【技术选型】Solr与Elasticsearch:性能差异及更多。如何决定哪一个最适合你
“Solr还是Elasticsearch ?至少这是我们从Sematext的咨询服务客户和潜在客户那里听到的普遍问题。Solr和Elasticsearch哪个更好?哪个更快?哪一种比较好?哪一个更容易管理?我们应该使用哪一个?从Solr迁移到Elasticsearch有什么好处吗?-还有很多。
这些都是伟大的问题,虽然不总是有明确的,普遍适用的答案。那么我们建议你使用哪一种呢?你最终如何选择?那么,让我们分享一下我们如何看待Solr和Elasticsearch的过去、现在和未来,让我们做一些比较,希望通过总结Solr和Elasticsearch之间最重要的差异,帮助您根据特定需求做出正确的选择。

如果您是Elasticsearch和Solr的新手,那么阅读我们的Elasticsearch教程和Solr教程可能会使您受益匪浅。
Elasticsearch和Solr是两个领先的、相互竞争的开源搜索引擎,任何曾经研究过(开源)搜索的人都知道它们。它们都是围绕核心的底层搜索库Lucene构建的,但是它们在可伸缩性、部署便利性、社区存在性等功能方面有所不同。对于静态数据,Solr有更多的优势,因为它有缓存,并且能够使用一个非反向读取器进行面形和排序——例如,电子商务。另一方面,Elasticsearch更适合——而且使用频率更高——用于timeseries数据用例,比如日志分析用例。
在选择Solr和Elasticsearch时,它们都有各自的优缺点,因此没有对错之分。虽然看起来Elasticsearch更受欢迎,但根据您的需要和期望,它们的适用性可能更好或更差。
我们希望这两个领先的开源搜索引擎的对比能够提供足够的信息和指导,帮助您为您的组织做出正确的选择:
比较Solr和Elasticsearch:主要区别是什么?
两个搜索引擎都在迅速发展,因此,无需多说,以下是关于Elasticsearch和Solr之间差异的最新信息:
1. Solr与Elasticsearch Engine的性能和可伸缩性基准测试
在性能方面,Solr和Elasticsearch大致相同。我们说“粗略”是因为没有人做过好的、全面的、公正的基准。对于95%的用例来说,这两个选择在性能方面都很好,剩下的5%需要用它们特定的数据和特定的访问模式来测试这两个解决方案。
也就是说,如果您的数据大多是静态的,并且需要数据分析的完全精度和非常快的性能,那么应该考虑Solr。
你也可以观看视频从我们的两个工程师——拉和拉法ł给并排Elasticsearch & Solr第2部分——性能和可伸缩性(或者你可以查看演示幻灯片)在柏林流行语。这次演讲——包括现场演示、视频演示和幻灯片——深入探讨了Elasticsearch和Solr如何伸缩和执行,这些见解在2015年仍然有效。
Radu和Rafal向与会者展示了如何针对两个常见用例调整Elasticsearch和Solr:日志和产品搜索。然后他们展示了调谐后得到的数字。还分享了一些最佳实践,用于扩展大规模的Elasticsearch和Solr集群;例如,如何将数据划分为考虑增长的碎片和索引/集合,何时使用路由,以及如何确保协调的节点不会失去响应。
