机器学习
【机器学习】24个终极数据科学(机器学习)项目,提升您的知识和技能:中级
视频号

微信公众号

知识星球

介绍
数据科学(机器学习)项目为你提供了一种很有前途的方式来开启你在该领域的职业生涯。你不仅可以通过应用数据科学来学习数据科学,还可以在简历上展示项目!如今,招聘人员通过求职者的工作来评估其潜力,而不太重视证书。如果你只是告诉他们你知道多少,如果你没有什么可以展示给他们,那也没关系!这是大多数人挣扎和错过的地方。
你以前可能已经解决过几个问题,但如果你不能让它看起来很好看,很容易解释,那么别人怎么会知道你的能力呢?这就是这些项目将帮助你的地方。想想你将在这些项目上花费的时间,比如你的培训课程。你练习的时间越多,你就会变得越好!
我们确保为您提供来自不同领域的各种问题的体验。我们相信,每个人都必须学会巧妙地处理大量数据,因此包括了大型数据集。此外,我们还确保所有数据集都是开放的,可以免费访问。
- 介绍
- 有用信息
- 初级数据科学项目
- 中级数据科学项目
- 高级数据科学项目
- 结论
- 常见问题
为了帮助您决定从哪里开始,我们将此列表分为3个级别,即:
- 初级:该级别由数据集组成,这些数据集非常容易使用,不需要复杂的数据科学技术。您可以使用基本的回归或分类算法来解决这些问题。此外,这些数据集有足够多的开放式教程可以让您继续学习。在这个列表中,我们还提供了教程来帮助您入门。您也可以在这里查看AV的“数据科学导论”课程!
- 中级:该级别由性质上更具挑战性的数据集组成。它由中大型数据集组成,这些数据集需要一些严肃的模式识别技能。此外,功能工程将在这里发挥作用。ML技术的使用没有限制;阳光下的一切都可以使用。
- 高级级别:该级别最适合理解神经网络、深度学习、推荐系统等高级主题的人。这里还介绍了高维数据集。此外,现在是发挥创造力的时候了。看看最好的数据科学家在他们的工作和代码中所带来的创造力。
你想掌握机器学习和深度学习吗?这里有一个全面的计划,详细介绍了机器学习和深度学习的概念,以及25个以上的现实生活项目!
中级数据科学项目
1.黑色星期五数据集
该数据集包括在零售店捕获的销售交易。这是一个经典的数据集,可以从多种购物体验中探索和扩展您的功能工程技能和日常理解。这是一个回归问题。该数据集有550069行和12列。
问题:预测购买金额。
Start: Get Data | Tutorial: Get Here
2.人类活动识别数据集
该数据集是从通过内置惯性传感器的智能手机拍摄的30名受试者的记录中收集的。许多机器学习课程将这些数据用于教学目的。现在轮到你了。这是一个多分类的问题。该数据集有10299行和561列。
问题:预测人类的活动类别。
Start: Get Data | Tutorial: Get Here
3.文本挖掘数据集
该数据集最初来自2007年举行的暹罗文本挖掘大赛。数据包括描述某些飞行中出现的问题的航空安全报告。这是一个多分类、高维的问题。它有21519行和30438列。
问题:根据文档的标签对文档进行分类。
Start: Get Data | Tutorial: Get Here
4.行程历史数据集
该数据集来自美国的一家共享单车服务公司。此数据集要求您练习专业数据挖掘技能。从2010年(第4季度)起按季度提供数据。每个文件有7列。这是一个分类问题。
问题:预测用户的类别。
Start: Get Data | Tutorial: Get Here
5.百万首歌曲数据集
你知道数据科学也可以用于娱乐业吗?现在自己动手吧。这个数据集提出了一个回归任务。它由5,15345个观测值和90个变量组成。然而,这只是关于一百万首歌曲的原始数据数据库的一小部分。
问题:预测歌曲的发行年份。
Start: Get Data | Tutorial: Get Here
6.人口普查收入数据集
这是一个不平衡的分类问题,也是一个经典的机器学习问题。你知道,机器学习正被广泛用于解决不平衡的问题,如癌症检测、欺诈检测等。是时候弄脏你的手了。该数据集有48842行和14列。为了获得指导,您可以检查这个不平衡的数据项目。
问题:预测美国人口的收入阶层。
Start: Get Data | Tutorial: Get Here
7.电影镜头数据集
你建立了推荐系统了吗?给你机会!该数据集是数据科学行业中最受欢迎和引用的数据集之一。它有多种尺寸可供选择。这里我用了一个相当小的尺寸。6000名用户对4000部电影的评分为100万。
问题:向用户推荐新电影。
Start: Get Data | Tutorial: Get Here
8.Twitter分类数据集
使用Twitter数据已经成为情绪分析问题的一个组成部分。如果你想在这个领域为自己开辟一个利基市场,你会很高兴地应对这个数据集带来的挑战。该数据集大小为3MB,有31962条推文。
问题:识别哪些推文是仇恨推文,哪些不是。
- 118 次浏览
【机器学习】24个终极数据科学(机器学习)项目,提升您的知识和技能:入门级别
视频号
微信公众号
知识星球
介绍
数据科学(机器学习)项目为你提供了一种很有前途的方式来开启你在该领域的职业生涯。你不仅可以通过应用数据科学来学习数据科学,还可以在简历上展示项目!如今,招聘人员通过求职者的工作来评估其潜力,而不太重视证书。如果你只是告诉他们你知道多少,如果你没有什么可以展示给他们,那也没关系!这是大多数人挣扎和错过的地方。
你以前可能已经解决过几个问题,但如果你不能让它看起来很好看,很容易解释,那么别人怎么会知道你的能力呢?这就是这些项目将帮助你的地方。想想你将在这些项目上花费的时间,比如你的培训课程。你练习的时间越多,你就会变得越好!
我们确保为您提供来自不同领域的各种问题的体验。我们相信,每个人都必须学会巧妙地处理大量数据,因此包括了大型数据集。此外,我们还确保所有数据集都是开放的,可以免费访问。
- 介绍
- 有用信息
- 初级数据科学项目
- 中级数据科学项目
- 高级数据科学项目
- 结论
- 常见问题
为了帮助您决定从哪里开始,我们将此列表分为3个级别,即:
- 初级:该级别由数据集组成,这些数据集非常容易使用,不需要复杂的数据科学技术。您可以使用基本的回归或分类算法来解决这些问题。此外,这些数据集有足够多的开放式教程可以让您继续学习。在这个列表中,我们还提供了教程来帮助您入门。您也可以在这里查看AV的“数据科学导论”课程!
- 中级:该级别由性质上更具挑战性的数据集组成。它由中大型数据集组成,这些数据集需要一些严肃的模式识别技能。此外,功能工程将在这里发挥作用。ML技术的使用没有限制;阳光下的一切都可以使用。
- 高级级别:该级别最适合理解神经网络、深度学习、推荐系统等高级主题的人。这里还介绍了高维数据集。此外,现在是发挥创造力的时候了。看看最好的数据科学家在他们的工作和代码中所带来的创造力。
你想掌握机器学习和深度学习吗?这里有一个全面的计划,详细介绍了机器学习和深度学习的概念,以及25个以上的现实生活项目!
初级数据科学项目
1.虹膜数据集

这可能是模式识别文献中最通用、最简单、最有资源的数据集。没有什么比Iris数据集更简单的了,可以学习分类技术。如果你是数据科学的新手,这是你的起点。数据只有150行和4列。
问题:根据可用属性预测花朵的类别。
Start: Get Data | Tutorial: Get Here
让我们看看Iris数据,并在下面的实时编码窗口中建立一个Logistic回归模型。
'''
IRIS DATASET
'''
# required libraries
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
# read the dataset
data = pd.read_csv('Iris.csv')
print(data.head())
print('\n\nColumn Names\n\n')
print(data.columns)
#label encode the target variable
encode = LabelEncoder()
data.Species = encode.fit_transform(data.Species)
print(data.head())
# train-test-split
train , test = train_test_split(data,test_size=0.2,random_state=0)
print('shape of training data : ',train.shape)
print('shape of testing data',test.shape)
# seperate the target and independent variable
train_x = train.drop(columns=['Species'],axis=1)
train_y = train['Species']
test_x = test.drop(columns=['Species'],axis=1)
test_y = test['Species']
# create the object of the model
model = LogisticRegression()
model.fit(train_x,train_y)
predict = model.predict(test_x)
print('Predicted Values on Test Data',encode.inverse_transform(predict))
print('\n\nAccuracy Score on test data : \n\n')
print(accuracy_score(test_y,predict))
2.贷款预测数据集
在所有行业中,保险领域是分析和数据科学方法使用最多的行业之一。该数据集为您提供了使用保险公司数据集的体验——那里面临哪些挑战,使用了哪些策略,哪些变量影响结果等。这是一个分类问题。该数据有615行和13列。
问题:预测贷款是否会获得批准。
Start: Get Data | Tutorial: Get Here
让我们看看贷款数据,并在下面的实时编码窗口中建立一个逻辑回归模型。
'''
LOAN DATASET
'''
# required libraries
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
# read the dataset
data = pd.read_csv('train_ctrUa4K.csv')
print(data.head())
print('\n\nColumn Names\n\n')
print(data.columns)
#label encode the target variable
encode = LabelEncoder()
data.Loan_Status = encode.fit_transform(data.Loan_Status)
# drop the null values
data.dropna(how='any',inplace=True)
# train-test-split
train , test = train_test_split(data,test_size=0.2,random_state=0)
# seperate the target and independent variable
train_x = train.drop(columns=['Loan_ID','Loan_Status'],axis=1)
train_y = train['Loan_Status']
test_x = test.drop(columns=['Loan_ID','Loan_Status'],axis=1)
test_y = test['Loan_Status']
# encode the data
train_x = pd.get_dummies(train_x)
test_x = pd.get_dummies(test_x)
print('shape of training data : ',train_x.shape)
print('shape of testing data : ',test_x.shape)
# create the object of the model
model = LogisticRegression()
model.fit(train_x,train_y)
predict = model.predict(test_x)
print('Predicted Values on Test Data',predict)
print('\n\nAccuracy Score on test data : \n\n')
print(accuracy_score(test_y,predict))
3.Bigmart销售数据集
零售业是另一个广泛使用分析来优化业务流程的行业。产品布局、库存管理、定制优惠、产品捆绑等任务正在使用数据科学技术巧妙地处理。顾名思义,这些数据包括销售商店的交易记录。这是一个回归问题。该数据包含8523行12个变量。
问题:预测商店的销售额。
Start: Get Data | Tutorial: Get Here
让我们看看大卖场的销售数据,并在下面的实时编码窗口中建立一个线性回归模型。
'''
The following code is for the Linear Regression
Created by- ANALYTICS VIDHYA
'''
# importing required libraries
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# read the train and test dataset
train_data = pd.read_csv('train.csv')
test_data = pd.read_csv('test.csv')
print(train_data.head())
# shape of the dataset
print('\nShape of training data :',train_data.shape)
print('\nShape of testing data :',test_data.shape)
# Now, we need to predict the missing target variable in the test data
# target variable - Item_Outlet_Sales
# seperate the independent and target variable on training data
train_x = train_data.drop(columns=['Item_Outlet_Sales'],axis=1)
train_y = train_data['Item_Outlet_Sales']
# seperate the independent and target variable on training data
test_x = test_data.drop(columns=['Item_Outlet_Sales'],axis=1)
test_y = test_data['Item_Outlet_Sales']
'''
Create the object of the Linear Regression model
You can also add other parameters and test your code here
Some parameters are : fit_intercept and normalize
Documentation of sklearn LinearRegression:
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html
'''
model = LinearRegression()
# fit the model with the training data
model.fit(train_x,train_y)
# coefficeints of the trained model
print('\nCoefficient of model :', model.coef_)
# intercept of the model
print('\nIntercept of model',model.intercept_)
# predict the target on the test dataset
predict_train = model.predict(train_x)
print('\nItem_Outlet_Sales on training data',predict_train)
# Root Mean Squared Error on training dataset
rmse_train = mean_squared_error(train_y,predict_train)**(0.5)
print('\nRMSE on train dataset : ', rmse_train)
# predict the target on the testing dataset
predict_test = model.predict(test_x)
print('\nItem_Outlet_Sales on test data',predict_test)
# Root Mean Squared Error on testing dataset
rmse_test = mean_squared_error(test_y,predict_test)**(0.5)
print('\nRMSE on test dataset : ', rmse_test)
4.波士顿住房数据集
这是模式识别文献中使用的另一个流行数据集。数据集来自波士顿(美国)的房地产行业。这是一个回归问题。该数据有506行和14列。因此,这是一个相当小的数据集,你可以在这里尝试任何技术,而不用担心笔记本电脑的内存被过度使用。
问题:预测自住房屋的中值。
Start: Get Data | Tutorial: Get Here
5.时间序列分析数据集
时间序列是数据科学中最常用的技术之一。它有着广泛的应用——天气预报、预测销售额、分析同比趋势等。该数据集特定于时间序列,这里的挑战是预测一种交通方式的交通量。数据有**行和**列。
问题:预测新交通方式的交通量。
Start: Get Data | Tutorial: Get Here
6.葡萄酒质量数据集
这是数据科学初学者最喜欢的数据集之一。它分为2个数据集。您可以对此数据执行回归和分类任务。它将测试您在不同领域的理解——异常值检测、特征选择和不平衡数据。该数据集中有4898行和12列。
问题:预测葡萄酒的质量。
Start: Get Data | Tutorial: Get Here
7.土耳其学生评估数据集
该数据集基于学生为不同课程填写的评估表。它具有不同的属性,包括出勤率、难度、每个评估问题的分数等。这是一个无人监督的学习问题。该数据集有5820行和33列。
问题:使用分类和聚类技术来处理数据。
Start: Get Data | Tutorial: Get Here
8.高度和重量数据集
这是一个相当简单的问题,非常适合刚开始从事数据科学的人。这是一个回归问题。该数据集有25000行和3列(索引、高度和权重)。
问题:预测一个人的身高或体重。
Start: Get Data | Tutorial: Get Here
如果你是数据科学世界的新手,Analytics Vidhya为初学者策划了一门全面的课程——“数据科学导论”!我们将介绍Python的基础知识,然后转到统计学,最后介绍各种建模技术。
- 54 次浏览
【机器学习】24个终极数据科学(机器学习)项目,提升您的知识和技能:高级
视频号
微信公众号
知识星球
介绍
数据科学(机器学习)项目为你提供了一种很有前途的方式来开启你在该领域的职业生涯。你不仅可以通过应用数据科学来学习数据科学,还可以在简历上展示项目!如今,招聘人员通过求职者的工作来评估其潜力,而不太重视证书。如果你只是告诉他们你知道多少,如果你没有什么可以展示给他们,那也没关系!这是大多数人挣扎和错过的地方。
你以前可能已经解决过几个问题,但如果你不能让它看起来很好看,很容易解释,那么别人怎么会知道你的能力呢?这就是这些项目将帮助你的地方。想想你将在这些项目上花费的时间,比如你的培训课程。你练习的时间越多,你就会变得越好!
我们确保为您提供来自不同领域的各种问题的体验。我们相信,每个人都必须学会巧妙地处理大量数据,因此包括了大型数据集。此外,我们还确保所有数据集都是开放的,可以免费访问。
- 介绍
- 有用信息
- 初级数据科学项目
- 中级数据科学项目
- 高级数据科学项目
- 结论
- 常见问题
为了帮助您决定从哪里开始,我们将此列表分为3个级别,即:
- 初级:该级别由数据集组成,这些数据集非常容易使用,不需要复杂的数据科学技术。您可以使用基本的回归或分类算法来解决这些问题。此外,这些数据集有足够多的开放式教程可以让您继续学习。在这个列表中,我们还提供了教程来帮助您入门。您也可以在这里查看AV的“数据科学导论”课程!
- 中级:该级别由性质上更具挑战性的数据集组成。它由中大型数据集组成,这些数据集需要一些严肃的模式识别技能。此外,功能工程将在这里发挥作用。ML技术的使用没有限制;阳光下的一切都可以使用。
- 高级级别:该级别最适合理解神经网络、深度学习、推荐系统等高级主题的人。这里还介绍了高维数据集。此外,现在是发挥创造力的时候了。看看最好的数据科学家在他们的工作和代码中所带来的创造力。
你想掌握机器学习和深度学习吗?这里有一个全面的计划,详细介绍了机器学习和深度学习的概念,以及25个以上的现实生活项目!
