混沌工程
混沌工程 intelligentx- 102 次浏览
【DevOps】什么是混沌工程?
测试您可以预测的事故是必不可少的。但是随着数字化转型和云原生架构带来的复杂性,团队需要一种方法来确保应用程序能够承受生产的“混乱”。混沌工程满足了这一需求,因此组织可以提供在任何条件下都可以正常运行的强大、有弹性的云原生应用程序。
什么是混沌工程?
混沌工程是一种测试分布式软件的方法,它故意引入故障和错误场景,以验证其在面对随机中断时的弹性。这些中断可能导致应用程序以不可预测的方式做出响应,并可能在压力下崩溃。混沌工程师问为什么。
从业者将软件置于受控的模拟危机中,以测试不稳定的行为。危机可能是技术、自然或恶意事件,例如影响数据中心可用性的地震或感染应用程序和网站的网络攻击。随着软件性能下降或失败,混沌工程师的发现使开发人员能够在代码中添加弹性,因此应用程序在紧急情况下保持完好。
随着混沌工程师对他们的测试越来越有信心,他们改变了更多的变量并扩大了灾难的范围。许多灾难场景和结果使混沌工程师能够更好地模拟应用程序和微服务发生的情况,这使他们能够与开发人员共享越来越多的智能,以完善软件和云原生基础设施。
混沌工程的历史
Netflix 出于需要开创了混沌工程。 2009 年,在线视频供应商迁移到 AWS 云基础设施,为越来越多的观众提供娱乐。但是云带来了新的复杂性,例如不断增加的连接和依赖关系。与娱乐公司在其数据中心看到的负载平衡问题相比,它产生了更多的不确定性。如果云中的任何接触点出现故障,观众体验的质量可能会下降。因此,该组织寻求降低复杂性并提高生产质量。
2010 年,Netflix 推出了一项技术,可以随机关闭生产软件实例——比如在服务器机房里放一只猴子——以测试云如何处理其服务。于是,工具混沌猴诞生了。
混沌工程在 Netflix 等组织中变得成熟,并催生了 Gremlin (2016) 等技术,变得更有针对性和知识化。这门科学催生了专业的混沌工程师,他们致力于破坏云软件和与之交互的本地系统,以使其具有弹性。现在,混沌工程是一个成熟的职业,它会挑起托管的麻烦来稳定云软件。
混沌工程是如何工作的?
混沌工程从了解软件的预期行为开始。
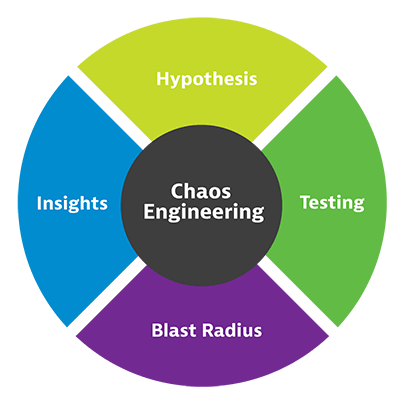
- 假设。工程师问自己,如果他们改变一个变量会发生什么。如果他们随机终止服务,他们假设服务将继续不间断。问题和假设形成假设(The question and the assumption form a hypothesis)。
- 测试。为了检验这个假设,混沌工程师将模拟的不确定性与负载测试相结合,并观察交付应用程序的服务、基础设施、网络和设备的动荡迹象。堆栈中的任何故障都会破坏假设。
- 爆炸半径。通过隔离和研究故障,工程师可以了解在不稳定的云条件下会发生什么。测试造成的任何损坏或影响都称为“爆炸半径”。混沌工程师可以通过控制测试来管理爆炸半径。
- 见解。这些发现形成了对软件开发和交付过程的输入,因此新软件和微服务将更好地应对不可预见的事件。
为了减轻对生产环境的破坏,混沌工程师从非生产环境开始,然后以可控的方式慢慢扩展到生产环境。一旦建立,混沌工程就成为微调服务水平指标和目标、改进警报和构建更高效仪表板的有效方法,因此您知道您正在收集准确观察和分析环境所需的所有数据。
谁使用混沌工程?
混沌工程通常起源于 DevOps 中的小团队,通常涉及在预生产和生产环境中运行的应用程序。因为它可以触及许多系统,混沌工程可以产生广泛的影响,影响整个组织的群体和利益相关者。
跨越硬件、网络和云基础设施的中断可能需要网络和基础设施架构师、风险专家、安全团队甚至采购官员的投入和参与。这是好事。测试的范围越大,混沌工程就越有用。
尽管一个小团队通常拥有和管理混沌工程工作,但这是一种通常需要来自村庄的投入并为村庄提供利益的做法。
混沌测试的好处
您可以通过测试应用程序的限制获得的洞察力为您的开发团队和您的整体业务带来很多好处。这只是健康、管理良好的混沌工程实践的一些好处。
- 提高弹性和可靠性。混沌测试丰富了组织关于软件在压力下如何执行以及如何使其更具弹性的情报。
- 加速创新。来自混沌测试的情报返回给开发人员,他们可以实施设计更改,使软件更耐用并提高生产质量。
- 推进协作。开发人员并不是唯一看到优势的群体。混沌工程师从他们的实验中收集到的见解提升了技术团队的专业知识,从而缩短了响应时间和更好的协作。
- 加快事件响应速度。通过了解可能出现的故障情况,这些团队可以加快故障排除、维修和事件响应速度。
- 提高客户满意度。更高的弹性和更快的响应时间意味着更少的停机时间。来自开发和 SRE 团队的更大创新和协作意味着更好的软件能够以高效和高性能快速满足新客户的需求。
- 提升业务成果。混沌测试还可以通过更快的价值实现时间、节省时间、金钱和资源以及产生更好的底线来扩展组织的竞争优势。
组织的软件越有弹性,消费者和企业客户就越能享受其服务而不会分心或失望。
混沌工程的挑战和陷阱
尽管混沌测试的好处是显而易见的,但它是一种应该慎重进行的实践。以下是最关心的问题和挑战。
- 不必要的损坏。混沌测试的主要问题是可能造成不必要的损坏。混沌工程可能导致超出合理测试允许的实际损失。为了限制发现应用程序漏洞的成本,组织应避免超出指定爆炸范围的测试。目标是控制爆炸半径,以便您可以查明故障原因,而无需引入新的故障点。
- 缺乏可观察性。建立这种控制说起来容易做起来难。缺乏对爆炸半径可能影响的所有系统的端到端可观察性和监控是一个常见问题。如果没有全面的可观察性,可能很难理解关键依赖关系与非关键依赖关系,或者很难有足够的上下文来理解故障或降级的真正业务影响,以便确定修复的优先级。缺乏可见性还可能使团队难以确定问题的确切根本原因,这会使补救计划复杂化。
- 不清楚启动系统状态。另一个问题是在测试运行之前清楚地了解系统的启动状态。如果没有这种清晰度,团队可能难以理解测试的真实效果。这会降低混沌测试的有效性,并使下游系统面临更大的风险,并使控制爆炸半径变得更加困难。
如何开始混沌工程
与任何科学实验一样,开始使用混沌工程需要一些准备、组织以及监控和测量结果的能力。
- 了解您的环境的起始状态。要计划一个控制良好的混沌测试,您应该了解您的环境的应用程序、微服务和架构设计,以便您能够识别测试的效果。拥有一个可以与最终状态进行比较的基线可以创建一个蓝图,用于在测试期间进行监控并在之后分析结果。
- 询问可能出现的问题并建立假设。清楚了解系统的启动状态后,询问可能出现的问题。清楚了解系统的启动状态后,询问可能出现的问题。了解服务水平指标和服务水平目标,并将它们用作建立系统应如何在压力下工作的假设的基础。
- 一次引入一个变量。为了控制爆炸半径,一次只引入一点混乱,这样你就可以欣赏结果。准备好在特定条件下中止实验,以免对生产软件造成伤害,并且如果出现问题,也要有回滚计划。在测试期间,尝试反驳假设以发现需要关注的领域以提高系统弹性。
- 监测并记录结果。监控实验以记录应用程序行为中的任何细微差别。分析结果以查看应用程序如何响应以及测试是否达到了团队的期望。使用调查工具来了解减速和故障的确切根本原因。
控制混乱
像 Gremlin 这样的解决方案提供了关键的管理工具来计划和执行混沌工程实验。它使实验具有可重复性和可扩展性,因此团队可以将它们应用于相同或更大堆栈的未来实验。
Dynatrace 的自动和智能可观察性提供了对混沌测试效果的洞察,因此工程师可以谨慎地进行混沌实验。为了监控爆炸半径,Dynatrace 观察了正在进行混沌实验的系统。通过对整个软件堆栈的可见性,Dynatrace 提供了关键的上下文分析,以隔离混沌测试暴露的故障的根本原因。
Dynatrace 的有效监控为进行混沌测试的工程师提供了必不可少的全景镜头,帮助他们了解依赖关系并预测中断将如何影响整个系统。如果混乱超出预期,Dynatrace 的洞察力可帮助团队快速修复对应用程序功能的任何实际损害。
组织可以在数字化转型的任何阶段实现应用程序弹性,而混沌工程是一个很好的工具。然而,在玩火之前,至关重要的是要采取正确的措施来预测和应对这种方法可能带来的大量故障情况。
- 195 次浏览
【混沌工程】2021 混沌工程状态
在过去的十二年里,我有机会参与并见证了混沌工程的发展。出身卑微,最常遇到的问题是“你为什么要这样做?”到今天的位置,帮助确保世界顶级公司的可靠性,这是一段相当长的旅程。
我第一次开始实践这门学科,早在它有名字之前几年,在亚马逊,我们的工作就是防止零售网站宕机。当我们取得成功时,Netflix 写了他们关于 Chaos Monkey 的规范博客文章(十年前的今年 7 月)。这个想法成为主流,许多工程师都被迷住了。在亚马逊完成任务后,我急忙加入 Netflix,深入研究这个领域。我们能够进一步推动艺术发展,构建跨越整个 Netflix 生态系统的以开发人员为中心的解决方案,最终带来另外 9 个可用性和世界知名的客户体验。
五年前,我的联合创始人 Matthew Fornaciari 和我创立了 Gremlin,其使命很简单:建立更可靠的互联网。我们都欣喜若狂地看到这次实践已经走了多远。社区中的许多人都渴望获得更多关于如何最好地利用这种方法的数据,因此我们很自豪地展示了第一份混沌工程状态报告。
全球的工程团队使用 Chaos Engineering 故意将危害注入他们的系统、监控影响并修复故障,以免对客户体验产生负面影响。这样做,他们避免了代价高昂的停机,同时减少了 MTTD 和 MTTR,让他们的团队为未知做好准备,并保护客户体验。事实上,Gartner 预计,到 2023 年,将混沌工程实践作为 SRE 计划一部分的 80% 的组织将其平均解决时间 (MTTR) 减少 90%。我们从首份混沌工程状态报告中看到了同样的相似之处:表现最好的混沌工程团队拥有四个 9 的可用性,MTTR 不到一小时。
科尔顿安德鲁斯
格雷姆林首席执行官
主要发现
- 增加可用性和减少 MTTR 是混沌工程最常见的两个好处
- 经常进行混沌工程实验的团队有 >99.9% 的可用性
- 23% 的团队的平均解决时间 (MTTR) 不到 1 小时,60% 的团队不到 12 小时
- 网络攻击是最常运行的实验,与报告的主要故障一致
- 虽然仍然是一种新兴实践,但大多数受访者 (60%) 至少运行过一次混沌工程攻击
- 34% 的受访者在生产环境中进行混沌工程实验
Things break
调查显示,前 20% 的受访者拥有超过四个 9 的服务,这是一个令人印象深刻的水平。 23% 的团队的平均解决时间 (MTTR) 不到 1 小时,60% 的团队平均解决时间 (MTTR) 不到 12 小时。
您的服务的平均可用性是多少?
