【微服务架构】让我们谈谈“拥有”他们的数据的微服务
前几天我和一位同事讨论了我的微服务将用来公开特定数据集的接口的设计。 数据由我的微服务保存在 Elastic Search 中,并根据最终用户将选择的过滤器以不同的形式由 UI 使用和呈现。 当我仅仅提出让 UI 后端直接从 Elastic Search 查询数据的亵渎想法时,经典的“微服务不应该暴露其底层数据存储”的论点被点燃了。

- Who owns the data??
暴露数据的服务
我会从头开始。 微服务可以以任何方式或使用他们希望的任何技术公开数据,具体取决于用例。
让我们想象一个简单的数据项并通过一些示例。
有问题的数据项将是这个表示消息的简单 JSON 对象:
{
id: 2321387
sender: “Joe”
message_content: “Hello World Message”
}
公开这些数据的最无争议的方式可能是:
- · REST API
- · GraphQL
这些是“纯”API,因为它们提供了接口和底层数据存储的完全解耦。 今天我可能会在 Couchbase 中保存数据,明天在 Redis 中,下周我会将其移动到 S3。 如果我改变实现,消费者不需要知道任何事情。
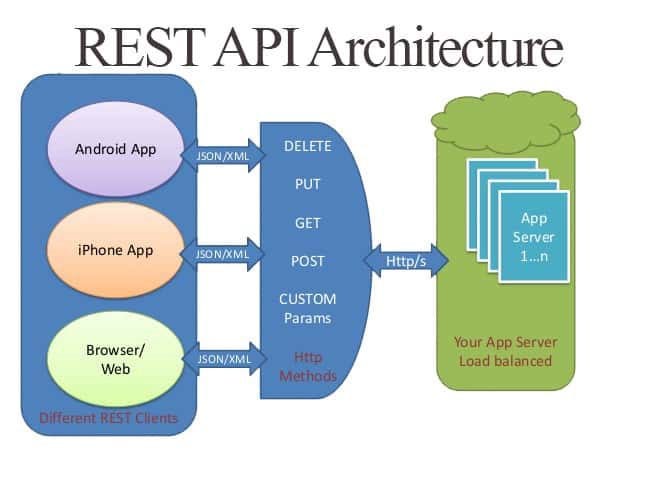
- Exposing Data via REST API — Not Controversial
那么消息队列中的消息呢? 像 Kafka 或 RabbitMQ 之类的东西? 软件工程社区仍将这些技术定义为公开数据的非争议方式。 在许多产品的架构中,微服务通过消息队列相互通信,对吗? 如果我想将我的实现从 Kafka 更改为 RabbitMQ 会发生什么,消费者是否也需要更改他们的实现? 他们当然会,但您可能会争辩说,完全改变产品中的整个消息传递技术确实不太可能。
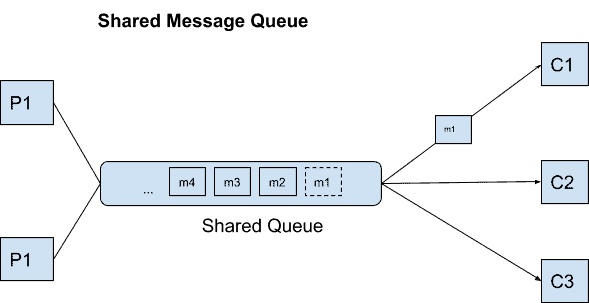
- Exposing Data via Message Queues — Not Controversial
现在让我们朝这个方向再走一步。 数据仓库和数据湖呢? 将您的数据保存在 S3 中并让消费者使用 Athena/Presto/BigQuery 在其上运行查询怎么样? 在这个用例中封装数据发生了什么? 令人惊讶的是,“接口-数据存储解耦”范式的纯粹主义者根本不认为这是一种不好的做法。
我试图争辩说,数据湖/仓库用例与通过 Elastic Search、Couchbase、Redis 或任何其他技术公开数据之间没有真正的区别。 数据的位置不是问题,因此解耦不是解决方案。 我们以错误的方式看待这个问题。
内部数据 VS 公开数据
真正的区别应该是您定义为服务的“内部”数据或状态,以及您定义为服务的“公开”数据。问题不在于您选择使用哪种技术存储数据。
内部数据是其位置和架构可以更改而不事先通知的数据。它完全在服务和拥有团队内部,任何消费者都不应该依赖它。一天它可以是内存中的 HashMap,另一天它可以是 DynamoDB 中的一个表,第三天开发人员可以决定将它存储在 S3 中,因为它太大而且太贵了。只要将这些数据定义为内部数据,我们就可以在任何时间点引入“破坏性更改”,因为它不会“破坏”任何消费者。
