数据挖掘
【数据挖掘】数据挖掘-系统
视频号

微信公众号

知识星球

有各种各样的数据挖掘系统可用。数据挖掘系统可以集成以下技术——
- 空间数据分析
- 信息检索
- 模式识别
- 图像分析
- 信号处理
- 计算机图形学
- Web技术
- 商业
- 生物信息学
数据挖掘系统分类
数据挖掘系统可以根据以下标准进行分类-
- 数据库技术
- 统计数字
- 机器学习
- 信息科学
- 可视化
- 其他专业
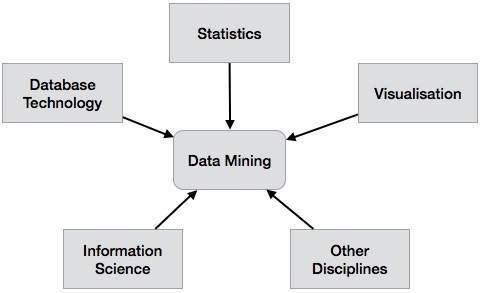
除此之外,数据挖掘系统还可以基于(a)挖掘的数据库、(b)挖掘的知识、(c)使用的技术和(d)适应的应用的类型进行分类。
基于挖掘数据库的分类
我们可以根据挖掘的数据库类型对数据挖掘系统进行分类。数据库系统可以根据不同的标准进行分类,如数据模型、数据类型等,数据挖掘系统也可以进行相应的分类。
例如,如果我们根据数据模型对数据库进行分类,那么我们可能有一个关系型、事务型、对象关系型或数据仓库挖掘系统。
基于挖掘知识类型的分类
我们可以根据挖掘的知识类型对数据挖掘系统进行分类。这意味着数据挖掘系统是根据诸如−
- 刻画
- 区别/辨别
- 关联与相关性分析
- 分类
- 预言
- 异常值分析
- 进化分析
基于所使用技术的分类
我们可以根据使用的技术类型对数据挖掘系统进行分类。我们可以根据所涉及的用户交互程度或所采用的分析方法来描述这些技术。
基于自适应应用程序的分类
我们可以根据所适应的应用程序对数据挖掘系统进行分类。这些应用程序如下-
- 金融
- 电信
- 脱氧核糖核酸
- 股票市场
- 电子邮件
数据挖掘系统与DB/DW系统的集成
如果数据挖掘系统没有与数据库或数据仓库系统集成,那么就没有可通信的系统。这种方案被称为非耦合方案。在该方案中,主要关注数据挖掘设计和开发高效有效的算法来挖掘可用的数据集。
集成方案列表如下-
- 无耦合-在该方案中,数据挖掘系统不使用任何数据库或数据仓库功能。它从特定的源获取数据,并使用一些数据挖掘算法处理这些数据。数据挖掘结果存储在另一个文件中。
- 松散耦合——在这个方案中,数据挖掘系统可能会使用数据库和数据仓库系统的一些功能。它从这些系统管理的呼吸数据中提取数据,并对这些数据进行数据挖掘。然后,它将挖掘结果存储在文件中,或者存储在数据库或数据仓库中的指定位置。
- 半紧耦合-在该方案中,数据挖掘系统与数据库或数据仓库系统链接,除此之外,还可以在数据库中提供一些数据挖掘原语的有效实现。
- 紧密耦合——在这种耦合方案中,数据挖掘系统平滑地集成到数据库或数据仓库系统中。数据挖掘子系统被视为信息系统的一个功能组件。
- 64 次浏览
【数据挖掘】数据挖掘架构的类型
视频号
微信公众号
知识星球
介绍
数据挖掘是对大数据集进行筛选,以找到可用于应对业务挑战的模式和相关性。企业可以使用数据挖掘技术和技术来预测未来趋势并做出更好的商业决策。数据挖掘是从海量数据中提取潜在价值和以前未发现的信息的关键过程。数据挖掘过程由几个组件组成。
什么是数据挖掘架构?
