API架构
- 299 次浏览
【API设计】API架构 - 为 REST API 设计最佳实践
一般来说,只要 HTTP 协议存在,Web 服务就已经存在。但是,自从云计算出现以来,它们已成为实现客户端与服务和数据交互的无处不在的方法。
作为一名开发人员,我很幸运能够使用一些仍然围绕@work 的 SOAP 服务。但是,我主要使用 REST,这是一种用于开发 API 和 Web 服务的基于资源的架构风格。
在我职业生涯的大部分时间里,我都参与了构建、设计和使用 API 的项目。
我见过的大多数 API 都“声称”是“RESTful” —— 意思是符合 REST 架构的原则和约束。
然而,我与少数几个合作过的人给 REST 一个非常非常糟糕的代表。
HTTP 状态代码的不准确使用、纯文本响应、不一致的模式、插入端点的动词……我觉得我已经看到了这一切(或者至少,很多)。
因此,我决定写一篇文章来描述我个人认为设计 REST API 时的一些最佳实践。
只是为了让我们清楚……
我并不声称自己是权威,也不打算推断以下实践与任何“神圣的 REST 原则”100% 同步(如果存在这样的事情)。 我从我自己在整个职业生涯中构建和使用不同 API 的经验中拼凑出这些想法。
另外,我也不会假装精通 REST API 设计! 我相信这是一门艺术/运动——你练习得越多,你得到的就越好。
我将列出一些代码片段作为“糟糕设计的例子”。 如果它们看起来像你会写的东西,那很好! 🙂 唯一重要的是我们一起学习。
这里有一些技巧、建议和指导,可以帮助您设计出色的 REST API,让您的消费者(和开发人员)满意。
1. 学习HTTP的基础知识
如果您渴望构建一个设计良好的 REST API,您必须了解 HTTP 协议的基础知识。我坚信这将帮助您做出好的设计选择。
我发现 Mozilla 开发人员网络文档上的 HTTP 概述是有关此主题的非常全面的参考。
虽然,就 REST API 设计而言,这是一个适用于 RESTful 设计的 HTTP TLDR:
HTTP 有动词(动作或方法):GET、POST、PUT、PATCH 和 DELETE 是最常见的。
REST 是面向资源的,资源由 URI 表示:/library/
端点是动词和 URI 的组合,例如:GET: /books/
端点可以解释为对资源执行的操作。示例: POST: /books/ 可能意味着“创建一本新书”。
概括地说,动词映射到 CRUD 操作:GET 表示读取,POST 表示创建,PUT 和 PATCH 表示更新,DELETE 表示删除
响应的状态由其状态代码指定:1xx 表示信息,2xx 表示成功,3xx 表示重定向,4xx 表示客户端错误和 5xx 表示服务器错误
当然,您可以使用 HTTP 协议为 REST API 设计提供的其他内容,但我相信您必须牢记这些基本内容。
2.不返回纯文本
尽管这不是任何 REST 架构风格强加或强制的,但大多数 REST API 按照惯例使用 JSON 作为数据格式。
但是,仅返回包含 JSON 格式字符串的响应正文还不够好。 您仍应指定 Content-Type 标头。 它必须设置为值 application/json。
这在处理应用程序/编程客户端时尤为重要(例如,另一个服务/API 通过 Python 中的请求库与您的 API 交互) — 其中一些依赖此标头来准确解码响应。
💡专业提示:您可以使用 Firefox 轻松验证响应的内容类型。 它具有内置的漂亮显示内容类型:application/json 的响应。 🔥
在 Firefox 中,“Content-Type: text/plain”看起来……很简单。
“Content-Type: application/json” 不错,这是多么漂亮和实用。🕺
3. 不要在 URI 中使用动词
到目前为止,如果您已经了解了基础知识,您就会开始意识到将动词放在 URI 中不是 RESTful。
这是因为 HTTP 动词应该足以准确描述对资源执行的操作。
示例:假设您正在提供一个端点来生成和检索一本书的封面。 我会注意到 :param 是 URI 参数的占位符(如 ID 或 slug)。 您的第一个想法可能是创建一个与此类似的端点:
GET: /books/:slug/generateBookCover/
但是,GET 方法在语法上足以说明我们正在检索(“GETting”)一本书的封面。 所以,让我们使用:
GET: /books/:slug/bookCover/
同样,对于创建新书的端点:
# Don’t do this POST: /books/createNewBook/ # Do this POST: /books/
4.资源使用复数名词
这可能很难确定,是否应该对资源名词使用复数形式或单数形式。
我们应该使用 /book/:id/ (单数)还是 /books/:id/ (复数)?
我个人的建议是使用复数形式。
为什么? 因为它非常适合所有类型的端点。
我可以看到 GET /book/2/ 很好。 但是 GET /book/ 呢? 我们是要拿到图书馆里唯一的一本书,还是两本书,还是全部?
为了防止这种歧义,让我们保持一致(💡软件职业建议!)并在任何地方使用复数:
GET: /books/2/ POST: /books/ ...
5.在响应正文中返回错误详细信息
当 API 服务器处理错误时,在 JSON 正文中返回错误详细信息很方便(*并且推荐*)以帮助消费者进行调试。 如果您包含受错误影响的字段,那就更好了!
{
"error": "Invalid payload.",
"detail": {
"name": "This field is required."
}
}
6. 特别注意 HTTP 状态码
我觉得这个很重要。如果您需要从本文中记住一件事,那可能就是它。
您的 API 可能做的最糟糕的事情是返回带有 200 OK 状态代码的错误响应。
这只是糟糕的语义。相反,返回一个准确描述错误类型的有意义的 HTTP 状态代码。
不过,您可能想知道,“但我按照您的建议在响应正文中发送了错误详细信息,那有什么问题呢?”
让我给你讲一个故事。 🙂
我曾经不得不集成一个 API,它为每个响应返回 200 OK 并通过状态字段指示请求是否成功:
{
"status": "success",
"data": {}
}
尽管 HTTP 状态代码返回 200 OK,但我不能绝对确定它没有无法处理我的请求。
事实上,API 可以像这样返回响应:
HTTP/1.1 200 OK
Content-Type: text/html
{
"status": "failure",
"data": {
"error": "Expected at least three items in the list."
}
}
(是的——它也返回了 HTML 内容。因为,为什么不呢?)
因此,在读取数据之前,我必须检查状态代码和临时状态字段以确保一切正常。
太烦人了! 🤦♂️
这种设计是真正的禁忌,因为它破坏了 API 与其消费者之间的信任。您开始担心 API 可能会骗您。
所有这些都非常非 RESTful。 你应该怎么做?
使用 HTTP 状态代码,仅使用响应正文提供错误详细信息。
HTTP/1.1 400 错误请求
HTTP/1.1 400 Bad Request
Content-Type: application/json
{
"error": "Expected at least three items in the list."
}
7. 你应该一致地使用 HTTP 状态码
一旦您掌握了 HTTP 状态代码,您应该致力于始终如一地使用它们。
例如,如果您选择 POST 端点在某处返回 201 Created,则对每个 POST 端点使用相同的 HTTP 状态代码。
为什么? 因为消费者不必担心在哪种情况下哪个端点上的哪个方法将返回哪个状态代码。
所以,要可预测(一致)。 如果您必须偏离惯例,请将其记录在带有大标志的地方。
通常,我坚持以下模式:
GET: 200 OK PUT: 200 OK POST: 201 Created PATCH: 200 OK DELETE: 204 No Content
8.不要嵌套资源
您现在可能已经注意到 REST API 处理资源。检索列表或资源的单个实例很简单。但是,当您处理相关资源时会发生什么?
例如,假设我们要检索特定作者的书籍列表 - name=Cagan 的作者。基本上有两种选择。
第一个选项是将书籍资源嵌套在作者资源下,例如:
GET: /authors/Cagan/books/
一些架构师推荐这种约定,因为它确实代表了作者与其书籍之间的一对多关系。
但是,现在还不清楚您请求的是什么类型的资源。是作者吗?是书吗? …
同样扁平比嵌套更好,所以必须有更好的方法......而且有! :)
我个人的建议是直接使用查询字符串参数过滤书籍资源:
GET: /books?author=Cagan
这显然意味着:“获取作者姓名 Cagan 的所有书籍”,对吗? 🙂
9. 优雅地处理尾部斜杠
URIs 是否应该有一个斜杠/ 并不是一个真正的争论。您应该简单地选择一种方式或另一种方式(即带有或不带有尾部斜杠),坚持使用它并在客户端使用错误的约定时优雅地重定向客户端。
(我承认,我自己不止一次犯过这个罪。🙈)
讲故事的时间! 📙 有一天,当我将 REST API 集成到我的一个项目中时,我在每次调用时不断收到 HTTP 500 内部错误。我使用的端点看起来像这样:
POST: /buckets
我很生气,我终其一生都无法弄清楚我到底做错了什么。 🤪
最后,结果是服务器出现故障,因为我缺少尾部斜杠!所以,我开始使用:
POST: /buckets/
Aaaand 之后一切顺利。 🤦♂️
API 尚未修复,但希望您可以为您的消费者避免此类问题。
💡专业提示:大多数基于 Web 的框架(Angular、React 等)都有一个选项可以优雅地重定向到 URL 的尾随或非尾随版本。找到该选项并尽早激活它。
10.利用查询字符串进行过滤和分页
大多数时候,一个简单的端点不足以满足各种复杂的业务案例。
您的消费者可能希望检索满足特定条件的项目,或一次少量检索它们以提高性能。
这正是过滤和分页的目的。
通过过滤,消费者可以指定返回的项目应该具有的参数(或属性)。
分页允许消费者检索数据集的一部分。最简单的一种分页是页码分页,它由一个page和一个page_size决定。
现在,问题是:您如何在 REST API 中合并这些功能?
我的回答是:使用查询字符串。
我会说为什么你应该使用查询字符串进行分页是很明显的。它看起来像这样:
GET: /books?page=1&page_size=10
但是,过滤可能不太明显。起初,您可能会想到做这样的事情来检索仅已出版书籍的列表:
GET: /books/published/
设计问题:已发布不是资源!相反,它是您正在检索的数据的特征。那种事情应该放在查询字符串中。
所以最后,用户可以像这样检索“包含 20 个项目的已出版书籍的第二页”:
GET: /books?published=true&page=2&page_size=10
非常明确,不是吗?
