大数据时代
大数据时代 intelligentx- 367 次浏览
Spark生态



【Spark】介绍Databricks运行时7.0中提供的Apache Spark 3.0
我们激动地宣布,作为Databricks运行时7.0的一部分,可以在Databricks上使用Apache SparkTM 3.0.0版本。3.0.0版本包含超过3400个补丁,是开源社区做出巨大贡献的顶峰,带来了Python和SQL功能方面的重大进步,并关注于开发和生产的易用性。这些举措反映了该项目如何发展,以满足更多的用例和更广泛的受众,今年是它作为一个开源项目的10周年纪念日。
以下是Spark 3.0最大的新特性:
- TPC-DS比Spark 2.4的性能提高了2倍,支持自适应查询执行、动态分区剪枝和其他优化
- ANSI SQL合规
- 对panda api进行了重大改进,包括Python类型提示和额外的panda udf
- 更好的Python错误处理,简化PySpark异常
- 结构化流的新UI
- 调用R用户定义函数的速度可达到40x
- 3400多张Jira票已经解决
采用这个版本的Apache Spark不需要做大的代码更改。有关更多信息,请查看迁移指南。
庆祝Spark发展和演变的10年
Spark的前身是加州大学伯克利分校的AMPlab实验室,这是一个专注于数据密集型计算的研究实验室。AMPlab的研究人员与大型互联网公司合作研究他们的数据和人工智能问题,但是他们发现这些同样的问题也会被所有拥有大量且不断增长的数据的公司所面临。该团队开发了一个新的引擎来处理这些新兴的工作负载,同时使开发人员更容易访问用于处理大数据的api。
社区的贡献很快就加入进来,将Spark扩展到不同的领域,提供了围绕流、Python和SQL的新功能,这些模式现在构成了Spark的一些主要用例。这种持续的投资为它带来了今天的火花,成为数据处理、数据科学、机器学习和数据分析工作负载事实上的引擎。Apache Spark 3.0延续了这一趋势,显著改进了对SQL和Python(目前Spark使用最广泛的两种语言)的支持,并对Spark其余部分的性能和可操作性进行了优化。
改进Spark SQL引擎
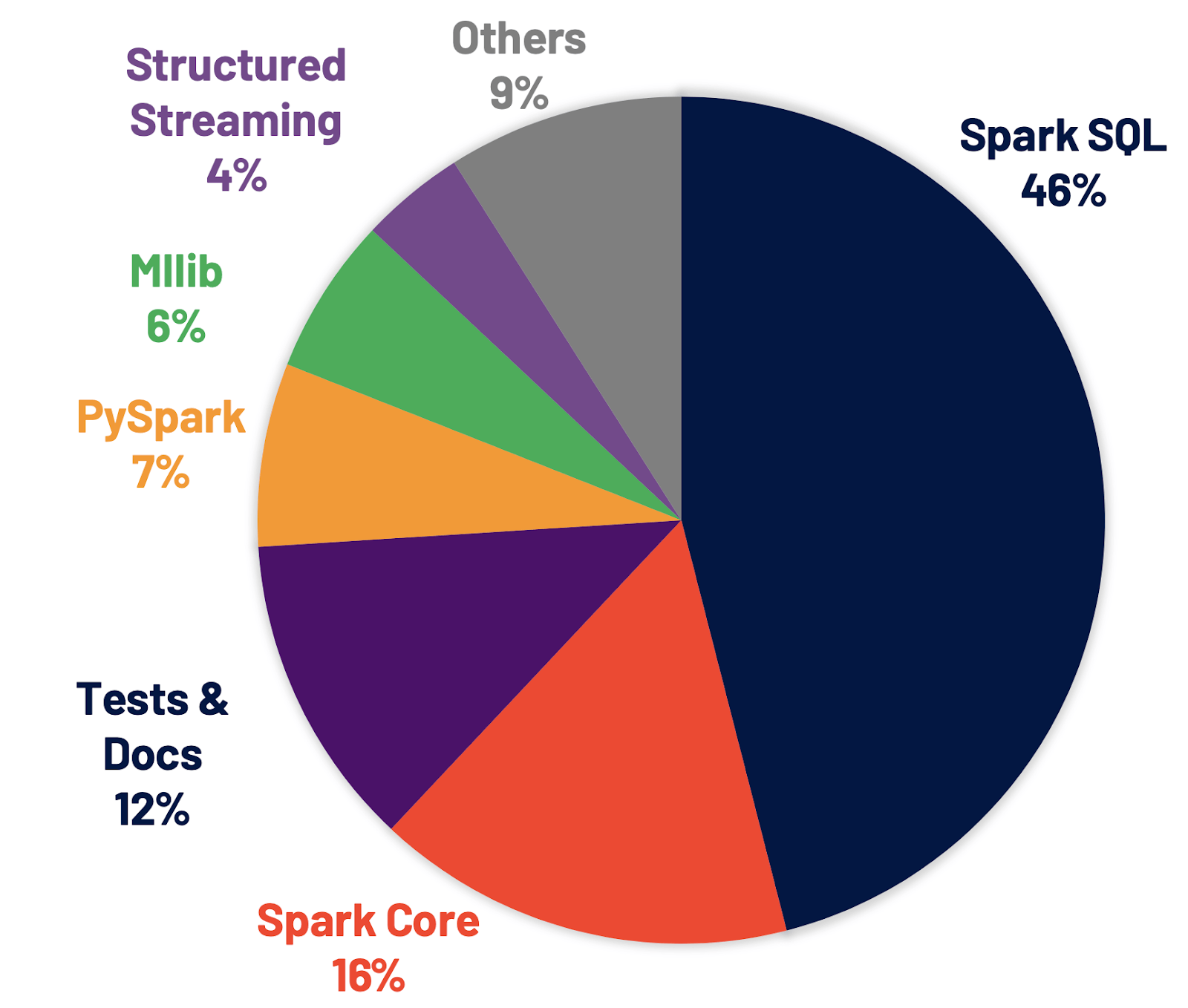
Spark SQL是支持大多数Spark应用程序的引擎。例如,在Databricks上,我们发现超过90%的Spark API调用使用DataFrame、Dataset和SQL API以及其他由SQL优化器优化的库。这意味着即使是Python和Scala开发人员也要通过Spark SQL引擎来传递他们的大部分工作。在Spark 3.0版本中,46%的补丁是针对SQL的,从而提高了性能和ANSI兼容性。如下所示,Spark 3.0在运行时的总体性能大约比Spark 2.4好2倍。接下来,我们将解释Spark SQL引擎中的四个新特性。

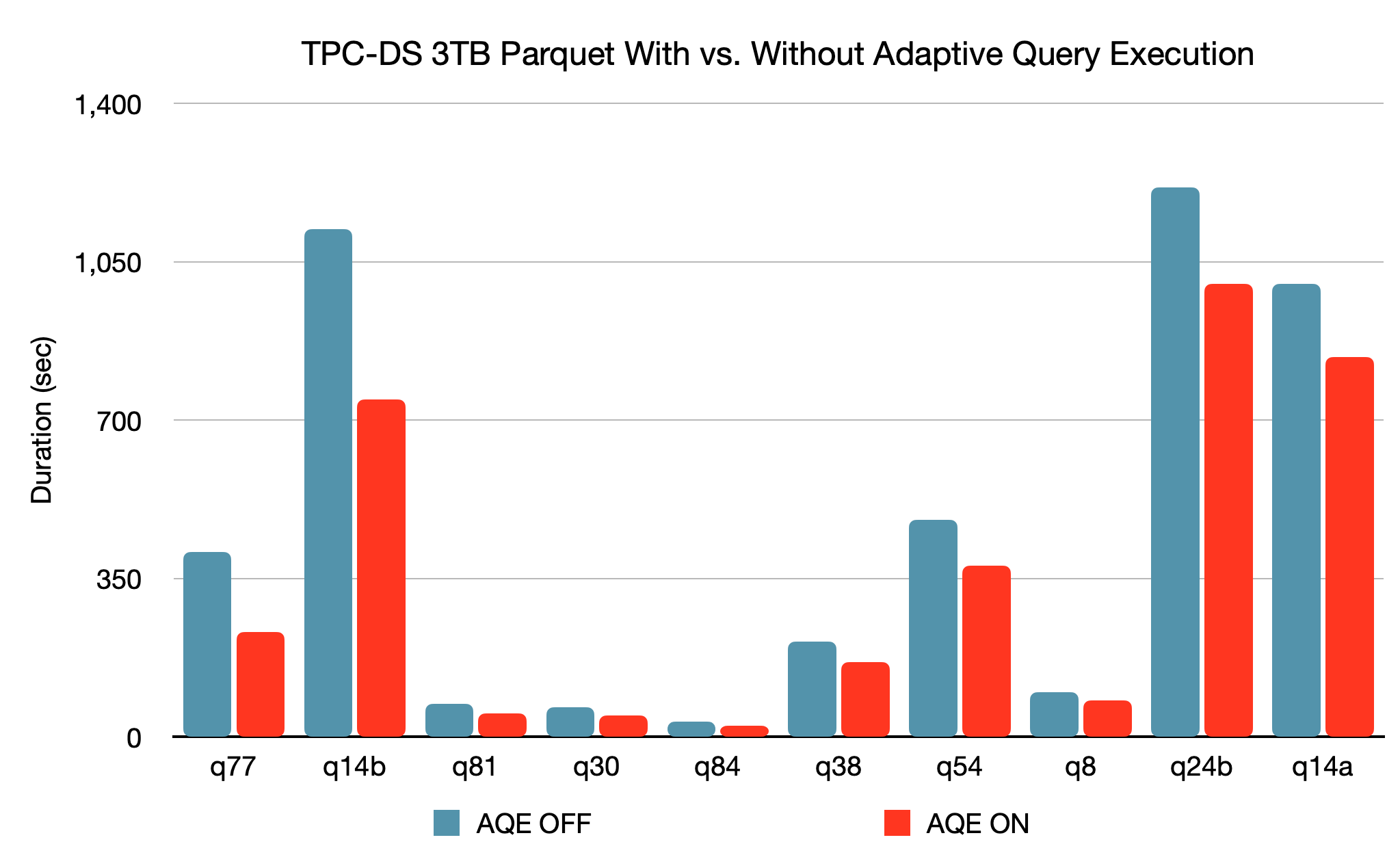
新的自适应查询执行(AQE)框架通过在运行时生成更好的执行计划来改进性能和简化调优,即使初始计划由于缺乏/不准确的数据统计和错误估计的成本而不是最优的。由于Spark中的存储和计算分离,数据到达可能是不可预测的。由于所有这些原因,与传统系统相比,Spark的运行时适应性变得更加关键。这个版本引入了三个主要的自适应优化:
- 动态合并洗牌分区可以简化甚至避免调整洗牌分区的数量。用户可以在开始时设置相对大量的转移分区,然后AQE可以在运行时将相邻的小分区合并为较大的分区。
- 动态切换连接策略可以部分避免执行由于缺少统计信息和/或大小估计错误而导致的次优计划。这种自适应优化可以在运行时自动将排序合并连接转换为广播散列连接,从而进一步简化调优并提高性能。
- 动态优化倾斜连接是另一个关键的性能增强,因为倾斜连接会导致工作的极度不平衡并严重降低性能。在AQE从shuffle文件统计数据中检测到任何倾斜后,它可以将倾斜分区分割成更小的分区,并将它们与另一端的相应分区连接起来。该优化可以并行化倾斜处理,获得更好的整体性能。
基于3TB的TPC-DS基准测试,与没有AQE相比,Spark与AQE可以对两个查询产生超过1.5倍的性能加速,对另外37个查询产生超过1.1倍的性能加速。

