DevOps概览
DevOps概览 intelligentxDevOps
- 172 次浏览
【DevOps】DORA度量和SPACE度量:软件开发领导者的比较综述-BlueOptima
视频号

微信公众号

知识星球

软件开发领域引入了许多框架、方法和指标,以优化流程、确保质量并提高整体性能。其中,两组关键指标——DORA和SPACE——分别在衡量DevOps实践和团队能力的有效性方面发挥着关键作用。
DORA指标:衡量DevOps的有效性
DORA(DevOps Research and Assessment)是一个缩写词,代表四个关键指标:部署频率(DF)、变更交付周期(LT)、恢复服务时间(TRS)和变更失败率(CFR)。DORA指标被广泛用于评估DevOps和持续交付实践的性能。
- 部署频率(Deployment Frequency):此度量标准衡量团队将代码部署到生产环境的频率。频率越高,性能越好,因为这意味着团队可以更快地交付更改和功能。
- 变更交付周期(Lead Time for Changes):它表示从代码变更开始到交付到生产的时间量。更短的交付周期意味着更快的交付和对业务需求的响应。然而,更快的交付周期与更好的编码输出并不相关。
- 恢复服务的时间(Time to Restore Service):此指标是指故障或停机后恢复服务所需的时间。时间越短,表示事件响应过程越有效。
- 更改失败率(Change Failure Rate):它计算导致生产失败的部署的百分比。故障率越低,软件质量越高。
SPACE度量标准:评估团队能力
SPACE是一个新兴的框架,旨在评估软件开发团队的能力。它代表满意度与幸福感、绩效、活动、协作与沟通以及效率与流量。
- 满意度和幸福感(Satisfaction & Well-Being):考察团队的士气、幸福感和整体幸福感。内容团队通常可以提高参与度和生产力。
- 绩效(Performance):注重交付工作的质量、可靠性和有效性。高绩效与客户满意度和潜在的更多商机相关。
- 活动(Activity):监控任务参与度和完成率,以衡量工作量管理和团队效率。
- 协作与沟通(Collaboration & Communicatio):评估团队在沟通中的协同作用和有效性,这对解决问题和适应能力至关重要。
- 效率和流程(Efficiency & Flow):评估流程和资源利用的有效性,识别瓶颈并协助战略规划。
对比:DORA与SPACE
乍一看,DORA和SPACE的目标可能相似——优化软件开发团队的性能和效率。然而,仔细观察就会发现,这两个指标服务于组织发展的不同方面,并且在许多方面是互补的。
重点领域
- DORA:该框架旨在优化DevOps流程。它主要关注与代码部署、服务恢复和更改管理相关的运营效率。DORA提供了一个观察软件开发生命周期的视角,提供了可以指导技术优化的反馈。
- SPACE:与DORA不同,SPACE旨在优化团队的能力和福祉。它超越了技术流程,还包括团队士气、沟通和整体幸福感等“软”因素。SPACE本质上更以人为本,为团队如何更好地作为人类系统工作提供见解。
最终目标
- DORA:最终目标是改进技术流程,使其精简、高效和稳健。指标旨在减少瓶颈和故障,从而最大限度地提高开发管道的有效性。
- 空间:最终目标更广泛——旨在培养一个团队高效、满意、协作良好、资源高效的环境。这确保了更好的生产力、更低的人员流动率和更高的员工满意度。
测量工具
- DORA:这里的指标通常是定量的,可以通过连续集成/连续部署(CI/CD)工具、事件管理系统以及日志和监控系统自动收集。
- SPACE:指标更加多样化,包括满意度和幸福感的调查和访谈等定性数据,以及活动的任务完成率或绩效的项目交付时间表等定量数据。
谁受益?
- DORA:通常,这些指标对直接参与流程优化的技术领导者、DevOps工程师和运营经理最有用。
- SPACE:这些指标服务于更广泛的受众,包括对团队管理的硬和软方面感兴趣的人力资源专业人员、项目经理和团队领导者。
相互关联性
虽然DORA和SPACE的指标侧重于不同的方面,但它们并不相互排斥。它们可以是高度互补的。例如,一个在“效率和流量”的SPACE指标上得分很高的团队可能会发现更容易改进DORA指标,如“变更交付周期”相反,稳健的DORA指标可以创建一个团队更容易协作和沟通的环境,从而改进SPACE指标。
总之,虽然DORA的目标是开发过程的“如何”,但SPACE的重点是“谁”要使一个组织真正敏捷、有弹性和实用,请同时考虑这两个指标。
指标弱点
DORA指标缺陷:
- 鼓励速度高于质量:高度关注部署频率和变更交付周期可能会导致以牺牲彻底测试和质量为代价,优先考虑快速发布。
- 忽略更广泛的开发方面:专注于运营效率,同时可能忽略产品质量、用户满意度和开发团队的福祉。
- 激励措施不一致的风险:可以激励改善指标的行为,但不一定有助于项目和团队的整体成功或健康。
我们对超过600000名开发人员进行了一项研究,显示了依赖DORA指标时的固有缺陷。你可以在这里找到它。
SPACE框架缺陷:
- 测量的复杂性:捕捉和量化满意度和沟通等组成部分可能具有挑战性,导致实施和解释困难。
- 资源密集型:需要大量资源进行持续监控和分析,这可能会成为一些组织的障碍。
- 有限的适用性:虽然它是全面的,但在所有类型的软件开发项目或团队中可能并不同样有效,这限制了它在特定环境中的有用性。
- 320 次浏览
【DevOps】DevOps =速度+质量:如何改进DevOps中的测试,从规划到交付
成功出现在快速上市和优质产品开发的交叉点。如果您率先推出平庸的软件,您的先发优势就会受到影响。
随着DevOps的出现,您可以通过速度质量提供的创新已经从奇迹领域转变为现实的客户期望。如果加速开发没有价值,你的品牌就会受到影响。
考虑这些领域的软件测试改进,以便以DevOps的速度推动高级应用程序的部署。
如何在规划阶段改进DevOps测试
企业需要了解开发,以确保客户能够欣赏应用程序的外观。越早获得可见性,您就能越早解决对您的市场最重要的缺陷,并且您可以更快地部署竞争软件。正确的测试和开发方法可以提供透明度。
测试驱动开发(TDD)是一种标准的开发方法,它使用单元测试在开发人员进行每次更改后查找软件错误,因此他们可以快速修复错误。 TDD在应用程序编码级别拨入故障。企业需要一种方法,可以提供软件行为的透明度,并在软件质量方面大大提高用户的重要性。
行为驱动开发(BDD)是TDD的一个领域,它使用自然语言来确保业务所需的行为在软件内部发展。 BDD在业务利益相关者和开发人员之间建立共享词汇表,以便他们可以就软件变更的适当性进行沟通。使用BDD,DevOps商店可以证明他们正在灌输公司及其客户所需的功能和用户体验。
BDD支持业务在评估应用程序运行状况时的健康状况。 BDD提供业务级别的价值,确认开发正在进行中。
如何在编码阶段改进DevOps测试
企业需要缩短部署时间,同时保持软件质量。开发人员和测试人员之间的反馈循环中的任何延迟都会增加开发时间并设置质量漂移。将测试人员和开发人员聚集在一起可以加强这种循环。
在编码阶段,DevOps组织可以通过将测试人员与程序员配对来提高质量和开发。配对可确保测试人员编写的测试能够反映开发人员当时正在创建的功能。配对在软件准备就绪时通知测试人员,因此他们知道何时运行测试。
通过同步测试和开发,您可以快速提醒程序员,以便他们可以在将代码埋没到更多工作之前修复他们的代码。由此产生的反馈循环构建了动力,因此业务可以迅速启动应用程序。程序员和测试人员对彼此的工作有很多了解,并在他们一起工作时自己进行改进。这些知识使他们能够更好地利用测试和测试结果,并加快反馈循环。
如何在构建阶段改进DevOps测试
减少延迟和加速软件开发的另一个机会出现在构建阶段。在此阶段,测试透明度对于快速修复软件至关重要。
每个可以从测试结果可见性中受益的人都应该拥有它,包括负责创建,测试或修复软件的任何人。为了确保这种透明性,将测试绑定到持续集成(CI)构建过程,该过程构建更新的软件并允许您运行它以检查不完善之处。
将测试连接到CI构建过程有许多好处。当构建测试失败时,系统可以通知团队,以便他们可以快速响应。每次构建测试失败时的广泛沟通对于阻止释放向前发展至关重要,直到您修复有缺陷的功能和构建过程。
修复这些缺陷的关键部分是调整测试以适应下一个构建,以便测试剩余的缺陷。来自系统的警报可确保测试人员及时编写新测试。向开发人员和测试人员发送的系统通知可加快软件构建的通过标记,从而使业务快速进入分发阶段。
DevOps测试的一把伞
毕竟,为了提高质量,我们已经做了很多事情,不要通过有限的测试方法来冲破这个阶段。最好将一系列测试和类别混合在一起,然后充满信心地进行部署,而不是快速进行。
在测试阶段,一些DevOps组织试图通过从流程中删除测试人员并使用单元测试来更快地将版本推向生产。这种方法限制了您可以执行的测试的数量和质量。您可以尽快将软件投入生产,但可能会有更多错误。
如果您有测试人员为良好的覆盖范围定义特定的测试,您仍然可以相对快速地将软件投入生产。测试人员应在您的应用程序上编写并运行完全自动化的烟雾,功能和回归测试,以确保客户满意。
您需要进行冒烟测试以确保应用程序正确启动并访问其子系统。您需要进行功能检查以确保应用程序在各种用例中做出反应。并且您需要进行回归测试以确保之前仍然有效的功能仍然可以正常运行。
这种方法比单元测试更进一步,确定您的应用程序的适用性并确保您的客户对您的产品感到满意。
实现期望
质量和发展相互定义。没有成熟就没有发展,没有质量就没有成熟。没有增长和变化,质量就没有改善,这是随着适当的发展而来的。
由于质量和开发是以这种方式密不可分的,因此击败市场竞争的最佳方法是以DevOps的速度在整个开发生命周期中创新质量。质量可以更快地发展;发展可以达到更高。您需要同时满足或超出客户期望。
