大语言模型
视频号

微信公众号

知识星球

- 224 次浏览
【LLM】Alpaca:一个强大的、可复制的指令遵循模型
视频号
微信公众号
知识星球
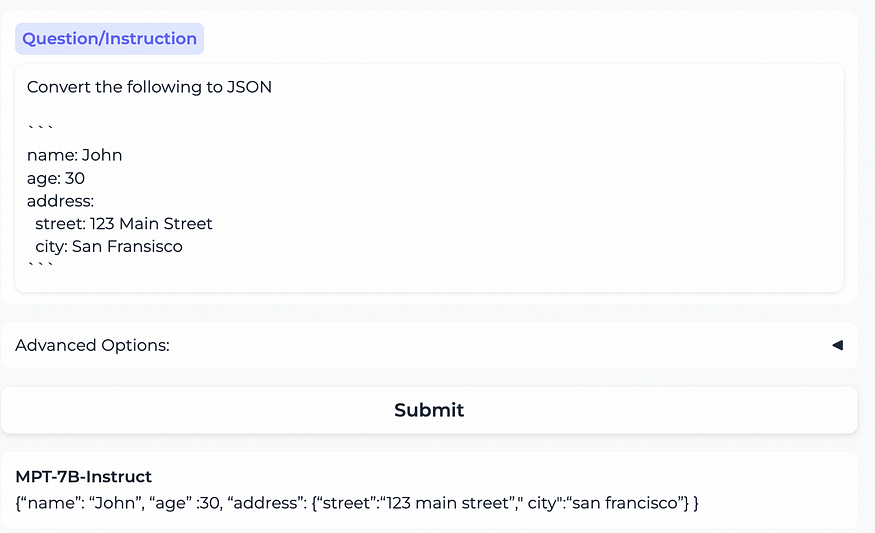
我们介绍了Alpaca 7B,这是一个在52K指令上从LLaMA 7B模型微调而来的模型。在我们对单圈指令遵循的初步评估中,Alpaca的行为在质量上与OpenAI的text-davinci-003相似,同时体积小得惊人,易于复制/便宜(<600美元)。
Web Demo GitHub
![]()
概述
GPT-3.5(text-davinci-003)、ChatGPT、Claude和Bing Chat等指令遵循模型的功能越来越强大。现在,许多用户定期与这些模型交互,甚至在工作中使用它们。然而,尽管指令遵循模型得到了广泛部署,但仍有许多不足之处:它们会产生虚假信息,传播社会刻板印象,并产生有毒语言。
为了在解决这些紧迫问题方面取得最大进展,学术界的参与至关重要。不幸的是,在学术界对指令遵循模型进行研究一直很困难,因为没有一个易于访问的模型在功能上接近OpenAI的text-davinci-003等闭源模型。
我们发布了一个名为Alpaca的指令遵循语言模型的研究结果,该模型是从Meta的LLaMA 7B模型中微调而来的。我们在52K指令上训练Alpaca模型,随后使用text-davinci-003以自学风格生成演示。在自我指导的评估集上,Alpaca表现出许多类似于OpenAI的text-davinci-003的行为,但它也出奇地小,易于复制/便宜。
我们正在发布我们的训练配方和数据,并打算在未来发布模型权重。我们还举办了一个互动演示,使研究社区能够更好地了解羊驼的行为。交互可能会暴露出意想不到的能力和失败,这将指导我们对这些模型的未来评估。我们还鼓励用户在我们的网络演示中报告任何相关行为,以便我们能够更好地理解和缓解这些行为。由于任何发布都有风险,我们将在稍后的博客文章中讨论我们对此次公开发布的思考过程。
我们强调,羊驼仅用于学术研究,禁止任何商业用途。这个决定有三个因素:首先,Alpaca是基于LLaMA的,它有非商业许可证,所以我们必须继承这个决定。其次,指令数据基于OpenAI的text-davinci-003,其使用条款禁止开发与OpenAI竞争的模型。最后,我们没有设计足够的安全措施,因此羊驼还没有准备好用于一般用途。
训练配方
在学术预算下训练高质量的教学跟随模型有两个重要挑战:强大的预训练语言模型和高质量的学习跟随数据。Meta最新发布的LLaMA模型解决了第一个挑战。对于第二个挑战,自学论文建议使用现有的强语言模型来自动生成教学数据。特别是,Alpaca是一个语言模型,根据OpenAI的text-davinci-003生成的演示,在52K指令上使用LLaMA 7B模型的监督学习进行微调。
下图说明了我们是如何获得羊驼模型的。对于数据,我们在自我指导方法的基础上生成了演示后的指令。我们从自指令种子集中的175个人工编写的指令输出对开始。然后,我们提示text-davinci-003使用上下文示例中的种子集生成更多指令。我们通过简化生成管道(详见GitHub)对自学方法进行了改进,并显著降低了成本。我们的数据生成过程产生了52K条独特的指令和相应的输出,使用OpenAI API的成本不到500美元。
有了这个遵循指令的数据集,我们利用全分割数据并行和混合精度训练等技术,使用Hugging Face的训练框架对LLaMA模型进行了微调。在我们的首次运行中,在8个80GB A100上微调7B LLaMA模型需要3个小时,这在大多数云计算提供商上的成本不到100美元。我们注意到,可以提高培训效率以进一步降低成本。
初步评估
为了评估Alpaca,我们对自我指导评估集的输入进行了人类评估(由5名学生作者进行)。该评估集由自学作者收集,涵盖了一系列面向用户的指令,包括电子邮件写作、社交媒体和生产力工具。我们对text-davinci-003和Alpaca 7B进行了盲配对比较,发现这两种型号的性能非常相似:Alpaca在与text-daviNC-003的比较中赢得了90胜,而Alpaca赢得了89胜。
考虑到模型的小尺寸和少量的指令跟随数据,我们对这个结果感到非常惊讶。除了利用这个静态评估集,我们还一直在交互测试Alpaca模型,发现Alpaca在不同的输入集上的行为通常与text-davinci-003类似。我们承认,我们的评估可能在规模和多样性方面受到限制。因此,我们发布了一个关于羊驼的互动演示,鼓励读者自己评估羊驼并给我们反馈。
在本节的其余部分中,我们将包括几个交互示例,以展示Alpaca的功能和局限性。
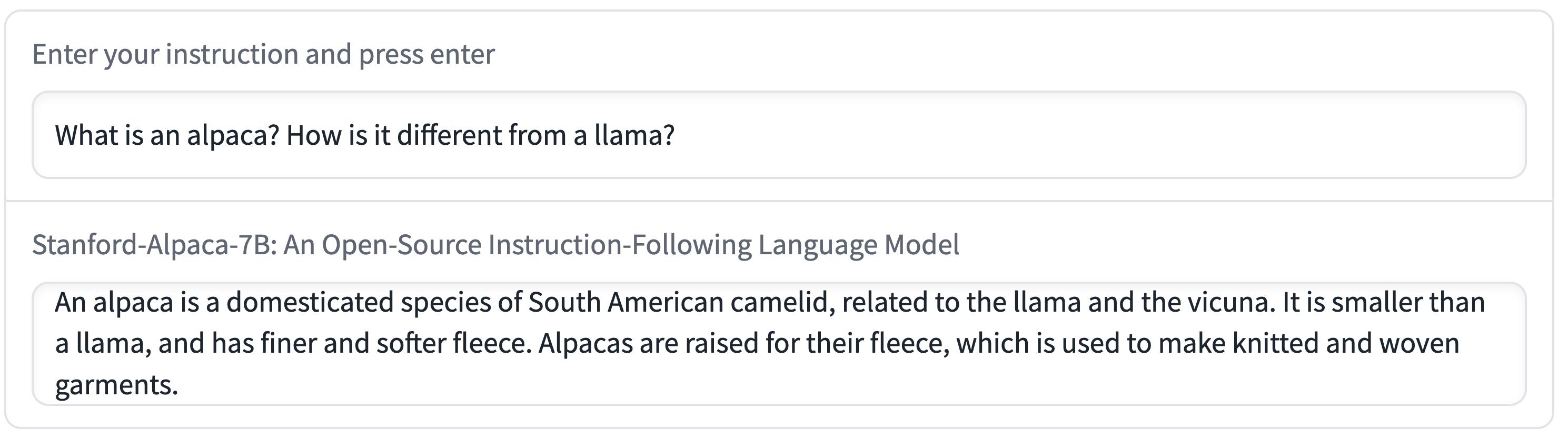
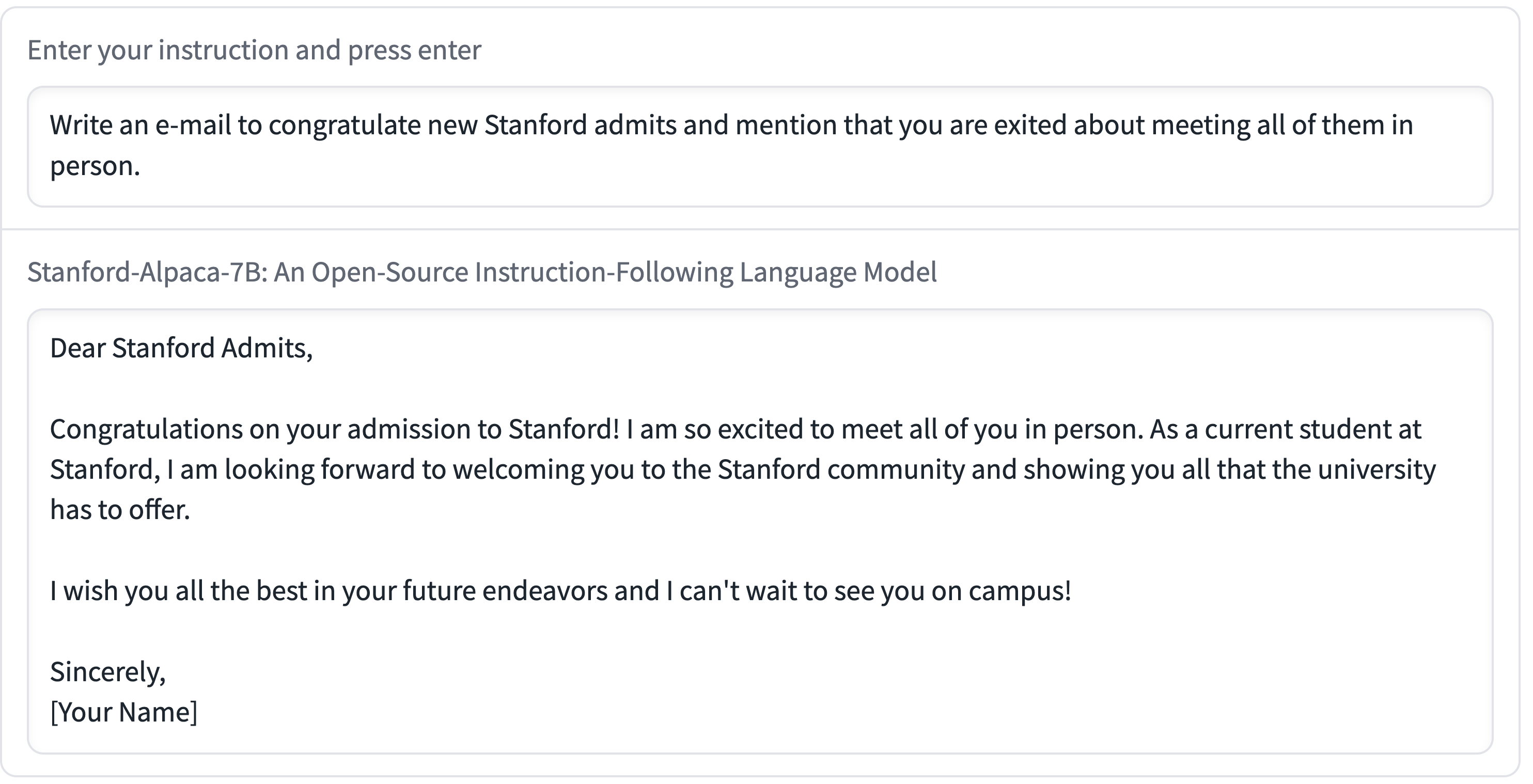
上面的例子表明,Alpaca的输出通常写得很好。我们注意到Alpaca反映了指令遵循数据集的一般风格。因此,Alpaca的回答通常比ChatGPT更短,这反映了text-davinci-003的输出更短。
已知限制
羊驼还表现出语言模型的几种常见缺陷,包括幻觉、毒性和刻板印象。幻觉似乎尤其是羊驼的常见故障模式,即使与text-davinci-003相比也是如此。
例如,在下图中,Alpaca错误地说坦桑尼亚的首都是达累斯萨拉姆,达累斯萨拉姆是坦桑尼亚最大的城市。(直到1974年,这里才被多多马取代。)
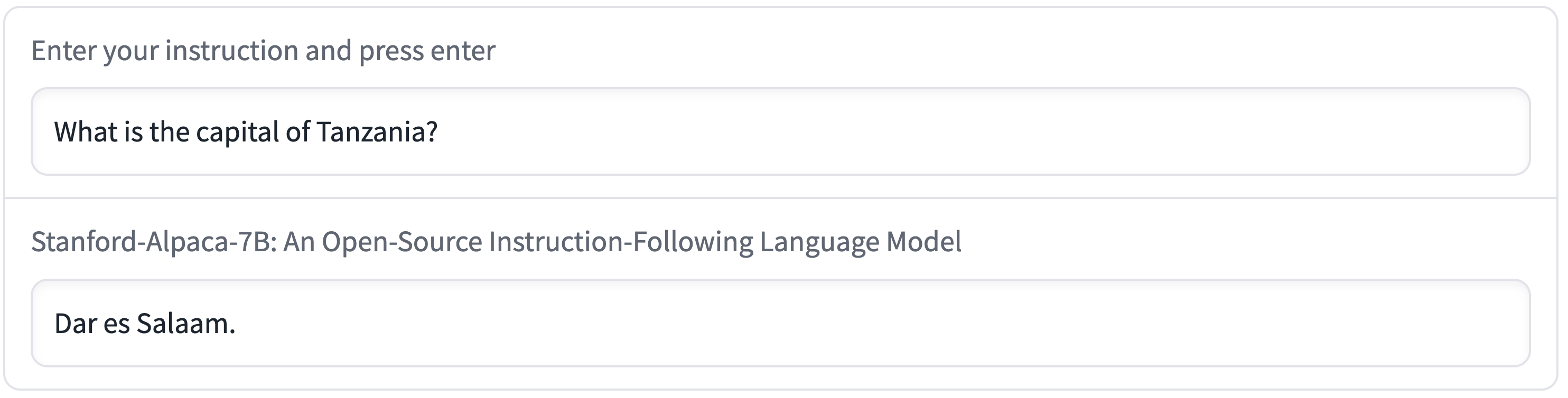
此外,Alpaca可以用来生成书写良好的输出,传播错误信息,如以下示例所示。
Alpaca可能包含许多与底层语言模型和指令调优数据相关的其他限制。然而,我们相信该工件仍然对社区有用,因为它提供了一个相对轻量级的模型,作为研究重要缺陷的基础。我们鼓励用户通过在网络演示中标记故障来帮助我们识别新的故障类型。总的来说,我们希望羊驼的发布能够促进对指令遵循模型及其与人类价值观一致性的进一步研究。
资产发布
我们今天发布以下资产:
- 演示:每个人都可以尝试羊驼的互动演示。
- 数据:52K演示用于微调羊驼。
- 数据生成过程:用于生成数据的代码。
- 培训代码:使用Hugging Face API微调模型。
我们打算在不久的将来释放以下资产:
- 模型权重:我们已联系Meta,以获得关于发布7B Alpaca和更大LLaMA模型的微调版本的Alpaca模型重量的指导。
发布决定
我们相信,释放上述资产将使学术界能够按照语言模型对教学进行受控的科学研究,从而产生更好的科学,并最终产生新的技术来解决这些模型的现有缺陷。
与此同时,任何释放都会带来一些风险。首先,我们认识到,发布我们的训练配方揭示了某些能力的可行性。一方面,这使更多的人(包括不良行为者)能够创建可能造成伤害的模型(无论是有意还是无意)。另一方面,这种意识可能会激励迅速的防御行动,尤其是学术界,他们现在有能力对这些模型进行更深入的安全研究。总的来说,我们认为这一特定版本对研究界的好处大于风险。
鉴于我们正在发布训练配方,我们认为,鉴于配方的简单性,发布数据、模型权重和训练代码所带来的进一步风险最小。与此同时,发布这些资产对可复制科学有着巨大的好处,因此学术界可以使用标准数据集、模型和代码进行受控比较并探索扩展。
为Alpaca部署交互式演示也会带来潜在风险,例如更广泛地传播有害内容,降低垃圾邮件、欺诈或虚假信息的门槛。我们已经制定了两种风险缓解策略。首先,我们使用OpenAI的内容调节API实现了一个内容过滤器,它可以过滤出OpenAI使用策略定义的有害内容。其次,我们使用Kirchenbauer等人2023中描述的方法对所有模型输出进行水印处理,以便其他人可以(以一定的概率)检测输出是否来自Alpaca 7B。最后,我们对使用演示有严格的条款和条件;它仅限于非商业用途和遵循LLaMA许可协议的用途。
我们知道,一旦我们发布模型权重,或者如果用户按照模型训练自己的指令,就可以规避这些缓解措施。然而,通过安装这些缓解措施,我们希望推进最佳实践,并最终制定负责任部署基础模型的社区规范。
未来发展方向
我们对羊驼带来的研究机会感到兴奋。未来有许多令人兴奋的方向:
- 评估:我们需要更严格地评估羊驼。我们将从HELM(语言模型的整体评估)开始,它有望发展到捕捉更具生成性的、遵循指令的场景。
- 安全:我们希望进一步研究羊驼的风险,并使用自动红队、审计和自适应测试等方法提高其安全性。
- 理解:我们希望更好地理解能力是如何从训练配方中产生的。您需要基本模型的哪些属性?当你扩大规模时会发生什么?指令数据需要哪些属性?在text-davinci-003上使用自我指导的替代方案是什么?
鸣谢
这项工作是在斯坦福以人为中心的人工智能研究所(HAI)和斯坦福自然语言处理(NLP)小组的支持下,在基础模型研究中心(CRFM)完成的。我们还特别感谢Yifan Mai为演示部署提供的工程支持。
Alpaca直接且关键地依赖于现有的作品。我们要感谢Meta AI Research培训并发布了LLaMA模型,感谢自学团队为我们提供了数据生成管道的基础,感谢Hugging Face为训练代码提供了基础,感谢OpenAI为我们铺平了道路并展示了可以实现的目标。
我们还想强调的是,在LLM和聊天模型之后,还有许多其他开放的教学努力,包括
OpenChatKit, Open Assistant, and Carper AI.
- 555 次浏览
【LLM】Cerebras GPT:一个开放的、计算高效的大型语言模型家族
视频号
微信公众号
知识星球
Cerebras开源了7个GPT-3模型,参数从1.11亿到130亿不等。这些模型使用Chinchilla公式进行训练,为准确性和计算效率树立了新的基准。
摘要
最先进的语言模型在训练方面极具挑战性;它们需要庞大的计算预算、复杂的分布式计算技术和深厚的ML专业知识。因此,很少有组织从头开始训练大型语言模型(LLM)。越来越多拥有资源和专业知识的人没有公开结果,这标志着几个月前的重大变化。
在Cerebras,我们相信要促进开放获取最先进的模型。考虑到这一点,我们很自豪地宣布向开源社区发布Cerebras GPT,这是一个由7个GPT模型组成的家族,参数范围从1.11亿到130亿不等。这些模型使用Chinchilla公式进行训练,在给定的计算预算下提供了最高的精度。与迄今为止任何公开可用的模型相比,Cerebras GPT具有更快的训练时间、更低的训练成本和更少的能量消耗。
所有模型都是在CS-2系统上训练的,CS-2系统是仙女座人工智能超级计算机的一部分,使用我们简单的数据并行权重流架构。由于不必担心模型分区,我们能够在短短几周内训练这些模型。训练这七个模型使我们能够推导出一个新的比例定律。缩放定律基于训练计算预算预测模型精度,在指导人工智能研究方面具有巨大影响力。据我们所知,Cerebras GPT是第一个预测公共数据集模型性能的缩放定律。
今天的版本旨在供任何人使用和复制。所有型号、重量和检查点都可以在Hugging Face和GitHub上使用Apache 2.0许可证。此外,我们在论文“Cerebras GPT:在Cerebras晶圆级集群上训练的开放计算优化语言模型”中提供了有关我们的训练方法和性能结果的详细信息。用于训练的Cerebras CS-2系统也可通过Cerebras Model Studio按需提供。
Cerebras GPT:开放式LLM开发的新模型
人工智能有可能改变世界经济,但它的使用越来越受到限制。最新的大型语言模型——OpenAI的GPT4——发布时没有关于其模型架构、训练数据、训练硬件或超参数的信息。越来越多的公司使用封闭的数据集构建大型模型,并仅通过API访问提供模型输出。
为了使LLM成为一种开放和可访问的技术,我们认为获得开放、可复制、免版税的最先进模型对于研究和商业应用都很重要。为此,我们使用最新的技术和我们称之为Cerebras GPT的开放数据集训练了一系列转换器模型。这些模型是第一个使用Chinchilla公式训练并通过Apache 2.0许可证发布的GPT模型家族。
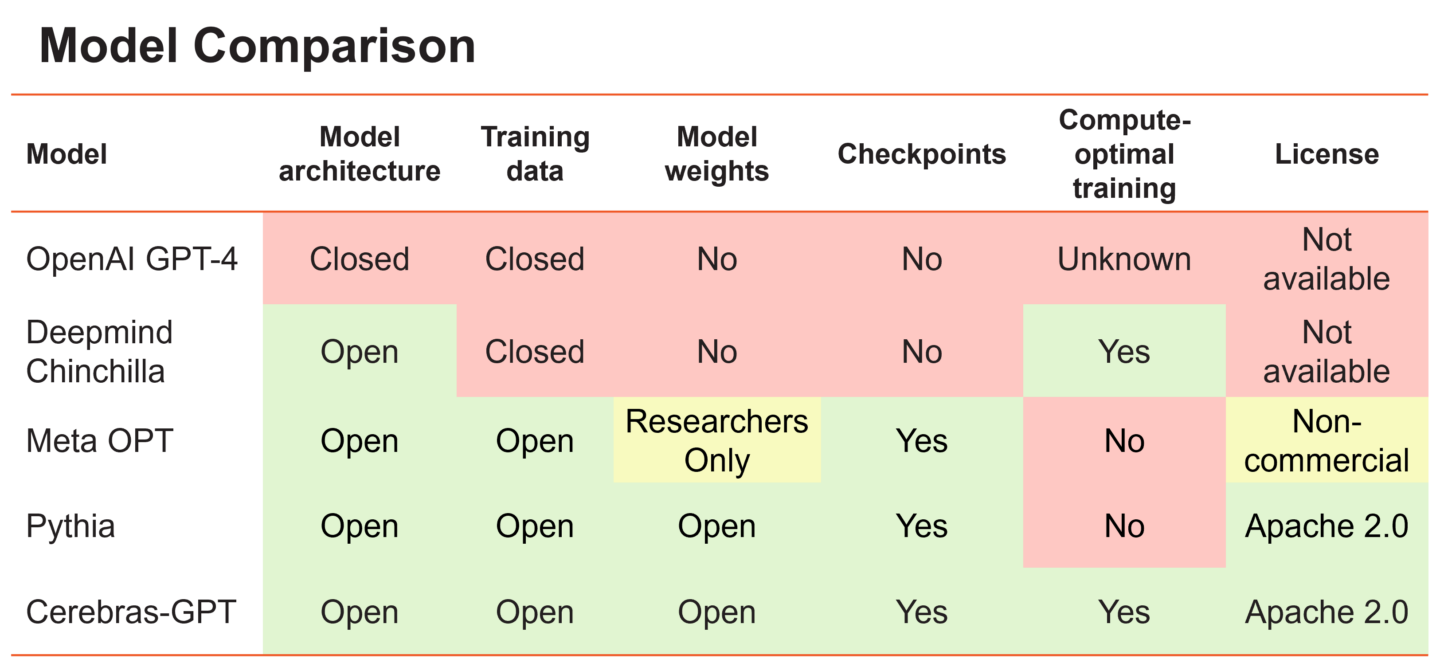
Figure 1. A comparison of different large language models and their openness and training philosophy.
大型语言模型可以大致分为两大阵营。第一组包括OpenAI的GPT-4和DeepMind的Chinchilla等模型,它们在私人数据上进行训练,以实现最高水平的准确性。然而,这些模型的训练权重和源代码对公众是不可用的。第二组包括Meta的OPT和Eleuther的Pythia等模型,它们是开源的,但没有以计算优化的方式进行训练。
所谓“计算最优”,我们指的是DeepMind的发现,当模型中的每个参数都使用20个数据令牌时,大型语言模型在固定的计算预算下实现了最高的精度。因此,应该在200亿个数据令牌上训练10亿个参数模型,以在固定的训练预算下达到最佳结果。这有时被称为“龙猫配方(Chinchilla recipe)”
这一发现的一个含义是,在训练一系列模型尺寸时,使用相同数量的训练数据并不是最佳的。例如,用太多数据训练一个小模型会导致收益递减,每个FLOP的精度增益较小——最好使用数据较少的大模型。相比之下,在太少的数据上训练的大型模型并没有发挥其潜力——最好缩小模型大小并为其提供更多的数据。在每种情况下,根据Chinchilla配方,每个参数使用20个令牌是最佳的。
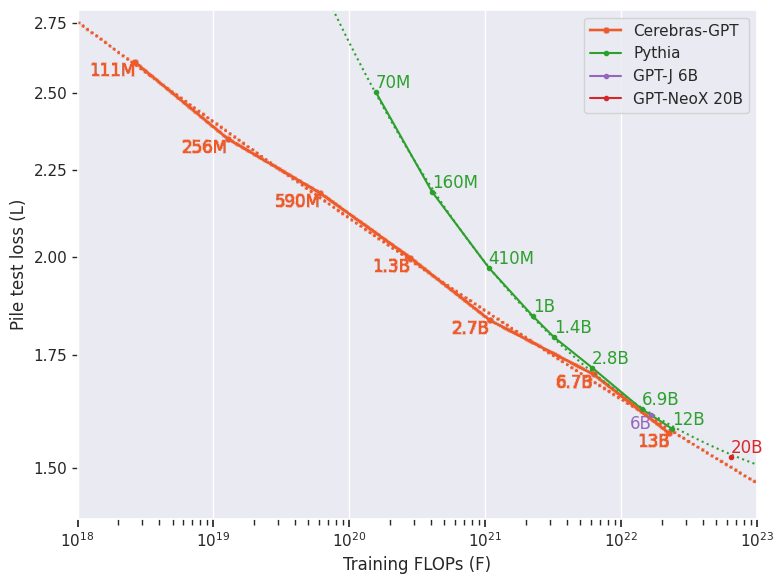 Figure 2. Cerebras-GPT vs. Pythia. Lower curves show greater compute efficiency for a given loss level.
Figure 2. Cerebras-GPT vs. Pythia. Lower curves show greater compute efficiency for a given loss level.
EleutherAI的Pythia开源模型套件对研究界非常有价值,因为它在受控训练方法下使用公共Pile数据集提供了广泛的模型大小。然而,Pythia在所有模型大小中使用固定数量的令牌进行训练,目的是在所有模型中提供一个苹果对苹果的基线。
Cerebras GPT旨在与Pythia互补,旨在使用相同的公共Pile数据集覆盖广泛的模型大小,并建立训练有效的缩放定律和模型族。Cerebras GPT由七个模型组成,参数分别为111M、256M、590M、1.3B、2.7B、6.7B和13B,所有这些模型都使用每个参数20个令牌进行训练。通过使用每个模型大小的最佳训练令牌,Cerebras GPT在所有模型大小中实现了每单位计算的最低损失(图2)。
新扩展定律
训练一个大型语言模型可能是一个昂贵且耗时的过程。它需要大量的计算资源和专业知识来优化模型的性能。解决这一挑战的一种方法是训练一系列不同大小的模型,这有助于建立描述训练计算和模型性能之间关系的缩放定律。
![]() Figure 3. Cerebras-GPT scaling law
Figure 3. Cerebras-GPT scaling law
缩放定律对LLM的开发至关重要,因为它们允许研究人员在训练前预测模型的预期损失,从而避免昂贵的超参数搜索。OpenAI是第一个建立缩放定律的人,该定律显示了计算和模型损失之间的幂律关系。DeepMind随后进行了Chinchilla研究,证明了计算和数据之间的最佳比例。然而,这些研究是使用封闭的数据集进行的,这使得它们很难将结果应用于其他数据集。
Cerebras GPT通过在开放式Pile数据集的基础上建立缩放定律,继续这一研究方向。由此产生的缩放定律为使用Pile训练任何大小的LLM提供了计算高效的配方。通过发表我们的研究结果,我们希望为社区提供宝贵的资源,并进一步推动大型语言模型的发展。
下游任务的模型性能
我们评估了Cerebras GPT在一些特定任务语言任务(如句子完成和问答)上的表现。这些都很重要,因为即使模型可能具有良好的自然语言理解能力,但这可能无法转化为专门的下游任务。我们表明,Cerebras GPT为大多数常见的下游任务保留了最先进的训练效率,如图4中的示例所示。值得注意的是,尽管以前的缩放定律已经显示了训练前损失的缩放,但这是首次发布显示下游自然语言任务的缩放结果。
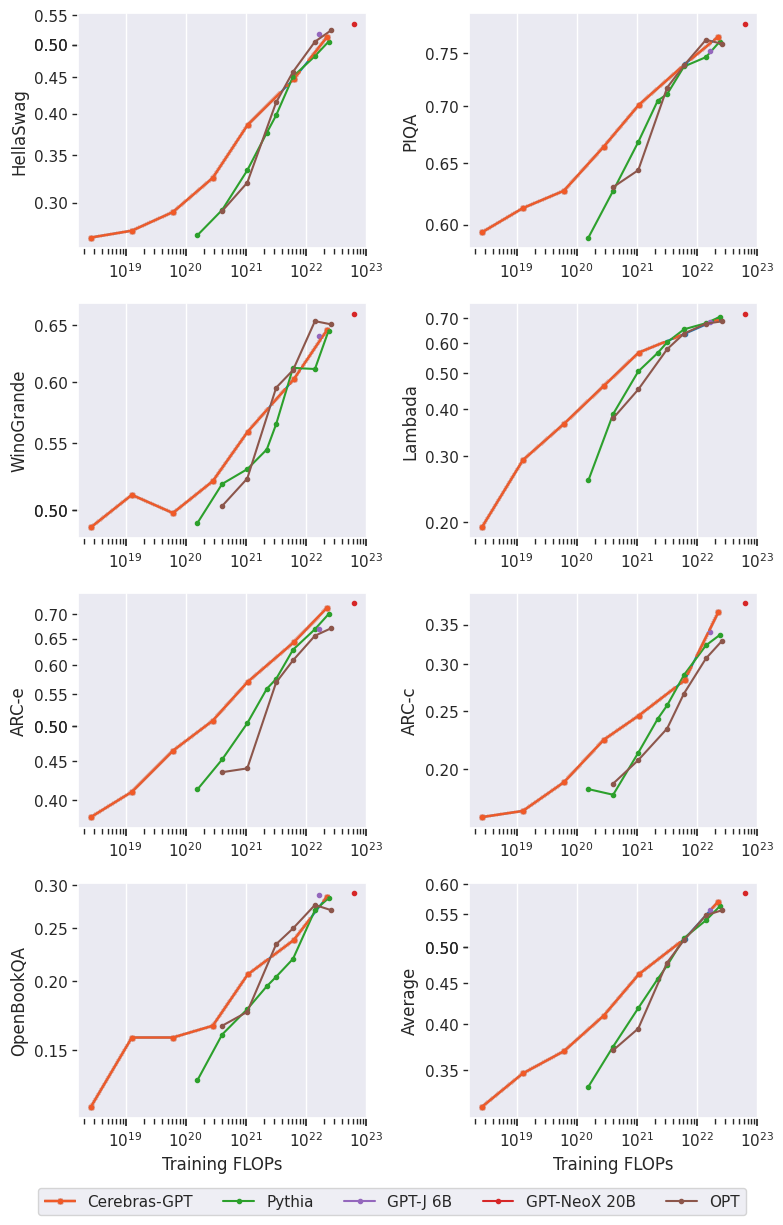 Figure 4 Example downstream task performance comparison of Cerebras-GPT and other open-source models. Cerebras-GPT preserves the training efficiency advantage across downstream tasks.
Figure 4 Example downstream task performance comparison of Cerebras-GPT and other open-source models. Cerebras-GPT preserves the training efficiency advantage across downstream tasks.
Cerebras CS-2:简单的数据并行训练
在GPU上训练非常大的模型需要大量的技术专业知识。在最近发布的GPT-4技术报告中,OpenAI仅在计算基础设施和扩展方面就贡献了30多个贡献者。为了理解原因,我们将查看图5所示GPU上现有的LLM缩放技术。
最简单的扩展方式是数据并行。数据并行缩放在每个设备中复制模型,并在这些设备上使用不同的训练批次,对其梯度进行平均。显然,这并不能解决模型大小的问题——如果整个模型不适合单个GPU,它就会失败。
一种常见的替代方法是流水线模型并行,它在不同的GPU上运行不同的层作为流水线。然而,随着管道的增长,激活内存会随着管道深度的二次方增加,这对于大型模型来说可能是令人望而却步的。为了避免这种情况,另一种常见的方法是在GPU之间划分层,称为张量模型并行,但这会在GPU之间强加大量的通信,这会使实现复杂化,并且可能很慢。
由于这些复杂性,目前没有单一的方法来扩展GPU集群。在GPU上训练大型模型需要一种具有各种形式并行性的混合方法;实现很复杂,很难提出,并且存在严重的性能问题
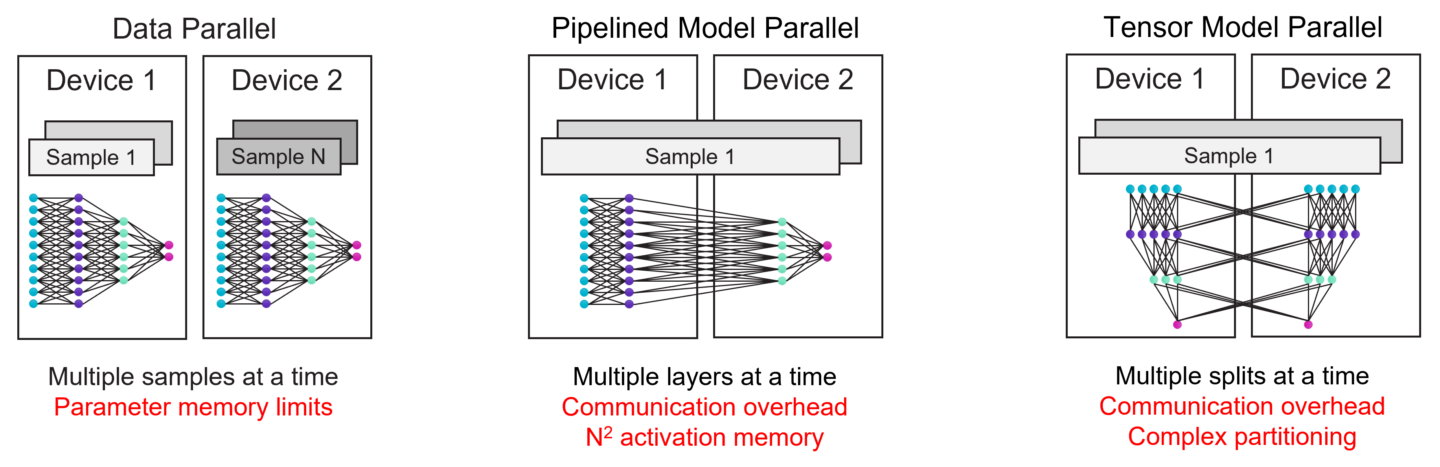
Figure 5 Existing scaling techniques on distributed GPU clusters and their challenges. Scaling on GPU clusters requires a complex combination of all forms of parallelism.
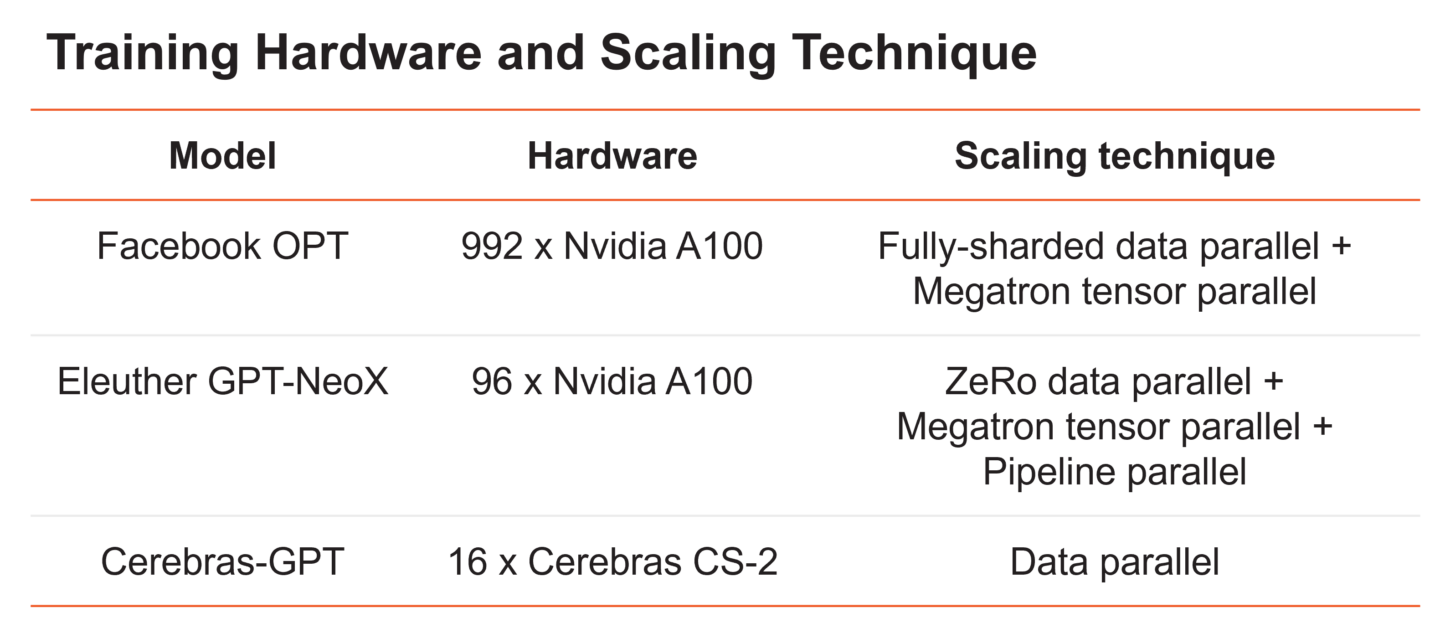
最近的两个大型语言模型说明了在许多GPU之间拆分大型语言模型所涉及的复杂性(图6)。Meta的OPT模型,参数范围从125M到175B,在992个GPU上使用数据并行性和张量并行性的组合以及各种内存优化技术进行训练。Eleuther的20B参数GPT-NeoX使用数据、张量和流水线并行度的组合,在96个GPU上训练模型。
在16个CS-2系统上使用标准数据并行性对脑GPT进行训练。这是可能的,因为Cerebras CS-2系统配备了足够的内存,即使是最大的模型也可以在单个设备上运行,而无需拆分模型。然后,我们围绕CS-2设计了专门构建的脑晶圆秤集群,以实现轻松的扩展。它使用一种称为权重流的硬件/软件联合设计的执行,可以在没有模型并行的情况下独立缩放模型大小和集群大小。使用这种体系结构,扩展到更大的集群就像更改配置文件中的系统数量一样简单,如图7所示。
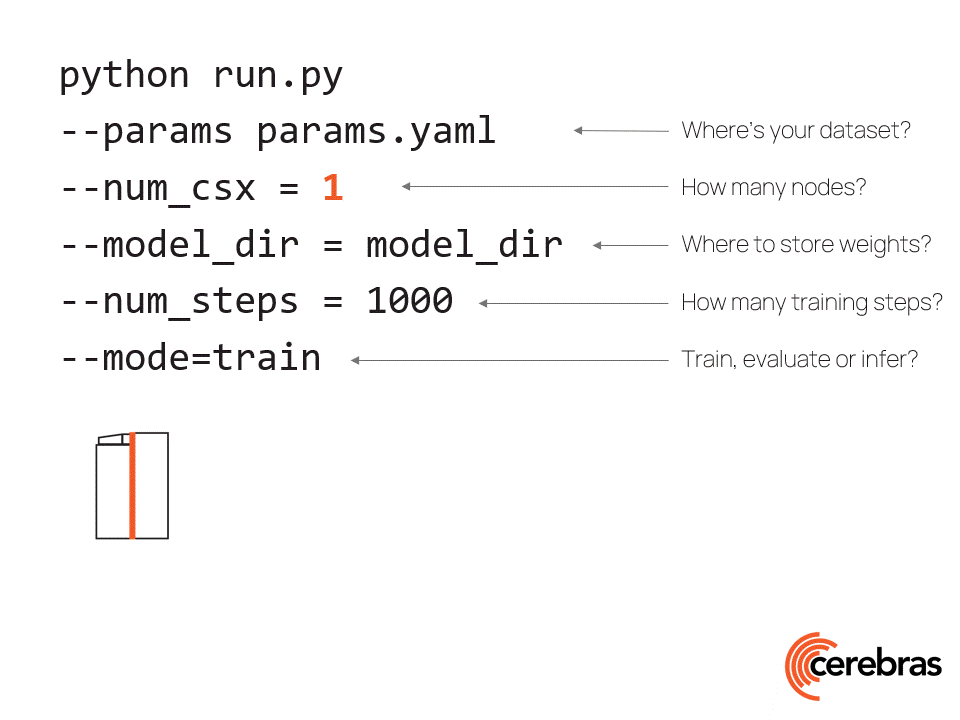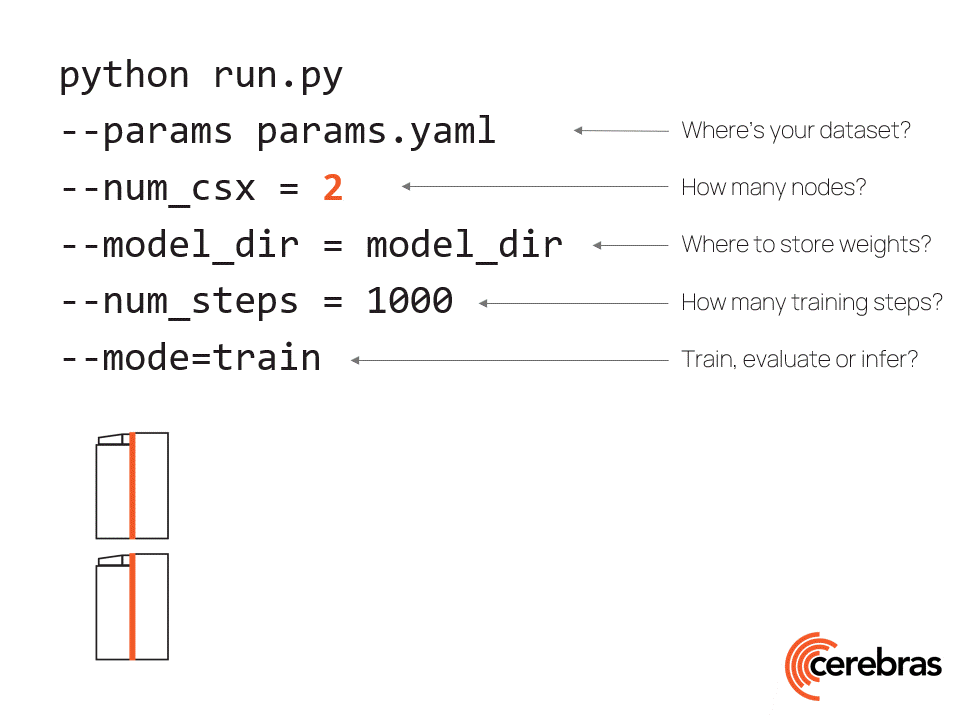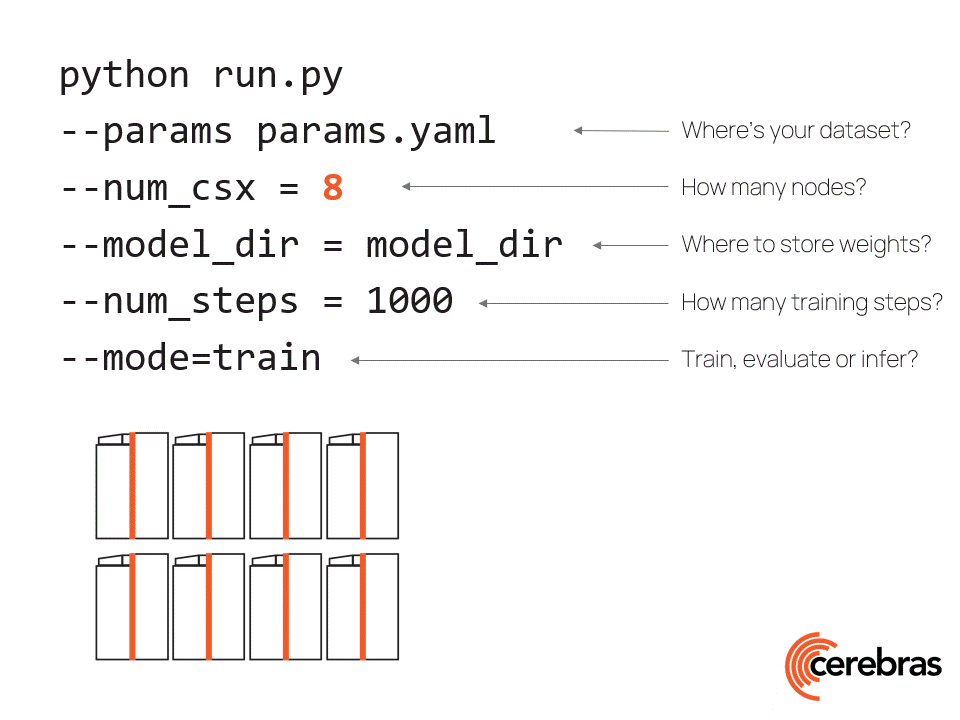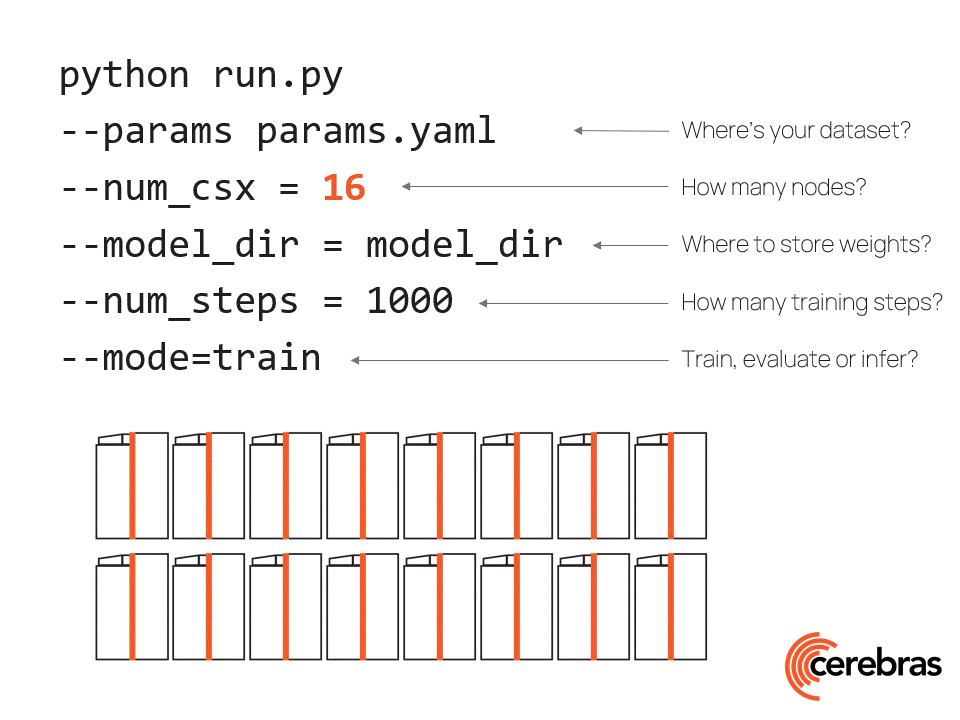 Figure 7. Push-button scaling to multiple CS-2 systems in the Cerebras Wafer-Scale Cluster using only simple data parallel scaling.
Figure 7. Push-button scaling to multiple CS-2 systems in the Cerebras Wafer-Scale Cluster using only simple data parallel scaling.
我们在一个名为仙女座的16x CS-2脑晶圆级集群上训练了所有的脑GPT模型。该集群使所有实验能够快速完成,而无需GPU集群所需的传统分布式系统工程和模型并行调整。最重要的是,它使我们的研究人员能够专注于ML的设计,而不是分布式系统。我们相信,轻松训练大型模型的能力是广泛社区的关键推动者,因此我们通过Cerebras AI模型工作室在云上提供了Cerebras晶圆级集群。
结论
在Cerebras,我们认为大型模型的民主化既需要解决培训基础设施的挑战,也需要向社区开放更多的模型。为此,我们设计了具有按钮缩放功能的Cerebras晶圆秤集群,我们正在开源Cerebras GPT家族的大型生成模型。我们希望,作为第一个具有最先进训练效率的公共大型GPT模型套件,Cerebras GPT将成为高效训练的配方,并作为进一步社区研究的参考。此外,我们正在通过Cerebras人工智能模型工作室在云上提供基础设施和模型。我们相信,只有通过更好的培训基础设施和更多的社区共享,我们才能共同推动大型生成性人工智能行业。
- 119 次浏览
【LLM】Falcon 已经登陆拥Hugging Face生态系统
视频号
微信公众号
知识星球
介绍
Falcon是阿布扎比技术创新研究所创建的一个新的最先进的语言模型家族,并根据Apache 2.0许可证发布。值得注意的是,Falcon-40B是第一款“真正开放”的机型,其功能可与当前的许多闭源机型相媲美。对于从业者、爱好者和行业来说,这是一个极好的消息,因为它为许多令人兴奋的用例打开了大门。
在本博客中,我们将深入研究Falcon模型:首先讨论是什么使它们独一无二,然后展示使用拥抱脸生态系统的工具在它们之上构建(推理、量化、微调等)是多么容易。
目录
- 猎鹰模型
- 演示
- 推论
- 评价
- 使用PEFT进行微调
- 结论
猎鹰模型
猎鹰家族由两个基本型号组成:猎鹰-40B和它的小兄弟猎鹰-7B。40B参数模型目前在Open LLM Leaderboard上名列前茅,而7B模型是其重量级别中最好的。
Falcon-40B需要约90GB的GPU内存——这是一个很大的数字,但仍低于Falcon表现出色的LLaMA-65B。另一方面,Falcon-7B只需要约15GB,即使在消费类硬件上也可以进行推理和微调。(在本博客的后面,我们将讨论如何利用量化使Falcon-40B即使在更便宜的GPU上也可以访问!)
TII还提供了Falcon-7B指令和Falcon-40B指令型号的指令版本。这些实验变体已经在指令和会话数据上进行了微调;因此,它们更适合于流行的助理式任务。如果你只是想快速玩模型,它们是你最好的选择。也可以根据社区构建的大量数据集构建自己的自定义指令版本。请继续阅读逐步教程!
Falcon-7B和Falcon-40B分别在1.5万亿和1万亿代币上进行了训练,符合优化推理的现代模型。Falcon模型高质量的关键因素是它们的训练数据,主要基于(>80%)RefinedWeb——一个基于CommonCrawl的新型大规模web数据集。TII没有收集分散的策划来源,而是专注于扩展和提高网络数据的质量,利用大规模的重复数据消除和严格的过滤来匹配其他语料库的质量。猎鹰模型在训练中仍然包括一些精心策划的来源(如Reddit的对话数据),但与GPT-3或PaLM等最先进的LLM相比,这一点要少得多。最棒的部分?TII公开发布了6000亿个RefinedWeb的代币摘录,供社区在自己的LLM中使用!
Falcon模型的另一个有趣的特性是它们使用了多查询注意力。普通的多头注意力方案每个头有一个查询、键和值;multiquery在所有头上共享一个键和值。
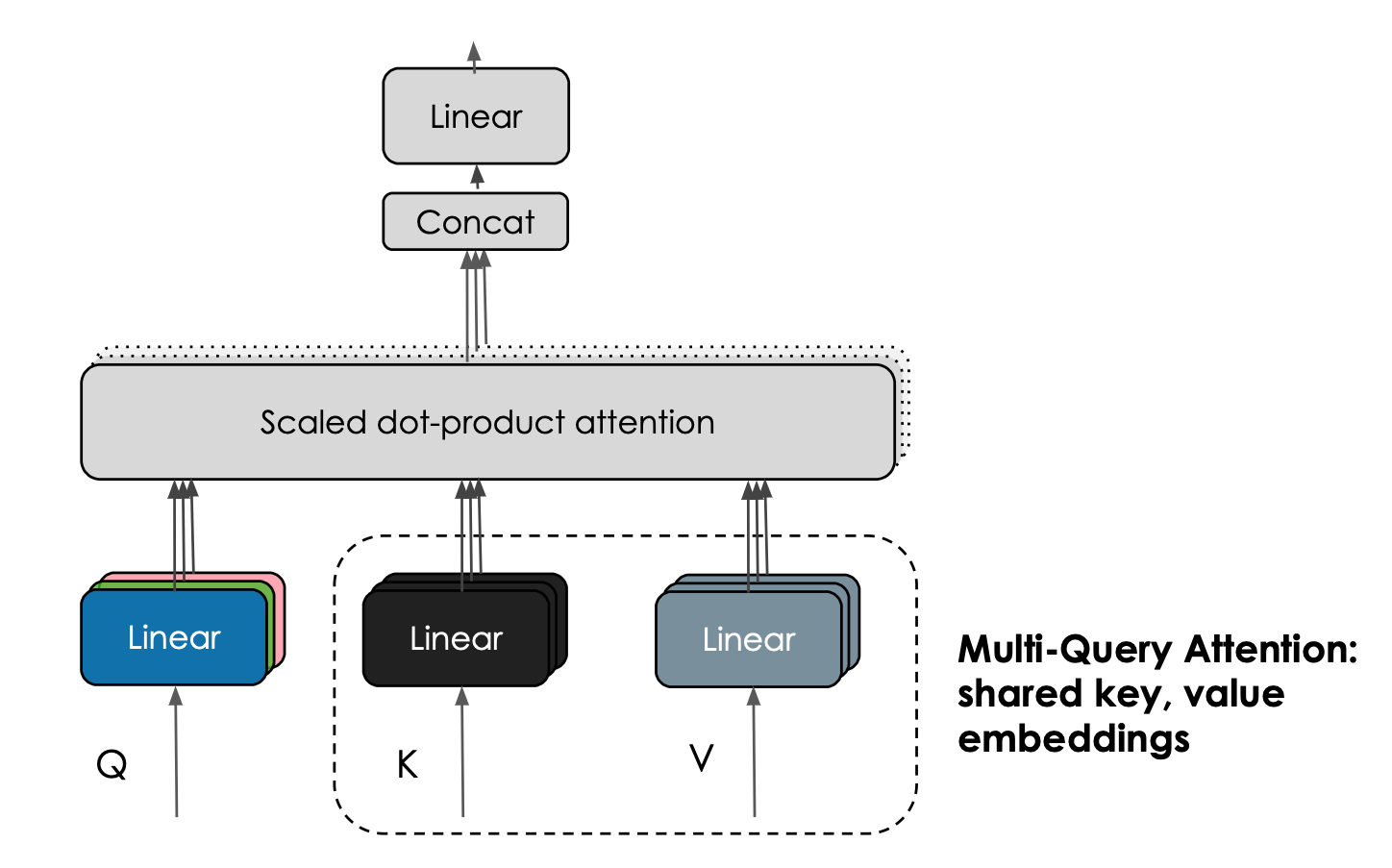
Multi-Query Attention shares keys and value embeddings across attention heads. Courtesy Harm de Vries.
这一技巧不会显著影响预训练,但它大大提高了推理的可扩展性:事实上,自回归解码过程中保持的K,V缓存现在明显更小(10-100倍,取决于架构的具体情况),降低了内存成本,并实现了新的优化,如状态性。
| Model | License | Commercial use? | Pretraining length [tokens] | Pretraining compute [PF-days] | Leaderboard score | K,V-cache size for a 2.048 context |
|---|---|---|---|---|---|---|
| StableLM-Alpha-7B | CC-BY-SA-4.0 | ✅ | 1,500B | 700 | 38.3* | 800MB |
| LLaMA-7B | LLaMA license | ❌ | 1,000B | 500 | 47.6 | 1,100MB |
| MPT-7B | Apache 2.0 | ✅ | 1,000B | 500 | 48.6 | 1,100MB |
| Falcon-7B | Apache 2.0 | ✅ | 1,500B | 700 | 48.8 | 20MB |
| LLaMA-33B | LLaMA license | ❌ | 1,500B | 3200 | 56.9 | 3,300MB |
| LLaMA-65B | LLaMA license | ❌ | 1,500B | 6300 | 58.3 | 5,400MB |
| Falcon-40B | Apache 2.0 | ✅ | 1,000B | 2800 | 60.4 | 240MB |
*score from the base version not available, we report the tuned version instead.
Demo
你可以在这个空间或下面嵌入的操场上轻松尝试大猎鹰模型(400亿参数!):
聊天机器人
Click on any example and press Enter in the input textbox!
Parameters▼
Instructions▼
HuggingFaceH4/falcon-chat-demo-for-blogbuilt with Gradio.Hosted on  Spaces
Spaces
在引擎盖下,这个游乐场使用了Hugging Face的文本生成推理,这是一个可扩展的Rust、Python和gRPC服务器,用于快速高效的文本生成。正是这项技术为HuggingChat提供了动力。
我们还构建了7B指令模型的Core ML版本,这就是它在M1 MacBook Pro上的运行方式:
视频展示了一个轻量级应用程序,它利用Swift库来完成繁重的任务:模型加载、标记化、输入准备、生成和解码。我们正忙于构建这个库,以使开发人员能够在所有类型的应用程序中集成强大的LLM,而无需重新发明轮子。它仍然有点粗糙,但我们迫不及待地想与您分享。同时,您可以从回购中下载Core ML权重,并亲自探索它们!
推论
您可以使用熟悉的transformers API在自己的硬件上运行模型,但需要注意以下几个细节:
- 模型是使用bfloat16数据类型训练的,因此我们建议您使用相同的数据类型。这需要CUDA的最新版本,并且在现代卡上效果最好。您也可以尝试使用float16运行推理,但请记住,模型是使用bfloat16评估的。
- 您需要允许远程代码执行。这是因为模型使用了一种新的架构,该架构还不是转换器的一部分——相反,所需的代码由模型作者在repo中提供。具体来说,如果允许远程执行(例如使用falcon-7b-instruction),将使用这些文件的代码:configuration_RW.py,modelling_RW.py。
考虑到这些因素,您可以使用transformers管道API加载7B指令模型,如下所示:
from transformers import AutoTokenizer
import transformers
import torch
model = "tiiuae/falcon-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)然后,您可以使用以下代码运行文本生成:
sequences = pipeline(
"Write a poem about Valencia.",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")你可能会得到以下内容:
Valencia, city of the sun
The city that glitters like a star
A city of a thousand colors
Where the night is illuminated by stars
Valencia, the city of my heart
Where the past is kept in a golden chest猎鹰40B的推论
运行40B型号具有挑战性,因为它的尺寸:它不适合一个具有80GB RAM的A100。以8位模式加载,可以在大约45 GB的RAM中运行,这适合A6000(48 GB),但不适合40 GB版本的A100。你会这样做:
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "tiiuae/falcon-40b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
load_in_8bit=True,
device_map="auto",
)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)但是,请注意,混合8位推理将使用torch.foat16而不是torch.bfloat16,因此请确保彻底测试结果。
如果安装了多个板卡并加速,则可以利用device_map=“auto”自动将模型层分布在不同的板卡上。如果需要,它甚至可以将一些层卸载到CPU,但这会影响推理速度。
还有可能使用最新版本的bitsandbytes、transformer和accelerate来使用4位加载。在这种情况下,40B型号需要大约27 GB的RAM才能运行。不幸的是,这比3090或4090等卡的可用内存略多,但足以在30或40 GB的卡上运行。
文本生成推理
文本生成推理是Hugging Face开发的一个可用于生产的推理容器,用于轻松部署大型语言模型。
其主要特点是:
- 连续批处理
- 使用服务器发送事件(SSE)的令牌流
- 张量并行性在多个GPU上实现更快的推理
- 使用自定义CUDA内核优化变压器代码
- 使用普罗米修斯和开放遥测进行生产准备日志记录、监测和跟踪
自v0.8.2以来,文本生成推理原生支持Falcon 7b和40b型号,而不依赖于Transformers的“信任远程代码”功能,从而实现气密部署和安全审计。此外,Falcon实现包括自定义CUDA内核,以显著降低端到端延迟。
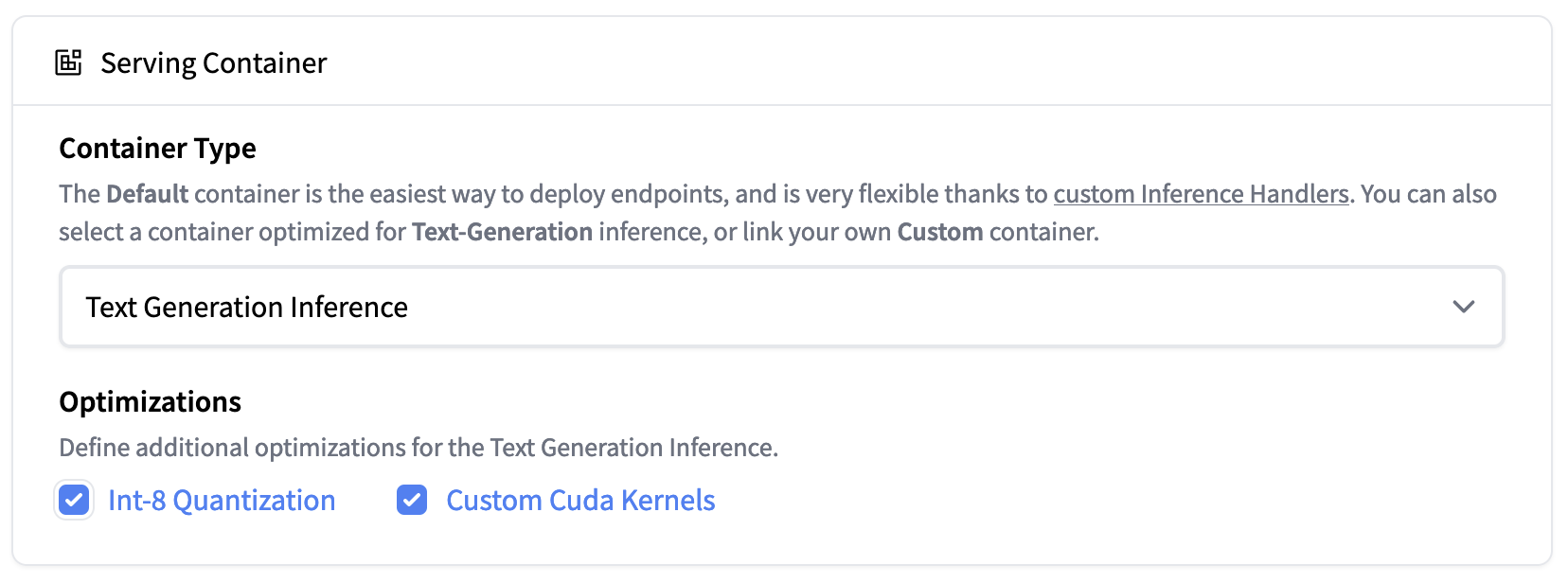 |
|---|
| Inference Endpoints now support Text Generation Inference. Deploy the Falcon 40B Instruct model easily on 1xA100 with Int-8 quantization |
文本生成推理现在集成在拥抱脸的推理端点中。要部署Falcon模型,请转到模型页面,然后单击deploy->InferenceEndpoints小部件。
对于7B型号,我们建议您选择“GPU[介质]-1x Nvidia A10G”。
对于40B型号,您需要在“GPU[xlarge]-1x Nvidia A100”上部署并激活量化:高级配置->服务容器->Int-8量化。注意:您可能需要通过电子邮件向请求配额升级api-enterprise@huggingface.co
评价
猎鹰模型有多好?Falcon作者的深入评估将很快发布,因此在此期间,我们通过开放LLM基准运行了基础模型和指导模型。该基准衡量LLM的推理能力及其在以下领域提供真实答案的能力:
- AI2推理挑战(ARC):小学多项选择科学问题。
- HellaSwag:围绕日常事件的常识推理。
- MMLU:57门科目的多项选择题(专业和学术)。
- TruthfulQA:测试模型从一组不正确的陈述中分离事实的能力。
结果表明,40B基础和指导模型非常强大,目前在LLM排行榜上分别排名第一和第二🏆!
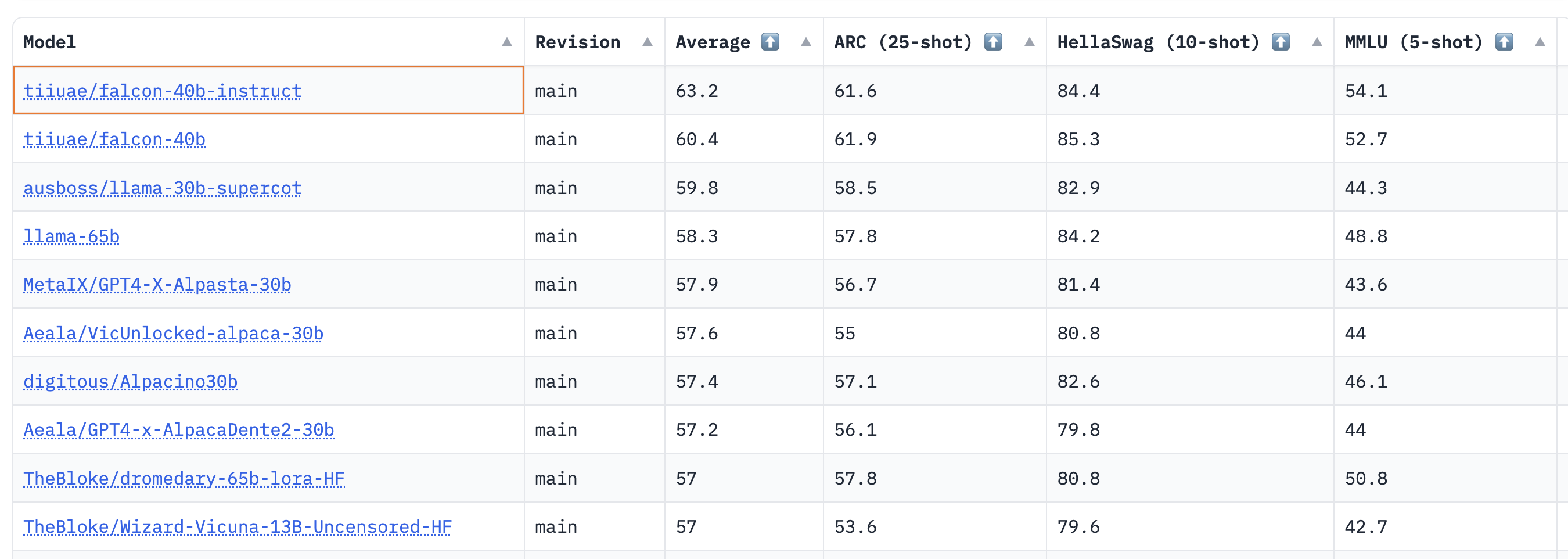
正如Thomas Wolf所指出的,这里一个令人惊讶的见解是,40B模型的预训练时间大约是LLaMa 65B所需计算量的一半(2800天对6300 PB),这表明我们还没有完全达到LLM预训练的“最佳”极限。
对于7B模型,我们看到基本模型比llama-7B更好,并超越了MosaicML的mpt-7B,成为目前该规模下最好的预训练LLM。排行榜上的热门模特入围名单如下:
| Model | Type | Average leaderboard score |
|---|---|---|
| tiiuae/falcon-40b-instruct | instruct | 63.2 |
| tiiuae/falcon-40b | base | 60.4 |
| llama-65b | base | 58.3 |
| TheBloke/dromedary-65b-lora-HF | instruct | 57 |
| stable-vicuna-13b | rlhf | 52.4 |
| llama-13b | base | 51.8 |
| TheBloke/wizardLM-7B-HF | instruct | 50.1 |
| tiiuae/falcon-7b | base | 48.8 |
| mosaicml/mpt-7b | base | 48.6 |
| tiiuae/falcon-7b-instruct | instruct | 48.4 |
| llama-7b | base | 47.6 |
尽管开放式LLM排行榜没有衡量聊天能力(其中人类评估是黄金标准),但猎鹰模型的这些初步结果非常令人鼓舞!
现在让我们来看看你如何微调自己的猎鹰模型——也许你的一个最终会登上排行榜的榜首🤗.
使用PEFT进行微调
训练10B+大小的模型在技术和计算上可能具有挑战性。在本节中,我们将介绍拥抱脸生态系统中可用的工具,这些工具可以在简单的硬件上有效地训练超大型号,并展示如何在单个NVIDIA T4(16GB-谷歌Colab)上微调Falcon-7b。
让我们看看如何在Guanaco数据集上训练Falcon,Guanaco是由大约10000个对话组成的开放助手数据集的高质量子集。有了PEFT库,我们可以使用最近的QLoRA方法来微调放置在冻结4位模型顶部的适配器。您可以在这篇博客文章中了解更多关于4位量化模型集成的信息。
因为当使用低秩适配器(LoRA)时,只有一小部分模型是可训练的,所以学习参数的数量和训练工件的大小都大大减少了。如下面的屏幕截图所示,保存的7B参数模型只有65MB(float16中为15GB)。
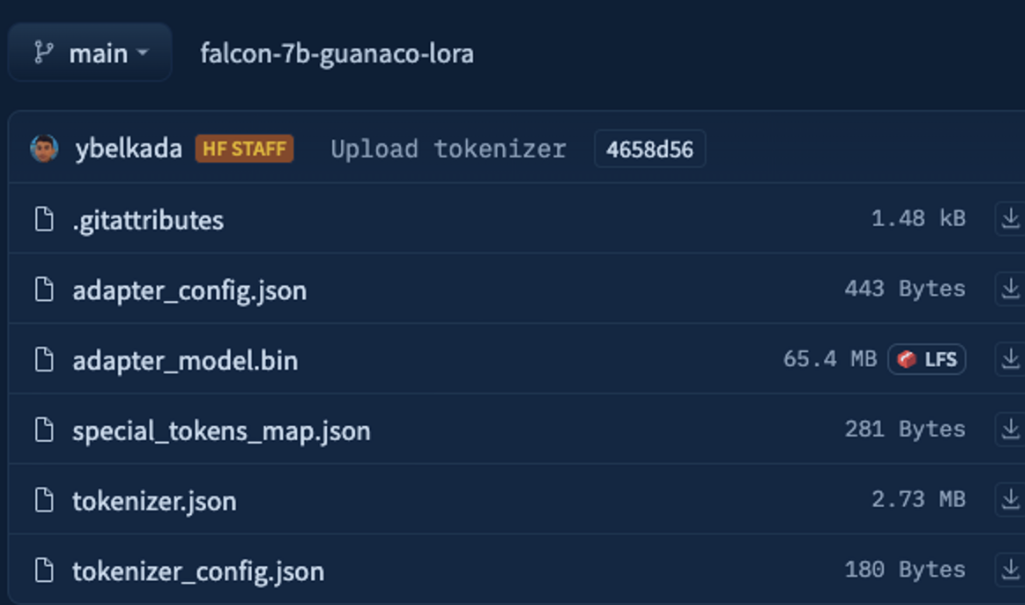
最终存储库只有65MB的重量,而原始模型的一半精度约为15GB
更具体地说,在选择了要适应的目标模块(在实践中是注意力模块的查询/关键层)之后,将小的可训练线性层附着在这些模块附近,如下所示)。然后将适配器产生的隐藏状态添加到原始状态,以获得最终的隐藏状态。

