【数据库选型】ClickHouse vs PostgreSQL vs TimescaleDB
目录
- 什么是ClickHouse?
- ClickHouse与PostgreSQL
- ClickHouse与TimescaleDB
- 结论
在过去的一年里,我们不断听到的一个数据库是ClickHouse,这是一个由Yandex最初构建并开源的面向列的OLAP数据库。
在这篇经过三个月研究和分析的详细文章中,我们回答了我们听到的最常见的问题,包括:
- 什么是ClickHouse(包括对其架构的深入了解)
- ClickHouse与PostgreSQL相比如何
- ClickHouse与TimescaleDB相比如何
- 与TimescaleDB相比,ClickHouse在时间序列数据方面的表现如何
向Timescale的工程师Alexander Kuzmenkov(最近是ClickHouse的核心开发人员)和Aleksander Alekseev(同时也是PostgreSQL的贡献者)大喊,他们帮助检查了我们的工作并让我们对这篇文章保持诚实。
标杆管理,而不是“标杆营销”(Benchmarking, not “Benchmarketing”)
在Timescale,我们非常认真地对待我们的基准。我们发现,在我们的行业中,有太多供应商偏向的“基准市场营销”,而没有足够诚实的“基准”。我们认为开发人员应该得到更好的服务。因此,我们竭尽全力真正了解我们正在比较的技术,并指出其他技术的闪光点(以及TimescaleDB可能的不足之处)。
您可以在我们的其他详细基准测试与AWS Timestream(29分钟读取)、MongoDB(19分钟读取)和InfluxDB(26分钟读取)中看到这一点。
我们也是真正喜欢学习和挖掘其他系统的数据库呆子。(这就是为什么这些帖子——包括这个帖子——这么长的几个原因!)
因此,为了更好地了解ClickHouse的优缺点,我们在过去的三个月和数百个小时里进行了基准测试、测试、阅读文档以及与贡献者合作。
ClickHouse在我们的测试中表现如何
ClickHouse是一项令人印象深刻的技术。在一些测试中,ClickHouse被证明是一个极快的数据库,能够比我们迄今为止测试过的任何其他数据库(包括TimescaleDB)更快地接收数据。在一些复杂的查询中,特别是那些进行复杂分组聚合的查询,ClickHouse是很难击败的。
但数据库中没有任何内容是免费的。ClickHouse之所以能够实现这些结果,是因为它的开发人员已经做出了具体的架构决策。这些架构决策也带来了局限性,尤其是与PostgreSQL和TimescaleDB相比。
ClickHouse的局限性/弱点包括:
- 在Time-Series Benchmark Suite中的几乎所有查询中,查询性能都低于TimescaleDB,但复杂聚合除外。
- 在小批量大小(例如100-300行/批)下,插入不良和磁盘使用率高出很多(例如,磁盘使用率比TimescaleDB高2.7倍)。
- 类似SQL的非标准查询语言,有几个限制(例如,不鼓励连接,语法有时不标准)
- 健壮的SQL数据库(如PostgreSQL或TimescaleDB)缺少其他功能:没有事务、没有相关子查询、没有存储过程、没有用户定义的函数、除了主索引和辅助索引之外没有索引管理、没有触发器。
- 无法以高速率和低延迟修改或删除数据,而必须批量删除和更新
- 批量删除和更新异步进行
- 因为数据修改是异步的,所以很难确保一致的备份:确保一致备份的唯一方法是停止对数据库的所有写入操作
- 缺少事务和数据一致性也会影响其他特性,如物化视图,因为服务器不能一次自动更新多个表。如果在向包含物化视图的表的多部分插入过程中出现中断,最终结果是数据的状态不一致。
我们列出这些缺点并不是因为我们认为ClickHouse是一个糟糕的数据库。实际上,我们认为它是一个很棒的数据库,更准确地说,是一个适合某些工作负载的很棒的数据库。作为开发人员,您需要为工作负载选择合适的工具。
为什么ClickHouse在某些情况下表现良好,但在其他情况下表现较差?
答案是底层架构。
数据库通常有两种基本架构,每种架构都有优缺点:在线事务处理(OLTP)和在线分析处理(OLAP)。
| OLTP | OLAP |
|---|---|
| Large and small datasets | Large datasets focused on reporting/analysis |
| Transactional data (the raw, individual records matter) | Pre-aggregated or transformed data to foster better reporting |
| Many users performing varied queries and updates on data across the system | Fewer users performing deep data analysis with few updates |
| SQL is the primary language for interaction | Often, but not always, utilizes a particular query language other than SQL |
ClickHouse、PostgreSQL和TimescaleDB体系结构
从较高的层次上讲,ClickHouse是一个为分析系统设计的优秀OLAP数据库。
相比之下,PostgreSQL是一个通用数据库,旨在成为一个多功能、可靠的OLTP数据库,用于具有高用户参与度的记录系统。
TimescaleDB是用于时间序列的关系数据库:专门构建在PostgreSQL上用于时间序列工作负载。它结合了PostgreSQL的优点和新功能,可以提高性能、降低成本,并为时间序列提供更好的总体开发体验。
因此,如果您发现自己需要对几乎不可变的大型数据集(即OLAP)执行快速分析查询,那么ClickHouse可能是更好的选择。
相反,如果您发现自己需要更通用的软件,那么它可以很好地为具有许多用户的应用程序提供支持,并且可能会频繁更新/删除,即OLTP、PostgreSQL可能是更好的选择。
如果您的应用程序具有时间序列数据,特别是如果您还希望PostgreSQL的多功能性,那么TimescaleDB可能是最佳选择。
时间序列基准套件结果汇总(TimescaleDB与ClickHouse)
我们可以看到这些架构决策对TimescaleDB和ClickHouse处理时间序列工作负载的影响。
在这个基准测试研究期间,我们花了数百个小时与ClickHouse和TimescaleDB合作。我们测试了从1亿行(10亿指标)到10亿行(100亿指标)的插入负载,从1亿到1000万的基数,以及其间的许多组合。我们真的想了解每个数据库是如何跨各种数据集工作的。
总的来说,对于插件,我们发现ClickHouse的表现优于批量较大的插件,但低于批量较小的插件。对于查询,我们发现ClickHouse在基准测试套件中的大多数查询中表现不佳,但复杂聚合除外。
插入性能