| 可靠性 | 占比 | |
| <=99% | 42.5% | |
| 99.5%-99.9% | 38.1% | |
| >=99.99% | 19.4% |
每月平均高严重性事件数 (Sev 0 和 1)
| 1-10 | 81.4% | |
| 10-20 | 18.6% |
您的平均解决时间 (MTTR) 是多少?
| MTTR | 占比 |
| <1 hour | 23.1% |
| 1 hour - 12 hours | 39.8% |
| 12 hours - 1 day | 15.5% |
| 1 day - 1 week | 15.2% |
| > 1 week | 0.5% |
| I don't know | 5.9% |
我们所做的其中一项更有益的事情是每天进行红色与蓝色攻击。 我们让平台团队介入,对我们和我们的服务进行攻击,并将其视为真实的生产事件,通过响应并查看我们所有的运行手册并确保我们被覆盖。
当事情确实发生时,最常见的原因是错误的代码推送和依赖问题。 这些不是相互排斥的。 来自一个团队的错误代码推送可能会导致另一个团队的服务中断。 在团队拥有独立服务的现代系统中,测试所有服务的故障恢复能力非常重要。 运行基于网络的混沌实验,例如延迟和黑洞,确保系统解耦并且可以独立失败,从而最大限度地减少服务中断的影响。
您的事件 (SEV0 和 1) 的百分比是由以下原因引起的:
| <20% | 21-40% | 41-60% | 61-80% | >80% | |
| 错误的代码部署(例如,部署到生产环境的代码中的错误导致事件) | 39% | 24% | 19% | 11.8% | 6.1% |
| 内部依赖问题(非 DB)(例如,贵公司运营的服务中断) | 41% | 25% | 20% | 10.1% | 3.7% |
| 配置错误(例如,云基础设施或容器编排器中的错误设置导致事件) | 48% | 23% | 14% | 10.1% | 5.2% |
| 网络问题(例如,ISP 或 DNS 中断) | 50% | 19% | 13% | 15.7% | 1.7% |
| 第 3 方依赖问题(非 DB)(例如,与支付处理器的连接断开) | 48% | 23% | 13% | 14.3% | 1.7% |
| 托管服务提供商问题(例如,云提供商 AZ 中断) | 61% | 14% | 9% | 12.5% | 3.9% |
| 机器/基础设施故障(本地)(例如,停电) | 64% | 14% | 6% | 12% | 4.4% |
| 数据库、消息传递或缓存问题(例如,导致事件的数据库节点丢失) | 58% | 18% | 18% | 5.2% | 1.2% |
| 未知 | 66% | 10% | 15% | 7.4% | 1% |
谁知道
可用性监控因公司而异。例如,Netflix 的流量非常稳定,他们可以使用服务器端每秒的视频启动次数来发现中断。与预测模式的任何偏差都表示中断。 Google 将真实用户监控与窗口结合使用来确定单个中断是否会产生重大影响,或者多个小事件是否会影响服务,从而对事件的原因进行更深入的分析。很少有公司像 Netflix 和 Google 那样拥有一致的流量模式和复杂的统计模型。这就是为什么使用综合监控的标准正常运行时间作为监控服务正常运行时间的最流行方法位于顶部,而许多组织使用多种方法和指标。我们惊喜地发现所有受访者都在监控可用性。这通常是团队为积极改善应用程序中的客户体验而采取的第一步。
您使用什么指标来定义可用性?
| 可用性指标 | 占比 |
| 错误率(失败请求/总请求) | 47.9% |
| 延迟 | 38.3% |
| 订单/交易与历史预测 | 21.6% |
| 成功请求/总请求 | 44% |
| 正常运行时间/总时间段 | 53.3% |
您如何监控可用性?
| 监控方式 | 占比 |
| 真实用户监控 | 37.1% |
| 健康检查/合成 | 64.4% |
| 服务器端响应 | 50.4% |
在查看谁收到有关可用性和性能的报告时,人们越接近操作应用程序,他们收到报告的可能性就越大也就不足为奇了。 我们相信,随着构建和运营的思维方式在组织中变得普遍,DevOps 将运维和开发紧密结合在一起的趋势是使开发人员与运维保持一致。 我们还相信,随着数字化程度的提高和在线用户体验变得更加重要,我们将看到接收可用性和绩效报告的 C 级员工的百分比增加。
谁监控或接收可用性报告?
| CEO | 15.7% |
| CFO or VP of Finance | 11.8% |
| CTO | 33.7% |
| VP | 30.2% |
| Managers | 51.1% |
| Ops | 61.4% |
| Developers | 54.5% |
| Other | 1.2% |
谁监控或接收性能报告?
| CEO | 12% |
| CFO or VP of Finance | 10.6% |
| CTO | 36.1% |
| VP | 28.3% |
| Managers | 51.8% |
| Ops | 53.8% |
| Developers | 54.1% |
| Other | 2% |
最好表现者
表现最好的人有 99.99% 以上的可用性和不到一小时的 MTTR(上面突出显示)。 为了获得这些令人印象深刻的数字,我们调查了团队使用的工具。 值得注意的是,自动缩放、负载平衡器、备份、部署的选择推出以及通过运行状况检查进行监控在顶级可用性组中更为常见。 其中一些,例如多区域,是昂贵的,而其他的,例如断路器和选择推出,是时间和工程专业知识的问题。
始终进行混沌实验的团队比从未进行过实验或临时进行实验的团队具有更高的可用性水平。 但 ad-hoc 实验是实践的重要组成部分,可用性 > 99.9% 的团队正在执行更多的 ad-hoc 实验。
混沌工程实验的频率(按可用性)
| Never performed an attack | Performed ad-hoc attacks | Quarterly attacks | Monthly attacks | Weekly attacks | Daily or more frequent attacks | |
| >99.9% | 25.7% | 28.4% | 16.2% | 6.8% | 17.6% | 5.4% |
| 99%-99.9%% | 35.7% | 25% | 11.6% | 10.3% | 8.5% | 8.9% |
| <99%% | 49.4% | 18.1% | 13.3% | 8.4% | 8.4% | 2.4% |
按可用性使用工具
| >99.9% | 99%-99.9% | <99% | |
|
Autoscaling |
65% | 52% | 43% |
| DNS failover/elastic IPs | 49% | 33% | 24% |
| Load balancers | 77% | 64% | 71% |
| Active-active multi-region, AZ or DC | 38% | 29% | 19% |
| Active-passive multi-region, AZ, or DC | 45% | 34% | 30% |
| Circuit breakers | 32% | 22% | 16% |
| Backups | 61% | 46% | 51% |
| DB replication | 51% | 47% | 37% |
| Retry logic | 41% | 33% | 31% |
| Select rollouts of deployments (Blue/Green, Canary, feature flags) | 51% | 36% | 27% |
| Cached static pages when dynamic unavailable | 26% | 26% | 19% |
| Monitoring with health checks | 70% | 58% | 53% |
混沌工程的演变
2010 年,Netflix 将 Chaos Monkey 引入他们的系统。 这种节点的伪随机故障是对实例和服务器随机故障的响应。 Netflix 希望团队为这些故障模式做好准备,因此他们加快了流程,要求对实例中断具有弹性。 它创建了对可靠性机制的测试,并迫使开发人员在构建时考虑到失败。 基于该项目的成功,Netflix 开源了 Chaos Monkey,并创建了 Chaos Engineer 角色。 从那时起,混沌工程已经发展到遵循科学过程,并且实验已经扩展到主机故障之外,以测试堆栈上下的故障。
谷歌搜索“混沌工程”
| 年份 | 搜索次数 |
| 2016 | 1290 |
| 2017 | 6990 |
| 2018 | 19100 |
| 2019 | 24800 |
| 2020 | 31317 |
对于失败中花费的每一美元,学习一美元的教训
-----“MASTER OF DISASTER”
------JESSE ROBBINS
2020 年,混沌工程成为主流,并成为 Politico 和彭博社的头条新闻。 Gremlin 举办了有史以来规模最大的混沌工程活动,有超过 3,500 名注册者。 Github 拥有超过 200 个混沌工程相关项目,拥有 16K+ 星。 最近,AWS 宣布他们自己的公开混沌工程产品 AWS 故障注入模拟器将于今年晚些时候推出。
Chaos Engineering today
混沌工程正变得越来越流行和改进:60% 的受访者表示他们已经运行过混沌工程攻击。 Chaos Engineering 的创建者 Netflix 和 Amazon 是尖端的大型组织,但我们也看到更成熟的组织和较小的团队采用。 使用混沌工程的团队的多样性也在增长。 最初的工程实践很快被站点可靠性工程 (SRE) 团队采用,现在许多平台、基础设施、运营和应用程序开发团队正在采用这种实践来提高其应用程序的可靠性。 主机故障,我们归类为状态类型攻击,远不如网络和资源攻击流行。 我们已经看到了模拟与依赖项的丢失连接或对服务的需求激增的情况。 我们还看到更多的组织将他们的实验转移到生产中,尽管这还处于早期阶段。
使用 Gremlin 平台的 459,548 次攻击
68% 的客户使用 K8S 攻击
您的组织多久练习一次混沌工程?
| 每日或更频繁的攻击 | 每周攻击 | 每月攻击 | 每季度攻击 | 执行临时攻击 | 从未进行过攻击 | |
| >10,000员工 | 5.7% | 8% | 4.6% | 16.1% | 31% | 34.5% |
| 5,001-10,000 员工 | 0% | 13.2% | 18.4% | 21.1% | 23.7% | 23.7% |
| 1,001-5,000 员工 | 8.3% | 11.1% | 8.3% | 9.7% | 22.2% | 40.3% |
| 100-1,000 员工 | 10.9% | 10.9% | 8.6% | 10.9% | 22.7% | 35.9% |
| <100 员工 | 3.7% | 7.3% | 9.8% | 8.5% | 15.9% | 54.9% |
哪些团队参与了混沌实验?
| Application Developers | 52% |
| C-level | 10% |
| Infrastructure | 42% |
| Managers | 32% |
| Operations | 49% |
| Platform or Architecture | 37% |
| SRE | 50% |
| VPs | 14% |
您的组织中有多少百分比使用混沌工程?
| 百分比 | |
| 76%+ | 7.3% |
| 51-75% | 17.7% |
| 26-50% | 21% |
| <25% | 54% |
你在什么环境下进行过混沌实验?
| Dev/Test | 63% |
| Staging | 50% |
| Production | 34% |
按类型划分的攻击百分比
| Network | 46% |
| Resource | 38% |
| State | 15% |
| Application | 1% |
按目标类型划分的攻击百分比
| Host | 70% |
| Container | 29% |
| Application | 1% |
混沌实验结果
混沌工程最令人兴奋和最有价值的方面之一是发现或验证错误。 这种做法可以更容易地在未知问题影响客户之前发现它们并确定事件的真正原因,从而加快修补过程。 对我们调查的回复中显示的另一个主要好处是更好地理解架构。 运行混沌实验有助于识别对我们的应用程序产生不利影响的紧密耦合或未知依赖关系,并且通常会消除创建微服务应用程序的许多好处。 从我们自己的产品中,我们发现客户经常发现事件、缓解问题并使用 Chaos Engineering 验证修复。 我们的调查受访者经常发现他们的应用程序在减少 MTTR 的同时提高了可用性。
使用混沌工程后,你体验到了什么好处?