The output activations original (frozen) pretrained weights (left) are augmented by a low rank adapter comprised of weight matrices A and B (right).
一旦经过训练,就不需要保存整个模型,因为基本模型一直处于冻结状态。此外,只要这些模块的输出隐藏状态被转换为与适配器相同的数据类型,就可以将模型保持在任何任意的数据类型(int8、fp4、fp16等)中——对于返回隐藏状态的位和字节模块(Linear8bitLt和Linear4bit)来说就是这样,它们的数据类型与原始未量化模块相同。
我们在Guanaco数据集上对Falcon模型的两个变体(7B和40B)进行了微调。我们在单个NVIDIA-T4 16GB上对7B型号进行了微调,在单个NVID IA A100 80GB上对40B型号进行了调整。我们使用了4位量化的基本模型和QLoRA方法,以及TRL库中最近的SFTTrainer。
这里提供了使用PEFT复制我们实验的完整脚本,但只需要几行代码即可快速运行SFTTrainer(为了简单起见,不需要PEFT):
from datasets import load_dataset
from trl import SFTTrainer
from transformers import AutoTokenizer, AutoModelForCausalLM
dataset = load_dataset("imdb", split="train")
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, trust_remote_code=True)
trainer = SFTTrainer(
model,
tokenizer=tokenizer
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=512,
)
trainer.train()查看原始的qlora存储库,了解有关评估经过训练的模型的更多详细信息。
微调资源
- Colab notebook to fine-tune Falcon-7B on Guanaco dataset using 4bit and PEFT
- Training code
- 40B model adapters (logs)
-
7B model adapters (logs)
结论
Falcon是一个令人兴奋的新的大型语言模型,可以用于商业应用。在这篇博客文章中,我们展示了它的功能,如何在自己的环境中运行它,以及如何在拥抱脸生态系统中轻松微调自定义数据。我们很高兴看到社区将用它来建设什么!
- 131 次浏览
【LLM】一个大模型能统治它们吗?
视频号
微信公众号
知识星球
对未来人工智能生态系统的预测
在过去的10年里,人工智能不断进步,每一次新的发展浪潮都能带来令人兴奋的新功能和应用。毫无疑问,最大的这一波浪潮是最近兴起的一种单一的通用人工智能模型,例如LLM,它可以用于从代码生成到图像理解再到科学推理的各种任务。
这些任务是以如此高保真的方式执行的,以至于正在定义和开发全新一代的技术应用程序。虽然考虑到潜在的影响令人兴奋,但这一失控的成功确实给我们留下了一个关于未来人工智能生态系统的令人深感不安的问题:
未来的人工智能格局会由单一的通用人工智能模型主导吗?
具体而言,未来的人工智能格局是否会:
- 由少数(<5)个实体主导,每个实体都有一个大型通用人工智能模型?
- 这些通用人工智能模型是否是推动所有重大人工智能技术进步和产品的关键组成部分?
随着ChatGPT和GPT-4等模型的发布,改变了我们对人工智能功能的理解,以及开发此类模型的成本不断上升,这已成为一种普遍的看法。
我们认为恰恰相反!
- 将会有许多实体为人工智能生态系统的发展做出贡献。
- 许多高效用的人工智能系统将出现,不同于(单一的)通用人工智能模型。
- 这些人工智能系统将结构复杂,由多个人工智能模型、API等提供动力,并将推动新的人工智能技术发展。
- 定义明确、高价值的工作流程将主要由专门的人工智能系统解决,而不是通用的人工智能模型。
我们可以用下图来说明我们对人工智能生态系统的预测:
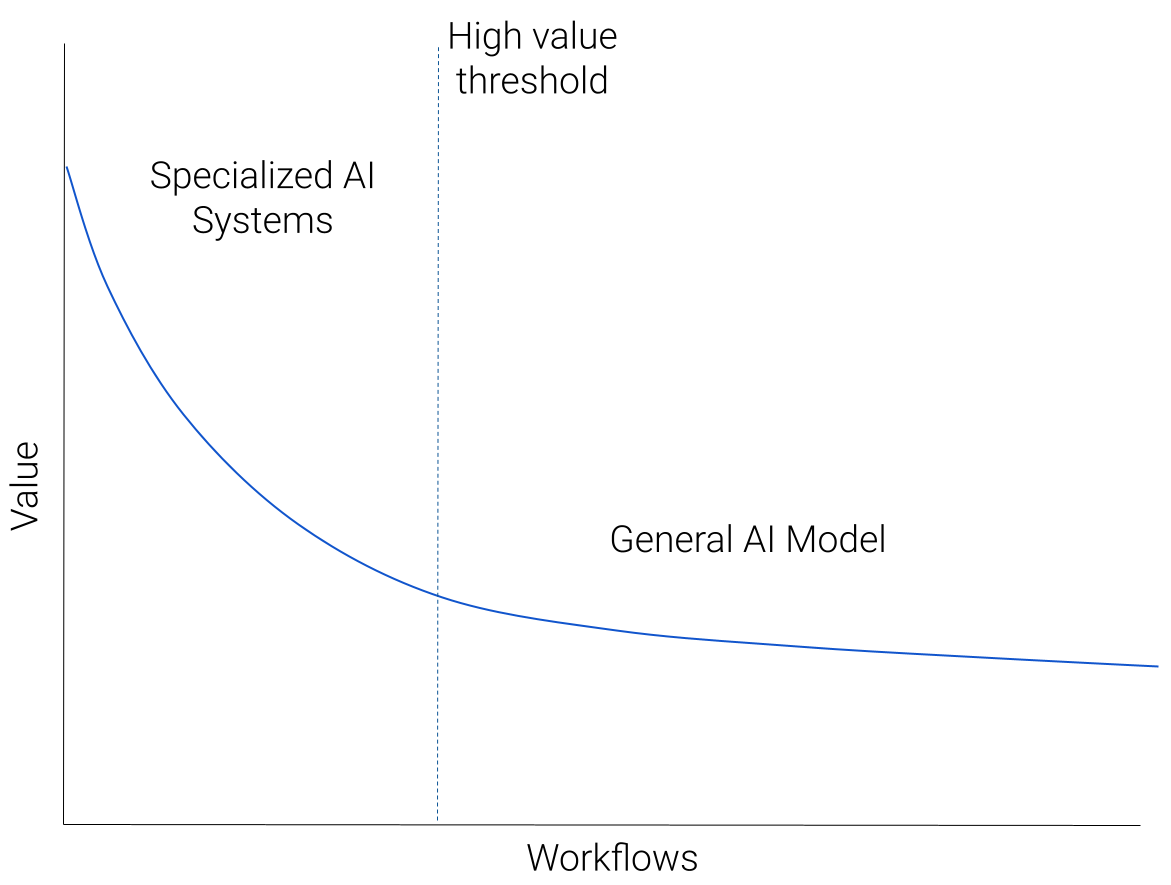
想象一下,我们采用了所有适用于基于人工智能的解决方案的工作流程,并按照“价值”的递减顺序绘制它们。价值可以是潜在的收入,也可以只是对用户的效用。将会有少量非常高价值的工作流-一个大市场或大量用户有明确定义的人工智能可解决的痛点。这将下降到一个由各种但价值较低的工作流组成的长长的、沉重的尾巴,代表人工智能可以帮助的许多自定义预测任务。
高价值工作流程的例子有哪些?现在还为时过早,但我们看到了编码助理、视觉内容创建、搜索和写作助理方面令人兴奋的发展。
低价值工作流程的沉重尾巴呢?这些将不那么明确地规定,由习俗环境引起的习俗需求。例如,通过分类对来自客户支持机器人的请求进行分类。
我们预测,图表的左上角(高价值工作流)将由专门的人工智能系统主导,随着我们沿着蓝色曲线向下到低价值工作流,通用人工智能模型将成为主要方法。
起初,这张照片看起来有些违反直觉。一些最先进的人工智能功能似乎来自通用模型。那么,为什么这些不应该主导高价值的工作流程呢?但是,考虑到生态系统可能如何演变,有许多重要因素支持这一观点,我们将在下面对此进行扩展。
专业化对质量至关重要
高价值的工作流程需要高质量,并奖励任何质量改进。任何应用于高价值工作流程的人工智能解决方案都会不断进行调整,以提高质量。由于工作流程特定的考虑因素导致了质量上的差距,这种调整导致了专业化。
专业化可以像调整特定于工作流程的数据一样简单,或者(更有可能)开发多个专门的人工智能组件。
我们可以通过考虑当前用于自动驾驶汽车的人工智能系统来了解一个具体的例子。这些系统有多个人工智能组件,从规划组件到检测组件以及用于数据标记和生成的组件。(如需更多详细信息,请参阅特斯拉的人工智能日演示。)
用GPT-4这样的通用人工智能模型天真地取代这个专门的人工智能系统将导致质量的灾难性下降。
但是,一个更先进的通用人工智能模型GPT-(4+n),在战略上应用,能执行这个工作流程吗?
我们可以进行一个思想实验,看看这可能会如何展开:
- 想象一下,GPT-(4+n)发布了,具有非常有用的功能,包括自动驾驶功能。
- 我们无法立即替换整个现有系统。
- 因此,我们确定了GPT-(4+n)最有用的功能,并考虑将这些功能作为另一个组件添加进来,可能是通过API调用。
- 然后对这个新系统进行测试,不可避免地会发现质量上的差距。
- 人们正在努力解决这些差距,当它们出现在特定的工作流程(自动驾驶)中时,就会开发出特定于工作流程的解决方案。
- 最终结果可能是API调用被一个新的专用AI组件完全替换,或者被其他专用组件增强。
虽然这个思想实验可能并不完全准确,但它说明了我们如何从一个通用的人工智能模型开始,然后对其进行实质性的专门化以提高质量。
总之,(1)高价值工作流程的质量很重要,(2)专业化有助于提高质量。
利用用户反馈
与质量考虑密切相关的是用户反馈的作用。有明确证据表明,对高质量的人类“使用”数据(如偏好、指令、提示和响应等)进行仔细调整,是推动通用人工智能模型能力的核心。
例如,在LLM中,RLHF(来自人类反馈的强化学习)和对类人指令/偏好数据的监督学习等技术对于获得高质量的生成和指令跟随行为至关重要。这一点在InstructGPT和ChatGPT中得到了显著的证明,目前正在推动一些LLM开发工作(Alpaca、Dolly、gpt4all)。
同样,我们希望用户反馈在推动人工智能在特定工作流程中的能力方面发挥关键作用。但要有效地整合这种反馈,就需要对人工智能系统进行细粒度的控制。我们不仅可能希望根据用户反馈仔细调整底层模型(由于成本和访问受限,一般人工智能模型很难实现),而且我们可能需要调整整个人工智能系统的结构,例如定义数据、人工智能模型和工具之间的交互。
从工程(各种微调方法、链接API调用、使用不同的AI组件)、成本(适应大型模型的成本很高)和安全(参数泄漏、数据共享)的角度来看,为通用AI模型设置这样的细粒度控制具有挑战性。
总之,用户反馈所需的细粒度控制更容易实现
专有数据和专有知识
许多高价值、特定于领域的工作流都依赖于丰富的专有数据集。这些工作流程的最佳人工智能解决方案需要对这些数据进行培训。然而,拥有这些数据集的实体将专注于保护其数据护城河,不太可能允许无限制地访问第三方进行人工智能培训。因此,这些实体将在内部或通过特定的合作伙伴关系建立专门用于这些工作流程的人工智能系统。这些将不同于一般的人工智能模型。
与此相关的是,许多领域也使用专有知识——这是一个只有少数人类专家才能理解的“商业秘密”。例如,为台积电尖端芯片制造提供动力的技术,或顶级对冲基金使用的定量算法。利用这些专有知识的人工智能解决方案将再次在内部构建,专门用于这些工作流程。
这些是“构建与购买”计算的例子,这种计算在之前的许多技术周期中都发生过,并且在这一波浪潮中也会重复出现。
人工智能模型的商品化
在努力开发GPT-4等昂贵的专有模型的同时,也在努力构建和发布Llama等人工智能模型,然后快速优化,甚至可以在手机上运行(!)
这些是(1)基于成本的效用和(2)效率之间激烈而持续的竞争的例子。
效率是指在保持效用的同时,降低人工智能新进展的成本的快速过程。发生这种情况的原因有几个关键属性:
- 人工智能领域在合作、发表研究和开源方面有着强大的根基,从而实现了(精心发现的)技术见解的快速知识传播。
- 由于更好的硬件、基础设施和训练方法,训练流行人工智能模型的计算成本迅速下降。
- 收集、整理和开源数据集的努力有助于模型构建的民主化和质量的提高。
对于我们目前最强大的模型来说,效率似乎很可能会在竞争中获胜,从而导致这些模型的商品化。
通用人工智能模型的未来?
但这是否意味着所有大型通用人工智能模型都将被商品化?
这取决于另一个竞争者,基于成本的效用。如果人工智能模型有用但成本也很高,那么效率过程需要更长的时间才能运行——前期成本越高,降低成本所需的时间就越长。
- 如果成本保持在今天的水平,那么很可能会出现完全的商品化。
- 如果成本增加了一个数量级,但效用显示出回报递减,那么我们将再次看到商品化
- 如果成本增加了一个数量级,并且效用有成比例的收益,那么很可能会有少量成本很高的通用型号没有商品化。
哪种情况最有可能发生?
这很难确定。未来的人工智能模型肯定有构建的空间,可以使用更大数量/类型的数据和更多的计算。如果效用也继续增加,我们将有一些昂贵的通用人工智能模型用于大量多样、难以定义的工作流,如上图所示——为人工智能做的事情就像云为计算做的事情一样。
总结
尽管人工智能的发展浪潮持续了十年,但人工智能的未来看起来仍然比过去更加多事之秋!我们预计将出现一个丰富的生态系统,拥有各种高价值、专业的人工智能系统,由不同的人工智能组件提供动力,以及一些通用的人工智能模型,支持多种多样的人工智能工作流程。
- 82 次浏览
【LLM】什么是提示泄漏
视频号
微信公众号
知识星球
提示泄漏是一种提示注入形式,要求模型吐出自己的提示。
如下面的示例图1所示,攻击者更改user_input以尝试返回提示。预期目标与目标劫持(正常提示注入)不同,在目标劫持中,攻击者更改user_input以打印恶意指令1。

下面的图片2,同样来自remoteli.io示例,显示了一个Twitter用户让模型泄露其提示。

那又怎样?为什么有人要关心即时泄漏?
有时人们想对提示保密。例如,一家教育公司可能会像我5岁一样使用提示向我解释这一点来解释复杂的话题。如果提示被泄露,那么任何人都可以使用它,而无需通过该公司。
Microsoft Bing聊天
更值得注意的是,微软于23年2月7日发布了一款名为“新必应”的ChatGPT搜索引擎,该引擎被证明容易出现即时泄露。@kliu128的以下示例演示了给定的Bing搜索的早期版本,代码为“Sydney”,在给出提示3的片段时是如何受到影响的。这将允许用户在没有适当身份验证的情况下检索提示的其余部分。

随着最近基于GPT-3的初创公司的激增,以及可能需要数小时才能开发的更复杂的提示,这是一个真正令人担忧的问题。
实践
尝试通过将文本附加到以下提示4来泄漏该提示:
- Perez, F., & Ribeiro, I. (2022). Ignore Previous Prompt: Attack Techniques For Language Models. arXiv. https://doi.org/10.48550/ARXIV.2211.09527 ↩
- Willison, S. (2022). Prompt injection attacks against GPT-3. https://simonwillison.net/2022/Sep/12/prompt-injection/ ↩
- The entire prompt of Microsoft Bing Chat?! (Hi, Sydney.). (2023). https://twitter.com/kliu128/status/1623472922374574080 ↩
- Chase, H. (2022). adversarial-prompts. https://github.com/hwchase17/adversarial-prompts ↩
- 256 次浏览
【LLM】企业中的Cohere与OpenAI:首席信息官会选择哪一个?
视频号
微信公众号
知识星球
随着生成人工智能进入企业,一家由前谷歌员工创立的公司旨在超越微软支持的OpenAI。
OpenAI刚刚宣布了其流行的生成型人工智能产品ChatGPT的企业版。但在这种情况下,OpenAI是一个快速的追随者,而不是第一个进入市场的人。Cohere是一家总部位于多伦多的公司,与谷歌关系密切,已经在为企业带来生成性人工智能。
我与Cohere的总裁兼首席运营官Martin Kon就其机器学习模型如何在企业公司中使用进行了交谈。
Cohere只有几岁,但它有着令人印象深刻的血统。Cohere的两位创始人最近曾在谷歌大脑工作,这引发了当前围绕生成人工智能的热潮。2017年,谷歌大脑推出了自然语言处理(NLP)的“转换器”模型,即ChatGPT中的“T”。Cohere的首席执行官和首席技术官Aidan Gomez和Nick Frosst随后与Ivan Zhang合作,在Cohere将这种形式的NLP商业化。
Martin Kon上个月刚开始工作,对公司来说是全新的。但和创始人一样,他也与谷歌有联系,在加入Cohere之前,他在YouTube工作了六年。他被任命为Cohere的商业运营部门负责人,业务似乎正在蓬勃发展。
据Kon称,Cohere“在过去一年中,API调用量月环比增长了65%,开发人员数量也大致相同。”