高级数据科学项目
1.识别您的数字数据集
该数据集允许您研究、分析和识别图像中的元素。这正是你的相机通过图像识别来检测你的脸的方式!轮到你构建和测试这项技术了。这是一个数字识别问题。此数据集有7000个28 X 28大小的图像,总计31MB。
问题:从图像中识别数字。
Start: Get Data | Tutorial: Get Here
2.城市声音分类
当你开始你的机器学习之旅时,你会遇到一些简单的机器学习问题,比如巨大的生存预测。但当涉及到现实生活中的问题时,你仍然没有足够的练习。因此,这个练习问题旨在向您介绍通常分类场景中的音频处理。该数据集由10个类别的8732个城市声音摘录组成。
问题:根据音频对声音类型进行分类。
Start: Get Data | Tutorial: Get Here
3.Vox名人数据集
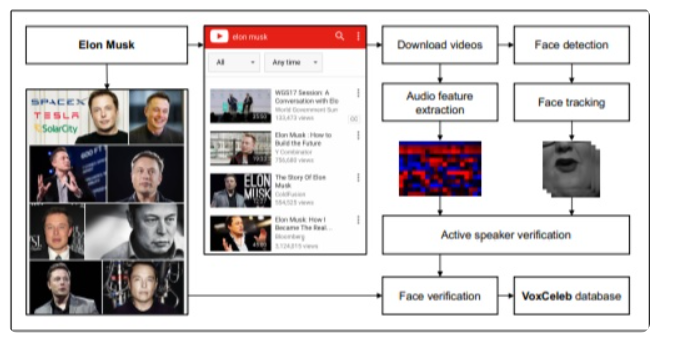
音频处理正迅速成为深度学习的一个重要领域,因此这是另一个具有挑战性的问题。该数据集用于大规模说话者识别,包含名人从YouTube视频中提取的单词。这是一个用于隔离和识别语音识别的有趣用例。该数据包含1251位名人发表的10万条言论。
问题:弄清楚这个声音属于哪个名人。
Start: Get Data | Tutorial: Get Here
4.ImageNet数据集

ImageNet提供了各种问题,包括对象检测、定位、分类和屏幕解析。所有图片均免费提供。你可以搜索任何类型的图像,并围绕它构建你的项目。截至目前,这个图像引擎拥有超过1500万张大小高达140GB的多种形状的图像。
问题:要解决的问题取决于您下载的图像类型。
Start: Get Data | Tutorial: Get Here
5.芝加哥犯罪数据集
如今,每个数据科学家都有能力处理大型数据集。当公司有计算能力处理完整的数据集时,他们不再喜欢处理样本。此数据集为您提供了在本地机器上处理大型数据集所需的亲身体验。问题很简单,但数据管理是关键!该数据集有600万次观测。这是一个多分类的问题。
问题:预测犯罪类型。
Start: Get Data | Tutorial: Get Here
6.印度演员数据集的年龄检测
对于任何一个深度学习爱好者来说,这都是一个引人入胜的挑战。该数据集包含数千张印度演员的照片,您的任务是确定他们的年龄。所有图像都是从视频帧中手动选择和裁剪的,从而在比例、姿势、表情、照明、年龄、分辨率、遮挡和化妆之间产生高度的可变性。训练集中有19906幅图像,测试集中有6636幅图像。
问题:预测演员的年龄。
Start: Get Data | Tutorial: Get Here
7.推荐引擎数据集
这是对高级推荐系统的挑战。在这个练习问题中,你会得到程序员的数据和他们之前解决的问题,以及他们解决特定问题所花费的时间。作为一名数据科学家,你建立的模型将帮助在线评委决定向用户推荐的下一级问题。
问题:根据用户的当前状态,预测解决问题所需的时间。
Start: Get Data
8.VisualQA数据集
VisualQA是一个包含关于图像的开放式问题的数据集。这些问题需要理解计算机视觉和语言。这个问题有一个自动评估指标。该数据集有265016张图像,每张图像有3个问题,每个问题有10个基本事实答案。
问题:使用深度学习技术回答关于图像的开放式问题。
Start: Get Data | Tutorial: Get Here
结论
在上面列出的24个数据集中,你应该先找到一个与你的技能相匹配的数据集。比如说,如果你是机器学习的初学者,从一开始就避免使用高级数据集。不要贪多嚼不烂,也不要因为还有多少事情要做而不知所措。相反,要专注于循序渐进。
完成2-3个项目后,在简历和GitHub个人资料中展示它们(非常重要!)。如今,许多招聘人员通过查看他们的GitHub档案来招聘候选人。你的动机不应该是做所有的项目,而是根据要解决的问题、领域和数据集大小来挑选选定的项目。如果您想了解完整的项目解决方案,请参阅本文。
常见问题
Q1.如何提高我的数据科学技能?
A.你可以通过跟上行业的新趋势和技术来提高你的数据科学技能。练习不同类型的数据科学项目是磨练你技能的另一种方式。本文列出了24个不同难度级别的免费项目,供您测试和提高技能。
Q2.哪些好的机器学习项目?
A.以下是一些不同难度的良好机器学习实践项目数据集:
- 初级项目:虹膜、贷款预测、大卖场销售、时间序列评估和学生评估。
- 中级项目:人类活动识别、文本挖掘、旅行历史、人口普查收入和推特分类。
- 高级项目:ImageNEt、数字识别、城市声音分类、年龄检测和推荐引擎。
Q3.一些初级数据科学项目是什么?
A.Iris数据集是一个很好的起点。其他初级数据科学项目包括贷款预测、大市场销售、时间序列评估、学生评估等。
- 76 次浏览
【机器学习】8家公司改变机器学习的使用方式
1.ChattyPeople
ChattyPeople是一个客户服务机器人,您可以无缝地使用您的Facebook Messenger和您的业务页面上的评论。它还提供了一种按需发送促销和交易给您的客户的方式,并与所有主要支付系统(包括PayPal和Stripe)进行整合。它可以帮助许多类型的企业,包括餐馆和洗衣机,提供伟大的服务,而不必在每个客户的互动上放置人类。
2.Skycatch
Skycatch是机器学习的早期领导者,可帮助公司大规模收集数据以重写其业务模式。采用自主无人机,航空成像技术及其专有分析工具套件,Skycatch可以开采矿山,太阳能,农业和建筑公司,以降低成本,提高现场安全。
3.Botworx
Botworx是一个人工智能动力平台,可提供适用于所有类型即时消息系统的真实对话。目标是让您的客户真正感觉到有人与他们在一起,而不是处理一个自动化的响应系统,对于他们处理的人员没有任何个性或敏感性,这可能会影响客户体验。结果是真正的客户参与,而不必将人员分配给提供该体验的工作。
4.POC医疗系统
POC医疗提供了一个点护理解决方案。其Pandora CDx提供了一种检测某些生物标志物来筛选乳腺癌的方法,通过使用具有内置机器学习技术的内置阅读机制的紧凑型微流体系统。它进一步应用于筛选其他类型的癌症,传染病和心血管疾病。在创建一个高效,自主的筛选系统中,该公司已经能够提供一种非常低成本的解决方案,可以为更多的人提供早期检测筛选,从而可以节省许多生命。
5.笛卡尔实验室
笛卡尔实验室使用机器学习来帮助组织更好地了解和预测世界各地的作物产量,以更好地准备避免短缺所需的食物。机器学习应用于卫星图像数据,以提供这些见解。希望这项技术可以帮助农业企业,保险和金融等众多行业以及政府机构。
6.弗林特
Flint将机器学习整合到其发票和信用卡处理平台中,以方便您处理这些业务的许多耗时的任务。它包括自动化任务,如付款提醒,确认,优惠券优惠,折扣等。其支付安全功能还增加了机器学习功能,以帮助企业保持在任何可疑活动之上,并发现任何可疑的交易模式。
7. TrademarkVision
TrademarkVision在其图像识别工具中使用机器学习技术来确定新的公司标志是否可以接受或者是否违反了现有商标。现在,欧盟的商标局现在使用这个系统,以前是一个繁琐,耗时且并不总是准确的过程,现在是快速,高效,准确的。
8.Fanuc
Fanuc是一家为工厂制造机器人的日本公司。 然而,这些不仅仅是磨机厂的机器人。 这些机器人可以在工作中学习新的技能。 使用机器学习算法,这些机器人具有人造智能,使他们能够以90%的准确度工作并完成新任务。
这些只是许多令人兴奋的机器学习项目中的一些。 未来已经到来,正在改变我们的工作方式,提供用技术分享世界的新途径。
- 53 次浏览
【机器学习】事件驱动架构与分析和机器学习集成
扩展架构扩展了基本参考架构,其概念展示了如何将数据科学,人工智能(AI)和机器学习整合到事件驱动的解决方案中。
为了获得机器学习模型或分析趋势和行为的数据,数据科学家必须从可以消费的形式开始使用数据。对于实时智能解决方案,数据科学家通常会检查系统中的事件历史记录和决策或操作记录。然后,他们将此数据减少为简化模型,该模型在新事件数据到达时对其进行评分。
获取数据科学家的数据
对于事件流,挑战在于处理无限数据或连续的事件流。为了使这些数据可供数据科学家使用,您必须捕获相关数据并将其存储,以便将其纳入分析和模型构建过程。
遵循事件驱动的参考体系结构,事件流可以是事件主干上的Kafka主题。从这里,您可以通过两种方式向数据科学家提供可用和可消耗的事件数据:
- 事件流或事件日志可以直接通过Kafka访问并进入分析过程。
- 事件流可以由流分析系统预处理并存储以供将来在分析过程中使用。您可以选择要使用的商店类型。 IBM Cloud Object Storage可用作经济高效的历史存储。
这两种方法都是有效的:通过流分析进行预处理,以便更好地处理数据或随时间存储数据以进行复杂的事件处理。更有趣的区别在于您使用预测机器学习模型来评估到达事件或流数据。在这种情况下,您可以使用流分析来提取和保存事件数据,以进行分析,建模,模型培训,以及根据到达的事件数据对派生模型进行评分。
事件和决策或行动数据在云对象存储中可用,用于通过流分析进行模型构建。可以通过调整和参数拟合,标准形式拟合,分类技术和文本分析方法来开发模型。
人工智能和机器学习框架越来越多地用于发现和训练有用的预测模型,作为手动参数化模型类型的替代方法。这些技术导致过程和数据流,其中预测模型通过使用来自事件和决策或动作存储的事件历史来离线训练,可能通过监督结果标记来增强。该流程通过从事件主干和流处理存储到“学习和分析”组件的路径来说明。
以这种方式训练的模型包括评分API,该评分API可以用新鲜事件数据调用以生成针对该特定上下文的未来行为和事件属性的基于模型的预测。然后将评分功能重新纳入流分析处理以生成预测和见解。
这些组合技术可以创建实时智能应用程序:
- 事件驱动的架构
- 通过使用事件风暴来识别预测性见解
- 使用机器学习为这些见解开发模型
- 使用流分析处理框架对洞察模型进行实时评分
这些应用程序具有可扩展性,可扩展性和适应性。他们近乎实时地回应新情况。由于事件驱动架构和流处理域中的松散耦合,您可以扩展它们以构建并从最初的最小可行产品(MVP)演变而来。
数据科学家工作台
要完成与分析和机器学习集成的扩展体系结构,请考虑数据科学家可用于派生模型的工具集和框架。 IBMWatson®Studio为数据科学家,应用程序开发人员和主题专家提供工具,以协作处理数据,以大规模构建和训练模型。有关更多信息,请参阅Watson Studio入门。
与传统系统集成
当您将数字业务应用程序创建为自包含系统时,您可能需要将传统应用程序和数据库集成到事件驱动系统中。传统系统可以通过两种方式直接进入事件驱动架构:
- 在传统应用程序与IBM®MQ连接的情况下,您可以直接从IBM MQ连接到事件主干中的Kafka。有关更多信息,请参阅Event Streams入门IBM MQ。
- 在数据库支持捕获数据更改的情况下,您可以将更改作为事件发布到Kafka和事件基础结构中。有关更多信息,请参阅没有更多孤岛:如何将您的数据库与Apache Kafka和CDC集成。
原文:https://www.ibm.com/cloud/garage/architectures/eventDrivenExtendedArchitecture
讨论:加入知识星球【首席架构师圈】
- 69 次浏览
【机器学习】人工智能和机器学习有何不同
在过去几年中,人工智能和机器学习这两个术语已经开始在技术新闻和网站中频繁出现。通常这两者被用作同义词,但许多专家认为它们具有微妙但真正的差异。
当然,专家们有时也不同意这些差异是什么。
然而,总的来说,有两件事情似乎很清楚:第一,人工智能(AI)这个术语比机器学习(ML)更早,其次,大多数人认为机器学习是人工智能的一个子集。
这种关系的最佳图形表现之一来自Nvidia的博客。它为理解人工智能和机器学习之间的差异提供了一个很好的起点。
人工智能与机器学习 - 首先,什么是人工智能?
计算机科学家已经以多种不同的方式定义了人工智能,但从本质上讲,人工智能涉及的是思考人类思维方式的机器。当然,很难确定机器是否在“思考”,因此在实际层面上,创建人工智能涉及创建一个善于做人类擅长的事情的计算机系统。
创造像人类一样聪明的机器的想法一直追溯到古希腊人,他们有关于神创造的自动机的神话。然而,实际上,这个想法直到1950年才真正起飞。
那一年,艾伦·图灵发表了一篇名为“计算机器和智能”的开创性论文,提出了机器是否可以思考的问题。他提出了着名的图灵测试,该测试基本上说,如果人类法官无法判断他是在与人或机器进行交互,那么可以说计算机是智能的。
人工智能这句话是由John McCarthy于1956年创造的,他在达特茅斯组织了一次专门讨论该主题的学术会议。在会议结束时,与会者建议进一步研究“猜想学习的每个方面或任何其他智能特征原则上可以如此精确地描述,以便可以使机器模拟它。将尝试找到如何使机器使用语言,形成抽象和概念,解决现在为人类保留的各种问题,并改善自己。“
该提案预示了当今人工智能中主要关注的许多主题,包括自然语言处理,图像识别和分类以及机器学习。
在第一次会议之后的几年里,人工智能研究蓬勃发展。然而,在几十年内,显而易见的是,制造真正可以说是为自己思考的机器的技术已经有很多年了。
但在过去十年中,人工智能已从科幻小说领域转移到科学事实领域。有关IBM Watson AI赢得游戏节目的故事显示,Jeopardy和谷歌的人工智能在Go游戏中击败人类冠军,将人工智能带回公众意识的最前沿。
今天,所有最大的科技公司都在投资人工智能项目,每当我们使用智能手机,社交媒体,网络搜索引擎或电子商务网站时,我们大多数人每天都会与人工智能软件进行互动。我们最常与之互动的人工智能类型之一是机器学习。
人工智能与机器学习 - 好的,那么什么是机器学习?