旨在帮助改变开发生命周期中剩余测试的QA平台可帮助您实现这些目标。 qTest将测试集成到敏捷和持续交付工作流程中,确保QA流程不断发展以适应新的开发计划。通过将测试集成到开发生命周期中,qTest可帮助组织以更短的周期时间发布高质量的软件。
讨论: 请加入只是星球【首席架构师圈】
- 105 次浏览
【DevOps】DevOps 工具一览
为 DevOps 生命周期的每个阶段选择工具。
DevOps 是敏捷方法的下一个演变。将开发和运营团队聚集在一起的文化转变。 DevOps 是一种涉及文化变革、新管理原则和有助于实施最佳实践的技术工具的实践。
当谈到 DevOps 工具链时,组织应该寻找能够改善协作、减少上下文切换、引入自动化以及利用可观察性和监控来更快地交付更好的软件的工具。
DevOps 工具链有两种主要方法:一体机或开放式工具链。一体式 DevOps 解决方案提供了一个通常不与其他第三方工具集成的完整解决方案。可以使用不同的工具针对团队的需求定制开放的工具链。 Atlassian 认为开放式工具链是最好的方法,因为它可以使用同类最佳的工具进行定制,以满足组织的独特需求。使用这种方法通常会提高时间效率并缩短上市时间。
阅读有关 DevOps 工具链的更多信息。
无论组织使用何种类型的 DevOps 工具链,DevOps 流程都需要使用正确的工具来解决 DevOps 生命周期的关键阶段:
- 计划
- 建造
- 持续集成和部署
- 监视器
- 操作
- 持续反馈
借助开放的 DevOps 工具链,所选工具涉及 DevOps 生命周期的多个阶段。以下部分展示了一些最流行的 DevOps 工具,但鉴于市场的性质,此列表经常更改。提供商添加了新功能,使他们能够跨越 DevOps 生命周期的更多阶段,每个季度都会宣布新的集成,在某些情况下,提供商会整合他们的产品以专注于其用户的特定问题。
计划
- Jira,
- Confluence ,
- slack
从敏捷手册中抽出一页,我们推荐允许开发和运营团队将工作分解为更小、更易于管理的块以加快部署的工具。这使您可以更快地向用户学习,并有助于根据反馈优化产品。寻找能够提供 sprint 计划、问题跟踪和允许协作的工具,例如 Jira。
另一个很好的做法是不断收集用户反馈,将其组织成可操作的输入,并为您的开发团队确定这些操作的优先级。寻找鼓励“异步头脑风暴”的工具(如果你愿意的话)。重要的是每个人都可以分享和评论任何东西:想法、策略、目标、要求、路线图和文档。
并且不要忘记集成和功能标志。无论您决定在何处确定功能或项目的范围,都应将其转换为开发积压中的用户故事。功能标志是代码库中的 if 语句,使团队能够打开和关闭功能。
有关此阶段的更多信息,请查看 Atlassian 产品经理关于待办事项梳理和优先级排序的帖子。
建造
生产相同的开发环境:
- Docker
- Kubernetes
虽然 Puppet 和 Chef 主要有利于运营,但开发人员使用 Kubernetes 和 Docker 等开源工具来配置单独的开发环境。针对虚拟的、一次性的生产副本进行编码可以帮助您完成更多工作。
当每个团队成员都在相同配置的环境中工作时,“在我的机器上工作!”不再好笑,因为它是真的(现在它只是好笑)。
基础设施即代码:
- Ansible
- Chief
- Docker
- Puppet
- Trrraform
开发人员创建模块化应用程序,因为它们更可靠和可维护。那么为什么不将这种想法扩展到 IT 基础架构呢?这可能很难应用于系统,因为它们总是在变化。所以我们通过使用代码来解决这个问题。
基础设施即代码意味着重新配置比修复更快,而且更加一致和可重复。这也意味着您可以使用与生产类似的配置轻松启动开发环境的变体。可以应用和重新应用供应代码以将服务器置于已知基线中。它可以存储在版本控制中。它可以进行测试,并入 CI(持续集成),并经过同行评审。
当机构知识被编入代码时,对运行手册和内部文档的需求就会消失。出现的是可重复的过程和可靠的系统。
源代码控制和协同编码:
- Github
- Gitlab
- Bitbucket
对代码进行源代码控制很重要。源代码控制工具有助于将代码存储在不同的链中,因此您可以通过共享这些更改来查看每个更改并更轻松地进行协作。您可以通过拉取请求完成的同行评审来提高代码质量和吞吐量,而不是在部署到生产之前等待变更批准委员会。
你问什么是拉取请求?拉取请求告诉您的团队您已推送到存储库中开发分支的更改。然后,您的团队可以审查提议的更改并讨论修改,然后再将它们集成到主代码行中。拉取请求提高了软件的质量,从而减少了错误/事件,从而降低了运营成本并加快了开发速度。
源代码控制工具应该与其他工具集成,这允许您连接代码开发和交付的不同部分。这使您可以了解该功能的代码是否在生产中运行。如果发生事件,可以检索代码以阐明事件。
持续集成和交付
持续集成:
- Jenkins
- AWS
- Bitbucket
- CircleCI
- Snyk
- Sonarsource
持续集成是每天多次将代码签入共享存储库并每次都对其进行测试的做法。这样,您可以自动及早发现问题,在最容易修复的时候修复它们,并尽早向您的用户推出新功能。
通过拉取请求进行代码审查需要分支并且风靡一时。 DevOps North Star 是一种工作流,它可以产生更少和更快的分支,并在不牺牲开发速度的情况下保持测试的严谨性。
寻找能够自动将您的测试应用到开发分支的工具,并让您选择在分支构建成功时推送到 main。除此之外,您还可以通过简单的集成从团队的实时聊天警报中获得持续的反馈。
了解 Bitbucket Pipelines 如何帮助您将代码从测试到生产自动化。
测试:
- Mabl
- Saucelabs
- XRay
- Zephyr
测试工具涵盖许多需求和功能,包括探索性测试、测试管理和编排。但是,对于 DevOps 工具链来说,自动化是必不可少的功能。从长远来看,自动化测试通过加快您的开发和测试周期而获得回报。在 DevOps 环境中,重要的另一个原因是:意识。
测试自动化可以通过尽早和经常进行来提高软件质量并降低风险。开发团队可以重复执行自动化测试,涵盖 UI 测试、安全扫描或负载测试等多个领域。它们还生成有助于识别风险区域的报告和趋势图。
风险是软件开发中的一个事实,但你无法减轻你无法预料的事情。帮您的运营团队一个忙,让他们和您一起窥探。寻找支持墙板的工具,让参与项目的每个人评论特定的构建或部署结果。工具的额外加分,使操作参与闪电式测试和探索性测试变得容易。
部署仪表板:
- Jira
发布软件最紧张的部分之一是将即将发布的版本的所有更改、测试和部署信息集中到一个地方。在发布之前,任何人最不需要的就是召开长时间的会议来报告状态。这就是发布仪表板的用武之地。
寻找具有与您的代码存储库和部署工具集成的单个仪表板的工具。在一个地方查找可以让您全面了解分支、构建、拉取请求和部署警告的内容。
自动化部署:
- Bitbucket
- Zephyr
没有适用于每个应用程序和 IT 环境的自动化部署的灵丹妙药。但是使用 Ruby 或 bash 将操作的运行手册转换为 cmd 可执行脚本是一种常见的启动方式。良好的工程实践至关重要。使用变量来分解主机名——为每个环境维护唯一的脚本或代码并不好玩(无论如何都错过了一半)。创建实用方法或脚本以避免重复代码。并同行评审您的脚本以对其进行完整性检查。
首先尝试将部署自动化到最低级别的环境,在那里您将最频繁地使用该自动化,然后将其一直复制到生产。如果不出意外,本练习会突出显示您的环境之间的差异,并生成一个用于标准化它们的任务列表。作为奖励,通过自动化标准化部署可以减少环境内部和环境之间的“服务器漂移”。
运营
应用程序和服务器性能监控:
- AppDynamics
- DataDog
- Slack
- Splunk
- New Relic
- Opsgenie
- Pingdom
- Nagios
- Dynatrace
- Hosted Graphite
- Sumo Logic
有两种类型的监控应该自动化:服务器监控和应用程序性能监控。
手动“置顶”一个盒子或测试你的 API 对抽查来说是很好的。但是要了解应用程序(和环境)的趋势和整体健康状况,您需要能够 24/7 全天候监听和记录数据的软件。持续的可观察性是成功的 DevOps 团队的关键能力。
寻找与您的群聊客户端集成的工具,以便警报直接发送到您团队的房间或专门的事件房间。
事件、变更和问题跟踪:
- Jira Service Management
- Jira Software
- Opsgenie
- Statuspage
解锁 DevOps 团队之间协作的关键是确保他们正在查看相同的工作。报告事件后会发生什么?它们是否与软件问题相关联并可追溯?进行更改时,它们是否与版本相关联?
没有什么比在不同系统中跟踪事件和软件开发项目更能阻碍 Dev 与 Ops 的合作了。寻找将事件、变更、问题和软件项目保存在一个平台上的工具,以便您可以更快地识别和修复问题。
持续反馈
- GetFeedback
- Slack
- Jira Service Management
- Pendo
客户已经在告诉您您是否构建了正确的东西——您只需要倾听。持续反馈包括定期收集反馈的文化和流程,以及从反馈中获得洞察力的工具。持续的反馈实践包括收集和审查 NPS 数据、流失调查、错误报告、支持票,甚至推文。在 DevOps 文化中,产品团队中的每个人都可以访问用户评论,因为它们有助于指导从发布计划到探索性测试会话的所有内容。
寻找将您的聊天工具与您最喜欢的调查平台集成的应用程序,以获得 NPS 风格的反馈。 Twitter 和/或 Facebook 也可以与聊天功能集成以提供实时反馈。为了更深入地了解来自社交媒体的反馈,值得投资一个可以使用历史数据提取报告的社交媒体管理平台。
分析和整合反馈在短期内可能会减慢开发速度,但从长远来看,它比发布没人想要的新功能更有效。
综上所述...