现在,Cohere已经将重点转移到将其大型语言模型和相关工具引入企业。
Kon说:“我们正在与组织中的开发人员,即AI/ML团队合作,将这些能力引入他们的组织。”。他声称,它的方法与OpenAI的方法有根本不同。
“OpenAI希望您将您的数据带到他们的模型中,这是Azure独有的。Cohere希望在您感到舒适的任何环境中,将我们的模型带到您的数据中。”
Cohere与OpenAI的技术比较
Cohere有两种类型的LLM(大型语言模型):生成和表示。前者是ChatGPT所做的,后者是为了理解语言(例如,做情感分析)。每种类型都有不同的尺寸:小、中、大和超大。模型的大小和工作速度之间存在各种权衡。
Cohere的基础模型有520亿个参数,基于斯坦福HELM排名(语言模型的整体评估)。斯坦福大学的HELM网站指出,这是Cohere模型的“xlarge”版本,是最大的版本。OpenAI的GPT-3 davinci模型是其最大的模型,被斯坦福大学列为具有175B个参数。
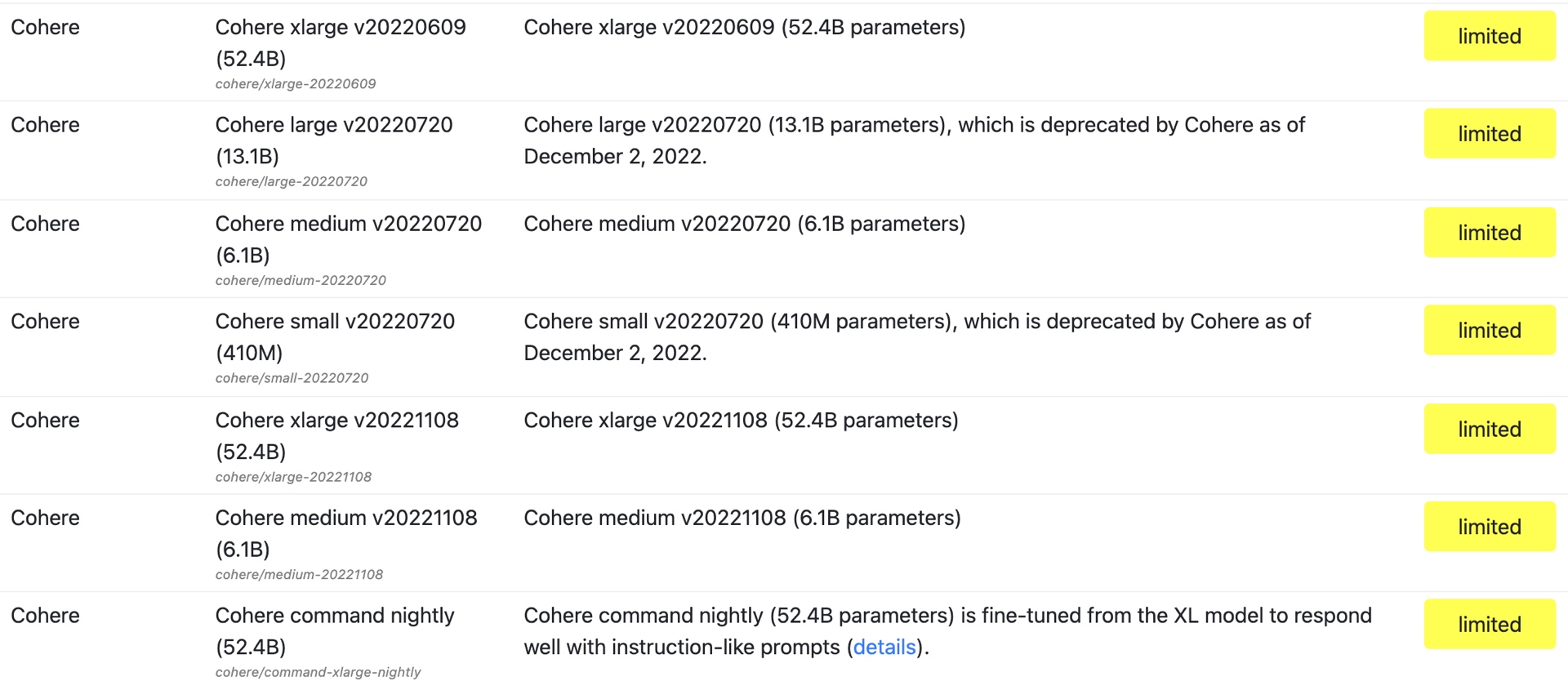
斯坦福HELM目录中的Cohere模型列表
 The primary models of OpenAI
The primary models of OpenAI
在我们的谈话中,Kon说Cohere的模型被证明可以更好地对抗GPT-3。我要求该公司对此进行验证,该公司向我指出了斯坦福大学的准确性测量结果。根据Cohere的说法,“研究表明,Cohere-xlarge模型比许多大3倍的知名模型实现了更高的精度,包括GPT-3、Jurasci-1 Jumbo和BLOOM(每个模型都有大约175B的参数)。”
然而,需要注意的是,Cohere的模型仅领先于GPT-3模型。OpenAI最新的GPT-3.5模型text-davinci-002和text-davicini-003的准确度都高于Cohere。事实上,根据HELM精度测量,这些模型目前在所有模型中排名最高(见下文)。
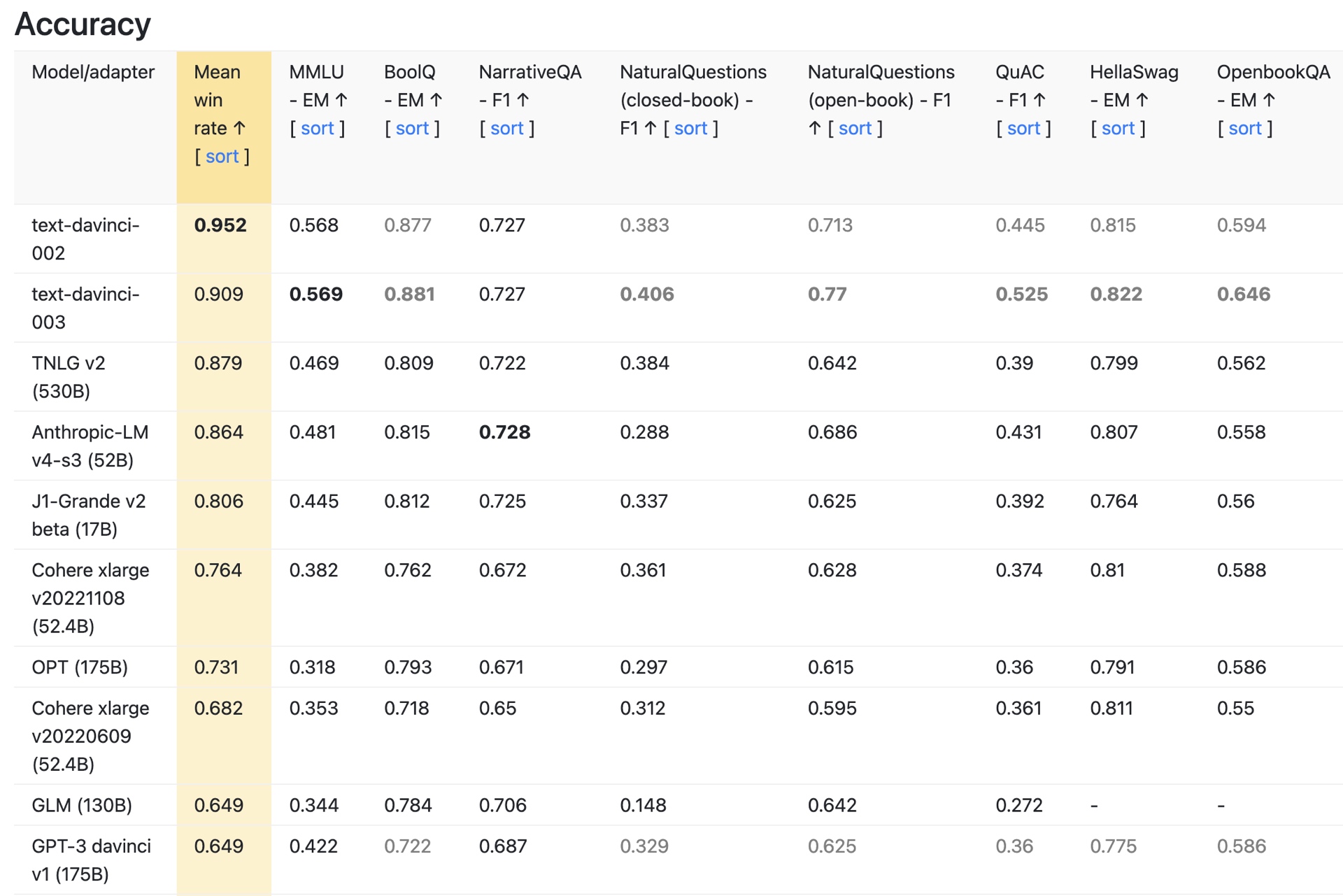 Stanford HELM tests for accuracy of ML models
Stanford HELM tests for accuracy of ML models
Kon告诉我,Cohere的最新型号Command(目前处于测试版)每周都会重新调整。他说:“这意味着,每周你都可以期待指挥性能的提高。”。
根据文件,Command是“一个生成模型,可以很好地响应类似指令的提示。”作为比较点,Davinci被OpenAI描述为擅长“复杂的意图、因果关系、对受众的总结”
企业使用案例
生成人工智能最早的用例是基于内容生成和摘要的——Stable Diffusion的图像生成器、ChatGPT的会话搜索引擎、GitHub的Copilot代码生成器等等。但我问Kon,它的技术还有哪些其他用例,尤其是对企业公司来说。
语义搜索引擎
他说,首先,公司正在使用它为自己的私人数据创建一种语义搜索引擎。
Kon说:“将语义搜索(上下文搜索)引入私人环境,比如组织内部的信息,这与我们习惯于谷歌搜索的方式类似。”。“因此,这使公司,尤其是跨国公司,能够在其内部拥有的每一份材料中搜索、分类或寻找情感——每一份文件、每一份客户通话记录、每一段视频聊天记录、电子邮件、文件等。”
他解释说,一个组织通常会将自己的数据添加到Cohere的一个基本模型中。他说,这将是“数量少得多、质量高得多的数据,通常是人类注释的强化学习”(这里的“较小”只是指与基础模型中的数十亿个参数相比)。除此之外,还有一个“对话”层,或者像ChatGPT这样的对话层。Cohere的对话模式处于内部测试阶段,他补充道。
数据分析
我早些时候问过大型零售商的示例用例是什么,Kon在这里回答了这个问题。
“假设你是一名零售商,你想[问]我们在玻利维亚的业务进展如何?然后[人工智能]可以说,这是从西班牙语或其他语言中提取的最新销售结果。不,[你说],我指的是批发业务。好吧,[它回答]让我从其他地方提取一些不同的东西。所以你基本上是在进行对话。你正在访问以一种非常安全的方式[这些数据],因为外部没有人能看到它——你没有把它输入ChatGPT,这是每个人都在做的事情。”
客服对话
他给我举了几个其他的例子,其中一个是从零售商客户的角度来看的。假设你买了一台电视,想退货;你可以与零售商的人工智能进行对话,实时查看当前的退货政策。
谷歌合作伙伴
运行机器学习工作负载,尤其是那些具有数十亿参数的工作负载,是极其耗费硬件的。所以我问Kon Cohere是如何处理的——他们主要是内部硬件,还是与任何平台公司合作?
毫不奇怪,考虑到创始人和孔本人的背景,Cohere与谷歌在硬件方面进行了合作。
“我们现在与谷歌有着战略关系,”孔说。“所以我相信我们是TPU(Tensor处理单元)的第一个消费者,也是最大的消费者除了谷歌本身。因此,我们有机会获得并能够负担得起这些巨大的计算资源,这些资源是我们需要预先培训的。这些模型需要四到六周的时间来训练——基本模型。我们的命令模型,我们可以每晚都做,因为这是一个小得多的数据量——但实际上是特定的数据——所以我们每周都做这些,但训练大约需要一个晚上。”
当然,谷歌本身也参与了人工智能的生成游戏。它有几个命名模糊的ML型号:T5、UL2、Flan-T5和PaLM。因此,就像云计算平台一样,企业人工智能市场正在转变为“马换课程”的局面。一些企业客户将是微软商店,因此可能倾向于OpenAI。其他将是谷歌云的客户。但许多人不想被束缚在一个单一的云平台上,而这正是Cohere最吸引人的地方。
显然,企业公司有巨大的机会通过生成人工智能技术超越竞争对手。至于生成人工智能的提供商,包括Cohere和OpenAI,我想不出今年有什么比这更令人兴奋的企业IT类别了。游戏开始了!
- 265 次浏览
【LLM】基础大型语言模型堆栈
视频号
微信公众号
知识星球
为所有LLM相关产品创建一个全面的图表几乎是不可能的任务。我的目标是创建一个产品分类法,定义各种LLM实现和用例。
诚然,某些产品会有重叠,涉及多个类别。
我研究了列出的每一种产品的功能,因此景观的类别和细分就是这项研究的结果。
每天都会发布新的生成产品,其中许多目前还无法获得。
如果我错过了任何重要的产品,或者如果你想让我访问原型,请在下面评论。
- 137 次浏览
【LLM】大型语言模型与ML基础结构堆栈的未来
视频号
微信公众号
知识星球
本文分享了我们对大型语言模型(LLM)将如何影响机器学习项目以及为其提供动力的基础设施堆栈的看法。我们相信,LLM和其他基础模型将作为ML堆栈中一个强大的新模型家族而被采用-增强而不是取代它。有关如何开始使用Metaflow进行LLM实验的技术细节,请参阅我们关于使用Metaflow训练Dolly模型的文章。
在过去的一年里,大型语言模型和计算机视觉已经经历了登月时刻。有一种感觉,一个全新的可能性宇宙已经打开,尽管没有人确切知道会发生什么变化,如何变化,何时变化,由谁改变。
目睹不可能变成可能,令人激动。这可能会迅速而发自内心地发生——想象一下,目睹莱特兄弟的首次飞行,阿姆斯特朗登上月球的第一步,或者现在的聊天GPT。然而,与以前的许多时候一样,我们可能在短期内高估了这些技术的影响,而在长期内低估了它们的效果。
虽然很容易看出最初的兴奋是如何产生过于生动的梦境和噩梦的,但长期影响往往被低估了,因为当一项新技术逐渐被越来越多样化的人和公司所使用时,很难想象会发生什么。
尽管互联网和网络在2001年非常受公众关注,但没有人能预测到TikTok的成功或互联网可租赁踏板车的普遍存在。与最初的乌托邦相比,长期的成功故事往往会让人感到奇怪的平凡,因为闪亮的新技术交织在我们的日常生活中,融合了过去和未来。
虽然我们无法预见新模式将如何影响我们未来的生活,但我们知道那里的旅程是什么样子的。我们需要通过以人为中心的软件包来提供新技术,使其易于使用,这样所有好奇的组织都可以开始独立创新,探索由自己的领域知识和未来愿景驱动的各种用例。
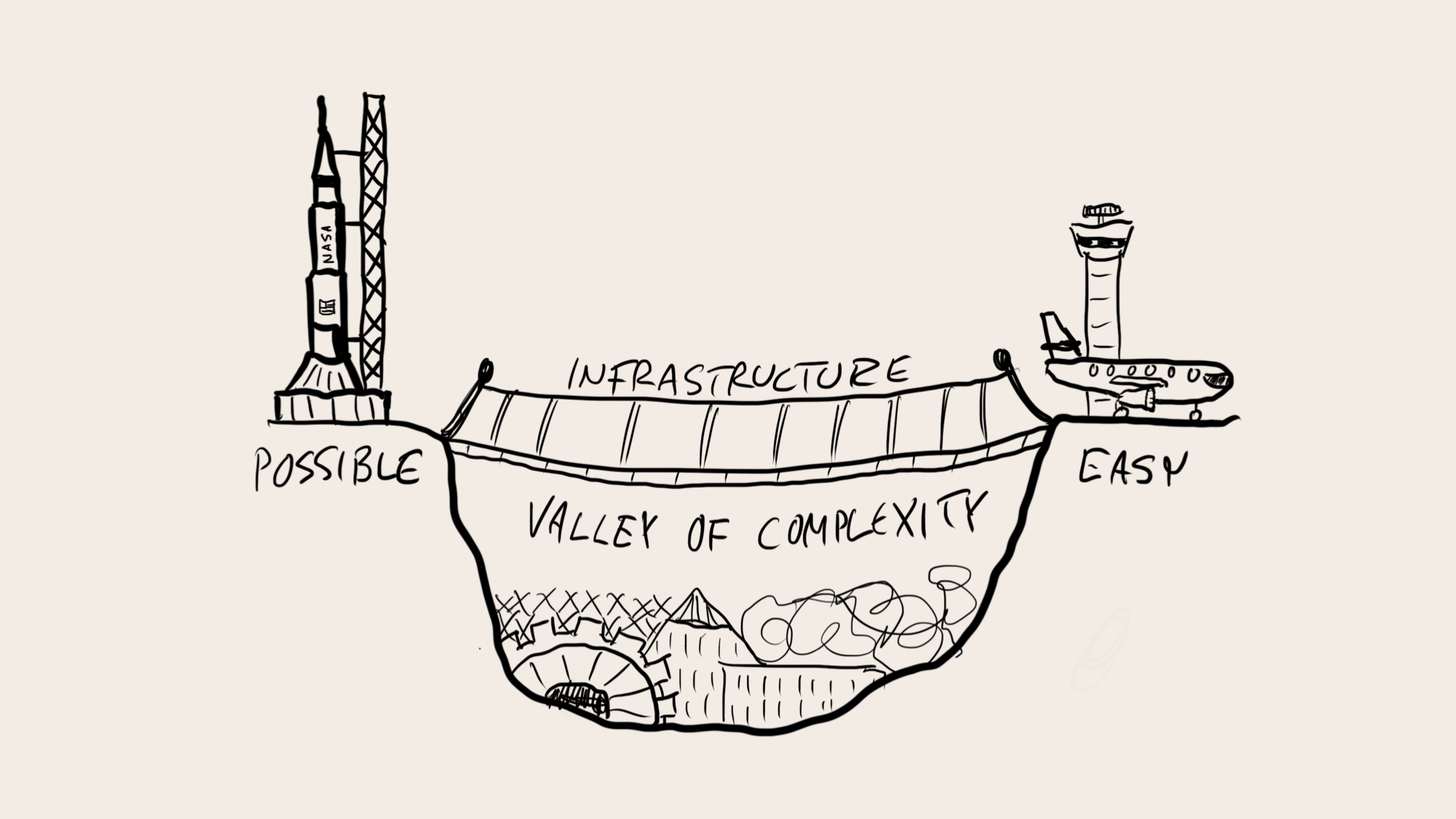
1943年,IBM总裁估计“可能有五台计算机的世界市场”,当时已经证明这台计算机的制造是可行的(至少在不考虑成本的情况下),但操作起来绝对痛苦(在大多数用例中,投资回报率都有问题)。同样,到2023年,人们可能会估计,世界只需要少数几个将通过API使用的大型语言模型,因为LLM的构建成本高得令人瞠目结舌,而且在今天操作起来很痛苦。
大型语言模型和ML基础设施堆栈
正如我们过去在计算机、互联网或移动应用程序中看到的那样,当新技术从一种由少数人控制的昂贵的派对把戏成熟为无数公司和个人可以轻松访问的东西时,真正的革命就会发生。从这些过去的采用曲线中学习,我们可以预测未来会发生什么。
首先,没有理由相信LLM和其他基金会模式会改变公司采用技术的方式。与任何其他技术组件一样,LLM的采用需要一轮又一轮的评估和实验。使用LLM的工作流需要开发并集成到周围的系统中,并且需要由人类不断改进、调整、监控和控制。和以前一样,一些公司准备比其他公司更早地踏上这段旅程。
其次,除了概念验证之外,新技术并不能免费提供不可预测或不受欢迎的用户体验。LLM将成为工具箱中的一个新工具,使公司能够提供令人愉快和差异化的体验,一些公司将学会比其他公司更好地利用这些体验。特别是,受监管行业的公司需要像对待其技术堆栈的任何其他部分一样谨慎对待LLM,因为监管机构肯定会把重点放在人工智能上。
从这个角度来看,LLM是ML基础设施堆栈中其他模型中的模型,其他层中的一层:
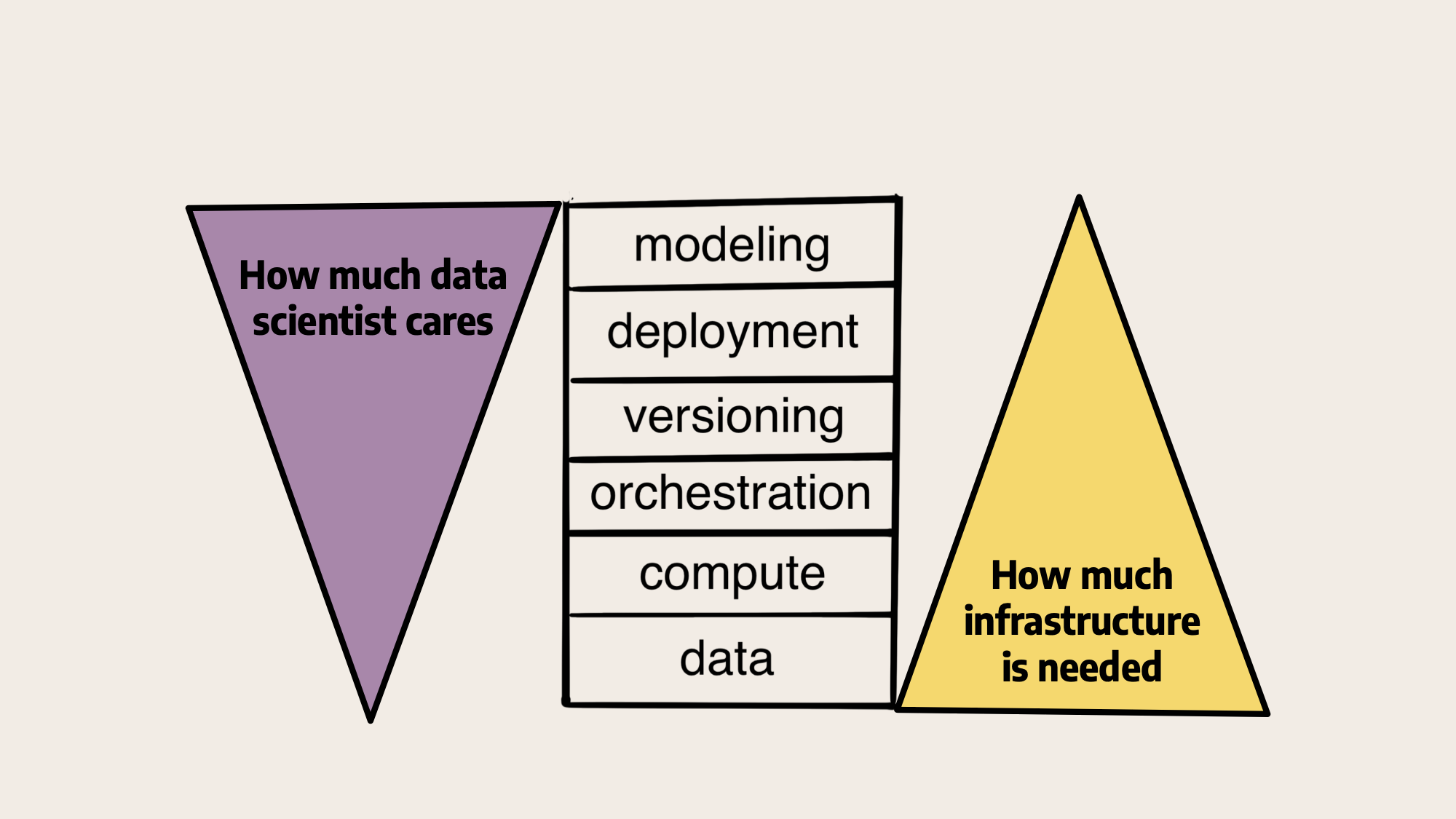
在我们对上面堆栈的原始说明中,左边的数据科学家主要关注与建模密切相关的问题,而逐渐较少关注较低级别的基础设施,而基础设施提供商,如我们在Outerbounds或内部平台团队,则相反。最近,LLM使每个人的注意力更加集中,如下所示:

大多数讨论都围绕着模型本身以及它们所带来的令人兴奋的演示展开。或者,在基础设施方面,重点是大规模的数据集或训练模型所需的巨大计算能力。中间的操作问题没有得到太多关注。我们相信,随着公司开始认真考虑如何在实践中使用这些模型,这种情况即将改变。
2025年及以后的ML项目
我们相信,LLM和其他基础模型将作为ML堆栈中一个强大的新模型家族被采用——对其进行扩充,而不是取代。在某些情况下,特别是当涉及文本和图像时,新技术将实现全新的用例。在其他情况下,它们将用于改进现有的ML模型和数据科学项目,如下所述。

根据用例的不同,公司选择拥有一些模型,如图中基于通用基础模型的微调LLM或嵌入生成LLM。在其他情况下,通过API使用供应商拥有的模型是有意义的。在任何情况下,公司都希望仔细考虑他们希望在其治理边界内拥有和控制系统的哪些部分,以及哪些功能可以安全地外包给第三方供应商。
所有这些系统都将由人类通过结合数据、代码和模型进行设计。相应地,ML基础设施堆栈所解决的所有基本问题都保持不变:系统需要轻松访问数据和计算。它们被构造为工作流,通过多个版本迭代构建。结果以各种方式部署,利用最适合每项工作的模型。
今天,一些人认为,与其他ML模型相比,LLM和其他基础模型将需要一种根本不同的方法。也许新型号太大、太复杂、太昂贵,大多数公司都无法处理。或者,可以提供一种通用的模式作为服务,减轻公司处理自己问题的需要。
我们认为有两种强大的顺风作为反作用力:
- 在工程方面,学术界、供应商和非营利组织的集体力量将生产许可的、优化的基础模型、数据集和库,这将使特定领域模型的培训和微调变得更加便宜,因此对于合理规模的公司来说是可以实现的。此外,模型蒸馏等技术可以从根本上减少生产模型的规模和成本。
- 在建模方面,许多公司将意识到,他们可以——也必须——将人工智能作为其通常ML计划的一部分。他们希望像以前一样保留对其数据、产品体验和专有IP的控制权,将其自定义模型保持在其治理边界内。
因此,更多的公司能够并且愿意独立创新。我们很可能会看到,拥有深度领域专业知识的公司构建的较小模型优于没有领域专业知识构建的通用模型。新的人工智能技术将成为那些学会将其无缝集成到现有产品和工作流程中的公司的竞争优势。
接下来的步骤
新的人工智能技术成为ML基础设施堆栈的一部分而不是替代品的一个重要含义是,您可以继续使用开源Metaflow等经得起未来考验的工具来实现数据和ML堆栈的现代化。现实地说,绝大多数公司仍处于ML之旅的早期阶段,因此从奠定坚实的基础开始是有意义的。
实现这一目标的所有工作都是相关的,一旦你准备好开始采用最新的人工智能技术,就会有回报。如果您想要以最少的工程工作量打下坚实的基础,我们可以让您快速开始使用托管Outerbounds平台,该平台为所有ML/AI实验和生产应用程序提供了一个易于使用、优化和安全的环境。
要了解更多关于Metaflow和基础模型的信息,请参阅我们关于以下主题的最新文章:使用Metaflow训练一个大型语言模型,以Dolly为特色,它演示了如何使用Metaflow微调最先进的LLM Databricks的Dolly。您也可以阅读我们以前关于使用稳定扩散生成图像和使用Whisper进行文本到语音翻译的文章。
- 316 次浏览
【LLM】大型语言模型导论
视频号
微信公众号
知识星球
大型语言模型(LLM)是使用深度学习算法处理和理解自然语言的基础机器学习模型。这些模型在大量文本数据上进行训练,以学习语言中的模式和实体关系。LLM可以执行多种类型的语言任务,如翻译语言、分析情感、聊天机器人对话等。他们可以理解复杂的文本数据,识别实体及其之间的关系,并生成连贯且语法准确的新文本。
学习目标
- 理解大型语言模型(LLM)的概念及其在自然语言处理中的重要性。
- 了解不同类型的流行LLM,如BERT、GPT-3和T5。
- 讨论开源LLM的应用程序和用例。
- LLM的拥抱脸API。
- 探讨LLM的未来影响,包括其对就业市场、沟通和整个社会的潜在影响。
这篇文章是作为数据科学博客的一部分发表的。
目录
- 什么是大型语言模型?
- 通用架构
- LLM示例
- 开源大型语言模型
- Bloom架构
- 拥抱面部API
- 示例1:句子完成
- 示例2:问答
- 示例3:总结
- LLM的未来影响
- 结论
- 常见问题解答
什么是大型语言模型?
大型语言模型是一种高级类型的语言模型,使用深度学习技术对大量文本数据进行训练。这些模型能够生成类似人类的文本并执行各种自然语言处理任务。
相反,语言模型的定义是指基于对文本语料库的分析,为单词序列分配概率的概念。语言模型可以具有不同的复杂性,从简单的n-gram模型到更复杂的神经网络模型。然而,“大型语言模型”一词通常指的是使用深度学习技术并具有大量参数的模型,参数范围从数百万到数十亿不等。这些模型可以捕捉语言中的复杂模式,并生成通常与人类书写的文本无法区分的文本。
通用架构
大型语言模型的架构主要由多层神经网络组成,如递归层、前馈层、嵌入层和注意力层。这些层一起工作来处理输入文本并生成输出预测。
- 嵌入层将输入文本中的每个单词转换为高维向量表示。这些嵌入捕获有关单词的语义和句法信息,并帮助模型理解上下文。
- 大型语言模型的前馈层具有多个完全连接的层,这些层将非线性变换应用于输入嵌入。这些层帮助模型从输入文本中学习更高层次的抽象。
- LLM的递归层被设计为按顺序解释来自输入文本的信息。这些层保持一个隐藏状态,该状态在每个时间步长都会更新,从而使模型能够捕获句子中单词之间的依赖关系。
- 注意力机制是LLM的另一个重要部分,它允许模型选择性地关注输入文本的不同部分。这种机制有助于模型关注输入文本最相关的部分,并生成更准确的预测。
LLM示例
让我们来看看一些流行的大型语言模型:
- GPT-3(Generative Pre-trained Transformer 3)–这是OpenAI开发的最大的大型语言模型之一。它有1750亿个参数,可以执行许多任务,包括文本生成、翻译和摘要。
- BERT(Bidirectional Encoder Representations from Transformers)-由谷歌开发,BERT是另一种流行的LLM,它是在大量文本数据的语料库上训练的。它可以理解句子的上下文,并对问题做出有意义的回答。
- XLNet——这个由卡内基梅隆大学和谷歌开发的LLM使用了一种新的语言建模方法,称为“置换语言建模”。它在语言任务方面取得了最先进的性能,包括语言生成和问答。
- T5(Text-to-Text Transfer Transformer))–T5由谷歌开发,接受过各种语言任务的培训,可以执行文本到文本的转换,如将文本翻译成另一种语言、创建摘要和回答问题。
- RoBERTa(Robustly Optimized BERT Pretraining Approach)-由Facebook AI Research开发,RoBERTa是一个改进的BERT版本,在多种语言任务上表现更好。
开源大型语言模型
开源LLM的出现彻底改变了自然语言处理领域,使研究人员、开发人员和企业更容易构建应用程序,利用这些模型的力量免费大规模构建产品。布鲁姆就是这样一个例子。这是第一个多语言大型语言模型(LLM),由有史以来参与单个研究项目的人工智能研究人员进行的最大规模的合作,以完全透明的方式进行训练。
凭借1760亿个参数(比OpenAI的GPT-3大),BLOOM可以用46种自然语言和13种编程语言生成文本。它基于1.6TB的文本数据进行训练,是莎士比亚全集的320倍。
Bloom架构
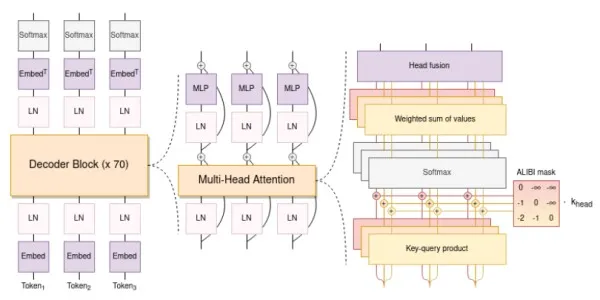
BLOOM的架构与GPT3(下一个令牌预测的自回归模型)有相似之处,但已经用46种不同的语言和13种编程语言进行了训练。它由一个只有解码器的架构组成,该架构具有多个嵌入层和多头注意力层。
Bloom的架构适用于多种语言的培训,并允许用户用不同的语言翻译和谈论某个主题。我们将在下面的代码中查看这些示例。
其他LLM
我们可以通过拥抱脸来利用连接到许多广泛可用的LLM的预训练模型的API。
Hugging Face API
让我们看看Hugging Face API如何帮助使用Bloom、Robertabase等LLM生成文本。首先,我们需要注册Hugging Face并复制令牌以进行API访问。注册后,将鼠标悬停在右上角的配置文件图标上,单击设置,然后单击访问令牌。
Example 1: Sentence Completion
让我们看看如何使用Bloom来完成句子。下面的代码使用API的拥抱脸标记发送带有输入文本和适当参数的API调用,以获得最佳响应。
import requests
from pprint import pprint
API_URL = 'https://api-inference.huggingface.co/models/bigscience/bloomz'
headers = {'Authorization': 'Entertheaccesskeyhere'}
# The Entertheaccesskeyhere is just a placeholder, which can be changed according to the user's access key
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
params = {'max_length': 200, 'top_k': 10, 'temperature': 2.5}
output = query({
'inputs': 'Sherlock Holmes is a',
'parameters': params,
})
pprint(output)可以修改温度和top_k值以获得更大或更小的段落,同时保持生成的文本与原始输入文本的相关性。我们从代码中得到以下输出:
[{'generated_text': 'Sherlock Holmes is a private investigator whose cases '
'have inspired several film productions'}]Let’s look at some more examples using other LLMs.
Example 2: Question Answers
我们可以使用Roberta-base模型的API,它可以作为参考和答复的来源。让我们更改有效载荷以提供有关我自己的一些信息,并让模型根据这些信息回答问题。
API_URL = 'https://api-inference.huggingface.co/models/deepset/roberta-base-squad2'
headers = {'Authorization': 'Entertheaccesskeyhere'}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
params = {'max_length': 200, 'top_k': 10, 'temperature': 2.5}
output = query({
'inputs': {
"question": "What's my profession?",
"context": "My name is Suvojit and I am a Senior Data Scientist"
},
'parameters': params
})
pprint(output)The code prints the below output correctly to the question – What is my profession?:
{'answer': 'Senior Data Scientist',
'end': 51,
'score': 0.7751647233963013,
'start': 30}Example 3: Summarization
我们可以使用大型语言模型进行总结。让我们总结一篇使用Bart-Larget-CNN模型描述大型语言模型的长文。我们修改了API URL并添加了以下输入文本:
API_URL = "https://api-inference.huggingface.co/models/facebook/bart-large-cnn"
headers = {'Authorization': 'Entertheaccesskeyhere'}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
params = {'do_sample': False}
full_text = '''AI applications are summarizing articles, writing stories and
engaging in long conversations — and large language models are doing
the heavy lifting.
A large language model, or LLM, is a deep learning model that can
understand, learn, summarize, translate, predict, and generate text and other
content based on knowledge gained from massive datasets.
Large language models - successful applications of
transformer models. They aren’t just for teaching AIs human languages,
but for understanding proteins, writing software code, and much, much more.
In addition to accelerating natural language processing applications —
like translation, chatbots, and AI assistants — large language models are
used in healthcare, software development, and use cases in many other fields.'''
output = query({
'inputs': full_text,
'parameters': params
})
pprint(output)输出将打印有关LLM的摘要文本:
[{'summary_text': 'Large language models - most successful '
'applications of transformer models. They aren’t just for '
'teaching AIs human languages, but for understanding '
'proteins, writing software code, and much, much more. They '
'are used in healthcare, software development and use cases '
'in many other fields.'}]
这些是将Hugging Face API用于常见大型语言模型的一些示例。
LLM的未来影响
近年来,人们对GPT-3等大型语言模型(LLM)和ChatGPT等聊天机器人产生了特别的兴趣,它们可以生成与人类编写的自然语言文本几乎没有区别的自然语言文字。尽管LLM在人工智能领域取得了突破,但人们担心它们对就业市场、通信和社会的影响。
LLM的一个主要担忧是它们有可能扰乱就业市场。随着时间的推移,大型语言模型将能够通过替换人类来执行任务,如法律文件和草案、客户支持聊天机器人、撰写新闻博客等。这可能会导致那些工作很容易自动化的人失业。
然而,需要注意的是,LLM并不能取代人类工人。它们只是一种工具,可以帮助人们在工作中提高生产力和效率。虽然一些工作可能是自动化的,但由于LLM提高了效率和生产力,也将创造新的工作岗位。例如,企业可能能够创建以前开发起来过于耗时或昂贵的新产品或服务。
LLM有可能以多种方式影响社会。例如,LLM可以用于创建个性化的教育或医疗保健计划,从而获得更好的患者和学生结果。LLM可以通过分析大量数据和产生见解来帮助企业和政府做出更好的决策。
结论
大型语言模型(LLM)彻底改变了自然语言处理领域,在文本生成和理解方面取得了新的进步。LLM可以从大数据中学习,了解其上下文和实体,并回答用户查询。这使它们成为在几个行业的各种任务中经常使用的一个很好的替代品。然而,人们对与这些模型相关的伦理影响和潜在偏见感到担忧。以批判的眼光对待LLM并评估其对社会的影响是很重要的。通过仔细使用和持续开发,LLM有可能在许多领域带来积极的变化,但我们应该意识到它们的局限性和道德影响。
主要收获:
- 大型语言模型(LLM)可以理解复杂的句子,理解实体和用户意图之间的关系,并生成连贯且语法正确的新文本
- 本文探讨了一些LLM的架构,包括嵌入层、前馈层、递归层和注意力层。
- 本文讨论了一些流行的LLM,如BERT、BERT、Bloom和GPT3,以及开源LLM的可用性。
- 拥抱脸API有助于用户使用LLM生成文本,如Bart大型CNN、Roberta、Bloom和Bart大型有线电视新闻网。
- LLM有望在未来彻底改变就业市场、通信和社会的某些领域。
常见问题解答
Q1.顶级的大型语言模型是什么?
答:顶级的大型语言模型包括GPT-3、GPT-2、BERT、T5和RoBERTa。这些模型能够生成高度逼真和连贯的文本,并执行各种自然语言处理任务,如语言翻译、文本摘要和问答。
Q2.为什么要使用大型语言模型?
答:之所以使用大型语言模型,是因为它们可以生成类似人类的文本,执行各种自然语言处理任务,并有可能彻底改变许多行业。它们可以提高语言翻译的准确性,帮助内容创建,改善搜索引擎结果,并增强虚拟助理的能力。大型语言模型对科学研究也很有价值,例如分析医学、社会学和语言学等领域的大量文本数据。
Q3.人工智能中的LLM是什么?
人工智能中的LLM指的是人工智能的语言模型,这些模型旨在使用自然语言处理技术理解和生成类似人类的文本。
Q4.NLP中的LLM是什么?
NLP中的LLM代表自然语言处理中的语言模型。这些模型支持与语言相关的任务,如文本分类、情感分析和机器翻译。
问题5.LLM模型的完整形式是什么?
答:LLM模型的完整形式是“大型语言模型”。这些模型是在大量文本数据上训练的,可以生成连贯且与上下文相关的文本。
问题6.NLP和LLM之间的区别是什么?
自然语言处理是人工智能的一个领域,专注于理解和处理人类语言。另一方面,LLM是NLP中使用的特定模型,由于其庞大的规模和生成文本的能力,它们擅长于语言相关的任务。
- 821 次浏览
【LLM】大型语言模型景观
视频号
微信公众号
知识星球
在过去的两年里,商业和开放LLM提供商的数量呈爆炸式增长,现在所有类型的语言任务都有许多选项可供选择。虽然与LLM交互的主要方式仍然是通过API和基本的游乐场,但我预计,在不久的将来,有助于加速其广泛采用的工具生态系统将成为一个不断增长的市场。
下图描述了当前大型语言模型(LLM)在功能、产品和工具生态系统方面的现状。

The TL;DR
- 大型语言模型(LLM)功能可分为五个领域:知识回答、翻译、文本生成、响应生成和分类。
- 分类可以说是当今企业需求中最重要的,而文本生成则是最令人印象深刻和最通用的。
- 商业产品和更通用的产品有 Cohere, GooseAI, OpenAI and AI21labs. GooseAI 目前只关注生成。
- 开源产品包括 Sphere, NLLB, Blender Bot, DialoGPT, GODEL and BLOOM.
- 工具生态系统仍处于萌芽状态,在许多领域都有机会。
LLM功能
- 分类
- 响应生成
- 文本生成
- 翻译
- 知识回答
各种LLM产品在不同程度上涵盖了这五个功能领域。
- 分类是一种监督学习形式,将文本分配给预定义的类。这与聚类有关,聚类是一种无监督的学习,语义相似的文本被分组在一起,没有任何预先存在的类。
- 响应生成是指从示例对话中创建对话流,并采用机器学习方法。其中,模型根据即时对话历史和最可能的下一个对话来确定下一个要呈现给用户的对话。
- 文本生成可以被描述为LLM的元能力,文本可以基于带有或不带有示例数据的简短描述来生成。生成是几乎所有LLM之间共享的功能。生成不仅可以通过少量的镜头学习数据得到广泛利用;通过铸造(即时工程),数据以某种方式决定了如何使用少数镜头学习数据。
- 翻译是指将文本从一种语言翻译成另一种语言。这是在没有任何中介语言的情况下直接完成的。点击此处了解更多信息。
- Knowledge Answering是知识密集型NLP(KI-NLP)的一种实现,它可以回答广泛的领域和一般问题,而无需查询API或利用传统的知识库。知识密集型NLP不是一种网络搜索,而是一种以语义搜索为基础的自包含知识库。
供品
Cohere、OpenAI、AI21labs、GooseAI、Blender Bot、DialoGPT、GODEL、BLOOM、NLLB、Sphere

目前的商业产品由三个较大的参与者(Cohere, AI21labs, OpenAI)和GooseAI.中一个新兴的较小实体组成。
开源实现往往不那么全面,在实现重点上更具体。
工具生态系统
以数据为中心的工具、游乐场、笔记本、提示工程工具、主机
LLM和游乐场
LLM是作为API访问的,因此使用它们的API所需的基本工具是命令行、开发环境或Jupyter笔记本;Cohere在推出内容方面做得非常好,这些内容展示了如何通过简单的脚本和集成将LLM应用于现实生活中的用例。
供应商还清楚地意识到,为了使LLM的实验和采用更容易,他们需要以游乐场的形式提供无代码环境,以暴露不同的任务和调整选项:这是了解可以实现什么的一个很好的起点。
下面是谷歌人工智能游乐场,这是一种与其他LLM提供商非常相似的方法。