公开数据是您向消费者公开并提交给它及其模式的数据。无论您是通过定义良好的 REST API、定义良好的 Kafka 消息、S3 中定义良好的 ORC 文件还是 Couchbase 中定义良好的记录来公开它都没有关系。只要您和您的消费者同意这是公开的公共数据,您就不能在不通知消费者的情况下引入重大更改。您甚至可以想象一个使用 2 个 Couchbase 存储桶的服务——一个用于内部数据,一个用于公开数据。同样,技术并不重要,重要的是数据用途的定义。
重要的是要澄清,即使这些数据被公开和共享,消费者也只能从中读取。在这种模式下,拥有服务仍然是唯一对公开数据具有写访问权限的实体(显然对内部数据也是如此)。您可以将其视为微服务的一种 CQRS 实现。
为什么你甚至想通过 Couchbase 或 Athena 而不是严格地通过 REST 或 GraphQL 等 WEB API 来公开你的数据,你可能会问。
Amazon Athena 就是一个很好的例子,因为它通过多台服务器并行运行您的查询,因此您的数据消费者可以利用 Athena 的强大功能进行快速的大数据查询。有什么选择?您会在自己的服务中构建类似的功能并通过 Web API 公开它们吗?您将如何通过 Web API 公开丰富的 SQL 语言? GraphQL 能否涵盖 SQL 提供的所有选项? API 是否会是您将在内部传递给 Athena 并将结果分页给消费者的通用字符串?
相同的概念可以应用于 Couchbase、DynamoDB、Aurora 或任何其他数据存储。创建这些工具是为了扩大规模,旨在每秒接受和响应数十万个请求。如果一切都严格通过您的服务进行,则意味着您的开发人员将需要在他们自己的服务中重写这些技术的功能,或者只是在逻辑上降级数据存储的真正底层功能。
总结
您需要在内部和共享之间逻辑划分数据。后者是您与世界共享的数据,而内部数据是您的消费者不需要知道的完全封装的实现。一个数据集可以被认为是内部的并且驻留在 State Store 中,而相同数据的投影可以驻留在同一个 State Store 中并暴露在外部。这完全取决于您的用例,以及向消费者公开数据以优化使用数据的最佳方式是什么。
评论1
SQL server 是隔离的,可独立部署的,通过网络消息与其他服务通信,拥有自己的数据,是唯一可以写入磁盘来持久化它的,那么它怎么不是微服务呢?因为它的边界是由技术要求而不是业务要求决定的?因为太复杂了?因为是第三方?荒谬的。没有人真正根据约束的类型来定义技术概念。
从本质上讲,您的文章侵蚀了微服务的概念,而这正是困扰人们的地方。就是“如果我们允许这样做,它会在哪里停止?”思维。但答案很简单:它不会停止。定义微服务的方式取决于组织内部解决方案的架构师。他们可以准确地确定什么是微服务,什么不是。作为一般概念,对微服务的限制是没有用的。
我会更进一步:微服务纯度(与任何其他类型或对纯度的追求一样,但这已经太笼统了)是有毒的。接受现实中任何值得该死的系统都是技术的混合体,其中微服务只是其中的一部分,这要健康得多。
评论2:
我基本同意,我们应该专注于逻辑划分数据,而纯粹的微服务架构是弊大于利的。 虽然有些观点我认为你没有做对。
当您质疑数据库和仓库是用来回答数千个请求而 API 只能处理一个请求时,问题在于 API 的扩展方式。 瘫痪 API 工作负载可以解决数据库必须提供的资源使用不足的问题。
另一件事是,如果您期望进行临时查询,他们可能应该使用另一种连接数据的方式。 这是BI系统存在的主要原因。
也许我在挑剔,但这些是我对这个主题的想法。 我不愿意让其他人看到我的数据:p
原文:https://blog.devgenius.io/lets-talk-about-microservices-owning-their-da…
本文:
- 68 次浏览