云架构



【云应用架构】Azure 云设计模式概览
这些设计模式对于在云中构建可靠、可扩展、安全的应用程序很有用。
每个模式都描述了该模式解决的问题、应用该模式的注意事项以及一个基于 Microsoft Azure 的示例。 大多数模式都包含代码示例或代码片段,它们展示了如何在 Azure 上实现该模式。 但是,大多数模式都与任何分布式系统相关,无论是托管在 Azure 上还是其他云平台上。
云开发面临的挑战
数据管理
数据管理是云应用的关键要素,影响着大部分质量属性。出于性能、可扩展性或可用性等原因,数据通常托管在不同的位置并跨多个服务器,这可能会带来一系列挑战。例如,必须保持数据一致性,并且数据通常需要跨不同位置同步。
设计与实施
好的设计包括组件设计和部署的一致性和连贯性、简化管理和开发的可维护性以及允许组件和子系统在其他应用程序和其他场景中使用的可重用性等因素。在设计和实施阶段做出的决策对云托管应用程序和服务的质量和总拥有成本产生巨大影响。
消息
云应用程序的分布式特性需要一个连接组件和服务的消息传递基础架构,理想情况下以松散耦合的方式来最大化可扩展性。异步消息传递被广泛使用,并提供了许多好处,但也带来了诸如消息排序、毒消息管理、幂等性等挑战。
模式目录
- 177 次浏览
【云架构】Azure虚拟数据中心:网络透视图
概观
将本地应用程序迁移到Azure为组织提供了安全且经济高效的基础架构的优势,即使应用程序迁移的变化很小。但是,为了充分利用云计算的灵活性,企业必须改进其架构以利用Azure功能。
Microsoft Azure提供具有企业级功能和可靠性的超大规模服务和基础架构。这些服务和基础架构提供了多种混合连接选择,因此客户可以选择通过公共Internet或私有Azure ExpressRoute连接访问它们。 Microsoft合作伙伴还通过提供经过优化以在Azure中运行的安全服务和虚拟设备来提供增强功能。
客户可以选择通过互联网或Azure ExpressRoute访问这些云服务,Azure ExpressRoute提供专用网络连接。借助Microsoft Azure平台,客户可以将其基础架构无缝扩展到云中并构建多层架构。 Microsoft合作伙伴还通过提供经过优化以在Azure中运行的安全服务和虚拟设备来提供增强功能。
什么是虚拟数据中心?
从一开始,云就是一个托管面向公众的应用程序的平台。企业开始了解云的价值,并开始将内部业务线应用程序迁移到云端。这些类型的应用程序带来了额外的安全性,可靠性,性能和成本考虑因素,这需要在提供云服务方面提供额外的灵活性。这为旨在提供这种灵活性的新基础架构和网络服务铺平了道路,同时也为扩展,灾难恢复和其他考虑因素提供了新功能。
云解决方案最初设计用于在公共频谱中托管单个相对隔离的应用程序。这种方法运作良好几年。然后,云解决方案的好处变得明显,并且在云上托管了多个大规模工作负载。解决一个或多个区域中部署的安全性,可靠性,性能和成本问题在整个云服务生命周期中变得至关重要。
以下云部署图显示了红色框中的安全间隙示例。黄色框显示了跨工作负载优化网络虚拟设备的空间。

虚拟数据中心(VDC)的概念源于扩展以支持企业工作负载的必要性,同时平衡处理在公共云中支持大规模应用程序时引入的问题的需求。
VDC实施不仅代表云中的应用程序工作负载,还代表网络,安全性,管理和基础架构(例如,DNS和目录服务)。随着越来越多的企业工作负载转移到Azure,重要的是要考虑这些工作负载所依赖的支持基础架构和对象。仔细考虑资源的结构可以避免必须管理的数百个“工作负载孤岛”的扩散分别具有独立的数据流,安全模型和合规性挑战。
VDC概念是一组建议和最佳实践,用于实现具有共同支持功能,特性和基础结构的单独但相关的实体的集合。通过VDC的镜头查看您的工作负载,您可以实现由于规模经济而降低的成本,通过组件和数据流集中优化的安全性,以及更轻松的操作,管理和合规性审计。
注意
重要的是要了解VDC不是一个独立的Azure产品,而是各种功能和功能的组合,以满足您的确切要求。 VDC是一种考虑您的工作负载和Azure使用情况的方法,可以最大限度地提高云中的资源和功能。这是一种在Azure中构建IT服务的模块化方法,同时尊重企业的组织角色和职责。
VDC实施可以帮助企业在以下方案中将工作负载和应用程序迁移到Azure中:
- 托管多个相关工作负载。
- 将工作负载从本地环境迁移到Azure。
- 跨工作负载实施共享或集中的安全性和访问要求。
- 为大型企业适当地混合Azure DevOps和集中式IT。
解锁VDC优势的关键是集中式中心和分支网络拓扑结构,其中包含Azure服务和功能:
- Azure Virtual Network,
- Network security groups,
- Virtual network peering,
- User-defined routes, and
- Azure Identity with role-based access control (RBAC) and optionally Azure Firewall, Azure DNS, Azure Front Door, and Azure Virtual WAN.
谁应该实施虚拟数据中心?
任何决定采用云的Azure客户都可以从配置一组资源的效率中受益,供所有应用程序共同使用。根据规模,即使是单个应用程序也可以从使用用于构建VDC实现的模式和组件中受益。
如果您的组织拥有用于IT,网络,安全性或合规性的集中式团队或部门,那么实施VDC可以帮助实施策略点,职责分离,并确保底层公共组件的一致性,同时为应用程序团队提供尽可能多的自由和控制。适合您的要求。
正在寻找DevOps的组织也可以使用VDC概念来提供授权的Azure资源,并确保他们在该组内具有完全控制权(公共订阅中的订阅或资源组),但网络和安全边界保持合规通过集线器VNet和资源组中的集中策略。
实施虚拟数据中心的注意事项
在设计VDC实施时,需要考虑几个关键问题:
身份和目录服务
身份和目录服务是所有数据中心的关键方面,包括本地和云。身份与VDC实施中的服务访问和授权的所有方面相关。为帮助确保只有授权用户和进程访问Azure帐户和资源,Azure使用多种类型的凭据进行身份验证。其中包括密码(访问Azure帐户),加密密钥,数字签名和证书。 Azure多重身份验证是访问Azure服务的附加安全层。多重身份验证通过一系列简单的验证选项(电话,短信或移动应用程序通知)提供强大的身份验证,并允许客户选择他们喜欢的方法。
任何大型企业都需要定义身份管理流程,该流程描述VDC实施内部或跨VDC实施的个人身份,身份验证,授权,角色和权限的管理。此过程的目标应该是提高安全性和生产力,同时降低成本,停机时间和重复的手动任务。
企业组织可能需要针对不同业务线的高要求的服务组合,并且员工在涉及不同项目时通常具有不同的角色。 VDC要求不同团队之间的良好合作,每个团队都有特定的角色定义,以使系统运行良好的治理。责任,访问和权利矩阵可能很复杂。 VDC中的身份管理是通过Azure Active Directory(Azure AD)和基于角色的访问控制(RBAC)实现的。
目录服务是一种共享信息基础结构,用于定位,管理,管理和组织日常项目和网络资源。这些资源可以包括卷,文件夹,文件,打印机,用户,组,设备和其他对象。目标服务器将网络上的每个资源视为对象。有关资源的信息存储为与该资源或对象关联的属性的集合。
所有Microsoft在线业务服务都依赖Azure Active Directory(Azure AD)来登录和其他身份需求。 Azure Active Directory是一种全面,高度可用的身份和访问管理云解决方案,它结合了核心目录服务,高级身份管理和应用程序访问管理。 Azure AD可以与本地Active Directory集成,以便为所有基于云和本地托管的本地应用程序启用单点登录。本地Active Directory的用户属性可以自动同步到Azure AD。
单个全局管理员不需要在VDC实现中分配所有权限。相反,目录服务中的每个特定部门,用户组或服务都可以拥有在VDC实施中管理自己的资源所需的权限。构建权限需要平衡。权限过多会影响性能效率,权限过少或松散会增加安全风险。 Azure基于角色的访问控制(RBAC)通过为VDC实施中的资源提供细粒度的访问管理,有助于解决此问题。
安全基础设施
安全基础结构是指VDC实现的特定虚拟网段中的流量隔离。该基础结构指定了如何在VDC实现中控制入口和出口。 Azure基于多租户架构,可通过使用VNet隔离,访问控制列表(ACL),负载平衡器,IP过滤器和流量策略来防止部署之间的未授权和无意的流量。网络地址转换(NAT)将内部网络流量与外部流量分开。
Azure结构将基础架构资源分配给租户工作负载,并管理与虚拟机(VM)之间的通信。 Azure虚拟机管理程序强制虚拟机之间的内存和进程分离,并安全地将网络流量路由到客户操作系统租户。
连接到云
VDC实施需要连接到外部网络,以便为客户,合作伙伴和/或内部用户提供服务。这种连接需求不仅指互联网,还指本地网络和数据中心。
客户通过使用Azure防火墙或其他类型的虚拟网络设备(NVA),使用用户定义的路由的自定义路由策略以及使用网络安全组的网络过滤来控制哪些服务可以访问并可从公共Internet访问。我们建议所有面向Internet的资源也受Azure DDoS保护标准的保护。
企业可能需要将其VDC实施连接到本地数据中心或其他资源。在设计有效的体系结构时,Azure与本地网络之间的这种连接是一个至关重要的方面。企业有两种不同的方式来创建这种互连:通过互联网传输或通过私人直接连接。
Azure站点到站点VPN是通过安全加密连接(IPsec / IKE隧道)建立的本地网络和VDC实施之间的Internet上的互连服务。 Azure站点到站点的连接非常灵活,可以快速创建,并且不需要任何进一步的采购,因为所有连接都通过Internet连接。
对于大量VPN连接,Azure虚拟WAN是一种网络服务,可通过Azure提供优化的自动分支到分支连接。虚拟WAN允许您连接和配置分支设备以与Azure通信。连接和配置可以手动完成,也可以通过虚拟WAN伙伴使用首选提供商设备完成。使用首选提供程序设备可以简化使用,简化连接和配置管理。 Azure WAN内置仪表板提供即时故障排除洞察,可帮助您节省时间,并为您提供查看大规模站点到站点连接的简便方法。
ExpressRoute是一种Azure连接服务,可在VDC实施与任何本地网络之间实现专用连接。 ExpressRoute连接不会通过公共Internet,提供更高的安全性,可靠性和更高的速度(高达10 Gbps)以及一致的延迟。 ExpressRoute对VDC实施非常有用,因为ExpressRoute客户可以获得与私有连接相关的合规性规则的好处。使用ExpressRoute Direct,您可以以100 Gbps的速度直接连接到Microsoft路由器,以满足具有更大带宽需求的客户。
部署ExpressRoute连接通常涉及与ExpressRoute服务提供商合作。对于需要快速启动的客户,通常最初使用站点到站点VPN在VDC实施和本地资源之间建立连接,然后在与服务提供商的物理互连完成后迁移到ExpressRoute连接。
云中的连接
VNets和VNet对等是VDC实现中的基本网络连接服务。 VNet保证了VDC资源的自然隔离边界,VNet对等允许同一Azure区域内甚至跨区域的不同VNets之间的相互通信。 VNet内部和VNets之间的流量控制需要匹配通过访问控制列表(网络安全组),网络虚拟设备和自定义路由表(用户定义的路由)指定的一组安全规则。
虚拟数据中心概述
拓扑
Hub and spoke是用于为虚拟数据中心实现设计网络拓扑的模型。
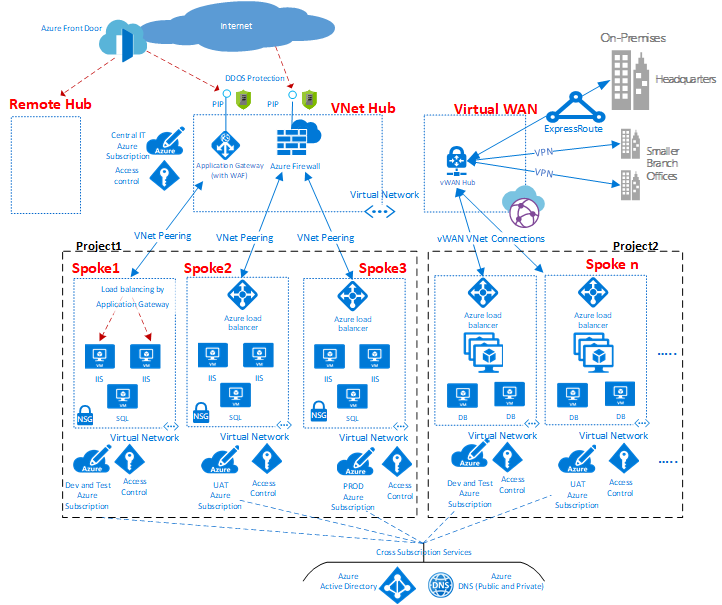
如图所示,Azure中可以使用两种类型的中心和辐条设计。用于通信,共享资源和集中安全策略(图中的VNet Hub),或虚拟WAN类型(图中的虚拟WAN),用于大规模分支到分支和分支到Azure通信。
集线器是中央网络区域,用于控制和检查不同区域之间的入口或出口流量:互联网,内部部署和辐条。中心和分支拓扑为IT部门提供了一种在中央位置实施安全策略的有效方法。它还可以减少错误配置和暴露的可能性。
集线器通常包含辐条消耗的公共服务组件。以下示例是常见的中央服务:
- Windows Active Directory基础结构,用于对从不受信任的网络访问的第三方进行用户身份验证,然后才能访问分支中的工作负载。它包括相关的Active Directory联合身份验证服务(AD FS)。
- 一种DNS服务,用于解析辐条中工作负载的命名,如果未使用Azure DNS,则访问本地和Internet上的资源。
- 公钥基础结构(PKI),用于在工作负载上实现单点登录。
- 辐条网络区域和互联网之间的TCP和UDP流量的流量控制。
- 辐条和内部部署之间的流量控制。
- 如果需要,可以在一个辐条和另一个辐条之间进
VDC通过在多个辐条之间使用共享中心基础设施来降低总体成本。
每个辐条的角色可以是托管不同类型的工作负载。辐条还提供了一种模块化方法,可以重复部署相同的工作负载。例如开发和测试,用户验收测试,预生产和生产。辐条还可以隔离并启用组织内的不同组。 Azure DevOps组就是一个例子。在辐条内部,可以部署基本工作负载或复杂的多层工作负载,并在层之间进行流量控制。
订阅限制和多个集线器
在Azure中,每个组件(无论何种类型)都部署在Azure订阅中。在不同Azure订阅中隔离Azure组件可以满足不同LOB的要求,例如设置差异化的访问和授权级别。
单个VDC实施可以扩展到大量辐条,但是,与每个IT系统一样,存在平台限制。中心部署绑定到特定的Azure订阅,该订阅具有限制和限制(例如,最大数量的VNet对等;有关详细信息,请参阅Azure订阅和服务限制,配额和约束)。在限制可能成为问题的情况下,通过将模型从单个集线器辐条扩展到集线器和辐条集群,架构可以进一步扩展。可以使用VNet对等,ExpressRoute,虚拟WAN或站点到站点VPN来连接一个或多个Azure区域中的多个集线器。

多个集线器的引入增加了系统的成本和管理工作量。只有通过可扩展性,系统限制或冗余以及最终用户性能或灾难恢复的区域复制才能证明这一点。在需要多个集线器的场景中,所有集线器都应努力提供相同的服务集,以便于操作。
