【数据仓库系例】数据仓库设计
视频号

微信公众号

知识星球

数据仓库是一个单一的数据存储库,其中来自多个数据源的记录被集成用于在线业务分析处理(OLAP)。这意味着数据仓库需要满足整个组织内所有业务阶段的需求。因此,数据仓库的设计是一个非常复杂、漫长的过程,因此容易出错。此外,业务分析功能会随着时间的推移而变化,这会导致系统需求的变化。因此,数据仓库和OLAP系统是动态的,设计过程是连续的。
数据仓库的设计采用了一种不同于行业中视图物化的方法。它将数据仓库视为具有特定需求的数据库系统,例如回答与管理相关的查询。设计的目标是如何提取、转换和加载来自多个数据源的记录(ETL),以将其组织在数据库中作为数据仓库。
有两种方法
- “自上而下”的方法
- “自下而上”的方法
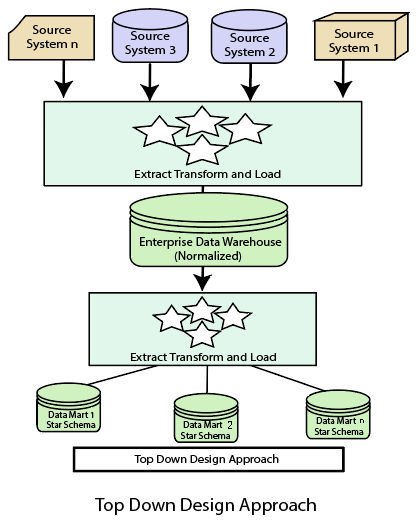
自上而下的设计方法
在“自上而下”的设计方法中,数据仓库被描述为一个面向主题、时变、非易失性和集成的数据存储库,用于整个企业。来自不同来源的数据被验证、重新格式化并保存在标准化(最高3NF)数据库中作为数据仓库。数据仓库存储“原子”信息,即最低粒度级别的数据,从中可以通过选择特定业务主题或特定部门所需的数据来构建维度数据集市。方法是一种数据驱动的方法,因为首先收集和集成信息,然后制定构建数据集市的主体的业务需求。这种方法的优点是它支持单个集成数据源。因此,由它构建的数据集市在重叠时将具有一致性。
自上而下设计的优点
- 数据集市是从数据仓库中加载的。
- 从数据仓库开发新的数据集市非常容易。
自上而下设计的缺点
- 这种技术对于不断变化的部门需求是不灵活的。
- 实施该项目的成本很高。
自下而上的设计方法
在“自下而上”的方法中,数据仓库被描述为“用于查询和分析的事务数据特定架构的副本”,术语为星形模式。在这种方法中,首先创建一个数据集市,以便为特定的业务流程(或主题)提供必要的报告和分析功能。因此,与Inmon的数据驱动方法相比,它需要是一种业务驱动的方法。
数据集市包括最低粒度的数据,如果需要,还包括聚合数据。非规范化维度数据库取代了数据仓库的规范化数据库,以满足数据仓库的数据交付要求。使用这种方法,要使用数据集市集作为企业数据仓库,数据集市的构建应考虑到一致的维度,定义普通对象在不同的数据集市中表示相同。一致的维度将数据集市连接起来,形成一个数据仓库,通常称为虚拟数据仓库。
“自下而上”设计方法的优点是它具有快速的ROI,因为开发一个数据集市,一个针对单个主题的数据仓库,比开发一个企业范围的数据仓库花费的时间和精力要少得多。此外,失败的风险甚至更小。这种方法本质上是渐进的。这种方法可以让项目团队学习和成长。
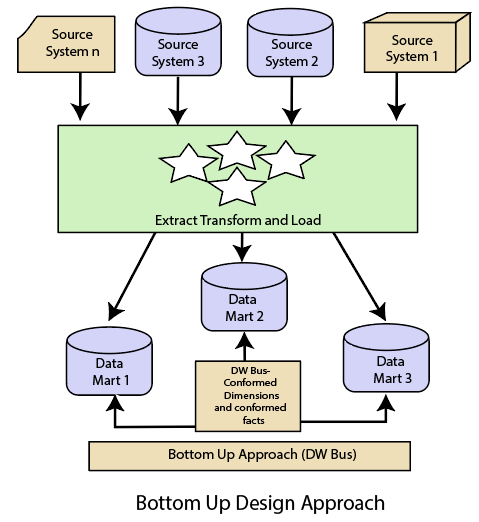
自下而上设计的优点
- 可以快速生成文档。
- 数据仓库可以扩展以适应新的业务单元。
- 它只是开发新的数据集市,然后与其他数据集市集成。
自下而上设计的缺点
- 在自下而上的方法设计中,数据仓库和数据集市的位置是颠倒的。
区分自上而下的设计方法和自下而上的设计方法
| 自上而下的设计方法 | 自下而上的设计方法 |
|---|---|
| 将大问题分解为更小的子问题。 | 解决了基本的低级问题,并将它们集成到更高的问题中。 |
| 固有的架构,而不是几个数据集市的联合。 | 内在递增的;可以首先调度重要的数据集市。 |
| 内容信息的单一中央存储。 | 存储的部门信息。 |
| 集中的规则和控制。 | 部门规则和控制。 |
| 它包括冗余信息。 | 可以删除冗余。 |
| 如果重复实施,可能会很快看到效果。 | 失败风险更小,投资回报率高,技术证明。 |
- 52 次浏览