【计算机视觉】人脸识别101
起初,您可能想知道:
- 我们如何使用线性代数(矩阵/向量)将某人的面部图像解释为数学?
- 系统如何能够从包含人脸的图像中识别出某人?
- 我们如何让计算机了解某人的脸?
如果您想知道上面列出的事情之一是非常好的,因为您很想了解人脸识别,因此为什么我会给您一些关于此的见解,希望您能够掌握什么是人脸识别以及背后发生的事情现场。
人脸识别不就是图像分类吗?
它们相似,但不能一视同仁。当您训练图像分类模型时,通常您有一个包含 n 个类的数据集,并且对于每个类,您有许多图像。假设每个类有 100 张图像。但是,当你想建立人脸识别系统时,你可能只有一张某人的照片。同样在图像分类中,你想在不同的类之间进行分类,或者你可以说对象。在人脸识别中,它们都是人脸。因此,您需要获得能够区分每个人面部的特征。但是,如果您了解图像分类的工作原理,您将轻松学习人脸识别。
人脑的魔力
最常见的机器学习任务(例如图像分类)或最常用的数据集(例如预测房价)都可以使用一个机器学习过程来完成。您可以只输入您的数据,输出将仅由一个进程给出。但是,人脸识别就不一样了。
首先,您需要从图像中找到所有人脸(人脸检测)。然后,您需要从面部中看到与其他人不同的独特特征(特征提取)。最后,您将提取的特征与您已经见过的所有人进行比较,并根据您的知识找到该人。
上帝免费给我们这个过程,我们需要欣赏上帝给我们的所有东西。即使是现在,人造机器仍然无法像我们免费提供的大脑那样识别面部。
特征脸(这些不是鬼的照片)
为了能够知道我们如何从图像中获取特征脸,首先我们需要知道如何在数学中表示图像,什么是特征值以及什么是 PCA。但首先,什么是特征脸?

图像表示
假设人脸已经被预处理为正方形图像
在计算机中,灰度图像由 NxN 矩阵表示。但是为了便于操作,我们将把这个矩阵转换为 N²x1,只需将矩阵分解为一个 tall 向量即可。但是,想象一下,如果我们有一个 200 x 200 像素的人脸图像。因此,如果我们将图像转换为矢量,我们将拥有 40000x1 的矢量,当我们有这么多图像时,我们将在 40000 维空间中处理所有内容。想象一下当你想要处理任何东西时的成本。因此,PCA 通过创建低维空间来帮助我们降低成本。
那么,什么是特征脸和 PCA?
为了获得特征脸,首先我们将 PCA 应用于我们的数据集。根据维基百科的 PCA,PCA 是计算主成分并使用它们对数据执行基础更改的过程,有时仅使用前几个主成分而忽略其余部分。因此,如果我们想减少数据的维度,可以使用 PCA。
在我们将 PCA 应用于我们的数据集之后,我们得到了称为主成分 (PC) 的东西。 PCA 的 PC 是协方差矩阵的特征向量。我们从这一步得到的特征向量就是我们所说的特征脸。现在,我们知道名称 eigenface 是从使用 eigenvalue 和 eigenvector 的帮助来获取特征的过程中派生的。
渔脸
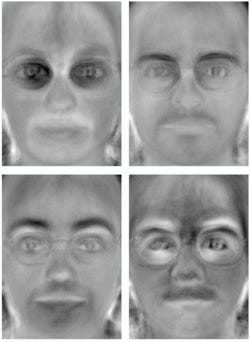
2011 年,Aleix Martinez 提出了一种替代我们之前讨论的特征脸的方法,称为 Fisherface。 eigenface 和 Fisherface 的主要区别在于 eigenface 使用 PCA,而 Fisherface 使用不同的方法使用 LDA。在我们将 LDA 应用到我们的数据集创建一个新的子空间表示之后,创建该子空间的基向量称为 Fisherface。如果您对fisherfaces 感兴趣,您可以阅读这个网站,其中讨论了您需要了解的所有信息。
PCA 与 LDA
简单来说,LDA 和 PCA 的区别在于 LDA 不是最大化方差,而是希望最小化投影类的方差,并找到最大化类均值之间分离的轴。 PCA 也是一种无监督学习算法,而 LDA 是一种监督学习算法。
特征脸与渔脸
Peter N. Belhumeur、Joao~ P. Hespanha 和 David J. Kriegman 发表了一篇题为“Eigenfaces vs. Fisherfaces: Recognition Using Class Specific Linear Projection”的论文。得出的结论是:
- 如果测试集中的图像与训练集相似,则 eigenface 和 fisherface 都表现良好
- Fisherface 在对光照变化进行外推和插值方面明显更好,并且在同时处理光照和表情变化方面也表现出色。
- 通过去除三个最大的主成分,我们可以改进特征脸方法,但仍然比fisherface有更高的错误率
它是最好的吗?