数据挖掘架构是选择、探索和建模大量数据的过程,以发现以前未知的规律或关系,为数据库所有者生成清晰而有价值的结果。数据挖掘使用自动化或半自动化过程来探索和分析大量数据,以确定实用的设计和程序。
任何数据挖掘系统的主要组件都是:
- 数据源
- 数据仓库服务器
- 数据挖掘引擎
- 模式评估模块
- 图形用户界面
- 知识库。
对数据挖掘架构的需求
数据挖掘架构有助于发现大数据集中的异常、趋势和相关性,以便预测结果。然后,组织利用这些信息来提高销售额、降低开支、加强客户关系、降低风险以及做其他事情。
数据挖掘架构的类型
无耦合:
无耦合数据挖掘系统从特定的数据源(如文件系统)获取数据,使用主要的数据挖掘方法进行分析,并将结果保存到文件系统。使用无耦合数据挖掘架构从特定数据源检索数据。它不使用数据库来获取数据,这通常是一种非常高效和准确的方法。数据挖掘的无耦合设计是无效的,应该只用于极其简单的数据挖掘任务。尽管不建议数据挖掘系统采用无耦合设计,但它可用于基本的数据挖掘过程。
松耦合:
数据挖掘系统从数据库或数据仓库接收数据,使用数据挖掘技术对其进行处理,并将结果保存在松散耦合的数据挖掘架构中的这些系统中。这种设计适用于不需要太多可扩展性或速度的基于内存的数据挖掘系统。具有松散耦合架构的数据挖掘系统从数据库中检索数据并将其保存在这些系统中。基于内存的数据挖掘架构是这种挖掘的重点。
半紧耦合:
在半紧密耦合的数据挖掘架构中,数据挖掘系统除了与数据库或数据仓库系统接口之外,还采用许多数据库或数据仓系统功能来完成数据挖掘活动,例如排序、索引和聚合。它倾向于利用各种数据仓库系统的优势。排序、索引和聚合都是其中的一部分。为了提高效率,在这种设计中,可以将临时结果保存在数据库中。
紧密耦合:
数据库或数据仓库被认为是数据挖掘系统的信息检索组件,该系统在紧密耦合的数据挖掘架构中采用集成。数据挖掘作业利用数据库或数据仓库的所有属性。该设计提供了系统的可扩展性、卓越的性能和集成的数据。数据仓库是该架构中最重要的组件之一,其特性用于执行数据挖掘操作。可扩展性、性能和集成数据都是此设计的特点。
紧密耦合的数据挖掘架构分为三层:
- 数据层:数据库或数据仓库系统就是数据层的一个例子。该层充当所有数据源之间的桥梁。数据挖掘的结果保存在数据层中。因此,我们可以以报告或其他类型的可视化形式向最终用户提供。
- 数据挖掘的应用层:其目的是从数据库中检索信息。这里需要某种转换过程。也就是说,必须将数据转换为所需的格式。然后必须使用各种数据挖掘方法对数据进行处理。
- 前端层:它具有简单易用的用户界面。这是通过与数据挖掘系统交互来完成的。在前端层,为用户显示数据挖掘结果。
数据挖掘架构的优势
- 根据特定产品的受欢迎程度帮助公司优化生产,从而为公司节省成本。
- 帮助企业识别、吸引和留住消费者。
- 帮助公司改善客户关系。
- 通过有效预测未来的模式,它有助于预防未来的威胁。
- 将数据压缩为有价值的信息,从而提供新的趋势和特殊的模式。
数据挖掘架构的缺点
- 缺乏安全性也可能使数据处于危险之中,因为数据可能包含敏感的消费者信息。
- 不正确的数据可能导致不正确的输出。
- 大型数据集极难处理。
- 工作量过大需要高绩效团队和员工培训。
- 巨额支出的需求也可以被视为一个问题,因为数据收集可能需要大量资源,而且成本高昂。
常见问题
解释数据挖掘中的聚类?
数据挖掘中的聚类是将一组抽象对象分类为相关元素组。数据聚类用于图像处理、数据分析、模式识别和市场研究等。它有助于根据从在线搜索或其他媒体获取的数据识别位置并对文档进行分类。它主要用于识别检查在线交易欺诈的程序。
什么是文本挖掘?
文本挖掘,也称为数据挖掘,是将非结构化文本转换为结构化格式的行为,以揭示新的见解和重要模式。
结论
在本文中,我们广泛讨论了数据挖掘架构的类型。
您可以访问图书馆,查看由编码忍者团队策划的更令人兴奋的博客和文章。
我们希望这篇博客能帮助您增强对数据挖掘的了解,如果您想了解更多信息,请查看数据挖掘与数据仓库、DBMS中的异常和访谈问题。
- 78 次浏览
【数据挖掘】数据挖掘架构的类型和组成部分
视频号
微信公众号
知识星球
数据挖掘是指从已经收集的数据中检测和提取新的模式。数据挖掘是统计学和计算机科学领域的融合,旨在发现超大数据集中的模式,然后将其转换为可理解的结构以供日后使用。
数据挖掘的体系结构:
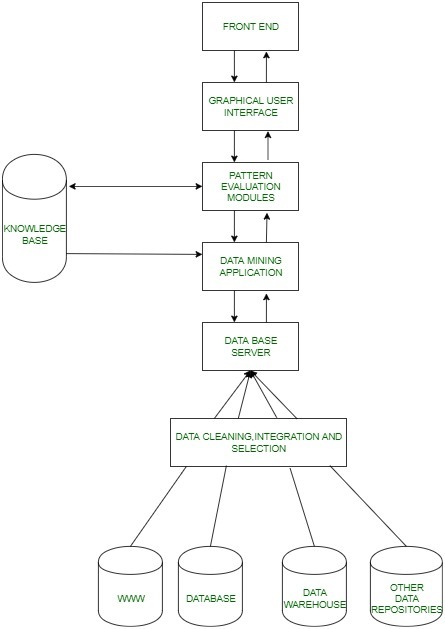
基本工作:
- 这一切都始于用户提出某些数据挖掘请求,然后这些请求被发送到数据挖掘引擎进行模式评估。
- 这些应用程序试图使用已存在的数据库来查找查询的解决方案。
- 然后提取的元数据被发送到数据挖掘引擎以进行适当的分析,数据挖掘引擎有时与模式评估模块交互以确定结果。
- 然后,使用合适的接口以易于理解的方式将该结果发送到前端。
数据挖掘架构各部分的详细描述如下:
- 数据源:数据库、万维网(WWW)和数据仓库是数据源的组成部分。这些来源中的数据可以是纯文本、电子表格或其他形式的媒体,如照片或视频。WWW是最大的数据来源之一。
- 数据库服务器:数据库服务器包含准备处理的实际数据。它根据用户的请求执行处理数据检索的任务。
- 数据挖掘引擎:它是数据挖掘架构的核心组件之一,可以执行各种数据挖掘技术,如关联、分类、特征化、聚类、预测等。
- 模式评估模块:他们负责在数据中找到有趣的模式,有时他们还与数据库服务器交互,以产生用户请求的结果。
