数据沿袭



【数据沿袭】列级沿袭来到 DataHub
视频号
微信公众号
知识星球
通过DataHub,我们致力于帮助用户发现、信任其组织中的数据并对其采取行动。上游和下游谱系,即了解数据产品的来源和使用方式,对于实现这一点至关重要。
这就是为什么我们非常兴奋地实现了列级沿袭,这是DataHub最需要的功能之一!
关于DataHub中的血统
当我们构建DataHub的Lineage功能时,我们希望提供组织数据的生产、转换和消费的端到端可视性,无论是通过什么平台进行策划。为此,DataHub中的沿袭旨在跨多个平台、数据集、管道、图表和仪表板跟踪沿袭。
一旦我们推出了Lineage,下一个显而易见的步骤就是进一步实现列的端到端沿袭可视化。
我们为什么建立列级谱系
列级沿袭具有强大的潜力
- 主动影响分析和
- 反应式数据调试。
方法如下。它不仅可以让您知道是否存在依赖关系,还可以帮助您准确地了解依赖关系是如何存在的。这意味着您可以理解列是如何计算的,这样您就可以回答以下问题:
- 哪些根输入列用于构造此列?
- 此列是否读取任何敏感数据?
- 采用了什么方法来进行汇总?
这也意味着你可以了解列是如何使用的,这样你就可以回答以下问题:
- 我可以安全地否决这个字段吗?
- 哪些仪表板正在对此列进行可视化?
法规遵从性要求是将此功能作为优先事项的另一个原因。一些DataHub用户处理敏感数据,需要完全了解具有PII的列,以及它们如何链接到下游仪表板中的目标表。
列级沿袭帮助他们将列之间的点与PII和面向用户的仪表板连接起来,这样他们就可以采取预防措施来确保这些数据的敏感性。
在DataHub中构建列级沿袭
可视化沿袭元数据无疑是一个挑战。表现得太少,就达不到目的。显示得太多,它可能会变得笨重,难以可视化和使用。
在构建列级沿袭时,我们的重点是确保它干净且易于理解。这样做的方法是允许用户根据需要查看尽可能多或尽可能少的内容。
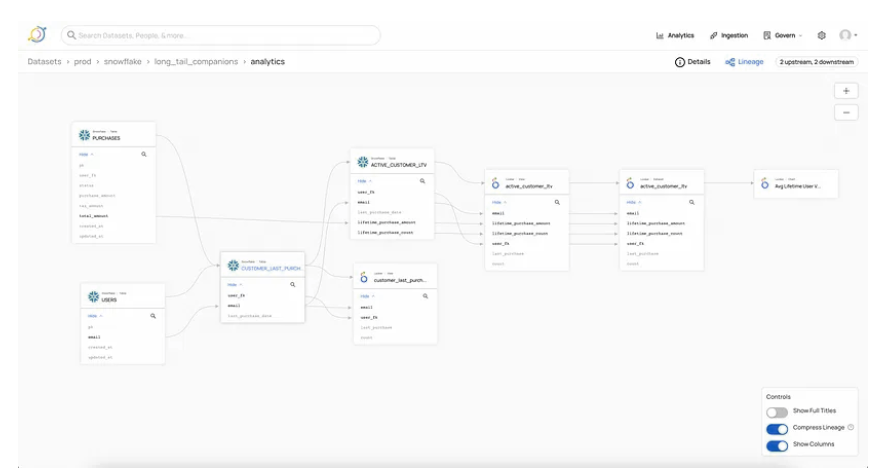
DataHub Controls that let you view just what you need
DataHub中的列级沿袭体验
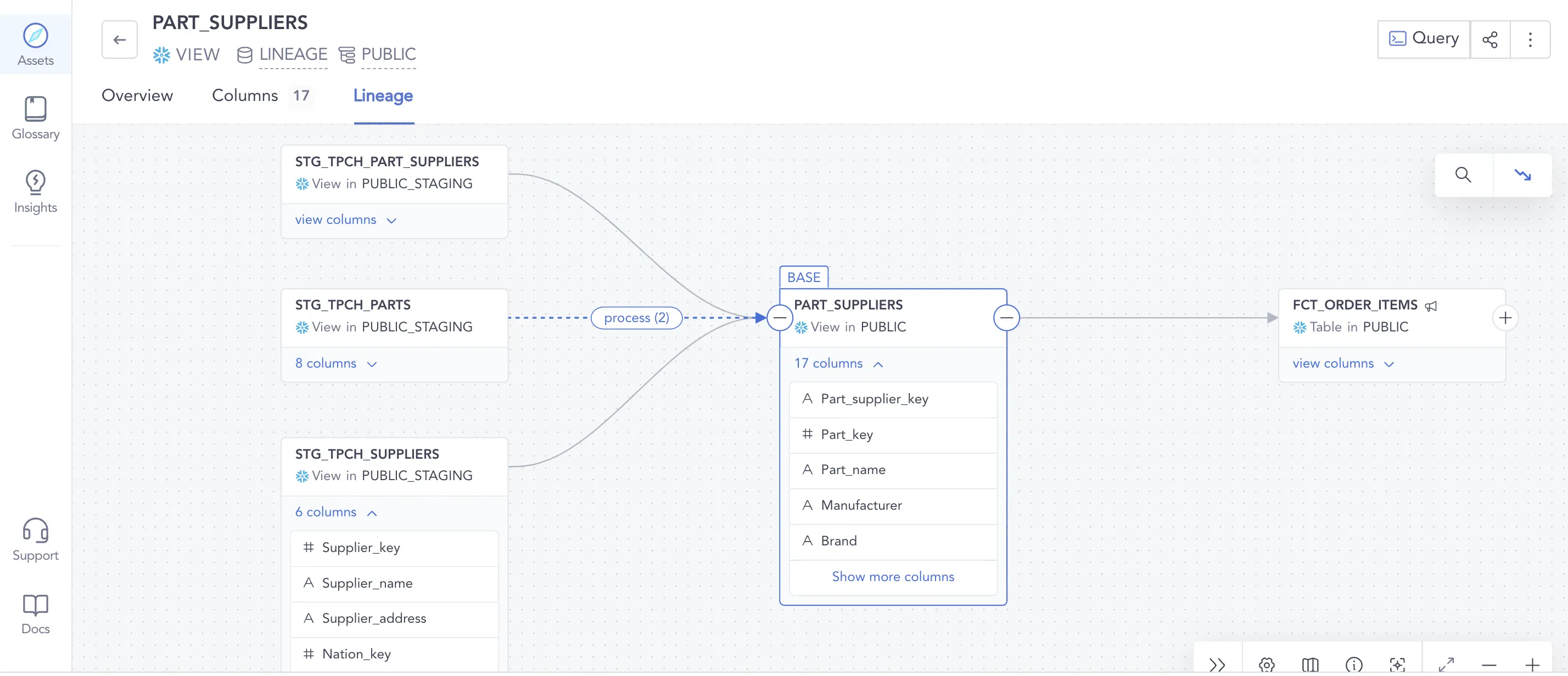
以下是您在DataHub中获得的列级沿袭:
- 用于发出列级沿袭的API
- 从Snowflake和Looker中自动提取列级谱系
- 谱系资源管理器中的列级谱系可视化
- 单列的影响分析
在DataHub中使用列级沿袭
1.查看列级沿袭
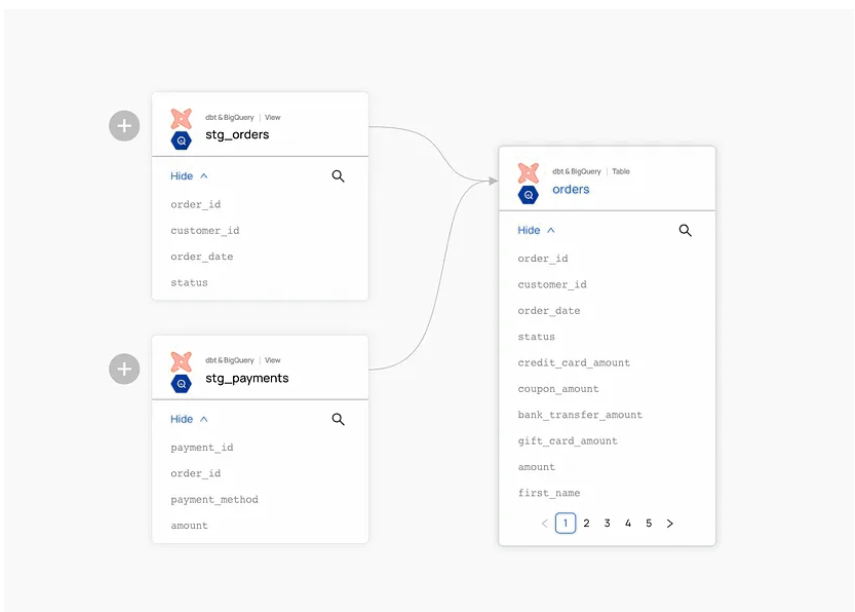
切换“显示列”控件以在表级和列级沿袭之间切换,只需单击一次,而不会切换选项卡或丢失上下文。
2.列级影响分析
只需单击表的架构,然后选择要分析其影响的列。右键单击菜单,如下所示,以查看其沿袭。
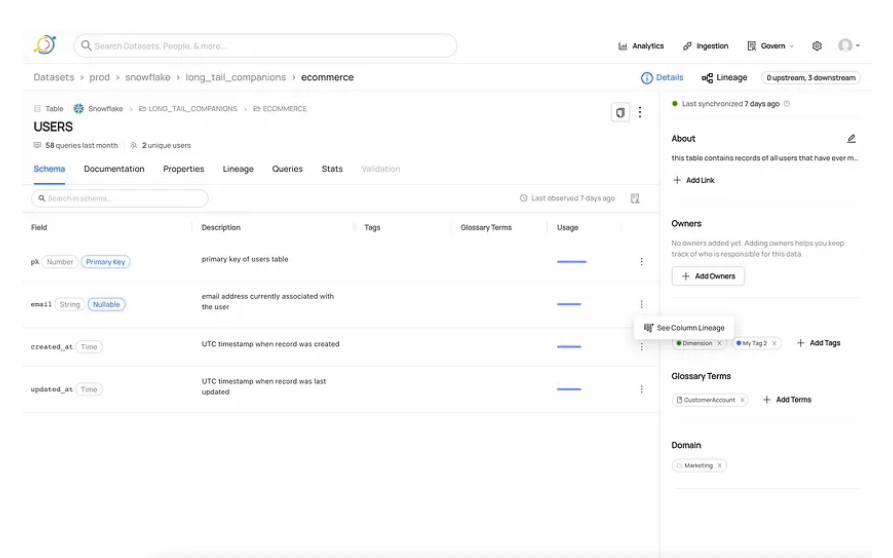
血统资源管理器会向您展示您需要了解的内容。
例如,您可以通过使用下面显示的过滤器将分离度设置为1、2或3+来查看直接使用“电子邮件”列的资产。