11、了解401 Unauthorized和403 Forbidden的区别
如果我每次看到开发人员甚至一些有经验的架构师都把它搞砸的话,我有一个季度的时间……
在处理 REST API 中的安全错误时,很容易混淆错误是与身份验证还是授权(也称为权限)有关 — 过去一直发生在我身上。
这是我的备忘单,用于了解我正在处理的内容,具体取决于情况:
- 消费者是否未提供身份验证凭据?他们的 SSO 令牌是否无效/超时? 👉 401 未经授权。
- 消费者是否通过了正确的身份验证,但他们没有访问资源所需的权限/适当的许可? 👉 403 禁止。
12.善用HTTP 202 Accepted
我发现 202 Accepted 是 201 Created 的一个非常方便的替代品。它基本上意味着:
我,服务器,已理解您的请求。我还没有创建资源(还),但这很好。
我发现 202 Accepted 特别适用于两种主要情况:
- 如果资源将作为未来处理的结果创建 - 例如:在作业/进程完成后。
- 如果资源已经以某种方式存在,但这不应被解释为错误。
13. 使用专门用于 REST API 的 Web 框架
作为最后一个最佳实践,让我们讨论这个问题:您实际上如何在您的 API 中实施最佳实践?
大多数情况下,您希望创建一个快速的 API,以便一些服务可以相互交互。
Python 开发者会使用 Flask,JavaScript 开发者会使用 Node(Express),他们会实现一些简单的路由来处理 HTTP 请求。
这种方法的问题在于,该框架通常不针对构建 REST API 服务器。
例如,Flask 和 Express 都是两个非常通用的框架,但它们并不是专门用来帮助您构建 REST API 的。
因此,您必须采取额外的步骤在 API 中实施最佳实践。大多数时候,懒惰或缺乏时间意味着你不会付出努力——并且会给你的消费者留下一个古怪的 API。
解决方案很简单:为工作使用正确的工具。
新框架已经出现在各种语言中,专门用于构建 REST API。它们可帮助您轻松遵循最佳实践,而不会牺牲生产力。
在 Python 中,我发现的最好的 API 框架之一是 Falcon。它就像 Flask 一样简单易用,非常快速且非常适合在几分钟内构建 REST API。
Falcon:减轻我们 0.0564 多个世纪以来 API 的负担。
如果你更喜欢 Django 类型的人,那么首选是 Django REST 框架。 它不是那么直观,但非常强大。
在 Node 中,Restify 似乎也是一个不错的选择,尽管我还没有开始尝试。
我强烈建议您试一试这些框架。 它们将帮助您构建美观、优雅且设计良好的 REST API。
结束语
我们都应该努力使 API 使用起来很愉快。 两者都是为了消费者和我们自己的开发人员。
我希望本文能帮助您学习一些技巧,并启发您构建更好的 REST API 的技术。 对我来说,它归结为良好的语义、简单性和常识。
REST API 设计是一门艺术,比什么都重要。
如果您对我上面分享的任何提示有不同的方法,请分享。 我很想听听。
与此同时,让他们的 API 不断涌现!
原文:https://abdulrwahab.medium.com/api-architecture-best-practices-for-desi…
- 203 次浏览
【API 架构】 REST API 的性能最佳实践
在我之前的部分中,我分享了一些关于如何设计有效的 REST API 的最佳实践。
一个深思熟虑的设计还必须考虑 API 的性能方面。 如果 API 不能满足不断增长的请求以及不断变化的业务和/或客户需求,那么好的设计就毫无意义。
那么……什么是 API 性能?
就像任何性能一样,API 性能很大程度上取决于 API 如何响应和运行,以响应它收到的不同类型的请求。
示例:假设我们有一个面向客户的应用程序,用于显示客户的当前订单。 我们的应用程序从 API 获取订单详细信息。 但是现在,客户表示他们希望在一个地方查看所有订单(过去和当前)。 因此,我们构建了一个我的订单页面来显示客户的所有订单。 这意味着,我们的 API 现在将返回比以前更多的数据和更大的有效载荷。
我们如何确保我们的 API 能够将所有数据返回给我们的客户,而不会出现诸如延迟、服务器端错误和过多请求之类的问题?
性能提升技巧
1- 减少和限制有效载荷大小
响应数据的超大负载会减慢请求完成、其他服务调用的速度,并影响性能下降。 如您所知,现在我们正在为客户退回所有订单,而不仅仅是他们当前的订单,我们将不得不处理一些性能下降问题。
我们可以使用 GZip 压缩来减少我们的有效载荷大小。
这减少了我们在 Web 应用程序(客户端)上响应的下载大小,并提高了上传速度或某些实体(订单)的创建。
我们可以在 Web API 上使用 Deflate 压缩。
或者,我们可以将 Accept-Encodingrequest 标头更新为 gzip 。
2- 启用缓存
缓存是提高 API 性能的最简单方法之一。 如果我们有频繁返回相同响应的请求,那么该响应的缓存版本有助于避免额外的服务调用/数据库查询。
您需要确保在使用缓存定期使缓存中的数据无效时,尤其是在发生新数据更新时。
示例:假设我们的客户想要订购汽车零件,我们的应用调用一些汽车零件 API 来获取零件价格。 由于响应(部分价格)每周仅更改一次(@ 12:00am),因此我们可以在此之前的剩余时间内缓存响应。 这使我们不必每次都重新调用以返回相同的零件价格。
3-提供足够的网速
即使是设计最稳健的 API,缓慢的网络也会降低其性能。 不可靠的网络可能会导致停机,从而导致您的组织违反 SLA、服务条款和您可能对客户做出的承诺。 投资合适的网络基础设施很重要,这样我们才能保持所需的性能水平。
这可以通过利用和购买足够的云资源和基础设施来实现(例如:在 AWS 中,分配适当数量的 EC2 实例,使用网络负载均衡器)。
此外,如果您有大量后台进程,请在单独的线程上运行这些进程以避免阻塞请求。 您还可以使用镜像和内容交付网络 (CDN)(例如 CloudFront)来更快地处理全球不同地区的请求。
4- 防止意外调用、减速和滥用
您可能会遇到这样的情况,即您的 API 遭受 DDoS 攻击,这种攻击可能是恶意的、有意的,也可能是工程师调用 API 以从某个本地应用程序循环执行时无意的。
您可以通过测量交易并监控每个 IP 地址或每个 SSO/JWT 令牌(如果客户/调用应用程序在调用 API 之前获得授权)发生的交易数量来避免这种情况。
这种速率限制方法有助于减少会减慢 API 速度的过多请求,有助于处理意外调用/执行,并主动监控和识别可能的恶意活动。
5- 尝试在 PUT 上使用 PATCH
PUT 和 PATCH 操作会产生相同的结果,这是工程师之间的一个普遍误解。
它们在更新资源方面相似,但它们各自执行更新的方式不同。
PUT 操作通过向整个资源发送更新来更新资源。
PATCH 操作仅对需要更新的资源应用部分更新。 产生的 PATCH 调用产生更小的有效载荷,并大规模提高性能。
💡专业提示:尽管PATCH调用可以限制请求大小,但您应该注意它不是幂等的。 这意味着,PATCH 可能会通过一系列多次调用产生不同的结果。 因此,您应该仔细考虑使用 PATCH 请求的应用程序,并确保在需要时以幂等方式实现它们。 如果没有,请使用 PUT 请求。

6- 启用日志记录、监控和警报
这可能是您将在此处阅读的最重要的提示之一。 如果你应该从这篇文章中学到一件事,那就应该是这个! 没有就这一点进行谈判。
拥有日志、监控和警报可帮助工程师在问题成为问题之前对其进行诊断和修复。 许多 API(基于 Express/Node 的、Java、Go)都有用于评估以下内容的预定义端点:
/health/metrics
如果您没有启用日志记录,并且存在潜在问题,您将无法跟踪源,或特定请求中出现问题的位置。
如果您没有启用监控,您将无法从分析的角度了解某些问题或错误发生的频率。 这将阻止您考虑可能的解决方案。
而且……如果您没有启用警报,您将不知道是否存在问题,直到客户(或更糟的是,客户)报告它。 害怕!
7- 启用分页
分页有助于从多个响应中创建内容桶。 这种优化有助于改进响应,同时保留传输/显示给客户的数据。
您可以标准化、细分和限制响应,这有助于降低结果的复杂性,并通过仅提供客户要求的响应/结果来改善整体客户体验。
结束语
我们知道 API 非常棒,如果针对性能进行适当的优化和增强,它可以非常强大地为企业和客户提供出色的体验。
业务需求和客户期望总是随着时间的推移而发展。 作为负责任的工程师,我们可以决定如何以高性能的方式构建 API,这可以帮助我们实现并超越我们的目标。
这些技巧只是冰山一角,适用于一般设置中的所有 API。 根据您的特定 API 和用例、它与哪些服务交互、调用它的频率、调用它的位置等,您可能需要以不同的方式实现这些技巧。
原文:https://abdulrwahab.medium.com/api-architecture-performance-best-practi…
- 181 次浏览
Comments
【API】什么是 API 管理,为什么它很重要?
当今复杂的数字生态系统由许多相互关联的部分组成。 API 作为看门人和连接器在其中发挥着关键作用——提供了许多最终用户甚至没有注意到的自动化机会和效率。
企业密切关注 API。它们对于应用程序、数据和各种客户交互的功能至关重要。
这使得 API 管理成为几乎每个部门的组织的重要主题。根据 Zion Market Research 的数据,2017 年至 2022 年间,全球 API 管理市场预计将以 33.4% 的复合年增长率增长,到 2022 年将达到 34.3616 亿。
阅读本文以了解 API 管理是什么、它为组织带来的好处以及如何为您的业务获取正确的 API 管理解决方案。
什么是 API 管理?
API 管理是一组流程,用于分发、控制和分析组织用来跨云连接应用程序和数据并与外部世界连接的 API。
API 管理的主要目标是使创建自己的 API 或使用外部 API 的组织能够监控其活动并满足使用 API 的开发和应用程序的需求。这就是他们如何确保所有 API 的使用均符合公司政策并以适当的安全级别进行管理。
通过在您的组织和外部世界的边缘部署 API 管理,您可以获得从安全性和可追溯性到通信效率的重要功能。
API 管理由许多移动块组成,这些块通常合并到一个整体解决方案中。在 BlueSoft,我们采取了不同的方法。我们的解决方案 Agama API 在开发时考虑到了微服务模式,以使组织能够充分利用其 API 生态系统。许多企业现在转向微服务架构,因为它有助于加速软件开发。我们已经预料到了这一点,并准备了一个解决方案来帮助他们完成他们的旅程。
API 管理对 IT 世界的影响
API的功能究竟是什么?它们公开组织的数据并通过应用程序提供其资产。 API 还用于向客户、员工和合作伙伴交互添加数字层。
这就是 API 管理如此重要的原因。它为开发人员和企业提供了用于保护、扩展、管理、分析和货币化 API 程序的工具。
一项详细研究 API 采用在数字化转型计划中的作用的研究表明,API 是关键推动因素。结果显示,71% 的受访组织预计到 2022 年 API 调用量将增加。
API 管理的好处

改善客户体验
API 推动新应用程序的快速发展,并在各种渠道中创造无缝体验,满足客户的需求。由于连接性的提高,不同行业的组织可以在全新的水平上提供响应性和便利性。例如,API 带来了您必须自己构建的个性化和增值服务。
可扩展性
企业正在处理比以往更多的应用程序和数据。他们需要不断扩大规模,同时培养创新文化——通常是通过创建和发布新的 API。通过在整个 API 生命周期中简化访问并减少技术负担,API 管理支持可扩展性。
更严格的安全性
当多方(从内部开发人员到合作组织和客户)都可以访问 API 时,安全性成为关键焦点。当您的应用程序是分布式和断开连接时,管理数据访问可能会很棘手。
您需要采取一切可能的措施来保护敏感数据,并确保正确分配和管理权限。如果没有 API 管理解决方案,很难实现这一目标,因为您无法利用其可见性和一致性。
避免关键系统的变化
API 管理解决方案可以利用现有系统,并允许您避免对公司每天使用的关键系统进行任何更改。
变得更加敏捷和响应迅速
能够实时快速创建和发布任何端点有助于企业保持敏捷并变得更具适应性。
数据驱动的决策
API 管理解决方案收集和分析数据,让您深入了解使用模式、设备和地理位置——所有这些都旨在推动更明智的决策。
最大化开发人员性能
您的开发人员可以使用集中式生命周期管理解决方案来了解和分析整套 API 和 Web 服务。他们在一个集中的面板中获得出色的服务可见性和可追溯性,从而提高团队的工作效率。
由于专用的开发人员门户,开发人员还可以享受更轻松和自动化的文档管理。借助 Sandbox 等模块,API 管理工具还支持与外部开发团队进行测试。
API管理是如何实现的?
