自然语言理解
- 91 次浏览
【自然语言处理】机器学习自动文本摘要——概述

摘要是将一段文本压缩为较短版本的任务,减少初始文本的大小,同时保留关键信息元素和内容的含义。由于手动文本摘要是一项耗时且通常费力的任务,因此任务的自动化越来越受欢迎,因此构成了学术研究的强大动力。
文本摘要在各种 NLP 相关任务中都有重要的应用,例如文本分类、问答、法律文本摘要、新闻摘要和标题生成。此外,摘要的生成可以作为中间阶段集成到这些系统中,这有助于减少文档的长度。
在大数据时代,各种来源的文本数据量呈爆炸式增长。大量的文本是不可估量的信息和知识来源,需要对其进行有效总结才能发挥作用。越来越多的文档可用性要求在 NLP 领域对自动文本摘要进行详尽的研究。自动文本摘要的任务是在没有任何人工帮助的情况下生成简洁流畅的摘要,同时保留原始文本文档的含义。
这是非常具有挑战性的,因为当我们人类总结一段文本时,我们通常会完全阅读它以发展我们的理解,然后写一个摘要突出其要点。由于计算机缺乏人类知识和语言能力,这使得自动文本摘要成为一项非常困难和重要的任务。
已经为此任务提出了基于机器学习的各种模型。大多数这些方法将此问题建模为分类问题,输出是否在摘要中包含一个句子。其他方法使用了主题信息、潜在语义分析 (LSA)、序列到序列模型、强化学习和对抗性过程。
通常,自动摘要有两种不同的方法:提取和抽象。
提取方法
抽取式摘要根据评分函数直接从文档中提取句子以形成连贯的摘要。此方法通过识别文本的重要部分裁剪出来并将部分内容拼接在一起以生成精简版本。

通过识别文本的重要部分,将部分内容剪裁并拼接在一起以生成精简版本,从而进行提取式摘要工作。因此,它们仅依赖于从原始文本中提取句子。
因此,它们仅依赖于从原始文本中提取句子。今天的大多数摘要研究都集中在提取性摘要上,一旦它更容易并产生自然语法摘要,需要相对较少的语言分析。此外,提取摘要包含输入中最重要的句子,可以是单个文档或多个文档。
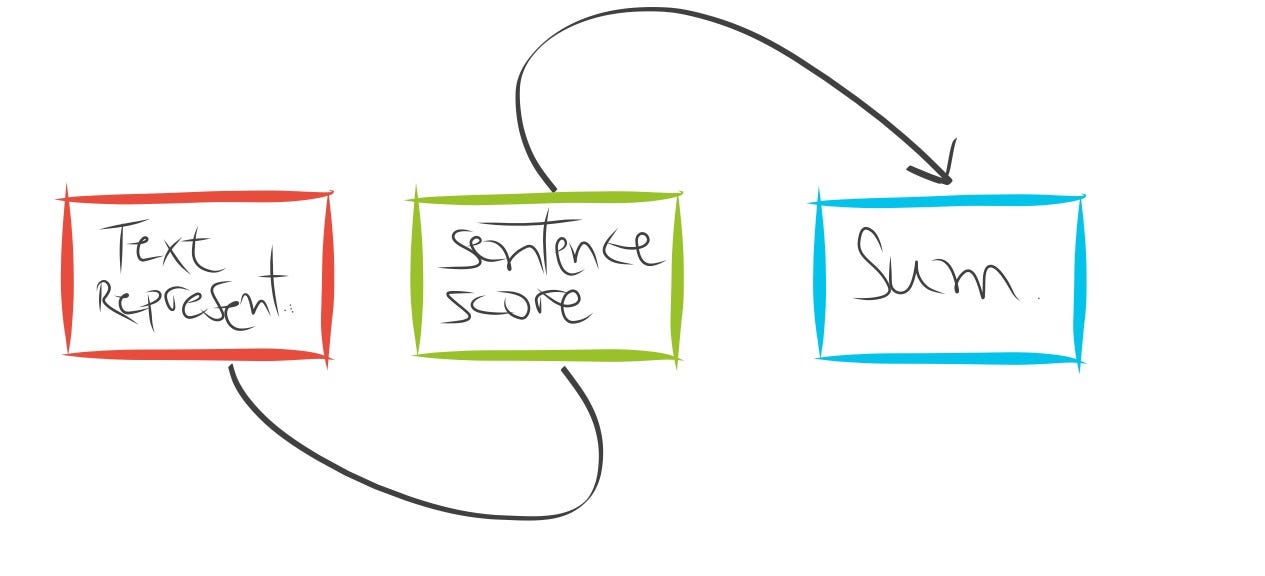
提取摘要系统的典型流程包括:
- 构建用于查找显着内容的输入文本的中间表示。通常,它通过计算给定矩阵中每个句子的 TF 度量来工作。
- 根据表示对句子进行评分,为每个句子分配一个值,表示它在摘要中被选中的概率。
- 根据前 k 个最重要的句子生成摘要。一些研究使用潜在语义分析(LSA)来识别语义重要的句子。
要从总结中获得 LSA 模型的良好起点,请查看这篇论文和这篇论文。此 github 存储库中提供了用于 Python 中提取文本摘要的 LSA 实现。比如我用这段代码做了如下总结:
原文:
De acordo com o especialista da Certsys (empresa que tem trabalhado naimplementação e alteração de fluxos desses robôs), Diego Howës, as empresas têm buscado incrementar os bots de atendimento ao público interno no possãess co à mão informações sobre a doença, tipos de cuidado, boas práticas de higiene e orientações gerais sobre a otimização do home office。 Já os negócios que buscam se comunicar com o público externo enxergam outras necessidades。 “Temos clientes de varejo que pediram para que fossem criados novos fluxos abordando o tema, e informando aos consumidores que as entregas dos produtos adquiridos online podem sofrer algum atraso”, comenta Howës, da Certemarsesco足够的时刻。 