【大语言模型】超越聊天GPT的炒作(II)
视频号

微信公众号

知识星球

在本系列的第一部分中,我们描述了ChatGPT背后的技术、它的工作原理、它的应用程序以及组织在加入宣传列车之前应该意识到的局限性。当你试图辨别这项技术为你的组织带来的机会时,你可能会面临以下方面的不确定性迷雾:
- 我们应该使用ChatGPT,以及更广泛的人工智能来解决哪些业务问题?(产品市场匹配度)
- 我们可以解决ChatGPT和AI的哪些业务问题?(适合问题解决方案)
- 利用或创造此类人工智能能力所需的精力和成本是多少?
- 相关风险是什么?我们如何减少这些风险?
- 我们如何快速可靠地实现价值?
在这篇文章中,我们通过对人工智能的广泛看法来解决这些问题,并分享我们从提供人工智能解决方案的经验中提炼出的五条建议。
1.产品市场适应性:从客户问题开始,而不是从工具开始
随着ChatGPT的兴奋,人们很容易陷入技术至上的陷阱——我们有一把闪亮的锤子,我们能用它打什么?人工智能项目的一个常见商业错误是从可用数据或当前的人工智能技术开始。相反,从一个特定的客户问题开始。
如果没有一个由客户声音支持的明确而令人信服的问题,我们将发现自己处于一个真空中,很快就会充满“专家”但未经证实的假设。来自竞争对手媒体声称的威胁和重视“了解”而非实验的领导文化的压力可能会导致数月的工程投资浪费。正如彼得·德鲁克的名言:“没有什么比高效地做一些根本不应该做的事情更无用的了。”
有几种做法可以用来提高我们在正确的事情上下注的几率。Discovery就是这样一种实践,它帮助我们在客户斗争、愿景、问题空间、价值主张和高价值用例中发展清晰性。这项为期几周的投资,让合适的人——客户、产品、业务利益相关者(而不仅仅是数据科学家和工程师)——参与进来,可以帮助我们专注于为客户和业务带来价值的想法,避免将人们的时间浪费在没有结果的工作上。
ML画布和假设画布等工具可用于评估使用人工智能解决我们最紧迫问题的价值主张和可行性(见图1)。