API 管理解决方案旨在使 API 创建、部署、发布和维护更容易和更精简。
不可否认,每个单独的 API 管理工具都带有一组独特的功能。大多数都提供安全、文档、沙盒环境和高可用性等核心功能。
如今,组织内部构建 API 管理解决方案或从第三方提供商处购买作为服务。在 Facebook、Google 和 Twitter 等科技巨头的推动下,开放 API 运动促进了 API 对轻量级 JSON 和 REST 服务的依赖,而不是传统的面向服务架构 (SOA)。现代工具经常使用这些格式。
API 管理软件必须包含哪些内容
以下是您在为您的业务选择正确的 API 管理工具时应该寻找的必备功能:
- 提供 API 文档以及开发人员入职流程(例如注册和帐户管理)的开发人员门户。
- 自动化和控制您的 API 和使用它们的应用程序之间的连接。
- 一个 API 网关,作为所有客户端的单一入口点,并确定它们如何通过策略与 API 交互。
- API 生命周期管理涵盖从设计、实施到退役的整个周期。
- 通过使用合同实现 API 货币化。您可以通过基于 API 调用次数等指标定义的合约,通过访问 API 背后的微服务获利。
- 能够监控来自单个应用程序的 API 流量,因此您可以了解您的 API 发生了什么——例如,哪个消费者或应用程序调用了哪个 API,以及失败的频率或多少 API(以及原因)。
- 多个 API 实现和版本之间的一致性。
- 提高应用程序性能的内存管理和缓存机制。
- 保护 API 不被滥用并确保将正确权限授予正确人员的安全程序和策略。
- 一个清晰的状态流来帮助 API 管理员——负责管理生产中可见的内容并负责哪个 API 在哪里工作的人。
如何知道您找到了正确的工具?
通过考虑可靠性、灵活性、API 行为质量、速度和成本等因素来衡量 API 管理的成功与否。
使用 Agama API 管理您的 API
我们的解决方案 Agama API 包括核心功能,例如 API 设计、发布分析、监控、安全和货币化。此外,它非常灵活,可以轻松与您的监控系统连接。
它的架构适用于两种替代方案:
- API管理解决方案负责数据转换的地方,
- 并且它是一个代理层,通过添加机制来保护通信,以启用缓存,这要归功于缓存。
我们可以在本地基础设施(数据中心)、公共云或混合环境中部署 Agama API。
在 BlueSoft,我们不遵循“黑盒方法”,可以根据您的独特需求轻松定制我们的 API 管理平台。我们知道,真正的价值与您的想法的独特性以及我们带来的不可或缺的标准化有关。
我们的专家可以帮助您部署、更改、支持和创建部署环境。我们经常建议我们的客户如何以务实的方式引入正确的机制。
最好的部分?您不必处理许可限制,例如用户限制、交易或处理能力。 Agama API 中没有这样的限制。
API 已经在塑造我们的数字生态系统方面发挥着关键作用。通过使用可靠的 API 管理解决方案(如 Agama API)来充分利用它们。
原文:https://bluesoft.com/what-is-api-management-and-why-is-it-important/
- 174 次浏览
【API架构】REST API 行业辩论:OData vs GraphQL vs ORDS
本文比较了标准 API 和服务,以通过 Internet 查询数据以进行分析、集成和数据管理。
Progress 的高级软件工程师 Jeff Leinbach 和 Progress 的开发布道者 Saikrishna Teja Bobba 进行了这项研究,以帮助您决定在您的应用程序或分析/数据管理工具中考虑采用哪种标准 API。我们对比了 OData、GraphQL 和 ORDS 之间的区别,它们是用于通过 Internet 查询和更新数据的标准 API 和服务。重点是实现跨 API 的互操作性,以进行分析、集成和数据管理。
我们一直在根据 AWS re:Invent、Oracle OpenWorld、Dreamforce、API World 等行业活动中的大量讨论跟踪这些主题。 Progress 在数据访问标准(包括 ODBC、JDBC、ADO.NET 和现在的 OData (REST))的开发和贡献方面也拥有丰富的传统,并且是第一个加入 OData 技术委员会的成员。
什么是 REST?
REST(表示状态传输)或 RESTful Web 服务是在 Internet 上的计算机系统之间提供互操作性的一种方式。符合 REST 的 Web 服务允许请求系统使用一组统一且预定义的无状态操作来访问和操作 Web 资源的文本表示。 RESTful 实现使用 HTTP、URI、JSON 和 XML 等标准。
重要的是要注意 REST 是一种架构风格,而不是标准。
通过 Internet 查询数据的标准 API
OData
OData 最初由 Microsoft 于 2007 年开发,是一种 OASIS 标准 REST API,建立在 Microsoft、SAP、CA、IBM 和 Salesforce 等公司之间。它允许以简单和标准的方式创建和使用可查询和可互操作的 RESTful API。 OData 为您提供了一组丰富的查询功能,并因其开源方法以及出色的可扩展性而迅速获得支持。
GraphQL
GraphQL 于 2012 年在 Facebook 内部开发,在 2015 年公开发布之前,是一种部署在 Facebook、Shopify 和 Intuit 等公司的数据查询语言。 GraphQL 为您的 API 中的数据提供了完整且易于理解的描述,使客户能够准确地询问他们需要什么,使 API 更容易随着时间的推移而发展,并支持强大的开发人员工具。
ORDS
ORDS(Oracle REST 数据服务)是 Oracle REST 服务,它为以 Oracle 为中心的应用程序提供类似的标准化。它使具有 SQL 和其他数据库技能的开发人员能够构建对 Oracle 数据库的企业级数据访问 API,当今的现代、最先进的应用程序开发人员希望使用这些 API,并且确实越来越需要使用这些 API 来构建应用程序。 Oracle 的 60 个小组使用 ORDS,包括 Oracle Database、Times Ten 和 NoSQL。
对比标准 API
图 1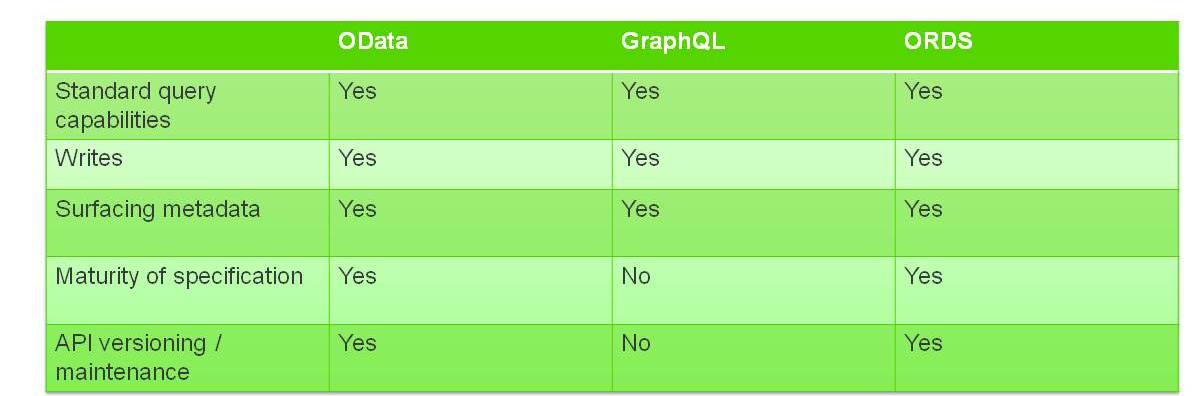
对比图 1 中的标准 API 的标准是基于实现与多个数据源的互操作性。 关于这种比较需要注意的一点是规范的成熟度。 尽管 GraphQL 越来越受欢迎,但在广泛采用、最佳实践和工具方面的成熟度仍然存在问题。
在 API 版本控制/维护下,您会认为“否”是不好的,但实际上是好的。 这是 GraphQL 的优势之一,我稍后会介绍。
图 2
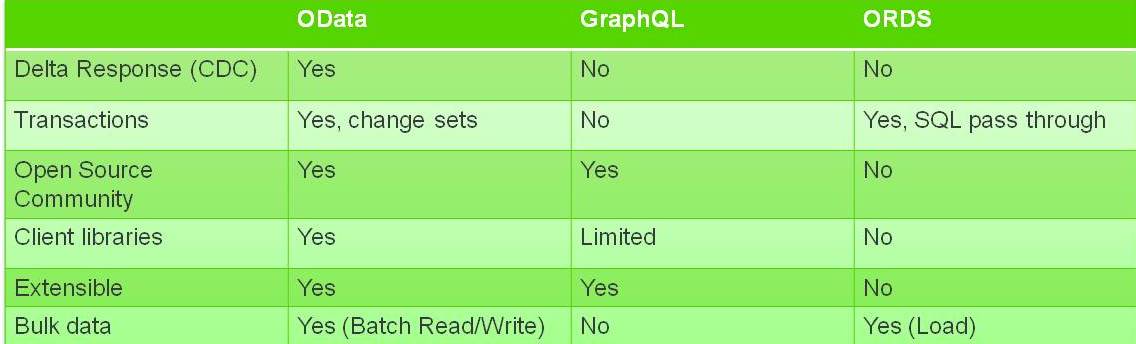
在图 2 中,我们完成了对要考虑的其他标准的初步分析,并将在以后的文章中扩展这些领域。