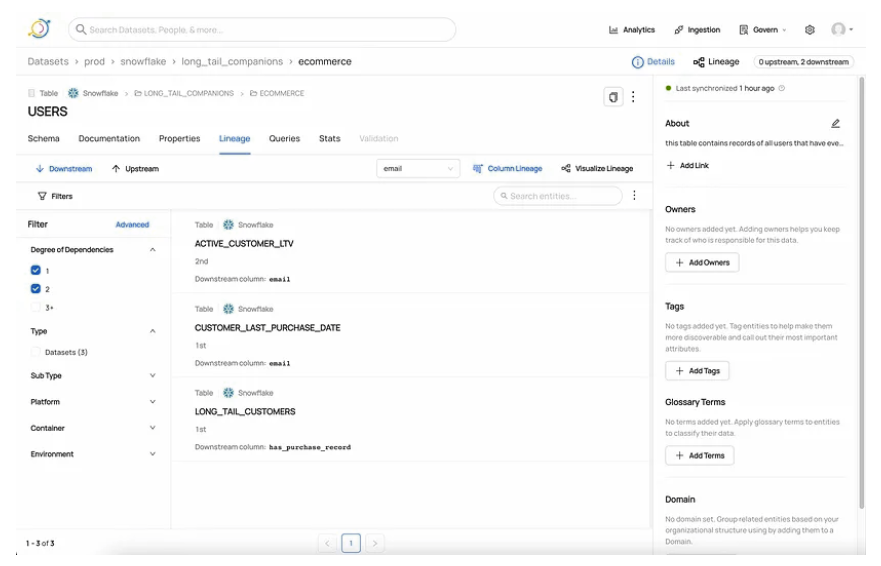
要查看进一步的向上/向下,您所需要做的就是将过滤器设置为更高/更远的依赖度。
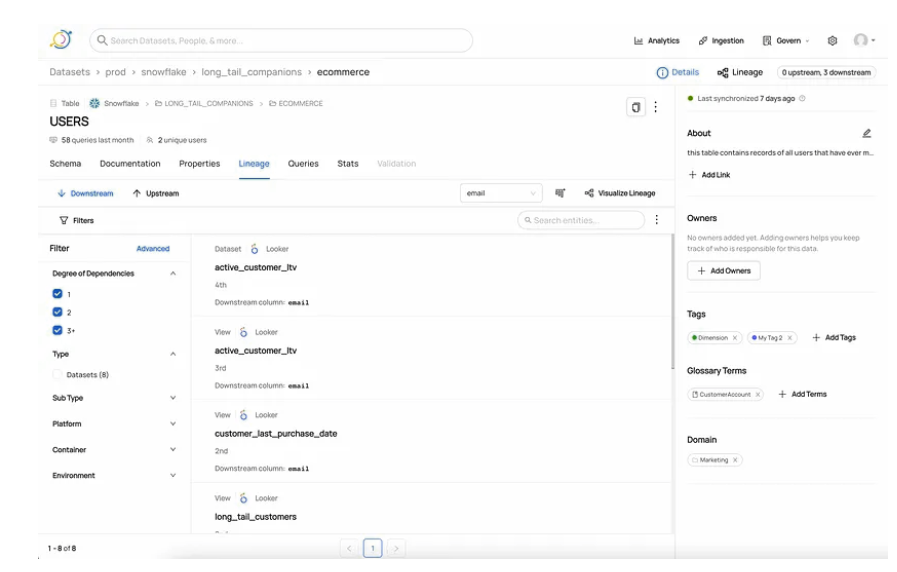
您也可以使用“Visualize Lineage”旁边的下拉列表来选择您感兴趣的沿袭的任何列。如果您想恢复到表级沿袭,请立即单击此下拉列表右侧的按钮。
如果您对下游的资产和通往那里的路径感到好奇,请单击列以查看列之间的路径。
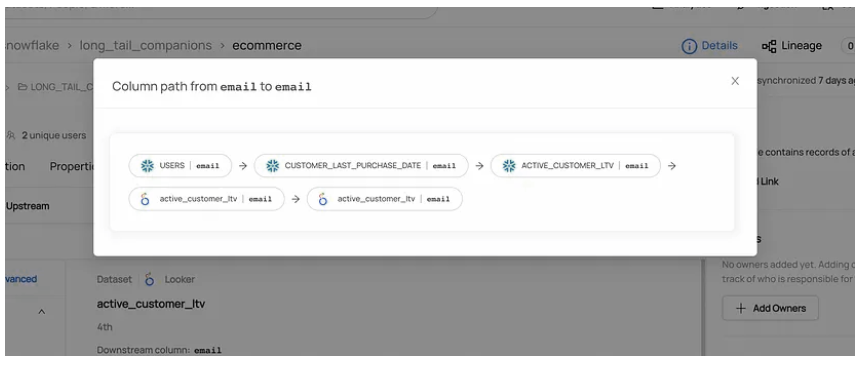
DataHub还可以向您显示多个路径,这些路径对应于一列连接到另一列的不同情况。
列级沿袭的下一步是什么?
- 查看用于派生列的转换逻辑
- 从BigQuery和Redshift开始,其他SQL源的自动列沿袭提取(2022年第4季度)
- 支持Spark,Tableau(2023年第一季度)
想要查看列级沿袭的操作吗?在我们的九月市政厅观看Chris Collins的走秀!
- 107 次浏览
【数据沿袭】数据沿袭揭秘
视频号
微信公众号
知识星球
信任大数据需要了解其数据沿袭。 没有数据沿袭,大数据就成了电话游戏中最后一句话的代名词。 第一个人的原始数据(例如,“孔雀鱼在鲨鱼缸中游泳”)在最后一个人结束时会变成完全不同的东西(例如,“旋转和吠叫的小狗,发臭”)。 电话游戏玩家看起来很困惑,他们不明白原始数据是如何变得完全不同的。 糟糕的数据沿袭也是如此,因为企业的数据资产流经其数据架构。
客户、监管机构和企业发现在使用企业大数据后玩电话游戏变得不那么有趣了。 IDC 的 Stewart Bond 表示,企业需要安全且合规的数据。 这些数据需要在需要的时间和地点可用。 随着多个最终用户、平台和各种格式(如视频、文本、图像和音频)的来源,对干净大数据的需求变得更加复杂。 通过将大数据远程存储在云中,它是如何到达那里的就变得不那么明显了。 了解数据沿袭可以解决这些类型的问题以及更多问题。
什么是数据沿袭?
数据沿袭描述数据来源、移动、特征和质量。 根据 Stewart Bond 的说法,谱系通常描述大数据从哪里开始以及它如何改变为最终结果。 技术项目使用这种传统的数据沿袭方法。 例如,在一家大型技术公司创建新的临床医生/患者系统期间,项目成员会参考表和连接的映射,以指导使用什么 SQL 来选择、汇总或分组数据。 程序员将更新代码以生成所需的值,而 QA 将阅读这些计划以预测破坏软件的方法。 虽然此方法只是一个开始,但数据沿袭需要扩展定义。
仅将传统方法应用于数据沿袭时,数据会遇到障碍,尤其是主数据:有关人员、流程和构成业务核心的事物的信息。 例如,团队成员必须为处理国外交易的大型银行部门开发新的检查程序。 QA 和软件工程师在从其他银行部门获取一组有效的测试数据时遇到了问题。 如果项目经理包括额外的数据沿袭方面,例如谁使用大数据、它意味着什么、何时访问数据、为什么存储数据以及数据元素如何相关,这些障碍本可以得到缓解,缩短 开发和测试的时间框架。 有意义的数据沿袭需要包含多个维度:谁、什么、在哪里、为什么以及如何。
为什么要跟踪血统?