在 Atlassian,我们相信拥有与开发和运营团队喜欢使用的工具集成的 DevOps 工具链的重要性。这就是我们构建 DevOps 平台以与 171 多家领先的第三方供应商集成的原因,使您能够在所使用的工具中做出最佳决策。因为 DevOps 不应该从单一供应商那里购买,而应该构建。
原文:https://www.atlassian.com/devops/devops-tools
本文:
- 177 次浏览
【DevOps】网站可靠性工程:DevOps 2.0
在DevOps中有没有更好的时间?电视节目如“兴趣人物”和“先生机器人“正在越来越好地显示开发人员的实际工作,使用大量的工作代码。像迈克尔·曼(Michael Mann)的“黑帽”(Blackhat)这样的电影(2015)在几个场景中赢得了Google安全团队的DevOps准确性的赞誉。环顾四周,您将发现DevOps文化过滤出来的更广泛的社会元素,如各界人士讨论他们的正常运行时间或快速接近的代码锁。
另一方面,DevOps中最大的棘手也许是开发人员和运营团队通常不会很顺利。开发人员希望在非常紧张的时间表下赶上前期的一些开创性的代码,而运营团队则尽量减缓每个人的下落情况,以发现事故或恶意行为者的系统性风险。两队都希望能够获得更好的用户体验,但到达那里的时候,就会成为一种权力斗争。
将DevOps融合在一起的梦想是对于可以半开半场的人。这种分裂的愿望正是SRE(现场可靠性工程师)的重点。
定义SRE
在介绍SRE这个术语时,Google的工程副总裁Ben Treynor说:
“当您要求软件工程师设计操作功能时,会发生什么。 SRE从根本上做了一些运维团队历来做的工作,但是使用具有软件专业知识的工程师,并且就这些工程师固有地倾向于并且有能力将自动化替代为手动劳动。“
回到2010年,Facebook SRE Mark Schonbach解释了他这样做:
“我是站点可靠性工程师(SRE)的小团队的一部分,这些工作人员日夜工作,以确保您和全球其他4.0亿用户能够访问Facebook,网站加载速度快,所有功能正在... ...我们经常在飞行中擅长工具,帮助我们管理和执行复杂的维护程序,这些程序是世界上最大的,即使不是最大的memcached足迹。我们开发自动化工具来配置新服务器,重新分配现有服务器,以及检测和修复不正常行为的应用程序或服务器。
SREs来自哪里?
可靠性工程是一个从业务世界发展而来的概念,已经有100多年了。第二次世界大战后,IEEE成立了可靠性协会,与电子系统密切相关。十年来,五十九(99.999)成为应用绩效管理的黄金标准。该标准导致创建了一类操作专家,他们知道足够的代码来恢复站点,并将最后的稳定版本尽可能快地重新投入生产。
Treynor解释了在谷歌创造这个新类别的动力,他的典型的幽默幽默:“您通常在操作角色看到的与工程角色相反的一件事是,不仅在责任方面,而且背景和的词汇,最终的尊重。对我来说,这是病态。“
SREs使用哪些工具集?
对于SRE,稳定性和正常运行时间的首要任务。但是,他们应该能够承担起责任,并将自己的方式编入危险之中,而不是添加到开发团队的待办事项列表中。就Google而言,SRE通常是软件工程师,其中有一层网络培训。通常,Google软件工程师必须表现出:
Google自己的Golang和OO语言,如C ++,Python或Java
一种辅助语言,如JavaScript,CSS和HTML,PHP,Ruby,Scheme,Perl等
高级领域,如AI研究,加密,编译器,UX设计等
与其他编码人员联系
除了这些精通之外,Google的SRE必须具备网络工程,Unix系统管理员或更多通用网络/操作技能(如LDAP和DNS)的经验。
SRE的关键作用
艾默生网络能源公司(Emerson Network Power)的一份报告显示,停机时间每小时耗资约30万美元。最明显的影响是流量尖峰下降,电子商务网站在最近的AppDynamics白皮书中被覆盖。然而,Treynor还指出,标准开发商与操作系统的摩擦力如何以其他方式成本高昂。经典的冲突从功能更新发布之前的操作提供给开发人员的支持清单开始。当用户喜欢新开发的功能时,开发者赢得越早越好。同时,在正常运行时间报告中最多有9次操作时,操作胜出。所有变化带来不稳定;你如何调整自己的兴趣?
Treynor的答案是对那些与用户满意度指标有关的人的救济,但并不是那些有心脏病的人。他说,
“100%是基本上所有的错误的可靠性目标。也许起搏器是一个很好的例外!但是,一般来说,对于您可以想到的任何软件服务或系统,100%不是正确的可靠性目标,因为没有用户可以告诉100%可用的系统之间的差异,假设有99.999%的可用性。因为通常情况下,您正在运行的用户和软件服务之间存在许多其他事情,这些边际差异会丢失到其他一切可能出错的噪点上。“
这种反应将焦点从针对用户期望的准确代理的具体正常运行时间指标转移到基于市场现实的可靠性指标。 Treynor解释说,
“如果100%是系统错误的可靠性目标,那么系统的正确的可靠性目标是什么?我建议这是一个产品问题。这不是一个技术问题。考虑到他们支付多少,无论是直接还是间接,以及他们的替代方案,用户都会满意的是什么。
谁雇用SREs?
简单的答案是“每个人”,从软件/硬件巨头如苹果到金融门户如晨星到非营利机构,如劳伦斯伯克利国家实验室。伯克利是一个组织的一个很好的例子,既是能源研究的前沿,同时也保留着一些非常古老的遗留系统。确保几代技术的可靠性是一个巨大的挑战。以下是伯克利实验室负责SREs的工作:
Linux系统管理技能来监控和管理由控制室桥梁负责的系统的可靠性。
开发和维护用于支持NERSC中HPC社区的监控工具,使用C,C ++,Python,Java或Perl等编程语言。
在设计软件,工作流程和流程方面提供改进组监控能力的输入,以确保NERSC和ESnet提供的HPC服务的高可用性。
支持测试和实施新的监控工具,工作流程和新功能,为生产中的系统提供高可用性。
通过管理组件升级和更换(软件,硬盘,卡,电缆等)来协助数据集群的直接硬件支持,以确保节点有效地返回生产服务。
帮助调查和评估新技术和解决方案,推动集团的能力向前发展,超越用户需求,并说服受到激励的员工转型创新,持续改进。
与维基百科的在线公司相比,技能简介,其中SRE任务往往不那么技术性和外交性较强:
提高自动化,工具和流程以支持开发和部署
与工程团队建立深厚的合作伙伴关系,致力于改善用户体验
参加冲刺规划会议,并支持部门间协调
排除站点中断和性能问题,包括通话响应
帮助提供系统和服务,包括配置管理
支持能力规划,现场演示分析和其他分析
帮助一般操作问题,包括机票和其他正在进行的维护任务
在过去一年中,出现了更加战略性的决策层面的转变,反映了客户请求和故障转移程序日益增加的自动化。即使像IBM这样的传统公司,由于物联网议程的推进,SREs也可以使用一些最新的平台。例如,爱尔兰IBM的一个SRE开放课程需要OpenStack Heat,Urban Code Deploy,Chef,Jenkins,ELK,Splunk,Collect D和Graphite等方面的经验。
SREs如何变化
现在的网络世界和现在十年前的SRE进入现场是截然不同的。此后,移动已经重新定义了开发周期,轻松访问基于云的数据中心已将微服务引入主流IT基础架构。 Startups定期使用Rest和JSON作为移动应用程序的首选协议。根据精益创业的原则,DevOps通常是小型,更集中的团队,作为集体SRE。
您会发现开发和运营之间有更多的协作和更少的冲突,只是因为持续的交付模式将开发和运营的责任分解为一个周期。 DevOps这个术语可能会消失,因为两个不同的部门合并在新的世界中,其中UX是一切,更新可能会每周推出。无论在任何给定的SRE工作描述中有多少个9,这个职业生涯路径似乎为您提供最高的工作安全可靠性。
本文:https://jiagoushi.pro/site-reliability-engineering-devops-20
- 134 次浏览
【DevOps指标】成功的9个关键DevOps指标
视频号
微信公众号
知识星球
祝贺你已经建立了DevOps实践。现在,完成了艰苦的工作,制定了DevOps指标和DevOps KPI,您可以坐下来放松,见证您的Dev和Ops团队之间的合作,因为他们可以更快地交付质量更好的软件。
要是那样容易就好了。
为什么度量在DevOps中很重要?
当我们审视当今的应用程序、微服务和DevOps团队时,我们看到领导者的任务是使用分布在多个位置的系统中的新技术来支持复杂的分布式应用程序。正因为如此,我们衡量和理解关键服务和应用程序的方式也发生了变化。
什么是DevOps指标?