标准查询能力
图 3
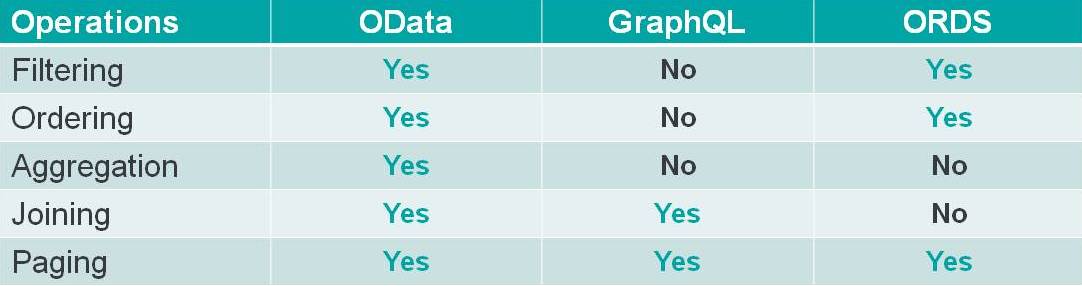
图 3 突出显示了通过开放标准接口访问数据的通用标准。 OData 全面支持所有这些查询功能。您可以使用 GraphQL 和 ORDS 执行其中一些操作,但它们没有标准化或以实现互操作性的方式记录。
GraphQL 与 REST 非常相似,因为它定义了与 Web 服务交互的方式,但它并没有告诉你服务的作用。因此,您可以通过创建可以调用的函数来进行过滤、排序和连接等操作,但应用程序开发人员必须了解它们在语义上的工作方式才能知道它们的行为是什么。
使用 ORDS,您可以进行聚合和连接,但这是通过创建您可以调用的自定义函数来完成的。但是应用程序必须知道这些函数做了什么才能理解如何解释结果。没有元数据或标准行为定义可以告诉应用程序会发生什么。
呈现元数据
图 4
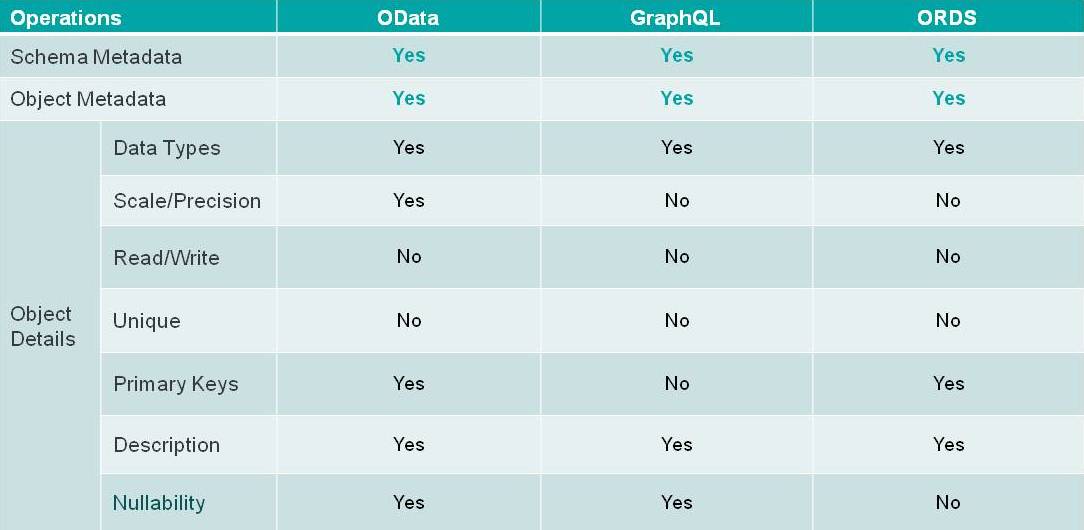
图 4 比较了表面元数据,这是分析和数据管理应用程序的核心,需要以可互操作的方式以编程方式对模式进行逆向工程。
这些 API 中的每一个都在努力解决这个问题,但是 GraphQL 和 ORDS 不会告诉您数据的规模和精度,而 OData 会。 GraphQL 也不会告诉您主键,ORDS 也不会告诉您可空性。此信息对于应用程序能够知道它可以对每个特定字段做什么和不能做什么很重要。
API 版本控制和维护
一个令人头疼的问题是在 API 更改时处理应用程序的更新,同时还要维护旧版本。导致 REST API 令人头疼的最大问题是,当您查询端点时会返回所有字段。 API 开发人员无法了解客户是否依赖特定领域的信息。客户端开发人员必须处理所有返回的字段,即使他们不需要这些信息。
GraphQL 通过强制客户端准确指定他们需要哪些字段来解决 API 版本控制和维护问题。 API 开发人员可以主动联系已知的字段使用者,以迁移已弃用的字段。响应包括有关哪些字段已弃用的信息。
OData 通过提供一个选择列表来将返回的字段数限制为应用程序所需的字段数,从而提供类似的功能。这减少了应用程序中的响应大小和处理。但是,它没有提供一种机制来指示字段已被弃用。
OData 更加灵活,因为可以轻松编写查询以返回所有字段。 OData 正在将模式版本控制添加到规范中以解决此问题。
例子
为了直观地说明使用这些 API 的差异,以下两个代码示例展示了如何在 GraphQL 和 OData 中执行“排序依据”。

在 All Opportunities 函数调用的 GraphQL 示例中,从名称上可以看出它的作用。 但是,GraphQL 中没有任何内容可以告诉您可以为这些参数传递什么以及指定为参数的值如何导致函数运行。 并且这种行为在不同实现的基础上可能会有所不同。

相比之下,当您使用 orderBy 查询参数时,OData 会准确地告诉您它的行为方式,因为它的行为被定义为规范的一部分。
建议

GraphQL 几乎就像一种编程语言,这使得它非常灵活。它功能强大,但使用它意味着您的应用程序与特定 GraphQL 服务的实现方式紧密耦合。没有办法笼统地描述它是如何工作的。
对于习惯于处理 Web 服务的人来说,GraphQL 也可能有点尴尬,因为为了查询数据,您不需要执行 GET 操作,这就是您从普通 REST Web 服务获取结果的方式。您执行 POST,准确定义要包含在响应中的字段和函数。
因此,尽管 GraphQL 使您能够从元数据中确定哪些字段和函数可用,但您仍然不知道它们在语义上的含义。
消除进入障碍
本文主要关注 API 使用者,但 GraphQL 开发 API 的门槛要低得多。如果你正在做一个快速的项目,GraphQL 可能是要走的路。但是你仍然有你的应用程序与你的实现紧密耦合的问题。
OData 确实很强大,但是伴随着很多繁重的工作,因为您必须遵守标准的所有行为。您必须符合 OData 的最低行为级别。这为服务开发人员设置了更大的进入壁垒。
但是,您可以利用我们的混合技术来生成标准
REST API (OData)。 我们利用我们的混合技术完成所有繁重的工作,以生成标准的 REST API (OData)。 我们使用 OData 完成所有繁重的工作,因此您不必担心遵守标准。 我们为您降低了进入门槛。
此外,还有许多 OData 客户端可以帮助您快速轻松地启动和运行 OData 服务。 如果您正在开发一个新的应用程序,有很多已经支持 OData 的应用程序,以及可以为您提供帮助的 OData 客户端库。
如果您想了解如何嵌入我们的混合技术以使用 OData 通过 REST 公开数据,请立即与我们的一位数据连接专家交谈。
原文:https://www.progress.com/blogs/rest-api-industry-debate-odata-vs-graphq…
- 161 次浏览
【API架构】REST API 设计的原则和最佳实践
这篇最佳实践文章面向对创建 RESTful Web 服务感兴趣的开发人员,这些服务提供跨多个服务套件的高可靠性和一致性; 遵循这些准则; 服务定位于内部和外部客户快速、广泛、公开采用。
这是一个完整的图表,可以轻松理解 REST API 的原理、方法和最佳实践。
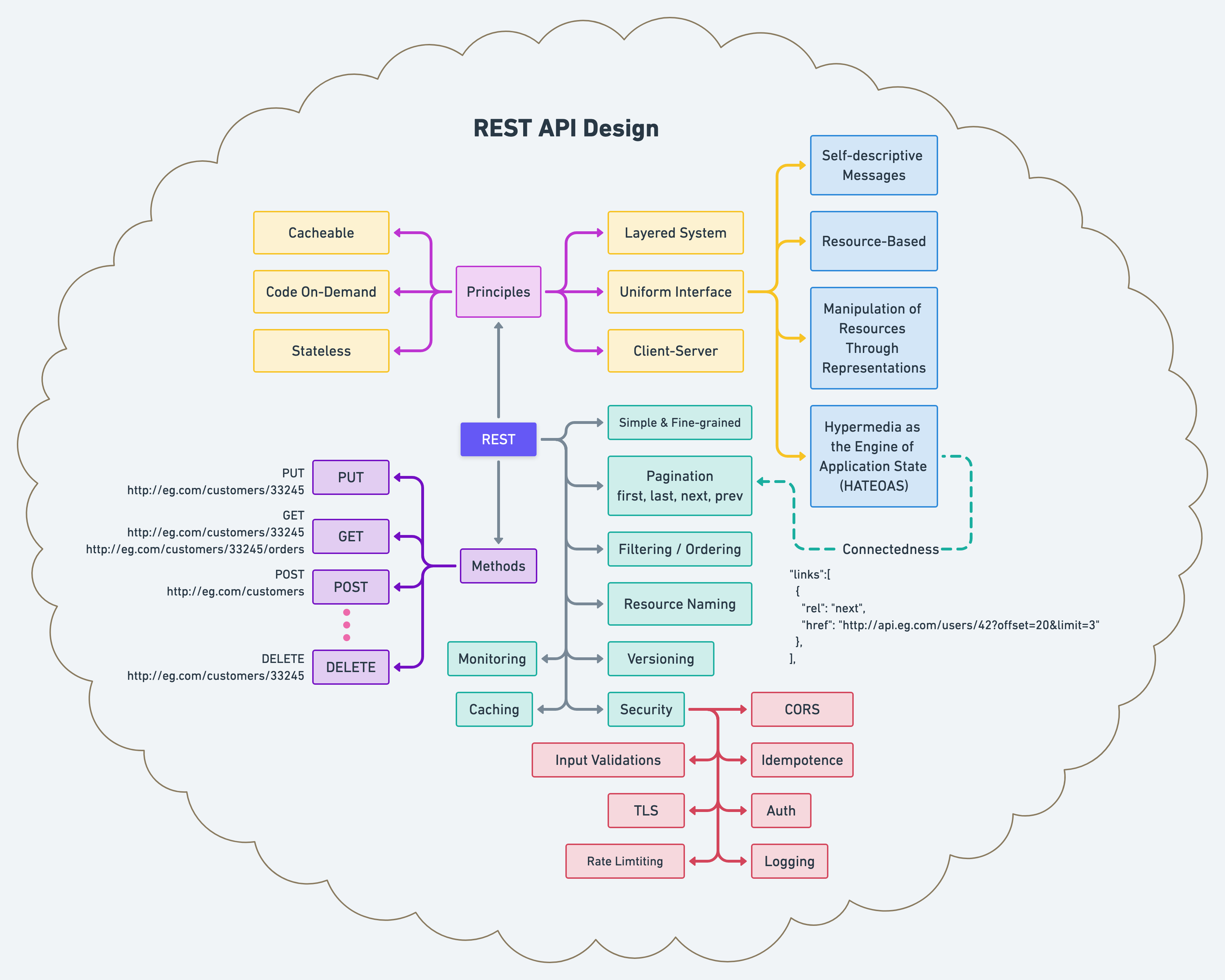 现在,让我们从每个盒子的原理开始详细说明它。
现在,让我们从每个盒子的原理开始详细说明它。
六项原则/约束
- 客户端-服务器:关注点分离是客户端-服务器约束背后的原则。通过将用户界面问题与数据存储问题分开,我们提高了用户界面跨多个平台的可移植性,并通过简化服务器组件提高了可扩展性。
- 无状态:通信必须是无状态的,如客户端-无状态-服务器 (CSS) 风格。从客户端到服务器的每个请求都必须包含理解请求所需的所有信息。因此,会话状态完全保留在客户端上。
- 可缓存:为了提高网络效率,我们添加了缓存约束以形成客户端-缓存-无状态-服务器风格。缓存约束要求数据响应带有隐式或显式标签为可缓存或不可缓存的请求。如果响应是可缓存的,则客户端缓存有权为以后的等效请求重用该响应数据。
- 分层系统:客户端通常无法判断它是直接连接到终端服务器还是沿途的中介。中间服务器可以通过启用负载平衡和提供共享缓存来提高系统可扩展性。层也可以强制执行安全策略。
- 按需代码:REST 允许通过下载和执行小程序或脚本形式的代码来扩展客户端功能。通过减少需要预先实现的功能数量来简化客户端。它允许在部署后下载功能,提高了系统的可扩展性。
- 统一接口:通过将通用性的软件工程原理应用于组件接口,简化了整个系统架构,提高了交互的可见性。实现与它们提供的服务分离,这鼓励了独立的可进化性。 REST 定义了四个接口约束:资源的识别、通过表示的资源操作、自描述消息和作为应用程序状态引擎的超媒体。
- 自描述消息:每条消息都包含足够的信息来描述如何处理消息。