| 提高可用性 | 47% |
|
缩短平均解决时间 (MTTR) mean time to resolution |
45% |
|
缩短平均检测时间 (MTTD) mean time to detection |
41% |
| 减少了交付到生产环境的错误数量 | 38% |
| 减少中断次数 | 37% |
| 减少页面数 | 25% |
混沌工程的未来
采用/扩展混沌工程的最大障碍是什么?
| 缺乏认识 | 20% |
| 其他优先事项 | 20% |
| 缺乏经验 | 20% |
| 时间不够 | 17% |
| 安全问题 | 12% |
| 害怕出事 | 11% |
采用混沌工程的最大障碍是缺乏意识和经验。紧随其后的是“其他优先事项”,但有趣的是,超过 10% 的人提到担心可能出现问题也是一个禁忌。确实,在实践混沌工程时,我们正在将故障注入系统,但使用遵循科学原理的现代方法,并有条不紊地将实验隔离到单一服务中,我们可以有意识地实践而不破坏客户体验。
我们相信混沌工程的下一阶段涉及向更广泛的受众开放这一重要的测试过程,并使其更容易在更多环境中安全地进行实验。随着实践的成熟和工具的发展,我们希望工程师和操作员能够更容易和更快地设计和运行实验,以提高其系统跨环境的可靠性——今天,30% 的受访者正在生产中运行混沌实验。我们相信,混沌实验将变得更有针对性和自动化,同时也变得更加普遍和频繁。
我们对混沌工程的未来及其在使系统更可靠方面的作用感到兴奋。
人口统计
本报告的数据源包括一项包含 400 多个回复的综合调查和 Gremlin 的产品数据。 调查受访者来自各种规模和行业,主要是软件和服务。 混沌工程的采用已经冲击了企业,近 50% 的受访者为员工人数超过 1,000 人的公司工作,近 20% 的受访者为员工人数超过 10,000 人的公司工作。
该调查强调了云计算的一个转折点,近 60% 的受访者在云中运行大部分工作负载,并使用 CI/CD 管道。 容器和 Kubernetes 正在达到类似的成熟度,但调查证实服务网格仍处于早期阶段。 最常见的云平台是 AWS,占比接近 40%,GCP、Azure 和本地云平台紧随其后,占比约为 11-12%。
400 多名合格的受访者
贵公司有多少员工?
| >10,000 | 21.4% |
| 5,001-10,000 | 9.3% |
| 1,001-5,000 | 17.7% |
| 100-1,000 | 31.4% |
| <100 | 20.1% |
你的公司几岁了?
| Over 25 years old | 25.8% |
| 10 to 25 years old | 32.9% |
| 2 to 10 years old | 27.3% |
| Less than 2 years old | 14% |
贵公司属于哪个行业?
| Software & Services | 50.2% |
| Banks, Insurance & Financial Services | 23.2% |
| Energy Equipment & Services | 0.7% |
| Retail & eCommerce | 18.3% |
| Technology Hardware, Semiconductors, & Related Equipment | 7.6% |
你的职位是什么?
| Software Engineer | 32.2% |
| SRE | 25.3% |
| Engineering Manager | 18.2% |
| System Administrator | 8.8% |
| Non-technical Executive (ex: CEO, COO, CMO, CRO) | 4.9% |
| Technical Executive (ex: CTO, CISO, CIO) | 10.6% |
云中占生产工作负载的百分比是多少?
| >75% | 35.1% |
| 51-75% | 23.1% |
| 25-50% | 21.4% |
| <25% | 20.4% |
使用 CI/CD 管道部署的生产工作负载的百分比是多少?
| >75% | 39.8% |
| 51-75% | 21.1% |
| 25-50% | 20.4% |
| <25% | 18.7% |
百分之几的生产工作负载使用容器?
| >75% | 27.5% |
| 51-75% | 19.9% |
| 25-50% | 23.6% |
| <25% | 29% |
百分之几的生产工作负载使用 Kubernetes(或其他容器编排器)?
| >75% | 19.4% |
| 51-75% | 22.4% |
| 25-50% | 18.4% |
| <25% | 39.8% |
百分之多少的生产环境路由利用了服务网格?
| >75% | 0.1% |
| 51-75% | 116.5% |
| 25-50% | 17.9% |
| <25% | 55.5% |
除了检查调查结果外,我们还汇总了有关 Gremlin 用户技术环境的信息,以了解哪些特定工具和堆栈层最常成为混沌工程实验的目标。 这些发现如下。
您的云提供商是什么?
| Amazon Web Services | 38% |
| Google Cloud Platform | 12% |
| Microsoft Azure | 12% |
| Oracle | 2% |
| Private Cloud (On Premises) | 11% |
你的容器编排器是什么?
| Amazon Elastic Container Service | 13% |
| Amazon Elastic Kubernetes Service | 19% |
| Custom Kubernetes | 16% |
| Google Kubernetes Engine | 12% |
| OpenShift | 6% |
您的消息传递提供者( messaging provider)是什么?
| ActiveMQ | 5% |
| AWS SQS | 17% |
| Kafka | 25% |
| IBM MQ | 1% |
| RabbitMQ | 13% |
你的监控工具是什么?
| Amazon CloudWatch | 28% |
| Datadog | 13% |
| Grafana | 18% |
| New Relic | 9% |
| Prometheus | 18% |
你的数据库是什么?
| Cassandra | 5% |
| DynamoDb | 14% |
| MongoDB | 16% |
| MySQL | 22% |
| Postgres | 22% |
贡献者
Dynatrace
Dynatrace 提供软件智能以简化云复杂性并加速数字化转型。 借助自动和智能的大规模可观察性,我们的一体化平台可提供有关应用程序性能和安全性、底层基础架构以及所有用户体验的准确答案,使组织能够更快地创新、更有效地协作并交付更多 以更少的努力获得价值。
Epsagon
Epsagon 使团队能够立即可视化、理解和优化他们的微服务架构。 借助我们独特的轻量级自动仪表,消除了与其他 APM 解决方案相关的数据和手动工作方面的空白,从而显着减少了问题检测、根本原因分析和解决时间。
Grafana Labs
Grafana Labs 提供了一个围绕 Grafana 构建的开放且可组合的监控和可观察性平台,Grafana 是用于仪表板和可视化的领先开源技术。 超过 1,000 家客户(如 Bloomberg、JP Morgan Chase、eBay、PayPal 和 Sony)使用 Grafana Labs,全球有超过 600,000 个 Grafana 活跃安装。 商业产品包括 Grafana Cloud,一个集成了 Prometheus 和 Graphite(指标)的托管堆栈,Grafana Enterprise,一个具有企业功能、插件和支持的 Grafana 增强版; Loki(原木)和 Tempo(痕迹)与 Grafana; 和 Grafana Metrics Enterprise,它为大规模运行的大型组织提供 Prometheus 即服务。
LaunchDarkly
LaunchDarkly 由 Edith Harbaugh 和 John Kodumal 于 2014 年创立,是软件团队用来构建更好的软件、更快、风险更低的功能管理平台。 开发团队使用功能管理作为将代码部署与功能发布分开的最佳实践。 使用 LaunchDarkly,团队可以控制从概念到发布再到价值的整个功能生命周期。 每天为超过 1 万亿个功能标志提供服务,LaunchDarkly 被 Atlassian、Microsoft 和 CircleCI 的团队使用。
PagerDuty
PagerDuty, Inc. (NYSE:PD) 是数字运营管理领域的领导者。 在一个永远在线的世界中,各种规模的组织都信任 PagerDuty 可以帮助他们每次都为客户提供完美的数字体验。 团队使用 PagerDuty 实时识别问题和机会,并召集合适的人员更快地解决问题并在未来预防问题。 知名客户包括 GE、思科、基因泰克、艺电、Cox Automotive、Netflix、Shopify、Zoom、DoorDash、Lululemon 等。
- 153 次浏览
【混沌工程】Wikipedia Chaos engineering
混沌工程是在系统上进行实验的学科,目的是建立对系统在生产中承受动荡条件的能力的信心。
概念
在软件开发中,一个给定的软件系统在保证足够服务质量的同时容忍故障的能力——通常被概括为弹性——通常被指定为一项要求。但是,由于截止日期短或缺乏该领域的知识等因素,开发团队经常无法满足这一要求。混沌工程是一种满足弹性要求的技术。
混沌工程可用于实现针对基础设施故障、网络故障和应用程序故障的弹性。
历史
在 2011 年监督 Netflix 向云迁移的过程中,[2][3] Greg Orzell 的想法是通过设置一个工具来解决缺乏足够的弹性测试的问题,该工具会导致其生产环境(Netflix 客户使用的环境)出现故障。其目的是从假设没有故障的开发模型转变为故障被认为是不可避免的模型,从而促使开发人员将内置弹性视为一种义务而不是一种选择:
“在 Netflix,我们的自由和责任文化使我们不强迫工程师以特定方式设计他们的代码。相反,我们发现我们可以通过隔离服务器中和和将它们推向极致。我们创建了 Chaos Monkey,这是一个随机选择服务器并在正常活动时间内禁用它的程序。有些人会觉得这很疯狂,但我们不能依赖随机发生的事件来测试我们的面对这一事件的后果时采取的行为。知道这种情况会经常发生,因此工程师之间建立了强烈的一致性,以建立冗余和流程自动化以在此类事件中幸存下来,而不影响数百万 Netflix 用户。Chaos Monkey 是我们的一员提高我们服务质量的最有效工具。”[4]
通过定期“杀死”软件服务的随机实例,可以测试冗余架构以验证服务器故障不会明显影响客户。
混沌工程的概念与 Martin Fowler 于 2012 年首次提出的 Phoenix Servers 很接近。 [5]
扰动(Perturbation)模型
混沌工程工具实现了扰动模型。扰动,也称为湍流,旨在模拟生产中可能发生的罕见或灾难性事件。为了最大化混沌工程的附加值,预计扰动是现实的。 [6]
服务器关闭
一种扰动模型包括随机关闭服务器。 Netflix 的 Chaos Monkey 就是这种扰动模型的实现。
延迟注入
引入通信延迟以模拟网络中的退化或中断。例如,Chaos Mesh 支持延迟注入。
资源枯竭
吃掉给定的资源。例如,Gremlin 可以填满磁盘。
混沌工程工具
Chaos Monkey
Chaos Monkey 是 Netflix 于 2011 年发明的一种工具,用于测试其 IT 基础架构的弹性。 [2]它通过故意禁用 Netflix 生产网络中的计算机来测试剩余系统如何响应中断来工作。 Chaos Monkey 现在是名为 Simian Army 的更大工具套件的一部分,旨在模拟和测试对各种系统故障和边缘情况的响应。
Chaos Monkey 背后的代码由 Netflix 于 2012 年在 Apache 2.0 许可下发布。
“混沌猴”这个名字在安东尼奥·加西亚·马丁内斯的《混沌猴》一书中有解释:
- 想象一只猴子进入“数据中心”,这些服务器“农场”承载着我们在线活动的所有关键功能。猴子随机撕开电缆,破坏设备并归还所有经过手的东西[即扔粪便]。 IT 经理面临的挑战是设计他们负责的信息系统,以便它能够在这些猴子的情况下工作,没有人知道它们何时到达以及它们将破坏什么。
Simian Army
Simian Army 是 Netflix 开发的一套工具,用于测试其亚马逊网络服务基础设施的可靠性、安全性或弹性,包括以下工具:
在Simian Army 等级的最顶端,Chaos Kong 放弃了一个完整的 AWS“区域”。 虽然很少见,但确实会发生整个区域的损失,Chaos Kong 模拟了系统对此类事件的响应和恢复。
Chaos Gorilla 放弃了一个完整的亚马逊“可用区”(一个或多个服务于一个地理区域的完整数据中心)。
ChaosMachine
ChaosMachine 是一个在 JVM 的应用程序级别进行混沌工程的工具。它专注于通过注入异常来分析应用程序中涉及的每个 try-catch 块的错误处理能力。
Proofdock混沌工程平台
Proofdock 是一个混沌工程平台,专注于并利用 Microsoft Azure 平台和 Azure DevOps 服务。用户可以在基础设施、平台和应用程序级别注入故障。
Gremlin
Gremlin 是一个“故障即服务”平台。
Facebook Storm
为了应对数据中心的损失,Facebook 定期测试其基础设施对极端事件的抵抗力。该程序被称为 Storm Project,它模拟大规模数据中心故障。
Days of Chaos
Voyages-sncf.com 于 2017 年创建了“混沌之日”,将预生产故障的模拟游戏化。他们在 2017 DevOps REX 会议上展示了他们的结果。
See also
- Fault injection
- Fault tolerance
- Fault-tolerant computer system
- Data redundancy
- Error detection and correction
- Fall back and forward
- Resilience (network)
- Robustness (computer science)
本文:
- 150 次浏览
【混沌工程】什么是混沌工程?