辐条之间的互连
在单个辐条中,可以实现复杂的多层工作负载。可以使用同一VNet中的子网(每个层一个)实现多层配置,并使用网络安全组过滤流。
架构师可能希望跨多个虚拟网络部署多层工作负载。通过虚拟网络对等,辐条可以连接到同一集线器或不同集线器中的其他辐条。此方案的典型示例是应用程序处理服务器位于一个辐条或虚拟网络中的情况。数据库部署在不同的辐条或虚拟网络中。在这种情况下,很容易将辐条与虚拟网络对等互连,从而避免通过集线器进行转换。应执行仔细的体系结构和安全性检查,以确保绕过集线器不会绕过可能仅存在于集线器中的重要安全性或审核点。
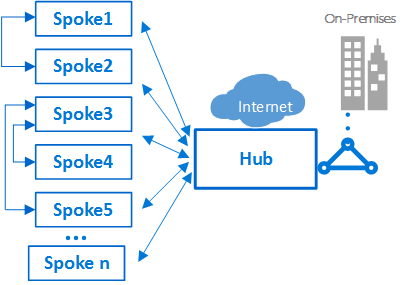
辐条也可以与作为集线器的辐条互连。此方法创建两级层次结构:较高级别(级别0)的轮辐成为层次结构的较低轮辐(级别1)的中心。 VDC实施的辐条需要将流量转发到中央集线器,以便流量可以在本地网络或公共互联网中传输到其目的地。具有两级集线器的体系结构引入了复杂的路由,消除了简单的集线器 - 辐条关系的好处。
虽然Azure允许复杂的拓扑结构,但VDC概念的核心原则之一是可重复性和简单性。为了最大限度地减少管理工作,简单的中心辐条设计是我们推荐的VDC参考架构。
组件
虚拟数据中心由四种基本组件类型组成:基础架构,外围网络,工作负载和监控。
每种组件类型都包含各种Azure功能和资源。您的VDC实现由多个组件类型的实例和相同组件类型的多个变体组成。例如,您可能有许多不同的,逻辑上分离的工作负载实例,它们代表不同的应用程序。您可以使用这些不同的组件类型和实例来最终构建VDC。
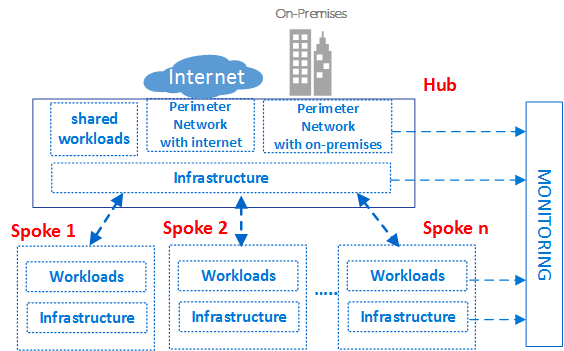
前面的VDC高级概念体系结构显示了在轮辐辐射拓扑的不同区域中使用的不同组件类型。该图显示了体系结构各个部分中的基础结构组件。
作为一般的良好实践,访问权限和特权应该是基于组的。处理组而不是单个用户可以通过提供跨团队管理它的一致方式来简化访问策略的维护,并有助于最大限度地减少配置错误。在适当的组中分配和删除用户有助于使特定用户的权限保持最新。
每个角色组的名称都应该有唯一的前缀。此前缀可以轻松识别哪个组与哪个工作负载相关联。例如,托管身份验证服务的工作负载可能具有名为AuthServiceNetOps,AuthServiceSecOps,AuthServiceDevOps和AuthServiceInfraOps的组。集中角色或与特定服务无关的角色可能以公司为前提。例如CorpNetOps。
许多组织使用以下组的变体来提供角色的主要细分:
- 中央IT集团Corp拥有控制基础架构组件的所有权。网络和安全性的例子。该组需要在订阅,控制中心以及辐条中的网络参与者权限方面担任贡献者。大型组织经常在多个团队之间分配这些管理职责。例如,网络运营CorpNetOps小组专门关注网络和安全运营CorpSecOps小组负责防火墙和安全策略。在这种特定情况下,需要创建两个不同的组来分配这些自定义角色。
- 开发测试组AppDevOps负责部署应用程序或服务工作负载。该组担任IaaS部署或一个或多个PaaS贡献者角色的虚拟机贡献者角色。请参阅Azure资源的内置角色。可选地,开发/测试团队可能需要对集线器内的安全策略(网络安全组)和路由策略(用户定义的路由)或特定辐条进行可见性。除了工作负载的贡献者角色之外,该组还需要网络阅读器的角色。
- 运营和维护组CorpInfraOps或AppInfraOps负责管理生产中的工作负载。该组需要成为任何生产订阅中的工作负载的订阅贡献者。一些组织还可能评估他们是否需要一个额外的升级支持团队组,其中包括生产中的订阅贡献者和中心中心订阅。附加组修复了生产环境中的潜在配置问题。
VDC的设计使得为管理集线器的中央IT组创建的组在工作负载级别具有相应的组。除了仅管理中心资源外,中央IT组还能够控制订阅的外部访问和顶级权限。工作负载组还能够独立于中央IT控制其VNet的资源和权限。
VDC被分区以跨不同的业务线(LOB)安全地托管多个项目。所有项目都需要不同的隔离环境(Dev,UAT,生产)。针对每个环境的单独Azure订阅提供了自然隔离。
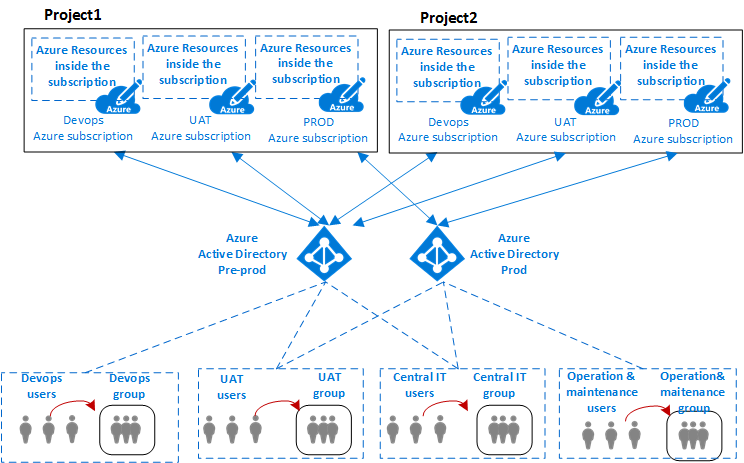
上图显示了组织的项目,用户和组与部署Azure组件的环境之间的关系。
通常在IT中,环境(或层)是部署和执行多个应用程序的系统。大型企业使用开发环境(进行更改和测试)和生产环境(最终用户使用的环境)。这些环境是分开的,通常在它们之间有几个暂存环境,以便在出现问题时允许分阶段部署(部署),测试和回滚。部署体系结构差别很大,但通常仍然遵循从开发(DEV)开始到生产结束(PROD)的基本过程。
这些类型的多层环境的通用体系结构包括用于开发和测试的Azure DevOps,用于分段的UAT和生产环境。组织可以利用单个或多个Azure AD租户来定义对这些环境的访问权限。上图显示了使用两个不同Azure AD租户的情况:一个用于Azure DevOps和UAT,另一个用于生产。
不同Azure AD租户的存在会强制实现环境之间的分离。同一组用户(例如中央IT)需要使用不同的URI进行身份验证,以访问不同的Azure AD租户,以修改Azure DevOps或项目的生产环境的角色或权限。访问不同环境的不同用户身份验证的存在减少了由人为错误导致的可能中断和其他问题。
组件类型:基础设施
此组件类型是大多数支持基础结构所在的位置。这也是您的集中式IT,安全和合规团队花费大部分时间的地方。
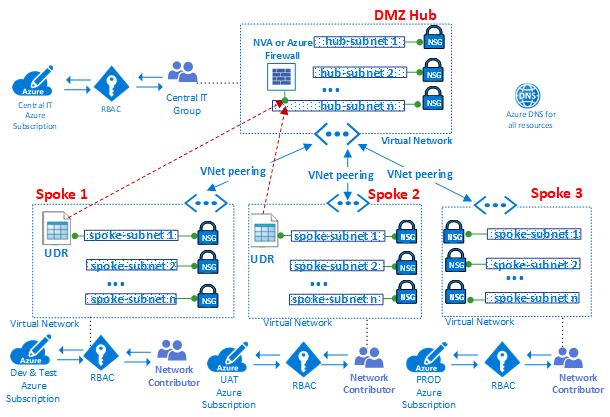
基础设施组件为VDC实施的不同组件提供互连,并且存在于集线器和辐条中。管理和维护基础架构组件的责任通常分配给中央IT和/或安全团队。
IT基础架构团队的主要任务之一是保证整个企业中IP地址架构的一致性。分配给VDC实施的专用IP地址空间必须一致,且不与内部部署网络上分配的专用IP地址重叠。
虽然本地边缘路由器或Azure环境中的NAT可以避免IP地址冲突,但它会增加基础架构组件的复杂性。管理的简单性是VDC的关键目标之一,因此使用NAT来处理IP问题并不是一种推荐的解决方案。
基础架构组件具有以下功能:
- 身份和目录服务。 Azure中对每种资源类型的访问权限由存储在目录服务中的标识控制。目录服务不仅存储用户列表,还存储特定Azure订阅中资源的访问权限。这些服务可以仅存在于云中,也可以与存储在Active Directory中的本地标识同步。
- 虚拟网络。虚拟网络是VDC的主要组件之一,使您能够在Azure平台上创建流量隔离边界。虚拟网络由单个或多个虚拟网段组成,每个网段都有一个特定的IP网络前缀(子网)。虚拟网络定义了一个内部周边区域,IaaS虚拟机和PaaS服务可以在其中建立私人通信。一个虚拟网络中的VM(和PaaS服务)无法直接与不同虚拟网络中的VM(和PaaS服务)通信,即使两个虚拟网络都是由同一客户在同一订阅下创建的。隔离是一项关键属性,可确保客户虚拟机和通信在虚拟网络中保持私密。
- 用户定义的路由。默认情况下,基于系统路由表路由虚拟网络中的流量。用户定义的路由是自定义路由表,网络管理员可以将其关联到一个或多个子网,以覆盖系统路由表的行为并定义虚拟网络中的通信路径。用户定义路由的存在可确保来自分支的出口流量通过特定的自定义VM或网络虚拟设备以及集线器和辐条中存在的负载平衡器进行传输。
- 网络安全组。网络安全组是一组安全规则,用作IP源,IP目标,协议,IP源端口和IP目标端口的流量过滤。网络安全组可以应用于子网,与Azure VM关联的虚拟NIC卡,或两者。网络安全组对于在集线器和辐条中实施正确的流量控制至关重要。网络安全组提供的安全级别是您打开的端口以及用于何种目的的功能。客户应该使用基于主机的防火墙(如IPtables或Windows防火墙)应用其他每个VM过滤器。
- DNS。 VDC实施的VNets中的资源名称解析通过DNS提供。 Azure为公共和专用名称解析提供DNS服务。专用区域在虚拟网络和虚拟网络中提供名称解析。您可以让私有区域不仅跨越同一区域中的虚拟网络,还跨越区域和订阅。对于公共解决方案,Azure DNS为DNS域提供托管服务,使用Microsoft Azure基础结构提供名称解析。通过在Azure中托管您的域,您可以使用与其他Azure服务相同的凭据,API,工具和计费来管理DNS记录。
- 订阅和资源组管理。订阅定义了在Azure中创建多组资源的自然边界。订阅中的资源在名为“资源组”的逻辑容器中组合在一起。资源组表示组织VDC实现资源的逻辑组。
- RBAC。通过RBAC,可以映射组织角色以及访问特定Azure资源的权限,从而允许您将用户限制为仅某个操作子集。使用RBAC,您可以通过为相关范围内的用户,组和应用程序分配适当的角色来授予访问权限。角色分配的范围可以是Azure订阅,资源组或单个资源。 RBAC允许继承权限。在父作用域中分配的角色也授予对其中包含的子项的访问权限。使用RBAC,您可以分离职责并仅授予他们执行工作所需的用户访问权限。例如,使用RBAC让一个员工管理订阅中的虚拟机,而另一个员工可以管理同一订阅中的SQL DB。
- VNet对等。用于创建VDC基础结构的基本功能是VNet Peering,这是一种通过Azure数据中心网络连接同一区域中的两个虚拟网络(VNets)的机制,或跨区域使用Azure全球主干网的机制。
组件类型:周边网络
外围网络组件支持本地或物理数据中心网络之间的网络连接,以及与Internet之间的任何连接。这也是您的网络和安全团队可能花费大部分时间的地方。
传入数据包应在到达辐条中的后端服务器之前流经集线器中的安全设备。例如防火墙,IDS和IPS。在离开网络之前,来自工作负载的互联网数据包也应该流经外围网络中的安全设备。此流程的目的是策略执行,检查和审计。
外围网络组件提供以下功能:
- 虚拟网络,用户定义的路由和网络安全组
- 网络虚拟设备
- Azure负载均衡器
- 具有Web应用程序防火墙(WAF)的Azure应用程序网关
- 公共知识产权
- Azure前门与Web应用程序防火墙(WAF)
- Azure防火墙
通常,中央IT和安全团队负责外围网络的需求定义和操作。
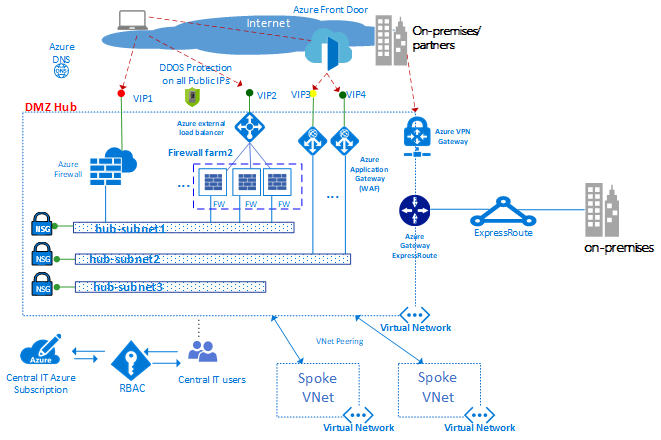
上图显示了两个可以访问互联网和本地网络的周边的强制执行,两者都驻留在DMZ中心。在DMZ中心,使用Web应用防火墙(WAF)和/或Azure防火墙的多个服务器场,可以扩展到Internet的外围网络以支持大量LOB。在集线器中还允许根据需要通过VPN或ExpressRoute进行连接。
- 虚拟网络。集线器通常构建在具有多个子网的虚拟网络上,以托管不同类型的服务,这些服务通过NVA,WAF和Azure应用程序网关实例过滤和检查进出互联网的流量。
- 用户定义的路由使用用户定义的路由,客户可以部署防火墙,IDS / IPS和其他虚拟设备,并通过这些安全设备路由网络流量,以实施安全边界策略,审计和检查。可以在集线器和辐条中创建用户定义的路由,以保证流量通过VDC实施使用的特定自定义VM,网络虚拟设备和负载平衡器进行转换。为了保证驻留在分支中的虚拟机生成的流量转移到正确的虚拟设备,需要在分支的子网中设置用户定义的路由,方法是将内部负载均衡器的前端IP地址设置为下一个-跳。内部负载均衡器将内部流量分配给虚拟设备(负载均衡器后端池)。
- Azure防火墙是一种托管的,基于云的网络安全服务,可保护您的Azure虚拟网络资源。它是一个完全状态的防火墙,具有内置的高可用性和不受限制的云可扩展性。您可以跨订阅和虚拟网络集中创建,实施和记录应用程序和网络连接策略。 Azure防火墙为您的虚拟网络资源使用静态公共IP地址。它允许外部防火墙识别源自您的虚拟网络的流量。该服务与Azure Monitor完全集成,用于记录和分析。
- 网络虚拟设备。在集线器中,可访问Internet的外围网络通常通过Azure防火墙实例或防火墙或Web应用程序防火墙(WAF)进行管理。
- 不同的LOB通常使用许多Web应用程序。这些应用程序往往遭受各种漏洞和潜在的攻击。 Web应用程序防火墙是一种特殊类型的产品,用于检测针对Web应用程序(HTTP / HTTPS)的攻击,比通用防火墙更深入。与传统防火墙技术相比,WAF具有一组保护内部Web服务器免受威胁的特定功能。
- Azure防火墙或NVA防火墙都使用通用管理平面,具有一组安全规则来保护辐条中托管的工作负载,并控制对本地网络的访问。 Azure防火墙内置可扩展性,而NVA防火墙可以在负载均衡器后面手动扩展。通常,与WAF相比,防火墙场具有较少的专用软件,但具有更广泛的应用范围,可以过滤和检查出口和入口中的任何类型的流量。如果使用NVA方法,则可以从Azure市场中找到并部署它们。
- 对于源自Internet的流量使用一组Azure防火墙(或NVA),对于源自本地的流量使用另一组Azure防火墙(或NVA)。两者仅使用一组防火墙是一种安全风险,因为它在两组网络流量之间不提供安全边界。使用单独的防火墙层可以降低检查安全规则的复杂性,并明确哪些规则对应于哪个传入网络请求。
- 我们建议您使用一组Azure防火墙实例或NVA来处理源自Internet的流量。使用另一个用于源自本地的流量。两者仅使用一组防火墙是一种安全风险,因为它在两组网络流量之间不提供安全边界。使用单独的防火墙层可降低检查安全规则的复杂性,并明确哪些规则对应于哪个传入网络请求。
- Azure负载均衡器提供高可用性第4层(TCP,UDP)服务,该服务可以在负载平衡集中定义的服务实例之间分配传入流量。从前端端点(公共IP端点或专用IP端点)发送到负载均衡器的流量可以通过或不使用地址转换重新分配到一组后端IP地址池(例如网络虚拟设备或VM)。
- Azure负载均衡器也可以探测各种服务器实例的运行状况,当实例无法响应探测时,负载均衡器会停止向不正常的实例发送流量。在VDC中,外部负载平衡器部署到集线器和辐条。在集线器中,负载平衡器用于有效地将流量路由到辐条中的服务,并且在辐条中,负载平衡器用于管理应用程序流量。
