列式数据存储
- 178 次浏览
【内存数据库】HANA和Oracle 12C哪个更快?
执行摘要
- SAP建议HANA在性能上比所有其他数据库都有优势,因为它的数据库运行速度是其他数据库的10万倍。
- 如果HANA真的比甲骨文快,我们就来讨论一下。

缺乏财务偏见注意:
互联网上有关SAP的绝大多数内容都是SAP、SAP合作伙伴或SAP付费在媒体网站上进行营销的媒体实体发布的营销小把戏。这些实体中的每一个都试图对读者隐藏自己的财务偏见。下面的文章很不一样。
- 首先,它是由一个研究实体出版的。
- 第二,没有人为这篇文章付费,它不是假装通知你,而被操纵向你出售软件或咨询服务。与谷歌关于这个话题的几乎所有其他文章不同,它没有任何公司的营销或销售部门的意见。
视频介绍:HANA与Oracle的比较
文字介绍(如果您观看了视频,请跳过)
HANA一直是SAP项目讨论的焦点。SAP的声明是巨大的,但有多少是真实的。SAP建议HANA在性能上比所有其他数据库都有优势,因为它的数据库运行速度是其他数据库的10万倍。由于硬件速度和数据库设计的混合,HANA与Oracle性能的混淆。SAPs使用HANA锁定其他数据库供应商的策略(如Teradata所声称的)。我们报道了SAP在不认证Oracle 12c for s/4HANA方面的利益冲突。您将从一个独立的来源了解这场辩论,了解HANA与Oracle之间的真相,以及SAP声称的多个方面。
本文的参考文献
如果您想查看本文和相关Brightwork文章的参考资料,请参阅此链接(https://www.brightworkresearch.com/references-for-brightwork-sap-hana-p…)。
*注:本文最初撰写于2016年4月,引用了SAP在此之前的一些文章。不过,该条已于2020年2月更新,几年后适用。
HANA的历史
SAP已经推广了HANA,其运行速度远远超过了任何其他数据库,这主要意味着HANA与Oracle的竞争。
这就是为什么SAP不将S/4(SAP的新ERP系统)等新应用程序移植到Oracle的逻辑(由于Oracle在支持SAP应用程序方面占有最大的市场份额,尽管SAP也瞄准了IBM和SQL Server)
这一论点甚至很少有独立党派调查这一问题。
HANA与Oracle之争:硬件速度与数据库设计的混合
HANA与Oracle之间的一个令人困惑的方面是,两个不同的主题混合在一起,就像它们是一个主题一样。
- 一个是硬件问题,因为SAP HANA需要将活动数据库移动到内存中。
- 第二个方面是数据库设计,即基于列的数据库。
SAP讨论这两个主题就像它们是同一个主题一样。
可以说,SAP在解释这种区别方面做得很差。我不认为SAP试图明确这一领域,主要是希望客户感到困惑。
- SAP的客户对潜在利益的来源越不清楚,谈判时SAP的优势就越大。
- 它就越有能力将SAP HANA与Oracle作为一种差异化产品进行市场营销。
- 它越能将SAP-HANA定位为值得付出沉重代价的公司。
SAP没有讨论的是SAP HANA如何既是一种技术战略,又是一种战略 有针对性的战略,将Oracle从SAP客户中推出。
带上女王:SAP把其他供应商排除在外的战略
这是SAP数十年来一直显著影响的一项战略的延伸,但有一点扭曲。SAP把ERP系统当作棋盘上的皇后,不让客户接触其他应用程序。
我们称之为“抢占女王”的软件战略。

通过宣布所有其他SAP应用程序都能更好地与queen集成,SAP的客户可以获得更低的实施风险。这最终是错误的——一个主要原因是SAP的应用程序的风险远远高于他们竞争对手的应用程序。
“夺魁”销售策略的结果
即使大多数供应商已经接近SAP与其适配器的集成,这一策略还是取得了巨大的成功。只有ERP系统是“完全集成的”。所有模块都运行在同一个数据库上,所有其他SAP应用程序都通过适配器连接,而且许多SAP收购的应用程序的适配器比非SAP应用程序的适配器差。
ERP系统的账户控制功能在文章中被描述为一个特洛伊木马 (http://www.brightworkresearch.com/erp/2016/04/09/erp-systems-trojan-hor…),ERP成为一个失控的章鱼(http://www.brightworkresearch.com/erp/2018/11/12/how-erp-is-similar-to-…)。
SAP不仅仅向一家公司销售ERP系统。ERP系统只是打入账户的楔子。像章鱼一样,SAP在不同的领域不断敲打,这些领域必须成为“SAP标准”。所使用的开发语言,其他应用程序也必须是SAP。现在SAP已经进入了数据库层。SAP正试图通过HANA将SAP客户挤出的主要供应商甲骨文(Oracle)也以同样的方式运作。
利用应用层控制推送到数据库层
一次性横向竞争,即应用层的竞争。HANA是这种封锁策略的一个转折点,但它将其带到了数据库层。这就是为什么SAP如此坚定地定位HANA与Oracle。它通过不认证Oracle的数据库来阻止Oracle(和其他数据库)与S/4竞争,即使Oracle、IBM和SQL Server没有理由不能完全支持S/4。进一步回顾一下,混合数据库中没有一个是开源的,即使像Postgresql或MariaDB这样的开源数据库可以很容易地支持SAP。这是一场垄断性的高开销和控制性软件供应商之间的战争。

一旦Oracle资源部门想大喊大叫,请记住,Oracle还比SAP更严格地限制为其应用程序认证的数据库。
代码下推和存储过程
为什么S/4HANA被限制为HANA,SAP的主要论点是SAP已经将一些S/4HANA代码推入了HANA,而不是针对Oracle或其他数据库。放入HANA的存储过程的逻辑是一个幌子,因为SAP使用S/4HANA的独占认证来推动HANA的销售,我们在SAP关于代码下推的论证一文中介绍了这一点。
让我们明确这个话题。
SAP不关心客户的性能是否提高。SAP推出了HANA,并表示它对HANA的做法有一个原因,那就是增加销售额,并将Oracle赶出客户。SAP咨询公司的SAP顾问重复HANA的谈话要点,他们不知道这些观点是否属实,通常也不在乎。他们发表声明以增加计费时间。
最后,SAP内部和SAP咨询公司的一般数据库知识相对较差。在Brightwork,我们忽略了SAP资源对HANA的评价,因为它与我们从SAP客户那里收到的数据点从不匹配。我们已经广泛地研究了我们可以访问的私有基准信息,或者HANA性能的证据和历史。
HANA与Oracle的真正机会是什么?