这是由 Github 用户 bytefish 进行的 AT&T Facedatabase 上 eigenface 和 fisherface 的 rank-1 识别图:
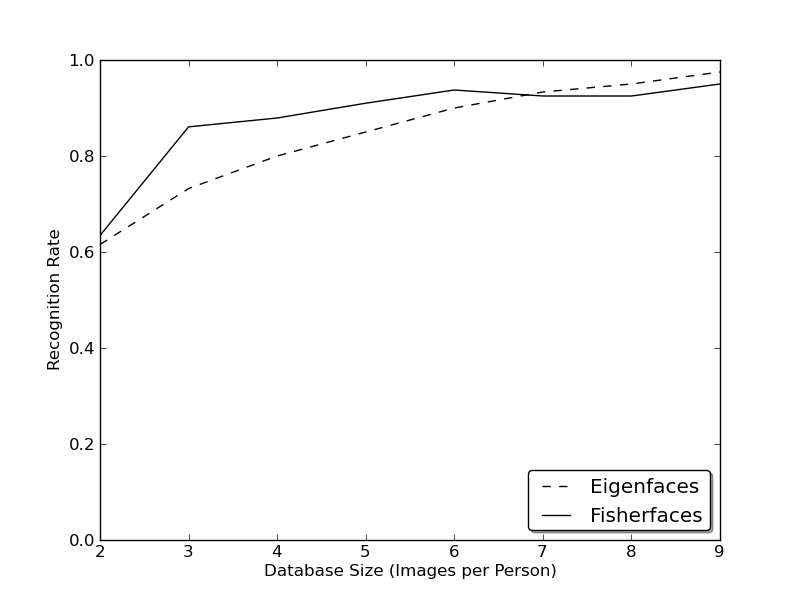
通过查看图表,我们知道每个人必须有 7-9 张图像,并且特征脸和渔人脸似乎收敛到相同的识别率值。 想象一下,当我们只有一张想要添加到我们知识中的人的图像时。
另一种方法:局部特征
一些研究人员的想法是不要将图像视为高维向量,但我们可以描述图像的局部特征。 作为人类,我们有时会用物理特征来描述某人的脸,例如他们的眼睛、鼻子、嘴巴的形状等等。 局部二进制模式,也称为 LBP,使用 2D 纹理分析。 LBP 的基本思想是通过比较每个像素与其相邻像素来总结图像的局部结构。 如果中心像素的强度大于等于其相邻像素的强度,我们将 1 分配给中心,否则为 0。

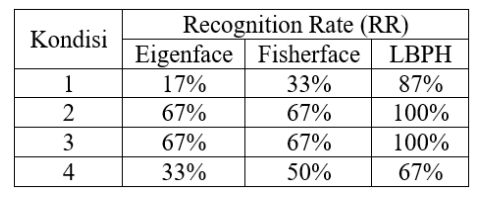
LBPH vs Eigenfaces vs Fisherfaces
Qadrisa Mutiara Detila 和 Eri Prasetyo Wibowo 在 2019 年发表了一篇期刊,比较了在 6 张面孔和 4 种不同条件下进行人脸识别的三种方法,结果如下表:
现在的一切不都是深度学习吗?
当然,人脸识别有很多深度学习方法。 在我们讨论了很多传统方法之后,我们将讨论一种称为 OpenFaces 的方法。
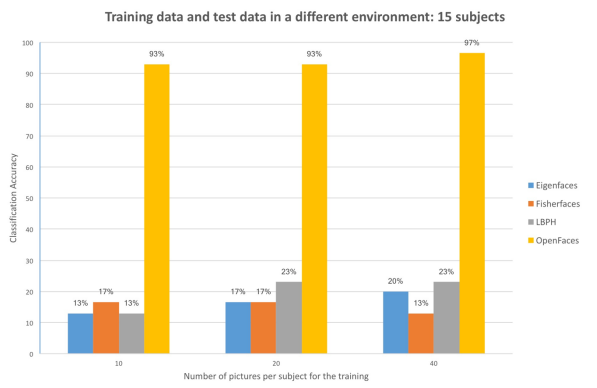
Comparison between traditional and deep learning face recognition, Nicolas Delbiaggio
Florian Schroff、Dmitry Kalenichenko 和 James Philbin 在 CVPR 2015 上发表了一篇名为 FaceNet: A Unified Embedding for Face Recognition and Clustering 的论文。 与大多数深度学习模型一样,该模型使用大量数据进行训练,包含 50 万张图像,在 LFW 基准数据集上获得了 92.9% 的准确率。
