计算机视觉
- 63 次浏览
【MLOps】生产用例的并行Stable Diffusion
视频号

微信公众号

知识星球


Tl;dr
- Stable Diffusion是一种令人兴奋的新图像生成技术,您可以轻松地在本地运行或使用Google Colab等工具;
- 这些工具非常适合探索和实验,但如果你想通过围绕Stable Diffusion构建自己的应用程序或大规模运行来将其提升到一个新的水平,那么这些工具就不合适了;
- Metaflow是一个开源的机器学习框架,为Netflix的数据科学家生产力开发,现在由Outerbounds支持,它允许您为生产用例大规模并行化Stable Diffusion,以高度可用的方式自动生成新图像。
有大量新兴的机器学习技术和技术允许人类使用计算机生成大量的自然语言(例如GPT-3)和图像,如DALL-E。最近,Stable Diffusion风靡全球,因为它允许任何拥有互联网连接和笔记本电脑(或手机!)的开发者使用Python通过提供文本提示来生成图像。
例如,使用拥抱脸库 Diffusers,,您可以用7行代码生成“尼古拉斯·凯奇作为教父(或其他任何人)的画作”。

Paintings of Nicolas Cage as He-Man, Thor, Superman, and the Godfather generated by Stable Diffusion.
在这篇文章中,我们展示了如何使用Metaflow,这是一个开源的机器学习框架,为Netflix的数据科学家生产力开发,现在由Outerbounds支持,为生产用例大规模并行化Stable Diffusion。在此过程中,我们展示了Metaflow如何允许您使用Stable Diffusion这样的模型作为真实产品的一部分,以高度可用的方式自动生成新图像。这篇文章中概述的模式已经准备好制作,并在数百家公司(如23andMe, Realtor.com, CNN, and Netflix等)与Metaflow进行了战斗测试。您可以在自己的系统中使用这些模式作为构建块。
我们还将展示,在大规模生成1000张这样的图像时,如何跟踪使用哪些提示和模型运行来生成哪些图像,以及Metaflow如何提供有用的元数据和开箱即用的模型/结果版本控制,以及可视化工具,这一点很重要。所有代码都可以在此存储库中找到。
作为一个示例,我们将展示如何使用Metaflow从许多提示样式对中快速生成图像,如下所示。您只会受到您对云(如AWS)帐户中可用GPU的访问限制:使用6个GPU在23分钟内同时为我们提供1680个图像,即每个GPU每分钟超过12个图像,但您可以生成的图像数量与您使用的GPU数量成比例,因此云是有限的!

Historic figures by historic styles using Stable Diffusion and Metaflow. Styles from left to right are: Banksy, Frida Kahlo, Vincent Van Gogh, Andy Warhol, Pablo Picasso, Jean-Michel Basquiat.
本地和Colab上使用Stable Diffusion及其局限性
有几种方法可以通过“拥抱面漫射器”库使用“稳定漫射”。其中两个最简单的是:
- 如果你的笔记本电脑上有GPU,你可以使用本地系统来遵循这个Github存储库README中的说明;
- 使用谷歌Colab免费利用基于云的GPU和这样的笔记本电脑。
用于在Colab笔记本中生成上面的“尼古拉斯·凯奇作为教父的画作”的7行代码是:

这两种方法都是启动和运行的好方法,它们允许您生成图像,但速度相对较慢。例如,使用Colab,谷歌的免费GPU供应将您的速率限制在每分钟3张左右。这就引出了一个问题:如果你想扩大规模以使用更多的GPU,你该如何琐碎地做到这一点?除此之外,Colab笔记本和本地计算非常适合实验和探索,但如果你想将Stable Diffusion模型嵌入到更大的应用程序中,还不清楚如何使用这些工具。
此外,当扩展以生成潜在数量级的更多图像时,对模型、运行和图像进行版本控制变得越来越重要。这并不是要给你的本地工作站或Colab笔记本蒙上阴影:他们从来没有打算实现这些目标,而且他们的工作做得很好!
但问题仍然存在:我们如何大规模扩展我们的Stable Diffusion图像生成,对我们的模型和图像进行版本化,并创建一个可以嵌入大型生产应用程序的机器学习工作流?Metaflow救援!
使用Metaflow实现具有Stable Diffusion的大规模并行图像生成
Metaflow使我们能够通过提供以下API来解决这些挑战:
- 通过分支实现大规模并行化,
- 版本控制,
- 数据科学和机器学习工作流程的生产协调,以及
- 可视化。
Metaflow API允许您使用越来越常见的有向无环图(DAG)抽象来开发、测试和部署机器学习工作流,其中您将工作流定义为一组步骤:这里的基本思想是,当使用Stable Diffusion生成图像时,您有一个分支工作流,其中
- 每个分支在不同的GPU上执行,并且
- 分支在连接步骤中连接在一起。
举个例子,假设我们想要生成大量的主题-风格对:给定大量的主题,通过提示并行化计算是有意义的。您可以在以下流程示意图中看到这种分支是如何工作的:
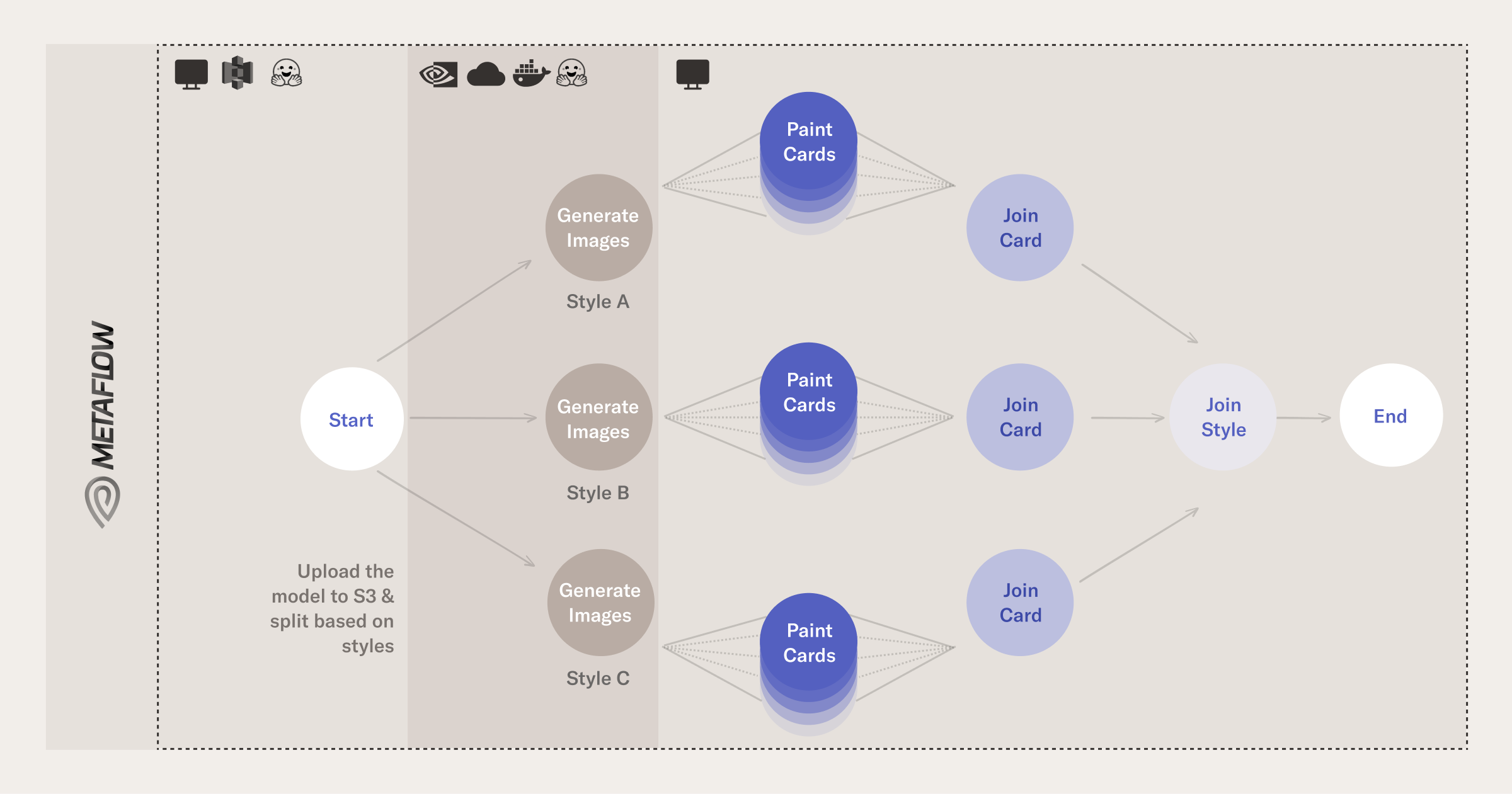
Visualization of the flow that generates images
generate_images步骤的关键元素如下(您可以在这里的存储库中看到整个步骤):
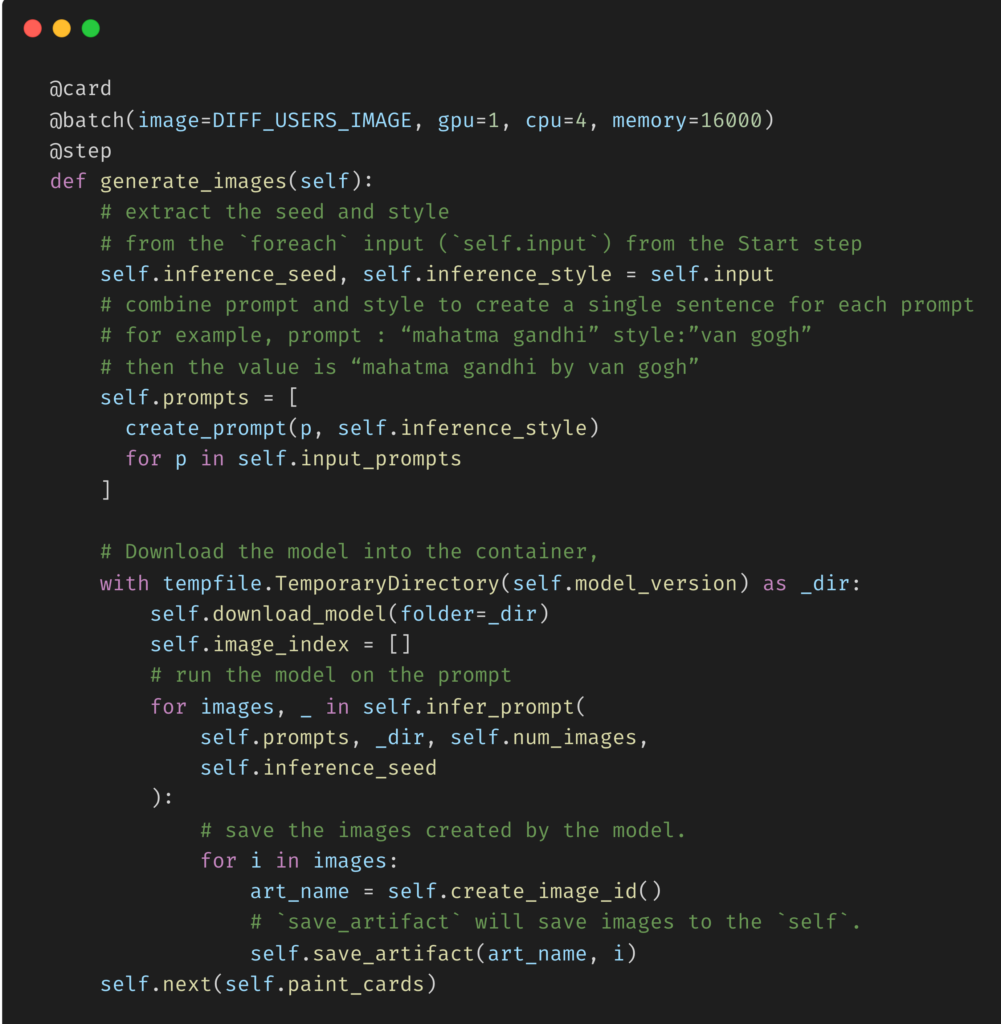
Key elements of the generate_images step
要了解这段代码中发生了什么,首先要注意,当从命令行执行Metaflow流时,用户已经包含了主题和样式。例如:
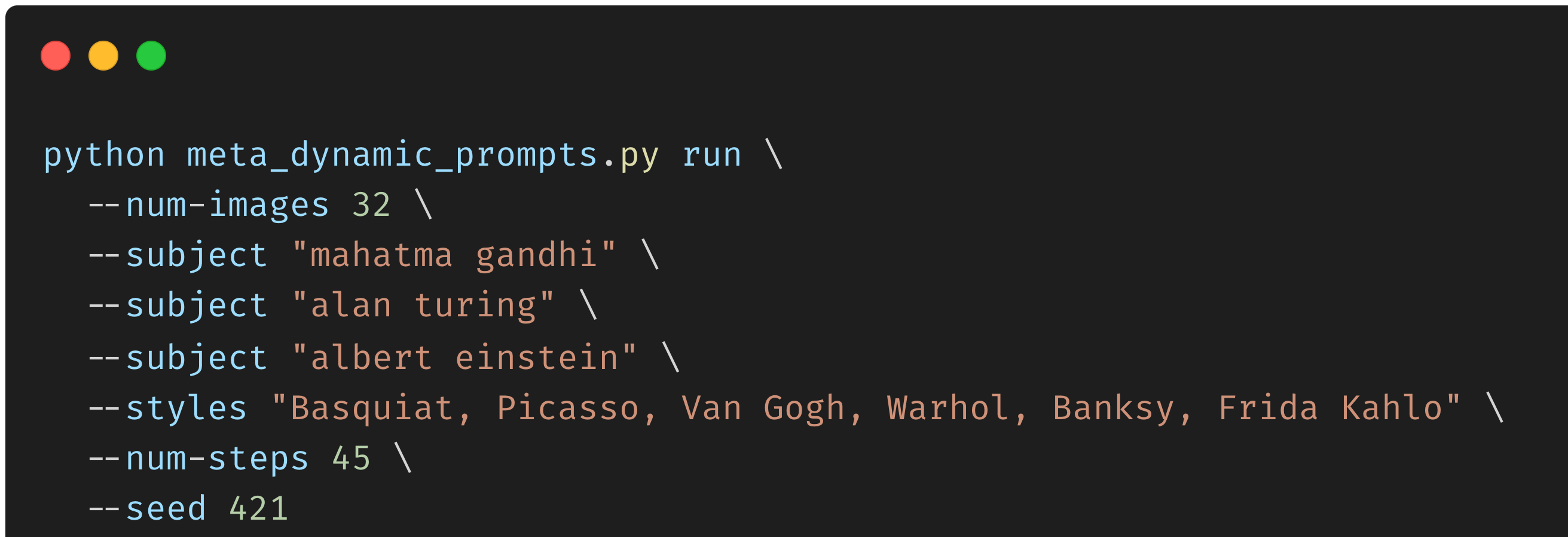
Command to run the image generation flow
样式、主题和种子(为了再现性)存储为一种称为Parameters的特殊类型的Metaflow对象,我们可以分别使用self.styles、self.subject和self.seed在整个流中访问它。更一般地说,self.X等实例变量可以在任何流步骤中使用,以创建和访问可以在步骤之间传递的对象。例如,在我们的开始步骤中,我们将随机种子和样式打包到实例变量self.style_rand_seeds中,如下所示:

正如generate_images步骤中的注释所指出的,我们正在做的是
- 在实例变量self.init中提取从开始步骤传递的种子和样式(之所以是self.init,是因为从一开始就有分支:有关更多技术细节,请查看Metaflow的foreach),
- 将主题和风格结合起来,为每个提示创建一个句子,例如主题“mahatma gandhi”和风格“van gogh”创建提示“mahatta gandhi by van gogh),以及
- 将模型下载到容器中,在提示下运行模型并保存模型创建的图像。
请注意,为了将计算发送到云,我们所需要做的就是将@batch装饰器添加到步骤generate_images中。Metaflow的这种可供性使数据科学家能够在原型代码和模型之间快速切换,并将它们发送到生产中,从而关闭了原型和生产模型之间的迭代循环。在这种情况下,我们使用的是AWS批处理,但您可以使用最适合您组织需求的云提供商。
关于整个流,关键在于(计算)细节,所以现在让我们更全面地了解Metaflow流中发生了什么,注意我们在运行流之前将Stable Diffusion模型从Hugging Face(HF)下载到本地工作站。
- start:[Local execution]我们将HF模型缓存到一个公共数据源(在我们的例子中,S3)。缓存后,根据主题/图像的数量并行运行接下来的步骤;
- generate_images:[Remote execution]对于每种风格,我们在一个独特的GPU上运行一个docker容器,该容器为主题+风格组合创建图像;
- paint_cards:[Local Execution]对于每种风格,我们将生成的图像分为多个批次,并使用Metaflow卡为每个批次生成可视化效果;
- join_cards:[Local Execution]我们为生成的卡加入并行化的分支;
- join_styles:[Local Execution]我们加入所有样式的并行分支;
- end:[Local execution]:结束步骤。
在paint_cards步骤完成执行后,用户可以访问Metaflow UI来检查模型创建的图像。用户可以监控不同任务的状态及其时间表:
https://outerbounds.com/assets/stable-diff-mf-ui-demo.mp4
探索Metaflow UI
您也可以自己在Metaflow UI中探索结果,并查看我们在执行代码时生成的图像。
一旦流完成运行,用户就可以使用Jupyter笔记本根据提示和/或样式搜索和过滤图像(我们在配套存储库中提供了这样一个笔记本)。由于Metaflow版本来自不同运行的所有工件,用户可以比较和对比多次运行的结果。随着模型、运行和图像的版本控制变得越来越重要,当扩展到生成1000张(如果不是1000张中的10张)图像时,这是关键:
https://outerbounds.com/assets/stable-diff-notebook.mp4
结论
Stable Diffusion是一种新的、流行的从文本提示生成图像的方法。在这篇文章中,我们看到了使用Stable Diffusion生成图像的几种方法,如Colab笔记本,这些方法非常适合探索和实验,但这些方法确实有局限性,使用Metaflow有以下启示:
- 并行性,因为您可以将机器学习工作流程扩展到任何云;
- 所有MLOps构建块都封装在一个方便的Python接口中(如版本控制、实验跟踪、工作流等);
- 最重要的是,您可以使用这些构建块实际构建一个生产级、高可用性、SLA满意的系统或应用程序。数百家公司在使用Metaflow之前就已经这样做了,因此该解决方案也是久经沙场的。
- 279 次浏览
【人工智能工程师】2021 年我如何提高计算机视觉技能