当优化器在编译时无法识别它可以跳过的分区时,将应用动态分区剪枝。
这在星型模式中并不少见,星型模式由一个或多个事实表组成,这些表引用任意数量的维度表。在这样的连接操作中,我们可以通过标识那些过滤维度表的分区来删除连接从事实表中读取的分区。在TPC-DS基准测试中,102个查询中有60个查询的速度显著提高了2倍到18倍。
ANSI SQL遵从性对于从其他SQL引擎到Spark SQL的工作负载迁移至关重要。
为了提高兼容性,该版本切换到预期的公历,还允许用户禁止使用保留的ANSI SQL关键字作为标识符。此外,我们还在数值操作中引入了运行时溢出检查,并在使用预定义模式将数据插入表时引入了编译时类型强制。这些新的验证可以提高数据质量。
连接提示:
虽然我们继续改进编译器,但不能保证编译器总是在每种情况下做出最优决策——连接算法的选择是基于统计和启发式的。当编译器无法做出最佳选择时,用户可以使用连接提示来影响优化器选择更好的计划。这个版本通过添加新的提示扩展了现有的连接提示:SHUFFLE_MERGE、SHUFFLE_HASH和SHUFFLE_REPLICATE_NL。
增强Python api: PySpark和Koalas
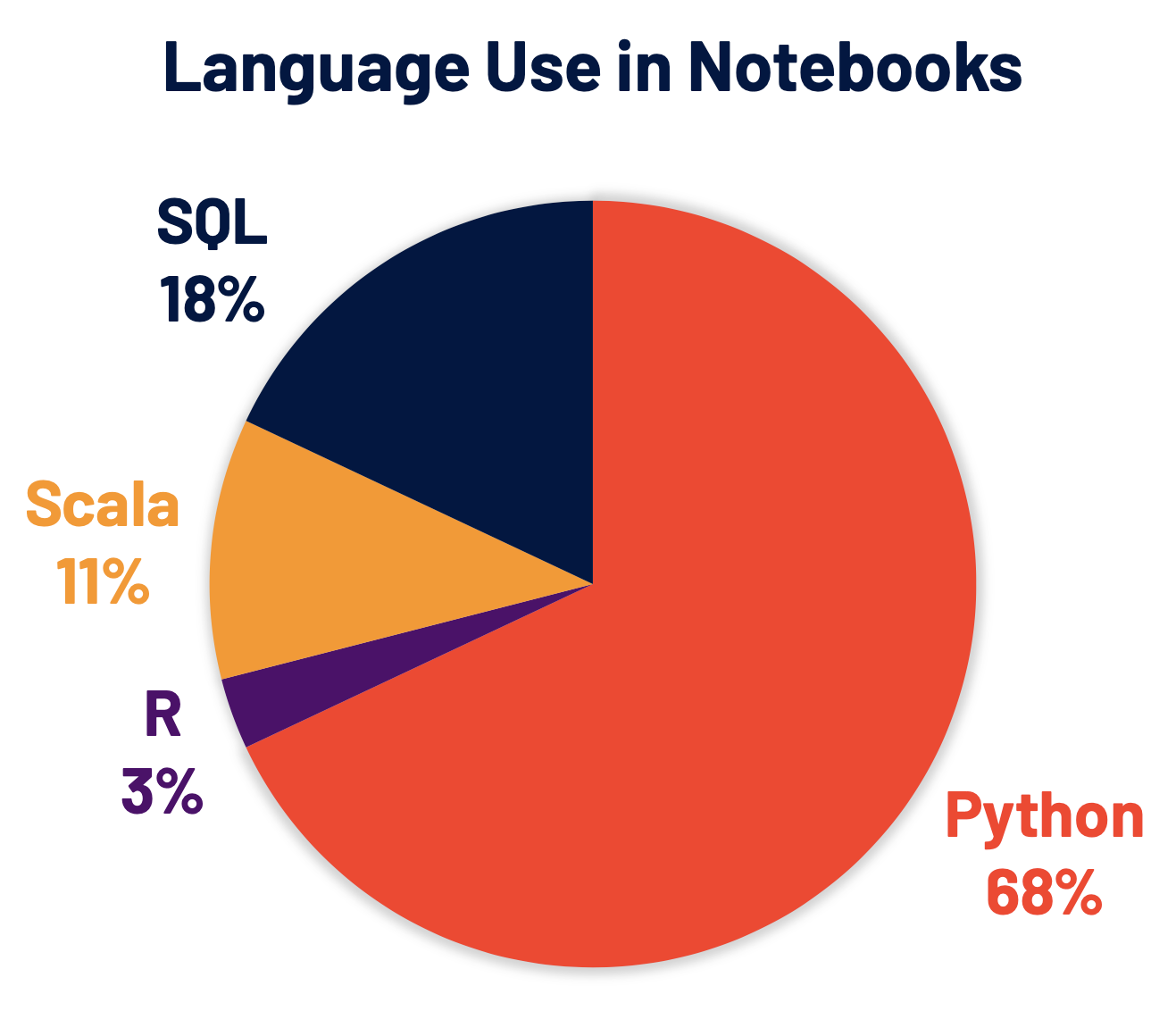
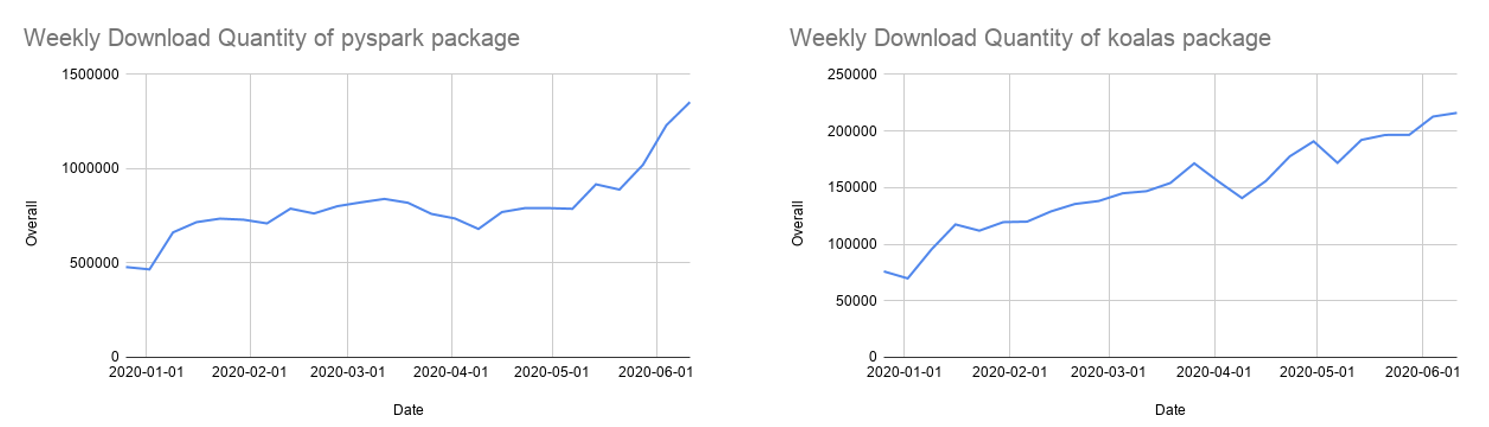
Python现在是Spark上使用最广泛的语言,因此,它是Spark 3.0开发的一个关键关注领域。Databricks上68%的笔记本命令是用Python编写的。Apache Spark Python API PySpark每月在Python包索引PyPI上的下载量超过500万次。
许多Python开发人员使用pandas API进行数据结构和数据分析,但是它仅限于单节点处理。我们还在继续开发考拉(Koalas),这是在Apache Spark上实现的panda API,使数据科学家在分布式环境中处理大数据时更有效率。Koalas不需要在PySpark中构建许多函数(例如,绘图支持),从而实现跨集群的高效性能。
经过一年多的发展,考拉对熊猫的API覆盖率接近80%。每月的PyPI下载量已经迅速增长到85万,而且考拉也以每两周发布一次的节奏迅速发展。虽然考拉可能是从单节点熊猫代码进行迁移的最简单方法,但许多考拉仍然使用PySpark api,而PySpark api也在日益流行。
Spark 3.0增强了PySpark api:
- 带有类型提示的pandas API:熊猫udf最初是在Spark 2.3中引入的,用于扩展PySpark中的用户定义函数,并将熊猫api集成到PySpark应用程序中。但是,当添加更多的UDF类型时,现有的接口很难理解。这个版本引入了一个新的panda UDF接口,它利用Python类型提示来解决panda UDF类型的激增问题。新的接口变得更加python化和自描述。
- pandas UDF的新类型和熊猫函数api:该版本添加了两种新的熊猫UDF类型,即对级数的迭代器添加级数的迭代器,对级数的迭代器添加多级数的迭代器。它对于数据预取和昂贵的初始化非常有用。另外,还添加了两个新的pandas-function api map和co- grouping map。更多的细节可以在这篇博客文章中找到。
- 更好的错误处理:PySpark错误处理对Python用户并不总是友好的。这个版本简化了PySpark异常,隐藏了不必要的JVM堆栈跟踪,并使它们更符合python风格。
改进Spark中的Python支持和可用性仍然是我们的最高优先级之一。
Hydrogen,流化和延展性
通过Spark 3.0,我们完成了Hydrogen项目的关键组件,并引入了改进流和可扩展性的新功能。
基于加速器的调度:
Hydrogen项目是Spark的一个主要项目,旨在更好地统一Spark上的深度学习和数据处理。gpu和其他加速器已被广泛用于加速深度学习工作负载。为了让Spark在目标平台上利用硬件加速器,这个版本增强了现有的调度器,使集群管理器能够感知加速器。用户可以在发现脚本的帮助下通过配置指定加速器。然后,用户可以调用新的RDD api来利用这些加速器。
用于结构化流的新UI:
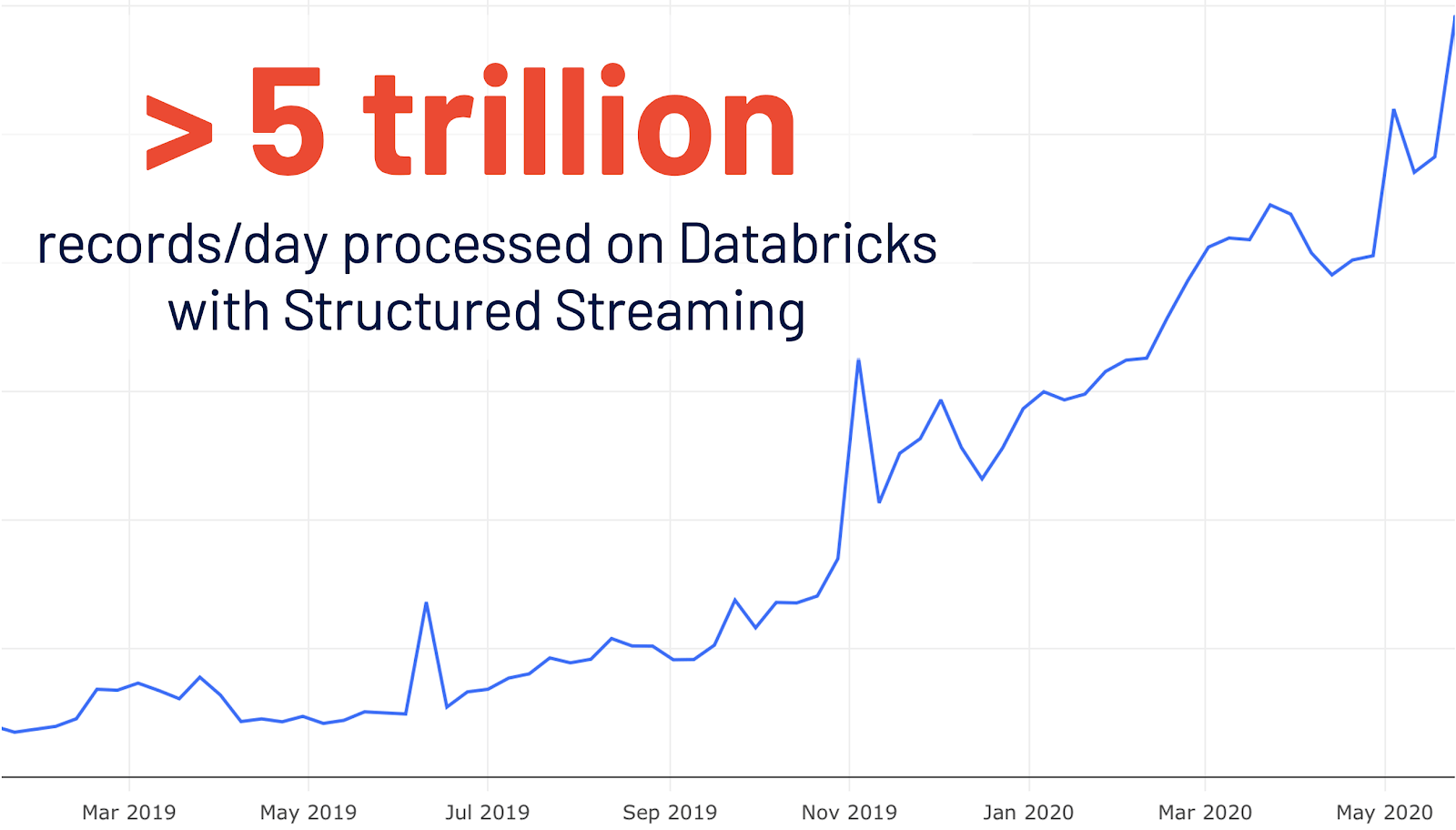
结构化流最初是在Spark 2.0中引入的。在数据库里的使用增长了4倍之后,每天有超过5万亿条记录在数据库里被结构化流媒体处理。这个版本添加了一个专用的新的Spark UI,用于检查这些流作业。这个新的UI提供了两组统计信息:1)已完成的流化查询作业的聚合信息和2)流化查询的详细统计信息。
可观察指标:
持续监控数据质量的变化是管理数据管道的一个非常理想的特性。这个版本引入了对批处理和流应用程序的监视。可观察指标是可以在查询(DataFrame)上定义的任意聚合函数。一旦一个DataFrame的执行达到一个完成点(例如,完成批处理查询或到达流历元),一个命名的事件就会发出,它包含了自最后一个完成点以来处理的数据的度量。
新的目录插件API:
现有的数据源API缺乏访问和操作外部数据源的元数据的能力。这个版本丰富了数据源V2 API,并引入了新的目录插件API。对于既实现了目录插件API又实现了数据源V2 API的外部数据源,在注册了相应的外部目录之后,用户可以通过多部分标识符直接操作外部表的数据和元数据。
Spark 3.0中的其他更新
Spark 3.0是该社区的一个主要发行版,解决了超过3400个Jira罚单。它是超过440名贡献者的贡献,包括个人和公司,如Databricks,谷歌,微软,英特尔,IBM,阿里巴巴,Facebook, Nvidia, Netflix, Adobe等。在这篇博客文章中,我们强调了Spark在SQL、Python和流媒体方面的一些关键改进,但是在这个3.0里程碑中,还有许多其他功能没有在这里介绍。在发布说明中了解更多信息,并发现Spark的所有其他改进,包括数据源、生态系统、监控等等。
现在就开始使用Spark 3.0吧
如果您想在Databricks运行时7.0中试用Apache Spark 3.0,请注册一个免费试用帐户,并在几分钟内启动。使用Spark 3.0就像在启动集群时选择version“7.0”一样简单。
本文:http://jiagoushi.pro/node/1190
讨论:请加入知识星球【首席架构师圈】或者加小号【jiagoushi_pro】或者微信圈【11107777】
- 115 次浏览
【Spark生态】Big SQL vs Spark SQL 100TB:它们如何叠加?
介绍:
SQL over Hadoop 领域的早期采用者现在正在创建大型数据库来存储他们更珍贵的商品和数据。 IBM在2014年10月发布了第一个(也是唯一一个)经过独立审计的Hadoop-DS基准测试时预测了这一趋势.Hadoop-DS是行业标准TPC-DS基准测试的衍生产品,经过定制,可以更好地匹配SQL over Hadoop空间的功能在Data Lake环境中。那时,IBM使用10TB的比例因子来比较Big SQL与其他领先的SQL Over Hadoop解决方案,即Hive 0.13和Impala 1.4.1。从那时起,所有产品都在性能和可扩展性方面取得了重大进步。 HortonWorks和Cloudera也投入了大量资金来丰富他们对SQL语言的支持(IBM已经在那里)。
Spark已成为开源社区中分析的最爱,Spark SQL允许用户使用熟悉的SQL语言向Spark提出问题。因此,有什么更好的方法来比较Spark的功能,而不是通过它的步伐,并使用Hadoop-DS基准来比较性能,吞吐量和SQL与Big SQL的兼容性。由于这是2017年,Data Lakes日渐变大,我们选择使用100TB的比例因子。
本研究将再次强调SQL over Hadoop引擎的需求,该引擎不仅快速高效,而且更重要的是可以成功地对大数据执行复杂查询。在选择SQL over Hadoop解决方案时,性能不是唯一的因素。该解决方案还需要由成熟且强大的运行时环境进行备份。成本仍然是采用SQL Over Hadoop解决方案的企业的主要吸引力之一(特别是与传统的RDBM相比),但无论出于何种原因,失败的查询将严重影响生产力并降低这些SQL相对于Hadoop解决方案的成本效益。没有交付。
摘要
在项目过程中,我们发现Big SQL是唯一能够在100 TB下执行所有未修改的99个查询的解决方案,可以比Spark SQL快3倍,同时使用更少的资源。 这些事实使我们得出结论,使用Big SQL的Data Professional比使用Spark SQL的数据提高了3倍。
测试环境:
Big SQL和Spark SQL测试都在同一个集群上执行。 该集群的构建基于Spark; 也就是说,它有大量的内存和SSD取代了传统的旋转磁盘。
使用了28节点集群,包括:
- 2 management nodes (Lenovo x3650 M5), collocated with data nodes
- 28 data nodes (Lenovo x3650 M5)
- 2 racks, 20x 2U servers per rack (42U racks)
- 1 switch, 100GbE, 32 ports, 1U, (Mellanox SN2700)
每个数据节点包括:
- CPU: 2x E5-2697 v4 @ 2.3GHz (Broardwell) (18c) Passmark: 23,054 / 46,108
- Memory: 1.5TB per server, 24x 64GB DDR4 2400MHz
- Flash Storage: 8x 2TB SSD PCIe MVMe (Intel DC P3700), 16TB per server
- Network: 100GbE adapter (Mellanox ConnectX-5 EN)
- IO Bandwidth per server: 16GB/s, Network bandwidth 12.5GB/s
- IO Bandwidth per cluster: 480GB/s, Network bandwidth 375GB/s
配置和调整:
产品的配置和调整由两个不同的团队进行; IBM的Big SQL性能团队和Spark SQL性能团队。
Spark团队使用了最新发布的Spark SQL 2.1版。 Spark的调优符合Hadoop-DS规范中规定的规则,但有一个关键的例外。传递给Spark SQL shell的执行程序属性的数量针对单流和4流运行进行了不同的调整。 4流运行中的每个流都传递了执行器值,该值是用于单个流运行的值的四分之一。这阻止了4流中的任何一个流都抓住了集群上的所有执行槽,这实际上会导致每个查询串行执行。虽然这很简单,有些人可能会说逻辑调整,但实际上不可能在生产集群上有效地执行此操作,在生产集群中不会知道并发执行查询的数量。但是,该团队决定,如果没有这一调整,就无法与Big SQL进行公平的比较。
Big SQL Worker
Big SQL团队使用了Big SQL版本4.3的技术预览版。技术预览包含对新功能的支持,其中每个物理节点可以托管多个Big SQL工作进程(以前,每个物理节点上只允许一个Big SQL工作进程)。单个物理节点上的多个Big SQL工作程序在Big SQL环境中提供了更大的操作并行化,从而提高了性能。考虑到测试集群中计算机的大量内存和CPU资源,团队将每个物理节点配置为包含12个Big SQL worker - 如图1所示。
与Spark SQL不同,Big SQL不需要基于并发查询流的数量进行微调,因此使用了单流和4流运行的相同配置。这是可能的,因为Big SQL具有成熟的自治,包括:
- 自调整内存管理器(STMM),它根据查询并发性动态管理消费者之间的内存分配
- 一个复杂的工作负载管理器(WLM),可以控制工作负载优先级,有助于维持一致的响应时间并实施SLA
- 在查询执行时自动调整并行度以考虑系统活动
这些都是关键功能,可以解决调整Big SQL的痛苦 - 无论是在基准测试环境还是现实环境中 - 多年来,组织一直认为这些功能在关系数据库中是必不可少的,以支持生产环境。那么为什么在Big SQL中找到这些功能而在Hadoop解决方案中找不到大多数其他SQL?简而言之,这是因为IBM围绕我们现有的关系数据库技术(已经在生产系统中运行了25年)构建了Big SQL的核心。因此,Big SQL具有强化,成熟且非常高效的SQL优化器和运行时,以及一组支持生产级部署的功能 - 这些是Big SQL世界级可伸缩性和性能的关键。
对于此基准测试,大多数Big SQL调优工作都集中在单个节点上共存的多个Big SQL工作者(这是此功能首次在此规模上进行了道路测试)。此功能在Big SQL v4.3 Technology Preview中可用,并且可以在安装后通过Ambari手动添加逻辑Big SQL worker。 Big SQL工程团队正在利用从本练习中获得的经验来改进自动化,并为Big SQL v4.3版本设置有意义的开箱即用默认值。因此,Big SQL客户不必自己进行任何调整。 Spark SQL团队的经验被用于创建一组最佳实践。在Spark SQL具有一组成熟的自我调整和工作负载管理功能之前,必须手动应用这些最佳实践。
查询执行:
使用100TB数据,使用Big SQL v4.3在4个并发查询流中成功执行了源自TPC-DS工作负载的所有99个查询(总共创建了396个查询)。在第一次运行三个Big SQL查询时,执行时间比预期的要长。使用统计视图和列组统计信息调整这些查询。这些独特的功能对Big SQL客户来说非常宝贵;允许他们收集有关复杂关系的详细信息,这些信息通常存在于现实数据中,从而提高性能。跨比例因子的Spark查询失败
图3:跨不同比例因子的Spark SQL查询
图4:Spark SQL查询失败的分类
虽然Spark SQL v2.1可以在1GB和1TB上成功执行所有99个查询(并且自v2.0以来已经能够执行),但是在10TB时两个查询失败,并且在100TB时失败的次数明显更多。在花费大量精力调整Spark(由Spark工程师,而不是Big SQL工程师)之后,总共可以在100TB的4个流中成功执行83个查询。为了确保苹果与苹果的比较,这组83个查询被用作比较Big SQL与Spark SQL性能的基础。图4:100TB的Big SQL vs Spark SQL查询细分
图5:100TB的Big SQL和Spark SQL查询细分
Spark故障可分为2大类; 1)查询未在合理的时间内完成(少于10小时),以及2)运行时故障。此外,几乎一半(7)的Spark SQL查询在100TB时失败,本质上是复杂的。事实的这种组合表明Spark SQL在更大规模的因素下与更复杂的查询斗争;因为Spark是一种缺乏现代RDBMS成熟度的相对较新的技术,所以这应该不会让人感到惊讶。这些发现也与2014年最初的Hadoop-DS工作一致; Hive和Impala都在使用复杂的查询(所有这些都是10TB),但Big SQL能够成功执行所有99个查询,在30TB的4个流中。
数据专业人员或任何用户的主要抑制因素是浪费宝贵的时间将有效查询重写为SQL解释器可以理解的表单,以及执行引擎可以成功完成的表单。重要信息本研究中的数据表明,使用Spark SQL的Data Professional将花费宝贵的时间重新编写或调整,每10个查询中有1个或2个(确切地说是16%)。不幸的是,对于不成熟的SQL引擎,尤其是SQL over Hadoop空间中的那些,通常就是这种情况。在10TB的原始Hadoop-DS评估中,Hive和Impala首先突出了这个问题,今天仍然适用于Spark SQL。值得注意的是,对于许多SQL over Hadoop引擎,以较低比例因子成功执行查询并不能保证真正的大数据成功。
构建一个100TB的数据库
毫无疑问,100TB这是一个大数据工作负载 - 最终数据库包含超过五万亿行:
大事实表被分区以利用Big SQL v4.2以后的新“分区消除串联连接密钥”功能。所有销售表都在各自的'* _SOLD_DATE_SK'列上进行了分区,并在各自的'* _RETURN_DATE_SK'列中返回表。以这种方式进行分区符合原始TPC-DS规范,并允许在查询执行期间删除分区 - 这可以极大地提高查询的时间和效率。图7:100TB数据库构建
图7:100TB数据库构建时间(秒)
数据库构建包括两个不同的操作,即加载阶段和统计信息收集阶段。加载阶段从数据生成器生成的原始文本中获取数据,并将其转换为Parquet存储格式。 Parquet是Big SQL和Spark SQL中查询的最佳存储格式,是这些测试的理想选择。加载阶段对于Big SQL和Spark SQL都是通用的,只需要超过39个小时即可完成。
39小时中的大部分用于加载STORE_SALES表的NULL分区(SS_SOLD_DATE_SK = NULL)。事实证明,STORE_SALES表在空分区上严重偏斜(大小约为570GB,而其他分区大约为20GB)。由于查询是重复执行的,而数据库构建是一次性操作,因此两个团队都没有专门用于提高负载性能的资源。但实际数据集中的严重偏差很常见。此数据集中所选分区列的严重偏差给执行某些更复杂的查询带来了挑战。工程团队致力于改进Big SQL Scheduler以应对这些挑战,这些改进将在Big SQL v4.3中提供。
收集统计信息使Big SQL基于成本的优化器能够就最有效的访问策略做出明智的决策,并且是Big SQL可以执行具有领先性能的所有99个TPC-DS查询的关键原因。目前,Spark SQL不需要收集相同级别的统计信息,因为它的优化程序还不够成熟,无法使用这些详细的统计信息。但是,随着Spark优化器的成熟,它对详细统计数据的依赖性会增加,收集所述统计数据的时间也会增加,但查询过程时间也会随之改善。
比较Big SQL和Spark SQL性能:
在现实生活中,单个用户不能单独使用组织的Hadoop集群。因此,我们专注于比较4个并发查询流中Big SQL和Spark SQL的性能。为了进行苹果与苹果的比较,生成的工作负载仅包括在合理的时间内(少于10小时)在Spark SQL中成功完成的83个查询。删除Spark SQL无法在10小时内完成的查询会使结果偏向于Spark,因为保留四个超时的查询几乎会使Spark SQL执行时间翻倍。
图8比较了在Spark SQL和Big SQL中完成所有4个流(总共332个查询)的83个查询所用的时间,以及Big SQL在4个流中完成所有99个查询所用的时间(总计396个查询)。 Spark SQL花了超过43个小时来完成测试,而Big SQL在13.5个小时内完成了相同数量的查询 - 使Big SQL比Spark SQL快3.2倍。
图8:4个查询流的100TB工作负载经历时间
图8:100TB的工作负载经历时间
事实上,Big SQL能够完成一个4流工作负载,每个流执行99个查询的完整补充,几乎比Spark SQL每个流执行83个查询快2倍。当您考虑到Spark SQL无法执行的16个查询中的7个是工作负载中最复杂的查询时,这会更令人印象深刻。
虽然对于Big SQL来说令人印象深刻,但如果查询集包含来自99的原始集合中的那些查询,那么性能差异会大得多,这些查询在10小时后在Spark SQL中超时。
重要信息将这些结果输入到现实环境中意味着使用Big SQL的数据专业人员的效率比使用Spark SQL的数据专业人员高三倍。图9:平均CPU消耗的比较
图9:100TB的4流的平均CPU消耗
对整个群集的CPU消耗的分析表明,Big SQL在工作负载持续时间内平均为76.4%,Spark SQL为88.2%。虽然Big SQL和Spark SQL之间消耗的用户CPU百分比大致相同,但Spark SQL的系统CPU几乎是Big SQL的3倍。系统CPU周期是不合需要的CPU周期,它们没有代表您的应用程序执行有用的工作。注意:两种产品的IO等待CPU时间可以忽略不计。
当然,由于Spark SQL测试需要花费3倍的时间才能完成,因此在执行工作负载中的所有332个查询的过程中,Spark SQL实际上消耗的CPU周期比Big SQL多3倍,系统CPU周期比Big SQL多9倍 - 突出显示随着Big SQL优化器和运行时的成熟,效率更高。 Big SQL不仅比Spark SQL快3.2倍,而且使用更少的CPU资源也实现了这一点。
图10:100TB(每个节点)的4个流的平均I / O速率
在检查测试期间进行的I / O量时,Big SQL的效率也会突出显示。 Spark SQL的平均读取速率平均比Big SQL大3.6倍,而其写入速率平均高出9.4倍。在测试期间推断平均I / O速率(Big SQL比Spark SQL快3.2倍),然后Spark SQL实际读取的数据几乎是Big SQL的12倍,并且写入数据增加了30倍。
图11:100TB(每个节点)的4个流的最大I / O速率
有趣的是,Big SQL具有更高的最大I / O吞吐量,表明在需要时,Big SQL可以通过I / O子系统提高吞吐量,而不是Spark SQL。
读取/写入的数据量的巨大差异,以及Big SQL可以更加强大地驱动I / O子系统的事实,是Big SQL中更高效率的简单但有效的指标。
重要信息将这一点重新回到现实生活中,我们的Data Professional不仅使用Big SQL提高了三倍的效率,而且使用更少的资源来完成工作,这反过来又允许其他数据专业人员在集群上运行更多分析同时.
是什么让这份报告有所不同?
已经有越来越多的基于Hadoop解决方案的SQL基准测试报告;一些显示解决方案x比y快许多倍,而其他人表明y比x快 - 但两者都是如此?我是许多竞争基准的老手,我可以诚实地说,通过定义测试的范围来赢得和失去基准。每个供应商都会最大限度地影响基准规范,以突出其自身产品的优势以及竞争对手的弱点。这正是今天SQL over Hadoop空间正在发生的事情,也是组织面对这些解决方案时过多的冲突性能信息的原因。那么,是什么让这份报告与众不同:
比例因子 - 毕竟,我们正在谈论大数据!这是唯一一份以100TB发布的报告。以较小比例因子发布的许多其他报告甚至不使用整个数据集。
它很全面。它不会挑选查询来强调一种解决方案相对于另一种解决方案的好处。根据最初的Hadoop-DS基准测试,IBM将苹果与苹果进行了比较,比较了适用于这两种产品的所有查询。
这些产品由两个竞争(但友好)的IBM团队调整,两者都在努力突出其产品的优势。最后,两个团队的经验将使他们各自的产品受益。
它遵循Hadoop-DS规范的规则(基于行业标准TPC-DS基准)
摘要:
毫无疑问,Spark SQL在很短的时间内已经走过了漫长的道路。 Spark SQL可以在100TB完成99个查询中的83个,这是开源社区推动这个项目的证明。但是,仍然没有替代产品的成熟度,而Big SQL的优势在于它建立在IBM的数据库技术之上。正是这种谱系在SQL over Hadoop空间中将Big SQL提升到了其他供应商之上。
图12:作者在Hadoop Marketplace上的SQL视图
图12:作者在Hadoop Marketplace上的SQL视图
作者对此空间的看法虽然相当不科学,如图12所示.Big SQL优于Hadoop解决方案的开源SQL包,主要是因为Big SQL继承了IBM数据库的大量丰富功能(和性能)。遗产。假设Spark SQL保持其当前的势头,它可能最终超过Big SQL的速度,可扩展性和功能。然而,随着技术的成熟,它们的改进速度会慢下来 - 毕竟,对于一年前的产品而言,仅仅因为在产品生命的早期阶段,将十年的产品改进10倍就更容易了 - 酒吧的周期要低得多。
总而言之,这份报告显示了Big SQL:
可以在100TB,4个并发流中执行所有99个TPC-DS查询,以及
可以这样做至少比Spark SQL快3倍,而且
使用较少的群集资源来实现此类领先的性能。
但对于考虑购买SQL over Hadoop解决方案的组织来说,这意味着什么呢?重要的是,简单来说,这意味着Big SQL使他们的数据专业人员和业务分析师的工作效率(至少)提高了3倍。使用Big SQL可能需要3个小时才能完成深度分析,使用Spark SQL需要9个小时(或一个工作日)。在一天内,Big SQL用户可以使用不同的输入组合运行3次分析,以模拟不同的场景。使用Spark SQL完成相同的分析至少需要3个工作日;可能更长,因为查询无法完成的可能性更高,调整Spark SQL查询所需的持续时间通常更长。
我们还提供YouTube视频(https://www.youtube.com/watch?v=M5zqykmEu9U),详细介绍了我们的体验。
- 99 次浏览
【大数据】Apache Flink vs Spark——一方会超越另一方吗?
视频号
微信公众号
知识星球
Apache Flink vs Spark,是大数据行业的热门新话题。了解Apache Spark是否会被Apache Flink推到图片之外。
Apache Spark和Apache Flink都是开源的分布式处理框架,旨在减少Hadoop Mapreduce在快速数据处理中的延迟。人们普遍误解Apache Flink将取代Spark,或者这两种大数据技术可能共存,从而满足容错、快速数据处理的类似需求。Apache Spark和Flink可能与那些没有使用过这两种技术,只熟悉Hadoop的人相似,很明显,他们会觉得Apache Flink的开发大多是多余的。但Flink之所以能够在游戏中保持领先,是因为它的流处理功能能够实时处理一行又一行的数据——这在Apache Spark的批处理方法中是不可能的。这使得Flink比Spark更快。
根据IBM的这项研究,我们每天创建大约2.5万亿字节的数据,而且这种数据生成速度仍在以前所未有的速度增长。从另一个角度来看,尽管万维网已经向公众开放了20多年,但世界上现有的所有数据中,约90%是在过去两年中创建的。在过去的十年里,随着互联网的发展,用户数量的增加和对内容日益增长的需求为Web 2.0铺平了道路。这是第一次允许用户在互联网上创建自己的数据,并准备被渴望数据的观众消费。
目录
- Apache Spark
- Spark的优点
- Apache闪烁
- Flink的优势
- Apache Flink vs Spark
- 成长故事——火花与闪烁
- 2021的增长故事——Spark和Flink
然后轮到社交媒体侵入我们的生活了。根据wersm(我们是社交媒体)的报告,脸书在一分钟内获得了超过400万个赞!在我们了解这些数据是如何消耗的之前,信息图中提到了其他流行来源产生的数据(取自同一项wersm研究)。