当每次插入的行数在5000到15000行之间时,两个数据库的速度都很快,ClickHouse的性能明显更好:
ClickHouse、PostgreSQL和TimescaleDB体系结构
从较高的层次上讲,ClickHouse是一个为分析系统设计的优秀OLAP数据库。
相比之下,PostgreSQL是一个通用数据库,旨在成为一个多功能、可靠的OLTP数据库,用于具有高用户参与度的记录系统。
TimescaleDB是用于时间序列的关系数据库:专门构建在PostgreSQL上用于时间序列工作负载。它结合了PostgreSQL的优点和新功能,可以提高性能、降低成本,并为时间序列提供更好的总体开发体验。
因此,如果您发现自己需要对几乎不可变的大型数据集(即OLAP)执行快速分析查询,那么ClickHouse可能是更好的选择。
相反,如果您发现自己需要更通用的软件,那么它可以很好地为具有许多用户的应用程序提供支持,并且可能会频繁更新/删除,即OLTP、PostgreSQL可能是更好的选择。
如果您的应用程序具有时间序列数据,特别是如果您还希望PostgreSQL的多功能性,那么TimescaleDB可能是最佳选择。
时间序列基准套件结果汇总(TimescaleDB与ClickHouse)
我们可以看到这些架构决策对TimescaleDB和ClickHouse处理时间序列工作负载的影响。
在这个基准测试研究期间,我们花了数百个小时与ClickHouse和TimescaleDB合作。我们测试了从1亿行(10亿指标)到10亿行(100亿指标)的插入负载,从1亿到1000万的基数,以及其间的许多组合。我们真的想了解每个数据库是如何跨各种数据集工作的。
总的来说,对于插件,我们发现ClickHouse的表现优于批量较大的插件,但低于批量较小的插件。对于查询,我们发现ClickHouse在基准测试套件中的大多数查询中表现不佳,但复杂聚合除外。
插入性能
当每次插入的行数在5000到15000行之间时,两个数据库的速度都很快,ClickHouse的性能明显更好:
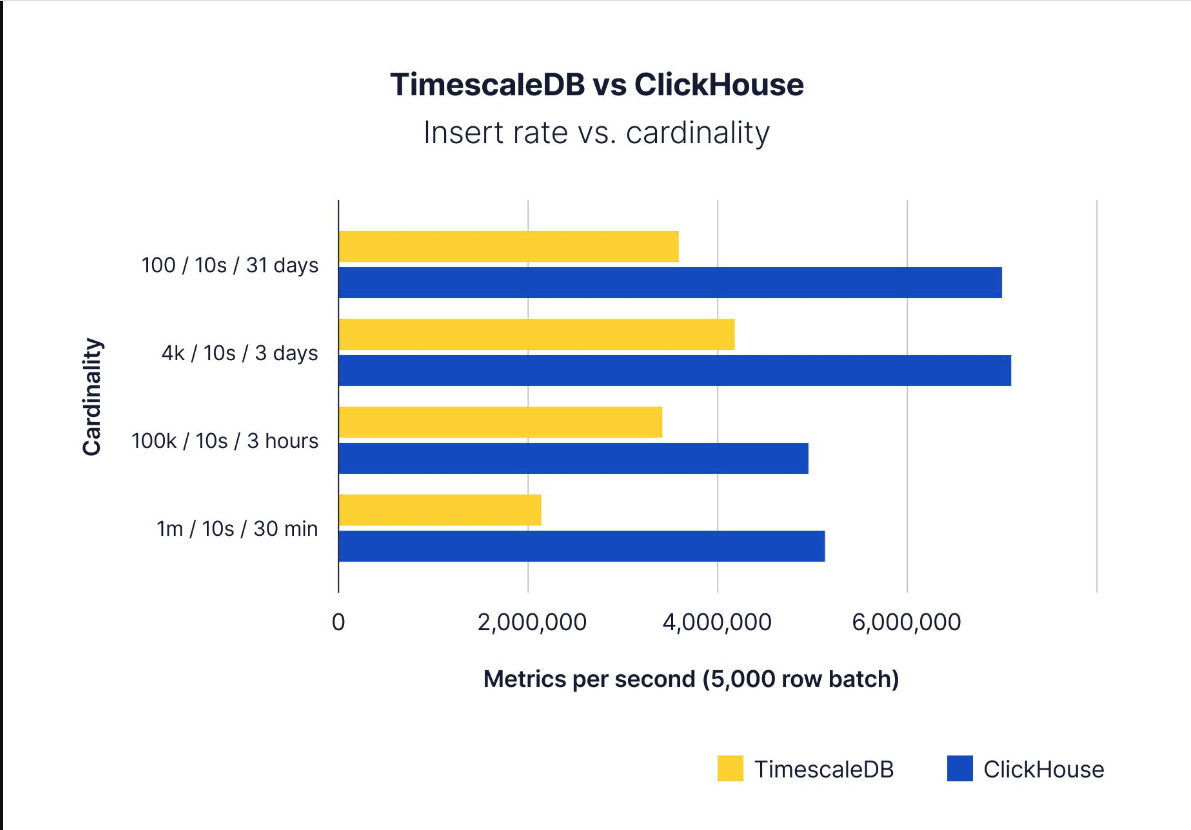
Performance comparison: ClickHouse outperforms TimescaleDB at all cardinalities when batch sizes are 5,000 rows or greater
然而,当批处理大小较小时,结果会以两种方式反转:插入速度和磁盘消耗。ClickHouse的批量较大,每批5000行,在测试期间消耗了约16GB的磁盘,而TimescaleDB消耗了约19GB的磁盘(均在压缩之前)。
使用较小的批处理大小,TimescaleDB不仅在100-300行/批之间保持了比ClickHouse更快的稳定插入速度,而且ClickHouse的磁盘使用量也高2.7倍。由于每个数据库的体系结构设计选择,应该可以预料到这种差异,但它仍然很有趣。
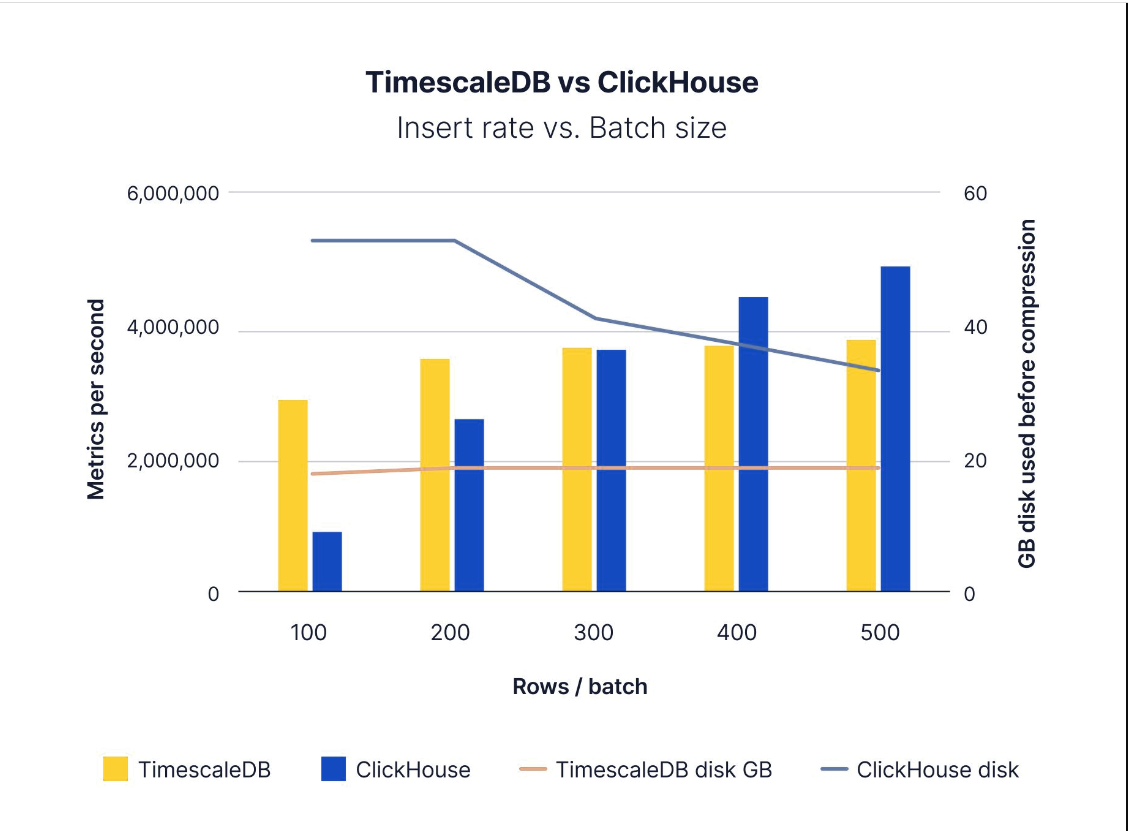
Performance comparison: Timescale outperforms ClickHouse with smaller batch sizes and uses 2.7x less disk space
查询性能
为了测试查询性能,我们使用了一个“标准”数据集,该数据集在三天内查询4000台主机的数据,总共有1亿行。在我们过去运行基准测试的经验中,我们发现这种基数和行计数可以作为基准测试的代表性数据集,因为它允许我们在几个小时内跨每个数据库运行许多摄取和查询周期。
基于ClickHouse作为快速OLAP数据库的声誉,我们预计ClickHouse在基准测试中的几乎所有查询中都会优于TimescaleDB。
当我们在没有压缩的情况下运行TimescaleDB时,ClickHouse确实表现得更好。
然而,当我们启用TimescaleDB压缩(这是推荐的方法)时,我们发现了相反的情况,TimescaleDB几乎在所有方面都表现出色:
Results of query benchmarking between TimescaleDB and ClickHouse. TimescaleDB outperforms in almost every query category
(对于那些想复制我们的研究结果或更好地理解ClickHouse和TimescaleDB在不同情况下的表现方式的人,请阅读整篇文章以了解详细信息。)
汽车与推土机
今天,我们生活在数据库的黄金时代:有太多的数据库,所有这些行(OLTP/OLAP/时间序列等)都变得模糊了。然而,每个数据库的架构都不同,因此有不同的优缺点。作为开发人员,您应该为工作选择合适的工具。
在花了大量时间与ClickHouse打交道,阅读他们的文档,并通过几周的基准测试,我们发现自己在重复这个简单的类比:
ClickHouse就像一台推土机,对于特定用例来说非常高效和高效。PostgreSQL(和TimescaleDB)就像一辆汽车:通用、可靠,在你生活中面临的大多数情况下都很有用。
大多数时候,“汽车”会满足你的需求。但如果你发现自己在做大量的“建筑”工作,无论如何,找一台“推土机”
我们不是唯一有这种感觉的人。以下是stingraycharles在HackerNews上分享的类似观点(我们不知道他是谁,但如果你正在阅读本文,那么stingraycharles——我们喜欢你的用户名):
“TimescaleDB有一个很好的时间序列故事,一个普通的数据仓库故事;Clickhouse有一个很棒的数据仓库案例,一个一般的时间序列案例,还有一个小小的集群故事(YMMV)。”
在本文的其余部分中,我们深入探讨了ClickHouse体系结构,然后重点介绍了ClickHouse、PostgreSQL和TimescaleDB的一些优缺点,这些都是由其每个开发人员(包括我们)所做的体系结构决策所导致的。最后,我们进行了更详细的时间序列基准分析。我们还详细描述了我们的测试环境,以便自己复制这些测试并验证我们的结果。
是的,我们是TimescaleDB的制造商,所以您可能不信任我们的分析。如果是这样,我们请您在接下来的几分钟内保持怀疑态度,并阅读本文的其余部分。正如你(希望如此)将看到的,我们花了很多时间来理解ClickHouse的对比:首先,确保我们以正确的方式进行基准测试,以便我们对ClickHouse公平;而且,因为我们本质上是数据库书呆子,并且非常想了解ClickHouse是如何构建的。
后续步骤
你对TimescaleDB感兴趣吗?最简单的入门方法是创建一个免费的TimescaleCloud帐户,这样您就可以访问一个完全托管的Timescale DB实例(30天内100%免费)。
如果您想自己托管TimescaleDB,您可以完全免费—访问我们的GitHub了解更多选项、获取安装说明等(⭐️ 非常感谢!🙏)
最后一件事:你可以加入我们的社区休闲活动,提问、获取建议,并与其他开发人员联系(我们正在7000人以上!)。我们,这篇文章的作者,在所有的渠道上都非常活跃——我们所有的工程师、团队时间尺度成员和许多热情的用户也是如此。
什么是ClickHouse?