我在 Medium 上休学了一年,从未发表过一篇关于计算机视觉的文章。事实是…
回想起来,我在这里发布的最后一篇文章是 2020 年 12 月 12 日,而且是很久以前的事了。事实是,我在我的游戏项目和其他一百万件事之间左右为难,比如工程研究、竞赛和项目、实习和我自学计算机视觉技能的时间。但是,尽管如此,那是很棒的一年,我不得不说,我为自己感到自豪,我仍然能够继续学习计算机视觉,甚至获得了该领域的实习机会。不用说,我从这份工作中学到了很多东西,这里是细目。
今年,我将全力撰写计算机视觉主题,我认为这些主题将对初学者/中级计算机视觉爱好者有所帮助。
随着我更多地接触到计算机视觉这个话题,我发现迫切需要让自己参与到现实世界的应用程序中,并停止从事只能在屏幕上工作的项目。巧合的是,在我的工程课程中有一个顶点项目,我们要为隔离中心的 Covid-19 患者设计一个送餐机器人。我们与一个团队一起,利用我们对计算机视觉的了解并将其应用于机器人本身。我们成功实施了数字识别等功能,有助于标记和识别患者。请记住,这一切都在嵌入式系统上,并且考虑到保持低成本,有很多约束和限制。尽管如此,我们在机器人的部署和生产方面仍然在同行中脱颖而出。

看,计算机视觉的应用不仅限于软件,更重要的是它如何与有限的硬件一起工作。我们发现自己处于一个独特的位置,可以改进我们所做的事情。当然,我们尝试了最有名的面部识别系统和许多其他功能,但它们根本不是我们打算使用的硬件的理想解决方案。因此,我提高计算机视觉技能的第一个技巧是通过硬件集成自己实施解决方案的实践经验。从那里,您将能够对不同的应用程序进行试验,并找出适合目标的应用程序。
提示 #1:通过硬件集成实现计算机视觉解决方案的实践经验无疑是有用的。
快进几个月,我发现自己在一家公司的 AI 团队工作,我的任务是从事几个计算机视觉项目。老实说,它们对我来说很有趣,我认为它们是对整个社会有益的项目。虽然这些项目是保密的,但我只能说这些项目属于水培和医疗领域。老实说,这些项目主要集中在软件方面,我没有参与其中的硬件集成部分。
可悲的是,我的实习期并没有让我在硬件集成阶段停留足够长的时间。
但有趣的是,我深入研究了计算机视觉的软件方面,从分析图像数据集、在学习了许多算法后手动提取特征到实现著名的深度学习模型。幸运的是(或者不幸的是),两周后,我遇到了一个我没想到的问题:缺少图像。您可能会欣赏本文中的另一个事实是,与 Kaggle 问题的世界不同,现实世界中的图像数据集从来没有很好地排列/组织/压缩/策划/准备/{you name it}……但它们无处不在。引用我在LinkedIn上发布的文章:
干净的数据集很难获得,它们通常来自数据和标签被巧妙地压缩在一个文件夹中供您下载的站点。现实世界的数据集会让您自己提取数据和标签。痛苦。不过挺好玩的

这让我想到了提示 #2:学习如何策划或准备好的图像数据集将是一项非凡的技能。
有了这个,这可能意味着您需要掌握 Photoshop 技能,或者您必须学习如何使用代码操作图像。我通过艰难的方式学到了这些,我会花费无数个小时来尝试修复图像,以便它在分布方面适合整个数据集,否则它很可能是一个异常值。请记住,人工智能团队负责研究和实施原型级解决方案,而不是成熟的解决方案,这解释了为什么有如此多的图像处理技能实验。
提示 #2:能够准备一个好的图像数据集,或者更重要的是,能够在计算机视觉项目中识别一个好的图像数据集是一项非凡的技能。
还记得我提到过水培和医疗领域吗?具体来说,这些不是我的研究领域,而且对我来说看起来很陌生的行话数量非常惊人。但也正是这些行话帮助我提高了计算机视觉技能。信不信由你,当我开始每个计算机视觉项目时,首先要做的就是阅读该主题并研究许多有助于我后来的“实验”的期刊论文。因为大多数项目都需要我们手动从图像中提取特征,所以我们应该事先知道这些特征是如何产生的。在医学领域,这些特征已经被科学证明了很多年,理想情况下,我们只需要遵循一定的规则来提取它们。你会认为它简单明了,因为我也这么认为。尽管认为有必要,但在这样的特征提取步骤上花费了太多时间。关键是,在任何计算机视觉项目中,我们都应该充分了解该主题,以便在继续之前了解我们正在处理的功能。这是我的第三个建议。
提示 #3:领域知识与计算机视觉工具带下的工具同样重要。
在开始编写代码来探索数据之前,通常需要做一些阅读以充分了解某个主题,然后再开始编写代码。
假设您已经经历了准备好的图像数据集的麻烦,阅读某些所需主题的麻烦,甚至使用代码处理一些特征提取的麻烦,现在是时候将数据呈现给 团队。 我曾经认为这很简单,因为我需要做的就是脱口而出结果并告诉他们推进项目所需的解决方案。 男孩,我又错了。
通常,团队已经对图像数据了解很多,有时甚至与您一样多,即使在图像处理步骤之后也是如此。 困难的是我们能够找到团队不知道的见解并以简短而准确的方式呈现它们。 这有点抽象,因为它需要经验,因为没有很多例子。 请记住,当我们作为计算机视觉工程师决定展示我们的发现时,我们应该比团队更了解数据。 这很重要。
提示#4:编译所有数据并将其呈现给团队需要时间,但团队没有一整天的空闲时间,因此演示文稿必须简短而准确。
此外,团队已经对数据了如指掌,因此找到可以使项目继续向前发展的见解至关重要。 做演示,不是那么有趣。 讲故事,不错。
2021 年是我生活的许多领域充满成长的一年,计算机视觉绝对是其中之一。 我希望你能在这篇文章中拿走一些关键点,这样你就可以为计算机视觉工程师的角色做好准备,但是当你在做的时候,记得要玩得开心,因为计算机视觉是一个有很多的领域 复活节彩蛋! 我将在我即将发表的文章中揭开它们的面纱。 :)
原文:https://medium.com/mlearning-ai/how-i-improved-my-computer-vision-skill…
本文:
- 56 次浏览
【机器视觉】物体检测需要多少张图像?
最少的数据量是多少? 您如何处理不平衡的数据问题?
- YOLOv5模型
- 韩国人行道数据集
- 最小数据集大小
- 对抗阶级失衡
- 如何更新模型
- 结论
- 参考

在本文中,我想回答关于对象检测模型的训练数据集的三个问题:
- 最大精度增益的最小数据集大小是多少?
- 你如何处理类不平衡问题?
- 用新数据更新已经训练好的模型的最佳方法是什么?
第一个问题的重要性怎么强调都不为过。预处理数据(收集、清理和注释数据)占 AI 开发的 80% 以上。因此,理想情况下,您希望以最大回报投资资源。
类不平衡问题是任何真正的 AI 项目的常见问题。具有大量数据的类的准确性可以很好地训练,而对于不常见的对象很难达到良好的准确性。欠采样和过采样是解决类不平衡问题的常用技术,我们将看到它们的效果。
更新已经训练好的模型变得越来越重要,因为 AI 模型无法规定其使用的上下文,因此经常需要适应新的领域。
我想使用 YOLOv5 和一个名为 Korean Sidewalk Dataset 的公共数据集来凭经验回答这些问题。
1. YOLOv5 模型
对象检测是指从图像或视频中检测对象实例的技术。在下图中,您可以看到由带有标签的边界框标记的“人”、“长凳”和“汽车”类的实例。