- 图形用户界面:由于用户无法完全理解数据挖掘过程的复杂性,因此图形用户界面有助于用户与数据挖掘系统进行有效沟通。
- 知识库:知识库是数据挖掘引擎的重要组成部分,在指导搜索结果模式方面非常有益。数据挖掘引擎有时也可以从知识库中获取输入。该知识库可以包含来自用户体验的数据。知识库的目的是使结果更加准确和可靠。
数据挖掘体系结构的类型:
- 无耦合:无耦合数据挖掘体系结构从特定数据源检索数据。它不使用数据库来检索数据,否则这是一种非常有效和准确的方法。数据挖掘的无耦合架构很差,仅用于执行非常简单的数据挖掘过程。
- 松散耦合:在松散耦合体系结构中,数据挖掘系统从数据库中检索数据并将数据存储在这些系统中。此挖掘适用于基于内存的数据挖掘体系结构。
- 半紧密耦合:它倾向于使用数据仓库系统的各种有利特性。它包括排序、索引和聚合。在这种体系结构中,可以将中间结果存储在数据库中以获得更好的性能。
- 紧密耦合:在该体系结构中,数据仓库被认为是其最重要的组件之一,其功能用于执行数据挖掘任务。此体系结构提供了可扩展性、性能和集成信息
数据挖掘的优势:
- 通过准确预测未来趋势,帮助预防未来的对手。
- 有助于做出重要决策。
- 将数据压缩为有价值的信息。
- 提供新的趋势和意想不到的模式。
- 帮助分析庞大的数据集。
- 帮助公司寻找、吸引和留住客户。
- 帮助公司改善与客户的关系。
- 协助公司根据某一产品的喜爱程度优化生产,从而为公司节省成本。
数据挖掘的缺点:
- 过度的工作强度需要高绩效的团队和员工培训。
- 大量投资的需求也可能被认为是一个问题,因为有时数据收集会消耗许多资源,而这些资源的成本很高。
- 缺乏安全性也可能使数据面临巨大风险,因为数据可能包含私人客户详细信息。
- 不准确的数据可能导致错误的输出。
- 庞大的数据库很难管理。
- 287 次浏览
【数据挖掘】网页抓取科普
Web抓取、Web收获或Web数据提取是用于从网站提取数据的数据抓取。[1]网络抓取软件可以直接使用超文本传输协议或通过网络浏览器访问万维网。
虽然web抓取可以由软件用户手动完成,但该术语通常指使用bot或web爬虫程序实现的自动化过程。它是一种复制形式,从web上收集和复制特定的数据,通常将其复制到中央本地数据库或电子表格中,供以后检索或分析。Web抓取Web页面包括获取和提取。[1][2]获取是页面的下载(当您查看页面时,浏览器会这样做)。因此,web爬行是web抓取的主要组成部分,用于获取页面供以后处理。一旦提取,就可以进行提取。页面的内容可以被解析、搜索、重新格式化,其数据可以被复制到电子表格中,等等。
Web scraper通常会从页面中删除一些内容,然后将其用于其他地方的其他用途。例如,查找和复制姓名和电话号码,或公司及其url到列表(联系信息抓取)。Web刮刮用于接触,和作为一个组件的应用程序用于Web索引、Web挖掘和数据挖掘,在线价格变化监测和价格比较,产品评论刮(看竞争),收集房地产上市,气象数据监测、网站变化检测研究,跟踪网络形象和声誉,Web mashup, Web数据集成。Web页面是使用基于文本的标记语言(HTML和XHTML)构建的,并且经常以文本形式包含大量有用的数据。然而,大多数web页面是为人类最终用户设计的,而不是为了便于自动化使用。因此,创建了用于抓取web内容的工具包。web scraper是一个用于从web站点提取数据的应用程序编程接口(API)。亚马逊AWS和谷歌等公司向终端用户免费提供网络抓取工具、服务和公共数据。较新的web抓取形式包括侦听来自web服务器的数据提要。例如,JSON通常用作客户机和web服务器之间的传输存储机制。有些网站使用一些方法来防止web抓取,比如检测和禁止机器人爬行(查看)它们的页面。作为回应,有一些web抓取系统依赖于使用DOM解析、计算机视觉和自然语言处理技术来模拟人类浏览,从而能够收集web页面内容进行离线解析。
历史
- web抓取的历史实际上要长得多,可以追溯到万维网(俗称“Internet”)诞生的年代。
- 1989年万维网诞生后,第一个网络机器人——万维网漫游者诞生于1993年6月,其目的仅仅是测量万维网的大小。
- 1993年12月,第一个基于爬虫的网络搜索引擎——JumpStation诞生。由于当时的web上没有那么多可用的网站,搜索引擎常常依赖于它们的人工网站管理员来收集和编辑链接,并将其转换成特定的格式。跳跃站带来了新的飞跃。它是第一个依靠网络机器人的WWW搜索引擎。
- 2000年,第一个Web API和API爬虫出现了。API代表应用程序编程接口。它是一个接口,通过提供构建块使开发程序更加容易。2000年,Salesforce和eBay推出了自己的API,程序员可以使用该API访问和下载一些向公众开放的数据。从那时起,许多网站为人们访问公共数据库提供web api。
- 2004年,《美丽的汤》发行。它是一个为Python设计的库。由于并非所有的网站都提供api,程序员们仍在致力于开发一种能够促进web抓取的方法。使用简单的命令,Beautiful Soup可以解析HTML容器中的内容。它被认为是用于web抓取的最复杂和最先进的库,也是当今最常见和最流行的方法之一。
--
技术