“如何存储这些巨大的数据?”这是一个让科技极客在过去十年的大部分时间里都很忙的问题陈述。社交媒体的突然兴起并没有让他们的任务变得更容易。然而,云计算等新时代的存储解决方案已经彻底改变了行业,并提供了尽可能好的解决方案。在当前的十年里,问题陈述已经转变为“如何处理海量数据?”数据分析成为最终目标,但在此之前,需要做大量工作来整合不同来源以不同格式存储的数据,并为处理和分析做好准备,这是一项艰巨的任务。
我们今天的两个主题——Apache Spark和Apache Flink——试图回答这个问题以及更多问题。
Apache Spark
Spark是一个开源的集群计算框架,拥有庞大的全球用户群。它是用Scala、Java、R和Python编写的,为程序员提供了一个基于容错、只读多组分布式数据项的应用程序编程接口(API)。自首次发布(2014年5月)以来的短短2年时间里,由于其速度快、易用性强以及能够处理复杂的分析需求,它在实时、内存和高级分析方面获得了广泛的接受。
Spark的优点
与传统的基于大数据和MapReduce的技术相比,Apache Spark有几个优势。突出的是。它本质上将MapReduce提升到了一个新的水平,其性能提高了数倍。Spark的一个关键区别是它能够将中间结果保存在内存中,而不是写回磁盘并再次从中读取,这对于基于迭代的用例至关重要。
- 速度–Spark执行批处理作业的速度是MapReduce的10到100倍。这并不意味着它在必须向磁盘写入数据(和从磁盘提取数据)时落后,因为它是大规模磁盘上排序的世界纪录保持者。
- 易用性–Apache Spark具有易于使用的API,专为在大型数据集上操作而构建。
- 统一引擎–Spark可以在Hadoop之上运行,利用其集群管理器(YARN)和底层存储(HDFS、HBase等)。然而,它也可以独立于Hadoop运行,与其他集群管理器和存储平台(如Cassandra和Amazon S3)合作。它还提供了更高级别的库,支持SQL查询、数据流、机器学习和图形处理。
- 从Java、Scala或Python中进行选择–Spark不会将您束缚在特定的语言上,而是允许您从流行的语言中进行选择,如Java、Scala、Python、R甚至Clojure。
- 内存中的数据共享–不同的作业可以在内存中共享数据,这使其成为迭代、交互和事件流处理任务的理想选择。
- 活跃、不断扩大的用户社区——活跃的用户社区使Spark在首次发布后的2年内稳定发布(2016年6月)。这充分说明了它在世界范围内的可接受性,这种可接受性正在上升。
Apache Flink
Apache Flink在德语中是“快速”或“灵活”的意思,是最新加入专注于大数据分析的开源框架名单的公司,这些框架正试图取代Hadoop老化的MapReduce,就像Spark一样。Flink于2016年3月发布了第一个API稳定版本,与Spark一样,它是为批处理数据的内存处理而构建的。当需要对同一数据进行重复传递时,此模型非常方便。这使其成为机器学习和其他需要自适应学习、自学习网络等的用例的理想候选者。随着物联网(IoT)空间的不可避免的繁荣,Flink用户社区有一些令人兴奋的挑战值得期待。
Flink的优势
实际的流处理引擎,可以近似于批处理,而不是相反。
- 更好的内存管理——显式内存管理消除了Spark框架中偶尔出现的峰值。
- 速度–它允许在同一节点上进行迭代处理,而不是让集群独立运行,从而管理更快的速度。它的性能可以通过调整来进一步调整,只重新处理发生变化的那部分数据,而不是整个数据集。与标准处理算法相比,它的速度提高了五倍。
- 配置较少
Apache Flink vs Spark
当Flink出现时,Apache Spark已经成为世界各地许多组织的快速内存大数据分析需求的事实框架。这让Flink显得多余。毕竟,在现有的数据处理引擎还没有定论的情况下,为什么还要需要另一个数据处理引擎?人们必须更深入地挖掘Flink的功能,以观察它的与众不同之处,尽管许多分析师将其称为“数据分析的4G”。
Flink瞄准并试图利用Spark设置中的一个小弱点。尽管出于随意讨论的目的,Spark并不纯粹是一个流处理引擎。正如Ian Pointer在InfoWorld的文章《Apache Flink:新的Hadoop竞争者与Spark较量》中所观察到的那样,Spark本质上是一种快速批处理操作,在一个时间单位内只处理一小部分传入数据。Spark在其官方文档中将其称为“微批量”。这个问题不太可能对操作有任何实际意义,除非用例需要低延迟(金融系统),因为毫秒级的延迟会造成重大影响。话虽如此,Flink几乎是一项正在进行的工作,目前还不能宣称取代Spark。
Flink是一个流处理框架,可以运行需要批处理的杂务,让您可以选择在两种模式下使用相同的算法,而不必求助于像Apache Storm这样需要低延迟响应的技术。
Spark和Flink都支持内存处理,这使它们在速度上优于其他框架。在实时处理传入数据方面,Flink无法与Spark抗衡,尽管它有能力执行实时处理任务。
Spark和Flink都可以处理迭代的内存处理。在速度方面,Flink占据了上风,因为它可以被编程为只处理发生变化的数据,这就是它在Spark之上的表现。
成长故事——Spark与Flink
任何软件框架都需要的不仅仅是技术专长,还需要帮助企业获得最大价值。在本节中,我们深入研究Databricks撰写的Apache Spark 2015 Year In Review文章,了解它在全球用户和开发人员社区中的表现。这一年共发布了4个版本(1.3到1.6),每个版本都有数百个修复程序来改进框架。吸引我们眼球的是贡献开发者数量的增长——从2014年的500人增长到2015年的1000多人!Spark的另一个值得注意的地方是它的用户很容易过渡到新版本。报告提到,在三个月内,大多数用户都会接受最新版本。这些事实增强了它作为最积极开发(和采用)的开源数据工具的声誉。
Flink在竞争中相对较晚,但2015年在其官方网站上的回顾表明了它为什么会成为最完整的开源流处理框架。Flink的github存储库(Get the repository–Here)显示,2015年社区规模翻了一番,从75个贡献者增加到150个。存储库分叉在这一年中增加了两倍多,存储库的恒星数量也增加了三倍多。从德国柏林开始,它的用户社区已经跨越各大洲发展到北美和亚洲。Flink Forward会议是Flink的又一个里程碑,有250多名与会者参加,100多名与会者从全球各地赶来,参加了来自谷歌、MongoDB、电信、NFLabs、RedHat、IBM、华为、爱立信、Capital One、Amadeus等组织的技术会谈。
尽管从这两个框架中选出一个作为明显的赢家还为时过早,但我们认为,与其让许多框架做同样的事情,不如让新进入者做不同的事情,补充现有的事情,而不是与它们竞争,从而更好地服务于科技世界。
2021的增长故事——Spark和Flink
任何软件框架都需要的不仅仅是技术专长,还需要帮助企业获得最大价值。在本节中,我们深入研究了过去十年对Apache Spark的回顾,以了解它在全球用户和开发人员社区中的表现。2020年,Apache 3.0发布,这是迄今为止最大的一次发布,有超过3400张已解决的社区Ticket。此版本的首要活动组件是Spark SQL,因为已解决的票证中约46%与SparkSQL引擎(所有数据帧API调用的底层引擎)有关。这次更新让世界见证了阿里巴巴基于Apache Hadoop和Spark的云E-MapReduce,创造了TPC-DS Benchmark的新世界纪录。如果您不知道,TPC-DS是基于SQL的大数据系统的第一个基准测试。Spark这个新版本的另一个值得注意的地方是,它收集了大量的Spark生态系统项目,包括 Koalas, Delta-Lake、推广Spark作为流行数据科学库(如sci-kit learn)的扩展后端等。吸引我们眼球的是,Spark社区注意到切换到最新版本的过程尽可能顺利。这些事实增强了它作为最积极开发(和采用)的开源数据工具的声誉。
Flink在比赛中相对较晚,但2020年Flink Forward全球虚拟会议
显示它拥有Apache软件基金会中最活跃的社区成员之一。Flink的GitHub存储库(Get the repository–Here)显示,该社区的规模已经大幅增长,从2015年的75个贡献者增长到现在的895个。社区成员的这种热情为Flink带来了许多令人兴奋的功能,如世界级的统一SQL、CDC集成、状态处理器API、Hive集成等等。
虽然在流媒体功能方面,Flink肯定被认为比Spark更快,但很难挑出其中一个作为明显的赢家,因为后者拥有更强大、更古老的社区支持。我们认为,与其让许多框架做同样的事情,不如让新进入者做不同的事情,补充现有的框架,而不是与它们竞争,从而更好地服务于科技世界。
- 592 次浏览
【大数据】Flink与Spark的对比:Flink和Spark的区别[2023]
视频号
微信公众号
知识星球
介绍
如今,大多数成功的企业都与技术领域有关,并在网上运营。他们的消费者活动每秒都会产生大量数据,这些数据需要高速处理,并以同样的速度产生结果。这些发展产生了对数据处理(如流处理和批处理)的需求。
有了这个,大数据可以通过多种方式进行存储、获取、分析和处理。因此,一旦接收到数据,就可以查询连续的数据流或集群,并且可以快速检测条件。Apache Flink和Apache Spark都是为此目的创建的开源平台。
然而,由于用户对研究Flink Vs Spark感兴趣,本文提供了它们的功能差异。
什么是Apache Flink?
Apache Flink是一个用于流处理的开源框架,它在分布式系统上以高性能、高稳定性和高准确性快速处理数据。它提供了低数据延迟和高容错性。Flink的显著特点是能够实时处理数据。它是由Apache软件基金会开发的。
什么是Apache Spark?
Apache Spark是一个开源的集群计算框架,工作速度非常快,用于大规模数据处理。它以速度、易用性和复杂的分析为基础,这使它在各个行业的企业中都很受欢迎。
它最初由加州大学伯克利分校开发,后来捐赠给了Apache软件基金会。
Flink与Spark
Apache Flink和Apache Spark都是通用数据处理平台,它们各自有许多应用程序。它们都可以在独立模式下使用,并且具有强大的性能。
它们有一些相似之处,例如类似的API和组件,但在数据处理方面有几个不同之处。以下是在检查Flink与Spark时的差异列表。
| Flink | Spark |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
结论
Flink和Spark都是在科技行业广受欢迎的大数据技术工具,因为它们为大数据问题提供了快速解决方案。但在分析Flink与Spark的速度时,Flink比Spark更好,因为它的底层架构。
另一方面,Spark拥有强大的社区支持和大量贡献者。在比较两者的流传输能力时,Flink处理数据流要好得多,而Spark处理微批处理。
通过本文,介绍了数据处理的基本知识,并对ApacheFlink和ApacheSpark进行了描述。对Flink和Spark的功能进行了比较和简要解释,根据处理速度给用户一个明显的赢家。然而,最终的选择取决于用户及其所需的功能。
- 457 次浏览
【大数据】为什么适用Ceph上运行Spark ?(三部分第一部分)
几年前,一些大公司开始运行Spark和Hadoop分析集群,使用共享Ceph对象存储来扩充和/或取代HDFS。
我们开始调查他们为什么要这么做,以及它的表现如何。
具体来说,我们想知道以下三个问题的第一手答案:
- 公司为什么要这么做?(这篇文章)
- 主流的分析作业会直接运行在Ceph对象存储上吗?(见“为什么Ceph上有Spark ?”(第三部分第二部分)”)
- 它的运行速度会比在HDFS上的本机慢多少?(见“为什么Ceph上有Spark ?”(第三部分)")
我们将在一个由三部分组成的博客系列中对这些问题提供摘要级别的答案。此外,对于那些想要更深入的人,我们将交叉链接到一个独立的参考体系结构博客系列,提供详细的描述、测试数据和配置场景。和Ceph在英特尔硬件上工作得更好,并帮助企业有效地扩大规模。
第1部分:公司为什么要这么做?
众人的敏捷,一人的力量。
许多分析集群的敏捷性,以及一个共享数据存储的能力。
(好吧…简单的对联已经够多了。)
以下是我在与30多家公司交谈后发现的一些常见问题:
- 共享相同分析集群的团队经常会感到沮丧,因为其他人的工作经常妨碍他们按时完成工作。
- 另外,一些团队希望在他们的集群中保持旧的分析工具版本的稳定性,而他们的同行团队需要加载最新和最好的工具版本。
- 因此,许多团队需要自己独立的分析集群,这样他们的工作就不会与其他团队争夺资源,因此他们可以根据自己的需求调整集群。
- 但是,每个单独的分析集群通常都有自己的非共享HDFS数据存储——创建数据竖井。
- 为了跨竖井提供对相同数据集的访问,数据平台团队经常在HDFS竖井之间复制数据集,试图保持它们的一致和最新。
- 结果,公司最终维护了许多独立的、固定的分析集群(一种情况下超过50个),每个集群都有自己的HDFS数据竖井,其中包含数据PBs的冗余副本,同时维护一个容易出错的脚本迷宫,以保持竖井之间的数据集更新。
- 但是,在不同的HDFS筒仓上维护5、10或20个多pb数据集副本的成本对许多公司来说都是高昂的(包括CapEx和OpEx)。
在图片中,他们的核心问题和最终选择如下所示:
 Figure 1. Core problems
Figure 1. Core problems