数据沿袭有很多好处,包括:
- 数据治理:根据 Meta Integration Technology 首席执行官兼总裁 Christian Bremeau 的说法,数据治理需要元数据管理。 这是确保大数据符合业务标准所必需的:“元数据管理解决方案的使命是从源头到另一端,”Bremeau 说。 数据沿袭解决方案将元数据拼接在一起,提供对数据使用和需要减轻的风险的“理解和验证”。
- 合规性:多个不同的利益相关者,包括客户、员工和审计员,需要信任报告的数据,同时快速响应商业机会和监管挑战。 他们需要知道一份报告,“信息是如何获得的……[在那里]?” ASG Technologies 前产品营销副总裁 Ian Rowlands 表示,跟踪数据沿袭提供了“报告正确反映数据”的证据。
- 数据质量:数据质量面临的挑战包括通过人员和流程进行数据移动、转换、解释和选择。 “当今的企业面临着可靠地证明数据来源和整个组织转换的压力,”Rowlands 说。 数据沿袭解决方案提供了了解“端到端流”何时发生的能力,包括:数据何时被转换,它意味着什么,以及数据质量如何从一个地方移动到另一个地方。
- 业务影响分析:正如邦德所指出的,企业需要了解内部部门和用户以及外部客户如何共享大数据,尤其是主数据,以及这些数据如何变化。 正如 Bremeau 所说,一位同事可能会问为什么在过去的某个季度(例如 2005 年第 4 季度)做出了错误的决定。同样,企业可能希望升级数据仓库,并且需要知道哪些系统和流程可能会破坏此操作。 回答这些类型的问题需要及时来回处理您的数据,这需要了解数据沿袭。
如何在您的业务中创建和使用数据沿袭
为了做出更好的决策并更快地响应商业机会和法规,企业必须有效地创建和使用数据沿袭。 好的策略包括:
- 记录数据的位置和方式:分解数据在业务中可能存在的位置,包括通过关键业务流程和这些流程之间的流动。 此外,了解技术沿袭或“物理数据流通过底层应用程序、服务、数据存储,”Rowlands 说。 以可重复、可靠且快速的方式跟踪数据移动到何处以及如何更改。
- 调查 5 W:如上所述,有意义的数据需要是多维的,超越了位置和方式。 查明谁在使用数据、数据的含义、捕获时间、使用时间以及存储和/或使用数据的原因。
- 理解关系:需要很好地理解数据之间的关系,包括数据如何在人、流程、服务和产品之间产生和移动。 数据管理者需要从内部实体(例如企业内的部门)、外部参与者(企业的买家和卖家)以及内部实体和外部参与者之间的交互中概念化这些信息。
- 自动化:正如 Bremeau 提到的,“手动维护语义映射是一场噩梦。 您需要的是一套自动执行此操作的工具。” 识别关键数据或主数据并使用自动化元数据应用程序扫描和收集有关数据沿袭的元数据变得至关重要。
案例研究:金融业和数据沿袭
数据沿袭已成为金融业必不可少的,特别是自从监管控制因 2007-2008 年金融危机而发生变化以来。 一家知名银行与 ASG Technologies(现为 Rocket Software)之间的案例研究描述了一家银行如何采取积极主动的战略,“创建世界一流的流程和战略,以自动化数据取证并解决整个组织的监管要求。” 该银行的信息架构 (IA) 团队探索了一系列工具,并为零售银行部门“与三个供应商进行了概念验证试验,包括部分 ASG 解决方案”。
探索的方法包括大型机测试、分布式环境和迁移以及转换。 IA 团队得出结论,ASG 的解决方案提供了实现其目标所需的“结果速度和总体影响”。 ASG 解决方案对银行的成功包括:
完成“100 个应用程序中的 10 个关键业务元素 (KBE)”的数据沿袭所节省的成本从 1,480,280 美元到 304,140 美元。
通过“手动数据沿袭和分析过程的 80 倍”提高效率。
在 180 小时内更快地解析“100 个系统(40 个简单系统、40 个中型系统和 20 个复合系统)中的一个数据元素,而手动执行时需要 14,400 小时。”
展望未来,该银行的 IA 团队计划继续使用 ASG 的解决方案执行数据沿袭,包括“40-50 个系统中 1000 个 KBE 的第二实施阶段”。 正如本案例研究所示,数据沿袭的力量可以最大限度地减少疑虑、增加信任并加快流程。
- 128 次浏览
【数据血统】开源数据血统工具-2023年最受欢迎的5个工具
视频号
微信公众号
知识星球
数据沿袭工具可帮助您在每一步跟踪数据的更改。从源捕获的数据在经过一系列数据工程过程(如清理、争论、集成、重构等)之前没有多大用处。要从数据中获得最大价值,您需要跟踪其来源和生命周期。
本文在考虑了一系列功能、集成功能和易用性后,列出了五种引人注目的开源数据沿袭工具。我们在文章末尾特别提到了一些即将出现的工具。
5种流行的开源数据沿袭工具
- Tokern
- Egeria
- Pachyderm
- OpenLineage
- TrueDat
什么是数据沿袭工具?
数据沿袭工具可帮助您在每一步跟踪数据的更改。从源捕获的数据在经过一系列数据工程过程(如清理、争论、集成、重构等)之前没有多大用处。要从数据中获得最大价值,您需要跟踪其来源和生命周期。
这些工具需要与当前的数据堆栈集成,其中可能包含一系列数据库、数据仓库、数据湖、ML管道和BI工具,以获取沿袭数据。获得一致的沿袭视图对于更有效地理解和使用数据至关重要,因此必须确定正确的数据沿袭工具。
在这里,我们特别关注目前深受用户欢迎的开源数据沿袭工具。
#1.Tokern
Tokern概述
Tokern是为云数据仓库和数据湖而建的。它采用了一种专门的方法,使您能够从Google BigQuery、AWS Redshift和Snowflake上托管的数据库和数据仓库中获取列级数据沿袭。SparkSQL、AWS Athena和Presto等更多来源正在开发中。
Tokern具有可观的集成能力,因为它可以很好地与大多数开源数据目录和ETL框架配合使用。
Tokern数据谱系特征
Tokern不久前发布,它考虑了最新的数据工程和设计模式。一个这样的例子是,除了从 dbcat (数据目录)构建数据沿袭外,Tokern还允许您从查询历史或ETL脚本构建数据沿袭,这使它成为BI和ETL工具集成的理想选择。
Tokern将数据目录和沿袭存储在PostgreSQL数据库中。您可以使用SQL访问此数据库进行进一步分析,也可以将其输入其他可视化和分析引擎。
可视化引擎Kedro-Viz和名为 NetworkX的网络图分析库是Tokern出色的可视化和分析功能的幕后推手。这些库可以帮助您“跟踪、可视化和分析列级沿袭数据”。您还可以使用Tokern’s SDKs or APIs与沿袭数据进行交互。
除了一流的数据沿袭功能外,Tokern还使用PIICatcher提供PII(个人身份信息)和PHI(个人健康信息)检测。这个内置工具结合了正则表达式和几个标准NLP库进行PII检测,如Spacy和Stanford NER。
Tokern
Documentation | Discord | Blog | GitHub
#2.Egeria
Egeria概述
Egeria被称为“世界上第一个开源元数据标准”。它提供了一种无缝集成数据工程工具的方法,以获得可靠和一致的元数据视图。除了对元数据进行编目和搜索外,此标准还允许您为数据沿袭跟踪、数据质量检查、PII识别等构建更高级的解决方案。
许多数据工程体系结构涉及各种数据工具之间许多可以避免的聊天。Egeria远离这一点,而是采用轮辐式模型,所有东西都经过Egeria。这样,您只需要使用一个工具进行对话。
Egeria数据谱系特征
Egeria中的数据沿袭利用众所周知的开放标准来捕获和存储数据沿袭,称为OpenLineage。OpenLineage还通过提供对数据的水平和垂直谱系的跟踪,使您能够更深入地了解数据。
Egeria监听源系统发出的Kafka事件,以捕获数据沿袭信息。一旦完成了这一点,谱系管理员就可以匹配和链接谱系图,而Egeria无法做到这一点。之后,谱系对商业消费都有好处。
Egeria中的数据沿袭功能与数据发现和管理、元数据来源等功能非常吻合。上面提到的功能以及Egeria的沿袭设计和架构使其成为一个非常引人注目、经过深思熟虑的数据治理和数据沿袭工具。
Egeria资源
Documentation | Medium | Slack | GitHub