“机器学习”这个短语也可以追溯到上个世纪中叶。 1959年,亚瑟·塞缪尔将机器学习定义为“没有明确编程就能学习的能力”。他继续创建了一个计算机检查器应用程序,这是第一个可以从自己的错误中学习并随着时间的推移改善其性能的程序之一。
与人工智能研究一样,机器学习在很长一段时间内都没有流行,但是当数据挖掘的概念在20世纪90年代开始起步时,机器学习又开始流行起来。数据挖掘使用算法来查找给定信息集中的模式。机器学习做同样的事情,但后来又向前迈进了一步 - 它根据学习内容改变了程序的行为。
最近变得非常流行的机器学习的一个应用是图像识别。首先必须训练这些应用程序 - 换句话说,人类必须查看一堆图片并告诉系统图片中的内容。经过数千次重复,软件可以了解哪些像素图案通常与马,狗,猫,花,树,房屋等相关联,并且可以很好地猜测图像的内容。
许多基于网络的公司也使用机器学习来为他们的推荐引擎提供动力。例如,当Facebook决定在您的新闻源中显示什么,当亚马逊突出您可能想要购买的产品时,以及当Netflix建议您可能想要观看的电影时,所有这些建议都基于现有数据中的模式所基于的预测。
目前,许多企业开始使用机器学习功能进行预测分析。随着大数据分析变得越来越流行,机器学习技术变得越来越普遍,并且它是许多分析工具中的标准功能。
实际上,机器学习已经与统计学,数据挖掘和预测分析联系在一起,有些人认为它应该被归类为与人工智能分开的领域。毕竟,系统可以展示AI功能,如自然语言处理或自动推理,而无需任何机器学习功能,机器学习系统不一定需要具有人工智能的任何其他功能。
其他人更喜欢使用术语“机器学习”,因为他们认为这听起来比“人工智能”更具技术性和可怕性。一位互联网评论者甚至表示,两者之间的区别在于“机器学习确实有效”。
然而,机器学习从一开始就是关于人工智能的讨论的一部分,而且这两者在今天上市的许多应用中仍然紧密相连。例如,个人助理和机器人通常具有许多不同的AI功能,包括ML。
人工智能和机器学习前沿:深度学习,神经网络和认知计算
当然,“机器学习”和“人工智能”并不是与计算机科学领域相关的唯一术语。 IBM经常使用术语“认知计算”,它或多或少是AI的同义词。
但是,其他一些术语确实具有非常独特的含义。例如,人工神经网络或神经网络是一种系统,旨在以类似于生物大脑工作方式的方式处理信息。事情会变得混乱,因为神经网络往往特别擅长机器学习,所以这两个术语有时会混淆。
此外,神经网络为深度学习提供了基础,深度学习是一种特殊的机器学习。深度学习使用一组在多个层中运行的机器学习算法。它可以部分地由使用GPU一次处理大量数据的系统实现。
如果你对所有这些不同的术语感到困惑,那么你并不孤单。计算机科学家继续辩论他们的确切定义,并可能在未来一段时间内。随着公司继续向人工智能和机器学习研究投入资金,可能会出现更多的术语,为问题增加更多的复杂性。
- 78 次浏览
【机器学习】机器学习如何赋能智能企业
当Google的AlphaGo算法在2016年击败Go世界冠军时,显然机器学习已经到来,并将显着塑造未来。作为一种能够在没有被明确编程的情况下学习的新型软件,机器学习将能够以人类头脑难以掌握的复杂程度访问和分析结构化和非结构化数据。从现在的语音识别和图像识别软件的质量以及自驾车的能力来看,我们已经可以看到自学习算法如何影响我们的生活。
五十年代以来,计算机科学家一直在追求人工智能。现在,由于最新的技术进步,包括大数据处理,增加的计算能力和更好的算法,计算机已经开始与人类一样被认为是竞争,甚至超越了这种能力。机器正在学习在图像和视频中写,说,寻找意义。未来,智能机器将越来越多地支持人类。我们将进入智慧型企业的时代。
机器学习将以多种方式为企业带来好处。组织能够加速和优化业务流程。企业领导者将获得更大的能力来检测他们的运营模式和客户互动模式,从而使他们能够识别相关的见解。机器学习可以简化用户与设备的交互,减少人为干预,并自动执行重复任务,让人们更多的时间专注于需要创造力和复杂的解决问题的工作。
机器学习显示承诺的地方
公众对机器学习的关注往往侧重于消费者应用,如推荐引擎和智能设备。但对于企业对企业的使用也是很有希望的。在B2B上下文中,我们设想机器智能将首先应用于以下领域:
智能业务流程。今天的许多业务流程仍然依靠严格的规则运行,并且依赖于人的互动。通常,这些过程涉及高度重复的工作,例如检查发票和旅行费用的准确性,或通过数百份简历来填补职位。通过让自学习算法在数据中找到模式和解决方案,而不是遵循预编程规则,某些业务系统将达到新的智能和效率水平。
智能基础设施。我们的经济依赖于基础设施的各种因素,包括能源,物流和IT,以及支持社会的服务,如教育和医疗保健。但是我们似乎已经在这些领域达到了效率高原,正如我们在业务流程中所做的一样。机器学习有可能找到更好和更灵活的规则来运行为增长提供基础的复杂且快速变化的系统。
数字助理和机器人。机器学习技术的最新进展表明,运行自学习算法的设备将比现在更独立运行。他们可以在某些参数中得出自己的结论,开发上下文敏感的行为,并且更直接地与人类进行交互。我们的设备 - 已经能够对我们的声音做出反应 - 将成为互动的,持续的学习助手,通过安排会议,翻译文档或分析文本和数据来帮助我们实现日常业务。
起点
数据是机器学习的燃料。为了让企业准备好接受机器学习,企业领导者必须认真努力,消除数据孤岛,并从供应商,合作伙伴和客户的生态系统获取数据。这样做是成功的关键先决条件。此外,组织需要开始识别机器改进的甜点,例如高度重复的工作。
在时间上,机器学习将像我们的电 - 我们很难想象没有它的世界。它将为商业环境带来智慧,发现新的市场机会,并使人们能够专注于增加价值的工作,而不是花时间进行冗长乏味的重复任务。
- 67 次浏览
【机器学习】机器学习工具总览
丰富的机器学习工具
当谈到训练计算机在没有明确编程的情况下采取行动时,存在大量来自机器学习领域的工具。学术界和行业专业人士使用这些工具在MRI扫描中构建从语音识别到癌症检测的多种应用。这些工具可在网上免费获得。如果您感兴趣,我已经编制了这些的排名(请参阅本页底部)以及一些区分它们的重要功能的概述。其中,从主页网站获取每种工具的描述,关注机器学习中的特定范例以及学术界和工业界的一些显着用途。
研究人员可以一次使用许多不同的库,编写自己的库,或者不引用任何特定的工具,因此很难量化每种库的相对采用。相反,搜索排名反映了5月份谷歌搜索每个工具的相对大小。该分数并不反映广泛采用,但为我们提供了一个很好的指示,表明正在使用哪些。注意*像“Caffe”这样的模糊名称被评为“Caffe机器学习”,不那么含糊。
机器学习工具总览
我已经将两个机器学习子领域Deep和Shallow Learning区分开来,这已成为过去几年中的一个重要分支。深度学习负责图像分类和语音识别的记录结果,因此由Google,Facebook和百度等大型数据公司牵头。相反,浅层学习方法包括各种不太前沿的分类,聚类和提升技术,如支持向量机。浅层学习方法仍然广泛应用于自然语言处理,脑计算机接口和信息检索等领域。
机器学习包和库的详细比较
此表还包含有关使用GPU的特定工具支持的信息。 GPU接口已经成为机器学习工具的一个重要特性,因为它可以加速大规模矩阵运算。这对深度学习方法的重要性是显而易见的。例如,在2015年5月初的GPU技术大会上,机器学习下的45个演讲中有39个是关于GPU加速的深度学习应用程序,这些应用程序来自31家主要的科技公司和8所大学。这一吸引力反映了Deep Networks对GPU辅助培训的巨大速度提升,因此是一项重要功能。
还提供了有关通过Hadoop或Spark在集群中分配计算的工具能力的信息。这已成为适合分布式计算的浅学习技术的重要论述点。同样,Deep Networks的分布式计算也成为一个讨论点,因为已经为分布式训练算法开发了新技术。
最后,附上一些关于学术界和工业界对这些工具的不同使用的补充说明。通过搜索机器学习出版物,演示文稿和分布式代码收集了哪些信息。 Google,Facebook和甲骨文的研究人员也支持了一些信息,非常感谢Greg Mori,Adam Pocock和Ronan Collobert。
这项研究的结果表明,目前有许多工具正在使用,目前还不确定哪种工具能够赢得狮子会在工业界或学术界的使用份额。
| Search Rank | Tool | Language | Type | Description “quote” | Use | GPU acceleration | Distributed computing | |
| 100 | Theano | Python | Library | umerical computation library for multi-dimensional arrays efficiently | Deep and shallow Learning | CUDA and Open CL | cuDNN Cutorch | |
| 78 | Torch 7 | Lua | Framework | Scientific computing framework with wide support for machine learning algorithms | Deep and shallow Learning | CUDA and Open CL, cuDNN | Cutorch | |
| 64 | R | R | Environment/ Language | Functional language and environment for statistics | Shallow Learning |
|
HiPLAR | |
| 52 | LIBSVM | Java and C++ | Library | A Library for Support Vector Machines | Support Vector Machines | CUDA | Not Yet | |
| 34 | scikit-learn | Python | Library | Machine Learning in Python | Shallow Learning | Not Yet | Not Yet | |
| 28 |
Spark MLLIB |
C++, APIs in JAVA, and Python | Library/API | Apache Spark’s scalable machine learning library | Shallow Learning | ScalaCL |
Spark and Hadoop |
|
| 24 | Matlab | Matlab | Environment/ Language | High-level technical computing language and interactive environment for algorithm development, data visualization, data analysis, and numerical analysis | Deep and Shallow Learning | Parallel Computing Toolbox (not-free not-open source) |
Distributed Computing Package (not-free not-open source) |
|
| 18 | Pylearn2 | Python | Library | Machine Learning | Deep Learning | CUDA and OpenCL, cuDNN | Not Yet | |
| 14 |
VowPal Wabbit |
C++ | Library | Out-of-core learning system | Shallow Learning | CUDA | Not Yet | |
| 13 | Caffe | C++ | Framework | Deep learning framework made with expression, speed, and modularity in mind | Deep Learning | CUDA and OpenCL, cuDNN | Not Yet | |
|
LIBLINEAR | Java and C++ | Library | A Library for Large Linear Classification | Support Vector Machines and Logistic Regression | CUDA | Not Yet | |
| 6 | Mahout | Java | Environment/ Framework | An environment for building scalable algorithms | Shallow Learning | JCUDA | Spark andHadoop | |
| 5 |
Accord. NET |
.Net | Framework | Machine learning | Deep and Shallow Learning | CUDA.net | Not Yet | |
| 5 | NLTK | Python | Library | Programs to work with human language data | Text Classification | Skits.cuda | Not Yet | |
| 4 |
Deep learning4j |
Java | Framework | Commercial-grade, open-source, distributed deep-learning library | Deep and shallow Learning | JClubas | Spark andHadoop | |
| 4 | Weka 3 | Java | Library | Collection of machine learning algorithms for data mining tasks | Shallow Learning | Not Yet |
Distributed Weka Spark |
|
| 4 | MLPY | Python | Library | Machine Learning | Shallow Learning | Skits.cuda | Not Yet | |
| 3 | Pandas | Python | Library | Data analysis and manipulation | Shallow Learning | Skits.cuda | Not Yet | |
| 1 | H20 | Java, Python and R | Environment/ Language | open source predictive analytics platform | Deep and Shallow Learning | Not Yet | Spark and Hadoop | |
| 0 | Cuda-covnet | C++ | Library | machine learning library forneural-network applications | Deep Neural Networks | CUDA | coming in Cuda-covnet2 | |
| 0 | Mallet | Java | Library | Package for statistical natural language processing | Shallow Learning | JCUDA | Spark and Hadoop | |
| 0 | JSAT | Java | Library | Statistical Analysis Tool | Shallow Learning | JCUDA | Spark and Hadoop | |
| 0 | MultiBoost | C++ | Library | Machine Learning | Boosting Algorithms | CUDA | Not Yet | |
| 0 | Shogun | C++ | Library | Machine Learning | Shallow Learning | CUDA | Not Yet | |
| 0 | MLPACK | C++ | Library | Machine Learning | Shallow Learning | CUDA | Not Yet | |
| 0 | DLIB | C++ | Library | Machine Learning | Shallow Learning | CUDA | Not Yet | |
| 0 | Ramp | Python | Library | Machine Learning | Shallow Learning | Skits.cuda | Not Yet | |
| 0 | Deepnet | Python | Library | GPU-based Machine Learning | Deep Learning | CUDA | Not Yet | |
| 0 | CUV | Python | Library | GPU-based Machine Learning | Deep Learning | CUDA | Not Yet | |
| 0 | APRIL-ANN | Lua | Library | Machine Learning | Deep Learning | Not Yet | Not Yet | |
| 0 | nnForge | C++ | Framework | GPU-basedMachine Learning | Convolutionl and fully-connected neural networks | CUDA | Not Yet | |
| 0 | PYML | Python | Framework | Object oriented framework for machine learning | SVMs and other kernel methods | Skits.cuda | Not Yet | |
| 0 | Milk | Python | Library | Machine Learning | Shallow Learning | Skits.cuda | Not Yet | |
| 0 | MDP | Python | Library | Machine Learning | Shallow Learning | Skits.cuda | Not Yet | |
| 0 |
|
Python | Library | Machine Learning | Shallow Learning | Skits.cuda | Not Yet | |
| 0 | PYMVPA | Python | Library | Machine Learning | Only Classification | Skits.cuda | Not Yet | |
| 0 |
|
Python | Library | Machine Learning | Shallow Learning | Skits.cuda | Not Yet | |
| 0 |
|
Python to R | API | Low-level interface to R | Shallow Learning | Skits.cuda | Not Yet | |
| 0 | NueroLab | Python | Library | Machine Learning | Feed Forward Neural Networks | Skits.cuda | Not Yet | |
| 0 | PythonXX | Python | Library | Machine Learning | Shallow Learning | Skits.cuda | Not Yet | |
| 0 | Hcluster | Python | Library | Machine Learning | Clustering Algorithms | Skits.cuda | Not Yet | |
| 0 | FYANN | C | Library | Machine Learning | Feed Forward Neural Networks | Not Yet | Not Yet | |
| 0 | PyANN | Python | Library | Machine Learning | Nearest Neighbours Classification | Not Yet | Not Yet | |
| 0 | FFNET | Python | Library | Machine Learning | FeedForwad NeuralNetwors | Not Yet | Not Yet |
帮助我们建立神经系统处理器的桥梁
Knowm Inc专注于开发像kT-RAM这样的神经系统处理器。 像杰弗里·辛顿这样的机器学习先驱者非常清楚,机器学习从根本上与计算能力有关。 我们称之为自适应电源问题,为了解决这个问题,我们需要新的工具来引领下一波智能机器。 虽然GPU(最终!)使我们能够展示在某些任务上接近人类水平的学习算法,但它们的能量和空间效率仍比生物学低100亿到10亿倍。 我们正把这个差距缩小到零。
我们有兴趣知道解决实际机器学习问题的人员,框架和算法最有用,因此我们可以集中精力构建kT-RAM和KnowmAPI的桥梁。 请在下面留言或联系我们告诉我们。
Misc. References
-
Bryan Catanzaro Senior Researcher, Baidu” Speech: The Next Generation” 05/28/2015 Talk given @ GPUTech conference 2015
-
Dhruv Batra CloudCV: Large-Scale Distributed Computer Vision as a Cloud Service” 05/28/2015 Talk given @ GPUTech conference 2015
-
Dilip Patolla. “A GPU based Satellite Image Analysis Tool” 05/28/2015 Talk given @ GPUTech conference 2015
-
Franco Mana. “A High-Density GPU Solution for DNN Training” 05/28/2015 Talk given @ GPUTech conference 2015</a
-
Hailin Jin. “Collaborative Feature Learning from Social Media” 05/28/2015 Talk given @ GPUTech conference 2015
-
Noel, Cyprian & Simon Osindero. “S5552 – Transparent Parallelization of Neural Network Training” 05/28/2015 Talk given @ GPUTech conference 2015
-
Rob Fergus. “S5581 – Visual Object Recognition using Deep Convolution Neural Networks” 05/28/2015 Talk given @ GPUTech conference 2015
-
Rodrigo Benenson ” Machine Learning Benchmark Results: MNIST” 05/28/2015
-
Rodrigo Benenson ” Machine Learning Benchmark Results: CIFAR” 05/28/2015
-
Tom Simonite “Baidu’s Artificial-Intelligence Supercomputer Beats Google at Image Recognition” 05/28/2015
- 87 次浏览
【机器学习】机器学习工程师的2020 路线图
受web开发人员路线图的启发,到2020年成为一名机器学习工程师。
下面是一组图表,展示了要成为一名机器学习工程师,你可以选择的路径和你想要采用的技术。我为我的一位老教授制作了这些图表,他想和他的大学生分享一些东西,给他们一个视角;在这里分享它们来帮助社区。
这些路线图的目的
这些路线图的目的是给你一个关于前景的概念,并在你对接下来要学习什么感到困惑时给你指导,而不是鼓励你去选择什么是流行的和流行的。您应该对为什么一种工具在某些情况下比另一种更适合有所了解,并且要记住,时髦和新潮并不意味着最适合这项工作。
写给初学者
这些路线图涵盖了下面列出的路径需要学习的所有内容。不要感到不知所措,如果你只是刚刚开始,你不需要一开始就学习。我们正在开发它们的初级版本,并将在2020年路线图发布后不久发布。

原文:https://github.com/chris-chris/ml-engineer-roadmap
本文:
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 83 次浏览
【机器学习】机器学习资料
构建可扩展的机器学习系统(一):你所需的架构设计知识
https://www.infoq.cn/article/LhsS8P27OTOhrE*A35lE
构建可扩展的机器学习系统(二):构建机器学习管道
https://www.infoq.cn/article/0b8zwZE847I-qlC6zDx0
- 133 次浏览
【机器学习】机器学习(ML)开发平台概述
Azure ML是许多包含基于代码的模型开发特性的ML平台之一,但它也是一个“studio”(如下所示)
本文是机器学习平台系列的第一篇。它由数字弹射器和PAPIs支持。
对于所有ML成熟度级别的组织来说,模型开发平台极大地减少了创建ML模型的时间和成本。这些平台可以是现成的,也可以是定制的,基于开源或商业软件。其中一些还作为模型部署平台,在少数情况下作为模型生命周期管理平台,但是它们的核心是运行模型培训管道。
根据模型开发平台的不同,培训管道或多或少是可定制的,它们可以在您自己的机器或云基础设施上运行。我们可以将ML开发平台分为以下几种类型:
- 半专用平台(例如用于文本或图像输入)
- 高级平台即服务(主要用于表格数据)
- 自托管工作室
- 云机器学习IDE
这个平台类型列表是通过增加灵活性来排序的——但是请注意,这是以增加模型开发、配置和维护的时间为代价的。Cloud ML ide是最灵活的,可以用于任何类型的数据。然而,大多数高级平台和工作室只处理表格数据。目前有数百种ML平台,因此我们不会尝试引用所有的ML平台,而是为每种类型提供各种平台。就让我们一探究竟吧!