From the Korean Sidewalk dataset
为了实现这样的壮举,对象检测模型需要定位目标对象的位置并识别它们属于哪些类别。前一个任务称为“对象定位”,后一个任务称为“对象分类”。
要训练对象检测模型,您需要提供一个数据集,其中包含图像以及相应的位置和标签信息。构建这样一个数据集是由人工在环完成的耗时且劳动密集型的工作。幸运的是,有许多公开可用的数据集。例如,用于对象检测的 COCO 数据集包含 80 个不同类别的图像和注释。
YOLOv5 是一系列使用 COCO 数据集进行预训练的对象检测模型。实验以yolov5s.pt为基础,通过迁移学习的方法进行训练。使用超参数的默认配置,批量大小和时期除外。批量大小固定为 16,并且在大多数实验中使用了 100 个 epoch。
2. 韩国人行道数据集
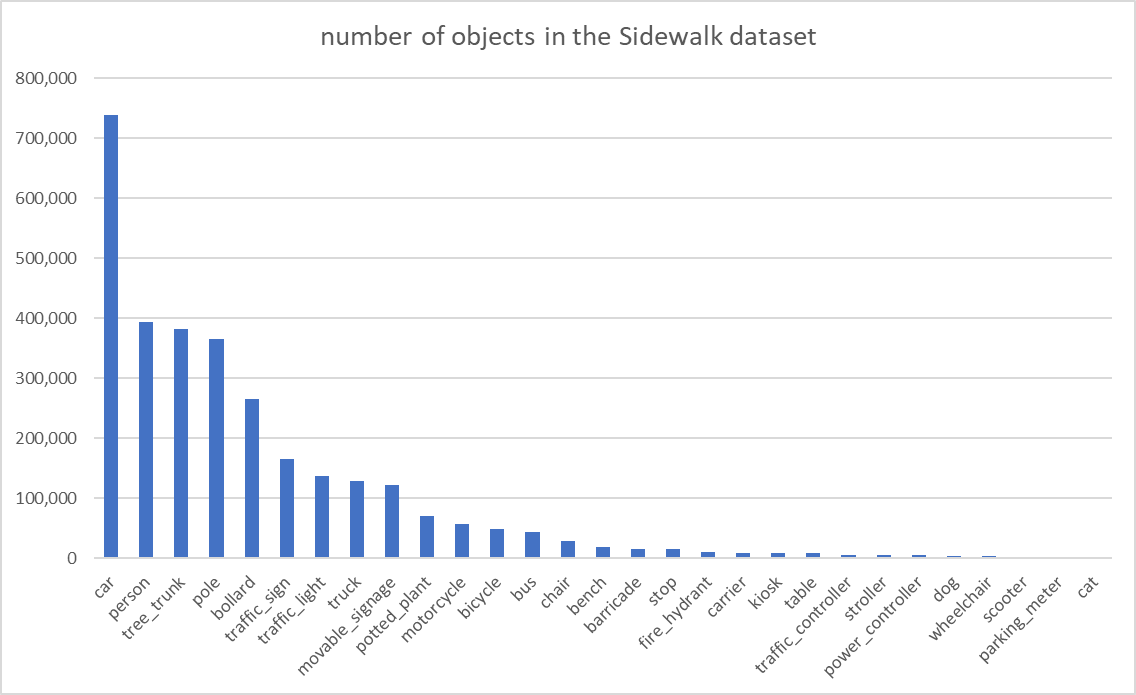
示例数据集是韩国人行道数据集。它是一个大规模的公共数据集,包含超过 670,000 张带有边界框、多边形分割、表面掩蔽或深度预测标签的图像。最初的目的是为 AI 模型构建一个训练数据集,以帮助有视力障碍的人自行导航。其中一半(352,810 张图像)带有边界框注释,我们可以使用这些边界框来训练对象检测模型。此处列出了数据集中的对象类标签列表和定量相对比率:
https://gist.github.com/changsin/dc2fa9758e1f3642eb0711e95a198fce/raw/a…
#,class,ratio(%) 1,car,24.10 2,person,12.85 3,tree_trunk,12.48 4,pole,11.91 5,bollard,8.66 6,traffic_sign,5.40 7,traffic_light,4.48 8,truck,4.21 9,movable_signage,4.02 10,potted_plant,2.29 11,motorcycle,1.84 12,bicycle,1.59 13,bus,1.43 14,chair,0.94 15,bench,0.65 16,barricade,0.52 17,stop,0.50 18,fire_hydrant,0.34 19,carrier,0.31 20,kiosk,0.31 21,table,0.28 22,traffic_controller,0.21 23,stroller,0.18 24,power_controller,0.18 25,dog,0.14 26,wheelchair,0.11 27,scooter,0.06 28,parking_meter,0.01 29,cat,0.01
实验只使用前 15 个类,它们分为训练集、验证集和测试集。 训练集和验证集之间的比例一直保持在 80:20。 使用单独的测试集来测量 mAP(平均精度)。
关于数据集需要注意的几点是:
- 不平衡:如您所见,数据集明显不平衡。 前 5 个类对象占所有对象的 70%,前 15 个类对象占所有对象的 90%。 最常见的对象类是“汽车”,占数据集的 24%。
- 同一个图像中的多个实例:在每个图像中,有多个相同类对象的实例。 例如,汽车类每个图像有 3-4 个实例。 这是可以理解的,因为这些图像是汽车通常在附近的人行道图像。 在图像中找到所有不同大小的实例对模型来说是一个额外的挑战。
- 去识别化:人行道图像包含一些个人信息,如面部和车牌号码。 为了保护隐私,包含 PII(个人身份信息)的图像在注释和以后分发之前会被“去识别”(模糊)。 这是一张突出显示模糊车牌的汽车图像。

数据集的三个特征都是人工智能开发中相当普遍的问题。给定真实的数据集,让我们检查一下我们在开始时提出的问题。
3. 最小数据集大小
根据 Saleh Shahinfar 等人的说法。 (2020) 在“我需要多少张图片?”在论文中,训练模型显示每个类大约有 150-500 张图像的拐点,早期的性能提升开始趋于平稳。
为了复制实验,准备了随机采样图像的数据集,每个数据集包含 100 张图像。它们作为训练数据集增量提供,并且在模型训练 100 个 epoch 后测量 mAP。为了比较不同类的性能增益,将它们分为 3 类:
- 前 5 名:汽车、人、tree_trunk、杆、系柱
- 前 10 名:traffic_sign、traffic_light、卡车、moveable_signage、potted_plant
- 前 15 名:摩托车、自行车、公共汽车、椅子、长凳
每组中的 mAP 被平均,结果证实了 Saleh 等人的观察。 (2020 年)。