Figure 2. Resulting Options
事实证明,AWS生态系统多年前就通过Hadoop S3A文件系统客户端为选择#3(见上面的图2)构建了一个解决方案。在AWS中,您可以在EC2实例上启动许多分析集群,并在它们之间在Amazon S3上共享数据集(例如,请参阅Cloudera CDH对Amazon S3的支持)。在启动新的集群后,不再有冗长的延迟混合HDFS存储,或者在集群终止时去staging HDFS数据。使用Hadoop S3A文件系统客户端,Spark/Hadoop作业和查询可以直接针对共享S3数据存储中的数据运行。
底线……越来越多的数据科学家和分析师习惯于在AWS上快速创建分析集群,访问共享数据集,而不需要耗时的HDFS数据混合和分离循环,并期望在本地拥有相同的功能。
Ceph是排名第一的开源私有云对象存储平台,提供与s3兼容的对象存储。对于那些希望为其本地分析师提供兼容s3的共享数据湖体验的公司来说,这是(现在也是)自然的选择。
要了解更多信息,请继续本系列的下一篇文章,“为什么在Ceph上使用Spark ?(第三部分):主流的分析作业会直接运行在Ceph对象存储上吗?
原文:https://www.redhat.com/en/blog/why-spark-ceph-part-1-3
本文:http://jiagoushi.pro/node/1502
讨论:请加入知识星球【首席架构师圈】或者小号【cea_csa_cto】或者QQ【2808908662】
- 146 次浏览
【大数据】为什么适用Ceph上运行Spark ?(三部分第三部分)
介绍
几年前,一些大公司开始运行Spark和Hadoop分析集群,使用共享Ceph对象存储来扩充和/或取代HDFS。
我们开始调查他们为什么要这么做,以及它的表现如何。
具体来说,我们Red Hat Storage解决方案架构团队想要知道以下三个问题的第一手答案:
- 公司为什么要这么做?(见“为什么Ceph上有Spark ?”(第三部分第一部分)”)
- 主流的分析作业会直接运行在Ceph对象存储上吗?(见“为什么Ceph上有Spark ?”(第三部分第二部分)”)
- 它的运行速度会比在HDFS上的本机慢多少?(这篇文章)
对于那些想要更深入,我们将交联到一个单独的architect-level博客系列,提供详细的描述,测试数据,和配置场景,我们记录与英特尔这个播客,我们谈论我们的关注使火花,Hadoop, Ceph在英特尔工作更好的硬件和帮助企业有效地扩展。
研究结果总结
我们用不同的工作负载做了Ceph和HDFS的测试(关于一般工作负载的描述,请参阅博客第2部分和第3部分)。正如预期的那样,价格/性能比较基于以下几个因素而有所不同。
显然,许多因素影响着整体解决方案的价格。由于存储容量通常是大数据解决方案价格的主要组成部分,我们在价格/性能比较中选择了它作为价格的简单代理。
在我们的比较中,影响存储容量价格的主要因素是使用的数据持久性方案。由于复制数据持久性为3倍,客户需要购买3PB的原始存储容量来获得1PB的可用容量。在erasure code 4:2的数据持久性下,客户只需要购买1.5PB的原始存储容量就可以得到1PB的可用容量。HDFS使用的主要数据持久性方案是3倍复制(对HDFS擦除编码的支持正在出现,但在一些发行版中仍处于试验阶段)。Ceph多年来一直支持擦除编码或3倍复制数据持久性方案。所有与我们合作的Spark-on-Ceph早期采用者都出于成本效率的原因使用擦除编码。因此,我们的大多数测试都是使用Ceph擦除编码的集群(我们选择EC 4:2)。我们还用Ceph的3倍复制集群进行了一些测试,为这些测试提供了苹果对苹果的比较。
使用上面提到的相对价格的代理,图1提供了一个HDFS v. Ceph价格/性能的总结:

Figure 1: Relative price/performance comparison, based on results from eight different workloads
图1描述了基于八种不同工作负载的价格/性能比较。这8个工作负载中的每一个都使用HDFS和Ceph存储后端运行。Ceph解决方案相对于HDFS解决方案的存储容量价格要么相同,要么少50%。当使用复制了3倍的Ceph集群运行工作负载时,存储容量的价格显示为与HDFS相同。当使用Ceph erasure编码的4:2集群运行工作负载时,Ceph存储容量的价格显示为比HDFS低50%。(参见前面关于数据持久性方案如何影响解决方案价格的讨论。)
例如,工作负载8对于Ceph或HDFS存储具有类似的性能,但是Ceph存储容量的价格是HDFS存储容量价格的50%,因为Ceph运行的是一个擦除编码的4:2集群。在其他示例中,工作负载1和2使用Ceph或HDFS存储具有类似的性能,并且具有相同的存储容量价格(工作负载1和2使用复制了3倍的Ceph集群运行)。
发现细节
这里提供了一些使用Ceph和HDFS存储测试的工作负载的细节,如图1所示。
细节1
这个工作负载是一个通过TestDFSIO比较聚合读吞吐量的简单测试。如图2所示,当Ceph也使用3x复制时,HDFS和Ceph之间进行了比较。当Ceph使用擦除编码4:2时,对于更少的并发客户端(<300),工作负载比HDFS或Ceph的3倍表现得更好。然而,在更多的客户机并发性下,Ceph 4:2上的工作负载性能由于主轴争用而下降(一个带有擦除编码的4:2存储的读取需要4次磁盘访问,而一个带有3倍复制存储的磁盘访问需要4次磁盘访问)。

Figure 2: TestDFSIO read results
细节2
这个工作负载比较了一个单用户执行一系列查询(54个TPC-DS查询,如博客2或3所述)的SparkSQL查询性能。如图3所示,当在HDFS或Ceph的3倍复制存储上运行时,总的查询时间是相当的。在运行Ceph EC4:2时,聚合查询时间翻了一番。

Figure 3: Single-user Spark query set results
细节3
该工作负载比较了10个用户每个并发执行一系列查询的Impala查询性能(54个TPC-DS查询由每个用户以随机顺序执行)。如图1所示,Ceph EC4:2上这个工作负载的总执行时间比HDFS慢了57%。但是,价格/性能几乎可以比较,因为HDFS的存储容量成本是Ceph EC4:2的2倍。
细节4
这种混合工作负载的特点是并发执行一个单用户运行SparkSQL查询(54个),每个10个用户运行Impala查询(每个54个),以及一个数据集合并/连接作业,用合成的点击流日志丰富TPC-DS web销售数据。如图1所示,Ceph EC4:2上这种混合工作负载的总执行时间比HDFS慢48%。但是,价格/性能几乎可以比较,因为HDFS的存储容量成本是Ceph EC4:2的2倍。
细节5
这个工作负载是通过TestDFSIO比较聚合写吞吐量的一个简单测试。如图1所示,这个工作负载在Ceph EC4:2上执行的平均速度比HDFS慢50%,跨一系列并发客户机/写入器。但是,价格/性能几乎可以比较,因为HDFS的存储容量成本是Ceph EC4:2的2倍。
细节6
这个工作负载比较了单用户执行一系列查询(54个TPC-DS查询,如博客2或3所述)的SparkSQL查询性能。如图3所示,当运行在HDFS或Ceph 3倍复制存储时,总的查询时间是相当的。在运行Ceph EC4:2时,聚合查询时间翻了一番。然而,在Ceph EC4:2上运行时,价格/性能几乎可以比较,因为HDFS的存储容量成本是Ceph EC4:2的2倍。
细节7
这个工作负载的特点是用合成的点击流日志丰富(合并/连接)TPC-DS网络销售数据,然后写入更新的网络销售数据。如图4所示,Ceph EC4:2上的工作负载比HDFS慢37%。但是,价格/性能对Ceph是有利的,因为HDFS的存储容量成本是Ceph EC4:2的2倍。