- 基于资源:在请求中使用 URI 作为资源标识符来标识单个资源。资源本身在概念上与返回给客户端的表示分开。
- 通过表示操作资源:当客户端表示资源(包括附加的任何元数据)时,它有足够的信息来修改或删除服务器上的资源,前提是它有这样做的权限。
- 超媒体作为应用程序状态引擎 (HATEOAS):客户端通过正文内容、查询字符串参数、请求标头和请求的 URI(资源名称)传递状态。服务通过正文内容、响应代码和响应头向客户端提供状态。
最佳实践
现在,让我们换个角度来了解 REST 的基本最佳实践,这是每个工程师都应该知道的。
- 保持简单和细粒度:创建模拟系统底层应用程序域或系统数据库架构的 API。最终,您将需要聚合服务——利用多种底层资源来减少闲聊的服务。
- 过滤和排序:对于大型数据集,从带宽的角度来看,限制返回的数据量至关重要。此外,我们可能希望指定要包含在响应中的资源的字段或属性,从而限制返回的数据量。我们最终想要查询特定值并对返回的数据进行排序。
- 版本控制:有很多方法可以破坏合同并对 API 开发中的客户产生负面影响。如果您不确定更改的后果,最好谨慎行事并考虑版本控制。在决定新版本是否合适或对现有表示的修改是否充分和可接受时,需要考虑几个因素。由于维护多个版本变得繁琐、复杂、容易出错且成本高昂,因此对于任何给定资源,您应该支持不超过两个版本。
- 缓存:缓存通过启用系统中的层来消除检索请求数据的远程调用来增强可扩展性。服务通过在响应(如 Cache-Control、Expires、Pragma、Last-Modified 等)上设置标头来提高缓存能力
- 分页:REST 的原则之一是连通性——通过超媒体链接。同时,没有它们,服务仍然有用。当链接在响应中返回时,API 变得更具自我描述性。对于支持分页的响应中返回的集合,“first”、“last”、“next”和“prev”链接至少是有益的。
- 资源命名:当资源命名正确时,API 是直观且易于使用的。做得不好,同样的 API 会让人感觉很笨拙,并且难以使用和理解。 RESTful API 适用于消费者。 URI 的名称和结构应该向这些消费者传达含义。通常很难知道数据边界应该是什么,但是通过了解您的数据,您很可能有能力进行尝试,并将什么作为代表返回给您的客户是有意义的。为您的客户设计,而不是为您的数据设计。
- - 复数:普遍接受的做法是始终在节点名称中使用复数形式,以保持您的 API URI 在所有 HTTP 方法中保持一致。原因是“客户”是服务套件中的一个集合,而 ID(例如 33245)指的是集合中的这些客户之一。
- 监控:确保添加各种监控以提高 API 的质量或性能。数据点可以是响应时间(P50、p90、P99)、状态代码(5XX、4XX 等)、网络带宽等等。
- 安全:
- - 授权/认证:对服务的授权与对任何应用程序的授权没有什么不同。问这个问题,“这个主体对给定资源是否有请求的权限?”
- - CORS:在服务器上实现 CORS 就像在响应中发送额外的 HTTP 标头一样简单,例如 Access-Control-Allow-Origin、Access-Control-Allow-Credentials 等
- - TLS:所有身份验证都应使用 SSL。 OAuth2 需要授权服务器和访问令牌凭据才能使用 TLS。
- - 幂等性:如果执行一次或多次,将产生相同结果的操作。根据其适用的上下文,它可能具有不同的含义。例如,在具有副作用的方法或子程序调用的情况下,这意味着修改后的状态在第一次调用后保持不变。
- - 输入验证:验证服务器上的所有输入。接受“已知”好的输入并拒绝错误的输入,防止 SQL 和 NoSQL 注入,将消息大小限制为字段的确切长度,服务应仅显示一般错误消息等等。
- - 限速:是一种限制网络流量的策略。它限制了某人在特定时间范围内重复操作的频率 - 例如,尝试登录帐户。
- - 记录:确保您不会意外记录任何个人身份信息 (PII)。
至此,我结束了这次学习,我希望你今天学到了一些新东西。请分享给更多的同事或朋友。最后,考虑成为Medium会员,谢谢!
参考:
原文:https://blog.devgenius.io/best-practice-and-cheat-sheet-for-rest-api-de…
- 353 次浏览
【API架构】什么是 REST
REST 是 REpresentational State Transfer 的首字母缩写词,是分布式超媒体系统的一种架构风格。罗伊菲尔丁于 2000 年在他的著名论文中首次提出了它。
与其他架构风格一样,REST 有其指导原则和约束。如果需要将服务接口称为 RESTful,则必须满足这些原则。
符合 REST 架构风格的 Web API(或 Web 服务)是 REST API。
1. REST 的指导原则
RESTful 架构的六个指导原则或约束是:
1.1 统一接口
通过将通用性原则应用于组件接口,我们可以简化整个系统架构并提高交互的可见性。
多个架构约束有助于获得统一的接口并指导组件的行为。
以下四个约束可以实现统一的 REST 接口:
- 资源标识——接口必须唯一标识客户端和服务器之间交互中涉及的每个资源。
- 通过表示(REpresentation)操作资源——资源在服务器响应中应该有统一的表示。 API 使用者应该使用这些表示来修改服务器中的资源状态。
- 自描述消息——每个资源表示应该携带足够的信息来描述如何处理消息。它还应该提供客户端可以对资源执行的附加操作的信息。
- 超媒体作为应用程序状态的引擎——客户端应该只有应用程序的初始 URI。客户端应用程序应该使用超链接动态驱动所有其他资源和交互。
1.2.客户端-服务器
客户端-服务器设计模式强制关注点分离,这有助于客户端和服务器组件独立发展。
通过将用户界面关注点(客户端)与数据存储关注点(服务器)分离,我们提高了用户界面跨多个平台的可移植性,并通过简化服务器组件来提高可扩展性。
在客户端和服务器发展的同时,我们必须确保客户端和服务器之间的接口/契约不会中断。
1.3.无状态
无状态要求从客户端到服务器的每个请求都必须包含理解和完成请求所需的所有信息。
服务器无法利用服务器上任何先前存储的上下文信息。
因此,客户端应用程序必须完全保持会话状态。
1.4.可缓存
可缓存约束要求响应应隐式或显式地将自身标记为可缓存或不可缓存。
如果响应是可缓存的,则客户端应用程序有权在稍后为等效请求和指定时间段重用响应数据。
1.5 分层系统
分层系统样式允许通过约束组件行为来由分层层组成架构。
例如,在分层系统中,每个组件都无法看到它们正在与之交互的直接层之外。
1.6 按需编码(可选)
REST 还允许通过以小程序或脚本的形式下载和执行代码来扩展客户端功能。
下载的代码通过减少需要预先实现的功能数量来简化客户端。服务器可以将部分功能以代码的形式交付给客户端,客户端只需要执行代码即可。
2. 什么是资源?