ClickHouse是“Clickstream Data Warehouse”的缩写,是一个专栏式OLAP数据库,最初是为Yandex Metrica的web分析而构建的。通常,ClickHouse以其高插入率、快速分析查询和类似SQL的方言而闻名。
Timeline of ClickHouse development (Full history here.)
我们是ClickHouse的粉丝。它是一个围绕某些体系结构决策构建的非常好的数据库,这使得它成为OLAP风格分析查询的一个很好的选择。特别是,在我们使用时间序列基准测试套件(TSBS)进行基准测试时,ClickHouse在数据接收方面的表现比我们迄今为止测试过的任何时间序列数据库(包括TimescaleDB)都要好,在一个实例上,当行被适当批处理时,平均每秒超过600k行。
但是数据库中没有任何内容是免费的,正如我们将在下面展示的那样,这种体系结构也对ClickHouse造成了很大的限制,使得许多类型的时间序列查询和一些插入工作负载的速度变慢。如果您的应用程序不符合ClickHouse(或TimescaleDB)的体系结构边界,那么您可能最终会遇到一个令人沮丧的开发体验,需要重新进行大量工作。
ClickHouse架构
ClickHouse是为具有特定特征的OLAP工作负载而设计的。从ClickHouse文档中可以看出,这类工作负载的一些要求:
- 绝大多数请求都是读访问。
- 数据以相当大的批量(>1000行)插入,而不是以单行插入;或者根本没有更新。
- 数据已添加到数据库,但未修改。
- 对于读取,数据库中处理了相当多的行,但只处理了列的一小部分。
- 表是“宽”的,这意味着它们包含大量列。
- 查询相对较少(通常每台服务器上有数百个查询,或者每秒更少)。
- 对于简单查询,允许大约50毫秒的延迟。
- 列值相当小:数字和短字符串(例如,每个URL 60字节)。
- 处理单个查询时需要高吞吐量(每台服务器每秒最多数十亿行)。
- 交易是不必要的。
- 数据一致性要求低。
- 每个查询有一个大表。所有的桌子都很小,只有一张除外。
- 查询结果明显小于源数据。换句话说,数据被过滤或聚合,因此结果适合于单个服务器的RAM。
ClickHouse是如何为这些工作负载设计的?以下是其体系结构的一些关键方面:
- 压缩的、面向列的存储
- 表引擎
- 索引
- 矢量计算引擎
压缩的、面向列的存储
首先,ClickHouse(与几乎所有OLAP数据库一样)是面向列的(或列的),这意味着同一表列的数据存储在一起。(相比之下,在几乎所有OLTP数据库都使用的面向行的存储中,相同表行的数据存储在一起。)
面向列的存储有几个优点:
- 如果查询只需要读取几列,那么读取数据的速度会快得多(不需要读取整行,只需要读取列)
- 将相同数据类型的列存储在一起会导致更大的可压缩性(尽管如我们所示,可以将列压缩构建为面向行的存储)。
Table engines
为了改进ClickHouse中数据的存储和处理,使用表“引擎”集合实现了列数据存储。表引擎确定表的类型和可用于处理存储在其中的数据的功能。
ClickHouse主要使用MergeTree表引擎作为数据写入和组合的基础。几乎所有其他的表引擎都是从MergeTree派生而来的,并允许在(稍后)处理数据以进行长期存储时自动执行其他功能。
(快速澄清:从这一点开始,每当我们提到MergeTree时,我们都指的是整个MergeTre体系结构设计和从中派生的所有表类型,除非我们指定了特定的MergeTree-type)
在较高的级别上,MergeTree允许将数据快速写入和存储到多个不可变文件(ClickHouse称为“部分”)。这些文件稍后会在将来的某个时候在后台进行处理,并合并为一个较大的部分,目的是减少磁盘上的部分总数(文件越少,以后读取数据的效率越高)。这是ClickHouse在大批量上惊人的高插入性能的关键原因之一。
表中的所有列存储在单独的部分(文件)中,每个列中的所有值都按主键的顺序存储。这种列分离和排序实现使未来的数据检索更加高效,特别是在计算大范围连续数据的聚合时。
索引
一旦数据被存储并合并到每个列的最有效部分集中,查询就需要知道如何高效地查找数据。为此,Clickhouse依赖于两种类型的索引:主索引和辅助索引(数据跳过)。
与知道如何定位表中任何行的传统OLTP BTree索引不同,ClickHouse主索引本质上是稀疏的,这意味着它没有指向主索引每个值位置的指针。相反,因为所有数据都是按主键顺序存储的,所以主索引每N行存储主键的值(默认情况下称为index_granuclear,8192)。这是为了实现特定的设计目标,即将主索引拟合到内存中,以实现极快的处理速度。
当您的查询模式适合这种索引样式时,稀疏特性可以帮助显著提高查询速度。一个限制是,您不能在特定列上创建其他索引来帮助改进不同的查询模式。我们稍后将对此进行更多讨论。
矢量计算引擎
ClickHouse的设计初衷是希望以其他OLAP数据库无法实现的方式进行“在线”查询处理。即使使用压缩和列式数据存储,大多数其他OLAP数据库仍然依赖增量处理来预计算聚合数据。通常是预先聚合的数据提供了速度和报告功能。
为了克服这些限制,ClickHouse实现了一系列矢量算法,用于逐列处理大型数据数组。通过矢量化计算,ClickHouse可以专门处理成千上万块或行(每列)中的数据进行多次计算。矢量化计算还提供了一个机会,可以编写更高效的代码,利用现代SIMD处理器,并使代码和数据更紧密地结合在一起,以获得更好的内存访问模式。
总的来说,这对于处理大型数据集和在有限的列集上编写复杂查询来说是一个很好的功能,随着我们探索更多利用列数据的机会,TimescaleDB可以从中受益。
也就是说,正如您将从基准测试结果中看到的,在TimescaleDB中启用压缩(将数据转换为压缩的列存储),可以以比ClickHouse更好的方式提高许多聚合查询的查询性能。
ClickHouse的缺点在于其架构(又名:没有免费的东西)
数据库架构中没有免费的内容。显然,ClickHouse的设计考虑了非常具体的工作量。同样,它也不是为其他类型的工作负载而设计的。
我们可以从ClickHouse文档中看到一组最初的缺点:
- 没有正式的交易。
- 无法以高速率和低延迟修改或删除已插入的数据。可以使用批删除和更新来清理或修改数据,例如,为了符合GDPR,但不适用于常规工作负载。
- 稀疏索引使得ClickHouse对于通过键检索单行的点查询来说没有那么有效。
有几个缺点值得详细说明:
- 不能在表中直接修改数据
- 有些“同步”操作实际上并不同步
- 类似SQL,但不完全是SQL
- 备份中没有数据一致性
MergeTree限制:不能在表中直接修改数据
ClickHouse中的所有表都是不可变的。无法直接更新或删除已存储的值。相反,UPDATE或DELETE数据的任何操作只能通过“ALTER TABLE”语句来完成,该语句应用过滤器,并在后台重新写入整个表(逐部分)以更新或删除相关数据。本质上,它只是应用了一些过滤器的另一个合并操作。
因此,存在多个MergeTree表引擎来解决此缺陷,以解决通常需要频繁修改数据的情况。然而,这可能导致意外行为和非标准查询。