什么是混沌工程?
混沌工程让您可以将您认为会发生的事情与系统中实际发生的事情进行比较。 您实际上是“故意破坏”以学习如何构建更具弹性的系统。
通过主动测试系统在压力下的响应方式,我们可以在故障出现之前识别并修复故障。 最终,混沌工程的目标是增强我们系统的稳定性和弹性。
混沌与可靠性工程技术作为构建可靠应用程序的基本学科正迅速获得关注。 在过去的几年里,许多组织——无论大小——都接受了混沌工程。
创建可靠的软件是现代云应用程序和架构的基本必要条件。 随着我们迁移到云或将我们的系统重新架构为云原生,我们的系统正在按设计分布,并且出现计划外故障和意外中断的可能性显着增加。 此外,转向 DevOps 会使可靠性测试更加复杂。

DevOps 抛弃了传统的可靠性测试
像 QA 和其他测试学科的出现是为了应对不断出现的问题并需要一种新的测试方法。
例如,单元测试验证我们编写的一些代码是否符合预期。集成测试验证我们编写的代码可以很好地与代码库的其余部分配合使用。有时我们会进行系统测试,试图验证整个系统是否符合设计规范。传统上,开发团队会传递他们的代码进行测试,以验证它是否按预期工作或发现需要修复的问题。
在这一点上,代码将被扔到一个运营团队的墙外,他们的工作是让代码在生产环境中运行。运维负责让东西运行起来,并且由于每个组织环境的独特性,各个运维团队都会提出自己的战略和计划。
DevOps 将开发和运营团队合并在一起,让他们共同承担生产准备和部署的责任。敏捷和 DevOps 软件流程将我们的开发和部署速度提高了几个数量级,因此我们可以更快地将产品和功能提供给客户。
但是,越快的代码被创建并检入到 master 中,QA 就越频繁地编写测试并且需要更多的测试。速度越快,偶尔出现错误的可能性就会越大。为了跟上步伐,测试已尽可能自动化。
此外,随着我们转向微服务和其他分布式、基于云的架构。这些分布式系统具有紧急行为,通过扩大和缩小规模来响应各种生产条件,以确保应用程序能够为不断增长的客户需求提供无缝体验。换句话说,这些系统从不遵循相同的路径来获得客户体验。紧急行为也意味着紧急失败。分布式系统会失败,但它们不太可能以同样的方式失败两次。
我们之前对测试的理解并不能解释当今独特且不断变化的生产环境。 DevOps 的 Ops 方面尽最大努力使事情顺利进行,但他们的任务通常只涉及将代码投入生产并希望获得最佳效果或回滚更改或在发生故障时进行修补程序。他们自动化了一些测试,但通常不会运行会发现由生产中的动荡条件引起的系统故障的测试。
传统的 QA 已经不够用了
DevOps 中缺少一些东西:混沌工程是您一直在寻找的测试方法。
传统的质量保证仅涵盖我们软件堆栈的应用层。 再多的传统 QA 测试或其他传统测试都无法验证我们的应用程序、其各种服务或整个系统是否会在任何条件下可靠地响应,无论是“按设计工作”还是在极端负载和异常情况下。
任何软件堆栈或应用程序层的故障都可能破坏客户体验。 传统的 QA 测试方法不会在这些潜在问题条件实际发生之前发现它们。
此外,大多数传统的 QA 活动都被其他团队吸收了。 许多测试现在由 CI/CD 管道自动化,并由 SRE 或 DevOps 团队监督。 发现和解决问题的责任已成为服务所有者的责任。 除此之外,不可否认的事实是,不可能建立准确模仿生产环境的测试和登台环境。

混沌工程如何帮助测试发展?
- 验证
- 更广泛的软件和基础设施场景
- 发现问题
- 传统测试无法暴露
- 安全地进行
- 并在生产中有效
- 帮助团队了解
- 系统在现实世界中的行为方式,而不仅仅是它们如何破坏或它们有什么错误
由于混沌工程可以在运行时测试代码质量,并且具有自动化和手动测试形式的潜力,因此该学科成为新质量评估工具箱中的强大工具。
早些时候我们解释了分布式系统是如何不断变化的,这意味着它们永远不会以相同的方式崩溃两次,但它们会崩溃。 Chaos Engineering 允许工程师在安全和受控的环境中模拟他们的系统如何响应故障,从而帮助企业防范这些故障。
我们使用混沌实验来模拟我们知道有可能导致问题的金丝雀实例上的事物,例如网络延迟。新服务在轻量级测试下是否有效?中等的?重的?我们努力推动新实例。在生产中。我们逐渐建立起来,甚至测试超出了我们期望的工作点。我们学到了东西。我们经常学到的东西会创造机会在下一次构建中进一步完善我们的工作。这在生产中是安全的,因为服务的其他实例正在处理客户需求;甚至没有人能说我们正在做混沌工程。
混沌工程是在当今复杂的现实中发现系统性问题的唯一方法,无论我们是否使用金丝雀部署。当网络延迟增加两微秒时,我们的 REST API 驱动的库存服务将如何表现?当大量延迟的请求全部并发到微服务时会发生什么?我们怎么知道?我们对其进行测试。
混沌工程入门
我们首先设计了一个小型混沌实验,其规模远小于我们认为可能造成麻烦的规模。接下来,我们限制爆炸半径和真正的潜在危害,以便在进行混沌测试时保证系统和数据的安全。然后,我们运行实验,完成后,我们仔细检查我们的监控和可观察性以及其他系统数据,看看我们学到了什么。
我们的混沌实验影响了什么?这些数据决定了我们如何优先考虑我们的工作,在我们发现的小问题变成大问题之前减轻它们(并且肯定会减轻我们立即发现的任何大问题!)。然后我们通过再次运行相同的混沌实验来跟进我们的工作,以确认我们的工作是有效的。
反复这样做,从小处着手,每次都修复我们发现的东西,很快就会加起来。我们的系统在处理我们无法控制或阻止的现实世界事件方面变得越来越好,例如当我们的云提供商发生意外中断时。
“哦,不!我们在 us-east-2 中的 Amazon S3 存储桶刚刚坏了?”不用担心,我们已经预料到了这一点,并且从客户的角度来看,我们的系统仍然表现良好。也许我们已经在 us-west-1 中进行了故障转移备份,并设计了我们的系统,以便在性能下降到一定水平时进行切换,而客户会注意到。
无论我们的解决方案是什么,我们都设计了它,我们实现了它,然后我们用混沌工程对其进行了测试。结果,当发生我们无法控制的生产故障时,它按预期工作,更重要的是,我们的客户甚至都不知道它发生了。
- 165 次浏览
【混沌工程】什么是混沌工程? 介绍、定义及更多
软件和系统开发是创新和解决未知问题的练习。 软件和系统是容易出错的,因为它们是由具有不同观点和技能的人(很可能是多人)制作的。 技术变得越来越分散和复杂,尤其是随着微服务的推动。 很少有人拥有完整的端到端知识 […]
软件和系统开发是创新和解决未知问题的练习。软件和系统是容易出错的,因为它们是由具有不同观点和技能的人(很可能是多人)制作的。技术变得越来越分散和复杂,尤其是随着微服务的推动。很少有人拥有整个系统的全部端到端知识。
类似于围绕态势感知的军事术语,战争迷雾,在现代发展中理解变化的总体影响可能很困难(发展迷雾)。再加上用户对系统始终可用的期望,测试系统的稳健性和对未知数的弹性可能只是:一个未知数。
混沌工程通过在整个应用程序和基础架构堆栈中注入故障,然后允许工程师验证行为并进行调整,从而使故障不会向用户显现,从而帮助解决未知问题。再加上站点可靠性工程实践的兴起,混沌工程试图计算不可能的影响。
混沌史
站点可靠性工程师的热门读物是 Nicholas Taleb 的《黑天鹅:极不可能的影响》(2007 年)。塔勒布在他的作品中介绍了黑天鹅的隐喻。塔勒布将黑天鹅事件分类,例如突然的自然灾害或在出版他的书时的商业活动,谷歌取得了惊人的空前成功。黑天鹅事件具有三个特征:不可预测,影响巨大,当它结束时,我们会设计一种解释,让黑天鹅看起来不那么随机。
在处理发展的迷雾时,我们很容易陷入分布式计算的谬误,这是计算机科学家 Peter Deutsch 提出的一组关键断言。一些主要的谬误是:网络可靠,延迟为零,带宽无限,并且只有一名管理员。消除谬误,您的服务将始终如一,并且随时可用。正如我们所知,系统和服务总是会起起落落——但是当涉及到开发未知的细节时,我们很容易忘记这一点。
例如,假设我们正在构建一些依赖 Amazon S3 进行对象存储的功能。如果我们正在为执行复杂处理的服务构建功能并且最终输出是在 S3 中写入或更新对象,我们作为工程师可能会假设 S3 将在那里。我们上下测试我们的功能,并为 S3 部分提供不太复杂的测试覆盖率。亚马逊网络服务在 2017 年发生了自己的黑天鹅事件,当时 S3 遭遇中断。我们认为会存在的东西(即使性能/写入 SLA 降低)也没有,分布式计算的谬误又回来咬我们。
S3 中断确实有助于确保我们接触到堆栈的所有部分,即使我们接触的部分看起来并不明显,这可能是由于我们对分布式计算的谬误的看法/迷雾。混沌工程和混沌实验带来了可控的混沌,因此我们可以摆脱这些类型的事件。
什么是混沌工程?