Web抓取是从万维网上自动挖掘数据或收集信息的过程。这是一个积极发展的领域,与语义web vision有着共同的目标,这是一个雄心勃勃的计划,仍然需要在文本处理、语义理解、人工智能和人机交互方面取得突破。当前的web抓取解决方案包括从需要人工操作的临时解决方案到能够将整个web站点转换为结构化信息的完全自动化的系统,这些系统具有一定的局限性。
人类的复制粘贴
有时候,即使是最好的网络抓取技术也无法取代人工检查和复制粘贴,有时候,这可能是唯一可行的解决方案,因为抓取网站明确设置了障碍,防止机器自动化。
文本模式匹配
从web页面提取信息的简单而强大的方法可以基于UNIX grep命令或编程语言(例如Perl或Python)的正则表达式匹配工具。
HTTP编程
通过使用套接字编程将HTTP请求发送到远程web服务器,可以检索静态和动态web页面。
HTML解析
许多网站都有大量的页面集合,这些页面是从底层的结构化资源(如数据库)动态生成的。相同类别的数据通常由公共脚本或模板编码到类似的页面中。在数据挖掘中,检测特定信息源中的模板、提取其内容并将其转换为关系形式的程序称为包装器。包装器生成算法假设包装器归纳系统的输入页面符合公共模板,并且可以根据URL公共模式轻松识别它们。此外,一些半结构化的数据查询语言,如XQuery和HTQL,可以用来解析HTML页面,检索和转换页面内容。
DOM parsing
进一步信息:文档对象模型通过嵌入成熟的web浏览器(如Internet Explorer或Mozilla浏览器控件),程序可以检索由客户端脚本生成的动态内容。这些浏览器控件还将web页面解析为一个DOM树,根据这个树,程序可以检索页面的一部分。
Vertical aggregation
垂直聚合有几家公司已经开发了垂直特定的收获平台。这些平台为特定的垂直领域创建和监控大量的“机器人”,没有“人工参与”(没有直接的人工参与),也没有与特定目标站点相关的工作。准备工作包括建立整个垂直平台的知识库,然后平台自动创建机器人。平台的健壮性是由它检索的信息的质量(通常是字段的数量)和可伸缩性(扩展到数百或数千个站点的速度)来衡量的。这种可扩展性主要用于针对常见的聚合器发现的复杂或太劳动密集型而无法获取内容的站点的长尾。
语义标注识别
被抓取的页面可能包含元数据或语义标记和注释,它们可用于定位特定的数据片段。如果注释像微格式那样嵌入到页面中,则可以将此技术视为DOM解析的特殊情况。在另一种情况下,组织成语义层的注释[4]与web页面分别存储和管理,所以抓取器可以在抓取页面之前从这一层检索数据模式和指令。
计算机视觉
网页分析有使用机器学习和计算机视觉的努力,试图识别和提取信息从网页通过解释网页视觉作为一个人可能.
软件
有许多可用的软件工具可用于定制web抓取解决方案。这个软件可能试图自动识别页面的数据结构或提供一个记录接口,消除了需要手工编写web-scraping代码,或某些脚本函数,可用于提取和转换的内容,和数据库接口,可以将刮数据存储在本地数据库中。一些web抓取软件也可以用来直接从API中提取数据。
示例工具
- Beautiful Soup 2004年创建的用于web抓取的开源Python库。
- cURL—用于传输(包括获取)数据的命令行工具和库,url支持多种HTTP方法(GET、POST、cookie等)。
- Data Toolbar- Internet Explorer、Mozilla Firefox和谷歌Chrome浏览器的web抓取附加组件,用于收集web页面中的结构化数据并将其转换为可加载到电子表格或数据库管理程序中的表格格式。
- gazpacho 用于检索和解析网页HTML内容的开源Python库。
- Diffbot -使用计算机视觉和机器学习自动提取数据的网页,解释网页视觉作为一个人可能。
- Heritrix -得到页面(很多)。它是一个网络爬虫设计的网络存档,由互联网档案(见Wayback机器)编写。
- HtmlUnit -无头浏览器,可用于检索网页,网页抓取等。
- HTTrack 免费和开放源代码的网络爬虫和离线浏览器,旨在下载网站。
- iMacros -一个用于记录、编码、共享和回放浏览器自动化(javascript)的浏览器扩展。
- Selenium (software)一个可移植的web应用程序软件测试框架。
- Jaxer
- Mozenda 是一个所见即所得的软件,提供云、现场和数据争吵服务。
- nokogiri 基于XPath或CSS选择器的HTML、XML、SAX和Reader解析器。
- OutWit Hub - Web抓取应用程序,包括内置的数据,图像,文件提取器和编辑器,用于自定义抓取器和自动探索和提取作业(免费和付费版本)。
- watir -开放源码Ruby库,可以像人们一样自动化测试和与浏览器交互。
- Wget—从web服务器检索内容的计算机程序。它是GNU项目的一部分。
- WSO2 Mashup Server –它支持通过HTTP、HTTPS和FTP协议进行下载。
- WSO2 Mashup服务器-雅虎查询语言(YQL) -
Javascript工具
- Greasemonkey
- node . js
- PhantomJS -脚本化的无头浏览器,用于自动化网页交互。
- jQuery
Web爬行框架
这些可以用来构建web抓取器。
- crapy
原文:https://en.wikipedia.org/wiki/Web_scraping