例如,如果只需要存储最近读取的值,则创建CollapsingMergeTree表类型是最佳选择。使用此表类型,将向表中添加一个附加列(称为“Sign”),该列指示当所有其他字段值都匹配时,哪一行是项目的当前状态。然后,ClickHouse将异步删除带有“Sign”的行,这些行相互抵消(值为1对-1),并在数据库中保留最新状态。
例如,考虑一种常见的数据库设计模式,其中传感器的最新值与长期时间序列表一起存储,以便快速查找。我们将此表称为SensorLastReading。在ClickHouse中,每当数据库中存储新信息时,该表都需要以下模式来存储最新的值。
传感器上次读取
| SensorID | Temp | Cpu | Sign |
|---|---|---|---|
| 1 | 55 | 78 | 1 |
当接收到新数据时,您需要向表中再添加两行,一行用于对旧值求反,另一行用于替换旧值。
| SensorID | Temp | Cpu | Sign |
|---|---|---|---|
| 1 | 55 | 78 | 1 |
| 1 | 55 | 78 | -1 |
| 1 | 40 | 35 | 1 |
在插入之后的某个时候,ClickHouse将合并更改,删除在Sign上相互取消的两行,只留下这一行:
| SensorID | Temp | Cpu | Sign |
|---|---|---|---|
| 1 | 40 | 35 | 1 |
但请记住,MergeTree操作是异步的,因此在执行类似折叠操作之前,可以对数据进行查询。因此,从CollapsingMergeTree表中获取数据的查询需要额外的工作,如将行乘以其“Sign”,以确保在表处于仍然包含重复数据的状态时获得正确的值。
这里是ClickHouse文档提供的一个解决方案,针对我们的示例数据进行了修改。注意,对于数字,可以通过将所有值乘以Sign列并添加HAVING子句来获得“正确”答案。
SELECT SensorID, sum(Temp * Sign) AS Temp, sum(Cpu * Sign) AS Cpu FROM SensorLastReading GROUP BY SensorId HAVING sum(Sign) > 0
同样,这里的价值在于,MergeTree表以事务和简单概念(如UPDATE和DELETE)为代价提供了真正快速的数据摄取,就像传统应用程序尝试使用这样的表一样。有了ClickHouse,管理这种数据工作流只需要更多的工作。
因为ClickHouse不是一个ACID数据库,所以这些后台修改(或者任何数据操作)都无法保证能够完成。因为没有事务隔离,任何在更新或删除修改(或我们前面提到的折叠修改)过程中接触数据的SELECT查询都将获得每个部分中当前的任何数据。例如,如果删除过程只修改了列的50%的部分,查询将从尚未处理的其余部分返回过期数据。
更重要的是,这适用于存储在ClickHouse中的所有数据,不仅是存储类似时间序列数据的大型分析型表,还包括相关元数据。例如,虽然可以理解时间序列数据通常只插入(很少更新),但随着时间的推移,以业务为中心的元数据表几乎总是有修改和更新。无论如何,您可以存储在ClickHouse中以进行复杂连接和深入分析的相关业务数据仍在MergeTree表(或MergeTree's的变体)中,因此,无论何时进行修改,更新或删除都需要进行完全重写(通过使用“ALTER table`)。
分布式MergeTree表
分布式表是异步修改可能导致您更改查询数据方式的另一个示例。如果应用程序将数据直接写入分布式表(而不是高级用户可能写入的不同群集节点),则首先将数据写入“启动器”节点,后者又会尽快将数据复制到后台的碎片。因为没有事务来验证数据是否作为两阶段提交(在PostgreSQL中可用)的一部分被移动,所以您的数据可能并不是您认为的那样。
如何处理分布式数据至少还有一个问题。由于ClickHouse不支持事务,并且数据处于不断移动的状态,因此无法保证集群节点状态的一致性。将100000行数据保存到分布式表并不能保证所有节点的备份都是一致的(我们稍后将讨论可靠性)。其中一些数据可能已被移动,而一些数据可能仍在传输中。
同样,这是精心设计的,所以ClickHouse中发生的事情没有什么特别的错误!当将ClickHouse与PostgreSQL和TimescaleDB之类的东西进行比较时,需要注意这一点。
有些“同步”操作实际上并不同步
ClickHouse中的大多数操作都不是同步的。但我们发现,即使一些标记为“synchronous”的也不是真正同步的。
在基准测试期间,一个特别的例子让我们感到惊讶,那就是“TRUNCATE”的工作原理。我们针对ClickHouse和TimescaleDB运行了许多测试周期,以确定行批量大小、工作线程甚至基数的变化如何影响每个数据库的性能。在每个周期结束时,我们将“TRUNCATE”每个服务器中的数据库,希望磁盘空间能够快速释放,以便开始下一个测试。在PostgreSQL(和其他OLTP数据库)中,这是一个原子操作。一旦截断完成,磁盘上的空间就会释放出来。

TRUNCATE是TimescaleDB/PostgreSQL中的一个原子操作,几乎可以立即释放磁盘
我们对ClickHouse也有同样的期望,因为文档中提到这是一个同步操作(而且ClickHouse中的大多数操作都不是同步的)。然而,事实证明,这些文件只会被标记为删除,而磁盘空间会在稍后的、未指定的时间在后台释放出来。这种情况何时发生没有具体的保证。

TRUNCATE is an asynchronous action in ClickHouse, freeing disk at some future time
对于我们的测试来说,这是一个小小的不便。我们必须在测试周期中加入10分钟的睡眠时间,以确保ClickHouse完全释放了磁盘空间。在实际情况中,像使用临时表的ETL处理一样,“TRUNCATE”实际上不会立即释放临时表数据,这可能会导致您修改当前进程。
我们指出其中的一些场景,只是为了强调一点,即ClickHouse并不是现代应用程序中记录系统(OLTP数据库)常用的许多功能的直接替代品。异步数据修改可能需要花费更多的精力才能有效地处理数据。
类似SQL,但不完全是SQL
在许多方面,ClickHouse选择SQL作为首选语言,走在了时代的前列。
ClickHouse在开发初期选择了使用SQL作为管理和查询数据的主要语言。考虑到对数据分析的关注,这是一个明智而明显的选择,因为SQL已经被广泛采用并被理解用于查询数据。
在ClickHouse中,SQL并不是为了满足部分用户社区的需要而添加的。也就是说,ClickHouse提供的是一种类似SQL的语言,不符合任何实际标准。
类SQL查询语言的挑战很多。例如,重新培训将访问数据库的用户(或编写访问数据库的应用程序)。另一个挑战是缺乏生态系统:使用SQL的连接器和工具不仅可以开箱即用,也就是说,它们需要一些修改(以及用户的知识)才能工作。
总的来说,ClickHouse能够很好地处理基本的SQL查询。
然而,由于数据的存储和处理方式与大多数SQL数据库不同,因此您可能希望从SQL数据库(例如,PostgreSQL、TimescaleDB)中使用许多命令和函数,但ClickHouse不支持这些命令和函数或对它们的支持有限:
- 未针对JOIN进行优化
- 除了主索引和辅助索引之外,没有索引管理
- 无递归CTE
- 无相关子查询或LATERAL联接
- 没有存储过程
- 没有用户定义的函数
- 没有触发器
ClickHouse最突出的一个例子是,join本质上是不受欢迎的,因为查询引擎缺乏优化两个或多个表的连接的能力。相反,我们鼓励用户使用单独的子选择语句查询表数据,然后使用类似“ANY INNER JOIN”的语句,严格查找连接两侧的唯一对(避免标准JOIN类型可能出现的笛卡尔积)。JOIN产品也没有缓存支持,因此如果一个表被多次联接,那么对该表的查询将被多次执行,从而进一步减慢查询速度。
例如,TSBS中的所有“double groupby”查询都按多个列分组,然后连接到标记表以获取最终输出的“hostname”。下面是如何为每个数据库编写查询。
Timescale数据库:
WITH cpu_avg AS ( SELECT time_bucket('1 hour', time) as hour, hostname, AVG(cpu_user) AS mean_cpu_user FROM cpu WHERE time >= '2021-01-01T12:30:00Z' AND time < '2021-01-02T12:30:00Z' GROUP BY 1, 2 ) SELECT hour, hostname, mean_cpu_user FROM cpu_avg JOIN tags ON cpu_avg.tags_id = tags.id ORDER BY hour, hostname;
ClickHouse:
SELECT hour, id, mean_cpu_user FROM ( SELECT toStartOfHour(created_at) AS hour, tags_id AS id, AVG(cpu_user) as mean_cpu_user FROM cpu WHERE (created_at >= '2021-01-01T12:30:00Z') AND (created_at < '2021-01-02T12:30:00Z') GROUP BY hour, id ) AS cpu_avg ANY INNER JOIN tags USING (id) ORDER BY hour ASC, id;
可靠性:备份中没有数据一致性
作为ClickHouse体系结构的一部分,需要考虑的最后一个方面是备份中没有数据一致性,而且它缺乏对事务的支持。如前所述,所有数据修改(甚至跨集群的切分)都是异步的,因此,确保一致备份的唯一方法是停止对数据库的所有写入,然后进行备份。数据恢复也面临同样的限制。
事务和数据一致性的缺乏也会影响其他特性,如物化视图,因为服务器不能一次原子地更新多个表。如果在向包含物化视图的表的多部分插入过程中出现中断,最终结果是数据的状态不一致。
ClickHouse意识到了这些缺点,并且肯定正在为将来的版本进行更新或计划更新。某种形式的事务支持已经讨论了一段时间,备份正在进行中,并被合并到代码的主要分支中,尽管还不建议在生产中使用。但即便如此,它也只为交易提供有限的支持。
ClickHouse与PostgreSQL
(正确的ClickHouse与PostgreSQL比较可能需要另外8000个单词。为了避免让这篇文章更长,我们选择了对两个数据库进行简短的比较,但如果有人想提供更详细的比较,我们很乐意阅读。)
如上所述,ClickHouse是一个架构良好的OLAP工作负载数据库。相反,PostgreSQL是一个架构良好的OLTP工作负载数据库。
此外,PostgreSQL不仅仅是一个OLTP数据库:它是增长最快、最受欢迎的OLTP数据库(DB Engines,StackOverflow,2021开发者调查)。
因此,我们不会比较ClickHouse和PostgreSQL的性能,因为继续之前的类比,这就像比较推土机和汽车的性能。这是为两个不同的目的而设计的两种不同的东西。
我们已经确定了为什么ClickHouse非常适合分析工作负载。现在让我们了解为什么PostgreSQL在事务性工作负载方面如此受欢迎:多功能性、可扩展性和可靠性。
PostgreSQL的通用性和扩展性
多功能性是PostgreSQL的突出优势之一。这是PostgreSQL最近在更广泛的技术社区复苏的主要原因之一。
PostgreSQL支持多种数据类型,包括数组、JSON等。它支持多种索引类型,不仅支持通用B树,还支持GIST、GIN等。全文搜索?检查基于角色的访问控制?检查当然,还有完整的SQL。
此外,通过使用扩展,PostgreSQL可以保留它擅长的东西,同时添加特定功能以提高开发工作的ROI。
您的应用程序需要地理空间数据吗?添加PostGIS扩展名。有利于时间序列数据工作负载的功能是什么?添加TimescaleDB。您的应用程序能从使用三角图搜索的功能中受益吗?添加pg_trgm。
凭借所有这些功能,PostgreSQL非常灵活,这意味着它基本上是经得起未来考验的。随着应用程序的变化或工作负载的变化,您将知道您仍然可以根据需要调整PostgreSQL。
(关于PostgreSQL强大可扩展性的一个具体示例,请阅读我们的工程团队如何使用客户操作员将函数编程构建到PostgreQL中。)
PostgreSQL可靠性
作为开发人员,我们决心面对这样一个事实:程序崩溃、服务器遇到硬件或电源故障、磁盘故障或出现损坏。您可以减轻这种风险(例如,稳健的软件工程实践、不间断电源、磁盘RAID等),但不能完全消除它;这是系统生命中的一个事实。
作为回应,数据库是通过一系列机制构建的,以进一步降低此类风险,包括流式复制到副本、完整快照备份和恢复、流式备份、强健的数据导出工具等。
PostgreSQL在20多年的开发和使用中受益匪浅,这不仅造就了一个可靠的数据库,还造就了一系列经过严格测试的工具:流式复制用于高可用性和只读副本,pg_dump和pg_recovery用于完整数据库快照,pg_basebackup和日志传送/流式传输用于增量备份和任意时间点恢复,pgBackrest或WAL-E用于连续归档到云存储,以及强大的COPY FROM和COPY to工具,用于快速导入/导出各种格式的数据。这使得PostgreSQL能够提供更大的“心灵平和”,因为衣柜中的所有骨架都已经找到(并解决)。
ClickHouse与TimescaleDB
TimescaleDB是建立在PostgreSQL之上的领先的时间序列关系数据库。它提供PostgreSQL所能提供的一切,外加一个完整的时间序列数据库。
因此,PostgreSQL的所有优点也适用于TimescaleDB,包括通用性和可靠性。
但TimescaleDB添加了一些关键功能,使其在时间序列数据方面表现更佳:
- Hypertables是TimescaleDB许多功能(如下所示)的基础,Hypertables提供跨时间和空间的自动分区数据,以实现更高性能的插入和查询
- 连续聚合-智能更新时间序列数据的物化视图。TimescleDB不是每次都重新创建物化视图,而是仅根据原始数据的底层更改更新数据。
- 列压缩—对大多数时间序列数据进行90%以上的高效数据压缩,大大提高了历史查询、长查询和窄查询的查询性能。