深度学习方法的优点是我们不需要很多人的图像来获得良好的性能,即使我们每个人只能使用一张图像。 在 FaceNet 中,该人脸将使用三个图像进行训练,称为锚图像 (A)、正图像 (P) 和负图像 (N)。
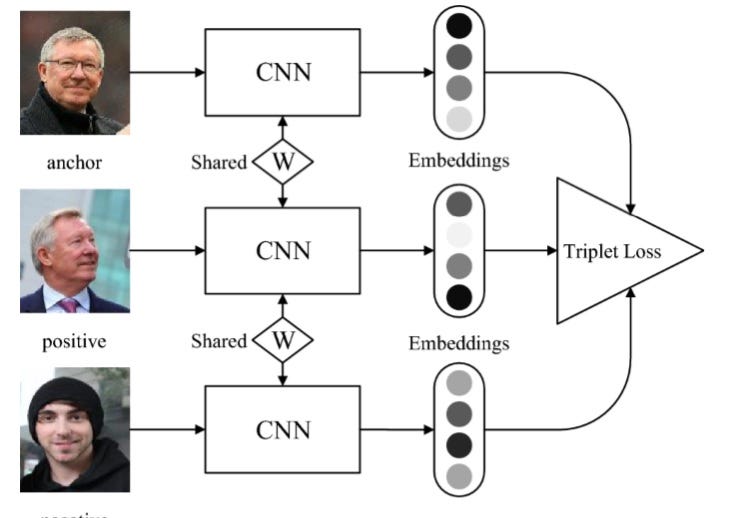
锚点和正面应该包含同一个人,而负面则不包含。 这里的想法是,我们希望某个人(A)的图像更接近与 A 属于同一个人的所有图像 P,同时与其他图像 N 保持最远的距离。
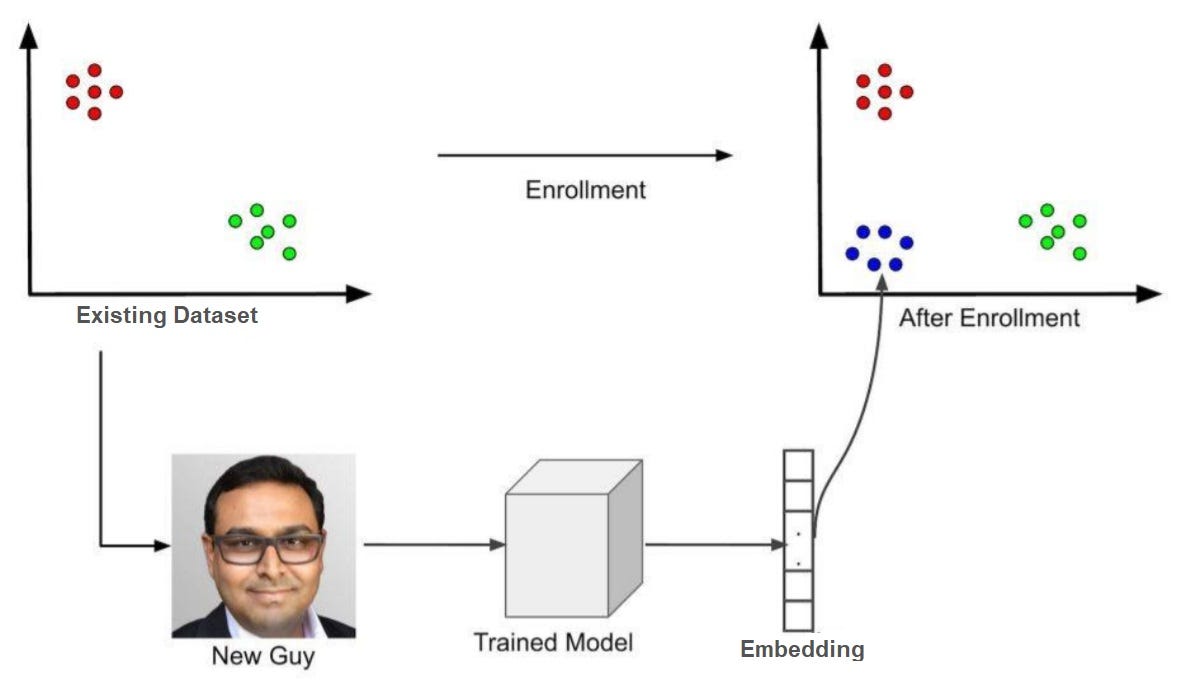
因此,如果我们要将一个人添加到我们的模型中,我们需要执行一个称为注册的过程。 这个过程的想法是我们想要在我们的子空间中找到人的位置(由上图中的蓝点定位)。 因此,在我们有了新人的位置之后,如果我们有一张图像在我们的蓝色向量附近有嵌入,我们可以确定该图像很可能是最近添加的新人。 在 FaceNet 中,我们通过一个人的图像得到一个与图像对应的 128 维特征描述符。
请注意,我最有可能使用了这个词,没有显示任何确定性,因为没有算法可以完美地识别一个人的图像,因此使用了最有可能这个词。
参考
https://docs.opencv.org/3.3.1/da/d60/tutorial_face_main.html
https://towardsdatascience.com/face-recognition-how-lbph-works-90ec258c…
https://www.pyimagesearch.com/2015/12/07/local-binary-patterns-with-pyt…
https://towardsdatascience.com/face-recognition-how-lbph-works-90ec258c…
https://m-shaeri.ir/blog/how-facenet-works-how-to-work-with-facenet/
http://cmusatyalab.github.io/openface/
原文:https://ahmadirfaan.medium.com/face-recognition-101-ee37fb79c977
本文:
- 86 次浏览