通过这个视频中提到的测试,我们看到了在静态数据上Solr是非常棒的。
更重要的是,与Elasticsearch相比,Solr中的facet是精确的,不会失去精度,这在Elasticsearch中并不总是正确的。在某些边缘情况下,您可能会发现Elasticsearch聚合中的结果并不精确,这是因为碎片中的数据是如何放置的。
2. 年龄、成熟度和搜索趋势
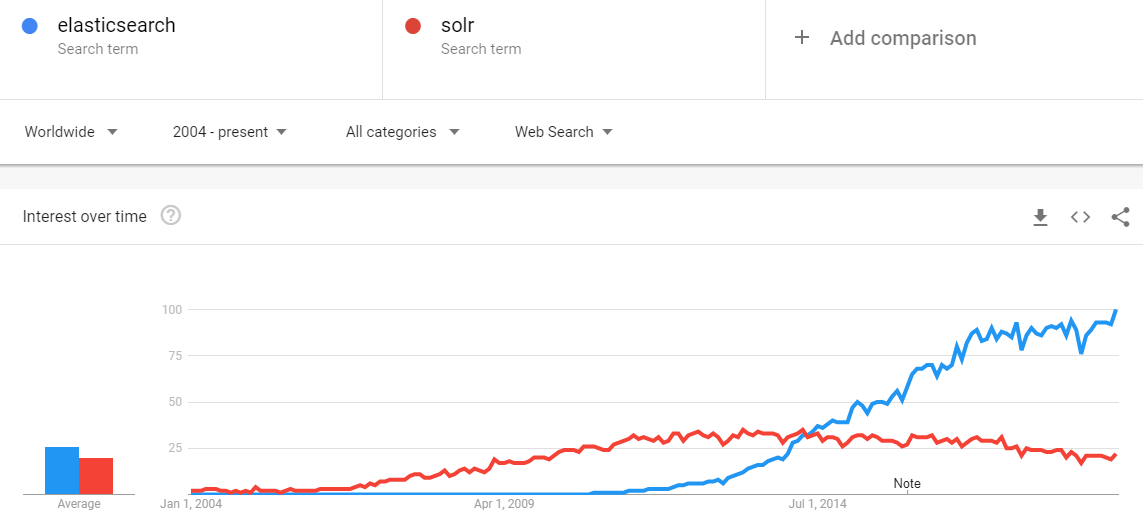
索拉还没死。根据db引擎,Elasticsearch和Solr都是开发人员社区中最流行的搜索引擎。以下是支持这一点的最新使用统计数据:
Apache Solr是一个成熟的项目,背后有一个活跃的大型开发和用户社区,以及Apache品牌。
Solr在2006年首次发布为开源版本,长期以来一直主导着搜索引擎领域,是任何需要搜索功能的人的首选引擎。它的成熟转化为丰富的功能,超越了普通的文本索引和搜索;如人脸识别、分组(即字段崩溃)、强大的过滤、可插入的文档处理、可插入的搜索链组件、语言检测等。
然后,在2010年左右,Elasticsearch作为另一种选择出现在市场上。那时,它还远没有Solr那么稳定,没有Solr那样的功能深度,没有认同度和品牌等等。但是它还有一些其他的优点:Elasticsearch还很年轻,建立在更现代的原则之上,针对更现代的用例,并使处理大索引和高查询率更容易。
此外,因为它是那么年轻,没有一个社区,它在跳跃前进的自由,不需要任何形式的共识或与他人合作(用户或开发人员),向后兼容,或者其他更成熟的软件通常必须处理。因此,它在Solr之前就公开了一些非常受欢迎的功能(例如,近实时搜索)。
从技术上讲,NRT搜索的能力实际上来自Lucene,它是Solr和Elasticsearch使用的底层搜索库。具有讽刺意味的是,由于Elasticsearch首先暴露了NRT搜索,人们将NRT搜索与Elasticsearch关联起来,尽管Solr和Lucene都是同一个Apache项目的一部分,因此,人们希望Solr首先具有如此高要求的功能。
Elasticsearch,更现代,呼吁几个团体的人和组织:
- 那些还没有自己的搜索引擎,也没有投入大量时间、金钱和精力去采用、整合搜索引擎的人。
- 那些需要处理大量数据、需要更容易地分片和复制数据(搜索索引)以及缩小或扩大搜索集群的公司
当然,让我们承认,也总会有一些人喜欢跳到新的闪亮的东西上。
快进到2020年。弹性搜索不再是新的,但它仍然闪亮。它弥补了与Solr的功能差距,在某些情况下甚至超过了它。它当然有更多的传闻。在这一点上,两个项目都非常成熟。两者都有很多特点。两者都是稳定的。我们不得不说,我们确实看到了更多的Elasticsearch集群问题,但我们认为这主要是因为以下几个原因:
- Elasticsearch在传统上更容易上手,这使得任何人都可以开箱即用,而不需要对其工作原理有太多了解。开始时这样做很好,但是当数据/集群增长时就会很危险。
- Elasticsearch使其易于伸缩,吸引了需要更多数据和更多节点的更大集群的用例。
- Elasticsearch更具动态性——当节点来来往往时,数据可以轻松地在集群中移动,这可能会影响集群的稳定性和性能。
