【数据技术】dbt v1.5-三大新事物
视频号

微信公众号

知识星球

数据契约、模型版本和模型访问
dbt首席执行官最近宣布,dbt 1.5将于4月底发布,其中包括一些重大变化。在本文中,我想总结一下dbt1.5中发布的3个主要新功能(包括数据合约)。
首先,让我们从用例开始——您有一个包含数千个模型的dbt项目,而且越来越难理解谁拥有什么数据模型,并将您的更改发送出去。
因此,你可以考虑的一种方法是让嵌入式数据团队(如财务、销售、产品)拥有某些数据模型——将它们放在子文件夹中,或者你甚至可以将你的大型dbt项目拆分为子项目,并将它们作为包导入(如软件“服务”)。例如:
SELECT * FROM {{ ref('sales_models', 'opportunities') }}第二种方法仍然有效地将两个dbt项目耦合在一起,因此您无法在不破坏下游一切的情况下更改sales_models dbt项目中的opportunities.sql模型。
dbt1.5包含3个新功能,有助于大规模运行dbt:
- 访问:定义谁(以及什么)可以引用dbt项目中的模型
- 契约:指定应用于模型的列、数据类型和约束。考虑dbt测试,但在构建模型之前运行
- 版本:能够创建单个dbt模型的多个版本,因此在不破坏下游模型的情况下更容易进行更改
我将在下面更详细地介绍这些功能,但在我看来,您不必将dbt项目拆分为多个项目来从这些新功能中获得价值。
这些功能是由dbt实验室构建的,目的是帮助将数据管道视为“服务”,并将大型dbt项目拆分为小型dbt项目,每个项目由一个团队所有。
在这种方法中,每个团队都能够快速迭代自己的dbt项目,并且通过合同/访问/版本控制,不必担心上游/下游会破坏他们所依赖(或依赖它们)的其他dbt项目的更改。
这可能对你有用,但可能不行,我在这篇文章中没有立场!
1.访问
设置谁/什么可以引用(ref)dbt模型:
- private:模型只能在同一组中引用
- protected:模型只能在同一个包/项目中引用(这是默认值)
- public:模型可以被任何组、包或项目引用
组在yml文件中定义,模型在yml中被分配访问权限和组,例如:
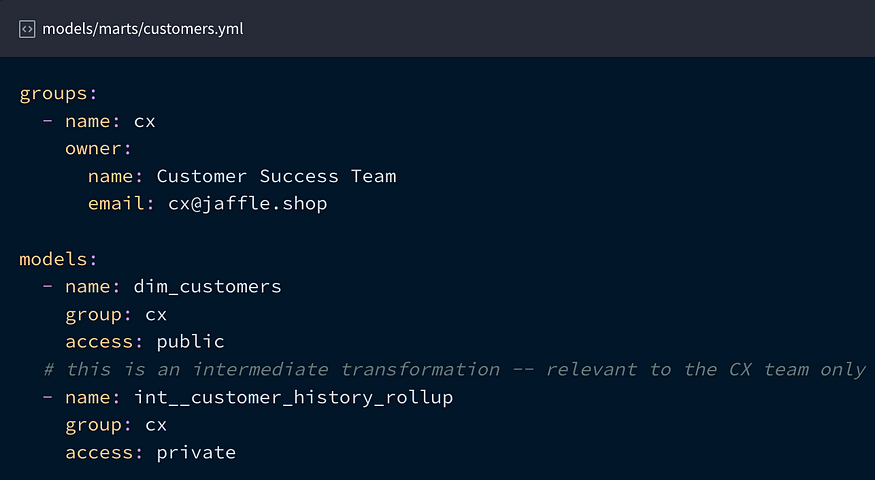
用例是什么?这是一种干净的表面处理方式,其他项目/人员可以(也不能!)使用它。结果是,您的团队具有较少的下游依赖性,因此开发速度更快,因为不必担心崩溃。
使用private与protected可以在dbt项目中实现这种干净的拆分,而如果您有多个dbt项目,则使用public与private/protected可以实现这种拆分。
2.合同
数据契约在某种程度上已经成为数据领域的热门话题,我将试图将其过于简单化为“数据生产者和数据消费者之间关于如何构建数据的协议”。
如果您将单个dbt项目拆分为多个子项目(“服务”),并且您的项目依赖于customer_success包中的dim_customers表,那么您希望知道数据将始终包含特定的列集,并具有给定的数据类型和约束。
如果你没有走上拆分单个dbt项目的道路,这甚至是相关的——如果你拥有models/finance中的一切,并且依赖models/customer_success中的模型,你可能会希望数据模型是一致的。
dbt测试在一定程度上解决了这些问题,但重要的是,它们在几个主要方面与合同不同:
- 测试在模型建立后运行,而合同在模型建立前运行
- 如果您删除了SQL文件中的一列,并且yml中有该列,那么dbt不会中断,它只会说它不存在。然而,如果yml是在合同下的,那么如果缺少一列,dbt就会中断
在dbt中,契约有三个组件:契约本身、列和约束。下面是一个例子:

一旦签订了合同,数据模型就必须包含指定的列,以及指定的数据类型和约束。如前所述,契约在模型运行之前强制执行,因此如果失败,模型将不会运行!
您可以阅读文档以查看可用的约束类型。
用例是什么?我觉得这很有用,无论你是有多个dbt项目,还是只是一个5人以下的小型数据团队。在运行之前,能够确保您的数据模型具有特定的列、约束和数据类型,这对关键数据管道非常有用!
3.版本
这建立在合同的基础上。如果您有数据模型的下游用户,并且希望对列进行更改,而不破坏任何内容或在下游进行大量重构,那么在dbt1.5中,您将能够创建共存的模型的单独版本。
所以,假设您更改了dim_customers模型(正在签订合同),删除了一个名为country_name的列。然后,您可以通过创建一个dim_customers_v1和一个dim_customers_v2-并在yml文件中指定差异来对模型进行版本设置:
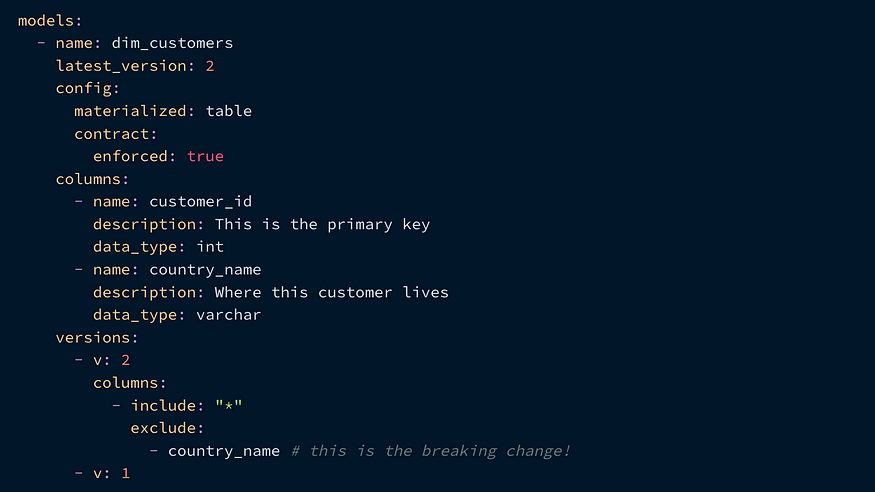
这实际上与创建一个全新的dbt模型相同,但没有为第二个模型创建新的yml条目。请注意,在这一点上,两个模型作为单独的表共存!
你可能会立刻想到一件事——如果我不想在我的数据模型中使用v1/2/3怎么办?dbt有一个可选的配置来处理这一问题:

因此,当您“关闭”v1时,您可以将defined_in:dim_customers放在v2下!
用例是什么?对于团队之间有很多下游依赖关系的大型组织来说,这是能够作为一个团队快速开发和交付新事物的救命稻草。通常,构建和发布数据模型更改以及处理下游影响必须在单个代码更改中完成,而现在它们可以单独处理。
然而,如果不仔细使用,我可以看到这种方法的一些陷阱:
- 下游用户指向不同的数据模型:如果你在不同版本之间更改过滤逻辑,那就特别痛苦!我认为defined_in配置总是指定表的“实时”版本在这里最有用
- 重构留给下游用户:如果在不破坏任何东西的情况下很容易更改模型,那么诱惑就是这样做,并将迁移到新版本的工作留给下游用户
你可以争辩说,第二点是下游用户拥有的有效东西,但如果你做出了真正的重大改变(例如订单<>客户的关系不再是1:1),那么这是一个巨大的责任!
总之,这个版本是dbt朝着允许更大的数据团队处理复杂的dbt生态系统迈出的一大步,但尽管新功能显然非常强大,但在实现之前需要仔细考虑!
感谢阅读。
- 118 次浏览