#3.Pachyderm公司
Pachyderm概述
与Tokern一样,Pachyderm是另一个专门的数据沿袭工具。Pachyderm的目标不是专注于云数据仓库,而是让开发人员能够以与语言和框架无关的方式构建机器学习管道。
Pachyderm已经实现了像lakeFS或Git这样的版本控制系统,以维护数据对象的沿袭。对这些对象的更改(比如提交)由Pachyderm捕获并存储,从而维护完整且不可变的事件审计跟踪。审计跟踪使您能够拥有用于查看和分析的数据沿袭图,并使您能够在任何时间点出于调试或法规遵从性原因重新生成数据和代码。
Pachyderm数据谱系特征
为了实现数据的无缝沿袭跟踪和版本控制,Pachyderm在一个名为PFS(PachydermFile system)的定制文件系统中使用了一个中央存储库,该存储库使用了类似AWS S3的对象存储。PFS有助于您的对象存储(如S3)成为具有完整历史记录的数据的唯一真实来源。
Pachyderm还在数据源中强制执行不变性,这使它能够为沿袭事件和数据对象分配全局ID。Pachyderm允许您在UI中将不可变的数据沿袭图作为DAG进行查看。上面提到的这两个特性在处理ML管道时都是有利的,并且您希望将结果跟踪回它们的输入。
Pachyderm集成了最广泛使用的数据库、数据仓库和数据湖。此外,使用基于SQL的接收工具,您可以将任何数据库中的数据导入Pachyderm。然而,Pachyderm作为一种通用的数据沿袭工具有其局限性,这就是为什么Pachyderm的大多数企业客户都使用它来处理MLOps、非结构化数据ETL和NLP工作负载。
Pachyderm资源
Documentation | Slack | Blog | GitHub
#4.OpenLineage
OpenLineage概述
DataKin,在WeWork开源 Marquez 后负责接管其开发的公司,也创建了OpenLineage。DataKin于2021年年中将OpenLineage项目作为沙盒项目移交给了Linux基金会。
OpenLineage深受 OpenTelemetry,的启发,它在数据可观察性空间中无处不在,旨在为数据谱系收集和分析建立一个开放的标准。
OpenLineage功能
集成是OpenLineage设计和使命的核心。它集成了ETL框架、数据编排引擎、元数据目录、数据质量引擎和数据沿袭工具。OpenLineage将JSONSchema用于API定义,支持各种语言和框架。Egeria是我们上面提到的一个流行的数据沿袭工具,它的核心元数据层建立在OpenLineage之上。
WeWork的Marquez也是OpenLineage架构的核心,因为Marquez提供UI和元数据存储库,而元数据集合API来自OpenLineag。OpenLineage还通过GraphQL和REST API向您公开。
OpenLineage是一个很有吸引力的选择,因为它将与大多数现有的数据工程堆栈舒适地结合在一起,并为您提供一系列令人兴奋和有价值的功能,以便全面收集、跟踪和分析数据的沿袭。
OpenLineage资源
Roadmap | Documentation | Slack
#5.TrueDat
TrueDat概述
TrueDat是一个完整的数据治理解决方案,允许您对数据进行详细的编目、搜索和跟踪。借助其数据沿袭功能,TrueDat还可以帮助您可视化数据的整个生命周期,让您深入了解数据随时间的推移。
TrueDat由BlueTab(一家IBM公司)于2
特别提示
其他一些工具将很快变得功能丰富和先进,足以成为该列表的一部分,如DataHub和Spline。
DataHub计划在2022年第一季度推出一项功能,涵盖BigQuery、dbt和Looker的列级沿袭。您可以在这里关注未来的发布。
Spline是另一个专门为Apache Spark创建的数据沿袭跟踪工具。然而,ABSOSS的团队计划将其打造成一个通用的数据沿袭收集工具。Spline上一次发布v0.7.5是在2021年10月。
如何选择正确的数据沿袭工具?
在我们与客户和数据团队一起处理数千个数据项目的经验中,我们发现血统对话往往没有切中要害。以下是评估沿袭工具时应该问的19个问题,以全面评估其深度、广度和实用性。
017年创建。自那以后,它一直在积极开发中,最新版本v4.39于2022年3月发布。
TrueDat数据沿袭功能
TrueDat允许您使用数据沿袭来分析数据库更改的影响,并更好地理解您的报告业务逻辑。它使您能够跟踪具有时间点可见性的数据对象的沿袭。
对于高级分析,还可以对沿袭对象应用过滤器,以检查沿袭图的特定部分。除了UI中沿袭的图形表示外,您还可以将收集的数据沿袭信息下载到CSV文件中。由于TrueDat提供了一套出色的数据治理和沿袭功能,它是解决数据沿袭问题的真正竞争者。
TrueDat资源
Documentation | Release Notes | GitHub
特别提示
其他一些工具将很快变得功能丰富和先进,足以成为该列表的一部分,如DataHub和Spline。
DataHub计划在2022年第一季度推出一项功能,涵盖BigQuery、dbt和Looker的列级沿袭。您可以在这里关注未来的发布。
Spline是另一个专门为Apache Spark创建的数据沿袭跟踪工具。然而,ABSOSS的团队计划将其打造成一个通用的数据沿袭收集工具。Spline上一次发布v0.7.5是在2021年10月。
如何选择正确的数据沿袭工具?
在我们与客户和数据团队一起处理数千个数据项目的经验中,我们发现血统对话往往没有切中要害。以下是评估沿袭工具时应该问的19个问题,以全面评估其深度、广度和实用性。
Download ebook —> The Ultimate Guide to Evaluating Data Lineage
Want to know more about how Atlan’s data lineage capabilities can help you?
数据沿袭工具:相关读取
- What Is Data Lineage & Why Is It Important?
- Data Lineage 101: Importance, Use Cases, and Their Role in Governance
- 5 Types of Data Lineage: Understand All Ways to View Your Data
- 6 Benefits of Data Lineage with Insights Into How Businesses Are Leveraging It
- Automated Data Lineage: Making Lineage Work For Everyone
- Open Source Data Lineage Tools: 5 Popular to Consider in 2023
- Amundsen Data Lineage Setup with dbt
- Data lineage for Snowflake and BigQuery
- Data Catalog vs. Data Lineage: Differences, Use Cases, and Evolution of Available Solutions
- 230 次浏览
【数据谱系】5种数据谱系:了解查看数据的所有方法
视频号
微信公众号
知识星球
数据谱系类型
有五种最常见的可用数据沿袭类型。他们是
- 描述性数据谱系
- 自动化数据沿袭
- 设计谱系
- 企业谱系
- 运营谱系
数据沿袭具有不同的类型,这些类型根据其生成方式、沿袭的预期用户以及生成的数据沿袭的记录方式进行分类。
存在不同类型的数据沿袭,因为您可能想问关于数据和可以从数据沿袭可见性中受益的多个利益相关者的多个问题。
例如,解决法规遵从性的沿袭视图可能本质上与解决根本原因分析或质量的沿袭视图不同。那么,我们如何开始思考数据谱系的类型?首先了解它们是如何分类的。
目录
- 常见类型的数据沿袭
- 数据谱系和关联类型的分类
- 基于文档方法的数据谱系
- 基于技术选择的血统
- 基于角色特定用例的血统
- 业务血统与技术血统
- 什么是数据来源?