Figure 4: Data set enrichment (merge/join/update) job results
细节8
这个工作负载比较了10个用户每个并发执行一系列查询的SparkSQL查询性能(54个TPC-DS查询由每个用户以随机顺序执行)。如图1所示,尽管只需要50%的存储容量成本,但Ceph EC4:2上这个工作负载的总执行时间与HDFS的大致相当。这个工作负载的价格/性能因此有利于Ceph的2倍。要更深入地了解这种工作负载性能,请参见图5。在这个盒须图中,每个点反映了单个SparkSQL查询执行时间。因为这10个用户中的每个都同时执行54个查询,所以每个系列有540个点。显示的三个系列是Ceph EC4:2(绿色)、Ceph 3x(红色)和HDFS 3x(蓝色)。Ceph EC4:2框显示了相当于HDFS 3倍的中间执行时间,并在中间2个四分位数显示了更一致的查询时间。

Figure 5: Multi-user Spark query set results
奖励结果部分:24小时摄入
我们的一个潜在Spark-on-Ceph客户最近要求我们说明Ceph集群在24小时内的持续摄取率。对于这些测试,我们使用了博客2 / 3中描述的实验室变体。如图6所示,我们在配置了700个HDD数据驱动器(Ceph OSDs)的Ceph EC4:2集群中测量了每天大约1.3 PiB的原始摄取速率。

Figure 6: Daily data ingest rate into Ceph clusters of various sizes
结论观察
总之,下面是我们对上述结果的成本/收益分析,总结了本系列博客。
Spark-on- ceph vs. Spark在传统HDFS上的好处:
- 通过减少重复减少资本支出:当多个分析集群需要访问相同的数据集时,减少购买在HDFS筒仓中存储重复数据集的冗余存储容量的PBs。
- 降低OpEx/risk:当多个分析集群需要访问相同的数据集时,消除HDFS竖井之间的脚本/调度数据集副本的成本,并降低在HDFS竖井上试图维护这些重复数据集之间的一致性时的人为错误风险。
- 从新的数据科学集群加速洞察:通过在共享数据存储库中原位分析数据,而不是在开始分析之前将数据复制到一个新集群,从而在创建新的数据科学集群时减少洞察时间。
- 满足不同数据团队的不同工具/版本需求:在团队之间共享数据集的同时,允许每个集群内的用户选择适合其工作的Spark/Hadoop工具集和版本,而不会干扰其他需要不同工具/版本的团队的用户。
- 适当大小的CapEx基础设施成本:通过适当大小的计算需求(vCPU/RAM),独立于存储容量需求(吞吐量/TB),减少传统HDFS集群中常见的计算或存储过度供应,通过增加通用节点(无论是否只需要更多的CPU核或存储容量)。
- 通过提高数据持久性效率来降低资本支出:Ceph erasure编码效率比HDFS默认的3倍复制降低了高达50%的存储容量购买的资本支出。
Spark-on- ceph vs. Spark在传统HDFS上:
- 查询性能:Spark/Impala查询任务执行时间延长0% ~ 131%(单用户和多用户并发测试)。
- 写作业性能:面向写作业(加载、转换、充实)的性能范围为37%-200%+更长的执行时间。[注意:当下游发行版对Hadoop S3A客户端采用以下上游增强Hadoop -13600、Hadoop -13786、Hadoop -12891]时,写作业性能有望显著改善。
- 混合工作负载性能:并发执行多个查询和充实作业的性能导致执行时间延长90%。
要了解更多细节(以及亲身体验此解决方案的机会),请继续关注这个Red Hat Storage博客位置的架构级博客系列。感谢你的阅读。
原文:https://www.redhat.com/en/blog/why-spark-ceph-part-3-3
本文:http://jiagoushi.pro/node/1504
讨论:请加入知识星球【首席架构师圈】或者小号【cea_csa_cto】或者QQ【2808908662】
- 249 次浏览
【大数据】为什么适用Ceph上运行Spark ?(三部分第二部分)
介绍
几年前,一些大公司开始运行Spark和Hadoop分析集群,使用共享Ceph对象存储来扩充和/或取代HDFS。
我们开始调查他们为什么要这么做,以及它的表现如何。
具体来说,我们想知道以下三个问题的第一手答案:
- 公司为什么要这么做?(见“为什么Ceph上有Spark ?”(第三部分第一部分)”)
- 主流的分析作业会直接运行在Ceph对象存储上吗?(这篇文章)
- 它的运行速度会比在HDFS上的本机慢多少?(见“为什么Ceph上的Spark(第三部分)”)
对于那些想要更深入,我们将交联到一个单独的architect-level博客系列提供详细描述,测试数据,和配置场景,我们记录与英特尔这个播客,我们谈论我们的关注使火花,Hadoop, Ceph在英特尔工作更好的硬件和帮助企业有效地扩展。
使用Ceph对象存储的基本分析管道
我们的早期采用者客户正在直接摄取、查询和转换数据到共享的Ceph对象存储。换句话说,他们的分析工作的目标数据位置是Ceph中的“s3://bucket-name/path-to-file- In -bucket”,而不是“hdfs:///path-to-file”。通过Spark、Hive和Impala等分析工具直接访问s3兼容的对象存储,可以通过Hadoop S3A客户端实现。
我们与几个客户合作,使用以下分析工具,成功地直接针对Ceph对象存储运行了1000多个分析作业:

Figure 1: Analytics tools tested with shared Ceph object store
除了运行像TestDFSIO这样的简单测试外,我们还希望运行能够代表现实世界工作负载的分析作业。为此,我们基于摄取、转换和查询作业的TPC-DS基准测试进行测试。TPC-DS生成合成数据集,并提供一组示例查询,用于模拟大型零售公司的分析环境,该公司拥有来自商店、目录和web的销售操作。它的模式有10个表,有些表中有数十亿条记录。它定义了99个预先配置的查询,我们从中选择了54个io密集的输出测试。与业内合作伙伴一起,我们还用模拟的点击流日志补充了TPC-DS数据集,比TPC-DS数据集大10倍,并添加了SparkSQL作业,以将这些日志与TPC-DS web销售数据连接起来。
总之,我们直接对Ceph对象存储运行了以下操作:
- 批量摄取(批量负荷工作-模拟1PB+/天的大容量流摄取)
- 摄取(MapReduce工作)
- 转换(Hive或SparkSQL作业,将纯文本数据转换为Parquet或ORC柱状压缩格式)
- 查询(Hive或SparkSQL作业-经常以批处理/非交互模式运行,因为这些工具会自动重启失败的作业)
- 交互式查询(Impala或Presto作业)
- 合并/连接(Hive或SparkSQL作业将半结构化的点击流数据与结构化的web销售数据连接起来)
架构概述
在过去的一年中,我们与4个大客户运行了上述测试的变体。一般来说,我们的架构是这样的:

Figure 2: High-level lab architecture
它工作了吗?
是的,上面描述的1000个分析任务成功完成了。SparkSQL、Hive、MapReduce、Impala作业都使用S3A客户端直接读写数据到共享的Ceph对象存储中。相关的架构级博客系列将详细记录所获得的经验教训和配置技术。
在本博客系列的最后一集中,我们将会看到最重要的一点——与传统HDFS相比,性能如何?有关答案,请继续阅读本系列的第3部分....
原文:https://www.redhat.com/en/blog/why-spark-ceph-part-2-3
本文:http://jiagoushi.pro/node/1503
讨论:请加入知识星球【首席架构师圈】或者小号【cea_csa_cto】或者QQ【2808908662】
- 88 次浏览
hadoop生态
- 285 次浏览
「大数据」Hadoop生态系统:分布式文件系统
Apache HDFS
Hadoop分布式文件系统(HDFS)提供了一种在多台计算机上存储大型文件的方法。 Hadoop和HDFS源自Google文件系统(GFS)文件。 在Hadoop 2.0.0之前,NameNode是HDFS集群中的单点故障(SPOF)。 使用Zookeeper,HDFS高可用性功能通过提供在具有热备用的主动/被动配置中的同一群集中运行两个冗余NameNode的选项来解决此问题。
- hadoop.apache.org
- 谷歌文件系统 - GFS文件
- Cloudera为何选择HDFS
- Hortonworks为何选择HDFS
Red Hat GlusterFS
GlusterFS是一个横向扩展的网络附加存储文件系统。 GlusterFS最初由Gluster,Inc。开发,然后由Red Hat,Inc。在2011年购买Gluster后开发。2012年6月,Red Hat Storage Server被宣布为商业支持的GlusterFS与Red Hat Enterprise Linux的集成。 Gluster文件系统,现在称为Red Hat Storage Server。
- www.gluster.org
- Red Hat Hadoop插件
Quantcast文件系统
QFS QFS是一个开源的分布式文件系统软件包,适用于大规模MapReduce或其他批处理工作负载。它被设计为Apache Hadoop HDFS的替代品,旨在为大规模处理集群提供更好的性能和成本效益。它是用C ++编写的,具有固定占用内存管理。 QFS使用Reed-Solomon纠错作为确保可靠访问数据的方法。
Reed-Solomon编码在大容量存储系统中被广泛使用以校正与介质缺陷相关的突发错误。 QFS不是存储每个文件的三个完整版本(如HDFS),而是需要三倍的存储空间,因此它只需要1.5倍的原始容量,因为它会跨九个不同的磁盘驱动器对数据进行条带化。
- QFS网站
- GitHub QFS
- HADOOP-8885
Ceph Filesystem
Ceph是一个免费的软件存储平台,旨在从单个分布式计算机集群中呈现对象,块和文件存储。 Ceph的主要目标是完全分发,没有单点故障,可扩展到exabyte级别,并且可以自由使用。数据被复制,使其具有容错能力。
- Ceph文件系统站点
- Ceph和Hadoop
- HADOOP-6253
Lustre文件系统
Lustre文件系统是一种高性能的分布式文件系统,适用于大型网络和高可用性环境。传统上,Lustre被配置为管理存储区域网络(SAN)内的远程数据存储磁盘设备,SAN是通过小型计算机系统接口(SCSI)协议进行通信的两个或多个远程连接的磁盘设备。这包括光纤通道,以太网光纤通道(FCoE),串行连接SCSI(SAS)甚至iSCSI。
使用Hadoop HDFS,该软件需要一个专用的计算机集群来运行。但是,为其他目的运行高性能计算集群的人通常不会运行HDFS,这会使他们拥有一堆计算能力,这些任务几乎肯定会受益于一些地图缩减,并且无法将这些功能用于运行Hadoop的。英特尔注意到了这一点,并且在其上周悄然发布的Hadoop发行版2.5版本中增加了对Lustre的支持:用于Apache Hadoop *软件的英特尔®HPC分发,这是一款将英特尔分布式Apache Hadoop软件与英特尔®结合的新产品适用于Lustre软件的企业版。这是与Lustre集成的唯一Apache Hadoop发行版,Lustre是许多世界上最快的超级计算机1使用的并行文件系统.
- wiki.lustre.org /
- 带有Lustre的Hadoop
- 英特尔HPC Hadoop
Alluxio
Alluxio是世界上第一个以内存为中心的虚拟分布式存储系统,它统一了数据访问并桥接了计算框架和底层存储系统。应用程序只需与Alluxio连接即可访问存储在任何底层存储系统中的数据。此外,Alluxio以内存为中心的架构使数据访问速度比现有解决方案快几个数量级。
在大数据生态系统中,Alluxio介于计算框架或作业(如Apache Spark,Apache MapReduce或Apache Flink)和各种存储系统(如Amazon S3,OpenStack Swift,GlusterFS,HDFS,Ceph或OSS)之间。 Alluxio为堆栈带来了显着的性能提升;例如,百度使用Alluxio将其数据分析性能提高了30倍。除了性能之外,Alluxio还将新工作负载与存储在传统存储系统中的数据相结合。用户可以使用其独立群集模式运行Alluxio,例如在Amazon EC2上运行,或者使用Apache Mesos或Apache Yarn启动Alluxio。
Alluxio兼容Hadoop。这意味着现有的Spark和MapReduce程序可以在Alluxio之上运行而无需更改任何代码。该项目是开源的(Apache License 2.0),并在多家公司部署。它是增长最快的开源项目之一。 Alluxio拥有不到三年的开源历史,吸引了来自50多家机构的160多名贡献者,包括阿里巴巴,Alluxio,百度,CMU,IBM,英特尔,NJU,红帽,加州大学伯克利分校和雅虎。该项目是Berkeley Data Analytics Stack(BDAS)的存储层,也是Fedora发行版的一部分。
- Alluxio网站
GridGain
GridGain是在Apache 2.0下获得许可的开源项目。该平台的主要部分之一是内存中的Apache Hadoop加速器,旨在通过将数据和计算都带入内存来加速HDFS和Map / Reduce。这项工作是通过GGFS-Hadoop兼容的内存文件系统完成的。对于I / O密集型作业,GridGain GGFS的性能比标准HDFS快近100倍。从GridGain Systems转述Dmitriy Setrakyan谈论有关Tachyon的GGFS:
GGFS允许对底层HDFS或任何其他Hadoop兼容文件系统进行直读和写入,而无需更改代码。从本质上讲,GGFS完全从集成中删除了ETL步骤。
GGFS能够选择和保留内存中的文件夹,光盘上的文件夹,以及同步或异步与底层(HD)FS同步的文件夹。
GridGain正致力于添加原生MapReduce组件,该组件将提供本机完整的Hadoop集成而无需更改API,就像Spark目前强迫您做的那样。基本上,GridGain MR + GGFS将允许以即插即用的方式将Hadoop完全或部分内存,而无需任何API更改。
- GridGain网站
XtreemFS
XtreemFS是一个通用存储系统,可满足单个部署中的大多数存储需求。它是开源的,不需要特殊的硬件或内核模块,可以安装在Linux,Windows和OS X上.XtreemFS运行分布式并通过复制提供弹性。 XtreemFS卷可以通过FUSE组件访问,该组件提供与POSIX类似语义的正常文件交互。此外,还包含Hadoops FileSystem接口的实现,使XtreemFS可以与Hadoop,Flink和Spark一起使用。 XtreemFS根据新BSD许可证授权。 XtreemFS项目由柏林Zuse研究所开发。该项目的开发由欧盟委员会自2006年以来根据拨款协议No. FP6-033576,FP7-ICT-257438和FP7-318521以及德国项目MoSGrid,“First We Take Berlin”,FFMK, GeoMultiSens和BBDC。
- XtreemFS站点
- 在XtreemFS上进行Flink。
- Spark XtreemFS
- 141 次浏览
「大数据」Hadoop生态系统:分布式计算系统
Apache Ignite
Apache Ignite In-Memory Data Fabric是一个分布式内存平台,用于实时计算和处理大规模数据集。它包括分布式键值内存存储,SQL功能,map-reduce和其他计算,分布式数据结构,连续查询,消息和事件子系统,Hadoop和Spark集成。 Ignite是用Java构建的,提供.NET和C ++ API。
- Apache Ignite
- Apache Ignite文档
Apache MapReduce
MapReduce是一种编程模型,用于在群集上使用并行分布式算法处理大型数据集。 Apache MapReduce源自Google MapReduce:大群集上的简化数据处理。当前的Apache MapReduce版本是基于Apache YARN Framework构建的。 YARN代表“Yet-Another-Resource-Negotiator”。它是一个新的框架,有助于编写任意分布式处理框架和应用程序。 YARN的执行模型比早期的MapReduce实现更通用。与原始的Apache Hadoop MapReduce(也称为MR1)不同,YARN可以运行不遵循MapReduce模型的应用程序。 Hadoop YARN试图将Apache Hadoop超越MapReduce进行数据处理。
- Apache MapReduce
- 谷歌MapReduce论文
- 编写YARN应用程序
Apache Pig
Pig提供了一个在Hadoop上并行执行数据流的引擎。它包括一种用于表达这些数据流的语言Pig Latin。 Pig Latin包含许多传统数据操作(连接,排序,过滤等)的运算符,以及用户开发自己的读取,处理和写入数据的功能。猪在Hadoop上运行。它利用了Hadoop分布式文件系统,HDFS和Hadoop的处理系统MapReduce。
Pig使用MapReduce来执行其所有数据处理。它编译Pig Latin脚本,用户将其写入一系列一个或多个MapReduce作业,然后执行它们。 Pig Latin看起来与您看到的许多编程语言不同。 Pig Latin中没有if语句或for循环。这是因为传统的过程和面向对象的编程语言描述了控制流,而数据流是程序的副作用。 Pig Latin专注于数据流。
- 1. pig.apache.org/
- 2.Pig examples by Alan Gates
JAQL
JAQL是一种功能性的声明性编程语言,专门用于处理大量结构化,半结构化和非结构化数据。顾名思义,JAQL的主要用途是处理存储为JSON文档的数据,但JAQL可以处理各种类型的数据。例如,它可以支持XML,逗号分隔值(CSV)数据和平面文件。 “JAQL中的SQL”功能允许程序员使用结构化SQL数据,同时使用JSON数据模型,该模型的限制性比结构化查询语言对应项更少。
具体来说,Jaql允许您选择,加入,分组和过滤存储在HDFS中的数据,就像Pig和Hive的混合一样。 Jaql的查询语言受到许多编程和查询语言的启发,包括Lisp,SQL,XQuery和Pig。
JAQL由IBM研究实验室的工作人员于2008年创建,并发布给开源。虽然它继续作为Google Code上的项目托管,其中可下载的版本在Apache 2.0许可下可用,但围绕JAQL的主要开发活动仍然以IBM为中心。该公司提供查询语言作为与InfoSphere BigInsights及其Hadoop平台相关联的工具套件的一部分。与工作流协调器一起使用,BigInsights中使用JAQL在存储,处理和分析作业之间交换数据。它还提供外部数据和服务的链接,包括关系数据库和机器学习数据。
- Google Code中的JAQL
- 什么是Jaql?byIBM
Apache Spark
数据分析集群计算框架最初是在加州大学伯克利分校的AMPLab中开发的。 Spark适用于Hadoop开源社区,构建于Hadoop分布式文件系统(HDFS)之上。但是,Spark为Hadoop MapReduce提供了一种更易于使用的替代方案,并且在某些应用程序中,其性能比Hadoop MapReduce等上一代系统快10倍。
Spark是一个用于编写快速分布式程序的框架。 Spark解决了与Hadoop MapReduce类似的问题,但具有快速的内存方法和干净的功能样式API。凭借其与Hadoop和内置工具集成的交互式查询分析(Shark),大规模图形处理和分析(Bagel)以及实时分析(Spark Streaming)的能力,它可以交互式地用于快速处理和查询大型数据集。
为了加快编程速度,Spark在Scala,Java和Python中提供了简洁,简洁的API。您还可以从Scala和Python shell以交互方式使用Spark来快速查询大数据集。 Spark也是Shark背后的引擎,Shark是一个完全与Apache Hive兼容的数据仓库系统,运行速度比Hive快100倍。
- Apache Spark
- Mirror of Spark on Github
- RDDs - Paper
- Spark: Cluster Computing... - Paper Spark Research
Apache Storm
Storm是一个复杂的事件处理器(CEP)和主要以Clojure编程语言编写的分布式计算框架。是一种分布式实时计算系统,用于处理快速,大量的数据流。 Storm是一种基于主工作者范式的架构。因此,Storm集群主要由主节点和工作节点组成,由Zookeeper协调完成。
Storm使用zeromq(0mq,zeromq),这是一个先进的可嵌入网络库。它提供了一个消息队列,但与面向消息的中间件(MOM)不同,0MQ系统可以在没有专用消息代理的情况下运行。该库旨在具有熟悉的套接字式API。
该项目最初由Nathan Marz和BackType团队创建,该项目在被Twitter收购后开源。 Storm最初是在2011年在BackType开发和部署的。经过7个月的开发,BackType于2011年7月被Twitter收购.Storm于2011年9月开源。
Hortonworks正在开发Storm-on-YARN版本,计划在2013年第四季度完成基础级集成。这是Hortonworks的计划。 Yahoo / Hortonworks还计划在不久的将来将github.com/yahoo/storm-yarn上的Storm-on-YARN代码转移到Apache Storm项目的子项目中。
Twitter最近发布了一款名为“Summingbird”的Hadoop-Storm Hybrid.Summingbird将这两个框架融合为一体,允许开发人员使用Storm进行短期处理,使用Hadoop进行深度数据潜水。旨在通过将批处理和流处理组合成混合系统来减轻批处理和流处理之间的权衡的系统。
- Storm Project/
- Storm-on-YARN
Apache Flink
Apache Flink(以前称为Stratosphere)在Java和Scala中具有强大的编程抽象,高性能运行时和自动程序优化。它具有对迭代,增量迭代和由大型DAG操作组成的程序的本机支持。
Flink是一个数据处理系统,是Hadoop MapReduce组件的替代品。它带有自己的运行时,而不是构建在MapReduce之上。因此,它可以完全独立于Hadoop生态系统工作。但是,Flink还可以访问Hadoop的分布式文件系统(HDFS)来读取和写入数据,以及Hadoop的下一代资源管理器(YARN)来配置群集资源。由于大多数Flink用户使用Hadoop HDFS来存储他们的数据,因此它已经提供了访问HDFS所需的库。
- Apache Flink incubator page
- Stratosphere site
Apache Apex
Apache Apex是一个基于Apache YARN的企业级大数据动态平台,它统一了流处理和批处理。它以高度可扩展,高性能,容错,有状态,安全,分布式和易于操作的方式处理大数据。它提供了一个简单的API,使用户能够编写或重用通用Java代码,从而降低编写大数据应用程序所需的专业知识。
Apache Apex-Malhar是Apache Apex平台的补充,它是一个运营商库,可实现希望快速开发应用程序的客户所需的通用业务逻辑功能。这些运营商提供对HDFS,S3,NFS,FTP和其他文件系统的访问; Kafka,ActiveMQ,RabbitMQ,JMS和其他消息系统; MySql,Cassandra,MongoDB,Redis,HBase,CouchDB和其他数据库以及JDBC连接器。该库还包括许多其他常见的业务逻辑模式,可帮助用户显着减少投入生产所需的时间。易于与所有其他大数据技术集成是Apache Apex-Malhar的主要任务之一。
GitHub上提供的Apex是DataTorrent商业产品DataTorrent RTS 3以及其他技术(如数据摄取工具dtIngest)所基于的核心技术。
- Apache Apex from DataTorrent
- Apache Apex main page
- Apache Apex Proposal
Netflix PigPen
PigPen是针对Clojure的map-reduce,它编译为Apache Pig。 Clojure是Rich Hickey创建的Lisp编程语言的方言,因此是一种功能通用语言,可在Java虚拟机,公共语言运行时和JavaScript引擎上运行。在PigPen中,没有特殊的用户定义函数(UDF)。定义Clojure函数,匿名或命名,并像在任何Clojure程序中一样使用它们。该工具由美国按需互联网流媒体提供商Netflix公司开源。
- GitHub上的PigPen
AMPLab SIMR
Apache Spark是在Apache YARN中开发的。但是,到目前为止,在Hadoop MapReduce v1集群上运行Apache Spark相对比较困难,即没有安装YARN的集群。通常,用户必须获得在某些机器子集上安装Spark / Scala的权限,这个过程可能非常耗时。 SIMR允许任何有权访问Hadoop MapReduce v1集群的人开箱即用。用户可以直接在Hadoop MapReduce v1之上运行Spark,而无需任何管理权限,也无需在任何节点上安装Spark或Scala。
- GitHub上的SIMR
Facebook Corona
“Map-Reduce的下一个版本”,基于自己的Hadoop分支。当前的MapReduce技术的Hadoop实现使用单个作业跟踪器,这会导致非常大的数据集出现扩展问题.Apache Hadoop开发人员有他们正在创建他们自己的下一代MapReduce,名为YARN,由于公司部署Hadoop和HDFS的高度定制化特性,Facebook工程师对此进行了评估,但是折扣也很明显。像YARN一样,Corona产生了多个工作跟踪器(每个工作一个,在Corona的案例中.
- 在Github上的Corona
Apache REEF
Apache REEF™(可保留评估程序执行框架)是一个用于为Apache Hadoop™YARN或Apache Mesos™等集群资源管理器开发可移植应用程序的库。 Apache REEF通过以下功能大大简化了这些资源管理器的开发:
集中控制流程:Apache REEF将分布式应用程序的混乱转变为单个机器中的事件,即作业驱动程序。事件包括容器分配,任务启动,完成和失败。对于失败,Apache REEF尽一切努力使任务抛出的实际“异常”可用于驱动程序。
任务运行时:Apache REEF提供名为Evaluator的Task运行时。评估器在REEF应用程序的每个容器中实例化。评估者可以将数据保存在任务之间的内存中,从而在REEF上实现高效的管道。
支持多个资源管理器:Apache REEF应用程序可以轻松地移植到任何受支持的资源管理器。此外,REEF中的新资源管理器很容易支持。
.NET和Java API:Apache REEF是在.NET中编写YARN或Mesos应用程序的唯一API。此外,单个REEF应用程序可以自由混合和匹配为.NET或Java编写的任务。
插件:Apache REEF允许插件(称为“服务”)扩充其功能集,而不会向核心添加膨胀。 REEF包括许多服务,例如任务MPI启发的组通信(广播,减少,收集,...)和数据入口之间基于名称的通信。
- Apache REEF网站
Apache Twill
Twill是ApacheHadoop®YARN的抽象,它降低了开发分布式应用程序的复杂性,使开发人员能够更专注于业务逻辑。 Twill使用一个简单的基于线程的模型,Java程序员会发现它很熟悉。 YARN可以被视为集群的计算结构,这意味着像Twill这样的YARN应用程序可以在任何Hadoop 2集群上运行。
YARN是一个开源应用程序,它允许Hadoop集群变成一组虚拟机。 Weave由Continuuity开发,最初位于Github上,是一个互补的开源应用程序,它使用类似于Java线程的编程模型,可以轻松编写分布式应用程序。为了消除与Apache上类似命名的项目(名为“Weaver”)的冲突,Weave的名称在转移到Apache孵化时更改为Twill。
斜纹作为扩展代理。 Twill是YARN和YARN上任何应用程序之间的中间件层。在开发Twill应用程序时,Twill处理YARN中的API,类似于Java熟悉的多线程应用程序。在Twill中构建多处理的分布式应用程序非常容易。
- Apache Twill Incubator
Damballa
Parkour图书馆使用LISP语言Clojure开发MapReduce程序。 Parkour旨在为Hadoop提供深入的Clojure集成。使用Parkour的程序是普通的Clojure程序,使用标准的Clojure函数而不是新的框架抽象。使用Parkour的程序也是完整的Hadoop程序,可以在原始Java Hadoop MapReduce中完全访问所有可能的内容。 1.跑酷GitHub项目
Apache Hama
Apache顶级开源项目,允许您在MapReduce之外进行高级分析。许多数据分析技术(如机器学习和图形算法)都需要迭代计算,这就是批量同步并行模型比“普通”MapReduce更有效的地方。
- Hama site
Datasalt Pangool
一种新的MapReduce范例。用于MR作业的新API,其级别高于Java。
- Pangool
- GitHub Pangool
Apache Tez
Tez是一个开发通用应用程序的提案,该应用程序可用于处理复杂的数据处理任务DAG,并在Apache Hadoop YARN上本机运行。 Tez将MapReduce范例概括为基于将计算表示为数据流图的更强大的框架。 Tez并不直接面向最终用户 - 实际上它使开发人员能够以更好的性能和灵活性构建最终用户应用程序。传统上,Hadoop是一个用于处理大量数据的批处理平台。但是,查询处理的近实时性能有很多用例。还有一些工作负载,例如机器学习,它们不适合MapReduce范例。 Tez帮助Hadoop解决这些用例问题。 Tez框架构成了Stinger计划的一部分(基于Hive的Hadoop基于低延迟的SQL类型查询接口)。
- Apache Tez孵化器
- Hortonworks Apache Tez页面
Apache DataFu
DataFu基于它提供了更高级语言的Hadoop MapReduce作业和函数的集合,以执行数据分析。它提供常见统计任务(例如分位数,采样),PageRank,流会话以及集合和包操作的功能。 DataFu还为MapReduce中的增量数据处理提供Hadoop作业。 DataFu是最初在LinkedIn开发的Pig UDF(包括PageRank,会话,集合操作,抽样等等)的集合。
- DataFu Apache孵化器
Pydoop
Pydoop是一个用于Hadoop的Python MapReduce和HDFS API,它基于C ++管道和C libhdfs API,允许编写具有HDFS访问权限的完整MapReduce应用程序。 Pydoop与Hadoop内置的Python编程解决方案相比有几个优点,即Hadoop Streaming和Jython:它是一个CPython包,它允许您访问所有标准库和第三方模块,其中一些可能不可用。
- SF Pydoop网站
- Pydoop GitHub项目
Kangaroo
来自Conductor的Kangaroo开源项目,用于编写消耗Kafka数据的MapReduce作业。介绍性帖子通过使用HFileOutputFormat的MapReduce作业解释了Conductor从Kafka到HBase的用例加载数据。与其他限制为每个Kafka分区的单个InputSplit的解决方案不同,Kangaroo可以在单个分区的流中以不同的偏移量启动多个消费者,以提高吞吐量和并行性。
- Kangaroo Introduction
- Kangaroo GitHub Project
TinkerPop
用Java编写的TinkerPop Graph计算框架。提供图形系统供应商可以实现的核心API。有各种类型的图形系统,包括内存中的图形库,OLTP图形数据库和OLAP图形处理器。实现核心接口后,可以使用图形遍历语言Gremlin查询基础图形系统,并使用启用TinkerPop的算法进行处理。对于许多人来说,TinkerPop被视为图形计算社区的JDBC。
- Apache Tinkerpop提案
- TinkerPop网站
Pachyderm MapReduce
Pachyderm是一款全新的MapReduce引擎,构建于Docker和CoreOS之上。在Pachyderm MapReduce(PMR)中,作业是Docker容器(微服务)中的HTTP服务器。您为Pachyderm提供Docker镜像,它将自动在整个群集中将其分发到您的数据旁边。数据通过HTTP发布到容器,结果存储回文件系统。您可以使用您想要的任何语言实现Web服务器并提取任何库。 Pachyderm还为系统中的所有作业及其依赖项创建DAG,并自动调度管道,使得每个作业在依赖关系完成之前不会运行。 Pachyderm中的所有东西都“在差异中说话”,因此它确切地知道哪些数据已经改变以及管道的哪些子集需要重新运行。 CoreOS是一个基于Chrome OS的开源轻量级操作系统,实际上CoreOS是Chrome OS的一个分支。 CoreOS仅提供在软件容器内部署应用程序所需的最少功能,以及用于服务发现和配置共享的内置机制
- Pachyderm站点
- Pachyderm介绍文章
Apache Beam
Apache Beam是一个开源的统一模型,用于定义和执行数据并行处理管道,以及一组特定于语言的SDK,用于构建管道和运行时特定的Runner以执行它们。
Beam背后的模型源于许多内部Google数据处理项目,包括MapReduce,FlumeJava和Millwheel。 该模型最初被称为“数据流模型”,最初实现为Google Cloud Dataflow,包括用于编写管道的GitHub上的Java SDK和用于在Google Cloud Platform上执行它们的完全托管服务。
2016年1月,Google和许多合作伙伴以Apache Beam(统一批量+ strEAM处理)的名义提交了数据流编程模型和SDK部分作为Apache孵化器提案。
- Apache Beam Proposal
- DataFlow Beam和Spark Comparasion
- 154 次浏览
【大数据】Hadoop死了吗?大数据分析的未来及其替代
视频号
微信公众号
知识星球
作为一个完整的开源大数据套件,Apache Hadoop在过去十年中深刻影响了整个大数据世界。然而,随着各种新兴技术的发展,Hadoop生态系统发生了巨大的变化。Hadoop真的死了吗?如果是,哪些产品/技术将取代它?大数据分析的未来前景如何?
本文将分析:
1.Hadoop的历史及其开源生态系统
2.云原生趋势下的新兴技术选择
3.未来10年大数据分析的未来展望
理解Hadoop:大数据简史及其作用
在过去的二十年里,我们一直生活在一个数据爆炸的时代。订单和仓储等传统业务中创建的数据量增长相对缓慢,在数据总量中的比例逐渐下降。

相反,大量的人类数据和机器数据(日志、物联网设备等)被收集和存储的数量远远超过了传统的商业数据。海量数据与人类能力之间存在着巨大的技术差距,催生了各种大数据技术。在这种背景下,我们所说的大数据时代已经形成。
2006年:Apache Hadoop在大数据处理领域的崛起
得益于“大数据”和有影响力的Apache开源软件项目社区,Hadoop迅速流行起来,并涌现出许多商业公司。
Hadoop就是这样一个功能齐全的大数据处理平台。它包含各种组件,以满足不同的功能要求,例如:
- 用于数据存储的HDFS
- 资源管理Yarn
- MapReduce和Spark用于数据计算和处理
- 用于关系数据收集的Sqoop
- 实时数据管道的Kafka
- 用于在线数据存储和访问的HBase
- 用于在线特别查询等的Impala。
Hadoop在诞生后不久就使用集群进行并行计算,打破了超级计算机保持的排序记录。它已被实力雄厚的公司和各种组织广泛采用。
市场上排名靠前的Hadoop分销商包括Cloudera、Hortonworks和MapR这三家供应商。此外,公共云供应商还在云上提供托管Hadoop服务,如AWS EMR、Azure HDinsight等,这些服务占据了Hadoop的大部分市场份额。
2018年:随着Cloudera和Hortonworks的合并,市场发生了变化
然而,在2018年,市场经历了剧烈的变化。一则震惊Hadoop生态系统的重大消息:Cloudera和Hortonworks合并。

