【数据架构】面向初创公司的现代数据堆栈
Chinese, Simplified

“为工作使用正确的工具!”
这句话一开始听起来很简单,但在实际方面实施起来却非常复杂。
早期的初创公司发现很难选择生态系统中可用的各种工具,因为它们的数据将如何演变是非常不可预测的。
需要现代数据堆栈
在过去 10 年中,软件行业在以下方面有所增长:
- 计算能力:AWS、Google Cloud 等公共云提供商以标准市场成本提供巨大的计算能力。
- 数据源:物联网生态系统、智能设备的兴起导致每天产生的数据量呈指数级增长。 2020 年,地球上的每个人每秒产生约 1.7MB 的数据。
- 业务利益相关者的数据素养:在原始软件行业,分析师过去常常手动挖掘 excel 电子表格,以获得有关数据的一些有价值的见解。如今,事实证明,许多 BI 工具在利用数据的力量和提供有价值的见解方面很有用,从而在业务利益相关者中培养了素养。
- 数据项目中的开源采用:在过去的 10 年中,行业已经看到开源社区的巨大增长。许多很酷的数据工具(~Apache Airflow、DBT、Metabase)在开源社区中蓬勃发展和发展。
从传统 ETL 到现代 ELT 的转变
在这个现代时代,大多数企业都在利用数据驱动的解决方案,我们看到了从原始的遗留 ETL 架构向 ELT 架构的一致转变。
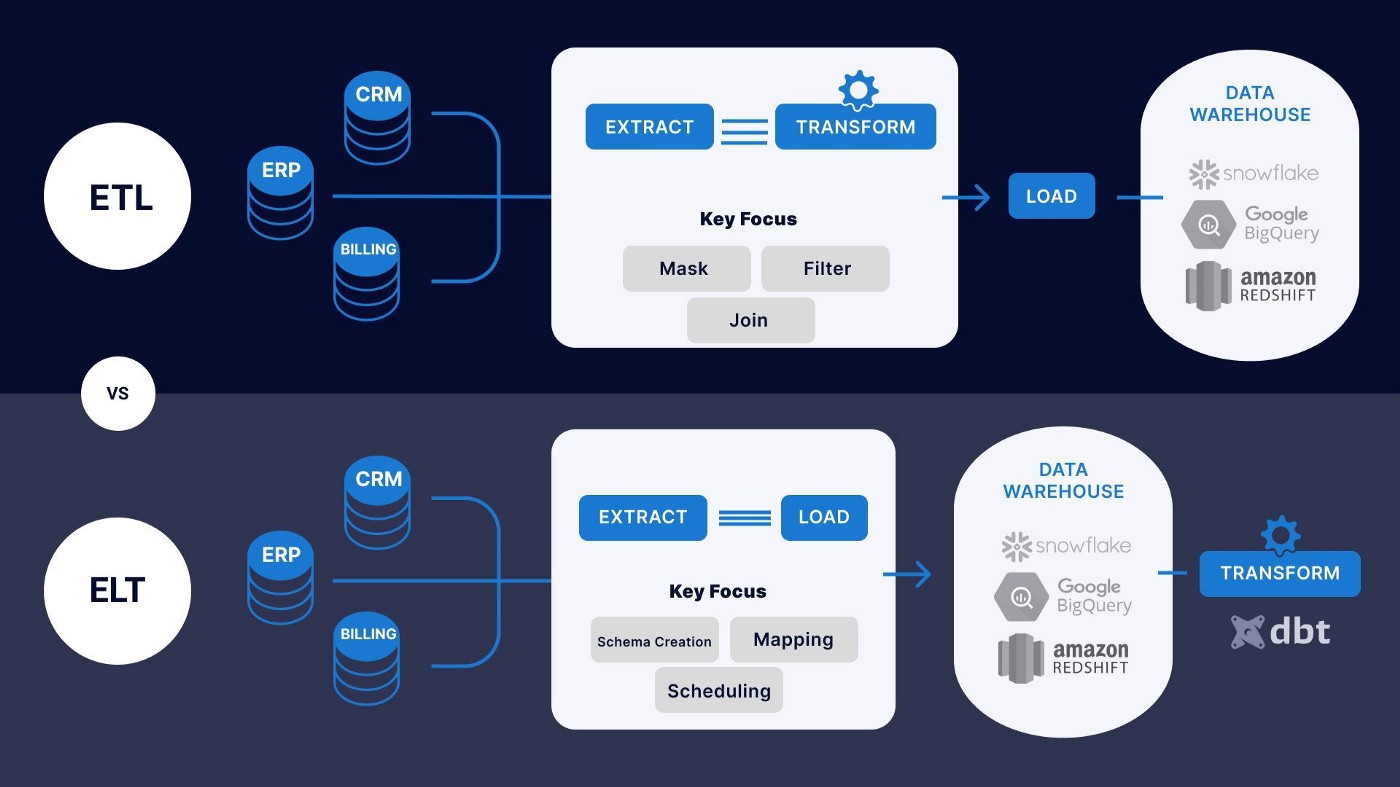
由于以下原因,现代 ELT 处理比传统 ETL 更受欢迎:
- 便宜、实惠且高效的云存储和分析服务。
- 传统 ETL 管道没有那么灵活,无法根据指数数据增长轻松适应。
- 与传统 ETL 相比,现代 ELT 速度更快,因为在将数据加载到仓库之前不涉及严格的转换阶段。
- 鉴于不需要用户定义的转换,ELT 工具非常擅长将源数据简单地插入目标系统,而用户的手动工作最少。
- 分析师可以根据需要使用 DBT 等工具对仓库中的数据执行转换,而无需事先考虑洞察力和数据类型。
初创公司的采用策略
正如本博客前面提到的,初创公司很难预测数据的演变,他们将要应对。
因此,早期初创公司在为其数据堆栈选择工具时应考虑以下事项:
- 其他初创公司和客户的高采用率和意识。
- 这适合数据堆栈的 ELT 模型。
- 数据库范式(例如结构化、地理空间、实体关系、搜索引擎),适合存储和查询其领域和市场产生的数据的要求。
- 付费 SaaS 工具的等效开源替代品。
提取和加载
从所有事件源(如 Web、应用程序、后端服务)收集数据,并将它们发送到数据仓库。
- 付费 SaaS 工具:Stitch、Fivetran
- 免费和开源替代品:Singer、Meltano、Airbyte
数据仓库
组织所有数据的结构化、非易失性、单一事实来源,我们可以在其中存储和查询所有数据。
- 付费:AWS Redshift、Google BigQuery、Snowflake
- 免费和开源替代品:Apache Druid
转换和建模
使用文档从原始数据创建模型以更好地使用。
- 付费:Dataform、DBT
- 免费和开源替代品:Talend Open Studio、Apache NiFi
编排
用于执行和编排处理数据流的作业的软件。
- 付费:Prefect.io
- 免费和开源替代品:Apache Airflow、Dagster
可视化和分析
为了更好地了解和解释来自不同数据源的数据。
- 付费:Tableau、Microsoft PowerBI、Grafana
- 免费和开源替代品:Metabase、D3js、DyGraphs
原文:https://medium.com/nybles/modern-data-stack-for-startups-b63bc383e1d0
- 224 次浏览
SEO Title
Modern Data Stack for Startups