有人提出,HANA的真正机会是公司将ERP和所有其他SAP应用程序放在HANA上。然后分析引擎就可以放在同一个硬件上。现在,不需要集成或转换,现在分析报告就在应用程序表之外。
SAP将所有数据放在HANA上的想法
在经历了五年多令人窒息的关于分析新世界的会议,以及最新的大数据和总体分析师的痴迷(这导致的好处远远少于最初的提议)之后,SAP提出,通过将所有公司数据放在HANA上,这一切都将变得更好。多方便啊。然而,我们现在是不是要把所有的硬件都改造成针对分析的优化?
另外,非SAP应用程序呢?他们不会坐在HANA上,所以他们必须被整合和改造。
SAP现在是否会认为这些应用程序是遗留的,因为它们不属于公司的“战略平台”?
其次,使用HANA是昂贵的。如何理解HANA和S/4HANA的定价,这是我们在本文中讨论的一个主题。HANA比甲骨文贵很多,甲骨文已经很贵了。如果遵循甲骨文的“建议”并激活更高端的功能,它就属于过高的类别。
HANA不贵…Hasso ?
哈索·普拉特纳(Hasso Plattner)一直认为SAP HANA并不昂贵。
通常,hasso platner将使用基于列的数据库中可用的压缩示例来减少占用空间。Hasso经常谈论压缩,因为HANA是按GB定价的,这对于数据库来说很奇怪,因为大多数商业数据库是按CPU定价的。如果Hasso或SAP客户代表能让数据库听起来比实际的要小,那么SAP就能获得更多的销售额。
但是,如果您与SAP客户主管交谈,他们会告诉您SAP HANA很贵。此外,他们会告诉你,由于这个原因,HANA很难定位;一旦价格标签回来,顾客就退缩了。我们经常为客户定价HANA,根本无法回避这样一个事实:HANA是竞争对手中最昂贵的数据库。
我们在如何理解S/4HANA和HANA定价的文章中讨论了HANA定价(https://www.brightworkresearch.com/saphana/2017/03/18/understanding-pri…)。
对于Hasso Plattner来说,在访谈中提出SAP-HANA如何在某种假设意义上不会太贵,这是一件简单的事情。但所有其他来源都指出,HANA相当昂贵。您将不会从Hasso购买HANA,而是从SAP客户经理那里购买。
哈索·普拉特纳的恒定误差
需要考虑的是,哈索的准确度在历史上相对较差,我没有看到分析师或传统IT媒体记录或评论这种不准确。
我对哈索关于哈纳的言论进行了详细的分析,当哈索说什么的时候,他通常是错的。
- 哈索将他的荣誉博士学位。作为一个真正的博士,正如我在文章中提到的,SAP的Hasso Plattner有博士学位吗。?
- 哈索经常谎报HANA的来历,就像我在文章中提到的哈索·普拉特纳和他的博士一样。学生们发明了HANA?,总体而言,它在计算主题和SAP方面都是一个不可靠的信息来源(什么有效,什么无效,什么真实,什么不真实)。
- Hasso撰写了支持其观点的“同行评审”期刊,正如我在文章中所述,Hasso Plattner对SAP HANA出版物的准确度如何?
哈索认为自己是一个教授和高度技术远见。然而,他的准确性使他接近一个销售人员。正如我们在文章托马斯·爱迪生、伊丽莎白·福尔摩斯和哈索·普拉特纳中所谈到的,哈索·普拉特纳应该因为撒谎而被裁掉多少?

正如我们在几段中所述,SAP永远不会允许与Oracle或其他数据库进行公平竞争,因为SAP知道自己会输。SAP既是该场景中的持枪者,又是监督枪战的实体,因为它是认证实体。SAP还有权阻止任何数据库提供商根据合作协议发布任何基准。
西方最快的数据库(HANA vs.Oracle)?
有证据表明,HANA并不是SAP所说的速度冠军。HANA的主要性能弱点之一很少被解决。HANA作为一个基于列的数据库,并不是非分析(Non-OLAP)应用程序的正确数据库设计。SAP曾说过,这是,但这是从计算机科学的角度看,不是真的。
尽管SAP掩盖了HANA不能100%基于列或面向列的事实。
正如我在文章中(https://www.brightworkresearch.com/saphana/2016/04/02/how-sap-hana-is-s…) 指出的 HANA的速度,用于插入、删除或更新——事务处理系统始终执行的操作是,基于列的表是 比基于行的慢。
面向行的数据库有 所谓关系数据库,但它是基于行的数据库。
数据库速度的大辩论
约翰·索特是一位为Oracle工作的作家,和Hasso一样,在这个主题上并不是一个独立的来源。然而,约翰在福布斯的文章中对HANA与Oracle的主题提出了一些好的观点。其中一个突出的问题是SAP在发布HANA事务处理性能基准时的异议。
SAP尚未发布在HANA上运行的任何事务处理应用程序的单一基准结果。为什么不?
我想说很明显为什么不。这是针对像ERP系统这样的事务处理系统。这些基准不会特别快。
在SAP Nation 2.0出版时,Vinnie Mirchandani是SAP HANA/Oracle 12C辩论的独立来源,他在《SAP Nation 2.0》(https://www.amazon.com/SAP-Nation-2-0-empire-disarray-ebook/dp/B013F5BK…)一书中写道, 强化了johnsoat关于基准的观点。
SAP对HANA基准的不透明并没有帮助。20年来,它的SD基准(衡量SAP在其Sales and Distribution(SD)模块中处理的客户订单行)一直是衡量新硬件和软件基础设施的黄金标准。它还没有使用HANA数据库发布这些指标。
约翰·阿普比的误导
有没有可能是SAP执行了基准测试,但很差,所以它只是停止报告结果?