DevOps指标和DevOps KPI对于确保您的DevOps流程、管道和工具达到其预期目标至关重要。与任何IT或业务项目一样,您需要跟踪关键的关键指标。
以下是九个关键的DevOps指标和DevOps KPI,它们将帮助您实现目标。
DevOps的四个主要指标是什么?DORA的四把钥匙
让我们从谷歌DevOps研究与评估(DORA)团队建立的四个最常见的指标开始,即“四个关键”。通过六年的研究,DORA团队确定了这四个关键指标是指DevOps团队的绩效,将他们从“低”排到“精英”,精英团队达到或超过组织绩效目标的可能性是他们的两倍。让我们深入了解这些DevOps KPI如何帮助您的团队更好地执行并交付更好的代码。
1.部署频率(Deployment frequency)
部署频率衡量团队成功发布到生产环境的频率。
随着越来越多的组织采用持续集成/持续交付(CI/CD),团队可以更频繁地发布,通常每天发布多次。高部署频率有助于组织更快地提供错误修复、改进和新功能。这也意味着开发人员可以更快地收到有价值的真实世界反馈,这使他们能够优先考虑最具影响力的修复和新功能。
部署频率衡量长期和短期效率。例如,通过每天或每周测量部署频率,您可以确定团队对流程更改的响应效率。长期跟踪部署频率可以指示您的部署速度是否随着时间的推移而提高。它还可以指示需要解决的任何瓶颈或服务延迟。
2.变更的交付周期( Lead time for changes)
变更的交付周期衡量提交的代码投入生产所需的时间。
此指标对于了解团队对特定应用程序相关问题的响应速度非常重要。交付周期越短通常越好,但交付周期越长并不总是表明存在问题。这可能只是表明一个复杂的项目自然需要更多的时间。变更的交付周期有助于团队了解其流程的有效性。
为了衡量变更的交付周期,您需要捕获提交发生的时间和部署发生的时间。改进这一指标的两个重要方法是在多个开发环境中实施质量保证测试,以及自动化测试和DevOps流程。
3.变更失败率( Change failure rate)
更改失败率衡量在生产中导致需要修复或回滚错误的失败的部署的百分比。
更改失败率着眼于尝试了多少次部署,以及这些部署中有多少在发布到生产中时导致失败。该指标衡量DevOps流程的稳定性和效率。要计算更改失败率,您需要部署的总数,以及将它们链接到由bug、GitHub事件标签、问题管理系统等导致的事件报告的能力。
更改失败率超过40%可能表明测试程序较差,这意味着团队需要进行超出必要的更改,从而降低效率。
衡量变更失败率背后的目标是实现更多DevOps流程的自动化。自动化程度的提高意味着发布的软件更加一致和可靠,更有可能在生产中取得成功。
4.恢复服务的平均时间 (Mean time to restore service)
平均恢复时间(MTTR)服务衡量组织从生产故障中恢复所需的时间。
在一个以99.999%的可用性为标准的世界里,衡量MTTR是确保弹性和稳定性的关键做法。在发生计划外停机或服务降级的情况下,MTTR可帮助团队了解哪些响应过程需要改进。要测量MTTR,您需要知道事件何时发生以及何时得到有效解决。为了更清楚地了解情况,了解是什么部署解决了事件,并分析用户体验数据以了解服务是否已有效恢复也很有帮助。
对于大多数系统,最佳MTTR可能小于一小时,而其他系统的MTTR小于一天。任何超过一天的时间都可能表明警报或监控不力,并可能导致更多受影响的系统。
为了实现快速MTTR指标,以小增量部署软件以降低风险,并部署自动化监控解决方案以预防故障。
五个补充DevOps KPI
DORA的“四个关键”为提高开发实践的性能奠定了良好的基础,但它们只是一个开始。以下是另外五个DevOps KPI,可帮助您的团队实现更优化的绩效。
5.缺陷逃逸率(Defect escape rate)
缺陷逃逸速度衡量“逃逸”测试并发布到生产中的bug数量。
此指标可帮助您确定测试过程的有效性和软件的总体质量。高的缺陷逃逸率表示过程需要改进和更多的自动化,而较低的比率(优选接近零)表示功能良好的测试程序和高质量的软件。
为了获得该度量的可见性,您需要跟踪在发布的代码和软件中发现的所有缺陷。这意味着要查看开发/QA和生产中的缺陷,以便深入了解从开发和QA进入生产的任何缺陷。通常,组织应该努力在发布进入生产之前找到QA中90%的缺陷。
6.平均检测时间(Mean time to detect)
平均检测时间(MTTD)衡量事件开始到发现之间的平均时间。
在其他DevOps度量中,此度量有助于确定您的监控和检测能力在支持系统可靠性和可用性方面的有效性。衡量MTTD受其他DevOps KPI指标的影响,包括平均故障时间(MTTF)和平均恢复时间(MTTR)。要计算MTTD,请将给定团队或项目的所有事件检测时间相加,然后除以事件总数。
MTTD面临的挑战是准确了解IT事件何时开始,这需要分析和评估历史基础设施KPI数据的能力。
7.自动化测试覆盖的代码百分比(Percentage of code covered by automated tests)
自动化测试覆盖的代码百分比衡量接受自动化测试的代码的比例。
自动化测试通常表明代码更稳定,尽管手动测试仍然可以在软件开发中发挥作用。自动化测试覆盖更高比例的代码是我们的目标,尽管总是有一些失败的测试是健康的——重要的是团队编写代码以按预期工作,而不仅仅是通过测试。
8.应用程序可用性(App availability)
应用程序可用性衡量应用程序完全运行和可访问以满足最终用户需求的时间比例。
高可用性系统旨在满足“五个9”(99.999%)这一黄金标准KPI。要准确衡量应用程序可用性,首先要确保您能够准确衡量真正的最终用户体验,而不仅仅是网络统计数据。虽然团队并不总是期望停机,但他们通常会因为维护而计划停机。计划内停机使DevOps和SRE团队成员之间的沟通对于解决不可预见的故障和确保前端和后端无缝运行至关重要。
9.应用程序使用和流量(Application usage and traffic)
应用程序使用情况和流量监控访问系统的用户数量,并通知许多其他指标,包括系统正常运行时间。
一旦您部署了软件,您就会想知道有多少用户正在访问您的系统,以及发生的事务数量,以确保一切正常运行。
例如,如果应用程序的流量和使用量过多,它可能会在压力下失败。同样,这些指标对于新部署和现有部署的间接反馈也很有用。如果使用量和/或流量下降,这可能是反馈,表明您所做的更改没有得到最终用户的好评。
拥有DevOps KPI(如这些应用程序使用情况和流量指标)可以让您查看是否有问题,以及何时出现流量异常峰值或其他异常使用或流量指标。同样,您可以针对专门支持关键应用程序的微服务来监控使用情况和流量。因此,您的DevOps团队可以使用这些指标来确保系统正常运行,并采取适当的行动,例如,恢复到以前的版本以使最终用户满意。
如何监控云资源和分布式系统的DevOps指标和KPI
一个成功的DevOps实践需要团队监控一组一致且有意义的DevOpsKPI,以确保流程、管道和工具满足更快交付更好软件的预期目标。
为了帮助团队了解DevOps工具和流程,Dynatrace为多云环境提供了自动的全栈可观察性。Dynatrace DevOps解决方案以人工智能为核心,从开发到生产,自动理解整个DevOps生命周期的数据。这种提供精确答案并与500多种技术集成的能力使团队能够定制和微调DevOps指标,自动化更多DevOps流程,并提高效率以获得卓越的用户体验。
- 171 次浏览
【DevOps指标】衡量成功的17个DevOps指标
视频号
微信公众号
知识星球
软件开发中的生产力一直很难衡量。与其他行业不同,编程行为并不容易并行化。开发过程的独特之处在于,它需要技术和沟通技能的多样化组合,这需要一套专门的DevOps指标来跟踪团队的生命体征。
软件开发的脉搏
并非所有指标都是平等的。根据上下文的不同,有些比其他更有用。我们选择衡量的东西可以帮助我们发现问题,或者在无关数据和非生产性目标背后掩盖问题。
在决定跟踪哪些DevOps指标时,我们应该考虑以下几点:
- 当人们感到被观察时,他们的行为就不一样了。这被称为霍桑效应,它会产生过度的压力。最好尽可能保持指标的非个人性和匿名性。
- 第一点还意味着,指标只能用于跟踪团队随时间的进展,而不能用于比较团队或个人。
- 过多地强调达到任意数字会产生与系统博弈的动机。Dave Farley和Jez Humble在这个问题上有这样的看法:
“测量代码行,开发人员将编写许多短代码行。测量修复的缺陷数量,测试人员将记录可以通过与开发人员快速讨论修复的错误。”
--持续交付:通过构建、测试和部署自动化实现可靠的软件发布
因此,在选择要用于跟踪团队进度的指标之前,每个人都应该知道,他们的唯一目的是跟踪进度并识别问题。它们不是为了表扬或惩罚个人。
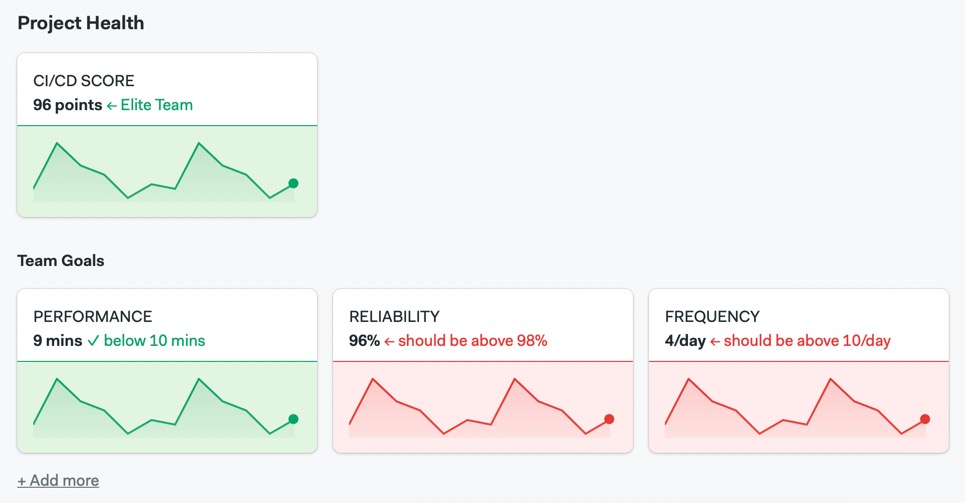
A dashboard with all the chosen DevOps metrics should be created, and it should be visible to everyone on the team.
四个DORA指标
DORA度量是我们衡量软件开发的主要工具。它们包括四个基准:
- 部署频率(DF):组织向用户成功发布产品或将其部署到生产中的频率。
- 变更交付周期(LT):承诺达到生产或发布所需的时间。
- 平均恢复服务时间(MTTR):组织从生产故障中恢复所需的时间。
- 变更失败率(CFR):导致生产失败的发布或部署的百分比。
开发团队可以分为四个级别之一:低、中、高和精英。
| Metric | Low | Medium | High | Elite |
|---|---|---|---|---|
| DF | fewer than 1 per 6 months | 1 per month to 1 per 6 months | 1 per week to 1 per month | On demand (multiple deploys per day) |
| LT | more than 6 months | 1 month to 6 months | 1 day to 1 week | Less than 1 hour |
| MTTR | more than 6 months | 1 day to 1 week | Less than a day | Less than 1 hour |
| CFR | 16 to 30% | 16 to 30% | 16 to 30% | 0 to 15% |
年复一年,DORA研究团队已经证明,高DORA分数是高绩效的可预测指标。因此,它们应该包含在任何涉及软件开发的度量策略中。
循环时间(Cycle time)
与DORA一样,循环时间也是生产力的另一个主要指标。它被定义为从我们决定添加功能到将其部署或发布给公众或客户之间的平均时间。
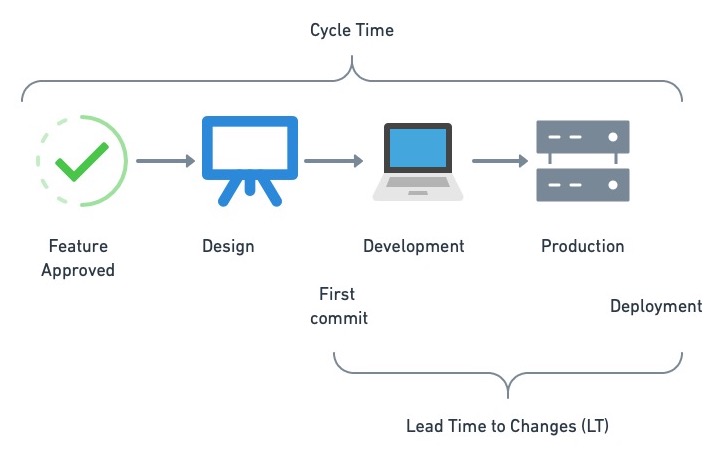
Cycle time spans the entirety of feature development; from inception to reality. Lead time to changes begins ticking when the first line of code for a feature is committed.
