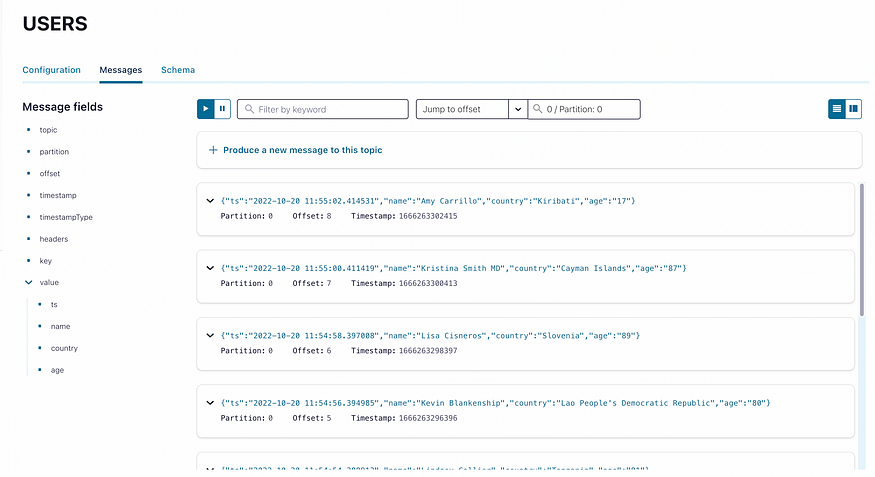
现在,下游消费者可能看起来像这样:
import json
import json
import os
from kafka import KafkaConsumer
BOOTSTRAP_SERVERS = (
"kafka:9092" if os.getenv("RUNTIME_ENVIRONMENT") == "DOCKER" else "localhost:9092"
)
TOPIC = "USERS"
def consume_messages():
consumer = KafkaConsumer(
TOPIC,
auto_offset_reset="earliest",
bootstrap_servers=BOOTSTRAP_SERVERS,
)
average_age = 0
user_count = 0
for msg in consumer:
idx, value = msg.key.decode("utf-8"), json.loads(msg.value)
average_age = (average_age * user_count + int(value["age"])) // (user_count + 1)
user_count += 1
print(
f"Received message {idx} -> {value} | Average age: {average_age} | User count: {user_count}"
)
if __name__ == "__main__":
consume_messages()这个基本消费者将阅读到达USERS主题的消息,计算其看到的所有用户的平均年龄,并将其打印到终端,如下所示:
{'ts': '2022-10-20 11:54:46.362432', 'name': 'Michael Hunt', 'country': 'Belgium', 'age': '40'}
| Average age: 40 | User count: 1
{'ts': '2022-10-20 11:54:48.367588', 'name': 'Sergio Williams', 'country': 'Greece', 'age': '49'}
| Average age: 44 | User count: 2
{'ts': '2022-10-20 11:54:50.372057', 'name': 'Mrs. Mary Davidson PhD', 'country': "Lao People's Democratic Republic", 'age': '54'}
| Average age: 47 | User count: 3现在让我们假设生产者在模式中引入了一个更改。假想来源服务决定给我们每个用户的出生日期,而不是他们的年龄,现在我们的制作人将是这样的:
for i in range(100):
data = {
"ts": datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f"),
"name": fake.name(),
"country": fake.country(),
"date-of-birth": str(fake.date_of_birth(tzinfo=None, minimum_age=0, maximum_age=100)),
}
producer.send(topic=TOPIC, key=str(i).encode("utf-8"), value=json.dumps(data).encode("utf-8"))
print(f"Sent message {i} -> {data}")
sleep(2)
正如我们可以在控制中心验证的那样,Kafka在同一主题中使用新模式存储这些数据没有问题。

但如果我们经营我们的消费者,我们就会遇到麻烦。
Traceback (most recent call last):
File "/Users/daniel.palma/Personal/data-contracts-kafka/consumer/main.py", line 34, in <module>
consume_messages()
File "/Users/daniel.palma/Personal/data-contracts-kafka/consumer/main.py", line 25, in consume_messages
average_age = (average_age * user_count + int(value["age"])) // (user_count + 1)
KeyError: 'age'当然,新唱片没有年龄密钥,所以我们的服务失败了。值得庆幸的是,我们知道生产商方面发生了什么,但想象一下,一个拥有成百上千生产商和消费者的大型组织,负责这些应用程序的团队只是以太不同的速度移动,无法手动通知每个下游消费者此类更改。
现在您有两个选项:
- 弄清楚发生了什么变化,更新使用者,重新启动服务,然后等待这种情况再次发生。
- 在生产者和消费者之间实现一个合同,该合同将尽早捕捉到这样的更改,从而使您能够为这样的模式演变做好准备。
第一个选项很容易实现(假设你可以自己破解这个问题!),但由于这些事情总是发生,所以不太经得起未来的考验。
第二个选项迫使双方就将要使用的模式达成一致,并允许系统在生产者将数据推送到Kafka之前强制执行它!