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 87 次浏览
【科普】数据挖掘
数据挖掘是在大型数据集中发现模式的过程,涉及机器学习、统计和数据库系统交叉使用的方法。[1]数据挖掘是计算机科学与统计学交叉的子领域,其总体目标是从数据集中提取信息(使用智能方法),并将信息转换为可理解的结构以供进一步使用。[1][2][3][4]数据挖掘是“数据库知识发现”过程或KDD的分析步骤。除了原始分析步骤,它还涉及数据库和数据管理方面、数据预处理、模型和推理考虑、兴趣度度量、复杂性考虑、发现结构的后处理、可视化和在线更新
术语“数据挖掘”是一个错误的名称,因为其目标是从大量数据中提取模式和知识,而不是数据本身的提取(挖掘)。它也是一个时髦的词,经常应用于任何形式的大规模数据或信息处理(收集、提取、仓储、分析和统计),以及计算机决策支持系统的任何应用,包括人工智能(如机器学习)和商业智能。《数据挖掘:用Java[8]实现的实用机器学习工具与技术》(主要涉及机器学习材料)一开始只是命名为《实用机器学习》(Practical machine learning tools and techniques with Java[8]),由于市场原因才添加了“数据挖掘”一词。通常,更一般的术语(大规模)数据分析和分析——或者,当涉及到实际方法时,人工智能和机器学习——更合适。
实际的数据挖掘任务是对大量数据进行半自动或自动分析,以提取以前未知的、有趣的模式,如数据记录组(集群分析)、异常记录(异常检测)和依赖关系(关联规则挖掘、顺序模式挖掘)。这通常涉及使用数据库技术,如空间索引。这些模式可以看作是输入数据的一种总结,可以用于进一步的分析,或者,例如,在机器学习和预测分析中。例如,数据挖掘步骤可以识别数据中的多个组,然后决策支持系统可以使用这些组获得更准确的预测结果。数据收集、数据准备、结果解释和报告都不是数据挖掘步骤的一部分,但是作为附加步骤确实属于整个KDD过程。
数据分析和数据挖掘的区别在于,数据分析是用来测试数据集上的模型和假设,例如,分析营销活动的有效性,而不管数据的数量;相反,数据挖掘使用机器学习和统计模型来揭示大量数据中的秘密或隐藏模式
相关术语数据挖掘、数据钓鱼和数据窥探是指使用数据挖掘方法对较大的总体数据集的某些部分进行抽样,这些数据集太小(或可能太小),无法对所发现的任何模式的有效性做出可靠的统计推断。然而,这些方法可以用于创建新的假设来测试更大的数据总体。
词源
在20世纪60年代,统计学家和经济学家使用数据打捞或数据挖掘等术语来指代他们认为的在没有先验假设的情况下分析数据的糟糕做法。经济学家迈克尔•洛弗尔(Michael Lovell)在1983年发表于《经济研究评论》(Review of Economic Studies)的一篇文章中,以类似的批评方式使用了“数据挖掘”一词。洛弗尔指出,这种做法“伪装成各种各样的别名,从“实验”(正面)到“钓鱼”或“窥探”(负面)
数据挖掘一词于1990年左右出现在数据库界,一般具有积极的含义。在20世纪80年代的很短一段时间内,人们使用了一个短语“数据库挖掘”™,但自从它被总部位于圣地亚哥的HNC公司注册为商标后,人们开始宣传他们的数据库挖掘工作站;[12]的研究人员因此转向了数据挖掘。其他使用的术语包括数据考古学、信息收集、信息发现、知识提取等。Gregory Piatetsky-Shapiro为同一主题的第一个研讨会(KDD-1989)创造了“数据库中的知识发现”这个术语,这个术语在人工智能和机器学习社区中变得更加流行。然而,数据挖掘这个术语在商界和新闻界变得越来越流行。目前,术语数据挖掘和知识发现可以互换使用。
在学术界,主要的研究论坛始于1995年,当时在AAAI的赞助下,首届数据挖掘和知识发现国际会议(KDD-95)在蒙特利尔召开。会议由Usama Fayyad和Ramasamy Uthurusamy共同主持。一年后的1996年,尤萨马·法耶德(Usama Fayyad)创办了Kluwer创办的《数据挖掘与知识发现》(Data Mining and Knowledge Discovery)杂志,担任主编。后来,他创办了SIGKDD通讯SIGKDD exploration。KDD国际会议成为数据挖掘领域最主要的高质量会议,研究论文提交的通过率低于18%。《数据挖掘与知识发现》是该领域的主要研究期刊。
背景
从数据中手工提取模式已经有几个世纪的历史了。早期识别数据模式的方法包括贝叶斯定理(1700年)和回归分析(1800年)。计算机技术的扩散、普及和日益强大的功能极大地提高了数据收集、存储和操作能力。随着数据集的规模和复杂性的增长,直接的“动手”数据分析越来越多地得到了间接的、自动化的数据处理的支持,这得益于计算机科学中的其他发现,如神经网络、聚类分析、遗传算法(1950年代)、决策树和决策规则(1960年代)以及支持向量机(1990年代)。数据挖掘是将这些方法应用于大数据集中,旨在揭示隐藏模式[15]的过程。桥梁的差距从应用统计和人工智能(通常提供的数学背景)数据库管理利用数据存储和索引在数据库中执行实际的学习和发现算法更有效,允许这些方法被应用到更大的数据集。
过程
数据库知识发现(KDD)过程通常定义为:
- 选择
- 预处理
- 转换
- 数据挖掘
- 解释/评价。[5]