快速的周期时间意味着团队能够以持续的速度始终如一地提供功能。
质量(Quality)
质量对不同的人意味着不同的东西。虽然一些团队强调遵守风格规则,但其他团队可能更关心安全风险或保持愉快的用户体验。重要的是,团队就他们的素质达成了一致。
我们可以使用混合参数来估计代码的质量。不满足预定质量条的情况应该导致CI管道失败。一些有价值的指标包括:
- 漏洞数量。
- 违反风格准则。
- 代码覆盖范围。
- 陈旧分支的数量。
- 循环复杂性。
- 破坏的架构约束。例如,确保一个模块中的代码不引用另一个模块的类。
客户反馈
客户的反馈可以有多种形式,例如打开的门票、使用模式、社交媒体上的提及,以及从净促销分数(NPS)调查中收集的信息。具体情况因业务和产品而异,但我们必须以某种具体形式代表客户的声音,因为归根结底,他们会买单。
员工满意度
我们必须关注的不仅仅是我们的用户和客户。开发人员、测试人员、质量和业务分析师、产品经理和经理也至关重要,因为我们需要他们来制造一个伟大的产品。最好的想法来自乐观、自信和休息良好的头脑。
员工满意度受到多种因素的影响,我们应该以某种方式衡量这些因素:
- 文件的全面性和更新程度如何?
- 加入一个新的开发人员有多容易?
- 员工是否觉得自己的声音被听到了?
- 工作/生活的平衡如何?有人精疲力竭吗?
- 工作场所是一个安全的环境,可以冒险和试验吗?
- 员工是否有正确的工具来完成他们的工作?
- 他们觉得自己可以安全地提出建设性的批评吗?
平均CI持续时间
软件开发是一种实验性的练习——我们做一些小的改变,看看它们是如何运作的。来自CI流水线的反馈最终确定了改变是否停留在代码库中。
当CI/CD过程缓慢时,以小增量工作会变得痛苦,因为开发人员要么等待看到结果,要么继续前进,并试图记住在结果出来时返回管道。无论哪种情况,都很难保持创意流。

CI管道的平均持续时间应以分钟为单位。我们的目标应该是不到10分钟,以保持开发人员的参与和代码的流动。如果你的管道太长,请查看Semaphore的测试优化指南。
CI每天运行次数
这是每天执行CI管道的次数。我们希望将这个数字保持在较高水平——每个活跃的开发人员至少运行4或5次——因为这意味着开发人员信任并依赖CI/CD过程。
当每天运行的CI减少时,可能是由于CI/CD系统使用缓慢或不方便造成的。
CI平均恢复时间(MTTR)
当构建不起作用时,我们无法进行测试、发布或部署。在这种情况下,每个人都应该停止他们正在做的事情,专注于恢复构建。平均恢复时间衡量一个团队修复损坏的CI构建平均需要多长时间。在衡量这个指标时,我们通常只关注主分支。
较长的恢复时间表明,我们需要努力使CI/CD过程更加稳健。我们还必须确保优先修复CI构建的习惯在团队文化中根深蒂固。
CI测试失败率
衡量CI管道因测试失败而失败的频率。测试是一个安全网,所以失败没有错。尽管如此,开发人员在提交代码之前应该在他们的机器上运行测试。如果失败率太高,这可能表明开发人员发现很难在本地运行测试。

CI test failure rate formula
CI成功率
CI成功率是成功的CI运行次数除以总运行次数。成功率低表明CI/CD过程很脆弱,需要更多的维护,或者开发人员过于频繁地合并未经测试的代码。

CI success rate
片状(Flakiness)
片状表示CI管道有多脆弱。片状构建在没有明显原因的情况下随机失败或成功。片状是由片状测试或不可靠的CI/CD平台引起的。缺陷测试会对CI运行时间、成功率和恢复时间产生负面影响。
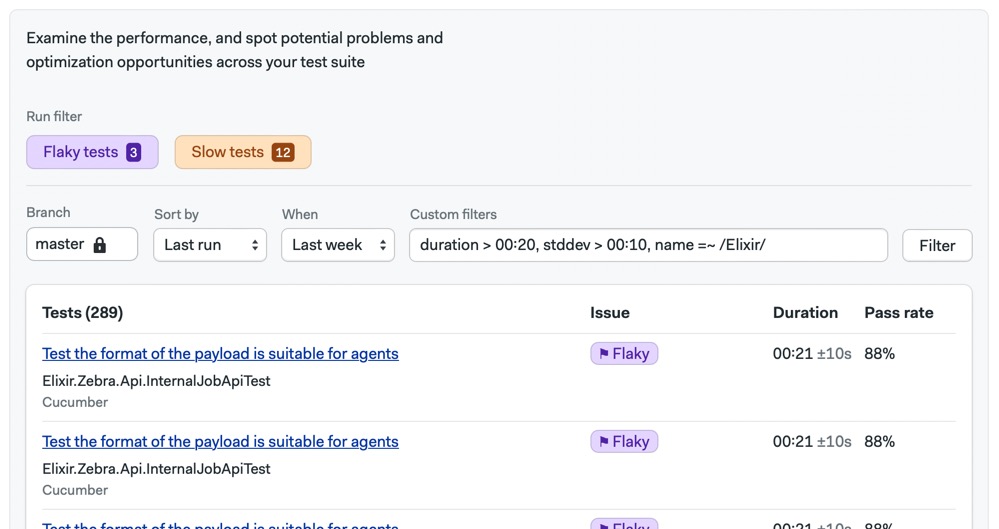
The Test Summary tab shows flaky and slow tests.
覆盖范围
代码覆盖率是测试套件覆盖的代码的百分比。这有点争议,因为众所周知,这是一个经常被滥用的指标。例如,要求100%的覆盖率并不能提高质量,相反,它会导致对琐碎代码进行不必要的测试。
和其他任何东西一样,适度使用覆盖率是有用的。例如,一个覆盖率为5%的项目无疑是测试不足,以至于测试结果没有向我们展示太多。
缺陷逃逸率
测量CI/CD进程未检测到的错误数。高值意味着测试不充分。在这种情况下,我们应该检查覆盖率值,然后重新评估测试套件的结构。我们的测试套件中可能需要更多类型的测试。

Defect Escape Ratio
正常运行时间
Uptime是应用程序可用时间的百分比。它越高,特定时期内的停机次数就越少。例如,99.9%的正常运行时间相当于每年8小时45分钟的停机时间。这个运营DevOps指标应该始终是我们衡量标准的一部分,因为每次站点或应用程序停机时,我们都有失去客户的风险。
正常运行时间值低表明基础结构、代码和/或部署过程中存在问题。
| Uptime | Total Yearly Downtime |
|---|---|
| 99.9 % | 8h 45m 56s |
| 99.99 % | 52m 35s |
| 99.999 % | 5m 15s |
| 99.9999 % | 31s |
服务水平指示器
签署服务级别协议(SLA)的企业必须注意正常运行时间,以避免罚款或其他处罚。服务级别指示器(SLI)将实际应用程序性能或正常运行时间与预定标准进行对比。
即使SLA没有生效,公司也可以建立内部服务水平目标(SLO),以实现相同的功能。
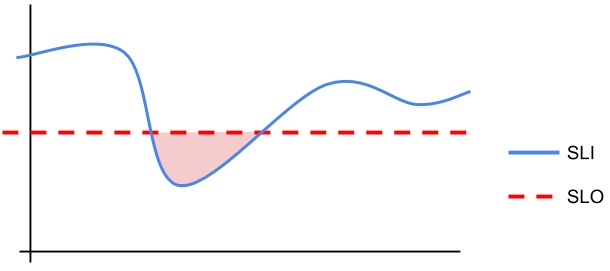
SLI shows reality versus SLA or SLO.
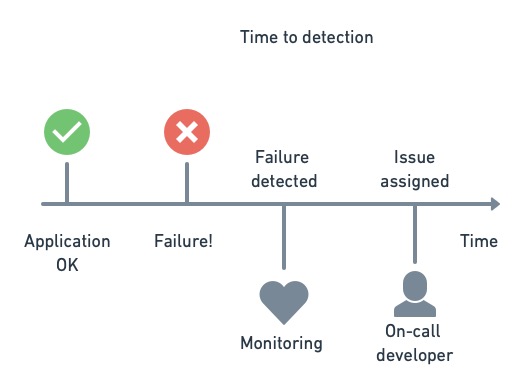
平均检测时间(Mean time to detection)
这是在发现问题并将其分配给相应团队之前,问题在生产中持续存在的平均时间。我们可以将其衡量为从问题开始到提出问题或罚单的时间。平均检测时间与监控的全面程度和通知的有效性直接相关。
平均无故障时间(Mean time between failures)
衡量系统或子系统的平均故障频率。这是一个适用于衡量应用程序子组件稳定性的指标。它可以帮助我们确定哪些部分需要重构。
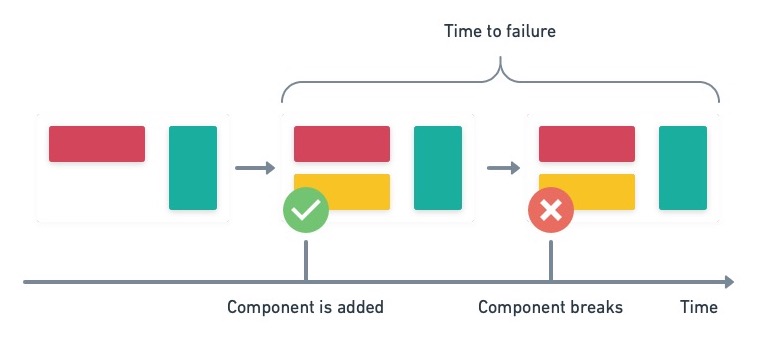
Time between failures.