REST 中信息的关键抽象是资源。我们可以命名的任何信息都可以是资源。例如,REST 资源可以是文档或图像、临时服务、其他资源的集合或非虚拟对象(例如,人)。
资源在任何特定时间的状态称为资源表示。
资源表示包括:
- 数据
- 描述数据的元数据
- 以及可以帮助客户过渡到下一个所需状态的超媒体链接。
一个 REST API 由一组相互关联的资源组成。这组资源称为 REST API 的资源模型。
2.1资源标识符
REST 使用资源标识符来识别客户端和服务器组件之间交互中涉及的每个资源。
2.2.超媒体
表示的数据格式称为媒体类型。媒体类型标识了一个规范,该规范定义了如何处理表示。
RESTful API 看起来像超文本。每个可寻址的信息单元都带有一个地址,可以是显式的(例如,链接和 id 属性),也可以是隐式的(例如,源自媒体类型定义和表示结构)。
超文本(或超媒体)意味着信息和控制的同时呈现,使得信息成为用户(或 automaton)获得选择和选择动作的可供性。
请记住,超文本在浏览器上不需要是 HTML(或 XML 或 JSON)。当机器了解数据格式和关系类型时,它们可以跟踪链接。
— Roy Fielding
2.3.自我描述
此外,资源表示应该是自描述的:客户端不需要知道资源是员工还是设备。它应该根据与资源相关联的媒体类型进行操作。
所以在实践中,我们将创建许多自定义媒体类型——通常是一种媒体类型与一种资源相关联。
每种媒体类型都定义了一个默认处理模型。例如,HTML 定义了超文本的呈现过程以及每个元素周围的浏览器行为。
媒体类型与资源方法没有关系,得到/ put / post / delete / ......除了某些媒体类型元素将定义像href属性的锚元素的进程模型的事实之外,veroct方法,在对应于 CDATA 编码的 href 属性的 URI 上调用检索请求 (GET)。”
3. 资源方法
与 REST 相关的另一件重要事情是资源方法。这些资源方法用于在任何资源的两种状态之间执行所需的转换。
很多人错误地将资源方法与 HTTP 方法(即 GET/PUT/POST/DELETE)相关联。 Roy Fielding 从未提及任何关于在何种条件下使用哪种方法的建议。他所强调的只是它应该是一个统一的界面。
例如,如果我们决定应用程序 API 将使用 HTTP POST 来更新资源——而不是大多数人推荐的 HTTP PUT——那没关系。尽管如此,应用程序界面仍将是 RESTful。
理想情况下,转换资源状态所需的一切都应该是资源表示的一部分——包括所有支持的方法以及它们将以何种形式离开表示。
我们应该输入一个 REST API,除了初始 URI(书签)和一组适合目标受众的标准化媒体类型(即任何可能使用该 API 的客户端都可以理解)之外,没有任何先验知识。
从那时起,所有应用程序状态转换都必须由客户端选择服务器提供的选项来驱动,这些选项存在于接收到的表示中,或者由用户对这些表示的操作暗示。
转换可能由客户对媒体类型和资源通信机制的了解确定(或限制),这两者都可以即时改进(例如,按需编码)。 [这里的失败意味着带外信息正在推动交互而不是超文本。]
4. REST和HTTP不一样
许多人更喜欢将 HTTP 与 REST 进行比较。 REST 和 HTTP 不一样。
REST != HTTP
尽管 REST 还打算使 Web(互联网)更加精简和标准,但 Roy fielding 提倡更严格地使用 REST 原则。这就是人们尝试将 REST 与 Web 进行比较的地方。
Roy fielding 在他的论文中没有提到任何实现方向——包括任何协议偏好甚至 HTTP。到目前为止,我们都在遵守 REST 的六项指导原则,我们可以将其称为我们的接口——RESTful。
五、总结
简而言之,在 REST 架构风格中,数据和功能被视为资源,并使用统一资源标识符 (URI) 进行访问。
通过使用一组简单的、定义明确的操作对资源进行操作。此外,资源必须与其表示分离,以便客户端可以访问各种格式的内容,例如 HTML、XML、纯文本、PDF、JPEG、JSON 等。
客户端和服务器通过使用标准化的接口和协议来交换资源的表示。通常 HTTP 是最常用的协议,但 REST 并不强制要求它。
有关资源的元数据可用并用于控制缓存、检测传输错误、协商适当的表示格式以及执行身份验证或访问控制。
最重要的是,与服务器的每次交互都必须是无状态的。
所有这些原则都有助于 RESTful 应用程序变得简单、轻量和快速。
参考:
- 129 次浏览
【API架构】使用 JSON API 的好处
在 API 工艺的世界里,没有比设计更受热议的领域了。 从 REST、gRPC 到 GraphQL,有许多方法可以设计和标准化 Web API 交互。 今天,我们将注意力转向另一种方法,JSON API,JSONAPI.org 上详细介绍的用于构建 API 的规范。
JSONAPI.org 中描述的 JSON API 非常适合使您的 JSON 响应格式更加一致。 以提高生产力和效率为目标,JSON API 因其可以消除多余的服务器请求的高效缓存功能而受到吹捧。
在这篇文章中,我们将定义 JSON API 是什么,并了解如何使用它来构建高效的 API。 我们将介绍 JSON API 的一些主要优点,并通过 FitBit 的案例研究了解该规范在实践中的应用情况。 希望本概述将介绍 JSON API 的新手,并帮助您判断它是否适合您的 API 场景。
什么是 JSON API (JSONAPI.org)?
JSON API 是一种适用于 HTTP 的格式。它描述了客户端应如何从服务器请求或编辑数据,以及服务器应如何响应所述请求。该规范的一个主要目标(现在是稳定的 v1.0)是优化 HTTP 请求;在请求数量和客户端和服务器之间交换的数据包大小方面。
“JSON API 是一种有线(Wire)协议,用于通过 HTTP 增量获取和更新图形”
——耶胡达·卡茨
在 JSON API 中,客户端和服务器都在请求文档中发送 JSON API 数据,带有以下标头,而不指定媒体类型参数:
Content-Type: application/vnd.api+json
JSON API 表示如何调用资源以及如何共享相关链接。 JSON 对象位于请求的根部,它必须包含资源数据、错误或元信息。数据以及与数据的关系可以通过 GET 调用来获取,如下所示:
GET /articles HTTP/1.1
Accept: application/vnd.api+json
以下是资源类型 `articles` 在 JSON API 响应中的显示方式:
// ...
{
"type": "articles",
"id": "1",
"attributes": {
"title": "Rails is Omakase"
},
"relationships": {
"author": {
"links": {
"self": "/articles/1/relationships/author",
"related": "/articles/1/author"
},
"data": { "type": "people", "id": "9" }
}
}
}
// ...到目前为止,相当标准的东西。 JSON API 支持创建、更新和删除资源的典型 CRUD 流程。 JSON API 将始终向后兼容,它是一个社区驱动的计划,在 Github 上接受拉取请求。
使用 JSON API 的好处
既然我们对 JSON API 是什么有了基本的了解,那么有哪些独特的优势使它脱颖而出?
复合文档
复合文档是 JSON API 中的一项独特功能,允许服务器将相关资源与请求的主要资源一起发送——如果实施得当,这可以减少必要的 HTTP 请求的数量。复合文档使用 include 参数工作,如下所示:
GET https://api.example.com/posts?include=author
这使您能够在初始请求中包含其他资源。
稀疏字段集
如果您使用复合文档来包含相关资源,您可能会遇到回复量大的问题。再一次,JSON API 有一个解决方案。
JSON API 的另一个独特方面是稀疏字段集,它使客户端只能从特定字段请求数据。它通过将要检索的字段添加到具有资源名称和所需字段的 URI 参数来工作。这提供了额外的定制,可以减少臃肿。它看起来像:
GET /articles?include=author&;fields[articles]=title,body&;fields[people]=name HTTP/1.1
Accept: application/vnd.api+json
稀疏字段集是一种标准化方法,它允许客户端仅指定他们希望从对象中包含在响应中的属性。 使用稀疏字段集,您只能获得所需的字段,提供独特的定制潜力,这对精益数据共享环境很有吸引力。
可选性
JSONAPI.org 中的许多功能都是可选的;您可以关闭或打开它们。这些功能使客户能够决定接受哪些资源,从而很好地适应精益的移动环境。让客户就如何检索和处理数据达成一致是有帮助的,因为它消除了冗余和优化以减少膨胀。
优化功能
JSON API 配备了许多功能来优化 API 返回包。 JSON API 中的特殊服务器端操作包括排序和分页;将返回资源的数量限制为子集的能力,包括 first、last、next 和 prev 链接。
缓存
在他的演讲中,Lee 强调了定义良好的资源如何提高缓存能力,从而提高最终用户的“感知速度”。
“因为数据变化影响的资源更少,所以数据变化时失效的资源更少”
在 JSON API 用例中,缓存本质上是内置在 HTTP 中的。由于使用 JSON API 的客户端以相同的方式访问数据,因此他们不需要将数据存储在不同的位置。这种设计可能需要转变思想,但如果使用得当,可以带来显着的优化优势。
JSON API 如何在实践中使用:FitBit 案例研究
让我们看看 JSON API 如何在实践中实现以设计高效的 API,使用 FitBit 作为现实生活中的案例研究。
Jeremiah Lee 在 FitBit 领导 API 开发 4 年,在此期间他参与了他们的 JSON API 采用。健身可穿戴公司 FitBit 拥有蓬勃发展的 API 程序;在每年 40 亿次请求中,有 1/4 是通过第三方应用程序完成的,收入可观。
符合 API 风格有助于标准化客户端
一个常见的问题是当不同的客户端类型偏好不同的方法来从服务器检索数据时。围绕功能区域形成的工程团队通常一次一个平台地逐步实施新功能,并在每个客户端中找到相反的约束。
Lee 描述了 FitBit 团队如何拥有四个主要客户:Android、iOS、Windows 和 Web。一个主要问题是 Android 和 iOS 对 API 应该如何运行有非常不同的想法。 iOS 更喜欢较少的网络请求和较大的 API 响应,而 Android 更喜欢更多的网络请求和较小的 API 响应。
为了将这些约束规范化为一致的数据模型,团队必须首先解决请求数量和请求大小之间的争论。 FitBit 团队在具有敌对数据网络的移动环境中工作,无法依赖理想的客户端连接。
相信 HTTP/2、TLS 1.3 和改进的 LTE 网络的日益普及,FitBit 团队决定他们可以减少请求的开销、发出并发请求并减少安全延迟问题,同时相信更多弹性连接。这将导致他们采用更小的资源和许多轻量级的 HTTP 请求。
JSON API 帮助创建一致的数据模型
“如果没有明确的指导,数据模型可能会变得混乱。”
——耶利米·李
Lee 描述了在 FitBit,他们的 API 如何开始类似于“视图模型”;现有端点变得超载,数据相关性松散,而不是范围广泛。团队正在根据用户体验视图重载端点。
随着客户体验随着时间的推移而发展,团队正在以任意方式拆分数据。由于没有权威或风格可以遵循,这造成了很多不一致。客户端和服务器数据模型之间的错位造成了问题。团队需要就如何检索数据和处理数据达成一致,并且需要能够以很少的开销检查数据更改。
他们倾向于使用 JSON API 来规范化他们的数据。使用 JSON API 定义数据之间关系的能力,他们能够建立客户端-服务器通信期望。
JSON API 有助于保持同步
FitBit 案例中的另一个问题是与服务器保持同步。他们的设备需要经常与服务器同步,并且这些数据也可以被第三方应用程序修改。
这些更改必须非常快速地反映在所有 API 客户端中。 JSON API 利用的 HTTP 缓存使他们能够防止召回过时的数据,从而减少冗余并提高最终用户的感知速度。根据 Lee 的说法,这真的开始在一个应用程序中叠加多种体验。
比较 JSON API 和 GraphQL
既然我们本质上是在讨论使用图形,为什么不使用 GraphQL 呢?虽然您可以使用 GraphQL 实现许多相同的功能,但 Lee 看到了采用 JSON API 的两个主要好处:分页和可缓存性。
分页是 GraphQL 没有专门解决的一个领域。或者,当客户端请求它们时,JSON API 会向客户端提供诸如 next 和 prev 之类的链接。由于 GraphQL 中的分页完全由客户端处理,Lee 认为这很不幸,因为客户端可能会在不知不觉中进行昂贵、耗时的数据库查询。
GraphQL 也没有利用 HTTP 缓存功能,因为它与协议无关。由于没有建议的通用方法,这意味着每个 GraphQL API 处理缓存的方式都会略有不同。
“我个人认为缓存对于客户端性能考虑来说太重要了,不能事后考虑”
——耶利米·李
Lee 还指出,使用 JSON API 意味着开发人员不必采用像 GraphQL 这样的另一个工具链,而是可以继续使用他们很可能已经熟悉的技术。
GraphQL 的许多好处,例如查询效率和减少往返调用,都可以在 JSON API 中使用稀疏字段集和复合文档进行匹配。 JSON API 因此可以提供与 GraphQL 相同的功能。
考虑将 JSON API 用于“实用”的 API 设计
JSON API LogoJeremiah Lee 称其为“务实”,我们必须同意。如上所述,让客户端和服务器共享一个通用数据模型(如 JSON API)有很多优点。
“JSONAPI.org 规范应该是您的智能默认设置”
——耶利米·李
虽然 JSON API 并不适合所有情况,但许多人声称它是客户端和服务器通过 HTTP 共享通用数据接口的一种很好的默认方式。凭借上面列出的优势,以及它的健康采用,JSON API 似乎是 API 风格的有力竞争者。
我们鼓励您自己阅读规范。您如何看待 JSONAPI.org?您使用什么规范来定义您的 API 和数据模型?