Ainda segundo o especialista, em todo o mercado é possível obervar uma tenência de automatização do atendimento à população, em busca de chatbots que trabalhem em canais de alto acesso, como o de WhatsApp, no causo Na área de saúde, a disseminação de informação sobre a pandemia do vírus tem sido um esforço realizado。
摘要文本:
De acordo com o especialista da Certsys (empresa que tem trabalhado naimplementação e alteração de fluxos desses robôs), Diego Howës, as empresas têm buscado incrementar os bots de atendimento ao público interno no possãess co à mão informações sobre a doença, tipos de cuidado, boas práticas de higiene e orientações gerais sobre a otimização do home office。 Já os negócios que buscam se comunicar com o público externo enxergam outras necessidades。 Na área de saúde, a disseminação de informação sobre a pandemia do vírus tem sido um esforço realizado。
最近的研究也将深度学习应用于提取摘要。例如,Sukriti 提出了一种使用深度学习模型的事实报告提取文本摘要方法,探索各种特征以改进为摘要选择的句子集。
Yong Zhang 提出了一种基于卷积神经网络的文档摘要框架来学习句子特征,并使用 CNN 模型进行句子排序联合进行句子排序。作者采用 Y. Kim 的原始分类模型来解决句子排序的回归过程。该论文中使用的神经架构由一个单一的卷积层复合而成,该卷积层构建在预训练的词向量之上,后跟一个最大池化层。作者对单文档和多文档摘要任务进行了实验,以评估所提出的模型。结果表明,与基线相比,该方法实现了具有竞争力甚至更好的性能。实验中使用的源代码可以在这里找到。
抽象概括
抽象摘要方法旨在通过使用高级自然语言技术解释文本以生成新的较短文本来生成摘要——其中的一部分可能不会作为原始文档的一部分出现,它传达了原始文本中最关键的信息,需要改写句子并结合全文信息以生成摘要,例如人工编写的摘要通常会这样做。事实上,可接受的抽象摘要涵盖输入中的核心信息,并且语言流畅。
因此,它们不限于简单地从原始文本中选择和重新排列段落。
抽象方法利用了深度学习的最新发展。由于它可以被视为一个序列映射任务,其中源文本应该映射到目标摘要,抽象方法利用了序列到序列模型最近的成功。这些模型由编码器和解码器组成,其中神经网络读取文本,对其进行编码,然后生成目标文本。
一般来说,构建抽象摘要是一项具有挑战性的任务,它比句子提取等数据驱动的方法相对困难,并且涉及复杂的语言建模。因此,尽管最近在神经机器翻译和序列到序列模型的进步启发下使用神经网络取得了进展,但它们在摘要生成方面仍远未达到人类水平。