Chirs Preinenerger和Daniel Newman的新闻
换句话说№1和№2 两个市场参与者相互拥抱以在市场中生存。随后,HPE宣布收购MapR。这些并购表明,尽管Hadoop非常受欢迎,但这些公司在运营中面临困难,很难赚钱。
在合并Hortonworks后,Cloudera宣布将对所有产品线收费,包括以前的开源版本。开源产品不再对所有用户开放,而是只对付费用户开放。

HDP发行版过去是免费的,现在不再维护和下载。它将来将合并为一个统一的CDP平台。
2021:观察Hadoop开源生态系统的衰落
2021年4月,Apache软件基金会宣布13个大数据相关项目退役,其中10个是Hadoop生态系统的一部分,如Eagle、Sentry、Tajo等。
现在,肩负着管理Hadoop集群使命的Apache Ambari成为2022年退役的第一个Apache项目。
2022年及以后:展望大数据的后Hadoop时代
Hadoop最终会被抛弃吗?我相信这不会很快发生。毕竟,Hadoop拥有大量用户,这意味着平台和应用程序迁移的成本过高。
因此,当前用户将继续使用它,但新用户的数量将逐渐减少。这就是我们所说的“后Hadoop时代”。
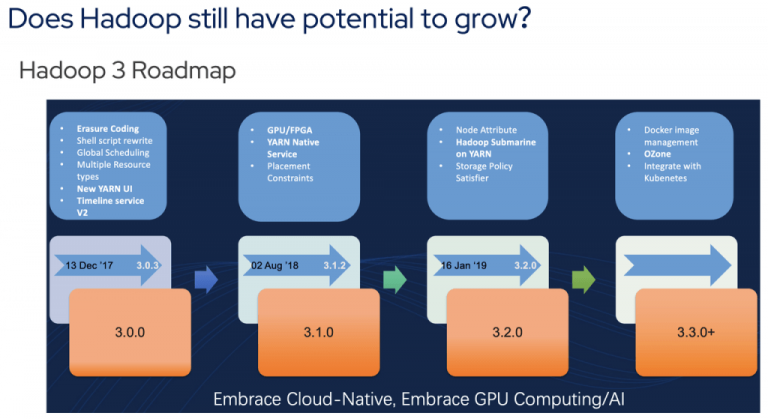
就Apache Hadoop的潜在增长而言,上述路线图取自Hadoop社区的一次会议。3.0之后,Hadoop的新特性显然不再那么好了。它们主要是关于与K8s和Docker的集成,这对大数据从业者来说没有那么大的吸引力。
是什么导致了Hadoop的衰落?
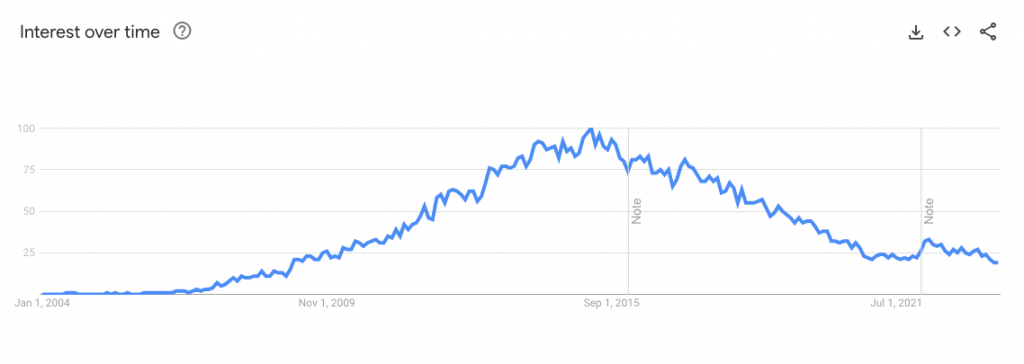
谷歌趋势显示,2014年至2017年,人们对Hadoop的兴趣达到了顶峰。在那之后,我们看到Hadoop的搜索量明显下降。Hadoop逐渐失去光环也就不足为奇了。任何技术都会经历发展、成熟和衰落的循环,任何技术都无法逃脱客观规律。
从Apache Hadoop及其生态系统的现状来看,有几个关键因素表明它最终会消亡。
数据分析和新兴技术的新市场需求
回顾Hadoop的发展历史,可以看出,软件框架的出现是因为对大数据存储的强烈需求。然而,在今天,用户对数据管理和分析有了新的需求,例如在线快速分析、存储和计算分离,或用于人工智能和机器学习的AI/ML。
在这些方面,Hadoop只能提供有限的支持。在这方面,它不能与一些新兴技术相比。比如Redis、Elastisearch、ClickHouse,这些都可以应用到大数据分析中。
对于客户来说,如果一项技术能够满足他们的需求,就不需要部署复杂的Hadoop平台。
快速增长的云供应商和服务对Hadoop相关性的影响
从另一个角度来看,云计算在过去十多年中发展迅速,不仅击败了IBM、HP等传统软件供应商,而且在一定程度上侵占了Hadoop的大数据市场。
早期,云供应商只在IaaS上部署Hadoop,例如AWS EMR(号称是世界上部署最多的Hadoop集群)。对于用户来说,云上托管的Hadoop服务可以随时启动和停止,数据可以在云供应商的数据服务平台上安全备份,使用方便,节省成本。
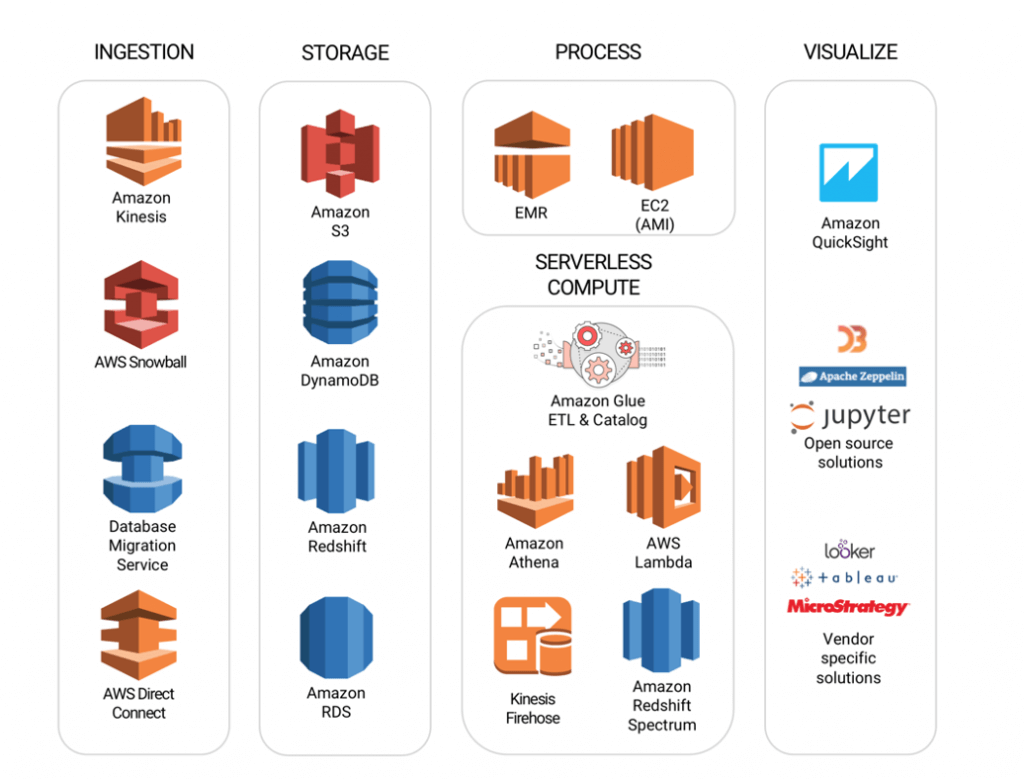
此外,云供应商为特定场景提供了一系列大数据服务,以形成一个完整的生态系统,如AWS S3实现的持久且低成本的数据存储、KV数据存储,以及Amazon DynamoDB实现的低延迟访问、分析大数据的无服务器查询服务Athena等。
检查Hadoop生态系统日益复杂的情况
除了不断提供新服务的新兴技术和云供应商,Hadoop本身也逐渐表现出“疲劳”。积木是一个不错的选择。然而,这增加了用户使用Hadoop生态系统组件的难度。
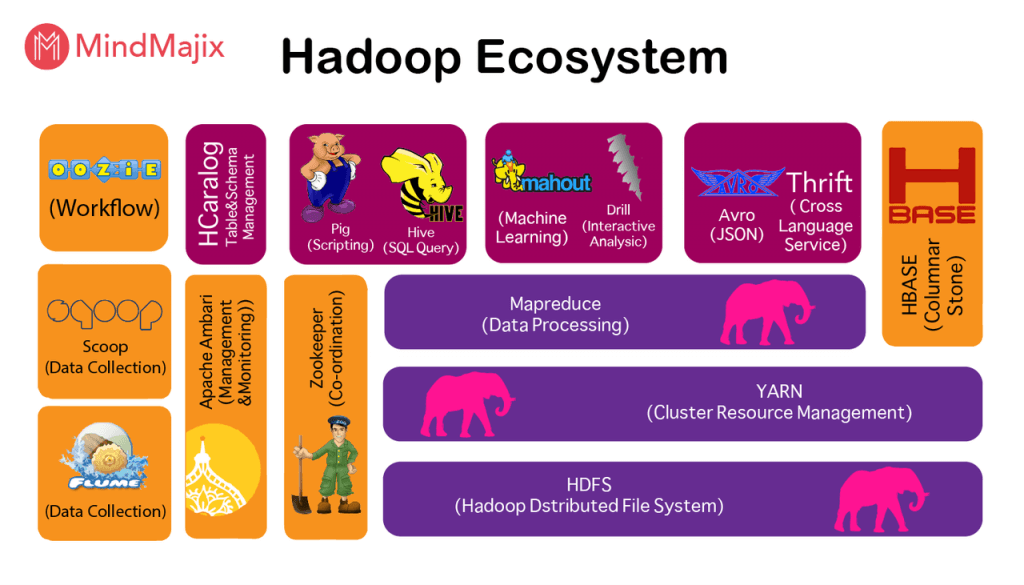
从上图中可以看出,Hadoop中已经有13个(如果不是更多的话)常用组件,这对Hadoop用户的学习和运维构成了巨大的挑战。
Cloudera和Hortonworks战略对Hadoop流行的影响

技术供应商Cloudera/Holtonworks无法在市场上发布高质量的免费产品。事实证明,他们早期的“免费版+付费版”双管齐下的方法行不通。Cloudera未来将只提供付费版的CDP,这标志着免费午餐的结束。目前还不知道其他制造商是否愿意提供免费产品。即使有这样一家制造商,其产品的稳定性和先进性仍然未知。毕竟,Hadoop的核心开发人员大多在Cloudera和Hortonworks工作。
Hadoop开源生态系统的不一致性分析
不要忘记Hadoop是Apache基金会托管的一个开源项目。Apache是为公共利益而设计的,公众可以免费获得、使用和分发。因此,如果你不想为此付费,有一个名为ApacheHadoop的选项可以免费使用。毕竟,大量的互联网公司仍然使用Apache Hadoop(按照他们的规模,只能使用开源版本)。如果他们可以,为什么我不能?
然而,开源软件质量一般,没有服务,也没有SLA保证。用户只能自己发现并解决问题。他们必须在社区中发布问题并等待结果。如果你对此没意见,那就雇佣几个工程师来尝试一下。顺便说一句,Hadoop开发或运维工程师很难雇佣,而且成本高昂。
超越Hadoop:探索大数据的替代解决方案
在后Hadoop时代,用户应该如何面对转型,他们可以选择什么?这完全取决于你有多少预算和你的技术能力。
后Hadoop市场技术供应商的关键成功因素
Hadoop生态系统中的供应商应该如何应对新时代?Apache Kylin和Kyligence的进化史就是一个很好的例子。
ApacheKylin项目和Kyligence都诞生于Hadoop时代。最初,所有Kyligence产品都运行在Hadoop上。大约4年前,Kyligence预见到客户需求正在慢慢转向云原生以及存储和计算的分离。
看到了这样的行业趋势,Kyligence对其原有的平台系统进行了大规模的改造。

2019年,Kyligence推出了Kyligence Cloud,并宣布脱离Hadoop平台。Kyligence Cloud在底层使用云原生架构,云供应商的对象存储服务,如AWS S3、ADLS等用于存储,Spark+容器化用于计算。它的资源可以直接连接到云平台上的IaaS服务和ECS。Kyligence不断扩展到多个云,并对架构进行微调,并于2021年宣布将ClickHouse等新技术合并到架构中。
改造后的体系结构带来了巨大的灵活性、可维护性和低TCO,并得到了市场的积极反馈。
技术供应商的关键成功因素(KSF)是在捕捉趋势和产品转型方面都要非常快速、敏感和大胆。
大数据和分析市场,尤其是在北美,已经成为一个非常热门和竞争激烈的市场,拥有其他行业无法与之竞争的非常敬业的投资者。供应商始终关注市场趋势,倾听用户的意见,观察他们的新需求,并根据这些输入不断迭代您的产品,这是非常重要的。
大数据和分析的未来趋势
技术将不断进步,肩负新使命的初创公司可能会来来去去,大公司仍有韧性。我写了一篇关于7个必知数据流行语的博客,并讨论了2022年的新兴趋势。为了简短起见,我只列出一些(而不是全部)研究过的有趣趋势,并与您分享一些关于它们的好文章:
- Metrics Store will rise as the ultimate solution to keep the “single source of truth” - The missing piece of the modern data stack
- The design concept of Data Mesh will continue to influence IT decision-makers - Whitepaper: The Data Mesh Shift
- Data API/Data-as-a-product is an abstract but real demand from the market - Every product will be a data product; Big Data, Cloud, AI, and Data Analytics Predictions for 2022
大数据分析中Apache Hadoop常见问题解答
我们涵盖了客户在Hadoop上分析大数据时经常提出的关键问题
Hadoop在大数据分析中的用途是什么?
Apache Hadoop是一个开源软件框架,用于大型数据集的分布式存储和处理。Hadoop在大数据分析中的主要作用包括高效处理大量数据,提供可扩展性、容错性和经济高效的解决方案。Hadoop还可以促进高级分析,如预测分析、数据挖掘和机器学习。
Apache Hadoop的核心组件和用例是什么?
Apache Hadoop的核心组件包括用于数据存储的Hadoop分布式文件系统(HDFS)、用于处理的MapReduce和用于资源管理的YARN。其主要用例涉及处理和存储海量数据集,进行大规模数据分析,以及支持医疗保健、金融、零售和电信等行业的高级数据驱动应用程序。
- 581 次浏览
大数据战略
【大数据】2022 年 10 项大数据和分析解决方案
2022 年将是大数据、人工智能和分析的分水岭,更多公司期待切实的业务成果。但从 IT 的角度来看,还有很多工作要做。以下是 IT 部门的 10 个新年大数据解决方案。
1. 建立数据保留政策
许多组织刚刚放弃了这个领域,完全避免了大数据保留的讨论。这可能是因为担心如果公司被迫为诉讼进行法律发现可能需要什么——但最有可能的是,由于没有人为它腾出时间,因此缺乏数据保留。
预计到 2025 年,全球数据将增长到 180 泽字节,而大数据占该数据的 80%,因此 2022 年是制定大数据保留政策并消除您不需要的数据的时候。
2. 定义大数据在数据结构中的作用
为了打破部门系统孤岛并将跨组织的数据提供给每个人进行分析和决策,IT 应该专注于将大数据以及更传统的结构化数据引入其构建的数据结构,以连接所有这些孤岛和存储库.
3. 开发更多无代码和低代码分析应用程序
为分析实施无代码和低代码报告工具可以更快地将更多分析报告交到最终用户手中,同时减轻 IT 工作量。
4. 重新评估已部署应用程序的商业价值
将分析应用程序投入生产是一件很棒的事情,但它现在是否像两年前首次部署时一样适用于业务?
业务不断变化。分析解决方案继续关注的内容与业务现在需要的内容之间必然存在“偏差”。
在 2022 年,有必要审查您当前部署的分析应用程序的有效性,以了解它们的性能以及它们是否仍能满足其设计的业务用例的需求。
5. 制定应用程序和数据维护策略
与结构化数据和应用程序一样,使用大数据和分析的那些也需要维护。然而,许多部署分析和大数据的组织并没有为维护锁定适当的程序。生产中的大数据和分析已经达到一定水平,应该开发和实践维护程序。
6. 提升 IT 技能
为了支持大数据运营和分析,员工需要新的 IT 技能。这可能需要数据分析、数据科学、大数据存储和处理管理方面的额外培训,以及使用新开发工具(如低代码和无代码分析)的能力。
7. 审查安全、隐私和可信来源
尤其是大数据可以从各种第三方来源获取。应定期审查这些来源是否符合公司安全和隐私标准,您自己的内部大数据也应如此。
8. 评估供应商对大数据和分析的支持
许多供应商提供用于大数据和分析的工具,但并非所有供应商都在您需要时提供相同程度的支持。与那些在使用大数据和分析工具方面为您的员工提供积极支持以及在关键项目期间提供指导的供应商合作非常重要。如果您正在与不提供您正在寻找的支持级别的供应商合作,建议找到提供支持的供应商。
9. 改进支持客户体验的大数据和分析
几乎每家公司都希望改善其客户的体验。这个过程的核心是开发面向客户的自动化和帮助帮助客户获取请求、问题和问题的答案。
使用 NLP(自然语言处理)和 AI(人工智能)来解释客户情绪和参与对话的面向客户的系统(例如聊天、电话服务员等)的自动化还远未成熟。
专注于在这些领域提高 NLP 和 AI 性能的公司将受益。
10. 更新顶部的大数据和分析讨论
当大数据和分析开始在组织中实施时,就开始了关于大数据和分析的第一次主要讨论。现在这些技术更加成熟,正在走向企业系统主流。 2022 年是 CIO 与其他 C 级高管和利益相关者重新召开会议以回顾 AI 和分析进展并确保他们对后续步骤的支持的好年头。
原文:https://www.techrepublic.com/article/10-big-data-and-analytics-resoluti…
本文
- 82 次浏览
【大数据】大数据已死,大数据分析万岁!
对于从金融服务和零售到制造和能源的几乎所有行业的企业来说,数据已成为最有价值的资产之一。在一项针对行业领导者的调查中,48.5% 的受访者表示,他们将在 2021 年利用数据推动所在行业的创新。
大数据是这一趋势的中心。该领域的重点是为传统数据处理软件无法处理的太大或复杂的数据集开发分析方法。
到 2022 年,全球大数据和商业分析市场的年收入预计将达到 2743 亿美元。
对于希望跟上数字经济和快速变化的市场现实的企业而言,大数据分析正在成为真正的游戏规则改变者。
为什么大数据数据分析如此重要?
1. 数据(和分析)的规模正在上升
每天,人类产生 2.5 万亿字节的新数据——移动性或物联网 (IoT) 等趋势推动了这一趋势。一个典型的组织在其运营中包括多个数字渠道——不仅是面向客户的渠道,如电子商务应用程序,还包括在生产和交付中发挥关键作用的后台系统。所有这些渠道都会产生数据。
为了利用这些数据,企业需要投资能够处理如此海量数据的专业大数据解决方案。否则,他们可能会错失建立竞争优势的机会(例如,为客户提供个性化体验)。
2. 数据是数据驱动业务转型的核心支柱
为了在市场上竞争并满足快速变化的客户需求,企业需要建立新的数字能力以提高数据驱动的成熟度。而每一次数据驱动的业务转型都依赖于组织收集、清理、处理和分析数据的能力。
根据 BCG 研究,2020 年,成功的数字化转型带来的收益增长比落后公司高出 180%。
3. 数据是 21 世纪的黄金
无论收入是如何产生的,企业都需要可靠的方法来收集、存储和管理。否则,他们无法改进业务流程以提供更好的结果。
不使用数据来深入了解其业务运作的公司将不会在现代数据驱动的世界中取得成功。他们需要了解数据才能在现代经济中蓬勃发展。
实施大数据分析的关键考虑因素
驾驭众多大数据技术具有挑战性
专家们使用三个带有独特技术挑战的“V”术语来定义大数据:
容量——海量数据集对处理、监控和存储提出了重大的技术要求。
速度——许多组织快速生成新数据,需要实时响应活动。大数据需要这种速度,尤其是涉及社交媒体平台、物联网和电子商务技术的公司。
多样性——在大数据中,数据格式的多样性带来了另一个挑战。大数据存储包括文字处理文档、电子邮件、演示文稿、图像、视频和其他格式。