- Azure Front Door(AFD)是Microsoft高度可用且可扩展的Web应用程序加速平台,全局HTTP负载均衡器,应用程序保护和内容交付网络。 AFD在Microsoft全球网络边缘的100多个位置运行,使您能够构建,操作和扩展动态Web应用程序和静态内容。 AFD为您的应用程序提供世界一流的最终用户性能,统一的区域/邮票维护自动化,BCDR自动化,统一的客户端/用户信息,缓存和服务洞察。该平台提供Azure本地开发,运营和支持的性能,可靠性和支持SLA,合规性认证和可审计安全实践。
- 应用程序网关Microsoft Azure应用程序网关是一种专用虚拟设备,提供应用程序交付控制器(ADC)即服务,为您的应用程序提供各种第7层负载平衡功能。它允许您通过将CPU密集型SSL终止卸载到应用程序网关来优化Web场的生产力。它还提供其他第7层路由功能,包括传入流量的循环分配,基于cookie的会话关联,基于URL路径的路由,以及在单个Application Gateway后面托管多个网站的功能。 Web应用程序防火墙(WAF)也作为应用程序网关WAF SKU的一部分提供。此SKU为Web应用程序提供保护,使其免受常见Web漏洞和漏洞攻击。 Application Gateway可以配置为面向Internet的网关,仅内部网关或两者的组合。
- 公共知识产权。使用某些Azure功能,您可以将服务端点关联到公共IP地址,以便可以从Internet访问您的资源。此端点使用网络地址转换(NAT)将流量路由到Azure虚拟网络上的内部地址和端口。此路径是外部流量进入虚拟网络的主要方式。您可以配置公共IP地址以确定传入的流量以及将其转换到虚拟网络的方式和位置。
- Azure DDoS保护标准在基本服务层上提供了专门针对Azure虚拟网络资源进行调整的其他缓解功能。 DDoS Protection Standard易于启用,无需更改应用程序。通过专用流量监控和机器学习算法来调整保护策略。策略应用于与虚拟网络中部署的资源相关联的公共IP地址。示例是Azure负载均衡器,Azure应用程序网关和Azure Service Fabric实例。在攻击期间和历史记录中,可以通过Azure Monitor视图获得实时遥测。可以通过Azure Application Gateway Web应用程序防火墙添加应用程序层保护。为IPv4 Azure公共IP地址提供保护。
组件类型:监控
监视组件提供所有其他组件类型的可见性和警报。所有团队都应该有权访问他们可以访问的组件和服务。如果您有一个集中的服务台或运营团队,则需要对这些组件提供的数据进行集成访问。
Azure提供不同类型的日志记录和监视服务,以跟踪Azure托管资源的行为。 Azure中工作负载的治理和控制不仅基于收集日志数据,还基于根据特定报告事件触发操作的能力。
Azure监视器。 Azure包括多个服务,这些服务分别在监视空间中执行特定角色或任务。这些服务共同提供了一个全面的解决方案,用于从您的应用程序和支持它们的Azure资源中收集,分析和处理遥测。他们还可以监视关键的本地资源,以提供混合监视环境。了解可用的工具和数据是为应用程序开发完整监视策略的第一步。
Azure中有两种主要类型的日志:
Azure活动日志(以前称为“操作日志”)提供对Azure订阅中的资源执行的操作的深入了解。这些日志报告订阅的控制平面事件。每个Azure资源都会生成审核日志。
Azure Monitor诊断日志是由资源生成的日志,该资源提供有关该资源操作的丰富,频繁的数据。这些日志的内容因资源类型而异。

跟踪网络安全组的日志非常重要,尤其是以下信息:
事件日志提供有关基于MAC地址应用于VM和实例角色的网络安全组规则的信息。
计数器日志跟踪每个网络安全组规则运行的次数,以拒绝或允许流量。
所有日志都可以存储在Azure存储帐户中,以进行审计,静态分析或备份。将日志存储在Azure存储帐户中时,客户可以使用不同类型的框架来检索,准备,分析和可视化此数据,以报告云资源的状态和运行状况。
大型企业应该已经获得了监控内部系统的标准框架。他们可以扩展该框架以集成由云部署生成的日志。通过使用Azure Log Analytics,组织可以将所有日志记录保留在云中。 Log Analytics作为基于云的服务实施。因此,只需最少的基础设施服务投资,即可快速完成并快速运行。 Log Analytics还与System Center Operations Manager等System Center组件集成,以将您现有的管理投资扩展到云中。
Log Analytics是Azure中的一项服务,可帮助收集,关联,搜索和操作由操作系统,应用程序和基础架构云组件生成的日志和性能数据。它使用集成的搜索和自定义仪表板为客户提供实时操作洞察,以分析VDC实施中所有工作负载的所有记录。
Azure网络观察程序提供了用于监视,诊断和查看指标以及启用或禁用Azure虚拟网络中资源日志的工具。这是一个多方面的服务,允许以下功能和更多:
- 监视虚拟机和端点之间的通信。
- 查看虚拟网络中的资源及其关系。
- 诊断进出VM的网络流量过滤问题。
- 诊断VM的网络路由问题。
- 诊断来自VM的出站连接。
- 从VM捕获数据包。
- 诊断Azure虚拟网络网关和连接的问题。
- 确定Azure区域和Internet服务提供商之间的相对延迟。
- 查看网络接口的安全规则。
- 查看网络指标。
- 分析进出网络安全组的流量。
- 查看网络资源的诊断日志。
Operations Management Suite内部的网络性能监视器解决方案可以提供端到端的详细网络信息。此信息包括Azure网络和本地网络的单个视图。该解决方案具有ExpressRoute和公共服务的特定监视器。
组件类型:工作负载
工作负载组件是实际应用程序和服务所在的位置。它也是您的应用程序开发团队花费大部分时间的地方。
工作量的可能性是无止境的以下是一些可能的工作负载类型:
内部LOB应用程序:业务线应用程序是对企业持续运营至关重要的计算机应用程序。 LOB应用程序有一些共同特征:
互动性。输入数据,并返回结果或报告。
数据驱动 - 数据密集型,频繁访问数据库或其他存储。
与组织内外的其他系统集成提供集成。
面向客户的网站(互联网或内部):与互联网交互的大多数应用程序都是网站。 Azure提供在IaaS VM或Azure Web Apps站点(PaaS)上运行网站的功能。 Azure Web Apps支持与VNets集成,允许在分支网络区域中部署Web应用程序。面向内部的网站不需要公开公共互联网端点,因为资源可以通过私有VNet的私有非互联网可路由地址访问。
大数据/分析:当数据需要扩展到大容量时,数据库可能无法正确扩展。 Hadoop技术提供了一个在大量节点上并行运行分布式查询的系统。客户可以选择在IaaS VM或PaaS(HDInsight)中运行数据工作负载。 HDInsight支持部署到基于位置的VNet,可以部署到VDC轮辐中的集群。
事件和消息传递:Azure事件中心是一种超大规模的遥测提取服务,可收集,转换和存储数百万个事件。作为分布式流媒体平台,它提供低延迟和可配置的时间保留,使您能够将大量遥测数据摄入Azure并从多个应用程序中读取该数据。使用事件中心,单个流可以支持实时和基于批处理的管道。
您可以通过Azure Service Bus在应用程序和服务之间实现高度可靠的云消息传递服务。它提供客户端和服务器之间的异步代理消息传递,结构化先进先出(FIFO)消息传递以及发布和订阅功能。
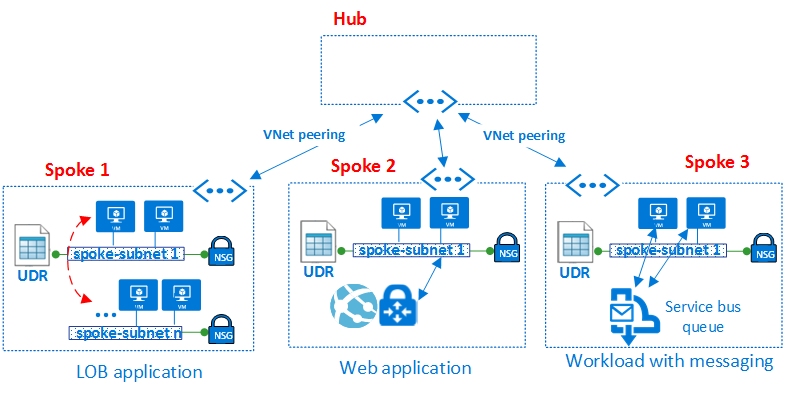
使VDC高度可用:多个VDC
到目前为止,本文主要关注单个VDC的设计,描述了有助于弹性的基本组件和体系结构。 Azure负载均衡器,NVA,可用性集,规模集等Azure功能以及其他机制有助于您在生产服务中构建可靠的SLA级别的系统。
但是,由于单个VDC通常在单个区域内实施,因此可能容易受到影响整个区域的任何重大中断的影响。需要高SLA的客户必须通过在位于不同区域的两个(或更多)VDC实施中部署相同项目来保护服务。
除了SLA问题之外,还有几种常见的场景,其中部署多个VDC实现是有意义的:
- 区域或全球存在。
- 灾难恢复。
- 一种在数据中心之间转移流量的机制。
区域/全球存在
Azure数据中心遍布全球众多地区。选择多个Azure数据中心时,客户需要考虑两个相关因素:地理距离和延迟。要提供最佳用户体验,请评估每个VDC实施之间的地理距离以及每个VDC实施与最终用户之间的距离。
托管VDC实施的区域必须符合贵组织运营的任何法律管辖区制定的监管要求。
灾难恢复
灾难恢复计划的设计取决于工作负载的类型以及在不同VDC实现之间同步这些工作负载状态的能力。理想情况下,大多数客户需要快速故障转移机制,这可能需要在运行多个VDC实施的部署之间进行应用程序数据同步。但是,在设计灾难恢复计划时,重要的是要考虑大多数应用程序对此数据同步可能导致的延迟敏感。
不同VDC实现中的应用程序的同步和心跳监视要求它们通过网络进行通信。可以通过以下方式连接不同区域的两个VDC实现:
- VNet对等 - VNet对等可以跨区域连接集线器。
- 当每个VDC实现中的集线器连接到同一ExpressRoute电路时,ExpressRoute私有对等。
- 多个ExpressRoute电路通过您的公司骨干网和连接到ExpressRoute电路的多个VDC实现连接。
- 每个Azure区域中VDC实施的集线器区域之间的站点到站点VPN连接。
通常,VNet对等或ExpressRoute连接是首选的网络连接类型,因为在通过Microsoft骨干网传输时具有更高的带宽和一致的延迟级别。
我们建议客户运行网络资格测试以验证这些连接的延迟和带宽,并根据结果确定同步或异步数据复制是否合适。鉴于最佳恢复时间目标(RTO),权衡这些结果也很重要。
灾难恢复:将流量从一个地区转移到另一个地区
Azure流量管理器定期检查不同VDC实施中公共端点的服务运行状况,如果这些端点发生故障,它将使用域名系统(DNS)自动路由到辅助VDC。
由于它使用DNS,因此Traffic Manager仅用于Azure公共端点。该服务通常用于在VDC实施的健康实例中控制或转移到Azure VM和Web Apps的流量。即使在整个Azure区域出现故障的情况下,流量管理器也具有弹性,并且可以根据多个条件控制不同VDC中服务端点的用户流量分布。例如,特定VDC实施中的服务失败,或选择具有最低网络延迟的VDC实施。
摘要
虚拟数据中心是一种数据中心迁移方法,可在Azure中创建可扩展的体系结构,从而最大限度地利用云资源,降低成本并简化系统治理。 VDC基于中心和分支网络拓扑,在集线器中提供通用共享服务,并允许辐条中的特定应用程序和工作负载。 VDC还匹配公司角色的结构,其中不同的部门(如中央IT,DevOps,运营和维护)在执行其特定角色时协同工作。 VDC满足“提升和转移”迁移的要求,但也为本机云部署提供了许多优势。
参考
本文档讨论了以下功能。点击链接了解更多信息。
| Network Features | Load Balancing | Connectivity |
|---|---|---|
| Azure Virtual Networks Network Security Groups Network Security Group Logs User-Defined Routes Network Virtual Appliances Public IP Addresses Azure DDoS Azure Firewall Azure DNS |
Azure Front Door Azure Load Balancer (L3) Application Gateway (L7) [Web Application Firewall][WAF] Azure Traffic Manager |
VNet Peering Virtual Private Network Virtual WAN ExpressRoute ExpressRoute Direct |
| Other Azure Services |
|---|
| Azure Web Apps HDInsights (Hadoop) Event Hubs Service Bus |
原文:https://docs.microsoft.com/en-us/azure/architecture/vdc/networking-virtual-datacenter
本文:https://jiagoushi.pro/azure-virtual-datacenter-network-perspective
讨论:请加入知识星球【首席架构师圈】
- 223 次浏览
【云架构】用于保护和监控云应用的安全性
了解安全云开发,部署和操作所需的安全组件。
保护云中的应用程序和环境
云计算通过提供随时可用的基础架构,平台和软件服务,提供简化的应用程序开发和交付。但是,对安全性的担忧是企业的主要抑制因素。当您计划采用云时,共享责任模型,风险管理和合规性可能是核心决定因素。将工作负载移至云时,安全要求和风险承受能力不会发生变化。
任何迁移到云都需要一个由企业首席信息安全官(CISO)驱动的有效控制框架。控制框架必须评估和管理业务目标的风险。您必须将这些控制实施并扩展到云环境,同时将成本保持在IT预算范围内。通过使用量化指标持续监控威胁,事件和控制性能对于企业安全迁移到云是至关重要的。
随着您的业务经历数字化转型,您将通过使用微服务架构构建云原生应用程序,并构建它们以全面接受DevOps。因此,您必须重新考虑安全体系结构和方法,以实现云原生应用程序的持续安全性。这些体系结构和方法与您过去用于单片企业应用程序的体系结构和方法不同。在将应用程序迁移到云并实现现代化时,请确保云提供可信赖的平台,以便与企业数据中心安全地集成。
云从根本上提供了一个从根本上重新思考和转变互联网安全实践的机会。传统的基于边界的安全控制和基础架构操作实践正在转变为以数据和工作负载为中心的云安全策略,技术和实践。安全性是客户与云提供商之间的共同责任。云是一个确保安全的机会!------ Nataraj Nagaratnam博士,杰出工程师,IBM云安全首席技术官
安全云解决方案的关键组件
在设计,构建,部署和管理云应用程序时,请考虑安全性以保护您的业务,基础架构,应用程序和数据。

- 如何在云原生应用程序中设计和提供持续安全性?
- 如何保护敏感数据并对数据拥有权限?
- 您如何在云原生和企业工作负载的安全平台上构建?