Devops指标只是衡量症状
指标是项目的重要标志。一个糟糕的指标是一种症状,而不是疾病。他们指出了问题的存在,但没有明确说明根本原因。虽然通过“管理”指标下的变量来解决问题可能很诱人,但这样做类似于自我治疗——它只会成功地隐藏症状。像任何一位好医生一样,一位好的工程师会进行调查,提出解决方案,并通过检查指标是否有所改进来确认其有效性。
- 225 次浏览
【DevOps效能】使用DORA指标成为精英团队
视频号
微信公众号
知识星球
几十年来,各组织一直在尝试衡量软件开发生产力。注意力往往集中在易于量化的指标上,如工时、提交的代码行、功能点或每次冲刺添加的功能。遗憾的是,这些都不足以预测团队生产力。这是一个如此复杂的问题,以至于有些人宣称它不可能解决。
尽管这些尝试都失败了,DORA还是着手制定发展生产力的衡量标准。
什么是DORA?
DORA(DevOps研究与评估)是一个由Nicole Forsgren、Jez Humble和Gene Kim于2015年成立的研究团队。该小组的目标是找到改进软件开发的方法。在七年的时间里,他们调查了数百个不同行业组织的数千名软件专业人员。
该团队的发现首次发表在《加速:精益软件和DevOps的科学》(2018)上。该书介绍了与高绩效组织相关的四个基准:DORA指标。
在上述书籍出版的同一年,谷歌收购了该集团,并成立了DORA研究项目,负责发布年度DevOps状态报告。
DORA指标是什么?
DORA的研究获得了突破性的见解,即在足够长的时间内,速度和质量之间没有权衡。换句话说,从长远来看,降低质量并不能带来更快的开发周期。
速度和稳定性都至关重要。以牺牲质量为代价来增加功能会导致不合格的代码、不稳定的发布和技术债务,最终扼杀进展。
DORA确定了软件开发的两个关键方面:
- 吞吐量:衡量新代码达到生产所需的时间。
- 稳定性:衡量部署失败的频率和修复的平均时间。
DORA用两个指标衡量稳定性:
- 恢复服务的时间(MTTR):组织(平均)从生产故障中恢复所需的时间。
- 变更失败率(CFR):导致生产失败的发布或部署的百分比。
在吞吐量方面,DORA又增加了两个指标:
- 部署频率(DF):组织向用户成功发布产品或将其部署到生产中的频率。
- 变更交付周期(LT):承诺达到生产或发布所需的时间。
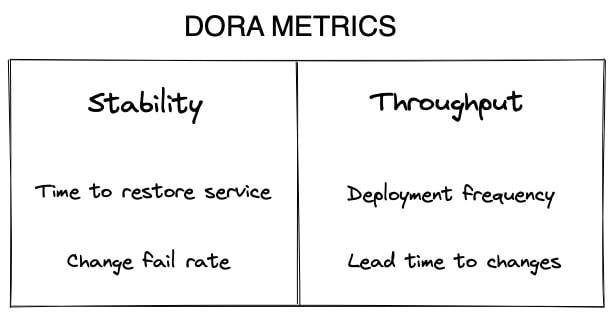
DORA衡量软件开发的两个方面:稳定性和吞吐量。
DORA指标采用以下4个级别进行测量:精英、高级、中级和低级。
| Metric | Low | Medium | High | Elite |
|---|---|---|---|---|
| 部署频率 | fewer than 1 per 6 months | 1 per month to 1 per 6 months | 1 per week to 1 per month | On demand (multiple deploys per day) |
| 变更的交付周期 | more than 6 months | 1 month to 6 months | 1 day to 1 week | Less than 1 hour |
| 恢复服务的时间 | more than 6 months | 1 day to 1 week | Less than a day | Less than 1 hour |
| 更改失败率 | 16 to 30% | 16 to 30% | 16 to 30% | 0 to 15% |
DORA水平
⚠️ 在《2022年DevOps状态报告》中,精英和高级被合并为一个层次。
根据《2021年DevOps状况报告》(PDF),不同级别的表现是惊人的。

💡 2021年,DORA团队引入了第五个指标:可靠性,通过评级组织如何达到或超过其可靠性目标来衡量运营绩效。
通过DORA指标达到精英水平
让我在本节的开头提出一些警告:
- DORA指标仅在跟踪团队在DevOps旅程中的进展时有效。它们不能用于比较团队或个人。
- 不应混淆目标和指标。由于所有指标都可以博弈,将指标等同于目标会导致不正当的激励。例如,如果管理层决定无论成本如何都要优化部署频率,那么部署他们能想到的任何微小更改都将符合团队的最大利益,无论它是否会为用户增加价值。
- 组织文化对团队绩效有着巨大的影响。我们稍后会在帖子中再次讨论这个问题。
好了,既然已经解决了,让我们继续吧。
在过去的几年里,精英球队的数量一直在增长。2018年,只有7%的团队或组织被视为精英。2021年,这一数字增长到26%。所以我们知道增长是可以实现的。
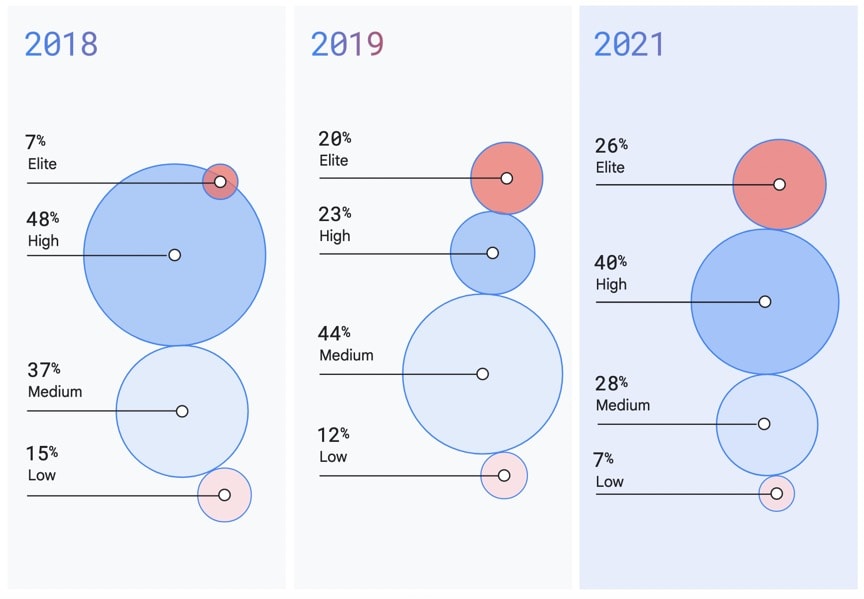
DevOps maturation of the software industry measured in DORA metrics. Source: State of DevOps Report 2021.
问题是如何使用DORA指标来提升团队或组织的比赛水平。度量中的错误值是一种症状。它表明存在组织、文化或技能问题需要解决。一旦对这些进行了管理,基本指标自然会得到改进。
提高吞吐量
生产周期较慢的组织部署频率较低,更改的交付周期较长。通常,我们可以通过优化连续集成和连续交付(CI/CD)、识别组织问题、加快测试套件以及减少部署摩擦来提高吞吐量。
问问自己,“是什么阻止我现在发布?”答案将揭示组织中的瓶颈。例如,您可能在代码评审上浪费了太多时间,等待QA批准更改,或者在其他团队完成其功能之前等待发布。
您可以通过多种方式提高吞吐量:
- 减小发布的大小。经常进行小型、安全的更换。如果某个功能还没有准备好进入黄金时段,请将其隐藏在功能标志后面或通过暗启动进行发布。
- 确保整个部署过程是自动化的,只需按下一个按钮即可完成。这意味着在部署过程中没有检查表,也没有人工干预。
- 采用基于主干的开发。它将减少合并冲突的机会,并鼓励合作。
- 通过管理缓慢的测试和删除零散的测试来优化持续集成的速度。
- 跟踪您在软件交付过程中的每个步骤上花费的时间。检查循环时间,找出可以节省时间的地方。
提高项目的稳定性
没有稳定性的速度最终会导致累积的技术债务,并花费更多的时间来修复错误,而不是发布功能。当稳定性指标看起来不好时,用户会有糟糕的体验,开发人员会把大部分时间花在灭火上,而不是编码上。
以下是一些可以用来提高稳定性的想法:
- 在CI管道中执行代码质量检查。拒绝发送不符合标准的代码。
- 加强代码同行评审过程,或尝试配对编程。
- 当灾难发生时,把重点放在恢复上,而不是所有其他任务上。
- 确保您的系统中有足够的监控和可观察性,以快速确定故障的原因。
- 每次发生严重停机时,都要召开“经验教训”会议。
- 在部署管道中使用烟雾测试,以避免在故障环境中部署。
- 实现部署的自动回滚。尝试金丝雀或蓝绿色部署。
生成性文化
也许不足为奇的是,《2021年DevOps现状》报告发现,精英团队与组织内的生成文化之间存在高度相关性。“生成文化”一词是由Ron Westrum创造的,用来描述一种包容、高度合作的文化,它提供了在不担心后果的情况下冒险所需的心理安全。
组织的文化超越了一个团队。它必须得到管理层的支持,由工程团队共享,并在整个公司进行维护。一种生成性的文化可以减少孤立,鼓励工程团队以外的合作。
|
不理智的 (以动力为导向) |
官僚的 (以规则为导向) |
生成 (以效能为导向) |
|---|---|---|
| Low cooperation | Modest cooperation | High cooperation |
| Messengers “shot” | Messengers neglected | Messengers trained |
| Responsibilities shirked | Narrow responsibilities | Risks are shared |
| Bridging discouraged | Bridging tolerated | Bridging encouraged |
| Failure leads to scapegoating | Failure leads to justice | Failure leads to inquiry |
| Novelty crushed | Novelty leads to problems | Novelty implemented |
资料来源:组织文化类型学,Ron Westrum博士,2004年。
结论
认为改进DORA指标会自动产生更好的团队是错误的。恰恰相反:一种包容、生成的文化自然会产生更高的基准。换言之,在低合作、规避风险的环境中,没有机会维持一支精英团队。将指标设定为目标不仅目光短浅,而且往往是一个组织误入病态或官僚文化的指标。
你想知道你的DORA分数是多少吗?进行DevOps快速检查并找出答案!
- 307 次浏览
【SRE】什么是站点可靠性工程?