半专业化平台:语言和愿景
语言平台允许用户根据自己的数据训练定制文本模型。输入将是使用给定语言的文本。对于视觉平台,输入将是图像或视频。对于语言和视觉平台来说,输出都是标识“概念”的标签。如果您愿意,这些可以是“专有的”概念(例如,我们组织内部的引用,例如项目名称或团队名称)。您将向平台提供自己的训练数据(输入和输出),它将自动创建您自己的ML模型。请注意,模型训练过程可能是不可定制的,但至少您能够快速创建工作模型。
视觉平台的例子有:Clarifai, Amazon Rekognition, and Google AutoML Vision。下面我们将展示如何使用Clarifai在2个API调用中创建模型:一个用于发送训练数据,另一个用于实际创建模型。
$ curl https://api.clarifai.com/v2/inputs -H "Authorization: Key YOUR_API_KEY" -H "Content-Type: application/json" -d '{ "inputs": [ { "data": {"image": {"base64": "'"$(base64 /home/user/object1.jpeg)"'"}, "concepts": [ {"id": "defect", "value": true} ] } ] }' $ curl https://api.clarifai.com/v2/models -H "Authorization: Key YOUR_API_KEY" -H "Content-Type: application/json" -d '{"model": { "name": "defect_detector", "output_info": { "data": {"concepts": [{"id": "defect"}]}, "output_config": { "concepts_mutually_exclusive": true, "closed_environment": false }}}}'
然后您就可以检查您的模型并评估其性能。
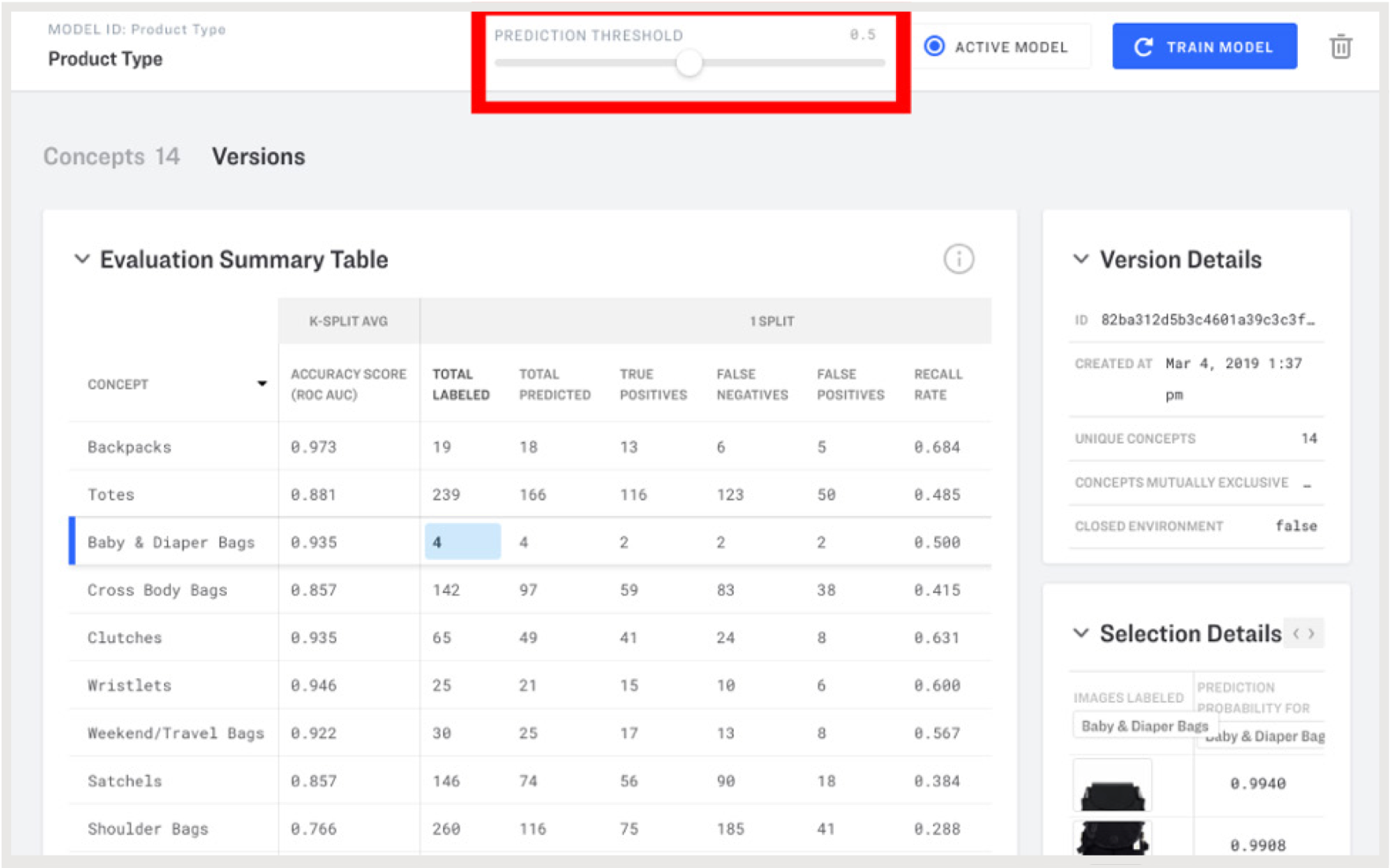
在Clarifai门户中进行模型评估和阈值调整
一些示例语言平台:Amazon understand、谷歌AutoML Natural Language和MonkeyLearn。Lateral是另一个有趣的API,它包括一个标记建议API(基于现有文本文档和标记)和一个推荐API,该API将类似的文档推荐给给定的文本文档。这使用了一种混合的方法,其中相关性是根据文本内容和用户行为决定的。
请注意,一些平台还提供数据注释服务,以帮助创建专有模型(例如,谷歌有一个众包数据标签服务)。如果您选择的平台没有这样的服务,则有专用的数据注释平台,如图8所示。
高级PaaS
作为服务的平台是最容易使用的,因为不需要安装,也不需要担心基础设施。高级功能包括:
- 问题类型的自动检测(例如,分类或回归)
- 数据的自动准备(如分类变量的编码、归一化、特征选择等)。
- 学习算法的自动化配置(具有元学习和超参数智能搜索的自动化)
这些平台对不太了解ML算法的人特别有用,领域专家或软件开发人员也可以访问它们。可以说,它们对数据科学家也很有用,因为它们允许更快的实验和更少的错误。这反过来又允许我们关注在从数据中学习之前和之后发生的所有事情——这在实践中是最重要的:收集ml准备好的数据,评估预测,并在软件中使用它们。
BigML
BigML是一个平台,它为分类和回归(决策树、随机森林、增强树、神经网络、线性和逻辑回归)提供了各种内置算法,这些算法支持数字特性、分类特性以及文本特性。它还提供了非监督学习算法(使用K-means和G-means聚类,使用隔离森林的异常检测,PCA,主题建模)和时间序列预测(指数平滑)。它的“优化”功能实现了自动化技术,可以在给定的时间预算内为给定的训练集、验证/测试集和性能度量找到最佳模型。它的“融合”功能创建了模型集合。
检查BigML自动创建的神经网络,带有交互式部分依赖图
BigML API允许用户在BigML云基础设施上大规模查询预测和触发模型训练。让我们假设BIGML_AUTH是一个包含BigML用户名和API密钥的环境变量。以下是调用API对给定的训练和测试数据集(通过其id识别)使用OptiML的方法,以最大化接受者操作特征(ROC)曲线(AUC)下的面积:
$ curl https://bigml.io/optiml?$BIGML_AUTH -d '{"dataset": "<training_dataset_id>", "test_dataset": "<test_dataset_id>", "metric": "area_under_roc_curve", "max_training_time": 3600 }'
该请求是异步的,将返回一个OptiML id。在一个小时(3600秒)后,可以点击API来获取创建的OptiML对象的信息,特别是包含为数据集找到的最佳模型的id的摘要。然后可以要求从这个模型进行预测:
$ MODEL_ID = curl https://bigml.io/optiml/<optiml_id>?$BIGML_AUTH | jq -r ".optiml.summary.model.best"$ curl https://bigml.io/predict?$BIGML_AUTH -d '{"model": "'"$MODEL_ID"'", "input_data": {"text": "I will never stay in this hotel again"}}'
BigML可能是本节介绍的平台中最容易使用的,但也是最不灵活的。ML实践者会发现缺失的功能,比如绘制学习曲线和使用自定义性能指标的能力。然而,BigML允许用户在他们的平台上用他们自己创建的称为WhizzML的语言执行脚本,这是一种专门用于机器学习的高级编程语言。这扩展了平台的功能。也是最封闭平台之一,因为它不与开源的,所以是有限的模型可以导出的格式,不可能导出脚本建模——然而,可以看到哪些算法和参数被用来创建一个模型。
谷歌的产品
谷歌AutoML表是一个beta版产品,与BigML有相似之处,但还不打算在关键应用程序中使用。它的UI更简单,而且该产品似乎更针对开发人员而不是领域专家。谷歌云推断API专注于时间序列预测。它是一个不包含UI的alpha产品,但更适合在生产中部署。
微软Azure ML
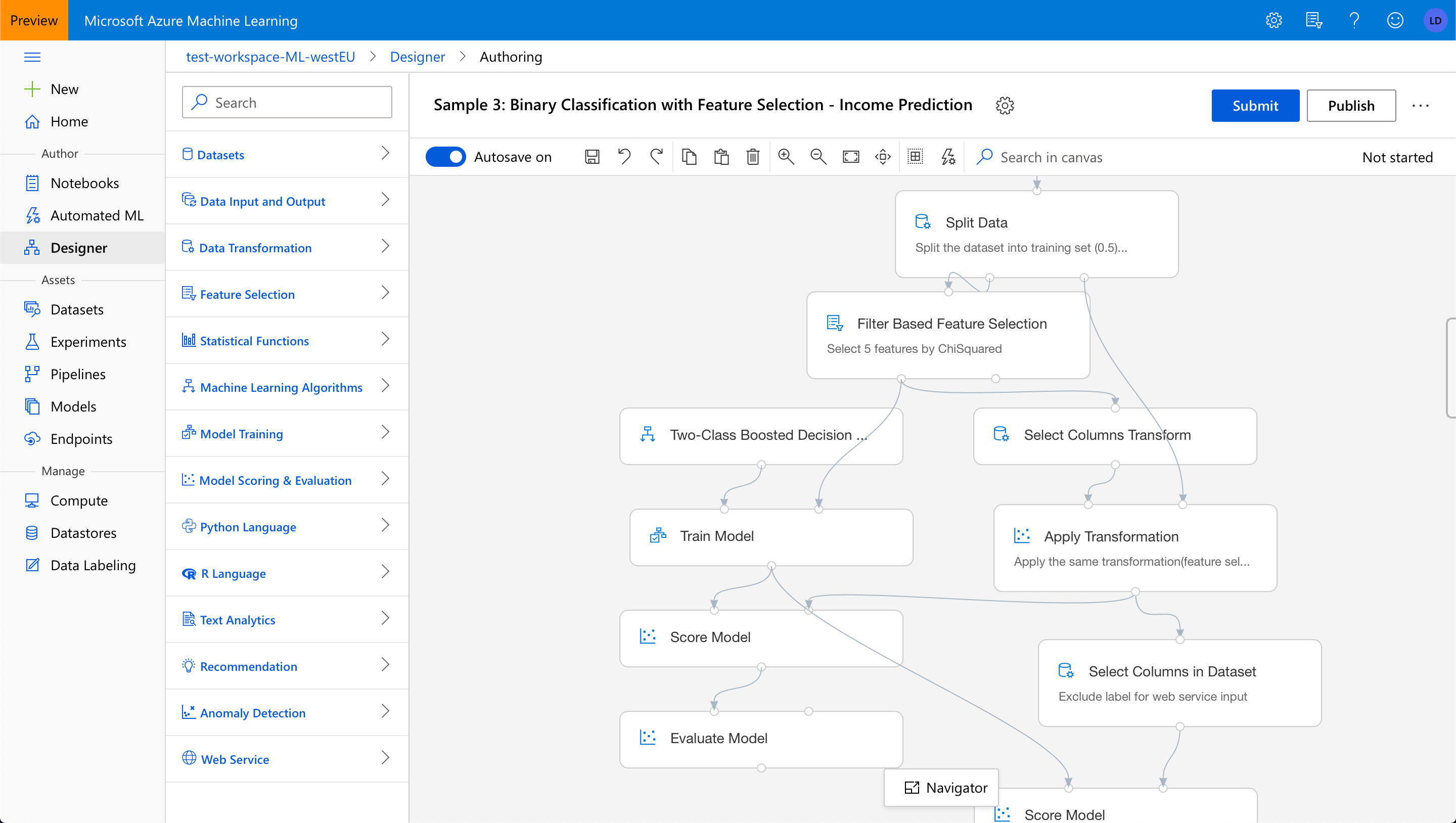
Microsoft Azure ML是一个MLaaS平台,提供了一个带有两个模型创作环境的工作室:自动化ML和设计器(以前称为“交互画布”)。该平台还可以将模型转换为可自动伸缩的预测api。设计者允许用户查看和可视化地编辑模型训练管道,即获取数据、准备数据和应用ML算法生成(和评估)预测模型的操作序列。通过避免接口捕获的潜在错误(例如,缺少数据操作的输入,或禁止的连接),设计器使理解管道变得更容易,但也使创建管道变得更容易。
微软Azure ML的设计师
Lobe
Lobe是微软于2018年收购的一项服务,它也提供交互式画布和自动功能,但也允许用户处理图像功能。它提供了一个易于使用的环境来自动建立神经网络模型,通过一个可视化的界面。模型是由可以完全控制的构件组成的(波瓣建立在TensorFlow和Keras之上);一些构建模块是预先训练的,这允许迁移学习。培训可以通过实时的交互式图表进行监控。训练好的模型可以通过开发人API提供,或者导出到Core ML和TensorFlow文件,在iOS和Android设备上运行。
图像和数字特征的ML模型的一系列操作的可视化编辑
自托管工作室
其他一些工作室也提供了不同名称的设计器——DataRobot称其为“蓝图”,Rapidminer和Dataiku称其为“工作流”——以及自动化功能。这里提到的ML开发平台被认为比以前的平台级别更低,因为它们不是“作为服务”提供的,需要安装并托管在我们自己的(集群)机器上。但是,它们具有在MLaaS产品中没有的有趣功能。
这些平台共有的一个共同点是它们都基于标准的开源ML库,并允许用户使用定制库和定制代码。它们允许用户将ML工作流/管道导出为Python脚本,并将经过训练的模型导出为各种开放格式,从而避免锁定。注意,上面提到的一些供应商还提供单独的部署和模型服务解决方案。
Dataiku
大泰库的数据科学工作室(DSS)有以下优势:
- 连接到许多类型的数据库。例如,数据源可以从CSV文件更改为Hadoop文件系统(HDFS) URI,而不需要更改ML管道的其余部分
- 可视化数据角力、特征工程和特征丰富,以改进数据,并帮助它在使用学习算法之前做好准备
- 提供内置算法的不同ML后端。例如,后端可以从scikit-learn更改为Spark MLlib,而不需要更改ML管道的其余部分
- 内置的聚类和异常检测算法
在Dataiku的数据科学工作室中比较MLlib模型的性能
DataRobot
DataRobot有以下优点:
- 自动功能工程
- 模型检查特征和预测解释的可视化
- 高级时间序列预测:几个内置算法(ARIMA, Facebook Prophet,梯度增强),回溯测试评估方法,平稳性自动检测,季节性,时间序列特征工程。
在DataRobot中的预测解释
H2O
H2O的无人驾驶人工智能与DataRobot类似。两者都有Python API。下面是对H2O Python API的start_experiment_sync方法的调用,它在精神上类似于BigML的HTTP API的OptiML方法:
params = h2oai.get_experiment_tuning_suggestion(
dataset_key=train.key,
target_col=target,
is_classification=True,
is_time_series=False,
config_overrides=None)experiment = h2oai.start_experiment_sync(
dataset_key=train.key,
testset_key=test.key,
target_col=target,
is_classification=True,
scorer='AUC',
accuracy=params['accuracy'],
time=params['time'],
interpretability=params['interpretability'],
enable_gpus=True,
seed=1234, # for reproducibility
cols_to_drop=['ID'])云机器学习IDE
我们最后一种类型的模型开发平台可以看作是托管在云上的用于机器学习的集成开发环境(IDE)。这些平台不提供以前提供的ML studio的高级功能,但是它们可以从云计算中获益。对于机器和深度学习从业者来说,使用云平台提供的强大的、配置了gpu的虚拟机(VMs)进行实验是一种常见的做法。这些云vm在创建特定于ml的云平台之前就已经可用了。这些平台使得实验运行速度更快,而且如果需要的话,也很容易24/7地进行。这些平台还可以对多核cpu、具有大量RAM的强大gpu和已经配置好的集群(例如,用于分布式学习、并行调优超参数和使用深度神经网络)进行大规模实验。用户只为他们使用的东西付费;无需预付购买昂贵硬件的费用。
新的特定于ml的云平台允许在预先配置的基础设施上访问Jupyter实验室环境,即基于web的ide。它们为云vm提供所有公共开放源码ML库。通常包括TensorBoard web服务器,用于监控基于tensorflow的实验的进程。Cloud ML ide的目标是使vm的可用速度比其他云服务更快(通常从几分钟到几秒),并使在这些(短期)vm上完成的工作更方便持久化。
Floyd
Floyd是一个很好的入门平台,因为它使用起来没有竞争对手那么复杂,但是仍然提供了一些不同的选项来运行ML实验。它提供了两种类型的cpu和两种类型的gpu的访问,根据我们的需要进行选择。实验可以通过两种不同的方式进行:
- 工作区,这是一个基于Jupyter实验室的IDE,用于交互式实验。它还提供了对TensorBoard的访问,以及一个类似的称为Metrics的特性,可以与任何ML库(不一定是TensorFlow)一起使用,以监视模型训练的进度
- 作业,用于作为脚本运行较长的实验。作业是从安装在我们自己机器上的命令行接口(CLI)工具启动的,与本地执行脚本的方式相同,但它们是在Floyd平台上运行的。CLI还允许用户标记作业和下载输出。浏览作业的历史记录、使用标记进行筛选以及查看历史记录中的结果摘要,这些功能都满足了实验跟踪器的功能。
- 另一个有用的特性是能够在云平台上存储大型数据集并与整个团队共享,因此不需要在本地下载数据集并保持同步。Floyd的基础设施建立在亚马逊北美的公共云之上,但Floyd也可以安装在私有云和本地云上,这是它区别于谷歌和亚马逊产品的一个方面。
谷歌AI平台笔记本
谷歌AI平台笔记本类似于Floyd工作区。它使用了该平台的深度学习VM映像和它的云TPUs(张量处理单元)。它内置了Git支持,并与谷歌AI Hub集成。谷歌AI Hub可以帮助发现其他人在组织内构建的内容(比如笔记本、管道和模型),在开始新的开发之前应该检查这些内容。由于笔记本是谷歌云产品,它提供了访问预配置/预安装的谷歌云平台库,如Dataflow和Dataproc来进行数据争论。GPU可以添加到平台使用的云VM中,也可以从云VM中移除,而Floyd被限制为每个VM只有1个GPU。
AWS SageMaker
SageMaker是Amazon的ML平台,它提供了类似的开发环境,便于在分布式模型训练和分布式超参数调优实验中使用集群计算。SageMaker允许用户通过其Python API和字典数据结构定义用于训练和验证的数据集,用于训练算法的超参数值,以及用于运行作业的资源,来定义模型训练作业。
training_params = \
{
"AlgorithmSpecification": {
"TrainingImage": image, # specify the training docker image
"TrainingInputMode": "File"
},
"RoleArn": role,
"OutputDataConfig": {
"S3OutputPath": 's3://{}/{}/output'.format(bucket)
},
"ResourceConfig": {
"InstanceCount": 1,
"InstanceType": "ml.p3.2xlarge",
"VolumeSizeInGB": 50
},
"TrainingJobName": "model_a",
"HyperParameters": {
"image_shape": "3,224,224",
"num_layers": "18",
"num_training_samples": "15420",
"num_classes": "257",
"mini_batch_size": "128",
"epochs": "2",
"learning_rate": "0.2",
"use_pretrained_model": "1"
},
"StoppingCondition": {
"MaxRuntimeInSeconds": 360000
},
"InputDataConfig": [
{
"ChannelName": "train",
"DataSource": {
"S3DataSource": {
"S3DataType": "S3Prefix",
"S3Uri": 's3://{}/train/'.format(bucket),
"S3DataDistributionType": "FullyReplicated"
}
},
"ContentType": "application/x-recordio",
"CompressionType": "None"
},
{
"ChannelName": "validation",
"DataSource": {
"S3DataSource": {
"S3DataType": "S3Prefix",
"S3Uri": 's3://{}/validation/'.format(bucket),
"S3DataDistributionType": "FullyReplicated"
}
},
"ContentType": "application/x-recordio",
"CompressionType": "None"
}
]
}
sagemaker.create_training_job(**training_params)
该平台还为各种ML任务提供了项目模板,包括一些高级任务,如序列到序列学习和强化学习。
Databricks
Databricks统一分析平台允许用户访问亚马逊或微软云平台上的集群计算。Databricks维护Apache Spark,这是一个领先的开源集群计算框架。该平台还允许访问Databricks的另一个开源框架MLflow,它有一个实验跟踪组件。MLflow被设计成可伸缩到大型数据集、大型输出文件(例如模型)和大量实验。它支持并行地启动多个运行(例如超参数调优)和在Spark上执行单独的运行。它可以从分布式存储系统中获取输入,并向分布式存储系统写入输出。
接下来的内容是:更多类型的ML平台和限制
我希望这篇文章使您相信模型开发平台的强大功能,并使您知道哪种类型最适合您。
在下一篇文章中,我将介绍其他类型的ML平台(部署的、垂直的、预先培训过的),我将提供一些技巧来帮助您为您的组织选择最佳的ML平台,我还将讨论这些平台的不足之处,以便构建真实的ML系统。跟随我得到通知!