- 结论
数据谱系的3种分类方式
- 记录血统的方式
- 用于衍生谱系的技术
- 与世系合作的利益相关者的要求
在这里,我们讨论了多种类型的数据谱系,例如描述性、自动化、设计、操作等,以及每种类型的重要性。
数据谱系和关联类型的分类
- 基于记录方法的血统
- 描述性数据谱系
- 自动化数据沿袭
- 基于技术选择的血统
- 设计谱系
- 企业谱系
- 操作谱系
- 基于角色特定用例的血统
- 业务数据谱系
- 技术和设计数据谱系
- 数据来源
要了解这些不同类型的数据谱系,请考虑跟踪营销活动绩效的报告示例。该报告每周更新一次,并记录有关广告支出和用户参与度的数据,而企业则使用这些数据来衡量营销ROI。
在整个生命周期中,该数据源可能会经历多次转换。不仅每周更新一次报告,还定期附上最近销售的信息;活动结束后,报告可以导出到数据仓库中进行长期存储。这些更改构成了跟踪数据谱系的基础。
根据您决定如何以及为什么跟踪该血统,您可能会得到不同类型的血统。
基于文档化方法的数据谱系
正如谱系专家Irina Steenbeek在本资源中指出的,从谱系记录的角度来看,我们可以有两种类型的数据谱系:描述性数据谱系和自动化数据谱系。
1.描述性数据谱系
描述性数据谱系是手动生成的。在上述营销报告的上下文中,描述性数据谱系可以是Word文档或文本文件,该文件记录了有关报告如何随时间更新以及其内容后来如何导出到数据仓库的信息。
2.自动化数据沿袭
或者,您可以基于报告创建自动数据沿袭。这种类型的数据沿袭将由数据沿袭工具生成,这些工具将自动跟踪报告在其整个生命周期中的更改和转换,然后提供包括数据更改详细信息在内的信息,以及帮助利益相关者了解数据如何更改的可视化。
基于技术选择的血统
Mandy Chessell指出,您还可以根据生成数据谱系的技术对数据谱系类型进行分类。三种主要类型包括设计谱系、业务谱系和运营谱系。
1.设计谱系
设计谱系侧重于识别导致给定数据状态的数据源和流。对于营销报告,设计谱系将记录有关哪些数据源形成报告、每周如何将新数据附加到报告中以及报告内容如何在不同报告系统之间移动的详细信息。
2.业务谱系
业务谱系根据业务信息描述数据的起源和演变。它没有显示每个数据流的每个组成部分,而是过滤并关注与业务直接相关的内容,例如广告支出、用户参与度和转化率的数据来源。
虽然这在某些方面与设计谱系相似,但主要区别在于业务谱系侧重于帮助做出以业务为中心的决策,而不是设计如何获取和处理信息的决策。
3.运营谱系
运营谱系描述了技术操作所基于的数据移动和转换。
技术谱系有助于在更深层次的粒度上跟踪数据:系统(数据库、应用程序、服务)、API、转换、SQL查询和表列。技术谱系有助于根本原因分析、调试管道问题、指导测试和重构。
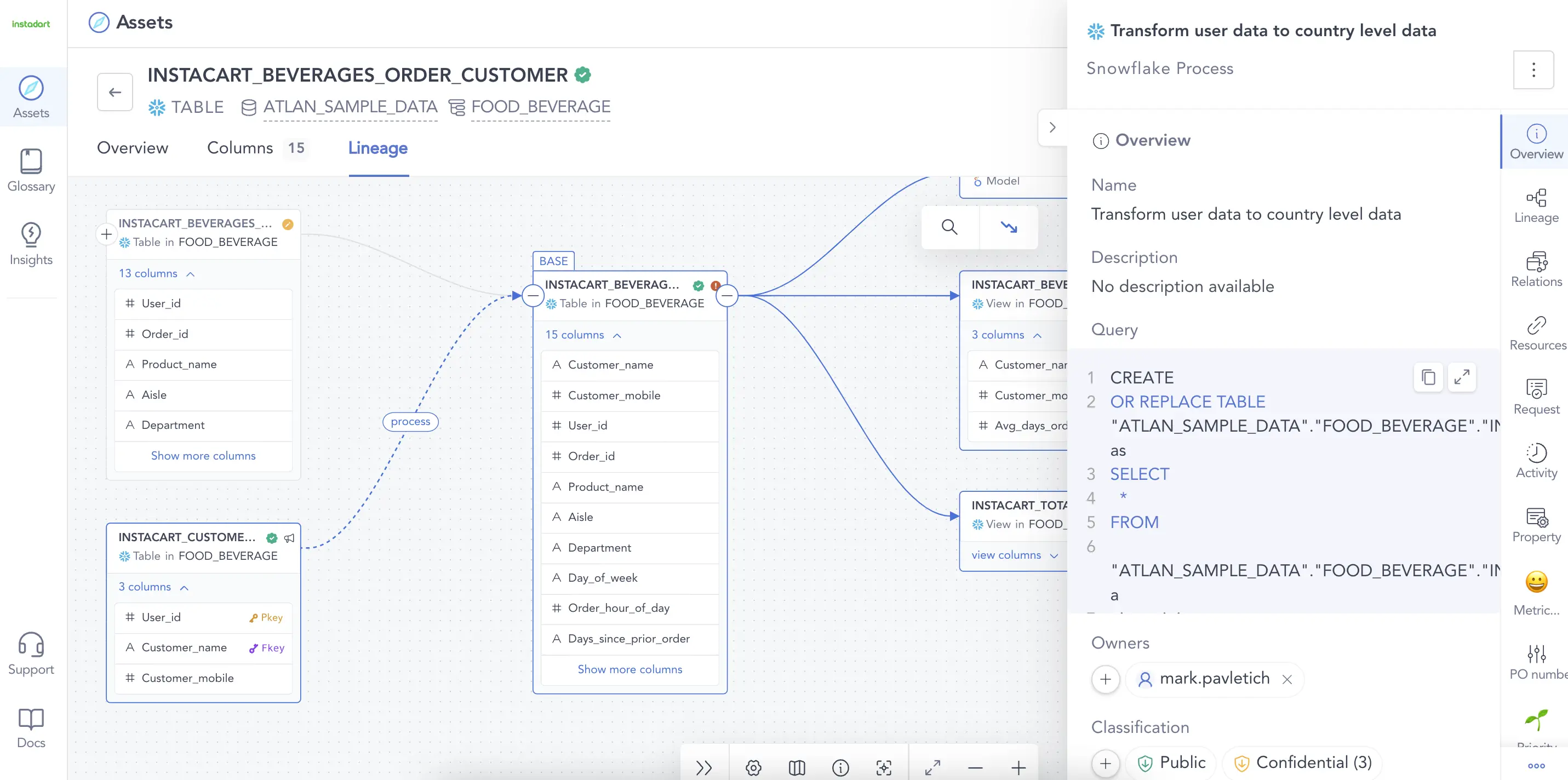
Operational data lineage helps debug issues, guide testing, and refactoring pipelines. Source: Atlan
这些类型的数据沿袭没有一种比其他类型更好或更差。相反,将它们视为服务于不同的目的并提供不同类型的信息。
基于角色特定用例的谱系
我们已经参考了Irina Steebeek关于数据谱系的文章。同一篇文章还讨论了对数据谱系进行分类的第三种方法,即从谁使用数据谱系的角度进行思考。
这种方法类似于基于谱系生成技术对数据谱系类型进行分类,因为不同的技术与不同的用例相一致。
一般来说,这里需要考虑两种主要的人物角色类型,以及两种类型的数据谱系:
1.业务数据谱系
如果数据消费者是非技术性的业务用户,其主要目标是了解数据如何影响业务,那么通常会产生业务谱系。
如上所述,业务数据沿袭避免了技术细节,专注于实现轻松的数据发现、验证数据的新鲜度和完整性、跟踪数据流到BI仪表板、跟踪数据更改及其下游影响。这些是对业务利益相关者(而不是技术团队)至关重要的信息实例。
2.技术和设计数据谱系
相比之下,技术利益相关者(如IT工程师和数据科学家)通常对数据谱系的技术和操作细节更感兴趣。技术谱系有助于确定数据来源(系统、流程、数据集API)和使用位置(BI/报告、ML数据集)。
这有助于数据架构师构建更好的管道设计,了解依赖关系,优化ETL作业,并确保遵守与数据处理相关的法规要求。
因为大多数企业都包括以业务为中心的利益相关者和技术利益相关者,所以通常需要为多种类型的人物角色定制两种类型的数据谱系。
业务血统与技术血统
技术谱系和业务谱系之间的主要区别在于,业务谱系侧重于影响业务优先级的数据来源和处理方面,例如哪个业务部门生产、消费或更新了数据。相反,技术谱系基于技术操作(如ETL日志、根本原因分析、影响分析和管道工作流)跟踪数据生命周期。
什么是数据来源?
如果不考虑数据来源,很难讨论数据谱系的类型。
数据来源是关于原始数据源的信息,例如数据的创建人、创建时间以及创建原因。
数据源详细信息可以作为文件、数据库或其他数据源(数据源、数据类型、数据大小、版本ID和转换步骤)附带的元数据。
数据谱系与数据来源
数据来源标识数据的来源。相比之下,数据谱系记录了数据到达当前形式所经历的完整过程。因此,数据来源是数据谱系的一个组成部分。但这不是唯一的组成部分。
例如,对于上面描述的营销报告,数据谱系将包括关于报告起源的完整细节,以及报告中的数据是如何随时间扩展并随后导出到数据库的。
但该报告的数据来源将仅详细说明该报告的原始创建。它将缺少有关数据附件或将数据移动到数据仓库的导出操作的信息。
数据线型类型常见问题解答
数据沿袭的不同类型是什么?
有五种最常见的可用数据沿袭类型。它们是1。描述性数据谱系,2。自动化数据沿袭,3。设计谱系,4。业务谱系,5。运营谱系。
结论
不同类型的数据谱系用于不同的目的,它们以不同的方式生成。在许多情况下,企业需要利用各种数据衍生类型和生成技术,以使其数据资产发挥最大价值。
- 385 次浏览
【数据谱系】开源数据谱系工具:2023年流行的5种工具
视频号
微信公众号
知识星球
数据沿袭工具可帮助您跟踪数据的每一步变化。从源捕获的数据在经过一系列数据工程过程(如清理、扯皮、集成、重塑等)之前没有多大用处。要从数据中获得最大价值,您需要跟踪数据的来源和生命周期。
我们看到世系对话经常失败。这里有19个问题来评估沿袭工具的深度、广度和实用性。下载免费指南。
本文在考虑了一系列特性、集成功能和易用性之后,列出了五个引人注目的开源数据衍生工具。在文章末尾,我们还特别提到了一些即将推出的工具。
5流行的开源数据衍生工具
- Tokern
- Egeria
- Pachyderm
- OpenLineage
- TrueDat
什么是数据沿袭工具?