- 虽然Solr传统上更适合于文本搜索,但Elasticsearch的目标是处理分析类型的查询,而这样的查询是有代价的。
尽管这听起来很可怕,但让我这样说吧——Elasticsearch暴露了大量的控制旋钮,人们可以玩来控制野兽。当然,关键是你必须知道所有可能的旋钮,知道它们的作用,并利用它们。例如,尽管你刚刚读过关于Elasticsearch的内容,但在我们的组织中,我们在几个不同的产品中都使用了它,尽管我们对Solr和Elasticsearch都很了解。
不是完全重叠的
Solr呢?Solr并没有完全静止不动。Elasticsearch的出现实际上对Solr及其开发人员和用户社区很有帮助。尽管Solr已经有14岁以上的历史,但它的开发速度比以往任何时候都要快。它现在也有一个友好的API。它还能够更容易地扩展和缩小集群,更动态地创建索引,动态地对它们进行分片,路由文档和查询,等等。注意:当人们提到SolrCloud时,他们指的是这种非常分布式的、类似于elasticsearch的Solr部署。
我们参加了在华盛顿特区举行的Lucene/Solr革命会议,并惊喜地看到:一个强大的社区,健康的项目,许多知名公司不仅使用Solr,而且通过采用、通过开发/工程时间对其进行投资,等等。如果你只关注新闻,你会被引导相信Solr已经死了,所有人都蜂拥到Elasticsearch。事实并非如此。Elasticsearch更新了,写起来自然更有趣。Solr是10多年前的新闻。当然,当Elasticsearch出现的时候,也有一些人从Solr转向Elasticsearch——一开始,根本没有Elasticsearch用户。
3.开源
Elasticsearch在开源日志管理用例中占主导地位——许多组织在Elasticsearch中索引他们的日志,使其可搜索。虽然Solr现在也可以用于此目的(请参阅Solr对日志进行索引和搜索,并对Solr进行日志调优),但它在此方面错过了人心。
Elasticsearch和Solr都是在Apache软件许可下发布的,然而,Solr是真正的开源——社区而不是代码。Solr代码并不总是那么漂亮,但是一旦该特性存在,它通常会一直存在,不会从代码库中删除。任何人都可以为Solr做出贡献,如果你对这个项目表现出兴趣和持续的支持,新的Solr开发人员(又名提交者)将根据成绩选出。此外,提交者来自不同的公司,并且没有单一的公司控制代码库。
另一方面,Elasticsearch在技术上是开源的,但在精神上却并非如此。任何人都可以在Github上看到源代码,任何人都可以改变它并提供贡献,但是只有Elastic的员工才能真正对Elasticsearch做出改变,所以你必须成为Elastic公司的一员才能成为提交者。
此外,Elasticsearch背后的公司Elastic混合了Apache 2.0软件许可下发布的代码,而code one只允许在商业许可下使用。毫无疑问,Elasticsearch用户社区对此并不满意。AWS在Apache许可下构建了自己的Elasticsearch发行版,并捆绑了许多特性,比如警报、安全等。您可以看到Sematext对AWS Elasticsearch开放发行版的回顾。