内置和附加安全性
组织中的云开发人员需要一种更简单,更有效的方法来保护他们的云原生应用程序。 云中的安全服务提供内置功能即服务,本地从云端提供。 这些服务可以与您的DevOps流程无缝集成。 开发人员可以通过在云中使用安全性来创建灵活,灵活且可扩展的解决方案。

同时,组织中的安全专家可以使用您的安全投资,或者将额外的安全功能或工具作为云的附件,以进行完整的安全管理。
要创建安全的云解决方案,请考虑以下安全性的关键组件:
- 管理身份和访问
- 保护基础架构,应用程序和数据
- 获得跨环境的可见性

管理身份和访问
管理身份并管理用户对云资源的访问。当您从云中使用基础架构时,管理与特权活动相关联的身份非常重要,例如由云管理员执行的任务。您还必须跟踪参与开发和运营的人员的活动。访问控制的另一个重要方面是管理用户和客户对云应用程序的访问。
保护基础架构,应用程序和数据
与传统数据中心一样,您必须在云上提供特定于租户的网络保护和隔离,以保护云基础架构。对于应用程序保护,请设计安全的开发和操作过程(Sec-Dev-Ops或Dev-Sec-Ops)。此过程包括识别和管理虚拟机(VM),容器和应用程序代码中的漏洞的步骤。对于数据保护,您的解决方案必须涵盖加密静态数据的技术,例如文件,对象和存储以及运动中的数据。您的解决方案还必须包括如何监控数据活动和流程以验证和审核外包到云的数据的步骤。
获得跨环境的可见性
持续监控云中的每个活动和事件,以实现内部部署和基于云的环境的完全可见性。通过跨云中的各种组件和服务实时收集和分析日志,您可以构建改进的虚拟基础架构安全性和可见性。
保护IBM Cloud上的工作负载
根据业务需求,公司采用不同类型的云,例如公共云,私有云和混合云。在选择适当的云部署模型时,请考虑应用程序类型,数据敏感性,业务流程重要性和目标用户群。
借助IBM Cloud,您可以在公共,私有或混合部署的任何组合中获得单一的开发和管理体验。如图所示,IBM Cloud平台包含许多内置安全功能(云中的安全性)。您可以根据所选的工作负载和部署模型(云上的安全性)添加额外的安全性。

在创建安全云解决方案时,您必须了解安全选项以及如何应用它们。 这些文章解释了安全云部署,开发和运营所需的安全组件。 它们描述了IBM Cloud的内置安全功能,并向您展示如何扩展和集成其他安全服务,以创建最安全的云解决方案。
![]()
Identity and access management
![]()
![]()
![]()
![]()
![]()
Security monitoring and intelligence
![]()
Security policy, governance, risk, and compliance
![]()
下一步是什么
既然您已了解安全性的概念和价值,请了解有关如何在安全性参考体系结构中构建安全应用程序的更多信息。
了解有关可用IBM Cloud产品和服务的更多信息。
原文:https://www.ibm.com/cloud/garage/architectures/securityArchitecture
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 57 次浏览
【云架构】通过新的优化视角查看云架构
仅仅让云部署工作不再是目标。关注构建和部署最佳解决方案的新指标和方法。
随着云计算架构的成熟,我们定义成功的方式也应该成熟。在2021,我指出,优化云计算更多的是二进制过程,而不是模拟过程。
我当时所说的仍然是正确的:“这关系到很多问题。未充分优化且成本高昂的架构(云架构)也许确实有效,但它们可能会导致企业每周损失数百万美元,而大多数人对此一无所知。30种技术被用于12种可能更好的技术,而不为改变而设计意味着业务敏捷性受到影响。”
为什么大多数云架构都没有得到很好的优化?在规划和设计阶段,大多数云架构师都会按照云架构课程中教给他们的内容来做,或者他们会将所读内容应用到大量的“如何云”参考资料中,或者他们甚至会采纳从以前的云架构项目和导师那里学到的技巧。所有这些都将引导架构师使用一系列通用参考模型、流程和技术堆栈,这些模型、流程和技术堆栈应该进行修改,以满足企业独特的业务需求。这种方法始终导致未充分优化的架构,这会给企业带来更多(或更多)的成本。发生什么事了?
要回答这个问题,让我们后退一步。优化的云架构实际上意味着什么?我在2020年10月定义了云架构优化的过程,并包括了一个要利用的高级模型。我甚至扩展了我的云架构课程,加入了这个概念,这个概念很快将在这里发布。
其次,我们需要认识到,过去的主要重点是让所有东西协同工作,而很少考虑它的工作效果如何或解决方案变得多么复杂。衡量成功的标准是“它有效吗?”不是“它工作得怎么样?”
在开发过程中,团队专注于云架构、迁移和网络新开发的方法,包括广域(元云架构)和窄域(微云架构)。现在,更多的是关于如何设计和部署云迁移和新的云本地开发,或者如何利用容器、无服务器或其他小型或大型云计算解决方案。相反,关键在于如何定义解决方案的目标。
IT和企业管理层普遍认识到,一个“有效”或“似乎具有创新性”的解决方案并不能真正告诉您为什么运营成本比预测成本高很多。今天,我们需要审核和评估云解决方案的最终状态,以明确衡量其成功与否。云部署的规划和开发阶段是规划和构建审计和评估程序的好地方,这些程序将在开发后进行,以衡量项目的总体ROI。
这种从端到端的观点将对构建和部署云及云相关解决方案的人造成一些干扰。大多数人相信他们的设计和构建都是最前沿的,并且采用了当时最好的解决方案。他们相信他们的设计是尽可能优化的。在大多数情况下,他们是错的。
过去10年中实施的大多数云解决方案都严重优化不足。如此之多,以至于如果公司对部署的内容和应该部署的内容进行诚实的审计,一个真正优化的云解决方案的完全不同的图景就会形成。也许容器的使用太多或不够。或者没有强制云原生重构,或者没有考虑这些优势。或者我所看到的新趋势,使多云变得比它需要的更复杂,并且未能定义常见的跨云服务,如安全和操作。在某些情况下,解决方案使用了太多的公共服务,但这些情况并不常见。
概括地说,云架构师应用了他们从书籍、视频、文章甚至我和其他专家报告技术应该如何利用的方法中学到的知识。架构师定义业务需求,然后将这些需求与最优化的解决方案相匹配。这是个好办法。
但是,假设供应商A拥有适用于您的财务运营的最佳原生应用程序,供应商B拥有适用于您的CRM需求的最佳原生应用程序,供应商C拥有适用于您的库存需求的最佳本机应用程序。为了满足这三个需求以及数十种其他选择(安全性、存储、网络等),使用多云来获得最佳产品可能不符合企业的总体最佳利益。这些选择中的每一个都增加了另一层复杂性和成本,很快就会超过额外的好处。
这并不意味着廉价使用用于构建云解决方案的技术。只是要知道,获得最优化的架构仍然是艺术多于科学。有时你需要投资更多的技术,有时需要投资更少的技术。重要的是定义尽可能接近优化的内容。
今天,云优化意味着我们必须审核和重新评估我们当前的云解决方案,然后再考虑进一步增加指标。这并不容易,但考虑到潜在的价值返回到业务。在某些情况下,云优化甚至可以挽救业务。
当有云解决方案可用时,“足够好”团队中的许多员工倾向于成为三只聪明的猴子中的一只或全部:他们不想听到、看到或谈论他们帮助部署或当前运行的云解决方案的任何坏话。相反,团队中似乎总是有人“等等,这要花多少钱?”谁意识到云解决方案将继续消耗企业资源,其消耗量将远远超过应有的水平。他们将是第一个建议或坚持进行审计的人。
- 94 次浏览
【云计算】什么是IT弹性(弹力)以及对备份用户意味着什么?
备份和恢复科学不断发展。二十年前,磁带系统是主要的备份技术;它足以保存您的数据。今天,备份已经发展到不仅包括数据的快速恢复,还包括用于执行业务操作的应用程序。认识到整个数据中心可以在一个事件中被摧毁,灾难恢复即服务(DRaaS)现在正成为组织业务连续性计划的主要组成部分。
但是,让所有这些恢复技术依赖于人类识别问题,诊断有效的解决方案,及时采取行动,并确保恢复成功使整个企业恢复过程处于危险之中。我们需要的是能够实时地根据预先编排的操作处理挑战,在应用程序和IT基础架构中构建智能,自导向功能的解决方案。
这是IT的韧性。
IT Resilience(ITR)保护您的数据
IT Resilience能够保护数据和应用程序免受任何类型的问题。它是通过采用一组工具和应用程序构建的,这些工具和应用程序将自动采取措施保护数据和应用程序免受任何类型的问题的影响。以ITR如何处理勒索软件为例。支持ITR的供应商提供的软件可以持续检查所有备份上的恶意软件感染,并可以轻松地将生产数据恢复到攻击前的状态。支持ITR的软件产品已经发展到支持生产数据中心和云之间的应用程序弹性和工作负载转移。
为什么你应该关心ITR
Gartner可能最着名的是他们的Magic Quadrants,这是一种报告格式,可以评估来自60多个IT市场的技术供应商到4个“象限”。目前,Unitrends被定位为2017年6月数据中心备份和恢复软件魔力象限的参与者,并作为灾难恢复即服务魔力象限的有远见者,也于2017年6月发布。还提及Unitrends作为代表2017年12月IT Resilience Orchestration Automation市场指南中的供应商。
虽然IT防灾市场目前很小,但它的规模和重要性都在不断提高。我们刚刚开始这项新技术。 ITR的早期阶段对客户提出了挑战。用户似乎被迫集成多个供应商和解决方案以实现IT弹性。
但为什么?
备份,DRaaS和ITR是彼此的自然扩展。 您可以使用专用备份设备保护内部部署和云应用程序以及物理和虚拟环境。 您还可以确保使用这些备份设备的DRaaS服务的正常运行时间。 如果供应商可以做到这一切,为什么他们不能自动化整个过程(故障转移,测试,合规报告等)以在出现威胁时自动响应?
有些供应商可以做到这一切。 供应商做到这一切的一个迹象是他们愿意提供DRaaS SLA。 他们非常肯定他们的恢复过程将按要求执行,他们愿意在财务上支持结果。 ITR可以提供可衡量,值得信赖和可重复的RPO和RTO指标,因为该技术可以自动化,每次都可以使用。
您的数据备份和业务连续性供应商能做到吗? 如果没有,也许你需要看一个能够更好地保护你公司和你的新服务提供商。
- 91 次浏览
【云计算】什么是不可变的基础设施?
介绍
在传统的可变服务器基础架构中,服务器会不断更新和修改。使用此类基础架构的工程师和管理员可以通过SSH连接到他们的服务器,手动升级或降级软件包,逐个服务器地调整配置文件,以及将新代码直接部署到现有服务器上。换句话说,这些服务器是可变的;它们可以在创建后进行更改。由可变服务器组成的基础设施本身可称为可变,传统或(贬低)手工艺。
不可变基础架构是另一种基础架构范例,其中服务器在部署后永远不会被修改。如果需要以任何方式更新,修复或修改某些内容,则会根据具有相应更改的公共映像构建新服务器以替换旧服务器。经过验证后,它们就会投入使用,而旧的则会退役。
不可变基础架构的好处包括基础架构中更高的一致性和可靠性,以及更简单,更可预测的部署过程。它可以缓解或完全防止可变基础架构中常见的问题,例如配置漂移和雪花服务器。但是,有效地使用它通常包括全面的部署自动化,云计算环境中的快速服务器配置,以及处理状态或短暂数据(如日志)的解决方案。
本文的其余部分将:
- 解释可变和不可变基础架构之间的概念和实际差异
- 描述使用不可变基础架构的优势并将复杂性置于语境中
- 概述不可变基础架构的实现细节和必要组件
可变和不可变基础设施之间的差异
可变基础和不可变基础设施之间最根本的区别在于它们的核心政策:前者的组件旨在在部署后进行更改;后者的组成部分旨在保持不变并最终被替换。本教程将这些组件作为服务器,但是还有其他方法可以实现不可变的基础结构,例如容器,它们应用相同的高级概念。
为了更深入,基于服务器的可变基础架构和不可变基础架构之间存在实际和概念上的差异。
从概念上讲,这两种基础设施在处理服务器的方法(例如创建,维护,更新,销毁)方面差异很大。这通常用“宠物与牛”类比来说明。
实际上,可变基础架构是一种更老的基础架构范例,它早于核心技术,如虚拟化和云计算,使不可变的基础架构成为可能和实用的。了解这段历史有助于将两者之间的概念差异以及在现代基础设施中使用其中一个或另一个的含义进行背景化。
接下来的两节将更详细地讨论这些差异。
实际差异:拥抱云
在虚拟化和云计算成为可能并且广泛可用之前,服务器基础架构以物理服务器为中心。这些物理服务器创建起来既昂贵又耗时;初始设置可能需要数天或数周,因为订购新硬件,配置机器,然后将其安装在colo或类似位置需要多长时间。
可变基础设施起源于此。由于更换服务器的成本非常高,因此尽可能在尽可能短的停机时间内尽可能长时间地使用您运行的服务器是最实际的。这意味着对于常规部署和更新有很多适当的更改,但对于出现问题时的临时修复,调整和补丁也是如此。频繁手动更改的结果是服务器变得难以复制,使每个服务器成为整个基础架构中独特且易碎的组件。
虚拟化和按需/云计算的出现代表了服务器架构的转折点。虚拟服务器虽然规模较小,但成本较低,可以在几分钟而不是几天或几周内创建和销毁。这使得新部署工作流和服务器管理技术首次成为可能,例如使用配置管理或云API快速,编程和自动配置新服务器。创建新虚拟服务器的速度和低成本使得不变性原则变得切实可行。
传统的可变基础设施最初是在使用物理服务器决定其管理可行性时开发的,并且随着技术的不断改进而不断发展。在部署之后修改服务器的范例在现代基础设施中仍然很常见。相比之下,不可变基础架构从一开始就设计为依赖基于虚拟化的技术来快速配置架构组件,如云计算的虚拟服务器。
概念差异:宠物与牛,雪花与凤凰
云计算先进的基本概念变化是服务器可以被认为是一次性的。考虑丢弃和更换物理服务器是非常不切实际的,但使用虚拟服务器,这样做不仅可行而且简单有效。
传统可变基础架构中的服务器是不可替代的,独特的系统必须始终保持运行。通过这种方式,它们就像宠物一样:独一无二,无法模仿,并且倾向于手工制作。失去一个可能是毁灭性的。另一方面,不可变基础架构中的服务器是一次性的,易于复制或使用自动化工具进行扩展。通过这种方式,他们就像牛一样:牛群中的众多群体中没有一个人是独一无二或不可或缺的。
引用Randy Bias,他首先将宠物与牛类比应用于云计算:
在旧的做事方式中,我们将服务器视为宠物,例如Bob邮件服务器。如果鲍勃摔倒,那就全都动手了。首席执行官无法收到他的电子邮件,这是世界末日。以新的方式,服务器被编号,就像牛群中的牛一样。例如,www001到www100。当一台服务器发生故障时,它会被取回,射击并在线路上更换。
另一种类似的方式来说明服务器处理方式之间差异的含义是雪花服务器和凤凰服务器的概念。
雪花服务器类似于宠物。它们是手工管理的服务器,经常更新和调整到位,从而形成独特的环境。 Phoenix服务器与牛类似。它们是始终从头开始构建的服务器,并且易于通过自动化过程重新创建(或“从灰烬中升起”)。
不可变的基础设施几乎完全由牛或凤凰服务器制成,而可变基础设施允许一些(或许多)宠物或雪花服务器。下一节将讨论两者的含义。
不可变基础设施的优势
要了解不可变基础架构的优势,有必要将可变基础架构的缺点置于语境中。
可变基础架构中的服务器可能会受到配置偏差的影响,这种情况在未记录的情况下,即兴更改会导致服务器的配置变得越来越不同,并且与审核,批准和最初部署的配置之间的配置越来越不同。这些越来越像雪花的服务器难以重现和替换,使得缩放和恢复问题变得困难。即使复制问题来调试它们也会变得具有挑战性,因为创建与生产环境匹配的临时环境很困难。
在许多手动修改之后,服务器的不同配置的重要性或必要性变得不清楚,因此更新或更改任何配置可能会产生意想不到的副作用。即使在最好的情况下,也不能保证对现有系统进行更改,这意味着依赖于这样做的部署可能会导致失败或将服务器置于未知状态。
考虑到这一点,使用不可变基础架构的主要好处是部署简单性,可靠性和一致性,所有这些最终可以最大限度地减少或消除许多常见的痛点和故障点。
已知良好的服务器状态和较少的部署失败
不可变基础架构中的所有部署都是通过基于经过验证和版本控制的映像配置新服务器来执行的。因此,这些部署不依赖于服务器的先前状态,因此不会失败 - 或者只是部分完成 - 因为它。
配置新服务器时,可以在投入使用之前对其进行测试,将实际部署过程减少到单个更新,以使新服务器可用,例如更新负载均衡器。换句话说,部署变为原子:要么成功完成,要么没有任何变化。
这使得部署更加可靠,并且还确保始终知道基础结构中每个服务器的状态。此外,此过程可以轻松实现蓝绿色部署或滚动版本,这意味着无需停机。
没有配置漂移或雪花服务器
通过使用文档检查更新的映像到版本控制并使用自动,统一的部署过程来部署具有该映像的替换服务器来实现不可变基础结构中的所有配置更改。 Shell访问服务器有时完全受限制。
通过消除雪花服务器和配置漂移的风险,这可以防止复杂或难以重现的设置。这还可以防止有人需要修改一个知之甚少的生产服务器,这种生产服务器存在高错误风险并导致停机或意外行为。
一致的登台环境和轻松的水平扩展
由于所有服务器都使用相同的创建过程,因此没有部署边缘情况。通过简化复制生产环境,可以防止混乱或不一致的登台环境,并通过无缝地允许您向基础架构添加更多相同的服务器来简化水平扩展。
简单的回滚和恢复过程
使用版本控制来保留图像历史记录也有助于处理生产问题。用于部署新映像的相同过程也可用于回滚到旧版本,在处理停机时添加额外的弹性并缩短恢复时间。
不可变基础设施实施细节
不可变的基础架构在其实现细节方面有一些要求和细微差别,特别是与传统的可变基础架构相比。