John Appleby是Bluefin Consulting的HANA全球负责人,也是一位著名的HANA倡导者,他提供了大量关于HANA的虚假信息,他对这个主题有这样的看法—SAP Nation 2.0中也有相关的记录。
“SAP Business Suite目前的答案很简单:必须横向扩展(Scale up)。这一建议在未来可能会改变,但即使是8插槽6TB系统也能满足95%的SAP客户的需要,而且世界上最大的Business Suite安装也能满足24 TB的SGI 32插槽的需要—这是在考虑简单的财务或数据老化之前提出来的,这两种方法都能显著减少内存占用。”
我不知道这是否是对交易基准缺乏透明度的直接回应,但如果是的话,这是一个不充分的回应。在我看来,约翰·阿普尔比正在改变他的回答的主题。
我们跟踪了约翰·阿普比的准确性,并展示了《Appleby精度检查器:约翰·阿普比在HANA上的准确性研究》(https://www.brightworkresearch.com/saphana/2019/04/03/the-appleby-paper…)一文。2013年,Appleby积极和虚假地宣传HANA,以使其公司准备出售给Mindtree,正如我们在文章《Appleby的虚假HANA声明和Mindtree收购》中所述(https://www.brightworkresearch.com/saphana/2019/04/06/applebys-false-ha…)。
Appleby(以前称为Hasso)枢轴
这个问题与HANA与Oracle上的事务处理系统的性能有关。约翰·阿普瑞很快讨论了公司应该购买更多硬件而不必担心的数量。约翰·阿普比在这里说什么?
他说“对于SAP业务套件”,然后他声明了这个套件的答案。
SAP业务套件中唯一准备好HANA的部分(在本报价时)是S/4 Finance。目前,关于S/4金融如何实施,有很多争论。
其次,我说,现在称为SAP HANA Enterprise Management的套件的其余部分目前无法购买。约翰·阿普比把他对未来时态的反应表述成现在时态。
事实上,扩大规模以获得尚未存在的东西是否至关重要?
Oracle Monkeying是否具有S/4认证?
JohnSoat还指出,尽管Oracle在一个特定基准上表现非常出色,但SAP不会证明结果,因为SAP声明Oracle操纵了测试。
现在我没有在审判中,所以我无法说出甲骨文做了什么或没有做什么。甲骨文有它的故事,SAP有他们的故事。索特在文章中对双方的立场都有很好的解释。
此外,Oracle性能数据库顾问StephanKohler也对这个主题有以下几点要说。
SAP已经回答了他们为什么不接受基准测试结果(您也可以在上面提到的文章“复制与粘贴”中找到这一点:“Oracle通过使用一个自定义设置来操纵其BW-EML基准测试,该设置涉及称为tr的数据库函数
igger和物化视图可能导致难以发现的数据不一致,并且在实际生产环境中不受支持。”)。原因是使用了触发器和物化视图,而这些应该是不受支持的。但是,如果SAP检查了他们自己的SAPnotes,您可以看到它得到了明确的支持,而且在SAP ECO Space中也得到了使用。SAPnote#105047:“物化视图–允许使用。
有关更多信息,请参阅SAP注释741478。“SAPnote#105047:”触发器–允许作为SAP标准系统的一部分使用(例如,根据SAP注释449891,增量转换ICNV,BW触发器/BI0/05*)。根据SAP Note 712777允许使用登录触发器。允许作为Oracle功能的一部分隐式使用(例如,在线重组、物化视图、GridControl/Enterprise Manager)。只要没有可用的扁平多维数据集作为替代,就允许在sapbw系统中与物化视图结合使用。没有SAP集成,SAP也不提供对此的支持。“自2016年第1季度起,测试版就提供了扁平立方体,因此与2015年起的Oracle基准测试无关。
这就引出了下一个话题,这是个大话题。
SAP不认证Oracle 12c的利益冲突
SAP现在完成了与所有硬件供应商的合作,使SAP在认证数据库时存在利益冲突;这是一种利益冲突,在投资汉纳之前,它没有这种利益冲突。曾经是一个简单的过程现在充斥着政治阴谋,人们现在必须分析SAP和Oracle的声明,看看谁说的是实话。
如果通过认证Oracle,SAP削减了他们在HANA的市场份额,那么SAP如何认证Oracle,也就是说,给他们一个公平的听证会?
Oracle12c模式转换&HANA与Oracle的新窍门
Oracle 12c可以在“模式”之间切换,在内存列的内存行中显示其中一个。这是一个严重的优势。ibmblu具有类似的能力。然而,没有太多证据表明,需要一个既能执行OLTP又能执行OLAP的数据库——并且设计一个能够同样好地处理每种类型数据库的数据库可能是不可行的。数据库的发展趋势与此相反,随着NoSQL等专业数据库设计的蓬勃发展,索引数据库也蓬勃发展。
然而,回到HANA与Oracle 12c的讨论:
- Oracle灵活的设计在性能上应该优于SAP HANA,而不是纯粹的分析应用程序。
- SAP提出的整个数据库应该是列式的逻辑从来没有意义,因为分析中使用的表很少。因此,为每个应用程序表使用分析优化表(列式)是否有意义?
- 关于Oracle内存数据库的成熟程度,目前有一个争论。SAP列出7000个SAP HANA客户。然而,大多数客户都知道他们不使用软件(即,它是货架软件)或测试系统,而不是实时系统。因此,SAP HANA技能仍然很难找到。
此外,Oracle的内存模式开关在许可证和维护方面都增加了Oracle 12c的价格。
SAP的作弊的基准
SAP有足够的机会证明他们在HANA方面的优势,但从未这样做。SAP从未允许在事务处理中使用一个比较基准,SD-HANA基准的隐藏问题(https://www.brightworkresearch.com/saphana/2019/03/29/the-hidden-issue-…)一文对此进行了介绍。由于HANA在事务流程基准测试中的表现如此糟糕,它创建了一个新的引用,试图掩盖这一事实。但他们提供的参考是围绕分析而设计的,这篇文章介绍了SAP的BW-EML基准测试的四个隐藏问题(https://www.brightworkresearch.com/saphana/2019/03/28/the-hidden-issues…)。由于许多公司都抱怨HANA的事务处理性能,这就引出了一个问题,即HANA在多大程度上可以支持ERP系统,这在文章HANA中被称为s/4HANA和ERP的不匹配(https://www.brightworkresearch.com/saphana/2017/12/05/hana-mismatch-s4h…)。
结论
使用oracle12c,oracle12c可以在基于行和基于列的表之间进行切换,并为同一个表进行切换,这是一项新功能。
据我所知,几乎所有关于HANA的SAP营销文档都是在这一开发之前编写的。如果我在SAP负责HANA营销,我就不想谈论Oracle 12c,因为我没有正确的答案。这是因为Oracle 12c破坏了在SAP上花费的大量精力,使SAP客户认为SAP HANA技术是SAP独有的,从而将SAP HANA定位为独特和更好的技术。
Oracle 12c的新功能 破坏多年来提出的一些SAP争议。SAP尚未涉及Oracle 12c,在SAP HANA上创建的大部分资料都是在Oracle 12c发布之前开发的。IBM和mssqlserver具有类似的列存储功能。不是因为开发它们有很大的理由,而是因为SAP通过其巨大的市场营销,将重点放在了这种类型的数据库功能上。
首先,SAP现在没有一个好的理由——或者说,如果它把客户的利益放在首位,只将新的SAP应用程序(如s/4)移植到SAP HANA是个好主意。
向客户口述数据库?