一个例子是 Alexander 等人的工作,他们通过探索一种完全数据驱动的方法来使用基于注意力的编码器 - 解码器方法生成抽象摘要,提出了一种用于抽象句子摘要 (NAMAS) 的神经注意力模型。注意机制已广泛用于序列到序列模型,其中解码器根据源端信息的注意力分数从编码器中提取信息。可以在此处找到从 NAMAS 论文中重现实验的代码。
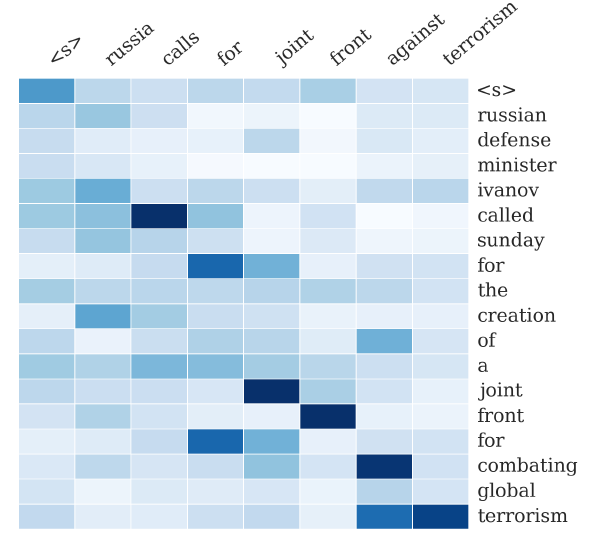
Alexander 等人基于注意力的总结的示例输出。热图表示输入(右)和生成的摘要(上)之间的软对齐。列表示生成每个单词后输入的分布。
最近的研究认为,用于抽象摘要的基于注意力的序列到序列模型可能会受到重复和语义不相关的影响,从而导致语法错误和对源文本主要思想的反映不足。 Junyang Lin 等人提出在每个时间步长的编码器输出之上实现一个门控单元,这是一个卷积所有编码器输出的 CNN,以解决这个问题。
基于 Vaswani 等人的卷积和自注意力,卷积门控单元设置一个门来过滤来自 RNN 编码器的源注释,以选择与全局语义相关的信息。换句话说,它使用 CNN 细化源上下文的表示,以改善单词表示与全局上下文的连接。与优于最先进方法的序列到序列模型相比,他们的模型能够减少重复。论文的源代码可以在这里找到。
其他抽象摘要方法借鉴了 Vinyals 等人的指针网络的概念,以解决序列到序列模型的不良行为。指针网络是一种基于神经注意力的序列到序列架构,它学习输出序列的条件概率,其中元素是与输入序列中的位置相对应的离散标记。
例如,Abigail See 等人。提出了一种称为 Pointer-Generator 的架构,它允许通过指向特定位置从输入序列中复制单词,而生成器允许从 50k 个单词的固定词汇表中生成单词。该架构可以被视为提取方法和抽象方法之间的平衡。
为了克服重复问题,本文采用了 Tu 等人的覆盖模型,该模型旨在克服神经机器翻译模型中源词覆盖不足的问题。具体来说,Abigail See 等人。定义了一个灵活的覆盖损失来惩罚重复关注相同的位置,只惩罚每个注意力分布和直到当前时间步长的覆盖之间的重叠,有助于防止重复关注。该模型的源代码可以在这里找到。

指针生成器模型。对于解码器中的每个时间步,从固定词汇表生成单词的概率与使用指针从源复制单词的概率由生成概率 p_{gen} 加权。对词汇分布和注意力分布进行加权求和得到最终分布。注意力分布可以看作是源词的概率分布,它告诉解码器在哪里生成下一个词。它用于产生编码器隐藏状态的加权和,称为上下文向量。
抽象摘要方面的其他研究借鉴了强化学习 (RL) 领域的概念来提高模型准确性。例如,陈等人。提出了一种以分层方式使用两个神经网络的混合提取-抽象架构,该架构使用 RL 引导提取器从源中选择显着句子,然后抽象地重写它们以生成摘要。
换句话说,该模型模拟了人类如何首先使用提取器代理来选择突出的句子或亮点来总结长文档,然后使用抽象器——编码器-对齐器-解码器模型——网络来重写这些提取的句子中的每一个。为了在可用的文档摘要对上训练提取器,该模型使用基于策略的强化学习 (RL) 和句子级度量奖励来连接提取器和抽象器网络并学习句子显着性。
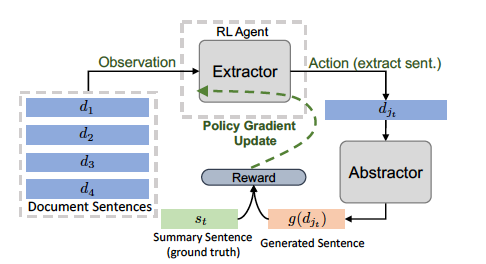
提取器的强化训练(针对一个提取步骤)及其与提取器的交互。
抽象器网络是一个基于注意力的编码器-解码器,它将提取的文档句子压缩并解释为简洁的摘要句子。 此外,抽象器有一个有用的机制来帮助直接复制一些词外 (OOV) 词。
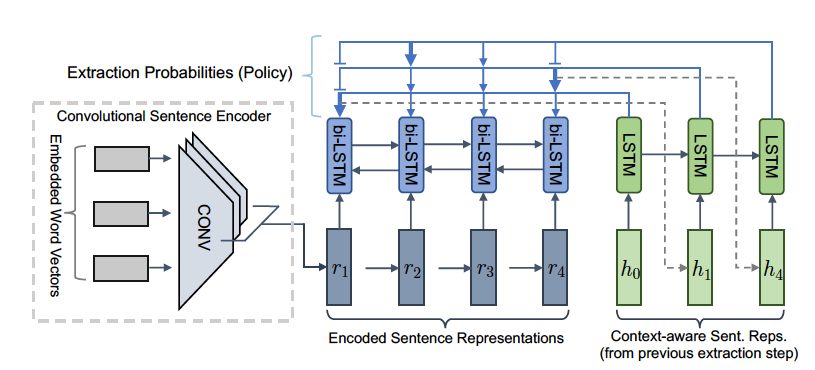
卷积提取器代理
提取器代理是一个卷积句子编码器,它根据输入的嵌入词向量计算每个句子的表示。此外,RNN 编码器计算上下文感知表示,然后 RNN 解码器在时间步长 t 选择句子。一旦选择了句子,上下文感知表示将在时间 t + 1 馈入解码器。
因此,该方法结合了抽象方法的优点,即简洁地重写句子并从完整词汇表中生成新词,同时采用中间提取行为来提高整体模型的质量、速度和稳定性。作者认为模型训练比以前的最先进技术快 4 倍。源代码和最佳预训练模型均已发布,以促进未来的研究。