原文:https://medium.com/@louisdorard/an-overview-of-ml-development-platforms-df953060b9a9
本文:http://jiagoushi.pro/node/1137
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 258 次浏览
【机器学习】轻松看懂机器学习十大常用算法
通过本篇文章大家可以对ML的常用算法形成常识性的认识。没有代码,没有复杂的理论推导,仅是图解,介绍这些算法是什么以及如何应用(例子主要是分类问题)。
今天的算法如下:
- 1、决策树
- 2、随机森林算法
- 3、逻辑回归
- 4、SVM
- 5、朴素贝叶斯
- 6、K 最近邻算法
- 7、K 均值算法
- 8、Adaboost 算法
- 9、神经网络
- 10、马尔可夫
1. 决策树
根据一些 feature 进行分类,每个节点提一个问题,通过判断,将数据分为两类,再继续提问。这些问题是根据已有数据学习出来的,再投入新数据的时候,就可以根据这棵树上的问题,将数据划分到合适的叶子上。

轻松看懂机器学习十大常用算法
2. 随机森林
在源数据中随机选取数据,组成几个子集。
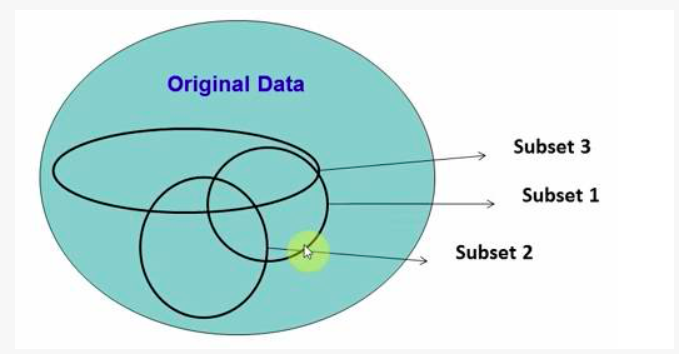
S 矩阵是源数据,有 1-N 条数据,A B C 是 feature,最后一列 C 是类别。
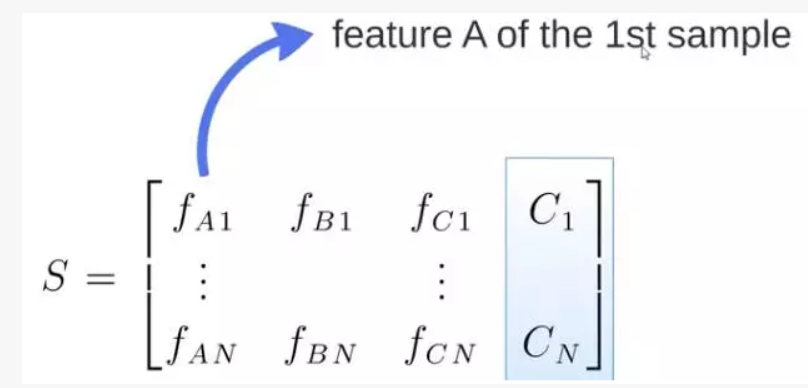
轻松看懂机器学习十大常用算法
由 S 随机生成 M 个子矩阵。

轻松看懂机器学习十大常用算法
这 M 个子集得到 M 个决策树。
将新数据投入到这 M 个树中,得到 M 个分类结果,计数看预测成哪一类的数目最多,就将此类别作为最后的预测结果。
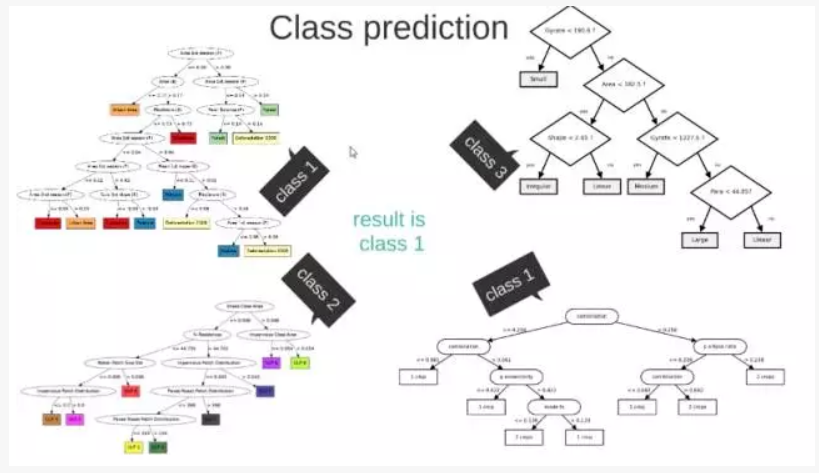
轻松看懂机器学习十大常用算法
3. 逻辑回归
当预测目标是概率这样的,值域需要满足大于等于0,小于等于1的,这个时候单纯的线性模型是做不到的,因为在定义域不在某个范围之内时,值域也超出了规定区间。
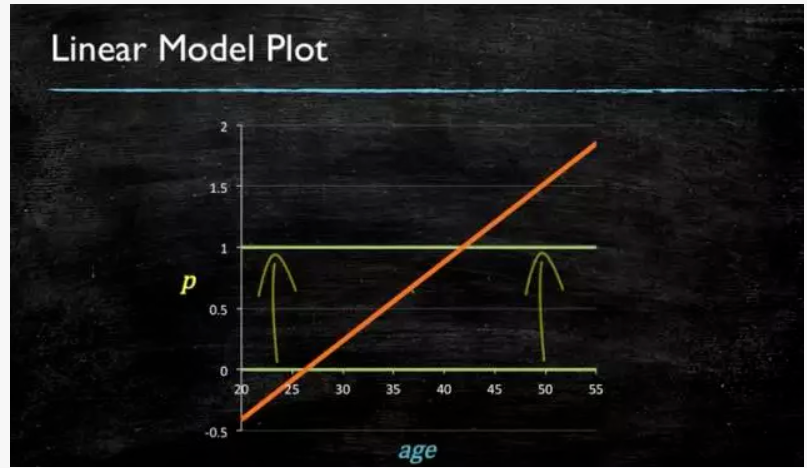
轻松看懂机器学习十大常用算法
所以此时需要这样的形状的模型会比较好。
轻松看懂机器学习十大常用算法
那么怎么得到这样的模型呢?
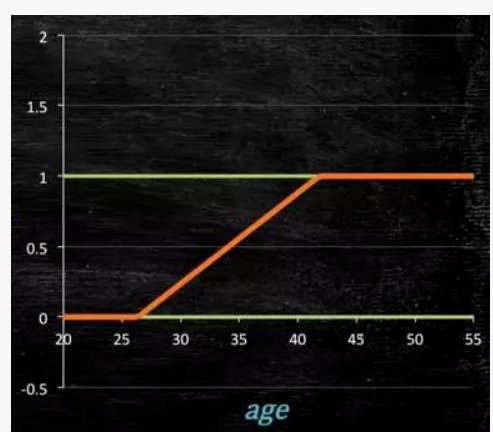
这个模型需要满足两个条件大于等于0,小于等于1。
大于等于0的模型可以选择绝对值,平方值,这里用指数函数,一定大于0。
小于等于1用除法,分子是自己,分母是自身加上1,那一定是小于1的了。
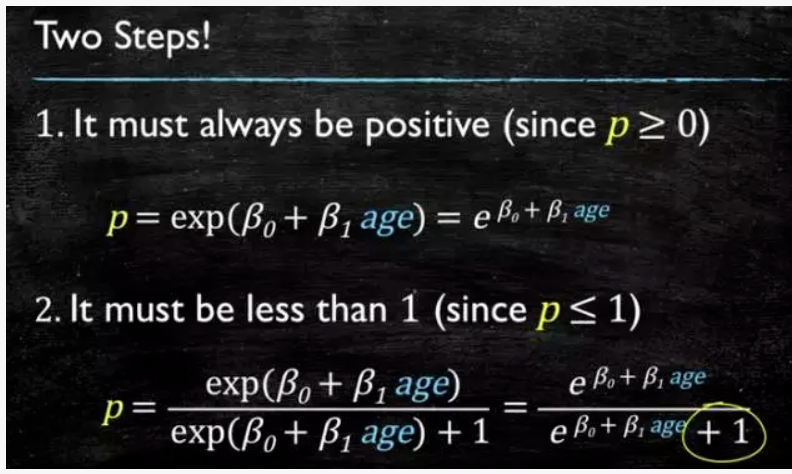
轻松看懂机器学习十大常用算法
再做一下变形,就得到了 logistic regression 模型。

轻松看懂机器学习十大常用算法
通过源数据计算可以得到相应的系数了。

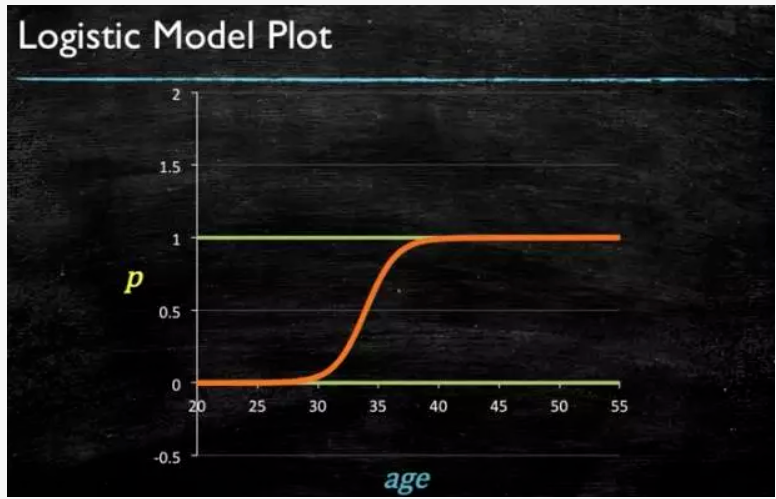
轻松看懂机器学习十大常用算法
最后得到 logistic 的图形。
轻松看懂机器学习十大常用算法
4. SVM
support vector machine。
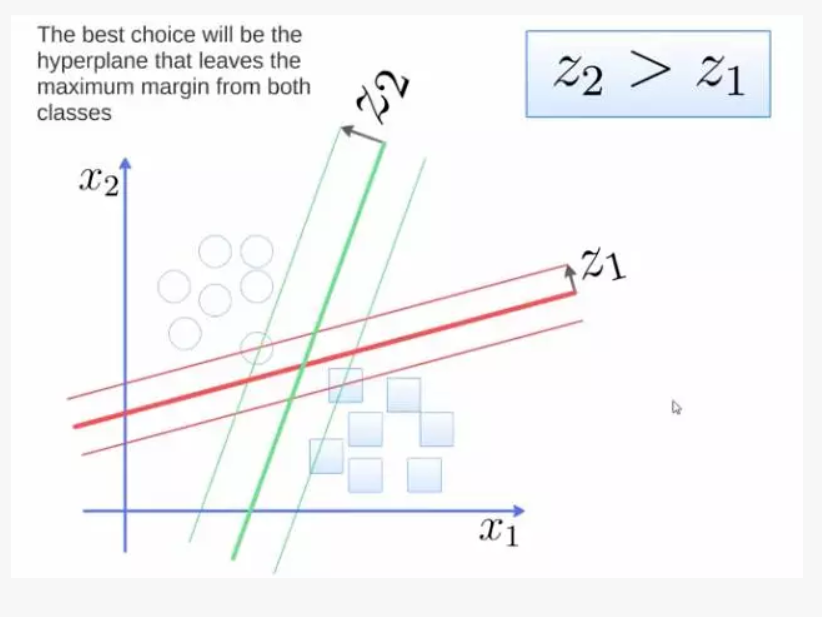
要将两类分开,想要得到一个超平面,最优的超平面是到两类的 margin 达到最大,margin 就是超平面与离它最近一点的距离,如下图,Z2>Z1,所以绿色的超平面比较好。
轻松看懂机器学习十大常用算法
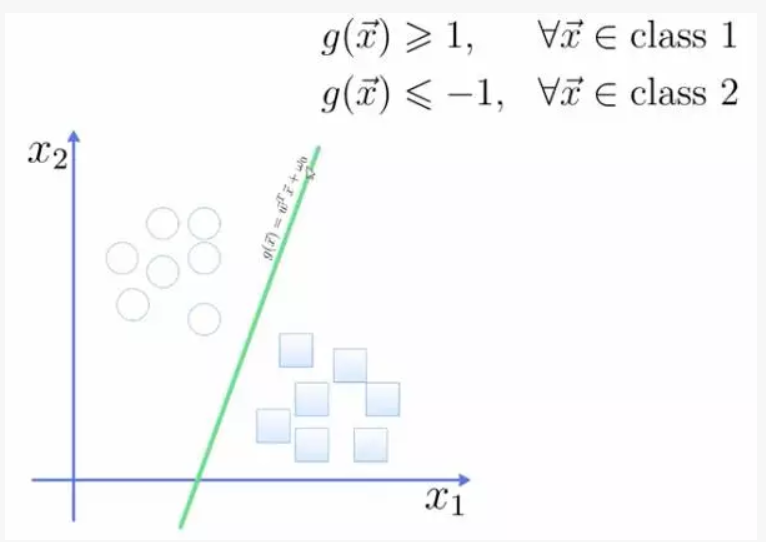
将这个超平面表示成一个线性方程,在线上方的一类,都大于等于1,另一类小于等于-1。
轻松看懂机器学习十大常用算法
点到面的距离根据图中的公式计算。
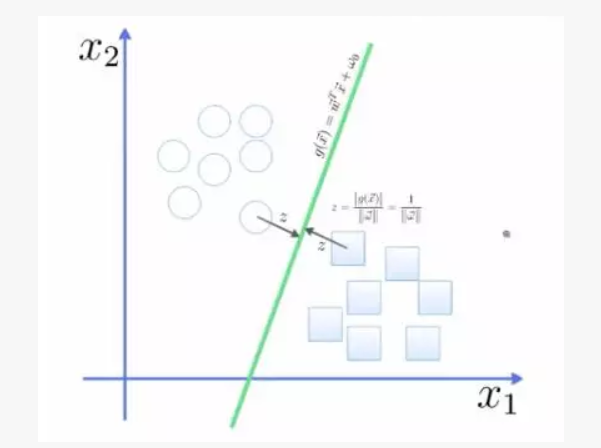
轻松看懂机器学习十大常用算法
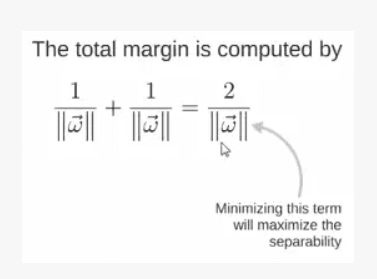
所以得到 total margin 的表达式如下,目标是最大化这个 margin,就需要最小化分母,于是变成了一个优化问题。
举个例子,三个点,找到最优的超平面,定义了 weight vector=(2,3)-(1,1)。
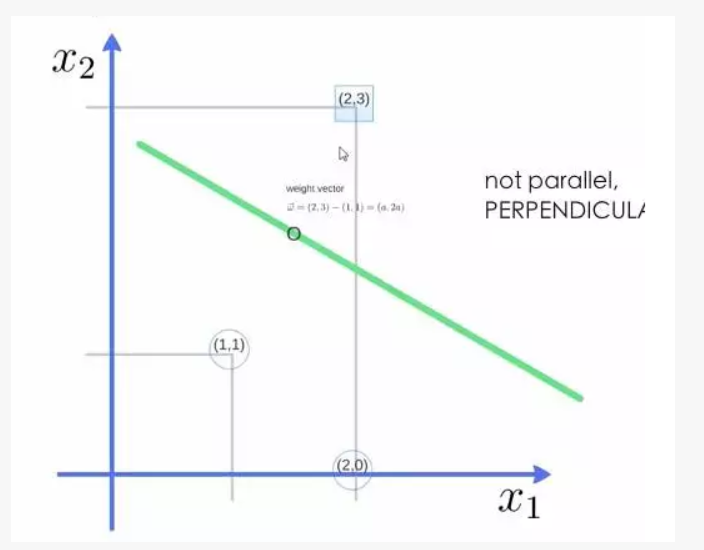
轻松看懂机器学习十大常用算法
得到 weight vector 为(a,2a),将两个点代入方程,代入(2,3)另其值=1,代入(1,1)另其值=-1,求解出 a 和 截矩 w0 的值,进而得到超平面的表达式。
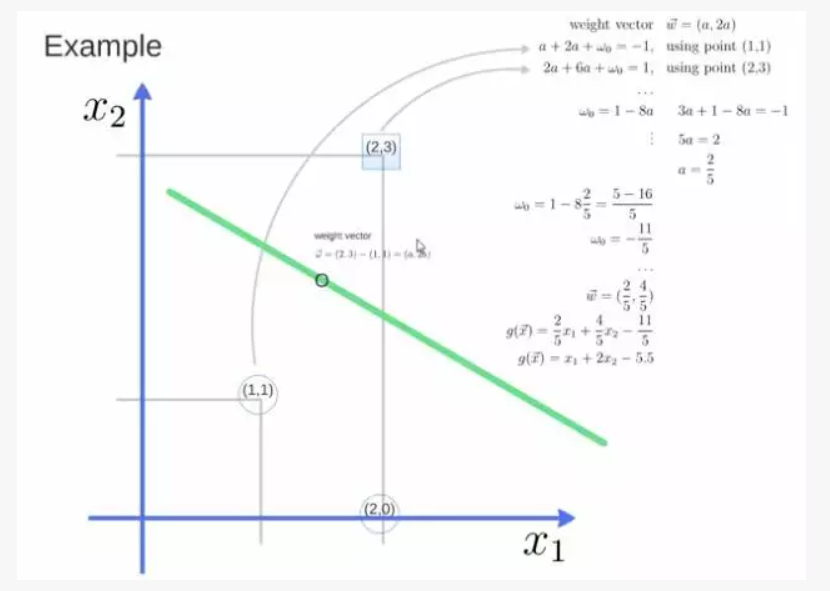
轻松看懂机器学习十大常用算法
a 求出来后,代入(a,2a)得到的就是 support vector。
a 和 w0 代入超平面的方程就是 support vector machine。
5. 朴素贝叶斯
举个在 NLP 的应用。
给一段文字,返回情感分类,这段文字的态度是positive,还是negative。
轻松看懂机器学习十大常用算法
为了解决这个问题,可以只看其中的一些单词。
轻松看懂机器学习十大常用算法
这段文字,将仅由一些单词和它们的计数代表。
轻松看懂机器学习十大常用算法
原始问题是:给你一句话,它属于哪一类。
通过 bayes rules 变成一个比较简单容易求得的问题。
问题变成,这一类中这句话出现的概率是多少,当然,别忘了公式里的另外两个概率。
举例:单词 love 在 positive 的情况下出现的概率是0.1,在 negative 的情况下出现的概率是0.001。
6. K 最近邻
k nearest neighbours。
给一个新的数据时,离它最近的 k 个点中,哪个类别多,这个数据就属于哪一类。
举例:要区分猫和狗,通过 claws 和 sound 两个feature来判断的话,圆形和三角形是已知分类的了,那么这个 star 代表的是哪一类呢。
轻松看懂机器学习十大常用算法
k=3时,这三条线链接的点就是最近的三个点,那么圆形多一些,所以这个 star 就是属于猫。
轻松看懂机器学习十大常用算法
7. K 均值
想要将一组数据,分为三类,粉色数值大,黄色数值小。
最开心先初始化,这里面选了最简单的 3,2,1 作为各类的初始值。
剩下的数据里,每个都与三个初始值计算距离,然后归类到离它最近的初始值所在类别。
轻松看懂机器学习十大常用算法
分好类后,计算每一类的平均值,作为新一轮的中心点。
轻松看懂机器学习十大常用算法
几轮之后,分组不再变化了,就可以停止了。
轻松看懂机器学习十大常用算法
轻松看懂机器学习十大常用算法
8. Adaboost
adaboost 是 bosting 的方法之一。
bosting就是把若干个分类效果并不好的分类器综合起来考虑,会得到一个效果比较好的分类器。
下图,左右两个决策树,单个看是效果不怎么好的,但是把同样的数据投入进去,把两个结果加起来考虑,就会增加可信度。
轻松看懂机器学习十大常用算法
adaboost 的栗子,手写识别中,在画板上可以抓取到很多 features,例如始点的方向,始点和终点的距离等等。
轻松看懂机器学习十大常用算法
training 的时候,会得到每个 feature 的 weight,例如2和3的开头部分很像,这个 feature 对分类起到的作用很小,它的权重也就会较小。
轻松看懂机器学习十大常用算法
而这个 alpha 角 就具有很强的识别性,这个 feature 的权重就会较大,最后的预测结果是综合考虑这些 feature 的结果。