前面的论点认为只有SAP才能提供足够快的数据库 很可能是假的。不管什么原因,这始终是一个软弱的论点。无应用程序供应商 应该向客户说明数据层。然而,SAP一再表示,它希望这样做。
SAP仍然相信在云端和本地运行新系统,但只有SAP S/4HANA才能在未来的一个软件版本中实现这一点。这将降低总体拥有成本(TCO),并加快迈向未来所需的步伐。数据输入、标准报告、分析和预测、数字会议室或多渠道客户交互等每一个应用领域都成为世界级的组件 就其本身而言。仅此一点就可以考虑更早地迁移到SAP S/4HANA哈索·普拉特纳
SAP对将IT行业赶回到过去的兴趣
在山景城的计算机历史博物馆里,有一个展览解释说,这个软件曾经是硬件供应商的专利。那时,软件不是一个“产业”,IBM发布的程序只能在IBM硬件上运行。软件没有单独收费,因此在软件层面没有竞争。
我们今天所知道的软件产业,是在与硬件脱钩之后才发展起来的。而这只是因为美国威胁要对专有软件模型和硬件供应商实施反垄断立法。HANA作为应用程序和数据库层之间的耦合,由一个供应商控制,将我们带回过去。
这将创建相当于专有应用程序/数据库的组合。
- SAP认为只有基于列的数据库才有前途的观点也是不正确的。
- 最后,对于那些了解数据库供应商及其历史的人来说 只有SAP能够开发出符合HANA速度能力的高性能数据库是不真实的。
SAP的论点并不是说它们等同于其他所有数据库供应商。使用HANA,它们比其他任何数据库供应商都优越。当然,这包括HANA与Oracle或其他任何人的竞争。
SAP当然可以而且将继续出售HANA与Oracle的竞争。但SAP一直提出的排他性观点已不再是一个可以相信的立场。
原文:https://www.brightworkresearch.com/which-is-faster-hana-or-oracle-12c/
本文:http://jiagoushi.pro/node/1492
讨论:请加入知识星球【首席架构师智库】或者小号【cea_csa_cto】或者QQ【2808908662】
- 148 次浏览
【列式数据库】Cassandra 101(介绍)
Cassandra 是一个简单的分布式 NoSQL 数据库。 分布式意味着 Cassandra 有多个相互连接的节点,负责存储和检索数据。 需要多个节点来实现 Cassandra 著名的可用性、可扩展性和高性能。
说到分布式系统,我们需要了解 CAP(Consistency, Availability & Partition Tolerance)定理。 根据它,“任何分布式数据存储只能提供这三个(即 CAP)保证中的两个”。 由于分布式系统中必然会发生网络故障,因此我们需要注意“分区容限”,以确保在由复制因子配置的节点之间保持数据的多个副本。 所以有两种选择,要么优先考虑可用性,要么在发生网络故障时优先考虑一致性。
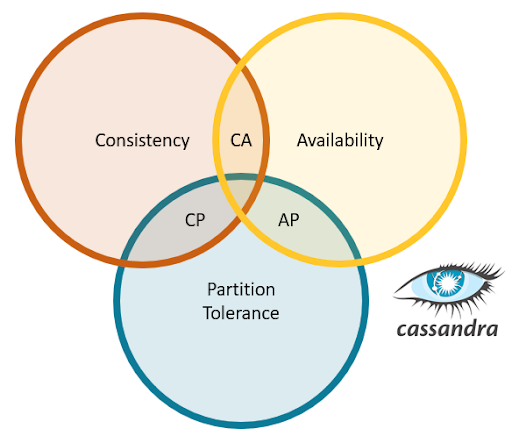
一般来说,Cassandra 被称为 AP(可用性和分区容限)数据库,因为那是 Cassandra 最适合的数据库。 然而,更高的一致性是可调的,牺牲了 Cassandra 中的可用性和性能,用于一些需要但 Cassandra 不适合的用例。
Cassandra 中使用的基本术语
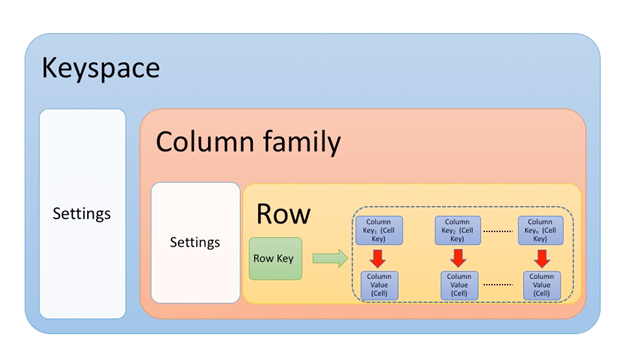
- 节点:运行 Cassandra 软件并存储数据子集的服务器。
- 集群:作为一个 Cassandra 数据库的许多节点的集合。
- Column :Cassandra 中用于存储数据字段的键和值的最小存储单元,也称为 Cell。
- 列族:特定用例的列集合。与表相同。
- 分区:它是表的特定节点上的数据子集。一个节点可以有多个分区。
- 分区键:一组列,用于标识数据在节点的特定分区中的位置。
- 聚类键:用于按排序顺序存储多条记录的列集。
- 行键:唯一标识数据库中记录的主键。主键 = 分区键 + 集群键
- Keyspace :用于组成多个列族的存储单元,类似于关系数据库中的模式
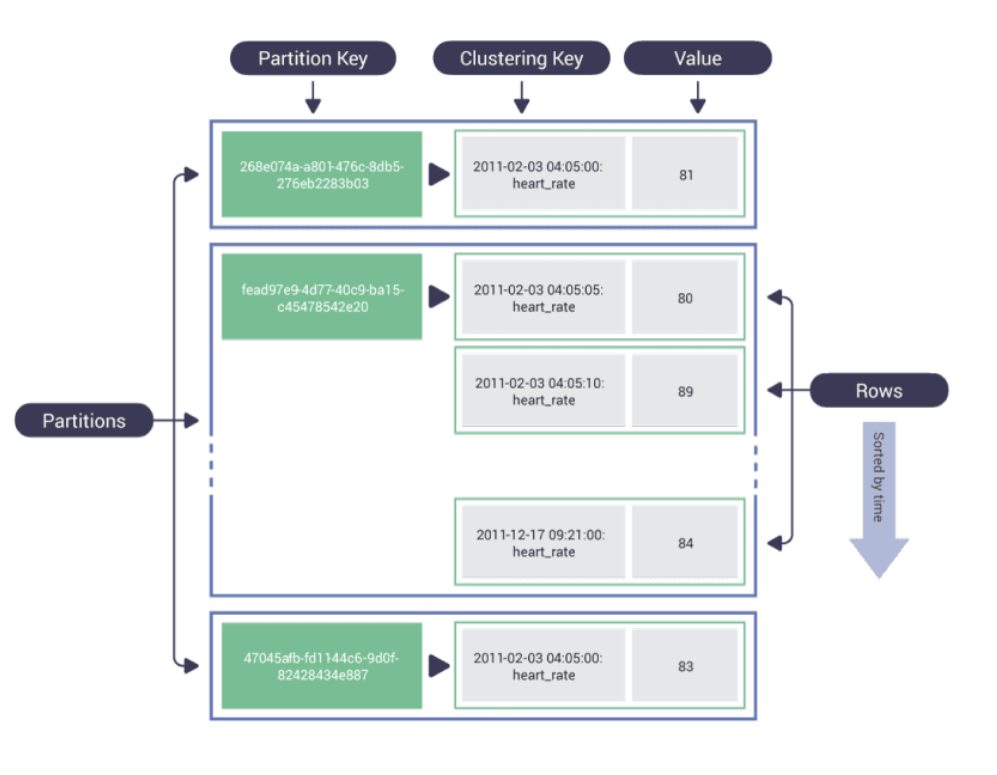
