【分布式架构】最终一致性:暗示的切换队列(Hinted Handoff Queue)
在这个博客系列中,我们将探讨最终的一致性,如果没有合适的词汇表,这个术语很难定义。这是许多分布式系统使用的一致性模型,包括XDB Enterprise Edition。为了理解最终的一致性,我们需要知道两个概念:暗示切换队列和反熵,这两个概念都需要特别注意。
第一部分
什么是暗示的切换队列?
尽管有一个很酷的名字,暗示切换(HH)队列并没有得到很多关注。HH队列有一项非常重要的工作,但是除非您是系统管理员,否则很少直接与它交互。让我们深入研究一下暗示的切换队列到底是什么,以及为什么它对您很重要。
为了讨论HH队列,我们必须稍微讨论一下分布式计算。像XDB Enterprise这样的系统作为分布式系统存在的一个原因是消除单点故障。InfluxDB Enterprise使用复制因子(Replication Factor,RF)来确定任何一组数据应该存在多少个副本。将RF设置为1以上意味着系统有更高的机会成功地为请求提供服务,并且在数据节点中断期间不会返回错误,这意味着我们不再只有一个可能丢失或不可用的数据副本。分布式系统也提出了独特的挑战:我们如何知道数据在整个系统中是一致的,尤其是在存储多个数据副本时?
首先,我们必须理解最终一致性所作的一些承诺。扰流板警报:系统中的数据最终必须一致。当我们从分布式系统请求信息时,有时我们收到的答案可能不会一致地返回。当数据在整个系统中存储和复制时,我们收到的答案有一些“漂移”,但随着时间的推移,这种“漂移”应该被消除。在实践中,这意味着最近的时间范围可能在其结果中具有最大的变化,但是这种变化被消除,因为系统通过确保在任何地方都可以获得相同信息的机制工作。

如果我们保证系统最终是一致的,我们如何解释失败的写入?数据节点离线的原因有很多,从磁盘空间耗尽到普通的旧硬件故障。如果一个节点在离线时丢失了数据点,它就永远不可能是一致的,因此,我们对最终一致性的承诺将变成谎言。
失败的写入也会影响整个系统的复制系数。维护指定的RF是我们必须遵守的另一个承诺,如果数据节点脱机,这也是写入的另一个可能的失败点。
例子