- Hyperfunctions-添加到PostgreSQL的以分析为中心的函数,通过近似百分位数、高效下采样和两步聚合等功能增强时间序列查询。
- 功能管道(本周发布!)-通过应用函数编程原理和Python的Pandas和PromQL等流行工具,从根本上改进开发人员在PostgreSQL和SQL中分析数据的人体工程学。
- 水平扩展(多节点)—跨多个节点的存储和分布式查询的时间序列数据的水平扩展。
时间序列数据的ClickHouse与TimescaleDB性能
时间序列数据之所以流行起来,是因为跟踪和分析事物随时间变化的价值在各个行业都变得显而易见:DevOps和IT监控、工业制造、金融交易和风险管理、传感器数据、广告技术、应用事件、智能家居系统、自动驾驶汽车、职业体育等等。
它与更传统的业务类型(OLTP)数据至少在两个主要方面有所不同:它主要是插入量大,数据的规模不断增长。这会影响数据收集和存储,以及我们如何分析价值本身。传统OLTP数据库通常无法每秒处理数百万事务,也无法提供有效的数据存储和维护方法。
时间序列数据也比一般分析(OLAP)数据更独特,因为查询通常具有时间成分,并且查询很少触及数据库中的每一行。
然而,在过去几年中,OLTP和OLAP数据库的功能之间的界限开始模糊。在过去十年中,许多NoSQL架构缓解了存储挑战,但仍然无法有效处理时间序列数据所需的查询和分析。
因此,许多应用程序试图在OLTP数据库的事务功能和OLAP数据库提供的大规模分析之间找到适当的平衡。因此,许多应用程序尝试使用ClickHouse是有道理的,它为时间序列数据提供了快速摄取和分析查询功能。
因此,让我们看看ClickHouse和TimescaleDB如何使用我们的标准TSBS基准比较时间序列工作负载。
性能基准
让我首先说,这不是一个我们在几个小时内完成的测试,然后再继续。事实上,就在昨天,在完成这篇博客帖子时,我们安装了最新版本的ClickHouse(3天前发布),并再次运行了所有测试,以确保获得尽可能好的数据!(基准,而非基准营销)
为了准备最后一组测试,我们分别在TimescaleDB和ClickHouse上运行了几十次基准测试——至少是几十次。我们尝试了不同的基数、生成数据的不同时间长度,以及对TimescaleDB的“chunk_time_interval”等易于控制的内容的不同设置。我们想真正了解每个数据库在典型的云硬件和我们在野外经常看到的规格下的性能。
我们还承认,大多数实际应用程序的工作方式与基准测试不同:首先接收数据,然后查询数据。但是,分离每个操作使我们能够了解在不同阶段哪些设置影响了每个数据库,这也使我们能够调整每个数据库的基准设置,以获得最佳性能。
最后,我们始终将这些基准测试视为一种学术和自我反思的体验。也就是说,花几百个小时处理这两个数据库通常会使我们考虑改进TimescaleDB(特别是)的方法,并仔细考虑何时我们可以而且应该说另一个数据库解决方案是特定工作负载的好选择。
机器配置
对于这个基准测试,我们有意识地决定使用基于云的硬件配置,这些配置对于初创企业和成长型企业的中等工作量来说是合理的。在以前的基准测试中,我们使用了具有专用RAID存储的较大机器,这是生产数据库环境的典型设置。
但是,随着时间的推移,我们看到越来越多的开发人员使用Kubernetes和模块化基础架构设置,而没有进行大量专门的存储和内存优化,因此在与我们在野外看到的更接近的实例上对每个数据库进行基准测试更为真实。当然,我们总是可以投入更多的硬件和资源来帮助实现峰值,但这通常无助于传达大多数现实应用程序的期望。
为此,为了比较插入和读取延迟性能,我们在AWS中使用了以下设置:
- 版本:TimescaleDB版本2.4.0,社区版,带PostgreSQL 13;ClickHouse 21.6.5版(测试时这两个数据库的最新非测试版)。
- 1台运行TSBS的远程客户端计算机,1台数据库服务器,两者位于同一云数据中心
- 实例大小:客户端和数据库服务器都运行在Amazon EC2虚拟机(m5.4xlarge)上,每个虚拟机有16个vCPU和64GB内存。
- 操作系统:服务器和客户机都运行Ubuntu 20.04.3
- 磁盘大小:1TB EBS GP2存储
- 部署方法:使用官方源通过apt-get安装
数据库配置
ClickHouse:没有对ClickHouse进行配置修改。我们只是根据他们的文档进行了安装。目前,ClickHouse还没有像timescaledb这样的工具。
TimescaleDB:对于TimescaleDB,我们遵循了时间刻度文档中的建议。具体来说,我们运行了timescaledb-tune并接受了基于EC2实例规范的配置建议。我们还在postgresql.conf中设置synchronous_commit=off。这是一种常见的性能配置,用于写入繁重的工作负载,同时仍保持事务性和日志完整性。
插入性能
为了提高插入性能,我们使用了以下数据集和配置。这些数据集是使用仅含cpu用例的时间序列基准套件创建的。
- 数据集:100-100000000台模拟设备每10秒生成10个CPU指标,读取间隔约为1亿次。
- 每个配置使用的间隔如下:100台设备31天;4000台设备3天;100000台设备需要3小时;30分钟,1000000
- 批量大小:插入是使用5000的批量大小制作的,ClickHouse和TimescaleDB都使用了该批量大小。我们尝试了多种批量大小,发现在大多数情况下,每个数据库每批5000到15000行之间的总体插入效率几乎没有差异。
- TimescaleDB块大小:我们根据数据量设置块时间,目标是每个配置总共7-16个块(这里有更多关于块的信息)。
最后,这些是使用5000行的批处理大小将TSBS客户机预生成的时间序列数据接收到每个数据库的性能数字。
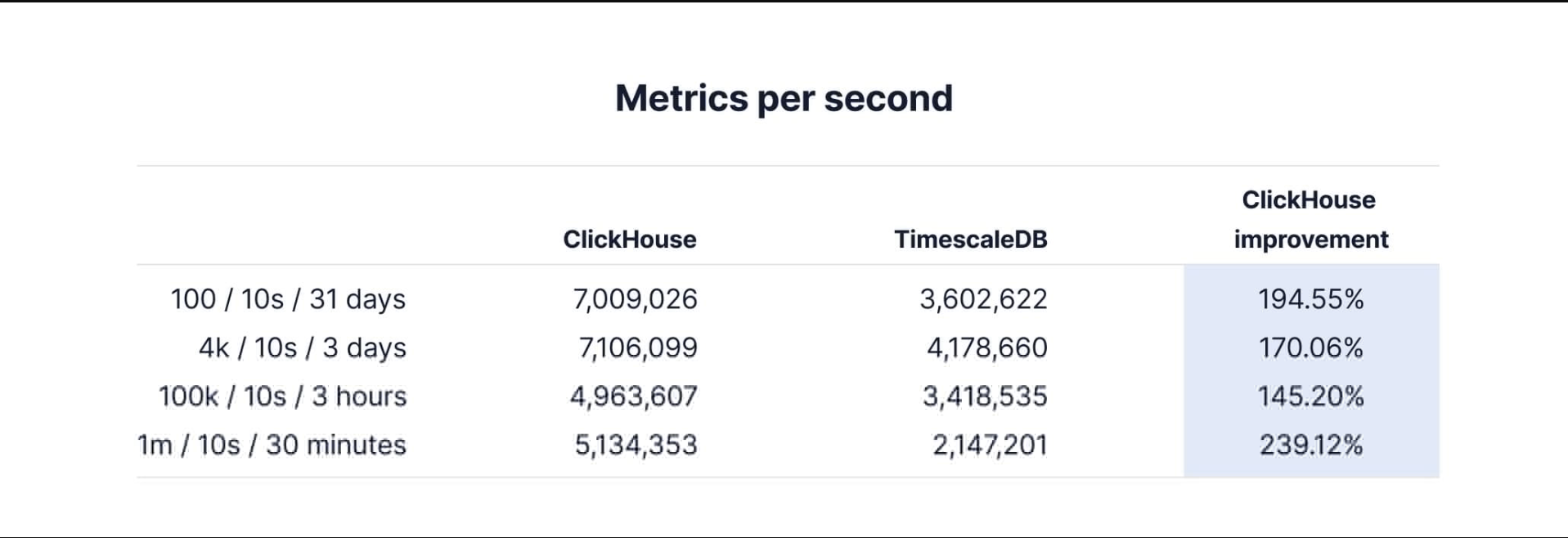
Insert performance comparison between ClickHouse and TimescaleDB with 5,000 row/batches
说实话,这并不让我们感到惊讶。我们最近看到了许多关于ClickHouse摄取性能的博客文章,由于ClickHouse使用了不同的存储体系结构和机制,不包括事务支持或ACID遵从性,所以我们通常预计它会更快。
然而,当你考虑到ClickHouse被设计成将接收到的行的每个“事务”都保存为单独的文件(稍后使用MergeTree架构进行合并)时,情况确实有所改变。事实证明,当您要接收的数据批次更少时,ClickHouse会比TimescaleDB慢得多,并且会消耗更多的磁盘空间。
(吸收1亿行,4000台主机,3天的数据-22GB的原始数据)
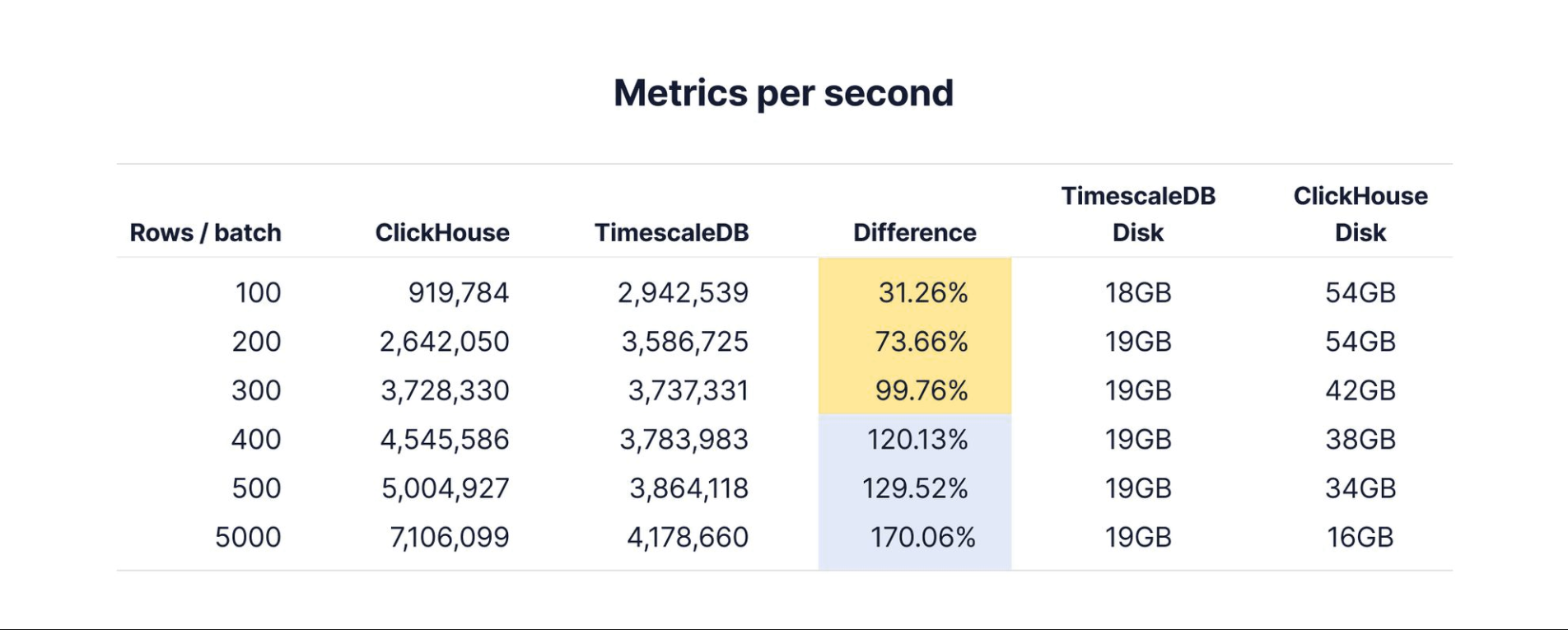
Insert performance comparison between ClickHouse and TimescaleDB using smaller batch sizes, which significantly impacts ClickHouse's performance and disk usage
你注意到上面的数字了吗?