资源
- Jeremiah Lee Slides with commentary
- Introduction to the JSON:API spec: Presentation by Marco Otte-Witte
- JSON API Homepage
- JSON API Specification
- JSON API Twitter
- JSON API Github
- JSON Patch: Can be used for incremental udpates
原文:https://nordicapis.com/the-benefits-of-using-json-api/
本文:
- 97 次浏览
【Open API】eBay为其所有RESTful公共api提供了OpenAPI规范(OAS)
今天,eBay宣布他们正在利用OpenAPI规范(OAS)来实现它所有的RESTful公共api。使用OpenAPI,开发人员可以下载一个eBay OpenAPI契约,生成代码并在几分钟内成功调用一个eBay API。api在eBay的开发者生态系统中扮演着重要的角色,帮助公司建立并向买家和卖家提供最好的体验。
“考虑到我们对OpenAPI周围的开发者生态系统的需求和了解,使用OpenAPI规范是一个一致的选择,”eBay Portland的总经理盖尔·弗雷德里克(Gail Frederick)和eBay副总裁开发生态系统说。“OpenAPI规范实际上是描述api的标准,在eBay基于微服务的新体系结构中扮演着关键角色。”
作为OpenAPI计划的成员和主席,我看到越来越多的公司转向基于分布式和微服务的体系结构,因为为用户构建高质量的体验并更快地将产品或服务推向市场是任何企业成功的关键。为支持这种转换而创建的技术和工具主要是由开放协作构建的,跨越了像Node这样的应用程序开发技术。像Kubernetes这样的容器编排。由于api是分布式组件之间的“粘合剂”,因此OAS标准在这一转换中扮演了中心角色。
易趣就是这样。随着eBay从单一的、集中的体系结构过渡到分布式的微服务体系结构,公司需要改进服务契约的开发、测试、发布以及与API规范集成的方式。
该公司对这种转变有一系列需求:
API契约需要满足跨不同技术堆栈的无缝探索和集成的需求,成为行业标准,并具有丰富的特性,以补充我们的技术标准和治理模型,因此需要探索新的规范。
主要的标准是人类和机器可读的规范、语言无关性的规范、厂商中立的规范和开源的规范。
Shekhar Banerjee, MTS高级架构师,eBay
由于其工具支持、完全可定制的堆栈、代码优先和契约优先的API开发方法,以及最重要的是,OpenAPI作为由OpenAPI首创的开放协作所领导的标准继续发展,OAS成为了一致的选择。迁移到OAS进一步推进了eBay对其开发者生态系统的使命,即通过不再使用sdk和花费更多时间编写API客户端代码来提高开发者的效率和生产力。
自2017年8月以来,eBay一直是OpenAPI计划的成员之一,也是业内最早发布基于OpenAPI 3.0规范的合同的公司之一。我们很高兴看到eBay继续支持我们的联盟以及其他开放合作项目,包括云本地计算基金会(CNCF)。
- 209 次浏览
【REST架构】OData、JsonAPI、GraphQL 有什么区别?
问题:
我在职业生涯中使用过很多 OData,现在我来自不同团队的同事中很少有人建议我们迁移到 JsonAPI 和 GraphQL,因为它与 Microsoft 无关。 我对这两种查询语言都没有太多经验。 据我所知,OData 是 Salesforce、IBM、Microsoft 使用的标准,并且非常成熟。 为什么要切换到 JsonAPI 和/或 GraphQL? 有真正的好处吗? JsonAPI 和 GraphQL 是新标准吗? 根据受欢迎程度更改公共 api 实现似乎没有用,尤其是在没有太大好处的情况下。
有人可以启发我吗?
答案:
OData 是与 JSON API 类似的规范。它们都描述了用于创建和使用 RESTful API 的标准协议。 GraphQL 是一种完全不同的 API 设计方法,并指定了一种查询 API 资源的不同方式。
OData:
自 2007 年以来在 Microsoft 设计和开发,由 OASIS 联盟标准化。最新版本 V4 已提交给 ISO/IEC JTC 1 以作为国际标准获得批准。技术委员会 (TC) 中的公司包括 CA Technologies、Citrix、IBM、Microsoft、Progress、Red Hat、SAP 和 SDL。
有许多用于流行编程语言的库 - .NET、Java、JavaScript、PHP 和 Ruby。该规范允许动态资源,并且有一个服务文档列出了所有 API 端点供客户端发现。此外,还有一个描述架构的元数据文档。
JSON API:
JSON API 最初由 Yehuda Katz 于 2013 年 5 月起草。这个初稿是从 Ember Data 的 REST 适配器隐式定义的 JSON 传输中提取的。该规范的当前稳定版本是 1.0。 JSON API 规范适用于大多数编程语言,包括客户端和服务器端。
JSON API 通过 JSON 文档中的链接属性支持 HATEOAS。其他功能包括分页、排序、过滤和关系。 JSON API 服务器生成的 JSON 文档非常冗长,带有许多嵌套属性。
GraphQL:
自 2015 年以来在 Facebook 开发。该规范仍是工作草案。它在 React 爱好者中很受欢迎,主要与 React 或 Vue.js 结合使用。与 GraphQL 类似的是 Falcor,它也相对较新。
虽然 GraphQL 使用 HTTP,但它不被视为 REST,而是 REST 的替代品。相反,它在单个(虚拟)JSON 文档中使用查询/响应模型。这种新模型更适合开发人员使用,但它相对于 REST 的优势是值得商榷的。鉴于其年轻,生态系统尚未成熟。
为了清楚和完整起见,我将 OpenAPI 包括在列表中,尽管它并不完全是 API 规范。这可能会让一些人感到困惑。 OpenAPI 标准是一种与语言无关的标准,用于描述和定义 API。例如,您的 API 可以遵循上述标准之一(不包括 GraphQL),也可以使用 OpenAPI 3 进行记录。
OpenAPI(又名 Swagger):
作为 OpenAPI Initiative 和 Linux 基金会的一部分开发。得到 Google、Microsoft、IBM、SAP、Oracle、Ebay 和 PayPal 等大型科技公司的支持。该规范的当前版本是 3.1.0。大多数编程语言都有实现,以及许多其他工具,如 Web UI 生成器等。
使用 OpenAPI 等规范获得的最好的东西是围绕它们的工具——API 文档页面的生成器、客户端 SDK 代码的生成器等。
这个标准可能是当今最常用于 API 声明、文档和代码生成的标准。它还受到云提供商(如 Amazon Web Services)在其 API 网关中的支持。
总之,OData 和 JSON API 都是 JSON 数据格式,它们在数据周围添加上下文和特征(例如链接),GraphQL 是一种完全不同的查询和变异 JSON 数据的新方法,而 OpenAPI 是声明和记录任何数据的标准方法RESTful API。
我个人的看法:
如您所见,有很多 RESTful 规范,而不是单一的通用标准。我同意 xumix 的观点——他们似乎都患有“这里没有发明”综合症。选择上述任何一项的好处都很小,特别是如果您的项目是中小型项目。您的 API 实现的规范是否重要?应该不多吧。只需专注于构建一致且记录良好的 API。
原文:https://stackoverflow.com/questions/44711161/what-is-the-difference-bet…
本文:
- 119 次浏览
【应用架构】有原则GraphQL
视频号

微信公众号

知识星球

尽管名为GraphQL,但它并不是一种简单的查询语言。这是一个全面解决现代应用与云服务之间连接问题的方案。因此,它构成了现代应用程序开发堆栈中一个新的重要层的基础:数据图。这个新层将公司的所有应用程序数据和服务集中在一个地方,具有一致的、安全的、易用的界面,这样任何人都可以在最小的摩擦下使用它。
在Apollo,我们从2015年就开始构建行业领先的数据图技术,我们估计我们的软件现在在超过90%的GraphQL实现中使用。多年来,我们与各种规模的公司中实现GraphQL的开发人员进行了数千次对话。我们希望分享我们所学到的知识,因此我们将他们的经验提炼为一组创建、维护和操作数据图的最佳实践。我们在这里将它们以10个GraphQL原则的形式呈现,分为三类,其格式受到了Twelve Factor应用程序的启发。
完整性原则
确保图定义良好、稳定且一致
1. 一个图
您的公司应该有一个统一的图表,而不是由每个团队创建的多个图表。
通过一个图形,你可以最大化GraphQL的价值:
- 可以通过一个查询访问更多的数据和服务
- 代码、查询、技能和经验可以跨团队移植
- 所有图形用户都可以查看的所有可用数据的中心目录
- 实现成本最小化,因为图形实现工作不重复
- 图的中央管理——例如,统一的访问控制策略——成为可能
当团队在没有协调工作的情况下创建他们自己的图表时,他们的图表几乎不可避免地会开始重叠,以不兼容的方式向图表添加相同的数据。在最好的情况下,这是昂贵的返工;在最坏的情况下,它会造成混乱。在公司的数据图采用过程中,应该尽可能早地遵循这一原则。
2. 联合实施
尽管只有一个图,但该图的实现应该跨多个团队联合。
如果没有高度专门化的基础设施,单片架构很难扩展,数据图也不例外。与在单个代码库中实现组织的整个数据图层不同,定义和实现图的责任应该划分到多个团队中。每个团队都应该负责维护公开他们的数据和服务的模式部分,同时拥有独立开发和在他们自己的发布周期上操作的灵活性。
这维护了图的单一、统一视图的价值,同时保持了整个公司的开发工作的分离。
3.跟踪注册表中的模式
应该有一个单一的事实来源来记录和跟踪图表。