许多组织选择Solr而不是Elasticsearch作为他们的竞争对手(例如Cloudera, Hortonworks, MapR等),尽管他们也与Elasticsearch合作。
社区和开发人员
Solr和Elasticsearch都拥有活跃的用户和开发人员社区,并且正在迅速开发中。
如果您需要向Solr或Elasticsearch添加某些缺失的功能,那么使用Solr可能会更幸运。诚然,古老的Solr JIRA问题仍然存在,但至少它们仍然是开放的,而不是关闭的。在Solr世界中,社区有更多的发言权,尽管最终还是由Solr开发人员来接受和处理贡献。
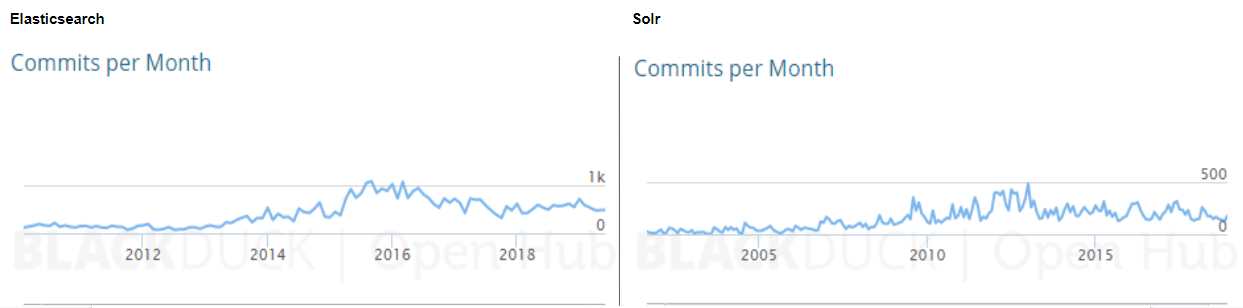
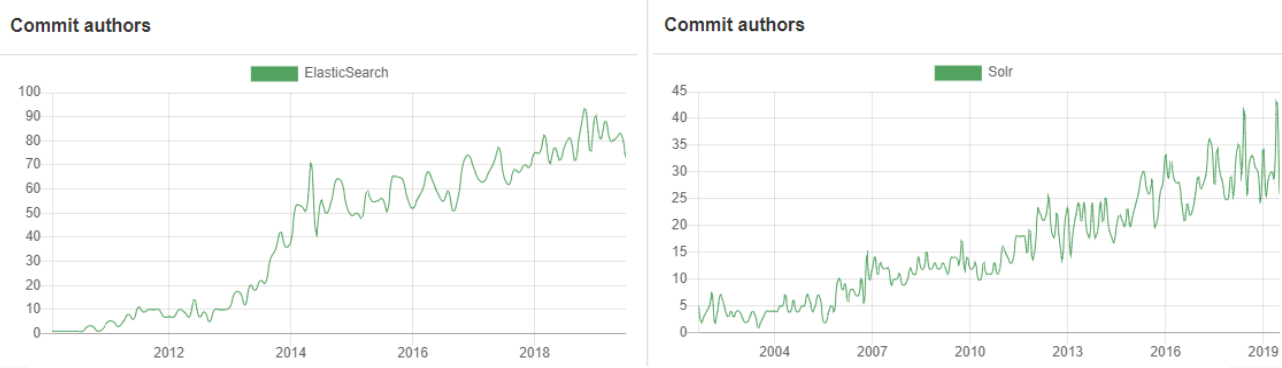
这里有一些图表来说明我们的意思:
Elasticsearch与Solr贡献者(来源:Opensee)单击放大
Elasticsearch vs. Solr Commits (source: Open Hub) click to enlarge
如您所见,Elasticsearch数量呈急剧上升趋势,现在Solr提交活动已超过两倍。这不是一种非常精确或绝对正确的比较开源项目的方法,但它给了我们一个想法。例如,Elasticsearch是在Github上开发的,这使得合并其他人的Pull请求变得非常容易,而Solr贡献者倾向于创建补丁,将它们上送到JIRA,在那里Solr提交者在应用之前对它们进行审查——这是一个不那么流畅的过程。此外,Elasticsearch存储库包含文档,而不仅仅是代码,而Solr在Wiki中保存文档。这使得对于Elasticsearch的提交和贡献者都有更高的数字。
4. 学习曲线和支持
Elasticsearch更容易启动—只需一个下载和一个命令就可以启动一切。Solr在传统上需要更多的工作和知识,但是Solr最近在消除这一点上取得了很大的进步,现在只需要改变它的声誉。
从操作上讲,Elasticsearch更简单一点,它只有一个过程。Solr在其elasticsearch式完全分布式部署模式(SolrCloud)中依赖于Apache ZooKeeper。ZooKeeper非常成熟,应用非常广泛,等等,但它还是另一个让人感动的部分。也就是说,如果您正在使用Hadoop、HBase、Spark、Kafka或其他一些较新的分布式软件,那么您可能已经在组织的某个地方运行了ZooKeeper。
虽然Elasticsearch有内置的类似于zookeperzen的组件,但ZooKeeper能更好地防止在Elasticsearch集群中有时会出现的可怕的裂脑问题。公平地说,Elasticsearch开发人员已经意识到这个问题,并在过去几年改进了Elasticsearch的这方面。
两者都有良好的商业支持(咨询、生产支持、培训、集成等)。两者都有很好的操作工具,不过Elasticsearch由于其API更易于使用,吸引了很多DevOps用户,因此围绕它形成了一个更活跃的工具生态系统。
5. 配置
让我们快速了解一下Solr和Elasticsearch是如何配置的。让我们从索引结构开始。