通过简单地遵循不变性的关键原则,技术上可以实现独立于任何自动化,工具或软件设计原则的不可变基础设施。但是,强烈建议使用以下组件(大致按优先顺序)以实现大规模实用性:
- 云计算环境中的服务器,或其他虚拟化环境(如容器,但会改变下面的一些其他要求)。这里的关键是通过自定义映像快速配置隔离实例,以及通过API或类似工具创建和销毁的自动化管理。
- 整个部署管道的完全自动化,理想情况下包括创建后的图像验证。设置此自动化会显着增加实施此基础架构的前期成本,但这是一次性成本,可以快速摊销。
- 面向服务的体系结构,将您的基础架构分离为通过网络进行通信的模块化逻辑离散单元。这使您可以充分利用云计算的产品,这些产品同样面向服务(例如IaaS,PaaS)。
- 无状态,易变的应用程序层,包括您的不可变服务器。这里的任何东西都可以在任何时候(易变)快速销毁和重建,而不会丢失任何数据(无状态)。
- 持久数据层,包括:
- 集中式日志记录,包含有关服务器部署的其他详细信息,例如通过版本或Git提交SHA进行映像识别。由于服务器在此基础结构中是一次性的(并且经常处理),因此即使在限制shell访问或服务器被销毁之后,外部存储日志和指标也允许调试。
- 数据库和任何其他有状态或短暂数据的外部数据存储,如DBaaS /云数据库和对象或块存储(云提供或自我管理)。当服务器易变时,您不能依赖本地存储,因此您需要将该数据存储在其他位置。
- 工程和运营团队致力于协作并致力于该方法。对于最终产品的所有简单性,在不可变的基础架构中有许多移动部件,没有人会知道所有这些部件。此外,在此基础架构中工作的某些方面可能是新的或在人们的舒适区之外,例如调试或在没有shell访问的情况下执行一次性任务。
有许多不同的方法来实现这些组件。选择一个主要取决于个人偏好和熟悉程度,以及您希望自己构建多少基础架构而不是依赖付费服务。
CI / CD工具可以成为部署管道自动化的好地方; Compose是DBaaS解决方案的一个选项; rsyslog和ELK是集中式日志记录的流行选择; Netflix的混沌猴在你的生产环境中随机杀死服务器,对你的最终设置来说是一次真正的试验。
结论
本文介绍了不可变基础架构,它与旧式可变基础架构之间的概念和实际差异,使用它的优势以及实现的详细信息。
知道是否或何时应该考虑迁移到不可变的基础设施可能很困难,并且没有明确定义的截止点或拐点。一种方法是实现本文中推荐的一些设计实践,例如配置管理,即使您仍然在很大程度上可变的环境中工作。这将在未来更容易过渡到不变性。
如果您的基础架构包含上述大多数组件,并且您发现自己遇到了扩展问题或者对部署过程的笨拙感到沮丧,那么现在可以开始评估不变性如何改善您的基础架构。
您可以从几家公司(包括Codeship,Chef,Koddi和Fugue)那里了解更多有关其不可变基础架构实施的文章。
- 143 次浏览
【容器云架构】AWS上的生产级KUBERNETES集群
在AWS云上进行生产等级K8S集群部署
这些AWS CloudFormation模板和脚本会在AWS私有VPC环境中自动根据您选择的配置设置一个灵活,安全,容错的Kubernetes集群。该项目的主要目的是:简单,轻松,无脚本,轻松地一步部署Kubernetes环境。
我们提供两个具有相同基础AWS VPC拓扑的部署版本:
- 全面:容错,生产级架构(多主站,多节点,NAT网关),
- 占用空间小:单个主机,单个NAT实例,单个节点部署(用于测试,演示,第一步)
Kubernetes Operations(“ kops”)项目和AWS CloudFormation(CFN)模板与引导脚本一起使用,有助于自动化整个过程。最终结果是具有100%Kops兼容性的100%Kubernetes集群,您可以从堡垒主机,通过OpenVPN或通过AWS ELB端点使用HTTPS API进行管理。
该项目将重点放在安全性,透明性和简单性上。本指南主要为计划在AWS上实现其Kubernetes工作负载的开发人员,IT架构师,管理员和DevOps专业人士创建。
完整规模架构

One-Click launch CloudFormation stack: Full scale
部署的资源
- 一个VPC:3个不同可用区中的3个私有子网和3个公共子网,通往S3和DynamoDB的网关类型私有链路路由(免费),
- 每个3个可用区中的每个公用子网中的三个NAT网关,
- 每个可用区的私有子网中AutoScaling组(单独的ASG)中的三个自我修复的Kubernetes Master实例,
- 一个AutoScaling组中的三个Node实例,遍及所有可用区,
- 1个可用区的公共子网中的一个自我修复堡垒主机,
- 四个弹性IP地址:3个用于NAT网关,1个用于堡垒主机,
- 一个内部(或公共:可选)ELB负载平衡器,用于通过HTTPS访问Kubernetes API,
- 堡垒主机和Kubernetes Docker Pod的两个CloudWatch Logs组(可选),
- 一个Lambda函数可通过AWS SSM正常拆除
- 两个安全组:1个用于堡垒主机,1个用于Kubernetes主机(主服务器和节点),
- 堡垒主机,K8s节点和主控主机的IAM角色,
- 一个用于Kops状态存储的S3存储桶,
- 一个用于VPC的Route53专用区域(可选)
小规模架构

One-Click launch CloudFormation stack: Small footprint
部署的资源
- 一个VPC:3个不同可用区中的3个私有子网和3个公共子网,通往S3和DynamoDB的网关类型私有链路路由(免费),
- 一个可用区的专用子网中的一个自我修复的Kubernetes Master实例,
- AutoScaling组中的一个Node实例,遍及所有可用区,
- 1个可用区的公共子网中的一个自我修复堡垒主机,
- 堡垒主机是专用子网的NAT实例路由器,
- 四个弹性IP地址:3个用于NAT网关,1个用于堡垒主机,
- 一个内部(或公共:可选)ELB负载平衡器,用于通过HTTPS访问Kubernetes API,
- 堡垒主机和Kubernetes Docker Pod的两个CloudWatch Logs组(可选),
- 一个Lambda函数可通过AWS SSM正常拆除
- 两个安全组:1个用于堡垒主机,1个用于Kubernetes主机(主服务器和节点)
- 堡垒主机,K8s节点和主控主机的IAM角色
- 一个用于Kops状态存储的S3存储桶,
- 一个用于VPC的Route53专用区域(可选)
如何建立集群?
在https://aws.amazon.com上注册一个AWS账户。
选择您喜欢的部署类型:
- Full scale deployment: Launch the AWS One-Click CloudFormation Stack: Full scale Template: View template
- Small fottprint deployment: Launch the AWS One-Click CloudFormation Stack: Small footprint Template: View template
创建群集(通过堡垒主机)持续约10-15分钟,请耐心等待。
- 遵循部署指南中的分步说明,连接到Kubernetes集群。
要自定义部署,您可以为Kubernetes集群和堡垒主机选择不同的实例类型,选择工作节点数,API端点类型,日志记录选项,OpenVPN安装,插件。
有关详细说明,请参阅部署指南。
创建群集(通过堡垒主机)持续约10分钟,请耐心等待。
创建clutser之后,只需通过SSH连接到堡垒主机,即可立即使用“ kops”,“ kubectl”和“ helm”命令,无需任何额外步骤!
日志
可选:如果您在模板选项中选择,则所有容器日志都将发送到AWS CloudWatch Logs。在这种情况下,本地“ kubectl”日志无法通过API调用在内部使用(例如kubectl logs ...命令:“守护程序的错误响应:已配置的日志记录驱动程序不支持读取”)请检查AWS CloudWatch / Logs / K8s *用于容器日志。
抽象论文
请查看此摘要文件,以了解此解决方案的高级细节。
参考资料
- Kubernetes Open-Source Documentation: https://kubernetes.io/docs/
- Calico Networking: http://docs.projectcalico.org/
- KOPS documentation: https://github.com/kubernetes/kops/blob/master/docs/aws.md ,https://github.com/kubernetes/kops/tree/master/docs
- Kubernetes Host OS versions: https://github.com/kubernetes/kops/blob/master/docs/images.md
- OpenVPN: https://github.com/tatobi/easy-openvpn
- Heptio Kubernetes Quick Start guide: https://aws.amazon.com/quickstart/architecture/heptio-kubernetes/
原文:https://tc2.hu/en/blog/production-grade-kubernetes-cluster-on-aws
本文:http://jiagoushi.pro/production-grade-kubernetes-cluster-aws
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 96 次浏览
【容器云架构】K8s 多区域部署 (Running k8s in multiple zones )
此页面描述了如何在多个区域中运行集群。
- 介绍
- 功能性
- 局限性
- 演练
介绍
Kubernetes 1.2增加了在多个故障区域中运行单个集群的支持(GCE称它们为“区域”,AWS称它们为“可用区域”,在这里我们将它们称为“区域”)。这是更广泛的集群联合功能的轻量级版本(以前被昵称为“ Ubernetes”)。完全集群联盟允许组合运行在不同区域或云提供商(或本地数据中心)中的各个Kubernetes集群。但是,许多用户只是想在其单个云提供商的多个区域中运行一个更可用的Kubernetes集群,而这正是1.2中的多区域支持所允许的(这以前被称为“ Ubernetes Lite”)。
对多区域的支持有一些限制:单个Kubernetes集群可以在多个区域中运行,但只能在同一区域(和云提供商)中运行。当前仅自动支持GCE和AWS(尽管很容易通过简单地安排将适当的标签添加到节点和卷来为其他云甚至裸机添加类似的支持)。
功能
启动节点后,kubelet会自动向其添加带有区域信息的标签。
Kubernetes会自动将复制控制器或服务中的Pod跨单个区域群集中的节点分布(以减少故障的影响)。对于多区域群集,此分布行为将跨区域扩展(以减少区域故障的影响) 。)(通过SelectorSpreadPriority实现)。这是尽力而为的布置,因此,如果群集中的区域是异构的(例如,不同数量的节点,不同类型的节点或不同的Pod资源要求),这可能会阻止Pod在整个区域中均匀分散。如果需要,可以使用同质区域(相同数量和类型的节点)来减少不等扩展的可能性。
创建永久卷后,PersistentVolumeLabel准入控制器会自动向其添加区域标签。然后,调度程序(通过VolumeZonePredicate谓词)将确保声明给定卷的吊舱仅与该卷位于同一区域中,因为无法跨区域附加卷。
局限性
多区域支持有一些重要限制:
- 我们假设不同的区域在网络中彼此靠近,所以我们不执行任何可感知区域的路由。特别是,通过服务的流量可能会跨越区域(即使支持该服务的某些Pod与客户端位于同一区域中),这可能会导致额外的延迟和成本。
- 卷区域关联性仅适用于PersistentVolume,并且如果直接在Pod规范中指定EBS卷,则将不起作用。
- 群集不能跨越云或区域(此功能将需要完整的联盟支持)。
- 尽管您的节点位于多个区域中,但默认情况下,kube-up当前会构建一个主节点。虽然服务的可用性很高,并且可以容忍区域丢失,但控制平面位于单个区域中。想要高可用性控制平面的用户应遵循高可用性说明。
卷限制
使用拓扑感知的卷绑定解决了以下限制。
- 当前使用动态预配置时的StatefulSet卷区域扩展当前与pod关联性或反关联性策略不兼容。
- 如果StatefulSet的名称包含破折号(“-”),则卷区域扩展可能无法提供跨区域的统一存储分布。
- 在Deployment或Pod规范中指定多个PVC时,需要为特定的单个区域配置StorageClass,或者需要在特定的区域中静态设置PV。另一个解决方法是使用StatefulSet,这将确保副本的所有卷都在同一区域中配置。
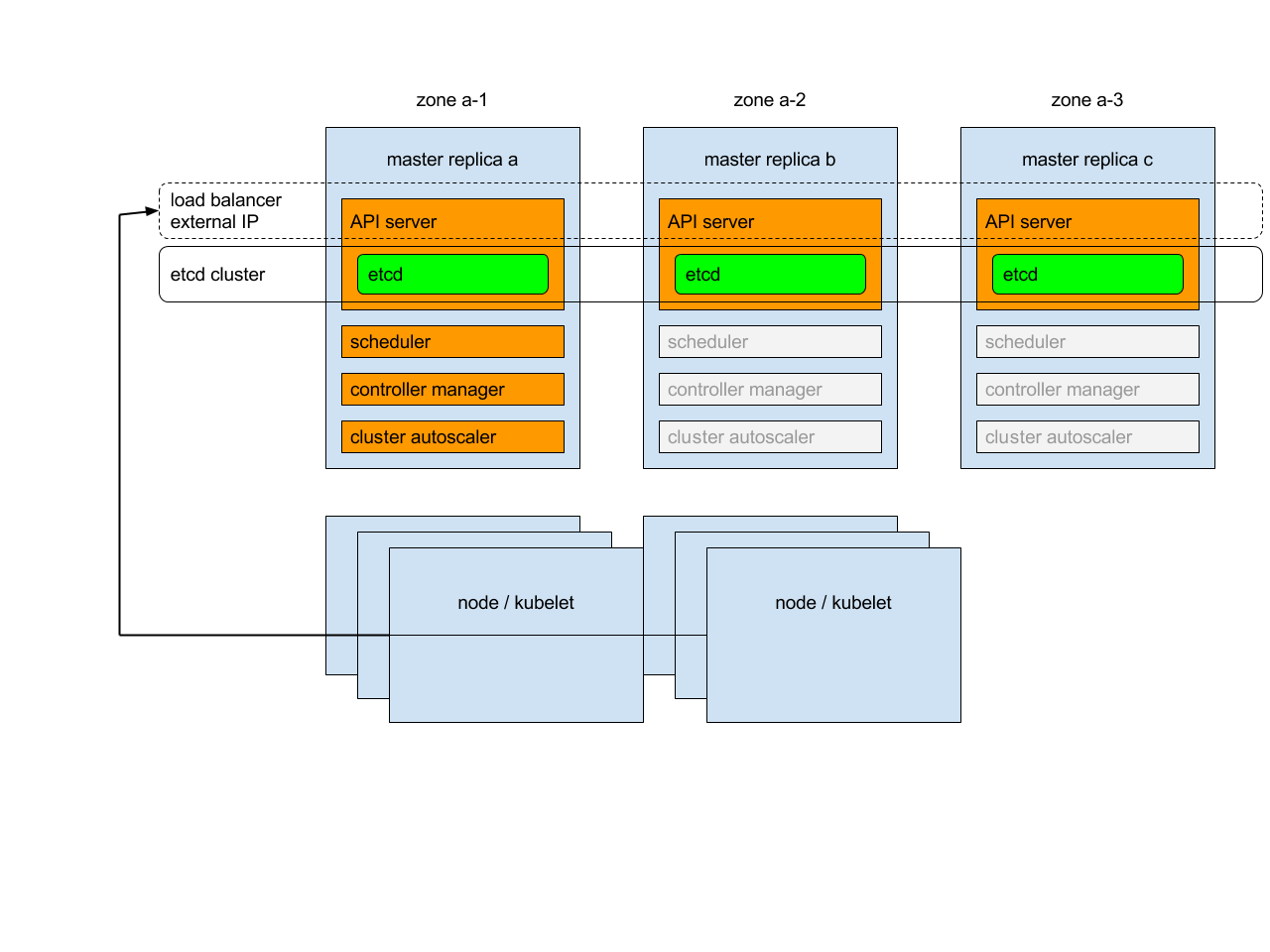
原文:https://kubernetes.io/docs/setup/best-practices/multiple-zones/
本文:http://jiagoushi.pro/running-k8s-multiple-zones
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 195 次浏览
【容器云架构】设置高可用性Kubernetes Master
您可以使用kube-up或kube-down脚本为Google Compute Engine复制Kubernetes masters。本文档介绍了如何使用kube-up / down脚本来管理高可用性(HA)masters,以及如何实现HA masters以与GCE一起使用。
- 在你开始之前
- 启动与HA兼容的集群
- 添加新的主副本
- 删除主副本
- 处理主副本故障
- 复制HA群集的主服务器的最佳做法
- 实施说明
- 补充阅读
在你开始之前
您需要具有Kubernetes集群,并且必须将kubectl命令行工具配置为与集群通信。如果您还没有集群,则可以使用Minikube创建一个集群,也可以使用以下Kubernetes游乐场之一:
要检查版本,请输入kubectl版本。
启动与HA兼容的集群
要创建新的HA兼容群集,必须在kube-up脚本中设置以下标志:
- MULTIZONE = true-防止从服务器默认区域以外的区域中删除主副本kubelet。如果要在不同区域中运行主副本,则为必需项(建议)。
- ENABLE_ETCD_QUORUM_READ = true-确保从所有API服务器进行的读取将返回最新数据。如果为true,则读取将定向到领导者etcd副本。将此值设置为true是可选的:读取将更可靠,但也将更慢。
(可选)您可以指定要在其中创建第一个主副本的GCE区域。设置以下标志:
- KUBE_GCE_ZONE = zone -第一个主副本将在其中运行的区域。
以下示例命令在GCE区域europe-west1-b中设置了HA兼容的集群:
MULTIZONE=true KUBE_GCE_ZONE=europe-west1-b ENABLE_ETCD_QUORUM_READS=true ./cluster/kube-up.sh
请注意,以上命令创建了一个具有一个主节点的集群;但是,您可以使用后续命令将新的主副本添加到群集中
添加新的主副本
创建与HA兼容的群集后,可以向其添加主副本。您可以通过使用带有以下标志的kube-up脚本来添加主副本:
- KUBE_REPLICATE_EXISTING_MASTER=true-创建现有masters的副本。
- KUBE_GCE_ZONE = zone-主副本将在其中运行的区域。必须与其他副本的区域位于同一区域。
您不需要设置MULTIZONE或ENABLE_ETCD_QUORUM_READS标志,因为这些标志是从启动HA兼容群集时继承的。
以下示例命令在现有的HA兼容群集上复制主服务器:
KUBE_GCE_ZONE=europe-west1-c KUBE_REPLICATE_EXISTING_MASTER=true ./cluster/kube-up.sh
删除主副本
您可以使用带有以下标志的kube-down脚本从HA群集中删除主副本:
- KUBE_DELETE_NODES = false-禁止删除kubelet。
- KUBE_GCE_ZONE = zone-将要从其中删除主副本的区域。
- KUBE_REPLICA_NAME =replica_name-(可选)要删除的主副本的名称。如果为空:将删除给定区域中的任何副本。
以下示例命令从现有的HA集群中删除主副本:
KUBE_DELETE_NODES=false KUBE_GCE_ZONE=europe-west1-c ./cluster/kube-down.sh
处理主副本故障
如果高可用性群集中的一个主副本失败,则最佳实践是从群集中删除该副本,并在同一区域中添加一个新副本。以下示例命令演示了此过程:
删除损坏的副本:
KUBE_DELETE_NODES=false KUBE_GCE_ZONE=replica_zone KUBE_REPLICA_NAME=replica_name ./cluster/kube-down.sh
添加一个新副本来代替旧副本:
KUBE_GCE_ZONE=replica-zone KUBE_REPLICATE_EXISTING_MASTER=true ./cluster/kube-up.sh
复制HA群集的主服务器的最佳做法
- 尝试将主副本放置在不同的区域中。在区域故障期间,放置在区域内的所有主设备都会发生故障。为了使区域失效,还要将节点放置在多个区域中(有关详细信息,请参阅多个区域)。
- 不要将群集与两个主副本一起使用。更改永久状态时,两副本群集上的共识要求两个副本同时运行。结果,两个副本都是必需的,任何副本的故障都会使群集变为多数故障状态。因此,就HA而言,两个副本群集不如单个副本群集。
- 添加主副本时,群集状态(etcd)将复制到新实例。如果群集很大,则可能需要很长时间才能复制其状态。可以通过迁移etcd数据目录来加快此操作,如此处所述(我们正在考虑在将来增加对etcd数据目录迁移的支持)。
实施说明
总览
每个主副本将在以下模式下运行以下组件:
- etcd实例:将使用共识将所有实例聚在一起;
- API服务器:每个服务器都将与本地etcd通信-群集中的所有API服务器将可用;
- 控制器,调度程序和集群自动缩放器:将使用租借机制-它们中的每个实例只有一个在集群中处于活动状态;
- 加载项管理员:每个管理员将独立工作,以使加载项保持同步。
此外,API服务器之前将有一个负载平衡器,它将外部和内部流量路由到它们。
负载均衡
启动第二个主副本时,将创建一个包含两个副本的负载均衡器,并将第一个副本的IP地址提升为负载均衡器的IP地址。同样,在删除倒数第二个主副本之后,将删除负载均衡器,并将其IP地址分配给最后剩余的副本。请注意,创建和删除负载平衡器是复杂的操作,传播它们可能需要一些时间(约20分钟)。
主服务和kubelets
系统没有尝试在Kubernetes服务中保留Kubernetes apiserver的最新列表,而是将所有流量定向到外部IP:
- 在一个主群集中,IP指向单个主群集,
- 在多主机集群中,IP指向主机前面的负载均衡器。
同样,外部IP将由kubelet用于与主机通信。
Master证书
Kubernetes为每个副本的外部公共IP和本地IP生成主TLS证书。没有用于副本的临时公共IP的证书;要通过其短暂的公共IP访问副本,必须跳过TLS验证。
集群etcd
为了允许etcd集群,将打开在etcd实例之间进行通信所需的端口(用于内部集群通信)。为了确保这种部署的安全性,etcd实例之间的通信使用SSL授权。
原文:https://kubernetes.io/docs/tasks/administer-cluster/highly-available-master/
本文:http://jiagoushi.pro/set-high-availability-kubernetes-masters
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 108 次浏览
【容器架构】将Debian vs Alpine作为基准Docker映像的基准
视频号
微信公众号
知识星球

大多数官方Docker映像都提供基于Debian和Alpine的映像,但两者之间有一些令人惊讶的性能结果。
自从Docker宣布他们开始在正式的Docker镜像中使用Alpine以来,我就跳槽并拥抱Alpine。
我的意思是,什么都不爱。它是Linux的最小发行版,攻击面非常小。将其作为容器中的基础映像运行似乎是完美的选择。
我写了一篇关于Alpine一年多以前的文章,并且一直以来一直在使用Alpine,而没有出现任何停止演出的问题。
为什么现在要比较这两个基本镜像?
我今天绝对没有醒来,想着“老兄,我想知道Debian在2018年如何成为Alpine作为基础Docker映像”。
真正发生的是,我整理了一篇文章,介绍了一个月前的一些Docker最佳实践,并将其引入了Reddit。
令我惊讶的是,它在Reddit社区获得了150多个投票,99%的投票评分和大量参与。
老实说,这就是我写这篇文章的原因。我使用Docker已经很长时间了,多年来,我选择了一些我认为很好的模式,但是我真的很想看看其他人在做什么,以便我可以改进。我一直在向别人学习。
发现关于Alpine的2种负面趋势
如果您通过Reddit评论,就会发现很多人评论DNS在Alpine中是如何随机失败的,而其他人则评论了某些类型的活动(例如连接到数据库的网络应用)的运行时性能不佳。
DNS查找问题:
我不是一个盲目听从一个人的评论的人,但是一旦有几个人开始提及同一件事,它就会变得很有趣。但是,如果没有某种类型的科学证据,我仍然无法相信一些评论。
幸运的是,有人链接到与Alpine相关的GitHub问题,其中包含更多信息。也许该错误会在适当的时候得到修复,但是在Alpine内部进行DNS查找似乎确实有些奇怪。
也可能与BusyBox中的9年错误有关(Alpine在后台使用此操作系统)。
我没有亲身经历过,但是我也没有运行过使用大规模Kubernetes集群的rofl规模的任何事情,因此也许我不受此问题的影响。
对我们来说幸运的是,Alpine拥有有关DNS查找为何可能失败的文档,并且还解释了为什么我从未遇到过此问题。很高兴知道。
常见的Web应用程序案例会降低运行时性能:
另一位Reddit用户提到,与Debian相比,使用Alpine作为基本映像时,其Node应用的运行速度降低了15%。他还提到自己的Python应用程序也较慢。
这位Reddit评论员甚至表示,他们每天运行500-700个单元测试的真实测试套件的速度差异为35%。那真的引起了我的注意。
当然,我回答了他,要求提供更具体的信息,因为像“慢15%”这样的词在不了解具体情况的情况下并不能说太多。
我们来回了几次,他提供了一些困难的数字,他让一个Python应用程序运行在一个容器中,该应用程序在另一个容器中运行的PostgreSQL中执行10,000个数据库选择。
# postgres:9.6.3 and python 2.7 Total test time 15.3489780426 seconds Total test time 13.5786788464 seconds Total test time 14.2057600021 seconds # postgres:9.6.3-alpine and python 2.7 Total test time 14.262032032 seconds Total test time 13.7757499218 seconds Total test time 14.1344659328 seconds # postgres 9.6.3 and python:2.7-alpine Total test time 18.1418809891 seconds Total test time 16.0904250145 seconds Total test time 17.1380209923 seconds
这说明Postgres映像在Alpine和Debian中的运行速度都一样快,但是当基于Alpine的Python映像尝试连接时,速度会明显下降。
这立刻让我认为,也许某些系统级软件包是这里的罪魁祸首。例如,使用Python和Ruby(和其他语言)的大多数流行的PostgreSQL连接库都需要在Debian上安装libpq-dev,在Alpine中安装postgresql-dev。
该软件包需要安装在映像中才能使用Python中的psycopg2和Ruby中的pg之类的软件包。它们使您可以从Web应用程序连接到PostgreSQL。
我们到了。现在我们有一些要测试的东西,并且是比较这两个基本镜像的真实原因。
测试两个基本镜像
在进入基准测试之前,需要指出的是,我不喜欢人为设计的微基准测试。当然,它们对于在语言/框架级别上测试回归非常有用,但是对于测试现实世界场景却毫无用处。
当人们感到“ flim flam Web框架每秒可以处理163,816个请求,而bibity bop仅处理97,471个请求/秒,这真是垃圾!”时,我总是睁大眼睛。
然后,您查看基准测试的功能,它所做的只是返回一个空的200响应。一旦执行序列化JSON或突然从模板返回HTML之类的操作,这两个框架就会变得越来越慢。
然后,您将诸如单个数据库调用之类的因素考虑在内,嘿,您知道什么,两个框架的速度下降了一个数量级。
对真实世界的Web应用程序进行基准测试
在撰写本文时,我将使用Flask课程的代码库的最新版本和完整版本,该版本运行Flask 1.0.2和所有最新的库版本。
这是一个尺寸适中的Flask应用程序,具有4,000多行代码,几个蓝图,并由SQLAlchemy驱动的PostreSQL数据库提供支持,并且还具有许多其他活动部件。
测试环境:
测试用例将是加载一个页面,该页面使用服务器呈现的模板返回HTML,还包括执行1个SELECT语句以按ID在数据库中查找用户。
Flask应用配置了:
- gunicorn with Flask in production mode (not debug mode)
- gunicorn running with 8 threads (gthread) and 8 workers
- Logging level INFO
测试系统(我的开发箱)配置有:
- i5 3.2GHz CPU with 16GB of RAM and an SSD
- Docker Compose to launch the project with no app bind volumes
- Docker for Windows to run the Docker daemon (rebooted between each test)
- WSL to run the Docker CLI
通用测试策略:
我将运行一个名为wrk的HTTP基准测试工具,以向Flask应用发出请求。对于每个基本映像,我将对其运行5次,并获得最快的结果。
我将使用Debian和Alpine作为基本映像执行此测试,而无需对代码库,应用程序配置,应用程序运行方式或测试机器进行其他更改。
我将在后台运行docker-compose up -d以启动Compose项目,并运行wrk -t8 -c50 -d30 <url to test>以使用8个线程启动wrk,同时保持与该页面的50个HTTP连接。测试将运行30秒。
剧透警报:在这两个测试案例中,我的CPU都达到约65%的最高负荷,因此我们不受CPU限制。
Debian设置
这是我使用的Dockerfile:
FROM python:2.7-slim LABEL maintainer="Nick Janetakis <nick.janetakis@gmail.com>" RUN apt-get update && apt-get install -qq -y \ build-essential libpq-dev --no-install-recommends WORKDIR /app COPY requirements.txt requirements.txt RUN pip install -r requirements.txt COPY . . RUN pip install --editable . CMD gunicorn -c "python:config.gunicorn" "snakeeyes.app:create_app()"
以下是基准测试结果:
nick@workstation:/e/tmp/bsawf$ docker-compose up -d Recreating snakeeyestest_celery_1 ... done Starting snakeeyestest_redis_1 ... done Starting snakeeyestest_postgres_1 ... done Recreating snakeeyestest_website_1 ... done nick@workstation:/e/tmp/bsawf$ wrk -t8 -c50 -d30 localhost:8000/subscription/pricing Running 30s test @ localhost:8000/subscription/pricing 8 threads and 50 connections Thread Stats Avg Stdev Max +/- Stdev Latency 167.45ms 171.80ms 1.99s 87.87% Req/Sec 39.13 29.99 168.00 74.85% 8468 requests in 30.05s, 56.17MB read Socket errors: connect 0, read 0, write 0, timeout 42 Requests/sec: 281.83 Transfer/sec: 1.87MB
Alpine 设置
这是我使用的Dockerfile:
FROM python:2.7-alpine LABEL maintainer="Nick Janetakis <nick.janetakis@gmail.com>" RUN apk update && apk add build-base postgresql-dev WORKDIR /app COPY requirements.txt requirements.txt RUN pip install -r requirements.txt COPY . . RUN pip install --editable . CMD gunicorn -c "python:config.gunicorn" "snakeeyes.app:create_app()"
以下是基准测试结果:
nick@workstation:/e/tmp/bsawf$ docker-compose up -d Recreating snakeeyestest_celery_1 ... done Starting snakeeyestest_redis_1 ... done Starting snakeeyestest_postgres_1 ... done Recreating snakeeyestest_website_1 ... done nick@workstation:/e/tmp/bsawf$ wrk -t8 -c50 -d30 localhost:8000/subscription/pricing Running 30s test @ localhost:8000/subscription/pricing 8 threads and 50 connections Thread Stats Avg Stdev Max +/- Stdev Latency 223.56ms 270.60ms 1.96s 88.41% Req/Sec 39.53 25.02 140.00 65.12% 8667 requests in 30.05s, 57.49MB read Socket errors: connect 0, read 0, write 0, timeout 20 Requests/sec: 288.38 Transfer/sec: 1.91MB
让我们来谈谈结果
有点古怪。我希望Debian能够打破Alpine的大门,然后进行一次远征军,将我使用的一切都更改为Debian。
如果您考虑系统差异,那么我可以说两个发行版的性能大致相同,尽管Alpine的stdev有点高,但是另一方面,Debian的超时时间更多。在如此短暂的测试中,这两者仍可能是差异。
我毫不怀疑这些Reddit评论员的结果,并且如果有任何发现,该测试表明并非所有测试用例都被等同创建。
我要指出的一件事是Reddit用户的测试执行了10,000条SELECT语句,而我的应用程序执行了1条SELECT语句。那是很大的区别。我想知道如果使用15个数据库查询而不是1个数据库查询,在更复杂的页面上会发生什么。
如果您想拿起手电筒,并使用不同的语言或Python版本创建更多的测试用例,请这样做,并告诉我们它的工作方式。
现在,我将继续使用Alpine,但是如果遇到问题或迫切需要切换的原因,那么我将切换到Debian。
本文:https://jiagoushi.pro/benchmarking-debian-vs-alpine-base-docker-image
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 1504 次浏览
【应用架构】在云上构建弹性应用程序
人们希望他们所依赖的应用程序在他们想要使用它们时可用。 为实现这一目标,企业开发团队必须从一开始就为其应用程序构建弹性。
弹性实践可确保您的应用程序在用户需要时可用。 实施弹性实践的一个好处是使您能够满足为企业应用程序建立的服务级别协议(SLA)。 要满足您的SLA,您必须确保您的应用程序具有高可用性,您已制定计划以应对灾难,并且您已为所需的所有关键基础架构,服务和数据建立了备份和恢复流程 运行你的应用程序。
弹性不能成为事后的想法。 尽管平台即服务具有编排功能,但仍需要考虑高可用性,灾难恢复和备份来设计和开发应用程序。
---Eduardo Patrocinio,杰出工程师,IBM云解决方案
在决定投入多少资金以使应用程序具有弹性时,需要考虑许多事项。要问的一些问题是:
- 该应用程序的SLA要求是什么?某些应用程序需要24/7/365可用性,而其他应用程序则要求不太严格。
- 您的灾难恢复要求是什么?