就像在版本控制系统中跟踪源代码很重要一样,在模式注册表中跟踪图形的定义也很重要。您的公司应该有一个模式注册表,它是图形的权威定义,而不是依赖于当前正在运行的进程或在开发人员的笔记本上检入的任何代码。像一个源代码控制系统,注册表的模式存储修改图,谁让他们的历史,它应该理解图像的多个版本的概念(例如,登台和生产,或不同的开发分支)的方式相似的软件开发过程。
模式注册中心应该成为系统的中心,为开发人员工具、工作流或任何业务流程提供支持,这些业务流程将受益于对数据图的感知,以及对数据图的任何实际或建议的更改。
敏捷原则
快速展开图形并不断调整它以适应不断变化的需求
4. 抽象的,需求模式法
模式应该作为一个抽象层,为使用者提供灵活性,同时隐藏服务实现细节。
GraphQL的很大一部分价值在于提供了服务和使用者之间的抽象,因此该模式不应该与特定的服务实现或特定的使用者紧密耦合,因为它们现在已经存在了。通过将实现细节排除在模式之外,应该可以重构实现图的服务——例如,从一个整体转换到微服务,或者改变服务实现的语言——而不影响该领域的应用程序。同样,模式不应该与特定应用程序获取数据的方式紧密耦合。如果新应用程序的功能与现有的应用程序类似,那么应该可以编写新应用程序,而对图形的修改应该最小。
要实现这一点,可以使用面向需求的模式的标准:该模式侧重于为应用程序开发人员提供良好的开发体验,并根据现有图构建新功能。以这个标准为目标将有助于防止图与将来可能更改的服务实现耦合,并有助于增加添加到图中的每个字段的重用价值。
5. 使用敏捷方法进行模式开发
模式应该根据实际需求逐步构建,并随着时间的推移平稳地演进。
提前定义组织所有数据的“完美模式”可能很有诱惑力。相反,真正使模式有价值的是它遵循实际用户需求的程度,而这些需求从来都不是预先完全知道的,并且是不断变化的。实现“完美模式”的真正途径是使图易于根据实际需要进行演化。
不应该推测性地将字段添加到模式中。理想情况下,每个字段应该只在响应消费者对附加功能的具体需求时添加,而设计的目的是最大限度地让其他有类似需求的消费者重用。
更新图形应该是一个连续的过程。与其每隔6个月或12个月发布一个新的图形“版本”,不如在必要时每天多次更改图形。可以随时添加新字段。要删除字段,首先要弃用它,然后在没有使用者使用它时删除它。模式注册表支持图形的这种敏捷演化,以及使每个人都知道可能影响他们的更改的流程和工具。这确保了只有完全审查过的变更才能投入生产。
6. 迭代地提高性能
性能管理应该是一个连续的、数据驱动的过程,能够平稳地适应不断变化的查询负载和服务实现。
数据图层是讨论服务团队和使用其服务的应用程序开发人员之间的性能和容量的最佳位置。这个对话应该是一个持续的过程,它使服务开发人员能够持续地、主动地了解消费者打算用他们的服务做什么。
与其优化图形的每一种可能的用法,不如将重点放在支持生产中所需的实际查询形状上。工具应该提取提议的新查询形状,并在它们投入生产之前将它们呈现给所有受影响的服务团队,这些团队具有延迟需求和预计的查询量。一旦查询进入生产环境,就应该持续监视它的性能。如果遵循这一原则,那么很容易将问题追溯到行为不符合预期的服务。
7. 使用图形元数据来增强开发人员的能力
开发人员应该在整个开发过程中对图形有丰富的认识。
GraphQL的主要价值在于它为开发人员提供了巨大的生产力提升。为了最大限度地提高性能,开发人员的工具应该让他们对数据图有普遍的认识,并贯穿于他们在整个开发生命周期中使用的所有工具。
每当开发人员进行与管理数据或连接到服务相关的工作时,他们的工具应该将关于图的实时信息放在手边。这些信息应该是最新的,工具应该是高度智能的,以有用和强大的方式将图形感知应用到当前的情况。如果处理得当,不仅会提高开发人员的工作效率和幸福感,而且GraphQL还会成为连接前端和后端团队的纽带,在整个开发生命周期中实现无缝对话。
一些数据图形感知工具的功能的实际例子包括:
- 开发人员可以在他们的编辑器中享受所有可用图形数据和服务的实时文档,而且总是最新的。
- 有关废弃字段的信息可以传播到使用这些字段的开发人员的编辑器中,并提供建议的替代方案
- 根据实时生产数据,在开发人员输入查询时,可以向他们显示查询的估计成本(以延迟或服务器资源计算)。
- 运维团队可以跟踪后端服务的负载,将其追溯到特定的应用程序、版本、功能,甚至代码行,从而全面了解开发人员如何使用其服务。
- 当服务开发人员对其模式进行更改时,可以作为持续集成过程的一部分自动确定更改的影响。如果更改会破坏现有的客户机(根据重播最近的生产使用情况确定),那么服务开发人员可以确定将受到影响的精确客户机、版本和开发人员。
- 当应用程序开发人员构建特性时,可以从他们的代码中提取支持这些特性的新查询,并与操作团队共享。有了这种认识,操作团队就可以提前提供所需的能力,并在开发过程的早期介入,如果查询不能在预期的范围内得到批准的话。
- 当应用程序是用类型化语言(如TypeScript、Java或Swift)开发的时候,类型信息可以从服务类型声明一直传播到应用程序的每一行代码,从而确保全堆栈类型的正确性和对错误的即时反馈。
操作原则
安全地将图部署到大规模生产环境中
8. 存取和需求控制
在每个客户端基础上授予对图形的访问权,并管理客户端可以访问什么以及如何访问它。
数据图中的授权具有两个同样重要的方面:访问控制和需求控制,前者表示允许用户访问哪些对象和字段,后者表示允许用户如何(以及多少)访问这些资源。虽然经常讨论访问控制,但也需要注意需求控制,因为它在GraphQL的任何生产部署中都是至关重要的。允许用户不考虑成本执行任何可能的查询是错误的,因为用户没有能力管理它对生产系统的影响。访问和需求控制都必须在充分了解数据图的语义和性能的情况下执行。在不分析实际发送的查询的情况下,仅将用户限制在每分钟特定的查询数量是不够的,因为查询可以访问大量的服务,而且查询的成本可以在多个数量级上变化。
验证在数据图也有两个方面:请求操作的应用程序,并使用这个应用程序的人。虽然访问控制中心的人使用应用程序,适当的需求控制至少取决于每个应用控制人均控制,应用程序的开发人员,而不是应用程序的用户负责应用程序所使用的特定查询的形状做它的工作。
控制需求的最佳方法包括:
- 当不受信任的用户访问生产系统时,他们应该只发送由经过验证的应用程序开发人员预先注册的查询,而不是允许他们使用应用程序的凭据发送任意查询。对于只分发给可信用户的内部应用程序来说,这有时并不严格。
- 对于预计将发送大量查询的应用程序,团队应该设计一个与更广泛的软件开发周期相一致的查询审批工作流,以便在查询进入生产之前对其进行审查。这可以确保它们不会获取不必要的数据,并且服务器的容量可以支持它们。
- 作为第二道防线,在执行查询之前估计它的成本,并为每个用户和每个应用程序制定查询成本预算,可以防止过度使用预先注册的操作,或者在无法进行预先注册的操作的情况下。
- 开发人员应该能够禁用特定应用程序在生产环境中发送特定查询的能力,无论是作为紧急情况下的安全网,还是发现第三方应用程序以不可接受的方式使用数据图。
9. 结构化的日志
捕获所有图形操作的结构化日志,并利用它们作为了解图形用法的主要工具。
可以捕获关于在图上执行的每个操作(读或写)的大量信息:哪些用户和应用程序执行了该操作、访问了哪些字段、实际执行操作的方式、如何执行操作,等等。这些资料非常宝贵,应当有系统地加以收集,供以后使用。它应该以结构化的、机器可读的格式捕获,而不是文本日志,这样就可以为尽可能多的目的利用它。
图形操作的记录称为跟踪。跟踪应该召集所有相关信息关于一个操作在一个地方,包括业务信息(谁做了手术,访问或改变,哪些功能的应用程序由哪些开发人员,是否成功,如何执行)和纯技术信息(后端服务联系,每个服务如何导致延迟,是否使用缓存)。
因为跟踪真正地捕获了一个图是如何被使用的,它们可以被用于广泛的用途:
- 了解是否可以删除废弃字段,或者是否可以删除仍在访问它的特定客户端,以及它们的重要性
- 根据实时的生产数据,实时地预测一个查询需要多长时间执行,因为开发人员正在他们的IDE中输入查询
- 自动检测生产中的问题(如增加的延迟或错误率)并诊断其根本原因
- 提供权威的审计跟踪,显示哪些用户访问了特定的记录
- 为商业智能查询提供支持(当天气炎热时,人们会在自己所在的地方更频繁地搜索冰激凌吗?)
- 根据API使用情况为合作伙伴生成发票,可以根据访问的特定字段或消耗的资源创建详细的成本模型
所有图形操作的跟踪应该集中在一个中心位置,这样就有了一个权威的跟踪流。然后,这个流可以通过管道进入其他可观察性系统(可能在对不支持graphql的现有系统进行简单转换之后),或者存储在一个或多个数据仓库中供以后使用(根据预算、用例和规模的需要进行汇总和取样)。
10. 将GraphQL层与服务层分离
采用分层架构,将数据图功能分解为单独的层,而不是整合到每个服务中。
在大多数API技术中,客户机不直接与服务器通信,除非在开发中。取而代之的是一种分层的方法,其中将一些问题(如负载平衡、缓存、服务位置或API密钥管理)分解为单独的一层。然后,可以将此层与后端服务分开设计、操作和伸缩。
GraphQL也不例外。与其将一个完整的数据图系统所需的所有功能都放到每个服务中,不如将大多数数据图功能分解成位于客户端和服务之间的独立层,让每个服务专注于服务于实际的客户端请求。这一层可以由多个进程组成,执行访问和需求控制、联合、跟踪收集和潜在的缓存等功能。这一层的某些部分是特定于graphql的,需要深入了解数据图,而负载平衡和客户端身份验证等其他功能可能由现有系统来执行。
即使在只有一个应用程序和一个服务的简单场景中,这个单独的层也是有价值的;否则,属于中间层的功能必须在服务器中实现。在复杂的应用程序中,这一层可能开始看起来像一个地理上分布的系统:通过多个入口点接收传入的查询,处理其中一些在网络的边缘边缘缓存的好处,路由子组件查询多个数据中心的公共云,民营,或由合作伙伴,最后这些组件组装成一个查询结果,同时记录跟踪,这是纪念整个操作。
在某些情况下,此数据图层将使用GraphQL与后端服务通信。但是,最常见的情况是,后端服务保持不变,并继续被它们现有的api(如REST、SOAP、gRPC、Thrift甚至SQL)访问,这些api与数据图对象之间的映射由构成数据图层一部分的服务器完成。
原文:https://principledgraphql.com
讨论:请加入知识星球【首席架构师圈】
- 89 次浏览
非常棒
非常棒