混沌工程是故意将故障注入系统以衡量弹性的科学。与任何科学方法一样,混沌工程专注于实验/假设,然后将结果与对照(稳态)进行比较。分布式系统中典型的混沌工程示例是关闭随机服务,以查看项目如何响应以及对用户旅程的损害表现在哪些方面。
如果您对应用程序需要运行的内容(计算、存储、网络和应用程序基础设施)进行横截面分析,则将故障或动荡条件注入该堆栈的任何部分都是有效的混沌工程实验。网络饱和或存储突然变得不稳定/满负荷是技术行业已知的故障,但混沌工程允许对这些故障进行更可控的测试,等等。由于可能会影响广泛的基础设施,混沌工程的用户和从业者几乎可以是支持应用程序/基础设施堆栈的任何人。
谁使用混沌工程?
由于混沌工程涉及广泛的技术和决策,混沌工程实验可能有多个利益相关者。爆炸半径越大(受测试和实验影响的范围),参与的利益相关者就越多。
根据应用程序堆栈的领域(计算、网络、存储和应用程序基础架构)以及目标基础架构所在的位置,这些团队的利益相关者可以参与其中。
如果爆炸半径很小并且可以在运行的容器中进行测试,那么应用程序开发团队可以进行测试,而不必担心突破容器。如果工作负载或基础设施的影响范围更广(例如,测试 Kubernetes 基础设施),平台工程团队很可能会参与其中。为未知提供覆盖是运行 Chaos 测试和寻找弱点的核心原因。
为什么要进行混沌测试?
开发的迷雾是非常真实的,尤其是对于更大的分布式系统、复杂系统和微服务实现。从应用程序的角度来看,每个单独的微服务都可以单独测试并确定按设计工作。正常的监控技术可以认为单个服务是健康的。
使用微服务模式,单个请求可以遍历多个服务以获得聚合响应来满足用户或其他服务的请求。服务之间的每个远程请求都在遍历额外的基础设施并跨越不同的应用程序边界,所有这些都可能失败。
如果一项琐碎或非琐碎的服务或基础设施在服务水平协议 (SLA) 范围内没有响应,系统的功能和用户旅程将受到怎样的影响?这正是混沌工程正在解决的问题。混沌工程实验的结果随后被用于创建一个更具弹性的系统。
混沌工程原理
《混沌工程原理》是一篇出色的宣言,描述了混沌工程的主要目标和原则。混沌工程原理进一步分解了四种类似于科学方法的实践。但是,与科学方法不同的是,假设系统是稳定的,然后寻找方差。越难中断稳态,系统的信心和稳健性就越高。
从定义基线开始(稳态)
了解什么是正常/稳定对于检测偏差/回归至关重要。根据您要测试的内容,拥有一个良好的指标,例如响应时间或更高级别的目标,例如在特定时间内完成用户旅程的能力,是衡量正常性的良好指标。实验中的稳态是对照组。
假设稳态将持续
与科学方法背道而驰,假设一个假设一直都是真的不会留下太多的余地。混沌工程旨在针对强大而稳定的系统运行,试图找出应用程序故障或基础设施故障等故障。对不稳定的系统运行混沌工程并没有提供太多价值,因为这些系统已经不可靠并且不稳定性是已知的。
引入变量/实验
与任何科学实验一样,混沌工程在实验中引入变量以查看系统如何响应。这些实验代表了影响应用程序四大支柱中的一个或多个的真实故障场景:计算、网络、存储和应用程序基础设施。例如,故障可能是硬件故障或网络中断。
尝试反驳假设
如果假设是针对稳态的,则稳态的任何方差或中断(对照组和实验组之间的差异)都反驳了稳定性假设。现在有了一个可以关注的领域,可以进行修复或设计更改,以使系统更加健壮和稳定。
在实施混沌工程实验时,实施混沌工程的原则会导致一些设计注意事项和最佳实践。
混沌工程最佳实践
在实施混沌工程或任何测试时,有三个支柱。第一个是提供足够的覆盖范围,第二个是确保经常运行实验并在生产中模拟/运行,第三个是最小化爆炸半径。
为估计的故障频率/影响提供覆盖范围
在软件中,您永远不会达到 100% 的测试覆盖率。建立覆盖需要时间,而考虑每个特定场景是一个白日梦。覆盖范围致力于使最有影响力的测试。在混沌工程中,这将测试会产生严重影响的项目,例如存储不可用或可能发生很多的项目,例如网络饱和或网络故障。
在您的管道中连续运行实验
软件、系统和基础设施确实会发生变化——每个人的状况/健康状况都可能会迅速发生变化。运行实验的好地方是在 CI/CD 管道中。 CI/CD 管道在进行更改时执行。衡量变革的潜在影响的最佳时机莫过于变革开始在管道中建立信心的旅程。
在生产中运行实验
正如在生产中进行测试的可怕想法一样,生产是用户所处的环境,流量峰值/负载是真实的。为了全面测试生产系统的稳健性/弹性,在生产环境中运行混沌工程实验将提供所需的见解。
最小化爆炸半径
因为你不能以科学的名义降低生产,所以限制混沌工程实验的爆炸半径是一种负责任的做法。专注于小实验,这些实验会告诉你你想要识别什么。专注于范围和测试。例如,两个特定服务之间的网络延迟。比赛日计划可以帮助计算爆炸半径和重点。
有了这些最佳实践,混沌工程是一门不同于负载测试的学科。
混沌工程和负载测试有什么区别?
当然,负载本身会带来混乱。我们通常将我们的系统设计为在多个部分中具有弹性(启动额外的计算、网络、持久性和/或应用程序节点以应对负载)。那是假设一切都在同一/适当的时间出现,因此我们可以领先于负载。
在计算机科学领域,Thundering Herd 问题(惊群问题)并不新鲜,但随着我们向更加分布式的架构迈进,它会更加普遍地表现出来。例如,Thundering Herd 问题可能在机器级别,因为大量进程被启动,另一个进程成为瓶颈(处理一个且仅一个新进程的能力)。在分布式架构中,Thundering Herd 可能是您的消息系统能够一次摄取大量消息/事件,但处理/持久化这些消息可能会成为瓶颈。如果您收到消息过多,您好 Thundering Herd。
负载测试肯定会帮助我们为雷鸣群做准备,这是一种压力,但是如果系统的一部分甚至不存在,或者游戏迟到了怎么办?这就是混沌工程的用武之地。如果没有混沌工程,一个非常难以测试的项目将是级联故障。历史上更等同于电网,级联故障是一个部分的故障可以触发其他部分的故障。在分布式系统领域,这是我们试图找到单点故障并确保我们的应用程序/基础设施足够健壮以处理故障。
今天,不乏工具和平台来帮助您实现混沌工程目标。
混沌工程工具
围绕混沌工程有很多进步和工具。很棒的资源列表是 Awesome Chaos Engineering 列表。此列表向构建 Chaos Engineering 的混沌测试工具致敬,向使 Chaos Engineering 更易于使用的新平台致敬。
混沌猴(Chaos Monkey)
Chaos Monkey 被公认为最早的混沌工程工具之一,由 Netflix 开发。最初的 Chaos Monkey 会随机禁用生产实例。最终,混沌猴成为了猿猴军团(Simian Army)的一员。尽管今天 Chaos Monkey 是一个独立的项目。
四面军(The Simian Army)
受原始 Chaos Monkey 成功的启发,Simian Army 是一系列工具(例如 Janitor Monkey、Latency Monkey、Security Monkey 和 Doctor Monkey),专注于引入不同类型的故障。今天,四面军退役了。
Gremlin 平台(Gremlin Platform)
Gremlin 是最早的 SaaS 混沌工程平台之一。 Gremlin 能够协调和测量打包在 SaaS 平台中的混沌工程实验。如果这是您第一次涉足混沌工程,Gremlin 提供了很多很棒的资源。
AWS 故障注入模拟器(AWS Fault Injection Simulator)
最近专注于 AWS 服务,AWS 提供了故障注入模拟器。如果您完全使用 AWS 平台并希望将混沌工程实验引入您的 AWS 环境,AWS FIS 是一个不错的选择。了解有关故障注入测试及其优势的更多信息。
无论您选择哪种工具,您的 CI/CD 管道都是运行和编排混沌工程实验的好地方。
试验您的 CI/CD 管道
随着在系统中建立信心的新方法开始受到关注,CI/CD 管道是协调建立信心步骤的好地方。混沌工程实验非常适合在 CI/CD 管道中运行。最近,Harness 和 Gremlin 创建了一个演示,展示了 CI/CD 管道和 Gremlin Experiments 之间的集成。
可能的艺术是让混沌工程实验的结果影响部署,或者如果部署到较低的环境,让 Harness 作为混沌工程实验和其他自动化测试的协调器。如需完整示例,请前往 Harness 社区了解更多信息。
线束(Harness )在这里提供帮助
Harness 软件交付平台是一个非常强大的平台,专门用于协调建立信任的步骤。 就像在任何实验中一样,混沌工程的一个支柱是有一个基线。 想象一下,您是一个团队的新手,例如 SRE 团队,该团队涵盖了数十个不是您自己编写的应用程序。 首次运行混沌工程测试将需要隔离或启动应用程序和相关基础设施的新发行版,以进行试验,而不会对生产产生影响。
如果您的应用程序不是通过强大的管道部署的,那么创建另一个隔离部署可能与正常部署应用程序的正常潮起潮落一样痛苦。 沿着混沌工程成熟之旅前进,因为混沌工程测试被视为强制覆盖,按照惯例,将它们集成到用于判断调用或故障策略的 Harness 工作流中很简单。
本文:https://jiagoushi.pro/what-chaos-engineering-intro-definition-more
- 145 次浏览
【混沌工程】故意破坏和混沌工程
在这一集中,Jason 与加拿大皇家银行的开发者宣传总监 Aaron Clark 聊天。 Aaron 分享了最初在 RBC 担任开发人员并从事早期云开发工作,然后过渡到他作为开发人员倡导者的角色的感觉。 Jason 和 Aaron 讨论了在组织内应用开源原则或“内部资源”的价值。他们的时间以继续教育和如何继续学习的讨论结束。
在本集中,我们将介绍:
- Aaron 谈到了作为开发人员的起步以及在 RBC 的云开发的早期阶段 (1:05)
- Aaron 讨论了向开发人员倡导过渡 (12:25)
- Aaron 确定了他在早期倡导开发人员时所取得的成功 (20:35)
- Jason 询问如何帮助开发人员完成长期维护项目或“可持续发展” (25:40)
- Jason 和 Aaron 讨论什么是“内部资源”以及为什么它在组织中很有价值 (29:29)
- Aaron 回答了“你如何使技能和知识保持最新?”这个问题。 (33:55)
- Aaron 谈论 RBC 的工作机会 (38:55)
参考链接:
加拿大皇家银行:https://www.rbcroyalbank.com
RBC 的机会:https://jobs.rbc.com/ca/en
成绩单
Aaron:我猜有些 PM 问过我的老板,“所以,Aaron 没有参加我们的平台状态会议,他并没有真正接受门票,也没有参加支持轮换。 Aaron 为云平台团队做了什么?”
杰森:[笑]。
Jason:欢迎收听 Break Things on Purpose,这是一个关于可靠性、学习和构建更好系统的播客。在这一集中,我们与加拿大皇家银行开发者宣传总监 Aaron Clark 进行了交谈。我们与他聊了聊他从开发人员到倡导者的旅程,在组织内应用开源原则(称为内部资源)的力量以及他继续学习的建议。
杰森:欢迎来到这个节目,亚伦。
亚伦:谢谢你邀请我,杰森。我的名字是亚伦克拉克。我是 RBC 的云开发倡导者。那就是加拿大皇家银行。从 2010 年 2 月起,我就在银行工作了……嗯。
Jason:那么,当你第一次加入银行时,你并不是开发者的拥护者?