The GooseAI playground view, with tuning options on the right.
这些游乐场允许您玩“提示工程”(这是您可以探索令人兴奋的文本生成功能的方式)。注意:我很惊讶,我们还没有看到第三方工具/市场等以LLM“即时工程”为重点的更大爆炸,就像我们在图像生成模型(如DALL-E和最近的稳定扩散)中看到的那样。
以数据为中心的工具
我渴望看到LLM更深入地集成到开发对话式人工智能和其他用例(如分析等)所需的“核心”工作流程中;很明显,LLM API及其嵌入空间的定位是解锁更强大的功能:
- 语义搜索(有助于探索非结构化数据)
- 聚类(需要识别对话主题或意图)
- 实体提取(通过文本生成)
- 分类(通过少数镜头学习示例,或对实际模型进行微调)
我不希望企业客户在供应商Playgrounds中做这种类型的工作,相反,我希望这些将是由LLM API提供支持的第三方工具(无论是对话式人工智能平台本身,还是专门的以数据为中心的解决方案)中包含的功能类型。
到目前为止,我只看到HumanFirst在这种以数据为中心的产品中集成LLM(而且它们目前似乎只支持Cohere)。
🤗拥抱脸
最后,LLM是大型模型,而且成本高昂且难以运行。
这里提到的大多数技术(除了商业LLM)都可以通过🤗拥抱脸。
您可以使用空间、模型卡或通过托管推断API与模型交互。有培训、部署和托管的选项。显然,托管和计算需求将是过度的,而且不容易被证明是合理的。
总结
LLM不是聊天机器人开发框架,不应将两者进行比较。会话人工智能中有特定的LLM用例,聊天机器人和语音机器人的实现肯定可以从利用LLM中受益。
- 249 次浏览
【LLM】构建LLM驱动的应用程序:您需要了解的内容
视频号
微信公众号
知识星球
构建LLM驱动的应用程序
对于有兴趣部署人工智能应用程序的开发人员来说,过去几周是令人兴奋的。该领域发展迅速,现在可以构建人工智能驱动的应用程序,而无需花费数月或数年时间学习机器学习的来龙去脉。这打开了一个充满可能性的全新世界,因为开发人员现在可以以前所未有的方式试验人工智能。
基础模型,特别是大型语言模型(LLM),现在对机器学习或数据科学背景很低或没有背景的开发人员来说是可以访问的。这些敏捷团队擅长快速迭代,可以快速开发、测试和完善在Product Hunt等平台上展示的创新应用程序。值得注意的是,与大多数数据和人工智能团队相比,这群开发人员的运作速度要快得多。
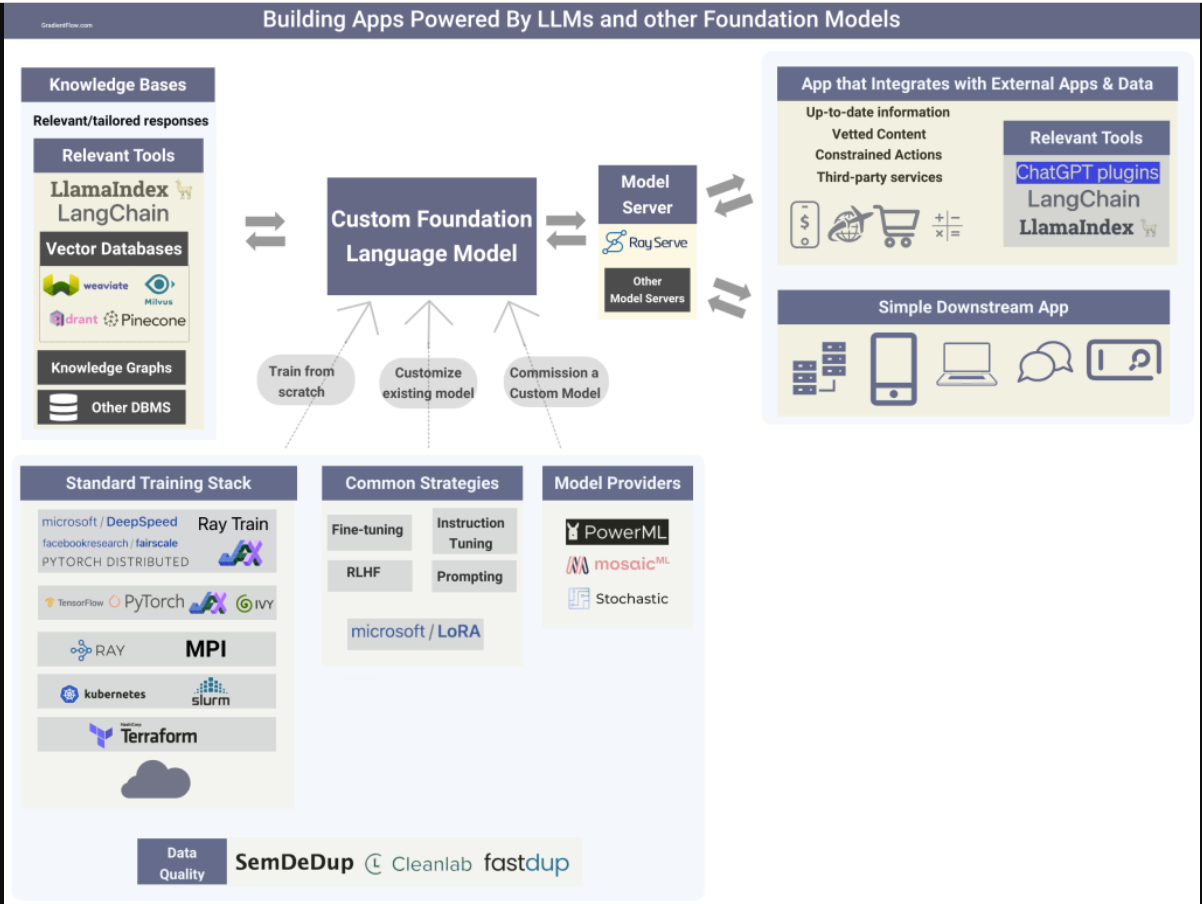
Building apps that rely on LLMs and other foundation models.
自定义模型
目前开发人员普遍采用的方法是通过API使用专有的LLM。然而,正如我们在最近的一篇文章中所解释的那样,领域特异性、安全性、隐私、法规、知识产权保护和控制等因素将促使更多组织选择投资于自己的定制LLM。例如,彭博社最近详细介绍了他们是如何建立BloombergGPT的,这是一家金融LLM。此外,几个经过精细调整的中型模型的例子吸引了研究人员和开发人员的注意,为更多的研究人员创建自己的自定义LLM铺平了道路。
- 委托定制模型:有一些新的初创公司提供必要的资源和专业知识,帮助公司调整甚至培训自己的大型语言模型。例如,PowerML使组织能够通过利用RLHF和对自己的数据进行微调技术来超越通用LLM的性能。
- 对现有模型进行微调:我在上一篇文章中描述了流行的微调技术。我预计会有更多的开源资源,包括具有适当许可证的模型和数据集,使团队能够将其作为构建自己的自定义模型的起点。例如,Cerebras刚刚在Apache 2.0许可证下开源了一组LLM。
- 从头开始训练模型:在对LLM的制作进行在线研究并从有训练工具经验的朋友那里收集见解后,很明显,有许多开源组件通常用于训练基础模型。分布式计算框架Ray被广泛用于训练基础模型。虽然PyTorch是许多LLM创建者使用的深度学习框架,但一些团队更喜欢JAX等替代框架,甚至是在中国流行的本土库。Ivy是一种创新的开源解决方案,能够在机器学习框架之间进行代码转换,促进各种来源之间的无缝协作和多功能性。
许多开发基础模型的组织都有专门的团队负责安全、协调和负责任的人工智能。选择建立自己的自定义模型的团队应该进行类似的投资。
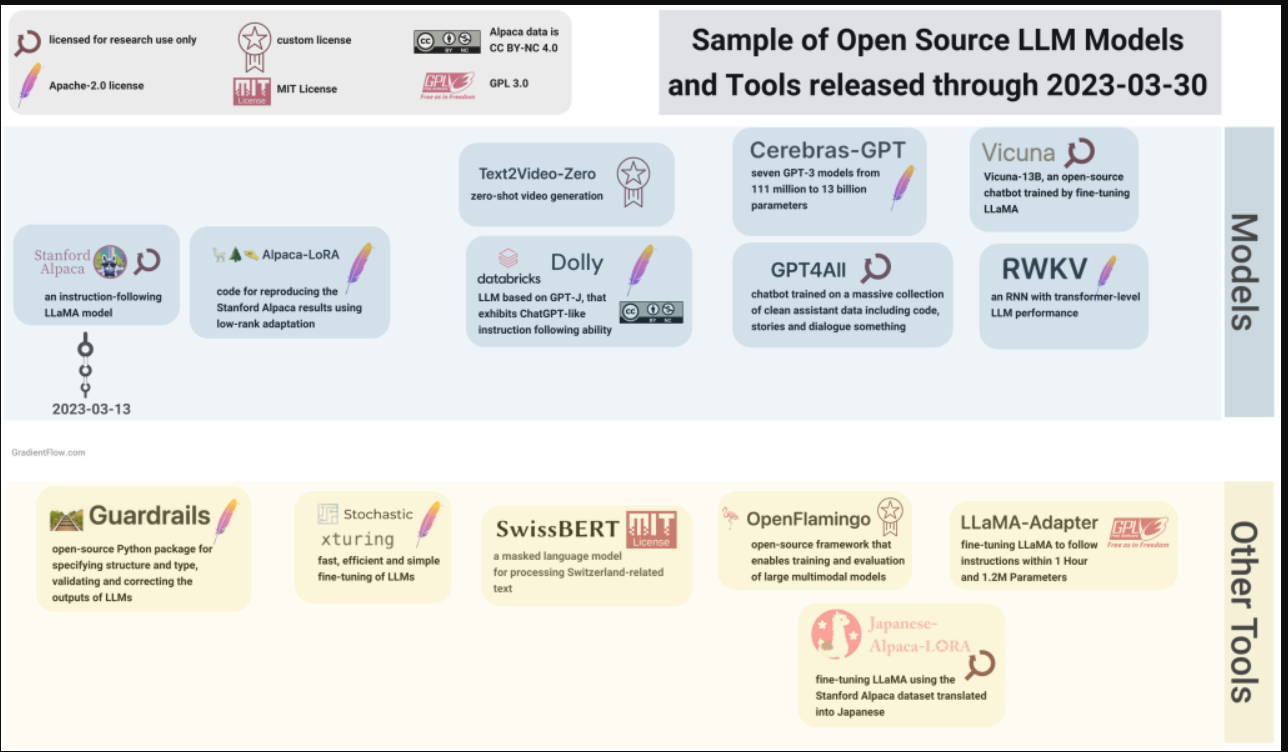
The recent proliferation of open-source models and tools has significantly expanded the available options for teams seeking to create custom LLMs.
第三方集成
OpenAI最近为其ChatGPT语言模型推出了一项名为“插件”的新功能,该功能允许开发人员创建可以访问最新信息、运行计算或使用第三方服务的工具。Expedia、Instacart和Shopify等公司已经使用该功能创建插件。第三方开发人员可以开发插件,从简单的计算器到更复杂的工具,如语言翻译和WolframAlpha集成。
正如Terraform的创建者所指出的那样,ChatGPT插件界面非常容易使用:“你为你的API编写一个OpenAPI清单,使用人类语言描述一切,就这样。你让模型知道如何进行身份验证、链接调用、处理中间的数据、格式化以供查看等等。绝对没有粘合代码。”
其他LLM提供商可能会提供类似的资源来帮助开发人员与外部服务集成。LangChain和LlamaIndex等开源工具很早就帮助开发人员构建依赖外部服务和源代码的应用程序。我预计在不久的将来,用于构建LLM支持的应用程序的第三方集成工具将迅速取得进展。
LangChain和LlamaIndex等工具,甚至是LLM之间插件共享的潜在开放协议,对寻求灵活交换模型或针对多个LLM提供商的开发人员具有吸引力。这样的工具允许开发人员将最佳LLM用于特定任务,而无需锁定在单个提供程序中。
知识库
知识图和其他外部数据源可以通过提供补充的、特定领域的事实信息来增强LLM。我们开始看到有助于连接现有数据源和格式的工具,包括连接矢量数据库等新系统。这些工具能够在结构化和非结构化数据上创建索引,从而实现上下文学习。此外,它们提供了一个用于查询索引和获得知识增强输出的接口,这增强了所提供信息的准确性和相关性。
服务模型
软件服务需要几个关键功能来满足现代计算的需求。它们必须具有响应能力、高可用性、安全性、灵活性和跨平台和系统的互操作性,同时能够处理大量用户并提供实时处理和分析能力。LLM的部署由于其规模、复杂性和成本而带来了独特的挑战。
- 开源库Ray Serve完全符合人工智能应用程序的要求,因为它使开发人员能够构建一个可扩展、高效和灵活的推理服务,能够集成多个机器学习模型和基于Python的业务逻辑。下面是一个如何使用Ray Serve部署LLM的示例。
- 更小、更精简的模型的兴起将提高LLM在一系列应用中的效率。我们开始看到令人印象深刻的LLM,如LLaMA和Chinchilla,它们的尺寸只是现有最大型号的一小部分。此外,压缩和优化技术,如修剪、量化和蒸馏,将在LLM的使用中发挥越来越重要的作用,遵循计算机视觉设定的路径,著名的早期例子是DistilBERT、Hugging Face DistilGPT2、distill-bloom和PyTorch量化。
总结
用于构建LLM驱动的应用程序的工具和资源的激增为开发人员打开了一个充满可能性的新世界。这些工具使开发人员能够利用人工智能的力量,而不必学习机器学习的复杂性。随着越来越多的组织投资于自己的自定义LLM,开源资源变得越来越广泛,LLM驱动的应用程序的前景将变得更加多样化和分散。这给开发人员带来了机遇和挑战。
重要的是要记住,权力越大,责任越大。组织必须投资于安全性、一致性和负责任的人工智能,以确保LLM驱动的应用程序用于积极和道德目的。

An early sign that more tools are on the way: the Winter/2023 YC batch includes new tools to help teams build, customize, deploy, and manage LLMs in the future.
数据交换播客
1.数据和人工智能是如何发生的。Chris Wiggins是哥伦比亚大学的教授,也是《纽约时报》的首席数据科学家。他还是《数据是如何发生的》一书的合著者,这是一本引人入胜的历史探索,探讨了从人口普查到优生学再到谷歌搜索,数据是如何被用作塑造社会的工具的。这本书追溯了数据的轨迹,探索了新的数学和计算技术,这些技术有助于塑造人、思想、社会和经济。
2.揭示人工智能趋势:开拓性研究和未知领域。Zeta Alpha创始人兼首席执行官Jakub Zavrel讨论了2022年被引用最多的100篇人工智能论文、今年的趋势研究主题,以及语言模型、多模态人工智能等的未来。他强调了变形金刚的主导地位、多模态模型的兴起、合成数据的重要性、自定义大语言模型、思维链推理和下一代搜索技术。

聚光灯
- 1.引入NLP测试。这个急需的开源工具有助于提高NLP模型的质量和可靠性。它使用简单,提供了全面的测试覆盖范围,有助于确保模型安全、有效和负责任。该库提供了50多种与流行的NLP库和任务兼容的测试类型,在部署到生产系统之前解决了模型质量方面的问题,如鲁棒性、偏差、公平性、表示性和准确性。
- 2..Microwave from BNH.。微波炉是一种免费的基于人工智能的偏见评估工具,旨在帮助企业遵守纽约市第144号地方法律。这项立法要求对自动化就业决策系统中的潜在偏见进行评估。它已被用于审计从财富100强公司到软件初创公司等客户的人工智能系统,帮助他们衡量和管理人工智能风险。
- 3.使用Alpa和Ray在1000 GPU规模下训练175B参数语言模型。Alpa是一个开源编译器系统,用于自动化和民主化大型深度学习模型的模型并行训练。它生成的并行化计划与手动调整模型并行训练系统相匹配或优于手动调整模型平行训练系统,即使是在为其设计的模型上也是如此。本文讨论了Alpa和Ray的集成,以训练一个175B参数模型,该模型等效于具有流水线并行性的GPT-3(OPT-175B)模型。基准测试表明,Alpa可以扩展到1000个GPU以上,实现最先进的峰值GPU利用率,并使用单行装饰器执行自动LLM并行化和分区。
如果您喜欢这篇文章,请鼓励您的朋友和同事订阅我们的时事通讯,以支持我们的工作:
- 103 次浏览
【LLM】认识MPT-7B:一套支持65k Token的开源商业LLM
视频号
微信公众号
知识星球
MosaicML发布了新的模型套件,并支持针对指令、聊天、故事等进行了优化的模型。
我最近创办了一份以人工智能为重点的教育通讯,该通讯已经有超过150000名订户。TheSequence是一个无BS(意思是没有炒作,没有新闻等)面向ML的时事通讯,需要5分钟的阅读时间。目标是让你了解机器学习项目、研究论文和概念的最新情况。请尝试订阅以下内容:
由于大型语言模型(LLM)的显著影响,世界正在经历一场变革。然而,对于资金充足的行业实验室之外的个人来说,培训和实施这些模式的过程可能是一项艰巨的任务。因此,围绕开源LLM的活动激增。突出的例子包括Meta的LLaMA系列、EleutherAI的Pythia系列、StabilityAI的StableLM系列和Berkeley AI Research的OpenLLaMA模型。
MosaicML最近推出了一个名为MPT(MosaicMLPretrained Transformer)的新模型系列,以解决上述模型遇到的限制。本版本旨在提供一个开源模型,该模型在商业上可行,并在各个方面超越LLaMA-7B的能力。我们的MPT型号系列的主要功能包括:
- ·商业使用许可证:与LLaMA不同,MPT型号系列获得商业应用许可。
- ·广泛的数据训练:MPT已经在大量数据上进行了训练,与LLaMA的1万亿代币相当,而Pythia、OpenLLaMA和StableLM分别使用3000亿、3000亿和8000亿代币。
- ·对长输入的特殊处理:MPT已准备好有效地处理极其长的输入。利用ALiBi,我们对该模型进行了高达65000个输入的训练,其处理输入的能力高达84000个代币,远远超过了其他开源模型的限制,这些模型通常在2000到4000个代币之间。
- ·优化快速训练和推理:MPT结合了FlashAttention和FasterTransformer等先进技术,实现了加速训练和推理过程。
- ·高效开源培训代码:MPT配备了精心设计的开源培训代码,强调效率和有效性。
MPT模型
MPT版本由几个针对不同功能进行优化的模型组成。
1) MPT-7B型
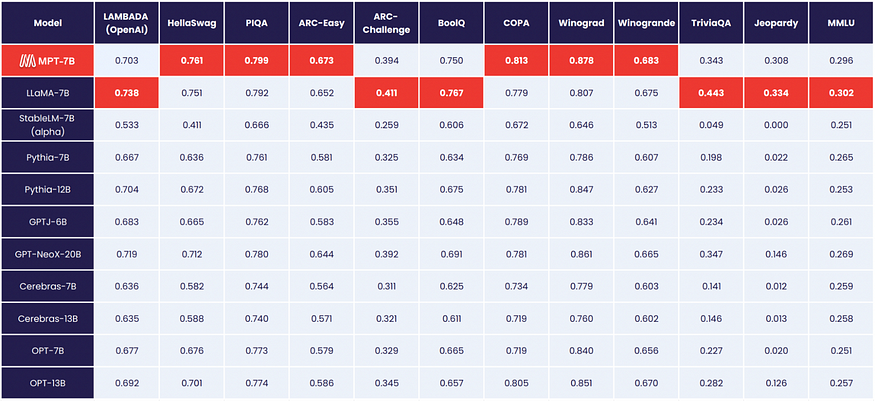
MPT-7B的性能水平与LLaMA-7B不相上下,在各种标准学术任务中超过了7B至20B范围内的其他开源模型的能力。为了评估该模型的质量,使用了11个广泛认可的开源基准进行了评估,这些基准通常用于情境学习(ICL)。这些基准是根据行业标准做法精心制定和评估的。此外,我们的团队精心策划的《危险边缘》基准被纳入其中,以衡量该模型在对复杂而苛刻的问题做出准确回答方面的熟练程度。
2) MPT-7B-StoryWriter-65K
大多数开源语言模型在处理仅包含几千个令牌的序列方面都有局限性。然而,随着MosaicML平台和由8xA100–80GB组成的单个节点的使用,MPT-7B的微调成为一个无缝过程,使其能够适应高达65k的上下文长度。这种适应如此广泛的上下文长度的非凡能力是由嵌入MPT-7B中的关键架构选择ALiBi实现的。
为了展示这种非凡的能力,并激发您对65k上下文窗口所呈现的可能性的想象力,MosaicML很自豪地推出了MPT-7B-StoryWriter-65k+。StoryWriter经历了一个涉及2500个步骤的微调过程,利用从books3语料库中发现的小说中提取的65k个象征性摘录。与预训练阶段类似,此微调过程依赖于下一个令牌预测目标。训练过程需要使用具有FSDP、激活检查点和1的微批量的Composer,以确保最佳的训练结果。

3) MPT-7B-Instruct
LLM预训练的传统方法包括训练模型以基于所提供的输入生成文本。然而,在实际应用中,我们期望LLM将输入解释为要遵循的指令。教学微调的目的是培训LLM在教学后续任务中表现出色。这种范式转变减少了对复杂的即时工程的依赖,使LLM更易于访问、直观和易于应用。在指令微调方面取得的进展可归因于FLAN、Alpaca和Dolly-15k等开源数据集的可用性。
为了满足商业需求,我们开发了一种称为MPT-7B-Directive的模型变体,专门为以下指令而设计。虽然我们很欣赏Dolly提供的商业许可,但我们希望有一个更大的数据集。为了实现这一点,我们用Anthropic的Helpful&Harmless数据集的一个子集增强了Dolly,使数据集的大小增加了四倍,同时确保了其商业可行性。
由此产生的组合数据集被用于对MPT-7B进行微调,从而创建了MPT-7B-Directive——一个具有特殊指令跟随功能的商业可用模型。利用其在1万亿代币上的广泛培训,MPT-7B-Directive预计即使与更大的美元v2–12b模型相比也具有竞争力。值得注意的是,Pythia-12B的基本模型,即美元-v2-12B的基础,仅在3000亿个代币上进行了训练。
4) MPT-7B-Chat
MosaicML通过开发MPT-7B-Chat(MPT-7B的会话变体)进一步扩展了其产品。MPT-7B-Chat使用多种数据集进行了微调,包括ShareGPT Vicuna、HC3、Alpaca、Helpful和Harmless以及Evol Instruction。这种细致的微调过程使MPT-7B-Chat具备了在各种会话任务和应用程序中脱颖而出的必要能力。ChatML格式的实现确保了向模型传输系统消息的简化和标准化方法,同时也防止了潜在的恶意提示注入。
虽然MPT-7B指令主要致力于为指令后续任务提供更自然、直观的界面,但MPT-7B-Chat旨在为用户提供无缝、引人入胜的多回合互动。通过利用其复杂的培训和微调,MPT-7B-Chat提供了增强的对话体验,促进了与模型的动态和互动交流。

架构
MPT系列模型的体系结构由一系列常见的构建块支持
1) 数据
为了确保MPT-7B是一个高质量的独立模型,能够适应广泛的下游应用,人们对预训练数据的选择给予了广泛的关注。用于预训练的数据由MosaicML从各种来源精心策划。这些来源的摘要见表2,附录部分提供了进一步的详细说明。使用EleutherAI GPT-NeoX-20B标记器对文本进行标记,并在由1万亿个标记组成的广泛数据集上对模型进行预训练。
该数据集的组成优先考虑英语自然语言文本,同时也融入了多样性元素,以适应未来的应用,如代码或科学模型。值得注意的是,该数据集包括来自最近发布的RedPajama数据集的部分。因此,数据集的网络爬行和维基百科部分富含2023年的最新信息,确保模型具备最新知识。
2) Tokenizer
出于标记化的目的,采用了EleutherAI GPT NeoX 20B标记化器,选择该标记化器是因为其所需的特性在标记化代码时被证明特别相关。这些特征包括:
- ·对各种数据的混合进行培训,包括代码(称为“The Pile”)。这确保了标记化器熟悉特定于代码的语法和结构。
- ·一致的空间划界:与GPT2标记器不同,GPT2标记化器根据前缀空间的存在进行不一致的标记化,GPT NeoX 20B标记化器在整个标记化过程中保持了一致的空间定界方法。
- ·为重复的空格字符合并标记:标记化器包括特定的标记,用于处理存在大量重复空格字符的实例。这使得能够对包含大量重复空格字符的文本进行卓越的压缩。
标记化器的词汇表大小设置为50257;然而,出于我们的目的,我们将模型词汇表大小扩展到50432,确保了有效标记化所需的令牌的全面覆盖。
3) 计算
MPT-7B模型使用MosaicML平台提供的一系列工具进行了训练。培训过程中使用的具体工具如下:
- ·计算:培训使用了Oracle Cloud的A100–40GB和A100–80GB GPU,它们以卓越的计算能力而闻名。
- ·编排和容错:MCLI和MosaicML平台在编排训练过程和确保容错方面发挥了至关重要的作用,从而提高了训练过程的效率和稳定性。
- ·数据:培训数据来源于OCI对象存储和流数据集,利用这些资源访问和管理必要的数据集。
- ·培训软件:使用的培训软件包括Composer、PyTorch FSDP(完全共享数据并行)和LLM Foundry。这些软件框架结合了先进的技术和简化的流程,促进了高效的模型培训。
正如许多团队所记录的那样,在数百到数千个GPU上训练具有数十亿参数的大型语言模型(LLM)是一项艰巨的挑战。训练过程中使用的硬件经常以各种创造性的方式遇到频繁和意想不到的故障。损失高峰可能会扰乱训练进度,因此监督训练的团队必须保持警惕,甚至需要在出现问题时进行手动干预以纠正问题。
然而,在MosaicML,专门的研究和工程团队已经投入了六个月的不懈努力来正面应对这些挑战。MPT-7B从开始到结束都是在1万亿个代币上无缝训练的,不需要人工干预。值得注意的是,训练过程没有表现出显著的损失峰值,不需要中间流学习速率调整或数据跳过,并且自动处理任何失效GPU的实例。
4) 推论
MPT的设计非常注重推理任务的速度、易部署性和成本效率。在性能方面,MPT在其层中展示了令人印象深刻的优化,利用了FlashAttention和低精度层rm等专业组件。与LLaMa-7B等其他7B型号相比,这种优化转化为MPT-7B卓越的开箱即用性能。事实上,MPT-7B的速度显著提高了1.5x-2x,使得仅使用HuggingFace和PyTorch就可以开发快速灵活的推理管道。这种组合使用户能够高效地部署MPT模型,同时享受增强的性能和简化的推理过程。
MPT-7B版本是市场上最完整的开源LLM系列之一。此版本的商业可用性代表了基础模型开源势头的一个重要里程碑。
- 264 次浏览
【Open AI】私有Azure OpenAI Serivce预想构架规划
视频号
微信公众号
知识星球
此文是写给广大的IT Infra背景群众看的,主要是提供落地架构设计参考,若你是想要知道OpenAI怎么用的,此文并无涉及,可以参考官方文件Azure OpenAI is now generally available
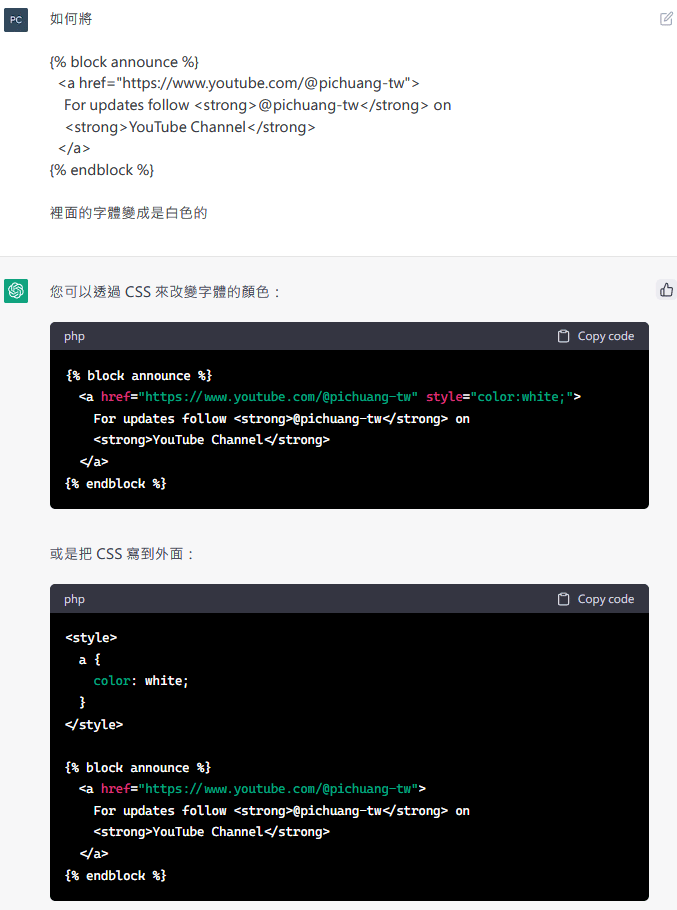
2022/11最惊吓到我的事情就是ChatGPT这服务的诞生,简直看到科技奇异点,然后没想到这服务的母公司OpenAI居然是Microsoft投资的,我只能说真的是可喜可贺和感到哀伤。
可喜可贺是我可以在很近的距离看到这技术将要创造的历史,感到哀伤是ChatGPT树立了一个相当惊人的技术屏障,都不知道以后新进或菜鸟工程师到底要怎么跟这个竞争,但幸好若问他做特别需要专业性问答的事情,这服务目前有可能会回答错误或乱答,譬如说问它网络除错或设计问题后,看起来我还不会失业:>
下图是标准工程师使用示例,本人对于HTML和CSS毫无理解,也不知道从何改,然后我就去问ChatGPT后,就改好了…
Azure OpenAI Service Architecture Pre Design
初探OpenAI Studio
目前预想私有构架上分为2个方案
- 生产环境规划
- PoC验证环境规划
方案1: Production生产私有环境规划

方案2: PoC验证私有环境规划
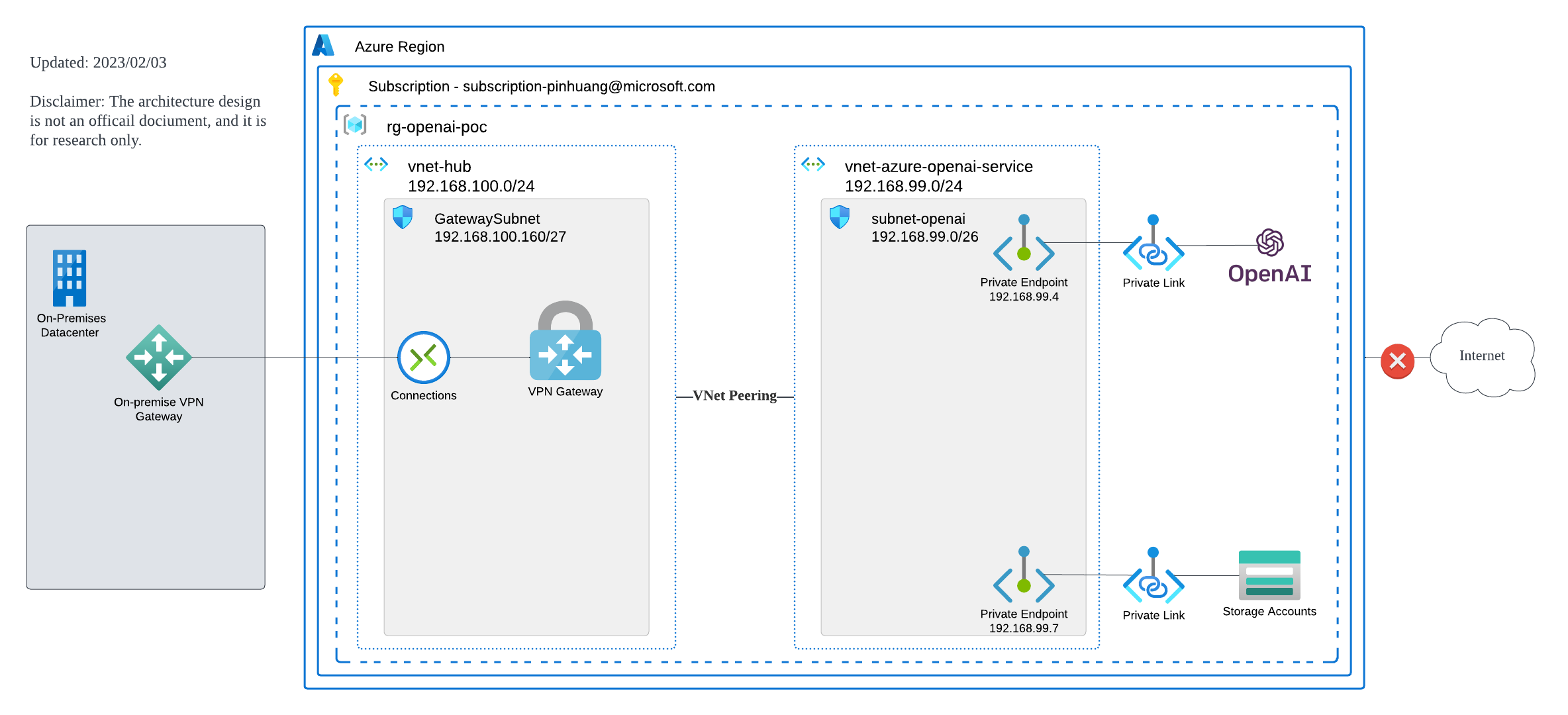
预想私有构架详解
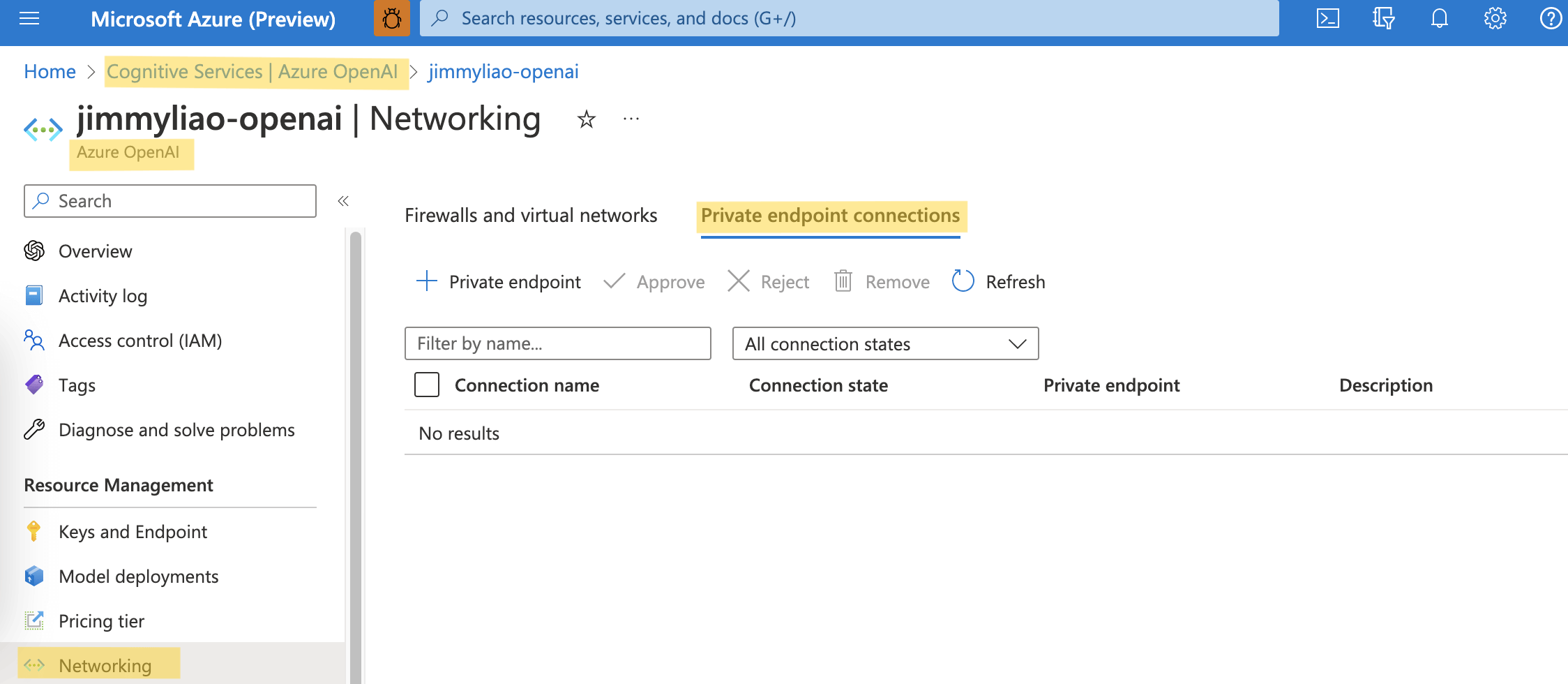
整体私有网络的构架关键核心是Azure Private Endpoint和Azure Private Link的使用,根据此文Private-link resource故可提供以下服务Private Endpoint给私有联机使用,此外这个服务是在Azure Cognitive Services底下,所以若你有既有构架的话可以直接沿用
| Private-link resource name | Resource type | Note |
|---|---|---|
| Azure OpenAI Services | Microsoft.CognitiveServices/accounts | 文件還沒有出來,但功能有 |
| Azure Key Vault | Microsoft.KeyVault/vaults | N/A |
| Azure Storage | Microsoft.Storage/storageAccounts | N/A |
| Azure Monitor | Microsoft.insights/privateLinkScopes | 這個是用 Azure Monitor Private Link Scope (AMPLS) |
| Azure Cognitive Services | Microsoft.CognitiveServices/accounts | N/A |
关于DNS,如果是完全新建服务的话,还要注意Azure Private DNS解析问题,但这是另一块需要额外讨论处理,解法不外乎2种常见作法:
- Azure Private DNS Resovler: Azure PaaS服务,本身有跨国构架需求,有Private DNS Zone管理需求相当推荐
- Customer DNS Forwarder: Azure VM +看你喜欢哪家的DNS,如AD / Infoblox / Bind9等,做Forwarder
关于云地联机,从地端环境连到Azure,不外乎就2种常见做法
- Azure ExpressRoute专线
- S2S VPN使用IPSec Tunnel
如果只是初期开启来试试的话,S2S VPN能用,后续训练数据量大起来的话,是蛮推荐使用ExpressRoute确保联机稳定和低延迟,详参鼠标点点之跨国Azure ExpressRoute网络构架
建议完整服务
下述的API Management/Application Gateway跟Azure OpenAI能力提供并无直接关系,故初期测试可以先以PoC验证环境规划样板为主,再后续加下列服务上去完善
此外关于API控管的部分,Azure OpenAI有提供Azure OpenAI Service Swagger API供程序呼叫使用,它角色如同常见的Backend APIs,服务本身没有做什么特别的保护,故前面可以使用API Management进行转换API和管制,而API Management前面还可以用Application Gateway保护API

- 245 次浏览
【OpenAI 】使用Azure OpenAI Service的企业架构注释
视频号
微信公众号
知识星球
入门
在Azure上出现了利用OpenAI的企业架构,所以自己用的笔记
1.ChatGPT× 使用Cognitive Search进行企业搜索

现在最烂的架构。可以在ChatGPT中搜索组织中的大量文档。很多企业首先开始在这个架构上实施。S官方Tech Blog报道记录了153K Views的惊人的View数。
- 示例说明如何仅从企业中的封闭数据生成文本,而不是基于在ChatGPT(gpt-35-turbo)模型中培训的数据生成文本
- 介绍了一种尽量避免令牌限制(4096)墙的方法
- 通过在文本中添加引用来生成可靠的响应
原文
日本评论文章
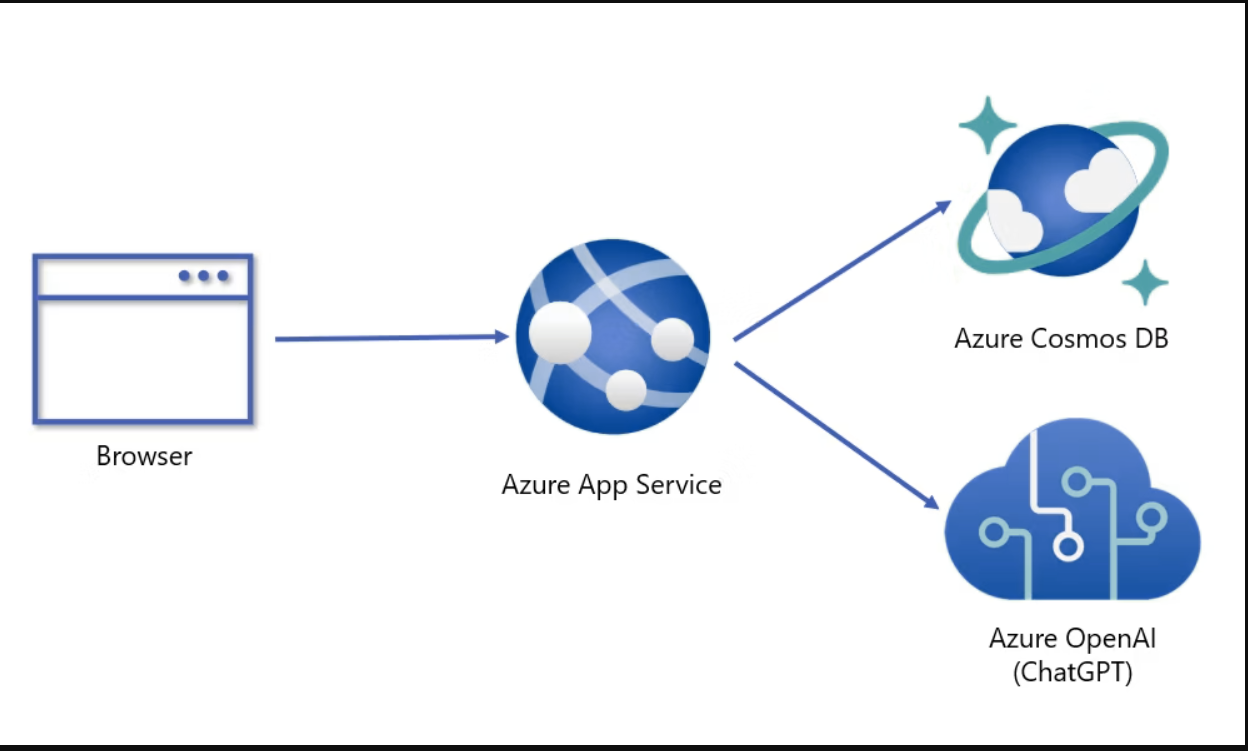
2.ChatGPT× 在CosmosDB中保存聊天历史记录
在CosmosDB中存储ChatGPT聊天历史记录的体系结构。带有Blazor Server前端。
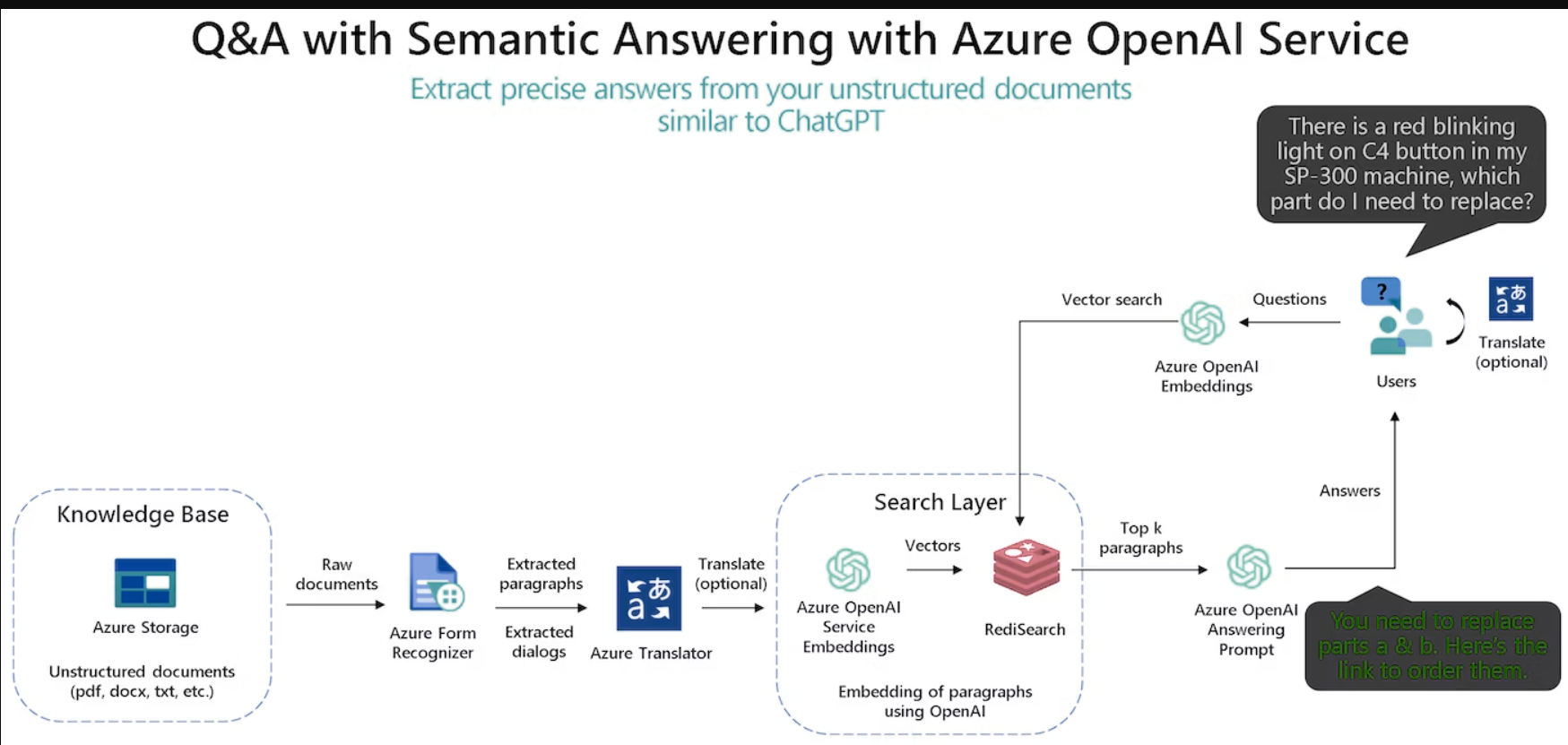
3.使用 ChatGPT × Azure Cache for Redis Enterprise 进行矢量搜索
在Azure OpenAI的Embeddings API中,将文档信息块转换为Embeddings,保存在Redis中。来自用户的查询也转换为嵌入式,进行近似最近邻搜索。
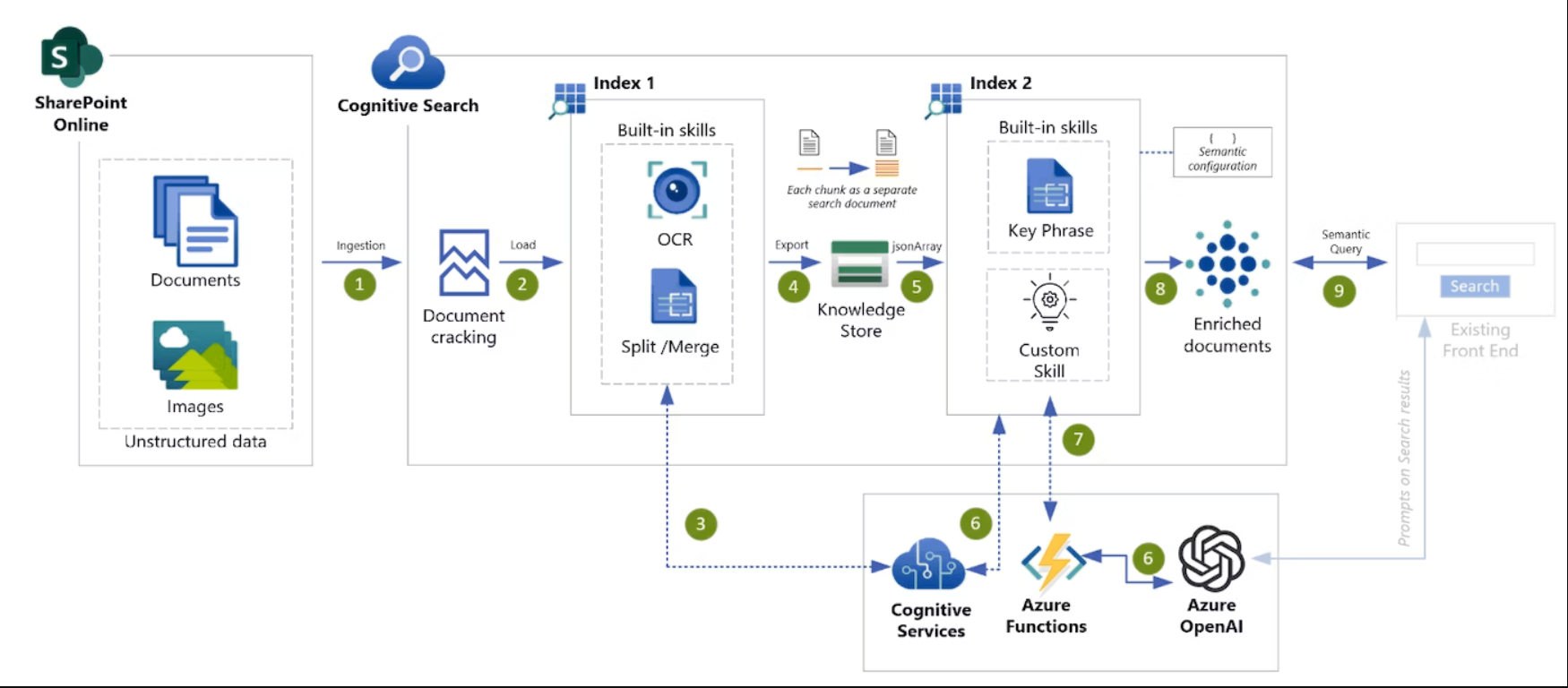
4.Azure OpenAI Custom Skill on Azure Cognitive Search
一种架构,通过调用Azure OpenAI作为Azure Cognitive Search的自定义技能来增强全文搜索索引。可以对文档附加摘要、分类、关键字短语提取、固有名词提取等信息。
5.GPT Smart Search Architecture
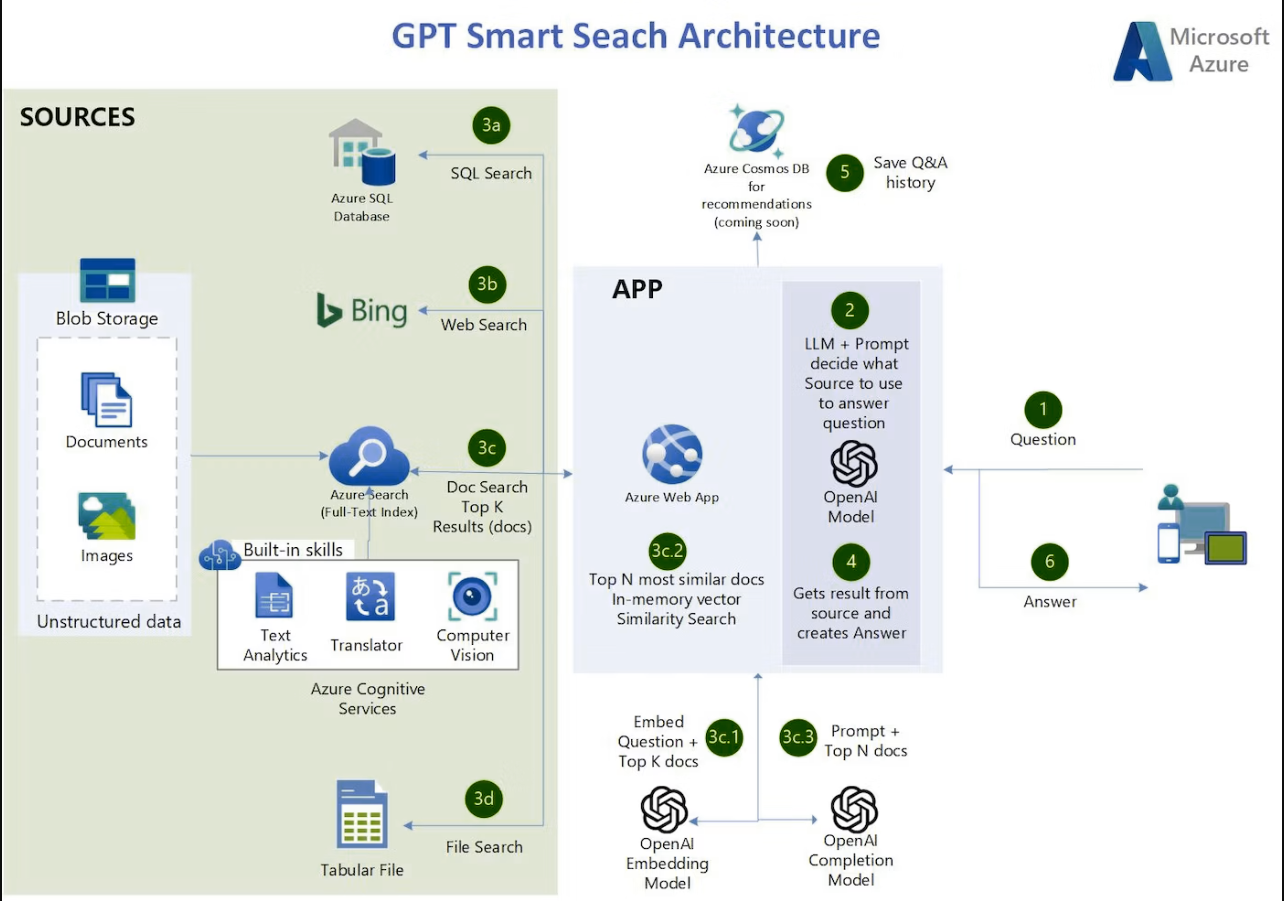
一种体系结构,它不仅将目标信息源扩展到Azure Cognitive Search,还扩展到Bing Search API、Azure SQL Database和CSV文件。使用LangChain进行管弦表演。
6.Azure OpenAI Enterprise Logging
一种架构,从预订管理员记录Azure OpenAI资源,并汇总访问源IP地址和令牌使用量。