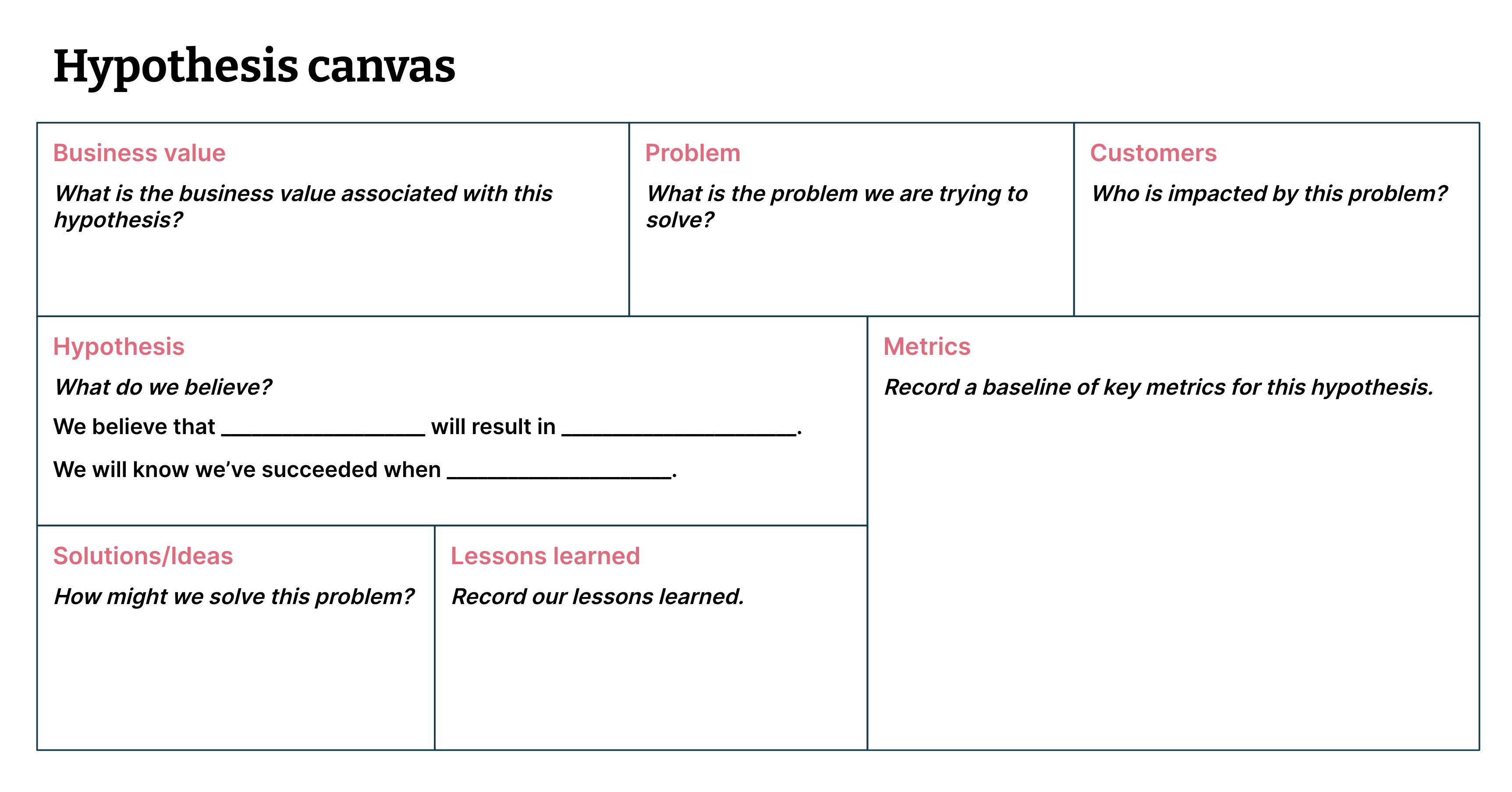
Figure 1: The hypothesis canvas helps us articulate and frame testable assumptions (i.e. hypotheses) (Image from Data-driven Hypothesis Development)
2.问题解决方案匹配:选择合适的人工智能工具来创造价值
本建议旨在扩展您的工具包,为您的高价值用例找到最合适、最具成本效益的方法,并避免在不必要的复杂人工智能技术上浪费精力。认识到,虽然ChatGPT可能会引发对话,但LLM可能不是解决您问题的正确方法。
除了LLM,根据我们的经验,还有其他人工智能技术可以有效地增强企业做出最佳日常运营和战略决策的能力,而且数据和计算资源要少得多(见图2)。
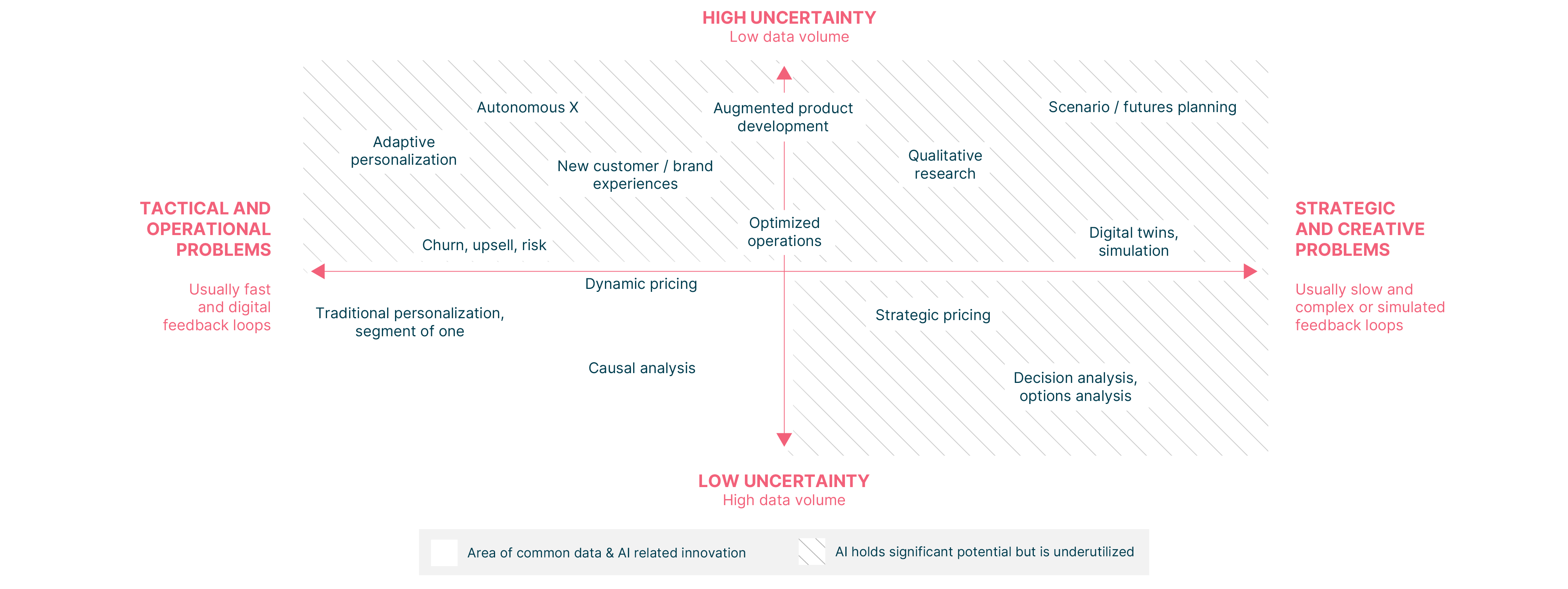
例如,在左上象限,Thoughtworks与芬兰生活方式设计公司Marimekko合作,并应用强化学习为客户创造适应性和个性化的购物体验。我们建立了一个决策工厂,可以实时从用户的行为中学习,不需要在公司的数字平台上扩展过去的数据资产或专业的数据科学技能。在发布的几个小时内,决策工厂的首页点击率提高了41%,五周后,每个用户的平均收入增加了24%。
在前两个象限的中间,我们应用运筹学技术创建了一个模型,帮助基蒂拉机场在旅游旺季缓解机场基础设施和资源的沉重压力。这将计划时间从3小时减少到30秒(减少了99.7%),并将机场相关航班延误的比例减少了61%(尽管航班数量比前一年增加了12%)。延误的减少导致预计每月节省50万欧元的成本,机场的净促销分数(NPS)提高了20分。
这些只是成熟的人工智能增强技术家族尚未开发潜力的一些例子。为您的问题选择正确的人工智能技术可以让您更智能地处理所策划的数据,这样做可以显著降低策划大量历史数据的成本、复杂性和风险。
3.努力:模型越大,误差面就越大

Artwork by Dougal McPherson