轻松看懂机器学习十大常用算法
9. 神经网络
Neural Networks 适合一个 input 可能落入至少两个类别里。
NN 由若干层神经元,和它们之间的联系组成。
第一层是 input 层,最后一层是 output 层。
在 hidden 层 和 output 层都有自己的 classifier。
轻松看懂机器学习十大常用算法
input 输入到网络中,被激活,计算的分数被传递到下一层,激活后面的神经层,最后 output 层的节点上的分数代表属于各类的分数,下图例子得到分类结果为 class 1。
同样的 input 被传输到不同的节点上,之所以会得到不同的结果是因为各自节点有不同的 weights 和 bias。
这也就是 forward propagation。
轻松看懂机器学习十大常用算法
10. 马尔可夫
Markov Chains 由 state 和 transitions 组成。
栗子,根据这一句话‘the quick brown fox jumps over the lazy dog’,要得到 markov chain。
步骤,先给每一个单词设定成一个状态,然后计算状态间转换的概率。
轻松看懂机器学习十大常用算法
这是一句话计算出来的概率,当你用大量文本去做统计的时候,会得到更大的状态转移矩阵,例如 the 后面可以连接的单词,及相应的概率。
轻松看懂机器学习十大常用算法
生活中,键盘输入法的备选结果也是一样的原理,模型会更高级。
轻松看懂机器学习十大常用算法
- 76 次浏览
【机器学习架构】一个真实世界机器学习系统的架构
本文是机器学习平台系列的第2部分。它由数字弹射器和 PAPIs支持。
在上一篇文章中,我概述了ML开发平台,它们的工作是帮助创建和打包ML模型。模型构建只是ML系统所需的众多功能中的一项。在这篇文章的最后,我提到了其他类型的ML平台以及构建现实世界ML系统时的限制。在我们能够讨论这些之前,我们需要回顾这些系统的所有组件,以及它们是如何相互连接的。
上面的图表关注的是“监督学习”系统(例如分类和回归)的客户机-服务器架构,其中预测由客户机请求,在服务器上进行。(旁注:在某些系统中,最好有客户端预测;其他的甚至可能鼓励客户端模型培训,但是在工业ML应用程序中使其高效的工具还不存在。)
ML系统组件的概述
在进一步研究之前,我建议下载上面的图表,并分割屏幕,以便在阅读本文其余部分的同时可以看到图表。
让我们假设“数据库”在创建ML系统之前就已经存在了。深灰色和紫色的组件将是新的组件被建立。那些应用ML模型进行预测的用紫色表示。矩形用于表示有望提供微服务的组件,这些组件通常通过具象状态传输(representational state transfer, REST) api访问并在无服务器平台上运行。
ML系统有两个“入口点”:请求预测的客户端和创建/更新模型的协调器。客户端代表将从ML系统获益的最终用户使用的应用程序。这可以是你用来订晚餐的智能手机应用程序,例如UberEats请求预定的交货时间——这在COVID-19封锁期间是一个大用例!
封锁前的照片,维基百科提供。有一个复杂的ML系统可以预测这个家伙什么时候到达他的目的地,每天成千上万次,在世界上数以百计的城市!希望这个系统使用的模型在过去几周内得到了更新……
协调器通常是由调度程序调用的程序(以便模型可以定期更新,例如每周更新),或者通过API调用(以便它可以成为持续集成/持续交付管道的一部分)。它负责在一个保密的测试数据集上评估模型构建器创建的模型。为此,它将测试预测发送给求值器。如果一个模型被认为足够好,那么它将被传递到模型服务器,通过API使其可用。这个API可以直接公开给客户端软件,但是通常需要在前端中实现特定于领域的逻辑。
假设有一个或多个(基线)模型可以作为api使用,但还没有集成到最终的应用程序中,您将通过跟踪生产数据的性能并通过监视器可视化来决定要集成哪个模型(以及它是否安全)。在我们的晚餐递送示例中,它将让您比较一个模型的ETD与刚刚交付的订单的实际交货时间。当新的模型版本可用时,客户端对预测的请求将通过前端逐步定向到新模型的API。这将为越来越多的终端用户完成,同时监视性能并检查新模型是否“破坏”了任何东西。ML系统的所有者和客户机应用程序的所有者将定期访问监视器的仪表板。
让我们以列表的形式重述一下上图中的所有组件:
- 事实(Ground-truth)收集器
- 数据贴标机
- 评估者
- 性能监视器
- Featurizer(特征化器)
- 协调器
- 模型构建器
- 模型服务器
- 前端
我们已经简单地提到了第3、4、6、7、8和9条。现在让我们提供更多的信息,复习一下#1、# 2和# 5!
# 1:事实收集器
在现实世界中,关键是能够不断获取新的数据供机器学习。有一种数据特别重要:地面真实数据。这与您希望ML模型预测的内容相对应,例如房地产的销售价格、与客户相关的事件(例如客户流失)或分配给输入对象的标签(例如传入消息中的“spam”)。有时候,你观察一个输入对象,你只需要等待一段时间来观察你想预测的对象;例如,您等待房产被出售,等待客户续订或取消订阅,等待用户与收件箱中的电子邮件交互。您可能希望用户在ML系统预测错误时让您知道(参见下面的插图)。如果您想让您的用户能够提供这种反馈,您将需要一个微服务来将其发送到其中。
以防你认为ML平台不重要…(什么?!)
# 2:数据贴标机
有时,您可以访问大量的输入数据,但是您需要手动创建相关的ground-truth数据。构建垃圾邮件检测器或从图像构建对象检测器时就是这样。有现成的和开源的web应用来简化数据标注(如Label Studio),也有专门的外包手工标注数据的服务(如图8和谷歌的数据标注服务)。
飞机分类:标签工作室在行动
# 3:评估者
当您有了供机器学习的初始数据集时,在开始构建任何ML模型之前,定义如何评估计划的ML系统是很重要的。除了测量预测精度,还需要通过特定于应用程序的性能指标和系统指标(如延迟和吞吐量)来评估短期和长期的影响。
模型评估有两个重要的目标:比较模型,以及决定将模型集成到应用程序中是否安全。评估可以在一组预先确定的测试用例上执行,因为它是已知的预测应该是什么(即基本事实)。可以检查错误分布,并将错误聚合到性能指标中。为此,评估者需要访问测试集的ground truth,这样当它在输入中得到预测时,它就可以计算预测错误并返回性能指标。
我建议在构建ML模型之前优先实现这个求值器。评估基线模型所作的预测,以提供参考。基线通常是基于输入特征(也就是特性)的启发式方法。它们可以是超级简单的、手工制作的规则……
- 对于流失预测,你的基线可以说,如果一个客户在过去30天内登录少于3次,他们很可能会流失;
- 对于食物送餐时间的预测,你的基线可以是上周所点餐餐厅和乘客的平均送餐时间。
在明天开发复杂的ML模型之前,看看你的基线今天是否能创造价值!
# 4: 性能监视器
决定是否可以将(基线)模型集成到应用程序中的下一步是在生产中遇到的输入(称为“生产数据”)上使用它,在类似于生产的设置中,并通过时间监控它的性能。
计算和监控生产数据的性能指标需要在数据库中获取和存储生产输入、基本事实和预测。性能监视器将由一个从数据库读取数据、调用评估器的程序和一个显示性能指标如何随时间发展的仪表板组成。一般来说,我们希望检查模型是否随时间运行良好,以及它们是否持续对集成它们的应用程序产生积极影响。还可以使用显示生产数据分布的数据可视化小部件对监视器进行增强,这样我们就可以确保它们符合预期,或者我们可以监视漂移和异常情况。
搅和模型的监视仪表板(源)
# 5: FEATURIZER(特征化机器)
在设计预测API时,需要决定API应该采用什么作为输入。例如,在对客户进行预测时,输入应该是客户的全部特性表示,还是仅仅是客户id?