可以获取在默认Azure OpenAI资源中无法监控的、完整的调用方IP地址、模型使用率、令牌使用率(输入输出)、输入提示详细信息、输出完成详细信息的度量。
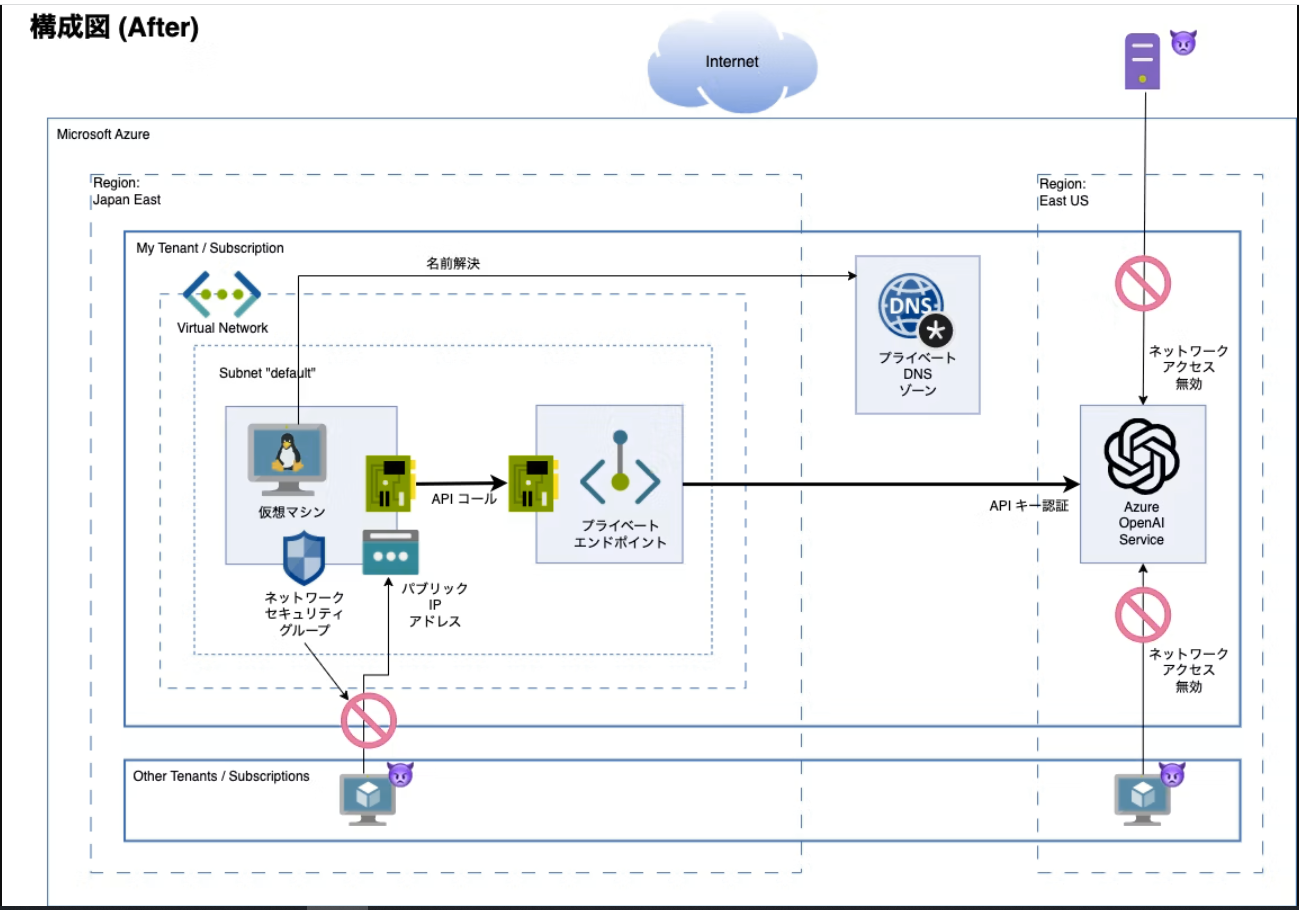
7.Azure OpenAI仅限于VNET的设置
构建步骤如下详细。企业安全部署Azure OpenAI Service时的基本设置。
当然,可以与其他Azure服务进行如下合作,也可以从启动前安全访问。模型也部署在使用预订的资源中。

8.Azure Speech Service× Azure OpenAI
将语音输入用Speech To Text文本化,与Azure OpenAI合作的架构。Cool的实时演示代码也被公开。

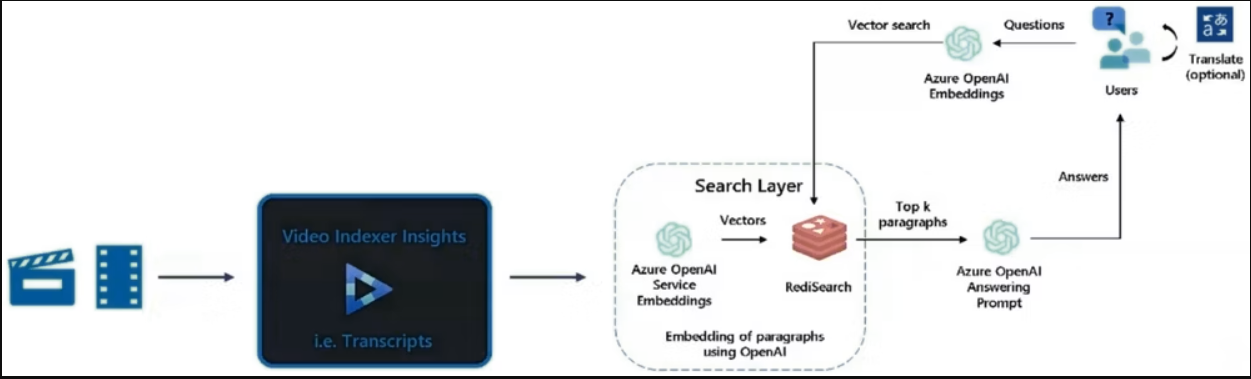
9.ChatGPT× Azure Video Indexer
使ChatGPT和Azure Video Indexer联合检索组织内的动画内容的架构。
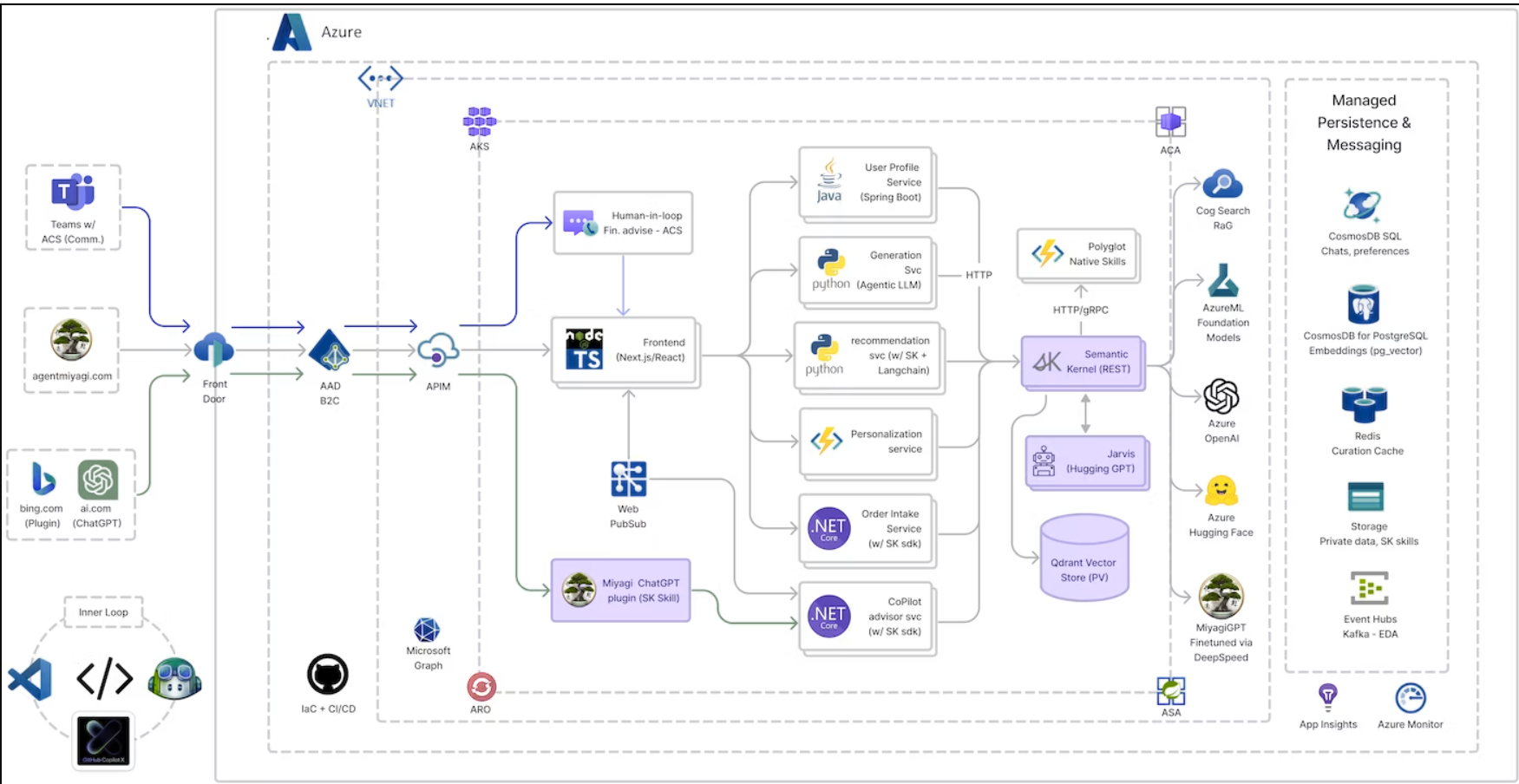
10.“Project Miyagi”Semantic Kernel体系结构
Azure-Supples中常见的全部承载体系结构。懦弱的人请注意阅览。
Semantic Kernel用于数据获取的管弦演示。TODO:需要拆卸以便于理解。Project Miyagi的Miyagi好像是电影最佳基德(The Karate Kid)的空手道天才Mr.Miyagi。
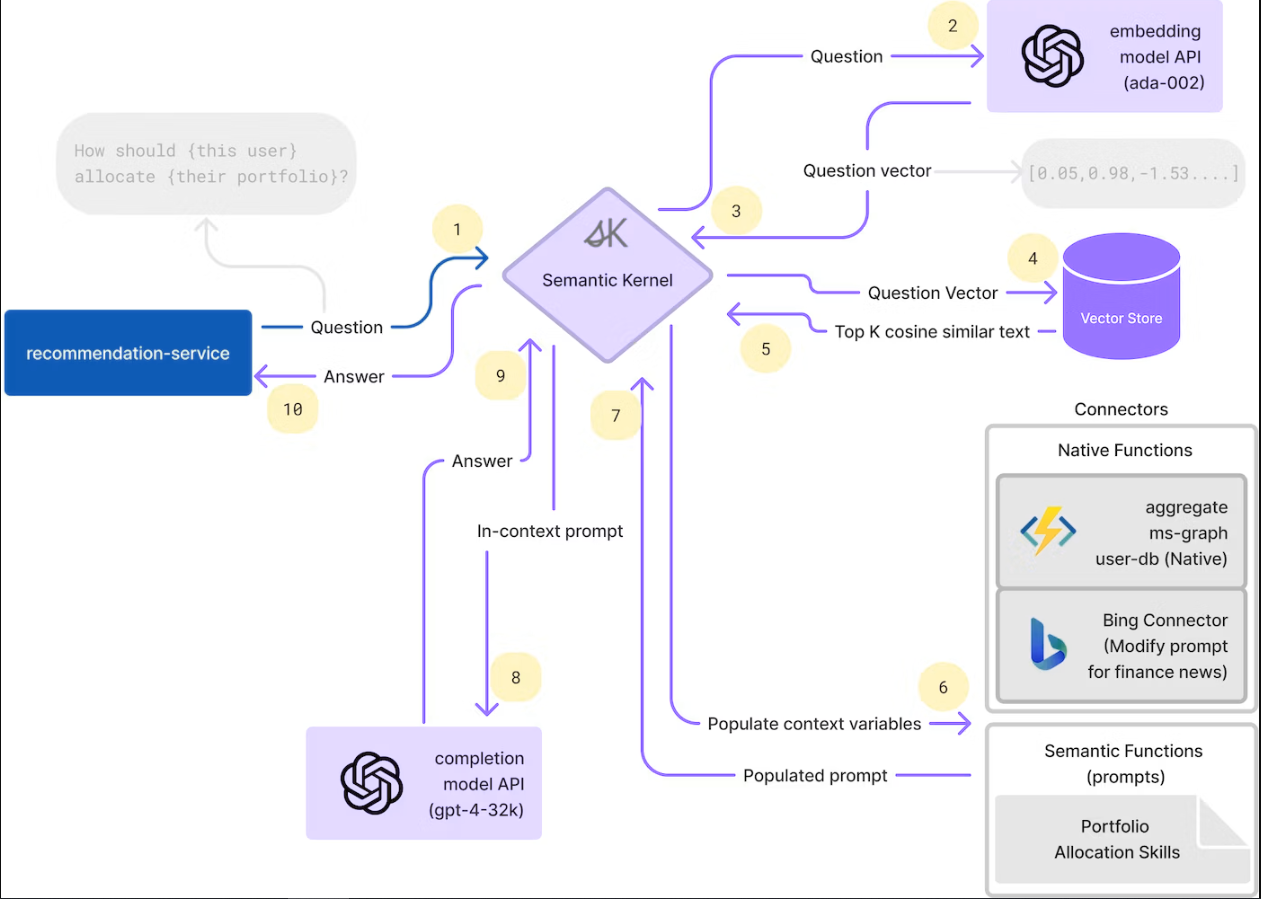
Semantic Kernel解说
Semantic Kernel是什么?面向这样的人的解说报道&动画
Semantic Kernel样品(C#)
| Simple chat summary | Use ready-to-use plugins and get plugins into your app easily. |
| Book creator | Use planner to deconstruct a complex goal and envision using the planner in your app. |
| Authentication and APIs | Use a basic connector pattern to authenticate and connect to an API and imagine integrating external data into your app's LLM AI. |
| GitHub repository Q&A | Use embeddings and memory to store recent data and allow you to query against it. |
| Copilot Chat Sample App | Build your own chat experience based on Semantic Kernel. |
最近追加了名为Copilot Chat的高功能聊天样本,需要检查。
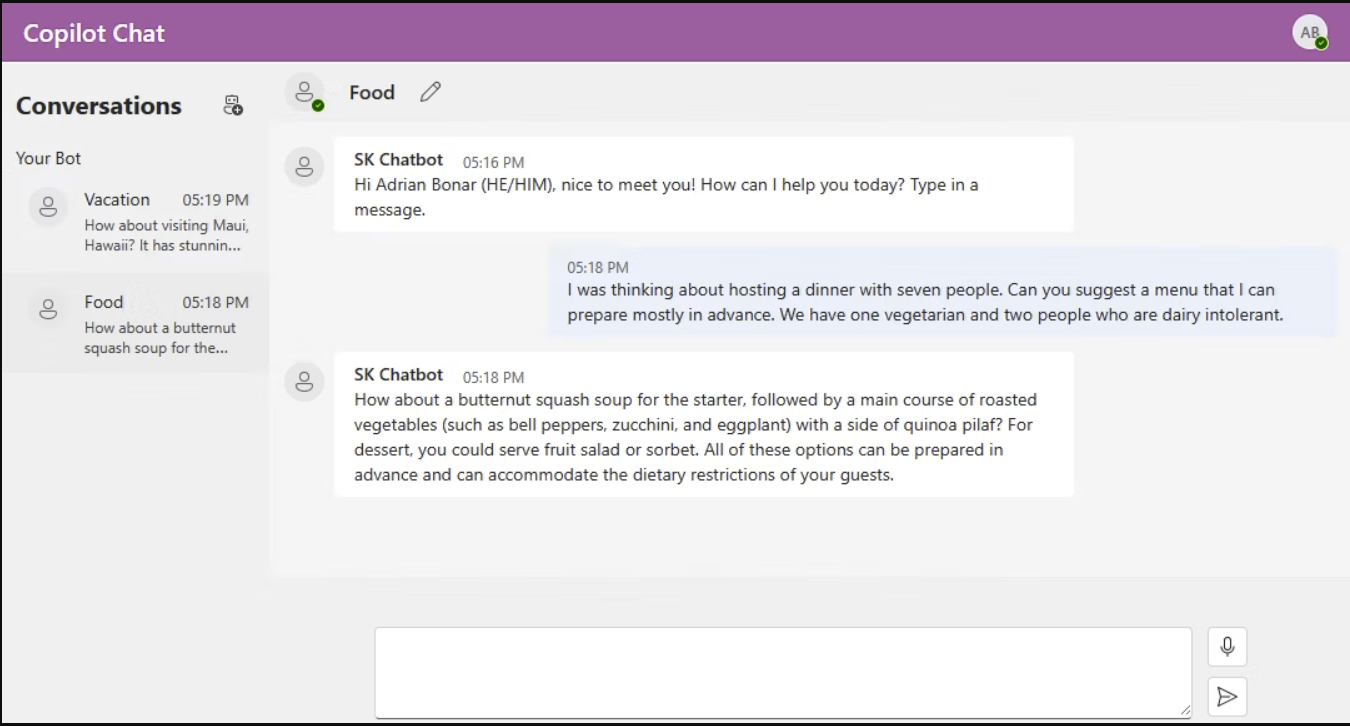
11. 使用语义内核创建您自己的 Copilot 系统的示例架构
LLM作为与各种企业内系统·DB联合的管弦乐器动作的例子。
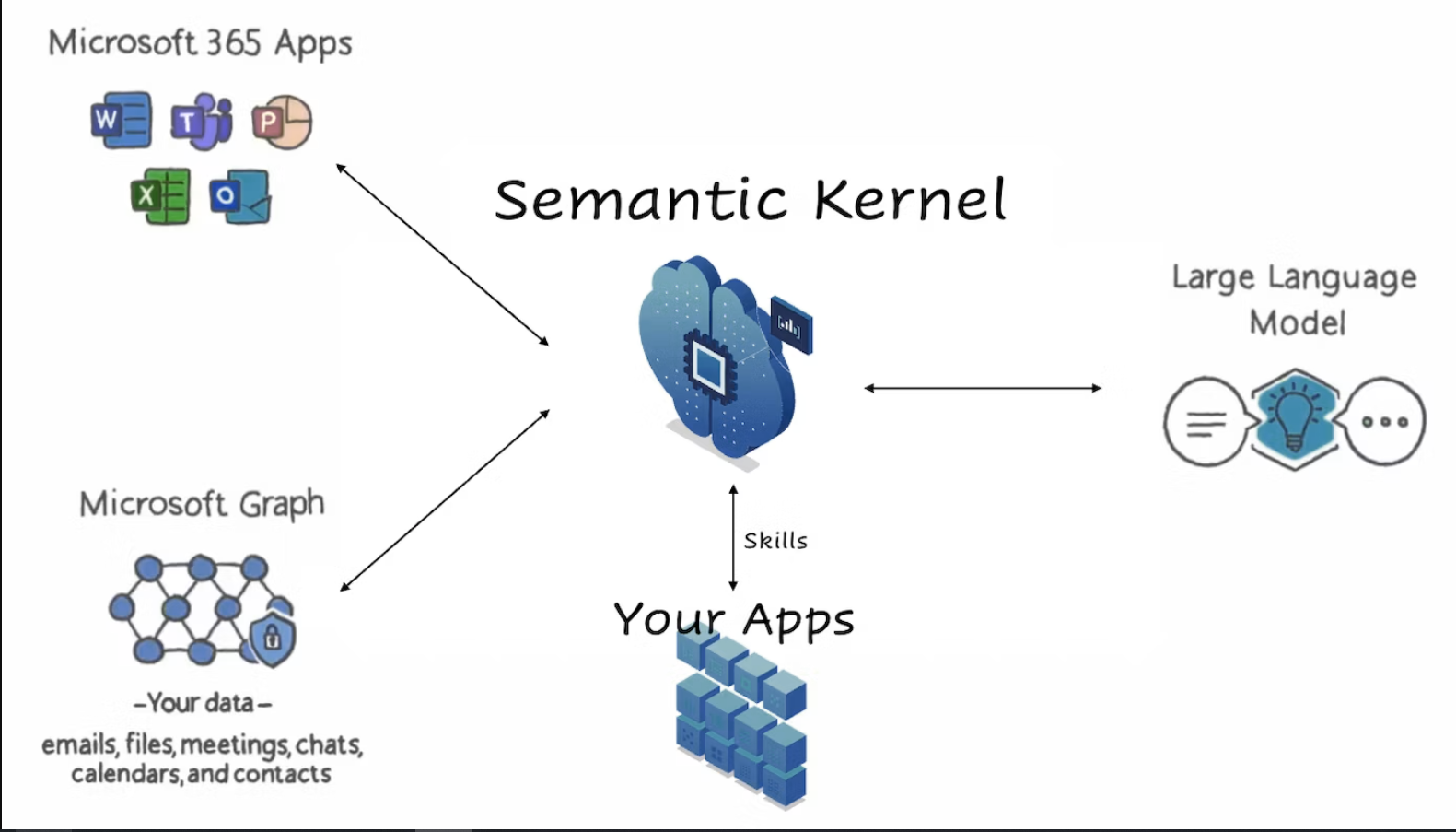
5/24 Build 2023 AI Copilot时代到来
请在“Copilot stack的LLM中心应用程序开发”中学习最新的开发方法
AI Copilot时代到来-Copilot stack开发LLM中心应用程序
参考動画
- 414 次浏览
【OpenAI 架构】Azure OpenAI服务中的“基础设施/安全内容”
视频号
微信公众号
知识星球
过去的几个月非常繁忙。我的客户数量增加了一倍,那些因假期而进入休眠状态的客户决定全力醒来。伴随着这种新的需求,出现了有趣的新用例和博客主题。
除非你一直生活在岩石下,否则你很清楚人工智能领域的大量创新和技术发展。似乎每天都有10篇关于OpenAI模型的文章(最近在ChatGPT上有一集搞笑的《南方公园》)。微软决定直接深入研究,并与OpenAI建立了合作伙伴关系。从这种合作关系中产生了Azure OpenAI服务,该服务在Azure基础设施上运行像ChatGPT这样的OpenAI模型。正如你所能想象的,这项服务对新的和现有的Azure客户都有很大的吸引力。
考虑到我在自己的客户中看到的需求,我决定看看服务中可用的安全控制(或我的一位数据同行所说的基础设施/安全)。在加入该服务之前,我使用兼职拉里的这篇精彩教程对OpenAI自己的服务进行了一些基本的实验。我发现他对一些示例代码的逐步演练在理解与服务交互的简单性方面非常出色。
在对如何与OpenAI的API交互有了非常基本的理解(我确实强调了基本的理解)之后,我决定了一个用例。我决定的用例是使用总结功能he davinci GPT-3模型来总结NIST关于零信任的文件。我感兴趣的是,它将从文档中提取哪些关键点,以及在完全阅读文档后,这些关键点是否与我从文档中得出的内容一致(重读文档仍在我的待办事项列表中!)。
在我能做任何很酷的事情之前,我必须加入这项服务。此时,客户必须使用Microsoft公共文档中描述的流程请求将其订阅加入该服务。在等待订阅时,我阅读了公共文档,重点是“基础设施/安全”方面的内容。与Azure中的大多数数据服务一样,客户可以绕过网络、静态加密和身份等安全控制的杠杆信息级别非常高,用处不大。很多人提到了单词,但没有真正解释这些功能在服务中启用时会“看起来”。还有一个问题是微软如何处理和保护数据,即服务的客户数据。
与所有云提供商一样,微软在共享责任模式下运营,即微软负责云的安全,而您(客户)则负责云内的安全。简单地说,微软在幕后管理着一些控制措施,微软把这些控制措施交给了客户,而客户有责任启用这些控制措施。微软在公开文档中描述了如何为Azure OpenAI服务处理和保护数据。客户还应查看Microsoft产品和服务数据保护附录以及特定的产品条款。另一个值得查看的资源是Microsoft Services Trust Portal中的文档。在信任门户中,您可以找到所有与合规性相关的文档,如SOC-2 Type II,它将提供有关Microsoft用于保护数据的流程和控制的详细信息。为了更深入地了解,您可以查看FedRAMP SSP(系统安全计划)。我通常会发现自己先浏览SOC2,然后经常通过阅读FedRAMP SSP中的相关章节来深入了解。我将让您通读并使用上面的文档(您应该为您使用的每一项服务都这样做)。出于这篇博客文章的目的,我将研究“云中的安全”。
我非常喜欢退一步,从高层架构的角度来看待事物。在阅读了文档之后,我设想以下Azure组件是受监管行业内任何服务实现所需的关键组件。

Azure OpenAI Azure组件
让我们浏览一下这些组件中的每一个。
第一个组件是Azure OpenAI服务实例,它是认知服务保护伞下的服务。Azure认知服务包括语音转文本、图像分析等现有服务。这是微软的一个好主意,因为它将允许管理Azure OpenAI服务的产品组(PG)利用认知服务保护伞下其他服务已经采用的现有架构标准。
下一个组件是Azure密钥保管库实例。在Azure OpenAI服务的实例中,有三种类型的数据可以存储在客户的服务实例中。我说可以,因为只有当您选择使用服务的特定功能和功能时,才会存储这些数据。这些数据包括您可能为微调模型提供的训练数据、微调模型本身以及提示和完成。只有当您选择训练自己的微调模型时,才会存储训练数据,并且训练数据可以在您完成微调模型的训练后立即删除。从与我聪明得多的同行交谈来看,需要创建微调模型的客户比例非常低。我听说只有1%的客户需要这样做,因为所包含的模型已经得到了非常有效的培训。提示和完成默认情况下存储30天,以供人工评估,以确保模型以不适当的方式使用。客户可以选择不使用本公开文档中概述的流程进行内容筛选。如果他们选择退出,这些数据将永远不会被存储。
如果客户选择使用创建此数据的功能,则当数据存储在Microsoft管理的边界内时,默认情况下会使用Microsoft管理的密钥对其进行静态加密。这意味着Microsoft管理密钥的授权和轮换。许多受监管的客户都有监管要求或内部策略,要求客户管理用于加密其环境中数据的任何密钥的授权和轮换。因此,微软等云提供商提供了使用CMK(客户托管密钥)的选项。在Azure中,这些CMK存储在客户订阅中的Azure密钥库实例中,客户控制对密钥的授权和访问。
Azure OpenAI服务支持使用CMK来保护其中三组数据中的至少两组。该文档不清楚是否可以使用CMK对提示和完成进行加密。如果你碰巧知道,请在评论中告诉我。请注意,目前您需要请求访问权限,才能通过Azure OpenAI服务批准您的CMK订阅。
接下来我们有虚拟网络、专用端点和Azure专用DNS。与认知服务保护伞中的其他服务一样,OpenAI服务支持私人端点,以此锁定对私人IP空间的网络访问。该服务的DNS命名空间为privatelink.openai.azure.com。最佳做法是让您在azure Private DNS中托管此区域,稍后我将在共享示例架构时看到。值得注意的是,Azure Open AI服务也支持我所说的服务防火墙。这允许您通过服务端点将对服务的访问限制在特定的一组公共IP(如企业的转发web代理)或特定的虚拟网络。
接下来,我们有Azure存储。如果您选择构建微调模型,则可以将培训数据上传到客户订阅内的Azure存储帐户。然后,客户的Azure OpenAI服务实例可以使用我稍后将在本文中解释的方法检索数据。
然后我们有了管理身份和Azure RBAC。对于该服务,托管身份用于访问存储在客户密钥库实例中的CMK。Azure RBAC将用于控制对Azure OpenAI Services实例的访问,以及用于调用服务API的密钥。回过头来看上面的组件,以及它们是如何组合在一起以提供跨身份、网络、加密和加密的安全控制的,我看到的如下所示。

对于运行模型的Azure OpenAI服务实例,您可以使用Azure RBAC锁定该服务。通过一组API密钥支持对服务的身份验证,您需要管理的轮换。或者,(我自己还没有测试过),您可以使用Azure AD身份验证来获得承载令牌,以对服务进行身份验证。通过使用专用端点限制对服务的访问,可以确保网络访问的安全。数据可选择使用存储在客户管理的密钥库实例中的CMK进行加密,以使客户能够控制对密钥的访问、轮换密钥以及审核这些密钥的使用情况。Azure OpenAI服务还提供日志和指标,这些日志和指标可以通过实例上配置的诊断设置传递到Azure存储、日志分析工作区或事件中心。您感兴趣的特定于安全性的日志是审核日志,可能还有提示日志和完成日志。
当客户选择使用CMK时使用的Azure密钥库实例可以访问使用Azure RBAC(当使用为Azure RBAC保险库策略启用的密钥库实例时)和托管身份控制的密钥。Azure OpenAI服务实例将使用分配给该服务的托管身份访问CMK。请注意,从今天起,您不能使用密钥保管库服务防火墙来限制网络访问。Azure认知服务不被视为密钥保管库的受信任Azure服务,因此在启用服务防火墙时不能允许网络访问。
如果客户选择在上传到服务之前将培训数据存储在Azure存储帐户中,则可以使用Azure RBAC或SAS令牌保护该帐户以供用户访问。由于SAS令牌对人类来说是一场噩梦,因此您需要使用Azure RBAC控制人类对数据的访问。Azure OpenAI服务本身目前不支持使用托管身份访问Azure存储。这意味着您需要使用SAS令牌来保护数据的安全,以便在上传过程中进行数据的非人工访问。由于Azure OpenAI服务还不支持访问Azure存储的托管身份,因此无法利用服务实例授权规则。在我的测试中,只允许Azure存储的可信服务似乎也不起作用。这意味着您需要允许所有公共网络访问存储帐户。您保护数据的手段将是SAS令牌,主要用于来自Azure OpenAI服务的访问。不太理想,但是嘿,服务很新。
那么,把我们所学到的一切放在一起,在架构上会是什么样子呢?

Azure OpenAI服务示例架构
以上是采用Azure VWAN的受监管组织中常见的架构示例。在这种模式中,所有与部署相关的服务实例都将被放置在一个专用的工作负载订阅中,如橙色轮廓所示。这包括包含Azure OpenAI服务私有端点的虚拟网络、Azure OpenAI Service实例、由Azure OpenAI Services实例使用的用户分配的托管身份、包含用于加密Azure OpenAI Service持有的数据的CMK的工作负载密钥库,以及用于暂存要上载到服务的训练数据的Azure存储帐户。
Azure OpenAI服务将确保其对专用端点的网络访问安全。Azure密钥保管库实例和存储帐户的网络访问都将对公共网络开放。对Azure密钥保管库数据的访问将通过Azure AD身份验证和Azure RBAC保管库策略进行授权。Azure存储帐户将使用Azure AD身份验证和Azure RBAC来控制人类用户的访问,并使用SAS令牌来控制来自Azure OpenAI服务实例的访问。
最后,尽管没有在图片中列出,但毫无疑问,应该制定Azure策略,以确保所有资源的外观与您和您的安全团队决定的资源外观一致。
随着该服务的发展和成熟,我希望通过支持访问存储帐户的托管身份以及将该服务添加到Azure Key Vault的可信服务中,来解决网络控制方面的一些差距。我也不会惊讶地看到一些类型的VNet注入或VNet集成将被引入,类似于Azure机器学习中的可用内容。
好吧,伙计们,我希望这能帮助你们基础设施和安全人员完成当天的“基础设施/安全工作”,现在你们可以更好地了解一些可以用来保护服务的杠杆和开关。随着我对服务和人工智能总体学习的进展,我计划添加一些帖子,这些帖子将深入了解该架构在实施时的外观。我让它在我的演示环境中运行,但现在时间非常有限。
谢谢各位,我希望你们的人工智能之旅和我的一样有趣!
查看我在此服务上的其他帖子:
- 175 次浏览
【大语言模型】NLP•检索增强生成之一
视频号
微信公众号
知识星球
- 概述
- 动机
- 神经检索
- 检索增强生成(RAG)流水线
- RAG的好处
- RAG与微调
- RAG合奏
- 使用特征矩阵选择矢量数据库
- 构建RAG管道
- 摄入
- Chucking
- 嵌入
- 句子嵌入:内容和原因
- 背景:与BERT等代币级别模型相比的差异
- 相关:句子转换器的训练过程与令牌级嵌入模型
- 句子变换器在RAG中的应用
- 句子嵌入:内容和原因
- 检索
- 标准/天真的方法
- 优势
- 缺点
- 语句窗口检索/从小到大分块
- 优势
- 缺点
- 自动合并检索器/层次检索器
- 优势
- 缺点
- 计算出理想的块大小
- 寻回器镶嵌和重新排列
- 使用近似最近邻进行检索
- 重新排序
- 标准/天真的方法
- 响应生成/合成
- 迷失在中间:语言模型如何使用长上下文
- “大海捞针”测试
- 摄入
- 组件式评估
- 检索度量
- 上下文精度
- 上下文回忆
- 上下文相关性
- 生成度量
- 脚踏实地
- 回答相关性
- 端到端评估
- 回答语义相似性
- 答案正确性
- 检索度量
- 多模式RAG
- 改进RAG系统
- 相关论文
- 知识密集型NLP任务的检索增强生成
- 主动检索增强生成
- 多模式检索增强生成器
- 假设文档嵌入(HyDE)
- RAGAS:检索增强生成的自动评估
- 微调还是检索?LLM中知识注入的比较
- 密集X检索:我们应该使用什么检索粒度?
- ARES:一种用于检索增强生成系统的自动评估框架
- 引用
概述
- 检索增强生成(RAG)是一种通过引入外部知识来增强语言模型生成的技术。
- 这通常是通过从大型文档语料库中检索相关信息并使用该信息来通知生成过程来完成的。
- 让我们深入研究以下细节。
动机
- 在许多情况下,客户拥有大量的专有文件,如技术手册,并要求从这些海量内容中提取特定信息。这项任务可以比作大海捞针。
- 最近,OpenAI推出了一种新的模型GPT4-Turbo,它拥有处理大型文档的能力,有可能解决这一需求。然而,由于“迷失在中间”现象,这种模式并不完全有效。这种现象反映了这样一种体验,即类似于完整阅读《圣经》,但很难回忆起《撒母耳记》之后的内容,模型往往会忘记位于上下文窗口中间的内容。
- 为了规避这一限制,已经开发了一种称为检索增强生成(RAG)的替代方法。这种方法包括为文档中的每个段落创建一个索引。当进行查询时,最相关的段落会被迅速识别,然后输入到像GPT4这样的大型语言模型(LLM)中。这种只提供选定段落而不是整个文档的策略,防止了LLM中的信息过载,并显著提高了结果的质量。
神经检索
- 在我们进入RAG之前,让我们花点时间全面讨论一下神经检索器。
- 神经检索器是一种使用神经网络将查询与相关文档匹配的信息检索模型。它们将查询和文档编码为密集向量表示,并计算它们之间的相似性得分。这使它们能够超越词汇匹配并获取语义相关性。
- 神经检索器代表着从传统的基于关键词的信息检索系统到能够理解文本数据中潜在含义和关系的信息检索方法的重大转变。以下是对它们如何工作及其意义的扩展解释:
- 以下是它们的一般操作方式:
- 矢量编码:
- 查询和文档都被转换为高维空间中的向量。这个过程是由基于神经网络的编码器完成的,这些编码器经过训练,可以捕捉文本的语义本质。
- 在训练过程中,这些模型经常接触大量的文本,使他们能够学习单词和短语之间的复杂模式和关系。
- 语义匹配:
- 使用诸如余弦相似度之类的度量来计算查询向量和文档向量之间的相似度。这允许系统根据内容的含义而不仅仅是关键字重叠来确定哪些文档与查询最相关。
- 这个过程可以捕捉到细微的关系,比如同义词或相关概念,而传统方法可能会错过这些关系。
- 矢量编码:
- 神经检索器的优点:
- 神经检索器可以理解术语的使用上下文,当查询或文档具有歧义或多重含义时,可以进行更准确的检索。
- 他们擅长处理长而复杂的查询,因为他们可以掌握整体意图,而不仅仅是孤立的术语。
- 许多神经检索器都是在多语言数据集上训练的,使它们能够有效地处理不同语言的查询。
- 挑战和注意事项:
- 神经模型,特别是那些用于编码大型文档的模型,需要大量的计算能力来进行训练和推理。
- 神经检索器的性能在很大程度上取决于它们所训练的数据,并且它们可能会继承训练数据中存在的偏差。
- 保持文档表示的最新状态是一项挑战,尤其是对于动态更改内容而言。
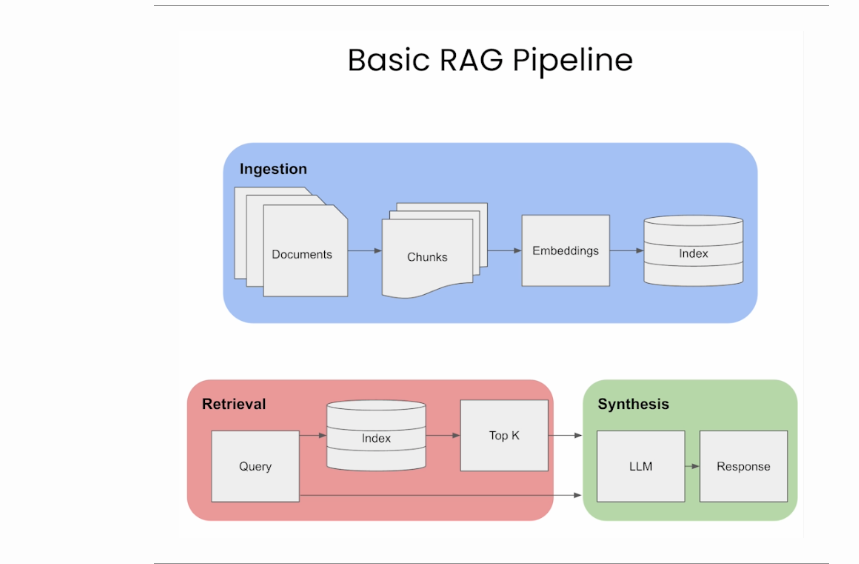
检索增强生成(RAG)流水线
- 有了RAG,LLM能够通过提供对数据库等外部知识源的访问,利用不一定在其权重中的知识和信息。
- 它利用检索器来找到相关的上下文来调节LLM,通过这种方式,RAG能够用相关的文档来增强LLM的知识库。
- 这里的检索器可以是以下任何一种,具体取决于是否需要语义检索:
- 矢量数据库:通常,使用BERT等模型嵌入查询,以生成密集的矢量嵌入。或者,像TF-IDF这样的传统方法可以用于稀疏嵌入。然后基于术语频率或语义相似性来进行搜索。
- 图形数据库:从文本中提取的实体关系构建知识库。这种方法是精确的,但可能需要精确的查询匹配,这在某些应用程序中可能会受到限制。
- 常规SQL数据库:提供结构化数据存储和检索,但可能缺乏矢量数据库的语义灵活性。
- 下面的图片来自Damien Benveniste博士,他谈到了RAG使用Graph和Vector数据库之间的区别。

- 在上面链接的帖子中,Damien表示,与矢量数据库相比,图形数据库更适合于检索增强生成(RAG)。虽然矢量数据库使用LLM编码的矢量对数据进行分区和索引,允许语义相似的矢量检索,但它们可能会获取不相关的数据。
- 另一方面,图形数据库从文本中提取的实体关系中构建知识库,使检索简洁明了。但是,它需要精确的查询匹配,这可能是有限制的。
- 一个潜在的解决方案可能是结合这两个数据库的优势:在图数据库中用矢量表示索引解析的实体关系,以实现更灵活的信息检索。这种混合模式是否存在还有待观察。
- 检索后,您可能希望通过添加排名和/或精细排名层来进一步筛选候选者,这些层允许您筛选出与业务规则不匹配、不针对用户、当前上下文或响应限制进行个性化设置的候选者。
- 让我们简要总结一下RAG的过程,然后深入研究它的优缺点:
- 矢量数据库创建:RAG首先将内部数据集转换为矢量,并将其存储在矢量数据库(或您选择的数据库)中。
- 用户输入:用户以自然语言提供查询,寻求答案或完成。
- 信息检索:检索机制扫描矢量数据库,以识别在语义上与用户的查询(也是嵌入的)相似的片段。然后将这些片段提供给LLM,以丰富其生成响应的上下文。
- 组合数据:从数据库中选择的数据段与用户的初始查询相组合,创建一个扩展的提示。
- 生成文本:放大的提示,填充了添加的上下文,然后提供给LLM,LLM制作最终的上下文感知响应。
- 下图(来源)显示了RAG的高级工作
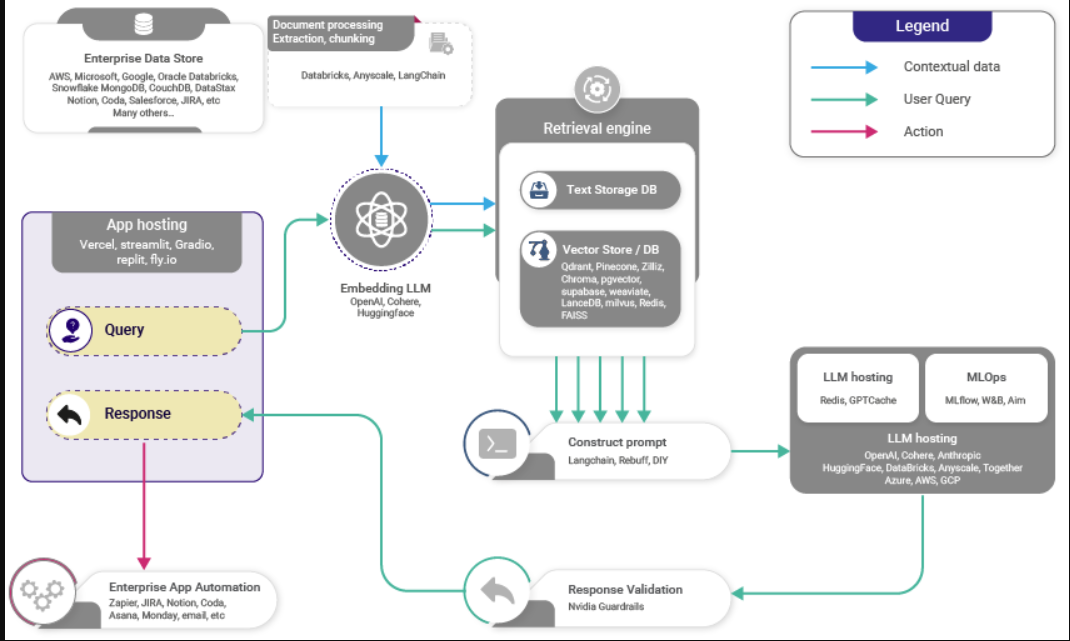
RAG的好处
- 那么,为什么要在应用程序中使用RAG呢?
- 有了RAG,LLM能够通过提供对外部知识库的访问,利用不一定在其权重中的知识和信息。
- RAG不需要模型再训练,节省了时间和计算资源。
- 即使使用有限的标记数据,它也很有效。
- 然而,它也有其缺点,即RAG的性能取决于检索器知识库的全面性和正确性。
- RAG最适合于未标记数据丰富但标记数据稀少的场景,非常适合于需要实时访问产品手册等特定信息的虚拟助理等应用程序。
- 有大量未标记数据但很少标记数据的场景:RAG在有大量可用数据的情况下很有用,但其中大多数数据没有以对训练模型有用的方式进行分类或标记。例如,互联网上有大量的文本,但其中大部分的组织方式并不能直接回答特定的问题。
- 此外,RAG是虚拟助理等应用程序的理想选择:Siri或Alexa等虚拟助理需要从各种来源获取信息,以实时回答问题。他们需要理解问题,检索相关信息,然后做出连贯准确的回答。
- 需要实时访问产品手册等特定信息:这是RAG模型特别有用的一个例子。想象一下,你问一个虚拟助理一个关于产品的特定问题,比如“我如何重置XYZ品牌的恒温器?”RAG模型将首先从产品手册或其他资源中检索相关信息,然后使用这些信息生成清晰、简洁的答案。
- 总之,RAG模型非常适合有大量可用信息的应用,但这些信息的组织或标记并不整齐。
- 下面,让我们来看看介绍RAG的出版物,以及原始论文是如何实现该框架的。
RAG与微调
下表(来源)比较了RAG与微调。