云与本地数据生态系统
大数据采用计划涉及许多费用。其中之一是支持大数据分析的基础设施设置成本极高。
选择本地解决方案的组织需要承担硬件、劳动力(例如新的管理员和开发人员角色)、用于维护数据中心的实用程序以及新软件开发的成本。具有严格安全要求的组织通常会选择本地设置。
基于云的大数据解决方案需要聘请专家并为云服务付费,以及设置和维护大数据解决方案开发所需的框架。需要灵活性的公司通常会选择云。
混合选项可能是一种具有成本效益的解决方案。一些数据将在云中存储和处理,而其他数据则在本地。
通过适当的数据治理利用自助服务
在您的运营中实施自助数据分析而不考虑治理框架可能会成为一个代价高昂的错误。
如今,随着越来越多的政府通过新的法律来规范访问和处理,数据合规性已成为每家公司都感兴趣的问题。 GDPR 是关于数据访问和使用的最全面的法律之一。
如果没有明确的数据治理标准,很难验证企业是否违反合规法律。数据治理也会影响整体数据质量。如果没有适当的治理框架,自助数据分析平台最终可能会处理质量较差的数据。
大数据分析对组织意味着什么?
以下是企业如何利用大数据分析的潜力来提高运营效率并提高员工的生产力:
- 创造推动力——任何部门的任何团队都可以使用数据分析洞察力,为决策制定和采取行动奠定坚实的基础。
- 利用数据平台——团队可以通过用户友好的平台访问数据,从而实现数据驱动的业务转型。
- 开发分析环境——大数据分析可以成为企业分析环境的核心要素。
- 可视化洞察力——分析解决方案附带强大的可视化工具,可让非技术团队和利益相关者获得洞察力。
在每个支柱中提升您的团队的技能——数据分析为支持您的员工的专业发展提供了机会。
从大处着眼,从小处着手
忽略此类数据驱动的解决方案会关闭许多机会的大门——最重要的是,重新定义您的竞争优势。
了解您在数据分析之旅中的当前状况是重要的第一步。您的数据生态系统的成熟度是您当前在各个领域(从财务业绩到客户服务)取得成功的一个缩影。
由大数据分析领域的主题专家创建的数据驱动成熟度模型提供了数据成熟度级别的全面视图,使您能够确定数据生态系统中需要改进的关键领域。对于希望在所有团队中实施数据驱动决策的组织来说,这是必不可少的。
数据驱动成熟度模型的好处
了解高质量、全面的数据生态系统的组成部分。
- 从上到下调查数据驱动战略的每个基石。
- 确定重要的变革领域,以实现重大的短期收益。
- 进行差距分析并专注于满足完美框架的要求。
数据驱动成熟度模型带来的新机遇
智能数据管理
- 您的员工能否正确存储、交换和理解数据?
- 您的数据环境安全可靠吗?
了解有关您的数据保护计划的更多信息,并确保您的数据环境安全且符合您的政策和标准。
加强您的治理
- 您的企业准备好做出数据驱动的决策了吗?
- 数据故事团队是否可以访问安全且有弹性的 IT 生态系统?
检查您的生态系统中的政策、流程、任务和参与者是否可以帮助您避免数据沼泽。
提高团队的效率
- 员工是否有可能在评估数据的同时仍有创造力?
- 您的数据计划是否有助于他们提高工作效率?
检查您的员工是否可以自由、独立地访问、监控甚至更改数据,以便利用机器学习等尖端技术。
获得利益相关者的支持
- 是否所有利益相关者都同意数据管理策略?
- 团队对您的数据管理计划的信心如何?
确保数据环境具有一致的愿景和路径。允许数据驱动的决策并易于访问。
总结起来
大数据分析是现代组织数据驱动战略的基石。通过仔细查看您当前的数据成熟度级别,顺应这一趋势并拥抱数据的力量。
原文:https://bluesoft.com/big-data-is-dead-long-live-big-data-analytics/
- 90 次浏览
【大数据战略】公司如何使用大数据和分析
主要组织如何使用数据和分析来指导战略和运营决策?高级领导层提供了对挑战和机遇的洞察。
组织的数据比以往任何时候都有更多的争议。但是实际上从这些数据中获得有意义的见解,并将知识转化为行动 - 说起来容易一些。我们与主要机构的六位高级领导人进行了交谈,并询问了采用先进分析技术的挑战和机遇:AIG首席科学官Murli Buluswar。 GE软件首席信息官Vince Campisi;美国运通首席风险官Ash Gupta; eBay全球客户优化和数据副总裁Zoher Karu; AT&T大数据高级副总裁Victor Nilson;和凯撒娱乐公司首席分析官Ruben Sigala。他们的评论的编辑记录如下。
访谈剧本
组织在采用分析方面面临的挑战
AIG首席科学官Murli Buluswar:从知识文化向学习文化演变的最大挑战 - 从一种文化来看,这种文化在很大程度上取决于对决策的启发式,这种文化更客观和数据驱动,并拥抱数据和技术的力量真的不是成本。最初,它主要是想象力和惯性。
过去几年我学到的是,恐惧的力量在演变自己的思想和行为方面是非常巨大的,今天提出问题,我们以前没有问我们的角色。而这是一种思维方式的改变 - 从一个以专家为本的思维方式变得更加活跃,更加注重学习,而不是一种固定的思维方式 - 我认为这对任何公司的可持续健康至关重要,大,小或中等。
凯撒娱乐公司首席分析官Ruben Sigala:我们发现具有挑战性的是什么,在与许多我仍然面临挑战的同行讨论中,我发现了一些工具,使组织能够通过过程高效地产生价值。在某些应用中,我听到个人的胜利,但是拥有更多类型的凝聚力的生态系统,这完全融合在一起,是我认为我们都在努力的一部分,部分原因在于它还处于早期阶段。虽然在过去几年中我们一直在谈论似乎相当多,但技术仍在变化中。消息来源仍在不断发展。
全球客户优化和数据副总裁Zoher Karu,eBay:最大的挑战之一就是数据隐私,什么是共享的,而不是共享的。而我的观点是消费者愿意分享,如果有回报的价值。单向共享不会再飞了。那么我们如何保护我们如何利用这些信息,并成为与消费者的合作伙伴,而不仅仅是一个供应商呢?
从分析中获取影响
Ruben Sigala:你必须从组织的章程开始。您必须非常具体地了解组织内功能的目标以及如何与更广泛的业务进行互动。有一些组织从关于传统功能,如营销,定价和其他具体领域的支持开始。此外,还有其他组织对业务有更广泛的认识。我想你必须首先定义该元素。
这有助于最佳地通知适当的结构,论坛,然后最终设置更细致的操作水平,如培训,招聘等。但是,如何开展业务,以及与更广泛的组织进行互动的方式是绝对关键的。从那里,一切都应该排队。这就是我们如何开始我们的道路。
通用电气软件首席信息官文斯·坎皮西(Vince Campisi):我们学到的其中之一就是当我们开始关注结果时,这是快速实现价值并让人们兴奋的机会的好方法。而且我们把我们带到了前所未有的地方。所以我们可以去一个特定的结果,并尝试组织一个数据集来完成这个结果。一旦你这样做,人们开始带来其他数据源和其他想要连接的东西。而且,真正需要你去一个你以后没有预料到的下一个结果的地方。你必须愿意在你对事物的想法上有一点敏捷和流动。但是,如果你从一个结果开始并提供它,你会惊讶于下一步需要什么。
美国运通首席风险官Ash Gupta:我们必须做的第一个改变就是使我们的数据质量更高。我们有很多数据,有时我们只是没有使用这些数据,而且我们现在不需要像现在那样对其质量给予太多的关注。那就是一个,以确保数据具有正确的血统,数据具有正确的允许目的来为客户服务。在我看来,这是一个旅程。我们取得了很大的进步,我们期望在我们的系统上继续取得进展。
第二个领域是与我们的人民合作,确定我们正在集中我们业务的某些方面。我们正在集中我们的能力,我们正在使其使用民主化。我认为另一方面是我们将自己认为是一个团队,而作为一个公司,我们自己没有足够的技能,我们需要在美国运通以外的各种实体进行合作。这种合作来自技术创新者,来自数据提供商,来自分析公司。我们需要为我们的业务同事和合作伙伴提供一个完整的包装,这是一个令人信服的论据,我们正在共同开发的东西,我们正在学习,我们正在相互依托。
影响的例子
AT&T高级副总裁Victor Nilson表示:我们始终以顾客的经验开始。这是最重要的。在我们的客户服务中心,我们有很多非常复杂的产品。即使简单的产品有时候也有非常复杂的潜在问题或解决方案,所以工作流程非常复杂。那么,当有交互作用的时候,我们如何同时简化客户关怀代理和客户的流程呢?
我们使用大数据技术分析所有不同的排列,以增加体验,以更快地解决或增强特定情况。我们把复杂的东西变成一个简单和可操作的东西。同时,我们可以分析这些数据,然后回头说:“我们是否在这种特殊情况下主动优化网络?”因此,我们不仅要优化客户服务,还要优化网络,在一起也是。
文斯·坎皮西(Vince Campisi):我会给你一个内部的观点和一个外部的观点。一个是我们在所谓的数字线程中做了很多工作,如何通过工程,制造和一切方式将创新连接到服务产品。 [更多关于公司“数字线”的方法,请参见“GE的杰夫·伊梅尔特(Jeff Immelt)在工业领域的数字化”。在此之前,我们重点关注辉煌的工厂。所以以驱动供应链优化为例。我们已经能够收集60多个与直接材料采购有关的信息,利用分析来查看新的关系,并使用机器学习来确定如何采购直接材料进入我们的产品的巨大的效率。
外部的例子是我们如何利用分析来真正使资产表现更好。我们称之为资产绩效管理。而且,我们开始启用数字行业,如数字风电场,您可以利用分析来帮助机器优化自身。因此,您可以帮助一个发电厂商,他们使用相同的风力,通过让风力发电机正确调整并了解如何优化风力,我们已经展示出能够生产高达10%的风力生产能量相当的风量。这是使用分析来帮助客户从现有资本投资中获得更多收益和更高生产力的一个例子。
赢得人才战争
Ruben Sigala:分析人才的竞争是极端的。在组织内维护和维护人才的基础是困难的,特别是如果你认为这是一个核心竞争力。我们主要关注的是开发一个平台,说明我们认为是一个价值主张,对于正在开始职业或维持这一领域职业生涯的个人来说,这是一个重要的。
当我们谈论价值主张时,我们使用一些术语,如有机会真正影响业务成果,进行广泛的分析练习,定期受到挑战。但总的来说,要成为组织的一部分,认为这是组织在市场竞争中的关键部分,然后定期执行。在一定程度上,要做到这一点,你必须有良好的培训计划,你必须有一个非常具体的形式与高级团队的互动。而且您也必须是组织的一部分,实际上是推动公司的战略。
Murli Buluswar:我发现,专注于科学创造的基本原理,我们的愿望是什么,以及如何成为这个团队的一部分将塑造团队成员的职业发展已经相当深刻地吸引了人才的素质,关心。那么当然,在日常生活中,承诺的日子更加艰巨。
是的,钱很重要。我对金钱的理念是我想要在第75百分位数范围内;我不想在第99百分位数。因为无论你身在何方,大多数人 - 特别是数据科学界的人 - 如果他们选择采取行动,他们有能力增加20%到30%的薪酬。我的意图不是试图减少差距。我的意图是创造一个环境和文化,他们看到他们正在学习;他们看到他们正在努力解决对公司,行业和社会影响更广泛的问题。他们是一个充满活力的团队的一部分,其灵感来自于为什么它存在,以及它如何界定成功。关注这一点,对我而言,是吸引我所需要的人才素质的绝对关键的推动因素,对于这个问题,任何其他人都需要。
发展正确的专业知识
维克多尼尔森:人才是一切,对吧?你必须拥有数据,显然,AT&T拥有丰富的数据。但没有天赋,没有意义。人才是区分者。合适的人才会找到正确的技术;正确的人才会解决问题。
我们已经帮助开发许多在开源社区中出现的新技术做出了贡献。我们拥有来自实验室的先进技术,我们拥有新兴的硅谷。但我们也拥有全国各地的主流人才,我们拥有非常先进的工程师,我们拥有各级管理人员,我们希望进一步发展人才。
所以我们今年仅提供了超过50,000个大数据相关的培训课程。我们正在继续前进。这是一个整体的连续体。这可能只是一个星期的新兵训练营,或者可能是先进的PhD级数据科学。但是,我们希望继续发展那些有能力和兴趣的人才。我们希望确保他们能够发展自己的技能,然后将其与工具结合起来,以最大限度地提高生产力。
Zoher Karu:人才在任何数据和分析之旅中至关重要。在我看来,分析人才本身已经不够了。我们不能有单一技能的人。我建立组织的方式是寻找有大,小的人。你可以专业的分析,但你可以在营销策略中很少。因为如果你没有未成年人,你将如何与组织的其他部分沟通?否则,纯粹的数据科学家将无法与数据库管理员谈话,例如谁无法与市场研究人员谈话,谁将无法与电子邮件渠道所有者谈话。您需要根据可以扩展的分析做出正确的业务决策。
- 67 次浏览