在任何情况下,完整的数字表示都是很常见的(就像文本或图像输入一样),但是在传递给模型之前必须对其进行计算。对于客户输入,有些特性已经存储在数据库中(例如,出生日期),而其他特性则需要进行计算。这可能是描述客户在某段时间内如何与产品交互的行为特性的情况:它们将通过查询和聚合记录客户与产品交互的数据来计算。
如果特性本质上不经常变化,则可以批量计算它们。但在ML用例中,比如UberEats的预期交付时间,我们可能会有快速变化的“热点”特性,需要实时计算;例如,某家餐厅在过去X分钟内的平均送餐时间。
这需要创建至少一个特性化微服务,它将根据输入的id为一批输入提取特性。您可能还需要一个实时的特性化微服务,但是这会增加ML系统的复杂性。
功能分析器可以查询各种数据库,并对查询的数据执行各种聚合和处理。它们可能具有参数(如上面示例中的分钟数X),这些参数可能会对模型的性能产生影响。
# 6 协调器
工作流
协调器位于ML系统的核心,并与许多其他组件交互。下面是它的工作流/管道中的步骤:
- 提取-转换-加载和分割(原始)数据到训练,验证,测试集
- 发送功能饱和化的培训/验证/测试集(如果有的话)
- 准备专用的训练/验证/测试集
- 将准备好的训练/验证集的uri以及要优化的指标发送到模型构建器
- 得到最优模型,应用于测试集,并将预测发送给评估者
- 获取性能值并决定是否可以将模型推到服务器(例如,用于对生产数据的卡纳塔测试)。
关于步骤3(“准备专用培训/验证/测试集”)的更多细节:
- 增强训练数据(例如,过采样/过采样,或旋转/翻转/裁剪图像)
- 预处理训练/验证/测试集,包括数据消毒(以便可以安全地用于建模或预测)和针对特定问题的准备(例如,图像去饱和和调整大小)。
运行工作流的方法
整个工作流可以手动执行,但是要频繁地更新模型,或者联合调优建模器和建模器的超参数,就必须实现自动化。这个工作流可以实现为一个简单的脚本并在单个线程上运行,但是通过并行运行可以提高计算效率。端到端ML平台允许这样做,并且可以提供一个环境来定义和运行完整的ML管道。与谷歌AI平台,例如,你可以使用谷歌云数据产品,如Dataprep (Trifacta争吵工具提供的数据),数据流(一个简化的流和批量数据处理工具),BigQuery (serverless云数据仓库),您可以定义一个培训应用程序基于TensorFlow或内置算法(例如XGBoost)。在处理重要的数据量时,Spark是一个流行的选择。Spark背后的Databricks公司也提供端到端平台。
或者,工作流的每一步都可以在不同的平台或不同的计算环境中运行。一种选择是在不同的Docker容器中执行这些步骤。Kubernetes是ML从业者中最流行的开源容器编排系统之一。Kubeflow和Seldon Core是开源工具,允许用户描述ML管道并将其转换为Kubernetes集群应用程序。这可以在本地环境中完成,并且应用程序可以运行在Kubernetes集群上,该集群可以安装在本地,也可以在云平台中提供——例如谷歌Kubernetes引擎,它被谷歌AI平台或Azure Kubernetes服务或Amazon EKS使用。Amazon还提供了一种与Kubernetes相对应的Fargate和ECS。Apache气流是另一个开源工作流管理工具,最初由Airbnb开发。气流已经成为协调一般IT任务(包括ML任务)执行的流行方式,它还与Kubernetes集成。
为更高级的工作流程的主动学习
正如前面所暗示的,可能需要领域专家访问一个数据标签器,在那里他们将被显示输入并被要求标记它们。这些标签将存储在数据库中,然后编配人员可以在培训/验证/测试数据中使用这些标签。提供标记的输入可以手动选择,也可以在协调器中进行编程。这可以通过观察模型正确但不确定的生产投入,或非常确定但不确定的生产投入——这是“主动学习”的基础。
# 7 模型构建器
模型构建器负责提供一个最佳的模型。为此,它在训练集上训练各种模型,并在验证集上评估它们,使用给定的度量,以评估最优性。注意,这与上一篇文章中探讨的OptiML示例相同:
$ curl https://bigml.io/optiml?$BIGML_AUTH -d '{"dataset": "<training_dataset_id>", "test_dataset": "<test_dataset_id>", "metric": "area_under_roc_curve", "max_training_time": 3600 }'
BigML通过它的API自动使模型可用,但是对于其他ML开发平台,您可能希望打包模型,将其保存为文件,并让您的模型服务器加载该文件。
在Azure ML上进行的“自动化ML”实验的结果。您可以下载找到的最佳模型,或者在Azure上部署它。
如果您使用不同的ML开发平台,或者根本不使用平台,那么以一种由专用服务自动创建模型的方式来构建您的系统是值得的,该服务需要对训练集、验证集和性能度量进行优化。
# 8 模型服务器
模型服务器的角色是处理针对给定模型的预测的API请求。为此,它加载保存在文件中的模型表示,并通过模型解释器将其应用到API请求中的输入;然后在API响应中返回预测。服务器应该允许并行处理多个API请求和模型更新。
下面是一个情绪分析模型的请求和响应示例,它只接受一个文本特性作为输入:
$ curl https://mydomain.com/sentiment
-H 'X-ApiKey: MY_API_KEY'
-d '{"input": "I love this series of articles on ML platforms"}'
{"prediction": 0.90827194878055087}
存在不同的模型表示,如ONNX和PMML。另一个标准实践是将模型作为计算环境中的对象保存在文件中。这还需要保存计算环境的表示,特别是它的依赖关系,这样就可以再次创建模型对象。在这种情况下,模型“解释器”仅仅由像model.predict(new_input)这样的东西组成。
# 9 前端
前端可以服务多种用途:
- 简化模型的输出,例如将一个类概率列表转换为最可能的类;
- 添加到模型的输出中,例如使用黑盒模型解释器并提供预测解释(与Indico的方法相同);
- 实现特定领域的逻辑,例如基于预测的决策,或接收到异常输入时的回退;
- 发送生产输入和模型预测,以便存储在生产数据库中;
- 测试新模型,通过查询预测(除了“实时”模型之外)并存储它们;这将允许监视器为这些新的候选模型绘制性能指标。
模型生命周期管理
如果一个新的候选模型在测试数据集中提供了比当前模型更好的性能,那么通过让前端返回这个模型对一小部分应用程序的最终用户的预测(金丝雀测试),就可以测试它对应用程序的实际影响。这要求评估者和监控器实现特定于应用程序的性能指标。测试用户可以从列表中选取,也可以通过他们的某个属性、地理位置选择,或者完全随机选择。在监视性能并确信新模型不会破坏任何东西时,开发人员可以逐步增加测试用户的比例,并执行A/B测试,进一步比较新模型和旧模型。如果新模型被证实更好,前端就会通过总是返回新模型的预测来“取代”旧模型。如果新模型最终破坏了系统,也可以通过前端实现回滚。
逐步将流量导向模型B,逐步淘汰模型A(来源)
结论
如果您对真实的ML感到好奇,那么我希望本文能够帮助您说明为什么ML开发平台和模型构建通常不足以创建对最终用户有实际影响的系统。
原文:https://medium.com/@louisdorard/architecture-of-a-real-world-machine-learning-system-795254bec646
本文:http://jiagoushi.pro/node/1136
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 308 次浏览
【科普】机器学习
机器学习(ML)是对计算机系统用于执行特定任务的算法和统计模型的科学研究,不需要使用明确的指令,而是依赖于模式和推理。它被视为人工智能的一个子集。机器学习算法建立一个基于样本数据的数学模型,称为“训练数据”,以便在不显式编程执行任务的情况下做出预测或决策。[1][2]:2机器学习算法被广泛应用于电子邮件过滤和计算机视觉等领域,在这些领域,很难或不可行地开发一种传统的算法来有效地执行任务。
机器学习与计算统计学密切相关,计算统计学侧重于使用计算机进行预测。数学优化的研究为机器学习领域提供了方法、理论和应用领域。数据挖掘是机器学习中的一个研究领域,主要通过无监督学习对数据进行探索性分析。在它的跨业务问题的应用中,机器学习也被称为预测分析。

概述
机器学习这个名字是阿瑟·塞缪尔在1959年创造的。[5]汤姆·m·米切尔提供了广泛引用,更正式的定义算法研究机器学习领域:“据说计算机程序从经验中学习E对一些类的任务T和性能测量P T,如果业绩任务以P,改善与体验E .”机器学习所涉及的任务的这个定义提供了一个基本的操作性定义,而不是用认知的术语来定义这个领域。这与阿兰·图灵在他的论文《计算机器与智能》中提出的“机器能思考吗?”的问题相呼应。在图灵的提议中,揭示了思维机器可能具有的各种特征,以及构建思维机器的各种含义。
机器学习任务
支持向量机是一种有监督的学习模型,它将数据分成由线性边界分割的区域。这里,线性边界将黑圈和白圈分开。
机器学习任务可以分为几个大类。在监督学习中,该算法从一组包含输入和期望输出的数据构建数学模型。例如,如果任务是确定一个图像是否包含某个对象,用于监督学习算法的训练数据将包括有该对象和没有该对象的图像(输入),并且每个图像将有一个标签(输出)来指定它是否包含该对象。在特殊情况下,输入可能只部分可用,或者仅限于特殊反馈。半监督学习算法从不完整的训练数据中开发数学模型,其中部分样本输入没有标签。
分类算法和回归算法是监督学习的两种类型。当输出被限制在一组有限的值时,使用分类算法。对于筛选电子邮件的分类算法,输入将是传入的电子邮件,输出将是将电子邮件归档的文件夹的名称。对于识别垃圾邮件的算法,输出将是“垃圾邮件”或“非垃圾邮件”的预测,由Boolean值true和false表示。回归算法是根据它们的连续输出来命名的,这意味着它们可能在一个范围内具有任何值。连续值的例子是一个对象的温度、长度或价格。
在无监督学习中,该算法从一组只包含输入而不包含期望输出标签的数据构建数学模型。无监督学习算法用于发现数据中的结构,如数据点的分组或聚类。无监督学习可以发现数据中的模式,并可以将输入分组到类别中,就像在特征学习中一样。降维是减少一组数据中“特征”或输入的数量的过程。
主动学习算法根据预算访问有限输入集的所需输出(培训标签),并优化将获得培训标签的输入的选择。当交互使用时,可以将它们呈现给人类用户进行标记。在动态环境中,增强学习算法以正强化或负强化的形式给出反馈,并应用于自动驾驶汽车或学习与人类对手进行游戏。[2]:3机器学习中的其他专门算法包括主题建模,其中计算机程序被给定一组自然语言文档,并找到其他包含类似主题的文档。在密度估计问题中,机器学习算法可以用来寻找不可观测的概率密度函数。元学习算法根据以前的经验学习它们自己的归纳偏见。在发展型机器人技术中,机器人学习算法产生自己的学习经验序列,也称为课程,通过自我引导的探索和与人类的社会互动,积累新的技能。这些机器人使用主动学习、成熟、运动协同和模仿等引导机制。(需要澄清)

历史和与其他领域的关系
参见:机器学习时间表
美国计算机游戏和人工智能领域的先驱阿瑟·塞缪尔(Arthur Samuel)于1959年在IBM工作时创造了“机器学习”一词。作为一项科学研究,机器学习源于对人工智能的探索。早在人工智能作为一门学术学科的早期,一些研究人员就对让机器从数据中学习产生了兴趣。他们试图用各种符号方法,以及当时被称为“神经网络”的方法来解决这个问题;这些主要是感知器和其他模型,后来发现是对统计的广义线性模型的重新发明。采用了[9]概率推理,特别是在自动医疗诊断中。[10]:488
然而,对逻辑的、基于知识的方法的日益重视,导致了人工智能和机器学习之间的裂痕。概率系统一直受到数据采集和表示的理论和实际问题的困扰。[10]:488到1980年,专家系统开始主导人工智能,统计数据不再受欢迎。[11]关于符号/基于知识的学习的工作在人工智能中继续进行,导致了归纳逻辑编程,但是更多的统计线研究现在已经超出了人工智能本身的领域,即模式识别和信息检索。大约在同一时期,人工智能和计算机科学放弃了对神经网络的研究。这条线也被其他学科的研究人员,包括Hopfield, Rumelhart和Hinton,在AI/CS领域之外,作为“连接主义”继续延伸。他们的主要成功是在20世纪80年代中期,随着反向传播的重新发明
机器学习,作为一个独立的领域重组,在20世纪90年代开始蓬勃发展。该领域的目标从实现人工智能转变为解决具有实用性的可解决问题。它将注意力从从人工智能继承的符号方法转移到从统计学和概率论借鉴的方法和模型上。[11]资讯科技署亦受惠于数码资讯的日益普及,以及透过互联网分发资讯的能力。
与数据挖掘的关系
机器学习和数据挖掘通常采用相同的方法和大幅重叠,但是当机器学习关注预测,基于已知的属性从训练数据,数据挖掘的重点是发现先前未知的属性数据(这是数据库中知识发现)的分析步骤。数据挖掘使用多种机器学习方法,但目标不同;另一方面,机器学习也使用数据挖掘方法作为“无监督学习”或作为预处理步骤来提高学习者的准确性。混淆这两个研究社区的(经常有单独的会议和单独的期刊,ECML PKDD成为一个主要例外)来自他们的工作基本假设:在机器学习中,性能评价通常是对已知的繁殖能力的知识,在知识发现和数据挖掘(KDD)的主要任务是发现未知的知识。对已知知识进行评价时,一种不知情(无监督)方法很容易被其他监督方法超越,而在典型的KDD任务中,由于训练数据的不可用,无法使用监督方法。
关系优化
机器学习与优化也有密切的联系:许多学习问题被表述为在一组训练示例上最小化一些损失函数。损失函数表示被训练的模型的预测与实际问题实例之间的差异(例如,在分类中,希望为实例分配一个标签,而模型被训练来正确预测一组示例的预先分配的标签)。这两个领域的不同之处在于泛化的目标:优化算法可以使训练集上的损失最小化,而机器学习则是将不可见样本上的损失最小化
相关统计数据
就方法而言,机器学习和统计学是密切相关的领域,但它们的主要目标是不同的:统计学从样本中得出总体推断,而机器学习则找到可概括的预测模式。根据迈克尔·i·乔丹的观点,机器学习的概念,从方法论原理到理论工具,在统计学上有着悠久的历史。他还建议将“数据科学”一词作为整个领域的占位符
Leo Breiman区分了两种统计建模范式:数据模型和算法模型,其中“算法模型”指的是或多或少像随机森林这样的机器学习算法。
一些统计学家采用了机器学习的方法,形成了一个他们称之为统计学习的综合领域
理论
主要文章:计算学习理论和统计学习理论
学习者的一个核心目标是总结经验。[2][17]概括在这种情况下是一个学习机器的能力进行准确的新,看不见的例子/任务后经历了学习的训练示例数据集。通常来自一些未知的概率分布(被认为是代表出现的空间)和学习者必须建立一个一般模型关于这个空间,使它在新情况下产生足够准确的预测。
机器学习算法及其性能的计算分析是计算机理论的一个分支,被称为计算学习理论。由于训练集是有限的,未来是不确定的,学习理论通常不能保证算法的性能。相反,性能的概率界限非常常见。偏方差分解是量化泛化误差的一种方法。
为了在泛化上下文中获得最佳性能,假设的复杂性应该与数据下的函数的复杂性相匹配。如果假设没有函数那么复杂,则模型对数据的拟合不足。如果模型的复杂度随响应增加而增加,则训练误差减小。但如果假设过于复杂,则模型容易出现过度拟合,泛化效果较差
学习理论家除了研究学习的性能界限外,还研究学习的时间复杂度和可行性。在计算学习理论中,如果计算可以在多项式时间内完成,则计算是可行的。有两种时间复杂度结果。正结果表明,一类函数可以在多项式时间内学习。负结果表明,某些类不能在多项式时间内学习。
方法
学习算法的类型
机器学习算法的类型在它们的方法、它们输入和输出的数据类型以及它们打算解决的任务或问题的类型上有所不同。
监督式学习
主要文章:监督学习
监督学习算法建立一组数据的数学模型,其中包含输入和期望的输出。该数据称为训练数据,由一组训练示例组成。每个训练示例都有一个或多个输入和期望的输出,也称为监视信号。在数学模型中,每个训练实例由一个数组或向量表示,有时称为特征向量,训练数据由一个矩阵表示。通过目标函数的迭代优化,监督学习算法学习一个函数,该函数可用于预测与新输入相关的输出。一个最优函数将允许算法正确地确定不属于训练数据一部分的输入的输出。随着时间的推移,一种提高其输出或预测准确性的算法据说已经学会了执行这项任务
监督学习算法包括分类和回归。当输出被限制在一个有限的值集时,使用[21]分类算法;当输出在一个范围内可以有任何数值时,使用回归算法。相似性学习是监督机器学习的一个领域,与回归和分类密切相关,但目标是通过使用相似性函数从示例中学习,该函数度量两个对象的相似性或相关性。它在排名、推荐系统、视觉识别跟踪、人脸验证和说话人验证等方面都有应用。
在半监督学习算法中,一些训练实例缺少训练标签,但仍然可以用来提高模型的质量。在弱监督学习中,训练标签是噪声的、有限的或不精确的;然而,这些标签通常更便宜,导致更大的有效培训集
无监督学习
主要文章:无监督学习
参见:聚类分析
无监督学习算法采用一组只包含输入的数据,在数据中找到结构,比如对数据点进行分组或聚类。因此,这些算法从没有标记、分类或分类的测试数据中学习。非监督学习算法不响应反馈,而是识别数据中的共性,并根据每个新数据中是否存在这些共性做出反应。无监督学习的一个核心应用是在统计的密度估计领域,[23]虽然无监督学习包含了其他领域,包括总结和解释数据特征。
聚类分析是将一组观测值分配到子集(称为聚类)中,使同一聚类中的观测值根据一个或多个预先指定的标准相似,而来自不同聚类的观测值不同。不同的聚类技术对数据的结构做出不同的假设,通常由一些相似度度量来定义和评估,例如,通过内部紧密度,或相同集群成员之间的相似性,以及集群之间的差异。其他方法基于估计的密度和图的连通性。
强化学习
主要文章:强化学习
强化学习是机器学习的一个领域,它关注的是软件代理如何在环境中采取行动,从而最大化累积奖励的概念。由于其通用性,该领域的研究涉及博弈论、控制理论、运筹学、信息论、基于仿真的优化、多智能体系统、群体智能、统计和遗传算法等多个学科。在机器学习中,环境通常表示为马尔可夫决策过程(MDP)。许多增强学习算法使用动态规划技术。[24]强化学习算法不假设MDP的精确数学模型的知识,而是在精确模型不可行的情况下使用。强化学习算法用于自动驾驶汽车或学习与人类对手进行游戏。
Feature学习
主要文章:特征学习
几种学习算法的目的是发现更好地表示训练期间提供的输入。经典的例子包括主成分分析和聚类分析。特征学习算法,也称为表示学习算法,通常试图保存输入的信息,但也以使其有用的方式进行转换,通常作为执行分类或预测之前的预处理步骤。这种技术允许重构来自未知数据生成分布的输入,但不一定忠实于在该分布下不可信的配置。这取代了手工的特性工程,允许机器学习特性并使用它们来执行特定的任务。
特征学习可以是监督的,也可以是非监督的。在监督特征学习中,特征是通过标记输入数据来学习的。例子包括人工神经网络、多层感知器和监督字典学习。在无监督特征学习中,特征是用无标记的输入数据来学习的。例子包括字典学习,独立成分分析,自动编码器,矩阵分解[26]和各种形式的聚类
流形学习算法是在学习表示是低维的约束下进行的。稀疏编码算法试图在学习表示为稀疏的约束下实现这一点,这意味着数学模型有许多零。多线性子空间学习算法的目标是直接从多维数据的张量表示中学习低维表示,而不是将它们重新构造成高维向量。[30]深度学习算法发现多个层次的表示,或一个层次的特征,与高层次,更抽象的特征定义(或产生)较低层次的特征。有人认为,智能机器是一种学习一种表示方法的机器,这种方法能解开解释观测数据变化的潜在因素
特征学习的动机是这样一个事实,即机器学习任务(如分类)通常需要数学上和计算上方便处理的输入。然而,真实世界的数据,如图像、视频和感官数据,并没有屈服于通过算法定义特定特征的尝试。另一种方法是通过检查发现这些特性或表示,而不依赖于显式算法。
稀疏字典学习
主要文章:稀疏字典学习
稀疏字典学习是一种特征学习方法,训练实例用基函数的线性组合表示,假设为稀疏矩阵。该方法具有很强的NP-hard性质,难以近似求解。稀疏字典学习的一种常用启发式方法是K-SVD算法。稀疏字典学习已应用于多种语境中。在分类中,问题是确定一个以前未见过的训练示例属于哪个类。对于已经构建了每个类的字典,一个新的训练示例与对应的字典最稀疏表示的类相关联。稀疏字典学习也被应用于图像去噪。关键思想是一个干净的图像块可以用图像字典稀疏地表示,但是噪声不能
异常检测
主要文章:异常检测
在数据挖掘中,异常检测,也称为离群点检测,是指通过与大多数数据的显著差异来识别引起怀疑的稀有项目、事件或观测结果。通常,异常项表示一个问题,如银行欺诈、结构缺陷、医疗问题或文本中的错误。异常被称为异常值、新奇、噪声、偏差和异常
特别是在滥用和网络入侵检测的背景下,有趣的对象往往不是罕见的对象,而是活动中的突发事件。这种模式不符合将异常值定义为稀有对象的常见统计定义,许多异常值检测方法(尤其是无监督算法)将无法检测到此类数据,除非对其进行了适当的聚合。相反,一个聚类分析算法可能能够检测到这些模式形成的微簇
目前存在三大类异常检测技术。[37]无监督异常检测技术检测未标记测试数据集中的异常,假设数据集中的大多数实例都是正常的,通过寻找实例似乎符合最小剩余的数据集。监督异常检测技术需要一个数据集被贴上“正常”和“不正常”,包括训练一个分类器(其他统计分类问题的关键区别是孤立点检测)的固有的不平衡的性质。半监督异常检测技术从给定的正常训练数据集构建一个表示正常行为的模型,然后测试模型生成测试实例的可能性。
关联规则
主要文章:关联规则学习
参见:归纳逻辑编程
关联规则学习是一种基于规则的机器学习方法,用于发现大型数据库中变量之间的关系。它的目的是识别在数据库中发现的强规则,使用一些度量“兴趣度”的方法
基于规则的机器学习是任何机器学习方法的通称,它识别、学习或演化“规则”来存储、操作或应用知识。基于规则的机器学习算法的定义特征是识别和利用一组关系规则,这些关系规则共同表示系统捕获的知识。这与其他机器学习算法形成了对比,其他机器学习算法通常识别一个奇异模型,该模型可以普遍应用于任何实例,以便做出预测。基于规则的机器学习方法包括学习分类器系统、关联规则学习和人工免疫系统。
基于强大的规则的概念,Rakesh Agrawal,托马斯Imieliński和阿伦阁下介绍关联规则发现规律的产品之间在大规模事务记录的数据在超市销售点(POS)系统。例如,在超市的销售数据中发现的规则{displaystyle \{mathrm {onion,potatoes}} right tarrow \{burger}}}表明,如果顾客同时购买洋葱和土豆,他们也可能购买汉堡肉。这些信息可以作为决定营销活动的基础,如促销定价或产品植入。除了市场篮子分析之外,关联规则目前还应用于Web使用挖掘、入侵检测、持续生产和生物信息学等应用领域。与序列挖掘相反,关联规则学习通常不考虑事务内或事务间项的顺序。
学习分类器系统(LCS)是一组基于规则的机器学习算法,它将发现组件(通常是遗传算法)与学习组件组合在一起,执行监督学习、强化学习或非监督学习。他们试图确定一组上下文相关的规则,这些规则以分段的方式集体存储和应用知识,以便做出预测.