然而,它存在于这个主题的许多变体中,例如跨行业数据挖掘标准流程(CRISP-DM),它定义了六个阶段:
- 业务的理解
- 数据的理解
- 数据准备
- 建模
- 评价
- 部署
或简化的过程,如(1)预处理、(2)数据挖掘和(3)结果验证。
在2002年、2004年、2007年和2014年进行的调查显示,CRISP-DM方法是数据采掘者使用的主要方法。[16]是在这些民意调查中提到的唯一其他数据挖掘标准。然而,使用CRISP-DM的人数是使用的3-4倍。几个研究团队发表了对数据挖掘过程模型的综述,[17][18]和Azevedo and Santos在2008年对CRISP-DM和SEMMA进行了比较
预处理
在使用数据挖掘算法之前,必须装配一个目标数据集。由于数据挖掘只能揭示数据中实际存在的模式,因此目标数据集必须足够大,以包含这些模式,同时保持足够简洁,以便在可接受的时间限制内进行挖掘。数据的常见来源是数据集市或数据仓库。预处理是数据挖掘前分析多元数据集的基础。然后清除目标集。数据清理删除包含噪声和数据丢失的观测结果。
数据挖掘
数据挖掘包括六种常见的任务:[5]
- 异常检测(离群值/变化/偏差检测)-识别不寻常的数据记录,可能是有趣的或需要进一步研究的数据错误。
- 关联规则学习(依赖关系建模)——搜索变量之间的关系。例如,超市可能会收集顾客购买习惯的数据。使用关联规则学习,超市可以确定哪些产品经常一起购买,并将这些信息用于营销目的。这有时被称为市场篮子分析。
- 集群——是发现数据中以某种方式或其他方式“相似”的组和结构的任务,而不需要在数据中使用已知的结构。
- 分类—是将已知结构一般化,以应用于新数据的任务。例如,电子邮件程序可能尝试将电子邮件分类为“合法”或“垃圾邮件”。
- 回归——试图找到一个对数据建模误差最小的函数,即用于估计数据或数据集之间的关系。
- 摘要-提供更紧凑的数据集表示,包括可视化和报表生成。
结果验证
这是统计学家泰勒·维根(Tyler Vigen)通过机器人挖掘数据得出的一个数据示例,它显然显示了赢得拼字比赛的最佳单词与美国被有毒蜘蛛咬死的人数之间的密切联系。趋势上的相似性显然是一种巧合。
数据挖掘可能在无意中被滥用,然后产生的结果似乎很重要;但它们实际上不能预测未来的行为,也不能在新的数据样本上重现,而且用处不大。通常,这是由于调查了太多的假设,而没有进行适当的统计假设检验。在机器学习中,这个问题的一个简单版本被称为过度拟合,但在过程的不同阶段也可能出现同样的问题,因此,如果完全适用,火车/测试分离可能不足以防止这种情况的发生
从数据中发现知识的最后一步是验证数据挖掘算法产生的模式是否发生在更广泛的数据集中。数据挖掘算法发现的模式不一定都是有效的。数据挖掘算法通常会在训练集中发现一般数据集中不存在的模式,这称为过拟合。为了克服这个问题,评估使用了一组未经数据挖掘算法训练的测试数据。将学到的模式应用于这个测试集,并将结果输出与期望的输出进行比较。例如,一个试图区分“垃圾邮件”和“合法”电子邮件的数据挖掘算法将在一组训练样本电子邮件上进行训练。一旦经过训练,所学习的模式将应用于未经训练的电子邮件测试集。这些模式的准确性可以通过它们正确分类的电子邮件数量来衡量。可以使用多种统计方法来评估算法,如ROC曲线。
如果所学习的模式不能满足所需的标准,则有必要重新评估和更改预处理和数据挖掘步骤。如果所学习的模式确实符合所需的标准,那么最后一步就是解释所学习的模式并将其转化为知识。
研究
该领域的主要专业机构是计算机械协会(ACM)的知识发现和数据挖掘特别兴趣小组(SIG)。自从1989年以来,这个ACM团体已经主办了一个年度国际会议并且出版了它的会议录,[23]并且自从1999年以来它已经出版了一个双年度学术期刊命名为“SIGKDD探索”
关于数据挖掘的计算机科学会议包括:
- CIKM会议- ACM信息与知识管理会议
- 欧洲机器学习与数据库知识发现原理与实践会议
- 关于知识发现和数据挖掘的ACM SIGKDD会议
数据挖掘主题也出现在许多数据管理/数据库会议上,例如ICDE会议、SIGMOD会议和国际大型数据库会议
标准
已经有一些为数据挖掘过程定义标准的工作,例如1999年的欧洲跨行业数据挖掘标准过程(CRISP-DM 1.0)和2004年的Java数据挖掘标准(JDM 1.0)。这些流程的后续开发(CRISP-DM 2.0和JDM 2.0)在2006年非常活跃,但此后一直停滞不前。JDM 2.0在没有达成最终草案的情况下被撤回。
对于交换提取的模型(特别是用于预测分析),关键标准是预测模型标记语言(PMML),这是数据挖掘组(DMG)开发的一种基于xml的语言,许多数据挖掘应用程序都支持这种语言作为交换格式。顾名思义,它只涵盖预测模型,这是一项对业务应用程序非常重要的特定数据挖掘任务。然而,覆盖(例如)子空间聚类的扩展已经独立于DMG.[25]提出
值得注意的使用
如今,只要有数字数据可用,就可以使用数据挖掘。数据挖掘的显著例子可以在商业、医学、科学和监视中找到。
关注私隐及操守
虽然“数据挖掘”一词本身可能没有伦理含义,但它常常与与人们的行为(伦理和其他方面)相关的信息挖掘联系在一起
在某些情况和上下文中,数据挖掘的使用方式可能会引发关于隐私、合法性和伦理的问题。特别是,为国家安全或执法目的而对政府或商业数据集进行数据挖掘,例如在“全面信息意识计划”或“建议”中,已经引起了对隐私的关注