让我们研究一下最简单的示例:具有2个数据节点和一个RF=2的数据库的XDB Enterprise。数据通过某个收集代理(例如Telegraf)到达您喜爱的负载平衡器,负载平衡器将写操作(也读取,但在本例中我们将使用写操作)分发到底层数据节点。通常,负载平衡器以循环方式分发写操作。接收数据的数据节点存储并复制数据(将其发送到另一个数据节点),瞧:RF达到2。
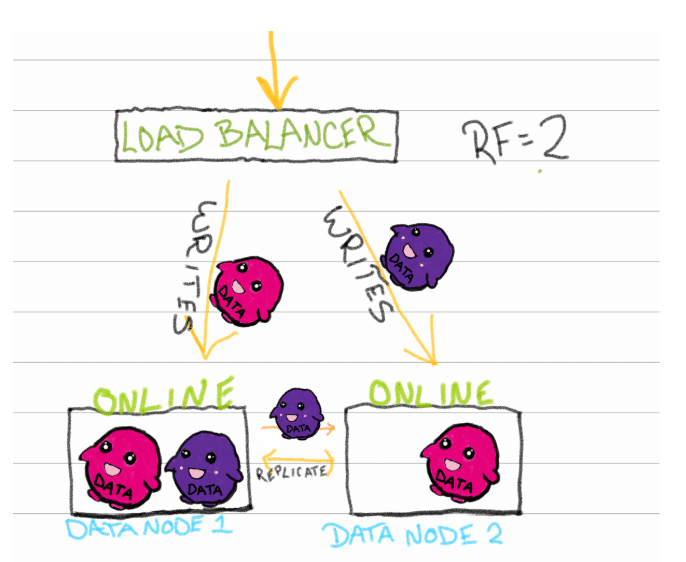
注意:图中未显示的是元节点,您可以在这里阅读。
我们仍然需要一个失败或延迟写入的解决方案。假设系统中的一个节点在物理上过热并离线。如果没有备份,任何不成功的写入都会被完全删除,再也看不到。
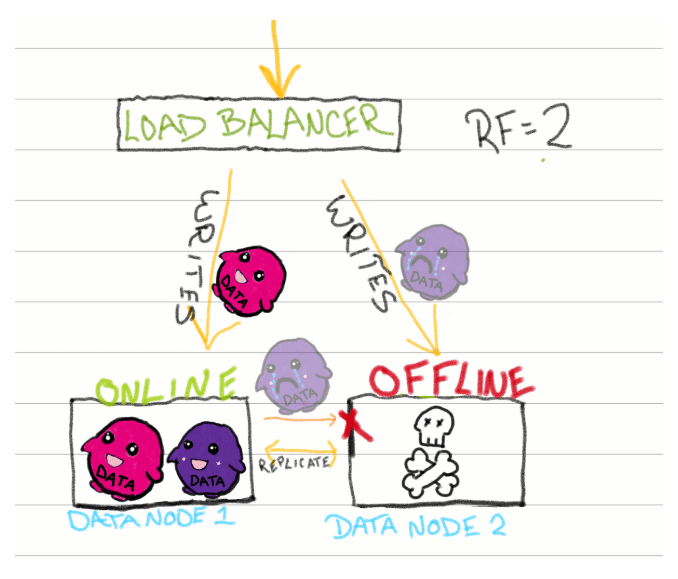
进入HH队列。
HH队列是一个持久的、基于磁盘的队列。它是XDB企业的一个基本部分,它试图确保最终的一致性,这是一种机制,确保所有的数据节点最终在它们之间拥有一组一致的数据。对于xdbenterprise,HH队列是实现最终一致性和确保最终实现每个数据库的数据复制因子的一个重要部分。
现在,让我们重温一下集群中的一个数据节点离线的场景。节点脱机的原因有很多:硬件缺陷、磁盘空间限制,甚至是定期维护。如果没有暗示的切换队列,不成功的写操作在存储之前就死了,但是现在我们有了一个安全的地方让它们着陆。
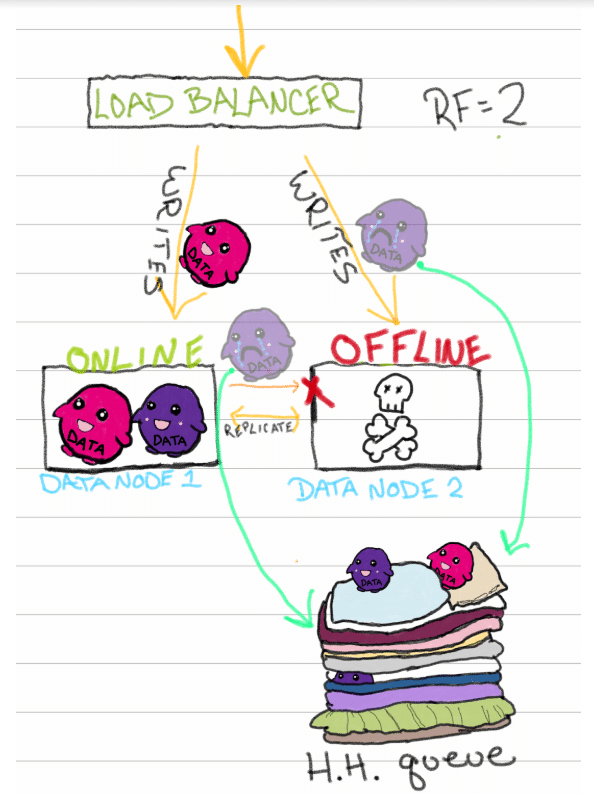
任何不成功的写入都会被定向到HH队列,当节点恢复联机时,它会检查HH队列中是否有挂起的写入。然后节点可以完成写操作,直到队列耗尽。Bam最终实现了一致性。
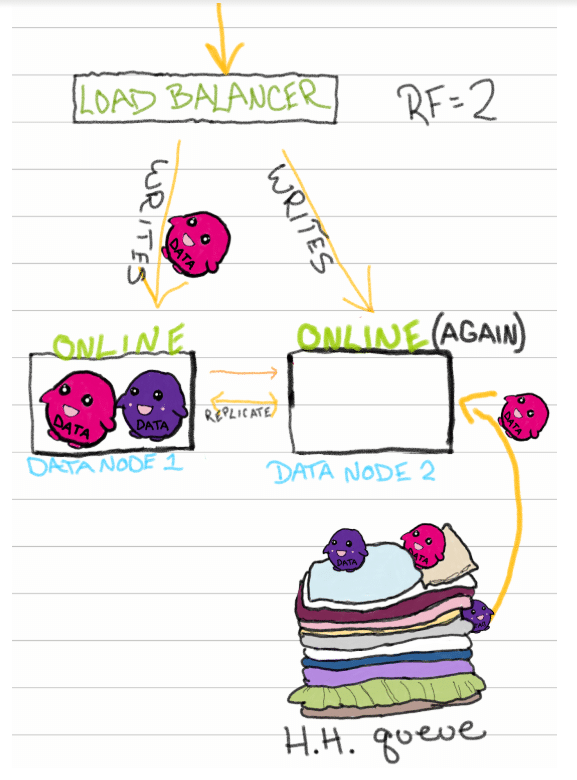
摘要
这是一个最终一致的集群内部发生的情况,但是外部有一些考虑因素:当数据成功写入一个节点,但无法正确复制时,用户看到成功还是失败?HH队列中的健康模式是什么样的?如果HH队列不断地充满和耗尽,对整个系统健康意味着什么?在下一篇文章中,我们将讨论如何解决和识别XDB企业集群中的问题模式。
原文:https://www.influxdata.com/blog/eventual-consistency-hhq/
本文:http://jiagoushi.pro/node/1454
讨论:请加入知识星球【首席架构师圈】或者微信【jiagoushi_pro】或者QQ群【11107777】
- 225 次浏览