由于每个图像有多个实例,尤其是汽车类实例,前 5 个类的性能在大约 300 个图像早期趋于平稳。无论如何,趋势是明确的。大约 150-500 张图像似乎是看到性能提升的拐点。前 15 名的 mAP 遵循类似的模式,只是由于对象数量较少,它追赶得很慢。
4. 对抗阶级失衡
在之前的实验中,前 5 名从一开始就表现出不错的性能提升,但是前 10 名和前 15 名的类追赶得很慢,即使添加了 1000 张图像,它们的 mAP 仍然与前 5 名相差甚远。显而易见原因是缺乏数据。所以让我们解决这个问题。
有两种常见的方法来解决类不平衡问题。第一种方法称为“欠采样”,这意味着从多数类中抽取更少的样本。过采样则相反。您从少数族裔中抽取更多样本。由于我们的数据集严重不平衡,让我们两者都做:即对多数类进行欠采样,对少数类进行过采样。结果是一个重新采样的数据集。
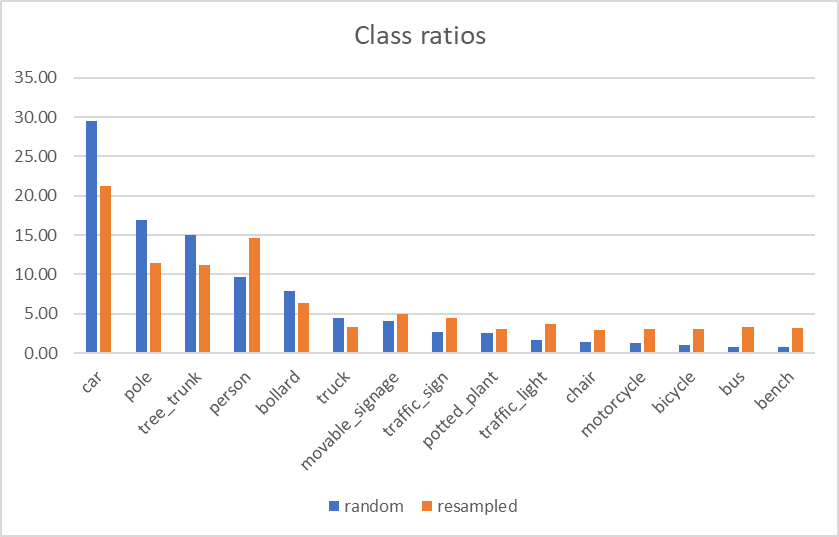
由于数据的性质,完全平衡的数据集是不可能的。 例如,在对公共汽车或摩托车进行采样时,您也被迫采用汽车实例。
重新采样数据集的准确性显示了改进。
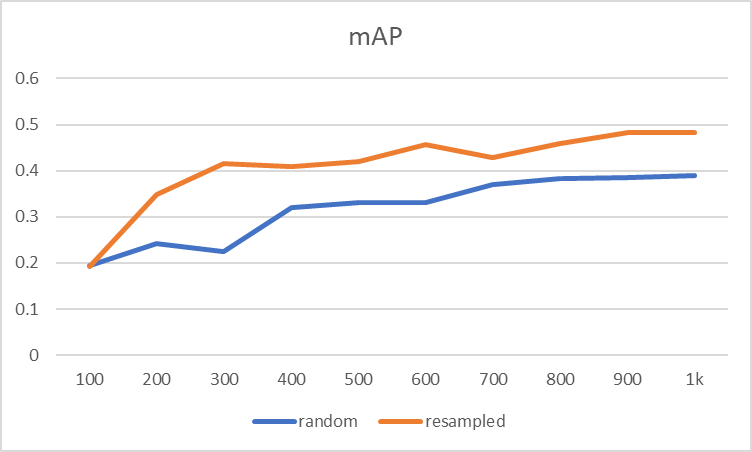
然而,这种改进不能从表面上看。 少数类的数据相对较多意味着多数类的数据较少。 随着少数类的准确度提高,多数类的准确度可能会更差。 我们如何确定是否是这种情况?
加权平均值是考虑到其数据点的相对重要性的平均值。 在我们的例子中,如果我们将每个类的平均值乘以该类的数据点数,然后取平均值,我们将得到整个数据集的加权平均值。
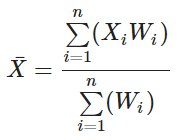
结果显示重采样数据集的改进不太显着。
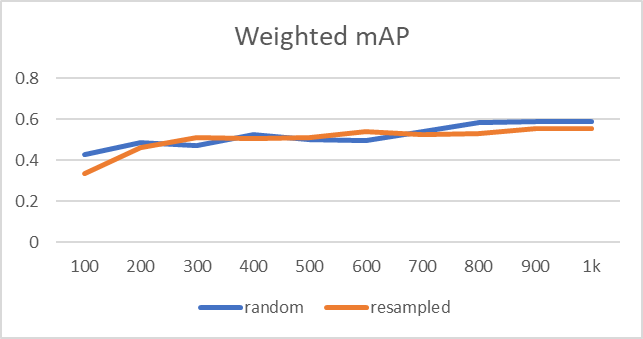
换句话说,数据的绝对数量和模型的准确性之间似乎存在直接的相关性,以至于对大多数类别的抽样不足会对它们的准确性产生负面影响。 我们可以从结果中吸取的教训是,在训练模型时需要有一个抽样策略和适当的指标。
5.如何更新模型
部署模型时,它可能会遇到不同的类分布或未经训练的新对象。 因此,通常根据监测结果定期更新模型。 更新模型时,数据集可以有两种不同的策略:
- 仅使用新数据
- 使用新旧数据的组合数据集
结果很清楚。 对于随机样本数据集和重采样(过采样和欠采样)数据集,新旧数据的组合数据集提供了更好的训练结果。

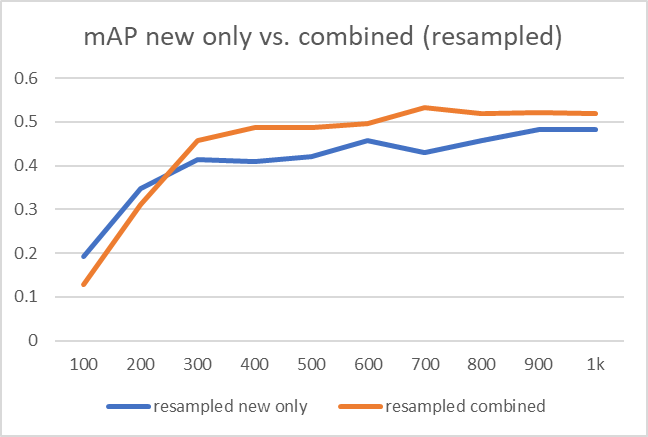
我们需要回答的另一个问题是是从头开始训练模型还是每次都进行迁移学习。 最后的图表显示了判决。
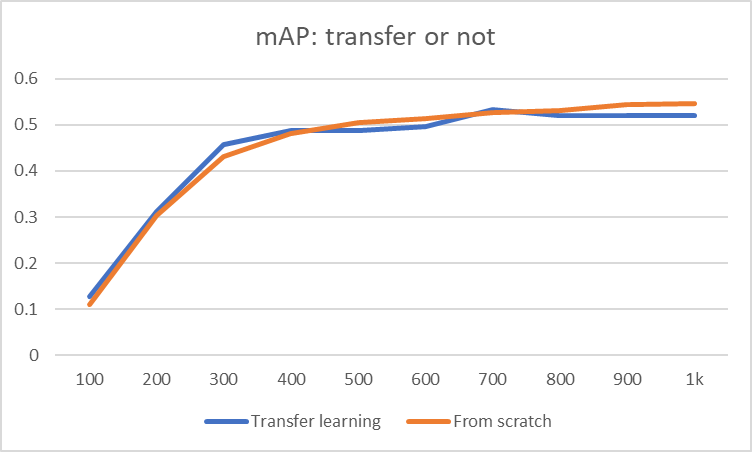
两种训练策略似乎没有区别。 唯一的区别是迁移学习可以让您更早地收敛,因为要训练的新数据较少,因此您可以通过迁移学习节省时间。
结论
以下是我们从实验中学到的:
- 用于训练的最小图像数据数量约为 150-500。
- 使用欠采样和过采样来补偿类不平衡问题,但要注意重新平衡的数据集分布。
- 要更新模型,请在新旧数据的组合数据集上进行迁移学习。
“我们需要多少张图像来训练一个模型?”这个问题的正确答案。 应该是“我不知道”或“这取决于”。 但我希望你学会了如何计划收集所需的数据以及训练对象检测模型的最佳实践。 谢谢阅读。
参考
- Junghwan Cho, et al. “HOW MUCH DATA IS NEEDED TO TRAIN A MEDICAL IMAGE DEEP LEARNING SYSTEM TO ACHIEVE NECESSARY HIGH ACCURACY?” (2016)
- Saleh Shahinfar, et al. “How many images do I need?: Understanding how sample size per class affects deep learning model performance metrics for balanced designs in autonomous wildlife monitoring.”(2020)
原文:https://changsin.medium.com/how-many-images-do-you-need-for-object-dete…
- 192 次浏览
【计算机视觉】人脸识别101
起初,您可能想知道:
- 我们如何使用线性代数(矩阵/向量)将某人的面部图像解释为数学?
- 系统如何能够从包含人脸的图像中识别出某人?
- 我们如何让计算机了解某人的脸?
如果您想知道上面列出的事情之一是非常好的,因为您很想了解人脸识别,因此为什么我会给您一些关于此的见解,希望您能够掌握什么是人脸识别以及背后发生的事情现场。
人脸识别不就是图像分类吗?
它们相似,但不能一视同仁。当您训练图像分类模型时,通常您有一个包含 n 个类的数据集,并且对于每个类,您有许多图像。假设每个类有 100 张图像。但是,当你想建立人脸识别系统时,你可能只有一张某人的照片。同样在图像分类中,你想在不同的类之间进行分类,或者你可以说对象。在人脸识别中,它们都是人脸。因此,您需要获得能够区分每个人面部的特征。但是,如果您了解图像分类的工作原理,您将轻松学习人脸识别。
人脑的魔力
最常见的机器学习任务(例如图像分类)或最常用的数据集(例如预测房价)都可以使用一个机器学习过程来完成。您可以只输入您的数据,输出将仅由一个进程给出。但是,人脸识别就不一样了。
首先,您需要从图像中找到所有人脸(人脸检测)。然后,您需要从面部中看到与其他人不同的独特特征(特征提取)。最后,您将提取的特征与您已经见过的所有人进行比较,并根据您的知识找到该人。
上帝免费给我们这个过程,我们需要欣赏上帝给我们的所有东西。即使是现在,人造机器仍然无法像我们免费提供的大脑那样识别面部。
特征脸(这些不是鬼的照片)
为了能够知道我们如何从图像中获取特征脸,首先我们需要知道如何在数学中表示图像,什么是特征值以及什么是 PCA。但首先,什么是特征脸?