可能没有任何集群键列具有与分区键相同的行/主键。虽然分区键的主要目的不是作为主键,而是将数据分布在不同小分区的不同节点上。但是,分区键绝对不应该具有低基数,您是否应该具有非常高的基数取决于您查询数据的用例和数据大小。
当我们有聚类键(这里是时间戳字段)时,下图会更清楚:
Cassandra 擅长什么
- 高可用性:Cassandra 没有单点故障,即在大多数节点仍然可用和连接的情况下始终可用于读取和写入。这是可以实现的,因为 C* 中没有主从拓扑,所有节点都是相同的(当然,这些节点上的数据可能因集群中少数节点上的复制而不同)。所以即使你没有很强的一致性、可扩展性和性能要求,只是想拥有跨不同区域的高可用数据库,Cassandra 也是一个不错的选择。这就是为什么 Kong(API Gateway) 也将其用作数据库选择之一。
- 写入负载的水平可扩展性和高性能:这是可以实现的,因为我们可以有多个节点来处理不同分区的写入负载,并且在单个节点内,Cassandra 以仅追加方式将新数据写入名为 commitlog 的文件,该文件会写入磁盘更快(与 Kafka 相同)。除此之外,Cassandra 使用 memtables 将新数据存储在内存中,然后定期将数据从内存刷新到称为 SSTable 的数据文件中。因此,提交日志仅用于节点故障场景。
- 数据大小水平可扩展:这是可以实现的,因为我们可以在集群中添加更多节点来处理更多数据。
- 读取负载水平可扩展(有条件):基于单个分区键从 Cassandra 查询数据是快速且可扩展的,但有一些因素可能会影响性能和可扩展性。例如,如果单个分区中有太多数据,或者正在为同一分区键更新数据,导致数据驻留在同一分区的不同数据文件(SSTables)中。尽管有不同的 SSTable 压缩策略来最大限度地减少影响,但需要根据确切的用例以及使用 Cassandra 数据库时最重要的部分数据建模仔细测试事情。
Cassandra不擅长或根本不支持的地方
- ACID(原子性,一致性,隔离性,持久性)合规性:不支持金融系统等应用程序所需的。
- 聚合函数:Cassandra 不适合计数、最大值、平均值等聚合。
- 联接:不支持,尽管数据非规范化是 Cassandra 中的一种常见做法,用于将查询的相关数据保存在一个分区中,但这应该在限制范围内。
- 排序:Cassandra 仅支持对聚类列进行排序,并且一旦插入,您就无法更改聚类列的值。所以在 Cassandra 中排序是一个设计决策。
- 新用例:我们需要根据查询模式将数据存储在 Cassandra 中,因此如果出现任何新需求,除非我们按照 Cassandra 数据建模要求再次存储数据,否则很难处理它。
概括
在这篇文章中,我们了解了 Cassandra 的基础知识,它的用例以及我们需要小心或避免使用 Cassandra 的地方。
我们将在即将发布的帖子中介绍更高级的场景和用例,在此之前,请务必为这篇文章鼓掌,并关注我以在未来查看更多此类帖子。
原文:https://itsmanish.medium.com/cassandra-101-introduction-eb7556a85bc
- 157 次浏览
【列式数据库】利用Apache Cassandra 4.0中的虚拟表
多亏了CASSANDRA-7622,Apache CASSANDRA 4.0有了一个名为“虚拟表”的新功能在本文中,我们将讨论虚拟表、它们在Apache Cassandra 4.0中的实现,以及如何使用它们来提高集群的可观察性。
虚拟表本质上是位于API之上的表接口,而不是存储在磁盘上的数据。它们可以在数据库级别进行交互,但不支持“普通”表所具有的所有功能。Cassandra中的虚拟表不能写入、更改、删除或截断,也不能支持其他索引、函数或物化视图。
此外,虚拟表只能存在于虚拟键空间中。虚拟键空间是由Cassandra管理的特殊键空间。它们不是复制的,只针对本地节点。
Apache Cassandra 4.0安装了两个虚拟密钥空间:
- System_virtual_schema:包含所有虚拟表和键空间(包括其本身)的模式数据
- System_views:Cassandra中唯一真实的虚拟键空间
那么你能用它们做什么呢?