在Solr中,需要托管模式文件(以前的schema.xml)来定义索引结构、定义字段及其类型。当然,您可以将所有字段定义为动态字段并动态地创建它们,但是您仍然至少需要某种程度的索引配置。但是在大多数情况下,您将创建一个schema.xml来匹配您的数据结构。
Elasticsearch有点不同——它可以称为无模式搜索。你可能会问,这到底是什么意思。简而言之,这意味着可以启动Elasticsearch并开始向它发送文档,以便在不创建任何索引模式的情况下为它们建立索引,而Elasticsearch将尝试猜测字段类型。它并不总是100%准确的,至少与手动创建索引映射相比是这样,但它工作得相当好。
当然,您也可以定义索引结构(称为映射),然后使用这些映射创建索引,或者甚至为索引中存在的每种类型创建映射文件,并让Elasticsearch在创建新索引时使用它。听起来很酷,对吧?此外,当在索引的文档中发现一个以前未见的新字段时,Elasticsearch将尝试创建该字段并猜测其类型。可以想象,这种行为是可以关闭的。
让我们讨论一下Solr和Elasticsearch的实际配置。在Solr中,所有组件、搜索处理程序、索引特定内容(如合并因子或缓冲区、缓存等)的配置都在solrconfig.xml文件中定义。每次更改之后,都需要重新启动Solr节点或重新加载它。
在Elasticsearch中的所有配置都被写入到Elasticsearch.yml文件,它只是另一个配置文件。然而,这并不是存储和更改Elasticsearch设置的唯一方法。Elasticsearch公开的许多设置(虽然不是全部)可以在活动集群中更改——例如,您可以更改碎片和副本在集群中的放置方式,而Elasticsearch节点不需要重新启动。在Elasticsearch碎片放置控制中了解更多。
6. 节点的发现
Elasticsearch和Solr之间的另一个主要区别是节点发现和集群管理。发现的主要目的是监视节点的状态,选择主节点,在某些情况下还存储共享的配置文件。
当集群最初形成时,当一个新的节点加入或集群中的某个节点发生故障时,根据给定的条件,必须有一些东西来决定应该做什么。这是所谓的节点发现的职责之一。
Elasticsearch使用它自己的发现实现Zen,为了实现全容错(即不受网络分割的影响),建议至少有三个专用主节点。Solr使用Apache ZooKeeper进行发现和领袖选举。在这种情况下,建议使用外部ZooKeeper集成,对于容错和完全可用的SolrCloud集群,它至少需要三个ZooKeeper实例。
Apache Solr使用一种不同的方法来处理搜索集群。Solr使用Apache ZooKeeper集成——它基本上是一个或多个一起运行的ZooKeeper实例。ZooKeeper用于存储配置文件和监控——用于跟踪所有节点的状态和整个集群的状态。为了让新节点加入现有的集群,Solr需要知道要连接到哪个ZooKeeper集合。
原文:https://sematext.com/blog/solr-vs-elasticsearch-differences/
本文:
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 255 次浏览