- 总结上表:
- 检索系统(RAG)使LLM系统能够访问真实的、受访问控制的、及时的信息。微调无法做到这一点,因此没有竞争。
- 微调(而非RAG)调整LLM的风格、音调和词汇,使您的语言“画笔”与所需的领域和风格相匹配
- 总而言之,首先关注RAG。一个成功的LLM应用程序必须将专用数据连接到LLM工作流。一旦您有了第一个完整的应用程序,您就可以添加微调来改进系统的风格和词汇。如果RAG与数据的连接构建不正确,那么微调将无法挽救您的生命。
RAG合奏/合唱
- 利用RAG系统的集成为模型生成丰富且上下文准确的文本的能力提供了实质性的升级。以下是该程序如何工作的增强细分:
- 知识来源:RAG模型从外部知识库中检索信息,以增强其在特定领域的知识。这些可以包括维基百科、书籍、新闻、数据库等领域的文章、表格、图像等。
- 组合来源:在推理时,多个检索器可以从不同的语料库中提取相关内容。例如,一个检索器搜索维基百科,另一个搜索新闻来源。他们的结果被连接到一组汇集的候选者中。
- 排名:该模型根据汇集的候选人与上下文的相关性对其进行排名。
- 选择:选择排名靠前的候选者,以调节语言模型的生成条件。
- 集合:可以集合专门针对不同语料库的独立RAG模型。它们的输出被合并、排序并进行投票。
- 多个知识源可以通过汇集和集合来增强RAG模型。仔细的排名和选择有助于整合这些不同的来源,以提高世代。
- 使用多个检索器时需要记住的一件事是,在合并它们以形成响应之前,对每个检索器的不同输出进行排序。这可以通过多种方式实现,使用LTR算法、多武装土匪框架、多目标优化,或根据特定的业务用例。
使用特征矩阵选择矢量数据库
- 为了比较过多的Vector DB产品,一个突出Vector DB之间的差异以及在哪个场景中使用哪个的特征矩阵是必不可少的。
- VectorHub的Vector DB Comparison (Vector DB Comparison by VectorHub)提供了一个跨越37家供应商和29个功能的强大比较(截至本文撰写之时)。

- 作为次要资源,下表(来源)(source)显示了Vector DB在各种功能维度上提供的一些流行功能的比较:

在此处访问完整的电子表格
- 96 次浏览
【大语言模型】NLP•检索增强生成之三
视频号
微信公众号
知识星球
- 概述
- 动机
- 神经检索
- 检索增强生成(RAG)流水线
- RAG的好处
- RAG与微调
- RAG合奏
- 使用特征矩阵选择矢量数据库
- 构建RAG管道
- 摄入
- Chucking
- 嵌入
- 句子嵌入:内容和原因
- 背景:与BERT等代币级别模型相比的差异
- 相关:句子转换器的训练过程与令牌级嵌入模型
- 句子变换器在RAG中的应用
- 句子嵌入:内容和原因
- 检索
- 标准/天真的方法
- 优势
- 缺点
- 语句窗口检索/从小到大分块
- 优势
- 缺点
- 自动合并检索器/层次检索器
- 优势
- 缺点
- 计算出理想的块大小
- 寻回器镶嵌和重新排列
- 使用近似最近邻进行检索
- 重新排序
- 标准/天真的方法
- 响应生成/合成
- 迷失在中间:语言模型如何使用长上下文
- “大海捞针”测试
- 摄入
- 组件式评估
- 检索度量
- 上下文精度
- 上下文回忆
- 上下文相关性
- 生成度量
- 脚踏实地
- 回答相关性
- 端到端评估
- 回答语义相似性
- 答案正确性
- 检索度量
- 多模式RAG
- 改进RAG系统
- 相关论文
- 知识密集型NLP任务的检索增强生成
- 主动检索增强生成
- 多模式检索增强生成器
- 假设文档嵌入(HyDE)
- RAGAS:检索增强生成的自动评估
- 微调还是检索?LLM中知识注入的比较
- 密集X检索:我们应该使用什么检索粒度?
- ARES:一种用于检索增强生成系统的自动评估框架
- 引用
构建RAG管道
检索
让我们来看三种不同类型的检索:标准检索、语句窗口检索和自动合并检索。这些方法中的每一种都有特定的优势和劣势,其适用性取决于RAG任务的要求,包括数据集的性质、查询的复杂性以及响应中的特定性和上下文理解之间的期望平衡。
标准/天真的方法
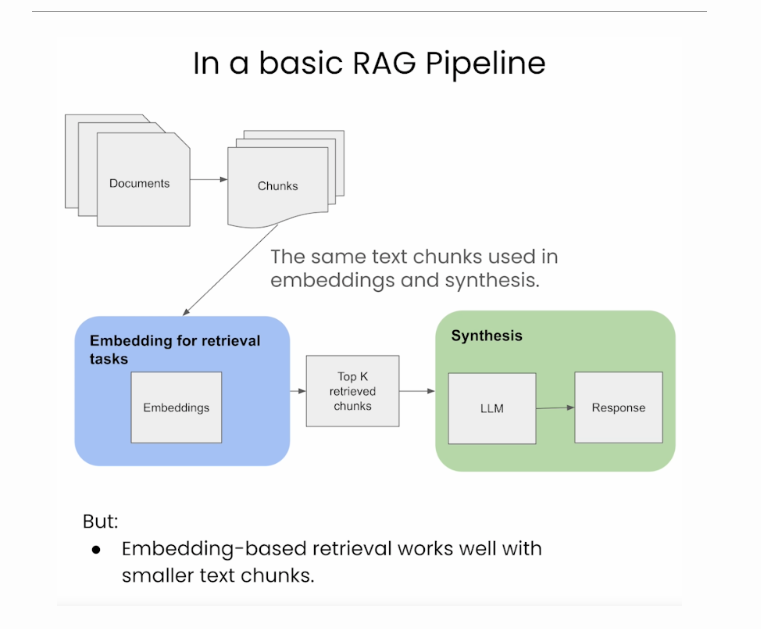
正如我们在下面的图片(来源)中看到的,标准管道使用相同的文本块进行索引/嵌入以及输出合成。
在大型语言模型(LLM)中的检索增强生成(RAG)的背景下,以下是三种方法的优缺点:
优势
简单高效:这种方法简单高效,使用相同的文本块进行嵌入和合成,简化了检索过程。
数据处理的一致性:它保持了检索和合成阶段使用的数据的一致性。
缺点
有限的上下文理解:LLM可能需要更大的合成窗口来生成更好的响应,而这种方法可能无法充分提供。
次优响应的可能性:由于上下文有限,LLM可能没有足够的信息来生成最相关和准确的响应。
语句窗口检索/从小到大分块
句子窗口方法将文档分解为较小的单元,例如句子或小的句子组。
它对检索任务(存储在Vector DB中的较小块)的嵌入进行解耦,但对于合成,它在检索到的块周围的上下文中添加回来,如下图所示(来源)。
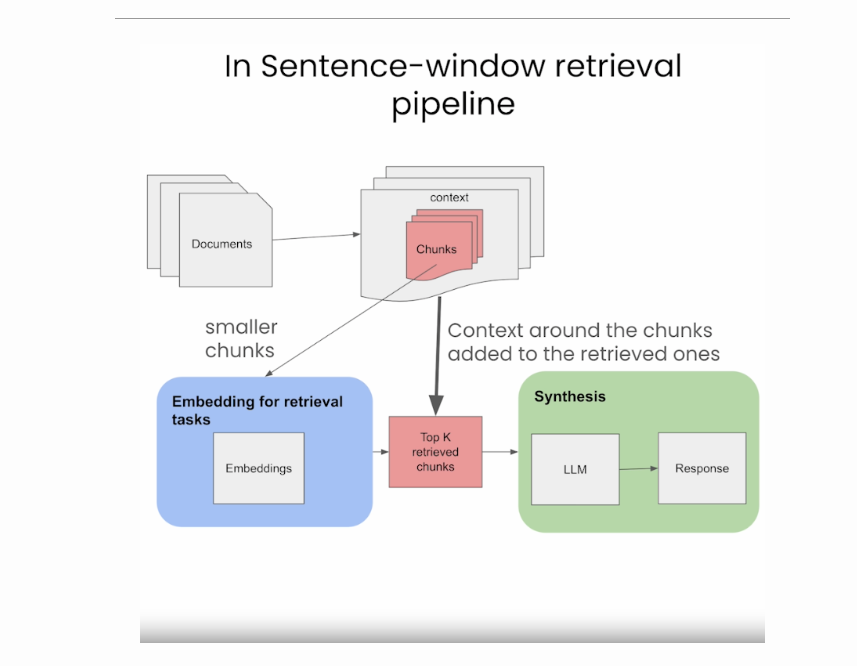
在检索过程中,我们通过相似性搜索来检索与查询最相关的句子,并将该句子替换为完整的周围上下文(使用上下文周围的静态句子窗口,通过检索原始检索的句子周围的句子来实现),如下图所示(来源)。
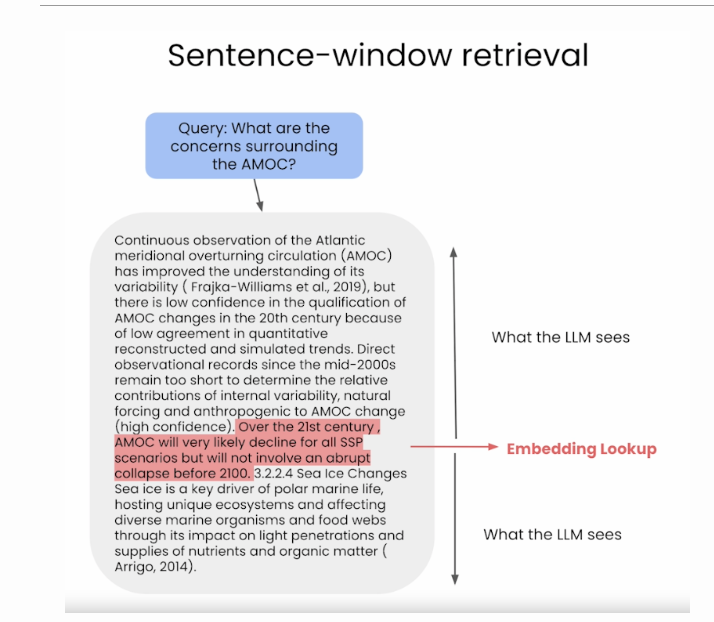
优势
增强了检索的特异性:通过将文档分解为更小的单元,可以更精确地检索与查询直接相关的分段。
上下文丰富的合成:它围绕检索到的块重新引入上下文进行合成,为LLM提供了更广泛的理解来制定响应。
平衡方法:这种方法在重点检索和上下文丰富性之间取得了平衡,有可能提高响应质量。
缺点
复杂性增加:管理单独的检索和合成过程增加了管道的复杂性。
潜在的上下文差距:如果添加回来的周围信息不够全面,就有可能错过更广泛的上下文。
自动合并检索器/层次检索器
下面的图片(来源)说明了自动合并检索是如何工作的,因为它不会像天真的方法那样检索一堆碎片块。
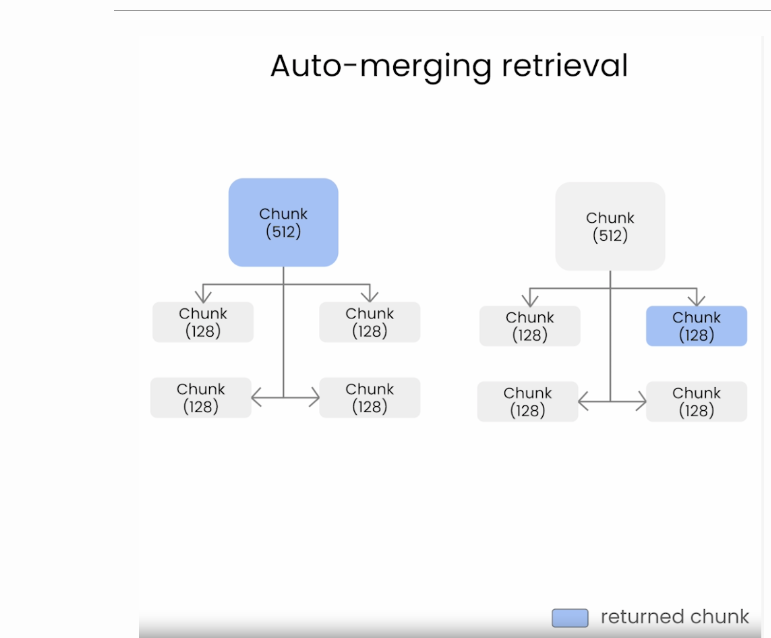
如下图所示,如果块大小较小,那么天真方法中的碎片化情况会更糟(来源)。
自动合并检索旨在组合(或合并)来自多个文本源或片段的信息,以创建对查询的更全面和上下文相关的响应。当没有单个文档或分段完全回答查询,而是答案在于组合来自多个来源的信息时,这种方法尤其有用。
它允许将较小的块合并为较大的父块。它通过以下步骤实现:
定义链接到父块的较小块的层次结构。
如果链接到父块的较小块的集合超过某个阈值(例如余弦相似性),则将较小块“合并”到较大的父块中。
该方法最终将检索父块以获得更好的上下文。
优势
全面的情境回应:通过合并来自多个来源的信息,它可以创建更全面、更具情境相关性的回应。
减少碎片化:这种方法解决了碎片化信息检索的问题,这在幼稚的方法中很常见,尤其是对于较小的块大小。
动态内容集成:它将较小的块动态地组合成更大、信息量更大的块,增强了提供给LLM的信息的丰富性。
缺点
层次结构和阈值管理的复杂性:定义层次结构和为合并设置适当阈值的过程是复杂的,对有效运作至关重要。
过度概括的风险:有可能合并过多或无关的信息,导致反应过于宽泛或偏离主题。
计算强度:由于合并和管理文本块的层次结构需要额外的步骤,这种方法的计算强度可能更高。
计算出理想的块大小
通常,在构建RAG应用程序时,有许多检索参数/策略需要决定(例如,从块大小到矢量与关键字与混合搜索)。让我们放大区块大小方面。
构建RAG系统包括为检索器组件将处理的文档确定理想的块大小。理想的块大小取决于几个因素:
数据特征:数据的性质至关重要。对于文本文件,请考虑段落或小节的平均长度。如果文档结构良好,有不同的部分,这些自然的划分可能会成为分块的良好基础。
检索器约束:您选择的检索器模型(如BM25、TF-IDF或DPR等神经检索器)可能对输入长度有限制。确保块与这些约束兼容是至关重要的。
内存和计算资源:较大的块大小会导致更高的内存使用率和计算开销。平衡块大小与可用资源,以确保高效处理。
任务要求:任务的性质(例如,问题回答、文档摘要)会影响理想的块大小。对于详细的任务,较小的块可能更有效地捕捉特定的细节,而更广泛的任务可能受益于较大的块来捕捉更多的上下文。
实验:通常,确定理想块大小的最佳方法是通过经验测试。使用不同的块大小运行实验,并评估验证集的性能,以找到粒度和上下文之间的最佳平衡。
重叠考虑:有时,块之间有重叠是有益的,以确保在边界处不会遗漏重要信息。根据任务和数据特征确定适当的重叠大小。
总之,确定RAG系统的理想块大小是一种平衡行为,包括考虑数据的特性、检索器模型的局限性、可支配的资源、任务的具体要求和经验实验。这是一个可能需要迭代和微调才能获得最佳结果的过程。
寻回器镶嵌和重新排列
思考:如果我们可以一次尝试一堆块大小,然后让一个重新排序的人来修剪结果呢?
这实现了两个目的:
假设重新排序器具有合理的性能水平,通过汇集来自多个块大小的结果来获得更好(尽管成本更高)的检索结果。
一种对不同的检索策略进行基准测试的方法(w.r.t.重新排序)。
过程如下:
以多种不同的方式对同一文档进行分块,例如使用分块大小:128、256、512和1024。
在检索过程中,我们从每个检索器中提取相关的块,从而将它们组合在一起进行检索。
使用重新排序器对结果进行排序/修剪。
下图(来源)描述了这一过程。

根据LlamaIndex的评估结果,集成方法的忠诚度指标略有上升,表明检索结果的相关性略高。但是,成对的比较会导致对这两种方法的同等偏好,这使得组合是否更好仍然值得怀疑。
注意,除了块大小之外,集合策略也可以应用于RAG管道的其他方面,例如向量与关键字与混合搜索等。
使用近似最近邻进行检索
下一步是考虑从索引中选择哪个近似近邻(ANN)库。选择最佳选项的一个选项是查看此处的排行榜。
更多关于人工神经网络的信息可以在人工神经网络引物中找到。
重新排序
RAG中的重新排序是指根据检索到的文档或信息片段与给定查询或任务的相关性对其进行评估和排序的过程。
RAG中使用了不同类型的重新排序技术:
词汇重新排序:这涉及到根据查询和检索到的文档之间的词汇相似性进行重新排序。像BM25或与TF-IDF向量的余弦相似性这样的方法是常见的。
语义重新排序:这种类型的重新排序使用语义理解来判断文档的相关性。它通常涉及像BERT或其他基于转换器的模型这样的神经模型,以理解不仅仅是单词重叠之外的上下文和含义。
学习排序(LTR)方法:这些方法包括根据从查询和文档中提取的特征,专门针对文档排序任务(逐点、成对和列表)训练模型。这可以包括词汇、语义和其他特征的混合。
混合方法:这些方法结合了词汇和语义方法,可能与用户反馈或特定领域特征等其他信号,以提高重新排名。
神经LTR方法在这一阶段最常用,因为候选集仅限于几十个样本。用于重新排序的一些常见神经模型包括:
使用BERT的多阶段文档排序(单BERT和双BERT)
用于文本排名的预训练转换器BERT及更高版本
清单T5
ListBERT
响应生成/合成
RAG管道的最后一步是生成返回给用户的响应。在这一步骤中,模型将检索到的信息与其预先训练的知识进行合成,以生成连贯且与上下文相关的响应。这一过程包括整合从各种来源收集的见解,确保准确性和相关性,并制定一个不仅信息丰富,而且与用户原始查询一致的响应,保持自然和对话的语气。
请注意,在创建扩展提示时(使用检索到的top-k
组块),以便LLM进行知情响应生成,在输入序列的开始或结束处战略性地放置重要信息可以增强RAG系统的有效性,从而使系统更具性能。以下论文对此进行了总结。
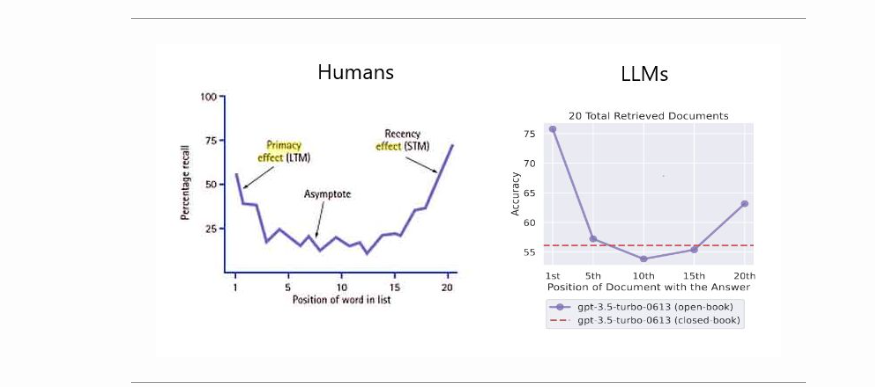
迷失在中间:语言模型如何使用长上下文
虽然最近的语言模型能够将长上下文作为输入,但人们对语言模型使用长上下文的情况知之甚少。
来自斯坦福大学、加州大学伯克利分校Percy Liang实验室的刘等人和Samaya AI的这篇论文分析了语言模型在两项任务中的性能,这两项任务需要在输入上下文中识别相关信息:多文档问答和键值检索。简单地说,他们通过识别上下文中的相关信息来分析和评估LLM如何使用上下文。
他们测试了开源(MPT-30B-Instruction,LongChat-13B)和闭源(OpenAI的GPT-3.5-Turbo和Anthropic的Claude 1.3)模型。他们使用多文档问答,其中上下文包括多个检索到的文档和一个正确答案,其位置被打乱。进行键值对检索以分析较长的上下文是否会影响性能。
他们发现,当相关信息出现在输入上下文的开头或结尾时,性能通常最高,而当模型必须在长上下文的中间访问相关信息时,性能会显著下降。换言之,他们的研究结果基本上表明,当回答查询的相关信息出现在上下文窗口的中间,对其开始和结束都有强烈的偏见时,重试增强(RAG)性能会受到影响。
相关信息刚开始时的最佳性能。
性能随着上下文长度的增加而降低。
检索到的文档过多会影响性能。
通过排名阶段改进检索和提示创建步骤可能会将性能提高20%。
如果提示适合原始上下文,则扩展上下文模型(GPT-3.5-Turbo与GPT-3.5-Turbo(16K))并不更好。
考虑到RAG从外部数据库中检索信息,该数据库通常包含被分割成块的较长文本。即使使用分割块,上下文窗口也会很快变大,至少比“正常”的问题或指令大得多。此外,即使对于显式长上下文模型,性能也会随着输入上下文的增长而显著降低。他们的分析提供了对语言模型如何使用其输入上下文的更好理解,并为未来的长上下文模型提供了新的评估协议。
“在基于变换器的LLM架构中,没有特定的归纳偏见可以解释为什么文档中间的文本的检索性能会更差。我怀疑这都是因为训练数据和人类写作方式:最重要的信息通常在开头或结尾(请参阅论文摘要和结论部分),然后是LLM如何在训练中参数化注意力权重。”来源
换句话说,人类文本工件的构建方式通常是长文本的开头和结尾最重要,这可能是对这项工作中观察到的特征的潜在解释。
你也可以用人类面临的两种流行的认知偏见(首要偏见和近因偏见)来建模,如下图所示(来源)。
最后的结论是,将检索与排名相结合(如在推荐系统中)应该会在RAG中产生最佳的问题回答性能。
下图(来源)显示了论文中提出的想法的概述:“LLM更善于在输入上下文的开头或结尾使用信息”。
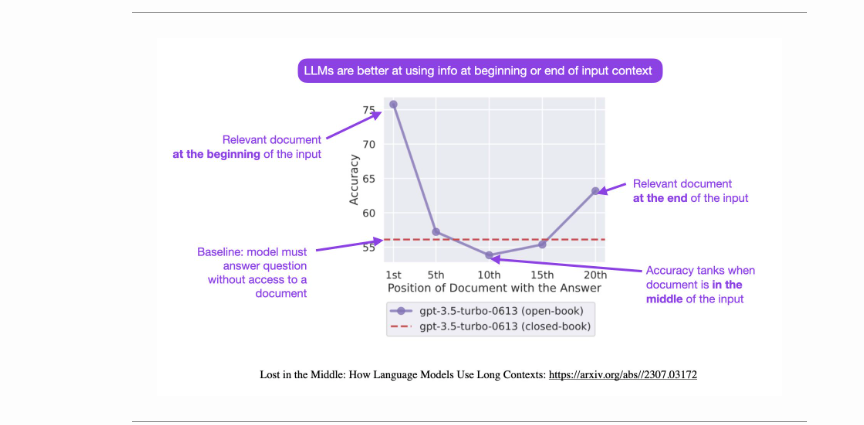
下图说明了改变相关信息(包含答案的文件)的位置对多文档问答性能的影响。较低的位置更接近输入上下文的开始。当相关信息位于上下文的最开始或最结尾时,性能通常最高,而当模型必须在其输入上下文的中间对信息进行推理时,性能会迅速下降。

“大海捞针”测试
为了理解长上下文LLM在其提示的各个部分的上下文内检索能力,可以进行简单的“大海捞针”分析。这种方法包括将特定的、有针对性的信息(“针”)嵌入到更大、更复杂的文本体(“干草堆”)中。其目的是测试LLM在大量其他数据中识别和利用这一特定信息的能力。
实际上,分析可能涉及将一个独特的事实或数据点插入一个冗长的、看似无关的文本中。LLM将被赋予任务或查询的任务,这些任务或查询要求它调用或应用这些嵌入的信息。这种设置模拟了真实世界中的情况,在这种情况下,基本细节通常隐藏在大量内容中,检索这些细节的能力至关重要。
实验的结构可以评估LLM性能的各个方面。例如,“针”的位置可以变化——在文本的早期、中期或后期——以查看模型的检索能力是否会根据信息位置而变化。此外,可以修改周围“干草堆”的复杂性,以测试LLM在不同程度的上下文困难下的性能。通过分析LLM在这些场景中的表现,可以深入了解其上下文检索功能和潜在的改进领域。
这可以使用Needle In A Haystack库来完成。下图显示了OpenAI的GPT-4-128K在不同上下文长度下的(顶部)和(底部)性能。
下图(来源)显示了Claude 2.1基于提示上下文长度区域的长上下文问答错误。平均而言,与克劳德2相比,克劳德2.1的错误答案减少了30%。
然而,在Claude 2.1博客的Long context提示中,Anthropic指出,添加“这是上下文中最相关的一句话:”到Claude的回复开始时,将原始评估的得分从27%提高到98%!博客中的下图显示了Claude 2.1在整个200K令牌上下文窗口中检索单个句子时的表现。本实验使用上述提示技巧来引导克劳德回忆最相关的句子。
- 98 次浏览
【大语言模型】NLP•检索增强生成之二
视频号
微信公众号
知识星球
- 概述
- 动机
- 神经检索
- 检索增强生成(RAG)流水线
- RAG的好处
- RAG与微调
- RAG合奏
- 使用特征矩阵选择矢量数据库
- 构建RAG管道
- 摄入
- Chucking
- 嵌入
- 句子嵌入:内容和原因
- 背景:与BERT等代币级别模型相比的差异
- 相关:句子转换器的训练过程与令牌级嵌入模型
- 句子变换器在RAG中的应用
- 句子嵌入:内容和原因
- 检索
- 标准/天真的方法
- 优势
- 缺点
- 语句窗口检索/从小到大分块
- 优势
- 缺点
- 自动合并检索器/层次检索器
- 优势
- 缺点
- 计算出理想的块大小
- 寻回器镶嵌和重新排列
- 使用近似最近邻进行检索
- 重新排序
- 标准/天真的方法
- 响应生成/合成
- 迷失在中间:语言模型如何使用长上下文
- “大海捞针”测试
- 摄入
- 组件式评估
- 检索度量
- 上下文精度
- 上下文回忆
- 上下文相关性
- 生成度量
- 脚踏实地
- 回答相关性
- 端到端评估
- 回答语义相似性
- 答案正确性
- 检索度量
- 多模式RAG
- 改进RAG系统
- 相关论文
- 知识密集型NLP任务的检索增强生成
- 主动检索增强生成
- 多模式检索增强生成器
- 假设文档嵌入(HyDE)
- RAGAS:检索增强生成的自动评估
- 微调还是检索?LLM中知识注入的比较
- 密集X检索:我们应该使用什么检索粒度?
- ARES:一种用于检索增强生成系统的自动评估框架
- 引用
构建RAG管道
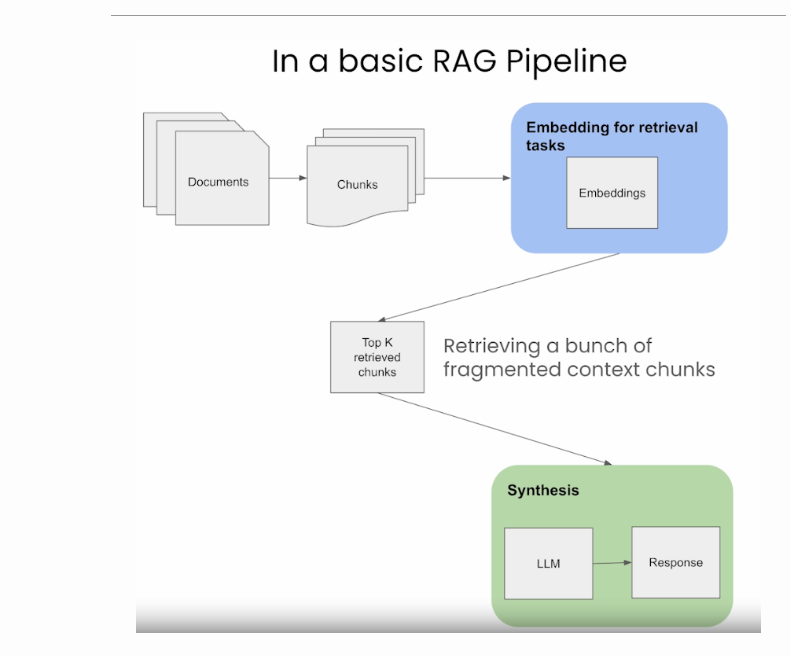
下图(来源)直观地概述了RAG的三个不同步骤:摄入、检索和合成/反应生成。
在下面的部分中,我们将讨论这些关键领域。
摄入(Ingestion)
Chucking(分块)
- 分块是将提示和/或要检索的文档划分为更小的、可管理的段或块的过程。这些块可以通过固定的大小来定义,例如特定数量的字符、句子或段落。
- 在RAG中,每个块都被编码到嵌入向量中以供检索。更小、更精确的块会导致用户的查询和内容之间更精细的匹配,从而增强检索到的信息的准确性和相关性。
- 较大的块可能包括不相关的信息,从而引入噪声并可能降低检索准确性。通过控制区块大小,RAG可以在全面性和准确性之间保持平衡。
- 因此,接下来自然会出现的问题是,如何为您的用例选择正确的块大小?RAG中块大小的选择至关重要。它需要足够小以确保相关性并减少噪声,但要足够大以保持上下文的完整性。让我们看看下面从Pinecone中引用的几种方法:
- 固定大小的区块划分:只需决定区块中的代币数量,以及它们之间是否应该重叠。块之间的重叠保证了块之间的语义上下文损失最小。这个选项在计算上很便宜,而且实现起来很简单。
text = "..." # your text
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator = "\n\n",
chunk_size = 256,
chunk_overlap = 20
)
docs = text_splitter.create_documents([text])- 上下文感知分块:内容感知分块利用文本的内在结构来创建更有意义和上下文相关性的分块。以下是实现这一目标的几种方法:
- 句子拆分。此方法与为嵌入句子级内容而优化的模型相一致。可以使用不同的工具和技术进行句子拆分:
- 朴素拆分:一种使用句号和换行来拆分句子的基本方法。实例
text = "..." # Your text
docs = text.split(".")这种方法很快,但可能会忽略复杂的句子结构。
- NLTK(自然语言工具包):一个用于语言处理的综合Python库。NLTK包括一个句子标记器,可以有效地将文本拆分为句子。实例
text = "..." # Your text
from langchain.text_splitter import NLTKTextSplitter
text_splitter = NLTKTextSplitter()
docs = text_splitter.split_text(text)- spaCy:一个用于NLP任务的高级Python库,spaCy提供了高效的句子分割。实例
text = "..." # Your text
from langchain.text_splitter import SpacyTextSplitter
text_splitter = SpacyTextSplitter()
docs = text_splitter.split_text(text)- 递归分块:递归分块是一种使用各种分隔符分层分割文本的迭代方法。它适用于通过递归应用不同的标准来创建大小或结构相似的块。例如,使用LangChain:
text = "..." # Your text
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 256,
chunk_overlap = 20
)
docs = text_splitter.create_documents([text])- 专用分块:对于Markdown或LaTeX等格式化内容,可以应用专用分块来保持原始结构:
- Markdown Chunking:识别Markdown语法并根据结构划分内容。实例
from langchain.text_splitter import MarkdownTextSplitter
markdown_text = "..."
markdown_splitter = MarkdownTextSplitter(chunk_size=100, chunk_overlap=0)
docs = markdown_splitter.create_documents([markdown_text])- LaTeX分块:解析LaTeX命令和环境以分块内容,同时保留其逻辑组织。
“根据经验,如果文本块在没有周围上下文的情况下对人类有意义,那么它对语言模型也有意义。因此,在语料库中找到文档的最佳块大小对于确保搜索结果的准确性和相关性至关重要。”(来源)
嵌入
- 一旦你的提示被适当地分块,下一步就是嵌入它。在RAG中嵌入提示和文档包括将用户的查询(提示)和知识库中的文档转换为一种可以有效比较相关性的格式。这一过程对于RAG响应用户查询从其知识库中检索最相关信息的能力至关重要。以下是它的典型工作方式:
- 帮助选择最适合您任务的嵌入模型的一个选项是查看HuggingFace的海量文本嵌入基准(MTEB)排行榜。。有一个问题是可以使用密集嵌入还是稀疏嵌入,所以让我们看看下面每种嵌入的好处:
- 稀疏嵌入:像TF-IDF这样的稀疏嵌入非常适合在提示和文档之间进行词法匹配。最适合关键字相关性至关重要的应用程序。它的计算强度较低,但可能无法捕捉到文本中更深层次的语义。
- 语义嵌入:语义嵌入,如BERT或句子BERT,自然地适用于RAG用例。
- BERT:适用于捕捉文档和查询中的上下文细微差别。与稀疏嵌入相比,需要更多的计算资源,但提供了语义更丰富的嵌入。
- 句子ERT:非常适合于句子层面的上下文和意义很重要的场景。它在对BERT的深刻上下文理解和对简洁、有意义的句子表达的需求之间取得了平衡。这通常是RAG的首选路线。
句子嵌入:内容和原因
背景:与BERT等代币级别模型相比的差异
- 作为一个概述,让我们看看句子转换器与BERT等令牌级嵌入模型相比有何不同。
- 句子转换器是对传统BERT模型的修改,专门为生成完整句子的嵌入(即句子嵌入)而定制。他们培训方法的主要区别在于:
- 目的:训练BERT来预测一句话中的掩蔽词和下一句话的预测。它是为理解一个句子中的单词及其上下文而优化的。另一方面,句子转换器被专门训练来理解整个句子的含义。它们生成具有相似含义的句子在嵌入空间中接近的嵌入。
- 嵌入级别:主要区别在于嵌入级别。BERT为句子中的每个标记(单词或子单词)提供嵌入,而句子转换器为整个句子提供单个嵌入。
- 训练数据和任务:虽然BERT主要在大型文本语料库上进行训练,任务侧重于理解上下文中的单词,但句子转换器通常在包括句子对的数据集上进行训练。这项培训的重点是相似性和相关性,教模型如何理解和比较整个句子的含义。
- 暹罗和三元组网络结构:句子变换器经常使用暹罗或三元组的网络结构。这些网络包括处理成对或三元组的句子,并调整模型,使相似的句子具有相似的嵌入,而不同的句子具有不同的嵌入。这与BERT的训练不同,后者本质上不涉及单独句子的直接比较。
- 针对特定任务的微调:句子转换器通常针对特定任务进行微调,如语义相似性、转述识别或信息检索。与BERT相比,这种微调更侧重于句子层面的理解,BERT可能会针对更广泛的NLP任务进行微调,如问答、情绪分析等,侧重于单词或短语层面的理解。
- 适用性:BERT和类似模型更适用于需要在标记级别理解的任务(如命名实体识别、问答),而句子转换器更适用于依赖于句子级别理解(如语义搜索、句子相似性)的任务。
- 生成句子嵌入或相似性任务的效率:在标准BERT中,生成句子嵌入通常涉及将其中一个隐藏层(通常是第一个标记[CLS])的输出作为整个句子的表示。然而,对于句子级别的任务,这种方法并不总是最优的。句子转换器经过专门优化,可以生成更有意义和有用的句子嵌入,因此对于涉及句子相似性计算的任务更有效。由于它们为每个句子生成一个向量,因此与令牌级模型相比,计算句子之间的相似性得分在计算上不那么密集。
- 总之,虽然BERT是一种专注于单词级上下文的通用语言理解模型,但句子转换器专门用于理解和比较整个句子的含义,使其更有效地执行需要句子级语义理解的任务。
相关:句子转换器的训练过程与令牌级嵌入模型
- 让我们来看看与BERT等令牌级嵌入模型相比,句子转换器是如何以不同的方式进行训练的。
- 句子转换器被训练为在句子级别生成嵌入,这是一种与BERT等令牌级别嵌入模型不同的方法。以下是他们的培训概述,以及它与代币级别模型的区别:
- 模型架构:句子转换器通常从类似于BERT或其他转换器架构的基本模型开始。然而,重点是为整个输入句子输出单个嵌入向量,而不是单个标记。
- 训练数据:它们在各种数据集上进行训练,通常包括已知句子之间关系(如相似性、转述)的成对或成组句子。
- 训练目标:BERT是在掩蔽语言建模(预测缺失单词)和下一句预测等目标上进行预训练的,这些目标侧重于在表征水平上理解上下文。另一方面,句子转换器是专门训练来理解句子层面的上下文和关系的。他们的训练目标通常是最小化语义相似句子的嵌入之间的距离,同时最大化不相似句子的插入之间的距离。这是通过对比损失函数实现的,如三元组损失、余弦相似性损失等。
- 输出表示:在BERT中,句子级表示通常来源于特殊令牌的嵌入(如[CLS])或通过池化令牌嵌入(以及平均、MaxPooling或串联它们)。句子转换器被设计为直接输出有意义的句子级表示。
- 下游任务的微调:句子转换器可以在特定任务上进行微调,例如语义文本相似性,在这些任务中,模型学习生成嵌入,捕捉整个句子的细微含义。
- 总之,句子转换器专门针对在句子级别生成表示进行了优化,侧重于捕捉句子的整体语义,这使得它们在涉及句子相似性和聚类的任务中特别有用。这与BERT等标记级别模型形成了对比,其更侧重于在更广泛的上下文中理解和表示单个令牌的含义。
句子变换器在RAG中的应用
- 现在,让我们来看看为什么句子转换器是生成RAG嵌入的首选模型。
- RAG利用句子转换器来理解和比较句子的语义内容。这种集成在模型需要在生成响应之前检索相关信息的场景中特别有用。以下是句子转换器在RAG设置中的作用:
- 改进的文档检索:句子转换器经过训练,可以生成捕捉句子语义的嵌入。在RAG设置中,这些嵌入可以用于将查询(如用户的问题)与数据库中最相关的文档或段落进行匹配。这是至关重要的,因为生成的响应的质量通常取决于检索到的信息的相关性。
- 高效的语义搜索:传统的基于关键字的搜索方法可能难以理解查询的上下文或语义细微差别。句子转换器通过提供语义上有意义的嵌入,实现了超越关键字匹配的更细微的搜索。这意味着RAG的检索组件可以找到与查询语义相关的文档,即使它们不包含确切的关键字。
- 上下文理解以获得更好的响应:通过使用句子转换器,RAG模型可以更好地理解输入查询和潜在源文档内容的上下文和细微差别。这导致了更准确、更适合上下文的响应,因为模型的生成组件有更相关、更容易理解的信息可供使用。
- 信息检索中的可伸缩性:句子转换器可以通过预计算所有文档的嵌入来有效地处理大型文档数据库。这使得检索过程更快、更具可扩展性,因为模型只需要在运行时计算查询的嵌入,然后快速找到最接近的文档嵌入。
- 增强生成过程:在RAG设置中,生成组件受益于检索组件提供相关的、语义丰富的信息的能力。这使得语言模型生成的响应不仅在上下文上准确,而且比模型本身所训练的信息范围更广。
- 总之,句子转换器通过实现更有效的信息语义搜索和检索,增强了具有LLM的RAG模型的检索能力。这提高了需要理解和基于大量文本数据生成响应的任务的性能,如问答、聊天机器人和信息提取。
- 54 次浏览
【大语言模型】NLP•检索增强生成之五
视频号
微信公众号
知识星球
- 概述
- 动机
- 神经检索
- 检索增强生成(RAG)流水线
- RAG的好处
- RAG与微调
- RAG合奏
- 使用特征矩阵选择矢量数据库
- 构建RAG管道
- 摄入
- Chucking
- 嵌入
- 句子嵌入:内容和原因
- 背景:与BERT等代币级别模型相比的差异
- 相关:句子转换器的训练过程与令牌级嵌入模型
- 句子变换器在RAG中的应用
- 句子嵌入:内容和原因
- 检索
- 标准/天真的方法
- 优势
- 缺点
- 语句窗口检索/从小到大分块
- 优势
- 缺点
- 自动合并检索器/层次检索器
- 优势
- 缺点
- 计算出理想的块大小
- 寻回器镶嵌和重新排列
- 使用近似最近邻进行检索
- 重新排序
- 标准/天真的方法
- 响应生成/合成
- 迷失在中间:语言模型如何使用长上下文
- “大海捞针”测试
- 摄入
- 组件式评估
- 检索度量
- 上下文精度
- 上下文回忆
- 上下文相关性
- 生成度量
- 脚踏实地
- 回答相关性
- 端到端评估
- 回答语义相似性
- 答案正确性
- 检索度量
- 多模式RAG
- 改进RAG系统
- 相关论文
- 知识密集型NLP任务的检索增强生成
- 主动检索增强生成
- 多模式检索增强生成器
- 假设文档嵌入(HyDE)
- RAGAS:检索增强生成的自动评估
- 微调还是检索?LLM中知识注入的比较
- 密集X检索:我们应该使用什么检索粒度?
- ARES:一种用于检索增强生成系统的自动评估框架
- 引用
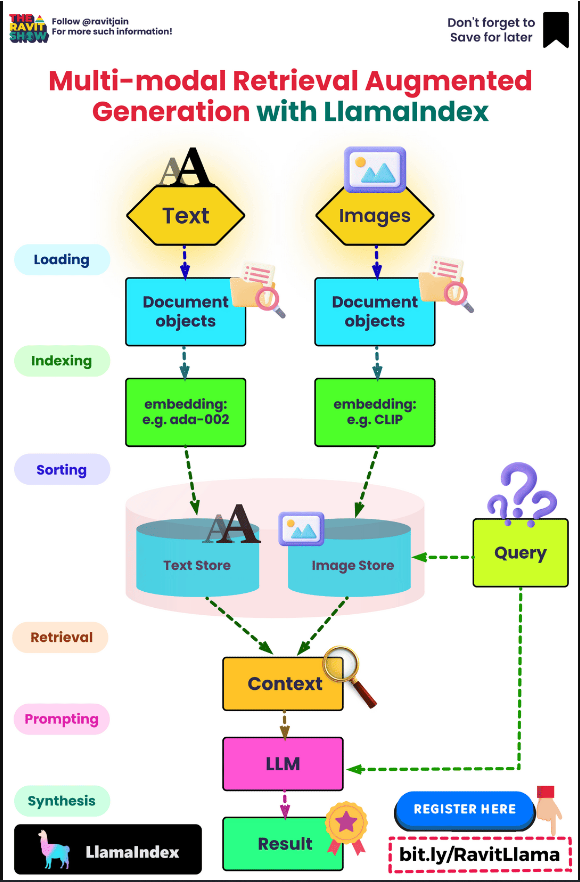
多模式RAG
- 许多文档包含混合的内容类型,包括文本和图像。然而,在大多数RAG应用程序中,图像中捕获的信息都会丢失。随着多模式LLM(如GPT-4V)的出现,如何在RAG中利用图像是值得考虑的。
- 以下是使用LangChain在RAG中使用图像的三种方法:
- 选项1:
- 使用多模式嵌入(如CLIP)来嵌入图像和文本。
- 使用相似性搜索检索两者。
- 将原始图像和文本块传递到多模式LLM以进行答案合成。
- 选项2:
- 使用多模式LLM(如GPT-4V、LLaVA或FUYU-8b)从图像中生成文本摘要。
- 嵌入和检索文本。
- 将文本块传递给LLM进行答案合成。
- 选项1:
- 选项3:
- 使用多模式LLM(如GPT-4V、LLaVA或FUYU-8b)从图像中生成文本摘要。
- 嵌入和检索带有原始图像参考的图像摘要。您可以使用带有矢量数据库(如Chroma)的多矢量检索器来存储原始文本和图像及其摘要以供检索。
- 将原始图像和文本块传递到多模式LLM以进行答案合成。
- 选项2适用于多模态LLM不能用于答案合成的情况(例如,成本等)。
下图(来源)概述了上述三种选项。
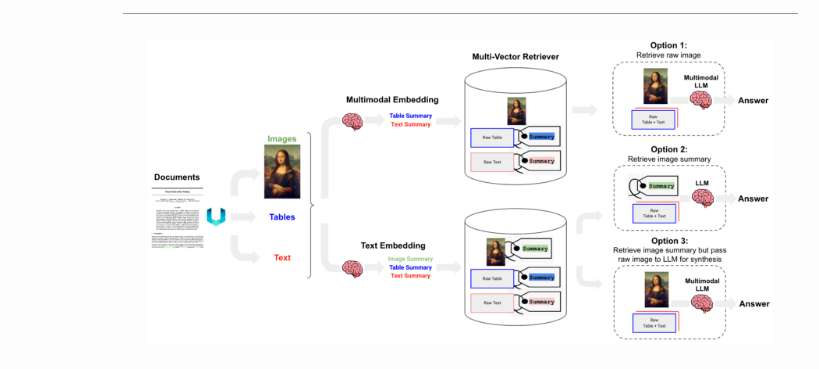
- LangChain提供选项1和选项3的食谱。
- 以下信息图(来源)还提供了多式联运RAG的顶级概述:
改进RAG系统
- 为了增强和完善RAG系统,请考虑以下三种结构化方法,每种方法都附有全面的指南和实际实施:
- 重新排序检索结果:一种基本而有效的方法是使用重新排序模型来细化通过初始检索获得的结果。这种方法优先考虑更相关的结果,从而提高生成内容的整体质量。MonoT5、MonoBERT、DuoBERT等都是可以用作重新排序的深度模型的示例。有关此技术的详细探索,请参阅Mahesh Deshwal提供的指南和代码示例。
- FLARE技术:在重新排序之后,应该探索FLARE方法。每当生成的内容的片段的置信水平低于指定阈值时,该技术就动态地查询互联网(也可以是本地知识库)。这克服了传统RAG系统的一个显著限制,传统RAG通常只在一开始查询知识库,然后产生最终输出。Akash Desai的指南和代码演练提供了对该技术的深刻理解和实际应用。有关FLARE技术的更多信息,请参阅Active Retrieval Augmented Generation一节。
- HyDE方法:最后,HyDE技术引入了一个创新概念,即响应查询生成假设文档。然后将该文档转换为嵌入向量。该方法的唯一性在于使用向量来识别语料库嵌入空间内的相似邻域,从而基于向量相似度来检索相似的真实文档。要深入研究这种方法,请参阅Akash Desai的指南和代码实现。在没有相关标签的精确零样本密集检索部分中,更多关于HyDE技术。
- 这些方法中的每一种都提供了一种独特的方法来完善RAG系统,有助于获得更准确和与上下文相关的结果。
相关论文
知识密集型NLP任务的检索增强生成