这么早就发现变化可以保证下游消费者了解模式的演变,因为如果不实际更新存储我们合同的模式注册表,生产者就无法继续使用新的模式,而且如果双方都不同意,更新合同是不可能的。
输入架构注册表
让我们用以下代码段在schema Registry中注册我们的初始模式
client = SchemaRegistryClient(url="http://127.0.0.1:8081")
class User(BaseModel):
ts: datetime.datetime
name: str
country: str
age: int
schema_id = client.register("USERS-value", User.schema_json(), schema_type="JSON")
print(schema_id)Pydantic和python模式注册表客户端是两个很好的库,可以在这里为我们提供帮助。正如您所看到的,我们根据所选择的主题命名策略,将模式分配给USERS主题的值。
为了验证,我们可以再次检查控制中心:
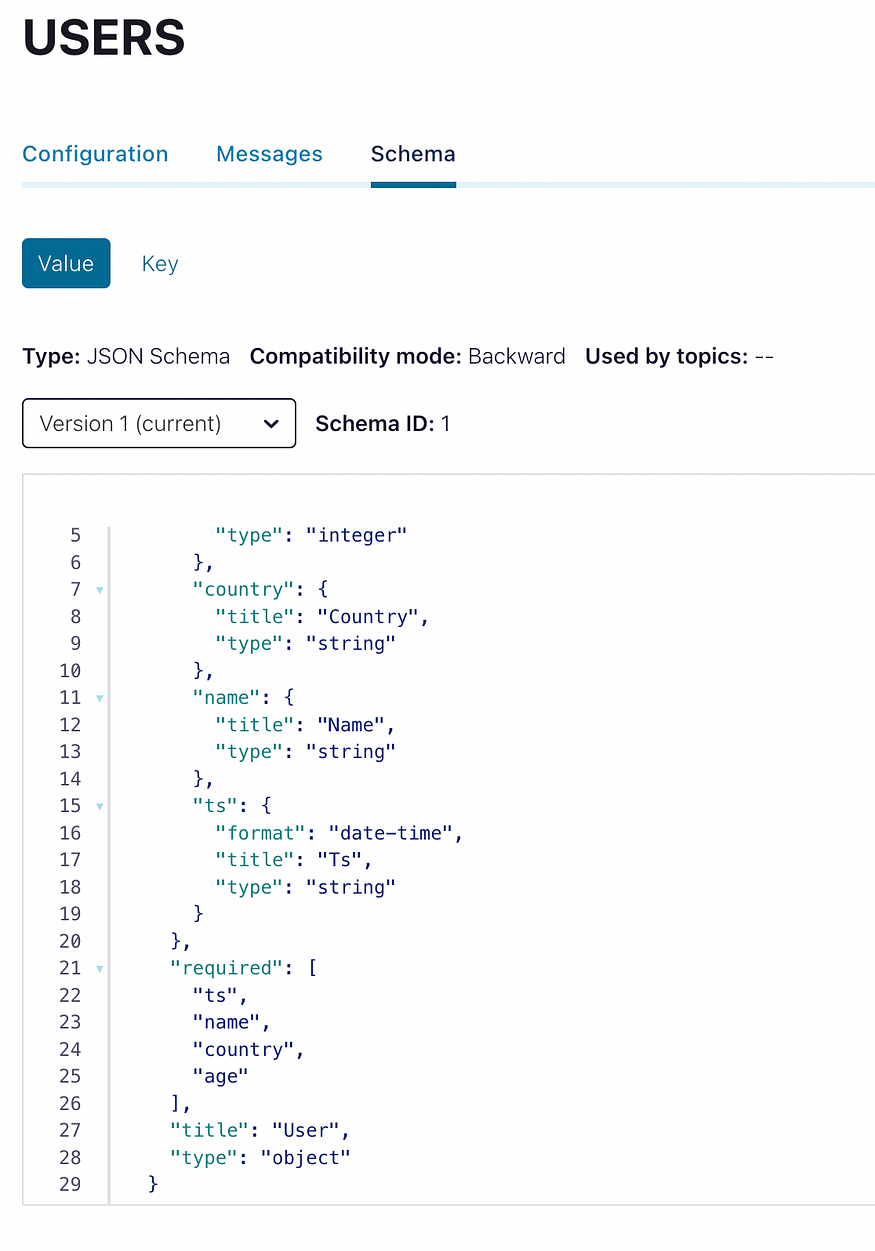
分配给主题的模式消息值
现在只需要稍微重构我们的生产者,在发送消息之前进行兼容性检查。
client = SchemaRegistryClient(url="http://127.0.0.1:8081")
class User(BaseModel):
ts: str
name: str
country: str
age: int
for i in range(100):
data = User(
ts=datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f"),
name=fake.name(),
country=fake.country(),
age=fake.random_int(min=0, max=100),
)
# Get the latest schema from the registry and serialize the message with it
compatibility = client.test_compatibility("USERS-value", data.schema_json(), schema_type="JSON")
if not compatibility:
raise Exception("Schema is not compatible with the latest version")
producer.send(topic=TOPIC, key=str(i).encode("utf-8"), value=json.dumps(data.dict()).encode("utf-8"))
print(f"Sent message {i} -> {data}")
sleep(2)
我们只需获取模式的最新版本,并将其与要发送的数据的模式进行比较。在我们的案例中,测试将通过,因为我们在上面注册的模式与我们在这里推出的模式完全相同。