数据沿袭工具可帮助您跟踪数据的每一步变化。从源捕获的数据在经过一系列数据工程过程(如清理、扯皮、集成、重塑等)之前没有多大用处。要从数据中获得最大价值,您需要跟踪数据的来源和生命周期。
这些工具需要与当前的数据堆栈集成,其中可能包含一系列数据库、数据仓库、数据湖、ML管道和BI工具以获取沿袭数据。获得一致的沿袭视图对于更有效地理解和使用数据至关重要,因此必须确定正确的数据沿袭工具。
在这里,我们特别关注当前受用户欢迎的开源数据衍生工具。
#1.Tokern
Tokern概述
Tokern是为云数据仓库和数据湖而建的。它采用了一种专门的方法,使您能够从Google BigQuery、AWS Redshift和Snowflake上托管的数据库和数据仓库中获取列级数据血统。SparkSQL、AWS Athena和Presto等更多资源正在开发中。
Tokern具有可观的集成能力,因为它与大多数开源数据目录和ETL框架配合得很好。
Tokern数据谱系特征
Tokern不久前发布,它考虑了最新的数据工程和设计模式。一个这样的例子是,除了从dbcat(数据目录)构建数据谱系之外,Tokern还允许您从查询历史或ETL脚本构建数据谱系,这是BI和ETL工具集成的理想选择。
Tokern将数据目录和谱系存储在PostgreSQL数据库中。您可以使用SQL访问该数据库进行进一步分析,或将其输入其他可视化和分析引擎。
Kedro Viz,一个可视化引擎,以及一个名为NetworkX的网络图分析库,是Tokern出色的可视化和分析能力的背后。这些库帮助您“跟踪、可视化和分析列级沿袭数据”。您还可以使用Tokern的SDK或API与血统数据交互。
除了一流的数据沿袭功能外,Tokern还使用PIICatcher提供PII(个人可识别信息)和PHI(个人健康信息)检测。这个内置工具利用正则表达式和几个标准NLP库的组合进行PII检测,例如Spacy和Stanford NER。
Tokern资源
Documentation | Discord | Blog | GitHub
#2.Egeria
Egeria概述
Egeria被称为“世界上第一个开源元数据标准”。它提供了一种无缝集成数据工程工具的方法,以获得可靠和一致的元数据视图。除了编目和搜索元数据之外,该标准还允许您为数据谱系跟踪、数据质量检查、PII识别等构建更高级的解决方案。
许多数据工程架构涉及各种数据工具之间的大量可避免的闲聊。Egeria远离这一点,而是在一个中心辐射模式下工作,所有的东西都通过Egeria。这样,您只需使用一个工具进行对话。
Egeria数据谱系特征
Egeria中的数据谱系利用众所周知的开放标准来捕获和存储称为OpenLineage的数据谱系。OpenLineage还可以通过跟踪数据的水平和垂直血统,让您对数据有更深入的了解。
Egeria监听源系统发出的Kafka事件,以获取数据谱系信息。一旦完成了这一点,血统管理员就可以匹配和链接血统图,而Egeria无法做到这一点。之后,血统对商业消费都很有好处。
Egeria中的数据谱系特性与数据发现和管理、元数据来源等特性非常吻合。上面提到的特性以及Egeria的谱系设计和架构使其成为一个非常引人注目的、经过深思熟虑的数据治理和数据谱系工具。
Egeria资源
Documentation | Medium | Slack | GitHub
#3.Pachyderm
Pachyderm概述
与Tokern一样,Pachyderm是另一个专门的数据谱系工具。Pachyderm的目标不是专注于云数据仓库,而是让开发人员能够以语言和框架无关的方式构建机器学习管道。
Pachyderm已经实现了像lakeFS或Git这样的版本控制系统,以维护数据对象的沿袭。对这些对象的更改(即提交)由Pachyderm捕获并存储,从而维护事件的完整且不可变的审计跟踪。审计跟踪使您能够拥有用于查看和分析的数据沿袭图,并允许您在任何时间点出于调试或合规性原因复制数据和代码。
Pachyderm数据谱系特征
为了实现对数据的无缝数据沿袭跟踪和版本控制,Pachyderm在定制的文件系统PFS(PachydermFile system)中使用了一个使用AWS S3等对象存储的中央存储库。PFS帮助您的对象存储(如S3)成为具有完整历史的数据的唯一真实来源。
Pachyderm还在数据源上强制执行不变性,这允许它为沿袭事件和数据对象分配全局ID。Pachyderm允许您在UI中将不可变数据谱系图视为DAG。在处理ML管道时,上面提到的这两个特性都是有利的,您希望将结果跟踪回它们的输入。
Pachyderm与最广泛使用的数据库、数据仓库和数据湖集成。此外,使用基于SQL的摄取工具,您可以将任何数据库中的数据导入Pachyderm。然而,Pachyderm作为通用数据沿袭工具存在局限性,这就是为什么大多数Pachyderm的企业客户使用它来处理MLOps、非结构化数据ETL和NLP工作负载的原因。
Pachyderm资源
Documentation | Slack | Blog | GitHub
#4.OpenLineage
OpenLineage概述
在WeWork开源后,负责接管Marquez开发的DataKin公司也创建了OpenLineage。DataKin于21年年中将OpenLineage项目作为沙箱项目移交给了Linux基金会。
OpenLineage深受OpenTelemetry的启发,它在数据可观测性领域无处不在,旨在为数据谱系收集和分析建立一个开放的标准。
OpenLineage功能
集成是OpenLineage设计和使命的核心。它与ETL框架、数据编排引擎、元数据目录、数据质量引擎和数据沿袭工具集成。OpenLineage使用JSONSchema作为API定义,支持各种语言和框架。Egeria是我们上面提到的一个流行的数据沿袭工具,它的核心元数据层构建在OpenLineage之上。
WeWork的Marquez也是OpenLineage架构的核心,因为Marquez提供了UI和元数据存储库,而元数据收集API来自OpenLineage。OpenLineage还通过GraphQL和REST API向您公开。
OpenLineage是一个很有吸引力的选项,因为它可以与大多数现有的数据工程堆栈轻松共存,并为您提供一系列令人兴奋和有价值的功能,以全面收集、跟踪和分析数据的沿袭。
OpenLineage资源
Roadmap | Documentation | Slack
#5.TrueDat
TrueDat概述
TrueDat是一个完整的数据治理解决方案,允许您对数据进行详细的编目、搜索和跟踪。借助其数据衍生功能,TrueDat还可以帮助您可视化数据的整个生命周期,让您深入了解数据随时间变化的过程。
TrueDat由BlueTab(IBM公司)于2017年创建。此后,它一直在积极开发中,最新版本v4.39于2022年3月发布。
TrueDat数据沿袭特征
TrueDat允许您使用数据谱系来分析数据库更改的影响,并更好地理解报告业务逻辑。它允许您使用时间点可见性跟踪数据对象的沿袭。
对于高级分析,还可以对沿袭对象应用过滤器,以检查沿袭图的特定部分。除了UI中血统的图形表示外,还可以将收集的数据血统信息下载到CSV文件中。由于TrueDat提供了一组优秀的数据治理和沿袭功能,它是解决数据沿袭问题的真正竞争者。
TrueDat资源
Documentation | Release Notes | GitHub
特别提及事项
其他一些工具将很快变得功能丰富和先进,足以成为该列表的一部分,例如DataHub和Spline。
- DataHub计划于2022年第一季度推出一项功能,涵盖BigQuery、dbt和Looker的列级沿袭。你可以在这里关注未来的版本。
- Spline是另一个专门为ApacheSpark创建的数据沿袭跟踪工具。然而,ABSOSS的团队计划将其打造成一个通用的数据谱系收集工具。Spline的最后一个版本v0.7.5是在2021 10月发布的。
如何选择正确的数据衍生工具?
在我们与客户以及我们自己作为一个数据团队处理数千个数据项目的经验中,我们发现,血统对话往往没有抓住重点。以下是在评估谱系工具以全面评估其深度、广度和实用性时应该问的19个问题。
- 493 次浏览
【数据谱系】数据谱系101:重要性、用例及其在治理中的作用
视频号
微信公众号
知识星球
数据谱系提供了有关数据起源于何处以及自生成以来如何聚合、转换或以其他方式修改数据的关键上下文。
继续阅读,深入了解数据衍生是如何工作的,为什么它很重要,以及您可以利用哪些工具和最佳实践来帮助自动化衍生生成。
什么是数据血统?