工程领导者的入门读物
站点可靠性工程 (SRE) 是将 IT 运营职责与软件开发相结合的结果。对于 SRE,有责任满足为他们管理的服务设定的服务水平目标 (SLO) 和我们在合同中承诺的服务水平协议 (SLA)。
SLO 设定了可靠性目标,通常称为错误预算。在系统运行时收集数据,并将其编译为服务级别指标 (SLI),以帮助指导 SRE 做出关于系统哪些部分需要优先增强的决策。为了帮助解决这个问题,工程师可以自动化任何事情,而不是重复任务。这种自动化通过消除工作来创造更多的工程师时间,这些时间可以花在使站点越来越可靠上。
对可靠性的关注是区分 DevOps 和站点可靠性工程的主要因素,而不是自动化。
对可靠性的关注是区分 DevOps 和站点可靠性工程的主要因素,而不是自动化。在 SRE 团队中,工程师承担责任,即构建软件的人也将其交付并在生产中拥有它。从这个意义上说,SRE 有时被称为 DevOps 的下一阶段。
将这种自动化期望应用到操作任务中,使成为站点可靠性工程师的软件开发人员和系统管理员的任务是学习如何处理可能超出他们以前经验的复杂问题。现在,人们期望他们处理延迟、性能、高可用性 (HA)、复杂的分布式生产系统、系统监控、应急响应和灾难恢复等问题,甚至只需要绝对必要的人工交互即可进行变更管理。这导致越来越高的效率。
SRE 团队是软件开发、系统管理和 IT 运营全部合并在一起的。作为系统管理员、开发人员或 dba,任何给定成员都可能是最强的,但没有成员只做一件事。他们都朝着一个共同的目标共同努力,没有传统的墙壁阻碍沟通和节奏。
本文:
现场可靠性工程的基础和好处是什么?
站点可靠性工程的基本原理很容易解释,但需要一些工作才能应用。我们从基本理解开始,即当今的计算机系统和平台具有前所未有的固有复杂性。
我们的系统很复杂
我们架构中的移动部件和离散的功能单元的数量是巨大的,任何一个人都不可能在任何特定时刻完全理解。此外,我们的系统在不断变化。正在增加新的容量。故障转移系统。负载均衡。金丝雀部署。不再需要的旧容器不断被移除。
过去我们在纸上设计系统,绘制系统图和系统架构,而今天我们的系统在墨迹未干之前就已经发生了变化,任何尝试都这样做了。它们充其量只能被认为是近似值。
自动化帮助我们管理复杂性
如今,大型系统的大部分管理都涉及平凡的重复性任务。由于营销部门发送了一封特殊的机会销售电子邮件后,大量在线购物者涌入我们的网站,我们的负载增加了?提升容量?因为报税季结束了,每个按时报税的人都已经完成并且已经收到了他们的结果,所以负担已经减轻了?删除不需要的冗余应用程序服务器。
没有工程师愿意一遍又一遍地做同样的事情。重复很快就会变得乏味,并导致寻找新的有趣挑战的工作。我们喜欢解决问题并提出有用的解决方案。我们更喜欢它,因为它可以让我们摆脱不喜欢的任务,让我们有更多的时间去做有趣和有益的工作。
当自动化可靠并且使我们的系统对高影响事件更具弹性时,我们更喜欢自动化。当我们不必扑灭由比典型数量更多的并发用户引起的隐喻火灾时,我们都非常感激。当我们的系统在这成为问题之前进行监控、警报甚至做出反应时,每个人都会受益。
谁从现场可靠性工程师那里受益?
任何大到需要超过少数人来管理其系统的公司都将从站点可靠性工程中受益。任何拥有足够大或足够重要以要求 99% 或更高可用性的系统的人都会受益。如果正常运行时间很重要,那么实施良好的 SRE 将帮助您改进它。
最大的好处来自拥有大量用户的公司,无论是公司内部还是外部客户。此外,处理大量数据或工作负载从资源繁重到轻量化的公司。
在这些情况下,许多公司正在将其大部分处理和计算能力转移到基于云的服务上。有些人已将所有内容都移至云端,而另一些人则有理由使用混合架构,将个人身份信息 (PII) 或公司财务等敏感数据保留在内部,同时将其他处理移至云端。还有一些人拥有使用虚拟化或内部云的内部拥有的数据中心。
站点可靠性工程师每天都做什么?
站点可靠性工程师首先查看系统,然后执行最简单和最平凡的任务并将它们自动化。这可以腾出更多时间来编写新功能并为潜在问题做准备。
站点可靠性工程师往往来自软件开发背景或系统或运营背景。我们所有人都花时间完成这些任务:编写代码和管理系统。这就是为什么我们既适合知道什么对自动化有用,也适合编写执行自动化的代码。
减灾
在处理最简单的容易实现的任务的同时,我们还研究了减灾和准备计划,并编写了运行手册,计划在坏事发生时如何处理坏事。
高级和初级 SRE 都值得一起尝试尽可能多地自动化已发现的缓解任务:当响应时间很慢时启动额外的数据库服务器,当 CPU 使用率或网络容量变得有点过时时重新路由过载的应用程序服务器周围的流量接近容量,等等。
配置和使用可观察性监控
所有这些都需要良好的监控,以实现对系统的可观察性以及组件是否按预期运行。猜猜谁负责这件事?是的,SRE。监控需要了解系统以及哪些数据是有意义和有用的。它还需要良好的工具并花时间学习如何很好地使用它。
我们可以监控“一切”,但这样做的结果是大量信息,这些信息势不可挡,很快就会被忽视。相反,我们会花时间深思熟虑地考虑哪些指标告诉我们我们需要了解系统的哪些信息,最好在影响用户的问题发生之前以及在停机时间发生之前很久。
我们无法捕捉到所有东西,但科学地这样做可以帮助我们捕捉到我们知道需要捕捉的尽可能多的东西,同时防止我们因过多的噪音和分心而受到干扰。
网站和软件维护
为了安全和最新,必须维护一个系统。当您以质量、稳定性和安全性为目标时,不能接受过时的软件版本或旧配置。
SRE 会花费一些时间来确保及时正确更新软件。他们可能会自动执行诸如版本检查、安全证书等到期日期和依赖需求之类的事情。
事故管理和事故修复
它就在名称中,“站点可靠性”。 SRE 的主要任务之一是保持站点正常运行,当站点因出现故障而停止运行时,尽快使其恢复正常运行。
发生了一个事件。发出警报。寻呼机职责。随叫随到的 SRE 停止了她正在做的任何事情,并开始努力找出问题所在。待命团队中的每个人都聚集在一起,可能是亲自聚会,也可能是通过视频或音频电话会议。信息被收集和共享。事件手册和运行手册被提取出来,用于确定要查看的内容的优先级,并尝试让事情再次正常运行。如果他们无法提供帮助(有时会发生这种情况),则会讨论想法和潜在的修复方法。职责分散在团队成员之间。每个人都齐心协力进行任何研究和任务,以使系统备份、运行和可用。
有几个指标可用于衡量事件响应的速度和效率,例如:
- 平均检测时间 (MTTD),测量发现问题所需的平均时间
- 平均解决时间 (MTTR),衡量修复故障系统所需的时间
- 平均无故障时间 (MTTF),即有缺陷的系统在出现故障之前可以继续运行的平均时间;这类似于正常运行时间,可帮助团队在系统组件停止工作之前计划未来更换系统组件
- 平均故障间隔时间 (MTBF),用于衡量系统或组件正常工作的平均时间
防止数据丢失
SRE 最著名且看似显而易见的工作是维护系统可用性。也许不那么明显,但更重要的是保持我们数据的完整性。耐用性。防止数据丢失。
数据是我们系统中最重要的东西。每个组件的存在都是为了处理数据或为数据做某事。输入(接收)数据、存储数据、处理数据、转换数据、使用数据、输出数据,不胜枚举。
有些数据是专有的。有些是敏感的。许多类型的数据只能根据严格的监管标准进行处理。
没有好的数据,我们的系统就没有价值。如果我们的数据没有得到适当的保护而被盗,我们可能会被罚款、被起诉,甚至破产,而委托我们的客户会以我们必须努力防止的方式变得脆弱。
如果我们的数据存储损坏或数据库崩溃,我们最好希望我们有良好的备份系统和内置冗余。SRE 也对此负责,这是另一个需要好的工具和知道如何使用它的地方。
防止过去的问题再次发生
SRE 会查看过去的问题事件并尝试防止它们再次发生。这就是诸如无责回顾之类的活动非常有价值的地方。逐个问题地讨论一个问题,注意发生了什么以及如何发生的,而不让任何人成为替罪羊,这将引发有用的想法和参与,以防止问题再次发生。
有趣的部分是当我们开始自动化缓解并使用一点混沌工程对其进行测试以向自己证明我们实际上已经预防了未来的灾难。
事件分析
这些术语可以以两种方式使用。我们可以分析正在进行的事件,寻找如何修复和恢复。这包含在事故维修中。在这里,我们正在考虑另一种分析,即在解决问题并且一切恢复正常之后发生的分析。
有些地方将信息收集和呈现过程称为事后分析。我们更愿意称其为回顾展。无论名称如何,SRE 文化都坚持以无可指责的方式完成。我们不是在寻找替罪羊,而是在学习。这不是关于谁犯了错误(即使事件是由人为错误引起的),因为人为错误通常是因为有人做了他们不应该被工具或软件允许做的事情。
有关事件的每个可用细节都收集在一起,按逻辑(通常是时间顺序)顺序组装,并由团队呈现。我们分享是为了学习。
有时,回顾会在整个公司或至少在受影响的业务部门之间共享。有时,它甚至被公开分享。在这些情况下,还包括有关如何解决问题以及如何减轻或防止再次发生问题的信息。
学习和分享技能
站点可靠性工程的很大一部分是透视。 SRE 团队致力于互惠互利;以让尽可能多的人受益的方式共享信息。得到这份工作并不是学习的结束。作为成熟和成功的 SRE 团队的一部分,了解系统并对其进行良好管理并不是最后阶段。这种相互尊重、分享、团队合作以及专注于共同构建更美好的未来系统而不是担心上次“谁打破它”的理念是关键。
高级 SRE 会花时间使用专门编写的入职手册来教授初级 SRE,这些手册通过指导和积极交流最佳实践和机构知识来编写他们需要学习的主要任务。做好站点可靠性工程绝对需要在每个团队内部和跨团队发展一个社区。这里的失败最终将导致实践的失败。
具有演讲天赋的工程师通常会在会议和其他活动中找到分享他们知识的机会,通常由其他 SRE 和 DevOps 从业者以及想要了解更多实践的人参加。这为学习新技能、了解新技术以及交叉授粉和混合跨公司工作的实践提供了绝佳机会。最喜欢分享的一件事是停电故事。 SRE 有一种讲故事的能力,可以以一种引人入胜的方式传达有意义的信息。
此外,还有很多机会可以在网上找到其他从业者。许多人为公司或在他们的个人网站上写博客文章来分享他们正在学习的东西。我们在 Twitter、Meetup 组、Reddit、一些 LinkedIn 社区组和专门的 Slack 主题频道(透明时刻……最后一个链接指向 Gremlin 赞助的 Chaos Engineering Slack,它有来自整个行业的参与者很好)超越格雷姆林)。
站点可靠性工程是如何开始的?