亚伦:对。因此,我自 2019 年以来一直担任现在的职务。自 2017 年以来,我一直是云计划的一部分。早在 2010 年,我就以 Java 开发人员的身份加入。所以,作为一名开发人员,我的背景对 Java 非常重要。 Java 和 Spring Boot,现在。
我加入了皇家银行众多职能领域之一的一系列 Java 应用程序的工作。银行很大。这是人们有时难以掌握的事情之一。这是一个如此庞大的组织。我们大概有 100,000 名……是的,有 100,000 名员工,其中大约 10,000 名从事技术工作,因此开发人员、开发人员相邻的角色(如业务分析师和 QE)、运营和支持以及所有这些角色。
这是一个大组织。当你加入组织时,这是一件有趣的事情。因此,我加入了一个名为 Risk IT 的小组。我们只构建面向内部的应用程序。我在那里做了一堆东西。
我是一个多面手,我对 DevOps 的所有事情都感兴趣。我在 Risk 中设置了第一批 Hudson 服务器之一——嗯,在银行中,但特别是在 Risk 中——我在一边管理它,因为没有其他人在做,它需要做。在这样做了几年并从事了许多不同的项目之后,我偶尔只是,“我们需要这个项目成功,一开始就有一个良好的基础,所以亚伦,你在这个项目上做了六个月然后你正在做一些不同的事情。”这真的很有趣。同时,我总是担心这样一个问题,如果你不坚持很长时间,你永远不会知道你可能做出的错误决定的后果,因为你不必处理它。
杰森:[笑]。
亚伦:这就像我希望我在这里做出正确决定的另一面。它看起来很不错,人们似乎对此很满意,但我总是担心这一点。就像,在一个角色中工作了几年,你构建了一些东西,然后它在生产中,你正在运行它并且你正在处理,“哦,我做出了这个当时似乎是个好主意的决定.事实证明这是个坏主意。下次不要这样。”如果你不留在一个角色中,你永远不会学到这一点。
当我在风险 IT 部门工作了四到五年,所以我会与一群可能留在这个项目上的团队一起工作,他们会来问我问题。就像,我没有消失。在接下来的几个月或其他任何时间里,我都不会在那个项目上工作。然后我搬到了该组织的另一个部门,比如一个名为 Finance IT 的姊妹组,它运行某种类型的东西——为银行构建和运行总账。或者至少对于部分资本市场而言。
随着组织的移动,它变得模糊。团体合并和分散等等。那个小组,我实际上有一些有趣的东西,当我开始研究更多的东西时,比如云,看着云,银行开始引入云。所以,我仍然在应用程序开发方面,但我对此很感兴趣。我参加过 OSCON 之类的会议,开始听说和了解 Docker、Kubernetes、Spring Boot 之类的东西,我觉得这是一些非常简洁的东西。
我在银行早期的 Hadoop 集群之一上开发基于 Spark 的 ETL 系统。所以,我一直觉得,超级,超级幸运,我做了很多这样的事情,在所有这些新事物在组织中真正新生的时候就开始工作。我也得到了非常支持的领导。所以,就像我正在做的那样——持续集成服务器,它完全在旁边;我参与了一堆重用想法,我们有这个更大的群体;我们正在做很多类似的事情;让我们分享一些图书馆和类似的东西。那是在成为任何,比如,开发者倡导者或任何类似的东西之前,我正在从事这些工作。
基本上,我实际上得到了一年的资金来促进和从事重用活动。那就是——我学到了很多,我犯了很多错误,我现在,比如,告诉我在我目前的角色中做出的一些决定,但我正在做这一切,我几乎把它描述为我有点因为我在这个团队工作,所以对我现有的项目征税,但我还有这件事要做。而且我可能需要花一个上午的时间而不是为您的项目工作,因为我必须为某人维护这台构建机器。我得到了非常支持的领导。他们很棒。
他们认识到这些活动的价值,并没有真正争论我正在从预算中说我应该做的任何事情上抽出时间,这真的很好。所以,我开始这样做,我在金融部门工作,因为云团队开始经历改造——银行最初的新生云团队——我从应用程序开发端做云的事情,但同时在我的团队中,每当有什么令人惊讶的事情被打破,有人遇到紧急情况需要有人介入并聪明地解决问题时,那个人就变成了我。从这个意义上说,我遇到了很多干扰。很高兴成为那个开始工作的人,“哦,这东西需要拯救。帮助我们,亚伦。”
这太妙了;感觉真的很好,对,直到你花了很多时间做这件事,而你不能做你真正感兴趣的事情。所以,我实际上决定搬到云团队工作关于定义我们如何为云构建应用程序的方式,这真的是——这是一个非常好的时机。那是在银行的早期阶段,所以没有人真正知道我们将如何构建应用程序,我们将如何将它们放在云上,这种结构是什么样的?我必须做大量的阅读、研究和向其他人学习。一个关键的事情,比如,一个像银行一样行动缓慢并且在技术选择方面有点规避风险的非常大的组织,人们总是表现得好像这总是一件坏事。
有时是因为我们有时没有采用我们真正能从中获得很多好处的东西,但另一方面,当我们接触到很多这些技术和平台时,一堆锋利的边缘已经被打磨掉了。就像世界上的 Facebook 和 Twitter 一样,他们已经采用了它,他们已经发现了所有这些问题,并且像用胶带一样把它们粘在一起。他们发现,“哦,我们需要在这个系统中内置实际的,比如,安全性”,或者类似的东西,他们已经解决了。所以,当我们谈到它时,其中一些问题已经不存在了。我们不必与他们打交道。
在一个更保守的组织中,这是一个被低估的积极因素。所以,我们认为我们可以从中学到很多东西。当我们研究微服务以及类似 Spring Boot Spring Cloud 时,最初被引入组织的云部分主要围绕 Cloud Foundry。我们正在帮助一些初始应用程序团队构建他们的应用程序,我们可能过度设计了其中一些应用程序,从某种意义上说,我们正在证明构建这些应用程序并不迫切需要的模式。就像,您可能刚刚使用 Web 应用程序和关系数据库完成了它,它会很好。
但我们正在证明一些模式,你如何使用微服务和类似的东西构建更大规模的东西。我们了解了很多关于这样做太早的复杂性,但我们也了解了很多关于如何做到这一点的知识,以便我们可以教其他应用程序团队。这就是我加入的那种团队,我不是云上的平台操作员,但我正在与开发团队合作,与开发团队一起构建东西,以帮助他们学习如何为云构建东西。这是我第一次真正接触到银行的范围和规模。我曾在较小的小组中工作,当您开始与银行的较大部分进行互动时,您开始遇到的一件事就是,有多少孤岛,技术堆栈的多样性那种规模的组织。
比如,我们有使用 Java 的领域,我们有使用 .NET Framework 的领域,我们有很多 Python 的领域,我们有很多 Node 的领域,尤其是当组织开始构建更多的 Web 应用程序时。当你使用 Angular 构建东西并使用 npm 作为前端时,你也在使用 Node 在后端构建东西。无论这是否是一个好的技术选择,很多时候你都是在用你所拥有的东西来构建。即使在 Java 中,我们也会有团队使用 Spring Boot 构建,并且很多团队都在这样做,但是其他人对 Google Guice 感兴趣,所以他们正在构建——而不是 Spring,他们使用 Google Guice 作为他们的依赖注入框架。
或者他们有一个……比如,有大型机,对吧?您拥有庞大的技术堆栈,许多人仍在其中构建 Java EE 应用程序,并试图将其从 Java EE 的旧肮脏时代发展为更好的现代方式。一些技术对话是这样的,“好吧,你可以使用其他技术;没关系,但如果你正在使用它,而我们在这里使用其他东西,我们将无法互相帮助。当我解决问题时,我也无法真正帮助您解决问题。你必须用你的框架自己解决它。”
我曾经和一个在 Java 中使用 Vertex 的团队交谈过,我问他们:“你们为什么使用 Vertex?”他们说,“嗯,这就是我们团队所知道的。”我当时想,“从我们必须交付的意义上说,这是一个很好的技术选择。这就是我们所知道的,所以这就是我们知道我们可以成功的事情,而不是在尝试交付某些东西的同时在工作中实际学习新东西。”如果不是彻底失败,这通常是挑战的秘诀。
杰森:是的。所以,这听起来像是你进来的地方;如果所有这些团队都在做非常不同的事情,对——
亚伦:嗯嗯。
杰森:这有好有坏,对吧?这就是微服务的全部意义在于独立的团队,每个人都解耦,速度更快。但是,利用从一个团队到另一个团队的一些经验,并真正开始分享这些最佳实践,也有巨大的优势——尤其是在 RBC 规模的组织中。我猜这就是你现在在当前角色中发挥作用的地方。
亚伦:是的。这就是我们如何灵活地让人们在标准化的同时做出自己的选择,这样我们就不会出现这种巨大的蔓延,这样我们就可以在事物的基础上再接再厉?这开始是我开始真正参与社区事务并进行开发者宣传的地方。这实际上是如何发生的一部分——这是我非常幸运并且拥有优秀领导者的另一个案例——我作为云平台团队的一员工作,我曾经是一个特殊项目组,几个人离开了;我是最后一个离开的。就像,“好吧,你不能成为自己的部门,所以你是云平台的一部分。”但我不是运营商。我不接受支持轮换。
而且我表面上是在构建工具,但我主要是在做内部资源。这就是 RBC 内部资源社区开始发展的地方。我是innersource 社区的创始成员之一,并开始了这一进程。我们已经为云构建了一堆库,所以这些是内部源代码的第一批项目,我使用 OIDC 维护 Java 和 Spring 库。这有点早于 Spring Security 对 OIDC 的原生支持——所以 Open ID Connect——
我做了很多这样的事情,我支持试图采用该库的应用程序团队,我参与了其他一些早期开发人员体验的事情,你抱怨这件事作为开发人员很糟糕;为什么我们必须这样做?您被邀请参加 VP 的每周例会进行讨论,现在您正忙于尝试修复开发人员体验的某些部分。我正在这样做,我猜有些 PM 问我的老板,“所以,Aaron 没有参加我们的平台状态会议,他并没有真正接受门票,他也没有参加支持轮换。 Aaron 为云平台团队做了什么?”