无论批处理大小如何,TimescaleDB在压缩之前始终使用每个数据摄取基准消耗约19GB的磁盘空间。这是chunk_time_interval的结果,它决定了为给定的时间序列数据范围创建多少块。虽然较小的批处理可能会降低接收速度,但会为相同的数据创建相同的块,从而产生一致的磁盘使用模式。在压缩之前,很容易看到TimescaleDB无论批大小如何,都会持续消耗相同数量的磁盘空间。
相比之下,ClickHouse存储需求与需要写入的文件数量相关(这部分取决于要保存的行批的大小),实际上,在将数据合并到更大的文件之前,将数据保存到ClickHouse需要更多的存储空间。即使在500行的批处理中,对于22GB大小的源数据文件,ClickHouse消耗的磁盘空间也比TimescaleDB多1.75倍。
读取延迟
对于基准读取延迟,我们对每个数据库使用以下设置(机器配置与插入比较中使用的配置相同):
- 数据集:4000/10000模拟设备每10秒生成10个CPU指标,持续3天(100M+读取间隔,1B+指标)
- 我们还启用了TimescaleDB上的本机压缩。除了最近的数据块外,我们压缩了所有数据,使其保持未压缩状态。通常建议使用这种配置,其中未压缩的原始数据保存在最近的时间段,而较旧的数据被压缩,从而提高查询效率(有关更多信息,请参阅我们的压缩文档)。我们用于启用压缩的参数如下:我们按tags_id列进行分段,并按时间降序和usage_user列进行排序。
在读取(即查询)延迟时,结果更复杂。与插入不同,插入主要取决于基数大小(可能还有批大小),可能的查询范围基本上是无限的,特别是对于像SQL这样强大的语言。通常,对读取延迟进行基准测试的最佳方法是使用计划执行的实际查询进行基准测试。对于这种情况,我们使用一组广泛的查询来模拟最常见的查询模式。
下面显示的结果是每个查询类型的1000个查询的中间值。此图表中的延迟均以毫秒为单位显示,另一列显示TimescaleDB与ClickHouse相比的相对性能(当TimescaleDB更快时以绿色突出显示,当ClickHouse更快时以蓝色突出显示)。
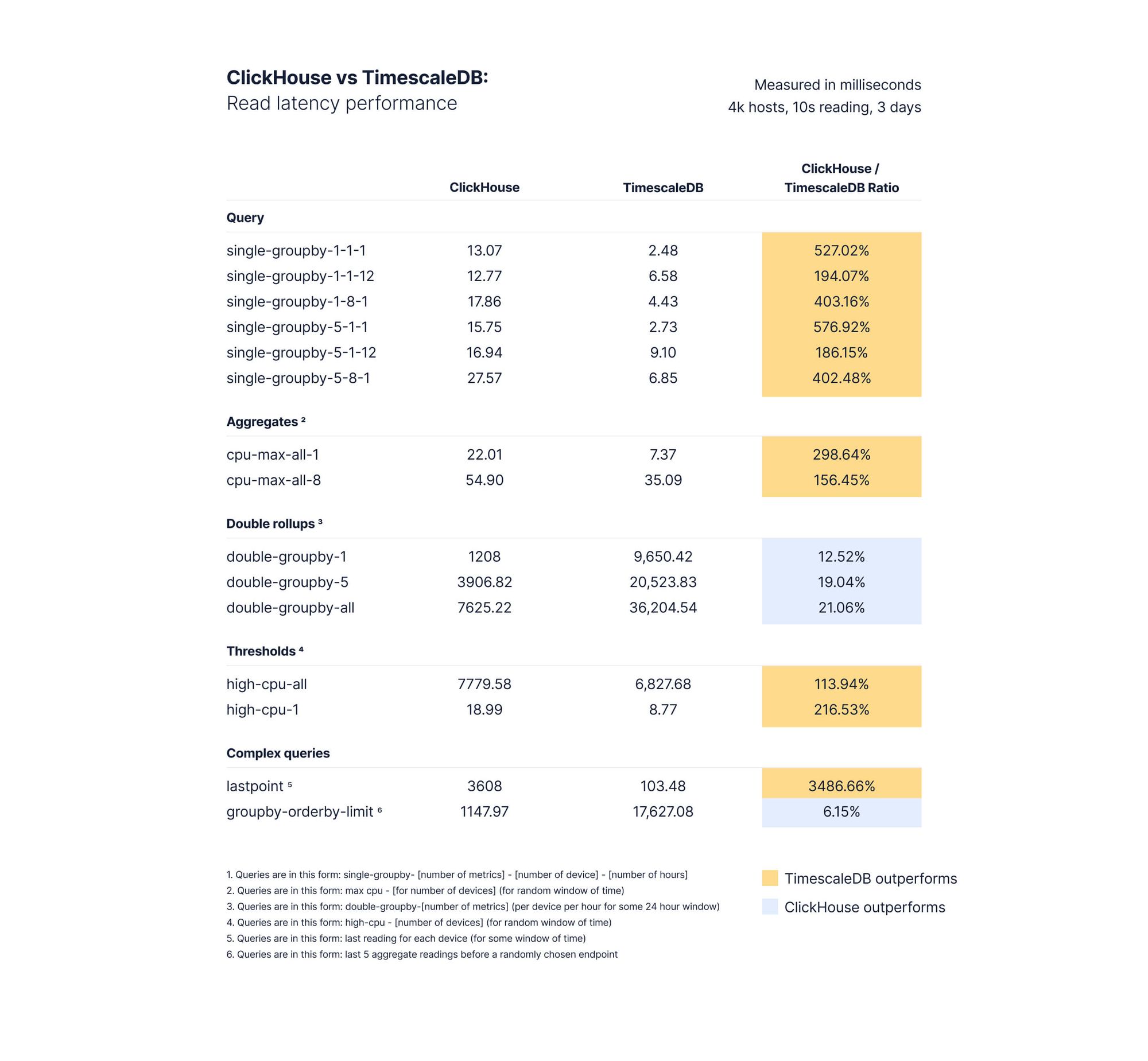
Results of benchmarking query performance of 4,000 hosts with 100 million rows of data
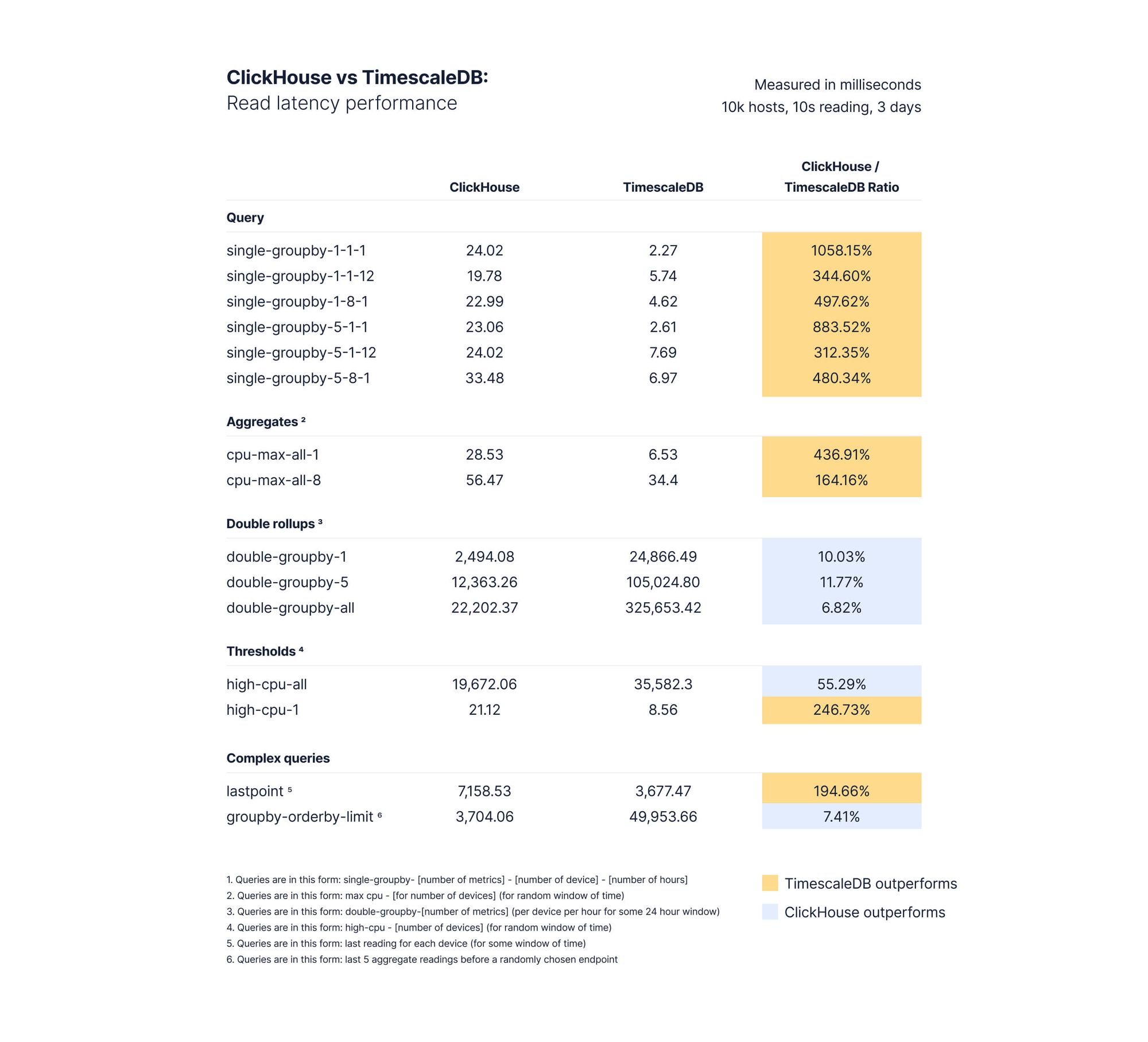
Results of benchmarking query performance of 10,000 hosts with 100 million rows of data
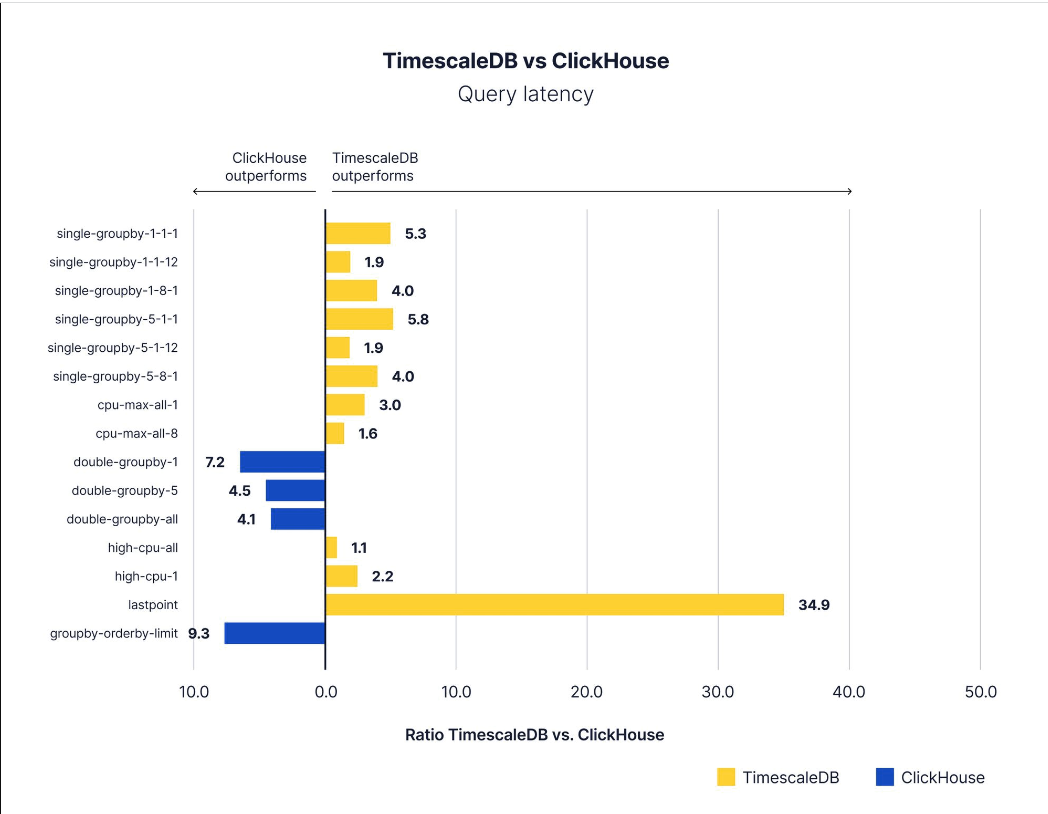
简单滚动
对于简单的汇总(即单个groupby),当在单个主机上聚合一个指标1或12小时,或在一个或多个主机上聚合多个指标(1小时或12小时)时,TimescaleDB通常在低基数和高基数方面都优于ClickHouse。特别是,TimescaleDB在4000和10000台设备的配置上表现出高达1058%的ClickHouse性能,每个读取间隔生成10个独特的指标。
AGGREGATES
在计算1个设备的简单聚合时,TimescaleDB在任何数量的设备上都始终优于ClickHouse。在我们的基准测试中,TimescaleDB在4000台设备上聚合8个指标时,其性能达到了ClickHouse的156%,在10000台设备上集合8个指标后,其性能提高了164%。TimescaleDB在高端场景中再次超越ClickHouse。
DOUBLE ROLLUPS
ClickHouse在查询延迟方面始终优于TimescaleDB的一组查询是按时间和另一个维度(例如,GROUPBY time、deviceId)聚合度量的双汇总查询。下面我们将详细讨论为什么会这样,但这也并非完全出乎意料。
THRESHOLDS
当根据阈值选择行时,TimescaleDB在计算单个设备的阈值时显示出249-357%的ClickHouse性能,但在计算随机时间窗口中所有设备的阈值后,仅显示出130-58%的ClickHouse性能。
COMPLEX QUERIES
对于超出汇总或阈值的复杂查询,比较有点微妙,特别是在查看TimescaleDB时。区别在于TimescaleDB让您可以控制压缩哪些块。在大多数时间序列应用程序中,尤其是像物联网这样的应用程序,经常需要通过某种聚合来查找某个项的最新值或前X个项的列表。这是lastpoint和groupby orderby limit查询的基准。