历史可以追溯到 2000 年代初,早于市场较好的术语 DevOps。 “站点可靠性工程师”这个头衔是由 Google 的工程副总裁 Ben Treynor 发明的,他最终负责成千上万的软件工程师。他的LinkedIn个人资料说,
如果 Google 停止工作,那是我的错。
亚马逊和 Netflix 等其他公司也在类似的时间开始了类似的活动。他们所有人都在寻找方法,使他们已经大规模的部署更加可靠、高效和可扩展。然而,是谷歌的一个团队根据公司的实践写了一本关于 SRE 的书。
除了将软件工程和运营角色结合起来之外,最大的变化是视角的转变。从出现问题时的被动灭火转变为主动强化基础设施是一件大事。它需要预先更加集中注意力,但最终可以通过防止潜在的失败来节省 SRE 员工的时间和公司的资金。
正是这种观点转变导致了混沌工程的创建,作为 SRE 和 DevOps 从业者所接受的一种实践。任何想要证明实施的缓解方案和预防措施确实有效的人突然手头有工具可以做到这一点。
站点可靠性工程师的报酬是多少?
我们在 SRE 与 DevOps 中更深入地讨论了这个问题——它们能共存还是竞争?简短的回答是,薪水很大程度上取决于地点、工程师经验和公司等因素。
截至 2020 年初,美国各地站点可靠性工程师的年薪范围从低端的约 75,000 美元到某些极端偏远情况下的约 450,000 美元或更多。美国的平均工资约为 236,000 美元。在网站可靠性工程师的薪水和库存中赚多少钱中了解更多信息。
成为站点可靠性工程师需要哪些技能?
我们在 SRE 的角色和责任中更深入地讨论了这个问题。
一流的站点可靠性工程师候选人将有一个自然的优先级排序过程。也就是说,他们能够筛选信息并辨别什么是重要的,什么不是。他们还将具有出色的人际沟通技巧。
他们还将拥有一套技能,包括一定程度的熟悉:
- Git 和 GitHub 和/或 GitLab 等主机
- Vim(因为这个编辑器在你可能遇到的几乎任何服务器上都可以广泛使用)
- Linux 基础知识,如包管理、用户帐户管理以及目录和文件权限
- 基本的服务器软件管理,例如 Apache httpd 或 Nginx
- SSH
- Shell 脚本,例如使用 Bash
- 使用 Python 和 Go 甚至 Rust 等语言进行编程
- 自动化
- 联网
- 监控、日志记录和可观察性
- 测试,包括编写单元测试和用于 CI 的测试的能力
- 数据库,包括 MySQL 和 Postgres 等关系数据库,以及至少熟悉 Cassandra、MongoDB 和 Neo4j 等较新的 NoSQL/NewSQL 选项
那些刚进入 SRE 初级职位的人预计不会一开始就了解所有这些,但预计会了解在他们被雇用的系统上成功运行以保持和高效运行所需的内容。有关更多信息,请参阅我们的示例 SRE 职位描述和面试问题文章。
SRE 使用什么工具?
站点可靠性工程有时会很混乱。它一直在变化。在这种环境中管理工作需要计划。跨团队标准化工具集始终是一个好主意。
- 首先,SRE 必须能够跟踪工作和进度才能取得成功。为此,SRE 组织使用的首批工具之一是一个很好的问题跟踪器,如 JIRA 或 Pivotal Tracker。
SRE 将许多工具与他们管理的软件一起编写。将该代码放在像 Git 这样的存储库中是至关重要的。让每个人都使用相同的 IDE、库和构建过程(例如 Jenkins 或 Spinnaker 等 CI/CD 工具)可以使协作更加高效和顺畅。
- 将 SRE 团队拥有的服务部署到更广泛的云应用程序架构中的过程很重要。许多团队为此使用 Docker 或 Kubernetes 等容器。
团队通常会自动化他们所能做的一切,包括配置。 Ansible 和 Terraform 等工具对此很有用。
站点可靠性工程如何适应更广泛的工程组织?
在拥有大型云部署的年轻组织中,SRE 角色可能是常态。在仍然拥有企业拥有的数据中心和专门的开发与运营团队的旧组织中,SRE 可能是新的、独特的角色。进化似乎只是反向快速。
在过渡期(在某些情况下可能持续多年),公司可能有一个开发团队仍在使用瀑布方法进行产品开发,并将代码扔给负责使该代码在生产中工作的操作人员。当然,这只是在经过变更审查委员会的多次审查和批准、在测试和阶段环境中的部署等之后。
这些公司可能同时拥有新团队作为试点项目运行,并获得使用敏捷开发方法、DevOps 和/或站点可靠性工程实践以及自动化 CI/CD 管道的许可。这些与更传统的团队并肩作战,有时可能被视为竞争对手。
证明站点可靠性工程的价值的最佳方法是精益求精。学习观点。制定核心价值观。以前所未有的速度推动稳定和需要的功能,并让编写代码的人负责保持其在生产中的良好运行。
团队可能由传统的开发人员/工程师角色、运营专家、监控专家等组成,只有少数团队成员拥有“站点可靠性工程师”的头衔。这并不罕见。在这样的地方,整个团队都拥有代码和运营方面,而 SRE 通常是最了解管理代码的人;构建、部署、配置等。数据库工程师可能仍然是专注于数据可靠性的人,但 SRE 在从她的知识中受益的同时,有助于扩大视野。
归根结底,SRE 是关于协作和合作的,将具有不同技能的人聚集在一起,实现共同目标,让他们有效地分享知识和责任,从而提高系统效率和正常运行时间。
我们如何创建我们的第一个站点可靠性工程团队?
成功的最好方法是首先知道我们正在努力完成什么。我们经常看到项目或范式转变始于太少的计划。当我们学习并需要适应不断变化的环境时,我们希望我们的实施具有灵活性,但我们仍然需要制定计划。
我们首先定义我们的需求。我们希望 SRE 团队做什么?管理?一个好的开始是计划这个新团队将接管一个相对较小的服务或系统。
为什么?因为在这一点上,更广泛的组织正在同时学习文化和流程,并且您希望建立您的第一个团队以取得成功,因为他们有两倍的学习量要做。开始为即将发生的事情准备整个组织。他们需要时间来适应这样一个团队运行的想法。有些人可能会退缩。倾听他们,温柔地教导和引导,但不要走神。
接下来,考虑一下该团队成功所需的工具。不要急于购买它们,因为您可能会聘请一组经验丰富的工程师,他们知道更好的方法和更好的工具,但至少对典型成本进行研究,以便您可以设定初步的预算预期。
这个团队将包括多少人?您是否需要 24/7/365,或者这是一个可以根据需要与一两个随叫随到的人一起工作标准时间的团队?我们建议您的第一个团队使用后者,学习如何在低风险的事情上实施 SRE,然后向上移动。
定义你想在这个 SRE 团队中培养的文化。把它写下来,这样你就可以在接下来创建的工作列表中描述它。
要继续您的员工人数计划,请为您希望为该团队雇用的每个理想候选人编写职位描述。请记住,并非每个人都来自相同的背景,这就是您想要的——多视角!明确团队成员的责任和期望。
决定团队成员是否都将被称为“站点可靠性工程师”,还是将 SRE 与传统角色和头衔混合使用?请记住,单个团队成员可能有专长,但他们都应该为整个团队的所有需求和角色做出贡献,因此您需要灵活的人,他们在分享自己的专业知识时乐于一起学习。
现在,设置第一年的工资预算、团队预算和工具预算。估计比你认为你需要的要高。
我们建议雇佣一批经验丰富的 SRE,他们首先热爱自己的工作。预计最初的 3-4 名领导者将通过了解当今存在的情况、其运作方式以及思考他们想要如何接管来开始工作。考虑内部和外部招聘的混合,以帮助使这一过程在制度上顺利进行,同时也提供一些新的见解和观点。
这些第一批员工需要一点时间来了解彼此的个性、优势和才能,以及他们在整个团队中看到的任何差距。当他们告诉你他们作为一个团队需要什么才能取得成功时,请相信他们的直觉。询问他们接下来要雇用谁,并将他们包括在团队成长过程中。
让他们将运行的系统的经验和学到的知识指导事情从这里开始。
我们如何衡量 SRE 团队的成功?
这里有一些想法。如果我们从编制停机时间和导致问题的故障列表开始,即使没有停机时间,并了解这对公司来说有多么昂贵,那么我们可以将其作为衡量基准。
如果我们实施良好的 SRE 实践并为我们的工程师提供我们团队成功所需的工具和人数,您应该会看到停机时间等事件的数量和严重程度的减少,同时看到更快的响应时间和更小的客户和业务影响。
站点可靠性工程的大部分内容是衡量正确的事情并使用该数据来确定未来的工作优先级。当我们得到错误的初始测量和指标时,我们一注意到就会改变。最好转向新的工具、不同的指标和不断发展的政策,而不是仅仅因为我们有一个想要衡量的现有基线而坚持我们现有的东西。
我们知道我们的正常运行时间何时提高。我们知道我们的网站何时或多或少地响应。我们知道内部和外部客户何时对提供给他们的服务感到满意。衡量你认为最重要的东西,并专注于改进它。当您对该指标的成功感到满意时,请关注另一个指标。主要是选择一些东西来改进和改进它。集中改进,即使是小的改进,加起来。
站点可靠性工程不仅仅是加速灾难恢复。它是关于防止停机,提高系统对压力源的响应能力,并使我们的系统尽可能高效和可靠。
- 449 次浏览