- 来自Facebook人工智能研究、伦敦大学学院和纽约大学的Lewis等人的论文介绍了将预先训练的参数记忆和非参数记忆相结合的检索增强生成(RAG)模型,用于语言生成任务。
- 针对大型预训练语言模型的局限性,如访问和精确操作知识的困难,RAG模型将预训练的序列到序列(seq2seq)模型与维基百科的密集向量索引合并,由神经检索器访问。
- RAG框架包括两个模型:RAG序列,对整个序列使用相同的检索文档;RAG令牌,允许每个令牌有不同的段落。
- 检索组件Dense Passage Retriever(DPR)使用双编码器架构以及基于BERT的文档和查询编码器。发电机组件采用BART大型、经过预训练的seq2seq变压器,参数为400M。
- RAG模型在检索器和生成器组件上联合训练,而无需直接监督要检索的文档,使用Adam的随机梯度下降。培训使用维基百科转储作为非参数知识源,分为2100万个100个单词块。
- 用于查询/文档嵌入和检索的方法和模型以及RAG框架的端到端结构概述如下:
- 查询/文档嵌入:
- 检索组件Dense Passage Retriever(DPR)遵循双编码器架构。
- DPR使用BERTBASE作为文档和查询编码器的基础。
- 对于文档z,稠密表示d(z)由文档编码器BERTd生成.
- 对于查询x,一个查询表示q(x)由查询编码器BERTq产生.
- 创建嵌入使得给定查询的相关文档在嵌入空间中接近,从而允许有效检索。
- 检索过程:
- 检索过程包括计算前k
- 这本质上是最大内积搜索(MIPS)问题。
- MIPS问题在亚线性时间内近似求解,以有效地检索相关文档。
- 端到端结构:
- RAG模型使用输入序列x来检索文本文档z,然后将其用作生成目标序列y的附加上下文。
- 发电机组件使用BART大型预训练seq2seq变压器进行建模,该变压器具有400M参数。BART-large将输入x与检索到的内容z组合以用于生成。
- RAG序列模型使用相同的检索文档来生成完整的序列,而RAG令牌模型可以使用每个令牌的不同段落。
- 培训过程包括联合培训检索器和生成器组件,而无需直接监督应检索的文档。训练使用Adam的随机梯度下降来最小化每个目标的负边缘对数似然。
- 值得注意的是,文档编码器BERTd在训练期间保持固定,避免了文档索引的定期更新。
- 该文件的下图概述了所提出的方法。他们将预先训练的检索器(查询编码器+文档索引)与预先训练的seq2seq模型(生成器)相结合,并对端到端进行微调。对于查询x
,他们使用最大内积搜索(MIPS)来查找前K个文档zi.对于最终预测y,他们对待z作为一个潜在变量,并在给定不同文献的seq2seq预测上边缘化
- 在开放域QA任务中,RAG建立了新的最先进的结果,优于参数seq2seq模型和特定任务的检索和提取架构。RAG模型显示,即使在任何检索到的文档中都没有正确的答案,也能够生成正确的答案。
- RAG序列在Open MS-MARCO NLG中超过了BART,表明更少的幻觉和更真实的文本生成。RAG代币在《危险边缘》问题生成中的表现优于RAG序列,显示出更高的真实性和特异性。
- 在FEVER事实验证任务中,RAG模型取得了接近最先进模型的结果,这些模型需要更复杂的体系结构和中间检索监督。
- 这项研究展示了混合生成模型的有效性,将参数记忆和非参数记忆相结合,为一系列NLP任务组合这些组件提供了新的方向。
- 密码交互式演示。
主动检索增强生成
- 尽管大型语言模型(LLM)具有非凡的理解和生成语言的能力,但它们往往会产生幻觉,并产生事实上不准确的输出。
- 通过从外部知识资源中检索信息来增强LLM是一个很有前途的解决方案。大多数现有的检索增强LLM都采用了仅基于输入检索一次信息的检索和生成设置。然而,在涉及长文本生成的更一般的场景中,这是有限的,在整个生成过程中不断收集信息是至关重要的。在过去的一些工作中,在生成输出的同时多次检索信息,这些输出大多使用以前的上下文作为查询以固定的间隔检索文档。
- 江等人在CMU、Sea AI Lab和EMNLP 2023中的Meta AI发表的这篇论文提出了前瞻性主动三元增强生成(FLARE),这是一种解决大型语言模型(LLM)产生事实上不准确内容的趋势的方法。
- FLARE迭代地使用对即将出现的语句的预测来主动决定在整个生成过程中何时检索以及检索什么,从而通过动态、多阶段的外部信息检索增强LLM。
- 与使用固定间隔或基于输入的检索的传统检索和生成模型不同,FLARE的目标是持续收集信息以生成长文本,从而减少幻觉和事实不准确。
- 当生成由概率阈值确定的低置信度令牌时,系统触发检索。这可以预测未来的内容,形成查询以检索相关文档以进行重新生成。
- 下图显示了FLARE。从用户输入x开始和初始检索结果Dx,FLARE迭代生成一个临时的下一句话(以灰色斜体显示),并检查它是否包含低概率标记(以下划线表示)。如果是(步骤2和3),则系统检索相关文档并重新生成句子。

- FLARE在四个长格式、知识密集型生成任务/数据集上进行了测试,显示出卓越或有竞争力的性能,证明了它在解决现有检索增强LLM的局限性方面的有效性。
- 该模型适用于现有的LLM,如GPT-3.5上的实现所示,并使用现成的检索器和Bing搜索引擎。
- 代码
多模式检索增强生成器
- 这篇由Google Research的Chen等人撰写的论文提出了多模式检索增强变换器(MuRAG),它旨在将检索过程扩展到文本之外,包括图像或结构化数据等其他模式,然后可以与文本信息一起使用,为生成过程提供信息。
- MuRAG的神奇之处在于它的两阶段训练方法:预训练和微调,每一个都经过精心设计,以建立模型利用大量多模态知识的能力。
- MuRAG的主要目标是将视觉和文本知识结合到语言模型中,以提高其多模式问答的能力。
- MuRAG的独特之处在于它能够访问外部非参数多模式记忆(图像和文本)来增强语言生成,解决了以前模型中纯文本检索的局限性。
- MuRAG具有双编码器架构,将预训练的视觉转换器(ViT)和文本编码器(T5)模型相结合,以创建骨干编码器,从而能够将图像-文本对、仅图像和仅文本输入编码为统一/联合多模式表示。
- MuRAG是在图像文本数据(LAION,概念字幕)和纯文本数据(PAQ,VQA)的混合上预训练的。它使用对比损失来检索相关知识,使用生成损失来预测答案。它采用了一个两阶段的训练管道:先用小的批内内存进行初始训练,然后用大的全局内存进行训练。
- 在检索器阶段,MuRAG将任何模态的查询q作为输入,并从图像-文本对的存储器M中检索。具体来说,我们应用骨干编码器fθ来编码查询q,并在所有候选存储器m∈m上使用最大内积搜索(MIPS)来找到前k个最近邻居TopK(mÜq)=[m1,…,mk]。形式上,我们定义TopK(MŞq)如下所示:
TopK(M∣q)=Topm∈Mfθ(q)[CLS]⋅fθ(m)[CLS]
- 在读取器阶段,检索(原始图像块)与查询q组合,作为增强输入[m1,……,mk,q],将其馈送到骨干编码器fθ,以产生检索增强编码。解码器模型gθ使用对该表示的关注来逐个标记地生成文本输出y=y1,…,yn。
p(yiŞyi−1)=gθ(yiÜfθ)(TopK(MÜq);qy1:i−1)
- 其中y从给定的词汇表V中解码.
- 下图来自原始论文(来源),显示了模型如何利用外部存储库来检索图像和文本片段中封装的各种知识。然后利用这种多模式信息来增强生成过程。上半部分概述了预训练阶段的设置,而下半部分指定了微调阶段的框架。

- 该过程总结如下:
- 对于检索,MuRAG使用最大内积搜索来找到前k个
- 记忆中最相关的图像-文本对给出了一个问题。这里的“内存”是指模型可以从中检索信息的外部知识库。具体地说,存储器包含大量的图像-文本对集合,这些对在训练之前由骨干编码器离线编码。
- 在训练和推理过程中,给定一个问题,MuRAG的检索器模块将使用最大内积搜索来搜索该内存,以找到最相关的图像-文本对。
- 存储器充当知识源,可以包含各种类型的多模式数据,如与下游任务相关的带标题的图像、文本段落、表格等。
- 例如,当对WebQA数据集进行微调时,内存中包含从维基百科中提取的110万个图像文本对,模型可以从中检索这些图像文本对来回答问题。
- 因此,总之,记忆是编码在多模式空间中的大型非参数外部知识库,MuRAG通过学习从给定的问题中检索相关知识,以增强其语言生成能力。内存提供了世界知识,以补充隐含存储在模型参数中的内容。
- 为了阅读,检索到的多模式上下文与问题嵌入相结合,并输入解码器以生成答案。
- MuRAG在WebQA和MultimodalQA这两个多模式QA数据集上实现了最先进的结果,比纯文本方法的准确率高出10-20%。它展示了结合视觉和文本知识的价值。
- 关键的局限性是对大规模预训练数据的依赖、计算成本以及视觉推理(如计数对象)中的问题。但总的来说,MuRAG代表了在构建基于视觉的语言模型方面的一个重要进展。
假设文档嵌入(HyDE)
- 来自CMU和滑铁卢大学的Gao等人发表在《无相关性标签的精确零样本密集检索》中,提出了一种创新方法,称为假设文档嵌入(HyDE),用于在无相关性标签情况下进行有效的零样本密集检索。HyDE利用指令遵循的语言模型(如InstructionGPT)来生成一个捕获相关性模式的假设文档,尽管它可能包含事实上的不准确之处。然后,像Contriever这样的无监督对比编码器将该文档编码为嵌入向量,以在语料库嵌入空间中识别相似的真实文档,有效地过滤掉不正确的细节。
- HyDE的实现结合了InstructGPT(GPT-3模型)和Contriever模型,利用OpenAI操场的默认温度设置进行生成。对于英语检索任务,使用纯英语的Contriever模型,而对于非英语任务,使用多语言的mContriever。
- 以下图片说明了HyDE模型。将显示文档片段。HyDE在不更改底层GPT-3和Contriever/mContriever模型的情况下为所有类型的查询提供服务。

- 实验使用Pyserini工具包进行。结果表明,HyDE比最先进的无监督密集检索器Contriever有了显著的改进,在各种任务和语言中具有与微调检索器相当的强大性能。具体而言,在网络搜索和低资源任务中,HyDE在精度和面向回忆的指标方面表现出了相当大的改进。即使与微调后的车型相比,它仍然具有竞争力,尤其是在召回方面。在多语言检索中,HyDE改进了mContriever模型,并优于在MS-MARCO上微调的非Contriever模式。然而,经过微调的mContrieverFT在性能上存在一些差距,这可能是由于非英语语言培训不足。
- 进一步的分析探讨了使用HyDE的不同生成模型和微调编码器的效果。更大的语言模型带来了更大的改进,HyDE使用微调编码器表明,功能较弱的指令语言模型可能会影响微调检索器的性能。
- HyDE的一个可能的缺陷是,它可能会产生潜在的“幻觉”,因为它生成的假设文件可能包含虚构或不准确的细节。之所以出现这种现象,是因为HyDE使用指令遵循的语言模型(如InstructionGPT)来基于查询生成文档。生成的文档旨在捕捉查询的相关性模式,但由于它是在没有直接引用真实世界数据的情况下创建的,因此可能包含虚假或虚构的信息。HyDE的这一方面是对其在零样本检索场景中操作的能力的权衡,在该场景中,它创建了上下文相关但不一定是事实准确的文档来指导检索过程。
- 最后,本文介绍了语言模型和密集编码器/检索器之间交互的新范式,表明强大而灵活的语言模型可以有效地处理相关性建模和指令理解。这种方法消除了对相关性标签的需求,在搜索系统生命的初始阶段提供了实用性,并为多跳检索/QA和会话搜索等任务的进一步进步铺平了道路。
RAGAS:检索增强生成的自动评估
- 本文由卡迪夫大学爆炸梯度的Es等人和AMPLYFI介绍了RAGAS,这是一个用于检索增强生成(RAG)系统的无参考评估框架。
- RAGAS专注于评估RAG系统的性能,如检索系统在提供相关上下文方面的有效性、LLM利用该上下文的能力以及生成的总体质量。
- 该框架提出了一套指标来评估这些维度,而不依赖于基本事实人类注释。
- RAGAS侧重于三个质量方面:忠实性、答案相关性和上下文相关性。
- 忠实:定义为生成的答案在多大程度上基于所提供的上下文。它是使用公式来测量的:F=|V||s|其中,|V|是上下文支持的语句数,|s|是从答案中提取的语句总数。
- 答案相关性:该指标评估答案在多大程度上解决了给定的问题。它是通过从答案中生成潜在问题并使用公式测量它们与原始问题的相似性来计算的:AR=1n∑ni=1sim(q,qi),其中q是原始问题,qi是生成的问题,sim表示它们嵌入之间的余弦相似性。
- 上下文相关性:衡量检索到的上下文仅包含回答问题所需信息的程度。它是使用提取的相关句子占上下文中总句子的比例来量化的:CR=提取的句子数量与c(q)中的句子总数之比
- 本文使用WikiEval数据集验证了RAGAS,证明了其在评估这些方面时与人类判断的一致性。
- 作者认为,RAGAS有助于RAG系统更快、更高效的评估周期,由于LLM的快速采用,这一点至关重要。
- RAGAS是使用WikiEval数据集进行验证的,该数据集包括问题-上下文-答案三元组,用人类对忠实性、答案相关性和上下文相关性的判断进行注释。
- 评估表明,RAGAS与人类判断密切一致,尤其是在评估忠诚度和答案相关性方面。
- 代码
微调还是检索?LLM中知识注入的比较
- 这篇由微软的Ovadia等人撰写的论文对大型语言模型(LLM)中的知识注入方法进行了深入的比较。所解决的核心问题是,在提高知识密集型任务的LLM性能方面,无监督微调(USFT)是否比检索增强生成(RAG)更有效。
- 研究人员使用从维基百科上刮来的知识库和GPT-4创建的时事问题数据集,重点研究LLM记忆、理解和检索事实数据的能力。该研究采用了Llama2-7B、Mistral-7B和Orca2-7B等模型,根据大规模多任务语言理解评估(MMLU)基准和当前事件数据集对它们进行任务评估。
- 探索了两种知识注入方法:微调,它使用特定任务的数据继续模型的预训练过程,以及检索增强生成(RAG),它使用外部知识源来增强LLM的响应。本文还深入研究了基于监督、无监督和强化学习的微调方法。
- 关键发现是,RAG在知识注入方面优于无监督微调。使用外部知识源的RAG在知识注入方面明显比单独的USFT更有效,甚至比RAG和微调的组合更有效,特别是在问题直接对应于辅助数据集的情况下。这表明,USFT在将新知识嵌入模型参数方面可能没有那么有效。
- 下图显示了知识注入框架的可视化。
- 请注意,在这种情况下,USFT是预训练的直接延续(因此在文献中也称为连续预训练),预测数据集上的下一个令牌。有趣的是,对同一事实进行多次转述的微调显著提高了基线表现,表明了信息的重复和多样化呈现对有效知识同化的重要性。
- 作者通过抓取维基百科上与各种主题相关的文章创建了一个知识库,用于微调和RAG。此外,使用GPT-4生成了一个关于时事的多项选择题数据集,并创建了转述来扩充该数据集。
- 该研究的局限性包括只关注无监督微调,而没有探索有监督微调或从人类反馈中强化学习(RLHF)。该研究还注意到,各实验的准确性表现差异很大,因此很难确定结果的统计显著性。
- 这篇论文还质疑了为什么基线模型在有四个选项的多项选择题中没有达到25%的准确率,这表明这些任务可能不能代表真正的“看不见”的知识。此外,这项研究主要评估简单的知识或事实任务,而没有深入研究推理能力。
- 总之,虽然微调可能是有益的,但RAG被认为是LLM中知识注入的一种优越方法,尤其是对于涉及新信息的任务。研究结果突出了使用各种微调技术和辅助知识库进行该领域进一步研究的潜力。
密集X检索:我们应该使用什么检索粒度?
- RAG管道设计中的一个关键选择是分块:它应该是句子级、段落级还是章节级?此选择会显著影响您的检索和响应生成性能。
- 来自华盛顿大学、腾讯人工智能实验室、宾夕法尼亚大学、卡内基梅隆大学的Chen等人的这篇论文介绍了一种在开放域NLP任务中使用“命题”作为检索单元,而不是传统的文档段落或句子进行密集检索的新方法。命题被定义为文本中的原子表达式,以简洁、自包含的自然语言格式封装不同的事实。检索粒度的这种变化对检索和下游任务性能都有显著影响。
- 命题遵循三个关键原则:
- 每个命题都包含了不同的含义,共同代表了整个文本的语义。
- 它们是最小的、不可分割的,确保了准确性和清晰度。
- 每一个命题都是语境化的和自成一体的,包括所有必要的文本语境(如引用),以便于充分理解。
- 作者开发了一个名为“命题器”的文本生成模型,将维基百科页面划分为命题。该模型分两步进行了微调,首先提示GPT-4生成段落到命题对,然后微调Flan-T5大型模型。
- 命题作为检索单元的有效性使用FACTOIDWIKI数据集进行评估,该数据集是一个经过处理的英语维基百科转储,分为段落、句子和命题。实验在五个开放域QA数据集上进行:自然问题(NQ)、TriviaQA(TQA)、网络问题(WebQ)、SQuAD和实体问题(EQ)。比较了六种不同的密集寻回器模型:SimCSE、Contriever、DPR、ANCE、TAS-B和GTR。
- 下图说明了这样一个事实,即在命题层面上对检索语料库进行分割和索引是一种简单而有效的策略,可以提高密集检索器在推理时的泛化性能(a,B)。我们实证比较了当密集检索器与维基百科在100个单词的段落、句子或命题(C,D)水平上进行索引时,检索和下游开放域QA任务的性能
.

- 后果
- 段落检索性能:在所有数据集和模型中,基于命题的检索始终优于句子和段落级别的检索。这一点在SimCSE和Contriever等无监督寻回器中尤为明显,它们显示出平均值Recall@5分别提高12.0%和9.3%。
- 跨任务泛化:命题检索的优势在跨任务泛化设置中最为明显,尤其是对于不太常见的实体的查询。与检索器模型训练期间未发现的数据集中的其他粒度相比,它显示出显著的改进。
- 下游QA性能:在先检索后读取的设置中,基于命题的检索导致更强的下游QA性能。这对于无监督和有监督的寻回犬来说都是如此,精确匹配(EM)得分显著提高。
- 问题相关信息密度:命题被证明提供了更高密度的相关信息,导致正确答案更频繁地出现在前l个检索词中。与句子和段落检索相比,这是一个显著的优势,尤其是在100-200个单词的范围内。
- 错误分析:该研究还强调了每个检索粒度的典型错误类型。例如,段落级检索经常遇到实体模糊的问题,而命题检索在多跳推理任务中面临挑战。
- 该论文的图表显示,在段落检索任务和下游开放域QA任务中,通过命题进行检索都能产生最佳的检索性能,例如,以Contriever或GTR作为骨干检索器。
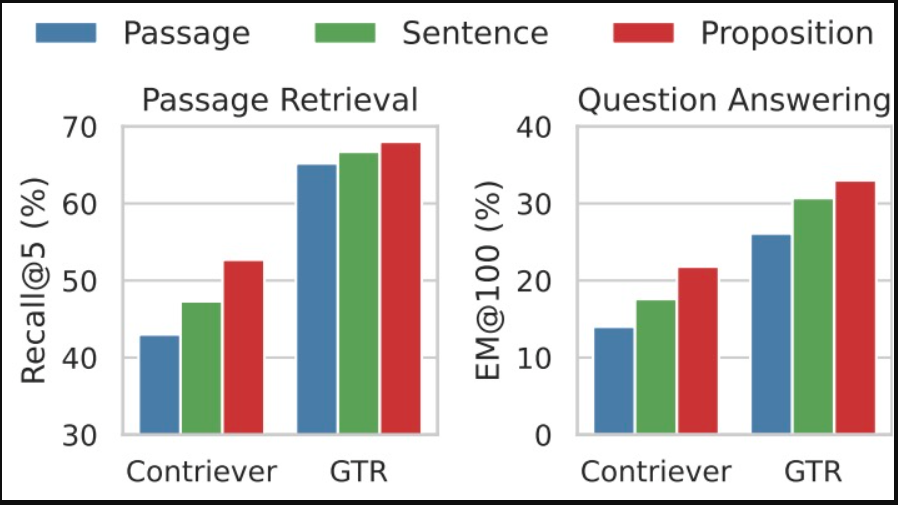
- 研究表明,使用命题作为检索单元显著提高了密集检索性能和下游QA任务的准确性,优于传统的基于段落和句子的方法。FACTOIDWIKI及其2.5亿个命题的引入有望促进未来信息检索的研究。
ARES:一种用于检索增强生成系统的自动评估框架
- 本文由斯坦福大学和加州大学伯克利分校的Saad Falcon等人介绍了ARES(自动RAG评估系统),用于从上下文相关性、答案忠实性和答案相关性的角度评估检索增强生成(RAG)系统。
- ARES使用语言模型生成合成训练数据,并微调轻量级LM判断,以评估单个RAG组件。它利用一小组人工注释的数据点进行预测推理(PPI),为其预测提供统计保证。
- 该框架分为三个阶段:
- LLM生成合成数据集:ARES使用生成LLM(如FLAN-T5 XXL)来创建从目标语料库段落中导出的问答对的合成数据集。这一阶段包括积极和消极的培训例子。
- 准备LLM评委:使用合成数据集,针对三个分类任务——上下文相关性、答案忠实性和答案相关性——对单独的轻量级LM模型进行微调。这些模型是使用对比学习目标进行调整的。
- 使用置信区间对RAG系统进行排名:
- 在准备好LLM评委后,下一步包括使用他们对各种RAG系统进行评分和排名。这个过程从每个RAG方法的域查询文档答案三元组中的ARES采样开始。然后,评委们给每个三元组贴上标签,评估上下文相关性、答案忠实度和答案相关性。对每个域内三元组的这些标签进行平均,以评估RAG系统在三个度量中的性能。
- 虽然平均得分可以被报告为每个RAG系统的质量指标,但这些得分是基于未标记的数据和来自综合训练的LLM法官的预测,这可能会引入噪声。另一种选择是仅依靠一个小的人类偏好验证集进行评估,检查每个RAG系统与人类注释的一致程度。然而,这种方法需要分别标记每个RAG系统的输出,这可能耗时且昂贵。
- 为了提高评估的精度,ARES采用了预测推理(PPI)。PPI是一种统计方法,通过利用对较大的未注释数据集的预测,缩小对较小注释数据集预测的置信区间。它结合了标记数据点和ARES对非注释数据点的判断预测,为RAG系统性能构建了更严格的置信区间。
- PPI涉及在人类偏好验证集上使用LLM判断来学习整流函数。该函数构建了ML模型性能的置信集,考虑了较大的无注释数据集中的每个ML预测。置信集有助于为ML模型的平均性能(例如,其上下文相关性、答案忠实性或答案相关性准确性)创建更精确的置信区间。通过将人类偏好验证集与更大的数据点集与ML预测相集成,PPI为ML模型性能开发了可靠的置信区间,优于传统的推理方法。
- PPI整流器功能解决LLM法官所犯的错误,并为RAG系统的成功率和失败率生成置信界限。它估计在上下文相关性、答案忠实性和答案相关性方面的表现。PPI还允许以指定的概率水平来估计置信区间;在这些实验中,使用了标准的95%α。
- 最后,确定RAG的每个分量的精度置信区间,并使用这些区间的中点对RAG系统进行排序。这种排名能够比较同一系统内的不同RAG系统和配置,有助于确定特定领域的最佳方法。
- 总之,ARES使用PPI对RAG系统进行评分和排序,使用人类偏好验证集来计算置信区间。PPI的工作原理是首先生成大样本数据点的预测,然后人工注释小子集。这些注释用于计算整个数据集的置信区间,确保系统评估能力的准确性。
- 为了实现对RAG系统进行评分并与其他RAG配置进行比较的ARES,需要三个组件:
- 评估标准(例如上下文相关性、答案忠实性和/或答案相关性)的注释查询、文档和答案三元组的人类偏好验证集。应该至少有50个例子,但几百个例子是理想的。
- 一组为数不多的示例,用于在系统中对上下文相关性、答案忠实度和/或答案相关性进行评分。
- RAG系统输出的一组更大的未标记查询文档答案三元组用于评分。
- 论文中的下图显示了ARES的概述:作为输入,ARES管道需要一个域内通道集、一个由150个或更多注释数据点组成的人类偏好验证集,以及五个域内查询和答案的少数镜头示例,这些示例用于在合成数据生成中提示LLM。为了让LLM评委做好评估准备,我们首先从语料库段落中生成综合查询和答案。使用我们生成的训练三元组和对比学习框架,我们对LLM进行微调,以根据三个标准对查询-段落-答案三元组进行分类:上下文相关性、答案忠实性和答案相关性。最后,我们使用LLM判断来评估RAG系统,并使用PPI和人类偏好验证集生成排名的置信界限。

- 在KILT和SuperGLUE的数据集上进行的实验证明了ARES在评估RAG系统方面的准确性,优于现有的自动评估方法,如RAGAS。ARES在各个领域都很有效,即使在查询和文档发生领域变化的情况下也能保持准确性。
- 本文强调了ARES在跨领域应用中的优势及其局限性,例如它无法在剧烈的领域变化(例如,语言变化、文本到代码)中进行概括。它还探索了使用GPT-4生成标签作为PPI过程中人工注释的替代品的潜力。
- ARES代码和数据集可在GitHub上进行复制和部署。
- 165 次浏览
【大语言模型】NLP•检索增强生成之四
视频号
微信公众号
知识星球
- 概述
- 动机
- 神经检索
- 检索增强生成(RAG)流水线
- RAG的好处
- RAG与微调
- RAG合奏
- 使用特征矩阵选择矢量数据库
- 构建RAG管道
- 摄入
- Chucking
- 嵌入
- 句子嵌入:内容和原因
- 背景:与BERT等代币级别模型相比的差异
- 相关:句子转换器的训练过程与令牌级嵌入模型
- 句子变换器在RAG中的应用
- 句子嵌入:内容和原因
- 检索
- 标准/天真的方法
- 优势
- 缺点
- 语句窗口检索/从小到大分块
- 优势
- 缺点
- 自动合并检索器/层次检索器
- 优势
- 缺点
- 计算出理想的块大小
- 寻回器镶嵌和重新排列
- 使用近似最近邻进行检索
- 重新排序
- 标准/天真的方法
- 响应生成/合成
- 迷失在中间:语言模型如何使用长上下文
- “大海捞针”测试
- 摄入
- 组件式评估
- 检索度量
- 上下文精度
- 上下文回忆
- 上下文相关性
- 生成度量
- 脚踏实地
- 回答相关性
- 端到端评估
- 回答语义相似性
- 答案正确性
- 检索度量
- 多模式RAG
- 改进RAG系统
- 相关论文
- 知识密集型NLP任务的检索增强生成
- 主动检索增强生成
- 多模式检索增强生成器
- 假设文档嵌入(HyDE)
- RAGAS:检索增强生成的自动评估
- 微调还是检索?LLM中知识注入的比较
- 密集X检索:我们应该使用什么检索粒度?
- ARES:一种用于检索增强生成系统的自动评估框架
- 引用
组件式评估
- LLM的RAG系统中的组件评估包括单独评估系统的各个组件。这种方法通常检查检索组件和生成组件的性能,检索组件从数据库或语料库中获取相关信息,生成组件基于检索到的数据合成响应。通过单独评估这些组成部分,研究人员可以确定整个RAG系统中需要改进的特定领域,从而在LLM中实现更高效、更准确的信息检索和响应生成。
- 虽然上下文精度、上下文回忆和上下文相关性等指标可以深入了解RAG系统的检索组件的性能,但基础性和答案相关性可以了解生成的质量。
- 明确地
- 评估检索的指标:上下文相关性、上下文回忆和上下文精度,它们共同评估响应用户查询检索到的信息的相关性、完整性和准确性。Context Precision侧重于系统对相关项目进行更高排名的能力,Context Recall评估系统检索上下文所有相关部分的效果,Context Correlation衡量检索到的信息与用户查询的一致性。这些指标确保了检索系统在提供最相关和最完整的上下文以生成准确响应方面的有效性。
- 评估生成的指标:可信度和答案相关性,分别衡量生成的答案与给定上下文的事实一致性及其与原始问题的相关性。忠实注重答案的事实准确性,确保所有的说法都能从给定的上下文中推断出来。答案相关性评估答案在多大程度上解决了最初的问题,从而惩罚了不完整或多余的回答。这些度量确保生成组件生成上下文适当且语义相关的答案。
- 这四个方面的调和平均值为您提供了总体分数(也称为ragas分数),这是衡量RAG系统在所有重要方面性能的单一指标。
- 大多数测量不需要任何标记的数据,这使得用户更容易运行它,而不用担心首先构建人工注释的测试数据集。为了运行ragas,您只需要几个问题,如果您使用context_recall,则需要一个参考答案。
- 总的来说,这些指标提供了RAG系统检索性能的全面视图,可以使用用于评估RAG管道(如Ragas或TruLens)的库来实现,并提供有关RAG管道性能的详细见解,重点关注检索和生成的内容在上下文和事实上对用户查询的响应。具体来说,Ragas提供了专门为单独评估RAG管道的每个组件而定制的指标。这种方法补充了对您的系统进行更广泛的系统级端到端评估(详见端到端评价),使您能够更深入地了解RAG系统在复杂的上下文和事实准确性至关重要的现实场景中的表现。下图(来源)显示了Ragas提供的指标,这些指标是为单独评估RAG管道的每个组件(检索、生成)而定制的。
- 下图(来源)显示了可用于评估RAG的“三重”指标:基础性(也称为可信度)、答案相关性和上下文相关性。请注意,上下文精确性和上下文回忆也很重要,最近在Ragas的新版本中引入了它们。

检索度量
- 在LLM的背景下评估RAG的检索组件包括评估系统检索相关信息的有效性,以支持生成准确且符合上下文的响应。
上下文精度
- 类别:上下文对齐和精度
- 重点:评估RAG系统在结果中排名较高的背景下对地面实况相关项目进行排名的准确性。在响应查询时,确定最相关的信息块是否按优先级排列在最前列至关重要。
- 测量方法:使用一个公式,该公式考虑了前K个结果中是否存在真阳性(相关项目排名正确)和假阳性(无关项目排名错误)。这通常使用问题及其上下文信息进行评估。
- 评估方法:通过首先识别上下文的前K个块中的真阳性和假阳性,然后计算K处的精度来计算度量。上下文精度的公式如下:

- 其中k表示上下文中考虑的块的总数。上下文精度的值介于0和1之间,分数越高表示上下文与查询的相关项的对齐越精确。
上下文回忆
- 类别:上下文对齐和回忆
- 焦点:评估RAG系统检索到的上下文与注释答案一致的程度,被视为基本事实。它专门衡量系统检索与基本事实答案直接相关的上下文所有相关部分的能力。
- 测量方法:通过分析基本事实答案中的句子与检索到的上下文之间的对应关系来计算上下文回忆。它可以使用评估基本事实句子对检索到的上下文的归因的方法来测量。
- 评估方法:这个过程包括识别基本事实答案中的每一句话,并确定它是否在检索到的上下文中表示。上下文召回的计算公式如下:
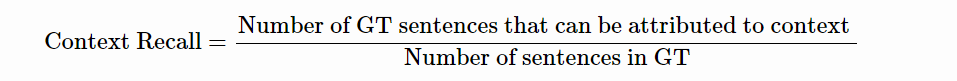
- 实例
- 问题:法国在哪里,首都是什么?
- 基本事实:法国位于西欧,首都是巴黎。
- 高上下文回忆示例:上下文包括法国在西欧的信息,并提到巴黎是其首都。
- 低语境回忆示例:语境谈论法国的地理特征和历史,但没有提及其首都。
- 在该度量中,值的范围在0和1之间,值越高表示在将检索到的上下文与基本事实答案对齐方面的性能越好。
上下文相关性
- 类别:上下文一致性和相关性
- 集中
- “返回的段落是否与回答给定的问题相关?”
- 测量RAG系统检索的上下文或内容与用户查询的一致性。它专门评估检索到的信息是否与给定的查询相关和合适,确保只包括基本信息以有效地处理查询。
- 测量方法:可以使用较小的BERT风格模型、嵌入距离或LLM进行测量。该方法包括通过识别检索到的上下文中与回答给定问题直接相关的句子来估计上下文相关性的值。
- 评估方法:包括两个步骤:首先,使用语义相似性度量来识别相关句子,为每个句子生成相关性得分。接下来是对整体上下文相关性的量化,其中使用以下公式计算最终得分:

- 示例:
- 高度语境相关性的例子:对于“法国的首都是什么?”这样的问题,高度相关的语境是“西欧的法国包括中世纪城市、高山村庄和地中海海滩。其首都巴黎以其时装店、包括卢浮宫在内的古典艺术博物馆和埃菲尔铁塔等纪念碑而闻名。”
- 低上下文相关性示例:对于同一个问题,不太相关的上下文将包括额外的、不相关的信息,例如“该国也以其葡萄酒和精致的美食而闻名。拉斯科的古代洞穴绘画、里昂的罗马剧院和广阔的凡尔赛宫证明了其丰富的历史。”
- 该指标确保RAG系统提供简洁且直接相关的信息,提高了对特定查询的响应的效率和准确性。
生成度量
- 在LLM的背景下评估RAG的生成部分包括评估系统将检索到的信息无缝集成到连贯、上下文相关和语言准确的响应中的能力,确保检索到的数据和生成语言技能的和谐融合。简单地说,这些指标共同提供了一种细致入微的多维方法来评估RAG系统,不仅强调信息的检索,还强调其上下文相关性、事实准确性以及与用户查询的语义一致性。
脚踏实地
- 类别:事实一致与语义相似
- 集中
- “生成的答案是否忠实于检索到的段落?或者它是否包含段落之外的幻觉或推断陈述?”
- 该度量评估模型的响应和检索到的文档之间的事实一致性和语义相似性。它确保生成的响应在上下文中是适当的,并以检索到的信息为事实依据。具体来说,它评估模型答案中的所有声明是否可以直接从给定的上下文中推断出来。
- 测量方法:可以使用自然语言推理(NLI)模型、大型语言模型(LLM)以及自动化系统和人类判断的组合来测量基础性。忠诚度得分是通过将生成的答案中的主张与给定上下文中的主张进行比较来计算的,使用以下公式:

- 评估方法:利用思维链(CoT)提示来模拟推理过程,通过自动化系统(用于语义匹配和事实核查)和人类判断的混合方法,在0或1的范围内对对齐进行评分。评估过程包括从生成的答案中识别一组索赔,并将这些索赔中的每一项与给定的上下文进行交叉检查,以确定其事实一致性。
- 示例:
- 高忠实度的例子:对于“爱因斯坦是在哪里和什么时候出生的?”这个问题,在“阿尔伯特·爱因斯坦(1879年3月14日出生)是一位德国出生的理论物理学家”的背景下,高忠实度答案是“爱因斯坦1879年三月14日出生在德国。”
- 低忠诚度的例子:对于同样的问题和背景,低忠诚度的答案是“爱因斯坦于1879年3月20日出生在德国。”
- 这一指标对于确保RAG系统生成的响应的可靠性和可信度至关重要,因为它直接关系到响应查询提供的信息的准确性和事实一致性。
回答相关性
- 类别:反应质量和语义相关性
- 集中
- “给定查询和检索到的文章,生成的答案是否相关?”
- 此度量评估模型生成的答案与用户查询的相关性。它评估生成的答案与给定提示的相关性,惩罚不完整或包含冗余信息的答案。它不考虑事实,而是侧重于对最初问题的回答的直接性和适当性。
- 测量方法:使用BERT风格的模型、嵌入距离或LLM进行量化。该度量是使用从答案和原始问题生成的多个问题之间的平均余弦相似性来计算的,没有参考。此测量的公式为:

- 其中q是原始问题,qi是由答案生成的问题,sim表示它们的嵌入之间的余弦相似性。
- 评估过程:包括多次提示LLM为生成的答案生成适当的问题,然后测量这些生成的问题与原始问题之间的平均余弦相似性。其基本思想是,如果生成的答案准确地解决了最初的问题,LLM应该能够从与原始问题紧密一致的答案中生成问题。
- 示例:
- 低相关性答案示例:对于“法国在哪里,首都是什么?”这个问题,低相关性答案是“法国在西欧。”
- 高相关性答案示例:对于同一个问题,高相关性答案是“法国在西欧,巴黎是其首都。”
这一指标对于确保RAG系统提供的答案不仅准确,而且完整,直接解决用户的查询而不包括不必要的细节至关重要。
- 下图(来源)显示了Answer Correlation的输出格式。

端到端评估
- 评估管道的端到端性能也至关重要,因为它直接影响用户体验。Ragas提供了可用于评估管道整体性能的指标,确保进行全面评估。
回答语义相似性
- 类别:答案质量和语义一致性
- 焦点:评估RAG系统生成的答案与基本事实之间的语义相似程度。该指标专门评估生成的答案的含义与基本事实的含义的反映程度。
- 测量方法:使用交叉编码器模型来测量该度量,该模型旨在计算语义相似性得分。这些模型分析生成的答案和基本事实的语义内容。
- 评估方法:该方法包括将生成的答案与基本事实进行比较,以确定语义重叠的程度。语义相似性在0到1的范围内进行量化,其中得分越高表示生成的答案与基本事实之间的一致性越大。答案语义相似性的公式是隐含地基于语义重叠的评估,而不是直接的公式。
- 实例
- 基本事实:阿尔伯特·爱因斯坦的相对论彻底改变了我们对宇宙的理解。
- 高度相似的答案:爱因斯坦开创性的相对论改变了我们对宇宙的理解。
- 低相似性答案:艾萨克·牛顿的运动定律极大地影响了经典物理学。
- 在这个指标中,更高的分数反映了生成的响应在语义上与基本事实的接近程度方面的更好质量,这表明答案更准确且与上下文相关。
答案正确性
- 类别:答案的准确性和正确性
- 焦点:与基本事实相比,该指标评估RAG系统生成的答案的准确性。它不仅强调语义上的相似性,而且强调生成的答案相对于基本事实的事实正确性。
- 测量方法:评估答案的正确性包括评估语义相似性和事实相似性。使用加权方案来集成这些方面,加权方案可以包括使用交叉编码器模型或用于语义分析的其他复杂方法。用户还可以应用阈值以二进制方式解释分数。
- 评估方法:该方法需要将生成的答案与基本事实进行比较,以评估语义和事实的一致性。这两个方面的综合评估产生了答案正确性得分,其范围从0到1,其中得分越高表示准确性越高,并且与基本事实一致。
- 实例
- 基本事实:爱因斯坦1879年出生于德国。
- 答案正确率高的例子:1879年,爱因斯坦在德国出生。
- 答案正确率低的例子:爱因斯坦1879年出生于西班牙。
- 该指标强调了不仅要理解用户查询的上下文和内容(如上下文相关性评估),还要确保提供的答案在事实和语义上与既定事实一致,从而确保RAG系统的高质量响应的重要性。
- 86 次浏览
【大语言模型】𝐋𝐋𝐌𝐬 路线图: 从nlp基础知识到理解llms的精心策划的内容列表
视频号
微信公众号
知识星球
📌 𝐍𝐋𝐏
📚 𝐂𝐨𝐮𝐫𝐬𝐞: NLP specialization https://lnkd.in/eZQc9hTu
📑 𝐀𝐫𝐭𝐢𝐜𝐥𝐞: NLP word representations basics: https://lnkd.in/eFqSJYxa
📑 𝐀𝐫𝐭𝐢𝐜𝐥𝐞: Attention is all you need: https://lnkd.in/erP6xex8
📹 𝐕𝐢𝐝𝐞𝐨: Word embedding, Word2Vec: https://lnkd.in/eweB-sjU
📹 𝐕𝐢𝐝𝐞𝐨: Decoder only Transformers: https://lnkd.in/e-ewtNXJ
📌 𝐋𝐚𝐫𝐠𝐞 𝐋𝐚𝐧𝐠𝐮𝐚𝐠𝐞 𝐌𝐨𝐝𝐞𝐥𝐬
📚 𝐂𝐨𝐮𝐫𝐬𝐞: Understanding Large Language Models https://lnkd.in/ehjGtA8U
📚 𝐂𝐨𝐮𝐫𝐬𝐞: Hands on LLM course by Maxime Labonne https://lnkd.in/e_xNSZyY
📚 𝐂𝐨𝐮𝐫𝐬𝐞: Hans on LLM by Paul Iusztin and Pau Labarta Bajo https://lnkd.in/eevAYGky
📑 𝐀𝐫𝐭𝐢𝐜𝐥𝐞: LLM Patterns: https://lnkd.in/eJT3m9Ck
📌 𝐅𝐨𝐮𝐧𝐝𝐚𝐭𝐢𝐨𝐧 & 𝐏𝐫𝐞-𝐭𝐫𝐚𝐢𝐧𝐞𝐝 𝐌𝐨𝐝𝐞𝐥𝐬
📚 𝐂𝐨𝐮𝐫𝐬𝐞: NLP course Hugging Face https://lnkd.in/e-RjcYGu
📚 𝐂𝐨𝐮𝐫𝐬𝐞: NLP & LLM Course by Cohere https://lnkd.in/eKys6E5U
📚 𝐂𝐨𝐮𝐫𝐬𝐞: Fine-tuning Large Language Models (short): https://lnkd.in/ehVRv-ZE
llms
📑 𝐀𝐫𝐭𝐢𝐜𝐥𝐞: Improving Language Understanding by Generative Pre-Training https://lnkd.in/eg9FDgXq
📑 𝐀𝐫𝐭𝐢𝐜𝐥𝐞: gpt3 Language Models are Few-Shot Learners https://lnkd.in/e7CN3J-t
📌 𝐑𝐀𝐆 𝐒𝐲𝐬𝐭𝐞𝐦𝐬
📚 𝐂𝐨𝐮𝐫𝐬𝐞: Semantic Search : https://lnkd.in/eRak73U9
📚 𝐂𝐨𝐮𝐫𝐬𝐞: Building Applications with Vector Databases (short) by DeepLearning.AI https://lnkd.in/etxjqdJs
📑 𝐀𝐫𝐭𝐢𝐜𝐥𝐞: RAG for Knowledge-Intensive NLP Tasks https://lnkd.in/eGwmUbHs
📌 𝐆𝐞𝐧 𝐀𝐈
📚 𝐂𝐨𝐮𝐫𝐬𝐞: Generative Path by Google: https://lnkd.in/eyms3zrM
📚 𝐂𝐨𝐮𝐫𝐬𝐞: Full-stack LLM https://lnkd.in/eEvnJ3W7
📚 𝐂𝐨𝐮𝐫𝐬𝐞: Deploying GPT and Pre-trained Models https://lnkd.in/eXfhFHnj
📚 𝐂𝐨𝐮𝐫𝐬𝐞: RLHF (short): https://lnkd.in/e4bG_k6J
📑 𝐀𝐫𝐭𝐢𝐜𝐥𝐞: Prompt Engineering basics: https://lnkd.in/eYK_fWQV
📌 𝐋𝐋𝐌𝐎𝐏𝐬
📚 𝐂𝐨𝐮𝐫𝐬𝐞: LLMOps (short) https://lnkd.in/e7nT4A_2
📚 𝐂𝐨𝐮𝐫𝐬𝐞 Functions, Tools and Agents with LangChain (short) https://lnkd.in/eEWvf8-d
📚 𝐂𝐨𝐮𝐫𝐬𝐞 : Automated testing LLMOPs (short) https://lnkd.in/e6ZCeytC
- 63 次浏览
【数据】ChatGPT、大型语言模型与数据库技术和分析咨询的未来
视频号
微信公众号
知识星球
每个人都在谈论ChatGPT、生成性人工智能模型及其可能对白领工作、软件工程(如Github Co-Pilot)以及现代数据堆栈中更贴近家庭的数据角色产生的影响。我们甚至可以使用生成人工智能为这个博客创建一个开场白,让插画师放心,至少他们的工作暂时相对安全。
Rittman Analytics是一家典型的“精品”现代数据堆栈咨询公司,有包括我在内的8名团队成员,我们所有人都是每天与数据和客户合作的实践从业者,提供从战略建议到实施和用户支持的一系列服务。
我们通常在任何时候都有大约六个客户项目同时运行,花大量时间与客户进行面对面(现在通常是虚拟的)会议,在我们这边进行项目管理,并负责确保整个项目按预期交付。
我们为自己的技能和客户的推荐感到骄傲……但在他们的工作被淘汰之前,送奶工、公交车售票员、商业街旅行社、水蛭收集者、蟾蜍医生和锣农也是如此。那么,最新版本的OpenAI大型语言模型交互式聊天服务ChatGPT-4能否取代分析工程师的角色,甚至取代对分析顾问的需求?
我在OpenAI网站上开始了一个新的ChatGPT会话,并为一家咨询公司的分析项目做了一个启动简报。
ChatGPT直接定义了一个合理的启动模式,尽管它一开始就犯了一个基本的SQL语法错误。事实上,BigQuery现在确实支持主键和外键约束,但没有强制执行它们,而是使用它们向BigQuery的查询计划器提供额外的模式元数据,而这个新DDL功能的正确语法是primary key(column_name)NOT ENFORCED。
ChatGPT方法中另一个更微妙但更长期、更显著的不足之处是,它只对能够满足用户字面请求的最低限度的表模式进行建模,而不是一个更全面的模式,无论是体验还是进一步的质疑,都会导致您创建该模式。但是,除了每个表的DDL中的语法错误外,它确实为所给出的请求创建了一个合理的模式。
然后,我要求ChatGPT创建一个dbt包,该包从每个Fivetran源的暂存数据集中获取原始数据,对其进行集成和转换,然后将其加载到它刚刚定义的架构的事实表和维度表中。
然后,我给ChatGPT一个更具挑战性的任务,即不仅在客户端名称完全匹配的情况下,而且在它们听起来相似的情况下消除重复。当使用Hubspot等来源的公司名称时,这通常是一项要求。在Hubspot中,销售代表在记录新的销售交易时输入单个公司名称的许多变体,但您希望在查看该账户的交易历史记录时,这些交易解析为单个公司名称。
ChatGPT自信地提出使用BigQuery的Jaro-Winkler字符串相似性函数来实现这一点,并为我重写了dbt代码。