正如我们之前在其他数据库(InfluxDB和MongoDB)中所展示的,以及ClickHouse本身所记录的那样,获取项目的单个有序值并不是类似MergeTree的/OLAP数据库的用例,通常因为没有可以为时间、键和值定义的有序索引。这意味着询问项目的最新值仍然会导致对OLAP数据库中的数据进行更密集的扫描。
我们在结果中看到了这一点。在搜索数据库中每个项目的最新值(lastpoint)时,TimescaleDB比ClickHouse快3486%左右。这是因为在接收数据时,最新的未压缩块通常会保存这些值的大部分,这是一个很好的例子,说明为什么压缩的灵活性会对应用程序的性能产生重大影响。
然而,我们完全承认,压缩并不总是对每个查询表单都返回良好的结果。在最后一个复杂的查询中,ClickHouse以相当大的速度超过TimescaleDB,几乎快了15倍。我们的结果没有显示,从未压缩块(最近的块)读取的查询比ClickHouse快17倍,平均每个查询64毫秒。TimescaleDB中的查询如下所示:
SELECT time_bucket('60 seconds', time) AS minute, max(usage_user) FROM cpu WHERE time < '2021-01-03 15:17:45.311177 +0000' GROUP BY minute ORDER BY minute DESC LIMIT 5
正如您可能猜测的那样,当块被解压缩时,可以使用PostgreSQL索引按时间快速排序数据。压缩区块时,必须首先解压缩与谓词匹配的数据(上例中为“WHERE time<”2021-01-03 15:17:45.31177+0000”),然后再对其进行排序和搜索。
当“lastpoint”查询的数据落在未压缩的块中时(对于具有诸如“WHERE time<now()-INTERVAL‘6 hours’”谓词的短期查询,通常是这种情况),结果令人吃惊。
(未压缩区块查询,4k主机)
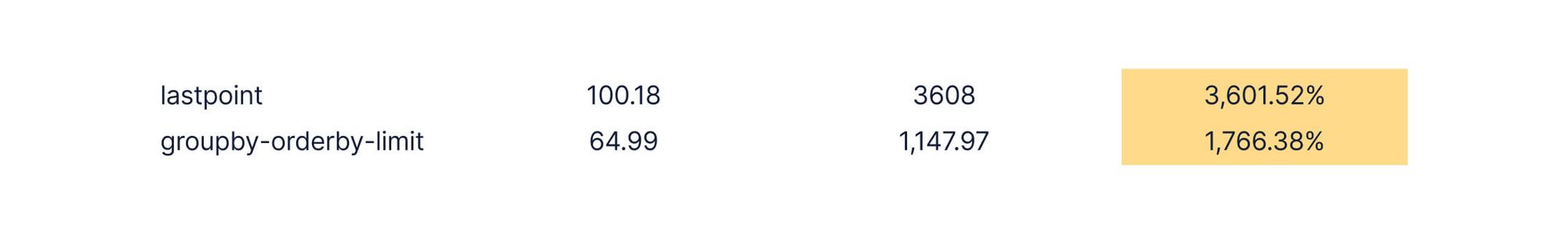
Query latency performance when lastpoint and groupby-orderby-limit queries use an uncompressed chunk in TimescaleDB
最后一组查询的关键结论之一是,数据库提供的功能可能会对应用程序的性能产生重大影响。有时它只是工作,而其他时候能够微调数据存储方式可能会改变游戏规则。
读取延迟性能摘要
- 对于简单查询,无论是否使用本机压缩,TimescaleDB都优于ClickHouse。
- 对于典型的聚合,即使在许多值和项中,TimescaleDB也优于ClickHouse。
- ClickHouse执行更复杂的双汇总,每次都优于TimescaleDB。在某种程度上,我们对这种差距感到惊讶,并将继续了解如何更好地适应对原始时间序列数据的此类查询。在实际应用程序中,解决这种差异的一个方法是使用连续聚合来预聚合数据。
- 当根据阈值选择行时,TimescaleDB的性能优于ClickHouse,速度快了250%。
- 对于一些复杂的查询,特别是像“lastpoint”这样的标准查询,TimescaleDB的性能大大优于ClickHouse
- 最后,根据查询的时间范围,TimescaleDB在分组和有序查询方面比ClickHouse快得多(高达1760%)。当这些类型的查询进一步回到压缩块时,ClickHouse的性能优于TimescaleDB,因为必须解压缩更多的数据才能找到合适的max()值来排序。
结论
你成功了!感谢您抽出时间阅读我们的详细报告。
了解ClickHouse,然后将其与PostgreSQL和TimescaleDB进行比较,使我们意识到在当今的数据库市场上有很多选择,但通常仍然只有一个合适的工具来完成这项工作。
在决定使用哪一个应用程序之前,我们建议后退一步,分析您的堆栈、团队的技能以及您现在和将来的需求。现在选择最适合您的情况的技术,可以在未来带来所有不同。相反,您希望选择一种随您发展和成长的体系结构,而不是一种在数据开始从生产应用程序流动时迫使您从头开始的体系结构。
我们总是对反馈感兴趣,我们将继续与更大的社区分享我们的见解。
- 1303 次浏览