在当前的迭代中,虚拟表大大简化了管理和监视Apache Cassandra所需的工具。访问度量一直是通过Java管理扩展(JMX)实现的,但对于虚拟表,这些度量中的许多现在通过虚拟表公开。
以下是system_views键空间中包含的虚拟表列表:
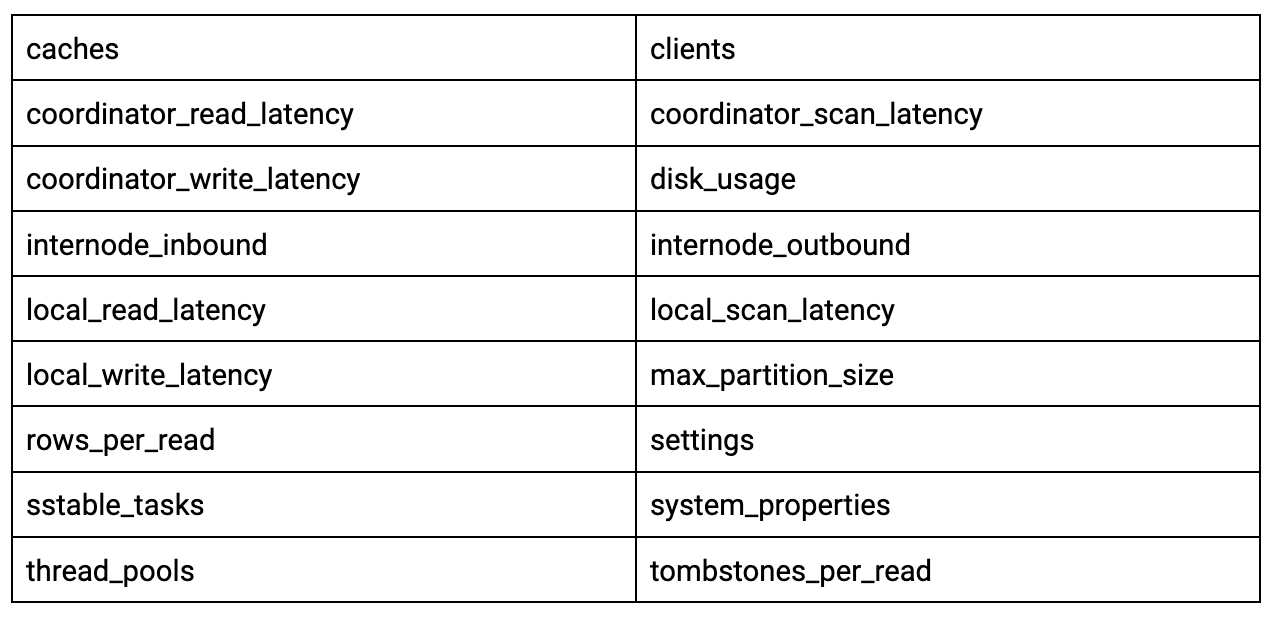
让我们来看一些简单的例子。
设置
你是否曾经在一个讨论论坛上为一个集群在线解决问题,结果却被问到:“你的压缩吞吐量是多少?”或者,“你使用了多少memtable_flush_编写器?”
之前,你必须检查卡桑德拉。该节点上的yaml文件——假设您有权访问它。现在,您可以简单地查询它:
> SELECT * FROM settings
WHERE name='compaction_throughput_mb_per_sec';name | value
----------------------------------+-------
compaction_throughput_mb_per_sec | 64(1 rows)
> SELECT * FROM settings
WHERE name='memtable_flush_writers';name | value
------------------------+-------
memtable_flush_writers | 2(1 rows)
正如您所见,使用Cassandra查询配置参数从来都不容易!
系统属性
相关的系统属性也通过虚拟表公开。当您的企业安全团队发现安全漏洞并需要了解节点的Java运行时环境(JRE)时,这一点非常有用:
> SELECT * FROM system_properties
WHERE name IN ('java.vm.name','java.version');name | value
--------------+--------------------------
java.version | 11.0.10
java.vm.name | OpenJDK 64-Bit Server VM
请注意,由于虚拟表仅特定于本地节点,因此使用IN-CQL操作符不会产生性能问题。
类似地,如果您正在处理一个新集群,并且想知道日志写入的位置,可以使用:
> SELECT * FROM system_properties
WHERE name='cassandra.logdir';name | value
------------------+-------------
cassandra.logdir | bin/../logs
这样,您可以快速查看Cassandra的相关系统属性。以前,获取此信息的唯一窗口是通过SSH(Secure Shell)连接上运行的命令。
节点性能指标
在Apache Cassandra 4.0之前,您只能通过JMX接口访问性能指标。但通过虚拟表,您可以看到集群中特定节点的性能。
假设你想了解更多关于跟踪“书呆子假期”的表格的阅读模式该数据存储在rows_per_read表中,您可以按键空间和表名查询它:
> SELECT * FROM rows_per_read
WHERE keyspace_name='datastax'
AND table_name='nerd_holidays';keyspace_name | table_name | count | max | p50th | p99th
---------------+---------------+-------+-----+-------+-------
datastax | nerd_holidays | 6 | 24 | 14 | 24
或者,您希望查看此节点的密钥缓存统计信息:
> SELECT * FROM caches
WHERE name='keys';name | capacity_bytes | entry_count | hit_count | hit_ratio | recent_hit_rate_per_second | recent_request_rate_per_second | request_count | size_bytes
------+----------------+-------------+-----------+-----------+----------------------------+--------------------------------+---------------+------------
keys | 104857600 | 65 | 311 | 0.827128 | 0 | 0 | 376 | 6488
这提供了一种使用Cassandra查看性能指标的简单方法。与使用附加工具(如JConsole或JMXTerm)直接与JVM交互相比,这是一个巨大的改进。
图1。通过JMXTerm与Apache Cassandra交互。有人真的错过了这样做吗?