除了…BigQuery没有JARO_WINKLER字符串函数。在写这篇博客时,你能得到的最接近的方法是创建一个UDF(用户定义函数),据我所知,唯一具有Jaro Winkler功能的数据库服务器是Oracle数据库,即使这样,它也是Oracle UTL_MATCH函数的一个参数,而不是SQL函数本身。
事实上,ChatGPT似乎已经发明了自己的BigQuery SQL函数,然后自信地将其作为解决方案交给了我,但这段代码无法运行,任何没有BigQuery开发经验的人都不知道哪里出了问题,下一步该怎么办。
然后,我继续提出进一步的请求,公平地说,ChatGPT很好地处理了这些请求,清楚地了解了每个来源提供的一组列,以及它们如何映射到发票、发票ID和发票日期等常见概念,以及已付款、未付款和未付款发票等概念。
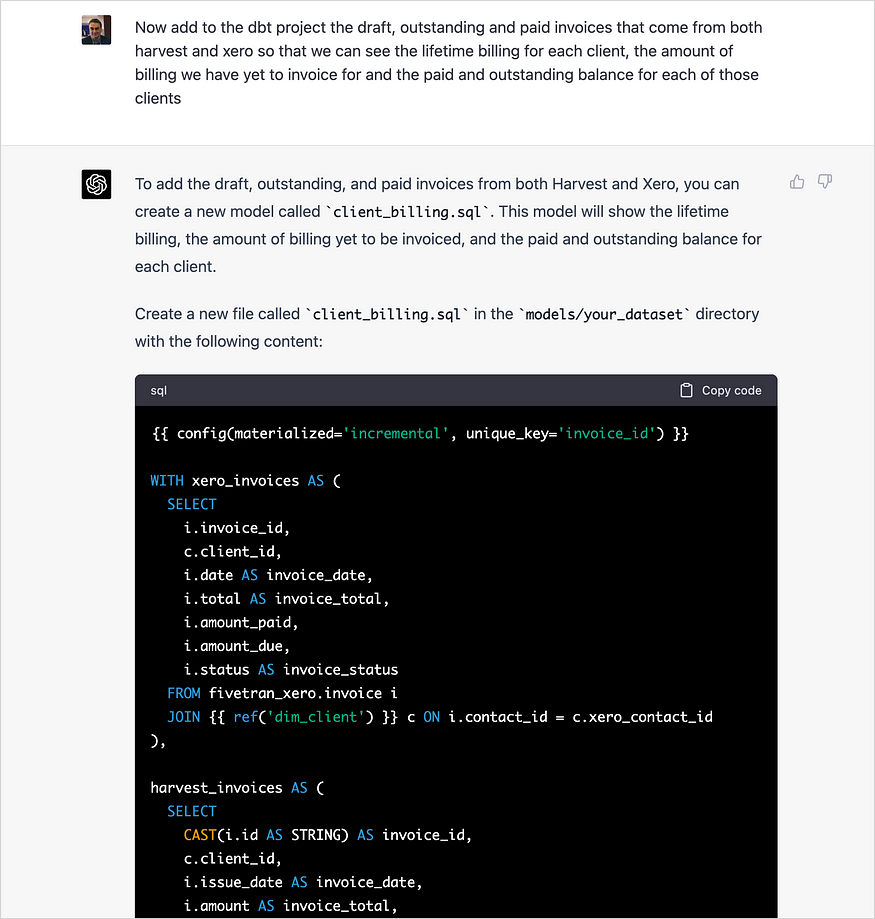
当我要求它添加员工利用率的计算时,它也毫不退缩,尽管在实践中,我们通常会在软件包中添加一个日期脊柱表,以帮助计算所有日子的总产能,而不仅仅是员工实际工作过的产能。
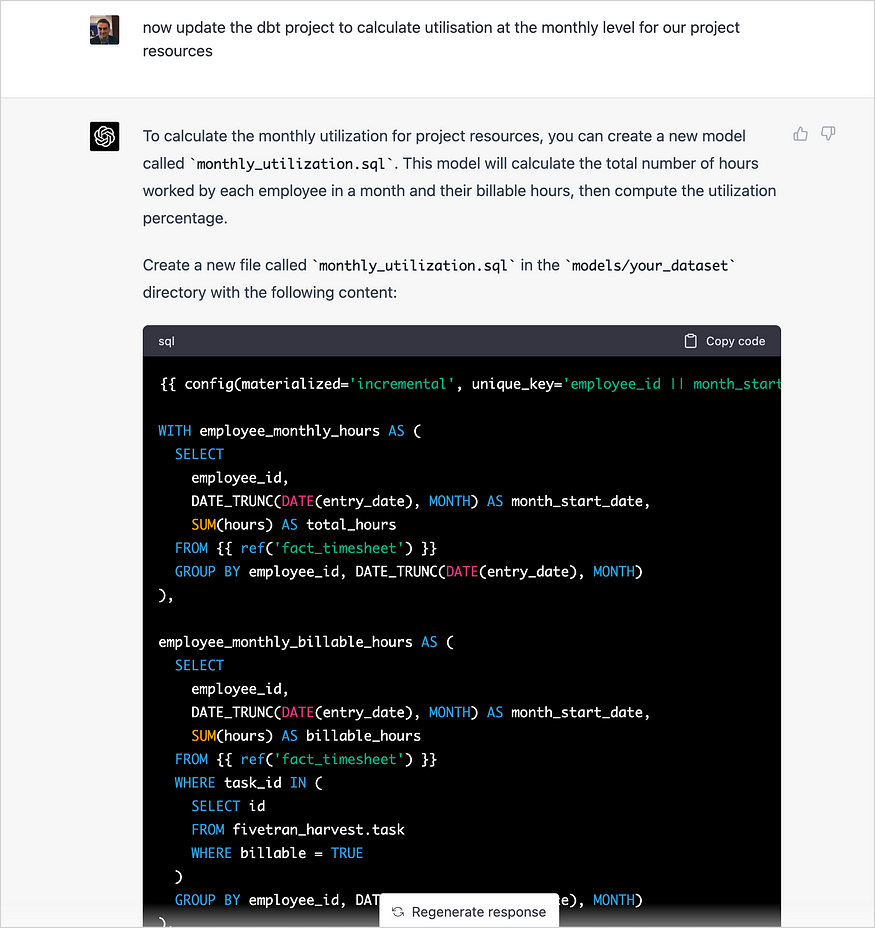
我甚至要求ChatGPT从我们的HRMS系统Humaans引入数据,建议它使用该服务的REST API为数据创建一个数据提取器,然后将其加载到我们的BigQuery数据库中。然后,它提供了其解决方案的概述,并生成Python代码以连接到Humaan的REST API,下载相关数据,然后使用其Python-客户端将其加载到BigQuery中。
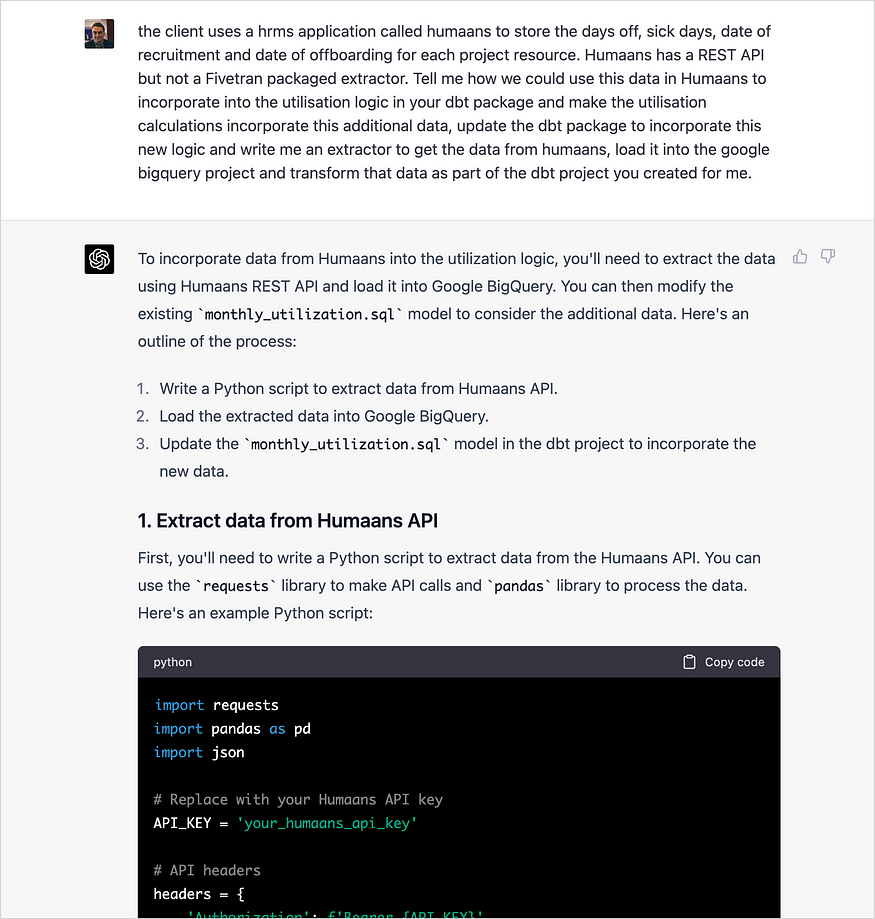
它不是最健壮的解决方案,也没有考虑如何调度和编排Python脚本或dbt包,但它是一个很好的初始原型。
更重要的是,如果你是一个在Fiverr等网站上从事dbt工作的自由职业者,或者是一个通过大量生成由解决方案架构师严格指定的dbt代码来学习专业的初级开发人员,那么ChatGPT很可能会做得更好。
它甚至可以在生成的代码中包含我们的命名标准。
目前,尽管ChatGPT在同一个整体聊天会话中保留了早期指令的上下文,但我们需要在我们启动的任何新聊天会话中提供这些标准的详细信息。
然而,在不久的将来,咨询公司和其他组织将有可能创建自己的LLM(大型语言模型),其中包含特定领域的培训数据,如我们位于私人git repos中的dbt代码库,以及我们的命名标准、标准操作程序和解决方案手册,这些共同构成了我们服务背后的价值和IP。
有些事情,比如添加到dbt中的最新功能,会使仅在某个时间点收集的数据上训练的GPT模型出错。当我要求它在包中已经创建的模型上添加一个dbt语义层时,它最初会根据暴露、dbt中的度量和语义层的前置光标给出一个答案,然后提出一个SQL视图,为该暴露提供一组非规范化的列。
然后,我纠正了它,并提出了一个使用dbt最新版本中引入的度量功能的解决方案,对此,ChatGPT首先做出道歉回应,然后是一个修改后的解决方案——这对于将度量和语义层合并到包中来说是一个不错的开端。
然而,就我们这样的dbt首选合作伙伴的响应而言,这确实不够,因为这里需要考虑的不仅仅是实现这一特定功能的命令语法。
通过使用dbt的语义层,您可以含蓄地选择将自己限制在现代数据堆栈生态系统中那些与dbt语义层、代理服务器和其他启用技术兼容的BI和其他工具上;同样,如果你选择了Looker的通用语义模型或Cube目前功能更丰富但也更小众的语义模型等替代方案,那么你就隐含地在选择更广泛的解决方案,而对于对这一技术领域知之甚少的客户来说,这是不明显的。
不过,如果你要求ChatGPT给你一个技术建议,它对技术选择并不缺乏意见。在最初要求它为我提供一种将数据从仓库同步回Hubspot CRM的方法后,我问它反向ETL工具是否是更好的解决方案,如果是,我推荐一个。
对于Hightouch来说,它很好地推荐了他们的工具,这提醒我尝试将ChatGPT的培训数据与Rittman Analytics相结合,以便它向我们推荐dbt咨询服务,即使只是咨询公司位于英国布莱顿的那些服务,这是一家精品咨询公司,在社交媒体上有着强大的影响力。
数据棚,不管他们是谁,总部设在利兹,似乎专注于基于Azure和AWS的现代数据堆栈解决方案,而不是基于dbt、Looker和BigQuery的解决方案(如果你们正在阅读这篇文章,想知道自己是如何被拖入这篇文章的,大家好,这并不意味着冒犯)。
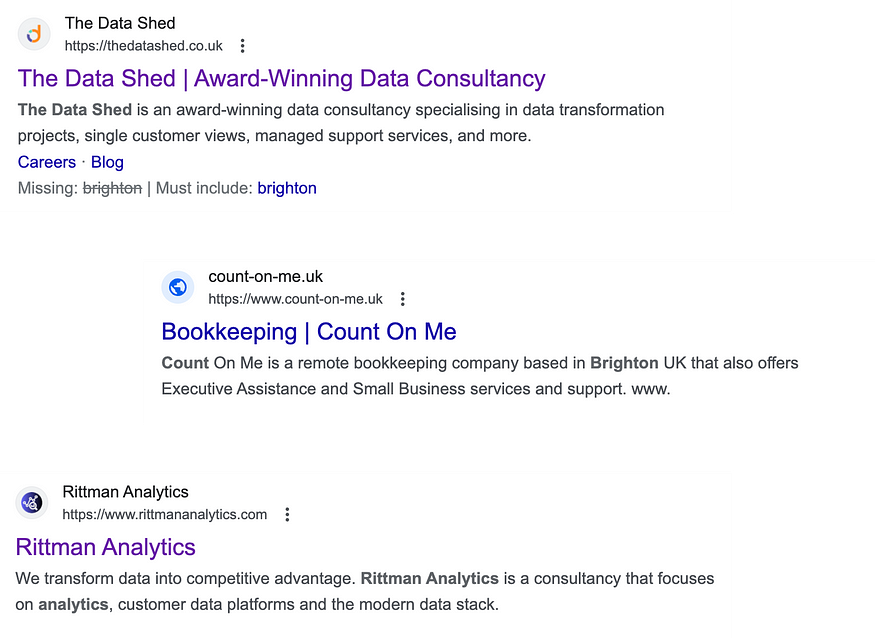
事实上,Dataform是一家现已倒闭的产品初创公司,正在打造dbt的竞争对手,该公司最近已并入谷歌云平台,因此不知道为什么它们是这些服务的下一个推荐。最奇怪的是,Count甚至不存在,除了作为本地簿记服务使用的标记行,直到我用我们的实际公司名称提示ChatGPT,它才最终认可我们;我认为LLM优化加入SEO优化是我们未来在线营销战略的重要组成部分。
因此,我问ChatGPT如何最好地利用它来改进我们咨询公司的产品、服务和内部流程。
它当然可以处理相对简单的,或者至少相对容易定义的任务,甚至不会试图方便地忘记内务管理任务,比如编写包文档,这会占用编码和其他更有趣的工作的时间。
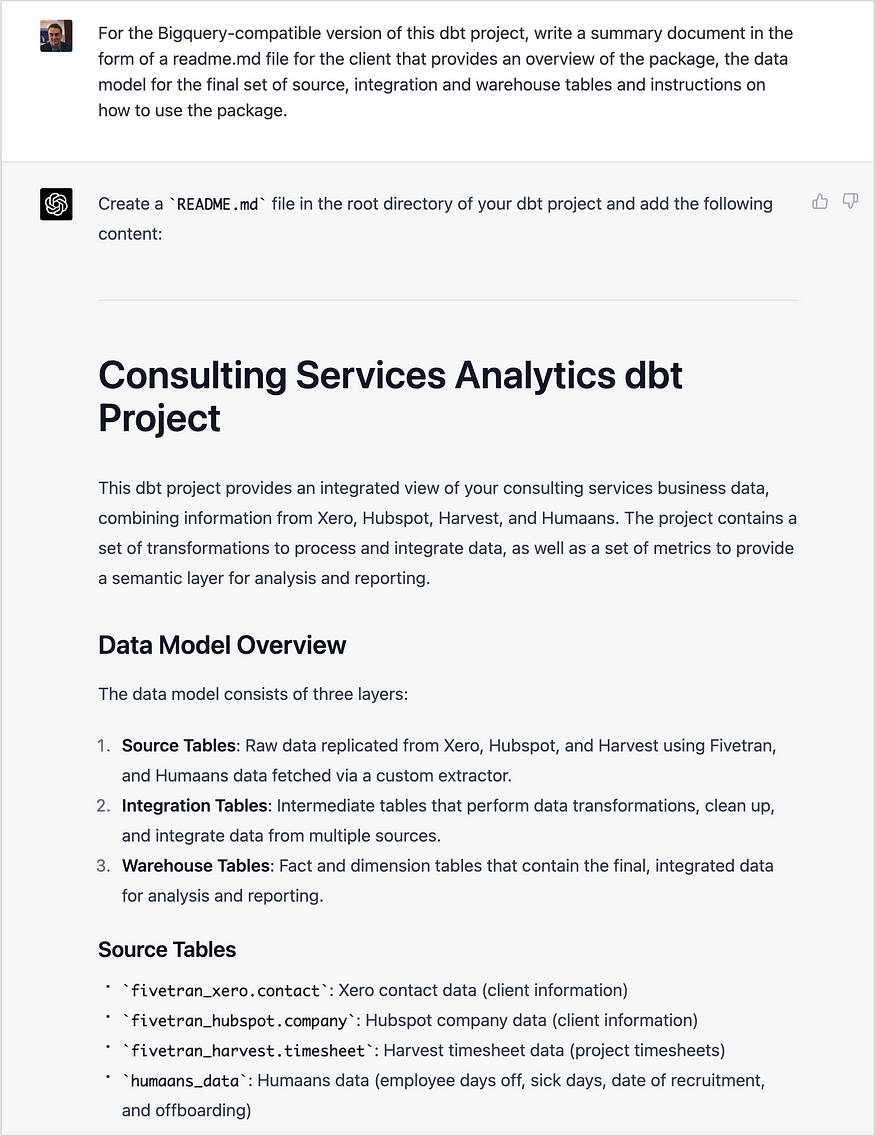
但它会犯错误,并发出怒吼,比如这个项目中的JARO_WINKLER,只做你要求它做的事情,不再做。因此,它本质上是另一个初级开发人员,充满热情、意见和似是而非的废话,如果得到适当的监督和指导,可以提高高级顾问的生产力,但你不敢让客户单独为他们的数据分析策略提供建议。
对于一个知道自己想要什么、认为自己知道如何做、只需要找到一个能满足自己要求的人的潜在客户来说,这更是一个危险的前景。这些客户往往是最危险的(但也很有娱乐性和开放性)客户,他们最需要的是从自己身上节省开支,并转向真正满足他们需求的解决方案,而不是完全按照他们的要求提供,然后很快就会失败。
毫无疑问,未来生成型人工智能、公共服务(如ChatGPT)以及这些基础模型上的特定领域版本的迭代将使IT和计算看起来像是工业革命的开始。
但是,交付一个成功、有价值和可扩展的现代数据堆栈实现,不仅仅是编写dbt、Looker和Python代码,从定义要解决的实际问题开始,并确保交付的内容有意义,解决了客户的问题,并实现了突破、转换互动机构和Torticity等企业在刚刚添加到我们网站的新客户证明中描述的业务转型和创新服务类型。
感兴趣吗?了解更多信息
Rittman Analytics是一家专注于现代数据堆栈的精品分析咨询公司,它可以帮助您集中数据源,优化营销活动,并为您的最终用户和数据团队提供最佳实践和现代分析工作流程,由一组管理机器人、,热情的胡言乱语的大型语言模型,做所有繁重的工作。
如果您正在寻求一些帮助和帮助来分析和理解您的客户行为,或者使用现代、灵活和模块化的数据堆栈来帮助建立您的分析能力和数据团队,请立即联系我们,组织一次100%免费、无义务的电话会议-我们很乐意收到您的来信!
- 76 次浏览
【数据架构】将LLM应用于企业数据:概念、关注点和热点
视频号
微信公众号
知识星球
要求GPT-4在押韵的同时证明存在无穷多的素数,它就能实现。但如果问一下你的球队上个季度的表现和计划,结果会惨败。这说明了大型语言模型(“LLM”)的一个根本挑战:它们很好地掌握了一般的公共知识(如素数理论),但完全不知道专有的非公开信息(您的团队上个季度是如何做到的)[1]而且专有信息对绝大多数企业使用工作流至关重要。一个了解公共互联网的模型很可爱,但对大多数组织来说,它的原始形式用处不大。
在过去的一年里,我有幸与许多将LLM应用于企业用例的组织合作。这篇文章详细介绍了任何踏上这段旅程的人都应该知道的关键概念和关注点,以及我认为LLM将如何发展以及对ML产品战略的影响。它面向的是产品经理、设计师、工程师和其他读者,他们对LLM如何“在引擎盖下”工作知之甚少或一无所知,但对学习概念感兴趣,而不涉及技术细节。
四个概念
提示工程、上下文窗口和嵌入
使LLM对专有数据进行推理的最简单方法是在模型的提示中提供专有数据。大多数LLM都会正确回答以下问题:“我们有两个客户,A和B,他们分别花了10万美元和20万美元。谁是我们最大的客户,他们花了多少钱?”我们刚刚完成了一些基本的提示工程,在查询(第二句)前加上上下文(第一句)。
但在现实世界中,我们可能有成千上万或数百万的客户。考虑到上下文中包含的每个单词都需要花钱,我们如何决定哪些信息应该进入上下文?这就是嵌入的用武之地。嵌入是一种将文本转换为数字向量的方法,其中相似的文本生成相似的向量(在N维空间中“紧密相连”的向量)。[2] 我们可能会嵌入网站文本、文档,甚至可能是SharePoint、Google Docs或Notion的整个语料库。然后,对于每个用户提示,我们将其嵌入,并从我们的文本语料库中找到与提示向量最相似的向量。
例如,如果我们在维基百科上嵌入了关于动物的页面,而用户问了一个关于狩猎的问题,我们的搜索会对维基百科上关于狮子、斑马和长颈鹿的文章进行高度排名。这使我们能够识别与提示最相似的文本块,从而最有可能回答它。[3]我们将这些最相似的文字块包括在提示前的上下文中,这样提示就有望包含LLM回答问题所需的所有信息。
微调
嵌入的一个缺点是,对LLM的每次调用都需要在传递提示时传递所有上下文。LLM甚至连最基本的企业特定概念都没有“记忆”。由于大多数基于云的LLM提供商对每个提示令牌收费,这可能会很快变得昂贵。[4]
微调允许LLM理解特定于企业的概念,而无需在每个提示中包含这些概念。我们采用了一个基础模型,该模型已经对数十亿个学习参数中的一般知识进行了编码,并调整这些参数以反映特定的企业知识,同时仍然保留基本的一般知识。[5] 当我们使用新的微调模型生成推论时,我们可以“免费”获得企业知识。
与嵌入/提示工程(底层模型是第三方黑盒)相比,微调更接近于经典的机器学习,ML团队从头开始创建自己的模型。微调需要一个带有标记观测值的训练数据集;微调模型对训练数据的质量和数量高度敏感。我们还需要做出配置决策(时期数量、学习率等),安排长期的培训工作,并跟踪模型版本。一些基础模型提供程序提供了一些抽象掉这种复杂性的API,有些则没有。
虽然微调模型的推断可能更便宜,但昂贵的培训工作可能会超过这一点。[6] 一些基础模型提供商(如OpenAI)只支持对滞后边缘模型进行微调(因此不支持ChatGPT或GPT-4)。
Evals
LLM提出的一个新颖而重大的挑战是测量复杂输出的质量。经典的ML团队已经尝试了真实的方法来测量简单输出的准确性,比如数字预测或分类。但LLM的大多数企业用例都涉及生成数万到数千个单词的响应。复杂到需要十多个单词的概念通常可以用多种方式表达。因此,即使我们有一个经过人工验证的“专家”响应,将模型响应与专家响应进行精确的字符串匹配也是一个过于严格的测试,并且会低估模型响应的质量。
由OpenAI开源的 Evals框架是解决这个问题的一种方法。该框架需要一个标记的测试集(其中提示与“专家”响应相匹配),但它允许在模型和专家响应之间进行广泛类型的比较。例如,是模型生成的答案:专家答案的子集或超集;事实上与专家的答案相当;比专家的答案简洁多少?需要注意的是,Evals使用LLM执行这些检查。如果“checker”LLM中存在缺陷,则eval结果本身可能不准确。
对抗性例子
如果您在生产中使用LLM,您需要确信它能够安全地处理被误导或恶意的用户输入。对于大多数企业来说,出发点是确保该模型不会传播虚假信息。这意味着一个系统知道自己的局限性,知道什么时候该说“我不知道”。这里有很多战术方法。它可以通过即时工程来完成,并使用即时语言,如“如果无法用上面提供的上下文回答问题,请回答‘我不知道’”)。可以通过提供范围外的培训示例进行微调,专家的回答是“我不知道”。
企业还需要防范恶意用户输入,例如即时黑客攻击。限制系统可接受的输入和输出的格式和长度可以是一个简单有效的开始。如果你只为内部用户服务,那么预防措施是个好主意,如果你为外部用户服务,预防措施也是必不可少的。
三个关注点
偏见永久化
最受欢迎的LLM(OpenAI/GPT-4、Google/Bard)的开发人员已经努力将他们的模型与人类偏好相一致,并部署了复杂的调节层。如果你让GPT-4或巴德给你讲一个种族主义或厌女的笑话,他们会礼貌地拒绝。[7]
这是个好消息。坏消息是,这种针对社会偏见的温和并不一定能防止制度偏见。想象一下,我们的客户支持团队有对特定类型客户无礼的历史。如果历史上的客户支持对话被天真地用来构建一个新的人工智能系统(例如,通过微调),该系统很可能会复制这种偏见。
如果你正在使用过去的数据来训练人工智能模型(无论是经典模型还是生成模型),请仔细检查哪些过去的情况你想延续到未来,哪些不想。有时,在不直接使用过去的数据的情况下,设置原则并根据这些原则工作更容易(例如,通过即时工程)。
模型锁定
除非你一直生活在岩石下,否则你知道生成人工智能模型的发展速度非常快。给定一个企业用例,目前最好的LLM可能不是六个月内的最佳解决方案,几乎可以肯定也不会是六年内的最佳方案。聪明的ML团队知道他们在某个时刻需要切换模型。
但是还有另外两个主要的原因来构建简单的LLM“交换”。首先,许多基础模型提供商一直在努力支持呈指数级增长的用户量,导致服务中断和降级。在系统中构建后备基础模型是个好主意。其次,在系统中测试多个基础模型(“赛马”)以了解哪一个表现最好是非常有用的。根据上面关于Evals的部分,通常很难通过分析来衡量模型质量,所以有时你只想运行两个模型,并对响应进行定性比较。
数据泄露
阅读您正在考虑使用的任何基础模型的条款和条件。如果模型提供者有权在未来的模型培训中使用用户输入,那就令人担忧了。LLM如此之大,以至于特定的用户查询/响应可能会直接编码在未来的模型版本中,然后该版本的任何用户都可以访问。想象一下,您所在组织的一位用户询问“我如何清理执行XYZ的代码?[此处为您的专有机密代码]”。如果模型提供商随后使用此查询来重新培训他们的LLM,则LLM的新版本可能会了解到您的专有代码是解决用例XYZ的好方法。如果竞争对手询问如何执行XYZ,LLM可能会“泄露”您的源代码或类似内容。
OpenAI现在允许用户选择不使用他们的数据来训练模型,这是一个很好的先例,但并不是每个模型提供商都效仿了他们。一些组织也在探索在自己的虚拟私有云中运行LLM;这是人们对开源LLM感兴趣的一个关键原因。
两个热门话题
快速工程将主导微调
当我第一次开始将LLM应用于企业时,我对微调比对即时工程更感兴趣。微调感觉它遵守了我习惯的经典ML系统的原则:争论一些数据,生成训练/测试数据集,开始训练工作,等待一段时间,根据一些指标评估结果。
但我逐渐相信,对于大多数企业用例来说,即时工程(使用嵌入)是一种更好的方法。首先,即时工程的迭代周期远比微调快,因为没有模型训练,这可能需要数小时或数天的时间。更改提示和生成新的响应可以在几分钟内完成。相反,就模型训练而言,微调是一个不可逆转的过程;如果您使用了不正确的训练数据或出现了更好的基础模型,则需要重新启动微调工作。其次,即时工程所需的ML概念知识要少得多,如神经网络超参数优化、训练作业编排或数据争论。微调通常需要经验丰富的ML工程师,而快速工程通常可以由没有ML经验的软件工程师完成。第三,即时工程更适用于快速增长的模型链接策略,在该策略中,复杂的请求被分解为更小的组成请求,每个请求都可以分配给不同的LLM。有时,最好的“组成模型”是经过微调的模型。[8] 但企业的大部分增值工作是(i)弄清楚如何分解他们的问题,(ii)为每个组成部分编写提示,以及(iii)为每个部分确定最佳的现成模型;这不在于创建自己的微调模型。
快速工程的优势可能会随着时间的推移而扩大。如今,提示工程需要长而昂贵的提示(因为每个提示中都必须包含上下文)。但我敢打赌,随着模型提供商空间变得更有竞争力,提供商想出了如何更便宜地培训LLM,每个代币的成本会迅速下降。今天,提示工程也受到最大提示大小的限制,但是,OpenAI已经为GPT-4的每个提示接受32K令牌(约40页平均英文文本),Anthropic的Claude接受100K令牌(大约15页)。我敢打赌,在不久的将来会出现更大的上下文窗口。
数据不再是曾经的护城河
随着LLM越来越善于产生人类可解释的推理,考虑人类如何使用数据进行推理以及这对LLM意味着什么是有用的。[9] 人类实际上并不使用太多数据!大多数时候,我们进行“零镜头学习”,这只是意味着我们在回答问题时不附带一组示例问答对。提问者只是提供了问题,我们根据逻辑、原则、启发法、偏见等进行回答。
这与几年前的LLM不同,后者只擅长少数镜头学习,在那里你需要在提示中包括一些示例问答对。它与经典ML非常不同,在经典ML中,模型需要在数百、数千或数百万个问答对上进行训练。
我坚信,LLM用例中越来越多的主导份额将是“零样本”。LLM将能够在没有任何用户提供的示例的情况下回答大多数问题。他们需要以指令、策略、假设等形式进行及时的工程设计。例如,这篇文章使用GPT-4来审查代码中的安全漏洞;该方法不需要关于易受攻击代码的过去实例的数据。拥有明确的指示、政策和假设将变得越来越重要,但拥有大量高质量、有标签的专有数据将变得不那么重要。
如果您正在积极地将LLM应用于您的企业数据,我很想听听您发现哪些有效,哪些无效。请留言评论!
脚注
- [1] 直到最近,LLM还不知道最近的公共知识——例如,GPT-4是根据截至2021年9月收集的信息进行培训的。然而,GPT-4和Bard的消费者界面现在能够查询开放的互联网并收集有关最近事件的信息。因此,最近性作为LLM的知识限制正在迅速消失。
- [2] 嵌入可以处理所有类型的数据结构,而不仅仅是文本。
- [3] 整个嵌入工作流发生在调用LLM之前。例如,OpenAI建议使用其ada-002模型进行嵌入,该模型比任何领先的GPT模型都更便宜、更快。
- [4] 记号是单词或词性。下面很好地解释了为什么语言模型使用标记而不是单词。
- [5] 学习到的参数数量可能在数百万到数万亿之间。如今,最广泛使用的有限责任公司拥有数十亿美元。
- [6] 作弊的推论并不是必然的;对于具有8K上下文窗口的GPT-4,OpenAI每1k代币收取0.03–0.06美元(分别取决于代币是输入还是输出)。Davinci(一种滞后模型)的微调版本每1k代币收费0.12美元。
- [7] 当然,这些都是OpenAI和谷歌雇佣的人。由于许多人不同意这些组织的价值观,他们不同意温和政策。
- [8] 例如,GOAT是针对算术进行微调的开源模型LLaMA的一个版本。它在许多算术基准测试上都优于GPT-4。大多数企业的工作流程都需要算术运算;在链式方法下,工作流中涉及算术的部分将被识别并路由到GOAT。对于这样一家企业来说,大力投资于良好的路由和与GOAT的集成是有道理的,但在我看来,不要微调他们自己的算术LLM。
- [9] 关于今天的LLM是否真的能推理,以及实际推理的含义(它需要意识吗?自我意识吗?代理;这篇论文有许多很好的例子。
- 120 次浏览
【知识检索架构】LLM的知识检索架构(2023)
视频号
微信公众号
知识星球
在大型语言模型的研究和应用方面,他是一个令人着迷的时代。每天都有新的进展!
在本指南中,我将分享我对基于数据的语言模型应用程序的当前体系结构最佳实践的分析。即使以大型语言模型的标准来看,这个特定的子学科也正经历着惊人的研究兴趣——在本指南中,我引用了8篇研究论文和4个软件项目,平均首次发表日期为2022年11月22日。
概述
在几乎所有大型语言模型(LLM)的实际应用中,在某些情况下,您希望语言模型基于特定数据生成答案,而不是基于模型的训练集提供通用答案。例如,公司聊天机器人应该能够参考公司网站上的特定文章,律师的分析工具应该能够参考同一案件以前的文件。引入这些外部数据的方式是一个关键的设计问题。
在高层次上,有两种主要方法来引用特定数据:
- 在模型提示中插入数据作为上下文,并指示响应使用该信息
- 通过提供数百或数千个提示<>完成对来微调模型
现有LLM知识检索的不足
这两种方法都有各自的显著缺点。
对于基于上下文的方法:
- 模型的上下文大小有限,最新的“davinci-003”模型在一个请求中只能处理多达4000个令牌。许多文件不适合这种情况。
- 处理更多的令牌相当于处理时间更长。在面向客户的场景中,这会损害用户体验。
- 处理更多令牌意味着更高的API成本,如果上下文中的信息没有针对性,则可能不会导致更准确的响应。
对于微调方法:
- 生成提示<>完成对既耗时又可能昂贵。
- 许多要从中引用信息的存储库都相当大。例如,如果你的申请是为参加美国MLE的医学生提供的学习援助,那么一个综合模型必须提供多个学科的培训示例。
- 一些外部数据源变化很快。例如,基于每天或每周移交的未结案例队列来重新培训客户支持模型并不是最佳的。
- 围绕微调的最佳实践仍在制定中。LLM本身可以用来帮助生成训练数据,但这可能需要一些复杂度才能有效。
解决方案,简化

上面的设计有各种各样的名字,最常见的是“检索增强生成”或“RETRO”。链接和相关概念:
- RAG(Retrieval-Augmented Generation):知识密集型NLP任务的检索增强生成
- RETRO:通过从数万亿个令牌中检索来改进语言模型
- REALM(Retrieval-Augmented Language Model Pre-Training):检索增强语言模型预训练
检索增强生成(RAG)
a)从语言模型(非参数)外部检索相关数据,以及b)在LLM的提示中使用上下文来增强数据。该体系结构干净地绕过了微调和仅上下文方法的大多数限制。
检索
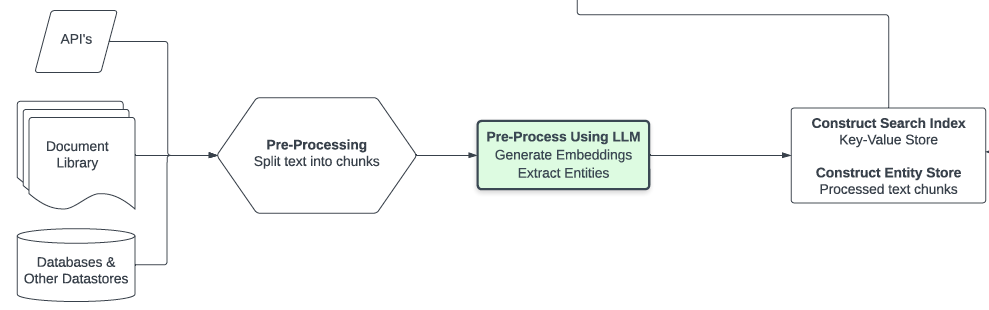
相关信息的检索值得进一步解释。正如您所看到的,数据可能来自多个来源,具体取决于用例。为了使数据有用,数据的大小必须足够小,以便多个部分能够适应上下文,并且必须有某种方法来识别相关性。因此,一个典型的先决条件是将文本拆分为多个部分(例如,通过LangChain包中的实用程序),然后计算这些块上的嵌入。
语言模型嵌入是文本中概念的数字表示,似乎有着无尽的用途。以下是它们的工作原理:嵌入模型将文本转换为一个大的、有分数的向量,可以有效地与其他有分数的矢量进行比较,以帮助执行推荐、分类和搜索(+更多)任务。我们将这个计算的结果存储到我通常称之为搜索索引和实体存储的地方——下面将对此进行更深入的讨论。
回到流程——当用户提交问题时,LLM会以多种方式处理消息,但关键步骤是计算另一个嵌入——这次是用户文本的嵌入。现在,我们可以通过将新的嵌入向量与预先计算的完整向量集进行比较来从语义上搜索搜索索引和实体存储。这种语义搜索基于语言模型的“习得”概念,并不局限于搜索关键词。根据这次搜索的结果,我们可以定量地识别一个或多个相关的文本块,这些文本块可以帮助告知用户的问题。
增强
使用相关的文本块构建提示非常简单。提示以一些基本的提示工程开始,指示模型避免“产生幻觉”,即编造一个虚假但听起来合理的答案。如果适用,我们指导模型以特定的格式回答问题,例如“高”、“中”或“低”的顺序排名。最后,我们提供了相关信息,语言模型可以使用特定的数据来回答这些信息。在最简单的形式中,我们只需附加(“文档1:”+文本块1+“\n文档2:”+文本组块2+…),直到上下文被填充。
最后,将组合提示发送到大型语言模型。完成后会解析出一个答案,并将其传递给用户。
就是这样!虽然这是一个简单的设计版本,但它价格低廉、准确,非常适合许多轻量级用例。我已经在一个行业原型中使用了这种设置,并取得了巨大的成功。这种方法的即插即用版本可以在openai食谱库中找到,这是一个方便的起点。
高级设计
我想花点时间讨论一下可能进入检索增强生成体系结构的几个研究进展。我相信,应用LLM产品将在6到9个月内实现这些功能中的大部分。
生成然后读取管道
这类方法包括在检索相关数据之前用LLM处理用户输入。
基本上,用户的问题缺乏信息性答案所显示的一些相关性模式。例如,“Python中列表理解的语法是什么?”与代码库中的示例有很大不同,例如代码段“newlist=[x For x in tables if“customer”in x]”。一种提出的方法使用“假设的文档嵌入”来生成假设的上下文文档,该文档可能包含虚假的细节,但模仿真实的答案。嵌入此文档并在数据存储中搜索相关的(真实的)示例会检索到更相关的结果;相关结果用于生成用户看到的实际答案。
类似的方法名为generate-then-read(GenRead),它通过在多个上下文文档生成上实现集群算法来建立在实践的基础上。实际上,它生成了多个示例上下文,并确保它们以有意义的方式有所不同。这种方法使语言模型倾向于返回更多样的假设上下文文档建议,这种建议(嵌入后)从数据存储中返回更多不同的结果,并导致更高的完成机会,包括准确的答案。
用于LLM索引和响应合成的改进数据结构
GPT索引项目非常出色,值得一读。它利用了一组由langauge模型创建并针对其进行了优化的数据结构。GPT索引支持以下更详细描述的多种类型的索引。基本的响应合成是“选择前k个相关文档并将其附加到上下文中”,但有多种策略可以实现这一点。
- 列表索引-每个节点表示一个文本块,否则未更改。在默认设置中,所有节点都被组合到上下文中(响应合成步骤)。

- 矢量存储索引-这相当于我在上一节中解释的简单设计。每个文本块都与嵌入一起存储;将查询嵌入与文档嵌入进行比较,将返回k个最相似的文档以提供给上下文。
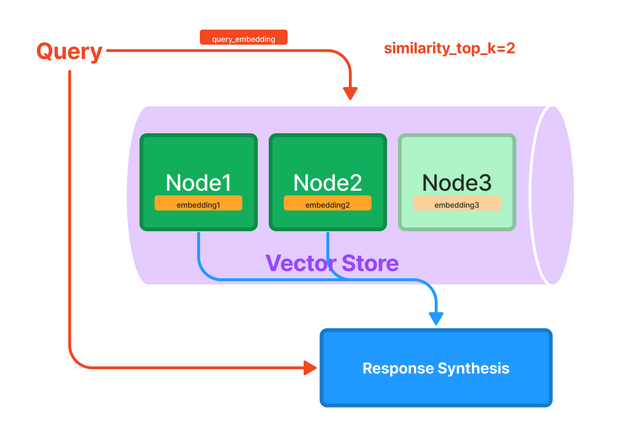
- 关键字索引-这支持对特定字符串进行快速高效的词汇搜索。

- 树索引-当数据被组织到层次结构中时,这非常有用。考虑临床文档应用程序:您可能希望文本既包括高级说明(“以下是改善心脏健康的一般方法”),也包括低级说明(参考副作用和特定降压药物方案的说明)。有几种不同的方法可以遍历树来生成响应,其中两种方法如下所示。
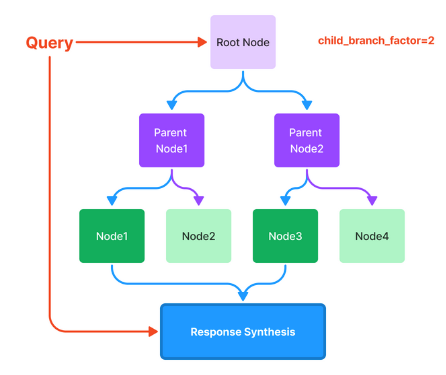
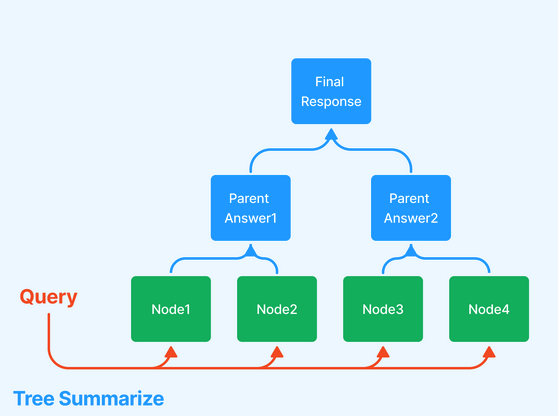
- GPT索引提供了索引的可组合性,这意味着您可以在其他索引的基础上构建索引。例如,在代码助理场景中,您可以在内部GitHub存储库上建立一个树索引,在维基百科上建立另一个树指数。然后,在树索引上叠加一个关键字索引。
扩展上下文大小
这篇文章中概述的一些方法听起来很“技巧”,因为它们涉及到当前模型中相对较小的上下文大小的变通方法。有大量的研究工作旨在扩大这一限制。
- GPT-4预计将在未来1-3个月内完成。据传它有更大的上下文大小。
- 这篇来自谷歌人工智能公司的论文对工程权衡进行了一些探索。其中一种配置允许上下文长度高达43000个令牌。
- 一种新的状态空间模型体系结构随着上下文大小线性扩展,而不是像在变换器模型中那样呈二次方扩展。虽然该模型在其他领域的性能落后,但它表明,大量的研究工作都是针对改善模型考虑因素,如上下文大小。
在我看来,上下文大小的进步将随着对更多数据检索的需求而扩展;换言之,可以放心地假设,即使在某些配置不断发展的情况下,仍然需要进行文本拆分和细化。
持续状态(例如会话历史记录)
当LLM以对话的形式呈现给用户时,一个主要的挑战是在上下文中维护对话历史。
对相关战略的概述超出了本员额的范围;有关最近涉及渐进式摘要和知识检索的代码演示示例,请参阅此LangChain示例。
资源和进一步阅读
- GPT Index
- Haystack library for semantic search and other NLP applications
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- LangChain
- How to implement Q&A against your documentation with GPT3, embeddings and Datasette
- FAISS for vector similarity calculations
- Generate rather than Retrieve: Large Language Models are Strong Context Generators
- Implementation Code
- 436 次浏览