数据谱系是关于数据起源和演化的信息。数据谱系是数据在其整个生命周期中旅程的可视化。血统有助于跟踪来自源的数据、数据如何在管道中传输、数据经过的转换(连接、过滤器、聚合)、数据的使用位置以及用户。监控血统的透明性对于确保数据完整性和可用性至关重要。
正如Mandy Chessell所解释的,除非你了解“数据的来源及其所进行的转换”,否则你无法“理解报告中提供的数据或分析计算中使用的数据的真正含义”
换言之,当您了解数据谱系时,您就知道数据最初产生的位置,以及数据在生成时和分析时之间可能发生的变化。此外,了解数据谱系提供了跟踪和排除数据质量问题和分析错误所需的可视性。
类似地,数据谱系类似于您在邮件中订购产品时可能收到的发货信息。装运信息告诉货物的原产地,货物在运输途中经过的地点,以及货物是否与其他物品包装在一起。
如果货物丢失或延迟,或者您最终没有收到您购买的物品,这些细节至关重要。同样,数据谱系允许您跟踪数据的来源、移动和转换,以便您可以调查和解决数据传输过程中出现的任何问题。
Data lineage helps track the journey of the data in its entire life cycle. Source: Atlan
数据血统示例
作为真实世界中数据谱系的一个示例,假设客户在您的帮助台平台中提交技术支持请求。支持请求会在帮助台系统中生成一张票据。该票据包含客户姓名、联系信息和请求详情等信息,是原始数据源,并存储在专有的帮助台平台中。
然而,稍后,在您的IT团队对票据做出响应并关闭请求后,票据数据将被导出到一个云数据仓库,如Snowflake,在那里您可以更容易地长期存储并对其进行分析。原始票据中的信息仍然存在,但现在已被转换为适合数据仓库中的一组列。它还可以与来自其他系统(如CRM软件)的数据一起存储,这些系统被聚合到同一数据仓库中。
如果此时您想分析数据(例如,如果您想生成有关客户交互或IT团队活动的报告,您可能会这样做),那么了解票据数据的来源可能与数据仓库中的其他数据不同,这一点很重要。这些信息将帮助您编写更有效的查询,以便与数据交互并提取相关信息。它还可以帮助您清理数据质量问题,例如包含客户姓名和联系信息的冗余列。
更进一步,当您决定将数据从数据仓库转储到平面文件并将其上传到“冷”云对象数据服务(如AWS Glacier)时,源于票据系统的数据可以再次转换,在那里您可以以低成本长期保留数据。
如果在某个时刻您决定将数据从冷库中取出并再次分析,您可能会想了解数据的谱系。如果您想重建数据的原始状态,了解数据源于票据系统,导出到数据仓库,然后导出到不同的云存储平台是至关重要的。如果您只知道数据曾经是位于对象存储桶中的文本文件,那么您将无法了解数据的格式化原因,也无法了解如何将其转换回一种状态,从而使您能够更有效地分析数据或提高其质量。
为什么数据血统很重要?
数据沿袭之所以重要,主要原因是它为跟踪数据在不同数据源和管道之间的移动提供了至关重要的可见性,并为这些管道提供了透明度。
当您了解数据的谱系时,您可以:
- 提高数据质量
- 集成数据
- 跨业务共享数据
- 满足法规遵从性要求
提高数据质量
通过识别数据经过的步骤以达到当前状态,数据谱系可以帮助您了解数据集中冗余、错误、不准确或其他数据质量问题的根源。
更快地集成数据
了解数据沿袭为执行数据集成或进一步数据聚合提供了关键的可见性和上下文,而不会丢失数据的原始形式。
跨业务共享数据
当您知道数据来自何处以及数据是如何演变的时,您可以通过为每个业务部门或利益相关者提供最适合他们的数据版本,从而更准确地与他们共享数据。
满足法规遵从性要求
如果您需要满足法规遵从性规则,了解数据的来源至关重要。例如,GDPR可能要求您从集成了个人识别信息(PII)的数据库中删除包含个人识别信息的数据。数据沿袭信息将帮助您更有效地分解PII,同时保留其余数据。
这样的好处就是为什么大公司在管理数据谱系方面进行大量投资的原因。他们知道,仅仅了解数据的“结束状态”是不够的,这意味着数据当前的格式化或存储方式。为了提高数据质量、简化分析并满足数据隐私和合规要求,他们需要在其业务中流动的众多数据管道中实现完整的可追溯性和透明度。
例如,Slack使用数据沿袭来改进其合规性工作。正如该公司所指出的那样,尽管“GDPR合规不需要数据血统……但这使其更容易实现。”这是因为了解数据如何随着时间的推移而变化,可以提高Slack识别受GDPR规定约束的数据的能力。
同样,对于Netflix来说,了解数据谱系是改善决策的更广泛努力的一部分。为此,该公司广泛投资开发了“一个完整、准确的数据谱系系统,使决策者能够赢得关键时刻”
了解更多:数据谱系在数据治理中的6大好处
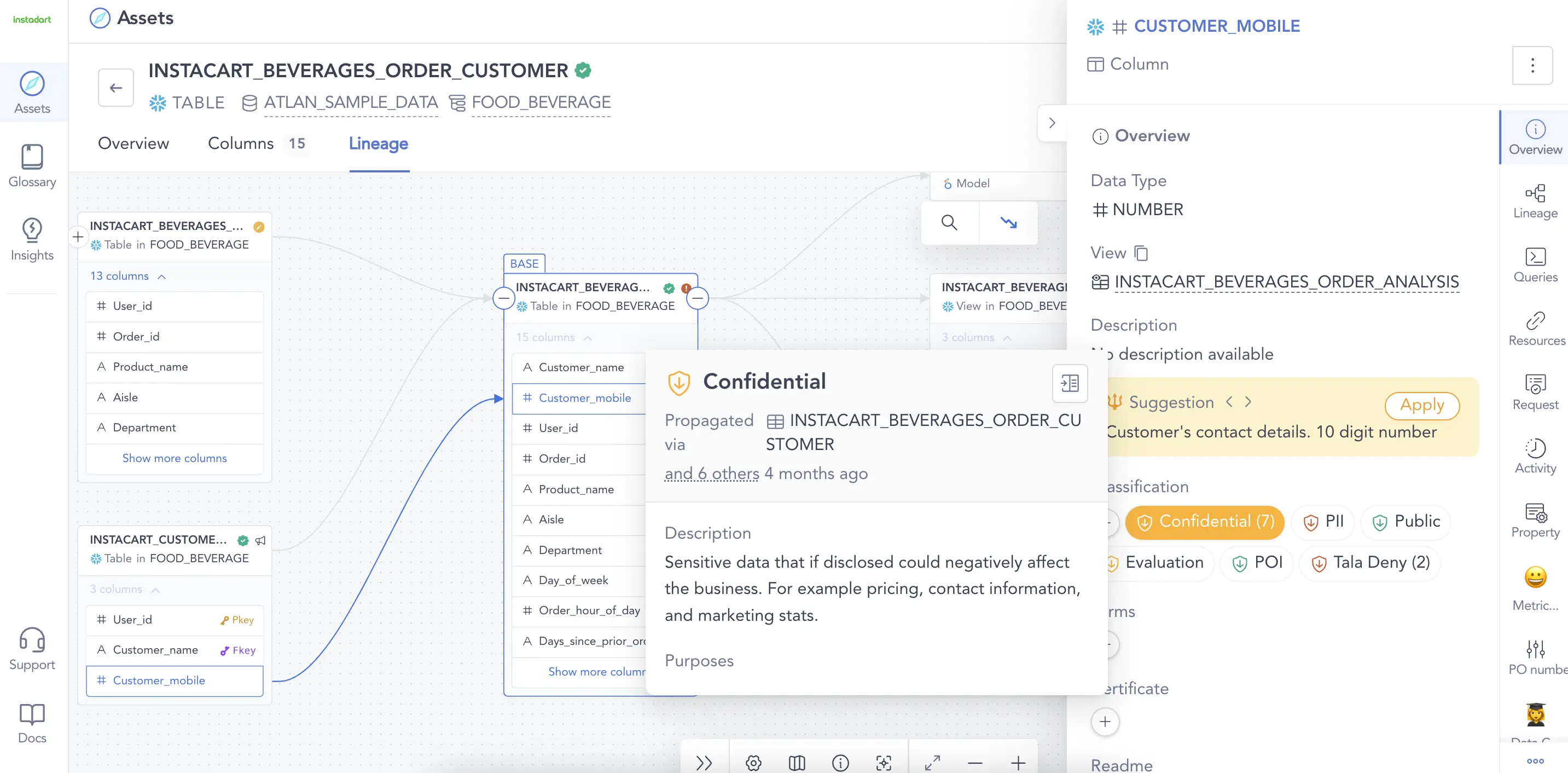
Visualize classification propagation on the lineage path. Source: Atlan
数据谱系:典型用例
- 执行根本原因分析
- 生成报告
- 不推荐列
- 设置数据保留规则
数据谱系支持各种数据用例,不仅适用于IT团队,也适用于整个企业的利益相关者。
执行根本原因分析
如果您需要追踪由数据质量问题引发的问题的根本原因,那么了解数据的来源至关重要。例如,用户登录请求可能会失败,因为存储登录凭据的数据库已被修改。如果您知道发生了哪些数据转换,则可以更容易地进行更正,以解决登录问题。
Data lineage helps root-cause analysis by tracking transformations across the data life cycle. Source: Atlan
生成报告
各种业务部门(如IT、营销、销售等)可能希望根据数据生成报告。如果利益相关者能够从更广泛的数据集中分解最相关的数据,那么这些报告将更快生成,更准确。例如,销售团队可能希望从包含与客户相关的更广泛信息的数据库中提取与销售相关的数据。