图像表示
假设人脸已经被预处理为正方形图像
在计算机中,灰度图像由 NxN 矩阵表示。但是为了便于操作,我们将把这个矩阵转换为 N²x1,只需将矩阵分解为一个 tall 向量即可。但是,想象一下,如果我们有一个 200 x 200 像素的人脸图像。因此,如果我们将图像转换为矢量,我们将拥有 40000x1 的矢量,当我们有这么多图像时,我们将在 40000 维空间中处理所有内容。想象一下当你想要处理任何东西时的成本。因此,PCA 通过创建低维空间来帮助我们降低成本。
那么,什么是特征脸和 PCA?
为了获得特征脸,首先我们将 PCA 应用于我们的数据集。根据维基百科的 PCA,PCA 是计算主成分并使用它们对数据执行基础更改的过程,有时仅使用前几个主成分而忽略其余部分。因此,如果我们想减少数据的维度,可以使用 PCA。
在我们将 PCA 应用于我们的数据集之后,我们得到了称为主成分 (PC) 的东西。 PCA 的 PC 是协方差矩阵的特征向量。我们从这一步得到的特征向量就是我们所说的特征脸。现在,我们知道名称 eigenface 是从使用 eigenvalue 和 eigenvector 的帮助来获取特征的过程中派生的。
渔脸
2011 年,Aleix Martinez 提出了一种替代我们之前讨论的特征脸的方法,称为 Fisherface。 eigenface 和 Fisherface 的主要区别在于 eigenface 使用 PCA,而 Fisherface 使用不同的方法使用 LDA。在我们将 LDA 应用到我们的数据集创建一个新的子空间表示之后,创建该子空间的基向量称为 Fisherface。如果您对fisherfaces 感兴趣,您可以阅读这个网站,其中讨论了您需要了解的所有信息。
PCA 与 LDA
简单来说,LDA 和 PCA 的区别在于 LDA 不是最大化方差,而是希望最小化投影类的方差,并找到最大化类均值之间分离的轴。 PCA 也是一种无监督学习算法,而 LDA 是一种监督学习算法。
特征脸与渔脸
Peter N. Belhumeur、Joao~ P. Hespanha 和 David J. Kriegman 发表了一篇题为“Eigenfaces vs. Fisherfaces: Recognition Using Class Specific Linear Projection”的论文。得出的结论是:
- 如果测试集中的图像与训练集相似,则 eigenface 和 fisherface 都表现良好
- Fisherface 在对光照变化进行外推和插值方面明显更好,并且在同时处理光照和表情变化方面也表现出色。
- 通过去除三个最大的主成分,我们可以改进特征脸方法,但仍然比fisherface有更高的错误率
它是最好的吗?
这是由 Github 用户 bytefish 进行的 AT&T Facedatabase 上 eigenface 和 fisherface 的 rank-1 识别图:
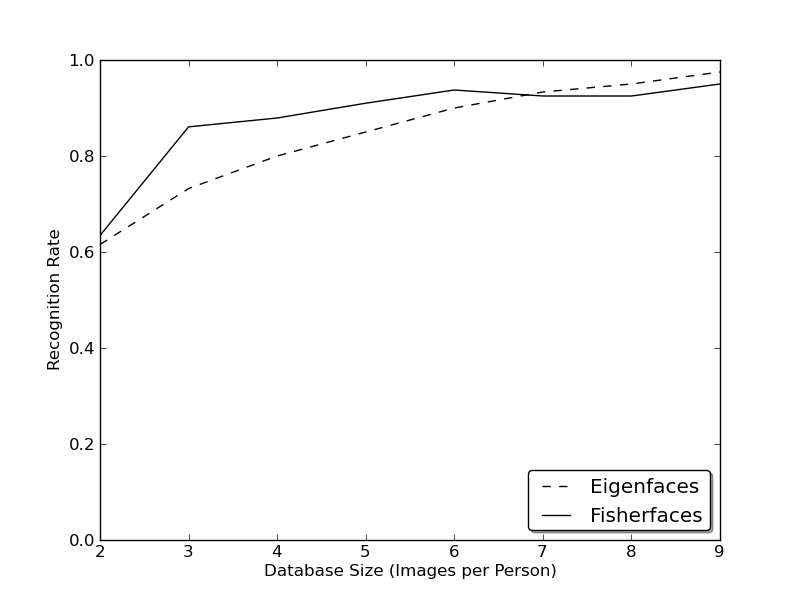
通过查看图表,我们知道每个人必须有 7-9 张图像,并且特征脸和渔人脸似乎收敛到相同的识别率值。 想象一下,当我们只有一张想要添加到我们知识中的人的图像时。
另一种方法:局部特征
一些研究人员的想法是不要将图像视为高维向量,但我们可以描述图像的局部特征。 作为人类,我们有时会用物理特征来描述某人的脸,例如他们的眼睛、鼻子、嘴巴的形状等等。 局部二进制模式,也称为 LBP,使用 2D 纹理分析。 LBP 的基本思想是通过比较每个像素与其相邻像素来总结图像的局部结构。 如果中心像素的强度大于等于其相邻像素的强度,我们将 1 分配给中心,否则为 0。