与ChatGPT同时代的一个鲜为人知的是Meta的Galactica AI,它接受了4800万篇研究论文的训练,旨在支持科学写作。然而,演示仅两天后就被关闭了,因为它产生了错误信息和伪科学,同时听起来非常权威和令人信服。
这个警示故事有两个启示。首先,向模型抛出堆积如山的数据并不意味着我们会得到与我们的意图和期望一致的结果。其次,在没有全面测试的情况下创建和生产ML模型会给人类和社会带来巨大的成本。这也增加了企业声誉和财务损失的风险。在最近的一篇报道中,谷歌发言人对此表示赞同,他们表示谷歌巴德的“1000亿美元错误”强调了“严格测试过程的重要性”
我们可以而且必须测试人工智能模型。我们可以通过使用一系列ML测试技术来做到这一点,以便在发布任何模型之前发现错误和危害的来源。通过定义模型适应度函数——“足够好”或“比以前更好”的客观衡量标准——我们可以测试我们的模型,并在问题导致生产问题之前发现问题。如果我们努力阐明这些模型适应度函数,那么我们最终可能会发现它不适合生产。对于生成型人工智能应用程序来说,这将是一项不平凡的工作,应该在决定追求哪些机会时加以考虑。
我们还必须从安全角度测试系统,并进行威胁建模练习,以确定潜在的故障模式(例如,对抗性攻击和即时注入)。对于机器学习从业者来说,缺乏测试会导致无休止的辛劳和生产事故。如果您要确保您的投资能够带来高质量和令人愉快的产品,那么全面的测试策略至关重要。
4.风险:治理和道德需要成为一个指导框架,而不是事后思考
“人工智能伦理与其他伦理并不是分开的,而是孤立在自己更性感的空间里。伦理就是伦理,甚至人工智能伦理最终也是关于我们如何对待他人以及如何保护人权,尤其是最弱势群体的人权。”-Rachel Thomas
Thoughtworks赞助的《麻省理工学院负责任技术状况报告》指出,负责任技术不是一种让人感觉良好的陈词滥调,而是一种有形的组织特征,有助于更好地获得和留住客户,改善品牌认知,防止负面后果和相关的品牌风险。