总结
虚拟桌子是Cassandra的一个受欢迎的补充。能够通过cqlsh以编程方式访问配置属性、系统变量和度量是一个巨大的时间节省。通过这种方法,您可以大大简化对有价值的可观测数据的访问。
最后,以下是关键要点:
- 虚拟表是查看单个节点数据的快速方法
- 无需访问cassandra即可验证配置属性。yaml文件
- 与Cassandra相关的系统属性可以在没有SSH连接的情况下进行验证
- 现在可以不用JMX查询许多指标
关注媒体上的DataStax,获取有关所有内容Cassandra、流媒体、Kubernetes等的独家帖子。要加入一个由来自世界各地的开发人员组成的繁忙社区,并留在数据循环中,请关注Twitter和LinkedIn上的DataStaxDev。
Resources
- Virtual Tables | Apache Cassandra Documentation
- CASSANDRA-7622 — Implement virtual tables
- Arithmetic Operators in Apache Cassandra 4.0
- Deploy Apache Cassandra 4.0 on Kubernetes and AWS
- 3 Things You Should Know About Data Consistency, Distribution, and Replication with Apache Cassandra
原文:https://medium.com/building-the-open-data-stack/leveraging-virtual-tabl…
本文
- 75 次浏览
【列式数据库】将YugabyteDB与其他数据库进行比较
查看YugabyteDB与分布式SQL和NoSQL类别中的其他操作数据库的比较。要获得详细的比较,请单击数据库名称。
分布式SQL数据库
| 特性 | CockroachDB | TiDB | Vitess | Amazon Aurora | Google Cloud Spanner | YugabyteDB |
|---|---|---|---|---|---|---|
| 水平写入可伸缩性(带有自动分片和再平衡) | 是 | 是 | 是 | 是 | 是 | 是 |
| 自动故障转移和修复 | 是 | 是 | 否 | 是 | 是 | 是 |
| 分布式ACID事务 | 是 | 是 | 否 | 是 | 是 | 是 |
| SQL外键 | 是 | 否 | 是 | 是 | 是 | 是 |
| SQL Joins | 是 | 是 | 是 | 是 | 是 | 是 |
| 可序列化的隔离级别 | 是 | 否 | 是 | 是 | 是 | 是 |
| 跨多个DC/区域的全球一致性 | 是 | 不确定 | 否 | 否 | 是 | 是 |
| 追随者读取 | 否 | 是 | 是 | 是 | 否 | 是 |
| 内置的企业特性(如CDC) | 否 | 是 | 是 | 是 | 是 | 是 |
| SQL 兼容性 | PostgreSQL | MySQL | MySQL | MySQL, PostgreSQL | Proprietary | PostgreSQL |
| 开源 | Apache 2.0 | Apache 2.0 | Apache 2.0 |
NoSQL databases
| 特性 | Mongo | Foundation | Apache Cassandra | Amazon Dynamo | MS Azure Cosmos | Yugabyte |
|---|---|---|---|---|---|---|
| 水平写入可伸缩性(带有自动分片和再平衡) | 是 | 是 | 是 | 是 | 是 | 是 |
| 自动故障转移和修复 | 是 | 是 | 是 | 是 | 是 | 是 |
| 分布式ACID事务 | 是 | 是 | 否 | 是 | 否 | 是 |
| 共识驱动、强一致性复制 | 否 | 是 | 否 | 否 | 否 | 是 |
| 强一致性二级索引 | 否 | 是 | 否 | 否 | 否 | 是 |
| 多重读取一致性级别 | 是 | 是 | 是 | 是 | 是 | 是 |
| 高数据密度 | 否 | 否 | 否 | 否 | 否 | 是 |
| API | MongoQL |
Proprietary
KV, Mongo QL |
Cassandra QL | Proprietary KV, Document | Cassandra QL, Mongo QL | Yugabyte Cloud QL w/ native document modeling |
| 开源 | Apache 2.0 | Apache 2.0 | Apache 2.0 |
请注意
关于第三方数据库的任何特定功能的或是基于我们对公开信息的最大努力的理解。我们总是建议读者进行自己的独立研究,以了解更详细的细节。
原文:https://docs.yugabyte.com/latest/comparisons/
本文:
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 273 次浏览
【宽列数据库】Apache Cassandra 简介——NoSQL 世界的“兰博基尼”
欢迎阅读我们关于 Apache Cassandra® 的五部分系列的第一篇文章。作为一个无限可扩展的数据库,Cassandra 被广泛认为是 NoSQL 数据库世界的兰博基尼。在这篇文章中,我们将向您介绍 NoSQL 数据库、CAP 定理,并解释 Cassandra 的工作原理。
Apache Cassandra® 是绝大多数财富 100 强公司使用的分布式 NoSQL 数据库。通过帮助 Apple、Facebook 和 Netflix 等公司以可靠、可扩展的方式处理大量快速移动的数据,Cassandra 已成为我们今天所依赖的关键任务功能的关键。
在这篇基于我们介绍 Apache Cassandra 的视频教程的帖子中,我们将:
- 讨论 NoSQL 数据库以及专用数据库的强大功能
- 介绍 Cassandra,一个点对点数据库
- 解释一致性、可用性和分区容限 (CAP) 定理(即分布式系统定律)
- 演示如何使用表和分区构造数据
- 分享可以在 GitHub 上完成的动手练习
从 SQL 到 NoSQL:为什么要发明 NoSQL
关系数据库管理系统 (RDBMS) 主导了市场数十年。然后,随着 Apple、Facebook 和 Instagram 等大型科技公司的崛起,全球数据领域在过去十年中飙升了 15 倍。而且,RDBMS 根本没有准备好应对新的数据量,也没有准备好应对新的性能要求。
Figure 1. Skyrocketing data needs.
NoSQL 的发明不仅是为了应对海量数据,而且也是为了应对速度(速度要求)和多样性(市场上所有不同类型的数据和数据关系)的挑战。
除了像 Cassandra 这样的表格数据库,我们还看到了其他类型的 NoSQL 数据库的兴起,例如:
- 时间序列数据库(例如 Prometheus)
- 文档数据库(例如 MongoDB)
- 图数据库(例如 DataStax Graph)
- 分类帐数据库(例如 Amazon QLDB)
- 键/值数据库(例如 Amazon DynamoDB)
是什么让Cassandra 如此强大?
Cassandra 以其大规模的性能而闻名,被认为是 NoSQL 数据库世界的兰博基尼:它本质上是无限可扩展的。没有领导节点,Cassandra 是一个点对点系统。
例如,在 Netflix,Cassandra 在其最活跃的单个集群上运行 3000 万次操作/秒,98% 的流数据存储在 Cassandra 上。 Apple 运行 160,000 多个 Cassandra 实例和数千个集群。
Cassandra 强大的功能有 8 个:
- 大数据就绪:分布式架构上的分区使数据库能够处理任何大小的数据:PB 级。需要更多音量?添加更多节点。
- 读写性能:单个节点的性能非常好,但具有多个节点和数据中心的集群将吞吐量提升到一个新的水平。去中心化(无领导架构)意味着每个节点都可以处理任何请求,读取或写入。
- 线性可扩展性:对容量或速度没有限制,也没有新节点的开销。 Cassandra 可根据您的需求进行扩展。
- 最高可用性:理论上,由于复制、分散和拓扑感知放置策略,您可以实现 100% 的正常运行时间。
- 自我修复和自动化:大型集群的操作可能会让人筋疲力尽。 Cassandra 集群减轻了很多麻烦,因为它们很智能——能够自动扩展、更改数据替换和恢复。
- 地理分布:多数据中心部署赋予了卓越的容灾能力,同时让您的数据靠近您的客户,无论他们身在何处。
- 平台无关:Cassandra 不受任何平台或服务提供商的约束,它允许您轻松构建混合云和多云解决方案。
- 独立于供应商:Cassandra 不属于任何商业供应商,而是由非营利性开源 Apache 软件基金会提供,确保开放可用性和持续开发。
Cassandra 是如何工作的?