- 你的备份策略是什么?是否有审计所需的关键数据?
- 您的应用程序及其操作的数据是否需要考虑安全性,隐私和合规性规定?
- 是否存在行业特定要求,这些要求决定了您的应用程序必须具有多大的弹性?
- 您的应用程序处理什么类型的工作负载(认知,传统,高容量事务或其他)?
- 您的应用程序部署基础架构(网络,内部部署,云)如何影响您的弹性要求?
- 您的应用程序的性能要求是什么?它们如何影响弹性?
- 定义SLA时,请考虑预算和时间限制。有什么权衡,他们可以接受吗?
以下部分说明了构建弹性应用程序时必须考虑的三个方面:高可用性,灾难恢复和备份。
高可用性的架构师
开发高可用性应用程序可确保您满足SLA的运营可用性。启用高可用性需要:
- 立即检测和解决故障。
- 一种应用程序体系结构,可确保不存在单点故障。
- 内置故障转移功能可确保在数据中心停机时提供可用性。
智能集成全局负载平衡技术可跨多个地理位置的服务器资源分配应用程序流量。当单个地理位置发生故障时,您的应用程序仍然可用,因为流量被重定向到其他地理位置。
您可以看到一个示例,说明Garage Method for Cloud团队在实施高可用性架构中如何实现99.999%的可用性。
做好准备 - 制定灾难恢复程序
灾难恢复要求企业积极主动并提前考虑确定灾难发生时需要恢复的内容。灾害可以采取多种形式,从地震和洪水等自然灾害到纵火等人为灾害和其他恶意行为。
必须在灾难发生之前编写策略和程序,以帮助团队安全有效地恢复。在编写策略和过程时,请考虑以下事项:
- 您是否拥有联系灾难地点团队成员所需的所有信息?
- 您是否清楚地了解了灾难发生时可能受影响的物理资产,包括从建筑物到硬件的所有内容?
- 是否有文档化的程序来确保关键任务应用程序可以在不同的位置运行它们?
- 您是否已将关键数据的备份存储在第二个安全位置,以确保您不会丢失运行业务所需的数据?
建立备份和恢复计划
备份的概念涉及保证在数据损坏或意外或故意删除数据等事件发生时不会中断您的业务。
大多数企业还要求保留其数据的子集,以确保遵守治理策略。例如,IT公司可能要求团队在产品发布后保留与发布相关的法律文档5到10年。备份用于保护您的数据并保持您的应用程序正常运行。
我该备份什么?
在为云应用程序实施备份时,必须备份应用程序本身,运行应用程序的基础架构(如VM)以及应用程序所需的数据。
云原生应用程序备份
编写云原生应用程序时,必须设计失败并确保能够恢复应用程序正常运行所需的所有服务和数据。
除了备份正在运行的应用程序之外,还必须考虑备份源代码存储库,以确保在存储库损坏或不可用时可以进行恢复。
数据库备份
确保备份数据库,并且可以在硬件,软件,网络或组合故障(可能导致一个或多个数据库不可用)的情况下切换到备份。为了确保可以进行恢复,您必须备份操作状态和数据库中存储的数据。
VMware备份
如果您将VM用作物理基础架构的一部分,请考虑以下问题:
您是否希望能够执行机器映像还原?
您是否需要保护虚拟,物理或两者兼有的基础架构?
您更喜欢代理,无代理或SAN级数据副本吗? (各有利弊。)
您有多个需要数据保护的站点吗?
什么类型的许可模式适合您?
可以使用工具备份和还原虚拟环境。这些工具允许您决定是备份还原还原完整的VM,卷还是文件。
备份并还原到云
云备份(也称为在线备份)是一种备份数据的策略,涉及通过专有或公共网络将数据副本发送到场外服务器。这可用于活动数据和存档数据。存档是指单个记录或专门为长期保留和将来参考而选择的历史记录集合。通常不会每天访问存档数据。
在考虑了需要备份的内容以确保应用程序及其运行环境的弹性之后,还需要考虑必须从备份还原应用程序和基础结构时会发生什么。您必须构建备份和还原过程以考虑以下因素:
- 备份需要多长时间?
- 从备份恢复需要多长时间?
- 您的备份需要多少空间?
- 您多久进行一次备份?
每个问题的答案可能因云应用程序的每个部分而异。每个答案取决于您的应用程序的特定特征,您愿意承担的风险,以及备份和恢复过程的成本。
下一步是什么?
IBM认为,在云应用程序中构建弹性是在云上开发和部署应用程序的关键成功因素。既然您已了解构建弹性应用程序的概念和价值,那么请立即开始实施弹性参考架构。
每个企业都必须仔细考虑您开发的应用程序的弹性要求。 IBM可以帮助您深入了解对我们的客户有用的解决方案,并提供愿意帮助您发现最适合您的企业的专家。
讨论:请加入知识星球【首席架构师圈】
- 79 次浏览
【软件架构】Michael Perry关于不可变架构、CAP定理和CRDTs
在InfoQ播客的这一集中,查尔斯·哈姆伯与迈克尔·佩里谈论了他的书《永恒建筑的艺术》。他们讨论的主题包括分布式计算的八个谬误:由L Peter Deutsch和Sun Microsystems的其他人提出的一组断言,描述了新加入分布式应用程序的程序员总是做出的错误假设。其他主题包括Pat Helland的论文“不变性改变一切”、Eric Brewer的CAP定理、最终一致性、位置无关身份和CRDT。他们还讨论了如何将Perry倡导的构建分布式系统的方法引入到需要与可变下游系统集成的真实企业应用程序中。
关键点
- 以不变的方式构建系统意味着您可以将思考系统拓扑的想法与思考其行为和数据的想法分离开来。
- 使这种方法发挥作用的核心是独立于位置的身份——不关心数据存储位置的身份。
- Eric Brewer的CAP定理指出,对于分布式系统中需要的三个属性——一致性、可用性和分区容差——只有同时实现其中两个属性才有可能。在现实世界的分布式系统中,我们通常会放松一个约束,例如一致性。
- CRDT,例如用于Google文档的treedoc,是一种数据类型,它允许我们通过一种优于最终一致性的一致性保证(称为强最终一致性)来放松一致性。
- 不遵循不变性原则的一个副作用是系统可能不是幂等的。发件箱模式((outbox pattern )是我们将发生这种情况的可能性降至最低的一种方法。
介绍
查尔斯·亨伯:大家好,欢迎收看InfoQ播客。我是Charles Humble,该节目的共同主持人之一,也是云计算本土咨询公司Container Solutions的主编。我今天的客人是迈克尔·佩里。迈克尔是改善企业的首席顾问。他录制了许多Pluralsight课程,包括为企业构建分布式系统的密码学基础知识和模式。他最近还出版了一本书,书名为《不可变架构的艺术》,我发现这本书很吸引人,我也认为这是一本非常及时的书,思考我们如何构建分布式系统,以及我们如何才能做得更好。这就是我们今天要讨论的。迈克尔,欢迎收看InfoQ播客。
迈克尔·佩里:谢谢你,查尔斯。很高兴来到这里。
Pat Helland的“不变性改变一切”论文和分布式计算的八个谬误对您有多大影响?
查尔斯·亨伯:你在书中提到了几件事,我想我们也应该提到这些事,给听众一些背景知识。第一件是帕特·海兰德的论文,“不变性改变一切”“,由ACM于2016年出版。第二个是分布式计算的八个谬误,来自太阳微系统公司。我一定会链接到show notes中的这两个。我很感兴趣的是,当你在书中发展思想时,这两篇文章对你的思想有多大的影响。
迈克尔·佩里:是的,我想说这些谬论影响了我职业生涯的大部分时间。这些错误我已经犯过很多次了。所以当我开始写这本书的时候,我真的很想帮助人们认识到他们在自己的工作中犯了那些错误,当他们做出的假设正好落入这些谬误中时。然后当我看Pat Helland关于不变性的论文时,不变性改变了一切,他确实经历了一系列我们使用不变性来解决一些现实问题的地方,从硬盘如何组织到计算机网络如何工作。我发现不变性确实是在所有这些不同系统中解决这些谬误的关键因素。
为什么我们默认为可变系统?
Charles Humble:就我自己而言,我知道当我考虑系统时,我自然会默认使用可变性,这可能是因为我的很多编程背景都是面向对象的语言,比如Java和C。但我怀疑这是一件很平常的事。我认为这是我们作为程序员通常做的事情,除非我们主要从事函数式编程。我很好奇你为什么这么认为?为什么我们默认为可变系统?
迈克尔·佩里:有两个原因。第一,这就是世界的运作方式。我们看到事情一直在变化。我们在软件中所做的很多工作都是通过对现实世界建模来解决问题。因此,如果我们用易变性来建模,这似乎是自然选择。另一方面是计算机的工作方式。计算机有可以更改其值的内存,它们有硬盘,我们可以用另一个文件的内容覆盖一个文件。所以他们的工作方式是多变的。因此,将这些可变工具应用于可变问题似乎是正确的选择。你为什么要绕道不变性,回来模拟一个可变的世界?这是违反直觉的。
什么是不变的架构?
Charles Humble:不变的架构是一个非常有趣的标题。我们已经说过,大多数程序员都是通过函数式编程来实现不变性的。既然如此,那么您如何将这些想法应用到架构中呢?什么是不变的架构?
MichaelPerry:从函数式编程的上下文开始,我们使用不变性来解释程序的行为,这有助于我们处理并发性之类的问题,这样我们就可以知道这就是价值所在。在我所看到的函数的范围内,没有其他我看不到的改变它的东西。现在,当我们从单个进程或一些内存中获取这些信息,并将其应用于分布式系统的行为时,现在我们谈论的是持久性存储,我们谈论的是在线消息,如果我们没有必要的工具来解释分布式系统的行为,那么,要实现我们真正想要实现的目标将非常困难。
比如,如果我问集群中的两个不同节点相同的问题,我会得到相同的答案吗?这是一种保证,我们称之为一致性,这非常重要。所以我们希望能够思考我什么时候才能达到一致性,一致性到底意味着什么?当涉及到建模问题时,通常了解系统如何处于特定状态与了解特定状态是什么一样重要。因此,记录这段历史有时真的很重要。历史就其本质而言是不可改变的。事情一旦发生,就已经发生了。你可以写下这一历史事实,它永远不会改变。因此,我认为将不变性带回我们的工具集中以解决分布式问题非常方便,非常有用。
Charles Humble:我们应该澄清听众可能存在的一些误解,我突然想到的一点是不可变架构和不可变基础设施之间的区别,因为不可变基础设施显然是一个在过去几年中被广泛使用的术语。你能给我们一个什么是它的定义,以及它是如何比较的吗?
迈克尔·佩里:不变的基础设施是一种描述虚拟机的实践,通常是所有的服务,它们所连接的网络,你说这就是状态,我不打算进去更新虚拟机的状态或更新网络配置的状态。相反,如果我想部署一个新的状态,我将并行部署它,传输所有流量,然后拆除原来的一个。因此,这是一个典型的想法,即将云资源视为商品,而不是你命名和关心的东西。
查尔斯·亨伯:另外一件事我们也许应该谈谈,因为如果你没有读过这本书,并且你不熟悉其中的思想,这可能是一个合理的假设,那就是当我们谈论不变的架构时,我们不是在谈论不能改变的架构,因为这显然是一个可怕的想法。
迈克尔·佩里:是的,那太糟糕了。我们讨论的不是不可变性的概念,并将其作为软件架构的核心,然后如何部署它,而是如果您愿意,可以将其部署在不可变的基础设施上。这是一个完全独立的问题。
你能给我们快速复习一下CAP定理吗?
查尔斯·亨伯:现在埃里克·布鲁尔的CAP定理支撑了书中的许多思想,以及我们在本次采访的其余部分将要讨论的许多内容。那么,如果听众从上次看这本书以来忘记了其中的一些细节,你能给他们一点复习吗?
迈克尔·佩里:这是埃里克·布鲁尔的猜想,给定一致性、可用性和分区容差,这是分布式系统中需要的三个属性,只有同时实现其中两个属性才有可能。所以一致性就是我刚才描述的。如果你问两个不同的节点相同的问题,你会得到相同的答案。可用性是指您将在合理的时间内得到答复。分区容忍度是指系统将继续维护这些问题,即使节点不能相互通信,网络中存在分区。所以CAP定理说你们只能选择两个。
你能帮我们解决两位将军的问题吗?
查尔斯·亨伯:你曾多次提到一致性问题,在书中你用两位将军的问题作为例证,我非常喜欢。你能不能也给不熟悉的听众一个简短的总结?
迈克尔·佩里:这是一个可以追溯到很久以前的一致性的例子。我不能声称自己是这本书的作者,但我发现它真的很吸引人。这个想法是这样的,你有几个将军在被围困的城市外领导军队,他们必须决定什么时候进攻。所以他们切断了补给线,并且派了侦察兵去调查,这座城市现在是否足够虚弱,可以进攻?如果只有一支军队进攻,那么进攻就会失败。他们必须同时进攻。所以他们必须同意,他们要么明天进攻,要么不进攻。因此,你的工作是制定一个协议,根据该协议,你可以保证,如果一支军队同意明天进攻,那么他们知道他们有一个保证,另一支军队也同意。
所以你可以这样想,“好吧,我要派一名侦察兵,或者我要派一名信使去见另一位将军,然后那名信使会说,‘我们明天要进攻’,然后我得到了保证。”不,你没有。你不知道那个信使真的到了另一个营地。他们可能被抓获了。因此,也许可以在你的协议中添加一个响应。所以我派了一个信使,说我们明天要攻击,我希望得到回应,然后在收到回应之前我不会攻击。那么,现在其他军队能知道他们要进攻了吗?因为他们只是要发送一条回应信息,他们不知道是否成功。所以你继续这个推理,最终你会发现没有任何协议可以保证你在某个特定的时间点达到一致性。
查尔斯·亨伯:据我所知,你能绕过这一点的唯一方法就是基本上放松一种或另一种约束。
迈克尔·佩里:是的,没错。所以如果你放松限制,“好吧,我们明天就要进攻。”现在没有最后期限了。只要需要,您可以继续协议。然后你也会放松那些你不会攻击的约束,除非你得到了对方的保证,因为这是问题的关键。你不能得到那个保证。因此,相反,我们会说我们将继续发送消息,直到我们都知道这个决定已经做出。因此,在这些宽松的约束下,你可以找到解决方案,而解决方案实际上非常简单。这些宽松的约束实际上映射到了最终一致性的概念。所以这给了我们一种方法,我们可以说明强一致性,如CAP定理所要求的,和最终的一致性,以及一些放松的约束之间的权衡。
真实世界中的最终一致性
Charles Humble:也许,在我职业生涯的早期,我就试图让这一点更具体一些,所以在20世纪90年代末,我想,我正在开发一个基本上是早期互联网银行应用程序的系统。因此,它将一个web前端放在一些背景为绿色屏幕大型机的东西上。我做的其中一件事是一个屏幕,可以向客户显示余额,这听起来似乎是一个非常小的问题,结果几乎是不可能的,因为您有待定的事务,各种大型机可能会为批处理作业每天同步一次,只是有时候批处理作业没有运行。你可能有来自提款机网络或信用卡机的交易,还有那些我们不知道或者我们知道会发生的事情,但它们仍然被保存在某处等等。
我想当时我不知道“最终一致性”这个词,但这基本上就是我们要处理的问题。因此,该项目的大部分时间都花在了与企业的对话上,即“什么是可接受的准确度,因为我们不能达到100%。那么,我们如何才能达到一个我们都能同意的程度,'是的,这很好'”,在我看来,这似乎说明了我们在谈论什么。
迈克尔·佩里:是的,这是一个非常好的真实世界的例子,正好说明了我们正在讨论的问题。因此,人们可能会认为,“好吧,既然两位将军的问题是,如果你可以在不放弃可用性的情况下拥有一个网络分区,那么就不可能实现强一致性”,那么你可能会想,“好吧,像ATM这样的东西不可能工作,但它们确实工作。那么我们如何解决这个问题呢?”我们通过在业务领域中加入这些放松的约束来解决这个问题。因此,是的,我们允许客户提取一些钱,即使我们不能保证他们的余额超过20美元,例如。我们仍然允许该事务,因为我们知道我们已经从问题域本身获得了一些补偿。
查尔斯·亨伯:问题是,如果我的时间足够快和幸运的话,我可能可以从一台提款机中提款,然后跑到另一台提款机中进行另一次提款,即使我的账户不允许,我最终也会透支,但如果企业说,“好吧,没关系”,那就没关系了。
迈克尔·佩里:是的。如果他们能将其转化为收入流,那就更好了。
位置独立身份的目的是什么?