归纳逻辑规划(ILP)是一种使用逻辑规划作为输入示例、背景知识和假设的统一表示的规则学习方法。给定已知背景知识的编码和一组表示为事实逻辑数据库的示例,ILP系统将派生出一个假设的逻辑程序,其中包含所有正面和没有负面示例。归纳式编程是一个相关的领域,它考虑用任何一种编程语言来表示假设(而不仅仅是逻辑编程),比如函数程序。
归纳逻辑规划在生物信息学和自然语言处理中特别有用。Gordon Plotkin和Ehud Shapiro为逻辑环境下的归纳机器学习奠定了初步的理论基础。[42][43][44] Shapiro在1981年建立了他们的第一个实现(模型推理系统):一个Prolog程序,它从正反两个例子中归纳推理逻辑程序。这里的归纳法是指哲学上的归纳法,它提出一种理论来解释观察到的事实,而不是数学上的归纳法,来证明一个有序集合的所有成员的一个属性。
模型
执行机器学习包括创建一个模型,该模型根据一些训练数据进行训练,然后可以处理额外的数据进行预测。各种类型的模型已被用于机器学习系统的研究。
人工神经网络
主要文章:人工神经网络
参见:深度学习
人工神经网络是一组相互连接的节点,类似于大脑中巨大的神经元网络。这里,每个圆形节点表示一个人工神经元,箭头表示从一个人工神经元的输出到另一个人工神经元的输入的连接。
人工神经网络(ANNs),或称连接系统,是一种计算系统,模模糊糊地受到构成动物大脑的生物神经网络的启发。这类系统通过考虑实例“学习”执行任务,通常不需要编写任何特定于任务的规则。
人工神经网络是一种基于一系列被称为“人工神经元”的连接单元或节点的模型,这些单元或节点对生物大脑中的神经元进行松散的建模。每一个连接,就像生物大脑中的突触一样,都能将信息,即一个“信号”,从一个人工神经元传递到另一个。一个接收到信号的人工神经元可以处理它,然后向连接到它的其他人工神经元发出信号。在一般的人工神经网络实现中,连接人工神经元的信号是实数,每个人工神经元的输出由其输入和的非线性函数计算。人工神经元之间的连接称为“边缘”。人工神经元和边缘的重量通常会随着学习的进展而调整。重量增加或减少连接时信号的强度。人工神经元可能有一个阈值,只有当聚合信号超过该阈值时才发送信号。通常,人工神经元被聚集成层。不同的层可能对它们的输入执行不同类型的转换。信号从第一层(输入层)传递到最后一层(输出层),可能经过多次遍历这些层。
人工神经网络方法的最初目标是像人脑一样解决问题。然而,随着时间的推移,注意力转向执行特定的任务,导致偏离生物学。人工神经网络已被用于各种任务,包括计算机视觉、语音识别、机器翻译、社交网络过滤、玩棋盘和视频游戏以及医疗诊断。
深度学习由人工神经网络中的多个隐含层组成。这种方法试图模拟人脑将光和声音处理成视觉和听觉的方式。深度学习的一些成功应用是计算机视觉和语音识别
决策树
主要文章:决策树学习
决策树学习使用决策树作为预测模型,从对项目的观察(在分支中表示)到对项目目标值的结论(在叶子中表示)。它是统计、数据挖掘和机器学习中常用的预测建模方法之一。目标变量可以取一组离散值的树模型称为分类树;在这些树结构中,叶子表示类标签,分支表示导致这些类标签的特征的连接。目标变量可以取连续值(通常是实数)的决策树称为回归树。在决策分析中,决策树可以用来直观、明确地表示决策和决策制定。在数据挖掘中,决策树描述数据,但生成的分类树可以作为决策的输入。
支持向量机
主要文章:支持向量机
支持向量机(svm)又称支持向量网络,是一套用于分类和回归的相关监督学习方法。给出一组训练样本,每个样本都被标记为两类中的一种,SVM训练算法建立一个模型,预测一个新样本是否属于这两类。支持向量机训练算法是一种非概率的、二进制的、线性的分类器,尽管在概率分类设置中存在Platt缩放等方法来使用支持向量机。除了执行线性分类,支持向量机还可以使用所谓的内核技巧有效地执行非线性分类,隐式地将它们的输入映射到高维特征空间。
贝叶斯网络
主要文章:贝叶斯网络
一个简单的贝叶斯网络。雨水影响洒水器是否启动,雨水和洒水器共同影响草地是否湿润。
贝叶斯网络、信念网络或有向无环图模型是一种用有向无环图(DAG)表示一组随机变量及其条件独立性的概率图形模型。例如,贝叶斯网络可以表示疾病和症状之间的概率关系。给定症状,该网络可以用来计算各种疾病出现的概率。有效的算法可以执行推理和学习。贝叶斯网络是一种动态贝叶斯网络,它可以对语音信号或蛋白质序列等变量序列进行建模。能够表示和解决不确定性下决策问题的贝叶斯网络的推广称为影响图。
遗传算法
主要文章:遗传算法
遗传算法(GA)是一种模仿自然选择过程的搜索算法和启发式技术,利用突变和交叉等方法生成新的基因型,希望找到一个给定问题的良好解决方案。在机器学习中,遗传算法在20世纪80年代和90年代被使用。相反,机器学习技术被用来提高遗传和进化算法的性能
训练模型
通常,机器学习模型需要大量的数据才能运行良好。通常,在训练机器学习模型时,需要从训练集中收集大量具有代表性的数据样本。训练集中的数据可以是多种多样的,如文本语料库、图像集合和从服务的单个用户收集的数据。在训练机器学习模型时要注意过度拟合。
联合学习
主要文章:联邦学习
联邦学习是一种训练机器学习模型的新方法,它分散了训练过程,允许通过不需要将用户的数据发送到集中的服务器来维护用户的隐私。这还通过将培训过程分散到许多设备来提高效率。例如,Gboard使用联邦机器学习来训练用户手机上的搜索查询预测模型,而无需将单个搜索返回到谷歌.[51]
应用程序
机器学习有很多应用,包括:
2006年,在线电影公司Netflix举办了首届“Netflix大奖”(Netflix Prize)竞赛,目的是寻找一个程序,更好地预测用户偏好,并将其现有Cinematch电影推荐算法的准确度提高至少10%。一个由AT&T实验室的研究人员组成的联合团队与团队Big Chaos和Pragmatic Theory合作建立了一个集成模型,赢得了2009年的大奖,奖金100万美元。[52]颁奖后不久,Netflix意识到观众的评分并不是他们观看模式的最佳指标(“一切都是推荐”),于是他们相应地改变了推荐引擎。[53]中国英语学习网2010年,《华尔街日报》(The Wall Street Journal)报道了Rebellion Research公司及其利用机器学习预测金融危机的做法。2012年,Sun Microsystems联合创始人维诺德·科斯拉(Vinod Khosla)预测,未来20年,80%的医生工作将被自动化机器学习医疗诊断软件取代。[55] 2014年,有报道称,机器学习算法已经被应用于艺术史领域来研究美术绘画,这可能揭示了艺术家们之前未被认识到的影响。施普林格Nature在2019年出版了第一本使用机器学习的研究书籍。
限制
尽管机器学习在某些领域已经发生了革命性的变化,但机器学习程序往往无法提供预期的结果。造成这种情况的原因有很多:缺乏(合适的)数据、缺乏对数据的访问、数据偏见、隐私问题、选择不当的任务和算法、错误的工具和人员、缺乏资源以及评估问题。[61]
2018年,优步(Uber)的一辆自动驾驶汽车未能发现一名行人,该行人在碰撞后死亡。[62]即使经过多年的时间和数十亿美元的投资,将机器学习应用于IBM Watson系统的医疗保健尝试也未能成功。[63][64]
偏见
主要文章:算法偏差
机器学习方法尤其会受到不同数据偏差的影响。仅针对当前客户的机器学习系统可能无法预测未在培训数据中表示的新客户组的需求。当机器学习以人造数据为训练对象时,很可能会拾起已经存在于社会中的相同的结构性和无意识偏见。[65]从数据中学习的语言模型已被证明含有类似人类的偏见。【66】【67】用于犯罪风险评估的机器学习系统被发现对黑人有偏见。【68】【69】在2015年,谷歌的照片经常将黑人贴上大猩猩的标签,【70】而在2018年,这一问题仍然没有得到很好的解决,但据报道,谷歌仍在使用这种方法将所有大猩猩从训练数据中移除,因此根本无法识别真正的大猩猩。[71]在其他许多系统中也发现了类似的识别非白人的问题。【72】2016年,微软测试了一款从Twitter学习的聊天机器人,它很快学会了种族主义和性别歧视的语言。[73]由于这些挑战,机器学习的有效使用可能需要更长的时间才能被其他领域采用。[74]包括李飞飞在内的人工智能科学家越来越多地表达了他们对减少机器学习偏见、推动机器学习造福人类的担忧。它受到人们的启发,由人们创造,最重要的是,它影响着人们。这是一个强大的工具,我们才刚刚开始了解,这是一个深刻的责任。”
模型的评估
机器学习分类可以验证模型精度评估技术像抵抗的方法,将训练集和测试集的数据(训练集传统2/3和1/3测试集名称)和评估培训的性能模型在测试集上。相比之下,K-fold-cross-validation方法将数据随机划分为K个子集,每个子集分别考虑1个子集进行评估,其余的K-1子集进行模型训练。除了坚持和交叉验证方法外,bootstrap还可以用来评估模型的准确性,bootstrap从数据集中抽取n个实例进行替换。[76]
除了总体准确性外,研究人员还经常报告敏感性和特异性,分别表示真实阳性率(TPR)和真实阴阳率(TNR)。同样,调查人员有时报告假阳性率(FPR)和假阴性率(FNR)。然而,这些比率并不能揭示它们的分子和分母。总工作特性(TOC)是表达模型诊断能力的一种有效方法。TOC表示前面提到的费率的分子和分母,因此TOC提供的信息比常用的接收机工作特性(ROC)和曲线下ROC相关面积(AUC)更多。[77]
道德
机器学习提出了一系列伦理问题。对带有偏见的数据集进行训练的系统在使用时可能表现出这些偏见(算法偏见),从而将文化偏见数字化。[78]例如,使用一家实行种族主义招聘政策的公司的招聘数据,可能会导致机器学习系统复制这种偏见,根据应聘者与先前成功应聘者的相似度对他们进行评分。[79][80]负责收集系统使用的算法规则的数据和文档,因此是机器学习的关键部分。
因为语言中含有偏见,训练语言语料库的机器也必然会学习偏见。[81]
与个人偏见无关的其他形式的道德挑战在医疗保健领域更为常见。卫生保健专业人士担心,这些系统可能不是为公众利益而设计的,而是作为产生收入的机器。在美国尤其如此,在那里,改善医疗保健和增加利润是一个永恒的道德难题。例如,这些算法可以被设计为向患者提供不必要的测试或药物,而算法的所有者持有这些测试或药物的股份。机器学习在医疗保健领域有着巨大的潜力,它可以为专业人士提供一个伟大的工具来诊断、治疗,甚至为患者规划康复路径,但这要等到前面提到的个人偏见得到解决,而这些“贪婪”偏见得到解决之后才能实现。【82】
软件
包含多种机器学习算法的软件包包括:
Free and open-source software
- CNTK
- Deeplearning4j
- ELKI
- Keras
- Caffe
- ML.NET
- Mahout
- Mallet
- mlpack
- MXNet
- Neural Lab
- GNU Octave
- OpenNN
- Orange
- scikit-learn
- Keras
- Shogun
- Spark MLlib
- Apache SystemML
- TensorFlow
- ROOT (TMVA with ROOT)
- Torch / PyTorch
- Weka / MOA
- Yooreeka
- R
Proprietary software with free and open-source editions
Proprietary software
- Amazon Machine Learning
- Angoss KnowledgeSTUDIO
- Azure Machine Learning
- Ayasdi
- IBM Data Science Experience
- Google Prediction API
- IBM SPSS Modeler
- KXEN Modeler
- LIONsolver
- Mathematica
- MATLAB
- Microsoft Azure Machine Learning
- Neural Designer
- NeuroSolutions
- Oracle Data Mining
- Oracle AI Platform Cloud Service
- RCASE
- SAS Enterprise Miner
- SequenceL
- Splunk
- STATISTICA Data Miner
See also
- Automated machine learning
- Big data
- Explanation-based learning
- Important publications in machine learning
- List of datasets for machine learning research
- Predictive analytics
- Quantum machine learning
- Machine-learning applications in bioinformatics
原文:https://en.wikipedia.org/wiki/Machine_learning
本文:https://pub.intelligentx.net/wikipedia-machine-learning
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 123 次浏览