LBPH vs Eigenfaces vs Fisherfaces
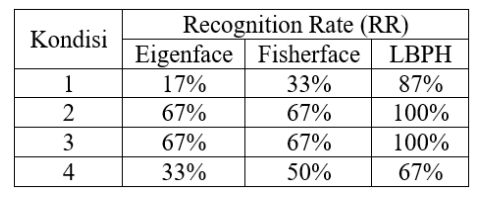
Qadrisa Mutiara Detila 和 Eri Prasetyo Wibowo 在 2019 年发表了一篇期刊,比较了在 6 张面孔和 4 种不同条件下进行人脸识别的三种方法,结果如下表:
现在的一切不都是深度学习吗?
当然,人脸识别有很多深度学习方法。 在我们讨论了很多传统方法之后,我们将讨论一种称为 OpenFaces 的方法。
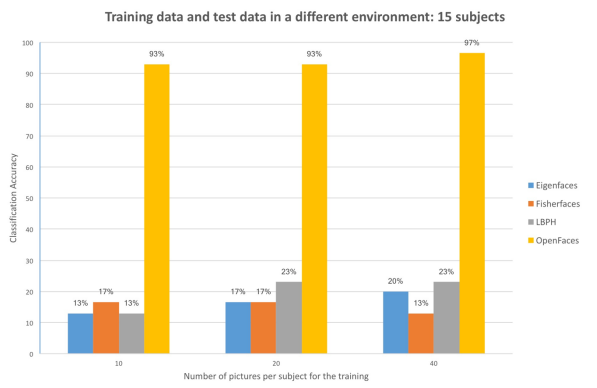
Comparison between traditional and deep learning face recognition, Nicolas Delbiaggio
Florian Schroff、Dmitry Kalenichenko 和 James Philbin 在 CVPR 2015 上发表了一篇名为 FaceNet: A Unified Embedding for Face Recognition and Clustering 的论文。 与大多数深度学习模型一样,该模型使用大量数据进行训练,包含 50 万张图像,在 LFW 基准数据集上获得了 92.9% 的准确率。
深度学习方法的优点是我们不需要很多人的图像来获得良好的性能,即使我们每个人只能使用一张图像。 在 FaceNet 中,该人脸将使用三个图像进行训练,称为锚图像 (A)、正图像 (P) 和负图像 (N)。
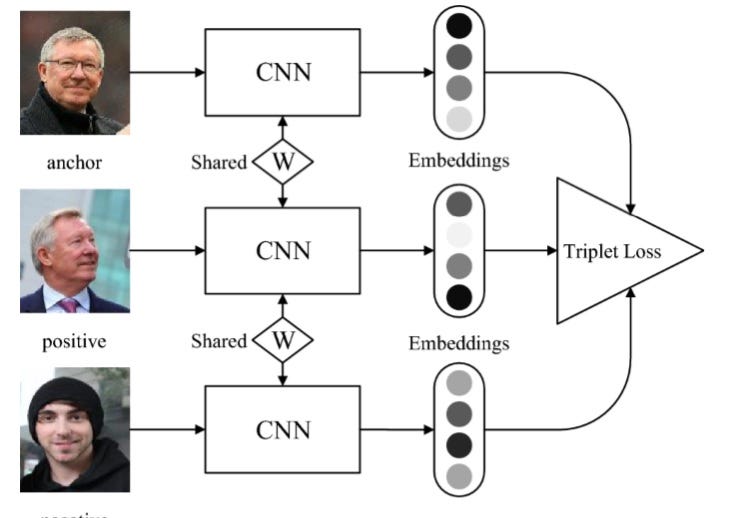
锚点和正面应该包含同一个人,而负面则不包含。 这里的想法是,我们希望某个人(A)的图像更接近与 A 属于同一个人的所有图像 P,同时与其他图像 N 保持最远的距离。
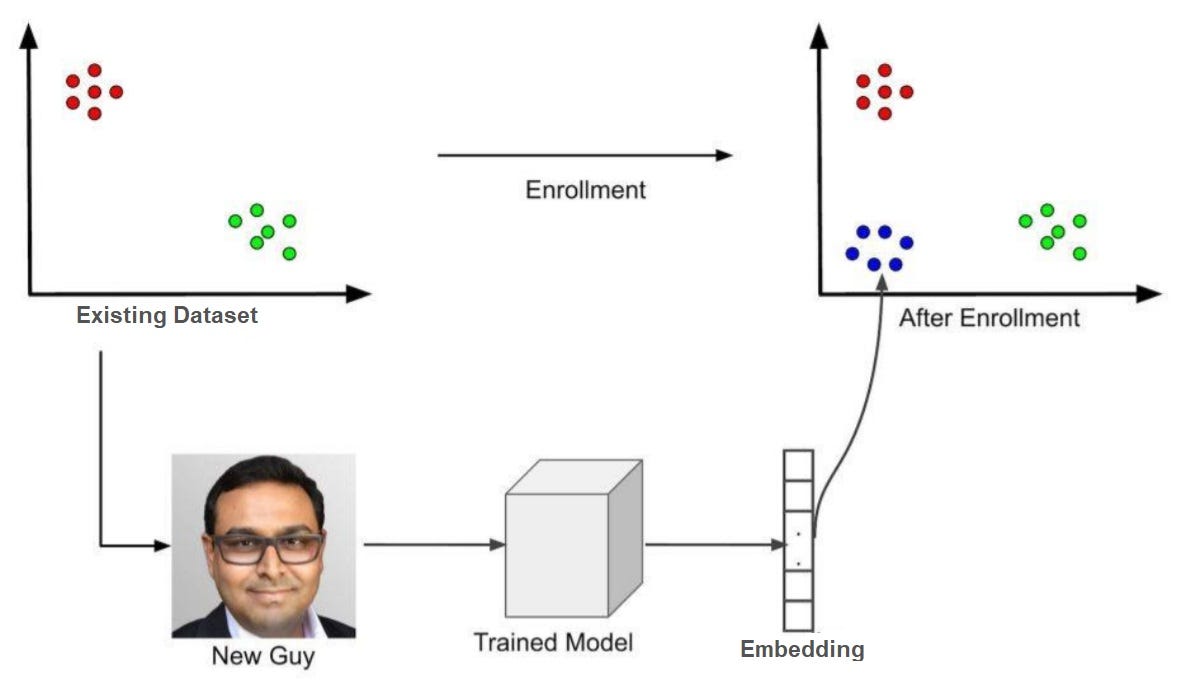
因此,如果我们要将一个人添加到我们的模型中,我们需要执行一个称为注册的过程。 这个过程的想法是我们想要在我们的子空间中找到人的位置(由上图中的蓝点定位)。 因此,在我们有了新人的位置之后,如果我们有一张图像在我们的蓝色向量附近有嵌入,我们可以确定该图像很可能是最近添加的新人。 在 FaceNet 中,我们通过一个人的图像得到一个与图像对应的 128 维特征描述符。
请注意,我最有可能使用了这个词,没有显示任何确定性,因为没有算法可以完美地识别一个人的图像,因此使用了最有可能这个词。
参考
https://docs.opencv.org/3.3.1/da/d60/tutorial_face_main.html
https://towardsdatascience.com/face-recognition-how-lbph-works-90ec258c…
https://www.pyimagesearch.com/2015/12/07/local-binary-patterns-with-pyt…
https://towardsdatascience.com/face-recognition-how-lbph-works-90ec258c…
https://m-shaeri.ir/blog/how-facenet-works-how-to-work-with-facenet/
http://cmusatyalab.github.io/openface/
原文:https://ahmadirfaan.medium.com/face-recognition-101-ee37fb79c977
本文:
- 86 次浏览
【计算机视觉】先进的计算机视觉CNN架构
视频号
微信公众号
知识星球
GoogleNet Inception和ResNet中的可视化
可视化有助于探索负责提取特定特征的层。在建立CNN模型的过程中,可视化层与计算训练误差(准确性)和验证误差一样重要。它还通过可视化和嵌入具有当前需求指定权重的所需滤波器,帮助使用预先训练的模型进行迁移学习。可视化可以应用于类激活、过滤器和激活函数的热图。
GoogleNet Inception
在GoogleNet Inception中,多个大小的滤波器与1×1的卷积一起应用于同一级别。并非总是可以使用相同的滤波器来从图像中检测对象。例如,当对下面的图像进行对象检测和特征提取时,有必要对左边的图像(棕色狗的特写)使用较大的滤波器,对右边的图像(背景中有树的狗)使用较小的滤波器。

(有关GoogleNet Inception的架构图,请参阅https://web.cs.hacettepe.edu.tr/~aykut/classes/spring2016/bil722/slides…,第31-32页。)
GoogleNet Inception通过增加模型相对于深度的宽度来帮助避免过度拟合。随着模型的深度增加以捕获更多的特征,激活函数负责防止模型由于过拟合训练数据而过于笼统。
下图描述了一般(简单)和过拟合(复杂)模型。

在GoogleNet Inception中,具有不同大小的过滤器被应用于单个输入,因为如上面的狗的例子所述,通过特征提取的对象检测是不同的。在同一级别使用多个大小的过滤器可以确保容易地检测到不同图像中不同大小的对象。
在应用滤波器之前,将输入与1×1矩阵进行卷积,从而减少对图像进行的计算次数。例如,大小为14×14×480的输入与大小为5×5×48的滤波器卷积会导致(14×14 x 48)×(5×5 x 480)=1.129亿次计算。但是,如果在与3×3卷积之前将图像与1×1卷积,则计算次数降至(14×14×16)×(1×1×480)=150万和(14×14*48)×(5×5×16)=380万。过滤器串联用于收集该初始块的所有过滤器。
初始块也可以有一个辅助分支。辅助分支存在于训练时间架构中,但不存在于测试时间架构中。当它们鼓励在分类器的较低阶段进行区分时,它们在分类过程中引入了更多的攻击性。它们增加了传播回来的梯度信号,并提供了额外的正则化。
ResNet
如果神经网络太深,损失函数的梯度将向零发展,这是一个被称为“消失梯度”的问题。ResNet用于解决这个问题,方法是从后面的层向后跳过连接到最初的层。
ResNet(残差网络)包含四个残差块:Layer1、Layer2、Layer3和Layer4。(有关ResNet的体系结构图,请参阅https://towardsdatascience.com/understanding-and-visualizing-resnets-44….)
每个块包含不同数量的残差单元,这些残差单元以独特的方法执行一组卷积。通过最大池化来增强每个块,以减少空间维度。
如下所示,残差单元有两种类型:基线残差单元和瓶颈残差单元。