负责任的人工智能是一个新兴但不断发展的领域,有一些评估技术,如数据伦理画布、故障模式和影响分析等,可以用来评估产品的道德风险。通过让相关利益相关者(包括产品、工程、法律、交付、安全、治理、测试用户等)参与进来,“将道德向左转移”(在流程的早期转移道德考虑因素)总是有益的,以确定:
- 产品的故障模式和危害源
- 可能妥协或滥用产品的行为者,以及如何
- 易受不利影响的部门
- 针对每种风险的相应缓解策略
我们确定的风险(其中风险=可能性x影响)必须与其他交付风险一起持续积极管理。这些评估不是一次性的复选框练习;它们应该成为组织的数据治理和ML治理框架的一部分,同时考虑到治理是如何轻量级和可操作的。
5.执行:通过精益产品工程实践加速实验和交付
许多组织和团队在开始他们的AI/ML之旅时寄予厚望,但由于不可预见的时间沉淀和不可预测的弯路,几乎不可避免地难以实现人工智能的潜力——魔鬼在于数据细节。2019年,据报道,87%的数据科学项目从未投入生产。2021,即使在已成功在生产中部署ML模型的公司中,64%的公司需要一个多月才能部署新模型,而2020年这一比例为56%。
这些实现价值的障碍让所有相关人员——高管、投资赞助商、ML从业者和产品团队等——感到沮丧。好消息是,事情不一定非得这样。
根据我们的经验,精益交付实践一直帮助我们通过以下方式迭代构建正确的东西:
- 专注于客户的声音
- 不断改进我们的流程以增加价值流
- 构建人工智能解决方案时减少浪费
机器学习的持续交付(CD4ML)还可以通过加速实验和提高可靠性来帮助我们改善业务成果。高管和工程领导者可以通过倡导有效的工程和交付实践,帮助引导组织实现这些理想的结果。
离别的思绪
在“人工智能接管世界”的主流媒体时代精神中,我们的经验促使我们走向一个更平衡的观点:即人类仍然是世界变革的推动者,人工智能最适合增强而不是取代人类。但是,如果没有谨慎、意图和诚信,一些团体创建的制度可能弊大于利。作为技术人员,我们有能力也有责任设计负责任的、以人为中心的、人工智能支持的系统,以改善彼此的结果。
- 46 次浏览