在 Cassandra 中,所有服务器都是平等的。与传统架构不同,其中有一个用于写入/读取的领导服务器和用于只读的跟随服务器,导致单点故障,Cassandra 的无领导(对等)架构将数据分布在集群内的多个节点(也称为数据中心或环)。
Figure 2. Apache Cassandra structure.
一个节点代表一个 Cassandra 实例,每个节点存储几 TB 的数据。节点“八卦”或交换有关自身和集群中其他节点的状态信息,以实现数据一致性。当一个节点出现故障时,应用程序会联系另一个节点,确保 100% 的正常运行时间。
在 Cassandra 中,数据被复制。复制因子 (RF) 表示用于存储数据的节点数。如果 RF = 1,则每个分区都存储在一个节点上。如果 RF = 2,则每个分区都存储在两个节点上,依此类推。行业标准是三倍的复制因子,尽管在某些情况下需要使用更多或更少的节点。
有关更详细的说明,请观看我们的 Cassandra 简介教程,以了解数据复制在 Cassandra 上的工作原理。
CAP 定理:Cassandra 是 AP 还是 CP?
著名的“CAP”定理指出,分布式数据库系统在发生故障情况下只能保证这三个特性中的两个:一致性、可用性和分区容错性:
- 一致性:这意味着“没有陈旧的数据”。查询返回最新的值。如果其中一台服务器返回过时的信息,则您的系统不一致。
- 可用性:这基本上意味着“正常运行时间”。如果服务器出现故障但仍然给出响应,那么您的系统是可用的。
- 分区容限:这是分布式系统在“网络分区”中生存的能力。网络分区意味着部分服务器无法到达第二部分。
Figure 3. CAP Theorem governing databases.
包括 Cassandra 在内的任何数据库系统都必须保证分区容错性:它必须在数据丢失或系统故障期间继续运行。为了实现分区容错,数据库必须优先考虑一致性而不是可用性“CP”,或者可用性优先于一致性或“AP”。
Cassandra 通常被描述为“AP”系统,这意味着它在确保数据可用性方面犯了错误,即使这意味着牺牲一致性。但这还不是全部。 Cassandra 具有可配置的一致性:您可以设置所需的一致性级别,并根据您的用例将其调整为更多的 AP 或 CP。如果您想更深入地了解,您可以在我们的视频教程中找到更详细的说明。
Cassandra 如何构建和分发数据?
Cassandra 的先天架构可以在数千台服务器上处理和分发大量数据,而不会出现停机。每个 Cassandra 节点甚至每个 Cassandra 驱动程序都知道集群中的数据分配(称为令牌感知),因此您的应用程序几乎可以联系任何服务器并获得快速响应。
Figure 4. Data distribution across multiple nodes.
Cassandra 使用基于键的分区。 Cassandra 数据结构的主要组成部分包括:
- Keyspace:数据容器,类似于模式,包含多个表。
- 表:在分区中存储数据的一组列、主键和行。
- 分区:一组行以及相同的分区令牌(Cassandra 中的基本访问单元)。
- 行:表中的单个结构化数据项。
Figure 5. Overall data structure on Cassandra.
Cassandra 将数据存储在分区中,表示跨集群的表中的一组行。每一行都包含一个分区键——一个或多个列,这些列被散列以确定数据如何在集群中的节点之间分布。
为什么要分区?因为这使得缩放变得更加容易!大数据不适合单个服务器。取而代之的是,它被分成很容易分布在数十、数百甚至数千台服务器上的块,如果需要,可以添加更多。
为表设置分区键后,分区器会将分区键中的值转换为令牌(也称为散列),并为每个节点分配一个称为令牌范围的数据范围。
Cassandra 然后通过令牌值自动在集群中分配每一行数据。如果您需要扩大规模,只需添加一个新节点,您的数据就会根据新的令牌范围分配重新分配。另一方面,您也可以轻松缩小规模。
数据架构师需要知道如何在创建数据模型之前创建准确快速地返回查询的分区。一旦为表设置了主键,就无法更改。
相反,您需要创建一个新表并迁移所有新数据。要更好地了解如何创建良好的分区,请观看我们的视频教程以逐步了解真实示例。
Cassandra 的动手练习
现在,让我们使用 DataStax 的 Astra DB 在云中创建您自己的 Cassandra 数据库。注册一个 Astra DB 帐户并选择 80 GB 的免费套餐。使用数据库名称、键空间名称、提供程序和区域设置您的数据库。我们的 GitHub 和视频教程将介绍:
- Creating your Astra DB instance
- Creating tables
- Executing CRUD (create, read, update, delete) operations
无论您是加入我们的现场研讨会还是按照自己的步调进行,存储库都会向您展示强大的分布式 NoSQL 数据库 Apache Cassandra 最重要的基础知识,供每位想要尝试学习新数据库的开发人员使用:创建表和 CRUD 操作.
结论
我们希望您喜欢这个对 Cassandra 的初步介绍,其中包含帮助您入门的基本练习。请继续关注 Cassandra 在高级数据建模和数据库性能基准测试等主题上的更多实际应用。
同时,如果您想了解有关 Cassandra 的更多信息,请查看我们在 DataStax Academy 上的 Apache Cassandra 课程,并加入我们的社区,与该领域的专家讨论 NoSQL。您还可以阅读我们关于如何使用 Cassandra 部署机器学习模型的帖子。
Resources
- Apache Cassandra: Open-source NoSQL Database
- DataStax Astra DB: Multi-cloud DBaaS built on Apache Cassandra
- Astra DB Sign Up
- DataStax Apache Cassandra Course
- YouTube Tutorial: Introduction to Apache Cassandra
- Introduction to Apache Cassandra GitHub
- DataStax Enterprise Graph
- DataStax Academy
- Real-World Machine Learning with Apache Cassandra and Apache Spark (Part 1)
- Build CRUD Operations with Node JS and Python on DataStax Astra DB
- Data Age 2025: The Datasphere and Data-readiness From Edge to Core
原文:https://medium.com/building-the-open-data-stack/introduction-to-apache-…
本文:
- 263 次浏览