基线残差单元包含两个具有批量归一化和ReLU激活的3×3卷积。
瓶颈残差单元由三个堆叠运算组成,其中包含一系列1×1、3×3和1×1卷积运算。这两个1×1操作是为减小和恢复尺寸而设计的。3×3卷积用于对密度较小的特征向量进行运算。此外,在每次卷积之后和ReLU非线性之前应用批量归一化。
- 37 次浏览
【计算机视觉】基于视觉的人工智能用例
视频号
微信公众号
知识星球
检测面部表情的代码示例和解释
人脸检测和定位为面部表情识别(FER)铺平了道路,它有许多应用,从娱乐(人脸过滤器)到驾驶员安全(情绪分析)。
使用高通®人工智能神经处理SDK,开发人员可以在Snapdragon®移动平台上实现经过训练的神经网络。以下页面描述了FER基于视觉的人工智能用例,包括面部表情分类和应用程序测试。
实时人脸检测与验证
Real-time Facial Detection and Validation
利用计算机视觉和人工智能识别面部表情,提高车辆安全性
基于视觉的ML应用程序的功能测试
Functional Testing of Vision-based ML Applications
ML模型和应用程序检测睡意的测试场景和测试案例
面部关键点检测
Facial Keypoint Detection
使用CNN检测面部关键点,并将其用于带有面部过滤器的应用程序
面部表情识别——第1部分:Ubuntu上的解决方案管道
Facial Expression Recognition — Part 1: Solution Pipeline on Ubuntu
预处理数据集、训练模型并在桌面上运行推理
面部表情识别——第二部分:安卓系统上的解决方案管道
Facial Expression Recognition — Part 2: Solution Pipeline on Android
预处理数据集、训练模型并在桌面上运行推理
使用基准工具进行绩效分析
高通神经处理SDK中包含的工具
Performance Analysis Using Benchmarking Tools
Snapdragon和高通神经处理SDK是高通技术股份有限公司和/或其子公司的产品
- 37 次浏览
【计算机视觉】用于计算机视觉的深度学习和卷积神经网络
视频号
微信公众号
知识星球
在CNN的卷积和池化层内部
为什么我们在人工智能中使用生物学概念和术语“神经网络”来解决实时问题?
在20世纪中期对猫进行的一项实验中,研究人员Hubel和Wiesel确定,神经元在结构上是这样排列的,即一些神经元在暴露于垂直边缘时会发光,另一些则在暴露于水平或对角边缘时发光。用于特定任务的专用组件的概念是卷积神经网络(CNNs)解决人脸识别或图像对象检测等问题的基础。
卷积和滤波器
卷积是两个函数的运算,产生第三个函数和结果输出函数。它是通过从不同级别的图像中提取特征来实现的。特征可以是边、曲线、直线或任何类似的几何特征。
细胞神经网络使用滤波器——本质上是数字阵列——进行特征识别。滤波器应具有与其输入相同的深度;因此,表示图像的6×6阵列应该具有6×6滤波器。滤波器也称为神经元或核。
考虑在CNN中使用滤波器进行特征识别的示例。下面的示例过滤器检测图像中的一条直线:

用于检测直线的过滤器
在下面的图像中,相同的过滤器应用于两个不同的图像。
第一个图像包含一条手绘线——数字1——和一个表示它的数组:
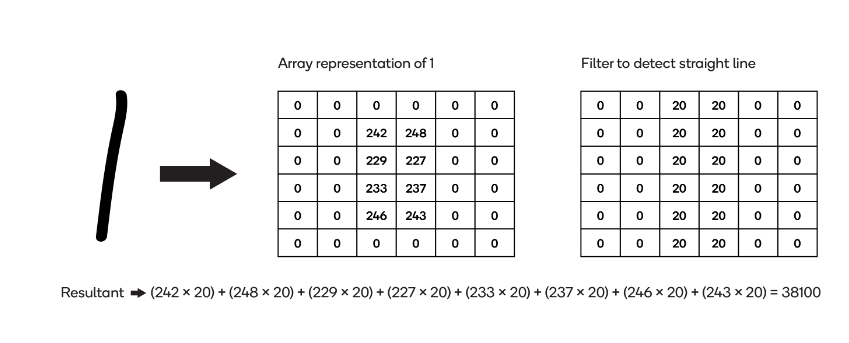
对具有直线的图像应用过滤器
两个数组的乘积之和(“结果”)为38100。
下一个图像包含手绘数字2(不是直线)和表示它的数组:

对没有直线的图像应用过滤器
数组中与过滤器中对齐的非零条目较少,因此结果28700远低于第一个图像中的结果。
这说明了CNN的过滤。下图描述了一个样本卷积神经网络的架构。

CNN架构
以下是描述细胞神经网络时常用的术语。
激活
激活是用于获得神经网络中节点输出的函数。在细胞神经网络中,激活函数表示结果的线性或非线性。它们将结果映射到(0,-1)或(-1,1)。常用的激活函数有sigmoid、tanh和Relu。
功能图
卷积过程的结果被称为特征图。下面显示的是一个计算卷积运算输出维度的公式:
- An image matrix (volume) of dimension (h × w × d)
- A filter (fh × fw × d)
- Outputs a volume dimension (h – fh + 1) × (w – fw + 1) × 1
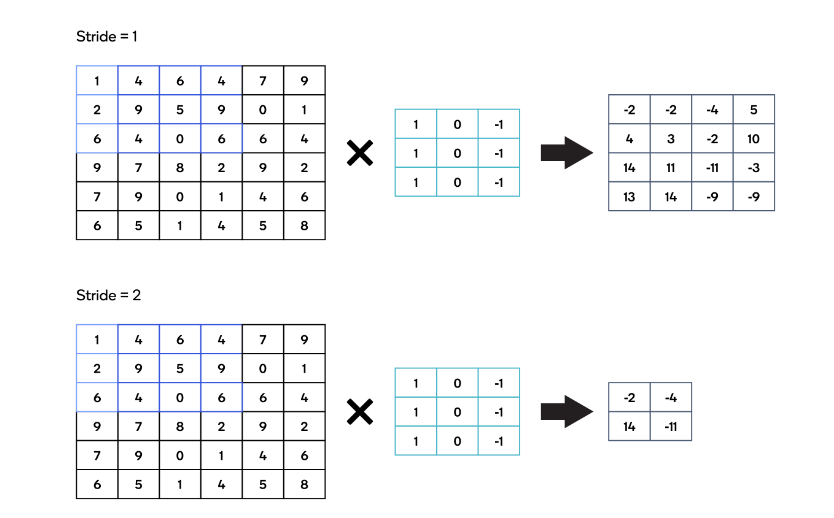
大步走 (Stride)
Stride描述了内核在图像上水平和垂直移动以执行完整卷积运算的位置数。
大步走
Pooling
池用于减小表示的空间大小。它是在特征图上执行的。
最大池化和平均池化是最常用的池化方法。池化操作在卷积操作之后执行,以在表示进入下一层之前减小表示的输入大小。

Pooling in CNN
压扁层:Flattened layer
平坦层用于将n维向量转换为一维向量。在我们的例子中,我们将结构化的二维图像转换为一维向量,这是神经网络的输入层。
完全连接层:Fully connected layer
完全连接层将一层的每个神经元连接到另一层的每一个神经元。为激活函数给出了全连通层的最后一层,从而有助于分类。
- 106 次浏览
【计算机视觉】计算机视觉CNN架构
视频号
微信公众号
知识星球
三种用于组合层以提高准确性的经典网络架构
从本质上讲,神经网络复制了人类从错误中学习的相同过程。除了神经过程外,CNN中的卷积还执行特征提取过程。
以下是三个经典的网络及其基础架构。
LeNet-5
LeNet是第一个CNN架构,也是基于梯度的学习的一个例子。
LeNet是在改良的NIST或MNIST数据集上进行训练的,旨在识别支票上的手写数字。改变权重和超参数,使得损失函数上的梯度发散达到最小。但正如在计算机视觉中使用的那样,LeNet中的权重和超参数是手动设计的。LeNet的输入是32×32,在没有放大的情况下是可见的,远远大于最初写入的字符的大小。大的输入允许捕获图像中的微小特征。
LeNet由卷积层、子采样层和全连通层组成。(有关LeNet-5的架构图,请参阅http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf,第7页)。
- 卷积层从图像中提取特征。
- 子采样层包括将激活函数应用于来自卷积层的输入,并对通过应用激活函数获得的输出执行池化处理。
- 完全连接层将一层的每个神经元连接到另一层的每一个神经元。完全连接层的最后一层被保留用于激活函数以帮助分类。
AlexNet
LeNet体系结构表明,增加网络深度可以提高准确性。AlexNet体系结构包含了这一教训。AlexNet由五个卷积层和三个完全连接层组成。
AlexNet使用ReLu(整流线性单元)作为其激活函数。ReLu代替传统的sigmoid或tanh函数用于将非线性引入网络。与传统的激活函数相比,ReLu对正值的响应更大,对负值的响应为零,确保并非所有神经元在任何给定时间都是活跃的。ReLu所需的计算时间也低于sigmoid和tanh。
ReLu的另一个优点是它可以去除(丢弃)死亡的神经元,如下所示。

Dropout in AlexNet
开发者可以设置丢弃不活动神经元的比率。Dropout有助于避免AlexNet中的过拟合。
当在ImageNet LSVRC-2012数据集上训练时,AlexNet实现了15.3%的相对较低的错误率,而非CNN的错误率为26.2%。(有关AlexNet的体系结构图,请参阅https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-con…,第5页。
VGG-Net(视觉几何组)
AlexNet展示了使用较大过滤器的价值。为了达到最先进的水平,VGG-Net在一个系列中使用了3×3个滤波器。这增加了网络的深度,这在检测图像中的特征方面是有效的。(有关VGG-Net的架构图,在包含1000个类的数据集上进行训练和测试,每个类中有1000个图像,请参阅

- 32 次浏览