查尔斯·亨伯:当然,是的。寄给你后者或其他东西,我们要收你20英镑。因此,在书中的一章中,你谈到了独立于位置的身份。再一次,我发现这真的很有趣。那么,这样做的目的是什么?
迈克尔·佩里:我认为这是使这种建筑发挥作用的基石之一。通常,如果我们使用的是关系数据库,我们将有一个自动递增的ID作为列之一。因此,我们将使用插入时生成的ID作为存储的记录的标识。该标识仅在特定数据库集群中有效。所以它与一个特定的位置有关。您可以想象几个不同的场景,其中相同的实体、相同的对象在不同的位置具有不同的标识。如果存储脱机备份,我们可能只是对其执行相同的SQL语句,但随后生成不同的ID。或者我们可能有两个不同的副本,它们都接受写操作,因此它们都可能分配相同的ID,但分配两个不同的对象。
因此,使用与某个位置相关的身份是给我们带来麻烦的原因之一。这让我们陷入了一个糟糕的境地。所以我在书中探讨的是一组我们可以选择的独立于位置的身份。他们不关心数据存储在哪里。一个很好的例子是散列。因此,您获取您试图存储的值,假设它是一幅图像,一张照片,然后您将计算一个SHA-512散列。不管是谁计算,哈希值都是一样的。因此,如果你使用它作为照片的标识,而不是文件名,那么该标识将是独立于位置的。因此,通过使用独立于位置的标识,您可以让分布式系统中的不同机器相互谈论对象,并知道它们在谈论同一件事情。
Charles Humble:鉴于位置独立性是不变架构的一个特性,那么您如何保证两个节点最终会得出相同的结论?
迈克尔·佩里:这是一些真正优秀的数学论文发挥作用的地方。因此,如果你有一个基于收集不可变记录的系统,你必须对你收集的记录有一些保证,以确保每个人都以同样的方式解释它们。因此,其中一个保证与这些事件的顺序,这些消息的顺序有关。如果你必须以相同的顺序播放所有消息,以使两个节点获得相同的结果,那么这些消息就不是我们所说的相互交换的,就像代数中的交换属性,A+B等于B+A。因此如果我们可以保证,如果我以不同的顺序接收消息,我们仍然计算相同的结果,然后我们可以说我们的消息处理程序正在进行通信。
因此,我们现在可以将其应用到分布式系统中,如果我们提出一个与plus类似的操作,它是一个交换操作,并且只使用该操作来计算当前状态,那么现在我们可以在该操作的基础上构建分布式系统,并免费获得该保证。所以我喜欢使用的操作是set union。如果我收到两个不同的对象,把它们放进集合中,然后我把这些集合合并在一起,我会得到一个包含这两个对象的集合,其他人可以以不同的顺序接收它们,合并它们,它们仍然会得到相同的集合,因为集合不知道事物在集合中出现的顺序。现在,如果你能在集合并集运算的基础上构建你的整个系统,那么你真的取得了进展。你可以有一些强有力的保证最终达到同样的状态。
你能给我们举一两个例子,说明书中的一些思想在现实世界中的应用吗?
Charles Humble:为了让这更具体一点,你能给我们举一两个例子,说明书中的一些思想在现实世界中的应用,也许是你所从事的应用中的应用吗?
迈克尔·佩里:例如,几年前我设计的一个系统是用于执法的。因此,随着时间的推移,一个案例发生了不同的变化。所以你可能会想,“好吧,改变一个案例。你说的是一些变异的案例。”但我们实际上收集的是变化本身,这些变化是不变的。所以改变说,“好吧,这就是我们正在讨论的情况,现在确定这个情况,并以独立于位置的方式进行,这样每个人都知道你正在谈论的是哪一个。然后是谁做出了改变?最重要的是,他们在做出改变时有哪些信息?”所以现在这必须在将来的某个时候得到管理员的批准。因此,由于这是执法信息和有关现行案件的信息,我们必须确切地知道这些信息来自何处。我们必须知道这是经过核实的。
因此,在核实这些信息的同时,其他执法人员看到的案件中没有这些新信息。因此,他们可以进行自己的编辑,从而生成有关案例更改的新的不变事实。因此,最终可能会有两名不同的官员对案件的同一部分进行更改,但他们中的任何一人都尚未获得批准。所以两个人都不知道另一个。所以如果你把它放在一个有向无环图中,现在你会有一个图,其中这两个节点没有相互引用。他们不知道另一个存在。现在你把这组音符的集合并起来,你会得到一个有两片叶子的图。它有两个地方,你可以说,“这是那个图的终点。”
现在看到这个形状,管理员可以看到,“哦,好吧,这里有一个并发编辑”,他们可以选择批准一个,拒绝另一个,或者他们可以选择合并这两个信息本身,从而产生第三个编辑事实,现在与前两个有因果关系。所以它指向另外两个,创建一个现在只有一个叶节点的图。这是一个真实的例子,说明了我们是如何将不变性的思想,集合联合的思想引入到问题领域的,这不是为了解决分布式系统的任何问题,而是为了解决实际领域的问题。
Charles Humble:在这本书中,你还使用了Git和Docker的例子,以及区块链作为以类似方式工作的系统的例子,这些系统展示了不变架构系统的一些相同特征。所以你能不能拿一个,用它来扩展我们的一些想法?
迈克尔·佩里:事实上,我刚才提到的执法应用程序的例子,实际上非常类似于我们在团队中工作时一直在软件中解决的问题,就是我们在不知道其他人同时进行的更改的情况下更改源代码。它们可能没有经过拉请求过程,因此它们不是主分支的一部分,因此它们不是我们当前正在做的工作的前身。但我们能够在版本控制系统中记录这一点,因为我们有父提交的提交。所以提交是一个不可变的记录,指向历史上的一条记录,它说,“好的,这个新的事实是在了解以前的事实的基础上,根据以前的事实创建的。”
还有另一个例子,我们在使用不变性,我们在使用这个想法,合并有向无环图,以解决一个实际问题。作为开发人员,这是我们更熟悉的一个。事实上,它也解决了分布式系统的问题,因为我可以脱机工作。我可以让我的机器与远程设备断开连接,我仍然可以非常高效地工作。我知道,当我重新联机时,我最终会与远程设备和我团队的其他成员保持一致。
CRDT如何融入到图片中?
Charles Humble:让我们来思考一下数据类型,你在书中谈到了CRDT,这是我的InfoQ同事韦斯·赖斯(Wes Reisz)去年在播客的一集上与彼得·博根(Peter Bourgon)谈到的一个话题。因此,我将在节目说明中链接到这一点。但是,为了把我们大家联系在一起,你能谈谈CRDT以及它们如何融入故事中吗?
迈克尔·佩里:一种无冲突的复制数据类型,相当多。但它是一种数据类型,所以你可能会想到链表,你可能会想到有向无环图。这是一组数据类型为operations的状态,它在内部执行的操作就像更新或合并一样。那么这两件事意味着什么呢?更新是为了在CRDT中记录一些新信息而执行的操作,而合并是当我们了解该CRDT的其他系统副本时将执行的操作。因此,如果我们在一个节点上工作,用户正在交互,然后他们按下一个按钮,他们想要执行一个操作,我们将在CRDT的副本上执行更新。然后,当我们与服务器或对等方交谈时,这就是我们要与其他人合并的地方。
因此,CRDT只是一组通用规则,用于我们如何保证数据结构,以确保它最终在所有不同副本中达到一致状态。CRDT非常令人兴奋,因为它们有一个比最终一致性更好的一致性保证。这叫做强最终一致性。这是一种保证,CRDT在收到相同的更新后将达到一致的状态,而不一定是在他们都有机会相互交谈并达成共识时,例如,使用Paxos算法。因此,一旦所有节点完成所有更新,它们就处于相同的状态。对于最终的一致性来说,这是一个非常有力的保证,我发现这对我所有工作的基础非常有用。
谷歌文档中如何使用CRDT?
Charles Humble:CRDT已经在一些非常重要的知名应用中使用。我想最著名的可能是谷歌文档。因此他们有一种特殊的CRDT数据类型,称之为Treedoc,Treedoc用于处理多个用户编辑同一文档时发生的同步。那么,你能谈谈这一点吗?这与你自己在该领域的工作相比如何?
迈克尔·佩里:是的,我想说的是,像Treedoc这样的东西都是非常具体的CRDT,旨在解决特定的问题。因此Treedoc解决了文档的协作编辑问题,而且协作可以是实时的,就像我们在Google Docs中看到的那样,它可以离线,并在文档上线后支持合并。它们提供的最终一致性保证是,最终每个人都会在屏幕上看到相同的文本。你不会看到一些人先看一段再看另一段,而有些人看的顺序相反。因此,Treedoc和其他CRDT是针对其特定问题开发的。我的目标是开发一种更通用的CRDT。我提出的一个例子是,合并操作是一个集合并集,它所讨论的状态是一个有向无环图。因此,如果可以执行两个有向无环图的集合并集,那么可以保证执行这些操作的任意两个节点将实现相同的图。
现在有一个CRDT的另一个方面,我以前没有提到过。这是一个投影函数。有一种方法,你可以采取内部状态和投影到应用程序可以看到的地方。因此,在Treedoc的情况下,投影函数为您提供了一个充满文本的屏幕,但内部状态不仅仅是文本。仅仅文本中没有足够的信息来保证您可以合并它。同样地,在这个使用有向无环图的应用程序中,投影函数是如何查询一个图,以了解应用程序的当前状态?可能会有很多图形提供相同的当前状态,因为在用户执行该操作时,信息对用户是隐藏的。所以人们无法看到所有发生的事情的全部历史。他们只能看到最终结果是什么。
作为一名应用程序开发人员,如果你能给我一组历史事实,我可以把它们组织成一个有向无环图,你给我一个投影函数,告诉我如何向你的用户显示这个有向无环图,那么这就是我所需要的,我可以解决最终一致性很强的问题,我可以在节点之间同步数据,我可以脱机工作,我可以存储脱机发生的事情,然后将它们排队等待稍后发送到服务器。因此,通过以不同的方式描述问题,您可以立即获得所有这些功能。
您认为采用这种方法构建分布式系统的主要好处是什么?
Charles Humble:提高一个级别,您认为采用这种方法构建分布式系统的主要好处是什么?
迈克尔·佩里:我认为,主要的好处是,您可以将思考系统拓扑的想法与思考其行为和数据的想法分离开来。很多时候,当我们在构建应用程序时,我们将如何将其存储到文件、如何设计消息、如何订阅队列以及所有这些拓扑思想融合在一起,我们正在解决这些业务问题。那么,我如何设计一条消息来表示业务中的这一特定操作呢?因此,您最终必须为构建的每个应用程序解决分布式系统中的相同问题。因此,如果你能将它们解耦,你可以说,“好吧,在这一点上,我试图解决一个分布式系统的问题,但现在我考虑的是拓扑,现在只考虑问题域,”那么你就更容易对问题域进行推理,知道你能做什么和不能做什么,让它更具体一点。
在你的问题域中,你可能会遇到一个问题,那就是你想为某个特定的时间预订一个房间。所以当时只有一次会议可以在那个房间举行。因此,这是一个很难解决的问题。所以你可以用拓扑来解决这个问题,比如说,“好吧,有一台机器做出了这个决定,如果我收到另一个预订房间的请求,那台机器就会锁定到那个记录并拒绝第二个请求。”所以拓扑瓶颈的想法,锁定的想法,这是你问题的一部分。那么预订房间的欲望是你问题的另一部分。
那么,你能做些什么呢?把这些不可变架构的概念拿出来,说他们允许我做什么保证,他们不允许我做什么保证?你可以通过这一点进行推理,并意识到没有一个通用的解决方案来预订房间,并保证只有一个人在那个特定的时间预订了房间。在这一点上,你可以说,“好的,在这一点上,我需要引入一个拓扑解决方案来解决这个问题。”然后,所有不依赖于这些强约束类型的问题,以及所有不依赖于这些强约束的问题,都可以用更一般的方法来解决。
如何开始向企业应用程序引入一种不变的方法?
Charles Humble:现在,如果我决定在典型的大型企业应用程序中采用这种方法,我所预见的挑战是,我将与下游系统交谈,这些系统可能是我无法控制的,它们不会遵循您提倡的那种不变的方法。所以我很好奇我该怎么办。例如,您在书中提到了发件箱模式,显然这是我们将这些概念引入典型企业环境的一种方法。所以,也许你可以更笼统地谈一谈,如果听众觉得这些做法适合他们的特定问题,你会如何建议他们采用这些做法?
迈克尔·佩里:这总是最难的问题。所以其中一个解决方案,发件箱模式,你刚才提到的,是一种方式,我可以在我的不可变架构中学习新的不可变事实,我可以与不遵循不可变原则的外部系统交谈。因此,不遵循不变性原则的一个副作用是,这个外部系统可能不是幂等的。这是一个奇特的数学单词,意思是如果我发送两次相同的消息,它可能会复制效果。因此,如果我使用HTTP POST,然后它返回它刚刚发布的内容的URL,如果我没有收到第一个,我可能会尝试再次发布,它可能会插入一条新记录,生成一个新ID,然后返回一个新URL,所以这只是重复了工作。
所以发件箱模式是一种方法,我们不能保证我们解决幂等问题,而只是最小化它发生的概率。这是一个想法,首先,在我们的系统中引入一个拓扑瓶颈。所以这只是一种说法,我们只会有一台机器与该API进行通信。我们不会尝试从不同的机器同时与API对话。其次,一台机器将记录发送给第三方的所有信息。现在,journal可以将API请求链接回不可变系统中的事实,而在可能需要调用此API之前,让我调用API,再次检查,我仍然需要调用API。让我调用API。我可能不知道第一个电话是否还在等着。所以这本日记至少能帮助我们了解这一点。
它不允许我们跟踪消息是否传到了另一边,所以我们仍然有可能他们听到了第一条消息,但是我们超时了,然后他们收到了一条重复的消息。它至少使窗口最小化了一点。这是本书中讨论的模式之一,关于如何与尚未遵循不变性实践的第三方系统集成,但希望在很多人阅读本书之后,这将不再是一个问题,一切都将是不变性的,这将是一个美好的世界。
查尔斯·亨伯:希望如此。如果听众想了解更多,你会建议他们下一步去哪里?
迈克尔·佩里:从immutablearchitecture.com开始。在这个网站上,你可以直接从Apress或Amazon上找到购买这本书的链接,你也可以找到与我联系的方法,了解有关不可变架构的知识,以及你可以与我一起参与书籍学习的方法。
查尔斯·亨伯:迈克尔·佩里,非常感谢你抽出时间参加本周的InfoQ播客。
提到
- Pat Helland’s paper "Immutability Changes Everything"
- The fallacies of distributed computing
- Peter Bourgon on Gossip, Paxos, Microservices in Go, and CRDTs at SoundCloud
- The Art of Immutable Architecture
原文:https://www.infoq.com/podcasts/michael-perry-crdts-art-of-immutable-arc…
- 100 次浏览