数据挖掘需要数据准备工作,数据准备工作揭示了损害机密性和隐私义务的信息或模式。实现此目的的一种常见方法是通过数据聚合。数据聚合涉及以一种便于分析的方式将数据组合在一起(可能来自不同的数据源)(但这也可能使私有的、个人级别的数据的标识成为可推断的或明显的)。这本身并不是数据挖掘,而是分析前准备数据的结果。当数据一旦被编译,数据采集器或任何能够访问新编译数据集的人就能够识别特定的个人,特别是当数据最初是匿名的时候,对个人隐私的威胁就会发挥作用
这是推荐的[根据谁?]在收集数据前应注意以下事项
- 数据收集及任何(已知)数据挖掘项目的目的;
- 资料将如何使用;
- 谁将能够挖掘数据并使用数据及其衍生物;
- 有关存取资料的保安状况;
- 如何更新收集的数据。
还可以修改数据,使之匿名,以便不容易识别个人。然而,即使是“匿名”的数据集也可能包含足够的信息来识别个人,就像记者能够根据一组由美国在线无意中发布的搜索历史记录找到几个人一样
无意中泄露的个人身份信息导致提供者违反了公平的信息实践。这种不检点的行为可能会对指定的个人造成经济、情感或身体上的伤害。在一起侵犯隐私的案件中,沃尔格林的客户在2011年对该公司提起诉讼,指控该公司向数据挖掘公司出售处方信息,而数据挖掘公司反过来又向制药公司提供数据
欧洲局势
欧洲有相当严格的隐私法,正在努力进一步加强消费者的权利。然而,美国和欧盟的安全港原则目前有效地将欧洲用户暴露在美国公司的隐私剥削之下。由于爱德华·斯诺登(Edward Snowden)披露了全球监控信息,撤销该协议的讨论越来越多,尤其是数据将完全暴露给美国国家安全局(National Security Agency),而达成协议的努力已经失败。[引文需要]
美国的情况
在美国,美国国会通过了《健康保险可携性与责任法案》(HIPAA)等监管控制措施,解决了人们对隐私的担忧。《HIPAA》要求个人就其提供的信息及其目前和未来的用途提供“知情同意”。根据《生物技术商业周刊》的一篇文章,AAHC说:“在实践中,HIPAA可能不会提供比研究领域长期存在的规定更大的保护。”更重要的是,该规则通过知情同意进行保护的目标是达到普通人无法理解的程度。这强调了在数据聚合和挖掘实践中数据匿名的必要性。
美国的信息隐私立法,如HIPAA和《家庭教育权利和隐私法》(FERPA),只适用于每一项此类法律所涉及的特定领域。美国大多数企业对数据挖掘的使用不受任何法律的控制。
著作权法
欧洲局势
由于欧洲著作权法和数据库法缺乏灵活性,未经著作权人许可而进行网络挖掘等非著作权作品是不合法的。在欧洲,如果数据库是纯数据,那么很可能没有版权,但是数据库的权利可能存在,因此数据挖掘受到数据库指令的约束。根据Hargreaves review的建议,这导致英国政府在2014年修订了其版权法,允许内容挖掘作为限制和例外。这是继日本之后,世界上第二个在数据挖掘方面破例的国家。然而,由于版权指令的限制,英国的例外只允许用于非商业目的的内容挖掘。英国版权法也不允许这一条款被合同条款所覆盖。2013年,欧盟委员会(European Commission)以《欧洲许可证》(licence for Europe)的名义,促进了利益相关者对文本和数据挖掘的讨论。[38]中国英语学习网由于把解决这一法律问题的重点放在发放许可证上,而不是限制和例外,导致大学、研究人员、图书馆、民间社会团体和开放获取出版商的代表在2013年5月离开利益攸关方对话
美国的情况
与欧洲形成鲜明对比的是,美国版权法的灵活性,尤其是合理使用,意味着美国以及以色列、台湾和韩国等其它合理使用国家的内容开采被视为合法。由于内容挖掘具有变革性,即它不会取代原作,因此在合理使用下被视为合法。例如,作为谷歌图书和解协议的一部分,该案主审法官裁定,谷歌对版权所有图书的数字化项目是合法的,部分原因是数字化项目所展示的革命性用途——其中之一是文本和数据挖掘。
软件
类别:数据挖掘和机器学习软件。
免费的开源数据挖掘软件和应用程序
以下应用程序在免费/开源许可下可用。对应用程序源代码的公共访问也是可用的。
- Carrot2:文本和搜索结果聚类框架。
- Chemicalize.org:一个化学结构挖掘器和web搜索引擎。
- ELKI:一个用Java语言编写的具有高级聚类分析和异常值检测方法的大学研究项目。
- GATE:一种自然语言处理和语言工程工具。
- KNIME: Konstanz Information Miner,一个用户友好且全面的数据分析框架。
- Massive Online Analysis (MOA): :利用Java编程语言中的概念漂移工具,实时挖掘大数据流。
- MEPX -基于遗传规划变量的回归和分类问题的跨平台工具。
- flex:一个软件包,允许用户与用任何编程语言编写的第三方机器学习包集成,跨多个计算节点并行执行分类分析,并生成分类结果的HTML报告。
- mlpack:用c++语言编写的一组随时可用的机器学习算法。
- NLTK(自然语言工具包):一套用于Python语言的符号和统计自然语言处理(NLP)的库和程序。
- OpenNN:开放的神经网络库。
- Orange:用Python语言编写的基于组件的数据挖掘和机器学习软件包。
- R:一种用于统计计算、数据挖掘和图形处理的编程语言和软件环境。它是GNU项目的一部分。
- scikit-learn是一个用于Python编程语言的开源机器学习库