杰森:[笑]。
Aaron:我的老板说,“嗯,Aaron 还参与了很多其他非常有价值的事情。”此时我正在做的另一件事是主持技术讲座系列演讲,这是一种内部会议式的讲座,我们从组织内部聘请专家,并尝试跨越我们发现的那些孤岛机器学习专家;来解释一下 TensorFlow 是如何工作的。来解释一下 Spark 是如何工作的,为什么它很棒。我们让这些专家来为 RBC 员工做内部演示。我正在这样做,并与我们拥有的联合组织者一起为运行该系列活动提供所有支持工作。
在年底,当他们启动一项新计划以真正专注于我们如何开始促进云采用,而不仅仅是人们到达平台并开始使用它并自己弄清楚时 - 你只能得到到目前为止——我的老板让我坐下来。他说。 “所以,我们真的很喜欢你一直在做的所有事情,所有这些社区的事情和类似的事情,所以我们现在要把它作为你的工作。”这就是我到达那里的方式。这不像我申请成为开发者倡导者。我一边做所有这些事情,突然之间,我 75% 的时间都花在了所有这些副项目上,这成了我的工作。
所以,这并不是最可复制的职业道路,但它是其中之一,比如,参与其中是找到你热衷的领域的好方法。所以,我改变了我的标题。只要您的经理批准,您就可以在我们的某些系统中这样做,所以我将我的头衔从非常通用的“高级技术系统分析师”更改为“开发者倡导者。”那时我开始做更多的研究,了解实际的开发者倡导者做什么,因为我想成为开发者倡导者。我想说我是开发者倡导者。
在组织中最长的时间里,我是公司里唯一拥有这个头衔的人,这很有趣,因为没有人知道该怎么处理我,因为我不像——我是不是——我不是导演,我不是副总裁。就像……但我也不只是一个普通的开发者。哪里——我不适合这个层次结构。这很好,因为人们不再担心什么是标题和类似的东西,他们只是听我说的话。因此,我确实会与开发团队进行设计咨询,确保他们知道自己在做什么,或者在他们开始使用云时意识到一堆陷阱。
我会建立很多样本,很多文档,做很多社区参与,所以去参加我们内部的活动,做很多这样的事情。我已经在做很多内源性的东西——演讲系列——但现在这是我的正式工作,它帮助我跨越了很多这些孤岛,并且非常横向地工作。这是我的工作与普通开发人员的不同部分之一,我的工作是涵盖与云有关的任何事情——至少是我觉得有趣的事情,或者我的老板告诉我需要工作的事情——以及任何地方的任何事情在接触的组织中。所以,一个用 Kubernetes 做事的开发团队,我可以去和他们谈谈。如果他们在资本市场上建立了一些可能有用的东西,我可以说,“嘿,你能把它分享到内部资源中,以便其他人也可以在这项工作的基础上发展吗?”
这真的很棒,因为我与所有这些其他团体建立了所有这些关系。在某种程度上,这也是云程序一开始就需要我做的。我向我的一位朋友解释说,这是我现在的工作。他们就像,“这听起来对你来说是一份完美的工作,因为你是技术人员,但你真的很擅长与人相处。”我想,“我是吗?我想我现在已经做了这么长时间了。”
随着我们越来越多地进行下去,另一部分是因为我与所有这些开发团队交谈,我没有被孤立,我对我正在使用的特定事物没有那么隧道,现在我可以与平台团队交谈并真正代表应用程序开发人员的观点。因为我不是在搭建平台。他们有他们的优先事项,他们有他们不得不担心的事情;我不必处理那个。我的工作是带来应用程序开发人员的视角。这就是我的背景。
我不是操作员;我不关心支持轮换,我不关心平台的一堆琐碎的事情和辛劳。有时,我的工作就是说,嘿,这份文档是善意的。我理解您是如何从平台团队的角度以及您优先考虑并想向人们解释的事情的角度来编写此文档的,但作为应用程序开发人员,我不需要构建在您的平台上运行的东西所需的信息以我能够消费的方式呈现。所以,我也喜欢向平台提供客户反馈说,“这件事很难”,或者,“你要求应用程序团队处理的这件事,他们不想关心关于那个。他们不应该关心这件事。”还有那种东西。
所以,我最终成为了这个人类路由器,有时平台团队会说,“你知道有谁在做这个,谁在使用这个东西吗?”或者找一个应用团队说,“你应该和那边的那个团队谈谈,因为他们也在做同样的事情,或者他们正在为同样的事情苦苦挣扎,你应该合作。”或者,“他们已经解决了这个问题。”因为我不了解我们使用的每一种编程语言,也不了解所有的框架,但我知道我向谁询问了 Python 问题,并且我会派团队去找那个人。然后,当我开始做这个社区工作时,其中的一部分实际上是建立社区。
最大的成功之一是,我们有一个名为“云采用”的 Slack 频道。这是每个人都去问他们的问题的地方,关于我如何做这件事来把东西放在 Cloud Foundry 上,把它放在 Kubernetes 上?我该怎么做呢?我不明白。有时我一整天都在上 Slack 频道,回答问题,非常乐于助人,并试图记录事情,试图了解人们在做什么。
这是我的一整天,有时。花了一段时间才习惯这实际上是来自开发人员背景的成功的一天。我习惯于建造东西,所以我觉得自己很成功,因为我建造了一些我可以向你展示的东西,我今天做到了。然后我会有几天和一群人交谈,但我没有任何东西可以给你看。就像,担任这个角色的困难部分。
但最大的成功之一是我们建立了这个不仅仅是我的社区。其他想要帮助人们的人,他们只是不同开发团队的开发人员,他们会看到我提出问题或回答问题,然后他们会知道答案并插话。当我开始承担更多任务时还有更多其他活动,然后我会去——我会回到 Slack 看看,哦,有一堆问题。哦,事实证明,人们能够自助。从建立社区的角度来看,这就是成功。
现在我已经通过 Tech Talks 完成了几次,包括一些开发人员体验工作,一些云采用工作,我在内部被问到,当我们围绕诸如此类的事情建立新社区时,你如何建立社区现场可靠性工程。我们将如何做到这一点?所以,我明白了——这感觉很奇怪,但这是我现在一直在做的事情之一。就像,这是一个巨大的角色,因为所有的范围。我可以和云中的任何人接触任何东西。
与角色以及银行相关的范围之一是,我们不仅拥有所有这些技术堆栈,而且我们还拥有非常非常多样化的技术敏锐度,其中有一些已经是 Kubernetes 专家的人。无论我做什么,他们都会成功。他们会弄清楚的,因为他们就是那种性格,他们会找到所有的信息。如果有的话,由于作为受监管银行的风险要求和合规要求,我们为管理我们的环境和保护环境而实施的一些限制,这些都会成为阻碍。有时我会解释为什么会有这些东西。有时我同意人们的看法。 “是的,很糟糕。我不想这样做。”
但与此同时,你会有他们只想进来、写代码、回家的人。他们不想考虑除此之外的技术。他们不一定要去自己学习东西。这不是世界末日。对于那些不断学习、不断涉足和修补的人来说,这听起来很奇怪,就像我一样,但你仍然需要人们保持开灯,同时完成所有其他工作。而那些乐于这样做的人,这也很有价值。
因为如果我担任那个角色,我会不高兴。一个快乐的人,比如,这对整个组织都有好处。但是他们需要学习的东西,需要向他们解释的东西,他们需要成功的帮助是不同的。那么,挑战之一就是弄清楚如何应对所有这些客户?有时甚至这些客户的答案是——这是关于我的角色的事情之一——就像定义是客户成功一样。
如果你试图放在云端的应用程序不应该放在云端,我的工作就是告诉你不要把它放在云端。把你放到云端不是我的工作。我希望你成功,而不仅仅是到达那里。我可能会在一个下午把你的东西放到云端,但如果我走开它就坏了,就像,你不知道该怎么做。所以,关于我们如何教人们自助服务,我们如何让我们的内部系统更加自助服务的很多事情,这些都是我现在所关注的事情。
范围这么大,我该如何管理自己的时间?就像,我需要弄清楚我没有将一千件事情向前推进一英寸,但我正在将事情完成。而且我正在学习,在不管理人员的同时,仍然委派并与社区合作,与更广泛的云平台团队合作,围绕我如何放手并帮助其他人做事?
杰森:所以,你提到了我认为非常有趣的东西,对,帮助人们完成目标的目标,对吧?而且我认为这是一件非常有趣的事情,因为我认为,在那个倡导角色中,通常会有这样的想法,比如,我会帮助你摆脱困境,然后你可以继续前进,而不知道他们在哪里'最终走向。这种联系又回到了你之前所说的关于作为一名开发人员开始的事情,你在那里构建东西,你只是,比如,释放它,[笑]你不会想到,你知道,那天二,操作,维护,持续的东西。所以,我很好奇,随着你在事业上的进步,当你从帮助人们中获得更多智慧时,当你帮助人们完成任务时会是什么样子,同样的心态是一个将运行相当长一段时间的应用程序。即使在短期内,你知道,如果这是一个短期的事情,但我觉得在银行,大多数事情可能有点长期存在。你如何平衡呢?您如何处理这个问题,帮助人们完成工作,但同时牢记他们必须这样做——这个应用程序必须保持生存并且必须维护?
Aaron:是的,很多都是——比如,我们使用的术语是可持续发展。其中一部分是消除摩擦,试图让开发人员能够专注于,我猜,行业中经常使用的术语是他们的内部循环。毫不奇怪,银行经常有很多摩擦很大的流程。有很多开放的票,等待事情。这是我与开发团队对话的部分,我问他们:“有哪些困难的事情?你不喜欢的东西是什么?你希望你不必做或关心的事情是什么?”
当你和他们交谈时,其中一些是在字里行间读出来的;与其说是采访他们。就像,任何类型的需求收集,通常不是他们说什么,而是他们说什么然后你看,哦,这就是问题所在;我们如何解决这个问题,以便人们可以到达他们需要去的地方?这种形式的反馈是我对我们建立的系统、我们在平台周围建立的流程、我们所研究的一些工具的一些反馈。我真的非常喜欢 Docker 和 Solomon Hykes 的理念,“包括电池但可拆卸”。我希望开发人员有一个高基线作为起点。
这部分来自我使用 Cloud Foundry 的经验。 Cloud Foundry 为很多事情提供了非常好的开箱即用的开发体验,“我只有一个 Web 应用程序。运行它。是 Nginx;这是一些 HTML 页面;我不需要知道所有的细节。让它去吧,把网址给我。”
我希望为应用程序团队提供更多这样的服务,因为他们有很高的工作基线作为起点。每个组织最终都会在他们拥有的地方构建这个——比如 Netflix:Netflix OSS 或带有 Finagle 的 Twitter——在他们拥有的地方,“这是我想要插入的周边部分,每个人都可以作为起点。我们如何提供安全保障?我们如何提供所有这些是应用程序团队主要关注的部分,他们必须做,我们知道他们必须做?”其中一些是只有在云上才开始出现的东西,并试图为应用程序团队提供更多的东西,这样他们就可以专注于业务,只在需要时才进入杂草。
Jason:当你在谈论这些框架时,你知道,拥有人们可以拥有的高质量或高基线工具,对,为他们配备一个不错的工具箱,我猜你的内部资源'正在努力也有助于促进这一点。
亚伦:哦,非常好。随着我们的发展和成熟,我们的内部资源组织,其中很大一部分也是其他团体,他们在那里找到了我们需要的东西。他们会说——它最初是,“我们建造了这个。我们会将其放入内部资源中。”但是你得到的是非常有针对性和特定于他们的团队的东西,也许其他人可以使用它,但如果不稍微弯曲它,他们就无法使用它。
而且我讨厌弯曲软件来适应它。这是其中一件事——在我们拥有现有流程的企业环境中,这是一件非常普遍的事情,我们需要采用它,然后将其弯曲直到它适合我们现有的流程,而不是采用某些工具使用的标准方法,因为我们不想改变我们的流程。这会变得很困难,因为你会遇到奇怪的边缘情况,因为我们弯曲了它,所以它正在做一些奇怪的事情。就像,嗯,那不是它的错。随着我们开始做更多的内部资源,更多的事情真正首先成为内部资源,团队意识到我们需要一起解决这个问题。
让我们一起开始工作,让我们将 API 设计为一个组。 API 设计真的非常非常难。以及我们如何使用共享库或服务来做事。作为一个团队,我们会看到更多这样的事情,更常见的事情是,“嗯,这是我们需要的东西。我们将在内部源中启动它,我们会让一些人使用它,他们将成为我们的测试版客户。我们会在没有真正专门针对应用程序和应用程序团队的需求的情况下通知它。”
因为他们都有特定的需求。这就是“包含但可移动”部分的用武之地。我们如何在我们拥有通用解决方案并且您可以插入您的细节的情况下可扩展地构建东西?而且我们仍然——就像,这不是一个容易的问题。我们仍在解决它,我们仍在努力解决它,我们正在做得更好。
很多问题只是我们如何才能日复一日、年复一年地改进,以使其中一些事情变得更好?甚至我们的持续集成和交付管道到我们的云,所有这些都在不断变化和不断发展。我们支持多种语言;我们支持不同语言的多个版本;我们正在谈论,嘿,我们需要开始采用 Java 17。我们的库或管道还没有这样做,但我们可能应该继续这样做,因为它已经发布了 - 什么 - 快一年了?并且真正致力于分解其中一些我们为当时需要的东西而构建的东西,但现在感觉有点死板。我们如何拉出碎片?