在消费者方面,我们可以做同样的事情,验证传入消息的模式,如果出现意外情况,则快速失败。
现在,如果我们改变我们的制片人模式,发送出生日期,而不是像这样的年龄
client = SchemaRegistryClient(url="http://127.0.0.1:8081")
class User(BaseModel):
ts: str
name: str
country: str
date_of_birth: str
for i in range(100):
data = User(
ts=datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f"),
name=fake.name(),
country=fake.country(),
date_of_birth=str(fake.date_of_birth(tzinfo=None, minimum_age=0, maximum_age=100)),
)
# Get the latest schema from the registry and serialize the message with it
compatibility = client.test_compatibility("USERS-value", data.schema_json(), schema_type="JSON")
if not compatibility:
raise Exception("Schema is not compatible with the latest version")
producer.send(topic=TOPIC, key=str(i).encode("utf-8"), value=json.dumps(data.dict()).encode("utf-8"))
print(f"Sent message {i} -> {data}")
sleep(2)我们的兼容性检查将立即失败并引发异常
异常:架构与最新版本不兼容
这正是我们想要的!强制执行这样的检查使生产者和消费者之间的合作更加容易,因为他们都可以放心,他们所期望的事情会发生。惊喜越少越好。
为了记录在案,这些验证可以在Kafka中的主题级别上强制执行,但本练习的目的是展示数据契约的更一般的概念,而不是Kafka特定的东西。
更新合同的过程是在模式注册表中注册新版本的模式,这迫使我们创建一个公共的(可审查的!)更新,可以讨论,如果达成一致,可以在消费者方面跟进。
数据合同可以包含任何内容,唯一的假设是双方同意(并强制执行!)其内容。
单独存储合同使我们的体系结构能够在不同的地方重用它们,这增加了我们的灵活性,同时随着合同用户数量的增加,可能出现的意外数量也呈指数级减少。
价值(有吗?)
所有关于数据合同的理论讨论都很难真正看到它们如何提供价值,但如果我们专注于它应该解决的问题,我们可以很快看到它们有多有用。
此外,这个示例在中间使用了一个基本的Kafka设置,因为到目前为止,我只看到了关于这个主题的抽象文章或在大型系统上的实现,所以我认为从一个最小的实现开始将有助于了解整个事情从长远来看是如何帮助我们的。
- 74 次浏览