弃用列
为了优化数据存储成本和加快分析速度,能够从数据库中删除冗余或过时的列是很有帮助的。数据沿袭允许您自信地进行这些更改,因为您可以轻松地确定列存在的原因并确定它是否仍然相关。数据沿袭还可以让您跟踪哪些列已弃用,以防以后需要这些信息。
设置数据保留规则
法规遵从性、安全性或治理要求可能要求您在一定时间内存储某些类型的数据。在某些情况下,您可能还需要在给定时间段后删除数据。使用数据沿袭,您将知道哪些特定记录受哪些保留策略的约束,即使您在最初创建记录时已聚合或转换了这些记录。反过来,您可以在细粒度的基础上定义适当的数据保留规则。
数据沿袭和数据治理
尽管数据沿袭与数据治理(即管理数据完整性、质量、可用性和隐私的过程)不是一回事,但它们是密切相关的主题。
当您能够看到数据沿袭时,您可以实现数据治理目标,例如:
- 自动识别受特殊数据治理要求约束的敏感信息(如PII)。
- 在数据源和管道中自动传播数据治理策略。
- 通过包含数据沿袭信息的报告和审计日志,证明您满足了数据治理要求。
数据系列最佳实践
考虑到您的业务可能管理的数据源和管道众多,建立数据沿袭策略可能具有挑战性。为了使流程尽可能简单有效,请考虑以下最佳做法:
- 自动生成数据沿袭
- 跟踪多种类型的血统
- 使数据沿袭发挥作用
- 全面跟踪数据沿袭
自动生成数据沿袭
首先也是最重要的,利用数据沿袭自动化工具(我们将在下面详细讨论)来跟踪数据沿袭。自动化工具不仅加快了流程,还降低了在手动跟踪血统时由于人为疏忽而导致的错误风险。
跟踪多种类型的血统
正如我们在下面讨论的,有几种类型的数据沿袭。每个都从不同的角度跟踪数据。您跟踪的谱系类型越多,您对数据来源的了解就越多。
使数据沿袭发挥作用
不要仅仅为了数据血统而跟踪数据血统。相反,使用数据沿袭作为优化业务其他部分的基础,例如设置和部署有效的数据治理策略。
全面跟踪数据沿袭
与其只跟踪某些数据源的谱系,不如着眼于在业务的所有部分建立所有数据源和管道的谱系。您永远不知道何时需要深入了解数据谱系,即使是对于一个看起来晦涩或不重要的数据源。
这样的实践可以确保数据衍生推动业务价值——这应该是您的最终目标。它们还有助于使数据沿袭尽可能高效,从而减轻it和数据团队的负担。
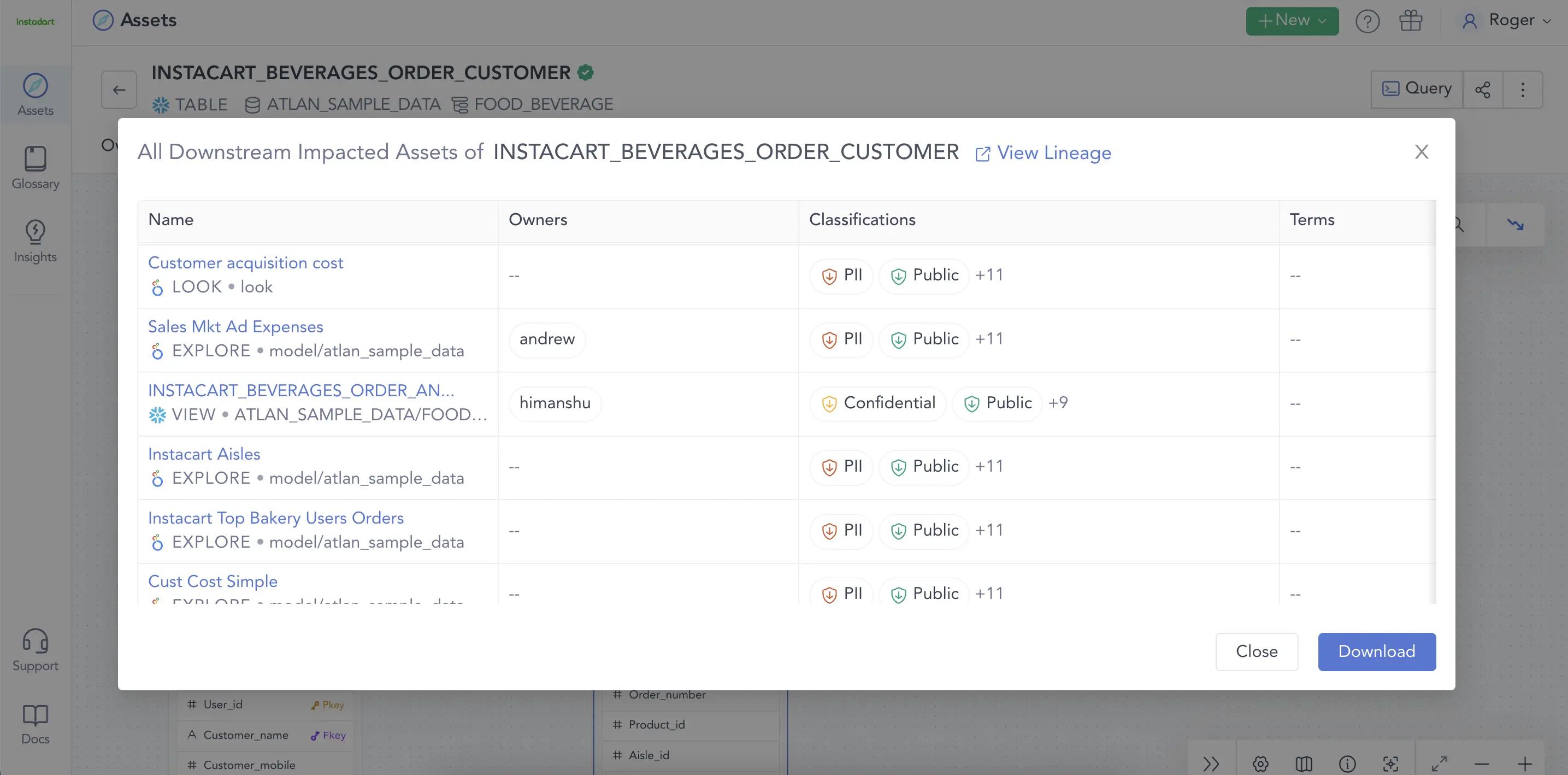
Data lineage helps predict the possible downstream impact of a transformation. Source: Atlan
数据谱系类型
正如我们注意到的,有多种形式的数据谱系。它们是根据数据谱系的记录方式、用于生成特定于用例和人物角色的谱系或谱系的技术来定义的。看看不同类型的数据谱系是如何分类的。
- 基于记录方法的血统
- 描述性数据谱系
- 自动化数据沿袭
- 基于技术选择的血统
- 设计谱系
- 企业谱系
- 操作谱系
- 基于角色特定用例的血统
- 业务数据谱系
- 技术和设计数据谱系
- 数据来源(Data provenance)
那么,当您制定数据沿袭策略时,您将希望在方法中采用多维的方法。考虑您将用于生成数据谱系的多个过程,以及数据谱系的多种用例,并创建一个包含所有这些的策略。
了解更多:数据谱系类型:了解查看数据的所有方式
自动化数据系列
同样,对于大多数企业来说,手动生成所有数据谱系既不实用,也不可扩展。相反,他们希望利用自动化数据沿袭。
自动化数据谱系是使用自动化工具来增强数据的可追溯性和透明度。此外,自动化数据谱系减少了生成谱系时人为错误的风险。它还使企业中的任何人——不仅仅是具有技术技能的工程师——都可以追踪数据来源和转换。
了解更多信息:通过自动化数据衍生更好地了解您的数据
自动化数据系列工具
使用您可以使用的自动化数据衍生工具,您可以:
- 全面摄取数据
- 可视化数据沿袭
- 管理治理
- 合作
全面摄取数据
- 自动化数据沿袭工具可以识别整个业务中的数据,允许您跟踪所依赖的任何和所有数据的沿袭。
可视化数据沿袭
- 自动化工具通过用户友好的仪表板显示数据谱系,使任何人都可以轻松了解数据来源和移动。
管理治理
- 通过将数据治理工具与数据谱系自动化工具集成,您可以根据创建的谱系自动实施和传播治理策略。
合作
- 数据沿袭自动化工具还包括简化利益相关者之间围绕数据沿袭可见性和问题的协作的功能。
数据谱系工具:评估提示
市场上有越来越多的数据衍生自动化工具。要找到最适合您的需求,请考虑:
- 您的数据源
- 您的数据沿袭要求
- 可视化功能
- 易于部署
您的数据源
最好的数据自动化解决方案可以处理任何类型的数据,但有些解决方案只支持某些类型的数据源,例如数据库。
您的数据沿袭要求
正如我们注意到的,有几种类型的数据沿袭。最灵活的工具可以生成多种类型的数据谱系——技术谱系、业务谱系等等——而不是将您局限于特定的数据谱系视图和特定的用例。
可视化功能
通过可视化来解释数据的能力对于向非技术利益相关者展示数据谱系尤其重要。工程师可能能够解析以文本形式显示的技术数据沿袭记录,但非技术利益相关者将受益于仪表板,该仪表板使其易于查看和与数据沿袭详细信息交互。
易于部署
虽然每个数据衍生平台都需要一定程度的定制和与您的环境集成,但不需要IT部门进行内部部署或日常维护的托管解决方案提供了最低的准入门槛。
Learn more: 5 best open-source data lineage tools to consider in 2023
数据谱系:下一步是什么?
数据谱系是准确数据分析、报告和管理的基础。它在定义和满足数据治理和法规遵从性要求方面也发挥着核心作用。它使您的企业中的任何人都能够充分利用数据来回答复杂的问题,尤其是当您利用数据谱系自动化工具来实现整个组织中利益相关者对数据谱系的民主化访问时。
- 283 次浏览