最近的其他研究提出将对抗性过程和强化学习相结合进行抽象总结。一个例子是 Liu 等人。 (2017),他的工作提出了一个对抗性框架来联合训练一个生成模型和一个类似于 Goodfellow 等人的判别模型。 (2014)。在该框架中,生成模型将原始文本作为输入并使用强化学习生成摘要以优化生成器以获得高回报的摘要。此外,鉴别器模型试图将基本事实摘要与生成器生成的摘要区分开来。
判别器实现为文本分类器,学习将生成的摘要分类为机器或人工生成的,而生成器的训练过程是最大化判别器出错的概率。这个想法是这种对抗性过程最终可以让生成器生成合理且高质量的抽象摘要。作者在这里提供了补充材料。源代码可在此 github 存储库中找到。
简而言之
自动文本摘要是一个令人兴奋的研究领域,在行业中有多种应用。通过将大量信息压缩成简短的内容,摘要可以帮助许多下游应用程序,例如创建新闻摘要、报告生成、新闻摘要和标题生成。有两种突出的摘要算法类型。
首先,抽取式摘要系统通过复制和重新排列原文中的段落来形成摘要。其次,抽象摘要系统会生成新的短语,重新措辞或使用原始文本中没有的词。由于抽象概括的困难,过去的大部分工作都是抽象的。
提取方法更容易,因为从源文档中复制大量文本可确保良好的语法水平和准确性。另一方面,对于高质量总结至关重要的复杂能力,例如释义、概括或结合现实世界的知识,只有在抽象框架中才有可能。尽管抽象摘要是一项更具挑战性的任务,但由于深度学习领域的最新发展,迄今为止已经取得了许多进展。
引用为
@misc{luisfredgs2020,
title = "Automatic Text Summarization with Machine Learning — An overview",
author = "Gonçalves, Luís",
year = "2020",
howpublished = {https://medium.com/luisfredgs/automatic-text-summarization-with-machine…},
}
References
1. Extractive Text Summarization using Neural Networks — Sinha et al.(2018)
2. Extractive document summarization based on convolutional neural networks — Y. Zhang et al. (2016)
3. A Neural Attention Model for Abstractive Sentence Summarization — Rush et al.(2015)
4. Global Encoding for Abstractive Summarization — Lin et al.(2018)
5. Summarization with Pointer-Generator Networks — See et al.(2017)
6. Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting — Chen and Bansal(2018)
7. Generative Adversarial Network for Abstractive Text Summarization — Liu et al.(2017)
8. Using Latent Semantic Analysis in Text Summarization and Summary Evaluation — Josef Steinberger and Karel Jezek. (2003)
9. Text summarization using Latent Semantic Analysis — Makbule et al. (2011)
原文:https://medium.com/luisfredgs/automatic-text-summarization-with-machine…
- 248 次浏览