在 log4j CVE 和对行业的广泛影响之后,组织中的一大推动力是我们需要围绕软件供应链做更彻底的工作,围绕知道我们拥有什么,确保我们进行扫描和一切.这就是管道工作的用武之地。我正在就管道问题进行咨询,并提供大量客户反馈;我们有一个团队全职工作。但是做很多这样的事情并尝试为我们需要的东西而构建,但也不要将自己与更广泛的行业隔离开来。就像,从工具的角度来看,我的噩梦是我们限制事物,我们围绕安全或政策或类似的东西做出决定,我们将自己与更广泛的 CNCF 工具生态系统隔离开来,我们不能使用其中任何一个工具。这就像,好吧,现在我们必须自己构建一些东西,或者——我们永远不会像外部社区那样做。或者我们只会有一些糟糕的流程,没有人会高兴,所以要弄清楚所有这些。
杰森:是的。你提到的关于保持速度和拥有这些标准的一件事让我想起,你知道,类似于我之前的经历,基本上,我在一个我们说我们想开放的组织-source,我们使用了开源,这基本上意味着我们分叉了一些东西,然后对它进行了我们自己的奇怪修改。这意味着,就像现在,它不是真正的开源;这就像一个奇怪的、被黑客入侵的东西,你必须不断维护并努力让它与最新的东西保持同步。听起来你在一个更好的位置,但我很好奇,在跟上最新的东西方面,你是怎么做到的,对吧?因为你提到银行,显然慢了一点,采用更成熟的软件,但是你,对,你站在最前沿,你正在努力收集你可以使用的最佳实践和新技术银行,作为一个没有使用最新、最棒的东西的人,你如何做到这一点?您如何使这些技能和知识保持最新?
Aaron:我尝试阅读,我尝试腾出时间阅读 The New Stack 之类的东西,收听有关技术的播客。这是一个非常广泛的行业。我能跟上的只有这么多。这总是可以追溯到很久以前的对话之一,在那里我会与我的老板就我去参加会议的商业主张进行对话,并解释,比如,在一个组织中获取知识的成本是多少?虽然我们可以引入顾问,或者我们可以雇用人员,例如,当您雇用新人时,他们会带来他们先前存在的经验。所以,如果有人进来并且他们知道 Hadoop,他们可以提供有关 Hadoop 解决这个问题的信息和想法吗?也许,也许不是。
如果我对 Hadoop 或 Kubernetes 一无所知,或者……比如在我的工具中使用 Tilt 或 Skaffold 之类的东西,我不想在这个项目上打赌。这是我参加会议的收获之一,现在一切都是虚拟的,我实际上需要留出更多时间来观看视频。就像,没有那个专门的一周是一个问题,我只是断开了连接,我没有处理任何事情。当你在工作时,即使 KubeCon 或 Microsoft Build,我仍然在做我的日常工作,我收到 Slack 消息,而且我不觉得我可以忽略别人。我可能应该花更多的时间,但我如何保持最新状态的一部分。
它真的做了很多阅读和研究,做这样的对话,比如,我们邀请你去哪里的 DX Buzz……我解释了那个事件——它与内部扬声器相邻——我解释说因为我有积压的视频来自我没有看的会议,如果我让其他人和我一起吃午饭来观看这些视频,我必须看视频,因为我正在主持会议来讨论它,现在我至少会看一个月。事实证明,这在组织内部传播知识、与人交谈是一件非常成功的事情。而我做的另一部分,尤其是在工具方面,我仍然在构建东西。尽管我不像以前那样编写代码,但我带来了应用程序开发人员的观点,但我不再每天都编写代码了。
我总是说这会让我很痛苦。它不是。我仍然在想它,当我开始编写代码时,我一直在寻找如何改进这个设置?我怎样才能使用这个工具?我可以试试吗?这是否更好?这对我来说更顺畅,所以我不担心这件事吗?
然后在开发人员体验小组、我们的 DevOps 团队、我们的平台团队中更广泛地传播这些信息,并与这些团队讨论他们使用的东西。就像,我们在一个小组中使用 Argo CD,我没怎么接触过,但我知道他们有很多专业知识,所以和他们谈谈。 “你怎么用这个?这对我有什么好处?我该如何进行这项工作?我也怎么用?”
Jason:我认为这太不可思议了,[笑] 正如你一直在聊天的那样,你提到银行使用或正在使用的工具和技术有很多。两者兼而有之——这很有趣,就像银行里发生了很多事情一样;你如何管理这一切?但我认为这也非常有趣,因为它表明人们对找到正确的解决方案和找到正确的工具很感兴趣,而不是真正超级强烈地与一种特定的工具或一种固定的做事方式结合,我认为这很酷。我们在这里的时间即将结束,所以我确实想问你,在我们签字之前,亚伦,你有什么想要插入的东西,有什么想要宣传的吗?
Aaron:是的,云计划正在招聘大量人员。我们所有的平台团队都有很多职位空缺。我的云采用团队可能有职位空缺。所以,如果你觉得这家银行听起来很有趣——这家银行非常稳定;这总是一件好事——但是银行……关于银行的事情,我最初加入银行时说,“哦,我会在这里两年,我会感到无聊,我会离开,”和现在已经12年了,我还在银行。因为我提到了组织的范围和规模,所以总会有一些有趣的事情发生在某个地方。
所以,如果你对云平台的东西感兴趣,我们有一个巨大的云平台。如果你在——比如,你想做机器学习,我们有一个完整的组织。毫不奇怪,我们在银行拥有大量数据,并且有一个完整的组织来处理各种不同的事情,包括机器学习、深度学习、数据分析、大数据等。就像,如果你认为这很有趣,即使你不是专门在加拿大多伦多,你也可以在组织中找到一个有趣的角色,如果这会让你变得疯狂。
杰森:太棒了。我们将发布我们提到的所有内容的链接,这是一个吨。但是去看看我们吧,gremlin.com/podcast 是你可以找到本集节目说明的地方,我们将提供所有内容的链接。亚伦,非常感谢你加入我们。很高兴有你。
亚伦:非常感谢你邀请我,杰森。我很高兴我们必须这样做。
Jason:有关上述所有信息的链接,请访问我们的网站 gremlin.com/podcast。如果您喜欢这一集,请订阅 Spotify、Apple 播客或您最喜欢的播客平台上的 Break Things on Purpose 播客。我们的主题曲名为 Komiku 的《Battle of Pogs》,可在loyaltyfreakmusic.com 上找到。
本文:https://jiagoushi.pro/podcast-break-things-purpose-developer-advocacy-a…
- 61 次浏览
【混沌工程】混沌工程原理
混沌工程是在系统上进行实验的学科,目的是建立对系统承受生产中动荡条件的能力的信心。
大规模分布式软件系统的进步正在改变软件工程的游戏规则。作为一个行业,我们迅速采用提高开发灵活性和部署速度的做法。紧随这些好处之后的一个紧迫问题是:我们对投入生产的复杂系统有多少信心?
即使分布式系统中的所有单个服务都正常运行,这些服务之间的交互也会导致不可预测的结果。不可预测的结果,加上影响生产环境的罕见但具有破坏性的现实世界事件,使这些分布式系统本质上是混乱的。
我们需要在弱点出现在系统范围的异常行为中之前识别它们。系统性弱点可能表现为: 服务不可用时不正确的回退设置;从调整不当的超时重试风暴;当下游依赖收到过多流量时中断;单点故障崩溃时的级联故障;等等。我们必须在最重要的弱点影响生产中的客户之前主动解决它们。我们需要一种方法来管理这些系统中固有的混乱,利用不断提高的灵活性和速度,并对我们的生产部署充满信心,尽管它们代表着复杂性。
一种基于经验的、基于系统的方法可以大规模解决分布式系统中的混乱问题,并建立对这些系统承受现实条件的能力的信心。我们通过在受控实验中观察分布式系统的行为来了解它。我们称之为混沌工程。
实践中的混乱
为了专门解决大规模分布式系统的不确定性,混沌工程可以被认为是促进实验以发现系统弱点。这些实验遵循四个步骤:
- 首先将“稳态”定义为系统的一些可测量的输出,表明正常行为。
- 假设这种稳定状态将在对照组和实验组中继续存在。
- 引入反映现实世界事件的变量,例如服务器崩溃、硬盘驱动器故障、网络连接中断等。
- 尝试通过寻找对照组和实验组之间的稳态差异来反驳该假设。
破坏稳定状态越难,我们对系统行为的信心就越大。如果发现了一个弱点,我们现在就有了一个改进目标,以便在该行为在整个系统中显现之前进行改进。
高级原理
以下原理描述了混沌工程的理想应用,应用于上述实验过程。遵循这些原则的程度与我们对大规模分布式系统的信心密切相关。
围绕稳态行为建立假设
关注系统的可测量输出,而不是系统的内部属性。在短时间内对该输出的测量构成了系统稳定状态的代表。整个系统的吞吐量、错误率、延迟百分位数等都可以是代表稳态行为的感兴趣的指标。通过在实验期间关注系统行为模式,Chaos 验证系统确实有效,而不是试图验证它是如何工作的。
改变现实世界的事件
混沌变量反映了现实世界的事件。通过潜在影响或估计频率对事件进行优先级排序。考虑与硬件故障(如服务器死亡)、软件故障(如格式错误的响应)以及非故障事件(如流量激增或扩展事件)相对应的事件。任何能够破坏稳态的事件都是混沌实验中的潜在变量。
在生产环境中运行实验
系统的行为因环境和流量模式而异。由于利用率的行为随时可能发生变化,因此对真实流量进行采样是可靠捕获请求路径的唯一方法。为了保证系统运行方式的真实性以及与当前部署系统的相关性,Chaos 强烈倾向于直接在生产流量上进行试验。
自动化实验以连续运行
手动运行实验是劳动密集型的,最终是不可持续的。自动化实验并连续运行它们。混沌工程将自动化构建到系统中,以驱动编排和分析。
最小化爆炸半径
在生产中进行试验有可能导致不必要的客户痛苦。虽然必须考虑一些短期的负面影响,但混沌工程师有责任和义务确保将实验的后果最小化并加以控制。
混沌工程是一种强大的实践,它已经改变了世界上一些最大规模运营中软件的设计和工程方式。在其他实践涉及速度和灵活性的地方,Chaos 专门解决了这些分布式系统中的系统性不确定性。混沌原则为大规模快速创新提供信心,并为客户提供他们应得的高质量体验。
- 130 次浏览