- Torch:一个面向Lua编程语言和科学计算框架的开源深度学习库,广泛支持机器学习算法。
- UIMA: UIMA(非结构化信息管理体系结构)是用于分析文本、音频和视频等非结构化内容的组件框架,最初由IBM开发。
- Weka:一套用Java编程语言编写的机器学习软件应用程序。
专有数据挖掘软件和应用程序
以下应用程序在专有许可下可用。
- Angoss knowledge gestudio:数据挖掘工具
- Clarabridge:文本分析产品。
- LIONsolver:用于数据挖掘、商业智能和建模的集成软件应用程序,实现了学习和智能优化(LION)方法。
- Megaputer智能:数据和文本挖掘软件称为PolyAnalyst。
- Microsoft Analysis Services::微软提供的数据挖掘软件。
- NetOwl:支持数据挖掘的多语言文本和实体分析产品套件。
- Oracle数据挖掘:由Oracle公司开发的数据挖掘软件。
- PSeven: DATADVANCE提供的工程仿真分析自动化、多学科优化和数据挖掘平台。
- Qlucore组学资源管理器:数据挖掘软件。
- RapidMiner:用于机器学习和数据挖掘实验的环境。
- SAS企业采集器:SAS研究所提供的数据挖掘软件。
- SPSS Modeler: IBM提供的数据挖掘软件。
- STATISTICA :StatSoft提供的数据挖掘软件。
- Tanagra:面向可视化的数据挖掘软件,也用于教学。
- Vertica:数据挖掘软件由惠普提供。
See also
- Methods
- Agent mining
- Anomaly/outlier/change detection
- Association rule learning
- Bayesian networks
- Classification
- Cluster analysis
- Decision trees
- Ensemble learning
- Factor analysis
- Genetic algorithms
- Intention mining
- Learning classifier system
- Multilinear subspace learning
- Neural networks
- Regression analysis
- Sequence mining
- Structured data analysis
- Support vector machines
- Text mining
- Time series analysis
- Application domains
- Analytics
- Behavior informatics
- Big data
- Bioinformatics
- Business intelligence
- Data analysis
- Data warehouse
- Decision support system
- Domain driven data mining
- Drug discovery
- Exploratory data analysis
- Predictive analytics
- Web mining
- Application examples
Main article: Examples of data mining
See also: Category:Applied data mining.
- Automatic number plate recognition in the United Kingdom
- Customer analytics
- Educational data mining
- National Security Agency
- Quantitative structure–activity relationship
- Surveillance / Mass surveillance (e.g., Stellar Wind)
- Related topics
Data mining is about analyzing data; for information about extracting information out of data, see:
- Data integration
- Data transformation
- Electronic discovery
- Information extraction
- Information integration
- Named-entity recognition
- Profiling (information science)
- Psychometrics
- Social media mining
- Surveillance capitalism
- Web scraping
- Other resources
原文:https://en.wikipedia.org/wiki/Data_mining
本文:https://pub.intelligentx.net/wikipedia-data-mining
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 118 次浏览